Embed Size (px)
Citation preview

Building Big Data Analytical Applications at Scale Using Existing ETL Skillsets
Prepared for:
By Mike Ferguson Intelligent Business Strategies
June 2015
WH
ITE
PA
PE
R INTELLIGENT
BUSINESS STRATEGIES

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 2
Table of Contents Big Data Analytics – Market Adoption ............................................................................... 3
Popular Use Cases Driving Adoption of Big Data Analytics ............................... 3 Next Generation Big Data Analytics ................................................................... 5
Big Data Analytics on Hadoop – A Short History .............................................................. 6
Batch Analysis With Hadoop MapReduce .......................................................... 6 Beyond Batch Analytics - The Emergence of Spark ........................................... 6 Real-Time Analytics on Hadoop Using Storm .................................................... 7 The Lambda Architecture ................................................................................... 7
Problems with Big Data Analytic Application Development ............................................... 9
Typical Data Science Skillsets And The Dependency On Programming ............ 9 The Slow Pace Of Building Big Data Analytic Applications ................................ 9 Challenges In Exploiting Big Data Analytics ....................................................... 9
Requirements for Reducing Time To Value From Big Data Analytics ............................. 10 Reducing Time To Value Using Talend ........................................................................... 11
How Talend Supports Data Integration on Hadoop .......................................... 11 From ETL to Analytical Workflows .................................................................... 12 Using Talend to Generate Big Data Analytic Applications ................................ 12 Business Benefits from Analytical Workflows ................................................... 13 Talend Case Study: Otto .................................................................................. 13
Conclusions ..................................................................................................................... 14

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 3
BIG DATA ANALYTICS – MARKET ADOPTION In the last few years, the growth in market adoption of big data technologies for the purpose of analysis of new data sources has grown significantly. Several surveys show that the growth is set to continue over the next few years. As an example a June 20141 survey showed that 73% of respondents have invested or plan to invest in big data in the next 24 months with only 13% in production. Leading the way was communications and media with 53% of organizations surveyed having already invested and a further 33% planning investments in big data technologies. Another survey2 of 1139 respondents in 2015 showed that the number of organizations with deployed or implemented data-driven projects has increased by 125% over the past year. In that same survey, the most common sources of data were customer databases (63%), email (61%), transactional data (53%), worksheets (51%) and word documents (48%). However, what is really interesting about this survey, is that respondents said that the top two types of employees with big data skillsets making data initiatives possible today were business analysts (59%), database programmers (55%) while in future this would shift to business analysts (23%), data architects (23%) i.e. a much greater dependency on data specialists. There are many reasons why companies are adopting big data technologies. However the main reason is because of the potential value that analysing new data from internal and external sources can bring. For example, by analysing on-line clickstream data, social media data and SEC filings, existing customer insight can be significantly enriched which, in turn can improve customer engagement. By automatically analysing sensor data in real-time, problems in manufacturing production lines and distribution chains can be detected or predicted and action taken to continually keep them optimised. These two examples address two of the top priorities often identified by CEOs. These are:
• Improvements in customer retention, loyalty and growth
• Improvements in operational effectiveness
You might argue that traditional data warehouses have been at the centre of these two priorities for a long time. However when you look at competition today, there is no doubt that additional insight is now needed if these two priorities are to be realised. The only way that additional insight can be produced is by analysing new forms of data, which, because of its variety, volume and velocity, often requires big data technologies and advanced analytics to deliver competitive advantage.
