Embed Size (px)
Citation preview

1
Chương 9
Các mô hình hồi quy đa thức (Gujarati: Econometrics by example, 2011)1.
Người dịch và diễn giải: Phùng Thanh Bình
http://vnp.edu.vn/
C Trong chương 8, chúng ta đã xem xét các mô hình logit và probit trong đó mục tiêu là phải chọn giữa hai lựa chọn rời rạc: hút hay là không hút. Các mô hình như thế được gọi là các mô hình hồi quy nhị phân. Nhưng có nhiều trường hợp ở đó chúng ta có thể phải chọn giữa nhiều phương án đời rạc. Các mô hình như thế được gọi là các mô hình hồi quy đa thức (MRM – multinomial regression models). Một vài ví dụ như sau:
1. Chọn phương tiện giao thông: xe hơi, xe buýt, tàu hỏa, xe đạp. 2. Chọn các nhã hiệu ngủ cốc. 3. Chọn ứng viên tổng thống: dân chủ, cộng hòa hay độc lập. 4. Chọn lựa giáo dục: cấp 3, đại học, sau đại học. 5. Chọn trường đào tạo MBA: Harvard, MIT, Chicago, Stanford. 6. Chọn công việc: không đi làm, làm bán thời gian, hoặc làm toàn thời gian. 7. Mua xe: Mỹ, Nhật, Châu Âu.
Dĩ nhiên, còn nhiều ví dụ hơn có thể được trích dẫn ra trong đó một người tiêu dùng đối diện với nhiều lựa chọn khác nhau.
Chúng ta ước lượng các mô hình liên quan đến việc lựa chọn giữa nhiều phương án khác nhau như thế nào? Ở phần tiếp theo chúng ta sẽ xem xét một số kỹ thuật được sử dụng phổ biến trong thực tế. Nhưng trước khi tiếp tục, có lẽ cần lưu ý rằng có nhiều tên gọi khác nhau cho các mô hình như thế: polytomous hoặc polychotomous (multiple category) regression models. Vì nhiều mục đích thảo luận mà chúng ta sẽ sử dụng thuật ngữ multinomial models cho tất cả các mô hình này.
9.1 Bản chất của các mô hình hồi quy đa thức
Từ đầu chúng ta có thể phân biệt giữa MRM định danh hoặc không theo thứ bậc và MRM theo thứ bậc. Ví dụ, lựa chọn phương tiện giao thông là MRM định danh bởi vì không có một trật tự thứ bậc cụ thể nào giữa các lựa chọn khác nhau. Trái lại, nếu bạn đang trả lời bảng câu hỏi trong đó có câu hỏi là một phát biểu và yêu cầu bạn trả lời theo một thang đo có 3 lựa chọn, chẳng hạn như không đồng ý (do not agree), hơi đồng ý (somewhat agree), hoàn toàn đồng ý (completely agree), thì đó là một ví dụ về MRM theo thứ bậc.
1 Hiện nay đã có ấn bản mới (lần 2, năm 2015). Dữ liệu của phiên bản 2011: https://www.macmillanihe.com/companion/Gujarati-Econometrics-By-Example/student-zone/

2
Trong chương này, chúng ta xem xét các mô hình MRM định danh và thảo luận các mô hình MRM theo thứ bậc ở chương tiếp theo.
Thậm chí trong các mô hình MRM định danh, chúng ta cần phải phân biệt 3 trường hợp sau đây:
1. Mô hình MRM định danh với dữ liệu đặc thù của người chọn (chooser-specific data hoặc individual-specific data).
2. Mô hình MRM định danh với dữ liệu đặc thù của lựa chọn (choice-specific data). 3. Mô hình MRM với dữ liệu kết hợp giữa đặc thù của người chọn và đặc thù củ lựa
chọn, hoặc còn gọi là mô hình MRM định danh hỗn hợp (mixed nominal MRM).
Lưu ý rằng chúng ta đang sử dụng thuật ngữ “chooser” để thể hiện một cá nhân hoặc một người ra quyết định, nghĩa là người phải thực hiện lựa chọn giữa nhiều phương án (alternatives). Chúng ta sử dụng thuật ngữ “choice” để thể hiện các phương án (alternatives) hoặc các lựa chọn (options) mà một người đang đối diện. Ngữ cảnh cụ thể của vấn đề sẽ làm rõ thuật ngữ nào mà chúng ta đang quan tâm.
MRM định danh với dữ liệu đặc thù của người chọn hay đặc thù của cá nhân
Trong mô hình này, các lựa chọn phụ thuộc vào các đặc điểm của người chọn, chẳng hạn như tuổi, thu nhập, giáo dục, tôn giáo, và các yếu tố tương tự. Ví dụ, trong các lựa chọn giáo dục, chẳng hạn như giáo dục phổ thông, giáo dục cao đẳng hệ hai năm, giáo dục đại học bốn năm, và sau đại học, thì tuổi, thu nhập gia đình, tôn giáo, và giáo dục của cha mẹ là một số biến sẽ ảnh hưởng đến sự lựa chọn. Các biến này là đặc thù đối với người chọn.
Các loại mô hình này thường được ước lượng bằng các mô hình logit đa thức (MLM – multinomial logit) hoặc probit đa thức (MPM – multinomial probit)2. Câu hỏi chủ yếu mà các mô hình này trả lời là: Các đặc biểm của người chọn ảnh hưởng như thế nào đến việc lựa chọn của họ về một phương án cụ thể giữa một tập hợp nhiều phương án? Vì thế MLM là phù hợp khi các biến giải thích thay đổi khác nhau giữa các cá nhân.
MRM định danh với dữ liệu đặc thù của lựa chọn
Giả sử chúng ta phải chọn giữa bốn loại bánh quy dòn: Nhãn hiệu tư nhân (private label), Sunshine, Keebler, và Nabisco. Chúng ta có dữ liệu về giá của các loại bánh quy dòn này, cách trưng bày được sử dụng bởi các nhãn hiệu này, và các thuộc tính đặc biệt được sử dụng bởi các nhãn hiệu này. Nói cách khác, chúng ta có các đặc điểm đặc thù của lựa chọn (choice-specific characteristics). Tuy nhiên, trong mô hình này chúng ta không có các đặc điểm đặc thù của cá nhân (individual-specific characteristics). Các mô hình như thế thường được ước lượng bằng các mô hình logit có điều kiện (CLM – conditional logit) hoặc probit có điều kiện (CPM – conditional probit). Câu hỏi chính mà các mô hình như thế trả lời là: Các đặc điểm hoặc thuộc tính của các phương án khác nhau có ảnh hưởng đến sự lựa chọn của cá nhân giữa chúng hay không? Ví dụ, người ta có mua xe dựa trên các thuốc tính, như màu sắc, hình dáng, quảng cáo thương mại, và các đặc
2 Bởi vì sự phức tạp tương đối về mặt toán học, nên trong thực tế MLM thường được sử dụng hơn so với MPM. Vì thế, chúng ta sẽ giới hạn thảo luận của chúng ta nhiều vào MLM.

