Embed Size (px)
Citation preview

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
1
REPETITORIUM DER ANGEWANDTE STATISTIK II 4 EINFÜHRUNG IN DAS TESTEN VON UNTERSCHIEDSHYPOTHESEN I: 1-STICHPROBENVERGLEICHE 4.1 Der Gauß-Test (z-Test) Problemstellung:
Vom Mittelwert µ einer mit bekannter Varianz σ2 normalverteilten Messgröße liegt eine Vermutung H1 (Alternativhypothese, alternative hypothesis) vor, z.B. in der Form H1: µ ≠ µ0 (µ0 ist ein fester, vorgegebener Wert); die Menge der µ, für die H1 nicht zutrifft, bildet die Nullhypothese (null hypothesis) H0: µ = µ0; mit dem Gauß-Test wird eine Entscheidung zwischen H0 und H1 angestrebt.
Schema der Problemlösung:
• Beobachten Testentscheidung baut auf Beobachtungsdaten auf. Es liegen n Beobachtungswerte x1, x2,…, xn mit dem arithmetischen Mittel x vor.
• Modellieren: Jedes xi ist die Realisierung einer N(µ, σ2)-verteilten Zufallsvariablen Xi (i=1,2,…,n). Der Mittelwert µ ist unbekannt, die Varianz σ2 jedoch bekannt. Das Stichprobenmittel X ist normalverteilt mit dem Mittelwert µ und der Varianz σ2/n.
• Präzisieren: Entscheidungsalternativen: H0: µ = µ0 versus H1: µ ≠ µ0 (Test auf Abweichung mit 2-seitigen Hypothesen, two-sided alternative) Signifikanzniveau (significance level): α-Fehler (meist α=5% angenommen)
Anmerkung: Kontrolle des β-Fehlers erfolgt meist im Nachhinein, in dem die relevante Abweichung ∆=µ−µ0 gesetzt wird und die Testschärfe (Power)= P(Entscheidung für H1| µ=µ0+∆) berechnet wird. Besser ist eine Planung des Stichprobenumfangs n im Vorhinein zu vorgegebener Power=1-β und relevanter Abweichung ∆.
• Entscheiden:
Hilfsgröße (Testgröße, test statistic) n
XTG
/0
σµ−= bilden (ist unter H0
standardnormalverteilt); Einsetzen von x für X � Realisierung TGs der Testgröße. Entscheidungsregel: a) mit P-Wert P= P(TG < - |TGs| oder TG > |TGs|) = 2[1 – Φ(|TGs|)]: H0 ablehnen, wenn P < α. b) mit Quantilen: H0 ablehnen, wenn |TGs| > z1-α/2.

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
2
Ergänzungen:
• Einseitige Hypothesen (one-sided alternatives): - Test auf Überschreitung mit den Hypothesen: H0: µ ≤ µ0 versus H1: µ > µ0
Entscheidungsregel: H0 ablehnen, wenn P= P(TG > TGs)=1-Φ(TGs) < α bzw. wenn TGs > z1-α
- Test auf Unterschreitung mit den Hypothesen: H0: µ ≥ µ0 versus H1: µ < µ0 Entscheidungsregel: H0 ablehnen, wenn P= P(TG < TGs)=Φ(TGs) < α bzw. wenn TGs < - z1-α
• Gütefunktion (power function): Die Fehlerrisken (α-Fehler, β-Fehler) werden in der sog. Gütefunktion (Power) G zusammengefasst: G(µ) = P(Ablehnung von H0 | µ) = Wahrscheinlichkeit, auf Grund einer Zufallsstichprobe gegen H0 zu entscheiden, wenn der Populationsmittelwert µ ist. Es gilt: G(µ) ≤ α, wenn H0 zutrifft; wenn H1 zutrifft ist die Güte umso besser, je näher G(µ) bei 1 liegt (d.h. je kleiner das β-Risiko β(µ) = 1 - G(µ) ist).
- Gütefunktion des 2-seitigen Gauß-Tests:
−+−Φ+
−−−Φ= −−n
zn
zG//
)( 02/1
02/1 σ
µµσ
µµµ αα
- Gütefunktion des 1-seitigen Gauß-Tests auf Überschreitung:
−+−Φ= −
nzG
/)( 0
1 σµµµ α
• Mindeststichprobenumfang:
Die Fehlerrisken α und β, die relevante Abweichung ∆=|µ−µ0| und der Stichprobenumfang n sind voneinander abhängig. Dies ermöglicht es, bei vorgegebenen Werten von α, ß und ∆ den Stichprobenumfang zu bestimmen, d.h. eine Planung des Stichprobenumfangsvorzunehmen. Näherungsformeln für den notwendigen Stichprobenumfang n, um auf Niveau α mit der Sicherheit 1-ß eine Entscheidung für H1 herbeizuführen, wenn µ von µ0 um ∆ ≠ 0 im Sinne der Alternativhypothese abweicht:
Abb. 4.1: Gütefunktionen des 1- seitigen Gauß-Tests H0: µ ≤ µ0 gegen H1 : µ > µ0
für die Stichprobenumfänge n=5, 10, 20 (obere Grafik) und des 2-seitigen Gauß-Tests H0: µ = µ0 gegen H1 : µ ≠ µ0 für die Stichprobenumfänge n=10 und n=50 (untere Grafik). Horizontal ist die auf σ bezogene Abweichung δ=(µ-µ0)/σ des Mittelwerts vom Sollwert µ0 aufgetragen, vertikal kann man die entsprechenden Gütefunktionswerte G*(δ)=G((µ-µ0)/σ) ablesen.

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
3
( )
( ) )Hypothesen seitige-1(für
),Hypothesen seitige-2(für
211
2
212/1
2
βα
βα
σ
σ
−−
−−
+
∆≈
+
∆≈
zzn
zzn
• Nicht-signifikante Testergebnisse:
Wenn eine Entscheidung für H1 auf dem vorgegebenen Signifikanzniveau α nicht möglich ist, spricht man von einem nicht-signifikantem Ergebnis. Ein nicht-signifikantes Ergebnis erlaubt nur dann eine Entscheidung für H0, wenn die Power ausreichend groß ist (zumindest 80%).
• R-Funktion: z.test() im Paket „TeachingDemos“ 4.2 Einstichproben t-Test (One-Sample t Test) Problemstellung:
Es soll entschieden werden, ob der Mittelwert µ einer normalverteilten Zufallsvariablen von einem vorgegebenen Sollwert µ0 abweicht (oder µ0 überschreitet bzw. unterschreitet).
Ablaufschema: • Beobachtungsdaten:
Beobachtungswerte x1, x2, ... , xn � Mittelwert, Varianz s2.
• Modell: xi ist Realisierung von Xi ~ N(µ, σ2), (i =1,2, ... ,n).
• Hypothesen: 2-seitige Hypothesen: H0 : µ = µ0 vs. H1 : µ ≠ µ0 (Fall II) 1-seitige Hypothesen: H0 : µ ≤ µ0 vs. H1 : µ > µ0 (Fall Ia) H0 : µ ≥ µ0 vs. H1 : µ < µ0 (Fall Ib) Signifikanzniveau: α
• Testgröße:
010 unter
/µµµ =≅−= −nt
nS
XTG
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
4
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P < α, wobei P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall II) bzw. P=P(TG ≥ |TGs|) (Fall Ia) bzw. P=P(TG ≤ -|TGs|) (Fall Ib).
• Entscheidung mit Quantilen:
H0 auf Testniveau α ablehnen, wenn |TGs| > tn-1,1-α/2 (Fall II), TGs < tn-1,α (Fall Ia) bzw. TGs < - tn-1,1-α (Fall Ib)
• Planung des Stichprobenumfanges: Um auf dem Niveau α mit der Sicherheit 1-β eine Entscheidung für H1 herbeizuführen, wenn µ von µ0 um ∆ ≠ 0 im Sinne der Alternativhypothese abweicht, ist das dafür notwendige n näherungsweise (etwa ab n=20)
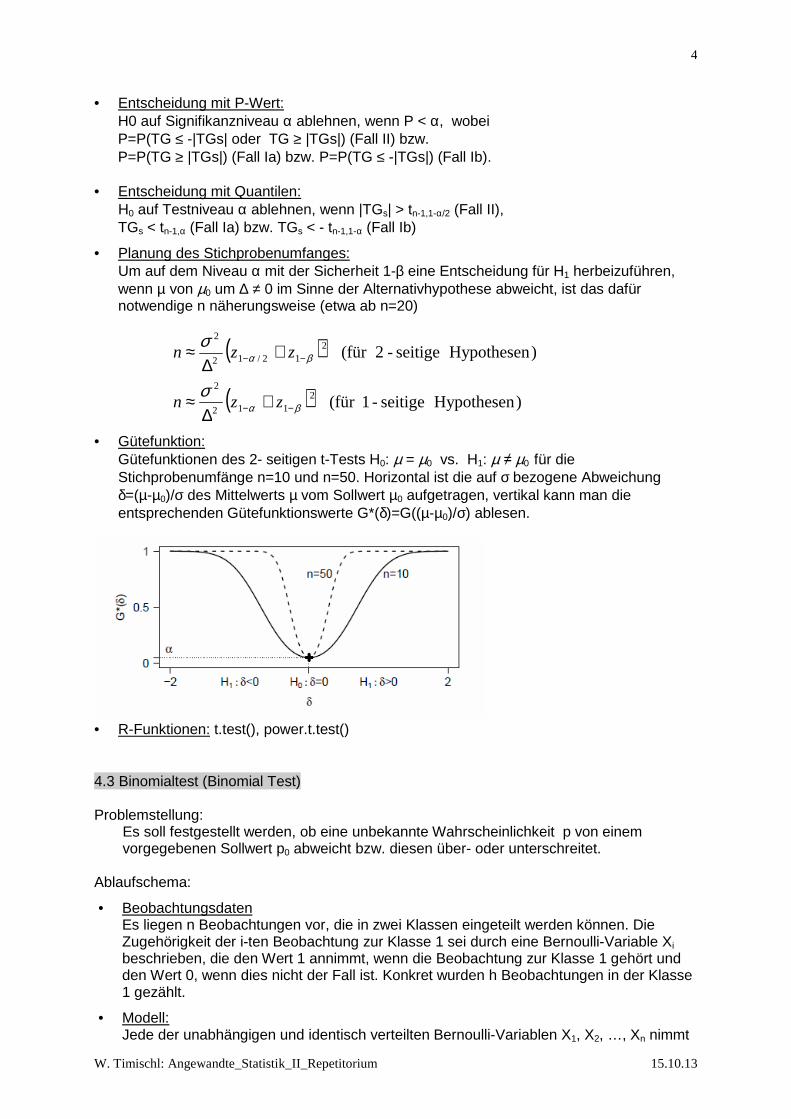
• Gütefunktion:
Gütefunktionen des 2- seitigen t-Tests H0: µ = µ0 vs. H1: µ ≠ µ0 für die Stichprobenumfänge n=10 und n=50. Horizontal ist die auf σ bezogene Abweichung δ=(µ-µ0)/σ des Mittelwerts µ vom Sollwert µ0 aufgetragen, vertikal kann man die entsprechenden Gütefunktionswerte G*(δ)=G((µ-µ0)/σ) ablesen.
• R-Funktionen: t.test(), power.t.test()
4.3 Binomialtest (Binomial Test) Problemstellung:
Es soll festgestellt werden, ob eine unbekannte Wahrscheinlichkeit p von einem vorgegebenen Sollwert p0 abweicht bzw. diesen über- oder unterschreitet.
Ablaufschema:
• Beobachtungsdaten Es liegen n Beobachtungen vor, die in zwei Klassen eingeteilt werden können. Die Zugehörigkeit der i-ten Beobachtung zur Klasse 1 sei durch eine Bernoulli-Variable Xi beschrieben, die den Wert 1 annimmt, wenn die Beobachtung zur Klasse 1 gehört und den Wert 0, wenn dies nicht der Fall ist. Konkret wurden h Beobachtungen in der Klasse 1 gezählt.
• Modell: Jede der unabhängigen und identisch verteilten Bernoulli-Variablen X1, X2, …, Xn nimmt
( )
( ) )Hypothesen seitige-1(für
)Hypothesen seitige-2(für
2112
2
212/12
2
βα
βα
σ
σ
−−
−−
+∆
≈
+∆
≈
zzn
zzn

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
5
mit der Wahrscheinlichkeit p den Wert 1 an. Die Anzahl H der Wiederholungen in Klasse 1 ist Bn,p –verteilt.
• Hypothesen: - H0: p =p0 gegen H1 : p ≠ p0 (Variante II, 2-seitiger Test) - H0: p ≤ p0 gegen H1 : p > p0 (Variante Ia, 1-seitiger Test auf Überschreitung) - H0: p ≥ p0 gegen H1 : p < p0 (Variante Ib, 1-seitiger Test auf Unterschreitung)
• Testgröße:
Anzahl TG=H der Beobachtungen in der Klasse 1; TG ~ Bn,p0 für p=p0. Normalverteilungsapproximation (Voraussetzung: np0(1-p0)>9):
00
00
0 :Hfür )1,0(~)1(
* ppNpnp
npHTG =
−−
=
Für die konkrete Beobachtungsreihe ist H=h. .
• Entscheidung mit P-Wert: Bei vorgegebenem α wird H0 abgelehnt, wenn der P-Wert kleiner als α ist. - Exakter Binomialtest:
Testvariante Ia: P=1 - FB(h-1), Testvariante Ib: P= FB(h), Testvariante II: P= FB (np0-d)+1- FB (np0+d-1) FB bezeichnet die Verteilungsfunktion der Bn,p0-Verteilung, d=|h-np0|.
- Approximativer Binomialtest (mit Stetigkeitskorrektur) Testvariante Ia: P≈ 1-FN(h-0.5) Testvariante Ib: P≈ FN(h+0.5) Testvariante II: P≈ 2FN(np_0-d+0.5) FN ist die Verteilungsfunktion der N(µ, σ2)-Verteilung mit µ=np0 und σ0
2=np0(1-p0); d=|h-np0| ist die Abweichung der beobachteten Anzahl vom Mittelwert.
• (Approximative) Entscheidung mit Quantilen:
H0 auf Testniveau α ablehnen, wenn TG*s-p0>0.5+z1-α σ0 (Variante Ia) bzw. TG*s-p0>0.5-z1-α σ0 (Variante Ib) bzw. |TG*s-p0|> 0.5+ z1-α/2 σ0 (Variante II) gilt; z1-α und z1-α/2 sind das (1-α)- bzw. das (1-α/2)- Quantil der N(0, 1)-Verteilung und σ0
2=np0(1-p0).
• Planung des Stichprobenumfangs Um auf dem Niveau α mit der Sicherheit 1- β eine Entscheidung für H1 herbeizuführen, wenn p von p0 um ∆ ≠ 0 im Sinne der Alternativhypothese abweicht, kann im Falle der 1-seitigen Testvarianten Ia und Ib das erforderliche Mindest-n näherungsweise aus
( )( ) ;
arcsin2arcsin22
0
211
pp
zzn
−
+≈ −− βα
bestimmt werden; im Falle der 2-seitigen Testvariante II ist z1-α durch z1-α/2 zu ersetzen.
• R-Funktionen: binom.test(), prop.test()
4.4 χ2 – Test (χ2 goodness-of-fit test) Problemstellung 1:

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
6
Es soll entschieden werden, ob die beobachteten Häufigkeiten einer mehrstufig skalierten Zufallsvariablen von einem vorgegebenen Verhältnis abweichen.
Ablaufschema: • Beobachtungsdaten und Modell:
Es liegen n Beobachtungen einer k-stufig skalierten Variablen vor, d.h. einer (nicht notwendigerweise quantitativen) Variablen mit k>1 Ausprägungen (Klassen) a1, a2,…, ak. Die Ausprägung ai wird an oi Untersuchungseinheiten beobachtet. Jede Beobachtung ist das Ergebnis eines Zufallsexperimentes, das n-mal wiederholt wird. Dabei ist pi die Wahrscheinlichkeit, dass eine Wiederholung mit der Ausprägung ai auftritt. Für die Anzahl Oi der Wiederholungen mit der Ausprägung ai ist der Mittelwert Ei=E(Oi)=npi zu erwarten.
• Hypothesen und Testgröße:
Die Wahrscheinlichkeiten pi (i=1,2,…, k) werden zweiseitig an Hand der Hypothesen H0: pi = p0i (i=1,2, ..., k) gegen H1: pi ≠ p0i für wenigstens ein i
mit vorgegebenen Sollwerten p0i verglichen. Die Testentscheidung stützt sich auf die Chiquadrat-Summe (Goodness of Fit-Statistik)
( ) ( )∑∑
==
−=
−==
k
i i
iik
i i
ii
np
npO
E
EOGFTG
1 0
20
1
2
als Testgröße, die asymptotisch χ2-verteilt ist mit k-1 Freiheitsgraden. Ersetzt man die Oi durch die beobachteten Häufigkeiten oi, erhält man die Realisierung TGs der Testgröße.
• Entscheidung:
Bei vorgegebenem Signifikanzniveau α wird H0 abgelehnt, wenn der P-Wert kleiner als α ist. Mit der Verteilungsfunktion Fk-1 der χ2
k-1-Verteilung erhält man aus P=1-Fk-1(TGs) eine Näherung für den P-Wert.
Der Ablehnungsbereich ist näherungsweise durch das mit dem (1-α)-Quantil χ2
k-1,α der χ2
k-1-Verteilung gebildeten Intervall TG = GF > χ2k-1,α gegeben.
Die Näherung ist ausreichend genau, wenn alle erwarteten Häufigkeiten Ei>5 sind
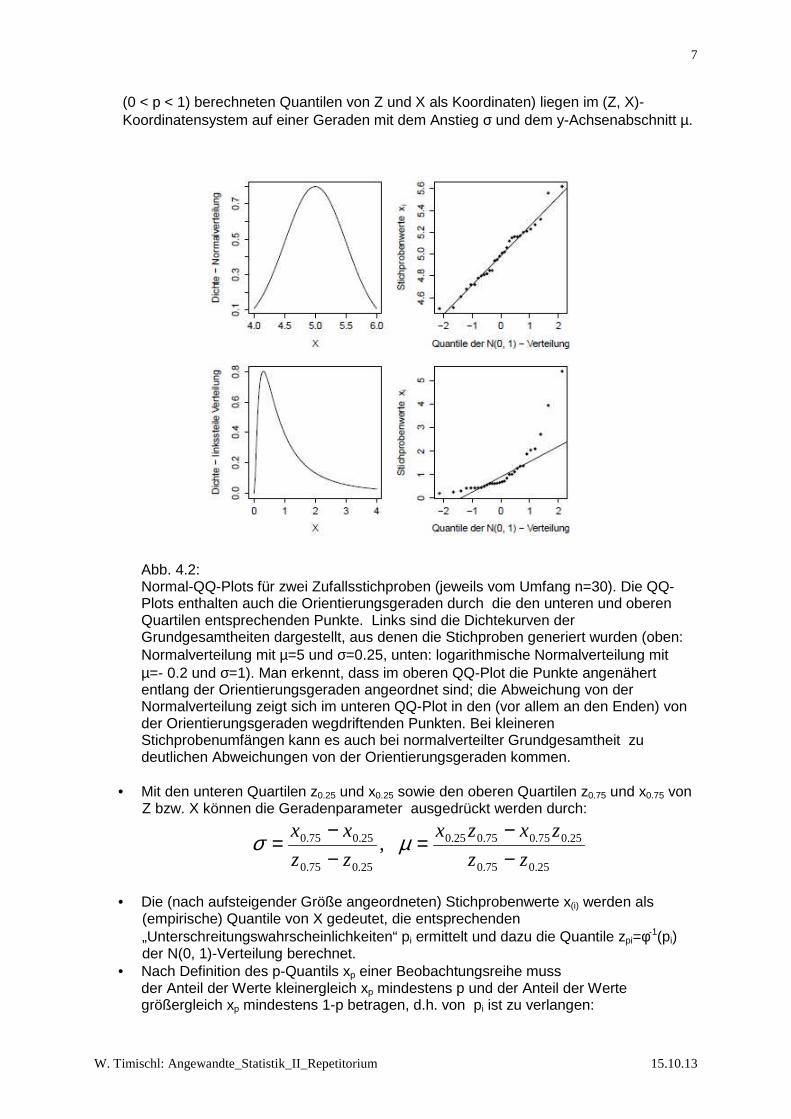
• R-Funktion: chisq.test() 4.5 Überprüfung der Normalverteilungsannahme 4.5.1. Grafische Überprüfung mit dem Normal-QQ-Plot Mit dem Normal-Quantil-Quantil-Diagramm (kurz Normal-QQ-Plot) kann man an Hand der Werte x1, x2, …, xn einer Zufallsstichprobe von X auf grafischem Wege beurteilen, ob die Daten gegen die Annahme „X ist normalverteilt“ sprechen (vgl. Abb. 4.4). Theoretische Grundlage: • Wenn X N(µ, σ2) – verteilt ist, besteht zwischen dem p-Quantil xp von X und dem
entsprechenden Quantil zp der N(0, 1)-verteilten Zufallsvariablen Z=(X-µ)/σ der lineare Zusammenhang xp = σ zp + µ. Die Punkte P(zp, xp) mit den für verschiedene Werte von p
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
7
(0 < p < 1) berechneten Quantilen von Z und X als Koordinaten) liegen im (Z, X)-Koordinatensystem auf einer Geraden mit dem Anstieg σ und dem y-Achsenabschnitt µ.
Abb. 4.2: Normal-QQ-Plots für zwei Zufallsstichproben (jeweils vom Umfang n=30). Die QQ-Plots enthalten auch die Orientierungsgeraden durch die den unteren und oberen Quartilen entsprechenden Punkte. Links sind die Dichtekurven der Grundgesamtheiten dargestellt, aus denen die Stichproben generiert wurden (oben: Normalverteilung mit µ=5 und σ=0.25, unten: logarithmische Normalverteilung mit µ=- 0.2 und σ=1). Man erkennt, dass im oberen QQ-Plot die Punkte angenähert entlang der Orientierungsgeraden angeordnet sind; die Abweichung von der Normalverteilung zeigt sich im unteren QQ-Plot in den (vor allem an den Enden) von der Orientierungsgeraden wegdriftenden Punkten. Bei kleineren Stichprobenumfängen kann es auch bei normalverteilter Grundgesamtheit zu deutlichen Abweichungen von der Orientierungsgeraden kommen.
• Mit den unteren Quartilen z0.25 und x0.25 sowie den oberen Quartilen z0.75 und x0.75 von
Z bzw. X können die Geradenparameter ausgedrückt werden durch:
25.075.0
25.075.075.025.0
25.075.0
25.075.0 ,zz
zxzx
zz
xx
−−
=−−
= µσ
• Die (nach aufsteigender Größe angeordneten) Stichprobenwerte x(i) werden als
(empirische) Quantile von X gedeutet, die entsprechenden „Unterschreitungswahrscheinlichkeiten“ pi ermittelt und dazu die Quantile zpi=φ-1(pi) der N(0, 1)-Verteilung berechnet.
• Nach Definition des p-Quantils xp einer Beobachtungsreihe muss der Anteil der Werte kleinergleich xp mindestens p und der Anteil der Werte größergleich xp mindestens 1-p betragen, d.h. von pi ist zu verlangen:

