Embed Size (px)
Citation preview

CSE 8383 Superscalar Processor 1
Superscalar Processor
Abdullah A Alasmari
&
Eid S. Alharbi

CSE 8383 Superscalar Processor 2
Outlines
Pipeline & HazardsPipeline & Hazards Superscalar Instruction issue policy Register renaming MIPS R10000 Advanced Superscalar Summary

CSE 8383 Superscalar Processor 3
Pipeline & Hazards
Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls• Ideal pipeline CPI: measure of the maximum
performance attainable by the implementation• Structural hazards: HW cannot support this combination
of instructions• Data hazards: Instruction depends on result of prior
instruction still in the pipeline• Control hazards: Caused by delay between the fetching
of instructions and decisions about changes in control flow (branches and jumps)

CSE 8383 Superscalar Processor 4
Hazards
Structural Hazards:• Have as many functional units as needed
Data Hazards solutions:• Execute instructions in order. Use score-board to
eliminate data hazards by stalling instructions• Execute instructions out or order, as soon as operands
are available, but graduate them in order. • Use register renaming to avoid WAR and WAW data
hazards
Control Hazards solutions:• Use branch prediction:
Make sure that the branch is resolved before registers are modified

CSE 8383 Superscalar Processor 5
Branch prediction
What do we need to predict for a jump/branch?• jump:
the target address, which can be stored in the same instruction or computed from the current PC plus a displacement
• Return from subroutine ret:the return address, which is obtained from the stack
(increasing the SP and reading from memory)
• conditional branch:the target address, which is usually computed from the
current PC plus a displacementIs the branch going to branch or continue with next
instruction?

CSE 8383 Superscalar Processor 6
Outlines
Pipeline & Hazards SuperscalarSuperscalar Instruction issue policy Register renaming MIPS R10000 Advanced Superscalar Summary

CSE 8383 Superscalar Processor 7
Multiple Instruction Issue
Multiple instructions issued each cycle better performance
• increase instruction throughput• decrease in CPI (below 1)
greater hardware complexity. harder code scheduling job for the compiler
Superscalar processors instructions are scheduled by the hardware different numbers of instructions may be issued
simultaneously
VLIW (“very long instruction word”) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big
instruction

CSE 8383 Superscalar Processor 8
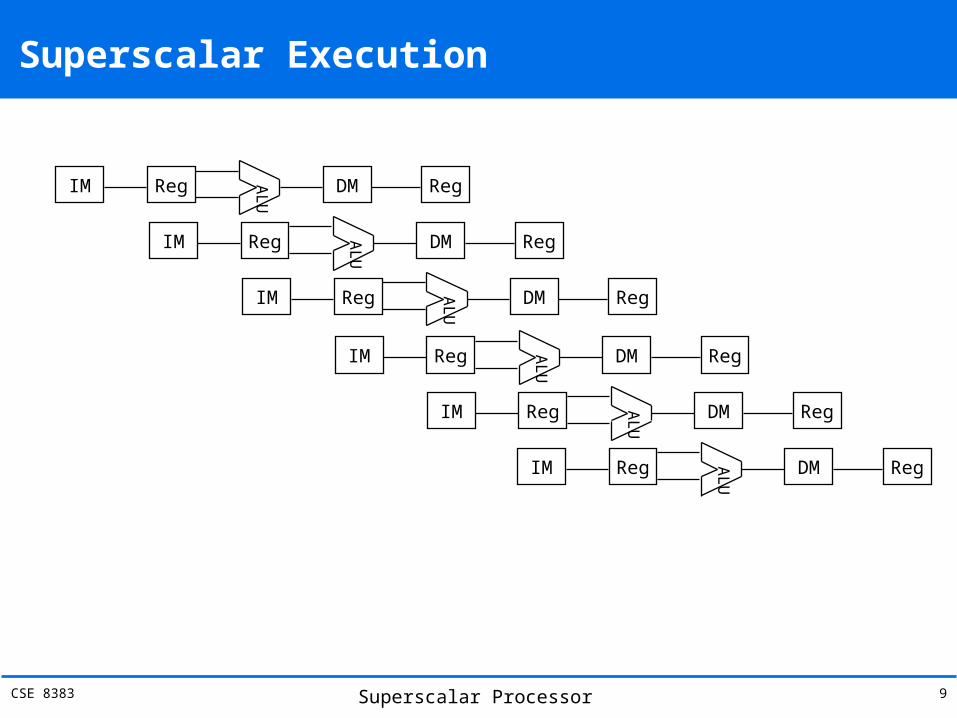
What is Superscalar?
A machine designed to improve the performance execution of scalar instructions; where one instruction per cycle.
Superscalar architecture allows several instructions to be issued and completed per clock cycle
consists of a number of pipeline that are working in parallel Common instructions (arithmetic, load/store, conditional
branch) can be initiated and executed independently in different pipelines
Executed in an order different from the program order Equally applicable to RISC & CISC, In practice usually RISC
CSE 8383 Superscalar Processor 9
Superscalar Execution
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
CSE 8383 Superscalar Processor 10
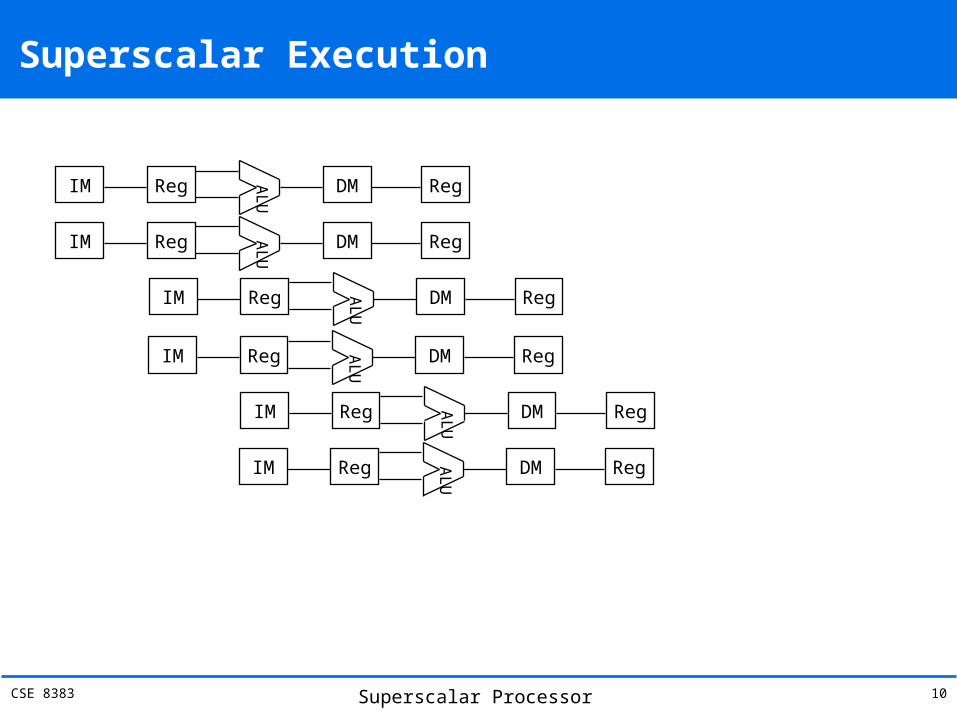
Superscalar Execution
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg
IM Reg
ALU DM Reg

