Embed Size (px)
Citation preview

Capítulo 5
Inferência no Modelo de Regressão Simples: Estimação
de Intervalos, Teste de Hipóteses e Previsão

Hipóteses do Modelo de Regressão Linear Simples
1 2t t ty x e RS1.
RS2.
RS3.
RS4.
RS5.
RS6.
( ) 0tE e 1 2( )t tE y x
2var( ) var( )t te y
cov( , ) cov( , ) 0i j i je e y y
não é variável aleatória e assume pelo menos dois valores distintos
tx
2~ (0, )te N
2
1 2~ [( ), ]t ty N x
(opcional)

Do Capítulo 4
2 2
1 1 2
2
2 2 2
~ ,( )
~ ,( )
t
t
t
xb N
T x x
b Nx x
2
2ˆ
ˆ2
te
T
Este Capítulo introduz ferramentas adicionais da inferência estatística: estimação de intervalos, previsão, intervalos de previsão e testes de hipóteses.

5.1 Estimação de Intervalos
5.1.1 A Teoria
Obtemos, de b2 , uma variável aleatória normal padronizada, subtraindo sua média e dividindo o resultado pelo seu desvio padrão:
2 2
2
~ (0,1)var( )
bZ N
b
(5.1.1)
A variável aleatória padronizada Z é normalmente distribuída com média 0 e variância 1.

5.5.1a A Distribuição Qui-Quadrado
• Variáveis aleatórias com distribuição qui-quadrado surgem quando elevamos ao quadrado variáveis aleatória normais, N(0,1).
Se Z1, Z2 , ..., Zm denotam m variáveis aleatórias independentes N(0,1), então
2 2 2 2
1 2 ( )~m mV Z Z Z (5.1.2)
• A notação é lida como: a variável aleatória V tem uma distribuição qui-quadrado com m graus de liberdade.
2
( )~ mV

2
( )
2
( )
[ ]
var[ ] var 2
m
m
E V E m
V m
(5.1.3)
• V não deve ser negativa, v 0 • A distribuição tem uma longa calda, ou é assimétrica à direita. • À medida que os graus de liberdade m aumentam, a distribuição se torna mais simétrica e com o forma de um “sino”. • À medida que m aumenta, a distribuição qui-quadrado converge para (e essencialmente se torna) uma distribuição normal.

5.5.1b A distribuição de probabilidade de 2
• O termo de erro aleatório et tem uma distribuição normal, 2~ (0, )te N
• Padronize a variável aleatória dividindo-a pelo seu desvio padrão, de tal forma que
/ ~ (0,1)te N2 2
(1)( / ) ~te •
• Se todos os erros aleatórios são independentes, então
2 2 2 2
21 2( )~t TT
t
e e e e
(5.1.4)
• V não tem uma distribuição porque os resíduos de mínimos quadrados não são variáveis aleatórias independentes.
2
( )T

• Todos resíduos T , , dependem dos estimadores de mínimos quadrados b1 e b2. Isso pode ser mostrado pelo fato de apenas T2 dos resíduos de mínimos quadrados serem independentes no modelo de regressão linear simples.
1 2t t te y b b x
22
( 2)2
ˆ( 2)~ T
TV
• Nós não estabelecemos que a variável aleatória qui-quadrado V é estatisticamente independente dos estimadores de mínimos quadrados, mas agora afirmamos que é.

5.1.1c A Distribuição t
• Uma variável aleatória “t” (minúscula) é formada pela divisão de uma variável aleatória normal padronizada, Z~N(0,1), pela raiz quadrada de uma variável aleatória independente qui-quadrado, , que é dividida por seus graus de liberdade, m.
2
( )~ mV
Se Z ~ N(0,1) e , e se Z e V são independentes, então
2
( )~ mV
( )~ m
Zt t
Vm
(5.1.7)
• O formato da distribuição t é completamente determinada pelos graus de liberdade, m, e a distribuição é representada por t(m). • A distribuição t tem um “pico menos agudo” e é mais dispersa do que a N(0,1).

• A distribuição t é simétrica, com média E[t(m)]=0 e variância var[t(m)]=m/(m2).
• À medida que os graus de liberdade m, a t(m) distribuição se aproxima de uma normal padronizada, N(0,1).
5.1.1d Um Resultado Chave
2 2
2
2
2 2
2 2
2 2
2 2 2 2
22
( )
ˆ ˆ( 2)2
( )2
ep( )ˆvar( )
t
t
b
x xZ bt
V TT
x xT
b b
bb
(5.1.8)
A distribuição t escrita em
função do parâmetro beta.