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
8
i/n ≥ pi und (n-i+1)/n ≥ 1-pi d.h. (i-1)/n ≤ pi ≤ i/n.
• Zur Fixierung von pi auf einen Wert des Intervalls verwenden wir die Festlegung: Für n>10 ist pi einfach die Intervallmitte (i-0.5)/n, für n ≤ 10 wird pi aus der Formel pi = (i- 3/8)(n + ¼) bestimmt.
• R-Funktion: qqnorm(), qqline() 4.5.2. Shapiro-Wilk-Test Der Shapiro-Wilk-Test wurde speziell zur Überprüfung der Annahme (=Nullhypothese) entwickelt, dass eine metrische Zufallsvariable X normalverteilt ist. Die Nullhypothese wird auf dem Niveau α abgelehnt, wenn der P-Wert kleiner als α ist. Theoretischer Hintergrund: Die Teststatistik W des Shapiro-Wilk-Tests ist als Quotient von zwei Schätzfunktionen für die Varianz σ2 der hypothetischen Normalverteilung konstruiert. Die eine Schätzfunktion (im Nenner) ist die Stichprobenvarianz, die andere (im Zähler) hängt mit dem Anstieg der Orientierungsgeraden im QQ-Plot zusammen. Die Berechnung der Teststatistik ist aufwendig und praktisch nur mit einschlägiger Software zu bewältigen. Für die Interpretation ist wichtig zu wissen, dass W nichtnegativ ist und den Wert 1 nicht überschreiten kann. Wenn H0 (Normalverteilungsannahme) gilt, dann nimmt W Werte nahe bei 1 an, kleinere Werte von W sprechen gegen H0. Z.B. ist bei einem Stichprobenumfang n=10 die Nullhypothese auf 5%igem Signifikanzniveau abzulehnen, wenn W den kritischen Wert 0.842 unterschreitet. • R-Funktion: shapiro.test() 4.6 Grundlagen der Qualitätssicherung Statistische Prozesslenkung
Qualitätsregelkarten (control chart)
Wir betrachten den Einsatz von Qualitätsregelkarten zur Klärung der Frage, ob ein Prozess „beherrscht“ ist. Für einen beherrschten Prozess bleibt die Verteilung des Qualitätsmerkmals X im Laufe des Prozesses unverändert. Wenn X – wie wir annehmen wollen - normalverteilt ist, bedeutet dies, dass die Werte von X mit einer festen Fehlervarianz σ2 zufällig um einen festen Mittelwert (dem Fertigungsmittelwert) µ streuen. Große oder systematische in eine Richtung gehende Abweichungen vom Mittelwert deuten eine (unerwünschte) Änderung des Mittelwertes und/oder der Standardabweichung an, die z.B. durch Störungen in der Fertigungsanlage bedingt sein können.
Mittelwertkarte (control chart for the mean)
Die Eingriffsgrenzen (action limits) der Mittelwertkarte ( x -Karte) werden aus der
Forderung P( X < UEG) = P( X > OEG) = 0,5% bestimmt; daraus ergibt sich:
;/ˆˆO ,/ˆˆ 995,0995,0 nzEGnzUEG σµσµ +=−=
analog werden die Warngrenzen (warning limits) aus der Forderung P( X < UWG) =
P( X > OWG) = 2,5%, d.h.

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
9
./ˆˆOW ,/ˆˆ975,0975,0 nzGnzUWG σµσµ +=−=
In diesen Formeln sind µ und σ Schätzwerte für den Fertigungsmittelwert µ und die
Fertigungsstreuung σ. Den Schätzwert µ gewinnt man durch Mittelung der
Stichprobenmittelwerte über die Erhebungszeitpunkte; analog wird σ2 durch den Mittelwert der Stichprobenvarianzen geschätzt, die Quadratwurzel dieses Mittelwerts ist schließlich der gesuchte Schätzwert σ für σ. Neben den Eingriffs- und Warngrenzen ist
in der x -Karte auch der Schätzwert µ für den Fertigungsmittelwert (als Mittellinie MLµ =
µ parallel zur Zeitachse) eingezeichnet.
s-Karte (contrtol chart for the standard deviation)
Die Eingriffsgrenzen der s-Karte werden aus der Forderung P(S2 < UEG2) = P(S2 > OEG2) = 0,5% bestimmt; daraus ergibt sich:
.1
ˆ , 1
ˆ2
995.0,1
2
005.0,1
−=
−= −−
nOEG
nUEG nn χ
σχ
σ
analog werden die Warngrenzen aus der Forderung P(S2 < UWG2) = P(S2 > OWG2) = 2,5% bestimmt, d.h.
.1
ˆ , 1
ˆ2
975.0,12
025.0,1
−=
−= −−
nOWG
nUWG nn χ
σχ
σ
Für die Mittellinie der s-Karte ergibt sich die Lage:
.
2
12
1
2mit ˆ][
−Γ
Γ
−===
n
n
nkkSEML nns σ
R-package: qcc Annahmestichprobenprüfung
Problemstellung: Die Annahmestichprobenprüfung (acceptance sampling) wird zur Eingangsprüfung oder Endkontrolle von Prüflosen (=Zusammenfassung von unter vergleichbaren Bedingungen hergestellten Einheiten) verwendet. Die Überprüfung erfolgt mit einer so genannten Stichprobenanweisung, die über den Umfang der Prüfstichprobe sowie über die Entscheidung für die Annahme oder die Zurückweisung des Prüfloses Auskunft gibt.
Prüfung auf fehlerhafte Einheiten (Attributprüfung, acceptance sampling for attributes):
• Verteilungsmodell: Es sei N der Umfang des Prüfloses, a die Anzahl der schlechten Einheiten im Prüflos (Ausschusszahl), p = a/N der Fehleranteil (bzw. Ausschussanteil) und n der Umfang der Prüfstichprobe. Die Stichprobennahme aus dem Prüflos möge dem Modell der „Zufallsziehung ohne Zurücklegen“ folgen; dann ist die Anzahl X der schlechten Einheiten in der Prüfstichprobe hypergeometrisch verteilt.
• Annahmewahrscheinlichkeit: Es sei vereinbart, dass das Prüflos mit dem Umfang n im Falle X ≤ c angenommen und im Falle X > c abgelehnt wird (c ist die maximal zulässige Anzahl von Ausschusseinheiten, acceptance number). Die Wahrscheinlichkeit Pa, dass nach dieser kurz als (n,c)-Plan bezeichneten Stichprobenanweisung (sampling plan) das Prüflos
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
10
angenommen wird, ist in Abhängigkeit vom Ausschussanteil p=a/N (a=0, 1, 2, …, N) gegeben durch:
Unter der Voraussetzung n/N < 0,1 und N > 60 können die Verteilungsfunktionswerte HN,n,p(x) mit ausreichender Genauigkeit durch die entsprechenden Werte der Binomialverteilung Bn,p approximiert werden; die Formel für die Annahmewahrscheinlichkeit vereinfacht sich damit auf: Auf der Grundlage dieser Approximation kann zu einem vorgegebenen Wert γ der Annahmewahrscheinlichkeit Pa(p|n,c) der entsprechende Ausschussanteil pγ berechnet werden:
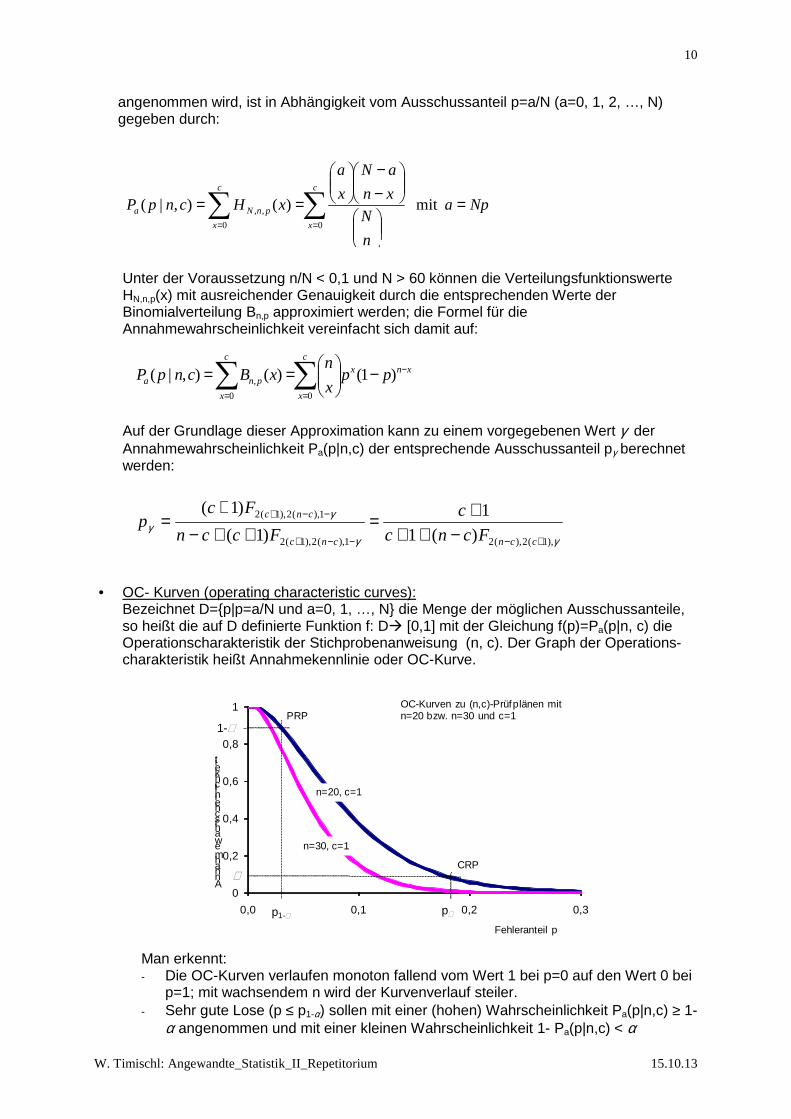
• OC- Kurven (operating characteristic curves): Bezeichnet D={p|p=a/N und a=0, 1, …, N} die Menge der möglichen Ausschussanteile, so heißt die auf D definierte Funktion f: D� [0,1] mit der Gleichung f(p)=Pa(p|n, c) die Operationscharakteristik der Stichprobenanweisung (n, c). Der Graph der Operations-charakteristik heißt Annahmekennlinie oder OC-Kurve.
0
0,2
0,4
0,6
0,8
1
0,0 0,1 0,2 0,3
Annahmewahrscheinlichkeit
Fehleranteil p
n=20, c=1
n=30, c=1
p1-�
1-�
p�
�
PRP
CRP
OC-Kurven zu (n,c)-Prüfplänen mit n=20 bzw. n=30 und c=1
Man erkennt: - Die OC-Kurven verlaufen monoton fallend vom Wert 1 bei p=0 auf den Wert 0 bei
p=1; mit wachsendem n wird der Kurvenverlauf steiler. - Sehr gute Lose (p ≤ p1-α) sollen mit einer (hohen) Wahrscheinlichkeit Pa(p|n,c) ≥ 1-
α angenommen und mit einer kleinen Wahrscheinlichkeit 1- Pa(p|n,c) < α
Npa
n
N
xn
aN
x
a
xHcnpPc
x
c
x
pnNa =
−−
== ∑∑==
mit )(),|(00
,,
)1()(),|(00
, ∑∑=
−
=
−
==
c
x
xnxc
x
pna ppx
nxBcnpP
γγ
γγ
),1(2),(21),(2),1(2
1),(2),1(2
)(1
1
)1(
)1(
+−−−+
−−+
−+++=
++−+
=ccncnc
cnc
Fcnc
c
Fccn
Fcp

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
11
(irrtümlich) zurückgewiesen werden; α ist z.B. 10% oder 5% und heißt das Lieferantenrisiko; p1-α wird Annahmegrenze (kurz AQL, acceptable quality level) genannt. Der Punkt (p1-α, 1-α) auf der OC-Kurve heißt auch Producer Risk Point (PRP).
- Sehr schlechte Lose (p ≥ pβ) sollen mit einer (kleinen) Wahrscheinlichkeit Pa(p|n,c) ≤ β (irrtümlich) angenommen und mit einer großen Wahrscheinlichkeit 1- Pa(p|n,c) > 1-β zurückgewiesen werden; β ist wie α z.B. 10% oder 5% und heißt das Abnehmerrisiko; pβ wird Ablehngrenze (kurz LQL, limiting quality level) genannt. Der Punkt (pβ, β) auf der OC-Kurve wird auch Consumer Risk Point (CRP) genannt.
• Auswahl einer geeigneten Stichprobenanweisung:
Zur Bestimmung der Parameter n und c werden die Gleichungen Pa(p1-α|n,c) = 1-α und Pa(pβ|n,c) = β herangezogen, die in geometrischer Deutung verlangen, dass die Punkte (p1-α,1-α) und (pβ,β) auf der OC liegen. Diese Vorgaben entsprechen den Forderungen, dass das Prüflos bis zum (kleinen) Fehleranteil p1-α, zumindest mit der (hohen) Wahrscheinlichkeit 1-α und ab dem (hohen) Fehleranteil pβ höchstens mit der (kleinen) Wahrscheinlichkeit β angenommen wird. Eine Auflösung des Gleichungssystems Pa(p1-α|n,c) = 1-α, Pa(pβ|n,c) = β ist nur auf numerischem Wege möglich. Um ganzzahlige Lösungswerte für n und c zu finden, müssen die Gleichungen i. Allg. als Ungleichungen Pa(p1-α|n,c) ≥ 1-α, Pa(pβ|n,c) ≤ β betrachtet werden.
Annahmeprüfung bei einem quantitativen Merkmal (acceptance sampling by variables):
• Annahmewahrscheinlichkeit und OC-Kurve: Wir setzen das Merkmal X als normalverteilt mit den Parametern µ und σ2 voraus und nehmen an, dass der Fertigungsmittelwert µ unbekannt, die Fertigungsstreuung σ2 der Einfachheit halber aber bekannt ist. Ferner beschränken wir uns auf den Fall, dass X nur mit einer kleinen Wahrscheinlichkeit p eine vorgegebene obere Toleranzgrenze To überschreiten soll (einseitiges Kriterium „nach oben“). Wegen P(X ≤ To) = 1 – P(X > To) = 1- p, ist To das (1-p)-Quantil der Verteilung von X. Es folgt, dass die standardisierte Größe (To -µ)/σ gleich dem (1-p)-Quantil z1-p der Standardnormalverteilung ist, d.h. der Fertigungsmittel-wert kann in der Form µ = To -σz1-
p dargestellt werden. Die Wahrscheinlichkeit p ist der zu erwartende Anteil von schlechten Einheiten (mit X> To). Zur Schätzung des Fertigungsmittelwerts µ wird dem Prüflos (vom Umfang N) eine Zufallsstichprobe vom Umfang n<N entnommen und daraus der Stichprobenmittelwert
X bestimmt. Damit wird nun die folgende Prüfvorschrift formuliert: Das Los wird
angenommen, wenn X ≤ To - kσ gilt. Die Konstante k ist der sogenannte Annahmefaktor und neben der Größe n der Prüfstichprobe die zweite Kennzahl des Prüfplans für ein metrisches Merkmal. Für die Annahmewahrscheinlichkeit ergibt sich in Abhängigkeit vom Fertigungsmittelwert µ die Formel
bzw. in Abhängigkeit vom Fehleranteil p, wenn µ = To -σz1-p substituiert wird, die Formel:
( ) ( )
−−
Φ==
−−≤−=−≤= nk
T
n
kT
n
XPkTXPknP oo
oa σµ
σµσ
σµσµµ
//,|
( ) [ ]( )nkzknpP pa −Φ= −1,|
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
12
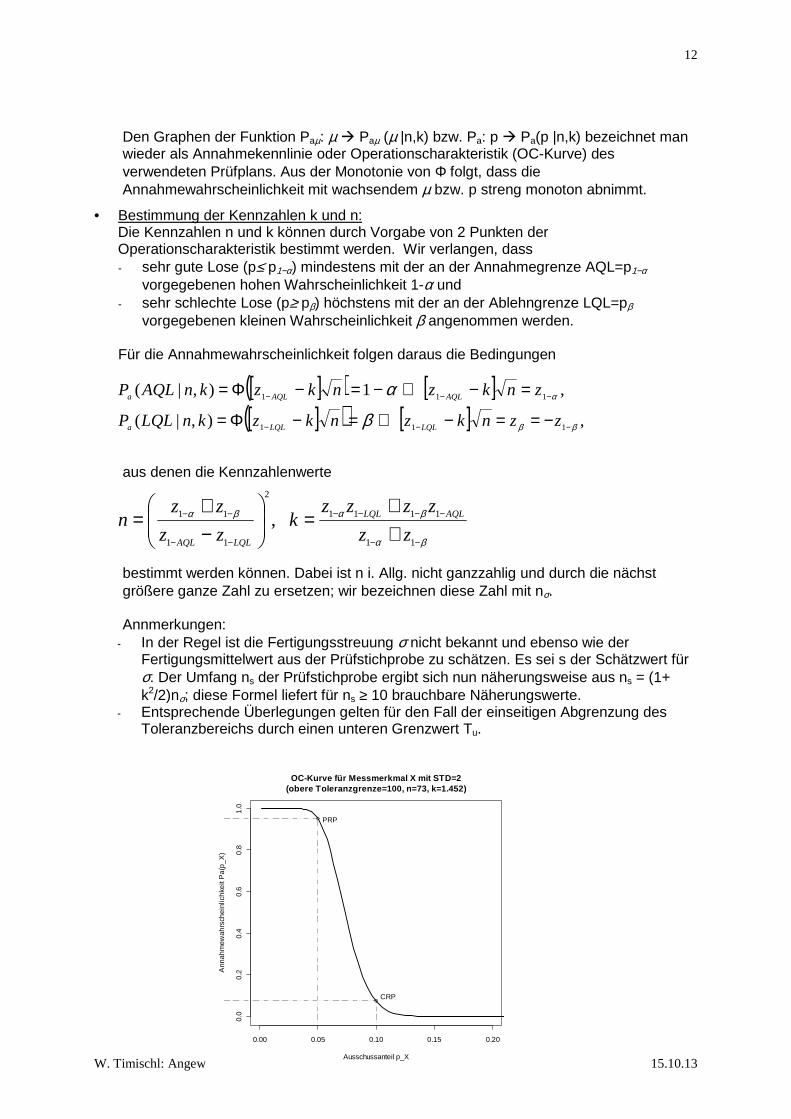
Den Graphen der Funktion Paµ: µ � Paµ (µ |n,k) bzw. Pa: p � Pa(p |n,k) bezeichnet man wieder als Annahmekennlinie oder Operationscharakteristik (OC-Kurve) des verwendeten Prüfplans. Aus der Monotonie von Φ folgt, dass die Annahmewahrscheinlichkeit mit wachsendem µ bzw. p streng monoton abnimmt.
• Bestimmung der Kennzahlen k und n: Die Kennzahlen n und k können durch Vorgabe von 2 Punkten der Operationscharakteristik bestimmt werden. Wir verlangen, dass - sehr gute Lose (p≤ p1−α) mindestens mit der an der Annahmegrenze AQL=p1−α
vorgegebenen hohen Wahrscheinlichkeit 1-α und - sehr schlechte Lose (p≥ pβ) höchstens mit der an der Ablehngrenze LQL=pβ
vorgegebenen kleinen Wahrscheinlichkeit β angenommen werden. Für die Annahmewahrscheinlichkeit folgen daraus die Bedingungen
aus denen die Kennzahlenwerte bestimmt werden können. Dabei ist n i. Allg. nicht ganzzahlig und durch die nächst größere ganze Zahl zu ersetzen; wir bezeichnen diese Zahl mit nσ. Annmerkungen:
- In der Regel ist die Fertigungsstreuung σ nicht bekannt und ebenso wie der Fertigungsmittelwert aus der Prüfstichprobe zu schätzen. Es sei s der Schätzwert für σ. Der Umfang ns der Prüfstichprobe ergibt sich nun näherungsweise aus ns = (1+ k2/2)nσ; diese Formel liefert für ns ≥ 10 brauchbare Näherungswerte.
- Entsprechende Überlegungen gelten für den Fall der einseitigen Abgrenzung des Toleranzbereichs durch einen unteren Grenzwert Tu.
[ ]( ) [ ][ ]( ) [ ] ,),|(
,1),|(
111
111
ββ
α
β
α
−−−
−−−
−==−⇔=−Φ=
=−⇔−=−Φ=
zznkznkzknLQLP
znkznkzknAQLP
LQLLQLa
AQLAQLa
βα
βαβα
−−
−−−−
−−
−−
++
=
−+
=11
1111
2
11
11 ,zz
zzzzk
zz
zzn AQLLQL
LQLAQL
0.00 0.05 0.10 0.15 0.20
0.0
0.2
0.4
0.6
0.8
1.0
OC-Kurve für Messmerkmal X mit STD=2(obere Toleranzgrenze=100, n=73, k=1.452)
Ausschussanteil p_X
Ann
ahm
ewah
rsch
einl
ichk
eit P
a(p_
X)
PRP
CRP

