Embed Size (px)
Citation preview

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 1/87
The Essentials of Computer Organization and Architecture (Null & Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 2/87
The Essentials of Computer Organization and Architecture (Null & Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 3/87
So named because they originally offered asmaller instruction set as compared to CISC
machines. The original idea was to provide a set of
minimal instructions that could carry out allessential operations: data movement, ALU
operations, and branching. Only explicit load and store instructions
were permitted access to memory.
The Essential of Computer Organization and Architecture (Nul l & Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 4/87
Complex instructions set designs were motivated bythe high cost of memory. Having more complexitypacked into each instruction meant that programscould be smaller, thus occupying less storage.
CISCA ISAs employ variable-length instructions, whichkeep the simple instructions short, while also allowingfor longer, more complicated instructions.
Include a large number of instructions that directlyaccess memory ² dense, powerful, variable-lengthsetoff instructions, which results in a varying number ofclock cycles per instruction.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 5/87
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 6/87
Computer performance, as measured by program execution
time, is directly proportional to clock cycle time, the number
of clock cycles per instruction, and the number of instructions
in the program. Shortening the clock cycle, when possible,
results in improved performance for RISC as well as CI
SC.
Otherwise, CISC machines increase performance by
reducing the number of instructions per program. RISC
computers minimize the number of cycles per instruction. Yet,
both architectures can produce identical results in
approximately the same amount of time.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 7/87
CISC machines rely on microcode to tackle instruction
complexity. Microcode tells the processor how to
execute each instruction.
RISC architectures take a different approach. Most RISC
instructions execute in one clock cycle. To accomplish
this speed up, microprogrammed control is replaced by
hardwire control, which is faster at executing
instructions. This makes it easier to do instructionpipelining, but more difficult to deal with complexity at
the hardware level.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 8/87
Over the years, several attempts have
been made to find a satisfactory way to
categorize computer architectures. Themost accepted taxonomy is the one
proposed by Michael Flynn in 1972.
Flynn·s taxonomy considers two factors:
¾ The number of instructions
¾ The number of data steams that flow into theprocessor.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 9/87
A machine can have either one or multiplestreams of data, and can have either oneor multiple processors working on this data.
This gives us 4 possible combinations:SISD (Single instruction stream, single data stream);
SIMD (Single instruction stream, multiple data stream);
MISD (multiple instruction streams, single data
stream);
MIMD (multiple instruction stream, multiple data
stream).
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 10/87
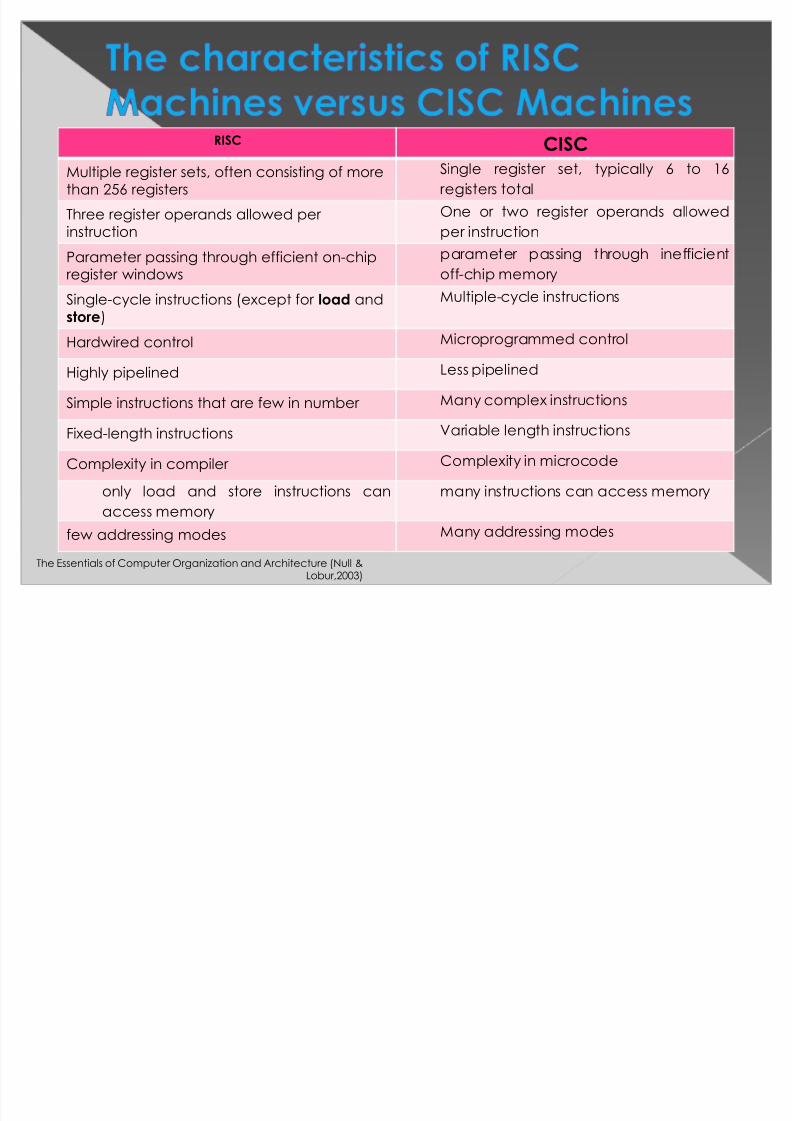
RISC CISC
Multiple register sets, often consisting of more
than 256 registers
Single register set, typically 6 to 16
registers total
Three register operands allowed per
instruction
One or two register operands allowed
per instruction
Parameter passing through efficient on-chip
register windows
parameter passing through inefficient
off-chip memorySingle-cycle instructions (except for load and
store)
Multiple-cycle instructions
