Embed Size (px)
Citation preview

Agnieszka Nowak - Brzezińska
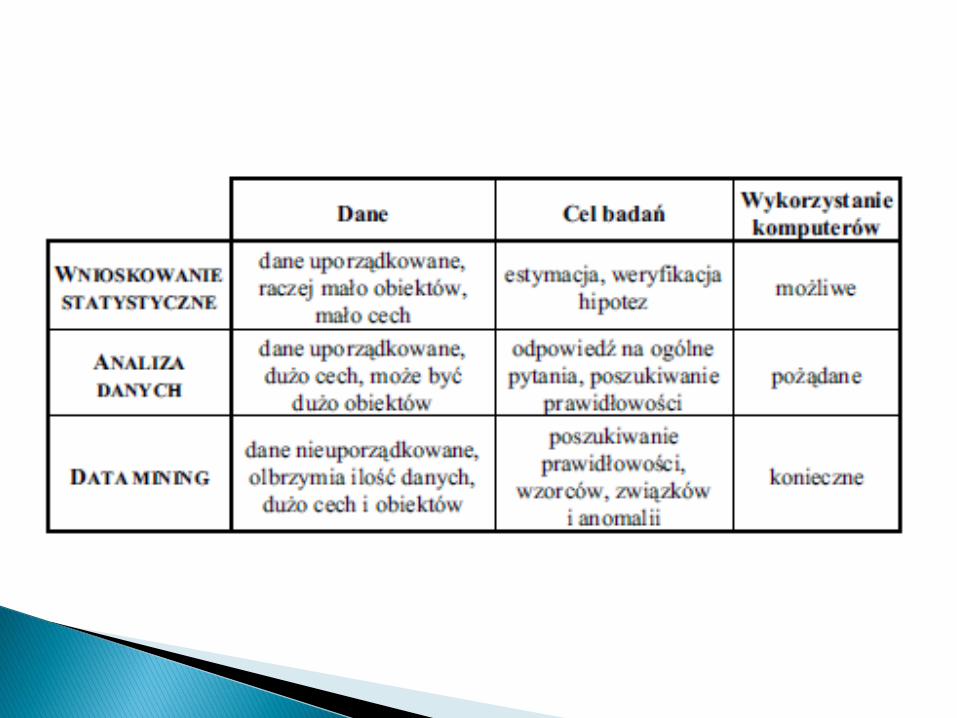


Gdy zbiór zdarzeń elementarnych jest skończony, odwzorowywanie go w zbiór liczb (czyli tworzenie zmiennej losowej) może być mniej użyteczne niż w przypadku zmiennej losowej ciągłej.

Jeśli zbiór zdarzeń elementarnych nie wykazuje naturalnego uporządkowania, mówimy o skali nominalnej◦ Przykłady: grupa krwi (0,A,B,AB), rozpoznanie,
czynnik etiologiczny, sympatie polityczne (PO,PiS,PSL,...), wyznanie, narodowość, rasa...

Gdy w zbiorze zdarzeń istnieje naturalne uporządkowanie, ale wprowadzanie odległości nie ma sensu, mamy do czynienia ze skalą porządkową.◦ Przykłady: wynik leczenia (pogorszenie,b.z.,
poprawa), wykształcenie (brak, podst., średnie, wyższe), WBC (poniżej, w normie, powyżej)

Gdy w skończonym zbiorze zdarzeń elementarnych istnieje odległość, pre-zentacja wyników w postaci zmiennej losowej jest w pełni uzasadniona.◦ Przykłady: tętno, WBC (tys./mm3), liczba dzieci
Gdy liczba możliwych wartości jest duża, traktujemy taką zmienną jako ciągłą.

Pojęcie skali pomiarowej ma zastosowanie nie tylko do zmiennych losowych (wyników pomiarów), ale także w odniesieniu do wielkości kontrolowanych w eksperymencie (czynników).

Pojecie hipotezy statystycznej ewoluowało przez setki lat. Pierwszezachowane
wzmianki o koncepcie hipotezy można znaleźć w pracy „Teoria Matematyki”greckiego filozofa Geminus’a (pierwsze dziesięciolecia naszej ery).
Termin „hipoteza” był przez wieki używany w astrologii oraz fizyce.Przykładami sa prace Gottfrieda Wilhelma Leibniz’a („Nowe hipotezyfizyczne”, 1671) oraz Isaaca Newtona („Hipotezy o świetle”, 1675).
Wzmianki o pierwszej hipotezie zweryfikowanej na gruncie analizystatystycznej dotyczą pracy medyka Johna Arbuthnota (1667 – 1735), który wroku 1710 opublikował w Royal Society pracę „An argument for DivineProvidence, taken from the constant regularity observ’d in the births of bothsexes”. W pracy tej przedstawił roczne liczby urodzeń chłopców orazdziewcząt w Londynie z lat 1625-1710 oraz zauważył, że w każdym rokurodziło sie więcej chłopców niż dziewcząt. Obliczając stosowneprawdopodobieństwa – na ich podstawie stwierdził, że częstość urodzinchłopców jest statystycznie istotnie większa niż częstość urodzin dziewcząt.

Przez kolejny wiek uczeni stawiając iweryfikując hipotezy statystyczne kierowalisię intuicją.
Dopiero w latach dwudziestych XX wiekuaksjomatyczne podstawy dla zagadnieniatestowania opracowali Jerzy Spława-Neyman(matematyk polskiego pochodzenia) i EgonPearson (syn znakomitego statystyka KarlaPearsona).

hipotezy proste
hipotezy złożone
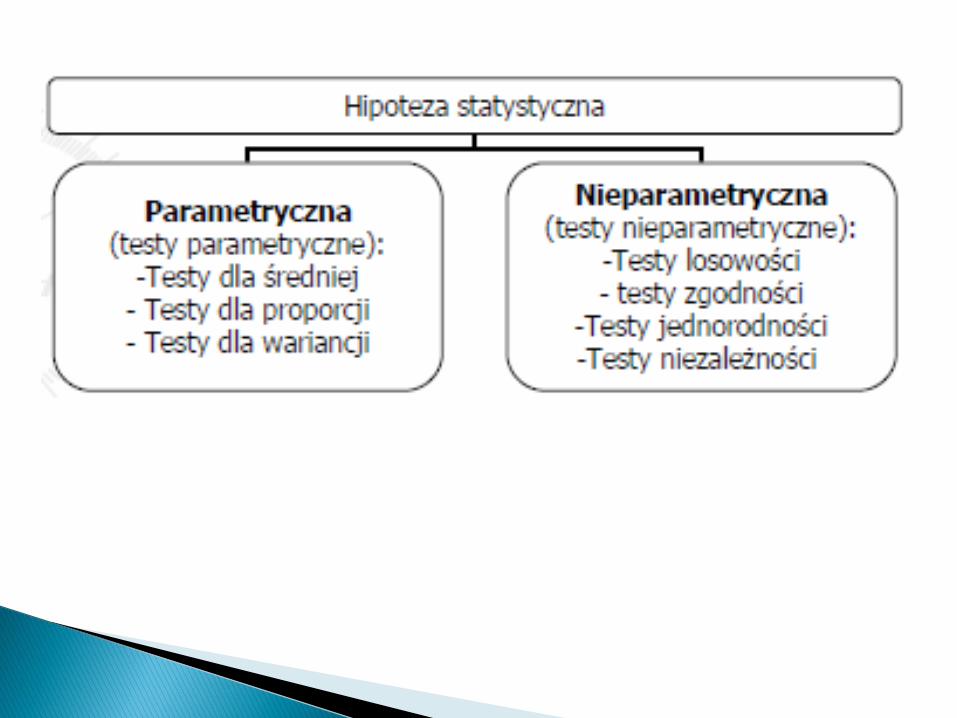
hipotezy parametryczne
hipotezy nieparametryczne

Hipoteza statystyczna: każdy sąd o populacjigeneralnej wydany na podstawie badań częściowych,dający się zweryfikować metodami statystycznymi,czyli na podstawie wyników badań próby.
Hipoteza parametryczna: hipoteza dotyczącaparametrów rozkładu statystycznego.
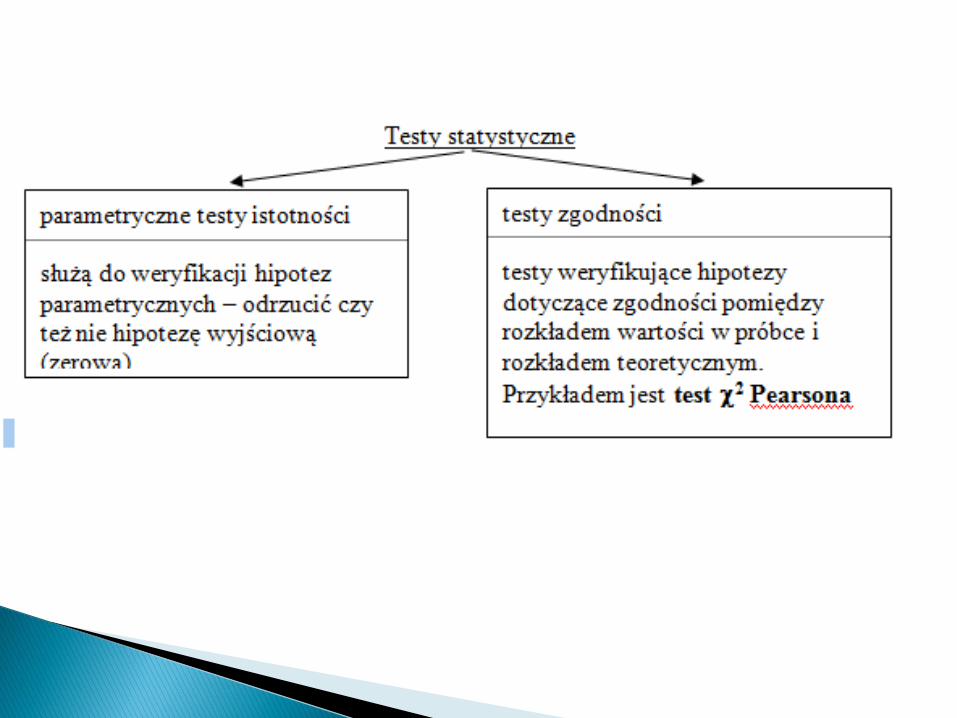
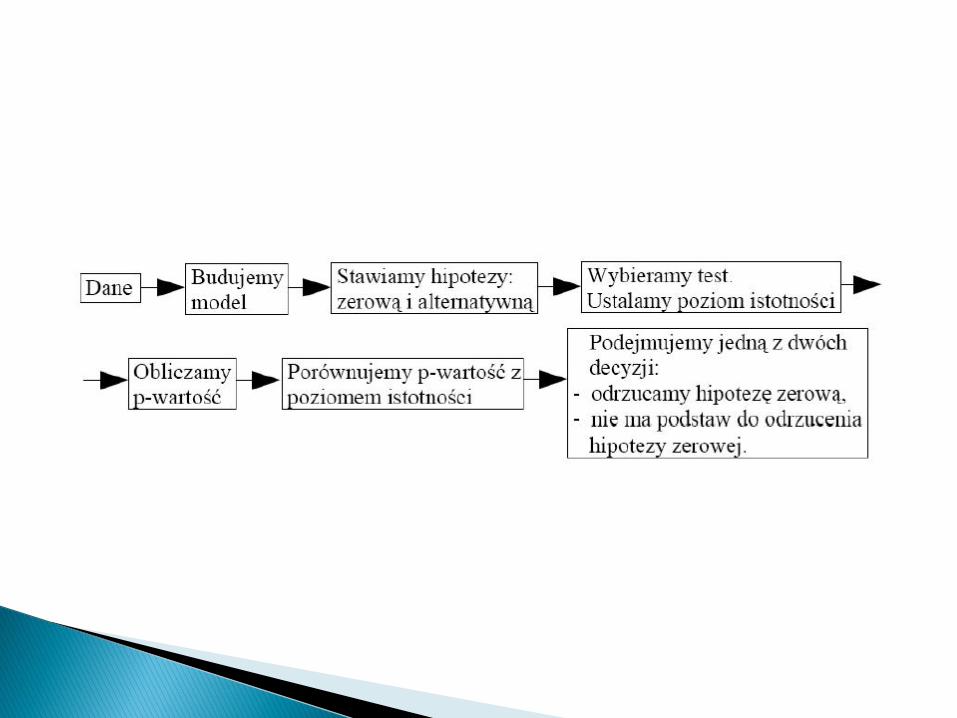
Hipotezy weryfikujemy za pomocą testówstatystycznych.
Test statystyczny: metoda postępowania, którakażdej próbce x1, x2, ...,xn przyporządkowuje zustalonym prawdopodobieństwem decyzjeodrzucenia lub przyjęcia sprawdzanej hipotezy.

Test statystyczny to procedura pozwalająca oszacować prawdopodobieństwo spełnienia
pewnej hipotezy statystycznej w populacji na podstawie danych pochodzących z próby
losowej

Testy parametryczne – weryfikują hipotezy dotyczącewartości parametrów rozkładu badanej populacji(najczęściej średnie, wariancje, odsetki). W większościprzypadków statystyki testowe obliczane są przywykorzystaniu bezpośrednich danych pochodzących zpróby, a ich rozkład zależy od rozkładu analizowanychzmiennych.
Testy nieparametryczne – służą do weryfikacji różnorakichhipotez, lecz nie są one bezpośrednio powiązane zparametrami rozkładu (bywają wyjątki). Dotyczą one raczejsamej postaci rozkładu (kształtu), podobieństwa pomiędzyrozkładami, losowości. Testy te operują na danych„przekształconych” – najczęściej rang, wobec czegorozkład statystyki z próby nie zależy bezpośrednio odrozkładu danych.

wartości badanych zmiennych: średnia wzrost
mężczyzn w wieku 30 lat wynosi 179 cm
różnicy między grupami osobników wzakresie rozpatrywanej cechy: lek A skuteczniej
zwiększa krzepliwość krwi niż lek B
zależności między badanymi cechami: istnieje
silna zależność pomiędzy ilością wypalanych papierosów a
zachorowalnością na nowotwór płuc
porównania rozkładu zmiennych: zmienna masa
ciała ma rozkład normalny

Weryfikacja hipotez statystycznychpolega na zastosowaniu określonegoschematu postępowania zwanegotestem statystycznym, któryrozstrzyga, przy jakich wynikach zpróby sprawdzoną hipotezę należyodrzucić, a przy jakich nie mapodstaw do jej odrzucenia.

parametryczne (służą do weryfikacji hipotezparametrycznych) i
testy nieparametryczne – weryfikacja hipoteznieparametrycznych.
Hipoteza, która podlega sprawdzeniu zwanajest hipotezą zerową (H0). Konkurencyjną dlaniej hipotezą jest hipoteza alternatywna (HA).Hipoteza zerowa - ma najczęściej miejscewówczas, gdy domniemamy, że pomiędzyrozpatrywanymi parametrami lub rozkładamidwóch czy też kilku populacji nie ma różnic.

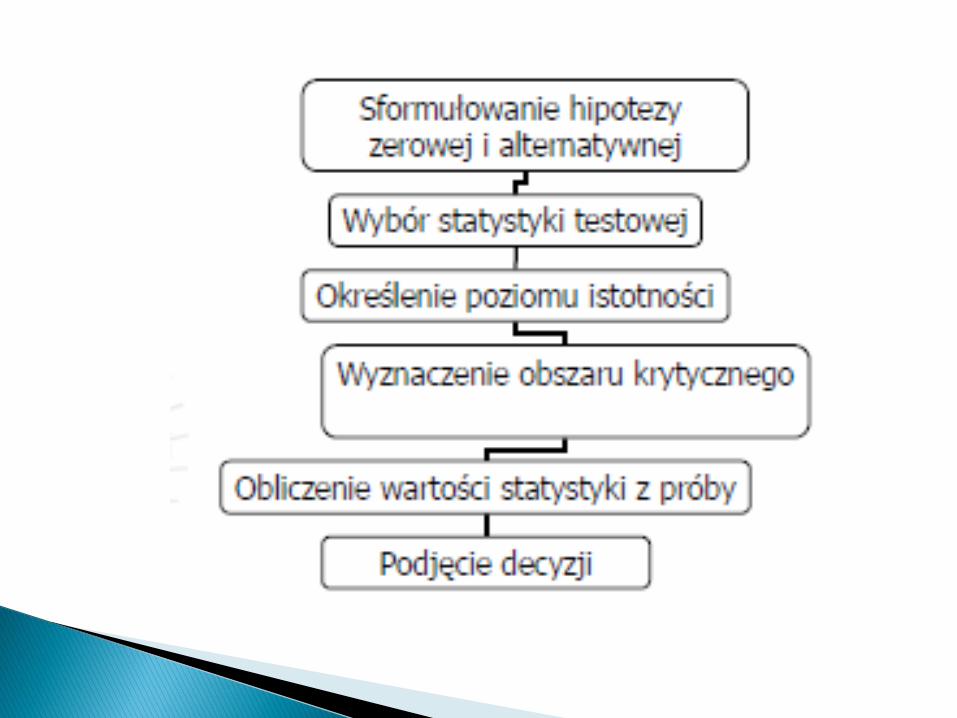
1. Sformułowanie tezy rzeczowej i ustaleniu hipotez H0 i Ha;
2. Wyboru właściwej funkcji testowej (statystyki z próby);
3. Przyjęciu stosownego poziomu istotności ;
4. Odczytaniu wartości krytycznych w tablicach dystrybuanty
właściwego rozkładu i ustaleniu obszaru krytycznego;
5. Odrzuceniu hipotezy zerowej na korzyść hipotezy
alternatywnej, gdy funkcja testowa obliczona z próby
znajduje się w obszarze krytycznym i nie odrzucenie jej,
gdy funkcja testowa jest poza obszarem krytycznym.

Najpierw trzeba dysponowad modelami, które mogąopisywad badaną zbiorowośd. Takim bardzo ogólnymmodelem, który może byd zastosowany do opisuzachowania się cechy w populacji, jest tzw. Zmiennalosowa. Jest to wielkośd, która w wyniku „doświadczenia”przyjmuje różne wartości, przy czym przed doświadczeniemnie jesteśmy w stanie określid z absolutną pewnością, jakawartośd właśnie się pojawi (zrealizuje).
Co najwyżej potrafimy określid zbiór możliwych wartości,jakie mogą pojawid się, oraz odpowiadające imprawdopodobieostwa.

Prawdopodobieostwa te muszą sumowad się do jedności.Funkcja, która opisuje sposób przyporządkowaniaprawdopodobieostw poszczególnym wartościom zmiennejlosowej, nazywa się rozkładem prawdopodobieostwa.
Zmienne losowe dzielą się na skokowe i ciągłe. Rozkład prawdopodobieostwa może byd przedstawianyprzy użyciu różnych funkcji. Najbardziej uniwersalna jestdystrybuanta, która podaje prawdopodobieostwo tego, żezmienna losowa przyjmie wartości mniejszą od zadanejliczby.
Przy zmiennych skokowych korzystamy z funkcji rozkładuprawdopodobieostwa, która przyporządkowujeprawdopodobieostwo konkretnym wartościom.

