Embed Size (px)
Citation preview

55:035 Computer Architecture and Organization
Lecture 7
155:035 Computer Architecture and Organization

Outline Cache Memory Introduction Memory Hierarchy Direct-Mapped Cache Set-Associative Cache Cache Sizes Cache Performance
255:035 Computer Architecture and Organization

Memory access time is important to performance! Users want large memories with fast access times
ideally unlimited fast memory To use an analogy, think of a bookshelf containing
many books: Suppose you are writing a paper on birds. You go to the bookshelf, pull out
some of the books on birds and place them on the desk. As you start to look through them you realize that you need more references. So you go back to the bookshelf and get more books on birds and put them on the desk. Now as you begin to write your paper, you have many of the references you need on the desk in front of you.
This is an example of the principle of locality:This principle states that programs access a relatively small portion of their address space at any instant of time.
Introduction
355:035 Computer Architecture and Organization
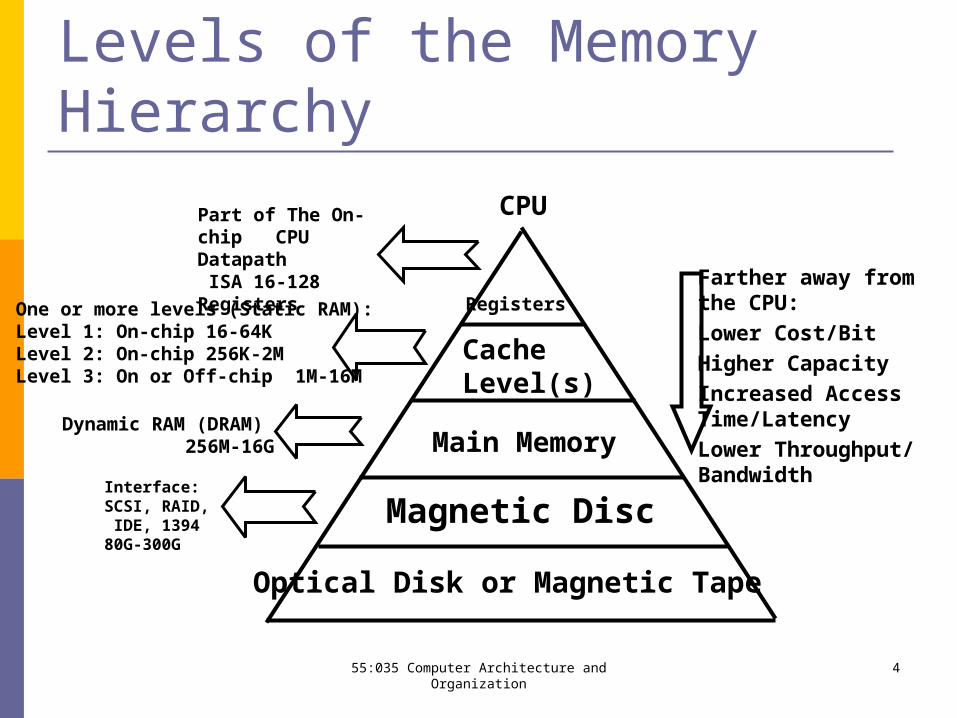
Levels of the Memory Hierarchy
55:035 Computer Architecture and Organization 4
Part of The On-chip CPU Datapath ISA 16-128 Registers
One or more levels (Static RAM):Level 1: On-chip 16-64K Level 2: On-chip 256K-2MLevel 3: On or Off-chip 1M-16M
Registers
CacheLevel(s)
Main Memory
Magnetic Disc
Optical Disk or Magnetic Tape
Farther away from the CPU:
Lower Cost/Bit
Higher Capacity
Increased AccessTime/Latency
Lower Throughput/Bandwidth
Dynamic RAM (DRAM) 256M-16G
Interface:SCSI, RAID, IDE, 139480G-300G
CPU
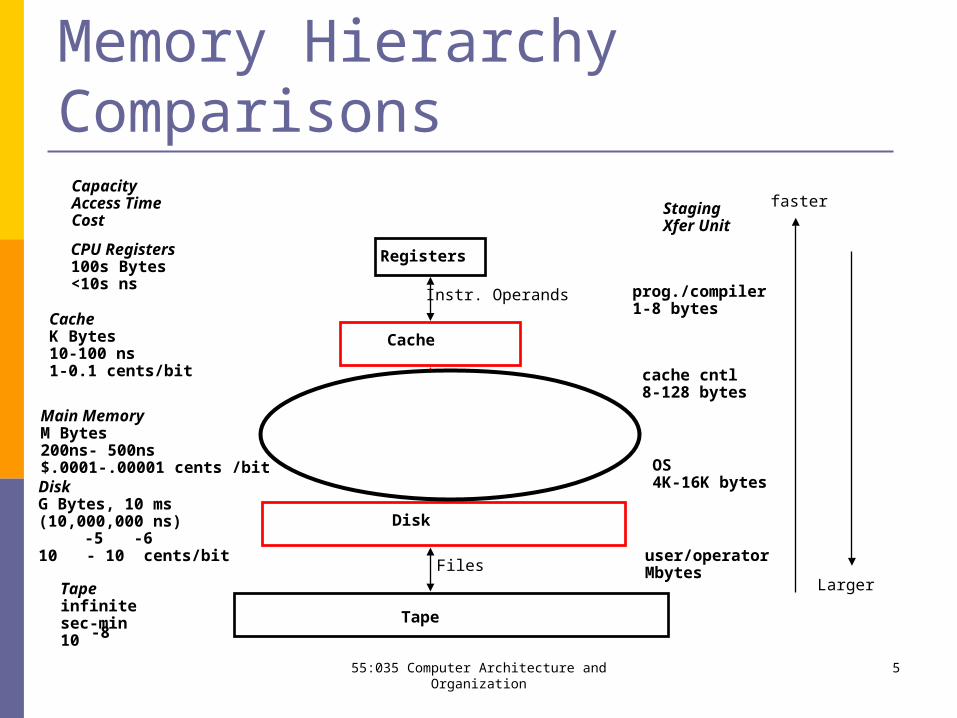
Memory Hierarchy Comparisons
55:035 Computer Architecture and Organization 5
CPU Registers100s Bytes<10s ns
CacheK Bytes10-100 ns1-0.1 cents/bit
Main MemoryM Bytes200ns- 500ns$.0001-.00001 cents /bitDiskG Bytes, 10 ms (10,000,000 ns)
10 - 10 cents/bit-5 -6
CapacityAccess TimeCost
Tapeinfinitesec-min10 -8
Registers
Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
StagingXfer Unit
prog./compiler1-8 bytes
cache cntl8-128 bytes
OS4K-16K bytes
user/operatorMbytes
faster
Larger

We can exploit the natural locality in programs by implementing the memory of a computer as a memory hierarchy.
Multiple levels of memory with different speeds and sizes. The fastest memories are more expensive, and usually much smaller in size
(see figure).
The user has the illusion of a memory that is both large and fast. Accomplished by using efficient methods for memory structure and organization.
Memory Hierarchy
655:035 Computer Architecture and Organization

55:035 Computer Architecture and Organization 7
Inventor of Cache
M. V. Wilkes, “Slave Memories and Dynamic Storage Allocation,”IEEE Transactions on Electronic Computers, vol. EC-14, no. 2,pp. 270-271, April 1965.
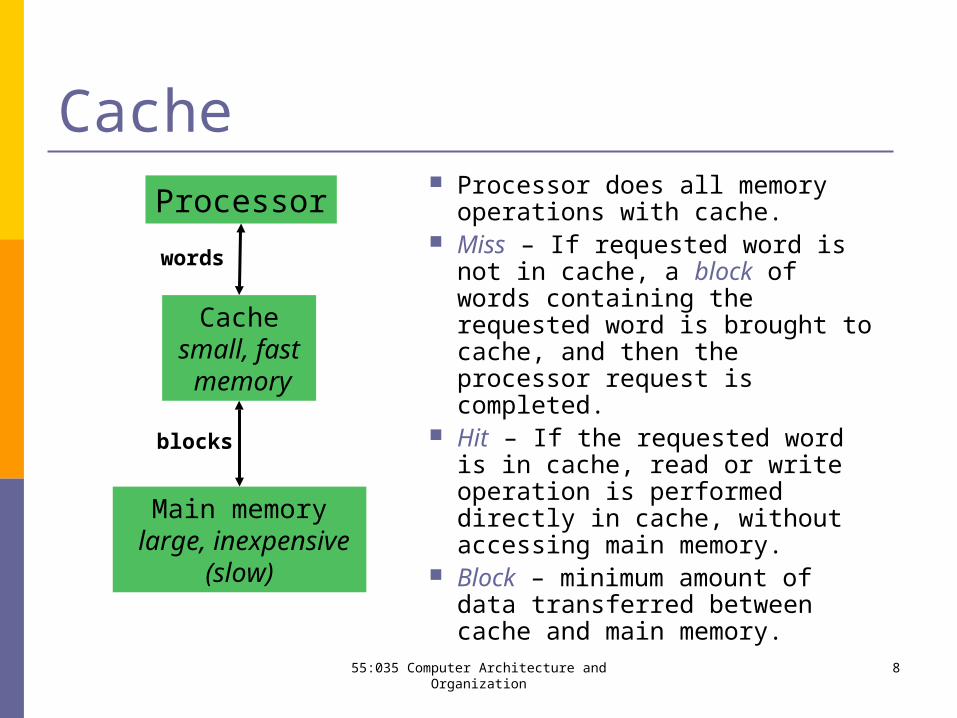
55:035 Computer Architecture and Organization 8
Cache Processor does all memory
operations with cache. Miss – If requested word is not in
cache, a block of words containing the requested word is brought to cache, and then the processor request is completed.
Hit – If the requested word is in cache, read or write operation is performed directly in cache, without accessing main memory.
Block – minimum amount of data transferred between cache and main memory.
Processor
Cache small, fast
memory
Main memory large, inexpensive
(slow)
words
blocks

55:035 Computer Architecture and Organization 9
The Locality Principle A program tends to access data that form a physical
cluster in the memory – multiple accesses may be made within the same block.
Physical localities are temporal and may shift over longer periods of time – data not used for some time is less likely to be used in the future. Upon miss, the least recently used (LRU) block can be overwritten by a new block.
P. J. Denning, “The Locality Principle,” Communications of the ACM, vol. 48, no. 7, pp. 19-24, July 2005.

