Embed Size (px)
Citation preview

TellMeFirst
Giuseppe Futia1, Antonio Vetrò1, Giuseppe Rizzo2
A Knowledge Domain Discovery Framework
THE HAGUE, NETHERLANDS – Feb 12th 2016
1- Nexa Center for Internet and Society, DAUIN, Politecnico di Torino 2- Istituto Superiore Mario Boella (ISMB)

Nexa Center forInternet & Society
2
Interdisciplinary Research
Digital Culture
Support to Policy
Community
http://nexa.polito.it/
@nexacenter

What is TellMeFirst and how it works
How we build a generalist training set based on DBpedia and
Wikipedia
What is a domain training set (wrt the generalist one)
How we create a domain training set using a configurable pipeline
Agenda
3

What is TellMeFirst andhow it works
4
5
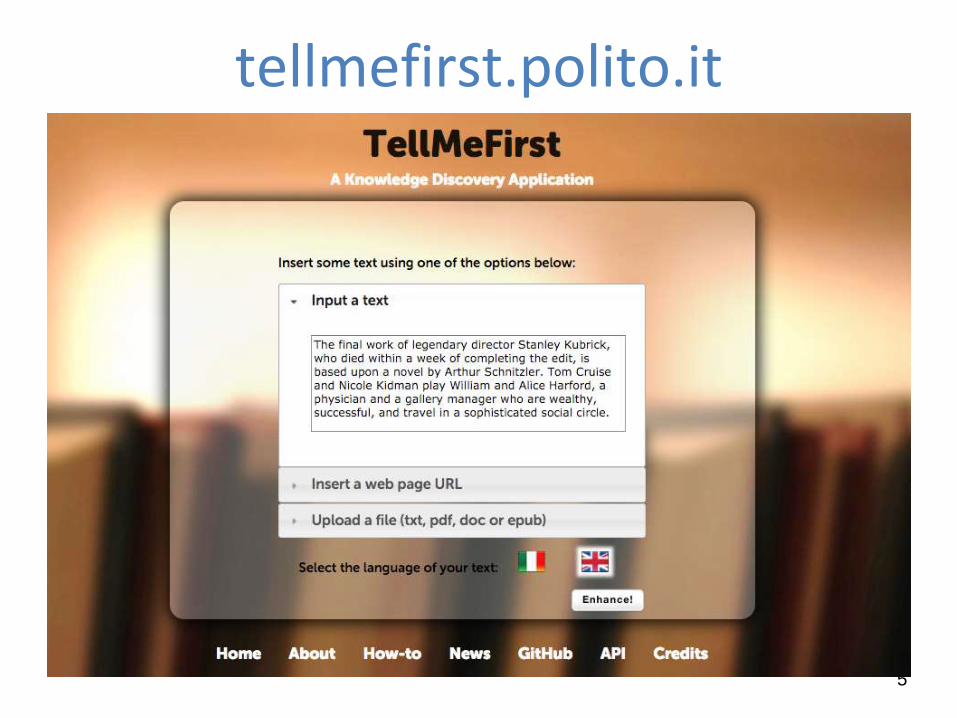
tellmefirst.polito.it
6
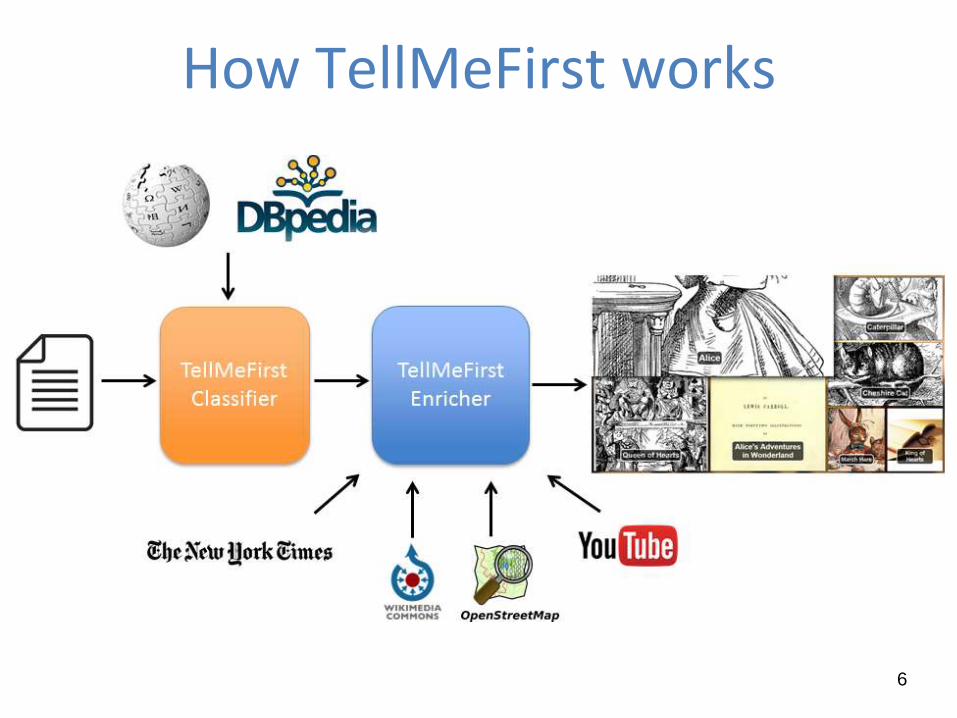
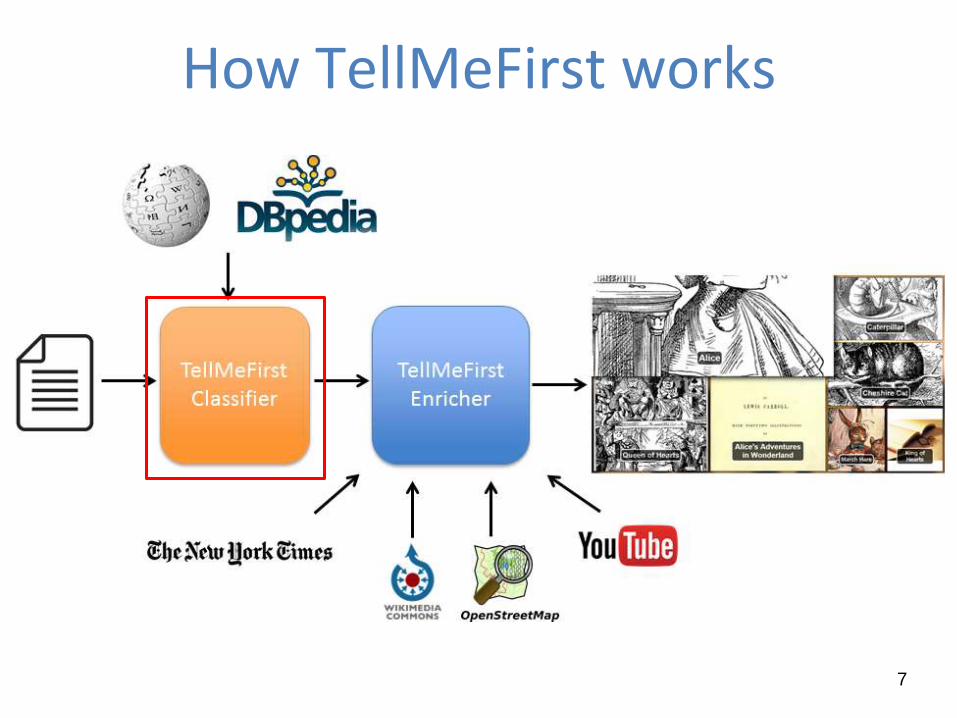
How TellMeFirst works
7
How TellMeFirst works