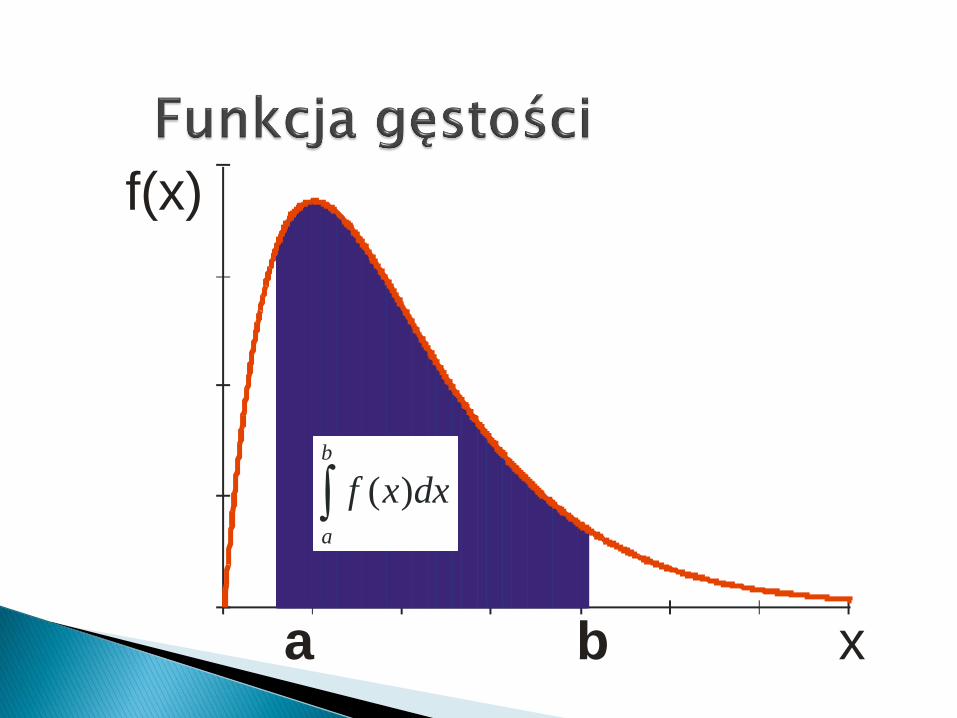
Przy zmiennych losowych ciągłych stosujemy funkcjęgęstości prawdopodobieostwa. Pokazuje ona jakprawdopodobieostwo rozkłada się w przedziale zmiennościdanej zmiennej losowej.
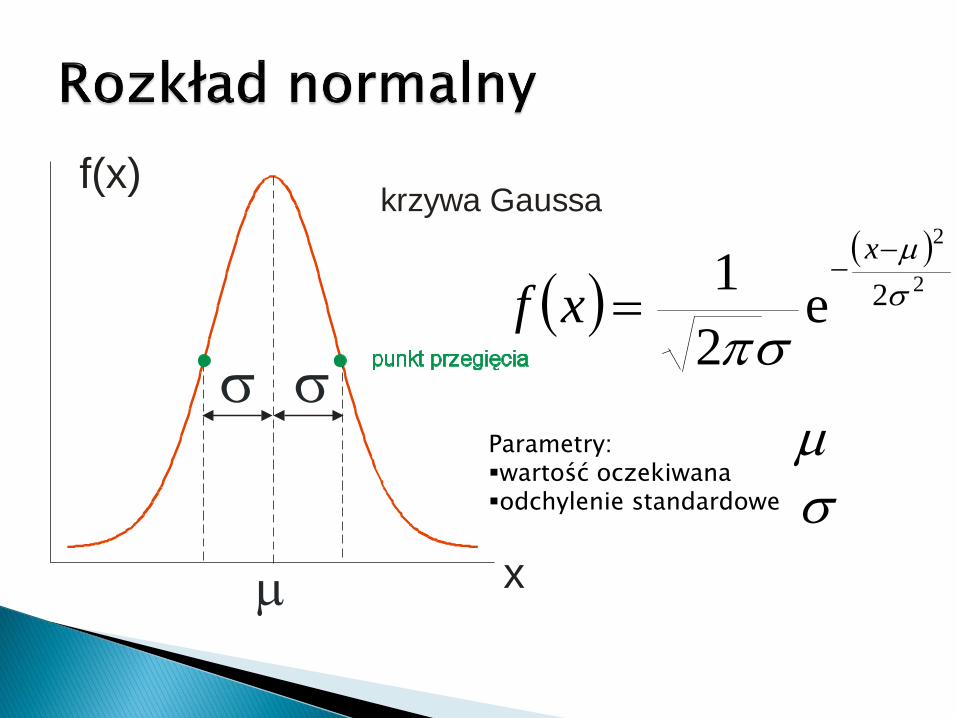
Wśród rozkładów prawdopodobieostwa zmiennej ciągłejnajczęściej mówi się o rozkładzie normalnym. Funkcjagęstości tego rozkładu ma kształt dzwonowaty,symetryczny.
Większośd zjawisk kształtowanych przez naturę czyzakłóceo czysto losowych rozkłada się wg tej funkcji.
Dodatkowo wiele zmiennych losowych po prostychprzekształceniach da się sprowadzid do rozkładunormalnego.
b
a
dxxf )(
a b x
f(x)
x
f(x)krzywa Gaussa
2
2
2e2
1
x
xf
Parametry:wartość oczekiwanaodchylenie standardowe
-4 -2 0 2 4
0.0
0.1
0.2
0.3
0.4
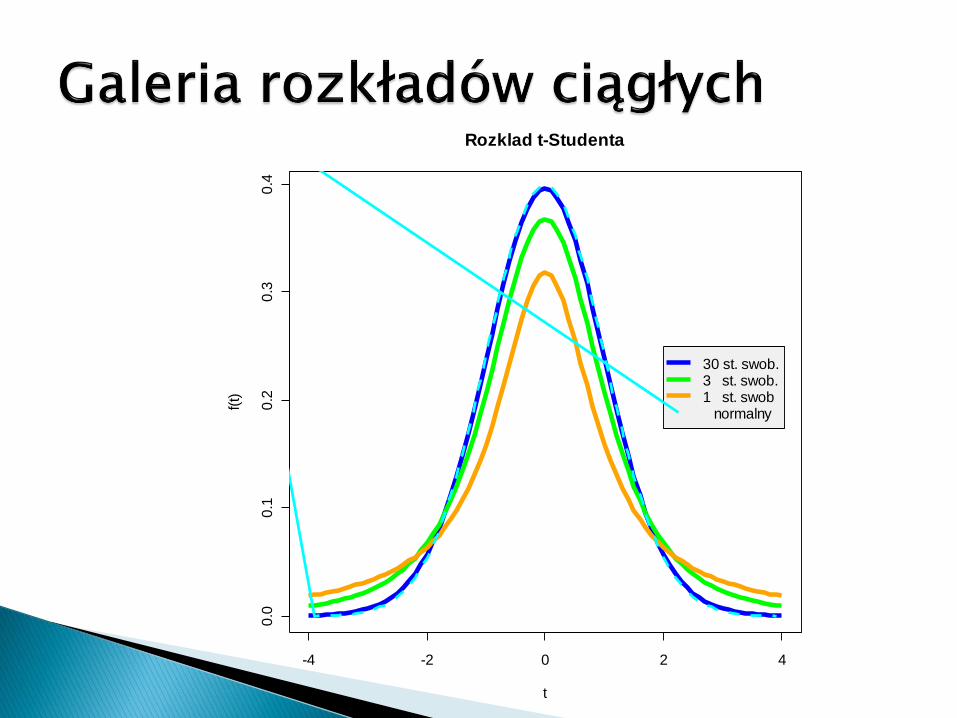
Rozklad t-Studenta
t
f(t)
30 st. swob.3 st. swob.1 st. swob normalny
0 5 10 15 20
0.0
0.1
0.2
0.3
0.4
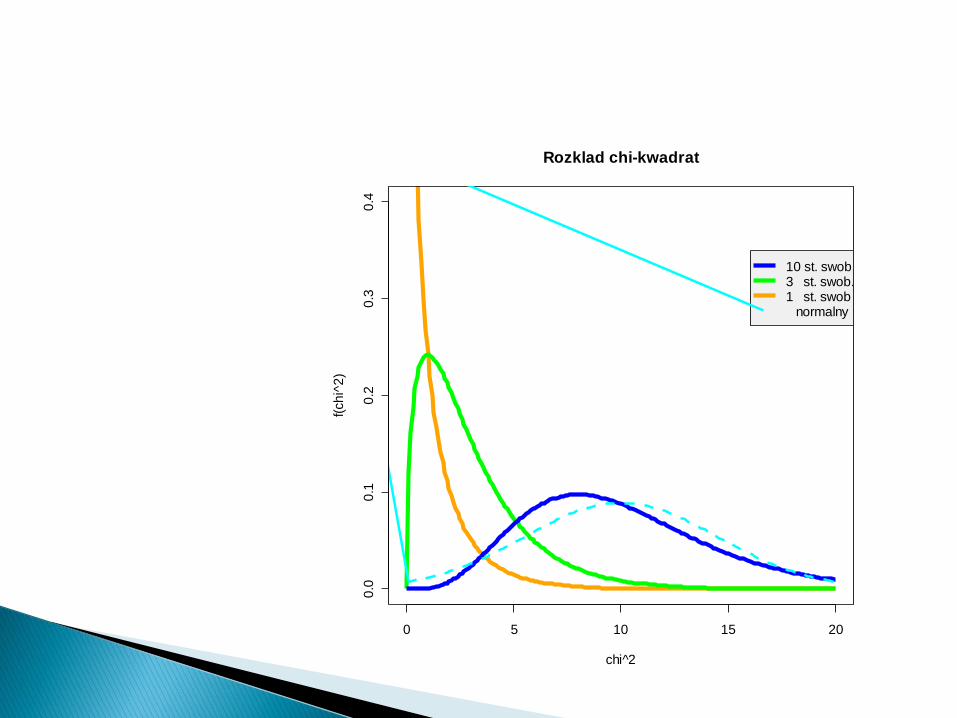
Rozklad chi-kwadrat
chi^2
f(ch
i^2
)
10 st. swob.3 st. swob.1 st. swob normalny
0 5 10 15 20
0.0
00
.05
0.1
00
.15
x
f(x)
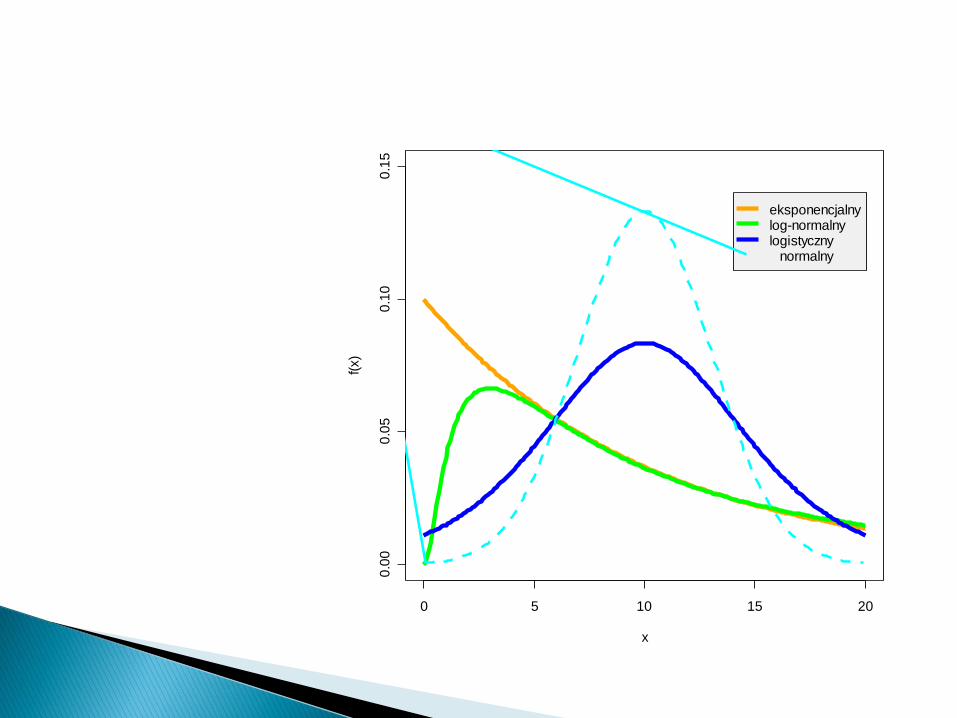
eksponencjalnylog-normalnylogistyczny normalny

Zmienna losowa może byd również opisana przypomocy pewnych charakterystyk liczbowych, z którychwiele jest jednocześnie parametrami funkcjiopisujących rozkład prawdopodobieostwa.
Najczęściej mowa tu o miarach położenia (wartośdprzeciętna, modalna, mediana, kwantyle) oraz miarachzmienności (wariancja, odchylenie standardowe,współczynnik zmienności, odchylenie dwiartkowe).
Kształt rozkładu jest charakteryzowany przez miaryasymetrii, spłaszczenia i koncentracji.

O wiele częściej jest jednak tak, ze nie znamy typu rozkładuani wartości parametrów. I wtedy przychodzi z pomocąwspomniane wcześniej wnioskowanie statystyczne.Wnioskujemy o zbiorowości (populacji) na podstawiepróby.
Poprawnośd wnioskowania zależy przede wszystkim odtego, czy próba dobrze reprezentuje analizowanąpopulację, czy struktura próby jest jak najbardziej zbliżonado struktury populacji.
Reprezentatywnośd próby jest zapewniona, gdy próba jestlosowa.
Jednak losowośd nie zawsze jest oczywista.

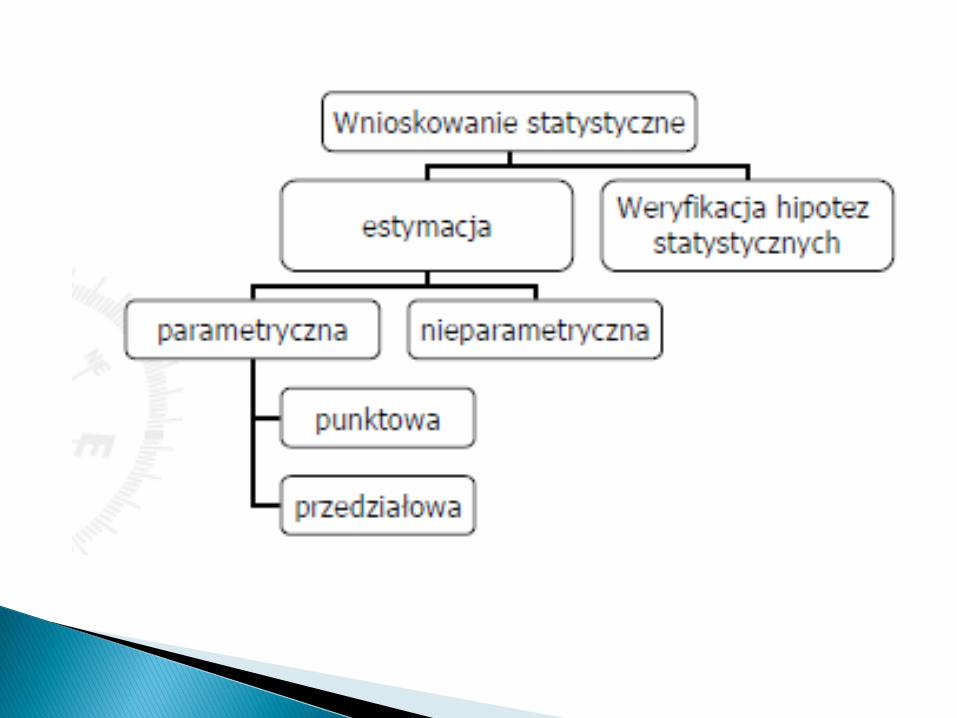
Obejmuje 2 grupy metod:
Estymację oraz
Weryfikację hipotez statystycznych.

Szacowanie, odgadywanie rozkładu lub wartościparametróww populacji na podstawie próby.
Estymacja rozkładu to estymacja nieparametryczna.Najprostszą metodą jest tu obliczanie częstości orazrysowanie histogramu, który pozwala wstępnie określidtyp rozkładu.
Estymacja parametryczna wykorzystuje pewnecharakterystyki liczbowe wyliczane z próby.

Ponieważ próba jest losowa, to i estymator jestzmienną losową posiadającą własny rozkładprawdopodobieostwa.
Wymaga się, aby estymatory były zgodne (czyli wmiaręwzrostu liczebności próby coraz precyzyjniejodgadywały szacowany parametr), nieobciążone(średnio trafiające w nieznany parametr), efektywne(zapewniające mały błąd estymacji) oraz odporne(mało wrażliwe na błędy w danych).

Jeżeli przyjmujemy, ze nieznana wartośd parametru jestrówna ocenie (wartości estymatora) otrzymanej wpróbie, to mamy do czynienia z estymacją punktową.
Można też wykorzystywad informacje o rozkładzieestymatora i konstruowad tzw. Przedziały ufności, czyliprzedziały liczbowe, o których z dużą ufnością(zazwyczaj 95 %) możemy powiedzied, że zawierają wsobie nieznaną, szukaną wartośd parametru.

Pozwala przy pomocy testów statystycznych(TS) zweryfikować hipotezę (sąd) o rozkładzielub parametrze populacji.
TS to procedura pozwalająca odrzucić badanąhipotezę z małym ryzykiem popełnienia błędupolegającego na odrzuceniu hipotezyprawdziwej.
Ryzyko to mierzone jest tzw. poziomemistotności, który przez większość badaczyprzyjmowany jest na poziomie 0,05.

Przy korzystaniu z TS badacz musi sformułowadhipotezę zerową (rozkład jest określonego typu,parametr jest równy konkretnej liczbie, parametry wdwóch populacjach są równe, itp.) oraz hipotezęalternatywą.

Niezmiernie ważnym jest wybór właściwego testustatystycznego i sprawdzenie założeo przez niegowymaganych.
Testy parametryczne wymagają, aby rozkład badanej cechybył określonego typu (zazwyczaj normalny), a testynieparametryczne wolne są od takich założeo.
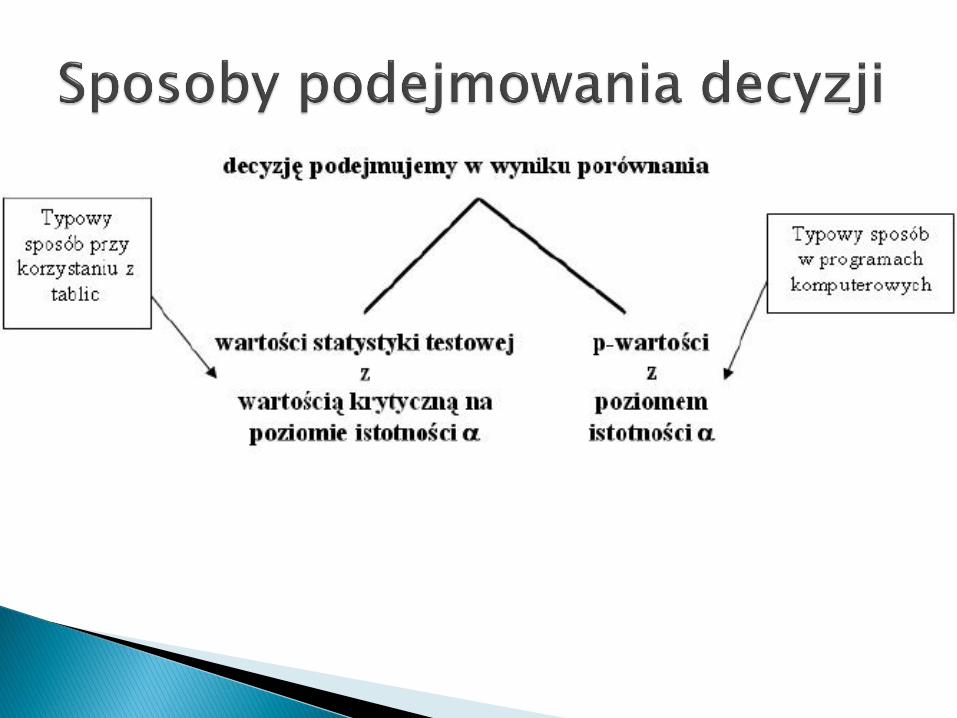
Dawniej oceniało się to poprzez odczytywanie z tablic tzw.Wartości krytycznych i porównywanie z nimi empirycznejwartości statystyki testowej.
Obecnie wszystkie statystyczne pakiety komputerowepodają wartośd p, która jest prawdopodobieostwemotrzymania wyniku bardziej przeczącą hipotezie zerowej niżten rezultat, który właśnie otrzymaliśmy.

