Embed Size (px)
Citation preview

Case study: Building bi-directional DR
Joep Piscaer, VMware vExpert, VCDX #101

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Introduction
Joep Piscaer ● Consulting Architect at OGD ict-diensten
● VMware VCDX5 #101, vExpert 2009, 2011, 2012
● Know Veeam since 2007 and in love with them ever since
(best. VMworld. parties. ever.)

Agenda
Introduction
Project goals, requirements and constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Project Goals
Replace current (cloud-based) DR solution ● RTO is weeks; all data needs to be replicated back to our site
● RPO is ∞; current solution doesn’t have all data (no OS-disks)
● Backups are not application-level consistent
Develop bi-directional DR for two separate infrastructures ● We have a internal IT infrastructure but also a cloud service provider
infrastructure; both are highly virtualized
‘Eat your own dogfood’ ● Use hard- and software we known implement at customers regularly

Project Requirements
RTO and RPO need to be improved ● RTO needs to be reduced from ‘weeks’ to ‘hours’
● RPO needs to be reduced from ‘∞’ to ‘a day’
Transactionally consistent application state
back-ups of mission critical and other VMs
Be able to restore individual application and file items but
also complete disks, virtual machines and clusters. ● Backup needs to be available locally for fast application item restores
● Backup needs to be available remotely for DR-purposes

Project Constraints
WAN link too slow to do initial seed ● During first months of project, WAN capacity was only 20 Mbit/s
After project completion, WAN capacity upped to 100 Mbit/s
● We used two 16x 1TB SuperMicro servers as temporary backup repository;
offline initial seed by physically swapping them
and mapping jobs to backup files
Due to ‘eat your own dogfood’, we could only use a very
limited set of products, including Veeam B&R

Customer Background
2 infrastructures on separate sites
About 25 hosts in 3 clusters
About 250 VMs total ● PXE-booted Citrix XenApp VMs (excluded from backup)
● Exchange and Zarafa groupware environments
− Additional scripts required to create consistent snapshots for Zarafa
● About 12 TB of data
About 1000 users overall

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Overview
Two Dell PowerEdge R510 servers with 24 GB RAM ● 12x 3TB nearline SAS disks in RAID-6 for 27 TB backup repository
● 4 gigabit NICs dedicated to iSCSI for direct SAN access
Two Veeam v6.0 consoles / installations
Distributed backup architecture ● Multiple proxies
● Multiple repositories
Enterprise Manager installed on one site

Overview
We leveraged ● Application-aware image processing
● Instant VM Recovery and vPower NFS
● Virtual Labs
● SureBackup

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A
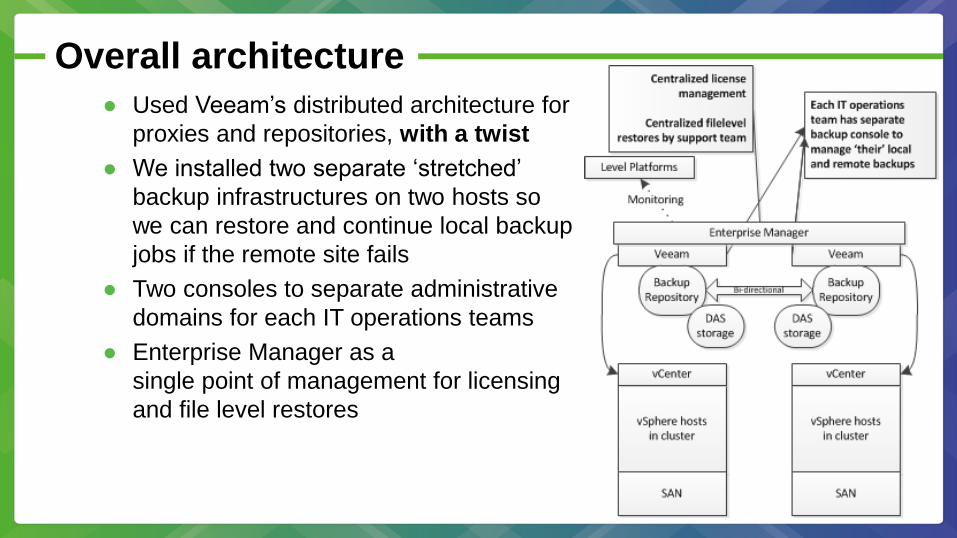
Overall architecture
● Used Veeam’s distributed architecture for
proxies and repositories, with a twist
● We installed two separate ‘stretched’
backup infrastructures on two hosts so
we can restore and continue local backup
jobs if the remote site fails
● Two consoles to separate administrative
domains for each IT operations teams
● Enterprise Manager as a
single point of management for licensing
and file level restores

