Embed Size (px)
Citation preview

BochumerLinguistische
Arbeitsberichte18
IGGSA Shared Taskon Source and Target Extraction
from Political Speeches
Bochumer LinguistischeArbeitsberichte
Herausgeberin Stefanie Dipper
Die online publizierte Reihe bdquoBochumer Linguistische Arbeitsberichteldquo (BLA) gibtin unregelmaumlszligigen Abstaumlnden Forschungsberichte Abschluss- oder sonstige Ar-beiten der Bochumer Linguistik heraus die einfach und schnell der Oumlffentlichkeitzugaumlnglich gemacht werden sollen Sie koumlnnen zu einem spaumlteren Zeitpunkt aneinem anderen Publikationsort erscheinen Der thematische Schwerpunkt derReihe liegt auf Arbeiten aus den Bereichen der Computerlinguistik der allge-meinen und theoretischen Sprachwissenschaft und der Psycholinguistik
The online publication series ldquoBochumer Linguistische Arbeitsberichterdquo (BLA)releases at irregular intervals research reports theses and various other academicworks from the Bochum Linguistics Department which are to be made easily andpromptly available for the public At a later stage they can also be publishedby other publishing companies The thematic focus of the series lies on worksfrom the fields of computational linguistics general and theoretical linguisticsand psycholinguistics
c13 Das Copyright verbleibt beim Autor
Band 18 (November 2016)
Herausgeberin Stefanie DipperSprachwissenschaftliches InstitutRuhr-Universitaumlt BochumUniversitaumltsstr 15044801 Bochum
Erscheinungsjahr 2016ISSN 2190-0949
Josef Ruppenhofer Julia Maria Struszlig and MichaelWiegand (Eds)
IGGSA Shared Taskon Source and Target Extraction
from Political Speeches
2016
Bochumer Linguistische Arbeitsberichte
(BLA 18)
Contents
Preface iii
1 Overview of the IGGSA 2016 Shared Task on Source and Target Extrac-tion from Political SpeechesJosef Ruppenhofer Julia Maria Struszlig and Michael Wiegand 1
2 System documentation for the IGGSA Shared Task 2016Leonard Kriese 10
3 Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political SpeechesMichael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Koumlnig Leonie LappArtuur Leeuwenberg Martin Wolf and Maximilian Wolf 14
ii
Preface
The Shared Task on Source and Target Extraction from Political Speeches (STEPS)first ran in 2014 and is organized by the Interest Group on German Sentiment Analysis(IGGSA) This volume presents the proceedings of the workshop of the second iterationof the shared task The workshop was held at KONVENS 2016 at Ruhr-UniversityBochum on September 22 2016
As in the first edition of the shared task the main focus of STEPS was on fine-grainedsentiment analysis and offered a full task as well as two subtasks for the extractionSubjective Expressions andor their respective Sources and Targets
In order to make the task more accessible the annotation schema was revised for thisyearrsquos edition and an adjudicated gold standard was used for the evaluation In contrastto the pilot task this iteration provided training data for the participants opening theShared Task for systems based on machine learning approaches
The gold standard1 as well as the evaluation tool2 have been made publicly availableto the research community via the STEPSrsquo website
We would like to thank the GSCL for their financial support in annotating the 2014test data which were available as training data in this iteration A special thanks alsogoes to Stephanie Koumlser for her support on preparing and carrying out the annotationof this yearrsquos test data Finally we would like to thank all the participants for theircontributions and discussions at the workshop
The organizers
1httpiggsasharedtask2016githubiopagestask20descriptionhtmldata2httpiggsasharedtask2016githubiopagestask20descriptionhtmlscorer
iii
Overview of the IGGSA 2016 Shared Task on Source and TargetExtraction from Political Speeches
Josef Ruppenhoferlowast Julia Maria StruszligDagger Michael Wiegandlowast Institute for German Language Mannheim
Dagger Dept of Information Science and Language Technology Hildesheim University Spoken Language Systems Saarland University
ruppenhoferids-mannheimdejuliastrussuni-hildesheimde
michaelwiegandlsvuni-saarlandde
Abstract
We present the second iteration of IGGSArsquosShared Task on Sentiment Analysis for Ger-man It resumes the STEPS task of IG-GSArsquos 2014 evaluation campaign SourceSubjective Expression and Target Extrac-tion from Political Speeches As beforethe task is focused on fine-grained senti-ment analysis extracting sources and tar-gets with their associated subjective expres-sions from a corpus of speeches given inthe Swiss parliament The second itera-tion exhibits some differences howevermainly the use of an adjudicated gold stan-dard and the availability of training dataThe shared task had 2 participants submit-ting 7 runs for the full task and 3 runsfor each of the subtasks We evaluatethe results and compare them to the base-lines provided by the previous iterationThe shared task homepage can be foundat httpiggsasharedtask2016githubio
1 Introduction
Beyond detecting the presence of opinions (or morebroadly subjectivity) opinion mining and senti-ment analysis increasingly focus on determiningvarious attributes of opinions Among them arethe polarity (or valence) of an opinion (positivenegative or neutral) its intensity (or strength) andalso its source (or holder) as well as its target (ortopic)
The last two attributes are the focus of the IG-GSA shared task we want to determine whoseopinion is expressed and what entity or event it isabout Specific source and target extraction capa-bilities are required for the application of sentimentanalysis to unrestricted language text where thisinformation cannot be obtained from meta-data and
where opinions by multiple sources and about mul-tiple maybe related targets appear alongside eachother
Our shared task was organized under the aus-pices of the Interest Group of German SentimentAnalysis1 (IGGSA) The shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) constitutes the seconditeration of an evaluation campaign for source andtarget extraction on German language data Forthis shared task publicly available resources havebeen created which can serve as training and testcorpora for the evaluation of opinion source andtarget extraction in German
2 Task Description
The task calls for the identification of subjectiveexpressions sources and targets in parliamentaryspeeches While these texts can be expected tobe opinionated they pose the twin challenges thatsources other than the speaker may be relevant andthat the targets though constrained by topic canvary widely
21 Dataset
The STEPS data set stems from the debates ofthe Swiss parliament (Schweizer Bundesversamm-lung) This particular data set was originally se-lected with the following considerations in mindFirst the source data is freely available to the pub-lic and we may re-distribute it with our annotationsWe were not able to fully ascertain the copyright sit-uation for German parliamentary speeches whichwe had also considered using Second this type oftext poses the interesting challenge of dealing withmultiple sources and targets that cannot be gleanedeasily from meta-data but need to be retrieved fromthe running text
1httpssitesgooglecomsiteiggsahome
IGGSA Shared Task Workshop Sept 2016
1
As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Bochumer LinguistischeArbeitsberichte
Herausgeberin Stefanie Dipper
Die online publizierte Reihe bdquoBochumer Linguistische Arbeitsberichteldquo (BLA) gibtin unregelmaumlszligigen Abstaumlnden Forschungsberichte Abschluss- oder sonstige Ar-beiten der Bochumer Linguistik heraus die einfach und schnell der Oumlffentlichkeitzugaumlnglich gemacht werden sollen Sie koumlnnen zu einem spaumlteren Zeitpunkt aneinem anderen Publikationsort erscheinen Der thematische Schwerpunkt derReihe liegt auf Arbeiten aus den Bereichen der Computerlinguistik der allge-meinen und theoretischen Sprachwissenschaft und der Psycholinguistik
The online publication series ldquoBochumer Linguistische Arbeitsberichterdquo (BLA)releases at irregular intervals research reports theses and various other academicworks from the Bochum Linguistics Department which are to be made easily andpromptly available for the public At a later stage they can also be publishedby other publishing companies The thematic focus of the series lies on worksfrom the fields of computational linguistics general and theoretical linguisticsand psycholinguistics
c13 Das Copyright verbleibt beim Autor
Band 18 (November 2016)
Herausgeberin Stefanie DipperSprachwissenschaftliches InstitutRuhr-Universitaumlt BochumUniversitaumltsstr 15044801 Bochum
Erscheinungsjahr 2016ISSN 2190-0949
Josef Ruppenhofer Julia Maria Struszlig and MichaelWiegand (Eds)
IGGSA Shared Taskon Source and Target Extraction
from Political Speeches
2016
Bochumer Linguistische Arbeitsberichte
(BLA 18)
Contents
Preface iii
1 Overview of the IGGSA 2016 Shared Task on Source and Target Extrac-tion from Political SpeechesJosef Ruppenhofer Julia Maria Struszlig and Michael Wiegand 1
2 System documentation for the IGGSA Shared Task 2016Leonard Kriese 10
3 Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political SpeechesMichael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Koumlnig Leonie LappArtuur Leeuwenberg Martin Wolf and Maximilian Wolf 14
ii
Preface
The Shared Task on Source and Target Extraction from Political Speeches (STEPS)first ran in 2014 and is organized by the Interest Group on German Sentiment Analysis(IGGSA) This volume presents the proceedings of the workshop of the second iterationof the shared task The workshop was held at KONVENS 2016 at Ruhr-UniversityBochum on September 22 2016
As in the first edition of the shared task the main focus of STEPS was on fine-grainedsentiment analysis and offered a full task as well as two subtasks for the extractionSubjective Expressions andor their respective Sources and Targets
In order to make the task more accessible the annotation schema was revised for thisyearrsquos edition and an adjudicated gold standard was used for the evaluation In contrastto the pilot task this iteration provided training data for the participants opening theShared Task for systems based on machine learning approaches
The gold standard1 as well as the evaluation tool2 have been made publicly availableto the research community via the STEPSrsquo website
We would like to thank the GSCL for their financial support in annotating the 2014test data which were available as training data in this iteration A special thanks alsogoes to Stephanie Koumlser for her support on preparing and carrying out the annotationof this yearrsquos test data Finally we would like to thank all the participants for theircontributions and discussions at the workshop
The organizers
1httpiggsasharedtask2016githubiopagestask20descriptionhtmldata2httpiggsasharedtask2016githubiopagestask20descriptionhtmlscorer
iii
Overview of the IGGSA 2016 Shared Task on Source and TargetExtraction from Political Speeches
Josef Ruppenhoferlowast Julia Maria StruszligDagger Michael Wiegandlowast Institute for German Language Mannheim
Dagger Dept of Information Science and Language Technology Hildesheim University Spoken Language Systems Saarland University
ruppenhoferids-mannheimdejuliastrussuni-hildesheimde
michaelwiegandlsvuni-saarlandde
Abstract
We present the second iteration of IGGSArsquosShared Task on Sentiment Analysis for Ger-man It resumes the STEPS task of IG-GSArsquos 2014 evaluation campaign SourceSubjective Expression and Target Extrac-tion from Political Speeches As beforethe task is focused on fine-grained senti-ment analysis extracting sources and tar-gets with their associated subjective expres-sions from a corpus of speeches given inthe Swiss parliament The second itera-tion exhibits some differences howevermainly the use of an adjudicated gold stan-dard and the availability of training dataThe shared task had 2 participants submit-ting 7 runs for the full task and 3 runsfor each of the subtasks We evaluatethe results and compare them to the base-lines provided by the previous iterationThe shared task homepage can be foundat httpiggsasharedtask2016githubio
1 Introduction
Beyond detecting the presence of opinions (or morebroadly subjectivity) opinion mining and senti-ment analysis increasingly focus on determiningvarious attributes of opinions Among them arethe polarity (or valence) of an opinion (positivenegative or neutral) its intensity (or strength) andalso its source (or holder) as well as its target (ortopic)
The last two attributes are the focus of the IG-GSA shared task we want to determine whoseopinion is expressed and what entity or event it isabout Specific source and target extraction capa-bilities are required for the application of sentimentanalysis to unrestricted language text where thisinformation cannot be obtained from meta-data and
where opinions by multiple sources and about mul-tiple maybe related targets appear alongside eachother
Our shared task was organized under the aus-pices of the Interest Group of German SentimentAnalysis1 (IGGSA) The shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) constitutes the seconditeration of an evaluation campaign for source andtarget extraction on German language data Forthis shared task publicly available resources havebeen created which can serve as training and testcorpora for the evaluation of opinion source andtarget extraction in German
2 Task Description
The task calls for the identification of subjectiveexpressions sources and targets in parliamentaryspeeches While these texts can be expected tobe opinionated they pose the twin challenges thatsources other than the speaker may be relevant andthat the targets though constrained by topic canvary widely
21 Dataset
