Embed Size (px)
Citation preview

1Center for Human Computer Communication
Department of Computer Science, OG I
Designing Robust Multimodal Systems for Designing Robust Multimodal Systems for Diverse Users and Mobile EnvironmentsDiverse Users and Mobile Environments
Sharon [email protected]; http://www.cse.ogi.edu/CHCC/

2Center for Human Computer Communication
Department of Computer Science, OG I
Introduction to Perceptive Multimodal Introduction to Perceptive Multimodal InterfacesInterfaces
• Multimodal interfaces recognize combined natural human input modes (speech & pen, speech & lip movements)
• Radical departure from GUIs in basic features, interface design & architectural underpinnings
• Rapid development in 1990s of bimodal systems• New fusion & language processing techniques• Diversification of mode combinations & applications• More general & robust hybrid architectures

3Center for Human Computer Communication
Department of Computer Science, OG I
Advantages of Multimodal Advantages of Multimodal InterfacesInterfaces
• Flexibility & expressive power • Support for users’ preferred interaction style • Accommodate more users,** tasks, environments** • Improved error handling & robustness** • Support for new forms of computing, including mobile
& pervasive interfaces• Permit multifunctional & tailored mobile interfaces,
adapted to user, task & environment

4Center for Human Computer Communication
Department of Computer Science, OG I
The Challenge of Robustness:The Challenge of Robustness:Unimodal Speech Technology’s Achilles’ Unimodal Speech Technology’s Achilles’
Heel Heel
• Recognition errors currently limit commercialization of speech technology, especially for:– Spontaneous interactive speech– Diverse speakers & speaking styles (e.g.,
accented)– Speech in natural field environments (e.g.,
mobile)• 20-50% drop in accuracy typical for real-world
usage conditions

5Center for Human Computer Communication
Department of Computer Science, OG I
Improved Error Handling in Improved Error Handling in Flexible Multimodal InterfacesFlexible Multimodal Interfaces
• Users can avoid errors through mode selection• Users’ multimodal language is simplified, which
reduces complexity of NLP & avoids errors• Users mode switch after system errors, which
undercuts error spirals & facilitates recovery• Multimodal architectures potentially can support
“mutual disambiguation” of input signals

Example of Mutual Disambiguation: Example of Mutual Disambiguation: QuickSet Interface during Multimodal “PAN” QuickSet Interface during Multimodal “PAN”
CommandCommand
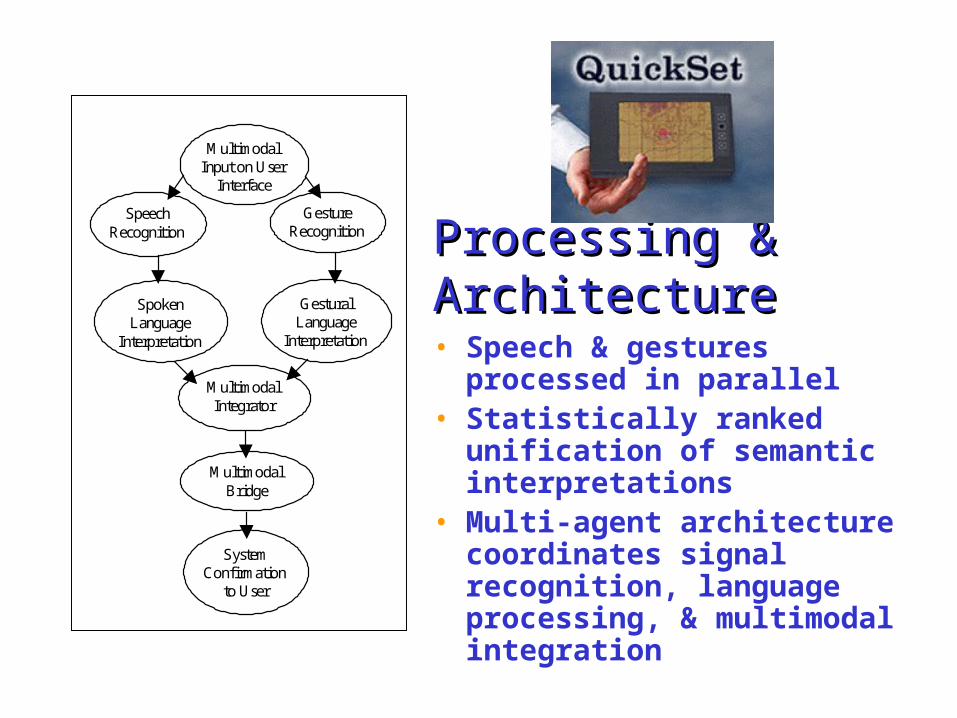
Processing & Processing & ArchitectureArchitecture• Speech & gestures
processed in parallel • Statistically ranked
unification of semantic interpretations
• Multi-agent architecture coordinates signal recognition, language processing, & multimodal integration
MultimodalInput on User
Interface
SpeechRecognition
SpokenLanguage
Interpretation
GestureRecognition
GesturalLanguage
Interpretation
MultimodalIntegrator
MultimodalBridge
SystemConfirmation
to User

