Embed Size (px)
Citation preview

Stephen Ogutu
www.ogutu.org
Data mining with SpagoBI, Weka and Oracle.

1
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Copyright © 2013 by Stephen Ogutu
All rights reserved, including the right to reproduce this book or portions thereof in any form whatsoever.
For information, address:
Stephen Ogutu,
P.O. Box 8031-00200
Nairobi Kenya.
Trademarks: All other trademarks are the property of their respective owners. Stephen Ogutu is not
associated with any product or vendor mentioned in this book.
Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts
in preparing this book, they make no representations or warranties with respect to the accuracy or
completeness of the contents of this book and specifically disclaim any implied warranties or
merchantability or fitness for a particular purpose. No warranty may be created or extended by sales
representatives or written sales materials. The advice and strategies contained herein may not be suitable
for your situation. You should consult with a professional where appropriate. Neither the publisher nor
author shall be liable for any loss or profit or any other commercial damages, including but not limited to
special, incidental, consequential, or other damages.

2
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Dedication
This book is dedicated to the memory of my late mother, a great woman. My beautiful wife
Sheila for her unending support and my two cute children Emmanuel and Shallin.
Acknowledgments
Special thanks to the SpagoBI community and the ow2 consortium. Thank you all for creating a
great product and documenting it effectively.

3
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Introduction. In most places I have seen people use business intelligence tools purely for OLAP, creating
reports and charts. However business intelligence tools are much more powerful than this. In this
tutorial, we will look at a real world example of using SpagoBI to discover patterns hidden in a
large data set of millions of records containg the US census data. According to Wikipedia, data
mining is the computational process of discovering patterns in large data sets involving methods
at the intersection of artificial intelligence, machine learning, statistics, and database systems.
The overall goal of the data mining process is to extract information from a data set and
transform it into an understandable structure for further use.

4
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
The Problem We will assume that you are a military recruiter and your problem is to find a list of people who qualifies
to join the army. You want people who have a certain group of qualities. They must not be children,
should not be earning too much and therefore already comfortable and not interested in joining the
army. Should not have served in the army before e.t.c. To aid in your work, you have been given a large
dataset of 2.4 million records from the last census with ID number so you can get the contacts of the
people. You want to mine the data using BI so that it groups for you potential candidates to reduce the
time taken to recruit. You don’t want to run after people who are not interested in joining the army.
Preparing the data. For us to use SpagoBI to perform data mining, we will need to load the data to be analyzed into a
relational database. We will be using Oracle since it is the most popular enterprise database and also
because we need to simulate as far as possible a real world scenario. So where will we get the data?
Download the data from http://archive.ics.uci.edu/ml/machine-learning-databases/census1990-
mld/USCensus1990.data.txt and save it to your computer. It is a large file, 352MB of data. The data is in
a CSV format so the first thing we need to do is import it into the Oracle database.
If you have no prior experience with Oracle, see my book “SpagoBI, ORACLE and OLAP” available here
http://www.scribd.com/doc/133975956/SpagoBI-with-ORACLE-11g
Loading the data. We need to load the data into Oracle before we can perform data mining with SpagoBI. Start your
database and login as user sys.
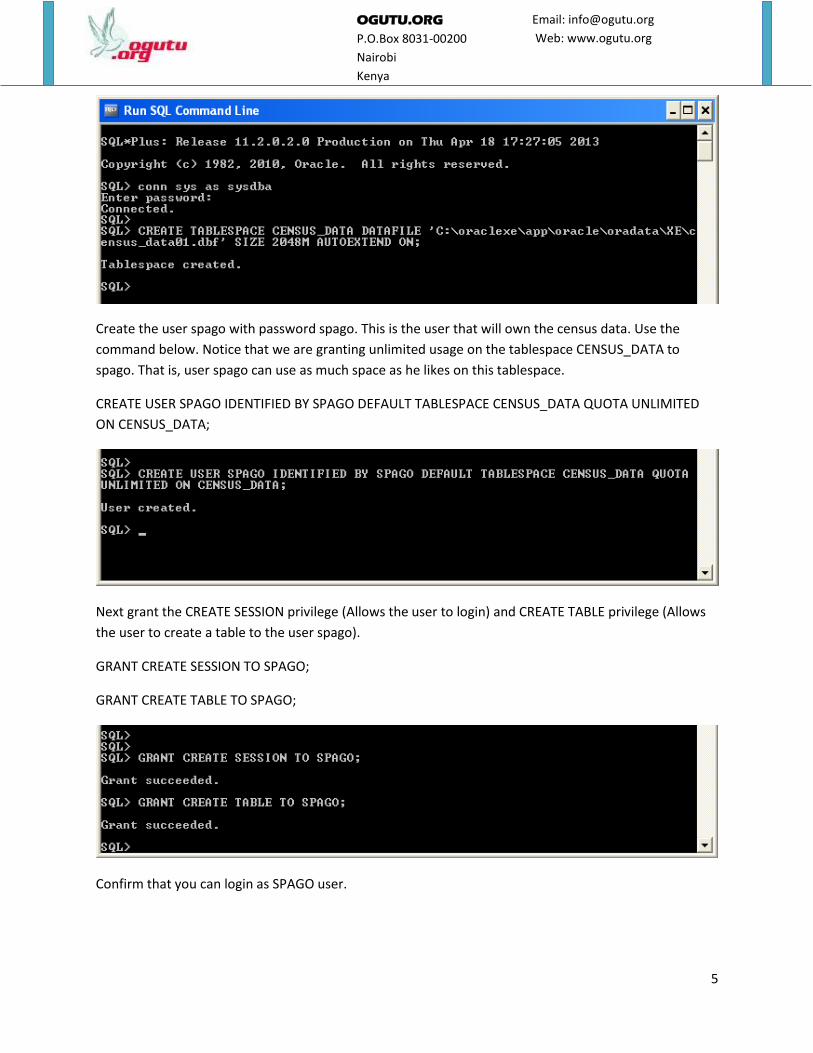
Create a tablespace that will hold your census data. This tablespace should be 2GB in size but can extend
if needed. (A tablespace is a logical container where table data is kept). I will place the datafile for my
tablespace in drive C:\ as that is where I have space. Use the command below.
CREATE TABLESPACE CENSUS_DATA DATAFILE 'C:\oraclexe\app\oracle\oradata\XE\census_data01.dbf'
SIZE 2048M AUTOEXTEND ON;
5
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Create the user spago with password spago. This is the user that will own the census data. Use the
command below. Notice that we are granting unlimited usage on the tablespace CENSUS_DATA to
spago. That is, user spago can use as much space as he likes on this tablespace.
CREATE USER SPAGO IDENTIFIED BY SPAGO DEFAULT TABLESPACE CENSUS_DATA QUOTA UNLIMITED
ON CENSUS_DATA;
Next grant the CREATE SESSION privilege (Allows the user to login) and CREATE TABLE privilege (Allows
the user to create a table to the user spago).
GRANT CREATE SESSION TO SPAGO;
GRANT CREATE TABLE TO SPAGO;
Confirm that you can login as SPAGO user.

6
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Next, create the table that will hold the data from the USCensus1990.data.txt file you downloaded
previously. Below is the script for creating this table. Save it as C:\US\table.sql
To create the table, execute the query as shown below when logged in as user spago.
SQL*Loader The table is now prepared and all that remains is to load the data into it. To load the data, we are going
to use an Oracle tool called SQL loader. This is a tool that loads data from a flat file into an oracle
database. For SQL loader to work, it needs a control file which tells it where the data is and into which
table into the database we should load the file. Below is a sample control file we will use.
CREATE TABLE CENSUS
(caseid INT,dAge INT,dAncstry1 INT,dAncstry2 INT,iAvail INT,iCitizen INT,iClass INT,dDepart INT,iDisabl1
INT,iDisabl2 INT,iEnglish INT,iFeb55 INT,iFertil INT,dHispanic INT,dHour89 INT,dHours INT,iImmigr
INT,dIncome1 INT,dIncome2 INT,dIncome3 INT,dIncome4 INT,dIncome5 INT,dIncome6 INT,dIncome7
INT,dIncome8 INT,dIndustry INT,iKorean INT,iLang1 INT,iLooking INT,iMarital INT,iMay75880 INT,iMeans
INT,iMilitary INT,iMobility INT,iMobillim INT,dOccup INT,iOthrserv INT,iPerscare INT,dPOB INT,dPoverty
INT,dPwgt1 INT,iRagechld INT,dRearning INT,iRelat1 INT,iRelat2 INT,iRemplpar INT,iRiders INT,iRlabor
INT,iRownchld INT,dRpincome INT,iRPOB INT,iRrelchld INT,iRspouse INT,iRvetserv INT,iSchool INT,iSept80
INT,iSex INT,iSubfam1 INT,iSubfam2 INT,iTmpabsnt INT,dTravtime INT,iVietnam INT,dWeek89 INT,iWork89
INT,iWorklwk INT,iWWII INT,iYearsch INT,iYearwrk INT,dYrsserv INT);
load data
infile 'C:\US\USCensus1990.data.txt'
into table CENSUS
fields terminated by "," optionally enclosed by '"'
(caseid ,dAge ,dAncstry1 ,dAncstry2 ,iAvail ,iCitizen ,iClass ,dDepart ,iDisabl1 ,iDisabl2 ,iEnglish
,iFeb55 ,iFertil ,dHispanic ,dHour89 ,dHours ,iImmigr ,dIncome1 ,dIncome2 ,dIncome3 ,dIncome4
,dIncome5 ,dIncome6 ,dIncome7 ,dIncome8 ,dIndustry ,iKorean ,iLang1 ,iLooking ,iMarital
,iMay75880 ,iMeans ,iMilitary ,iMobility ,iMobillim ,dOccup ,iOthrserv ,iPerscare ,dPOB ,dPoverty
,dPwgt1 ,iRagechld ,dRearning ,iRelat1 ,iRelat2 ,iRemplpar ,iRiders ,iRlabor ,iRownchld ,dRpincome
,iRPOB ,iRrelchld ,iRspouse ,iRvetserv ,iSchool ,iSept80 ,iSex ,iSubfam1 ,iSubfam2 ,iTmpabsnt
,dTravtime ,iVietnam ,dWeek89 ,iWork89 ,iWorklwk ,iWWII ,iYearsch ,iYearwrk ,dYrsserv )
7
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
The line infile 'C:\US\USCensus1990.data.txt' tells us that this is the source of the data. The data will be
loaded into the table census and the data is separated by commas. The values in bracket displays the
columns of the table. Save the file with the text as control.ctl in the folder C:\US\control.ctl. We are now
ready to load the data. Launch command prompt and at the terminal, type the commands below.
