Embed Size (px)
DESCRIPTION
CPSC 614:Graduate Computer Architecture Memory System II. Based on lectures by Prof. David Culler Prof. David Patterson UC Berkeley. Virtual Memory. Terminology. Page: a virtual memory block Page fault: a virtual memory miss - PowerPoint PPT Presentation
Citation preview

CPSC 614:Graduate Computer Architecture
Memory System II
Based on lectures by
Prof. David Culler
Prof. David Patterson
UC Berkeley

Virtual Memory
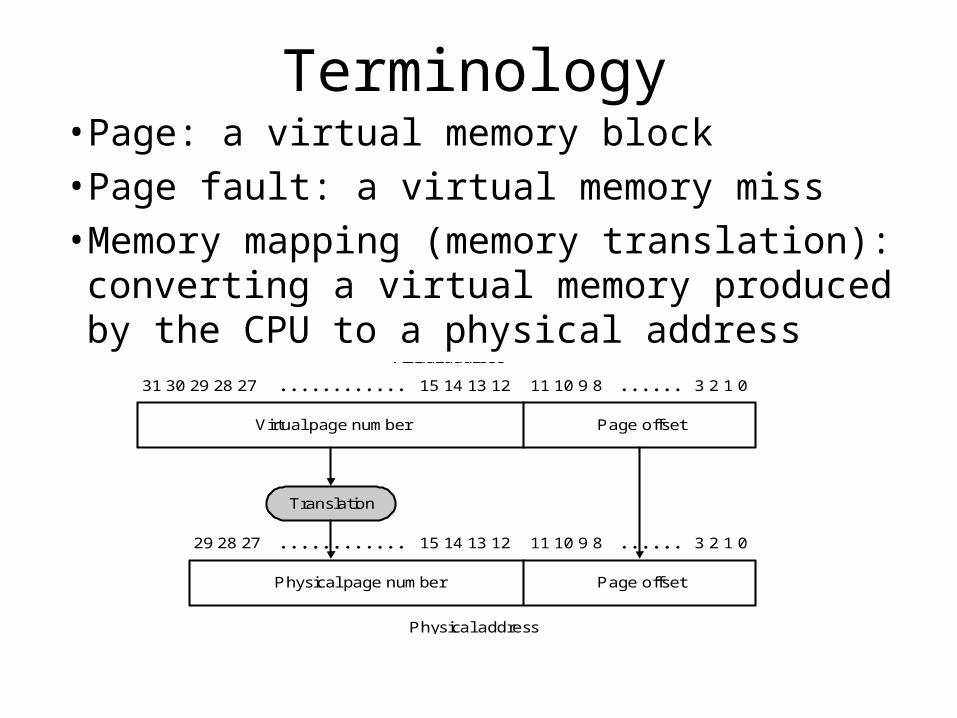
Terminology• Page: a virtual memory block• Page fault: a virtual memory miss• Memory mapping (memory translation):
converting a virtual memory produced by the CPU to a physical address
3 2 1 011 10 9 815 14 13 1231 30 29 28 27
Page offsetVirtual page number
Virtual address
3 2 1 011 10 9 815 14 13 1229 28 27
Page offsetPhysical page number
Physical address
Translation
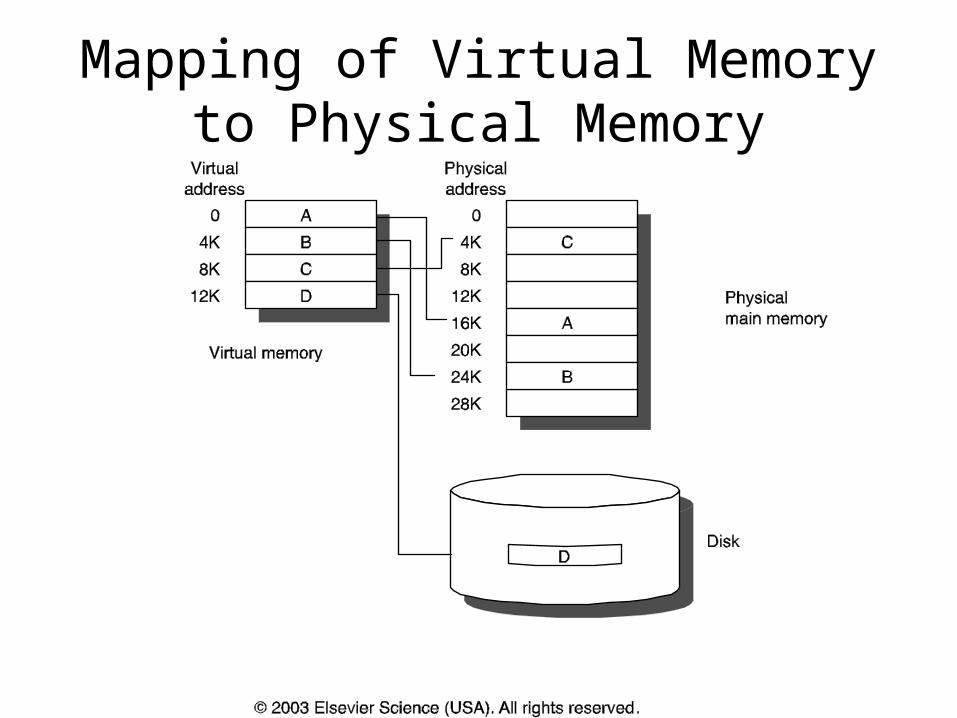
Mapping of Virtual Memory to Physical Memory
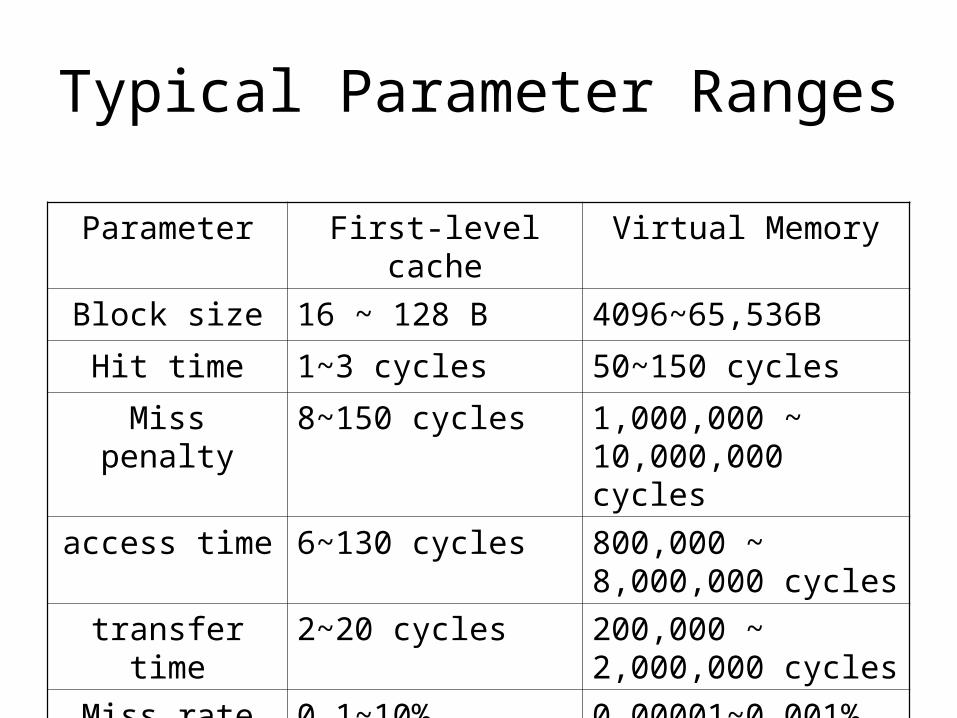
Typical Parameter Ranges
Parameter First-level cache Virtual Memory
Block size 16 ~ 128 B 4096~65,536B
Hit time 1~3 cycles 50~150 cycles
Miss penalty 8~150 cycles 1,000,000 ~ 10,000,000 cycles
access time 6~130 cycles 800,000 ~ 8,000,000 cycles
transfer time 2~20 cycles 200,000 ~ 2,000,000 cycles
Miss rate 0.1~10% 0.00001~0.001%