Hardwired control Microprogrammed control
Highly pipelined Less pipelined
Simple instructions that are few in number Many complex instructions
Fixed-length instructions Variable length instructions
Complexity in compiler Complexity in microcode
only load and store instructions can
access memory
many instructions can access memory
few addressing modes Many addressing modes
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 11/87

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 12/87
Dedicated
Cluster Parallel
Computer(DCPC)- collection of workstations
specifically collected to work on a givenparallel computation. The workstationshave common software and file systems,are managed by a single entity,communicate via the Internet, and aren·tused as workstations.
Pile of PCs (POPC) ² is a cluster of
dedicated heterogeneous hardware usedto build a parallel system.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 13/87
The power of today·s digital computers is
strongly astounding. Internal processor
parallelism has contributed to thisincreased power through superscalar ad
superpipelined architectures.
Superscalar is a design methodology that
allows multiple instructions to be executedsimultaneously in each cycle.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 14/87
Execution units are superscalar components. Execution units consist offloating-point adders and multipliers,integer adders and multipliers, and other specialized components.
Instruction fetch unit retrieves multipleinstructions simultaneously from memory.This unit, in turn, passes the instructions to acomplex decoding unit that determines
whether the instructions are independent or whether a dependency of some sort exists.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 15/87
VLIW processors rely entirely onthe compiler. They are packedwith independent instructions into
one long instruction, which, inturn, tells the execution units whatto do.
VLIW compiler creates very longinstructions.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 16/87
Often referred to as supercomputers.
They are specialized, heavily pipelined
processors that perform efficient
operations on entire vectors andmatrices at once. This class of processor
is suited for applications that can benefit
from a high degree of parallelism, such
as weather forecasting, medicaldiagnoses, and image processing.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 17/87
are often divided into two categories
according to how the instructions access
their operands:Register-register vector processors require that
all operations use registers as source anddestination operands.
Memory-memory vector processors allowoperands from memory to be routed directlyto the arithmetic unit. The results of the
operation are then streamed back to memory.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 18/87
are specialized registers that can hold
several vector elements at one time. The
register element are sent one element ata time to a vector pipeline, and the
output from the pipeline is sent back to
the vector registers one element at a
time. These registers are, therefore, FIFO queues capable of holding many values.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 19/87
Interconnection networks
are often categorizedaccording to topology,
routing strategy, and
switching technique.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 20/87
The Network Topology is the way in
which the components areinterconnected is a major determining
factor in the overhead cost of passingmessage. Message passing efficiency is
limited by:Bandwith ² the information carrying capacity
of the network.
Message Latency ² the time required for thefirst bit of a message to reach its destination.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 21/87
T ransport latency ² the time the messagespends in the network.