POPULAR USE CASES DRIVING ADOPTION OF BIG DATA ANALYTICS The number of business and IT use cases that are driving adoption of big data technologies such as Hadoop, stream computing and analytics has grown considerably over the last few years to the extent that you can see examples 1 Gartner survey published September 2014 http://www.gartner.com/newsroom/id/2848718
2 IDG Enterprises Big Data and Analytics Survey, 2015 http://www.idgenterprise.com/report/2015-big-data-and-analytics-survey
Market adoption of big data technologies is growing rapidly
In future there will be a greater reliance on business analysts and data architects in big data environments
The potential value from analysing new data is a key reason why big data adoption is on the increase
Additional insights about customers and business operations are now needed to remain competitive
Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 4
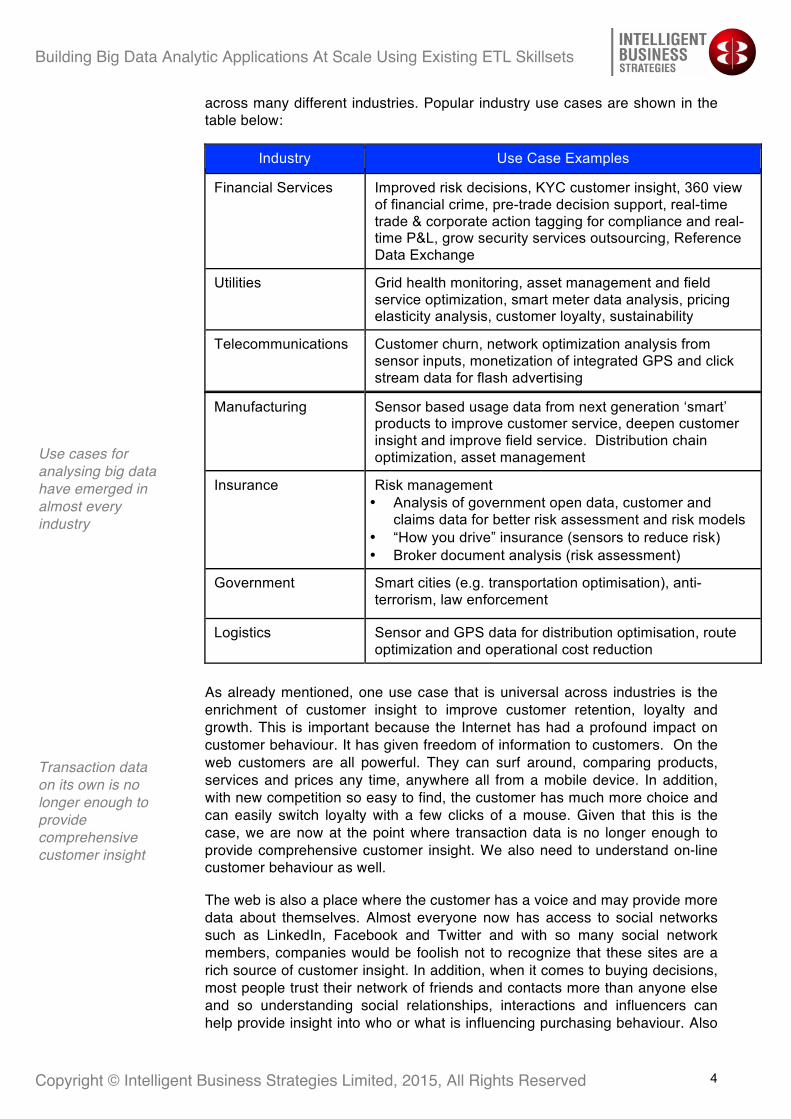
across many different industries. Popular industry use cases are shown in the table below:
Industry Use Case Examples
Financial Services Improved risk decisions, KYC customer insight, 360 view of financial crime, pre-trade decision support, real-time trade & corporate action tagging for compliance and real-time P&L, grow security services outsourcing, Reference Data Exchange
Utilities Grid health monitoring, asset management and field service optimization, smart meter data analysis, pricing elasticity analysis, customer loyalty, sustainability
Telecommunications Customer churn, network optimization analysis from sensor inputs, monetization of integrated GPS and click stream data for flash advertising
Manufacturing Sensor based usage data from next generation ‘smart’ products to improve customer service, deepen customer insight and improve field service. Distribution chain optimization, asset management
Insurance Risk management • Analysis of government open data, customer and
claims data for better risk assessment and risk models • “How you drive” insurance (sensors to reduce risk) • Broker document analysis (risk assessment)
Government Smart cities (e.g. transportation optimisation), anti-terrorism, law enforcement
Logistics Sensor and GPS data for distribution optimisation, route optimization and operational cost reduction
As already mentioned, one use case that is universal across industries is the enrichment of customer insight to improve customer retention, loyalty and growth. This is important because the Internet has had a profound impact on customer behaviour. It has given freedom of information to customers. On the web customers are all powerful. They can surf around, comparing products, services and prices any time, anywhere all from a mobile device. In addition, with new competition so easy to find, the customer has much more choice and can easily switch loyalty with a few clicks of a mouse. Given that this is the case, we are now at the point where transaction data is no longer enough to provide comprehensive customer insight. We also need to understand on-line customer behaviour as well.