The STEPS data set stems from the debates ofthe Swiss parliament (Schweizer Bundesversamm-lung) This particular data set was originally se-lected with the following considerations in mindFirst the source data is freely available to the pub-lic and we may re-distribute it with our annotationsWe were not able to fully ascertain the copyright sit-uation for German parliamentary speeches whichwe had also considered using Second this type oftext poses the interesting challenge of dealing withmultiple sources and targets that cannot be gleanedeasily from meta-data but need to be retrieved fromthe running text
1httpssitesgooglecomsiteiggsahome
IGGSA Shared Task Workshop Sept 2016
1
As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Josef Ruppenhofer Julia Maria Struszlig and MichaelWiegand (Eds)
IGGSA Shared Taskon Source and Target Extraction
from Political Speeches
2016
Bochumer Linguistische Arbeitsberichte
(BLA 18)
Contents
Preface iii
1 Overview of the IGGSA 2016 Shared Task on Source and Target Extrac-tion from Political SpeechesJosef Ruppenhofer Julia Maria Struszlig and Michael Wiegand 1
2 System documentation for the IGGSA Shared Task 2016Leonard Kriese 10
3 Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political SpeechesMichael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Koumlnig Leonie LappArtuur Leeuwenberg Martin Wolf and Maximilian Wolf 14
ii
Preface
The Shared Task on Source and Target Extraction from Political Speeches (STEPS)first ran in 2014 and is organized by the Interest Group on German Sentiment Analysis(IGGSA) This volume presents the proceedings of the workshop of the second iterationof the shared task The workshop was held at KONVENS 2016 at Ruhr-UniversityBochum on September 22 2016
As in the first edition of the shared task the main focus of STEPS was on fine-grainedsentiment analysis and offered a full task as well as two subtasks for the extractionSubjective Expressions andor their respective Sources and Targets
In order to make the task more accessible the annotation schema was revised for thisyearrsquos edition and an adjudicated gold standard was used for the evaluation In contrastto the pilot task this iteration provided training data for the participants opening theShared Task for systems based on machine learning approaches
The gold standard1 as well as the evaluation tool2 have been made publicly availableto the research community via the STEPSrsquo website
We would like to thank the GSCL for their financial support in annotating the 2014test data which were available as training data in this iteration A special thanks alsogoes to Stephanie Koumlser for her support on preparing and carrying out the annotationof this yearrsquos test data Finally we would like to thank all the participants for theircontributions and discussions at the workshop
The organizers
1httpiggsasharedtask2016githubiopagestask20descriptionhtmldata2httpiggsasharedtask2016githubiopagestask20descriptionhtmlscorer
iii
Overview of the IGGSA 2016 Shared Task on Source and TargetExtraction from Political Speeches
Josef Ruppenhoferlowast Julia Maria StruszligDagger Michael Wiegandlowast Institute for German Language Mannheim
Dagger Dept of Information Science and Language Technology Hildesheim University Spoken Language Systems Saarland University
ruppenhoferids-mannheimdejuliastrussuni-hildesheimde
michaelwiegandlsvuni-saarlandde
Abstract
We present the second iteration of IGGSArsquosShared Task on Sentiment Analysis for Ger-man It resumes the STEPS task of IG-GSArsquos 2014 evaluation campaign SourceSubjective Expression and Target Extrac-tion from Political Speeches As beforethe task is focused on fine-grained senti-ment analysis extracting sources and tar-gets with their associated subjective expres-sions from a corpus of speeches given inthe Swiss parliament The second itera-tion exhibits some differences howevermainly the use of an adjudicated gold stan-dard and the availability of training dataThe shared task had 2 participants submit-ting 7 runs for the full task and 3 runsfor each of the subtasks We evaluatethe results and compare them to the base-lines provided by the previous iterationThe shared task homepage can be foundat httpiggsasharedtask2016githubio
1 Introduction
Beyond detecting the presence of opinions (or morebroadly subjectivity) opinion mining and senti-ment analysis increasingly focus on determiningvarious attributes of opinions Among them arethe polarity (or valence) of an opinion (positivenegative or neutral) its intensity (or strength) andalso its source (or holder) as well as its target (ortopic)
The last two attributes are the focus of the IG-GSA shared task we want to determine whoseopinion is expressed and what entity or event it isabout Specific source and target extraction capa-bilities are required for the application of sentimentanalysis to unrestricted language text where thisinformation cannot be obtained from meta-data and
where opinions by multiple sources and about mul-tiple maybe related targets appear alongside eachother
Our shared task was organized under the aus-pices of the Interest Group of German SentimentAnalysis1 (IGGSA) The shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) constitutes the seconditeration of an evaluation campaign for source andtarget extraction on German language data Forthis shared task publicly available resources havebeen created which can serve as training and testcorpora for the evaluation of opinion source andtarget extraction in German
2 Task Description
The task calls for the identification of subjectiveexpressions sources and targets in parliamentaryspeeches While these texts can be expected tobe opinionated they pose the twin challenges thatsources other than the speaker may be relevant andthat the targets though constrained by topic canvary widely
21 Dataset
The STEPS data set stems from the debates ofthe Swiss parliament (Schweizer Bundesversamm-lung) This particular data set was originally se-lected with the following considerations in mindFirst the source data is freely available to the pub-lic and we may re-distribute it with our annotationsWe were not able to fully ascertain the copyright sit-uation for German parliamentary speeches whichwe had also considered using Second this type oftext poses the interesting challenge of dealing withmultiple sources and targets that cannot be gleanedeasily from meta-data but need to be retrieved fromthe running text
1httpssitesgooglecomsiteiggsahome
IGGSA Shared Task Workshop Sept 2016
1
As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Contents
Preface iii
1 Overview of the IGGSA 2016 Shared Task on Source and Target Extrac-tion from Political SpeechesJosef Ruppenhofer Julia Maria Struszlig and Michael Wiegand 1
2 System documentation for the IGGSA Shared Task 2016Leonard Kriese 10
3 Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political SpeechesMichael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Koumlnig Leonie LappArtuur Leeuwenberg Martin Wolf and Maximilian Wolf 14
ii
Preface
The Shared Task on Source and Target Extraction from Political Speeches (STEPS)first ran in 2014 and is organized by the Interest Group on German Sentiment Analysis(IGGSA) This volume presents the proceedings of the workshop of the second iterationof the shared task The workshop was held at KONVENS 2016 at Ruhr-UniversityBochum on September 22 2016
As in the first edition of the shared task the main focus of STEPS was on fine-grainedsentiment analysis and offered a full task as well as two subtasks for the extractionSubjective Expressions andor their respective Sources and Targets
In order to make the task more accessible the annotation schema was revised for thisyearrsquos edition and an adjudicated gold standard was used for the evaluation In contrastto the pilot task this iteration provided training data for the participants opening theShared Task for systems based on machine learning approaches
The gold standard1 as well as the evaluation tool2 have been made publicly availableto the research community via the STEPSrsquo website
We would like to thank the GSCL for their financial support in annotating the 2014test data which were available as training data in this iteration A special thanks alsogoes to Stephanie Koumlser for her support on preparing and carrying out the annotationof this yearrsquos test data Finally we would like to thank all the participants for theircontributions and discussions at the workshop
The organizers
1httpiggsasharedtask2016githubiopagestask20descriptionhtmldata2httpiggsasharedtask2016githubiopagestask20descriptionhtmlscorer
iii
Overview of the IGGSA 2016 Shared Task on Source and TargetExtraction from Political Speeches
Josef Ruppenhoferlowast Julia Maria StruszligDagger Michael Wiegandlowast Institute for German Language Mannheim
Dagger Dept of Information Science and Language Technology Hildesheim University Spoken Language Systems Saarland University
ruppenhoferids-mannheimdejuliastrussuni-hildesheimde
michaelwiegandlsvuni-saarlandde
Abstract
We present the second iteration of IGGSArsquosShared Task on Sentiment Analysis for Ger-man It resumes the STEPS task of IG-GSArsquos 2014 evaluation campaign SourceSubjective Expression and Target Extrac-tion from Political Speeches As beforethe task is focused on fine-grained senti-ment analysis extracting sources and tar-gets with their associated subjective expres-sions from a corpus of speeches given inthe Swiss parliament The second itera-tion exhibits some differences howevermainly the use of an adjudicated gold stan-dard and the availability of training dataThe shared task had 2 participants submit-ting 7 runs for the full task and 3 runsfor each of the subtasks We evaluatethe results and compare them to the base-lines provided by the previous iterationThe shared task homepage can be foundat httpiggsasharedtask2016githubio
1 Introduction
Beyond detecting the presence of opinions (or morebroadly subjectivity) opinion mining and senti-ment analysis increasingly focus on determiningvarious attributes of opinions Among them arethe polarity (or valence) of an opinion (positivenegative or neutral) its intensity (or strength) andalso its source (or holder) as well as its target (ortopic)
The last two attributes are the focus of the IG-GSA shared task we want to determine whoseopinion is expressed and what entity or event it isabout Specific source and target extraction capa-bilities are required for the application of sentimentanalysis to unrestricted language text where thisinformation cannot be obtained from meta-data and
where opinions by multiple sources and about mul-tiple maybe related targets appear alongside eachother
Our shared task was organized under the aus-pices of the Interest Group of German SentimentAnalysis1 (IGGSA) The shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) constitutes the seconditeration of an evaluation campaign for source andtarget extraction on German language data Forthis shared task publicly available resources havebeen created which can serve as training and testcorpora for the evaluation of opinion source andtarget extraction in German
2 Task Description
The task calls for the identification of subjectiveexpressions sources and targets in parliamentaryspeeches While these texts can be expected tobe opinionated they pose the twin challenges thatsources other than the speaker may be relevant andthat the targets though constrained by topic canvary widely
21 Dataset
The STEPS data set stems from the debates ofthe Swiss parliament (Schweizer Bundesversamm-lung) This particular data set was originally se-lected with the following considerations in mindFirst the source data is freely available to the pub-lic and we may re-distribute it with our annotationsWe were not able to fully ascertain the copyright sit-uation for German parliamentary speeches whichwe had also considered using Second this type oftext poses the interesting challenge of dealing withmultiple sources and targets that cannot be gleanedeasily from meta-data but need to be retrieved fromthe running text
1httpssitesgooglecomsiteiggsahome
IGGSA Shared Task Workshop Sept 2016
1
As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Preface
The Shared Task on Source and Target Extraction from Political Speeches (STEPS)first ran in 2014 and is organized by the Interest Group on German Sentiment Analysis(IGGSA) This volume presents the proceedings of the workshop of the second iterationof the shared task The workshop was held at KONVENS 2016 at Ruhr-UniversityBochum on September 22 2016
As in the first edition of the shared task the main focus of STEPS was on fine-grainedsentiment analysis and offered a full task as well as two subtasks for the extractionSubjective Expressions andor their respective Sources and Targets
In order to make the task more accessible the annotation schema was revised for thisyearrsquos edition and an adjudicated gold standard was used for the evaluation In contrastto the pilot task this iteration provided training data for the participants opening theShared Task for systems based on machine learning approaches
The gold standard1 as well as the evaluation tool2 have been made publicly availableto the research community via the STEPSrsquo website
We would like to thank the GSCL for their financial support in annotating the 2014test data which were available as training data in this iteration A special thanks alsogoes to Stephanie Koumlser for her support on preparing and carrying out the annotationof this yearrsquos test data Finally we would like to thank all the participants for theircontributions and discussions at the workshop
The organizers
1httpiggsasharedtask2016githubiopagestask20descriptionhtmldata2httpiggsasharedtask2016githubiopagestask20descriptionhtmlscorer
iii
Overview of the IGGSA 2016 Shared Task on Source and TargetExtraction from Political Speeches
Josef Ruppenhoferlowast Julia Maria StruszligDagger Michael Wiegandlowast Institute for German Language Mannheim
Dagger Dept of Information Science and Language Technology Hildesheim University Spoken Language Systems Saarland University
ruppenhoferids-mannheimdejuliastrussuni-hildesheimde
michaelwiegandlsvuni-saarlandde
Abstract
