Embed Size (px)
Citation preview

Cryptographic methods for privacy aware computing: applications

Outline Review: three basic methods Two applications
Distributed decision tree with horizontally partitioned data
Distributed k-means with vertically partitioned data

Three basic methods 1-out-K Oblivious Transfer Random share Homomorphic encryption
* Cost is the major concern

Two example protocols The basic idea is
Do not release original data Exchange intermediate result
Applying the three basic methods to securely combine them

Building decision trees over horizontally partitioned data Horizontally partitioned data
Each party owns a number of records
Entropy-based information gain The classical metric for training decision
tree (ID3 algorithm)
Major ideas in the protocol
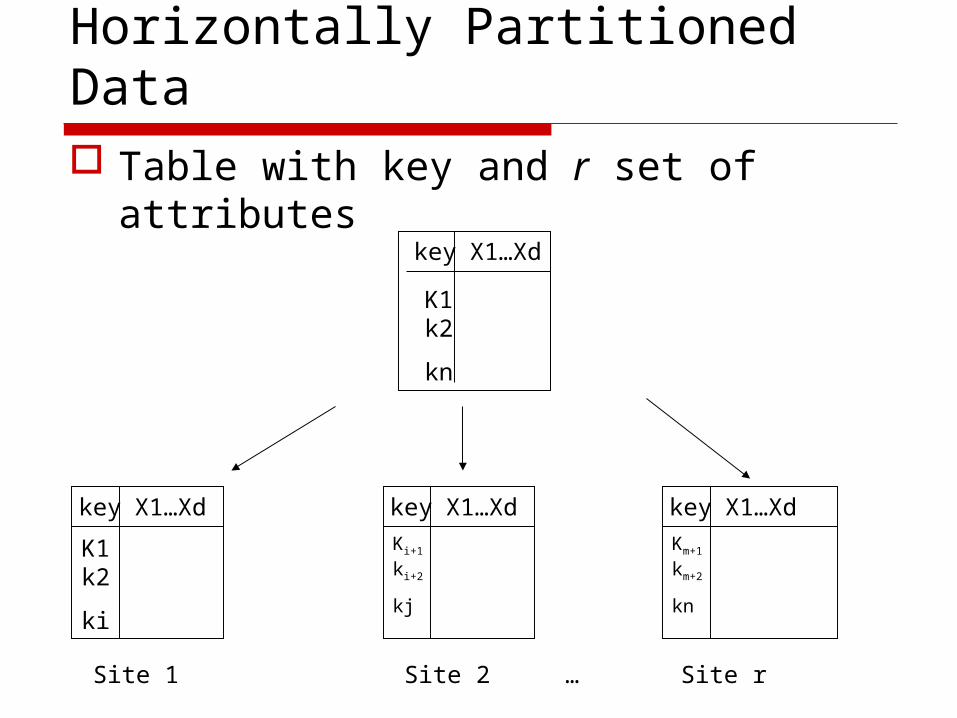
Horizontally Partitioned Data Table with key and r set of attributes
key X1…Xd
key X1…Xd
Site 1
key X1…Xd
Site 2
key X1…Xd
Site r…
K1k2
kn
K1k2
ki
Ki+1
ki+2
kj
Km+1
km+2
kn

Review decision tree algorithm (ID3 algorithm) Find the cut that maximizes gain
certain attribute Ai, sorted v1…vn Certain value in the attribute
For categorical data we use Ai=vi For numerical data we use Ai<vi
Ai label
v1v2
vn
l1l2
ln
cutE(): Entropy of label distribution
2
1
)()()(i
ii SEN
nSEcutGain
Choose the attribute/value that gives the highest gain!
Ai<vi?yes no
Aj<vj? …

Key points Calculating entropy
Ai label
v1v2
vn
l1l2
ln
cut
)()(
log)(log)()(Slabelv
vv
Slabelv n
n
n
nvPvPSEntropy
The key is calculating x log x, where x is the sum of values from the two partiesP1 and P2 , i.e., x1 and x2, respectively
-decomposed to several steps-Each step each party knows only a random share of the result

stepsStep1: compute shares for xlnx = (u1+u2)(v1+v2) * a major protocol is used to compute ln x = v1 + v2
Step 2: for a condition Ai<vi, find the random shares for E(S), E(S1) and E(S2) respectively.
Step3: repeat step1&2 to all possible (Ai, vi) pairs
Step4: a circuit gate to determine which (Ai, vi) pair results in maximum gain. (Yao’s protocol)

