Embed Size (px)
Citation preview

Future Generation Computer Systems 21 (2005) 151–161
Adaptive grid job scheduling with genetic algorithms
Yang Gaoa,∗, Hongqiang Rongb, Joshua Zhexue Huangc
a State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing 210093, Chinab The Department of Computer Science, The University of Hong Kong, Hong Kong, China
c E-business Technology Institute, The University of Hong Kong, Hong Kong, China
Available online 30 October 2004
Abstract
This paper proposes two models for predicting the completion time of jobs in a service Grid. The single service model predictsthe completion time of a job in a Grid that provides only one type of service. The multiple services model predicts the completiontime of a job that runs in a Grid which offers multiple types of services. We have developed two algorithms that use the predictivemodels to schedule jobs at both system level and application level. In application-level scheduling, genetic algorithms are usedto minimize the average completion time of jobs through optimal job allocation on each node. The experimental results haveshown that the scheduling system using the adaptive scheduling algorithms can allocate service jobs efficiently and effectively.© 2004 Elsevier B.V. All rights reserved.
Keywords:Service Grid; Adaptive job scheduling; Prediction; Genetic algorithms
1
gefmffig
h(
on-
alityll asostare, amoretero-en-onof
delation
0d
. Introduction
Intelligence will be a key feature in the nexteneration of Grid computing. An intelligent Gridnvironment will contain more intelligent functions
or resource management, security, Grid servicearketing, collaboration and so on[20,21]. These
unctions will make the Grid environment more ef-cient, secure, economic in using resources, intelli-ent and easy to use. Intelligent resource management
∗ Corresponding author.E-mail addresses:[email protected] (Yang Gao),
[email protected] (Hongqiang Rong); [email protected] Zhexue Huang)
is a core component in the intelligent Grid envirment.
Grid resource management provides functionfor discovery and publishing of resources as wescheduling, submission and monitoring of jobs. Mfunctions are standardized in the Grid middlewGlobus toolkit. One exception is job schedulingkey element in resource management that needssophisticated implementations because of the hegeneity of the Grid nodes. One interesting implemtation method is to build job scheduling servicestop of Grid middleware to meet the requirementsspecific applications[14].
Effective job scheduling in Grid requires to mothe available resources on Grid nodes and comput
167-739X/$ – see front matter © 2004 Elsevier B.V. All rights reserved.oi:10.1016/j.future.2004.09.033

152 Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161
requests of jobs, determine the current load of the sys-tem, and predict the job execution time. Job schedulingin parallel and cluster computing is focussed on esti-mating the system load from experience with a perfor-mance model[19]. Their goals are to achieve best per-formance and load balancing across the entire system.When applied to Grid environments those methods of-ten result in poor performance due to the heterogeneityof Grid resources. Grid job scheduling focuses on thejob execution time because of the open, dynamic Gridenvironment[17]. The jobs arrive at a Grid in variousload and types. For example, in a given time slot, theGrid may need to schedule a single task, multiple inde-pendent tasks, or a collaborative task. Facing varyingsituations intelligent Grid environments need differentscheduling policies and algorithms to handle differentkinds of tasks[14].
Heuristic scheduling algorithms are often used inheterogenous computing environments. These algo-rithms use historical data of execution time and systemload, and explicit constraints to schedule jobs[1,7,13].However, in dynamic Grid environments the executiontime and workload cannot be determined in advance.Therefore, Grid scheduling needs predictive models.
In this paper, we propose two models for predict-ing the completion time of jobs in a Grid. The modelsare designed for a service Grid focussing on businessintelligence services that often involve a lot of dataand many complex algorithms. The service Grid pro-vides an economic platform for business intelligences ingj jobsa . Ana de-v shallu arm-i thmi f allj odei d tos Thee ulings cana
k isr es beda ssed.
In Section4, the adaptive system-level and application-level scheduling algorithms are discussed in details.Some simulation experiments are presented in Section5. Finally, we draw some conclusions in Section6.
2. Related work
Krauter et al. surveyed a few existing Grid resourcemanagement systems in[14]. They analyzed the cur-rent systems based on a classification of developmentorganization, system status, scheduling and reschedul-ing policies. However, the characteristics and differ-ences of current Grid job scheduling algorithms werenot discussed in detail.
An adaptive scheduling strategy and its correspond-ing algorithm were investigated in the two well knownAppLes and GrADS projects[3,11]. The strategy sep-arates the application-oriented module from the com-mon module. Jobs are scheduled by the user-definedperformance model, which is a shortcoming while theadvantage is that the search space is reduced[11].