The web is also a place where the customer has a voice and may provide more data about themselves. Almost everyone now has access to social networks such as LinkedIn, Facebook and Twitter and with so many social network members, companies would be foolish not to recognize that these sites are a rich source of customer insight. In addition, when it comes to buying decisions, most people trust their network of friends and contacts more than anyone else and so understanding social relationships, interactions and influencers can help provide insight into who or what is influencing purchasing behaviour. Also
Use cases for analysing big data have emerged in almost every industry
Transaction data on its own is no longer enough to provide comprehensive customer insight

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 5
people are quick to compare products and prices and share this information with others across these networks making potential buyers better informed. Review web sites also provide customers with ways to rate products and services giving prospective buyers ways to find reassurance before making purchasing decisions. Also, if negative sentiment is voiced on social networks it can spread quickly. All of this can impact on customer loyalty, retention and growth. Therefore, in addition to needing to analyse clickstream data to understand on-line behaviour, there is also a need to understand social networks and social interactions to determine sentiment, highlight influencers and to determine the overall potential value of customers’ social networks to the business. All of this is driving big data adoption.
NEXT GENERATION BIG DATA ANALYTICS One point worth noting is that while analysing new types of data to produce new insight is extremely valuable, it would be even more valuable if the insight produced was automatically delivered to where it was needed. If improvements to customer retention, loyalty and growth and improvements to operational effectiveness are to be achieved, big data analytics needs to do more than prepare data at scale and analyse that data to discover and predict new insight. To be really effective, we have to go beyond that and deliver the insight to the customer/field worker facing applications that need it so that insight is available at the point of need. This requires data-driven analytic applications with automated delivery of actionable insight. Making this happen will really deliver business value.
Click stream and social media data are also needed
Customer opinion about products and services is also of value
Data-driven big data analytic applications should automate the delivery of actionable insight to the point of need

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 6
BIG DATA ANALYTICS ON HADOOP – A SHORT HISTORY
At the heart of many data-driven projects is Apache Hadoop. Hadoop is an open source software stack made up of a number of components that are designed to support data intensive distributed applications. It enables batch, interactive and streaming analytic applications to use thousands of computers or computer nodes to ingest, process and analyse petabytes of data. Besides the open source Apache version, several commercial distributions of Hadoop are available in the marketplace, many of which run on dedicated hardware appliances and some of which also run in a cloud computing environment.
BATCH ANALYSIS WITH HADOOP MAPREDUCE In the early stages of Hadoop, from 2007 up until around mid 2013, the main way to work with data in the Hadoop Distributed File System (HDFS) was do so through the MapReduce style of coding applications and the MapReduce framework. This is a batch processing framework with low-level application programming interfaces (APIs) that works by taking the application to the data rather than the data to the application. MapReduce applications can be written in a range of popular procedural programming languages such as Java, C++ and Python. In addition, scripts written in declarative languages such as PIG, HiveQL and JAQL can also be compiled to MapReduce code. MapReduce requires programmers to develop applications with two core operations – map and reduce. These operations work in parallel on data partitioned across hundreds or thousands of nodes in a Hadoop cluster. During execution, the output data sets from map processing are set down on disk and shuffled to form the input data to the reduce operators. While this has worked well, the biggest problems with MapReduce have been performance and the high bar on skillsets. You had to be a developer with mathematical skills and the ability to use low level APIs in order to build big data analytical applications.
