Embed Size (px)
Citation preview

République Algérienne Démocratique et Populaire MINISÈTRE DE L’ENSEIGNEMENT SUPÉRIEUR ET DE LA RECHERCHE SCIENTIFIQUE
MÉMOIRE DE MAGISTÈRE
Présenté à
L’UNIVERSITÉ MENTOURI CONSTANTINE
FACULTÉ DES SCIENCES DE L’INGÉNIEUR
DÉPARTEMENT D’ÉLECTRONIQUE
Par
TENIOU Samir
Pour l’obtention du diplôme de magistère en électronique
Option : Contrôle
Thème
Analyse de la Commande Prédictive Floue :
Algorithmes et Méthodologies de Solution
Soutenu publiquement le 02 Décembre 2009 devant le jury composé de :
Mr. FILALI Salim Prof. Université Mentouri Constantine Président
Mr. BELARBI Khaled Prof. Univertsité Mentouri Constantine Rapporteur
Mr. HAMMOUDI Zoheir M. C. Université Mentouri Constantine Examinateur
Mr. BOUTAMINA Brahim M. C. Université Mentouri Constantine Examinateur


République Algérienne Démocratique et Populaire MINISÈTRE DE L’ENSEIGNEMENT SUPÉRIEUR ET DE LA RECHERCHE SCIENTIFIQUE
MÉMOIRE DE MAGISTÈRE
Présenté à
L’UNIVERSITÉ MENTOURI CONSTANTINE
FACULTÉ DES SCIENCES DE L’INGÉNIEUR
DÉPARTEMENT D’ÉLECTRONIQUE
Par
TENIOU Samir
Pour l’obtention du diplôme de magistère en électronique
Option : Contrôle
Thème
Analyse de la Commande Prédictive Floue :
Algorithmes et Méthodologies de Solution
Soutenu publiquement le 02 Décembre 2009 devant le jury composé de :
Mr. FILALI Salim Prof. Université Mentouri Constantine Président
Mr. BELARBI Khaled Prof. Univertsité Mentouri Constantine Rapporteur
Mr. HAMMOUDI Zoheir M. C. Université Mentouri Constantine Examinateur
Mr. BOUTAMINA Brahim M. C. Université Mentouri Constantine Examinateur

Remerciements
Ce travail a été réalisé au laboratoire d’automatique et de robotique, département
d’électronique, Université Mentouri Constantine.
Je tiens à exprimer ma reconnaissance et ma profonde gratitude à Monsieur BELARBI
Khaled, professeur à l’université Mentouri Constantine, pour avoir assuré l’encadrement de ce
travail. Son aide, sa grande disponibilité, sa gentillesse ont joué un rôle essentiel dans
l’aboutissement de ce travail. Son expérience et ses conseils précieux ont contribué à ma
formation scientifique.
J’exprime mes vifs remerciements à Monsieur FILALI Salim, professeur à l’université
Mentouri Constantine, qui m’a fait l’honneur de présider ce jury.
Mes sincères remerciements vont également à Messieurs HAMMOUDI Zoheir et
BOUTAMINA Brahim, Maitres de Conférences à l’université Mentouri Constantine qui ont
bien voulu examiner ce mémoire.
Enfin, mes remerciements vont aussi à mes parents pour leur patience, leurs encouragements
continus et leur soutien inconditionnel. Qu’il trouve ici toute ma gratitude et mon amour.

Table des matières
1
Table des matières
Notations et abréviations 3
Introduction 5
1. Commande prédictive à base de modèle 7
1.1 Commande prédictive linéaire……………………………………………. 7
1.1.1 Modèle…………………………….. ……………........................... 7
1.1.2 Fonction coût……………………………………........................... 8
1.1.3 Contraintes………………………………………………………... 8
1.1.4 Prédiction…..................................................................................... 9
1.1.5 Problème sans contraintes………………………………………... 10
1.1.6 Problème avec contraintes………………………………………... 11
1.2 Résolution du problème d’optimisation pour la commande prédictive
linéaire……………………………………………………………………. 13
1.2.1 Méthode de l’ensemble actif……………………………………... 13
1.2.2 Méthode du point intérieur……………………………………….. 14
1.2.3 L’approche LMI………………………………………………….. 15
1.2.4 Programmation Quadratique multiparamétrique (MPQP)……….. 16
1.3 Commande prédictive non linéaire……………………………………….. 18
1.3.1 Formulation générale……………………………………………... 19
1.3.2 Solution du problème de la commande prédictive non linéaire….. 20
1.4 Stabilité de la commande prédictive……………………………………… 21
2. La commande prédictive floue à base de modèle d’état et ses méthodologies de
solutions 23
2.1 Commande prédictive floue……………………………………………. 23
2.1.1 Prise de décision dans un environnement flou……………………. 23
2.1.2 Commande prédictive floue à base de modèle d’état……………...24
2.2 La méthode branch and bound……………………………………………. 25
2.3 Commande prédictive floue linéaire avec fonctions d’appartenance
gaussiennes……………………………………………………………………….. 26

Table des matières
2
2.3.1 Définition du problème…………………………………………… 26
2.3.2 Les prédictions……………………………………………………. 27
2.3.3 Solution………………………………………………………….... 28
2.4 Solution analytique pour les systèmes du premier ordre…………………. 30
2.4.1 Définitions………………………………………………………… 30
2.4.2 Solution…………………………………………………………… 31
3. Exemples d’applications 39
3.1 Programmation dynamique avec branch and bound……………………... 39
3.1.1 Système non linéaire 1er ordre……………………………………. 39
3.1.2 Système non linéaire 2ème ordre…………………………………... 41
3.2 Méthode analytique avec contraintes et objectifs gaussiens……………... 43
3.2.1 Système linéaire 2ème ordre……………………………………….. 43
3.3 Méthode analytique système du premier ordre…………………………... 45
Conclusion 48
Bibliographie 59

Notations et abréviations
3
Notations et abréviations
Symboles
Ensemble de nombres entiers positifs
Ensemble de nombres réels
Ensemble de vecteurs à coefficients réels de dimension
| Prédiction de la variable à l’instant à partir des valeurs connues jusqu’à
L’instant
Notation générale pour la transposée d’une matrice
0 Notation générale pour une matrice strictement définie positive
0 Notation générale pour une matrice définie positive
Matrice identité de dimension
0 Matrice nulle de dimension
Opérateur retard (pour un signal , 1 )
L’argument correspondant à la valeur minimale de la fonction
Acronymes
BB «Branch and Bound»
CARIMA « Controlled Auto-Regressive Integrated Moving Average »
DMC «Dynamic Matrix Control»
DP Programmation dynamique (« Dynamic Programming »)
FDP Programmation dynamique floue (« Fuzzy Dynamic Programming »)
FMBPC Commande prédictive floue à base de modèle (« Fuzzy Model Based Predictive
Control »)
GPC Commande Prédictive Généralisée (« Generalized Predictive Control »)

Notations et abréviations
4
KKT Karush-Kuhn-Tucker
LMI Inégalité matricielle linéaire (« Linear Matrix Inequality »)
LP Programmation linéaire (« Linear Programming »)
MAC « Model Algorithmic Control »
MBFPC Commande prédictive floue à base de modèle (« Model Based Fuzzy Predictive
Control »)
MBPC Commande prédictive à base de modèle (« Model Based Predictive Control »)
MPHC «Model Predictive Heuristic Control»
MPQP Programmation quadratique multiparamétrique (« multiparametric Quadratic
Programming »)
PFC « Predictive Funcional Control »
QP Programmation quadratique (« Quadratic Programming »)
SQP Programmation quadratique séquentielle (« Sequential Quadratic
Programming»)

Introduction
5
Introduction
La commande prédictive à base de modèle notée ’’MBPC’’ (Model Based Predictive
Control) est apparue vers la fin des années 70, et depuis elle n’a pas cessé de se développer.
MBPC n'indique pas une stratégie de commande spécifique mais plutôt des méthodes de
contrôles qui font l'utilisation explicite d'un modèle du processus pour obtenir le signal de
commande en minimisant une fonction coût. L’idée principale des commandes prédictives est
basée sur l’utilisation d’un modèle du système à commander pour prédire sa sortie sur un
certain horizon, l’élaboration d’une séquence de commandes futures minimisant une fonction
coût, l’application du premier élément de la séquence optimale précédente sur le système et la
répétition de la procédure complète à la prochaine période d’échantillonnage [MRRS00].
C’est le principe de l’horizon fuyant. MBPC implique alors la résolution d’un problème
d’optimisation de dimension finie à chaque période d’échantillonnage. Il est clair que le
temps d’obtention de la solution joue un rôle important dans l’application de cette stratégie en
temps réel. Si pour les systèmes lents à grande période d’échantillonnage, l’application des
méthodes numériques ne pose pas de problème, pour les systèmes rapides échantillonnés à
haute fréquence tels que les moteurs, robots…, la solution numérique en ligne du problème
d’optimisation peut être impraticable. Aussi, il est utile de rechercher des solutions
analytiques rapides et efficaces. Plusieurs chercheurs se sont alors penchés sur ce sujet. Le
résultat de ces recherches a été assez fructueux pour les systèmes à base de modèle de
prédiction linéaire [BMDP02, HOV04, JPS00, TON03, WMY09].
Dans ce mémoire, nous nous intéressons aux méthodologies de solution de la
commande prédictive floue basée sur les notions d’objectifs et contraintes flous introduites
par Bellman et Zadeh [BZ70], Model Based Fuzzy Predictive Control, MBFPC. Le problème
de la commande prédictive floue est alors de trouver la confluence maximale entre les
objectifs et les contraintes flous sur un horizon fini. Notre but est de proposer et d’analyser les
possibilités de résolution du problème d’optimisation associé à la MBFPC. Trois types de
solution sont identifiés :
- La méthode de programmation dynamique et branch and bound,

Introduction
6
- Une méthode analytique basée sur des contraintes et des objectifs flous de type
gaussien,
- Une méthode analytique pour les systèmes linéaires du premier ordre.
Pour cela ce mémoire est organisé comme suit :
Dans le premier chapitre, nous rappelons les éléments de base de la commande prédictive
et les méthodes de résolution du problème d’optimisation associé.
Dans le second chapitre nous introduisons la MBFPC et présenterons les méthodes de
solutions du problème d’optimisation proposées.
Dans le troisième chapitre nous donnerons les résultats de simulation pour les trois
méthodes appliquées à des problèmes de référence.

Chapitre1. Commande prédictive à base de modèle
7
Chapitre 1
Commande prédictive à base de modèle
Ce chapitre introduit le cadre général de la famille de lois de commande prédictives
[CB99]. Nous abordons les méthodes de résolution du problème d’optimisation associé à la
commande prédictive linéaire et non linéaire. Nous terminons le chapitre par un survol rapide
sur l’étude de la stabilité.
1.1 Commande prédictive linéaire
1.1.1 Modèle
L’approche prédictive la plus proche de la théorie standard pour les systèmes linéaires est
certainement celle qui considère un modèle par représentation d’état :
1 (1.1)
(1.2)
(1.3)
Où , le vecteur d’état à l’instant , le vecteur de commande à
l’instant , le vecteur des sorties mesurées, le vecteur des sorties à
contrôler, , , et des matrices de dimension correspondante.
Les sorties contrôlées peuvent en principe dépendre de
, 0 (1.4)
Ce qui compliquerait le calcul de la commande légèrement. Cette complication peut être
évitée, sans rien perdre, en définissant un nouveau vecteur de sorties contrôlées
(1.5)
qui dépend seulement de : .
Dans tous ce qui suit nous supposons que , ce qui est souvent le cas, nous
utilisons pour noter et , et pour noter et .