The NetSolve project[5] uses different schedulingalgorithms for different applications. The completiontime of a job is estimated by an experiential perfor-mance model and a load model. A dynamic job queueis used for task farming. The queue length can adap-tively be adjusted from the average request responsetime of history statistics. This adaptive scheduling al-gorithm is regarded as a system-level approach[6]. Ina tep,d
aget b re-qf tem[ portp rcesw
delf us-i rket,p on-t wos st-o em.T dle-w tion,
ervices. Predicting the completion time of a comob is based on the historical execution data of pastnd the number of jobs running on the Grid nodesdaptive system-level job scheduling algorithm iseloped to schedule a single job to the node thatse the shortest time to execute the job. For task f
ng, an adaptive application-level scheduling algoris used to minimize the average completion time oobs through an optimal allocation of jobs on each nn the service Grid. Genetic algorithms are applieolve the job scheduling problem in task framing.xperimental results have shown that the schedystem using the adaptive scheduling algorithmsllocate service jobs efficiently and effectively.
The paper is organized as follows. Related woreviewed in Section2. In Section3, a unified resourccheduling framework of a service Grid is descrind three resource scheduling policies are discu
ddition, a system framework to schedule multi-sata-dependent jobs is given in[2].
The Condor[17] system uses the Classad languo describe machine states, job constrains and jouirements. The Matchmaking algorithm[16] is used
or job scheduling in the centralized scheduling sys18]. The extended version of Classad is used to suparallel jobs and mapping between jobs and resouith the experiential performance model[15].Buyya et al. [4] proposed an economics mo
or Grid resource management and scheduling,ng marketing concepts such as commodity maosted price modelling, bargaining modelling, c
ract net modelling, auction modelling and others. Tcheduling algorithms for time-optimization and coptimization were designed in the Nimrod systhe Legion system uses three object-oriented midare components, Enactor, Scheduler and Collec

Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161 153
Table 1Features of major Grid job scheduling algorithms
System Scheduleorganization
Class of jobs Scheduling policy Performance estimation Reschedule Adaptive
AppLes Centralized Single task User defined Predictive state estimation model Online AdaptiveNetSolve Decentralized Single task Least task computation time Defined performance equation Batch None
Task farming Optimize the task queue Based on historical knowledge AdaptiveCondor Centralized Single task Match-making None Online None
Parallel tasks System utilizationNimrod Distributed Task farming Cost optimal or time optimal None Batch AdaptiveLegion Hierarchical Single task System oriented None Online None
for resource management[8]. Different from Legion,the Globus project uses a layered architecture in re-source management[12]. Integrated with Web services,Globus can easily solve the cross-operation problemsof heterogenous platforms. Also, by means of welldeveloped generic services, such as GRIS, GIIS andGRAM, it becomes very easy to describe, discover andpublish resource information in Globus[10,12]. Whatneeded is the high-level scheduling policies and algo-rithms for different systems like Nimrod/G, AppLes,Condor-G and Ninf-G.
Table 1summarizes the major features of currentGrid job scheduling systems.
3. Job scheduling framework
3.1. Architecture
Fig. 1 shows a layered architecture of a ser-vice Grid that takes the following characteristics intoaccount:
(1) Dynamics of Grid.The capacity of computationor services is distributed and dynamic. The avail-able resources of each node vary over time and thechanges of resources affect the Grid system. Forexample, when a new service is added in a node,other nodes in the same Grid must be aware of thechange at once. However, this change shall have
ar-ents.rent
( n-runize
resource utilization. The strength of this autonomyvaries at different levels of the Grid architecture.Generally speaking, the higher a level, the moreautonomous.
(3) Diversity of tasks.Various tasks consume differentresources, including computing power and appli-cations. The constrains on each tasks are also dif-ferent. Some tasks require to be done in the shortestexecution time while others require the lowest cost.Even some tasks don’t specify any constrain. Sincethe resources required by tasks could be fully dis-tributed in the entire Grid system, it is necessaryto classify tasks and design diversiform schedul-ing policies and algorithms for different task cate-gories.
(4) Adaptation of Grid.The functions of Grid are real-ized through middle services. In order to increasethe resource utilization and support QoS, the ser-vices should be adaptive to historical and predictiveinformation.
Logically, the architecture is divided into four lev-els: the Virtual Organization level, the Grid level, theAdmin Domain level and the Node level. The Nodelevel can be a computer, a service-provider and a stor-age resource.
The Admin Domain level consists of machinegroups, named as Admin Domains (AD), in which allnodes belong to one organization. For example inFig.1, AD1 belongs to the Computer Center and AD2 be-l oneh , anda therh ceso odesi op-e
very little impact on other Grid nodes. A hierchical architecture can meet these requiremThe capacity of resource management is diffeat different levels.
2) Autonomy of Grid nodes.Each node is indepedent. A node itself determines whether or not toa new job, how to schedule it and how to optim
ongs to the Department of Computer Science. Onand each AD can be regarded as a whole systemll nodes in it have a common objective. On the oand, an AD can fully centrally control the resourf its nodes but cannot operate the resources of n
n other ADs directly. In this view, all nodes are corative in the same AD.

154 Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161
Fig. 1. The layered architecture of a service Grid.
A Grid can have many ADs connected together andhave good collaboration and trust relationship betweenthe ADs. For example, Grid1 inFig. 1 can be a Gridin Hong Kong and Grid2 is a Grid in Nanjing, China.However, Grids are independent to each other, userscan submit tasks to a Grid from its Portal.
