Embed Size (px)
Citation preview

Business Intelligence and Market Data Research
Tom Maddox,
Solutions Architect

So … as a community, we’ve been doing
big for a while…

And it keeps getting bigger
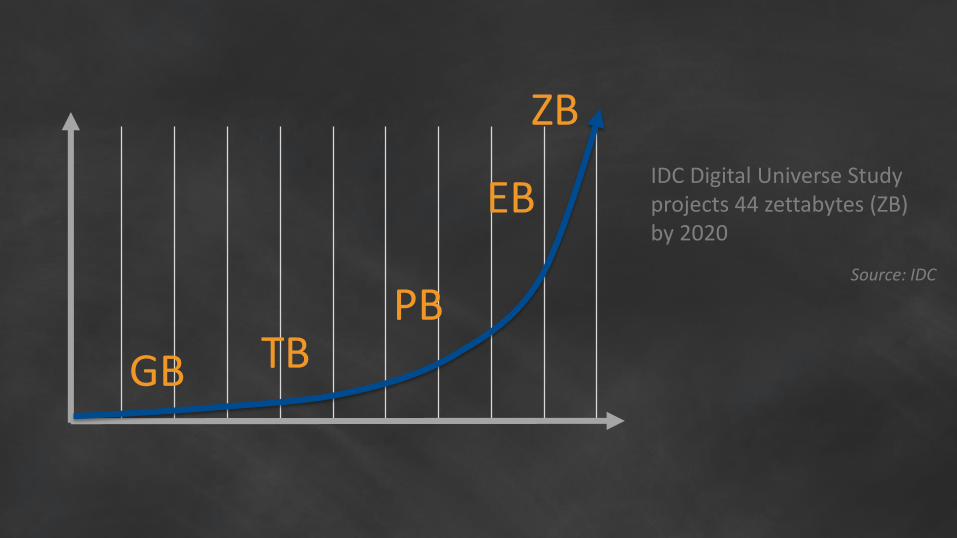
GB TBPB
IDC Digital Universe Study projects 44 zettabytes (ZB) by 2020
Source: IDC
ZB
EB
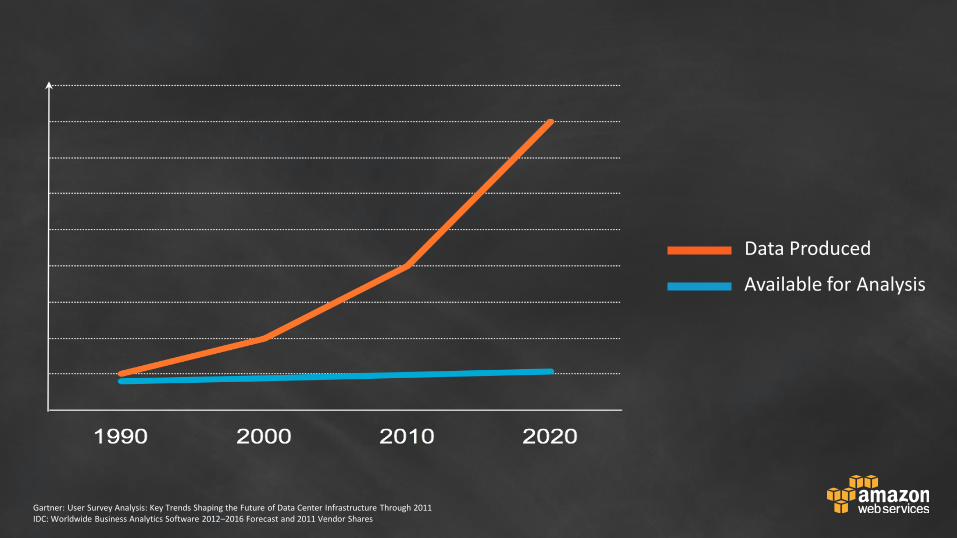
Data Produced
Available for Analysis
Gartner: User Survey Analysis: Key Trends Shaping the Future of Data Center Infrastructure Through 2011 IDC: Worldwide Business Analytics Software 2012–2016 Forecast and 2011 Vendor Shares
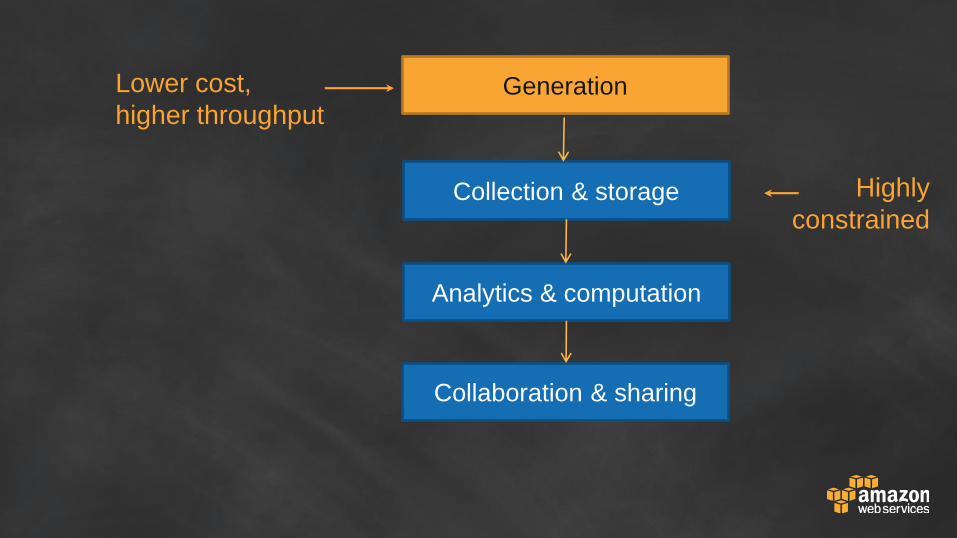
Generation
Collection & storage
Analytics & computation
Collaboration & sharing
Highly
constrained
Lower cost,
higher throughput

Big Gap in turning data into actionable
information

WANTED: Very large dataset seeks scalable storage & compute for short term
relationship, possibly longer?

