Embed Size (px)
Citation preview

MATEMATICA APPLICATA E STATISTICA, Ing.Inf./El. 2014
CALCOLO COMBINATORIO.
Ogni volta che ci disponiamo a studiare, in realta gia riconosciamo - almeno implici-tamente - che cio che (ancora) non sappiamo supera di molto quello che sappiamo; chericchissima e la mobilita e vivacita della nostra mente; che la storia dell’umanita nonincomincia ne finisce con la nostra presenza nel mondo. Ma lo studio serve anche perabilitarti a lasciare nel mondo un’impronta che, per quanto dovesse sembrare piccola, nonpotrebbe mancare: la tua.
Una disposizione semplice di n oggetti a k a k e una k¡upla ordinata di k oggettiscelti tra gli n dati (ovviamente: k · n).Ad es. le disposizioni di 3 oggetti a, b, c a 2 a 2 (n = 3, k = 2), sono:
(a, b), (b, c), (c, a), (b, a), (c, b), (a, c).
Si dice anche ”disposizione semplice di n oggetti in classe k”. L’aggettivo ”semplice”vuol dire ”senza ripetizioni”; il nome ”disposizione” vuol dire che ha importanza l’ordine.
Proposizione. Il numero di disposizioni semplici di n oggetti a k a k e il prodotto di knumeri naturali decrescenti a partire da n:
D(n; k) = n(n¡ 1)...(n¡ k + 1)
Infatti: riempiamo k caselle in ordine: nella prima ho n possibilita di scelta, nella seconda(n¡ 1), ..., nella k¡esima ho n¡ k + 1 possibilita di scelta.
Ad es. in quanti modi 5 amici possono sedersi su tre sedili numerati di un treno?La domanda da importanza all’ordine (primo sedile, secondo sedile, terzo sedile), e nonci sono ripetizioni della stessa persona. Quindi si tratta delle disposizioni semplici di 5persone a 3 a 3: D(5; 3) = 5 ¢ 4 ¢ 3 = 60 modi diversi di occupare i tre posti!
Una permutazione di n oggetti e una n¡ upla i cui elementi sono tutti gli n oggetti.Detto altrimenti: e una disposizione semplice degli n oggetti: si tratta del caso k = n.
Propos. Il numero di permutazioni di n oggetti e il prodotto dei primi n numeri naturali:
P (n) = n(n¡ 1)...4 ¢ 3 ¢ 2 ¢ 1 ´ n!
[ Il simbolo n! si legge ”n fattoriale” e designa il prodotto dei primi n numeri naturali ].
Infatti: una permutazione di n oggetti una disposizione semplice di n oggetti ad n ad n.Quindi P (n) = D(n;n) = n!
1

Ad es.: in quanti modi 5 clienti possono mettersi in fila allo sportello di banca? Risposta:tanti quanti i modi di mettere in ordine 5 persone; cioe il numero di permutazioni di 5oggetti: 5! = 5 ¢ 4 ¢ 3 ¢ 2 ¢ 1 = 120.
Una combinazione semplice di n oggetti a k a k e un sottoinsieme -senza strutturad’ordine- di k oggetti scelti tra gli n.Si dice anche ”combinazione semplice di n oggetti in classe k”. L’aggettivo ”semplice” vuoldire ”senza ripetizioni”; il nome ”combinazione” vuol dire che non ha importanza l’ordine.
Ad es. le combinazioni dei 3 oggetti a, b, c, a 2 a 2 sono:
fa, bg, fb, cg, fa, cg.
Si noti: fa,bg= fb,ag. Per gli insiemi astratti (per i quali si usa la parentesi graffa) nonvige alcuna struttura d’ordine.
Propos. Il numero di combinazioni semplici di n oggetti a k a k e:
C(n; k) =n(n¡ 1)...(n¡ k + 1)
k!
che si suole indicare anche col simbolonk
e si suole scrivere in forma piu compatta:
nk
=n!
k!(n¡ k)! .
Infatti: per ciascuna combinazione di k oggetti, esistono P (k) modi di metterli in ordine.Quindi il numero di disposizioni e piu grande del numero di combinazioni e precisamente:
D(n; k) = C(n; k) ¢ P (k) ) C(n; k) =D(n; k)
P (k)
dal che segue l’enunciato.
Ad es. in quanti modi si possono nominare comitati di 4 persone da un gruppo di 9persone? La domanda non da importanza all’ordine e inoltre ogni persona nel comitatonon ha ripetizione; quindi si tratta delle combinazioni semplici di 9 oggetti a 4 a 4:
C(9; 4) =94
= 9!/[4!(9¡ 4)!] = 9 ¢ 8 ¢ 7 ¢ 6/4 ¢ 3 ¢ 2 ¢ 1 = 126.
Altro es.: quante colonne posso compilare al Totocalcio con 5 ”due”, 6 ”uno” e 2 ”x”?Risposta: prima mi domando quante colonne con 13 caselle hanno 5 ”due” e gli altri
simboli diversi da ”due”: C(13; 5) =135
. Poi mi domando quante colonne con 8
2

caselle riempite solo con ”uno” e con ”x” hanno esattamente 6 ”uno”: C(8; 6) =86
.
Allora la risposta e il prodotto:135
¢ 86
Una disposizione con ripetizione di n oggetti a k a k e una k¡ upla i cui elementisono gli n oggetti dati, con la possibilita di ripetizione.Si noti che k puo anche essere maggiore di n. Si dice anche: ”disposizione con ripetizionedi n oggetti in classe k”. Il nome ”disposizione” vuol dire che ha importanza l’ordine;l’espressione ”con ripetizione” vuol dire che sono permesse ripetizioni.
Ad esempio ecco le diposizioni con ripetizione dei tre oggetti dati a, b, c a due a due(quindi: n = 3, k = 2):
(a, a), (a, b), (b, a), (b, b), (b, c), (c, b), (a, c), (c, a), (c, c)
Proposiz. Il numero di disposizioni con ripetizione di n oggetti a k a k e:
DR(n; k) = nk.
Infatti: ogni disposizione una k-upla. Occupiamo le k posizioni di k¡upla in ordine:nella prima posizione ho n possibilita, nella seconda ho ancora n possibilita, ecc. Quindi:numero di oggetti elevato al numero di posizioni. O anche: numero di oggetti elevato alnumero di classe.
Ad esempio: quante schedine di totocalcio posso compilare? La domanda da importanzaall’ ordine e si ammettono ovviamente ripetizioni. Ogni schedina e una 13¡upla di simboliscelti fra 1, 2, x. Il numero di schedine possibili e il numero di disposizioni con ripetizionedei 3 simboli 1, 2,x, a 13 a 13:
DR(3; 13) = 313.
Una combinazione con ripetizione di n oggetti a k a k si ottiene scegliendo alcunioggetti fra gli n oggetti dati e contandoli zero o una o piu volte in modo che la sommadelle molteplicita sia uguale a k..Si dice anche: ”combinazione con ripetizione di n oggetti in classe k”. Il nome ”com-binazione” vuol dire che non ha importanza l’ordine; l’espressione ”con ripetizione” vuoldire che sono permesse ripetizioni (quindi, tra l’altro, puo essere k > n).
Ad es. le combinazioni con ripetizione dei 3 oggetti a, b, c a 2 a 2 sono:
aa, ab, ac, bb, bc, cc.
Senza dimostrazione diamo la proposizione:
3

Prop. Il numero delle combinazioni con ripetizione di n oggetti a k a k e:
CR(n; k) =n+ k ¡ 1
k
Es.: Il numero di combinazioni con ripetizione di tre oggetti a due a due:
CR(3; 2) =3 + 2¡ 1
2=
42
= 6.
Infine ecco due proposizioni immancabili dovunque si parli di calcolo combinatorio:
Proposizione. Facendo la convenzione 0! = 1 e chiamando anche in questi casink
la quantita n!/[k!(n¡ k)!], vale la seguente formula binomiale di Newton:
(a+ b)n =n0
an +n1
an−1b+ ...+ nn¡ 1 abn−1 + n
nbn =
ovvero, in notazione compatta,
(a+ b)n =n
k=0
nk
an−kbk.
Dim.(a+ b)n = (a+ b)(a+ b)...(a+ b) [n volte]
e una lunga somma che contiene piu volte l’addendo generico an−kbk. Fissiamo k, conk · n. Quante volte appare tale addendo? Tante volte quante sono le scelte di k parentesitra le n date, in cui pescare b ¢ b ¢ ... ¢ b k volte (automaticamente allora si pesca a ¢ ... ¢ anelle rimanenti n¡ k parentesi). In altre parole: tante volte quante sono le combinazionisemplici di k oggetti tra gli n dati. Cioe
nk
volte. Quindi tale addendo va’ moltiplicato
pernk
e la somma va fatta rispetto a k come enunciato.
Esercizio: provare la proprieta dei coefficienti binomiali:
n¡ 1k ¡ 1 +
n¡ 1k
=nk
.
[Grazie a questa si costruisce il famoso ”triangolo di Tartaglia”]. Per ispezione diretta:
(n¡ 1)!(k ¡ 1)!(n¡ k)! +
(n¡ 1)!k!(n¡ 1¡ k)! =
(n¡ 1)!k + (n¡ 1)!(n¡ k)k!(n¡ k)! =
4

=(n¡ 1)!(k + n¡ k)
k!(n¡ k)! =n
n¡ k .
SPAZIO DI PROBABILITA
In effetti - questo e il mio pensiero - dobbiamo riscoprire che prima di essere simpaticio antipatici, belli o brutti, milanisti o juventini, rock o lenti (per dirla con Celentano), disinistra o di destra, io e te siamo soprattutto ””domanda””. Noi siamo domanda a noistessi, siamo stupore per il nostro essere invitati senza invito, convocati senza convocazione,alla festa e partita della vita. Da una tale consapevolezza, quella di esere domanda a noistessi, tutto prende il suo avvio.
Def. Sia Ω un insieme. Una famiglia Σ di sottoinsiemi di Ω si dice σ¡algebra se:1) Ω, ; 2 Σ2) A 2 Σ ) Ω¡A ´ AC 2 Σ3) A1, A2, ... 2 Σ ) A1 [A2 [ ... 2 Σ
In altri termini, una famiglia Σ di sottoinsiemi di Ω e una σ¡algebra se comprende Ωstesso e l’insieme vuoto, e inoltre e chiusa rispetto alla complementazione e all’unionefinita e all’unione numerabile. Ma allora, per la legge di De Morgan, Σ e chiusa ancherispetto all’intersezione. Quindi tutte le operazioni importanti tra insiemi danno insiemiche restano in Σ.
Def. Uno spazio di probabilita e una terna (Ω,Σ, P ) dove: Ω e un insieme non vuoto, Σe una σ¡algebra di sottoinsiemi di Ω (detta famiglia degli eventi), P e una legge a valoriin [0, 1] (detta probabilita) tali che
1) per ogni evento A 2 Σ esiste il numero P (A) compreso fra 0 ed 1 detto ”probabilitadell’ evento A”;
2) P (Ω) = 1, P (;) = 0;3) la probabilita P e numerabilmente additiva su ogni successione di eventi a due a
due disgiunti:
dati gli eventi fAigi∈N , con Ai \Aj = ;, foralli6= j, si ha
P [ [∞i=1Ai ] =∞
i=1
P (Ai) ´ limn→∞
n
i=1
P (Ai).
[ In particolare per ogni coppia di eventi A,B disgiunti si ha P (A[B) = P (A)+P (B). ]
Teorema (regola di addizione per eventi arbitrari). Se A,B sono eventi arbitrari inuno spazio di probabilita Ω, allora
P (A [B) = P (A) + P (B)¡ P (A \B).
5

Dim. Scriviamo A come unione disgiunta di A¡B e A\B, e analogamente facciamo perB :
A = (A¡B) [ (A \B), B = (B ¡A) [ (A \B).Allora applicando due volte l’additivita (3):
P (A) + P (B) = P (A¡B) + P (A \B) + P (B ¡A) + P (A \B) =
= P [(A¡B) [ (A \B) [ (B ¡A)] + P (A \B) = P (A [B) + P (A \B)da cui la tesi sottraendo P (A \B) al primo e all’ultimo membro.
Teorema (regola di complementazione) Se E ½ Ω e un evento ed EC ´ Ω ¡ Ee l’evento complementare, si ha
P (E) = 1¡ P (EC).
Dim. Si puo applicare la (3) perche sono due eventi disgiunti.
Oss. Se lo spazio di probabilita Ω e costituito da un numero finito di elementi, lafamiglia Σ degli eventi coincide con la famiglia di tutti i sottoinsiemi di Ω. In tal caso,se gli elementi di Ω sono ωi, i = 1, 2, ..., n,, si fa spesso l’ipotesi di ”eventi elementariequiprobabili”, il che significa attribuire probabilita 1
n a ciascun evento elementare fωig.E’ in questo caso che vale la definizione classica di probabilita come ”numero dei casifavorevoli diviso il numero di casi possibili”.Esempio tipico e il dado non truccato, dove si definisce:
Ω = f1, 2, 3, 4, 5, 6g, P (1) = 1
6, ..., P (6) =
1
6.
Cosi’ potremo calcolare, ad es., la probabilita degli eventi
A : esce un numero pari, B : esce un numero minore di 3
P (A) = P (2) + P (4) + P (6) =1
2, P (B) = P (1) + P (2) =
1
3
Altro esempio tipico e il lancio, singolo o multiplo, di una moneta non truccata. Ad es.la probabilita che in cinque lanci di una moneta esca ”testa” almeno una volta si trovaintroducendo l’appropriato spazio di probabilita
Ω= insieme delle 5-uple ordinate di lettere ”T” o ”C”
In questo spazio l’evento ”non esce alcuna testa” e costituito dall’unica 5-upla (C,C,C,C,C)per cui l’evento A = ”esce almeno una testa” ha probabilita
P (A) = 1¡ P (AC) = 31
32.
6

Altro esempio: la probabilita che almeno due fra 20 persone abbiano compleannonello stesso giorno dell’anno e superiore o inferiore a 1
2?Basta calcolare la probabilita dell’evento complementare. Per l’evento complementare (”i20 compleanni sono tutti distinti”) il numero di casi favorevoli e il numero di disposizionisemplici di 365 oggetti a 20 a 20; il numero di casi possibili e il numero di disposizioni conripetizione di 365 oggetti a 20 a 20:
365 ¢ 364 ¢ ... ¢ 347 ¢ 346(365)20
= (365
365)(364
365)...(
347
365)(346
365)
Al gentile lettore vedere se il complemento a 1 di tale numero e superiore o inferiore a 1/2.
PROBABILITA CONDIZIONATA. EVENTI INDIPENDENTI
Siamo, pertanto, inutilmente singolari, eppure siamo: su questa distanza si accendeil desiderio di un perche, il desiderio di una direzione, il desiderio di un senso, e, quandoquesto desiderio si trasforma in volonta di ricerca, solo allora appare la speciale bellezza eprofondita di cio che chiamiamo studio.
Spesso si usa la probabilita di un evento B sotto la condizione che avvenga un altroevento A.
Def.Si dice probabilita condizionata di B dato A
P (BjA) := P (A \B)P (A)
, [ P (A) > 0 ].
Es. - Spazio del lancio di un dado. La probabilita condizionata di B=”esca un numeropari maggiore di 2” dato l’evento A= ”esce un numero pari”:
P (BjA) = P (f4, 6g \ f2, 4, 6g)/P (f2, 4, 6g) = 2/6
3/6= 2/3.
Dalla definizione stessa di probabilita condizionata appare evidente il seguente:
Teorema della probabilita composta. Se gli eventi A, B hanno entrambi probabilitanon nulla
P (A \B) = P (A)P (BjA) = P (B)P (AjB).
Es. - Tipicamente ci vuole la formula di probabilita composta quando si fannoestrazioni senza restituzione. Ad es. da una scatola contenente 10 viti, di cui tre difettose, siestraggono due viti senza restituzione. Con quale probabilita nessuna delle due e difettosa?
7

Considero gli eventi DC1 ”prima vite estratta non difettosa”, D
C2 = ”seconda estratta
non difettosa”. Estraendo senza rimessa, l’evento DC1 ha modificato la situazione nella
scatola:
P (DC1 ) = 7/10, P (D
C2 jDC
1 ) = 6/9, P (DC1 \DC
2 ) = P (DC1 )P (D
C2 jDC
1 ) = (7
10)(6
9) ' 47%
Def. In uno spazio di probabilita (Ω,Σ, P ) due eventi A,B sono indipendenti se
P (A \B) = P (A)P (B).
Tre eventi A1, A2, A3 sono indipendenti se
P (Ai \Aj) = P (Ai)P (Aj),8i6= j, e P (A1 \A2 \A3) = P (A1)P (A2)P (A3)
m eventiA1, A2, ..., Am sono indipendenti se la probablita dell’intersezione di una qualunquesottofamiglia di essi e uguale al prodotto delle probabilita degli eventi di tale sottofamiglia.
Quando A,B sono indipendenti, dalla definizione di probabilita condizionata si ha
P (AjB) = P (A), P (BjA) = P (B)
il che significa che la probabilita di A non dipende dal verificarsi o meno di B, e viceversa:cio motiva l’aggettivo ”indipendente”.
Es. Un test diagnostico di una malattia e corretto nel 98% dei casi. Ripetendo due volteil test sullo stesso soggetto, qual e la probabilita di un doppio errore? Sia A=”errore nelprimo uso del test”, B=”errore nel secondo uso del test”. Essendo due eventi indipendenti,
P (A \B) = P (A)P (B) = (2/100)(2/100) = 4/10000 = 0, 04%.
Teorema di probabilita totale. Data una ”partizione” H1,H2, ...,Hn, ... di Ω (cioe[iHi = Ω con Hi \Hj = ;, 8i6= j, ) si ha
P (B) =i
P (Hi)P (BjHi)
Dim Sia fHigi una partizione di Ω (finita o infinita, non importa). Allora f(Hi \B)gi euna partizione di B e per l’additivita numerabile si ha:
P (B) =i
P (Hi \B).
Per definizione di probabilita condizionata,
P (Hi \B) = P (Hi)P (BjHi)
8

e, sommando rispetto all’ indice i,
P (B ´i
P (Hi \B) = P (Hi)P (BjHi).
Es. Com’e noto, le trasfusioni di sangue sono possibili: dal gruppo O a tutti gruppi; daA ai gruppi A, AB; da B ai gruppi B, AB; da AB al solo gruppo AB. Supponiamo ancheche le frequenze relative dei gruppi sanguigni siano note, allora le identifichiamo con leprobabilita:
P (O) = 52%, P (A) = 32%, P (B) = 10%, P (AB) = 6%.
Qual e la probabilita che un individuo, scelto a caso, possa donare sangue a un individuopure scelto a caso ?Si usa il teorema della probabilita totale. Infatti la probabilita di D (= un individuopuo donare) sapendo A (= l’individuo e di gruppo A) e una probabilita condizionata e laconosciamo perche i destinatari del suo sangue sono A oppure AB:
P (DjA) = P (A [AB) = 32/100 + 6/100 = 38/100; e cosi’ via.
QuindiP (D) = P (DjO) ¢ P (O) + P (DjA) ¢ P (A)++P (DjB) ¢ P (B) + P (DjAB) ¢ P (AB) =
= (52/100) ¢ 1 + (32/100 + 6/100) ¢ (32/100)++(10/100 + 6/100) ¢ (10/100) + (6/100)(6/100) ' 66%.
Formula di Bayes In forma semplice:
P (AjB) = P (A)P (BjA)P (B)
In forma generale la formula di Bayes si enuncia: data una partizione fHigi di Ω si ha
P (HijB) = P (BjHi)P (Hi)k P (BjHk)P (Hk)
.
Dim. In forma semplice segue direttamente dal teorema della probabilita composta. Siaora lo spazio ripartito in eventi disgiunti Hi, la cui unione sia Ω. La formula di Bayesnella forma semplice applicata ad Hi e B per i fissato da:
P (HijB) = P (BjHi) ¢ P (Hi)P (B)
9

dove ora basta sostituire nel denominatore la formula di probabilita totale.
Es. Con la formula di Bayes ottengo la probabilita di A dato B sapendo la probabilita diB dato A. Aiuta nelle diagnosi. Ad es. se teoricamente la probabilita del sintomo B datala malattia A e il 30%, posso calcolare la probabilita che un paziente affetto dal sintomoB abbia la malattia A:
P (AjB) = P (BjA)P (A)P (B)
Se, ad es., la percentuale della malattia e del sintomo in Emilia e rispettivamente P (A) =0, 15 e P (B) = 0, 05, la probabilita di malattia A dato il sintomo B e:
P (AjB) = (30/100)(15/100)
5/100=90
100.
Dunque la presenza del sintomo segnala la presenza della malattia nel 90% dei casi.
Es. Lampadine escono per il 60% da una linea di produzione A e per il 40% dalla lineaB. Dalla prima linea esce un 2% di difettose, dall’altra esce un 3.8% di difettose. Conquale probabilita una lampadina difettosa e uscita dalla linea A?
Se D e l’evento ”difettosa” i dati del problema sono:
P (DjA) = 0.02, P (DjB) = 0.038, P (A) = 0.6, P (B) = 0.4
Il numero che cerchiamo e la probabilita condizionata di A dato D:
P (AjD) = P (DjA) ¢ P (A)P (DjA) ¢ P (A) + P (DjAC) ¢ P (AC) =
=(0.02)(0.6)
(0.02)(0.6) + (0.038)(0.4)=
0.012
0.012 + 0.0152= 0.441 = 44.1%
Es. Si sa che una proporzione 0.005 dei soggetti di una citta e colpita da un virus.L’affidabilita dei test diagnostici e 0.98 sui malati e 0.80 sui sani: cioe il test risultapositivo sul 98% dei malati, e negativo sull’80% dei sani. Qual e la probabilita di essersano posto che il test sia stato positivo?
Consideriamo gli eventi: S= sano, SC = malato, T−=test negativo; T+=test positivo.Sappiamo che
P (SC) = 0.005, P (T−jS) = 0.80, P (T+jSC) = 0.98.Vogliamo P (SjT+), che calcoleremo con la formula di Bayes:
P (SjT+) = P (T+jS) ¢ P (S)P (T+jS) ¢ P (S) + P (T+jSC) ¢ P (SC) =
=(0.995)(0.20)
(0.20)(0.995) + (0.98)(0.005)= 0.976
10

Incredibilmente alta: ma se stiamo dentro una categoria a rischio, avremmo una incidenzadi malattia P (SC) piu elevata, e dunque questa probabilita di errore piu contenuta.
VARIABILI ALEATORIE
Nello stesso modo in cui l’uomo e una domanda a se stesso (lo stupore), analoga-mente e una domanda di fronte al mondo (la ricerca). Per questo si pone sempre instato di verifica dell’ambiente che lo circonda, delle soluzioni che ha ricevuto da altri, delleconvinzioni che circolano come verita sacrosante. L’uomo ha dentro di se questa continuatensione alla ricerca... e ciascuno deve onorare questo tratto che ci contraddistingue daglialtri animali.
Def. Consideriamo uno spazio di probabilita (Ω,Σ, P ). Si dice variabile aleatoria unafunzione X : Ω ! R che ad ogni elemento ω 2 Ω fa corrispondere un numero X(ω) 2 R,in modo che ogni insieme fω : a < X(ω) · bg appartenga alla σ¡algebra Σ (cioe allafamiglia degli eventi dello spazio Ω). Tale evento sara anche indicato piu concisamente”a < X · b”.Es. Se Ω = f1, 2, ..., 6g e lo spazio di probabilita per il lancio del dado non truccato,definiamo X:= ”numero uscente da un lancio”, cioe X(1) := 1, ..., X(6) := 6. Potremoallora introdurre e calcolare la probabilita che X = 5, che 1 < X · 4, ecc.:
P (1 < X · 4) = P (X = 2) + P (X = 3) + P (X = 4) =1
2
P (X ¸ 3) = P (X = 3) + ...+ P (X = 6) =2
3, P (X · 1, 5) = 1
6.
Definiamo un’altra variabile casuale sullo stesso Ω : sia Y := 0 se l’esito del lancio e pari,Y := 1 se l’esito del lancio e dispari. Cosi:
P (Y = 0) = 1/2, P (Y = 1) = 1/2, P (1 < Y · 4) = 0, ...ecc.
Def. Ad ogni variabile aleatoria X e associata una misura su R chiamata legge diprobabilita (o ”distribuzione”, o semplicemente ”legge”) relativa ad X, indicata PX ecosi definita:
8a, b 2 R, a < b, PX( (a, b]) := P (a < X · b).In tal caso si dice che X e distribuita secondo la legge PX : X » PX .N.B. Conoscendo X conosciamo la legge o distribuzione associata ad X. Al contrario,conoscendo come e distribuita X, non sappiamo necessariamente tutto suX: ad esempio lalegge o distribuzione di X non dice da sola che relazioni ha X con altre variabili. Quandodue o piu v.a. sono distribuite secondo la stessa legge si dicono ”identicamente distribuite”.
11