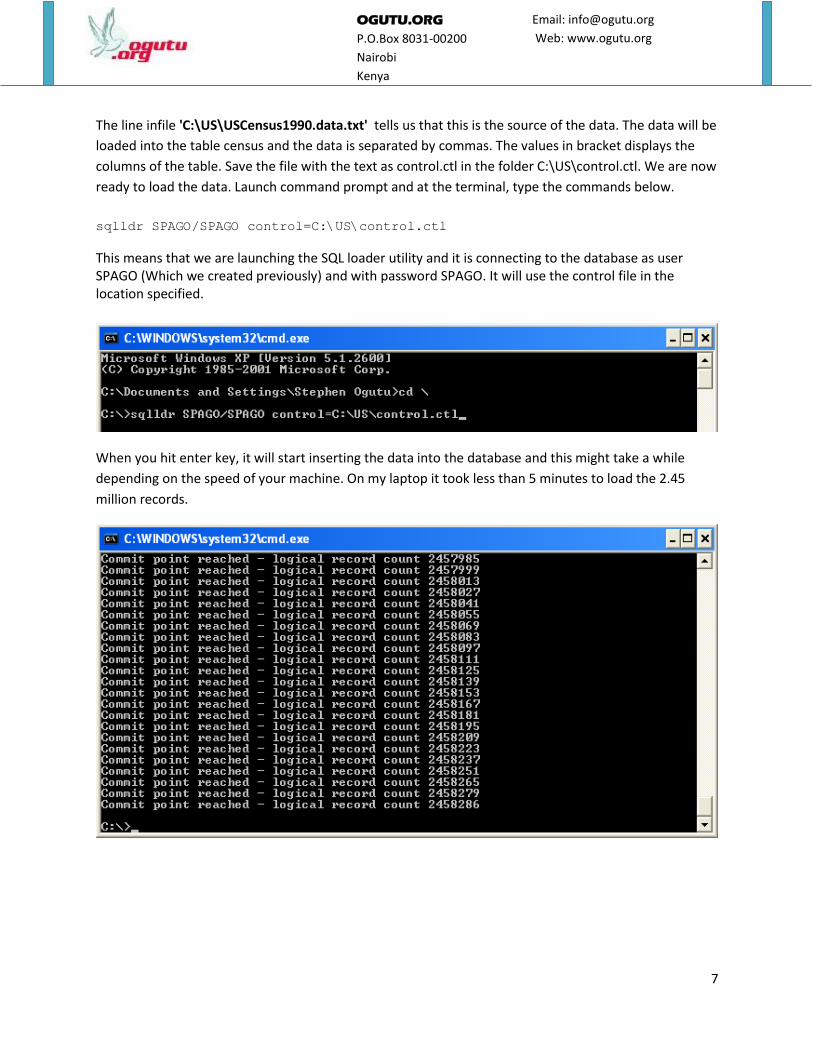
sqlldr SPAGO/SPAGO control=C:\US\control.ctl
This means that we are launching the SQL loader utility and it is connecting to the database as user SPAGO (Which we created previously) and with password SPAGO. It will use the control file in the location specified.
When you hit enter key, it will start inserting the data into the database and this might take a while
depending on the speed of your machine. On my laptop it took less than 5 minutes to load the 2.45
million records.

8
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
WEKA SpagoBI uses software called Weka (Waikato Environment for Knowledge Analysis) which is a collection
of machine learning algorithms developed at the University of Waikato, New Zealand. Though Weka
supports many algorithms, only cluster analysis is supported in SpagoBI and therefore we will limit
ourselves to clustering for the remainder of this document.
Cluster analysis Clustering is a method used to discover natural groups in data without prior knowledge of the groups.
Suppose you have a database of an insurance company and you run a clustering algorithm against it,
what details might you discover? It might will give you groups of policy holders with high claim cost who
you can blacklist from your firm and groups with low claim cost who you can do business with. This is an
example of how data mining can be used in the real world. Marketers also use clustering algorithms to
discover certain groups in their customer data whom they target with specific products. In the Telco
sector, you might discover that young people call mostly at a particular time of the day or use more of a
certain service e.g. internet data as opposed to voice and you can use this information to target them
with offers for internet data bundle. Clustering has many other uses in marketing, image processing,
medicine etc. Looking at the census data that is now in our database, it makes no sense at all but once
we start analyzing it, we might discover interesting details from it. The particular algorithm we will be
using is called the k-means algorithm.
Downloading Weka. Download Weka 3.6.1 from http://sourceforge.net/projects/weka/files/?source=navbar and install it
into your computer. Next put the Oracle jdbc library to your computers class path so that Weka will be
able to find it when connecting to Oracle database. The Oracle library is in the path
C:\oraclexe\app\oracle\product\11.2.0\server\jdbc\lib\ojdbc6.jar. This may differ if you installed
express edition on a different path.
9
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
JDBC Driver Now Weka needs to know where the Oracle JDBC driver is. We tell it by modifying the file Oracle
DatabaseUtils.props which can be found in the jar file C:\Program Files\Weka-3-6\weka.jar. You
have three options.
1. Modify the file DatabaseUtils.props to include the Oracle setting by navigating to the
location where you installed Weka e.g. C:\Program Files\Weka-3-6, right click on weka.jar and
open using winrar.
10
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
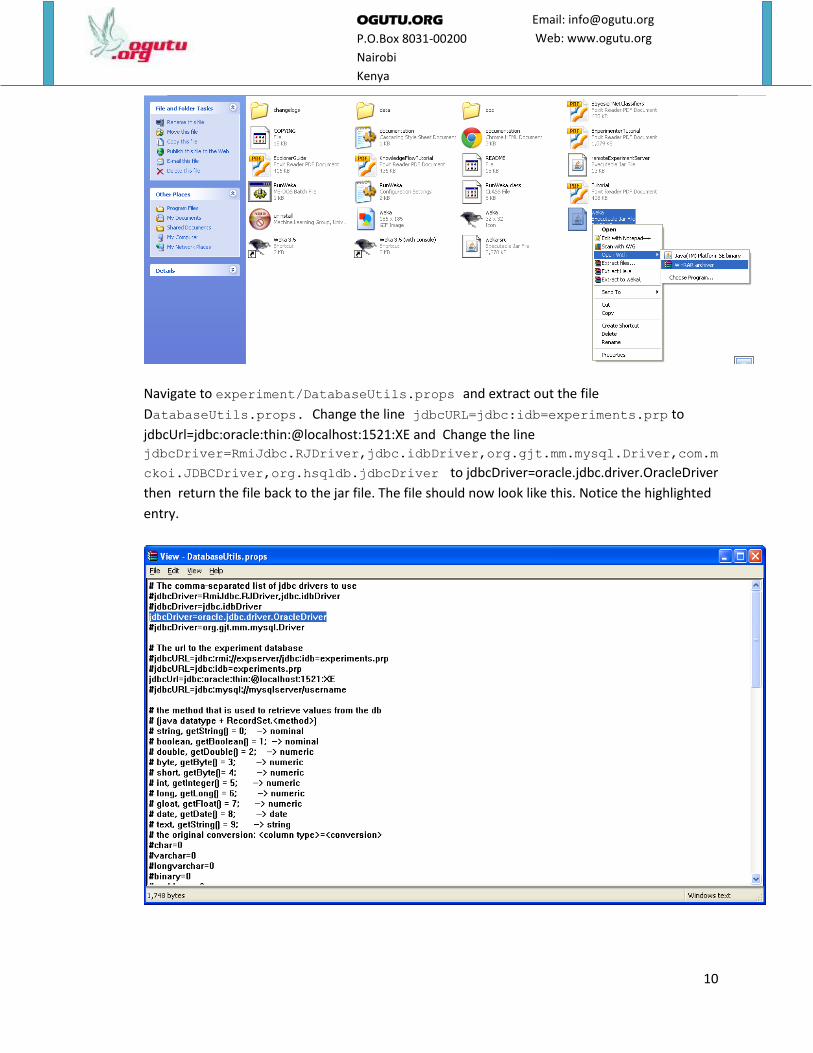
Navigate to experiment/DatabaseUtils.props and extract out the file
DatabaseUtils.props. Change the line jdbcURL=jdbc:idb=experiments.prp to
jdbcUrl=jdbc:oracle:thin:@localhost:1521:XE and Change the line jdbcDriver=RmiJdbc.RJDriver,jdbc.idbDriver,org.gjt.mm.mysql.Driver,com.m
ckoi.JDBCDriver,org.hsqldb.jdbcDriver to jdbcDriver=oracle.jdbc.driver.OracleDriver
then return the file back to the jar file. The file should now look like this. Notice the highlighted
entry.
11
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
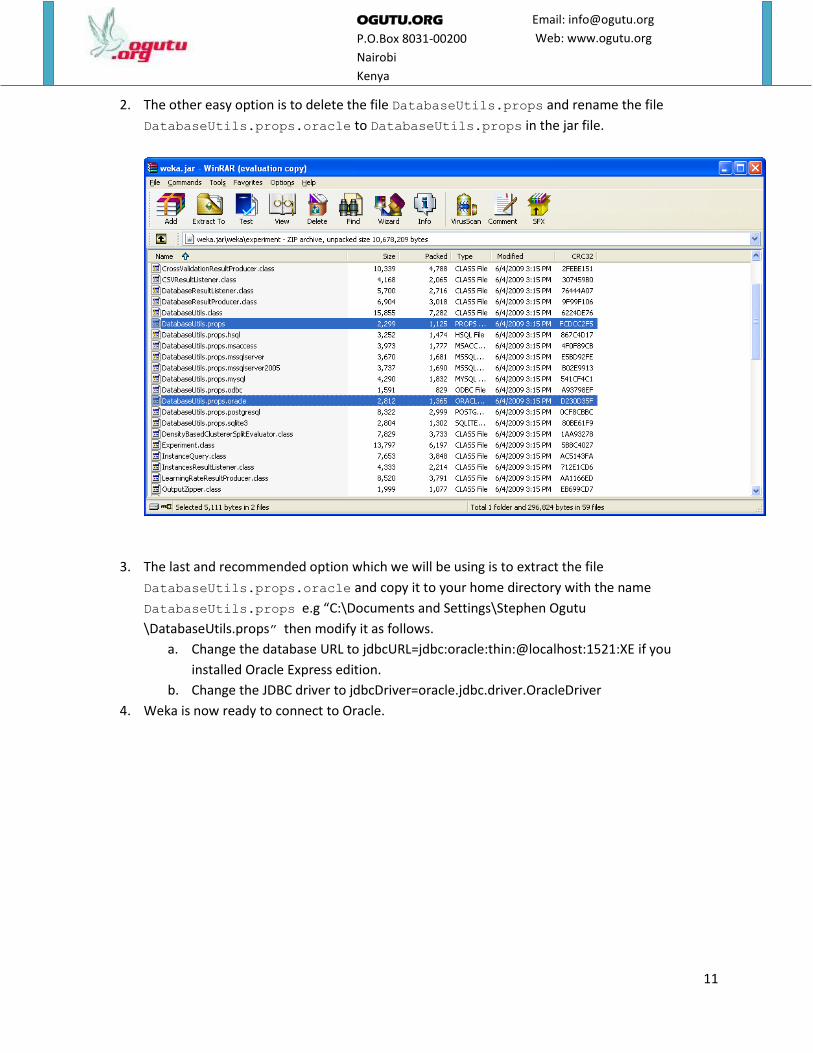
2. The other easy option is to delete the file DatabaseUtils.props and rename the file
DatabaseUtils.props.oracle to DatabaseUtils.props in the jar file.
