Embed Size (px)
Citation preview

328 Int. J. Advanced Intelligence Paradigms, Vol. 6, No. 4, 2014
Copyright © 2014 Inderscience Enterprises Ltd.
An intelligent system for author attribution based on a hybrid feature set
Ahmed Fawzi Otoom*, Emad E. Abdallah, Maen Hammad, Mohammad Bsoul and Alaa E. Abdallah Faculty of Prince Al-Hussein Bin Abdullah II for Information Technology, The Hashemite University, Zarqa, Jordan Email: [email protected] Email: [email protected] Email: [email protected] Email: [email protected] Email: [email protected] *Corresponding author
Abstract: Authorship analysis is a long explored area in the computational research. Recently, there has been growing interest in developing intelligent systems that are capable of authorship identification. Inspired by recent works, we address the problem of author attribution of Arabic text. This area, in specific, has not been targeted in the literature except for few studies. However, it is a challenging problem as there are linguistic complexities associated with the Arabic language including elongation and inflection challenges. For this purpose, we propose a novel hybrid feature set consisting of: lexical, syntactic, structural and content-specific features for 456 instances belonging to seven different Arabic authors. For validation, we run extensive experiments with different intelligent classifiers and show the strength of the proposed feature set. Our results show that the proposed feature set has proved successful with a classification performance accuracy of 88% with the hold-out test and 82% with the cross-validation test.
Keywords: authorship attribution; Arabic text features; intelligent classifiers; hybrid feature set.
Reference to this paper should be made as follows: Otoom, A.F., Abdallah, E.E., Hammad, M., Bsoul, M. and Abdallah, A.E. (2014) ‘An intelligent system for author attribution based on a hybrid feature set’, Int. J. Advanced Intelligence Paradigms, Vol. 6, No. 4, pp.328–345.
Biographical notes: Ahmed Fawzi Otoom is an Assistant Professor in the Software Engineering Department at the Hashemite University, Jordan. He holds a PhD in Computer Science from the University of Technology, Sydney (UTS), Australia, 2010. In 2003, he received his MS in Software Engineering from the University of Western Sydney, Australia. In 2002, he received his BS in Computer Science from Jordan University of Science and Technology, Jordan. During his PhD, he worked as a Research Assistant in iNext Research Centre at the University of Technology, Sydney (UTS). His main research interests include pattern recognition techniques and its applications to computer vision and security.

An intelligent system for author attribution based on a hybrid feature set 329
Emad E. Abdallah received his PhD in Computer Science from Concordia University in 2008, where he worked on multimedia security, pattern recognition and 3D object recognition. He received his BS in Computer Science from Yarmouk University, Jordan, and MS in Computer Science from the University of Jordan, in 2000 and 2004, respectively. He is currently an Assistant Professor in the Department of Computer Information Systems at the Hashemite University (HU), Jordan. Prior to joining HU, he was a Software Developer at SAP Labs Montreal. His current research interests include computer graphics, multi-media security, pattern recognition, and computer networks.
Maen Hammad is an Assistant Professor in Software Engineering Department at The Hashemite University, Jordan. He completed his PhD in Computer Science at Kent State University, USA in 2010. He received his Master in Computer Science from Al-Yarmouk University, Jordan and his BS in Computer Science from The Hashemite University, Jordan. His research interest is software engineering with focus on software evolution and maintenance, program comprehension and mining software repositories.
Mohammad Bsoul is an Associate Professor in the Computer Science Department of The Hashemite University. He received his BSc in Computer Science from Jordan University of Science and Technology, Jordan, his Master degree from University of Western Sydney, Australia, and his PhD degree from Loughborough University, UK. His research interests include wireless sensor networks, grid computing, distributed systems, and performance evaluation.
Alaa E. Abdallah is an Assistant Professor in the Department of Computer Science of Hashemite University, having joined in 2011. He obtained his BSc in Computer Science from Yarmouk University in 2000, MSc in Computer Science from University of Jordan in 2003, and PhD in Computer Science from Concordia University, Montreal-Canada, in 2008. Prior to joining Hashemite University, he was a Network Researcher at consulting private company in Montreal (2008–2011). His research interest includes the routing protocols for ad hoc networks, parallel and distributed systems, and multimedia security.
This paper is a revised and expanded version of a paper entitled ‘Towards author identification of Arabic text articles’ presented at 5th International Conference on Information and Communication Systems, Jordan, 1–3 April 2014.
1 Introduction and related work
In recent years, there has been growing attention to the diverse applications associated with machine learning techniques. These techniques are concerned with automatic discovery of regularities or patterns in data through the use of computer algorithms and with the use of those patterns to take actions such as classifying data into different categories (Otoom, 2010). An interesting application of these techniques is author attribution and its basic idea is to assign a written piece of text to one author out of a possible group of authors. It is a long explored area of research going back to the early ‘60s with a famous example, the Federalist Papers case (Mosteller and Wallace, 1964). In this case, a dispute occurred between three different authors over a series of written essays. This specific case raised the attention for an approach to solve such dispute and it

330 A.F. Otoom et al.
became a milestone for scholars working in this research area (Stamatatos, 2009; Zheng et al., 2006).
Author attribution is an interesting field of a broader area named authorship analysis which has recently attracted attention mainly for its distinctive applications. An example of these applications is e-mail authorship identification (Abbasi and Chen, 2005; De Vel et al., 2001), where the main aim is to identify the author of misused e-mails like junk mails or mails of offensive or threatening type. Another application is computer forensics; like identifying the people behind distributing pirated software and child pornography materials (De Vel et al., 2001). Authorship analysis is also desirable for solving disputes over copyrighted material (Grant, 2007) or literary works (Hoover, 2004).
The main aim of authorship analysis is to study the characteristics of a piece of writing to draw conclusions about it. It can be categorised into three main fields: authorship attribution or identification, author characterisation and similarity detection (Zheng et al., 2006). The main aim of authorship attribution is to determine the probability of a piece of writing being produced by an author given a history of writings by this author (e.g., Abdallah et al., 2013). A closed area to this field but clearly different from it is text categorisation which aims to categorise a set of text documents based on its content. Applications of text categorisation include document filtering and document retrieval (De Vel et al., 2001). Author characterisation intends to generate the author profile based on his/her writing style (e.g., Koppel et al., 2002). The profile gives knowledge about the characteristics of the author such as gender and educational and cultural background. Another interesting area of authorship analysis is similarity detection, which compares multiple pieces of writing and determines whether they were produced by a single author without the identification of the author (e.g., Clough, 2000). It is applied for the purpose of detecting plagiarism including a complete or partial replication of a piece of work without the permission of the original author (De Vel et al., 2001; Zheng et al., 2006).
