Embed Size (px)
Citation preview

An Approach to Detecting Domain Errors Using Formal Specification-BasedTesting∗
Yuting CHEN, Shaoying LIUFaculty of Computer and Information Sciences
Hosei University, Tokyo, JapanE-mail: {i0t49001, sliu}@k.hosei.ac.jp
Abstract
Domain testing, a technique for testing software or por-tions of software dominated by numerical processing, is in-tended to detect domain errors that usually arise from in-correct implementations of designed domains. This paperdescribes our on-going work aiming to provide support forrevealing domain errors using formal specifications. In ourapproach, formal specifications serve as a means for do-main modeling. We describe a strong domain testing strat-egy that guide testers to select a set of test points so thatthe potential domain errors can be effectively detected, andapply our approach in two case studies for test cases gen-eration.
Keywords: domain errors, domain testing, formal spec-ification, SOFL, test point selection
1 Introduction
Specification-based software testing is a way to enhancethe reliability of software systems[1][2][3][4]. It advocatesthe idea that test cases are generated based on the functionalspecifications of systems. Recent approaches[5][6][7][8] tospecification-based testing are mostly concerned with for-mal specifications. A formal specification defines a sys-tem and its desired properties using a language with amathematically-defined syntax and semantics, thus it pro-vides a significant opportunity for rigorous functional test-ing.
This paper describes our on-going work aiming to pro-vide support for revealing domain errors using formal spec-ifications. A classification of program errors with strongintuitive appeal is the division into domain errors and com-putation errors, in which domain errors usually arise from
∗This work is supported by the Ministry of Education, Culture, Sports,Science and Technology of Japan under Grant-in-Aid for Scientific Re-search on Priority Areas (No.15017280).
the predicate faults in conditional statements, or from as-signment faults in program[9]. A domain error can bemanifested by a shift or a tilt in some segment (border)of the path domain boundary, and therefore incorrect out-put is generated due to executing a wrong path through theprogram[10].
In this paper, we introduce a strong domain testing strat-egy based on formal specifications. Domain testing, whichwas proposed as a relatively sophisticated form of bound-ary value testing, is used to test software or portions of soft-ware dominated by numerical processing[2]. Domain test-ing is applicable whenever the input domain is divided intosub domains by the program’s decision statements. Severaldomain testing strategies have been proposed to catch do-main errors[9][10][11][12][13][14], and our strong strategyis different in the following two aspects:
1. the test points are to check the consistency of a pro-gram domain with its specification domain, that is, weselect a set of test points from a specification domainand check whether they belong to its program domain;
A test point is a set of values of all of the input variablesconsisting of one value for each variable. In our approach,the test points are selected not from an executable programbut from a formal specification. Since a specification servesas the basis for a “contract” or mutually agreed expectationbetween customer and supplier, and rigorous refinement re-quires that a program should be consistent with its speci-fication, the test points derived from the formal specifica-tion to reflect the user requirements may serve as the “usecases”. Besides, in order to derive a program domain, thetesters need to make a great effort to analyze the programand its conditional structure. Because a formal specifica-tion defines a system at an abstract level, the cost of domainmodeling and test point selection will likely be decreased.
2. the selected test points can effectively cover the givendomain and reveal most domain errors.
1

Domain errors usually include: closure bug, bordershift “up” or “down”, border tilt, extra boundary, missingboundary[2]. Most domain testing strategies are concernedwith the issue of how to reveal closure bugs, border tilt er-rors, and border shift errors, but are blind to the extra bound-ary. These strategies are probably good enough for testingordinary software, but for life critical software, or for soft-ware that creates considerable financial exposure, one mightwant to play it safe and use stronger methods to guaranteethat sneaky bugs will not be unnoticed. Our strategy has anability to cover a specification domain and to discover all ofthe above mentioned domain errors.
The remainder of this paper is organized as follows. Sec-tion 2 and 3 briefly introduce the related work and a formalspecification viewpoint of domain errors, respectively. Sec-tion 4 presents how to select test points from a specificationdomain. Section 5 introduces our objective specificationlanguage-SOFL and shows two case studies of generatingtest points from formal specifications. Finally in Section 6,we give conclusions and point out future research.
2 Related Work
A path domain of a program is surrounded by a bound-ary. A boundary can usually be divided into borders, eachof which corresponds to a predicate interpretation of thepath condition[9]. A border may either be closed or openedwith respect to that domain. A closed border belongs tothe path domain and comes from a predicate that contains≤, ≥, or =. An open border is not part of the path domainand comes from a predicate that contains <, >, or �=. Thepoint at which the borders intersect is a vertex.
Domain testing was initially proposed by White andCohen[9][10], who indicated that points near the bound-ary of a path domain are more sensitive to program faultsthan other points, and then developed systematic strategiesaimed at revealing domain errors within some error bound.
The first domain testing strategy of White and Cohen,known as the N × 1 strategy, begins with a path that hasbeen chosen from program by some path selection method.Assume the given border of an N−dimensional linear caseis closed and represents an inequality predicate interpreta-tion, N × 1 strategy requires two types of points to be se-lected as test cases: ON points lie on the given border, andOFF points lie slightly off the given border on the openside of it. TheN × 1 strategy usesN ON points to identifythe given border, and one OFF point to ensure that the cor-rect border does not lie on the open side of the given border.When we test an open border, the roles of the ON and OFFpoints are reversed. The N × 1 domain-testing techniquewas for inequality borders. If the given border is an equal-ity constraint, White and Cohen proposed a N × 3 strategy,which requires N ON points and three OFF points.
