Embed Size (px)
Citation preview

Balanced Iterative Reducing and Clustering using Hierarchies
Jan Oberst27 January 2009
BIRCH+ Example Implementation of BIRCH in Python
2
3
4

Clustering
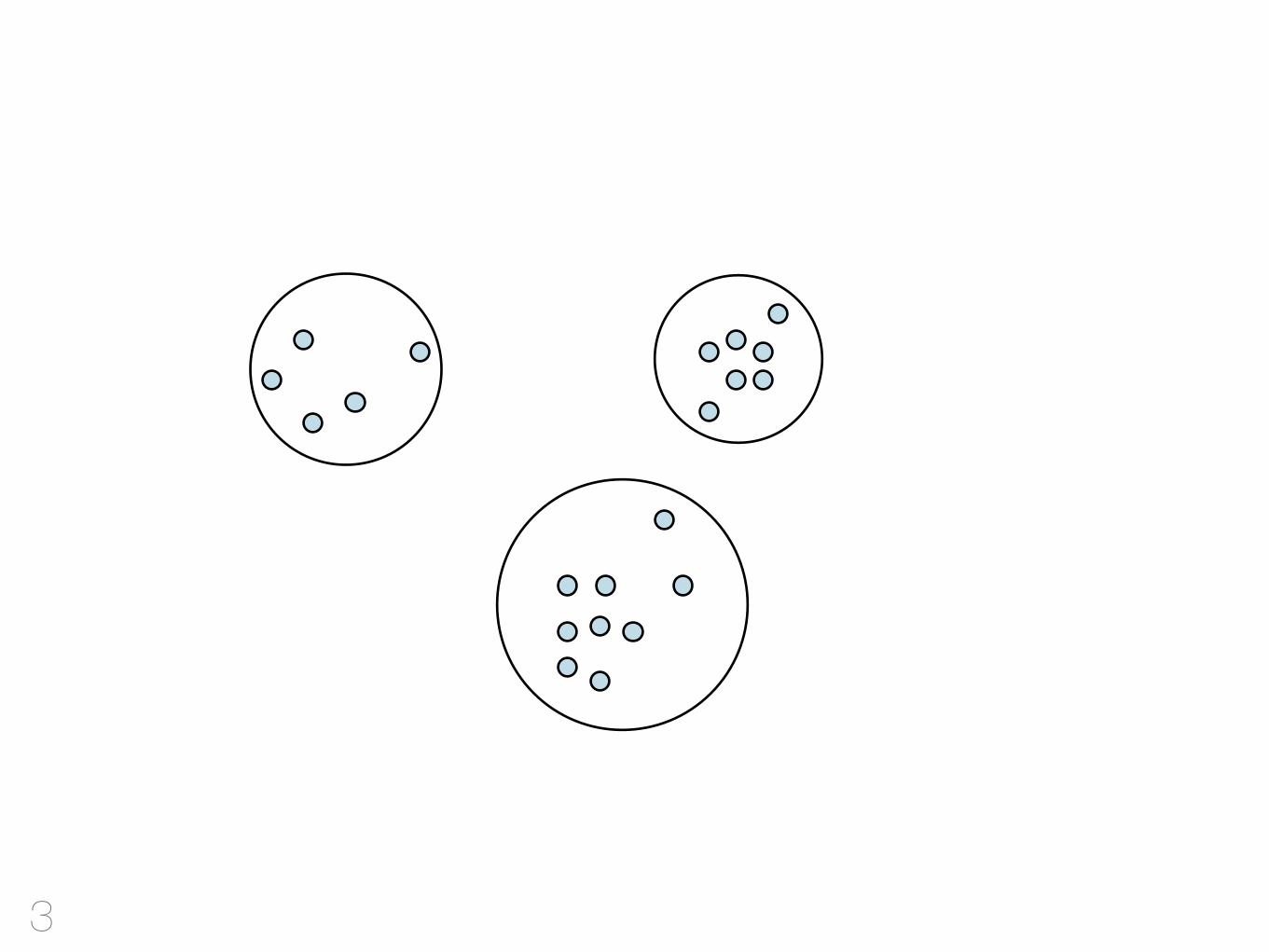
Ziel: Ähnliche Punkte gruppierenHaben n PunkteSuchen sinnvolle Cluster
Ähnlichkeit?Es gibt kein “bestes” clustering
5

Distanz
Distanz zweier PunkteViele mögliche FunktionenHier: Kartesisches Koordinatensystem
6

