Embed Size (px)
Citation preview

1
Burroughs B5500 multiprocessor. These machines were designed to support HLLs, such as Algol. They used a stack architecture, but part of the stack was also addressable as registers.

2
COMP 740:COMP 740:Computer Architecture and Computer Architecture and ImplementationImplementation
Montek SinghMontek Singh
Thu, April 2, 2009Thu, April 2, 2009
Topic: Topic: Multiprocessors IMultiprocessors I
33
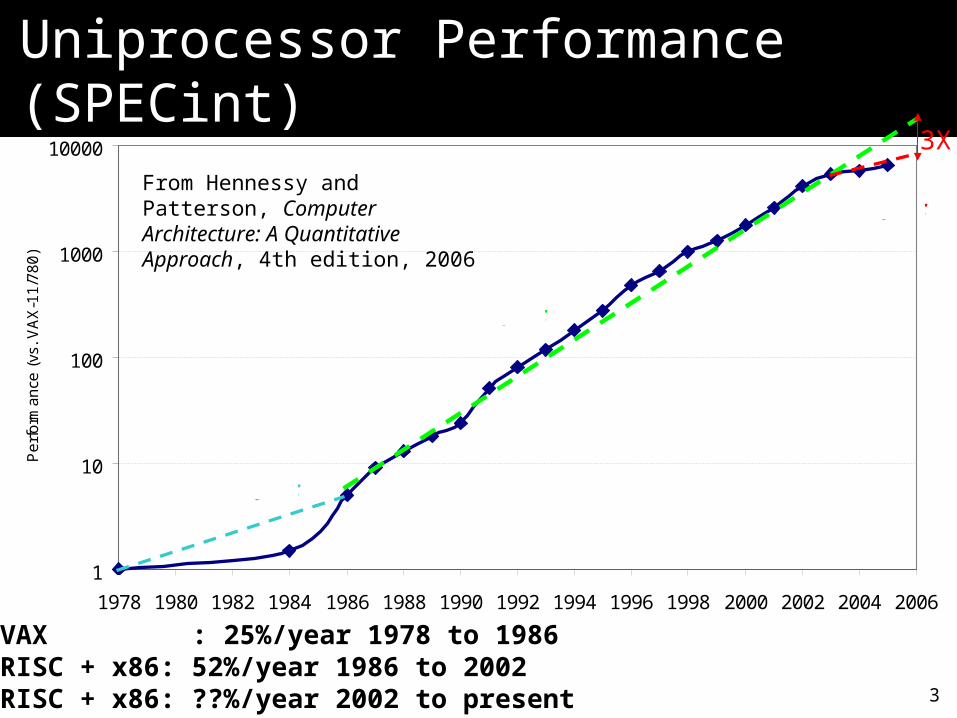
Uniprocessor Performance Uniprocessor Performance (SPECint)(SPECint)
1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
Pe
rfo
rma
nce
(vs
. V
AX
-11
/78
0)
25%/year
52%/year
??%/year
• VAX : 25%/year 1978 to 1986• RISC + x86: 52%/year 1986 to 2002• RISC + x86: ??%/year 2002 to present
From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, 2006
3X

44
Déjà vu all over again?Déjà vu all over again?“… “… today’s processors … are nearing an impasse as technologies today’s processors … are nearing an impasse as technologies
approach the speed of light..”approach the speed of light..” David Mitchell, David Mitchell, The Transputer: The Time Is NowThe Transputer: The Time Is Now ( (19891989))
Transputer had bad timing (Uniprocessor performanceTransputer had bad timing (Uniprocessor performance)) Procrastination rewarded: 2X seq. perf. / 1.5 years Procrastination rewarded: 2X seq. perf. / 1.5 years
““We are dedicating all of our future product development to We are dedicating all of our future product development to multicore designs. … This is a sea change in computing”multicore designs. … This is a sea change in computing”
Paul Otellini, President, Intel (Paul Otellini, President, Intel (20052005) ) All microprocessor companies switch to MP (2X CPUs / 2 yrs)All microprocessor companies switch to MP (2X CPUs / 2 yrs)
Procrastination penalized: 2X sequential perf. / 5 yrs Procrastination penalized: 2X sequential perf. / 5 yrs
Manufacturer/YearManufacturer/Year AMD/’05AMD/’05 Intel/’06Intel/’06 IBM/’04IBM/’04 Sun/’05Sun/’05
Processors/chipProcessors/chip 22 22 22 88Threads/ProcessorThreads/Processor 11 22 22 44
Threads/chipThreads/chip 22 44 44 3232
55
Other Factors Other Factors Multiprocessors Multiprocessors Growth in data-intensive applicationsGrowth in data-intensive applications
Data bases, file servers, … Data bases, file servers, … Growing interest in servers, server perf.Growing interest in servers, server perf. Increasing desktop perf. less important Increasing desktop perf. less important
Outside of graphicsOutside of graphics Improved understanding in how to use Improved understanding in how to use
multiprocessors effectively multiprocessors effectively Especially server where significant natural TLPEspecially server where significant natural TLP
Advantage of leveraging design investment by Advantage of leveraging design investment by replication replication Rather than unique designRather than unique design