There are two types of locality:TEMPORAL LOCALITY
(locality in time) If an item is referenced, it will likely be referenced again soon. Data is reused.
SPATIAL LOCALITY(locality in space) If an item is referenced, items in neighboring addresses will likely be referenced soon
Most programs contain natural locality in structure. For example, most programs contain loops in which the instructions and data need to be accessed repeatedly. This is an example of temporal locality.
Instructions are usually accessed sequentially, so they contain a high amount of spatial locality.
Also, data access to elements in an array is another example of spatial locality.
Temporal & Spatial Locality
1055:035 Computer Architecture and Organization
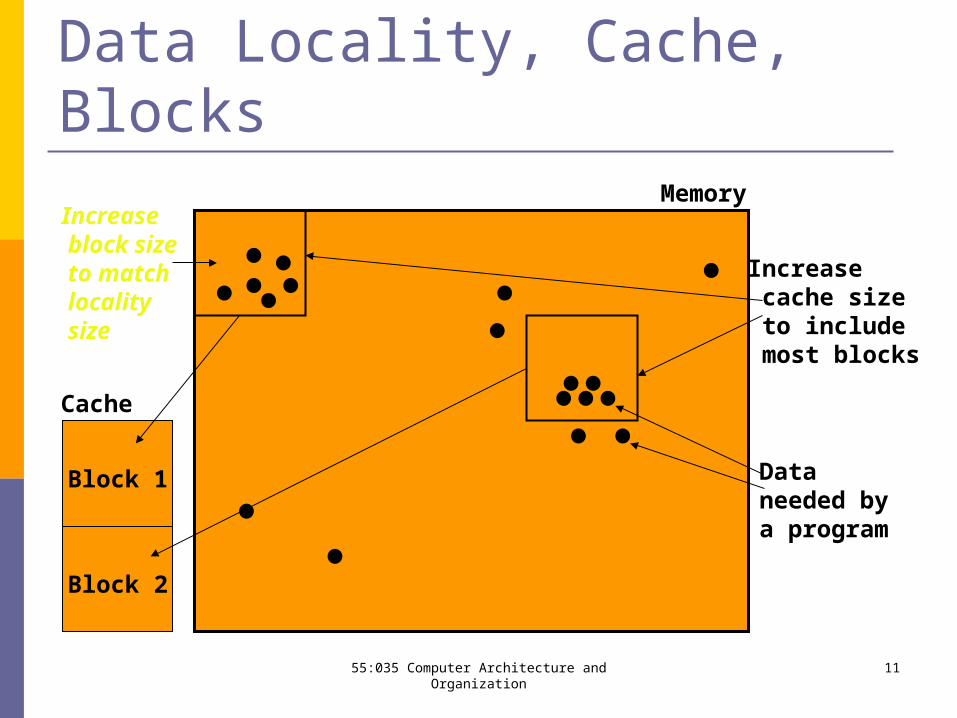
55:035 Computer Architecture and Organization 11
Data Locality, Cache, Blocks
Increase block size to match locality size
Increase cache size to include most blocks
Dataneeded bya program
Block 1
Block 2
Memory
Cache
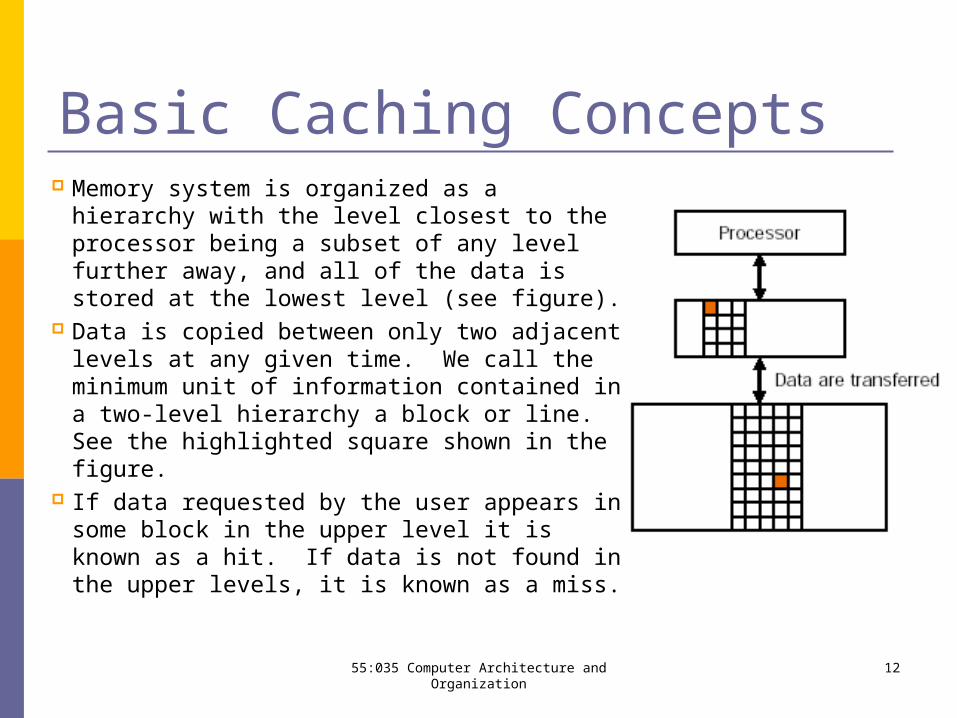
Memory system is organized as a hierarchy with the level closest to the processor being a subset of any level further away, and all of the data is stored at the lowest level (see figure).
Data is copied between only two adjacent levels at any given time. We call the minimum unit of information contained in a two-level hierarchy a block or line. See the highlighted square shown in the figure.
If data requested by the user appears in some block in the upper level it is known as a hit. If data is not found in the upper levels, it is known as a miss.
55:035 Computer Architecture and Organization 12
Basic Caching Concepts
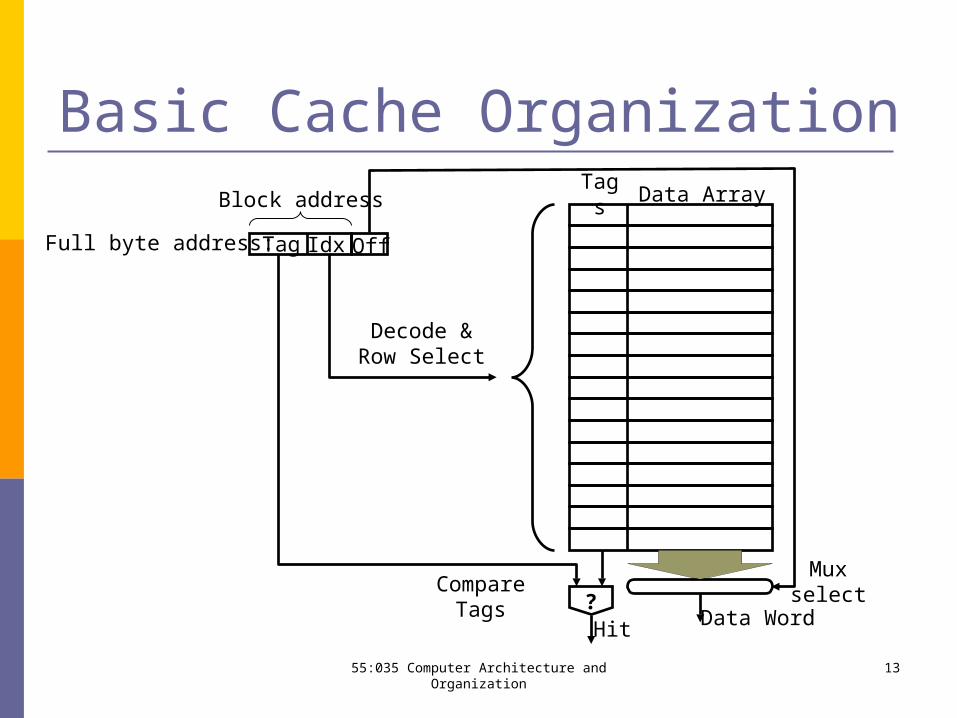
Basic Cache OrganizationTag
sData Array
Full byte address:
Decode & Row Select
?Compare Tags
Hit
Tag Idx Off
Data Word
Muxselect
Block address
1355:035 Computer Architecture and Organization
55:035 Computer Architecture and Organization 14
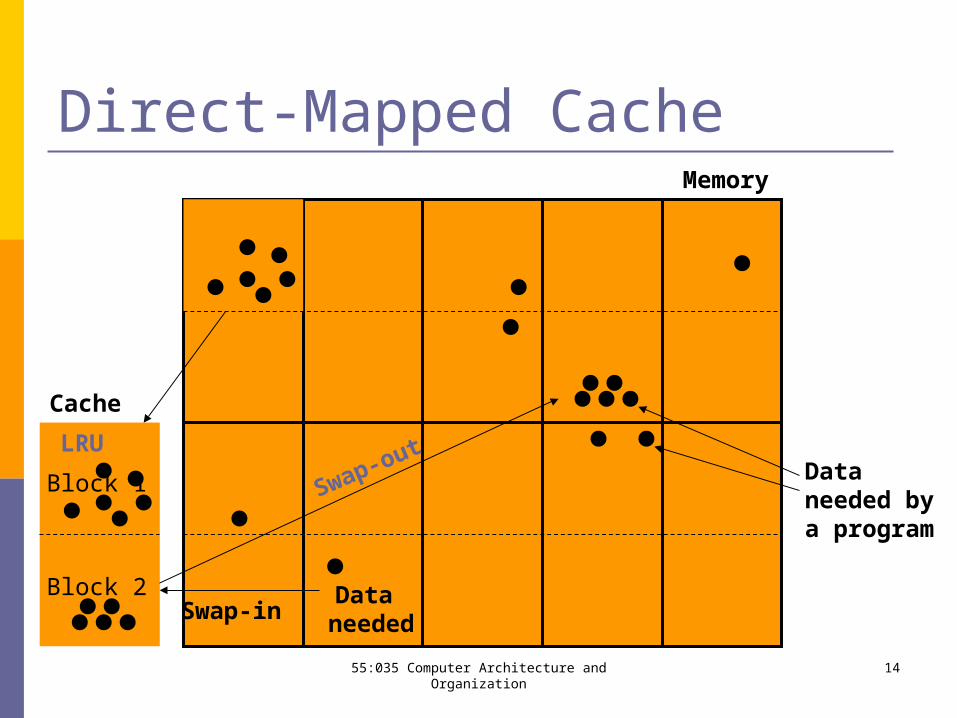
Direct-Mapped Cache
Dataneeded bya program
Memory
Cache
Data needed
Swap-out
Swap-in
LRU
Block 1
Block 2
55:035 Computer Architecture and Organization 15
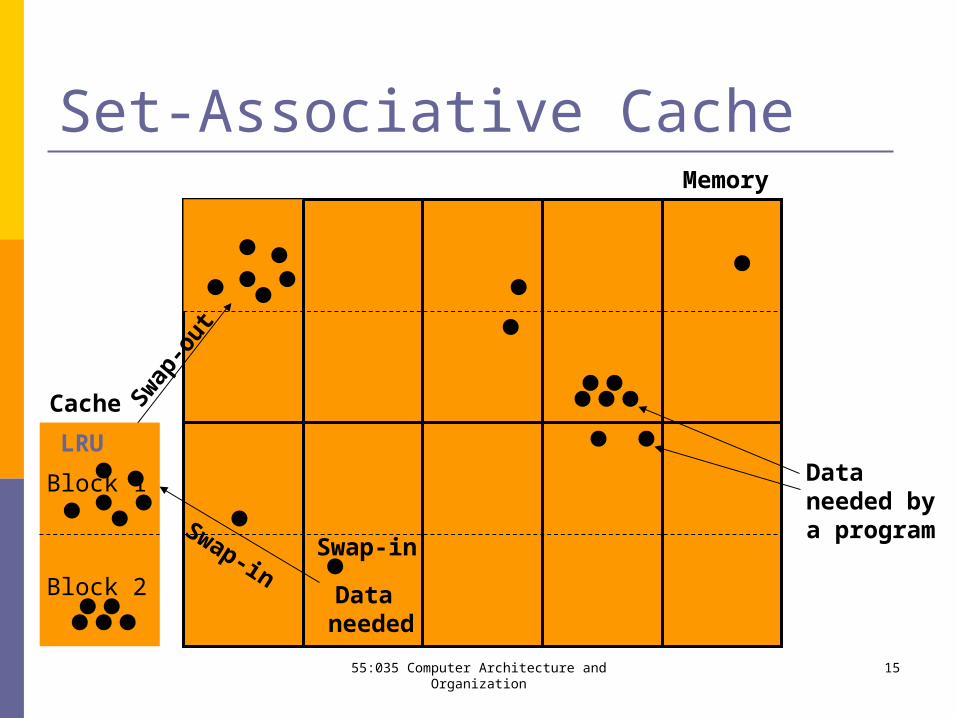
Set-Associative Cache
Dataneeded bya program
Memory
Cache
Data needed
Swap-in
Swap
-out
LRU
Block 1
Block 2
Swap-in
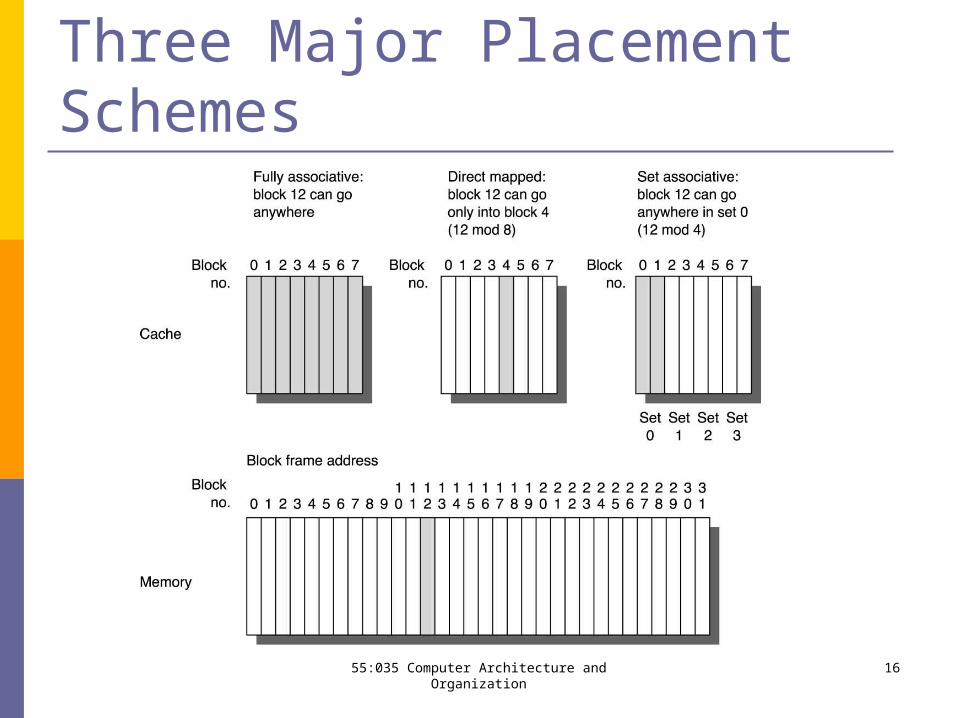
Three Major Placement Schemes
1655:035 Computer Architecture and Organization

