Embed Size (px)
Citation preview

1
CS143: Index

2
Topics to Learn
• Important concepts– Dense index vs. sparse index– Primary index vs. secondary index
(= clustering index vs. non-clustering index)– Tree-based vs. hash-based index
• Tree-based index– Indexed sequential file– B+-tree
• Hash-based index– Static hashing– Extendible hashing
3
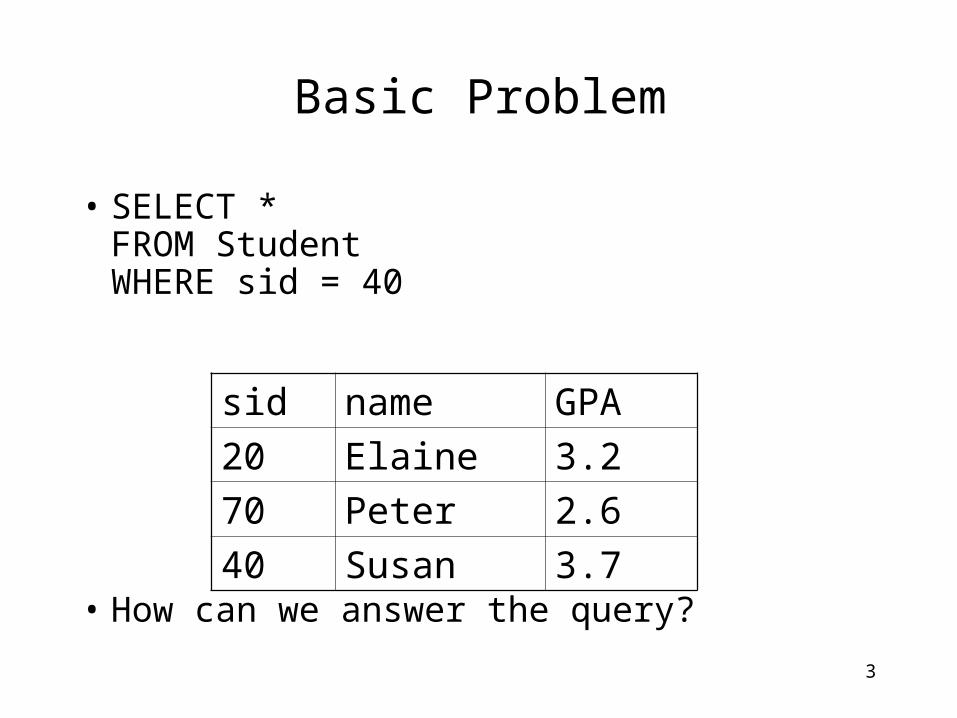
Basic Problem
• SELECT *FROM StudentWHERE sid = 40
• How can we answer the query?
sid name GPA
20 Elaine 3.2
70 Peter 2.6
40 Susan 3.7
4
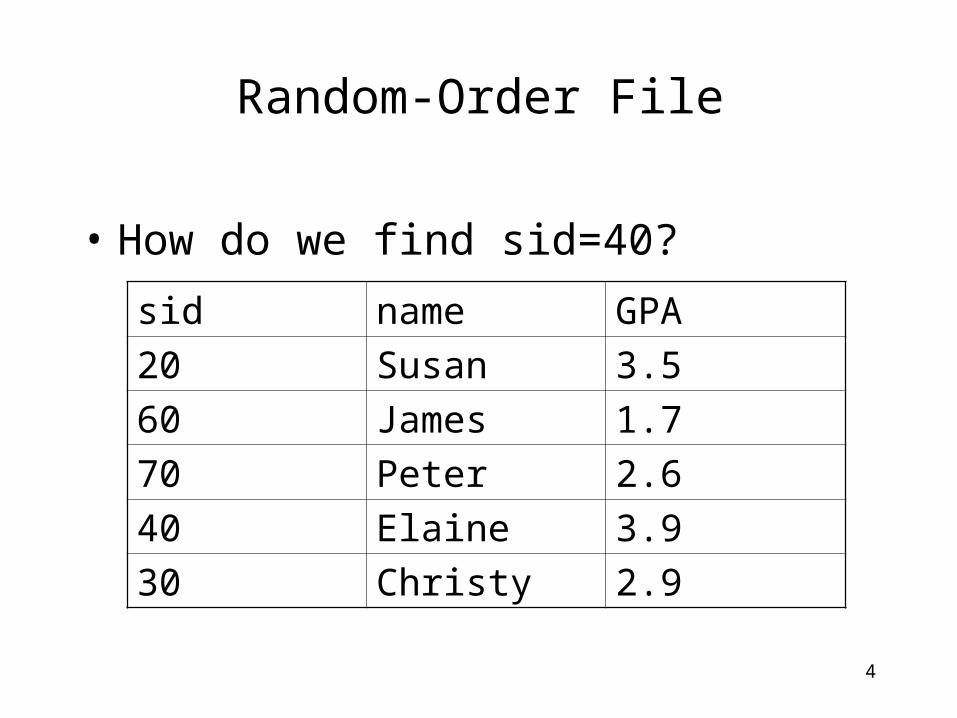
Random-Order File
• How do we find sid=40?
sid name GPA
20 Susan 3.5
60 James 1.7
70 Peter 2.6
40 Elaine 3.9
30 Christy 2.9
5
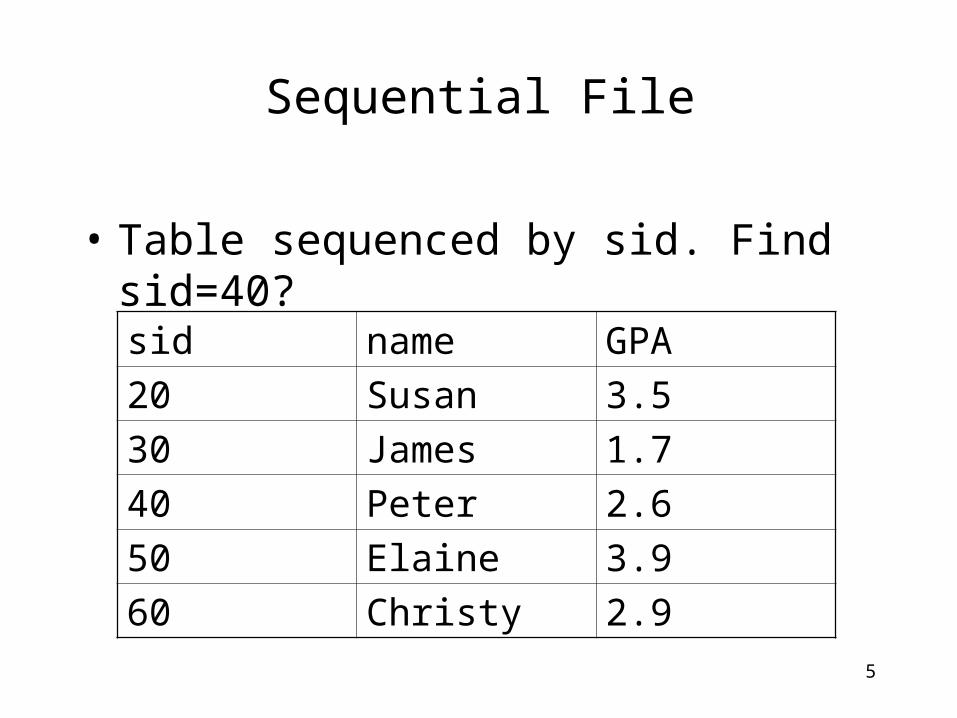
Sequential File
• Table sequenced by sid. Find sid=40?sid name GPA
20 Susan 3.5
30 James 1.7
40 Peter 2.6
50 Elaine 3.9
60 Christy 2.9

6
Binary Search
• 100,000 records• Q: How many blocks to read?
• Any better way?– In a library, how do we find a book?
7
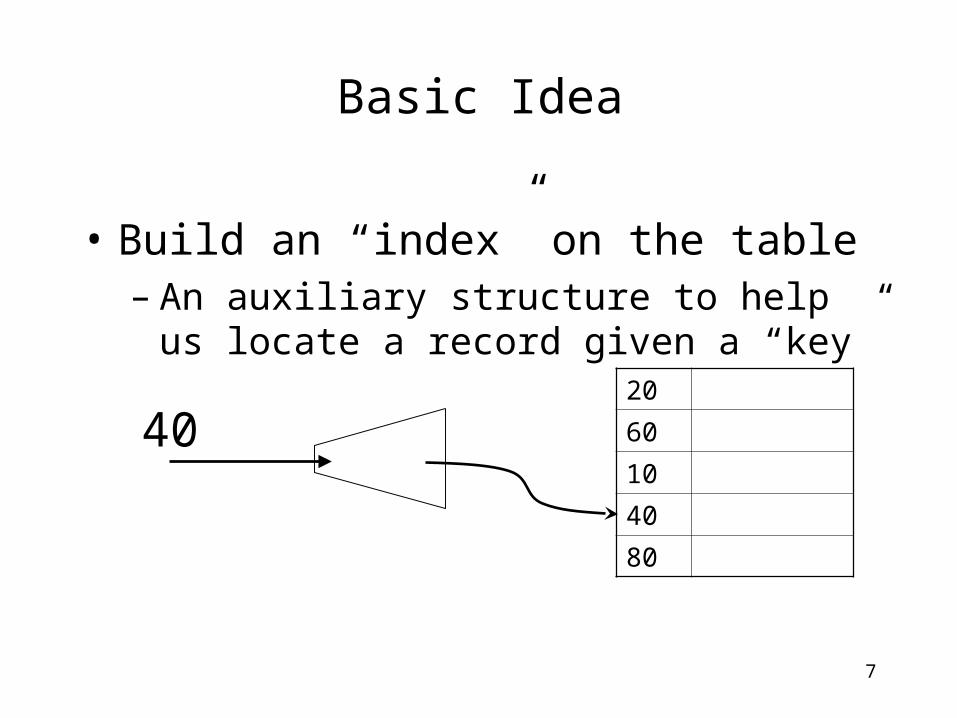
Basic Idea
• Build an “index” on the table– An auxiliary structure to help us
locate a record given a “key”20
60
10
40
80
40

8
Dense, Primary Index
• Primary index (clustering index)– Index on the search key
• Dense index– (key, pointer) pair for every
record
• Find the key from index and follow pointer– Maybe through binary search
• Q: Why dense index?– Isn’t binary search on the file
the same?
2010
4030
6050
8070
10090
Dense Index
10203040
50607080
90100110120
Sequential File

9
Why Dense Index?
• Example– 10,000,000 records (900-bytes/rec)– 4-byte search key, 4-byte pointer– 4096-byte block. Unspanned tuples
• Q: How many blocks for table (how big)?
• Q: How many blocks for index (how big)?

10
Sparse, Primary Index
• Sparse index– (key, pointer) pair per
every “block”– (key, pointer) pair points
to the first record in the block
• Q: How can we find 60?
Sequential File
2010
4030
6050
8070
10090
Sparse Index
10305070
90110130150

11
Multi-level index
Sequential File
2010
4030
6050
8070
10090
Sparse 2nd level10305070
90110130150
170190210230
1090
170250
330410490570
1st level
Q: Why multi-level index?
Q: Does dense, 2nd level index make sense?

12
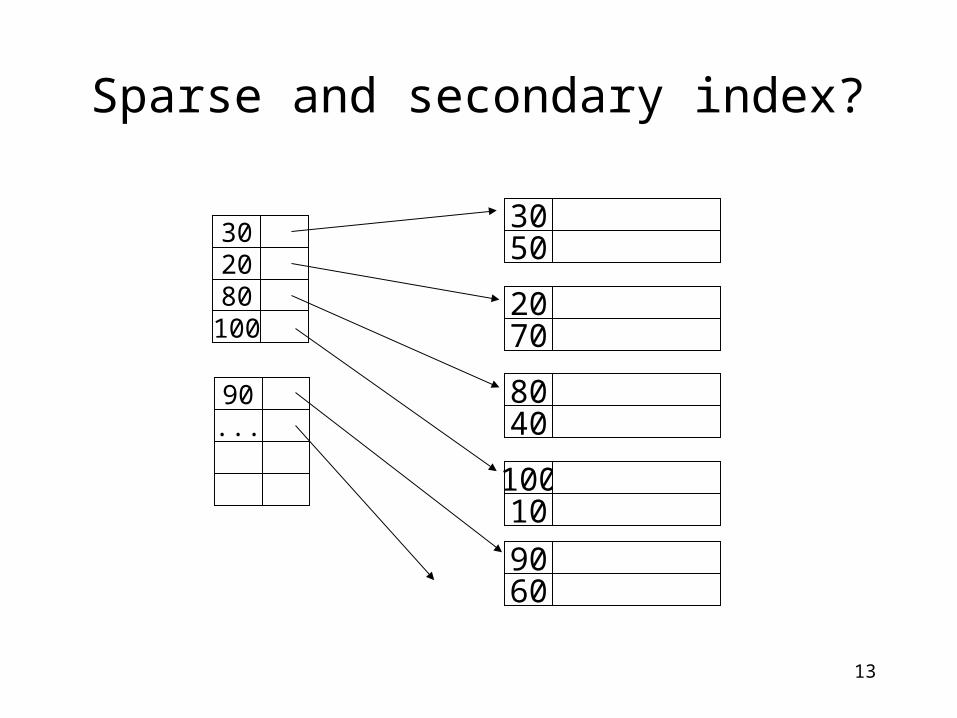
Secondary (non-clustering) Index
• Secondary (non-clustering) index– When tuples in the table
are not ordered by the index search key
• Index on a non-search-key for sequential file
• Unordered file
• Q: What index?– Does sparse index make
sense?
Sequencefield
5030
7020
4080
10100
6090
13
Sparse and secondary index?
5030
7020
4080
10100
6090
302080
100
90...
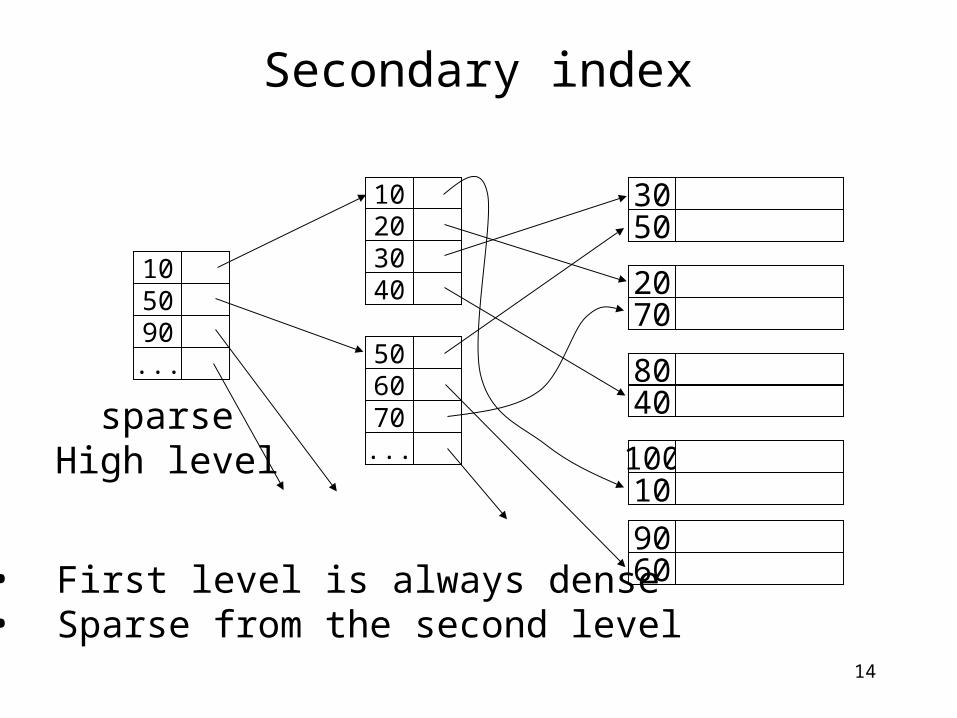
14
Secondary index
5030
7020
4080
10100
6090
10203040
506070...
105090...
sparseHigh level
• First level is always dense• Sparse from the second level

15
Important terms• Dense index vs. sparse index• Primary index vs. secondary index
– Clustering index vs. non-clustering index
• Multi-level index• Indexed sequential file
– Sometimes called ISAM (indexed sequential access method)
• Search key ( primary key)
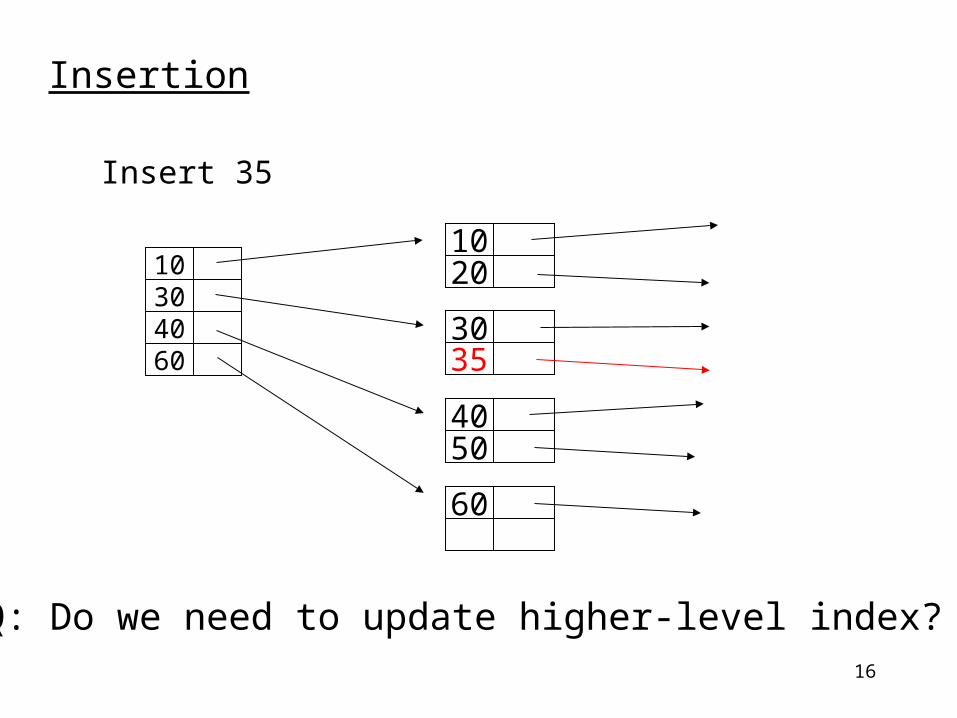
16
Insertion
2010
30
5040
60
10304060
Insert 35
Q: Do we need to update higher-level index?
35
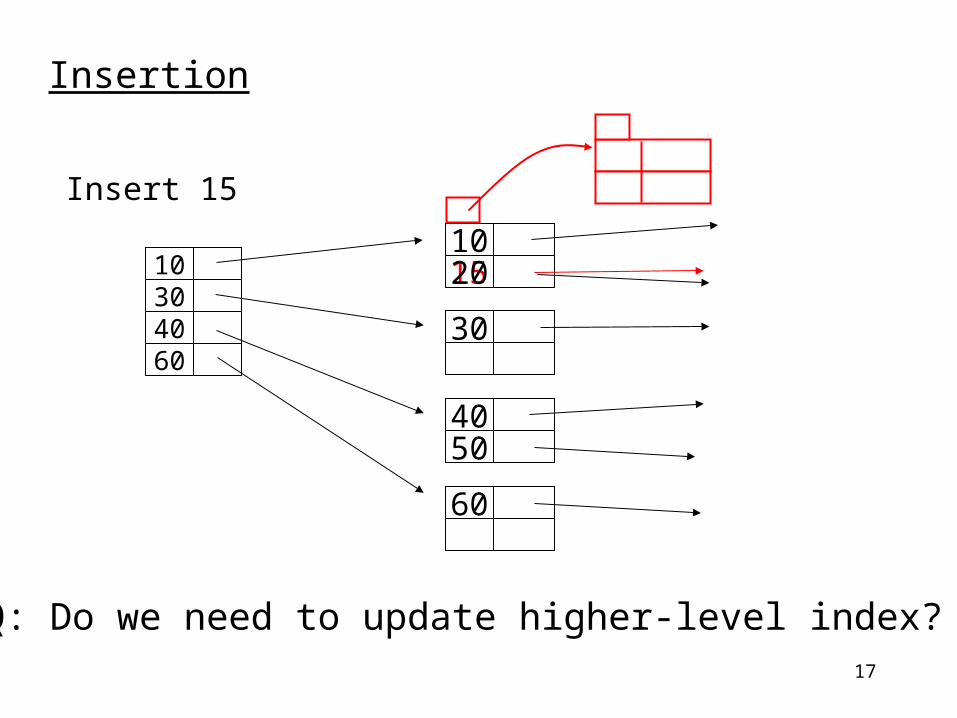
17
Insertion
10
30
5040
60
10304060
Insert 15
Q: Do we need to update higher-level index?
1520
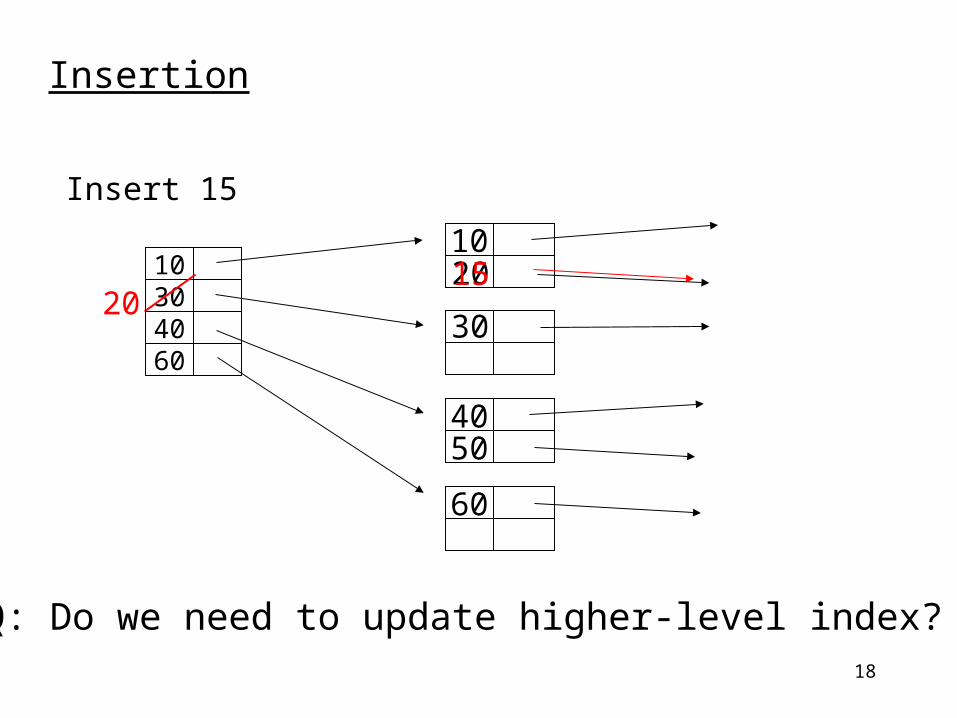
18
Insertion
10
5040
60
10304060
Q: Do we need to update higher-level index?
2020
30
15
Insert 15
19
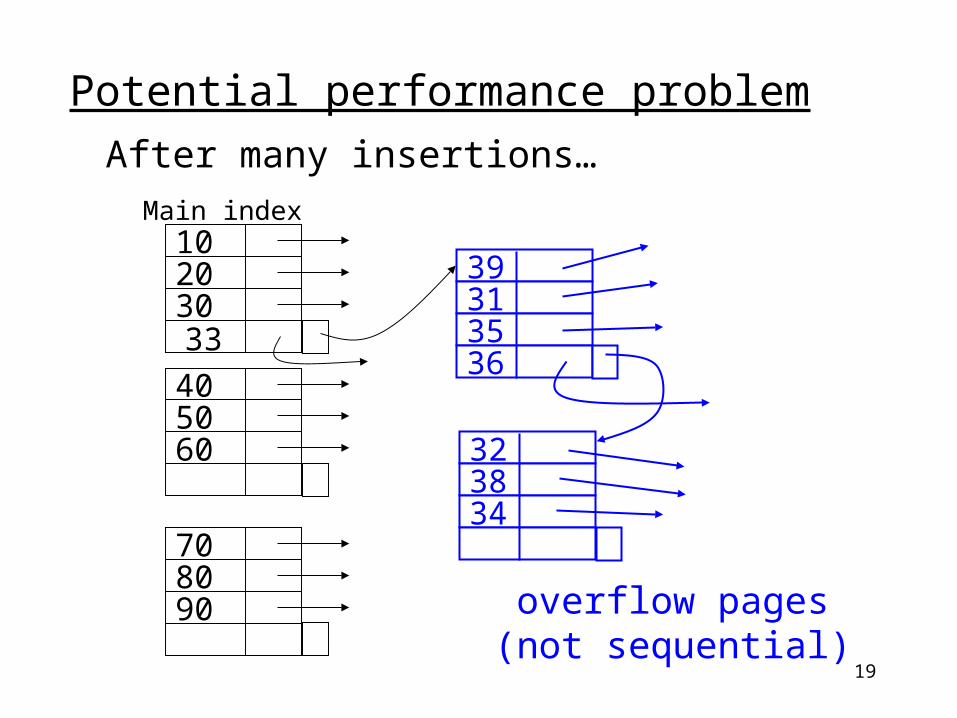
Potential performance problemAfter many insertions…
102030
405060
708090
39313536
323834
33
overflow pages(not sequential)
Main index