Overhead ² Message processing activitiesin the sender and receiver.
Interconnection networks can be either:Static ² are used mainly for message passing
and include a variety of types, many of whichare familiar. Processors are typicallyinterconnected using static networks, whereasprocessor memory pairs usually employdynamic networks.
Dynamic ² allow the path between twoentities (either two processors or aprocessor and a memory) to change fromone communication to the next.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 22/87
are those in which all components areconnected to all other components.Star-connected networks have a central hub
through which all messages must pass.Linear array/ring networks allow any entity to
directly communicate with its two neighbors, but
any other communication has to go through
multiple entities to arrive at its destination.
Mesh network links entity to four or six neighbors.Extensions of this network include those that wraparound, similar to how a linear network can wrap
around to form a ring.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 23/87
arrange entities in noncyclic structures, whichhave the potential for communicationbottlenecks forming at the roots.
Hypercube networks are multidimensional
extensions of mesh networks in which dimensionhas two processors.
Some highly complex problems cannot be
solved using the traditional model ofcomputation. Alternative architectures are
necessary for specific applications.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 24/87
Dataflow computers allow data to drivecomputation, rather than the other way
around. Neutral networks learn to solve
problems of the highest complexity.
Systolic arrays harness the power ofsmall processing elements, pushing data
throughout the array until the problem issolved.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 25/87
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
PERFORMANCEPERFORMANCE
MEASUREMENT ANDMEASUREMENT ANDANALYSISANALYSIS

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 26/87
This equation is fundamental in
measuring computer performance and
measures the CPU time:
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 27/87
Where the time per program is therequired CPU time. Analysis of this revealsthat CPU optimization can have adramatic effect on performance basedon this equation.
RISC machines try to reduce the number of cycles per instruction, and CISCmachines try to reduce the number of
instructions per program.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 28/87
CPU optimization is not only the way toincrease system performance. Memoryand I/O also weigh heavily on systemthroughput.
For increasing the overall performanceof a system, we have the followingoptions:CPU optimization ² maximize the speed and
efficiency of operations performed by the CPU(the performance equation addresses thisoptimization).
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 29/87
Memory optimization ² Maximize the
efficiency of a code·s memorymanagement.
I/O optimization ² Maximize the
efficiency of input/output operations.
An application whose overall
performance is limited by one of theabove is said to be CPU bound, or I/O bound, respectively.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 30/87
Computer performance assessment is a
quantitative science. Mathematical andstatistical tools give us many ways in
which to rate the overall performance ofa system and the performance of its
constituent components.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 31/87
In comparing the performance of two
systems we measure the time that ittakes for each system to perform the
same amount of work. If the sameprogram is run on two systems, System A
is n times as fast as System B if:
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 32/87
System A is x% faster than System B if:
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
These formulas are useful in comparing the average
performance of one system with the averageperformance another.

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 33/87
if we have five measurements, and we addthem together and divide by five, then theresult is the arithmetic mean. When peoplerefer to the average results of some metric
they are actually referring to the arithmeticaverage of the price sampled at somegiven frequency.