Hipotezę zerową należy odrzucid, gdy wartośd p jestmniejsza od przyjętego poziomu istotności.
Jeżeli natomiast wartośd p jest większa od poziomuistotności, nie oznacza to udowodnienia prawdziwościhipotezy zerowej.
Mówimy wtedy po prostu, ze nie ma podstaw doodrzucenia tej hipotezy, a więc potwierdzamy hipotezęalternatywną – i tylko tyle, i aż tyle.

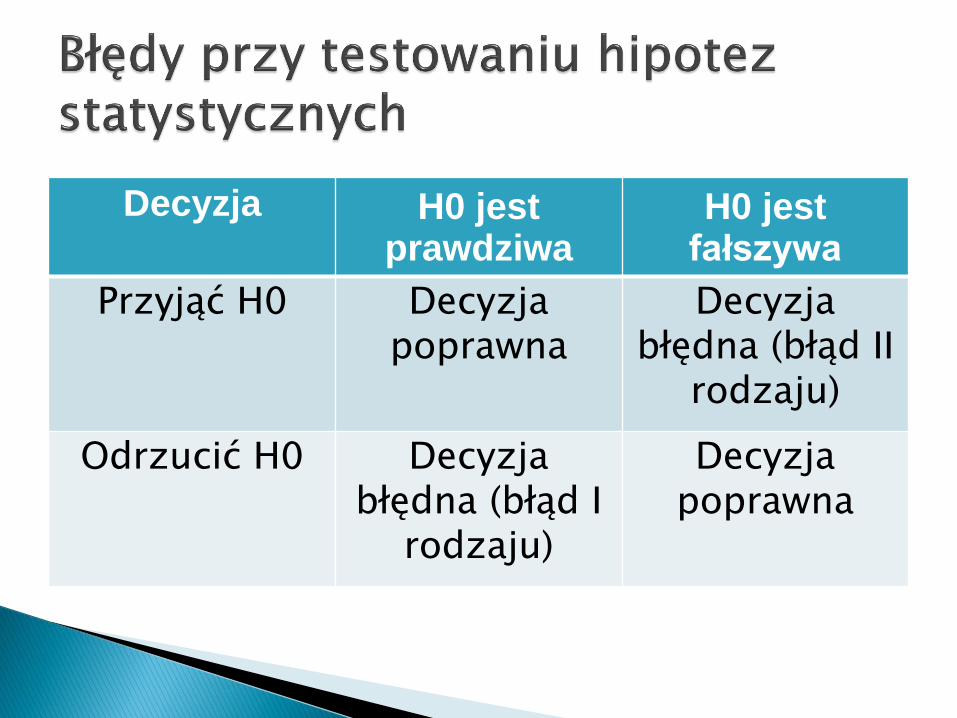
Przy weryfikacji hipotez statystycznych można podjądpoprawną decyzję lub można popełnid jeden z dwóchbłędów:
— błąd I rodzaju polegający na odrzuceniu testowanejhipotezy H0, gdy jest ona prawdziwa;
— błąd II rodzaju polegający na przyjęciu hipotezy H0,gdy jest ona fałszywa (tzn. prawdziwa jest hipotezaalternatywna HA).
Decyzja H0 jest prawdziwa
H0 jest fałszywa
Przyjąć H0 Decyzja poprawna
Decyzjabłędna (błąd II
rodzaju)
Odrzucić H0 Decyzja błędna (błąd I
rodzaju)
Decyzja poprawna

Aby skonstruowad test statystyczny pozwalający weryfikowadhipotezę H0, należy określid następujące elementy:
wybrad statystykę testową stosownie do treści postawionejhipotezy H0;
ustalid dopuszczalne prawdopodobieostwo błędupierwszego rodzaju, tzn. ustalid poziom istotności testu;
określid hipotezę alternatywną;
wyznaczyd zbiór krytyczny tak, aby przy danym poziomieistotności zminimalizowad prawdopodobieostwo błędudrugiego rodzaju.

Testem istotności nazywamy test, którego celem jestjedynie zweryfikowanie jednej wysuniętej hipotezy podkątem jej fałszywości z pominięciem innych hipotez.
Testy istotności uwzględniają jedynieprawdopodobieostwo popełnienia błędu I rodzaju.
Należy pamiętad, że nieodrzucenie weryfikowanejhipotezy H0 nie oznacza jej przyjęcia.

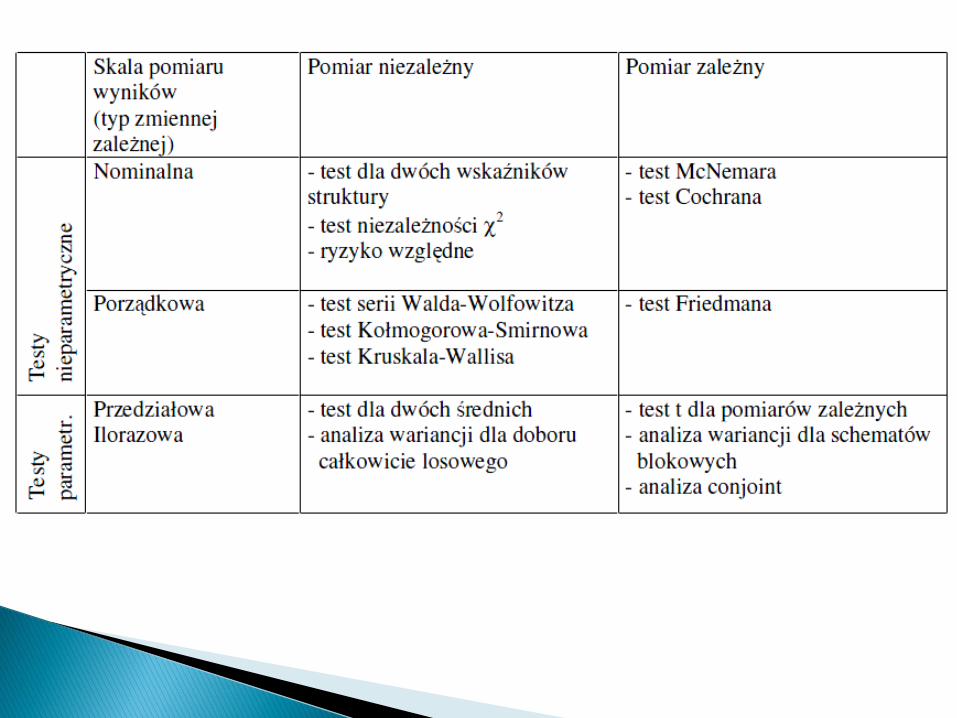
W badaniach medycznych najczęściej spotykanymproblemem statystycznym jest porównanie dwóchpopulacji pod względem jednej cechy lub dwóch cech.Metody takich porównao można podzielid na dwie grupy:
porównywanie pewnych parametrów populacji (średnie,odchylenia standardowe) - wówczas stosuje się najczęściejtesty parametryczne;
porównanie pewnych cech, które nie są parametrami (np.kształt rozkładu) - w takich przypadkach zwykle stosuje siętesty nieparametryczne.

Wprawdzie parametr jest bardziej poszukiwaną iważniejszą charakterystyką, zarówno populacji, jak ipojedynczego człowieka, jednakże jego brak niezmusza do rezygnacji z badao statystycznych.
W medycynie i biologii bardzo często przeprowadza siębadania porównujące wartości dwóch lub kilkuśrednich.

Należy zapamiętać, że w procesie weryfikacji hipotezprzez błąd nie rozumie się typowego błęduobliczeniowego, lecz tzw. błąd wnioskowania
Wyróżnia się dwa podstawowe rodzaje błędów w testachstatystycznych
– Błąd I rodzaju (poziom istotności α) – polega na tym, żeodrzucamy badaną hipotezę H0 podczas gdy jest onaprawdziwa
– Błąd II rodzaju (β) – polega na tym, że przyjmujemy badanąhipotezę H0 podczas gdy jest ona fałszywa
Pożądane jest aby oba te błędy były jak najmniejsze,jednakże w praktyce jest tak, że obniżenie jednego z nichpowoduje wzrost drugiego
Jedynym wyjściem jest minimalizowanie błędu II rodzaju,przy ustalonej wielkości błędu I rodzaju (poziomuistotności).

Przez pojęcie mocy testu rozumie sięprawdopodobieństwo odrzucenia hipotezy zerowejkiedy jest ona fałszywa.
Innymi słowy moc testu = 1 – β (1-prawdop.błędu IIrodzaju) .
Test statystyczny może być mocny gdy w większościprzypadków jest w stanie odrzucić fałszywą H0.
Test statystyczny może być słaby gdy istnieje dużeprawdopodobieństwo przyjęcia H0 pomimo jejfałszywości.
W badaniach klinicznych, badaniach nad nowymilekami, etc. minimalna moc testu powinna wynosić0,8.
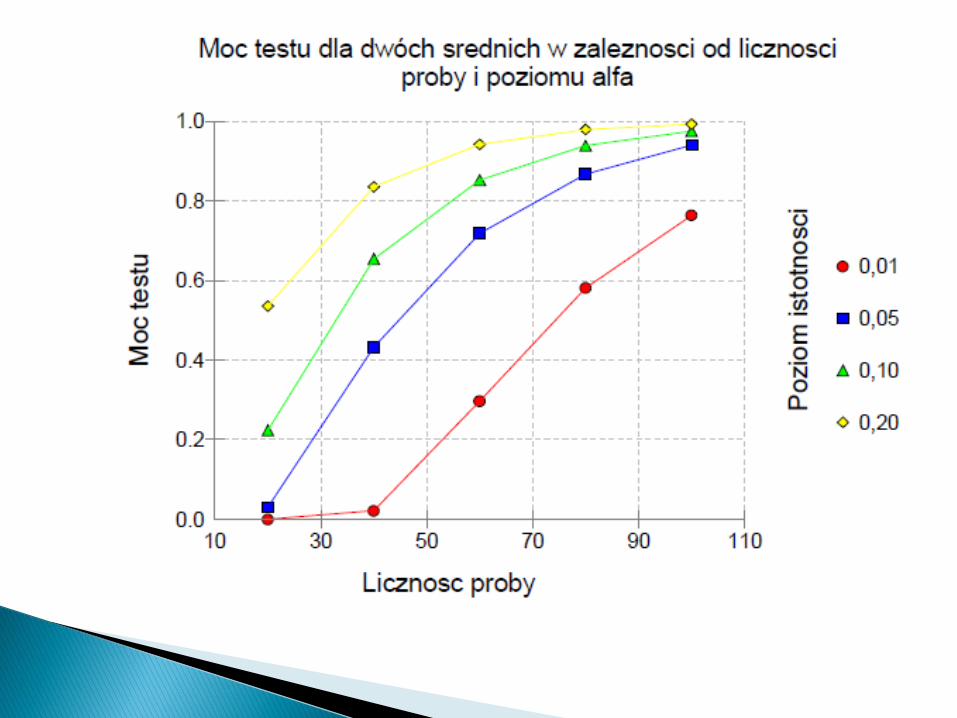

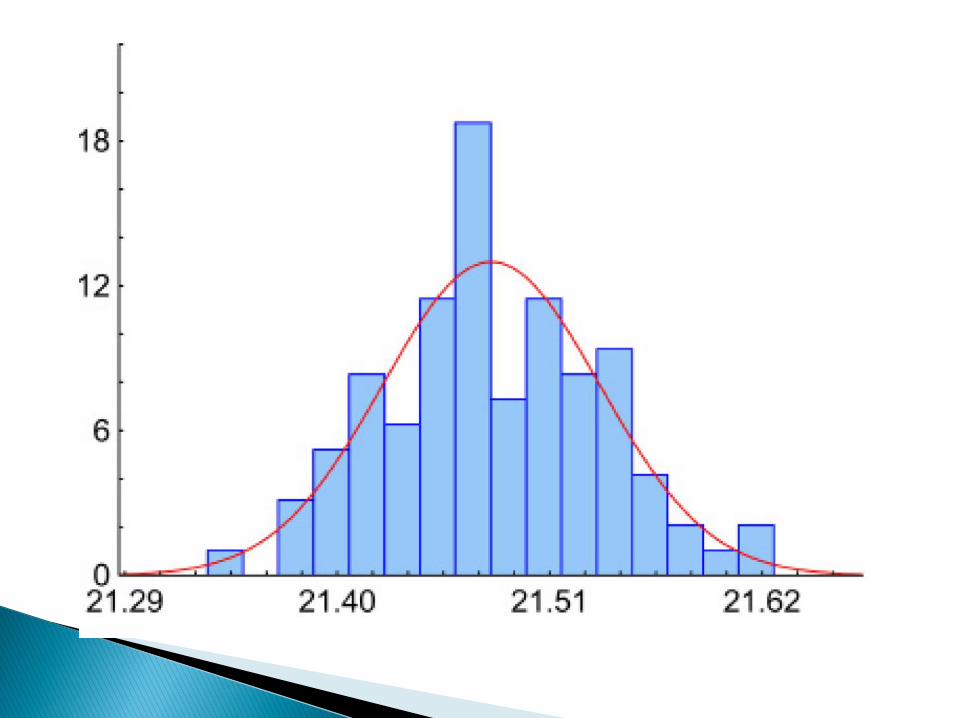
Testy normalności rozkładu są specyficznymi testamibadającymi zgodność danego rozkładu z rozkłademnormalnym
Rozkład normalny jest najczęściej wykorzystywanymrozkładem w statystyce, gdyż wiele cech ma właśnierozkład zbliżony do niego
Ma specyficzne własności (m.in.):– Jest symetryczny (obserwacje rozkładają się równomiernie
wokół średniej: średnia=mediana=dominanta)– 68,27 % wyników jest w przedziale (m -σ, m + σ)– 95,45 % wyników jest w przedziale (m -2σ, m +2σ)– 99,73 % wyników jest w przedziale (m -3σ, m + 3σ)Założenie o normalności rozkładu wymagane jest często w
przypadku testów parametrycznych
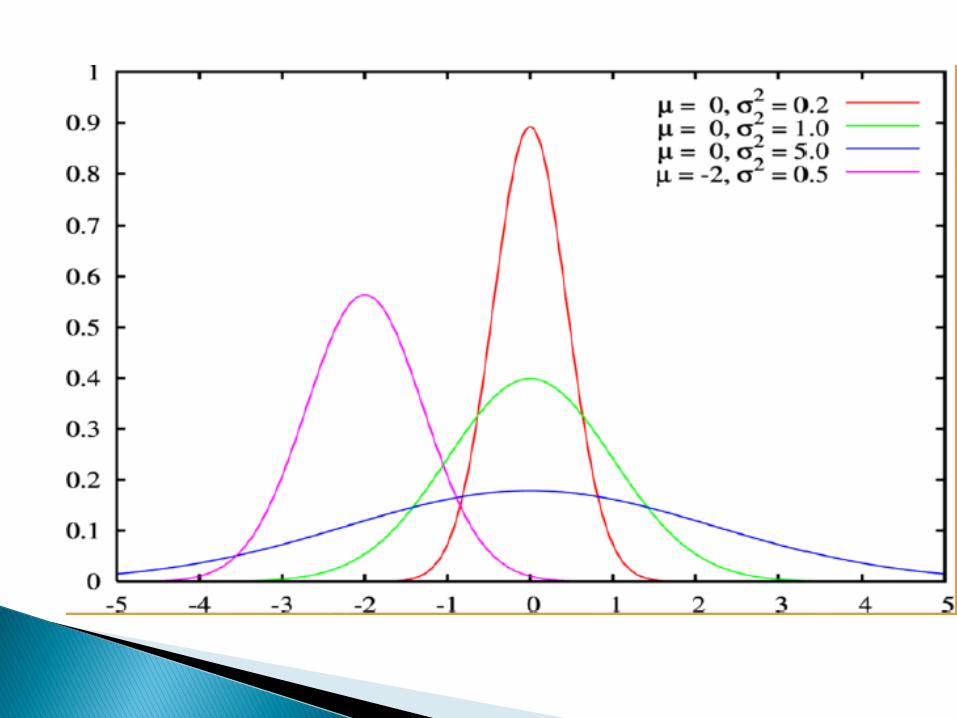

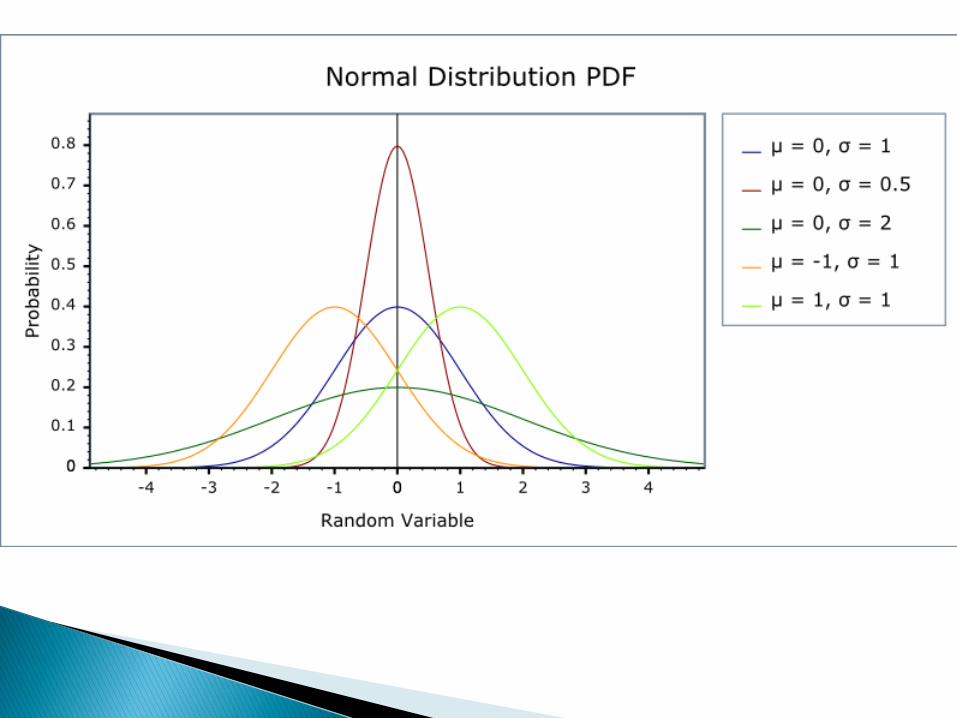
Wśród licznych rozkładów ciągłychnajwiększe znaczenie w statystyce posiadarozkład normalny. W przyrodzie bowiemistnieje silna tendencja rozkładania zbiorówwokół średnich w pewien charakterystycznysposób, zwany rozkładem normalnym(Gaussa).
Kształt krzywej rozkładu normalnego (krzywao kształcie dzwonu, biegnąca donieskończoności w obu kierunkach) zależy od2 parametrów: oraz µ.

