Embed Size (px)
DESCRIPTION
METEOR: M etric for E valuation of T ranslation with E xplicit Or dering An Automatic Metric for MT Evaluation with Improved Correlations with Human Judgments. Alon Lavie and Satanjeev Banerjee Language Technologies Institute Carnegie Mellon University With help from: - PowerPoint PPT Presentation
Citation preview

METEOR:Metric for Evaluation of Translation with Explicit Ordering
An Automatic Metric for MT Evaluationwith Improved Correlations with Human Judgments
Alon Lavie and Satanjeev Banerjee
Language Technologies InstituteCarnegie Mellon University
With help from: Kenji Sagae, Shyamsundar Jayaraman

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
2
Similarity-based MT Evaluation Metrics
• Assess the “quality” of an MT system by comparing its output with human produced “reference” translations
• Premise: the more similar (in meaning) the translation is to the reference, the better
• Goal: an algorithm that is capable of accurately approximating the similarity
• Wide Range of metrics, mostly focusing on word-level correspondences:– Edit-distance metrics: Levenshtein, WER, PIWER, …– Ngram-based metrics: Precision, Recall, F1-measure, BLEU,
NIST, GTM…• Main Issue: perfect word matching is very crude
estimate for sentence-level similarity in meaning

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
3
Desirable Automatic Metric
• High-levels of correlation with quantified human notions of translation quality
• Sensitive to small differences in MT quality between systems and versions of systems
• Consistent – same MT system on similar texts should produce similar scores
• Reliable – MT systems that score similarly will perform similarly
• General – applicable to a wide range of domains and scenarios
• Fast and lightweight – easy to run

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
4
Some Weaknesses in BLEU• BLUE matches word ngrams of MT-translation with multiple
reference translations simultaneously Precision-based metric– Is this better than matching with each reference translation
separately and selecting the best match?• BLEU Compensates for Recall by factoring in a “Brevity
Penalty” (BP)– Is the BP adequate in compensating for lack of Recall?
• BLEU’s ngram matching requires exact word matches– Can stemming and synonyms improve the similarity measure and
improve correlation with human scores?• All matched words weigh equally in BLEU
– Can a scheme for weighing word contributions improve correlation with human scores?
• BLEU’s Higher order ngrams account for fluency and grammaticality, ngrams are geometrically averaged– Geometric ngram averaging is volatile to “zero” scores. Can we
account for fluency/grammaticality via other means?

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
5
Unigram-based Metrics
• Unigram Precision: fraction of words in the MT that appear in the reference
• Unigram Recall: fraction of the words in the reference translation that appear in the MT
• F1= P*R/0.5*(P+R)• Fmean = P*R/(0.9*P+0.1*R)• Generalized Unigram matches:
– Exact word matches, stems, synonyms
• Match with each reference separately and select the best match for each sentence

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
6
The METEOR Metric
• Main new ideas:– Reintroduce Recall and combine it with Precision as
score components– Look only at unigram Precision and Recall– Align MT output with each reference individually and
take score of best pairing– Matching takes into account word inflection
variations (via stemming) and synonyms (via WordNet synsets)
– Address fluency via a direct penalty: how fragmented is the matching of the MT output with the reference?

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
7
The Alignment Matcher
• Find the best word-to-word alignment match between two strings of words– Each word in a string can match at most one word in
the other string– Matches can be based on generalized criteria: word
identity, stem identity, synonymy…– Find the alignment of highest cardinality with
minimal number of crossing branches• Optimal search is NP-complete
– Clever search with pruning is very fast and has near optimal results
• Greedy three-stage matching: exact, stem, synonyms

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
8
The Full METEOR Metric
• Matcher explicitly aligns matched words between MT and reference
• Matcher returns fragment count (frag) – used to calculate average fragmentation– (frag -1)/(length-1)
• METEOR score calculated as a discounted Fmean score– Discounting factor: DF = 0.5 * (frag**3)– Final score: Fmean * (1- DF)
• Scores can be calculated at sentence-level• Aggregate score calculated over entire test set (similar
to BLEU)
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
9
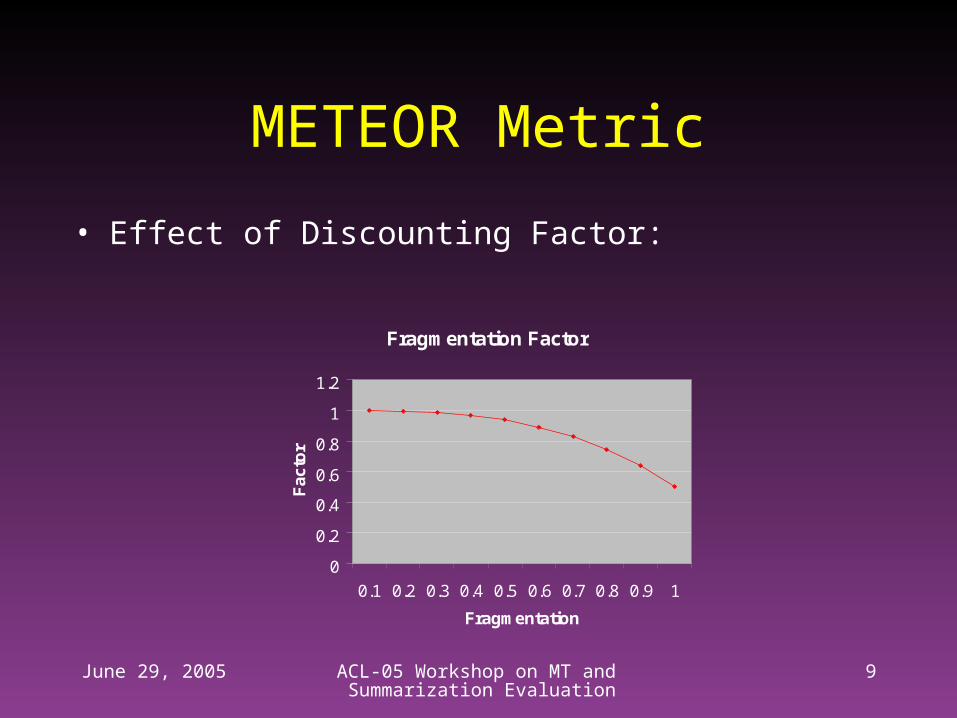
METEOR Metric
• Effect of Discounting Factor:
Fragmentation Factor
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fragmentation
Fa
cto
r