Design Issues
• A page fault takes millions of cycles to process.– Pages should be large enough to amortize the high
access time. (4KB ~ 64KB)– Fully associative placement of pages is used.– Page faults can be handled in software.– Write-back (Write-through scheme does not work.)

Where to Place a Page and How to Find it
• Fully associative placement
• A page table is used to located pages.– Resides in memory
– Indexed with the page number from the virtual address and contains the corresponding physical page number.
– Each program has its own page table.
– To indicate the location of the page table in memory, the page table register is used.
– A valid bit in each entry (off: the page is not in memory => page fault)
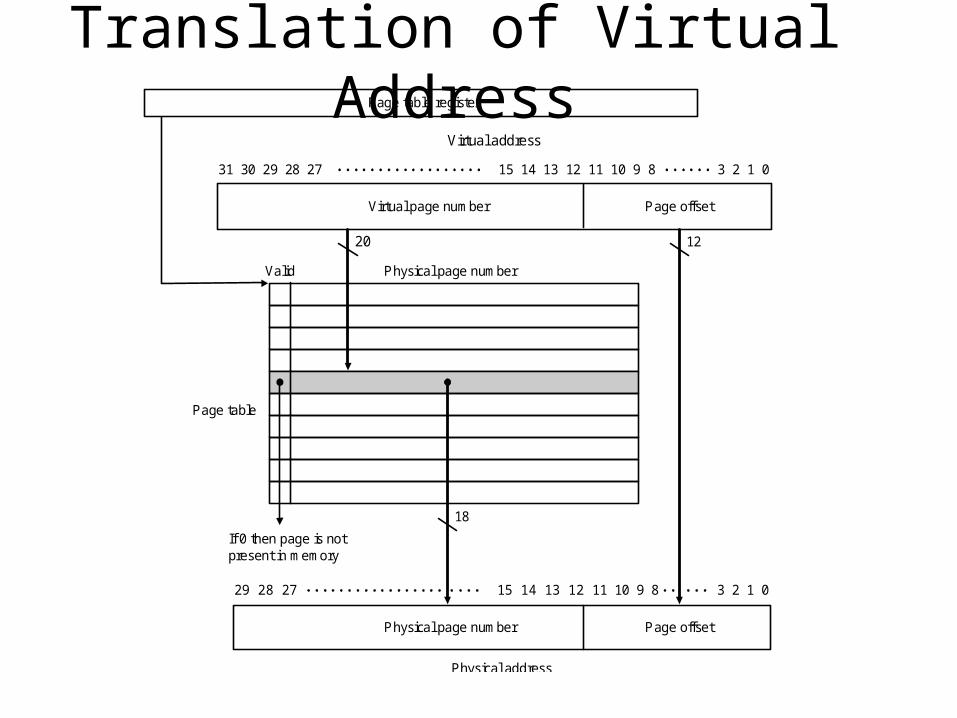
Translation of Virtual Address
Page offsetVirtual page number
Virtual address
Page offsetPhysical page number
Physical address
Physical page numberValid
If 0 then page is notpresent in memory
Page table register
Page table
20 12
18
31 30 29 28 27 15 14 13 12 11 10 9 8 3 2 1 0
29 28 27 15 14 13 12 11 10 9 8 3 2 1 0
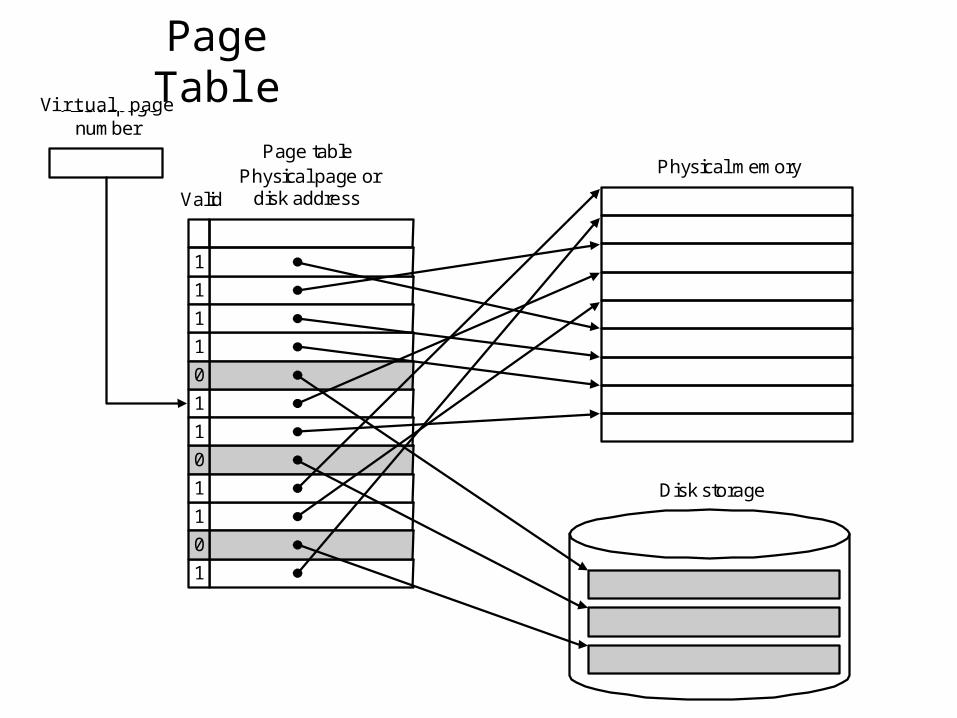
Page Table
Physical memory
Disk storage
Valid
1
1
1
1
0
1
1
0
1
1
0
1
Page table
Virtual pagenumber
Physical page ordisk address
Virtual page

Writes in Virtual Memory• Writes to the next level of memory hierarchy (disk) take
millions of cycles.• Write-through (with write buffer) is not practical.• Write-back (copy back): Virtual memory systems
perform the individual writes into the page in memory and copy the page back to disk when it is replaced.
• Dirty bit: indicates the page has been modified.

