Embed Size (px)
Citation preview

Data CleaningJacob Lurye
CS265
KATARA: A Data Cleaning System Powered by Knowledge Bases and Crowdsourcing. Xu Chu, John Morcos, Ihab F. Ilyas, Mourad Ouzzani, Paolo Papotti, Nan Tang, Yin Ye SIGMOD Conference 2015

Let’s talk dirty data
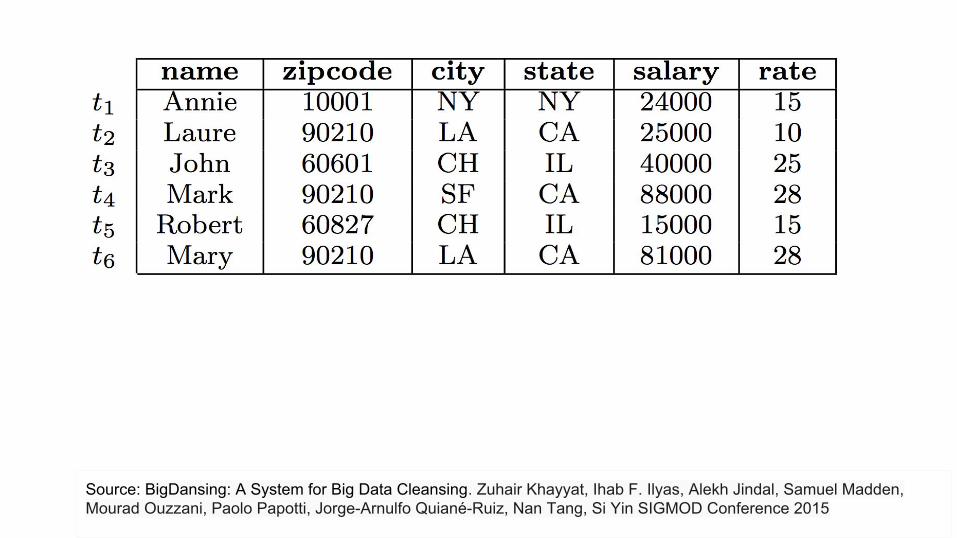
Source: BigDansing: A System for Big Data Cleansing. Zuhair Khayyat, Ihab F. Ilyas, Alekh Jindal, Samuel Madden, Mourad Ouzzani, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Nan Tang, Si Yin SIGMOD Conference 2015
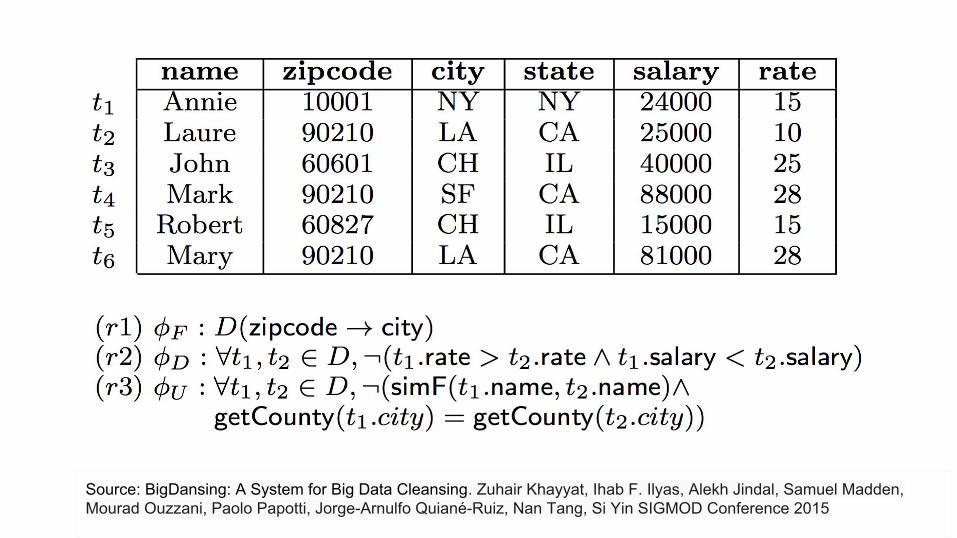
Source: BigDansing: A System for Big Data Cleansing. Zuhair Khayyat, Ihab F. Ilyas, Alekh Jindal, Samuel Madden, Mourad Ouzzani, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Nan Tang, Si Yin SIGMOD Conference 2015
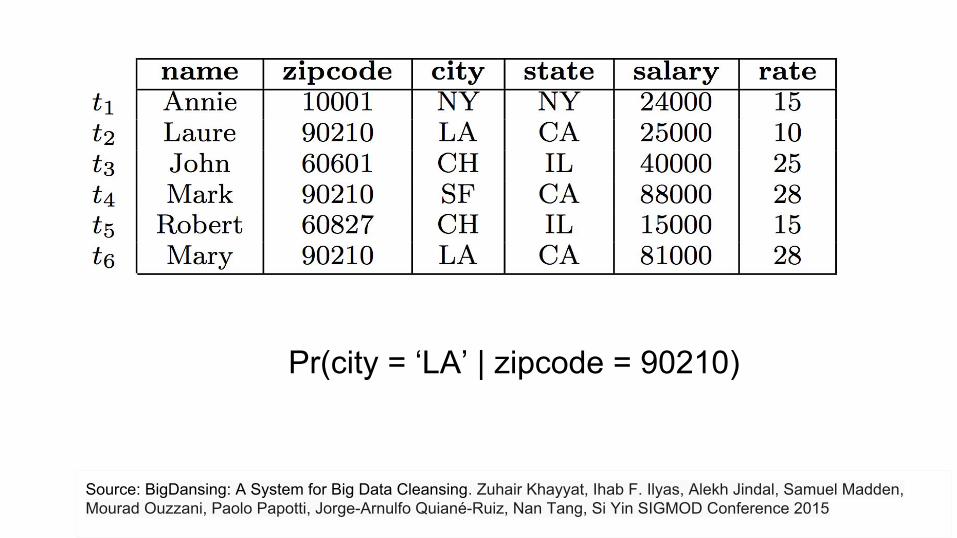
Source: BigDansing: A System for Big Data Cleansing. Zuhair Khayyat, Ihab F. Ilyas, Alekh Jindal, Samuel Madden, Mourad Ouzzani, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Nan Tang, Si Yin SIGMOD Conference 2015
Pr(city = ‘LA’ | zipcode = 90210)

A B C D E F G
Rossi Italy Rome Verona Italian Proto 1.78
Klate S. Africa Pretoria Pirates Afrikaans P. Eliz. 1.69
Pirlo Italy Madrid Juve Italian Flero 1.77
Integrity constraints?
Machine learning?