Hello Cloud.
(Amazon Web Services)

On demand Pay as you go
Uniform Available

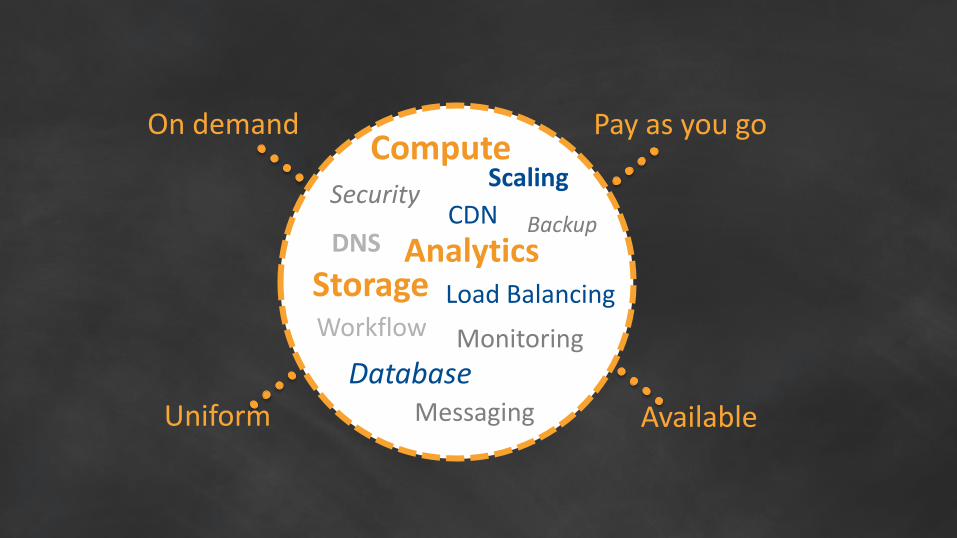
SecurityScaling
Analytics
DatabaseMonitoring
Messaging
Workflow
DNS
Load Balancing
BackupCDN
On demand Pay as you go
Uniform Available
Compute
Storage
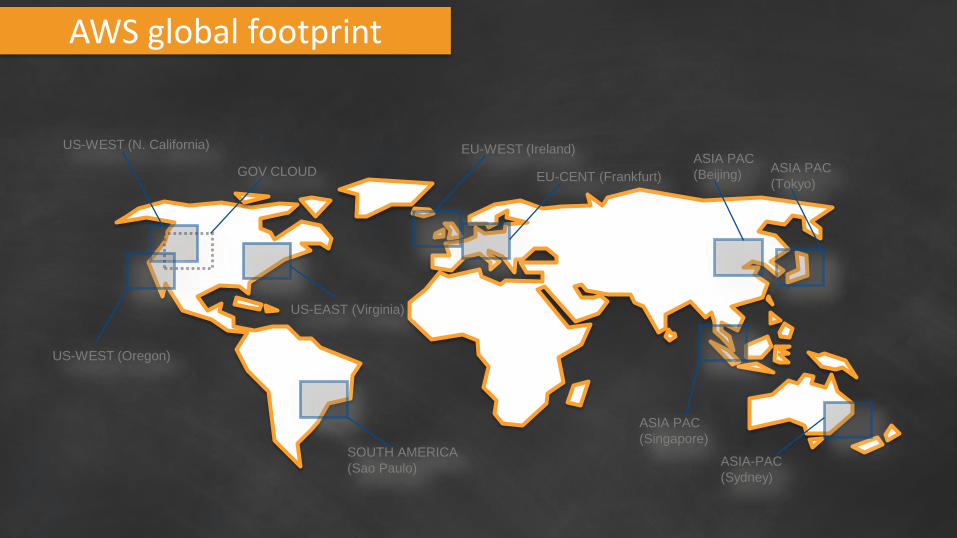
AWS global footprint
US-WEST (N. California) EU-WEST (Ireland)
ASIA PAC
(Tokyo)
ASIA PAC
(Singapore)
US-WEST (Oregon)
SOUTH AMERICA
(Sao Paulo)
US-EAST (Virginia)
GOV CLOUD
ASIA-PAC
(Sydney)
EU-CENT (Frankfurt)
ASIA PAC
(Beijing)

Enterprise Applications
Platform Services
Administration & Security
Core Services
Infrastructure
AnalyticsApp
Services
Deployment &
Management
Mobile
Services
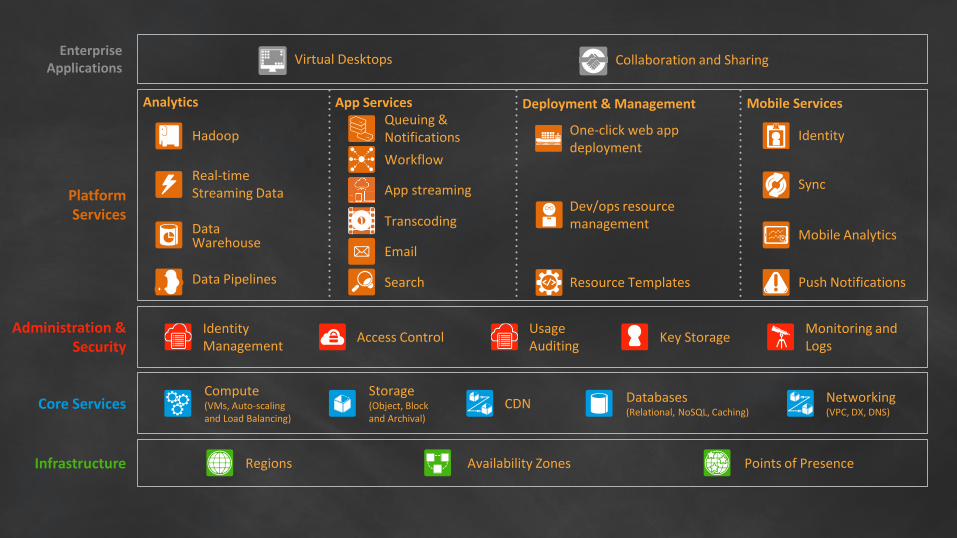
Infrastructure Regions Points of PresenceAvailability Zones
Core ServicesStorage(Object, Block and Archival)
Compute(VMs, Auto-scaling and Load Balancing)
Databases(Relational, NoSQL, Caching)
Networking(VPC, DX, DNS)
CDN
Access ControlUsage Auditing
Monitoring and Logs
Administration & Security
Key StorageIdentityManagement
Platform Services
Deployment & Management
One-click web app deployment
Dev/ops resourcemanagement
Resource Templates Push Notifications
Mobile Services
Mobile Analytics
Identity
Sync
App Services
Workflow
Transcoding
Search
Queuing &Notifications
App streaming
Analytics
Hadoop
Data Pipelines
Data Warehouse
Real-timeStreaming Data
EnterpriseApplications
Virtual Desktops Collaboration and Sharing