5.1.2 Obtenção de Estimativas de Intervalo
Se as hipótese RS1-RS6 do modelo de regressão linear simples são mantidas, então:
( 2)~ , 1,2ep( )
k kT
k
bt t k
b
(5.1.9)
Para k=2
2 2( 2)
2
~ ep( )
T
bt t
b
(5.1.10)
Em que:
2
2 2 22
ˆˆ ˆvar( ) e ep( ) var( )
( )t
b b bx x
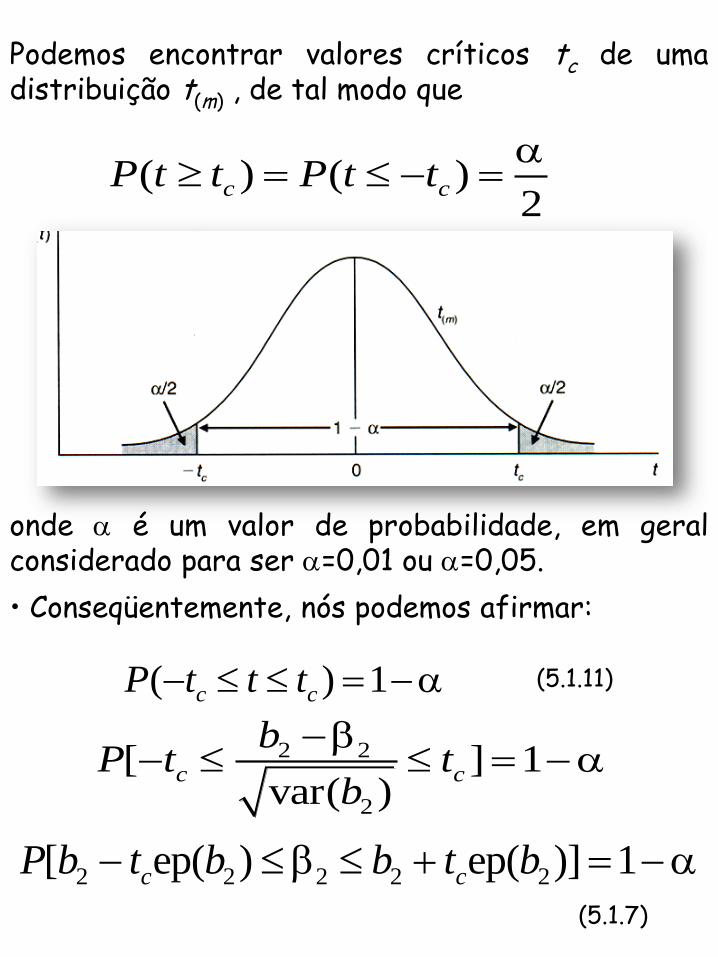
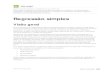
Podemos encontrar valores críticos tc de uma distribuição t(m) , de tal modo que
( ) ( )2
c cP t t P t t
onde é um valor de probabilidade, em geral considerado para ser =0,01 ou =0,05.
• Conseqüentemente, nós podemos afirmar:
( ) 1c cP t t t (5.1.11)
2 2
2
[ ] 1var( )
c c
bP t t
b
2 2 2 2 2[ ep( ) ep( )] 1c cP b t b b t b
(5.1.7)
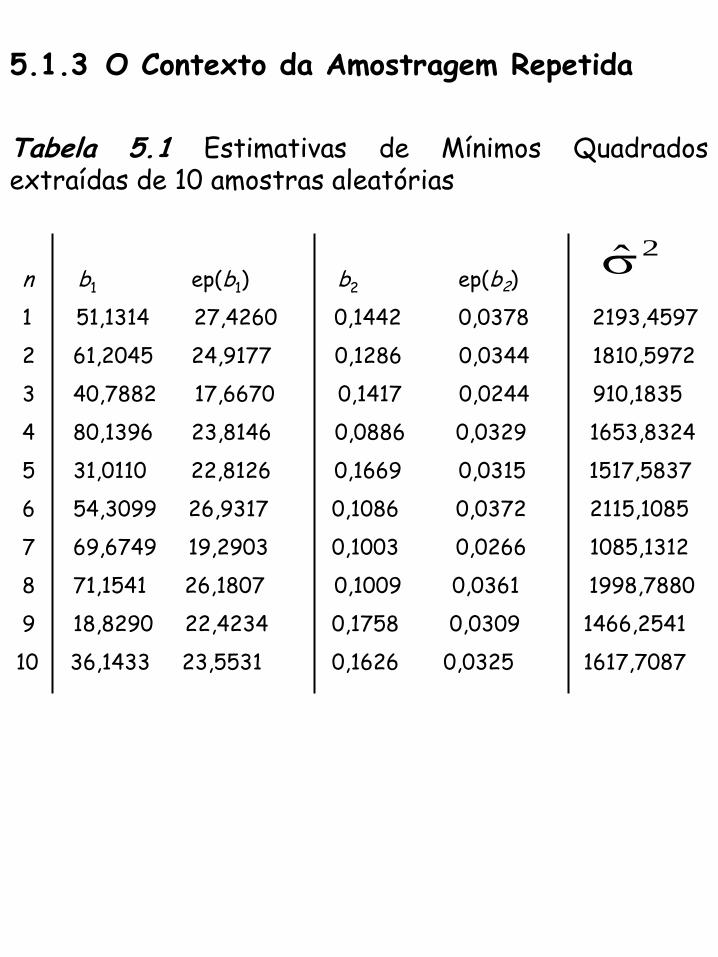
5.1.3 O Contexto da Amostragem Repetida
Tabela 5.1 Estimativas de Mínimos Quadrados extraídas de 10 amostras aleatórias
n b1 ep(b1) b2 ep(b2)
1 51,1314 27,4260 0,1442 0,0378 2193,4597
2 61,2045 24,9177 0,1286 0,0344 1810,5972