CSE 8383 Superscalar Processor 11
How Does it Work?
Require: instruction fetch
• fetching of multiple instructions at once• dynamic branch prediction & fetching beyond conditional
branches
instruction issue• methods for determining which instructions can be issued
next• the ability to issue multiple instructions in parallel
instruction commit• methods for committing several instructions in fetch order
duplicate & more complex hardware
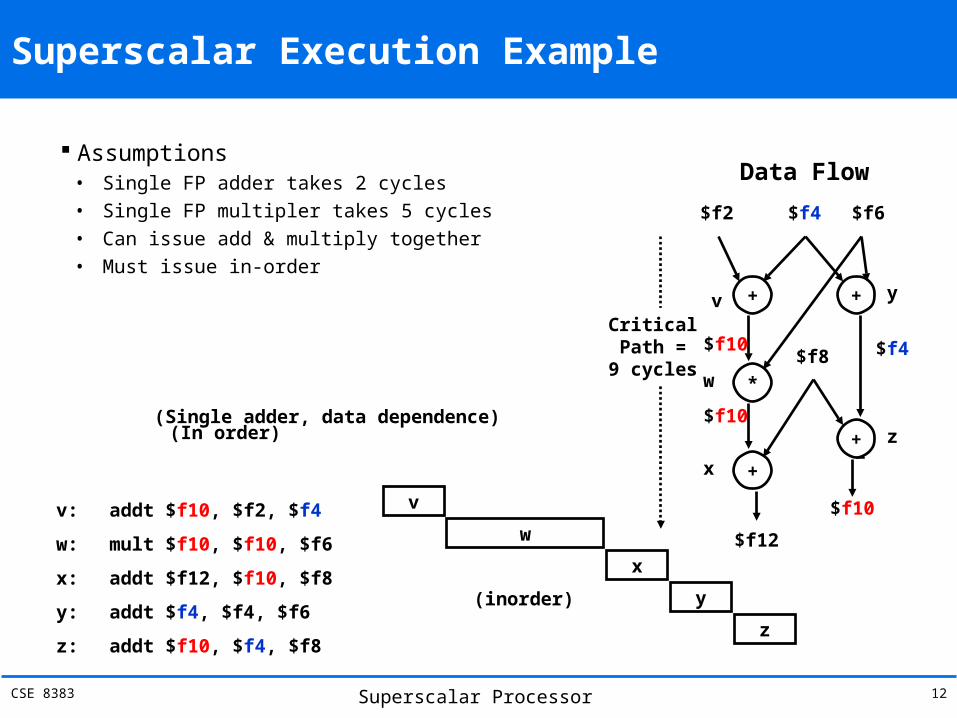
CSE 8383 Superscalar Processor 12
Assumptions• Single FP adder takes 2 cycles• Single FP multipler takes 5 cycles• Can issue add & multiply together• Must issue in-order
v: addt $f10, $f2, $f4
w: mult $f10, $f10, $f6
x: addt $f12, $f10, $f8
y: addt $f4, $f4, $f6
z: addt $f10, $f4, $f8
(Single adder, data dependence)(In order)
v
w
x
y(inorder)
z
Data Flow
+ +
*
+
$f2 $f4 $f6
$f4
$f10
$f8
yv
xz
CriticalPath =
9 cycles
+
w
z
$f12
$f10
$f10
Superscalar Execution Example
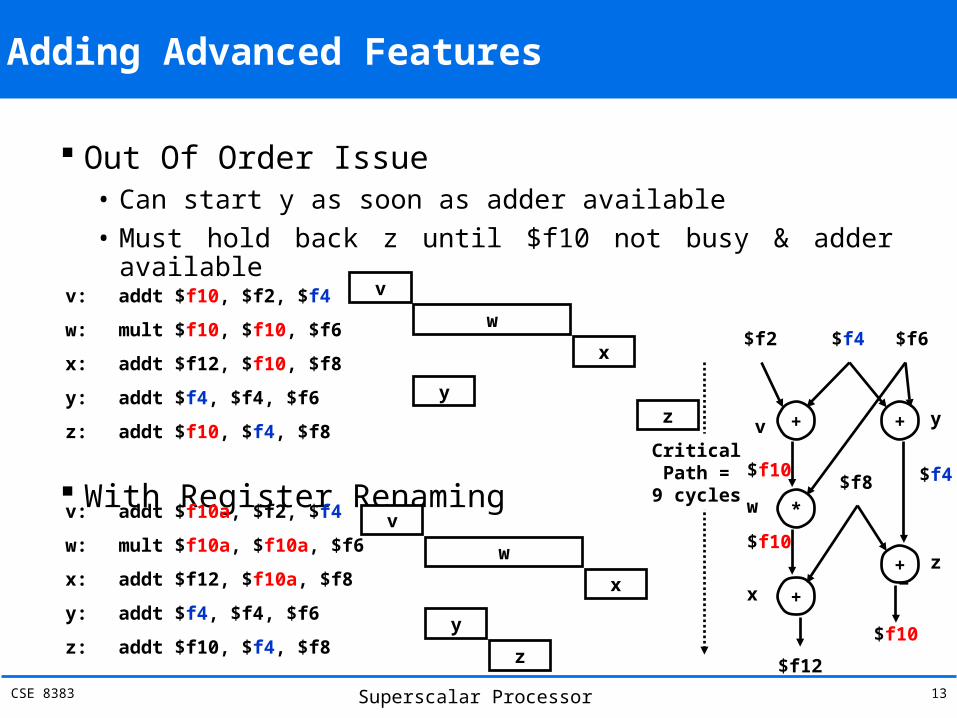
CSE 8383 Superscalar Processor 13
Adding Advanced Features
Out Of Order Issue• Can start y as soon as adder available• Must hold back z until $f10 not busy & adder available
With Register Renaming
v
w
x
yz
v
w
x
y
z
v: addt $f10, $f2, $f4
w: mult $f10, $f10, $f6
x: addt $f12, $f10, $f8
y: addt $f4, $f4, $f6
z: addt $f10, $f4, $f8
v: addt $f10a, $f2, $f4
w: mult $f10a, $f10a, $f6
x: addt $f12, $f10a, $f8
y: addt $f4, $f4, $f6
z: addt $f10, $f4, $f8
+ +
*
+
$f2 $f4 $f6
$f4
$f10
$f8
yv
xz
CriticalPath =
9 cycles
+
w
z
$f12
$f10
$f10