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
13
• R-Funktionen: OC2c(), find.plan(), OCvar() im Paket “AcceptanceSampling”
4.5 Musterbeispiele 1. Bei der Herstellung einer bestimmten Zigarettensorte soll ein Nikotingehalt X (in mg) von
12 Einheiten nicht überschritten werden. Zur regelmäßigen Kontrolle werden Prüfstichproben von je 20 Zigaretten zufällig einem Produktionslos entnommen und der Nikotingehalt bestimmt. Für eine Prüfstichprobe ergab sich das arithmetische Mittel
14.12=x . Für die Standardabweichung von X möge der (sehr genaue) Schätzwert 1.5 Einheiten zur Verfügung stehen.
a. Es ist mit dem Gauß-Test zu zeigen, dass 14.12=x auf 5%igem Niveau keine signifikante Überschreitung des Sollwerts 12 anzeigt.
b. Welche Sicherheit hat man, mit dem Test eine Abweichung des Mittelwerts vom Sollwert, die so groß wie die beobachtete Abweichung des arithmetischen Mittels vom Sollwert ist, als signifikant zu erkennen?
Präzisierung der Aufgabe: Der Gauß-Test kann angewendet werden, wenn das Untersuchungsmerkmal X (der Nikotingehalt) N(µ, σ2)-verteilt und σ bekannt ist; wir setzen näherungsweise σ=1.5. Es liegt ein 1-seitiges Testproblem mit den Hypothesen H0: µ ≤ µ0 (µ=µ0) gegen H1: µ > µ0 vor. Der Sollwert ist µ0 =12, Stichprobenumfang ist n=20. Teilaufgabe 1a (1-seitiger Gauß-Test):
Lösungsansatz und numerische Lösung: Als Wert der Testgröße ergibt sich
.4174.05.1/20)1214.12(/)( 0 =−=−= σµ nxTGs
damit erhält man den P-Wert P=1 - Φ(TGs)=0.3382; dabei bezeichnet Φ die Verteilungsfunktion der Standardnormalverteilung. Lösung mit R: > # 1a > n <- 20; xquer <- 12.14; sigma <- 1.5 > mu0 <- 12; alpha <- 0.05 > # H0: mu = mu0 versus H1: mu <> mu0 > tgs <- (xquer-mu0)*sqrt(n)/sigma; P <- 1-pnorm(tgs) > print(cbind(xquer, mu0, tgs, P), digits=4) xquer mu0 tgs P [1,] 12.14 12 0.4174 0.3382
Ergebnis: Wegen P ≥ α=0.05 kann H0 nicht abgelehnt werden. Der Testausgang ist auf dem 5%igem Testniveau nichtsignifikant.
Teilaufgabe 1b (Berechnung der Gütefunktion des 1-seitigen Gauß-Tests):
Lösungsansatz und numerische Lösung: Bei nichtsignifikantem Testausgang stellt sich die Frage, ob H0 zutrifft. Diese Frage kann nur dann bejaht werden, wenn die Sicherheit groß ist (jedenfalls größer als 80%), mit dem Test eine Abweichung des Mittelwerts m vom Sollwert m0, die so groß wie die beobachtete Abweichung des arithmetischen Mittels 14.12=x vom Sollwert µ0 =12 ist, als signifikant zu erkennen. Dazu wird der Wert der Gütefunktion für den 1-seitigen Gauß-Test auf Überschreitung an der Stelle µ=12.14 berechnet. Es ergibt sich:

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
14
.1098.020/5.1
1214.12)14.12( 05.01 =
−+−Φ= −zG
Lösung mit R: > # 1b > n <- 20; xquer <- 12.14; sigma <- 1.5; mu0 <- 12; > tgs <- (xquer-mu0)*sqrt(n)/sigma > alpha <- 0.05; zq <- qnorm(1-alpha); G <- pnorm(-zq + tgs) > print(cbind(xquer, mu0, tgs, zq, G), digits=4) xquer mu0 tgs zq G [1,] 12.14 12 0.4174 1.645 0.1098
Ergebnis: Wir haben mit unserer Versuchsanlage also nur eine Sicherheit von rund 11%, die beobachtete Abweichung als signifikant zu erkennen.
2. Von einer Messstelle wurden die folgenden Werte der Variablen X (SO2-Konzentration
der Luft in mg/m3) gemeldet: 32, 41, 33, 35, 34. a. Weicht die mittlere SO2-Konzentration signifikant vom Wert µo=30 ab? (alpha=5%) b. Welcher Mindeststichprobenumfang müsste geplant werden, um mit dem Test eine
Abweichung vom Referenzwert µo um 5% (des Referenzwertes) mit einer Sicherheit von 95% erkennen zu können?
Präzisierung der Aufgabe: Wir nehmen an, dass X normalverteilt ist mit dem Mittelwert µ und der Varianz σ2. Teilaufgabe 2a (1-Stichproben t-Test):
Lösungsansatz und numerische Lösung: In der Teilaufgabe a) ist gefragt, ob µ von µ0=30 abweicht, d.h. es geht um den Vergleich eines Mittelwerts mit einem Sollwert. Die Alternativhypothese lautet H1: µ <> 30, die Nullhypothese ist H0: µ =30. Die Testentscheidung wird mit dem 1-Stichproben-t -Test auf dem Testniveau alpha=5% durchgeführt. Aus der Stichprobe entnimmt man den Stichprobenumfang n sowie die Schätzwerte für µ und σ. Lösung mit R: > # Aufgabe 2a > so2 <- c(32, 41, 33, 35, 34) > n <- length(so2) > xquer <- mean(so2) > s <- sd(so2) > options(digits=4) > print(cbind(n, xquer, s)) n xquer s [1,] 5 35 3.536 > t.test(so2, alternative="two.sided", mu=30, conf.level=0.95) One Sample t-test data: so2 t = 3.162, df = 4, pppp----value = 0.03411value = 0.03411value = 0.03411value = 0.03411 alternative hypothesis: true mean is not equal to 30 95 percent confidence interval: 30.61 39.39 sample estimates: mean of x 35 Ergebnis: Wegen p-value = 0.03411 <0.05 wird H0: µ<>30 abgelehnt, d.h. die mittlere SO2-Konzentration weicht auf 5%igem Testniveau signifikant vom Sollwert 30 ab.

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
15
Teilaufgabe 2b (Mindeststichprobenumfang):
Lösungsansatz und numerische Lösung: In der Teilaufgabe b) wird nach dem erforderlichen Mindeststichprobenumfang n_mindest (Anzahl der Messwiederholungen) gefragt, um mit dem in 3a) durchgeführten t-Test die Abweichung delta=1,5 (5% von µ0) vom Sollwert µ0 mit der Sicherheit 1-ß= 0,95 als signifikant zu erkennen. Die Bestimmung des Mindeststichprobenumfangs erfolgt (näherungsweise) mit der Formel
( )2
12/12
2
min βα
σ−− +
∆≈ zzn dest
oder einfacher mit der R-Prozedur power.t.test(). Lösung mit R: > # Aufgabe 2b > so2=c(32, 41, 33, 35, 34) > s <- sd(so2) > soll <- 30 > delta <- 0.05*soll > print(cbind(soll, delta, s)) soll delta s [1,] 30 1.5 3.536 > power.t.test(delta=delta, sd=s, sig.level=0.05, power=0.95, + type ="one.sample", alternative="two.sided") One-sample t test power calculation n = 74.14 delta = 1.5 sd = 3.536 sig.level = 0.05 power = 0.95 alternative = two.sided Ergebnis: Es ist ein Mindeststichprobenumfang von n_mindest=75 erforderlich, um mit dem auf 5%igen Signifikanzniveau geführten t-Test die Abweichung delta=1,5 vom Sollwert 30 mit einer Sicherheit von 95% als signifikant zu erkennen.
3. In einer Studie mit 5 Probanden wurde eine bestimmte Zielgröße X am Studienbeginn (Xb) und – nach erfolgter Behandlung - am Studienende (Xe) gemessen. c. Man erfasse die Wirkung der Behandlung durch die Differenz Y= Xe - Xb und prüfe,
ob der Mittelwert von Y signifikant von Null abweicht (alpha=5%). d. Welcher Stichprobenumfang müsste geplant werden, um die halbe beobachte
Differenz der mittleren Wirkungen mit einer Sicherheit von 90% als signifikant zu erkennen?
Proband Xb Xe
1 2 3 4 5
67 63 44 27 32
69 71 46 26 35
Präzisierung der Aufgabe: Wir nehmen an, dass die Wirkung Y=Xe – Xb normalverteilt ist mit dem Mittelwert µ und der Varianz σ2.

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
16
Teilaufgabe 3a (1-Stichproben t-Test):
Lösungsansatz und numerische Lösung: In der Teilaufgabe a) ist gefragt, ob µ von µ0=0 abweicht, d.h. es geht um den Vergleich eines Mittelwerts mit einem Sollwert. Die Alternativhypothese lautet H1: µ<>0, die Nullhypothese ist H0: µ=0. Die Testentscheidung wird mit dem 1-Stichproben-t -Test auf dem Testniveau alpha=5% durchgeführt. Aus der Stichprobe entnimmt man den Stichprobenumfang n sowie die Schätzwerte yquer und s für µ bzw σ. Lösung mit R: > # Aufgabe 3a > xb <- c(67, 63, 44, 27, 32) > xe <- c(69, 71, 46, 26, 35) > y <- xe - xb > print(cbind(xb, xe, y)) xb xe y [1,] 67 69 2 [2,] 63 71 8 [3,] 44 46 2 [4,] 27 26 -1 [5,] 32 35 3 > n <- length(y) > yquer <- mean(y) > s <- sd(y) > options(digits=4) > print(cbind(n, yquer, s)) n yquer s [1,] 5 2.8 3.271 > t.test(y, alternative="two.sided", mu=0, conf.level=0.95) One Sample t-test data: y t = 1.914, df = 4, pppp----value = 0.1281value = 0.1281value = 0.1281value = 0.1281 alternative hypothesis: true mean is not equal to 0 95 percent confidence interval: -1.262 6.862 sample estimates: mean of x 2.8 Ergebnis: Wegen p-value = 0.1281>=0.05 kann H0: µ<>0 nicht abgelehnt werden, d.h. die mittlere Wirkung weicht auf 5%igem Testniveau nicht signifikant vom Sollwert 0 ab. Teilaufgabe 3b (Mindeststichprobenumfang):
Lösungsansatz und numerische Lösung: In der Teilaufgabe b) wird nach dem erforderlichen Mindeststichprobenumfang n_mindest (Anzahl der Messwiederholungen) gefragt, um mit dem in 3a) durchgeführten t-Test die halbe beobachtete Abweichung des Stichprobenmittelwerts yqer vom Sollwert 0 mit der Sicherheit 1-ß= 0,90 als signifikant zu erkennen. Die Bestimmung des Mindeststichprobenumfangs erfolgt mit der R-Prozedur power.t.test(). Lösung mit R: > # Aufgabe 3b > xb <- c(67, 63, 44, 27, 32) > xe <- c(69, 71, 46, 26, 35) > y <- xe - xb > soll <- 0 > s <- sd(y) > delta <- abs(mean(y)/2- soll) > print(cbind(soll, delta)) soll delta [1,] 0 1.4

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
17
> options(digits=4) > power.t.test(delta=delta, sd=s, sig.level=0.05, power=0.90, + type ="one.sample", alternative="two.sided") One-sample t test power calculation n = 59.32n = 59.32n = 59.32n = 59.32 delta = 1.4 sd = 3.271 sig.level = 0.05 power = 0.9 alternative = two.sided Ergebnis: Es ist ein Mindeststichprobenumfang von n_mindest=60 erforderlich, um mit dem auf 5%igen Signifikanzniveau geführten t-Test die halbe beobachtete Abweichung delta=1,4 der mittleren Wirkung vom Sollwert 0 mit einer Sicherheit von 90% als signifikant zu erkennen.
4. In einer Studie wurde ein Blutparameter am Beginn und am Ende einer Therapie
bestimmt. Es ergab sich, dass bei 35 Probanden eine Veränderung des Parameters eintrat, und zwar lag der Wert bei 15 Probanden vorher im Normbereich und nachher außerhalb und bei 20 Probanden vorher außerhalb und nachher im Normbereich. e. Weicht der Anteil der Veränderungen von „vorher außerhalb“ in „nachher innerhalb“
signifikant von 0.5 ab (alpha = 5%)? f. Welcher Anzahl von Probanden mit einer Veränderung müsste man haben, um mit
dem Test die beobachtete Abweichung des Anteils von 0.5 mit einer Sicherheit von 90% als signifikant zu erkennen?
Präzisierung der Aufgabe: Wir bezeichnen die Zufallsvariable „Veränderung des Blutparameters auf Grund der Therapie“ mit X. X ist eine zweistufige Zufallsvariable mit den Werten „vorher außerhalb� nachher innerhalb“ bzw. „vorher innerhalb � nachher außerhalb“. Die Anzahl der Veränderungen von „vorher außerhalb� nachher innerhalb“ ist binomialverteilt mit den Parametern p = P(Veränderung von „vorher außerhalb� nachher innerhalb“) und n = 35. Teilaufgabe 4a (zweiseitiger Binomialtest):
Lösungsansatz und numerische Lösung: In der Teilaufgabe a) ist gefragt, ob p von 0,5 abweicht, d.h. es geht um einen Vergleich einer Wahrscheinlichkeit mit einem Sollwert. Die Alternativhypothese lautet H1: p <> 0,5, die Nullhypothese ist H0: p=0,5. Die Testentscheidung wird mit dem Binomialtest auf dem Testniveau alpha=5% durchgeführt. Aus der Stichprobe entnimmt man den Stichprobenumfang n=35 sowie die Anzahl m = 20 der Probanden mit einer Veränderung von „vorher außerhalb� nachher innerhalb“. Lösung mit R: > # 4a > n <- 35 > m <- 20 > alpha <- 0.05 > soll=0.5 > # H0: p=0.5 versus H1: p<>0.5 > binom.test(m, n, p=soll, alternative="two.sided", conf.level=0.95) Exact binomial test data: m and n number of successes = 20, number of trials = 35, pppp----value = 0.4996value = 0.4996value = 0.4996value = 0.4996 alternative hypothesis: true probability of success is not equal to 0.5 95 percent confidence interval: 0.3935309 0.7367728

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
18
sample estimates: probability of success 0.5714286 Ergebnis: Wegen p-value = 0.4996 >= 0.05 kann H0: p=0.5 nicht abgelehnt werden! Teilaufgabe 4b (Mindeststichprobenumfang):
Lösungsansatz und numerische Lösung: In der Teilaufgabe b) wird nach dem erforderlichen Mindeststichprobenumfang n_mindest (Anzahl der Probanden mit einer Veränderung) gefragt, um mit dem in 1a) durchgeführten Binomialtest die beobachtete Abweichung delta=|20/35-0,5| mit der Sicherheit 1-ß= 0,9 als signifikant zu erkennen. Approximative Bestimmung des Mindeststichprobenumfangs mit der Formel ((Die Formel liefert vertretbare Näherungswerte, wenn n >20 und 10<= np0 < n-10 ist.):
( )2
12/12min 4
1βα −− +
∆≈ zzn dest
Lösung mit R: > # 4b (Approximation) > delta <- abs(m/n-0.5) > power <- 0.9 > alpha <- 0.05 > n_mindest <- 1/4/delta^2*(qnorm(1-alpha/2)+qnorm(power))^2 > options(digits=4) > print(cbind(delta, alpha, power, n_mindest)) delta alpha power n_mindestdelta alpha power n_mindestdelta alpha power n_mindestdelta alpha power n_mindest [1,] 0.07143 0.05 0.9 514.9[1,] 0.07143 0.05 0.9 514.9[1,] 0.07143 0.05 0.9 514.9[1,] 0.07143 0.05 0.9 514.9
Ergebnis: Es ist ein Mindeststichprobenumfang von n_mindest=515 erforderlich, um mit dem auf 5%igen Signifikanzniveau geführten Test die Abweichung delta=0.07143 vom Sollwert 0.5 mit einer Sicherheit von 90% als signifikant zu erkennen.
5. Im Rahmen einer Untersuchung des Ernährungsstatus von Schulkindern aus den Regionen A und B wurde u.a. das Gesamtcholesterin (in mg/dl) stichprobenartig erfasst. g. Man prüfe für die Region A auf 5%igem Niveau, ob der Anteil von Schulkindern in der
optimalen Kategorie signifikant über p0 = 0,5 liegt. h. Welcher Stichprobenumfang müsste geplant werden, um mit dem Binomialtest auf
dem Niveau alpha = 5% eine Überschreitung des Referenzwertes p0 = 0.5 um 0.1 mit 90%iger Sicherheit erkennen zu können?
Gesamtcholesterin Region A Region B <170 (optimal) >=170 (Risiko)
95 60
80 50
Präzisierung der Aufgabe: Wir bezeichnen die Zufallsvariable „Gesamtcholesterin“ mit X. X ist auf einer zweistufigen Skala mit den Werten „<170 (optimal)“ bzw. „>=170 (Risiko)“ dargestellt. Die Anzahl der Schulkinder mit einem optimalen X-Wert ist binomialverteilt mit den Parametern p = P(ein Schulkind in Region A hat einen optimalen X-Wert) und n = 95+60 = 155 (Region A). Teilaufgabe 5a (einseitiger Binomialtest):
Lösungsansatz und numerische Lösung: In der Teilaufgabe a) ist gefragt, ob p größer als 0,5 ist; die Alternativhypothese lautet also H1: p>0,5; die Nullhypothese ist H0: p<=0,5. Die Testentscheidung wird mit dem Binomialtest auf dem Testniveau alpha=5% durchgeführt. Aus der Stichprobe entnimmt man den

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
19
Stichprobenumfang n=155 (Region A) sowie die Anzahl m = 95 der Schulkinder mit einem optimalen Cholesterinwert. Lösung mit R: > # Aufgabe 5a > m <- 95 > n <- 95+60 > alpha <- 0.05 > soll=0.5 > # H0: p<=0.5 versus H1: p>0.5 > binom.test(m, n, p=soll, alternative="greater", conf.level=0.95) Exact binomial test data: m and n number of successes = 95, number of trials = 155, pppp----value = 0.003066value = 0.003066value = 0.003066value = 0.003066 alternative hypothesis: true probability of success is greater than 0.5 95 percent confidence interval: 0.5440993 1.0000000 sample estimates: probability of success 0.6129032 Ergebnis: Wegen p-value = 0.003066 <0.05 wird H0: p<=0.5 abgelehnt, d.h. der Anteil der Schulkinder mit einem optimalen Cholesterinwert liegt auf 5%igem Testniveau signifikant über 0,5. Teilaufgabe 5b (Mindeststichprobenumfang):
Lösungsansatz und numerische Lösung: In der Teilaufgabe b) wird nach dem erforderlichen Mindeststichprobenumfang n_mindest (Anzahl der Schulkinder) gefragt, um mit dem in 2a) durchgeführten Binomialtest die Überschreitung delta=0,1 des Sollwertes p0=0,5 mit der Sicherheit 1-ß= 0.9 als signifikant zu erkennen. Die Bestimmung des Mindeststichprobenumfangs erfolgt näherungsweise mit der Formel (Die Formel liefert vertretbare Näherungswerte, wenn n >20 und 10<= np0 < n-10 ist.):
( )2
112min 4
1βα −− +
∆≈ zzn dest
Lösung mit R: > # Aufgabe 2b (Approximation) > delta <- 0.1 > power <- 0.9 > alpha <- 0.05 > n_mindest <- 1/4/delta^2*(qnorm(1-alpha)+qnorm(power))^2 > options(digits=4) > print(cbind(delta, alpha, power, n_mindest)) delta alpha power n_mindestdelta alpha power n_mindestdelta alpha power n_mindestdelta alpha power n_mindest [1,] 0.1 0.05 0.9 214.1[1,] 0.1 0.05 0.9 214.1[1,] 0.1 0.05 0.9 214.1[1,] 0.1 0.05 0.9 214.1 Ergebnis: Es ist ein Mindeststichprobenumfang von n_mindest=215 erforderlich, um mit dem auf 5%igen Signifikanzniveau geführten Binomialtest die Überschreitung delta=0.1 des Sollwertes p0=0.5 mit einer Sicherheit von 90% als signifikant zu erkennen.
6. Bei einen Fertigungsprozess werden Lose vom Umfang N=10000 Stück auf fehlerhafte
Einheiten geprüft (Gut/Schlecht-Prüfung). Der Prüfplan sieht Stichproben vom Umfang n=89 und die Annahmezahl c=2 vor. Kann damit ein Lieferantenrisiko von höchstens 5% an der Gutgrenze AQL=1% sowie ein Konsumentenrisiko von höchstens 10% an der Schlechtgrenze LQL=6% sicher gestellt werden? Präzisierung der Aufgabe:

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
20
Wegen n/N<0.1 und N>60 kann die Annahmewahrscheinlichkeit in Abhängigkeit vom Ausschussanteil p mit guter Näherung durch die Binomialverteilung dargestellt werden.
Lösungsansatz und numerische Lösung: Zur Lösung der Aufgabe sind die Annahmewahrscheinlichkeiten Pa(AQL| 89, 2) und Pa(LQL| 89, 2) an der Gut- bzw. Schlechtgrenze zu bestimmen. Es ist: Wegen Pa(AQL|89,2)=93,97% ≥ 90% ist die erforderliche Mindestannahmewahrscheinlichkeit im Punkt PRP erfüllt. Auch im Punkt CRP wird wegen Pa(LQL|89,2)=9.19% ≤ 10% die vorgegebene Maximalwahrscheinlichkeit nicht überschritten. Lösung mit R: > library(AcceptanceSampling) > PPbinom <- OC2c(89, 2, type="binom") > assess(PPbinom, PRP=c(0.01, 0.9), CRP=c(0.06, 0.1)) Acceptance Sampling Plan (binomial) Sample 1 Sample size(s) 89 Acc. Number(s) 2 Rej. Number(s) 3 Plan CAN meet desired risk point(s): Quality RP P(accept) Plan P(accept) PRP 0.01 0.9 0.93968992 CRP 0.06 0.1 0.09186935
Ergebnis: Für den Prüfplan n=89 und c=2 sind die Forderungen an die Operationscharakteristik (Mindestannahmewahercheinlichkeiten von 90% für p ≤ 0.01 sowie eine maximale Annahmewahrscheinlichkeit von 10% für p ≥ 0.06) erfüllt.
7. Es gelte die Annahme, dass das in einem Produktionsprozess an Werkstücken zu
überprüfende Merkmal X angenähert normalverteilt sei. Ein Werkstück gelte als fehlerhaft, wenn ein bestimmter Grenzwert To überschritten wird. Zur Festlegung der Operationscharakteristik wird ein Lieferantenrisiko von 5% an der Gutgrenze AQL=1.5% und ein Abnehmerrisiko von 5% an der Schlechtgrenze LQL = 10% vereinbart. Man bestimme die Kennwerte n und k eines geeigneten Prüfplans. Dabei nehme man die Varianz von X als bekannt an.
Präzisierung der Aufgabe: Man beachte, dass ein Los angenommen wird, wenn der Mittelwert der Prüfstichprobe um die k-fache Standardabweichung unter dem Grenzwert To liegt. Die Wahrscheinlichkeit dafür ist in
Abhängigkeit vom Ausschussanteil p durch ( ) [ ]( )nkzknpP pa −Φ= −1,| gegeben. Der
Ausschussanteil p ist gleich der Überschreitungswahrscheinlichkeit des Grenzwert To.
Lösungsansatz und numerische Lösung: Aus den an der Gut- und Schlechtgrenze vorgegebenen Annahmewahrscheinlichkeiten sind die Kenngrößen n (Umfang der Prüfstichprobe) und k (Annahmezahl) zu bestimmen.
An der Gutgrenze p=0.015 soll 95.0985.0 )( d.h., ,95.0),|01.0( znkzknPa =−= gelten, für
und für die Schlechtgrenze p=0.1 wird 95.09.0 )( d.h., ,05.0),|1.0( znkzknPa −=−=
%.19.9)06.01(06.089
)2,89|06.0(
%,97.93)01.01(01.089
)2,89|01.0(
2
0
89
2
0
89
=−
=
=−
=
∑
∑
=
−
=
−
x
xxa
x
xxa
xP
xP