Distanz
Innere Distanz in einem Cluster“Durchmesser”: möglichst gering
Äußere Distanz zwischen Cluster“Abstand”: möglichst groß
7
BIRCH
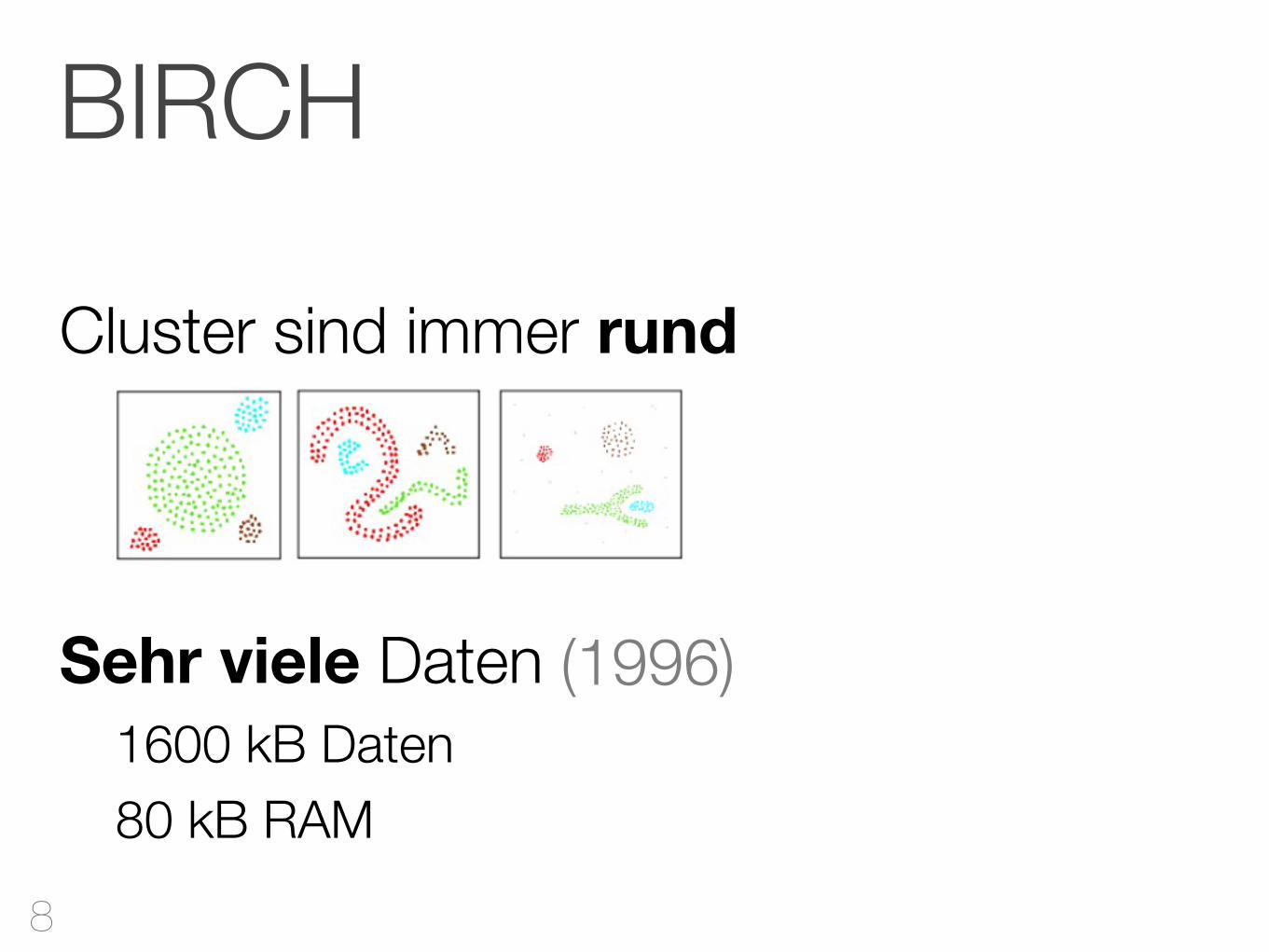
