Embed Size (px)
Citation preview

Cooperative Secondary Authorization RecyclingQiang Wei, Student Member, IEEE, Matei Ripeanu, and
Konstantin Beznosov, Member, IEEE
Abstract—As enterprise systems, Grids, and other distributed applications scale up and become increasingly complex, their
authorization infrastructures—based predominantly on the request-response paradigm—are facing the challenges of fragility and poor
scalability. We propose an approach where each application server recycles previously received authorizations and shares them with
other application servers to mask authorization server failures and network delays. This paper presents the design of our cooperative
secondary authorization recycling system and its evaluation using simulation and prototype implementation. The results demonstrate
that our approach improves the availability and performance of authorization infrastructures. Specifically, by sharing authorizations,
the cache hit rate—an indirect metric of availability—can reach 70 percent, even when only 10 percent of authorizations are cached.
Depending on the deployment scenario, the average time for authorizing an application request can be reduced by up to a factor of
two compared with systems that do not employ cooperation.
Index Terms—Access control, authorization recycling, cooperative secondary authorization recycling, cooperation.
Ç
1 INTRODUCTION
ARCHITECTURES of modern access control solutions [1], [2],[3], [4], [5] are based on the request-response para-
digm, illustrated in the dashed box in Fig. 1. In thisparadigm, a policy enforcement point (PEP) interceptsapplication requests, obtains access control decisions (a.k.a.authorizations) from the policy decision point (PDP), andenforces those decisions.
In large enterprise systems, PDPs are commonly imple-
mented as logically centralized authorization servers, provid-
ing important benefits: consistent policy enforcement across
multiple PEPs and reduced administration costs of author-
ization policies. As with all centralized architectures, this
architecture has two critical drawbacks: the PDP is a single
point of failure, as well as a potential performance bottleneck.The single point of failure property of the PDP leads to
reduced availability: the authorization server may not be
reachable due to a failure (transient, intermittent, or
permanent) of the network, of the software located in the
critical path (e.g., OS), of the hardware, or even from a
misconfiguration of the supporting infrastructure. A con-
ventional approach to improving the availability of a
distributed infrastructure is failure masking through re-
dundancy of either information or time or through physical
redundancy [6]. However, redundancy and other general
purpose fault-tolerant techniques for distributed systems
scale poorly and become technically and economically
infeasible when the number of entities in the system reaches
thousands [7], [8]. (For instance, eBay has 12,000 servers and
15,000 application server instances [9].)
In a massive-scale enterprise system with nontrivialauthorization policies, making authorization decisions isoften computationally expensive due to the complexity ofthe policies involved and the large size of the resource anduser populations. Thus, the centralized PDP often becomesa performance bottleneck [10]. Additionally, the commu-nication delay between the PEP and the PDP can makeauthorization overhead prohibitively high.
The state-of-the-practice approach to improving overallsystem availability and reducing authorization processingdelays observed by the client is to cache authorizations at eachPEP—what we refer to as authorization recycling. Existingauthorization solutions commonly provide PEP-side caching[1], [2], [3]. These solutions, however, only employ a simpleform of authorization recycling: a cached authorization isreused only if the authorization request in question exactlymatches the original request for which the authorization wasmade. We refer to such reuse as precise recycling.
To improve authorization system availability and reducedelay, Crampton et al. [11] propose the Secondary andApproximate Authorization Model (SAAM), which adds asecondary decision point (SDP) to the request-responseparadigm (Fig. 1). The SDP is collocated with the PEP andcan resolve authorization requests not only by preciserecycling but also by computing approximate authorizationsfrom cached authorizations. The use of approximate author-izations improves the availability and performance of theaccess control subsystem, which ultimately improves theobserved availability and performance of the applicationsthemselves.
In SAAM, however, each SDP serves only its own PEP,which means that cached authorizations are reusable only forthe requests made through the same PEP. In this paper, wepropose an approach where SDPs cooperate to serve all PEPsin a community of applications. Our results show that SDPcooperation further improves the resilience of the authoriza-tion infrastructure to network and authorization serverfailures and reduces the delay in producing authorizations.
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009 275
. The authors are with the Department of Electrical and ComputerEngineering, University of British Columbia, 2332 Main Mall, Vancouver,BC V6T 1Z4, Canada. E-mail: {qiangw, matei, beznosov}@ece.ubc.ca.
Manuscript received 15 Oct. 2007; revised 27 Apr. 2008; accepted 8 May2008; published online 15 May 2008.Recommended for acceptance by M. Singhal.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number TPDS-2007-10-0378.Digital Object Identifier no. 10.1109/TPDS.2008.80.
1045-9219/09/$25.00 � 2009 IEEE Published by the IEEE Computer Society

We believe that our approach is especially applicable tothe distributed systems involving either cooperatingparties, such as Grid systems, or replicated services, suchas load-balanced clusters. Cooperating parties or repli-cated services usually have similar users and resourcesand use centralized authorization servers to enforceconsistent access control policies. Therefore, authorizationscan often be shared among parties or services, bringingbenefits to each other.
This paper makes the following contributions:
. We propose the concept of cooperative secondaryauthorization recycling (CSAR), analyze its designrequirements, and propose a concrete architecture.
. We use simulations and a prototype to evaluateCSAR’s feasibility and benefits. Evaluation resultsshow that by adding cooperation to SAAM, ourapproach further improves the availability andperformance of authorization infrastructures. Speci-fically, the overall cache hit rate can reach 70 percenteven with only 10 percent of authorizations cached.This high hit rate results in more requests beingresolved locally or by cooperating SDPs, when theauthorization server is unavailable or slow, thusincreasing the availability of authorization infrastruc-ture and reducing the load of the authorizationserver. Additionally, our experiments show thatrequest processing time can be reduced by up to afactor of two.
The rest of this paper is organized as follows: Section 2presents SAAM definitions and algorithms. Section 3 de-scribes CSAR design. Section 4 evaluates CSAR’s perfor-mance through simulation and a prototype implementation.Section 5 discusses related work. We conclude our work inSection 6.
2 SECONDARY AND APPROXIMATE AUTHORIZATION
MODEL (SAAM)
SAAM [11] is a general framework for making use ofcached PDP responses to compute approximate responses fornew authorization requests. An authorization request is atuple ðs; o; a; c; iÞ, where s is the subject, o is the object, a isthe access right, c is the request contextual information, andi is the request identifier. Two requests are equivalent if they
only differ in their identifiers. An authorization response torequest ðs; o; a; c; iÞ is a tuple ðr; i; E; dÞ, where r is theresponse identifier, i is the corresponding request identifier,d is the decision, and E is the evidence. The evidence is a listof response identifiers that were used for computing aresponse and can be used to verify the correctness of theresponse.
In addition, SAAM defines the primary, secondary,precise, and approximate authorization responses. Theprimary response is a response made by the PDP, and thesecondary response is a response produced by an SDP. Aresponse is precise if it is a primary response to the requestin question or a response to an equivalent request. Other-wise, if the SDP infers the response based on the responsesto other requests, the response is approximate.
In general, the SDP infers approximate responses basedon cached primary responses and any information that canbe deduced from the application request and systemenvironment. The greater the number of cached responses,the greater the information available to the SDP. As moreand more PDP responses are cached, the SDP will become abetter and better PDP simulator.
The above abstractions are independent of the specifics ofthe application and access control policy in question. For eachclass of access control policies, however, specific algorithmsfor inferring approximate responses—generated according toa particular access control policy—need to be provided. Thispaper is based on the SAAMBLP algorithms [11]—SAAMauthorization recycling algorithms for the Bell-LaPadula(BLP) access control model [12].
The BLP model specifies how information can flowwithin the system based on security labels attached to eachsubject and object. A security function � maps S [O to L,where S and O are sets of subjects and objects, and L is aset of security labels. Collectively, the labels form a lattice.The “� ” is a partial order relation between security labels(read as “is dominated by”). Subject s is allowed read
access to object o if s has discretionary read access to o and�ðoÞ � �ðsÞ, while append access is allowed if s hasdiscretionary write access to o and �ðoÞ � �ðsÞ.
The SAAMBLP inference algorithms use cached responsesto infer information about the relative ordering on securitylabels associated with subjects and objects. If, for example,three requests, ðs1; o1; read; c1; i1Þ, ðs2; o1; append; c2; i2Þ, andðs2; o2; read; c3; i3Þ are allowed by the PDP, and the corre-sponding responses are r1, r2 and r3, it can be inferred that�ðs1Þ > �ðo1Þ > �ðs2Þ > �ðo2Þ. Therefore, a request ðs1; o2;read; c4; i4Þ should also be allowed, and the correspondingresponse is ðr4; i4; ½r1; r2; r3�; allowÞ. SAAMBLP uses a specialdata structure called dominance graph to record the relativeordering on subject and object security labels and evaluates arequest by finding a path between two nodes in this directedacyclic graph.
Crampton et al. [11] present simulation results thatdemonstrate the effectiveness of their approach. With only10 percent of authorizations cached, the SDP can resolveover 30 percent more authorization requests than aconventional PEP with caching. CSAR is, in essence, adistributed version of SAAM. The distribution and co-operation among SDPs can further improve access controlsystem availability and performance, as our evaluationresults demonstrate.
276 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009
Fig. 1. SAAM adds an SDP to the traditional authorization system based
on the request-response paradigm.

