Embed Size (px)
Citation preview

Contents lists available at ScienceDirect
Information Systems
Information Systems 36 (2011) 174–191
0306-43
doi:10.1
$ Thi
Researc
initiativ
S-Cube� Cor
E-m
rita.lenz
riccardo
matteo.
(W. Pen
journal homepage: www.elsevier.com/locate/infosys
A unified multimedia and semantic perspective for data retrieval inthe semantic web$
Claudio Gennaro a, Rita Lenzi b, Federica Mandreoli b,d, Riccardo Martoglia b,�,Matteo Mordacchini a, Wilma Penzo c,d, Simona Sassatelli b
a ISTI - CNR, Pisa, Italyb DII - University of Modena e Reggio Emilia, Italyc DEIS - University of Bologna, Italyd IEIIT - BO/CNR, Bologna, Italy
a r t i c l e i n f o
Keywords:
PDMS
Network organization
Query routing
Semantics
Multimedia data
79/$ - see front matter & 2010 Elsevier B.V. A
016/j.is.2010.07.002
s work has been partially supported by
h Council in the context of the NeP4B Projec
e ‘‘Ricerca a tema libero’’ and by the IST F
(Grant Agreement no. 215483).
responding author.
ail addresses: [email protected] (C. G
[email protected] (R. Lenzi), federica.mandreoli@un
[email protected] (R. Martoglia),
[email protected] (M. Mordacchini), w
zo), [email protected] (S. Sassatelli)
a b s t r a c t
In recent years, the emerging diffusion of peer-to-peer networks is going beyond the
single-domain paradigm like, for instance, the mono-thematic file sharing one (e.g.
Napster for music). Peers are more and more heterogeneous data sources which need to
share data with commercial, educational, and/or collaboration purposes, just to mention
a few. Moreover, in current information processing applications data cannot be
meaningfully searched by precise database queries that would return exact matches
(e.g. when dealing with multimedia, proteomic, statistical data).
In this paper we move a step towards multi-domain multi-type data sharing
systems by introducing an advanced technological infrastructure which enables users to
meet these new emerging needs.
A fundamental issue in this context is data heterogeneity, which is pervasive and
intrinsically present both at intensional level where, due to peers’ autonomy, different
semantic descriptions of the available information are provided, and at extensional
level, where multiple data types can coexist, also including content-based searchable
data types such as multimedia data.
Our proposal relies on a Peer Data Management Systems (PDMS) framework to
present innovative network organization and query routing mechanisms which exploit
both peers’ data description and data content to achieve effective and efficient network
management and data retrieval in such a context. The validity of our proposal is
demonstrated by an absolutely satisfactory experimental evaluation on a real setting.
& 2010 Elsevier B.V. All rights reserved.
ll rights reserved.
the Italian National
t and of the research
P7 European Project
ennaro),
imo.it (F. Mandreoli),
.
1. Introduction
The ever-growing and widespread availability of datafrom Internet information sources has placed great intereston the potential of information sharing. This awareness hasled to the flourishing of Peer-to-Peer systems, i.e. systemswith distributed computing capabilities, where each peerexchanges information and services directly with otherpeers.
Nevertheless, in recent years these systems havedemonstrated to be too much restrictive as to the

1 SC is a keyword to denote the descriptor scalable color for image
color according to the MPEG-7 standard.
C. Gennaro et al. / Information Systems 36 (2011) 174–191 175
potentialities they offer for data retrieval. More precisely,they do not appropriately support new information sharingneeds which are going beyond the single-domain paradigmlike, for instance, the mono-thematic file sharing one (e.g.Napster for music).
On the other hand, the Web fosters the vision of anInternet-based global agora where peers are more andmore heterogeneous data sources which need to sharevarious data types with commercial, educational, and/orcollaboration purposes, just to mention a few. Moreover, incurrent information processing applications data cannot bemeaningfully searched by precise database queries thatwould return exact matches [1]. This is particularly true forthe multimedia domain which is par excellence the onewhere data are commonly searched by similarity on itscontent. However, several other data domains show thesame needs. We refer to biochemical entities, medicalobservations, weather forecast, and so on.
In this paper we move a step towards multi-domainmulti-type data sharing systems by introducing an ad-vanced technological infrastructure which enables users tomeet these new emerging needs.
In the scenario we consider, peers are autonomousentities which expose the data they want to share witheach other for interoperability purposes. A fundamentalissue in this context is data heterogeneity, which ispervasive and intrinsically present both at intensional levelwhere, due to peers’ autonomy, different semantic descrip-tions of the available information are provided, and atextensional level, where multiple data types can coexist,also including content-based searchable data types.
A recent framework which well models peer interoper-ability in this scenario is represented by Peer DataManagement Systems (PDMSs). Indeed, PDMSs have beenaddressed in [2,3] as one powerful means for large-scaledata sharing among semantic peers, as they ensureinformation exchange and cooperation, while also com-pletely preserving full peer autonomy, network scalabilityand dynamism. In a PDMS, peers are heterogeneous datasources, each having its own content modeled upon a localschema that represents the peer’s domain of interests.Because of the absence of a common understanding of thevocabularies used at each peer’s schema, semantic relation-ships, called mappings, are established locally betweenpairs of peers, thus implementing a decentralized schemamediation. Hence, joining a PDMS is inherently a moreheavyweight operation than joining a P2P file-sharingsystem, since some semantic relationships need to bespecified. This effort is definitely payed back in contextslike the one considered, where, for instance, the member-ship changes infrequently or it is restricted due to securityor consistency requirements [3]. As an example, this is thecase of companies which organize and coordinate them-selves in order to develop common and shared opportu-nities, while respecting their own autonomy andheterogeneity (e.g. enterprises belonging to the sameholding). In these contexts, peers are likely to stay availablethe majority of the time, though being able to join (or addnew data) very easily. Thus, the essentially stable nature ofa PDMS makes the system quite different from a traditionalP2P setting where peers are online very shortly.
As far as the language for data representation isconsidered, we rely on OWL as Semantic Web standardfor data sharing. A sample OWL-based scenario of a PDMSconcerning data about floor covering is shown in Fig. 1. Theboxes on the right-hand part of the figure depict excerpts ofthe OWL ontologies exposed by peers Peer1 and Peer2.Data sources include content-based searchable data, suchas images of products offered by peers. This information isrepresented by means of appropriate OWL properties in thepeers’ ontologies (e.g. image in Peer1’s ontology of Fig. 1).
The presence of this kind of data types gives rise to theneed of a powerful query language which enables the usersto also express content-based, aka similarity, predicates. Asan example, let us consider the query shown in the shadedbox on the left-hand side of Fig. 1. The query is formulatedby using a SPARQL-like language properly extended tosupport similarity predicates on multimedia data, and asksPeer1 for ‘‘Companies that sell Italian tiles similar to therepresented one and that cost less than 30 euros’’: the LIKEoperator in the FILTER clause is used to search for imageswhose similarity on color1 with the image provided asargument is greater than 0.3. Moreover, the query alsospecifies the number of expected results in the LIMIT clause.
In a PDMS, queries are answered globally: starting fromthe querying peer p, a query q is first evaluated against thep’s local repository, then p forwards q towards itsneighborhood and each receiving peer behaves in the sameway. Therefore, answers to q can come from any peer pu ofthe network that is connected to p through a semantic pathof mappings. Since a query is formulated on p’s ontology, inorder to be answered by pu, the query has to bereformulated according to its own ontology. To thispurpose, semantic mappings are used in a multi-stepreformulation of q along the semantic path connecting p
to pu [4,5]. For instance, in Fig. 1 the concept origin maytranslate to country when the query is forwarded to Peer2.
In this context, query answers are inevitably approxi-mated. On the one hand, each reformulation step may leadto some semantic approximation and, consequently, thereturned data may not exactly fit the data descriptionspecified in the original query. On the other hand, when asimilarity predicate is evaluated at a peer, the returneddata are intrinsically approximated as to its content.
This paper leverages such a query answering misalign-ment as a means for efficiently and effectively supportingquery processing in our context. To this purpose, we movealong two main directions.
First, we introduce an innovative network organization
technique which exploits peers’ data description and datacontent to instantiate the network topology according tothe linkage closeness of similar peers. This gets two mainadvantages: (1) it reduces the information loss that it islikely to be along long paths in the PDMS because ofmissing (or incomplete) mappings [4,6], and (2) it can savecomputational efforts due to the evaluation of similaritypredicates, which is known to be a very costly operation[1], on irrelevant peers, by favoring the execution of

SELECT ?company WHERE {?tile a Tile. ?tile company ?company ?tile price ?price . ?tile origin ?origin . ?tile image ?image . FILTER((?price < 30) && (?origin = ‘Italy’) && LIKE(?image,‘myimg.jpg’,SC, 0.3))} LIMIT 100
Fig. 1. Reference scenario.
C. Gennaro et al. / Information Systems 36 (2011) 174–191176
similarity queries in a neighborhood of similar peers in thenetwork.
Second, we present a query routing mechanism whichmaximizes: (1) effectiveness of retrieval by combining datadescription and data content relevance of the potentialmatches which can be found in each query forwardingdirection, and (2) efficiency of query execution since itminimizes the network load by cutting off useless subnet-works.
To the authors’ knowledge, the advanced technologicalinfrastructure we present is the first research proposalspecifically devised to support query processing in a multi-domain multi-type data sharing system. In particular, it isgeneral with regard to the types of data to be shared, inthat it is parametric with respect to the evaluation of peers’similarity from different points of view.
We experienced our proposal on the stimulating scenar-io considered in the ongoing Italian Council co-fundedNeP4B (Networked Peers for Business) Project, whose aim isto develop an advanced technological infrastructure forsmall and medium enterprises (SMEs) to allow them tosearch for partners, exchange data, and negotiate withoutlimitations and constraints. In this context, we focused onmultimedia data like images, video, and so on. However, thepresented framework is general with regard to the types ofdata to be shared, and thus it naturally supports any othercontent-searchable data domain.
The organization of the paper is as follows. We start byproviding a formal specification of the semantics of queryanswering, where each answer is characterized by a scorewhich expresses the overall relevance of the answer fromboth data description and data content perspectives(Section 2). The proposed model does not compel to afixed semantics but rather it is founded on a fuzzy
settlement which proved to be sound for a formalcharacterization of the approximations originated in thenetwork for both data description [7] and data content [8].
We proceed by presenting our network organizationapproach (Section 3) which dynamically organizes thenetwork in Semantic Multimedia Overlay Networks(SMONs) and assists each newly entering peer in selecting
the overlay network closest as to its data description andcontents. Then, within each overlay network, the peer isassisted in a fine-grained selection of its own neighborsamong its most similar peers according to both semanticand content aspects. The obtained approach extends thework in [6] in that it generalizes it to the application of aglobal peers’ distance function which combines severalpeers’ perspectives, the data description and the datacontent ones, in an innovative multi-domain multi-typedata sharing view. In particular, a multimedia distancefunction is introduced to evaluate data content similarityand specific properties the global distance function mustsatisfy to make the approach applicable are presented.Furthermore, our proposal for an effective peer placementin the network is scalable, incremental and self-adaptive inthe creation and maintenance of SMONs as clusters ofsimilar peers.
Then, we introduce our query routing mechanism(Section 4) which exploits both peers’ semantic and datacontent information to build two data structures, aSemantic Routing Index (SRI) and a Multimedia RoutingIndex (MRI), which effectively and efficiently support queryanswering in the network. SRIs and MRIs are scalable anddistributed index structures specifically devised for locat-ing the most relevant directions to forward a query to fromdata description and data content perspectives, respec-tively. In particular, from the data content point of view,the evaluation of the relevance of a direction goes beyondtraditional approaches [9] which only take into account thecardinality of potential matches, but rather it combinesquantitative aspects with an estimate of data contentsimilarity, thus emphasizing a qualitative evaluation.
We also show how routing strategies (Section 5)influence the order of the returned answers. This allowsdifferent query processing approaches to be implemented,based on the specific network needs and policies.
The validity of the proposal is then proved by theextensive experiments we conducted on different settings(Section 6). We complete our work with a discussion onrelated work (Section 7) and finally we draw our conclu-sions (Section 8).