CSE 8383 Superscalar Processor 14
Outlines
Pipeline & Hazards Superscalar Instruction issue policyInstruction issue policy Register renaming MIPS R10000 Advanced Superscalar Summary
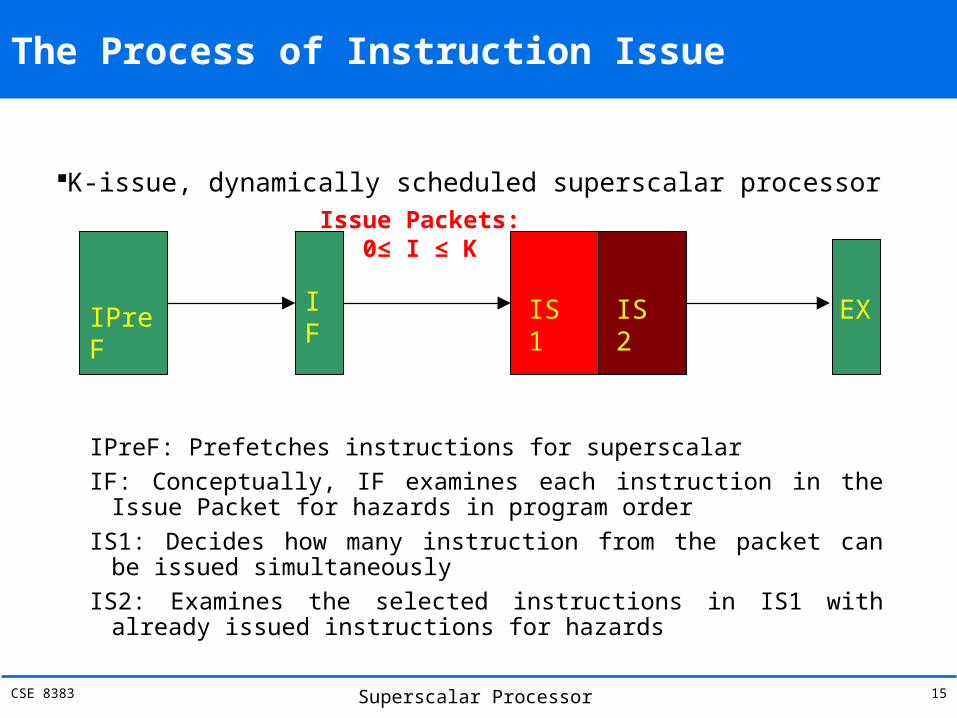
CSE 8383 Superscalar Processor 15
The Process of Instruction Issue
K-issue, dynamically scheduled superscalar processor
IPreF: Prefetches instructions for superscalarIF: Conceptually, IF examines each instruction in the Issue
Packet for hazards in program orderIS1: Decides how many instruction from the packet can be
issued simultaneouslyIS2: Examines the selected instructions in IS1 with already
issued instructions for hazards
IPreFIF EXIS1 IS2
Issue Packets:0≤ I ≤ K