Technologies and techniques for
working productively with data,
at any scale.
Big Data
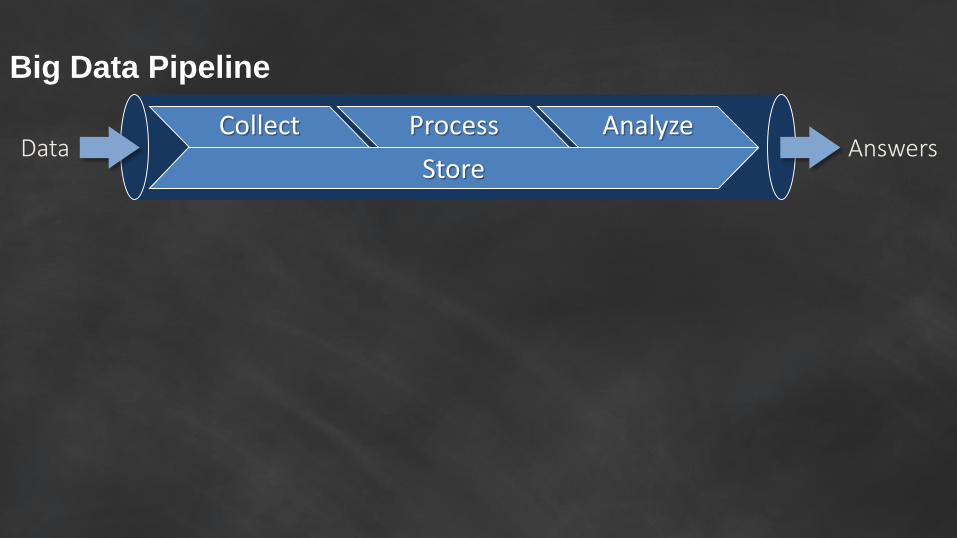
Big Data Pipeline
Data AnswersCollect Process Analyze
Store
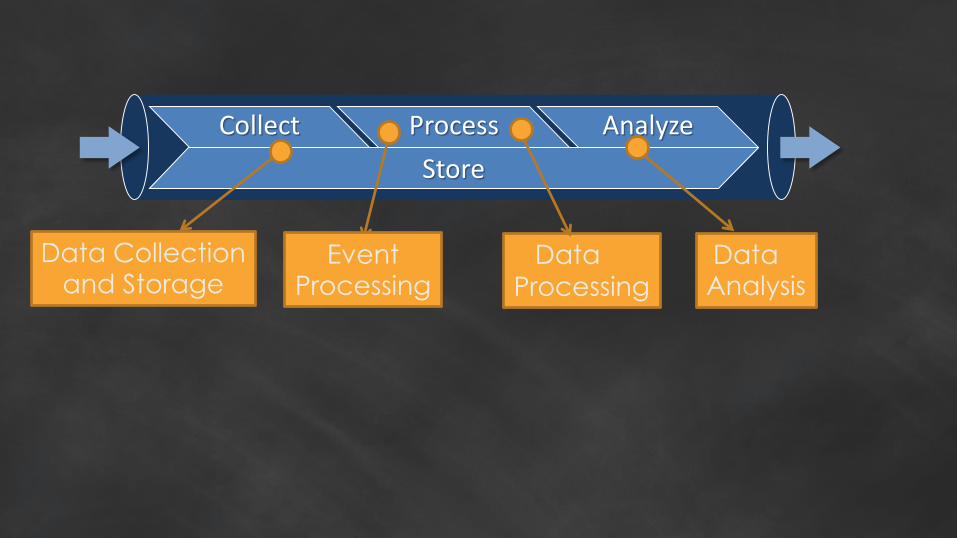
Collect Process Analyze
Store
Data Collectionand Storage
DataProcessing
EventProcessing
Data Analysis
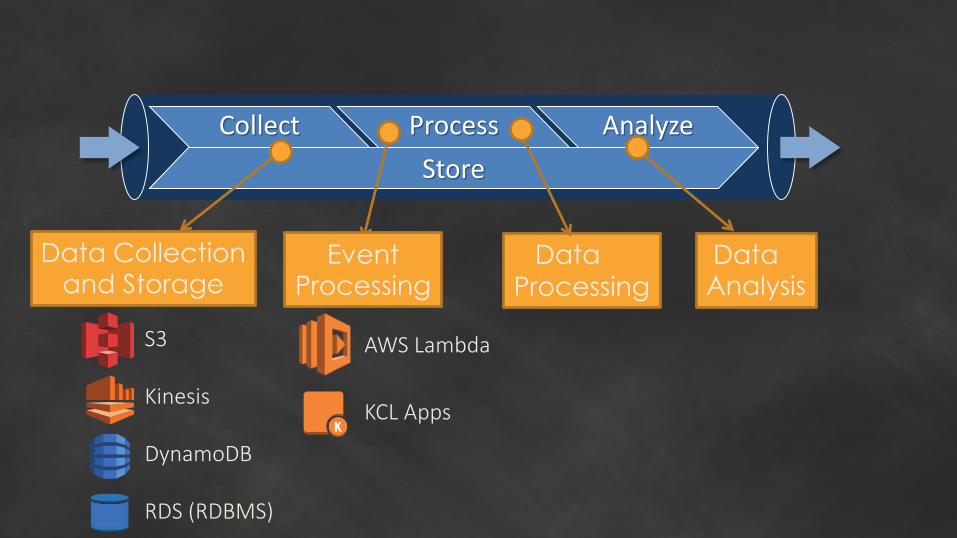
S3
Kinesis
DynamoDB
RDS (RDBMS)
AWS Lambda
KCL Apps
Collect Process Analyze
Store
Data Collectionand Storage
DataProcessing
EventProcessing
Data Analysis

Store anything
Object storage
Scalable
99.999999999% durability
Amazon S3
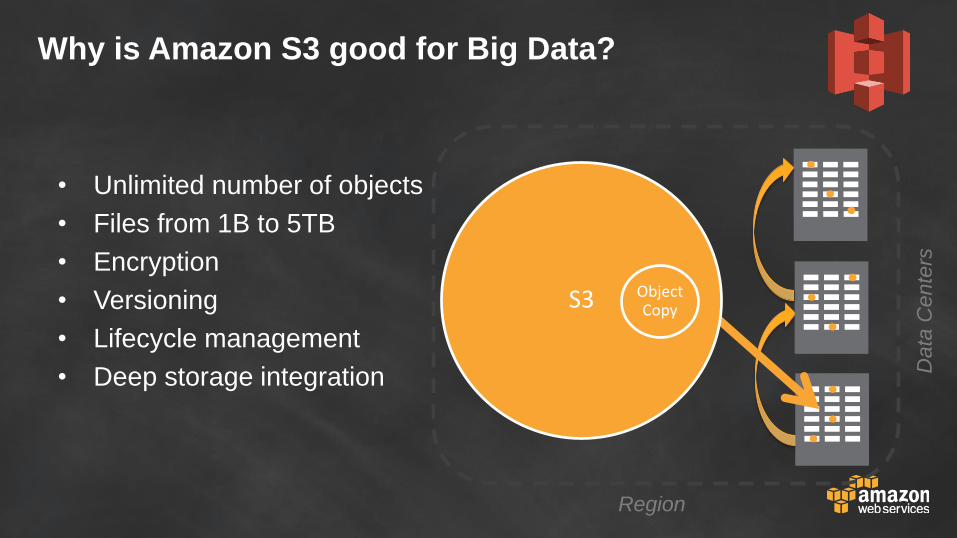
Why is Amazon S3 good for Big Data?
• Unlimited number of objects
• Files from 1B to 5TB
• Encryption
• Versioning
• Lifecycle management
• Deep storage integration
Object Cop
y
S3 Object Copy
Region
Da
ta C
ente
rs