C. Gennaro et al. / Information Systems 36 (2011) 174–191 177
2. Answering queries in a PDMSs
The main aim of this section is to propose a semantics foranswering queries in a PDMS network where two kinds ofapproximations characterize answers: the one given by theevaluation of similarity predicates, and the other one due tothe reformulation of queries along paths of mappings.
2.1. Preliminaries
We denote with P the set of peers in the network. Eachpeer p 2 P stores a set of local data instances I, modeledupon a local OWL ontology O where we make thesimplifying assumption that O is represented through aset of ontology classes {C1,y,Ck}.2 From O, we distinguishcontent-searchable concepts as those concepts in O whichrefer to content-searchable data (e.g. image). Further, wewill denote with Ci(I) the projection of I for concept Ci. Peersare pairwise connected in a semantic network throughsemantic mappings between peers’ ontologies. For our
f :: ¼/triple_patternS/filter_patternS/triple_patternS :: ¼ triplej/triple_patternS4/triple_patternS/filter_patternS :: ¼jj/filter_patternS4/filter_patternSj
/filter_patternS3/filter_patternSjð/filter_patternSÞ
purposes, we abstract from the specific format thatsemantic mappings may have. For this reason, we considera simplified scenario where semantic mappings areassumed to be directional, pairwise and one-to-one. Theapproach we propose can be straightforwardly applied tomore complex mappings relying on query expressions asproposed, for instance, in [4]. For our purposes, mappingsare extended with scores quantifying the strength of therelationship between the involved concepts. Their fuzzyinterpretation is given in the following.
Definition 1 (Semantic mapping). A semantic mapping froma source schema Oj to a target schema Oi, not necessarily
?tile a Tile4?tile company ?company4?tile price ?price4?tile origin ?origin4?tile image ?image4?priceo304?origin¼
‘ Italy’ 4?image� ðSC,0:3Þ‘ myimg:jpg’ .
distinct, is a fuzzy relation MðOi,OjÞDOi � Oj where eachinstance ðC,CuÞ has a membership grade denoted asmðC,CuÞ 2 ½0,1�. This fuzzy relation satisfies the followingproperties: (1) it is a 0-function, i.e. for each C 2 Oi, it existsexactly one Cu in Oj such that mðC,CuÞZ0; (2) it is reflexive,i.e. given Oi=Oj, for each C 2 Oi mðC,CÞ ¼ 1.
For instance, Peer1 of Fig. 1 maintains two mappingrelations: the mappings towards Peer2 (M(O1,O2)) andPeer3 (M(O1,O3)). M(O1,O2) may associate Peer1’s concept
2 Note that in OWL properties are specified through classes. In the
following, without loss of generality, we will use the terms ‘‘class’’ and
‘‘concept’’ without distinction. Further, whenever more than one peer will
be considered, we will use subscript notation to distinguish different
peers, peer ontologies and data instances.
origin to Peer2’s concept country with a score of 0.73,thus expressing that a semantic approximation is detectedbetween the two concepts (for instance, the country mightbe only a part of an origin).
Note that for the examples and experimental evaluationof this paper, we adopted the semantic matching algorithmproposed in [10]; however, this paper is not concerned withhow semantic mappings are created. The problem of how togenerate high quality semantic mappings is an entire fieldof investigation in itself. For an accurate selection andevaluation of matchers, we refer the interested reader to[11] where a comprehensive analysis of the schemamatching problems and solutions space is presented.
2.2. Semantics of query answering
A query is posed on the ontology of the queried peer.Query conditions are expressed using predicates that canbe combined in logical formulas through logical connec-tives, according to the syntax:
where triple is an RDF triple and a filter j is a predicatewhere relational ð ¼ , o ,4 , o ¼ ,4 ¼ , aÞ and similarityð � ðF,tÞÞ operators operate on RDF terms and values. Inparticular, � ðF,tÞ translates the LIKE operator where F is afeature (e.g. color or texture for images) and t is thespecified similarity threshold. Without loss of generality,we assume that the set of features which similaritypredicates can be formulated on is extensible and dependson the kind of managed content-searchable data and thateach feature F is associated with a query language keyword.
For instance, the WHERE clause of the reference querytranslates to the following query formula:
Each peer p receiving a query first retrieves the answersfrom its own local data I then it reformulates the querytowards its own neighborhood.
The evaluation of a given query formula f on a local datainstance i 2 I is given by a score s(f,i) in [0,1] which sayshow much i satisfies f. The value of s(f,i) depends on theevaluation on i of the filters j1, . . . ,jn that compose thefilter-pattern of f, according to a scoring function sfunj, thatis: sðf ðj1, . . . ,jnÞ,iÞ ¼ sfunjðsðj1,iÞ, . . . ,sðjn,iÞÞ. Note thatfilters are predicates of two types: relational and similaritypredicates. A relational predicate is a predicate whichevaluates to either 1 (true) or 0 (false). Instead, theevaluation of a similarity predicate j follows a non-Boolean semantics and returns a score sðj,iÞ in [0,1] whichdenotes the grade of approximation of the data instance i
with respect to j. It is set to 0 when the similarity of i w.r.t.

C. Gennaro et al. / Information Systems 36 (2011) 174–191178
the predicate value is smaller than the specified threshold t,and to the grade of approximation measured, otherwise.The scoring function sfunj evaluates f by combining the useof a t-norm ðs4Þ for scoring conjunctions of filter evalua-tions, and the use of a t-conorm (s3) for scoring disjunc-tions. A t-norm (resp., t-conorm) is a binary function on theunit interval that satisfies the boundary condition (i.e.s4ðs,1Þ ¼ s, and resp., s3ðs,0Þ ¼ s), as well as the mono-tonicity, the commutativity, and the associativity proper-ties.3 The use of t-norms and t-conorms generalizes thequery evaluation model with respect to the use of specificfunctions. Therefore, the query answers retrieved from theevaluation of f on p’s local data is given byAnsðf ,pÞ ¼ fði,sðf ,iÞÞji 2 I,sðf ,iÞ40g, i.e. it is the set of localdata instances which satisfy f, possibly with a certain gradeof approximation.
Due to the heterogeneity of schemas, any reformulationa peer pi performs on a given query formula f towards oneof its neighbors, say pj, gives rise to a semantic approxima-tion which depends on the strength of the relationshipbetween each concept in f and the mapped concept in Oj.Such an approximation is quantified by a scoring functionsfunc which combines the pj’s mapping scores on f’sconcepts: sðf ,pjÞ ¼ sfuncðmðC1,C 01Þ, . . . ,mðCn,C 0nÞÞ whereC1,y,Cn are the concepts in Oi involved in the queryformula, and C 01, . . . ,C 0n are the corresponding concepts in Oj
according to M(Oi,Oj). sfunc is a t-norm ðs4Þ as all theinvolved concepts are specified in the triple_pattern of f andtriples can only be combined through conjunctions.
Starting from the queried peer, the system can accessdata on any peer in the network which is connectedthrough a semantic path of mappings. When the query isforwarded through a semantic path, it undergoes a multi-step reformulation which involves a chain of semanticapproximations. The semantic approximation given by asemantic path p1-p2- � � �-pm (in the following denotedas Pp1 ,...,pm ), where the submitted query formula f1 under-goes a chain of reformulations f1-f2- � � �-fm, can beobtained by composing the semantic approximationscores associated with all the reformulation steps:sðf1,Pp1 ,...,pm Þ ¼ sfunrðsðf1,p2Þ,sðf2,p3Þ, . . . ,sðfm�1,pmÞÞ, wheresfunr is a t-norm ðs4Þ which composes the scores of queryreformulations along a semantic path of mappings.
Summing up, given a query formula f submitted to apeer p, the set of accessed peers Pu¼ fp1, . . . ,pmg,
4 and thepath Pp,...,pj
used to reformulate f over each peer pj in Pu, thesemantics of answering f over fpg [ Pu is the union of thequery answers collected in each accessed peer: Ansðf ,pÞ [Ansðf ,Pp,...,p1
Þ [ � � � [ Ansðf ,Pp,...,pm Þ where Ansðf ,Pp,...,pjÞ con-
tains the set of the results collected in the accessed peer pj,and each result is a data instance having a grade ofapproximation given by the combination of the approx-imation local to pj together with the semantic approxi-mation given by the path Pp,...,pj
: Ansðf ,Pp,...,pjÞ ¼
fði,sgðsðf ,iÞ,sðf ,Pp,...,pjÞÞÞjði,sðf ,iÞÞ 2 Ansðf ,pjÞg, where sg is a
t-norm ðs4Þ used for score combination.
3 Examples of t-norms are the min and the algebraic product operators,
whereas examples of t-conorms are the max and the algebraic sum
operators.4 Note that Pu not necessarily covers the whole network (i.e. PuDP).
As observed before, as far as the starting queried peer isinvolved, no semantic approximation occurs as no refor-mulation is required (i.e. s(f,Pp)=1).
3. Network construction
For a given peer, the linkage closeness to similar peers isa crucial issue for query processing to be both efficient andeffective. In particular, the similarity between peers shouldtake into account both semantic and content aspects. Tothis end, we envision a Semantic Multimedia OverlayNetwork (SMON) as an overlay network composed of a setof peers which are similar w.r.t. both these perspectives. Inthis section, we define an automatic network organizationapproach which assists each newly entering peer in theselection of the best neighbors, i.e. those having bothsimilar concepts and similar multimedia objects. Peers areassigned to one or more SMONs on the basis of their ownsemantic and multimedia contents. This operation is areally challenging one. From a semantic point of view, thelack of a common understanding among the peers’ localdictionaries implies that similar or even the same contentsin different peers can be described by different concepts.On the other hand, from a multimedia point of view, twopeers might have semantically related contents (i.e. theymight both contain data about different kinds of marblemanufactured products) but different multimedia contents(i.e. one could contain color pictures of marble tiles, and theother one black and white pictures about the same subject).Consider, for instance, our reference scenario as depicted inFig. 2: peers from 1 to 5 contain data (text and pictures)about floor covering, however each peer uses its ownconcepts to describe it (e.g. tile in Peer1 and Peer2, slabin Peer3, and so on). Some of these peers contain colorimages (Peer1 and Peer3), while others contain black andwhite images (Peer2, Peer4 and Peer5). Moreover, somepeers contain information about marble monuments (Peer5and Peer6). In this case, the network has beenautomatically organized into two SMONs, where peersfrom 1 to 4 belong to SMON1 (floor covering, with peerswith similar images being close to each other), Peer6belongs to SMON2 (marble monuments), while Peer5belongs to both.
The construction of SMONs found on the semanticclustering approach presented in [6] and extends it toinclude information on multimedia data, in line with avision of a multi-domain, multi-type data sharing system.In particular, the network construction solution in [6] relieson a distance function between peers. In the next section,we introduce a distance definition properly tailored to aSMON scenario.
3.1. On distance definition
Several alternatives are possible for the distance func-tion as the approach in [6] only requires it is a metric.Nevertheless, the goodness of the obtained results isheavily dependent from its effectiveness. We propose asemantic-multimedia distance smd which is a combinationof a semantic distance sd (Section 3.1.1) with a multimedia