3 COOPERATIVE SECONDARY AUTHORIZATION
RECYCLING (CSAR)
This section presents the design requirements for coopera-
tive authorization recycling, the CSAR system architecture
and, finally, the detailed CSAR design.
3.1 Design Requirements
The CSAR system aims to improve the availability and
performance of access control infrastructures by sharing
authorization information among cooperative SDPs. Each
SDP resolves the requests from its own PEP by locally
making secondary authorization decisions by involving
other cooperative SDPs in the authorization process and/or
by passing the request to the PDP.Since the system involves caching and cooperation, we
consider the following design requirements:
. Low overhead. As each SDP participates in makingauthorizations for some nonlocal requests, its load isincreased. The design should therefore minimizethis additional computational overhead.
. Ability to deal with malicious SDPs. As each PEPenforces responses that are possibly offered bynonlocal SDPs, the PEP should be prepared to dealwith those SDPs that after being compromisedbecome malicious. For example, it should verifythe validity of each secondary response by tracing itback to a trusted source.
. Consistency. Brewer [13] conjectures and Gilbertand Lynch [14] prove that distributed systemscannot simultaneously provide the following threeproperties: availability, consistency, and partitiontolerance. We believe that availability and partitiontolerance are essential properties that an accesscontrol system should offer. We thus relax consis-tency requirements in the following sense: withrespect to an update action, various components ofthe system can be inconsistent for at most a user-configured finite time interval.
. Configurability. The system should be configurableto adapt to different performance objectives atvarious deployments. For example, a deploymentwith a set of latency-sensitive applications mayrequire that requests are resolved in minimal time.A deployment with applications generating a highvolume of authorization requests, on the other hand,should attempt to eagerly exploit caching and theinference of approximate authorizations to reduceload on the PDP, the bottleneck of the system.
. Backward compatibility. The system should bebackward compatible so that minimal changes arerequired to existing infrastructures—i.e., PEPs andPDPs—in order to switch to CSAR.
3.2 System Architecture
This section presents an overview of the system architecture
and discusses our design decisions in addressing the
configurability and backward compatibility requirements.As illustrated in Fig. 2, a CSAR deployment contains
multiple PEPs, SDPs, and one PDP. Each SDP is host
collocated with its PEP at an application server. Both thePEP and SDP are either part of the application or of theunderlying middleware. The PDP is located at the authoriza-tion server and provides authorization decisions to allapplications. The PEPs mediate the application requestsfrom clients, generate authorization requests from applica-tion requests, and enforce the authorization decisions madeby either the PDP or SDPs.
For increased availability and lower load on the centralPDP, our design exploits the cooperation between SDPs.Each SDP computes responses to requests from its PEP andcan participate in computing responses to requests fromother SDPs. Thus, authorization requests and responses aretransferred not only between the application server and theauthorization server but also between cooperating applica-tion servers.
CSAR is configurable to optimize the performancerequirements of each individual deployment. Dependingon the specific application, geographic distribution, andnetwork characteristics of each individual deployment,performance objectives can vary from reducing the overallload on the PDP to minimizing client-perceived latency andto minimizing the network traffic generated.
Configurability is achieved by controlling the degree ofconcurrency in the set of operations involved in resolving arequest: 1) the local SDP can resolve the request using datacached locally, 2) the local SDP can forward the request toother cooperative SDPs to resolve it using their cached data,and 3) the local SDP can forward the request to the PDP. Ifthe performance objective is to reduce latency, then theabove three steps can be performed concurrently, and theSDP will use the first response received. If the objective is toreduce network traffic and/or the load at the central PDP,then the above three steps are performed sequentially.
CSAR is designed to be easily integrated with existingaccess control systems. Each SDP provides the same policyevaluation interface to its PEP as the PDP, thus the CSAR
WEI ET AL.: COOPERATIVE SECONDARY AUTHORIZATION RECYCLING 277
Fig. 2. CSAR introduces cooperation between SDPs.

system can be deployed incrementally without requiringany change to existing PEP or PDP components. Similarly,in systems that already employ authorization caching butdo not use CSAR, the SDP can offer the same interface andprotocol as the legacy component.
3.3 Discovery Service
One essential component enabling cooperative SDPs to sharetheir authorizations is the discovery service (DS), whichhelps an SDP find other SDPs that might be able to resolve arequest. A naive approach to implementing the discoveryfunctionality is request broadcasting: whenever an SDPreceives a request from its PEP, it broadcasts the request to allother cooperating SDPs. All SDPs attempt to resolve therequest, and the PEP enforces the response it receives first.This approach is straightforward and might be effectivewhen the number of cooperating SDPs is small, and the costof broadcasting is low. However, it has two importantdrawbacks. First, it inevitably increases the load on all SDPs.Second, it causes high traffic overhead when SDPs aregeographically distributed. To address these two drawbacks,we introduced the DS to achieve a selective requestsdistribution: an SDP in CSAR selectively sends requests onlyto those SDPs that are likely to be able to resolve them.
For an SDP to resolve a request, the SDP’s cache mustcontain at least both the subject and object of the request. Ifeither one is missing, there is no way for the SDP to infer therelationship between the subject and object and thus fails tocompute a secondary response. The role of the DS is to storeand retrieve the mapping between subject/object and SDPaddresses. In particular, the DS provides an interface withthe following two functions: put and get. Given a subject oran object and the address of an SDP, the put function storesthe mapping ðsubject=object; SDPaddressÞ. A put operationcan be interpreted as “this SDP knows something about thesubject/object.” Given a subject and object pair, the getfunction returns a list of SDP addresses that are mapped toboth the subject and object. The results returned by the getoperation can be interpreted as “these SDPs know some-thing about both the subject and object and thus might beable to resolve the request involving them.”
Using DS avoids broadcasting requests to all cooperatingSDPs. Whenever an SDP receives a primary response to arequest, it calls the put function to register itself in the DS asa suitable SDP for both the subject and object of the request.When cooperation is required, the SDP calls the get functionto retrieve from the DS a set of addresses of those SDPs thatmight be able to resolve the request.
Note that the DS is only logically centralized but canhave a scalable and resilient implementation. In fact, anideal DS should be distributed and collocated with eachSDP to provide high availability and low latency: each SDPcan make a local get or put call to publish or discovercooperative SDPs, and the failure of one DS node will notaffect others. Compared to the PDP, the DS is both simple, itonly performs put and get operations, and in general, it doesnot depend on the specifics of any particular securitypolicy. As a result, a scalable and resilient implementationof DS is easier to achieve.
For instance, one can use a Bloom filter to achieve adistributed DS implementation, similar to the summary
cache [15] approach. Each SDP builds a Bloom filter from thesubjects or objects of cached requests and sends the bit arrayplus the specification of the hash functions to the other SDPs.The bit array is the summary of the subjects/objects that thisSDP has stored in its cache. Each SDP periodically broadcastsits summary to all cooperating SDPs. Using all summariesreceived, a specific SDP has a global image of the set ofsubjects/objects stored in each SDP’s cache, although theinformation could be outdated or partially wrong.
For a small-scale cooperation, a centralized DS imple-mentation might be feasible where various approaches canbe used to reduce its load and improve its scalability. Thefirst approach is to reduce the number of get calls. Forinstance, SDPs can cache the results from the DS for a smallperiod of time. This method can also contribute to reducingthe latency. The second approach is to reduce the number ofput calls. For example, SDPs can update the DS in batchmode instead of calling the DS for each primary response.
3.4 Adversary Model
In our adversary model, an attacker can eavesdrop, spoof,or replay any network traffic or compromise an applicationserver host with its PEP(s) and SDP(s). The adversary canalso compromise the client computer(s) and the DS. There-fore, there could be malicious clients, PEPs, SDPs, and DS inthe system.
As a CSAR system includes multiple distributed compo-nents, our design assumes different degrees of trust inthem. The PDP is the ultimate authority for access controldecisions, and we assume that all PEPs trust1 the decisionsmade by the PDP. We also assume that the policy changemanger (introduced later in Section 3.6) is trusted because itis collocated and tightly integrated with the PDP. Wefurther assume that each PEP trusts those decisions that itreceives from its own SDP. However, an SDP does notnecessarily trust other SDPs in the system.
3.5 Mitigating Threats
Based on the adversary model presented in the previoussection, we now describe how our design enables mitigationof the threats due to malicious SDPs and DS.
A malicious DS can return false or no SDP addresses,resulting in threats of three types: 1) the SDP sends requeststo those SDPs that actually cannot resolve them, 2) all therequests are directed to a few targeted SDPs, 3) the SDPdoes not have addresses of any other SDP. In all three cases,a malicious DS impacts system performance throughincreased network traffic, or response delays, or computa-tional load on SDPs, and thus can mount a denial-of-service(DoS) attack. However, a malicious DS cannot not impactsystem correctness because every SDP can always resort toquerying just the PDP if the SDP detects that the DS ismalicious.
To detect a malicious DS, an SDP can track howsuccessful the remote SDPs whose addresses the DSprovides are in resolving authorization requests. A benignDS, which always provides correct information, will have arelatively good track record, with just few SDPs unable toresolve requests. Even though colluding SDPs can worsen
278 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009
1. By “trust” we mean that if a trusted component turns to be malicious,it can compromise the security of the system.

the track record of a DS, we do not believe such an attack tobe of practical benefit to the adversary.