Chapitre1. Commande prédictive à base de modèle
8
1.1.2 Fonction coût
La fonction coût à minimiser à chaque période d’échantillonnage pénalise les déviations
des sorties prédites | d’une trajectoire de référence | en plus des
variations du vecteur de commande ∆ 1 , elle est souvent donnée par
la forme quadratique
∑ | | ∑ ∆ | (1.6)
Où
(1.7)
l’horizon de prédiction, l’horizon de commande, et ∆ | 0 pour
, 0, 0 sont les matrices de pondération.
On peut définir la commande prédictive linéaire comme une loi de rétroaction
qui minimise . Il n’est pas nécessaire de commencer immédiatement la
pénalisation des déviations des sorties prédites | de la trajectoire de référence
| (si 1) car il peut exister un retard entre l’application de la commande et
la réponse du système à celle-ci. La forme de la fonction coût (1.6) implique que le vecteur
erreur | | est pénalisé à chaque point dans l’intervalle .
Dans certain cas un terme de la forme ∑ | est ajouté à la fonction coût (1.6)
qui permet de prendre en considération l’effort de la commande dans l’élaboration de la loi
de commande.
1.1.3 Contraintes
Les contraintes ci-dessous doivent être satisfaites sur tout l’horizon de prédiction et de
commande :
∆ | , … , ∆ 1| , 1 0 (1.8)
| , … , 1| , 1 0 (1.9)
| , … , , 1 0 (1.10)
, et sont des matrices de dimension appropriée. Les contraintes de cette forme peuvent
représenter le taux de variation possible des actionneurs entre deux périodes
d’échantillonnage (1.8), limitation physique des actionneurs (1.9) et les contraintes sur les
sorties à contrôler (1.10).

Chapitre1. Commande prédictive à base de modèle
9
1.1.4 Prédiction
Supposons que le vecteur d’état est mesurable, i.e., | ( . Le
calcul des sorties prédites | se fait par itération du modèle (1.1)-(1.3)
1| | (1.11)
2| 1| 1| (1.12)
| 1| (1.13)
| 1| 1| (1.14)
| … 1| (1.15)
Rappelons que ∆ | | 1| et que les entrées
peuvent changer seulement aux instants , 1, … , 1 , et reste constantes après
| 1 pour 1. Alors
| ∆ | 1 (1.16)
1| ∆ 1| ∆ | 1 (1.17)
1| ∆ 1| … ∆ | 1 (1.18)
Ainsi nous obtenons
1| ∆ | 1 (1.19)
2| ∆ | 1 ∆ 1| ∆ |
1 (1.20)
∆ | B∆ 1| 1 (1.21)
| … ∆ |
… ∆ 1| … 1 (1.22)
1| … ∆ |
… ∆ 1| … 1 (1.23)
… ∆ |
… … ∆ 1| (1.24)
… 1
Finalement sous forme matricielle

Chapitre1. Commande prédictive à base de modèle
10
1|
|1|
∑∑
∑
1
00
∑∑
∑ ∑
∆ |
∆ 1| (1.25)
D’après (1.3) les prédictions de sont données par
1|
0 00 0
0 0
1| (1.26)
1.1.5 Problème sans contraintes
Nous pouvons mettre la fonction coût (1.6) sous la forme
∆ (1.27)
Où
|
|
∆
∆ |
∆ 1|
Les matrices de pondération et sont données par
0 00 1 0
0 0
0 0 00 1 0
0 0 1
À partir de (1.25) et (1.26), a la forme suivante
Ψ Υ 1 Θ∆ (1.28)
Définissons
Ψ Υ 1 (1.29)
Alors
Θ∆ ∆ (1.30)

Chapitre1. Commande prédictive à base de modèle
11
∆ Θ Θ∆ ∆ ∆ (1.31)
2∆ Θ ∆ Θ Θ ∆ (1.32)
Qui a la forme
∆ ∆ ∆ (1.33)
Où 2Θ (1.34)
Θ Θ (1.35)
On voit que et ne dépendent pas de ∆ . Comme 0 et 0 alors 0 ce qui
garantie la convexité de . Dans ce cas la condition pour que ∆ soit un optimum
global de est que le gradient s’annule à ce point. De l’équation (1.33)
∆ 2 ∆ (1.36)
Alors la séquence des variations de commande futures optimales est
∆ (1.37)
existe car 0.
Seulement la partie correspondant au premier pas de la séquence optimale est appliquée au
système :
∆ , 0 , … , 0 ∆ (1.38) 1 fois
∆ 1 (1.39)
1.1.6 Problème avec contraintes
Rappelons (1.8)-(1.10) que les contraintes sont de la forme
∆1
0 (1.40)
1
0 (1.41)
1
0 (1.42)
Où | , , 1| .
Il faut exprimer (1.40)-(1.42) comme des contraintes sur ∆ . Pour cela supposons que
, , , , (1.43)
Où chaque est de dimension et est de dimension 1. Alors (1.41) peut être
réécrite comme
∑ 1| 0 (1.44)

Chapitre1. Commande prédictive à base de modèle
12
Puisque 1| 1 ∑ ∆ | ,
On peut écrire (1.44) comme
∑ ∆ | ∑ ∆ 1| … ∆ 1|
∑ 1 0 (1.45)
Définissons ∑ et , … , . Ainsi (1.41) peut être écrite comme
∆ 1 (1.46) Vecteur connu à l’instant k
Alors (1.41) a été convertie en une contrainte inégalité linéaire sur ∆ .
Il faut faire la même chose pour (1.42). En remplaçant (1.28) dans (1.42)
Ψ Υ 1 Θ∆1
0 (1.47)
En prenant Γ , , où est la dernière colonne de , nous obtenons
Γ Ψ Υ 1 ΓΘ∆ 0
Ou encore
ΓΘ∆ Γ Ψ Υ 1 (1.48)
Finalement, il est clair que (1.40) peut facilement être mise sous la forme
W∆ (1.49)
Les inégalités (1.46), (1.48) et (1.49) qui sont identiques à (1.40), (1.41) et (1.42) (ensemble
des contraintes) peuvent être assemblées dans une seul inégalité
ΓΘW
∆1
Γ Ψ Υ 1 (1.50)
La fonction coût que nous devons minimiser est la même que dans le cas sans contraintes.
Ainsi de (1.33), à chaque instant (à chaque période d’échantillonnage) il faut résoudre en
ligne le problème d’optimisation avec contraintes suivant :
Minimiser ∆ ∆ G ∆
sous la contrainte (1.50).
Ce problème à la forme générale :
min Φ ;
Ω 1.51
Qui est un problème de programmation quadratique (QP). Il existe des méthodes efficaces
pour résoudre ce type de programmes. Nous traitons par la suite quelque méthodologie de
solution.

Chapitre1. Commande prédictive à base de modèle
13
1.2 Résolution du problème d’optimisation pour la commande
prédictive linéaire avec contraintes
On a vu au paragraphe 1.1.6 que la loi de commande prédictive avec contraintes implique la
résolution d’un problème de programmation quadratique différent à chaque période
d’échantillonnage. On examine dans ce paragraphe les algorithmes les plus utilisée pour la
résolution d’un tel problème en mentionnant leurs avantages et inconvénients.
Remarque : On considère qu’un algorithme de commande prédictive se base sur des
méthodes en ligne si l’implémentation prend en compte les mesures courantes des paramètres
de contexte et fait appel à des programmes itératifs pour résoudre des problèmes classiques de
programmation quadratique :
min∆ ∆ ∆ ∆ 0 (1.52)
Sous les contraintes
F∆ (1.53)
Ω∆ (1.54)
Ces méthodes en ligne doivent être différentiées d’une autre classe de méthodes dites
explicites qui construisent hors ligne la fonction et se résume ensuite à son
évaluation en temps réel.
1.2.1 Méthode de l’ensemble actif
Il s’agit ici d’une des méthodes les plus connues pour résoudre les problèmes QP. Elle
doit son nom au fait que la procédure essaie itérativement de trouver la séparation entre
l’ensemble de contraintes actives et inactives pour la solution optimale par la résolution d’une
suite de problèmes QP avec contraintes égalité. L’ensemble de contraintes actives est
l’ensemble (1.53) en plus d’un sous ensemble de (1.54) qui vérifie l’égalité Ω ∆ .
L’ensemble de contraintes inactives est le sous ensemble de (1.54) qui vérifie l’inégalité
stricte Ω ∆ . Les problèmes QP avec contraintes égalité se résument par projection à
la résolution d’un problème sans contraintes, ce qui constitue un avantage certain en terme de
temps de calcul. Seules les idées de base sont présentées ci-dessous, les détails peuvent être
consultés dans [FLE81].

Chapitre1. Commande prédictive à base de modèle
14
Si l’on connaît un point initial admissible ∆ vérifiant les contraintes (1.53) et (1.54), on
peut alors identifier les inégalités saturées (active) et ensuite construire une matrice
, et un vecteur , en regroupant toutes les contraintes égalité
mais aussi les composantes de et qui correspondent aux inégalités saturées.
Avec les méthodes d’ensemble actif, le nombre d’itérations pour trouver la solution optimale
exacte est fini si le problème n’est pas susceptible de rencontrer de dégénérescence [FLE81].
Même si dans le pire cas la complexité peut être exponentielle en fonction de la taille des
contraintes, pour des problèmes de taille faible les performances restent indéniables.
L’avantage de la méthode d’ensemble actif réside dans la simplicité de construction des
solutions particulières à chaque itération. Dès lors, pour des ensembles de contraintes de
complexité moyenne, la méthode d’ensemble actif reste une des solutions les plus
performantes pour les algorithmes prédictifs en ligne. Les méthodes d’ensemble actif ne sont
pas recommandées pour des problèmes de grande taille car le nombre d’itérations peut
augmenter significativement à cause du nombre élevé de combinaisons possibles.
1.2.2 Méthode du point intérieur
Ces algorithmes font partie de la classe dite « primal-dual path following methods »,
qui utilise une fonction barrière et des algorithmes de type Newton. Leurs racines ne sont
historiquement pas très éloignées [KAR84] et leur développement a été prodigieux. Ces
algorithmes peuvent être vus comme une généralisation des méthodes d’optimisation non
linéaire classiques pour les problèmes d’optimisation avec contraintes convexes. Leurs
performances font qu’ils sont particulièrement adaptés aux problèmes d’optimisation convexe
de grandes dimensions.
Si l’on considère comme formulation de départ le problème lié à la commande prédictive :
arg min∆ ∆ ∆ ∆ (1.55)
Sous les contraintes
Ω∆ (1.56)
La première étape consiste à construire une fonction barrière (ou de pénalité intérieure) qui
devient infinie sur la frontière du domaine faisable. Des choix typiques pour cette fonction
peuvent être :

Chapitre1. Commande prédictive à base de modèle
15
∆ ∑ log Ω ∆ ou ∆ ∑Ω ∆
(1.57)
Avec Ω la i-ème ligne de et la i-eme composante du vecteur . En utilisant cette
fonction, l’optimisation (1.55)-(1.56) peut être remplacée par :
∆ arg min∆ 0.5∆ ∆ ∆ ∆ (1.58)
Avec un scalaire jouant le rôle de pondération. La formulation (1.58) caractérise un
problème d’optimisation non linéaire sans contraintes qui peut être résolu par des méthodes
classiques de type Newton. L’intégration de la fonction barrière dans le critère d’optimisation
évite le débordement du domaine faisable durant la recherche de la solution optimale, en
garantissant donc le fait que les solutions intermédiaires sont faisables. Si la solution optimale
est ∆ pour le problème initial, en augmentant la pondération , la solution de (1.58) va
évoluer de sorte que ∆ ∆ quand
∞ , améliorant donc la qualité de la solution jusqu’à la limite ∆ ∆
avec suffisamment petit. Le chemin suivi par ∆ s’appelle la « trajectoire centrale ».
Les méthodes les plus efficaces travaillent simultanément sur le problème primal et dual. Les
méthodes du point intérieur deviennent de plus en plus populaires, au détriment des méthodes
d’ensemble actif, car leur facteur de convergence est polynomial. En contrepartie, la charge
de calcul par itération est plus importante, ce qui les rend inadaptées pour des problèmes de
petite taille. Les performances sont fortement liées aux précautions prises pour éviter les
problèmes de conditionnement numérique.
1.2.3 L’approche LMI
Le développement de méthodes de programmation semi-définie, en liaison avec la
formulation des problèmes fondamentaux d’automatique en termes d’inégalités matricielles
linéaires (LMI), a ouvert un domaine de recherche très productif. La commande prédictive
n’échappe pas à la règle et, par le biais de LMI, de nouvelles constructions deviennent
possibles pour l’implémentation de lois de commande optimales selon le principe de l’horizon
glissant.
Le principe, résumé par Kothare et al. [KBM96] consiste à minimiser une borne
supérieure de la fonction coût à horizon infini avec des restrictions sur l’entrée et la sortie. La
formulation ne conduit plus à la résolution d’un problème QP mais se réduit à la solution d’un
problème d’optimisation convexe à base d’inégalités matricielles linéaires. Des résultats
existent garantissant que la stratégie proposée assure la stabilité du système. En outre, cette