20
Traditional Index (ISAM)
• Advantage– Simple– Sequential blocks
• Disadvantage– Not suitable for updates– Becomes ugly (loses sequentiality and
balance) over time

21
B+Tree
• Most popular index structure in RDBMS
• Advantage– Suitable for dynamic updates– Balanced– Minimum space usage guarantee
• Disadvantage– Non-sequential index blocks
22
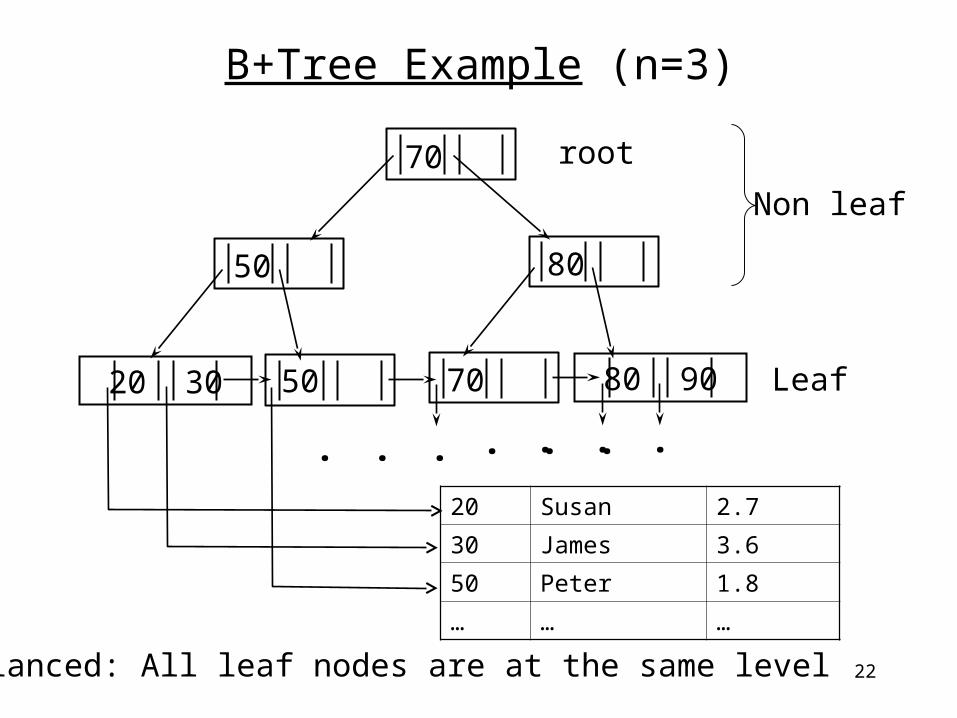
B+Tree Example (n=3)
20 30 50 80 90 70
50 80
70
Leaf
Non leaf
root
20 Susan 2.7
30 James 3.6
50 Peter 1.8
… … …
...
......
Balanced: All leaf nodes are at the same level

23
• n: max # of pointers in a node• All pointers (except the last one) point to tuples • At least half of the pointers are used. (more precisely, (n+1)/2 pointers)
Sample Leaf Node (n=3)
20 30
From a non-leaf node
Last pointer: to the next leaf node
20 Susan 2.7
30 James 3.6
50 Peter 1.8
… … …
points to tuple
24
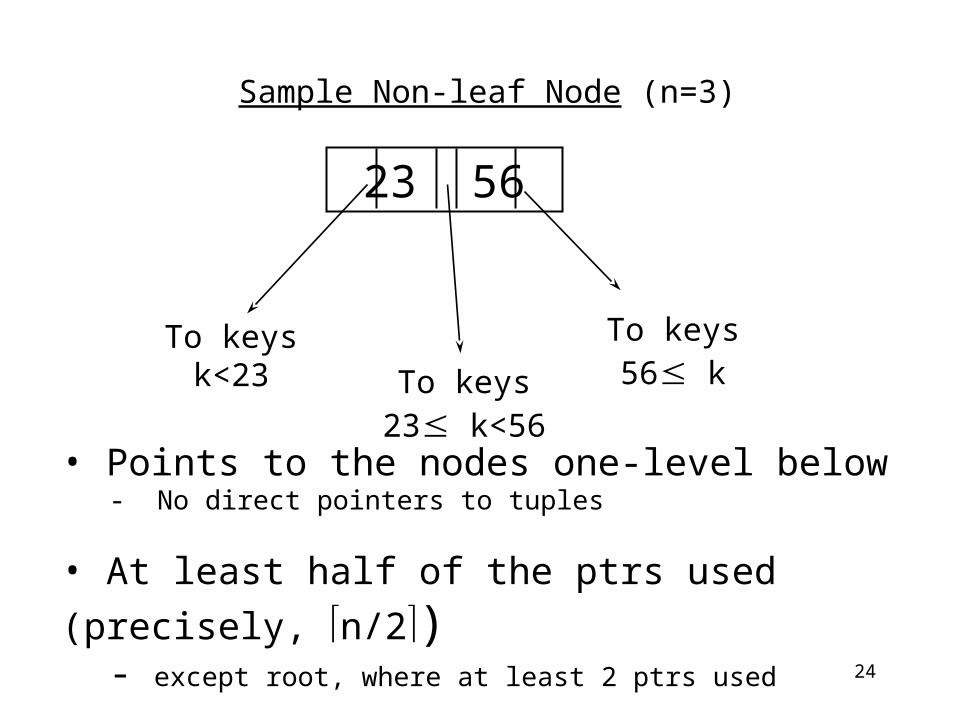
• Points to the nodes one-level below- No direct pointers to tuples
• At least half of the ptrs used (precisely, n/2)- except root, where at least 2 ptrs used
Sample Non-leaf Node (n=3)
23 56
To keys23 k<56
To keys56 k
To keysk<23
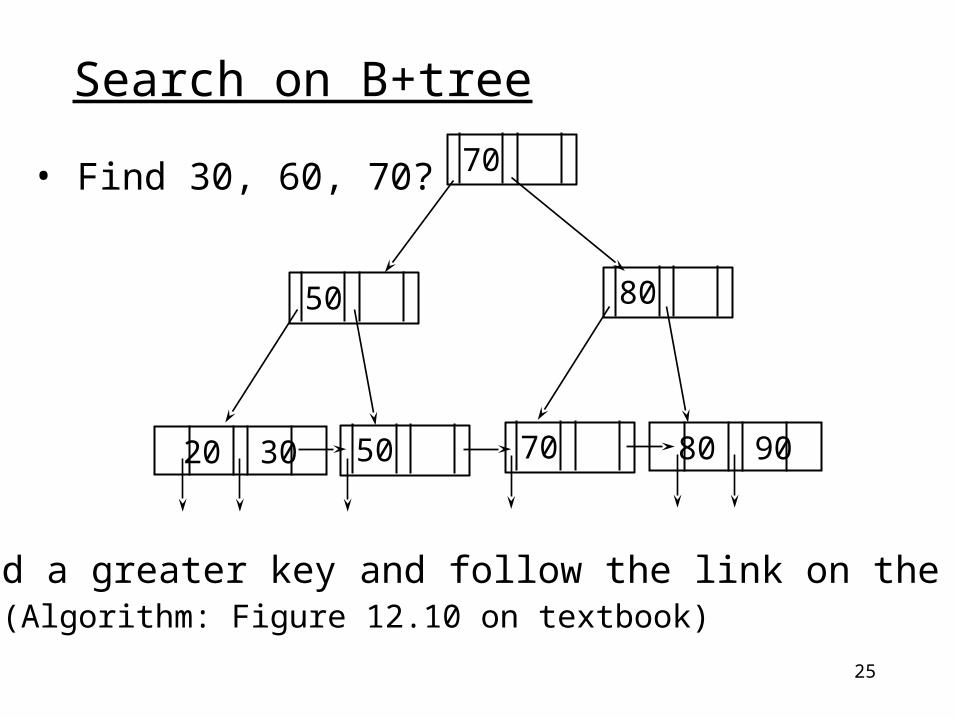
25
• Find a greater key and follow the link on the left (Algorithm: Figure 12.10 on textbook)
• Find 30, 60, 70?
Search on B+tree
20 30 80 90
70
50 80
7050
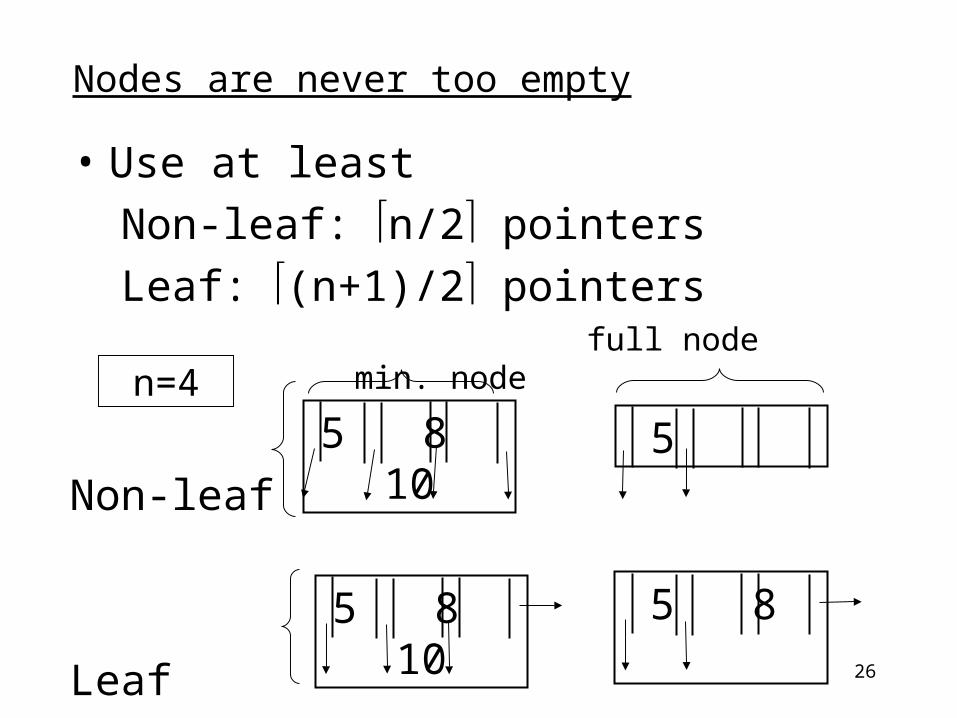
26
Nodes are never too empty
• Use at leastNon-leaf: n/2 pointersLeaf: (n+1)/2 pointers
full node min. node
Non-leaf
Leaf
n=45 8 10 5
5 8 10 5 8

27
Non-leaf(non-root) n n-1 n/2 n/2-1
Leaf(non-root) n n-1
Root n n-1 2 1
Max Max Min Min Ptrs keys ptrs keys
(n+1)/2 (n-1)/2
Number of Ptrs/Keys for B+tree

28
(a) simple case (no overflow)(b) leaf overflow(c) non-leaf overflow(d) new root
B+Tree Insertion

29
(a) Simple case (no overflow)
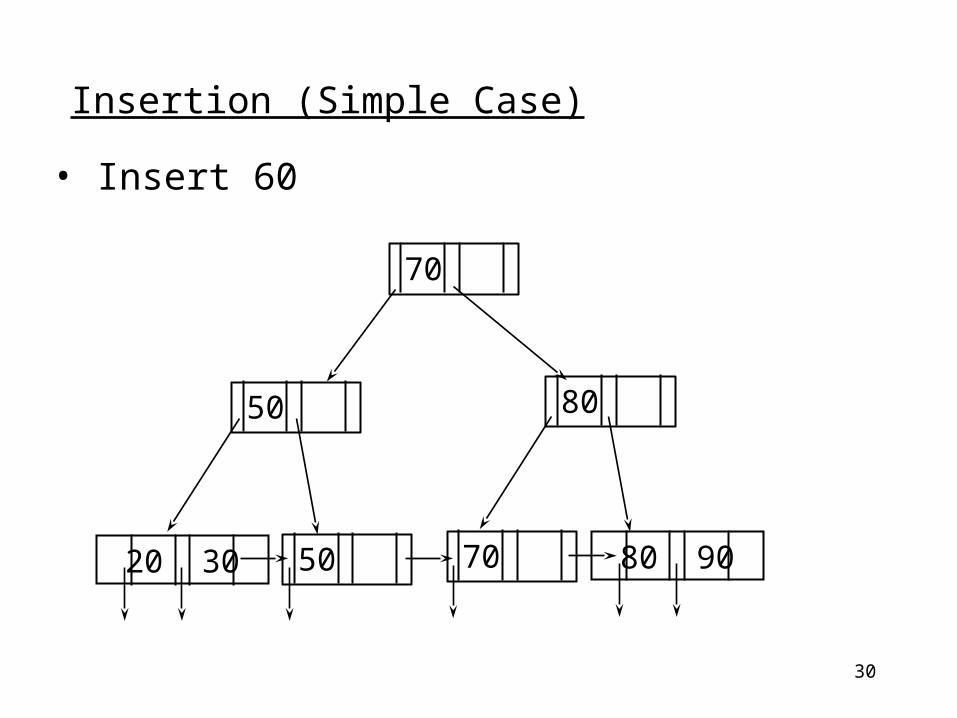
30
• Insert 60
Insertion (Simple Case)
20 30 80 90
70
50 80
7050
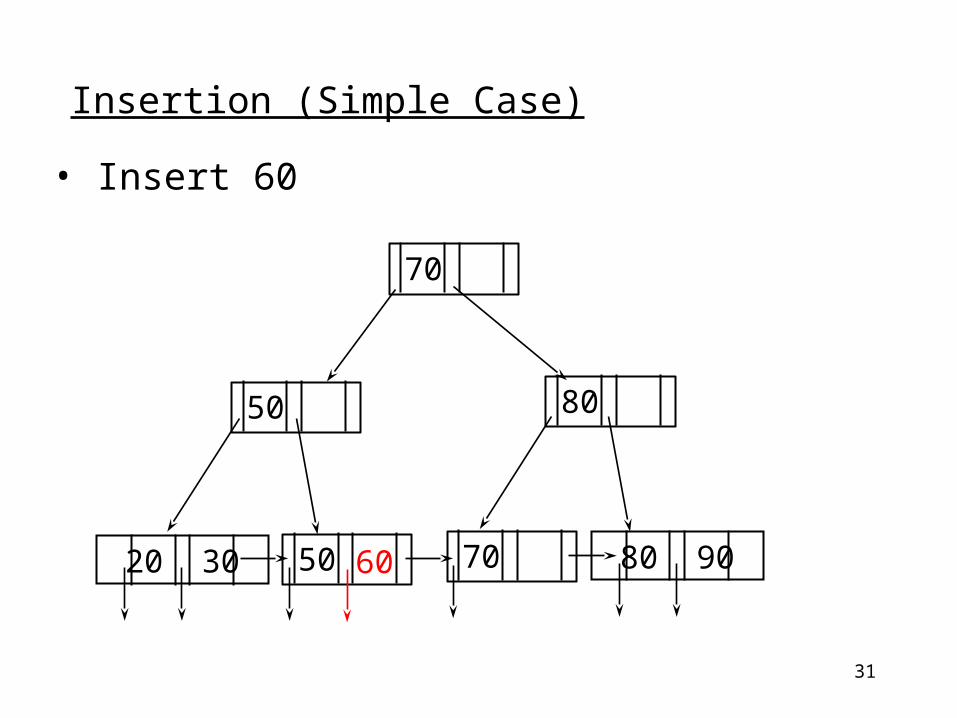
31
• Insert 60
Insertion (Simple Case)
20 30 80 90
70
50 80
7050 60

32
(b) Leaf overflow
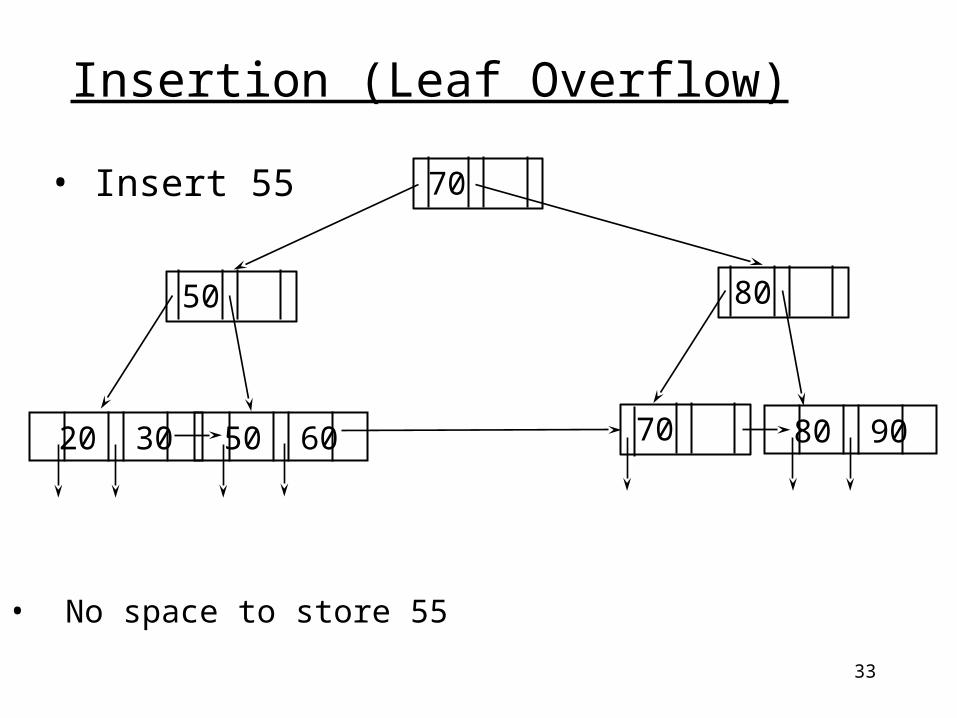
33
• Insert 55
• No space to store 55
Insertion (Leaf Overflow)
20 30 50 60 80 90
70
50 80
70
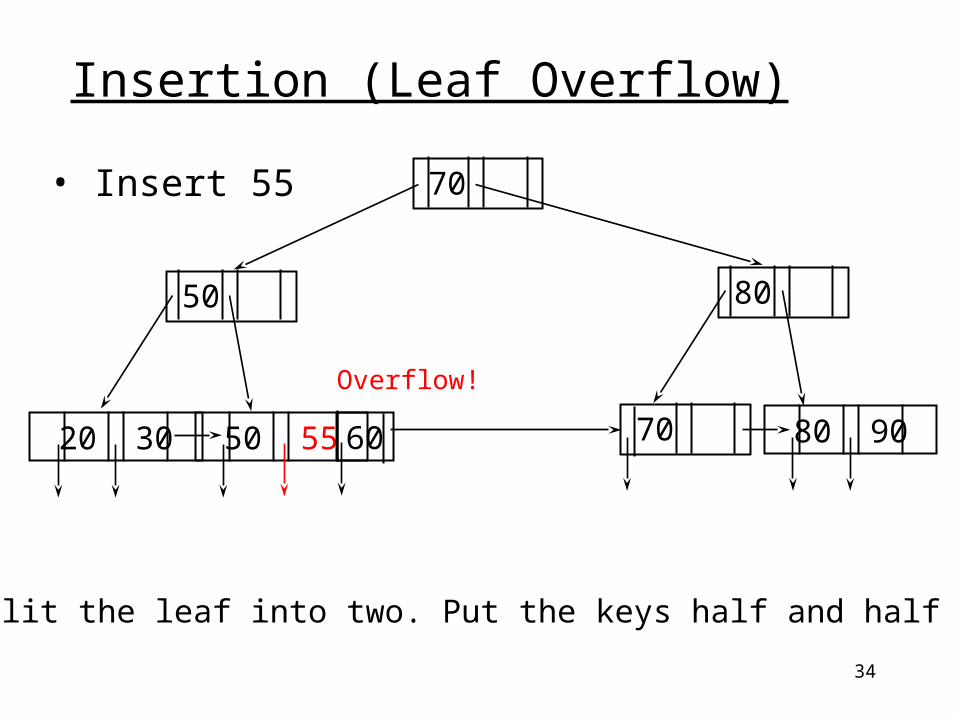
34
50 55
• Insert 55
• Split the leaf into two. Put the keys half and half
Insertion (Leaf Overflow)
20 30 80 90 60
Overflow!
70
50 80
70
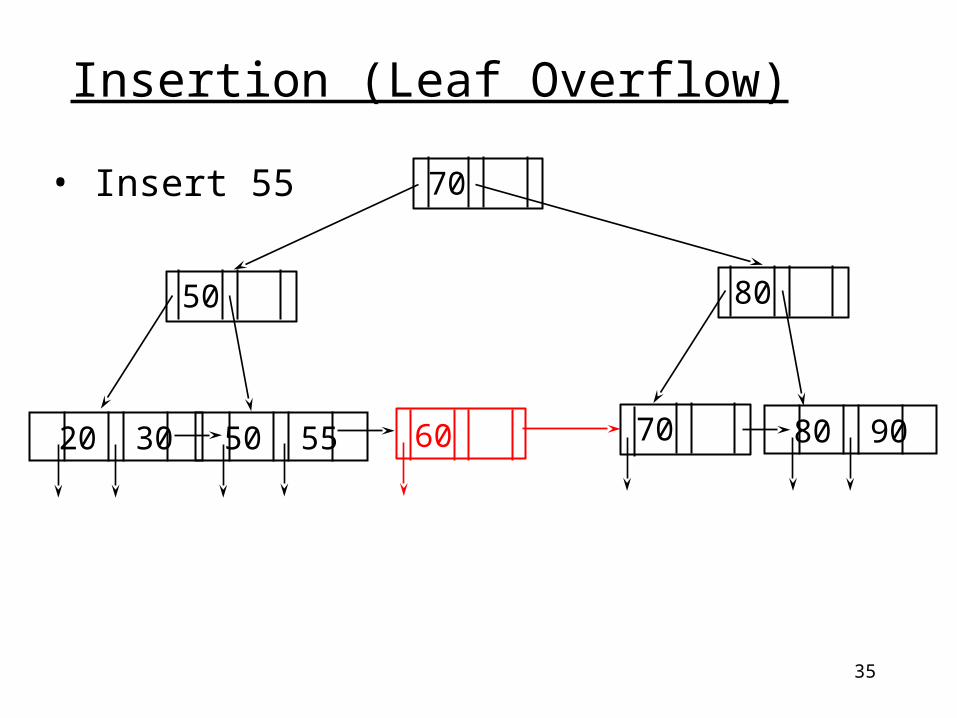
35
• Insert 55
Insertion (Leaf Overflow)
20 30 50 55 80 90
70
50 80
7060
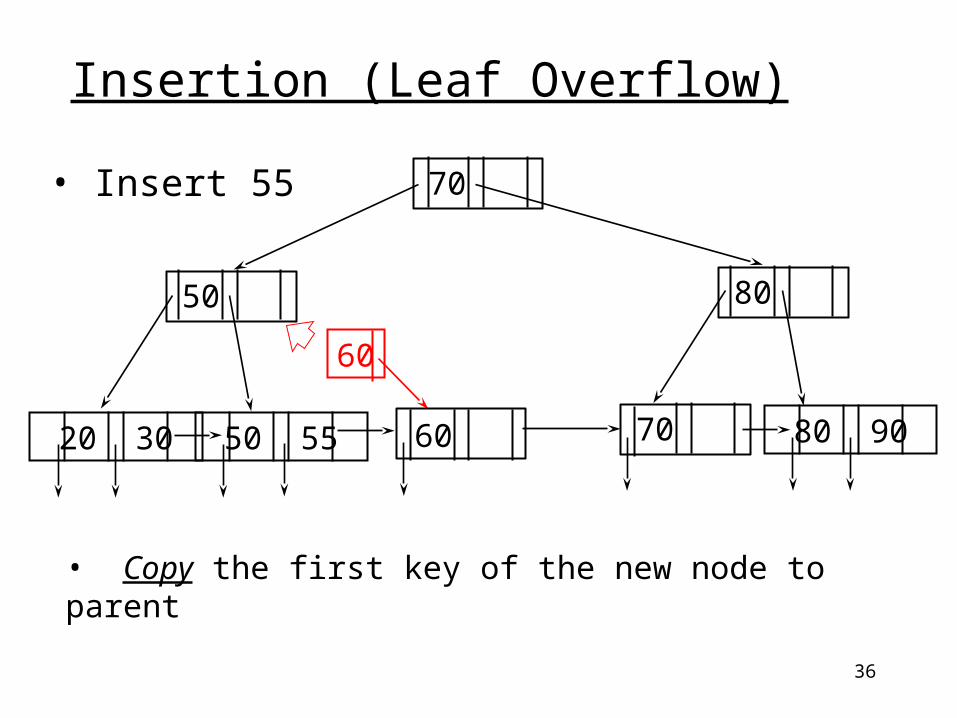
36
• Insert 55
• Copy the first key of the new node to parent
Insertion (Leaf Overflow)
20 30 50 55 80 90
60
70
50 80
7060
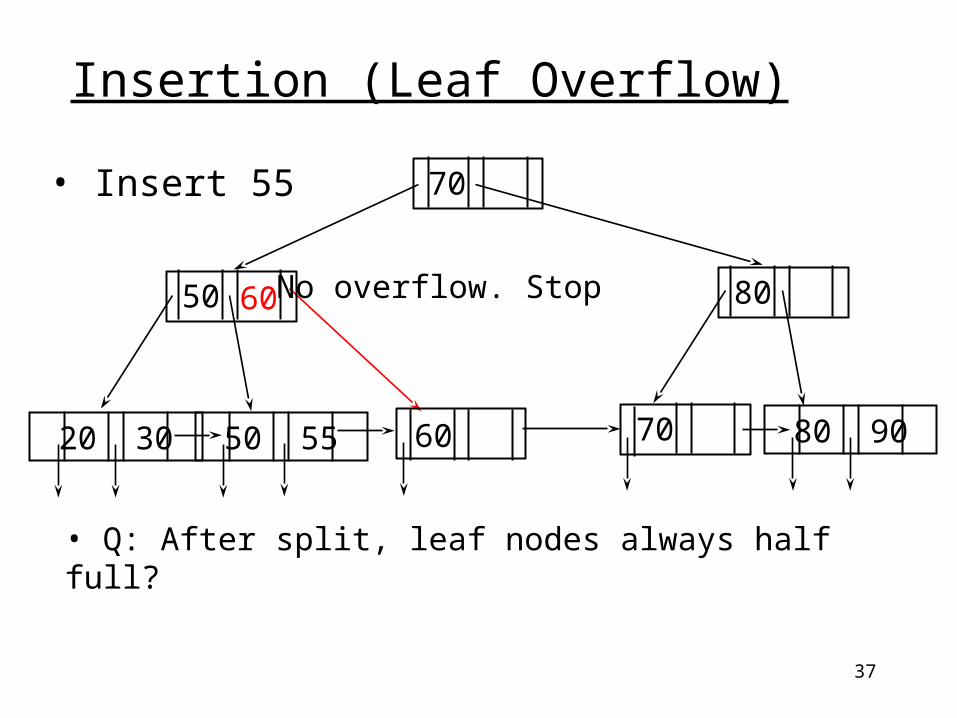
37
• Insert 55
Insertion (Leaf Overflow)
20 30 50 55 80 90
• Q: After split, leaf nodes always half full?
No overflow. Stop
70
50 80
70
60
60