Real-time processing
High throughput; elastic
Easy to use
S3, Redshift, DynamoDB Integrations
Amazon Kinesis
Streams
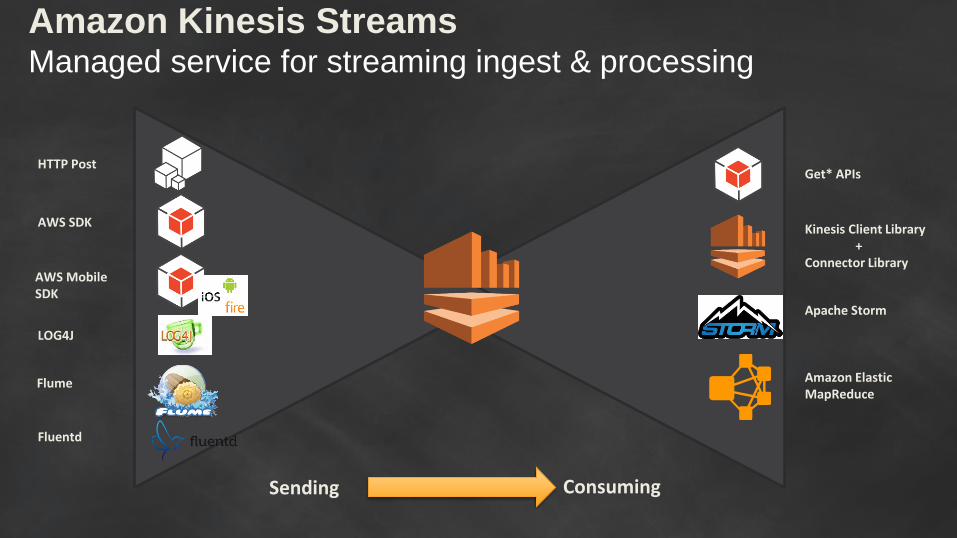
Amazon Kinesis StreamsManaged service for streaming ingest & processing
Sending Consuming
HTTP Post
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client Library+
Connector Library
Apache Storm
Amazon Elastic MapReduce
AWS Mobile SDK
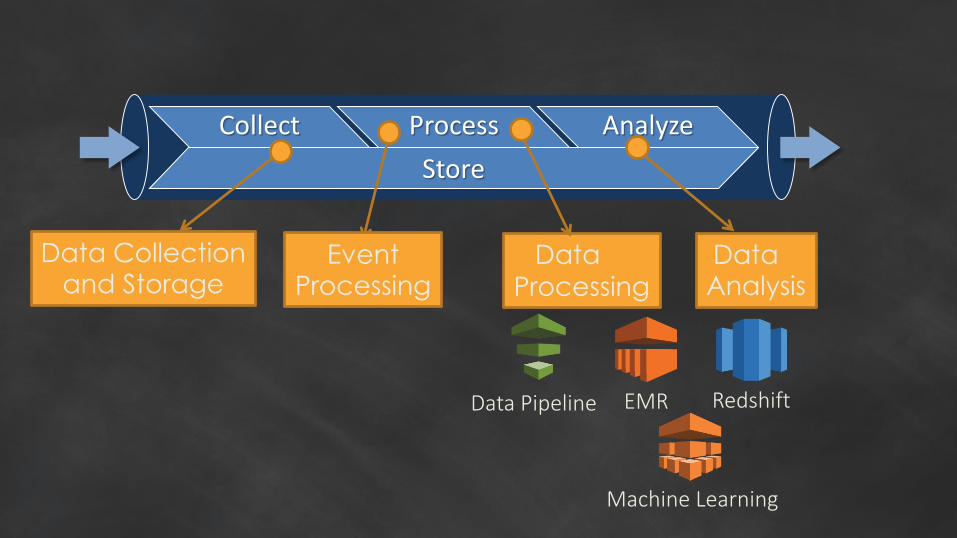
Collect Process Analyze
Store
EMR Redshift
Machine Learning
Data Pipeline
Data Collectionand Storage
DataProcessing
EventProcessing
Data Analysis

From one instance…

…to thousands

Hadoop/HDFS clusters
Hive, Spark, MapReduce
Easy to use; fully managed
On-demand and spot pricing
Amazon EMR

Easy to add and remove compute capacity on your cluster
Match compute
demands with
cluster sizing.
Resizable clusters
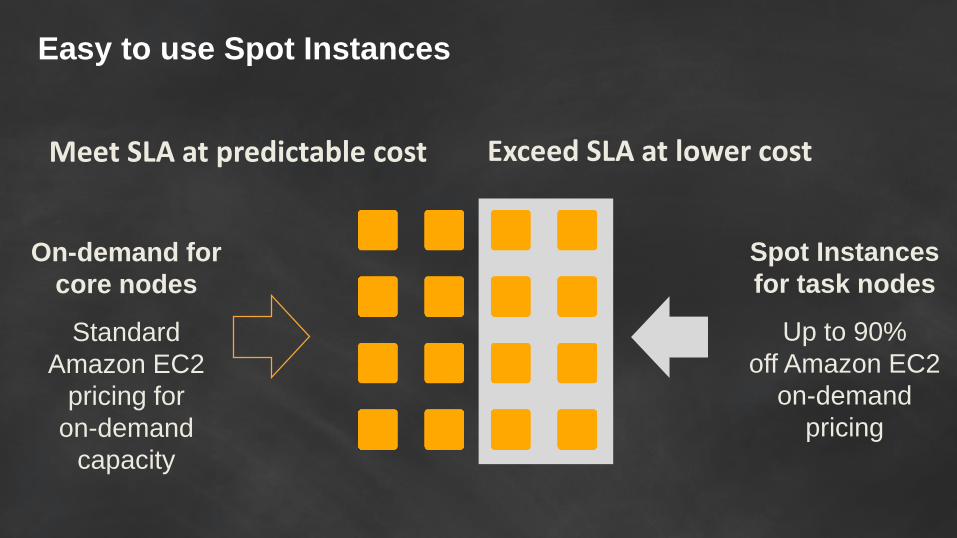
Spot Instances
for task nodes
Up to 90%
off Amazon EC2
on-demand
pricing
On-demand for
core nodes
Standard
Amazon EC2
pricing for
on-demand
capacity
Easy to use Spot Instances
Meet SLA at predictable cost Exceed SLA at lower cost