Clarke et al. [11] showed that certain domain errorswent undetected by the White and Cohen strategy, and pro-posed two strategies intended to improve domain testing. Ifa given border contains V vertices, their V × V strategyrequires V ON points selected as close as possible to eachvertex, and V OFF points chosen at a uniform distance fromthe given border. Their V ×1 strategy requires V ON pointsand one OFF point.
[14] described a simplified version of domain testing thatis applicable to arbitrary types of predicates and detects er-rors from domains with both linear and nonlinear bound-aries. In addition, an approach to path selection was used inconjunction with the simplified domain testing strategy.
Few commercial tools implement proper domain testing,since the early domain testing strategies have several draw-backs to limit their application in industry[2][14]. The tech-niques of domain modeling and test point selection frompractical programs are still immature because of the com-plexity of programs. Furthermore, domain errors can bebroken up further into two classes: path selection errors andmissing path errors. A path selection error happens whenboth the correct paths and the wrong paths exist in the pro-gram, and a wrong path is selected and executed by any ofthe test points. A missing path error means a required predi-cate does not appear in the given program to be tested. Mostdomain testing strategies based on programs lack the abilityto detect the latter.
Domain testing strategies are also widely applied inspecification-based testing. [5] applied formal methods tosoftware testing, in which domain testing is integrated ina test template framework to generate tests from Z speci-fications. [15][16] and [17] describe domain testing usingBoolean specifications and character string predicates, re-spectively. However, these studies are mostly concernedwith unit testing, but not with integration testing, which isnecessary for large-scale systems development in industry.Secondly, we believe that the early domain testing strate-gies should not be directly adopted to specification-basedtesting, because they were proposed to select test pointsfrom a hypothetically incorrect program domain, while dur-ing specification-based testing, the specification domainsare usually supposed to be consistent and valid. In addi-tion, bugs are more insidious than ever we expect them tobe[12]. Our study shows that domain errors exist not onlyaround the border, but also probably everywhere. To ad-dress this problem, we need more powerful domain testingstrategies for selecting test points based on formal specifi-cations, which is especially necessary and important for lifecritical systems.
2

3 A Specification Viewpoint of Domain Er-rors
Traditionally, a domain error can be manifested by amissing boundary, an extra boundary, a wrong closure, ashift or a tilt in some segment (border) of the path domainboundary[2], as Figure 1 shows, and therefore incorrect out-put is generated due to executing wrong paths[10]. From theviewpoint of a specification, it is much easy to rigorouslydefine a domain error by comparing a specification domainand its program domain.
B
A
Incor rect
Cor rect
(a) Cl osur e Bug (b) Bor der Shi f t Er ror
Incor r ect
Cor r ect
Incor rect
Cor rect
I ncor rect
Cor r ect
(c) Bor der Ti l t Er r or(d) Ext r a Boundary
(e) Mi ssi ng Boundary
Cor rect
Cor r ect Border Incor rect BorderCl osur e Bug x<=5 x<5
Border Shi f t Er ror x<=5 x<=3Border Ti l t Er ror x<y x<2y
Ext ra Boundary x<y x<y and x<2y
Mi ssi ng Boundary x<y and x<2y x<y
Exampl e:
Figure 1. Types of domain errors
Assuming a generic function f in a formal specificationcan be refined to f ′ in a program, we have a specificationdomain (SD) and a program domain (PD), in which SDis defined explicitly or implicitly by f , and PD is derivedfrom paths of control flows in a program. Suppose the twodomains can be mapped into one space, the rigorous refine-ment requires SD ⊆ PD. Then domain errors can be de-fined as follows:
Definition 1 Domain errors refer to faults in a programwhich are caused by the violation of the consistency be-tween the program domain and the specification domain,i.e., ∃x∈SD• x /∈ PD.
This definition does not conflict with that proposed by[9][10]. A function can be expressed by one of the follow-ing representations: a process or a path in a control/data
flow diagram; a predicate in a Z specification; a precondi-tion and a postcondition in a VDM specification; a proce-dure, a statement block, or a decision in a structural pro-gram; or a method in an object oriented program. Thusa domain error caused by the violation of the consistencybetween a program domain and its specification domain in-duces the wrong paths of the program to be taken duringexecution.
The relations between a PD and a SD of the same func-tion can be categorized as
Case (1) Disjoint : PD ∩ SD = ∅
Case (2) Equivalence : PD = SD
Case (3) Subset : PD ⊂ SD
Case (4) Superset : PD ⊃ SD
Case (5) Overlap : SD− PD �= ∅ and
PD − SD �= ∅ and PD ∩ SD �= ∅
These relations are illustrated by the Venn diagram inFigure 2, where domain errors exist in Cases (1), (3) and(5). In the next section, we will introduce a domain testingstrategy to detect domain errors from a formal specificationdomain. This strategy is stronger than the N × 1 strategy,N×3 strategy, and V ×V strategy in that it has the same ef-fectiveness as the early strategies in revealing closure bugs,border shift errors, and border tilt errors, but it has an abilityto detect the extra boundary which the previous strategiesare blind to.