8Center for Human Computer Communication
Department of Computer Science, OG I
General Research QuestionsGeneral Research Questions
• To what extent can a multimodal system support mutual disambiguation of input signals?
• How much is robustness improved in a multimodal system, compared with a unimodal one?
• In what usage contexts and for what user groups is robustness most enhanced by a multimodal system?
• What are the asymmetries between modes in disambiguation likelihoods?

9Center for Human Computer Communication
Department of Computer Science, OG I
Study 1- Research MethodStudy 1- Research Method
• Quickset testing with map-based tasks(community fire & flood management)
• 16 users— 8 native speakers & 8 accented (varied Asian, European & African accents)
• Research design— completely-crossed factorial with between-subjects factors: (1) Speaker status (accented, native)
(2) Gender• Corpus of 2,000 multimodal commands
processed by QuickSet

10Center for Human Computer Communication
Department of Computer Science, OG I
VideotapeVideotape
Multimodal system processing
for accented and mobile users

11Center for Human Computer Communication
Department of Computer Science, OG I
Study 1- ResultsStudy 1- Results
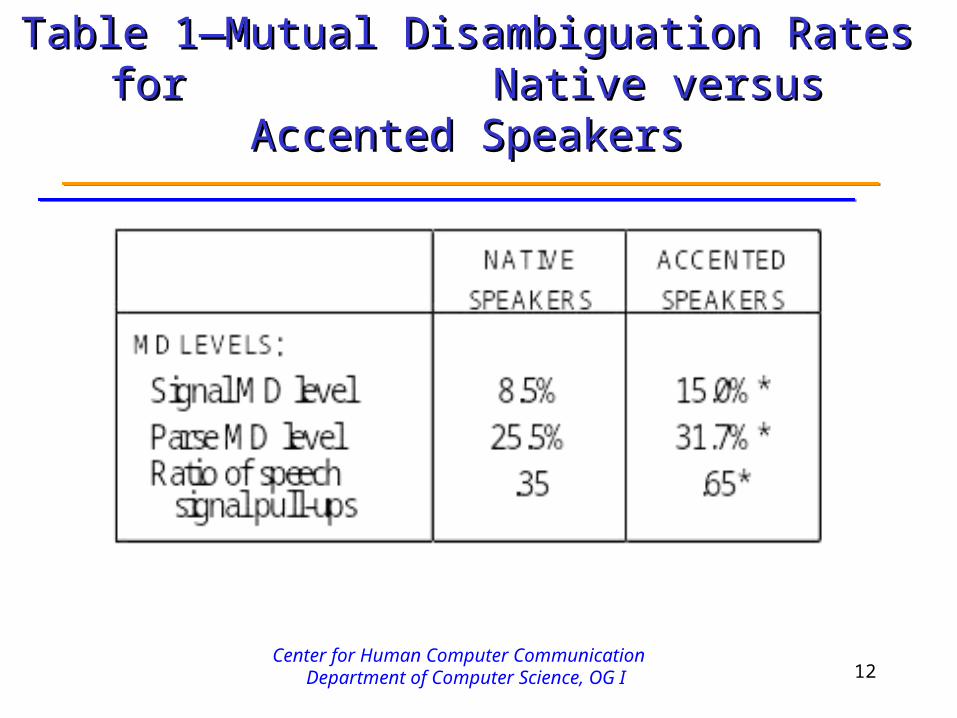
• 1 in 8 multimodal commands succeeded due to mutual disambiguation (MD) of input signals
• MD levels significantly higher for accented speakers than native ones—
15% vs 8.5% of utterances• Ratio of speech to total signal pull-ups differed for
users— .65 accented vs .35 native• Results replicated across signal & parse-level MD
12Center for Human Computer Communication
Department of Computer Science, OG I
Table 1—Mutual Disambiguation Rates for Table 1—Mutual Disambiguation Rates for Native versus Accented Speakers Native versus Accented Speakers