Cluster sind immer rund
Sehr viele Daten1600 kB Daten80 kB RAM
8
(1996)
9
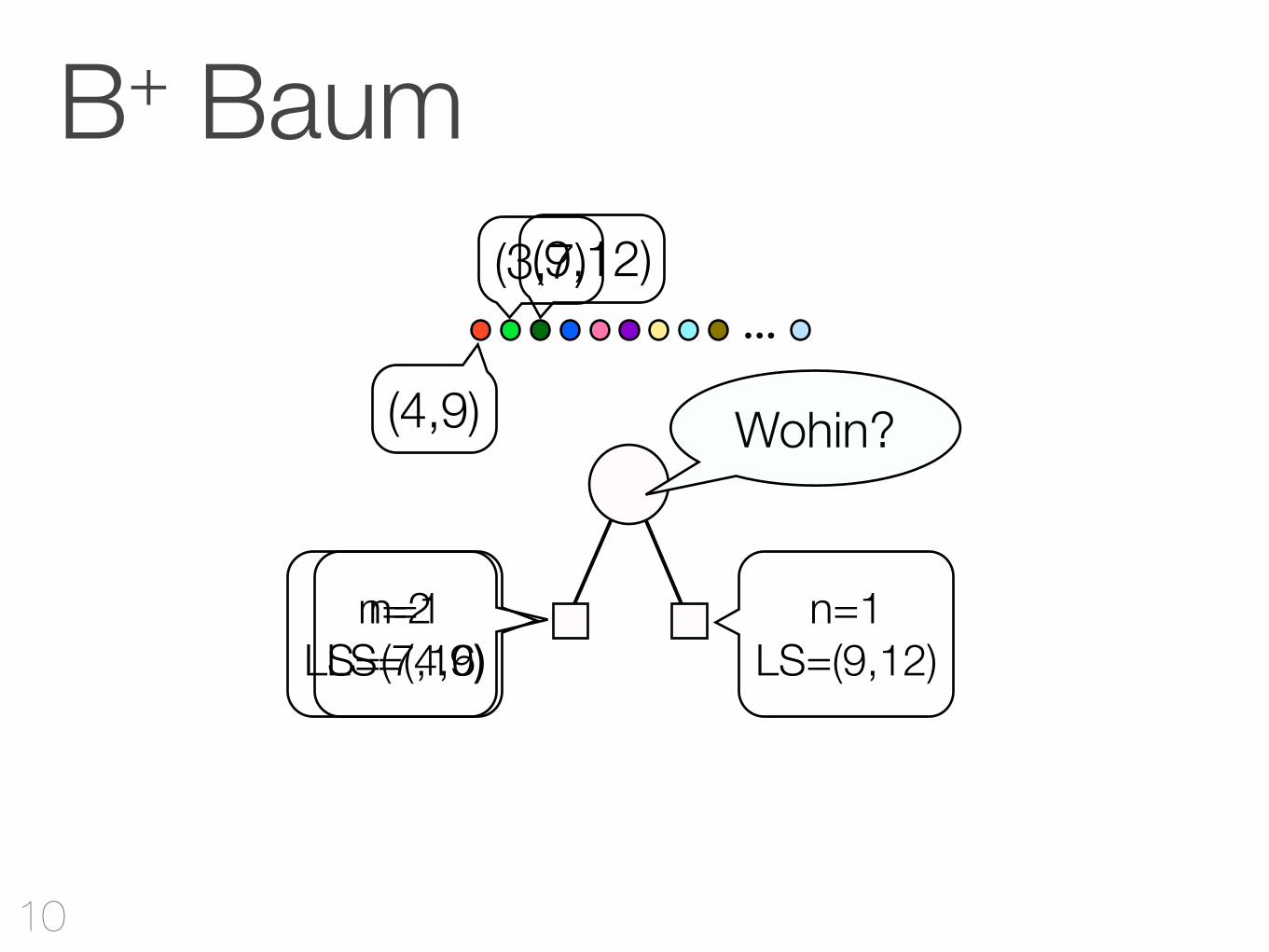
Wohin?
B+ Baum
10
...
n=1LS=(4,9)
(4,9)
(3,7)
n=2LS=(7,16)