66
Flynn’s TaxonomyFlynn’s Taxonomy Flynn classified by data and control in 1966Flynn classified by data and control in 1966
SIMD SIMD Data Level Parallelism Data Level Parallelism MIMD MIMD Thread Level Parallelism Thread Level Parallelism MIMD popular because MIMD popular because
Flexible: N pgms and 1 multithreaded pgmFlexible: N pgms and 1 multithreaded pgm Cost-effective: same MPU in desktop & MIMDCost-effective: same MPU in desktop & MIMD
Single Instruction Single Single Instruction Single Data (SISD)Data (SISD)
(Uniprocessor)(Uniprocessor)
Single Instruction Multiple Single Instruction Multiple Data Data SIMDSIMD
(single PC: Vector, CM-2)(single PC: Vector, CM-2)
Multiple Instruction Single Multiple Instruction Single Data (MISD)Data (MISD)
(????)(????)
Multiple Instruction Multiple Instruction Multiple Data Multiple Data MIMDMIMD
(Clusters, SMP servers)(Clusters, SMP servers)
M.J. Flynn, "Very High-Speed Computers", Proc. of the IEEE, V 54, 1900-1909, Dec. 1966.

77
Back to BasicsBack to Basics Parallel Architecture = Computer Architecture Parallel Architecture = Computer Architecture
+ Communication Architecture+ Communication Architecture
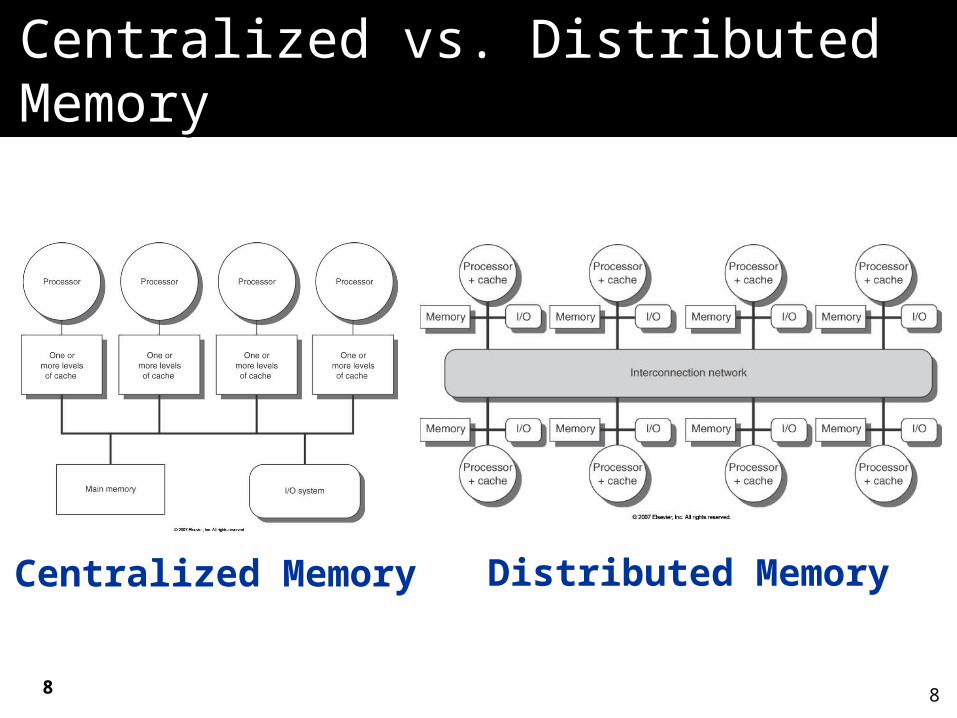
2 classes of multiprocessors WRT memory:2 classes of multiprocessors WRT memory:1.1. Centralized Memory Multiprocessor Centralized Memory Multiprocessor
< few dozen processor chips (and < 100 cores) in 2006< few dozen processor chips (and < 100 cores) in 2006 Small enough to share single, centralized memorySmall enough to share single, centralized memory
2.2. Physically Distributed-Memory multiprocessorPhysically Distributed-Memory multiprocessor Larger number chips and cores than 1.Larger number chips and cores than 1. BW demands BW demands Memory distributed among processors Memory distributed among processors
88
Centralized vs. Distributed Centralized vs. Distributed MemoryMemory
Centralized Memory Distributed Memory