38
(c) Non-leaf overflow
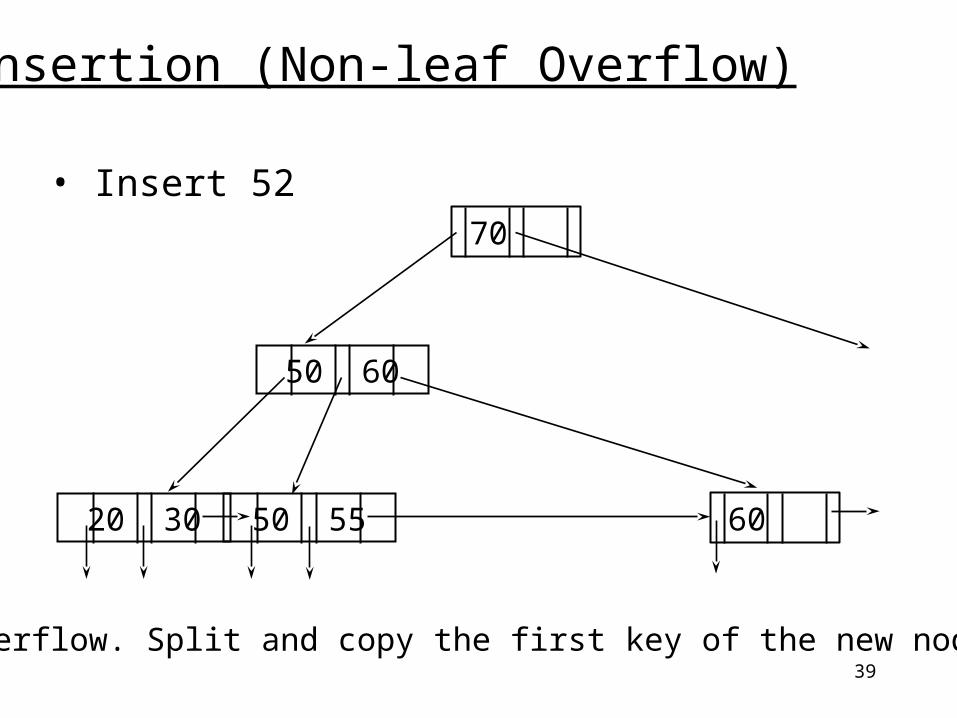
39
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 55
50 60
Leaf overflow. Split and copy the first key of the new node
60
70
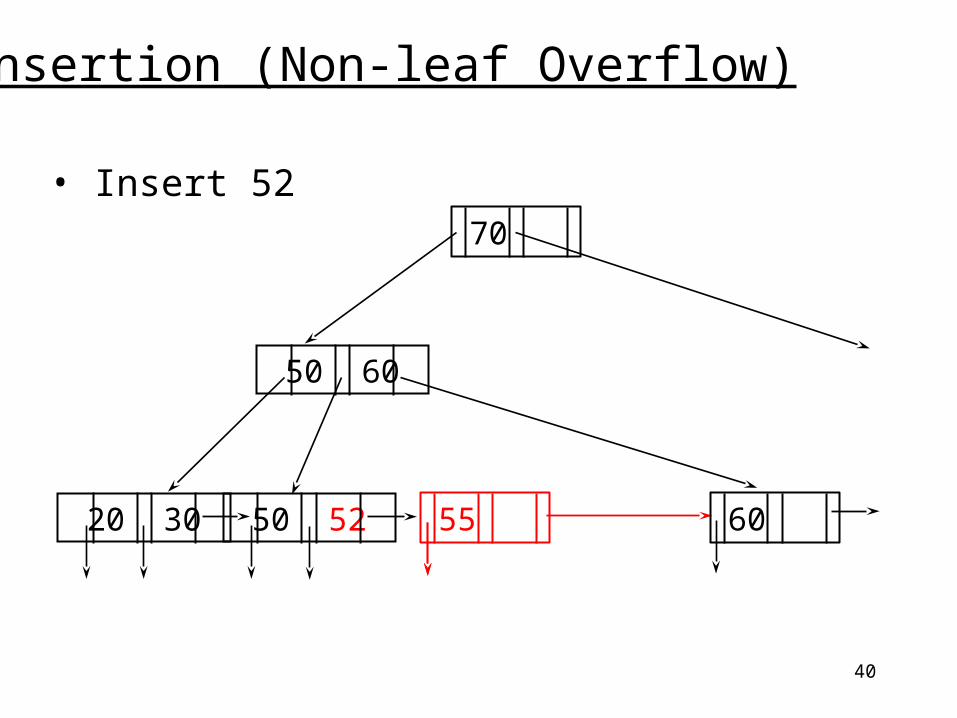
40
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 52
50 60
55 60
70
41
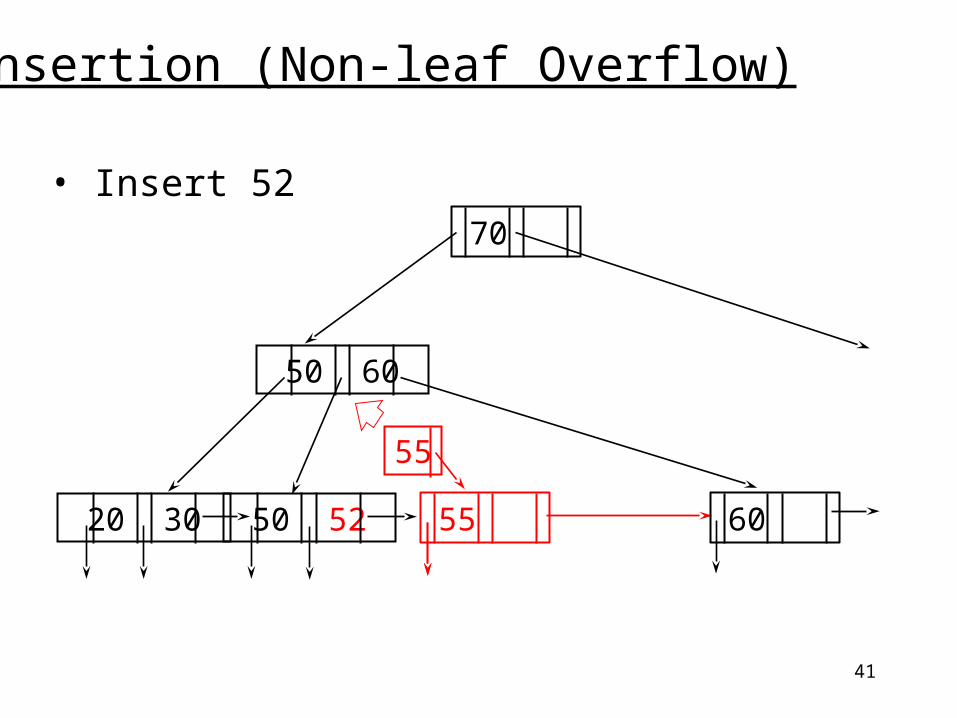
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 52
50 60
55
55 60
70
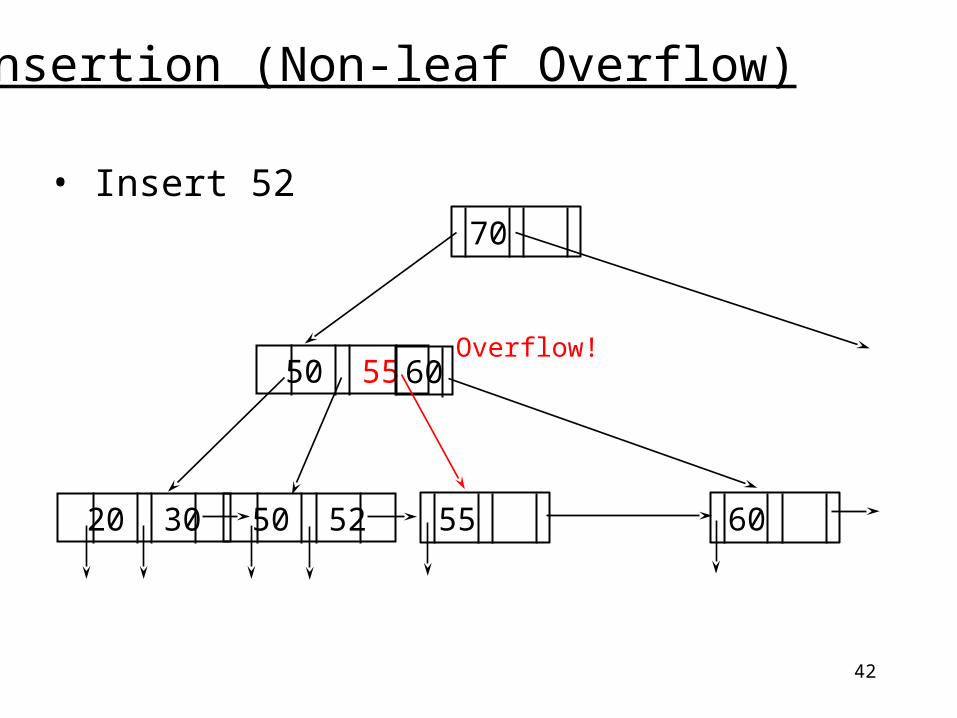
42
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 52
50 55 60Overflow!
55 60
70
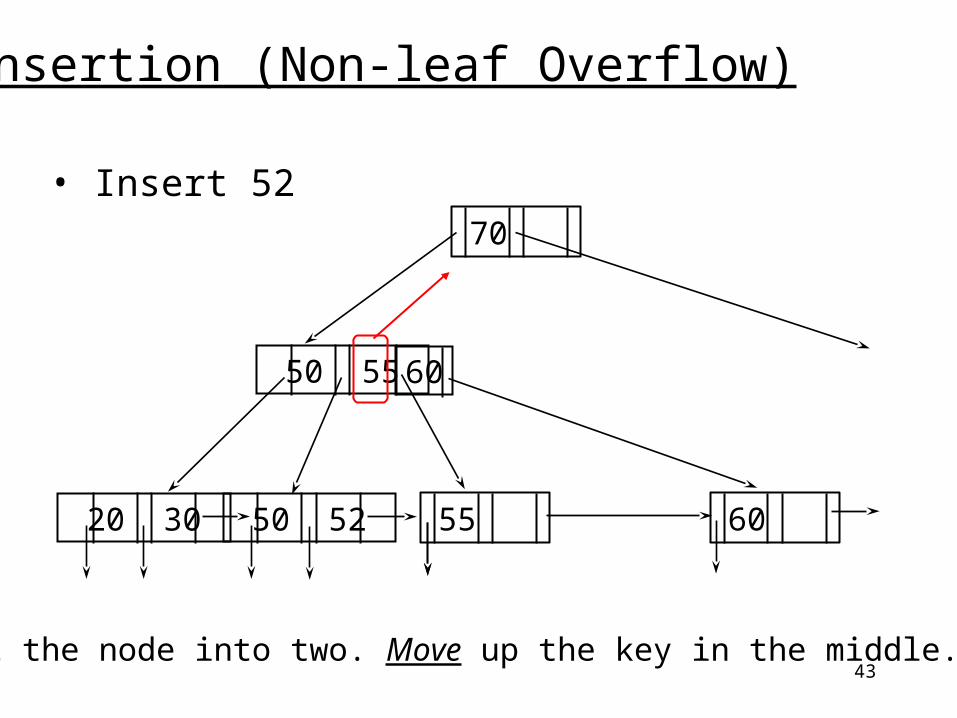
43
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 52
50 55
Split the node into two. Move up the key in the middle.
60
55 60
70
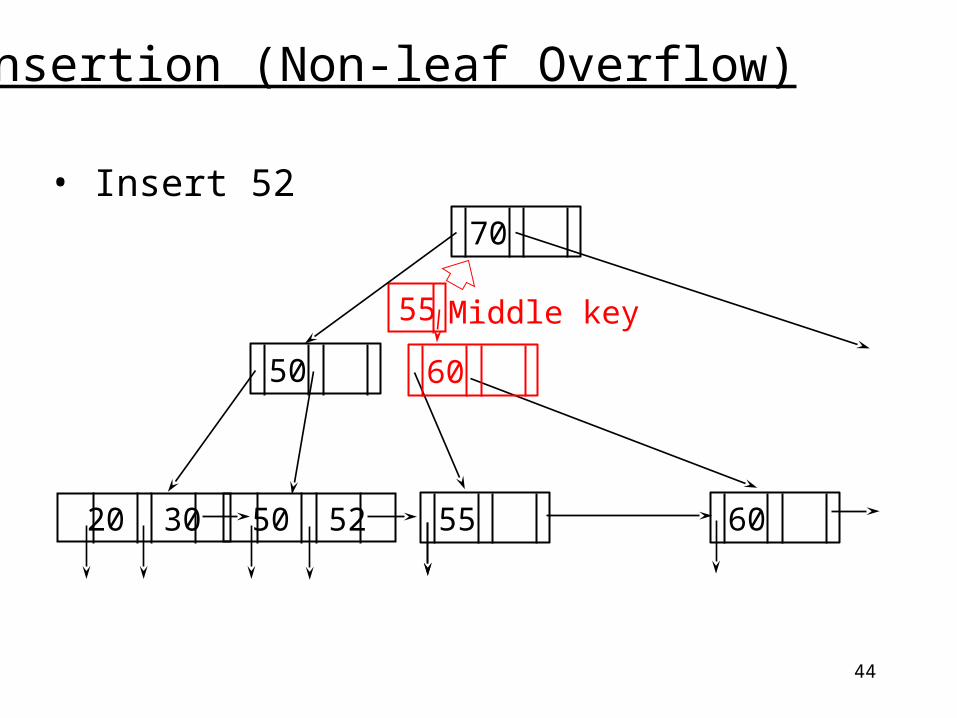
44
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 52
55 Middle key
55
6050
60
70
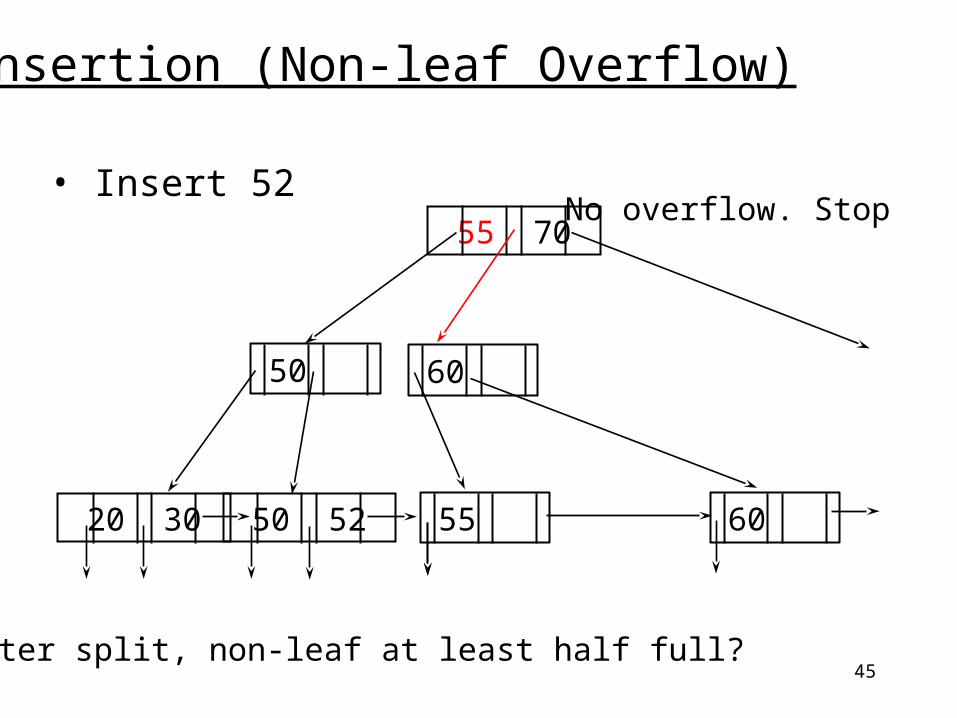
45
Insertion (Non-leaf Overflow)
• Insert 52
20 30 50 52
55 70 No overflow. Stop
Q: After split, non-leaf at least half full?
55
6050
60

46
(d) New root
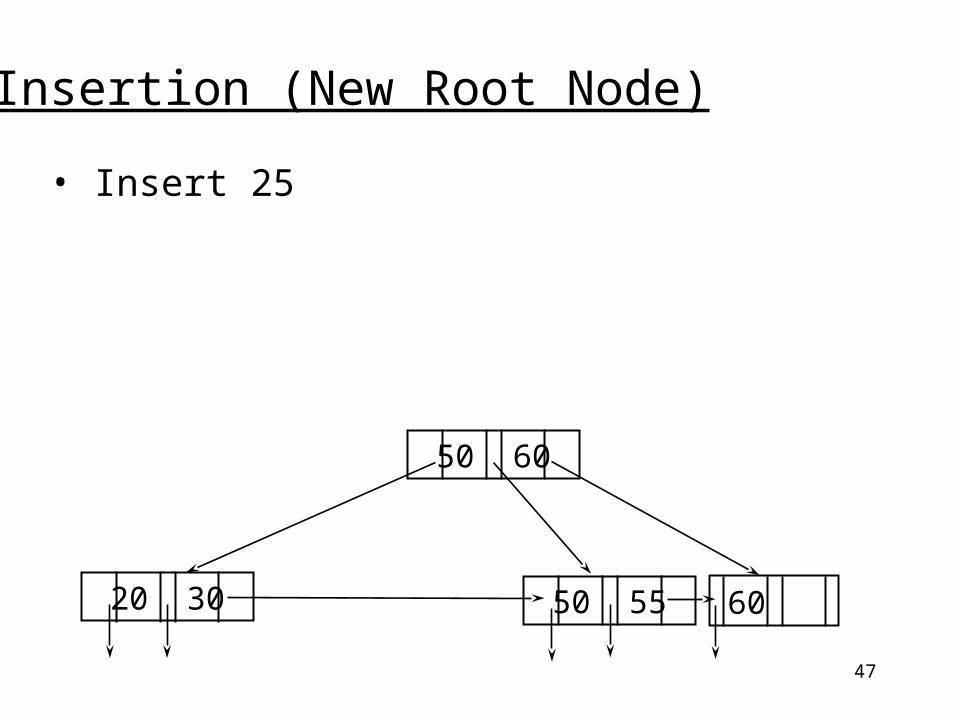
47
Insertion (New Root Node)
• Insert 25
20 30 50 55
50 60
60
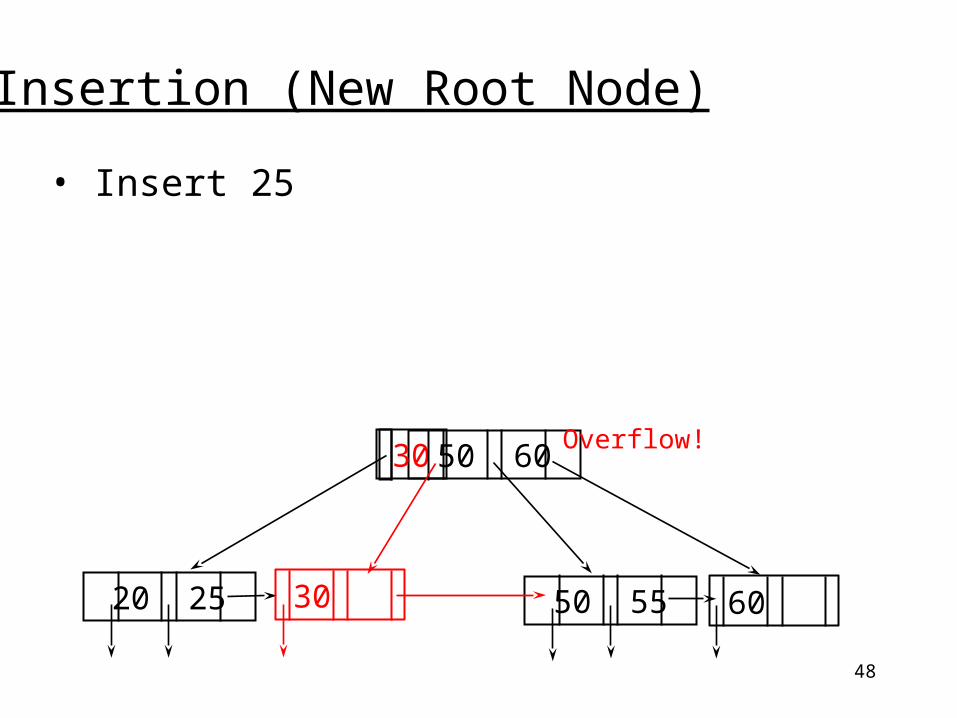
48
Insertion (New Root Node)
• Insert 25
20 25 50 55
50 60 30
Overflow!
6030
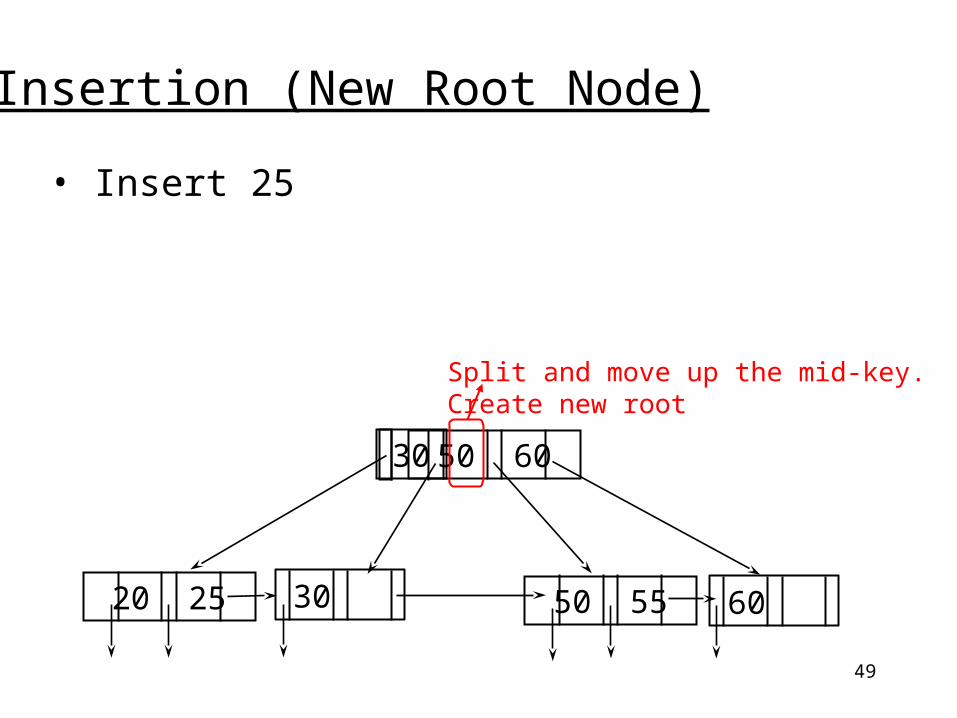
49
Insertion (New Root Node)
• Insert 25
20 25 50 55
50 60 30
Split and move up the mid-key.Create new root
6030
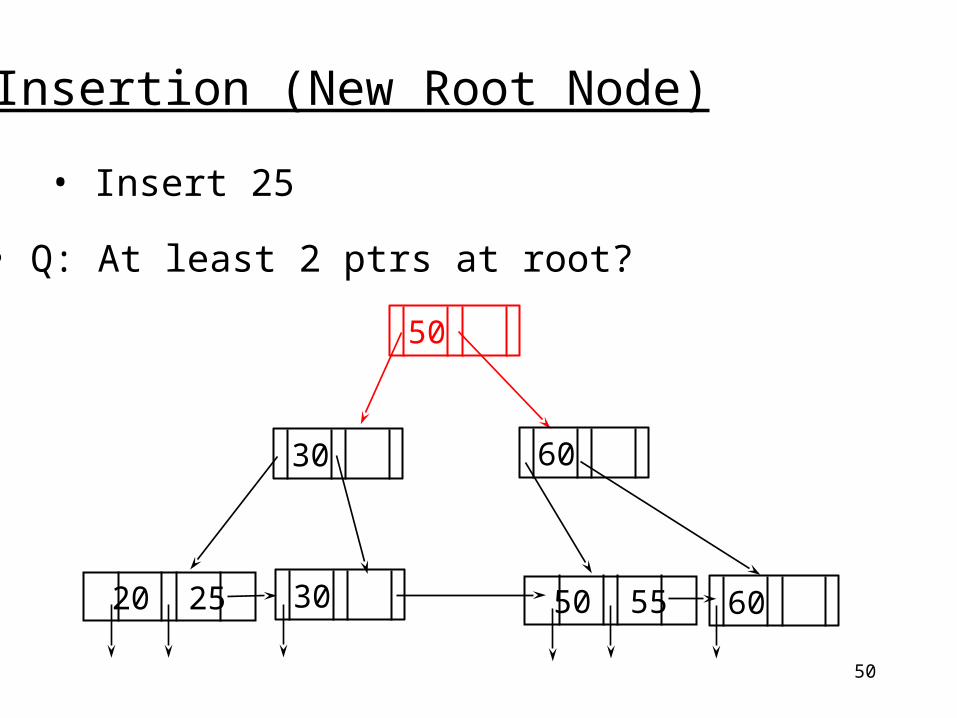
50
Insertion (New Root Node)
• Insert 25
20 25 50 55
• Q: At least 2 ptrs at root?
60
6030
30
50

