Embed Size (px)
Citation preview

Issued: November, 2014
IBM® Platform LSF®
Best Practices IBM Platform LSF 9.1.3 and
IBM GPFS in Large Clusters
Jin Ma
Platform LSF Developer
IBM Canada

Issued: November, 2014
Table of Contents
IBM Platform LSF 9.1.3 and IBM GPFS in Large Clusters ............................ 1
Executive Summary ............................................................................................. 3
Introduction .......................................................................................................... 4
Minimizing the impact of network connection and node failures ............... 5
Minimizing interference among LSF, GPFS, and applications running on
GPFS ....................................................................................................................... 5
Deploy dedicated Network Shared Disk (NSD) servers and storage for
LSF .................................................................................................................... 5
Pre-configure a large inode pool.................................................................. 6
Install GPFS V3.5.0.19 or above.................................................................... 6
Configure LSB_JOB_TMPDIR and LSF_TMPDIR ..................................... 7
Configure JOB_SPOOL_DIR ........................................................................ 8
Specify the LSF job current working directory and output directory .... 9
Best Practices....................................................................................................... 11
Conclusion .......................................................................................................... 12
Further reading................................................................................................... 13
Contributors ........................................................................................................ 13
Notices ................................................................................................................. 14
Trademarks ................................................................................................... 15
Contacting IBM ............................................................................................ 15

Issued: November, 2014
Executive Summary This Best Practice Guide provides suggestions and solutions for smooth deployment of
IBM Platform LSF and IBM General Parallel File System (GPFS) in a large cluster to
achieve high job throughput and cluster reliability, performance, and scalability.

Issued: November, 2014
Introduction Experience from past deployment of Platform LSF and IBM GPFS together on large
clusters reveals that additional fine-tuning of the two systems is required to minimize
interference and to achieve high job throughput as well as optimal cluster stability,
performance, and scalability.
Possible issues fall into the following groups:
1. LSF and GPFS both depend on network stability and robustness of recovery.
If LSF is installed on GPFS, this dependency is amplified – if GPFS fails, LSF will
also crash. Common problems include:
Node expel issue
GPFS unmount causing LSF daemon crash if installed on GPFS
2. LSF and GPFS are affected by heavy application load (CPU, memory, network
I/O), resulting in node expel issues.
3. GPFS performance issue: inode pool auto expansion can cause GPFS to hang for
several minutes.
4. GPFS hangs because of how LSF accesses the file system. If LSF is also installed
on GPFS or needs to accesses GPFS, LSF does not respond or crashes.
/tmp requires at least 100 MB of free space. If many users mount /tmp to a
shared GPFS directory GPFS can crash due to lack of /tmp space.
GPFS also can hang when tokens are revoked with multiple clients creating
and removing sub-directories or frequent file read/write under the same top
directory. For example, if /tmp is mounted on a shared GPFS directory on a
diskless node, LSF creates a job temporary directory (/tmp/.<jobID>) when
each job is dispatched. This directory is then removed after the job finishes,
which can cause GPFS to hang.
This Best Practice Guide provides solutions aimed at avoiding or minimizing these
issues.
Note: IBM Platform LSF 9.1.3 patch #247132 or later is required for these
recommendations.