Direct-Mapped Placement A block can only go into one place in the cache
Determined by the block’s address (in memory space) The index number for block placement is usually given by some low-
order bits of block’s address.
This can also be expressed as:(Index) =
(Block address) mod (Number of blocks in cache)
Note that in a direct-mapped cache, Block placement & replacement choices are both completely
determined by the address of the new block that is to be accessed.
1755:035 Computer Architecture and Organization
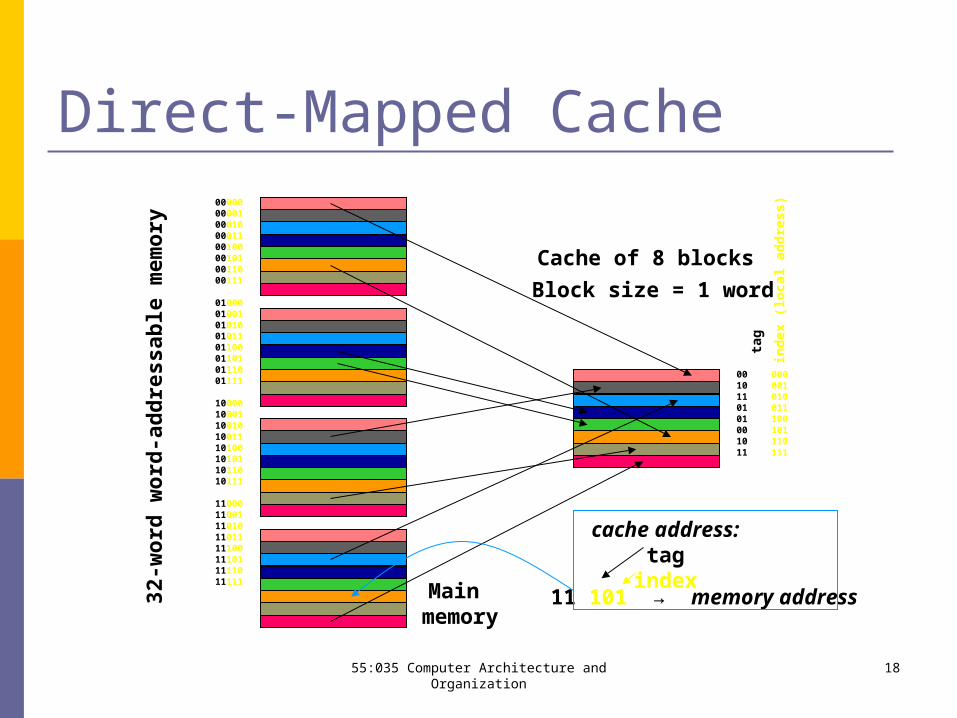
55:035 Computer Architecture and Organization 18
Direct-Mapped Cache
000001010011100101110111
0000000001000100001100100001010011000111
0100001001010100101101100011010111001111
1000010001100101001110100101011011010111
1100011001110101101111100111011111011111
Main memory
Cache of 8 blocks
11 101 → memory address
cache address: tag
index 32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
ind
ex (
loca
l ad
dre
ss)
tag
0010110101001011
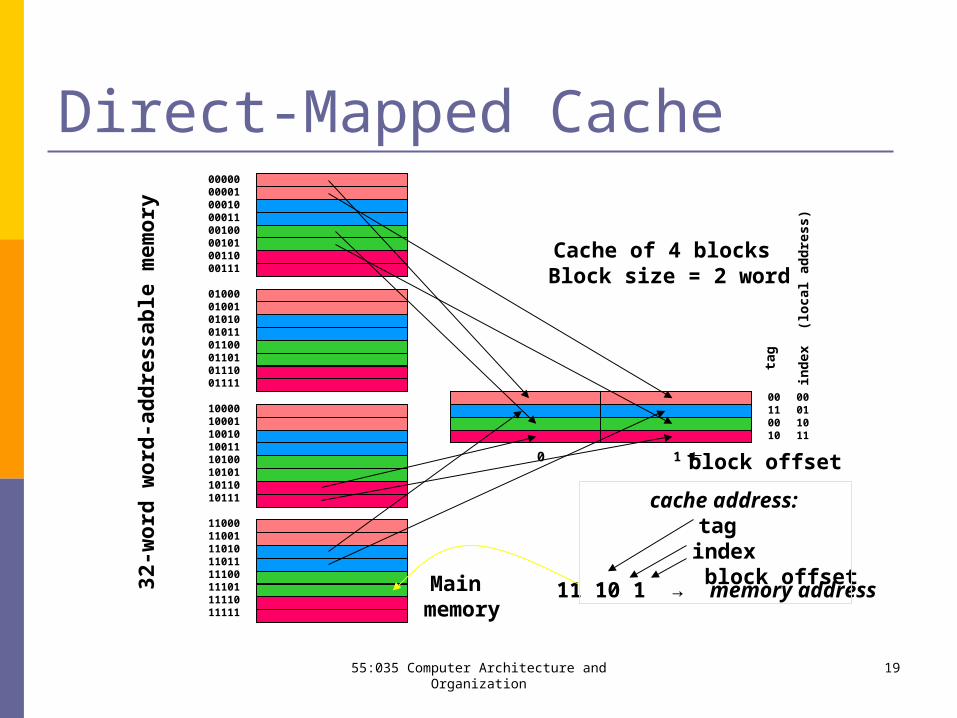
55:035 Computer Architecture and Organization 19
Direct-Mapped Cache
00011011
0000000001000100001100100001010011000111
0100001001010100101101100011010111001111
1000010001100101001110100101011011010111
1100011001110101101111100111011111011111
Main memory
Cache of 4 blocks
11 10 1 → memory address
cache address:tag
index block offset 3
2-w
ord
wo
rd-a
dd
ress
able
mem
ory
Block size = 2 word
ind
ex (
loca
l ad
dre
ss)
tag
00110010
block offset0 1
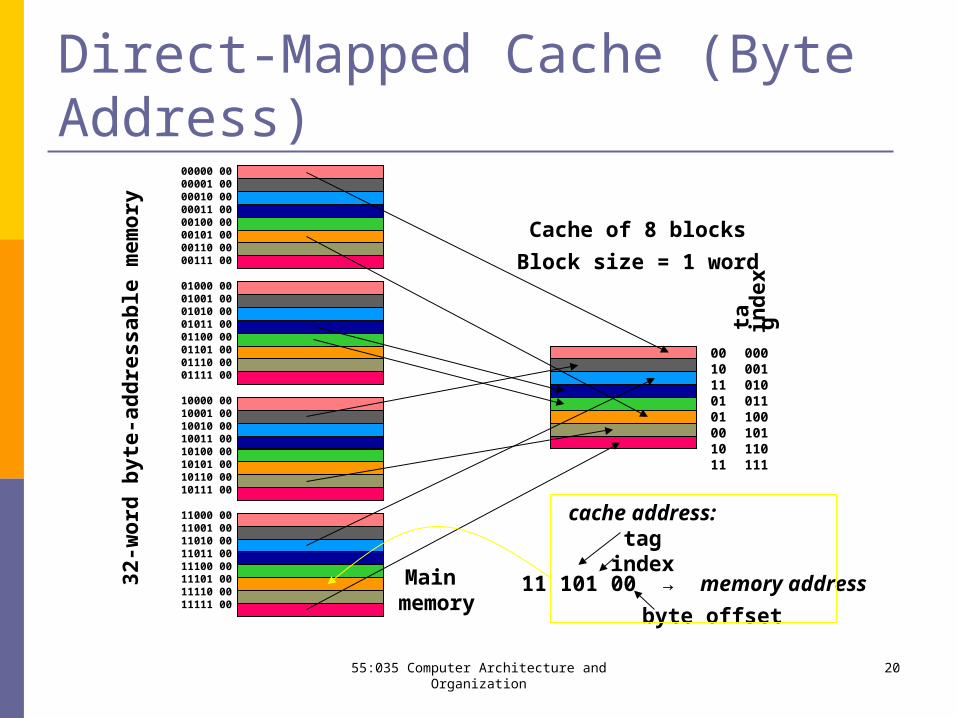
55:035 Computer Architecture and Organization 20
Direct-Mapped Cache (Byte Address)
000001010011100101110111
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00
Main memory
Cache of 8 blocks
11 101 00 → memory address
cache address: tag
index 32-
wo
rd b
yte-
add
ress
able
mem
ory
Block size = 1 word
ind
ex
tag
0010110101001011
byte offset
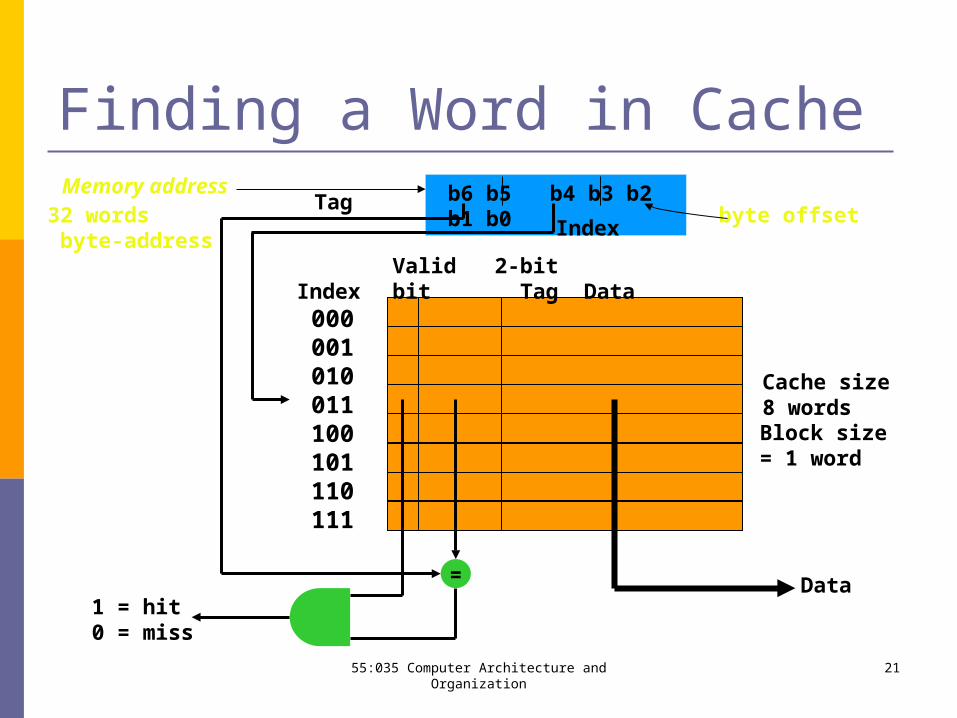
55:035 Computer Architecture and Organization 21
Finding a Word in Cache
Valid 2-bit Index bit Tag Data 000 001 010 011 100 101 110 111
byte offset b6 b5 b4 b3 b2 b1 b0
= Data1 = hit0 = miss
TagIndex
Memory address
Cache size8 wordsBlock size= 1 word
32 words byte-address
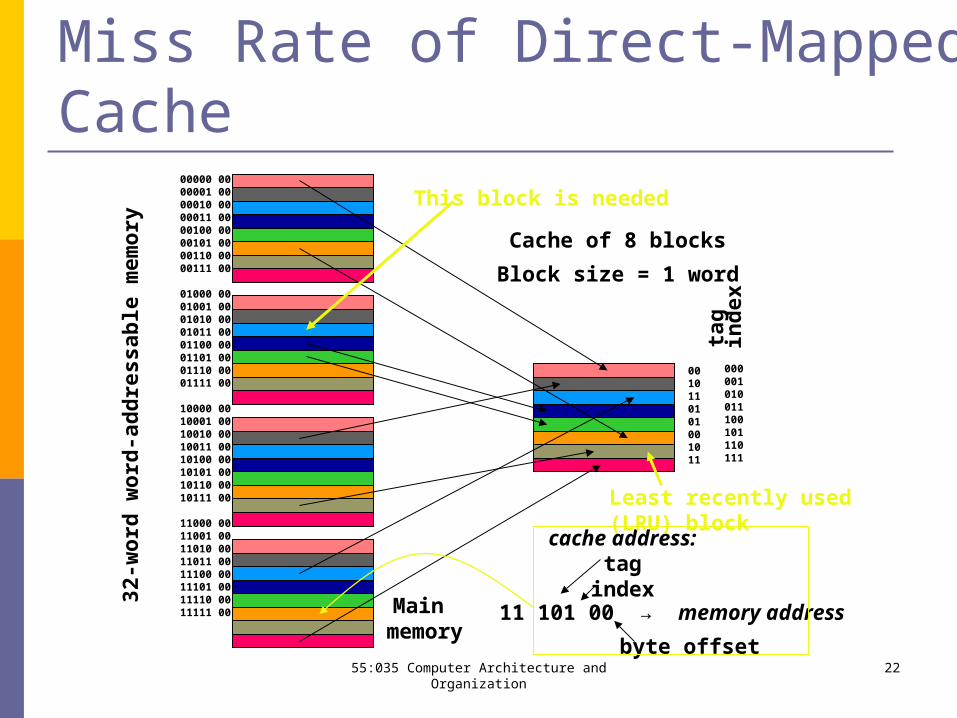
55:035 Computer Architecture and Organization 22
Miss Rate of Direct-Mapped Cache
000001010011100101110111
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00 Main
memory
Cache of 8 blocks
11 101 00 → memory address
cache address: tag
index 32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
ind
ex
tag
0010110101001011
byte offset
Least recently used(LRU) block
This block is needed