Amazon S3 as your persistent data store
• Separate compute and storage
• Resize and shut down Amazon EMR clusters with
no data loss
• Point multiple Amazon EMR clusters at same data
in Amazon S3
EMR
EMR
Amazon
S3
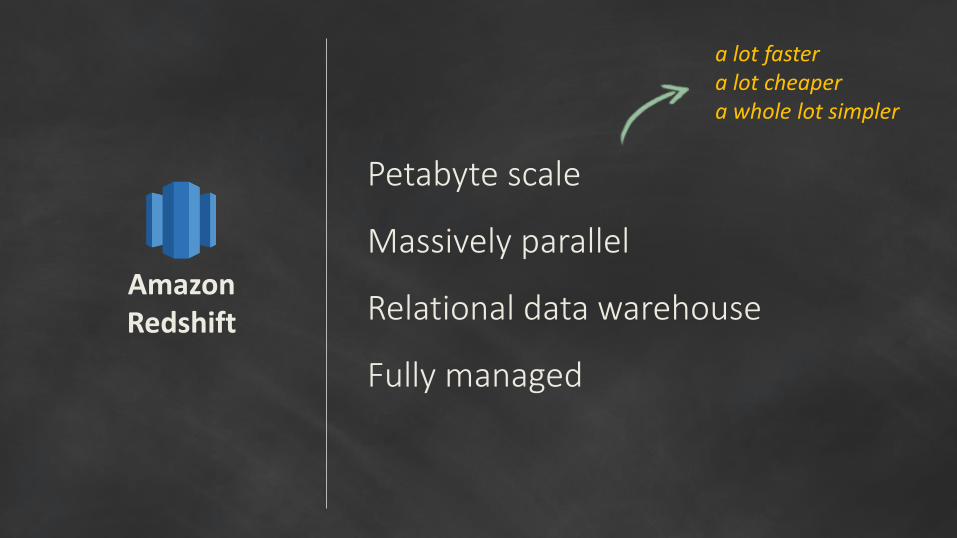
Petabyte scale
Massively parallel
Relational data warehouse
Fully managed
Amazon Redshift
a lot fastera lot cheapera whole lot simpler
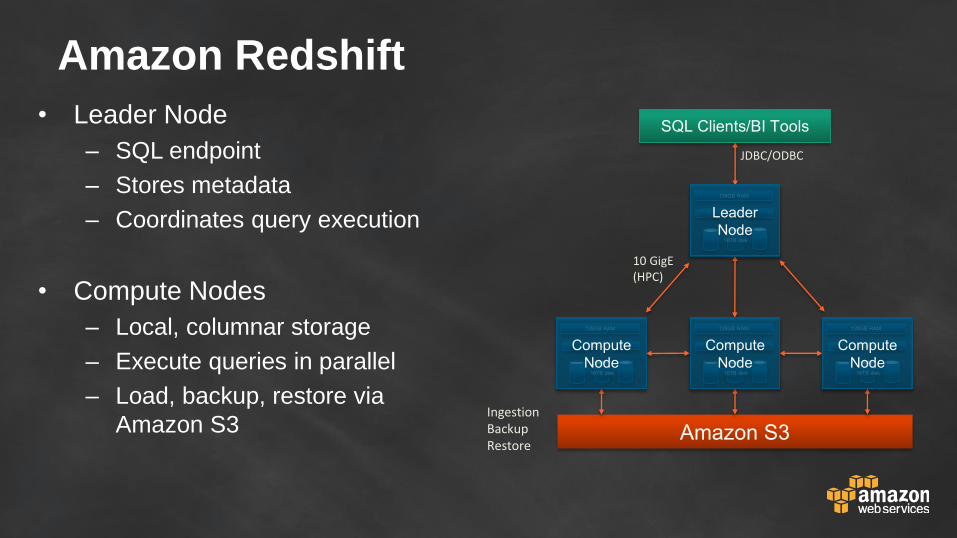
Amazon Redshift
• Leader Node
– SQL endpoint
– Stores metadata
– Coordinates query execution
• Compute Nodes
– Local, columnar storage
– Execute queries in parallel
– Load, backup, restore via
Amazon S3
10 GigE(HPC)
IngestionBackupRestore
JDBC/ODBC