We present the second iteration of IGGSArsquosShared Task on Sentiment Analysis for Ger-man It resumes the STEPS task of IG-GSArsquos 2014 evaluation campaign SourceSubjective Expression and Target Extrac-tion from Political Speeches As beforethe task is focused on fine-grained senti-ment analysis extracting sources and tar-gets with their associated subjective expres-sions from a corpus of speeches given inthe Swiss parliament The second itera-tion exhibits some differences howevermainly the use of an adjudicated gold stan-dard and the availability of training dataThe shared task had 2 participants submit-ting 7 runs for the full task and 3 runsfor each of the subtasks We evaluatethe results and compare them to the base-lines provided by the previous iterationThe shared task homepage can be foundat httpiggsasharedtask2016githubio
1 Introduction
Beyond detecting the presence of opinions (or morebroadly subjectivity) opinion mining and senti-ment analysis increasingly focus on determiningvarious attributes of opinions Among them arethe polarity (or valence) of an opinion (positivenegative or neutral) its intensity (or strength) andalso its source (or holder) as well as its target (ortopic)
The last two attributes are the focus of the IG-GSA shared task we want to determine whoseopinion is expressed and what entity or event it isabout Specific source and target extraction capa-bilities are required for the application of sentimentanalysis to unrestricted language text where thisinformation cannot be obtained from meta-data and
where opinions by multiple sources and about mul-tiple maybe related targets appear alongside eachother
Our shared task was organized under the aus-pices of the Interest Group of German SentimentAnalysis1 (IGGSA) The shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) constitutes the seconditeration of an evaluation campaign for source andtarget extraction on German language data Forthis shared task publicly available resources havebeen created which can serve as training and testcorpora for the evaluation of opinion source andtarget extraction in German
2 Task Description
The task calls for the identification of subjectiveexpressions sources and targets in parliamentaryspeeches While these texts can be expected tobe opinionated they pose the twin challenges thatsources other than the speaker may be relevant andthat the targets though constrained by topic canvary widely
21 Dataset
The STEPS data set stems from the debates ofthe Swiss parliament (Schweizer Bundesversamm-lung) This particular data set was originally se-lected with the following considerations in mindFirst the source data is freely available to the pub-lic and we may re-distribute it with our annotationsWe were not able to fully ascertain the copyright sit-uation for German parliamentary speeches whichwe had also considered using Second this type oftext poses the interesting challenge of dealing withmultiple sources and targets that cannot be gleanedeasily from meta-data but need to be retrieved fromthe running text
1httpssitesgooglecomsiteiggsahome
IGGSA Shared Task Workshop Sept 2016
1
As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Overview of the IGGSA 2016 Shared Task on Source and TargetExtraction from Political Speeches
Josef Ruppenhoferlowast Julia Maria StruszligDagger Michael Wiegandlowast Institute for German Language Mannheim
Dagger Dept of Information Science and Language Technology Hildesheim University Spoken Language Systems Saarland University
ruppenhoferids-mannheimdejuliastrussuni-hildesheimde
michaelwiegandlsvuni-saarlandde
Abstract
We present the second iteration of IGGSArsquosShared Task on Sentiment Analysis for Ger-man It resumes the STEPS task of IG-GSArsquos 2014 evaluation campaign SourceSubjective Expression and Target Extrac-tion from Political Speeches As beforethe task is focused on fine-grained senti-ment analysis extracting sources and tar-gets with their associated subjective expres-sions from a corpus of speeches given inthe Swiss parliament The second itera-tion exhibits some differences howevermainly the use of an adjudicated gold stan-dard and the availability of training dataThe shared task had 2 participants submit-ting 7 runs for the full task and 3 runsfor each of the subtasks We evaluatethe results and compare them to the base-lines provided by the previous iterationThe shared task homepage can be foundat httpiggsasharedtask2016githubio
1 Introduction
Beyond detecting the presence of opinions (or morebroadly subjectivity) opinion mining and senti-ment analysis increasingly focus on determiningvarious attributes of opinions Among them arethe polarity (or valence) of an opinion (positivenegative or neutral) its intensity (or strength) andalso its source (or holder) as well as its target (ortopic)
The last two attributes are the focus of the IG-GSA shared task we want to determine whoseopinion is expressed and what entity or event it isabout Specific source and target extraction capa-bilities are required for the application of sentimentanalysis to unrestricted language text where thisinformation cannot be obtained from meta-data and
where opinions by multiple sources and about mul-tiple maybe related targets appear alongside eachother
Our shared task was organized under the aus-pices of the Interest Group of German SentimentAnalysis1 (IGGSA) The shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) constitutes the seconditeration of an evaluation campaign for source andtarget extraction on German language data Forthis shared task publicly available resources havebeen created which can serve as training and testcorpora for the evaluation of opinion source andtarget extraction in German
2 Task Description
The task calls for the identification of subjectiveexpressions sources and targets in parliamentaryspeeches While these texts can be expected tobe opinionated they pose the twin challenges thatsources other than the speaker may be relevant andthat the targets though constrained by topic canvary widely
21 Dataset
The STEPS data set stems from the debates ofthe Swiss parliament (Schweizer Bundesversamm-lung) This particular data set was originally se-lected with the following considerations in mindFirst the source data is freely available to the pub-lic and we may re-distribute it with our annotationsWe were not able to fully ascertain the copyright sit-uation for German parliamentary speeches whichwe had also considered using Second this type oftext poses the interesting challenge of dealing withmultiple sources and targets that cannot be gleanedeasily from meta-data but need to be retrieved fromthe running text
1httpssitesgooglecomsiteiggsahome
IGGSA Shared Task Workshop Sept 2016
1
As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

As the Swiss parliament is a multi-lingual bodywe were careful to exclude not only non-Germanspeeches but also German speeches that constituteresponses to or comments on speeches hecklingand side questions in other languages This wayour annotators did not have to label any Germandata whose correct understanding might rely onmaterial in a language that they might not be ableto interpret correctly
Some potential linguistic difficulties consistedin peculiarities of Swiss German found in the dataFor instance the vocabulary of Swiss German issometimes subtly different from standard GermanFor instance the verb vorprellen is used in thefollowing example rather than vorpreschen whichwould be expected for German spoken in Germany
(1) Es ist unglaublich Weil die Aussen-ministerin vorgeprellt ist kann man dasnicht mehr zurucknehmen (Hans FehrFruhjahrsession 2008 Zweite Sitzung ndash04032008)2
lsquoIt is incredible because the foreign secre-tary acted rashly we cannot take that backagainrsquo
In order to limit any negative impact that mightcome from misreadings of the Swiss German byour annotators who were German and Austrianrather than Swiss we selected speeches about whatwe deemed to be non-parochial issues For instancewe picked texts on international affairs rather thanones about Swiss municipal governance
The training data for the 2016 shared task com-prises annotations on 605 sentences It represents asingle adjudicated version of the three-fold annota-tions that served as test data in the first iteration ofthe shared task in 2014 The test data for the 2016shared task was newly annotated It consists of 581sentences that were drawn from the same sourcenamely speeches from the Swiss parliament on thesame set of topics as used for the training data
Technically the annotated STEPS data was cre-ated using the following pre-processing pipelineSentence segmentation and tokenization was doneusing OpenNLP3 followed by lemmatization withthe TreeTagger (Schmid 1994) constituency pars-ing by the Berkeley parser (Petrov and Klein2007) and final conversion of the parse trees
2httpwwwparlamentchabframesetdn4802263473d_n_4802_263473_263632htm
3httpopennlpapacheorg
into TigerXML-Format using TIGER-tools (Lez-ius 2002) To perform the annotation we used theSalto-Tool (Burchardt et al 2006)4
22 Continuity with and Differences toPrevious Annotation
Through our annotation scheme5 we provide an-notations at the expression level No sentenceor document-level annotations are manually per-formed or automatically derived
As on the first iteration of the shared task therewere no restrictions imposed on annotations Thesources and targets could refer to any actor or is-sue as we did not focus on anything in particularThe subjective expressions could be verbs nounsadjectives adverbs or multi-words
The definition of subjective expressions (SE) thatwe used is broad and based on well-known proto-types It is inspired by Wilson and Wiebe (2005)lsquosuse of the superordinate notion private state asdefined by Quirk et al (1985) ldquoAs a result the an-notation scheme is centered on the notion of privatestate a general term that covers opinions beliefsthoughts feelings emotions goals evaluationsand judgmentsrdquo
bull evaluation (positive or negative)toll lsquogreatrsquo doof lsquostupidrsquo
bull (un)certaintyzweifeln lsquodoubtrsquo gewiss lsquocertainrsquo
bull emphasissicherlichbestimmt lsquocertainlyrsquo
bull speech actssagen lsquosayrsquo ankundigen lsquoannouncersquo
bull mental processesdenken lsquothinkrsquo glauben lsquobelieversquo
Beyond giving the prototypes we did not seekto impose on our annotators any particular defini-tion of subjective or opinion expressions from thelinguistic natural language processing or psycho-logical literature related to subjectivity appraisalemotion or related notions
4In addition to the XML files with the subjectivity annota-tions we also distributed to the shared task participants severalother files containing further aligned annotations of the textThese were annotations for named entities and of dependencyrather than constituency parses
5See httpiggsasharedtask2016githubiodataguide_2016pdf for the the guidelines weused
IGGSA Shared Task Workshop Sept 2016
2
Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Formally in terms of subjective expressionsthere were several noticeable changes made relativeto the first iteration First unlike in the 2014 itera-tion of the shared task punctuation marks (such asexclamation marks) could no longer be annotatedSecond while in the first iteration only the headnoun of a light verb construction was identified asthe subjective expression in this iteration the lightverbs were also to be included in the subjectiveexpression Annotators were instructed to observethe handling of candidate expressions in commondictionaries if a light verb is mentioned as partof an entry it should be labeled as part of the sub-jective expression Thus the combination Angsthaben (lit lsquohave fearrsquo) represents a single subjec-tive expression whereas in the first edition of theshared task only the noun Angst was treated as thesubjective expression A third change concernedcompounds We decided to no longer annotatesub-lexically This meant that compounds such asStaatstrauer lsquonational mourningrsquo would only betreated as subjective expressions but that we wouldnot break up the word and label the head -trauer asa subjective expression and the modifier Staats asa Source Instead we label the whole word only asa subjective expression
As before in marking subjective expressionsthe annotators were told to select minimal spansThis guidance was given because we had decidedthat within the scope of this shared task we wouldforgo any treatment of polarity and intensity Ac-cordingly negation intensifiers and attenuators andany other expressions that might affect a minimalexpressionrsquos polarity or intensity could be ignored
When labeling sources and targets annotatorswere asked to first consider syntactic and semanticdependents of the subjective expressions If sourcesand targets were locally unrealized the annotatorscould annotate other phrases in the context Wherea subjective expression represented the view of theimplicit speaker or text author annotators wereasked to indicate this by setting a flag SprecherlsquoSpeakerrsquo on the the source element Typical casesof subjective expressions are evaluative adjectivessuch as toll rsquogreatrsquo in (2)
(2) Das ist naturlich schon tollrsquoOf course thatrsquos really greatrsquo
For all three types of labels subjective expres-sions sources and targets annotators had the op-tion of using an additional flag to mark an annota-tion as Unsicher lsquoUncertainrsquo if they were unsure
whether the span should really be labeled with therelevant category
In addition instances of subjective expressionsand sources could be marked as Inferiert lsquoInferredrsquoIn the case of subjective expressions this coversfor instance cases where annotators were not sureif an expression constituted a polar fact or an inher-ently subjective expression In the case of sourcesthe lsquoinferredrsquo label applies to cases where the ref-erents cannot be annotated as local dependentsbut have to be found in the context An exam-ple is sentence (3) where the source of Strategienaufzuzeigen rsquoto lay out strategiesrsquo is not a directgrammatical dependent of that complex predicateInstead it can be found rsquohigher uprsquo as a comple-ment of the noun Ziel rsquogoalrsquo which governs theverb phrase that aufzuzeigen heads6