Design Choices
Each host has one proxy;
Each host has two repositories ● One owned by the local console
● One owned by the remote console
Local SQL Express databases ● Size of environment didn’t require move to ‘full’ SQL Server
● Totally independent backup environment required
Use Application-aware image processing for consistency
Optimize all jobs for WAN replication

Job Type
We had no space available on primary SAN storage ● ‘Replication’ job type replicates from proxy to proxy, requires standby host
and can only store in native (VMX/VMDK) format on VMFS datastores
Therefore, we chose ‘regular’ job type ● We cannot replicate the local backup.
This means each VM would be touched twice every day:
once by the job that stores the VM on the local repository
once by the job that stores the VM on the remote repository

Deduplication and Compression
Compression set to ‘best’ for all jobs
Deduplication happens both at source ● before data is sent to repository, significantly improving performance
and at target ● to achieve additional reduction for jobs with multiple VMs
Block level deduplication optimized for WAN ● Using 256KB block size instead of default 1024KB size
If anything happens to target we can seed the locally stored
backups again using the two 16x 1TB SuperMicro servers
CBT is designed to handle such usage cases.

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Job Type
Advantages of Replication job type: ● Files stored in native VMware format
● Restores are parallel
● No need to choose between reverse and forward incremental
● No vPower NFS or Instant VM recovery needed
− VMs run at full I/O speed
− Number of VMs that can be powered on depends on infrastructure
no dependency on backup server
− No additional migration like Storage vMotion needed after recovery
● Advanced features like re-IP, failback available

Job Type
Pitfalls of using regular jobs: ● Files stored in Veeam file format; manual interaction required to restore
− This increases RTO and makes restores sequential
− Other solutions provide (semi-)parallel restores, keeping RTO down
● Need to make difficult choice between reversed and forward incremental
● Instant VM Recovery uses vPower NFS;
− recovered VMs will not run at full I/O speed
− affects number of VMs that can be powered on after total site failure
− Storage vMotion required to complete recovery of each VM
● No Re-IP and failback and other specific functionality
available in ‘Replication’ job type

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Backup Method
We chose ‘reverse incremental’: ● Uses the least amount of disk space to store backups
− We wanted to maximize retention for jobs stored on local repository.
We set retention for jobs stored on remote repository to two restore
point as these backups are only for DR-purposes
● Calculations to produce reverse incremental done on (remote) repository
− Full backup file is rebuilt every day on remote repository
− Our physical backup servers have enough oomph to handle 3x I/O load
− Minimize stress on WAN link; only changed blocks are sent over WAN
● Last backup is always full
− No periodic full needed
− Imagine replicating a full backup of every VM over WAN every week

Why not replicate the local backup?
Veeam’s distributed architecture supports this use case: ● Proxy and repository at local site for local backups
● Proxy at local site and repository at remote site for remote backups
No suitable Windows-based tool was found that does block
level replication ● None of the tools integrate with Veeam’s proxy architecture
and aren’t intelligent enough to understand the reverse incremental files
to do smart changed block replication
These tools take forever to create changed block indexes and begin
replication which has a very negative effect on RPO
● Didn’t want to use custom (Powershell) scripts
makes your solution harder to manage, upgrade and support

Evaluation of lessons learned
Re-evaluate job type: ‘regular’ or ‘replication’ ● Replication job type requires standby host and capacity on SAN
− We didn’t anticipate this and didn’t have SAN capacity to spare
● Regular jobs require touching source VM’s twice
− Wasn’t a problem at first, started to become cumbersome as we grew
Re-evaluate forward or reverse incremental modes for replication ● Both have pros and cons for replication; choice is very hard to make
● We chose to maximize retention and use reverse incremental
Re-evaluate Hot Add (“Virtual Appliance”) mode ● Much faster compared to Direct SAN Acces with thin provisioned disks
● Restores are much faster compared to Direct SAN Access mode

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Live Demo

Agenda
Introduction
Project description, goals, requirements, constraints
High level overview: product and component overview
Backup and DR Approach and architecture
How to improve RTO (Recovery Time Objective)
Find your bottlenecks
Technical deep dive and live demo
Q & A

Q & A





