3
điểm khuyến mãi? Vì thế, CLM hoặc CPM là phù hợp khi các biến giải thích thay đổi khác nhau giữa các phương án.
Khác biệt giữa MLM và CLM đã được Powers và Xie3 tóm tắt như sau:
Trong mô hình logit đa thức chuẩn, các biến giải thích là không đổi với các phân loại của kết quả (outcome categories), nhưng các tham số thay đổi với kết quả. Trong mô hình logit có điều kiện, các biến giải thích thay đổi theo kết quả cũng như theo cá nhân, trong khi đó các tham số được giả định cố định qua tất cả các phân loại kết quả.
MRM hỗn hợp
Ở đây chúng ta có dữ liệu về cả các đặc điểm đặc thù của người chọn và đặc thù của lựa chọn. Các mô hình như thế cũng có thể được ước lượng bằng mô hình logit có điều kiện bằng cách đưa thêm các biến giả vào mô hình. Ví dụ, khi chọn mu axe hơi, các thuộc tính của các chiếc xem cũng như thu nhập và tuổi của cá nhân có thể ảnh hưởng đến lựa chọn của họ về chiếc xe.
Vì chủ đề về các mô hình đa lựa chọn (multi-choice) là khá rộng, nên chúng ta sẽ chỉ xem xét các vấn đề cơ bản của MLM, CLM, và MXL (mô hình logit hỗn hợp, mixed logit model) và để người đọc tham khảo các tài liệu để có các thảo luận mở rộng thêm về các mô hình này4.
9.2 Mô hình logit đa thức (MLM): chọn trường
Để minh họa mô hình MLM, chúng ta xem xét một ví dụ về chọn trường. Dữ liệu bao gồm 1000 người tốt nghiệp phổ thông họ đang đứng trước ba lựa chọn: không đi học cao đẳng, học cao đẳng hệ hai năm, và học cao đẳng hệ bốn năm. Chúng ta mã hóa các lựa chọn này là 1, 2 và 35. Lưu ý rằng chúng ta xử lý các lựa chọn này như các biến định danh, mặc dù chúng ta có thể xử lý chúng theo thứ bậc. Xem Table 9.1 trên trang web đồng hành cùng cuốn sách.
Một người tốt nghiệp phổ thông quyết định giữa các lựa chọn này như thế nào? Về mặc trực giác, chúng ta có thể nói rằng sự lựa chọn sẽ phụ thuộc vào sự thỏa mãn (hoặc sự hữu dụng theo thuật ngữ kinh tế học) mà một sinh viên nhận được từ giáo dục bậc cao hơn. Sinh viên sẽ chọn một phương án mang đến cho mình sự thỏa mãn cao nhất có thể. Vì thế, lựa chọn đó sẽ có xác suất được chọn cao nhất.
Để biết điều này có thể được thực hiện như thế nào, chúng ta đặt:
Yij = 1, nếu cá nhân i chọn phương án j (j = 1, 2, và 3 trong trường hợp hiện tại).
3 Xem Daniel A. Powers and Yu Xie, Statistical Methods for Categorical Data Analysis, 2nd edn, Emerald Publishers, UK, 2008, p. 256. 4 Một thảo luận toàn diện với nhiều ví dụ, xem J. Scott Long and Jeremy Freese, Regression Models for Categorical Dependent Variables Using Stata, Stata Press, 2nd edn, Stata Corporation LP, College Station, Texas và William H. Greene, Econometric Analysis, 6th edn, Pearson/Prentice-Hall, New Jersey, 2008, Ch. 23. 5 Dữ liệu gốc lấy từ Nghiên cứu giáo dục quốc gia năm 1988 và được sao chép lại trong R. Carter Hill, William E. Griffiths, and Guay C. Lim, Principles of Econometrics, 3rd edn, John Wiley & Sons, New York, 2008.

4
= 0, cho các phương án khác (không được chọn).
Ngoài ra, chúng ta đặt:
[
Trong đó, Pr là xác suất.
Vì thế, i1, i2, i3 thể hiện các xác suất mà các nhân i lần lượt chọn phương án 1, 2, hoặc 3 – đó là các phương án không đi học cao đẳng, học cao đẳng hệ hai năm, và học cao đẳng hệ bốn năm. Nếu đây là các phương án duy nhất mà một cá nhân đối diện, thì rõ ràng:
Điều này là bởi vì tổng các xác suất các biến cố đầy đủ và loại trừ lẫn nhau phải là 1.
Chúng ta sẽ gọi các là các xác suất đáp ứng (response probabilities).
Điều này có nghĩa rằng trong ví dụ của chúng ta nếu chúng ta xác định hai xác suất bất kỳ, thì xác suất thứ ba được xác định một cách tự động. Nói cách khác, chúng ta không thể ước lượng ba xác suất một cách độc lập.
Bây giờ các nhân tố hoặc các biến quyết định xác suất chọn một phương án cụ thể là gì? Trong ví dụ về chọn trường của chúng ta, chúng ta có thông tin về các biến sau đây:
X2 = hscath = 1 nếu người tốt nghiệp trường Công giáo, và 0 nếu các trường khác.
X3 = grades = điểm trung bình các môn toán, anh văn, và khoa học xã hội trên thang điểm 13, với 1 là điểm cao nhất và 13 là điểm thấp nhất. Vì thế, điểm cao hơn thể hiện thành tích học thuật kém.
X4 = faminc = tổng thu nhập gia đình năm 1991 tính bằng 1000 đôla.
X5 = famsiz = số thành viên trong gia đình.
X6 = parcoll = 1 nếu cha mẹ được giáo dục tốt nhất tốt nghiệp cao đẳng hoặc có bằng cấp cao.
X7 = 1 nếu là nữ.
X8 = 1 nếu là người da đen.
Chúng ta sẽ sử dụng X1 để thể hiện hệ số cắt.
Lưu ý rằng một số biến là định tính hoặc biến giả (X2, X6, X7, X8) và một số là biến định lượng (X3, X4, X5). Cũng lưu ý rằng sẽ có vài yếu tố ngẫu nhiên sẽ cũng ảnh hưởng đến sự lựa chọn, và các yếu tố này sẽ được ký hiện bằng hạng nhiễu khi ước lượng mô hình.
Khái quát hóa mô hình logit hai biến được thảo luận ở chương 8, chúng ta có thể viết mô hình logit đa thức (MLM) như sau:

5
Lưu ý rằng chúng ta để ký hiệu dưới j ở hệ số cắt và hệ số dốc để nhắc chúng ta nhớ rằng các giá trị của các hệ số này có thể khác nhau giữa các lựa chọn. Nói cách khác, một người tốt nghiệp phổ thông không muốn tiếp tục đi học cao đẳng sẽ gán một trọng số khác cho mỗi biến giải thích hơn một người tốt nghiệp phổ thông muốn đi học cao đẳng hệ hai năm hoặc học cao đẳng hệ bốn năm. Tương tự, một người tốt nghiệp phổ thông muốn đi học cao đẳng hệ hai năm nhưng không đi học cao đẳng hệ bốn năm sẽ gán các trọng số khác (hoặc tầm quan trọng) cho các biến giải thích khác nhau.
Cũng cần nhớ rằng nếu chúng ta có nhiều hơn một biến giải thích trong mô hình, thì X
sẽ đại diện một véctơ của các biến và thì sẽ là một véctơ của các hệ số. Vì vậy, nếu chúng ta quyết định đưa 7 biến giải thích được liệt kê ở trên, thì chúng ta sẽ có 7 hệ số dốc và những hệ số dốc này có thể khác nhau giữa các lựa chọn. Nói cách khác, ba xác suất được ước lượng từ phương trình (9.2) có thể có các hệ số khác nhau cho các biến giải thích. Thực vậy, chúng ta sẽ ước lượng ba phương trình hồi quy.
Như chúng ta đã lưu ý trước đây, chúng ta không thể ước lượng tất cả ba xác suất một cách độc lập. Thực tế phổ biến trong MLM là chọn một phân loại hoặc một lựa chọn làm phân loại cơ sở (base category), phân loại tham chiếu (reference category), hoặc phân loại so sánh (comparison category) và gán các giá trị hệ số của nó bằng 0. Vì vậy,
nếu chúng ta chọn phân loại thứ nhất (không đi học cao đẳng) và cho 1 = 0 và 1 = 0, thì chúng ta có các giá trị ước lượng sau đây của các xác suất cho ba lựa chọn:
Cần lưu ý rằng mặc dù các biến giải thích giống nhau xuất hiện trong mỗi biểu thức xác suất (đáp ứng), nhưng các hệ số của chúng sẽ không nhất thiết giống nhau. Một lần nữa nên nhớ rằng nếu chúng ta có nhiều hơn một biến giải thích, thì các biến X sẽ đại diện
một véctơ của các biến và sẽ đại diện một véctơ của các hệ số.
Nếu bạn cộng ba xác suất được cho trong các phương trình (9.3), (9.4), và (9.5), thì bạn sẽ có một giá trị bằng 1, bởi vì ở đây chúng ta có ba lựa chọn loại trừ lẫn nhau.