(3) Es war jedoch nicht Ziel des vorliegenden[Berichtes Source] an dieser Stelle Strate-gien aufzuzeigen zeitlichem Fokusauf das Berichtsjahr zu beschreibenrsquoHowever it wasnrsquot the goal of the reportat hand to lay out strategies here rsquo
Note that unlike in the first iteration we de-cided to forego the annotation of inferred targets aswe felt they would be too difficult to retrieve auto-matically Also we limited contextual annotationto the same sentence as the subjective expressionIn other words annotators could not mark sourcementions in preceding sentences
Likewise whereas in the first iteration the anno-tators were asked to use a flag Rhetorisches Stilmit-tel lsquoRhetorical devicersquo for subjective expressioninstances where subjectivity was conveyed throughsome kind of rhetorical device such as repetitionsuch instances were ruled out of the remit of thisshared task Accordingly no such instances occurin our data Even more importantly whereas forthe first iteration we had asked annotators to alsoannotate polar facts and mark them with a flag forthe second iteration we decided to exclude polarfacts from annotation altogether as they had led tolow agreement among the annotators in the firstiteration of the task What we had called polarfacts in the guidelines of the 2014 task we wouldnow call inferred opinions of the sort arising fromevents that affect their participants positively or
6Grammatically speaking this is an instance of what iscalled control
IGGSA Shared Task Workshop Sept 2016
3
2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

2014 2016Fleiss κ Cohenrsquos κ obsagr
subj expr 039 072 091sources 057 080 096targets 046 060 080
Table 1 Comparison of IAA values for 2014 and2016 iterations of the shared task
negatively7 For instance for a sentence such as100-year old driver crashes into school crowd onemight infer a negative attitude of the author towardsthe driver especially if the context emphasizes thedriverrsquos culpability or argues generally against let-ting older drivers keep their permits
As in the first iteration the annotation guide-lines gave annotators the option to mark particularsubjective expressions as Schweizerdeutsch lsquoSwissGermanrsquo when they involved language usage thatthey were not fully familiar with Such cases couldthen be excluded or weighted differently for thepurposes of system evaluation In our annotationthese markings were in fact very rare with only onesuch instance in the training data and none in thetest data
23 Interannotator Agreement
We calculated agreement in terms of a token-basedκ value Given that in our annotation scheme a sin-gle token can be eg a target of one subjective ex-pression while itself being a subjective expressionas well we need to calculate three kappa valuescovering the binary distinctions between presenceof each label and its absence
In the first iteration of the shared task we calcu-lated a multi-κ measure for our three annotators onthe basis of their annotations of the 605 sentencesin the full test set of the 2014 shared task (Daviesand Fleiss 1982) For this second iteration twoannotators performed double annotation on 50 sen-tences as the basis for IAA calculation For lackof resources the rest of the data was singly anno-tated We calculated Cohenrsquos kappa values AsTable 1 suggests inter-annotator agreement wasconsiderably improved This allowed participantsto use the annotated and adjudicated 2014 test dataas training data in this iteration of the shared task
7The terminology for these cases is somewhat in fluxDeng et al (2013) talk about benefactivemalefactive eventsand alternatively of goodForbadFor events Later work byWiebersquos group as well as work by Ruppenhofer and Brandes(2015) speaks more generally of effect events
24 Subtasks
As did the first iteration the second iteration of-fered a full task as well as two subtasks
Full task Identification of subjective expressionswith their respective sources and targets
Subtask 1 Participants are given the subjective ex-pressions and are only asked to identify opin-ion sources
Subtask 2 Participants are given the subjective ex-pressions and are only asked to identify opin-ion targets
Participants could choose any combination ofthe tasks
25 Evaluation Metrics
The runs that were submitted by the participantsof the shared task were evaluated on different lev-els according to the task they chose to participatein For the full task there was an evaluation of thesubjective expressions as well as the targets andsources for subjective expressions matching thesystemrsquos annotations against those in the gold stan-dard For subtasks 1 and 2 we evaluated only thesources or targets respectively as the subjectiveexpressions were already given
In the first iteration of the STEPS task we eval-uated each submitted run against each of our threeannotators individually rather than against a singlegold-standard The intent behind that choice wasto retain the variation between the annotators Inthe current second iteration the evaluation is sim-pler as we switched over to a single adjudicatedreference annotation as our gold standard
We use recall to measure the proportion of cor-rect system annotations with respect to the goldstandard annotations Additionally precision wascalculated so as to give the fraction of correct sys-tem annotations relative to all the system annota-tions
In this present iteration of the shared task weuse a strict measure for our primary evaluation ofsystem performance requiring precise span overlapfor a match 8
8By contrast in the first iteration of the shared task wehad counted a match when there was partial span overlapIn addition we had used the Dice coefficient to assess theoverlap between a system annotation and a gold standardannotation Equally for inter-annotator-agreement we hadcounted a match when there was partial span overlap
IGGSA Shared Task Workshop Sept 2016
4
Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Identification of Subjective ExpressionsLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0350 0239 0293 0346 0346 0507 0351p 0482 0570 0555 0564 0564 0654 0572r 0275 0151 0199 0249 0249 0414 0253
Identification of SourcesLK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
system type rule-based rule-based rule-based rule-based supervised rule-basedf1 0183 0155 0208 0258 0259 0318 0262p 0272 0449 0418 0420 0421 0502 0425r 0138 0094 0138 0186 0187 0233 0190
Identification of Targetssystem type LK Run1 UDS Run1 UDS Run2 UDS Run3 UDS Run4 UDS Run5 UDS Run6lowast
rule-based rule-based rule-based rule-based supervised rule-basedf1 0143 0184 0199 0253 0256 0225 0261p 0204 0476 0453 0448 0450 0323 0440r 0110 0114 0127 0176 0179 0173 0185
Table 2 Full task evaluation results based on the micro averages (results marked with a rsquorsquo are latesubmission)
26 ResultsTwo groups participated in our full task submittingone and six different runs respectively Table 2shows the results for each of the submitted runsbased on the micro average of exact matches Thesystem that produced UDS Run1 presents a base-line It is the rule-based system that UDS had usedin the previous iteration of this shared task Sincethis baseline system is publicly available the scoresfor UDS Run1 can easily be replicated
The rule-based runs submitted by UDS thisyear9 (ie UDS Run2 UDS Run3 UDS Run4 andUDS Run6) implement several extensions that pro-vide functionalities missing from the first incarna-tion of the UDS system
bull detection of grammatically-induced sentimentand the extraction of its corresponding sourcesand targets
bull handling multiword expressions as subjectiveexpressions and the extraction of their corre-sponding sources and targets
bull normalization of dependency parses with re-gard to coordination
Please consult UDSrsquos participation paper for detailsabout these extensions of the baseline system
The runs provided by Potsdam are also rule-based but they are focused on achieving generaliza-tion beyond the instances of subjective expressions
9The UDS systems have been developed under the super-vision of Michael Wiegand one of the workshop organizers
and their sources and targets seen in the trainingdata They do so based on representing the relationsbetween subjective expressions and their sourcesand targets in terms of paths through constituencyparse trees Potsdamrsquos Run 1 (LK Run1) seeks gen-eralization for the subjective expressions alreadyobserved in the training data by merging all thepaths of any two subjective expressions that shareany path in the training data
All the submitted runs show improvements overthe baseline system for the three challenges in thefull task with the exception of LK Run1 on targetidentification While the supervised system usedfor Run 5 of the UDS group achieved the best re-sults for the detection of subjective expressions andsources the rule based system of UDSrsquos Run 6handled the identification of targets better
When considering partial matches as well theresults on detecting sources improve only slightlybut show big improvements on targets with up to25 points A graphical comparison between exactand partial matches can be found in Figure 1
The results also show that the poor f1-measurescan be mainly attributed to lacking recall In otherwords the systems miss a large portion of the man-ual annotations
The two participating groups also submitted oneand two runs for each of the subtasks respectivelySince the baseline system only supports the extrac-tion of sources and targets according to the defini-tion of the full task a baseline score for the twosubtasks could not be provided
The results in Table 3 show improvements in
IGGSA Shared Task Workshop Sept 2016
5
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23
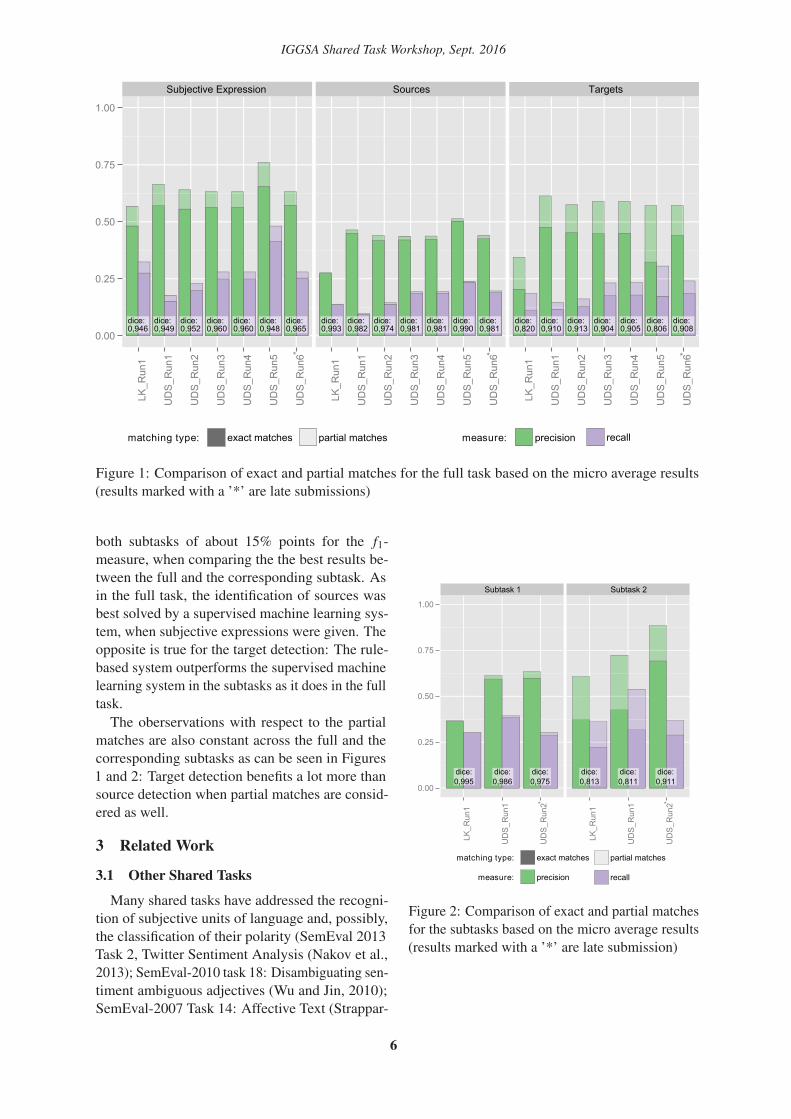
Figure 1 Comparison of exact and partial matches for the full task based on the micro average results
(results marked with a rsquorsquo are late submissions)
both subtasks of about 15 points for the f1-
measure when comparing the the best results be-
tween the full and the corresponding subtask As
in the full task the identification of sources was
best solved by a supervised machine learning sys-
tem when subjective expressions were given The
opposite is true for the target detection The rule-
based system outperforms the supervised machine
learning system in the subtasks as it does in the full
task
The oberservations with respect to the partial
matches are also constant across the full and the
corresponding subtasks as can be seen in Figures
1 and 2 Target detection benefits a lot more than
source detection when partial matches are consid-
ered as well
3 Related Work
31 Other Shared Tasks
Many shared tasks have addressed the recogni-
tion of subjective units of language and possibly
the classification of their polarity (SemEval 2013
Task 2 Twitter Sentiment Analysis (Nakov et al
2013) SemEval-2010 task 18 Disambiguating sen-
timent ambiguous adjectives (Wu and Jin 2010)
SemEval-2007 Task 14 Affective Text (Strappar-
Figure 2 Comparison of exact and partial matches
for the subtasks based on the micro average results
(results marked with a rsquorsquo are late submission)
IGGSA Shared Task Workshop Sept 2016
6
Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Subtask 1 Identification of SourcesLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0329 0466 0387p 0362 0594 0599r 0301 0383 0286
Subtask 2 Identification of TargetsLK Run1 UDS Run1 UDS Run2lowast
system type supervised rule-basedf1 0278 0363 0407p 0373 0426 0692r 0222 0317 0289
Table 3 Subtasks evaluation results based on themicro averages (results marked with a rsquorsquo are latesubmissions)
ava and Mihalcea 2007) inter alia)Only of late have shared tasks included the ex-
traction of sources and targets Some relativelyearly work that is relevant to the task presentedhere was done in the context of the Japanese NT-CIR10 Project In the NTCIR-6 Opinion AnalysisPilot Task (Seki et al 2007) which was offered forChinese Japanese and English sources and targetshad to be found relative to whole opinionated sen-tences rather than individual subjective expressionsHowever the task allowed for multiple opinionsources to be recorded for a given sentence if therewere multiple expressions of opinion The opin-ion source for a sentence could occur anywherein the document In the evaluation as necessaryco-reference information was used to (manually)check whether a system response was part of thecorrect chain of co-referring mentions The sen-tences in the document were judged as either rele-vant or non-relevant to the topic (=target) Polaritywas determined at the sentence level For sentenceswith more than one opinion expressed the polarityof the main opinion was carried over to the sen-tence as a whole All sentences were annotatedby three raters allowing for strict and lenient (bymajority vote) evaluation The subsequent Multi-lingual Opinion Analysis tasks NTCIR-7 (Seki etal 2008) and NTCIR-8 (Seki et al 2010) werebasically similar in their setup to NTCIR-6
While our shared task focussed on German themost important difference to the shared tasks orga-nized by NTCIR is that it defined the source and tar-get extraction task at the level of individual subjec-tive expressions There was no comparable sharedtask annotating at the expression level rendering
10NII [National Institute of Informatics] Test Collection forIR Systems
existing guidelines impractical and necessitatingthe development of completely new guidelines