99
Centralized Memory Centralized Memory Multiprocessor Multiprocessor Also called symmetric multiprocessors (SMPs)Also called symmetric multiprocessors (SMPs)
because single main memory has a symmetric because single main memory has a symmetric relationship to all processorsrelationship to all processors
Large caches and single memory can satisfy Large caches and single memory can satisfy memory demands of small number of memory demands of small number of processorsprocessors Can scale to a few dozen processors by using a switch Can scale to a few dozen processors by using a switch
instead of bus, and many memory banksinstead of bus, and many memory banks Although scaling beyond that is technically Although scaling beyond that is technically
conceivable, it becomes less attractive as the number conceivable, it becomes less attractive as the number of processors sharing centralized memory increasesof processors sharing centralized memory increases

1010
Distributed Memory Distributed Memory Multiprocessor Multiprocessor Pros:Pros:
Cost-effective way to scale memory bandwidth Cost-effective way to scale memory bandwidth If most accesses are to local memoryIf most accesses are to local memory
Reduces latency of local memory accessesReduces latency of local memory accesses
Cons:Cons: Communicating data between processors more Communicating data between processors more
complexcomplex Must change software to take advantage of increased Must change software to take advantage of increased
memory BWmemory BW

1111
2 Models for Comm and Mem 2 Models for Comm and Mem ArchArch1.1. Communication occurs explicitlyCommunication occurs explicitly
by passing messages among the processors: by passing messages among the processors: message-passing multiprocessorsmessage-passing multiprocessors
2.2. Communication occurs implicitlyCommunication occurs implicitly through a shared address space (via loads and through a shared address space (via loads and
stores): stores): shared memory multiprocessorsshared memory multiprocessors Either:Either:
UMA (Uniform Memory Access time) for shared address, UMA (Uniform Memory Access time) for shared address, centralized memory MPcentralized memory MP
NUMA (Non Uniform Memory Access time multiprocessor) NUMA (Non Uniform Memory Access time multiprocessor) for shared address, distributed memory MPfor shared address, distributed memory MP
Note: In past, confusion whether “sharing” means Note: In past, confusion whether “sharing” means sharing physical memory (Symmetric MP) or sharing sharing physical memory (Symmetric MP) or sharing address spaceaddress space
1212
Challenges of Parallel ProcessingChallenges of Parallel Processing First challenge is Amdahl’s Law:First challenge is Amdahl’s Law:
what % of program inherently sequential?what % of program inherently sequential?
Suppose 80X speedup from 100 processors. What Suppose 80X speedup from 100 processors. What fraction of original program can be sequential?fraction of original program can be sequential?
a. 10%a. 10%b. 5%b. 5%c. 1%c. 1%d. <1%d. <1%

1414
Challenges of Parallel ProcessingChallenges of Parallel Processing Second challenge: long latency to remote Second challenge: long latency to remote
memorymemory Suppose 32 CPU MP, 2GHz, 200 ns remote memory, Suppose 32 CPU MP, 2GHz, 200 ns remote memory,
all local accesses hit memory hierarchy and base CPI all local accesses hit memory hierarchy and base CPI is 0.5. (Remote access = 200/0.5 = 400 clock cycles.)is 0.5. (Remote access = 200/0.5 = 400 clock cycles.)
What is performance impact if 0.2% instructions What is performance impact if 0.2% instructions involve remote access?involve remote access?a. 1.5Xa. 1.5Xb. 2.0Xb. 2.0Xc. 2.5Xc. 2.5X