In this work, we target an interesting field of authorship analysis which is authorship attribution of Arabic text articles. Our main aim is to develop a smart system that is capable of identifying the author of an Arabic newspaper article based on deep analysis of a variety of writings for a number of different authors. Simply, the proposed approach works as follows: newspaper articles of seven different authors are used to train and build a classifier. Once it is trained, a new article is given to the classifier and it should be smart enough to identify its author. To build such system, it is very important to have a robust feature (characteristic) set that is strong enough to distinguish between the different authors. Taxonomy of features has been proposed in the literature for this purpose and can be divided into four main types: lexical, syntactic, structural, and content-specific features. Lexical features are word or character based features where text is viewed as a sequence of tokens grouped into sentences. Each token corresponds to a word, number, character, and others. Examples of these features include vocabulary richness, word length, sentence length, characters count and others (Holmes, 1998; Stamatatos, 2009; De Vel et al., 2001; Zheng et al., 2006).
Syntactic features are more related to the language pattern and they determine how to syntactically form a sentence. It is common that authors tend to use similar syntactic patterns in their writings. Some researchers consider it more reliable compared to lexical features (Stamatatos, 2009), and it was shown in Baayen et al. (2002) that including these features can improve the accuracy of author identification. Examples of these features

An intelligent system for author attribution based on a hybrid feature set 331
include the use of function words such as ‘the’, ‘if’, ‘to’, ‘while’, ‘upon’. Part of speech (POS) and punctuation usage are other examples of these features.
Structural features are related to the style the author follows in his/her writing. It is believed that each author has a certain structure in the way of writing. Examples of these features are the use of indentation and paragraph length (De Vel et al., 2001; Zheng et al., 2006). The last set of features is content-specific features which are content related features or keywords frequency. Different from the abovementioned types, these features are application dependant measures and incorporating them can improve the performance of the classifier. In works like Zheng et al. (2003), content-specific features contributed positively in improving the performance of the author identification classifier.
For building an intelligent system, it is very important to have a strong learning algorithm in conjunction with a robust feature set. Generally, classification approaches can be divided into profile-based and instance-based approaches. In profile-based approaches, all the training text related to an author is put in one text file and a cumulative representation of the author style is extracted. In other words, the difference between the texts written by the same author is not considered (Stamatatos, 2009; Kourtis and Stamatatos, 2011). This approach is often referred to as a generative approach; given a set of class labels, {Ck}k=1…K, generative classifiers model the class likelihoods, p(y | Ck), and estimate the priors, p(Ck), for each of the Ck individually. Once class densities are learnt, classification is attained by computing the likelihood of a new observation and assigning the observation to the class label providing the maximum posterior value p(Ck | y) ∝ p(y | Ck)p(Ck) (Otoom, 2010).
Examples of these approaches include principle component analysis (PCA), probabilistic PCA (PPCA), factor analysis (FA), Gaussian mixture models (GMM), hidden Markov models, Naïve Bayes and BayesNet [see Bishop (2006) for an overview about these methods].
On the other hand, instance-based approaches treat each training text related to an author individually as a separate instance (Stamatatos, 2009; Kourtis and Stamatatos, 2011). This approach is referred to as discriminative approach; it emphasises the modelling of class boundaries without attempting to model the entire underlying class density (Otoom, 2010). Examples of this model include support vector machines (SVM), decision trees, boosting and neural networks [see Bishop (2006) for an overview about these methods].
Generally, learning approaches have proved useful and successful for the purpose of author identification. In Tweedie et al. (1996), a classifier based on neural networks has been applied for the Federalist Paper case and a reasonable accuracy has been achieved. In Diederich et al. (2000), the authors applied SVM for the purpose of classifying newspaper writings associated with seven different writers. Accuracy results ranging from 60% to 80% has been achieved from this study. In the work of De Vel et al. (2001), SVM has also been implemented for the purpose of e-mail author identification of three authors and an average accuracy of 80% is achieved. Another example is the work of Khmelev (2000), where the generative model of Markov chains has been applied for authorship attribution based on the probabilities of subsequent letters. Generally, each of these methods has its positives and negatives and there is no unique algorithm that can be generalised as the best among the others.
In this paper, we propose the application of machine learning algorithms for the purpose of Arabic text author identification. This problem has not been targeted in the literature except in few studies. For example, the authors in Abbasi and Chen (2005)

332 A.F. Otoom et al.
targeted the problem of analysing the Arabic web content for the purpose of identifying any security threats. However, the authors did not propose any specific features to the language used but rather general features.
Arabic text author attribution is a challenging problem as there are linguistic complexities associated with the Arabic language. Arabic words length is shorter than English words and this has a negative effect on the lexical features extracted (elongation challenge) (Abbasi and Chen, 2005). Another challenge with the Arabic language is inflection as a similar word root can have many stems by adding affixes but the meaning of these stems is totally different (Abbasi and Chen, 2005). Because of the abovementioned challenges, we propose a robust hybrid dataset that has common well known text features in conjunction with certain features that are specific to the Arabic language grammar. To prove the effectiveness of the proposed method, we run extensive experiments with well-known intelligent classification algorithms and using two validation methods.
The rest of this paper is organised as follows: In Section 2, we explain the feature extraction part. Section 3 gives an overview about the classification algorithms used in our experiments. In Section 4, we present the experimental results on the proposed feature set. Finally, Section 5 concludes the paper and suggests future work.
2 Feature extraction
As discussed earlier, pattern recognition is concerned with automatic discovery of patterns in data through the use of computer algorithms where these patterns are used for data classification. A pattern is represented in terms of P measurements or features and is viewed as a point in a P-dimensional feature space. The group of these features in this space is referred to as feature set. The effectiveness of the feature set is determined of how well patterns from different classes can be separated (Otoom, 2010). For text articles, feature sets provide a description of the written text in an article. Typical feature sets for texts include lexical, syntactic, structural, and content-specific features.