6
Các biểu thức xác suất được cho trong các phương trình (9.3), (9.4), và (9.5) rõ ràng là phi tuyến. Nhưng bây giờ hãy xem xét các biểu thức sau đây:
Các biểu thức6 (9.6) và (9.7) giống với mô hình logit hai biến được thảo luận trong chương 8. Nghĩa là, các logit là các hàm tuyến tính của (các) biến giải thích. Nhớ rằng các logit đơn giản là các log của tỷ số odds. Và tỷ số odds cho chúng ta biết phương án j được ưa thích hơn phương án l là bao nhiêu.
Bây giờ câu hỏi nêu ra là tại sao không ước lượng các logit hai biến bằng cách sử dụng các kỹ thuật mà chúng đã học ở chương 8? Tuy nhiên, đây không phải là một thủ tục được đề xuất vì nhiều lý do. Thứ nhất, mỗi trong các logit hai biến sẽ được dựa trên một cỡ mẫu khác nhau. Vì thế, nếu chúng ta ước lượng (9.6), thì các quan sát cho phương án chọn trường thứ 3 sẽ sẽ bị bỏ ra. Thứ hai, ước lượng riêng lẻ các logit hai biến sẽ không nhất thiết bảo đảm rằng ba xác suất được ước lượng cộng lại sẽ bằng 1. Thứ ba, các sai số chuẩn của các hệ số ước lượng nói chung sẽ nhỏ hơn nếu tất cả các logit được ước lượng cùng với nhau hơn là nếu chúng ta phải ước lượng mỗi logit một cách độc lập.
Vì các lý do này mà các mô hình (9.6) và (9.7) được ước lượng đồng thời bằng phương pháp hợp lý tối đa (ML). Đối với ví dụ của chúng ta, trước hết chúng ta cho thấy các giá trị ước lượng ML có được từ phần mềm Stata (Bảng 9.2) và sau đó thảo luận các kết quả này.
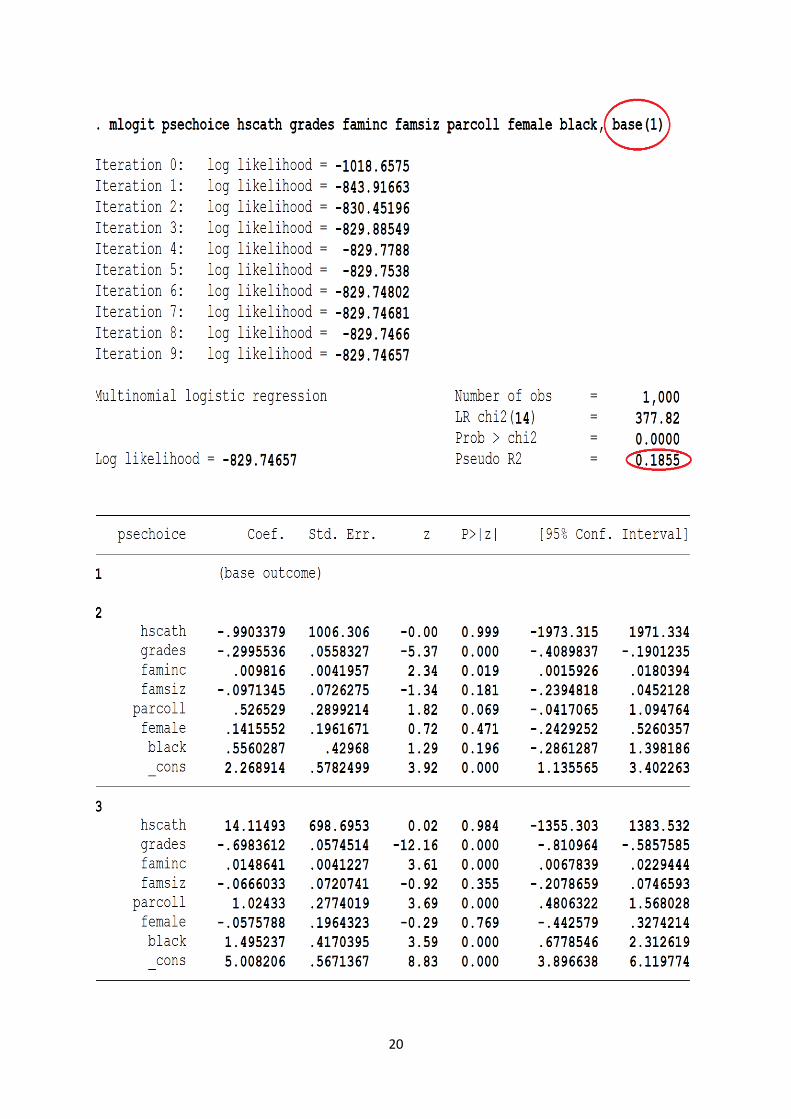
Trước hết lưu ý rằng chúng ta chọn psechoice = 1 (không đi học cao đẳng) làm phân loại cơ sở, mặc dù bạn có thể chọn bất kỳ phân loại nào làm phân loại cơ sở. Nếu chúng ta chọn một cơ sở khác, thì các hệ số được trình bày ở trên sẽ thay đổi. Nhưng bất kể lựa chọn nào làm phân loại cơ sở, thì các xác suất ước lượng của ba lựa chọn sẽ vẫn giống nhau.
6 Từ phương trình (9.6) lni2 - lni1 = 2 + 2Xi, và từ phương trình (9.7) lni3 - lni1 = 3 + 3Xi. Vì thế, lni2 –
ln(i2/lni3) = (2 - 3) + (2 - 3)Xi, biểu thức này cho biết log của tỷ số odds của việc chọn phương án 2 hơn là phương án 3.

7
Bảng 9.2: Mô hình logistic đa thức về chọn trường.
Các hệ số được trình bày trong bảng ở trên phải được giải thích trong mối quan hệ với phân loại tham chiếu, (lựa chọn) 1 trong ví dụ hiện tại.
Kết quả Stata được chia thành hai bảng (panels). Bảng thứ nhất đưa ra các giá trị của các hệ số khác nhau của phương án chọn trường số 2 (học cao đẳng hệ hai năm) trong mối quan hệ với phương án chọn trường số 1 (không đi học cao đẳng). Nghĩa là, nó đưa ra các giá trị ước lượng của logit (9.6) và bảng thứ hai đưa ra các thông tin tương tự cho phương án chọn trường số 3 (học cao đẳng hệ bốn năm) trong mối quan hệ với phương án chọn trường số 1 (không đi học cao đẳng). Nghĩa là, nó đưa ra các giá trị ước lượng của logit (9.7).
Trước khi chúng ta giải thích các kết quả này, chúng ta hãy ý nghĩa thống kê của các hệ số ước lượng. Vì cỡ mẫu khá lớn, nên chúng ta sử dụng thống kê z (chuẩn hóa) thay vì thống kê t để kiểm định ý nghĩa thống kê7. Bảng ở trên cho các giá trị z cũng như các giá trị xác suất p (mức ý nghĩa chính xác) của các giá trị z này. Trong bảng 1, các biến điểm, thu nhập gia đình, và giáo dục của cha mẹ và trong bảng 2, các biến điểm, thu nhập gia đình, giáo dục của cha mẹ, và người da đen có ý nghĩa thống kê.
7 Nhớ lại rằng khi cỡ mẫu tăng vô cùng thì phân phối t hội tụ về phân phối chuẩn.