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
21
verlangt. Drückt man z.B. k aus der ersten Gleichung durch n aus und setzt in die zweite Gleichung ein, folgt schließlich n=13.7 ≈ 14. Einsetzen des gerundeten Wertes von n in die erste Gleichung führt auf k = 1.73. Lösung mit R: > library(AcceptanceSampling) > xx <- find.plan(PRP=c(0.015, 0.95), CRP=c(0.1, 0.05), type="normal", s.type="known") > xx $n [1] 14 $k [1] 1.730485 $s.type [1] "known" Ergebnis: Die vorgegebenen Forderungen werden mit Prüfplankenngrößen n=14 und k=1.73 erfüllt. Nach diesem Prüfplan wird das Los angenommen, wenn der Mittelwert der Prüfstichprobe vom Umfang n=14 den vorgegebenen Grenzwert um mindestens k=1,73 Standardabweichungen unterschreitet.
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
22
5 EINFÜHRUNG IN DAS TESTEN VON UNTERSCHIEDSHYPOTHESEN II: 2-STICHPROBENVERGLEICHE UND 1-FAKTORIELLE VARIANZANALYSE 5.1. Zwei grundlegende Versuchsanlagen
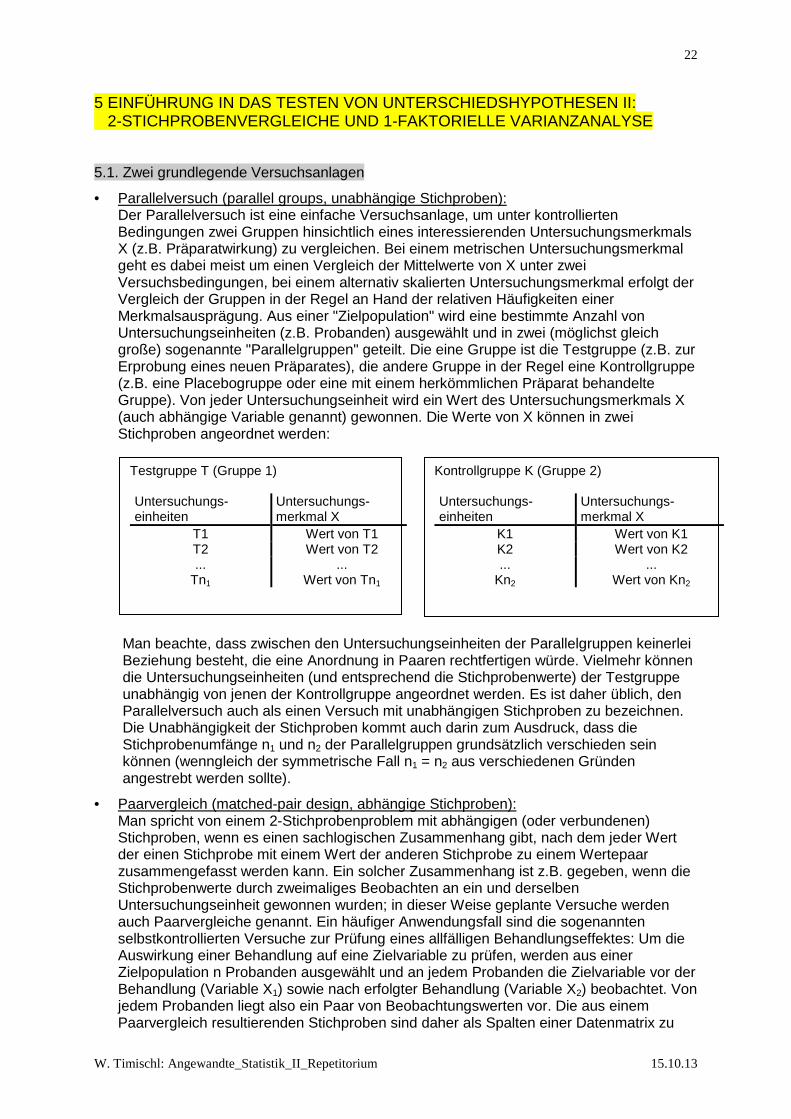
• Parallelversuch (parallel groups, unabhängige Stichproben): Der Parallelversuch ist eine einfache Versuchsanlage, um unter kontrollierten Bedingungen zwei Gruppen hinsichtlich eines interessierenden Untersuchungsmerkmals X (z.B. Präparatwirkung) zu vergleichen. Bei einem metrischen Untersuchungsmerkmal geht es dabei meist um einen Vergleich der Mittelwerte von X unter zwei Versuchsbedingungen, bei einem alternativ skalierten Untersuchungsmerkmal erfolgt der Vergleich der Gruppen in der Regel an Hand der relativen Häufigkeiten einer Merkmalsausprägung. Aus einer "Zielpopulation" wird eine bestimmte Anzahl von Untersuchungseinheiten (z.B. Probanden) ausgewählt und in zwei (möglichst gleich große) sogenannte "Parallelgruppen" geteilt. Die eine Gruppe ist die Testgruppe (z.B. zur Erprobung eines neuen Präparates), die andere Gruppe in der Regel eine Kontrollgruppe (z.B. eine Placebogruppe oder eine mit einem herkömmlichen Präparat behandelte Gruppe). Von jeder Untersuchungseinheit wird ein Wert des Untersuchungsmerkmals X (auch abhängige Variable genannt) gewonnen. Die Werte von X können in zwei Stichproben angeordnet werden:
Man beachte, dass zwischen den Untersuchungseinheiten der Parallelgruppen keinerlei Beziehung besteht, die eine Anordnung in Paaren rechtfertigen würde. Vielmehr können die Untersuchungseinheiten (und entsprechend die Stichprobenwerte) der Testgruppe unabhängig von jenen der Kontrollgruppe angeordnet werden. Es ist daher üblich, den Parallelversuch auch als einen Versuch mit unabhängigen Stichproben zu bezeichnen. Die Unabhängigkeit der Stichproben kommt auch darin zum Ausdruck, dass die Stichprobenumfänge n1 und n2 der Parallelgruppen grundsätzlich verschieden sein können (wenngleich der symmetrische Fall n1 = n2 aus verschiedenen Gründen angestrebt werden sollte).
• Paarvergleich (matched-pair design, abhängige Stichproben): Man spricht von einem 2-Stichprobenproblem mit abhängigen (oder verbundenen) Stichproben, wenn es einen sachlogischen Zusammenhang gibt, nach dem jeder Wert der einen Stichprobe mit einem Wert der anderen Stichprobe zu einem Wertepaar zusammengefasst werden kann. Ein solcher Zusammenhang ist z.B. gegeben, wenn die Stichprobenwerte durch zweimaliges Beobachten an ein und derselben Untersuchungseinheit gewonnen wurden; in dieser Weise geplante Versuche werden auch Paarvergleiche genannt. Ein häufiger Anwendungsfall sind die sogenannten selbstkontrollierten Versuche zur Prüfung eines allfälligen Behandlungseffektes: Um die Auswirkung einer Behandlung auf eine Zielvariable zu prüfen, werden aus einer Zielpopulation n Probanden ausgewählt und an jedem Probanden die Zielvariable vor der Behandlung (Variable X1) sowie nach erfolgter Behandlung (Variable X2) beobachtet. Von jedem Probanden liegt also ein Paar von Beobachtungswerten vor. Die aus einem Paarvergleich resultierenden Stichproben sind daher als Spalten einer Datenmatrix zu
Testgruppe T (Gruppe 1) Untersuchungs-einheiten
Untersuchungs-merkmal X
T1 Wert von T1 T2 Wert von T2 ... ...
Tn1 Wert von Tn1
Kontrollgruppe K (Gruppe 2) Untersuchungs-einheiten
Untersuchungs-merkmal X
K1 Wert von K1 K2 Wert von K2 ... ...
Kn2 Wert von Kn2

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
23
sehen, in der jede Zeile einem „Block“ (z.B. einem Probanden) entspricht, über den die Stichprobenwerte zu Wertepaaren verbunden werden:
5.2 Zweistichprobenvergleiche bei metrischen Variablen im Rahmen von Parallelversuchen 2-Stichproben t-Test (two-sample t-test):
Problemstellung:
Es soll im Rahmen eines Parallelversuchs festgestellt werden, ob sich die Mittelwerte µ1 und µ2 einer Variablen X unter zwei Versuchsbedingungen unterscheiden. Dabei wird X unter jeder Versuchsbedingung als normalverteilt und mit gleichen Varianzen vorausgesetzt.
Ablaufschema: • Beobachtungsdaten:
zwei (voneinander unabhängige) Stichproben x11, x21, ..., xn1,1 bzw. x12, x22, ..., xn2,2 � Mittelwerte 1x und 2x , Varianzen s2
1 und s22
• Modell: xi1 ist eine Realisation von Xi1 ~ N(µ1, σ2
1) (i=1,2,...,n1)
� Stichprobenfunktionen 1X , S21
xi2 ist eine Realisation von Xi2 ~ N(µ2, σ22) (i=1,2,...,n1)
� Stichprobenfunktionen 2X , S22
Es gelte: σ21 = σ2
2 (Varianzhomogenität)
• Hypothesen: 2-seitige Hypothesen: H0: µ1 = µ2 vs. H1: µ1 ≠ µ2 (Fall II) 1-seitige Hypothesen: H0: µ1 ≤ µ2 vs. H1: µ1 > µ2 (Fall Ia) H0: µ1 ≥ µ2 vs. H1: µ1 < µ2 (Fall Ib)
Signifikanzniveau: α
• Testgröße: • Entscheidung mit Quantilen:
H0 auf Signifikanzniveau α ablehnen, wenn |TGs| > tn1+ n2 - 2,1-α/2 (Fall II) bzw. TGs > tn1 + n2 -
2,1- α (Fall Ia) bzw. TGs < tn1 + n2 - 2, α (Fall Ib)
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P < α wobei
Untersuchungseinheiten X1 Stichprobe 1
X2 Stichprobe 2
U1 1. Wert von U1 2. Wert von U1 U2 1. Wert von U2 2. Wert von U2 ... ... ... Un 1. Wert von Un 2. Wert von Un
2
)1()1(mit )(für
11 21
222
211
21 2
21
21
21 −+−+−
==≅+
−= −+ nn
SnSnSt
nnS
XXTG pnn
p
µµ

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
24
P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall II) bzw. P=P(TG ≥ |TGs|) (Fall Ia) bzw. P=P(TG ≤ -|TGs|) (Fall Ib).
• Planung des Stichprobenumfanges: Um auf Niveau α mit Sicherheit 1-β eine Entscheidung für H1 herbeizuführen, wenn µ1 von µ2 um ∆ ≠ 0 im Sinne der Alternativhypothese abweicht, ist der dafür notwendige Stichprobenumfang (Voraussetzung für Abschätzung: symmetrische Versuchsanlage mit n=n1=n2 und n ≥ 20):
F-Test: Problemstellung:
Es soll im Rahmen eines Parallelversuchs festgestellt werden, ob sich die Varianzen σ12
und σ22 einer Variablen X unter zwei Versuchsbedingungen unterscheiden. X wird unter
jeder Versuchsbedingung als normalverteilt vorausgesetzt.
Ablaufschema: • Beobachtungsdaten:
zwei (voneinander unabhängige) Stichproben x11, x21, ..., xn1,1 und x12, x22, ..., xn2,2 � Varianzen s2
1 bzw. s22
• Modell: xi1 ist eine Realisation von Xi1 ~ N(µ1, σ2
1) (i=1,2,...,n1) xi2 ist eine Realisation von Xi2 ~ N(µ2, σ2
2) (i=1,2,...,n1) � Stichprobenvarianzen S2
1,S22
• Hypothesen: 2-seitige Hypothesen: H0: σ1
2 = σ22 vs. H1: σ1
2 ≠ σ22 (Fall II)
1-seitige Hypothesen: H0: σ12 ≤ σ2
2 vs. H1: σ12 > σ2
2 (Fall Ia) H0: σ1
2 ≥ σ22 vs. H1: σ1
2 < σ22 (Fall Ib)
Signifikanzniveau: α
• Testgröße: • Entscheidung mit Quantilen:
H0 auf Testniveau α ablehnen, wenn TGs < Fn1-1, n2-1, α/2 oder TGs >Fn1-1, n2-1,1-α/2 (Fall II) bzw. TGs > Fn1-1, n2-1,1-α (Fall Ia) bzw. TGs < Fn1-1, n2-1, α (Fall Ib). Hinweis: Bildet man die Testgröße so, dass die größere Varianz im Zähler steht, reduziert sich im Fall I die Bedingung auf TGs > Fn1-1, n2-1,1-α/2.
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P < α, wobei P=P(1/TG≤1/TGs oder TG≥TGs) (Fall II) bzw. P=P(TG≥TGs) (Fall Ia) bzw. P=P(1/TG≤ 1/TGs) (Fall Ib). Hinweis: TGs so ansetzen, dass die größere Varianz im Zähler steht; die Variablen TG und 1/TG haben unterschiedliche Zähler- bzw. Nennerfreiheitsgrade!
( )
( ) )Hypothesen seitige-(1 2
bzw. )Hypothesen seitige-(2 2
2112
2
212/12
2
βα
βα
σ
σ
−−
−−
+∆
≈
+∆
≈
zzn
zzn
22
211,12
2
21 für
21σσ =≅= −− nnF
S
STG

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
25
Anmerkung: Wird der F-Test in Verbindung mit dem 2-Stichproben t-Test als „Vortest“ zum Nachweis der Varianzhomogenität eingesetzt, kann das Gesamtirrtumsrisiko αg für beide Testentscheidungen bis knapp 2α ansteigen. Diesen nicht erwünschten Nebeneffekt vermeidet man, wenn als Alternative zum Mittelwertvergleich mit dem 2-Stichproben t-Test und dem F-Test als Vortest der nicht ganz so „scharfe“ Welch-Test eingesetzt wird (siehe weiter unten).
U – Test (Wilcoxon-Rangsummentest, Mann-Whitney rank-sum test):
Problemstellung:
Es soll im Rahmen eines Parallelversuchs festgestellt werden, ob sich die Mittelwerte µ1 und µ2 einer Variablen X unter zwei Versuchsbedingungen unterscheiden, wobei von X unter jeder Versuchsbedingung die gleiche Verteilung (nicht notwendigerweise eine Normalverteilung) vorausgesetzt wird.
Ablaufschema: • Beobachtungsdaten:
Stichproben x11, x21, ..., xn1,1 und x12, x22, ..., xn2,2 � rangskalierte Stichroben: beide Stichproben kombinieren und nach aufsteigender Größe anordnen; Stichprobenwerte von 1 bis n1+n2 durchnummerieren und Ordnungsnummern den Stichprobenwerten xi1 und xi2 als Rangzahlen ri1 bzw. ri2 zuordnen; bei gleichen Stichprobenwerten erfolgt Bindungskorrektur. Aufsummieren der Rangzahlen ergibt die Rangsummen r1 und r2.
• Modell: Jedes xi1 (xi2) ist Realisation einer Zufallsvariablen Xi1 (Xi2) mit Verteilungsfunktion F1 (F2). F1 und F2 unterscheiden sich nur in der Lage, d.h., Graph von F2 geht durch Verschiebung um ein bestimmtes θ in Richtung der positiven horizontalen Achse in Graphen von F1 über. Die Rangsummenwerte r1 und r2 sind Realisationen der Zufallsvariablen R1 bzw. R2.
• Hypothesen:
2-seitige Hypothesen: H0: θ = 0 vs. H1: θ ≠ 0 (Fall II) 1-seitige Hypothesen: H0: θ ≤ 0 vs. H1: θ > 0 (Fall Ia) H0: θ ≥ 0 vs. H1: θ < 0 (Fall Ib)
Signifikanzniveau: α
• Testgröße: TG = U = n1n2 + n1(n1+1)/2 - R1; für θ = 0 gilt: E[U]=n1n2/2, Var[U]= n1n2(n1+n2+1)/12; Approximation bei großen Stichproben (n1>20 oder n2>20):
• Entscheidung mit Quantilen (große Stichproben):
H0 auf Testniveau α ablehnen, wenn |TGs| > z1-α/2 (Fall II) bzw. TGs > z1-α (Fall Ia) bzw. TGs < zα (Fall Ib).
• Entscheidung mit P-Wert (große Stichproben): H0 auf Signifikanzniveau α ablehnen, wenn P < α wobei P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall II) bzw. P=P(TG ≥ |TGs|) (Fall Ia) bzw. P=P(TG ≤ -|TGs|) (Fall Ib).
)1,0(][
][' N
UVar
UEUTG ≅−=

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
26
Welch – Test (two sample t-test with unequal variances):
Problemstellung: Es soll im Rahmen eines Parallelversuchs festgestellt werden, ob sich die Mittelwerte µ1 und µ2 einer Variablen X unter zwei Versuchsbedingungen unterscheiden, wobei X unter jeder Versuchsbedingung als normalverteilt vorausgesetzt wird.
Ablaufschema: • Beobachtungsdaten, Modell, Hypothesen:
wie beim 2-Stichproben t-Test bis auf die Voraussetzung der Varianzhomogenität.
• Testgröße: • Entscheidung:
H0 auf Testniveau α ablehnen, wenn |TGs| > tf,1-α/2 (Fall II), TGs > tf,1-α (Fall Ia), TGs > tf, α (Fall Ib) mit:
5.3 Unterschiedshypothesen bei metrischen Variablen im Rahmen von Paarvergleichen Differenzen- t-Test (paired t-test, t-Test für abhängige Stichproben):
Problemstellung: Es soll im Rahmen eines Paarvergleichs (mit abhängigen Stichproben) festgestellt werden, ob sich die Mittelwerte µ1 und µ2 der Variablen X1 bzw. X2 (zB zu zwei aufeinanderfolgenden Zeitpunkten beobachtete Merkmale) unterscheiden. Dabei werden X1 und X2 als normalverteilt vorausgesetzt.
Ablaufschema: • Beobachtungsdaten:
n Wertepaare (x11, x12), (x21, x22), ..., (xn,1, xn,2) durch Messung der Variablen X1 (Mittelwert µ1) und X2 (Mittelwert µ2) an n Untersuchungseinheiten � Differenzenstichprobe d1=x12 - x11, d2=x22 - x21, ..., dn=xn2 - xn1 mit Mittelwert md und die Varianz sd
2
• Modell: Jedes di ist Realisation von Di ∝ N(µd, σd
2) mit µd=µ2-µ1 � Stichprobenmittel MD ∝ N(µd, σd
2/n), Stichprobenvarianz SD2
• Hypothesen: 2-seitige Hypothesen: H0: µd = 0 vs. H1: µd ≠ 0 (Fall II) 1-seitige Hypothesen: H0: µd ≤ 0 vs. H1: µd > 0 (Fall Ia) H0: µd ≥ 0 vs. H1: µd < 0 (Fall Ib) Signifikanzniveau: α
• Testgröße:
// 2
221
21
21
nSnS
XXTG
+
−=
( )( ) ( ) Zahl)ganze auf(gerundet
)1/(/)1/(/
//
2
2
2
2
21
2
1
2
1
2
2221
21
−+−+≈
nnsnns
nsnsf
0für /
1 =≅= − dn
D
D tnS
MTG µ

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
27
• Entscheidung mit Quantilen: H0 auf Testniveau α ablehnen, wenn |TGs| > tn-1,1-α/2 (Fall II) bzw. TGs > tn-1,1-α (Fall Ia) bzw. TGs < tn-1,α (Fall Ib).
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P < α wobei P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall II) bzw. P=P(TG ≥ |TGs|) (Fall Ia) bzw. P=P(TG ≤ -|TGs|) (Fall Ib).
• Planung des Stichprobenumfangs: Um auf Niveau α mit der Sicherheit 1-β eine Entscheidung für H1 herbeizuführen, wenn µd von 0 um ∆ ≠ 0 im Sinne der Alternativhypothese abweicht, ist das dafür notwendige n näherungsweise (etwa ab n = 20) im Fall II:
in den Fällen Ia und Ib ist z1-α/2 durch z1-α zu ersetzen.
Wilcoxon-Test (Wilcoxon signed-rank test):
Problemstellung: Es soll im Rahmen eines Paarvergleichs (mit abhängigen Stichproben) festgestellt werden, ob sich die Mittelwerte µ1 und µ2 der Variablen X1 bzw. X2 (zB zu zwei aufeinanderfolgenden Zeitpunkten beobachtete Merkmale) unterscheiden. Dabei wird D= X2 - X1 als nicht normalverteilt vorausgesetzt.
Ablaufschema: • Beobachtungsdaten:
n Wertepaare (x11, x12), (x21, x22), ..., (xn,1, xn,2) � Differenzenstichprobe d1=x12 - x11, d2=x22 - x21, ..., dn=xn2 - xn1 (Paare mit übereinstimmenden Werten bleiben unberücksichtigt); Paardifferenzen hinsichtlich Absolutbeträgen nach aufsteigender Größe anordnen und durchnummerieren, Ordnungsnummern den Paardifferenzen als Rangzahlen zuordnen (Bindungskorrektur bei gleichen Absolutbeträgen). t+ = Summe der zu den positiven Paardifferenzen gehörenden Rangzahlen.
• Modell: Jedes di ist die Realisation einer Zufallsvariablen Di mit einer stetigen und symmetrisch um den Median ζ liegenden Verteilungsfunktion; t+ =Realisation von T+.
• Hypothesen und Testgröße: 2-seitige Hypothesen: H0: ζ = 0 vs. H1: ζ ≠ 0 (Fall I) 1-seitige Hypothesen: H0: ζ ≤ 0 vs. H1: ζ > 0 (Fall IIa)
H0: ζ ≥ 0 vs. H1: ζ < 0 (Fall IIb) Signifikanzniveau: α Testgröße: TG = T+ Für ζ = 0 (H0) gilt: E[T+]=n(n+1)/4, Var[T+]= n(n+1)(2n+1)/24) Approximation bei großen Stichproben (n >20):
• Entscheidung mit Quantilen (große Stichproben):
H0 auf Testniveau α ablehnen, wenn |TGs| > z1-α/2 (Fall I) bzw. TGs > z1-α (Fall IIa) bzw. TGs < zα (Fall IIb).
( )212/12
2
βασ
−− +∆
≈ zzn d
)1,0(][
][' N
TVar
TETTG ≅−=
+
++