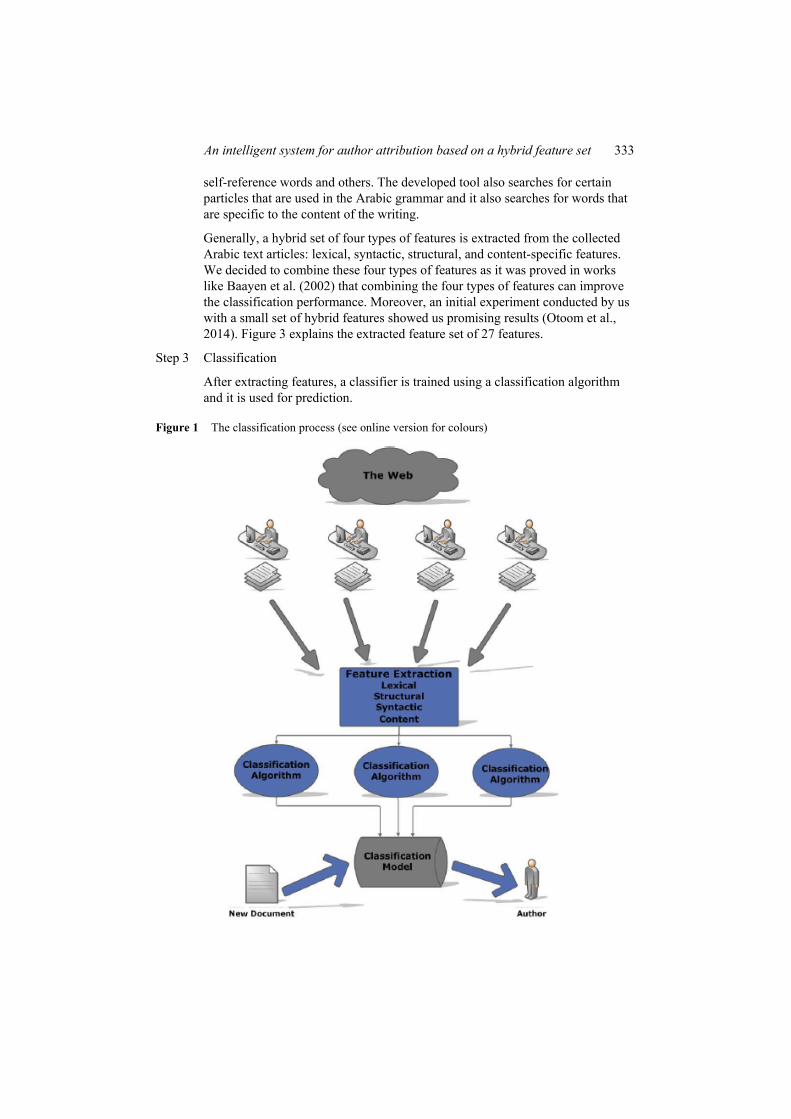
In this work, the following procedure is followed for authorship identification (see Figure 1):
Step 1 Data collection
Data is collected from the internet for text articles related to each of the seven authors. These articles are online newspaper articles in different topics including political, sport, and other topics. In this work, we collected 456 articles for seven Arabic writers (for simplicity, we refer to writer as W) where the number of articles (instances) per writer is explained in Table 1. Moreover, Figure 2 gives examples of these articles for the seven different authors.
Step 2 Feature extraction
A feature extractor is run over the collected articles to extract important information in these articles. It is a tool built using JAVA programming language that runs over the words of each text article and extracts important information from it. It measures the sizes of words and sentences and searches for plural and distinct words in each text article. Moreover, it counts certain types of words like words related to question, words that contain digits,
An intelligent system for author attribution based on a hybrid feature set 333
self-reference words and others. The developed tool also searches for certain particles that are used in the Arabic grammar and it also searches for words that are specific to the content of the writing.
Generally, a hybrid set of four types of features is extracted from the collected Arabic text articles: lexical, syntactic, structural, and content-specific features. We decided to combine these four types of features as it was proved in works like Baayen et al. (2002) that combining the four types of features can improve the classification performance. Moreover, an initial experiment conducted by us with a small set of hybrid features showed us promising results (Otoom et al., 2014). Figure 3 explains the extracted feature set of 27 features.
Step 3 Classification
After extracting features, a classifier is trained using a classification algorithm and it is used for prediction.
Figure 1 The classification process (see online version for colours)

334 A.F. Otoom et al.
Table 1 # of instances per class
Writer name # of instances
W1 49 articles W2 75 articles W3 61 articles W4 62 articles W5 74 articles W6 78 articles W7 57 articles
Figure 2 Examples of parts of Arabic newspaper articles written by seven different authors along with their English translations on the right hand side of the figure
Note: From highest to lowest: W1,W2,W3,W4,W5,W6, and W7 (for simplicity we refer to writer as W).

An intelligent system for author attribution based on a hybrid feature set 335
Figure 3 The feature set; it uses four feature types: lexical, structural, syntactic and content features (see online version for colours)
As it is clear from Figure 3, 27 features of four types are extracted from the 456 Arabic articles. The big words and small words features return the number of words whose length is greater or less than the average length of words related to the same author. The average, short and long sentences features return the number of average, short and long sentences. The small and big statement features return the number of small statements and big statements in the articles related to the same author.
Regarding the complexity feature, it reflects how hard the readability of the text written by the author is and it is calculated as the number of distinct words divided by the total number of words.
For the syntactic features, special characters feature returns the number of special characters in the article (e.g., punctuations, question mark, brackets,..). The plural words feature returns the number of plural words. In Arabic, plural words are not simply recognised as in English where the addition of ‘s’ or ‘es’ can simply translate many words from single to plural. However, our feature extractor uses an intelligent method to detect plural words in the Arabic text. There are certain words in Arabic that are used in question statements and the question words feature returns a count of these words. The contain-digit feature represents a count for the words that contain digits in them.
As noted in Figure 3, there is a subset of syntactic features that are categorised under Arabic specific grammar (ASG) features. These features are commonly used in the Arabic language and they have a certain effect in terms of grammar in relation to the following nouns. Usually, writers tend to use certain type of these features in their writings and thus we decided to include them in the feature set as they may help in improving the discrimination between the different authors.
In addition, we used the positive and negative emotions features, which are examples of the emotions features that reflect the emotions expressed in the human writing and it

336 A.F. Otoom et al.
can be positive or negative. The self-reference feature is the subject to speak of himself/herself or itself. Moreover, cognitive words are important in any author identification problem. Finally, economic, religious, sport and political words are content-specific features and they indicate the number of each of these words in the article.
Thus, we ended up with a dataset that contains 456 instances and each instance is represented with a normalised feature vector of a 27-dimension space.