Another more recent shared task related toSTEPS is the Sentiment Slot Filling track (SSF)that was part of the Shared Task for KnowledgeBase Population of the Text Analysis Conference(TAC) organised by the National Institute of Stan-dards and Technology (NIST) (Mitchell 2013)The major distinguishing characteristic of thatshared task which is offered exclusively for En-glish language data lies in its retrieval-like setupIn our task systems have to extract all possibletriplets of subjective expression opinion sourceand target from a given text By contrast in SSFthe task is to retrieve sources that have some opin-ion towards a given target entity or targets of somegiven opinion sources In both cases the polarity ofthe underlying opinion is also specified within SSFThe given targets or sources are considered a typeof query The opinion sources and targets are tobe retrieved from a document collection11 UnlikeSTEPS SSF uses heterogeneous text documentsincluding both newswire and discussion forum datafrom the Web
32 Systems for Source and Target Extraction
Throughout the rise of sentiment analysis therehave been various systems tackling either targetextraction (eg Stoyanov and Cardie (2008)) orsource extraction (eg Choi et al (2005) Wilsonet al (2005)) Only recently has work on automaticsystems for the extraction of complete fine-grainedopinions picked up significantly Deng and Wiebe(2015a) as part of their work on opinion infer-ence build on existing opinion analysis systemsto construct a new system that extracts triplets ofsources polarities and targets from the MPQA 30corpus Deng and Wiebe (2015b)12 Their systemextracts directly encoded opinions that is ones thatare not inferred but directly conveyed by lexico-grammatical means as the basis for subsequentinference of implicit opinions To extract explicitopinions Deng and Wiebe (2015a)rsquos system incor-porates among others a prior system by Yang andCardie (2013) That earlier system is trained toextract triplets of source span opinion span and tar-
11In 2014 the text from which entities are to be retrieved isrestricted to one document per query
12Note that the specific (spans of the) subjective expressionswhich give rise to the polarity and which interrelate source andtarget are not directly modeled in Deng and Wiebe (2015a)lsquostask set-up
IGGSA Shared Task Workshop Sept 2016
7
get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

get span but is adapted to the earlier 20 version ofMPQA which lacked the entity and event targetsavailable in version 30 of the corpus13
A difference between the above mentioned sys-tems and the approach taken here which is alsoembodied by the system of Wiegand et al (2014)is that we tie source and target extraction explic-itly to the analysis of predicate-argument structures(and ideally semantic roles) whereas the formersystems and the corpora they evaluate against aremuch less strongly guided by these considerations
4 Conclusion and Outlook
We reported on the second iteration of theSTEPS shared task for German sentiment analysisOur task focused on the discovery of subjectiveexpressions and their related entities in politicalspeeches
Based on feedback and reflection following thefirst iteration we made a baseline system availableso as to lower the barrier for participation in seconditeration of the shared task and to allow participantsto focus their efforts on specific ideas and meth-ods We also changed the evaluation setup so thata single reference annotation was used rather thanmatching against a variety of different referencesThis simpler evaluation mode provided participantswith a clear objective function that could be learntand made sure that the upper bound for systemperformance would be 100 precisionrecallF1-score whereas it was lower for the first iterationgiven that existing differences between the annota-tors necessarily led to false positives and negatives
Despite these changes in the end the task hadonly 2 participants We therefore again soughtfeedback from actual and potential participants atthe end of the IGGSA workshop in order to be ableto tailor the tasks better in a future iteration
Acknowledgments
We would like to thank Simon Clematide for help-ing us get access to the Swiss data for the STEPStask For her support in preparing and carrying outthe annotations of this data we would like to thankStephanie Koser
We are happy to acknowledge the finanical sup-port that the GSCL (German Society for Compu-
13Deng and Wiebe (2015a) also use two more systems thatidentify opinion spans and polarities but which either do notextract sources and targets at all (Yang and Cardie 2014)or assume that the writer is always the source (Socher et al2013)
tational Linguistics) granted us in 2014 for the an-notation of the training data which served as testdata in the first iteration of the IGGSA shared task
Josef Ruppenhofer was partially supported bythe German Research Foundation (DFG) undergrant RU 18732-1
Michael Wiegand was partially supported by theGerman Research Foundataion (DFG) under grantWI 42042-1
ReferencesAljoscha Burchardt Katrin Erk Anette Frank Andrea
Kowalski and Sebastian Pado 2006 SALTO - AVersatile Multi-Level Annotation Tool In Proceed-ings of the 5th Conference on Language Resourcesand Evaluation pages 517ndash520
Yejin Choi Claire Cardie Ellen Riloff and SiddharthPatwardhan 2005 Identifying sources of opinionswith conditional random fields and extraction pat-terns In Proceedings of Human Language Technol-ogy Conference and Conference on Empirical Meth-ods in Natural Language Processing pages 355ndash362 Vancouver British Columbia Canada OctoberAssociation for Computational Linguistics
Mark Davies and Joseph L Fleiss 1982 Measur-ing agreement for multinomial data Biometrics38(4)1047ndash1051
Lingjia Deng and Janyce Wiebe 2015a Joint predic-tion for entityevent-level sentiment analysis usingprobabilistic soft logic models In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing pages 179ndash189 LisbonPortugal September Association for ComputationalLinguistics
Lingjia Deng and Janyce Wiebe 2015b Mpqa 30 Anentityevent-level sentiment corpus In Proceedingsof the 2015 Conference of the North American Chap-ter of the Association for Computational LinguisticsHuman Language Technologies pages 1323ndash1328Denver Colorado MayndashJune Association for Com-putational Linguistics
Lingjia Deng Yoonjung Choi and Janyce Wiebe2013 Benefactivemalefactive event and writer at-titude annotation In Proceedings of the 51st AnnualMeeting of the Association for Computational Lin-guistics (Volume 2 Short Papers) pages 120ndash125Sofia Bulgaria August Association for Computa-tional Linguistics
Wolfgang Lezius 2002 TIGERsearch - Ein Such-werkzeug fur Baumbanken In Stephan Buse-mann editor Proceedings of KONVENS 2002Saarbrucken Germany
Margaret Mitchell 2013 Overview of the TAC2013Knowledge Base Population Evaluation English
IGGSA Shared Task Workshop Sept 2016
8
Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Sentiment Slot Filling In Proceedings of theText Analysis Conference (TAC) Gaithersburg MDUSA
Preslav Nakov Sara Rosenthal Zornitsa KozarevaVeselin Stoyanov Alan Ritter and Theresa Wilson2013 SemEval-2013 Task 2 Sentiment Analysis inTwitter In Second Joint Conference on Lexical andComputational Semantics (SEM) Volume 2 Pro-ceedings of the Seventh International Workshop onSemantic Evaluation (SemEval 2013) pages 312ndash320 Atlanta and Georgia and USA Association forComputational Linguistics
Slav Petrov and Dan Klein 2007 Improved inferencefor unlexicalized parsing In Human Language Tech-nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
Randolph Quirk Sidney Greenbaum Geoffry Leechand Jan Svartvik 1985 A comprehensive grammarof the English language Longman
Josef Ruppenhofer and Jasper Brandes 2015 Extend-ing effect annotation with lexical decomposition InProceedings of the 6th Workshop in ComputationalApproaches to Subjectivity and Sentiment Analysispages 67ndash76
Helmut Schmid 1994 Probabilistic part-of-speechtagging using decision trees In Proceedings of Inter-national Conference on New Methods in LanguageProcessing Manchester UK
Yohei Seki David Kirk Evans Lun-Wei Ku Hsin-HsiChen Noriko Kando and Chin-Yew Lin 2007Overview of opinion analysis pilot task at ntcir-6 InProceedings of NTCIR-6 Workshop Meeting pages265ndash278
Yohei Seki David Kirk Evans Lun-Wei Ku Le SunHsin-Hsi Chen and Noriko Kando 2008 Overviewof multilingual opinion analysis task at NTCIR-7In Proceedings of the 7th NTCIR Workshop Meet-ing on Evaluation of Information Access Technolo-gies Information Retrieval Question Answeringand Cross-Lingual Information Access pages 185ndash203
Yohei Seki Lun-Wei Ku Le Sun Hsin-Hsi Chen andNoriko Kando 2010 Overview of MultilingualOpinion Analysis Task at NTCIR-8 A Step TowardCross Lingual Opinion Analysis In Proceedings ofthe 8th NTCIR Workshop Meeting on Evaluation ofInformation Access Technologies Information Re-trieval Question Answering and Cross-Lingual In-formation Access pages 209ndash220
Richard Socher Alex Perelygin Jean Wu JasonChuang Christopher D Manning Andrew Ng andChristopher Potts 2013 Recursive deep modelsfor semantic compositionality over a sentiment tree-bank In Proceedings of the 2013 Conference on
Empirical Methods in Natural Language Processingpages 1631ndash1642 Seattle Washington USA Octo-ber Association for Computational Linguistics
Veselin Stoyanov and Claire Cardie 2008 Topicidentification for fine-grained opinion analysis InProceedings of the 22nd International Conferenceon Computational Linguistics (Coling 2008) pages817ndash824 Manchester UK August Coling 2008 Or-ganizing Committee
Carlo Strapparava and Rada Mihalcea 2007SemEval-2007 Task 14 Affective Text In EnekoAgirre Lluıs Marquez and Richard Wicentowskieditors Proceedings of the Fourth InternationalWorkshop on Semantic Evaluations (SemEval-2007)pages 70ndash74 Association for Computational Lin-guistics
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland univer-sityrsquos participation in the german sentiment analy-sis shared task (gestalt) In Gertrud Faaszligand JosefRuppenhofer editors Workshop Proceedings of the12th Edition of the KONVENS Conference pages174ndash184 Hildesheim Germany October Univer-sitat Heidelberg
Theresa Wilson and Janyce Wiebe 2005 Annotatingattributions and private states In Proceedings of theWorkshop on Frontiers in Corpus Annotations II Piein the Sky pages 53ndash60 Ann Arbor Michigan JuneAssociation for Computational Linguistics
Theresa Wilson Paul Hoffmann Swapna Somasun-daran Jason Kessler Janyce Wiebe Yejin ChoiClaire Cardie Ellen Riloff and Siddharth Patward-han 2005 Opinionfinder A system for subjectivityanalysis In Proceedings of HLTEMNLP on Inter-active Demonstrations HLT-Demo rsquo05 pages 34ndash35 Stroudsburg PA USA Association for Compu-tational Linguistics
Yunfang Wu and Peng Jin 2010 SemEval-2010 Task18 Disambiguating Sentiment Ambiguous Adjec-tives In Katrin Erk and Carlo Strapparava editorsProceedings of the 5th International Workshop onSemantic Evaluation pages 81ndash85 Stroudsburg andPA and USA Association for Computational Lin-guistics
Bishan Yang and Claire Cardie 2013 Joint inferencefor fine-grained opinion extraction In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1 Long Papers)pages 1640ndash1649 Sofia Bulgaria August Associa-tion for Computational Linguistics
Bishan Yang and Claire Cardie 2014 Context-awarelearning for sentence-level sentiment analysis withposterior regularization In Proceedings of the 52ndAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1 Long Papers) pages325ndash335 Baltimore Maryland June Associationfor Computational Linguistics
IGGSA Shared Task Workshop Sept 2016
9
System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

System documentation for the IGGSA Shared Task 2016
Leonard KrieseUniversitat Potsdam
Department LinguistikKarl-Liebknecht-Straszlige 24-25
14476 Potsdamleonardkriesehotmailde
Abstract
This is a brief documentation of a systemwhich was created to compete in the sharedtask on Source Subjective Expression andTarget Extraction from Political Speeches(STEPS) The systemrsquos model is createdfrom supervised learning on using the pro-vided training data and is learning a lexiconof subjective expressions Then a slightlydifferent model will be presented that gen-eralizes a little bit from the training data
1 Introduction
This is a documentation of a system which hasbeen created within the context of the IGGSAShared Task 2016 STEPS1 Briefly the main goalwas to find subjective expressions (SE) that arefunctioning as opinion triggers their sources theoriginator of an SE and their targets the scopeof an opinion The system was aimed to performon the domain of parliament speeches from theSwiss Parliament The systemrsquos model was trainedon the training data provided alongside the sharedtask and was from the same domain preprocessedwith constituency parses from the Berkley Parser(Petrov and Klein 2007) and had annotations ofSEs and their respective targets and sources
The model is using a mapping from groupedSEs to a set of rdquopath-bundlesrdquo syntactic relationsbetween SE source and target Since the learnedSEs are a lexicon derived from the training data andare very domain-dependent there will be a secondmodel presented which generalizes slightly fromthe training data by using the SentiWS (Remuset al 2010) as a lexicon of SEs There the part-of-speech tag of each word from the SentiWS ismapped to a set of path-bundles
1Source Subjective Expression and Target Extraction fromPolitical Speeches(STEPS)
2 System description
Participants were free in the way they could de-velop the system They just had to identify sub-jective expressions and their corresponding targetand source Our system is using a lexical approachto find the subjective expressions and a syntacticapproach in finding the corresponding target andsource First all the words in the training data werelemmatized with the TreeTagger (Schmid 1995)to keep the number of considered words as low aspossible Then the SE lexicon was derived fromall the SEs in the training data For each SE in thetraining data its path-bundle a syntactic relationto the SErsquos target and source was stored Thesepath-bundles were derived from the constituency-parses from the Berkley Parser For each sentencein the test data all the words were checked if theywere SE candidates If they were their syntacticsurroundings were checked as well If these werealso valid a target and source was annotated Thetest data was also lemmatized