Semantic-MultimediaPeers
Peer1
SMON1FLOOR COVERING
Peer3Peer2 Peer5Peer4
{statue, …}
{monument, fountain, …}SMON2MARBLE MONUMENTS
Peer6
{tile, …}
{floor, …}{tile, floor, carpet, …}
{slab, …}{parquet, slab, …}
COLOR IMAGES
B/W IMAGES
Fig. 2. Example of network organization for the reference scenario.
C. Gennaro et al. / Information Systems 36 (2011) 174–191 179
distance md) (Section 3.1.2). Specifically, given two peers pi,pj, and two sets of concepts C�i DOi,C
�j DOj
smdðC�i ,C�j Þ ¼ sdðC�i ,C�j Þ �mdðC�i ,C�j Þ
sd, md, and smd must be metric functions. Recall that afunction d : X � X-R is a metric on a set X iff the followingconditions hold:
1.
dðx,yÞ40 with xay and d(x,x)=0 (non-negativity); 2. d(x,y)=d(y,x) (symmetry); 3. dðx,yÞrdðx,zÞþdðz,yÞ (triangle inequality).For smd to be a metric, the combination operator � mustpreserve the metric properties. Examples of � are linear
combination (smdðC�i ,C�j Þ ¼ a � sdðC�i ,C�j Þþb �mdðC�i ,C�j Þ, with
a40, b40, aþb¼ 1) and quadratic sum ðsmdðC�i ,C�j Þ ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffisdðC�i ,C�j Þ
2þmdðC�i ,C�j Þ
2q
Þ.
Our approach however is general and sd and md can bechosen as the most suitable according to the types of datato be shared. The same applies for the choice of �, providedthat the above properties are satisfied. In our proposal, weassume that sd and md take values in [0,1]. This is areasonable assumption since common distance functionsdeveloped in the Computational Linguistics field as well asin the content-based Information Retrieval context evalu-ate in [0,1] or usually can be normalized to it.
3.1.1. Semantic distance
One of the best ways of exploiting the semantics of theinvolved concepts is to correlate them by adopting knowl-edge-based distances, which take advantage of linguisticinformation extracted from external knowledge sources. Inthis paper, we consider one of the options studied in [6], i.e.the adaptation of the Leacock–Chodorow [12] distance, oneof the most effective distances in the ComputationalLinguistics field, exploiting the well-known and widelyavailable WordNet (WN) thesaurus.
Definition 2 (Semantic distance). The semantic distancesd(Ci,Cj) between two given concepts Ci and Cj is quantifiedby comparing their WN hypernymy hierarchies and is
defined as
sdðCi,CjÞ ¼
lenðCi,CjÞ
2 � Hif (lcaðCi,CjÞ
1 otherwise
8<:
where len(Ci,Cj) is the number of links connecting Ci and Cj inthe hypernymy hierarchy, and H is the height of the hierarchy(16 in WN). sd takes values between 0 (equal concepts orsynonyms) and 1 (completely unrelated concepts).
The distance function sd is extended to sets of conceptsC*. We define sd(Ci*, Cj*) as the distance valuesdðClsdðC
�i Þ,ClsdðC
�j ÞÞ between the Ci*’s clustroid, Clsd(C*i),
and the C*j’s clustroid, Clsd(C*j).
Definition 3 (Clustroid). Given a metric space ðD,dÞ definedby a domain of objects D and a distance function d, theclustroid Cld(D) of a set D 2 D of objects is the object o 2 D
with the minimum DistFactor, where DistFactorðoÞ ¼Pou2Dd2ðo,ouÞ.
3.1.2. Multimedia distance
The multimedia distance md(C*i, C*j) provides a measureof the closeness between the multimedia objects under-lying C*i and those underlying C*j. To this end, eachmultimedia object is represented through a set of features(e.g. color and textures for images). We denote with XFu thevalue of object X under the feature Fu and without loss ofgenerality we assume that for each feature Fu a metricspace ðDFu ,duÞ exists on the feature domain DFu , and thateach du takes values between 0 and 1.
The metric distance d between a pair of objects (X,Y) isdefined as a linear combination of the distinct metricdistances du, where each du is defined on the basis of theu-th feature extracted from each object:
dðX,YÞ ¼ a1d1ðXF1 ,YF1 Þþ � � � þaLdLðX
FL ,YFL Þ
where L is the number of considered features, au 2 R,a1þ � � � þaL ¼ 1, are scalar coefficients, and XFu ,YFu 2 DFu . Itis worth noting that d is a metric and takes values between0 and 1.
Similarly to sd(C*i, C*j) and starting from the distanced(X,Y) defined between any pair of multimedia objects, we

C. Gennaro et al. / Information Systems 36 (2011) 174–191180
could extend md to sets of concepts as follows:
mdðC�i ,C�j Þ ¼ a1d1ðCld1ðC�i ðIiÞ
F1 Þ,Cld1ðC�j ðIjÞ
F1 ÞÞþ � � �
þaLdLðCldLðC�i ðIiÞ
FL Þ,CldLðC�j ðIjÞ
FL ÞÞ
where C�ðIÞFu ¼ fXFu jX 2 CðIÞ,C 2 C�g and both C�i ðIiÞFu and
C�j ðIjÞFu are not empty.
Several possible cluster distances are available in theliterature (for a survey see for instance [13]), however sinceour aim is to exploit the extensibility of the metric spaceapproach, we must base our distance on the use ofclustroids (or medoids) of the data in peers, whichonly use pairwise distance of objects. This solution hashowever the disadvantage that finding the clustroids canbe very costly when the number of involved objects is largesince its computation implies scanning the entire peerdataset and computing all possible pairwise distances.Moreover, in a multimedia context the choice of clustroidsas cluster representatives is somehow questionable, be-cause the clustroids are not necessarily at the center of acluster. For these reasons, we do not compute clustroidsbut rather we exploit a set of reference objects to generate avector space where we approximately compute thecentroid of the objects in C�ðIÞFu , for each Fu. Thisapproximation uses histograms as a mean to recorddistance statistics.
In particular, for each feature Fu, each peer buildsdifferent histograms. Each histogram exploits one of themu reference objects Rk, with k=1,y,mu,5 and representsthe distribution of the distances between the Fu value of the
reference object Rk, RFu
k and the Fu values of the objects in
C(I). Formally, given an interval ½aFu ,bFu � in the feature
domain DFu , we select hFuþ1 division points 0raFu ¼ aFu
0 o
aFu
1 o � � �oaFu
hFu¼ bFu r1 such that ½aFu ,bFu � is partitioned
into hFu disjoint intervals ½aFu
i�1,aFu
i Þ, i¼ 1, . . . ,hFu . Given a
peer p with a content-searchable concept C and local data I,
for each reference object RFu
k we build the histogram
FHistðCðIÞÞRFuk
¼ ðFHistðCðIÞ,1ÞRFuk
, . . . ,FHistðCðIÞ,hFu ÞRFuk
Þ, where
FHist (C(I),i) is the number of objects X in C(I) for which
duðXFu ,RFu
k Þ 2 ½aFu
i�1,aFu
i Þ. This histogram gives us a concise
description of all the multimedia objects underlying C andowned by a peer p and it represents how these objects
are distributed with respect to the reference object RFu
k .
Starting from FHistðCðIÞÞRFuk
we define the histogram of a set
of concepts C* in p, C�DO, as FHistðC�ðIÞÞRFuk
¼
SC2C�FHistðCðIÞÞRFuk
, where C 2 C� is a multimedia concept.
Histogram data can be exploited to compute a pseudo-
centroid of C*(I) in the vector space generated by itsreference objects. In particular, given XFu 2 DFu , function T :DFu-Rmu transforms XFu as follows:
TðXFu Þ ¼ ðduðXFu ,RFu
1 Þ, . . . ,duðXFu ,RFu
muÞÞ
Then, the pseudo-centroid CeFu ðC�ðIÞÞ is computed byestimating the mean distance of the available objects fromthe mu reference objects, thus approximating the centroid
5 Note that, with a minimal abuse of notation, we mean to have mu
potentially distinct reference objects for each feature Fu.
distances from the reference objects, as follows:
CeFu ðC�ðIÞÞ
¼
PhFu
i ¼ 1
aFu
i þaFu
i�1
2FHistðC�ðIÞ,iÞRFu
1PhFu
i ¼ 1 FHistðC�ðIÞ,iÞRFu1
, . . . ,
PhFu
i ¼ 1
aFu
i þaFu
i�1
2FHistðC�ðIÞ,iÞRFu
muPhFu
i ¼ 1 FHistðC�ðIÞ,iÞRFumu
0BB@
1CCA
Definition 4 (Multimedia distance). The multimedia dis-tance md(C*i, C*j) is defined as the linear combination of theL1 distances6 of the pseudo-centroids of C*i(Ii) and C*j(Ij)w.r.t. each feature Fu, i.e.
mdðC�i ,C�j Þ ¼ a1L1ðCeF1 ðC�i ðIiÞÞ,CeF1 ðC�j ðIjÞÞÞþ � � �
þaLL1ðCeFL ðC�i ðIiÞÞ,CeFL ðC�j ðIjÞÞÞ
when both C*i(Ii) and C*j(Ij) are not empty. Otherwise,mdðC�i ,C�j Þ ¼ 0 when C�i ðIiÞ ¼ C�j ðIjÞ ¼ |, whereas mdðC�i ,C�j Þ ¼1 when C�i ðIiÞ ¼ | or C�j ðIjÞ ¼ |.
3.2. Exploiting the combined distance for neighbor selection
The network evolves incrementally to assimilate enter-ing peers. When a peer joins the system, it first performs acoarse-grained neighbor selection by accessing an Access
Point Structure (APS) [6]. This is a ‘‘light’’ and scalablestructure which maintains summarized descriptions aboutthe SMONs available in the network in order to help thenewly entering peers to decide which SMONs to join orwhether to form new SMONs. It is conceptually centralizedbut it can be stored in a distributed manner amongdifferent peers, for instance, by means of a DistributedHash Table (DHT). The APS ignores the linkage among peersand provides an abstraction of the SMONs as clusters ofconcepts and multimedia data.
In order for the APS to be a ‘‘light’’ structure whichscales to the large, we do not keep all concepts andmultimedia objects at the APS level, and follow anapproach similar to the one adopted in [14] for clusteringlarge datasets. For each SMON, the APS provides a semantic
summary and a multimedia summary, which express themain characteristics of the SMON from both the semanticand the multimedia points of view, by treating its conceptsas well as its multimedia objects collectively. In particular,among other information, the semantic summary includesthe semantic clustroid Clsd(C*) of the set C* of conceptsbelonging to the SMON (Section 3.1.1). On the other hand,the multimedia summary includes a set of multimediapseudo-centroids CeFu ðClsdðC
�ÞðIÞÞ for the objects underlyingthe clustroid Clsd(C*), one for each of the available featuresFu (Section 3.1.2). Consider again, for instance, our networkorganization example in Fig. 2: Fig. 3 shows the contents ofthe network APS, where for simplicity we suppose theexistence of a single multimedia feature and two referenceobjects. Each SMON semantic summary is exemplified bymeans of its clustroid (Peer1’s concept tile for SMON1and Peer5’s concept monument for SMON2), while themultimedia summaries show the corresponding pseudo-centroids. See also the lower part of the figure for a visual
6 The L1 distance is also known as Chebyshev distance.