3 40,7882 17,6670 0,1417 0,0244 910,1835
4 80,1396 23,8146 0,0886 0,0329 1653,8324
5 31,0110 22,8126 0,1669 0,0315 1517,5837
6 54,3099 26,9317 0,1086 0,0372 2115,1085
7 69,6749 19,2903 0,1003 0,0266 1085,1312
8 71,1541 26,1807 0,1009 0,0361 1998,7880
9 18,8290 22,4234 0,1758 0,0309 1466,2541
10 36,1433 23,5531 0,1626 0,0325 1617,7087
2
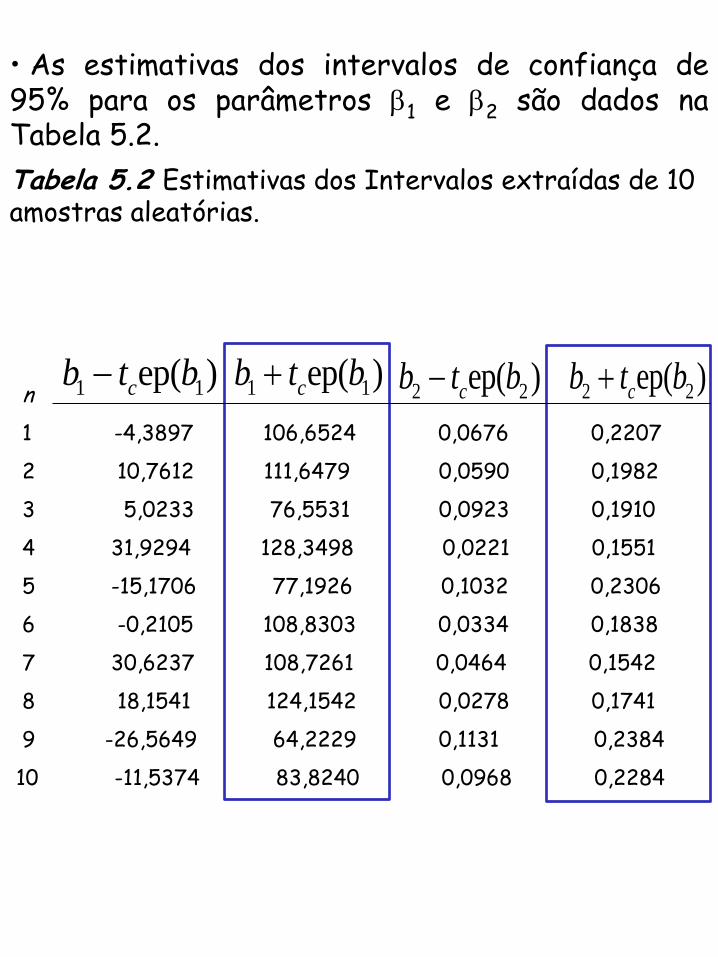
• As estimativas dos intervalos de confiança de 95% para os parâmetros 1 e 2 são dados na Tabela 5.2.
Tabela 5.2 Estimativas dos Intervalos extraídas de 10 amostras aleatórias.
n
1 -4,3897 106,6524 0,0676 0,2207
2 10,7612 111,6479 0,0590 0,1982
3 5,0233 76,5531 0,0923 0,1910
4 31,9294 128,3498 0,0221 0,1551
5 -15,1706 77,1926 0,1032 0,2306
6 -0,2105 108,8303 0,0334 0,1838
7 30,6237 108,7261 0,0464 0,1542
8 18,1541 124,1542 0,0278 0,1741
9 -26,5649 64,2229 0,1131 0,2384
10 -11,5374 83,8240 0,0968 0,2284
1 1ep( ) cb t b 1 1ep( ) cb t b2 2ep( ) cb t b 2 2ep( ) cb t b