3. The last and recommended option which we will be using is to extract the file
DatabaseUtils.props.oracle and copy it to your home directory with the name
DatabaseUtils.props e.g “C:\Documents and Settings\Stephen Ogutu
\DatabaseUtils.props” then modify it as follows.
a. Change the database URL to jdbcURL=jdbc:oracle:thin:@localhost:1521:XE if you
installed Oracle Express edition.
b. Change the JDBC driver to jdbcDriver=oracle.jdbc.driver.OracleDriver
4. Weka is now ready to connect to Oracle.
12
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
A simple analysis with weka. Now start Weka and click on explorer.
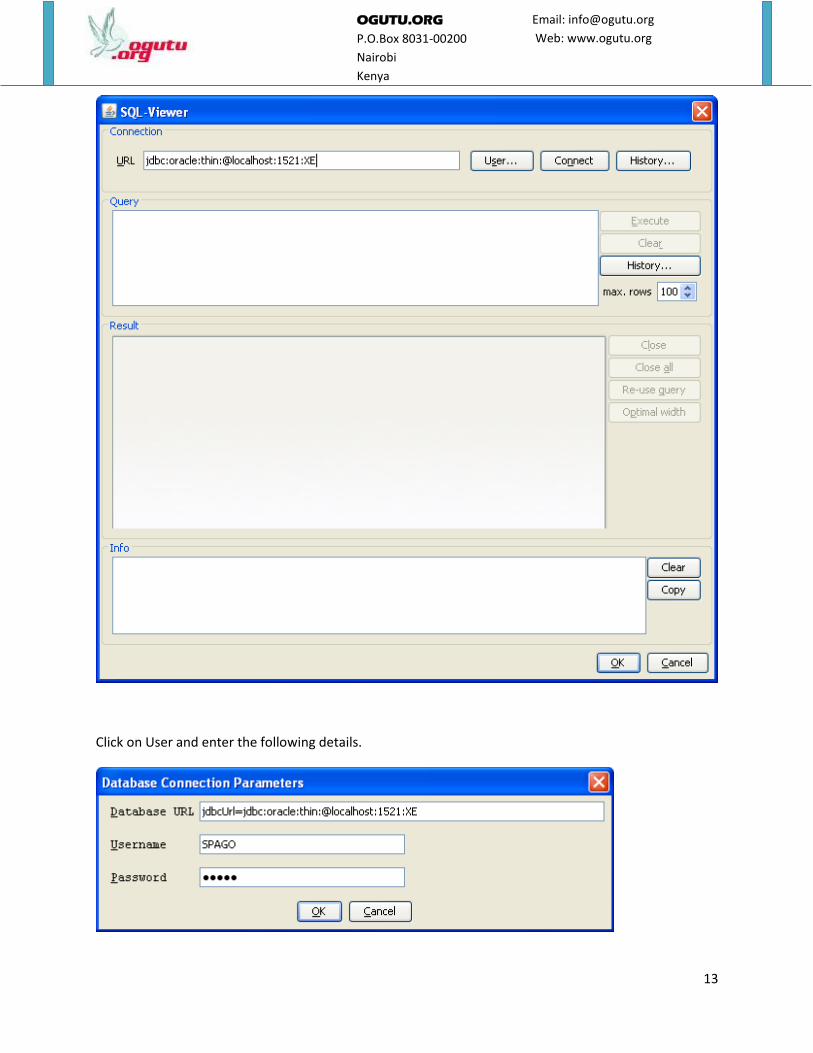
To select the source of data that we need to analyze click on Open DB icon and under the URL, enter
jdbcUrl=jdbc:oracle:thin:@localhost:1521:XE as shown below.
13
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Click on User and enter the following details.
14
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
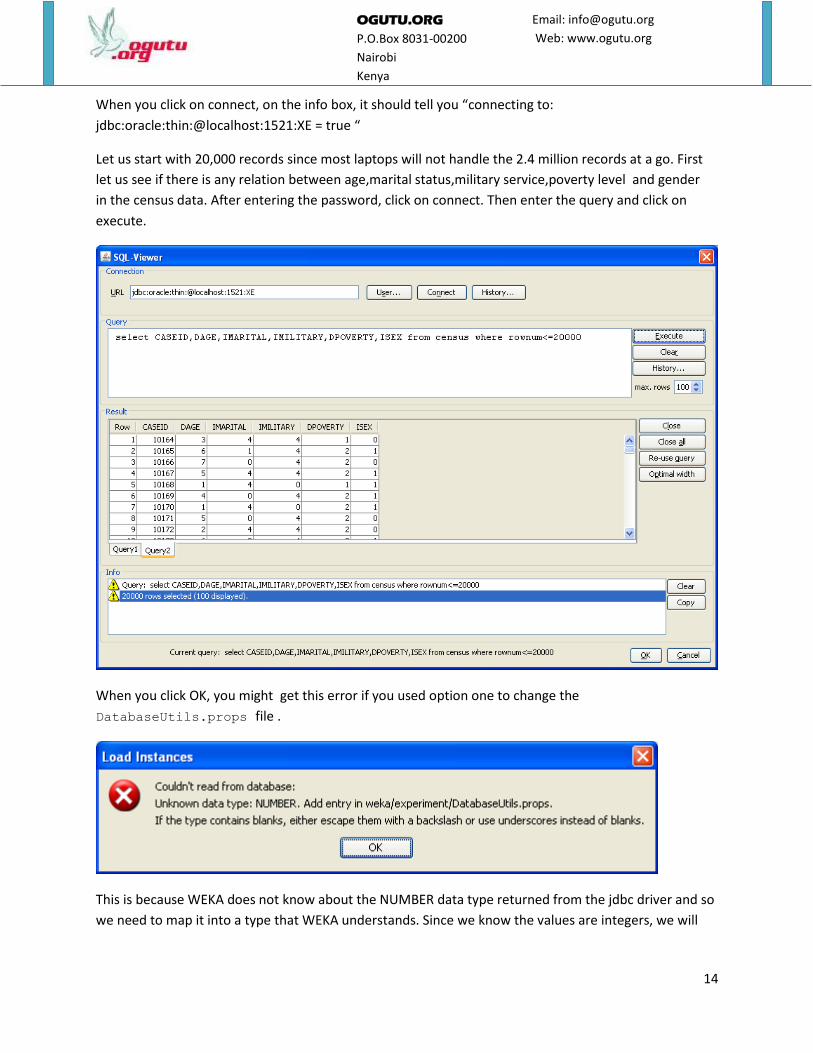
When you click on connect, on the info box, it should tell you “connecting to:
jdbc:oracle:thin:@localhost:1521:XE = true “
Let us start with 20,000 records since most laptops will not handle the 2.4 million records at a go. First
let us see if there is any relation between age,marital status,military service,poverty level and gender
in the census data. After entering the password, click on connect. Then enter the query and click on
execute.
When you click OK, you might get this error if you used option one to change the
DatabaseUtils.props file .
This is because WEKA does not know about the NUMBER data type returned from the jdbc driver and so
we need to map it into a type that WEKA understands. Since we know the values are integers, we will
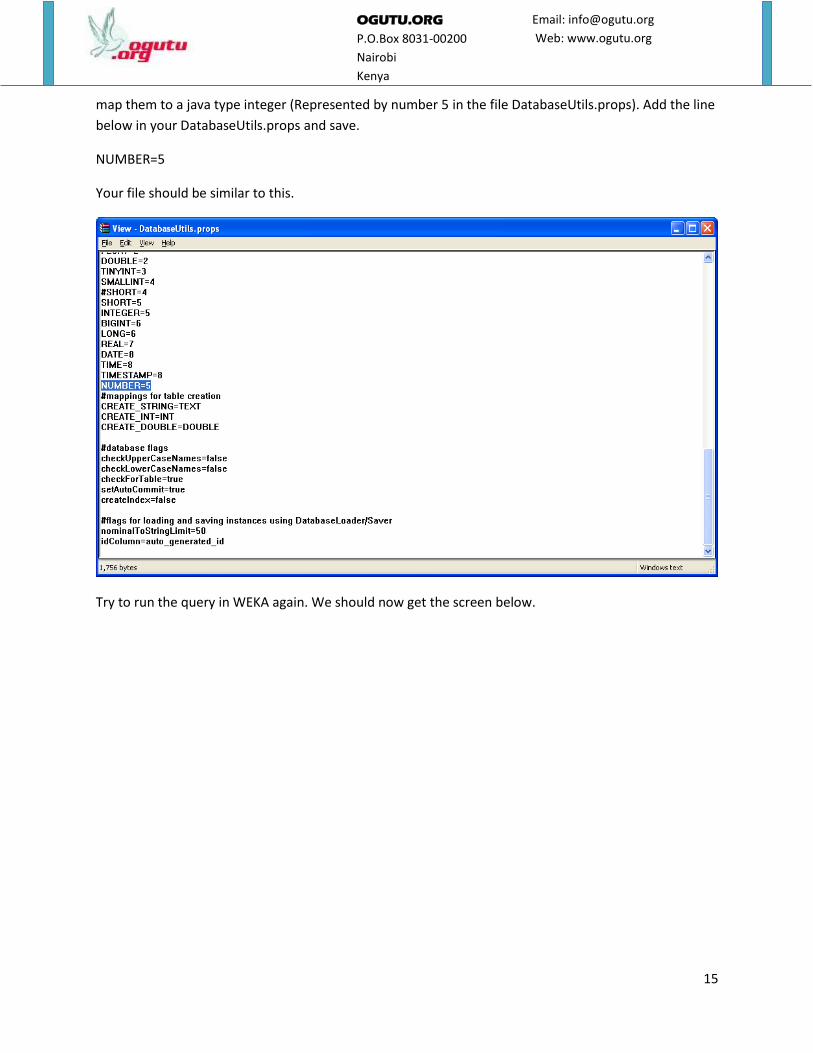
15
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
map them to a java type integer (Represented by number 5 in the file DatabaseUtils.props). Add the line
below in your DatabaseUtils.props and save.
NUMBER=5
Your file should be similar to this.
Try to run the query in WEKA again. We should now get the screen below.