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
28
• Entscheidung mit P-Wert (große Stichproben): H0 auf Signifikanzniveau α ablehnen, wenn P < α wobei P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall I) bzw. P=P(TG ≥ |TGs|) (Fall IIa) bzw. P=P(TG ≤ -|TGs|) (Fall IIb).
5.4 Zweistichprobenvergleiche bei dichotomen Variablen Vergleich von zwei Wahrscheinlichkeitren mit unabhängigen Stichproben (comparison of two probabilities using independent samples):
Problemstellung: Es soll im Rahmen eines Parallelversuchs festgestellt werden, ob sich die Wahrscheinlichkeiten eines unter zwei Versuchsbedingungen betrachteten Ereignisses unterscheiden. Dabei wird ein Parallelversuch mit großen Stichproben vorausgesetzt.
Ablaufschema: • Beobachtungsdaten:
X = zweistufiges Merkmal mit den Werten a1, a2; Beobachtung von X unter zwei Bedingungen � 2 unabhängige Stichproben (Gruppen) � Zusammenfassung in Vierfeldertafel:
• Modell: X ist in jeder Gruppe zweipunktverteilt mit den Parametern p1=P(X=a1|Gruppe 1) bzw. p2=P(X=a1|Gruppe 2)
• Hypothesen: 2-seitige Hypothesen: H0: p1 = p2 vs. H1: p1 ≠ p2 (Fall II)
1-seitige Hypothesen: H0: p1 ≤ p2 vs. H1: p1 > p2 (Fall Ia) H0: p1 ≥ p2 vs. H1: p1 < p2 (Fall Ib)
Signifikanzniveau: α
• Testgröße:
Faustformel: n..>60, n1.n.1/n..>5, n1.n.2/n..>5, n2.n.1/n..>5, n2.n.2/n..>5
• Entscheidung mit Quantilen: H0 auf Testniveau α ablehnen, wenn |TGs| > z1-α/2 (Fall II) bzw. TGs > z1-α (Fall Ia) bzw. TGs < zα (Fall Ib).
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P<α, wobei P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall II) bzw. P=P(TG ≥ |TGs|) (Fall Ia) bzw. P=P(TG ≤ -|TGs|) (Fall Ib).
• Planung des Stichprobenumfanges:
( )(approx.) für )1,0( 21
.2.12.1.
21122211.. ppNnnnn
nnnnnTG =≅
−=
Untersuchungs- merkmal X
Gruppe 1 Gruppe 2 (Zeilen-) Summen
Wert a1 n11 n12 n1. Wert a2 n21 n22 n2.
(Spalten-) Summen
n.1=n1
vorgegeben n.2=n2 vorgegeben
n.. =n1+n2

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
29
Notwendiger Mindeststichprobenumfang n (=n1=n2), um auf dem Niveau α mit der Sicherheit 1-β eine Entscheidung für H1 herbeizuführen, wenn p1 von p2 um ∆ ≠ 0 im Sinne der Alternativhypothese abweicht:
( ) ( ) Ib) Ia, (Fall 2
1 bzw. II) (Fall
2
1 2112
212/12 βαβα −−−− +
∆≈+
∆≈ zznzzn
Vergleich von zwei Wahrscheinlichkeiten mit abhängigen Stichproben (comparison of two probabilities using dependent samples):
Problemstellung: Es soll für zweistufige Merkmale X1, X2 (Werte a1 bzw. a2) im Rahmen eines Paarvergleichs festgestellt werden, ob sich die Wahrscheinlichkeiten, dass X1 bzw. X2 den Wert a1 annimmt, unterscheiden.
Ablaufschema: • Beobachtungsdaten:
Beobachtung von X1 und X2 an n Untersuchungseinheiten ergibt die absolutem Häufigkeiten n11, n12, n21, n22 der Ereignisse „X1=a1 und X2=a1“, „X1=a1 und X2=a2“, „X1=a2 und X2=a1“ bzw. „X1=a2 und X2=a2“.
• Hypothesen: p1.= P(X1=a1) = P(X1=a1 und X2=a1) + P(X1=a1 und X2=a2), p.1= P(X2=a1) = P(X2=a1 und X1=a1) + P(X2=a1 und X1=a2), p12 = P(X1=a1 und X2=a2), p21 = P(X2=a1 und X1=a2); H0 : p1.= p.1 vs. H1 : p1. ≠ p.1 � H0: p12 = p21 vs. H1 : p12 ≠ p21 � H0 : p12*:=p12/(p12+ p21) = p21 /(p12+ p21) =: p21* vs. H1 : p12* ≠ p21* � H0 : p12* = ½ vs. H1 : p12* ≠ ½ (wegen p12*+ p21*=1) Signifikanzniveau: α
• Testgröße (Binomialtest): TG = H12 ~ Bn*,p0 (falls H0 gilt) (H12 = Anzahl der Untersuchungseinheiten mit X1=a1 und X2=a2, n*=n12+n21, p0=1/2; Realisierung der Testgröße TGs=n12) Testgröße (McNemar-Statistik, Normalverteilungsapproximation): (H21 = Anzahl der Untersuchungseinheiten mit X1=a2 und X2=a1. Realisierung der Testgröße TGs).
• Entscheidung mit dem P-Wert (Binomialtest) P=1- FB(µ0-d)+1- FB(µ0+d-1) < α ⇒ H0 ablehnen (FB die Verteilungsfunktion der Bn*,1/2-Verteilung, µ0=n*/2, d= |n12-µ0|=|n12 - n21|/2).
• Entscheidung mit dem P-Wert (Normalverteilungsapproximation) P=1- F1(TGs) < α ⇒ H0 ablehnen (F1 die Verteilungsfunktion der χ2
1 –Verteilung).
• Planung des Stichprobenumfangs: Notwendiger Mindeststichprobenumfang n* (=n12+n21), um auf dem Niveau α mit der Sicherheit 1-β eine Entscheidung für H1 herbeizuführen, wenn p12* von 1/2 um ∆ ≠ 0 abweicht:
∆−+
∆≈ −−
212/12
414
1* βα zzn
( ))9
4für (approx. Hunter ~
1|| 21120
21
2112
22112 >+
+−−= nn
HH
HHTG χ

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
30
5.5 Zweistichprobenvergleiche bei mehrstufig skalierten Variablen Homogenitätsprüfung mit dem Chiquadrat-Tes t (comparison of two frequency distributions):
Problemstellung: Es soll für ein mehrstufiges Merkmal mit m>2 Werten im Rahmen eines Parallelversuchs festgestellt werden, ob sich die unter zwei Bedingungen beobachteten Häufigkeitsverteilungen unterscheiden. Vorausgesetzt werden „große“ Stichproben“.
Ablaufschema: • Beobachtungsdaten:
X = m -stufiges Merkmal mit Werten a1, a2, ..., am , Beobachtung von X unter zwei Bedingungen � 2 unabhängige Stichproben (Gruppen) � Zusammenfassung in m×2-Tafel:
• Modell: X ist in jeder Gruppe m-punktverteilt mit den Parametern pi1=P(X=ai|Gruppe 1) bzw. pi2=P(X=a1|Gruppe 2) (i=1,2,...,m)
• Hypothesen: H0: pi1 = pi2 vs. H1: nicht alle pi1 = pi2 (i=1,2,...,m) Signifikanzniveau: α
• Testgröße (Faustformel: alle eij ≥ 1 und max. 20% der eij < 5): • Entscheidung mit Quantilen:
H0 auf Testniveau α ablehnen, wenn TGs > χ2m-1,1-α.
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P= P(TG ≥ |TGs|)<α.
( )
n
nne
e
enGFTG
jiij
m
m
i j ij
ijij
..
02
11
2
1
2
mit
(approx.) Hunter
=
≅−
== −= =∑∑ χ
Untersuchungs-merkmal X
Gruppe 1 Gruppe 2 (Zeilen-) Summen
Wert a1 n11 n12 n1. Wert a2 n21 n22 n2. ... ... ... ... Wert am nm1 nm2 nm.
(Spalten-) n.1=n1 n.2=n2 n =n1+n2

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
31
5.6 Einfaktorielle Varianzanalyse
Problemstellung - Globaltest: Die 1-faktorielle Varianzanalyse ermöglicht es unter gewissen Voraussetzungen, die Mittelwerte aus k >2 unabhängigen Stichproben im Rahmen der Globalhypothesen H0: „Alle k Mittelwerte sind gleich“ vs. H1: „Wenigstens 2 Mittelwerte sind verschieden“ vergleichen zu können.
Ablaufschema: • Beobachtungsdaten:
Variable Y unter k Versuchsbedingungen (= Faktorstufen) wiederholt (an nj Untersuchungseinheiten auf der Faktorstufe j) gemessen � k unabhängige Stichproben � Anordnung in Datentabelle (yij = Messwert von der i-ten Untersuchungseinheit unter der j -Versuchsbedingung):
Versuchsbedingung (Faktorstufe) 1 2 ... j ... k
Wiederholungen y11 y12 ... y1j ... y1k y21 y22 ... y2j ... y2k ... ... ... ... ... ... yi1 yi2 ... yij ... yik ... ... ... ... ... ... yn1,1 yn2,2 ... ynj,j ... ynk,k Anzahl n1 n2 ... nj ... nk Mittelwert m1 m2 ... mj ... mk Varianz s1
2 s22 ... sj
2 ... sk2
• Modell:
Jedes yij ist eine Realisation einer N(µj,σ2)-verteilten Zufallsvariablen Yij mit der Darstellung: Es bedeuten: − µj das Mittelwert auf der j-ten Faktorstufe
(geschätzt durch mj); − µ eine Konstante (geschätzt durch das aus allen Stichprobenwerten berechnete
Gesamtmittel m); − τj eine den Behandlungseffekt auf der j-ten Stufe zum Ausdruck bringende Konstante
(geschätzt durch mj -m und mit der Normierung τ1+ τ2+ ... + τk=0); − Eij den Versuchsfehler (für alle Wiederholungen und Faktorstufen unabhängig N(0,
σ2)-verteilt); Schätzung der Fehlervarianz σ2 durch: • Hypothesen und Testgröße:
Globaltest: H0: µ1 = µ2 = ... = µk vs. H1: wenigstens zwei der µj unterscheiden sich
∑∑==
−==
−=
k
jjj
k
jj snSQEnN
kN
SQEMQE
1
2
1
)1( und
mit
ijjijjij EEY ++=+= τµµ

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
32
Zusammenfassung der relevanten Rechengrößen in der ANOVA-Tafel:
Variations- ursache
Quadrat- summe
Freiheits- grad
Mittlere Quadrat- summe
Test- größe
Faktor F (Bedingung)
SQF k -1 MQF= SQF/(k-1)
TG= MQF/MQE
Versuchs- fehler
SQE N - k MQE= SQE/(N-k)
Summe SQT n - 1
SQT = (n1-1)s12+(n2-1)s2
2+...+(n2-1)s22
• Entscheidung:
H0 auf Testniveau α ablehnen, wenn TGs > Fk-1,N-k,1-α.
Überprüfung der Varianzhomogenität (Levene-Test):
Ablaufschema: • Daten:
Variable Y unter k Versuchsbedingungen (= Faktorstufen) wiederholt (an nj Untersuchungseinheiten auf der Faktorstufe j) gemessen � k unabhängige Stichproben � Anordnung in Datentabelle (yij = Messwert von der i-ten Untersuchungseinheit unter der j -Versuchsbedingung:
Versuchsbedingung (Faktorstufe)
1 2 ... j ... k Wiederholungen y11 y12 ... y1j ... y1k y21 y22 ... y2j ... y2k ... ... ... ... ... ... yn1,1 yn2,2 ... ynj,j ... ynk,k Anzahl n1 n2 ... nj ... nk Mittelwert m1 m2 ... mj ... mk
N = n1 + n2 +... + nk
• Modell:
Jedes yij ist eine Realisation Zufallsvariablen Yij, die auf der j-ten Faktorstufe N(µj,σj
2)-verteilt ist. • Hypothesen:
H0: σ12 = σ2
2 = ... = σk2 vs.
H1: wenigstens zwei der σj2 unterscheiden sich
• Testgröße:
Beobachtungen Yij auf der j-ten Faktorstufe werden durch Abstände Zij=|Yij - mj| vom jeweiligen Stichprobenmittel mj ersetzt � modifizierte Datentabelle
( )∑=
−−
−=−
=
≅=
k
j
jj
kNk
mmnSQFk
SQFMQF
FMQE
MQFTG
1
2
,1
,1
mit

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
33
Versuchsbedingung (Faktorstufe) 1 2 ... j ... k
Wiederholungen z11 z12 ... z1j ... z1k z21 z22 ... z2j ... z2k ... ... ... ... ... ... zn1,1 zn2,2 ... znj,j ... znk,k Anzahl n1 n2 ... nj ... nk z-Mittelwerte m1(z) m2(z) ... mj(z) ... mk(z) z-Varianzen s1
2(z) s22(z) ... sj
2(z) ... sk2(z)
Idee: Wenn Varianzhomogenität vorliegt, stimmen die Mittelwerte mj(z) bis auf zufallsbedingte Abweichungen überein. Prüfung der Abweichungen im Rahmen einer einfaktoriellen ANOVA mit der Testgröße: (m(z) ist das aus allen z-Werten berechnete Gesamtmittel).
• Entscheidung: H0 auf Testniveau α ablehnen, wenn TG(z)s > Fk-1,N-k,1-α.
5.7 Musterbeispiele 1. Die Wirkungen eines Testpräparates A und eines Kontrollpräparate B seien durch die
prozentuelle Abnahme Y des systolischen Blutdrucks vom Beginn bis zum Ende der Therapie ausgedrückt. Im Rahmen eines Parallelversuchs wurden die Präparatwirkungen jeweils an 5 Testpersonen gemessen, wobei die Personen der „Testgruppe A“ von den Personen der „Kontrollgruppe B“ verschieden sind. Als Messwerte ergaben sich: 23, 18, 13, 19, 27 (Gruppe A) bzw. 20, 15, 10, 25, 21 (Gruppe B).
a. Man untersuche an Hand der folgenden Daten, ob sich die mittleren Präparatwirkungen signifikant (α = 5%) unterscheiden.
b. Beurteilen Sie die Versuchsplanung (Stichprobenumfang)!
Präzisierung der Aufgabe: Wir bezeichnen mit YA die Wirkung des Testpräparates A und mit YB die Wirkung des Kontrollpräparates B. Beide Variablen werden als normalverteilt vorausgesetzt mit den Mittelwerten µA bzw. µB. Teilaufgabe 1a (t-Test)
Lösungsansatz und rechnerische Lösung: In der Teilaufgabe a) ist gefragt, ob der Mittelwert µA von µB verschieden ist. Es geht also um einen Vergleich zweier Mittelwerte von als normalverteilt angenommenen Merkmalen. Die Alternativhypothese lautet H1: µA ≠ µB, die Nullhypothese ist H0: µA = µB. Die Testentscheidung wird mit dem t-Test für unabhängige Stichproben (Parallelversuch) auf dem Testniveau alpha=5% durchgeführt. Wir wenden die Variante des Welch-Tests an, der keine
( )
[ ]∑
∑
=
=
−−
=
−−
=
=
k
jjj
k
jjj
zmzmnk
MQF
zsnkN
zMQE
zMQE
zMQFzTG
1
2
1
2
)()(1
1
und )(11
)(
mit )()(
)(

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
34
Varianzhomogenität voraussetzt. Dem Test geht eine kurze Datenbeschreibung voran, die die Stichprobenumfänge nA und nB, die Mittelwerte mA und mB sowie die Standardabweichungen sA und sB der beiden Stichproben enthält.
Lösung mit R: > ya <- c(23, 18, 13, 19, 27) > yb <- c(20, 15, 10, 25, 21) > # Deskriptive Statistiken > n_A <- length(ya) > n_B <- length(yb) > m_A <- mean(ya) > m_B <- mean(yb) > s_A <- sd(ya) > s_B <- sd(yb) > options(digits=4) > print(cbind(n_A, m_A, s_A)) n_A m_A s_A [1,] 5 20 5.292 > print(cbind(n_B, m_B, s_B))
n_B m_B s_B [1,] 5 18.2 5.805 > # Parallelversuch: t-Test für unabhängige Stichproben (Variante WELCH-Test) > # H0: kein Unterschied, H1: Unterschied in der mittleren Wirkung > t.test(ya, yb, alternative="two.sided", paired=FALSE, mu=0) Welch Two Sample t-test data: ya and yb t = 0.5124, df = 7.932, p-value = 0.6223 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -6.313 9.913 sample estimates: mean of x mean of y 20.0 18.2
Ergebnis: Wegen p-value = 0.623 >= 0.05 kann H0: µA = µB nicht abgelehnt werden (nichtsignifikantes Ergebnis)! Teilaufgabe 1b (Mindeststichprobenumfang)
Lösungsansatz und rechnerische Lösung: In der Teilaufgabe b) ist die Versuchsplanung zu beurteilen. Der Versuch ist ausreichend gut geplant, wenn der erforderliche Mindeststichprobenumfang n_mindest (d.h. jener Stichprobenumfang, der geplant werden muss, um mit einer hohen Sicherheit (Power) – wir wählen diese 90% - einen signifikanten Testausgang zu erhalten) kleiner oder gleich den (übereinstimmenden) Stichprobenumfängen in 1a) ist. Die Formel liefert einen brauchbaren Näherungswert für n_mindest, soferne dieser größer oder gleich 20 ist. In der Formel bedeutet s die „gepoolte“ Standardabweichung sp der beiden Stichproben, d.h. Ferner ist ∆ der Betrag |mA – mB| der Differenz der Stichprobenmittelwerte sowie z1-α/2 und z1-ß die Quantile der Standardnormalverteilung zu den Unterschreitungswahrscheinlichkeiten 1-α/2 bzw. 1-ß (hier ist α=5% das Testniveau und 1-ß=0.9 die Power).
Lösung mit R: > ya <- c(23, 18, 13, 19, 27) > yb <- c(20, 15, 10, 25, 21) > # Deskriptive Statistiken
( ) 2 2
12/12
2
βα
σ−− +
∆≈ zzn
2
)1()1( 22
−+−+−=
BA
BBAAp nn
snsns

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
35
> n_A <- length(ya) > n_B <- length(yb) > m_A <- mean(ya) > m_B <- mean(yb) > s_A <- sd(ya) > s_B <- sd(yb) > options(digits=4) > s_p <- sqrt(((n_A-1)*s_A^2+(n_B-1)*s_B^2)/(n_A+n_B-2)) > delta <- abs(m_A - m_B) > print(cbind(delta, s_p)) delta s_p [1,] 1.8 5.554 > # Bestimmung des erforderlichen Mindeststichprobenumfangs, um mit dem Welch-Test > # den beobachteten Mittelwertunterschied mit einer Sicherheit von 90% als > # signifikant ungleich null zu erkennen. > power.t.test(delta=abs(m_A-m_B), sd=s_p, sig.level=0.05, power=0.9, + alternative="two.sided", type="two.sample") Two-sample t test power calculation n = 201.1 delta = 1.8 sd = 5.554 sig.level = 0.05 power = 0.9 alternative = two.sided NOTE: n is number in *each* group
Ergebnis: Es ist ein Mindeststichprobenumfang von n_mindest=202 erforderlich, um im Rahmen eines Parallelversuchsmit dem auf 5%igen Signifikanzniveau geführten Test die Differenz delta = 1.8 der Stichprobenmittelwerte mit einer Sicherheit von 90% als signifikant zu erkennen.
2. Man nehme nun an, dass die Studie von Aufgabe 1 als Paarvergleich geplant wurde. Das heißt, der jeweils erste Wert der A- und B-Stichprobe stammen von derselben Versuchsperson, ebenfalls die zweiten Werte usw.
a. Ist ein signifikanter Unterschied in den mittleren Wirkungen feststellbar? Als Testniveau nehme man wieder 5%.
b. Wie ist die Versuchsplanung zu beurteilen (Stichprobenumfang)?
Präzisierung der Aufgabe: Wie in Aufgabe 1 bezeichnen wir mit YA die Präparatwirkung in der Diagnosegruppe A und mit YB die entsprechende Wirkung in der Gruppe B. Beide Variablen werden als normalverteilt vorausgesetzt mit den Mittelwerten µA bzw. µB. Im Gegensatz zu Aufgabe 1 werden nun die Merkmalswerte an ein und denselben Personen gemessen, d.h. jede Person bekommt zuerst das Präparat A und dann – nachdem die Wirkung abgeklungen ist – das Präparat B. Teilaufgabe 2a (Differenzen t-Test )
Lösungsansatz und numerische Lösung: In der Teilaufgabe a) ist gefragt, ob die mittlere Wirkungen µA und µB voneinander verschieden sind. Bildet man die Differenz µ= µA - µB kann man die Frage auch so formulieren, ob die Mittelwertdifferenz µ von Null verschieden ist. Es geht also um einen Vergleich des Mittelwerts von YA-YB mit dem Sollwert 0. Die Alternativhypothese lautet H1:µ≠0, die Nullhypothese ist H0:µ=0. Die Testentscheidung wird mit dem t-Test für abhängige Stichproben (Paarvergleich) auf dem Testniveau alpha=5% durchgeführt.
Lösung mit R: > ya <- c(23, 18, 13, 19, 27) > yb <- c(20, 15, 10, 25, 21) > # Paarvergleich: t-Test für abhängige Stichproben > # H0: Mittelwertdifferenz=0, H1: Mittelwertdifferenz <> 0 > yab <- ya-yb # Differenzstichprobe > print(yab)