Chapitre1. Commande prédictive à base de modèle
16
formulation permet d’optimiser de façon significative les résultats de problèmes de
commande robuste développés par le biais de la théorie des LMIs.
Cette approche se base sur l’utilisation de programmes d’optimisation spécifiques tout
en essayant de ne pas s’éloigner des principes fondamentaux de la commande prédictive.
Cette démarche est inverse des cas précédents pour lesquels les objectifs de commande
définissaient un problème d’optimisation où l’on recherchait ensuite le meilleur algorithme de
résolution. A partir de cette observation, la critique que l’on peut formuler est liée au fait que
les programmes LMI minimisent une limite supérieure du critère et que cette limite risque
d’être assez conservative. Du point de vue charge de calcul, même si les solveurs LMI sont
relativement performants, les matrices manipulées sont de taille assez conséquente de sorte
que ces méthodologies restent applicables avant tout pour des dynamiques relativement
lentes. Les avantages de la méthode sont liés à l’utilisation des horizons infinis de prédiction,
à la robustesse en stabilité et en performances. Un autre point fort de la méthode est que si la
faisabilité est acquise à l’instant elle sera sur un horizon de prédiction infini.
1.2.4 Programmation Quadratique multiparamétrique (MPQP)
Il s’agit d’un développement relativement récent qui est toujours un domaine de
recherche active. Si les trois méthodes décrites précédemment se résument à l’emploi de
techniques performantes permettant de résoudre en ligne une certaine classe de problèmes
d’optimisation, cette méthode conduit à l’implémentation de la même stratégie de commande
prédictive par l’intermédiaire de l’évaluation d’une fonction explicite du vecteur d’état. Cette
fonction est construite hors ligne de sorte que le temps de calcul de la commande en ligne se
trouve considérablement allégé. La solution numérique des problèmes d’optimisation est dite
explicite l’orsqu’un calcul direct des variables dépendantes (arguments optimaux, optimum)
peut être réalisé à partir de quantités connues, le calcul est alors explicite. La solution
explicite est du type :
: telle que (1.59)
D’une manière générale le problème d’optimisation de la commande prédictive linéaire est
structuré par la relation :

Chapitre1. Commande prédictive à base de modèle
17
arg min 0.5
Sous les contraintes : (1.60)
Où: , , 1 ( est le vecteur d’optimisation,
0, et , , , , sont facilement obtenues des paramètres de la fonction coût et
des contraintes. Le problème d’optimisation (1.60) est un QP qui dépend de l’état courant
, c’est pour ça que l’implémentation de la loi de commande prédictive nécessite la
résolution d’un QP en ligne à chaque période d’échantillonnage. Pour cela, l’application de la
commande prédictive a été limitée à des systèmes relativement lents.
Dans [BMDP02] les auteurs ont proposé une nouvelle approche d’implémentation de la
MBPC où tout l’effort de calcul se fait hors ligne. L’idée est basée sur l’observation que dans
(1.60), le vecteur d’état peut être considéré comme un vecteur de paramètres. En
d’autres termes, la loi de commande MBPC solution du problème (1.60) est une fonction du
vecteur . La communauté de recherche opérationnelle a adressé les problèmes
d’optimisation dépendants d’un vecteur de paramètres comme programmes
multiparamétriques. Selon cette terminologie, (1.60) est un programme quadratique
multiparamétrique (MPQP). Une fois le problème multiparamétrique (1.60) a été résolu hors
ligne, i.e. la solution de (1.60) a été trouvé, la loi MBPC est disponible
explicitement 0 0 . Il a été démontré dans [BMDP02] que la solution
du problème MPQP est continue et linéaire par morceaux en .
D’où :
(1.61)
Où sont des régions critiques polyédriques qui couvrent les états faisables.
Pratiquement, l’expression globale de la loi MBPC est pré-calculée hors ligne et stockée dans
un tableau (look-up table) contenant comme index les régions polyédriques dans l’espace des
paramètres et comme information les fonctions linéaires en l’état du système qui

Chapitre1. Commande prédictive à base de modèle
18
correspondent à la commande optimale. A l’aide de cette table, l’implémentation en ligne de
la commande prédictive explicite doit suivre les étapes suivantes :
1) Mesurer (ou estimer) le vecteur des paramètres courants ;
2) Rechercher dans la table la région critique contenant ;
3) Utiliser la loi linéaire de commande par retour d’état correspondant à cette région
active ;
4) Réitérer la démarche à partir de 1).
Le rôle de l’index dans la table est de permettre une association rapide des valeurs
recherchées, à savoir ici les commandes. Cette identification se fait en ligne et peut engendrer
une charge informatique importante si le nombre de partitions est élevé. C’est l’inconvénient
majeur de cette méthode. Pour remédier à ça plusieurs méthodes ont été proposées [TON03,
OD05, WMY09].
1.3 Commande prédictive non linéaire
Dans beaucoup de situations l'opération du processus exige des changements fréquents d'un
point de fonctionnement à un autre et, en conséquence, un modèle non-linéaire doit être
utilisé. L'utilisation de la commande prédictive non linéaire est justifiée dans les secteurs où
les non-linéarités de processus sont fortes et les demandes du marché exigent des
changements fréquents en régimes de fonctionnement. Bien que le nombre d'applications de
la commande prédictive non linéaire soit encore limité, son potentiel est vraiment grand et la
MPC employant des modèles non linéaires est susceptible de devenir plus commun car les
utilisateurs exigent un rendement plus élevé et les nouveaux outils de logiciel rendent les
modèles non linéaires plus aisément disponibles. D'un point de vue théorique employer un
modèle non linéaire change le problème d’optimisation d'un QP convexe en programme non
linéaire non convexe, dont la solution est beaucoup plus difficile. Il n'y a aucune garantie, par
exemple, que l'optimum global peut être trouvé.

Chapitre1. Commande prédictive à base de modèle
19
1.3.1 Formulation générale
Soit un système non linéaire échantillonné décrit par l’équation aux différences suivante :
1 , (1.62)
Où est l’état du système, son entrée de commande et est une application continue de
dans . L’indice est associé à une période d’échantillonnage qui est supposée
constante. La commande est supposée appartenir à un ensemble compact et convexe de
:
(1.63)
Il est supposé aussi que l’ensemble admissible contient l’origine dans son intérieur, à
savoir :
0
La raison pour la quelle l’origine joue un rôle particulier est que l’origine représente l’état
désiré (après un changement de coordonnées adéquat). Il est ainsi supposé que l’origine est un
point d’équilibre du système avec la commande 0, soit : 0,0 0. L’objectif de la loi
de commande est de stabiliser le système en tout en garantissant que les trajectoires de l’état
du système restent dans un ensemble convexe et fermé :
(1.64)
Ceci traduit divers types de contraintes, à savoir, des contraintes de sécurité, des contraintes
de respect des spécifications ou tout simplement de validité de modèle.
Lorsque le système se trouve à l’état à l’instant d’échantillonnage , une fonction de coût
est associée à chaque profil de commande de la façon suivante :
, , ∑ , (1.65)
Où le profil de commande est donné par :
1 1
Et où dans (1.65) désigne l’état du système à l’instant lorsque le profil de commande
est appliqué.

Chapitre1. Commande prédictive à base de modèle
20
Notons que la fonction de coût contient une pénalisation sur l’état final . En
plus du terme de pondération sur l’état final, une contrainte finale explicite sur l’état peut
aussi être utilisée. Elle peut s’écrire d’une façon générale comme suit :
(1.66)
Où est un sous-ensemble fermé et convexe de .
Il est à remarquer que, dans certaines formulations, aucune contrainte finale sur l’état n’est
présente, ceci revient simplement à prendre .
Le profil de commande est admissible si les trajectoires qui en résultent satisfont les
contraintes (1.63), (1.64) et (1.66), le problème de commande optimale suivant peut alors être
défini pour le système à l’état à l’instant :
min , ,
sous les contraintes (1.63), (1.64) et (1.66) (1.67)
Il s’agit donc d’un problème d’optimisation, généralement non convexe, dans lequel la
variable de décision est le profil de commande . L’existence de solution au
problème (1.67) est généralement assurée par le résultat d’analyse élémentaire suivant : toute
fonction continue atteint son minimum sur tout ensemble compact. La possibilité d’invoquer
ce résultat pour garantir l’existence de solutions justifie les hypothèses suivantes :
• Les fonctions , et dans (1.62) et (1.65) sont continues ;
• L’ensemble admissible est compact ;
• Les ensembles et sont fermés.
Le principe de la commande prédictive (ou commande à horizon fuyant) est d’appliquer
pendant chaque période d’échantillonnage , 1 la première commande de la séquence
optimale.
1.3.2 Solution du problème de la commande prédictive non linéaire
Comme on l’a vu dans la section précédente, l’utilisation d’un modèle non linéaire
change le problème de commande d'un programme quadratique convexe en un problème non
linéaire non convexe, qui est beaucoup plus difficile à résoudre et ne fournit aucune garantie

Chapitre1. Commande prédictive à base de modèle
21
que l'optimum global peut être trouvé. Comme dans la commande en temps réel l'optimum
doit être obtenu en un intervalle de temps limité, le temps nécessaire pour trouver l'optimum
(ou une approximation acceptable) est une question importante.
Le problème est souvent résolu en utilisant des techniques de Programmation quadratique
séquentielle (SQP). Ce sont des extensions des méthodes de Newton pour converger à la
solution des conditions de Karush-Kuhn-Tucker (KKT) du problème d'optimisation avec
contraintes. La méthode doit garantir la convergence rapide et doit être capable de prendre en
considération les problèmes de mal conditionnement et les non linéarités fortes. Beaucoup de
problèmes peuvent apparaître en appliquant la méthode, telle que la disponibilité des dérivés
seconds ou la faisabilité de la solution intermédiaire. Plusieurs variantes de la méthode
originale existent pour surmonter ces problèmes.
Une autre méthode très utilisé pour résoudre le problème de la commande prédictive
non linéaire est la programmation dynamique (DP) [BEL57]. La commande prédictive non
linéaire est la fille de la commande optimale puisque la résolution, à chaque période
d’échantillonnage, d’un problème de commande optimale est au cœur de la définition même
de la MBPC non linéaire.
1.4 Stabilité de la commande prédictive
Même si le problème de la commande prédictive est résolu parfaitement à chaque
instant de décision, son utilisation ne conduit pas nécessairement à un système stable en
boucle fermé. Le problème de la stabilité qui pourrait surgir lorsque le principe de l’horizon
fuyant est utilisé sans précaution particulière a été soulevé très tôt par Kalman en 1960. En
effet, Kalman a fait observer que, même pour les systèmes linéaires : « L’optimalité
n’implique pas la stabilité ».
Accompagnant le succès de la MBPC dans ce contexte industriel, des travaux
académiques commençaient à voir le jour visant à caractériser les conditions de stabilité. Le
passage aux représentations d’état des systèmes a certainement amorcé le virage dans la
bonne direction. Le pas décisif a été franchi par [KG88] où la première preuve formelle de
stabilité asymptotique de la boucle fermée pour un système non linéaire sous la MBPC a été
démontrée en utilisant une méthode de Lyapunov. Depuis une floraison de formulations a vu

Chapitre1. Commande prédictive à base de modèle
22
le jour. Aujourd’hui, grâce à [MRRS00], une vision épurée et extrêmement synthétique des
conditions de stabilité des schémas de la MBPC est ainsi disponible.

