Embed Size (px)
Citation preview

Expert Systems with Applications 40 (2013) 5210–5218
Contents lists available at SciVerse ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
A cluster-DEE-based strategy to empower protein design
0957-4174/$ - see front matter � 2013 Elsevier Ltd. All rights reserved.http://dx.doi.org/10.1016/j.eswa.2013.03.011
⇑ Corresponding author.E-mail address: [email protected] (M. Dorn).
Rafael K. de Andrades, Márcio Dorn ⇑, Daniel S. Farenzena, Luis C. LambFederal University of Rio Grande do Sul, Institute of Informatics, Av. Bento Gonçalves 9500, 91501-970 Porto Alegre, RS, Brazil
a r t i c l e i n f o a b s t r a c t
Keywords:Integrated intelligent methodsProtein designStructural bioinformaticsClustering algorithmsBoolean Satisfiability problemDead-End-Elimination
The Medical and Pharmaceutical industries have shown high interest in the precise engineering of pro-tein hormones and enzymes that perform existing functions under a wide range of conditions. Proteinsare responsible for the execution of different functions in the cell: catalysis in chemical reactions, trans-port and storage, regulation and recognition control. Computational Protein Design (CPD) investigates therelationship between 3-D structures of proteins and amino acid sequences and looks for all sequencesthat will fold into such 3-D structure. Many computational methods and algorithms have been proposedover the last years, but the problem still remains a challenge for Mathematicians, Computer Scientists,Bioinformaticians and Structural Biologists. In this article we present a new method for the protein designproblem. Clustering techniques and a Dead-End-Elimination algorithm are combined with a SAT problemrepresentation of the CPD problem in order to design the amino acid sequences. The obtained resultsillustrate the accuracy of the proposed method, suggesting that integrated Artificial Intelligence tech-niques are useful tools to solve such an intricate problem.
� 2013 Elsevier Ltd. All rights reserved.
1. Introduction
Computational Protein Design (CPD) is one of the most impor-tant research problems in Computational Molecular Biology(Lippow and Tidor, 1997; Tian, 2010). The Medical and Pharmaceu-tical industries are widely interested in precisely understandinghow to engineer protein hormones and enzymes that performexisting functions under a wide range of conditions. Proteins arelong sequences of 20 different amino acid residues that in physio-logical conditions adopt a unique 3-D structure (Lehninger et al.,2005). This structure is important because it determines the func-tion of the protein in the cell, for example, catalysis in chemicalreactions, transport and storage, regulation, recognition and con-trol (Lesk, 2002). Protein design has become a powerful approachfor understanding the relationship between amino acid sequenceand 3-D structure and consequently to study the functional aspectsof the protein (Sander et al., 1992). The ability to design sequencescompatible with a fold may also be useful in structural and func-tional Genomics, with the identification of functionally importantdomains in sequences of proteins.
The general goal of CPD is to identify an amino acid sequencethat folds into a particular protein 3-D structure with a desiredfunction (Fig. 2). Protein design can be considered as the inverseof the protein folding (PF) problem (Osguthorpe, 2000) becauseit starts with the structure rather than the sequence and looksfor all sequences that will fold into such 3-D structure. Considering
that there are 20 naturally occurring amino acids for each position,the combinatorial complexity of the problem amounts to 20110 or10130 (Floudas et al., 2006).
Over the last decade, a tremendous advance in protein designwas witnessed. The maturation of a number of component technol-ogies, including optimization algorithms and combinatorial dis-crete search, contributed for advances in CPD research.Techniques such as Dead-End-Elimination (Georgiev et al., 2008;Desmet et al., 1992), Integer Programing (Xie and Sahinidis,2006) and Monte Carlo (Yang and Saven, 2005; Hom and Mayo,2006; Allen and Mayo, 2006) have been applied to protein design,but the problem still remains very challenging. In this article, wepresent a new method based on clustering strategy, Dead-End-Elimination techniques and SAT-based methods to determine theamino acid sequence of protein 3-D structures.
The remainder of the paper is structured as follows. Section 2contextualizes the protein design problem and basic concepts usedin this article. Section 3 introduces the computational and AI tech-niques used in the proposed method. Section 4 introduces the newhybrid method for protein design. Section 5 reports several resultsillustrating the effectiveness of our method. Section 6 concludesand points out directions for further research.
2. Preliminaries
2.1. Protein structure and protein design
A peptide is a molecule composed of two or more amino acidresidues chained by a bond called the peptide bond. There are 20

R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218 5211
different amino acid residues in nature (Lodish et al., 1990) andeach amino acid residue is a molecule containing both amine andcarboxyl functional groups. The various amino acids differ in whichside chain (R group) is attached to their alpha carbon (Lodish et al.,1990; Lehninger et al., 2005). Larger peptides are generally referredto as polypeptides or proteins (Creighton, 1990). A peptide hasthree main chain torsion angles, namely phi (/), psi (w) and omega(x).
In the model peptide (Fig. 1) the bonds between N and Ca, andbetween Ca and C are free to rotate. These rotations are describedby the / and w torsion angles, respectively. The rotational freedomabout the / (Ca-N) and w (Ca-C) angles is limited by steric hin-drance between the side chain of the residue and the peptide back-bone. Consequently, the possible conformation of a givenpolypeptide chain is quite limited (Ramachandran and Sasisekha-ran, 1968; Branden and Tooze, 1998). Side-chains also presentdihedral angles and the number of v angles depends on the residuetype (Table 1).
Protein design starts with the structure (set of torsion angles,for example) and looks for all sequences that will fold into such3-D structure. In rational protein design, the scientist uses detailedknowledge of the structure and function of the protein to make de-sired changes. The design of proteins that fold to a specified targetbackbone structure is of great interest of the Medical and the Phar-maceutical Industries. Additional material related to PD can befound in Dahiyat and Mayo (1997), Park et al. (2011), Gueroisand de La Paz (2006), Samish et al. (2011), Hom and Mayo(2006), Yang and Saven (2005), Lippow and Tidor (1997), Tian(2010), Sander et al. (1992), Voigt et al. (2000), Pokala and Handel(2000) and Floudas et al. (2006). A good review about proteinstructure can be found in Tramontano (2006), Lesk (2002), Brandenand Tooze (1998) and Altman and Dugan (2005).