Def. Una variabile aleatoria X e discreta se1) c’e un insieme finito o numerabile di valori xj, ( j = 1, ..., n oppure j 2 N ) tali che
P (X = xj) > 0,
2) la somma delle probabilita e uno: j P (X = xj) = 1.
Quindi una variabile aleatoria discreta assume solo un insieme discreto di valori xj conrispettive probabilita pj ´ P (X = xj) > 0. In altre parole, la sua distribuzione o legge ediscreta nel senso che e una misura di tipo ”atomico”: essa si concentra su un insieme alpiu discreto di valori xj attribuendo ad essi masse positive pj > 0.
Ecco tre rappresentazioni equivalenti di una legge PX asociata ad una v.a. X discreta.Se X e discreta, una prima ovvia rappresentazione di PX e per elencazione: si elencano ivalori possibili di X e le rispettive probabilita:
X » x1, x2, ...p1, p2, ...
Una seconda rappresentazione equivalente di PX e la ”funzione di probabilita” della v.a.X:
f(x) =pj , se x = xj (j = 1, 2, ...)
0, altrove.
Una terza rappresentazione equivalente di PX e la ”funzione di ripartizione” della v.a. X:
8x 2 R, F (x) := P (X · x) =xjx
f(xj).
Quest’ultima e una funzione a gradini:
F (x) =
⎧⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎩
0, x < x1
p1, x1 · x < x2p1 + p2, x2 · x < x3...
p1 + ...+ pn−1, xn−1 · x < xn...
Poiche f(xj) = P (X = xj), la funzione di ripartizione ha il significato:
F (x) = P (X · x), P (a < X · b) = F (b)¡ F (a).
Es. Lancio di un dado: la funzione di probabilita e
f(x) =16 se x=k
0, altrove
12

ed F (x) = 0 per x < 1, F (x) = 1/6 per 1 · x < 2, ...,F (x) = 5/6 per 5 · x < 6,F (x) = 1,8x ¸ 6.
Es. Sullo spazio di probabilita del lancio di due dadi (i cui elementi sono le 36 coppie(1, 1), (1, 2),...,(6, 5), (6, 6) ) sia Z := somma dei due numeri uscenti. Quindi:
Z :2 3 4 5 6 7 8 9 10 11 12136
236
336
436
536
636
536
436
336
236
136
Per esercizio: descrivere il grafico di f(x) e di F (x).
Def. Una v.a. X e assolutamente continua se la funzione di ripartizione
x ! F (x) ´ P (X · x)
e rappresentabile come funzione integrale di una funzione f(¢) ¸ 0:
8x 2 R, F (x) =x
−∞f(t)dt
La funzione f(¢) e supposta almeno integrabile, ed e detta densita di probabilita della v.a.X.
OSS. Qui e altrove si usano integrali ”impropri”, cioe integrali definiti dove un estremo diintegrazione (o entrambi gli estremi) e 1. Il significato e:
x
−∞f(t)dt := lim
R→∞
x
−Rf(t)dt,
+∞
−∞f(t)dt := lim
R→∞
R
−Rf(t)dt, ecc.
Oss. La funzione f, che appare sotto il segno di integrale, si chiama densita di proba-bilita o semplicemente ”densita” della v.a. Derivando ambo i membri, avremo
F (x) = f(x), in ogni x dove f sia continua.
13
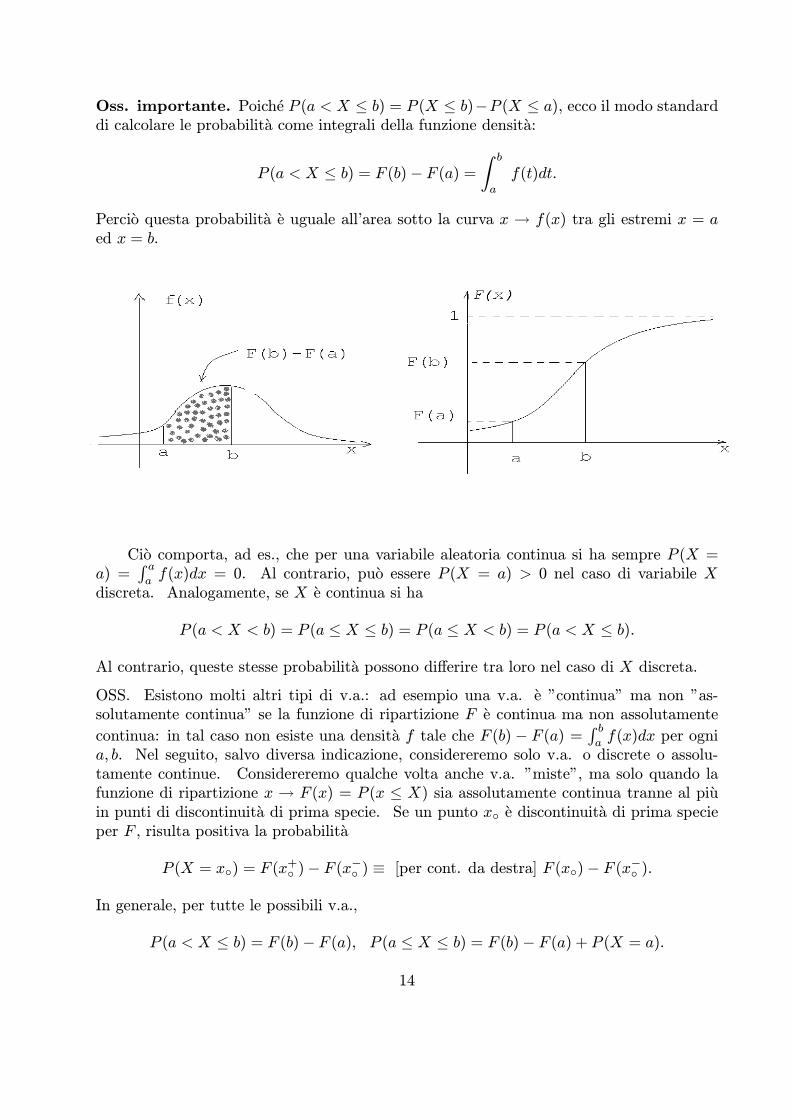
Oss. importante. Poiche P (a < X · b) = P (X · b)¡P (X · a), ecco il modo standarddi calcolare le probabilita come integrali della funzione densita:
P (a < X · b) = F (b)¡ F (a) =b
a
f(t)dt.
Percio questa probabilita e uguale all’area sotto la curva x ! f(x) tra gli estremi x = aed x = b.
Cio comporta, ad es., che per una variabile aleatoria continua si ha sempre P (X =a) =
a
af(x)dx = 0. Al contrario, puo essere P (X = a) > 0 nel caso di variabile X
discreta. Analogamente, se X e continua si ha
P (a < X < b) = P (a · X · b) = P (a · X < b) = P (a < X · b).
Al contrario, queste stesse probabilita possono differire tra loro nel caso di X discreta.
OSS. Esistono molti altri tipi di v.a.: ad esempio una v.a. e ”continua” ma non ”as-solutamente continua” se la funzione di ripartizione F e continua ma non assolutamente
continua: in tal caso non esiste una densita f tale che F (b)¡ F (a) = b
af(x)dx per ogni
a, b. Nel seguito, salvo diversa indicazione, considereremo solo v.a. o discrete o assolu-tamente continue. Considereremo qualche volta anche v.a. ”miste”, ma solo quando lafunzione di ripartizione x ! F (x) = P (x · X) sia assolutamente continua tranne al piuin punti di discontinuita di prima specie. Se un punto x e discontinuita di prima specieper F , risulta positiva la probabilita
P (X = x) = F (x+ )¡ F (x− ) ´ [per cont. da destra] F (x)¡ F (x− ).
In generale, per tutte le possibili v.a.,
P (a < X · b) = F (b)¡ F (a), P (a · X · b) = F (b)¡ F (a) + P (X = a).
14
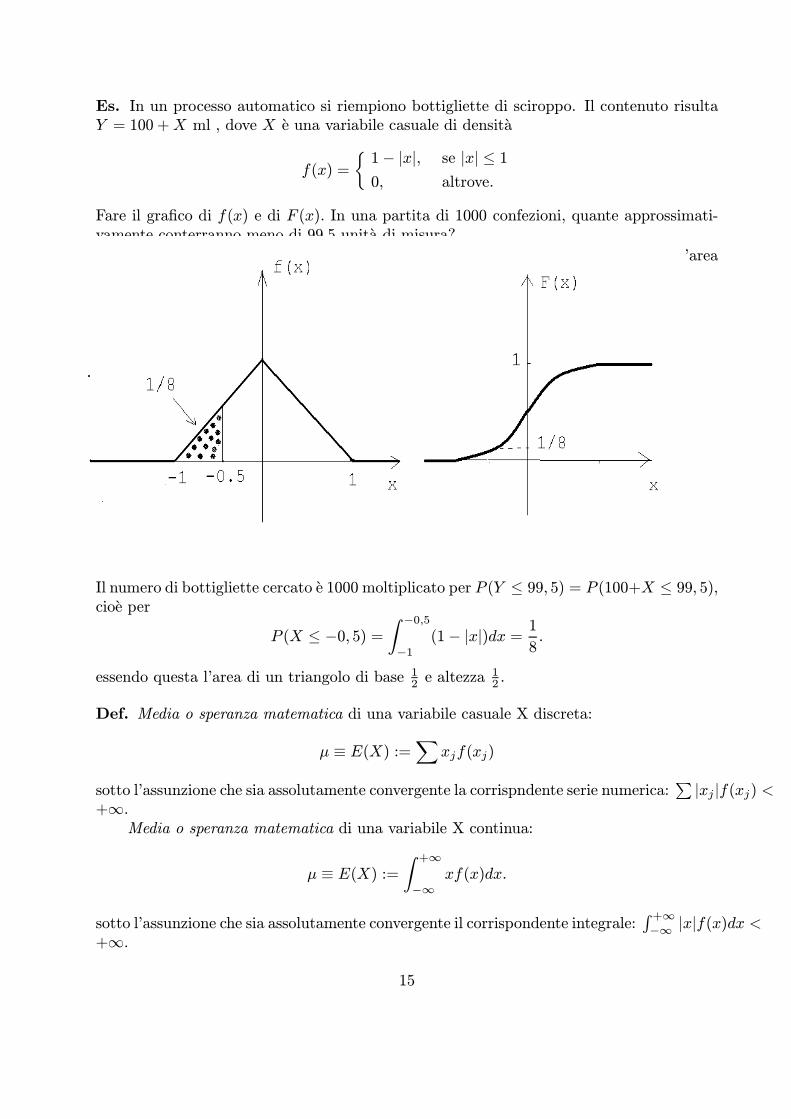
Es. In un processo automatico si riempiono bottigliette di sciroppo. Il contenuto risultaY = 100 +X ml , dove X e una variabile casuale di densita
f(x) =1¡ jxj, se jxj · 10, altrove.
Fare il grafico di f(x) e di F (x). In una partita di 1000 confezioni, quante approssimati-vamente conterranno meno di 99,5 unita di misura?
E’ facile verificare che f e una densita, perche1
−1 f(x)dx = 1, essendo questa l’areadi un triangolo di base 2 e altezza 1.
Il numero di bottigliette cercato e 1000 moltiplicato per P (Y · 99, 5) = P (100+X · 99, 5),cioe per
P (X · ¡0, 5) =−0,5
−1(1¡ jxj)dx = 1
8.
essendo questa l’area di un triangolo di base 12 e altezza
12 .
Def. Media o speranza matematica di una variabile casuale X discreta:
μ ´ E(X) := xjf(xj)
sotto l’assunzione che sia assolutamente convergente la corrispndente serie numerica: jxj jf(xj) <+1.
Media o speranza matematica di una variabile X continua:
μ ´ E(X) :=+∞
−∞xf(x)dx.
sotto l’assunzione che sia assolutamente convergente il corrispondente integrale:+∞−∞ jxjf(x)dx <
+1.
15

Oss. La media (o valor medio o speranza) appena definita dipende dalla variabile casualeesaminata; essa, nel caso discreto, e la somma dei valori xj moltiplicati per le rispettiveprobabilita f(xj) ´ P (X = xj).
Invece, per evitare confusioni, si rammenti che la somma di tutte le probabilita f(xj)e uno, qualunque sia la variabile casuale X: f(xj) = P (X = xj) = 1. Nel casocontinuo, l’integrale su tutto R della densita e 1:
+∞
−∞f(x)dx = P (¡1 < X < +1) = 1.
Def. Si dice varianza di una variabile casuale X discreta
σ2 ´ V ar(X) :=j
(xj ¡ μ)2f(xj).
Varianza di una variabile casuale X continua:
σ2 ´ V ar(X) :=+∞
−∞(x¡ μ)2f(x)dx.
La radice quadrata della varianza si dice deviazione standard e si indica σ.Oss. La varianza e nulla solo quando X e una variabile casuale discreta con funzione diprobabilita tale che f(x1) = 1 in un certo punto x1, ed f(x) = 0 altrove. Tranne questounico caso, che interessa la teoria della probabilita solo come caso-limite, si ha sempreσ2 > 0.
Es. Se un’epidemia colpisce il 30% della popolazione, la probabilita di contagio perun singolo e di p = 0.30. La variabile casuale
X :0 10.7 0.3
ha media e varianza rispettivamente μ = 0 ¢ 0.7 + 1 ¢ 0.3 = 0.3 e
σ2 = (0¡ 0.3)2 ¢ 0.7 + (1¡ 0.3)2 ¢ 0.3 = 63/1000 + 147/1000 = 0, 21
Sommando n variabili casuali identiche ad X si ottiene la variabile casuale Z = numerodi individui contagiati in un gruppo di n persone. Ad es. se n = 2 avremo la variabilecasuale che puo assumere i valori 0 o 1 o 2 :
Z :=0 1 2
(7/10)2 2 ¢ (7/10)(3/10) (3/10)2
Quindi in un gruppo di due persone il numero atteso di persone contagiate e:
μ = E(Z) = 0 ¢ 0.49 + 1 ¢ 0.42 + 2 ¢ 0.09 = 0.6
16
(non ridere, please: non e detto che la media sia uno dei valori assunti dalla variabilealeatoria), con deviazione standard dalla media:
σ = (0¡ 0.6)2 ¢ 0.49 + (1¡ 0.6)2 ¢ 0.42 + (2¡ 0.6)2 ¢ 0.09.
Intuitivamente: la media e tanto piu rappresentativa della v.a. quanto piu piccola e ladeviazione standard. La varianza (e anche la deviazione standard) in certo senso misuraquanto e dispersa la variabile casuale rispetto alla media.
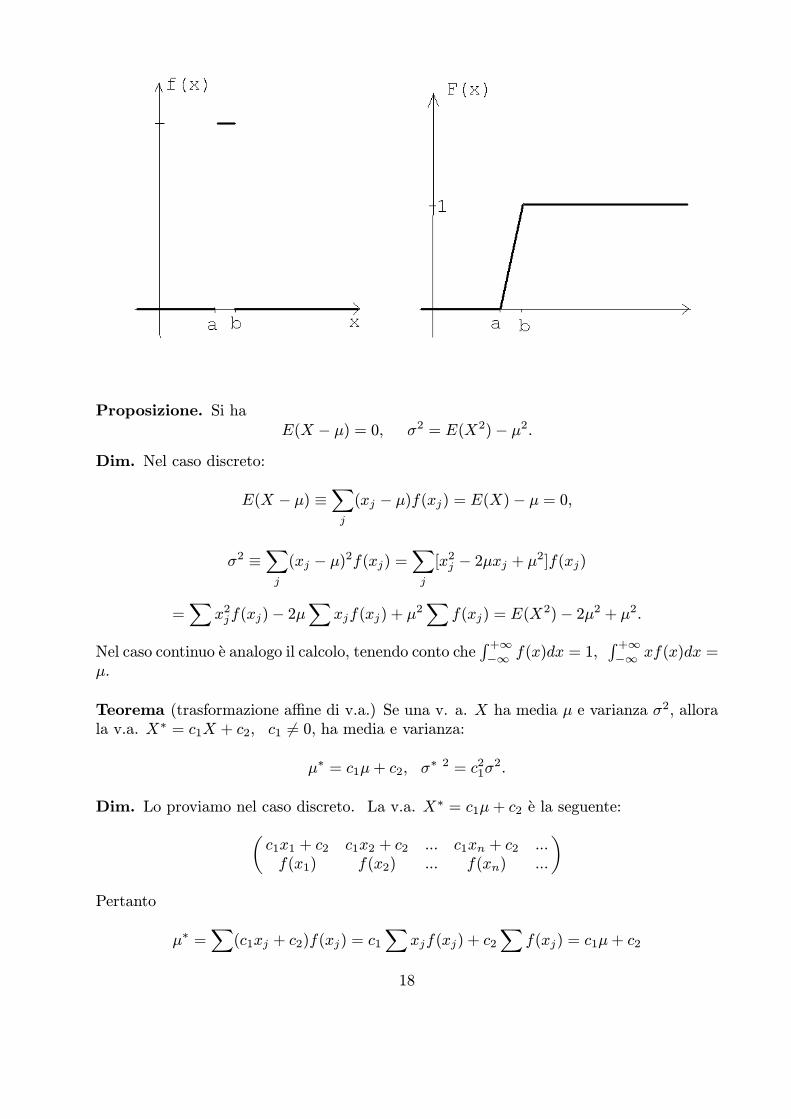
Es. Sia X distribuita uniformemente nell’intervallo [0, b], cioe X e definita completamentedalla densita:
f(x) =1bse 0 · x · b
0 altrove.
Ecco dunque media e varianza:
μ =b
0
xdx = b/2, σ2 =b
0
(x¡ b/2)2b−1dx = b2/12
Se poi X e uniforme in [a, b], cioe f(x) =1b−a se 0 · x · b0 altrove,
allora abbiamo la seguente
Proposizione La v.a. uniforme nell’intervallo [a, b], X » U([a, b]), ha media e varianza:
E(X) =a+ b
2, V ar(X) =
(b¡ a)212
Si nota da qui che la varianza e grande o piccola a seconda che b¡a lo sia: essa e un indicedella dispersione della variabile X rispetto alla media.
17
Proposizione. Si haE(X ¡ μ) = 0, σ2 = E(X2)¡ μ2.
Dim. Nel caso discreto:
E(X ¡ μ) ´j
(xj ¡ μ)f(xj) = E(X)¡ μ = 0,
σ2 ´j
(xj ¡ μ)2f(xj) =j
[x2j ¡ 2μxj + μ2]f(xj)
= x2jf(xj)¡ 2μ xjf(xj) + μ2 f(xj) = E(X2)¡ 2μ2 + μ2.
Nel caso continuo e analogo il calcolo, tenendo conto che+∞−∞ f(x)dx = 1,
+∞−∞ xf(x)dx =
μ.
Teorema (trasformazione affine di v.a.) Se una v. a. X ha media μ e varianza σ2, allorala v.a. X∗ = c1X + c2, c1 6= 0, ha media e varianza:
μ∗ = c1μ+ c2, σ∗ 2 = c21σ2.
Dim. Lo proviamo nel caso discreto. La v.a. X∗ = c1μ+ c2 e la seguente:
c1x1 + c2 c1x2 + c2 ... c1xn + c2 ...f(x1) f(x2) ... f(xn) ...
Pertanto
μ∗ = (c1xj + c2)f(xj) = c1 xjf(xj) + c2 f(xj) = c1μ+ c2
18

(σ∗)2 = (c1xj + c2 ¡ c1μ¡ c2)2f(xj) =
= (c1)2 (xj ¡ μ)2f(xj) = (c1)
2σ2
Corollario (variabile standardizzata) Se X ha media μ e varianza σ2, allora la cor-rispondente variabile aleatoria
Z =X ¡ μ
σ
ha media 0 e varianza 1.Dim. Basta prendere c1 = 1/σ, c2 = ¡μ/σ. c1X+c2 = 1/σ X¡μ/σ ha media e varianzarispettivamente:
μ/σ ¡ μ/σ = 0, c21σ2 = (σ−1)2σ2 = 1.
Infine, ecco la funzione generatrice dei momenti, utile a calcolare di fatto media evarianza.
Lemma sulla funzione generatrice. Sia X una v.a. Se esistono finiti i momenti E[Xn],8n 2 N , e se esiste finita la funzione,
G(t) = E[etX ] =j e
txjf(xj), nel caso discreto
+∞−∞ etxf(x) dx nel caso continuo
(t 2 R),
allora G(t) soddisfa
E(X) ´ μ = G (0), E(X2) = G (0), ... , E(Xn) = G(n)(0).
G e detta ”funzione generatrice dei momenti”.Dim. Infatti, derivando sotto il segno di serie (o di integrale)
G (t) = E[d
dtetX ] = E[ XetX ], G (t) = E[
d2
dt2etX ] = E[ X2etX ].
I momenti sono dunque:
G (t)jt=0 = E(X), G (t)jt=0 = E(X2), ..., G(n)(0) = E(Xn).
LEGGE DI PROBABILITA BINOMIALE
Tutti siamo dentro un fiume che inizia prima di noi e continuera dopo di noi. Perquesto il primo passo di ogni concreta ricerca e quello di ricostruire il filo rosso delle nozionigia acquisite, dei punti di non ritorno, dei convincimenti ormai assodati, ed e importantenon solo comprendere l’esito delle ricerche precedenti, ma anche lo sviluppo interno di
19

esse, per allenare il cervello a interrogare in modo innovativo il mondo che di fronte anoi. Questo e quanto ordinariamente si compie all’universita.
Def. Sia 0 < p < 1,, n 2 N. Sia q = 1¡p. Una v.a. discretaX e ”binomiale di parametri ne p” (o anche: segue una legge binomiale di parametri n e p) se ha funzione di probabilita:
P (X = k) ´ f(k) = nk
pkqn−k, k = 0, 1, ..., n
ossia:
X :0 1 2 ... n¡ 2 n¡ 1 nqn npqn−1 n!
2!(n−2)!p2qn−2 ... n!
(n−2)!2!pn−2q2 npn−1q pn
Notevole il caso n = 1, 0 < p < 1: una v.a. X che assuma solo i valori 0 e 1 con probabilita(1¡ p) e p rispettivamente, segue una legge di Bernoulli:
X :0 1
(1¡ p) p.
Teorema. Si considerino n prove indipendenti di un esperimento casuale a due esiti. Sep e la probabilita di successo in una singola prova e q = 1¡ p, la probabilita che in n proveindipendenti si abbiano esattamente k successi e
nk
pkqn−k, k = 0, 1, ..., n.
Dim. Abbiamo gia definito che cosa si intende per eventi indipendenti e abbiamo sopracostruito lo spazio di probabilita dello schema successo-insuccesso. Definiamo:
X = ”numero di successi nell’ambito di n prove”.
Vogliamo provare che X e una v.a binomiale. Un particolare evento elementare e
fωg = f(1, ..., 1, 0, ..., 0)g
il che significa: successo nelle prime k prove e insuccesso nelle rimanenti n¡ k. Esso avraprobabilita
P (fωg) = p ¢ p ¢ ... ¢ p ¢ q ¢ q... ¢ q = pkqn−k
in virtu dell’indipendenza. Ma questa n-upla e solo un particolare modo di avere k successi.Ora, posso etichettare le n prove con 1, ..., n, e ci sono C(n; k) modi di scegliere k di queste
20