Issued: November, 2014
Minimizing the impact of network connection and
node failures Both GPFS and LSF rely on a healthy network and nodes to function properly. Network
and node failures can be catastrophic to workload efficiency and data integrity.
Maintaining a healthy network and nodes are key for smooth cluster operations.
A single node failure or connection issue triggers GPFS to expel the node from the cluster
to recover and protect data integrity. Node expel operations not only affect the
problematic nodes but can also have a ripple effect cascading onto other healthy nodes.
If LSF is also installed on GPFS, LSF daemon processes crash if GPFS is unmounted.
It is better to make LSF use a totally different network from that of GPFS and
applications.
Before installing, testing, and starting LSF and GPFS, you must run a network and node
health check. IBM has published best practices for node and network health checking
tools and procedures. See the references in “Further reading” for more information.
Minimizing interference among LSF, GPFS, and
applications running on GPFS
Deploy dedicated Network Shared Disk (NSD) servers and
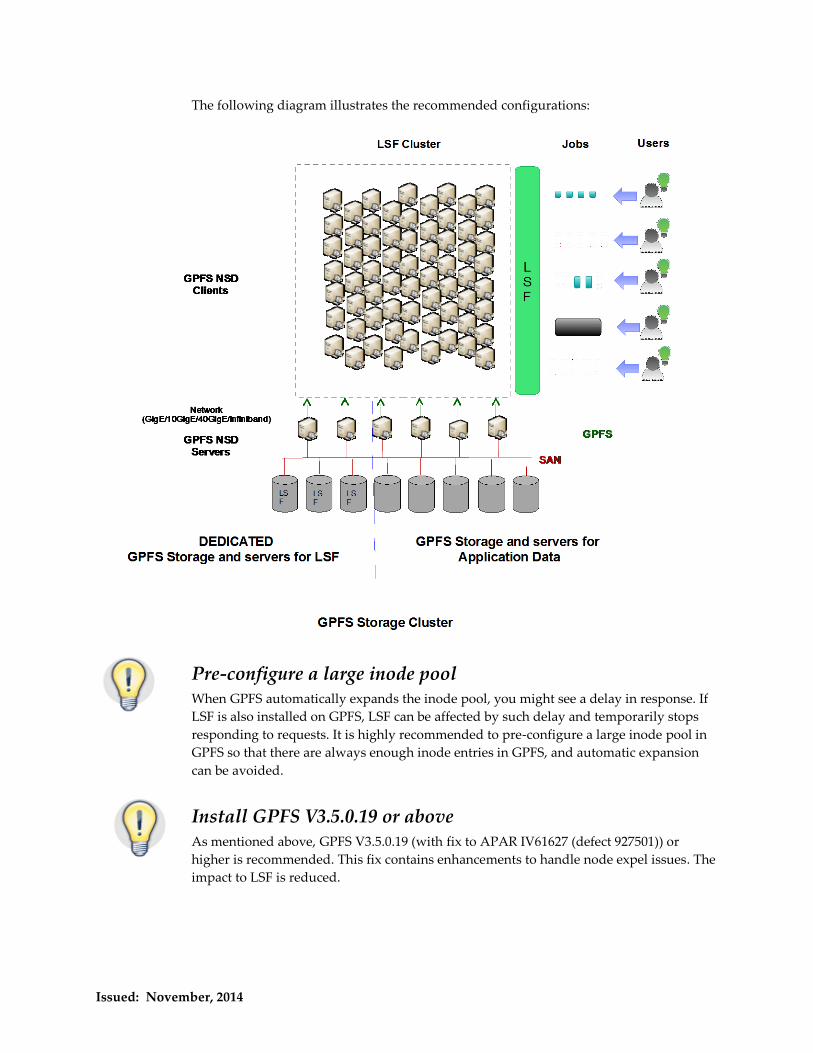
storage for LSF The main idea is to isolate LSF from GPFS and applications running on it. Ideally, the file
systems for LSF and GPFS that are used by applications should be totally separated. If
this is difficult to be implemented and LSF must be installed on GPFS, the next best
option is to assign dedicated NSD servers and storage for LSF. User applications should
not access these NSD servers and storage for LSF.
Issued: November, 2014
The following diagram illustrates the recommended configurations:
Pre-configure a large inode pool When GPFS automatically expands the inode pool, you might see a delay in response. If
LSF is also installed on GPFS, LSF can be affected by such delay and temporarily stops
responding to requests. It is highly recommended to pre-configure a large inode pool in
GPFS so that there are always enough inode entries in GPFS, and automatic expansion
can be avoided.
Install GPFS V3.5.0.19 or above As mentioned above, GPFS V3.5.0.19 (with fix to APAR IV61627 (defect 927501)) or
higher is recommended. This fix contains enhancements to handle node expel issues. The
impact to LSF is reduced.

Issued: November, 2014
Configure LSB_JOB_TMPDIR and LSF_TMPDIR The GPFS daemon requires 100 MB of free space under /tmp on each node. In order to
avoid LSF jobs from competing with GPFS for /tmp space, set LSF_TMPDIR in
lsf.conf to a directory to GPFS.
LSF creates job-specific temporary directory for each job (<jobID>.tmpdir) and
removes this directory after the job finishes. Frequent directory creation and deletion
under the same directory by multiple GPFS clients can cause GPFS to revoke tokens to
protect data integrity. This can significantly affect LSF performance and job throughput.
Set the following parameters in lsf.conf:
LSB_JOB_TMPDIR=/gpfs/shared_dir/%H
LSF_TMPDIR=/tmp # Or not defined.
You should create LSB_JOB_TMPDIR as well as all sub-directories of LSF server host
names with the right permission before running jobs in LSF. If LSB_JOB_TMPDIR is
defined on a shared file system, all users should be able to write to this directory from all
hosts. If LSB_JOB_TMPDIR sub-directories are not created ahead of time, LSF creates
them.
If you change LSB_JOB_TMPDIR run
badmin hrestart all to make the new setting take effect.
Issued: November, 2014
Configure JOB_SPOOL_DIR In lsb.params, set JOB_SPOOL_DIR to the directory where you want to store the job
files as well as stderr and stdout files for each job after job is dispatched to a host.
These LSF temporary files are cleaned after job finishes. The default location is user's
HOME directory ($HOME/.lsbatch).
Similar to the job-specific temporary directory, multiple clients reading and writing files
under the same directory triggers the token revoke action, which can cause delays in
accessing GPFS. Job setup becomes sequential with direct impact on LSF job throughput
and longer turnaround time.
If JOB_SPOOL_DIR is set on GPFS or user HOME directory is on GPFS, you must add %H
to the path so that JOB_SPOOL_DIR will be located under the sub-directory with the
name of the first execution host for the job:
JOB_SPOOL_DIR=%H
or
JOB_SPOOL_DIR=/gpfs/shared/%H
If you specify JOB_SPOOL_DIR=%H, the actual job spool directory is created under
$HOME/.lsbatch/%H.
LSF creates the %H subdirectory with permission 700.
If you specify JOB_SPOOL_DIR=/gpfs/shared/%H, LSF creates the %H subdirectory
with permission 777.
You can use other patterns in JOB_SPOOL_DIR:
%H #first execution host
%U #job exec user name
%C #Execution cluster name
%JG #job group
%P #job project