CSE 8383 Superscalar Processor 16
Instruction Issue Policy
Instruction Issue Policy refers to the protocol used to issue instruction
The three types of ordering are• Order in which instructions are fetched• Order in which instructions are executed• Order in which instructions change registers and memory

CSE 8383 Superscalar Processor 17
Instruction Issue Policy
The simplest policy is to execute and complete instruction in their sequential order
To improve parallelism, the processor has to look ahead and try to find independent instructions to execute in parallel
Thus, instructions will be executed in an order different from the strictly sequential one, with the restriction that the result must be correct
Execution policies:
i. In-order issue with in-order completion
ii. In-order issue with out-order completion
iii. Out-of-order issue with out-of-order completion

CSE 8383 Superscalar Processor 18
In-Order Issue with In-Order Completion
Instructions are issued in the exact order that would correspond to sequential execution [In-order Issue] and result are written in the same order [In-order Completion]

CSE 8383 Superscalar Processor 19
In-Order Issue with Out-of-Order Completion
Result are written in different order An output dependency exists if two instructions
are writing into the same location Output dependency
R3R3:= R3 + R5; (I1)R4:= R3 + 1; (I2)
R3R3:= R5 + 1; (I3)R7:= R3 + R4; (I4)
• If I3 completes before I1, the result from I1 will be wrong.

CSE 8383 Superscalar Processor 20
Out-of-Order Issue with Out-of-Order Completion
With in-order issue, no new instruction can be issued when processor has detected a conflict and is stalled, until after the conflict has been resolved
As such, the processor is not allowed to look ahead for further instructions, which could be executed in parallel
Out-of-order issue tries to resolve the above problem by taking a set of decoded instructions into an instruction window (buffer)
When a functional unit becomes available, an instruction from the window may be issued to the execute stage
Any instruction may be issued, provided that:
i. it needs a particular functional unit that is available
ii. no conflict or dependencies blocking this instruction

CSE 8383 Superscalar Processor 21
Outlines
Pipeline & Hazards Superscalar Instruction issue policy Register renamingRegister renaming MIPS R10000 Advanced Superscalar Summary

CSE 8383 Superscalar Processor 22
Antidependency
Read-Write dependencyDIV.D F0, F1, F2 (I1)
ADD.D F3, F0, F4 (I2)
SUB.D F4, F5, F6 (I3)
MUL.D F3, F5, F4 (I4)
I3 can not complete before I2 starts as I2 needs a value in F4 and I3 changes F4
An antidependency exists if an instruction uses a location as an operand while a following one is writing into that location;
if the first one is still using the location when the second one writes into it, an error occurs:

CSE 8383 Superscalar Processor 23
Register Renaming
Output dependencies and antidependencies can be treated
similarly to true data dependencies as normal conflicts, by
delaying the execution of a certain instruction until it can
be executed Parallelism could be improved by eliminating output
dependencies and antidependencies, which are not real
data dependencies These artificial dependencies can be eliminated by
automatically allocating new registers to values, when such dependencies has been detected
This technique is called register renaming