When it is used properly, the weightedarithmetic mean improves on the arithmetic
average because it can give us a clear picture of the expected behaviour of thesystem.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 34/87
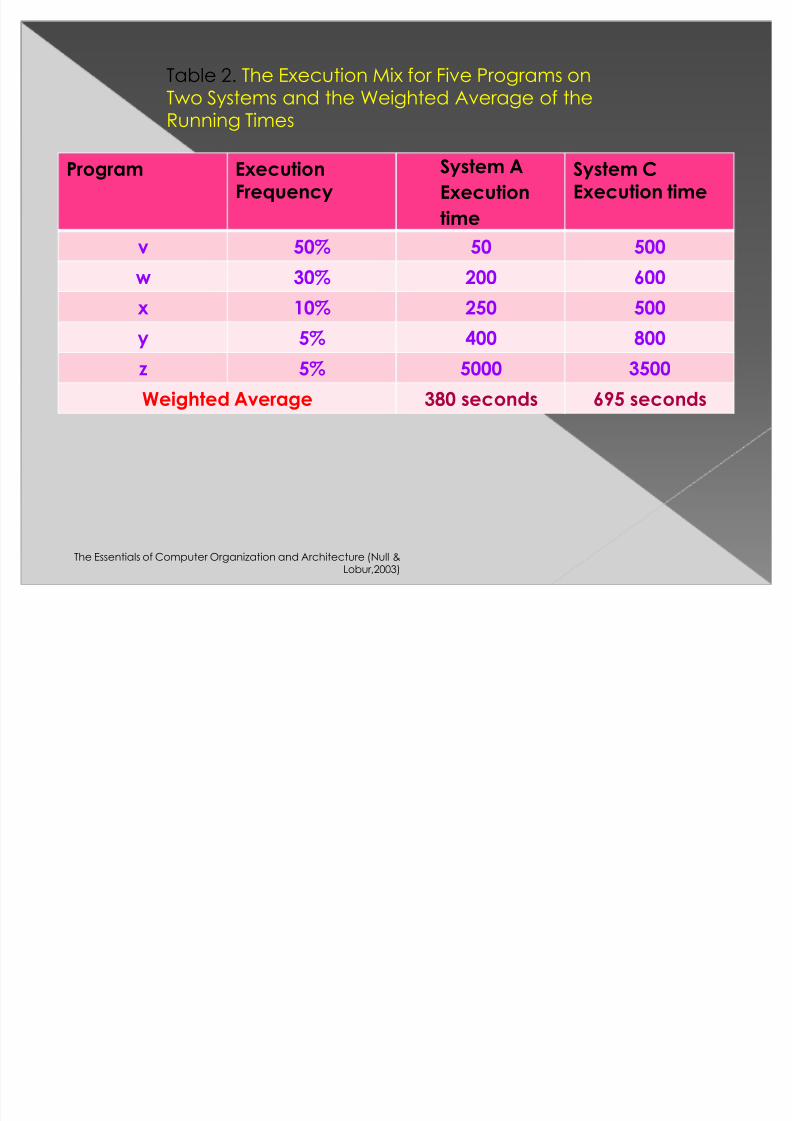
Program Execution
Frequency
System A
Execution
time
SystemC
Execution time
v 50% 50 500
w 30% 200 600x 10% 250 500
y 5% 400 800
z 5% 5000 3500
WeightedAverage 380 seconds 695 seconds
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
Table 2. The Execution Mix for Five Programs onTwo Systems and the Weighted Average of theRunning Times

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 35/87
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
For example, on System A, for every 100 of thecombined executions of programs v , w, x, y,
and z, program runs 5 times. The weightedaverage of the execution times for these fiveprograms running on System A is:
50 X 0.5 + 200 X 0.3 + 250 X 0.1 + 400 X 0.05 + 5000 X 0.05 = 380.
A similar calculation reveals that the weightedaverage of the execution times for these fiveprograms running on System B is 695 seconds.Using the weighted average, we now seeclearly that System A is about 83% faster thanSystem C for this particular workload.

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 36/87
Computer buyers are often intimidated
by the numbers cited in computer sales
literature. Even when the correct
statistics are used, they are not easy for many people to understand. The
´quantitativeµ information supplied by
vendors always lends an aura of
credibility to the vendor·s claims ofsuperior performance.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 37/87
Reputable vendors cite these
measurements without distortion. Buteven excellent metrics are subject to
misuse.
Some important fallacies that one may
likely to encounter in buying software or
hardware:
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 38/87
In early 2002, a full page advertisement
was running in major business and trade
magazines. The gist of the add was, ´W e ran a test of our product and published
the results. Vendor X did not publish
results for the same test for his product,
therefore, our product is faster.µ
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 39/87
All you really know are the statistics cited in
the ad. It says absolutely nothing about therelative performance of the products. Sometimes, the fallacy of incomplete
information takes the form of a vendor citing only the good test results while failing
to mention that less favourable test resultswere also obtained on the same system atthe same time.
Another way in which incompleteinformation manifests itself is when a vendor cites only ´peakµ performance numbers,omitting the average or more commonlyexpected case.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 40/87
Imprecise words such as ´more,µ ´less,µ
µnearly,µ ´practically,µ ´almost,µ and
their synonyms should always raiseimmediate alarm when cited in the
context of assessing the relative
performance of systems.
