Embed Size (px)
Citation preview

Home of Redis
Analytics at the Real-Time Speed of BusinessManish GuptaCMO, Redis Labs
February 8, 2017
2
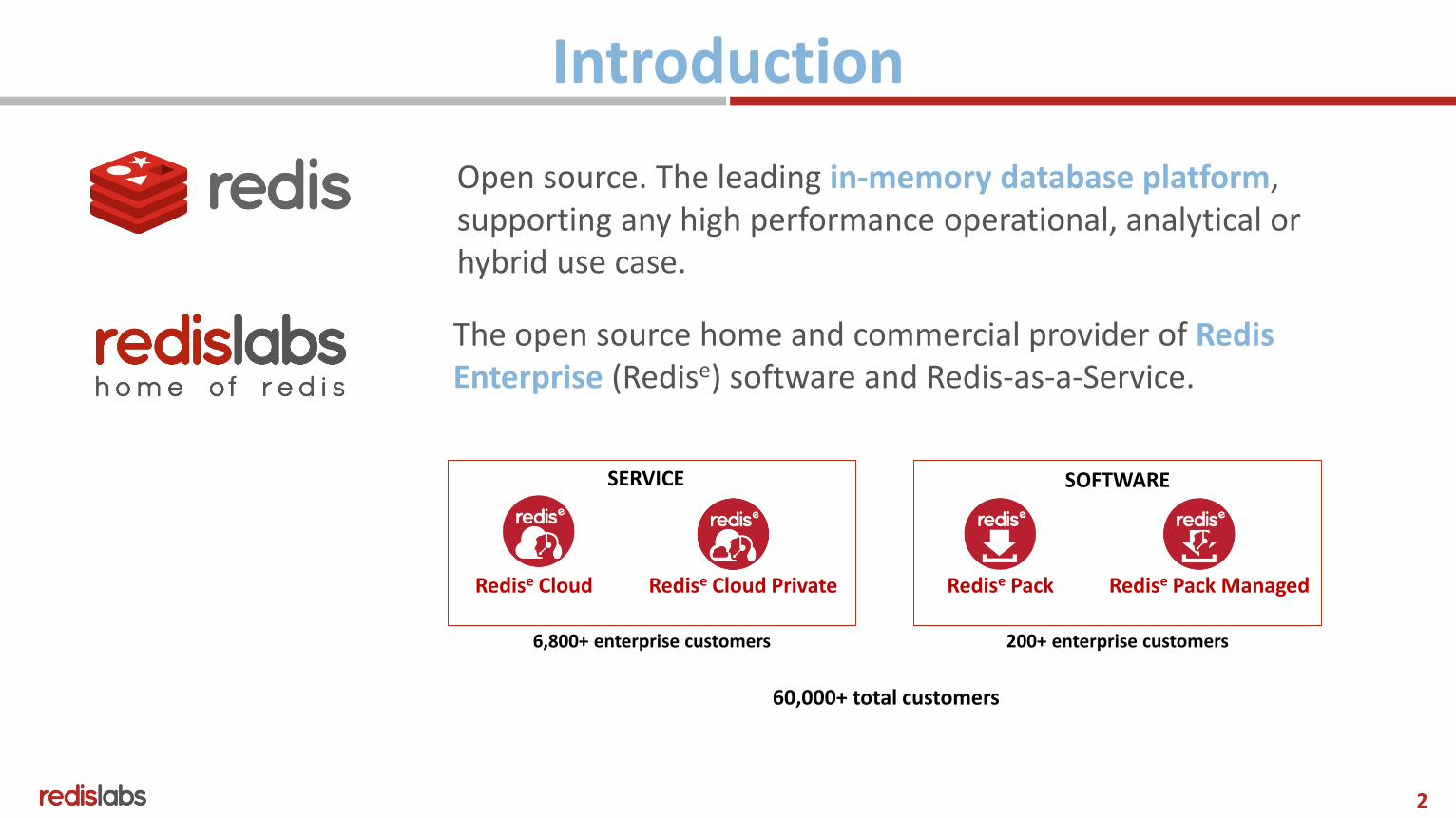
Introduction
The open source home and commercial provider of RedisEnterprise (Redise) software and Redis-as-a-Service.