SD PD
PD
SD
SD
PD
SD PD
SD ,PD
5 Overlap
2 Equiva lence
1 D isjoint
3 Subset
4 Superset
Figure 2. Relations between a SD and a PD
3

4 A Strong Domain Testing Strategy
We now revisit the original domain testing intuitionbased on programs: detecting a domain error is equivalentto determining whether a border shift or tilt has occurred.When we emphasis on some special areas of a specificationdomain, such as the vertices and the borders, domain errorscan frequently be detected.
However, an open border is not included in the domainof interest and therefore does not allow the testers to selecttest points on it. Our strategy is first to replace every openborder of the specification domain with an adjacent closedborder so that test points can be selected effectively. Specif-ically, every open border δ of the given specification domainis replaced by a parallel and adjacent closed border δ′ in itsopen side, and |δ − δ
′| ≤ ε, where ε, a distance betweenδ and δ
′, tends to be 0. Suppose ε = 0.001 in Figure 3(a),our strategy suggests to select three kinds of test points ina practical specification domain covered by the shadows, asFigure 3(b) shows. In this 2-dimensional linear case, weadd an alphabetic token for each test point in Figure 3(b).
10
1
0 x1
x2
101
0x1
x2
10
10
1
1
b da
ol
i
e
c
k
h
nm
g
j
f
1. 001
9. 999
1. 001 9. 999
(a) SD: 1<x1<10 and 1<x2<10
( b)SD’ : 1. 001≤ x1≤ 9. 999 and 1. 001≤ x2≤ 9. 999
Figure 3. A graphic representation of a spec-ification domain and test points
The foremost kind of test points is the vertices. The ver-tices are reasonable to serve as test points, especially whenthe borders of the domain are linear, since the vertices candetermine all linear (N − 1)-dimensional borders of an N-dimensional space. If a linear program border has an offsetto its requirements, the vertices of the program domain canfavorably reveal it because not all of them fall in the pro-
gram domain. In Figure 3(b), the 2-dimisional case has fourvertices {a, d, l, o} to serve as the test points.
With some other appropriately chosen test points on theborders, the testers can reveal another kind of domain er-rors, as Figure 4(a) shows. In this figure, small arrows areused to indicate which side of the border is the actual do-main. Here an incorrect program border go undetected bythe vertices {a,b} when the program border intersects thespecification border and {a, b} are still included in the pro-gram domain. Test points only selected on the segment be-tween c and d can detect this domain error. In Figure 3(b),the test points on the boundary are {b, c, e, h, i, k, m, n}.
A
B
C
Speci f i cat i on bor der
Pr ogr am border
a b
c d
(a)
(b)
Figure 4. Two kinds of domain errors
The third kind of test points of our strategy is to de-tect the domain errors concealed inside the domain. Forinstance, we design a following implementation for Fig-ure 3(a), which holds a hole inside the SD, as Figure 4(b)shows.
PROGRAM A(x1 : real, x2 : real )x3 : realBEGIN
if (x1 > 3 and x1 < 9 and
x2 > 3 and x2 < 9)then op2;−−−−−−incorrect operationelse op1;−−−−−−−correct operation
END
In Figure 4(b), the specification domain {1 < x1 < 10
and 1 < x2 < 10} includes area B and C, and the programdomain {x1 > 3 and x1 < 9 and x2 > 3 and x2 < 9}includes area A and B. Since all the borders and the verticesof the specification domain are contained in the programdomain, the first and the second kinds of test points cannotreveal the hole. Thus, a third kind of test points inside the
4

specification domain, such as {f , g, j} in Figure 3(b), areintroduced.
In some research, test points on the boundary and insidea domain are selected randomly. In our approach, we sug-gest two rules to improve the coverage of the test points toa domain of interest. Since domain errors on the boundary(or inside the domain) can be regard as holes in anN−1 (orN) dimensional space, the rules can be applied to selectingthe second and the third kinds of test points.
Rule 1. A test point should not close to the others if they havethe similar testing intentions.
The probability of a set of test points to detect domain er-rors is greatly affected by the distances among these points.Assuming there exists one and only one domain error in aone-dimensional domain {0 ≤ x ≤ 10}, we have two ver-tices {(x = 0), (x = 10)} and a third point (x = a) serv-ing as the test points, as Figure 5 shows. Then the domainerror can be easily detected if one of its borders falls in in-terval (0, a) and another falls in (a,10). The probability of(x = a) to detect this domain error, which is a conditionalprobability, is p = a
10×
10−a
10. If the third test point is close
to any of the vertices, its capability of revealing a domainerror will decrease.
0 10a
x
Figure 5. A one-dimensional domain withthree test points
Rule 1 can be extended to an N dimensional case for se-lecting a number of test points because two adjacent pointsusually detect the same domain error. That is why theN×1strategy would adopt the OFF point in the center of a border.
Rule 2. Given an appropriate length R, the set of test pointscan reveal any continuous domain errors with radiusgreater than R.
Rule 2 can serve as a guideline to the testers to achievea good coverage in a given specification domain. We user to represent the radius of each possible domain error, asFigure 6(a) shows, which describes the minimal bound ofthe domain error. Then R = f(SD, T ) is to estimate theradius of the maximal possible domain errors undetected byT in SD, where SD is a specification domain and T = {ζ
1,
ζ2, ..., ζ
n} is a set of test points.