A B C D E F G
Rossi Italy Rome Verona Italian Proto 1.78
Klate S. Africa Pretoria Pirates Afrikaans P. Eliz. 1.69
Pirlo Italy Madrid Juve Italian Flero 1.77
We need something more...
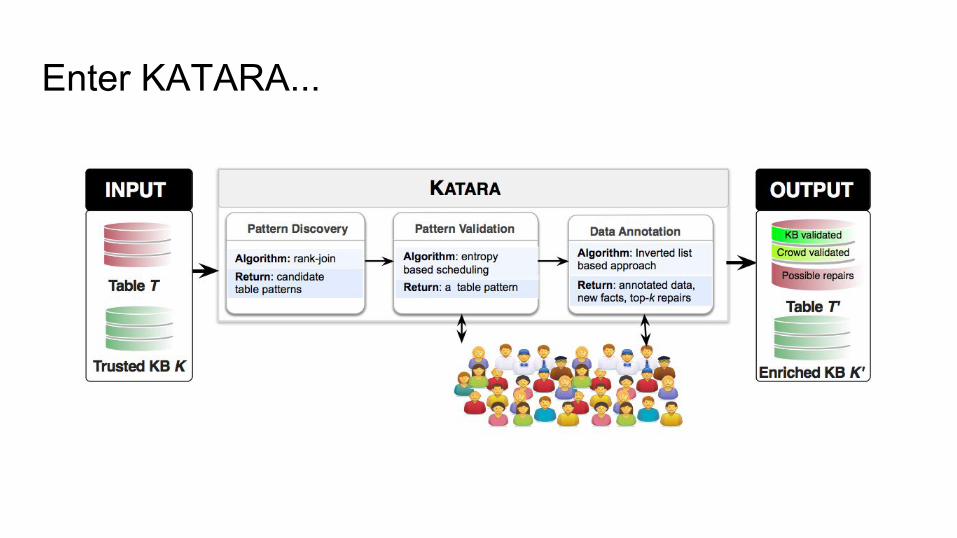
Enter KATARA...

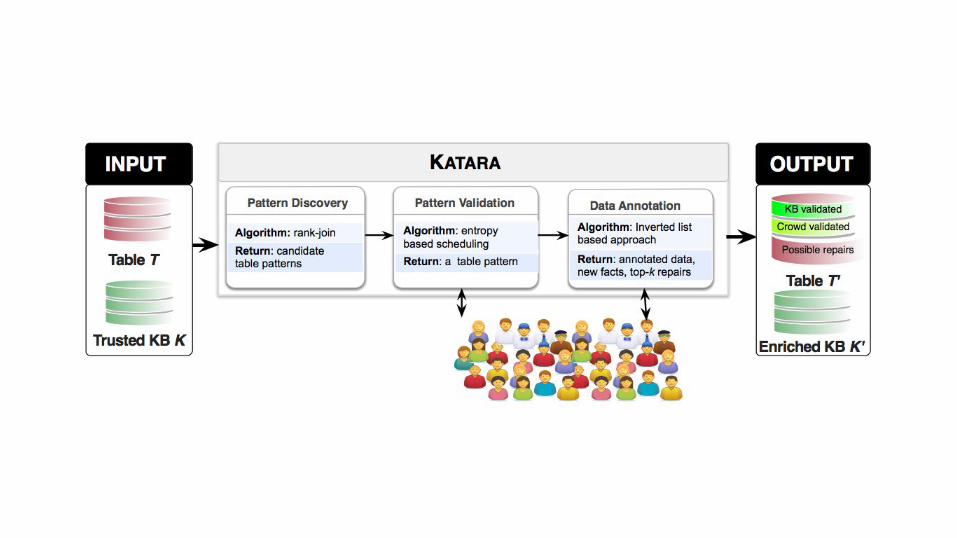
What is KATARA?
1. Table pattern definition and discovery (using KBs)2. Table pattern validation via crowdsourcing3. Data annotation4. Repair recommendation

What is a knowledge base, and how can it help us clean data?


Resource Description Framework

Resource Description Framework
Resource (and URIs)

Resource Description Framework
Literals
10,500,000

Resource Description Framework
Properties
10,500,000
directorOf
budgetOf

Resource Description Framework
Classes and Instances
Spielberg is an instance of class Director
E.T is an instance of class Sci-Fi Movie which is a subclass of Movie

So how does this all relate back to data cleaning?
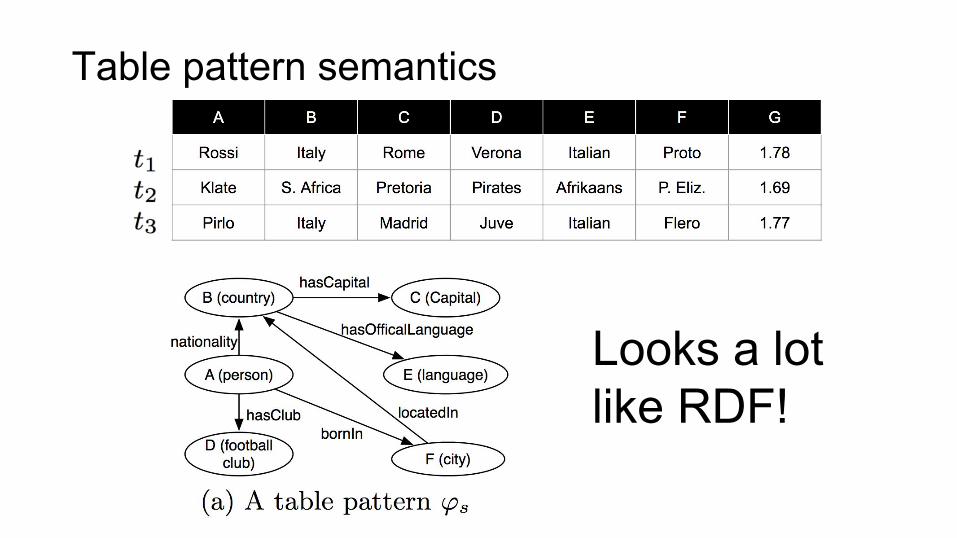
Table pattern semantics
Looks a lot like RDF!

