Embed Size (px)
Citation preview

CRITICAL SYSTEMS PROPERTIES
Survey and Taxonomy

OVERVIEW What is a critical system? What are its properties? Try to classify the properties. How the different properties are
compatible.

Critical system There is a lot of disagreement
concerning the definition of “critical system”.
There are FOUR different views on the subject.
There are differing views on the relationship between properties and the compatibility of techniques from these approaches.

The Different Approaches Dependability Approach Safety Approach Security Approach Real time systems Approach

Dependability Approach Introduced by Jean Claude Laprie. A Dependable system is one for which the
reliance may justifiably be placed on both its “correctness” and “continuity of its delivery”
“correctness” pertains to the conformity with requirements, specifications etc.
“Dependability” encapsulates the technical meaning of terms such as reliability, safety, survivability,security and fault tolerance.

Failure Failure is defined as the inability to
provide a required service from the system because of faults.
Failure is a property of the external behavior of a system.
Failures can be either a)Benign or b)Catastrophic

Benign Failure The consequences of failure =
Benefits provided by normal operation.
Catastrophic Failure The consequences of failure >>
Benefits provided by normal operation.
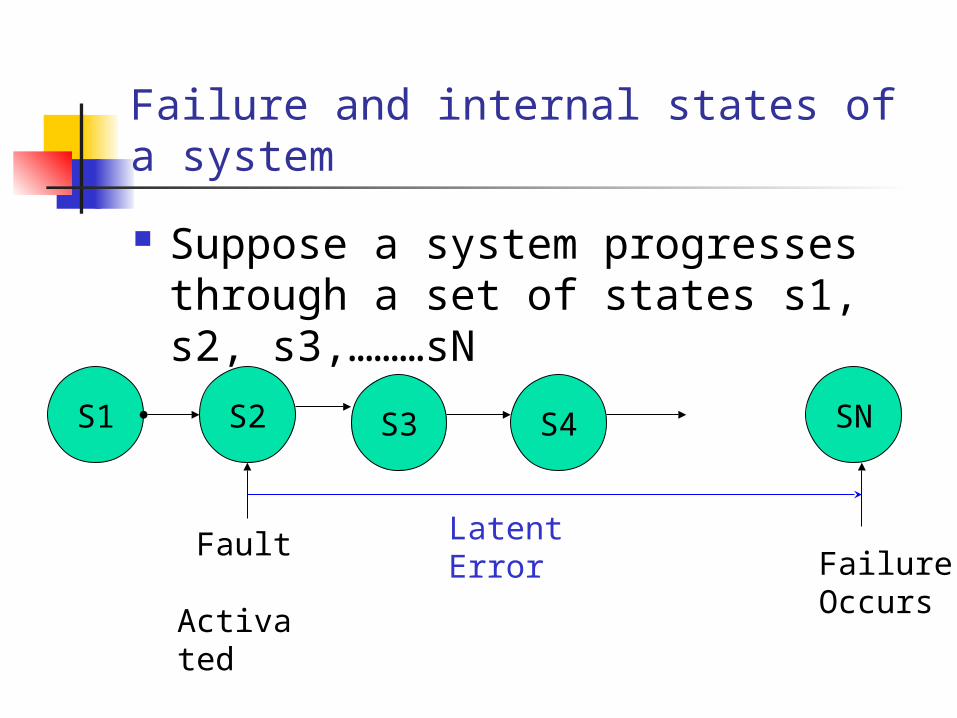
Failure and internal states of a system
Suppose a system progresses through a set of states s1, s2, s3,………sN
S1 S3 S4 SNS2
FailureOccurs
Fault Activated
Latent Error

Fault Tolerant system The error or fault is latent from the
state of activation until it manifests itself in the effective fault state.
A Fault tolerant system attempts to detect and correct such latent errors before they become effective.

Steps in Fault Tolerance Error Detection – Detect the latent
error before the effective fault state.
This can be done by internal consistency checks or by comparison with redundant computations.
Internal tests are often referred as B.I.S.T
(built in self tests)

Error recovery – The erroneous state is replaced by an acceptable valid state.
Error recovery could be either forward error recovery or backward error recovery.
e.g – Exception handling is an example of forward recovery.
Another alternative to error recovery is FAULT MASKING. This is done through modular redundancy wherein several components perform each computation independently and the final result is selected by majority voting.

Failure Semantics This defines the behavior that a component
may exhibit when it fails to provide its standard correct behavior.
Omission failure –fails to respond to an input Timing failure – when a correct response is delivered
but outside the real time interval. Response failure – When a component performs an
incorrect state change. Crash failure – When a component performs an
omission failure and thereafter performs no other action until restarted.
Arbitrary (Byzanite) failures – Totally uncontrolled and can display different symptoms to different observers.