The top Virtual Organization (VO) level combinesall Grids together. VO must maintain a unique en-try address list of the gatekeepers of all Grids in or-der to locate them. Besides the entry address list, anoverall resource list is also kept in VO and updatedasynchronously. The actual resource management andscheduling services are distributed in the VO. Here, theconcept of VO is similar to Grid Market where one Gridmay compete and negotiate with other Grids.
3.2. Classification of scheduling policies
As illustrated inFig. 1, the scheduling policies andobjectives in each level are different. Essentially, thereis no Grid scheduling process on a physical node. Whena new job arrives, one or more nodes are assigned to runit. Unlike parallel computing and cluster computing,the Grid does not schedule all CPUs for this job. The op-erating system of the node will handle the job schedul-ing after a job is submitted to the node. Meanwhile, theGrid will not determine how to run a job on a node.The OS-level scheduling is not in this paper’s scope.
When a single job arrives at a Grid or an Admin Do-m lings ands edul-i thew vily
loaded, the scheduling system has to realize the loadbalancing, and increase the system throughput and re-source utilization under restricted conditions. We clas-sify this kind of scheduling as system-level scheduling,whose objective is to optimize the system performance.
If multiple jobs arrive within a unit scheduling timeslot, the scheduling system shall allocate an appropri-ate number of jobs to every node in order to finish thesejobs under a defined objective. Obviously, the objectiveis usually the minimal average execution time. Thisscheduling policy is application-oriented so we call itapplication-level scheduling. In fact, application-levelscheduling deals with two kinds of tasks. One is taskfarming, meaning that numerous independent tasks ar-rive simultaneously. The other is collaborative task thatcan be divided into several dependent subtasks.
If a Grid lacks of enough resources to completethe new coming tasks, the Grid scheduling systemwill migrate some tasks to other Grids. Because acentral resource management system does not exist,we must apply a distributed scheduling algorithm tothe VO level. Considering the autonomy of Grids,some negotiation technologies are needed to findappropriate Grids to finish the tasks. We call thisscheduling as Grid-level scheduling.
4. Adaptive job scheduling models andalgorithms
4s
dent.T nd
ain within an unit scheduling time slot, the scheduystem will analyze the load situation of every nodeelect one node to run this job. In this stage, the schng policy is to optimize the total performance ofhole system. Especially, if the Grid system is hea
.1. Model and algorithm for system-levelcheduling
Most tasks to an open Grid system are indepenhey are submitted to the Grid at different time a

Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161 155
consume different resources and time to execute. Thesystem load shows a light-tailed distribution mostly andmay occasionally have a heavily-tailed distribution[9].Within a given unit time slot we can separately solvetwo job scheduling problems: (1) scheduling a singlejob arriving at Grid, and (2) scheduling multiple ar-riving jobs. In this section we discuss the model andalgorithm of system-level scheduling to solve the firstproblem. The application-level scheduling will be dis-cussed in next section.
Theoretically, the precise execution time of a jobcannot be determined in advance because of the loaddynamics and many other unknowns. This is a ‘Haltmachine’ problem. We can only predict the possibleexecution time of a job from historical experiences anduse this prediction to schedule the job. In a serviceGrid, a job is related to a particular service that hasbeen used before. Therefore, the computational per-formance and ability to process different sizes of datafor the service can be known or learned incrementallyfrom the historical usage data of the service. The dif-ficult part is to deal with the dynamic load of the sys-tem that affects the execution time of the job to besubmitted.
To simplify this problem, we can define asingleservice model. We assume that the Grid provides onlyone type of service and only one task arrives in anyunit time slot. Without considering the system load, theadaptive system-level scheduling algorithm can predictthe execution time of a job on a node from historicalu
T
f an bsoi mena l
v e
p me
es -l he
nth job.
T nm,E(t + 1) = (1 − αn
m(t))T nm,E(t) + αn
m(t)T nm,R(t),
n = 2, 3, 4, . . . (2)
whereT nm,E(t + 1) is the predicted execution time of
thenth job on nodem, which hasn − 1 running jobsof the same service.T n
m,E(t) andT nm,R(t) on the right
side are the last historical values of expected executiontime and actual execution time, respectively, andαn
m(t)is the learning rate.