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
10
The METEOR Metric
• Example:– Reference: “the Iraqi weapons are to be handed over to the
army within two weeks”– MT output: “in two weeks Iraq’s weapons will give army”
• Matching: Ref: Iraqi weapons army two weeks MT: two weeks Iraq’s weapons army• P = 5/8 =0.625 R = 5/14 = 0.357 • Fmean = 10*P*R/(9P+R) = 0.3731• Fragmentation: 3 frags of 5 words = (3-1)/(5-1) = 0.50• Discounting factor: DF = 0.5 * (frag**3) = 0.0625• Final score: Fmean * (1- DF) = 0.3731*0.9375 = 0.3498

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
11
Evaluating METEOR
• How do we know if a metric is better?– Better correlation with human judgments of
MT output– Reduced score variability on MT sentence
outputs that are ranked equivalent by humans
– Higher and less variable scores on scoring human translations (references) against other human (reference) translations

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
12
Correlation with Human Judgments
• Human judgment scores for adequacy and fluency, each [1-5] (or sum them together)
• Pearson or spearman (rank) correlations• Correlation of metric scores with human scores at the
system level– Can rank systems– Even coarse metrics can have high correlations
• Correlation of metric scores with human scores at the sentence level– Evaluates score correlations at a fine-grained level– Very large number of data points, multiple systems– Pearson correlation– Look at metric score variability for MT sentences scored as
equally good by humans