8
Trong các hồi quy bội, chúng ta sử dụng R2 như một thước đo về mức độ phù hợp của mô hình được chọn. Giá trị R2 nằm giữa 0 và 1. Giá trị R2 càng gần 1, thì mô hình càng phù hợp. Nhưng R2 thông thường không thực hiện tốt vai trò này đối với mô hình MLM8. Tuy nhiên, thước đo pseudo R2 được phát triển bởi McFadden, được định nghĩa như sau:
Trong đó, Lfit = tỷ số hợp lý (likelihood ratio) của mô hình được ước lượng và L0 = tỷ số hợp lý của mô hình không có biến giải thích nào. Đối với ví dụ của chúng ta, pseudo R2 là khoảng 0.1855.
Thay vì dùng pseudo R2 chúng ta có thể sử dụng kiểm định LR (likelihood ratio test), thống kê này nói chung được tính sẵn khi chúng ta sử dụng phương pháp ML. Dưới giả thuyết Ho cho rằng không có hệ số dốc nào có ý nghĩa thống kê. LR theo phân phối Chi
bình phương (2) với bậc tự do bằng số hệ số dốc được ước lượng, 14 trong trường hợp
hiện tại. LR ước lượng 377 là có ý nghĩa thống kê cao, vì giá trị xác suất p thực tế bằng 0. Điều này cho thấy rằng mô hình mà chúng ta chọn là rất phù hợp, mặc dù không phải mỗi hệ số dốc đều có ý nghĩa thống kê.
Chúng ta giải thích các kết quả được cho trong bảng ở trên như thế nào? Có nhiều cách giải thích các kết quả này như được mô tả dưới đây.
Giải thích theo các tỷ số odds
Ví dụ, lấy phương trình (9.6), phương trình này cho ta log của tỷ số odds (tứ logit) ủng hộ phương án chọn trường số 2 hơn phương án chọn trường số 1 – nghĩa là học cao đẳng hệ hai năm hơn là không đi học cao đẳng. Hệ số dương của một biến giải thích cho biết tỷ số odds tăng cho lựa chọn 2 hơn lựa chọn 1, khi giữ nguyên các biến giải thích khác. Tương tự, một hệ số âm của một biến giải thích hàm ý rằng tỷ số odds ủng hộ không đi học cao đẳng lớn hơn so với đi học cao đẳng hệ hai năm. Vì thế, từ bảng 1 của Bảng 9.2 chúng ta thấy rằng nếu thu nhập gia đình tăng, thì tỷ số odds của đi học cao đẳng hệ hai năm tăng so với không đi học cao đẳng, khi các biến giải thích khác được giữ nguyên không đổi. Tương tự, hệ số âm của biến điểm số hàm ý rằng tỷ số odds ủng hộ việc không đi học cao đẳng lớn hơn đi học cao đẳng hệ hai năm, khi các biến giải thích khác được giữ nguyên không đổi (hãy nhớ biến điểm số được mã hóa như thế nào trong ví dụ này). Cách giải thích tương tự được áp dụng cho bảng thứ 2 của Bảng 9.2.
Cụ thể, chúng ta hãy giải thích hệ số của biến điểm trung bình. Khi các biến khác được giữ cố định, nếu điểm trung bình tăng thêm một đơn vị, thì log của cơ hội (chance) thích đi học cao đẳng hệ hai năm hơn không đi học cao đẳng giảm khoảng 0.2995. Nói cách
khác, -0.2995 cho biết thay đổi trong ln(2i / 1i) theo một thay đổi đơn vị trong điểm
trung bình. Vì thế, nếu chúng ta lấy anti-log của ln(2i / 1i), thì chúng ta có 2i/1i = e-
0.2995 = 0.7412. Nghĩa là, tỷ số odds ủng hộ chọn đi học cao đẳng hệ hai năm so với không
8 Nói chung điều này đúng cho mọi mô hình hồi quy phi tuyến (ở tham số).

9
đi học chỉ khoảng 74%. Kết quả này nghe có vẽ phản trực giá, nhưng nhớ rằng một điểm số cao hơn theo thang đo 13 có nghĩa là thành tích học thuật càng tệ. Nhân tiện, tỷ số odds cũng được gọi là tỷ số rủi ro tương đối (LRR – relative risk ratios).
Giải thích theo các xác suất
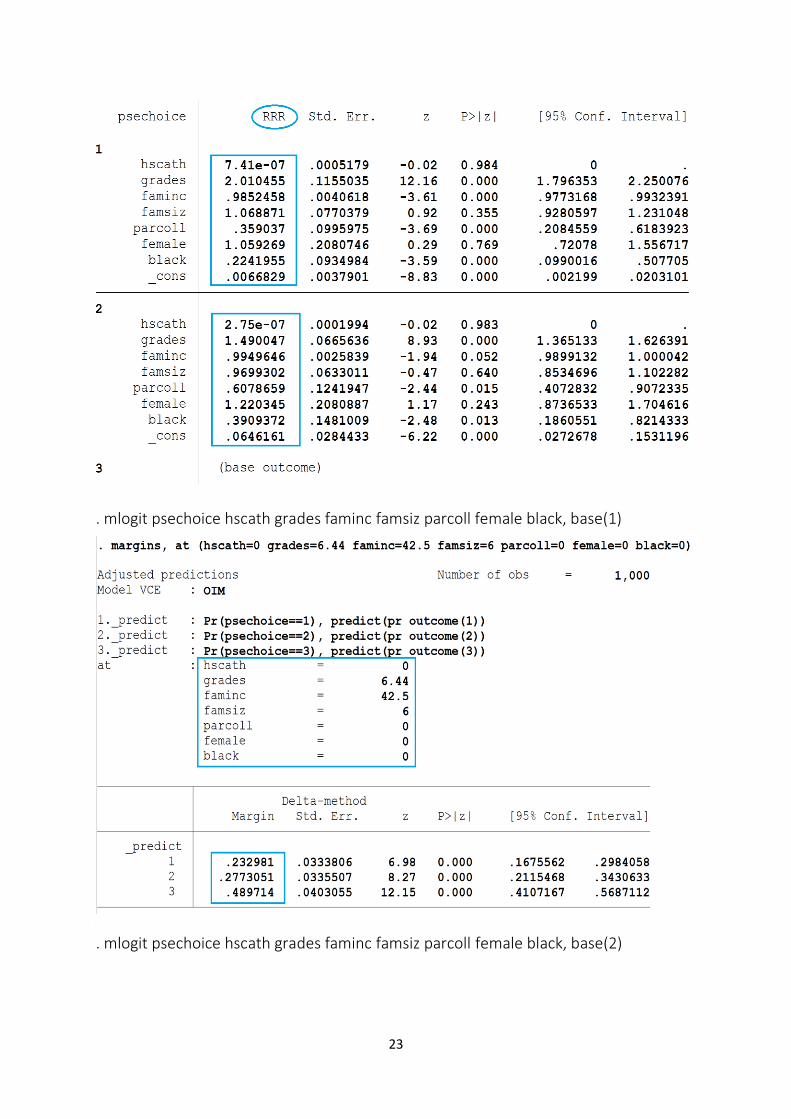
Một khi các tham số đã được ước lượng, thì chúng ta có thể tính ba xác suất như đã thấy trong các phương trình (9.3), (9.4), và (9.5), đây là mục tiêu chính của mô hình MLM. Vì chúng ta có 1000 quan sát và 7 biến giải thích, nên sẽ chán ngắt để ước tính các xác suất này cho tất cả các cá nhân. Tuy nhiên, với lệnh thích hợp, Stata có thể tính các xác suất như thế. Nhưng công việc này có thể được giảm thiểu nếu chúng ta tính ba xác suất tại các giá trị trung bình của 8 biến. Các xác suất ước lượng cho 1000 người được cho trong bảng dữ liệu.
Để minh họa, ví dụ cho cá nhân thứ 10, một người da trắng có cha mẹ không có bằng cấp cao và không đi học ở một trường công giáo, có điểm trung bình là 6.44, thu nhập gia đình là 42.5, và gia đình có 6 người, các xác suất của anh ta cho phương án 1 (không đi học cao đẳng) là 0.2329, cho phương án 2 (học cao đẳng hệ hai năm) là 0.2773, và cho phương án 3 (học cao đẳng hệ bốn năm) là 0.4897; các xác suất này cộng lại là 0.9999 hoặc hầu như bằng 1 vì do làm tròn sai số. Vì thế, đối với cá nhân này thì xác suất cao nhất là khoảng 0.49 (tức đi học cao đẳng hệ bốn năm). Cá nhân này thực sự đã chọn học cao đẳng hệ bốn năm.
Dĩ nhiên, không phải lúc nào các xác suất ước lượng cũng thực sự phù hợp với các lựa chọ thực sự được thực hiện bởi các cá nhân. Trong nhiều trường hợp, lựa chọn thực sự khác so với xác suất ước lượng của lựa chọn đó. Đó là lý do tại sao tốt hơn là tính toán các xác suất lựa chọn tại các giá trị trung bình của các biến. Chúng ta để bạn đọc tự tính các xác suất này9.
Các ảnh hưởng biên lên xác suất
Chúng ta có thể biết tác động của một thay đổi đơn vị trong giá trị của một biến giải thích lên xác suất lựa chọn, khi giữa nguyên tất cả các biến giải thích khác không đổi.
Nghĩa là, chúng ta có thể biết ij/Xik, đó là đạo hàm riêng phần của ij theo biến giải thích thứ k. Tuy nhiên, các tính toán tác động biên là phức tạp. Không chỉ có thế, tác động biên của Xk on xác suất lựa chọn có thể có một dấu khác so với dấu của hệ số của biến Xk. Điều này xảy ra bởi vì trong MLM tất cả các tham số (không chỉ hệ số của Xk) liên quan đến việc tính toán tác động biên của Xk lên xác suất lựa chọn10.
Vì lý do này mà trong thực tế tốt hơn là nên tập trung vào tỷ số odds hoặc tỷ số rủi ro tương đối.
9 Các giá trị trung bình của các biến giải thích cho 1000 quan sát là như sau: chọn trường, 2.305; chọn trường công giáo, 0.019; điểm số, 6.53039; thu nhập gia đình, 51.3935; quy mô gia đình, 4.206; giáo dục bậc cao của cha mẹ, 0.308; nữ, 0.496; da đen, 0.056; chọn trường phương án 1, 0.222; chọn trường phương án 2, 0.251; và chọn trường phương án 3, 0.527.
10 Điều này có thể được thấy từ biểu thức sau đây: ij/Xik = ij(j - ∑ 𝜋𝑖𝑗𝐽𝑗=2 𝛽𝑗).