3 Classification
The main aim of classification is to build an intelligent system that is capable of recognising a new text article and assigning it to one of the seven authors. As discussed earlier, classifiers can be divided into: generative and discriminative. In this work, we experiment with two widely known generative approaches, Naïve Bayes and BayesNet. In addition, we experiment with popular discriminative algorithms that include: SVM, random forest (RF) and MultiBoostAB which are all available as part of the WEKA package, a publicly available toolbox for automatic classification (Witten and Frank, 2000).
3.1 Classifiers
1 Naïve Bayes: is a probabilistic classifier based on applying Bayes’ theorem with naive independence assumptions. Naïve Bayes classifier assumes that the presence (or absence) of a particular feature of a class is unrelated to the presence (or absence) of any other feature, given the class variable (Witten and Frank, 2000).
2 BayesNet: enables the use of a Bayesian network learning using various search algorithms and quality measures. It provides data structures such as network structure, conditional probability distributions, and others (Witten and Frank, 2000).
3 SVM: maps pattern vectors to a higher dimensional feature space where a maximal separating hyperplane is constructed. For a two class problem, two parallel hyperplanes (canonical) are constructed on each side of the separating hyperplane that separates the data. The points that lie on the separating hyperplane are called support vectors. The distance between canonical hyperplanes and the separating hyperplan is called margin. The main idea is to maximise the margin between the classes by selecting a minimum number of support vectors (Otoom, 2010; Bishop, 2006). In this work, we implement a variant of the SVM, which is sequential minimal optimisation. It breaks optimisation problem into a series of smallest possible sub-problems, which are then solved analytically (Witten and Frank, 2000).
4 RF: is an ensemble classifier that consists of many decision trees and outputs the class that is the mode of the classes output by individual trees (Witten and Frank, 2000).
5 MultiBoostAB: is a variant of Adaboost or adaptive boosting which is a well-known method for boosting. Adaboost produces a very accurate classification rule by combining moderately inaccurate weak classifiers. In this work, we implement a variant of the AdaBoost algorithm, which is MultiBoostAB. It combines wagging

An intelligent system for author attribution based on a hybrid feature set 337
and boosting such as their combination retains Adaboost bias reduction while adding wagging’s variance reduction to that already obtained by Adaboost. Thus, the combination may outperform either in isolation (Otoom, 2010; Witten and Frank, 2000).
3.2 Performance evaluation
The performance of the classifier is evaluated in terms of classification accuracy and average false positive rate. Classification accuracy is calculated as the proportion of the number of correctly classified articles against the total number of tested articles
Number of correctly classified examplesAccuracyTotal number of tested examples
=
False positive rate (FPR) is calculated as the proportion of all text articles predicted wrongly against the sum of the true negatives (TN) and the false positives (FP)
.FPFPRTN FP
=+
4 Experimental results and analysis
Experiments are conducted in order to evaluate the performance of the proposed feature set. We carried out two experiments to validate the proposed feature set with the selected algorithms. The first validation method is the hold-out test and the second method is the cross-validation test. In addition, we carried out a third experiment to evaluate the classification performance with the inclusion of ASG features and without it.
4.1 Experiment 1: hold-out test
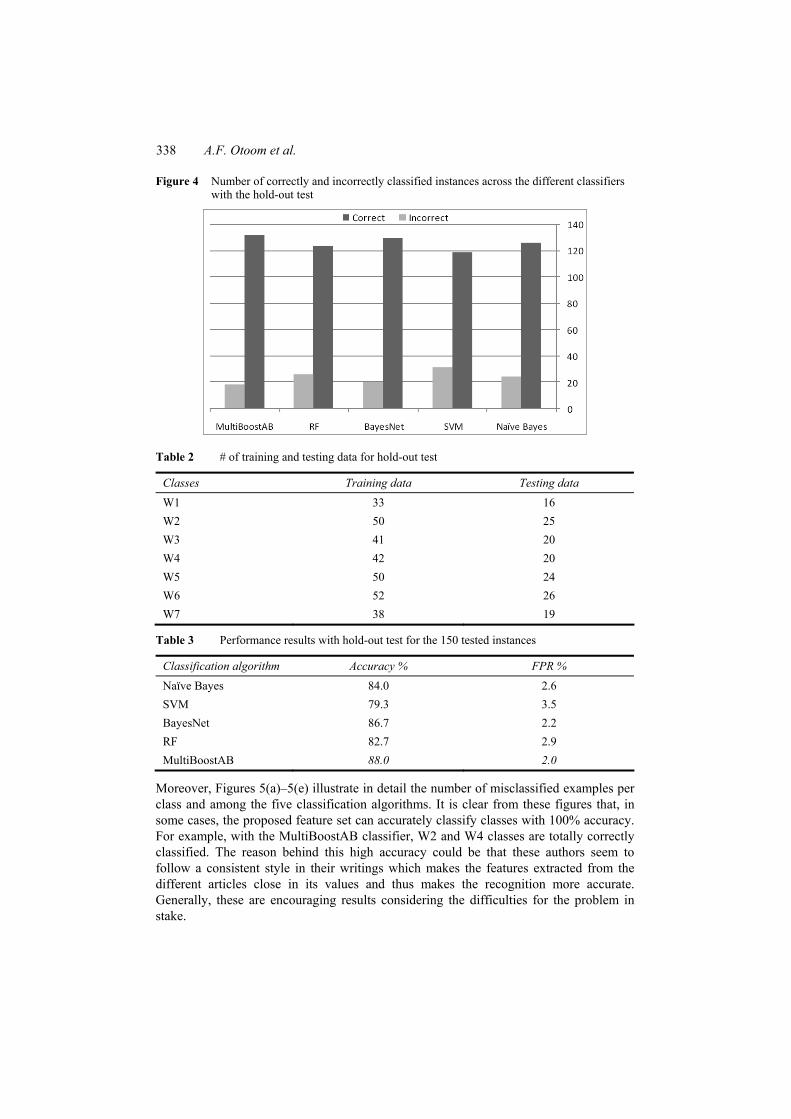
For the first validation method, we partitioned the 456 text articles into two independent datasets. Almost 2/3 of the data is used to train the classifier and build the classification model using a certain classification algorithm. After that, the testing data are tested by the model and the predicted instances are compared with the original ones and the accuracy and false positive rates are calculated. Table 2 shows the number of samples used for training and testing for each of the seven classes. Figure 4 shows the number of correctly and incorrectly classified instances across different classifiers. Moreover, Table 3 shows the accuracy and false positive rates of the proposed feature set using the abovementioned classification algorithms. It is clear from this table that the proposed feature set is powerful for discriminating between the seven classes with a performance accuracy of 88% and low FPR of 2% with the MultiBoostAB algorithm. This achieved accuracy is considered high given the high number of classes which makes it challenging for distinguishing between them. Moreover, the different writing habits for each author and the different topics they may write about especially in the Arabic language makes it a challenging task to recognise the author of the text. In general, the proposed feature set proved to be effective in this problem.