etichette tra le n date: proprio il numero di combinazioni di n oggetti a k a k. QuindiP (X = k) e semplicemente pkqn−k moltiplicato per questo numero:
P (X = k) ´ f(k) = nk
pkqn−k, k = 0, 1, ..., n
Si noti che effettivamente la somma di tutte le probabilita e 1:
n
k=0
nk
pkqn−k = (p+ q)n = 1n = 1,
per la formula binomiale di Newton. Inoltre
Proposiz. Media e varianza di una v.a. binomiale X » B(n, p) sono:
μ = np, σ2 = npq.
Dim. La funzione generatrice dei momenti di X e
G(t) = E(etX) =n
k=1
etknk
pkqn−k = (pet + q)n
Percio i momenti di grado 1 e 2 sono:
E(X) = G (t)jt=0 = n(pet + q)n−1 ¢ petjt=0 = np,
E(X2) = G (t)jt=0 = f n(n¡ 1)(pet + q)n−2 ¢ (pet)2 + n(pet + q)n−1 ¢ pet gjt=0.Dunque μ = E(X) = G (0) = np,, mentre
σ2 = E(X2)¡ μ2 = (n2 ¡ n)p2 + np¡ (np)2 = ¡np2 + np = np(1¡ p).
[ Ecco la traccia anche di un altro argomento, piu intuitivo: il numero X di successinell’ambito di n prove puo scriversi come somma X1+X2+ ...+Xn dove, per i = 1, 2, ..., n,
Xi = num. di successi nell’ambito della i¡esima prova .
Ma ciascun
Xi :0 1q p
, i = 1, ..., n
ha media e varianzaE(Xi) = 0 ¢ q + 1 ¢ p = p
σ2 = (0¡ p)2 ¢ q + (1¡ p)2 ¢ p = p2q + q2p = pq(p+ q) = pq.
21
Poiche, come vedremo, la media di una somma e uguale alla somma delle medie, E(X) =np. Vedremo piu avanti la definizione di piu v.a. ”indipendenti”, constateremo che le Xisono indipendenti e vedremo che la varianza di una somma di v.a. indipendenti e ugualealla somma delle varianze: dunque V ar(X) = npq. ]
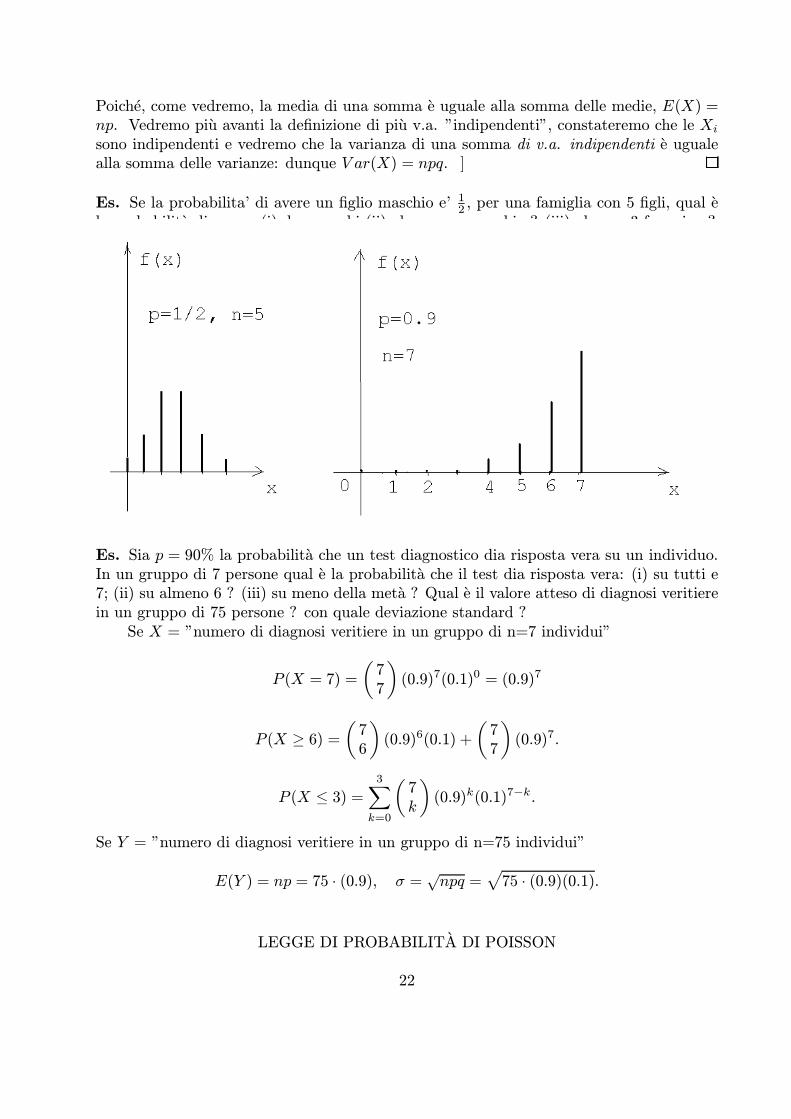
Es. Se la probabilita’ di avere un figlio maschio e’ 12 , per una famiglia con 5 figli, qual ela probabilita di avere: (i) due maschi (ii) almeno un maschio ? (iii) almeno 3 femmine ?Sia X = ”numero di maschi fra n = 5 figli:
P (X = 2) =52
(1
2)2(1
2)3 = 10 ¢ (1/2)5 = 10/32
P (X ¸ 1) = 1¡ P (X = 0) = 1¡ 50
(1
2)0(1
2)5 = 1¡ (1/32) = 31/32
P (X · 2) =2
k=0
5k
(1
2)k(1
2)5−k = (1/32) + 5 ¢ (1/32) + 10 ¢ (1/32) = 1/2.
Es. Sia p = 90% la probabilita che un test diagnostico dia risposta vera su un individuo.In un gruppo di 7 persone qual e la probabilita che il test dia risposta vera: (i) su tutti e7; (ii) su almeno 6 ? (iii) su meno della meta ? Qual e il valore atteso di diagnosi veritierein un gruppo di 75 persone ? con quale deviazione standard ?
Se X = ”numero di diagnosi veritiere in un gruppo di n=7 individui”
P (X = 7) =77
(0.9)7(0.1)0 = (0.9)7
P (X ¸ 6) = 76
(0.9)6(0.1) +77
(0.9)7.
P (X · 3) =3
k=0
7k
(0.9)k(0.1)7−k.
Se Y = ”numero di diagnosi veritiere in un gruppo di n=75 individui”
E(Y ) = np = 75 ¢ (0.9), σ =pnpq = 75 ¢ (0.9)(0.1).
LEGGE DI PROBABILITA DI POISSON
22

Il segreto per vivere tutto cio senza pesantezza e quello di sforzarsi, attraverso lerisposte che i libri ci riportano, di rintracciare le domande degli uomini e delle donne chehanno atraversato l’avventura della vita prima di noi. Certo, tu potresti dirmi che oggiviviamo in un’epoca ricchissima di informazioni e che c’ sempre ””mamma”” Google.com,che confeziona i dati desiderati in 0.15 secondi... Eppure fare ricerca e regalarsi del tempoprezioso per cogliere le domande giuste, per farle vivere e maturare, per permettere loro dicondurci verso le risposte e verso altre domande. Caro amico, cara amica, amate ledomande con tutte le vostre forze.
Def. X e una v.a. di Poisson di parametro μ se puo assumere gli infinti valori k = 0, 1, 2, ...
con probabilita P (X = k) = f(k) = μk
k! e−μ :
X :0 1 2 3 ... k ...e−μ μe−μ μ2
2! e−μ μ3
3! e−μ ... μk
k! e−μ ...
Si osservi che effettivamente la somma di tutte le probabilita e 1:
+∞
k=0
μk
k!e−μ = eμ ¢ e−μ = 1,
essendo +∞k=0
xk
k! = ex (e la ben nota serie esponenziale). Inoltre (fatto curioso) la media
e uguale alla varianza:
Prop. Se X e una v.a. di Poisson con parametro μ, allora E(X) = μ e V ar(X) = μ.Dim. La funzione generatrice dei momenti e:
G(t) ´ E[ etX ] =∞
k=0
etke−μμk
k!= e−μ exp[μet].
PercioE(X) = G (t)jt=0 = e−μμet exp[μet]jt=0 = μ.
Inoltre
E(X2) = G (t)jt=0 = f e−μμet exp[μet] + e−μ(μet)2 exp[μet] gjt = 0
. PercioV ar(X) = E(X2)¡ μ2 = μ+ μ2 ¡ μ2 = μ.
La v.a. di Poisson e un buon modello per il numero di fenomeni casuali distribuiti con unadata densita media μ nell’unita di tempo o nell’unita di volume o nell’unita di superficie:numero di chiamate a un centralino telefonico per minuto; numero di automobili a un
23

casello per ora; numero di infortuni stradali per settimana; numero di stelle per unita divolume abbastanza grande...
Es.Nel 1910 Rutherford e Geiger provarono che il numero di particelle α emesse al secondoda una sostanza radioattiva era una v.a. di Poisson con μ = 0.5. Qual e la probabilita diosservare due o piu particelle durante un secondo ?
P (X ¸ 2) =+∞
k=2
(0, 5)k
k!e−μ =
= 1¡ P (X = 0)¡ P (X = 1) = 1¡ e−0.5 ¡ 0.5 ¢ e0.5 = 1¡ 0.91 = 9%
Es. Una certa sospensione batterica contiene 5 batteri per cm3 (valor medio). Qual e laprobabilita che un campione causale di 1 cm3 contenga (i) nessun batterio (ii) al piu duebatteri (iii) almeno 5 batteri ?
P (X = 0) = e−5; P (X · 2) = e−5(1 + 5 + 252!)
P (X ¸ 5) = 1¡ P (X · 4) = 1¡ e−5(1 + 5 + 252!+125
6+625
24)
Es. Per valutare il numero di batteri in una sospensione se ne cerca la diluizione limitealla quale si trova ancora almeno un batterio capace di riprodursi. Ad es. se diluendo undm3latte con fattore 1
10 ,1100 ,
1103 ,
1104 troviamo, dopo incubazione, sviluppo dei batteri;
mentre troviamo sterile la diluizione con fattore 1105 ; allora grossolanamente diremo che il
latte conteneva circa 10.000 germi per dm3. Per raffinare, usiamo la distribuzione di Poissone inoculiamo in 20 tubi la sospensione diluita con fattore 1
104 . Se vi sono in media μ batteriper dm3 di diluito, vi sara una proporzione P (X = 0) = e−μ di tubi che non riceverannoalcun batterio e percio saranno sterili. Poniamo di trovare sterili 12 tubi su 20. Ebbene,avremo e−μ = 12
20 = 0.6 cioe μ = ¡log(0.6) =¡(loge10) ¢ log10(0.6) = ¡2.3026 ¢ (¡0.222)= 0.51. Allora la concentrazione di batteri nel latte e 0.51 ¢ 104= 5.1 ¢ 103 germi per dm3.
LEGGE DI PROBABILITA’ GEOMETRICA
Problema Un dado viene lanciato piu volte finche non si ottiene 6. Qual e la probabilitache occorrano esattamente k lanci?Risposta. E la probabilita che per k ¡ 1 lanci esca ”insuccesso” ed esca ”successo” la k¡esima volta: se T e il numero di lanci necessari ad avere successo,
P (T = k) = p(1¡ p)k−1 = 1
6(5
6)k−1, k = 1, 2, ...
Piu in generale, in ogni schema successo-insucccesso nel quale la probabilita di successoin una singola prova sia p 2 (0, 1), si puo definire la v.a. geometrica
T := num. di prove necessarie ad avere successo.
24

Diversamente dalla v.a. binomiale, i valori possibili di T sono tutti i numeri naturali:
T :1 2 ... k ...p pq ... pqk−1 ...
.
La funzione di probabilita e semplicemente
f(k) = P (T = k) = p ¢ qk−1, q = 1¡ p, k = 1, 2, 3, ...Sommando questi termini si ottiene la serie geometrica:
∞
k=1
f(k) = p∞
k=1
qk−1 = p∞
j=0
qj =p
1¡ q =p
1¡ (1¡ p) = 1.
La v.a. geometrica si puo anche riguardare come un tempo di attesa, misurato in numerodi prove:
T := tempo di attesa del primo successo.
[ Invece qualche autore chiama v.a. geometrica X = T ¡ 1, cioe ”numero di insuccessiprecedenti il primo successo”, con funzione di probabilita P (X = j) = pqj , j = 0, 1... ].
Es. Un arciere ha probabilita 13 di far centro in un bersaglio. Trovare la probabilita che
gli occorra un numero di prove maggiore di 3.Sia T =”numero di prove necessarie al primo centro nel bersaglio”, sapendo che la prob-abilita di far centro e 1/3. Allora T e geometrica di parametro 1/3. L’evento T > 3 haprobabilita
P (T ¸ 4) = 1¡ P (T = 1)¡ P (T = 2)¡ P (T = 3) =
= 1¡ 13¡ 13¢ 23¡ 13¢ (23)2 =
= 1¡ 13[1 + 0.666 + 0.444] = 1¡ (2.111)/3 ' 29.6%
LEGGE DI PROBABILITA NORMALE O DI GAUSS
Il francese conaissance,che deriva dal verbo connaitre,ci invita a scoprire la pro-fonda parentela tra i due verbi e i relativi sostantivi, nascondendo nel seno del verboconnaitre (e della parola conaissance) il verbo che dice ””venire alla luce””. E cosasignificherebbe, appunto, conoscere,se non esattamente un nascere un’altra volta conuna nuova coscienza, con uno sguardo sulla vita?
Def. Siano μ 2 R, σ > 0. La v.a. continua X e normale con parametri μ, σ, e si scriveX ' N(μ,σ2), sse la densita e:
f(x) =1
σp2π
e−(x−μ)2/2σ2 .
25
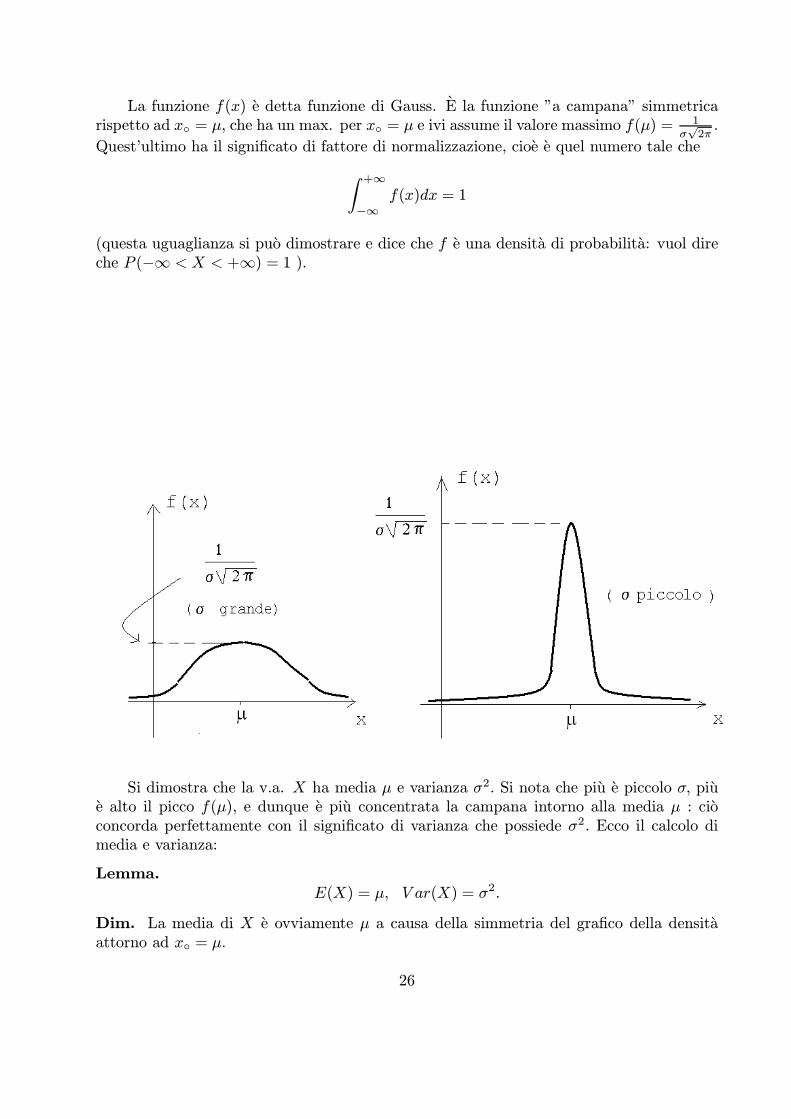
La funzione f(x) e detta funzione di Gauss. E la funzione ”a campana” simmetricarispetto ad x = μ, che ha un max. per x = μ e ivi assume il valore massimo f(μ) = 1
σ√2π.
Quest’ultimo ha il significato di fattore di normalizzazione, cioe e quel numero tale che
+∞
−∞f(x)dx = 1
(questa uguaglianza si puo dimostrare e dice che f e una densita di probabilita: vuol direche P (¡1 < X < +1) = 1 ).
Si dimostra che la v.a. X ha media μ e varianza σ2. Si nota che piu e piccolo σ, piue alto il picco f(μ), e dunque e piu concentrata la campana intorno alla media μ : cioconcorda perfettamente con il significato di varianza che possiede σ2. Ecco il calcolo dimedia e varianza:
Lemma.E(X) = μ, V ar(X) = σ2.
Dim. La media di X e ovviamente μ a causa della simmetria del grafico della densitaattorno ad x = μ.
26
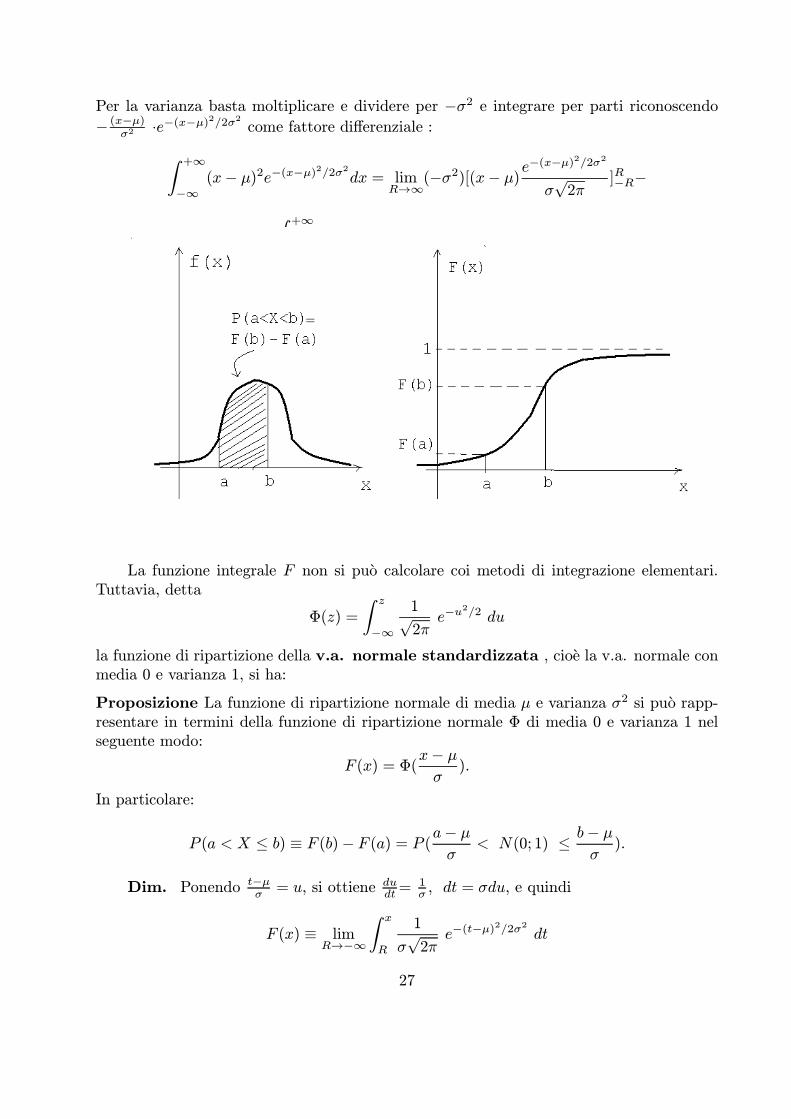
Per la varianza basta moltiplicare e dividere per ¡σ2 e integrare per parti riconoscendo¡ (x−μ)
σ2 ¢e−(x−μ)2/2σ2 come fattore differenziale :+∞
−∞(x¡ μ)2e−(x−μ)
2/2σ2dx = limR→∞
(¡σ2)[(x¡ μ)e−(x−μ)
2/2σ2
σp2π
]R−R¡
¡(¡σ2)+∞
−∞f(x)dx = σ2 ¢ P (¡1 < X < +1) = σ2.
Dalla espressione della densita otteniamo la funzione di ripartizione:
F (x) =x
−∞
1
σp2π
e−(t−μ)2/2σ2 dt,
tale che
P (a < X < b) = F (b)¡ F (a) =b
a
1
σp2π
e−(t−μ)2/2σ2 dt.
La funzione integrale F non si puo calcolare coi metodi di integrazione elementari.Tuttavia, detta
Φ(z) =z
−∞
1p2π
e−u2/2 du
la funzione di ripartizione della v.a. normale standardizzata , cioe la v.a. normale conmedia 0 e varianza 1, si ha:
Proposizione La funzione di ripartizione normale di media μ e varianza σ2 si puo rapp-resentare in termini della funzione di ripartizione normale Φ di media 0 e varianza 1 nelseguente modo:
F (x) = Φ(x¡ μ
σ).
In particolare:
P (a < X · b) ´ F (b)¡ F (a) = P (a¡ μ
σ< N(0; 1) · b¡ μ
σ).
Dim. Ponendo t−μσ = u, si ottiene du
dt=1σ , dt = σdu, e quindi
F (x) ´ limR→−∞
x
R
1
σp2π
e−(t−μ)2/2σ2 dt
27
= limR→−∞
x−μσ
R−μσ
1
σp2π
e−u2/2σdu =
x−μσ
−∞
1p2πe−u
2/2du ´ Φ(x¡ μ
σ).
Conseguenza: se X e normale, anche (X ¡ μ)/σ e normale. Inoltre, come ogni standard-izzata, (X ¡ μ)/σ e standard. Quindi (X ¡ μ)/σ e normale standard, cioe N(0; 1).
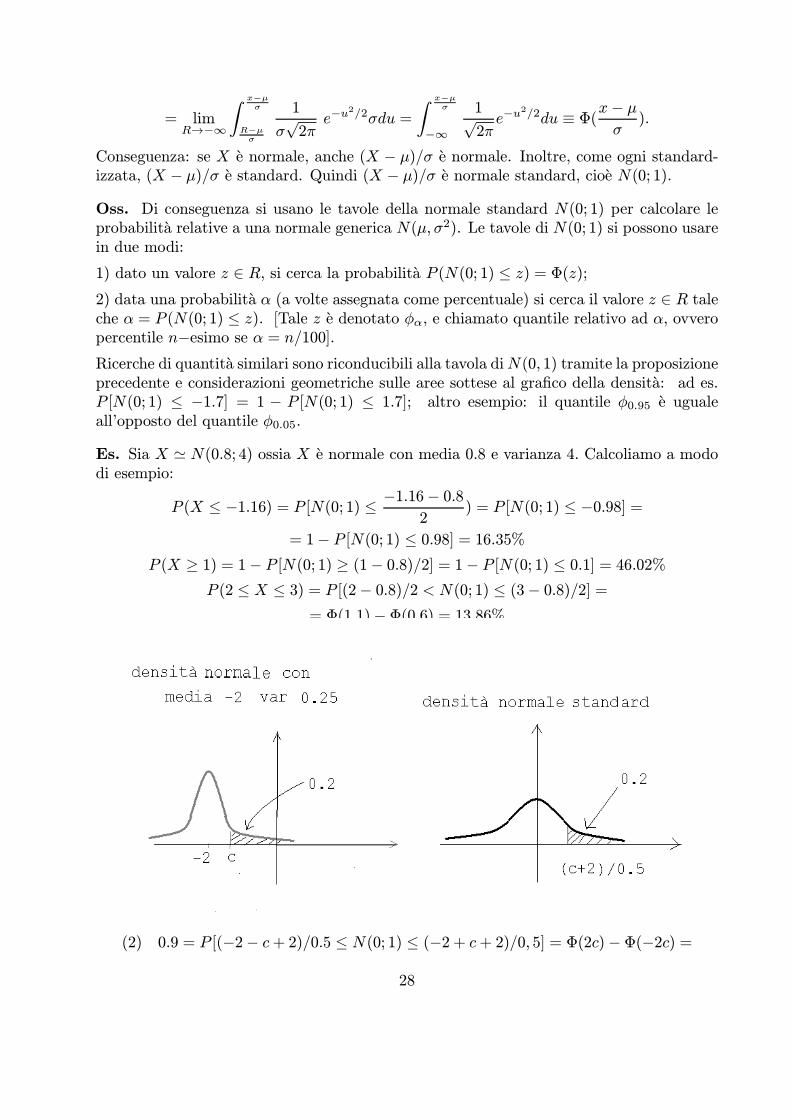
Oss. Di conseguenza si usano le tavole della normale standard N(0; 1) per calcolare leprobabilita relative a una normale generica N(μ, σ2). Le tavole di N(0; 1) si possono usarein due modi:
1) dato un valore z 2 R, si cerca la probabilita P (N(0; 1) · z) = Φ(z);2) data una probabilita α (a volte assegnata come percentuale) si cerca il valore z 2 R taleche α = P (N(0; 1) · z). [Tale z e denotato φα, e chiamato quantile relativo ad α, ovveropercentile n¡esimo se α = n/100].Ricerche di quantita similari sono riconducibili alla tavola diN(0, 1) tramite la proposizioneprecedente e considerazioni geometriche sulle aree sottese al grafico della densita: ad es.P [N(0; 1) · ¡1.7] = 1 ¡ P [N(0; 1) · 1.7]; altro esempio: il quantile φ0.95 e ugualeall’opposto del quantile φ0.05.
Es. Sia X ' N(0.8; 4) ossia X e normale con media 0.8 e varianza 4. Calcoliamo a mododi esempio:
P (X · ¡1.16) = P [N(0; 1) · ¡1.16¡ 0.82
) = P [N(0; 1) · ¡0.98] == 1¡ P [N(0; 1) · 0.98] = 16.35%
P (X ¸ 1) = 1¡ P [N(0; 1) ¸ (1¡ 0.8)/2] = 1¡ P [N(0; 1) · 0.1] = 46.02%P (2 · X · 3) = P [(2¡ 0.8)/2 < N(0; 1) · (3¡ 0.8)/2] =
= Φ(1.1)¡ Φ(0.6) = 13.86%Es. Sia X ' N(¡2; 0.25). Determinare c 2 R tale che(1) P (X ¸ c) = 0.2 ; (2) P (¡2¡ c · X · ¡2 + c) = 0.90 (3) P (X · c) = 0.43;
(1) 0.2 = P [N(0; 1) ¸ (c+ 2)/0.5]; (c+ 2)/0.5 = φ0.80 = 0.84; c = ¡1.58.
(2) 0.9 = P [(¡2¡ c+ 2)/0.5 · N(0; 1) · (¡2 + c+ 2)/0, 5] = Φ(2c)¡ Φ(¡2c) =
28