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
23
Chapitre 2
La commande prédictive floue à base de modèle d’état
et ses méthodologies de solutions
Dans ce chapitre, nous introduisons les méthodes de résolution du problème
d’optimisation associé à la commande prédictive floue [BM07, CMB02, SK01, TD05]. Nous
commençons par rappeler les principes de base de la prise de décision dans un environnement
flou de Bellman Zadeh, ensuite nous poserons le problème d’optimisation de la MBFPC. Les
solutions proposées seront ensuite détaillées.
2.1 Commande prédictive Floue
2.1.1 Prise de décision dans un environnement flou
Soit l’ensemble des alternatives possibles contenant la solution du problème de la
prise de décision floue considérée. Un objectif flou G est un ensemble flou de X caractérisé
par sa fonction d’appartenance )(xGµ . De la même manière, une contrainte floue C est un
ensemble flou de U caractérisé par sa fonction d’appartenance )(uCµ . Considérons un
objectif flou et une contrainte floue selon le mécanisme de décision de Bellman et Zadeh [2],
la décision floue D résultante est donnée par l’intersection de l’objectif G et de la contrainte
C, c’est-à-dire:
)()()( uxu CGD µµµ ∧= (2.1)
∧ indique un opérateur du type t-norm, par exemple minimum ou produit. Dans le
mécanisme de prise de décision floue, une décision optimale fait référence à la décision avec
le plus grand degré d’appartenance (meilleure décision). Cette décision optimale est aussi
appelée maximisation de la décision. Sous forme mathématique cette dernière s’exprime
comme suit:
Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
24
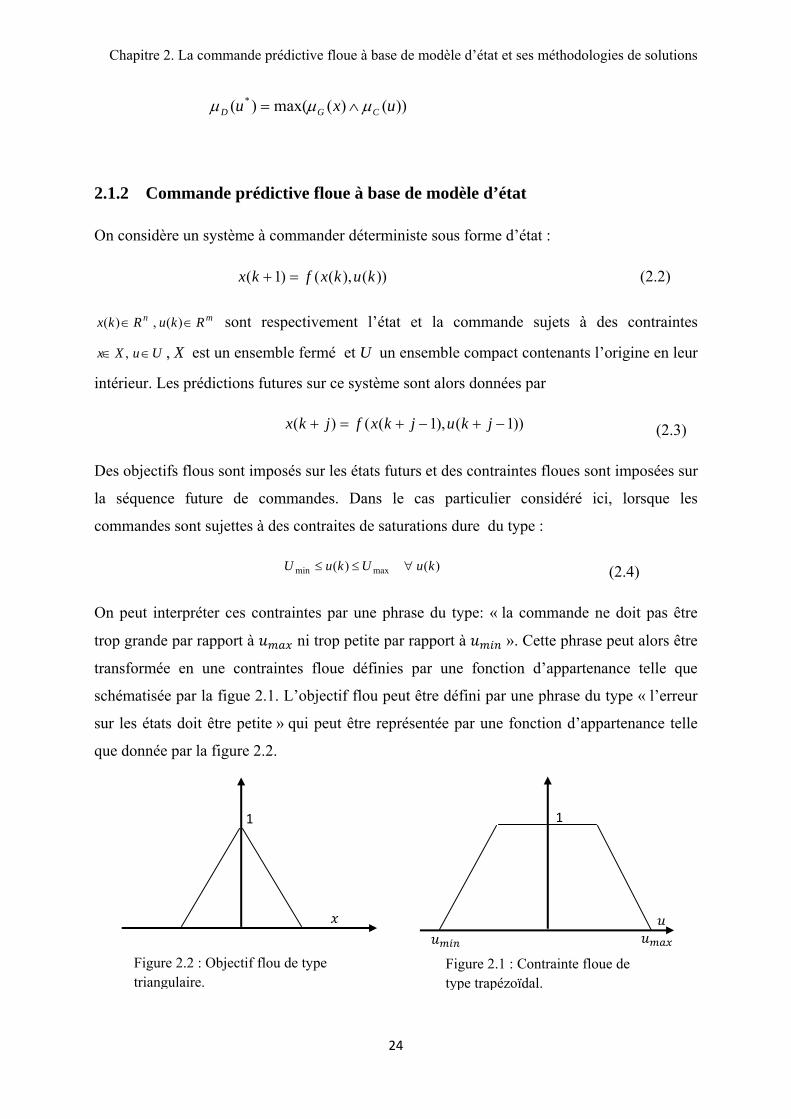
Figure 2.1 : Contrainte floue de type trapézoïdal.
Figure 2.2 : Objectif flou de type triangulaire.
))()(max()( * uxu CGD µµµ ∧=
2.1.2 Commande prédictive floue à base de modèle d’état
On considère un système à commander déterministe sous forme d’état :
))(),(()1( kukxfkx =+ (2.2)
mn RkuRkx ∈∈ )(,)( sont respectivement l’état et la commande sujets à des contraintes
UuXx ∈∈ , , X est un ensemble fermé et U un ensemble compact contenants l’origine en leur
intérieur. Les prédictions futures sur ce système sont alors données par
))1(),1(()( −+−+=+ jkujkxfjkx (2.3)
Des objectifs flous sont imposés sur les états futurs et des contraintes floues sont imposées sur
la séquence future de commandes. Dans le cas particulier considéré ici, lorsque les
commandes sont sujettes à des contraites de saturations dure du type :
)()( maxmin kuUkuU ∀≤≤ (2.4)
On peut interpréter ces contraintes par une phrase du type: « la commande ne doit pas être
trop grande par rapport à ni trop petite par rapport à ». Cette phrase peut alors être
transformée en une contraintes floue définies par une fonction d’appartenance telle que
schématisée par la figue 2.1. L’objectif flou peut être défini par une phrase du type « l’erreur
sur les états doit être petite » qui peut être représentée par une fonction d’appartenance telle
que donnée par la figure 2.2.
1 1

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
25
Pour définir la commande prédictive floue, on impose qu’à chaque instant de prédiction
j=1….N, les commandes 1 sont sujettes à des contraintes floues jC avec une
fonction d’appartenance et les variables d’état sont sujettes à des objectifs
flous jG avec une fonction d’appartenance . On définit alors la fonction coût pour la
commande prédictive floues par:
))(())((...)(())(())(),(( Nkx1Nku1kxkukxkuJ NN11 GCGCN +∧−+∧∧+∧= µµµµ (2.5)
Cette fonction est positive et inférieur ou égale à l’unité.
A partir de ce qui précède, le problème de la MBFPC est de trouver la séquence optimale de
commande qui résout le problème :
Max ))(),(( kxkuJ N (2.6)
Sous N1j1jku1jkxfjkx ...)(),(()(ˆ =−+−+=+
Dans ce qui suit nous introduisons des méthodes de solutions de ce problème. La première
approche est générale et s’applique a tous type de problème [BM07], la deuxième s’applique
aux algorithmes à base de modèle de prédiction linéaire, la troisième aux systèmes linéaires
du premier ordre.
2.2 La méthode branch and bound
La méthode branch and bound est associée à une arborescence dont les sommets
correspondent à des solutions réalisables. Elle repose sur deux principes :
• Détermination du chemin optimal initial
• Exploration de l’arbre à la recherche du chemin optimal
Elle est détaillée dans [BM07]

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
26
2.3 Commande prédictive floue linéaire avec fonctions
d’appartenance gaussiennes
L’inconvénient majeur de la FMBPC est la lourdeur et la complexité du problème
d’optimisation qui doit être résolu à chaque période d’échantillonnage. La forme arbitraire des
fonctions d’appartenance de la fonction de coût floue et les opérateurs d’agrégation utilisés
rendent le problème d’optimisation non convexe en général. Pour remédier à ça, plusieurs
méthodes peuvent être utilisées. Dans ce qui suit, nous montrons qu’en utilisant des fonctions
d’appartenance et des opérateurs d’agrégation adéquats, une solution analytique de la loi de
commande FMBPC dans le cas des systèmes linéaires peut être obtenue.
2.3.1 Définition du problème
Soit un système linéaire échantillonné décrit par l’équation aux différences suivante :
1 (2.7)
Où : le vecteur d’état du système à l’instant ,
le vecteur de commande à l’instant . et des
matrices de dimension correspondante.
La commande prédictive floue peut être définie comme une loi de rétroaction
qui maximise une fonction de coût floue .
Où :
| 1| (2.8)
| (2.9)
1| 1 (2.10)
Supposons que les objectifs et les contraintes flous sont sous formes gaussiennes et que
l’opérateur d’agrégation est le produit :
/ (2.11)
/ (2.12)

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
27
Alors :
(2.13)
2.3.2 Les prédictions
A partir de (2.7), on peut facilement obtenir par récurrence la relation suivante :
| 1 2
1 (2.14)
D’où :
1|2|3|
|
0 0 00 0
0
|1|2|
1|
(2.15)
Ou sous forme compacte :
(2.16)
Où :
1|2|3|
|
; ;
0 0 00 0
0 ;
|1|2|
1|
.

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
28
Ce qui permet de mettre la fonction coût sous la forme :
, Γ Γ (2.17)
Où : Γ
0 00 0
0 0
;
1/ 0 00 1/ 0
0 0 1/
(2.18)
Γ
0 00 0
0 0
;
1/ 0 00 1/ 0
0 0 1/
(2.19)
2.3.3 Solution
En remplaçant (2.16) dans (2.17) on obtient :
, Γ Γ 2 Γ Γ (2.20)
Qui a la forme :
, , (2.21)
Où :
, Γ Γ 2 Γ Γ (2.22)
est connu à l’instant .
Les dimensions des vecteurs et des matrices correspondants sont données dans le tableau
(2.1).

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
29
Matrices Dimensions
Γ
Γ
1
1
1
Tableau (2.1) : dimensions des vecteurs et des matrices correspondants
Le gradient de est donné par :
, , (2.23)
Connaissant l’expression de (2.22), le vecteur gradient peut être réécrit sous forme :
2 Γ Γ Γ , (2.24)
En annulant ce dernier, on obtient l’optimum :
Γ Γ Γ (2.25)
Qui a la forme :
(2.26)
Où : Γ Γ Γ (2.27)
Pour savoir si est un maximum de , il faut dériver encore le gradient (2.23) pour
obtenir la matrice Hessiènne :
(2.28)
Sachant que 0, alors :
(2.29)
Connaissant l’expression de (2.22), on peut calculer sa matrice Hessiènne :
2 Γ Γ (2.30)
D’où :
2 Γ Γ (2.31)

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
30
Figure 2.3 : Objectif flou triangulaire S1 S2
1
1 2 3 4
1
Figure 2.4 : Contrainte floue trapézoïdale
Nous remarquons de (2.18) et (2.19) que Γ et Γ sont strictement définies positives. Alors
0 (2.32)
Ce qui confirme que l’expression de donnée par (2.19) est un maximum. La loi de
commande prédictive floue est alors donnée par :
, 0 , … , 0 (2.33) 1 fois
2.4 Solution analytique pour les systèmes du premier ordre
2.4.1 Définitions
L’inconvénient des formes Gaussiennes de la section précédente est que les contraintes ne
sont pas vraiment claires. La vérification des contraintes sur les entrées de commande et/ou
les états se fait en simulation par des tatonnements sur les valeurs 1,… , et
1,… , . Pour cela, nous considérons dans cette section deux formes très utilisées à
savoir : triangulaire pour l’objectif flou (cf. Figure 2.3) et trapézoïdale pour la contrainte
floue (cf. Figure 2.4).

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
31
2.4. Solution
Dans ce qui suit, nous allons montrer qu’une solution analytique de la loi de commande
prédictive floue est possible pour un modèle de prédiction du premier ordre avec ces fonctions
d’appartenance en utilisant le minimum comme opérateur d’agrégation. Soit un système
linéaire échantillonné décrit par l’équation aux différences suivante :
1 (2.34)
Où : l’état du système à l’instant , la commande à l’instant et , .
Pour des raisons de simplicité, supposons que les fonctions d’appartenance (cf. Figures 2.3 et
2.4) sont symétriques : , , et que 0, 0.
Remarque : Une solution analytique est aussi possible dans le cas où les fonctions
d’appartenance sont non symétriques et dans le cas où et/ou sont négatifs.
La fonction de coût floue est alors donnée par la relation :
, 1 1 2
… 1 (2.35)
Où : est l’horizon de prédiction et de commandes (supposés égaux), est l’opérateur min,
et sont données dans fig. 2.3-2.4. La séquence de commandes optimales
, 1 , … , 1 qui maximise (2.35) et la fonction de coût
partielle sont données dans la proposition suivante :
Proposition 1 :
I) Si 1 alors :
1°
2°
3°
4° é
(2.36)

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
32
,
1°
2° 1
3°
4° 0
2.37
Pour 1 , … , .
II) Si 1 alors :
1° ∑
– ∑
2° –
3° –
4°
5° ∑
– ∑
6° é ∑ – ∑
2.38
,
1° ∑∑
– ∑
2° –
3° 1 –
4°
5° ∑∑
– ∑
6° 0 ∑ – ∑
2.39
Pour 1 , … , .
Démonstration : La démonstration se fait par récurrence.