1616
Challenges of Parallel ProcessingChallenges of Parallel Processing1.1. Application parallelism – primarily via new Application parallelism – primarily via new
algorithms that have better parallel algorithms that have better parallel performanceperformance
2.2. Long remote latency impactLong remote latency impact For example, reduce frequency of remote accesses For example, reduce frequency of remote accesses
either by either by Caching shared data (HW) Caching shared data (HW) Restructuring the data layout to make more accesses Restructuring the data layout to make more accesses
local (SW)local (SW) We’ll look at reducing latency via cachesWe’ll look at reducing latency via caches

1717
T1 (“Niagara”)T1 (“Niagara”) Target: Commercial server applicationsTarget: Commercial server applications
High thread level parallelism (TLP)High thread level parallelism (TLP)Large numbers of parallel client requestsLarge numbers of parallel client requests
Low instruction level parallelism (ILP)Low instruction level parallelism (ILP)High cache miss ratesHigh cache miss ratesMany unpredictable branchesMany unpredictable branchesFrequent load-load dependenciesFrequent load-load dependencies
Power, cooling, and space arePower, cooling, and space aremajor concerns for data centersmajor concerns for data centers
Metric: Performance/Watt/Sq. Ft.Metric: Performance/Watt/Sq. Ft. Approach: Multicore, Fine-grain Approach: Multicore, Fine-grain
multithreading, Simple pipeline, Small L1 multithreading, Simple pipeline, Small L1 caches, Shared L2caches, Shared L2
1818
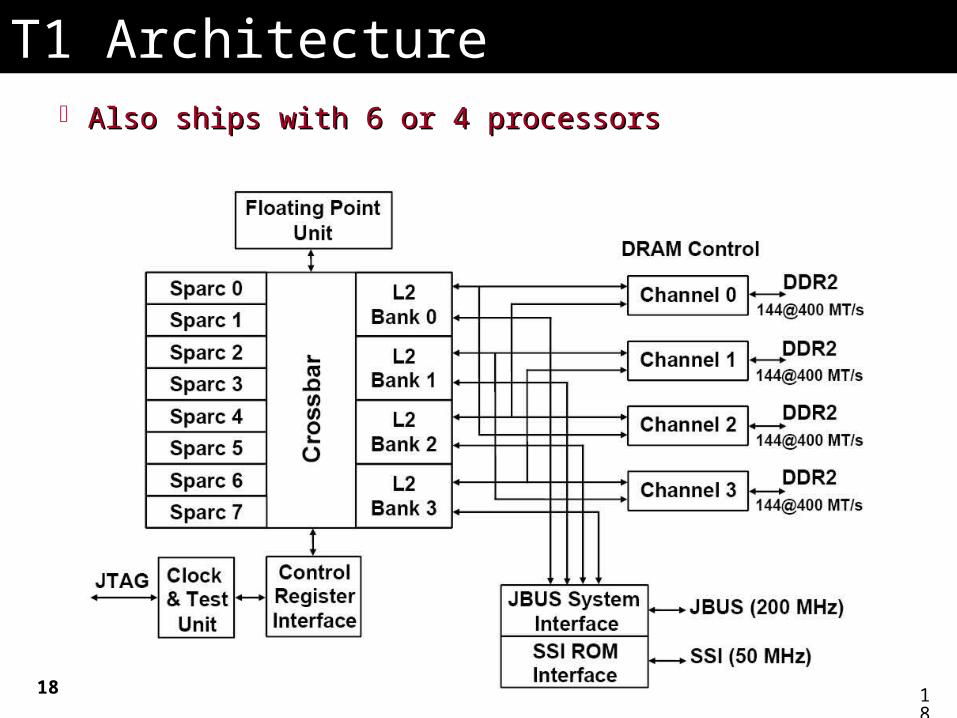
T1 ArchitectureT1 Architecture Also ships with 6 or 4 processorsAlso ships with 6 or 4 processors
1919
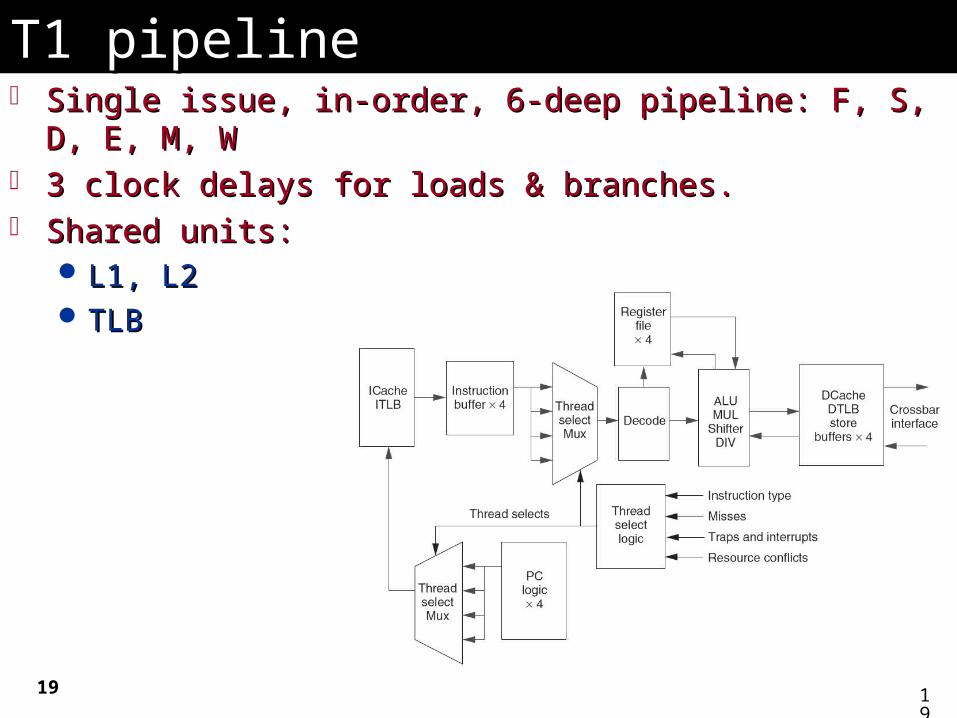
T1 pipelineT1 pipeline Single issue, in-order, 6-deep pipeline: F, S, D, E, M, W Single issue, in-order, 6-deep pipeline: F, S, D, E, M, W 3 clock delays for loads & branches.3 clock delays for loads & branches. Shared units: Shared units:
L1, L2L1, L2 TLB TLB