Formalizing pattern matching
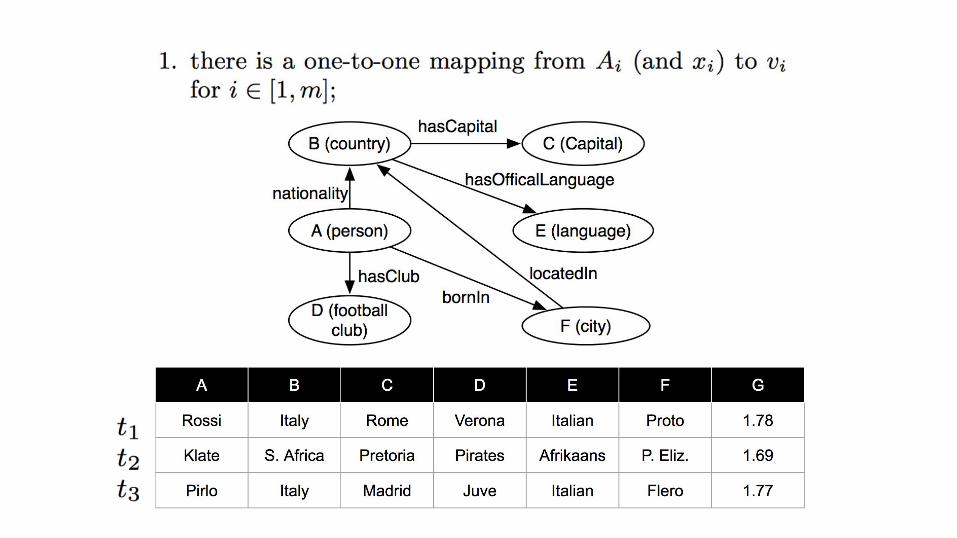
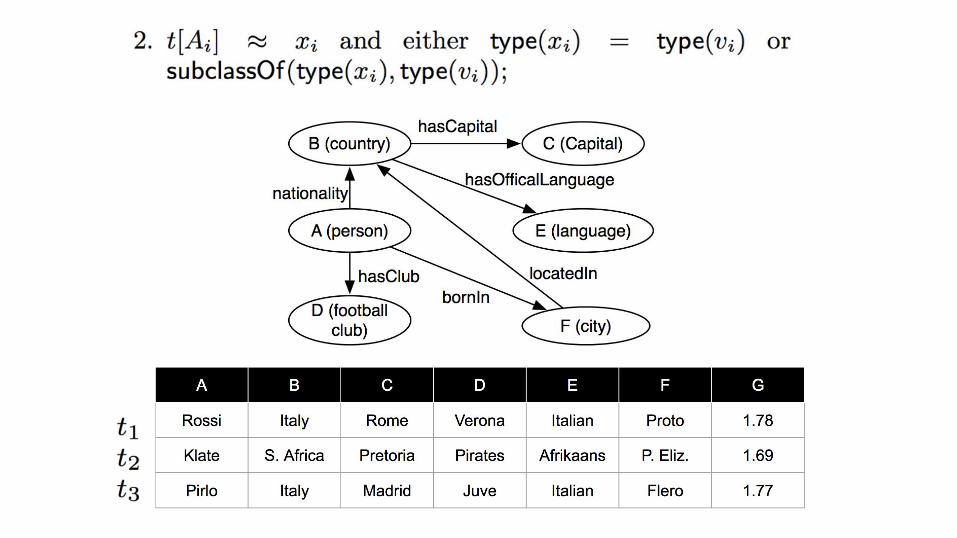
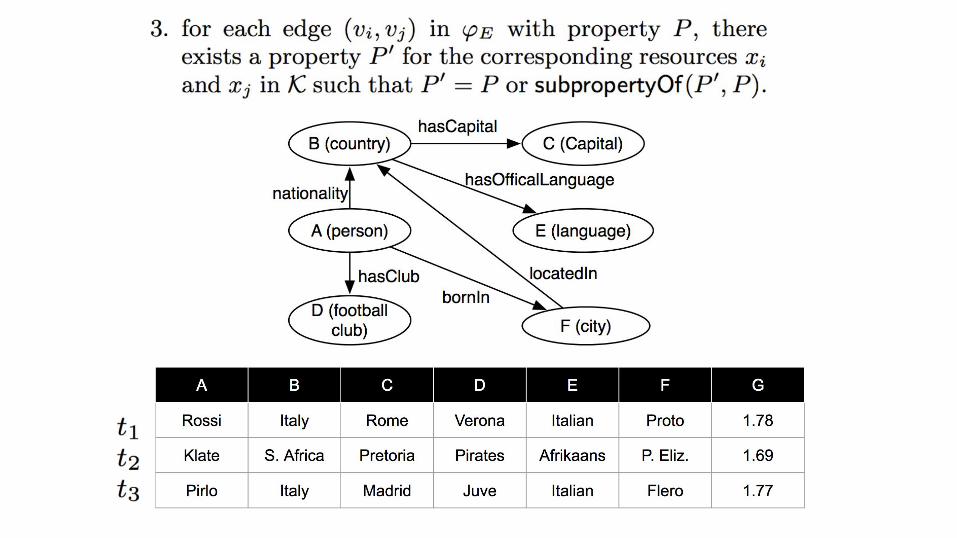