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
36
[1] 3 3 3 -6 6 > # Deskriptive Statistiken (Differenzstichprobe) > n_AB <- length(yab) > m_AB <- mean(yab) > s_AB <- sd(yab) > options(digits=4) > print(cbind(n_AB, m_AB, s_AB)) n_AB m_AB s_AB [1,] 5 1.8 4.55 > t.test(ya, yb, alternative="two.sided", paired=T, mu=0) Paired t-test data: ya and yb t = 0.8847, df = 4, pppp----value = 0.4263value = 0.4263value = 0.4263value = 0.4263 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -3.849 7.449 sample estimates: mean of the differences 1.8
Ergebnis: Wegen p-value = 0.4263 >= 0.05 kann H0: µ = µA - µB=0 nicht abgelehnt werden (nichtsignifikantes Ergebnis)! Teilaufgabe 2b (Mindeststichprobenumfang)
Lösungsansatz und numerische Lösung: In der Teilaufgabe b) ist die Versuchsplanung zu beurteilen. Der Versuch ist ausreichend gut geplant, wenn der erforderliche Mindeststichprobenumfang n_mindest (d.h. jener Stichprobenumfang, der geplant werden muss, um mit einer hohen Sicherheit (Power) – wir wählen diese 90% - einen signifikanten Testausgang zu erhalten) kleiner oder gleich dem Stichprobenumfang in 1a) ist. Die Formel liefert einen brauchbaren Näherungswert für n_mindest, soferne diese größer oder gleich 20 sind. In der Formel bedeutet s die Standardabweichung der Stichprobenwerte von YA-YB (Differenzstichprobe), D ist der Stichprobenmittelwert der Differenzstichprobe, z1-α/2 und z1-ß sind die Quantile der Standardnormalverteilung zu den Unterschreitungswahrscheinlichkeiten 1-α/2 bzw. 1-ß (hier ist α=5% das Testniveau und 1-ß=0.9 die Power).
Lösung mit R:
> ya <- c(23, 18, 13, 19, 27) > yb <- c(20, 15, 10, 25, 21) > options(digits=4) > m_AB <- mean(ya-yb) > s_AB <- sd(ya-yb) > delta <- abs(m_AB) > print(cbind(delta, s_AB)) delta s_AB [1,] 1.8 4.55 > # Bestimmung des erforderlichen Mindeststichprobenumfangs, um mit t-Test für abhängige Stichproben > # den beobachteten Mittelwertunterschied mit einer Sicherheit von 90% als signifikant ungleich null zu > # erkennen. > power.t.test(delta=abs(m_AB), sd=s_AB, sig.level=0.05, power=0.9, + alternative="two.sided", type="paired") Paired t test power calculation n = 69.08n = 69.08n = 69.08n = 69.08 delta = 1.8 sd = 4.55
( ) 2
12/12
2
min βα
σ−− +
∆≈ zzn dest

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
37
sig.level = 0.05 power = 0.9 alternative = two.sided NOTE: n is number of *pairs*, sd is std.dev. of *differences* within pairs
Ergebnis: Es ist ein Mindeststichprobenumfang von n_mindest=70 erforderlich, um im Rahmen eines Paarvergleichs mit dem auf 5%igen Signifikanzniveau geführten Test die Differenz delta = 1,8 der Stichprobenmittelwerte mit einer Sicherheit von 90% als signifikant zu erkennen.
3. Das Wachstum X einer Kultur (Gewicht in mg) wird in Abhängigkeit von 2 Nährlösungen
A und B gemessen. Es ergaben sich die folgenden Messwerte:
A 7,4 8,1 7,8 7,2 7,9 B 9,0 9,6 9,2 9,5 8,5
a. Man überprüfe, ob die Nährlösung einen signifikanten Einfluss auf das mittlere
Wachstum hat? (α = 5%) b. Ist die Annahme gleicher Varianzen gerechtfertigt?
Präzisierung der Aufgabe: Von einer Kultur liegen unter 2 Bedingungen (Nährlösung A, B) beobachtete Stichproben einer Wachstumsgröße X (Gewicht) vor. Wir bezeichnen die Wachstumsgröße unter der Bedingung A als XA und jene unter der Bedingung B als XB. Beide Variablen werden als normalverteilt vorausgesetzt mit den Mittelwerten µA bzw. µB. Teilaufgabe 3a (Welch-Test )
Lösungsansatz und numerische Lösung: Die in der Teilaufgabe a) gestellte Frage nach dem Einfluss der Nährlösungen auf das Wachstum, kann sich in einer Verschiedenartigkeit der Mittelwerte oder der Standardabweichungen der Variablen XA bzw. XB manifestieren. Bevor die Aufgabe gelöst werden kann, ist eine Präzisierung vorzunehmen. In der Mehrzahl der Anwendungsfälle geht es um eine allfällige, durch die Nährlösungen bedingte Ungleichheit der Mittelwerte. Die Alternativhypothese lautet in diesem Fall H1: µA ≠ µB, die Nullhypothese ist H0: µA = µB. Die Testentscheidung wird mit dem t-Test für unabhängige Stichproben (Parallelversuch) auf dem Testniveau α=5% durchgeführt. Wir wenden die Variante des Welch-Tests an, der keine Varianzhomogenität voraussetzt. Dem Test geht wieder eine kurze Datenbeschreibung voran, die die Stichprobenumfänge nA und nB, die Stichprobenmittelwerte mA und mB sowie die Standardabweichungen sA und sB der beiden Stichproben enthält.
Lösung mit R: > xa <- c(7.4, 8.1, 7.8, 7.2, 7.9) > xb <- c(9, 9.6, 9.2, 9.5, 8.5) > # Deskriptive Statistiken > n_A <- length(xa) > n_B <- length(xb) > m_A <- mean(xa) > m_B <- mean(xb) > s_A <- sd(xa) > s_B <- sd(xb) > print(cbind(n_A, m_A, s_A)) n_A m_A s_A [1,] 5 7.68 0.3701 > print(cbind(n_B, m_B, s_B)) n_B m_B s_B [1,] 5 9.16 0.4393 > # Parallelversuch: t-Test für unabhängige Stichproben (Variante WELCH-Test) > # H0: Mittelwert von XA = Mittelwert von XB > # H1: ... <> ... > t.test(xa, xb, alternative="two.sided", paired=FALSE, mu=0) Welch Two Sample t-test

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
38
data: xa and xb t = -5.761, df = 7.776, pppp----value = 0.0004706value = 0.0004706value = 0.0004706value = 0.0004706 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -2.0754 -0.8846 sample estimates: mean of x mean of y 7.68 9.16
Ergebnis: Wegen p-value = 0.0004706 < 0.05 ist H0: µA = µB abzulehnen, die Nährlösungen A und B haben einen verschiedenartigen Einfluss auf den Mittelwert der Wachstumsgröße (signifikantes Ergebnis)! Teilaufgabe 3b (F-Test)
Lösungsansatz und numerische Lösung: In der Teilaufgabe b) wird gefragt, ob die Annahme gleicher Varianzen der Variablen XA und XB gerechtfertigt ist. Zur Entscheidung über diese Frage wird mit einem F-Test ein Vergleich der Varianzen durchgeführt. Die Alternativhypothese lautet H1:σ2
A≠σ2B, die Nullhypothese ist
H0:σ2A=σ2
B. Die Testentscheidung wird mit dem F-Test auf dem Testniveau α=5% durchgeführt.
Lösung mit R: > xa <- c(7.4, 8.1, 7.8, 7.2, 7.9) > xb <- c(9, 9.6, 9.2, 9.5, 8.5) > options(digits=4) > # Überprüfung der Varianzhomogenität mit dem F-Test > # H0: Varianz von XA = Varianz von XB versus H1: Varianz von XA<>Varianz von XB > var.test(xa, xb, alternative="two.sided") F test to compare two variances data: xa and xb F = 0.7098, num df = 4, denom df = 4, pppp----valuevaluevaluevalue = 0.7479= 0.7479= 0.7479= 0.7479 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.0739 6.8177 sample estimates: ratio of variances 0.7098
Ergebnis: Wegen p-value = 0.4779 >= 0.05 kann H0: σ2
A = σ2B nicht abgelehnt werden. Bei der
Überprüfung der Varianzhomogenität wird der Test als „Falsifizierungsversuch“ der Gleichheit der Varianzen angesehen; geht der Versuch – wie in diesem Beispiel nichtsignifikant aus, bleibt am bei der Nullhypothese (ohne diese allerdings statistisch „bewiesen“ zu haben)
4. In einer Studie wurde untersucht, ob zwischen der Mortalität X in der Perinatalperiode und der Rauchergewohnheit (Raucher/Nichtraucher) Y während der Schwangerschaft ein Zusammenhang besteht. Folgende Daten stehen zur Verfügung: In der Kategorie "Raucher" gab es 50 Todesfälle (von insgesamt 1000), in der Kategorie "Nichtraucher" 50 von insgesamt 1600. Man zeige auf dem 5%-Niveau, dass sich die Mortalität in der Raucher- und Nichtrauchergruppe signifikant unterscheidet.
Präzisierung der Aufgabe: In dieser Aufgabe geht es um das Untersuchungsmerkmal X (Mortalität), das an Säuglingen beobachtet wird und auf einer 2-stufigen Skala mit den Skalenwerten „Säugling überlebt“ bzw. „Säugling stirbt“ dargestellt ist. X wird in Abhängigkeit vom Raucherverhalten Y während der Schwangerschaft betrachtet; auch Y ist 2-stufig mit den Werten „Raucherin“ und „Nichtraucherin“. Für jede Untersuchungseinheit (Säugling) besitzt X eine Zweipunktverteilung; es sei pR = P(Säugling stirbt| Raucherin) die Wahrscheinlichkeit, dass der Säugling einer rauchenden Mutter stirbt und pN = P(Säugling stirbt| Nichtraucherin) die Wahrscheinlichkeit, dass der Säugling einer nichtrauchenden Mutter stirbt. Das Raucherverhalten hat einen Einfluss auf die Mortalität, wenn pR ≠ pN .

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
39
Lösungsansatz und numerische Lösung: Die Alternativhypothese lautet H1: pR <> pN, die Nullhypothese H0: pR = pN ; in der Gruppe der Säuglinge von Raucherinnen sind 50 von 1000 gestorben, in der Gruppe der Säuglinge von Nichtraucherinnen insgesamt 50 von 1600; die Sterbewahrscheinlichkeiten pR und pN werden durch die Anteile 50/1000=0,05 bzw. 50/1600= 0,03145 geschätzt. Mit dem Chiquadrat-Test zum Vergleich zweier Wahrscheinlichkeiten ist zu prüfen, ob sich die beiden Anteile auf dem Testniveau 5%signifikant unterscheiden. Lösung mit R: > dead <- c(50, 50) > total <- c(1000, 1600) > # Test: Vergleich von 2 Wahrscheinlichkeiten mit unabhängigen Strichproben > # H0: Sterbewahrscheinlichkeit/Raucherin = Sterbewahrscheinlichkeit/Nichtraucherin > # H1: ... <> ... > prop.test(dead, total, alternative="two.sided") 2-sample test for equality of proportions with continuity correction data: dead out of total X-squared = 5.354, df = 1, pppp----value = 0.02067value = 0.02067value = 0.02067value = 0.02067 alternative hypothesis: two.sided 95 percent confidence interval: 0.001964 0.035536 sample estimates: prop 1 prop 2 0.05000 0.03125
Ergebnis: Wegen p-value = 0.02067 < 0.05 ist H0: pA = pB abzulehnen, das Raucherverhalten hat einen verschiedenartigen Einfluss auf die Mortalität (signifikantes Ergebnis)!
5. In einer Studie wurde ein Blutparameter am Beginn und am Ende einer Therapie bestimmt. Es ergab sich, dass bei 50 Probanden der Parameter vor und nach Ende der Studie im Normbereich lag, bei 15 Probanden lag der Wert vorher im Normbereich und nachher außerhalb, bei 20 Probanden vorher außerhalb und nachher im Normbereich und bei 10 vorher und nachher außerhalb des Normbereichs. Hat sich während der Studie eine signifikante Änderung hinsichtlich des Normbereichs ergeben (α = 5%)?
Präzisierung der Aufgabe: Das Untersuchungsmerkmal ist in dieser Aufgabe ein Blutparameter, der an 95 Probanden vor einer Behandlung (Variable Xvor) und nach der Behandlung (Variable Xnach) beobachtet wird. Dabei wird der Blutparameter auf einer 2-stufigen Skala dargestellt mit den Werten „liegt im Normbereich“ und „liegt außerhalb des Normbereichs“. Ein Einfluss der Behandlung auf den Blutparameter ist gegeben, wenn die Wahrscheinlichkeit p_ einer Veränderung vom Zustand „Xvor=im Normbereich“ in den Zustand „Xnach=außerhalb des Normbereichs“ ungleich der Wahrscheinlichkeit p+ einer Veränderung vom Zustand „Xvor=außerhalb des Normbereichs“ in den Zustand „Xnach=im Normbereich“ ist. Beschränkt man sich nur auf Probanden, die eine Veränderung in die eine oder andere Richtung aufweisen, ist wegen p_ + p+ =1 gleichwertig mit p_ ≠ p+ die Aussage p_ ≠ ½.
Lösungsansatz und numerische Lösung: Die Alternativhypothese lautet H1: p_ <> ½, die Nullhypothese H0: p_ =1/2. Für die Testentscheidung relevant sind die absoluten Häufigkeiten b=15 und c=20, mit denen Veränderungen vom Zustand „Xvor=im Normbereich“ in den Zustand „Xnach=außerhalb des Normbereichs“ bzw. in umgekehrter Richtung stattgefunden haben. Die Testentscheidung wird mit dem McNemar-Test herbeigeführt, der ein besonderer Fall des Binomialtests (Vergleich einer Wahrscheinlichkeit mit 1/2) ist. Als Testniveau ist 5% vorgegeben. Lösung mit R: > freq <- c(50, 15, 20, 10) > daten <- matrix(freq, ncol=2, byrow=TRUE, + dimnames=list("Beginn"=c("im", "außerhalb"),

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
40
+ "Ende"=c("im", "außerhalb"))) > daten Ende Beginn im außerhalb im 50 15 außerhalb 20 10 > # McNemar-Test für die Messung einer Veränderung mit 2 abhängigen Stichproben > # H0: Wahrscheinlichkeit für Änderung von „im“ nach „außerhalb“ = 0,5 > # H1: ... <> ... > mcnemar.test(daten) McNemar's Chi-squared test with continuity correction data: daten McNemar's chi-squared = 0.4571, df = 1, pppp----value = 0.499value = 0.499value = 0.499value = 0.499
Ergebnis: Wegen p-value = 0.499 ≥ 0.05 kann H0: p_ = 1/2 nicht abgelehnt werden (nichtsignifikantes Ergebnis)!
6. An vier verschiedenen Stellen eines Gewässers wurden die in der folgenden Tabelle
angeschriebenen Werte der Phosphatkonzentration Y (in mg/l) gemessen. Man prüfe auf 5%igem Testniveau, ob die mittlere Phosphatkonzentration von der Messstelle abhängt.
Messstelle (Faktorstufe)
1 2 3 4 Wiederholungen 1.20 1.00 1.45 1.30 0.75 0.85 1.60 1.20 1.15 1.45 1.35 1.35 0.80 1.25 1.50 1.50 0.90 1.10 1.70 1.00 Anzahl 5 5 5 5 Mittelwert 0.96 1.13 1.52 1.27 Varianz 0.04175 0.05325 0.01825 0.03450
Präzisierung der Aufgabe: Die Zielvariable Y hängt von einer Faktorvariablen (Messstelle) mit 4 Stufen ab. Es ist zu untersuchen, ob der Faktor sich auf die Stufenmittelwerte auswirkt. Dabei wird angenommen, dass die Zielvariable auf jeder Faktorstufe normalverteilt ist mit einem (möglicherweise) vom Faktor abhängigem Mittelwert. Die Varianzen von Y müssen auf den Faktorstufen übereinstimmen (die Varianzhomogenität ist separat zu prüfen). Als Testniveau wird 5% angenommen.
Lösungsansatz und numerische Lösung: Die Alternativhypothese lautet H1: wenigstens 2 Faktorstufenmittelwerte sind verschieden, die Nullhypothese H0: alle Faktorstufenmittelwerte stimmen überein. Die Entscheidung erfolgt mit dem Globaltest der Varianzanalyse. Im Anschluss daran wird die Voraussetzung (Homogenität der Stufenvarianzen) geprüft: H1: wenigstens 2 Stufenvarianzen sind verschieden, die Nullhypothese H0: alle Stufenvarianzen stimmen überein. Lösung mit R:
> # 1-faktorielle ANOVA > options(digits=6) > y <- c(1.20, 0.75, 1.15, 0.80, 0.90, + 1.00, 0.85, 1.45, 1.25, 1.10, + 1.45, 1.60, 1.35, 1.50, 1.70, + 1.30, 1.20, 1.35, 1.50, 1.00) # Messmerkmal > stelle <- factor(rep(1:4, each=5)) # stelle=Messstelle > daten <- data.frame(y, stelle); daten y stelle 1 1.20 1 2 0.75 1 3 1.15 1 4 0.80 1 5 0.90 1 6 1.00 2 7 0.85 2

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
41
8 1.45 2 9 1.25 2 10 1.10 2 11 1.45 3 12 1.60 3 13 1.35 3 14 1.50 3 15 1.70 3 16 1.30 4 17 1.20 4 18 1.35 4 19 1.50 4 20 1.00 4 > # Globaltest H0: "alle Mittelwerte gleich" vs. H1: "... ungleich" > model1 <- aov(formula=y~stelle, data=daten) > summary(model1) # erzeugt ANOVA-Tafel Df Sum Sq Mean Sq F value Pr(>F) stelle 3 0.841 0.28033 7.589 0.002230.002230.002230.00223 ** Residuals 16 0.591 0.03694 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 > # Darstellung der Stufenmittelwerte durch Boxplot > boxplot(y ~ stelle, data=daten)
1 2 3 4
0.8
1.0
1.2
1.4
1.6
> # Prüfung der Varianzhomogenität > z <- abs(model1$residuals) > daten2 <- data.frame(z, stelle) > model2 <- aov(formula=z~stelle, data=daten2) > summary(model2) Df Sum Sq Mean Sq F value Pr(>F) stelle 3 0.01718 0.005727 0.647 0.5960.5960.5960.596 Residuals 16 0.14164 0.008852
Ergebnis: a) Globaltest: Wegen p-value = 0.00223 < 0.05 ist H0: (Übereinstimmung der Stufenmittelwerte) abzulehnen, d.h., wenigstens zwei Stufenmittelwerte sind verschieden. b) Homogenitätsprüfung: Wegen p-value = 0.596 >= 0.05 kann H0: (Übereinstimmung der Stufenvarianzen) nicht abgelehnt werden, d.h. die Daten sprechen nicht gegen die Annahme der Varianzhomogenität.

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
42
6 KORRELATION UND REGRESSION: ERFASSUNG DER GEMEINSAMEN VARIATION VON ZUFALLSVARIABLEN 6.3 Korrelation bei zwei- und mehrstufigen Merkmalen Abhängigkeitsprüfung ( 2χ test of independence):
Problemstellung: Es soll festgestellt werden, ob die k≥2 stufige Variable X und die m≥2 stufige Variable Y voneinander abhängig variieren.
Ablaufschema: • Beobachtungsdaten:
X, Y diskrete Merkmale mit den Ausprägungen a1, a2, ..., ak bzw. b1, b2, ..., bm. Darstellung der an n Untersuchungseinheiten beobachteten Häufigkeiten nij der Merkmalskombinationen X=ai und Y=bj in einer Kontingenztafel mit k Zeilen und m Spalten:
• Modell: Es seien pi. und p.j die Wahrscheinlicheiten, dass X den Wert ai bzw. Y den Wert bj annimmt. Bei Unabhängigkeit von X und Y ist die Wahrscheinlichkeit der Wertekombination (ai,bj) durch pij=pi.p.j und die erwartete Häufigkeit von Untersuchungseinheiten mit dieser Wertekombination durch npi.p.j gegeben. Die erwartete Häufigkeit wird durch eij = ni.n.j/n geschätzt.
• Hypothesen und Testgröße: H0: X und Y sind unabhängig vs. H1 : X und Y sind abhängig
Hinweis: Approximation durch die Chiquadratverteilung umso besser, je größer n ist; jedenfalls sollten alle eij ≥1 sein und höchstens 20% der eij kleiner als 5 sein.
• Entscheidung mit Quantilen: H0 auf Testniveau α ablehnen, wenn TGs > χ2
(k-1)(m-1),1-α.
• Entscheidung mit P-Wert: H0 auf Signifikanzniveau α ablehnen, wenn P= P(TG ≥ |TGs|) < α.
Korrelationsmaße (=Kontingenzmaße) für mehrstufige Merkmale:
• k × m –Tafel - Kontingenzindex von Cramer (Cramer’s V):
( )n
nne
e
enGFT ji
ijmk
k
i
m
j ij
ijij ..2)1)(1(
1 1
2
mit =≅−
== −−= =∑∑ λ
( )[ ] 1V0 ,1),min
≤≤−
=mkn
GFV
Y X b1 ... bj ... bm Σ a1 n11 ... n1j ... n1m n1. ... ... ... ... ... ... ... ai ni1 ... nij ... nim ni. ... ... ... ... ... ... ... ak nk1 ... nkj ... nkm nk. Σ n.1 ... n.j ... n.m n