BEYOND BATCH ANALYTICS - THE EMERGENCE OF SPARK While MapReduce has and continues to serve a purpose, the emergence of Hadoop 2.0 and YARN3 has seen the momentum behind alternatives to MapReduce increase rapidly. The main reason for this is to break free from the performance weaknesses of MapReduce. One alternative that has stood out more than any other is Apache Spark. Spark is an in-memory cluster computing engine that offers batch, interactive, streaming and graph analytics processing all in a single environment. According to a recent survey4 of 2100 developers, 82% of respondents chose Spark to replace MapReduce. In addition 78% said they are using it to get faster batch processing of large datasets. Spark has APIs for Java, Scala and Python applications. It also has a machine learning library of analytic algorithms, an interactive shell and an in-
3 Yet Another Resource Negotiator – think of YARN as the operating system for Hadoop
4 Apache Spark – Preparing for the next wave of reactive big data, Typesafe 2015
Hadoop is at the centre of many big data initiatives
Hadoop was initialially aimed at batch analysis of stuctured and multi-structured data that was high in volume
Today, the emergence of Spark for batch, interactive, streaming and graph analytics on in-memory data is now where most are focussed

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 7
memory file system called Tachyon. Also languages like PIG are now running on Spark as well as MapReduce. The Spark framework is shown below:
Figure 1
REAL-TIME ANALYTICS ON HADOOP USING STORM In addition to Spark, another technology that has grown in popularity is Apache Storm. Apache Storm is a cluster engine for executing stream processing applications that perform real-time analysis on data-in-motion. Classic examples would include real-time analysis of sensor data to optimise production lines and distribution chains as described earlier. Another example is the real-time analysis of live clickstream data for personalised ad serving as users browse on-line. Up until Hadoop 2.0, Storm applications ran on their own dedicated cluster. However since the emergence of YARN, it is now possible to run Storm streaming analytic applications on a Hadoop cluster and, if required, filter variance data out of a stream to store in HDFS for subsequent offline analysis. In addition, to simplify and speed up Storm application development a software development kit called Trident is now available with a library of pre-defined code modules that can be exploited to build applications more quickly.
THE LAMBDA ARCHITECTURE Looking at this evolution, a new architecture has emerged that is designed to handle massive quantities of data by taking advantage of both batch and stream processing methods to solve many use cases. This new architecture is the Lambda architecture, shown in Figure 25. It is split into three layers, a batch layer, a speed layer and a serving layer.
The Lambda Architecture
Source: Wikipedia Figure 2
5 The diagram in Figure 2 is taken from Wikipedia
HDFS
Applications
Spark (+ Tachyon)
Spark Streaming
BlinkDB
Spark SQL GraphX SparkR
MLBase
MLlib
file file file file file file
Spark applications can make use of machine learning algorithms, SQL and graph analysis to process data at scale
Storm applications can process and analyse streaming data in near real time
The Lambda architecture suports both real-time and batch processing of data

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 8
The batch layer is responsible for storing data in HDFS and processing it via MapReduce or Spark analytic applications to produce integrated high value data and new insights. As more and more data is loaded into HDFS, these insights can be updated by re-running the MapReduce or Spark batch analytic applications as required.
The job of the speed layer is to process, integrate and analyse high velocity data streams in near real-time to produce insights about what is happening now, to interpret these insights and automate actions to keep the business optimised. In addition it should also be able to filter out near real-time data of interest and load it into HDFS for subsequent batch processing. A good example technology for the speed layer is Apache Kafka for messaging feeding streaming analytical applications on Apache Storm.