Issued: November, 2014
Put %H %U before all other variable patterns in directory
paths
It is also highly recommended that these directories are created ahead of time, so that
LSF does not need to create them. Make sure the permission is set properly:
If JOB_SPOOL_DIR is under $HOME, it should have 700 permission.
If JOB_SPOOL_DIR is under a shared directory, it should have 777 permission.
One exception is that if JOB_SPOOL_DIR=/shared_top/%U/ where %U is the first
pattern in the JOB_SPOOL_DIR, it should be of permission 700.
If JOB_SPOOL_DIR is pre-created, LSF will not change permissions. The LSF
administrator must create the JOB_SPOOL_DIR with proper permissions.
Specify the LSF job current working directory and output
directory You can specify the LSF job current working directory and output directory in LSF the
following ways:
bsub -cwd
LSB_JOB_CWD environment variable
JOB_CWD in application profile
DEFAULT_JOB_CWD in lsb.parms
bsub -outdir
DEFAULT_JOB_OUTDIR in lsb.params
The job will run under the specified working directory and generate files to the specified
output directory. If many jobs create and delete subdirectories under the same working
directory, the GPFS token revoke behavior is triggered and the response of GPFS will be
slowed down.
This can impact the overall job throughput as well as LSF performance if LSF is installed
and run on GPFS.
LSF supports the %H (host-based) pattern in the job working directory and output
directory. %H is replaced with host name of the first execution host of the job.
Issued: November, 2014
In addition to %H, you can also use the following patterns in the job current working
directory and output directory:
%J - jobid
%JG - job group
%I - index
%EJ - execution job id
%EI - execution index
%P - project name
%U - user name
%H - 1st execution host
%G – user group
Put %U and %H before any other subdirectories In general, you should put %U and %H before any other subdirectories in job current
working directory (cwd) and output directory (outdir) specifications. If access to
specified cwd or outdir is shared by multiple users, create subdirectories before the
cluster is started. See the topic Using Platform LSF job directories on the LSF product
family wiki on IBM developerWorks.

Issued: November, 2014
Best Practices
The key items of the best practices is to maintain healthy network
connections and isolate LSF from the application on GPFS in terms
of storage and servers to minimize interference.
Complete node health check and network connection verification.
Prepare and configure dedicated NSD servers and storage for LSF
use only. User applications use separate servers and storage.
Always keep LSF and GPFS binaries up-to-date.
Configure GPFS and LSF to use separate NSD servers and storage.
Configure a large inode pool in GPFS.
Configure LSB_JOB_TMPDIR, JOB_SPOOL_DIR, job current
working directory, and job output directory with %H (host-based)
pattern so that if LSF daemons can concurrently create or delete
sub-directories and read and write files on GPFS.
Pre-create per-host based directories with appropriate permission
on GPFS before you start LSF.

Issued: November, 2014
Conclusion The purpose of this best practice guide is to make LSF and GPFS deployment smooth and
simple by minimizing the impact from OS/network/hardware as well as interferences of
these two systems.
By completing the cluster health check and configuring LSF and GPFS in the
recommended way, the LSF job throughput should be improved. The cluster
performance, scalability, and usability are also enhanced.