A malicious SDP could generate any response it wants,for example, denying all requests and thus launching a DoSattack. Therefore, when an SDP receives a secondaryresponse from other SDPs, it verifies the authenticity andintegrity of the primary responses used to infer thatresponse, as well as the correctness of the inference.
To protect the authenticity and integrity of a primaryresponse while it is in transit between the PDP and the SDP,the PDP cryptographically signs the response. Then, anSDP can independently verify the primary response’sauthenticity and integrity by checking its signature, assum-ing it has access to the PDP’s public key. Recall that eachsecondary response includes an evidence list that containsthe primary responses used for inferring this response. Ifany primary response in the evidence cannot be verified,that secondary response is deemed to be incorrect.
To verify the correctness of a response, the SDP needs touse the knowledge of both the inference algorithm andevidence list. A secondary response is correct if the PDPwould compute the same response. The verification algo-rithm depends on the inference algorithm. In the case ofSAAMBLP, it is simply the inverse of the inference algorithm.Recall that the SAAMBLP inference algorithm searches thecached responses and identifies the relative ordering onsecurity labels associated with the request’s subjects andobjects. In contrast, the verification algorithm goes throughthe evidence list of primary responses by reading every twoconsecutive responses and checking whether the correctordering can be derived. To illustrate, consider the examplefrom Section 2. A remote SDP returns a response ðr4; i4;½r1; r2; r3�, allow) for request ðs1; o2; read; c4; i4Þ, where r1 is theprimary allow response for ðs1; o1; read; c1; i1Þ, r2 is theprimary allow response for ðs2; o1; append; c2; i2Þ, and r3 isthe primary allow response for ðs2; o2; read; c3; i3Þ. From theseresponses, the verification algorithm can determine that�ðs1Þ > �ðo1Þ > �ðs2Þ > �ðo2Þ. Therefore, s1 should be al-lowed to read o2, and thus, r4 is a correct response.
Verification of each approximate response unavoidablyintroduces additional computational cost, which depends onthe length of the evidence list. A malicious SDP might usethis property to attack the system. For example, a maliciousSDP can always return responses with a long evidence listthat is computationally expensive to verify. One way todefend against this attack is to set an upper bound to thetime that the verification process can take. An SDP thatalways returns long evidence lists will be blacklisted.
We defined four execution scenarios, listed below, tohelp manage the computational cost caused by responseverification. Based on the administration policy anddeployment environment, the verification process can beconfigured differently to achieve various trade-offs betweensecurity and performance.
. Total verification. All responses are verified.
. Allow verification. Only “allow” responses areverified. This configuration protects resources fromunauthorized access but might be vulnerable to DoSattacks.
. Random verification. Responses are randomlyselected for verification. This configuration can beused to detect malicious SDPs but cannot guarantee
that the system is perfectly correct, since some falseresponses may have been generated before thedetection.
. Offline verification. There is no real-time verifica-tion, but offline audits are performed.
3.6 Consistency
Similar to other distributed systems employing caching,CSAR needs to deal with cache consistency issues. In oursystem, SDP caches may become inconsistent when accesscontrol policy changes at the PDP. In this section, wedescribe how consistency is achieved in CSAR.
We first state our assumptions relevant to the accesscontrol systems. We assume that the PDP makes decisionsusing an access control policy stored persistently in a policystore of the authorization server. In practice, the policy storecan be a policy database or a collection of policy files. Wefurther assume that security administrators deploy andupdate policies through the policy administration point(PAP), which is consistent with the XACML architecture [16].To avoid modifying existing authorization servers andmaintain backward compatibility, we further add a policychange manager (PCM), collocated with the policy store. ThePCM monitors the policy store, detects policy changes, andinforms the SDPs about the changes. The refined architectureof the authorization server is presented in Fig. 3.
Based on the fact that not all policy changes are at thesame level of criticality, we divide policy changes into threetypes: critical, time-sensitive, and time-insensitive changes.By discriminating policy changes according to these types,system administrators can choose to achieve differentconsistency levels. In addition, system designers are ableto provide different consistency techniques to achieveefficiency for each type. Our design allows a CSARdeployment to support any combination of the three types.In the rest of this section, we define each type of policychange and discuss the consistency properties.
Critical changes of authorization policies are thosechanges that need to be propagated urgently throughoutthe enterprise applications, requiring immediate updates onall SDPs. When an administrator makes a critical change,our approach requires that she also specifies a time period tfor the change. CSAR will attempt to make the policychange by contacting all SDPs involved and must informthe administrator within time period t either a message that
WEI ET AL.: COOPERATIVE SECONDARY AUTHORIZATION RECYCLING 279
Fig. 3. The architecture enabling the support for policy changes.

the change has been successfully performed or a list of SDPsthat have not confirmed the change.
We developed a selective-flush approach to propagatingcritical policy changes. In this approach, only selectedpolicy changes are propagated, only selected SDPs areupdated, and only selected cache entries are flushed. Webelieve that this approach has the benefits of reducingserver overhead and network traffic. In the following, wesketch out the propagation process.
The PCM first determines which subjects and/or objects(a.k.a. entities) are affected by the policy change. Since mostmodern enterprise access control systems make decisionsby comparing security attributes (e.g., roles, clearance,sensitivity, and groups) of subjects and objects, the PCMmaps the policy change to the entities whose securityattributes are affected. For example, if permission p hasbeen revoked from role r, then the PCM determines allobjects of p (denoted by Op) and all subjects assigned to r(denoted by Sr).
The PCM then finds out which SDPs need to be notified ofthe policy change. Given the entities affected by the policychange, the PCM uses the DS to find those SDPs that mighthave responses for the affected entities in their caches. ThePCM sends the DS a policy change message containing theaffected entities, ðOp; SrÞ. Upon receiving the message, the DSfirst replies back with a list of the SDPs that have cached theresponses for the entities. Then, it removes correspondingentries from its map to reflect the flushing. After the PCMgets the list of SDPs from the DS, it multicasts the policychange message to these affected SDPs.
When an SDP receives a policy change message, itflushes those cached responses that contain the entities andthen acknowledges the results to the PCM. In the aboveexample, with revoking permission p from role r, the SDPwould flush those responses from its cache that containboth objects in Op and subjects in Sr.
In order for the selective-flush approach to be practical,the PCM should have the ability to quickly identify thesubjects or objects affected by the policy change. However,this procedure may not be trivial due to the complexities ofmodern access control systems. We have developedidentification algorithms for the policies based on the BLPmodel and will explore this issue for other access controlmodels in future research.
Time-sensitive changes in authorization policies are lessurgent than critical ones but still need to be propagatedwithin a known period of time. When an administratormakes a time-sensitive change, it is the PCM that computesthe time period t in which caches of all SDPs are guaranteedto become consistent with the change. As a result, eventhough the PDP starts making authorization decisions usingthe modified policy, the change becomes in effect through-out the CSAR deployment only after time period t. Noticethat this does not necessarily mean that the change itselfwill be reflected in the SDPs’ caches by then, only that thecaches will not use responses invalidated by the change.
CSAR employs a time-to-live (TTL) approach to processtime-sensitive changes. Every primary response is assigneda TTL that determines how long the response shouldremain valid in the cache, e.g., one day or one hour. Theassignment can be performed by either the SDP, the PDPitself, or a proxy, through which all responses from the PDPpass before arriving to the SDPs. The choice depends on the
deployment environment and backward compatibilityrequirements. Every SDP periodically purges from its cachethose responses whose TTL elapses.
The TTL value can also vary from response to response.Some responses (say, authorizing access to more valuableresources) can be assigned a smaller TTL than others. Forexample, for a BLP-based policy, the TTL for the responsesconcerning top-secret objects could be shorter than forconfidential objects.
When the administrator makes a time-insensitivechange, the system guarantees that all SDPs will eventuallybecome consistent with the change. No promises are given,however, about how long it will take. Support for time-insensitive changes is necessary because some systems maynot be able to afford the cost of, or are just not willing tosupport, critical or time-sensitive changes. A simpleapproach to supporting time-insensitive change is forsystem administrators to periodically restart the machineshosting the SDPs.
3.7 Eager Recycling
In previous sections, we explained how cooperation amongSDPs is achieved by resolving requests by remote SDPs. Inthis section, we describe an eager approach to recycling pastresponses. The goal is to further reduce the overhead trafficand response time.
The essence of cooperation is SDPs helping each other toreduce the cache miss rate at each SDP. We considered twotypes of cache misses: compulsory misses, which aregenerated by a subject’s first attempt to access an object,and communication/consistency misses, which occur when acache holds a stale authorization. With cooperation, the SDPcan avoid some of these misses by possibly gettingauthorizations from its cooperating SDPs.
Although cooperation helps to improve the overall cachehit rate, it leads to a small local cache hit rate at each SDP.The reason is that SAAM inference algorithms are basedpurely on cached primary responses. Without cooperation,the request is always sent to the PDP. The primary responsereturned from the PDP can then be cached and used forfuture inference. With cooperation, the request may beresolved by remote SDPs. The returned approximateresponse, however, is not useful for future inference, whicheventually leads to a small local hit rate.
A small local cache hit rate results in two problems.First, it leads to increased response time, as requests haveto be resolved by remote SDPs. Its impact is especiallysignificant when SDPs are located in a WAN. Second, itunavoidably increases the computational load of SDPsbecause each SDP has to resolve more requests for otherSDPs. Therefore, the cooperation should also lead to anincreased local cache hit rate. To this end, we propose theeager recycling approach, which takes advantage of theinformation in the evidence list.