= Φ(2c)¡ (1¡ Φ(2c)) = 2Φ(2c)¡ 1;Φ(2c) = (0.9 + 1)/2 = 0.95; 2c = φ0.95 = 1.64; c = 0.82
(3) 0.43 = P (X · c) = P [N(0; 1) · c+ 2
0.5]
da cui, essendo 43% < 50%, abbiamo (achtung!) che:
c+ 2
0.5= φ0.43 e negativo !!! ed uguale a = ¡φ0.57 = ¡0.18
e infine c = ¡2.09.OSS. Quanto spesso [=con quale probabilita] la variabile si discosta dalla media al piuper i primi tre multipli della deviazione standard?
P (μ¡ σ · X · μ+ σ) = P (¡1 · N(0; 1) · 1) ' 68%
P (μ¡ 2σ · X · μ+ 2σ) = P (¡2 · N(0; 1) · 2) ' 95, 5%P (μ¡ 3σ < X < μ+ 3σ) = P (¡3 < N(0; 1) < 3) ' 99, 7%.
Sara utile ricordare i quantili φ0.975 e φ0.995 della normale standard:
P (μ¡ 1, 96σ < X < μ+ 1, 96σ) = 95% perche 1.96 = φ0.975
P (μ¡ 2, 58σ < X < μ+ 2, 58σ) = 99% perche 2.58 = φ0.995.
Quando X e normale N(μ,σ), non solo conosciamo (come per tutte le v.a.) la mediae varianza di c1X + c2, ma risulta che anche c1X + c2 resta una v.a. normale:
Teorema Se X e normale con media μ e varianza σ2, allora X∗ = c1X + c2 (c1 > 0) enormale con media μ∗ = c1μ+ c2 e varianza (σ∗)2 = c21σ
2.
LEGGE DI PROBABILITA ESPONENZIALE; LEGGI GAMMA
Finche pensiamo che cio che per motivi di studio dobbiamo ””conoscere”” stia li da-vanti a noi come cosa morta da incamerare e che non ci sia richiesto altro che fare spazionella memoria a quell’informazione, allora la conosceza non mostrera la sua profondaverita. D’altro canto chi potrebbe sostenere a cuor leggero che la nascita di un nuovo es-sere umano sia un evento privo di sofferenza, di preoccupazioni, di attenzioni, di premuree di delicatezza? Qualcosa di analogo accade per la conoscenza/co-nascenza: senzauna serena apertura a mettere in questione cio che abbiamo gia appreso, senza la volontadi distruggere gli idoli e i pregiudizi che ci siamo costruiti, non ci e consentito l’accesso almondo vero e reale, e soprattutto non ci e consentito l’accesso al nostro io.
29
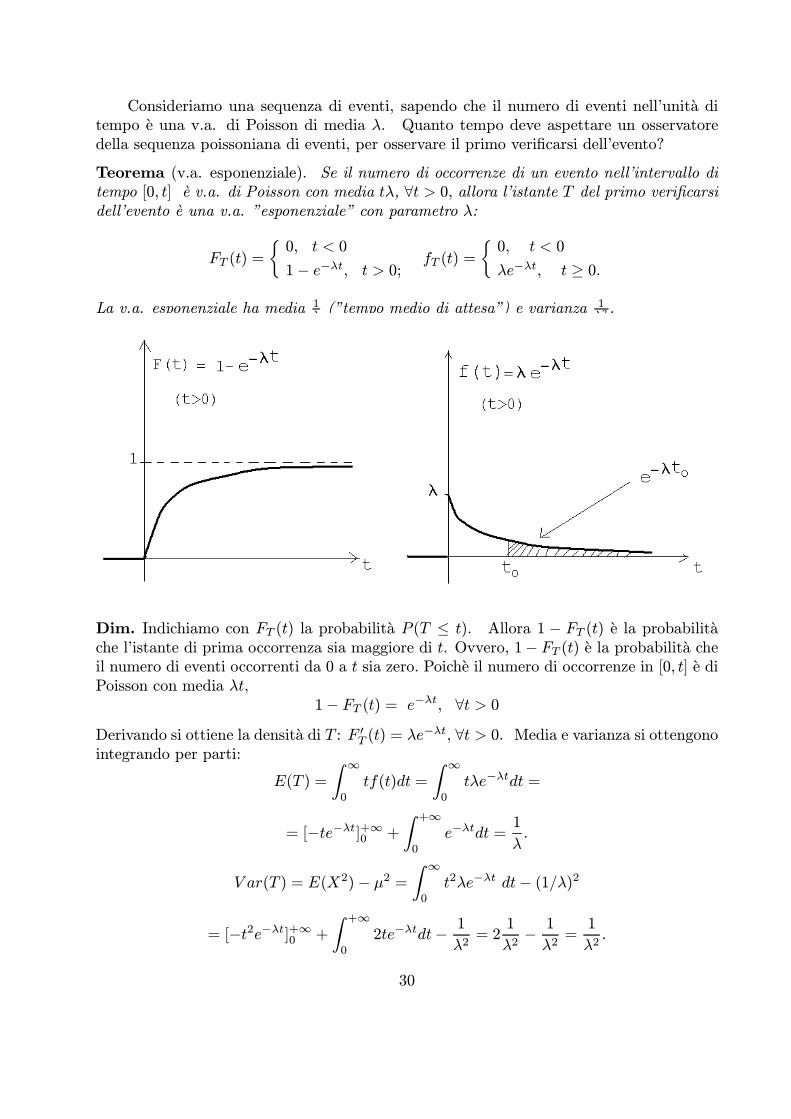
Consideriamo una sequenza di eventi, sapendo che il numero di eventi nell’unita ditempo e una v.a. di Poisson di media λ. Quanto tempo deve aspettare un osservatoredella sequenza poissoniana di eventi, per osservare il primo verificarsi dell’evento?
Teorema (v.a. esponenziale). Se il numero di occorrenze di un evento nell’intervallo ditempo [0, t] e v.a. di Poisson con media tλ, 8t > 0, allora l’istante T del primo verificarsidell’evento e una v.a. ”esponenziale” con parametro λ:
FT (t) =0, t < 0
1¡ e−λt, t > 0;fT (t) =
0, t < 0
λe−λt, t ¸ 0.
La v.a. esponenziale ha media 1λ (”tempo medio di attesa”) e varianza
1λ2 .
Dim. Indichiamo con FT (t) la probabilita P (T · t). Allora 1 ¡ FT (t) e la probabilitache l’istante di prima occorrenza sia maggiore di t. Ovvero, 1¡ FT (t) e la probabilita cheil numero di eventi occorrenti da 0 a t sia zero. Poiche il numero di occorrenze in [0, t] e diPoisson con media λt,
1¡ FT (t) = e−λt, 8t > 0Derivando si ottiene la densita di T : FT (t) = λe−λt, 8t > 0. Media e varianza si ottengonointegrando per parti:
E(T ) =∞
0
tf(t)dt =∞
0
tλe−λtdt =
= [¡te−λt]+∞0 ++∞
0
e−λtdt =1
λ.
V ar(T ) = E(X2)¡ μ2 =∞
0
t2λe−λt dt¡ (1/λ)2
= [¡t2e−λt]+∞0 ++∞
0
2te−λtdt¡ 1
λ2= 2
1
λ2¡ 1
λ2=1
λ2.
30
31
VETTORI ALEATORI, INDIPENDENZA E INCORRELAZIONE TRA V.A.
L’inquietudine di cui sto cercando di parlarti assomiglia all’esperienza dell’innamoramento,un tempo che ci assorbe, ci lascia attenzione ed energia solo per l’oggetto del nostro amore.E’ il tempo di una ferita e di una luce intensa, un abbaglio che ci mette sotto seque-stro. O si e’ innamorati totalmente o non si e innamorati affatto. Similmente quelladell’inquietudine e un’esperienza davvero unica, un’esperieza iniziatica e illuminante chepermette finalmente di accedere alla vera essenza dello studio e, nello stesso tempo, allaforte intrinseca carica umana che esso racchiude.
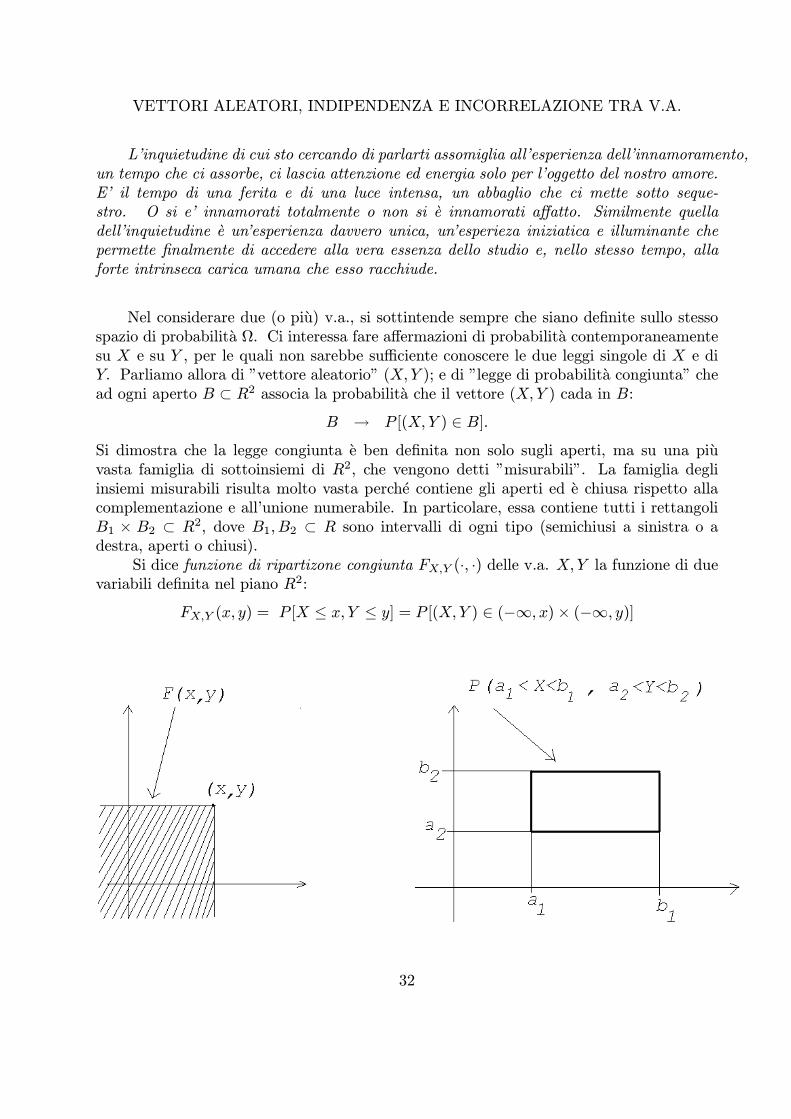
Nel considerare due (o piu) v.a., si sottintende sempre che siano definite sullo stessospazio di probabilita Ω. Ci interessa fare affermazioni di probabilita contemporaneamentesu X e su Y , per le quali non sarebbe sufficiente conoscere le due leggi singole di X e diY. Parliamo allora di ”vettore aleatorio” (X,Y ); e di ”legge di probabilita congiunta” chead ogni aperto B ½ R2 associa la probabilita che il vettore (X, Y ) cada in B:
B ! P [(X, Y ) 2 B].Si dimostra che la legge congiunta e ben definita non solo sugli aperti, ma su una piuvasta famiglia di sottoinsiemi di R2, che vengono detti ”misurabili”. La famiglia degliinsiemi misurabili risulta molto vasta perche contiene gli aperti ed e chiusa rispetto allacomplementazione e all’unione numerabile. In particolare, essa contiene tutti i rettangoliB1 £ B2 ½ R2, dove B1, B2 ½ R sono intervalli di ogni tipo (semichiusi a sinistra o adestra, aperti o chiusi).
Si dice funzione di ripartizone congiunta FX,Y (¢, ¢) delle v.a. X,Y la funzione di duevariabili definita nel piano R2:
FX,Y (x, y) = P [X · x, Y · y] = P [(X,Y ) 2 (¡1, x)£ (¡1, y)]
32

Essa contiene tutte le informazioni sulla legge congiunta B ! P [(X,Y ) 2 B]. Ad es. illettore puo verificare la seguente formula mediante considerazioni geometriche in R2:
P [a1 < X · b1, a2 < Y · b2] == FX,Y (b1, b2) + FX,Y (a1, a2)¡ FX,Y (a1, b2)¡ FX,Y (b1, a2).
Dalla funzione di ripartizione congiunta FX,Y si possono ricavare le singole FX , FY ,dette funzioni di ripartizione marginali:
FX(x) = P (X · x, Y < +1) = limy→∞FX,Y (x, y)
FY (y) = P (X < +1, Y · y) = limx→∞FX,Y (x, y)
Ora specializziamo il discorso, fin qui valido in generale, alle v.a. discrete e poi a quelleassolutamente continue.
Definiamo funzione di probabilita congiunta di due v.a. discrete X,Y la funzione di duevariabili
fX,Y (x, y) = P (X = x, Y = y).
La somma rispetto a tutte le coppie (x, y) su cui tale funzione e positiva fa’ 1. La funzionedi probabilita marginale fX sara allora:
fX(x) =y: fX,Y (x,y)>0
fX,Y (x, y)
e analoga espressione avra fY .
Def. Una legge congiunta di due v.a. X,Y si dice assolutamente continua se esiste unafunzione densita di probabilita congiunta: ossia una funzione non negativa e integrabile didue variabili fX,Y (x, y) tale che
P [(X, Y ) 2 B] =B
fX,Y (x, y)dxdy
per ogni insieme misurabile B di punti del piano.
33

Dalla densita si ottiene la funzione di ripartizione congiunta:
FX,Y (x, y) =x
−∞dx
y
−∞dyfX,Y (x, y)
e viceversa
fX,Y (x, y) =∂2
∂x∂yFX,Y (x, y)
in tutti i punti di continuita di f . La densita marginale e la funzione di ripartizionemarginale, ad es. della v.a. X, si ottengono in modo naturale:
fX(x) =+∞
−∞fX,Y (x, y) dy
FX(x) =x
−∞dx
+∞
−∞fX,Y (x, y) dy
DEF. - Le v.a. X1,X2, ..., Xn... sono indipendenti se per ogni n e per ogni scelta diintervalli reali A1, A2, ...An, si ha
P [X1 2 A1, X2 2 A2, ..., Xn 2 An] = P (X1 2 A1) ¢ P (X2 2 A2) ¢ ...P (Xn 2 An).
Due v.a. X,Y sono indipendenti se e solo se la funzione di ripartizione congiunta e ugualeal prodotto delle marginali:
FX,Y (x, y) = FX(x) ¢ FY (y), 8(x, y) 2 R2.
Le v.a. discrete X, Y sono indipendenti se e solo se la funzione di probabilita congiunta euguale al prodotto delle marginali; le v.a. assolutamente continue X,Y sono indipendentise e solo se la funzione densita congiunta e uguale al prodotto delle marginali:
fX,Y (x, y) = fX(x) ¢ fY (y), 8(x, y) 2 R2.
Il calcolo di media e varianza di X (o di Y ) a partire dalla funzione di probabilitacongiunta (o dalla densita congiunta) f(x, y) segue la definizione generale:
E[g(X, Y )] =i,j g(xi, yj) ¢ f(xi, yj) per v.a. discrete
R g(x, y)f(x, y)dx per v.a. assolutamente continue
per ogni funzione g(X,Y ) delle due v.a.Da qui si calcolano tutti i momenti, E[Xn] ed E[Y n], per n 2 N . In particolare i
momenti primi cioe le medieμx = E[X], μy = E[Y ]
34

e i secondi momenti centrati cioe le varianze:
σ2x = E[(X ¡E[X])2], σ2y = E[(Y ¡ E[Y ])2]
e anche il secondo momento misto centrato, detto ”covarianza”:
DEF. - Covarianza - La covarianza di due v.a. scalari X, Y e
Cov[X,Y ] := E[(X ¡ E[X])(Y ¡E[Y ])] = i,j(xi ¡ E[X])(yj ¡ E[Y ])fX,Y (xi, yj)R2(x¡ E[X])(y ¡E[Y ])fX,Y (x, y)dxdy
La covarianza da informazioni sulla variazione simultanea di due variabili. Covari-anza positiva significa che al crescere di X, cresce Y , perche mediamente gli scarti di Ysi dispongono con lo stesso segno degli scarti di Y . Se la covarianza e negativa, Y edecrescente al crescere di X.
Poiche l’operatore Media e lineare, l’operatore Covarianza e bilineare, cioe linearein ciascuno dei suoi argomenti.
PROPOSIZIONE: Valgono le regole di calcolo:
Cov(X,Y ) = E[XY ]¡ E[X]E[Y ]
V ar(aX + bY ) = a2 ¢ V ar(X) + 2ab ¢ Cov(X,Y ) + b2V ar(Y ), 8a, b 2 R.In particolare se Cov(X,Y ) = 0, allora V ar(X + Y ) = V ar(X) + V ar(Y ).Dim. - Si ha:
E[(X ¡E[X])(Y ¡ E[Y ])] = E[XY ]¡E[X]E[Y ]¡ E[Y ]E[X] + E[X]E[Y ]
da cui la prima uguaglianza. Ancora per la linearita dell’operatore Media si ottiene
V ar(X + Y ) = E[(X + Y ¡ E[X]¡ E[Y ])2] = E[(X ¡ E[X] + Y ¡ E[Y ])2] =
= E[ (X ¡E[X])2 + 2(X ¡ E[X])(Y ¡ E[Y ]) + (Y ¡ E[Y ])2 ] == V ar(X) + 2 ¢ Cov(X,Y ) + V ar(Y )
e analogamente si procede in presenza di coefficienti a, b diversi da 1. 4
ES. - Sia (X, Y ) un vettore aleatorio discreto con funzione di probabilita:
f(0, 3) = 0.10 f(0, 7) = 0.05f(1, 3) = 0.20 f(1, 7) = 0.15f(2, 3) = 0.20 f(2, 7) = 0.30
Allora i valori di X sono 0, 1, 2, i valori di Y sono 3, 7:
E[X] = 0 ¢ 0.15 + 1 ¢ 0.35 + 2 ¢ 0.50 = 1.35
35

E[Y ] = 3 ¢ 0.50 + 7 ¢ 0.50 = 5Cov(X, Y ) = E[XY ]¡ E[X]E[Y ] =
= 1 ¢ 3 ¢ 0.2 + 1 ¢ 7 ¢ 0.15 + 2 ¢ 3 ¢ 0.2 + 2 ¢ 7 ¢ 0.3 ¡ (1.35) ¢ 5 = 0.3Qual e ad es. la varianza di X + Y ? Dato che
E[X2]¡E[X]2 = 0.53, E[Y 2]¡ E[Y ]2 = 4
allora
V ar(X + Y ) = V ar(X) + 2 Cov(X,Y ) + V ar(Y ) = 0.53 + 2 ¢ 0.3 + 4 = 5.13
ES. - Sia (X,Y ) un vettore aleatorio con densita
fX,Y (x, y) = c(x2 + y) ¢ I[0,1]×[0,1](x, y) ´
c(x2 + y), (x, y) 2 [0, 1]£ [0, 1]0, altrove
dove c e un’opportuna costante. Dopo aver determinato c, trovare le densita marginali.Trovare le medie. Trovare la covarianza.
Sia Q il quadrato [0, 1] £ [0, 1], supporto della densita congiunta. La costante si trovanormalizzando:
1 =Q
c(x2 + y)dxdy = c1
0
1
0
(x2 + y)dydx =
c1
0
(x2 +1
2)dx = c(
1
3+1
2) =
5c
6) c = 6/5.
Per trovare la marginale di X si deve integrare la densita congiunta rispetto ad y; per lamarginale di Y si deve integrare la congiunta rispetto ad x:
fY (y) =1
0
6
5(x2 + y)dx = ... =
2
5(1 + 3y)I[0,1](y),
fX(x) =1
0
6
5(x2 + y)dy = ... =
3
5(2x2 + 1)I[0,1](x).
Dal fatto che fX(x)fY (y)6= f(x, y) si vede che X, Y non sono indipendenti.
E(X) =1
0
x ¢ 35(2x2 + 1)dx =
3
5
2x4
4+x2
2
1
0
=3
5(1
2+1
2) =
3
5
E(Y ) =1
0
y ¢ 25(1 + 3y)dy =
2
5
y2
2+3y3
3
1
0
=2
5(1
2+ 1) =
3
5.
36

E(XY ) =1
0
1
0
xy ¢ f(x, y)dxdy =1
0
1
0
6
5(x3y + xy2)dxdy =
=6
5
1
0
x3y2
2
1
0
dx+6
5
1
0
x
y3
3
1
0
dx =
=3
5
x4
4
1
0
+2
5
x2
2
1
0
=7
20
da cui
Cov(X,Y ) = E(XY )¡E(X)E(Y ) = 7
20¡ (3
5)2 = ¡ 1
100.4
DEF. - Correlation coefficient - The correlation coefficient, or correlation, of twoscalar r.v.’s X,Y having mean vector (μx,μy) and variances σ
2x,σ
2y, is
ρ ´ ρ(X,Y ) := E[X ¡ μxσx
¢ Y ¡ μyσy
]
THM. - The covariance and the correlation of two scalar r.v.’s X, Y satisfy
Cov(X,Y )2 · V ar(X)V ar(Y ) (Schwarz’s inequality),
¡1 · ρ(X,Y ) · 1respectively.
Proof - Since the expectation of a nonnegative variable is always nonnegative,
0 · E[(θjXj+ jY j)2] = θ2E[X2] + 2θE[jXY j] + E[Y 2], 8θ.
Thus a polynomial with degree 2 (in theta) does not take negative values, so that thediscriminant must be · 0:
E[jXY j]2 ¡ E[X2]E[Y 2] · 0, or E[jXY j]2 · E[X2]E[Y 2].
Replacing X and Y by X ¡ μx and Y ¡ μy, and using j f(t)g(t)dtj · jf(t)g(t)jdt, thisimplies
Cov(X,Y )2 · E[j(X ¡mux)(Y ¡ μy)j]2 · E[(X ¡ μx)2]E[(Y ¡ μy)
2] = V ar(X)V ar(Y )
Since ρ = Cov(X,Y )/ V ar(X)V ar(Y ), this also means
[ρ(X,Y )]2 · 1, i.e. ¡ 1 · ρ · +1. 4
37