(9,12)
n=1LS=(9,12)
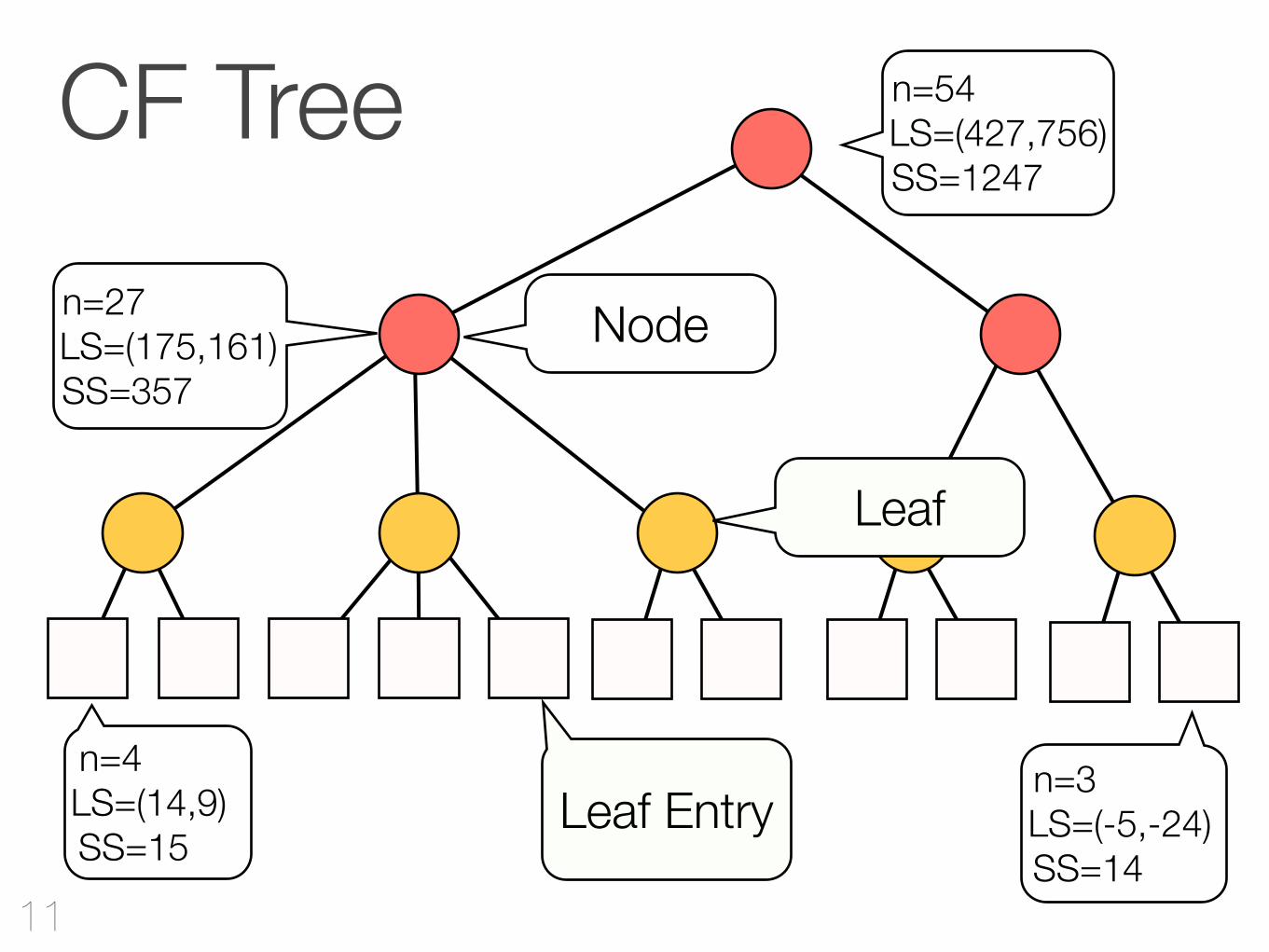
CF Tree
11
Node
Leaf
Leaf Entry
n=27LS=(175,161)SS=357
n=54LS=(427,756)SS=1247
n=4LS=(14,9)SS=15
n=3LS=(-5,-24)SS=14