Parametr µ to wartość średnia populacji,względem której rozkład jest symetryczny.
Parametr to odchylenie standardowestanowiące miarę rozrzutu, zmienność wokółśredniej µ. Najczęściej nie znamy prawdziwejwartości µ, lecz oceniamy (szacujemy ją) napodstawie średniej obliczonej z próby
Podobnie jeśli nie znamy , estymujemyodchylenie populacji na podstawie odchylenia wpróbie (s).
W rozkładzie normalnym: średnia, mediana imoda są sobie równe.
x

O zmiennej losowej X mówimy, że ma rozkład normalny, jeżeli jej gęstość prawdopodobieństwa określa równanie:
2)(
2
1
2
1)(
ix
i exf
f(xi)- gęstość=3.14159 (stosunek obwodu koła do średnicye=2,71828xi - wartości z przedziału (- ,+)

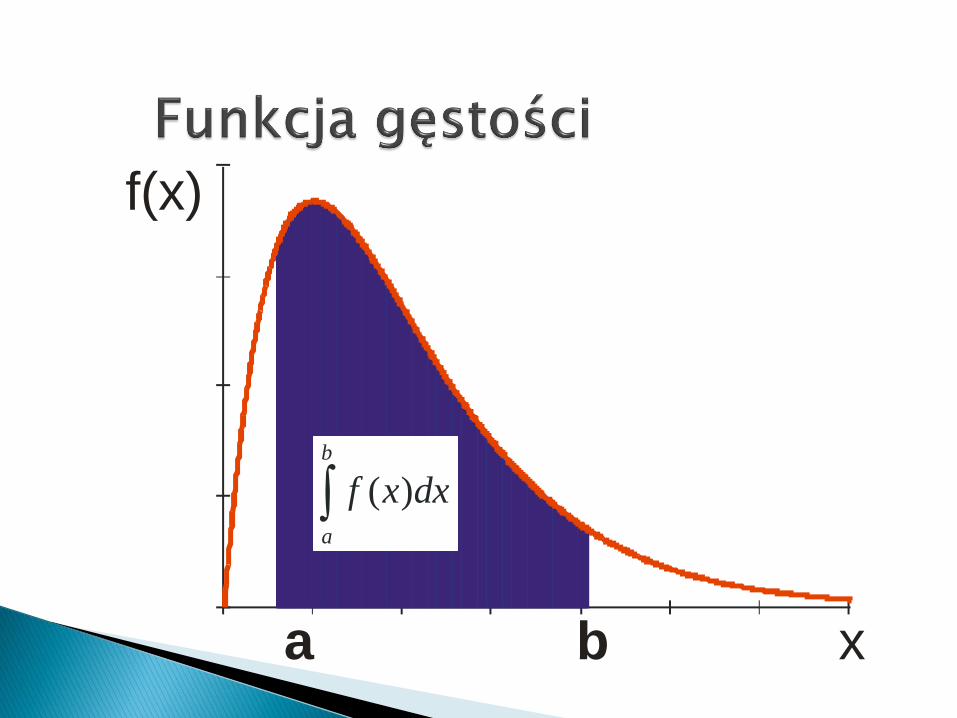
Równanie to pozwala m.in. określić poleobszaru pod krzywą pomiędzy dwomapunktami (x1 i x2) na osi poziomej, jeżeliznane są: średnia i odchylenie standardowe.Pole to równa się prawdopodobieństwu (P)tego, że zmienna losowa X posiadająca takirozkład ciągły przyjmie wartość określonegoprzedziału w granicach wyznaczonych przezte wartości (x1,x2).
Powierzchnia ta równa się:
2
1
2
22
)(
212
1)(
x
x
dxx
exXxP
b
a
dxxf )(
a b x
f(x)

Można dokonać transformacji dowolnegorozkładu normalnego do standaryzowanegorozkładu normalnego ze średnią równą 0 iodchyleniem standardowym 1.
Standaryzacji dokonujemy odejmując
od wartości xi i dzieląc różnicę przez (s).
Jeżeli zmienna X ma rozkład normalny ześrednią µ i wariancją 2, wówczas zmienna
ma również rozkład normalny ze średnią 0 iodchyleniem standardowym 1.
)(x
X
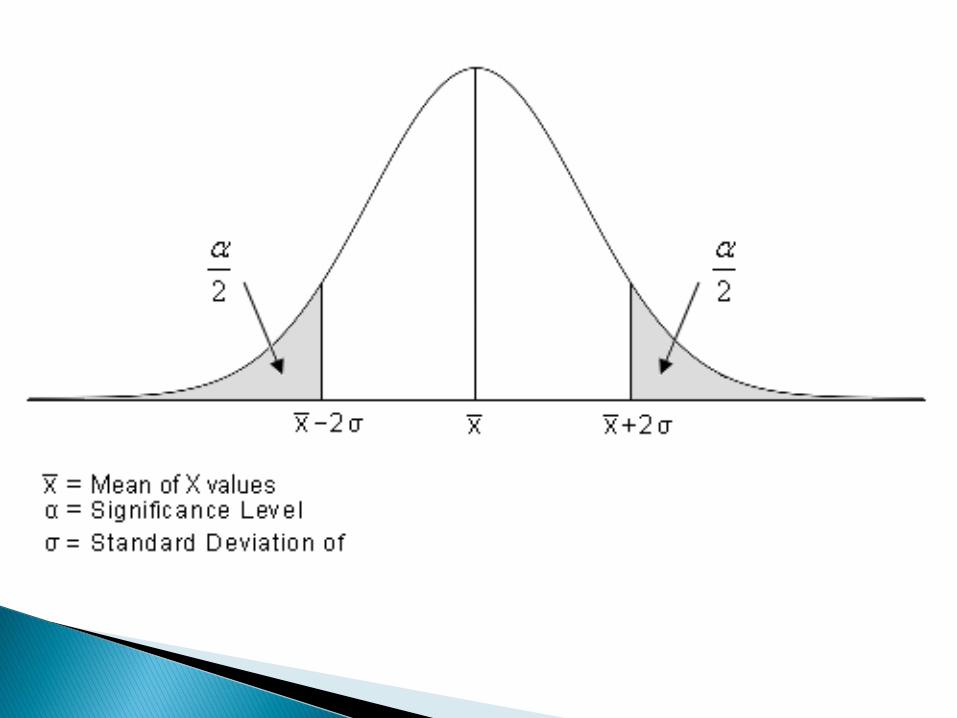

Prawdopodobieństwo pod krzywą normalnąodpowiadające całkowitej liczbie obserwacji(N) jest równe jedności. Przyjmując krzywąstandaryzowaną, gdzie N=100, możemy wokreślaniu powierzchni pod krzywą operowaćprocentami.

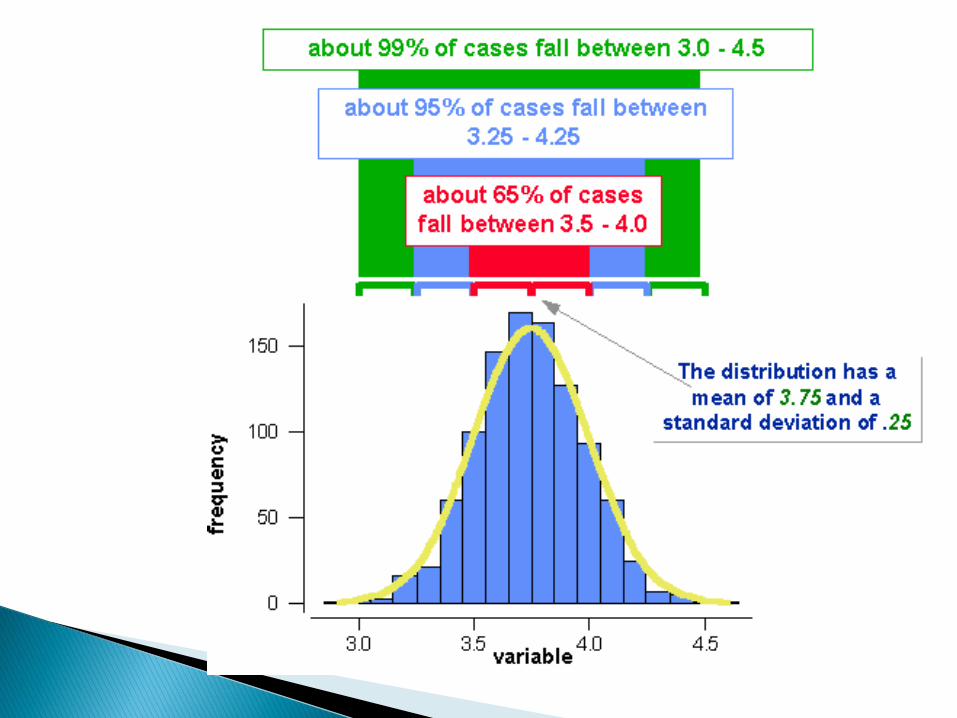
ok. 68% wszystkich wartości zmiennej odbiega od średniej oczekiwanej nie bardziej niż o jedno odchylenie
standardowe, ok. 95 % wszystkich wartości nie bardziej niż o dwa
odchylenia, a w zasadzie wszystkie wartości (99.8%) zmiennej nie odbiegają od oczekiwanej wartości średniej bardziej niż o
trzy odchylenia standardowe. Tak więc w przedziale (µ-,µ) i (µ,µ+ ) znajduje się ~34%
pomiarów (razem ~68%). Na powierzchnię środkowąkrzywej (µ ) przypada 2/3 całej powierzchni, tj. 68%(p=0,68).
W przedziale (µ-2,µ) i (µ,µ+ 2) powierzchnia pod krzywąstanowi 47,72% (razem ~95,5%).
Poza dwoma odchyleniami od średniej pozostaje po~2,25% pola pod krzywą normalną.

Kiedy cecha X ma rozkład normalny,wspomniane 95,5% odpowiadaprawdopodobieństwu, że 95,5% wynikówlosowo wybranych zawiera się w przedziale okońcach µ 2.
W granicach µ 3 powinno się znaleźć99,74% obserwacji.

Wynik z przedziału i
Oraz i nazywamy wmedycynie wynikiem kliniczno-diagnostycznie ostrzegawczym.
Wynik pomiędzy i jest diagnostyczniewątpliwy. Wynik powyżej wartości lubponiżej wskazuje na stan patologiczny.
sx 1 sx 2
sx 1 sx 2
sx 2 sx 3
sx 3
sx 3

Zmiana wartości średniej powodujeprzesunięcie krzywej rozkładu w lewo lub wprawo, podczas gdy zmiana odchylenia std.Zmienia wysokość lub szerokość krzywej, awięc wpływa na kształt rozkładu.
Parametrami kształtu rozkładu są: skośność ikurtoza

Charakteryzuje odchylenie rozkładu od symetrii.
Jeśli wartość standaryzowana skośności po standaryzacjijest wyraźnie różna od zera, wówczas dany rozkład jestasymetryczny, odstaje od charakterystyki rozkładunormalnego, który jest doskonale symetryczny.
Dla rozkładu lewoskośnego: 1 < 0
Dla rozkładu prawoskośnego: 1 > 0
N
xK
i
3
3
)()(
3
31
K

Dla rozkładu normalnego: średnia, mediana i moda są identyczne
Dla rozkładu lewoskośnego: średnia < mediana < moda
Dla rozkładu prawoskośnego: średnia > mediana > moda
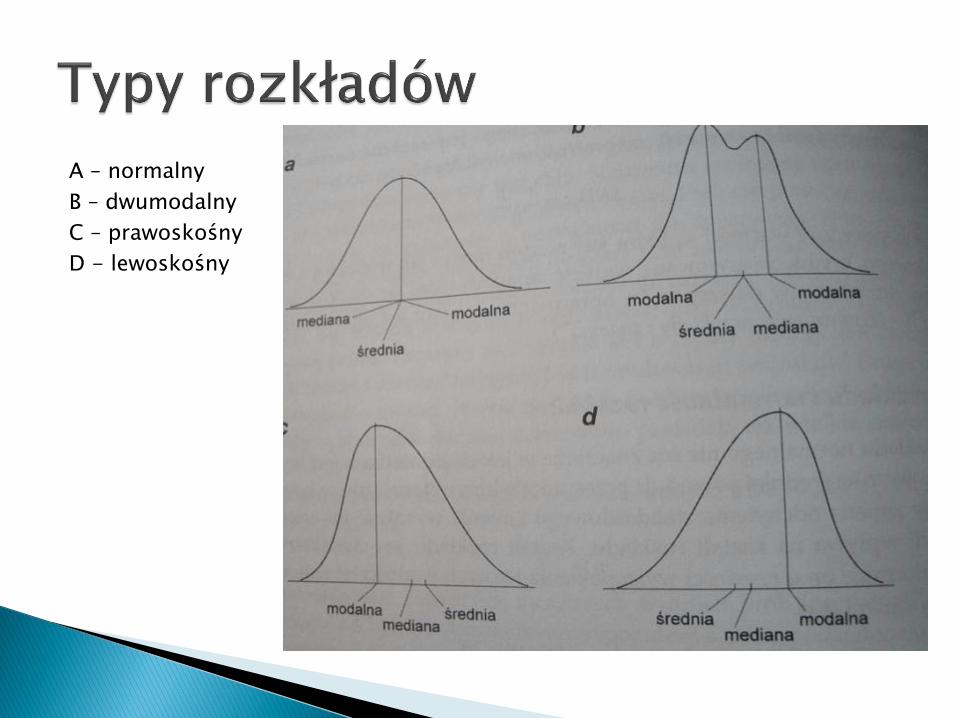
A – normalny
B – dwumodalny
C – prawoskośny
D - lewoskośny

Wyliczana jest z wzoru:
N
xK
i
4
4
)()(
34
42
K
Po standaryzacji: Kurtoza mierzy spiczastość rozkładu.

a) Rozkład mezokurtyczny (normalny)
b) Złożony rozkład 2 populacji, dla których średnie są w przybliżeniu równe, ale wariancje jednej są sporo większe od drugiej.
c) Rozkład leptokurtyczny (wysmukły)
d) Rozkład platykurtyczny (spłaszczony) – szczegolny przypadek dwumodalnego.
Jeżeli kurtoza jestwyraźnie < 0, wówczasrozkład jest albo bardziejspłaszczony odnormalnego albo bardziejwysmukły.Dla rozkładu normalnegokurtoza wynosi dokładnie0.Wartości 2> 0charakteryzują rozkładleptokurtyczny(wysmukły).Wartości 2< 0charakteryzują rozkładplatykurtyczny(spłaszczony).

Najczęściej świadczy o występowaniu dwóch niezależnych subpopulacji normalnych o zbliżonych średnich i różnych wariancjach.

Jest szczególnym przypadkiem rozkładu dwumodalnego, czyli takiego, który posiada 2 maksima.
Taki objaw wskazuje, że próba nie jest jednorodna i jej obserwacje pochodzą z 2 różnych populacji, z których każda ma rozkład normalny.
Takie próby powinno się rozdzielić i osobno analizować każdą.

Wnioski statystyczne, u podstawy których leżypewność wynosząca co najmniej 95% (p<0,05),nazywamy istotnymi.
Kiedy podstawą odrzucenia hipotezy jestprawdopodobieństwo błędu mniejsze niż 0,1%(np. przy =0,001), to wnioski takie określamyjako wysoce (bardzo) istotne (p<0,001).
Kiedy otrzymane w wyniku doświadczeniawartości zmiennej X mieszczą się w przedzialeustalonym na poziomie istotności , wówczashipotezę zerową odrzucamy. Z tego powoduprzedział ten nazywa się przedziałemkrytycznym.

Gdy mamy standardowy rozkład normalnyN(0,1) to każda wartość cechy xi oddalonajest od średniej 0 o określoną liczbę odchyleństandardowych (z).
Prawdopodobieństwo (skumulowaneczęstości – powierzchnia) dla wartości zmniejszych niż z=-1.96 wynosi 0,025 (2,5%).
Dla wartości mniejszych niż z=-2.58 toprawdopodobieństwo wynosi 0,005,
a prawdopodobieństwu 0,0005 odpowiadawartość z = -3.29.

Pobierając losowo z rozkładu normalnego pojedynczy element,mamy szansę 2.5% ze pierwszym wylosowanym elementembędzie liczba mniejsza od wartości średniej o więcej niż 1.96odchyleń standardowych oraz szansę 2.5% ze będzie to wartośćwiększa od wartości średniej o więcej niż 1.96 odchyleństandardowych.
Kiedy dla pojedynczego pomiaru a wartość |z|>1.96, czyli z<-1.96 lub z>1.96 to hipotezę H0, iż nasz pojedynczy pomiarpobrano losowo z rozkładu normalnego odrzucamy (p<0,05,wnioskowanie ze słusznością większą od 95%).
Kiedy dla pojedynczego pomiaru a wartość |z|>2.58 to hipotezęH0 odrzucamy z jeszcze większą pewnością, tzn. na poziomieistotności =0,01 (p<0,01, wnioskowanie ze słusznościąwiększą od 99%).
Kiedy dla pojedynczego pomiaru a wartość |z|>3.29 to hipotezęH0 odrzucamy z jeszcze większą pewnością, tzn. na poziomieistotności =0,001 (p<0,001, wnioskowanie ze słusznościąwiększą od 99,9%).

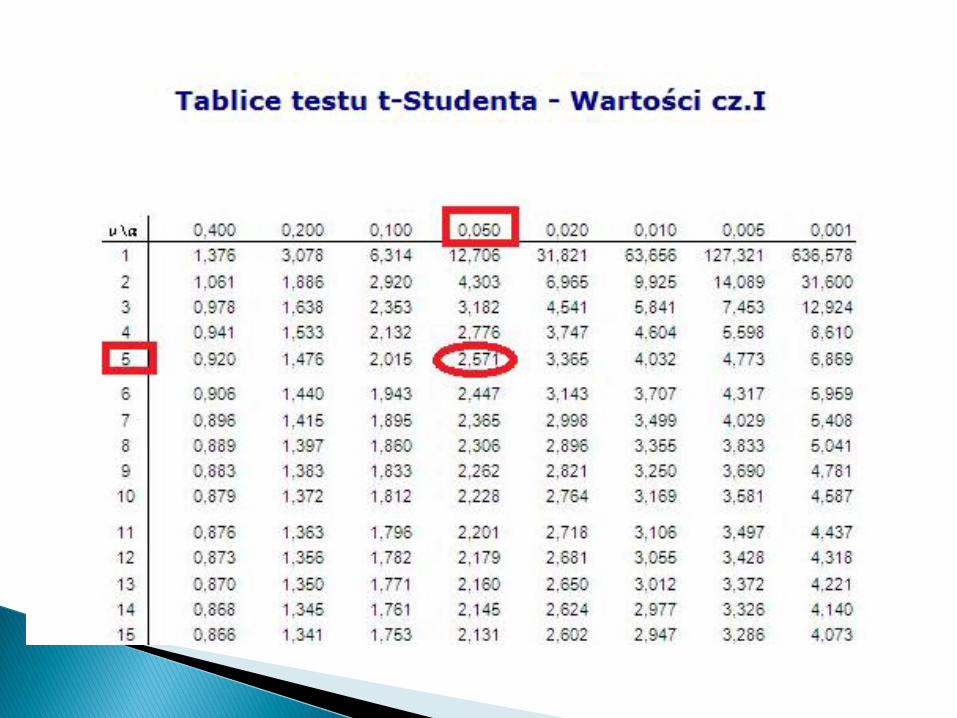
W wybranej losowo grupie studentów oznaczono zawartość hemoglobiny Hbwe krwi (g/100ml), otrzymując następujące dane: 14.0, 15.4, 13.7, 15.8,15.2, 15.7. Zweryfikować hipotezę, że średnia zawartość Hb w populacjimającej rozkład normalny, o nieznanej wariancji równa się 15g/100ml, doalternatywnej.
Rozwiązanie: inaczej – testujemy, czy losową próbę o liczności n=6, pobranoz populacji o rozkładzie normalnym ze średnią µ=15g/100 ml. Ponieważ nieznamy wariancji z populacji 2 i mamy małą próbę a więc do testowaniapowyższej hipotezy użyć możemy tylko rozkładu t. Wobec tego:
H0:µ=15
Ha:µ15
Obliczone wartości średniej, odchylenia standardowego, i wariancji wynosząodpowiednio Średnia µ=14.97, wariancja S2 = 0,804, odchyleniestandardowe s=0,36.
Wyliczamy wartość doświadczalną td:
Dla testu dwustronnego przy =0,05 odczytana wartość tabelaryczna tt/2(n-1)=t(0,025;5) = 2,57. Ponieważ td=0,08 < tt< 2.57, nie ma podstawdo odrzucenia hipotezy zerowej, że µ = 15g/100 ml (p>0,05).
08,036.0
97.1415
dt

rozkład populacji nie różni się istotnie odrozkładu normalnego,
wartość oczekiwana (średnia) badanej cechynie różni się istotnie od 20,
wartości oczekiwane (średnie) badanej cechyw dwóch grupach nie różnią się istotnie,
nie ma istotnej zależności pomiędzy dwomabadanymi cechami.

rozkład populacji różni się istotnie odrozkładu normalnego,
Wartość oczekiwana (średnia) badanej cechyjest istotnie większa od 20,
wartości oczekiwane (średnie) badanej cechyw dwóch grupach różnią się istotnie,
istnieje istotna zależność pomiędzy dwomabadanymi cechami.