SMON1 Peer1 {tile} {0.864, 0.932} … SMON2 Peer5 {monument} {0.567, 0.367} …
SEMANTIC SUMMARY MULTIMEDIA SUMMARY
Ce (Peer5 {monument} (I)):
0 0 20 10 0 0 20 10 0 0 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1
{ 0.567, 0.367 }
(20*0.5+10*0.7) / 30 (20*0.3+10*0.5) / 30
FHist (Peer5 {monument}(I))R1 FHist (Peer5 {monument}(I))R2
Fig. 3. APS contents for the reference scenario.
C. Gennaro et al. / Information Systems 36 (2011) 174–191 181
exemplification of the computation of SMON2’s pseudo-centroid.
The proposed approach provides incremental updat-ability whenever a new peer joins the SMON and speed-upcalculation of intra- and inter-cluster measurements. Inparticular, the SMON selection algorithm:
defi
computes a matrix DIST of the combined semantic-multimedia distances between each of the p’s conceptsand each of the semantic clustroids of the SMONs;
assigns each p’s concept Ci to the SMON SMONj forwhich the distance smdðCi,ClsdðC�j ÞÞ from SMONj’s clus-
troid Clsd(C*j) is the lowest one;
produces as outcome a placement function c whichassociates each peer’s concept to at most one SMON;
makes p enter each SMON which is associated to with atleast one concept.
Note that in the computation of the DIST matrix a thresholdrequirement T is used to control the SMON tightness orquality: each concept Ci is inserted into the SMON SMONj
closest to Ci if the threshold requirement T is not violateddue to the insertion (i.e. if its distance from Clsd(C*j) issmaller than T). As to the concepts for which nocorresponding SMON has been found, they are clusteredin groups and each group forms a new SMON7 for which asummarized description is computed and inserted in theAPS. This approach is also the one adopted by the first peerentering the system, as no SMON exists and the placementfunction c returns a void list (more details are given in [6]).
Further, the information stored in the APS describes thecurrent setting of the system and should consequently bekept updated to reflect the changes possibly occurring inthe network. The evolution of the APS is thus managed inan incremental fashion as new peers enter/leave thesystem. More precisely, when a peer enters a SMON, theSMON’s semantic and multimedia summaries have to beupdated. This includes the incremental maintenance of thesemantic clustroid and multimedia pseudo-centroids. Notethat the exact computation of the above values wouldrequire all the SMON’s concepts, which are not available atthe APS level. Nevertheless, we adopt the approximate
7 In this case, we adopt a standard agglomerative approach by
ning the distance between clusters as an average group linkage [15].
computation presented in [6] which only uses the clustroidand multimedia pseudo-centroids and whose correctness isshown in [14]. Disconnections are treated in a similar way.
After SMON selection, the peer starts to navigate thelink structure within each selected SMON with the aim ofsearching its preferred neighbors from both a semantic andmultimedia point of view. To select neighbors in a SMON,the entering peer starts from the semantic clustroid peerand it navigates the link structure by visiting (some of) thepeer’s immediate neighbors, then their immediate neigh-bors, and so on. Two neighbor selection policies aresupported: (1) a range-based selection, where the selectedpeers are those within a combined semantic-multimediadistance threshold and (2) a k-NN selection, which finds outthe k nearest peers from both points of views, the semanticand multimedia ones.8 For both policies, efficient algo-rithms which take advantage of specific index structuresdistributed across the network are exploited to reduce thesearch space (we refer the reader to [6] for a detaileddescription of these aspects).
4. Routing queries
Besides network construction, a further key challenge in aPDMS is query routing, i.e. the capability of selecting a smallsubset of relevant peers to forward a query to. Specifically,smart query routing strategies should be able to select, for agiven query and at each queried peer, the directions towardthe peers which are best suited for answering the queryformula, i.e. whose answers best fit its semantic andsimilarity conditions. This is especially fundamental in alarge PDMS network containing multimedia data, since theexecution of similarity predicates is known to be inherentlycostly, both from a CPU and from an I/O point of view [1].
For this purpose two scalable and distributed indexstructures are exploited to estimate the information loss dueto query rewriting (Section 4.1) and the satisfaction degreeof the similarity predicates (Section 4.2) for the subnetworkin each direction. Such estimation induces a ranking whichis used for answering a given query effectively, i.e.maximizing the relevance of the retrieved data instances,and efficiently, i.e. minimizing the network load due to theexploration of useless subnetworks (Section 4.3).
4.1. Semantic query routing
Whenever a peer pi selects one of its neighbors, say pj,for query forwarding, the query moves from pi to thesubnetwork rooted at pj and it might follow any of thesemantic paths originating at pj. Our main aim in thiscontext is to introduce a ranking approach which promotesthe pi’s neighbors whose subnetworks are the mostsemantically related to the query.
In order to model the semantic approximation of pj’ssubnetwork w.r.t. pi’s ontology, the semantic approxima-tions given by the paths in pj’s subnetwork are aggregated
8 It is worth noting that the topology of the network is heavily
influenced by the kind of neighbor selection policy each peer chooses
when it joins the network.

C. Gennaro et al. / Information Systems 36 (2011) 174–191182
into a measure reflecting the relevance of the subnetworkas a whole. To this end, the notion of semantic mapping is
generalized as follows. Let pnj denote the set of peers in the
subnetwork rooted at pj, Onj the set of ontologies
fOjkjpjk2 pn
j g, and Ppi ,...,pnj
the set of paths from pi to any
peer in pnj . A generalized mapping relates each concept C in
Oi to a set of concepts Cn in Onj taken from the mappings in
Ppi ,...,pnj
, according to an aggregated score which expresses
the semantic similarity between C and Cn.9
Definition 5 (Generalized semantic mapping). Let pi and pj
be two peers, not necessarily distinct, and g an aggregationfunction. A generalized semantic mapping between pi and pj
is a fuzzy relation MðOi,Onj Þ where each instance ðC,CnÞ is
such that: (1) Cn is the set of concepts {C1,y,Ch} associated
with C in Ppi ,...,pnj
and (2) mðC,CnÞ ¼ gðmðC,C1Þ, . . . ,mðC,ChÞÞ,
where each mðC,CkÞ, with k = 1,y,h, is the score obtained bythe composition of the scores of the query reformulationsalong the path in Ppi ,...,p
nj
connecting C to Ck.
As to the function g, the following properties must hold:g has to be a monotonic increasing, continuous, symmetric,idempotent function and it must respect the boundaryconditions g(0,y,0)=0 and g(1,y,1)=1 [16]. Several choicesare possible for g satisfying the above properties, forinstance functions such as the min, the max, anygeneralized mean (e.g. harmonic and arithmetic means),or any ordered weighted averaging (OWA) function (e.g. aweighted sum) [7].
For routing purposes, each peer p maintains a matrixnamed Semantic Routing Index (SRI), which contains themembership grades given by the generalized semanticmappings between itself and all its neighbors Nb(p) andwhich is used as a routing index.
Definition 6 (Semantic routing index). Let p be a peer withontology O={C1,y,Cm} and neighbors p1,y,pn. The p’sSemantic Routing Index is a matrix SRI of n+1 rows and m
columns, such that the first column refers to the localontology and SRI½0� ¼ 1 while any other entry SRI[i][j], fori=1,y,n j=1,y,m, is the membership grade mðCj,C
nj Þ of the
instance ðCj,Cnj Þ of the generalized semantic mapping
MðO,Oni Þ.
Intuitively, the higher is the score SRI[i][j], the morelikely the pi’s subnetwork will provide semanticallyrelevant results for the concept Cj. A sample of a portionof the Peer1’s SRI of the reference example is shown in thefollowing table.
9 Detail
s abou t the wa y C is related to Cn can be foun d in [7SRIPeer1
Tile origin company price material size ImagePeer1
1.0 1.0 1.0 1.0 1.0 1.0 1.0Peer2
0.85 0.70 0.83 0.95 0.83 0.92 1.0Peer3
0.65 0.85 0.75 0.0 0.95 0.74 1.0Besides the first row, which represents the knowledgeof Peer1’s local schema, it contains two entries, one for
].
the upward subnetwork rooted at Peer2, and one for thedownward one rooted at Peer3. For instance, from thestored scores, it follows that Peer3’s subnetwork betterapproximates the concept origin (score 0.85) than Peer2’sone (score 0.70). On the other hand, the concept price doesnot find any correspondence in Peer3 (score 0.0), and thus aquery including price will not be forwarded to Peer3, butrather it will towards Peer2 (score 0.95). More details aboutthe management of SRIs can be found in [7].
Note that the space required for storing an SRI at a peeris proportional to the number of the peer’s neighbors, andthus quite modest w.r.t. the number of peers which usuallyjoin a PDMS. This makes this distributed-index mechanismscalable in a P2P context. Further, SRIs construction andevolution is managed in an incremental fashion byexploiting the distributed protocol presented in [5].
4.2. Multimedia query routing
Any peer in the network solves a similarity predicatej:- Cj � ðFu ,tÞQ on the concept Cj w.r.t. the query object Q bylocally retrieving the set fX 2 CjðIÞjduðXFu ,QFu Þrrg, wherer=1�t. In this context, the histograms maintained at eachpeer can be used by other peers in the network to predictthe number of relevant objects which can be found locallyto the peer.
By extension, the histograms of the peers underlying agiven subnetwork can be used to estimate the relevance ofthe whole subnetwork with respect to j. To this end,each peer p maintains a set of Multimedia Routing Indices
(MRIs) for its neighborhood Nb(p), one for each referenceobject RFu
k .
Definition 7 (Multimedia routing index). Let p be a peerwith neighborhood Nb(p)={p1,y,pn} and ontologyO={C1,y,Cm}. The p’s Multimedia Routing Index is a matrixMRI for the reference object RFu
k where each entryMRIðp,RFu
k Þ½i�½j�, for i=1,y,n, j=1,y,m, is the aggregation ofthe histograms FHistðCjðIlÞÞRFu
k
for pl 2 pni . Formally,
MRIðp,RFu
k Þ½i�½j� can be recursively defined as follows:
MRIðp,RFu
k Þ½i�½j� ¼ FHistðCjðIiÞÞRFuk
þX
pl2NbðpiÞ�p
MRIðpi,RFu
k Þ½l�½j� ð1Þ
Given a similarity predicate j : Cj � ðFu ,tÞQ , we represent jas mu binary vectors QHistðRFu
1 Þ, . . . ,QHistðRFumuÞ, one for each
reference object RFu
k . QHistðRFu
k Þ ¼ ðbit0, . . . ,bithFu�1Þ has the
same length of the histogram MRIðp,RFu
k Þ½i�½j� and bitl=1 if
½al,alþ1� \ ½duðQFu ,RFu
k Þ�r,duðQFu ,RFu
k Þþr�a|, whereas bitl=0
otherwise (see Fig. 4).In order to determine the relevance of the subnetwork
underlying each neighbor pi 2 NbðpÞ of p w.r.t. j, weestimate the mean similarity of the potential matcheswhich can be found in the subnetwork rooted at p’sneighbor pi. For this purpose, we estimate, through each
reference object RFu
k , the distance between QFu and each
object XFu in each interval ½aFu
l�1,aFu
l �, i.e. each of the
MRIðp,RFu
k Þ½i�½j�½l� potential matches XFu , by considering the
fact that objects belonging to the same interval become