SELECT COUNT(*) FROM LOGS WHERE DATE = ‘09-JUNE-2013’
MIN: 01-JUNE-2013
MAX: 20-JUNE-2013
MIN: 08-JUNE-2013
MAX: 30-JUNE-2013
MIN: 12-JUNE-2013
MAX: 20-JUNE-2013
MIN: 02-JUNE-2013
MAX: 25-JUNE-2013
Unsorted Table
MIN: 01-JUNE-2013
MAX: 06-JUNE-2013
MIN: 07-JUNE-2013
MAX: 12-JUNE-2013
MIN: 13-JUNE-2013
MAX: 18-JUNE-2013
MIN: 19-JUNE-2013
MAX: 24-JUNE-2013
Sorted By Date
Benefit #1: Amazon Redshift is fastSort Keys and Zone Maps
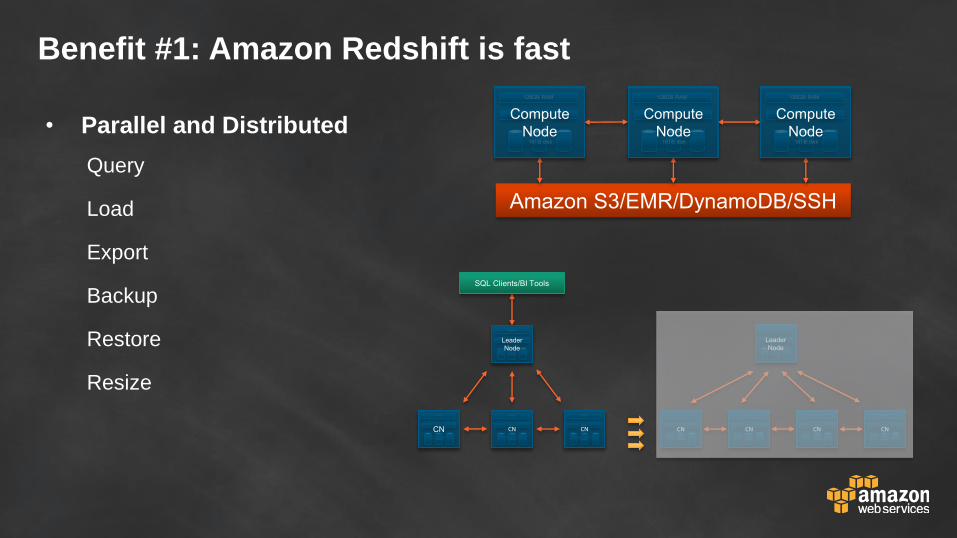
Benefit #1: Amazon Redshift is fast
• Parallel and Distributed
Query
Load
Export
Backup
Restore
Resize
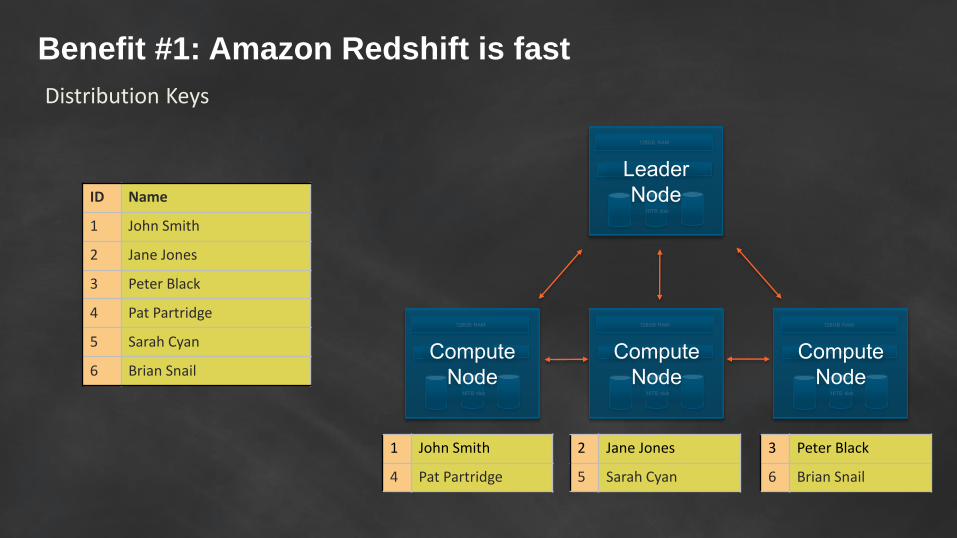
ID Name
1 John Smith
2 Jane Jones
3 Peter Black
4 Pat Partridge
5 Sarah Cyan
6 Brian Snail
1 John Smith
4 Pat Partridge
2 Jane Jones
5 Sarah Cyan
3 Peter Black
6 Brian Snail
Benefit #1: Amazon Redshift is fast
Distribution Keys

Benefit #1: Amazon Redshift is fast
H/W optimized for I/O intensive workloads, 4GB/sec/node
Enhanced networking, over 1M packets/sec/node
Choice of storage type, instance size
Regular cadence of auto-patched improvements
Example: Our new Dense Storage (HDD) instance type
Improved memory 2x, compute 2x, disk throughput 1.5x
Cost: same as our prior generation !

Benefit #2: Amazon Redshift is inexpensive
DS2 (HDD)Price Per Hour for
DW1.XL Single NodeEffective Annual
Price per TB compressed
On-Demand $ 0.850 $ 3,725
1 Year Reservation $ 0.500 $ 2,190
3 Year Reservation $ 0.228 $ 999
DC1 (SSD)Price Per Hour for
DW2.L Single NodeEffective Annual
Price per TB compressed
On-Demand $ 0.250 $ 13,690
1 Year Reservation $ 0.161 $ 8,795
3 Year Reservation $ 0.100 $ 5,500
Pricing is simple
Number of nodes x price/hour
No charge for leader node
No up front costs
Pay as you go
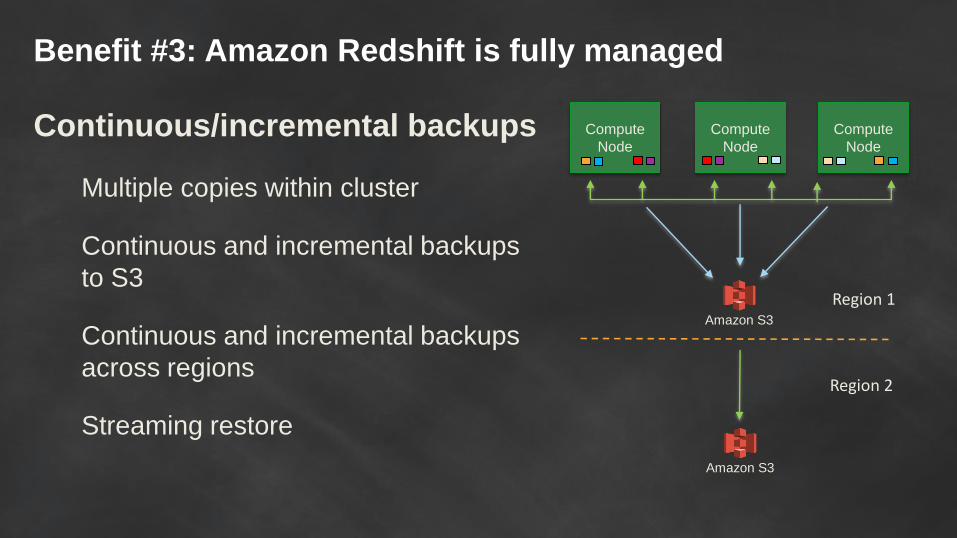
Benefit #3: Amazon Redshift is fully managed
Continuous/incremental backups
Multiple copies within cluster
Continuous and incremental backups
to S3
Continuous and incremental backups
across regions
Streaming restore
Amazon S3
Amazon S3
Region 1
Region 2
Compute
Node
Compute
Node
Compute
Node
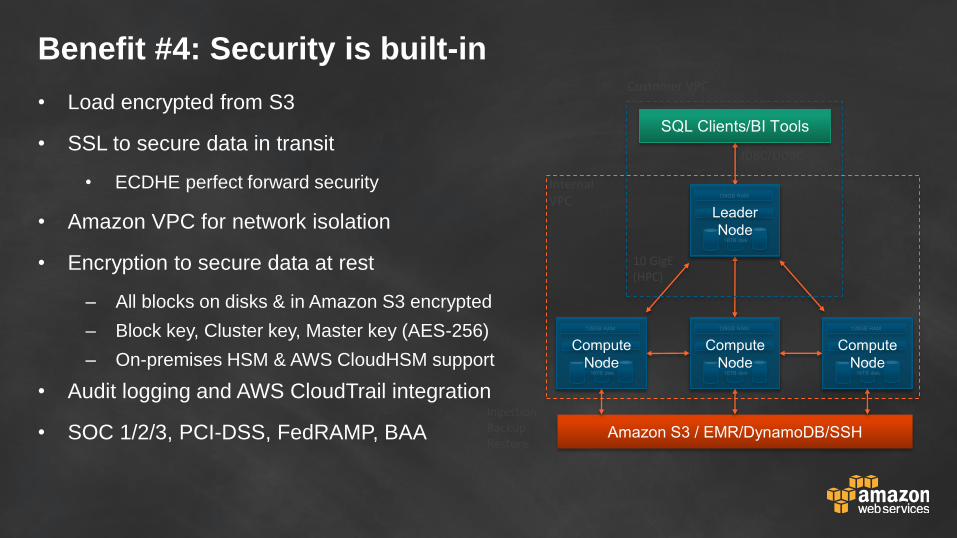
Benefit #4: Security is built-in
• Load encrypted from S3
• SSL to secure data in transit
• ECDHE perfect forward security
• Amazon VPC for network isolation
• Encryption to secure data at rest
– All blocks on disks & in Amazon S3 encrypted
– Block key, Cluster key, Master key (AES-256)
– On-premises HSM & AWS CloudHSM support
• Audit logging and AWS CloudTrail integration
• SOC 1/2/3, PCI-DSS, FedRAMP, BAA
10 GigE(HPC)
IngestionBackupRestore
Customer VPC
InternalVPC
JDBC/ODBC