8
TellMeFirst Classifier
TellMeFirst exploits an approach where the training set based on
DBpedia and Wikipedia is compared with the target document
In the training set, each DBpedia entity (i.e., Barack Obama) is
represented by all the Wikipedia paragraphs in which it appears
as wikilink (http://en.wikipedia.org/wiki/Barack_Obama)
A vector distance metric is used to understand how much a
Wikipedia paragraph is similar to the target document (Mendes,
2011)

How we build a generalist training set based on DBpedia and Wikipedia
9
Traditional approach(based on DBpedia Spotlight)
10

Traditional approach(based on DBpedia Spotlight)
11
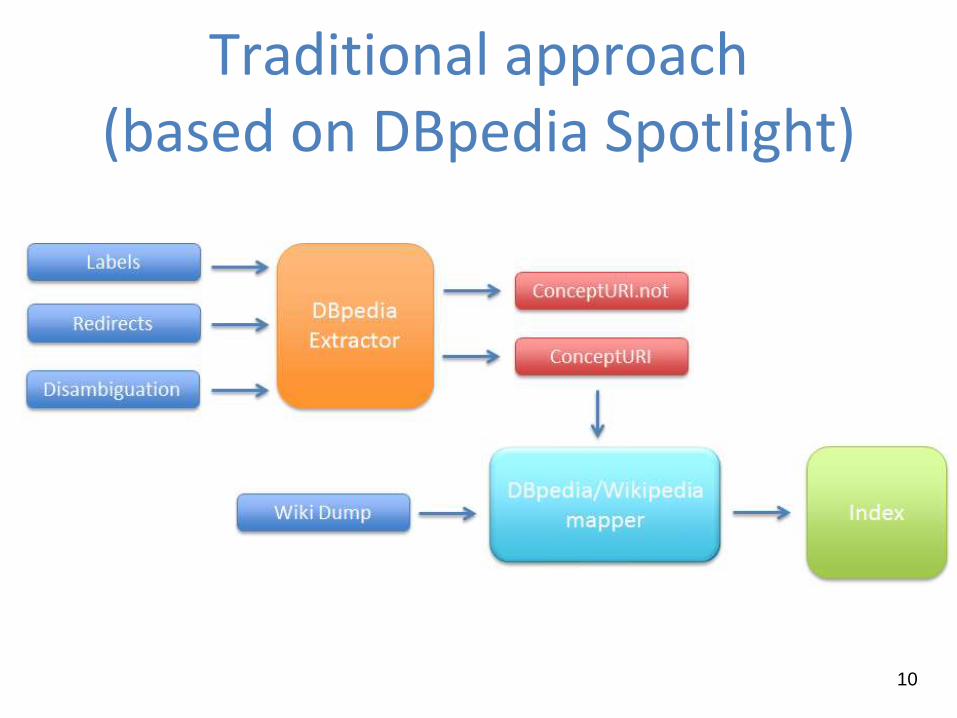
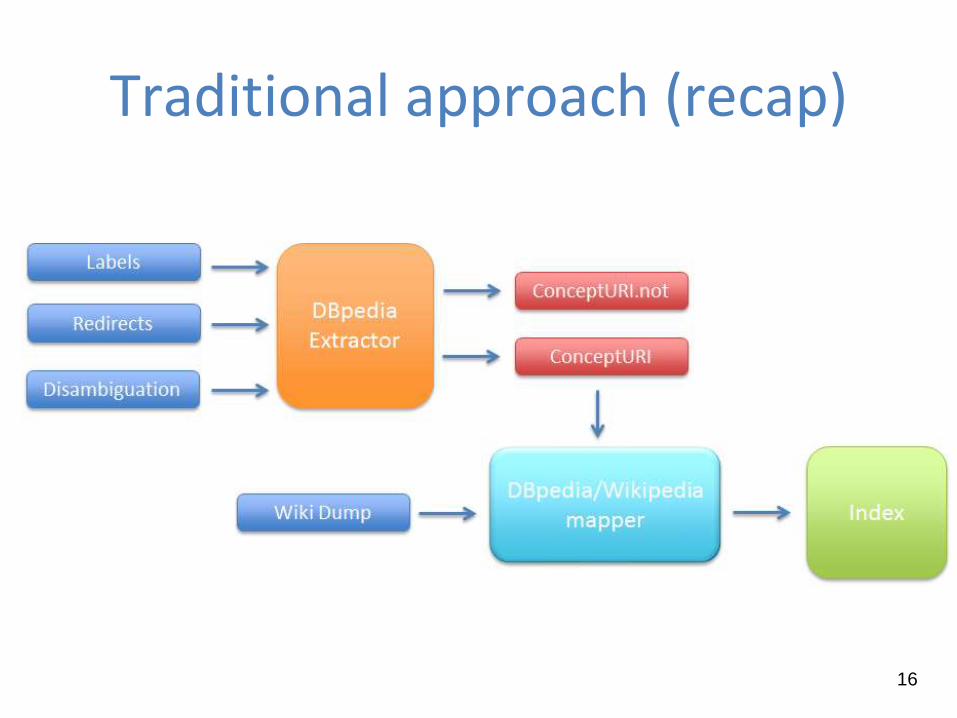
The DBpedia Extractor
It takes as input some datasets built through the DBpedia Information
Extraction Framework (such as labels, redirects, disambiguations)
The output is a list of “good” URIs that effectively represent entities
(avoiding disambiguations and redirects pages)
The DBpedia/Wikipedia Mapper
It maps “good” URIs on the dump of Wikipedia and then it creates a
Lucene Index that defines the training set