2.2. Energy functions
An energy function describes the internal energy of the proteinand its interactions with the environment in which it is inserted.In Protein design the goal is to find a sequence which generates a3-D protein structure with the global minimum of free energy thatcorresponds to the native or functional state of the protein (Osgu-thorpe, 2000; Tramontano, 2006). The energy function used forprotein design still contain elements accounting for van der Waalsforce, electrostatics, solvation, and hydrogen bonding.
A potential energy function incorporates two main types ofterms: bonded and non-bonded. The bonded terms (bonds, an-gles and torsions) are covalently linked. The bonded terms con-strain bond lengths and angles near their equilibrium values. The
Fig. 1. Chemical representation of two amino acid residues after the condensationreaction. The carboxyl group of one amino acid (amino acid 1) reacts with theamino group of the amino acid 2. A molecule of water is removed from two aminoacids to form a peptide bond and the x angle is formed (peptide bond). N isnitrogen, C and Ca are carbons.
bonded terms also include a torsional potential (torsion) thatmodels the periodic energy barriers encountered during bond rota-tion. The non-bonded potential includes: ionic bonds, hydrophobicinteractions, hydrogen bonds, van der Waals forces, and dipole–dipole bonds. van der Waals force is usually described by theequation for Lennard–Jones 6–12 potential (Boas and Harbury(2007)). There is a variety of potential energy functions used inprotein design. In this article we use the CHARMM potential energyfunction (Brooks et al., 1983; Field et al., 1998) (Eq. (1)).
Etotal ¼X
bonds
Kbðb� b0Þ2 þXUB
KUBðS� S0Þ2 þXangle
Khðh� h0Þ2
þX
dihedrals
Kvð1þ cosðgv � dÞÞ þX
impropers
Kimpðu�u0Þ2Þ
þX
nonbond
�Rminij
rij
� �12
� Rminij
rij
� �6" #
þqiqj
�1rijð1Þ
where Kb, KUB, Kh, Kv and Kimp are the bond, Urey Bradley angle(Hagler et al., 1979; Lifson and Warshel, 1968), dihedral angle andimproper dihedral angle force constants, respectively; b, S, h, vand u are the bond length, Urey-Bradley 1.3 distance, bond angle,dihedral angle and improper torsion angle, respectively. The sub-script zero represents the equilibrium value for the individualterms. Coulomb and Lennard–Jones 6–12 terms contribute tothe external or non-bonded interactions; � is the Lennard–Jones
(the depth of the potential well) and Rmin is the distance at the Len-nard–Jones minimum, qi is the partial atomic charge, �1 is theeffective dielectric constant, and rij is the distance between atomsi and j. Reviews of protein energy functions and their applicationcan be found in Lazaridis and Karplus (2000), Jorgensen and Tira-do-Rives (2005), Gordon et al. (1999) and Hao and Scheraga (1999).
3. Computational techniques applied to protein design
3.1. The Boolean Satisfiability problem
Boolean Satisfiability (SAT) is the problem of determining if agiven propositional logic formula can be satisfied given suitablevalue assignments (Selman et al., 1992). SAT is also a well-knownNP-complete decision problem (Cook, 1971) and require worst-case exponential time. However, state-of-the-art SAT algorithmsare effective at coping with large search spaces by exploiting theproblem structure when it exists (Marques-Silva, 2008). Recently,SAT solvers have been applied in combinatorial problems such asprotein folding and protein design (Gomes and Selman, 2005).
The notation for SAT instances usually follow the ConjunctiveNominal Form (CNF). The CNF of a Boolean function is a functionformula with the following structure:
/ ¼ _ici
ci ¼ ^jljð2Þ
where ci are referred as clauses and literal lj represents the variablexj or its negation :xj (Ollikainen et al., 2009). Thus, adding clauses isequivalent to adding constraints to variables xj, reducing the searchspace. Moreover, to describe a problem as a SAT instance, one addconstraints encoded as clauses to / until the SAT instance corre-sponds to the problem structure that is being solved. For instance,in protein design we state a rule R that rotamers ru and rv cannotexist simultaneously in a protein. If ri denotes the existence of rot-amer i in a protein, then we can encode rule R as :(ru ^ rv).
Since literals in SAT problems can be either a boolean variableor a boolean variable complement, constraint problems usingSAT can only encode discrete search spaces. Although there areSAT extensions to allow for continuous search spaces, we wantto keep the original definition so we can rely on modern, faster

Fig. 2. Schematic representation of the Protein Desgin Problem. The CPD problem starts with the 3-D structure of a protein and looks for all sequences that will fold into such3-D structure.
Table 1Number of v angles in each of the 20 amino acids. The vangles are used to fix the position of side-chain atoms ineach residue type.
Amino acid Number of v angles
GLY, ALA, PRO –SER, CYS, THR, VAL v1
ILE, LEU, ASP, ASN, v1,v2
HIS, PHE, TYR, TRPMET, GLU, GLN v1,v2,v3
LYS, ARG v1,v2,v3,v4
5212 R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218
SAT solving algorithms. In this article we propose and describe aSAT-based model for protein design that allows to search in theprotein design space in order to determine the amino acid se-quence of knwon 3-D protein structures. Supplementary materialrelated with Boolean Satisfiability and its application can be foundon Marques-Silva (2008), Wille et al. (2008), Dixon et al. (2004),Schaefer (1978) and Gomes et al. (2008).
3.2. Dead-End-Elimination algorithms
The Dead-End-Elimination algorithm (DEE) is a computationalstrategy that minimizes a function over a discrete set of indepen-dent variables (Gordon and Mayo, 1998). The basic idea is to iden-tify not allowed combinations of variables that cannot possiblyyield the global minimum and to refrain from searching suchcombinations further. These not allowed combinations, so-calleddead-ends, can be excluded from further consideration, therebysignificantly reducing the size of the combinatorial search space.The original description and proof of the Dead-End-Eliminationtheorem can be found in Desmet et al. (1992).