Cluster Features
Jeder Knoten ist ein Cluster!
12

Cluster Features
Knoten lassen sich aufsummieren!CF = (LS1+LS2, N1+N2, SS1+SS2)
13

Anzahl der Kinder
Linearsumme
Quadratsumme:
14
Cluster Feature

B+ Baum
Durchmesser eines Blattes D < T
Anzahl Einträge eines Blatts N < L
Anzahl Kinder eines Knoten N < B15

B+ Baum Parameter
Kleines T: Viele Blätter, tiefer Baum
Großes T: Große Blätter, flacher Baum
16

Das optimale T
Zu klein / zu groß?Ausprobieren!BIRCH beginnt mit T=0
Neues T wählen, von vorne beginnenSuche minimale DistanzNeues muss größer sein als das
17

Von Vorne beginnen
Bauen den Baum neu auf
Disk nicht angerührtBrauchen dafür doppelt soviel RAM
Entsorgen OutliersBlätter mit deutlich niedrigerer DichteAuf Disk schreiben, Später neu versuchen
18

Baum neu aufbauen
19
1. Beginnen beim ersten Blatt
2. Füge den kompletten Pfad in neuen Baum ein
3. Weiter links: einfügen Weiter rechts: den alten Pfad einfügen
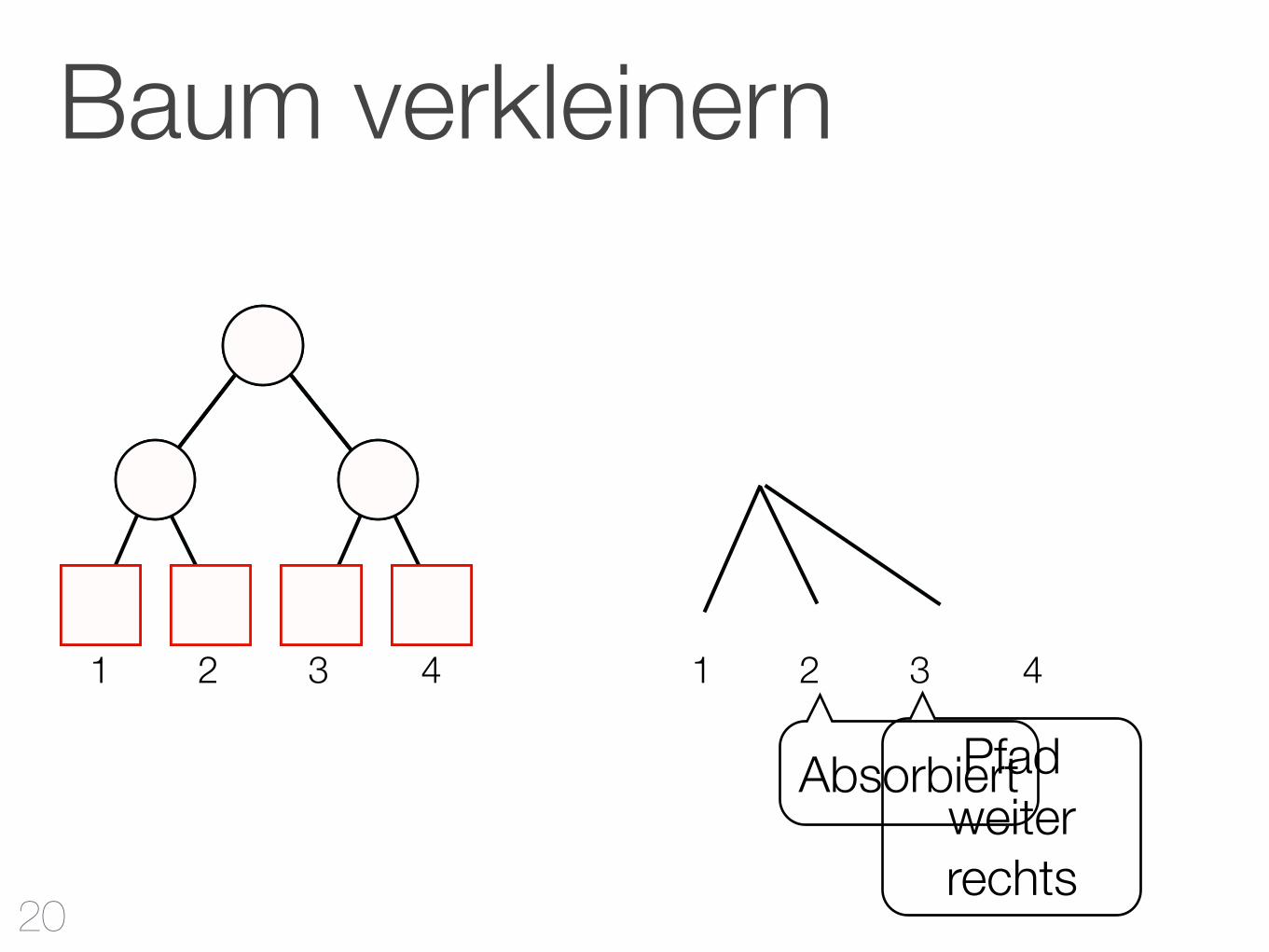
Baum verkleinern
20
1 2 3 4
Pfad weiter rechts
Absorbiert
1 2 3 4

Phase II
Vorbereitung für Phase 3Je nach Algorithmus notwendig
Falls Ausgabe von Phase 1 zu großWählen T größerEntsorgen mehr Outliers
21
Condensing (optional)

Phase III
Beliebiger Clustering Algorithmuslocal / non-localhierarchischAuch quadratische Laufzeit
22

Abstand zweier Cluster berechnen
Anzahl der Einträge
Linearsumme (Zentrum)
Quadratsumme (Abdeckung)
23

Phase III
Algorithmus sieht Blätter als PunkteDuck typing: Punkte haben Koordinaten!LS & SS verfeinern das Clustering
Algorithmus arbeitet mit dem BaumHierarchisches Clustering
24

25
Phase III

Phase IV
Lesen alle Daten nochmalJeder Punkt bekommt sein Cluster
QualitätNeuer Mittelpunkt: Durchschnitt aller PunktePhase 4 kann Probleme aus 1-3 behebenWenig RAM: In Phase 4 investieren
26
finish