55:035 Computer Architecture and Organization 23
Miss Rate of Direct-Mapped Cache
000001010011100101110111
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00 Main
memory
Cache of 8 blocks
11 101 00 → memory address
cache address: tag
index 32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
ind
ex
tag
00 / 01 / 00 / 10 xx xx xx xx xx 00 xx
byte offset
Memory references to addresses: 0, 8, 0, 6, 8, 16
1. miss
2. miss
4. miss
3. miss
5. miss
6. miss
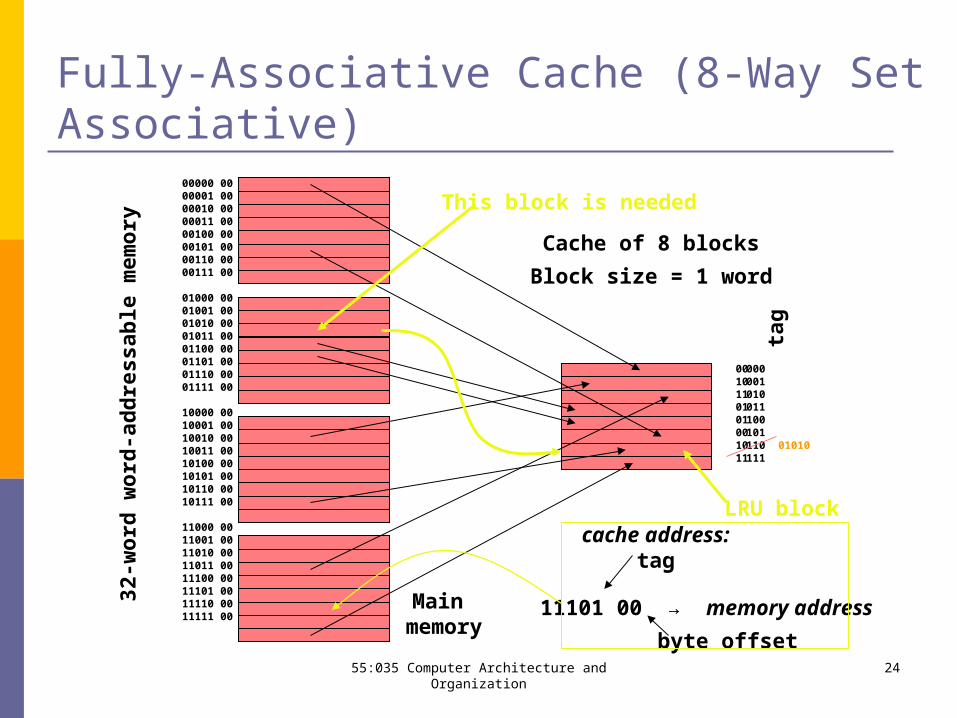
55:035 Computer Architecture and Organization 24
Fully-Associative Cache (8-Way Set Associative)
000001010011100101110 01010111
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00
Main memory
Cache of 8 blocks
11101 00 → memory address
cache address: tag
32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
tag
0010110101001011
byte offset
LRU block
This block is needed
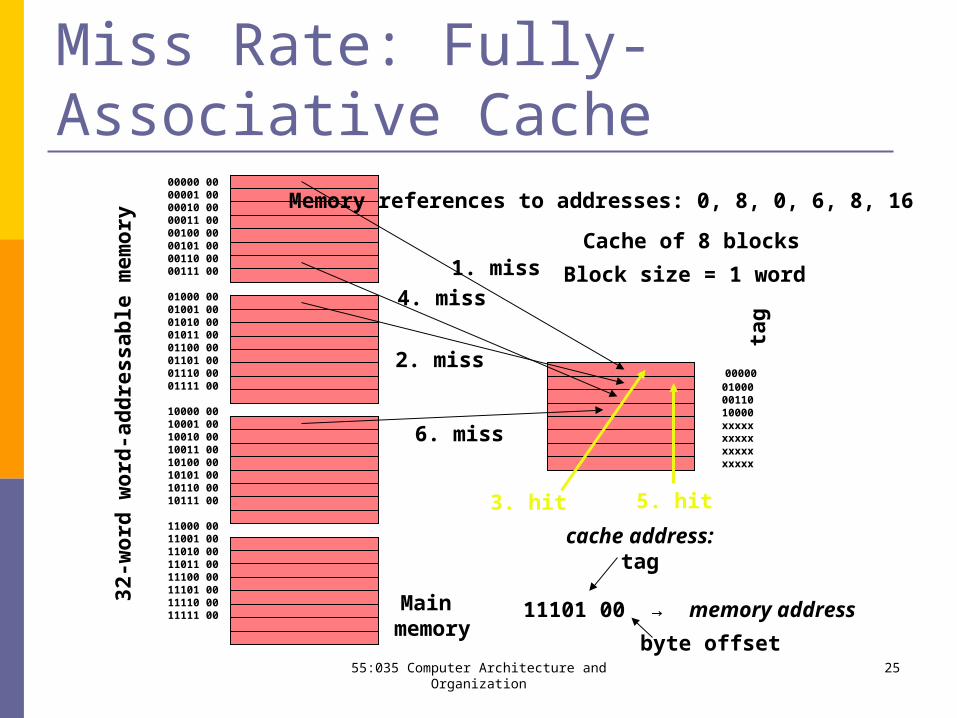
55:035 Computer Architecture and Organization 25
Miss Rate: Fully-Associative Cache
00000 01000 00110 10000 xxxxx xxxxx xxxxx xxxxx
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00
Main memory
Cache of 8 blocks
11101 00 → memory address
cache address: tag
32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
tag
byte offset
Memory references to addresses: 0, 8, 0, 6, 8, 16
1. miss
2. miss
3. hit
4. miss
5. hit
6. miss
55:035 Computer Architecture and Organization 26
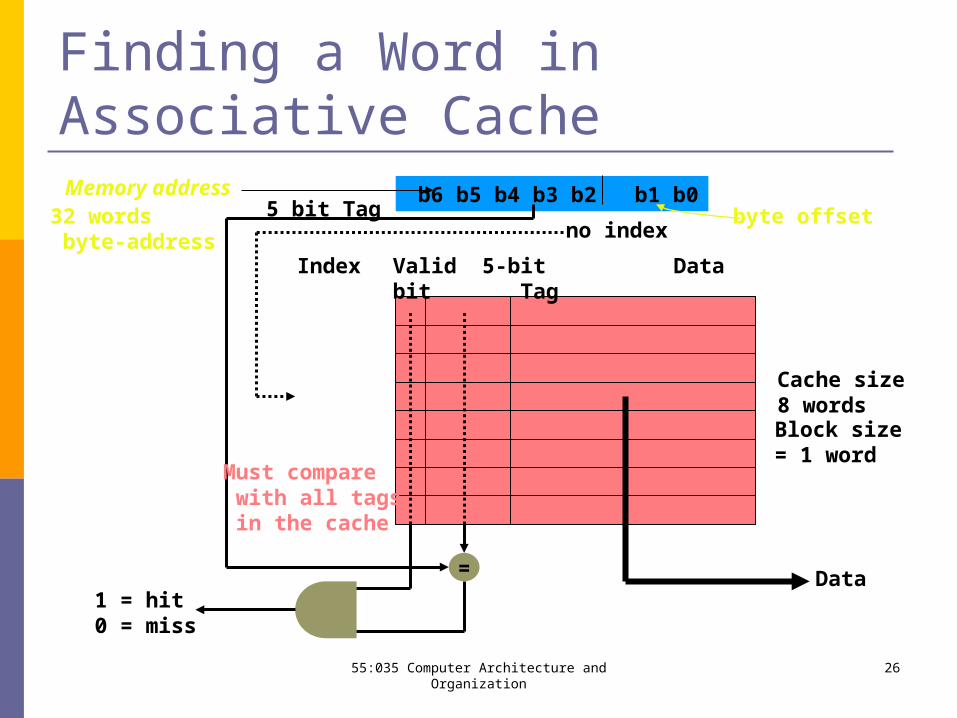
Finding a Word in Associative Cache
Index Valid 5-bit Databit Tag
byte offset b6 b5 b4 b3 b2 b1 b0
= Data1 = hit0 = miss
5 bit Tag no index
Memory address
Cache size8 wordsBlock size= 1 word
32 words byte-address
Must compare with all tags in the cache
55:035 Computer Architecture and Organization 27
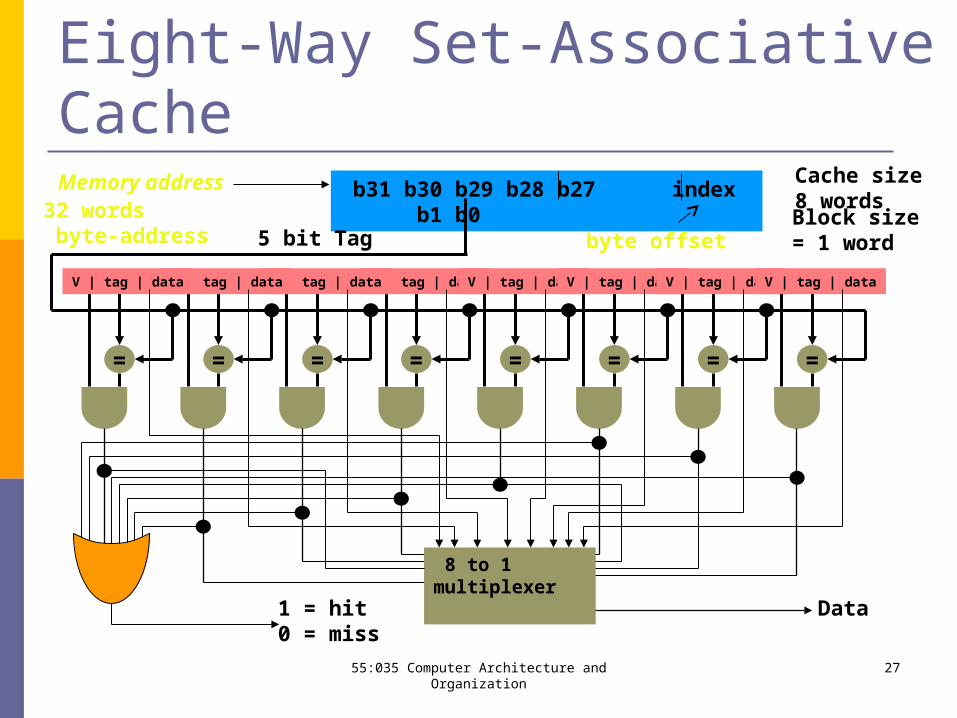
Eight-Way Set-Associative Cache
byte offset
b31 b30 b29 b28 b27 index b1 b0
Data1 = hit0 = miss
5 bit Tag
Memory address Cache size8 wordsBlock size= 1 word
32 words byte-address
=
V | tag | data
=
V | tag | data
=
V | tag | data
=
V | tag | data