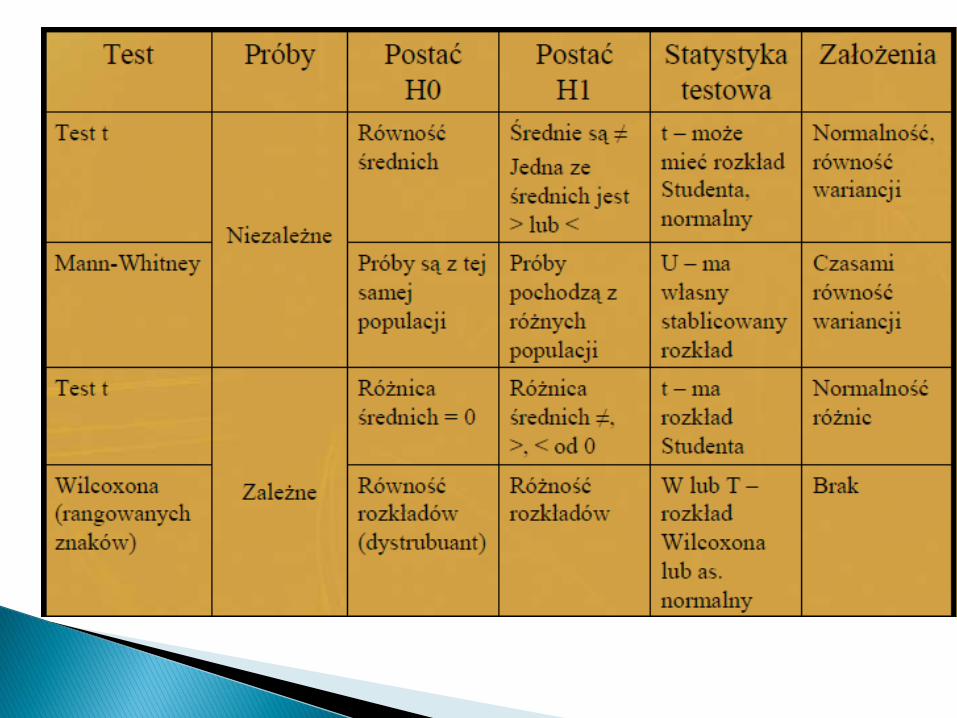
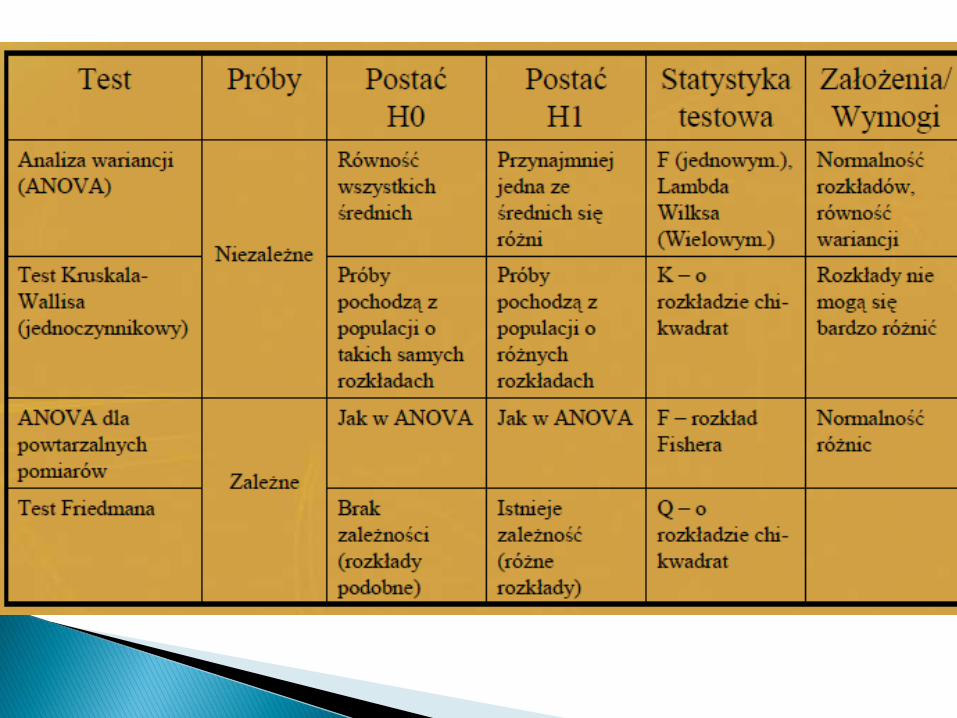
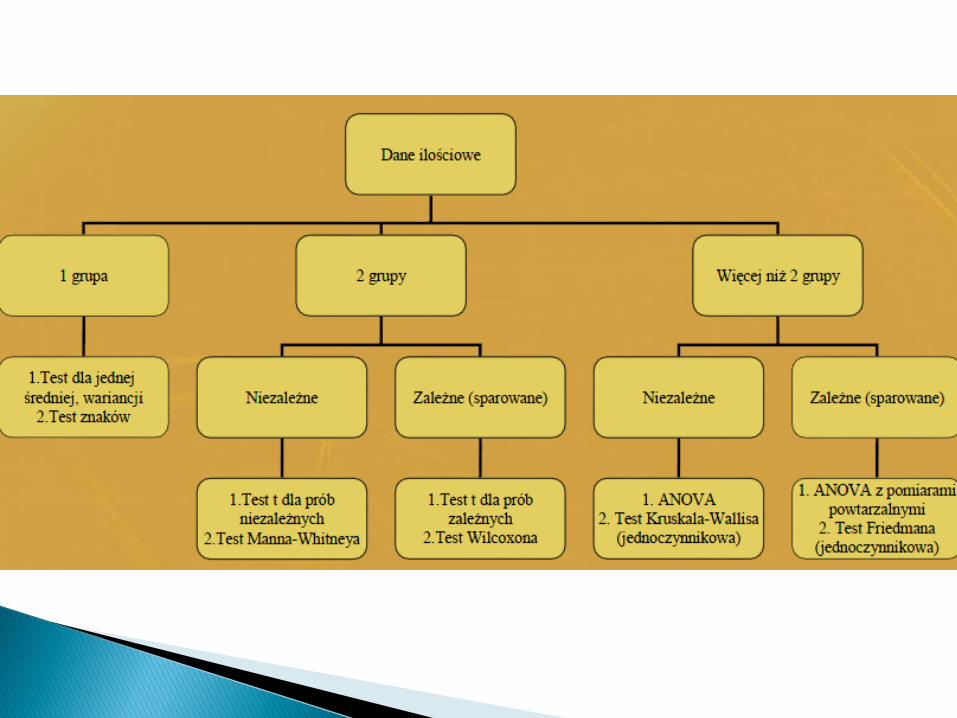
1. Próby niezależne - obserwacje wposzczególnych grupach dokonywane są naróżnych obiektach.
2. Próby zależne - obserwacje dokonywane sądwukrotnie na tych samych obiektach.

1. Porównanie poziomów parametrów medycznych dla dwóch grupsprowadza się z reguły do porównania przeciętnych poziomówzmiennych lub też porównania rozkładów analizowanego parametru
2. Należy ustalić czy próby są niezależne czy też zależne3. Czy znane są rozkłady cech w populacji, w próbkach ?4. Jeżeli spełnione są wszystkie założenia (głównie normalność,
ewentualnie równość wariancji, liczebność prób) należy wykonać testparametryczny:
– Test t dla prób niezależnych– Test t dla prób zależnych (założenie: rozkład różnic ma być zbliżony do
normalnego)5. W przypadku naruszenia jakiegokolwiek z założeń (np. jedna z grup
ma rozkład cechy istotnie różny od normalnego lub jest bardzo mała)wówczas wykonuje się test nieparametryczny:
– Dla prób niezależnych: test Manna-Whitneya-Wilcoxona– Dla prób zależnych: test kolejności par Wilcoxona (rangowanych znaków)Alternatywa: normalizacja danych, wykonywanie testów parametrycznych
na danych rangowanych.

Liczba grup do porównania nie powinna być za duża (teoretyczniekilkanaście, praktycznie najlepiej kilka).Jeżeli porównanie ma być reprezentatywne to próby powinny być
raczej liczne oraz mieć zbliżone liczności (nie powinnawystępować sytuacja, w której np. dwie grupy liczą po 40obserwacji, a trzecie 8).
Większość medycznych porównań wielu grup dotyczy poziomówanalizowanych parametrów medycznych (głównie średnie).
W przypadku zmiennych jakościowych porównuje się po prostuodsetki w kilku grupach (k>2).
Najczęściej mamy też do czynienia z analizą jednoczynnikową(jeden czynnik grupujący/efekt/zmienna zależna).
W przypadku wielu czynników można badać interakcje pomiędzyczynnikami (jeżeli jest to uzasadnione).

Wcześniejsze procedury testowe wykrywają tylko czyistnieje różnica w poziomach/rozkładach przynajmniejjednej z grup, tj. czy przynajmniej jedna z grup się różniod pozostałych.
Nie podają ile grup się różni i które z nich. W celu wykrycia różnic wykonuje się tzw. testy porównań
wielokrotnych (testy post-hoc/testy po fakcie). Testy post-hoc pokazują, które z grup mogą różnić się
istotnie pomiędzy sobą. Ich konstrukcja jest podobna do testu t dla dwóch grup,
jednakże co ważne biorą one pod uwagę poprawkę nailość wykonywanych porównań na tych samych danych(„korekcja” poziomu p) .
Nieuzasadnione jest stosowanie testu t lub Manna-Whitneya dla porównań wielokrotnych (są wyjątki).

p–wartość jest najmniejszym poziomemistotności testu, przy którym odrzucamyhipotezę zerową, zatem
jeżeli p–wartość , to odrzucamy H0,
jeżeli p–wartość>, to nie ma podstaw doodrzucenia H0.

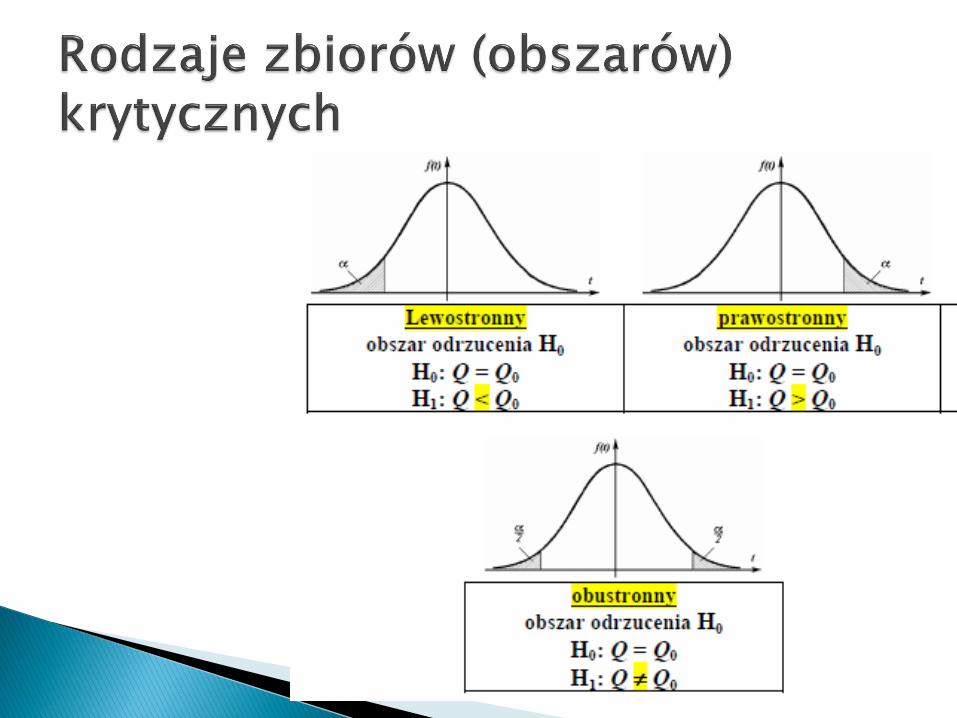
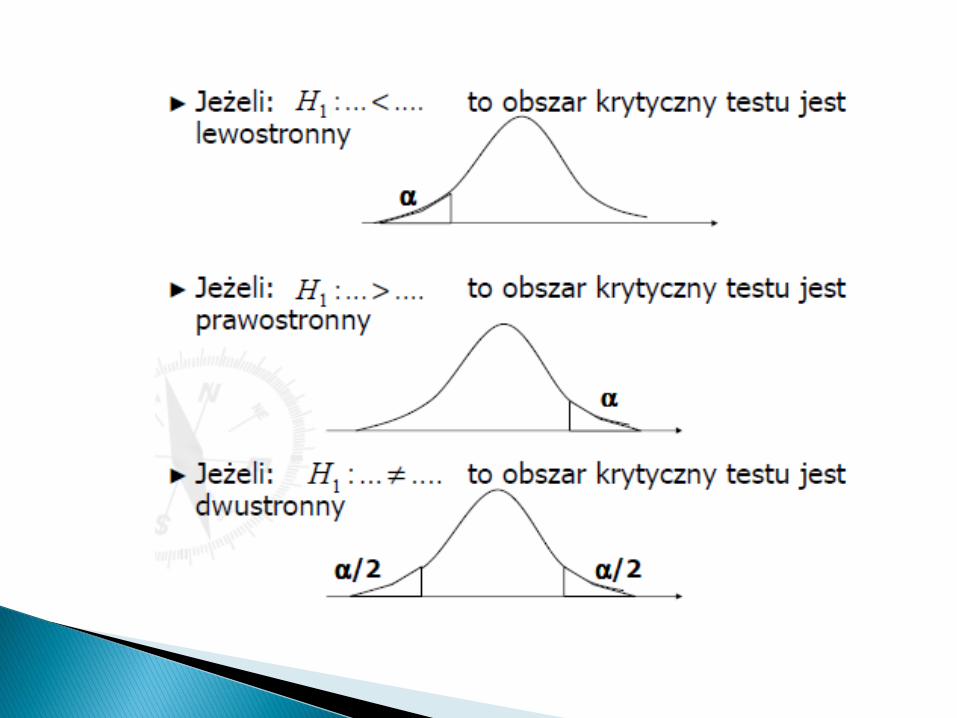
prawostronny obszar krytyczny:
P0(T T(x)),
lewostronny obszar krytyczny:
P0(T T(x)),
dwustronny obszar krytyczny:
2 min{ P0(T T(x)), P0(T T(x)) }.

Wynikiem testowania hipotez statystycznychjest jedna z dwóch decyzji:
1. "odrzucamy hipotezę zerową" tzn. Stwierdzamywystępowanie istotnych statystycznie różnic(zależności), na poziomie istotności ,
2. "nie ma podstaw do odrzucenia hipotezy zerowej", tzn.stwierdzamy brak istotnych statystycznieróżnic (zależności), na poziomie istotności .

Testy najmocniejsze – testy minimalizująceprawdopodobieństwo popełnienia błędu II rodzaju przyustalonym z góry poziomie prawdopodobieństwa popełnieniabłędu I rodzaju .
Moc testu M (w) – prawdopodobieństwo odrzucenia fałszywejhipotezy H0 i przyjęcia w to miejsce prawdziwej hipotezyalternatywnej:
Związek między mocą testu i prawdopodobieństwem błędu IIrodzaju:
1/ HwWPwM n
wMw 1

Służą one do weryfikacji hipotez parametrycznych,odnoszących się do parametrów rozkładu badanej cechy wpopulacji generalnej.
Najczęściej weryfikują sądy o takich parametrach populacjijak średnia arytmetyczna, wskaźnik struktury i wariancja.
Testy te konstruowane są przy założeniu znajomości postacidystrybuanty w populacji generalnej.
Biorąc pod uwagę zakres ich zastosowań, testy te możnapodzielić na dwie grupy:
1. Testy parametryczne służące do weryfikacji własnościpopulacji jednowymiarowych,
2. Testy parametryczne służące do porównania własnościdwóch populacji.

Testy parametryczne służące do weryfikacji własności populacjijednowymiarowych, a wśród nich wyróżnia się:
◦ testy dla średniej
◦ test dla proporcji (wskaźnika struktury)
◦ test dla wariancji
W testach tych oceny parametrów uzyskane z próby losowej są porównywanez hipotetycznymi wielkościami parametrów, traktowanymi jako pewienwzorzec.
Testy parametryczne służące do porównania własności dwóch populacji, doktórych należą:
◦ test dla dwóch średnich
◦ test dla dwóch proporcji
◦ test dla dwóch wariancji
Testy te porównują oceny parametrów, uzyskane z dwóch prób losowych.

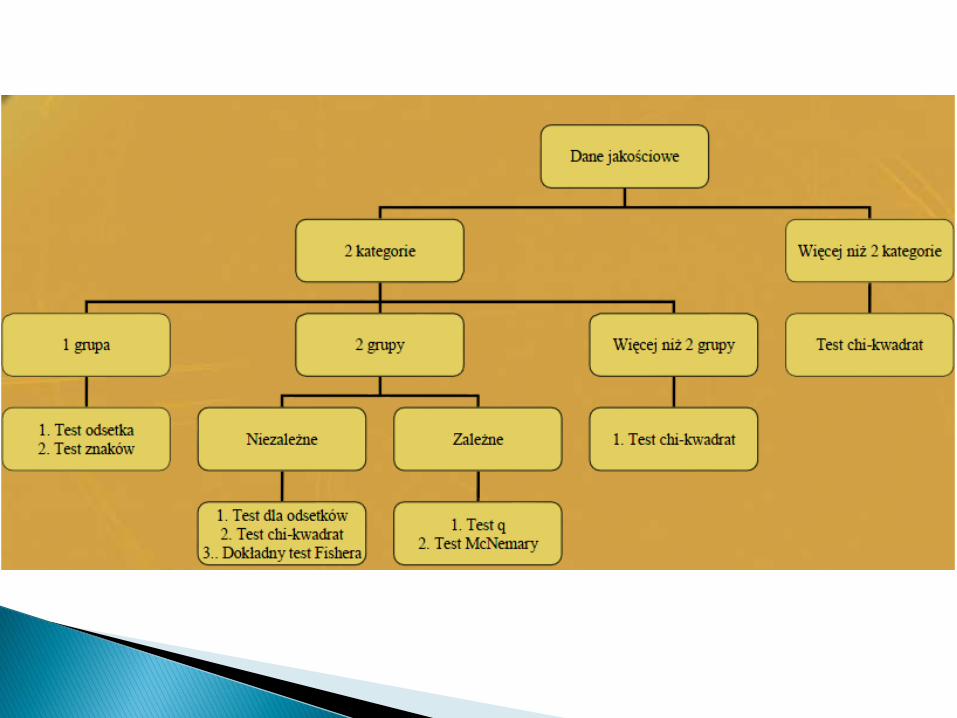
Służą do weryfikacji różnorodnych hipotez,dotyczących m.in. zgodności rozkładu cechy wpopulacji z określonym rozkładem teoretycznym,zgodności rozkładów w dwóch populacjach, atakże losowości doboru próby. Biorąc pod uwagęzakres ich zastosowań, testy te można podzielićna dwie grupy:
1. Testy nieparametryczne służące do porównaniawłasności dwóch populacji,
2. Testy nieparametryczne służące do weryfikacjiwłasności populacji jednowymiarowych

◦ test zgodności chi-kwadrat
◦ test zgodności λ Kołmogorowa
◦ test normalności Shapiro-Wilka
◦ test seriiDwa pierwsze testy zgodności oceniajązgodność rozkładu empirycznego zteoretycznym, natomiast test serii(losowości) weryfikuje hipotezę olosowym pochodzeniu obserwacjibadanej cechy w próbie.

◦ test Kołmogorowa-Smirnowa◦ test jednorodności chi-kwadrat◦ test mediany◦ test serii◦ test znaków
Budowa tych testów sprowadza się dooceny zgodności dwóch rozkładówempirycznych, otrzymanych z próbniezależnych (test Kołmogorowa-Smirnowa, jednorodności chi-kwadrat,test mediany, test serii), a takżezgodności rozkładów w próbachpołączonych (test znaków).