16
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
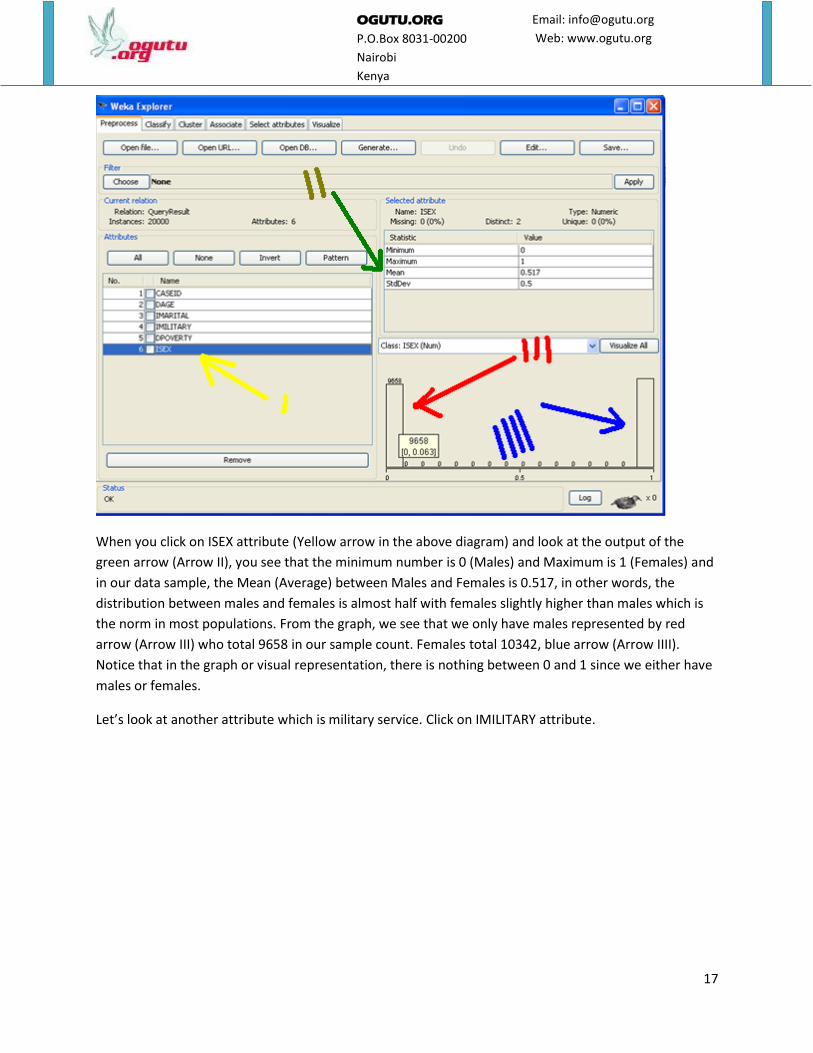
Understanding the output. Under Attributes, click on ISEX as shown below. This attribute (column displays the gender). Remember
the k-means algorithm that we will be using only accepts numbers so we need a way of converting the
gender representation Male or Female to number values. This has been achieved by using the number 1
for females and the number 0 for Males.
17
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
When you click on ISEX attribute (Yellow arrow in the above diagram) and look at the output of the
green arrow (Arrow II), you see that the minimum number is 0 (Males) and Maximum is 1 (Females) and
in our data sample, the Mean (Average) between Males and Females is 0.517, in other words, the
distribution between males and females is almost half with females slightly higher than males which is
the norm in most populations. From the graph, we see that we only have males represented by red
arrow (Arrow III) who total 9658 in our sample count. Females total 10342, blue arrow (Arrow IIII).
Notice that in the graph or visual representation, there is nothing between 0 and 1 since we either have
males or females.
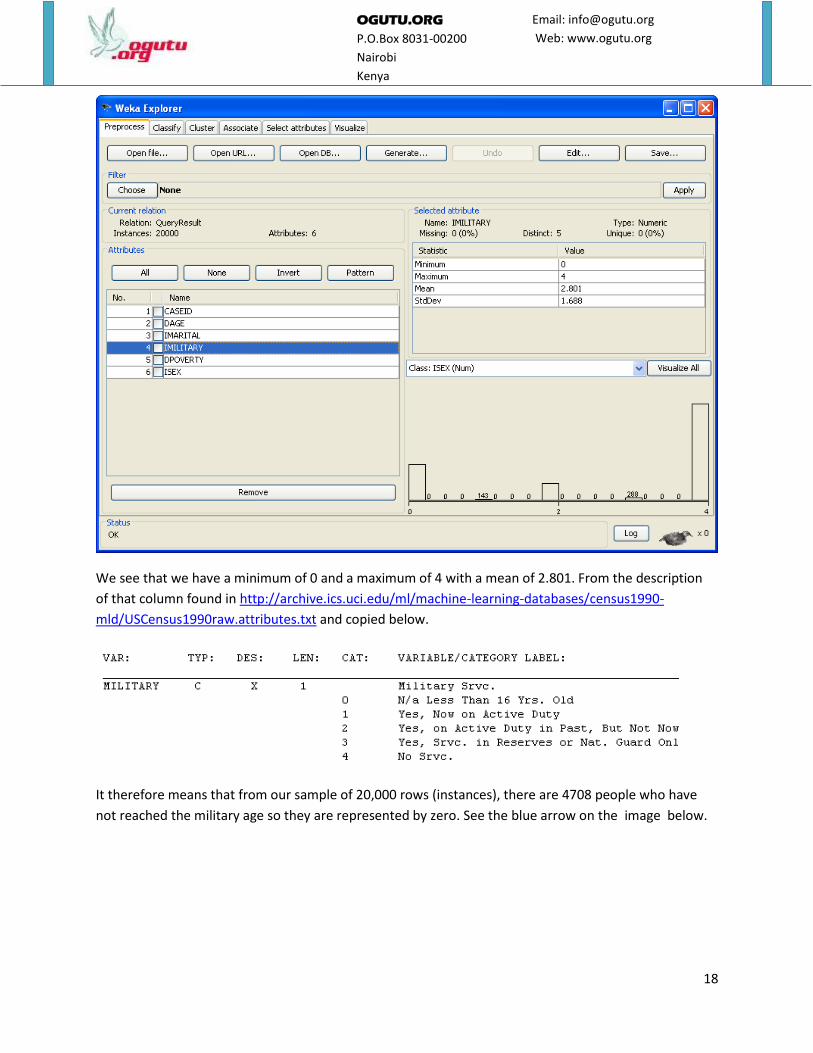
Let’s look at another attribute which is military service. Click on IMILITARY attribute.
18
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
We see that we have a minimum of 0 and a maximum of 4 with a mean of 2.801. From the description
of that column found in http://archive.ics.uci.edu/ml/machine-learning-databases/census1990-
mld/USCensus1990raw.attributes.txt and copied below.
It therefore means that from our sample of 20,000 rows (instances), there are 4708 people who have
not reached the military age so they are represented by zero. See the blue arrow on the image below.
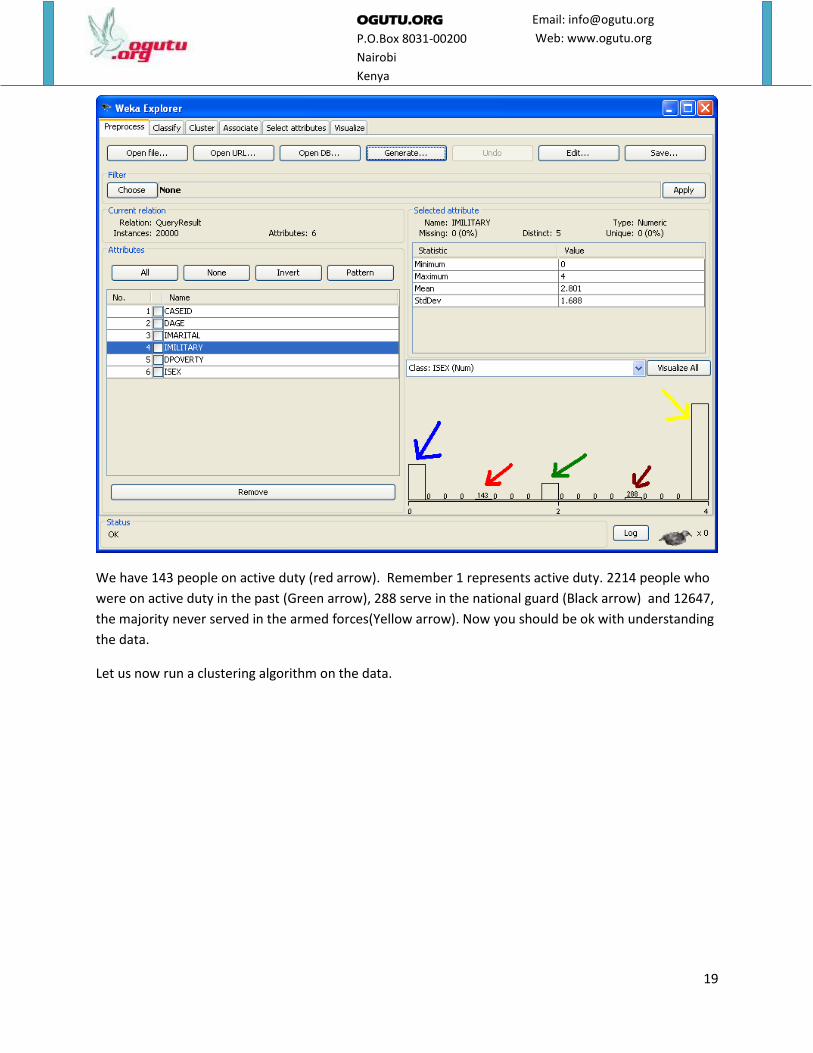
19
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
We have 143 people on active duty (red arrow). Remember 1 represents active duty. 2214 people who
were on active duty in the past (Green arrow), 288 serve in the national guard (Black arrow) and 12647,
the majority never served in the armed forces(Yellow arrow). Now you should be ok with understanding
the data.
Let us now run a clustering algorithm on the data.
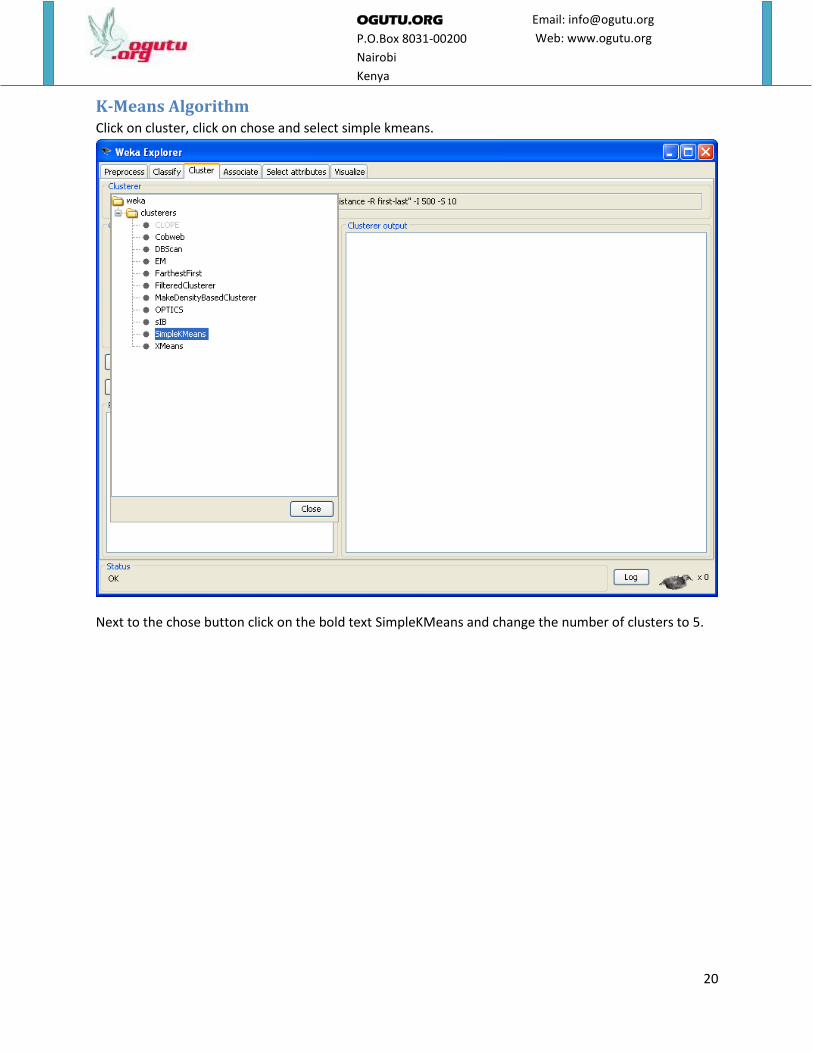
20
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
K-Means Algorithm Click on cluster, click on chose and select simple kmeans.