=
V | tag | data
=
V | tag | data
=
V | tag | data
=
V | tag | data
8 to 1 multiplexer
55:035 Computer Architecture and Organization 28
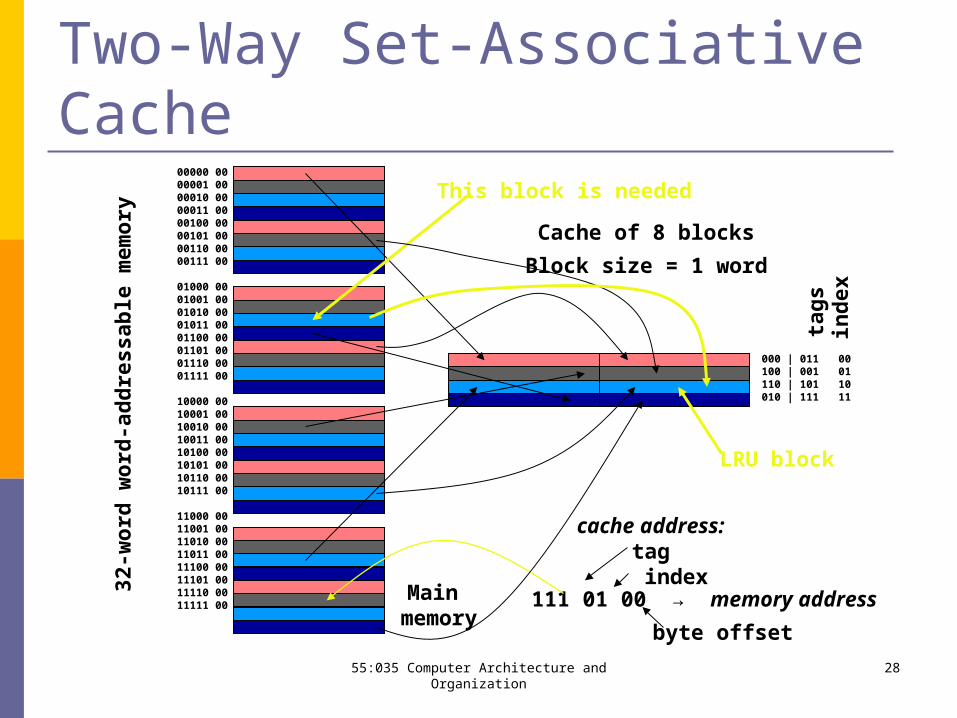
Two-Way Set-Associative Cache
00011011
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00
Main memory
Cache of 8 blocks
111 01 00 → memory address
cache address: tag
index 32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
ind
ex
tag
s
000 | 011100 | 001110 | 101010 | 111
byte offset
LRU block
This block is needed
55:035 Computer Architecture and Organization 29
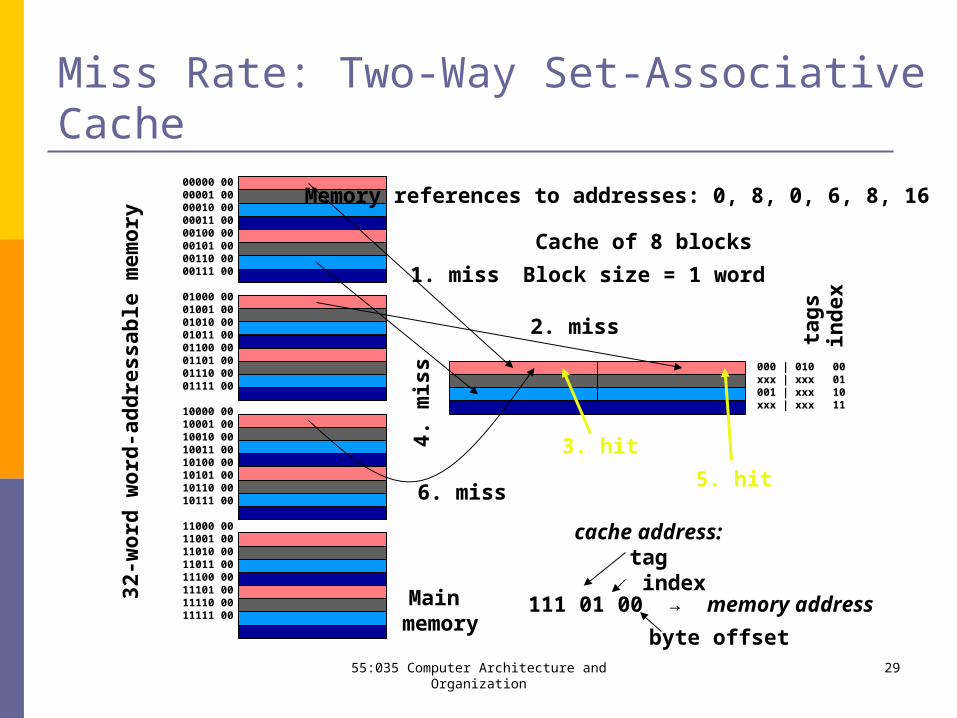
Miss Rate: Two-Way Set-Associative Cache
00011011
00000 0000001 0000010 0000011 0000100 0000101 0000110 0000111 00
01000 0001001 0001010 0001011 0001100 0001101 0001110 0001111 00
10000 0010001 0010010 0010011 0010100 0010101 0010110 0010111 00
11000 0011001 0011010 0011011 0011100 0011101 0011110 0011111 00
Main memory
Cache of 8 blocks
111 01 00 → memory address
cache address: tag
index 32-
wo
rd w
ord
-ad
dre
ssab
le m
emo
ry
Block size = 1 word
ind
ex
tag
s
000 | 010xxx | xxx001 | xxxxxx | xxx
byte offset
Memory references to addresses: 0, 8, 0, 6, 8, 16
1. miss
2. miss
4. m
iss
3. hit
5. hit6. miss
55:035 Computer Architecture and Organization 30
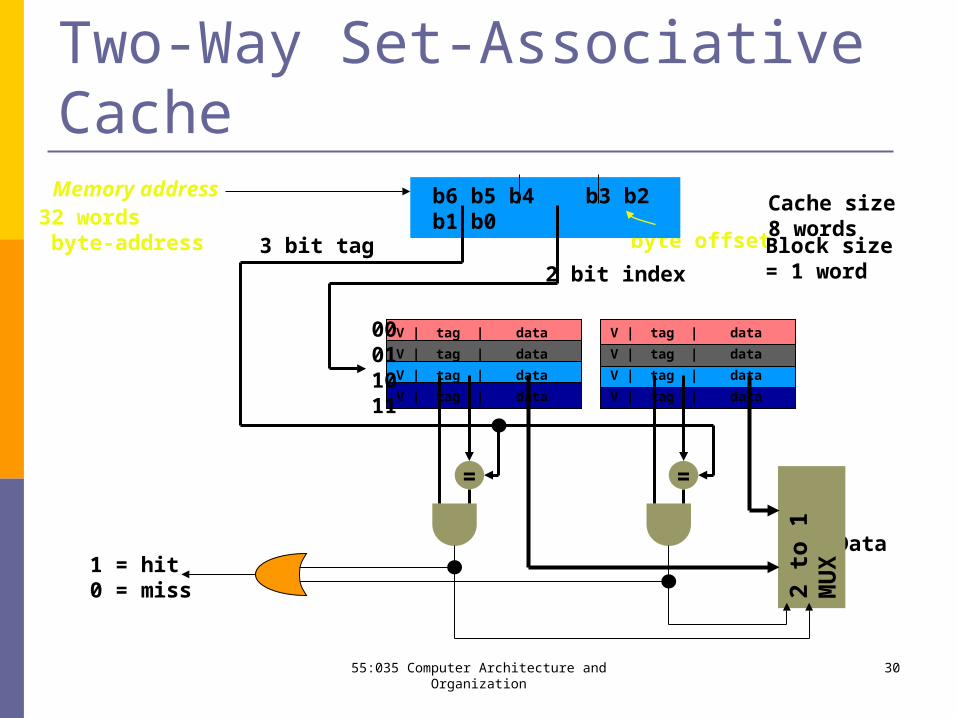
Two-Way Set-Associative Cache
byte offset
b6 b5 b4 b3 b2 b1 b0
Data1 = hit0 = miss
3 bit tag
Memory addressCache size8 wordsBlock size= 1 word
32 words byte-address
V | tag | data
V | tag | data
V | tag | data
V | tag | data
==
V | tag | data
V | tag | data
V | tag | data
V | tag | data
00011011
2 to
1 M
UX
2 bit index
55:035 Computer Architecture and Organization 31
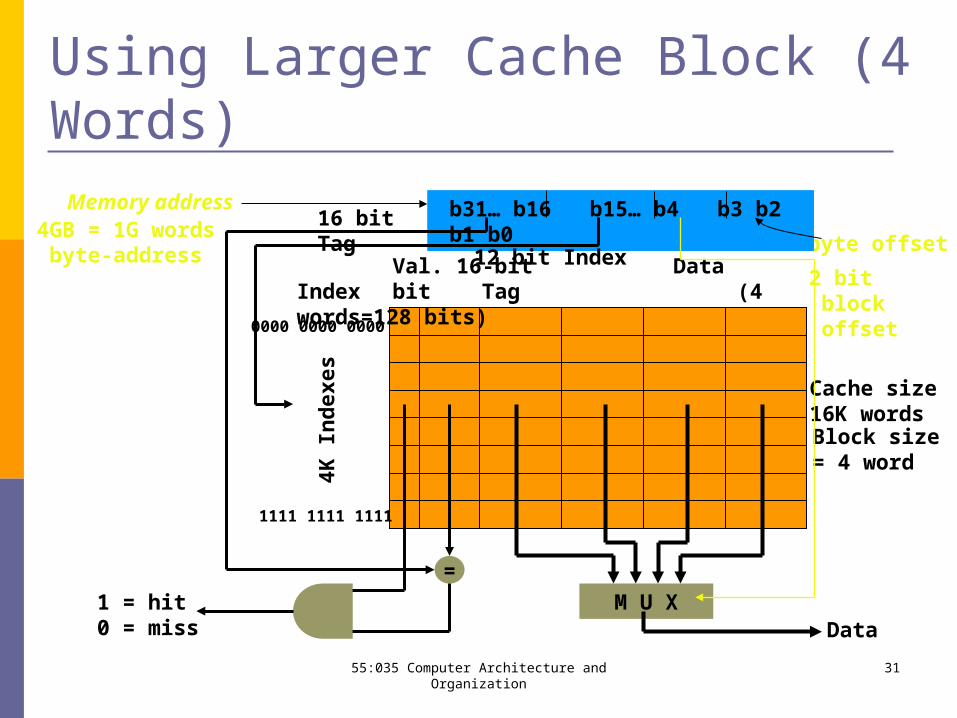
Using Larger Cache Block (4 Words)
Val. 16-bit DataIndex bit Tag (4 words=128 bits)
byte offset
b31… b16 b15… b4 b3 b2 b1 b0
=
Data1 = hit0 = miss
16 bit Tag
12 bit Index
Memory address
Cache size16K wordsBlock size= 4 word
4GB = 1G words byte-address
4K In
dex
es0000 0000 0000
1111 1111 1111
M U X
2 bit block offset