Test na wykrycie wyniku obarczonego błędem grubym.Przed wykonaniem testu zbiór wynikóweksperymentalnych (próbka statystyczna) zostajeuszeregowany według wzrastających wartości. Błędemgrubym może być obarczona największa lub najmniejszawartość wyniku w próbce. Dla tych wyników obliczane sąodpowiednio parametry Tmax i Tmin.Parametr o większej wartości porównywany jest następniez parametrem krytycznym testu Grubbsa, odpowiadającymrozmiarowi próbki statystycznej i wybranemu poziomowiufności. Wartość krytyczna statystyki tego testu obliczanajest na podstawie paramtetru t rozkładu Studenta dlazadanego poziomu ufności i liczby stopni swobody (n - 2,n - liczba pomiarów w serii). Jeśli wartośćeksperymentalna jest większa od wartości krytycznej,wówczas podejrzany wynik obarczony jest błędem grubymi można go odrzucić z zadanym poziomem ufności.

Dla sprawdzenia, czy dwa pomiary różnią sięmiędzy sobą stosujemy:
test znaków lub test Wilcoxona.
Pierwszy z nich wybieramy, gdy dane mająrozkład normalny, drugi, gdy nie.
Oba te testy dotyczą zmiennych zależnych,najczęściej są to pomiary pochodzące od tychsamych osób.
Hipoteza zerowa mówi, że wyniki obu próbeksą jednakowe.

Test znaków oparty jest na znakach różnicpomiędzy parami wyników.
Liczba plusów i minusów jest zliczana iporównywana z wartością teoretycznąumieszczoną w odpowiednich tabelach.
Tracimy informację niesioną przez liczbowewartości różnic.

Test kolejności par Wilcoxona uwzględniazarówno znak różnic, ich wielkość, jak ikolejność.
Po uporządkowaniu różnic w sposób rosnącysą im przypisywane rangi, a następniesumowane osobno rangi różnic dodatnich iujemnych.
Ich suma po porównaniu z tabelą wartościteoretycznych decyduje o przyjęciu lub niehipotezy zerowej.

1. Pierwszą rzeczą, jaką musimy zrobić, jestsprawdzenie, czy dane mają rozkładnormalny, wykonując testy normalnościrozkładu.
2. Następnie wybieramy Analiza / Testynieparameryczne / Dwie próby zależne... i woknie dialogowym zaznaczamy Wilcoxonlub Test znaków oraz przerzucamyzmienne, które chcemy poddać analizie.

Wiele testów parametrycznych wymaga, by danepochodziły z rozkładu zbliżonego donormalnego. Dlatego testy badające normalnośćrozkładów są tak istotne.
W testach tych zawsze przyjmuje się H0 - rozkładzmiennej jest normalny. Odrzucenie H0 jest wiecrównoznaczne z przyjęciem hipotezy, że rozkładzmiennej nie jest normalny. Brak podstaw doodrzucenia nie oznacza przyjęcia hipotezy onormalności rozkładu.
Musimy to jeszcze sprawdzić i w tym celusporządzane są wykresy prawdopodobieństwo -prawdopodobieństwo.

W pakiecie SPSS testy badające normalność rozkładudostępne są w Analiza / Opis statystyczny / Eksploracja itam wybierając opcję Wykresy... należy zaznaczyć Wykresynormalności z testami.
SPSS dla małych próbek wykonuje dwa testy: Test Kołmogorowa - Smirnowa z poprawką Lilleforsa,
która jest obliczana, gdy nie znamy średniej lubodchylenia standardowego całej populacji.
Test Shapiro - Wilka - najbardziej polecany, ale możedawać błędne wyniki dla próbek większych niż 2 tys.
Jeżeli komputer wskaże istotność mniejszą niżzadeklarowany poziom istotności, to hipotezę onormalności rozkładu odrzucamy, jeżeli większą - niemamy podstaw do odrzucenia. Należy wówczas ocenićnormalność na podstawie wykresów prawdopodobieństwo- prawdopodobieństwo.

Test chi-kwadrat (χ2) - każdy test statystyczny, wktórym statystyka testowa ma rozkład chi-kwadrat, jeśli teoretyczna zależność jestprawdziwa.
Test chi kwadrat służy sprawdzaniu hipotez.Innymi słowy wartość testu oceniana jest przypomocy rozkładu chi kwadrat.
Test najczęściej wykorzystywany w praktyce.Możemy go wykorzystywać do badania zgodnościzarówno cech mierzalnych, jak i niemierzalnych.Jest to jedyny test do badania zgodności cechniemierzalnych.

W ogólności zachodzi: gdzie: Oi - wartość mierzona, Ei - odpowiadająca wartość teoretyczna (oczekiwana), wynikająca z
hipotezy σi - odchylenie standardowe, n - liczba pomiarów.Zliczenia W szczególności gdy wartościami są zliczenia wtedy ich odchylenie
standardowe wynosi i równanie przechodzi na: Uwagi: przyjmuje się że wartość Ei powinna być większa lub równa 5 (spotyka
się też 10 - nie ma ścisłego wyprowadzenia, minimalnej wielkości).◦ czasem z tego powodu przy pomiarach wartości dyskretnych łączy się te wartości w
jeden przedział (patrz przykład).
przy pomiarze wartości ciągłej wartość teoretyczna to całka z rozkładuprawdopodobieństwa po odpowiednim przedziale z którego zliczanebyły wyniki.

test nieparametryczny używany do porównywania rozkładówjednowymiarowych cech statystycznych. Istnieją dwie głównewersje tego testu – dla jednej próby i dla dwóch prób.
Test dla jednej próby (zwany też testem zgodności λKołmogorowa) sprawdza, czy rozkład w populacji dla pewnejzmiennej losowej, różni się od założonego rozkładuteoretycznego, gdy znana jest jedynie pewna skończona liczbaobserwacji tej zmiennej (próba statystyczna). Częstowykorzystywany jest on w celu sprawdzenia, czy zmienna marozkład normalny. Dla celów testowania normalności zostałydokonane w teście drobne usprawnienia, znane jako testLillieforsa.
Istnieje też wersja testu dla dwóch prób, pozwalająca naporównanie rozkładów dwóch zmiennych losowych. Jego zaletąjest wrażliwość zarówno na różnice w położeniu, jak i w kształciedystrybuanty empirycznej porównywanych próbek.

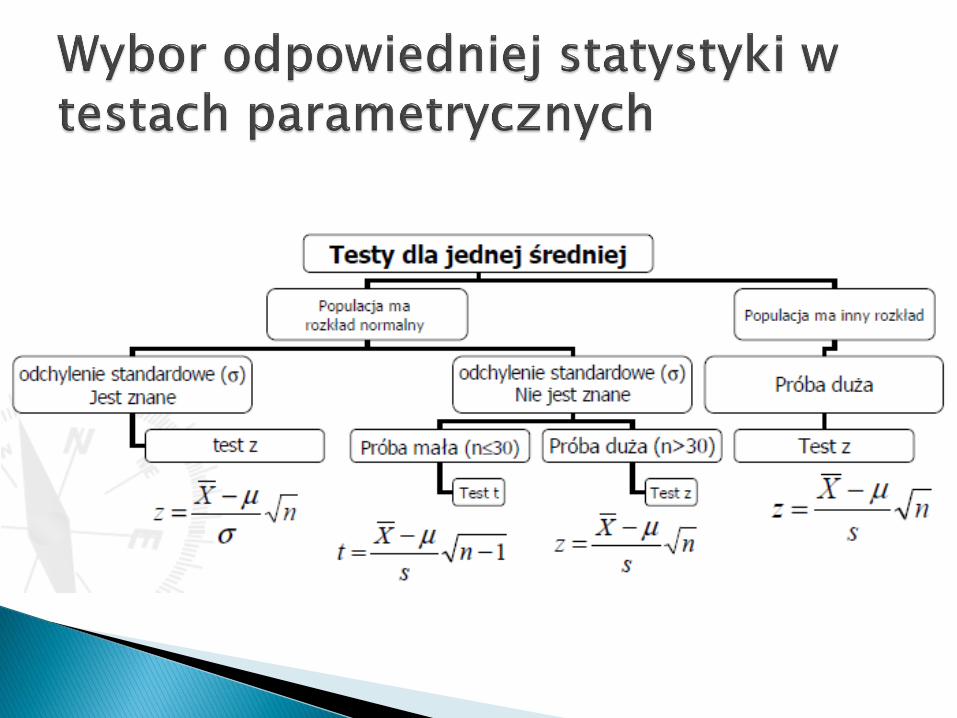
Testy dla średniej to grupa testów statystycznych, służących downioskowania o wartości średniej w populacji, z której pochodzi próbalosowa.
Hipotezę zerową i alternatywną oznaczamy w następujący sposób: H0: μ = μ0
Zakłada ona, że nieznana średnia w populacji μ jest równa średniejhipotetycznej μ0 H1: μ ≠ μ0 lub H1: μ > μ0 lub H1: μ < μ0
Jest ona zaprzeczeniem H0, występuje w trzech wersjach w zależności odsformułowania badanego problemu. Sprawdzianem hipotezy jeststatystyka testowa, która jest funkcją wyników próby losowej. Postaćfunkcji testowej (tzw. statystyki) zależy od trzech okoliczności:
rozkładu cechy w populacji znajomości wartości odchylenia standardowego w populacji liczebności próby Biorąc pod uwagę powyższe okoliczności, założoną przez nas hipotezę
możemy sprawdzić za pomocą trzech testów:

Jeżeli populacja ma rozkład normalny N(μ,σ) o nieznanejśredniej μ i znanym odchyleniu standardowym σ,natomiast liczebność próby n jest dowolna, wtedystatystyka ma postać:
gdzie: m - średnia z próby Jeżeli H0 jest prawdziwa, to statystyka testowa Z ma
rozkład asymptotycznie normalny. Wartość statystyki, którą obliczymy korzystając z
powyższego wzoru, oznaczamy jako z. Następnieporównujemy ją z wartością krytyczną testu zα , którąmożemy odczytać z tablic standaryzowanego rozkładunormalnego, uwzględniając poziom istotności α. Decyzję oodrzuceniu H0 podejmujemy, jeżeli wartość statystykiznajduje się w obszarze krytycznym. Jeżeli natomiastwartość ta znajdzie się poza obszarem krytycznym, nie mawtedy podstaw do odrzucenia H0.

Znane odchylenie Jeżeli populacja ma rozkład normalny N(μ,σ) o nieznanej średniej
μ i znanym odchyleniu standardowym σ, natomiast liczebnośćpróby n jest dowolna, wtedy statystyka ma postać:
gdzie: m - średnia z próby Jeżeli H0 jest prawdziwa, to statystyka testowa Z ma rozkład
asymptotycznie normalny. Wartość statystyki, którą obliczymy korzystając z powyższego
wzoru, oznaczamy jako z. Następnie porównujemy ją z wartościąkrytyczną testu zα , którą możemy odczytać z tablicstandaryzowanego rozkładu normalnego, uwzględniając poziomistotności α. Decyzję o odrzuceniu H0 podejmujemy, jeżeliwartość statystyki znajduje się w obszarze krytycznym. Jeżelinatomiast wartość ta znajdzie się poza obszarem krytycznym,nie ma wtedy podstaw do odrzucenia H0.

Jeżeli rozkład populacji jest normalny N(μ,σ), o nieznanejśredniej μ i nieznanym odchyleniu standardowym σ,natomiast liczebność próby jest mała (np. n<30), wtedystatystyka ma postać:
Jeżeli H0 jest prawdziwa, to statystyka testowa ma rozkładt-Studenta o liczbie stopni swobody ν = n-1.
Wartość statystyki, którą obliczymy korzystając zpowyższego wzoru, oznaczamy jako t. Następnieporównujemy ją z wartością krytyczną testu tα, którąodczytujemy z tablic rozkładu t-Studenta przy założonympoziomie istotności α oraz liczbie stopni swobody ν = n-1. Decyzję o odrzuceniu H0 podejmujemy, jeżeli wartośćstatystyki znajduje się w obszarze krytycznym. Jeżelinatomiast wartość ta znajdzie się poza obszaremkrytycznym, nie ma wtedy podstaw do odrzucenia H0.

Obszar krytyczny – to obszar odrzuceniahipotezy zerowej.
Położenie (postać obszaru krytycznego)wyznacza postać hipotezy alternatywnej.
Wielkość obszaru krytycznego jest równapoziomowi istotności.

Z tablic rozkładu statystyki odczytujemy
wartość krytyczną (graniczną wartość
obszaru krytycznego oddzielającą go od
reszty rozkładu)

Obliczamy wartość statystyki z próby „w”

1. Test chi-kwadrat
2. Test Kołmogorowa - Smirnowa dla jednej próbki
3. Test Kuipera (opracowana przez Kuipera jest modyfikacją testuKołmogorowa – Smirnowa poprawiającą jego właściwości wkrańcowych obszarach rozkładu)
4. Test Cramera-von Mises’a - Statystyka Cramera-von Mises’aporównuje obserwacje w próbce (traktowane jako próba losowa) zpróbą losową pobraną z hipotetycznego rozkładu.
5. Test Watsona - Jest to kolejna modyfikowana statystykaCramera-von Mises’a.
6. Test Andersona-Darlinga - Ocena stopnia dopasowaniadystrybuanty testowanego rozkładu z obliczoną na podstawiepróby dystrybuantą empiryczną. Test ten może być stosowanytylko dla kompletnych danych (bez w jakikolwiek sposóbbrakujących obserwacji).

1. Test normalności Lillieforsa. Jeżeli parametry rozkładuhipotetycznego są nieznane, to jak już wspomniano test K-S może dawać błędne wyniki. Jednak w przypadku rozkładunormalnego można w takiej sytuacji zastosować tę samąstatystykę zmodyfikowaną przez Lilleforsa. Dlatego też testten stosowany jest najczęściej do weryfikacji normalnościrozkładu.
2. Test normalności Shapiro-Wilka. W odróżnieniu odwcześniej opisanych testów zgodności w tym przypadkuwzrost wartości statystyki oznacza większą zgodnośćwyników z rozkładem normalnym. Jednak poziomprawdopodobieństwa odpowiadający tej statystyce testowejpodawany jest w programach statystycznych w ten samsposób, jak w innych testach tzn., jeżeli wartość spadnieponiżej ustalonego poziomu istotności testu, to hipotezę ozgodności z rozkładem normalnym odrzucamy.

Testy K-S2, Mann-Whitneya, Walda –Wolfowitza stosowane są wprzypadku zmiennych niezależnych. Pozostałe dwa testy sąalternatywą testu t dla zmiennych zależnych (parowanych).
Test Kołmogorowa-Smirnowa (dla dwóch próbek)
Test Kołmogorowa-Smirnowa (K-S2) pozwala określić, czy dwie próbki(niezależne) pochodzą z populacji o takim samym rozkładzie. Wodróżnieniu od testów parametrycznych test K-S2 jest nie tylkoczuły na położenie środka rozkładu czy jego szerokość, ale równieżna kształt rozkładu.
1. Kołmogorowa-Smirnowa (tzw. test K-S2),2. Mann-Whitneya,3. Walda –Wolfowitza,4. test znaków,5. Wilkoxona.

Do najczęściej stosowanych testówstatystycznych operujących na jednym zbiorzedanych należą:
test t-Studenta dla jednej średniej (sprawdzający,czy wyniki pochodzą z populacji o danejśredniej),
test Shapiro-Wilka na rozkład normalny(sprawdzający, czy próba pochodzi z populacji orozkładzie normalnym) oraz test z (sprawdzający,czy próba pochodzi z populacji o rozkładzienormalnym, gdy znane jest _ tej populacji).
Przy wnioskowaniu dla jednej średniej, w raziestwierdzenia rozkładu innego niż normalny,zamiast testu t stosuje sie test rang Wilcoxona.

Rozważmy np. wyniki np. 6 analizchemicznych — test posłuży do sprawdzenia,czy mogą pochodzić z populacji o średniejrównej 100:
96.1998.07103.5399.81101.60103.44

> dane = c(96.19,98.07,103.53,99.81,101.60,103.44)
> shapiro.test(dane) # czy rozkład jest normalny?
Shapiro-Wilk normality test
data: dane
W = 0.9271, p-value = 0.5581
> t.test(dane,mu=100) # tak, a zatem sprawdzamy testem Studenta
One Sample t-test
data: dane
t = 0.3634, df = 5, p-value = 0.7311
alternative hypothesis: true mean is not equal to 100
95 percent confidence interval:
97.32793 103.55207
sample estimates:
mean of x
100.44
wilcox.test(dane,mu=100) # tak byśmy sprawdzali, gdyby nie był
Wilcoxon signed rank test
data: dane
V = 11, p-value = 1
alternative hypothesis: true mu is not equal to 100

> ci = qnorm(1-0.05/2)
> ci
[1] 1.959964
> s = 3/sqrt(length(dane))
> s
[1] 1.224745
> mean(dane) + c(-s*ci,s*ci)
[1] 98.03954 102.84046
przedział ufności można bardzo prosto obliczyć ręcznie dla dowolnego . Załóżmy, że = 3, zas = 0.05:

Podstawowymi testami dla dwóch zbiorów danychsą:
test F-Snedecora na jednorodność wariancji(sprawdzający, czy wariancje obu prób różnią sięistotnie między sobą),
test t-Studenta dla dwóch średnich(porównujący, czy próby pochodzą z tej samejpopulacji; wykonywany w razie jednorodnejwariancji)
oraz test U-Manna-Whitneya, będący odmianątestu Wilcoxona, służący do stwierdzeniarówności średnich w razie uprzedniego wykrycianiejednorodności wariancji.

> dane2 = c(99.70,99.79,101.14,99.32,99.27,101.29)
> var.test(dane,dane2) # czy jest jednorodność wariancji?
F test to compare two variances
data: dane and dane2
F = 10.8575, num df = 5, denom df = 5, p-value = 0.02045
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
1.519295 77.591557
sample estimates: ratio of variances
10.85746
> wilcox.test(dane,dane2) # jednak różnice wariancji, wiec test Wilcoxona
Wilcoxon rank sum test
data: dane and dane2
W = 22, p-value = 0.5887 # dane sie istotnie nie różnią
alternative hypothesis: true mu is not equal to 0
> t.test(dane,dane2) # a tak byśmy zrobili, gdyby różnic nie było
Welch Two Sample t-test
data: dane and dane2
t = 0.2806, df = 5.913, p-value = 0.7886
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.751801 3.461801
sample estimates:
mean of x mean of y
100.440 100.085
Do poprzedniego zbioru danych dodamy drugi zbiór dane2 i przeprowadzimy te testy:

> dane2 = c(99.70,99.79,101.14,99.32,99.27,101.29)> var.test(dane,dane2) # czy jest jednorodność wariancji?F test to compare two variancesdata: dane and dane2F = 10.8575, num df = 5, denom df = 5, p-value = 0.02045alternative hypothesis: true ratio of variances is not equal to 195 percent confidence interval:1.519295 77.591557sample estimates: ratio of variances10.85746

> wilcox.test(dane,dane2) # jednak różnice wariancji, wiec test Wilcoxona
Wilcoxon rank sum test
data: dane and dane2
W = 22, p-value = 0.5887 # dane sie istotnie nie różnią
alternative hypothesis: true mu is not equal to 0
> t.test(dane,dane2) # a tak byśmy zrobili, gdyby różnic nie było
Welch Two Sample t-test
data: dane and dane2
t = 0.2806, df = 5.913, p-value = 0.7886
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.751801 3.461801
sample estimates:
mean of x mean of y
100.440 100.085

Jeśli zachodzi potrzeba wykonania testu zinnym niż 0.05, korzystamy z opcjiconf.level każdego testu (standardowo jest to0.95).
W funkcji t.test można również ustawićpaired=TRUE i w ten sposób policzyć test dladanych powiązanych parami.
Warto też zwrócić uwagę na parametr conf.intw funkcji wilcox.test, który pozwala naobliczenie przedziału ufności dla mediany.