As stated before, if an SDP succeeds in resolving arequest from another SDP, it returns a secondary response,which includes an evidence component. The evidencecontains a list of primary responses that have been usedto infer the secondary response. In eager recycling, thereceiving SDP incorporates those verified primary re-sponses into its local cache as if it received them from thePDP. By including these responses, the SDP’s cacheincreases faster and its chances of resolving future requests
280 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009

locally by inference also increases. Our evaluation resultsshow that this approach can reduce the response time by afactor of two.
4 EVALUATION
In evaluating CSAR, we wanted first to determine if ourdesign works. Then, we sought to estimate the achievablegains in terms of availability and performance anddetermine how they depend on factors such as the numberof cooperating SDPs and the frequency of policy changes.
We used both simulation and a prototype implementa-tion to evaluate CSAR. The simulation enabled us to studyavailability by hiding the complexity of underlyingcommunication, while the prototype enabled us to studyboth performance and availability in a more dynamic andrealistic environment. Additionally, we have integrated ourprototype with a real application to study the integrationcomplexity and the impact of application performance.
We used a similar setup for both the simulation andprototype experiments. The PDP made access controldecisions on either read or append requests using a BLP-based policy stored in an XML file. The BLP security latticecontained four security levels and three categories, 100 sub-jects and 100 objects, and uniformly assigned security labelsto them. The total number of possible requests was100� 100� 2 ¼ 20;000. The policy was enforced by all thePEPs. Each SDP implemented the same inference algorithm.While the subjects were the same for each SDP, the objectscould be different in order to simulate the request overlap.
4.1 Simulation-Based Evaluation
We used simulations to evaluate the benefits of cooperationto system availability and reducing load at the PDP. Weused the cache hit rate as an indirect metric for these twocharacteristics. A request resolved without contacting thePDP was considered a cache hit. A high cache hit rateresults in masking transient PDP failures (thus improvingthe availability of the access control system) and reducingthe load on the PDP (thus improving the scalability of thesystem).
We studied the influence of the following factors on thehit rate of one cooperating SDP:
a. the number of cooperating SDPs,b. the cache warmness at each SDP, defined as the ratio
of cached responses to the total number of possibleresponses,
c. the overlap rate between the resource spaces of twocooperating SDPs, defined as the ratio of the objectsowned by both SDPs to the objects owned only bythe studied SDP (the overlap rate served as ameasure of similarity between the resources of twocooperating SDPs),
d. whether the inference for approximate responseswas enabled or not, and
e. the popularity distribution of requests.
To conduct the experiments, we have modified theSAAM evaluation engine used in [11] to support coopera-tion. Each run of the evaluation engine involved fourstages. In the first stage, the engine generated subjects andobjects for each SDP, created a BLP lattice and assignedsecurity labels to both subjects and objects. To control the
overlap rate (e.g., 10 percent) between SDPs, we firstgenerated the object space for the SDP under study (e.g.,obj0-99). For each of the other SDPs, we then uniformlyselected the corresponding number of objects (e.g., 10)from the space of the SDP under study (e.g., obj5, obj23,etc.) and then generated the remaining objects sequentially(e.g., obj100-189).
Second, the engine created the warming set of requests foreach SDP: that is, the set containing all possible uniquerequests for that SDP. We also created a testing set for allSDPs, which comprised a sampling of requests uniformlyselected from the request space of the SDP under study. Inour experiment, the testing set contained 5,000 requests.Next, the simulation engine started operating by alternatingbetween warming and testing modes. In the warming mode(stage three), the engine used a subset of the requests fromeach warming set, evaluated them using the simulated PDP,and sent the responses to the corresponding SDP to buildup the cache. Once the desired cache warmness wasachieved, the engine switched into testing mode (stagefour), where the SDP cache was no longer updated. Weused this stage to evaluate the hit rate of each SDP atcontrolled fixed levels of cache warmness. The enginesubmitted requests from the testing set to all SDPs. If anySDP could resolve a request, it was a cache hit. The enginecalculated the hit rate as the ratio of the test requestsresolved by any SDP to all test requests at the end of thisphase. These last two stages were then repeated fordifferent levels of cache warmness, from 0 percent to100 percent in increments of 5 percent.
Simulation results were gathered on a commodity PCwith a 2.8-GHz Intel Pentium 4 processor and 1 Gbyte ofRAM. The simulation framework was written in Java andran on Sun’s 1.5.0 JRE. Experiments used the same cachewarmness for each SDP, and the same overlap rate betweenthe inspected SDP and every other cooperating SDP. Wesimulated three overlap rates: 10 percent, 50 percent, or100 percent. Each experiment was run 10 times, and theaverage results are reported. For a confidence level of95 percent, the maximum observed confidence interval was2.3 percent and the average was 0.5 percent.
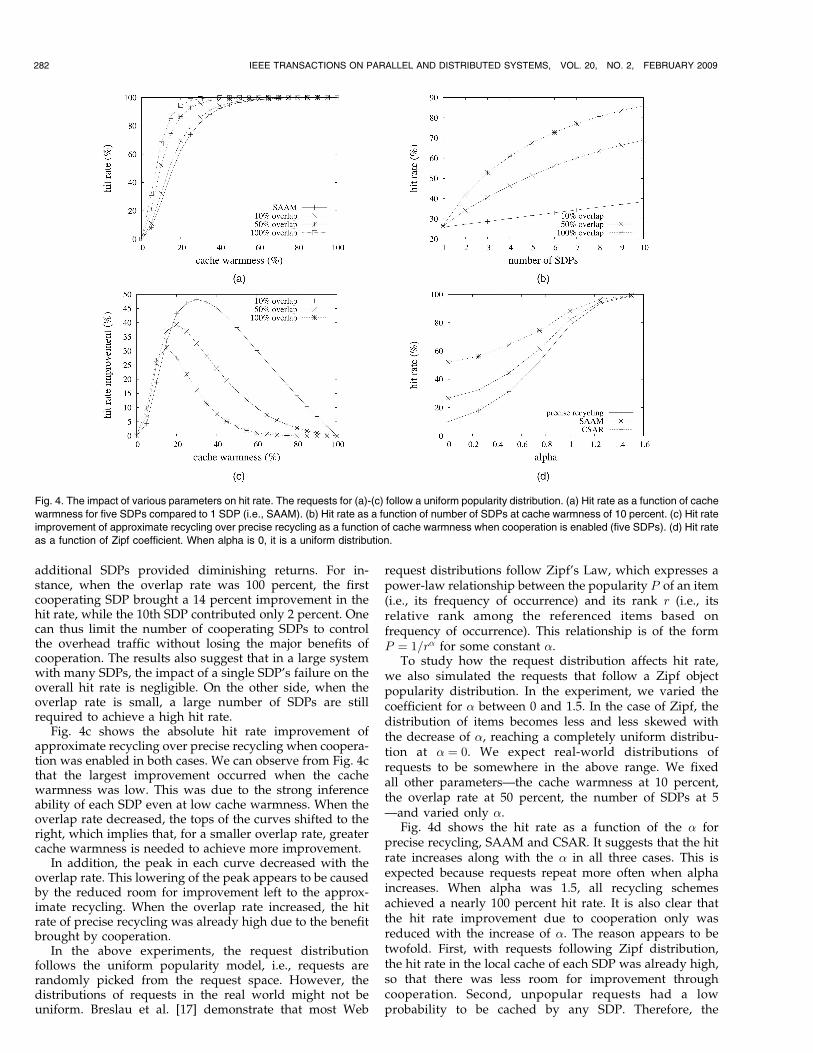
Fig. 4 shows the results for requests that followed auniform popularity distribution. Fig. 4a shows the depen-dency of the hit rate on cache warmness and overlap rate. Itcompares the hit rate for the case of one SDP, representingSAAM (bottom curve), with the hit rate achieved by fivecooperating SDPs. Fig. 4a suggests that, when cachewarmness was low (around 10 percent), the hit rate wasstill larger than 50 percent for overlap rates of 50 percentand up. In particular, when the overlap rate was 100 percent,CSAR achieved a hit rate of almost 70 percent at 10 percentcache warmness. In reality, low cache warmness can becaused by the characteristics of the workload by limitedstorage space or by frequently changing access controlpolicies. For a 10 percent overlap rate, however, CSARoutperformed SAAM by a mere 10 percent, which might notwarrant the cost of CSAR’s complexity.
Fig. 4b demonstrates the impact of the number ofcooperating SDPs on the hit rate under three overlap rates.In the experiment, we varied the number of SDPs from 1to 10, while maintaining 10 percent cache warmness at eachSDP. As expected, increasing the number of SDPs led tohigher hit rates. At the same time, the results indicate that
WEI ET AL.: COOPERATIVE SECONDARY AUTHORIZATION RECYCLING 281
additional SDPs provided diminishing returns. For in-stance, when the overlap rate was 100 percent, the firstcooperating SDP brought a 14 percent improvement in thehit rate, while the 10th SDP contributed only 2 percent. Onecan thus limit the number of cooperating SDPs to controlthe overhead traffic without losing the major benefits ofcooperation. The results also suggest that in a large systemwith many SDPs, the impact of a single SDP’s failure on theoverall hit rate is negligible. On the other side, when theoverlap rate is small, a large number of SDPs are stillrequired to achieve a high hit rate.