Peer1
Peer2
Peer3
Peer5
Peer4
Peer6
0 1 1 1 0
kR Q ruF
0 4 7 3 0 0 0 2 0 0
00310
2
1 0 4 0 1
1 1 2 0 0
2 11 0 1
0 4 7 3 0
Fig. 4. Construction process of the MRI (in light gray) from the histograms (in dark gray) (left) and representation of the query (right).
C. Gennaro et al. / Information Systems 36 (2011) 174–191 183
indistinguishable. In order to follow a safe approach for this
estimation, we lower bound duðXFu ,QFu Þ at each interval
½aFu
l�1,aFu
l �.
To this end, let us consider the two inequalities whichstraightforwardly follow from the triangle inequality
property duðXFu ,QFu ÞZ jduðXFu ,RFu
k Þ�duðQFu ,RFu
k Þj:
duðXFu ,QFu ÞZduðX
Fu ,RFu
k Þ�duðQFu ,RFu
k ÞZal�1�duðQFu ,RFu
k Þ ð2Þ
duðXFu ,QFu ÞZduðQ
Fu ,RFu
k Þ�duðXFu ,RFu
k ÞZduðQFu ,RFu
k Þ�al ð3Þ
We compute a lower bound for duðXFu ,QFu Þ, by considering
all cases for duðQFu ,RFu
k Þ to occur, which guarantee a positive
(at most 0) value for duðXFu ,QFu Þ:
1.
duðQFu ,RFuk Þoal�1: we estimate the lower bound with theright-hand part of Eq. (2);
2.
duðQFu ,RFuk ÞZal: we estimate the lower bound with theright-hand part of Eq. (3);
3.
al�1rduðQFu ,RFuk Þoal: the lower bound is 0 as QFu
belongs to the same interval as XFu .In summary, duðXFu ,QFu Þ is lower bounded by:
distLowerBoundl ¼maxðal�1�dðQFu ,RFu
k Þ,dðQFu ,RFu
k Þ�al,0Þ ð4Þ
Thus, the formula which provides the mean of the lowerbounded distances of the peers belonging to the subnet-work underlying each neighbor pi 2 NbðpÞ of p w.r.t. j,limited to the reference object RFu
k , is
MMatchkj½i�
¼
PhFu
l ¼ 1 distLowerBoundl � QHistðRFu
k Þ½l� �MRIðp,RFu
k Þ½i�½j�½l�PhFu
l ¼ 1 QHistðRFu
k Þ½l� �MRIðp,RFu
k Þ½i�½j�½l�
ð5Þ
where QHistðRFu
k Þ½l� and MRIðp,RFu
k Þ½i�½j�½l� are the l-th ele-ments of the vectors QHistðRFu
k Þ and MRIðp,RFu
k Þ½i�½j�, respec-tively.
Since we try to find the closest approximation toduðXFu ,QFu Þ, the following equation selects, among all RFu
k
such that QHistðRFu
k Þ½l� ¼ 1, the reference object RFu
k thatmaximizes the quantity MMatchk
j½i�. Finally, with a little
abuse of notation, the following formula provides aminimum value for the overall relevance of the subnetworkrooted at pi w.r.t. the similarity to j:
MMatchj½i� ¼ 1�maxk
MMatchkj½i� ð6Þ
Intuitively, the higher is MMatchj½i�, the more likely the pi’ssubnetwork will provide objects matching the similaritypredicate j. Generally speaking, very low or null MMatchjvalues denote subnetworks which do not provide usefulobjects and, thus, which will not need to be explored.
As an alternative, approximate, estimate, duðXFu ,QFu Þ 2
½aFu
l�1,aFu
l � could be calculated as jduðQFu ,RFu
k Þ�ðalþal�1Þ=2j,i.e. as the distance of QFu from the interval’s mean value.
4.3. Combined query routing
Whenever a peer p receives a query formula f, theinformation contained in p’s SRI and MRI s allows p to rankits own neighbors w.r.t. their ability to answer a givenquery effectively, i.e. maximizing the relevance of theretrieved data instances, and efficiently, i.e. minimizing thenetwork load due to the exploration of useless subnet-works.
More precisely, let us assume that f involves theconcepts C1,y,Cm and contains the similarity predicatesj1, . . . ,js and that Nb(p)={p1,y,pn}. For each neighbor pi,an overall score is computed by combining a score ofsemantic relevance w.r.t. C1,y,Cm with a score of multi-media relevance w.r.t. j1, . . . ,js:
Rpðf Þ½i� ¼ sgðsfunjðMMatchj1½i�, . . . ,MMatchjs
½i�Þ,
sfuncðSRI½i�½1�, . . . ,SRI½i�½m�ÞÞ ð7Þ
where sfunj is applied to a query formula fM whichcontains the query formula f and which is made up of alland only the similarity predicates j1, . . . ,js. It is worthnoting that the resulting neighborhood ranking is consis-tent with the approach adopted for query evaluation as itrelies on the functions sg, sfunj, sfunc which have beenintroduced in Section 2.2 for scoring query answers. Forthis reason, Rp(f) gives an intuition of the semantic and