W przypadku analizy statystycznej większejgrupy danych, np. wyników analizychemicznej wykonanej trzema metodami,konieczne jest umieszczenie wszystkichdanych w jednej ramce (dataframe).

> dane3 = c(91.50,96.74,108.17,94.22,99.18,105.48)
> danex = data.frame(wyniki=c(dane,dane2,dane3),metoda=rep(1:3,each=6))
> danex
Dołóżmy jeszcze kolejne 6 wyników do wektora dane3 i umieśćmy wszystko w ramce:
wyniki metoda
1 96.19 1
2 98.07 1
3 103.53 1
4 99.81 1
5 101.60 1
6 103.44 1
7 99.70 2
8 99.79 2
9 101.14 2
10 99.32 2
11 99.27 2
12 101.29 2
13 91.50 3
14 96.74 3
15 108.17 3
16 94.22 3
17 99.18 3
18 105.48 3

Na tak wykonanej ramce możemy wykonać jużposzczególne testy.
Do porównania jednorodności wariancji służytutaj test Bartletta, który jest rozwinięciem testuF-Snedecora na większą liczbę prób.
W razie stwierdzenia istotnych różnic w wariancjibadamy istotne różnice pomiędzy grupamiwyników testem Kruskala-Wallisa.
Jeśli nie ma podstaw do odrzucenia hipotezy ojednorodności wariancji, rekomendowanymtestem jest najprostszy wariant ANOVA.

> bartlett.test(wyniki ~ metoda,danex) # czy jest niejednorodność?Bartlett test for homogeneity of variancesdata: wyniki by metodaBartlett’s K-squared = 13.0145, df = 2, p-value = 0.001493> kruskal.test(wyniki~metoda,danex) # jest, wiec Kruskar-WallisKruskal-Wallis rank sum testdata: wyniki by metodaKruskal-Wallis chi-squared = 0.7836, df = 2, p-value = 0.6758> anova(aov(wyniki~metoda,danex)) # a tak, gdyby nie byłoAnalysis of Variance TableResponse: wynikiDf Sum Sq Mean Sq F value Pr(>F)metoda 1 4.502 4.502 0.2788 0.6047Residuals 16 258.325 16.145

Załóżmy, ze oznaczyliśmy w 4 próbkachzawartość jakiejś substancji, każda próbkębadaliśmy 4 metodami (w sumie 16 wyników).
Stosując dwuczynnikowy test ANOVA możnasprawdzić, czy wyniki różnią sie istotniemiedzy próbkami i miedzy metodami.
W tym celu znów tworzymy ramkęzawierającą wyniki oraz odpowiadające impróbki i metody:

> dane
wynik probka metoda
1 46.37278 1 1
2 48.49733 1 2
3 46.30928 1 3
4 43.56900 1 4
5 46.57548 2 1
6 42.92014 2 2
7 47.22845 2 3
8 42.46036 2 4
9 43.71306 3 1
10 47.35283 3 2
11 44.87579 3 3
12 46.06378 3 4
13 47.29096 4 1
14 44.50382 4 2
15 44.26496 4 3
16 45.35748 4 4

> anova(aov(wynik ~ probka + metoda,dane)) # test bez interakcjiAnalysis of Variance TableResponse: wynik
Df Sum Sq Mean Sq F value Pr(>F)probka 1 0.643 0.643 0.2013 0.6611metoda 1 5.050 5.050 1.5810 0.2307
Residuals 13 41.528 3.194> anova(aov(wynik ~ probka * metoda,dane)) # test z~interakcjamiAnalysis of Variance Table
Response: wynikDf Sum Sq Mean Sq F value Pr(>F)probka 1 0.643 0.643 0.1939 0.6675
metoda 1 5.050 5.050 1.5227 0.2408probka:metoda 1 1.728 1.728 0.5211 0.4842Residuals 12 39.800 3.317
Podany powyżej test z interakcjami nie ma sensu merytorycznego w tym przypadku, pokazano go tylko przykładowo

Załóżmy np. ze wśród 300 ankietowanych osób odpowiedz „tak” padła w 30 przypadkach. Daje to 10% ankietowanych. Czy można powiedzieć, że wśród ogółu populacji tylko 7% tak odpowiada?
Jaki jest przedział ufności dla tego prawdopodobieństwa?
> prop.test(30,300,p=0.07)1-sample proportions test with continuity correctiondata: 30 out of 300, null probability 0.07
X-squared = 3.6994, df = 1, p-value = 0.05443alternative hypothesis: true p is not equal to 0.0795 percent confidence interval:
0.0695477 0.1410547sample estimates:p
0.1

Jak widać, przedział ufności zawiera sie w granicy 6.9 — 14.1%, zatem 7% zawiera sie w nim (p nieznacznie większe niż 0.05).
Innym przykładem jest porównanie kilku takich wyników. Załóżmy, ze w innej 200-osobowej grupie odpowiedz padła u 25 osób, a w trzeciej, 500-osobowej, u 40 osób. Czy próby te pochodzą z tej samej populacji?
> prop.test(c(30,25,40),c(300,200,500))
3-sample test for equality of proportions without continuity
correction
data: c(30, 25, 40) out of c(300, 200, 500)
X-squared = 3.4894, df = 2, p-value = 0.1747
alternative hypothesis: two.sided
sample estimates:
prop 1 prop 2 prop 3
0.100 0.125 0.080
Jak widać, test nie wykazał istotnych różnic. Jeśli chcielibyśmy wprowadzić do testu poprawkę Yates’a, dodajemy parametr cont=TRUE.

Test 2 na zgodność rozkładu jest wbudowany w R pod funkcjachisq.test. W przypadku wnioskowania zgodności rozkładupierwszy wektor zawiera dane, a drugi prawdopodobieństwa ichwystąpienia w testowanym rozkładzie. Załóżmy, że w wyniku 60rzutów kostka otrzymaliśmy następujące ilości poszczególnychwyników 1 — 6: 6,12,9,11,15,7. Czy różnice pomiędzy wynikamiświadczą o tym, ze kostka jest nieprawidłowo skonstruowana,czy są przypadkowe?
> kostka=c(6,12,9,11,15,7)
> pr=rep(1/6,6) # prawdopodobieństwo każdego rzutu wynosi 1/6> pr[1] 0.1666667 0.1666667 0.1666667 0.1666667 0.1666667 0.1666667
> chisq.test(kostka,p=pr)Chi-squared test for given probabilitiesdata: kostka
X-squared = 5.6, df = 5, p-value = 0.3471

Jeśli parametrem funkcji chisq.test jest ramka, funkcjaprzeprowadza test 2 na niezależność.
Załóżmy, ze w grupie pacjentów badanych nowym lekiem 19pozostało bez poprawy, 41 odnotowało wyraźną poprawę, 60osób całkowicie wyzdrowiało. W grupie kontrolnej (leczonejdotychczasowymi lekami) wartości te wynosiły odpowiednio46,19,15. Czy nowy lek faktycznie jest lepszy? Jeśli tak, danepowinny być „zależne”, i tak tez jest:
> lek=c(19,41,60)> ctl=c(46,19,15)> chisq.test(cbind(lek,ctl)) # cbind tworzy ramke !
Pearson’s Chi-squared testdata: cbind(lek, ctl)X-squared = 39.8771, df = 2, p-value = 2.192e-09

Pakiet R posiada wbudowane algorytmy pozwalające naobliczanie gęstości, dystrybuanty i kwantyli najczęściejstosowanych rozkładów. Może również pracować jako precyzyjnygenerator liczb losowych.
Standardowo dostępne są następujące rozkłady: beta, binom,cauchy, chisq, exp, f, gamma, geom, hyper, lnorm, logis, nbinom, norm,pois, t, unif, weibull, wilcox.
Poprzedzając nazwę rozkładu literą d uzyskujemy funkcjęgęstości rozkładu. Analogicznie poprzedzając nazwę literą puzyskujemy wartości dystrybuanty.
Funkcja kwantylowa (poprzedzona q) podaje taki kwantyl, którypo lewej stronie wykresu gęstości zawiera określoneprawdopodobieństwo.
Generator liczb losowych dostępny jest przy poprzedzeniunazwy litera r.
Funkcje te pozwalają na traktowanie pakietu R jako zestawubardzo dokładnych tablic statystycznych.

> dnorm(0) # gęstość rozkładu normalnego w zerze[1] 0.3989423> pnorm(1)-pnorm(-1) # ile wartości mieści sie w N(0,1) w przedziale (0,1) ?[1] 0.6826895> qt(0.995,5) # wartość krytyczna t-Studenta dla 99% i 5 stopni swobody[1] 4.032143> qchisq(0.01,5) # wartość krytyczna chi-kwadrat dla 5 st. swobody i 99%[1] 0.5542981> dpois(0,0.1) # wartość prawdop. Poissona dla lambda 0.1 i n=0[1] 0.9048374> qf(0.99,5,6) # wartość krytyczna testu F dla n1=5, n2=6[1] 8.745895

Kilku słów wymaga wartość 0.995 (nie 0.99) wwywołaniu funkcji rozkładu t-Studenta.
Rozkład ten jest zwykle stosowany w kontekściedwustronnym, dlatego obszar krytyczny dzielimyrównomiernie na obu „końcach” rozkładu.
99% ufności oznacza, ze krytyczny 1% jestpodzielony na 2 końce i zawiera sie wprzedziałach (0, 0.05) oraz (0.995, 1).
Wartość tablicowa jest kwantylem obliczonym dlatakiego właśnie prawdopodobieństwa.
Analogicznie np. dla 95% będzie to 0.975, a dla99.9% — 0.9995.

Korzystając z funkcji generatora losowego można generować dowolne ciągi danych do późniejszej analizy. Wygenerujmy przykładowy zestaw 30 liczb o średniej 50 i odchyleniu standardowym 5, posiadających rozkład normalny:
> rnorm(30,50,5)[1] 53.43194 58.74333 53.27320 46.42251 53.93869 44.80035 55.57112
43.65090[9] 46.78265 55.88207 49.68947 52.65945 55.72740 48.75954 48.16239
50.89369[17] 51.23270 47.14778 57.83292 45.67989 45.98016 50.45368 44.41436
44.24023[25] 50.98059 48.69967 53.32837 48.09720 52.57135 49.64967

Oczywiście funkcja ta wygeneruje za każdymrazem całkowicie inne wartości, dlatego teżprowadząc analizy należy je zapamiętać wzmiennej, a potem używać tej zmiennej wdalszych operacjach.
Warto przy okazji wspomnieć o funkcji sample,generującej wektor danych wylosowanych zinnego wektora. Np. funkcjasample(1:6,10,replace=T) symuluje 10 rzutówkostka (losowanie ze zbioru 1:6), a dane mogąsie powtarzać. Jeśli nie jest podana liczbalosowanych danych (np. sample(1:6)), funkcjageneruje losowa permutacje wektora podanegojako parametr.

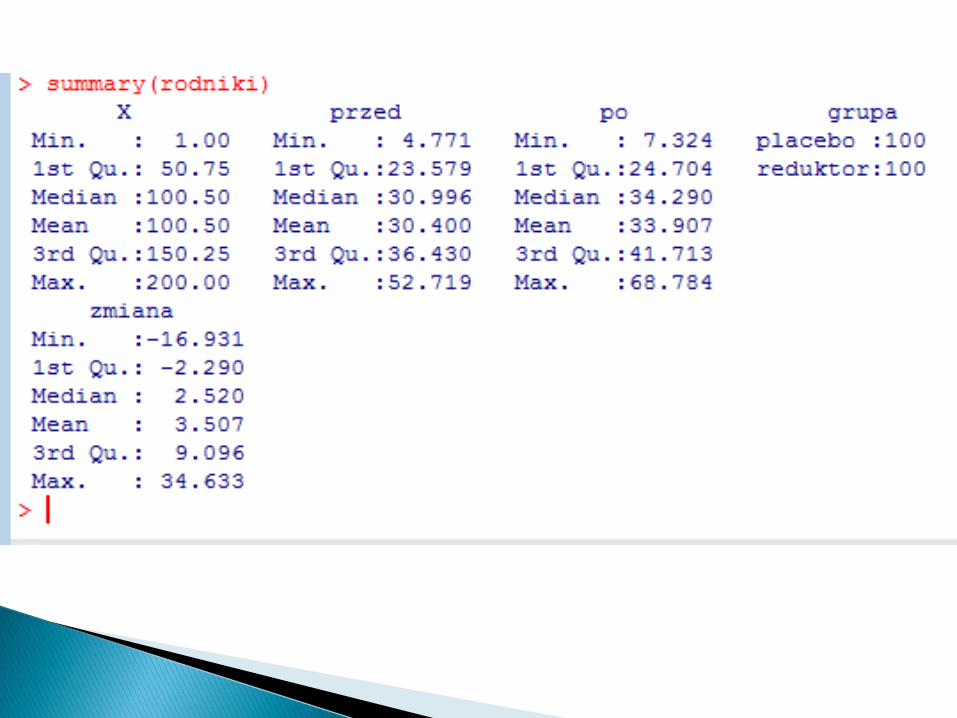
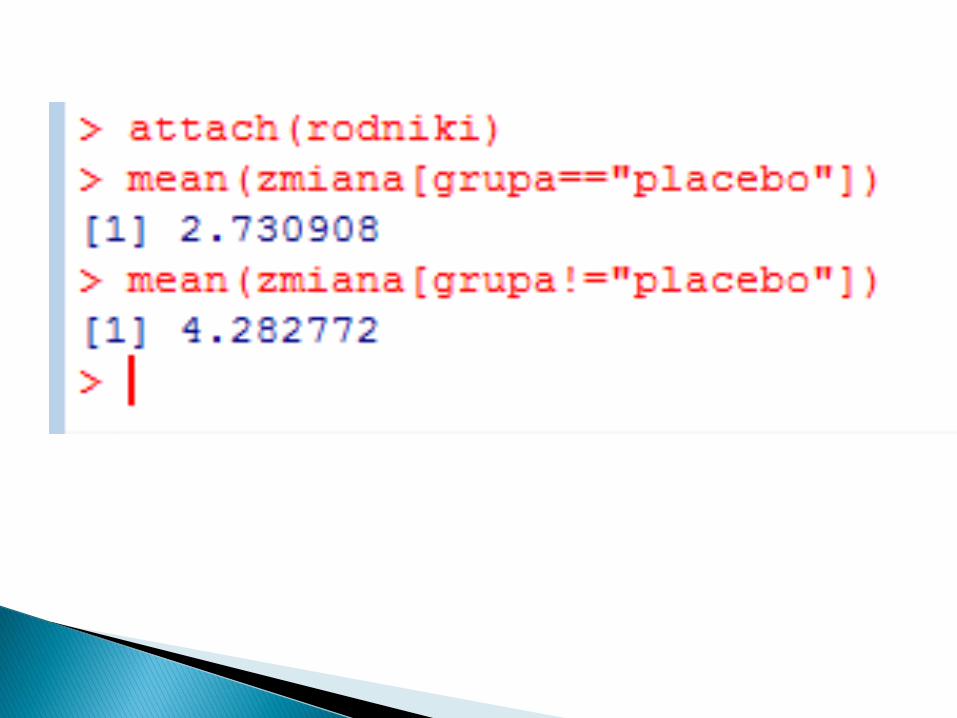
cudowne lekarstwo na wolne rodniki













rozstęp zmiennej

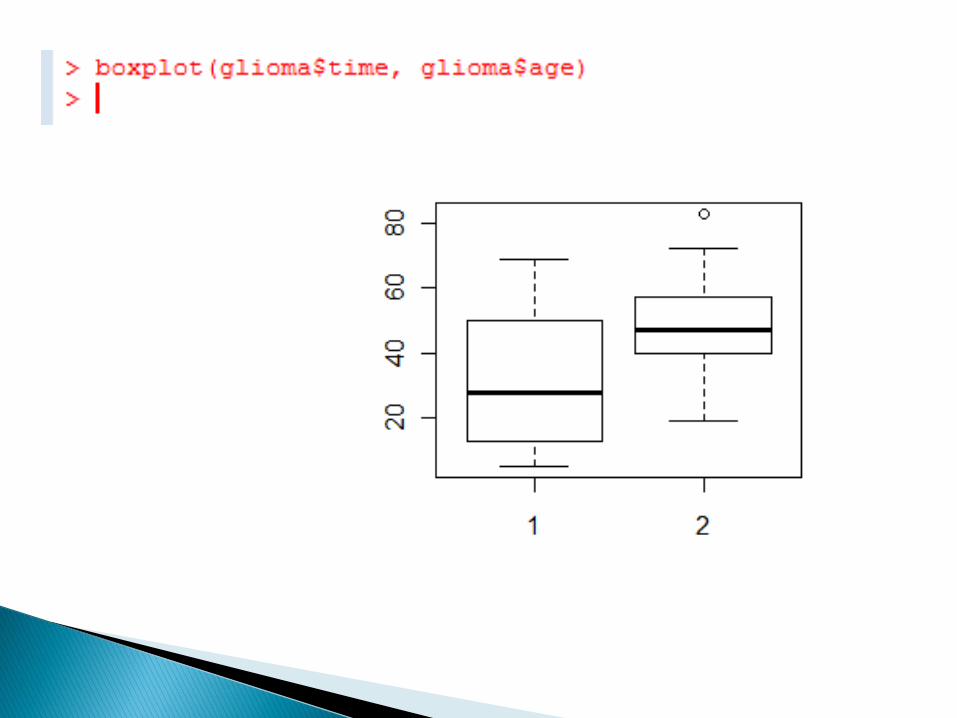
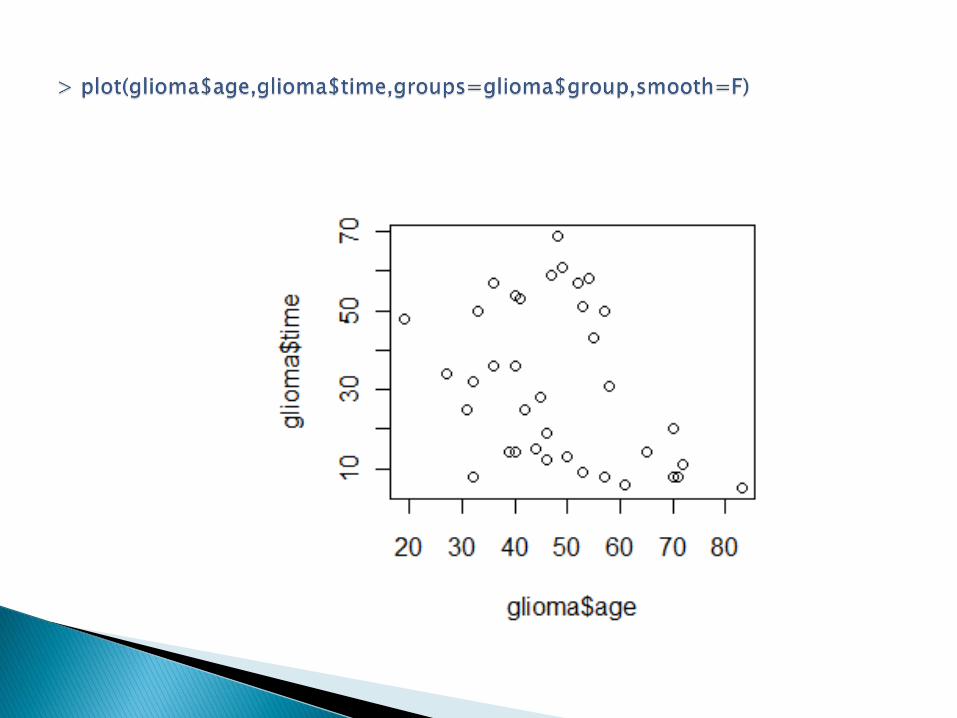
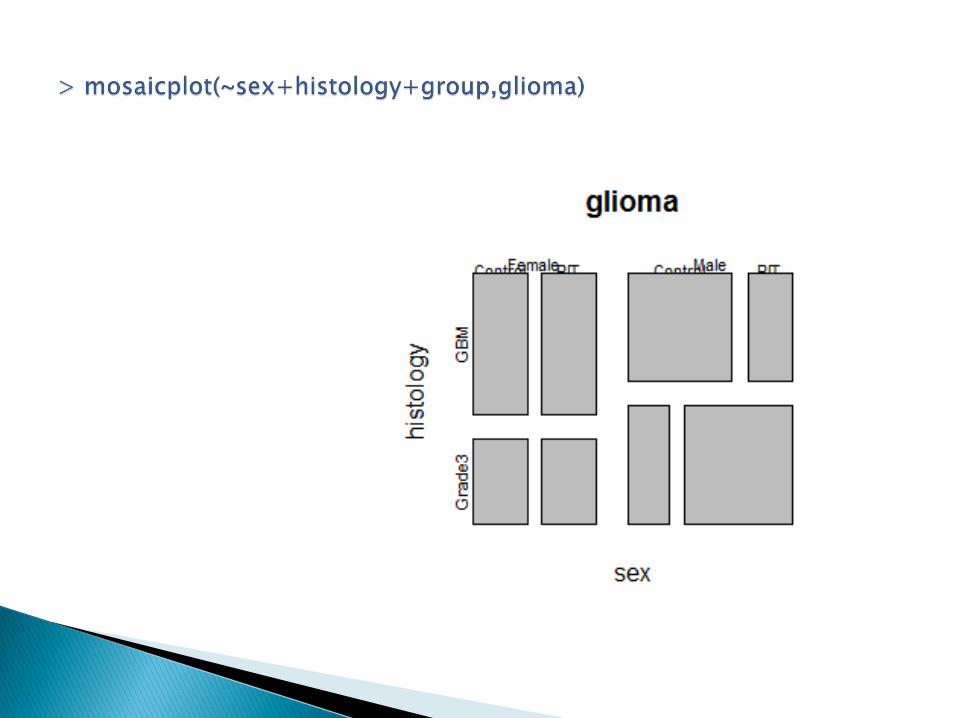
http://www.mini.pw.edu.pl/~mwojtys/sar/dane/coagulation.txt