Def. - Uncorrelation - Two scalar random variables , Y are said uncorrelated, ororthogonal, when Cov(X,Y ) = 0.
THEOREM - If X,Y are independent random variables, then they are uncorrelated.But the converse is not nrecessarily true:
X,Y independent ) X,Y uncorrelated
HoweverX,Y uncorrelated does not imply X,Y independent
Proof. -If X, Y are independent, then f(x, y) = fX(x) ¢ fY (y). So
E(XY ) =R2
xyf(x, y)dxdy =R
xfX(x)dxR
yfY (y)dy = μx ¢ μy.
But Cov(X, Y ) = E(XY )¡ μxμy, so that X,Y are uncorrelated.Now let U be uniformly distributed in [0, 1] and consider the r.v.’s
X = sin 2πU, Y = cos 2πU.
X and Y are not independent since Y has only two possible values if X is known. Howeverthey are orthogonal or uncorrelated:
E(X) =1
0
sin 2πt dt = 0, E(Y ) =1
0
cos 2πt dt = 0,
so that
Cov(X, Y ) = E(X ¢ Y ) =1
0
sin 2πt cos 2πt dt =1
2
1
0
sin 4πt dt = 0.
In this case the covariance is zero, but the variables are not independent. 4
ALTRI ESEMPI SUI VETTORI ALEATORI
Solo a questo punto, cioe quando compie l’esperienza dell’inquietudine, colui che studiaafferra d’un colpo che non si studia solo per uno scopo contingente (superare un esame o unconcorso) ne per pura gioia intellettuale, ma intuisce che lo studio e la strada maestra percogliere qualcosa di quel mistero che l’uomo e a se stesso e che semplicemente indichiamocome ”avventura della vita”. E cosa afferra colui ce si e lasciato catturare dall’inquietudinedello studio? ”Conosce” che solo mettendosi a servizio di qualcosa di piu grande di se stessopuo vivere una vita degna di essere definita umana.
38
Es. 1. Se X N(3; 25) ed Y N(¡1; 4) e sono indipendenti, trovare la densita di 4X ¡ 5Y .Risposta: sappiamo che ogni combinazione lineare c1X+c2Y di v.a. normali e indipendentie normale con media c1μ1 + c2μ2 e varianza c
21σ
21 + c
22σ
22. Dunque 4X ¡ 5Y e normale con
media e varianza:
μ = 4 ¢ 3¡ 5 ¢ (¡1) = 17; σ2 = 16 ¢ 25 + 5 ¢ 4 = 420
di cui e ben nota la densita.
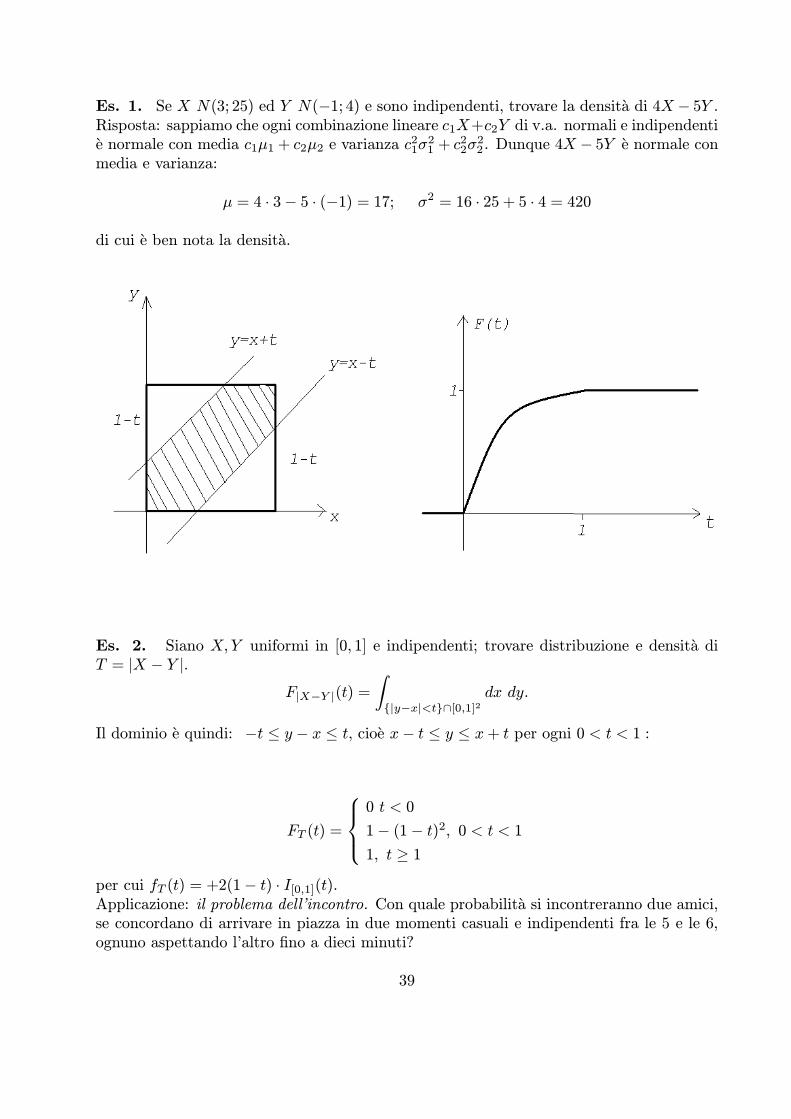
Es. 2. Siano X,Y uniformi in [0, 1] e indipendenti; trovare distribuzione e densita diT = jX ¡ Y j.
F|X−Y |(t) =|y−x|<t∩[0,1]2
dx dy.
Il dominio e quindi: ¡t · y ¡ x · t, cioe x¡ t · y · x+ t per ogni 0 < t < 1 :
FT (t) =
⎧⎪⎨⎪⎩0 t < 0
1¡ (1¡ t)2, 0 < t < 11, t ¸ 1
per cui fT (t) = +2(1¡ t) ¢ I[0,1](t).Applicazione: il problema dell’incontro. Con quale probabilita si incontreranno due amici,se concordano di arrivare in piazza in due momenti casuali e indipendenti fra le 5 e le 6,ognuno aspettando l’altro fino a dieci minuti?
39

Risposta: prendiamo l’ora per unita di misura, riportiamo all’ora ”zero” i due istantiindipendenti X e Y di arrivo X,Y » U [0, 1]; cerchiamo la probabilita che i due istantidifferiscano in valore assoluto al piu per 1/6 di ora:
P (jX ¡ Y j · 1/6) = 1¡ (5/6)2 = 1¡ (25/36) = 11/36.
Es. (con l’uso delle coordinate polari) - Nel caso che X1,X2 siano indipendenti e normali,con X1,X2 » N(0,σ2), che v.a. e Y = X2
1 +X22?
Per indipendenza la densita congiunta e il prodotto delle densita:
fX1,X2(x1, x2) =1
2πσ2exp[¡(x21 + x22)/2σ2]
che si puo mettere in coordinate polari (y = x21 + x22):
fX1,X2(y cos θ, y sin θ) =1
2πσ2e−y
2/2σ2 .
Si noti che e costante rispetto a θ; dunque l’integrazione fa’ la costante 2π; dunque
fpX21+X
22
(y) =y
σ2e−y
2/2σ2 ¢ I(0,∞)(y) (**)
Questa v.a. Y e la ben nota v.a. di Rayleigh con parametro σ2 .
40
APPROSSIMAZIONE
Conosci te stesso: questo impegno doveva essere assunto da chi desiderava entrare neltempio di Apollo, cioe da chi desiderava entrare in contatto con la sfera divina. Ebbene lastrada verso il cielo passa anche per la conoscenza, perche conoscendo, nasciamo di nuovo,ritorniamo alle nostre origini; conoscendo ci e consentito di accedere a quel mistero chealimenta le nostre radici piu remote, a quella trama di infinito su cui e scritta la nostraesistenza, a quello strano miscuglio di terra e di cielo che normalmente chiamiamo ””io””.
Per enunciare l’importante teorema di limite centrale ci serve la suddetta nozione diindipendenza, ma anche un’altra nozione: la ”convergenza in distribuzione”.
Def. La successione di v.a. reali fXngn converge in distribuzione (o ”debolmente”, o ”inlegge”) alla v.a X se e solo se, dette Fn ed F le rispettive funzioni distribuzione, si ha
limn→∞ Fn(x) = F (x)
per ogni punto x 2 R di continuita per F .Es. Prendiamo una successione di v.a. normali con media costante ma con varianzatendente a zero:
Xn » N(μ,σ2n), dove σn ! 0.
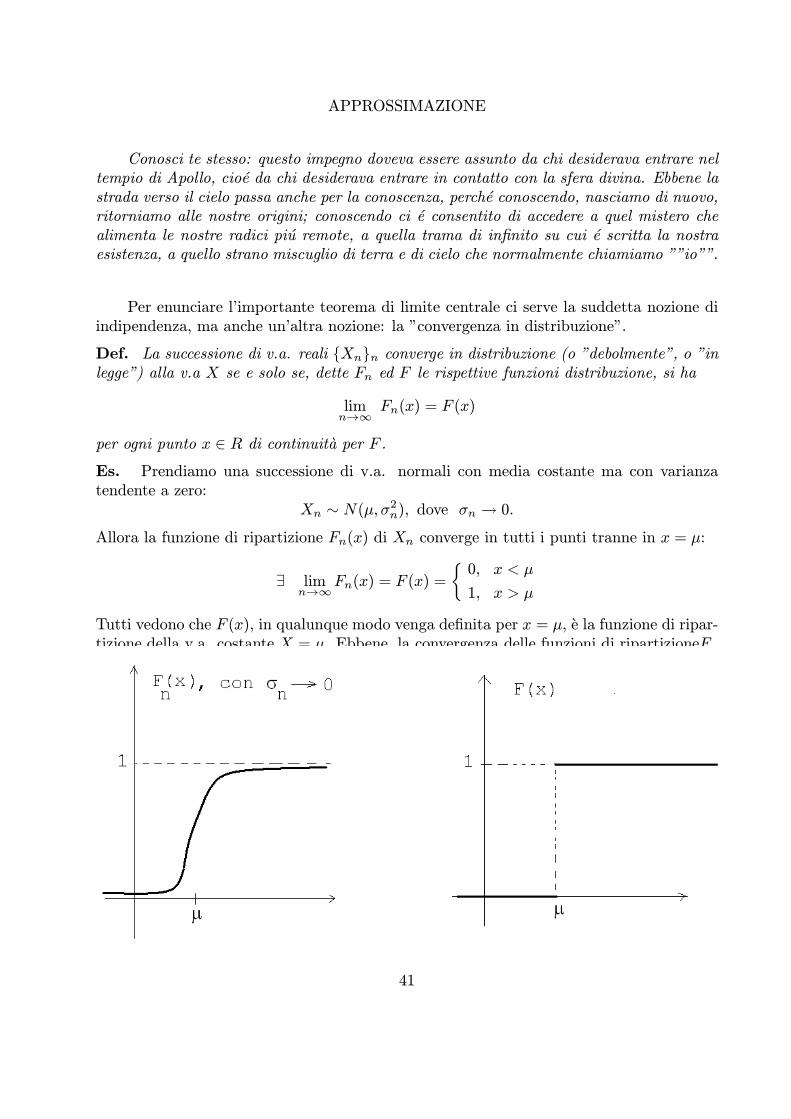
Allora la funzione di ripartizione Fn(x) di Xn converge in tutti i punti tranne in x = μ:
9 limn→∞Fn(x) = F (x) =
0, x < μ
1, x > μ
Tutti vedono che F (x), in qualunque modo venga definita per x = μ, e la funzione di ripar-tizione della v.a. costante X = μ. Ebbene, la convergenza delle funzioni di ripartizioneFnad F avviene proprio nei punti di continuita per F . Le v.a. normali Xn tendono allacostante μ in senso debole o ”in distribuzione”.
41

Teorema di limite centrale Sia fXngn una successione di v.a. indipendenti e iden-ticamente distribuite, di media μ e varianza finita σ2 > 0. Allora la loro somman¡esima standardizzata
Sn ¡ nμpnσ2
=X1 + ...+Xn ¡ nμ
σpn
converge in distribuzione ad una v.a. N(0, 1).[ Cio significa che per n! +1 si ha
P [Sn ¡ nμσpn
· x] ! P [N(0; 1) · x] ´ Φ(x), 8x 2 R]
OSS. Il teorema di limite centrale essenzialmente dice che se un fenomeno aleatorio puoessere riguardato come sovrapposizione di un gran numero n di fenomeni aleatori indipen-denti, aventi ciascuno una qualsiasi legge dello stesso tipo, allora tale fenomeno ha unadistribuzione che, per n! +1, converge alla normale.
Quindi per n sufficientemente grande, ai fini di calcolo Sn si puo trattare come se fossenormale con media nμ e varianza nσ2:
Sn ´ X1 +X2 + ...+Xn ' N(nμ;nσ2) approssimativamente
N.B. E il teorema di limite centrale che svela il comportamento asintotico di una bino-miale X » B(n, p) per p fissato ed n divergente. In tale regime, quando i calcoli conla legge binomiale diventerebbero troppo onerosi o proibitivi, viene in aiuto il teorema diapprossimazione della binomiale alla normale:
Teorema di approssimazione di De Moivre e LaplaceSiano k1, k2 interi qualunque non negativi. Sia Sn una successione di v.a. binomiali conparametri n 2 N, 0 < p < 1. Allora per p fissato ed n! +1 si ha
P [Sn ¡ nppnpq
· x] ! P [N(0; 1) · x] ´ Φ(x), 8x 2 R.
Dim. Una v.a. Sn » Bin(n; p) si puo’ ottenere come somma di v.a. di Bernoulli
Sn = Y1 + ...+ Yn, tali che Yi » 0 1q p
, i = 1, ..., n
Infatti si puo’ definire Yi = 0 se nell’i-esima prova c’e’ stato insuccesso, Yi = 1 se c’e statosuccesso. Se le prove sono indipendenti, le Yi sono variabili aleatorie indipendenti. In talmodo la somma parziale Sn delle Yi funge da contatore dei successi nell’ambito di n proveindipendenti. Inoltre ogni Yi ha la seguente media e varianza:
μ = E Yi = 0 ¢ q + 1 ¢ p = p
σ2 = V ar Yi = (0¡ p)2q + (1¡ p)2p = p2q + q2p = pq(p+ q) = pq
42
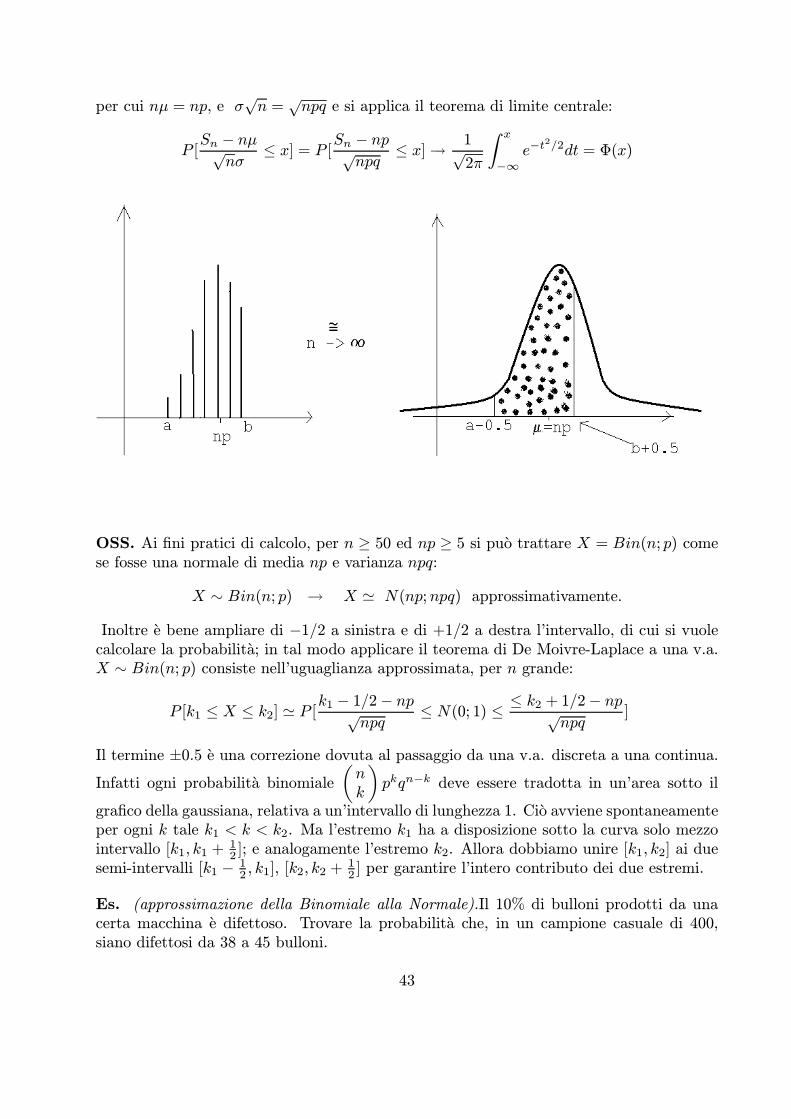
per cui nμ = np, e σpn =
pnpq e si applica il teorema di limite centrale:
P [Sn ¡ nμp
nσ· x] = P [Sn ¡ npp
npq· x]! 1p
2π
x
−∞e−t
2/2dt = Φ(x)
OSS. Ai fini pratici di calcolo, per n ¸ 50 ed np ¸ 5 si puo trattare X = Bin(n; p) comese fosse una normale di media np e varianza npq:
X » Bin(n; p) ! X ' N(np;npq) approssimativamente.
Inoltre e bene ampliare di ¡1/2 a sinistra e di +1/2 a destra l’intervallo, di cui si vuolecalcolare la probabilita; in tal modo applicare il teorema di De Moivre-Laplace a una v.a.X » Bin(n; p) consiste nell’uguaglianza approssimata, per n grande:
P [k1 · X · k2] ' P [k1 ¡ 1/2¡ nppnpq
· N(0; 1) · · k2 + 1/2¡ nppnpq
]
Il termine §0.5 e una correzione dovuta al passaggio da una v.a. discreta a una continua.Infatti ogni probabilita binomiale
nk
pkqn−k deve essere tradotta in un’area sotto il
grafico della gaussiana, relativa a un’intervallo di lunghezza 1. Cio avviene spontaneamenteper ogni k tale k1 < k < k2. Ma l’estremo k1 ha a disposizione sotto la curva solo mezzointervallo [k1, k1 +
12 ]; e analogamente l’estremo k2. Allora dobbiamo unire [k1, k2] ai due
semi-intervalli [k1 ¡ 12 , k1], [k2, k2 +
12 ] per garantire l’intero contributo dei due estremi.
Es. (approssimazione della Binomiale alla Normale).Il 10% di bulloni prodotti da unacerta macchina e difettoso. Trovare la probabilita che, in un campione casuale di 400,siano difettosi da 38 a 45 bulloni.
43

X » B(400, 110 ) ha media μ = np = 40, e varianza σ2 = npq = 36. Essendo minfnp, nqg ¸5 ed n > 50 e lecita l’approssimazione normale:
P (38 · X · 45) ' P [37.5¡ nppnpq
· N(0; 1) ·] = 45.5¡ nppnpq
]
= P [¡0.41 · N(0, 1) · 0.91] = Φ(0.91)¡Φ(¡0.41) = Φ(0.91)¡(1¡Φ(0.41)) = 0.818¡(1¡0.659) =Es. (approssimazione della Binomiale alla Normale). Determinare la probabilita di ot-tenere almeno (¸) 19 ”sette” in 100 lanci di una coppia di dadi equi.
La v.a. X = ”numero di ’sette’ nell’ambito di cento lanci” e binomiale con parametrin = 100 e p = 6
36 =16 . Allora
P (X ¸ 19) ' P [N(0, 1) ¸ 18.5¡ 100/6500/36
) = 1¡ Φ(0.2) = 0.421
Es. Il tempo di sopravvivenza di una lampada e v.a. esponenziale di media μ = 10 giorni.Appena si brucia, essa e sostituita. Trovare la probabilita che 40 lampade siano sufficientiper un anno.
Detta Xi la ”durata della i¡esima lampada”, per i = 1, ..., 40 le Xi sono indipendenti edesponenziali con parametro λ = 1
μ = 1/10. Sappiamo che E(Xi) = λ−1 = 10, V ar(Xi) =λ−2 = 100. Allora la loro somma ha media 40 ¢ 10 e varianza 40 ¢ 100 :
P (X1 +X2 + ...+X40 ¸ 365) ' P [N(0, 1) ¸ 365¡ 400p4000
] = 71%
Es. Si applica il teorema di limite centrale anche per approssimare certi processi detticammini aleatori (”random walks”). Come esempio, supponiamo che un ubriaco distiduecento passi da casa, ma riesca solo a fare, ogni unita di tempo, un passo a destra conprobabilita 1/2 o un passo a sinistra con probabilita 1/2. Quanti passi deve fare per avereprobabilita 20% di arrivare a casa?
Suggerimento: all’istante 0 poniamo l’ubriaco nell’origine, e per ogni j 2 N sia Xj =”spostamento al j-esimo istante”. Dunque
Xj » ¡1 112
12
μE(Xj) = ¡12+1
2= 0, σ2 = E(Xj)
2 ¡ E(Xj)2 = (¡1)2 12+ 12
1
2= 1
Sn ´ X1 + ...+Xn ' N(0;n)) 0.20 = P (Sn ¸ 200) ' P [N(0; 1) ¸ 200¡ 0pn
]
44