Fig. 4c shows the absolute hit rate improvement ofapproximate recycling over precise recycling when coopera-tion was enabled in both cases. We can observe from Fig. 4cthat the largest improvement occurred when the cachewarmness was low. This was due to the strong inferenceability of each SDP even at low cache warmness. When theoverlap rate decreased, the tops of the curves shifted to theright, which implies that, for a smaller overlap rate, greatercache warmness is needed to achieve more improvement.
In addition, the peak in each curve decreased with theoverlap rate. This lowering of the peak appears to be causedby the reduced room for improvement left to the approx-imate recycling. When the overlap rate increased, the hitrate of precise recycling was already high due to the benefitbrought by cooperation.
In the above experiments, the request distributionfollows the uniform popularity model, i.e., requests arerandomly picked from the request space. However, thedistributions of requests in the real world might not beuniform. Breslau et al. [17] demonstrate that most Web
request distributions follow Zipf’s Law, which expresses apower-law relationship between the popularity P of an item(i.e., its frequency of occurrence) and its rank r (i.e., itsrelative rank among the referenced items based onfrequency of occurrence). This relationship is of the formP ¼ 1=r� for some constant �.
To study how the request distribution affects hit rate,we also simulated the requests that follow a Zipf objectpopularity distribution. In the experiment, we varied thecoefficient for � between 0 and 1.5. In the case of Zipf, thedistribution of items becomes less and less skewed withthe decrease of �, reaching a completely uniform distribu-tion at � ¼ 0. We expect real-world distributions ofrequests to be somewhere in the above range. We fixedall other parameters—the cache warmness at 10 percent,the overlap rate at 50 percent, the number of SDPs at 5—and varied only �.
Fig. 4d shows the hit rate as a function of the � forprecise recycling, SAAM and CSAR. It suggests that the hitrate increases along with the � in all three cases. This isexpected because requests repeat more often when alphaincreases. When alpha was 1.5, all recycling schemesachieved a nearly 100 percent hit rate. It is also clear thatthe hit rate improvement due to cooperation only wasreduced with the increase of �. The reason appears to betwofold. First, with requests following Zipf distribution,the hit rate in the local cache of each SDP was already high,so that there was less room for improvement throughcooperation. Second, unpopular requests had a lowprobability to be cached by any SDP. Therefore, the
282 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009
Fig. 4. The impact of various parameters on hit rate. The requests for (a)-(c) follow a uniform popularity distribution. (a) Hit rate as a function of cache
warmness for five SDPs compared to 1 SDP (i.e., SAAM). (b) Hit rate as a function of number of SDPs at cache warmness of 10 percent. (c) Hit rate
improvement of approximate recycling over precise recycling as a function of cache warmness when cooperation is enabled (five SDPs). (d) Hit rate
as a function of Zipf coefficient. When alpha is 0, it is a uniform distribution.

requests that could not be resolved locally were unlikely tobe resolved by other SDPs either.
Summary. The simulation results suggest that combiningapproximate recycling and cooperation can help SDPs toachieve high hit rates, even when the cache warmness is low.This improvement in hit rate increases with SDPs’ resourceoverlap rate and the number of cooperating SDPs. We alsodemonstrate that when the distribution of requests is lessskewed, the improvement in hit rate is more significant.
4.2 Prototype-Based Evaluation
This section describes the design of our prototype and theresults of our experiments. The prototype system con-sisted of the implementations of PEP, SDP, DS, PDP, anda test driver, all of which communicated with each otherusing Java Remote Method Invocation (RMI). Each PEPreceived randomly generated requests from the test driverand called its local SDP for authorizations. Upon anauthorization request from its PEP, each SDP attemptedto resolve this request either sequentially or concurrently.Each SDP maintained a dynamic pool of worker threadsthat concurrently queried other SDPs. The DS used acustomized hash map that supported assigning multiplevalues (SDP addresses) to a single key (subject/object).
We implemented the PAP and the PCM according to thedesign described in Section 3.6. To simplify the prototype,the two components were process-collocated with the PDP.Additionally, we implemented the selective-flush approachfor propagating policy changes. To support responseverification, we generated a 1,024-bit RSA key pair for thePDP. Each SDP had a copy of the PDP’s public key. Afterthe PDP generated a primary response, it signed theresponse by computing a SHA1 digest of the responseand signing the digest with its private key. In the following,we present and discuss the results of evaluating theperformance of CSAR in terms of response time, the impactof policy changes on hit rate, and the integration of CSARwith a real application.
4.2.1 Evaluating Response Time
First, we compared the client-perceived response time ofCSAR with that of the other two authorization schemes:without caching and SAAM (without cooperation). Westudied three variations of CSAR: sequential authorization,concurrent authorization, and eager recycling. We alsoevaluated the impact of response verification on responsetime in the case of sequential authorization. We ranexperiments in the following three scenarios, which variedin terms of the network latency among SDPs and betweenSDPs and the PDP:
a. LAN-LAN. SDPs and the PDP were all deployed inthe same local area network (LAN), where theround-trip time (RTT) was less then 1 ms.
b. LAN-WAN. SDPs were deployed in the same LAN,which was separated from the PDP by a wide areanetwork (WAN). To simulate network delays be-tween SDPs and the PDP, we added a 40 ms delay toeach authorization request sent to the PDP.
c. WAN-WAN. All SDPs and the PDP were separatedfrom each other by a WAN. Again, we introduced a40 ms delay to simulate delays that possibly occur inboth the remote PDP and remote SDPs.
In the experiments, we did not intend to test everycombination of scenarios and authorization schemes but totest those most plausibly encountered ones in the realworld. For example, concurrent authorization and responseverification were only enabled in the WAN-WAN scenariowhen SDPs were remotely located. Using concurrentauthorization in this scenario can help to reduce the highcost of cache misses on remote SDPs due to communicationcosts. In addition, since the requests in such a scenario areobtained from remote SDPs that might be located in adifferent administrative domain, response verification ishighly desirable.
The experimental system consisted of a PDP, a DS, andfour PEP processes collocated with their SDPs. Note thatalthough the system contained only one DS instance, thisDS simulated an idealized implementation of a distributedDS, where each DS had up-to-date global state. This DSinstance could be deemed to be local to each SDP becausethe latency between the DS and the SDPs was less than 1 msand the DS was not overloaded. Each two collocatedPEPs and SDPs shared a commodity PC with a 2.8-GHzIntel Pentium 4 processor and 1 Gbyte of RAM. The DS andthe PDP ran on one of the two machines, while the testdriver ran on the other. The two machines were connectedby a 100 megabits per second LAN. In all experiments, wemade sure that both machines were not overloaded so thatthey were not the bottlenecks of the system and did notcause additional delays.
At the start of each experiment, the SDP caches wereempty. The test driver maintained one thread per PEP,simulating one client per PEP. Each thread sent randomlygenerated requests to its PEP sequentially. The test driverrecorded the response time for each request. After every100 requests, the test driver calculated the mean responsetime and used it as an indicator of the response time for thatperiod. We ran the experiment when the cache size waswithin 10,000 requests for each SDP at the end, which wasone-half the total number of possible requests. Fig. 5 showsthe plotted results for 100 percent overlap rate. For the sakeof better readability, we present the results for WAN-WANscenario in two graphs. The following conclusions regardingeach authorization scheme can be directly drawn in Fig. 5:
i. In the no-caching scheme, SDPs were not deployed,and PEPs sent authorization requests directly to thePDP. In the LAN-LAN scenario, this scheme achievedbest performance since it involved the least number ofRMI calls in our implementation. In the other twoscenarios, however, all of the average response timeswere slightly higher than 40 ms because all requestshad to be resolved by the remote PDP.