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
33
11
11
1
11
Figure 2.5 : 1 et en fonction de 1
Supposons que 1 .
De (2.35) et en utilisant le principe d’optimalité, nous avons :
1 argmax 1 , (2.40)
Où :
1
0 | 1 |1 | 1 |
1
1
(2.41)
0 | |
0
0 (2.42)
En remplaçant (2.34) dans (2.42) :
0 1 1
1
1
(2.43)
La figure suivante montre 1 et en fonction de
1 :
Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
34
1 11
1 1 1
1
1
1 ,
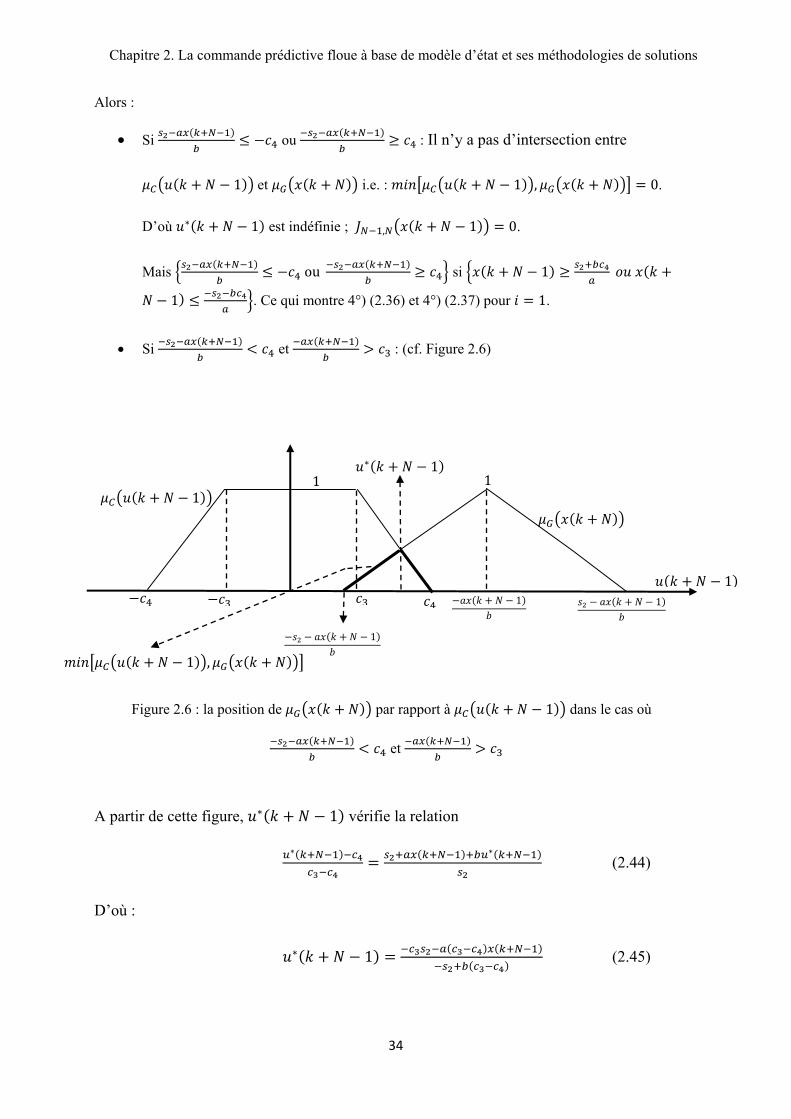
Figure 2.6 : la position de par rapport à 1 dans le cas où
et
1
Alors :
• Si ou : Il n’y a pas d’intersection entre
1 et i.e. : 1 , 0. D’où 1 est indéfinie ; , 1 0.
Mais ou si 1
1 . Ce qui montre 4°) (2.36) et 4°) (2.37) pour 1.
• Si et : (cf. Figure 2.6)
A partir de cette figure, 1 vérifie la relation
(2.44)
D’où :
1 (2.45)
Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
35
11
11
1
1
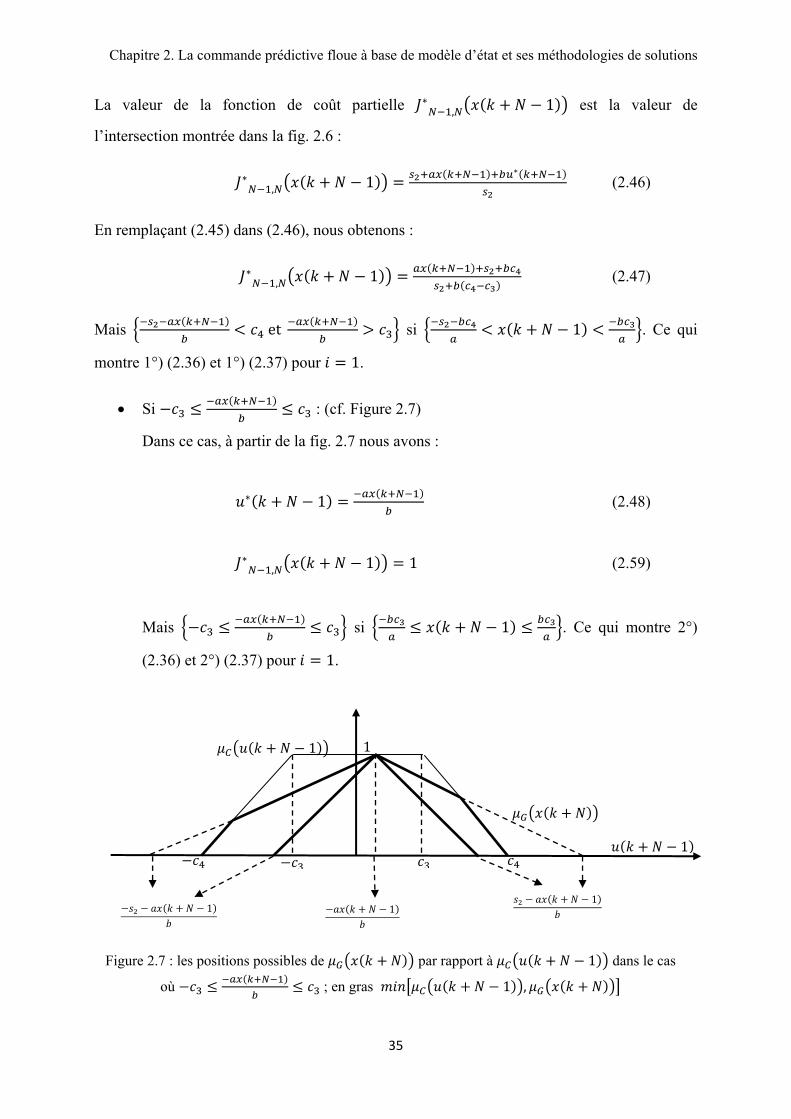
Figure 2.7 : les positions possibles de par rapport à 1 dans le cas
où ; en gras 1 ,
La valeur de la fonction de coût partielle , 1 est la valeur de
l’intersection montrée dans la fig. 2.6 :
, 1 (2.46)
En remplaçant (2.45) dans (2.46), nous obtenons :
, 1 (2.47)
Mais et si 1 . Ce qui
montre 1°) (2.36) et 1°) (2.37) pour 1.
• Si : (cf. Figure 2.7)
Dans ce cas, à partir de la fig. 2.7 nous avons :
1 (2.48)
, 1 1 (2.59)
Mais si 1 . Ce qui montre 2°)
(2.36) et 2°) (2.37) pour 1.
Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
36
,
1
1
1
1
11
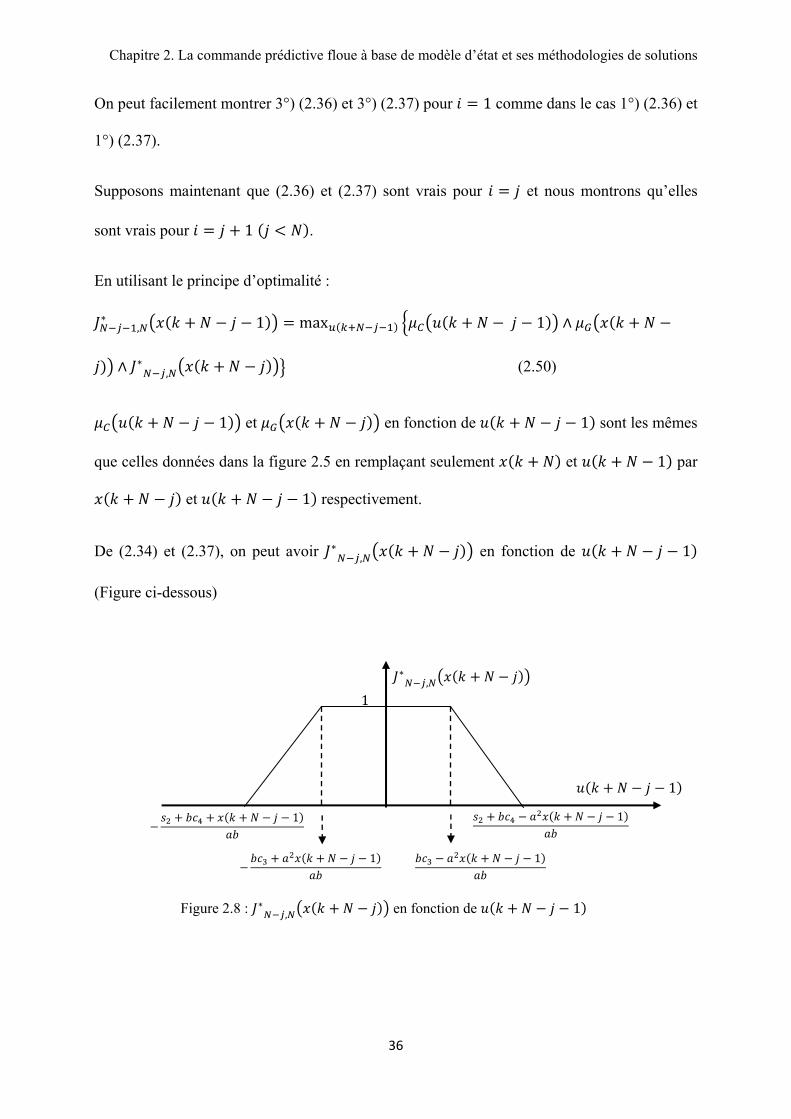
Figure 2.8 : , en fonction de 1
On peut facilement montrer 3°) (2.36) et 3°) (2.37) pour 1 comme dans le cas 1°) (2.36) et
1°) (2.37).
Supposons maintenant que (2.36) et (2.37) sont vrais pour et nous montrons qu’elles
sont vrais pour 1 .
En utilisant le principe d’optimalité :
, 1 max 1
, (2.50)
1 et en fonction de 1 sont les mêmes
que celles données dans la figure 2.5 en remplaçant seulement et 1 par
et 1 respectivement.
De (2.34) et (2.37), on peut avoir , en fonction de 1
(Figure ci-dessous)

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
37
On peut aussi facilement vérifier les trois relations suivantes :
1 (2.51)
1 (2.52)
1 (2.53)
(2.51) peut être vérifiée à partir de 0 ; (2.52) et (2.53) peuvent être vérifiées à
partir de la supposition 1 .
Dans ce cas, est complètement au-dessous de , .
D’où :
, (2.54)
Alors :
, 1 max 1 ,
(2.55)
1 argmax 1 ,
(2.56)
Qui est similaire à (2.40).
On peut alors montrer (2.36) et (2.37) pour 1 comme dans le cas où 1 vu
précédemment. On a ainsi montré que la validité des expressions (2.36) et (2.37) pour
implique leurs validité pour 1, ce qui complète la démonstration de la partie I de la
proposition1.
De la même manière (par récurrence), on peut montrer la partie II.
Corollaire 1 :
En utilisant les fonctions d’appartenance trapézoïdale et triangulaire (fig. 2.3 et 2.4) pour les
contraintes et le objectifs flous et le min comme opérateur d’agrégation, la loi de commande
prédictive floue appliquée sur le système (2.34) est linéaire par morceau
définie comme suit :

Chapitre 2. La commande prédictive floue à base de modèle d’état et ses méthodologies de solutions
38
I) Si 1 alors :
1°
2°
3°
4° é
(2.57)
II) Si 1 alors :
1° ∑ – ∑
2° –
3° –
4°
5° ∑ – ∑
6° é ∑ – ∑
2.58
Démonstration :
Dans le principe de l’horizon fuyant, seulement le premier pas de la séquence optimale qui est
appliqué au système. Alors pour avoir la loi de commande prédictive floue, il suffit seulement
de remplacer par dans (2.36) et (2.38).