51
B+Tree Insertion
• Leaf node overflow– The first key of the new node is
copied to the parent
• Non-leaf node overflow– The middle key is moved to the
parent
• Detailed algorithm: Figure 12.13

52
B+Tree Deletion
(a) Simple case (no underflow)(b) Leaf node, coalesce with neighbor (c) Leaf node, redistribute with neighbor(d) Non-leaf node, coalesce with neighbor(e) Non-leaf node, redistribute with neighbor
In the examples, n = 4– Underflow for non-leaf when fewer than n/2 = 2 ptrs– Underflow for leaf when fewer than (n+1)/2 = 3 ptrs– Nodes are labeled as a, b, c, d, …

53
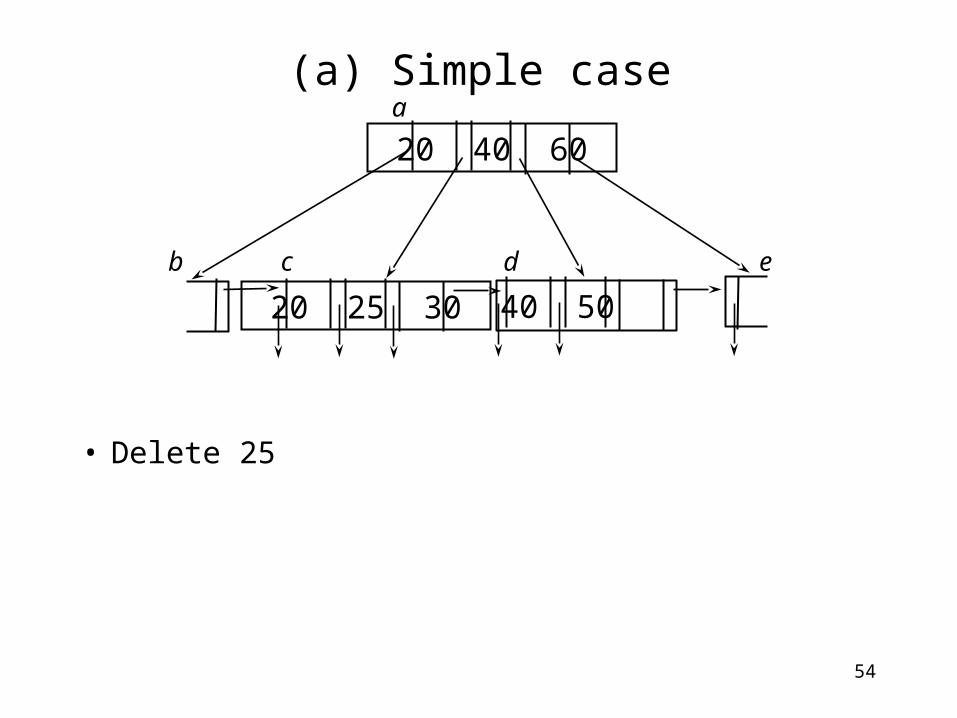
(a) Simple case (no underflow)
54
(a) Simple case
• Delete 25
20 25 30 40 50
20 40 60 a
b c d e
55
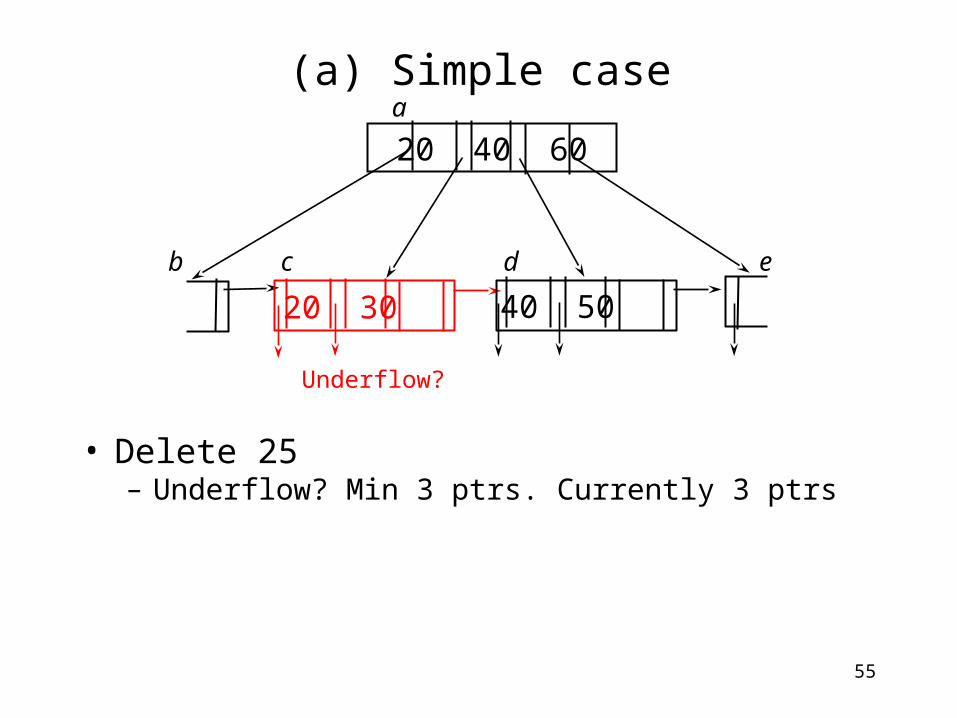
(a) Simple case
• Delete 25– Underflow? Min 3 ptrs. Currently 3 ptrs
20 30
20 40 60 a
b c d e
Underflow?
40 50
56
(b) Leaf node, coalesce with neighbor
57
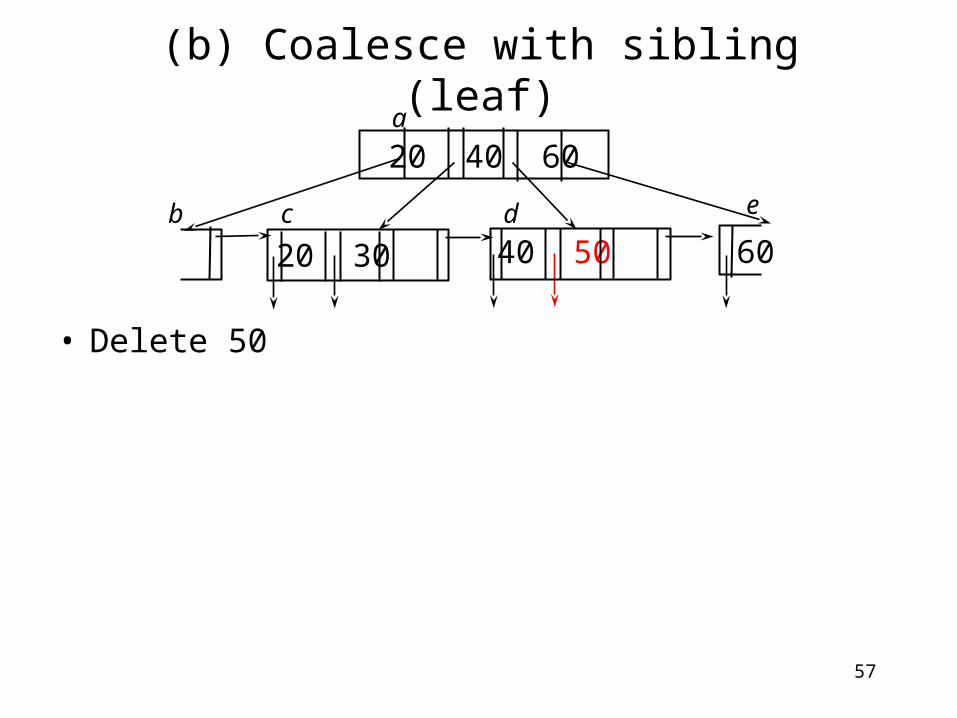
(b) Coalesce with sibling (leaf)
• Delete 50
20 30 40 50
20 40 60
60b c d
a
e
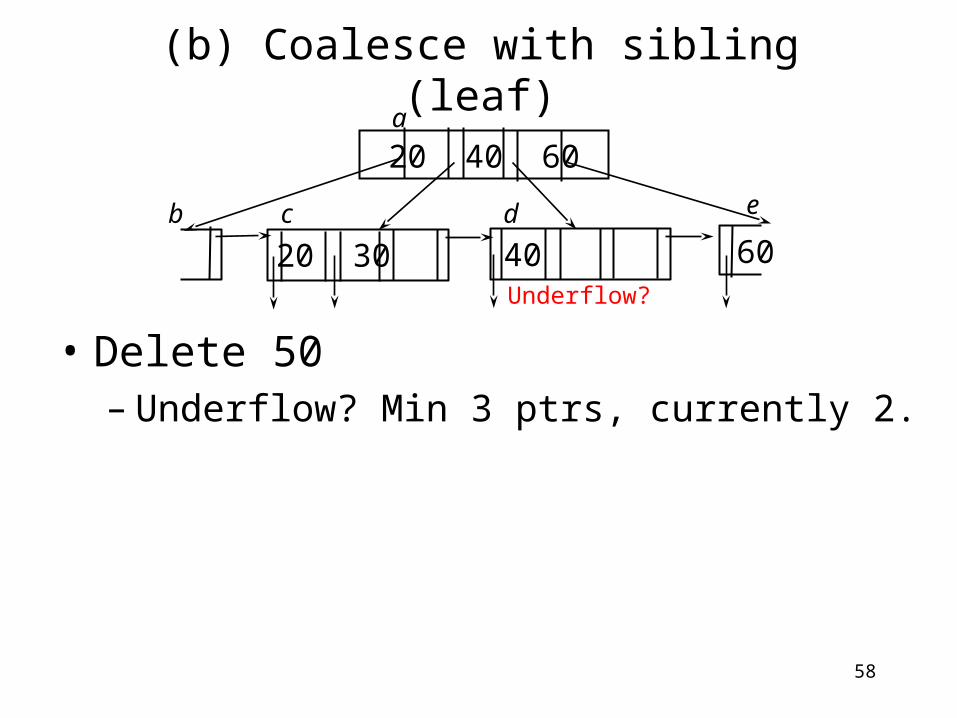
58
(b) Coalesce with sibling (leaf)
• Delete 50– Underflow? Min 3 ptrs, currently 2.
20 40 60
60b c d
a
Underflow?
4020 30
e
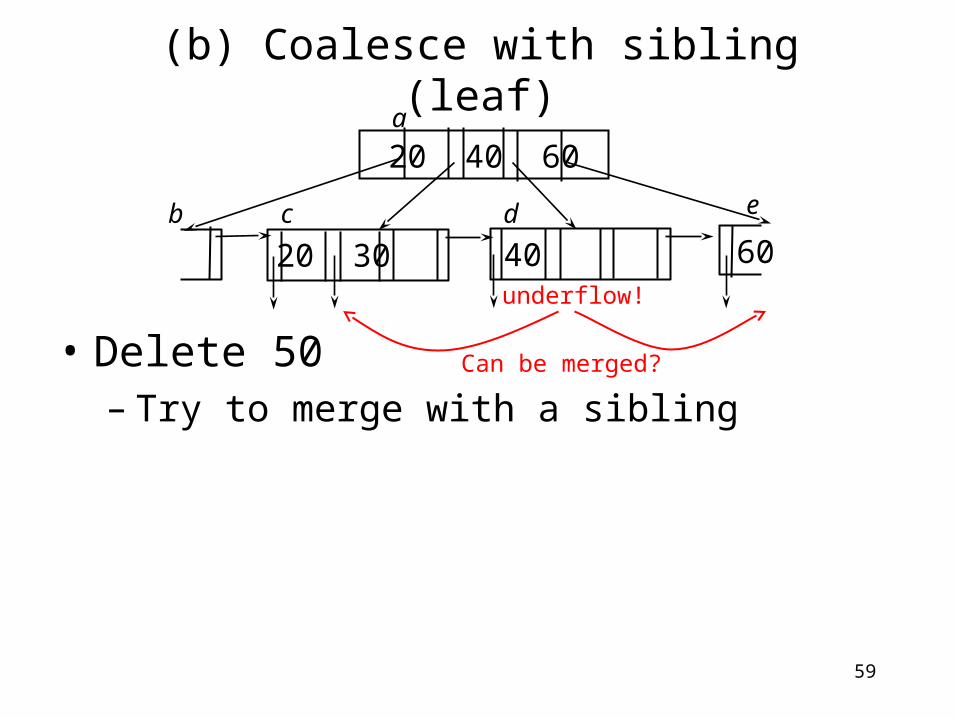
59
(b) Coalesce with sibling (leaf)
• Delete 50– Try to merge with a sibling
20 40 60
60b c d
a
underflow!
Can be merged?
4020 30
e
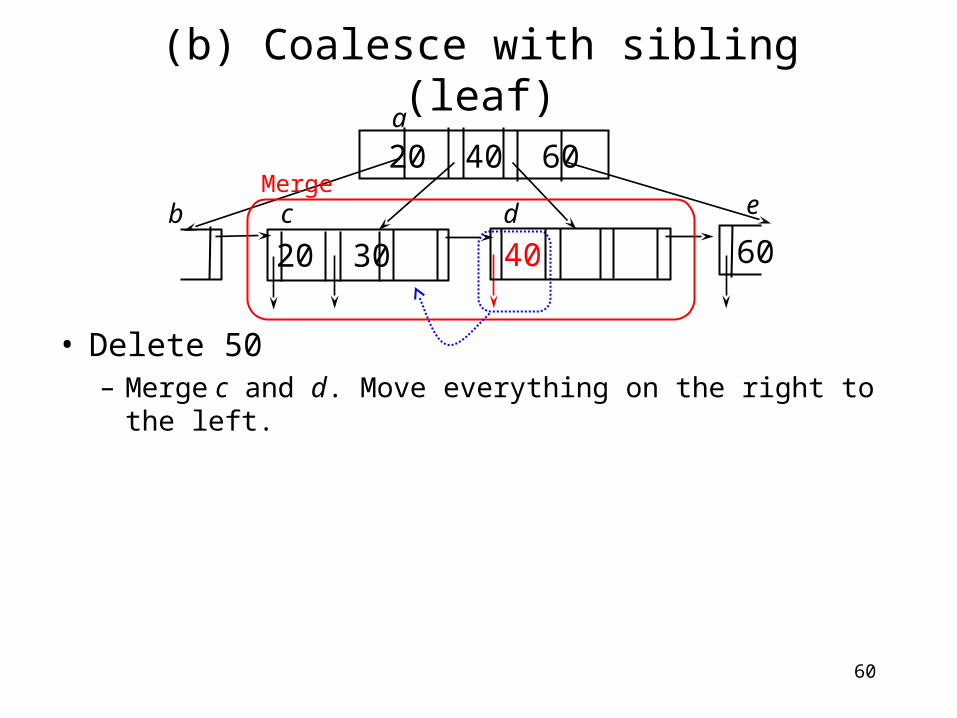
60
(b) Coalesce with sibling (leaf)
• Delete 50– Merge c and d. Move everything on the right to the
left.
20 40 60
60b c d
a
Merge
4020 30
e
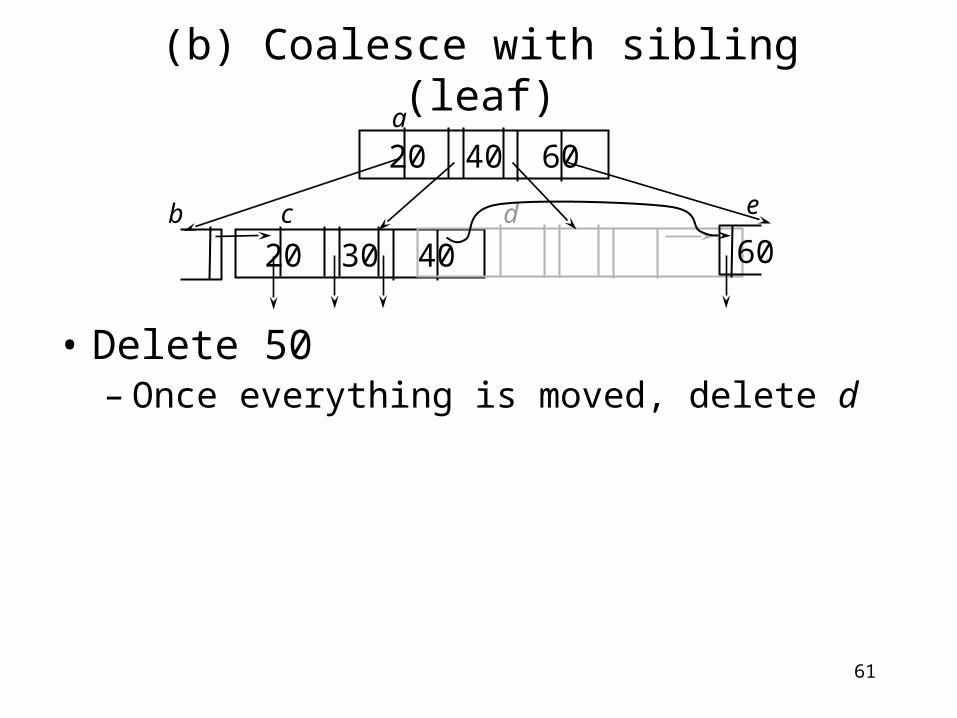
61
(b) Coalesce with sibling (leaf)
• Delete 50– Once everything is moved, delete d
20 30 40
20 40 60
60b c d
a
e
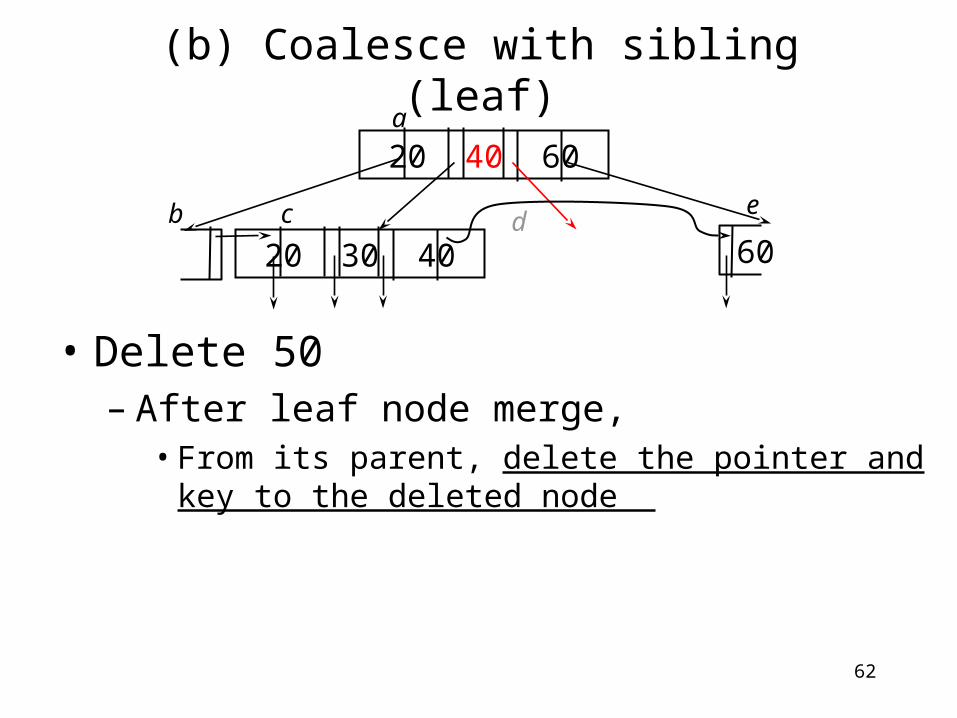
62
(b) Coalesce with sibling (leaf)
• Delete 50– After leaf node merge,
• From its parent, delete the pointer and key to the deleted node
20 30 40
20 40 60
60b c d
e
a
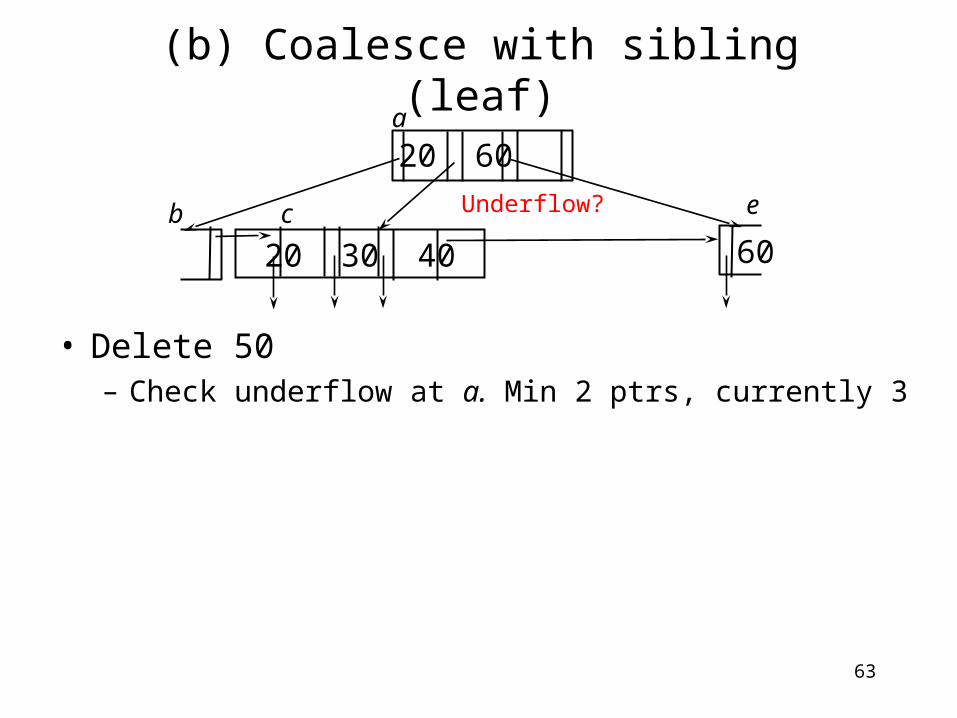
63
(b) Coalesce with sibling (leaf)
• Delete 50– Check underflow at a. Min 2 ptrs, currently 3
20 30 40
20 60
60b c
a
Underflow? e