Benefit #5: We innovate quickly
• Well over 100 new features added since launch
• Release every two weeks
• Automatic patching
Service Launch (2/14)
PDX (4/2)
Temp Credentials (4/11)
DUB (4/25)
SOC1/2/3 (5/8)
Unload Encrypted Files
NRT (6/5)
JDBC Fetch Size (6/27)
Unload logs (7/5)
SHA1 Builtin (7/15)
4 byte UTF-8 (7/18)
Sharing snapshots (7/18)
Statement Timeout (7/22)
Timezone, Epoch, Autoformat (7/25)
WLM Timeout/Wildcards (8/1)
CRC32 Builtin, CSV, Restore Progress (8/9)
Resource Level IAM (8/9)
PCI (8/22)
UTF-8 Substitution (8/29)
JSON, Regex, Cursors (9/10)
Split_part, Audit tables (10/3)
SIN/SYD (10/8)
HSM Support (11/11)
Kinesis EMR/HDFS/SSH copy, Distributed Tables, Audit
Logging/CloudTrail, Concurrency, Resize Perf.,
Approximate Count Distinct, SNS Alerts, Cross Region Backup
(11/13)
Distributed Tables, Single Node Cursor Support, Maximum Connections to 500 (12/13)
EIP Support for VPC Clusters (12/28)New query monitoring system
tables and diststyle all (1/13)
Redshift on DW2 (SSD) Nodes (1/23)
Compression for COPY from SSH, Fetch size support for single node clusters, new
system tables with commit stats, row_number(), strotol() and query termination (2/13)Resize progress indicator &
Cluster Version (3/21)
Regex_Substr, COPY from JSON (3/25)
50 slots, COPY from EMR, ECDHE ciphers (4/22)
3 new regex features, Unload to single file, FedRAMP(5/6)
Rename Cluster (6/2)
Copy from multiple regions, percentile_cont, percentile_disc
(6/30)
Free Trial (7/1)
pg_last_unload_count (9/15)
AES-128 S3 encryption (9/29)UTF-16 support (9/29)

Benefit #6: Amazon Redshift has a large ecosystem
Data Integration Systems IntegratorsBusiness Intelligence

Redshift is Awesome!
How can I just use it?
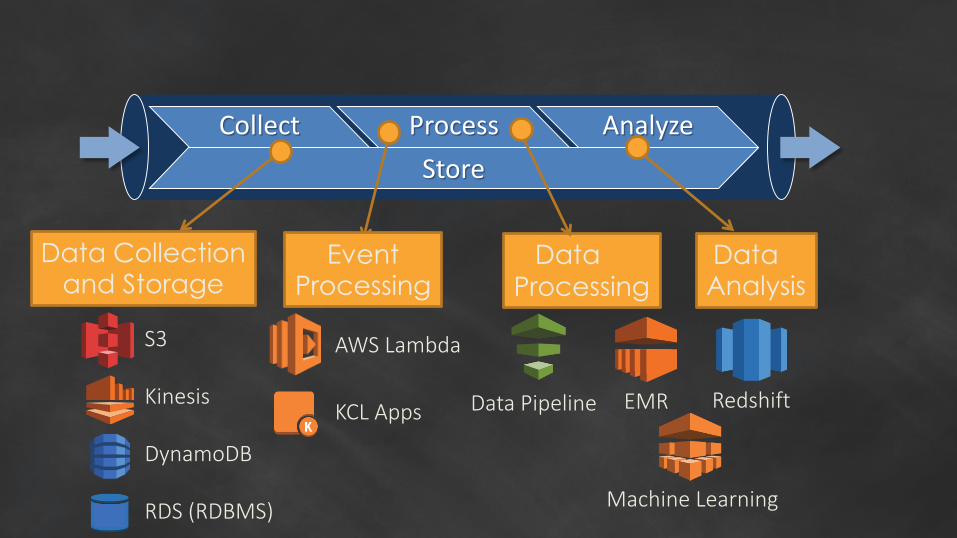
Collect Process Analyze
Store
EMR Redshift
Machine Learning
Data Pipeline
Data Collectionand Storage
DataProcessing
EventProcessing
Data Analysis
S3
Kinesis
DynamoDB
RDS (RDBMS)
AWS Lambda
KCL Apps
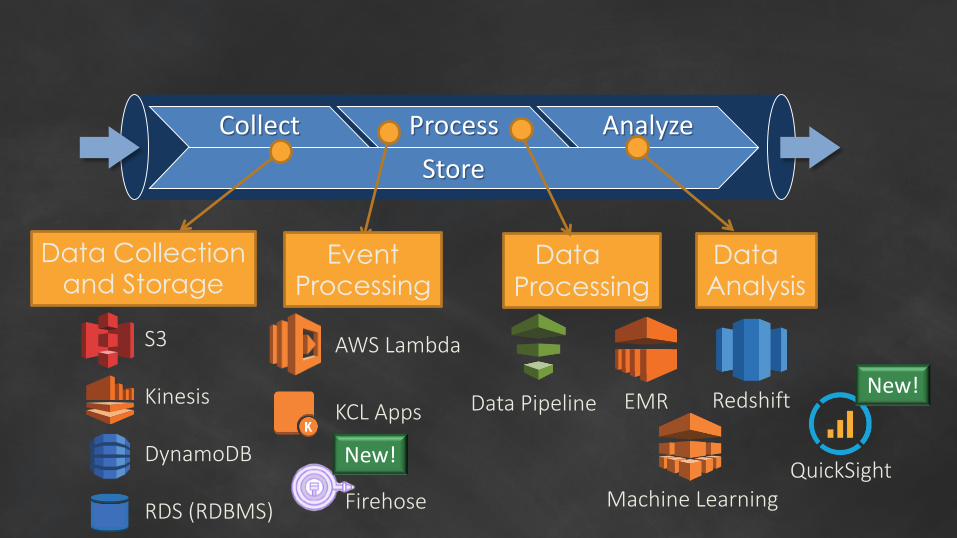
Collect Process Analyze
Store
EMR Redshift
Machine Learning
Data Pipeline
Data Collectionand Storage
DataProcessing
EventProcessing
Data Analysis
QuickSight
New!
S3
Kinesis
DynamoDB
RDS (RDBMS)
AWS Lambda
KCL Apps
Firehose
New!