Any domain error with a radius r > R can be well de-tected by T . For example, in Figure 6(b), we intuitively
R
a
b
cd
r
Domai n er r or
The r adi us of t hedomai n er r or
(a)r - t he radi us of a domai n er r or s
(b)R- t he radi us of t he maxi mum possi bl e domai ner ror undet ect ed by t he t est poi nt s {a, b, c, d}
Figure 6. Domain errors and their radiuses
predicate the possible domain error inside the domain of in-terest, which is undetected by the set of test points {a, b, c,d}, has a maximum radius R. When R → 0, T providesa reasonable way to make us confident that the program isimmune to continuous domain errors.
Note thatR does not depend on the number of test points.For example, if we have
R1 = f(SD, T1)
R2 = f(SD, T2)
where T1 = {ζ1, ζ2, ..., ζn} and T2 = {ζ1, ζ2, ..., ζ
n,
ζn+1}. Because T1 is a subset of T2, T2 is stronger in re-
vealing domain errors than T1. It is possible for R1 to equalto R2.
5 The Application of Domain Testing Strat-egy
In our work, we use SOFL (Structured Object-orientedFormal Language)[18] as the target specification languageto write formal specifications for operations (we call themprocesses) and to facilitate us to discuss our testing strat-egy. SOFL integrates DFDs, Petri nets, and VDM-SL, andit shares the important features with the commonly used for-mal specification languages, such as VDM-SL, Z, and Data
5

Flow Diagrams. Therefore, the result of our research repre-sented in this paper can also be easily applied to those re-lated notations with some modifications. In this section, wegive a brief introduction to SOFL specification and describetwo case studies of applying our domain testing strategy toselecting test cases.
5.1 An Introduction to SOFL
A SOFL specification is composed of a set of relatedmodules in a hierarchy of condition data flow diagrams(CDFDs), as Figure 7 shows.
3.33.1 3.2
1 4
3
2
1.4
1.3
1.2
1.1
s-module A1Constant, type, class, and/orvariable declarations Condition process1 Condition process2 Condition process3 Condition process4
s-module A3Constant, type, class, and/orvariable declarations Condition process3.1 Condition process3.2 Condition process3.3
s-module A2Constant, type, class, and/orvariable declarations Condition process1.1 Condition process1.2 Condition process1.3 Condition process1.4
(b) Hierarchical Structure of Specification Modules
(a) Hierarchical Condition Data Flow Diagram
A1
A2 A3
Figure 7. Structure of a SOFL system
A CDFD (e.g., A1 in Figure 7(a)) is a formalized DFDthat specifies how processes work together to provide func-tional behaviors. A CDFD usually consists of processes anddata flows. A data flow is labeled with a variable, whichrepresents a data transmission between two processes. Aprocess consists of five parts: name, input ports, outputports, precondition, and postcondition. It performs an ac-tion to transform input data flows satisfying preconditioninto output data flows that satisfy the postcondition.
For each CDFD, a specification module (e.g., moduleA1 in Figure 7(b)) is provided to define necessary types, re-lated variables and the functionality of all the processes inthe CDFD. A module is a functional abstraction: each dataitem is defined with an appropriate type and each process isdefined with a formal, textural notation based on the pred-icate logic. Modules and CDFDs are complementary: aCDFD describes the relationships among processes in termsof data flows, while the associated module describes theprecise functionality of each process. A CDFD providesa graphical view of a system, while the module supplies thedetails of the system in a textual form.
We assume the precondition of each process in the SOFLspecification contains the relational operators selected from
among the following: {≤, ≥, <, >, =, �=}, and in the post-condition, every output of the process is defined determin-istically based only on the input variables. Restricting at-tention to these simple predicates is consistent with restric-tions in earlier domain testing strategies, and a determin-istically process is helpful for domain computation of anintegrated path. Besides, since most formal specificationsof systems in industry, especially those of the life criticalsystems, would adopt linear processes so that they can berigorously refined to the programs.
5.2 A Framework of SOFL Specification BasedTesting
In this section we describe a framework for domain test-ing using formal specifications, as Figure 8 shows, in whicha SOFL specification is used as the basis both for imple-menting programs and for generating test cases. Duringthe refinement of a specification, each process or path isrefined to a corresponding part in the program. During test-ing, the processes and the paths serve as the tested objectsfor domain modeling and test cases generation. A testedobject defines a specification domain(SD) using input vari-able declarations and precondition predicates, and test casescan be directly generated from the SD using the above strat-egy. Finally, during the testing and evaluation, the testersexecute the program with the selected test cases, and reveala domain error when any of the expected functions are notfired.
Speci f -i cat i on
Program
Funct i onDat abase
Pat hDat abase
ProcessDat abase
Domai nDatabase
Test CasesDat abase
Test CasesGenerat or
Test andEval uat e
Ref i nement
Mappi ng
Funct i onRecongi zat i on
Domai nRecongi zat i on
Test sGenerat i on
Figure 8. A prototype of specification-basedtesting
5.2.1 Domain Modeling
Domain is the foundation of domain testing. A SOFL spec-ification domain is abstractly and precisely defined by aprocess, a path, or a set of CDFDs linked by data flows.
6

Formally a specification domain can be defined as a 5-tupleSD = (I, pre, V , B, G) where
1. I denotes a finite set of input variable declarations.
2. pre is the precondition of the process or path, whichdefines the set of all inputs satisfying the precondition.