If these terms are supported withappropriate data, their use may be
justified.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 41/87
This fallacy is by far the most common, andusually the hardest to defend against in acrowd (such as a computer procurementcommittee).
The pitch is, ´Our product is used by x% of theFortune 500 list of the largest companies inAmerica.µ
These nonquantitative considerations areindeed important factors in systems and
software selection. However, just because x%of the Fortune 500 use the product, it doesn·tmean that the product is suitable for your business.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 42/87
Performance Benchmarking Is the
science of making objective assessments
of the performance of one system over another.
Benchmarks are also useful for assessingperformance improvements obtained by
upgrading a computer or itscomponents.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 43/87
Good benchmarks enable to us to cut
through advertising hype and statisticaltricks.
Ultimately, good benchmarks will identify
the systems that provide goodperformance, at the most reasonable
cost.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 44/87
CPU speed, by itself, is a misleading
metric that is most often used by
computer vendors touting their systems·alleged superiority to all others.
A widely cited metric related to clock
rate is the millions of instructions per
second ( MIP S) metric.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 45/87
This measures the rate at which the systemcan execute a typical mix of floating pointand integer arithmetic instructions, as well
as logical operations. The greatest weakness of this metric is that
different machine architectures oftenrequire a different number of machine
cycles to carry out a given task. The MIPS metric does not take into account
the number of instructions necessary tocomplete a specific task.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 46/87
Megaflops (MFLOPS) is a metric that was originallyused in describing the power of supercomputers, butis now cited in personal computer literature.
The FLOPS metric is even more vexing than the MIPS metric because there is no agreement as to whatconstitutes a floating-point operation.
Furthermore, some computers use no floating-pointinstructions at all. Because the FLOPS metric takes intoaccount only floating-point operations, based solely
on this metric, these systems would be utterlyworthless. Nevertheless,MFLOPS, like MIPS, is a popular metric
with marketing people because it sounds like a´hardµ value and represents a simple and intuitiveconcept.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 47/87
Computer researchers have long sought
to define a single benchmark that would
allow fair and reliable performancecomparisons yet be independent of the
organization and architecture of any
type of system.
The quest for the ideal performancemeasure started in earnest in the late
1980s.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 48/87
It follows that one could write a programusing a third-generation language (such as
C), compile it and run it on various systems,and then measure the elapsed time for each run of the program o various systems.
The resulting execution time would lead toa single performance metric across all ofthe systems tested. Performance metricsderived in this manner are called manner are called synthetic benchmarks, becausethey don·t necessarily represent anyparticular workload or application.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 49/87
Three of the better known benchmarks
are the
Whetstone,
Linpack,
Dhrystone metrics.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 50/87
Whetstone benchmarking program waspublished in 1976 by Harold J. Curnow andBrian A. Wichman of the British NationalPhysical Laboratory.
Whetstone is floating-point intensive, withmany calls to library routines for computation of trigonometric andexponential functions.
Results are reported in Kilo-WhetstoneInstructions per Second (KWIPS) of Mega-Whetstone Instructions per Second (MWIPS).
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 51/87
Is a contraction of LINear algebra PACKage , isa collection of subroutines called Basic Linear Algebra Subroutines (BL AS), which solve
systems of linear equations using double-precision arithmetic.
Jack Dongarra, Jim Bunch, Cleve Moler , andPete Stewart of the Argonne NationalLaboratory developed Linpack in 1984 tomeasure the performance of supercomputers.
It was originally written in FORTRAN 77 and hassubsequently been rewritten in C and Java.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 52/87
High-speed floating-point calculationscertainly aren·t important to everycomputer user. Recognizing this, Reinhold P.
Weicker of Siemens Nixdorf InformationSystems wrote a benchmarking program in1984 that focused in string manipulationand integer operations.
He called his program the Dhrystone
benchmark . The program is CPU bound,performing no I/O or system calls.
Dhrystone results are reported as Dhrystoneper second, not in DIPS or Mega-DIPS.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 53/87
Used to devise a more complex
benchmark that also produces easilyunderstood results.
Was founded in 1988 by a consortium of
computer manufacturers in cooperation
with the Electrical Engineering Times.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 54/87
Today, this group encompasses over 60member companies and three constituentcommittees. These committees are the:
Open Systems Group (OSG), which addressesworkstation, file server, and desktop computingenvironments.