The job of the serving layer is to store output from the batch and speed layers, and impose a schema on the data so that it can be queried interactively by front-end tools. Data could be stored in Apache Cassandra or HBase with query processing provided by a SQL on Hadoop offering such as Cloudera’s Impala, IBM Big SQL, Pivotal Hawk, or Spark SQL for example. In addition, by making streaming and batch data insights available for query processing in the serving layer, it becomes possible to query batch and real-time data to provide a holistic view of business performance.
Taken together, the batch and speed layers allow a business to produce new insights to add to what it already knows and to also improve operational effectiveness.
Lambda batch processing can be done by MapReduce and Spark Applications
Lambda real-time processing can be done by Spark streaming and Storm applications
Data from real-time and batch processing can be queried separately and together to produce new insights

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 9
PROBLEMS WITH BIG DATA ANALYTIC APPLICATION DEVELOPMENT
Given the potential business value of big data technologies and advanced analytics, there are still some challenges and barriers to adoption.
TYPICAL DATA SCIENCE SKILLSETS AND THE DEPENDENCY ON PROGRAMMING
One of the major challenges with big data and analytics is the high bar on skills needed and the availability of skilled personnel. This concern was reflected in the aforementioned 2015 big data survey6, where 48% of the 1139 respondents cited limited availability of skilled employees. Data scientists are difficult to come by when looking for a skill set that includes, skills in data engineering, mathematics, statistics, Java, Python or Scala programming, R programming, data visualisation and communication with business. Clearly the more reliance on programming the tougher it is to find the people you need. If there were some way to raise the level of abstraction where programming skills are no longer needed to prepare and integrate data, it would make a significant difference in getting started with this technology.
THE SLOW PACE OF BUILDING BIG DATA ANALYTIC APPLICATIONS A second problem is the fact that if you want to prepare and analyse data using Apache Spark and Apache Storm, there is a significant reliance on the need to write code. Writing code takes a long time. It is also expensive, difficult to maintain over time and not very agile. The more code you have to write, the more testing there is and the slower things become. In a fast moving economy the ability to remain agile and respond quickly to market pressures matters a lot in todays market. Yet the reliance on programming would seem to run counter to those business needs.
One way of reducing the skill sets needed and to improve agility is to have technologies generate the code needed to exploit underlying big technology components. This would reduce the dependency on finding deeply skilled personnel. It would also speed up development by making less skilled business analysts more productive.
CHALLENGES IN EXPLOITING BIG DATA ANALYTICS Another challenge with big data is the speed at which technology is changing on big data platforms like Hadoop. Already we have seen multiple ways to build batch ‘data pipeline’ applications to prepare and analyse data e.g. via MapReduce and via Spark. In addition stream processing can be done in via Apache Storm or Spark Streaming. Graph analytics can be done using Giraph or Spark GraphX. Ideally, if the level of abstraction was high enough, the vendors should hide this from customers and select the best option for them. 6 IDG Enterprises Big Data & Analytics Survey, 2015 http://www.idgenterprise.com/report/2015-big-data-and-analytics-survey
Reliance on very highly skilled personnel is still a barrier to adoption
Less reliance on programming is needed
Writing code is time consuming and expensive
Technologies that generate code reduce the need for programmers, speed development and improve productivity
Vendors that generate code can help customers take advantage of new big data technology more rapidly

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 10
REQUIREMENTS FOR REDUCING TIME TO VALUE FROM BIG DATA ANALYTICS
So far we have seen that the demand for big data and analytics is increasing rapidly to allow companies to analyse new rich sources of structured and multi-structured data. In addition we have seen that Apache Spark and Apache Storm technologies running on Hadoop in a Lambda architecture are fast emerging as a way to produce new insights to add to what a company already knows and to also improve operational effectiveness. However we have also seen that there are obstacles in the way of productivity and agility that are slowing organisations down. This is happening both in terms of technology adoption and in producing actionable insight that can improve customer engagement and optimise business operations. What then is needed to reduce the time to value in a big data analytical environment? Ten key requirements to doing this are that it should be possible to:
1. Develop analytical models using third party tools, custom developed code or pre-built analytical algorithms and then be able to deploy these to run in parallel on big data platforms such as Hadoop clusters, stream processing clusters and analytical relational DBMSs
2. Publish developed analytical models (analytics) as services so that they can be consumed and invoked by data integration tools, BI tools and analytic applications that need to use them
3. Go beyond MapReduce and develop batch Apache Spark applications, without the need for programming, that can prepare and integrate data
4. Go beyond MapReduce and develop batch Apache Spark analytical applications without the need for programming, that can prepare, integrate and automatically analyse data using published analytics
5. Develop Apache Storm analytical applications without the need for programming that can prepare, integrate, automatically analyse and act on detected correlations in real-time streaming data.