3. V is a set of vertices of the domain.
4. B is a set of borders of the SD.
5. G is a graphical representation of the SD, if it is pos-sible to be drawn.
I and pre of the function under testing are explicitly or im-plicitly declared in a SOFL specification. For example, aprocess A is specified as
process A(x1, x2 : real )x3 : realpre 1 < x1 < 10 and 1 < x2 < 10
post x3 = x1+ x2
end_process
then
I = {x1 : real, x2 : real}, andpre = 1 < x1 < 10 and 1 < x2 < 10.
When the function under testing is a data-flow path re-sulting from application of certain path selection method toa CDFD, its I and pre are implicitly defined. The set ofinput variable declarations of a process Proc in the path ofinterest can be divided into I ′ and I ′′, where I ′ and I ′′ arean exterior inputs set and an interior inputs set, respectively.That is, the input variables in I ′ transferred to Proc are notproduced by any processes in the given path, while those inI ′′ are. Assuming a path integrates n processes {Proc1,Proc2, ..., Procn}, and Proci(1 ≤ i ≤ n) has a vari-able declarations: Ii = I ′
i∪ I ′′
i, path has I = ∪1≤i≤nI
′i,
and pre is computed through the conjunction of all con-ditions on path. Consider a CDFD path shown as Figure9, I ′ = {x1 : real, x2 : real, x4 : real, x7 : real}, and thepath condition, i.e., the pre of this path, is
1 < x1 < 10 and 1 < x2 < 10 and (x4 > 4 orx4 < 2) and 5 < x1+ x2 < 15 and 1 < x4 < 10 and(x1+ x2) ∗ x4 > 100 and −∞< x7 < +∞
V and B are another two substantial parts for test pointselection. Note that the borders of the SD are closed sothat they are consistent to our strategy. For example, thedomain of process A contains 4 vertices: {(1.001, 1.001),(1.001, 9.999), (9.999, 1.001), (9.999, 9.999)}, and fourclosed borders:
A
D
C
B
x1
x2
x4
x3
x5
x6
x7
x8
process A(x1, x2: real )x3: real
pre 1<x1<10 and 1<x2<10
post x3=x1+x2
end_process
process C(x3, x5: real )x6: real
pre 5<x3<15 and -10<x5<-1
post x6=x3*x5
end_process
process B(x4:real )x5: real
pre x4>4 or x4<2
post x5=-x4
end_process
process D(x6, x7: real )x8: real
pre x6<-100
post x8=x6+x7
end_process
Figure 9. A path in a SOFL specification
{(x1 = 1.001 and 9.999 ≥ x2 ≥ 1.001)
(x2 = 1.001 and 9.999 ≥ x1 ≥ 1.001)
(x1 = 9.999 and 9.999 ≥ x2 ≥ 1.001)
(x2 = 9.999 and 9.999 ≥ x1 ≥ 1.001)}
G, the graphical expression of a domain, is intuitive for userto select some test points. When the domain is a convexpolyhedron in less than 3-dimisional space, sometimes wecan provide a graphical representation of the domain, oth-erwise it can be omitted. The graphic representation of thedomain of process A is shown as Figure 3(b).
Some formal specification languages, such as Z, do notsupport explicit preconditions. [5] shows how to extract thedomain from a Z specification for unit testing, and the inte-gration condition can also be rigorously computed throughthe above method for integration testing.
5.2.2 Test points Selection
In our framework, we use the strong strategy to select testpoints. Note that for a given SD, we have several ways tosatisfy Rule 2.
1. With an appropriate radiusR, the tester selects a small-est set of test points T to satisfy R so that they reach astable state in the SD.
2. Choose the best from several sets of test points {T1,T2, ..., Tn}. Ti is the best if Ri = min(R1, R2, . . .,Rn), 1 ≤ i ≤ n.
7

3. Select tests evenly and regularly from the SD, so thatthe tests can be well satisfy an appropriate radius R.
The first method selects the best set of test points in adomain, however, the algorithm is very complex, especiallywhen the domain space is high dimensional. The secondmethod requires several set of test points in advance andhas a comparison. The third one, which usually produces anumber of redundant test points, is the simplest.
5.3 Case Studies
We conducted two case studies to demonstrate how toselect the test points using the strong strategy. The first casestudy is a simple but classical triangle problem, and the sec-ond one is a more practical problem in [2] to calculate tax.
5.3.1 Triangle Problem
The triangle problem is to determine whether three inputreal number can form a triangle. We model this problem asa process Triangle_Problem, and write its specification inSOFL as follows:
process Triangle_Problem(x, y, z : real) result : bool
pre 1000 > x > 0 and 1000 > y > 0 and
1000 > z > 0 and x+ y > z and
x+ z > y and y + z > x
post result = true
end_process
Suppose this specification is implemented as a program.To carry out a domain testing of the program, we select testpoints in two steps:
1. Select one of the input variables, such as z, and gen-erate test points for it. In this case, we assumeR = 50 in the domain {1000 > z > 0}, andthe test points of z satisfying our strategy can be{0.0001(MIN), 100, 200, 300, 400, 500, 600, 700,800, 900, 999.9999(MAX)}.