13Center for Human Computer Communication
Department of Computer Science, OG I
Table 2- Recognition Rate Differentials between Table 2- Recognition Rate Differentials between Native and Accented Speakers for Speech, Native and Accented Speakers for Speech,
Gesture and Multimodal Commands Gesture and Multimodal Commands

14Center for Human Computer Communication
Department of Computer Science, OG I
Study 1- Results (cont.)Study 1- Results (cont.)
Compared to traditional speech processing, spoken language processed within a multimodal architecture yielded:
41.3% reduction in total speech error rate
No gender or practice effects found in MD rates

15Center for Human Computer Communication
Department of Computer Science, OG I
Study 2- Research MethodStudy 2- Research Method
• QuickSet testing with same 100 map-based tasks
• Main study:– 16 users with high-end mic (close-talking, noise-canceling)– Research design completely-crossed factorial:
(1) Usage Context- Stationary vs Mobile (within subjects) (2) Gender• Replication:
– 6 users with low-end mic (built-in, no noise cancellation) – Compared stationary vs mobile

16Center for Human Computer Communication
Department of Computer Science, OG I
Study 2- Research AnalysesStudy 2- Research Analyses
• Corpus of 2,600 multimodal commands
• Signal amplitude, background noise & SNR estimated for each command
• Mutual disambiguation & multimodal system recognition rates analyzed in relation to dynamic signal data

17Center for Human Computer Communication
Department of Computer Science, OG I
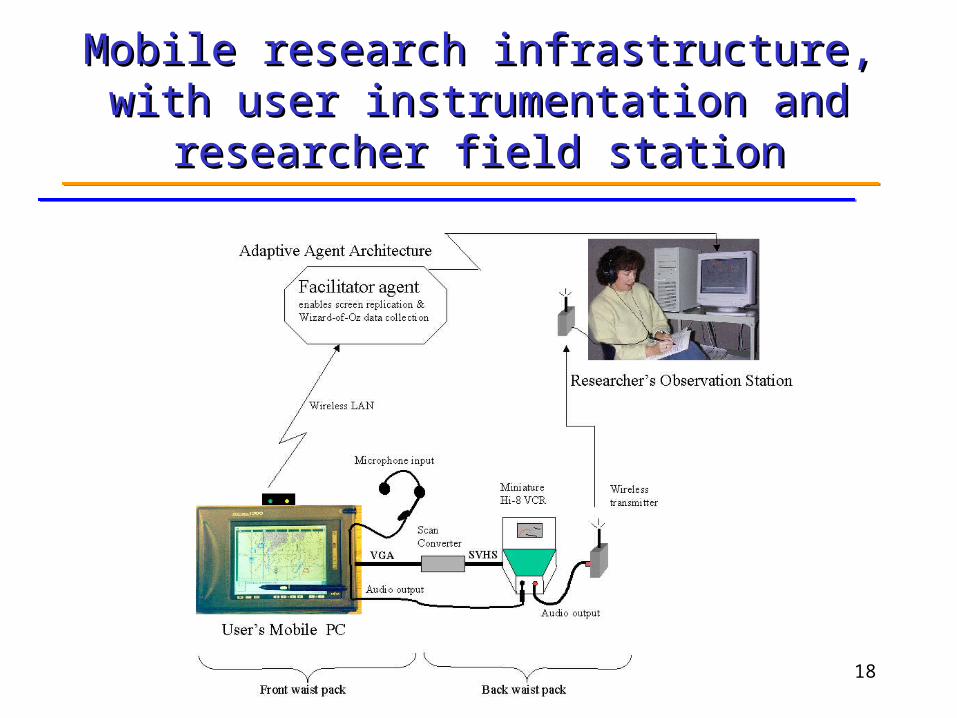
Mobile user with hand-held system & close-Mobile user with hand-held system & close-talking headset in moderately noisy environmenttalking headset in moderately noisy environment
(40-60 dB noise)(40-60 dB noise)
18Center for Human Computer Communication
Department of Computer Science, OG I
Mobile research infrastructure, with user Mobile research infrastructure, with user instrumentation and researcher field instrumentation and researcher field
stationstation