TLB (Translation Lookaside Buffer)
• Each memory access by a program takes at least twice as long.
– One to obtain the physical address in the page table– One to get the data
• TLB (Translation Lookaside Buffer)– A cache that holds only page table mapping– Includes the reference bit, the dirty bit, and the valid bit.
– We don’t need to access the page table on every reference.

TLB Structure
Dirty
Ref
Valid
Virtual Page # Physical Page #
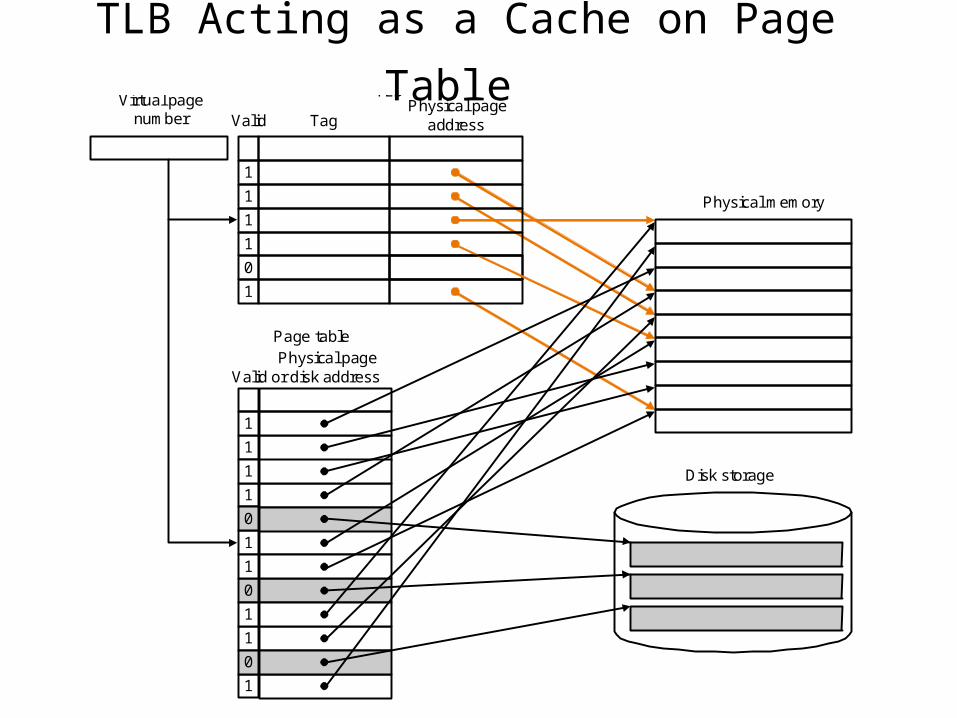
TLB Acting as a Cache on Page Table
Valid
1
1
1
1
0
1
1
0
1
1
0
1
Page table
Physical pageaddressValid
TLB
1
1
1
1
0
1
TagVirtual page
number
Physical pageor disk address
Physical memory
Disk storage

TLB Design Issues
• When a TLB entry is replaced, we need to copy the reference and dirty bits back to the page table entry.
• Write-back (due to small miss rate)
• Fully associative mapping (due to small TLB)
–If larger TLBs are used, no or small associativity can be used.
• Randomly choose an entry to replace.
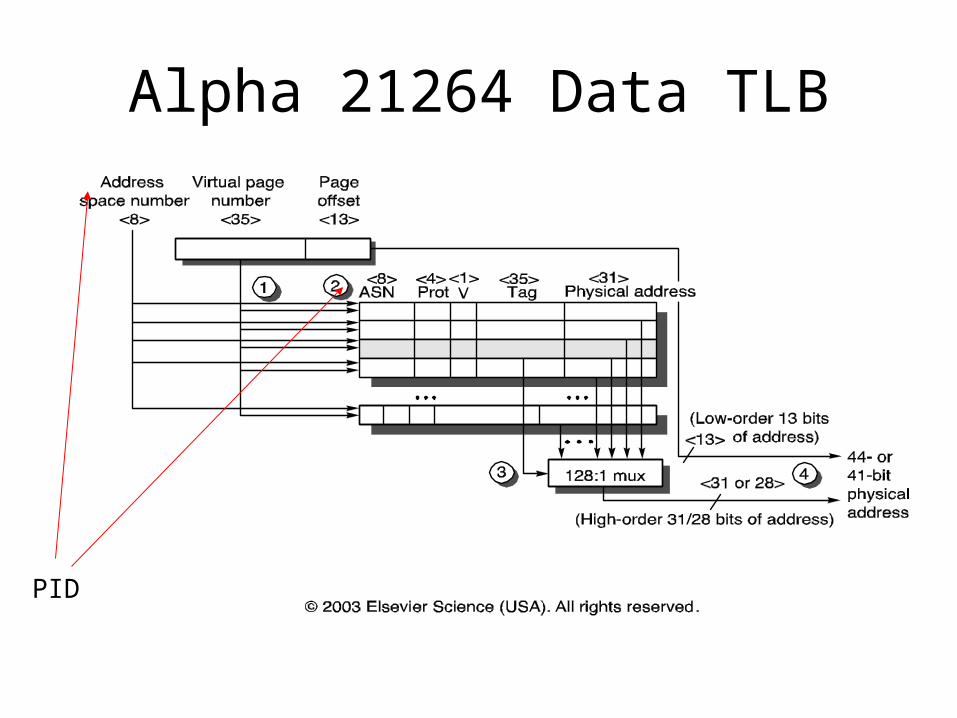
Alpha 21264 Data TLB
PID
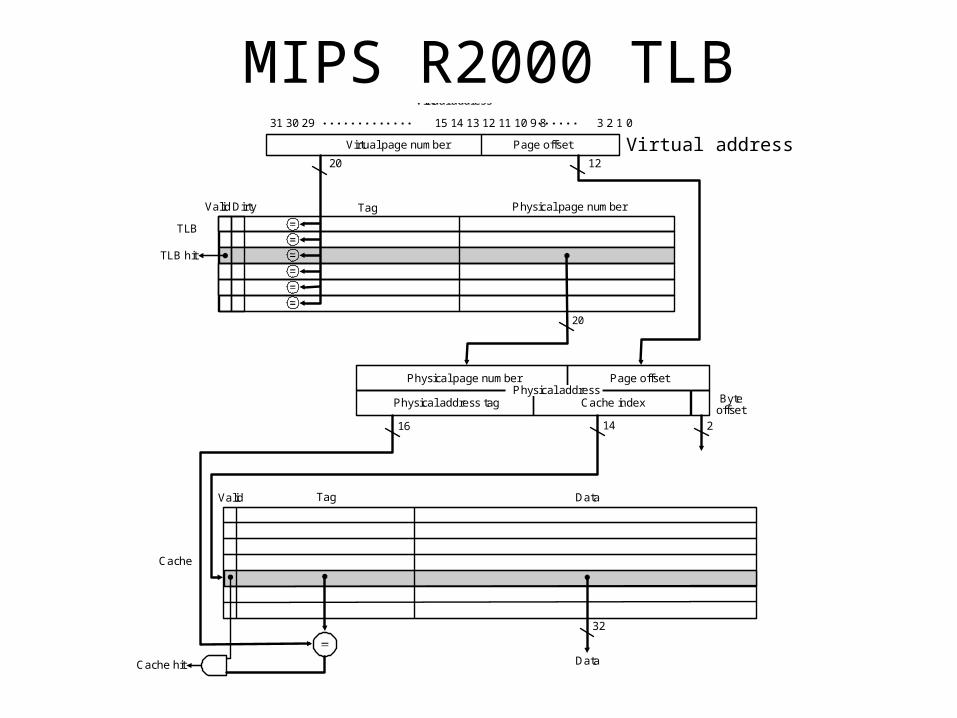
MIPS R2000 TLB
Valid Tag Data
Page offset
Page offset
Virtual page number
Virtual address
Physical page numberValid
1220
20
16 14
Cache index
32
Cache
DataCache hit
2
Byteoffset
Dirty Tag
TLB hit
Physical page number
Physical address tag
TLB
Physical address
31 30 29 15 14 13 12 11 10 9 8 3 2 1 0
Virtual address
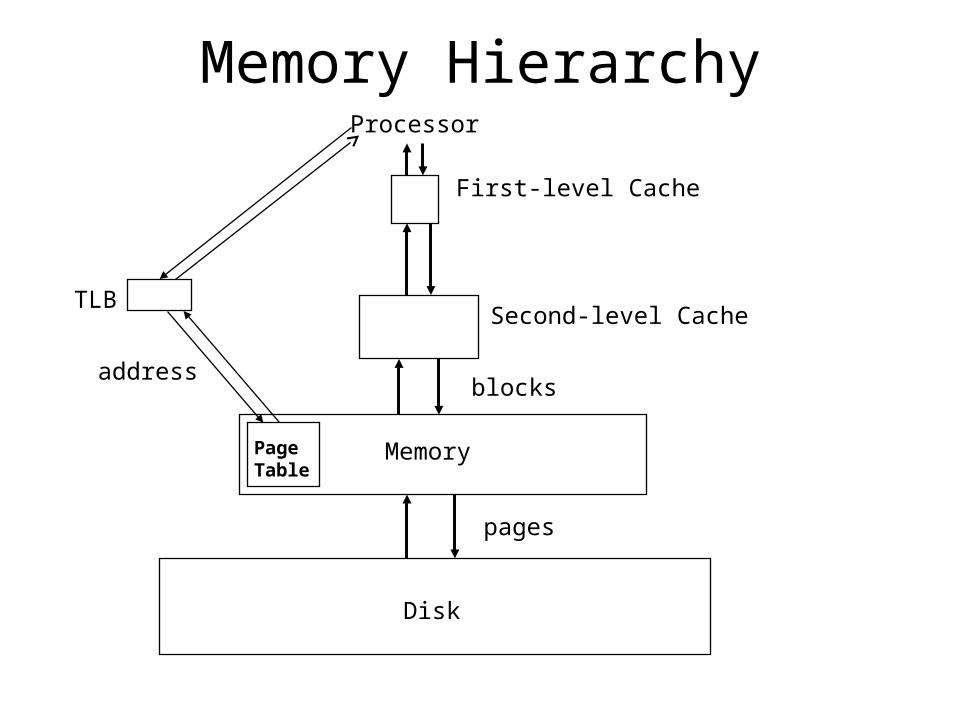
Memory Hierarchy
Disk
Memory
Second-level Cache
Processor
First-level Cache
TLB
Page Table
pages
blocksaddress