5.1.4 Uma Ilustração
• Para os dados das despesas com alimentação
2 2 2 2 2[ 2,024ep( ) 2,024ep( )]
0,95
P b b b b
(5.1.14)
• O valor crítico tc = 2,024, o qual é apropriado para = 0,05 e 38 graus de liberdade.
• Ele pode ser calculado com um pacote estatístico ou tabela própria.
• Para construir uma estimativa de intervalo para 2 , nós utilizamos a estimativa de mínimos quadrados b2 = 0,1283 , que tem um erro padrão
2 2ˆep( ) var( ) 0,0009326 0,0305b b
Um intervalo de confiança estimado de 95% para 2:
2 2ep( ) 0,1283 2,024(0,0305)=
= [0,0666;0,1900]
cb t b

5.2 Teste de Hipótese
Componentes dos Testes de Hipóteses
1. Uma hipótese nula, H0 2. Uma hipótese alternativa, H1 3. Um teste estatístico 4. Uma região de rejeição
5.2.1 A Hipótese Nula
A hipótese “nula”, que é denotada por H0 (H-zero), especifica um valor para um parâmetro. A hipótese nula pode ser escrita como , onde c é uma constante e é um importante valor no contexto de um modelo específico de regressão.
0 2:H c

5.2.2 A Hipótese Alternativa
Para a hipótese nula H0: 2 = c , três possibilidades de hipóteses alternativas são:
H1: 2 c. H1: 2 > c H1: 2 < c.
5.2.3 O Teste Estatístico
2 2( 2)
2
~ep( )
T
bt t
b
(5.2.1)
Se a hipótese nula H0: 2 = c é verdadeira, então:
2( 2)
2
~ep( )
T
b ct t
b
(5.2.2)
Se a hipótese nula não for verdadeira, então a estatística t na equação 5.2.2 não tem uma distribuição t com T2 graus de liberdade.

5.2.4 A Região de Rejeição
• O nível de significância do teste é usualmente escolhido como 0,01; 0,05 ou 0,10. • A região de rejeição é determinada ao encontrar os valores críticos tc tais como
( ) ( ) / 2c cP t t P t t
Regra de rejeição para um teste bicaudal: Se o valor da estatística do teste cair na região de rejeição, em qualquer uma das caudas da distribuição t, então nós rejeitamos a hipótese nula e não rejeitamos a alternativa.
• Os valores amostrais da estatística do teste na região central de não-rejeição são compatíveis com a hipótese nula e não constituem evidência contra sua veracidade.
• Encontrar um valor amostral da estatística do teste na região de não-rejeição não faz da hipótese nula uma hipótese verdadeira num sentido absoluto!
Se o valor da estatística do teste cair entre os valores críticos tc e tc, na região de não-rejeição, então nós não rejeitamos a hipótese nula.

5.2.5 O Exemplo da Despesa com Alimentação
Teste a hipótese nula que contra a alternativa que
2 0,10
2 0,10
, no modelo da despesa com alimentação.
Formato para o Teste de Hipóteses
1. Determine as hipóteses nula e alternativa. 2. Especifique a estatística do teste e sua
distribuição se a hipótese nula for verdadeira.
3. Selecione e determine a região de rejeição. 4. Calcule o valor amostral da estatística do
teste. 5. Faça sua conclusão.

Aplicação no exemplo da Despesa com Alimentação,
1. A hipótese nula é H0: 2 =0,10. A hipótese alternativa é H1: 2 0,10.
2. A estatística do teste , se a hipótese nula é verdadeira.
2( 2)
2
0,10~
ep( )T
bt t
b
3. Selecionando =0,05. O valor crítico tc é 2,024 para a distribuição t com (T 2) = 38 graus de liberdade.
4. Utilizando os dados da Tabela 3.1, a estimativa de mínimos quadrados de 2 é b2 = 0,1283, com erro padrão ep(b2)=0,0305. O valor da estatística do teste é
0,1283 0,100,93
0,0305t
5. Conclusão: como t=0,93 < tc=2,024, nós não rejeitamos a hipótese nula.

5.2.6 Erros do Tipo I e Tipo II
Nós tomamos a decisão correta se: • A hipótese nula é falsa e nós decidimos rejeitá-la. • A hipótese nula é verdadeira e nós decidimos não rejeitá-la.
Nossa decisão é incorreta se: • A hipótese nula é verdadeira e nós decidimos rejeitá-la (um erro do Tipo I) • A hipótese nula é falsa e nós decidimos não rejeitá-la (um erro do Tipo II)
Fatos sobre a probabilidade de cometer um erro do Tipo II:
• A probabilidade de cometer um erro do Tipo II varia inversamente ao nível de significância do teste, .
• Quanto mais perto estiver o valor verdadeiro do parâmetro do valor definido para ele na hipótese, maior a probabilidade de cometer um erro do Tipo II.
• Quanto maior o tamanho da amostra T, menor a probabilidade de ocorrência de erro do Tipo II, dado o nível de significância , que é a probabilidade de cometer erro do Tipo I.