) 200pn= φ0.80 ´ 0.84 ) n = 56690. 4
Es. Ogni giorno una ditta guadagna o perde un punto con probabilita 2/4 o 1/4 rispet-tivamente, mentre resta stazionaria con probabilita 1/4. Se questa tendenza perdura per100 giorni, con quale probabilita avra guadagnato almeno 22 punti?
Suggerimento: all’istante 0 poniamo S = 0; per ogni j 2 N siaXj = ”incremento (positivoo nullo o negativo) nel j-esimo giorno”. Quanto valgono μ e σ2 di Xj? Come si comporta,per n grande, il guadagno cumulativo Sn fino al giorno n? Quanto vale P (S100 ¸ 22) ?
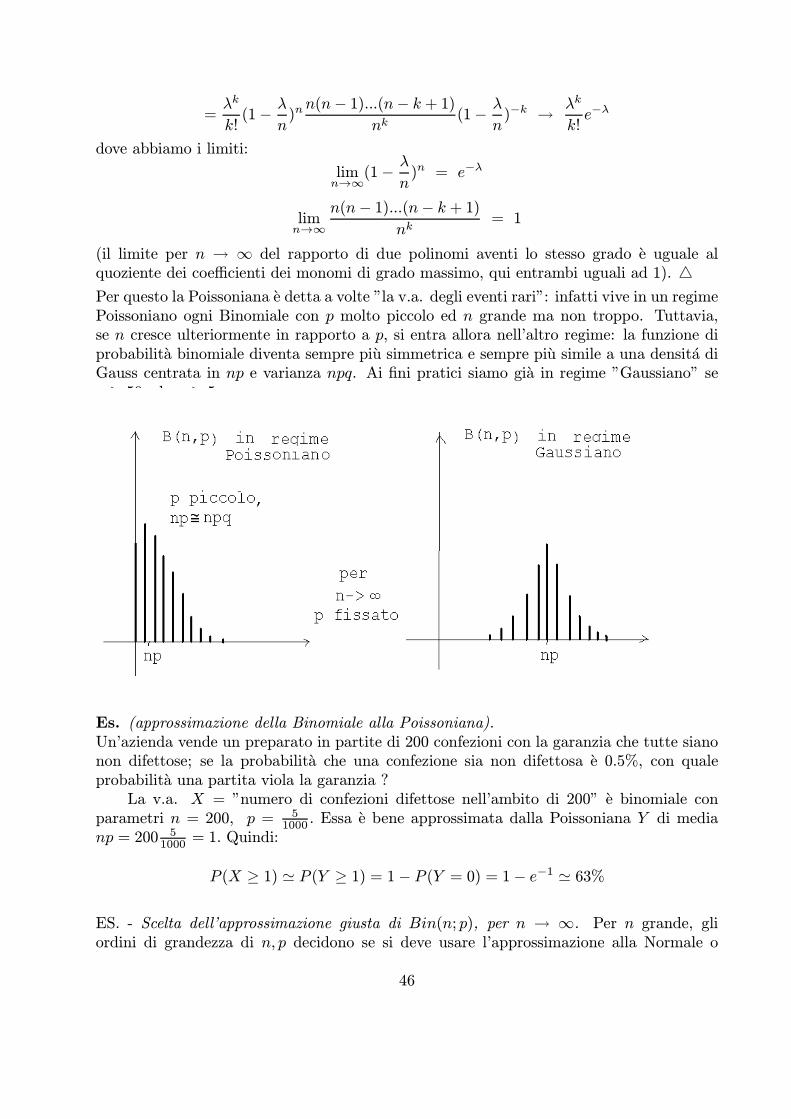
Sussiste anche un’approssimazione della v.a. binomiale alla v.a. di Poisson, sia purein un diverso regime:
TEOREMA - La Poissoniana di media μ si puo ottenere come caso limite della Binomialese
p! 0, ed n!1 in modo tale che la media np! μ.
In questo regime, in sostanza, n e grande e p e piccolo in modo che np ' npq (media 'varianza).Dim. - L’idea che giustifica questa approssimazione e abbastanza semplice: consideriamouna v.a. binomiale X » B(n, λn) e studiamo la sua funzione di probabilita per n!1:
P (X = k) =nk
(λ
n)k(1¡ λ
n)n−k =
n!
k!(n¡ k)!λk
nk(1¡ λ
n)n−k =
45
=λk
k!(1¡ λ
n)nn(n¡ 1)...(n¡ k + 1)
nk(1¡ λ
n)−k ! λk
k!e−λ
dove abbiamo i limiti:
limn→∞(1¡
λ
n)n = e−λ
limn→∞
n(n¡ 1)...(n¡ k + 1)nk
= 1
(il limite per n ! 1 del rapporto di due polinomi aventi lo stesso grado e uguale alquoziente dei coefficienti dei monomi di grado massimo, qui entrambi uguali ad 1). 4Per questo la Poissoniana e detta a volte ”la v.a. degli eventi rari”: infatti vive in un regimePoissoniano ogni Binomiale con p molto piccolo ed n grande ma non troppo. Tuttavia,se n cresce ulteriormente in rapporto a p, si entra allora nell’altro regime: la funzione diprobabilita binomiale diventa sempre piu simmetrica e sempre piu simile a una densita diGauss centrata in np e varianza npq. Ai fini pratici siamo gia in regime ”Gaussiano” sen ¸ 50 ed np ¸ 5.
Es. (approssimazione della Binomiale alla Poissoniana).Un’azienda vende un preparato in partite di 200 confezioni con la garanzia che tutte sianonon difettose; se la probabilita che una confezione sia non difettosa e 0.5%, con qualeprobabilita una partita viola la garanzia ?
La v.a. X = ”numero di confezioni difettose nell’ambito di 200” e binomiale conparametri n = 200, p = 5
1000 . Essa e bene approssimata dalla Poissoniana Y di medianp = 200 5
1000 = 1. Quindi:
P (X ¸ 1) ' P (Y ¸ 1) = 1¡ P (Y = 0) = 1¡ e−1 ' 63%
ES. - Scelta dell’approssimazione giusta di Bin(n; p), per n ! 1. Per n grande, gliordini di grandezza di n, p decidono se si deve usare l’approssimazione alla Normale o
46

l’approssimazione alla Poisson. Ad esempio: una certa lotteria istantanea ha probabilitadi vincita 0.01 per singolo biglietto. Si domanda:
a) la probabilita che fra 300 biglietti tale vincita si verifichi 2 o 3 volte; (b) la proba-bilita che fra 30000 biglietti quella vincita si verifichi da 295 a 310 volte (estremi inclusi)
Nel primo caso μ = np = 3 e si nota che np ' npq. Allora e appropriata l’approssimazionedi Bin(300; 0.01) a una v.a. Y » Poisson(μ = 3):
P (2 · X · 3) ' e−3(32
2!+33
3!) = 0.441
Nel secondo caso np = 300 ed e appropriata l’approssimazione della binomiale alla normale:
P (295 · X · 310) ' P [ 294.5¡ 300p297
· N(0; 1) · 310.5¡ 300p297
=
= Φ(0.60)¡ Φ(¡0.32) = Φ(0.60)¡ (1¡Φ(0.32)) = 0.725¡ 1 + 0.625 = 0.35 4
47

CALCOLO DI LEGGI
Essere afferrati da un problema, da una questione che e’ piu’ grande delle risposteconosciute e la cui soluzione non si lascia rintracciare in modo semplice e scontato, e’la vera esperienza dello studio. Si passa allora dallo studio (e dalla scuola) dell’obbligoall’obbligo (interiore) dello studio.
Vogliamo ottenere la legge di probabilita di una v.a. Y = g(X), conoscendo la leggedella v.a. X e la trasformazione g. L’ipotesi migliore e che g sia un diffeomorfismo R! R,cioe una funzione invertibile e differenziabile insieme con la sua inversa: questa ipotesi,come vedremo, garantisce l’esistenza di una densita fY di Y se esiste la densita fX di X.Ma vorremmo trattare anche situazioni meno fortunate, in cui ci sia solo invertibilit‘a atratti e/o un tipo di regolarita meno forte [ un tipico esempio puo essere g(x) = jxj ], maallora bisognera esaminare la situazione caso per caso.Il metodo piu comune e trovare prima la funzione di ripartizione FY (y), da cui si possonoricavare la funzione densita di probabilita [ o la funzione di probabilita fY (y) ] nei casi incui tali funzioni esistono. Avremo:
FY (y) = PX( g(x) · y ) se Y = g(X).
Es. Sia g una trasformazione affine: g(x) = ax+ b, con a > 0, b 2 R. La f.distribuzionedi Y = aX + b e:
FaX+b = P (aX + b · y) = P (X · y ¡ ba) = FX(
y ¡ ba).
Se X e continua con densita fX = FX , derivando troviamo
faX+b(y) =1
afX(
y ¡ ba).
Se X e discreta con funzione massa fX ,
faX+b(y) = fX(y ¡ ba).
Es. Sia Y = X2. Poiche g(x) = x2 ¸ 0, FX2(y) = 0, 8y < 0. Per y ¸ 0,
FX2(y) = P (X2 · y) = P (¡py · X · py) =
= FX(py)¡ FX(¡py) + P (X = ¡py) (*)
48

Se X e v.a. continua con funzione densita fX allora l’ultimo addendo e zero ed FX2(y) eun integrale: in tal caso, con la regola di derivazione composta, si ottiene la densita di Y :
fX2(y) =0, y < 0
[fX(py) + fX(¡py)] 1
2√y , y ¸ 0
Se X e discreta anche X2 e discreta, poiche ciascuno dei due primi termini di (¤) e unasomma di probabilita di valori puntuali. Percio:
fX2(y) =fX(
py) + fX(¡py), y ¸ 0
0, y < 0
Es. SiaY = A sinX, X » U [¡π/2,π/2], A > 0.
Si tratta di una sinusoide aleatoria, perche la fase X e v.a. uniforme nell’intervallo[¡π/2,π/2]. Visto che il codominio di g e [¡A,A], interessa FY (¢) per jyj < A:
FY (y) = P (A sinX · y) = P (sinX · y
A)
= P (X · arcsiny
A) = FX(arcsin
y
A)
D’altra parte la v.a. angolare X, essendo uniforme, ha funzioni densita e distribuzione:
8x 2 [¡π2,π
2], fX(x) =
1
π, FX(x) =
1
π(x+
π
2).
Percio
FY (y) =1
π(arcsin
y
A+π
2), jyj · A
Di conseguenza, la densita di Y e:
fY (y) =1πA (1¡ ( yA )2)−1/2, jyj < A,0, altrove
[Applicazione: la gittata di un proiettile di velocita iniziale v lanciato con inclinazione αe Y = (v2/g) sin(2α). Se l’angolo di sparo α e aleatorio e in particolare uniforme in unintervallo, la gittata segue una legge del tipo di quella appena ricavata. ]
TEOREMA FONDAMENTALE PER IL CALCOLO DI DENSITA’
Mentre frequentiamo le aule di un’universita’, in verita’ siamo tutti come in attesa,come in procinto di ricevere una chiamata. La chiamata di quel problema, di quel tema, di
49

quella domanda, di quella questione che si candidano a diventare ”il nostro problema”, ”ilnostro tema”, ”la nostra domanda”, ”la nostra questione”: la chiamata di cio’ che reca ilsigillo dell’inquietudine.
Rammentiamo che una v.a. e assolutamente continua se e assolutamente continua la suafunzione di ripartizione FX(¢); o, detto altrimenti, se X ammette una funzione densita diprobabilita.Enumeriamo alcune condizioni sulla trasformazione g sotto le quali g(X) e v.a. assoluta-mente continua se X e assolutamente continua. Vogliamo inoltre la funzione densita diY = g(X) in termini della funzione densita di X e delle derivate di g(¢).[Prima di enunciare tale teorema, puo essere utile al lettore richiamare la derivazione dellafunzione inversa: sotto le appropriate ipotesi, se y = g(x) ha inversa x = g−1(y)
dx
dy=d
dyg−1(y) =
1
g (x)jx=g−1(y)) = 1
dy/dx.
Ad esempio per y = sinx (¡π/2 < x < π/2) si ha x = arcsin y (¡1 < y < 1):dx
dy=d
dyarcsin y =
1ddxsin x
jx=x(y) =
=1
cosxjx=x(y) = 1p
1¡ sin2x jx=x(y) =1
1¡ y2 , ¡1 < y < 1 ].
E utile usare anche la funzione indicatrice di un insieme:
IA(x) =1, x 2 A0, x /2 A.
Teorema fondamentale per il calcolo di densita.a) Siano U, V due aperti di R e sia g : U ! V un diffeomorfismo, cioe una funzioneinvertibile e differenziabile insieme alla sua inversa. Se X e una v.a. assolutamentecontinua, allora Y = g(X) e una v.a. assolutamente continua con densita di probabilita
fY (y) = fX(x) ¢ jg (x)j−1jx=g−1(y) ¢ IV (y)
o anche fY (y) = fX [g−1(y)]j d
dyg−1(y)j ¢ IV (y).
b) Sia g : U ! V non necessariamente invertibile. Supponiamo che l’insieme dei puntisingolari di g cioe
Σg = fx 2 U : non esiste g (x) o g (x) = 0g,
50

sia finito. Per ogni numero y 2 V chiamiamo m(y) il numero dei punti non singolari chesono soluzioni dell’equazione g(x) = y:
m(y) 2 N se 9x1(y), ...xm(y) :
per k = 1, ...,m(y), g[xk(y)] = y, 9g [xk(y)]6= 0m(y) = 0 se non esiste x : g(x) = y e g (x)6= 0.
Ebbene, se X e una v.a. assolutamente continua allora anche g(X) e v.a. assolutamentecontinua con funzione densita
fY (y) =m(y)k=1 fX [xk(y)]jg [xk(y)]j−1, se m(y) > 0
0, se m(y) = 0
Dim. Per brevita ci limitiamo alla situazione (a), in cui g e diffeomorfismo, nel qual casovale la formula del cambio di variabile di integrazione:
U
h(x)dx =V
h[g−1(y)]j ddyg−1(y)jdy.
per ogni funzione integrabile nonnegativa h. Ora, una fY (¢) ¸ 0 e la densita di Y sse
P (Y 2 A) =A
fY (y)dy, 8A aperto ½ R.
Usando l’invertibilita di g e la formula del cambio di variabile di integrazione
P (Y 2 A) = P [g(X) 2 A] = P [X 2 g−1(A)] =
=g−1(A)
fX(x) dx =A
fX [ g−1(y)]j d
dyg−1(y)jdy
per ogni aperto A ½ V . L’uguaglianza si estende ad ogni aperto A di R se definiamo
fY (y) =fX [ g
−1(y)]j ddyg−1(y)j, y 2 V
0, altrove.
[ Ecco anche un argomento piu intuitivo, che pero esige di sapere la derivabilita dellefunzioni di ripartizioneF . Per y 2 V , se g e crescente
FY (y) = P [g(X) · y] = P [X · g−1(y)] = FX [g−1(y)].
Se g e decrescente,
FY (y) = P [g(X) · y] = P [X ¸ g−1(y)] = 1¡ FX [g−1(y)].
51
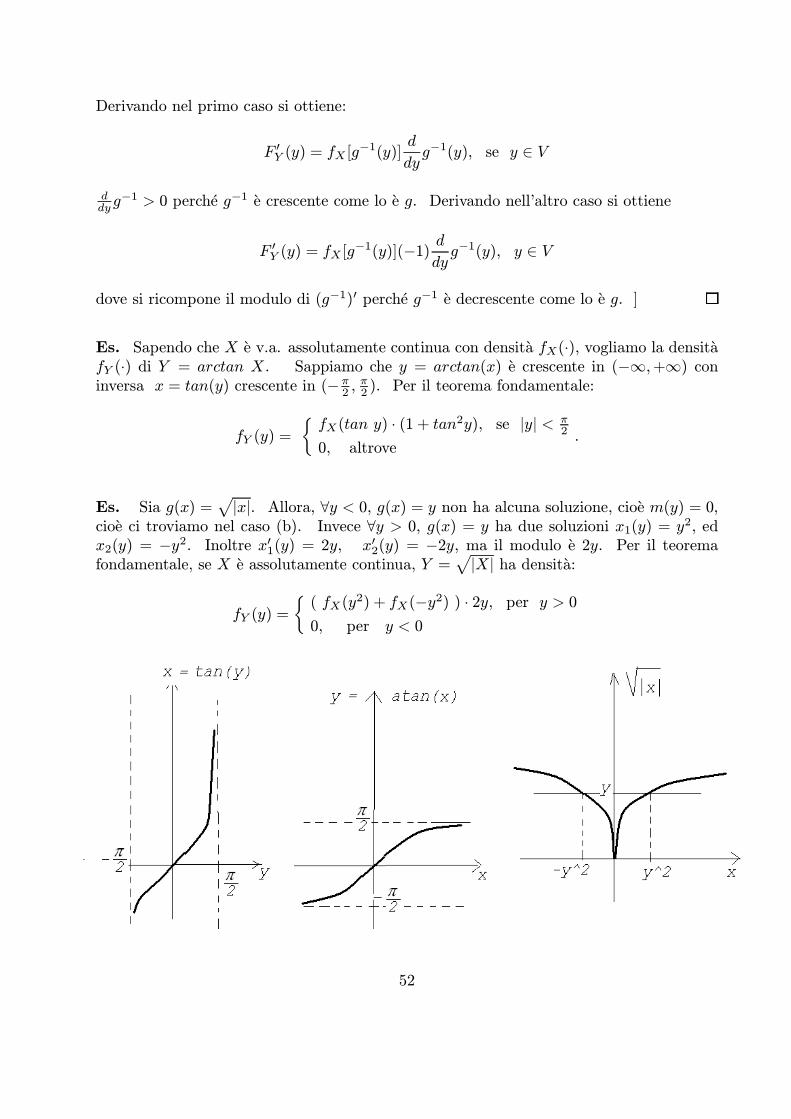
Derivando nel primo caso si ottiene:
FY (y) = fX [g−1(y)]
d
dyg−1(y), se y 2 V
ddy g−1 > 0 perche g−1 e crescente come lo e g. Derivando nell’altro caso si ottiene
FY (y) = fX [g−1(y)](¡1) d
dyg−1(y), y 2 V
dove si ricompone il modulo di (g−1) perche g−1 e decrescente come lo e g. ]
Es. Sapendo che X e v.a. assolutamente continua con densita fX(¢), vogliamo la densitafY (¢) di Y = arctan X. Sappiamo che y = arctan(x) e crescente in (¡1,+1) coninversa x = tan(y) crescente in (¡π
2 ,π2 ). Per il teorema fondamentale:
fY (y) =fX(tan y) ¢ (1 + tan2y), se jyj < π
2
0, altrove.
Es. Sia g(x) = jxj. Allora, 8y < 0, g(x) = y non ha alcuna soluzione, cioe m(y) = 0,cioe ci troviamo nel caso (b). Invece 8y > 0, g(x) = y ha due soluzioni x1(y) = y2, edx2(y) = ¡y2. Inoltre x1(y) = 2y, x2(y) = ¡2y, ma il modulo e 2y. Per il teoremafondamentale, se X e assolutamente continua, Y = jXj ha densita:
fY (y) =( fX(y
2) + fX(¡y2) ) ¢ 2y, per y > 00, per y < 0
52

Altro esercizio: mostrare che se X e v.a. assolutamente continua
f|X|(y) =fX(y) + fX(¡y), per y > 00, per y < 0
Problema. L’ampiezza X(t), ad un tempo t, del segnale emesso da un certo generatore disegnali aleatori, e una v.a. distribuita normalmente con parametri μ = 0, σ2 > 0. L’ondaX(t) passa attraverso un circuito quadrante; l’uscita Y (t), al tempo t, sia Y (t) = X2(t).Trovare la densita di Y (t).Risposta. Sia g(x) = x2. Allora, 8y < 0, g(x) = y non ha alcuna soluzione, cioem(y) = 0. Invece 8y > 0, g(x) = y ha due soluzioni x1(y) = py, ed x2(y) = ¡py. Inoltrex1(y) =
12√y , x2(y) = ¡ 1
2√y , e il modulo e in ogni caso
12√y . Per il teorema fondamentale,
se X e continua, Y = X2 ha densita:
fY (y) =( fX(
py) + fX(¡py) ) 1
2√y , per y > 0
0, per y < 0
Nel caso di X » N(0,σ2), essendo fX(x) = fX(¡x),
fY (y) =2 ¢ fX(py) 1
2√y , y > 0
0, altrove
cioe: fY (y) =1
σ√2πye−y/2σ
2
, y > 0
0, altrove.
Nel caso σ = 1, Y e la famosa v.a. χ2(1), detta ”chi quadrato con 1 grado di liberta”.
Allarghiamo il panorama con funzioni g che non necessariamente mutano una v.a.assolutamente continua in una g(X) continua. Tipicamente Y diventa v.a. mista (in partediscreta in parte assolutamente continua) nella seguente situazione:
Proposizione. Sia X v.a. assolutamente continua. Sia I un intervallo nel quale lafunzione g(¢) assume un valore costante:
8x 2 I ½ R, g(x) = y,
senza che esista un sovraintervallo proprio J in cui g(x) = y. In questo caso, la v.a. Yassume il valore y = g(x) con probabilita
P (Y = y) = P (X 2 I).
e se tale probabilita e non nulla, la v.a. Y e mista.Dim. Basta un attimo di riflessione.
53
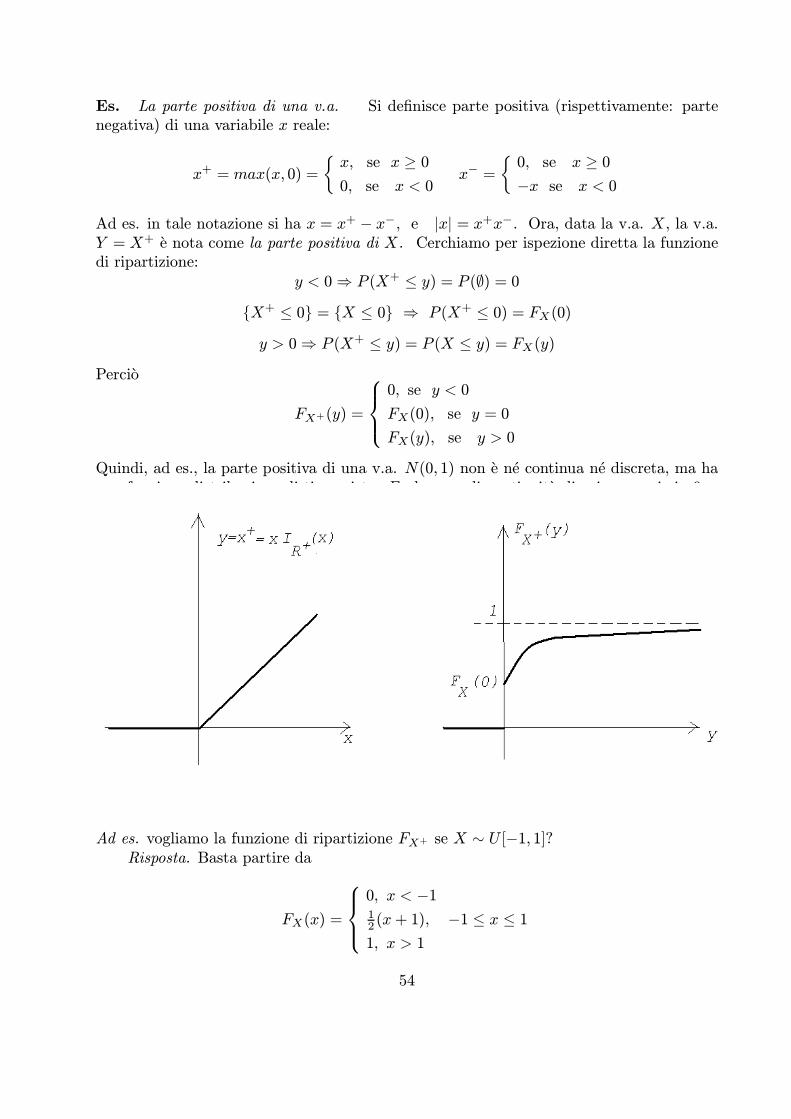
Es. La parte positiva di una v.a. Si definisce parte positiva (rispettivamente: partenegativa) di una variabile x reale:
x+ = max(x, 0) =x, se x ¸ 00, se x < 0
x− =0, se x ¸ 0¡x se x < 0
Ad es. in tale notazione si ha x = x+ ¡ x−, e jxj = x+x−. Ora, data la v.a. X, la v.a.Y = X+ e nota come la parte positiva di X. Cerchiamo per ispezione diretta la funzionedi ripartizione:
y < 0) P (X+ · y) = P (;) = 0fX+ · 0g = fX · 0g ) P (X+ · 0) = FX(0)y > 0) P (X+ · y) = P (X · y) = FX(y)
Percio
FX+(y) =
⎧⎪⎨⎪⎩0, se y < 0
FX(0), se y = 0
FX(y), se y > 0
Quindi, ad es., la parte positiva di una v.a. N(0, 1) non e ne continua ne discreta, ma hauna funzione distribuzione di tipo misto: FY ha una discontinuita di prima specie in 0, etale ”salto” e la massa di probabilita in 0.
Ad es. vogliamo la funzione di ripartizione FX+ se X » U [¡1, 1]?Risposta. Basta partire da
FX(x) =
⎧⎪⎨⎪⎩0, x < ¡112 (x+ 1), ¡1 · x · 11, x > 1
54