The outline of this paper is the approach ofderiving the syntactic relation of the SEs by intro-ducing the concepts of rdquominimal treesrdquo and rdquopath-bundlesrdquo (Section 21 and Section 22) will be pre-sented Then the clustering of SEs and their path-bundles will be explained (Section 23) and a moregeneralized model (Section 24)
21 Minimal Trees
We use the term rdquominimal treerdquo for a sub-tree ofa syntax tree given in the training data for eachsentence with the following property its root nodeis the least common ancestor of the SE target andsource2 From all the identified minimal trees socalled path-bundles were derived In Figure 1 and2 you can see such minimal trees These just focuson the part of the syntactic tree which relates to
2Like the lowest common multiple just for SE target andsource
IGGSA Shared Task Workshop Sept 2016
10
Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Figure 1 minimal tree covering auch die Schweizhat diese Ziele unterzeichnet
Figure 2 minimal tree covering Fur unsere inter-nationale Glaubwurdigkeit
SE source and target Following the root node ofthe minimal tree to the SE target and source path-bundles are extracted as you can see in (1) and(2)
22 Path-BundlesA path-bundle holds the paths in the minimal treefor the SE target and source to the root node of theminimal tree
(1) path-bundle for minimal tree in Figure 1SE [S VP VVPP]T [S VP NP]S [S NP]
(2) path-bundle for minimal tree in Figure 2SE [NP NN]T [NP PPOSAT]S [NP ADJA]
As you can see in (1) and (2) there is no dis-tinction between terminals and non-terminals heresince SEs are always terminals (or a group of ter-minals) and targets and sources are sometimes oneand the other A path-bundle is expressing a syntac-tic relation between the SE target and source andcan be seen as a syntactic pattern In practice manySEs have more than one path-bundleWhen the system is annotating a sentence egfrom the test data and an SE is detected the sys-tem checks the current syntax tree for one of the
path-bundles an SE might have If one bundle ap-plies source and target along with the SE will beannotatedAlso the flags which appear in the training dataare stored to a path-bundle and will be annotatedwhen the corresponding path-bundle applies
23 ClusteringAfter the training procedure every SE has its ownset of path-bundles To make the system moreopen to unseen data the SEs were clustered in thefollowing way if an SE shared at least one path-bundle with another SE they were put togetherinto a cluster The idea is if SEs share a syntacticpattern towards their target and source they arealso syntactically similar and hence should sharetheir path-bundles Rather than using a single SEmapped to a set of path-bundles the system usesa mapping of a set of SEs to the set of their path-bundles
(3) befurworten wunschen nachlebenbeschreiben schutzen versprechenverscharfen erreichen empfehlenausschreiben verlangen folgen mitun-terschreiben beizustellen eingreifenappellieren behandeln
(4) Regelung Bodenschutz Nichtein-treten Anreiz Verteidigung KommentatorKommissionsmotion VerkehrsbelastungJugendstrafgesetz RuckweisungsantragKonvention Neutralitatsthematik Europa-politik Debatte
(5) lehnen ab nehmen auf ordnen an
The clusters in (3) (4) and (5) are examples of whathas been clustered in the training This was doneautomatically and is presented here for illustrationAs future work we will consider manually merg-ing some of the clusters and testing whether thatimproves the performance
24 Second modelThe second model is generalizing a little bit fromthe lexicon of the training data since the firstmodel is very domain-dependent and should per-form much worse on another domain than on thetest data The generalization is done by exchangingthe lexicon learned from the training data with thewords from the SentiWS (Remus et al 2010)This model is thus more generalized and notdomain-dependent but neither domain-specific If
IGGSA Shared Task Workshop Sept 2016
11
a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

a word from the lexicon will be detected in a sen-tence then all path-bundles which begin with thesame pos-tag in the SE-path will be consideredfor finding the target and sourceIn general the sorting of the path-bundles is depen-dent from the leaf node in the SE-path since theprocedure is the following find an SE and checkif one of the path-bundles can be applied Maybethis can be done in a reverse way where every nodein a syntax tree is seen as a potential top-node ofa path-bundle and if a path-bundle can be appliedSE target and source will be annotated accordinglyThis could be a heuristic for finding SEs withoutthe use of a lexicon
3 Results
In this part the results of the two models whichran on the STEPS 2016 data will be presented
Measure Supervised SentiWSF1 SE exact 3502 3042F1 source exact 1829 1562F1 target exact 1432 1452Prec SE exact 4815 5840Prec source exact 2723 3466Prec target exact 2044 3211Rec SE exact 2751 2056Rec source exact 1377 1008Rec target exact 1102 938
Table 1 Results of the systemrsquos runs on the maintask
Measure Subtask AF1 source exact 3287Prec source exact 3623Rec source exact 3008
Subtask BF1 target exact 2783Prec target exact 3729Rec target exact 2220
Table 2 Results of the system run on the subtasks
The first system (Supervised) is the domain-dependent supervised system with the lexiconfrom the training data and was the system whichwas submitted to the IGGSA Shared Task 2016The second system (SentiWS) is the system withthe lexicon from the SentiWS Speaking about Ta-ble 1 with the results for the main task considering
the F1-measure the first system was better in find-ing SEs and sources but a little bit worse in findingtargetsThe second system the more general system wasbetter in the precision scores overall This meansin comparison to the supervised system that theclassified SEs targets and source were more cor-rect But it did no find as many as it should havefound as the first system according to the recallscores This leads to the assumption that the firstsystem might overgenerate and is therefore hittingmore of the true positives but is also making moremistakesLooking at Table 2 the systemic approach is justdifferent in terms of the lexicon of SEs and notin terms of the path-bundles So there is no dis-tinction between the two systems here since all theSEs were given in the subtasks and only the learnedpath-bundles determined the outcome of the sub-tasks For the system it seems easier to find theright sources rather than the right targets which isalso proven by the numbers in Table 1
4 Conclusion
In this documentation for the IGGSA Shared Task2016 an approach was presented which uses theprovided training data First a lexicon of SEs wasderived from the training data along with their path-bundles indicating where to find their respectivetarget and source Two generalization steps weremade by first clustering SEs which had syntac-tic similarities and second by exchanging the lexi-con derived from the training data with a domain-independent lexicon the SentiWSThe first very domain-dependent system per-formed better than the more general second systemaccording to the f-score But the second system didnot make as many mistakes in detecting SEs fromthe test data by looking at the precision score so itmight be worth to investigate into the direction ofusing a more general approach furtherThe approach of deriving path-bundles from syn-tax trees itself is domain-independent since it canbe easily applied to any kind of parse It wouldbe nice to see how the results will change whenother parsers like a dependency parser will beused This is something for the future work
ReferencesSlav Petrov and Dan Klein 2007 Improved inference
for unlexicalized parsing In Human Language Tech-
IGGSA Shared Task Workshop Sept 2016
12
nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

nologies 2007 The Conference of the North Amer-ican Chapter of the Association for ComputationalLinguistics Proceedings of the Main Conferencepages 404ndash411 Rochester New York April Asso-ciation for Computational Linguistics
R Remus U Quasthoff and G Heyer 2010 Sentiwsndash a publicly available german-language resourcefor sentiment analysis In Proceedings of the 7thInternational Language Resources and Evaluation(LRECrsquo10) pages 1168ndash1171
Helmut Schmid 1995 Improvements in part-of-speech tagging with an application to german InIn Proceedings of the ACL SIGDAT-Workshop Cite-seer
IGGSA Shared Task Workshop Sept 2016
13
Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Saarland Universityrsquos Participation in the Second Shared Task on SourceSubjective Expression and Target Extraction from Political Speeches
(STEPS-2016)Michael Wiegand Nadisha-Marie Aliman Tatjana Anikina Patrick CarrollMargarita Chikobava Erik Hahn Marina Haid Katja Konig Leonie Lapp
Artuur Leeuwenberg Martin Wolf Maximilian WolfSpoken Language Systems Saarland University
D-66123 Saarbrucken Germanymichaelwiegandlsvuni-saarlandde
Abstract
We report on the two systems we builtfor the second run of the shared task onSource Subjective Expression and Tar-get Extraction from Political Speeches(STEPS) The first system is a rule-basedsystem relying on a predicate lexicon spec-ifying extraction rules for verbs nounsand adjectives while the second is a su-pervised system trained on the adjudicatedtest data of the previous run of this sharedtask
1 Introduction
In this paper we describe our two systems for thesecond run of the shared task on Source Subjec-tive Expression and Target Extraction from Polit-ical Speeches (STEPS) organized by the InterestGroup on German Sentiment Analysis (IGGSA)In that task both opinion sources ie the entitiesthat utter an opinion and opinion targets ie theentities towards which an opinion is directed areextracted from German sentences The opinionsthemselves have also to be detected automaticallyThe sentences originate from debates of the SwissParliament (Schweizer Bundesversammlung)
The first system is a rule-based system relyingon a predicate lexicon specifying extraction rulesfor verbs nouns and adjectives while the secondis a supervised classifier trained on the adjudicatedtest data of the previous edition of this shared task(Ruppenhofer et al 2014)
2 Rule-based System
Our rule-based system is an extension of the rule-based system built for the first edition of thisshared task as described in Wiegand et al (2014)The pipeline of the rule-based system is displayedin Figure 1 The major assumption that underliesthis system is that the concrete opinion sources
and targets are largely determined by the opinionpredicate1 by which they are evoked Thereforethe task of extracting opinion sources and targets isa lexical problem and a lexicon for opinion pred-icates specifying the argument position of sourcesand targets is required For instance in Sentence(1) the sentiment is evoked by the predicate liebtthe source is realized by its subject Peter while thetarget is realized by its accusative object Maria
(1) [Peter]sourcesubj liebt [Maria]target
obja (Peter loves Maria)
With this assumption we can specify the demandsof an opinion sourcetarget extraction system Itshould be a tool that given a lexicon with argu-ment information about sources and targets foreach opinion predicate
bull checks each sentence for the presence of suchopinion predicates
bull syntactically analyzes each sentence and
bull determines whether constituents fulfillingthe respective argument information aboutsources and targets are present in the sen-tence
In the following we briefly describe the linguis-tic processing (Section 21) and the mechanismfor extracting rules (Section 22) Then we in-troduce the extensions we applied for this yearrsquossubmission (Section 23) For general informationregarding the architecture of the system we referthe reader to Wiegand et al (2014)
The version of the rule-based system that hasbeen revised for this yearrsquos shared task has beenmade publicly available2 allowing researchers to
1We currently consider opinion verbs nouns and adjec-tives as potential opinion predicates
2httpsgithubcommiwieggerman-opinion-role-extractor
IGGSA Shared Task Workshop Sept 2016
14
Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Figure 1 Processing pipeline of the rule-based system
test different sentiment lexicons with different ar-gument information about opinion sources and tar-gets
21 Linguistic ProcessingEven though the data for this task already comein a parsed format we felt the need to add fur-ther linguistic information In addition to the ex-isting constituency parse provided by the Berkeleyparser (Petrov et al 2006) we also included de-pendency parse information With that representa-tion relationships between opinion predicates andtheir sources and targets can be formulated moreintuitively3
As a dependency parser we chose ParZu (Sen-nrich et al 2009) We also carried out some nor-malization on the parse output in order to have amore compact representation To a large extentthe type of normalization we carry out is in linewith the output of dependency parsers for Englishsuch as the Stanford parser (de Marneffe et al2006) It is included since it largely facilitates writ-ing extraction rules The normalization includes
(a) active-passive normalization3As a matter of fact the most appropriate representation
for that task is semantic-role labeling (Ruppenhofer et al2008 Kim and Hovy 2006 Wiegand and Klakow 2012)however there currently do not exist any robust tools of thatkind for German
(b) conflating several multi-edge relationships toone-edge relationships
(c) particle-verb reconstruction
These normalization steps are explained in moredetail in Wiegand et al (2014)