Next to the chose button click on the bold text SimpleKMeans and change the number of clusters to 5.
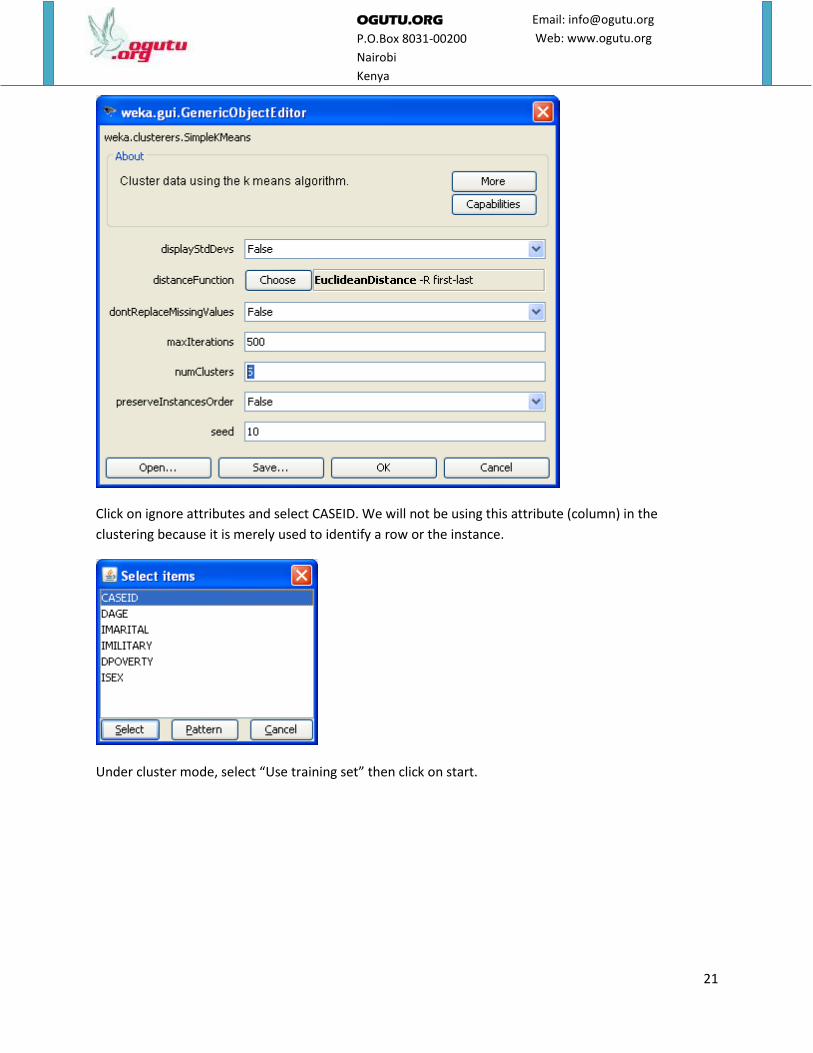
21
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Click on ignore attributes and select CASEID. We will not be using this attribute (column) in the
clustering because it is merely used to identify a row or the instance.
Under cluster mode, select “Use training set” then click on start.

22
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
From the results above, we can see that the data sample was 20000 (black arrow), the number of
attributes (columns) were 6 (yellow arrow) and out of these, CASEID was ignored. The data have been
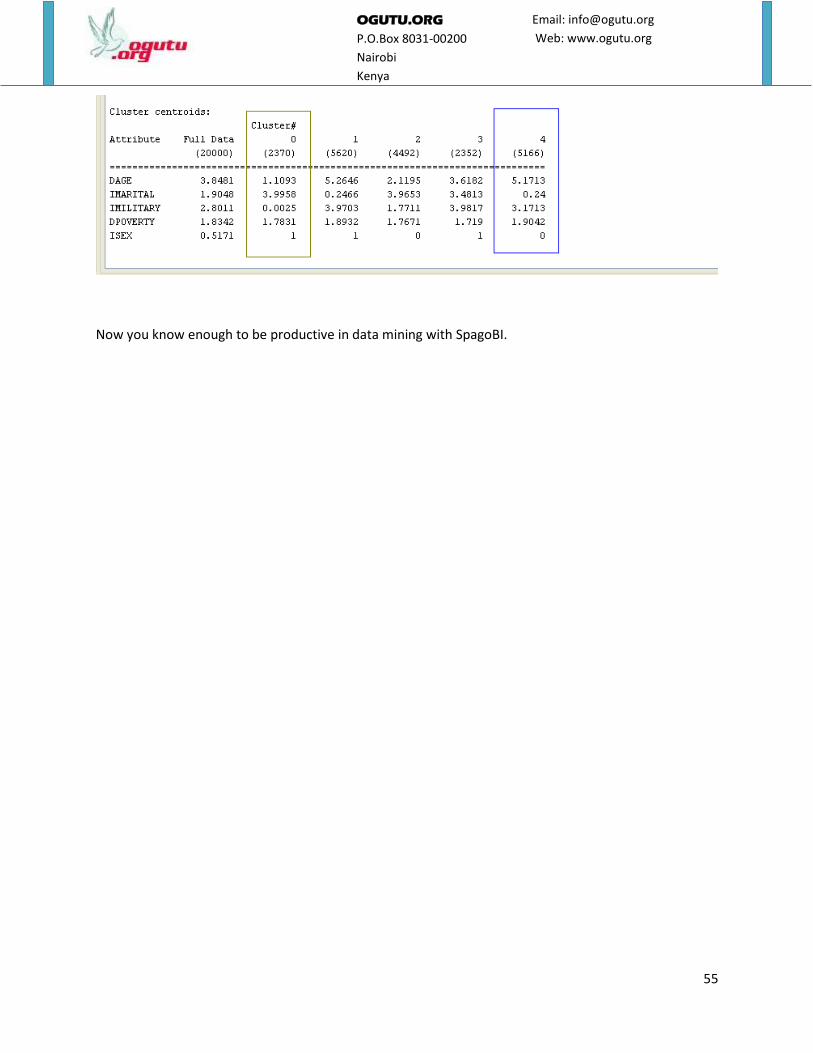
partitioned into 6 groups with similar characteristics. Let us look at cluster 0 (Green box).
1. It has a total population of 2370 people.
2. From the value of DAGE column which is 1.1093 and looking at the age function found here
http://archive.ics.uci.edu/ml/machine-learning-databases/census1990-
mld/USCensus1990.mapping.sql and copied below,

23
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
We can deduce that people in this cluster are less than 13 years old since the value 1.1093
rounded off to the nearest integer is 1.
3. The value of IMARITAL attribute is 3.9958 which rounded to the nearest integer is 4 and from
http://archive.ics.uci.edu/ml/machine-learning-databases/census1990-
mld/USCensus1990raw.attributes.txt which is copied below,
means that those in this cluster have never married since they are less than 15 years old.
4. The value of IMILITARY is 0.0025 which rounded to the nearest integer is 0 and from
http://archive.ics.uci.edu/ml/machine-learning-databases/census1990-
mld/USCensus1990raw.attributes.txt copied below

24
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
means they are under age and so have never been in military service.
5. The value of the attribute DPOVERTY is 1.8342 which rounded off to the nearest integer is 2 and
means not applicable.
6. Lastly the ISEX attribute is 1 which means they are females. In summary, this is a cluster which
consists of 2,370 female underage kids who have never been to the army. If you were employed
by the army to recruit soldiers, would you consider members in this cluster?
7. As an exercise, assume you are a recruiting agent for the army and you have this data. Find a
cluster of people who would make potential candidates.
References:
https://list.scms.waikato.ac.nz/pipermail/wekalist/2005-April/030088.html
http://archive.ics.uci.edu/ml/machine-learning-databases/census1990-
mld/USCensus1990raw.attributes.txt
http://www.kdd.org/explorations/issues/11-1-2009-07/p2V11n1.pdf
http://www.ibm.com/developerworks/opensource/library/os-weka1/index.html
25
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Enter SpagoBI We will be using SpagoBI to arrive at the same values we have got with the Weka explorer. The
advantage with SpagoBI is that we will be able to store the data so that we can analyze it with other
tools available in Spago like Qbe, charts and OLAP.
If you have never used SpagoBI before, see my introductory lessons to SpagoBI here
http://spagolabs.wordpress.com/2013/04/25/7/ or write me using the email xogutu@gmail .com for
the softcopy of the SpagoBI book.
Now SpagoBI needs a XML KnowledgeFlow layout file ( kfml) file which defines what we have just done
above in weka for it to work. For us to create a kfml file, start weka and choose knowledge flow.
Knowledge flow does a similar thing to explorer except that we put the items on a canvas and connect
them such that we can visualize how the data flows.
Here are the steps.
1. Under DataSources tab, select database loader, the arrow will change to a cross. Click on the
knowledge flow layout with the cross. It will deposit the Database Loader icon on the Layout.