Eigenschaften
27

local vs. nonlocal
BIRCHimmer auf Region beschränkt
NaivVergleiche mit allen Clustern
28
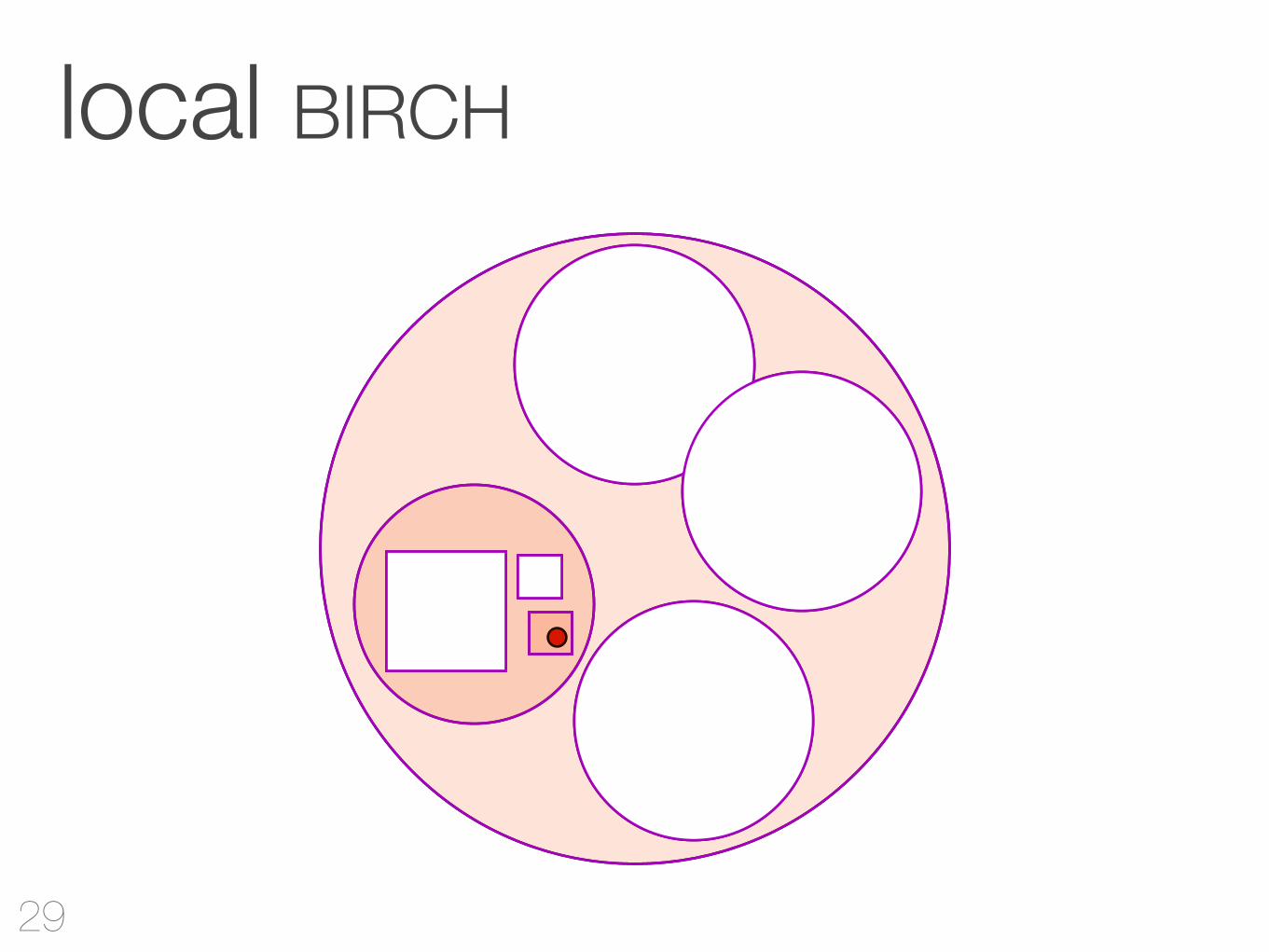
local BIRCH
29
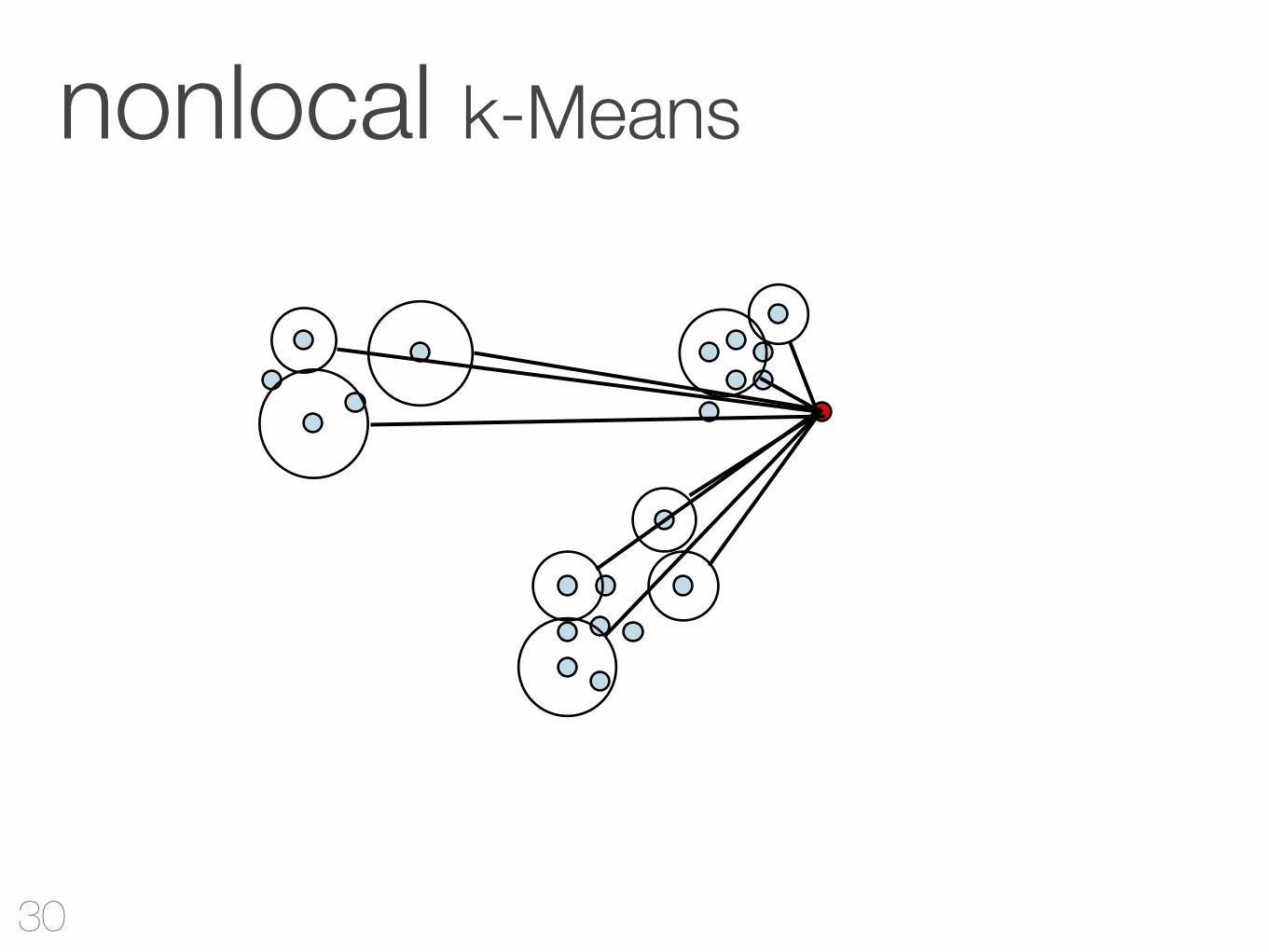
nonlocal k-Means
30