338 A.F. Otoom et al.
Figure 4 Number of correctly and incorrectly classified instances across the different classifiers with the hold-out test
Table 2 # of training and testing data for hold-out test
Classes Training data Testing data
W1 33 16 W2 50 25 W3 41 20 W4 42 20 W5 50 24 W6 52 26 W7 38 19
Table 3 Performance results with hold-out test for the 150 tested instances
Classification algorithm Accuracy % FPR %
Naïve Bayes 84.0 2.6 SVM 79.3 3.5 BayesNet 86.7 2.2 RF 82.7 2.9 MultiBoostAB 88.0 2.0
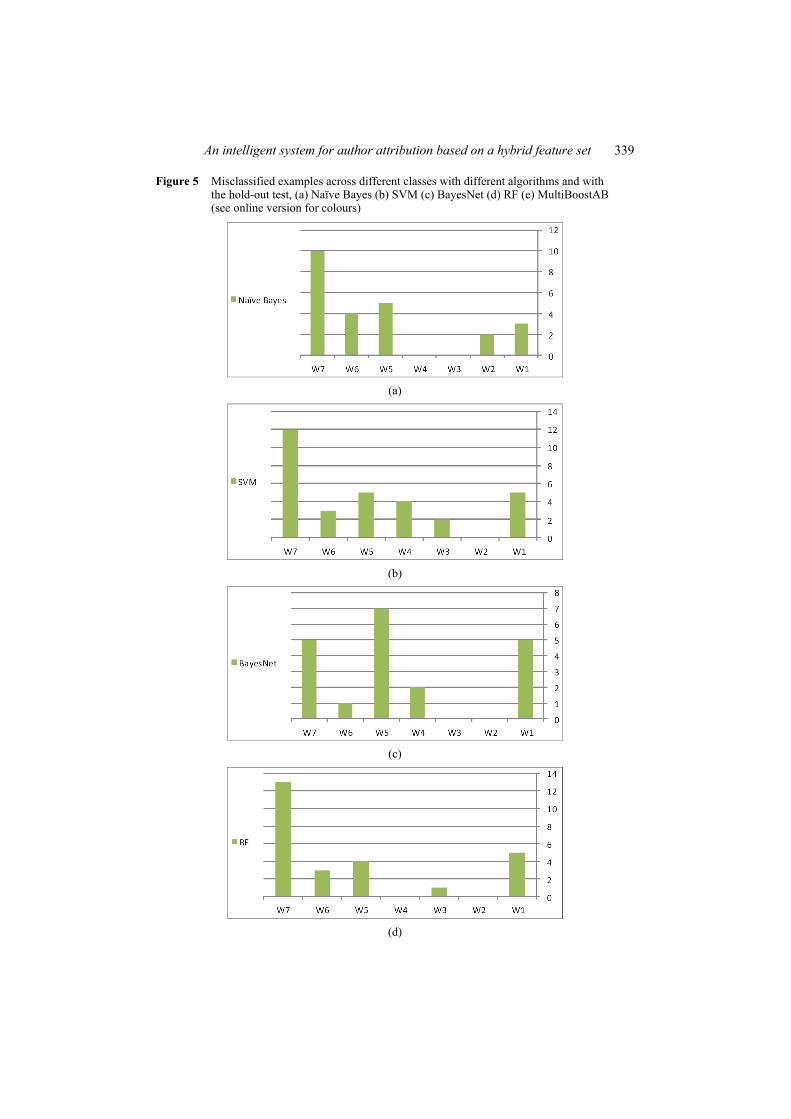
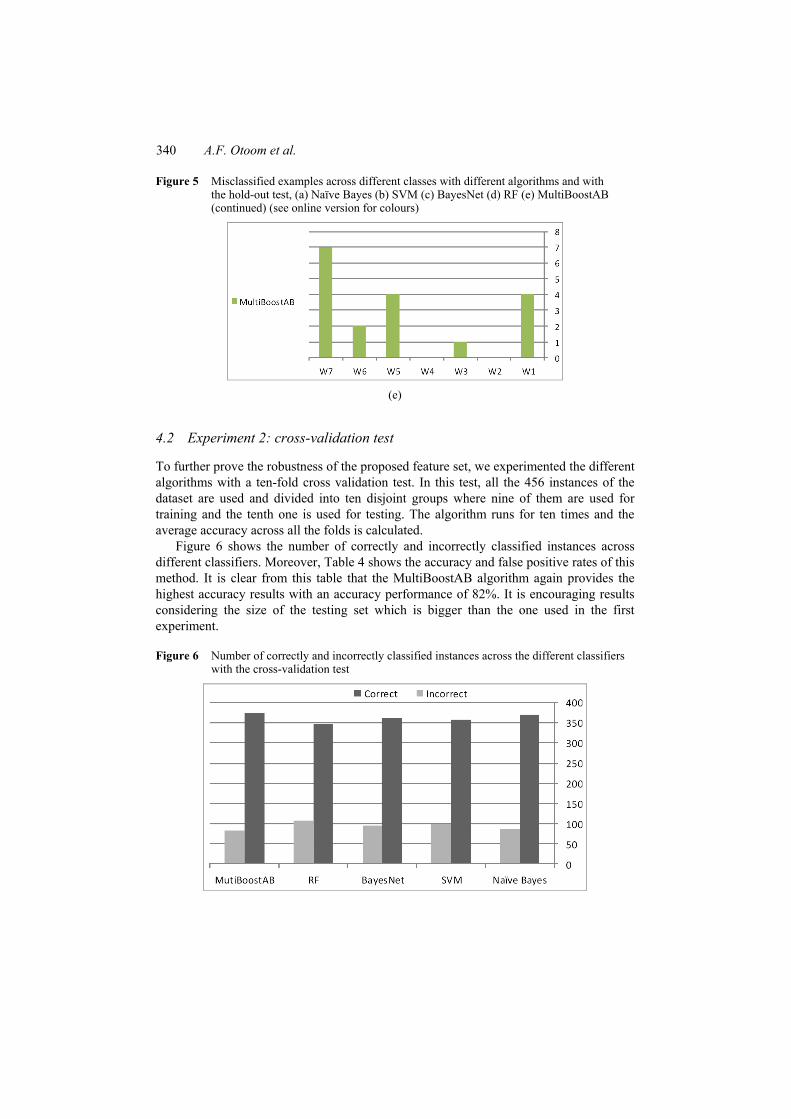
Moreover, Figures 5(a)–5(e) illustrate in detail the number of misclassified examples per class and among the five classification algorithms. It is clear from these figures that, in some cases, the proposed feature set can accurately classify classes with 100% accuracy. For example, with the MultiBoostAB classifier, W2 and W4 classes are totally correctly classified. The reason behind this high accuracy could be that these authors seem to follow a consistent style in their writings which makes the features extracted from the different articles close in its values and thus makes the recognition more accurate. Generally, these are encouraging results considering the difficulties for the problem in stake.