26
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
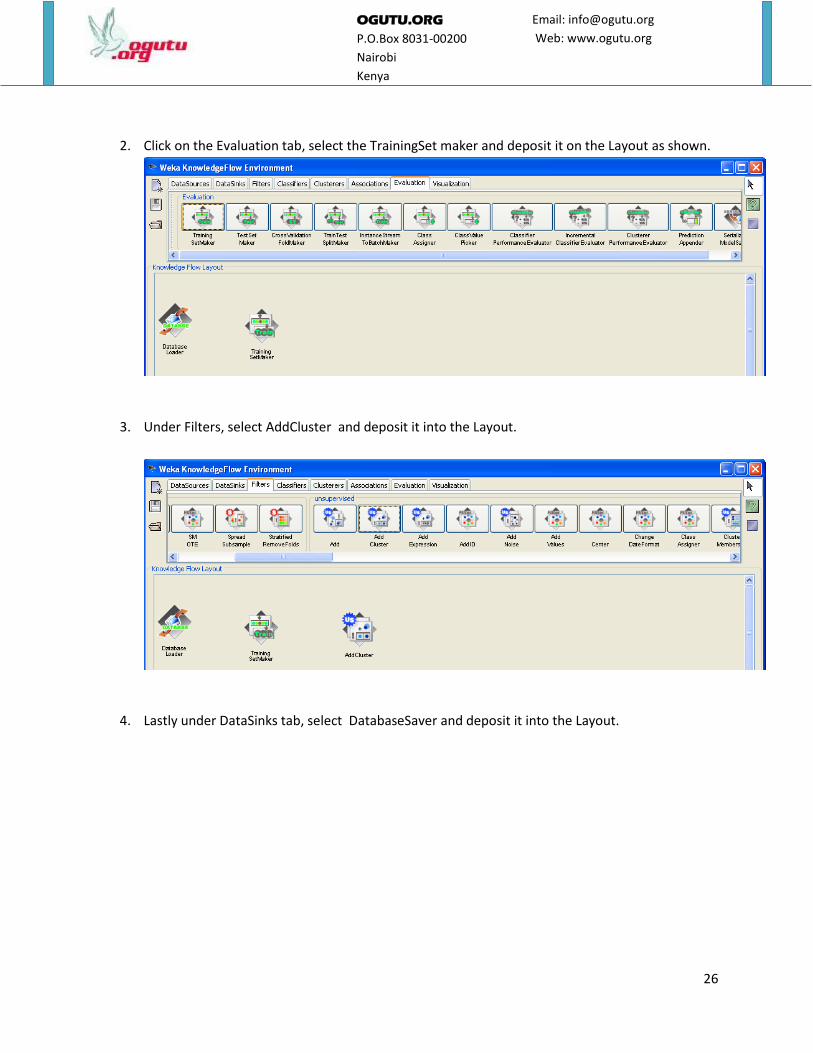
2. Click on the Evaluation tab, select the TrainingSet maker and deposit it on the Layout as shown.
3. Under Filters, select AddCluster and deposit it into the Layout.
4. Lastly under DataSinks tab, select DatabaseSaver and deposit it into the Layout.
27
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
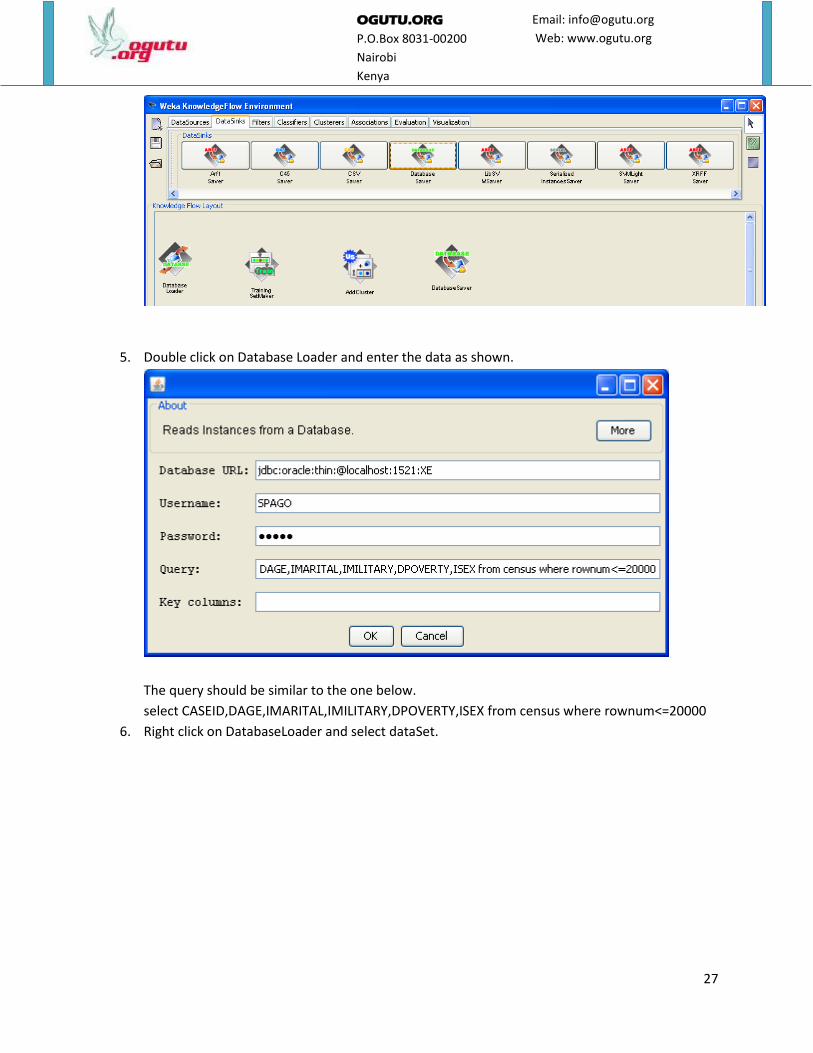
5. Double click on Database Loader and enter the data as shown.
The query should be similar to the one below.
select CASEID,DAGE,IMARITAL,IMILITARY,DPOVERTY,ISEX from census where rownum<=20000
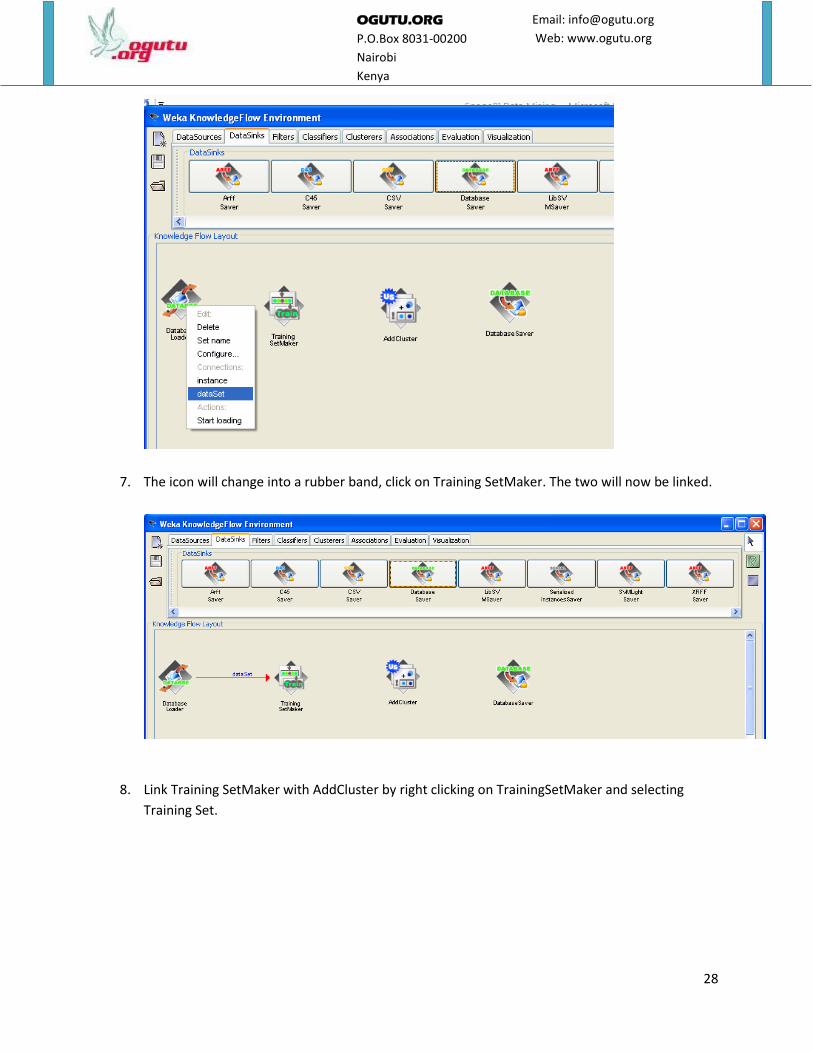
6. Right click on DatabaseLoader and select dataSet.
28
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
7. The icon will change into a rubber band, click on Training SetMaker. The two will now be linked.
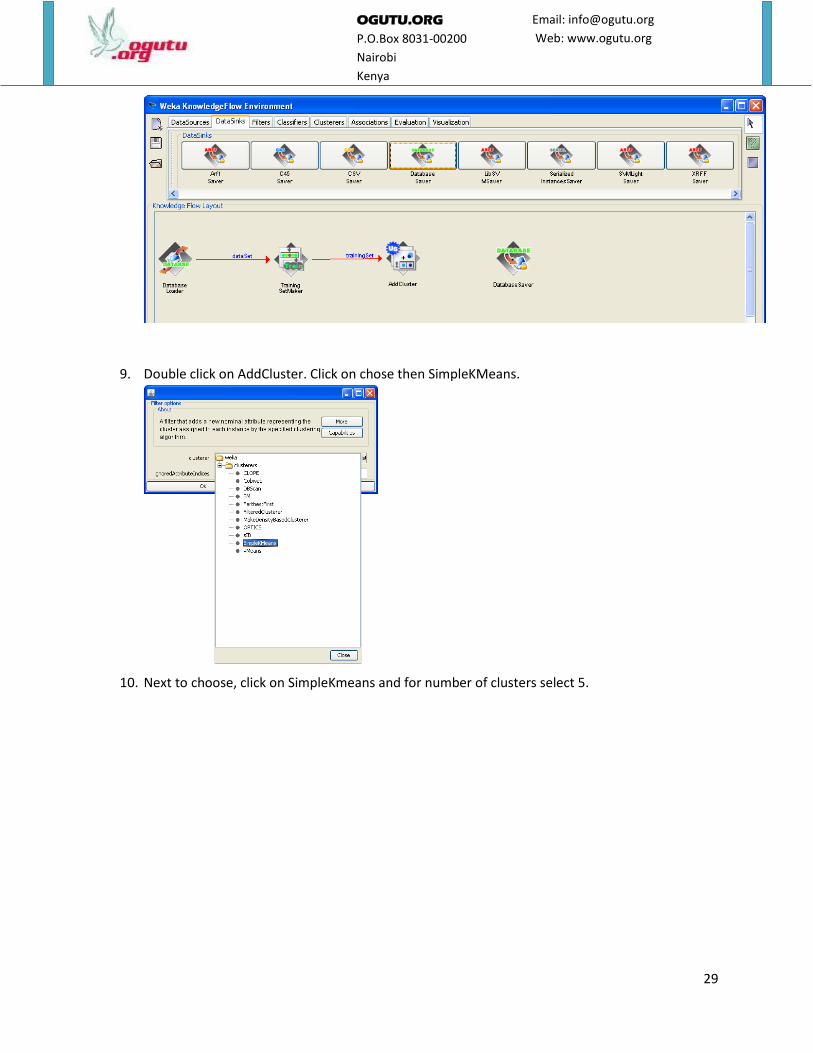
8. Link Training SetMaker with AddCluster by right clicking on TrainingSetMaker and selecting
Training Set.