So what do we do with this formalization?
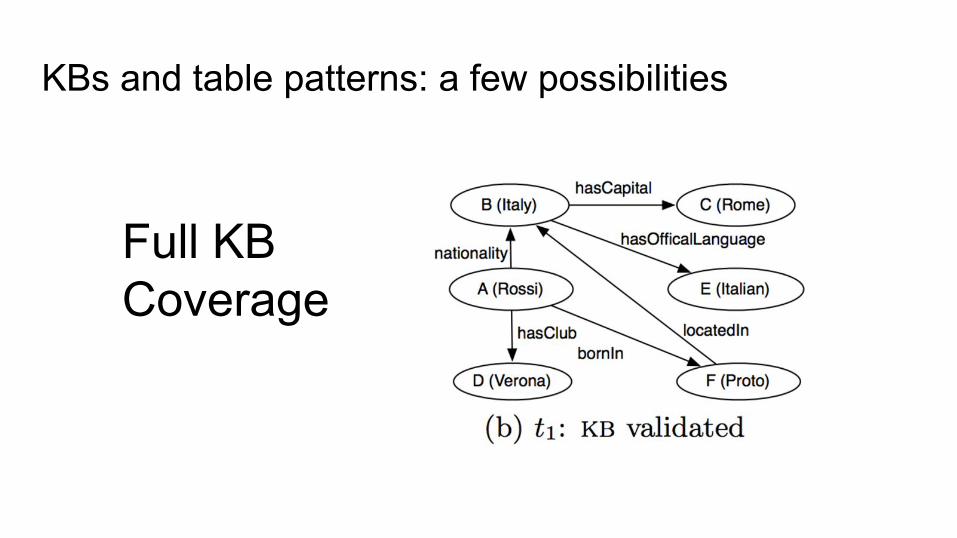
KBs and table patterns: a few possibilities
Full KB Coverage
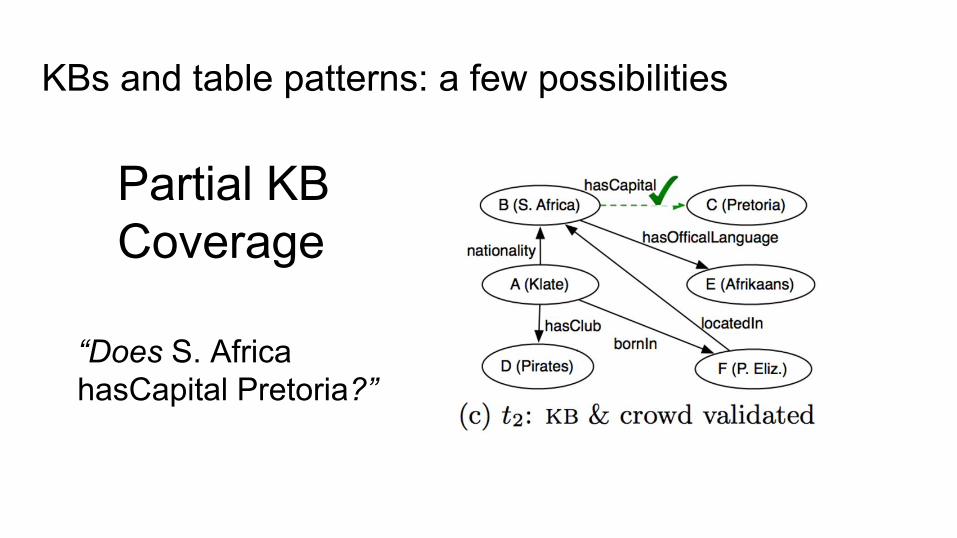
KBs and table patterns: a few possibilities
Partial KB Coverage
“Does S. Africa hasCapital Pretoria?”
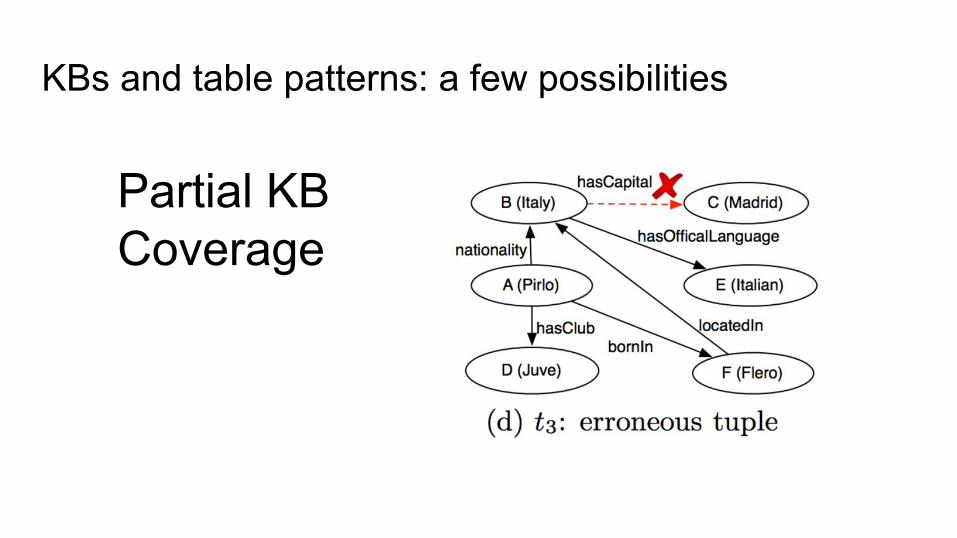
KBs and table patterns: a few possibilities
Partial KB Coverage

KBs and table patterns: a few possibilities
Not covered by the KB
“What are the possible relationships between Rossi and 1.78?”

How do we actually get knowledge from KBs?

SPARQL: a language for querying KBs
Get types and supertypes of resources with value t [ Ai ]

SPARQL: a language for querying KBs
Q1: get relationships where both attributes are resources
Q2: get relationships with one resource and one literal

So we’ve run our queries — what next?

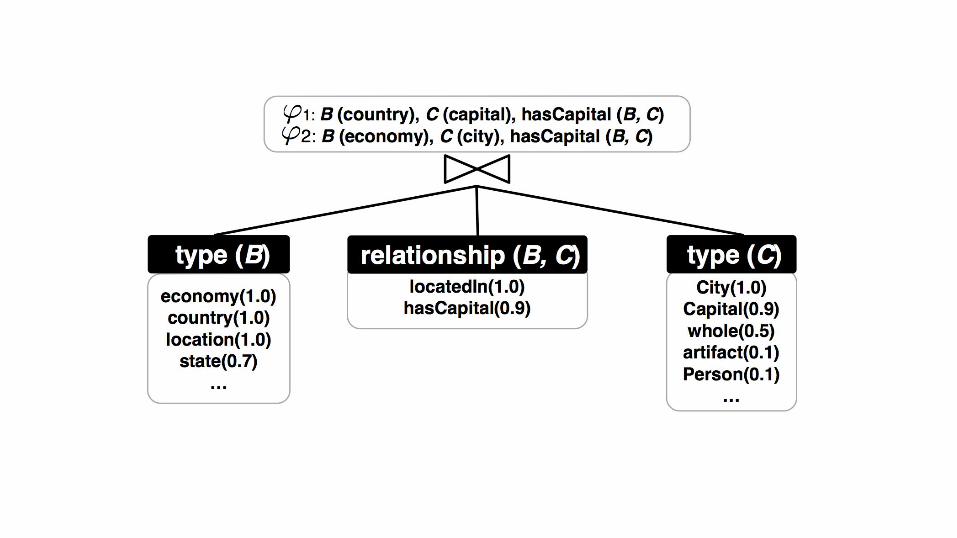
Evaluating KB types ( Ti ) for table attributes ( Ai )

Evaluating possible column relationships
prob. of any entity appearing in the subject of property P
prob. of any entity being of type T
prob. of an entity being of type T and appearing as subject of P

From PMI we get a measure of semantic coherence

Finally! A metric for scoring table patterns:

Generating the top-k patterns


We have the top-k patterns — now what?

We have the top-k patterns — now what?
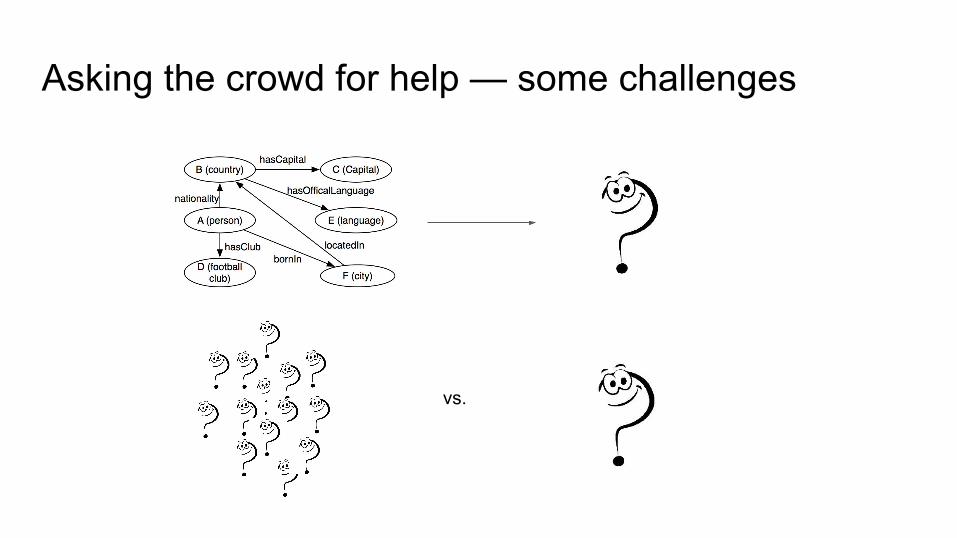
Asking the crowd for help — some challenges
vs.