12
Training set - A Lucene Index

What is a domain training set
13

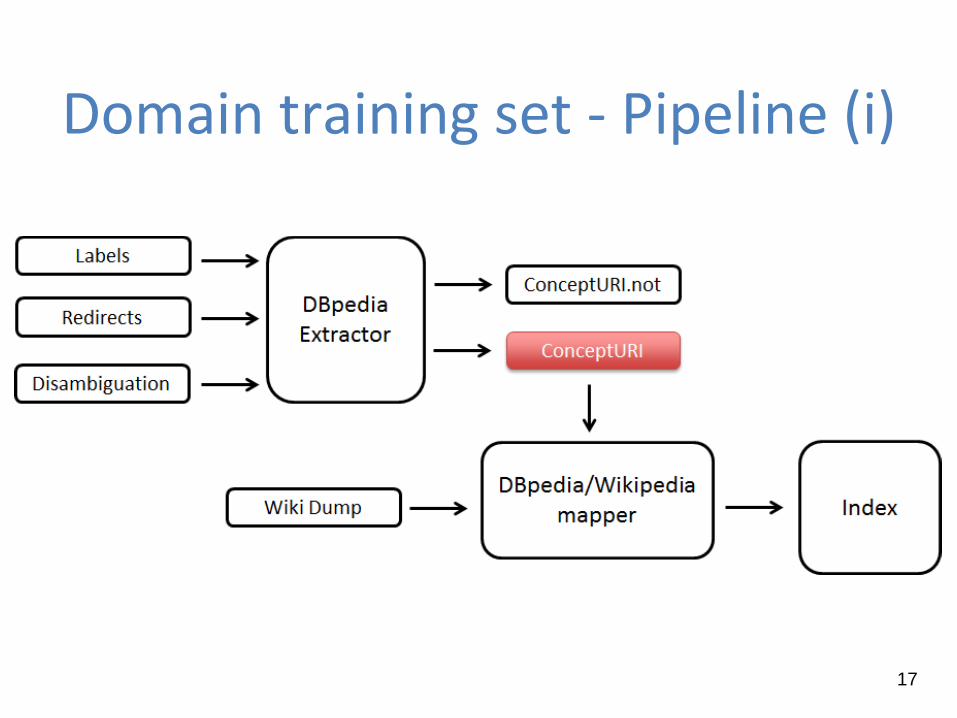
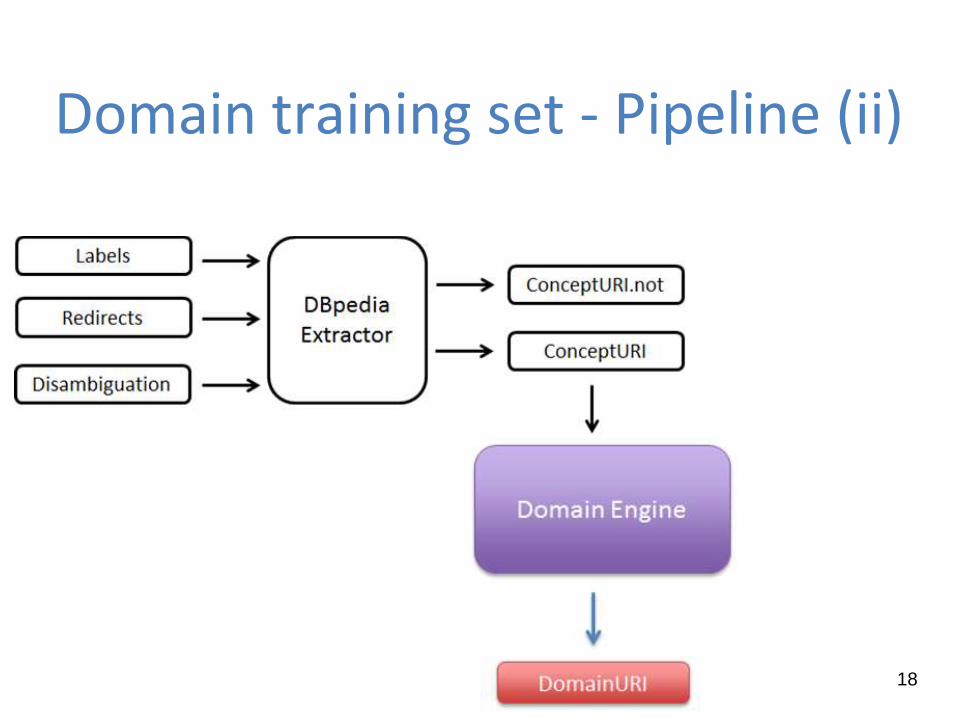
Domain training set
It contains a subset of DBpedia entities indexed in the generalist
training set
It is defined according to the domain of documents that you need
to classify
It is build through a software component properly driven by
SPARQL queries and advanced services (i.e., Linked Data
Recommenders), to create a new list of “good” URIs
14