C. Gennaro et al. / Information Systems 36 (2011) 174–191184
multimedia relevance of the potential matches which canbe found in each query forwarding direction.
As an example of how the aggregation process works, letus go back to the sample query in Fig. 1 and suppose Peer1obtains the scores in the following table:
Sem relevance
sfunc(y)
MM relevance
sfunjð. . .Þ
Combined relevance
sgðsfunjð. . .Þ,sfuncð. . .ÞÞ
Peer2
0.70 0.53 0.53Peer3
0.65 0.76 0.65If sg is the standard fuzzy conjunction min, we compute thefollowing final ranking: Peer3-Peer2. As a result, the mostpromising subnetwork will be the one rooted at neighborPeer3.
The obtained ranking is used to support several routingstrategies. This is the subject of the following section.
5. Routing strategies
Starting from the queried peer, the objective of anyquery processing mechanism is to answer requests bynavigating the network until a stopping condition isreached. A query is posed on the ontology of the queriedpeer and is represented as a tuple q¼ ðid,f ,t,nresÞ where: id
is a unique identifier for the query; f is the query formula;nres is the stopping condition specifying the desirednumber of results as argument of the LIMIT clause; andt is an optional relevance threshold. Then, query answerscan come from any peer in the PDMS that is connectedthrough a semantic path of mappings.
In this context, the adoption of query routing strategiesis a fundamental issue. Indeed, Section 2.2 shows that anypeer satisfying the query conditions may add new answersand different paths to the same peer may yield differentanswers. More precisely, at each reformulation step, a newpeer pNext 2 P is selected, among the unvisited ones, forquery forwarding. The adopted routing strategy is respon-sible for choosing pNext, thus determining the set of visitedpeers Pu and inducing an order c in Pu: ½pcð1Þ, . . . ,pcðmÞ�.Further, the visiting order determines the path Pp,...,pj
which is exploited to reach each peer pj 2 Pu and,consequently, the set of returned local answers and thesemantic approximation accumulated in reaching pj, i.e.Ansðf ,Pp,...,pj
Þ.Then, in order to increase the chance that users receive
first the answers which better satisfy the query conditions,several routing policies can be adopted to determine Pu.More precisely, as we explained in Section 4.3, when a peerp receives a query q it exploits its indices to compute aranking Rp(f) on its neighbors expressing the goodness oftheir subnetworks w.r.t. the query formula f.
Afterwards, different query forwarding criteria relyingon such ranked list are possible, designed around differentperformance priorities. In [17] two main families ofnavigation policies are introduced: The depth first (DF)query execution model, which pursues efficiency as itsmain objective, and the global (G) model, which is designedfor effectiveness. Both approaches are devised in adistributed manner through a protocol of message ex-
change, thus trying to minimize the information spanningover the network.
In particular, the DF model is efficiency-oriented sinceits main goal is to limit the query path. More precisely, withthe aim of speeding up the retrieval of some (but probablynot the best) results, the DF model only performs a localchoice among the neighbors of the current peer p, i.e. itexploits the only information provided by Rp(f).
Differently from the DF one, in the G model each peerchooses the best peer to forward the query to in a ‘‘global’’way: It does not limit its choice among the neighbors but itconsiders all the peers already ‘‘discovered’’ (i.e. for which anavigation path leading to them has been found) duringnetwork exploration and that have not been visited yet.More precisely, given the set Pu of visited peers, it exploitsthe information provided by
Sp2PuR
pðf Þ in order to select, ateach forwarding step, the best unvisited peer. Obviously,going back to potential distant peers has a cost in termsof efficiency, but always ensures the highest possibleeffectiveness, since the most promising discovered peersare always selected.
According to our query answering semantics, Pu is thusdefined as the ordered set of visited peers ½pcð1Þ, . . . ,pcðmÞ�
such that jfAnsðf ,pÞ [ Ansðf ,pcð1ÞÞ [ � � � [ Ansðf ,pcðmÞÞgjZnres
and jfAnsðf ,pÞ [ Ansðf ,pcð1ÞÞ [ � � � [ Ansðf ,pcðm�1ÞÞgjonres,where the ordering function c is given by the adoptedrouting strategy.
As to the optional threshold t, when t40, thosesubnetworks whose relevance (in terms of combinedrouting score) is smaller than t are not considered forquery forwarding. The underlying reason is that a forward-ing strategy which proceeds by going deeper and deepertoward poorly relevant network areas (i.e. not verysemantically related to the query and containing fewmultimedia matching objects) can exhibit bad perfor-mances and, thus, it is better to start backtracking towardsother directions. The adoption of a threshold t may thuspositively influence the composition of Pu, since ‘‘poorer’’subnetworks are not considered for query forwarding. Onthe other hand, a not-null threshold introduces a source ofincompleteness in the querying process, as the prunedsubnetworks might contain matching objects. Complete-ness can instead be guaranteed when t¼ 0, since subnet-works with a 0 routing score can be safely pruned.
6. Experiments
In this section we present a selection of the experimentswe performed in order to evaluate our network organiza-tion and query routing mechanisms.
The PDMS scenarios we consider in this evaluation areamong the most challenging we modeled and are derivedfrom the real world setting of the Italian Council co-fundedNeP4B project, i.e. a virtual business pole where logisticsoperators and client firms interact via an advanced e-commerce platform to achieve real-time matching ofdemand and offer of the different products. The corre-sponding PDMSs are networks of peers, each with its ownontology, and a repository of a large number of content-based searchable data, in our case product images.
C. Gennaro et al. / Information Systems 36 (2011) 174–191 185
The peer ontologies are derived from the real-worlddata and enlarged with new ontologies created byintroducing structural and terminological variationson the original ones. The ontologies differ for theircomplexity and dimension (their mean size is in the orderof a few dozens of elements), and represent productsbelonging to three main domains: floor covering, furnish-ing and clothing. In this way, peers in the same domainhave ontologies describing the same topic from differentpoints of view; moreover, they own multimedia datarelated to that topic. As to the multimedia contents,we used several thousands of images characterized bytwo MPEG-7 standard features: scalable color andedge histogram.
In the following experiments we consider two net-works: Network1, which consists of some dozens of peersand nearly 1000 multimedia objects, and the larger andmore complex Network2, consisting of hundreds ofpeers and nearly 20,000 multimedia objects. Both networksare automatically produced by the proposed networkorganization algorithms, which establish the connectionsamong peers according to the similarity between theircontents. Specifically, we employed a k-NN neighborselection policy, with k=3. Further, we also consider avariation of Network2, i.e. Network2b, which consists ofthe same peers and contents of Network2 but with arandomly defined topology.
Number of requested objects
ti
ti
Fig. 5. Evaluation of query processing effectiveness and efficiency on
Number of requested objects
ti
tic
Fig. 6. Evaluation of query processing effectiveness and efficiency on
In order to evaluate the benefits provided by thenetwork construction and routing techniques, and thusthe effectiveness and efficiency of the resulting queryanswering, we instantiate different queries on randomlyselected peers and we quantify the advantages on queryprocessing. In the next section we will give all the detailsabout these evaluations.
All the experiments are executed on the SUNRISE PDMSsimulation environment [18], through which we were ableto reproduce the main conditions characterizing thecomplex PDMS scenarios. The simulation engine is basedon SimJava 2.0, a discrete, event-based, general purposesimulator. The tests were executed on an Intel Core2 Duo2.4 GHz OSX workstation, equipped with 2 GB RAM and a160 GB SATA disk. Note that all the results we present arecomputed as a mean on several query executions and withthe algebraic product as t-norm function. Finally, unlessotherwise indicated, the routing strategy employed is thedepth-first (DF) search and the metric histograms arecomputed on 32 intervals, however in the final tests wealso analyze the effect of different routing strategies andhistogram resolutions.
6.1. Effectiveness and efficiency evaluation
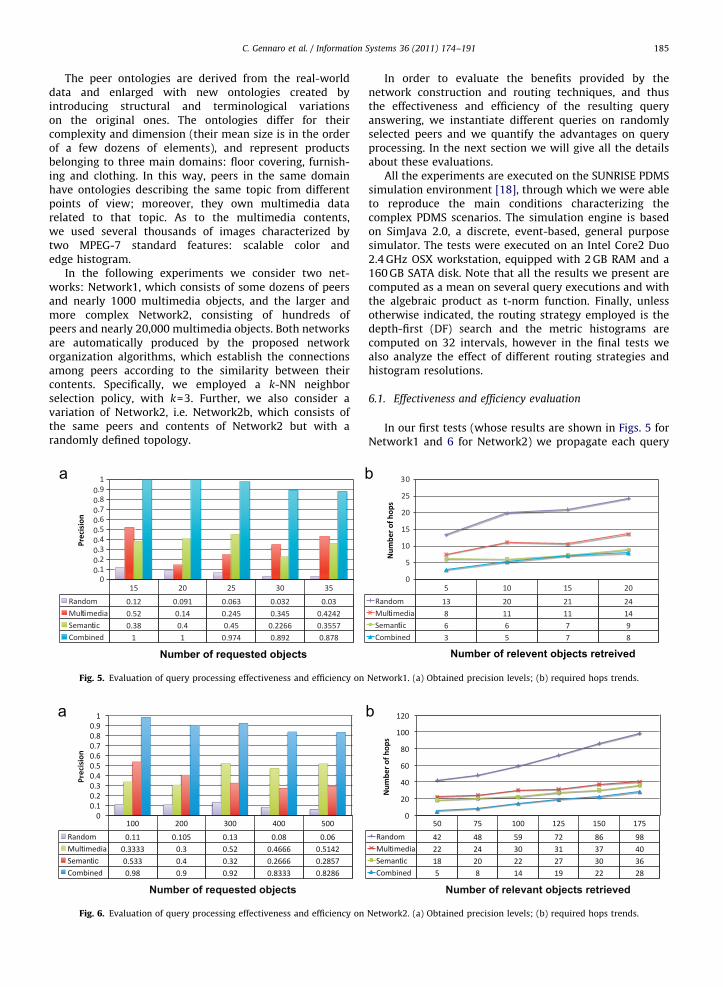
In our first tests (whose results are shown in Figs. 5 forNetwork1 and 6 for Network2) we propagate each query
Number of relevent objects retreived
ti
ti
Network1. (a) Obtained precision levels; (b) required hops trends.
ti
ti
Number of relevant objects retrieved
Network2. (a) Obtained precision levels; (b) required hops trends.
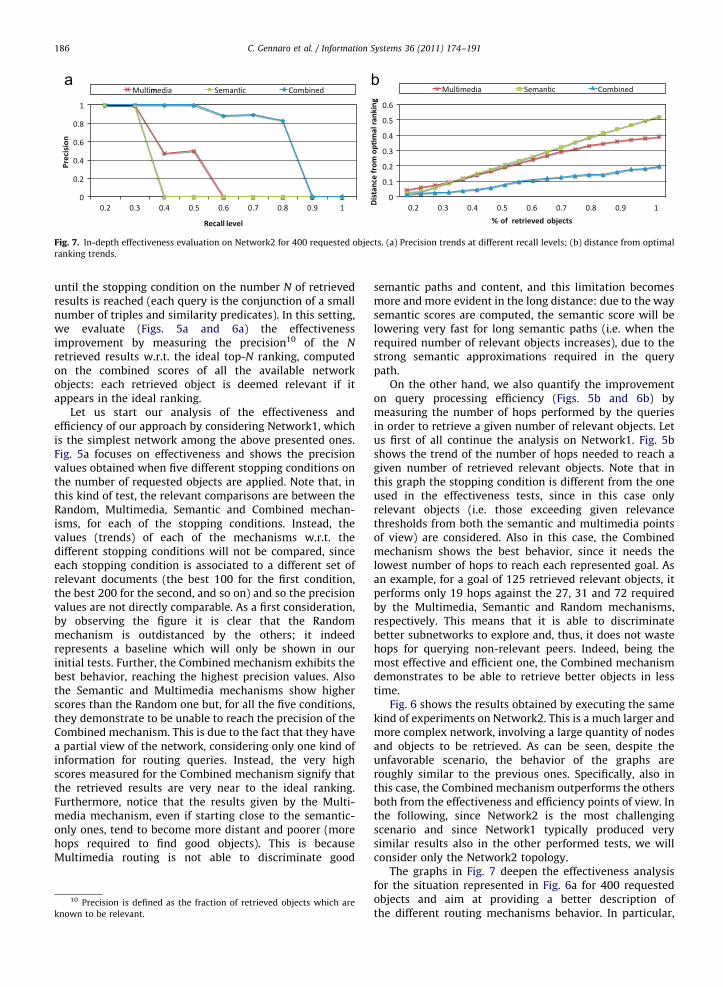
Fig. 7. In-depth effectiveness evaluation on Network2 for 400 requested objects. (a) Precision trends at different recall levels; (b) distance from optimal
ranking trends.
C. Gennaro et al. / Information Systems 36 (2011) 174–191186
until the stopping condition on the number N of retrievedresults is reached (each query is the conjunction of a smallnumber of triples and similarity predicates). In this setting,we evaluate (Figs. 5a and 6a) the effectivenessimprovement by measuring the precision10 of the N
retrieved results w.r.t. the ideal top-N ranking, computedon the combined scores of all the available networkobjects: each retrieved object is deemed relevant if itappears in the ideal ranking.
Let us start our analysis of the effectiveness andefficiency of our approach by considering Network1, whichis the simplest network among the above presented ones.Fig. 5a focuses on effectiveness and shows the precisionvalues obtained when five different stopping conditions onthe number of requested objects are applied. Note that, inthis kind of test, the relevant comparisons are between theRandom, Multimedia, Semantic and Combined mechan-isms, for each of the stopping conditions. Instead, thevalues (trends) of each of the mechanisms w.r.t. thedifferent stopping conditions will not be compared, sinceeach stopping condition is associated to a different set ofrelevant documents (the best 100 for the first condition,the best 200 for the second, and so on) and so the precisionvalues are not directly comparable. As a first consideration,by observing the figure it is clear that the Randommechanism is outdistanced by the others; it indeedrepresents a baseline which will only be shown in ourinitial tests. Further, the Combined mechanism exhibits thebest behavior, reaching the highest precision values. Alsothe Semantic and Multimedia mechanisms show higherscores than the Random one but, for all the five conditions,they demonstrate to be unable to reach the precision of theCombined mechanism. This is due to the fact that they havea partial view of the network, considering only one kind ofinformation for routing queries. Instead, the very highscores measured for the Combined mechanism signify thatthe retrieved results are very near to the ideal ranking.Furthermore, notice that the results given by the Multi-media mechanism, even if starting close to the semantic-only ones, tend to become more distant and poorer (morehops required to find good objects). This is becauseMultimedia routing is not able to discriminate good
10 Precision is defined as the fraction of retrieved objects which are
known to be relevant.
semantic paths and content, and this limitation becomesmore and more evident in the long distance: due to the waysemantic scores are computed, the semantic score will belowering very fast for long semantic paths (i.e. when therequired number of relevant objects increases), due to thestrong semantic approximations required in the querypath.
On the other hand, we also quantify the improvementon query processing efficiency (Figs. 5b and 6b) bymeasuring the number of hops performed by the queriesin order to retrieve a given number of relevant objects. Letus first of all continue the analysis on Network1. Fig. 5bshows the trend of the number of hops needed to reach agiven number of retrieved relevant objects. Note that inthis graph the stopping condition is different from the oneused in the effectiveness tests, since in this case onlyrelevant objects (i.e. those exceeding given relevancethresholds from both the semantic and multimedia pointsof view) are considered. Also in this case, the Combinedmechanism shows the best behavior, since it needs thelowest number of hops to reach each represented goal. Asan example, for a goal of 125 retrieved relevant objects, itperforms only 19 hops against the 27, 31 and 72 requiredby the Multimedia, Semantic and Random mechanisms,respectively. This means that it is able to discriminatebetter subnetworks to explore and, thus, it does not wastehops for querying non-relevant peers. Indeed, being themost effective and efficient one, the Combined mechanismdemonstrates to be able to retrieve better objects in lesstime.
Fig. 6 shows the results obtained by executing the samekind of experiments on Network2. This is a much larger andmore complex network, involving a large quantity of nodesand objects to be retrieved. As can be seen, despite theunfavorable scenario, the behavior of the graphs areroughly similar to the previous ones. Specifically, also inthis case, the Combined mechanism outperforms the othersboth from the effectiveness and efficiency points of view. Inthe following, since Network2 is the most challengingscenario and since Network1 typically produced verysimilar results also in the other performed tests, we willconsider only the Network2 topology.
The graphs in Fig. 7 deepen the effectiveness analysisfor the situation represented in Fig. 6a for 400 requestedobjects and aim at providing a better description ofthe different routing mechanisms behavior. In particular,
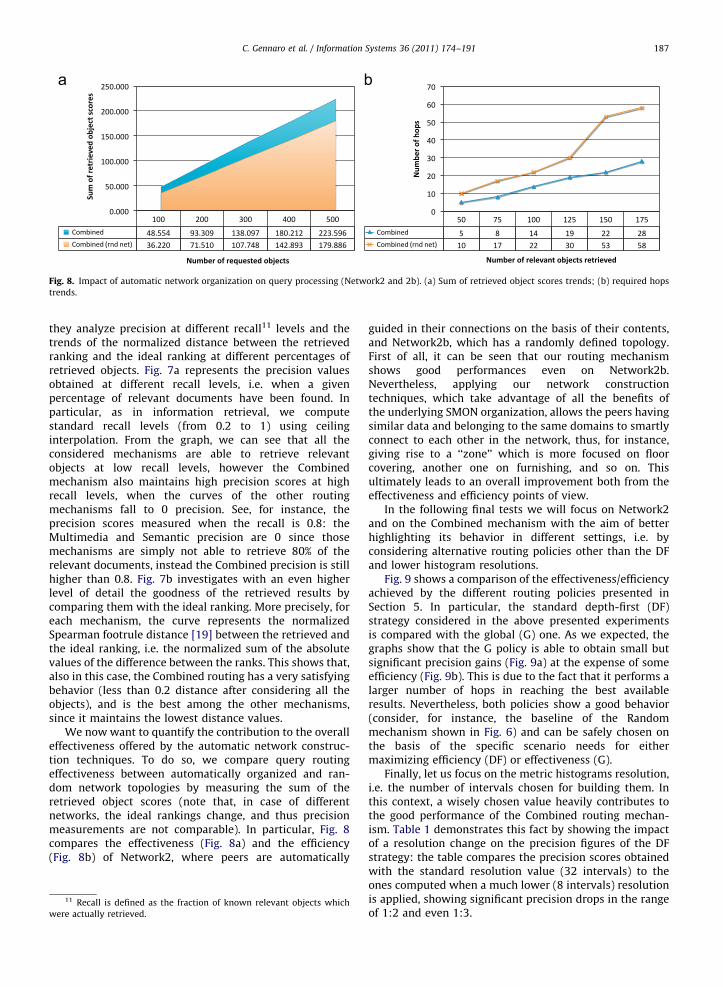
Fig. 8. Impact of automatic network organization on query processing (Network2 and 2b). (a) Sum of retrieved object scores trends; (b) required hops
trends.
C. Gennaro et al. / Information Systems 36 (2011) 174–191 187
they analyze precision at different recall11 levels and thetrends of the normalized distance between the retrievedranking and the ideal ranking at different percentages ofretrieved objects. Fig. 7a represents the precision valuesobtained at different recall levels, i.e. when a givenpercentage of relevant documents have been found. Inparticular, as in information retrieval, we computestandard recall levels (from 0.2 to 1) using ceilinginterpolation. From the graph, we can see that all theconsidered mechanisms are able to retrieve relevantobjects at low recall levels, however the Combinedmechanism also maintains high precision scores at highrecall levels, when the curves of the other routingmechanisms fall to 0 precision. See, for instance, theprecision scores measured when the recall is 0.8: theMultimedia and Semantic precision are 0 since thosemechanisms are simply not able to retrieve 80% of therelevant documents, instead the Combined precision is stillhigher than 0.8. Fig. 7b investigates with an even higherlevel of detail the goodness of the retrieved results bycomparing them with the ideal ranking. More precisely, foreach mechanism, the curve represents the normalizedSpearman footrule distance [19] between the retrieved andthe ideal ranking, i.e. the normalized sum of the absolutevalues of the difference between the ranks. This shows that,also in this case, the Combined routing has a very satisfyingbehavior (less than 0.2 distance after considering all theobjects), and is the best among the other mechanisms,since it maintains the lowest distance values.
We now want to quantify the contribution to the overalleffectiveness offered by the automatic network construc-tion techniques. To do so, we compare query routingeffectiveness between automatically organized and ran-dom network topologies by measuring the sum of theretrieved object scores (note that, in case of differentnetworks, the ideal rankings change, and thus precisionmeasurements are not comparable). In particular, Fig. 8compares the effectiveness (Fig. 8a) and the efficiency(Fig. 8b) of Network2, where peers are automatically
11 Recall is defined as the fraction of known relevant objects which
were actually retrieved.
guided in their connections on the basis of their contents,and Network2b, which has a randomly defined topology.First of all, it can be seen that our routing mechanismshows good performances even on Network2b.Nevertheless, applying our network constructiontechniques, which take advantage of all the benefits ofthe underlying SMON organization, allows the peers havingsimilar data and belonging to the same domains to smartlyconnect to each other in the network, thus, for instance,giving rise to a ‘‘zone’’ which is more focused on floorcovering, another one on furnishing, and so on. Thisultimately leads to an overall improvement both from theeffectiveness and efficiency points of view.
In the following final tests we will focus on Network2and on the Combined mechanism with the aim of betterhighlighting its behavior in different settings, i.e. byconsidering alternative routing policies other than the DFand lower histogram resolutions.
Fig. 9 shows a comparison of the effectiveness/efficiencyachieved by the different routing policies presented inSection 5. In particular, the standard depth-first (DF)strategy considered in the above presented experimentsis compared with the global (G) one. As we expected, thegraphs show that the G policy is able to obtain small butsignificant precision gains (Fig. 9a) at the expense of someefficiency (Fig. 9b). This is due to the fact that it performs alarger number of hops in reaching the best availableresults. Nevertheless, both policies show a good behavior(consider, for instance, the baseline of the Randommechanism shown in Fig. 6) and can be safely chosen onthe basis of the specific scenario needs for eithermaximizing efficiency (DF) or effectiveness (G).
Finally, let us focus on the metric histograms resolution,i.e. the number of intervals chosen for building them. Inthis context, a wisely chosen value heavily contributes tothe good performance of the Combined routing mechan-ism. Table 1 demonstrates this fact by showing the impactof a resolution change on the precision figures of the DFstrategy: the table compares the precision scores obtainedwith the standard resolution value (32 intervals) to theones computed when a much lower (8 intervals) resolutionis applied, showing significant precision drops in the rangeof 1:2 and even 1:3.
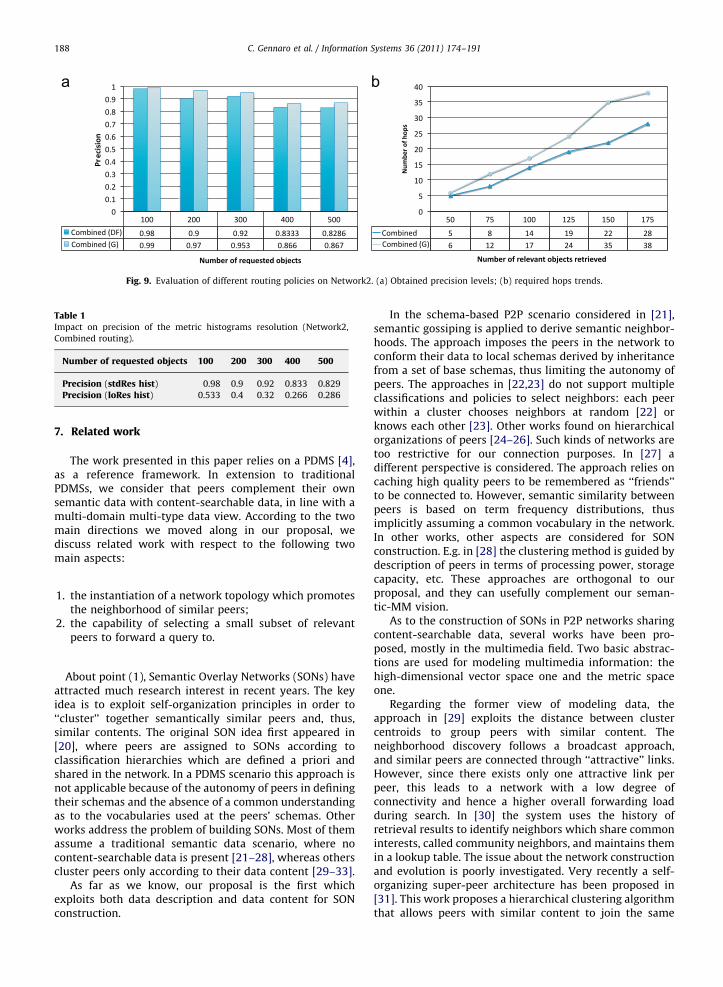
Table 1Impact on precision of the metric histograms resolution (Network2,
Combined routing).
Number of requested objects 100 200 300 400 500
Precision (stdRes hist) 0.98 0.9 0.92 0.833 0.829
Precision (loRes hist) 0.533 0.4 0.32 0.266 0.286
Fig. 9. Evaluation of different routing policies on Network2. (a) Obtained precision levels; (b) required hops trends.
C. Gennaro et al. / Information Systems 36 (2011) 174–191188
7. Related work
The work presented in this paper relies on a PDMS [4],as a reference framework. In extension to traditionalPDMSs, we consider that peers complement their ownsemantic data with content-searchable data, in line with amulti-domain multi-type data view. According to the twomain directions we moved along in our proposal, wediscuss related work with respect to the following twomain aspects:
1.
the instantiation of a network topology which promotesthe neighborhood of similar peers;2.
the capability of selecting a small subset of relevantpeers to forward a query to.About point (1), Semantic Overlay Networks (SONs) haveattracted much research interest in recent years. The keyidea is to exploit self-organization principles in order to‘‘cluster’’ together semantically similar peers and, thus,similar contents. The original SON idea first appeared in[20], where peers are assigned to SONs according toclassification hierarchies which are defined a priori andshared in the network. In a PDMS scenario this approach isnot applicable because of the autonomy of peers in definingtheir schemas and the absence of a common understandingas to the vocabularies used at the peers’ schemas. Otherworks address the problem of building SONs. Most of themassume a traditional semantic data scenario, where nocontent-searchable data is present [21–28], whereas otherscluster peers only according to their data content [29–33].
As far as we know, our proposal is the first whichexploits both data description and data content for SONconstruction.
In the schema-based P2P scenario considered in [21],semantic gossiping is applied to derive semantic neighbor-hoods. The approach imposes the peers in the network toconform their data to local schemas derived by inheritancefrom a set of base schemas, thus limiting the autonomy ofpeers. The approaches in [22,23] do not support multipleclassifications and policies to select neighbors: each peerwithin a cluster chooses neighbors at random [22] orknows each other [23]. Other works found on hierarchicalorganizations of peers [24–26]. Such kinds of networks aretoo restrictive for our connection purposes. In [27] adifferent perspective is considered. The approach relies oncaching high quality peers to be remembered as ‘‘friends’’to be connected to. However, semantic similarity betweenpeers is based on term frequency distributions, thusimplicitly assuming a common vocabulary in the network.In other works, other aspects are considered for SONconstruction. E.g. in [28] the clustering method is guided bydescription of peers in terms of processing power, storagecapacity, etc. These approaches are orthogonal to ourproposal, and they can usefully complement our seman-tic-MM vision.
As to the construction of SONs in P2P networks sharingcontent-searchable data, several works have been pro-posed, mostly in the multimedia field. Two basic abstrac-tions are used for modeling multimedia information: thehigh-dimensional vector space one and the metric spaceone.
Regarding the former view of modeling data, theapproach in [29] exploits the distance between clustercentroids to group peers with similar content. Theneighborhood discovery follows a broadcast approach,and similar peers are connected through ‘‘attractive’’ links.However, since there exists only one attractive link perpeer, this leads to a network with a low degree ofconnectivity and hence a higher overall forwarding loadduring search. In [30] the system uses the history ofretrieval results to identify neighbors which share commoninterests, called community neighbors, and maintains themin a lookup table. The issue about the network constructionand evolution is poorly investigated. Very recently a self-organizing super-peer architecture has been proposed in[31]. This work proposes a hierarchical clustering algorithmthat allows peers with similar content to join the same