2020
T1 Fine-Grained MultithreadingT1 Fine-Grained Multithreading Each core:Each core:
supports four threadssupports four threads has its own level one caches (16KB instr and 8 KB has its own level one caches (16KB instr and 8 KB
data)data) Switches to a new thread on each clock cycle Switches to a new thread on each clock cycle
Idle threads are bypassed in the scheduling Idle threads are bypassed in the scheduling – Waiting due to a pipeline delay or cache missWaiting due to a pipeline delay or cache miss
Processor is idle only when all 4 threads are idle or stalled Processor is idle only when all 4 threads are idle or stalled Both loads and branches incur a 3 cycle delay that Both loads and branches incur a 3 cycle delay that
can only be hidden by other threads can only be hidden by other threads
A single set of floating point functional units is A single set of floating point functional units is shared by all 8 coresshared by all 8 cores floating point performance not focus for T1floating point performance not focus for T1

2121
ConclusionConclusion Parallelism challenges: % parallelizable, long Parallelism challenges: % parallelizable, long
latency to remote memorylatency to remote memory Centralized vs. distributed memoryCentralized vs. distributed memory
Small MP vs. lower latency, larger BW for Larger MPSmall MP vs. lower latency, larger BW for Larger MP
Message Passing vs. Shared AddressMessage Passing vs. Shared Address Uniform access time vs. Non-uniform access timeUniform access time vs. Non-uniform access time
Cache criticalCache critical
Next:Next: Review of caching (App. C)Review of caching (App. C) Methods to ensure cache consistency in SMPsMethods to ensure cache consistency in SMPs