Faults Faults can be classified according
to the semantics of failures they may induce.
Faults can be due to Design faults Component faults Improper operational faults Environmental anomalies e.g
electromagnetic disturbances.

Fault tolerant system models A FT system that covers many different fault
modes may provide a different recovery mechanism for each, and will become complex which can itself create faults.
If we design to arbitrary failure we can cover all possible faults, however it becomes expensive and increases redundancy.
So the designer has to trade off the number of different kinds of faults that can be tolerated.

Hybrid Fault Model – This model can tolerate faults of several different kinds.
Trading off difficulty against number of different kinds of faults that can be tolerated is performed at run time w.r.t. to the faults that have actually arrived.

Transient Faults- common faults These are temp. faults generally due to
electromagnetic disturbances. These faults go away immediately leaving the devices running normally but may corrupt the state data.
Self Stabilization is a uniform mechanism for recovering from a variety of transient faults. It is a phenomena in which the physical processes automatically recover to a stable state.

Coordination Problem – If different components
simultaneously try to access some global data.
Solution – Encapsulate the different activities within transactions and run a distributed concurrency control algorithm.
Transactions also provide FAILURE ATOMICITY – If a transaction fails then any action it may have performed are undone.

The mechanisms and techniques associated with dependability approach tend to focus on reliability and fault tolerance and place less demand/stress on other factors.

Safety Engineering Approach The terms “reliability” and “safety” are
often misinterpreted. “Reliability” is concerned with the incidence
of failures. “Safety” is concerned with the occurrence
of accidents and mishaps. The basic idea of this approach is to focus
on the consequences that must be avoided rather than on the requirement of the system itself, as they may be the cause of the undesired consequence.

Hazards can be prevented by making sure that the states of the system that can lead to mishaps are avoided.
e.g. –Air traffic control ---prevent the root cause of a possible mid air collision by making sure that the planes do not get to near each other.

Definitions Damage – Is a measure of the loss in a
mishap. Severity of a hazard – Assessment of the
worst possible damage that could result. Danger – Probability of a hazard leading
to a mishap. Risk – Combination of hazard severity
+Danger. Hazard Analysis – Hazard identification +
Categorizing as per severity + exploring the probability of that happening.

SFTA(Software Fault Trace Analysis)
This is one of the application of hazard analysis in software.
Goal – Show that the logic contained in the software design will not cause mishaps.
To determine environment conditions that could lead to a mishap.

Dependability ---Safety Safety approach focuses on the
elimination of the undesired event while the dependability approach is more concerned with providing the expected service
Dependability tries to maximize the extent to which the system works well while safety approach tries to minimize the extent to which it can fail badly.

Secure Systems Approach Trusted to keep secrets Safeguard privacy Prevent unauthorized disclosure of info. Access Control Model—One in which the
hardware can control the “read” and ‘’write” access to data.
Integrity levels are assigned to processes and to the data, and processes are allowed to read data only of equal or higher integrity level, and to write data only of equal or lower integrity level.

Kernelization It’s a unique feature of the secure
systems approach, it ensures absence of unauthorized disclosure of info by a single mechanism called “security kernel” , also known as “reference monitor”
The security kernel can be thought as a stripped down OS that manages the protection facilities provided by the hardware and has functions to achieve the next three requirements.

Reference monitor The reference monitor is required to
be: CORRECT-enforce the security policy. COMPLETE – Mediate all accesses
between subjects and objects. TAMPERPROOF – Protect itself from
unauthorized modification.

Fault tolerance is a mechanism to ensure normal or acceptably degraded service despite the occurrence of faults, while kernelization is a mechanism for avoiding certain kinds of failure and do very little to ensure normal service.

Real time systems Approach
Real time systems are subject to both deadline and jitter(variability)constraints.
Hard real time- time deadline is very critical. Soft real time – time deadlines have a certain
degree of flexibility. Problems – in developing a real time system
are due to 1)deriving the timing constraints 2) constructing a scheduling algorithm

Organizing a real time system Cyclic Execution – Fixed scheduling of
tasks is executed cyclically at a fixed rate. Prob—can lead to low CPU usage, and its
fragility. Priority Driven – Each task has a certain
priority and the executive always runs the highest priority tasks.
Prob – “priority inversions” problems can be solved by “priority inheritance”.
Expensive context switching required.

The Alpha system scheduling is done according to a model of “benefit accrual”.
The benefit function associated with them indicates the overall benefit b(t) of completing the task at time t.
The Alpha system attempts to schedule activities in such a way that maximum overall benefit accrues---”best effort scheduling”.
This method is used in soft real time systems only.