64
(c) Leaf node, redistribute with neighbor
65
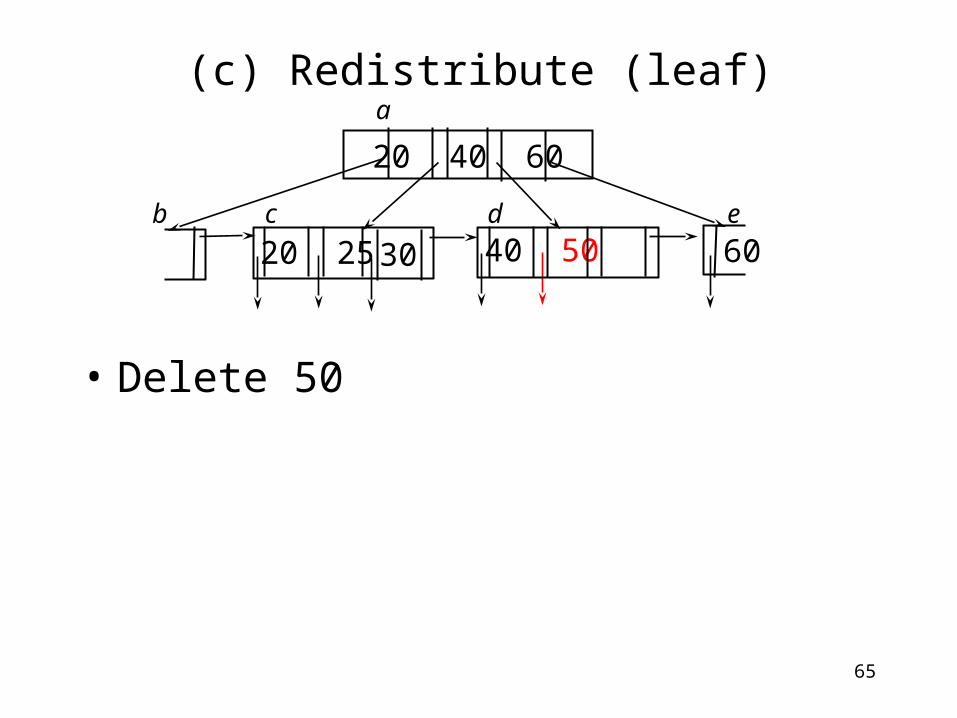
(c) Redistribute (leaf)
• Delete 50
20 40 60
60b c d e
a
40 5020 25 30
66
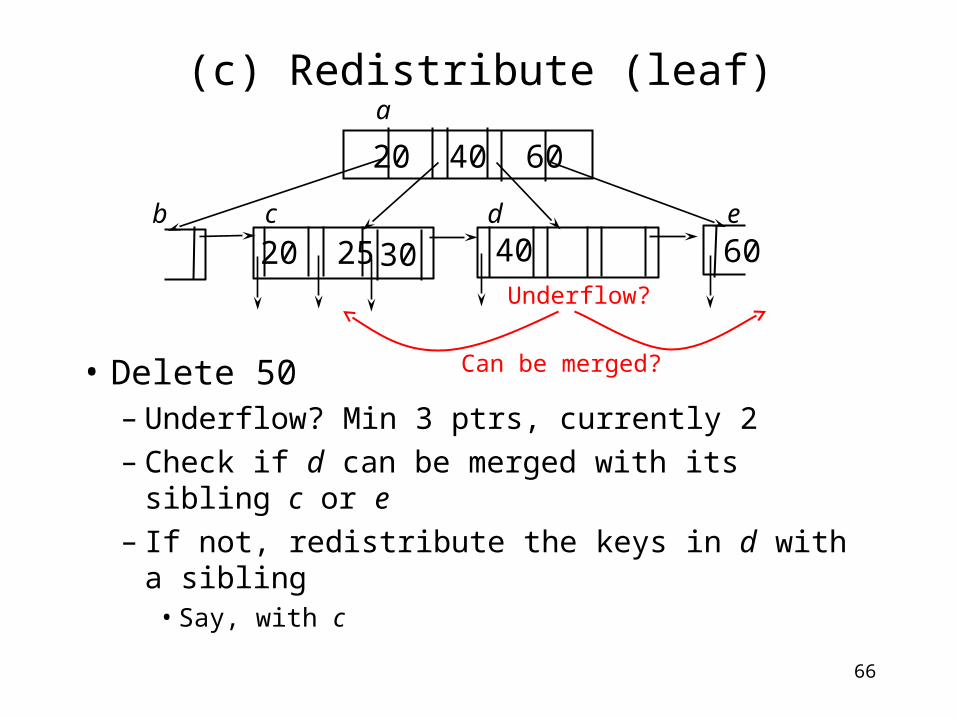
(c) Redistribute (leaf)
• Delete 50– Underflow? Min 3 ptrs, currently 2– Check if d can be merged with its sibling c or
e
– If not, redistribute the keys in d with a sibling• Say, with c
20 40 60
60b c d e
a
Underflow?
Can be merged?
4020 25 30
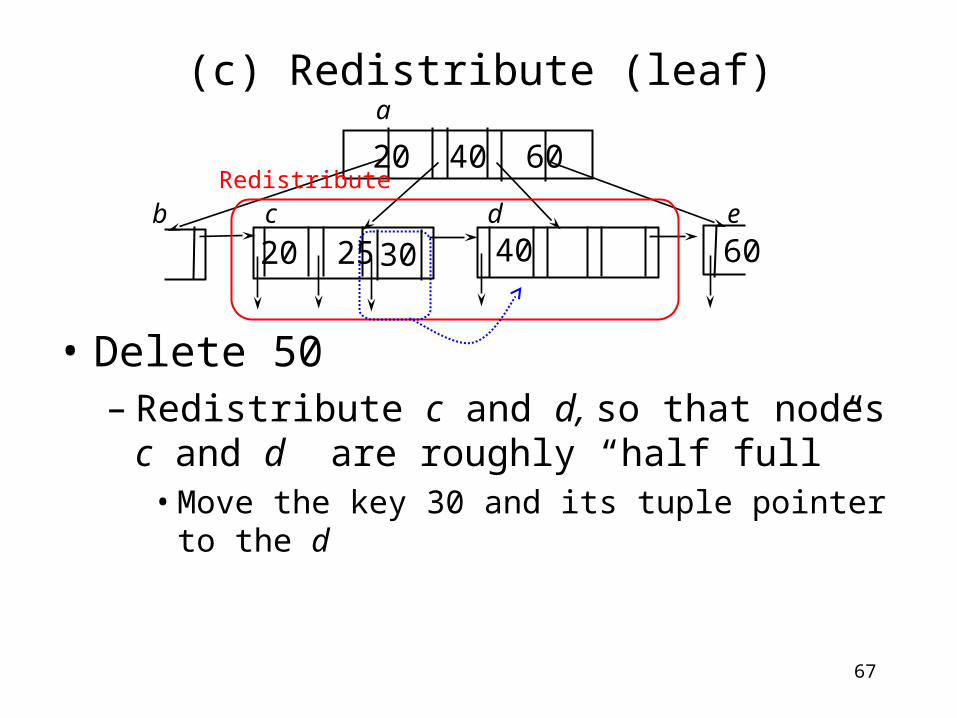
67
(c) Redistribute (leaf)
• Delete 50– Redistribute c and d, so that nodes c and
d are roughly “half full”• Move the key 30 and its tuple pointer to the
d
20 40 60
60b c d e
a
Redistribute
4020 25 30
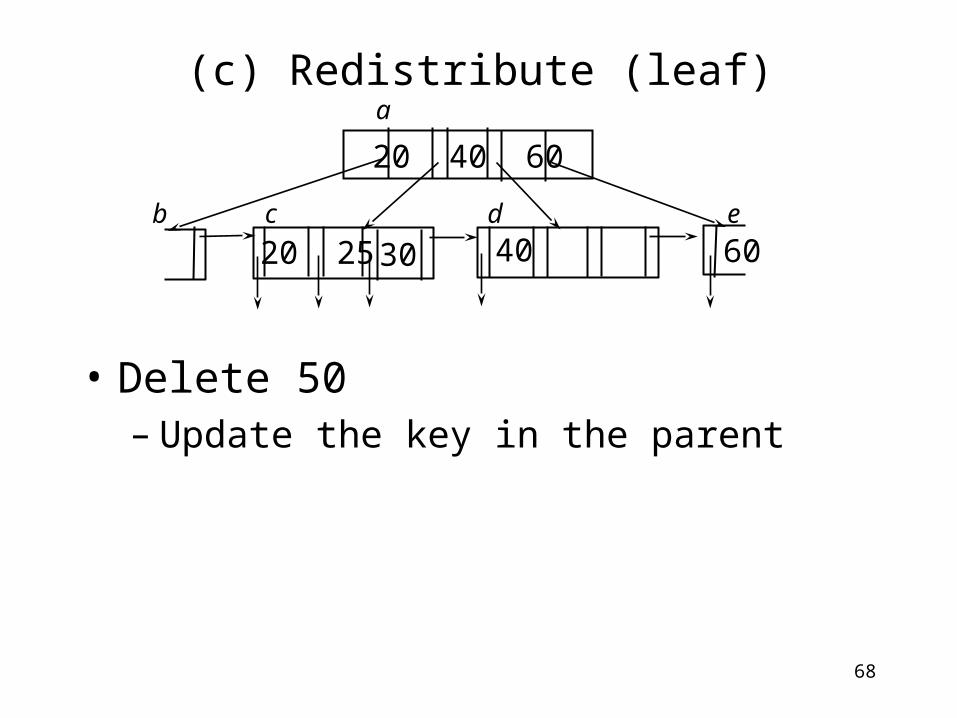
68
(c) Redistribute (leaf)
• Delete 50– Update the key in the parent
20 25
20 40 60
60b c d e
a
30 40
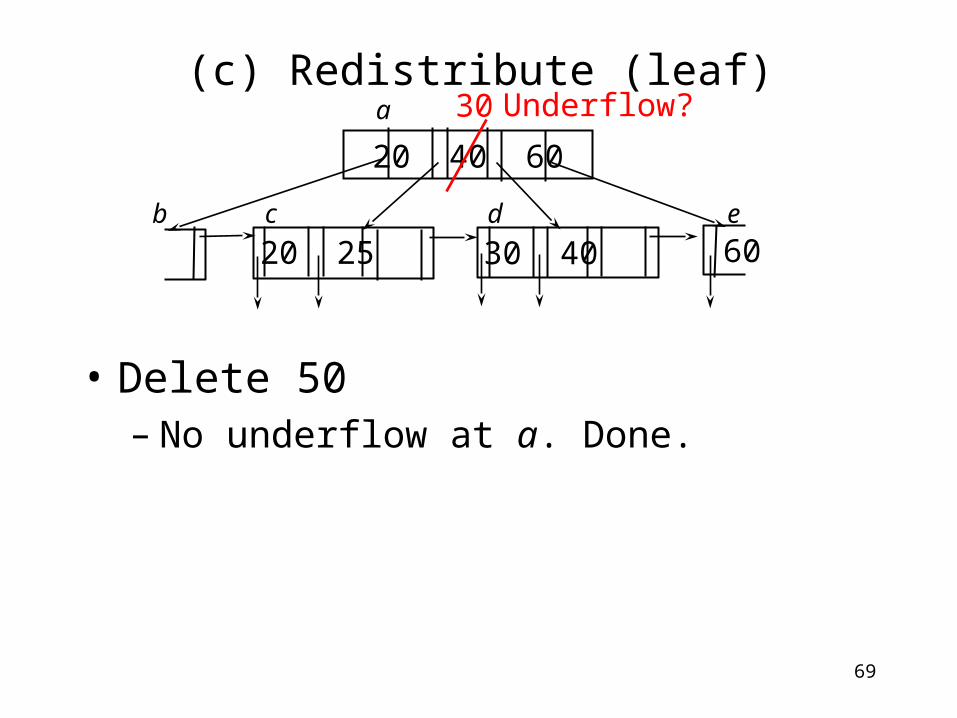
69
(c) Redistribute (leaf)
• Delete 50– No underflow at a. Done.
20 40 60
60b c d e
a 30 Underflow?
20 25 30 40

70
(d) Non-leaf node, coalesce with neighbor
71
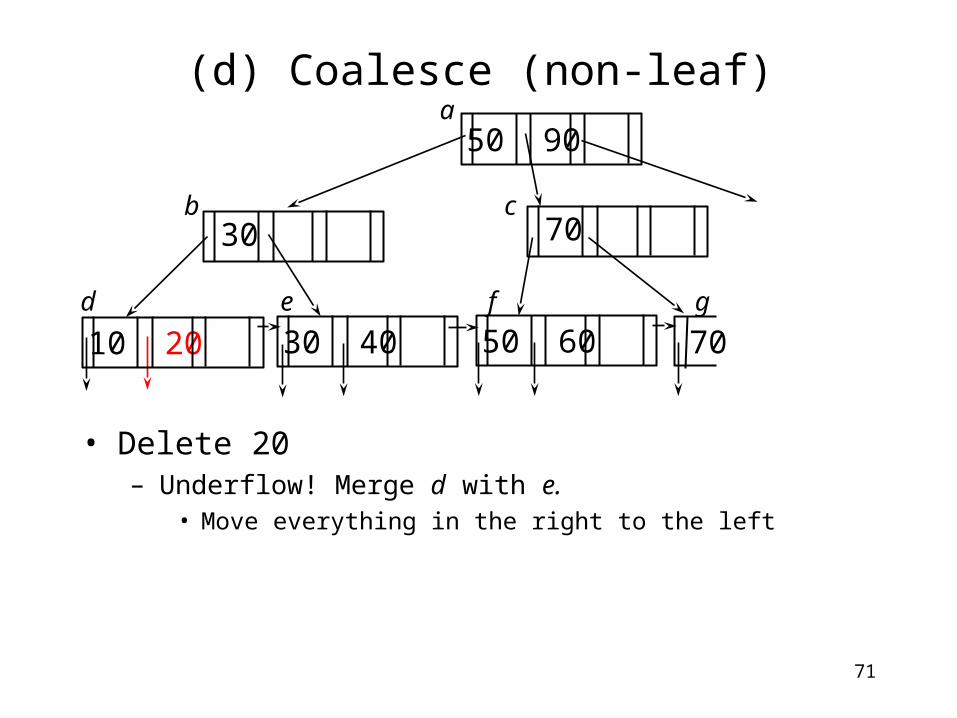
(d) Coalesce (non-leaf)
• Delete 20– Underflow! Merge d with e.
• Move everything in the right to the left
70
a
b c
d e f g
50 90
50 60
7030
30 4010 20
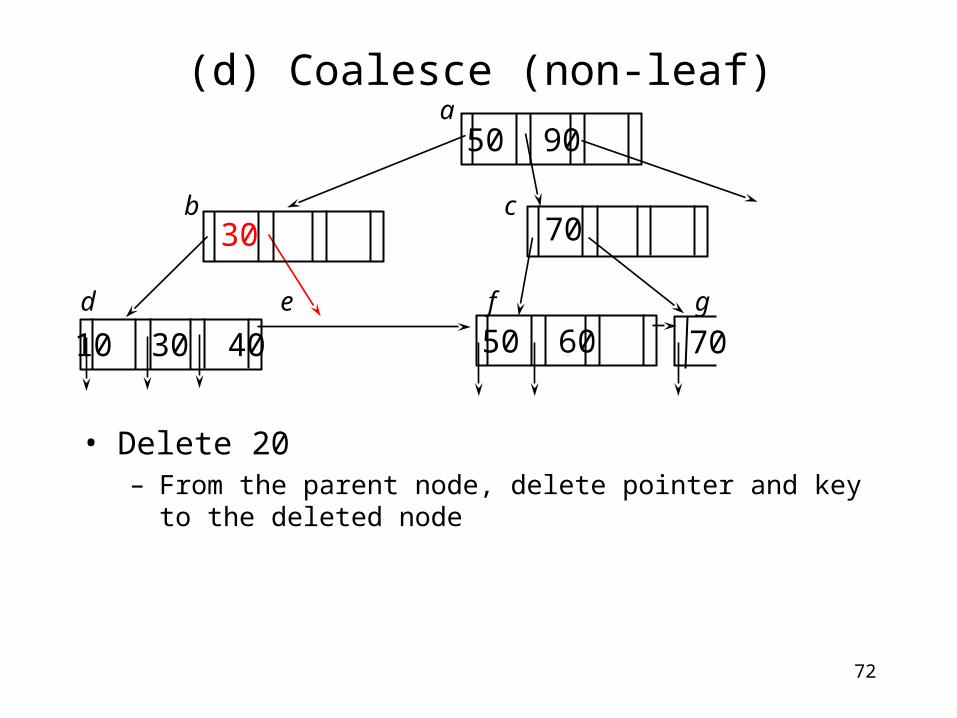
72
(d) Coalesce (non-leaf)
• Delete 20– From the parent node, delete pointer and key to the
deleted node
70
a
b c
d e f g
50 90
50 60
7030
10 30 40
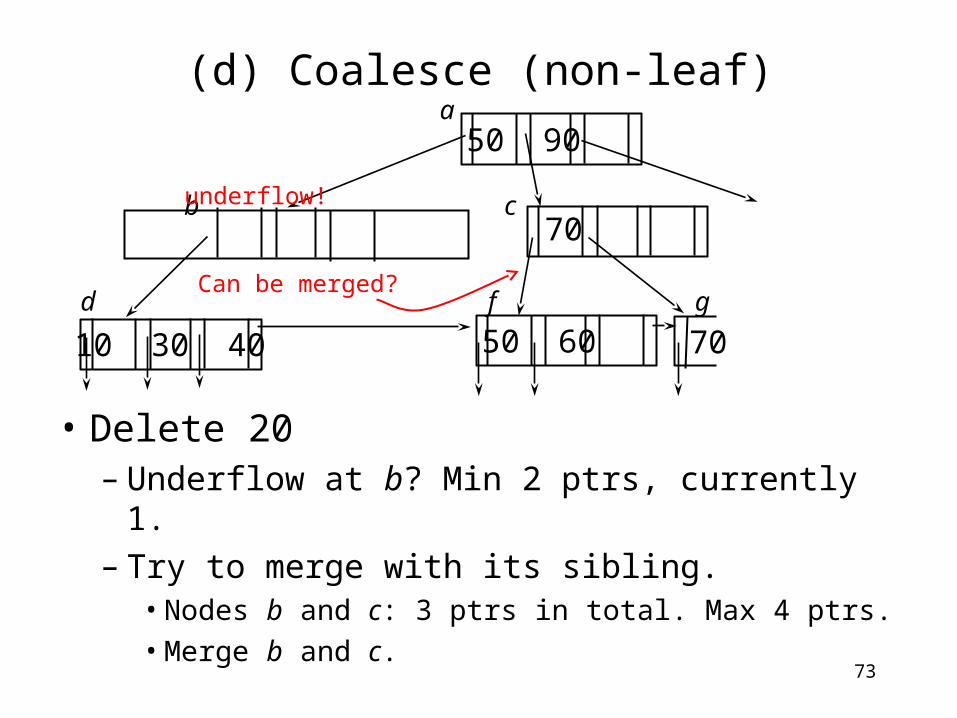
73
(d) Coalesce (non-leaf)
• Delete 20– Underflow at b? Min 2 ptrs, currently 1.– Try to merge with its sibling.
• Nodes b and c: 3 ptrs in total. Max 4 ptrs.• Merge b and c.
70
a
b c
d f g
underflow!
Can be merged?
50 90
50 60
70
10 30 40
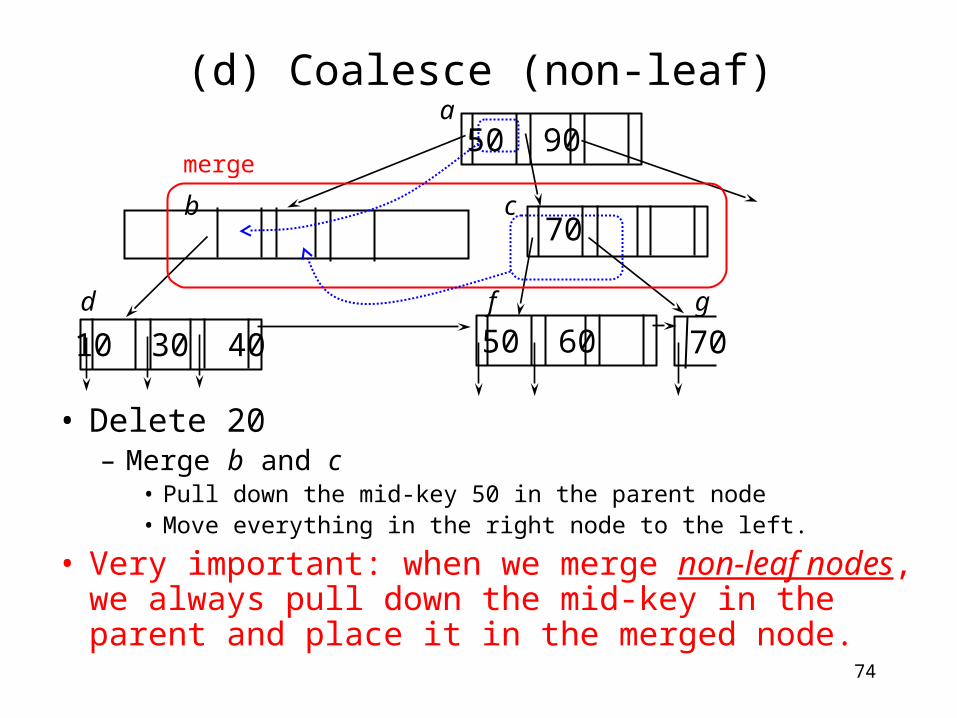
74
(d) Coalesce (non-leaf)
• Delete 20– Merge b and c
• Pull down the mid-key 50 in the parent node • Move everything in the right node to the left.
• Very important: when we merge non-leaf nodes, we always pull down the mid-key in the parent and place it in the merged node.
70
a
b c
d f g
merge50 90
50 60
70
10 30 40
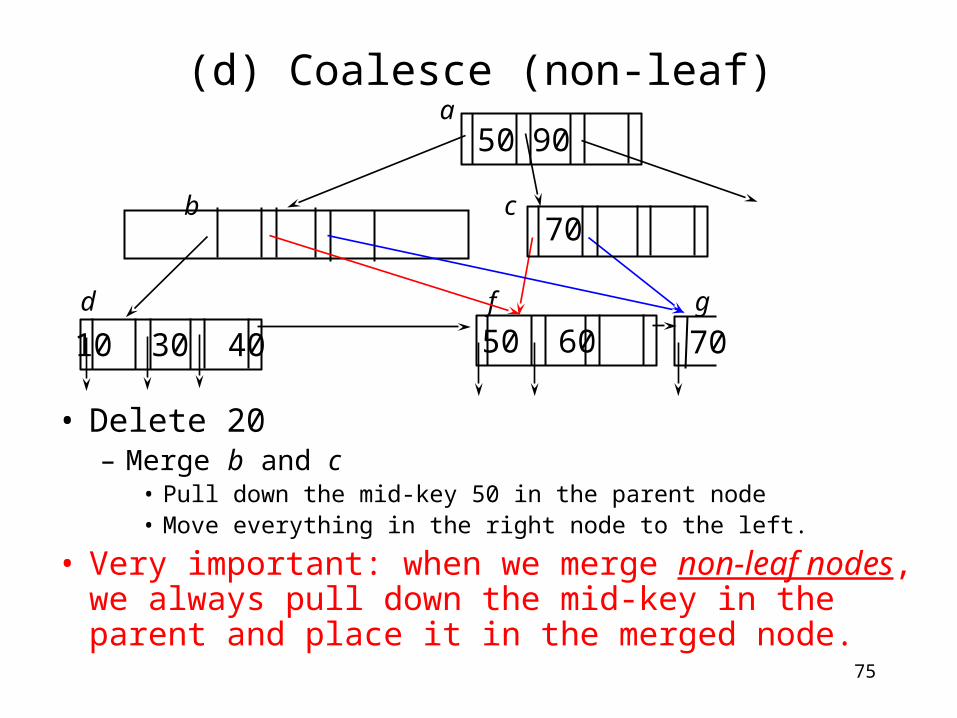
75
(d) Coalesce (non-leaf)
• Delete 20– Merge b and c
• Pull down the mid-key 50 in the parent node • Move everything in the right node to the left.
• Very important: when we merge non-leaf nodes, we always pull down the mid-key in the parent and place it in the merged node.
70
b c
d f g
50 60
70
9050a
10 30 40
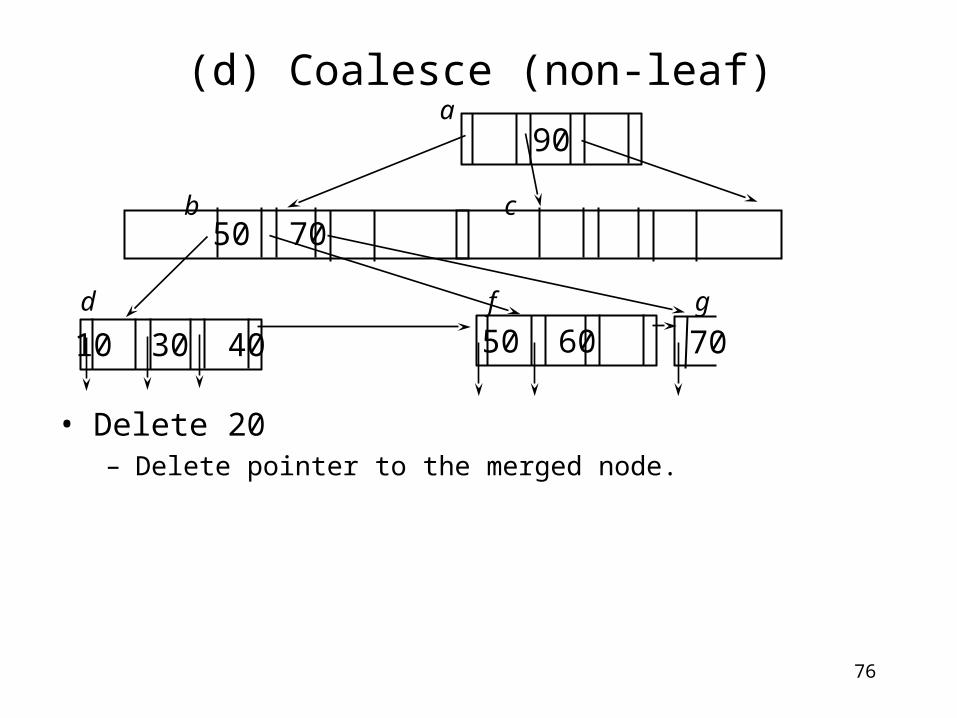
76
(d) Coalesce (non-leaf)
70
a
b c
d f g
90
50 60
50 70
• Delete 20– Delete pointer to the merged node.
10 30 40
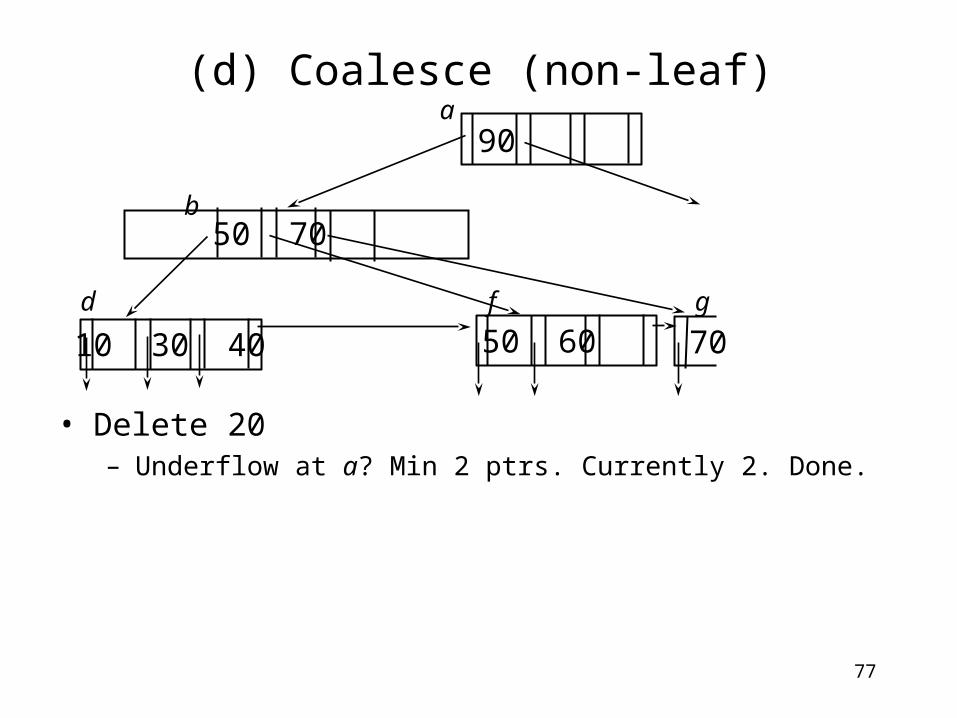
77
(d) Coalesce (non-leaf)
70
a
b
d f g
90
50 60
50 70
• Delete 20– Underflow at a? Min 2 ptrs. Currently 2. Done.
10 30 40