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
13
Evaluation Setup
• Data: LDC Released Common data-set (DARPA/TIDES 2003 Chinese-to-English and Arabic-to-English MT evaluation data)
• Chinese data: – 920 sentences, 4 reference translations– 7 systems
• Arabic data:– 664 sentences, 4 reference translations– 6 systems
• Metrics Compared: BLEU, P, R, F1, Fmean, METEOR (with several features)
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
14
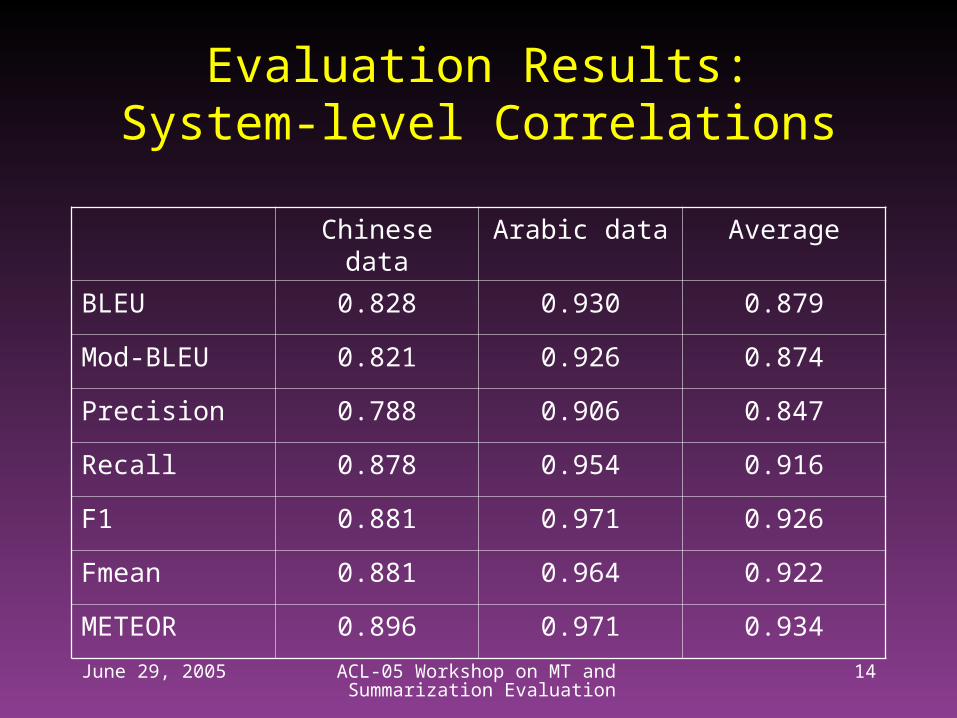
Evaluation Results:System-level Correlations
Chinese data Arabic data Average
BLEU 0.828 0.930 0.879
Mod-BLEU 0.821 0.926 0.874
Precision 0.788 0.906 0.847
Recall 0.878 0.954 0.916
F1 0.881 0.971 0.926
Fmean 0.881 0.964 0.922
METEOR 0.896 0.971 0.934
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
15
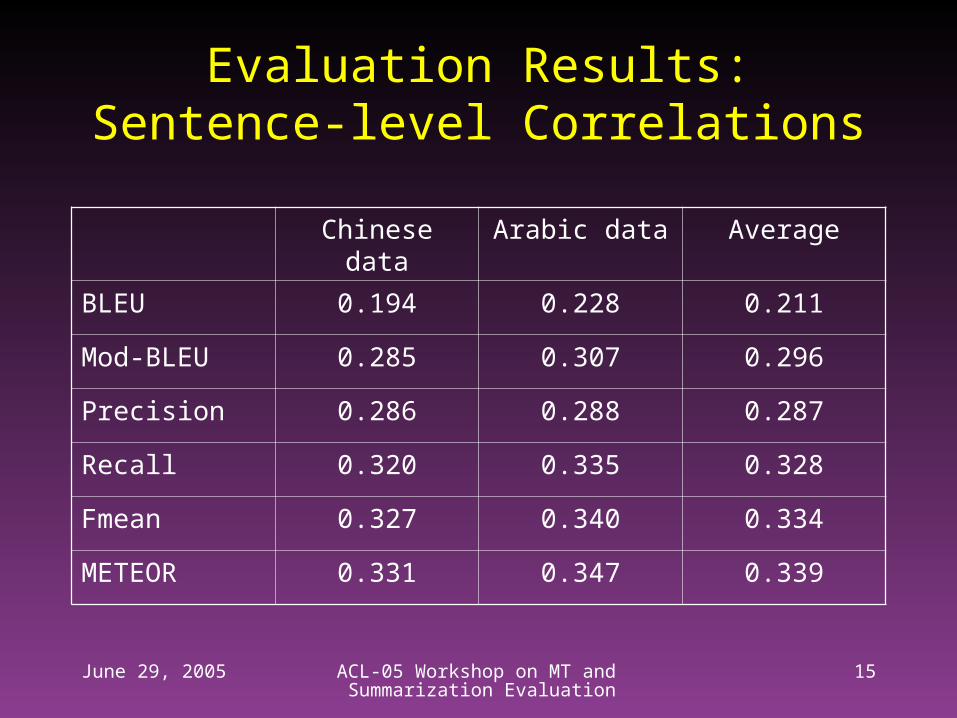
Evaluation Results:Sentence-level Correlations
Chinese data Arabic data Average
BLEU 0.194 0.228 0.211
Mod-BLEU 0.285 0.307 0.296
Precision 0.286 0.288 0.287
Recall 0.320 0.335 0.328
Fmean 0.327 0.340 0.334
METEOR 0.331 0.347 0.339
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
16
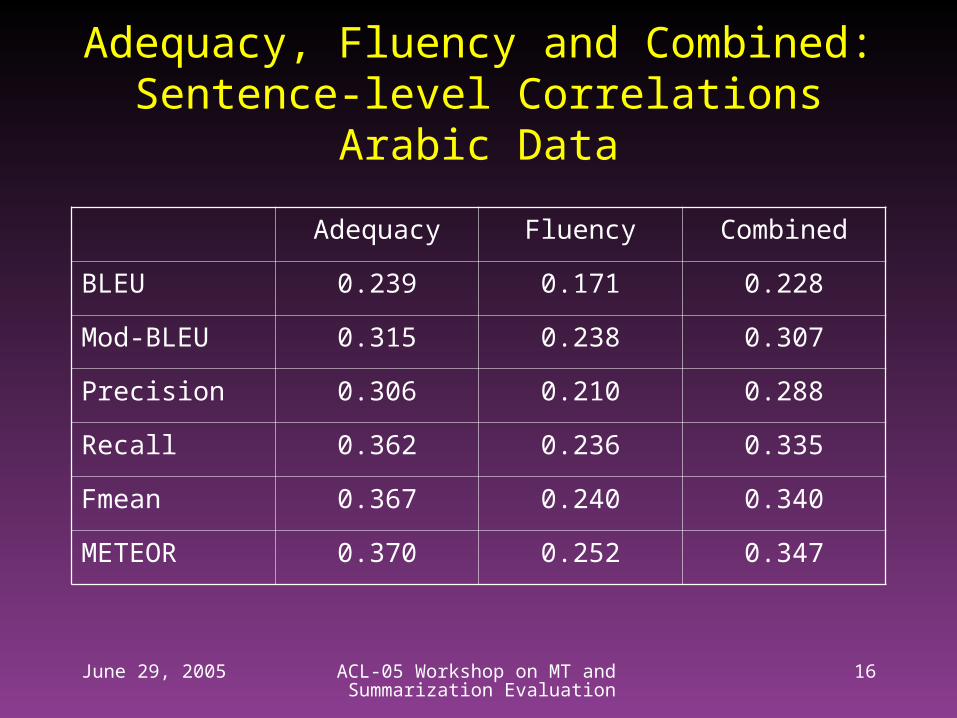