ii. In the noncooperative caching (SAAM) scheme,SDPs were deployed and available only to their ownPEPs. When a request was received, each SDP firsttried to resolve the request locally and then by thePDP. For the LAN-LAN scenario, this method didnot help reduce the latency because in our prototypeSDP was implemented as a separate process, andeach SDP authorization involved an RMI call. In theother two scenarios, response times decreasedconsistently with the number of requests becausemore requests were resolved locally. Note that thenetwork distance between SDPs does not affect the
WEI ET AL.: COOPERATIVE SECONDARY AUTHORIZATION RECYCLING 283
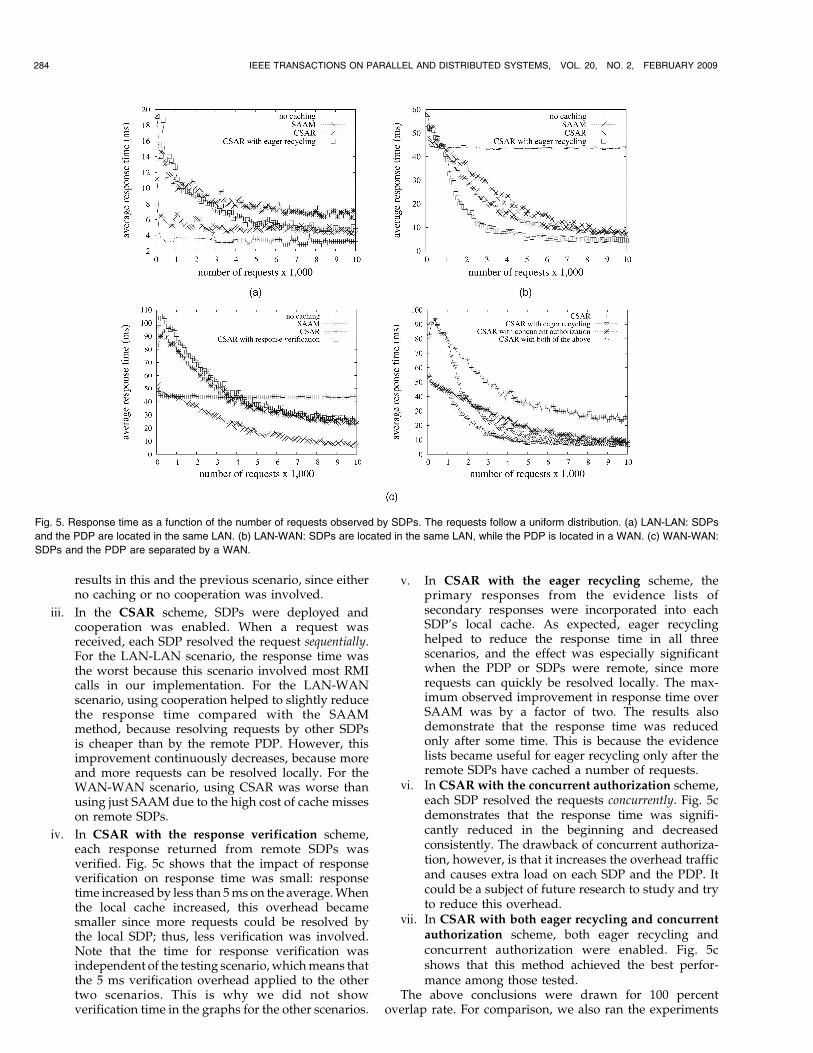
results in this and the previous scenario, since eitherno caching or no cooperation was involved.
iii. In the CSAR scheme, SDPs were deployed andcooperation was enabled. When a request wasreceived, each SDP resolved the request sequentially.For the LAN-LAN scenario, the response time wasthe worst because this scenario involved most RMIcalls in our implementation. For the LAN-WANscenario, using cooperation helped to slightly reducethe response time compared with the SAAMmethod, because resolving requests by other SDPsis cheaper than by the remote PDP. However, thisimprovement continuously decreases, because moreand more requests can be resolved locally. For theWAN-WAN scenario, using CSAR was worse thanusing just SAAM due to the high cost of cache misseson remote SDPs.
iv. In CSAR with the response verification scheme,each response returned from remote SDPs wasverified. Fig. 5c shows that the impact of responseverification on response time was small: responsetime increased by less than 5 ms on the average. Whenthe local cache increased, this overhead becamesmaller since more requests could be resolved bythe local SDP; thus, less verification was involved.Note that the time for response verification wasindependent of the testing scenario, which means thatthe 5 ms verification overhead applied to the othertwo scenarios. This is why we did not showverification time in the graphs for the other scenarios.
v. In CSAR with the eager recycling scheme, theprimary responses from the evidence lists ofsecondary responses were incorporated into eachSDP’s local cache. As expected, eager recyclinghelped to reduce the response time in all threescenarios, and the effect was especially significantwhen the PDP or SDPs were remote, since morerequests can quickly be resolved locally. The max-imum observed improvement in response time overSAAM was by a factor of two. The results alsodemonstrate that the response time was reducedonly after some time. This is because the evidencelists became useful for eager recycling only after theremote SDPs have cached a number of requests.
vi. In CSAR with the concurrent authorization scheme,each SDP resolved the requests concurrently. Fig. 5cdemonstrates that the response time was signifi-cantly reduced in the beginning and decreasedconsistently. The drawback of concurrent authoriza-tion, however, is that it increases the overhead trafficand causes extra load on each SDP and the PDP. Itcould be a subject of future research to study and tryto reduce this overhead.
vii. In CSAR with both eager recycling and concurrentauthorization scheme, both eager recycling andconcurrent authorization were enabled. Fig. 5cshows that this method achieved the best perfor-mance among those tested.
The above conclusions were drawn for 100 percentoverlap rate. For comparison, we also ran the experiments
284 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009
Fig. 5. Response time as a function of the number of requests observed by SDPs. The requests follow a uniform distribution. (a) LAN-LAN: SDPs
and the PDP are located in the same LAN. (b) LAN-WAN: SDPs are located in the same LAN, while the PDP is located in a WAN. (c) WAN-WAN:
SDPs and the PDP are separated by a WAN.
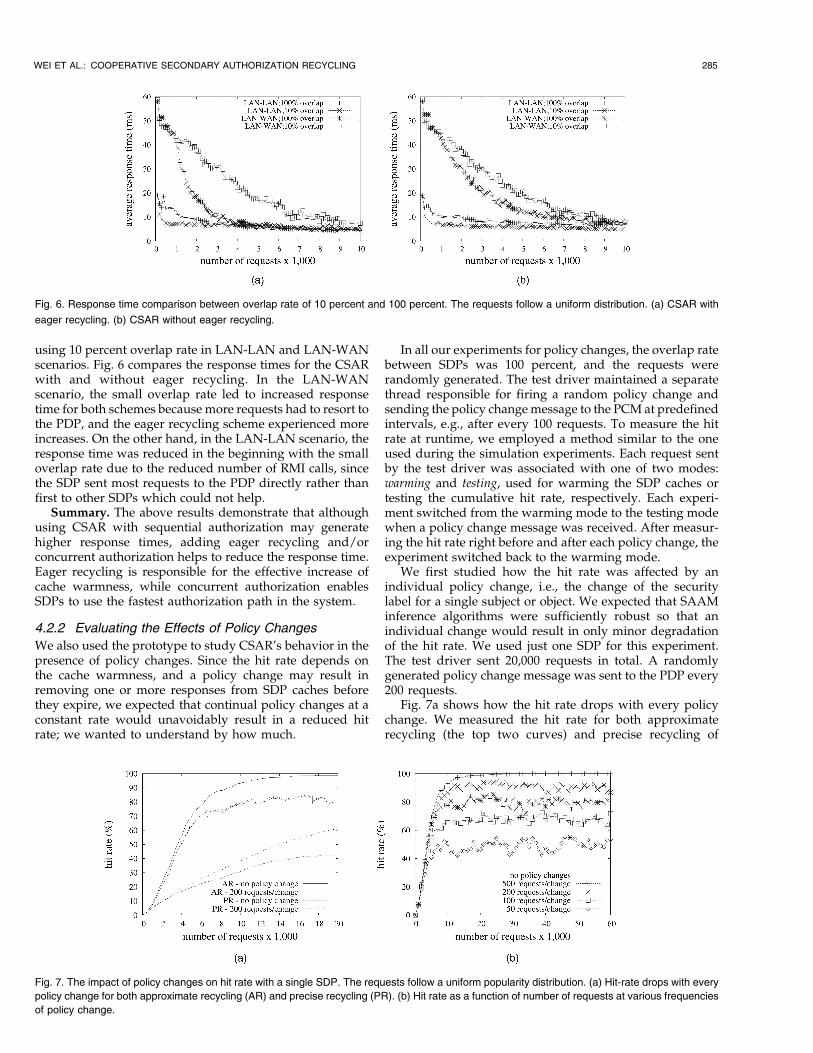
using 10 percent overlap rate in LAN-LAN and LAN-WANscenarios. Fig. 6 compares the response times for the CSARwith and without eager recycling. In the LAN-WANscenario, the small overlap rate led to increased responsetime for both schemes because more requests had to resort tothe PDP, and the eager recycling scheme experienced moreincreases. On the other hand, in the LAN-LAN scenario, theresponse time was reduced in the beginning with the smalloverlap rate due to the reduced number of RMI calls, sincethe SDP sent most requests to the PDP directly rather thanfirst to other SDPs which could not help.
Summary. The above results demonstrate that althoughusing CSAR with sequential authorization may generatehigher response times, adding eager recycling and/orconcurrent authorization helps to reduce the response time.Eager recycling is responsible for the effective increase ofcache warmness, while concurrent authorization enablesSDPs to use the fastest authorization path in the system.
4.2.2 Evaluating the Effects of Policy Changes
We also used the prototype to study CSAR’s behavior in thepresence of policy changes. Since the hit rate depends onthe cache warmness, and a policy change may result inremoving one or more responses from SDP caches beforethey expire, we expected that continual policy changes at aconstant rate would unavoidably result in a reduced hitrate; we wanted to understand by how much.
In all our experiments for policy changes, the overlap ratebetween SDPs was 100 percent, and the requests wererandomly generated. The test driver maintained a separatethread responsible for firing a random policy change andsending the policy change message to the PCM at predefinedintervals, e.g., after every 100 requests. To measure the hitrate at runtime, we employed a method similar to the oneused during the simulation experiments. Each request sentby the test driver was associated with one of two modes:warming and testing, used for warming the SDP caches ortesting the cumulative hit rate, respectively. Each experi-ment switched from the warming mode to the testing modewhen a policy change message was received. After measur-ing the hit rate right before and after each policy change, theexperiment switched back to the warming mode.