78
(e) Non-leaf node, redistribute with neighbor
79
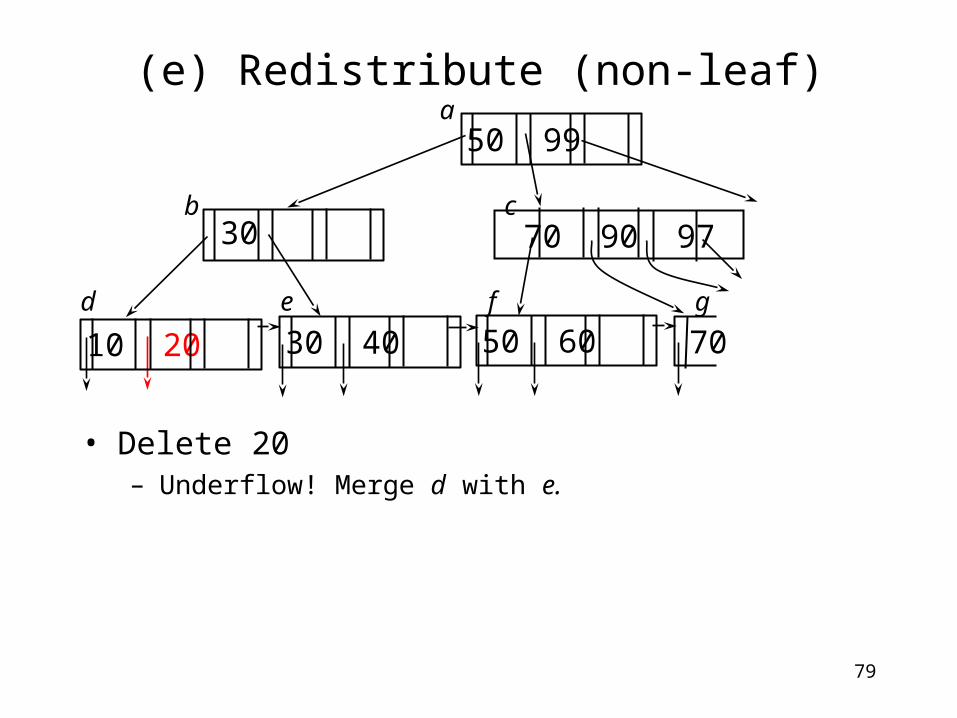
(e) Redistribute (non-leaf)
• Delete 20– Underflow! Merge d with e.
70
70 90 97
a
b c
d e f g
50 60
50 99
30
30 4010 20
80
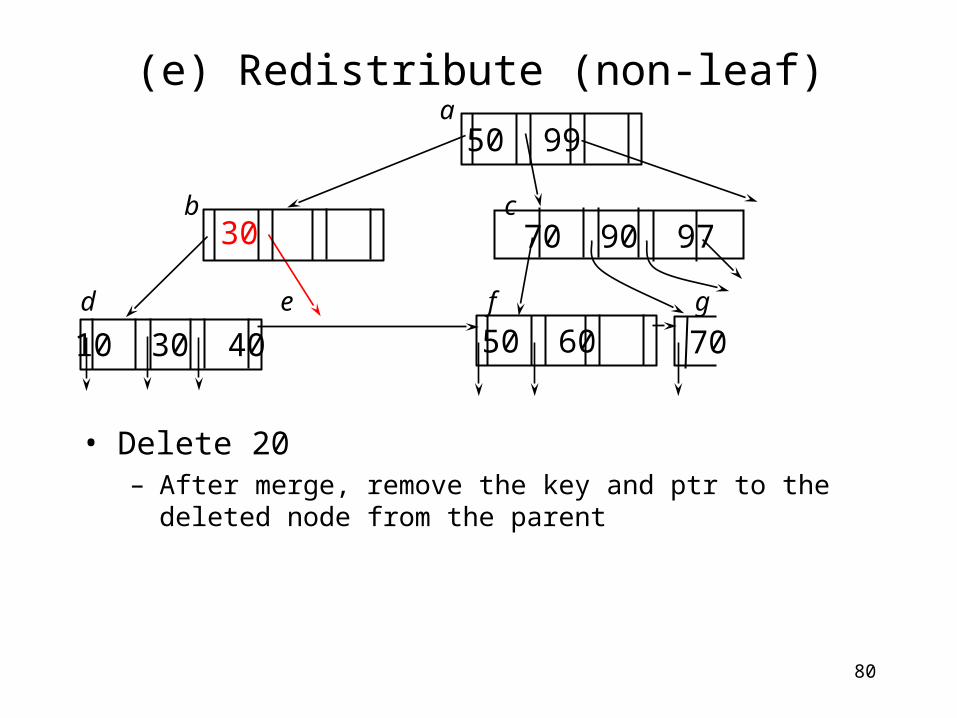
(e) Redistribute (non-leaf)
• Delete 20– After merge, remove the key and ptr to the deleted
node from the parent
70
70 90 97
a
b c
d e f g
50 60
50 99
30
10 30 40
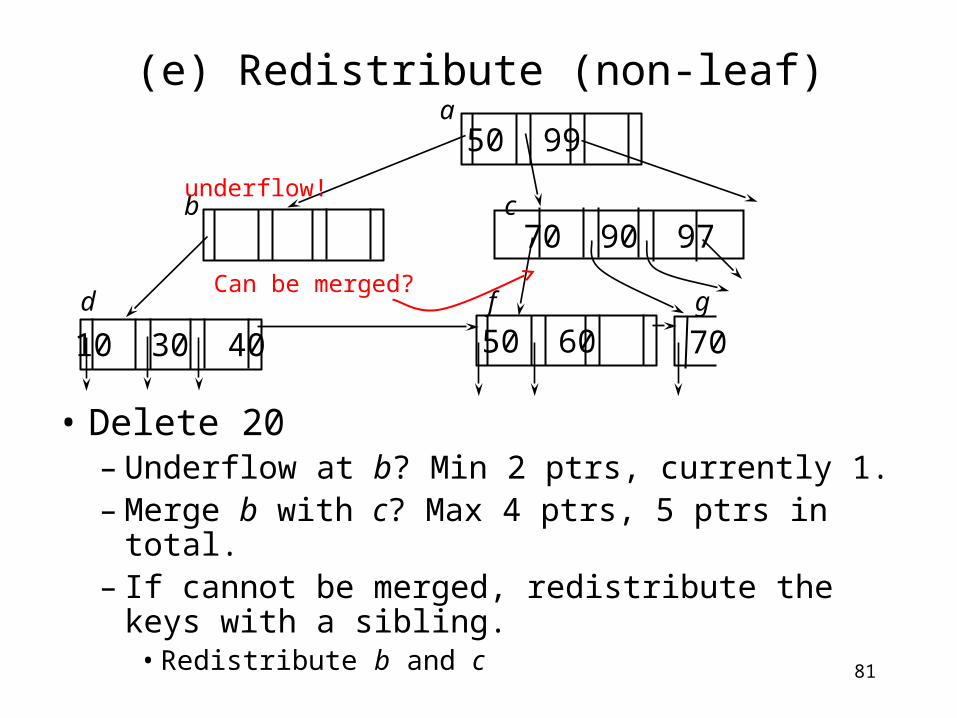
81
(e) Redistribute (non-leaf)
• Delete 20– Underflow at b? Min 2 ptrs, currently 1.– Merge b with c? Max 4 ptrs, 5 ptrs in total.– If cannot be merged, redistribute the keys
with a sibling.• Redistribute b and c
70
70 90 97
a
b c
d f g
underflow!
Can be merged?
50 60
50 99
10 30 40
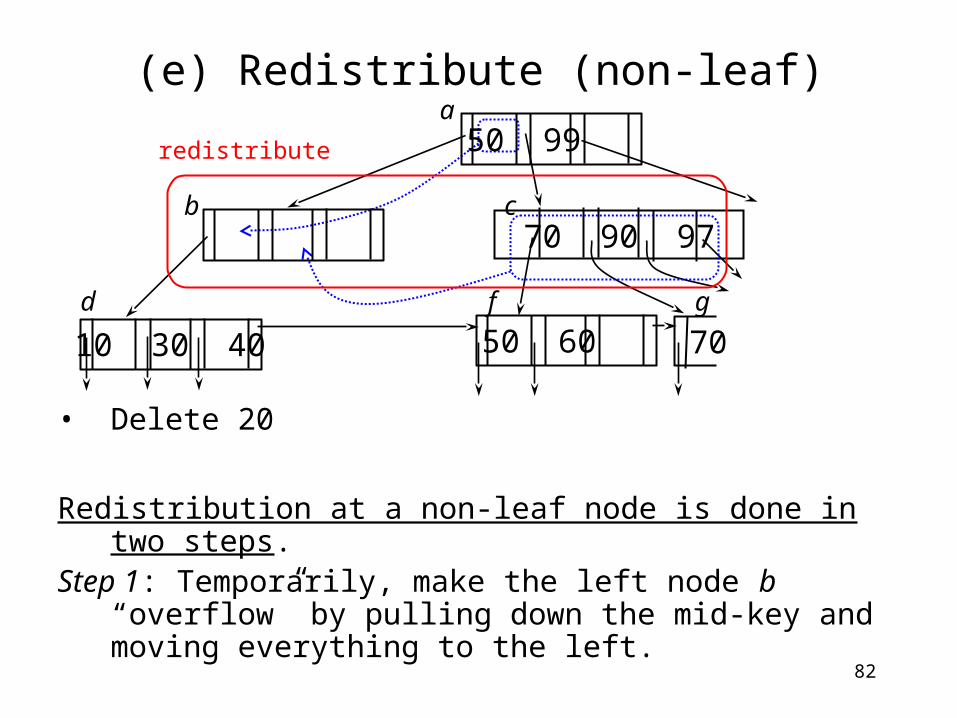
82
(e) Redistribute (non-leaf)
• Delete 20
Redistribution at a non-leaf node is done in two steps.
Step 1: Temporarily, make the left node b “overflow” by pulling down the mid-key and moving everything to the left.
70
70 90 97
a
b c
d f g
redistribute
50 60
50 99
10 30 40
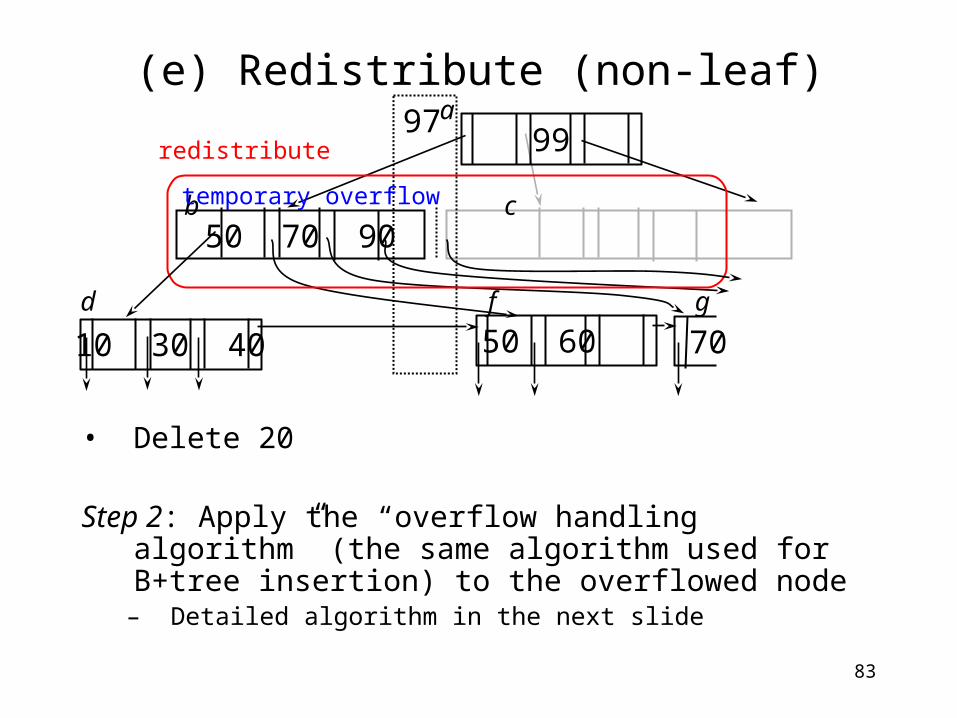
83
(e) Redistribute (non-leaf)
• Delete 20
Step 2: Apply the “overflow handling algorithm” (the same algorithm used for B+tree insertion) to the overflowed node– Detailed algorithm in the next slide
70
50 70 90
a
b c
d f g
redistribute 97
temporary overflow
50 60
99
10 30 40
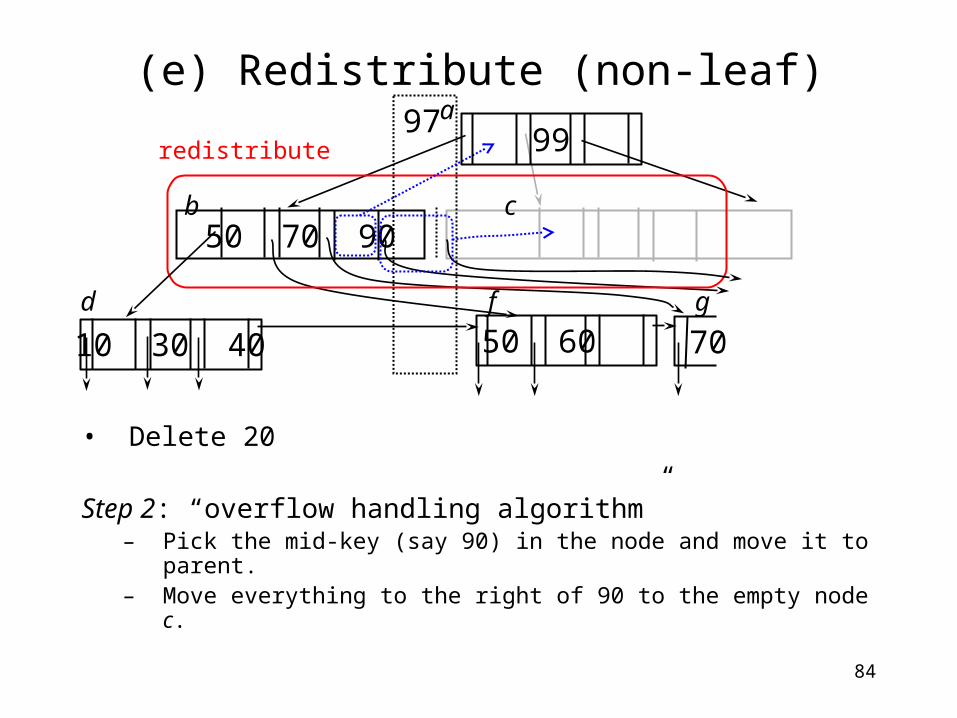
84
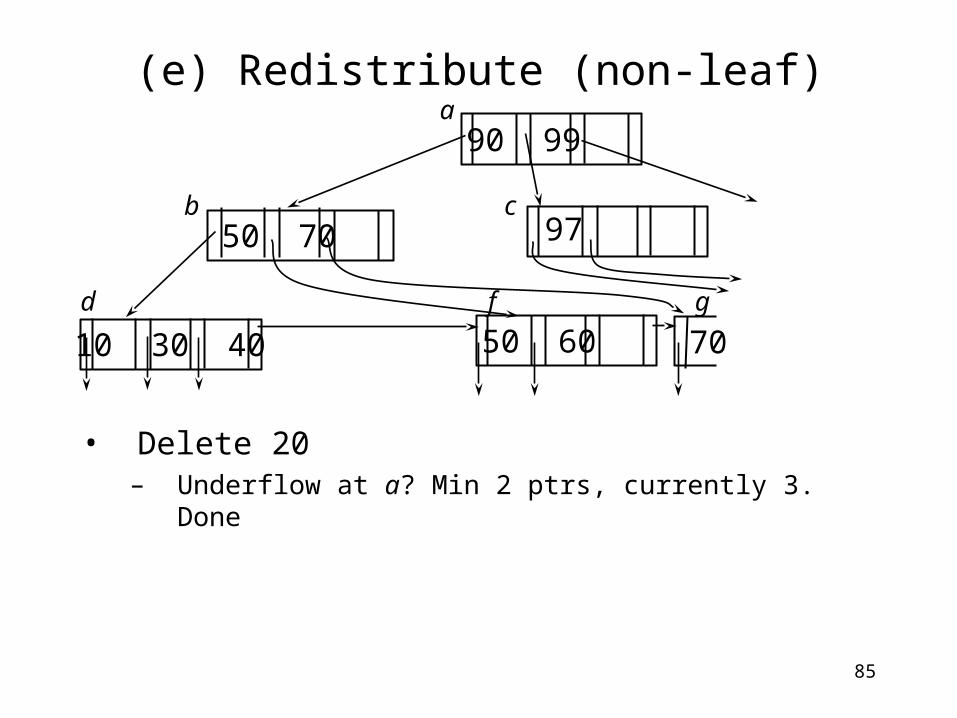
(e) Redistribute (non-leaf)
• Delete 20
Step 2: “overflow handling algorithm”– Pick the mid-key (say 90) in the node and move it to
parent.– Move everything to the right of 90 to the empty node c.
70
50 70 90
a
b c
d f g
redistribute 97
50 60
99
10 30 40
85
(e) Redistribute (non-leaf)
• Delete 20– Underflow at a? Min 2 ptrs, currently 3. Done
70
a
b c
d f g
50 60
90 99
9750 70
10 30 40

86
Important Points
• Remember: – For leaf node merging, we delete the mid-key
from the parent– For non-leaf node merging/redistribution, we
pull down the mid-key from their parent.
• Exact algorithm: Figure 12.17• In practice
– Coalescing is often not implemented• Too hard and not worth it

87
Where does n come from?
• n determined by– Size of a node– Size of search key– Size of an index pointer
• Q: 1024B node, 10B key, 8B ptr n?
88
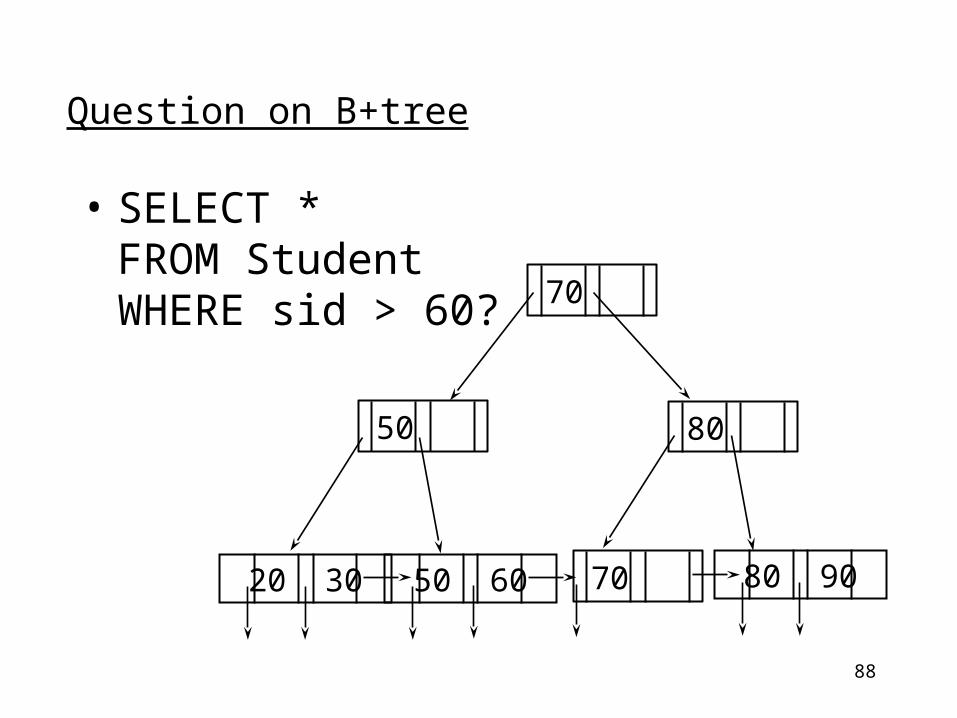
Question on B+tree
• SELECT *FROM StudentWHERE sid > 60?
20 30 50 60 80 90
70
50 80
70

89
Summary on tree index
• Issues to consider– Sparse vs. dense– Primary (clustering) vs. secondary (non-
clustering)
• Indexed sequential file (ISAM)– Simple algorithm. Sequential blocks– Not suitable for dynamic environment
• B+trees– Balanced, minimum space guarantee– Insertion, deletion algorithms

90
Index Creation in SQL
• CREATE INDEX <indexname> ON <table>(<attr>,<attr>,…)
• Example– CREATE INDEX stidx ONStudent(sid)• Creates a B+tree on the attributes• Speeds up lookup on sid

91
Primary (Clustering) Index• MySQL:
– Primary key becomes the clustering index • DB2:
– CREATE INDEX idx ON Student(sid) CLUSTER
– Tuples in the table are sequenced by sid• Oracle: Index-Organized Table (IOT)
– CREATE TABLE T ( ...
) ORGANIZATION INDEX– B+tree on primary key– Tuples are stored at the leaf nodes of B+tree
• Periodic reorganization may still be necessary to improve range scan performance