DEE is commonly used in Computational Protein Design for thecombinatorial optimization problem of assigning amino acids atprotein positions, where the energy of a desired protein structureshould be minimized (Goldstein, 1994; Pierce et al., 2000). Eachposition assignment of a DEE algorithm is a tuple P ? K � v 1 �v2 � v3 � v4 where K is an aminoacid and va,a 2 [1,4] is a torsionangle describing the aminoacid geometry. Therefore, the combina-torial search is generated by applying all P configurations in E.However, exploring all the generated search space is computation-ally intractable due to the large number of conformations. The DEEcomes in hand to reduce the search space generated by E excludingfrom the search the combination of P assignments that possibly al-ways evaluate to a higher energy state. Each excluded P assign-ments is a ‘‘dead-end’’ and is an input for the DEE algorithm toavoid exploring all search spaces. If a lower energy state is found,the P assignments that results in such energy state are combined
as a ‘‘dead-end’’ with the previous ‘‘dead-ends’’ as input to a newiteration of the DEE algorithm, this time with a more completedescription of ‘‘dead-ends’’. If the algorithm stops without findinga new P assignment, we conclude that no lower energy state ispossible and pick the last ‘‘dead-end’’ added as the best solutionfor the minimization problem. Moreover, we may add as a condi-tion that the algorithm halts whenever a lower bound of energy le-vel is found, or a time constraint, as there is no guarantee thatthere is another lower energy state.
In the proposed method the search for a lower energy level and‘‘dead-ends’’ used as input at each DEE algorithm iteration aremodelled as SAT clauses (Ollikainen et al., 2009). Additional mate-rial related with Dead-End-Elimination and its application to PD
can be found in Schrauber et al. (1993), Pierce et al. (2000), Spriet(2003), Desmet et al. (1992), Xie and Sahinidis (2006), Voigt et al.(2000), Georgiev et al. (2008), Georgiev and Donald (2007), Bharg-avi et al. (2003) and Ollikainen et al. (2009).
3.3. Clustering algorithms
Clustering techniques are applied when there is no class to bepredicted but rather when the instances are to be divided into nat-ural groups. Cluster analysis or clustering can be defined as the pro-cess of organizing objects into groups whose instances are similarin some way (Everitt et al., 2011; Witten et al., 2011). In the classi-cal k-means clustering algorithm (MacQueen, 1967) a set of n datapoints (a1, a2, . . . , an) is partitioned into p groups S = {s1,s2, . . . ,sp} inorder to minimize a function of quadratic error (Eq. (3)).
E ¼Xp
i¼1
Xaj2Si
kaj � lik2 ð3Þ
where kaj � lik2 is a chosen distance measure between a data pointai and the cluster center li.
In the proposed method for protein design Expectation Maximi-zation (EM) (Dempster et al., 1977) is used to data clustering. Thismethod estimates missing parameters of probabilistic models andis composed by two main steps: (1) The Expectation step relatedwith the calculation of the cluster probabilities and (2) the Maxi-mization step that computes the distribution parameters and theirlikelihood given the data. The EM algorithm iterates until theparameters being optimized reach a fixpoint or until the log-likeli-hood function reaches its maximum. A set of parameters arerecomputed until a desired convergence value is achieved. For eachindividual instance is assigned a probability a certain set of attri-bute values would assume given they were members of a specificcluster. When compared with the K-means algorithm, EM has astrong statistical basis and is more robust to deal with noisy data.

R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218 5213
A complete description of the EM algorithm can be found in Demp-ster et al. (1977) and Witten et al. (2011).
4. The proposed method for CPD
The proposed method for the protein design problem is com-posed of 6 steps:
(1) obtaining structural data from experimentally determinedproteins;
(2) selecting side-chain rotamers from amino acid residues;(3) clustering long side-chain v angles;(4) representing the protein conformational space in a Conjun-
tive Normal Form;(5) applying DEE to eliminate not allowed rotamers;(6) solving the formula and determining the amino acid
sequence. Below, each of these steps are detailed.
4.1. Obtaining structural data from experimentally determinedproteins
A set K = [a1./,a1.w,a1.v1,a1.v2, a1.v3,a1.v4; . . . ;an./,an.w,an.v1,an.v2,an.v3,an.v4] of torsion angles and the number of vangles (Table 1) of each amino acid residue are used as input tothe proposed method. ai represent an unknown target amino acidresidue. Phi (/), Psi (w), Chi1(v1), Chi2 (v2), Chi3 (v3) and Chi4(v4) point out the backbone and side-chain torsion angles of eachai residue. The backbone torsion angles (/ and w) of the proteinare kept rigid and are used to search the Dunbrack Backbone-Dependent Library1 (Dunbrack and Karplus, 2003; Shapovalov andDunbrack, 2011) for template conformations.
For each position i of an amino acid residue (ai) from the targetsequence, rotamers are selected from the Dunbrack Backbone-Dependent Library. A new library for the target amino acid se-quence composed by n arrays of rotamers, one for each amino acidresidue, is built. The rotamers of different amino acid residues willbe used to alter the target amino acid sequence in order to find se-quence with the lowest potential energy (Fig. 1).
4.2. Selecting side-chain rotamers from amino acid residues
The previous step builds a set of possible rotamers (v angles) foreach amino acid residue i. When this number of rotamers is largethe problem becomes computationally intractable (Pierce andWinfree, 2002; Floudas et al., 2006). For a small protein composedby 8 amino acid residues and assuming an average of 30 possiblerotamers per amino acid residue, the number of possible sequencesgenerated will be 6.561 � 1011(830) combinations. This numbergrows rapidly when the number of amino acids residues is in-creased. In this step the rotamer library is processed in order to de-crease the number of v conformations in the base protein library.The rotamer probability is used to eliminate and reduce the num-ber of rotamers. The rotamer probability is provided by the Dun-brack backbone-dependent library (Eq. (4)) (Shapovalov andDunbrack, 2011)
Pðrj/;wÞ ¼ qð/;wjrÞPðrÞPr0qð/;wjr0ÞPðr0Þ
ð4Þ
where, for each rotamer r of a given residue type, the probabilitydensity estimate q(/,wjr) is calculated and the Bayes’ rule is usedto invert this density to produce an estimate of the rotamer proba-bility P(rj/,w) (Shapovalov and Dunbrack, 2011). All rotamers with
1 The backbone-dependent rotamer library consists of rotamer frequencies, meandihedral angles and variances of the backbone dihedral angle.
a probability less than 1% are discarded. This procedure reduces thetotal number of rotamers in approximately 25%. At the end of thisstep a reduced set of rotamers conformations containing only rota-mers with a high probability is obtained (Fig. 3-A). Here, the re-duced library is called ROTLIB.