55:035 Computer Architecture and Organization 32
Main memory
Size=W words
Number of Tag and Index BitsCache Size= w words
Each word in cache has unique index (local addr.)Number of index bits = log2w
Index bits are shared with block offset when a block contains more words than 1
Assume partitions of w words each in the main memory.
W/w such partitions, each identified by a tagNumber of tag bits = log2(W/w)

55:035 Computer Architecture and Organization 33
How Many Bits Does Cache Have? Consider a main memory:
32 words; byte address is 7 bits wide: b6 b5 b4 b3 b2 b1 b0 Each word is 32 bits wide
Assume that cache block size is 1 word (32 bits data) and it contains 8 blocks.
Cache requires, for each word: 2 bit tag, and one valid bit Total storage needed in cache
= #blocks in cache × (data bits/block + tag bits + valid bit)
= 8 (32+2+1) = 280 bits
Physical storage/Data storage = 280/256 = 1.094

55:035 Computer Architecture and Organization 34
A More Realistic Cache Consider 4 GB, byte-addressable main memory:
1Gwords; byte address is 32 bits wide: b31…b16 b15…b2 b1 b0 Each word is 32 bits wide
Assume that cache block size is 1 word (32 bits data) and it contains 64 KB data, or 16K words, i.e., 16K blocks.
Number of cache index bits = 14, because 16K = 214
Tag size = 32 – byte offset – #index bits = 32 – 2 – 14 = 16 bits Cache requires, for each word:
16 bit tag, and one valid bit Total storage needed in cache
= #blocks in cache × (data bits/block + tag size + valid bits)= 214(32+16+1) = 16×210×49 = 784×210 bits = 784 Kb = 98 KB
Physical storage/Data storage = 98/64 = 1.53But, need to increase the block size to match the size of locality.