Decomposing table patterns into questions
Column Type Validation
Relationship Validation

So we have our questions — in what order should we ask them?

Maximizing uncertainty reduction
prob. of pattern pi
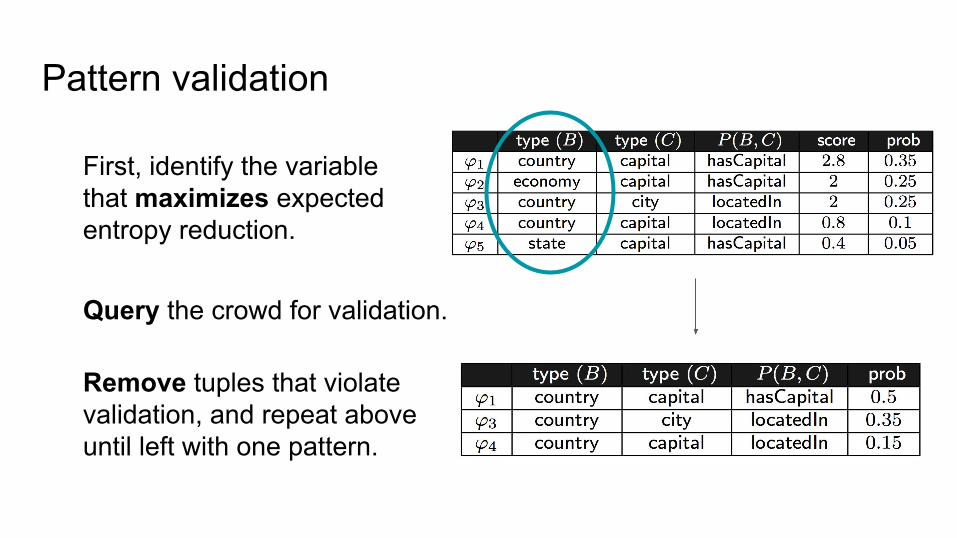
Pattern validation
First, identify the variable that maximizes expected entropy reduction.
Remove tuples that violate validation, and repeat above until left with one pattern.
Query the crowd for validation.

Wait — what about the “data cleaning” part?

Recognizing erroneous tuples
Just execute a SPARQL query on the tuple.
Fully covered? Otherwise, we need the crowd.
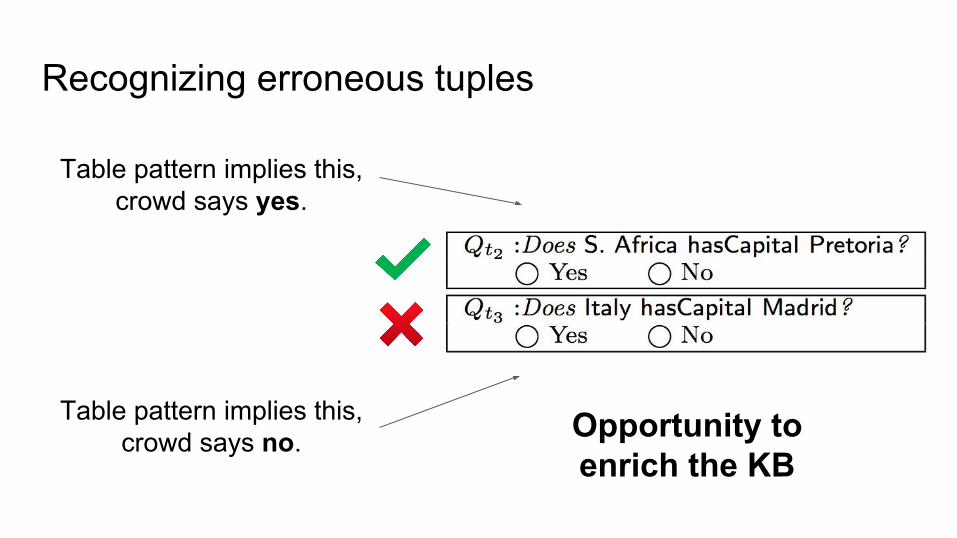
Recognizing erroneous tuples
Table pattern implies this, crowd says yes.
Table pattern implies this, crowd says no. Opportunity to
enrich the KB
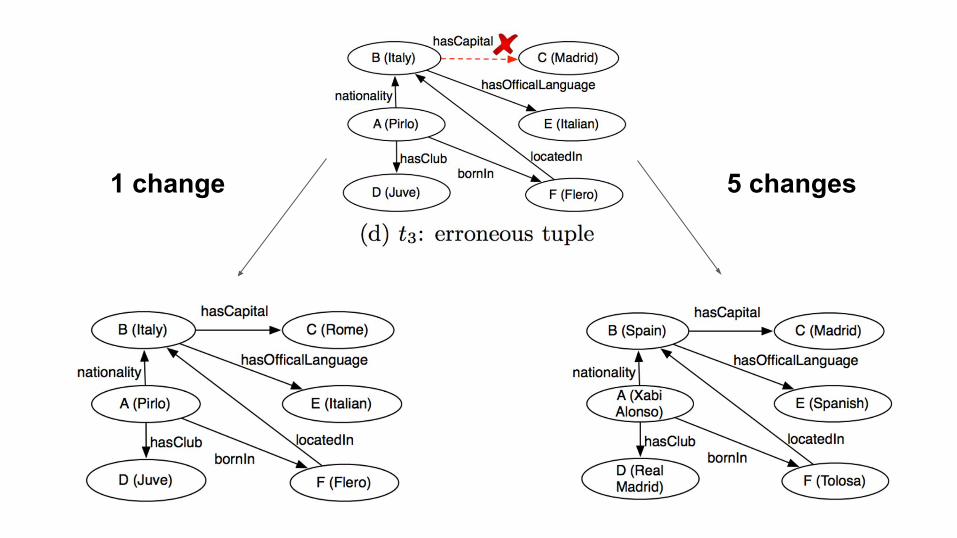
1 change 5 changes