4.3. Clustering long side-chain v angles
Despite the reduction of the number of rotamers obtained in thelast step, the resulting rotamer library (ROTLIB) contains severalconformations with small differences. In turn this represents aredundancy in the rotamers associated to each amino acid residueof the backbone-dependent library. In order to eliminate thisredundancy and reduce the total number of rotamers of each ami-no acid residue a clustering strategy is applied (Section 3.3). TheExpectation Maximization (EM) algorithm (Dempster et al., 1977)is used to cluster the rotamers from the ROTLIB.
EM clustering algorithm considers the different probabilities ofdistribution of each individual cluster in order to identify whichset of clusters are more favorable for a given set of rotamers. It be-gins clustering the ri rotamers of ROTLIB based in the K-meansalgorithm (MacQueen, 1967) to obtain an initial solution. K-meansminimizes a function of quadratic error (Eq. (3)), where p clustersare present. After determining the initial solution, the probabilityof a ri rotamer belonging to one of the p clusters is calculated(Expectation step of the EM algorithm). From this probability, dis-tribution parameters are calculated and the probabilities of distri-bution for each cluster p are ‘‘Maximized’’ (Witten et al., 2011).One of the input parameters of the clustering algorithm is thenumber of clusters to be identified. Determining the optimal num-ber of clusters is a difficult task and many strategies can be foundin the literature (Dudoit and Fridlyand, 2002; Krzanowski and Lai,1988).
A strategy to determine the optimal number of cluster wasdeveloped considering conformational proprieties of the biologicaldata. In nature the v1 (N, CA, CB, ⁄G⁄) angle is subject to restric-tions between the g side chain atom (s) and the main chain(Fig. 4). The different conformations of the side chain v1 are refer-eed as gauche (+), trans and gauche (�). The most abundantconformation is gauche (+) in which the g side-chain atom (s)is opposite to the residues of the carbonyl group of the main chainwhen viewed along the CB-CA bond. The second most abundantconformation is trans in which the side-chain g atom (s) isopposite the main chain nitrogen (N). The least abundant confor-mation is gauche (�) which occurs when the side chain is oppo-site the hydrogen substituent on the CA atom. This conformation isunstable because the g atom is in close contact with the main chainCO and NH groups. In general, for v1 angle the gauche (+), transand gauche (�) present its values close to �65.0�, 180.0�, 63.0�,respectively (Morris et al., 1992). Bhargavi et al. report the valuesof gauche (+), trans and gauche (�) to v2 and v3 (Bhargaviet al., 2003): v2 (� �67.0�, �179.0�, �70.0�); v3 (�68.0�, ��179.0�,� �67.0�). In experimental observations the gauche
(+), trans and gauche (�), there is a standard deviation of30� around these values. The patterns gauche (+), trans andgauche (�) and the standard deviation are used to determinethe optimal number of the p clusters.
The rotamers with the same number of v angles are selectedfrom the ROTLIB. For the v1 and v2 torsion angles the strategy be-gins the clustering process using p = 1. If after the clustering pro-cess there is a cluster with a standard deviation above 30�, thenumber of clusters are increased (p = p + 1) and the clustering pro-cess is repeated. The processs stop when all predicted clusters havea standard deviation less than 30�. The central goal of this strategyis ensure that rotamers associated to a conformation pattern(gauche (+), trans and gauche (-)) do not occur in another.

Fig. 3. Schematic representation of the clustering process. (A) represent the reduce library ROTLIB obtained after the probabilistic analysis. (B) represents the clustering ofside-chain v angles. (C) represent the reduced CLULIB library of rotamers.
Fig. 4. Side chain torsion angles of the amino acid Lysine. The torsion angles arenamed v1 (N,CA,CB,⁄G⁄), v2 (CA,CB,⁄G,⁄D⁄), v3 (CB,⁄G,⁄D,⁄E⁄), v4 (⁄G,⁄D,⁄E,⁄Z⁄).
5214 R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218
Rotamers v3 and v4 are not clustered because the most externalside-chain angles vary with great freedom whereas they can haveless contact with neighbour side-chains. In the clustering step onlythe v1 and v2 of the amino acid residues that present v3 and v4. v3
and v4 are selected statically. This property is enhanced if theneighbour side-chain has a smaller length, thus avoiding close con-tact with the long side-chain. Therefore, the external angles of a rot-amer side-chain (v3 and v4) suffer less energy restrictions thusobtaining a large degree of freedom. The rotamer angles v3 and v4
of a cluster group are defined by the predominance of rotamer an-gles of gauche (+), trans and gauche (�). For example, in agroup with 10 rotamers where 7 residues have v3 into gauche
(�) and 6 residues with v4 into trans, the resulting clustered rot-amer of this group will have v3 into gauche (�) and v4 into trans.
After the clustering step the mean value of each cluster is usedto built a new reduce library of rotamers. Here, this new library iscalled CLULIB (Fig. 3 - C). The clustering step reduces the numberof rotamers of the ROTLIB in approximately 50%.
4.4. Representing the protein conformational space in a CNF
After the clustering step, the protein sequence space is repre-sented as a SAT problem. Let S = {rj=1, . . . ,rj=m} the set of m availablerotamers obtained from the CLULIB for a position i of the unknownamino acid sequence K, than the target unknown amino acid se-quence can be now represented as a set K = {Si=1, . . . ,Si=n}, whereS is a set of available rotamers for the target amino acid residuein position i.
The SAT representation of the search space represents all possi-ble solutions using all available rotamers rj. Each rotamer residue
related to an amino acid position i obtained from the libraryCLULIB is indexed as an unique boolean variable. For each possibleassignments of rotamers rj for a given position i in the unknownamino acid sequence a boolean clause is created (Fig. 5).
Just one variable into each clause can be assigned as TRUE in asolution. This encoding model ensure that rotamers of a given po-sition will never be assigned to another position of the backbone.In other words, constraint clauses are needed to ensures that nomore than an unique rotamer will be assigned to a position ofthe main chain. We added clauses to the CNF formula to restrictthe assignment and to ensure this condition. These constraintswere defined for each clause combining the negation of eachvariable belonging to Si. This SAT scheme generates a robuststructured SAT-CNF that encodes all possible conformations ofthe solution space using all available rotamers present in S.