10
Thận trọng khi sử dụng MLM: sự độc lập của các phương án không liên quan (IIA – independence of irrelevant alternatives)
Một giả định rất quan trọng của MLM là hạng nhiễu trong ước lượng ij, tức xác suất
lựa chọn của cá nhân i cho phương án j, là độc lập với hạng nhiễu trong ước lượng ik,
tức xác suất lựa chọn của cá nhân i cho phương án k (k j). Điều này có nghĩa rằng các phương án mà cá nhân đối diện phải đủ khác biệt với nhau. Đây gọi là IIA. Nói một cách khác, IIA yêu cầu khi so sánh phương án j và k, thì các phương án khác là không liên quan (irrelevant).
Để biết tại sao giả định IIA có thể bị vi phạm, chúng ta có thể xem xét nghịch lý cổ điển ‘xe buýt đỏ, xe buýt xanh’. Giả sử một người đi làm bằng vé tháng (commuter) có hai lựa chọn: đi làm bằng xe hơi hoặc bằng xe buýt. Xác suất lựa chọn ở đây là ½. Vì thế, tỷ số của hai xác suất là 1.
Bây giờ giả sử một dịch vụ xe buýt khác được giới thiệu, dịch vụ này giống nhau ở tất cả các thuộc tính (attributes), nhưng nó được sơn mà đỏ trong khi đó xe buýt trước đây được sơn màu xanh. Trong trường hợp này, bạn có thể kỳ vọng xác suất lựa chọn là 1/3 cho mỗi phương tiện giao thông. Mặc dù trong thực tế, những người đi làm bằng vé tháng có thể không quan tâm gì đến xe buýt màu đỏ hay xe buýt màu xanh. Xác suất lựa chọn cho xe hơi vẫn là ½, nhưng xác suất cho mỗi lựa chọn xem buýt là ¼. Vì thế, tỷ số xác suất lựa chọn xe hơi và xác suất lựa chọn dịch vụ xe buýt là 2 thay vì 1. Rõ ràng, giả định IIA bị vi phạm bởi vì một số lựa chọn là không độc lập, như yêu cầu bởi IIA.
Kết luận của ví dụ này là các mô hình MLM không nên được xem xét nếu các phương án là các thay thế gần cho nhau (close substitutes)11.
9.3 Mô hình logit có điều kiện (CLM)
Như đã lưu ý trước đây, MLM thích hợp khi các biến giải thích khác nhau giữa các cá nhân và CLM thích hợp khi các biến giải thích khác nhau giữa các lựa chọn. Trong CLM, chúng ta không thể có các biến giải thích mà chúng khác nhau giữa các cá nhân12. Về mặt trực giác, chúng ta có thể thấy tại sao. Giả sử chúng ta phải lựa chọn giữa 4 phương tiện giao thông để đi làm: xe hơi, tàu điện, taxi, và xe đạp; mỗi phương tiện có các đặc điểm riêng của nó. Nếu chúng ta cũng muốn đưa các đặc điểm của một cá nhân vào, ví dụ thu nhập, thì nó sẽ không thể ước lượng hệ số của thu nhập bởi vì giá trị thu nhập của cá nhân đó sẽ giống nhau cho cả bốn phương tiện giao thông.
Để ước lượng CLM, chúng ta viết lại phương trình (9.2) như sau:
11 Hausman và McFadden đã phát triển một kiểm định giả thuyết IIA, nhưng Long và Freese, op cit., (p. 244) không khuyến khích sử dụng kiểm định này. Chúng ta có thể cho phép tương quan giữa các hạng nhiễu của các xác suất lựa chọn bằng cách xem xét sử dụng mô hình probit đa thức. Nhưng bởi vì nó phức tạp, nên trong thực tế nhiều nhà nghiên cứu thích sử dụng MLM. 12 Nhưng nếu chúng ta xem xét MLM hỗn hợp (=MXL), thì chúng ta có thể đưa các đặc điểm cá nhân bằng cách sử dụng các biến giả thích hợp, như được thảo luận ở Mục 9.4.