An intelligent system for author attribution based on a hybrid feature set 339
Figure 5 Misclassified examples across different classes with different algorithms and with the hold-out test, (a) Naïve Bayes (b) SVM (c) BayesNet (d) RF (e) MultiBoostAB (see online version for colours)
(a)
(b)
(c)
(d)
340 A.F. Otoom et al.
Figure 5 Misclassified examples across different classes with different algorithms and with the hold-out test, (a) Naïve Bayes (b) SVM (c) BayesNet (d) RF (e) MultiBoostAB (continued) (see online version for colours)
(e)
4.2 Experiment 2: cross-validation test
To further prove the robustness of the proposed feature set, we experimented the different algorithms with a ten-fold cross validation test. In this test, all the 456 instances of the dataset are used and divided into ten disjoint groups where nine of them are used for training and the tenth one is used for testing. The algorithm runs for ten times and the average accuracy across all the folds is calculated.
Figure 6 shows the number of correctly and incorrectly classified instances across different classifiers. Moreover, Table 4 shows the accuracy and false positive rates of this method. It is clear from this table that the MultiBoostAB algorithm again provides the highest accuracy results with an accuracy performance of 82%. It is encouraging results considering the size of the testing set which is bigger than the one used in the first experiment.
Figure 6 Number of correctly and incorrectly classified instances across the different classifiers with the cross-validation test
An intelligent system for author attribution based on a hybrid feature set 341
Table 4 Performance results with ten-fold cross validation
Classification algorithm Accuracy % FPR %
Naïve Bayes 81.1 3.1 SVM 78.3 3.7 BayesNet 79.2 3.5 RF 76.3 3.9 MultiBoostAB 82.0 3.0
Usually, with the cross-validation test the results decrease from the ones with the hold-out test as the algorithm runs over ten testing datasets rather than one testing dataset. However, the results remain stable with slight decreases and there are no dramatic changes between the two validation tests.