C. Gennaro et al. / Information Systems 36 (2011) 174–191 189
super-peer. As already said, this kind of network architec-ture is too restrictive for our connection purposes. Ref. [32]uses a space partitioning technique in high-dimensionalspaces for clustering peers with similar content. The peersadopt a self-organizing approach in which each peer canreconfigure its neighboring peers on the basis of the resultsof past queries.
As to the latter way of modeling multimediainformation, a useful abstraction is provided by themathematical notion of metric space, where similaritybetween two objects is determined by means of a distancefunction. The advantage of the metric space approach todata searching is its ‘‘extensibility’’. Metric space techni-ques can be applied to many specific search problemsquite different in nature, from information retrieval tosignal processing, geographic databases, computationalbiology, etc. [1].
The metric space abstraction and the notion of socialnetwork is used in [33]. Similarly to [32], the networkevolves as the queries are processed in the network andthe results are stored in the query history of eachpeer. These network self-organizing approaches are morequery-oriented rather than data-oriented, therefore theyneed a training phase to become efficient.
As to point (2), i.e. query routing, in the last fewyears much work has focused on this issue in P2Psystems, with the aim of effectively and efficientlyquerying both semantic [24,25,34–41] and content-search-able [29,30,32,33,42–45] data.
Also for this issue, as far as we know, no proposal existswhich operates on both these kinds of data in an integratedapproach.
From a semantic data perspective, some works discussid/keyword-based search of documents [34–36], someassume a common vocabulary/ontology is shared bypeers in the network [37,38], some address scalability ofquery routing by means of a properly tailored super-peertopology for the network [25], or by adapting their ownsemantic topology according to the observation of queryanswering [39,41]. Most of these proposals are based onIR-style and machine-learning techniques exploitingquantitative information about the retrieved results[24,35–37,39,40] and do not take into account effectivelythe presence of heterogeneous semantic knowledge aboutthe contents of the peers in the network: for instance, in[40] peers are assumed to share the same set of keywordsthey store data about, whereas in [39] each peer approx-imates the query concepts with any concept (through theuse of wildcards), thus disregarding the semantic similaritybetween them. Then, all of them (except [37]) providerouting techniques which either assume distributed indiceswhich are indeed conceptually global [34,36], or supportcompletely decentralized search algorithms which, never-theless, exploit information about neighboring peers only.More precisely, the only work [37] proposes a routingmechanism which does not limit the peer’s capability ofselecting peers to the information available at a 1-hophorizon. However, the specific data structures proposed by[37], although providing a summary of subnetworks’content to suggest a direction to send a query to, yet arelimited to answering only IR-style queries.
As to routing queries in networks sharing content-searchable data, most works have focused on multimediadata.
Regarding the high-dimensional vector space abstrac-tion, the routing mechanisms for similarity search onunstructured P2P systems presented in the following tworesearches are based on compact peer data representations.In [42] histograms summarizing the other peers’ data areused at query time to determine the most promising peers.This approach is not scalable, since each peer has globalknowledge of the network. This aspect is, however,subsequently explored in [43], in which every peer locallygenerates its own (smaller) summary, and only thesesummaries are then shared with other peers. In [32], eachpeer forms a partial knowledge of the data distribution ofthe network to guide queries to promising peers. Thispartial knowledge is limited to a horizon specified by atime-to-live (TTL) constraints. Because of its TTL routingstrategy, each peer must contact all its neighbors and thereis no possibility of ranking them with respect to therelevance with the query. The routing policy of [29]exploits the so-called Firework Query Model, which startsflooding the query along random links until reaching arelevant subnetwork where attractive links are followed.This query model, however, does not guarantee higheffectiveness since it relies on ‘‘random walks’’. A similarobjection applies to routing algorithm of [30], which floodsthe query through the network formed by the communityneighbors.
The first P2P routing algorithms for similarity search onmetric spaces have been proposed for structured P2Pnetworks (see [46] for an overview). In the same view,[44] proposes an approach to reduce the cost of indexingobjects by clustering the data at each peer and thenindexing only the resulting clusters. The routing mechan-ism is guided by the underlying structured network. In[45], routing indices based on peers’ data cluster summar-ization are applied in a super-peer architecture. In thatresearch, the extensive use of centroids during the queryprocessing and the fact that the experimental evaluation iscarried out only on high-dimensional datasets, leave someconcern about its applicability to metric spaces. The routingalgorithm proposed in [33] follows the common worldconcepts for searching, in which the knowledge aboutanswers to previous queries is exploited to route queriesefficiently, and a randomized mechanism is used to explorenew and unvisited parts of the network. The routingalgorithm relies on the analysis of a predefined and limitednumber of queries in the history of each peer. Further, apolicy of friends-of-friends query forwarding is adopted forquery routing, without considering any ranking betweenthe peers.
8. Concluding remarks
We presented an advanced technological infrastructurefor effectively and efficiently supporting query processingin a multi-domain multi-type data sharing system. Theapproach is innovative in that, to the authors’ knowledge, it