Caches and Memory Systems II:

Improving Cache Performance
1. Reduce the miss rate,
2. Reduce the miss penalty, or
3. Reduce the time to hit in the cache.
yMissPenaltMissRateHitTimeAMAT

1. Fast Hit times via Small and Simple Caches
• Why Alpha 21164 has 8KB Instruction and 8KB data cache + 96KB second level cache?– Small data cache and clock rate– L1 cache matched to clock rate– L2… caches do not need to match clock rate
• Direct Mapped, on chip– On-chip cache avoids large off-chip delay– Same reason for on-chip cache in Intel Xeon processors
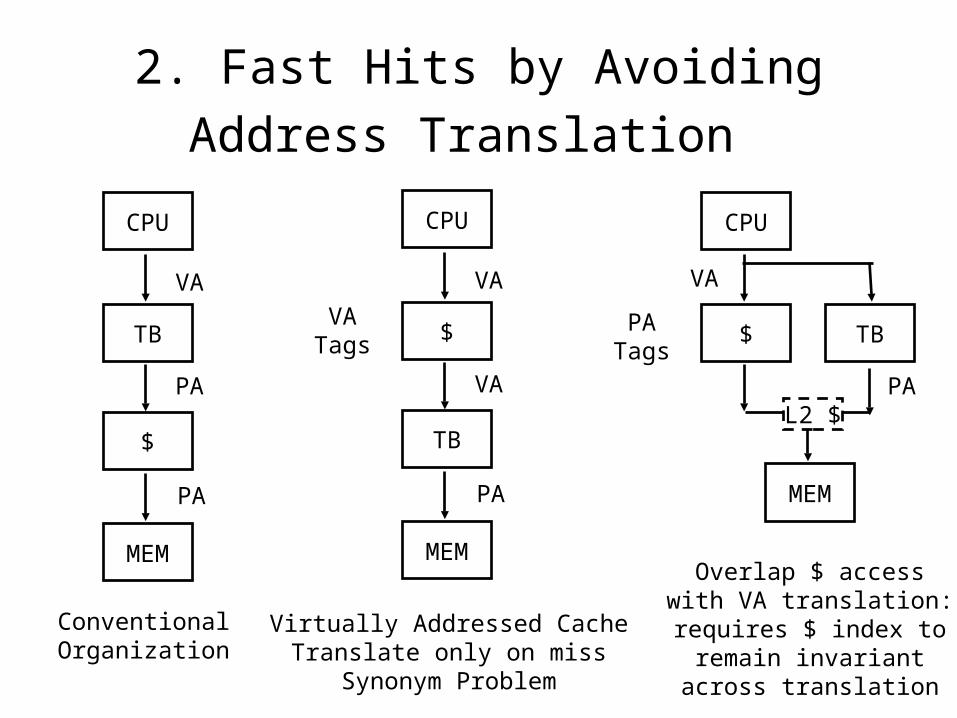
2. Fast Hits by Avoiding Address
Translation CPU
TB
$
MEM
VA
PA
PA
ConventionalOrganization
CPU
$
TB
MEM
VA
VA
PA
Virtually Addressed CacheTranslate only on miss
Synonym Problem
CPU
$ TB
MEM
VA
PATags
PA
Overlap $ accesswith VA translation:requires $ index to
remain invariantacross translation
VATags
L2 $