Open source. The leading in-memory database platform, supporting any high performance operational, analytical or hybrid use case.
6,800+ enterprise customers 200+ enterprise customers
60,000+ total customers
Redise Cloud PrivateRedise Cloud Redise Pack ManagedRedise Pack
SERVICE SOFTWARE
3
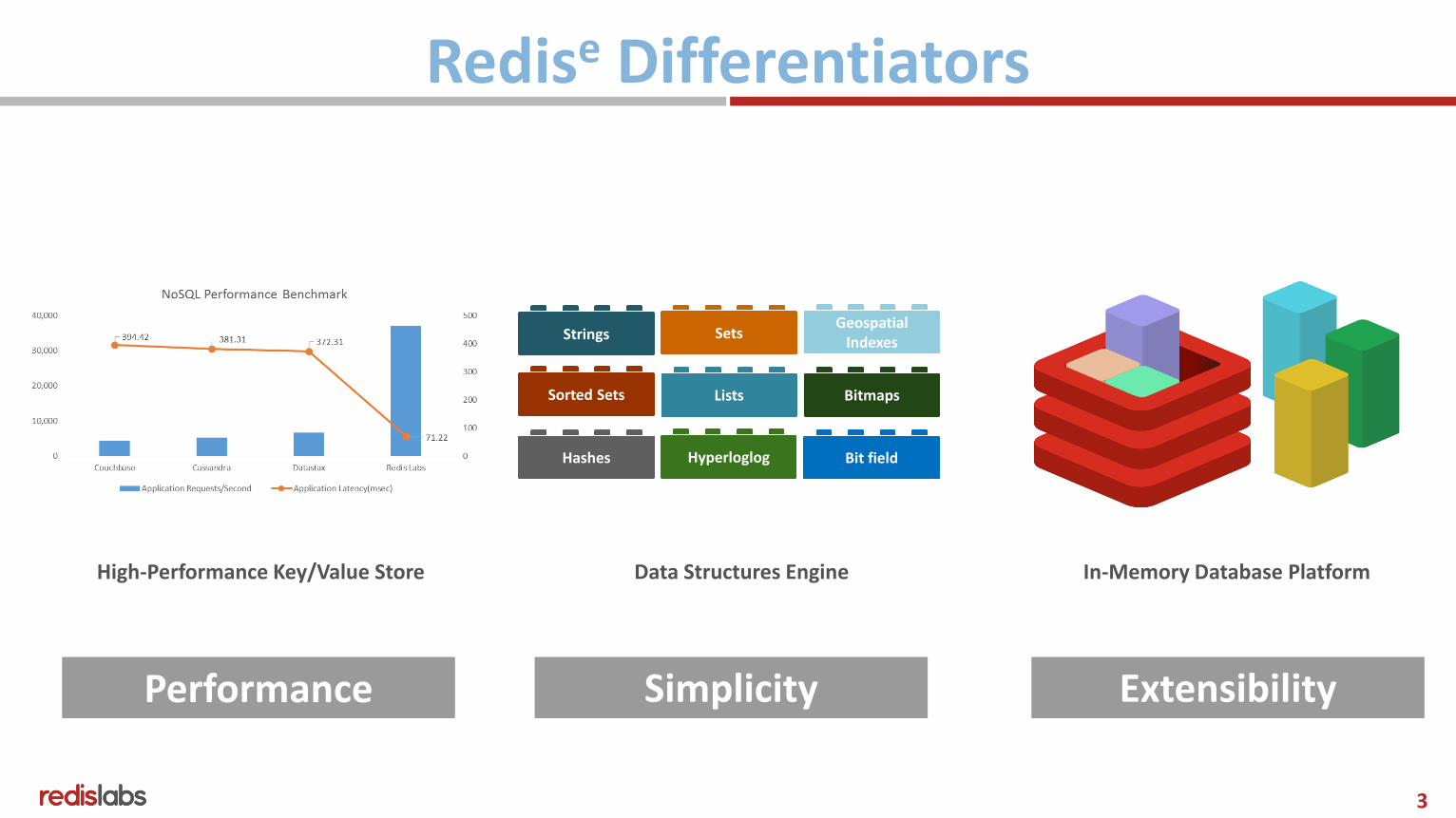
Redise Differentiators
Simplicity Extensibility Performance
ListsSorted Sets
Hashes Hyperloglog
Geospatial Indexes
Bitmaps
SetsStrings
Bit field