2. K-means over vertically partitioned data
Vertically partitioned data Normal K-means algorithm
Applying secure sum and secure comparison among multi-sites in the secure distributed algorithm
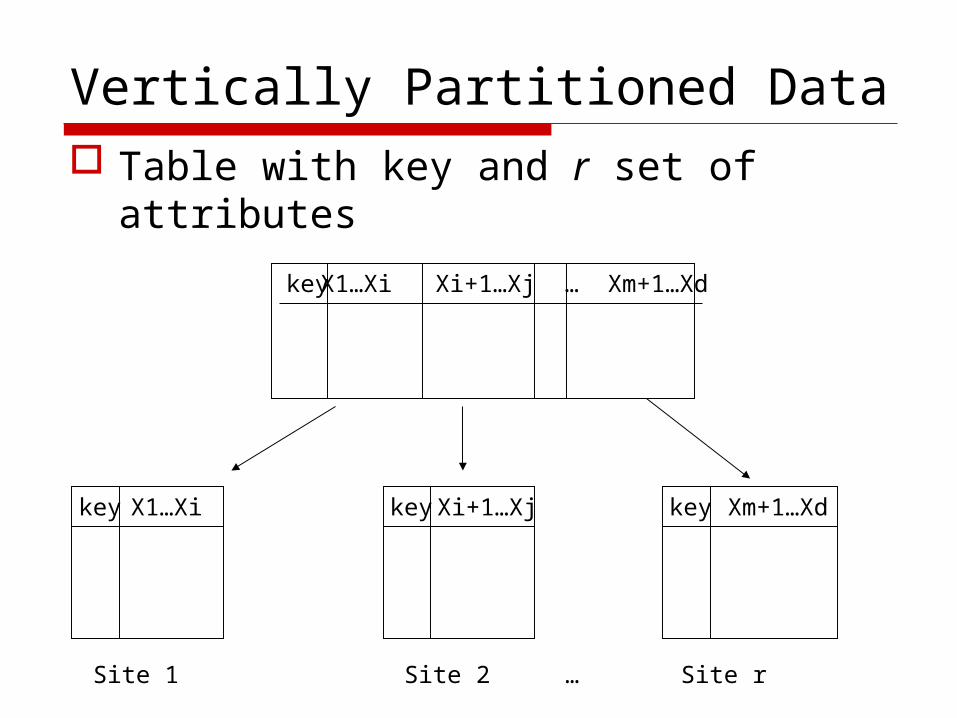
Vertically Partitioned Data Table with key and r set of attributes
key X1…Xi Xi+1…Xj … Xm+1…Xd
key X1…Xi
Site 1
key Xi+1…Xj
Site 2
key Xm+1…Xd
Site r…

Motivation Naïve approach: send all data to a
trusted site and do k-mean clustering there Costly Trusted third party?
Preferable: distributed privacy preserving k-means

Basic K-means algorithm 4 main steps:
step1.Randomly select k initial cluster centers (k means)
repeat
step 2. Assign any point i to its closest cluster center
step 3. Recalculate the k means with the new point assignment
Until step 4. the k means do not change

Distributed k-means Why k-means can be done over
vertically partitioned data Distance calculation is decomposable All of the 4 steps are decomposable The most costly part (step 2 and 3) can
be done locally We will focus on the step 2 (Assign any
point i to its closest cluster center)

step 1 All sites share the index of the initial
random k records as the centroids
µ11 … µ1i
Site 1 Site 2 Site r…
µk1 … µki
µ1i+1 … µ1j
µki+1 … µkj
µ1m …µ1d
µkm … µkd
µ1
µk

Step 2: Assign any point x to its closest cluster
center1. Calculate distance of point X (X1, X2, … Xd) to each
cluster center µk
-- each distance calculation is decomposable! d2 = [(X1- µk1)2 +… (Xi- µki)2] + [(Xi+1- µki+1)2 +… (Xj- µkj)2] + …
2. Compare the k full distances to find the minimum one
Site1 site2
Partial distances: d1 + d2 + …
For each X, each site has a k-element vector that is the result for thepartial distance to the k centroids, notated as Xi

Privacy concerns for step 2 Some concerns:
Partial distances d1, d2 … may breach privacy (the Xi and µki ) – need to hide it
distance of a point to each cluster may breach privacy – need to hide it
Basic ideas to ensure security Disguise the partial distances Compare distances so that only the comparison result
is learned Permute the order of clusters so the real meaning of
the comparison results is unknown. Need at least 3 non-colluding sites (P1, P2, Pr)