Problem: Flushes on Context Switch• Send virtual address to cache? Called Virtually Addressed Cache or just
Virtual Cache vs. Physical Cache– Every time process is switched logically must flush the cache; otherwise get false hits
• Cost is time to flush + “compulsory” misses from empty cache– But still have aliases (sometimes called synonyms);
Two different virtual addresses map to same physical address– I/O must interact with cache, so need virtual address
• Solution to aliases– HW guarantees covers index field & direct mapped, they must be unique;
called page coloring
• Solution to cache flush– Add process identifier tag that identifies process as well as address within process:
can’t get a hit if wrong process
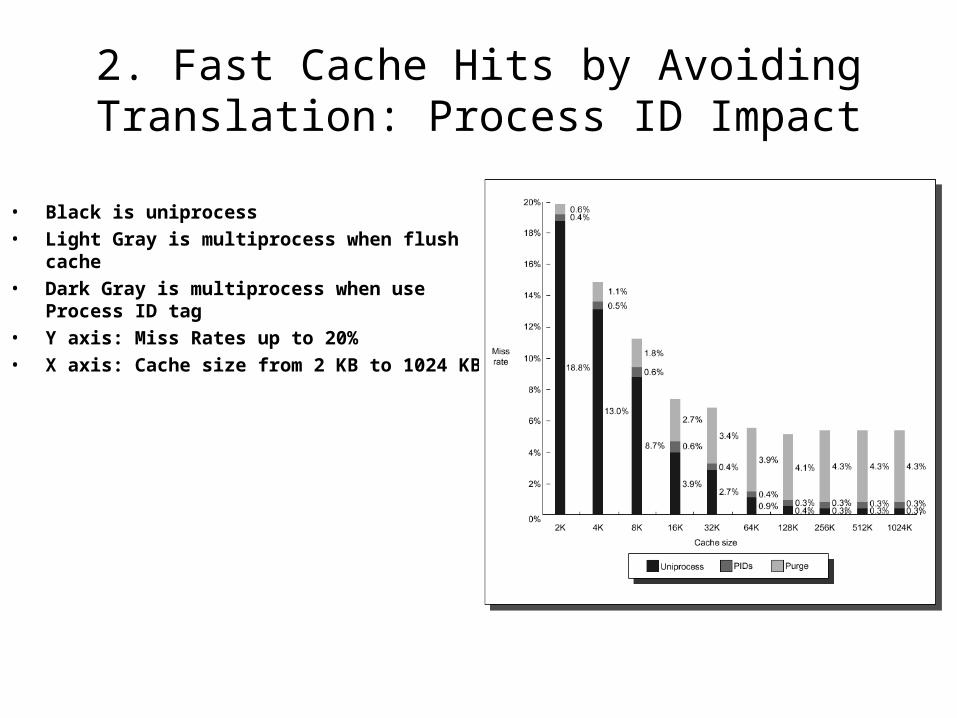
2. Fast Cache Hits by Avoiding Translation: Process ID Impact
• Black is uniprocess
• Light Gray is multiprocess when flush cache
• Dark Gray is multiprocess when use Process ID tag
• Y axis: Miss Rates up to 20%
• X axis: Cache size from 2 KB to 1024 KB

2. Fast Cache Hits by Avoiding Translation: Index with Physical Portion of Address
• If index is physical part of address, can start tag access in parallel with translation so that can compare to physical tag
Limits cache to page size: what if want bigger caches and uses same trick?– Higher associativity moves barrier to right– Page coloring
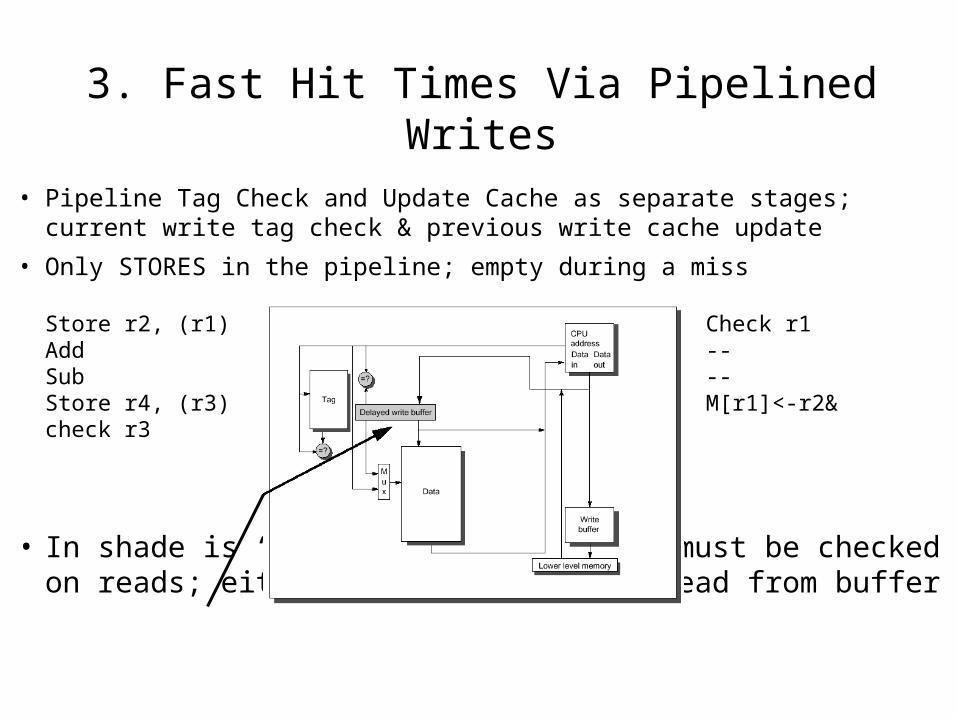
• Pipeline Tag Check and Update Cache as separate stages; current write tag check & previous write cache update
• Only STORES in the pipeline; empty during a miss
Store r2, (r1) Check r1Add --Sub --Store r4, (r3) M[r1]<-r2& check r3
• In shade is “Delayed Write Buffer”; must be checked on reads; either complete write or read from buffer
3. Fast Hit Times Via Pipelined Writes

4. Fast Writes on Misses Via Small Subblocks
• If most writes are 1 word, subblock size is 1 word, & write through then always write subblock & tag immediately – Tag match and valid bit already set: Writing the block was proper, & nothing
lost by setting valid bit on again.– Tag match and valid bit not set: The tag match means that this is the proper
block; writing the data into the subblock makes it appropriate to turn the valid bit on.
– Tag mismatch: This is a miss and will modify the data portion of the block. Since write-through cache, no harm was done; memory still has an up-to-date copy of the old value. Only the tag to the address of the write and the valid bits of the other subblock need be changed because the valid bit for this subblock has already been set
• Doesn’t work with write back due to last case

5: Fast Hits by pipelining Cache
Case Study: MIPS R4000 • 8 Stage Pipeline:
– IF–first half of fetching of instruction; PC selection happens here as well as initiation of instruction cache access.
– IS–second half of access to instruction cache. – RF–instruction decode and register fetch, hazard checking and
also instruction cache hit detection.– EX–execution, which includes effective address calculation,
ALU operation, and branch target computation and condition evaluation.
– DF–data fetch, first half of access to data cache.– DS–second half of access to data cache.– TC–tag check, determine whether the data cache access hit.– WB–write back for loads and register-register operations.
• What is impact on Load delay? – Need 2 instructions between a load and its use!