5.2.7 O Valor-p do Teste de Hipótese
O valor-p do teste é calculado encontrando qual é a probabilidade da distribuição t tomar um valor igual ou maior do que o valor absoluto do valor amostral da estatística do teste.
Regra de rejeição para um teste bicaudal: quando o valor-p do teste de hipótese é menor do que o valor escolhido de , então o procedimento do teste leva a rejeição da hipótese nula.
• Se o valor-p for maior do que , nós não rejeitamos a hipótese nula. • No exemplo da despesa com alimentação, o valor-p para o teste de H0: 2 = 0,10 contra H1: 2 0,10 é p=0,3601, no qual é a área nas caldas da distribuição t(38), onde |t|0,9263
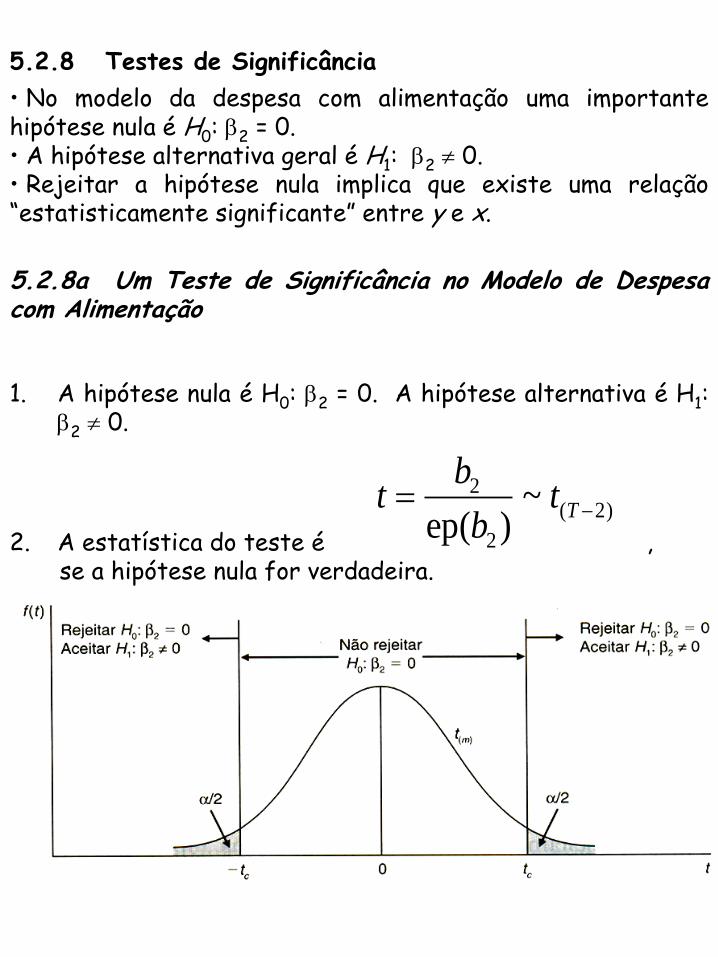
5.2.8 Testes de Significância
• No modelo da despesa com alimentação uma importante hipótese nula é H0: 2 = 0. • A hipótese alternativa geral é H1: 2 0. • Rejeitar a hipótese nula implica que existe uma relação “estatisticamente significante” entre y e x.
5.2.8a Um Teste de Significância no Modelo de Despesa com Alimentação
1. A hipótese nula é H0: 2 = 0. A hipótese alternativa é H1: 2 0.
2. A estatística do teste é , se a hipótese nula for verdadeira.
2( 2)
2
~ep( )
T
bt t
b
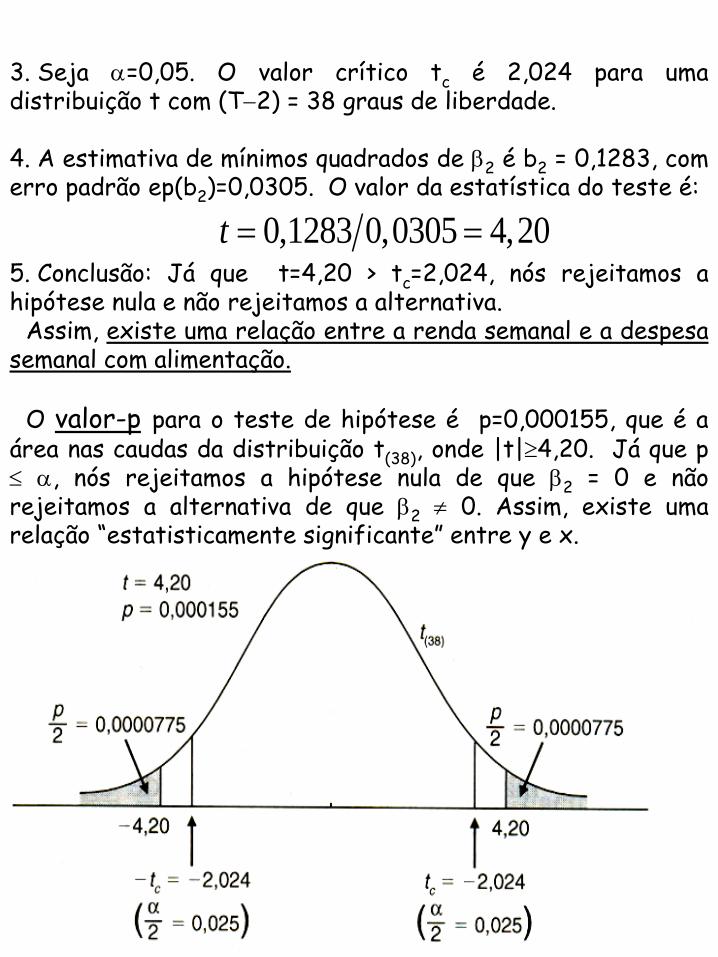
3. Seja =0,05. O valor crítico tc é 2,024 para uma distribuição t com (T2) = 38 graus de liberdade.
4. A estimativa de mínimos quadrados de 2 é b2 = 0,1283, com erro padrão ep(b2)=0,0305. O valor da estatística do teste é:
5. Conclusão: Já que t=4,20 > tc=2,024, nós rejeitamos a hipótese nula e não rejeitamos a alternativa.
Assim, existe uma relação entre a renda semanal e a despesa semanal com alimentação.
O valor-p para o teste de hipótese é p=0,000155, que é a
área nas caudas da distribuição t(38), onde |t|4,20. Já que p , nós rejeitamos a hipótese nula de que 2 = 0 e não rejeitamos a alternativa de que 2 0. Assim, existe uma relação “estatisticamente significante” entre y e x.
0,1283 0,0305 4,20t