Adequacy, Fluency and Combined:Sentence-level Correlations
Arabic Data
Adequacy Fluency Combined
BLEU 0.239 0.171 0.228
Mod-BLEU 0.315 0.238 0.307
Precision 0.306 0.210 0.288
Recall 0.362 0.236 0.335
Fmean 0.367 0.240 0.340
METEOR 0.370 0.252 0.347
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
17
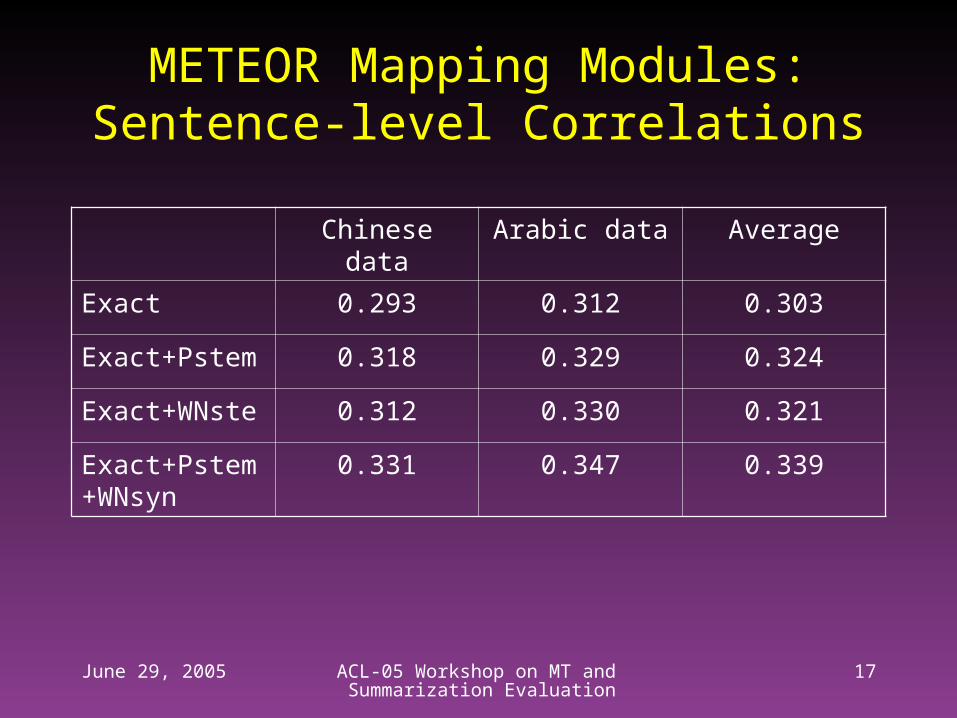
METEOR Mapping Modules:Sentence-level Correlations
Chinese data Arabic data Average
Exact 0.293 0.312 0.303
Exact+Pstem 0.318 0.329 0.324
Exact+WNste 0.312 0.330 0.321
Exact+Pstem+WNsyn
0.331 0.347 0.339
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
18
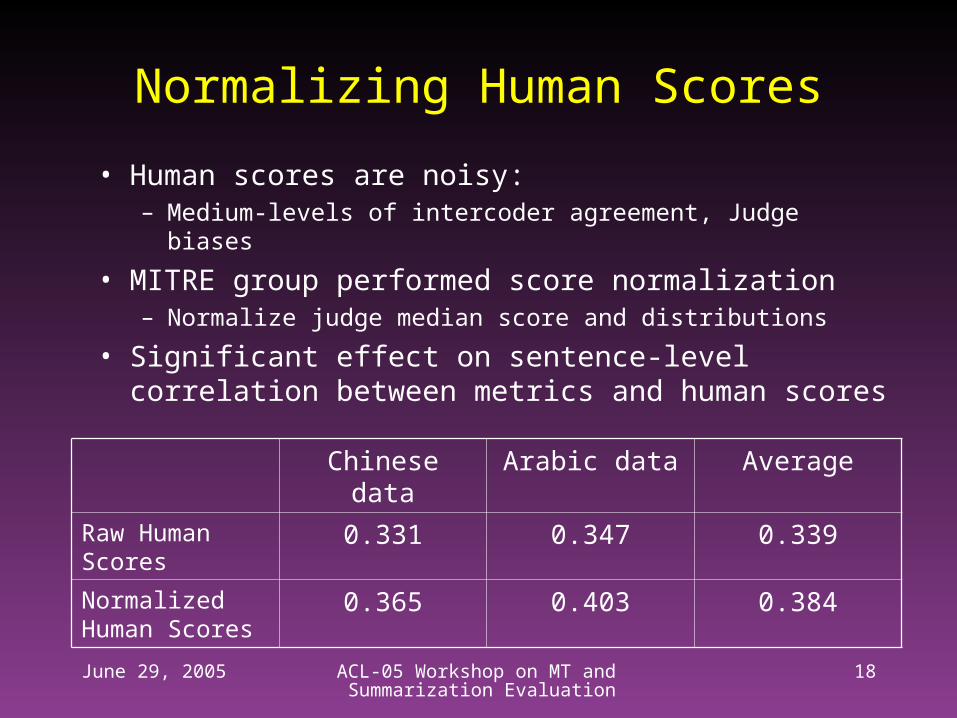
Normalizing Human Scores
Chinese data Arabic data Average
Raw Human Scores
0.331 0.347 0.339
Normalized Human Scores
0.365 0.403 0.384
• Human scores are noisy:– Medium-levels of intercoder agreement, Judge biases
• MITRE group performed score normalization– Normalize judge median score and distributions
• Significant effect on sentence-level correlation between metrics and human scores
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
19
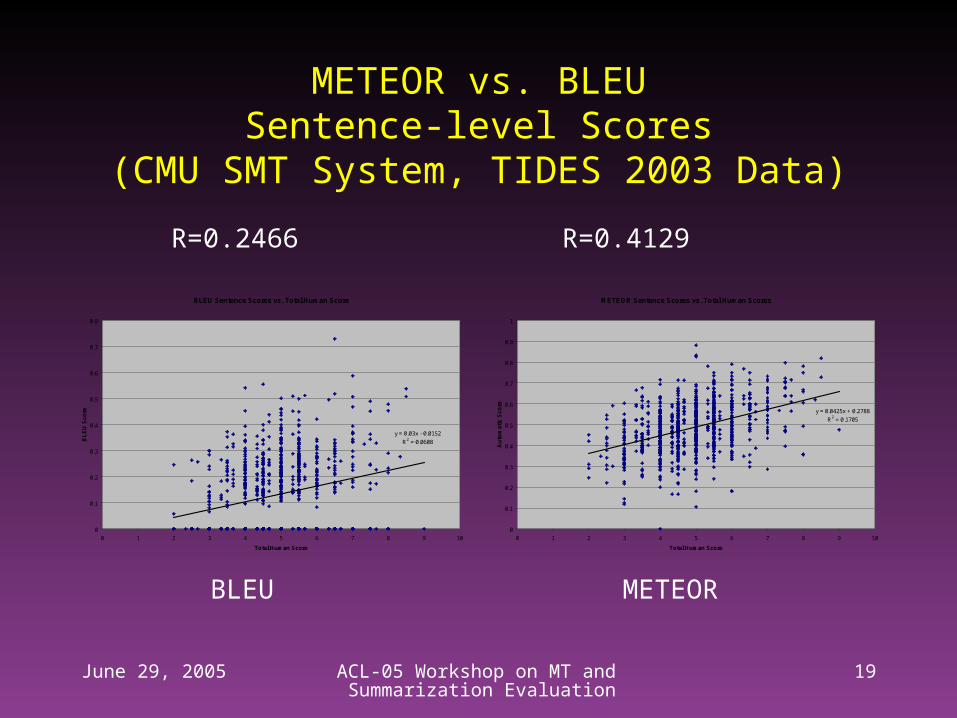
METEOR vs. BLEUSentence-level Scores
(CMU SMT System, TIDES 2003 Data)