High-Performance Key/Value Store Data Structures Engine In-Memory Database Platform

4
+
5
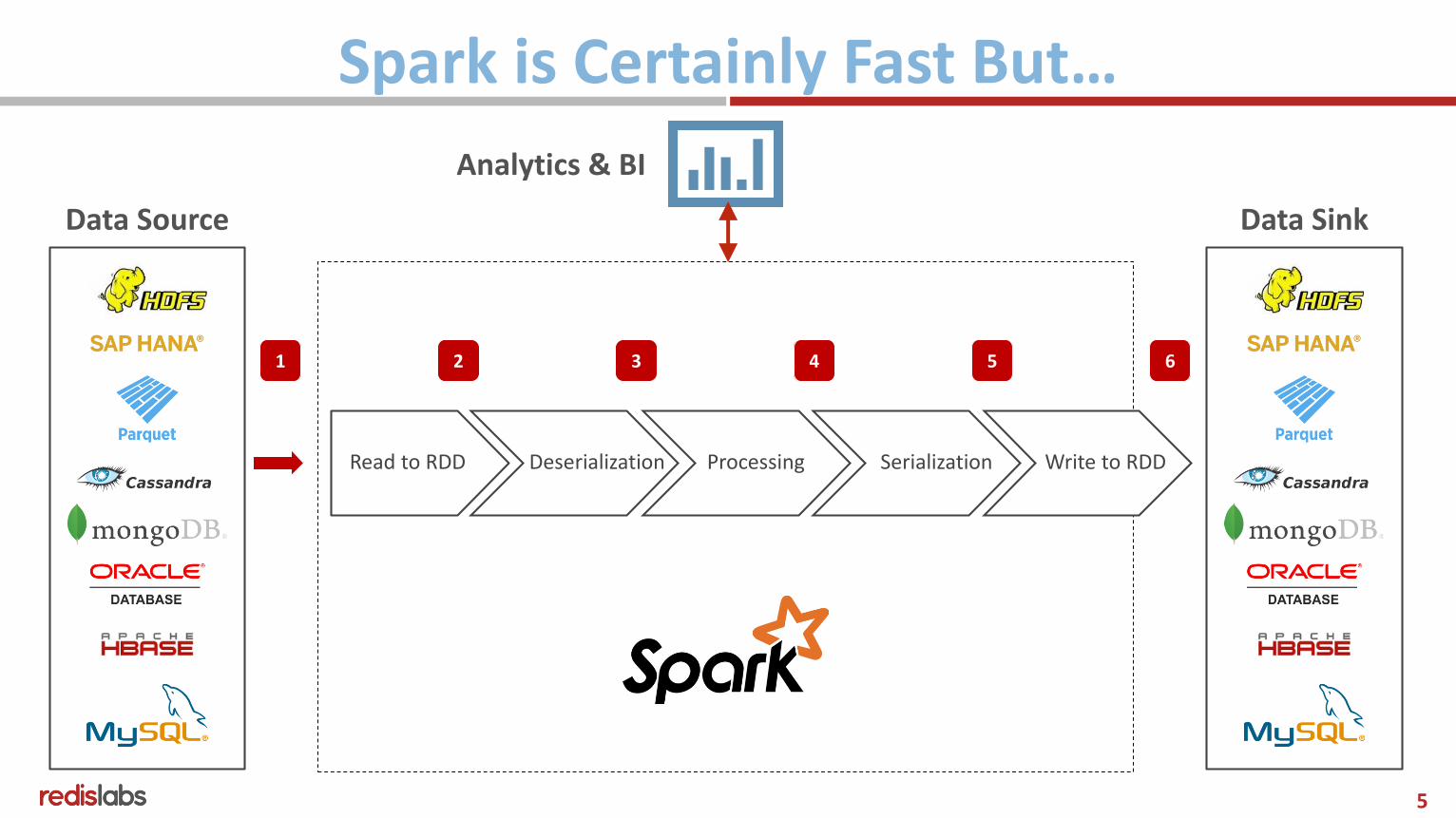
Spark is Certainly Fast But…
Read to RDD Deserialization Processing Serialization Write to RDD
Analytics & BI
1 2 3 4 5 6
Data SinkData Source
6
Spark SQL &Data Frame
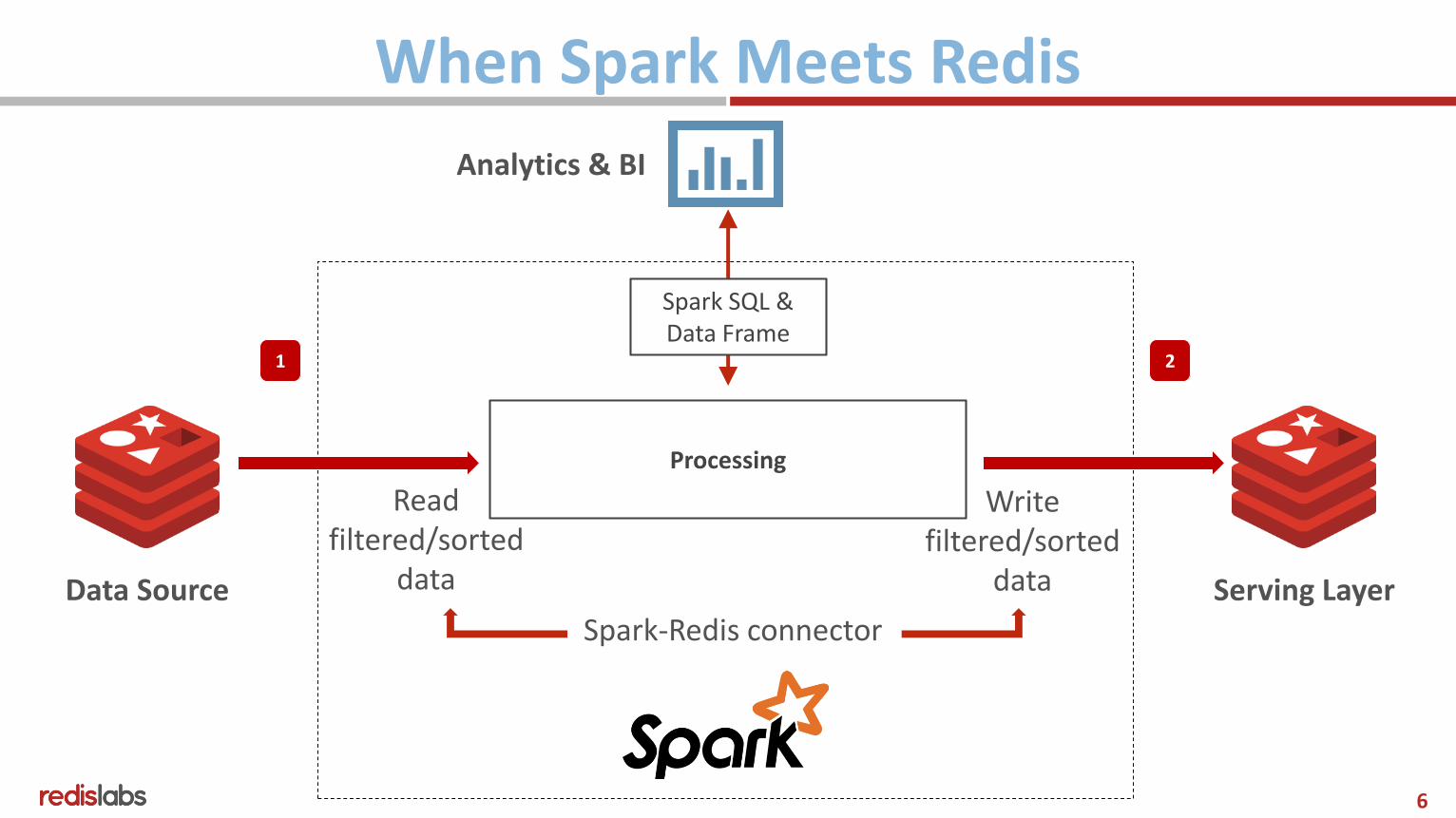
When Spark Meets Redis
Data Source Serving Layer
Analytics & BI
1 2
Processing
Spark-Redis connector
Read filtered/sorted
data
Writefiltered/sorted
data
7
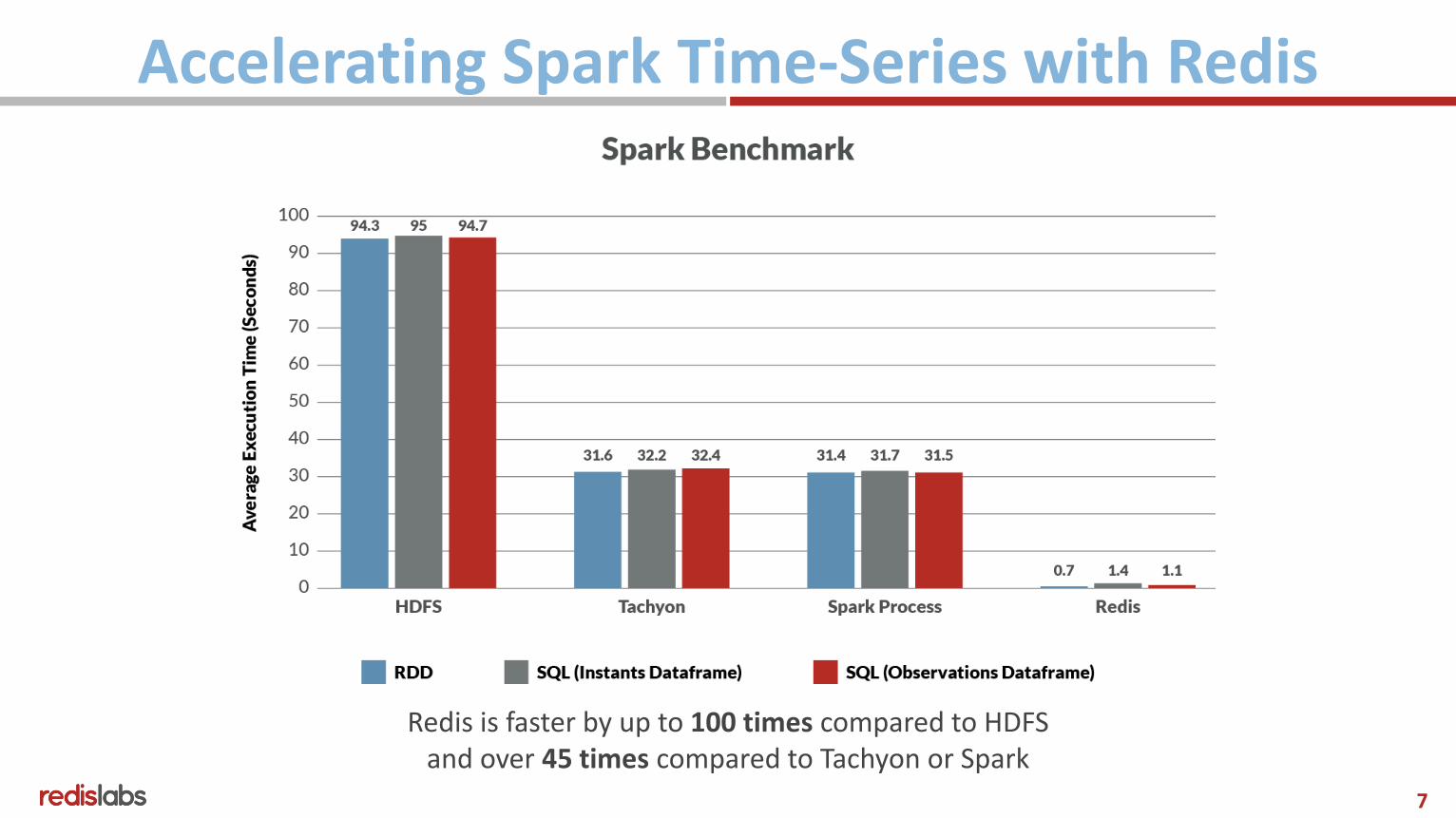
Accelerating Spark Time-Series with Redis