29
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
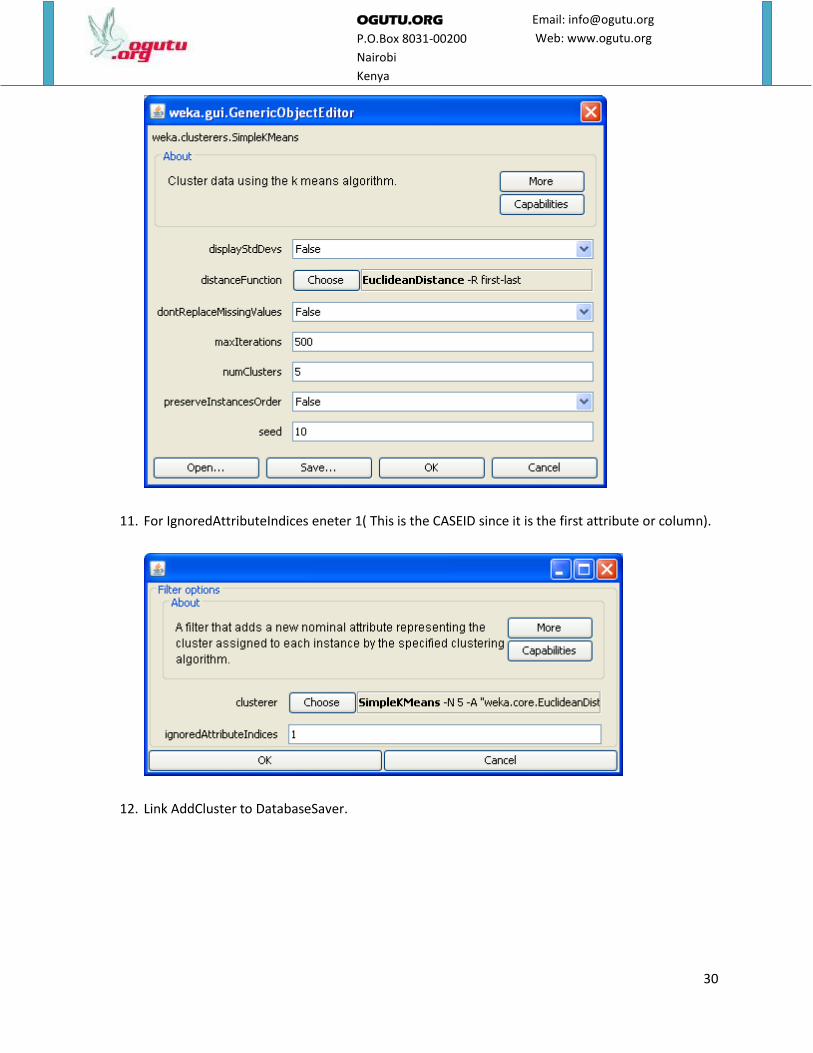
9. Double click on AddCluster. Click on chose then SimpleKMeans.
10. Next to choose, click on SimpleKmeans and for number of clusters select 5.
30
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
11. For IgnoredAttributeIndices eneter 1( This is the CASEID since it is the first attribute or column).
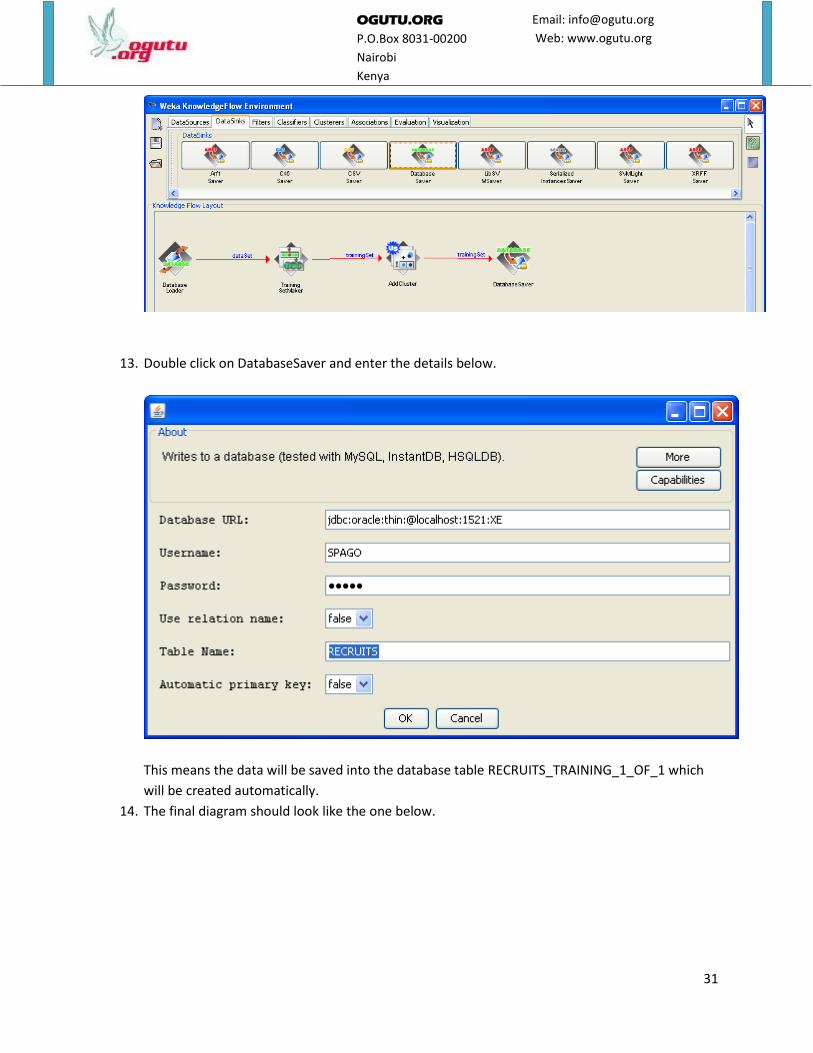
12. Link AddCluster to DatabaseSaver.
31
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
13. Double click on DatabaseSaver and enter the details below.
This means the data will be saved into the database table RECRUITS_TRAINING_1_OF_1 which
will be created automatically.
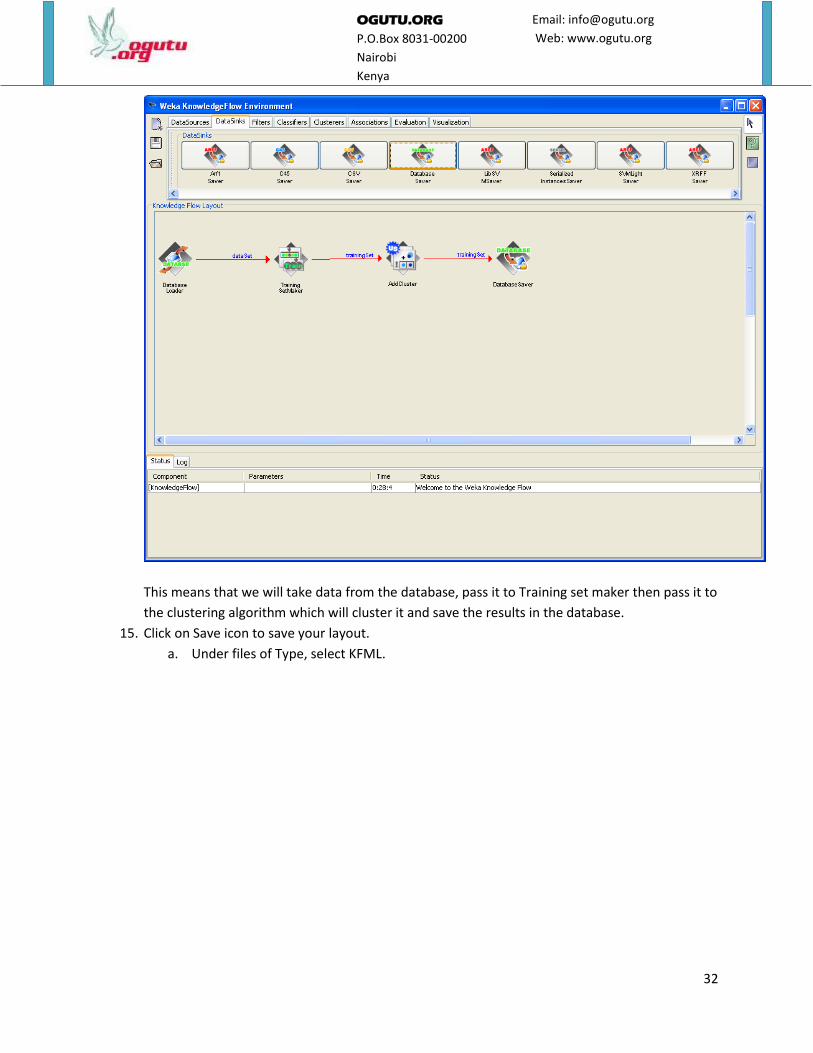
14. The final diagram should look like the one below.
32
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
This means that we will take data from the database, pass it to Training set maker then pass it to
the clustering algorithm which will cluster it and save the results in the database.
15. Click on Save icon to save your layout.
a. Under files of Type, select KFML.
33
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
b. For file name enter Recruit.
Click on Save.