4.5. Dead-End-Elimination to eliminate not allowed rotamers
In a practical application of Protein design the search spacemust be even more constrained because of the long execution time.Dead-End-Elimination is a powerful pruning method used to re-move rotamers with little contribution to the stabilization of thetertiary structure of a polypeptide. DEE reduces each Si set remov-ing rotamers that increase the conformational energy of the struc-ture. The goal of the DEE algorithm is reduce the conformationalsearch space allowing just the use of rotamers that correspond tothe minimal global energy of the conformation. Let rx and ry twopossible rotamers for the position i of the unknown amino acid se-quence, if rx always represents a more energy favorable reductionthan ry in position i, the rotamer rx always makes the protein struc-ture more stable and ry can be eliminated.
The CHARMM potential energy described in Section 2.2 was usedto evaluate the energy of each rotamer E(ri). A Goldstein DEE algo-rithm to constraint the generated CNF formula was developedbased on the work of Goldstein (1994). Therefore, the DEE methodadds to the CNF formula an unitary negated clause for each prunedrotamer (Fig. 5-B). This eliminates the set of non-unusable rota-mers of the solution sequences.
4.6. Solving the CNF formula to determine the amino acid sequence
A SAT Solver must be applied in this boolean CNF clauses togenerate the amino acid residues. The SatZoo (Eén and Sorensson,

Fig. 5. SAT encoding. (A) represent the protein conformational space in CNF. (B) Apply DEE to eliminate not allowed rotamers. (C) Solve the CNF formula to determine theamino acid sequence.
Fig. 6. Ribbon representation of 3-D protein structures of the seven study cases. Magenta represents the target region used as input in our protein design method. (A)Experimental 3-D structure of the protein with PDB ID = 1ARE; (B) Experimental 3-D structure of the protein with PDB ID = 1ZDD; (C) Experimental 3-D structure of theprotein with PDB ID = 1WG7; (D) Experimental 3-D structure of the protein with PDB ID = 2OMM; (E) Experimental 3-D structure of the protein with PDB ID = 1J9I; (F)Experimental 3-D protein structure of the protein with PDB ID = 3DI0 and (G) Experimental 3-D structure of the protein with PDB ID = 1OEH. Amino acid side chains are notshown for clarity. Graphics were generated by PYMOL (Pymol Website, 2012). (For interpretation of the references to colour in this figure legend, the reader is referred to theweb version of this article.)
R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218 5215
2004) SAT solver was used in this step to determine the amino acidsequences.
5. Experiments and results
The proposed method was applied to design the amino acid se-quence of eight fragments of seven 3-D protein structures obtainedfrom the Protein Data Bank (PDB) (Berman et al., 2000): 1ARE(Hoffman et al., 1993) (Fig. 6-A); 1ZDD (Starovasnik et al., 1997)(Fig. 6-B); 1WG72. (Fig. 6-C); 2OMM (Sawaya et al., 2007) (Fig. 6-D); 1J9I (de Beer et al., 2002) (Fig. 6-E); 3DI0 (Girish et al., 2008)(Fig. 6-F); 1OEH (Zahn, 2003) (Fig. 6-G). Fig. 6 illustrates the 3-Dstructure of the proteins used in our experiments, those highlightedin magenta represent the target fragments used as input in ourmethod. Disparate segments of secondary structure were selectedin order to evaluate the efficacy of the proposed method in differentclasses of 3-D protein structures.
2 http://www.rcsb.org/pdb/explore/explore.do?structureId=1WG7
Table 2 column 1–4 present, respectively, the PDB identificationnumber of the protein, the amino acid sequence of the selectedsegment of the 3-D structure, the number of amino acid residuesof the segment and the location of this segment in the whole se-quence of the native 3-D protein structure. As input in our methodwe analyse the 3-D structure of each target segment and identifythe number of side-chain torsion angles (v angles) of each aminoacid residue position of the target segment. For each amino acidposition on the target fragment we calculate the phi (/), (w) andchi (v) angles (Step 1 of the proposed CPD method).
For each position of the target segment, rotamers are selectedfrom the Dunbrack Backbone-Dependent Library (Step 2 of the pro-posed method). All rotamers with a probability less than 1% arediscarded resulting a reduction of 25% of the number of rotamers(Step 3). The EM clustering algorithm is applied to the resultingdata from Step 3 and a new library of rotamers is built containinga reduced number of rotamers. The clustering procedure elimi-nates the redundancy of backbone-dependent library. Table 3shows for each target 3-D protein structure segment the number
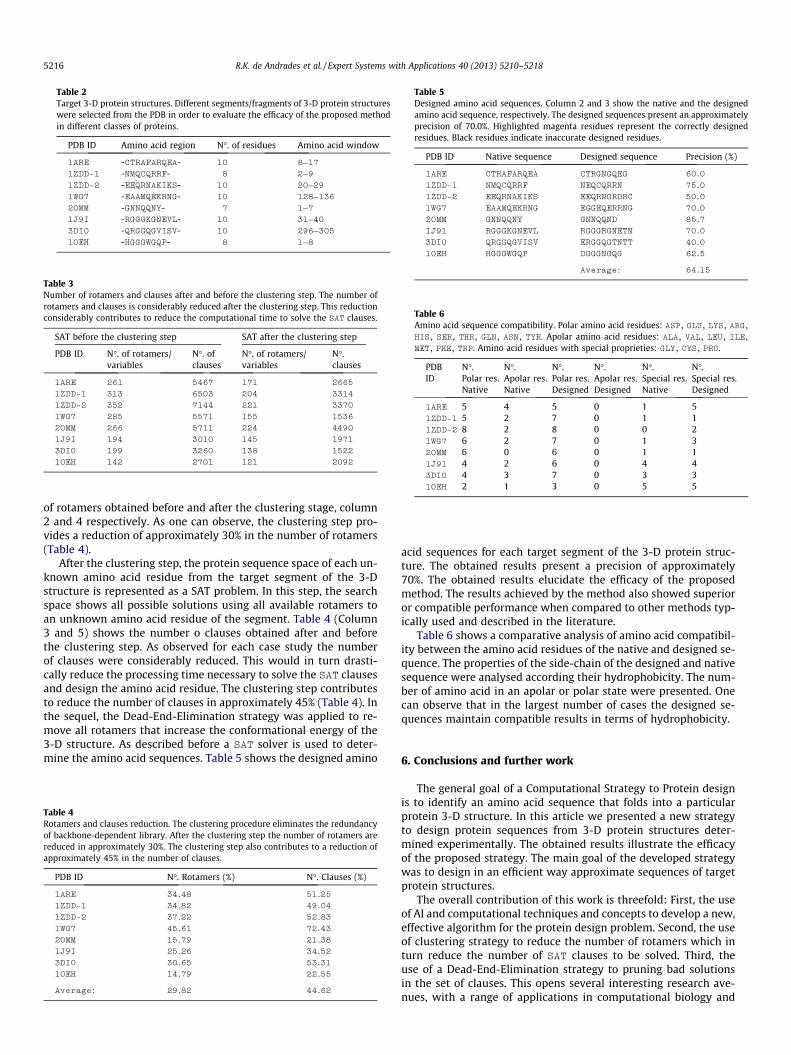
Table 2Target 3-D protein structures. Different segments/fragments of 3-D protein structureswere selected from the PDB in order to evaluate the efficacy of the proposed methodin different classes of proteins.