11
Trong đó, ij là xác suất liên quan đến lựa chọn hoặc phương án thứ j.
Lưu ý khác biệt quan trọng giữa các phương trình (9.2) và (9.10) là: trong phương trình
(9.2) thì và khác nhau giữa các lựa chọn, vì thế chúng được gán ký hiệu dưới j, trong khi đó trong phương trình (9.10) thì không có gán giá trị dưới vào chúng. Nghĩa là, trong (9.10) có một hệ số cắt duy nhất và một hệ số dốc duy nhất (hoặc một véctơ các hệ số dốc nếu có nhiều hơn một biến giải thích). Một khác biệt nữa giữa MLM và CLM là các biến giải thích có hai ký hiệu dưới (i và j) trong CLM, trong khi trong MLM chỉ có một ký hiệu dưới (i). Trong MLM thì ký hiệu dưới i khác nhau giữa các cá nhân (ví dụ biến thu nhập trong mô hình chọn trường), nhưng giống nhau qua các phương án. Trái lại, trong CLM thì ký hiệu dưới j của một cá nhân khác nhau qua các phương án.
Giống như MLM, CLM cũng được ước lượng bằng phương pháp hợp lý tối đa. Nhưng trong MLM, và để dễ dàng giải thích, CLM có thể được thể hiện dưới dạng logit như sau:
[Phương trình này phát biểu rằng log-odds giữa các phương án j và m là tỷ lệ theo khác biệt giữa các giá trị của chủ thể (subject’’s values) trên các biến giải thích, khác biệt được tính trọng số bằng hệ số hồi quy ước lượng hoặc các hệ số nếu có nhiều hơn một
biến giải thích, trong trường hợp đó sẽ thể hiện một véctơ của các hệ số.
Trước khi đi tiếp, chúng ta xem xét một ví dụ cụ thể.
Chọn phương tiện di chuyển
Một vấn đề phổ biến là một lữ khách đối diện là phải quyết định phương tiện giao thông. Vấn đề này được nghiên cứu bởi Greene và Hensher, giữa nhiều người khác13. Ở đây dữ liệu bao gồm 840 quan sát trên 4 phương tiện di chuyển của 210 cá nhân. Các biến được sử dụng trong phân tích này như sau:
Mode = Lựa chọn: máy bay, tàu hỏa, xe buýt, hoặc xe hơi riêng.
Time = Thời gian chờ ở ga/trạm, bằng 0 cho xe hơi riêng.
Invc = Chi phí trên xe – thành phần chi phí.
Invt = Thời gian di chuyển trên xe.
GC = Thước đo chi phí tổng quát14.
13 Để biết thêm về thảo luận của nghiên cứu này và về dữ liệu, xem http://pages.stern.nyu.edu/~wgreene/Text/econometricanalysis.htm. 14 Thước đo này bằng tổng chi phí Invc và Invt và chi phí cơ hội của thời gian cá nhân.
12
Hinc = Thu nhập của hộ.
Psize = Quy mô nhóm trong phương tiện được chọn. [
Xem Table 9.3 trên trang web đồng hành cùng cuốn sách.
Time, invc, invt, và GC là các biến đặc thù của lựa chọn (choice-specific variables), vì chúng khác nhau giữa các lựa chọn. Hinc và Psize là các biến đặc thù của cá nhân (individual-specific variables) và chúng không thể được đưa vào mô hình CLM bởi vì các giá trị của chúng là giống nhau qua các phương tiện giao thông. Dĩ nhiên, nếu chúng ta xem xét mô hình hỗn hợp (mixed model), thì chúng ta có thể đưa cả các biến đặc thù của lựa chọn và đặc thù của cá nhân vào mô hình.
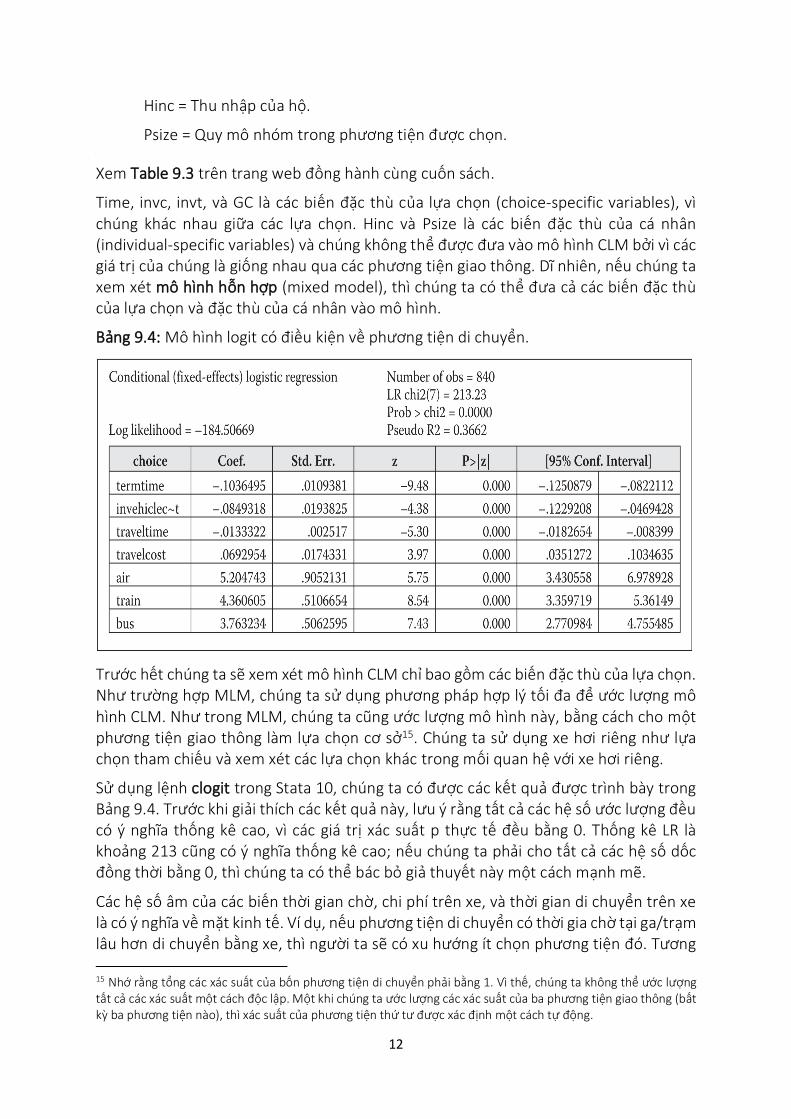
Bảng 9.4: Mô hình logit có điều kiện về phương tiện di chuyển.
Trước hết chúng ta sẽ xem xét mô hình CLM chỉ bao gồm các biến đặc thù của lựa chọn. Như trường hợp MLM, chúng ta sử dụng phương pháp hợp lý tối đa để ước lượng mô hình CLM. Như trong MLM, chúng ta cũng ước lượng mô hình này, bằng cách cho một phương tiện giao thông làm lựa chọn cơ sở15. Chúng ta sử dụng xe hơi riêng như lựa chọn tham chiếu và xem xét các lựa chọn khác trong mối quan hệ với xe hơi riêng.
Sử dụng lệnh clogit trong Stata 10, chúng ta có được các kết quả được trình bày trong Bảng 9.4. Trước khi giải thích các kết quả này, lưu ý rằng tất cả các hệ số ước lượng đều có ý nghĩa thống kê cao, vì các giá trị xác suất p thực tế đều bằng 0. Thống kê LR là khoảng 213 cũng có ý nghĩa thống kê cao; nếu chúng ta phải cho tất cả các hệ số dốc đồng thời bằng 0, thì chúng ta có thể bác bỏ giả thuyết này một cách mạnh mẽ.
Các hệ số âm của các biến thời gian chờ, chi phí trên xe, và thời gian di chuyển trên xe là có ý nghĩa về mặt kinh tế. Ví dụ, nếu phương tiện di chuyển có thời gia chờ tại ga/trạm lâu hơn di chuyển bằng xe, thì người ta sẽ có xu hướng ít chọn phương tiện đó. Tương
15 Nhớ rằng tổng các xác suất của bốn phương tiện di chuyển phải bằng 1. Vì thế, chúng ta không thể ước lượng tất cả các xác suất một cách độc lập. Một khi chúng ta ước lượng các xác suất của ba phương tiện giao thông (bất kỳ ba phương tiện nào), thì xác suất của phương tiện thứ tư được xác định một cách tự động.
13
tự, nếu thời gia đi lại của một phương tiện giao thông lớn hơn so với đi bằng xe riêng, thì phương tiện đó ít có khả năng được chọn bởi một cá nhân. Dấu dương của chi phí đi lại, có bao gồm chi phí cơ hội, cũng có ý nghĩa theo cách mà người ta sẽ chọn phương tiện giao thông có chi phí cơ hội thấp hơn so với đi xe hơi riêng.
Các hệ số cắt của air, train, và bus trong Bảng 9.4 là các hệ số cắt đặc thù của lựa chọn.
Một cách khác để xem các kết quả được trình bày trong bảng trên là theo các tỷ số odds, các kết quả này được trình bày trong Bảng 9.5.
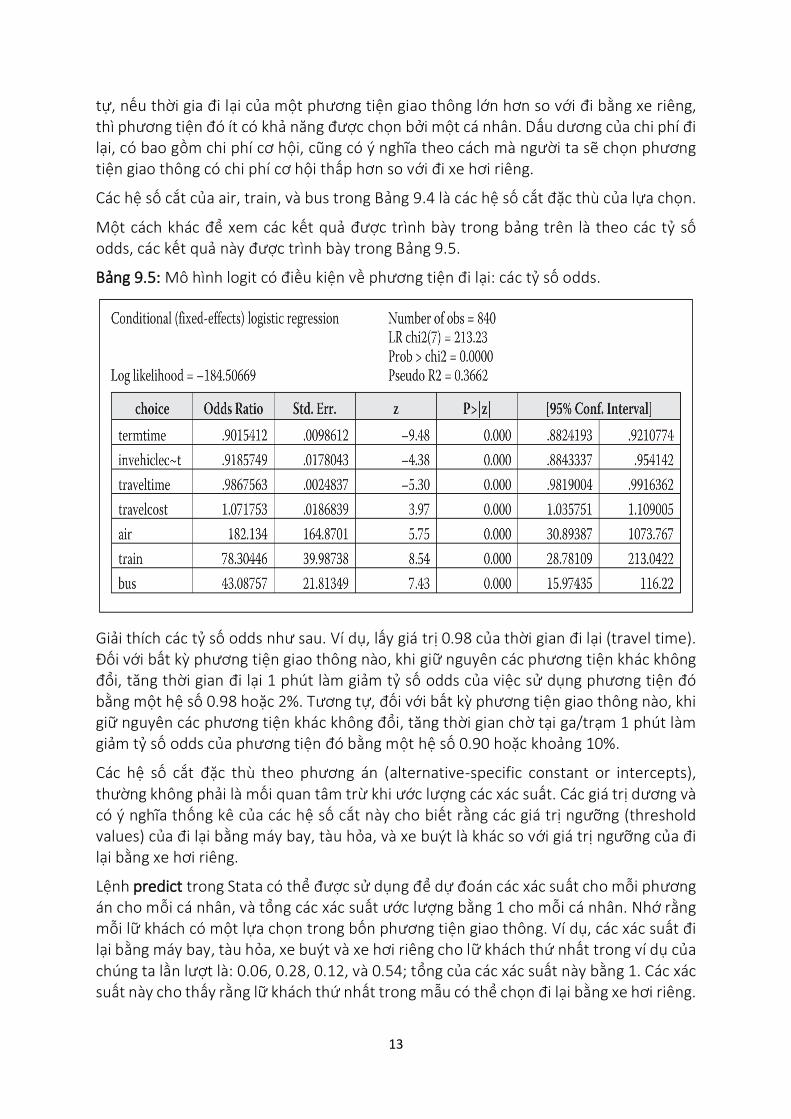
Bảng 9.5: Mô hình logit có điều kiện về phương tiện đi lại: các tỷ số odds.
Giải thích các tỷ số odds như sau. Ví dụ, lấy giá trị 0.98 của thời gian đi lại (travel time). Đối với bất kỳ phương tiện giao thông nào, khi giữ nguyên các phương tiện khác không đổi, tăng thời gian đi lại 1 phút làm giảm tỷ số odds của việc sử dụng phương tiện đó bằng một hệ số 0.98 hoặc 2%. Tương tự, đối với bất kỳ phương tiện giao thông nào, khi giữ nguyên các phương tiện khác không đổi, tăng thời gian chờ tại ga/trạm 1 phút làm giảm tỷ số odds của phương tiện đó bằng một hệ số 0.90 hoặc khoảng 10%.
Các hệ số cắt đặc thù theo phương án (alternative-specific constant or intercepts), thường không phải là mối quan tâm trừ khi ước lượng các xác suất. Các giá trị dương và có ý nghĩa thống kê của các hệ số cắt này cho biết rằng các giá trị ngưỡng (threshold values) của đi lại bằng máy bay, tàu hỏa, và xe buýt là khác so với giá trị ngưỡng của đi lại bằng xe hơi riêng.
Lệnh predict trong Stata có thể được sử dụng để dự đoán các xác suất cho mỗi phương án cho mỗi cá nhân, và tổng các xác suất ước lượng bằng 1 cho mỗi cá nhân. Nhớ rằng mỗi lữ khách có một lựa chọn trong bốn phương tiện giao thông. Ví dụ, các xác suất đi lại bằng máy bay, tàu hỏa, xe buýt và xe hơi riêng cho lữ khách thứ nhất trong ví dụ của chúng ta lần lượt là: 0.06, 0.28, 0.12, và 0.54; tổng của các xác suất này bằng 1. Các xác suất này cho thấy rằng lữ khách thứ nhất trong mẫu có thể chọn đi lại bằng xe hơi riêng.