6. Develop Apache Storm applications, without programming, that can prepare, integrate, analyse and filter out data of interest in near real time from live data streams to store in Hadoop for subsequent analysis
7. Develop the aforementioned Spark and Storm analytic applications using data integration workflows so that practiced ETL developers can retain their skills and use them to build big data analytic applications more rapidly. This would significantly improve productivity
8. Publish analytic workflows as services so that entire workflows can themselves be consumed as transforms and used in other higher-level analytic workflows. In other words it should be possible to nest analytic workflows to build powerful data driven analytic applications without the need for programming
9. Publish analytical workflows that produce new insights from data in Hadoop to integrate with and enrich customer data in an MDM system
10. Support both the speed and batch layer of the Lambda architecture
There are some key requirements that if met will signigicantly reduce time to value
Development of in-Hadoop, in-stream and in-database analytics
Ability to consume analytics in other tools
Support Spark for in-memory batch processing at scale
Support Storm for real-time stream processing
Be able to develop analytics and analytic applications without programming
Support nested workflows
Enrich customer master data with new data and insights

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 11
REDUCING TIME TO VALUE USING TALEND So far we have looked at the business drivers for analysing big data, the evolution of technologies on Apache Hadoop, the emergence of the Lambda architecture to cater for real-time and batch oriented analysis of data and defined key requirements to reduce time to value. This section of the paper looks at how one vendor has embraced big data, the steps it has taken to exploit big data platform technologies and how it has stepped up to meet the key requirements defined earlier in order to reduce time to value in a big data environment. That vendor is Talend. Talend is a provider of data and application integration software and was one of the early movers in embracing big data technologies. In this paper we look at Talend data integration tooling.
HOW TALEND SUPPORTS DATA INTEGRATION ON HADOOP Talend’s Big Data Integration software can load, clean, transform, and enrich data inside Hadoop without the need for programming. Data integration developers can use Talend to graphically build data integration workflows that clean, transform and integrate data on Hadoop. That means that existing people already using Talend for data warehousing or to integrate master data, can continue with their existing skill sets and the familiar Talend workflow-based user interface to process data on Hadoop. All they need to do is to exploit the additional transforms provided for big data processing and drag and drop these into data integration workflows in a similar fashion to how they already work on RDBMSs. Talend also supports machine learning which helps to create analytical applications from a familiar workflow based user interface. Once a workflow has been built graphically, Talend then generates the necessary Java code to run either batch or near real-time stream processing applications on Hadoop. For batch processing, both MapReduce and Spark are supported. Spark is shown in Figure 1.
Figure 1
Data Cleansing and Integration Tool
High Speed Generation of In-Memory Data Driven Analytical Applications On Hadoop
Extract Parse Clean Transform Analyse Load Insights
e.g. generate Java Spark applications
e.g. To prepare data for analysis using in-memory Spark applications To prepare and analyse data using in-memory Spark applications
More than just an ETL tool Automated generation of data driven analytic applications that get data, accelerate data preparation and automatically analyse to produce insight Reduce time to insight and to make decisions
Key Advantage
Copyright © Intelligent Business Strategies 1992-2015!