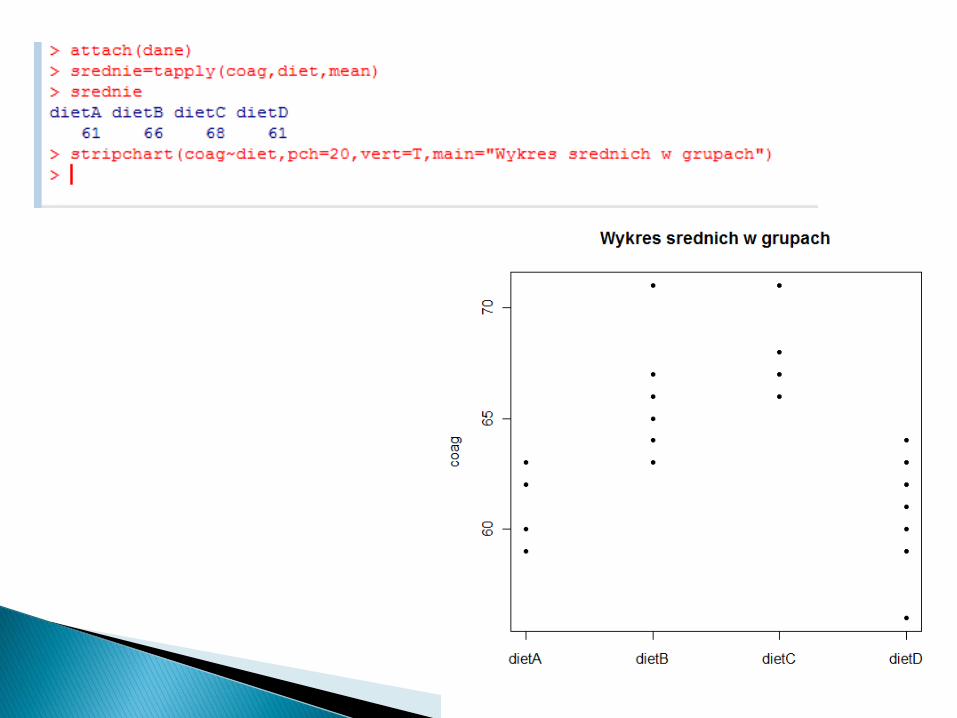
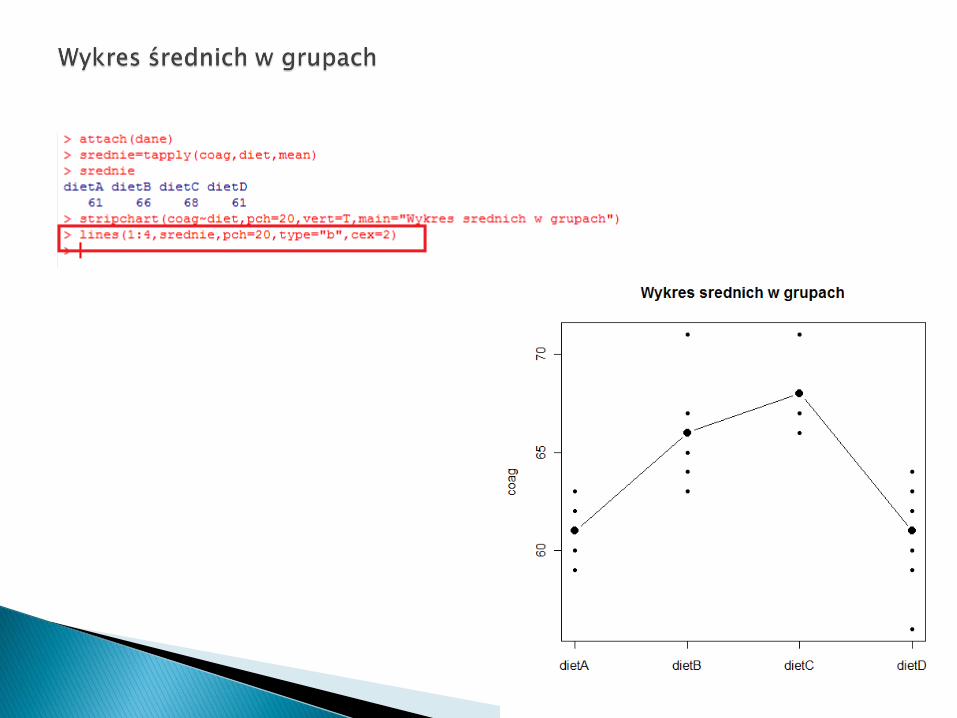

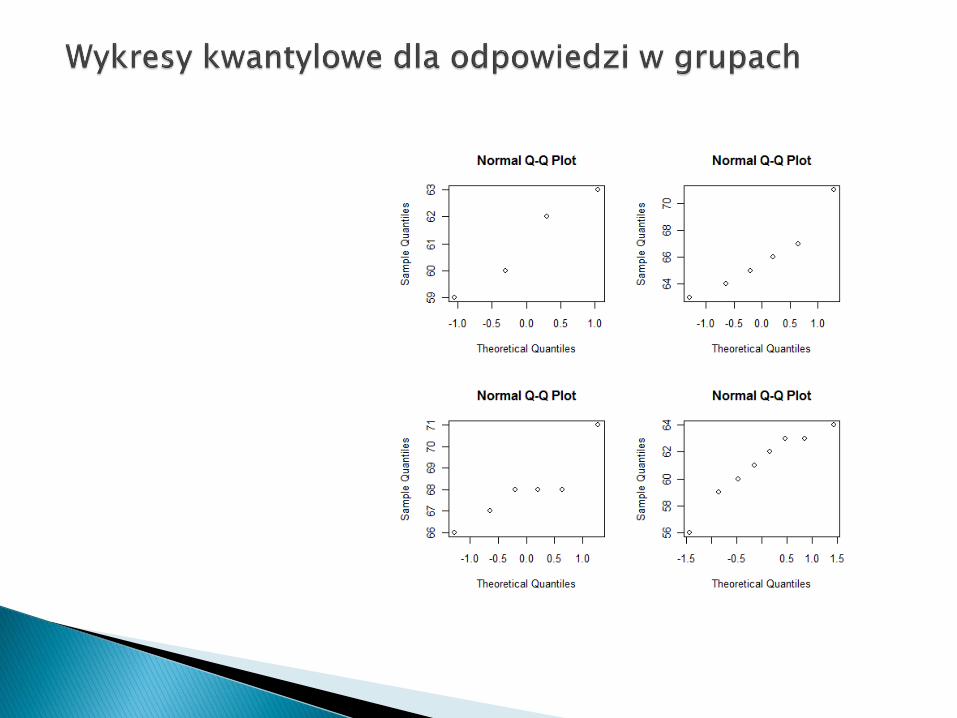

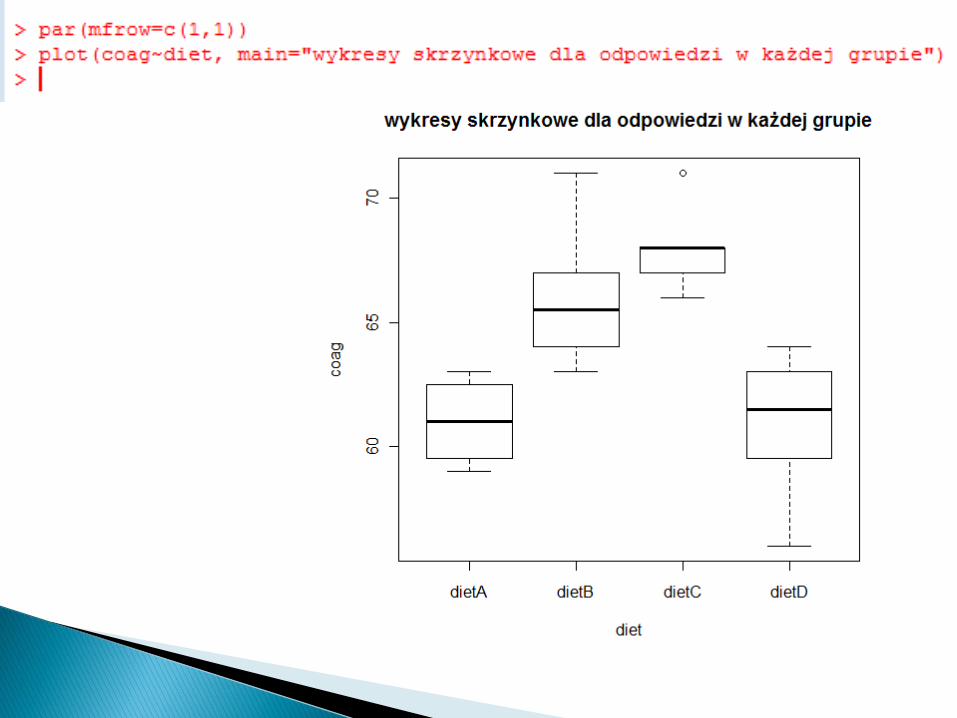
Szukamy: - obserwacji odstających, - skośności rozkładów (niesymetryczne
skrzynki) - nierówności wariancji (nierówne wielkości
skrzynek)
Dla zbioru coagulation nieregularności na wykresie skrzynkowym wynikają raczej z malej liczby obserwacji.

Test równości wariancji w grupach
(Używamy poziomu istotności 0.01, bo proceduryzwiązane z ANOVA są w miarę odporne naodstępstwo od założenia o równych wariancjach wgrupach)
# TEST BARTLETTA (nie jest najlepszy, bonieodporny na odstępstwo od założenia onormalności rozkładu w grupach)
bartlett.test(coag~diet)

TEST LEVENE'A (odporny na odstępstwo odzałożenia o normalności rozkładu wgrupach)
# Liczymy wartości bezwzględne rezyduów iużywamy ich jako zmiennej odpowiedzi wanalizie wariancji:

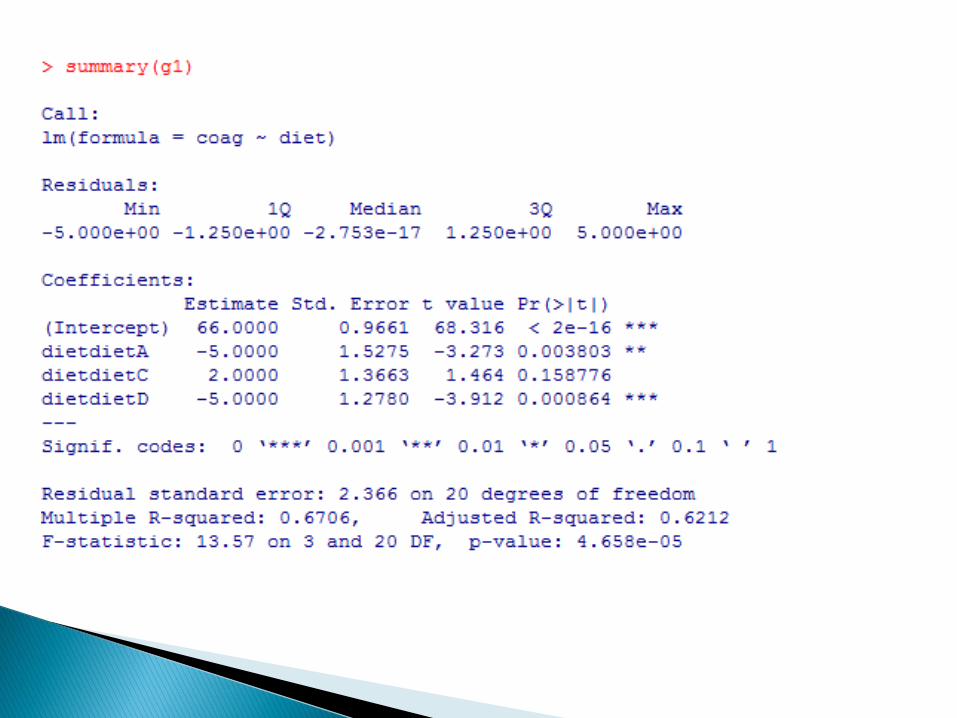
Na podstawie wyniku testu F stwierdzamy, ze istnieją różnice w średnich miedzy grupami

Zatem dietA jest poziomem odniesienia.
średnia na poziomie dietA: 61
średnia na poziomie dietB: 61+5
średnia na poziomie dietC: 61+7
średnia na poziomie dietD: 61-0





za poziom istotności pojedynczego testu przyjmujemyalfa/k*, gdzie k* to liczba par, które porównujemy. UWAGA:Tak dobrany poziom istotności jest mniejszy od zadanegoalfa; ponadto dla dużych k* procedura ta jest bezużyteczna,bo praktycznie nigdy nie odrzuca hipotezy zerowej.
Tutaj k*=6, zatem wyznaczamy kwantyl rozkładu t-Studentao N-k=24-4=20 stopniach swobody rzędu 1-alfa/(2*6)
Wartość krytyczna:
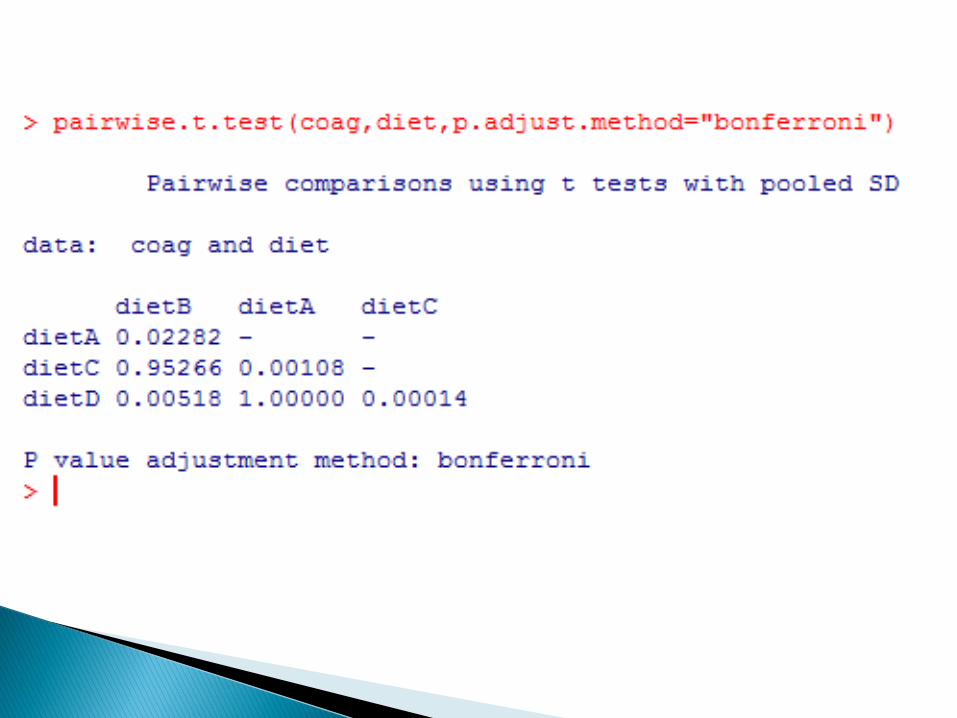

poziom istotności oparty jest na rozkładziemaksymalnej różnicy pomiędzy średnimi (takzwanym "studentyzowanym rozkładzierozstępu" dla próby z rozkładu normalnego).
Wartość krytyczna:
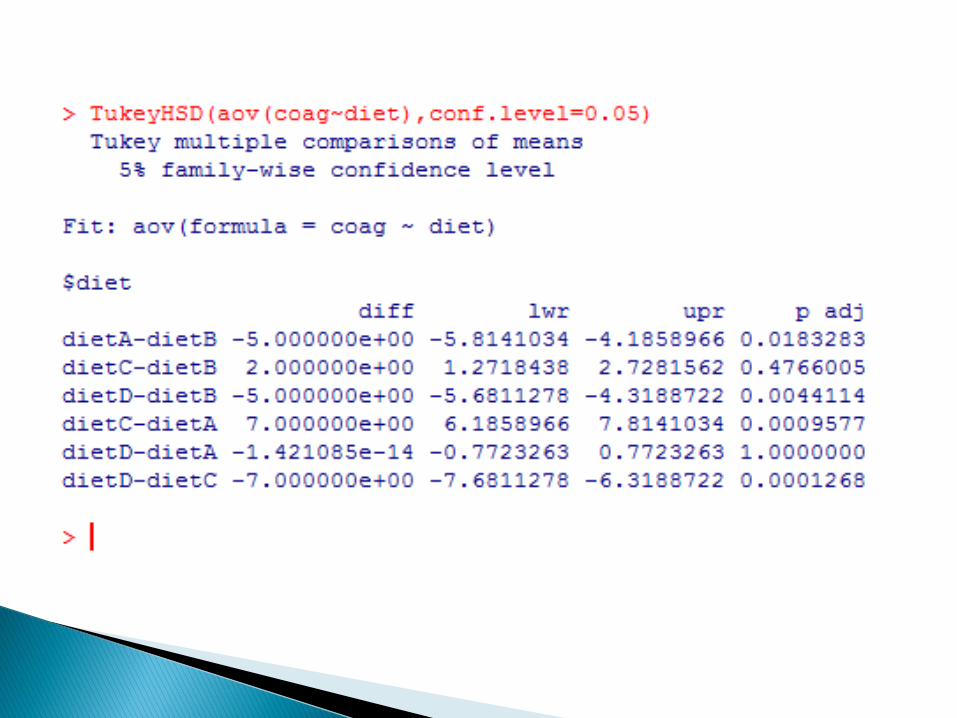

zalecana, gdy analizuje sie kontrastypomiędzy więcej niż dwiema średnimi.
PRZYKLAD: Czy średni czas krzepnięcia krwidla kur karmionych zgodnie z dietą A i Bróżni się istotnie od średniego czasu dla kurkarmionych zgodnie z dieta C i D?



















![Careless Whisper [Nowak]](https://img.pdfslide.net/doc/110x75/577c78ac1a28abe05490a3a6/careless-whisper-nowak.jpg)