PDB ID Amino acid region N�. of residues Amino acid window
1ARE -CTRAFARQEA- 10 8–17
1ZDD-1 -NMQCQRRF- 8 2–9
1ZDD-2 -EEQRNAKIKS- 10 20–29
1WG7 -EAAMQEKRNG- 10 128–136
2OMM -GNNQQNY- 7 1–7
1J9I -RGGGKGNEVL- 10 31–40
3DI0 -QRGGQGVISV- 10 296–305
1OEH -HGGGWGQP- 8 1–8
Table 5Designed amino acid sequences. Column 2 and 3 show the native and the designedamino acid sequence, respectively. The designed sequences present an approximatelyprecision of 70.0%. Highlighted magenta residues represent the correctly designedresidues. Black residues indicate inaccurate designed residues.
PDB ID Native sequence Designed sequence Precision (%)
1ARE CTRAFARQEA CTRGNGQEG 60.0
1ZDD-1 NMQCQRRF NEQCQRRN 75.0
1ZDD-2 EEQRNAKIKS EEQRNGRDRC 50.0
1WG7 EAAMQEKRNG EGGEQERRNG 70.0
2OMM GNNQQNY GNNQQND 85.7
1J91 RGGGKGNEVL RGGGRGNETN 70.0
3DI0 QRGGQGVISV ERGGQGTNTT 40.0
1OEH HGGGWGQP DGGGNGQG 62.5
5216 R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218
Table 6Amino acid sequence compatibility. Polar amino acid residues: ASP, GLU, LYS, ARG,HIS, SER, THR, GLN, ASN, TYR. Apolar amino acid residues: ALA, VAL, LEU, ILE,MET, PHE, TRP. Amino acid residues with special proprieties: GLY, CYS, PRO.
PDBID
N�.Polar res.Native
N�.Apolar res.Native
N�.Polar res.Designed
N�.Apolar res.Designed
N�.Special res.Native
N�.Special res.Designed
1ARE 5 4 5 0 1 51ZDD-1 5 2 7 0 1 11ZDD-2 8 2 8 0 0 21WG7 6 2 7 0 1 32OMM 6 0 6 0 1 11J91 4 2 6 0 4 43DIO 4 3 7 0 3 31OEH 2 1 3 0 5 5
Average: 64.15
Table 3Number of rotamers and clauses after and before the clustering step. The number ofrotamers and clauses is considerably reduced after the clustering step. This reductionconsiderably contributes to reduce the computational time to solve the SAT clauses.
SAT before the clustering step SAT after the clustering step
PDB ID N�. of rotamers/variables
N�. ofclauses
N�. of rotamers/variables
N�.clauses
1ARE 261 5467 171 2665
1ZDD-1 313 6503 204 3314
1ZDD-2 352 7144 221 3370
1WG7 285 5571 155 1536
2OMM 266 5711 224 4490
1J9I 194 3010 145 1971
3DI0 199 3260 138 1522
1OEH 142 2701 121 2092
of rotamers obtained before and after the clustering stage, column2 and 4 respectively. As one can observe, the clustering step pro-vides a reduction of approximately 30% in the number of rotamers(Table 4).
After the clustering step, the protein sequence space of each un-known amino acid residue from the target segment of the 3-Dstructure is represented as a SAT problem. In this step, the searchspace shows all possible solutions using all available rotamers toan unknown amino acid residue of the segment. Table 4 (Column3 and 5) shows the number o clauses obtained after and beforethe clustering step. As observed for each case study the numberof clauses were considerably reduced. This would in turn drasti-cally reduce the processing time necessary to solve the SAT clausesand design the amino acid residue. The clustering step contributesto reduce the number of clauses in approximately 45% (Table 4). Inthe sequel, the Dead-End-Elimination strategy was applied to re-move all rotamers that increase the conformational energy of the3-D structure. As described before a SAT solver is used to deter-mine the amino acid sequences. Table 5 shows the designed amino
Table 4Rotamers and clauses reduction. The clustering procedure eliminates the redundancyof backbone-dependent library. After the clustering step the number of rotamers arereduced in approximately 30%. The clustering step also contributes to a reduction ofapproximately 45% in the number of clauses.
PDB ID N�. Rotamers (%) N�. Clauses (%)
1ARE 34.48 51.25
1ZDD-1 34.82 49.04
1ZDD-2 37.22 52.83
1WG7 45.61 72.43
2OMM 15.79 21.38
1J9I 25.26 34.52
3DI0 30.65 53.31
1OEH 14.79 22.55
Average: 29.82 44.62
acid sequences for each target segment of the 3-D protein struc-ture. The obtained results present a precision of approximately70%. The obtained results elucidate the efficacy of the proposedmethod. The results achieved by the method also showed superioror compatible performance when compared to other methods typ-ically used and described in the literature.
Table 6 shows a comparative analysis of amino acid compatibil-ity between the amino acid residues of the native and designed se-quence. The properties of the side-chain of the designed and nativesequence were analysed according their hydrophobicity. The num-ber of amino acid in an apolar or polar state were presented. Onecan observe that in the largest number of cases the designed se-quences maintain compatible results in terms of hydrophobicity.
6. Conclusions and further work
The general goal of a Computational Strategy to Protein designis to identify an amino acid sequence that folds into a particularprotein 3-D structure. In this article we presented a new strategyto design protein sequences from 3-D protein structures deter-mined experimentally. The obtained results illustrate the efficacyof the proposed strategy. The main goal of the developed strategywas to design in an efficient way approximate sequences of targetprotein structures.