High-Performance Group (HPG), which focuseson enterprise-level multiprocessor systems andsupercomputers.
Graphics Performance Characterization Group(GPC), which concentrates on multimedia and
graphics-intensive systems.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 55/87
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)
Network
Organization and
Architecture

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 56/87
The United States government createdan organization called the AdvancedResearch P rojects Agency ( ARP A )for advancement of their technology.
It occurred to someone that byestablishing communication links into the
few supercomputers that were scatteredall over the United States, computationalresources could be shared by like-minded researchers (ARPAnet).
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 57/87
ARPAnet gradually expanded to includemore government and research institutions.
President Reagan changed the name ofARPA to the Defense Advanced ResearchProjects Network (D ARPA), ARPAnet
became DARPAnet.
However, military researchers eventuallyabandoned DARPAnet in favor of more
secure channels.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 58/87
In 1985, the National Science Foundation
established its own network, NSFnet, tosupport its scientific and academic
research.
Consequently, when the militaryabandoned DARPAnet, NSFnet
absorbed it, and became what we nowknow as the Internet.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 59/87
Datagram was the protocol device responsible for the robustness of DARPAnet.
Because it connected many different kinds ofnetworks, DARPAnet was said to be Internetwork.
Internet Message Processor (IMP) took care ofprotocol translation from the language of DARPAnet
to the communications language native to the hostsystem.
The idea of the Internet is a free and open world ofinformation sharing, with the destiny of this world
being shaped collaboratively by the people andideas in it.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 60/87
Internet standards are formulated through ademocratic process that takes place under
the auspices of the Internet ArchitectureBoard (IAB) , which itself operates under theoversight of the non-profit Internet Society(ISOC).
The Internet Engineering Task Force (IETF) isa loose alliance of industry experts thatdevelops detailed specifications for Internet
protocols.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 61/87
The IETF publishes all proposed standards
in the form of Requests for Comment(RFCs).
The two most important RFCs ² RFC 791
(Internet Protocol Version 4) and RFC 793
(Transmission Control Protocol)- form the
foundation of today·s global Internet.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 62/87
Is the theoretical model for many
storage and data communicationinterfaces and protocols.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 63/87
Open systems means that systemconnectivity would not be proprietary toany single vendor.
The ISO·s work is called a reference modelbecause virtually no commercial systemuses all of the features precisely as specifiedin the model.
The OSI RM contains seven protocol layers,starting with physical mediainterconnections at Layer 1, throughapplications at Layer 7.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 64/87
Assumes the job of carrying a signal from
here to there.
It receives a stream of bits from the DataLink layer above it, encodes those bits,
and places them on thecommunications medium in
accordance with agreed-on protocolsand signaling standards.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 65/87
Organizes message bytes into frames of
suitable size for transmission along the
physical medium.
The timing of frame transmission is called
flow control.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 66/87
The Network layer doesn·t do much
except add addressing information to
the PDUs from the Transport layer , andthen pass them on to the Data Link layer.
This layer also ensures that the size of itsPDUs is compatible with all of the
equipment between the source and thedestination.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 67/87
Provides quality assurance functions for the layers above it in the protocol stack.
It contributes yet another level of end-to-end acknowledgment and error correction through its handshaking withthe Transport Layer at the other end ofthe connection.
This is the lowest layer of the OSI modelat which there is any awareness of thenetwork or its protocols.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 68/87
This layer arbitrates the dialogue betweentwo communicating nodes, opening andclosing that dialogue as necessary.
It controls the direction and mode, which iseither half-duplex (one direction at a time)or full-duplex (in both directions at once ).
Checkpoints are issued each time a
packet, or block of data, areacknowledged as received in goodcondition.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 69/87
Provides high-level data interpretation
services for the Application layer above
it. Presentation layer services are also
called into play if we use encryption or certain types of data compression during
the communication session.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 70/87
Supplies meaningful information and
services to users at one end of the
communication and interfaces withsystem resources (programs and data
files) at the other end of the
communication.
Provides a suite of programs that can beinvoked as the user sees fit.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 71/87
TCP/IP, because of its popularity within
the academic and scientific
communications communities, becamethe de facto global data
communication standard.