We also employed a semantic filter for the de-tection of opinion sources Since such entities canonly represent persons or groups of persons weemployed a named-entity recognizer (Benikova etal 2015) to recognize person names and Ger-maNet (Hamp and Feldweg 1997) to establishthat a common noun represents a person or a groupof persons
22 The Extraction Rules
The heart of the rule-based system is a lexiconthat specifies the (possible) argument positions ofsources and targets So far there does not existany lexicon with that specific information whichis why we came up with a set of default rules forthe different parts of speech The set of opinionpredicates are the subjective expressions from thePolArt system (Klenner et al 2009) Every men-tion of such expressions will be considered as amention of an opinion predicate that is we do notcarry out any subjectivity word-sense disambigua-tion (Akkaya et al 2009)
IGGSA Shared Task Workshop Sept 2016
15
These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

These default extraction rules are designed insuch a way that for a large fraction of opinion pred-icates with the pertaining part of speech they arecorrect The rules are illustrated in Table 1 Wecurrently have distinct rules for verbs nouns andadjectives All rules have in common that for everyopinion predicate mention at most one source andat most one target is assigned The rules mostly ad-here to the dependency relation labels of ParZu4
The rule for verbs assumes sources in subjectand targets in object position (1) Note that fortargets we specify a priority list That is themost preferred argument position is a dative ob-ject (objd) the second most preferred position isan accusative object (obja) etc In computationalterms this means that the classifier checks the en-tire priority list (from left to right) until a rela-tion has matched in the sentence to be classifiedFor prepositional complements we also allow awildcard symbol (pobj-) that matches all prepo-sitional complements irrespective of its particularhead eg uber das Freihandelsabkommen (pobj-ueber) in (2)
(2) [Deutschland und die USA]sourcesubj streiten
[uber das Freihandelsabkommen]targetpobjminusueber
(Germany and the USA quarrel over the freetrade agreement)
For nouns we allow determiners (possessives)(3) and genitive modifiers (4) as opinion sourceswhereas targets are considered to occur as preposi-tional objects
(3) [Sein]sourcedet Hass [auf die Regierung]target
pobjminusauf
(His hatred towards the government )
(4) Die Haltung [der Kanzlerin]sourcegmod [zur
Energiewende]targetpobjminuszu
(The chancellorrsquos attitude towards the energyrevolution )
The rule for adjectives is different from the oth-ers since it assumes the source of the adjective tobe the speaker of the utterance Only the targethas a surface realization Either it is an attributiveadjective (5) or it is the subject of a predicativeadjective (6)
4The definition of those dependency labels is available athttpsgithubcomrsennrichParZublobmasterLABELSmd
Part of Speech Source Targetverb subj objd obja objc obji s objp-noun det gmod objp-adjective author attr-rev subj
Table 1 Extraction rules for verb noun and adjec-tive opinion predicates
(5) Das ist ein [guter]targetattrminusrev Vorschlag
(This is a good proposal)
(6) [Der Vorschlag]targetsubj ist gut
(The proposal is good)
Our rule-based system is designed in such a waythat in principle it would also allow more thanone opinion frame to be evoked by the same opin-ion predicate For example in Peter uberzeugtMariaPeter convinces Maria one frame sees Pe-ter as source and Maria as target and anotherframe where the roles are switched Our defaultrules do not include such cases since such prop-erty is specific to particular opinion predicates
23 Extensions
In this subsection we present the extensions weadded to the existing rule-based system from theprevious iteration of this shared task
231 Partial Analysis
Our system has been modified in such a way thatit can now accept a partial analysis as input andprocess it further By that we mean the existingannotation of subjective expressions as specifiedby the subtask of this shared task Given such in-put the system just assigns sources and targetsfor these existing expressions (We also imple-mented another mode in which the opinion predi-cates according the given sentiment lexicon wouldadditionally be recognized including their opinionroles) Opinion predicates are typically ambigu-ous our lexicon-based approach is therefore lim-ited This is a well-known and well-researchedproblem On the other hand the task of extract-ing opinion sources and targets given some opin-ion predicates is a completely different task whichis comparatively less well researched Our modeallowing partial analysis as input should allow re-searchers interested in opinion role extraction tohave a suitable test bed without caring for the de-tection of subjectivity
IGGSA Shared Task Workshop Sept 2016
16
232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

232 Grammatically-Induced Sentiment
An important aspect of opinion-role extraction thatwas completely ignored in the initial version ofthe rule-based system is the sentiment that is notevoked by common opinion predicates but senti-ment that is evoked by certain grammatical con-structions We focus on certain types of modali-ties (7) and tenses (8) Such type of sentiment isdetected without our extraction lexicon (sect22)
(7) [Kinder sollten nicht auf der Straszligespielen]target source speaker(Children should not play on the street)
(8) [Er wird mal ein guter Lehrer sein]target
source speaker(He is going to become a good teacher)
(9) Der Puls des Patienten wird gemessen(The patientrsquos pulse is measured)
It is triggered by certain types of lexical unitsthat is modal verbs such as sollte or auxiliaryverbs such as werden However unlike the lexicalunits from our extraction lexicon some of theseverbs require some further disambiguation For in-stance the German auxiliary werden is not exclu-sively used to indicate future tense as in (8) but itis also used for building passive voice (9) There-fore our module carries out some contextual dis-ambiguation of these words
Grammatically-induced sentiment also system-atically differs from lexical sentiment in the wayin which opinion roles are expressed While forlexical sentiment the argument position of thesources and targets is dependent on the specificlexical unit that conveys the sentiment and there-fore has to be specified by lexical rules the typesof grammatically-induced sentiment that we covershare the same argument positions for sources andtargets Typically the source is the speaker of theutterance and the target is the entire sentence inwhich the tense or modal occurs Of course incase of compound sentences the scope of the tar-get is only restricted to the clause in which the aux-iliarymodal verb occurs (10)
(10) [Er wird mal ein guter Lehrer sein]target da ergut erklaren kann source speaker(He is going to become a good teacher sincehe can explain things well)
233 Morphological AnalysisOpinion sources are typically persons or groupsof persons In order to ensure that only NPs thatmatch this semantic type are classified as sourceswe employed a semantic filter that used the predic-tion of a named-entity recognizer in case of propernouns and GermaNet (Hamp and Feldweg 1997)in case of common nouns The latter approachhowever is limited considering the high frequencyof compounding in German We observed thatin case an opinion source was represented by acompound such as SPD-Landtagsabgeordneter itcould not be established as a person since thatterm was not included in GermaNet We examinedwhether this coverage problem could be solved bymorphologically analyzing those compounds andthen only looking up their heads (eg Abgeord-neter) which are more likely to be included inGermaNet A similar experiment was carried outto match opinion predicates in compounds (egFruhjahrsaufschwung or Telefonterror) Our ini-tial experiments with morphisto (Zielinski and Si-mon 2009) however showed no improvement ineither opinion source extraction or subjectivity de-tection due to the high ambiguity in noun com-pound structures
234 Normalizing ConjunctionsIn the original version of our system we alreadyincorporated a set of normalization steps of simpli-fying the dependency parse (Wiegand et al 2014)The result was a more compact representation ofsentences that abstracts from the surface realiza-tion of a sentence This made it simpler to state ex-traction rules for the extraction of opinion sourcesand targets In our submission for this yearrsquos taskwe added a further normalization step dealing withconjunctions The original dependency parse typi-cally only directly connects one conjunct with thesyntactic roles relevant for opinion roles For in-stance in Figure 2(a) only lugt is connected withEr by a subject relation Therefore our originalsystem would only be able to establish that Er issome opinion role of lugt In such cases we alsoadd another edge with the subject relation connect-ing the second conjunct (betrugt) and its subject(Figure 2(b))
We also incorporate a set of rules to handle coor-dination for predicative and attributive adjectives5
5For nouns we could not figure out unambiguous rela-tions where adding further edges would have increased theextraction of sources or targets
IGGSA Shared Task Workshop Sept 2016
17
While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

While for predicative adjectives the subjective re-lation has to be duplicated for attributive adjec-tives the edge attr needs to be duplicated (see Fig-ure 3)
235 Alternative NLP ToolsWe critically assessed the choice of NLP toolsused in our original system and compared themwith alternatives
As far as both constituency and dependencyparsing is concerned it was not possible for us tofind more effective alternatives Either the corre-sponding parser could not be converted in our ex-isting format so that the system would still work asbefore or the parsing output was notably inferiorand produced worse extraction performance whenincorporated in our processing pipeline
As far as named-entity recognition is concernedwe replaced the original tagger the German modelfrom the Stanford named-entity tagger (Faruquiand Pado 2010) by a more recent tagger ie Ger-maNER (Benikova et al 2015) We primarily de-cided in favour of this replacement since the Stan-ford named-entity tagger occasionally overridesthe given sentence-boundary detection
24 Multiword ExpressionsNot every opinion predicate is a unigram token Sofar the only multiword expressions conveying sen-timent that our system was able to process werephrasal verbs as gab auf in (11)
(11) Er gab das Rauchen vor 10 Jahren auf(He gave up smoking 10 years ago)
We modified our system in such a way that ex-traction rules can now also be specified for ar-bitrary multiword expressions Matching multi-word expressions in German sentences is not triv-ial since
bull multiword expressions can be discontinuoussequences of tokens (eg (12) (13))
bull the order of tokens between the canonicalform and mentions in specific sentences mayvary (eg (13)) and
bull several tokens between the canonical formand mentions in specific sentences may differ(eg reflexive pronoun sich in (12))
In order to account for these properties our match-ing algorithm considers the dependency parse of
a sentence We identify a multiword expressionif the tokens of a particular expression are all di-rectly connected via edges in a dependency parseThe multiword expressions must hence form a con-nected subgraph of the parse in which all tokensof the multiword expression and only those are in-cluded
(12) sich benehmen wie die Axt im Walde (act likea brute)Er sagte dass ich mich benehmen wurdewie die Axt im Walde(He told me that I acted like a brute)
(13) sein wahres Gesicht zeigen (to show onersquostrue colours)Unter Alkoholeinfluss zeigte er sein wahresGesicht(Under the influence of alcohol he showedhis true colours)
Since we are not aware of any publicly avail-able lexicon for multiword expressions we ex-tract them automatically from a German corpusFor that we use the parsed deWaC (Baroni et al2009) We focus on those multiword expressionsthat follow a systematic pattern We chose reflex-ive verbs (eg sich freuen sich schamen sichfurchten) and light-verb constructions (eg Angsthaben Kummer machen Acht geben) In order toextract reflexive verbs we extracted opinion verbsfrequently occurring with a reflexive pronoun (werestrict the pronoun to be the accusative object ofthe verb) In order to extract light-verb construc-tions we first manually selected a set of commonlight verbs (eg haben machen geben) and thenlooked for opinion nouns that often co-occur withthese light verbs (we restrict the opinion noun tobe the accusative object of the light verb) In to-tal we thus extracted about 4700 multiword ex-pressions
3 Supervised System
Since we participated in the second edition of thisshared task it meant that we were able to ex-ploit the manually-labeled test data of the previousshared task (Ruppenhofer et al 2014) as trainingdata for a supervised classifier In the previous edi-tion also a supervised system was submitted how-ever it only considered as labeled training datatexts automatically translated from English to Ger-man Moreover only opinion sources were con-
IGGSA Shared Task Workshop Sept 2016
18
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23
(a) original dependency parse (b) normalized dependency parse
Figure 2 Illustration of normalizing dependency parses with verb coordination
(a) original dependency parse
(b) normalized dependency parse
Figure 3 Illustration of normalizing dependency parses with adjective coordination
Figure 4 Processing pipeline of the supervised system
IGGSA Shared Task Workshop Sept 2016
19
Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Type Feature Templateswords unigram features target word and its two predecessorssuccessors
bigrams features bigrams of neighboring words from unigram features