The dynamics of the system load makes it difficultto obtainT n
m,E(t). However, the ratio ofT nm(t)/T n−1
m (t)can be estimated. Using the ratios, the execution timeof thenth job on nodem can be predicted by
T nm,E(t + 1) =
n∏i=2
[(1 − αim(t))Φi
m(t) + αim(t)Ψi
m(t)]
× T 1m,E(t) (3)
where
Φim(t) = T i
m,E(t)
T i−1m,E(t)
(4)
Ψim(t) = T i
m,R(t)
T i−1m,R(t)
(5)
ac
ad-j tj ntf ondj nts Onei ivesa
a
ac stemt
anda ul-
sage of the service as follows:
1m,E(t + 1) = (1 − α1
m(t))T 1m,E(t) + α1
m(t)T 1m,R(t)
(1)
whereT 1m,E(t + 1) is the predicted execution time o
ew job on nodem, t is the number of times that the jof the service have been executed on nodem, T 1
m,R(t)s the actual execution time of the job on the saode, andα1
m(t) (< 1) is the learning rate.α1m(t) → 0
ndT 1m,E(t + 1) = T 1
m,E(t) as t → ∞. The historica
alues ofT 1m,E(t) and T 1
m,R(t) are obtained from th
revious executions andT 1m,E(0) can be obtained fro
xperiments.If there aren − 1 jobs (instances) of the sam
ervice already running on nodem, we use the folowing model to predict the execution time of t
ndαim(t) → 0 ast → ∞ andΦi
m(t), Ψim(t) approach
onstants.The model of predicting execution time and the
usting process are illustrated inFig. 2. When the firsob arrives at nodem, the Grid predicts its executioime based onT 1
m,E. If the second job arrives atm be-ore the first job ends, the Grid predicts the secob’s execution time based onT 2
m,E, and so on. Whehenth job ends, the system adjustsT n
m,E by T nm,R and
o forth. Here, we emphasize on two key points.s that the first job ends before the second job arrt nodem. The other is that the value ofT 1
m,R will be
ffected by the subsequent jobs. Therefore,T 1m,E will
lso be changed when usingT 1m,R to adjustT 1
m,E. Thehange reflects the capability of the scheduling syo predict the possible load on this node.
In order to explore the performance of each nodevoid the impact on the initial prediction, the sched

156 Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161
Fig. 2. Process of predicting the execution time in the single service model.
ing system applies the Roulette Wheel Selection to as-sign jobs as
R = Li/Li+1, i = 1, 2, . . . , M − 1
1 < R < ∞∑Mj=1 Lj = 1
(6)
whereM is the number of nodes andLi is the load ofnodei.
Theoretically, the node, which can complete this jobin the shortest time, has the biggest probability to getthis job. In the Roulette Wheel Selection,T
ni
i,E of allnodes are sorted in an ascending order. We allocateL1,the biggest proportion, to the node which can finish thejob in the shortest time. Then we allocateL2 to the nodewhich can finish the job in the second shortest time.This process continues untilLM is assigned to a node.The scheduling system generates a random probability,then selects the node according to the region where thisprobability drops in. In(6), the initial R is set a littlebigger than 1.R will increase as the system runs. Theindeterminate Roulette Wheel Selection will becomedeterminate best-fit selection afterR grows big enough.
Table 2 gives an improved best-fit schedul-ing algorithm for system-level scheduling based on
Table 2System-level scheduling algorithm
Initialize T 1i,E, α1
i for i = 1, . . . , M;R = 1.1;
;
Fig. 3. Process of predicting the execution time in the multiple ser-vice model.
(1), (3) and (6). At the beginning, the Grid system ini-tiates all parameters, and sets allT 1
m,E according tohistorical data. When a new job arrives, the Grid sys-tem predicts the execution time on each node and sortsthe prediction results. The scheduling system selects anode to run this job according to the revised RouletteWheel Selection. When the job finishes, the schedulingsystem records the real execution time and adjusts theprediction value. When another job of the same ser-vice arrives later, the scheduling system will schedulethe job based on new prediction values. The computa-tional complexity of this system-level scheduling algo-rithm is O(M), whereM is the number of nodes in aGrid.
4.2. Multiple services model
In the single service model, we assume that the Gridprovides only one type of service. In reality a Gridwill provide many types of services. In this section weextend the simple single service model to a multipleservices model.
Do while (receiving a new job){
Compute everyT nii,E for i = 1, . . . , M;
SortT nii,E;
AssignLi for theith node according toR;Generate randomly a probabilityProb;If (Prob <
∑ij=1 Li andProb ≥ ∑i−1
j=1 Li)Select theith node for this job;
When the job finishes, update the predicted completion timeUpdateR andα;
}
Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161 157
Let T n,sm,E be the predicted execution time of thenth
job of services on nodem on whichn − 1 jobs of thesame or different services are already running. In themultiple services model,T n,s
m,E can be computed as
Tn,sm,E(t + 1) =
n∏i=2
[(1 − αi,sm (t))Φi,s
m (t) + αi,sm (t)Ψi,s
m (t)]
× T1,sm,E(t) (7)
where
Φi,sm (t) = T
i,sm,E(t)
Ti−1,s′m,E (t)
(8)
Ψi,sm (t) = T
i,sm,R(t)
Ti−1,s′m,R (t)
(9)
s′ in (8) and (9)indicates a service that can be same ass or not. Therefore, the difference of(7) from Eq.(3)is that two subsequent jobs can be different services.