There are two versions of the Internet
Protocol in use today, Version 4 andVersion 6.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 72/87
It divides TCP packets into protocol data
units called datagrams, and then
attaches the routing informationrequired to get the datagrams to their
destinations.
Other fields for the IPv4 header are:
Version ² specifies the IP protocol versionbeing used.
Header length - gives the length of the header in 32-bit words.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 73/87
Type of Service ² controls the priority that the
datagram is given intermediate nodes.
Total Length ² gives the length of the entire IPdatagram in bytes.
Packet ID ² each datagram is assigned aserial number as it is placed on the network.
Flags ² specify whether the datagram may be
fragmented by intermediate node.
Fragment offset ² indicates the location of afragment within a certain datagram.
Time to Live (TTL) ² originally intended to
measure the number of seconds for which thedatagram would remain valid.
Protocol Number ² indicates which higher
layer protocol is sending the data that follows
the header. The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 74/87
Header Checksum ² this field iscalculated by first calculating the one·s
complement sum of all 16-bit words inthe header, and then taking the one·scomplement of this sum.
Source and Destination Address ² tellwhere the datagram is going.
IP Options ² Provides diagnosticinformation and routing controls.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 75/87
The IETF·s primary motivation in designing a successor to IPv4 was to extend IP·s address space beyond itscurrent 32-bit limit to 128 bits for both the source andthe destination host address.
The downside of having such a large address space
is that address management becomes critical. Ifaddresses are assigned haphazardly with noorganization in mind, effective packet routing wouldbecome impossible.
To head off this problem, the IETF came up with thehierarchical address organization that it calls theAggregatable Global Unicast Address Format.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 76/87
Version ² Always 0110 Traffic Class ² Ipv6 will eventually be able to tell the
difference between real-time transmissions and less time-sensitive data transport traffic.
Flow Label ² identifies a particular flow stream and
intermediate routers will route the packets in a manner consistent with the code in the flow field. Payload Length ² indicates the length of the payload in
bytes, which includes the size of additional headers. Next Header ² Indicates the type of header that follows
the main header.
Hop Limit ² with 16 bits, this field is much larger than inVersion 4, allowing 256 Hops.
Source and Destination Addresses ² Much larger, but withthe same meaning as in Version 4.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 77/87
Computer networks are oftenclassified according to their
geographic service areas.
The Essentials of Computer Organization and Architecture (Null &Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 78/87
Smallest networks.
LANs are typically used in a singlebuilding, or a group of buildings that arenear each other.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 79/87
networks that cover a city and its
environs.
Often span areas that are not under theownership of the people who also own
the network.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 80/87
Can cover multiple cities,
or span the entire world.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 81/87
There two general types of communicationsmedia : Guided transmission media andunguided transmission media.
Unguided media broadcast data over theairwaves using infrared, microwave,satellite, or broadcast radio carrier signals.
Guided media are physical connectors
such as copper wire or fiber optic cablethat directly connect each network node.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 82/87
Transmission media are connected to
clients, hosts, and other network devices
through network interfaces. Because these interfaces are often
implemented on removable circuitboards, they are commonly called
network interface cards, or simply NICs.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 83/87
In theory, they are dumb devices
functioning entirely without human
intervention. As such, they would containno network-addressable components.
However, some repeaters now offer high-level services to assist with network
management and troubleshooting.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 84/87
They receive incoming packetsfrom one or more locations and
broadcast the packets to one or more devices on the network.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 85/87
Layer 2 device that creates a point-to-
point connection between one of its
input ports and one of its output ports.
Can handle multiple communications
between the computers attached to
them.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 86/87
Provide a link between two similar network segments. Both can supportdifferent media.
Bridges join two similar types of networksso they look like one network.
A gateway is a point of entrance toanother network. Gateways are full-
featured computers that supplycommunications services spanning allseven OSI layers.
The Essentials of Computer Organization and Architecture (Null &
Lobur,2003)

8/8/2019 Computer Architecture - FINALS
http://slidepdf.com/reader/full/computer-architecture-finals 87/87
A router is a device or a piece of
software connected to at least two
networks that determine the destinationto which a packet should be forwarded.
Operating correctly, they make the
network fast and responsive.





