CSE 8383 Superscalar Processor 24
Register renaming
• DIV.D F0, F1, F2 DIV.D F0, F1, F2• ADD.D F3, F0, F4 ADD.D F3, F0, F4 • SUB.D F4, F5, F6 SUB.D T, F5, F6 • MUL.D F3, F5, F4 MUL.D S, F5, T
0205
2.64.2
22.6
F0F1F2F3F4F5
5.6F6
F31
Name Op1 DetOp2Div 520 F0Add 2.6Div F3Sub 5.622.6 F4Mul Sub5.6 F3
Register File Reservation Station
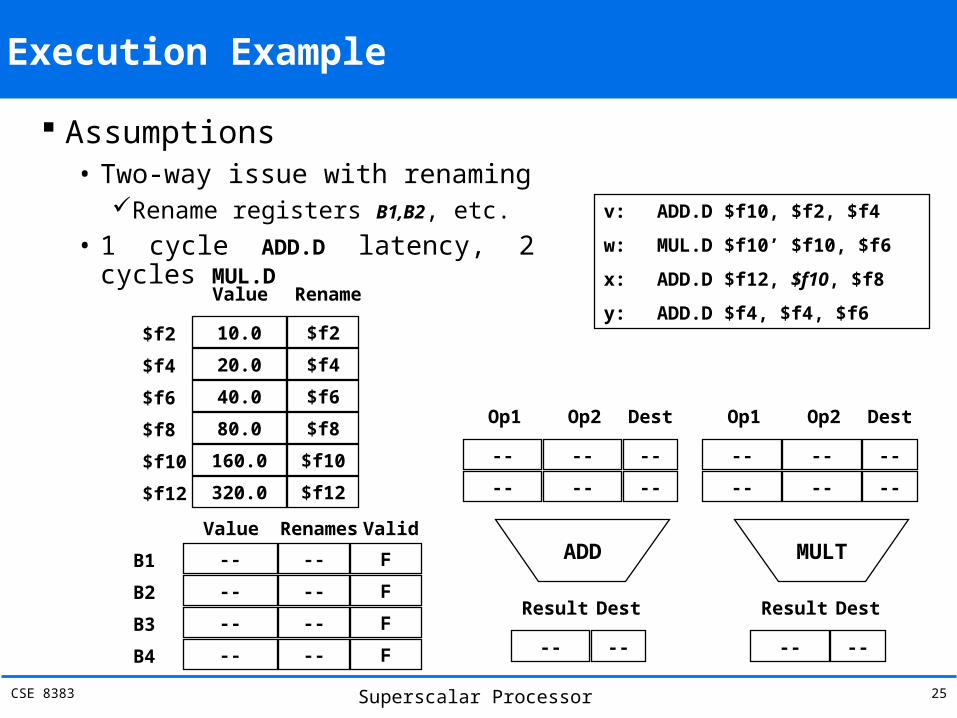
CSE 8383 Superscalar Processor 25
Execution Example
Assumptions• Two-way issue with renaming
Rename registers B1,B2, etc.
• 1 cycle ADD.D latency, 2 cycles MUL.D
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6 Value Rename
10.0$f2 $f2
20.0$f4 $f4
40.0$f6 $f6
80.0$f8 $f8
160.0$f10 $f10
320.0$f12 $f12
ADD
-- -- --
-- -- --
Op1 Op2 Dest
-- --
Result Dest
MULT
-- -- --
-- -- --
Op1 Op2 Dest
-- --
Result Dest
--B1 --
Value Renames
F
Valid
--B2 -- F
--B3 -- F
--B4 -- F
CSE 8383 Superscalar Processor 26
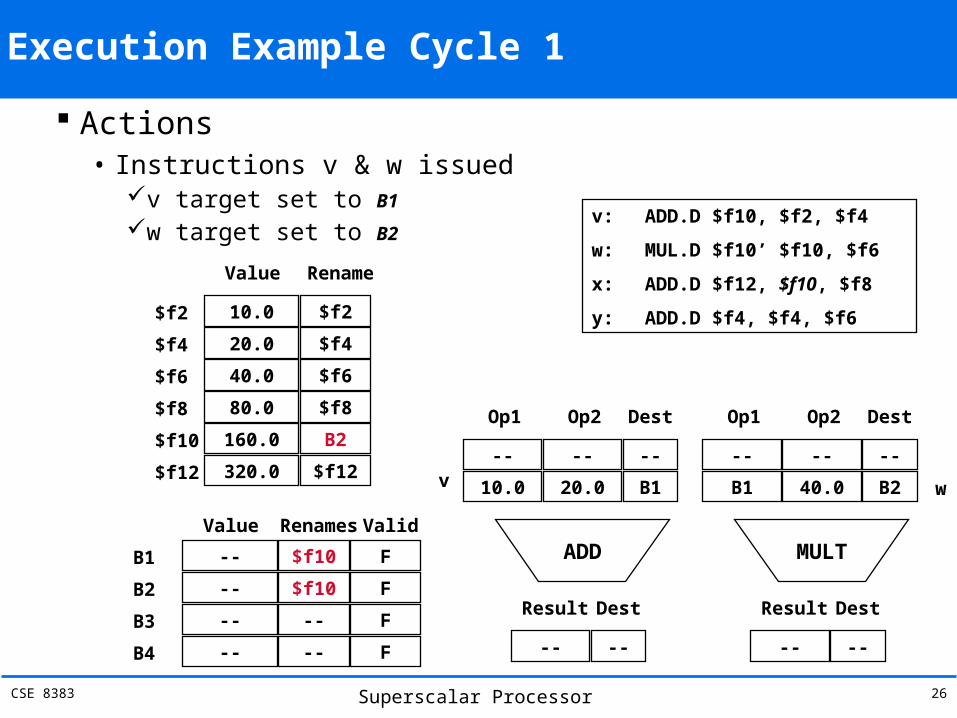
Execution Example Cycle 1
Actions• Instructions v & w issued
v target set to B1w target set to B2
Value Rename
10.0$f2 $f2
20.0$f4 $f4
40.0$f6 $f6
80.0$f8 $f8
160.0$f10 B2
320.0$f12 $f12
ADD
10.0 20.0 B1
-- -- --
Op1 Op2 Dest
-- --
Result Dest
MULT
B1 40.0 B2
-- -- --
Op1 Op2 Dest
-- --
Result Dest
v w
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6
--B1 $f10
Value Renames
F
Valid
--B2 $f10 F
--B3 -- F
--B4 -- F