Observação: “Estatisticamente significante”, contudo, não implica necessariamente em “economicamente significante”.
• Por exemplo, suponha que uma cadeia de supermercados planeja uma certa estratégia se .
2 0
• Adicionalmente, suponha que uma grande amostra de dados seja coletada, do qual se obtenha a estimativa b2 = 0,0001, com ep(b2) = 0,00001, produzindo a estatística t = 10,0.
• Nós rejeitaríamos a hipótese nula de que e não rejeitaríamos a alternativa de que . Onde b2 = 0,0001 é estatisticamente diferente de zero.
2 0
2 0
• Contudo, 0,0001 pode não ser economicamente diferente de zero e a cadeia de supermercados pode decidir pelo cancelamento da estratégia planejada.
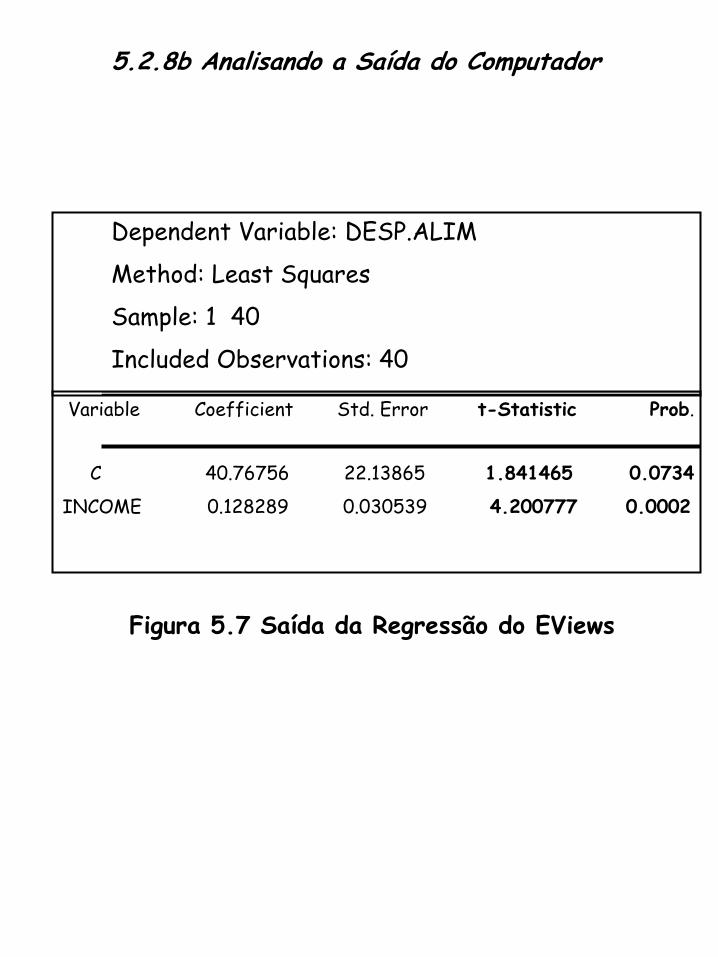
5.2.8b Analisando a Saída do Computador
Variable Coefficient Std. Error t-Statistic Prob.
C 40.76756 22.13865 1.841465 0.0734
INCOME 0.128289 0.030539 4.200777 0.0002
Dependent Variable: DESP.ALIM
Method: Least Squares
Sample: 1 40
Included Observations: 40
Figura 5.7 Saída da Regressão do EViews

5.2.9 Uma Relação entre os Testes de Hipóteses e a Estimação de Intervalos
•Existe uma relação algébrica entre testes de hipóteses bicaudais e estimativas de intervalos de confiança que em alguns casos é útil.
•Suponha que nós estamos testando a hipótese nula contra a alternativa . 0 : kH c 1 : kH c
•Se nós falharmos em rejeitar a hipótese nula ao nível de significância , então o valor c cairá dentro de um intervalo de (1)100% de confiança de k. •Inversamente, se nós rejeitarmos a hipótese nula, então c cairá fora do intervalo de (1)100% de confiança de k.
•Essa relação algébrica é verdadeira porque nós falhamos em rejeitar a hipótese nula quando
, ou quando
c ct t t
ep( )
kc c
k
b ct t
b
ep( ) ep( )k c k k c kb t b c b t b