Chapitre 3. Exemples d’applications
39
Chapitre 3
Exemples d’applications
Dans ce chapitre, nous allons présenter des exemples d’application pour mettre
en évidence l’efficacité de la commande prédictive floue dans la commande des
systèmes linéaires et non linéaires.
3.1 Programmation dynamique avec branch and bound 3.1.1 Système non linéaire 1er ordre
Soit le système non linéaire [BM07] et [SMR99] décrit par l’équation d’état suivante :
1 (3.1)
Où , sont l’état et la commande du système à l’instant . Le modèle de
prédiction utilisé est le modèle du système (3.1). L’objectif principal ici est de
stabiliser l’état du système autour de son point d’équilibre tout en restant dans le
domaine de tolérance de l’état suivant :
/| | 2.5 , i.e., 2.5 , 2.5 (3.2)
Les contraintes imposées sur la commande sont données par :
, 2 , 2 , i.e., /| | 2 (3.3)
Afin de réaliser notre objectif, nous allons exploiter la technique de programmation
dynamique avec Branch&Bound pour implanter la commande prédictive avec un
critère de décision floue. Dans ce contexte, l’implantation est faite avec les paramètres
suivants :
• L’horizon de prédiction est fixé à 1.
• Le pas de discrétisation de la commande et de l’état sont ∆ 0.1 et
∆ 0.2.
Chapitre 3. Exemples d’applications
40
0 2 4 6 8 10 12 14 16 18 200
0.5
1
1.5
2
2.5
3
Temps k
x (k
)
0 2 4 6 8 10 12 14 16 18 20-2
-1.8
-1.6
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
Temps k
u (k)
Figure 3.1 : Evolution de l’état
Figure 3.2 : Evolution de la commande
• Les fonctions d’appartenance associées à l’état et à la commande sont
choisies respectivement triangulaire et trapézoïdale avec 2.5,
2 et 1.5. (cf. Figures 2.3-2.4).
Dans ce cas, le critère de décision à optimiser est donné par :
, 1 1 (3.4)
1 1 2
Par application de l’algorithme de la programmation dynamique floue (FDP) et B&B
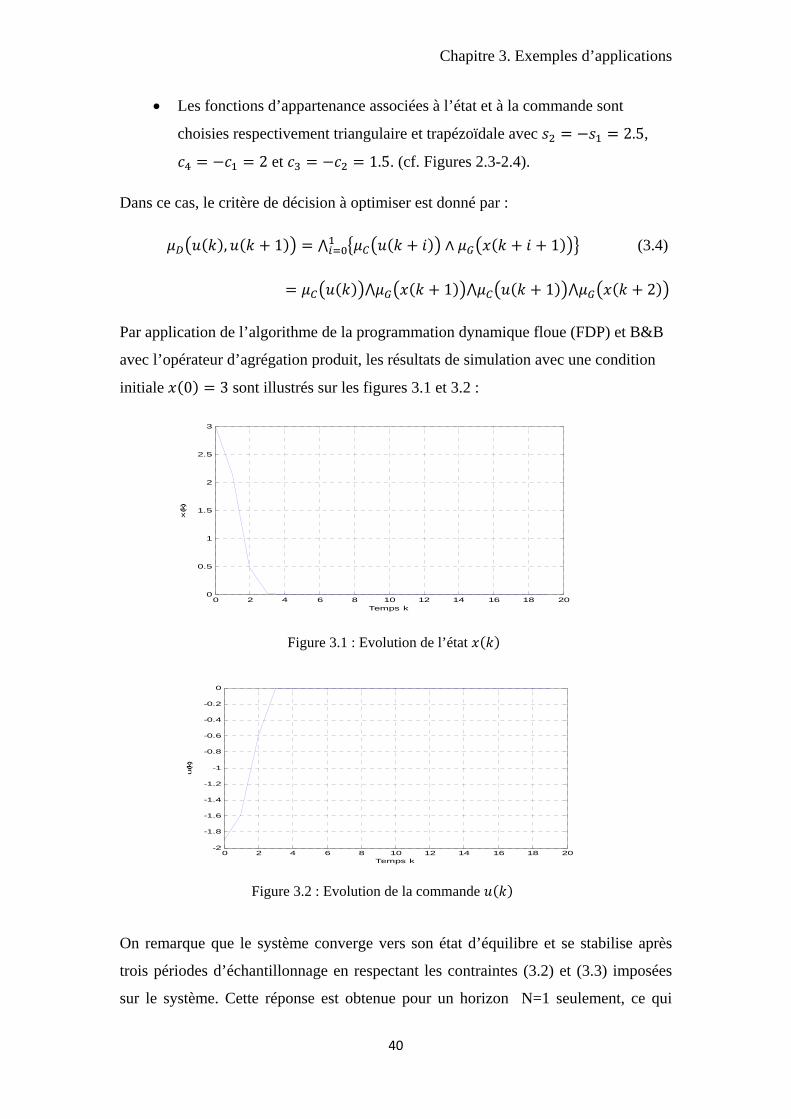
avec l’opérateur d’agrégation produit, les résultats de simulation avec une condition
initiale 0 3 sont illustrés sur les figures 3.1 et 3.2 :
On remarque que le système converge vers son état d’équilibre et se stabilise après
trois périodes d’échantillonnage en respectant les contraintes (3.2) et (3.3) imposées
sur le système. Cette réponse est obtenue pour un horizon N=1 seulement, ce qui
Chapitre 3. Exemples d’applications
41
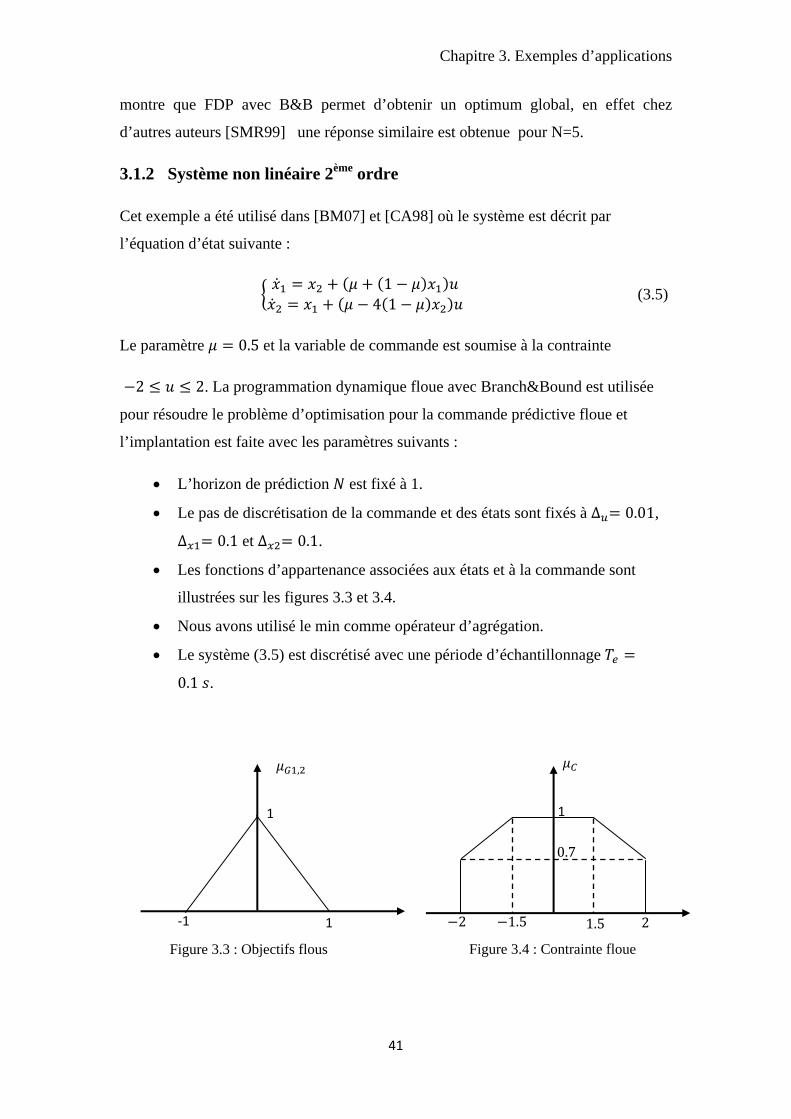
Figure 3.3 : Objectifs flous Figure 3.4 : Contrainte floue
‐1
1
1
1
,
2 2 1.5 1.5
0.7
montre que FDP avec B&B permet d’obtenir un optimum global, en effet chez
d’autres auteurs [SMR99] une réponse similaire est obtenue pour N=5.
3.1.2 Système non linéaire 2ème ordre
Cet exemple a été utilisé dans [BM07] et [CA98] où le système est décrit par
l’équation d’état suivante :
14 1 (3.5)
Le paramètre 0.5 et la variable de commande est soumise à la contrainte
2 2. La programmation dynamique floue avec Branch&Bound est utilisée
pour résoudre le problème d’optimisation pour la commande prédictive floue et
l’implantation est faite avec les paramètres suivants :
• L’horizon de prédiction est fixé à 1.
• Le pas de discrétisation de la commande et des états sont fixés à ∆ 0.01,
∆ 0.1 et ∆ 0.1.
• Les fonctions d’appartenance associées aux états et à la commande sont
illustrées sur les figures 3.3 et 3.4.
• Nous avons utilisé le min comme opérateur d’agrégation.
• Le système (3.5) est discrétisé avec une période d’échantillonnage
0.1 .
Chapitre 3. Exemples d’applications
42
0 1 2 3 4 5 6 7 8 9 10-0.2
0
0.2
0.4
0.6
0.8
1
1.2
T e m p s ( s )
x 1 (
k )
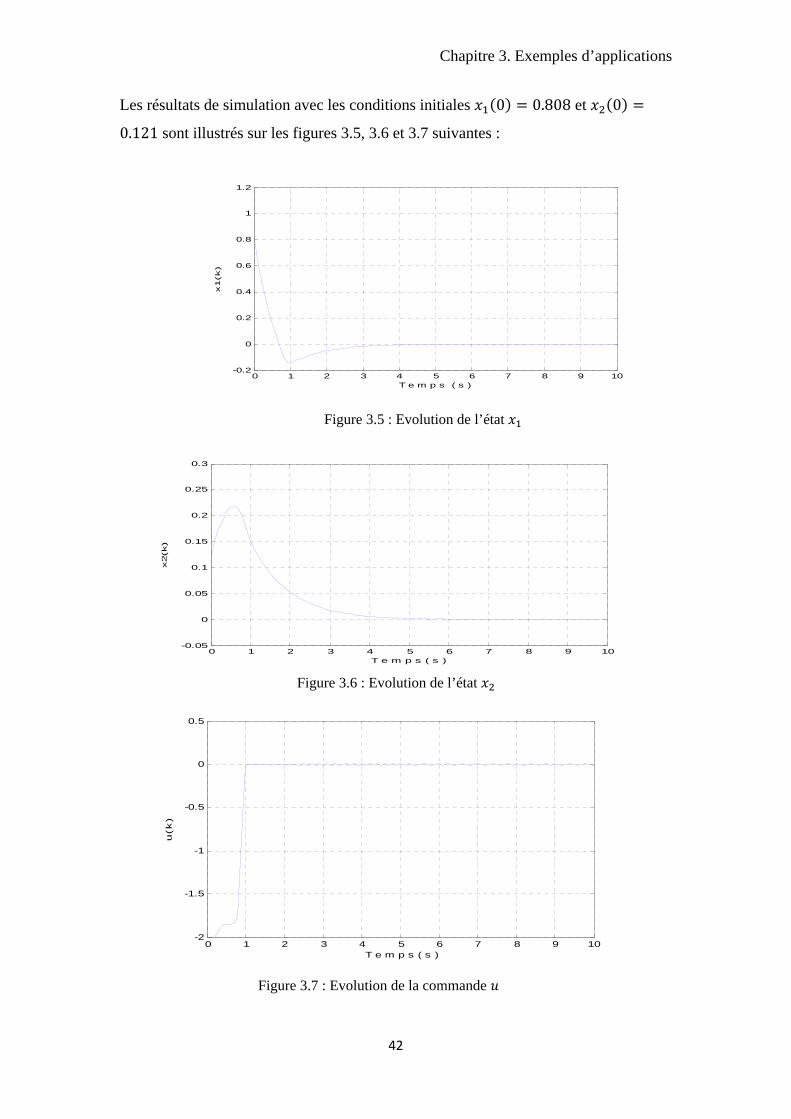
Figure 3.5 : Evolution de l’état
0 1 2 3 4 5 6 7 8 9 10-0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
T e m p s ( s )
x 2 ( k )
Figure 3.6 : Evolution de l’état
0 1 2 3 4 5 6 7 8 9 10-2
-1.5
-1
-0.5
0
0.5
T e m p s ( s )
u (
k )
Figure 3.7 : Evolution de la commande
Les résultats de simulation avec les conditions initiales 0 0.808 et 0
0.121 sont illustrés sur les figures 3.5, 3.6 et 3.7 suivantes :