14
Trong thực tế, anh ấy đã chọn đi lại bằng xe hơi. Dĩ nhiên, điều này không nhất thiết luôn luôn đúng cho tất cả các lữ khách.
Ngoài tỷ số odds, chúng ta cũng có thể tính ảnh hưởng biên của một sự thay đổi đơn vị trong giá trị của một biến giải thích lên các xác suất lựa chọn, khi tất cả các biến khác được giữ nguyên không đổi. Bạn sẽ nhớ lại rằng trong mô hình logit đa thức (MNL), tất cả các tham số dốc đều có liên quan đến việc xác định ảnh hưởng biên của một biến giải thích lên xác suất chọn phương án thứ m. Trái lại, trong mô hình logit có điều kiện (CLM), thì dấu của Bm, hệ số của biến giải thích thứ m, là dấu của ảnh hưởng biên của biến đó lên xác suất lựa chọn. Các tính toán thực sự của các ảnh hưởng biên này có thể được thực hiện bằng cách sử dụng thủ tục asclogit của Stata, chúng ta không theo đuổi vấn để này ở đây.
9.4 Mô hình logit hỗn hợp (MXL)
Như đã lưu ý, trong MLM chúng ta chỉ xem xét các thuộc tính đặc thù của chủ thể (subject-specific attributes), trong khi đó trong CLM chúng ta chỉ xem xét các đặc điểm hay thuộc tính đặc thù của lựa chọn. Nhưng trong MXL, chúng ta có thể bao gồm cả hai nhóm đặc điểm. Trong dữ liệu về phương tiện đi lại của chúng ta, chúng ta cũng có thông tin về thu nhập gia đình (hinc) và số thành viên (psize), tức số người đi du lịch cùng nhau. Đây là các đặc điểm đặc thù của chủ thể. Để đưa chúng vào phân tích, MXL tiến hành như sau:
Tương tác các biến đặc thù của chủ thể với ba phương tiện giao thông: air, train, và bus; nhớ rằng xe hơi riêng là phương tiện giao thông tham chiếu. Nói cách khác, nhân các biến đặc thù của chủ thể và ba phương tiện giao thông như sau:
Rồi sử dụng lệch clogit của Stata để có được các kết quả như được trình bày trong Bảng 9.6.
Một lần nữa, để giúp chúng ta giải thích các con số này, chúng ta sẽ tính các tỷ số odds (kết quả trình bày trong Bảng 9.7).
Tỷ số odds của biến thời gian chờ (terminal time), thời gian trên xe (in-vehicle time), và thời gian đi lại (travel time) cho biết một sự gia tăng đơn vị trong giá trị của mỗi biến này làm giảm sự hấp dẫn của phương tiện đó so với đi lại bằng xe hơi riêng. Nếu bạn nhìn vào tỷ số odds của các biến tương tác, ví dụ của thu nhập, chúng ta thấy rằng một sự gia tăng đơn vị trong thu nhập gia đình, làm giảm tỷ số odds của đi lại bằng tàu hỏa khoảng 5.75% [(1 – 0.94250)*100%], khi tất cả các yếu tố khác được giữ nguyên. Tương tự, nếu số thành viên đi cùng tăng thêm một người, thì tỷ số odds của đi lại bằng máy bay giảm khoảng 60.25% [(1 – 0.3975)*100%], khi tất cả các yếu tốt khác được giữ nguyên.
Chúng ta để cho bạn đọc tự giải thích các tỷ số odds khác.

15
Bảng 9.6: Mô hình logit có điều kiện hỗn hợp về phương tiện đi lại.
Bảng 9.7: Mô hình logit có điều kiện hỗn hợp về phương tiện đi lại: các tỷ số odds.

16
9.5 Tóm tắt và kết luận
Trong chương này, chúng ta đã xem xét ba mô hình: logit đa thức (MNL), logit có điều kiện (CLM), và logit hỗn hợp (MXL). Đối diện với các lựa chọn trong nhiều tình huống, các mô hình này cố gắng ước lượng các xác suất lựa chọn, nghĩa là, các xác suất chọn một phương án tốt nhất, tốt nhất theo nghĩa tối đa hóa sự hữu dụng hoặc sự thỏa mãn của người ra quyết định.
Trong mô hình MLM, các xác suất lựa chọn dựa trên các đặc điểm của cá nhân, trong khi đó trong mô hình CLM thì các xác suất này dựa trên các đặc điểm đặc thù của lựa chọn. Trong mô hình MXL, chúng ta kết hợp cả các đặc điểm đặc thù của cá nhân và các đặc điểm đặc thù của lựa chọn.
Tất cả các mô hình này đều được ước lượng bằng phương pháp hợp lý tối đa, vì các mô hình này là phi tuyến rất cao.
Một khi các mô hình đã được ước lượng, thì chúng ta có thể giải thích các hệ số thô (raw coefficients) hoặc chuyển chúng sang các tỷ số odds, vì các tỷ số odds dễ giải thích hơn. Chúng ta cũng có thể đánh giá đóng góp biên của các biến giải thích đến xác suất lựa chọn, mặc dù các tính toán này đôi khi là phức tạp. Tuy nhiên, các phần mềm thống kê như Stata có thể tính toán các ảnh hưởng biên tương đối dễ dàng.
Mục tiêu chính khi thảo luận các chủ đề này trong chương này là nhằm giới thiệu cho người bắt đầu về một lĩnh vực rất rộng của các mô hình đa lựa chọn. Ví dụ minh họa trong chương này cho thấy chúng ta có thể tiếp cận các mô hình này như thế nào. Một khi đã hiểu các vấn đề cơ bản, bạn đọc có thể tiếp tục chủ đề thách thức hơn trong lĩnh vực này bằng cách tìm hiểu các tài liệu tham khảo16. Các chủ đề nâng cao hơn nằm ngoài phạm vi của cuốn sách này. Nhưng chúng ta sẽ thảo luận thêm một chủ đề trong lĩnh vực này, đó là mô hình logit thứ bậc (ordinal or ordered logit) trong chương tiếp theo.
Kết luận, một cảnh báo cần lưu ý. Các mô hình được thảo luận trong chương này dựa trên giả định IIA, tức sự độc lập của các phương án không liên quan, nó có thể không phải lúc nào cũng đứng vững trong mỗi trường hợp trong thực tế. Nhớ lại ví dụ ‘xe buýt đỏ, xe buýt xanh’ mà chúng ta đã thảo luận trước đây. Mặc dù chúng ta có thể sử dụng các kiểm định theo kiểu Hausman để đánh giá IIA, nhưng các kiểm định này không phải lúc nào cũng cho ra kết quả tốt trong thực tế. Tuy nhiên, có nhiều kỹ thuật thay thế khác để xử lý vấn đề IIA, các kỹ thuật này chúng ta có thể tham khảo trong giáo trình của Long và Freese đã được trích dẫn trước đây.
16 Xem, Christiaan Heji, Paul de Boer, Philip Hans Frances, Teun Klock and Herman K. van Dijk, Econometrics Mthods with Applications in Economics and Business, Oxford University Press, UK, 2004, Ch. 6; A. Colin Cameron and Pravin K Trevedi, Microeconometrics: Methods and Applications, Cambridge University Press, New York, 2005, Ch. 15; Philip Hans Frances and Richard Papp, Quantitative Models in Marketing Research, Cambridge University Press, Cambridge, UK, 2001, Ch. 5.