We first studied how the hit rate was affected by anindividual policy change, i.e., the change of the securitylabel for a single subject or object. We expected that SAAMinference algorithms were sufficiently robust so that anindividual change would result in only minor degradationof the hit rate. We used just one SDP for this experiment.The test driver sent 20,000 requests in total. A randomlygenerated policy change message was sent to the PDP every200 requests.
Fig. 7a shows how the hit rate drops with every policychange. We measured the hit rate for both approximaterecycling (the top two curves) and precise recycling of
WEI ET AL.: COOPERATIVE SECONDARY AUTHORIZATION RECYCLING 285
Fig. 6. Response time comparison between overlap rate of 10 percent and 100 percent. The requests follow a uniform distribution. (a) CSAR with
eager recycling. (b) CSAR without eager recycling.
Fig. 7. The impact of policy changes on hit rate with a single SDP. The requests follow a uniform popularity distribution. (a) Hit-rate drops with every
policy change for both approximate recycling (AR) and precise recycling (PR). (b) Hit rate as a function of number of requests at various frequencies
of policy change.

authorizations by the SDP. For both types of recycling, thefigure shows the hit rate as a function of the number ofobserved requests, with policy change (lower curve) orwithout policy changes (upper curve). Because the hit ratewas measured just before and after each policy change,every kink in the curve indicates a hit-rate drop caused by apolicy change.
Fig. 7a indicates that the hit-rate drops are small for bothapproximate recycling and precise recycling. For approx-imate recycling, the largest hit-rate drop was 5 percent, andmost of the other drops were around 1 percent. After eachdrop, the curve climbed again because the cache sizeincreased with new requests.
Note that the curve for the approximate recycling withpolicy change is more ragged than it is for precise recycling.This result suggests, not surprisingly, that approximaterecycling is more sensitive to policy changes. The reason isthat approximate recycling employs an inference algorithmbased on a directed acyclic graph. A policy change couldpartition the graph or just increase its diameter, resulting ina greater reduction in the hit rate.
Although the hit-rate drop for each policy change wassmall, one can see that the cumulative effect of policy changescould be large. In Fig. 7a, the hit rate of approximate recyclingdecreased about 20 percent in total when the request numberreached 20,000. This result led us to another interestingquestion: Would the hit rate finally stabilize at some point?
To answer this question, we ran another experiment tostudy how the hit rate varied with continuous policychanges over a longer term. We used a larger number ofrequests (60,000) and measured the hit rate after every1,000 requests. We varied the frequency of policy changesfrom 50 to 500 requests per change.
Fig. 7b shows the hit rates as functions of the number ofobserved requests, with each curve corresponding to adifferent frequency of random policy changes. Because ofthe continuous policy change, one cannot see a perfectasymptote of curves. However, the curves indicate that thehit rates stabilize after 20,000 requests. We can thuscalculate the averages of the hit rates after 20,000 requestsand use them to represent the eventual stabilized hit rate.As we expected, the more frequent the policy changes were,the lower the stabilized hit rates were, since the responseswere removed from the SDP caches more frequently.
Fig. 7b also shows that each curve has a knee. The steepincrease in the hit rate before the knee implies thatincreased requests improve the hit rate dramatically in thisperiod. Once the number of requests passes the knee, the
benefit brought by caching further requests reaches theplateau of diminishing returns.
Finally, we studied how the hit rate under continuouspolicy changes could benefit from the cooperation. In theseexperiments, we varied the number of SDPs from 1 to 10.Figs. 8a and 8b show hit rates versus the number of requestsobserved when the policy changed every 50 and 100 requests.Fig. 8c compares the eventual stabilized hit rate for the twofrequencies of policy changes. As we expected, cooperationbetween SDPs improved the hit rate.
Note that when the number of SDPs increased, thecurves after the knee became smoother. This trend was adirect result of the impact of cooperation on the hit rate:cooperation between SDPs compensates for the hit ratedrops caused by the policy changes at each SDP.
Summary. Our results show that the impact of a singlepolicy change on the hit rate is small, while the cumulativeimpact can be large. Constant policy changes finally lead toa stabilized hit rate, which depends on the frequency of thepolicy change. In any case, cooperation helps to reduce thisimpact.
4.2.3 Integration with TPC-W
We have also integrated the CSAR prototype with TPC-W[18], an industry-standard e-commerce benchmark applica-tion that models an online bookstore such as Amazon.com.We added the PEP, the SDP, the PDP and a policy file to theoriginal TPC-W architecture. Our experience shows that ourprototype can be easily integrated with the Java-based TPC-W application. The PEP can be simply implemented as aJava servlet filter; our implementation of the PEP corre-sponded to about 100 lines of source code, and the PDP andSDP were reused from our prototype implementation withonly minor changes to the configuration file. Details onexperimental setup and benchmarking results can be foundin our technical report [19].
5 RELATED WORK
CSAR is related to several research areas, includingauthorization caching, collaborative security, and coopera-tive caching. This section briefly reviews the work in thesefields.
To improve the performance and availability of accesscontrol systems, caching has been employed in a numberof commercial systems [1], [2], [3], as well as severalacademic distributed access control systems [20], [21].None of these systems involves cooperation among caches,
286 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009
Fig. 8. The impact of SDP cooperation on hit rate when policy changes. The requests follow a uniform popularity distribution. The overlap rate
between SDPs is 100 percent. (a) Hit rate as a function of number of requests observed when policy changes every 100 requests. (b) Hit rate as a
function of number of requests observed when policy changes every 50 requests. (c) Comparison of stabilized hit rates.

and most of them adopt a TTL-based solution to managecache consistency.
To further improve the performance and availability ofaccess control systems, Beznosov [22] introduces theconcept of recycling approximate authorizations, whichextends the precise caching mechanism. Crampton et al. [11]develop SAAM by introducing the design of SDP andconcrete inference algorithms for BLP model. CSAR buildson SAAM and extends it by enabling applications to shareauthorizations. To the best of our knowledge, no previousresearch has proposed such cooperative recycling ofauthorizations.
A number of research projects propose cooperative accesscontrol frameworks that involve multiple cooperative PDPsthat resolve authorization requests. Beznosov et al. [23]present a resource access decision (RAD) service for CORBA-based distributed systems. The RAD service allows dynami-cally adding or removing PDPs that represent different sets ofpolices. In Stowe’s scheme [24], a PDP that receives anauthorization request from PEP forwards the request to othercollaborating PDPs and combines their responses later. EachPDP maintains a list of other trusted PDPs to which itforwards the request. Mazzuca [25] extends Stowe’s scheme.Besides issuing requests to other PDPs, each PDP can alsoretrieve policy from other PDPs and make decisions locally.These schemes all assume that a request needs to beauthorized by multiple PDPs, and each PDP maintainsdifferent policies. CSAR, on the other hand, focuses on thecollaboration of PEPs and assumes that they enforce the samepolicy. This is why we consider these schemes to beorthogonal to ours.
Our research can be considered a particular case of a moregeneral direction, known as collaborative security. This direc-tion aims at improving security of a large distributed systemthrough the collaboration of its components. A representativeexample of collaborative security is collaborative applicationcommunities [26], in which applications collaborate onidentifying previously unknown flaws and attacks andnotifying each other. Another example is Vigilante [27],which enables collaborative worm detection at end hosts butdoes not require hosts to trust each other. CSAR can beviewed as a collaborative security since different SDPscollaborate on resolving authorization requests to maskPDP failures or to improve performance.
Outside of the security domain, cooperative Web cachingis another related area. Web caching is a widely usedtechnique for reducing the latency observed by Webbrowsers, decreasing the aggregate bandwidth consumptionof an organization’s network and reducing the load on Webservers. Several projects have investigated decentralizedcooperative Web caching (please refer to [28] for a survey).Our approach differs from them in the following threeaspects. First, CSAR supports approximate authorizationsthat are not precached and must be computed dynamically.Second, the authorizations from other SDPs need to beverified to ensure authenticity, integrity, and correctness.Third, CSAR supports various consistency requirements.
6 CONCLUSION
As distributed systems scale up and become increasinglycomplex, their access control infrastructures face newchallenges. Conventional request-response authorization
architectures become fragile and scale poorly to massivescale. Caching authorization decisions has long been usedto improve access control infrastructure availability andperformance. In this paper, we build on this idea and on theidea of inferring approximate authorization decisions atintermediary control points and propose a cooperativeapproach to further improve the availability and perfor-mance of access control solutions. Our CSAR approachexploits the increased hit rate offered by a larger distributedcooperative cache of access control decisions. We believethat this solution is especially practical in distributedsystems involving cooperating parties or replicated servicesdue to the high overlap in their user/resource spaces andthe need for consistent policy enforcement.
This paper defines CSAR system requirements andpresents a detailed design that meets these requirements.We have introduced a response verification mechanism thatdoes not require cooperating SDPs to trust each other.Cache consistency is managed by dividing all of the policychanges into three categories and employing efficientconsistency techniques for each category.
A decision on whether to deploy CSAR depends on a fullcost-benefit analysis informed by application- and business-specific factors, for example, the precise characteristics of theapplication workload and deployment environment, anevaluation of the impact of system failures on businesscontinuity, and an evaluation of the complexity associatedcosts of the access control system. To inform this analysis, wehave evaluated CSAR’s application-independent benefits:higher system availability by masking network and PDPfailures through caching, lower response time for the accesscontrol subsystem, and increased scalability by reducing thePDP load, and costs, computational and generated trafficoverheads.