55:035 Computer Architecture and Organization 35
Cache Bits for 4-Word Block Consider 4 GB, byte-addressable main memory:
1Gwords; byte address is 32 bits wide: b31…b16 b15…b2 b1 b0 Each word is 32 bits wide
Assume that cache block size is 4 words (128 bits data) and it contains 64 KB data, or 16K words, i.e., 4K blocks.
Number of cache index bits = 12, because 4K = 212
Tag size = 32 – byte offset – #block offset bits – #index bits = 32 – 2 – 2 – 12 = 16 bits
Cache requires, for each word: 16 bit tag, and one valid bit Total storage needed in cache
= #blocks in cache × (data bits/block + tag size + valid bit)= 212(4×32+16+1) = 4×210×145 = 580×210 bits =580 Kb = 72.5 KB
Physical storage/Data storage = 72.5/64 = 1.13

Cache size equation Simple equation for the size of a cache:
(Cache size) = (Block size) × (Number of sets) × (Set Associativity)
Can relate to the size of various address fields:(Block size) = 2(# of offset bits)
(Number of sets) = 2(# of index bits)
(# of tag bits) = (# of memory address bits) (# of index bits) (# of offset bits)
Memory address
3655:035 Computer Architecture and Organization
55:035 Computer Architecture and Organization 37
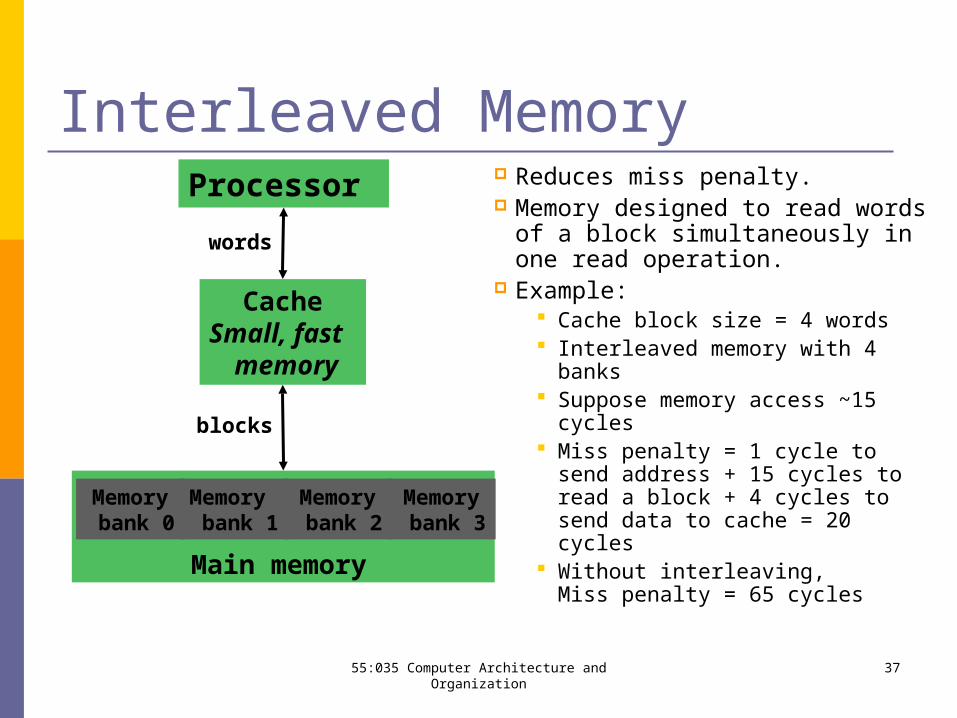
Interleaved Memory Reduces miss penalty. Memory designed to read words
of a block simultaneously in one read operation.
Example: Cache block size = 4 words Interleaved memory with 4 banks Suppose memory access ~15
cycles Miss penalty = 1 cycle to send
address + 15 cycles to read a block + 4 cycles to send data to cache = 20 cycles
Without interleaving,Miss penalty =
65 cycles
Processor
CacheSmall, fast
memory
words
blocks
Memory bank 0
Memory bank 1
Memory bank 2
Memory bank 3
Main memory

Cache Design The level’s design is described by four
behaviors: Block Placement:
Where could a new block be placed in the given level?
Block Identification: How is a existing block found, if it is in the level?
Block Replacement: Which existing block should be replaced, if necessary?
Write Strategy: How are writes to the block handled?
55:035 Computer Architecture and Organization 38

55:035 Computer Architecture and Organization 39
Handling a Miss Miss occurs when data at the required memory
address is not found in cache. Controller actions:
Stall pipeline Freeze contents of all registers Activate a separate cache controller
If cache is full select the least recently used (LRU) block in cache for over-writing If selected block has inconsistent data, take proper action
Copy the block containing the requested address from memory Restart Instruction

55:035 Computer Architecture and Organization 40
Miss During Instruction Fetch Send original PC value (PC – 4) to the memory. Instruct main memory to perform a read and wait
for the memory to complete the access. Write cache entry. Restart the instruction whose fetch failed.

55:035 Computer Architecture and Organization 41
Writing to Memory Cache and memory become inconsistent when
data is written into cache, but not to memory – the cache coherence problem.
Strategies to handle inconsistent data: Write-through
Write to memory and cache simultaneously always. Write to memory is ~100 times slower than to (L1) cache.
Write-back Write to cache and mark block as “dirty”. Write to memory occurs later, when dirty block is cast-out
from the cache to make room for another block

55:035 Computer Architecture and Organization 42
Writing to Memory: Write-Back Write-back (or copy back) writes only to cache but sets a
“dirty bit” in the block where write is performed. When a block with dirty bit “on” is to be overwritten in the
cache, it is first written to the memory. “Unnecessary” writes may occur for both write-through
and write-back write-through has extra writes because each store instruction
causes a transaction to memory (e.g. eight 32-bit transactions versus 1 32-byte burst transaction for a cache line)
write-back has extra writes because unmodified words in a cache line get written even if they haven’t been changed
penalty for write-through is much greater, thus write-back is far more popular
55:035 Computer Architecture and Organization 43
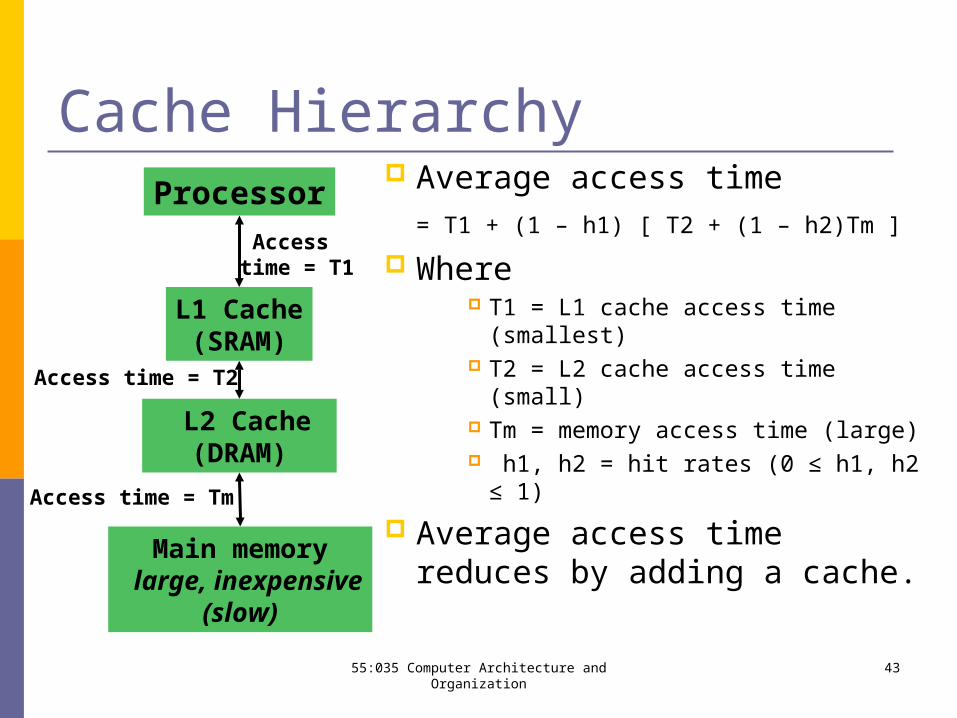
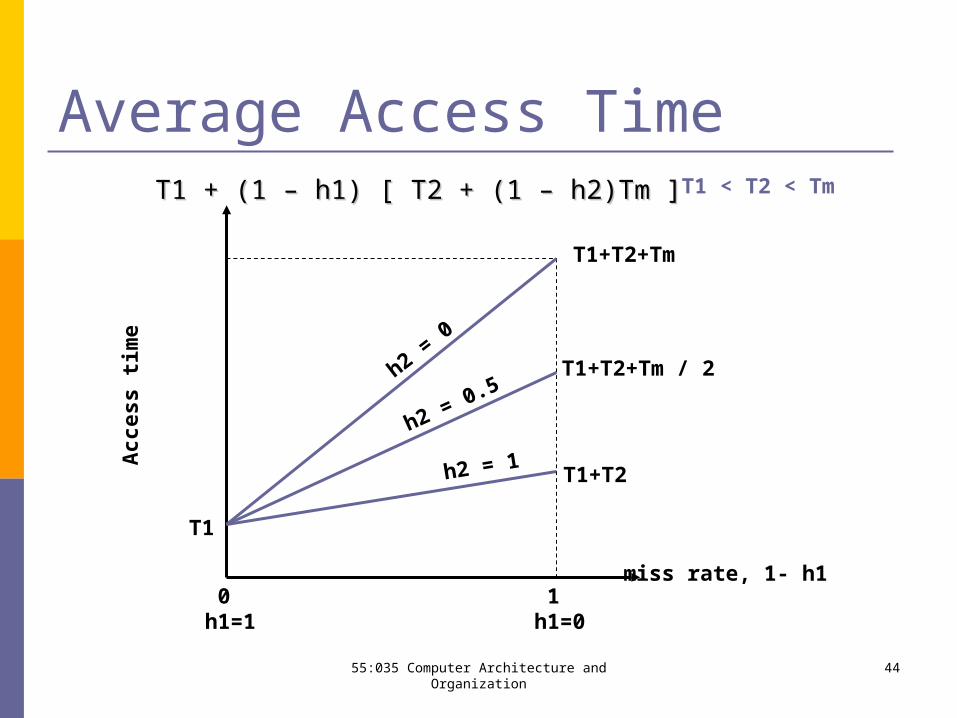
Cache Hierarchy Average access time
= T1 + (1 – h1) [ T2 + (1 – h2)Tm ]
Where T1 = L1 cache access time
(smallest) T2 = L2 cache access time (small) Tm = memory access time (large) h1, h2 = hit rates (0 ≤ h1, h2 ≤ 1)
Average access time reduces by adding a cache.
Processor
L1 Cache(SRAM)
Main memory large, inexpensive
(slow)
Access time = T1
Access time = Tm
L2 Cache (DRAM)
Access time = T2
55:035 Computer Architecture and Organization 44
Average Access Time
T1+T2+Tm
T1
0 h1=1
1 h1=0
miss rate, 1- h1
Acc
ess
tim
e
T1+T2+Tm / 2
T1+T2
T1 < T2 < Tm
h2 = 0
h2 = 1
h2 = 0.5
T1 + (1 – h1) [ T2 + (1 – h2)Tm ]T1 + (1 – h1) [ T2 + (1 – h2)Tm ]