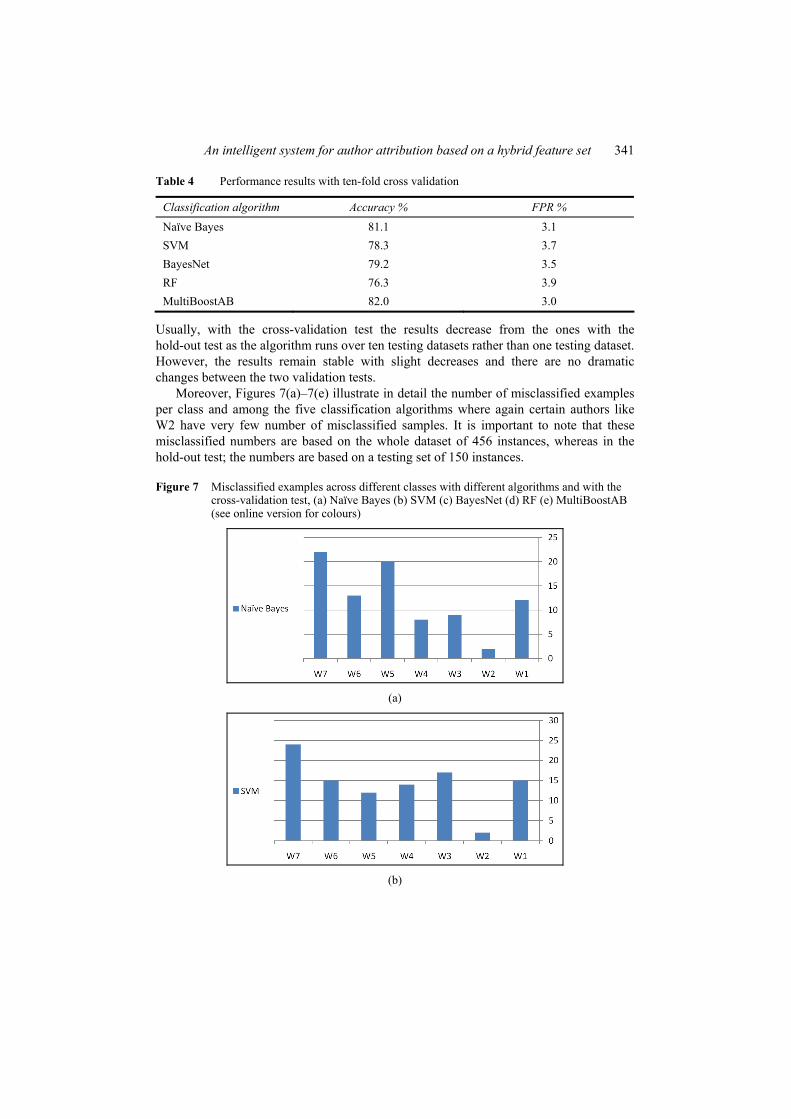
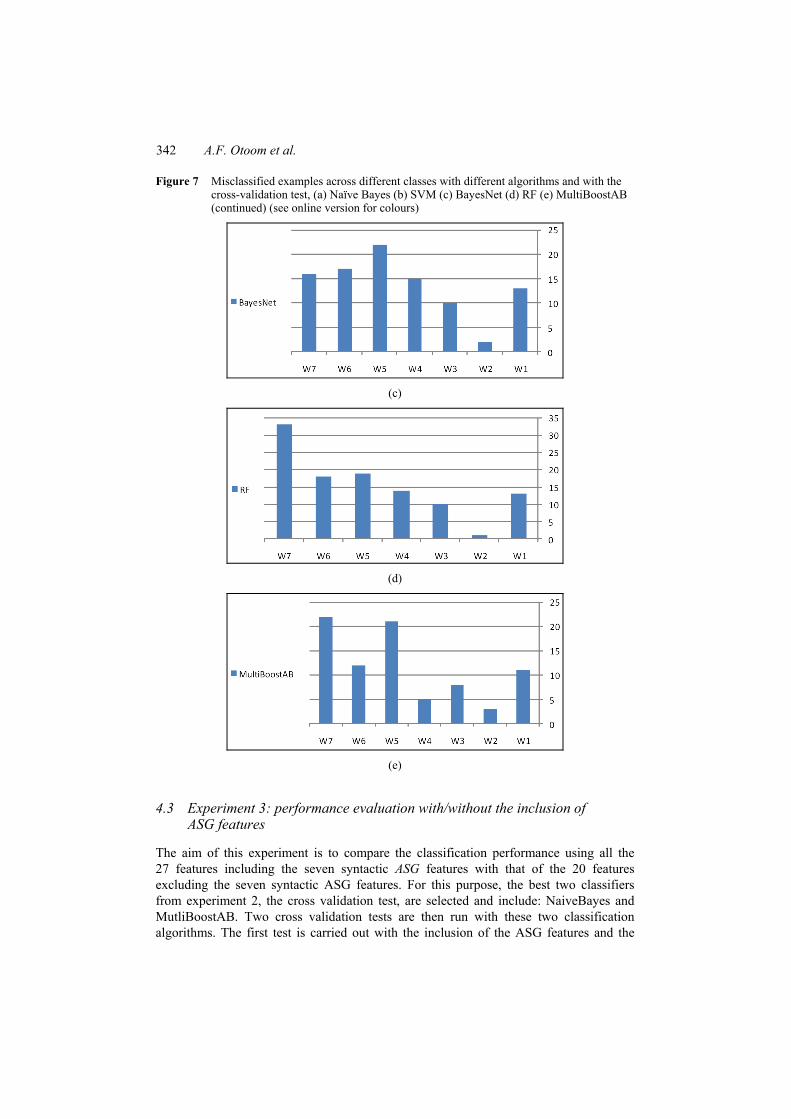
Moreover, Figures 7(a)–7(e) illustrate in detail the number of misclassified examples per class and among the five classification algorithms where again certain authors like W2 have very few number of misclassified samples. It is important to note that these misclassified numbers are based on the whole dataset of 456 instances, whereas in the hold-out test; the numbers are based on a testing set of 150 instances.
Figure 7 Misclassified examples across different classes with different algorithms and with the cross-validation test, (a) Naïve Bayes (b) SVM (c) BayesNet (d) RF (e) MultiBoostAB (see online version for colours)
(a)
(b)
342 A.F. Otoom et al.
Figure 7 Misclassified examples across different classes with different algorithms and with the cross-validation test, (a) Naïve Bayes (b) SVM (c) BayesNet (d) RF (e) MultiBoostAB (continued) (see online version for colours)
(c)
(d)
(e)
4.3 Experiment 3: performance evaluation with/without the inclusion of ASG features
The aim of this experiment is to compare the classification performance using all the 27 features including the seven syntactic ASG features with that of the 20 features excluding the seven syntactic ASG features. For this purpose, the best two classifiers from experiment 2, the cross validation test, are selected and include: NaiveBayes and MutliBoostAB. Two cross validation tests are then run with these two classification algorithms. The first test is carried out with the inclusion of the ASG features and the
An intelligent system for author attribution based on a hybrid feature set 343
second test is implemented without the inclusion of these features. Performance results are then compared.
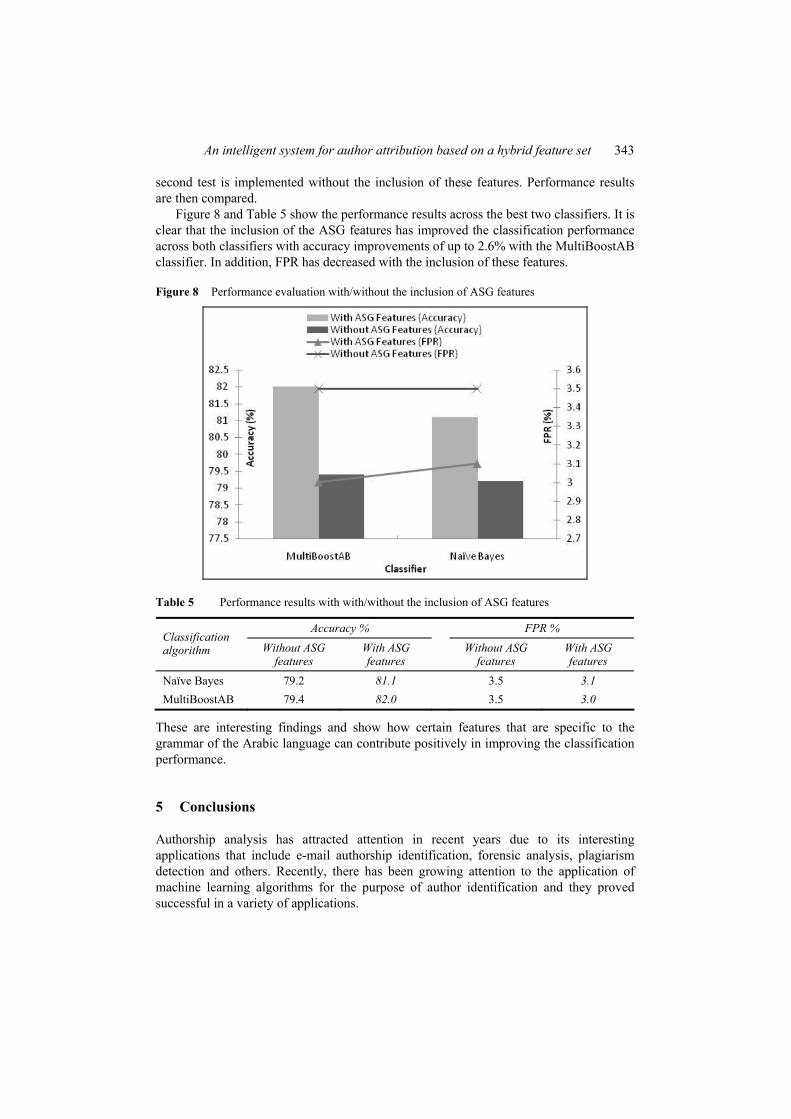
Figure 8 and Table 5 show the performance results across the best two classifiers. It is clear that the inclusion of the ASG features has improved the classification performance across both classifiers with accuracy improvements of up to 2.6% with the MultiBoostAB classifier. In addition, FPR has decreased with the inclusion of these features.