19Center for Human Computer Communication
Department of Computer Science, OG I
Study 2- ResultsStudy 2- Results
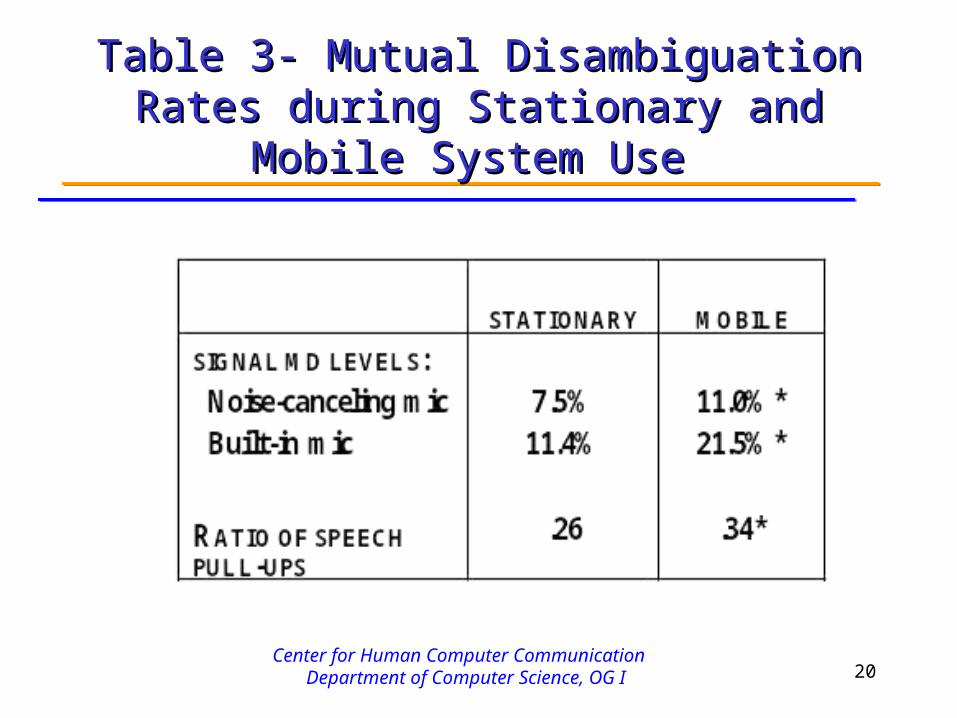
• 1 in 7 multimodal commands succeeded due to mutual disambiguation of input signals
• MD levels significantly higher during mobile than stationary system use—
16% vs 9.5% of utterances• Results replicated across signal and parse-level MD
20Center for Human Computer Communication
Department of Computer Science, OG I
Table 3- Mutual Disambiguation Rates Table 3- Mutual Disambiguation Rates during Stationary and Mobile System Useduring Stationary and Mobile System Use
21Center for Human Computer Communication
Department of Computer Science, OG I
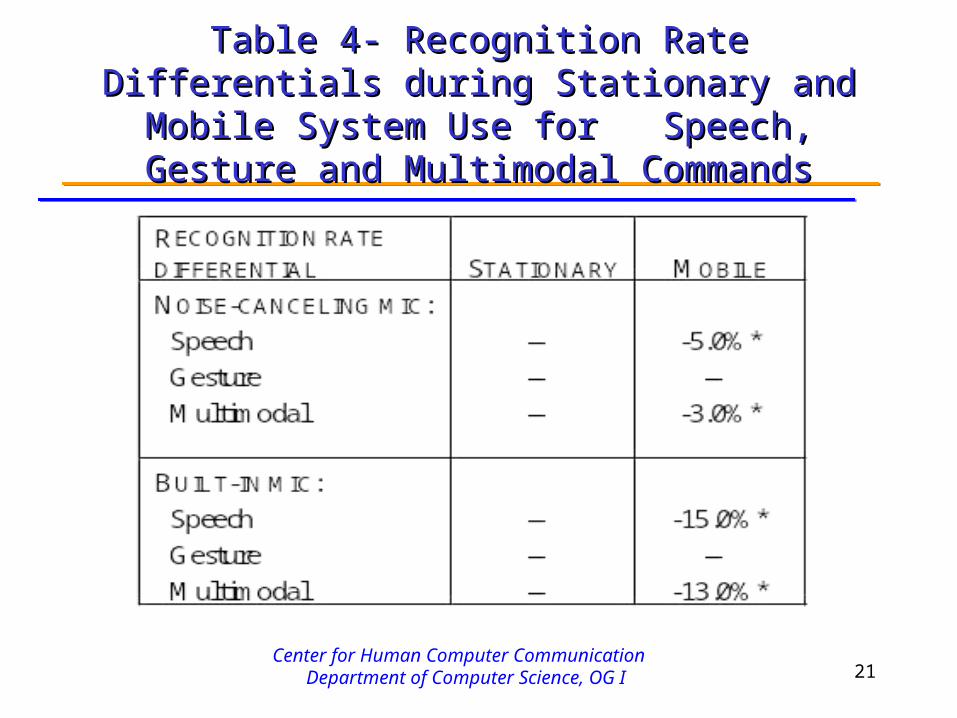
Table 4- Recognition Rate Differentials during Table 4- Recognition Rate Differentials during Stationary and Mobile System Use for Speech, Stationary and Mobile System Use for Speech,
Gesture and Multimodal CommandsGesture and Multimodal Commands