CSE 8383 Superscalar Processor 27
Execution Example Cycle 2
Actions• Instructions x & y issued
x & y targets set to B3 and B4
• Instruction v executed
Value Rename
10.0$f2 $f2
20.0$f4 B4
40.0$f6 $f6
80.0$f8 $f8
160.0$f10 B2
320.0$f12 B3
ADD
B2 80.0 B3
20.0 40.0 B4
Op1 Op2 Dest
30.0 B1
Result Dest
MULT
30.0 40.0 B2
-- -- --
Op1 Op2 Dest
-- --
Result Dest
v
wx
y
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6
30.0B1 $f10
Value Renames
T
Valid
--B2 $f10 F
--B3 $f12 F
--B4 $f4 F
CSE 8383 Superscalar Processor 28
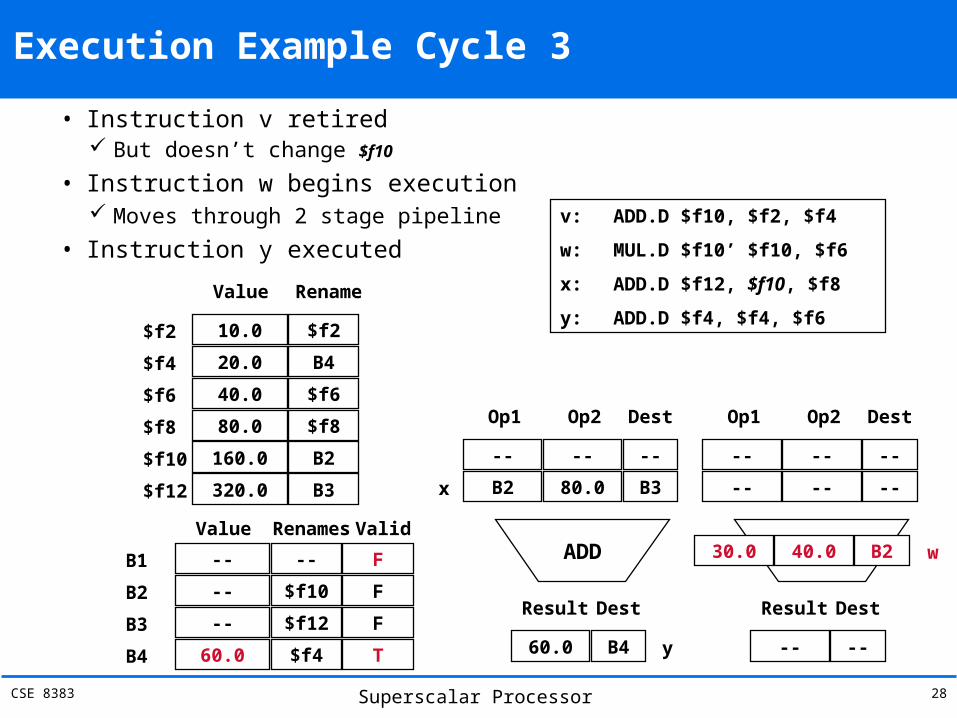
• Instruction v retiredBut doesn’t change $f10
• Instruction w begins executionMoves through 2 stage pipeline
• Instruction y executedValue Rename
10.0$f2 $f2
20.0$f4 B4
40.0$f6 $f6
80.0$f8 $f8
160.0$f10 B2
320.0$f12 B3
ADD
B2 80.0 B3
-- -- --
Op1 Op2 Dest
60.0 B4
Result Dest
MULT
-- -- --
-- -- --
Op1 Op2 Dest
-- --
Result Dest
y
x
30.0 40.0 B2 w
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6
--B1 --
Value Renames
F
Valid
--B2 $f10 F
--B3 $f12 F
60.0B4 $f4 T
Execution Example Cycle 3
CSE 8383 Superscalar Processor 29
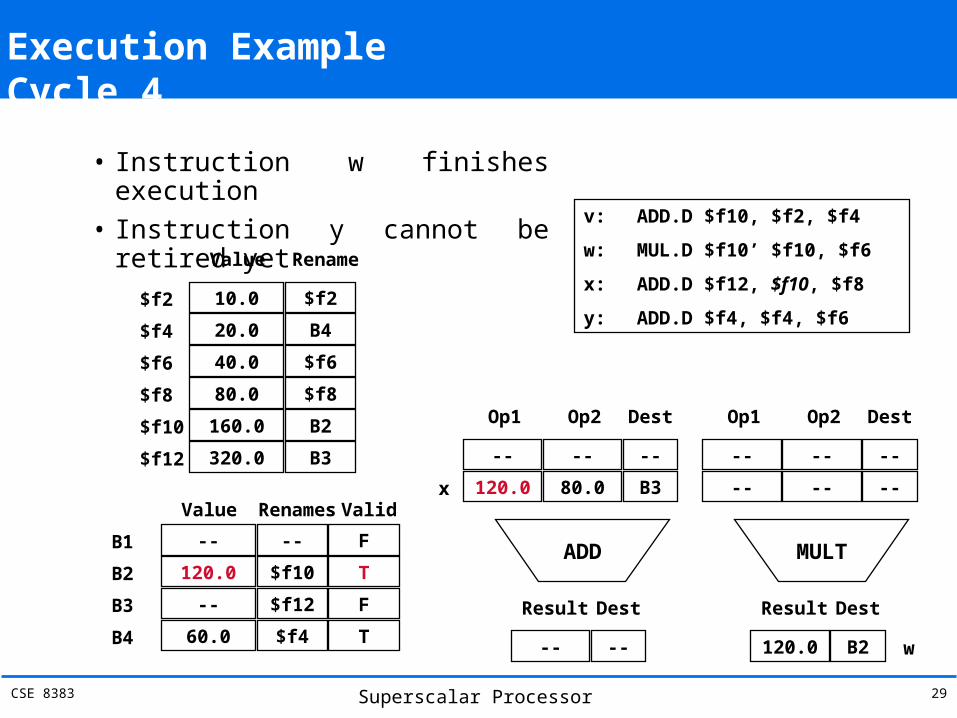
Execution Example Cycle 4
• Instruction w finishes execution• Instruction y cannot be retired
yetValue Rename
10.0$f2 $f2
20.0$f4 B4
40.0$f6 $f6
80.0$f8 $f8
160.0$f10 B2
320.0$f12 B3
ADD
120.0 80.0 B3
-- -- --
Op1 Op2 Dest
-- --
Result Dest
MULT
-- -- --
-- -- --
Op1 Op2 Dest
120.0 B2
Result Dest
w
x
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6
--B1 --
Value Renames
F
Valid
120.0B2 $f10 T
--B3 $f12 F
60.0B4 $f4 T