Skalierbarkeit
LinearIO “Should scale linearly with N”
KomprimiertHunderte Punkte in einem Cluster Feature
Single-passPhase IV nicht zwingend
31

Qualität
OutliersKönnen automatisch behandelt werdenMachen Algorithmus sogar schneller!
RAM NutzungKleine Limits = Viele Buckets = gute QualitätGroße Limits = Wenige Buckets = viele Daten
32

Über das Paper
33

Ergebnisse
34
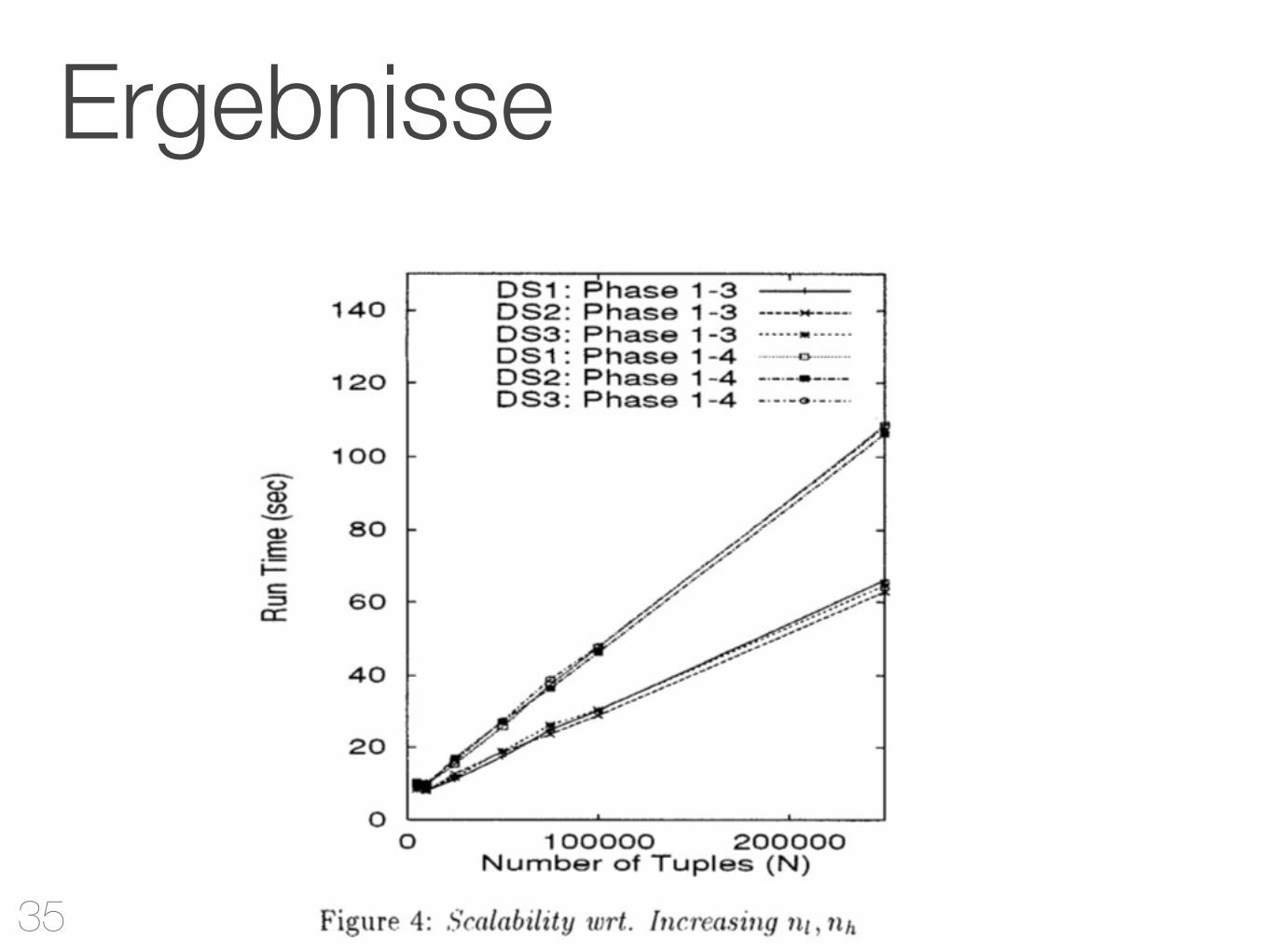
Ergebnisse
35

Ergebnisse
36

BIRCH
1996 ACM SIGMODInternational conference on Management of data
267 (Citeseer) / 1701 (Google) Citations
2006 Test of Time Award Winners
37
An efficient data clustering methodfor very large databasesTian ZhangRaghu RamakrishnanMiron Livny

Akademisch1996 - 1999 (?)
IBM, ~1999Santa Teresa Lab, San JoseDB2 Entwicklung
Microsoft, ~2004?
Tian Zhang
38
?

Raghu Ramakrishnan
AkademischB.Tech. IIT Madras,1983Ph.D. University of Texas at Austin,1987Professor, University of Wisconsin-Madison, 1987-ACM SIGKDD Innovation Award, 2008
Co-Founder QUIQ, 1999-2003collaborative customer support & knowledge managementAsk JeevesBusiness Objects, Compaq, Sun...
Yahoo! Research, 2006-Head of Community Systems GroupChief Scientist for Audience and Cloud Computing
39
Data Mining, Online Communities, Web-Scale Data Management

Miron Livny מירון לבני
AkademischB.Sc. Physics and Mathematics, Hebrew University, 1975M.Sc. Computer Science, Weizmann Institute of Science, 1978Ph.D. Weizmann Institute of Science, 1984 Professor, University of Wisconsin-Madison, 1984-
CondorHigh-Throughput Computing Systemdistributed parallelization of computationally intensive tasks
Open Science Grid
40
High Throughput Computing, Visual Data Exploration,Experiment Management Environments, Performance Evaluation

Recap
41

Fokus: SkalierbarkeitBaum immer komplett im RAMSingle-PassDaten ständig hinzufügen
CF-Tree: jeder Knoten ist ein ClusterCluster Features reichen aus
QualitätMehr RAM - bessere QualitätOutliers verbessern Qualität & Laufzeit42













![Übung Datenbanksysteme I Relationale Algebra - hpi.de · Thorsten Papenbrock | Übung Datenbanksysteme I – Relationale Algebra 5 Modellnummer Prozessorgeschwindigkeit [MHz] Festplattengröße](https://img.pdfslide.net/doc/110x75/5d670d8088c9931d358b8071/uebung-datenbanksysteme-i-relationale-algebra-hpide-thorsten-papenbrock-.jpg)