Redis is faster by up to 100 times compared to HDFS and over 45 times compared to Tachyon or Spark
8
Redis-ML
• A complex problem to solve
• Crowded with smart people
• Years of investment
• Tons of open source project
So Why ?
9
Machine / Deep Learning Stages
(1) Training (2) Creating a model (3) Serving the model
10
Machine / Deep Learning Stages
(1) Training (2) Creating a model (3) Serving the model
Homegrown
11
Machine / Deep Learning Stages
(1) Training (2) Creating a model (3) Serving the model

12
Accurate Model is Important
Otherwise….
The Ads serving company example:
If your model is too small, it’s not accurate; if too large, difficult to fit at app layer

13
Real World Challenge
• Ads serving company
• Need to serve 20,000 ads/sec @ 50msec data-center latency
• Runs 1k campaigns 1K random forest
• Each forest has 15K trees
• On average each tree has 7 levels (depth)
14
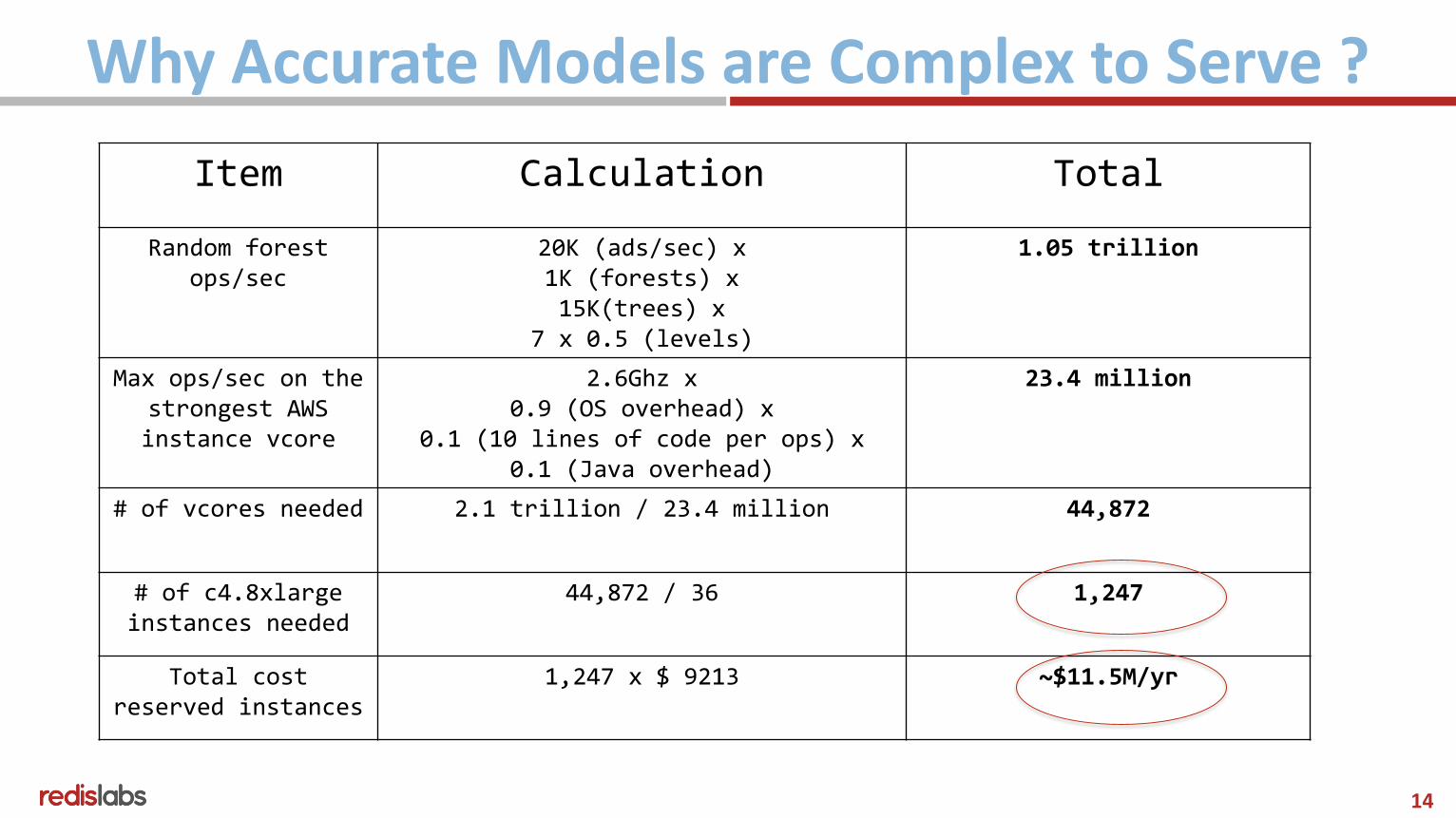
Why Accurate Models are Complex to Serve ?
Item Calculation Total
Random forest ops/sec