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
43
• Sonderfall k=m=2 (Vierfeldertafel):
Φ-Koeffizient (phi coefficient):
Chancenverhältnis (Odds Ratio): Definition:
2112
2211
2212
2111
/
/
pp
pp
pp
ppOR ==
Schätzung:
(1-α)-Konfodenzintervall: Ein approximatives (1-α)-Konfidenzintervall für den (näherungsweise normalverteilten) Logarithmus von OR ist:
222112112/1
2112
2211 1111ln
nnnnz
nn
nn+++± −α
Durch Entlogarithmieren der Grenzen erhält man schließlich die entsprechenden Grenzen für OR.
6.2 Produktmomentkorrelation
2-dimensionalen Normalverteilung (bivariate normal distribution):
Definition: X und Y heißen 2-dimensional normalverteilt mit den Mittelwerten µX, µY, den Standardabweichungen σX >0, σY >0 und dem Korrelationskoeffizienten ρXY (|ρXY| < 1), wenn sie mit Hilfe von 2 unabhängigen, N(0,1)-verteilten Zufallsvariablen Z1, Z2 wie folgt erzeugt werden können:
Veranschaulichung des Korrelationskoeffizenten (correlation coefficient): Generierung einer Zufallsstichprobe vom Umfang n =100 (µ1=µY=0,σX=σY=1) � Darstellung im Streudiagramm (scatter plot):
YXYYXYY
XX
ZZY
ZX
µρσρσ
µσ
+−+=
+=
22
1
1
1
10 , ≤Φ≤=Φn
GF
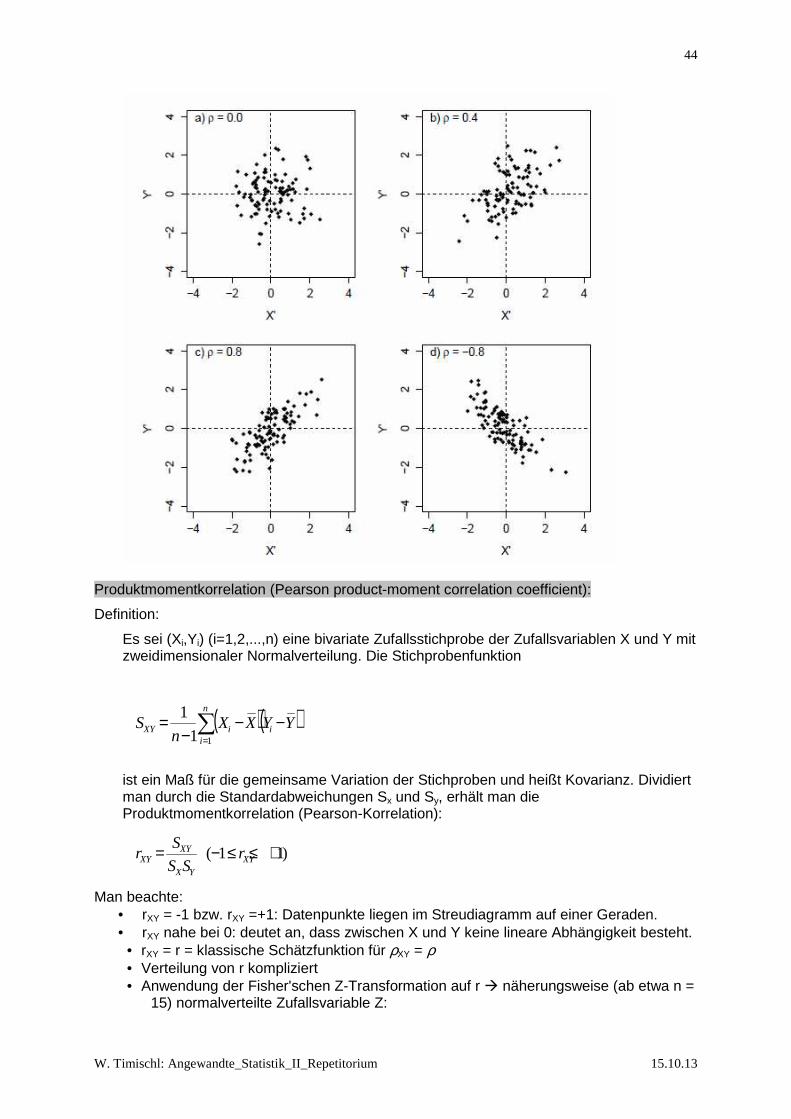
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
44
Produktmomentkorrelation (Pearson product-moment correlation coefficient):
Definition:
Es sei (Xi,Yi) (i=1,2,...,n) eine bivariate Zufallsstichprobe der Zufallsvariablen X und Y mit zweidimensionaler Normalverteilung. Die Stichprobenfunktion
ist ein Maß für die gemeinsame Variation der Stichproben und heißt Kovarianz. Dividiert man durch die Standardabweichungen Sx und Sy, erhält man die Produktmomentkorrelation (Pearson-Korrelation):
Man beachte: • rXY = -1 bzw. rXY =+1: Datenpunkte liegen im Streudiagramm auf einer Geraden. • rXY nahe bei 0: deutet an, dass zwischen X und Y keine lineare Abhängigkeit besteht.
• rXY = r = klassische Schätzfunktion für ρXY = ρ • Verteilung von r kompliziert • Anwendung der Fisher'schen Z-Transformation auf r � näherungsweise (ab etwa n =
15) normalverteilte Zufallsvariable Z:
( )( )∑=
−−−
=n
iiiXY YYXX
nS
11
1
)11( +≤≤−= XYYX
XYXY r
SS
Sr

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
45
• (1-α)-Konfidenzintervall [zu, zo] für Z(ρ)=µZ-ρ /[2(n-1)] mit • Rücktransformation von der Z- auf die r-Skala � (1-α)-Konfidenzintervall für ρ
Abhängigkeitsprüfung (test of independence):
Problemstellung: Es soll festgestellt werden, ob die Variablen X und Y abhängig sind, d.h. der Korrelationskoeffizient ρXY von Null abweicht. Dabei werden X und Y als zweidimensional normalverteilt vorausgesetzt.
Ablaufschema: • Beobachtungsdaten und Modell:
X und Y sind zweidimensional normalverteilt mit dem Korrelationsparameter ρXY � zweidimensionale Zufallsstichprobe (Xi, Yi) (i=1,2, ..., n) � Produktmomentkorrelation rXY
• Hypothesen und Testgröße: 1-seitige Hypothesen: H0: ρXY = 0 vs. H1: ρXY ≠ 0 (Fall II) 2-seitige Hypothesen: H0: ρXY ≤ 0 vs. H1: ρXY > 0 (Fall Ia), H0: ρXY ≥ 0 vs. H1: ρXY < 0 (Fall Ib)
• Entscheidung mit P-Wert:
H0 auf Signifikanzniveau α ablehnen, wenn P < α wobei P=P(TG ≤ -|TGs| oder TG ≥ |TGs|) (Fall II) bzw. P=P(TG ≥ |TGs|) (Fall Ia) bzw. P=P(TG ≤ -|TGs|) (Fall Ib).
• Entscheidung mit Quantilen:
H0 auf Testniveau α ablehnen, wenn |TGs| > tn-2,1-α/2 (Fall II), TGs > tn-2,1-α (Fall Ia) bzw. TGs < tn-2, α (Fall Ib).
6.2 Rangkorrelationskoeffizient von Spearman (Spearman rank correlation coefficient)
Zweck: Beschreibung des Zusammenhangs zwischen zwei Zufallsvariablen X und Y durch eine Maßzahl, wenn X und Y nichtlinear-monoton variieren.
)1,0(
3
1 ,
)1(21
1ln
2
1
mit 1
1ln
2
1)(:
2
NZ
nn
r
rrZrZ
Z
Z
ZZ
≈−
⇒
−≈
−+
−+
≈
−+
=→
σµ
σρ
ρρ
µ
Zo
Zu
zn
rrZz
zn
rrZz
σ
σ
α
α
2/1
2/1
)1(2)(
,)1(2
)(
−
−
+−
−=
−−
−=
+−
+−
1)2exp(
1)2exp(,
1)2exp(
1)2exp(
o
o
u
u
z
z
z
z
0für 1
222
=≅−
−= − XYn
XY
XY tr
nrTG ρ
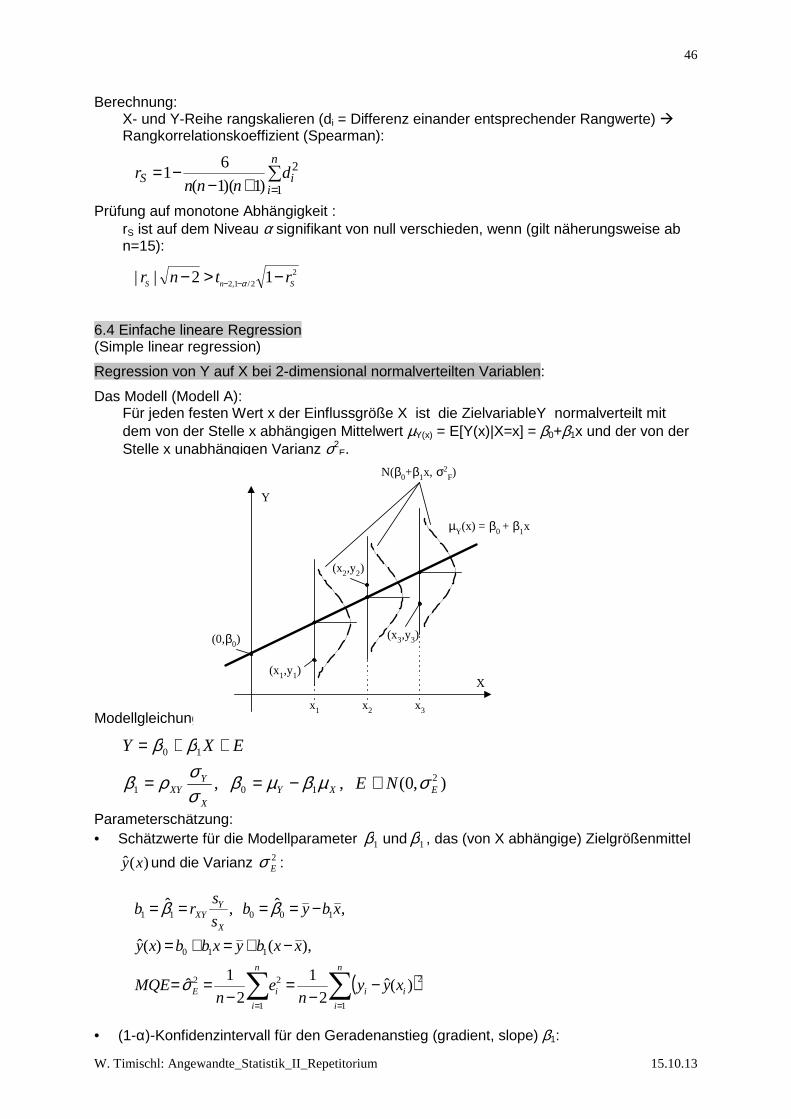
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
46
Berechnung: X- und Y-Reihe rangskalieren (di = Differenz einander entsprechender Rangwerte) � Rangkorrelationskoeffizient (Spearman):
Prüfung auf monotone Abhängigkeit : rS ist auf dem Niveau α signifikant von null verschieden, wenn (gilt näherungsweise ab n=15):
6.4 Einfache lineare Regression (Simple linear regression)
Regression von Y auf X bei 2-dimensional normalverteilten Variablen:
Das Modell (Modell A): Für jeden festen Wert x der Einflussgröße X ist die ZielvariableY normalverteilt mit dem von der Stelle x abhängigen Mittelwert µY(x) = E[Y(x)|X=x] = β0+β1x und der von der Stelle x unabhängigen Varianz σ2
E. Modellgleichungen: Parameterschätzung: • Schätzwerte für die Modellparameter 1β und 1β , das (von X abhängige) Zielgrößenmittel
)(ˆ xy und die Varianz 2Eσ :
• (1-α)-Konfidenzintervall für den Geradenanstieg (gradient, slope) β1:
∑=+−
−=n
iiS d
nnnr
1
2
)1)(1(
61
2
2/1,2 12|| SnS rtnr −>− −− α
( )∑∑==
−−
=−
==
−+=+=
−====
n
i
ii
n
i
iE
X
YXY
xyyn
en
MQE
xxbyxbbxy
xbybs
srb
1
2
1
22
110
10011
)(ˆ2
1
2
1ˆ
),()(ˆ
,ˆ ,ˆ
σ
ββ
(x1,y1)
N(β0+β1x, σ2F)
x2
X
Y
µY(x) = β0 + β1x
x1 x3
(0,β0)
(x2,y2)
(x3,y3)
),0( , , 2101
10
EXYX
YXY NE
EXY
σµβµβσσρβ
ββ
≅−==
++=
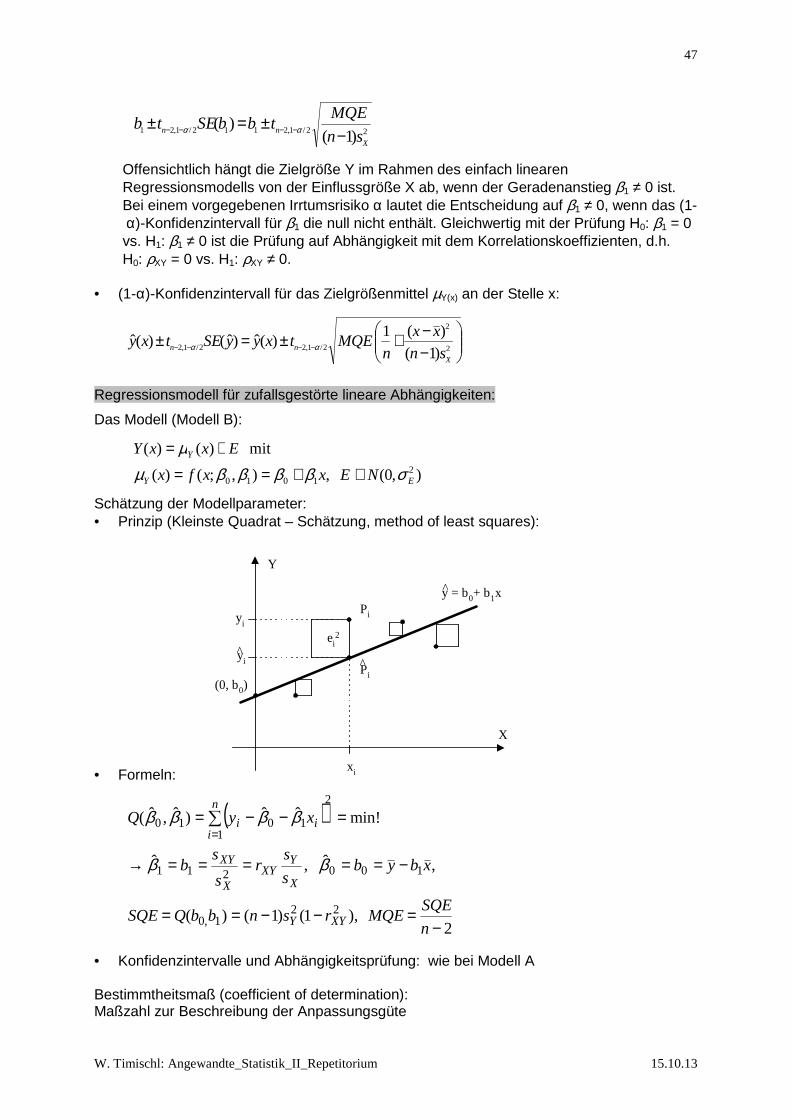
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
47
Offensichtlich hängt die Zielgröße Y im Rahmen des einfach linearen Regressionsmodells von der Einflussgröße X ab, wenn der Geradenanstieg β1 ≠ 0 ist. Bei einem vorgegebenen Irrtumsrisiko α lautet die Entscheidung auf β1 ≠ 0, wenn das (1- α)-Konfidenzintervall für β1 die null nicht enthält. Gleichwertig mit der Prüfung H0: β1 = 0 vs. H1: β1 ≠ 0 ist die Prüfung auf Abhängigkeit mit dem Korrelationskoeffizienten, d.h. H0: ρXY = 0 vs. H1: ρXY ≠ 0.
• (1-α)-Konfidenzintervall für das Zielgrößenmittel µY(x) an der Stelle x: Regressionsmodell für zufallsgestörte lineare Abhängigkeiten:
Das Modell (Modell B): Schätzung der Modellparameter: • Prinzip (Kleinste Quadrat – Schätzung, method of least squares): • Formeln:
• Konfidenzintervalle und Abhängigkeitsprüfung: wie bei Modell A
Bestimmtheitsmaß (coefficient of determination): Maßzahl zur Beschreibung der Anpassungsgüte
22/1,2112/1,21 )1()(
X
nn sn
MQEtbbSEtb
−±=± −−−− αα
−−+±=± −−−− 2
2
2/1,22/1,2 )1()(1
)(ˆ)ˆ()(ˆX
nn sn
xx
nMQEtxyySEtxy αα
),0( ,),;()(
mit )()(2
1010 EY
Y
NExxfx
ExxY
σββββµµ
≅+==
+=
( )
2 ),1()1()(
,ˆ ,ˆ
min!ˆˆ)ˆ,ˆ(
221,0
100211
2
11010
−=−−==
−=====→
=−−= ∑=
n
SQEMQErsnbbQSQE
xbybs
sr
s
sb
xyQ
XYY
X
YXY
X
XY
n
iii
ββ
ββββ
X
Y
xi
yi
yi
Pi
Pi
^ei
2
y = b0+ b1x^
(0, b0)

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
48
• Definition: Anteil der Varianz 2
ys der erwarteten Y-Werte )(ˆ ixy an der Varianz 2ys der beobachteten
Y-Werte; es gilt: • Interpretation:
o Es gilt: 0 ≤ B ≤ 1 o B = Anteil der durch X erklärten Variation von Y
Linearisierende Transformationen:
Nichtlineare Regressionsfunktion µY'(X') (Zielvariable Y', Einflussvariable X') � Linearisierende Transformation � lineare Regressionsfunktion µY(X): Aus der Geradengleichung y = β0+β1 x durch logarithmische bzw. reziproke Skalentransformationen ableitbare nichtlineare Funktionstypen:
Transformations- gleichungen
Nichtlineare Funktionsgleichung
Funktionstyp
x = ln x' y = ln y'
y' = β'0 x'β1 mit β'0=exp(β0)
Allometrische Funktion
x = x' y = ln y'
y' = β'0 exp(β1x') mit β'0=exp(β0)
Exponentialfunktion
x = x' y = 1/y'
y' = 1/(β0 + β1 x') Gebrochene lineare Funktion
x = 1/x' y = 1/y'
y' = x'/(β0x' + β1 ) Gebrochene lineare Funktion
Lineare Regression durch den Nullpunkt:
Das Modell (Modell C): Parameterschätzung:
• Schätzwerte für die Modellparameter 1β und 2Eσ :
• (1-α)-Konfidenzintervall für den Anstieg:
2
2
2
2ˆ
===
YX
XYXY
y
y
ss
sr
s
sB
),0( ,);()(
mit )()(2
11 EY
Y
NExxfx
ExxY
σββµµ
≅==
+=
∑∑∑
∑∑
===
==
−=
−=
==
n
i
i
n
i
ii
n
i
i
n
i
i
n
i
ii
xyxySQEn
SQEMQE
xyxb
1
2
2
11
2
1
2
1
11
mit 1
,β
∑=
−−−− ±=±n
i
i
nn
x
MQEtbbSEtb
1
2
2/1,1112/1,11 )( αα

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
49
6.5 LINEARE KALIBRATIONSFUNKTIONEN (linear calibration)
Problemstellung: In der instrumentellen Analytik wird die Bestimmung einer Größe X (z.B. einer Substanzmenge) oft indirekt über eine messbare Hilfsgröße Y (z.B. Leitfähigkeit) vorgenommen, aus denen dann mit Hilfe einer so genannten Kalibrationsfunktion der gesuchte Wert von X berechnet werden kann. Die Kalibrationsfunktion bestimmt man in der Regel so, dass man zu vorgegebenen Kalibrierproben (d.h. standardisierten Werten xi von X) die entsprechenden Werte yi der Hilfsgröße Y misst und eine Regression von Y auf X mit einer geeigneten Regressionsfunktion durchführt.
Bestimmung der Kalibrationsfunktion:
Wir beschränken uns auf den Fall, dass die Abhängigkeit für den betrachteten Wertebereich der Kalibrierproben durch ein lineares Regressionsmodell dargestellt werden kann, d.h., dass die Messwerte von Y durch die Gleichung
ExExfxY ++=+= 1010 ),;()( ββββ generiert werden können (Modell B der
einfachen linearen Regression); hier ist die mit E bezeichnete Fehlergröße normalverteilt
mit dem Mittelwert Null und der Varianz 2Eσ . Schätzwerte für die Modellparameter
01,ββ und 2Eσ sind nach Abschnitt 8.2:
)1()1(mit 2
ˆ
,ˆ ,ˆ
222
100211
XYYE
X
YXY
X
XY
rsnSQEn
SQEMQE
xbybs
sr
s
sb
−−=−
==
−=====
σ
ββ
Die mit den Schätzwerten b1 und b0 für den Anstieg bzw. y-Achsenabschnitt gebildete Regressionsfunktion f ermöglicht es, zu einem vorgegebenen Wert x von X den
Erwartungswert xbbbbxfy 1010 ),,(ˆ +== von Y zu berechnen. Dabei muss
vorausgesetzt werden, dass der Anstieg b1 auf einem vorgegebenen Testniveau α signifikant von Null abweicht, d.h., dass gilt:
2/1
221
2
)1(
1
2α−>
−=
−
−= t
MQE
snb
r
nrTG X
XY
XY
Rückschluss von Y auf X:
Wir wenden uns nun der „Umkehraufgabe“ zu: Ausgehend von der die beschriebene Weise bestimmten Regressionsfunktion f (f heißt in diesem Zusammenhang auch Kalibrationsfunktion) soll von Y auf X rückgeschlossen werden. Bei bekannten
Regressionsparametern 1β und 0β sowie bekanntem Erwartungswert η von Y ergibt
sich der gesuchte X-Wert ξ einfach aus der Regressionsgleichung: 10 /)( ββηξ −= .
Im Allgemeinen kennt man weder die Regressionsparameter 1β und 0β noch den
Erwartungswert η. Naheliegend ist nun folgende Vorgangsweise: Wir bilden den Mittelwert y′ aus m zum selben ξ gemessenen Y-Werten (im Extremfall kann m=1
sein), setzen y′ an Stelle von y in die Regressionsgleichung )(ˆ 1 xxbyy −+= ein
und lösen nach x auf. Die so erhaltene Größe – wir bezeichnen sie mit x - nehmen wir
als Schätzfunktion für x. Es ist also 1/)*ˆ(ˆ byyxx −+= . Für den Standardfehler

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
50
xsˆ von xergibt sich unter der Voraussetzung, dass 1.0/ 222/1 <= − TGtg α gilt, die
Näherung:
Damit berechnet man schließlich die Grenzen
eines approximativen (1-α)-Konfidenzintervalls für den gesuchten Wert ξ von X. Man beachte, dass die Genauigkeit der Schätzung von der Anzahl n der Kalibrierproben und vom Umfang m der Y-Stichprobe abhängt. Für ein optimales Design der Kalibrationsfunktion wird man ferner darauf achten, dass ( )yy −′ möglichst klein und
2Xs möglichst groß ist.
6.6 Musterbeispiele 1. An bestimmten von sechs verschiedenen Grasarten stammenden Chromosomen wurden
die Teillängen E und H des C-Band Euchromatins bzw. Heterochromatins gemessen (Angaben in µm; aus H.M. Thomas, Heredity, 46: 263-267, 1981). Man berechne die Produktmomentkorrelation rEH. Ist die Produktmomentkorrelation signifikant von null verschieden? (α = 5%)
E 71,00 74,00 67,50 62,5 52,75 53,00 H 6,00 5,00 5,00 3,00 2,75 4,25
Präzisierung der Aufgabe: Die Beschreibung des Zusammenhangs zwischen den Variablen E und H mit Hilfe der Produktmomentkorrelation setzt voraus, dass die Variablen zweidimensional normalverteilt sind.
Lösungsansatz und numerische Lösung: Die Lösung umfasst zunächst eine univariate Datenbeschreibung und die Überprüfung der Normalverteilungsannahme für E und H; hierbei lautet die Alternativhypothese H1 jeweils: Die Grundgesamtheit ist nicht normalverteilt. Für den Abhängigkeitstest lautet die Alternativhypothese H1: Korrelationskoeffizient ρEH ≠ 0, die Nullhypothese H0: Korrelationskoeffizient ρEH = 0. Die Nullhypothese ist zu verwerfen, wenn der P-Wert kleiner als das vorgegebene Testniveau ist.
Lösung mit R: > E <- c(71, 74, 67.5, 62.5, 52.75, 53) > H <- c(6, 5, 5, 3, 2.75, 4.25) > options(digits=4) > # univariate Statistiken > n_E <- length(E) > n_H <- length(H) > m_E <- mean(E) > m_H <- mean(H) > s_E <- sd(E) > s_H <- sd(H) > print(cbind(n_E, m_E, s_E)) n_E m_E s_E [1,] 6 63.46 9.048 > print(cbind(n_H, m_H, s_H)) n_H m_H s_H [1,] 6 4.333 1.262 > # Überprüfung der Normalverteilung
( )
−−′
++=22
1
2
1ˆ
)1(
11
|| Xx snb
yy
nmb
MQEs
xx stxGstxUG ˆ2/1ˆ2/1 ˆO und ˆ αα −− +=−=