92
Next topic
• Hash index– Static hashing– Extendible hashing

93
What is a Hash Table?
• Hash Table– Hash function
• h(k): key integer [0…n]• e.g., h(‘Susan’) = 7
– Array for keys: T[0…n]– Given a key k, store it in
T[h(k)]0
1 Neil
2
3 James
4 Susan
5
h(Susan) = 4h(James) = 3h(Neil) = 1
94
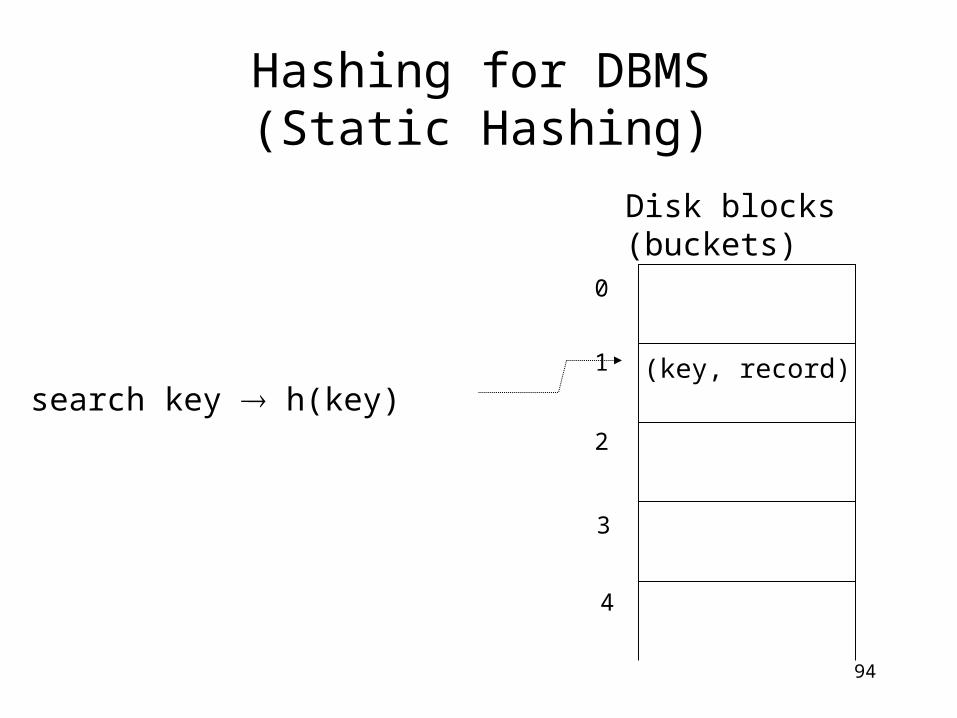
Hashing for DBMS(Static Hashing)
(key, record)
.
.
Disk blocks (buckets)
search key h(key)
0
1
2
3
4
95
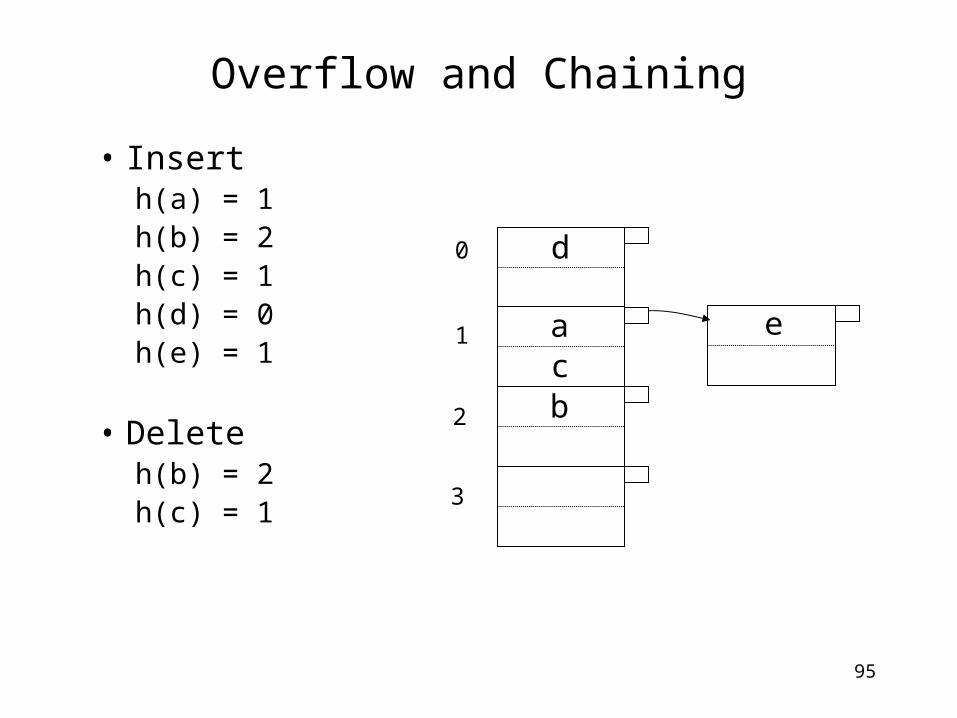
Overflow and Chaining
• Insert h(a) = 1h(b) = 2h(c) = 1h(d) = 0h(e) = 1
• Deleteh(b) = 2h(c) = 1
0
1
2
3
a
bc
d
e

96
Major Problem of Static Hashing
• How to cope with growth?– Data tends to grow in size– Overflow blocks unavoidable
102030
405060
708090
39313536
323834
33
overflow blockshash buckets
97
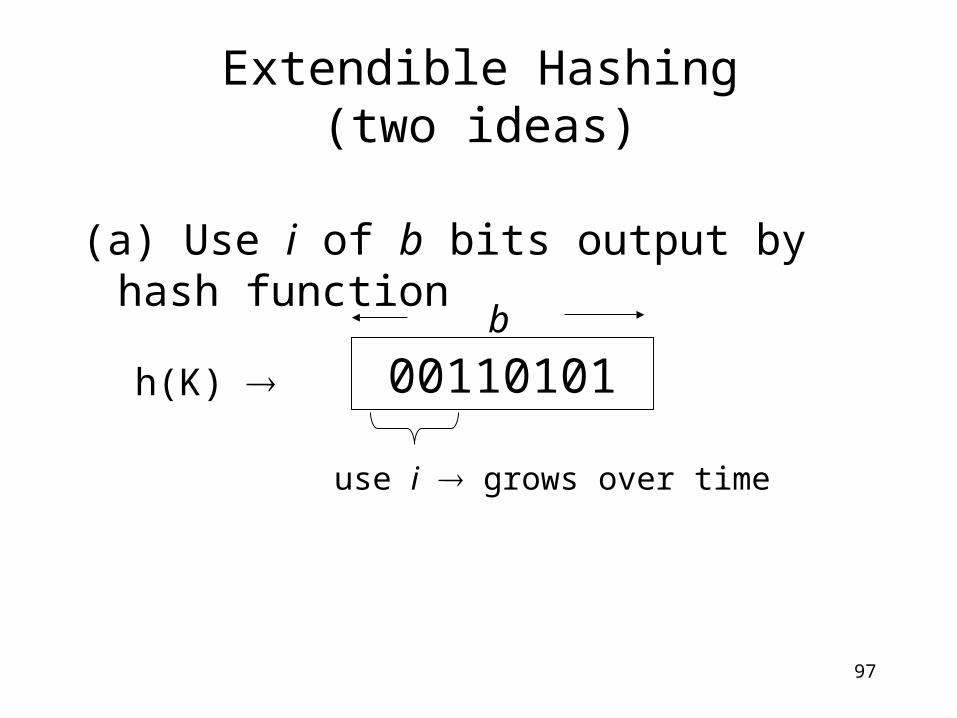
(a) Use i of b bits output by hash function
Extendible Hashing(two ideas)
00110101h(K)
b
use i grows over time
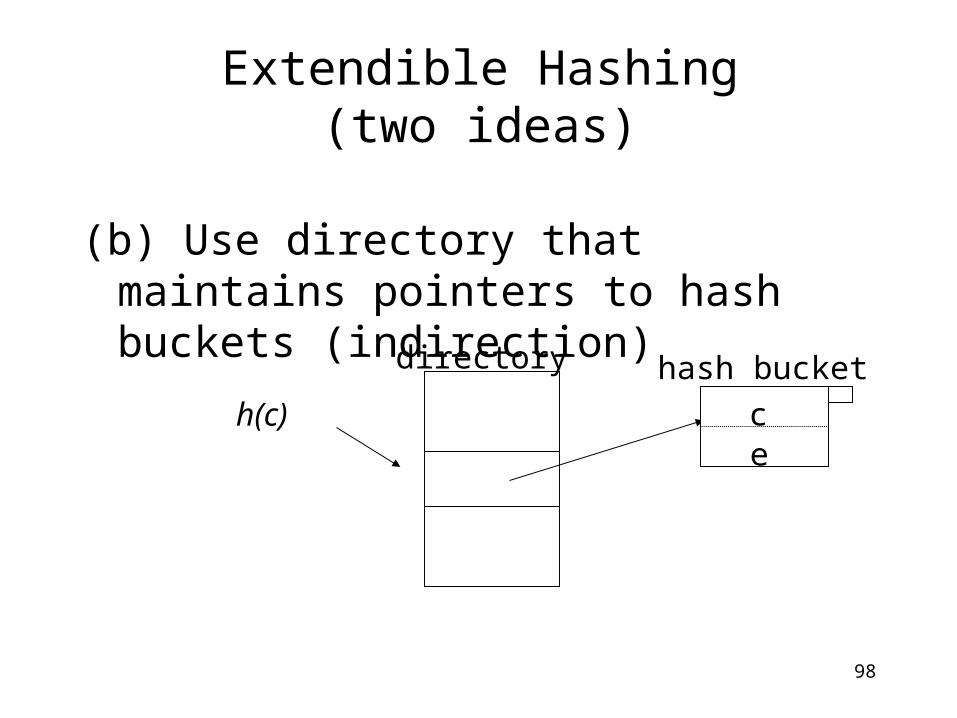
98
(b) Use directory that maintains pointers to hash buckets (indirection)
Extendible Hashing(two ideas)
.
.
.
.
ce
hash bucketdirectory
h(c)
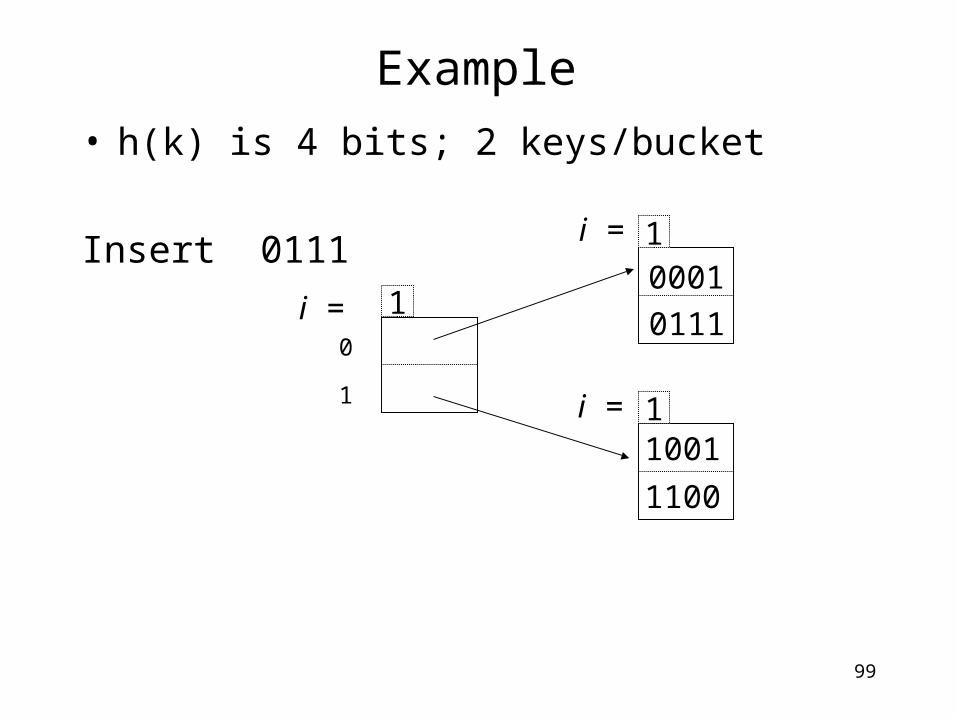
99
Example• h(k) is 4 bits; 2 keys/bucket
Insert 0111 1
1
0001
1001
1100
10
1
i =
i =
i =
0111
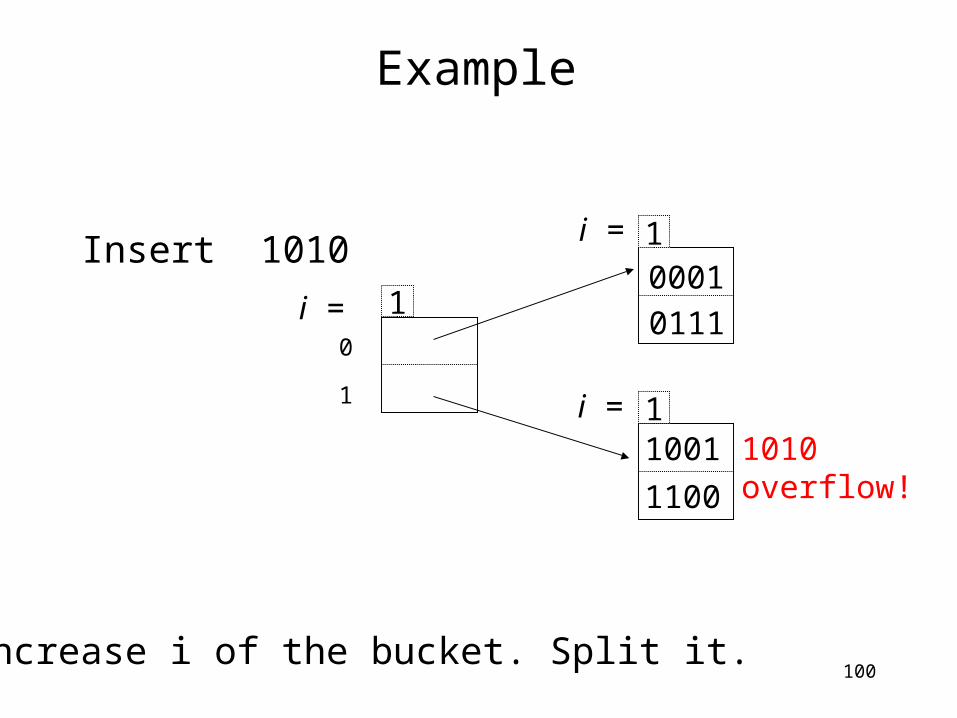
100
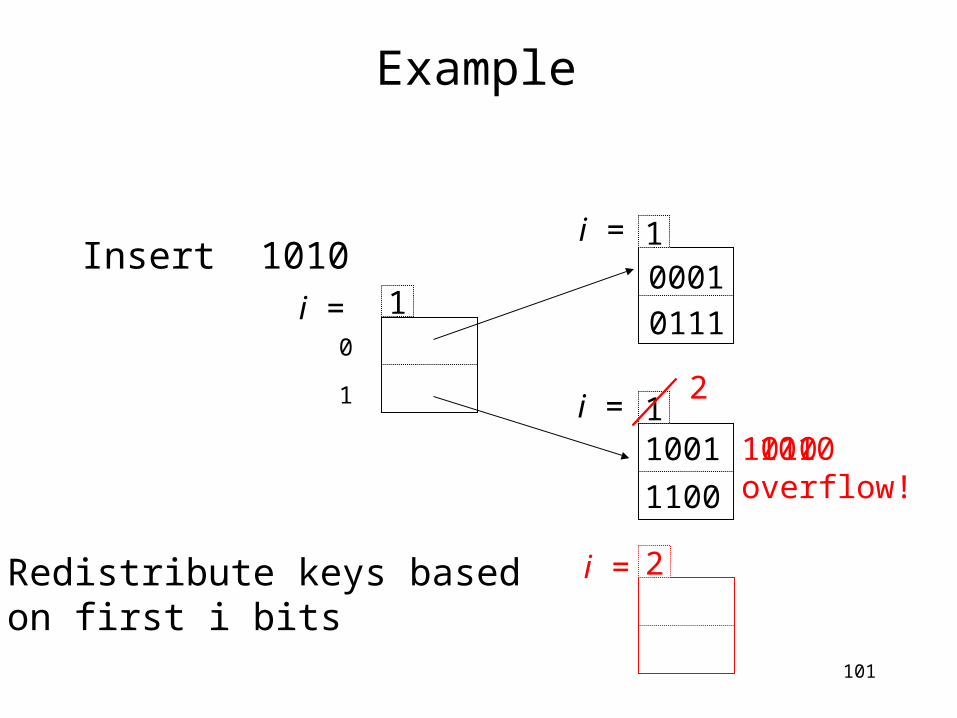
Example
Insert 1010 1
1
0001
1001
1100
0111
i =
i =
10
1
i =
1010overflow!
Increase i of the bucket. Split it.
101
Example
Insert 1010 1
1
0001
1001
1100
0111
10101010overflow!
2
Redistribute keys based on first i bits
i =
2i =
i =
10
1
i =
102
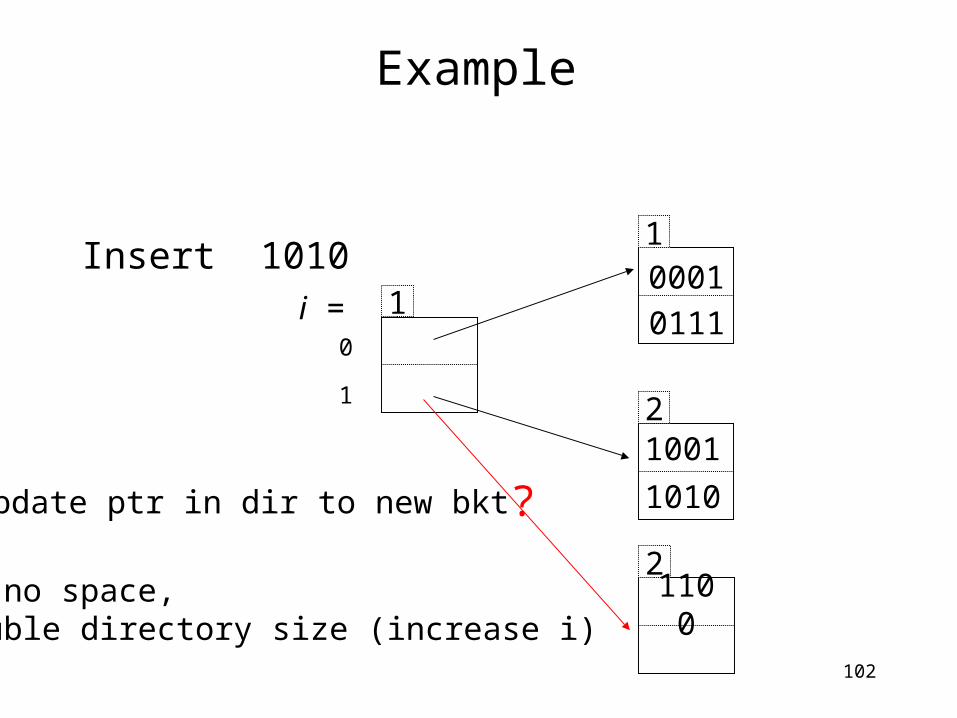
Example
Insert 1010 1
2
0001
1001
1010
0111
2110
0
Update ptr in dir to new bkt
10
1
i =
?
If no space, double directory size (increase i)
103
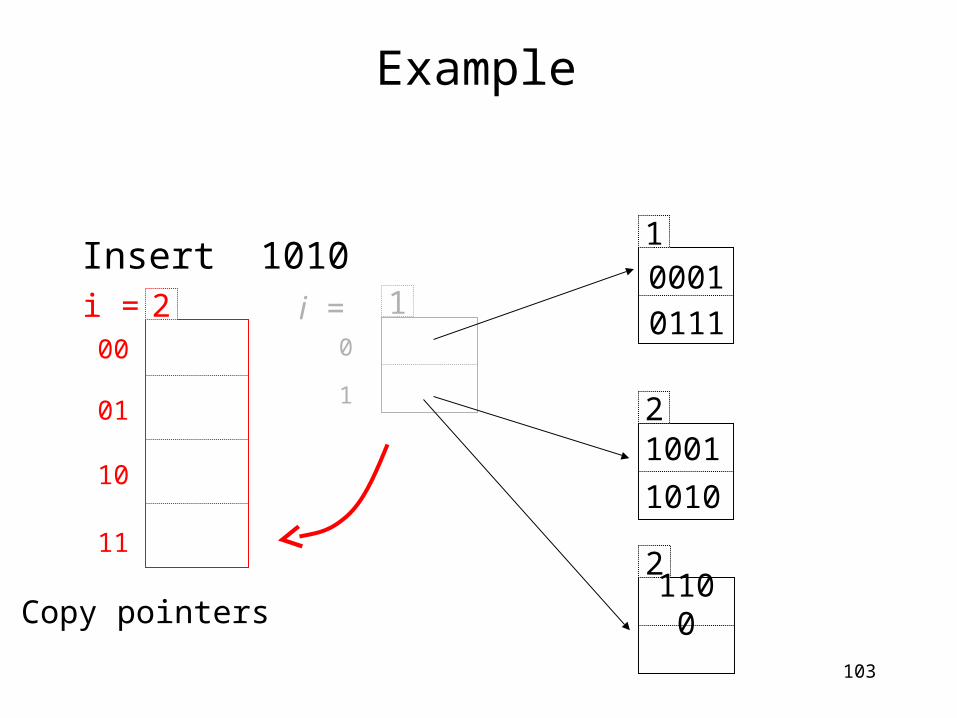
Example
Insert 1010 1
2
0001
1001
1010
0111
2110
0
10
1
i =00
01
10
11
2i =
Copy pointers
104
10
1
i =
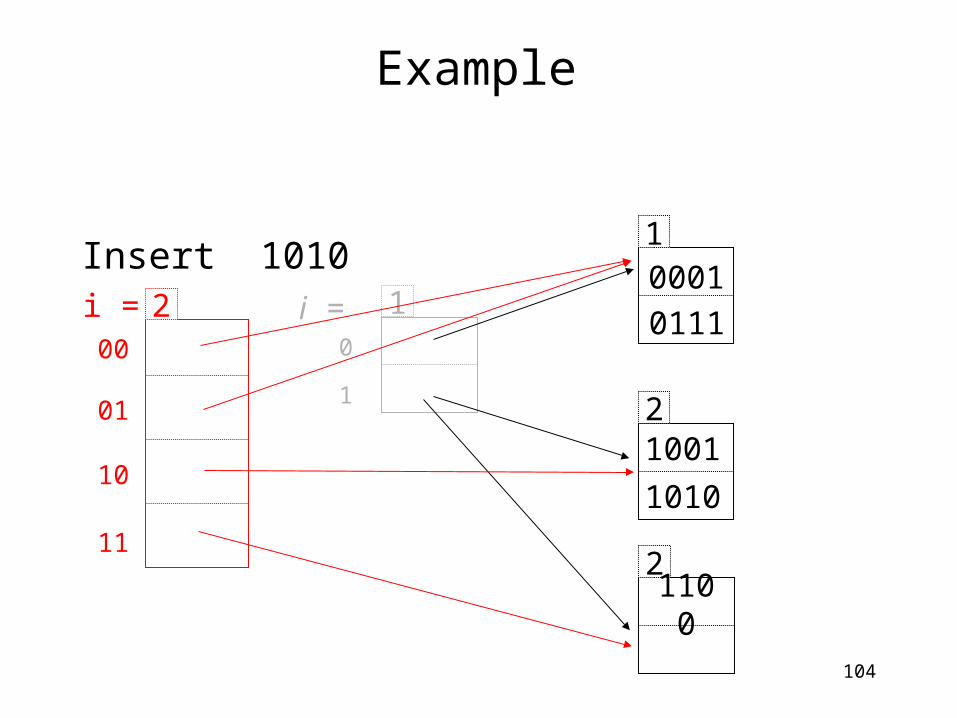
Example
Insert 1010 1
2
0001
1001
1010
0111
2110
0
00
01
10
11
2i =
105
Example
Insert 0000 1
2
0001
1001
1010
0111
2110
0
00
01
10
11
2i =
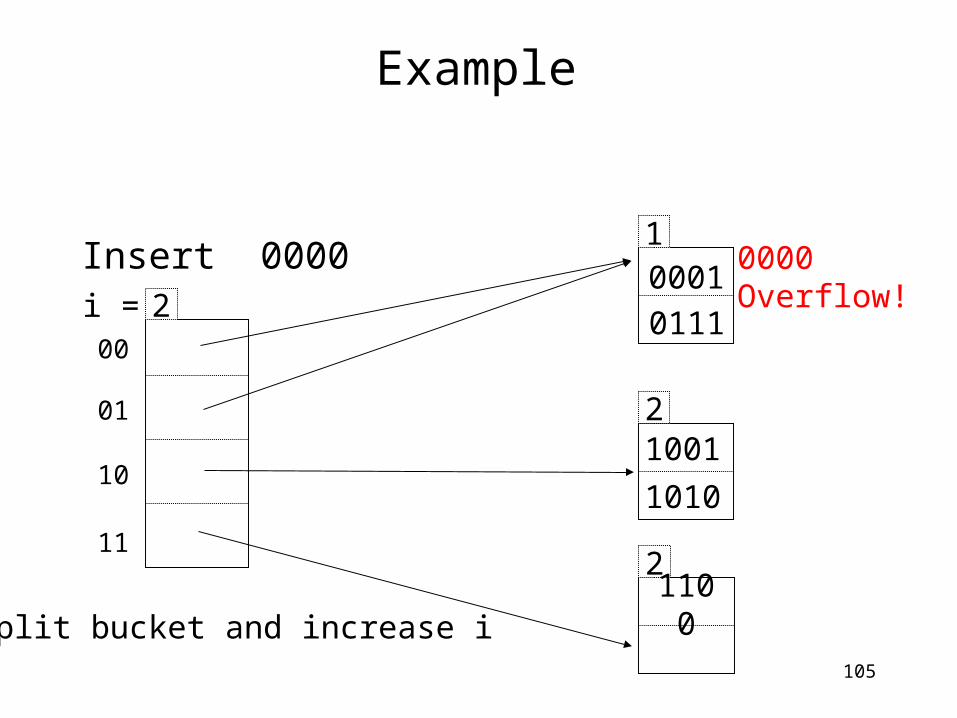
0000Overflow!
Split bucket and increase i
106
Example
Insert 0000 1
2
0001
1001
1010
0111
2110
0
00
01
10
11
2i =
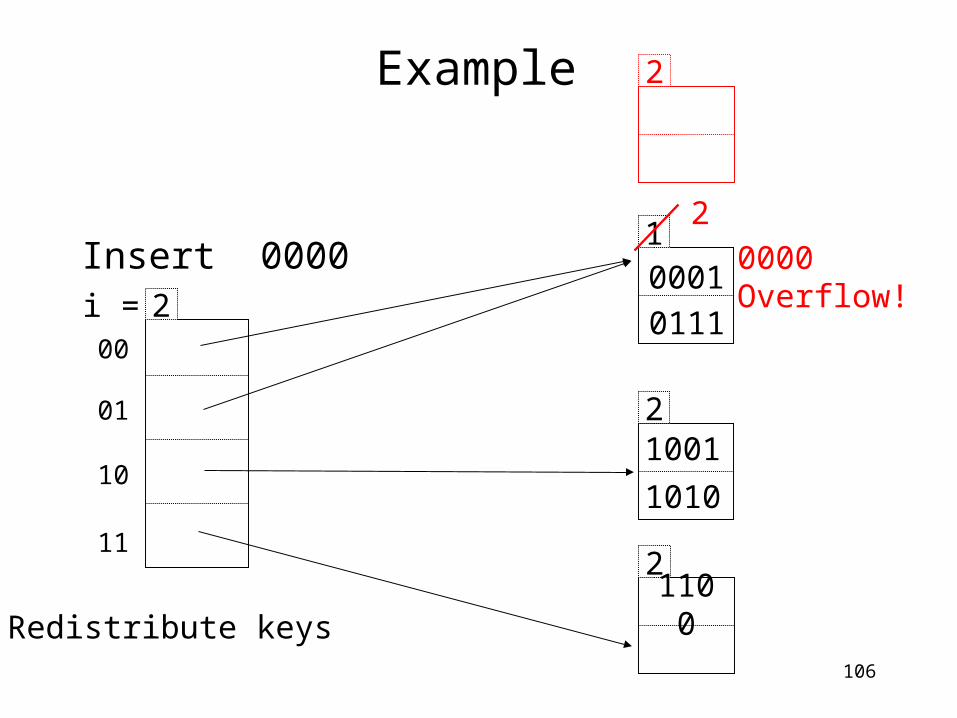
2
20000Overflow!
Redistribute keys
107
Example
Insert 0000 1
2
0111
1001
1010
2110
0
00
01
10
11
2i =
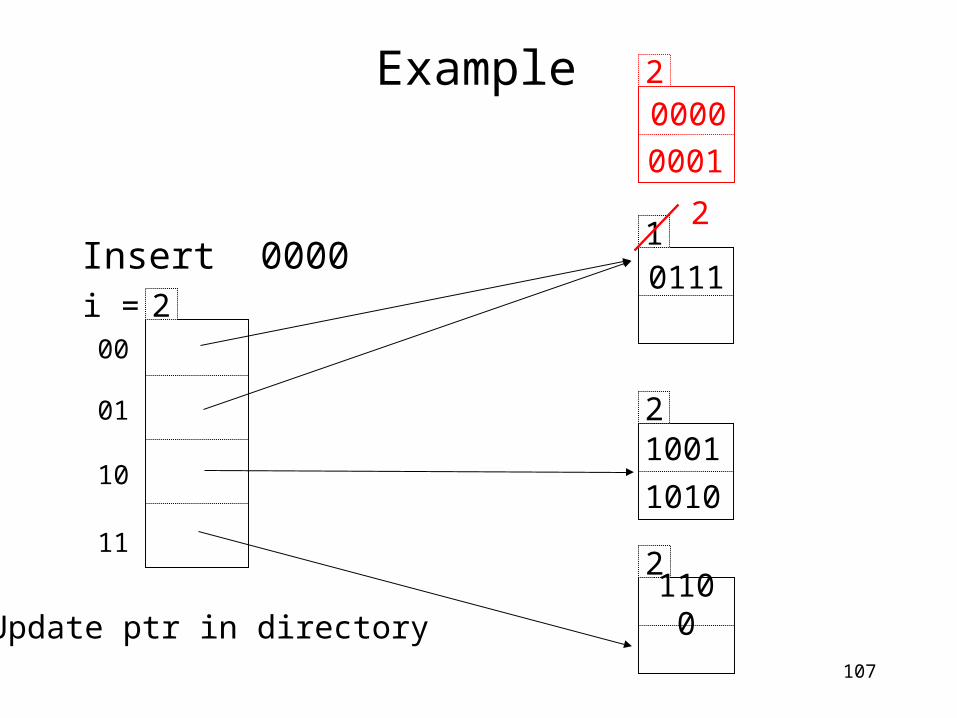
2
2
0000
0001
Update ptr in directory
108
Example
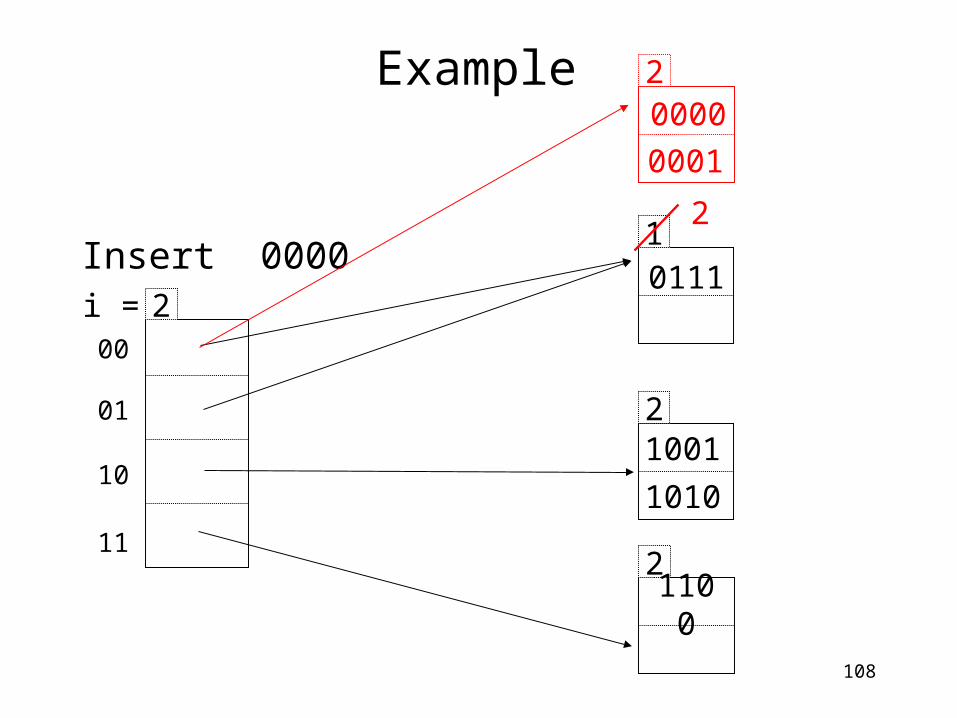
Insert 0000 1
2
0111
1001
1010
2110
0
00
01
10
11
2i =
2
2
0000
0001
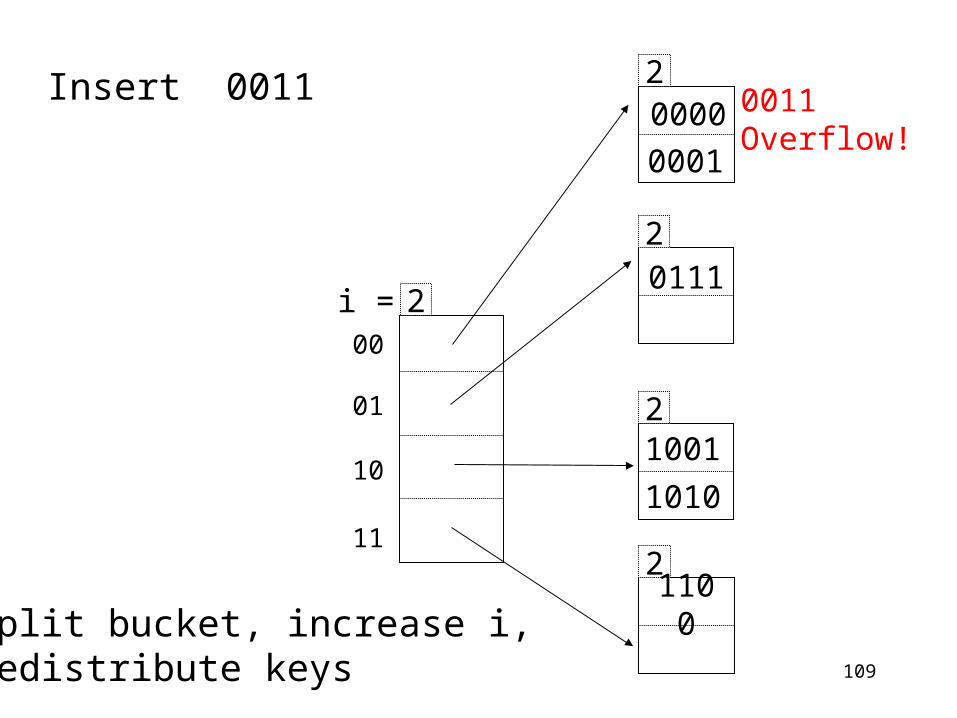
109
Insert 0011
2
2
0111
1001
1010
2110
0
00
01
10
11
2i =
20000
0001
0011Overflow!
Split bucket, increase i, redistribute keys
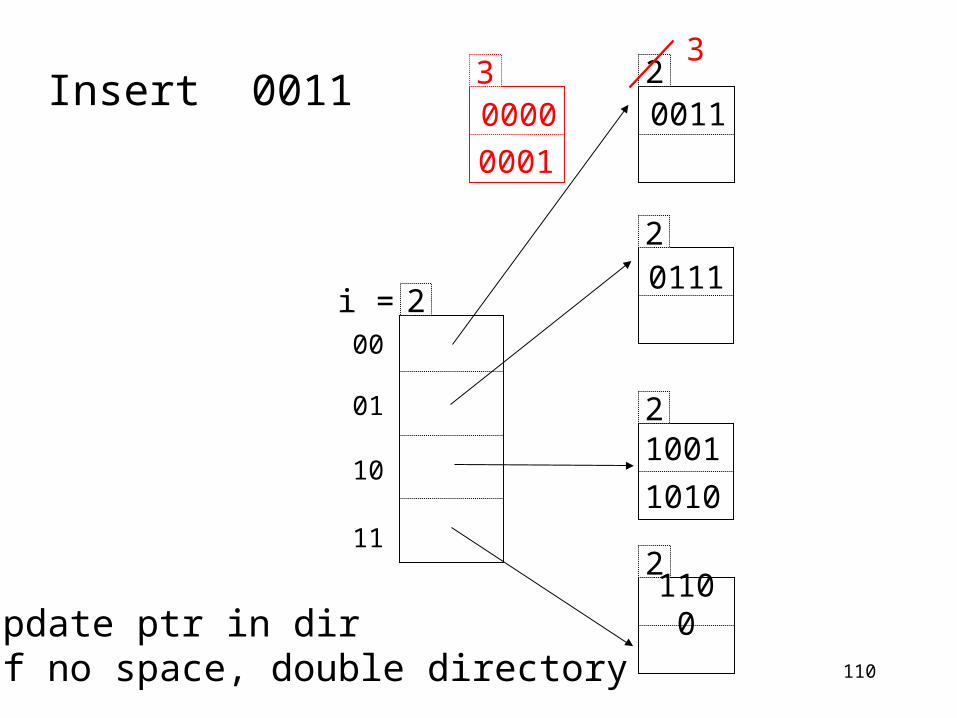
110
2
2
0111
1001
1010
2110
0
00
01
10
11
2i =
20011
Update ptr in dirIf no space, double directory
30000
0001
3Insert 0011
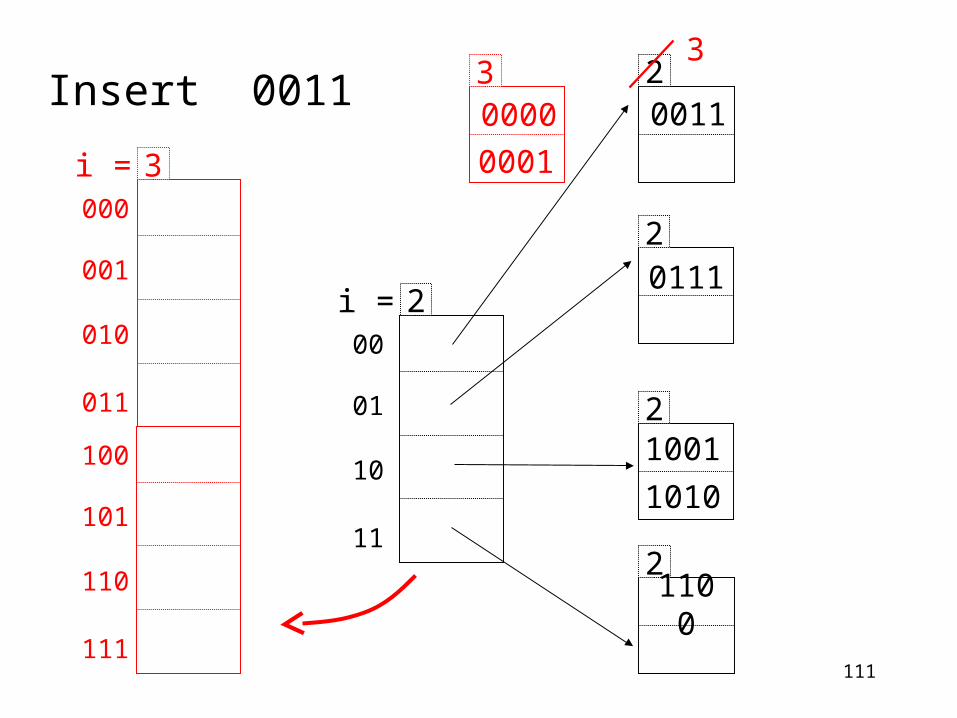
111
2
2
0111
1001
1010
2110
0
00
01
10
11
2i =
20011
30000
0001
3Insert 0011
000
001
010
011
3i =
100
101
110
111
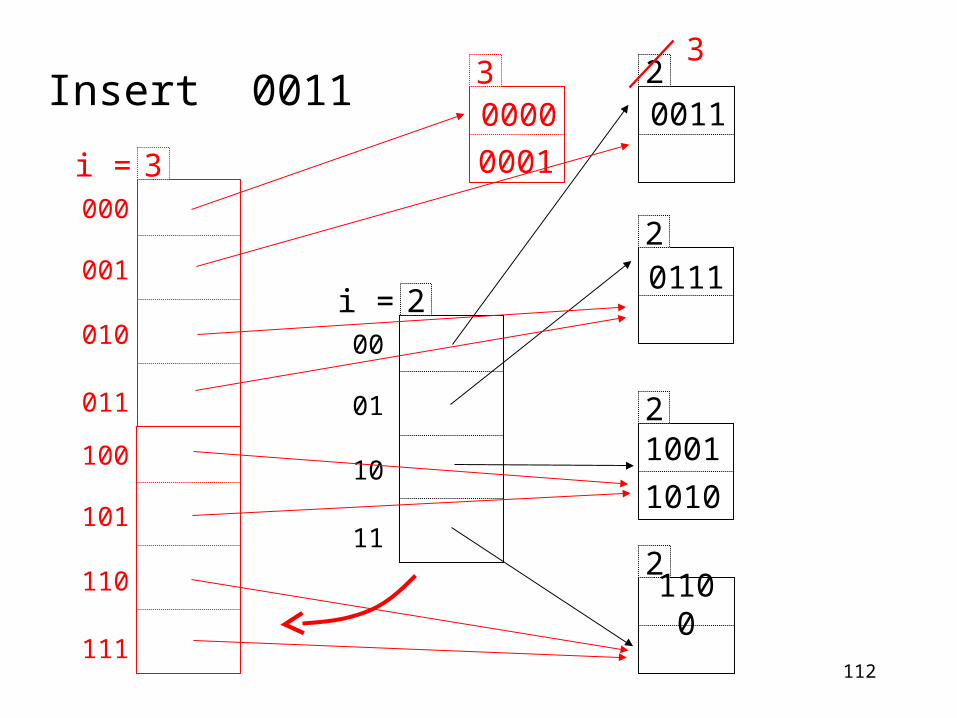
112
2
2
0111
1001
1010
2110
0
00
01
10
11
2i =
20011
30000
0001
3Insert 0011
000
001
010
011
3i =
100
101
110
111