Talend is an open source data integration vendor
Talend was one of the first data integration vendors to support Hadoop
Talend can generate batch MapReduce and Spark applications to integrate and analyse data on Hadoop

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 12
In the case of real-time stream processing, Talend also supports Apache Storm and Apache Kafka. This is shown in Figure 2.
Figure 2
FROM ETL TO ANALYTICAL WORKFLOWS In addition to building Extract, Transform and Load (ETL) workflows that run on Hadoop, Talend also makes it possible to include in-Hadoop analytics (e.g. Spark MLlib analytics) as transforms in ETL workflows. This means it is possible to go beyond ETL jobs that clean and integrate big data into a world where you can embed analytics in Talend workflows to create analytic applications that clean, integrate and analyse big data. Once a workflow is created, Talend automatically generates the code to run the analytic application at scale on Hadoop. This capability opens up the way for rapid development of big data analytic applications via a straightforward workflow based user interface with no programming.
USING TALEND TO GENERATE BIG DATA ANALYTIC APPLICATIONS In the case of batch data integration applications, these can run either as MapReduce applications or as in-memory Spark applications. Talend has supported MapReduce for some time with Spark support also now available. Typically Spark would run data integration jobs faster than MapReduce on a Hadoop cluster because Spark facilitates parallel processing of data in-memory without the need to set intermediate data down on disk.
In addition however, given that Talend can nest workflows, it becomes possible to embed analytical models inside Talend workflow based analytical applications, which can then be deployed to execute as a MapReduce or Spark analytical applications on Hadoop.
Furthermore, Talend also supports the ability to generate Apache Storm so called ‘topology applications’ on a Hadoop cluster. This means that Talend can also be used to develop near-real-time stream processing analytic applications
Data Cleansing and Integration Tool
High Speed In-Memory Streaming Analytical Applications On Hadoop – Talend Can Generate Storm Application Code
Extract Parse Clean Transform Analyse Load Insights
e.g. To prepare and analyse live streaming data in motion
e.g. generate Java Storm topology applications based on Trident
Accelerate data preparation and filtering in true real time Generate real-time analytic applications that can prepare data, analyse and act in real-time to optimise business operations
Key Advantage
Copyright © Intelligent Business Strategies 1992-2015!
Talend can also generate Storm applications to integrate and analyse streaming data in near real-time
Talend supports the ability to include analytics in ETL workflows
This turns ETL workflows into analytic applications
Talend Big Data Integration can generate batch and real-time analytical applications in addition to ETL processing on Hadoop

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 13
running on Storm, to analyse high velocity data. Examples could be near-real-time analysis of sensor data, clickstream data or markets data. Note that the ability to generate Storm applications goes beyond what traditional ETL tools can do as this makes it possible to generate applications that integrate data in-motion and not just data at rest.
BUSINESS BENEFITS FROM ANALYTICAL WORKFLOWS The capability of Talend to go beyond scalable data integration on Hadoop (a core competency) to now being able to generate batch and near real-time analytical applications for both Spark and Storm respectively really does yield a number of new business benefits that include:
• Significantly reduced time to value
• Significantly improved productivity in developing big data analytic applications
• Acceleration of data and analytical processing
• Support for generation of both near-real-time streaming analytic applications and batch applications
• Continued use of existing ETL skillsets in a big data environment
• No need for programming skills which reduces the dependency on hard to find developers
• Support for the Lambda architecture
TALEND CASE STUDY: OTTO An example of an organisation making use of the aforementioned Talend capabilities is Otto. Otto is a large German retailer who started using Talend to generate MapReduce batch jobs to integrate and prepare data for a self-learning forecasting system. Then, when Talend released support for Spark, they utilised this capability to generate analytic applications for Dynamic Pricing. In addition, they also took advantage of Talend to generate Storm real-time analytic applications to address the problem of shopping cart abandonment.