Real-time processing
No scaling needed
Batches events to S3 and then
Redshift
Configurable batch size or times
Amazon Kinesis
Firehose
New!
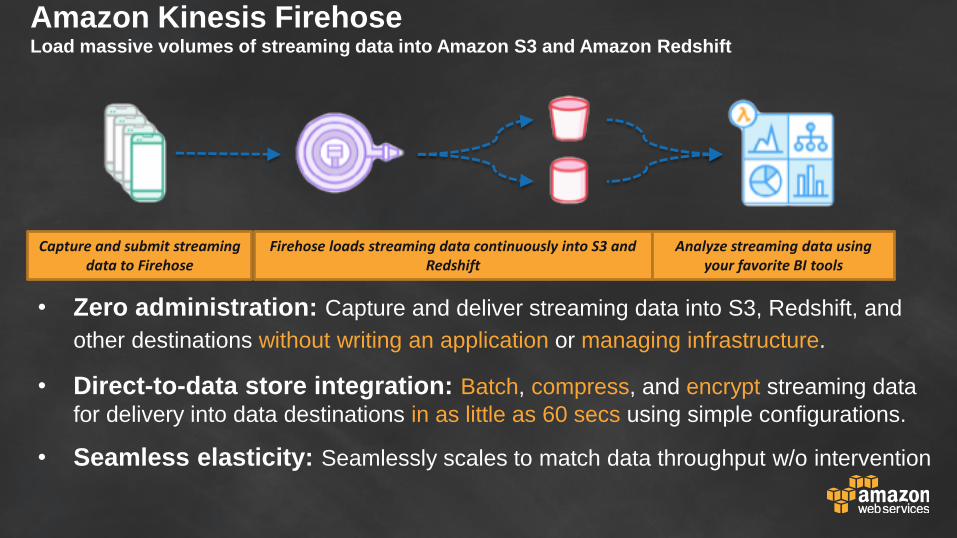
Amazon Kinesis FirehoseLoad massive volumes of streaming data into Amazon S3 and Amazon Redshift
• Zero administration: Capture and deliver streaming data into S3, Redshift, and
other destinations without writing an application or managing infrastructure.
• Direct-to-data store integration: Batch, compress, and encrypt streaming data
for delivery into data destinations in as little as 60 secs using simple configurations.
• Seamless elasticity: Seamlessly scales to match data throughput w/o intervention
Capture and submit streaming data to Firehose
Firehose loads streaming data continuously into S3 and Redshift
Analyze streaming data using your favorite BI tools

Powerful BI tool
No barriers to usage
Native integration with AWS data
stores
External data stores are ok too!
Note: Preview opens H1 2016
Amazon QuickSight
New!

Easy exploration of AWS data
• Securely discover and connect to AWS data
• Quickly explore AWS data sources
• Relational databases (Amazon RDS, Amazon RDS for Aurora,
Amazon Redshift)
• NoSQL databases (Amazon DynamoDB)
• Amazon EMR, Amazon S3, files (CSV, Excel, TSV, XLF, CLF)
• Streaming data sources (Amazon DynamoDB, Amazon
Kinesis)
• Easily import data from any table or file
• Automatic detection of data types
S3
Kinesis
DynamoDB
RDS (RDBMS)
EMR
Redshift

Fast insights with SPICE
• Super-fast, Parallel, In-memory optimized, Calculation Engine
• 2 to 4x compression columnar data
• Compiled queries with machine code generation
• Rich calculations
• SQL-like syntax
• Very fast response time to queries
• Fully managed – No hardware or software to license

Intuitive visualizations with AutoGraph
• Automatic detection of data types
• Optimal query generation
• Appropriate graph type selection
• Ability to customize the graph type
• Very fast response
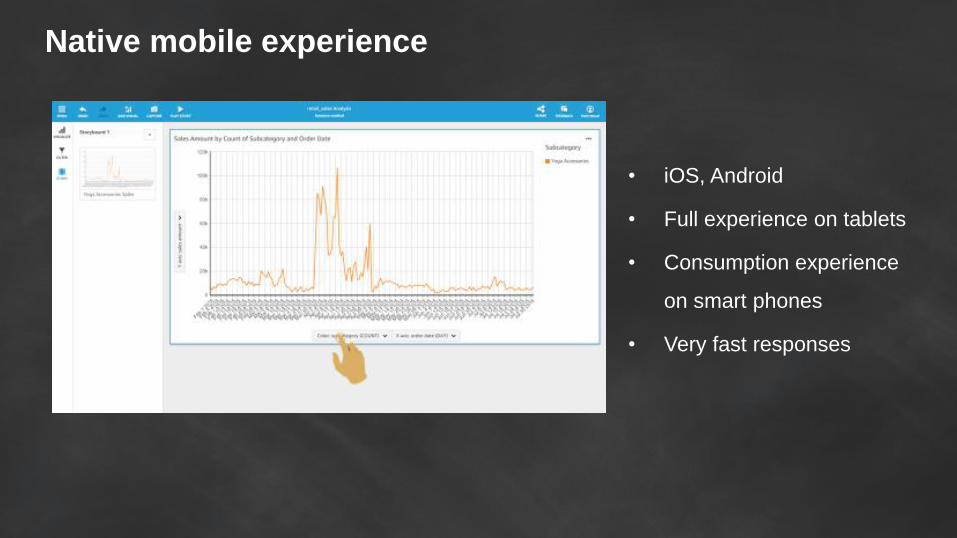
Native mobile experience
• iOS, Android
• Full experience on tablets
• Consumption experience
on smart phones
• Very fast responses

Tell a story with your data
• Capture the critical snapshot of analysis
• Build a sequence of analysis
• Share it securely
• Enable interactive exploration
• Very fast response

Demo!






