Issued: November, 2014
Further reading IBM Cluster Health Check
https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/
Welcome%20to%20High%20Performance%20Computing%20%28HPC%29%20C
entral/page/IBM%20Cluster%20Health%20Check
IBM GPFS Knowledge Centre:
http://www-01.ibm.com/support/knowledgecenter/SSFKCN/gpfs_welcome.html
Contributors
Enci Zhong
Chong Chen
Demin Zhang
Jiuwei Jiang

Issued: November, 2014
Notices This information was developed for products and services offered in the U.S.A.
IBM may not offer the products, services, or features discussed in this document in other
countries. Consult your local IBM representative for information on the products and services
currently available in your area. Any reference to an IBM product, program, or service is not
intended to state or imply that only that IBM product, program, or service may be used. Any
functionally equivalent product, program, or service that does not infringe any IBM
intellectual property right may be used instead. However, it is the user's responsibility to
evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in
this document. The furnishing of this document does not grant you any license to these
patents. You can send license inquiries, in writing, to:
IBM Director of Licensing
IBM Corporation
North Castle Drive
Armonk, NY 10504-1785
U.S.A.
The following paragraph does not apply to the United Kingdom or any other country where
such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES
CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER
EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-
INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do
not allow disclaimer of express or implied warranties in certain transactions, therefore, this
statement may not apply to you.
Without limiting the above disclaimers, IBM provides no representations or warranties
regarding the accuracy, reliability or serviceability of any information or recommendations
provided in this publication, or with respect to any results that may be obtained by the use of
the information or observance of any recommendations provided herein. The information
contained in this document has not been submitted to any formal IBM test and is distributed
AS IS. The use of this information or the implementation of any recommendations or
techniques herein is a customer responsibility and depends on the customer’s ability to
evaluate and integrate them into the customer’s operational environment. While each item
may have been reviewed by IBM for accuracy in a specific situation, there is no guarantee
that the same or similar results will be obtained elsewhere. Anyone attempting to adapt
these techniques to their own environment does so at their own risk.
This document and the information contained herein may be used solely in connection with
the IBM products discussed in this document.
This information could include technical inaccuracies or typographical errors. Changes are
periodically made to the information herein; these changes will be incorporated in new
editions of the publication. IBM may make improvements and/or changes in the product(s)
and/or the program(s) described in this publication at any time without notice.
Any references in this information to non-IBM websites are provided for convenience only
and do not in any manner serve as an endorsement of those websites. The materials at those
websites are not part of the materials for this IBM product and use of those websites is at your
own risk.
IBM may use or distribute any of the information you supply in any way it believes
appropriate without incurring any obligation to you.
Any performance data contained herein was determined in a controlled environment.
Therefore, the results obtained in other operating environments may vary significantly. Some
measurements may have been made on development-level systems and there is no
guarantee that these measurements will be the same on generally available systems.
Furthermore, some measurements may have been estimated through extrapolation. Actual
results may vary. Users of this document should verify the applicable data for their specific
environment.

Issued: November, 2014
Information concerning non-IBM products was obtained from the suppliers of those products,
their published announcements or other publicly available sources. IBM has not tested those
products and cannot confirm the accuracy of performance, compatibility or any other
claims related to non-IBM products. Questions on the capabilities of non-IBM products should
be addressed to the suppliers of those products.
All statements regarding IBM's future direction or intent are subject to change or withdrawal
without notice, and represent goals and objectives only.
This information contains examples of data and reports used in daily business operations. To
illustrate them as completely as possible, the examples include the names of individuals,
companies, brands, and products. All of these names are fictitious and any similarity to the
names and addresses used by an actual business enterprise is entirely coincidental.
COPYRIGHT LICENSE: © Copyright IBM Corporation 2014. All Rights Reserved.
This information contains sample application programs in source language, which illustrate
programming techniques on various operating platforms. You may copy, modify, and
distribute these sample programs in any form without payment to IBM, for the purposes of
developing, using, marketing or distributing application programs conforming to the
application programming interface for the operating platform for which the sample
programs are written. These examples have not been thoroughly tested under all conditions.
IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these
programs.
Trademarks IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International
Business Machines Corporation in the United States, other countries, or both. If these and
other IBM trademarked terms are marked on their first occurrence in this information with a
trademark symbol (® or ™), these symbols indicate U.S. registered or common law
trademarks owned by IBM at the time this information was published. Such trademarks may
also be registered or common law trademarks in other countries. A current list of IBM
trademarks is available on the Web at “Copyright and trademark information” at
www.ibm.com/legal/copytrade.shtml
Windows is a trademark of Microsoft Corporation in the United States, other countries, or
both.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.
Contacting IBM To provide feedback about this paper, write to [email protected]
To contact IBM in your country or region, check the IBM Directory of Worldwide
Contacts at http://www.ibm.com/planetwide
To learn more about IBM Platform products, go to
http://www.ibm.com/systems/platformcomputing/





