Chapitre 3. Exemples d’applications
43
Le système converge vers son état d’équilibre et se stabilise après quelques instants en
respectant la contrainte imposée sur l’entrée du système. Les petites oscillations
limites qui apparaissent sur ces figures sont dues à la discrétisation de l’espace d’état
et de commande. En diminuant le pas de discrétisation, ces derniers diminuent. De la
même façon que pour l’exemple précédent, ce résultat est obtenu pour N=1 alors que
chez les auteurs [CA98] il faut un horizon de N=10 pour un résultat similaire.
3.2 Méthode analytique avec contraintes et objectifs gaussiens 3.2.1 Système linéaire 2ème ordre
Soit le système 2ème ordre [BMDP02]
(3.6)
Où : , respectivement l’entée et la sortie du système à l’instant . la
variable de la transformé de Laplace.
La discrétisation de (3.6) avec une période d’échantillonnage 0.1 permet
d’obtenir la représentation d’état
1 0.7326 0.08610.1722 0.9909
0.06090.0064
0 1.4142 (3.7)
Où le vecteur d’état.
L’objectif est de stabilisé le système à l’origine tout en respectant la contrainte sur la
commande
2 2 (3.8)
Pour cela nous utilisons un contrôleur prédictif flou basé sur le problème
d’optimisation :
Chapitre 3. Exemples d’applications
44
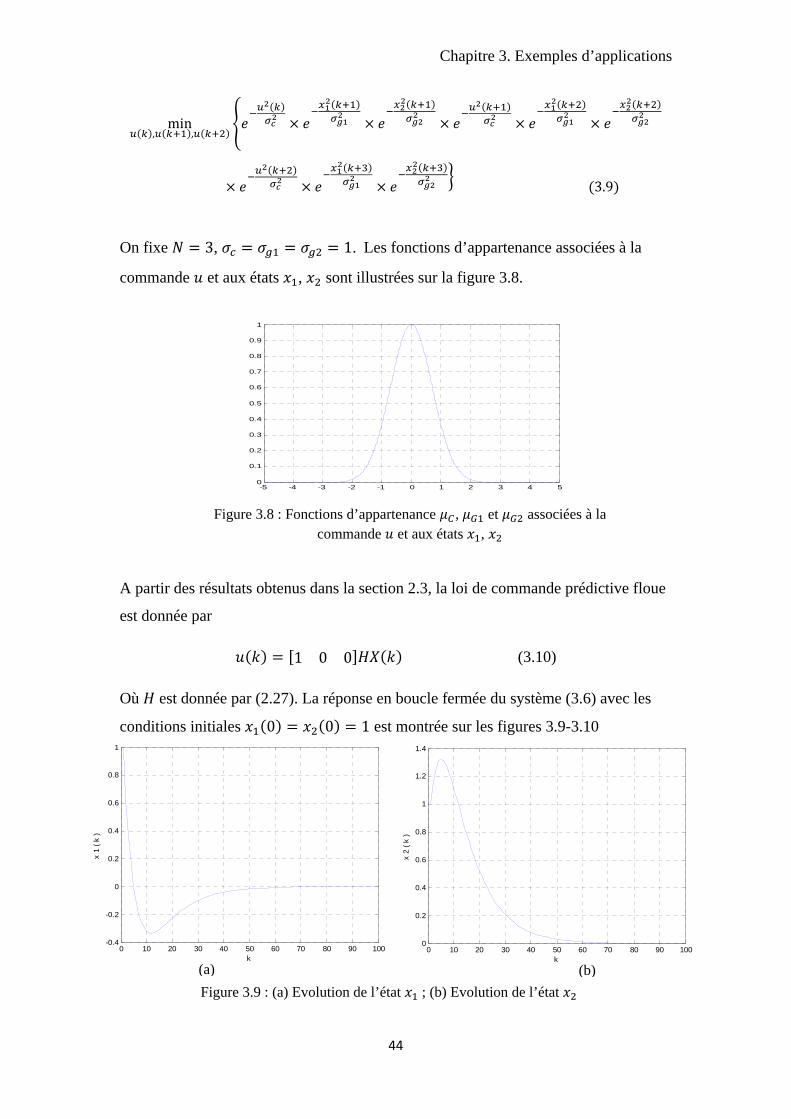
-5 -4 -3 -2 -1 0 1 2 3 4 50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Figure 3.8 : Fonctions d’appartenance , et associées à la commande et aux états ,
0 10 20 30 40 50 60 70 80 90 100-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
k
x 1
( k
)
0 10 20 30 40 50 60 70 80 90 1000
0.2
0.4
0.6
0.8
1
1.2
1.4
k
x 2
( k
)
Figure 3.9 : (a) Evolution de l’état ; (b) Evolution de l’état (a) (b)
min, ,
3.9
On fixe 3, 1. Les fonctions d’appartenance associées à la
commande et aux états , sont illustrées sur la figure 3.8.
A partir des résultats obtenus dans la section 2.3, la loi de commande prédictive floue
est donnée par
1 0 0 (3.10)
Où est donnée par (2.27). La réponse en boucle fermée du système (3.6) avec les
conditions initiales 0 0 1 est montrée sur les figures 3.9-3.10
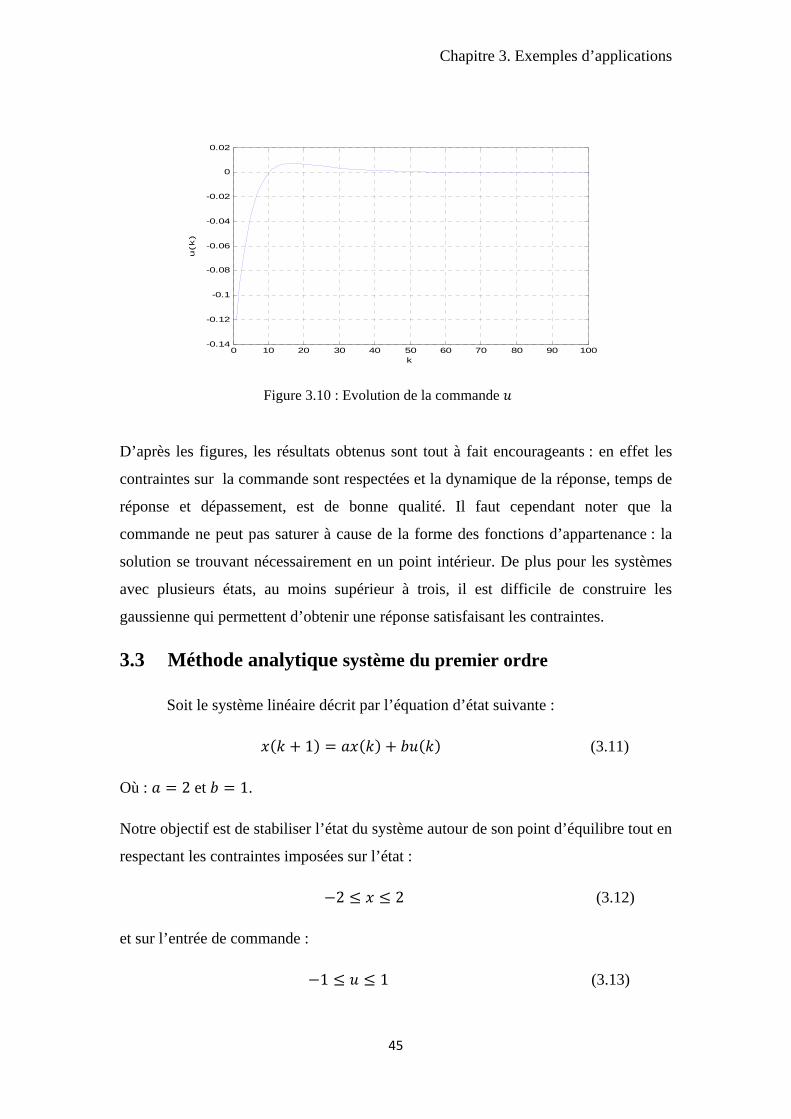
Chapitre 3. Exemples d’applications
45
0 10 20 30 40 50 60 70 80 90 100-0.14
-0.12
-0.1
-0.08
-0.06
-0.04
-0.02
0
0.02
k
u (
k )
Figure 3.10 : Evolution de la commande
D’après les figures, les résultats obtenus sont tout à fait encourageants : en effet les
contraintes sur la commande sont respectées et la dynamique de la réponse, temps de
réponse et dépassement, est de bonne qualité. Il faut cependant noter que la
commande ne peut pas saturer à cause de la forme des fonctions d’appartenance : la
solution se trouvant nécessairement en un point intérieur. De plus pour les systèmes
avec plusieurs états, au moins supérieur à trois, il est difficile de construire les
gaussienne qui permettent d’obtenir une réponse satisfaisant les contraintes.
3.3 Méthode analytique système du premier ordre
Soit le système linéaire décrit par l’équation d’état suivante :
1 (3.11)
Où : 2 et 1.
Notre objectif est de stabiliser l’état du système autour de son point d’équilibre tout en
respectant les contraintes imposées sur l’état :
2 2 (3.12)
et sur l’entrée de commande :
1 1 (3.13)
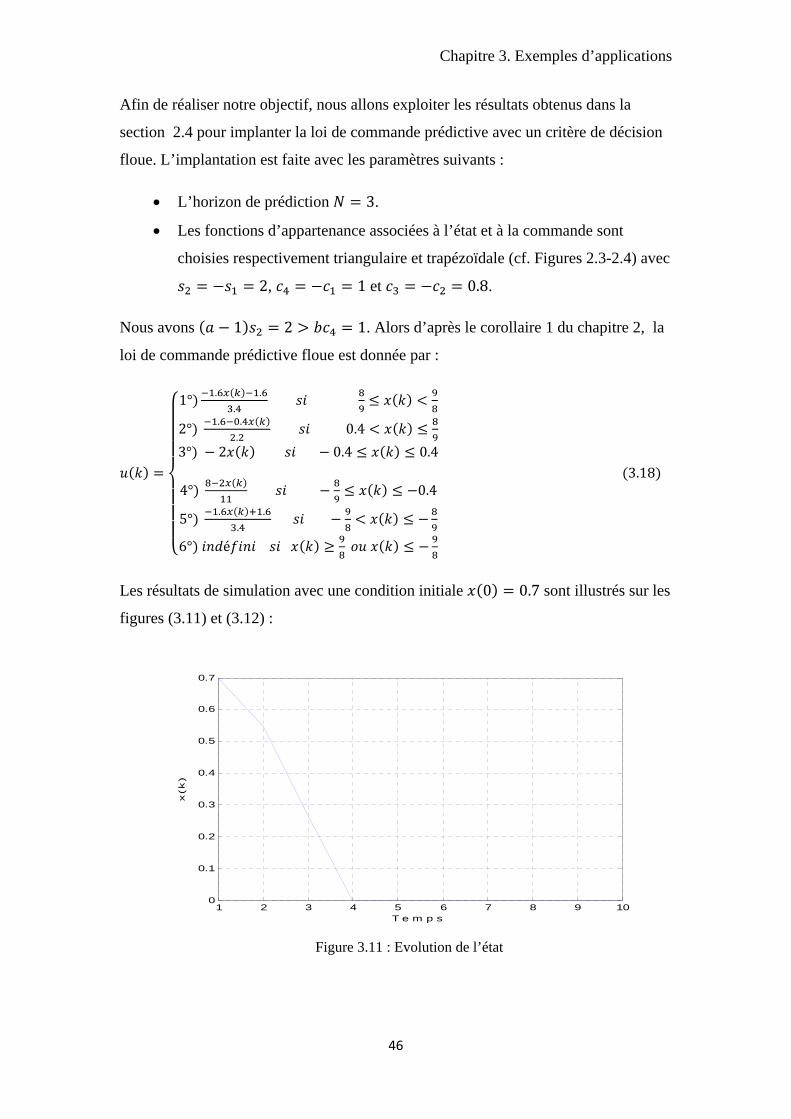
Chapitre 3. Exemples d’applications
46
1 2 3 4 5 6 7 8 9 100
0.1
0.2
0.3
0.4
0.5
0.6
0.7
T e m p s
x (
k )
Figure 3.11 : Evolution de l’état
Afin de réaliser notre objectif, nous allons exploiter les résultats obtenus dans la
section 2.4 pour implanter la loi de commande prédictive avec un critère de décision
floue. L’implantation est faite avec les paramètres suivants :
• L’horizon de prédiction 3.
• Les fonctions d’appartenance associées à l’état et à la commande sont
choisies respectivement triangulaire et trapézoïdale (cf. Figures 2.3-2.4) avec
2, 1 et 0.8.
Nous avons 1 2 1. Alors d’après le corollaire 1 du chapitre 2, la
loi de commande prédictive floue est donnée par :
1° . ..
2° . ..
0.43° 2 0.4 0.4
4° 0.4
5° . ..
6° é
3.18
Les résultats de simulation avec une condition initiale 0 0.7 sont illustrés sur les
figures (3.11) et (3.12) :
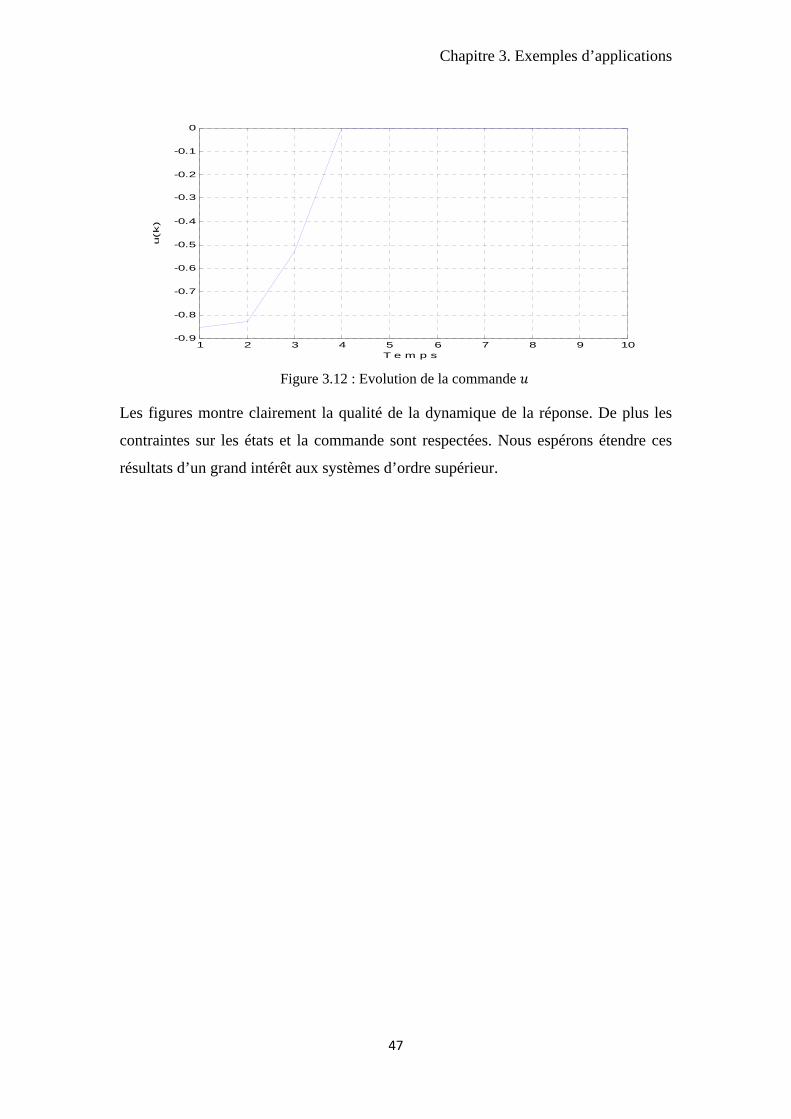
Chapitre 3. Exemples d’applications
47
1 2 3 4 5 6 7 8 9 10-0.9
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
T e m p s
u (
k )
Figure 3.12 : Evolution de la commande
Les figures montre clairement la qualité de la dynamique de la réponse. De plus les
contraintes sur les états et la commande sont respectées. Nous espérons étendre ces
résultats d’un grand intérêt aux systèmes d’ordre supérieur.