Experiments
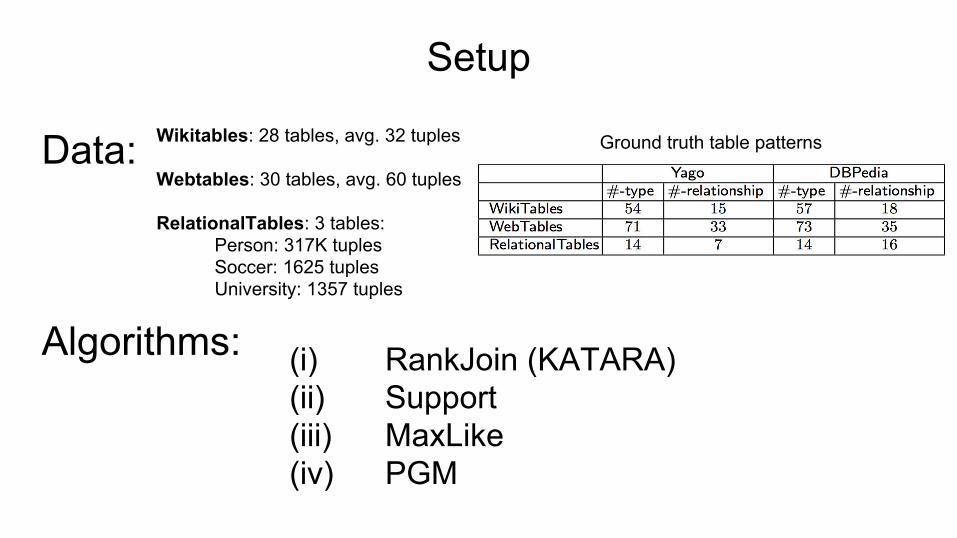
Setup
(i) RankJoin (KATARA)(ii) Support(iii) MaxLike(iv) PGM
Data:
Algorithms:
Wikitables: 28 tables, avg. 32 tuples
Webtables: 30 tables, avg. 60 tuples
RelationalTables: 3 tables: Person: 317K tuples Soccer: 1625 tuples University: 1357 tuples
Ground truth table patterns
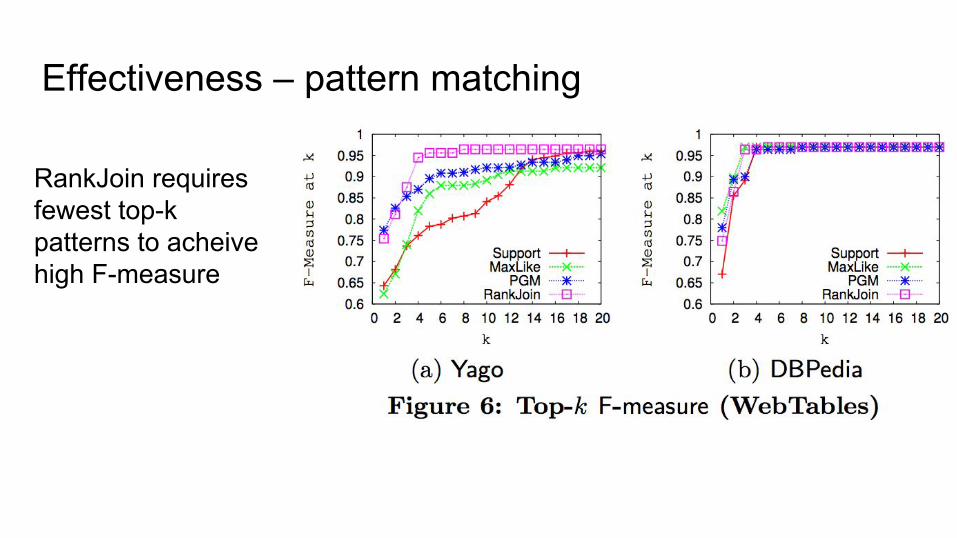
Effectiveness – pattern matching
RankJoin requires fewest top-k patterns to acheivehigh F-measure
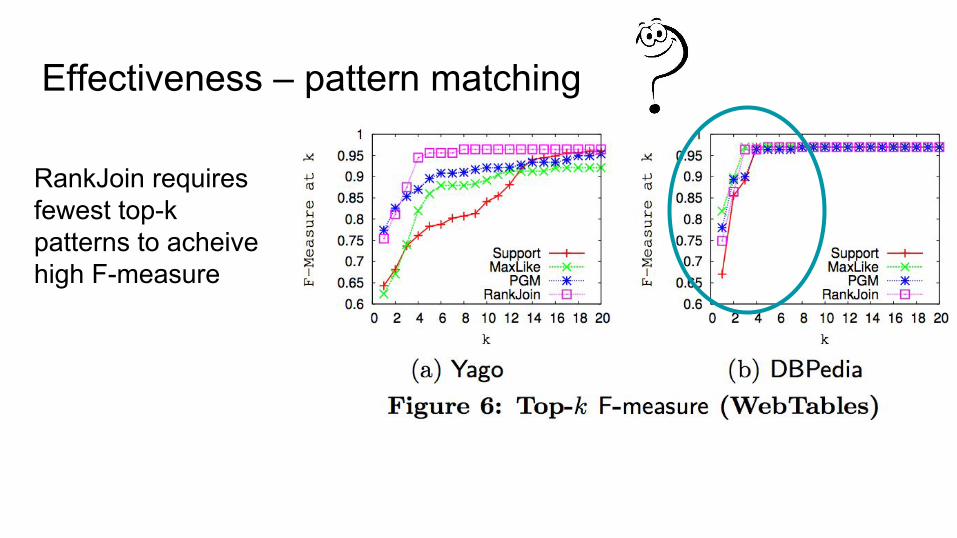
Effectiveness – pattern matching
RankJoin requires fewest top-k patterns to acheivehigh F-measure
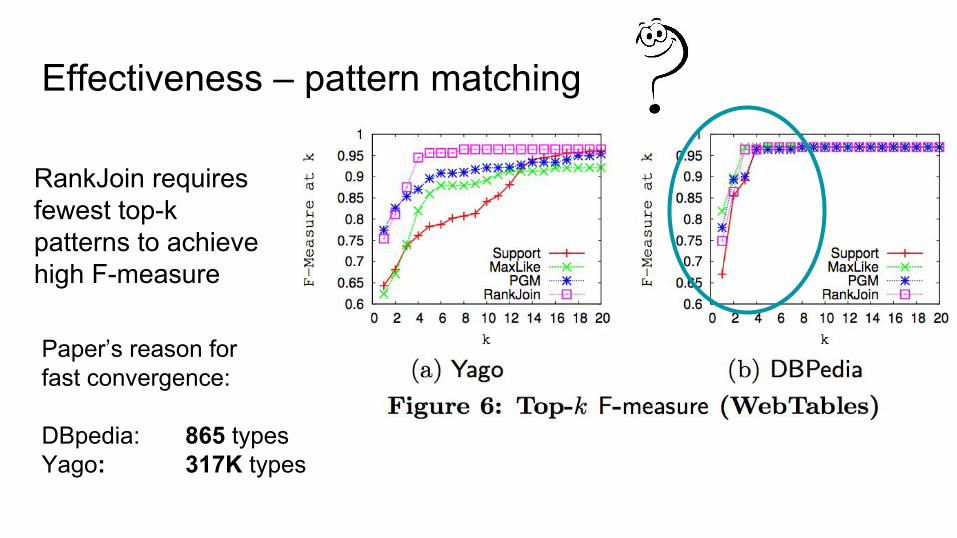