part of speech unigram features part-of-speech tag of target word and its two predecessorssuccessorsbigram features bigrams of neighboring part-of-speech tags from unigram featuresbigram features trigrams of neighboring part-of-speech tags from unigram features
sentiment lexicon is either of the words (window is that of the unigram features) an opinion predicate according to sentiment lexicon
Table 2 Feature templates employed for the CRF classifier to detect subjective expressions
sidered We believe that considering actual Ger-man text presents a much higher quality of train-ing data than text that has automatically been trans-lated into German
The processing pipeline of our supervised sys-tem is illustrated in Figure 4 For this approachwe employed the same NLP tools as in our rule-based system in order to ensure comparability
Our supervised system comprises two classi-fiers The first is to detect opinion predicates Forthat we employ a conditional random field (Laf-ferty et al 2001) As an implementation wechose CRF++6 As a motivation we chose asequence-labeling algorithm because the task ofdetecting opinion predicates is similar to other tag-ging problems such as part-of-speech tagging ornamed-entity recognition The feature templatesfor our sentiment tagger are displayed in Table 2We use CRF++ in its standard configuration as alabeling scheme we used the simple IO-notation
The second classifier extracts for an opinionpredicate detected by the CRF the correspondingopinion source or target if they exist For thissupport vector machines (SVM) were chosen Asan implementation we used SVMlight (Joachims1999) The instance space is a set of tuples com-prising candidate opinion roles and opinion pred-icates (detected by the previous sentiment detec-tion) We use different sets of candidate phrasesfor opinion sources and opinion targets For opin-ion sources the set of candidates is the set of nounphrases in a sentence Opinion sources are typi-cally persons or groups of persons and thereforeonly noun phrases are eligible to represent suchopinion role Opinion targets on the other handcannot be reduced to one semantic type Targetscan be various types of entities both animate andinanimate They can even represent entire propo-sitions As a consequence we consider every con-stituent phrase of a sentence as a candidate opiniontarget
6httpscodegooglecompcrfpp
SVM were chosen as a learning method sincethis task deals with a more complex instance spaceand SVM unlike sequence labelers allow a fairlystraightforward encoding of that instance spaceThe features we employed for this classifier are il-lustrated in Table 3
4 Experiments
In this section we evaluate the 7 runs officiallysubmitted to the shared task Table 4 displaysthe different properties of the different runs Thefirst 5 runs are rule-based systems while the lastrun is a supervised system Rule-Based-2014 isthe best rule-based system run in the previous it-eration of this shared task (Wiegand et al 2014)using the PolArt-sentiment lexicon (Klenner etal 2009) Rule-Based-2016-plain is as Rule-Based-2014 with various bugs removed Rule-Based-2016-gram is as Rule-Based-2016 with themodule on grammatically-induced sentiment anal-ysis (Section 232) switched on Rule-Based-2016-conj is as Rule-Based-2016-gram but alsowith normalization of conjunctions (Section 234)switched on The last system Supervised is thesupervised classifier presented in Section 3
Table 5 displays the (micro-average) perfor-mance (exact matches) of the different configura-tions on the full task SE evaluates the detectionof subjective expressions Source the detection ofopinion sources and Target the detection of opin-ion targets
Table 5 shows that the extensions made to the2014-system result in some improvement Thisimprovement is caused by a notable rise in re-call The normalization of conjunctions and thetreatment of multiword expressions only producemild performance increases We assume that thisis due to the fact that in the test data there areonly few cases of the conjunctions we deal withand also only few cases of the multiword expres-sions we extracted from a corpus If one com-pares the rule-based systems with the supervised
IGGSA Shared Task Workshop Sept 2016
20
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23
Type Featurescandidate opinion role phrase label of candidate opinion role (eg NP VP SBAR etc)
lemma of head of phrase representing candidate opinion rolepart-of-speech of head of phrase representing candidate opinion roleis head of phrase representing candidate opinion role some named entityis candidate opinion role at the beginning of the sentence
opinion predicate lemma of opinion predicatepart-of-speech of opinion predicate
relational distance between opinion role candidate and opinion predicatedependency path from opinion role candidate to opinion predicatepart-of-speech label of head of opinion role candidate and opinion predicatephrase label of opinion role candidate and part-of-speech tag of head of opinion predicate
Table 3 Features employed for the SVM classifier to extract opinion sources and targets
Run PropertiesRule-Based-2014 previous system (Wiegand et al 2014) as it was publicly available
Rule-Based-2016-plain as Rule-Based-2014 with various bugs removed
Rule-Based-2016-gram Rule-Based-2016 with module on grammatically-induced sentiment analysis (Section 232) switched on
Rule-Based-2016-conj as Rule-Based-2016-gram but also with normalization of conjunctions (Section 234) switched on
Rule-Based-2016-mwe as Rule-Based-2016-conj but also with additional multiword expressions as part of the sentiment lexicon (Section 24)
Supervised supervised learning system as discussed in Section 3
Table 4 The different properties of the different runs
Run Measure SE Source TargetRule-Based-2014 Prec 5701 4485 4764
Rec 1514 970 1141F 2393 1550 1841
Rule-Based-2016-plain Prec 5554 4183 4527Rec 1990 1383 1271F 2930 2079 1985
Rule-Based-2016-gram Prec 5636 4204 4483Rec 2495 1862 1763F 3459 2581 2530
Rule-Based-2016-conj Prec 5636 4211 4501Rec 2495 1867 1785F 3459 2588 2557
Rule-Based-2016-mwe Prec 5720 4552 4403Rec 2532 1895 1853F 3510 2622 2608
Supervised Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Table 5 Evaluation of the different runs of the Main Task
Run Task Measure SE Source TargetRule-Based-2016-mwe Full Task Prec 5720 4552 4403
Rec 2532 1895 1853F 3510 2622 2608
Subtask Prec 1000 5986 6924Rec 1000 2860 2887F 1000 3870 4075
Supervised Full Task Prec 6542 5024 3231Rec 4141 2325 1729F 5072 3179 2252
Subtask Prec 1000 5940 4260Rec 1000 3829 3169F 1000 4657 3635
Table 6 Evaluation of the Subtask
IGGSA Shared Task Workshop Sept 2016
21
system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

system one notices that on the detection of sub-jective expressions the supervised system largelyoutperforms the rule-based system Both preci-sion and recall are improved Obviously the su-pervised system is the only classifier capable ofdisambiguating subjective expressions (Akkaya etal 2009) Moreover it seems to detect more sub-jective expressions than are contained in a com-mon sentiment lexicon (which is the backbone ofthe subjectivity detection of the rule-based sys-tem) The supervised system however is less ef-fective on the extraction on targets Targets aremore difficult to extract than sources in generalsince they can be more heterogeneous linguisticentities Sources for instance are typically real-ized as noun phrases whereas targets can be dif-ferent types of phrases We also observed thatdue to the fact that many targets are comparablylarge spans parsing errors also affect this type ofopinion roles more frequently On the other handthe constituents typically representing sources ie(small) noun phrases can be correctly recognizedmore easily The supervised system may also out-perform the rule-based system on the extraction ofsources since it can memorize certain entities witha high prior likelihood to be sources For instancefirst person pronouns (eg I or we) are very likelycandidates for sources This type of informationcannot be incorporated in the rule-based classifier
Table 6 compares the best rule-based system(ie System-2016-mwe) and the supervised systemon both the full task and the subtask (again micro-average performance ndash exact matches) In the sub-task subjective expressions are already given andonly sources and targets have to be extracted Ob-viously the subtask is easier which can be seenby the notably higher performance scores on bothsource and target extraction for both approachesAs on the full task on the extraction of sourcesthe supervised system outperforms the rule-basedsystem while on the extraction of targets the rule-based system outperforms the supervised system
5 Conclusion
We reported on the two systems we devised forthe second edition of the shared task on SourceSubjective Expression and Target Extraction fromPolitical Speeches (STEPS) The first system is arule-based system relying on a predicate lexiconspecifying extraction rules for verbs nouns and ad-jectives while the second is a supervised classifier
trained on the adjudicated test data of the previousedition of this shared task
The supervised classifier scores well on thedetection of subjective expressions and opinionsources The rule-based system produces the bestscores for the extraction of targets Given the gen-eral low performance scores we assume that thetask of opinion source and target extraction stillrequires some further research
Acknowledgements
This work was partially supported by the German Research
Foundation (DFG) under grant WI 42042-1
ReferencesCem Akkaya Janyce Wiebe and Rada Mihalcea 2009
Subjectivity Word Sense Disambiguation In Pro-ceedings of the Conference on Empirical Methods inNatural Language Processing (EMNLP) pages 190ndash199 Singapore
Marco Baroni Silvia Bernardini Adriano Ferraresiand Eros Zanchetti 2009 The WaCky Wide WebA Collection of Very Large Linguistically ProcessedWeb-Crawled Corpora Language Resources andEvaluation 43(3)209ndash226
Darina Benikova Seid Muhie Yimam PrabhakaranSanthanam and Chris Biemann 2015 GermaNERFree Open German Named Entity Recognition ToolIn Proceedings of the International Conference ofthe German Society for Computational Linguisticsand Language Technology (GSCL) pages 31ndash38 Es-sen Germany
Marie-Catherine de Marneffe Bill MacCartney andChristopher D Manning 2006 Generating typeddependency parses from phrase structure parses InProceedings of the Conference on Language Re-sources and Evaluation (LREC) pages 449ndash454Genoa Italy
Manaal Faruqui and Sebastian Pado 2010 Trainingand Evaluating a German Named Entity Recognizerwith Semantic Generalization In Proceedings ofKONVENS Saarbrucken Germany
Birgit Hamp and Helmut Feldweg 1997 GermaNet -a Lexical-Semantic Net for German In Proceedingsof ACL workshop Automatic Information Extractionand Building of Lexical Semantic Resources for NLPApplications pages 9ndash15 Madrid Spain
Thorsten Joachims 1999 Making Large-Scale SVMLearning Practical In B Scholkopf C Burgesand A Smola editors Advances in Kernel Meth-ods - Support Vector Learning pages 169ndash184 MITPress
IGGSA Shared Task Workshop Sept 2016
22
Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23

Soo-Min Kim and Eduard Hovy 2006 ExtractingOpinions Opinion Holders and Topics Expressedin Online News Media Text In Proceedings of theACL Workshop on Sentiment and Subjectivity in Textpages 1ndash8 Sydney Australia
Manfred Klenner Angela Fahrni and Stefanos Pe-trakis 2009 PolArt A Robust Tool for Senti-ment Analysis In Proceedings of the Nordic Con-ference on Computational Linguistics (NoDaLiDa)pages 235ndash238 Odense Denmark
John Lafferty Andrew McCallum and FernandoPereira 2001 Conditional Random Fields Prob-abilistic Models for Segmenting and Labeling Se-quence Data In Proceedings of the Interna-tional Conference on Machine Learning (ICML)Williamstown MA USA
Slav Petrov Leon Barrett Romain Thibaux and DanKlein 2006 Learning Accurate Compact and In-terpretable Tree Annotation In Proceedings of theInternational Conference on Computational Linguis-tics and Annual Meeting of the Association for Com-putational Linguistics (COLINGACL) pages 433ndash440 Sydney Australia
Josef Ruppenhofer Swapna Somasundaran and JanyceWiebe 2008 Finding the Source and Targetsof Subjective Expressions In Proceedings of theConference on Language Resources and Evaluation(LREC) pages 2781ndash2788 Marrakech Morocco
Josef Ruppenhofer Roman Klinger Julia Maria StruszligJonathan Sonntag and Michael Wiegand 2014 IG-GSA Shared Tasks on German Sentiment Analysis(GESTALT) In G Faaszlig and J Ruppenhofer edi-tors Workshop Proceedings of the KONVENS Con-ference pages 164ndash173 Hildesheim Germany Uni-versitat Hildesheim
Rico Sennrich Gerold Schneider Martin Volk andMartin Warin 2009 A New Hybrid DependencyParser for German In Proceedings of the Ger-man Society for Computational Linguistics and Lan-guage Technology (GSCL) pages 115ndash124 Pots-dam German
Michael Wiegand and Dietrich Klakow 2012 Gener-alization Methods for In-Domain and Cross-DomainOpinion Holder Extraction In Proceedings of theConference on European Chapter of the Associationfor Computational Linguistics (EACL) pages 325ndash335 Avignon France
Michael Wiegand Christine Bocionek Andreas Con-rad Julia Dembowski Jorn Giesen Gregor Linnand Lennart Schmeling 2014 Saarland Univer-sityrsquos Participation in the GErman SenTiment AnaL-ysis shared Task (GESTALT) In G Faaszlig andJ Ruppenhofer editors Workshop Proceedingsof the KONVENS Conference pages 174ndash184Hildesheim Germany Universitat Hildesheim
Andrea Zielinski and Christian Simon 2009 Mor-phisto ndash An Open Source Morphological Analyzerfor German In Proceedings of the 2009 Conferenceon Finite-State Methods and Natural Language Pro-cessing Post-proceedings of the 7th InternationalWorkshop FSMNLP 2008 pages 224ndash231 IOS PressAmsterdam The Netherlands
IGGSA Shared Task Workshop Sept 2016
23





