CSE 8383 Superscalar Processor 30
Execution Example Cycle 5
• Instruction w retiredupdate $f10
• Instruction y cannot be retired yet
• Instruction x executedValue Rename
10.0$f2 $f2
20.0$f4 B4
40.0$f6 $f6
80.0$f8 $f8
120.0$f10 $f10
320.0$f12 B3
ADD
-- -- --
-- -- --
Op1 Op2 Dest
200.0 B3
Result Dest
MULT
-- -- --
-- -- --
Op1 Op2 Dest
-- --
Result Dest
x
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6
--B1 --
Value Renames
F
Valid
--B2 -- F
200.0B3 $f12 T
60.0B4 $f4 T
CSE 8383 Superscalar Processor 31
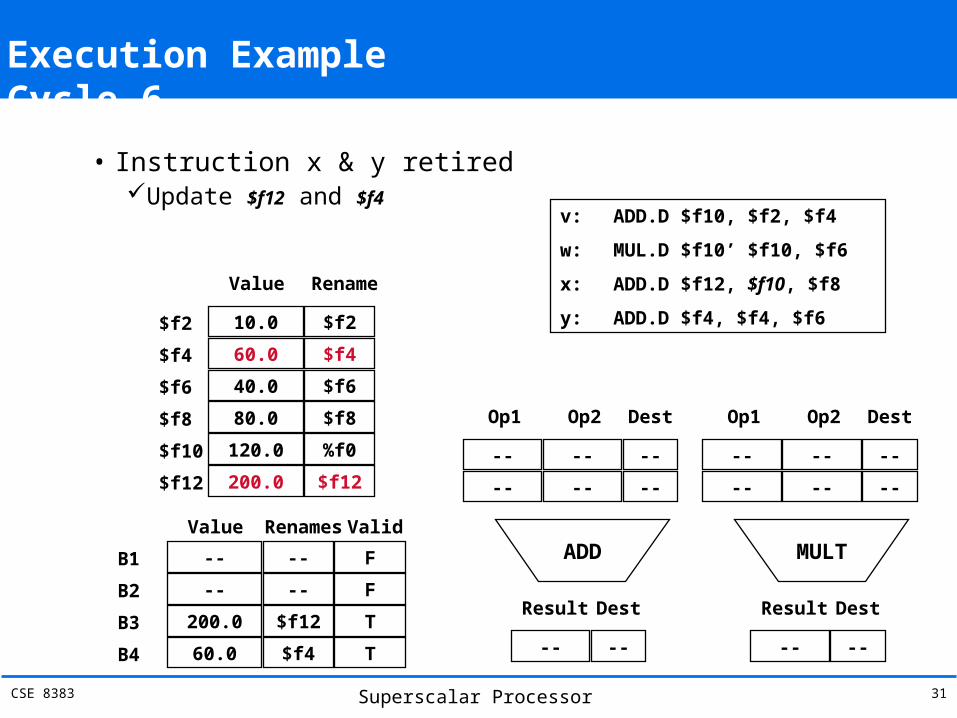
Execution Example Cycle 6
• Instruction x & y retiredUpdate $f12 and $f4
Value Rename
10.0$f2 $f2
60.0$f4 $f4
40.0$f6 $f6
80.0$f8 $f8
120.0$f10 %f0
200.0$f12 $f12
ADD
-- -- --
-- -- --
Op1 Op2 Dest
-- --
Result Dest
MULT
-- -- --
-- -- --
Op1 Op2 Dest
-- --
Result Dest
v: ADD.D $f10, $f2, $f4
w: MUL.D $f10’ $f10, $f6
x: ADD.D $f12, $f10, $f8
y: ADD.D $f4, $f4, $f6
--B1 --
Value Renames
F
Valid
--B2 -- F
200.0B3 $f12 T
60.0B4 $f4 T