55:035 Computer Architecture and Organization 45
Processor Performance Without Cache
5GHz processor, cycle time = 0.2ns Memory access time = 100ns = 500 cycles Ignoring memory access, Clocks Per Instruction
(CPI) = 1 Assuming no memory data access:
CPI = 1 + # stall cycles= 1 + 500 = 501

55:035 Computer Architecture and Organization 46
Performance with Level 1 Cache Assume hit rate, h1 = 0.95 L1 access time = 0.2ns = 1 cycle CPI = 1 + # stall cycles
= 1 + 0.05 x 500
= 26 Processor speed increase due to cache
= 501/26 = 19.3

55:035 Computer Architecture and Organization 47
Performance with L1 and L2 Caches Assume:
L1 hit rate, h1 = 0.95 L2 hit rate, h2 = 0.90 (this is very optimistic!) L2 access time = 5ns = 25 cycles
CPI = 1 + # stall cycles = 1 + 0.05 (25 + 0.10 x 500) = 1 + 3.75 = 4.75
Processor speed increase due to both caches = 501/4.75 = 105.5
Speed increase due to L2 cache = 26/4.75 = 5.47

If the tag bits do not match, then a miss occurs. Upon a cache miss:
The CPU is stalled Desired block of data is fetched from memory and placed in
cache. Execution is restarted at the cycle that caused the cache
miss.
Recall that we have two different types of memory accesses:
reads (loads) or writes (stores).
Thus, overall we can have 4 kinds of cache events: read hits, read misses, write hits and write misses.
55:035 Computer Architecture and Organization 48
Cache Miss Behavior

Fully-Associative Placement One alternative to direct-mapped is:
Allow block to fill any empty place in the cache. How do we then locate the block later?
Can associate each stored block with a tag Identifies the block’s home address in main memory.
When the block is needed, we can use the cache as an associative memory, using the tag to match all locations in parallel, to pull out the appropriate block.
4955:035 Computer Architecture and Organization

Set-Associative Placement The block address determines not a single location, but a
set. A set is several locations, grouped together.
(set #) = (Block address) mod (# of sets)
The block can be placed associatively anywhere within that set.
Where? This is part of the placement strategy.
If there are n locations in each set, the scheme is called “n-way set-associative”.
Direct mapped = 1-way set-associative. Fully associative = There is only 1 set.
5055:035 Computer Architecture and Organization

Replacement Strategies Which existing block do we replace, when a new block
comes in? With a direct-mapped cache:
There’s only one choice! (Same as placement)
With a (fully- or set-) associative cache: If any “way” in the set is empty, pick one of those Otherwise, there are many possible strategies:
(Pseudo-) Random: Simple, fast, and fairly effective (Pseudo-) Least-Recently Used (LRU)
Makes little difference in L2 (and higher) caches
5155:035 Computer Architecture and Organization

Write Strategies Most accesses are reads, not writes
Especially if instruction reads are included
Optimize for reads! Direct mapped can return value before valid check
Writes are more difficult, because: We can’t write to cache till we know the right block Object written may have various sizes (1-8 bytes)
When to synchronize cache with memory? Write through - Write to cache & to memory
Prone to stalls due to high mem. bandwidth requirements Write back - Write to memory upon replacement
Memory may be left out of date for a long time
5255:035 Computer Architecture and Organization

Action on Cache Hits vs. Misses Read hits:
Desirable
Read misses: Stall the CPU, fetch block from memory, deliver to cache, restart
Write hits: Write-through: replace data in cache and memory at same time Write-back: write the data only into the cache. It is written to
main memory only when it is replaced
Write misses: No write-allocate: write the data to memory only. Write-allocate: read the entire block into the cache, then write
the word55:035 Computer Architecture and Organization 53

Cache Hits vs. Cache Misses Consider the write-through strategy: every block written to cache
is automatically written to memory. Pro: Simple; memory is always up-to-date with the cache
No write-back required on block replacement. Con: Creates lots of extra traffic on the memory bus.
Write hit time may be increased if CPU must wait for bus. One solution to write time problem is to use a write buffer to store
the data while it is waiting to be written to memory. After storing data in cache and write buffer, processor can continue
execution. Alternately, a write-back strategy writes data to main memory
only a block is replaced. Pros: Reduces memory bandwidth used by writes. Cons: Complicates multi-processor systems
55:035 Computer Architecture and Organization 54

Hit/Miss Rate, Hit Time, Miss Penalty The hit rate or hit ratio is
fraction of memory accesses found in upper level.
The miss rate (= 1 – hit rate) is fraction of memory accesses not found in upper levels.
The hit time is the time to access the upper level of the memory hierarchy,
which includes the time needed to determine whether the access is a hit or miss.
The miss penalty is the time needed to replace a block in the upper level with a
corresponding block from the lower level. may include the time to write back an evicted block.
55:035 Computer Architecture and Organization 55

Cache Performance Analysis Performance is always a key issue for caches. We consider improving cache performance by:
(1) reducing the miss rate, and (2) reducing the miss penalty.
For (1) we can reduce the probability that different memory blocks will contend for the same cache location.
For (2), we can add additional levels to the hierarchy, which is called multilevel caching.
We can determine the CPU time as
55:035 Computer Architecture and Organization 56
CClsMemoryStalonCPUExecuti tCCCCCPUTime )(

Cache Performance The memory-stall clock cycles come from cache misses. It can be defined as the sum of the stall cycles coming
from writes + those coming from reads: Memory-Stall CC = Read-stall cycles + Write-stall cycles, where
55:035 Computer Architecture and Organization 57
PenaltyMissadRateMissadogram
adscyclesstallad ReRe
Pr
ReRe
rStallsWriteBuffePenaltyMissWriteRateMissWriteogram
WritescyclesstallWrite
Pr

Cache Performance Formulas Useful formulas for analyzing ISA/cache interactions :
(CPU time) = [(CPU cycles) + (Memory stall cycles)] × (Clock cycle time)
(Memory stall cycles) = (Instruction count) × (Accesses per instruction) × (Miss rate) × (Miss penalty)
But, are not the best measure for cache design by itself: Focus on time per-program, not per-access
But accesses-per-program isn’t up to the cache design We can limit our attention to individual accesses
Neglects hit penalty Cache design may affect #cycles taken even by a cache hit
Neglects cycle length May be impacted by a poor cache design
55:035 Computer Architecture and Organization 58

More Cache Performance Metrics Can split access time into instructions & data:
Avg. mem. acc. time =(% instruction accesses) × (inst. mem. access time) + (% data accesses) × (data mem. access time)
Another simple formula: CPU time = (CPU execution clock cycles + Memory stall clock
cycles) × cycle time Useful for exploring ISA changes
Can break stalls into reads and writes: Memory stall cycles =
(Reads × read miss rate × read miss penalty) + (Writes × write miss rate × write miss penalty)
55:035 Computer Architecture and Organization 59

Factoring out Instruction Count Gives (lumping together reads & writes):
May replace:
So that miss rates aren’t affected by redundant accesses to same location within an instruction.
penaltyMissrateMissInst
AccessesCPI
timecycleClockICtimeCPU
exec
ninstructio
MissesrateMiss
ninstructio
Accesses
6055:035 Computer Architecture and Organization

Improving Cache Performance Consider the cache performance equation:
It obviously follows that there are three basic ways to improve cache performance:
A. Reducing miss rate B. Reducing miss penalty C. Reducing hit time
Note that by Amdahl’s Law, there will be diminishing returns from reducing only hit time or amortized miss penalty by itself, instead of both together.
(Average memory access time) = (Hit time) + (Miss rate)×(Miss penalty) “Amortized miss penalty”
Reducing amortizedmiss penalty
6155:035 Computer Architecture and Organization
55:035 Computer Architecture and Organization 62
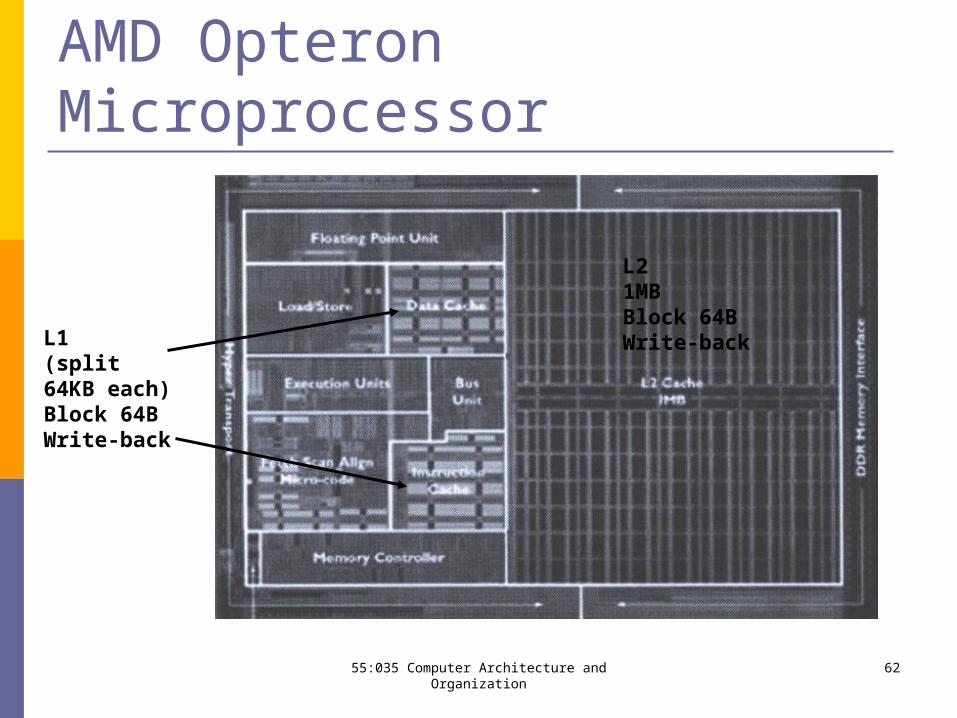
AMD Opteron Microprocessor
L1(split64KB each)Block 64BWrite-back
L21MBBlock 64BWrite-back


