Figure 8 Performance evaluation with/without the inclusion of ASG features
Table 5 Performance results with with/without the inclusion of ASG features
Accuracy % FPR % Classification algorithm Without ASG
features With ASG features
Without ASG features
With ASG features
Naïve Bayes 79.2 81.1 3.5 3.1 MultiBoostAB 79.4 82.0 3.5 3.0
These are interesting findings and show how certain features that are specific to the grammar of the Arabic language can contribute positively in improving the classification performance.
5 Conclusions
Authorship analysis has attracted attention in recent years due to its interesting applications that include e-mail authorship identification, forensic analysis, plagiarism detection and others. Recently, there has been growing attention to the application of machine learning algorithms for the purpose of author identification and they proved successful in a variety of applications.

344 A.F. Otoom et al.
In this paper, we targeted the problem of identifying the author of an Arabic newspaper article. It is a challenging problem due to the different difficulties associated with the Arabic language. A hybrid set of four types of writing features: lexical, structural, syntactic, and content features are extracted from 456 articles related to seven different authors. Inductive learning algorithms are then used to build an intelligent classification model to identify authors.
To prove the strength of the proposed feature set, we ran two experiments with five popular classification algorithms: Naïve Bayes, BayesNet, SVM, RF and MultiBoostAB. The first experiment is carried out with the hold-out test and an accuracy of 88% was achieved with the MultiBoostAB method proving the robustness of the proposed feature set. To further prove the strength of the proposed feature set, we ran a 10-fold cross validation test and the proposed feature set retained, to a certain degree, its accuracy result. In addition, we carried out a third experiment and showed the positive contribution of the Arabic grammar features.
In the future, we plan to develop a stand-alone application that can be commercially implemented and widely distributed.
References Abbasi, A. and Chen, H. (2005) ‘Applying authorship analysis to extremist-group web forum
messages’, Intelligent Systems Journal, Vol. 20, No. 5, pp.67–75. Abdallah, E.E., Abdallah, A.E., Bsoul, M., Otoom, A.F. and Al-Daoud, E. (2013) ‘Simplified
features for email authorship identification’, International Journal of Security and Networks, Vol. 8, No. 2, pp.72–81.
Baayen, H., van Halteren, H., Neijt, A. and Tweedie, F. (2002) ‘An experiment in authorship attribution’, Proc. of the 6th International Conference on Statistical Analysis of Textual Data (JADT), pp.29–37.
Bishop, C.M. (2006) Pattern Recognition and Machine Learning, Springer, New York, USA. Clough, P. (2000) Plagiarism in Natural and Programming Languages: An Overview of Current
Tools and Technologies, pp.1–31, Research Memoranda: CS-00-05, Department of Computer Science, University of Sheffield, UK.
De Vel, O., Anderson, A., Corney, M. and Mohay, G. (2001) ‘Mining e-mail content for author identification forensics’, ACM Sigmod Record, Vol. 30, No. 4, pp.55–64.
Diederich, J., Kindermann, J., Leopold, E. and Paass, G. (2000) ‘Authorship attribution with support vector machines’, Applied Intelligence, Vol. 19, Nos. 1–2, pp.109–123.
Grant, T. (2007) ‘Quantifying evidence in forensic authorship analysis’, International Journal of Speech, Language & the Law, Vol. 14, No. 1, pp.1–25.
Holmes, D.I. (1998) ‘The evolution of stylometry in humanities scholarship’, Literary and Linguistic Computing, Vol. 13, No. 3, pp.111–117.
Hoover, D.L. (2004) ‘Testing Burrows’s delta’, Literary and Linguistic Computing, Vol. 19, No. 4, pp.453–475.
Khmelev, D.V. (2000) ‘Disputed authorship resolution through using relative empirical entropy for Markov chains of letters in human language texts’, Journal of Quantitative Linguistics, Vol. 7, No. 3, pp.201–207.
Koppel, M., Argamon, S. and Shimoni, A.R. (2002) ‘Automatically categorizing written texts by author gender’, Literary and Linguistic Computing, Vol. 17, No. 4, pp.401–412.
Kourtis, I. and Stamatatos, E. (2011) ‘Author identification using semi-supervised learning’, Proc. of the 2011 Conference on Multilingual and Multimodal Information Access Evaluation, Amsterdam, The Netherlands.

An intelligent system for author attribution based on a hybrid feature set 345
Mosteller, F. and Wallace, D.L. (1964) Applied Bayesian and Classical Inference: The Case of the Federalist Papers, Springer-Verlag, New York.
Otoom, A.F. (2010) Effective Features Set and Dimensionality Reduction for Object Classification, University of Technology (UTS), Sydney.
Otoom, A.F., Abdullah, E.E., Jaafer, S., Hamdallh, A. and Amer, D. (2014) ‘Towards author identification of Arabic text articles’, Proc. of 5th International Conference on Information and Communication Systems, pp.1–4.
Stamatatos, E. (2009) ‘A survey of modern authorship attribution methods’, Journal of the American Society for information Science and Technology, Vol. 60, No. 3, pp.538–556.
Tweedie, F.J., Singh, S. and Holmes, D.I. (1996) ‘Neural network applications in stylometry: the federalist papers’, Computers and the Humanities, Vol. 30, No. 1, pp.1–10.
Witten, I.H. and Frank, E. (2000) Data Mining: Practical Machine Learning Tools with Java Implementations, Morgan Kaufmann, San Francisco, CA.
Zheng, R., Li, J., Chen, H. and Huang, Z. (2006) ‘A framework for authorship identification of online messages: writing style features and classification techniques’, Journal of the American Society for Information Science and Technology, Vol. 57, No. 3, pp.378–393.
Zheng, R., Qin, Y., Huang, Z. and Chen, H. (2003) ‘Authorship analysis in cybercrime investigation’, Proc. of Intelligence and Security Informatics, Springer, Berlin, Heidelberg, pp.59–73.





