Formal Models The Early Models – Assumed a system
composed of active subjects(programs operating on behalf of users) and passive objects(repositories of information)
Subjects could read & write according to restrictions imposed by an access control mechanism.
Probs- It allowed covert channels in which information is conveyed from a highly classified object to a more lowly cleared subject. Secondly, there was no semantic characterization of “read” and “write”.

Noninterference Model – The behavior perceived by a lowly cleared user should be independent of the actions of highly cleared users.
Inputs from lowly and highly cleared users are interleaved arbitrarily.

Assurance Methods Critical systems must not only satisfy their
critical properties, they must be seen to do so.Therefore rigorous methods of assurance are applied.
Critical systems tolerate extremely small probabilities of failure.
Highly reliable systems— may tolerate failure rates of 10-3 to 10-6 per hour.
Critical or Ultra critical systems – 10-7 to 10-12
per hour.

Estimating Failure rates Measure directly in a test environment. Calculate from known or measured failure
rates of its components plus the knowledge of its design or structure.
N version programming --- Uses two or more independently developed software versions in conjunction with comparison to avoid system failures.
Several studies indicate that a reduction in the “programming errors per thousand lines of source code” reduces the density of faults discovered in operation.

Taxonomy To identify combinations of critical
system properties that are compatible. Based on two attributes called
“interaction” and “coupling”. Interaction – Extent to which the behavior
of one component in a system can affect the behavior of other components. This can vary from ‘linear” to “complex”.
Linear interaction– components affect only those components that are functionally downstream of them.

Complex interaction – When a component may participate in different sequences of interactions with many other other components.
e.g. Computer systems that maintain global notions of coordination and consistency like distributed databases are considered to have complex interactions.
These interactions promote accidents and are hard to predict.

Coupling – This refers to the extent of “flexibility” or “slack” in the system.
Loosely coupled systems are usually less time constrained compared to tightly coupled systems.
e.g. – loosely coupled – telephone switching network.
tightly coupled – hard real time systems, they generally participate in complex interaction with the environment.
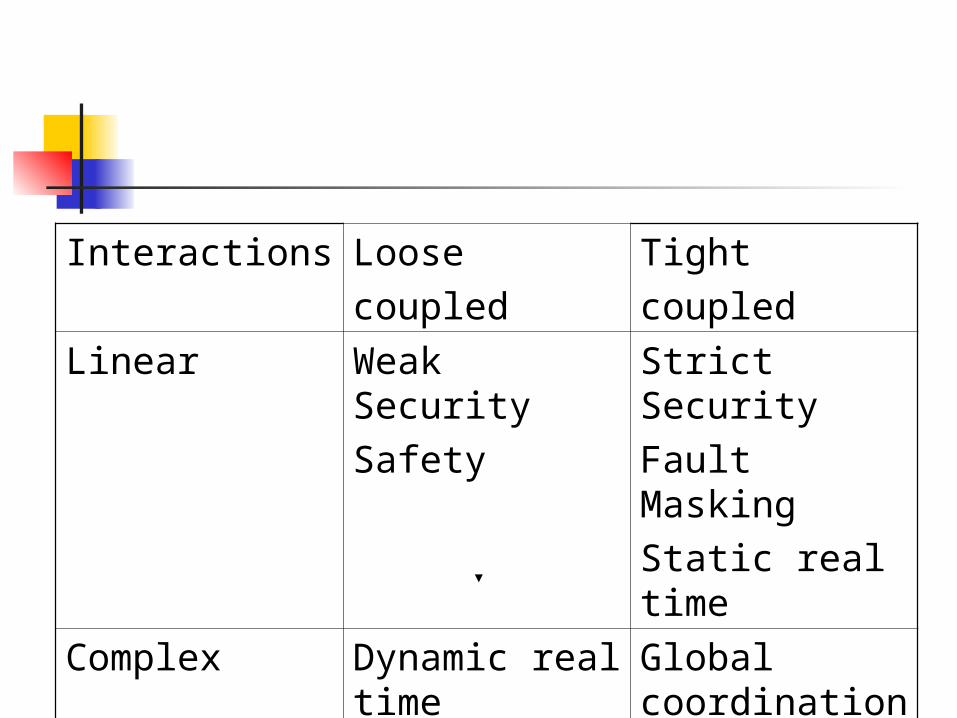
Interactions Loosecoupled
Tightcoupled
Linear Weak SecuritySafety
Strict SecurityFault MaskingStatic real time
Complex Dynamic real timeFault tolerance
Global coordination

Conclusion A critical computer system is one whose
malfunction could lead to unacceptable consequences.
The determination whether a system is critical is made by hazard analysis.
There are many fields that have critical systems with their own individual approaches, the author hopes to bring about some new ideas of cross fertilization.

Acknowledgement Critical System Properties: Survey and Taxonomy – John Rushby Computer Science Laboratory SRI International, CA





