5.2.10 Testes Unicaudais
• Testes unicaudais são utilizados para testar H0: k = c contra a hipótese alternativa H1: k > c, ou H1: k < c. • Para testar H0: k = c contra a alternativa H1: k > c, nós selecionamos a região de rejeição para valores da estatística do teste t que suportem a hipótese alternativa.
• Nós definimos a região de rejeição para valores de t maiores do que um valor crítico tc, extraído de uma distribuição t com T2 graus de liberdade, tal como ( )cP t t onde é o nível de significância do teste.
• A regra de decisão para um teste unicaudal é, “Rejeita-se H0: k = c e não se rejeita a alternativa H1: k > c se t tc.” Se t < tc, então nós não rejeitamos a hipótese nula. • O cálculo do valor-p está analogamente confinado a uma calda da distribuição

No exemplo da despesa com alimentação, teste H0: 2 = 0 contra a alternativa H1: 2 > 0.
1. A hipótese nula é H0: 2 = 0. A hipótese alternativa é H1: 2 > 0.
2. A estatística do teste é , se a hipótese nula for verdadeira.
2( 2)
2
~ep( )
T
bt t
b
3. Para o nível de significância =0,05, o valor crítico tc é 1,686 para uma distribuição t com T2=38 graus de liberdade.
4. A estimativa de mínimos quadrados de 2 é b2 = 0,1283, com erro padrão ep(b2) = 0,0305. Exatamente como no teste bicaudal, o valor da estatística do teste t é
0,12834,20
0,0305t
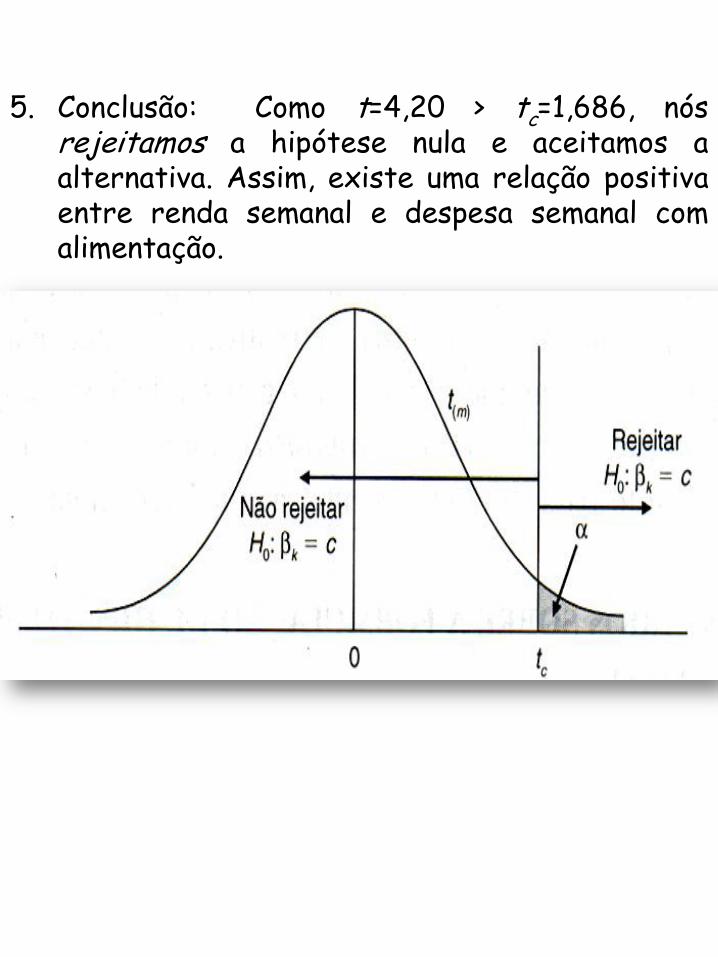
5. Conclusão: Como t=4,20 > tc=1,686, nós rejeitamos a hipótese nula e aceitamos a alternativa. Assim, existe uma relação positiva entre renda semanal e despesa semanal com alimentação.

5.2.11 Um Comentário na Construção das Hipóteses Nula e Alternativa
• A hipótese nula é geralmente escrita de tal modo que se nossa teoria estiver correta, então nós a rejeitaremos.
• Nós estabelecemos a hipótese nula para o caso de não existir relação entre as variáveis, H0: 2 = 0. Na hipótese alternativa, nós colocamos a conjuntura que nós gostaríamos de estabelecer, H1: 2 > 0.
• É importante estabelecer as hipóteses nula e alternativa antes de conduzirmos a análise da regressão.