The overall contribution of this work is threefold: First, the useof AI and computational techniques and concepts to develop a new,effective algorithm for the protein design problem. Second, the useof clustering strategy to reduce the number of rotamers which inturn reduce the number of SAT clauses to be solved. Third, theuse of a Dead-End-Elimination strategy to pruning bad solutionsin the set of clauses. This opens several interesting research ave-nues, with a range of applications in computational biology and

R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218 5217
bioinformatics. For instance, one could apply the developedmethod to other classes of proteins; second, one could test otherdifferent clustering algorithms; third, one could test the use of dif-ferent pruning techniques to reduce the number of SAT clauseseliminating the rotamers that increase the potential energy ofthe 3-D structure of the polypeptide.
Acknowledgements
This work was supported by grants from MCT/CNPq and CAPES –Brazil.
References
Allen, B., & Mayo, S. (2006). Dramatic performance enhancements for the fasteroptimization algorithm. Journal of Computational Chemistry, 27, 1071–1075.
Altman, R. B., & Dugan, J. M. (2005). Defining bioinformatics and structuralbioinformatics. Hoboken: John Wiley and Sons, Inc.
Berman, H., Westbrook, J., Feng, Z., Gilliland, G., Bath, T., Weissig, H., et al. (2000).The protein data bank. Nucleic Acids Research, 28(1), 235–242.
Bhargavi, G., Sheik, S. S., Velmurugan, D., & Sekar, K. (2003). Side-chainconformation angles of amino acids: Effect of temperature factor cut-off.Journal of Structural Biology, 143(3), 181–184.
Boas, F. E., & Harbury, P. B. (2007). Potential energy functions for protein design.Current Opinion in Structural Biology, 17(2), 199–204.
Branden, C., & Tooze, J. (1998). Introduction to protein structure (2nd ed.). New York:Garlang Publishing Inc.
Brooks, R., Bruccoleri, R., Olafson, B., States, D., Swaminathan, S., & Karplus, M.(1983). Charmm: A program for macromolecular energy, minimization, anddynamics calculations. Journal of Computational Chemistry, 4(2), 187–217.
Cook, S. (1971). The complexity of theorem proving procedures. In Proceedings of thethird annual ACM symposium on theory of computing (pp. 151–158). New York,USA.
Creighton, T. E. (1990). Protein folding. Biochemical Journal, 270, 1–16.Dahiyat, B., & Mayo, S. (1997). De novo protein design: Fully automated sequence
selection. Science, 278(5335), 82–87.de Beer, T., Fang, J., Ortega, M., Yang, Q., Maes, L., Duffy, C., et al. (2002). Insights into
specific DNA recognition during the assembly of a viral genome packagingmachine. Molecular Cell, 9, 981–991.
Dempster, A., Laird, N., & Rubin, D. (1977). Maximum likelihood from incompletedata via the em algorithm. Journal of the Royal Statistical Society, 39, 1–38.
Desmet, J., Maeyer, M., Hazes, B., & Lasters, I. (1992). The dead-end eliminationtheorem and its use in protein side-chain positioning. Nature, 356, 539–542.
Dixon, H., Ginsberg, M., & Parkes, A. (2004). Generalizing boolean satisfiability i:Background and survey of existing work. Journal of Artificial IntelligenceResearch, 21, 193–243.
Dudoit, S., & Fridlyand, J. (2002). A prediction-based resampling method forestimating the number of clusters in a dataset. Genome Biology, 3(7), 1–21.
Dunbrack, R., Jr., & Karplus, M. (2003). Backbone-dependent rotamer library forproteins: Application to side-chain prediction. Journal of Molecular Biology,230(2), 543–574.
Eén, N., & Sorensson, N. (2004). An extensible sat-solver. Lecture Notes in ComputerScience, 2919, 333–336.
Everitt, B. S., Landau, S., Leese, M., & Stahl, D. (2011). Cluster analysis (5th ed.). WestSussex: Wiley.
Field, M. J., Fischer, S., Gao, J., Guo, H., Ha, S., Joseph-McCarthy, D., et al. (1998). All-atom empirical potential for molecular modeling and dynamics studies ofproteins. Journal of Physical Chemistry, 102(18), 3586–3616.
Floudas, C., Fung, H., McAllister, S., Moennigmann, M., & Rajgaria, R. (2006).Advances in protein structure prediction and de novo protein design: A review.Chemical Engineering Science, 61(3), 966–988.
Georgiev, I., & Donald, B. R. (2007). Dead-end elimination with backbone flexibility.Bioinformatics, 23, 185–194.
Georgiev, I., Lilien, R., & Donald, B. (2008). The minimized dead-end eliminationcriterion and its application to protein redesign in a hybrid scoring and searchalgorithm for computing partition functions over molecular ensembles. Journalof Computational Chemistry, 29(10), 1527–1542.
Girish, T., Sharma, E., & Gopal, B. (2008). Structural and functional characterizationof staphylococcus aureus dihydrodipicolinate synthase. Febs Letters, 582,2923–2930.
Goldstein, R. F. (1994). Efficient rotamer elimination applied to protein side-chainsand related spinglasses. Biophysical Journal, 66, 1335–1340.
Gomes, C., Kautz, H., Sabharwal, A., & Selman, B. (2008). Satisfiability solvers.Foundations of artificial intelligence: Handbook of knowledge representation (Vol.3, pp. 89–134).
Gomes, C., & Selman, B. (2005). Computational science: Can get satisfaction. Nature,435, 751–752.
Gordon, D., Marshall, S., & Mayo, S. (1999). Energy functions for protein design.Current Opinion in Structural Biology, 9(4), 509–513.
Gordon, D., & Mayo, S. (1998). Radical performance enhancements forcombinatorial optimization algorithms based on the dead-end eliminationtheorem. Journal of Computational Chemistry, 19, 1505–1514.
Guerois, R., & de La Paz, M. L. (2006). Protein design: methods and applications (1sted.). Humana Press, Totowa, USA.
Hagler, A. T., Stern, P., Lifson, S., & Ariel, S. (1979). Urey-bradley force field, valenceforce field, and ab initio study of intramolecular forces in tri-tert-butylmethaneand isobutane. Journal of the American Chemical Society, 101(4), 813–819.
Hao, M., & Scheraga, H. (1999). Designing potential energy functions for proteinfolding. Current Opinion in Structural Biology, 9(2), 184–188.
Hoffman, R. C., Horvath, S. J., & Klevit, R. E. (1993). Structures of DNA-bindingmutant zinc finger domains: Implications for dna binding. Protein Science, 2(6),951–965.