113
Extendible Hashing: Deletion
• Two optionsa) No merging of bucketsb) Merge buckets and shrink directory
if possible
114
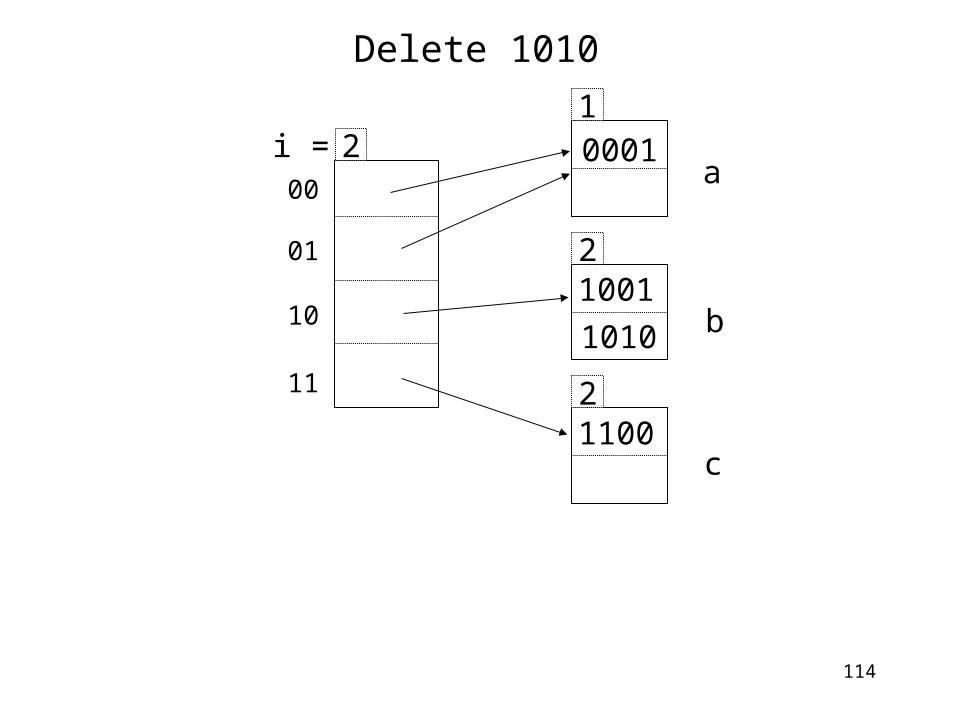
Delete 1010
10001
21001
21100
00
01
10
11
2i =a
b
c
1010
115
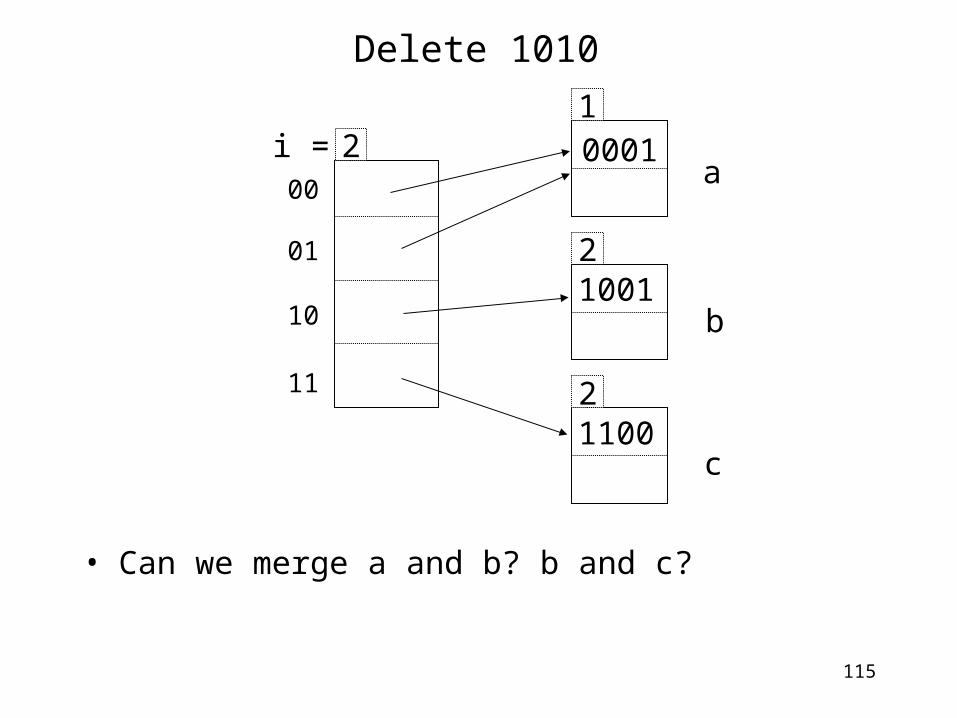
Delete 1010
• Can we merge a and b? b and c?
10001
21001
21100
00
01
10
11
2i =a
b
c

116
Delete 1010
Decrease i and merge buckets
10001
21001
00
01
10
11
2i =a
b
21100
c
1
1100
Update ptr in directory
Q: Can we shrink directory?
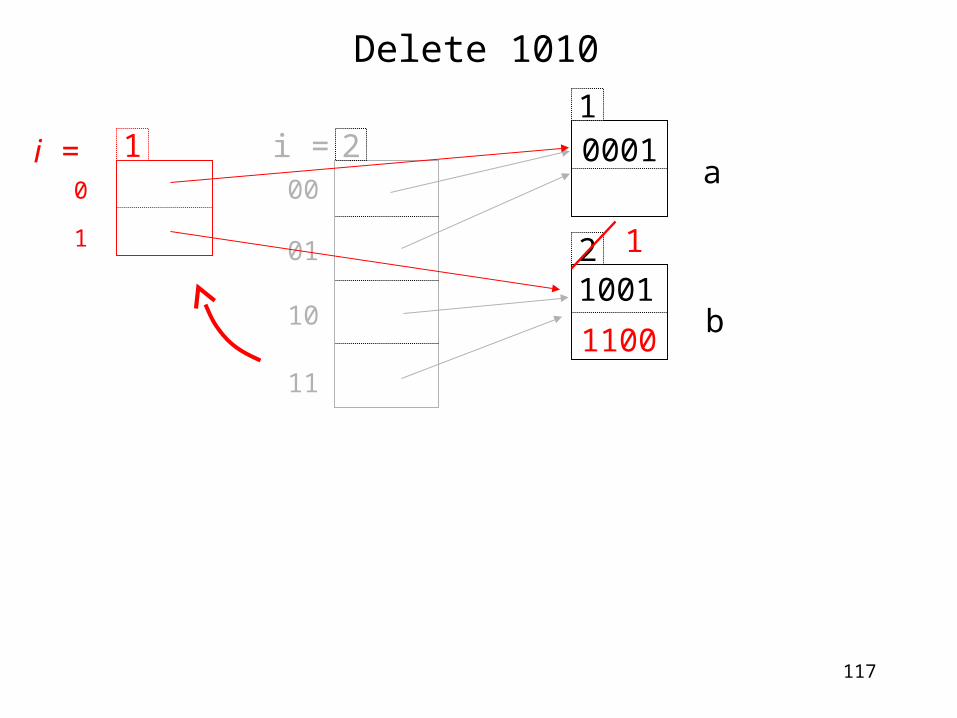
117
Delete 1010
10001
21001
00
01
10
11
2i =a
b
1
1100
10
1
i =

118
Bucket Merge Condition
• Bucket merge condition– Bucket i’s are the same– First (i-1) bits of the hash key are the
same
• Directory shrink condition– All bucket i’s are smaller than the
directory i

119
Questions on Extendible Hashing
• Can we provide minimum space guarantee?
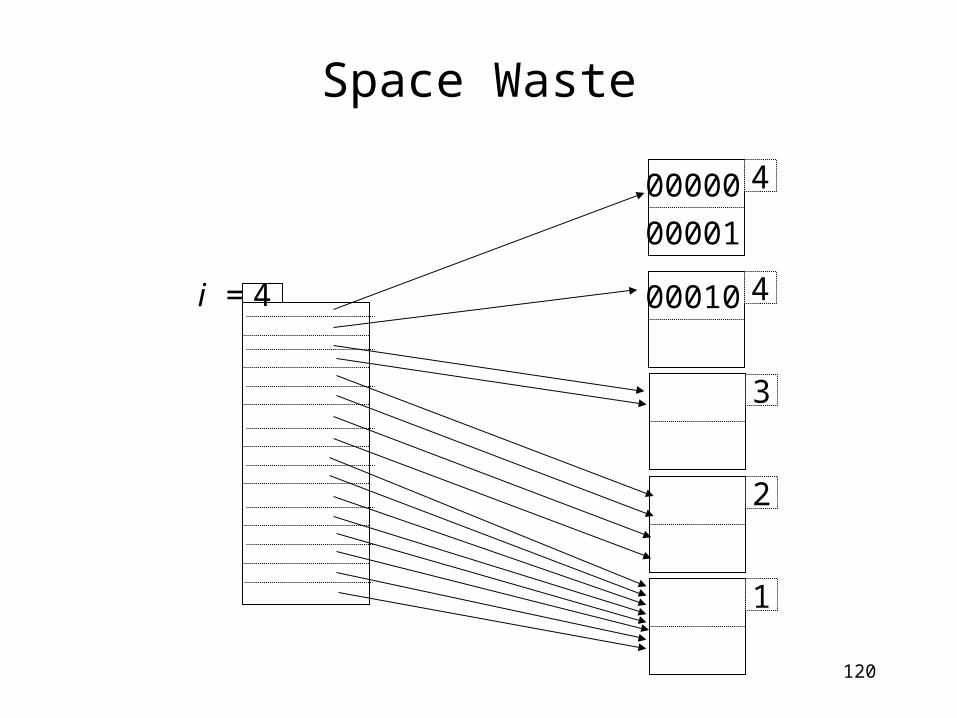
120
Space Waste
2
1
400010
400000
00001
4i =
3

121
Hash index summary
• Static hashing– Overflow and chaining
• Extendible hashing– Can handle growing files
• No periodic reorganizations
– Indirection• Up to 2 disk accesses to access a key
– Directory doubles in size• Not too bad if the data is not too large

122
Hashing vs. Tree
• Can an extendible-hash index support?SELECT *FROM RWHERE R.A > 5
• Which one is better, B+tree or Extendible hashing?
SELECT *FROM RWHERE R.A = 5





