Fig. 3shows how the predicted execution time of thenth job is calculated. As the predicted execution timesof all precedingn − 1 jobs are known, the schedul-ing path is known for a particular sequence of jobs, asshown by the light lines fromT 1,1
m,E toTn−1,sm,E . However,
unlike the single service model,Tn,sm,E(t) depends on the
scheduling path. In other words, different schedulingpaths result in different execution times when servicesi
v ln -tT aina desa inT
4
emoN em,w s toc s one jobs
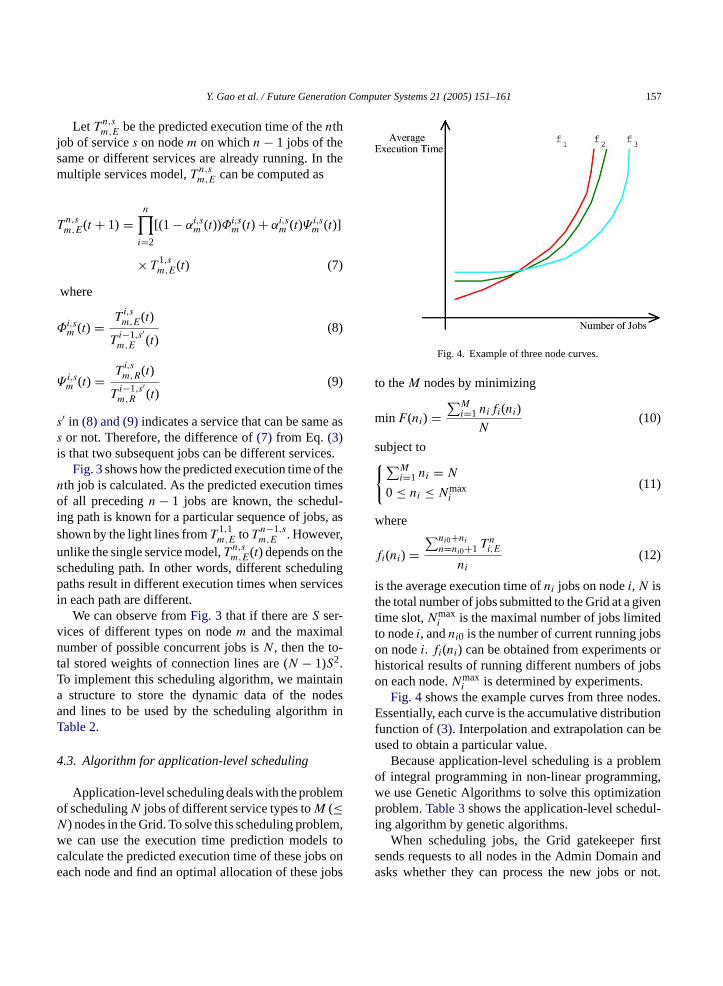
Fig. 4. Example of three node curves.
to theM nodes by minimizing
minF (ni) =∑M
i=1 nifi(ni)
N(10)
subject to{∑Mi=1 ni = N
0 ≤ ni ≤ Nmaxi
(11)
where
fi(ni) =∑ni0+ni
n=ni0+1 T ni,E
ni
(12)
is the average execution time ofni jobs on nodei, N isthe total number of jobs submitted to the Grid at a giventime slot,Nmax
i is the maximal number of jobs limitedto nodei, andni0 is the number of current running jobson nodei. fi(ni) can be obtained from experiments orhistorical results of running different numbers of jobson each node.Nmax
i is determined by experiments.Fig. 4shows the example curves from three nodes.
Essentially, each curve is the accumulative distributionfunction of(3). Interpolation and extrapolation can beused to obtain a particular value.
Because application-level scheduling is a problemof integral programming in non-linear programming,we use Genetic Algorithms to solve this optimizationproblem.Table 3shows the application-level schedul-ing algorithm by genetic algorithms.
When scheduling jobs, the Grid gatekeeper firsts anda not.
n each path are different.We can observe fromFig. 3 that if there areS ser-
ices of different types on nodem and the maximaumber of possible concurrent jobs isN, then the to
al stored weights of connection lines are (N − 1)S2.o implement this scheduling algorithm, we maintstructure to store the dynamic data of the no
nd lines to be used by the scheduling algorithmable 2.
.3. Algorithm for application-level scheduling
Application-level scheduling deals with the problf schedulingN jobs of different service types toM (≤) nodes in the Grid. To solve this scheduling proble can use the execution time prediction modelalculate the predicted execution time of these jobach node and find an optimal allocation of these
ends requests to all nodes in the Admin Domainsks whether they can process the new jobs or

158 Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161
Table 3Application-level scheduling algorithm
ComputeT nm,E for m = 1, . . . , M andn = 0, . . . , N;
Do while (receiving a task framingN){
t = 0; initializeP(t); evaluateP(t);while not finished do{
t = t + 1;selectP(t) from P(t − 1);reproduce pairs inP(t);evaluateP(t);
}}
Then, each node checks its current load and returns theinformation to the gatekeeper. The node which agreesto receive new jobs returns information about its cur-rent load status, including the number of the currentjobs and the average time of completing these jobs,T n
m,E. Receiving the information, the GA application-level scheduling algorithm generates the initial popula-tion, evaluates each individual’s fitness, and performsgenetic operations on the individuals with high fitnesssuch copying, crossover and mutation, to generate anew population. The genetic process continues withthe new population until a nearly optimal jobs assign-ment strategy is obtained. Finally, the jobs are assignedto each node based on the strategy.