Case Study: MIPS R4000
IF ISIF
RFISIF
EXRFISIF
DFEXRFISIF
DSDFEXRFISIF
TCDSDFEXRFISIF
WBTCDSDFEXRFISIF
TWO CycleLoad Latency
IF ISIF
RFISIF
EXRFISIF
DFEXRFISIF
DSDFEXRFISIF
TCDSDFEXRFISIF
WBTCDSDFEXRFISIF
THREE CycleBranch Latency(conditions evaluated during EX phase)
Delay slot plus two stallsBranch likely cancels delay slot if not taken
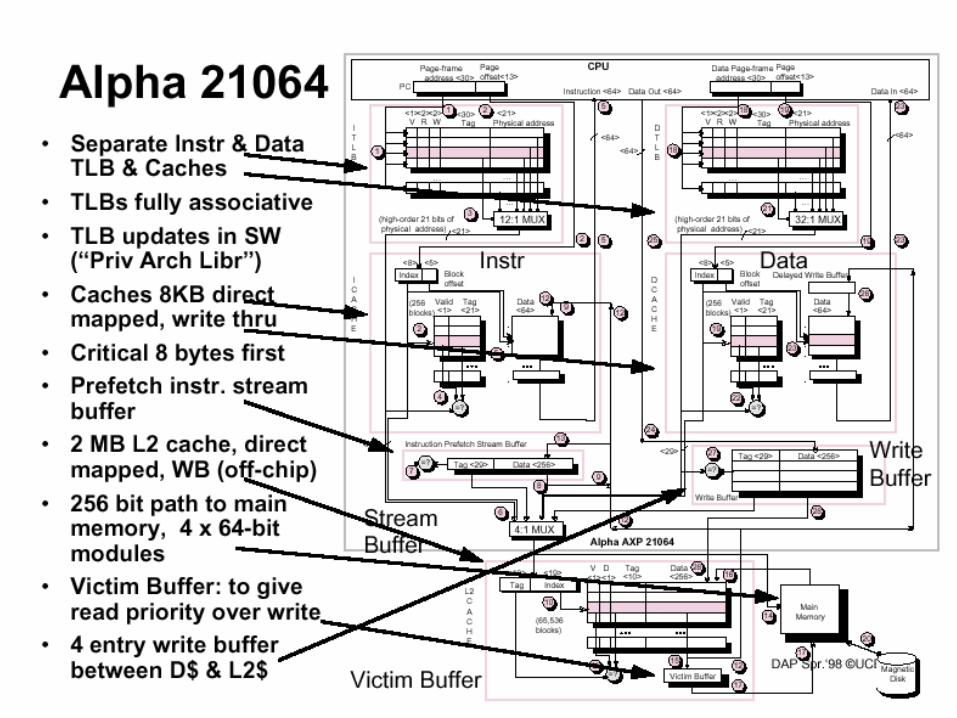
Alpha 21064• Separate Instr & Data TLB
& Caches• TLBs fully associative• TLB updates in SW
(“Priv Arch Libr”)• Caches 8KB direct mapped,
write thru• Critical 8 bytes first• Prefetch instr. stream buffer• 2 MB L2 cache, direct
mapped, WB (off-chip)• 256 bit path to main
memory, 4 x 64-bit modules
• Victim Buffer: to give read priority over write
• 4 entry write buffer between D$ & L2$
StreamBuffer
WriteBuffer
Victim Buffer
Instr Data
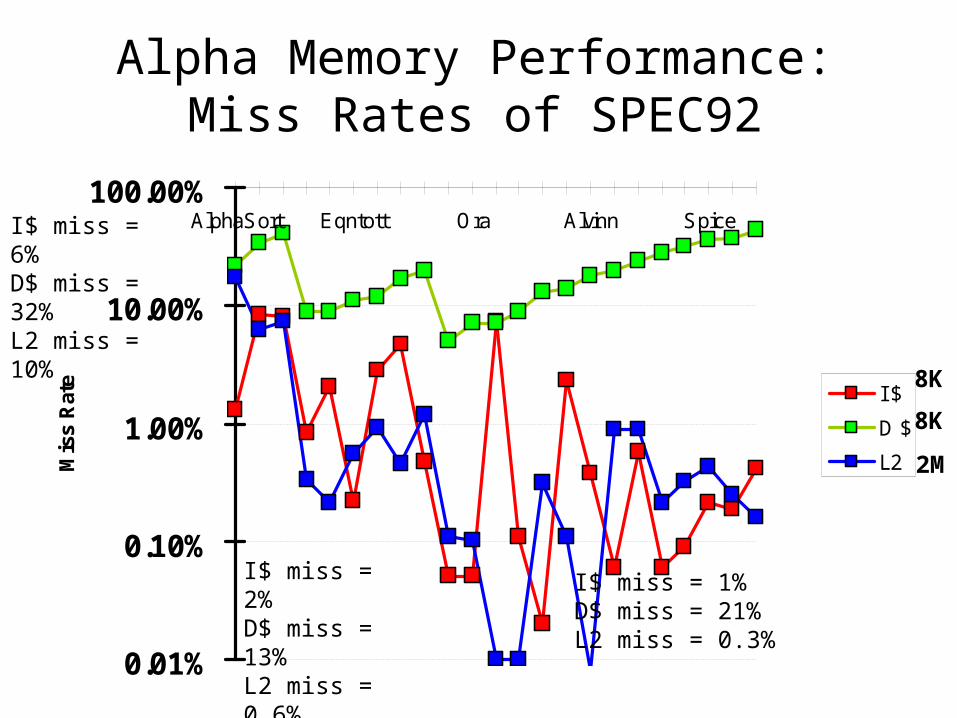
0.01%
0.10%
1.00%
10.00%
100.00%AlphaSort Eqntott Ora Alvinn Spice
Mis
s Rat
e I $
D $
L2
Alpha Memory Performance: Miss Rates of SPEC92
8K
8K
2M
I$ miss = 2%D$ miss = 13%L2 miss = 0.6%
I$ miss = 1%D$ miss = 21%L2 miss = 0.3%
I$ miss = 6%D$ miss = 32%L2 miss = 10%
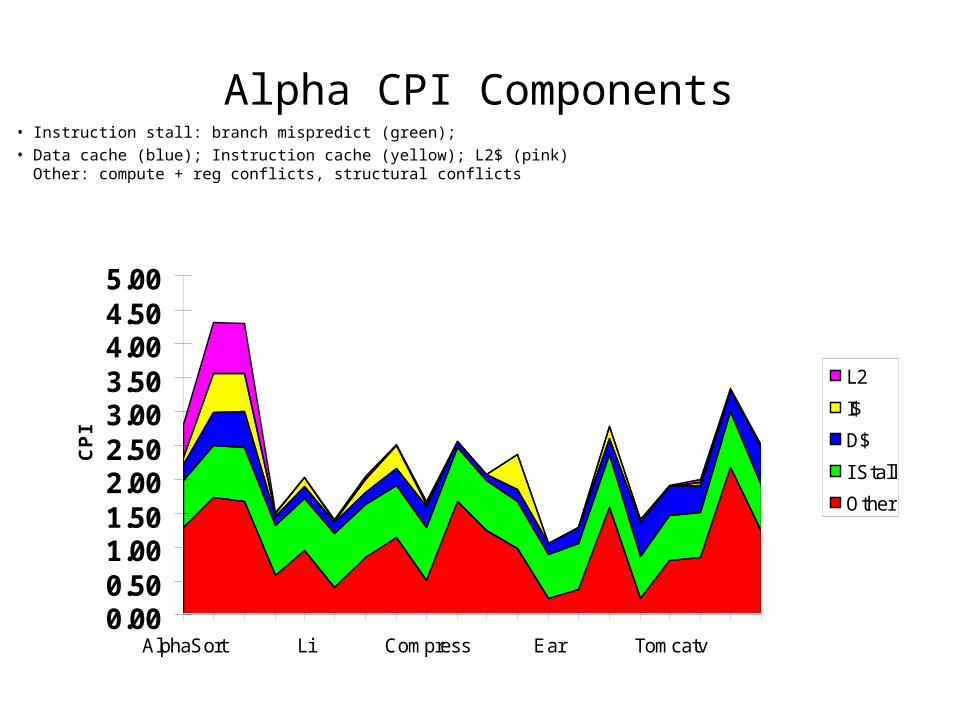
0.000.501.001.502.002.503.003.504.004.505.00
AlphaSort Li Compress Ear Tomcatv
CP
I
L2
I$
D$
I Stall
Other
Alpha CPI Components• Instruction stall: branch mispredict (green);• Data cache (blue); Instruction cache (yellow); L2$ (pink)