22Center for Human Computer Communication
Department of Computer Science, OG I
Study 2- Results (cont.)Study 2- Results (cont.)
Compared to traditional speech processing, spoken language processed within a multimodal architecture yielded:
19-35% reduction in total speech error rate (for noise-canceling & built-in mics, respectively)
No gender effects found in MD

23Center for Human Computer Communication
Department of Computer Science, OG I
• Multimodal architectures can support mutual disambiguation & improved robustness over unimodal processing
• Error rate reduction can be substantial— 20-40%• Multimodal systems can reduce or close the recognition rate
gap for challenging users (accented speakers) & usage contexts (mobile)
• Error-prone recognition technologies can be stabilized within a multimodal architecture, which functionmore reliably in real-world contexts
Conclusions

24Center for Human Computer Communication
Department of Computer Science, OG I
Future Directions & ChallengesFuture Directions & Challenges
• Intelligently adaptive processing, tailored for mobile usage patterns & diverse users
• Improved language & dialogue processing techniques, and hybrid multimodal architectures
• Novel mobile & pervasive multimodal concepts• Break the robustness barrier— reduce error rate (For more information— http://www.cse.ogi.edu/CHCC/)














![[Sara] Robust Correspondence Recognition for Computer Vision](https://img.pdfslide.net/doc/110x75/577d27a51a28ab4e1ea47201/sara-robust-correspondence-recognition-for-computer-vision.jpg)