How we build a domaintraining set using a configurable pipeline
15
Traditional approach (recap)
16
Domain training set - Pipeline (i)
17
Domain training set - Pipeline (ii)
18
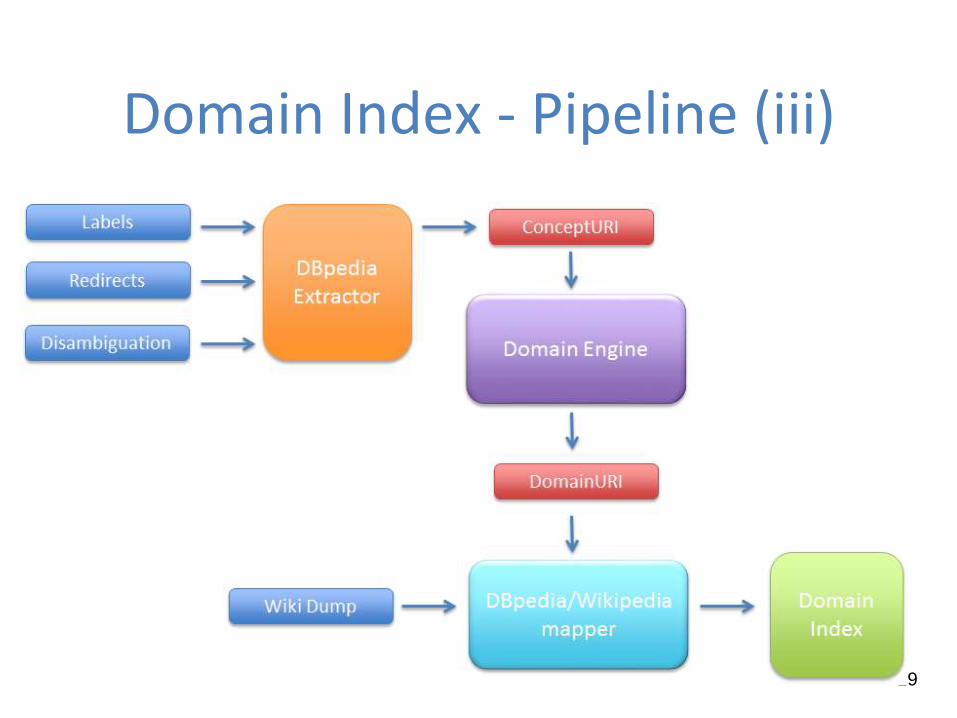
Domain Index - Pipeline (iii)
19

Domain Engine - SPARQL
20

Domain Engine - LDR
First implementation: Linked Data Recommender (LDR)
developed by the SoftEng group of the Politecnico di
Torino
Get all DBpedia categories from a DBpedia entity
Get DBpedia entities related to a specific DBpedia entity and a DBpedia
category
Pipeline: get new entities with LDR from resources
retrieved with SPARQL queries21

Example - ColosseumThe Colosseum or Coliseum (/kɒləˈsiːəm/ kol-ə-see-əm), also known as the
Flavian Amphitheatre (Latin: Amphitheatrum Flavium; Italian: Anfiteatro Flavio
[amfiteˈaːtro ˈflaːvjo] or Colosseo [kolosˈsɛːo]), is an oval amphitheatre in the
centre of the city of Rome, Italy. Built of concrete and sand, it is the largest
amphitheatre ever built and is considered one of the greatest works of
architecture and engineering ever.
The Colosseum is situated just east of the Roman Forum. Construction began
under the emperor Vespasian in 72 AD, and was completed in 80 AD under his
successor and heir Titus. Further modifications were made during the reign of
Domitian (81–96). These three emperors are known as the Flavian dynasty, and
the amphitheatre was named in Latin for its association with their family name
(Flavius).
22