The average execution time ofn jobs onM node iscalculated as
T nm,E =
∑ni=1 T i
m,E
n(13)
In real applications, a node may not be completely idlebut undertaking certain loadn0. Therefore, the valueof i will be in [n0 + 1, n0 + n] instead of [1, n].
In implementing the GA application-level schedul-ing algorithm, we encode the chromosomes with theform of n1n2n3 . . . nm−1 in the population. Because ofthe constraints(11), we only encode the number of as-signed jobs onM − 1 nodes. To simplify the operationsof selection, crossover and mutation, we use integralcoding instead of binary coding. In the initial popu-ln byr
dul-i fit-n ctive
function(10).
Fitness(Pj) = 1
F (ni)(14)
wherei = 1, 2, . . . , M − 1 andj = 1, 2, . . . , |P |. |P |is the size of the population,Pj represents thejth in-dividual in the population andF (ni) is defined in(10).Since the functionFitness(Pj) cannot respond to thedegree of the actual fitness precisely, we use the Re-mainder Stochastic Sampling with Replacement selec-tion (RSSR) method to select good individuals in theGA process. First, we hold two individuals with thehighest fitness values. Then we use the Roulette WheelSelection method to select remaining|P | − 2 individ-uals.
In the Roulette Wheel Selection, a random numberbetween 0 and 1 is generated. If this random number isbigger than
∑i−1j=1 Pr(Pj) and less than
∑ij=1 Pr(Pj),
the ith individual is reserved in the next population,where
Pr(Pj) = Pj∑|P |j=1 Pj
(15)
This selection process is repeated|P | − 2 times.In the process of crossover, two parent individ-
ual chromosomes,P1 = (n1n2 . . . nM−1) and P2 =(n′
1n′2 . . . n′
M−1), are recombined if they are at thepoints of crossover as below.{
γ quala intso oned cedi sultsa over,c r thep neda
O
F ex-p
ation, we define one individual asn1 = n2 = . . . =m−1 = [N/M]. Other individuals are determinedandomly changing some genes.
Because the objective for application-level scheng is to minimize the average execution time, theess function is defined as the inverse of the obje
O1 = [P1 + γ(P1 − P2)], γ ∈ [−0.5, 0.5]
O2 = [P1 − γ(P1 − P2)], γ ∈ [−0.5, 0.5](16)
is equal at the same genes location and not et different genes location. To satisfy the constraf (11), constraint satisfaction checking must be during the crossover process. If the newly produ
ndividuals cannot satisfy these constraints, the rere ignored and the process is repeated. Like crossonstraint satisfaction checking is also done afterocess of mutation. The mutation operation is defis
=[P + δ
(N
M
)], δ ∈ [−0.2, 0.2] (17)
inally, the number of iterations is determined byeriments.
Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161 159
Table 4The small service Grid environment
Node Name Number of CPU CPU frequency Memory Operating system Completion time of a single job (s)
1 PC1 1 1 GHz 256 MB Win2000 92 Server 2 550 MHz 2 GB NT 43 Sun420 2 450 MHz 1 GB Solaris 34 PC2 1 1 GHz 256 MB Linux 10
5. Experimental results and analysis
The experiments were conducted in a small four-node Grid of which each node provides a DiscreteFlourier Transform (DFT) service. The hardware con-figuration and operating systems used in the nodes aregiven inTable 4.
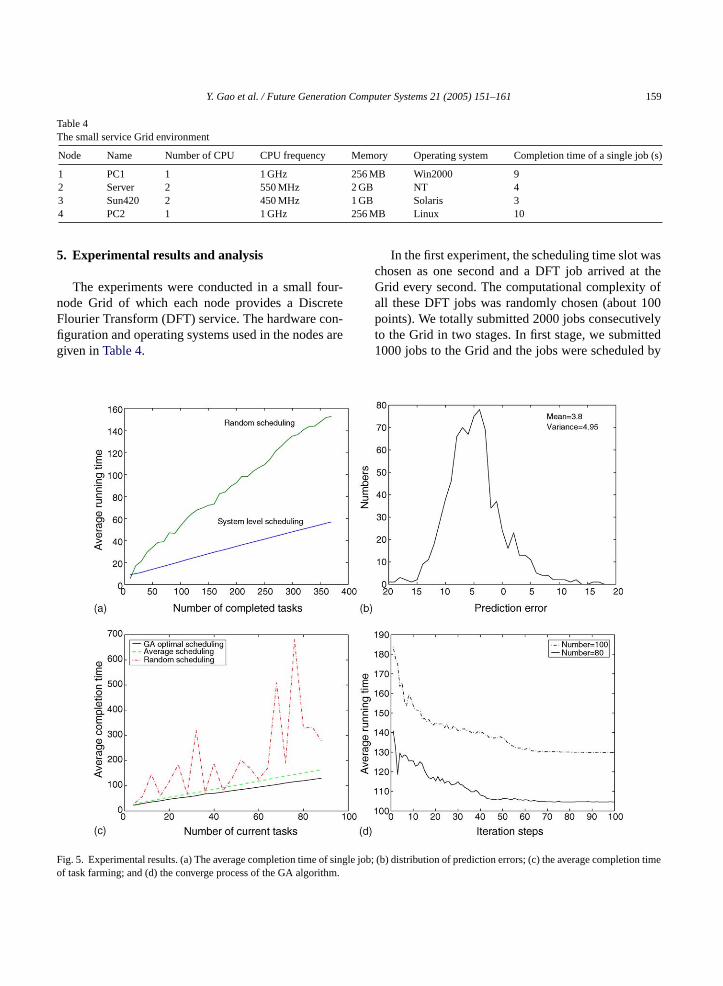
Fig. 5. Experimental results. (a) The average completion time of singlof task farming; and (d) the converge process of the GA algorithm.