C. Gennaro et al. / Information Systems 36 (2011) 174–191190
is the first research proposal specifically devised to thesepurposes.
Two main research issues have been addressed in thispaper: (1) network organization, by presenting a peerplacement mechanism which instantiate the networktopology according to the linkage closeness of similarpeers, thus reducing information loss as well as favoringthe evaluation of costly similarity predicates primarily in aneighborhood of similar peers and (2) query routing, byintroducing scalable and distributed index structureswhich locate the most relevant directions to forward aquery to, thus allowing to minimize the network load bycutting off useless subnetworks.
The solutions we have proposed for these issues foundtheir principles on both peers’ data description and datacontent and, most importantly, they comply with thesemantics of query answering.
The framework presented is general with regard to thetypes of data to be shared, since it is parametric on thedistance function used to evaluate semantic closenessbetween peers’ concepts, as well as it is parametric onthe distance functions to be used to search data w.r.t.similarity predicates.
The experiments we conducted on multimedia dataclearly show excellent results as to the effectiveness as wellas to the efficiency of the proposed approach. On the otherhand, the framework generality makes us confident that itshould show equally good behaviors with most content-searchable data domains.
References
[1] P. Zezula, G. Amato, V. Dohnal, M. Batko, Similarity search: the metricspace approach, Advances in Database Systems, vol. 32, Springer, 2006.
[2] P. Cudre-Mauroux, S. Agarwal, K. Aberer, GridVine: an infrastructurefor peer information management, IEEE Internet Computing 11 (5)(2007) 36–44.
[3] A. Halevy, Z. Ives, D. Suciu, I. Tatarinov, Schema mediation forlarge-scale semantic data sharing, The VLDB Journal 14 (1) (2005)68–83.
[4] A. Halevy, Z. Ives, J. Madhavan, P. Mork, D. Suciu, I. Tatarinov, ThePiazza peer data management system, IEEE Transactions on Knowl-edge and Data Engineering 16 (7) (2004) 787–798.
[5] F. Mandreoli, R. Martoglia, W. Penzo, S. Sassatelli, Data-sharing P2Pnetworks with semantic approximation capabilities, IEEE InternetComputing 13 (5) (2009) 60–70.
[6] S. Lodi, F. Mandreoli, R. Martoglia, W. Penzo, S. Sassatelli, Semanticpeer, here are the neighbors you want!, in: Proceedings of the 11thInternational Conference on Extending Database Technology (EDBT),2008, pp. 26–37.
[7] F. Mandreoli, R. Martoglia, W. Penzo, S. Sassatelli, SRI: exploitingsemantic information for effective query routing in a PDMS, in:Proceedings of the 8th ACM CIKM International Workshop on WebInformation and Data Management (WIDM), 2006, pp. 19–26.
[8] W. Penzo, Rewriting rules to permeate complex similarity and fuzzyqueries within a relational database system, IEEE Transactions onKnowledge and Data Engineering 17 (2) (2005) 255–270.
[9] C. Gennaro, M. Mordacchini, S. Orlando, F. Rabitti, MRoute: a peer-to-peer routing index for similarity search in metric spaces, in:Proceedings of the 5th International Workshop on Databases, Informa-tion Systems and Peer-to-Peer Computing (DBISP2P 2007), 2007.
[10] F. Mandreoli, R. Martoglia, P. Tiberio, Approximate query answeringfor a heterogeneous XML document base, in: Proceedings of the 8thInternational Conference on Web Information Systems Engineering(WISE), 2004, pp. 285–297.
[11] J. Euzenat, P. Shvaiko, Ontology Matching, Springer, 2007.[12] C. Leacock, M. Chodorow, Combining local context and wordnet
similarity for word sense identification, in: C. Fellbaum (Ed.), WordNet:An Electronic Lexical DatabaseMIT Press, 1998, pp. 256–283.
[13] R. Xu, I. Wunsch, Survey of clustering algorithms, IEEE Transactionson Neural Networks 16 (3) (2005) 645–678.
[14] V. Ganti, R. Ramakrishnan, J. Gehrke, A. Powell, J. French, Clustering largedatasets in arbitrary metric spaces, in: Proceedings of the 15thInternational Conference on Data Engineering (ICDE), 1999, pp. 502–511.
[15] A. Jain, M. Murty, P. Flynn, Data clustering: a review, ACM ComputingSurvey 31 (3) (1999) 264–323.
[16] G.J. Klir, B. Yuan, Fuzzy Sets and Fuzzy Logic: Theory andApplications, Prentice-Hall, 1995.
[17] F. Mandreoli, R. Martoglia, W. Penzo, S. Sassatelli, G. Villani,SRI@work: efficient and effective routing strategies in a PDMS, in:Proceedings of the 8th International Conference on Web InformationSystems Engineering (WISE), 2007, pp. 285–297.
[18] F. Mandreoli, R. Martoglia, W. Penzo, S. Sassatelli, G. Villani, SUNRISE:exploring PDMS networks with semantic routing indexes, in: Proceed-ings of the 4th European Semantic Web Conference (ESWC), 2007.
[19] P. Diaconis, R.L. Graham, Spearman’s footrule as a measure of disarray,Journal of the Royal Statistical Society 39 (2) (1977) 262–268.
[20] A. Crespo, H. Garcia-Molina, Semantic overlay networks for P2Psystems, in: Proceedings of the 3rd International Workshop onAgents and Peer-to-Peer Computing (AP2PC), 2004, pp. 1–13.
[21] K. Aberer, P. Cudre-Mauroux, M. Hauswirth, T.V. Pelt, GridVine: buildinginternet-scale semantic overlays networks, in: Proceedings of the 3rdInternational Semantic Web Conference (ISWC), 2004, pp. 107–121.
[22] M. Bawa, G. Manku, P. Raghavan, SETS: search enhanced by topicsegmentation, in: Proceedings of the 26th International ACM SIGIRConference, 2003, pp. 306–313.
[23] M. Li, W.-C. Lee, A. Sivasubramaniam, Semantic small world: anoverlay network for peer-to-peer search, in: Proceedings of the12th IEEE International Conference on Network Protocols (ICNP),2004, pp. 228–238.
[24] G. Koloniari, E. Pitoura, Content-based routing of path queries in peer-to-peer systems, in: Proceedings of the 9th International Conferenceon Extending Database Technology (EDBT), 2004, pp. 29–47.
[25] W. Nejdl, M. Wolpers, W. Siberski, C. Schmitz, M.T. Schlosser, I.Brunkhorst, A. Loser, Super-peer-based routing and clusteringstrategies for RDF-based peer-to-peer networks, in: Proceedings ofthe 12th ACM International World Wide Web Conference (WWW),2003, pp. 536–543.
[26] P. Triantafillou, C. Xiruhaki, M. Koubarakis, N. Ntarmos, Towards highperformance peer-to-peer content and resource sharing systems, in:Proceedings of the 1st Biennial Conference on Innovative DataSystems Research (CIDR), 2003.
[27] J. Parreira, S. Michel, G. Weikum, P2PDating: real life inspiredsemantic overlay networks for web search, Information Processingand Management 43 (3) (2007) 643–664.
[28] C. Doulkeridis, K. Nørvag, M. Vazirgiannis, DESENT: decentralizedand distributed semantic overlay generation in P2P networks, IEEEJournal on Selected Areas in Communications 25 (1) (2007) 25–34.
[29] I. King, C.H. Ng, K.C. Sia, Distributed content-based visual informationretrieval system on peer-to-peer networks, ACM Transactions onInformation Systems 22 (3) (2004) 477–501.
[30] I. Lee, L. Guan, Content-based image retrieval with automatedrelevance feedback over distributed peer-to-peer network, in: Inter-national Symposium on Circuits and Systems (ISCAS), 2004, pp. 5–8.
[31] C. Doulkeridis, A. Vlachou, K. Nørvag, Y. Kotidis, M. Vazirgiannis,Efficient search based on content similarity over self-organizing P2Pnetworks, Peer-to-Peer Networking and Applications.
[32] B. Cui, L. Xu, J. Zhao, Linking identical neighborly partitions for efficienthigh-dimensional similarity search in unstructured peer-to-peersystems, Distributed and Parallel Databases 26 (2–3) (2009) 207–229.
[33] J. Sedmidubsky, V. Dohnal, S. Barton, P. Zezula, A self-organized systemfor content-based search in multimedia, in: 10th IEEE InternationalSymposium on Multimedia (ISM), 2008, pp. 322–327.
[34] I. Stoica, R. Morris, D. Karger, F. Kaashoek, H. Balakrishnan,Chord: a scalable peer-to-peer lookup service for internet applica-tions, in: Proceedings of the 2001 ACM SIGCOMM Conference, 2001,pp. 149–160.
[35] B. Cooper, Using Information retrieval techniques to route queries inan infobeacons network, in: Proceedings of the 2nd InternationalWorkshop on Databases, Information Systems, and Peer-to-PeerComputing (DBISP2P), 2004, pp. 46–60.
[36] S. Michel, M. Bender, P. Triantafillou, G. Weikum, IQN routing:integrating quality and novelty in P2P querying and ranking, in:Proceedings of the 10th International Conference on ExtendingDatabase Technology (EDBT), 2006, pp. 149–166.
[37] A. Crespo, H. Garcia-Molina, Routing indices for peer-to-peersystems, in: Proceedings of the 22nd IEEE International Conferenceon Distributed Computing Systems (ICDCS), 2002, pp. 5–14.

C. Gennaro et al. / Information Systems 36 (2011) 174–191 191
[38] P. Haase, R. Siebes, F. van Harmelen, Peer selection in peer-to-peernetworks with semantic topologies, in: Proceedings of the Interna-tional Conference on Semantics in a Networked World (ICNSW),2004, pp. 108–125.
[39] C. Tempich, S. Staab, A. Wranik, REMINDIN’: semantic query routingin peer-to-peer networks based on social metaphors, in: Proceedingsof the 13th International Conference on World Wide Web (WWW),2004, pp. 640–649.
[40] S. Joseph, NeuroGrid: semantically routing queries in peer-to-peernetworks, in: Proceedings of the International Networking Work-shops, 2002, pp. 202–214.
[41] S. Montanelli, S. Castano, Semantically routing queries in peer-basedsystems: the H-Link approach, Knowledge Engineering Review 23 (1)(2008) 51–72.
[42] W. Muller, A. Henrich, Fast retrieval of high-dimensional featurevectors in p2p networks using compact peer data summaries, in:
Proceedings of the 5th ACM SIGMM International Workshop onMultimedia Information Retrieval (MIR), 2003, pp. 79–86.
[43] S.E. Allali, D. Blank, W. Muller, A. Henrich, Image data source selectionusing Gaussian mixture models, in: 5th International Workshop onAdaptive Multimedia Retrieval (AMR), 2007, pp. 170–181.
[44] Q.H. Vu, M. Lupu, S. Wu, SiMPSON: efficient similarity searchin metric spaces over P2P structured overlay networks, in:Proceedings of the 15th International Euro-Par Conference, 2009,pp. 498–510.
[45] C. Doulkeridis, A. Vlachou, Y. Kotidis, M. Vazirgiannis, Peer-to-peersimilarity search in metric spaces, in: Proceedings of the 33rdInternational Conference on Very Large Databases (VLDB), 2007,pp. 986–997.
[46] M. Batko, D. Novak, F. Falchi, P. Zezula, On scalability of the similaritysearch in the world of peers, in: Proceedings of the 1st InternationalConference on Scalable Information Systems (InfoScale), 2006, p. 20.

![Interoperable and Unified Multimedia Retrieval]{Interoperable and Unified Multimedia Retrieval in Distributed and Heterogeneous Environments](https://img.pdfslide.net/doc/110x75/545d3f5ab0af9fb32c8b4e29/interoperable-and-unified-multimedia-retrievalinteroperable-and-unified-multimedia-retrieval-in-distributed-and-heterogeneous-environments.jpg)



