Conclusion
48
Conclusion
Dans ce travail nous nous sommes intéressés aux méthodologies de solution pour la
commande prédictive floue à base de modèle d’état. Nous avons analysé la solution basée sur
la programmation dynamique avec branch and bound proposée dans un précédent travail.
Cette méthode est sensible à la dimension du problème, le temps de calcul augmente très vite
à moins d’avoir de très bonnes bornes pour éliminer les solutions non intéressantes. Nous
avons ensuite proposé deux méthodes de solution pour la MBFPC. La première est basée sur
des objectifs et contraintes flous de type gaussien pour des systèmes linéaires MIMO. Le
problème avec contraintes est alors transformé en un problème sans contraintes, on obtient
alors une solution analytique. Cette méthode devient cependant difficile à implanter pour des
systèmes avec un nombre d’états élevés, plus de trois. La seconde approche proposée est une
méthode de résolution analytique pour les systèmes du premier ordre avec des contraintes et
objectifs flous trapézoïdales et triangulaires. Cette approche nous a permis d’avoir une idée
sur les possibilités d’obtenir des solutions analytique pour des systèmes d’ordre élevé.

Bibliographie
49
Bibliographie
[BEL57] R. Bellman, “Dynamic Programming”, Princeton University Press, Princeton, 1957.
[BM07] K. Belarbi, F. Megri, “A Stable Model-Based Fuzzy Predictive Control Based on Fuzzy Dynamic Programming”, IEEE Transactions on Fuzzy Systems, Vol. 15, N°4, pp. 746-754, 2007.
[BMDP02] A. Bemporad, M. Morari, V. Dua, E.N. Pistikopoulos, “The Explicit Linear Quadratic Regulator for Constrained Systems”, Automatica, Vol. 38, pp. 3-20, 2002.
[BZ70] R. Bellman, L. A. Zadeh, “ Decision Making In a Fuzzy Environment”, Management Science, Vol. 17, No, December, 1970.
[CA98] H. Chen, F. Allgower, “A Quasi-Infinite Horizon Nonlinear Model Predictive Control Scheme with Guaranteed Stability”, Automatica, Vol. 34, N°10, pp. 1205-1217, 1998.
[CB99] E.F. Camacho, C. Bordons, “Model predictive control”, Ed. Springer-Verlag, London, 2004.
[CMB02] M. Chemachema, F. Megri, K. Belarbi, “A fuzzy dynamic programming solution to constrained non linear predictive control”, Proceedings of IEEE SMC02, Hammamet, Tunisia, 6-9 October 2002.
[CMT87] D.W. Clark, C.Mohtadi, P.S. Tuffs, “Generalized Predictive Control: Part I: The Basic Algorithm, Part II: Extensions and Interpretation”, Automatica, Vol. 23, N°2, pp.137-160, 1987.
[CR80] C.R. Cutler and B.L. Ramaker, “Dynamic matrix control – A computer control algorithm”, Automatic Control Conference, San Francisco, 1980.
[FLE81] R. Fletcher, “Practical Methods of Optimization 2: Constrained Optimization”,
John Wiley and Sons, Chichester, 1981.
[HOV04] S. Hovland, “Soft Constraints in Explicit MPC”, Master’s thesis, Dept. of Engineering Cybernetics, Norwegian University of Science and Technology, 2004.
[JPS00] T. A. Johansen, I. Petersen, O. Slupphaug, “Explicit suboptimal linear quadratic regulation with input and state constraints”, Proc. 39th IEEE conf. on Decision and Control, Sydney, 2000.
[KAR84] N. Karmarkar. “A new polynomial-time algorithm for linear programming”, Combinatorics, Vol. 4, pp. 373-395, 1984.

Bibliographie
50
[KBM96] M. V. Kothare, V. Balakrishnan, M. Morari, “Robust Constrained Model Predictive Control using Linear Matrix Inequalities”, Automatica, Vol. 32, N°10, pp. 1361-1379, 1996.
[KG88] S. S. Keerthi, E. G. Gilbert, “Optimal infinite horizon feedback laws for a general class of constrained discrete time systems: Stability and moving-horizon approximations”, Journal of Optimization Theory and Applications, Vol. 57, pp. 265–293, 1988.
[MRRS00] D.Q. Mayne, J.B. Rawlings, C.V. Rao, P.O.M. Scockaert, “Constrained model predictive control: Stability and optimality”, Automatica, Vol. 36, pp. 789-814, 2000.
[RRTP78] J. Richalet, A. Rault, J.L.Testud, J. Papon, “Model predictive heuristic control: application to industrial processes”, Automatica, Vol. 14, N°5, pp. 413-428, 1978.
[SK01] J. M. C. Sousa, U. Kaymak, “Model Predictive Control Using Fuzzy Decision Func-tions”, IEEE Transactions On Systems Man And Cybernetics-Part B, Vol.31, N°1, 2001.
[SMR99] P. O. M. Scokaert, D. Q. Mayne, J. B. Rawlings, “Suboptimal Model Predictive Control (Feasibility Implies Stability)”, IEEE Transaction on Automatic Control, Vol. 44, N°3, pp. 648-654, 1999.
[TD05] R. Thompson, A. Dexter, “A fuzzy decision making approach to temperature control in air conditioning system”, Control Eng. Pract., vol. 13, pp. 58–68, Jun. 2005.
[TON03] P. Tondel, “Constrained Optimal Control via Multiparametric Quadratic Programming”, PhD thesis NTNU, 2003.
[WMY09] C. Wen, X. Ma, B. E. Ydstie, “Analytical expression of explicit MPC solution via lattice piecewise-affine function”, Automatica, Vol. 45, pp. 910-917, 2009.

Résumé
Nous présentons dans ce mémoire des méthodologies de solution de la commande
prédictive floue.
Dans le cas général d’un système non linéaire la solution du problème est obtenue en
utilisant la programmation dynamique floue avec la technique Branch and Bound.
Pour les systèmes linéaires multivariables nous présentons une solution analytique
basée sur les ensembles flous Gaussien. Finalement et comme première étape, nous
proposons une solution analytique pour les systèmes linéaires monovariables du
premier ordre avec contraintes sur l’état et la commande.
Mots-clefs : Commande prédictive, objectif flou, contrainte floue, programmation
dynamique, optimisation.

ملخص
.نقدم في هذه المذآرة منهجية حلول التحكم التنبؤي الغامض
في الحالة العامة و من أجل أنظمة غير خطية فإننا نحصل على حل المسألة باستخدام البرمجة الديناميكية وطريقة
.Branch and Bound
األخير و في. المجموعات الغوصية الغامضة في حالة األنظمة الخطية المتعددة المتغيرات نستعرض حال تحليليا بإستخدام
.ية المقيدة ذات المرتبة األولىآمرحلة أولية نقترح حال تحليليا من أجل األنظمة الخط
. التحكم التنبؤي الغامض، الهدف الغامض، القيود الغامضة، البرمجة الديناميكية: آلمات مفتاحية
Abstract
In this work, we consider analysing solution procedures for model based fuzzy predictive
control. Three such solutions are proposed and analysed. For the general non linear case
dynamic programming with branch and bound is considered. For linear multi input multi
output systems, we introduce an analytical solution based on gaussian fuzzy sets. Finally, as
an initial proposal, we investigate the possibility of obtaining an analytical solution for first
order single input single output linear systems with constraints on state and control.
Keywords: Predictive control, fuzzy goal, fuzzy constraint, Dynamic programming, branch
and bound, optimization.



















![Commande Floue [Mode de Compatibilité]](https://img.pdfslide.net/doc/110x75/5695d10d1a28ab9b0294f067/commande-floue-mode-de-compatibilite.jpg)