CSE 8383 Superscalar Processor 32
Outlines
Pipeline & Hazards Superscalar Instruction issue policy Register renaming MIPS R10000MIPS R10000 Advanced Superscalar Summary

CSE 8383 Superscalar Processor 33
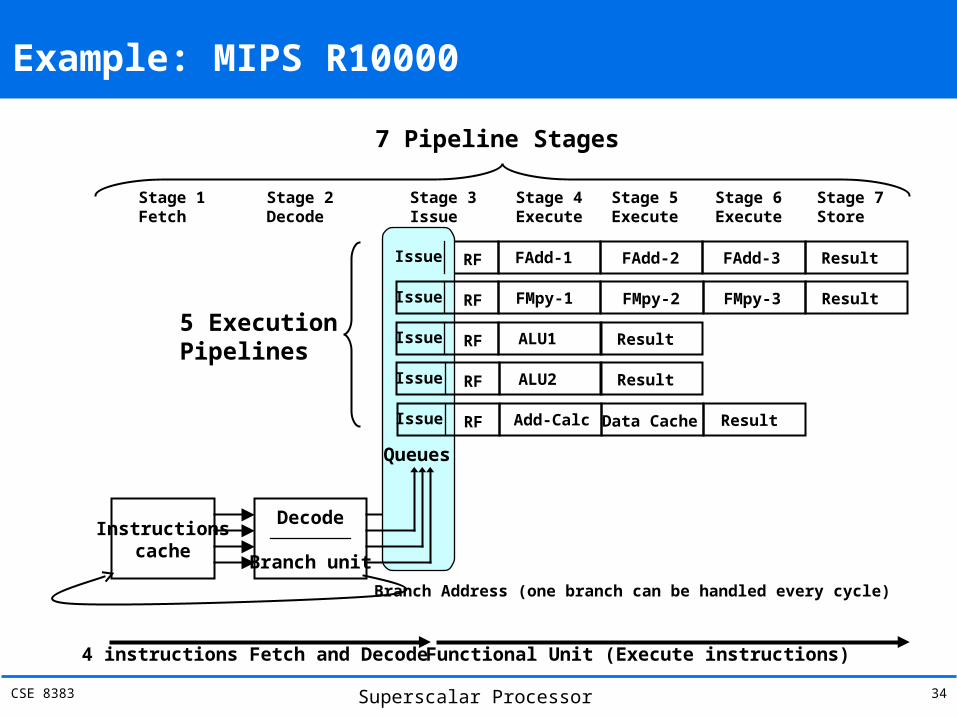
Example: MIPS R10000
Can decode 4 instructions per cycle Has 5 execution pipelines Uses dynamic scheduling and out-of-order
execution Does speculative branching Functional Units
• Integer ALU1• Integer ALU2• Load/Store Unit• Float Adder• Float Multiply
CSE 8383 Superscalar Processor 34
Example: MIPS R10000
Instructionscache
Decode
Branch unit
Issue RF FAdd-1 FAdd-2 FAdd-3 Result
Issue RF FMpy-1 FMpy-2 FMpy-3 Result
Issue RF ALU1 Result
Issue RF ALU2 Result
Issue RF Add-Calc Data Cache Result
Queues
7 Pipeline Stages
Stage 1Fetch
Stage 2Decode
Stage 3Issue
Stage 4Execute
Stage 5Execute
Stage 6Execute
Stage 7Store
4 instructions Fetch and Decode Functional Unit (Execute instructions)
Branch Address (one branch can be handled every cycle)
5 ExecutionPipelines

CSE 8383 Superscalar Processor 35
Outlines
Pipeline & Hazards Superscalar Instruction issue policy Register renaming MIPS R10000 Advanced SuperscalarAdvanced Superscalar Summary

CSE 8383 Superscalar Processor 36
Advanced Superscalar
Future Architecture Can issue 16 to 32 instructions Consist of 24 to 48 functional units Use advance branch prediction Advantage
• Enhancing performance
Disadvantage• Attempting to extract more instruction level parallelism
has diminishing returns on performance as the issue width increases
• Increasing Microprocessor complexity

CSE 8383 Superscalar Processor 37
Outlines
Pipeline & Hazards Superscalar Instruction issue policy Register renaming MIPS R10000 Advanced Superscalar SummarySummary

CSE 8383 Superscalar Processor 38
Summary
Superscalar is ILP mechanism to enhance the performance by increasing throughput.
It is limited by• True data dependency• Procedural (Control) dependency• Resource conflicts• Output dependency• Antidependency

CSE 8383 Superscalar Processor 39
Summary
Pros• The hardware solves everything:
Hardware detects potential parallelism between instructions;Hardware tries to issue as many instructions as possible in
parallel.Hardware solves register renaming.
Cons• Very complex
Much hardware is needed for run-time detection. There is a limit in how far we can go with this technique.
Power consumption can be very large!
• The window of executions limited this limits the capacity to detect potentially parallel instructions