Colosseum - Generalist training set
23

Colosseum - Domain training set
24

Comparison of results (i)
25
Titus, Vespasian, and Domitian are identified through the
generalist training set and are directly mentioned in the
text
Arch of Titus, Temple of Vespasian and Titus, obtained with
the domain training set, are related to emperors
mentioned in the previous point, but refer to the cultural
heritage of the Ancient Rome

Comparison of results (ii)
26
Flavian dynasty and Flavia entities are mentioned in the text,
but they are not so relevant for the cultural heritage
domain
The Great Fire of Rome is not strictly related to the entities
mentioned in the text, but it is relevant from an historical
point of view

Wrap up
27
TellMeFirst is a tool for classifying and enriching textual
documents using a training set based on DBpedia and
Wikipedia
We are capable to build a training set for TellMeFirst with a
configurable pipeline to get a subset of all DBpedia entities
Driving this configurable pipeline, we are able to create a training
set for a specific knowledge domain (such as cultural heritage)

Future developments
Define a training set for classifying scientific publications
available in Open Access
Build a GUI in order to enable domain experts to create a
domain training set, without a specific knowledge of
Linked Data framework
We are open to collaborations on TellMeFirst!
28

Acknowledgments
●Joint Open Lab of Telecom Italia
(http://www.telecomitalia.com/tit/it/innovazione/
i-luoghi-della-ricerca/joint-open-labs.html)
●Software Engineering Research Group (DAUIN),
Politecnico di Torino (http://softeng.polito.it/)
29

• Giuseppe Futia– Mail: [email protected]– Twitter: @giuseppe_futia
• Antonio Vetrò– Mail: [email protected]– Twitter: @phisaz
• Giuseppe Rizzo– Mail: [email protected]– Twitter: @giusepperizzo
Contacts

Appendix
31
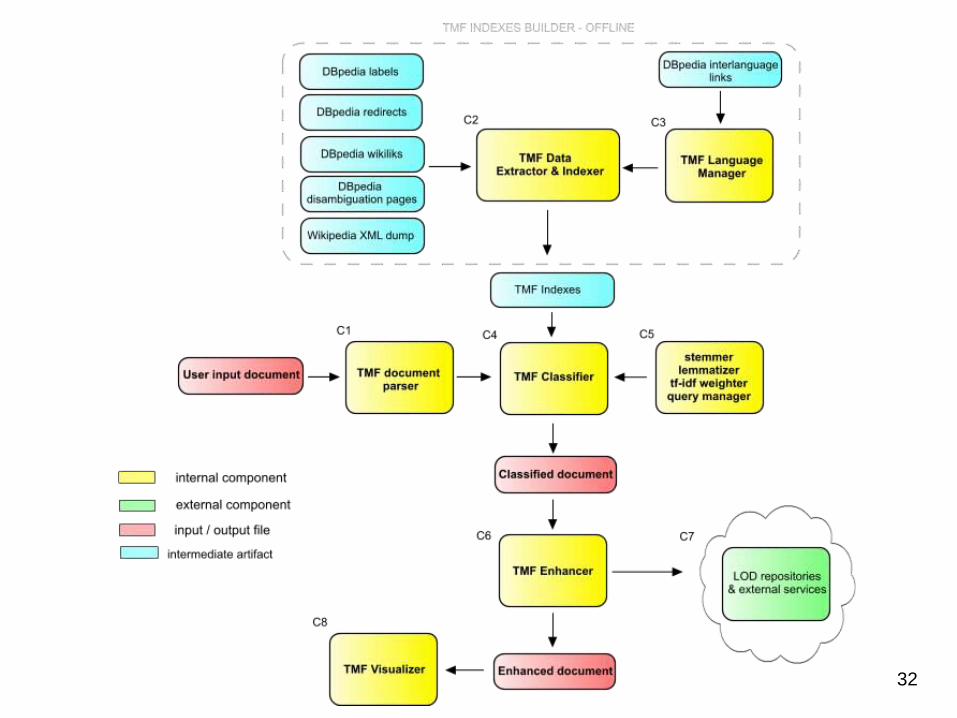
32



![Knowledge Discovery - Data Mining Methodologies – CRISP · Knowledge Discovery [Data Mining] Knowledge Discovery in Data is the non-trivial process of identifying valid novel potentially](https://img.pdfslide.net/doc/110x75/61218f60b7d6e94a816fea8c/knowledge-discovery-data-mining-methodologies-a-crisp-knowledge-discovery-data.jpg)