Other: compute + reg conflicts, structural conflicts
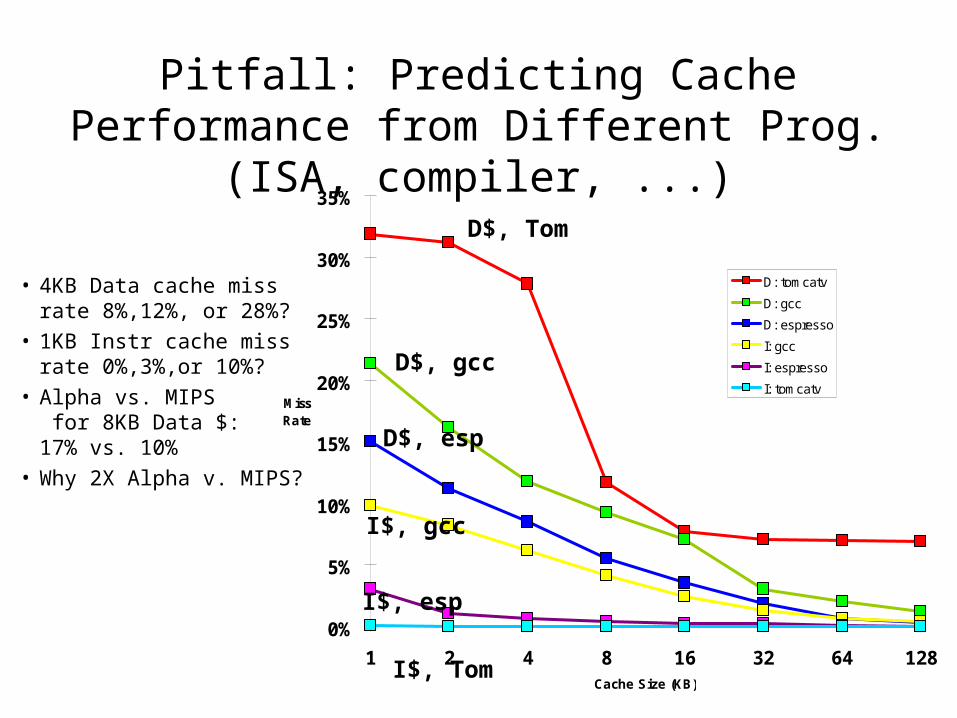
Pitfall: Predicting Cache Performance from Different Prog. (ISA, compiler, ...)
• 4KB Data cache miss rate 8%,12%, or 28%?
• 1KB Instr cache miss rate 0%,3%,or 10%?
• Alpha vs. MIPS for 8KB Data $:17% vs. 10%
• Why 2X Alpha v. MIPS?
0%
5%
10%
15%
20%
25%
30%
35%
1 2 4 8 16 32 64 128Cache Size (KB)
Miss Rate
D: tomcatv
D: gcc
D: espresso
I: gcc
I: espresso
I: tomcatv
D$, Tom
D$, gcc
D$, esp
I$, gcc
I$, esp
I$, Tom
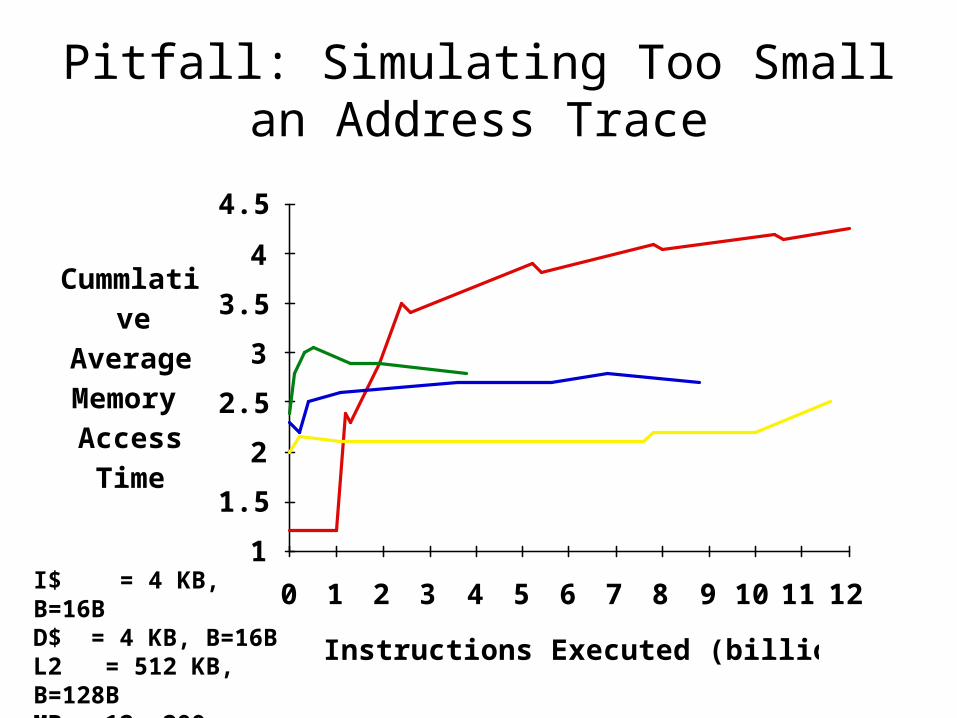
Instructions Executed (billions)
Cummlative
AverageMemoryAccessTime
1
1.5
2
2.5
3
3.5
4
4.5
0 1 2 3 4 5 6 7 8 9 10 11 12
Pitfall: Simulating Too Small an Address Trace
I$ = 4 KB, B=16BD$ = 4 KB, B=16BL2 = 512 KB, B=128BMP = 12, 200
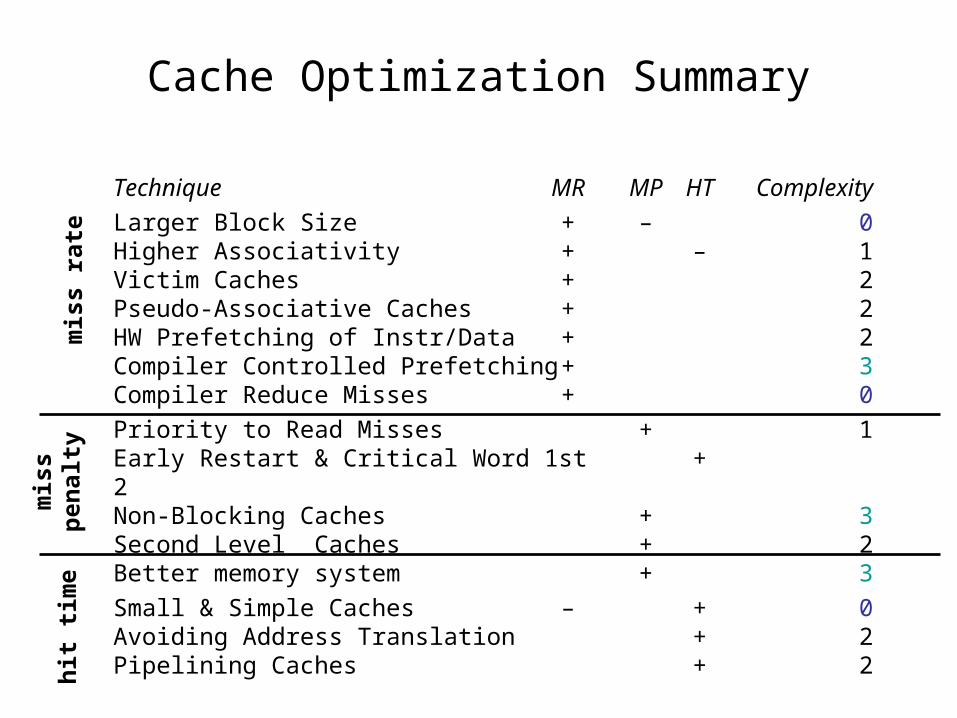
Cache Optimization Summary
Technique MR MP HT Complexity
Larger Block Size + – 0Higher Associativity + – 1Victim Caches + 2Pseudo-Associative Caches + 2HW Prefetching of Instr/Data + 2Compiler Controlled Prefetching + 3Compiler Reduce Misses + 0
Priority to Read Misses + 1Early Restart & Critical Word 1st + 2Non-Blocking Caches + 3Second Level Caches + 2Better memory system + 3
Small & Simple Caches – + 0Avoiding Address Translation + 2Pipelining Caches + 2
mis
s ra
teh
it t
ime
mis
sp
enal
ty
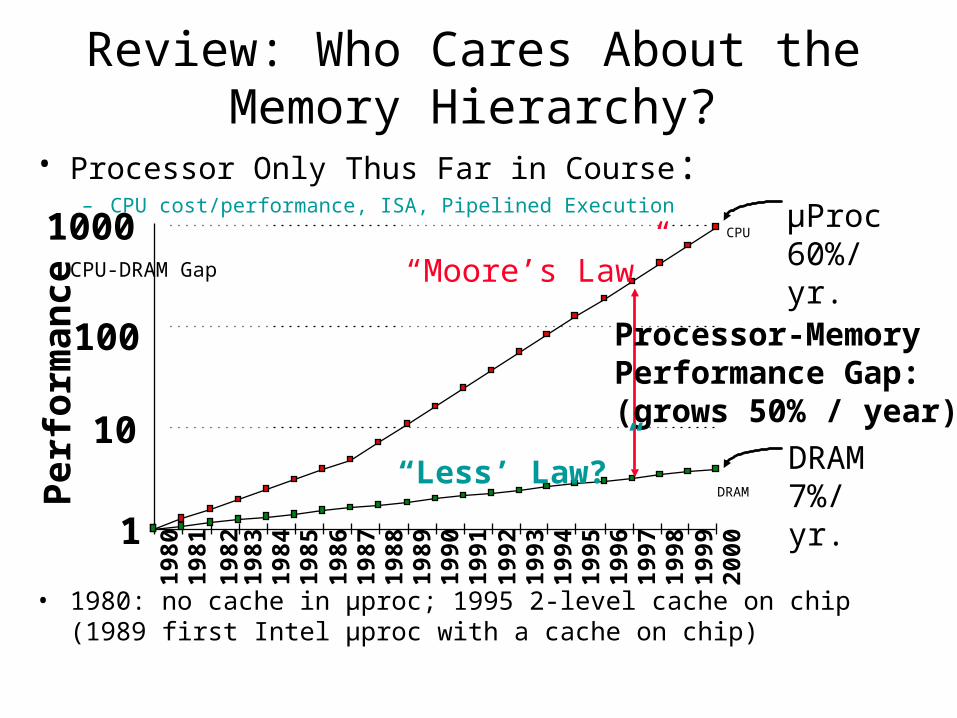
Review: Who Cares About the Memory Hierarchy?
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000
198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
“Moore’s Law”
• Processor Only Thus Far in Course:– CPU cost/performance, ISA, Pipelined Execution
CPU-DRAM Gap
• 1980: no cache in µproc; 1995 2-level cache on chip(1989 first Intel µproc with a cache on chip)
“Less’ Law?”

What happens on a Cache miss?• For in-order pipeline, 2 options:
– Freeze pipeline in Mem stage (popular early on: Sparc, R4000)IF ID EX Mem stall stall stall … stall
Mem Wr IF ID EX stall stall stall … stall
stall Ex Wr
– Use Full/Empty bits in registers + MSHR queue• MSHR = “Miss Status/Handler Registers” (Kroft)
Each entry in this queue keeps track of status of outstanding memory requests to one complete memory line.
– Per cache-line: keep info about memory address.– For each word: register (if any) that is waiting for result.– Used to “merge” multiple requests to one memory line
• New load creates MSHR entry and sets destination register to “Empty”. Load is “released” from pipeline.
• Attempt to use register before result returns causes instruction to block in decode stage.
• Limited “out-of-order” execution with respect to loads. Popular with in-order superscalar architectures.
• Out-of-order pipelines already have this functionality built in… (load queues, etc).





