Secure Computing of Step 2 Stage1: prepare for secure sum of partial
distances p1 generates V1+V2 + …Vr = 0, Vi is random k-element vector,
used to hide the partial distance for site i
P1 uses “Homomorphic encryption” to do randomization: (paillier encryption)Ei(Xi)Ei(Vi) = Ei(Xi+Vi)
Stage2: calculate secure sum for r-1 parties P1, P3, P4… Pr-1 send their perturbed and
permuted partial distances to Pr Pr sums up the r-1 partial distances (including its
own part)
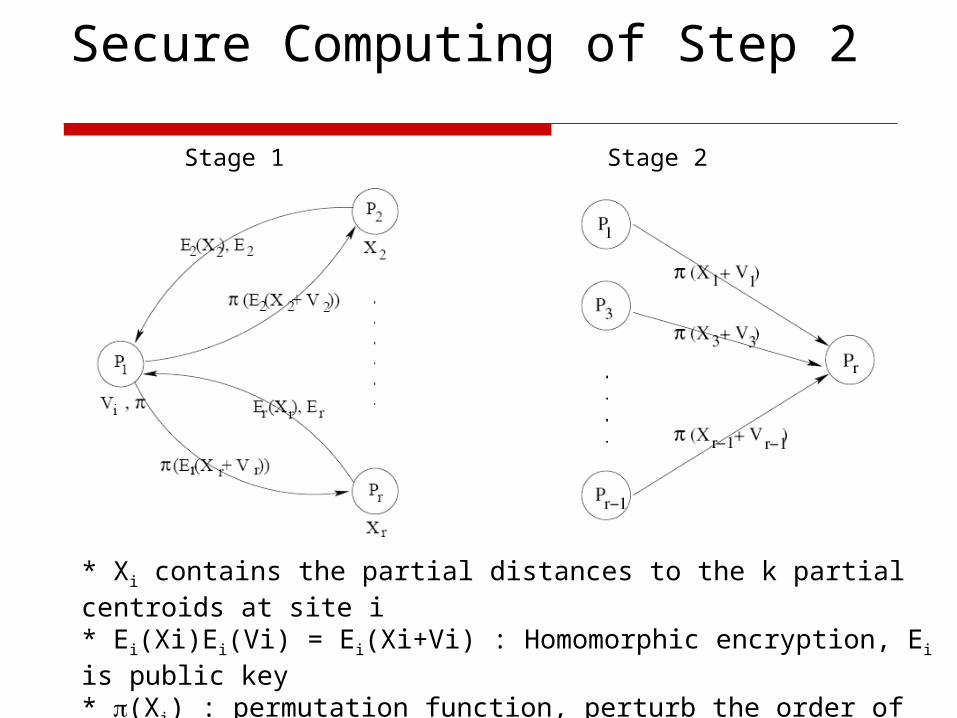
Secure Computing of Step 2
* Xi contains the partial distances to the k partial centroids at site i* Ei(Xi)Ei(Vi) = Ei(Xi+Vi) : Homomorphic encryption, Ei is public key* (Xi) : permutation function, perturb the order of elements in Xi* V1+V2 + …Vr = 0, Vi is used to hide the partial distances
Stage 1 Stage 2

Stage 3: secure_add_and_compare to find the minimum distance Involves only Pr and P2
Use a standard Secure Multiparty Computation protocol to find the result
Stage 4:
the index of minimum distance (permuted cluster id) is sent back to P1.
P1 knows the permutation function thus knows the original cluster id.
P1 broadcasts the cluster id to all parties.
212
2 m
r
imi
r
illi xxxx
K-1 comparisons:

Step 3: can be done locally Update partial means µi locally
according to the new cluster assignments.
X11 … X1i
Site 1 Site 2 Site r…
Xn1 … Xni
X1i+1 … X1j
Xni+1 … Xnj
X1m …X1d
Xnm … Xnd
Cluster 2
Cluster k
Cluster labels
X21 … X2iCluster k

Extra communication cost O(nrk)
n : # of records r: # of parties k: # of means
Also depends on # of iterations

Conclusion It is appealing to have cryptographic
privacy preserving protocols The cost is the major concern
It can be reduced using novel algorithms





![TAPAS: Trustworthy privacy-aware participatory - InfoLab · TAPAS: Trustworthy privacy-aware participatory sensing [39],isthatthemajorityofparticipantsgeneratecorrectdata.Thus,thedatawiththemajority](https://img.pdfslide.net/doc/110x75/5bda6e0209d3f2f6758caf9e/tapas-trustworthy-privacy-aware-participatory-infolab-tapas-trustworthy.jpg)