BLEU Sentence Scores vs. Total Human Score
y = 0.03x - 0.0152
R2 = 0.0608
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 1 2 3 4 5 6 7 8 9 10
Total Human Score
BL
EU
Sco
re
METEOR Sentence Scores vs. Total Human Scores
y = 0.0425x + 0.2788
R2 = 0.1705
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 1 2 3 4 5 6 7 8 9 10
Total Human Score
Au
tom
atic
Sco
re
R=0.2466 R=0.4129
BLEU METEOR
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
20
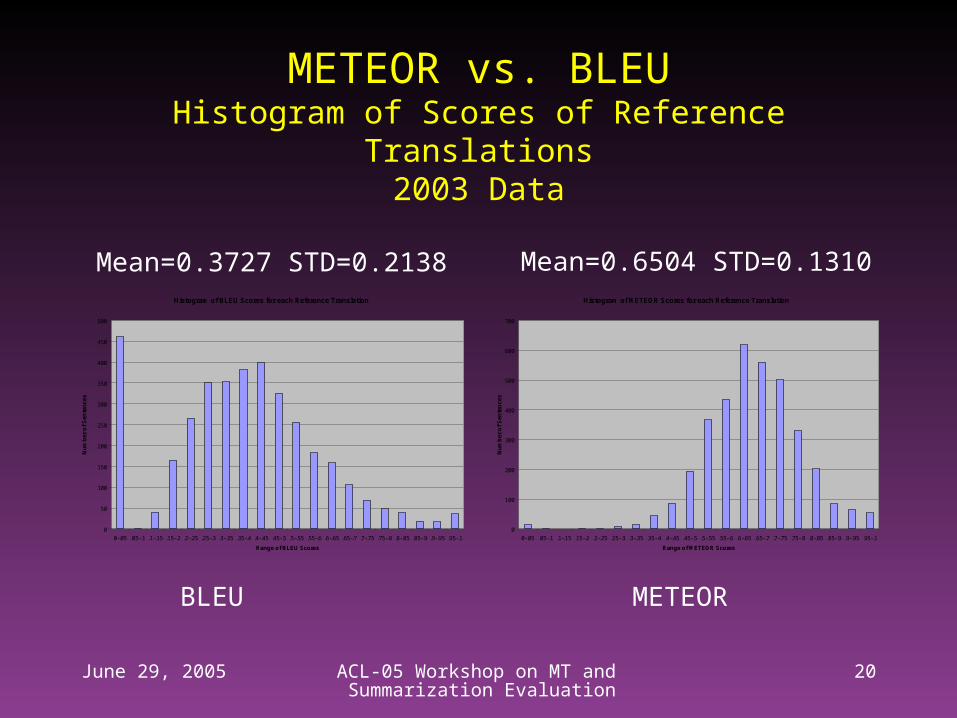
METEOR vs. BLEUHistogram of Scores of Reference Translations
2003 Data
Histogram of BLEU Scores for each Reference Translation
0
50
100
150
200
250
300
350
400
450
500
0-.05 .05-.1 .1-.15 .15-.2 .2-.25 .25-.3 .3-.35 .35-.4 .4-.45 .45-.5 .5-.55 .55-.6 .6-.65 .65-.7 .7-.75 .75-.8 .8-.85 .85-.9 .9-.95 .95-.1
Range of BLEU Scores
Nu
mb
er o
f S
ente
nce
s
Histogram of METEOR Scores for each Reference Translation
0
100
200
300
400
500
600
700
0-.05 .05-.1 .1-.15 .15-.2 .2-.25 .25-.3 .3-.35 .35-.4 .4-.45 .45-.5 .5-.55 .55-.6 .6-.65 .65-.7 .7-.75 .75-.8 .8-.85 .85-.9 .9-.95 .95-.1
Range of METEOR Scores
Nu
mb
er o
f S
ente
nce
s
BLEU METEOR
Mean=0.3727 STD=0.2138 Mean=0.6504 STD=0.1310