Talend can integrate and analyse data in motion and not just data at rest
The ability to generate code reduces time to value and improves productivity
It also breaks the dependency on programming skill sets as well as exploiting and protecting existing ETL skills

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 14
CONCLUSIONS There is no doubt that with demand increasing rapidly to implement data driven projects on big data technologies, the current shortage of skilled people is set to get worse. Data scientists are already in very short supply. To address this problem, companies are looking to technology suppliers to raise the level of abstraction to make it easier to build new data driven analytic applications that can process data at scale. They want technologies that allow them to reduce the dependency on software developers.
Talend’s Big Data Integration software allows existing ETL developers and trained data scientists to quickly build batch and near real-time big data analytical applications using a familiar ETL workflow based user interface without the need for programming. Talend supports the ability to generate code for Spark-based parallel, batch processing on in-memory Hadoop data. In addition, the same workflow interface along with additional transformations provides the ability to also generate code for near-real-time stream processing analytical applications on a Storm cluster. This significantly simplifies the development of analytic applications to process high velocity data, as again, no programming is needed.
Support for both Spark and Storm means that Talend can be used to develop a broad range of batch and real-time data integration and analytic applications using an approach that improves productivity and reduces development time. Maintenance of these applications is also much easier to do, as it is only a matter of changing a workflow with no need to look through code. Furthermore Talend also provides metadata lineage so that people can see how data was processed.
All of this capability makes Talend a competitive big data technology that allows organisations to start quickly using existing skillsets without the need to first find developers that understand how to write MapReduce, Spark and Storm applications on Hadoop. In addition the survey cited at the beginning of this paper showed that in future, there will be a greater reliance on business analysts and data architects in big data environments rather than business analysts and programmers. If that is the case, Talend’s strategy to make it easier for data architects to work in a big data environment alongside business analysts, sets them up very well for the future.
.
Companies want technologies that make it much easier to develop big data analytic applications
Talend Big Data Integration simplifies development of both batch and real-time analytic applications
Support for both batch and real-time means that a broad range of analytic applications can be developed using Talend products

Building Big Data Analytic Applications At Scale Using Existing ETL Skillsets
Copyright © Intelligent Business Strategies Limited, 2015, All Rights Reserved 15
About Intelligent Business Strategies Intelligent Business Strategies is a research and consulting company whose goal is to help companies understand and exploit new developments in business intelligence, analytical processing, data management and enterprise business integration. Together, these technologies help an organisation become an intelligent business.
Author Mike Ferguson is Managing Director of Intelligent Business Strategies Limited. As an analyst and consultant he specialises in business intelligence and enterprise business integration. With over 33 years of IT experience, Mike has consulted for dozens of companies on business intelligence strategy, big data, data governance, master data management and enterprise architecture. He has spoken at events all over the world and written numerous articles. He has written many articles, and blogs providing insights on the industry. Formerly he was a principal and co-founder of Codd and Date Europe Limited – the inventors of the Relational Model, a Chief Architect at Teradata on the Teradata DBMS and European Managing Director of Database Associates, an independent analyst organisation. He teaches popular master classes in Big Data Analytics, New Technologies for Business Intelligence and Data Warehousing, Enterprise Data Governance, Master Data Management, and Enterprise Business Integration.
INTELLIGENT BUSINESS STRATEGIES
Water Lane, Wilmslow Cheshire, SK9 5BG
England Telephone: (+44) 1625 520700
Internet URL: www.intelligentbusiness.biz E-mail: [email protected]
Building Big Data Analytic Applications at Scale Using Existing ETL Skillsets
Copyright © 2015 by Intelligent Business Strategies All rights reserved





