Effectiveness – pattern matching
RankJoin requires fewest top-k patterns to achievehigh F-measure
Paper’s reason for fast convergence:
DBpedia: 865 typesYago: 317K types
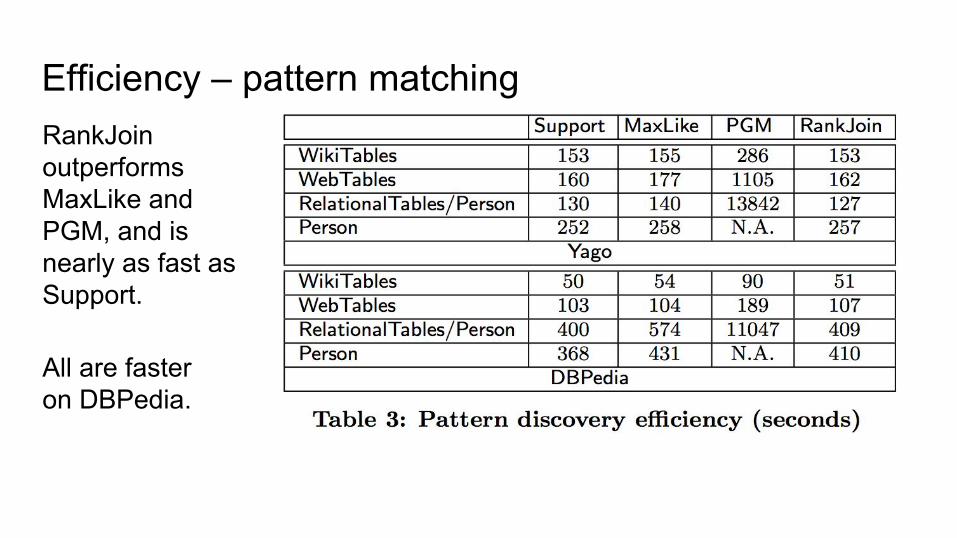
RankJoin outperformsMaxLike and PGM, and is nearly as fast as Support.
All are faster on DBPedia.
Efficiency – pattern matching
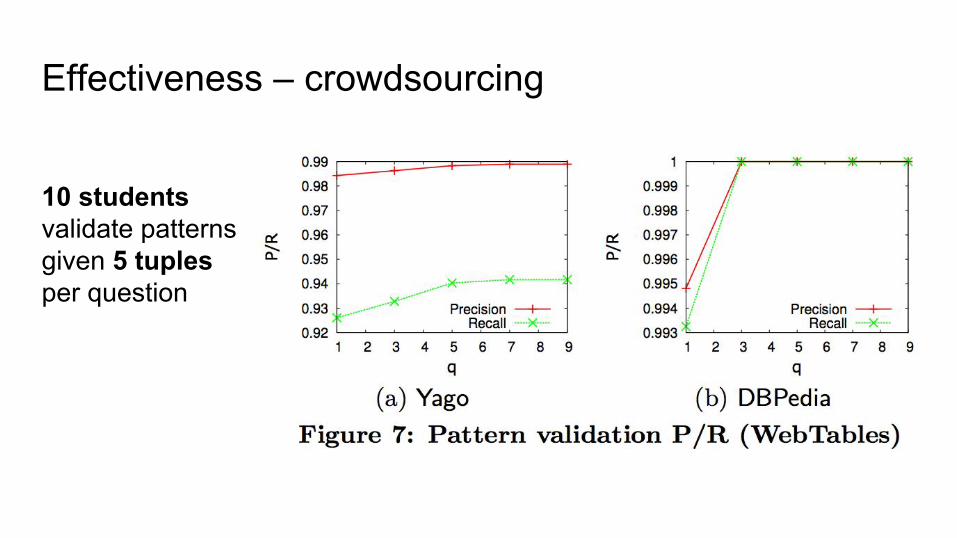
Effectiveness – crowdsourcing
10 students validate patternsgiven 5 tuples per question
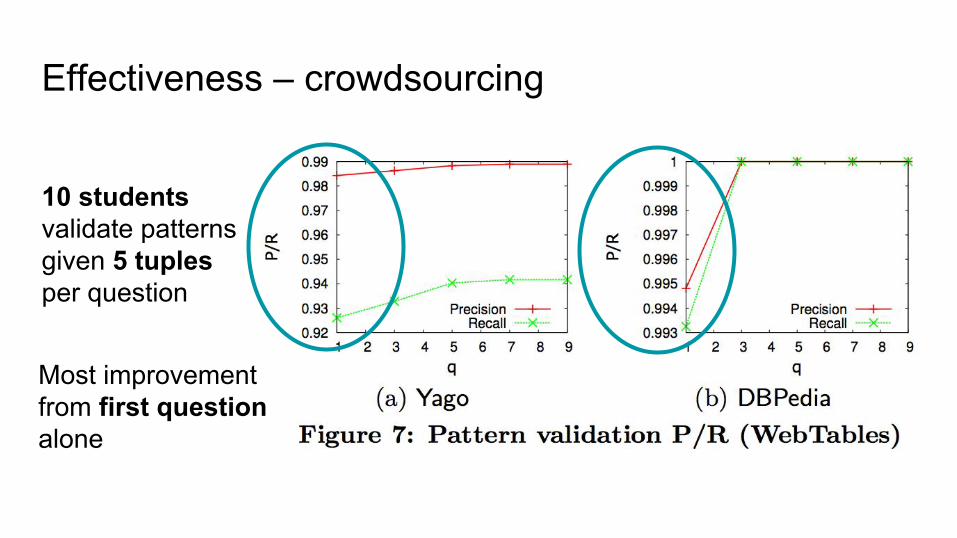
Effectiveness – crowdsourcing
10 students validate patternsgiven 5 tuples per question
Most improvementfrom first questionalone