Hom, G., & Mayo, S. (2006). A search algorithm ofr fixed-composition proteindesign. Journal of Computational Chemistry, 27, 375–378.
Jorgensen, W., & Tirado-Rives, J. (2005). Potential energy functions for atomic-levelsimulations of water and organic and biomolecular systems. Proceedings ofthe National Academy Sciences of the United States of America, 102(19),6665–6670.
Krzanowski, W., & Lai, Y. (1988). A criterion for determining the number of groupsin a data set using sum-of-squares clustering. Biometrics, 44, 23–34.
Lazaridis, T., & Karplus, M. (2000). Effective energy functions for protein structureprediction. Current Opinion in Structural Biology, 10(2), 139–145.
Lehninger, A., Nelson, D., & Cox, M. (2005). Principles of biochemistry (4th ed.). NewYork: W.H. Freeman.
Lesk, A. M. (2002). Introduction to bioinformatics (1st ed.). New York: OxfordUniversity Press Inc.
Lifson, S., & Warshel, A. (1968). Consistent force field for calculations ofconformations, vibrational spectra, and enthalpies of cycloalkane and nalkanemolecules. Journal of Chemical Physics, 49(14), 5116–5129.
Lippow, S., & Tidor, B. (1997). Progress in computational protein design. CurrentOpinion in Biotechnology, 18, 305–311.
Lodish, H., Berk, A., Matsudaira, P., Kaiser, C. A., Krieger, M., & Scott, M. (1990).Molecular cell biology. Scientific american books. New York: W.H.Freeman.
MacQueen, J. (1967). Some methods for classification and analysis of multivariateobservations. University of California Press.
Marques-Silva, J. (2008). Practical applications of Boolean satisfiability. Goteborg,Sweden: IEEE Press.
Morris, A., MacArthur, M., Hutchinson, E., & Thornton, J. (1992). Stereochemicalquality of protein structure coordinates. Proteins: Structure, Function, andBioinformatics, 12, 345–364.
Ollikainen, N., Sentovich, E., Coelho, C., Kuehlmann, A., & Kortemme, T. (2009). SAT-based protein design. San Jose, CA, USA: IEEE Press.
Osguthorpe, D. (2000). Ab initio protein folding. Current Opinion in StructuralBiology, 10(2), 146–152.
Park, S., Stowell, X., Wang, W., Yang, X., & Saven, J. (2011). Theoretical andcomputational protein design. Annual Review of Physical Chemistry, 62, 129–149.
Pierce, N., & Winfree, E. (2002). Protein design is NP-hard. Protein Engineering,15(10), 999–1009.
Pierce, N. A., Spriet, J. A., Desmet, J., & Mayo, S. L. (2000). Conformational splitting: Amore powerful criterion for dead-end elimination. Journal of ComputationalChemistry, 21, 999–1009.
Pokala, N., & Handel, T. (2000). Review: Protein design – where we were, where weare, where we’re going. Journal of Structural Biology, 134(2–3), 269–281.
Pymol Website. (2012). Pymol website. <http://www.pymol.org/>Ramachandran, G., & Sasisekharan, V. (1968). Conformation of polypeptides and
proteins. Advances in Protein Chemistry, 23, 238–438.Samish, I., Macdermaid, C., Perez-Aguilar, J., & Saven, J. (2011). Theoretical and
computational protein design. Annual Review of Physical Chemistry, 62, 129–149.Sander, C., Vriend, G., Bazan, F., Amnon, H., Nakamura, H., Ribas, L., et al. (1992).
Protein design on computers. Five new proteins: Shpilka, grendel, fingerclasp,leather and aida. Protein, 12(2), 105–110.
Sawaya, M. R., Sambashivan, S., Nelson, R., Ivanova, M. I., Sievers, S. A., Apostol, M. I.,et al. (2007). Atomic structures of amyloid cross-beta spines reveal varied stericzippers. Nature, 447(7143), 453–457.
Schaefer, T. (1978). The complexity of satisfiability problems. ACM Press.Schrauber, H., Eisenhaber, F., & Argos, P. (1993). Rotamers: To be or not to be? an
analysis of amino acid side-chain conformations in globular proteins. Journal ofMolecular Biology, 230(2), 592.
Selman, B., Levesque, H., & Mitchell, D. (1992). A new method for solving hardsatisfiability problems. In Proceedings of the national conference on artificialintelligence (pp. 440). San Jose, USA.
Shapovalov, M., & Dunbrack, R. Jr., (2011). Pendent rotamer library for proteinsderived from adaptive kernel density estimates and regressions. Structure, 19,844–858.
Spriet, J. (2003). Side-chain structure prediction based on dead-end elimination:Single split dee-criterion implementation and elimination power. Lecture Notesin Computer Science, 2812, 402–416.
Starovasnik, M., Braisted, A., & Wells, J. (1997). Structural mimicry of a nativeprotein by a minimized binding domain. Proceedings of the National AcademySciences of the United States of America, 94, 10080.
Tian, P. (2010). Computational protein design, from single domain soluble proteinsto membraneproteins. Chemical Society Reviews, 39, 2071.
Tramontano, A. (2006). Protein structure prediction (1st ed.). Weinheim: John Wileyand Sons, Inc.
Voigt, C., Gordon, D., & Mayo, S. (2000). Trading accuracy for speed: A quantitativecomparison of search algorithms in protein sequence design. Journal ofMolecular Biology, 299(3), 789–803.

5218 R.K. de Andrades et al. / Expert Systems with Applications 40 (2013) 5210–5218
Wille, R., Grosse, D., Soeken, M., & Drechsler, R. (2008). Using higher levels ofabstraction for solving optimization problems by Boolean satisfiability. Montpellier,France: IEEE Press.
Witten, I., Frank, E., & Hall, M. (2011). Data mining: Pratical machine learning toolsand techniques (3rd ed.). Burlington, USA: Elsevier.
Xie, W., & Sahinidis, N. V. (2006). Residue-rotamer-reduction algorithm for theprotein side-chain conformation problem. Bioinformatics, 22(2), 188–194.
Yang, X., & Saven, J. (2005). Computational methods for protein design and proteinsequence variability: Biase monte carlo and replica exchange. Chemical PhysicalLetters, 401, 205–210.
Zahn, R. (2003). The octapeptide repeats in mammalian prion protein constitute aph-dependent folding and aggregation site. Journal of Molecular Biology, 334,477.