2. Regard z as a constant in the formal specification, andselect values for x and y. For example, choosing z =100, we have a 2-dimensional domain:
I : {x : real,y : real}pre : 1000 > x > 0 and 1000 > y > 0 and x+ y > 100
and x+ 100 > y and y +100 > x
V : (x, y) = {(999.9999999, 999.9999999),(900, 999.9999999), (999.9999999,900),
(100, 0.0000001), (0.0000001,100)}
B : {x = 999.9999999, y = 999.9999999,
y = x+99.9999999, y = x− 99.9999999,
y = −x+ 100.0000001}
G : as Figure 10 shows
x
y= -x+z+0. 0000001
y=x+z - 0. 0000001
y=x - z+0. 0000001
x=999. 9999999
y=999. 9999999
Figure 10. A graphical expression of the tri-angle problem
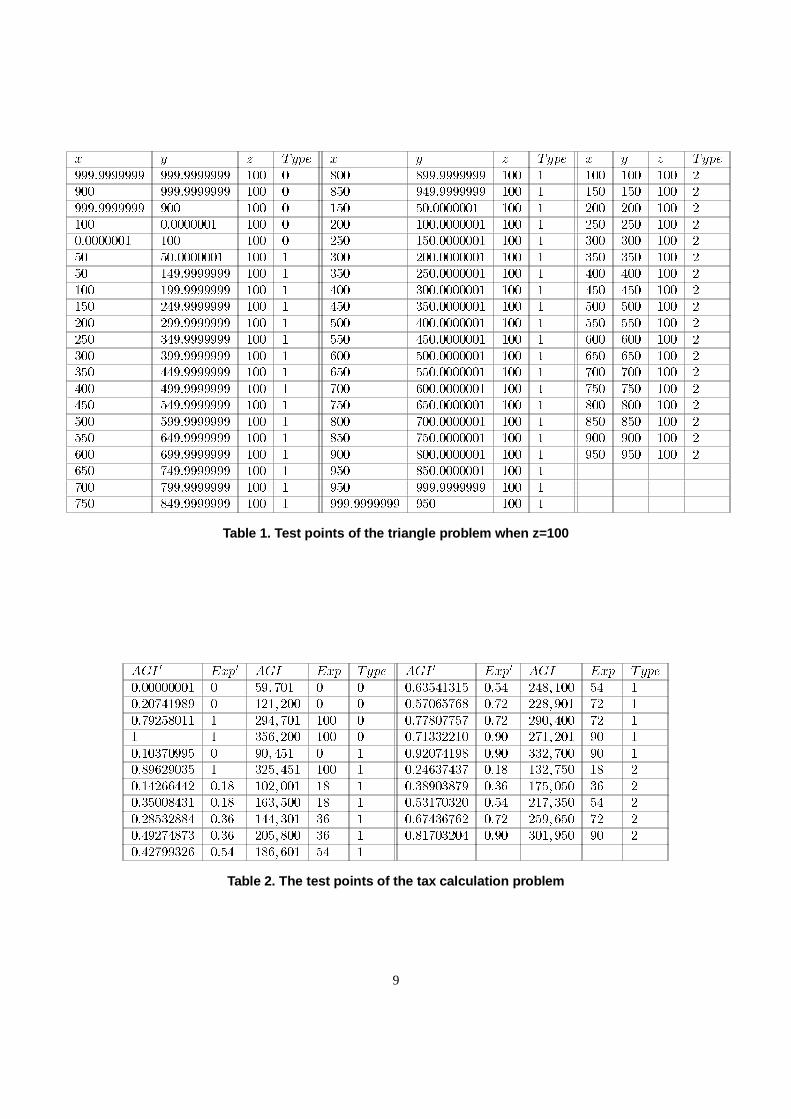
With R′ = 40 (on the borders) and R′′ = 40 (insidethe domain), the selected test points are shown in Table 1,where Type denotes whether the corresponding test point isa vertex (Type = 0), on a border (Type = 1), or inside thedomain (Type = 2).
5.3.2 Tax Calculation Problem
The tax calculation problem requires users to input two val-ues AGI and Exp, which represent Adjusted_Gross_incomeand Exemptions, respectively, and a tax is calculated ac-cording to a tax schedule. The tax schedule is:
32: AGI (Adjusted_Gross_income) Input
6e: Exp (Exemptions), 0 ≤ Exp ≤ 100 Input
38: Tax from tax rate schedule
8
x y z Type x y z Type x y z Type
999.9999999 999.9999999 100 0 800 899.9999999 100 1 100 100 100 2900 999.9999999 100 0 850 949.9999999 100 1 150 150 100 2999.9999999 900 100 0 150 50.0000001 100 1 200 200 100 2100 0.0000001 100 0 200 100.0000001 100 1 250 250 100 20.0000001 100 100 0 250 150.0000001 100 1 300 300 100 250 50.0000001 100 1 300 200.0000001 100 1 350 350 100 250 149.9999999 100 1 350 250.0000001 100 1 400 400 100 2100 199.9999999 100 1 400 300.0000001 100 1 450 450 100 2150 249.9999999 100 1 450 350.0000001 100 1 500 500 100 2200 299.9999999 100 1 500 400.0000001 100 1 550 550 100 2250 349.9999999 100 1 550 450.0000001 100 1 600 600 100 2300 399.9999999 100 1 600 500.0000001 100 1 650 650 100 2350 449.9999999 100 1 650 550.0000001 100 1 700 700 100 2400 499.9999999 100 1 700 600.0000001 100 1 750 750 100 2450 549.9999999 100 1 750 650.0000001 100 1 800 800 100 2500 599.9999999 100 1 800 700.0000001 100 1 850 850 100 2550 649.9999999 100 1 850 750.0000001 100 1 900 900 100 2600 699.9999999 100 1 900 800.0000001 100 1 950 950 100 2650 749.9999999 100 1 950 850.0000001 100 1700 799.9999999 100 1 950 999.9999999 100 1750 849.9999999 100 1 999.9999999 950 100 1
Table 1. Test points of the triangle problem when z=100
AGI ′ Exp′ AGI Exp Type AGI ′ Exp′ AGI Exp Type
0.00000001 0 59, 701 0 0 0.63541315 0.54 248,100 54 10.20741989 0 121,200 0 0 0.57065768 0.72 228,901 72 10.79258011 1 294,701 100 0 0.77807757 0.72 290,400 72 11 1 356,200 100 0 0.71332210 0.90 271,201 90 10.10370995 0 90, 451 0 1 0.92074198 0.90 332,700 90 10.89629035 1 325,451 100 1 0.24637437 0.18 132,750 18 20.14266442 0.18 102,001 18 1 0.38903879 0.36 175,050 36 20.35008431 0.18 163,500 18 1 0.53170320 0.54 217,350 54 20.28532884 0.36 144,301 36 1 0.67436762 0.72 259,650 72 20.49274873 0.36 205,800 36 1 0.81703204 0.90 301,950 90 20.42799326 0.54 186,601 54 1
Table 2. The test points of the tax calculation problem
9

Domain1 : tax = 0.0AGI <= 6,200 + 2,350Exp
Domain 2 : tax = 0.15AGI − 352.5Exp− 930.0AGI > 6, 200 + 2,350ExpAGI <= 28, 300 + 2,350Exp
Domain 3 : tax = 0.28AGI − 658.0Exp− 4, 609.0AGI > 28, 300 + 2, 350ExpAGI <= 59, 700 + 2,350Exp
Domain 4 : tax = 0.31AGI − 728.5Exp− 6, 400.0AGI > 59, 700 + 2, 350ExpAGI <= 121, 200 + 2, 350Exp
Domain 5 : tax = 0.36AGI − 846.0Exp− 12, 460AGI > 121,200 + 2,350ExpAGI <= 256, 200 + 2, 350Exp
Domain 6 : tax = 0.396AGI − 930.6Exp− 21,683.2AGI <= 256, 200 + 2, 350Exp
In each domain, a set of test points is selected using thestrong strategy. For instance, the steps to select test pointsfrom Domain 4 are as follows:
1. Converse the coordinate and rewrite the domain. Thiscase is simper than the triangle problem since that theprogram receives only two variables as inputs. How-ever, because AGI and Exp use different units, we needto converse the coordinate in order to select an appro-priate R. In this case, we rewrite domain 4 as:
I : {Exp′ : real, AGI ′ : real}
pre : 1 >= Exp′>= 0 and
AGI ′>=2350
2965Exp+ 0.00000001 and
AGI ′<= 615
2965+ 2350
2965Exp
V : (Exp′
, AGI ′) = {(0.00000001, 0), (0.20741989, 0),
(0.79258011, 1), (1,1)}
B : {Exp′= 0, Exp′= 1,AGI ′= 615
2965+ 2350
2965Exp,
AGI ′ = 2350
2965Exp+0.00000001}
2. Select test points shown as Table 2, with R′ = 0.1 (onthe borders) and R′′ = 0.15 (inside the domain).
5.3.3 Comparing the Effectiveness of the Strategies
We describe an experiment designed to use the results ofthe previously presented case studies to study the effective-ness of our approach and to generate empirical evidenceof its superiority over other strategies in revealing domainerrors. The results show that our strategy are more effec-tive, but less efficient in producing the test suites than otherstrategies do. The effectiveness and efficiency are calcu-lated as[19][20]
Effectiveness = Number of Domain Errors Detected
Total Number of Inserted Domain Errors
Efficiency =Effectiveness of the Set of Test Points
Time to Develop the Set of Test Points
Experiment Preparation We implemented the triangleproblem (Case Study 1) and the tax calculation problem(Case Study 2) with a group of programs in Java. Eachof these programs contains one and only one domain error(e.g., a border shift down, a border tilt, and so on), so thetester can determine whether a set of test points has the abil-ity to reveal the inserted error of a program. For instance,the specification domain of the triangle problem owns fiveborders, and we can deliberately conduct an offset of one ofits borders as a border shift error.
Table 3 summarizes the numbers of implementationswith different kinds of domain errors for the two case stud-ies. The experiment contains few closure bugs, bordershift up errors, and missing boundary errors, since that theyrarely happen in one continuous specification domain. Be-sides, from the viewpoint of rigorous refinement, we usu-ally do not regard a border shift up as a domain error of thegiven function, but a border shift down error of its neigh-boring function.
Case Study 1 Case Study 2Closure Bugs 0 3Border Shifts Down 15 12Border Tilt 15 12Extra Boundary 10 8Missing Boundary 0 0
Table 3. The numbers of implementations withinserted domain errors
Test Case Generation We manually produce test casesfrom formal specifications and from programs, respectively.The follow-up list indicates the strategies used in our exper-iment for comparison.
1. N × 1 strategy
2. N × 3 strategy
3. V × V strategy
4. random testing
5. a simplified domain testing strategy
6. our strong strategy
10

Closure Border Shifts Border Extra Time Effectiveness EfficiencyBugs Down Tilt Boundary (hours)
N × 1 strategyN × 3 strategy
specification V × V strategybased testing random testing
a simplified strategythe strong strategyN × 1 strategyN × 3 strategy
program based V × V strategytesting random testing
a simplified strategythe strong strategy
Table 4. The detections of various strategies to domain errors
Closure Bugs Border Shifts Border Tilt Extra Boundary Missing BoundaryN × 1 strategy(when the domain border is linear) • • • •
N × 3 strategy • • • •
V × V strategy(when the domain border is linear) • • • •
random testing •
a simplified strategy • • • •
the strong strategy • • • • •
Table 5. The ability of different strategies to detect domain errors
Testing and Evaluation We execute the programs withthe generated test points, and the detection of domain errorsis illustrated in Table 4.