Effectiveness – crowdsourcing
Question order matters.
MUVF (most uncertain variable first)
AVF (all variables independent)
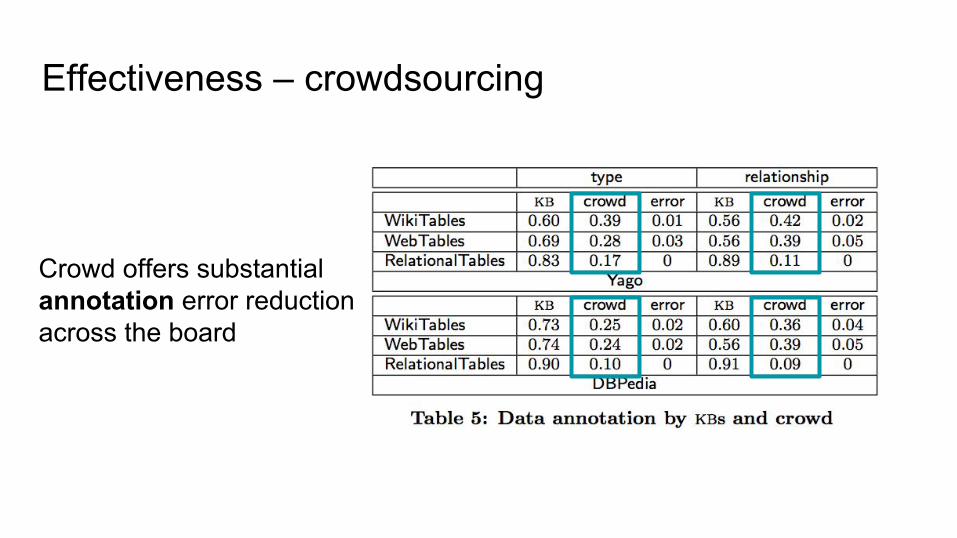
Effectiveness – crowdsourcing
Crowd offers substantialannotation error reduction across the board
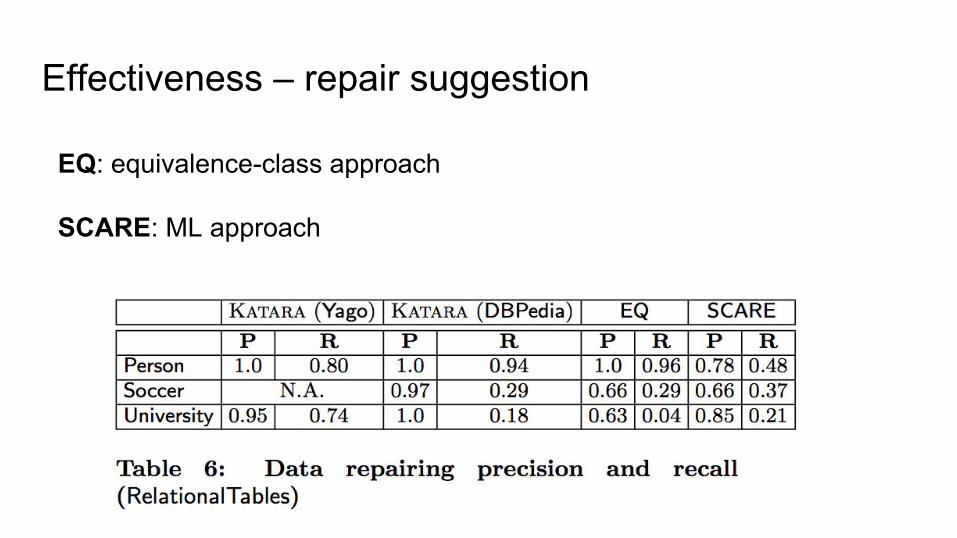
Effectiveness – repair suggestion
EQ: equivalence-class approach
SCARE: ML approach
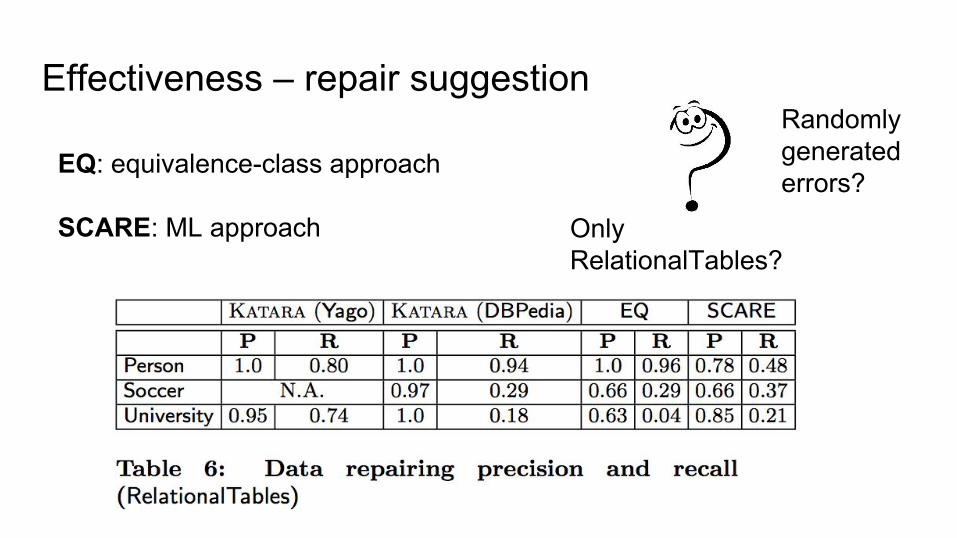
Effectiveness – repair suggestion
EQ: equivalence-class approach
SCARE: ML approach
Randomly generated errors?
Only RelationalTables?
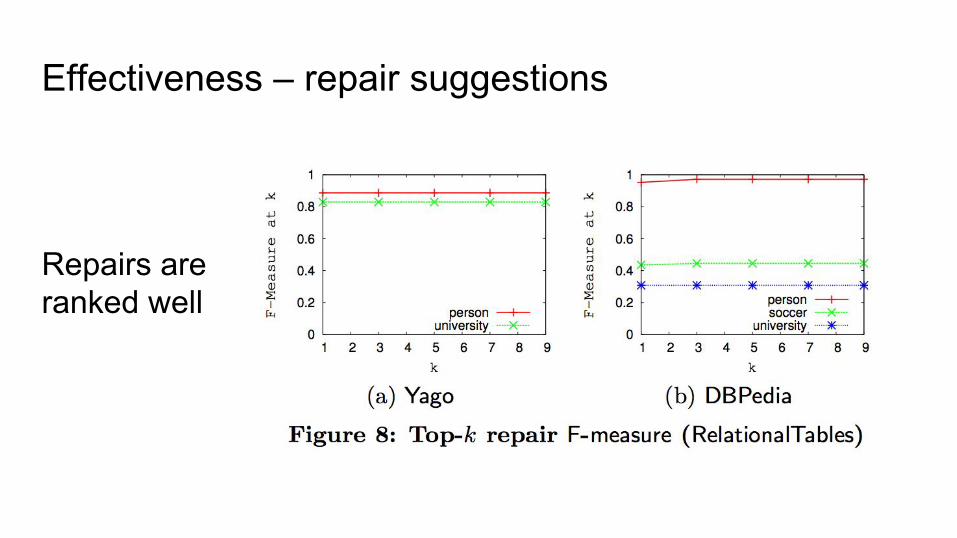
Effectiveness – repair suggestions
Repairs are ranked well

Thoughts on the experiments?

Next steps?

Some possible next steps
Cold start – no KBs, pure crowdsourced knowledge bootstrapping
Nth degree relationships – person is from city that is located in state that is located in country
Leveraging multiple KBs at once —DBpedia and Yago, not just either / or





