5.3 O Previsor de Mínimos Quadrados
Nós queremos prever o valor da variável dependente y0, dado um valor da variável explanatória x0, o qual é dado por
0 1 2 0 0y x e (5.3.1)
onde e0 é um erro aleatório. Esse erro aleatório tem média E(e0)=0 e variância var(e0)= . Nós também assumimos que cov(e0, et)=0.
2
O previsor de mínimos quadrados de y0 é
0 1 2 0y b b x (5.3.2)

o erro de previsão é (f)
0 0 1 2 0 1 2 0 0
1 1 2 2 0 0
ˆ ( )
( ) ( )
f y y b b x x e
b b x e
(5.3.3)
O valor esperado de f é:
0 0 1 1 2 2 0 0ˆ( ) ( ) ( ) ( ) ( )
0 0 0 0
E f E y y E b E b x E e
(5.3.4)
Pode ser demonstrado que
22 0
0 0 2
1 ( )ˆvar( ) var( ) 1
( )t
x xf y y
T x x
(5.3.5)

A variância do erro de previsão é estimada pela substituição de pelo seu estimador , 2 2
22 0
2
1 ( )ˆ ˆvar( ) 1
( )t
x xf
T x x
(5.3.6)
A raiz quadrada da variância estimada é o erro padrão da previsão,
ˆvarep f f (5.3.7)
Conseqüentemente, nós podemos construir uma variável aleatória normal padronizada como
~ (0,1)var( )
fN
f(5.3.8)

Então,
( 2)~ep( )ˆvar( )
T
f ft
ff (5.3.9)
Se tc é um valor crítico da distribuição , tal que P(t tc) = /2, então
( 2)Tt
( ) 1c cP t t t (5.3.10)
Então,
0 0ˆ
[ ] 1ep( )
c c
y yP t t
f
Simplificando essa expressão, obtemos
0 0 0ˆ ˆ[ ep( ) ep( )] 1c cP y t f y y t f
(5.3.11)
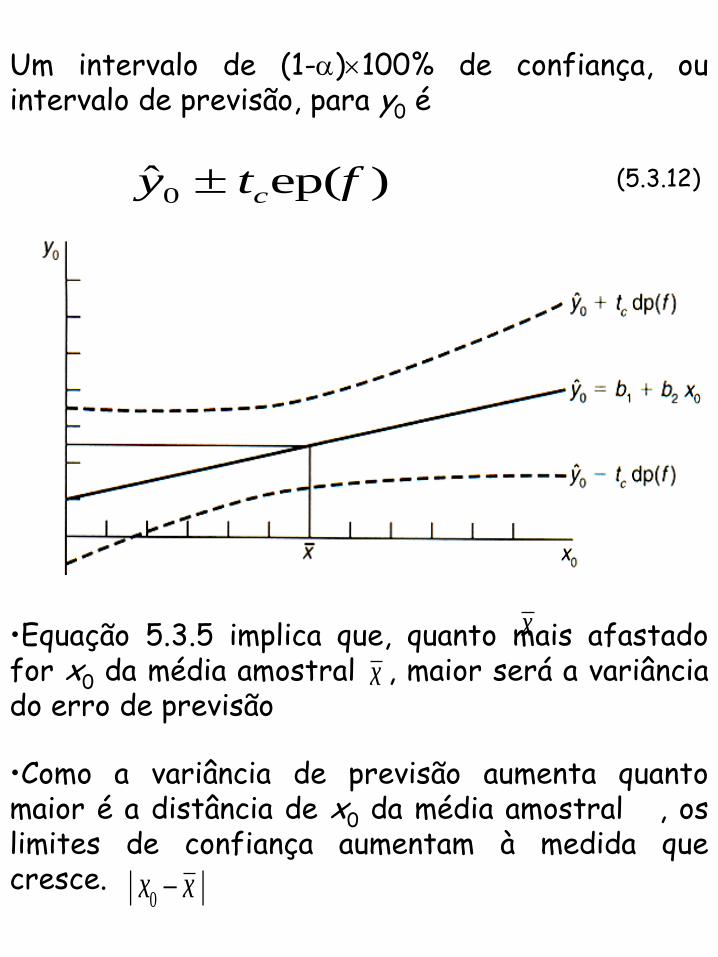
Um intervalo de (1-)100% de confiança, ou intervalo de previsão, para y0 é
0ˆ ep( )cy t f (5.3.12)
•Equação 5.3.5 implica que, quanto mais afastado for x0 da média amostral , maior será a variância do erro de previsão
x
•Como a variância de previsão aumenta quanto maior é a distância de x0 da média amostral , os limites de confiança aumentam à medida que cresce.
x
0| |x x

5.3.1 Previsão no Modelo da Despesa com Alimentação
A despesa semanal prevista com alimentação para um domicílio com renda semanal de x0 = $750 é
0 1 2 0ˆ 40,7676 0,1283(750) 136,98y b b x
A variância estimada do erro de previsão é
22 0
2
2
( )1ˆ ˆvar( ) 1
( )
1 (750 698)1429,2456 1 1467,4986
40 1532463
t
x xf
T x x
O erro padrão de previsão é então
ˆep( ) var( ) 1467,4986 38,3079f f

O intervalo de 95% de confiança para y0 é
0ˆ ep( ) 136,98 2,024(38,3079)
[59,44 a 214,52]
cy t f
• Nosso intervalo de previsão sugere que um domicílio com renda semanal de $750 gastará alguma coisa entre $59,44 e $214,52 com alimentação. • Um intervalo muito amplo significa que nosso ponto de previsão, $136,98, não é confiável. • Nós podemos melhorá-lo, mensurando o efeito de que outros fatores, além da renda, pode ter.