In the first experiment, the scheduling time slot waschosen as one second and a DFT job arrived at theGrid every second. The computational complexity ofall these DFT jobs was randomly chosen (about 100points). We totally submitted 2000 jobs consecutivelyto the Grid in two stages. In first stage, we submitted1000 jobs to the Grid and the jobs were scheduled by
e job; (b) distribution of prediction errors; (c) the average completion time

160 Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161
our system-level scheduling algorithms. After the first1000 jobs were all finished, we submitted the second1000 jobs that were allocated with the random schedul-ing method.Fig. 5ashows the comparisons of the av-erage execution time of the system-level schedulingalgorithm and the random scheduling method. It canbe seen fromFig. 5athat the former was much fasterthan the later. In fact, at the 1000th second, the Grid hasfinished more than 800 jobs scheduled by the system-level scheduling algorithm while only 400 jobs werecompleted by random scheduling.
Fig. 5bshows the differences between the predictedexecution time and the actual execution time of the1000 jobs scheduled by our approach. The horizontalaxis is the prediction error and the vertical axis rep-resents the number of corresponding jobs. The meanof the prediction errors was−3.8 s and the variancewas 4.95. We remark that this was quite good resultbecause the actual execution time was possibly severaldozens seconds. So, the prediction error of around 4 swas acceptable.
In the second experiment, we conducted 20 tests.In each test, we allowed several DFT jobs arrivingat the Grid within an unit scheduling time slot. Thenumber of jobs increased from 20 to 100.Fig. 5cshows the average execution time of jobs scheduledby application-level scheduling, average schedulingand random scheduling. It can be seen from the fig-ure that the performance of GA-based application-levelscheduling is the best. Although the curve of averages exe-c at oft wasa -v then out5
6
pre-d rid.T imeo ice.T tiont let hms
that use the predicted results to schedule jobs at bothsystem level and application level. In application-levelscheduling, we use genetic algorithms to minimize theaverage completion time of jobs through optimal joballocation on each node. The experimental results onthe single service model have shown that the schedul-ing system using the adaptive scheduling algorithmscan allocate service jobs efficiently and effectively.
Acknowledgements
The work of the first author was supported bythe NSFC (No. 60103012), the National OutstandingYouth Foundation of China (No. 60325207), the Na-tional Grand Fundamental Research 973 Program ofChina (No. 2002CB312002) and the NSF of JiangsuProvince, China (No. BK2003409).
References
[1] O. Beaumont, A. Legrand, Y. Robert, Optimal algorithms forscheduling divisible workloads on heterogeneous systems, in:Proceedings of the International Parallel and Distributed Pro-cessing Symposium, 2003.
[2] M. Beck, H. Casanova, J. Dongarra, T. Moore, J. Planck, F.Berman, R. Wolski, Logistical quality of service in NetSolve,Comput. Commun. 22 (11) (1999) 1034–1044.
[3] F. Berman, R. Wolski, The AppLes project: a status report, in:erlin,
my-owerf theer-
erverom-23.tive
igh
uris-nvi-
IEEE
Re-put.
stri-ling
cheduling was close to our method, its averageution time was about 20 s that was more than thhe GAs result when they scheduled 80 jobs. Thisn extremely disparity in time.Fig. 5dshows the conerge process of the GA algorithm. We found thatear-optimal allocation policy could converge in ab0 iterations.
. Conclusions
In this paper we have presented two models foricting the completion time of jobs in a service Ghe single service model predicts the completion tf a job in a Grid that provides only one type of servhe multiple services model predicts the comple
ime of a job that runs in a Grid which offers multipypes of services. We have developed two algorit
Proceedings of the Eighth NEC Research Symposium, BGermany, 1997.
[4] R. Buyya, J. Giddy, D. Abramson, An evaluation of econobased resource trading and scheduling on computational pGrids for parameter sweep applications, in: Proceedings oSecond International Workshop on Active Middleware Svices, Kluwer Academic Press, Pittsburgh, USA, 2000.