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
51
> shapiro.test(E) Shapiro-Wilk normality test data: E W = 0.8966, pppp----valuvaluvaluvalue = 0.3545e = 0.3545e = 0.3545e = 0.3545 > shapiro.test(H) Shapiro-Wilk normality test data: H W = 0.9278, pppp----value = 0.563value = 0.563value = 0.563value = 0.563 > # Schätzwert für die Pearson-Korrelation > # Test auf Abweichung von Nullkorrelation > cor.test(E, H, alternative="two.sided") Pearson's product-moment correlation data: E and H t = 2.107, df = 4, pppp----value = 0.1028value = 0.1028value = 0.1028value = 0.1028 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.2097 0.9674 sample estimates: cor 0.7253
Ergebnis: Die (univariate) Überprüfung der Normalverteilung ergibt auf Grund der P-Werte (0.3545 >=5% bzw. 0.563 ≥ 5%), dass die Daten nicht in Widerspruch zur jeweiligen Normalverteilungsannahme stehen. Da der P-Wert im Abhängigkeitstest ≥ 5% ist, kann die Nullhypothese (Korrelation zwischen E und H ist null) nicht abgelehnt werden; obwohl der Schätzwert der Pearsonkorrelation rEH=0.7253 deutlich von null abweicht, ergibt die Abhängigkeitsprüfung ein nichtsignifikantes Resultat!
2. In einer Studie wurde untersucht, ob zwischen der Mortalität in der Perinatalperiode
(Merkmal Y, Werte ja/nein) und dem Rauchen während der Schwangerschaft (Merkmal X, Werte ja/nein) ein Zusammenhang besteht. Zu diesem Zweck wurden Daten in einer Geburtenstation erhoben. Man berechne den Phi-Koeffizienten und das Odds-Ratio. Ist der Phi-Koeffizient auf 5%igem Testniveau von null verschieden?
Präzisierung der Aufgabe: Die Untersuchungseinheiten sind die Neugeborenen (an ihnen wird das Merkmal Y beobachtet) und deren Mütter (Merkmal X). Beide Merkmale sind zweistufig skaliert. Keine Zusammenhang zwischen den Merkmalen besteht genau dann, wenn der Anteil der Todesfälle nicht davon abhängt, ob die Mütter Raucher bzw. Nichtraucher sind.
Lösungsansatz und numerische Lösung: Die Prüfung, ob der Phi-Koeffizient signifikant von null abweicht, erfolgt mit dem Chiquadrat-Test; ist der ausgewiesene P-Wert kleiner als 5%, wird die Nullhypothese (keine Abhängigkeit, d.h. Phi-Koeffizient=0) abgelehnt (signifikanter Testausgang). Im Rahmen des Tests wird u.a. auch die Chiquadratsumme (Goodness of Fit - Statistik) GF bestimmt, mit der der PHI-Koeffizient (= Quadratwurzel aus GF/n) bestimmt wird; hier ist n der Umfang der bivariaten Stichprobe. Das Odds-Ratio ist gleich dem Verhältnis der Chancen „Sterben:Überleben mit und ohne Risikofaktor (Rauchen)“, d.h. gleich dem Verhältnis (246:8160)/(264:10710).
Lösung mit R: > options(digits=4)
Raucher XMortalität Y ja nein Σ (Zeilen)
ja 246 264 510nein 8160 10710 18870
Σ (Spalten) 8406 10974 19380

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
52
> freq <- matrix(c(246, 8160, 264, 10710), nrow=2, ncol=2, byrow=F, + dimnames=list(Mortalität=c("ja", "nein"), Raucher=c("ja", "nein"))) > # Wiedergabe der Matrix der beobachteten Häufigkeiten > freq Raucher Mortalität ja nein ja 246 264 nein 8160 10710 > # Prüfung auf Abhängigkeit > # H1: Abhängigkeit vs. H0: keine Abhängigkeit > testergebnis <- chisq.test(freq, correct=TRUE) > testergebnis Pearson's Chi-squared test with Yates' continuity correction data: freq X-squared = 4.837, df = 1, pppp----value = 0.02785value = 0.02785value = 0.02785value = 0.02785 > # Bestimmung des PHI-Koeffizienten > summary(testergebnis) Length Class Mode statistic 1 -none- numeric parameter 1 -none- numeric p.value 1 -none- numeric method 1 -none- character data.name 1 -none- character observed 4 -none- numeric expected 4 -none- numeric residuals 4 -none- numeric > testergebnis[1] $statistic X-squared 4.837 > chi2sum <- testergebnis[[1]] # Auswahl des numerischen Elementes der Liste > chi2sum X-squared 4.837 > phi <- sqrt(chi2sum/sum(freq)) > phi X-squared 0.0158 > # Bestimmung des Odds-Ratio (Chancenverhältnis) > OR <- (freq[1,1]/freq[2,1])/(freq[1,2]/freq[2,2]) > OR [1] 1.223
Ergebnis: Die Prüfung auf Abhängigkeit (bzw. Abweichung des PHI-Koeffizienten von null) ist wegen p-value = 0.02785 < 0.05 signifikant, d.h. es gilt H1 (Die Mortalität ist vom Raucherverhalten abhängig). Der Phi-Koeffizient ist in der Ergebnisdarstellung des Chiquadrat-Tests (testergebnis) das erste Element, auf dessen numerischen Inhalt mit testergebnis[[1]] zugegriffen werden kann; es folgt für den Phi-Koeffizienten der Wert 0,0158; für das Odds-Ratio ergibt sich 1.223 > 1, d.h. die Sterbechancen des Kindes einer rauchenden Mutter sind größer als jene einer nichtrauchenden.
3. Von einem Gebiet der Schweiz liegen aus 10 Wintern (Dezember bis März) die in der
folgenden Tabelle angeführten Werte der Schneehöhe X (in cm) und der Lawinenabgänge Y vor.
a) Man prüfe, ob Y von X (linear) abhängt? (α=5%) b) Wenn ja, stelle man die Abhängigkeit der Anzahl der Lawinenabgänge von der
Schneehöhe durch ein lineares Regressionsmodell dar. Was besagt das Bestimmtheitsmaß?
c) Welcher Werft von Y ist bei einer Schneehöhe von 400cm zu erwarten?
X 80 300 590 170 302 515 609 843 221 616 Y 31 44 78 65 75 38 51 104 37 91
Präzisierung der Aufgabe:
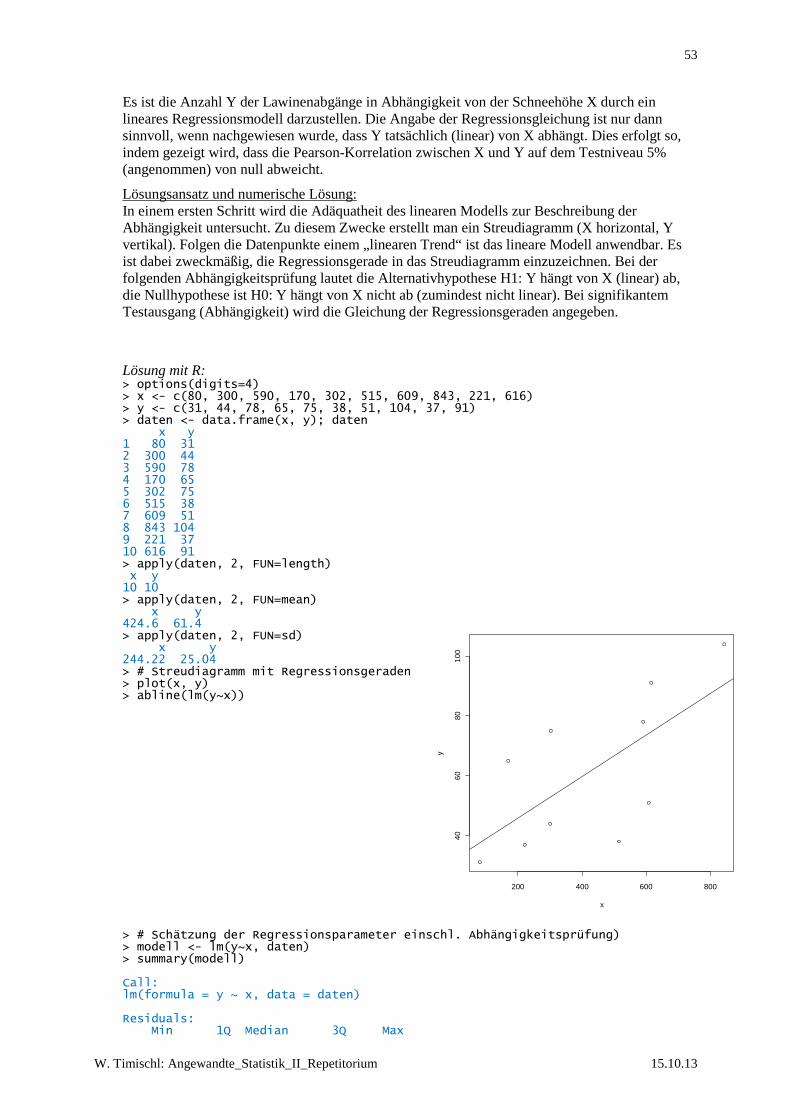
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
53
Es ist die Anzahl Y der Lawinenabgänge in Abhängigkeit von der Schneehöhe X durch ein lineares Regressionsmodell darzustellen. Die Angabe der Regressionsgleichung ist nur dann sinnvoll, wenn nachgewiesen wurde, dass Y tatsächlich (linear) von X abhängt. Dies erfolgt so, indem gezeigt wird, dass die Pearson-Korrelation zwischen X und Y auf dem Testniveau 5% (angenommen) von null abweicht.
Lösungsansatz und numerische Lösung: In einem ersten Schritt wird die Adäquatheit des linearen Modells zur Beschreibung der Abhängigkeit untersucht. Zu diesem Zwecke erstellt man ein Streudiagramm (X horizontal, Y vertikal). Folgen die Datenpunkte einem „linearen Trend“ ist das lineare Modell anwendbar. Es ist dabei zweckmäßig, die Regressionsgerade in das Streudiagramm einzuzeichnen. Bei der folgenden Abhängigkeitsprüfung lautet die Alternativhypothese H1: Y hängt von X (linear) ab, die Nullhypothese ist H0: Y hängt von X nicht ab (zumindest nicht linear). Bei signifikantem Testausgang (Abhängigkeit) wird die Gleichung der Regressionsgeraden angegeben.
Lösung mit R: > options(digits=4) > x <- c(80, 300, 590, 170, 302, 515, 609, 843, 221, 616) > y <- c(31, 44, 78, 65, 75, 38, 51, 104, 37, 91) > daten <- data.frame(x, y); daten x y 1 80 31 2 300 44 3 590 78 4 170 65 5 302 75 6 515 38 7 609 51 8 843 104 9 221 37 10 616 91 > apply(daten, 2, FUN=length) x y 10 10 > apply(daten, 2, FUN=mean) x y 424.6 61.4 > apply(daten, 2, FUN=sd) x y 244.22 25.04 > # Streudiagramm mit Regressionsgeraden > plot(x, y) > abline(lm(y~x)) > # Schätzung der Regressionsparameter einschl. Abhängigkeitsprüfung) > modell <- lm(y~x, daten) > summary(modell) Call: lm(formula = y ~ x, data = daten) Residuals: Min 1Q Median 3Q Max
200 400 600 800
4060
8010
0
x
y

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
54
-29.670 -9.899 -0.686 15.640 22.103 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 31.9522 12.9125 2.47 0.038 * x 0.0694 0.0267 2.60 0.032 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 19.6 on 8 degrees of freedom Multiple R-squared: 0.458, Adjusted R-squared: 0.39 F-statistic: 6.75 on 1 and 8 DF, p-value: 0.0317 > predict(modell, data.frame(x=c(400))) 1 59.69
Ergebnis: a) Aus dem Streudiagramm entnimmt man, dass die Datenpunkte durch eine Gerade ausgeglichen werden können. Die Abhängigkeitsprüfung ergibt den p-value = 0.0317 < 0.05; es folgt, dass H0 (keine lineare Abhängigkeit) abgelehnt werden kann, d.h. Y kann tatsächlich durch eine lineare Regressionsgleichung in Abhängigkeit von X dargestellt werden. b) Der Anstieg k der Regressionsgeraden ist 0.0694 (siehe unter Coefficients, bei x) und der y-Achsenabschnitt (Intercept) d = 31.9522; somit lautet die Regressionsgerade: y = kx + d = 0.0694x + 31.9522. Das Bestimmtheitsmaß beträgt B=0.458 (Multiple R-squared), d.h. 45.8% der Variation von Y können durch die Variation von X erklärt werden. c) Für x=400 ergibt sich für Y der Erwartungswert 60 (59.7). Man beachte, dass eine allfällige Hochschätzung von der Schneehöhe X auf die erwartete Zahl von Lawinenabgängen mit der Regressionsgleichung nur innerhalb des Variationsbereichs von X – also von etwa X = 80 bis X= 850 - möglich ist; die Abhängigkeit der Variablen Y von X ist offensichtlich nichtlinear (für X=0 müsste sich Y=0 ergeben), kann aber in einem begrenzten Bereich durch ein lineares Modell approximiert werden.
4. Der Energieumsatz E (in kJ pro kg Körpergewicht und Stunde) wurde in Abhängigkeit von der Laufgeschwindigkeit v (in m/s) gemessen. Man stelle die Abhängigkeit des Energieumsatzes von der Laufgeschwindigkeit durch ein geeignetes Regressionsmodell dar und prüfe, ob im Rahmen des Modells überhaupt ein signifikanter Einfluss der Geschwindigkeit auf den Energieumsatz besteht (α=5%). Hinweis: Logarithmiert man den Energieumsatz und die Laufgeschwindigkeit ergibt sich im Streudiagramm eine Punkteverteilung mit einem linearen Trend.
v 3,1 4,2 5,0 5,4 6,6 E 27,6 50,6 62,7 147,1 356,3
Präzisierung der Aufgabe: Es ist der Energieumsatz E in Abhängigkeit von der Laufgeschwindigkeit v durch ein geeignetes Regressionsmodell darzustellen. Man überzeugt sich durch ein Streudiagramm, dass sich mit den beobachteten Daten keine Punkteverteilung mit linearem Trend ergibt. Zum Zwecke der Linearisierung werden entsprechend dem Hinweis sowohl die E- als auch die v-Werte logarithmiert (man nehme z.B. natürliche Logarithmen). Wir bezeichnen die logarithmierten Variablen mit E’=ln(E) und v’=ln(v). Man überzeuge sich, dass das mit v’ und E’ gebildete Streudiagramm ein lineares Regressionsmodell zur Beschreibung der Abhängigkeit der Variablen E’ von v’ rechtfertigt. Die Angabe der Regressionsgleichung E’ = k v’ + d ist nur dann sinnvoll, wenn nachgewiesen wurde, dass E’ tatsächlich (linear) von v’ abhängt. Dies erfolgt, in dem gezeigt wird, dass die Pearson-Korrelation zwischen v’ und E’ auf dem Testniveau 5% (angenommen) von null abweicht.
Lösungsansatz und numerische Lösung: Die Lösungsschritte sind:
o Erstellung eines Streudiagramms mit den beobachteten Daten und der Erkenntnis daraus, dass die Punkteverteilung keinen linearen Trend besitzt.
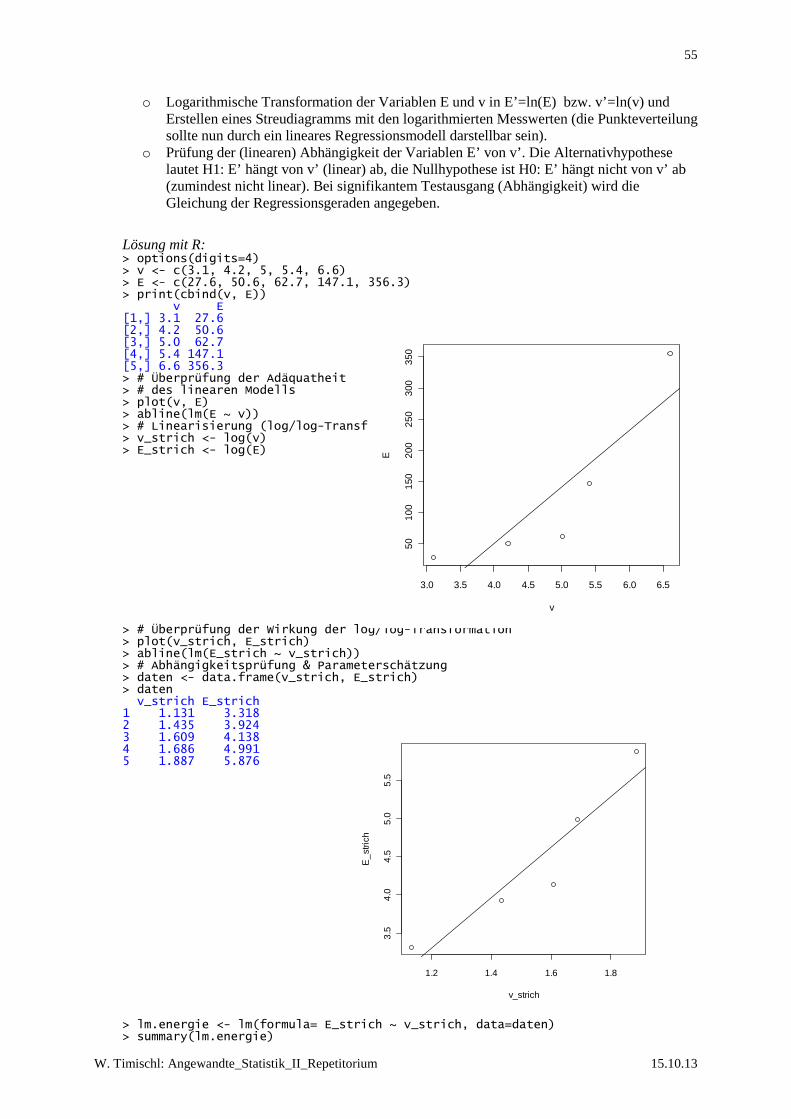
W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
55
o Logarithmische Transformation der Variablen E und v in E’=ln(E) bzw. v’=ln(v) und Erstellen eines Streudiagramms mit den logarithmierten Messwerten (die Punkteverteilung sollte nun durch ein lineares Regressionsmodell darstellbar sein).
o Prüfung der (linearen) Abhängigkeit der Variablen E’ von v’. Die Alternativhypothese lautet H1: E’ hängt von v’ (linear) ab, die Nullhypothese ist H0: E’ hängt nicht von v’ ab (zumindest nicht linear). Bei signifikantem Testausgang (Abhängigkeit) wird die Gleichung der Regressionsgeraden angegeben.
Lösung mit R: > options(digits=4) > v <- c(3.1, 4.2, 5, 5.4, 6.6) > E <- c(27.6, 50.6, 62.7, 147.1, 356.3) > print(cbind(v, E)) v E [1,] 3.1 27.6 [2,] 4.2 50.6 [3,] 5.0 62.7 [4,] 5.4 147.1 [5,] 6.6 356.3 > # Überprüfung der Adäquatheit > # des linearen Modells > plot(v, E) > abline(lm(E ~ v)) > # Linearisierung (log/log-Transf.) > v_strich <- log(v) > E_strich <- log(E) > # Überprüfung der Wirkung der log/log-Transformation > plot(v_strich, E_strich) > abline(lm(E_strich ~ v_strich)) > # Abhängigkeitsprüfung & Parameterschätzung > daten <- data.frame(v_strich, E_strich) > daten v_strich E_strich 1 1.131 3.318 2 1.435 3.924 3 1.609 4.138 4 1.686 4.991 5 1.887 5.876 > lm.energie <- lm(formula= E_strich ~ v_strich, data=daten) > summary(lm.energie)
3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5
5010
015
020
025
030
035
0
v
E
1.2 1.4 1.6 1.8
3.5
4.0
4.5
5.0
5.5
v_strich
E_s
trich

W. Timischl: Angewandte_Statistik_II_Repetitorium 15.10.13
56
Call: lm(formula = E_strich ~ v_strich, data = daten) Residuals: 1 2 3 4 5 0.250 -0.146 -0.508 0.091 0.313 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) ----0.6670.6670.6670.667 1.066 -0.63 0.576 v_strich 3.3013.3013.3013.301 0.679 4.86 0.017 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.386 on 3 degrees of freedom Multiple R-squared: 0.887, Adjusted R-squared: 0.85 F-statistic: 23.7 on 1 and 3 DF, pppp----value: 0.0166value: 0.0166value: 0.0166value: 0.0166
Ergebnis: Aus dem mit den E- und v-Werten gezeichneten Streudiagramm entnimmt man, dass die Datenpunkte nicht durch eine Gerade ausgeglichen werden können, es liegt eine eindeutig gekrümmte Anordnung der Datenpunkte vor. Nach Übergang zu den Variablen E’=ln(E) und v’=ln(v) erkennt man im (v’,E’)-Diagramm, dass nunmehr den Datenpunkten eine Gerade angepasst werden kann. Die Abhängigkeitsprüfung ergibt den p-value = 0.0166 < 0.05; es folgt, dass H0 (keine lineare Abhängigkeit) abgelehnt werden kann, d.h. E’ kann tatsächlich durch eine lineare Regressionsgleichung in Abhängigkeit von v’ dargestellt werden. Der Anstieg k der Regressionsgeraden ist 3,301 (siehe unter Coefficients, bei v_strich) und der y-Achsenabschnitt (Intercept) d = -0,667; somit lautet die Regressionsgerade: E’ = kv’ + d = 3,301v’ – 0,667; setzt man hier die Originalvariablen ein, folgt lnE = 3,301lnv – 0,667, Potenzieren mit der Basis e ergibt schließlich E = e-0,667v3,301 = 0,513 v3,301.





