La funzione di ripartizione di X+ concentra in 0 la massa che per X e distribuita in [¡1, 0] :
FX+(x) =
⎧⎪⎨⎪⎩0, x < 012 , x = 012 (x+ 1) 0 < x · 1
mentre vale 1, 8x ¸ 1.
Es. In un istante l’ampiezza X di un segnale emesso da un generatore di segnali aleatorie una v.a. normale N(0.3, 0.25). L’onda X passa attraverso un clipper dando in uscitaY = g[X], dove g(x) = 1 o 0 a seconda che x > 0 o x < 0. Trovare la funzione massa diprobabilita di Y per tale istante.Risposta: si capisce che Y e discreta con valori possibili dati da 1 e da 0.
P (Y = 0) = P (X < 0) = P (N(0, 1) <0¡ 0.30.5
) =
= 1¡ P (N(0, 1) · 0.6) = 1¡ 0.7257 = 27.43%P (Y = 1) = P (X > 0) = 72.57%
DENSITA’ CONDIZIONATE, MEDIE CONDIZIONATE
Ora riuscirai a intuire che quella domanda, quell’autentico interrogativo per chiunquesi avventuri sui sentieri della conoscenza sia proprio il seguente: Per chi studio? Per chimi impegno nel lavoro intellettuale? Altre risposte che puntassero a una visione strumen-tale del lavoro intelletuale (Per che cosa studio?) al termine delle nostre riflessioni sonoovviamente da scartare. In verita, tu studi per te: studi per allargare l’orizzonte del tuosguardo, per liberare la tua intelligenza da ogni pregiudizio e falso idolo che impedisconodi fare spazio a cio che di nuovo ci viene incontro, per allargare la nativa ospitalita dellatua anima sino ad accogliere il mondo intero.
Consideriamo due v.a. X,Y con una nota legge di probabilita congiunta:
A,B aperti di R ! P (X 2 A, Y 2 B).
Ora, il conoscere che la v.a. X ha assunto un particolare valore x induce un condiziona-mento della v.a. Y ; cioe puo apportare una modifica della legge di probabilita marginale diY. Nel caso discreto definiamo in modo del tutto elementare la funzione di probabilitacondizionata di Y data X: come rapporto
fY |X(ykjxi) := P (Y = ykjX = xi) =P (X = xi, Y = yk)
P (X = xi)=f(xi, yk)
fX(xi), 8i, k
55

tra la congiunta e la marginale della X.
ES. - Data la funzione di probabilita congiunta di X,Y :
f(1, 1) = 1/8, f(1, 2) = 1/4, f(2, 1) = 1/8, f(2, 2) = 1/2
trovare la fuzione di prob. condizionata di Y dato X = 2.Prima calcolo la marginale di X in 2: fX(2) =
18+
14 =
38 . Quindi il rapporto fra congiunta
e marginale:
fY |X(1j2) = f(2, 1)
fX(2)= (1/8) : (3/8) = 1/3; fY |X(2j2) = f(2, 2)
fX(2)=1/2
3/8= 4/3, 4
definisce la funzione di probabilita condizionata di Y dato X = 2.
Se invece la legge congiunta di X, Y e assolutamente continua, non posso definire
FY |X=x = P (Y · yjX = x) =P [X = x, Y · y)]
P (X = x)
perche il denominatore e zero; infatti se X e assolutamente, allora P (X = x) = 0,8x 2 R.Che fare? Raggiungere lo scopo con un limite, con una forma indeterminata 0/0, propriocome si fa’ in tutte le applicazioni fisiche dell’analisi matematica (per esempio per definirela velocita istantanea, l’accelarazione istantanea, etc. ).L’idea - informalmente - puo essere:
FY (y jx · X · x+ h) = P (x · X · x+ h, Y · y)P (x · X · x+ h) ¢ 1/h
1/h=
=1h
y
−∞ dηx+h
x fX,Y (ξ, η)dξ
1h
x+h
xfX(ξ)dξ
!
(per h! 0), !y
−∞ fX,Y (x, η)dηfX(x)
supponendo di poter applicare il teorema della media integrale. Cio motiva la seguentedefinizione di distribuzione condizionata.
Def. La funzione di ripartizione condizionata della v.a. Y dato fX = xg e per definizionela funzione di ripartizione dipendente dal parametro x:
FY |X(y jx) :=y
−∞ fX,Y (x, η) dηfX(x)
Essa e definita per ogni x tale che fX(x) > 0.
56

Per le x tali che fX(x) > 0, la funzione densita di probabilita condizionata fY |X(yjx) dellav.a. Y dato fX = xg e la densita dipendente dal parametro x
fY |X(yjx) := fX,Y (x, y)
fX(x).
Se la funzione di ripartizione condizionata e derivabile,
fY |X(yjx) =d FY |X(yjx)
dy.
OSS. Dunque la densita congiunta e uguale alla densita condizionata di Y dato X = xmoltiplicata per la densita marginale di X: :
fX,Y (x, y) = fY |X(yjx) ¢ fX(x).
In particolare, se la densita di probabilita marginale fY (y) della v.a. Y coincide con ladensita di probabilita condizionata fY |X(yjx), allora le due v.a. sono indipendenti; infattila densita congiunta risulta essere il prodotto delle due marginali:
fY (y) = fY |X(yjx) ) fX,Y (x, y) = fX(x) ¢ fY (y).
Inoltre sussiste una specie di teorema di Bayes per le densita condizionali. Infatti essendo
fX,Y (x, y) = fX|Y (xjy)fY (y) = fY |X(yjx)fX(x)
si ottiene
fX|Y (xjy) =fY |X ¢ fX(x)fY (y)
=fY |X ¢ fX(x)
∞−∞ fY |X(yjx)fX(x)dx
.
ES. Sia
fX,Y (x, y) =λ2e−λy, 0 < x < y0, altrove.
Trova: a) la densita marginale di Y ; b) la densita condizionata di X dato Y = y; e ilcorrispondente valore atteso condizionato.
Come sappiamo, la marginale di Y , come sappiamo, e l’integrale della densita congiuntarispetto ad x:
fY (y) =y
0
λ2e−λydx = λ2e−λy ¢ y
La densita condizionata e allora:
fX|Y (xjy) = fX,YfY
==λ2e−λyλ2e−λyy =
1y , 0 < x < y
0 altrove.
57

E[XjY = y] =y
0
x ¢ 1ydx =
x2
2
y
0
1
y=y
2. 4
ES. Ogni anno un tipo di macchina deve essere sottoposto ad alcuni arresti per manuten-zione. Questo numero di arresti X e v.a. di Poisson con parametro y. Ma anche y ealeatorio (ad es. puo dipendere dalla macchina) e assumiamo che esso segua una legge
fY (y) = ye−y ¢ I(0,∞)(y).
(a) Qual e la probabilita che una singola macchina sia sottoposta a k arresti in un anno?(b) Sapendo che una macchina ha subito k = 5 arresti l’anno scorso, qual e la migliorestima della sua ”propensione alla difettosita” Y ?
Risposta. Pur non dicendolo esplicitamente, il problema fornisce la funzione di probabilitacondizionata di X dato Y = y :
P (X = kjY = y) ´ fX|Y (kjy) = yk
k!e−y.
La densita congiunta e il prodotto fra questa e la densita della v.a. condizionante:
fX,Y (k, y) = fX|Y (kjy) ¢ fY (y) = yk
k!e−y ¢ ye−y ¢ I(0,+1)(y)
per cui
P (X = k) =∞
0
fX,Y (k, y) dy =∞
0
1
k!yk+1e−2y =
(posto τ = 2y) =∞
0
(1
2)k+2)τk+1k!e−τdτ =
k + 1
2k+2
(b) Si tratta di calcolare la media condizionata di Y dato X = 5, quindi occorre la densitacondizionata:
fY |X(yjk) = fX,Y (k, y)
fX(k)=
= [1
k!yk+1e−2y ] ¢ 2
k+2
k + 1=(2y)k+1 ¢ 2(k + 1)!
e−2y
Allora
E(Y jX = k) =∞
0
yfY |X(yjk) dy =
=∞
0
2k+2
(k + 1)!yk+2e−2ydy =
2k+2
(k + 1)!
∞
0
e−τ (τ
2)k+2
1
2dτ =
=(k + 2)!
2 ¢ (k + 1)! =k + 2
2, cioe E(Y jX = 5) =
7
2= 3.5
58

Essa e la migliore stima di Y in base al dato sperimentale k = 5.
Il seguente e un esempio di condizionamento del tutto elementare, ma anch’esso inqualche modo istruttivo.
Es. Tempo di guasto dopo rodaggio. Collaudiamo lampadine lasciandole accese fino alguasto (bruciatura del filamento). Un modello per il tempo di guasto T di una lampadinae la v.a. esponenziale, avente densita non nulla per t > 0:
8t > 0, fT (t) = λe−λt;1
λ= tempo medio di guasto.
Modifichiamo ora il modo di collaudare: attendiamo un tempo fisso t fino all’accensione,scartiamo le lampadine che all’istante t sono gia guaste, e collaudiamo solo quelle ancorafunzionanti. L’evento condizionante e insomma B = fT ¸ tg: cerchiamo la distribuzionecondizionata FT |B(tjB).
P (B) = P (T ¸ t) = 1¡ P (T · t) = 1¡ FT (t).
La probabilita dell’intersezione e
P [(T · t) \ (T ¸ t)] =FT (t)¡ FT (t), t ¸ t0 t < t.
Infatti e vuota l’intersezione fra i due eventi proprio quando t < t. Otteniamo allora:
FT |B(tjB) = P [(T · t) \ (T ¸ t)]P (T ¸ t) =
FT (t)−FT (t)1−FT (t) , t ¸ t
0 t < t.
Quindi la densita della v.a. ”tempo di guasto dopo rodaggio” e ottenuta derivando:
fT |B(tjB) =d FT |B(tjB)
dt=
fT (t)1−FT (t) , t ¸ t0, t < t.
Allora, in che modo il rodaggio modifica la densita esponenziale fT (t) originaria?
λe−λt
1¡ (1¡ e−λt) = λe−λ(t−t), t > t
La densita originaria e solo stata traslata: fT (t¡ t). Non c’e alcun vantaggio a fare unrodaggio. Se il tempo di guasto e esponenzialmente distribuito, il guasto sopravviene senzausura o meglio senza memoria, cioe indipendentemente da quanto tempo la lampadinaabbia gia funzionato.
Anche la v.a. discreta ”tempo d’attesa del primo successo” gode una simile assenza dimemoria (quindi anche il popolare ”tempo di attesa di un numero ritardatario” al lotto).
59

VETTORI ALEATORI GAUSSIANI
Il sapiente e anzitutto uno che sa distinguere e apprezzare l’alterita. Non si lasciailludere mai dai luoghi comuni del tipo: ”Siamo tutti uguali” o ”Ogni mondo e paese”.Sa che il mondo si regge su tante piccole differenze che debbono essere rispettate. Percioriconosce l’ambivalenza di ogni fenomeno, sforzandosi di considerarne le opposte polarita.
Assumiamo che X1, ..., Xn siano v.a. indipendenti con medie μ1, ...,μn , e varianzeσ21, ..., σ
2n. Scriviamo Xi 2 N(μi, σ2i ). Now, define the random vector X = (X1, ...,Xn)
T .Essendo v.a. indipendenti, la densita congiunta e il prodotto dlele marginali:
fX(x1, ..., xn) = fX1(x1) ¢ ¢ ¢ fXn(xn)
=n
i=1
1
σip2πexp
(xi ¡ μi)
2
2σ2i
1
(ni=1 σi)(2π)
n/2exp ¡1
2
n
i=1
xi ¡ μiσi
2
.
Introducendo il vettore media μ = (μ1, ...,μn)T , e la matrice
ΣX = diag(σ21 , ...,σ
2n),
la densita si scrive in forma compatta:
fX(x) =1
(2π)n/2pdetΣX
exp
¡12(x¡ μ)TΣ−1X (x¡ μ)
Def. Un vettore aleatorio X = (X1, ...,Xn) a valori in Rn e detto Gaussiano se la sua
densita di probabilita e data da:
fX(x1, ..., xn) =exp[ ¡ 1
2(x¡ μX)T (ΣX)
−1(x¡ μX)
(2π)n/2(det ΣX)1/2,
per x 2 Rn, dove μ = (μ1, ...,μn)T , e il (vettore colona) valor medio di X, e ΣX e definitapositiva e si chiama la matrice di varianza e covarianza:
ΣX =
⎛⎝ Cov(X1,X1) ... Cov(X1,Xn)... ... ...
Cov(Xn,X1) ... Cov(Xn, Xn)
⎞⎠ =⎛⎝ σ21 ... σ1n... ... ...σn1 ... σ2n
⎞⎠Un vettore aleatorio Gaussiano e spesso denotato X = (X1, ...,Xn) » N(μ; ΣX).
OSS. Poiche Cov(Xi,Xj) = Cov(Xj , Xi) la matrice CX e simmetrica.
60

Σ e definita positiva e simmetrica, percio gli autovalori λ1, ...λn di ΣX sono reali e positivi; ela matrice inversa (ΣX)
−1 e anch’essa definita positiva con autovalori 1/λ1, ..., 1/λn. Infinegli n autovettori di ΣX possono scegliersi ortonormali e coincidono con gli n autovettoridi Σ−1X .
Teorema - Nel caso di v.a. normali X1, ..,Xn, esse risultano incorrelate se e solo se essesono indipendenti.Dimostrazione - Quando le Xi sono a due a due incorrelate, Cov(Xi,Xj) = 0, 8i6= j, cioimplica che la matrice di varianza e covarianza e’ diagonale. Allora la forma quadratica,che compare nell’esponente della densita’ f , ha solo i termini quadratici puri. Quindil’esponenziale e’ il prodotto di esponenziali di ciascuna variabile, e la densita’ congiunta e’il prodotto delle densita’ marginali, cioe’ le Xi sono indipendenti. 4
ESEMPIO - Il vettore gaussiano (X, Y,Z) ha le tre medie nulle e ha matrice di covarianza⎛⎝ 3 1 ¡51 7 ¡3¡5 ¡3 10
⎞⎠Sia U la v.a. ottenuta proiettando (X,Y,Z) nella direzione d = (
√32 , 0,
12 ). Trovare
P (U · 0.5).Risoluzione: U =
√32 X +
12Z. Come combinazione lineare di variabli normali, anche
U e normale. Inoltre per linearita’ dell’operatore ”media”,
E(U) =
p3
2E(X) +
1
2E(Z) = 0
perche’ E(X) = E(Z) = 0. Infine la varianza si calcola con la formula V ar(X1 +X2) =V ar(X1) +2 ¢Cov(X1,X2) +V ar(X2). Facendo uso della matrice di covarianza, abbiamo:
V ar(
p3
2X +
1
2Z) = (
p3
2)2V ar(X) + 2 ¢
p3
2
1
2Cov(X,Z) + (
1
2)2V ar(Z)
=3
4+
p3
2¢ (¡5) + 10
4=65¡ 2p3
20' 3.07
Percio’ σ =p3.07 = 1.75 e infine, standardizzando U ,
P (U · 0.5) = P [N(0; 1) · 0.5
1.75] = P [N(0; 1) · 0.28] = 0.61.4
ESEMPIO - Le v.a. X, Y sono normali standard e indipendenti. Trovare: a) la densita di(X,X +Y ); b) la densita di (X,X
p2). c) Mostrare ce i vettori aleatori di (a) e (b) hanno
le stesse leggi marginali.
61

Usando l’incorrelazione fra X e Y , troviamo:
Cov(X,X + Y ) = V ar(X) +Cov(X,Y ) = 1 + 0 = 1
V ar(X + Y ) = V ar(X) + 2Cov(X,Y ) + V ar(Y ) = 1 + 1 = 2
V ar(Xp2) = 2, Cov(X,X
p2) =
p2V ar(X) =
p2,
da cui
Σ(X,X+Y ) =1 11 2
, Σ(X,X√2) =
1p2p
2 2.
Le leggi marginali si leggono nelle varianze (nella diagonale principale): nel primo caso
X » N(0; 1), X + Y » N(0; 2)
Nel secondo caso:X » N(0; 1), X
p2 » N(0; 2) 4
Gli stessi calcoli si possono effettuare per via matriciale: sussiste infatti la proposizione:
PROPOSIZIONE Se X = (X1, ...Xn)T e un vettore gaussiano con matrice di varianza
ecovarianza ΣX , e se A e una matrice n £ n, allora il vettore trasformato Y = AX egaussiano con matrice di varianza e covarianza
ΣY = AΣXAT .
DIM. - Sia Y = AX, con (A)i,j = aij . Allora
Yi =j
ai,jXj
Quindi in riga i e colonna k di ΣY troviamo:
Cov(Yi, Yk) = Cov(j
ai,jXj ,m
ak,mXm) =
= aijakmCov(Xj ,Xm) = aijσjmakm = (AΣAT )i,k. 4
Quindi, nell’esempio precedente, prima si evidenzia la matrice A della trasformazione(X,Y )! Z = (X,X + Y ):
Z =X
X + Y=
1 01 1
XY
´ A XY
62

poi si ottiene la matrice di varianza e covarianza:
ΣZ = A Σ(X,Y ) AT =
1 01 1
1 00 1
1 10 1
=
=1 11 2
TEOREMA - (Componenti principali di un vettore gaussiano X » N(μ;Σ). -Data un vettore aleatorio X » N(μ;Σ), con valori in Rn, la sua densita’ di probabilita’
congiunta f(x) e’ costante sull’ellissoide
fx 2 Rn : (x¡ μ)TΣ−1(x¡ μ) = c2gin Rn, essendo c una qualunque costante. Gli assi dell’ellissoide sono
§c λiei
dove (λi, ei) e’ una coppia di autovalore e autovettore della matrice di covarianza C(i = 1, .., n). Questi insiemi di livello sono detti gli ellissoidi della distribuzione nor-male n¡variata. La trasformazione in componenti principali
Y = GT (X ¡ μ)
muta le v.a. iniziali Xi in variabili Yi che sono indipendenti e normalmente distribuitecon media zero e varianza λi.
ProofLa matrice di varianza e covarianza Σ e’ simmetrica e definita positiva. Per il teorema
spettraleΣ = G L GT
dove L = Diag(λ1, ...,λn) e’ la matrice diagonale degli autovalori di Σ. e G e’ una ma-trice ortogonale le cui colonne sono i corrispondenti autovettori normalizzati. Mediante latrasformazione in componenti principali
y = GT (x¡ μ)
la forma quadratica di Σ si ricentra nell’origine e si diagonalizza:
(x¡ μ)TΣ(x¡ μ) ´i,k
σik(xi ¡ μi)(xk ¡ μk) =i
λiy2i
come anche quella di Σ−1:
(x¡ μ)T (Σ−1)(x¡ μ) ´i,k
(Σ−1)i,k(xi ¡ μi)(xk ¡ μk) =i
1
λiy2i
63

Quindi l’insieme di livello di f diventa
y :
n
i=1
1
λiy2i = c2g.
Questa e’ l’equazione di un ellissoide con semiassi di lunghezza cpλi. y1, ..., yn rappre-
sentano i diversi assi dell’ellissoide. La direzione degli assi e’ data dagli autovettori di Σperche’ y = GT (x¡μ) e’ una rotazione e G e’ ortogonale con colonne date dagli autovettoridi Σ. 4
ESEMPIO - DISTRIBUZIONE NORMALE BIVARIATA -
Avere una disciplina manifesta la capacita di dare il il giusto tempo a cio che e piu im-portante e il tempo giusto a cio che lo e di meno. Riflette le nostre profonde convinzioni.Non si identifica con un atteggiamento schematico (ora studio, ora pausa, ora studio).Vivere lo studio con disciplina comporta piuttosto concedere a noi stessi l’opportunita dicrescere, di dialtare gli orizzonti, di raffinare gli strumenti della nostra lettura e inter-rogazione del reale - cose che esigono inevitabilmente tempo, cura, passione, calma, con-centrazione, respiro sereno...
To obtain contours of a bivariate normal density we have to find the eigenvalues andeigenvectors of Σ. Suppose
μ1 = 5, μ2 = 8, Σ =12 99 25
.
Here the eiegnvalue equation becomes
0 = jΣ¡ λIj = det 12¡ λ 99 25¡ λ
= (12¡ λ)(25¡ λ)¡ 81 = 0.
The equation gives λ1 = 29.601, λ2 = 7.398. The corresponding normalized eigenvectorsare
e1 =.455.890
e2 =.890¡.455 .
The ellipse of constant probability density has center at μ = (5 , 8)T and axes §5.44 c e1and §2.72 ce2. The eigenvector e1 lies along the line which makes an angle ofcos−1(.455) = 62.92 with the X1 axis and passes through the point (5, 8) in the (X1,X2)plane. By principal component transformation y = GT (x¡ μ) ) where G = (e1, e2), theellipse has the equation
fy :n
i=1
1
λiy2i = c2g.
The ellipse as center at (y1 = 0, y2 = 0) and axes §c ¢ pλifi where fi, i = 1, 2, arethe eigenvectors of L = Diag(λ1,λ2). In terms of the new co-ordinate axes Y1, Y2, theeigenvectors are f1 = (1, 0)T , f2 = (0, 1)T . The lengths of the axes are c
pλi, i = 1, 2.
The axes Y1, Y2 are the Principal Components of Σ. 4
64

MATEMATICA APPLICATA E STATISTICA - - ESERCIZI
La disciplina dello studio ci consegna infine un ultimo grande segreto: imparare e sem-pre diventare discepoli di un maestro. Certo, l’apprendistato presso un maestro richiedeumilta, attenzione, pazienza, disponibilita, ma i benefici sono di gran lunga superioriall’impegno: perche i maestri sono coloro che ci insegnano ”come” - non semplicementeche cosa - pensare ( e vivere). Essi forgiano il nostro sguardo, il nostro modo di interrog-are la realta, di leggere un libro, di stendere una relazione. Il maestro non ti insegna unastrada. Ti insegna a leggere le mappe; se non ce ne sono, a costruirle.
1) Applicare la nozione classica di probabilita a semplici esperimenti aleatori.
1.A - Trova la probabilita che almeno due fra 14 persone abbiano lo stessa data dicompleanno.
R.] 0.223
1.B - In uno scaffale ci sono 10 libri, 3 di matematica e 7 di fisica; trova la probabilitache i 3 libri di matematica si trovino insieme.
R.] 6.66%
1.C - Un carattere e una lettera o una cifra. Una password e formata da 8 carattericol vincolo che almeno un carattere sia una cifra. a) Quante password possono esserci? b)Se vengono generati a caso 8 caratteri, e ogni carattere ha la stessa probabilita di essereuna delle 26 lettere o una delle 10 cifre, trova la probabilita che sia generata una passwordvalida.
[2.61 ¢ 1012; 0.925]
1.D - Un compilatore assegna ad ognuna delle variabili che intervengono in un pro-gramma una cella di memoria a caso, con indipendenza da una variabile all’altra. In caso diconflitto (cioe se due variabili sono assegnate alla stessa cella), l’ operazione di assegnazionedeve essere ripetuta. Se vi sono 100 celle di memoria e 4 variabili, qual e la probabilitache si verifichi almeno un conflitto?
R.] 5.89%
1.E - a) Un programma deve usare 8 processori fra A1, ..., A10. Trova la proba-bilita che venga usato il processore A1. b) Il programma deve usare 8 processori fraA1, ..., A30. Trova la probabilita che vengano usati esattamente due processori tra i pro-cessori A1, A2, A3, A4.
a) [4/5] b) 0.24
2) Applicare i teoremi sulla probabilita di una unione, di probabilita com-posta, delle probabilita totali, di Bayes.
65

2.A - Un sistema antincendio ha due congegni di attivazione. Il primo ha affidabilita0.9, cioe quando c’e il fuoco si attiva con probabilita 0.9. Il secondo, che lavora indipenden-temente, ha un’affidabilita 0.8. Se almeno uno dei congegni si attiva, il sistema funziona.Se si sviluppa il fuoco, trova la probabilita: a) che il sistema funzioni; b) che il sistema nonfunzioni; c) che ambedue i congegni si attivino; d) che solo il primo congegno si attivi.
[0.98; 0.02; 0.72; 0.18]
2.B - Un lotto di 10 componenti ne contiene 3 che sono difettose. Vengono estrattesenza rimessa due componenti. Sia D1 l‘evento per cui la prima e difettosa. Sia D2 l’eventoper cui la seconda e difettosa. Trovare: a) P (D2jD1) ; b) P (D1 \D2); c) P (DC
1 \D2) ;d) P (D2).
[2/9; 1/15; 7/30; 3/10]
2.C - Uno studente studia con probabilita 1/2. Gli viene presentato un quiz con 4risposte possibili. Se ha studiato da’ certamente la risposta esatta, se non ha studiatosceglie a caso una delle 4 risposte. Supponiamo che abbia dato risposta esatta: con cheprobabilita ha studiato davvero?
R.: 0.8
2.D - Un gene e composto di due alleli, ciascuno puo essere di tipo A oppure a. Nellapopolazione vi sono 3 tipi di individui: di tipo AA, Aa, e aa. Ciascun genitore trasmetteal figlio uno dei due alleli scelto a caso. Sapendo che inizialmente le proporzioni dei tretipi sono
AA :1
3Aa :
1
5aa :
7
15
quali saranno le proporzioni del tipo AAI , del tipo AaI , del tipo aaI alla generazionesuccessiva?
[ AAI : 0.1878 AaI : 0.4910 aaI : 0.3211 ]
2.E - In una regione una malattia colpisce il 5 per mille della popolazione. Un test eaffidabile con probabilita 0.99 tanto sui sani quanto sui malati [cioe: per un malato il teste postivo con probabilita 99%; per un sano il test e negativo con probabilita 0.99]. a)Se il risultato di una persona e positivo, trova la probabilita che la persona sia realmentemalata. b) Se il risultato e negativo, trova la probabilita che la persona sia in realtamalata.
[a) 0.332; b) 5.08 ¢ 10−5 ]2.F - In una regione una malattia colpisce il 4 per mille della popolazione. Un test e
affidabile con probabilita 0.94 sui sani e 0.88 sui malati [cioe: per un malato il test e postivocon probabilita 88%; per un sano il test e negativo con probabilita 0.94]. Assumiamo chei test ripetuti siano indipendenti. Se due test su una persona sono risultati positivi, trovala probabilita che la persona sia malata.
[0.46]
66