The results of our CSAR evaluation suggest that evenwith small caches (or low cache warmness), our coopera-tive authorization solution can offer significant benefits.Specifically, by recycling secondary authorizations be-tween SDPs, the hit rate can reach 70 percent even whenonly 10 percent of all possible authorization decisions arecached at each SDP. This high hit rate results in morerequests being resolved by the local and cooperatingSDPs, thus increasing availability of the authorizationinfrastructure and reducing the load on the authorizationserver. In addition, depending on the deployment scenar-io, request processing time is reduced by up to a factor oftwo, compared with solutions that do not cooperate.
ACKNOWLEDGMENTS
Members of the Laboratory for Education and Research inSecure Systems Engineering (LERSSE) gave valuable feed-back on the earlier drafts of this paper. The authors aregrateful to the anonymous reviewers for their helpfulcomments, Wing Leung for designing the SAAM evaluationalgorithms, Kyle Zeeuwen for the initial development of theSAAM simulation framework, as well as Craig Wilson andKasia Muldner for improving the readability of this paper.Research on CSAR by the first and third authors have beenpartially supported by the Canadian NSERC StrategicPartnership Program, Grant STPGP 322192-05.
WEI ET AL.: COOPERATIVE SECONDARY AUTHORIZATION RECYCLING 287

REFERENCES
[1] G. Karjoth, “Access Control with IBM Tivoli Access Manager,”ACM Trans. Information and Systems Security, vol. 6, no. 2,pp. 232-257, 2003.
[2] Entrust, “GetAccess Design and Administration Guide,” technicalreport, Entrust, Sept. 1999.
[3] Netegrity, “Siteminder Concepts Guide,” technical report,Netegrity, 2000.
[4] OMG, Common Object Services Specification, Security ServiceSpecification V1.8, 2002.
[5] L.G. DeMichiel, L.U. Yalcinalp, and S. Krishnan, EnterpriseJavaBeans Specification Version 2.0, Sun Microsystems, 2001.
[6] B. Johnson, “An Introduction to the Design and Analysis of Fault-Tolerant Systems,” Fault-Tolerant Computer System Design. pp. 1-87, Prentice Hall, 1996.
[7] Z. Kalbarczyk, R.K. Lyer, and L. Wang, “Application FaultTolerance with Armor Middleware,” IEEE Internet Computing,vol. 9, no. 2, pp. 28-38, 2005.
[8] W. Vogels, “How Wrong Can You Be? Getting Lost on theRoad to Massive Scalability,” Proc. Fifth Int’l Middleware Conf.(Middleware ’04), keynote address, Oct. 2004.
[9] P. Strong, “How eBay Scales with Networks and the Challenges,”Proc. 16th IEEE Int’l Symp. High-Performance Distributed Computing(HPDC ’07), invited talk, 2007.
[10] V. Nicomette and Y. Deswarte, “An Authorization Scheme forDistributed Object Systems,” Proc. IEEE Symp. Security and Privacy(S&P ’97), pp. 21-30, 1997.
[11] J. Crampton, W. Leung, and K. Beznosov, “Secondary andApproximate Authorizations Model and Its Application to Bell-LaPadula Policies,” Proc. 11th ACM Symp. Access Control Modelsand Technologies (SACMAT ’06), pp. 111-120, June 2006.
[12] D.E. Bell and L.J. LaPadula, “Secure Computer Systems: Mathe-matical Foundations,” Technical Report ESD-TR-74-244, MITRE,Mar. 1973.
[13] E.A. Brewer, “Towards Robust Distributed Systems,” Proc. ACMSymp. Principles of Distributed Computing (PODC ’00), invited talk,2000.
[14] S. Gilbert and N. Lynch, “Brewer’s Conjecture and the Feasibilityof Consistent, Available, Partition-Tolerant Web Services,”SIGACT News, vol. 33, no. 2, pp. 51-59, 2002.
[15] L. Fan, P. Cao, J. Almeida, and A.Z. Broder, “Summary Cache:A Scalable Wide-Area Web Cache Sharing Protocol,” IEEE/ACMTrans. Networking, vol. 8, no. 3, pp. 281-293, 2000.
[16] XACML, OASIS eXtensible Access Control Markup Language(XACML) Version 2.0, OASIS Standard, Feb. 2005.
[17] L. Breslau, P. Cao, L. Fan, G. Phillips, and S. Shenker, “WebCaching and Zipf-Like Distributions: Evidence and Implications,”Proc. IEEE INFOCOM ’99, pp. 126-134, 1999.
[18] TPC-W: Transactional Web Benchmark Version 1.8, http://www.tpc.org/tpcw/, 2002.
[19] Q. Wei, M. Ripeanu, and K. Beznosov, “Cooperative SecondaryAuthorization Recycling,” Technical Report LERSSE-TR-2008-02,Laboratory for Education and Research in Secure Systems Eng.,Univ. of British Columbia, Apr. 2008.
[20] L. Bauer, S. Garriss, and M.K. Reiter, “Distributed Proving inAccess-Control Systems,” Proc. IEEE Symp. Security and Privacy(S&P ’05), pp. 81-95, 2005.
[21] K. Borders, X. Zhao, and A. Prakash, “CPOL: High-PerformancePolicy Evaluation,” Proc. 12th ACM Conf. Computer and Comm.Security (CCS ’05), pp. 147-157, 2005.
[22] K. Beznosov, “Flooding and Recycling Authorizations,” Proc. NewSecurity Paradigms Workshop (NSPW ’05), pp. 67-72, Sept. 2005.
[23] K. Beznosov, Y. Deng, B. Blakley, C. Burt, and J. Barkley, “AResource Access Decision Service for CORBA-Based Distribu-ted Systems,” Proc. Ann. Computer Security Applications Conf.(ACSAC ’99), pp. 310-319, 1999.
[24] G.H. Stowe, “A Secure Network Node Approach to the PolicyDecision Point in Distributed Access Control,” technical report,Computer Science, Dartmouth College, June 2004.
[25] P.J. Mazzuca, “Access Control in a Distributed DecentralizedNetwork: An XML Approach to Network Security Using XACMLand SAML,” technical report, Computer Science, DartmouthCollege, Spring 2004.
[26] M. Locasto, S. Sidiroglou, and A.D. Keromytis, “SoftwareSelf-Healing Using Collaborative Application Communities,”Proc. Network and Distributed System Security Symp. (NDSS ’06),pp. 95-106, 2006.
[27] M. Costa, J. Crowcroft, M. Castro, A. Rowstron, L. Zhou, L. Zhang,and P. Barham, “Vigilante: End-to-End Containment of InternetWorms,” Proc. ACM Symp. Operating Systems Principles (SOSP),2005.
[28] J. Wang, “A Survey of Web Caching Schemes for the Internet,”SIGCOMM Computer Comm. Rev., vol. 29, no. 5, pp. 36-46, 1999.
Qiang Wei received the master’s degree ininformation engineering from Nanyang Techno-logical University (NTU) in 2002. He is a PhDcandidate in the Electrical and Computer En-gineering Department (ECE), University of BritishColumbia (UBC). His PhD dissertation focuseson improving the availability and performance ofaccess control system in large-scale distributedsystems. He works in the Laboratory for Educa-tion and Research in Secure Systems Engineer-
ing (LERSSE) under the supervision of Professors Konstantin Beznosovand Matei Ripeanu. Before joining UBC, he was a security softwareengineer at the Application Security Group, CrimsonLogic, Singapore.His research interests include distributed system security architecture,middleware security, software security, and peer-to-peer security. He is astudent member of the IEEE.
Matei Ripeanu received the PhD degree incomputer science from the University ofChicago in 2005. After a brief visiting periodwith the Argonne National Laboratory, hejoined the Electrical and Computer EngineeringDepartment, University of British Columbia asan assistant professor. He is broadly interestedin distributed systems with a focus on self-organization and decentralized control in large-scale Grid and peer-to-peer systems. He has
published in major academic conference proceedings on large-scaleGrid and peer-to-peer system characterization, on techniques toexploit the emergent characteristics of these systems and onsupporting scientific applications to run on these platforms.
Konstantin Beznosov received the PhD degreein computer science on engineering accesscontrol for distributed enterprise applicationsfrom Florida International University in 2000. Heis an assistant professor at the Department ofElectrical and Computer Engineering, Universityof British Columbia, Vancouver, Canada. Hefounded and leads the Laboratory for Educationand Research in Secure Systems Engineering(LERSSE). Prior to that, he was a security
architect with Hitachi Computer Products, Inc. (HICAM), where hedesigned and developed products for security integration of enterpriseapplications. Before HICAM, he consulted large telecommunication andbanking companies on the architecture of security solutions fordistributed enterprise applications, as a security architect at ConceptFive Technologies. He is a coauthor of Enterprise Security with EJB andCORBA and Mastering Web Services Security by Wiley ComputerPublishing and a contributor to Securing Web Services: Practical Usageof Standards and Specifications by Idea Group and the Handbook ofSoftware Engineering and Knowledge Engineering by World ScientificPublishing. He has published in major academic conferences on accesscontrol, distributed systems security, and usable security. He is amember of the IEEE and the IEEE Computer Society.
. For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
288 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 20, NO. 2, FEBRUARY 2009





