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
21
Future Work• Optimize fragmentation penalty function based
on training data• Extend Matcher to capture word correspondences
with semantic relatedness (synonyms and beyond)
• Evaluate importance and effect of the number of reference translations need for synthetic references
• Schemes for weighing the matched words – Based on their translation importance– Based on their similarity-level
• Consider other schemes for capturing fluency/grammaticality/coherence of MT output

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
22
Using METEOR
• METEOR software package freely available and downloadable on web:http://www.cs.cmu.edu/~alavie/METEOR/
• Required files and formats identical to BLEU if you know how to run BLEU, you know how to run METEOR!!
• We welcome comments and bug reports…

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
23
Conclusions
• Recall more important than Precision• Importance of focusing on sentence-level
correlations• Sentence-level correlations are still rather low
(and noisy), but significant steps in the right direction– Generalizing matchings with stemming and
synonyms gives a consistent improvement in correlations with human judgments
• Human judgment normalization is important and has significant effect

June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
24
Questions?
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
25
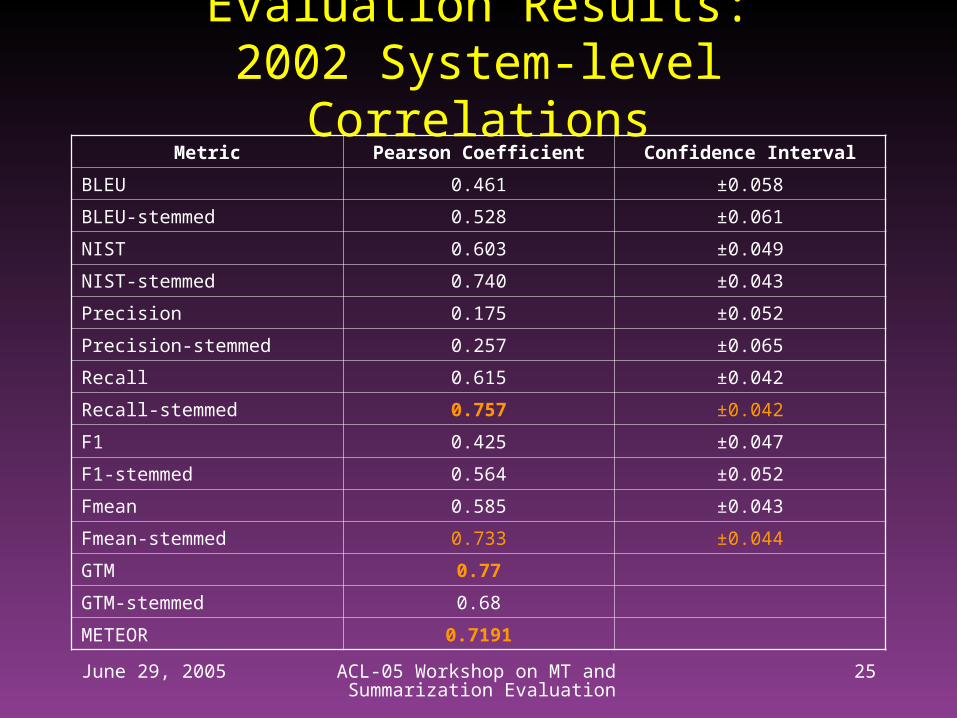
Evaluation Results:2002 System-level Correlations
Metric Pearson Coefficient Confidence Interval
BLEU 0.461 ±0.058
BLEU-stemmed 0.528 ±0.061