20K (ads/sec) x 1K (forests) x 15K(trees) x
7 x 0.5 (levels)
1.05 trillion
Max ops/sec on the strongest AWS instance vcore
2.6Ghz x 0.9 (OS overhead) x
0.1 (10 lines of code per ops) x 0.1 (Java overhead)
23.4 million
# of vcores needed 2.1 trillion / 23.4 million 44,872
# of c4.8xlarge instances needed
44,872 / 36 1,247
Total costreserved instances
1,247 x $ 9213 ~$11.5M/yr
15
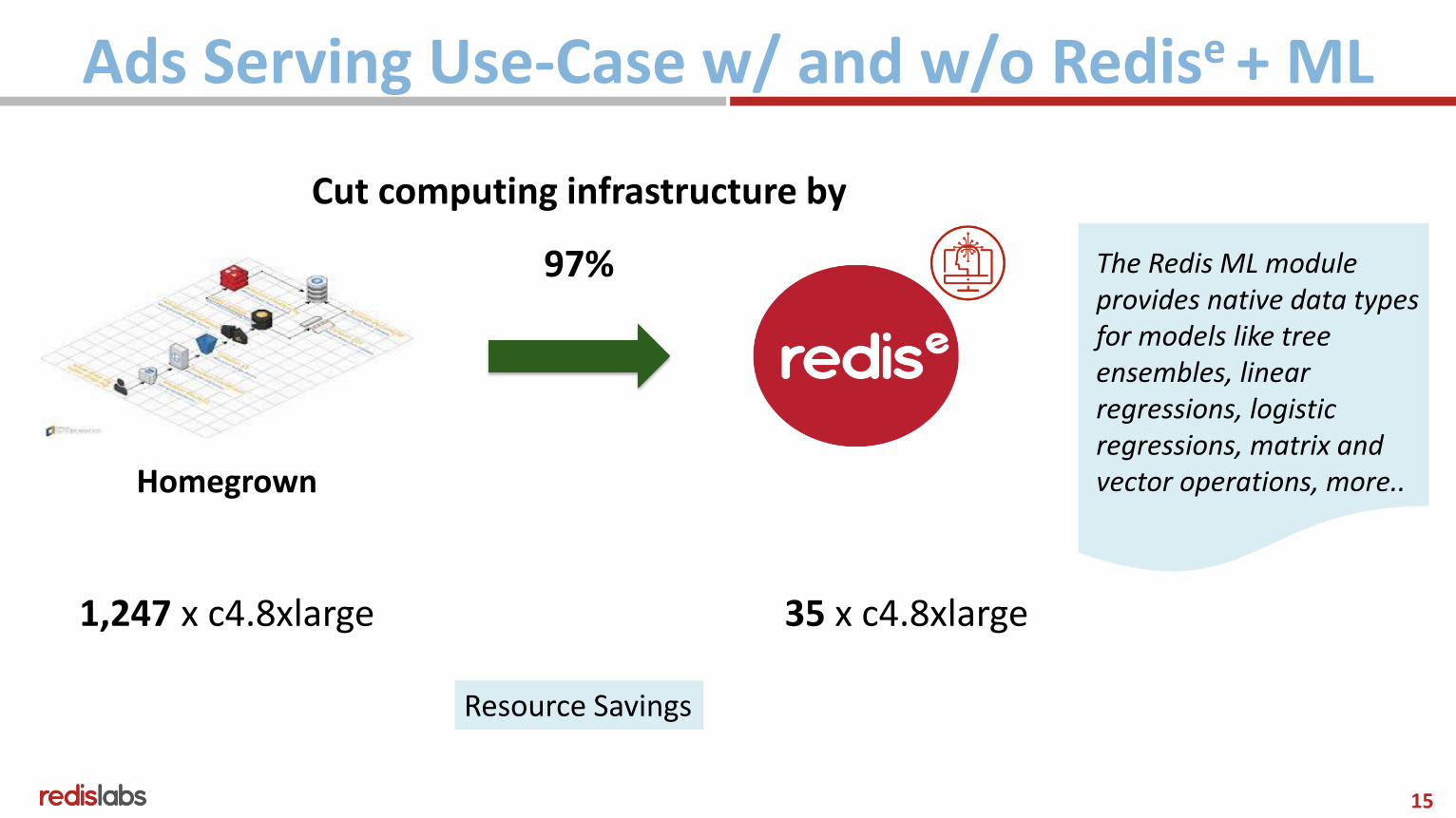
Ads Serving Use-Case w/ and w/o Redise + ML
Homegrown
1,247 x c4.8xlarge 35 x c4.8xlarge
Cut computing infrastructure by
97%
Resource Savings
The Redis ML module provides native data types for models like tree ensembles, linear regressions, logistic regressions, matrix and vector operations, more..

16
Ads Serving Use-Case w/ and w/o Redise + ML
msec msec
x2,000 Faster
Reduced Latency
Unlike training where Spark does parallel processing, serving is a serial process, so the Redis advantage increases as number of forests increase
17
Faster, resource efficient, highly
available categorization for real-
time interactive applications.
+

18
Resources
Dvir Volk : Senior Architect @Redis Labshttp://www.slideshare.net/SparkSummit/spark-summit-eu-talk-by-shay-nativ-and-dvir-volk
Getting Started with Spark and Redis:https://redislabs.com/docs/getting-started-with-spark-and-redis/
Spark ML package: https://github.com/RedisLabs/spark-redis-ml
Redis ML module: https://github.com/RedisLabsModules/redis-ml
More resources at: https://redislabs.com/solutions/use-cases/spark-and-redis/
19
RedisConf 2017






