Table 4 shows that the strong strategy has the highesteffectiveness to reveal domain errors both in specificationbased testing and in program based testing, but seems lessefficient than the other strategies. It is sufficient to use otherstrategies to test most of systems, while we believe that ourstrategy is useful in testing life critical systems because ofits effectiveness. Besides, the strong strategy has a low ef-ficiency because of the cost to manually develop the testsuites. The efficiency can be increased by enhancing thedegree of automation to generate test suites.
Our further studies show that the strong strategy is alsoable to detect the missing boundary. The abilities of dif-ferent strategies to reveal the specified domain errors areshown in Table 5.
6 Conclusions and Future Work
In this paper we propose an approach to domain test-ing using formal specifications. By this approach, domainsand test cases are generated from textual specifications andgraphical data flow diagrams. We also introduce a frame-work for domain testing based on SOFL specifications, and
apply it in two case studies to demonstrate the effectivenessof our strategy in detecting domain errors.
As future work, we plan to extend the current strategyto detect domain errors for other data structures, such asstring, set, and sequence. In addition, we are also interestedin investigating techniques for automatic test cases genera-tion and in constructing an effective tool to support the tech-niques.
7 Acknowledgments
We would like to thank all the members of the FormalEngineering Methods group for insightful discussions onthis research.
References
[1] J. Mcdermid. Software Engineering’s Reference Book.Butterworth-Heinemann Ltd, Oxford, 1991.
[2] B. Beizer. Black Box Testing-Techniques for Func-tional Testing of Software and Systems. John Wileyand Sons, Inc., New York, 1995.
11

[3] D. Richardson, O. O’Malley, and C. Tittle. Ap-proaches to specification-based testing. In Proceed-ings of the ACM SIGSOFT ’89 Third Symposium onSoftware Testing, Analysis, and Verification, pages 86– 96, Florida, United States, 1989.
[4] J. Offutt and A. Abdurazik. Using UML collabora-tion diagrams for static checking and test generation.In The Third International Conference on the Uni-fied Modeling Language (UML ’00), pages 383–395,York, UK, 2000.
[5] P. Stocks. Applying Formal Methods to Software Test-ing. PhD thesis, the university of queensland, 1993.
[6] J. Offutt, S. Liu, A. Abdurazik, and P. Ammann. Gen-erating test data from state-based specifications. TheJournal of Software Testing, Verification and Reliabil-ity, 13(1):25–53, 2003.
[7] J. Chang, D.J. Richardson, and S. Sankar. Structuralspecification-based testing with ADL. In Proceed-ings of the 1996 International Symposium on SoftwareTesting and Analysis, pages 62 – 70, San Diego, Cali-fornia, United States, 1996.
[8] V. Okun and P.E. Black. Issues in software testing withmodel checkers. In Proc. 2003 International Confer-ence on Dependable Systems and Networks, Califor-nia, United States, 2003. IEEE Computer Society.
[9] L.J. White and E.I. Cohen. A domain testing strat-egy for computer program testing. In IEEE Workshopon Software Testing and Documentation, Fort Laud-erdale, Florida, 1978.
[10] L.J. White and E.I. Cohen. A domain strategy for com-puter program testing. IEEE Transactions on SoftwareEngineering, 6:247–257, 1980.
[11] L. Clarke, H. Hassell, and D. Richardson. A closelook at domain testing. IEEE transaction on SoftwareEngineering, 8:380–398, 1982.
[12] B. Beizer. Software Testing Techniques. Van NostrandReinhold, 1990.
[13] F.H. Afifi, L.J. White, and S.J. Zeil. Testing for linearerrors in nonlinear computer programs. In Proceed-ings of the 14th International Conference on SoftwareEngineering, pages 81–91, Australia, 1992.
[14] B. Jeng. A simplified domain-testing strategy. ACMTransactions on Software Engineering and Methodol-ogy, 3(3):254–270, July 1994.
[15] A.M. Paradkar and K.C. Tai. Test generationfor boolean expressions. In Proc. IEEE Interna-tional Symposium on Software Reliability Engineer-ing, 1995.
[16] A.M. Paradkar, K.C. Tai, and M.A. Vouk. Automatictest generation for predicates. IEEE Transactions onReliability, 45(4), 1996.
[17] R. Zhao, M. R. Lyu, and Y. Min. Domain testing basedon character string predicate. In 12th Asian Test Sym-posium (ATS’03), Xiaran, China, 2003.
[18] S. Liu. Formal Engineering for Industrial SoftwareDevelopment-Using the SOFL Method. Springer-Verlag Berlin Heidelberg, Germany, 2004.
[19] J. Nielsen. Usability Engineering. Academic PressInc., San Diego, CA, 1993.
[20] J. T. Huber. Efficiency and effectiveness measuresto help guide the business of software engineering.Applications of Software Measurement, HP Labs Re-search Report, 1999.
12





