NIST 0.603 ±0.049
NIST-stemmed 0.740 ±0.043
Precision 0.175 ±0.052
Precision-stemmed 0.257 ±0.065
Recall 0.615 ±0.042
Recall-stemmed 0.757 ±0.042
F1 0.425 ±0.047
F1-stemmed 0.564 ±0.052
Fmean 0.585 ±0.043
Fmean-stemmed 0.733 ±0.044
GTM 0.77
GTM-stemmed 0.68
METEOR 0.7191
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
26
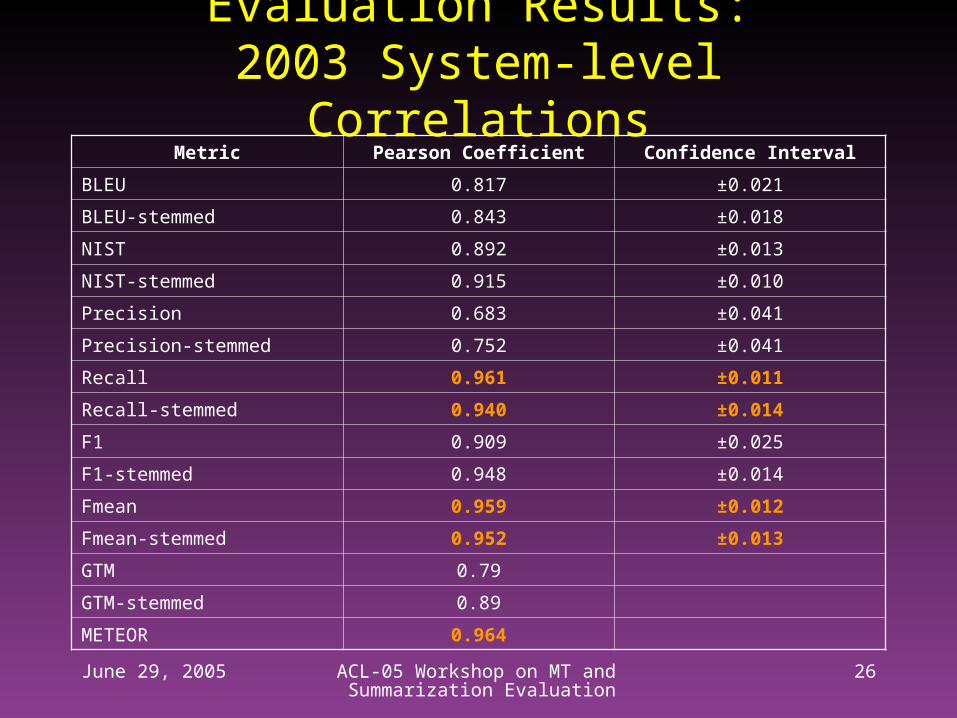
Evaluation Results:2003 System-level Correlations
Metric Pearson Coefficient Confidence Interval
BLEU 0.817 ±0.021
BLEU-stemmed 0.843 ±0.018
NIST 0.892 ±0.013
NIST-stemmed 0.915 ±0.010
Precision 0.683 ±0.041
Precision-stemmed 0.752 ±0.041
Recall 0.961 ±0.011
Recall-stemmed 0.940 ±0.014
F1 0.909 ±0.025
F1-stemmed 0.948 ±0.014
Fmean 0.959 ±0.012
Fmean-stemmed 0.952 ±0.013
GTM 0.79
GTM-stemmed 0.89
METEOR 0.964
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
27
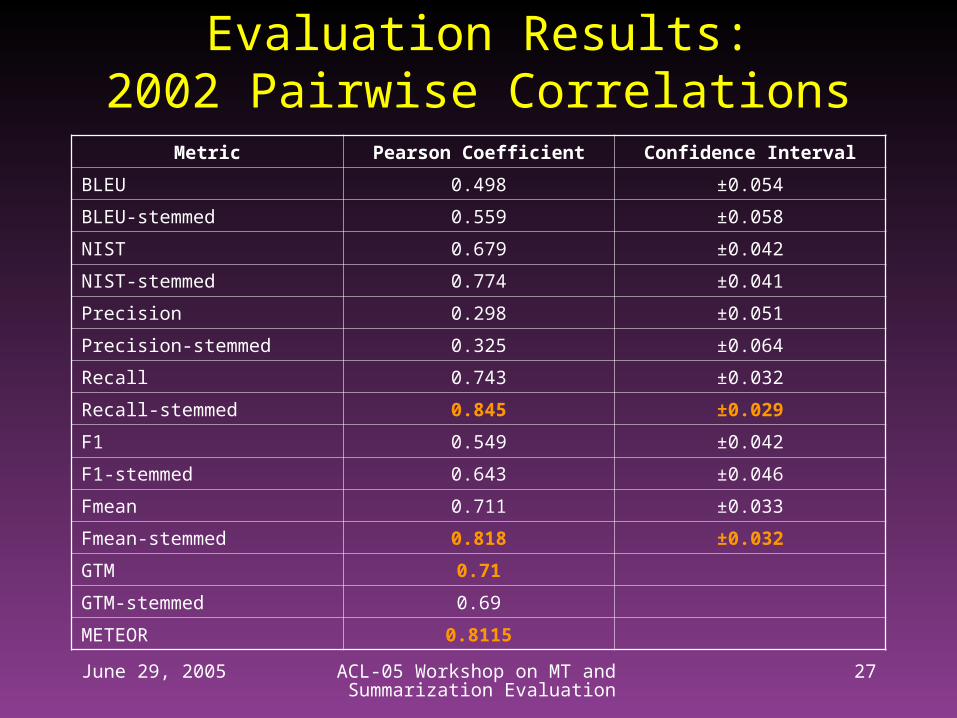
Evaluation Results:2002 Pairwise Correlations
Metric Pearson Coefficient Confidence Interval
BLEU 0.498 ±0.054
BLEU-stemmed 0.559 ±0.058
NIST 0.679 ±0.042
NIST-stemmed 0.774 ±0.041
Precision 0.298 ±0.051
Precision-stemmed 0.325 ±0.064
Recall 0.743 ±0.032
Recall-stemmed 0.845 ±0.029
F1 0.549 ±0.042
F1-stemmed 0.643 ±0.046
Fmean 0.711 ±0.033
Fmean-stemmed 0.818 ±0.032
GTM 0.71
GTM-stemmed 0.69
METEOR 0.8115
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
28
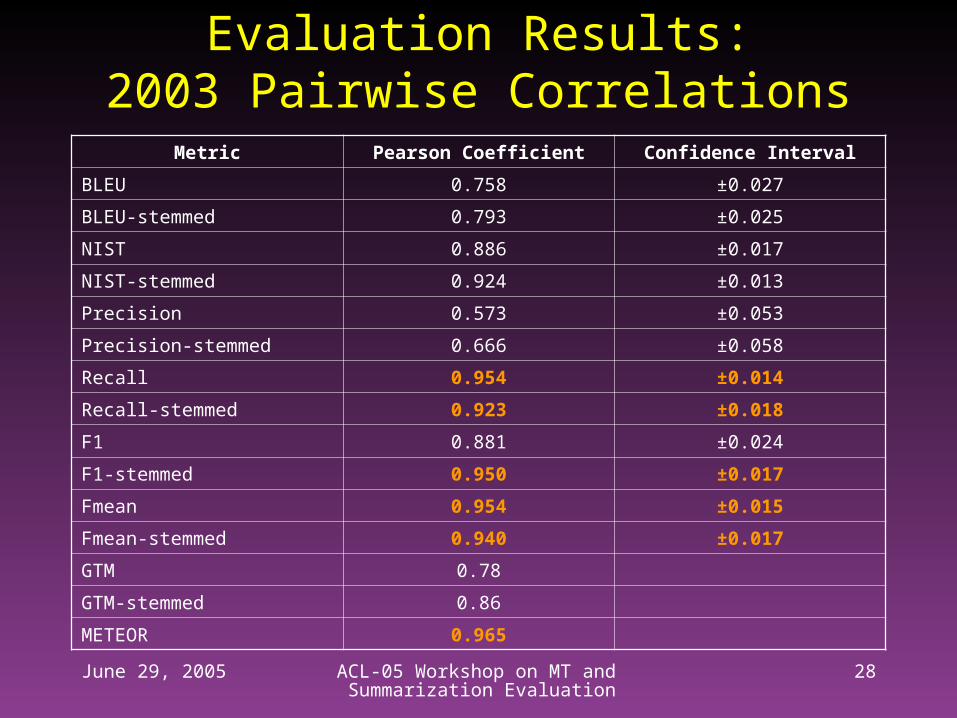
Evaluation Results:2003 Pairwise Correlations
Metric Pearson Coefficient Confidence Interval
BLEU 0.758 ±0.027
BLEU-stemmed 0.793 ±0.025
NIST 0.886 ±0.017
NIST-stemmed 0.924 ±0.013
Precision 0.573 ±0.053
Precision-stemmed 0.666 ±0.058
Recall 0.954 ±0.014