2.F - Il gruppo sanguigno A puo donare ai gruppi A, AB. Il gruppo B puo donare aigruppi B, AB. Il gruppo AB puo donare solo al gruppo AB. Il gruppo O puo donare atutti. Supponiamo che in una regione le proporzioni siano: per il gruppo A il 21%; per ilgruppo B il 43%; per il gruppo AB il 10%; per il gruppo O il 26%. Trova: a) la probabilitache un donatore a caso possa donare il sangue a una persona a caso; b) la probabilita che,se un donatore puo’ donare a un altro, allora quel donatore sia del gruppo B.
[0.563; 0.405]
2.G - L’urna I contiene 5 palline bianche e 9 palline rosse. L’urna II contiene 7 pallinebianche e 4 rosse. Una pallina e estratta dall’urna I e, senza osservare il colore, viene messanell’urna II. Poi viene estratta una pallina dall’urna II. Trova la probabilita che la primaestratta sia rossa, sapendo che la seconda estratta sia bianca.
[ 0.612]
3) Uso delle principali variabili aleatorie discrete e assolutamente continue.
3.A - Il numero X di difetti di un certo prodotto e 0, 1, 2, 3 con rispettive probabilita:
P (X = 0) = 0.38, P (X = 1) = 0.29, P (X = 2) = 0.20, P (X = 3) = 0.13
a) Trova la varianza di X; b) trova i valori della standardizzata di X.
[a) σ2 = 1.09, σ = 1.04; b) (¡1.03; ¡0.076; 0.88; 1.84) ]
3.B - Una ditta chimica vende un certo solvente in fusti da 10 Kg. Il numero X di fustiacquistati da un cliente a caso e una v.a. discreta con la seguente funzione di ripartizione:
per x = 1, 2, 3, 4, 5, F (x) = 4/10, 6/10, 8/10, 9/10, 1.
Inoltre chiamiamo Y il numero di Kg acquistati. Trova: a) il numero medio di fustiacquistati; b) la varianza del numero di Kg acquistati.
[a) μX = 2.3; b) σ2Y = 181 ]
3.C - Una v.a. X ha funzione densita di probabilita
f(x) =
⎧⎪⎨⎪⎩h, 1 < x < 3
2h, 3 < x < 6
h, 6 < x < 8
Trova: a) il valore h che rende f una densita di probabilita; b) la funzione di ripartizionedi X; c) il quantile 0.88 di X; d) il quantile 0.50 (”mediana”).
67

[a) 1/10;
b) F (x) =
⎧⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎩
0, x · 1(x¡ 1)/10, 1 < x < 3210 +
210 (x¡ 3), 3 < x < 6
810 +
110 (x¡ 6), 6 < x < 8
1, x ¸ 8c) 6.8 d) 4.5 ]
3.D - Per le nevicate in una certa regione, il numero X di cm di neve e una v.a. condensita di probabilita del tipo:
f(x) =
⎧⎪⎨⎪⎩c ¢ x, 0 · x · 5¡c ¢ (x¡ 10), 5 < x · 100, altrove
Trova: a) il fattore c di normalizzazione; b) la funzione di ripartizione di X; c) il 40-mopercentile di X.
[a) 1/25;
b) F (x) =
⎧⎪⎪⎪⎨⎪⎪⎪⎩0, x < 0x2
50 , 0 · x < 51025x¡ x2
50 ¡ 1, 5 < x · 101, x > 10
c) 4.472 ]
3.E - Sia X una v.a. assolutamente continua con funzione di ripartizione
F (x) =0, x < 0
1¡ e−x2 , x > 0
Trova: a) P (X > 0.8); b) la funzione densita di probabilita di X; c) il quantile 0.70 diX.
[ a) 0.52;
b) f(x) =0, x · 02xe−x
2
, x > 0
c) 1.09 ]
3.F - Una compagnia concede uno sconto sugli ordini che vengono pagati entro 30giorni. Su tutti gli ordini, il 10% riceve uno sconto. Si estraggono a caso 12 ordini. Trova:a) la probabilita che ricevano uno sconto meno di 4 sui 12; b) piu di 1 sui 12.
68

[ 0.974; 0.341 ]
3.G - Un’urna contiene 6 palline bianche e 10 rosse. Si estraggono 5 palline. Trovala probabilita che 2 o 3 siano rosse: a) se l’estrazione e con rimessa; b) se l’estrazione esenza rimessa.
[ 0.549; 0.618 ]
3.H - Un messaggio di 10 bit arriva o dalla sorgente A (con probabilita 1/3) o dallasorgente B (con probabilita 2/3); non puo’ venire in parte da A in parte da B. A mandai messaggi in modo che 1 ha probabilita 1/2 e 0 ha probabilita 1/2. Invece B manda imessaggi in modo che 1 ha probabilita 4/7 e 0 ha probabilita 3/7. Trova: a) la probabilitache in un messaggio ci siano 6 bit uguali ad 1; b) la probabilita che il messaggio venga daA, se il messaggio ricevuto contiene 6 bit uguali ad 1.
[0.2328; 0.2934 ]
3.I - Il numero medio di accessi a un sito web al minuto e 5. Trova la probablita chenei prossimi tre minuti ci siano esattamente 17 accessi.
[0.0847 ]
3.L - Diluendo latte in acqua distillata con fattore 10−1, 10−2, 10−3, 10−4 troviamo,dopo incubazione, sviluppo dei batteri; mentre troviamo sterile la diluizione con fattore10−5. Prendiamo 20 tubi con volume 1 cm3, e vi mettiamo la sospensione diluita confattore 10−4. Poniamo di trovare sterili 12 tubi su 20. Se il numero di batteri per cm3
e di Poisson, trovare: a) numero medio di batteri in un cm3 di sospensione diluita; b) ilnumero medio di batteri per cm3 di latte non diluito.
[ a) 0.51; b) 5100 ]
3.M - La probabilita che una lampadina bruci in un giorno e 0.1. Calcola la probabilitache essa bruci per la prima volta il 20-mo giorno del suo uso.
[ 0.0135 ]
3.N - I punteggi di un test di ammissione sono normalmente distribuiti, con media 480e varianza 8100. a) Se il peggior 25% dei candidati sara escluso, trova il minimo punteggioper essere ammessi. b) Se il miglior 12% dei candidati avra una borsa di studio, trova ilminimo punteggio per avere la borsa di studio.
[ a) ' 420 ; b) ' 586 ]
3.O - La concentrazione di zucchero per coltivare il penicillium deve essere circa 4.9mg/ml e, se eccede 6.0 mg/ml, il fungo muore e il processo deve essere fermato quel giorno.Trova la probabilita che il processo sia fermato: a) se la concentrazione di zucchero e’
69

normale con media 4.9 e varianza 0.36; b) se la concentrazione di zucchero e’ normale conmedia 5.2 e deviazione standard 0.4.
[ 0.0336; 0.0228 ]
3.P - La durata di un circuito integrato ha una distribuzione esponenziale con mediapari a due anni. a) Trova la probabilita’ che il circuito almeno (¸) 3 anni; b) se il circuitoe’ gia’ durato 4 anni, trova la probabilita’ che duri almeno (¸) altri 3 anni.
[ 0.223; 0.223 ]
4) Vettori aleatori, covarianza, indipendenza
4.A - Siano X,Y v.a. discrete con funzione di probabilita
f(1, 1) = 3/12 f(1, 2) = 1/12 f(1, 3) = 0f(2, 1) = 3/12 f(2, 2) = 0 f(2, 3) = 2/12f(3, 1) = 1/12 f(3, 2) = 1/2 f(3, 3) = 1/12
Trova: a) le medie di X, Y ; b) la covarianza di X,Y ; c) la varianza di (X + Y )
[ a) E(X) =23
12, E(Y ) =
5
3; b) Cov(X, Y ) =
2
9; c)
295
36]
4.B - Un vettore aleatorio (X,Y ) ha la densita congiunta:
f(x, y) = c ¢ e−(x+y)I(0,+∞)(x)I(x,+∞)(y)
dove c e la solita costante opportuna. a) Trova c; )¯trova le densita marginali di X,Y .
Sono v.a. indipendenti? ; c) trova P (X > Y ¡ 1)
[ c = 2; fX(x) = 2e−2xI(0,+∞)(x); fY (y) = 2e−2y(ey¡1)I(0,+∞)(y); P (X > Y¡1) = e¡ 1
e]
4.C - Una lampada e composta da 2 lampadine. La durata X di una lampadina,misurata in ore, e normale di media 800 e varianza 104. La durata Y dell’altra lampadinae normale di media 900 e varianza 22500. Le durate sono indipendenti. Trova: a) laprobabilita che la seconda duri 200 ore piu della prima. b) Si decide di usare la primalampadina e, quando questa brucia, di usare la seconda: trova la probabilita che la duratatotale sia maggiore di 2000 ore.
[ a) 0.2912 b) 0.0485 ]4.D - Due giovani decidono di incontrarsi tra le 17 e le 18 con l’accordo che nessuno
deve aspettare l’altro per piu di 10 minuti. Supponiamo che gli orari X ed Y in cui arrivanosiano indipendenti e uniformi. Trovare la probabilita che si incontrino.
70

[11/36 ]
4.E - Due v.a. discrete, X,Y , hanno funzione di probabilita congiunta:
Y 15 16X129 0.15 0.10130 0.10 0.20131 0.25 0.20
Trova: a) la media di X + Y ; b) E(XY ); c) la covarianza di X,Y .
a) μX + μY = 145.7; b) 2018.1 c) Cov(X,Y ) = E(XY )¡ μxμY = 0.
4.F - Due atleti arrivano al traguardo di una corsa in istanti X, Y indipendenti. L’unoarriva in un istante casuale X fra le 16 e le 17. L’altro arriva in un istante casuale Y fra le16.15 e le 17. Trova: a) la probabilita che sia Y ¸ X; b) la probabilita che sia jY ¡Xj · 15.
[ a) P (Y ¸ X) = 0.625 b) P (jY ¡Xj · 15) = 60·45−302/2−452/260·45 = 0.458 ]
4.G - Un componente elettronico e formato da due elementi uguali in parallelo (cioenon funziona se ambedue han cessato di funzionare); ciascuno dei due a sua volta e formatoda due elementi in serie (cioe non funziona se almeno uno dei due non funziona). Questidue elementi in serie hanno tempo di vita esponenziale di parametri rispettivamente λ1 =2/10, λ2 = 1/10 e si assume l’indipendenza. Sia U il tempo di vita globale. Trova: a) lafunzione di ripartizione di U ; b) la densita di U ; c) la media di U .
[ a) FU (t) = (1¡ e−3t/10)2 ¢ I[0,∞)(t)b) fU (t) = (
610e−3t/10 ¡ 6
10e−6t/10) ¢ I[0,∞)(t)
c) E(U) = 2 ¢ 103 ¡ 106 = 5 ]
4.H - Un componente elettronico e formato da due elementi in serie (cioe non funzionase almeno uno dei due non funziona), il primo dei quali ha un tempo di vita distribuitoesponenzialmente con parametro 1/12. Il secondo elemento e a sua volta formato da dueelementi in parallelo (cioe non funziona se ambedue non funzionano), aventi tempo di vitaesponenziale rispettivamente con parametro 3/12 e 3/12. Si suppone l’indipendenza. SiaU il tempo di vita globale. Trova: a) la funzione di ripartizione di U ; b) la densita di U ;c) la media di U .
[ a) FU (t) = (1¡ 2 ¢ e−4t/12 + e−7t/12) ¢ I[0,∞)(t)b) fU (t) = (
812e−4t/12 ¡ 7
12e−7t/12) ¢ I[0,∞)(t)
c) E(U) = 2 ¢ 124 ¡ 127 = 4.286 ]
5) Approssimare correttamente la binomiale alla Poissoniana, la binomialealla normale, la somma di variabili i.i.d. alla normale.
71

5.A - Viene lanciata 100 volte una coppia di dadi equi contando quante volte esce lasomma ”sette”. Trova: a) la probabilita’ che esca piu’ di 20 volte; b) la probabilita’ cheesca da 14 a 20 volte (estremi compresi).
[0.152; 0.6508 ]
5.B - Il 20% di componenti prodotti e’ difettoso. Ogni spedizione comprende 400pezzi. Se una spedizione contiene piu’ di 90 pezzi difettosi, puo’ essere restituita. Trova:a) la probabilita’ che una data spedizione venga restituita; b) se in un particolare giornovengono fatte 500 spedizioni, la probabilita’ che 60 o piu’ di queste spedizioni venganorestituite.
[ 0.0951; 0.0344 ]
5.C - La compagnia aerea VOLAREBASSO sa che il 5% dei passeggeri prenotati nonsi presenta all’imbarco. Allora arrischia l’overbooking e per un volo di 300 posti accetta310 prenotazioni. Con che probabilita resteranno delle persone a terra?
[ 0.0594 ]
5.D - Sia X una v.a. esponenziale di parametro λ = 2. a) Trova media e varianza diX. b) Siano X1, ...,X150 150 v.a. indipendenti e identicamente distribuite, Xi » exp(2).Poni S = X1 + ...+X150. Calcola approssimativamente P (S < 85).
[ μ = 1/2, σ2 = 1/4; P (S < 85) ' 0.948 ]
5.E - Il tempo di sopravvivenza di una lampada e v.a. esponenziale di media μ = 10giorni. Appena si brucia, essa e sostituita. a) Trova la probabilita che 40 lampade sianosufficienti per un anno. b) Trova quante lampade occorrono per tenere accesa la luce perun anno con probabilita 0.90.
[ 0.71; 46 ]
5.F - Un calcolatore addiziona un milione di numeri e in ognuna di queste addizionisi effettua un errore di arrotondamento; supponiamo che i singoli errori siano indipendentie abbiano distribuzione uniforme su [¡ 1
210−10, 1210
−10] (cioe supponiamo che la decimacifra decimale sia significativa). a) Qual e’ la deviazione standard del singolo errore? b)Qual e la probabilita che l’errore finale sia inferiore in valore assoluto a 1
210−7? (cioe qual
e la probabilita che la settima cifra decimale sia significativa?)
[2.88 ¢ 10−11; 0.92]
5.G - Un corpo ha 5000 atomi di una sostanza radioattiva. Ogni atomo decade in unminuto con probabilita 0.0004. Sia X il numero di atomi che decadono in un minuto. a)Trova la probabilita che decadano almeno 3 atomi. b) Se il corpo ha 5 ¢ 106 atomi dellasostanza radioattiva, trova la probabilita che decadano da 1980 a 2020 atomi.
72

[ a) 0.3233 b) 0.35 ]
5.H - Una certa lotteria istantanea ha probabilita di vincita 0.01 per singolo biglietto.Si domanda: a) la probabilita che fra 300 biglietti tale vincita si verifichi 2 o 3 volte; (b)la probabilita che fra 30000 biglietti quella vincita si verifichi da 295 a 310 volte (estremiinclusi)
[0.44; 0.35]
5.I - Supponiamo che un ubriaco disti duecento passi da casa, ma riesca solo a fare, ogniunita di tempo, un passo di avvicinamento con probabilita 1/2 o un passo di allontanamentocon probabilita 1/2. Quanti passi deve fare per avere probabilita 20% di arrivare a casa?
[56690]
6) Calcolo della legge di una funzione di una o piu’ variabili aleatorie.
6.A - Sia X una v.a. normale con media 0 e varianza 5. Sia Y = jXj. Trova: a) ladensita di probabilita di Y ; b) la media di Y.
[a)fY (y) =2√5√2πe−y
2/10 ¢ I[0,∞)(y) ; b)RjxjfX(x)dx = ... = 10/π. ]
6.B - Sia X una v.a. esponenziale con parametro 1/5. Sia Y =pX. Trova la densita
di probabilita di Y
[ fY (y) =25 ¢ ye−y
2/5 ¢ I[0,∞)(y). ]
6.C - Sia X una v.a. normale di media 0 e varianza 3. Trova la densita di probabilitadi Y = X10.
[ fY (y) =e−y
1/5/6
5√6π·y9/10 ¢ I[0,∞)(y). ]
6.D - Sia X una v.a. con densita di probabilita fX(x) =1252 x
2 ¢ e−5x ¢ I[0,∞)(x). SiaY = 1/X. Trova la densita di probabilita di Y.
[ fY (y) =1252 y−4 ¢ e−5/y ¢ I[0,∞)(y). ]
6.E - Sia X una v.a. normale con media 2 e varianza 20, e sia
Y = max(0,X) =X, X > 0
0, X · 0
Calcola: a) P (Y · 0), P (Y < 0); b) la funzione di ripartizione di Y .
[ a) P (Y · 0) = 0.330, P (Y < 0) = 0
73

b) FY (t) = P (Y · t) =
⎧⎪⎨⎪⎩0, t < 0
0.330, t = 0
FX(t), 8t > 0.]
6.F - Sia X una v.a. uniforme sull’intervallo (¡π/6, π/6). Sia Y = tan(X). Trova: a)la densita di probabilita di Y usando il teorema fondamentale; b) la funzione di ripartizionee la densita di probabilita di Y usando un metodo diretto.
[a) fY (y) =fX(x)
jg (x)j ¢ IV (y) = ... =3
π(1 + y2)¢ I(− 1√
3, 1√
3)(y) ].
b) FY (y) = P (X · arctan(y)) = ... =
⎧⎪⎨⎪⎩0, y < ¡ 1√
3
3π (arctan(y) +
π6 ), ¡ 1√
3· y < 1√
3
1, y ¸ 1/p3.
fY (y) =d
dyFY (y) =
3π(1+y2) , ¡ 1√
3< y < 1√
3,
0, altrove.
6.G - Sia X uniforme in [0, 1]. Trova la funzione di ripartizione della v.a. Y =max(X, 1¡X).
[ FY (t) =
⎧⎪⎨⎪⎩0, t < 1
2
2t¡ 1, 12 · t < 1,
1, t ¸ 1.]
7) Calcolo di densita condizionata, media condizionata.
7.A - Il vettore (X, Y ) ha una densita congiunta
fX,Y (x, y) =6
5(x2 + y)I[0,1]×[0,1] =
65 (x
2 + y), (x, y) 2 [0, 1]£ [0, 1]0, altrove
Trova: a) la densita condizionata di X data Y ; b) la media condizionata di X sapendoY = y.
[ fX|Y (xjY = y) = 3(x2 + y)
(1 + 3y); E(XjY = y) = 3
4(1 + 3y)+
3y
2(1 + 3y), 0 < y < 1.
74

7.B - Siano X,Y v.a. assolutamente continue con densita congiunta
fX,Y (x, y) = (x+ y) ¢ I(0,1)×(0,1)(x, y).
Trova: a) la funzione densita marginale di X; b) la funzione densita condizionata di Ydata X; c) la media condizionata di Y sapendo che X = 3
4 .
a) fX(x) = (x+12 ) ¢ I(0,1)(x) ;
b) fY |X(yjx) =(x+ y) ¢ I(0,1)2(x, y)
(x+ 12 )
;
c) E[Y jX =3
4] =
1
0
y ¢ fY |X(yj34)dy = ... = 0.566
7.C - Un’apparecchiatura ha un tempo di vita Y che segue una legge esponenziale diparametro x che dipende dalla qualita di uno dei materiali impiegati. Ma nel processo diproduzione x non e sotto controllo, e si assume distribuito come una v.a. esponenziale diparametro 2.
Trova: a) la densita marginale di Y ; b) la densita condizionata di X data Y .
[ fX,Y = fY |X ¢ fX = ... = 2x ¢ e−x(y+2) ¢ IR+×R+(x, y) ]
a) fY = fX,Y dx = ... =2
(2+y)2 ¢ IR+(y)
b) fX|Y =fX,YfY
= ... = x(y + 2)2e−x(y+2) ¢ IR+(x).
7.D - La densita congiunta di (X,Y ) e
f(x, y) =3x ¢ e−x(3+y), x, y > 00 altrove
Trova: a) la densita merginale di Y ; b) la densita condizionata di X data Y .
a) fY (y) = fX,Y dx = ... =3
3+y)2 ¢ IR+(y)
b) fX|Y (xjy) = fX,Y (x,y)fY (y)
= x(3 + y)2e−x(3+y) ¢ IR+(x). ]
7.E - Ogni anno un tipo di macchina deve essere sottoposto ad alcuni arresti per manuten-zione. Questo numero di arresti X e v.a. di Poisson con parametro y. Ma anche y ealeatorio (ad es. puo dipendere dalla macchina) e assumiamo che esso segua una legge
fY (y) = 3e−3y, y > 0; fY (y) = 0, y < 0
Trova: a) la probabilita che una singola macchina sia sottoposta a 3 arresti in un anno b)la miglior stima di y sapendo che ci sono stati k arresti.
75

a) P (X = k) ´ fX(k)(k) = ∞0 fX,Y (k, y)dy = ..., da cui fX(3) = 0.0117.
b) fY |X=k =fX,YfX(k)
= ..., da cui E(Y jX = k) = (k + 1)/4.
7.F - La densita di probabilita congiunta delle v.a. X ed Y e
fX,Y (x, y) =8xy, 0 · x · 1, 0 · y · x0, altrove.
Determina la media condizionata di Y sapendo che X = 12 .
[ 0.33 ]
8) Vettori aleatori gaussiani.
8.A - Il vettore gaussiano (X,Y, Z) ha le tre medie nulle e ha matrice di covarianza⎛⎝ 1 0 1/50 1 ¡1/41/5 ¡1/4 3
⎞⎠Sia U la v.a. ottenuta proiettando (X,Y, Z) nella direzione d = (0, 1√
2, 1√
2). Trova la
probabilita che sia U ¸ 0.9.[ 0.24 ]
8.B - Siano X1,X2 variabili N(0; 1) indipendenti. a) Trova la matrice di covarianzadi
Y1 = X1 ¡X2Y2 = X1 +X2
[ ΣY =2 00 2
]
8.C - Siano X1 » N(0; 1), X2 » N(0; 4) e indipendenti. Trova la matrice di varianzae covarianza di
Y1 = 3X1 ¡X2Y2 = X1 + 5X2
[ ΣY =13 ¡17¡17 101
]
8.D - Si sa che un segnale X segue una legge normale N(0, 1), ma non e osservatodirettamente. Cio che si osserva e una misurazione Y = X +W , dove W e un errore che
76

segue una legge N(0,σ2) con σ2 = 0.1, ed inoltre e indipendente da X. Calcola la matricedi varianza e covarianza di (X,Y ).
[1 11 1.1
]
8.E - Una vettore aleatorio gaussiano (X1, X2) ha vettore delle medie μ = (5, 8) ematrice di covarianza
C =12 99 25
.
Sia (Y1, Y2) il vettore aleatorio ottenuto da (X1,X2) con la trasformazione in componentiprincipali. a) Trova le varianze di Y1, Y2; b) trova i versori del riferimento proprio diY1, Y2.
[ a) σ2Y1 = 29.6, σ2Y2 = 7.40 ]
[ b) e1 = (0.455, 0.890), e2 = (0.890,¡0.455) ]
77





