17
Hướng dẫn Stata ( )
Mô tả các biến trong tập dữ liệu Table 9.1.
Mô tả biến lựa chọn trường: school choice.
Mô tả biến về giáo dục cao nhất của cha mẹ.

18
Mối quan hệ giữa giáo dục cao nhất của cha mẹ và chọn trường:
. tab parcoll psechoice, row
Thống kê tóm tắt các biến trong tập dữ liệu Table 9.1.

19
Liệt kê giá trị của các biến của cá nhân thứ 10 trong tập dữ liệu:
[
Các lệnh trong mô hình MLM:
Ước lượng mô hình:
mlogit psechoice hscath grades faminc famsiz parcoll female black, base(1)
[nếu lựa chọn 2 hoặc 3 làm phân loại cơ sở thì ta dùng base(2), base(3)]
Tính tỷ số odds hoặc tỷ số rủi ro tương đối (RRR):
mlogit psechoice hscath grades faminc famsiz parcoll female black, rrr base(1)
Tính xác suất các lựa chọn:
margins, atmeans hoặc margins, at(x1 =? X2 = ? … ) và sau đó vẽ đồ thị các xác suất lựa chọn bằng lệnh marginsplot.
20

21
. mlogit psechoice hscath grades faminc famsiz parcoll female black, rrr base(1)

22
. mlogit psechoice hscath grades faminc famsiz parcoll female black, rrr base(2)
. mlogit psechoice hscath grades faminc famsiz parcoll female black, rrr base(3)
23
. mlogit psechoice hscath grades faminc famsiz parcoll female black, base(1)
[
. mlogit psechoice hscath grades faminc famsiz parcoll female black, base(2)

24
. marginsplot
.2.3
.4.5
.6
Pro
bab
ility
1 2 3Outcome
Adjusted Predictions with 95% CIs

25
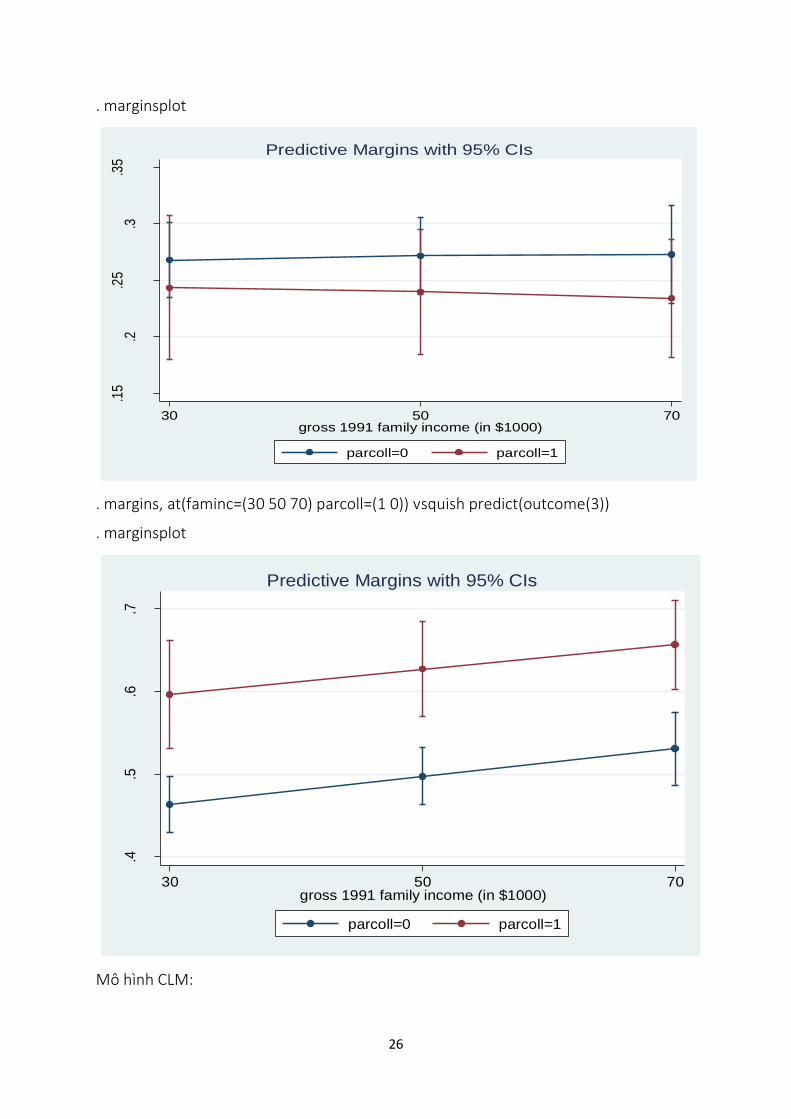
. margins, at(faminc=(30 50 70) parcoll=(1 0)) vsquish predict(outcome(1))
. marginsplot
. margins, at(faminc=(30 50 70) parcoll=(1 0)) vsquish predict(outcome(3))
.05
.1.1
5.2
.25
.3
Pr(
Pse
choic
e=
=1
)
30 50 70gross 1991 family income (in $1000)
parcoll=0 parcoll=1
Predictive Margins with 95% CIs
26
. marginsplot
. margins, at(faminc=(30 50 70) parcoll=(1 0)) vsquish predict(outcome(3))
. marginsplot
Mô hình CLM:
.15
.2.2
5.3
.35
Pr(
Pse
choi
ce=
=2)
30 50 70gross 1991 family income (in $1000)
parcoll=0 parcoll=1
Predictive Margins with 95% CIs
.4.5
.6.7
Pr(
Pse
choic
e=
=3
)
30 50 70gross 1991 family income (in $1000)
parcoll=0 parcoll=1
Predictive Margins with 95% CIs

27
. use "D:\My Blog\Econometrics by example\Table9_3.dta", clear

28

29
Sau khi hồi quy, chúng ta gỏ lệnh predict prob
list id prob in 1/20
Chúng ta sẽ thấy các xác suất lựa chọn từng phương tiện của 5 người đầu tiên:
asclogit choice termtime invehiclecost traveltime travelcost, case(id) alternatives(mode) basealternative(4) nolog

30
asclogit choice termtime invehiclecost traveltime travelcost, case(id) alternatives(mode) basealternative(4) nolog or
Mô hình MXL:

31
asclogit choice termtime invehiclecost traveltime travelcost, case(id) alternatives(mode) basealternative(4) casevars(income partysize) nolog
asclogit choice termtime invehiclecost traveltime travelcost, case(id) alternatives(mode) basealternative(4) casevars(income partysize) nolog or

32





