Recall-stemmed 0.923 ±0.018
F1 0.881 ±0.024
F1-stemmed 0.950 ±0.017
Fmean 0.954 ±0.015
Fmean-stemmed 0.940 ±0.017
GTM 0.78
GTM-stemmed 0.86
METEOR 0.965
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
29
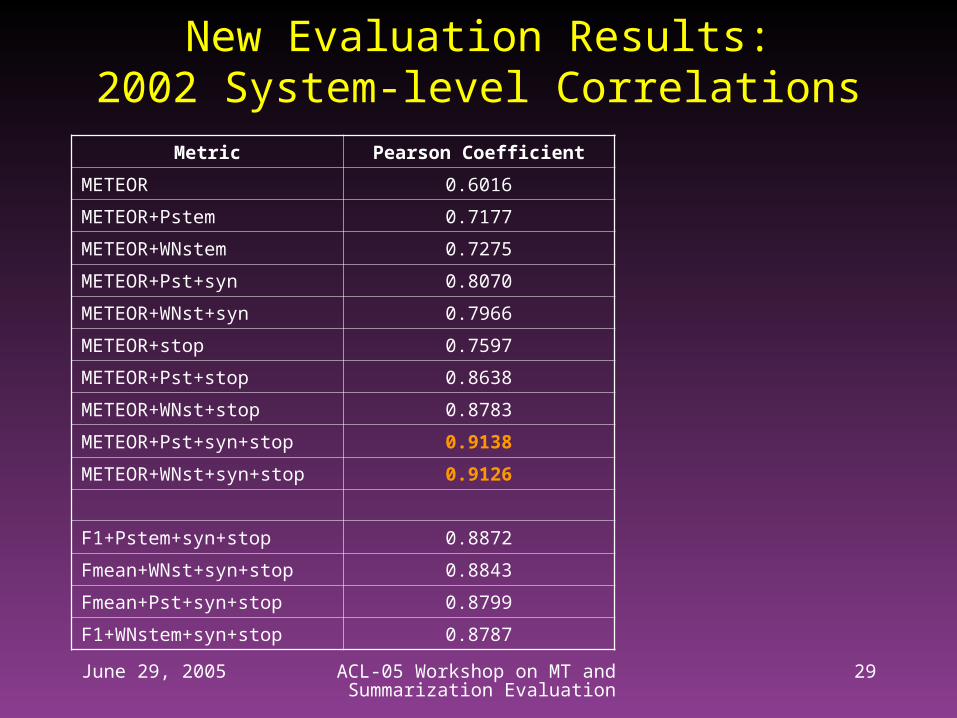
New Evaluation Results:2002 System-level Correlations
Metric Pearson Coefficient
METEOR 0.6016
METEOR+Pstem 0.7177
METEOR+WNstem 0.7275
METEOR+Pst+syn 0.8070
METEOR+WNst+syn 0.7966
METEOR+stop 0.7597
METEOR+Pst+stop 0.8638
METEOR+WNst+stop 0.8783
METEOR+Pst+syn+stop 0.9138
METEOR+WNst+syn+stop 0.9126
F1+Pstem+syn+stop 0.8872
Fmean+WNst+syn+stop 0.8843
Fmean+Pst+syn+stop 0.8799
F1+WNstem+syn+stop 0.8787
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
30
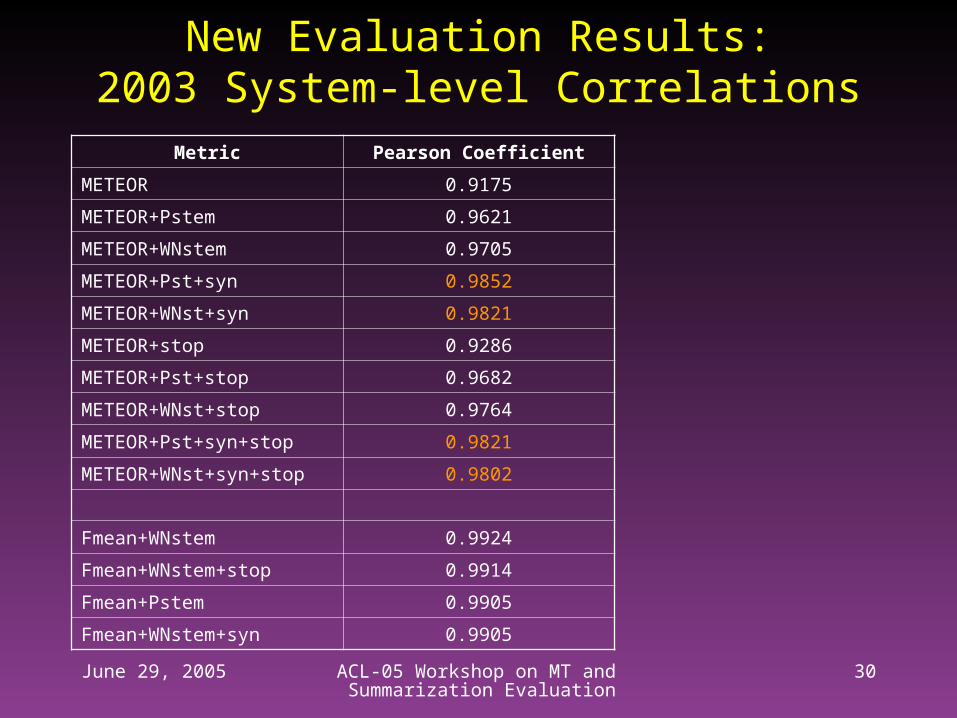
New Evaluation Results:2003 System-level Correlations
Metric Pearson Coefficient
METEOR 0.9175
METEOR+Pstem 0.9621
METEOR+WNstem 0.9705
METEOR+Pst+syn 0.9852
METEOR+WNst+syn 0.9821
METEOR+stop 0.9286
METEOR+Pst+stop 0.9682
METEOR+WNst+stop 0.9764
METEOR+Pst+syn+stop 0.9821
METEOR+WNst+syn+stop 0.9802
Fmean+WNstem 0.9924
Fmean+WNstem+stop 0.9914
Fmean+Pstem 0.9905
Fmean+WNstem+syn 0.9905
June 29, 2005 ACL-05 Workshop on MT and Summarization Evaluation
31
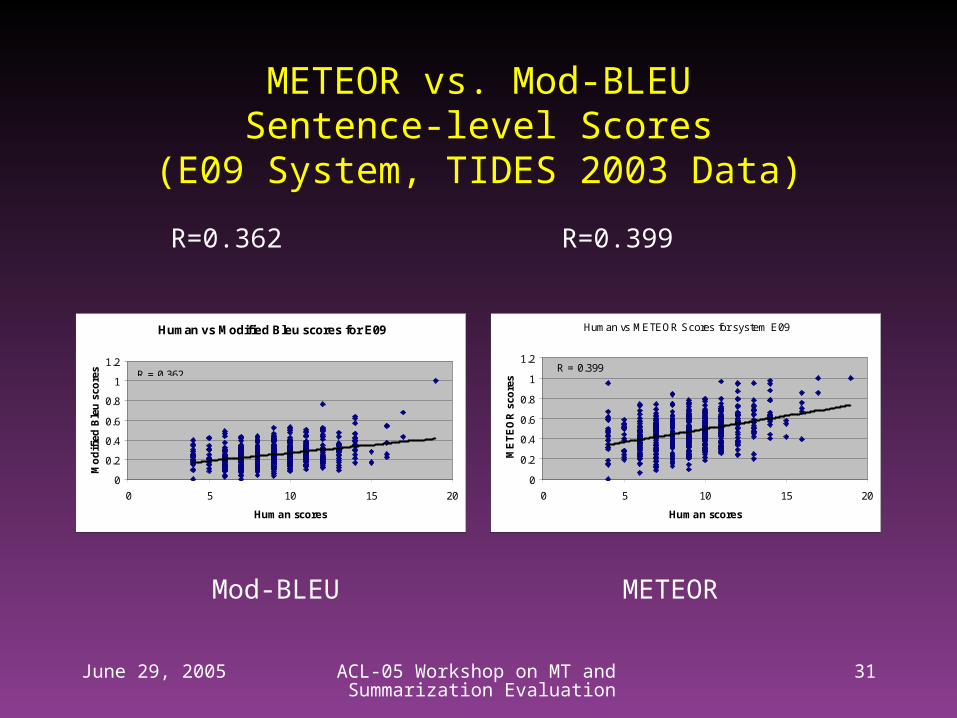
METEOR vs. Mod-BLEUSentence-level Scores
(E09 System, TIDES 2003 Data)
R=0.362 R=0.399
Mod-BLEU METEOR
Human vs METEOR Scores for system E09
0
0.2
0.4
0.6
0.8
1
1.2
0 5 10 15 20
Human scoresM
ET
EO
R s
core
s
R = 0.399
Human vs Modified Bleu scores for E09
0
0.2
0.4
0.6
0.8
1
1.2
0 5 10 15 20
Human scores
Mo
dif
ied
Ble
u s
core
s R = 0.362





