[5] H. Casanova, J. Dongarra, NetSolve: a network-enabled sfor solving computational science problems, Int. J. Supercput. Appl. High Performance Comput. 11 (3) (1997) 212–2
[6] H. Casanova, M. Kim, J.S. Plank, J.J. Dongarra, Adapscheduling for task farming with Grid middleware, Int. J. HPerformance Comput. Appl. 13 (3) (1999) 231–240.
[7] H. Casanova, A. Legrand, D. Zagorodnov, F. Berman, Hetics for scheduling parameter sweep applications in Grid eronments, in: Heterogeneous Computing Workshop 2000,Computer Society Press, 2000, pp. 349–363.
[8] S.J. Chapin, D. Katramatos, J. Karpovich, A. Grimshaw,source management in Legion, Future Generation ComSyst. 15 (5/6) (1999) 583–594.
[9] M.E. Crovella, Performance evaluation with heavy tailed dibutions, in: D.G. Feitelson, L. Rudolph (Eds.), Job Schedu

Y. Gao et al. / Future Generation Computer Systems 21 (2005) 151–161 161
Strategies for Parallel Processing, Lecture Notes in ComputerScience, Vol. 2001, Springer, Berlin, 2001, pp. 1–10.
[10] K. Czajkowski, I. Foster, N. Karonis, et al., A resource man-agement architecture for metacomputing systems, in: LectureNotes in Computer Science, Vol. 1459, Springer, Berlin, 1998,pp. 62–81.
[11] H. Dail, H. Casanova, F. Berman, A modular scheduling ap-proach for Grid application development environments, UCSDCSE Technical Report CS20020708, 2002.
[12] Globus,http://www.globus.org.[13] J.K. Kim, et al., Dynamic mapping in a heterogeneous envi-
ronment with tasks having priorities and multiple deadlines, in:Proceedings of the International Parallel and Distributed Pro-cessing Symposium, 2003.
[14] K. Krauter, R. Buyya, M. Maheswaran, A taxonomy and surveyof Grid resource management systems for distributed comput-ing, Software Pract. Exp. 2 (2002) 135–164.
[15] C. Liu, L. Yang, I. Foster, D. Angulo, Design and evaluation ofa resource selection framework for Grid applications, in: Pro-ceedings of the 11th IEEE Symposium on High-PerformanceDistributed Computing, 2002.
[16] R. Raman, M. Livey, M. Solomon, Matchmaking: distributedresource management for high throughput computing Proceed-ings of the Seventh IEEE International Symposium on HighPerformance Distributed Computing, Chicago, IL, July, 1998,pp. 140–146.
[17] D. Thain, T. Tannenbaum, M. Livny, Condor and the Grid, in:A.J.G. Hey, F. Berman, G.C. Fox (Eds.), Grid Computering:Making the Global Infrastructure a Reality, Wiley, West Sussex,England, 2003, pp. 299–335.
[18] D. Wright, Cheap cycles from the desktop to the dedicatedcluster: combining opportunistic and dedicated scheduling withCondor, in: Proceedings of Linux Clusters: The HPC Revolu-tion, Champain-Urbana, IL, USA, June, 2001.
[19] Y. Zhang, H. Ranke, J.E. Moreira, A. Sivasubramaniam, An in-uling,ci-
[ ecial–5.
[21] H. Zhuge, China’s E-Science knowledge Grid environment,IEEE Intell. Syst. 19 (1) (2004) 13–17.
Yang Gao is an associate professor at theDepartment of Computer Science, NanjingUniversity, China. He received a master de-gree from Nanjing University of Scienceand Technology in 1996, and a Ph.D. inComputer Science from the Nanjing Univer-sity in 2000. His current research interestsinclude distributed artificial intelligence andgrid computing.
HongqiangRongis a Ph.D. candidate in theDepartment of Computer Science, the Uni-versity of Hong Kong. He received his B.S.and M.S. degrees in Computer Science andEngineering from Harbin Institute of Tech-nology in China, in 1998 and 2000, respec-tively.
Joshua Zhexue Huangis the assistant di-rector of E-Business Technology Instituteat the University of Hong Kong. He re-ceived his Ph.D. degree from the Royal In-stitute of Technology in Sweden. Beforejoining ETI in 2000, he was a senior consul-tant at the Management Information Prin-ciples, Australia, consulting on data min-ing and business intelligence systems. From
t atin-
c Gridc
tegrated approach to parallel scheduling using gang-schedbackfilling, and migration, in: Lecture Notes in Computer Sence, Vol. 2221, Springer, Berlin, 2001, pp. 133–158.
20] H. Zhuge, Semantics, resource and Grid, editorial of the spissue of Future Generation Comput. Syst. 20 (1) (2004) 1
1994 to 1998 he was a research scientisCSIRO Australia. His research interests
lude data mining, machine learning, clustering algorithms, andomputing.





