16. We are done with Weka. You can close it.
34
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
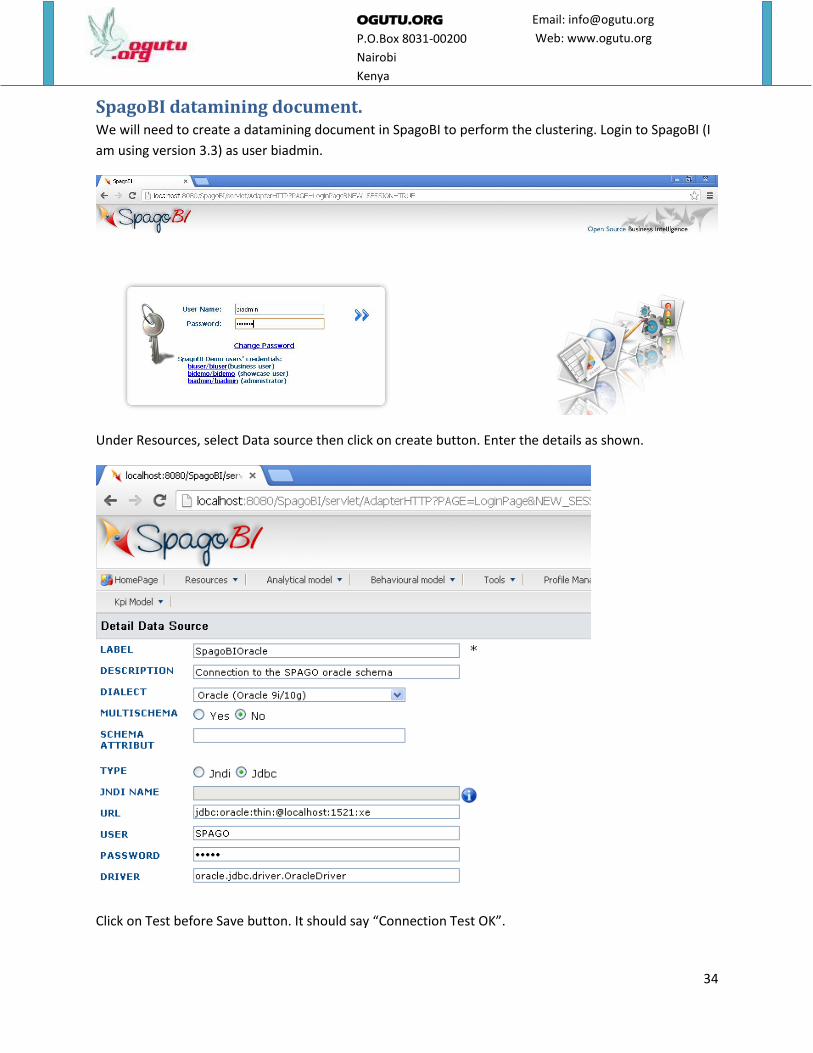
SpagoBI datamining document. We will need to create a datamining document in SpagoBI to perform the clustering. Login to SpagoBI (I
am using version 3.3) as user biadmin.
Under Resources, select Data source then click on create button. Enter the details as shown.
Click on Test before Save button. It should say “Connection Test OK”.
35
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
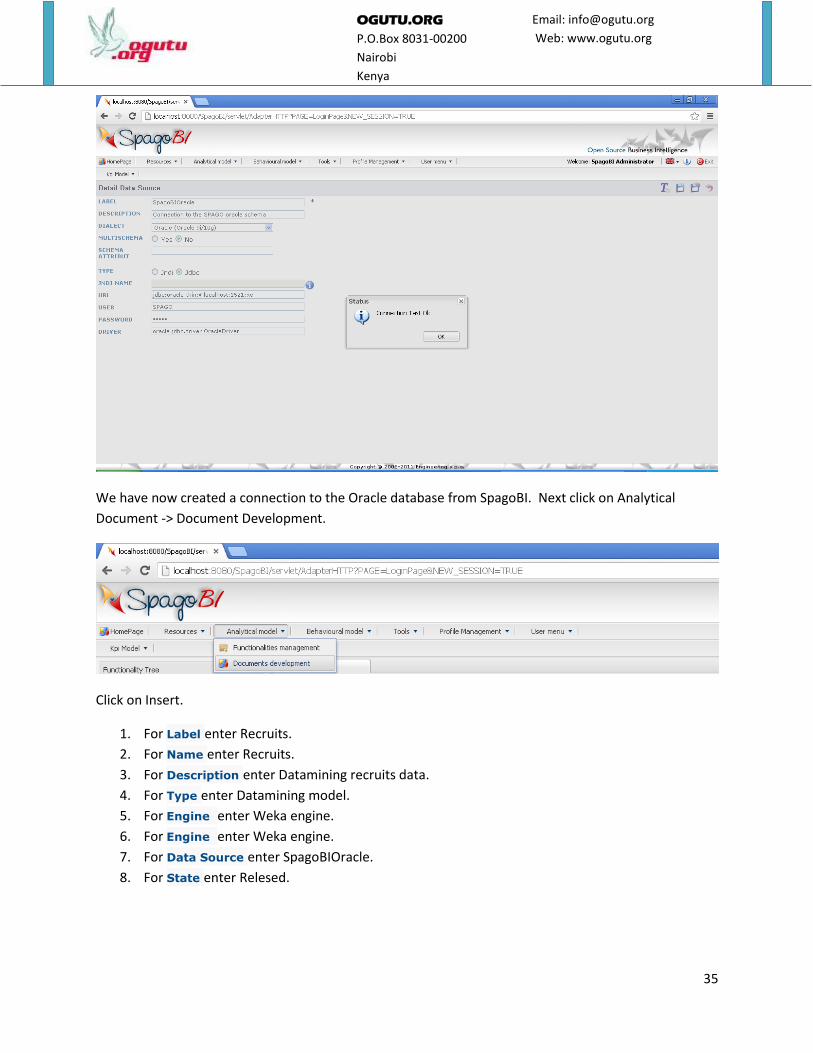
We have now created a connection to the Oracle database from SpagoBI. Next click on Analytical
Document -> Document Development.
Click on Insert.
1. For Label enter Recruits.
2. For Name enter Recruits.
3. For Description enter Datamining recruits data.
4. For Type enter Datamining model.
5. For Engine enter Weka engine.
6. For Engine enter Weka engine.
7. For Data Source enter SpagoBIOracle.
8. For State enter Relesed.
36
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
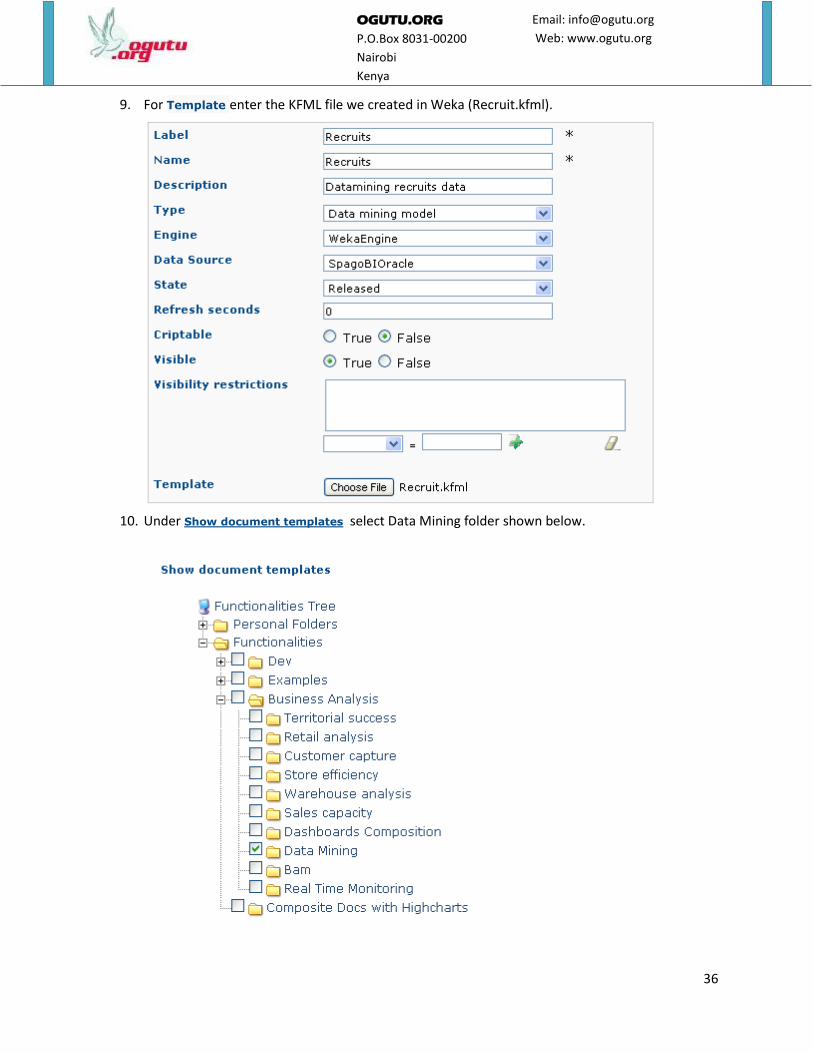
9. For Template enter the KFML file we created in Weka (Recruit.kfml).
10. Under Show document templates select Data Mining folder shown below.
37
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
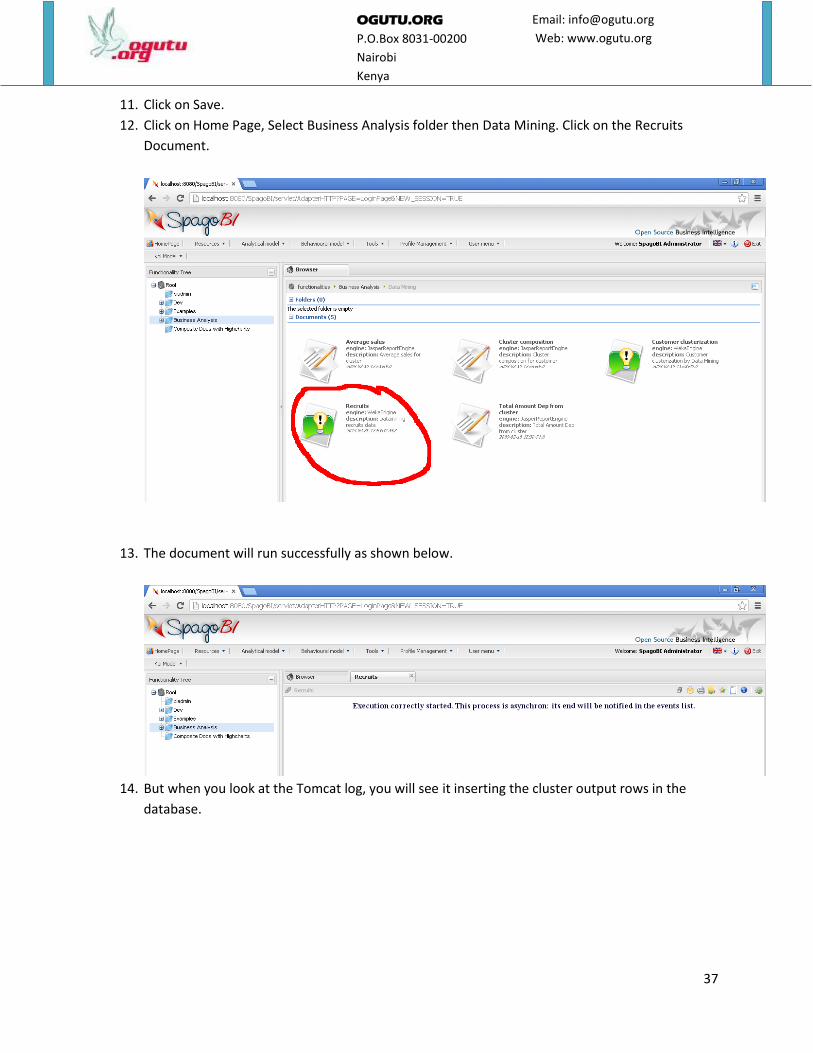
11. Click on Save.
12. Click on Home Page, Select Business Analysis folder then Data Mining. Click on the Recruits
Document.
13. The document will run successfully as shown below.
14. But when you look at the Tomcat log, you will see it inserting the cluster output rows in the
database.
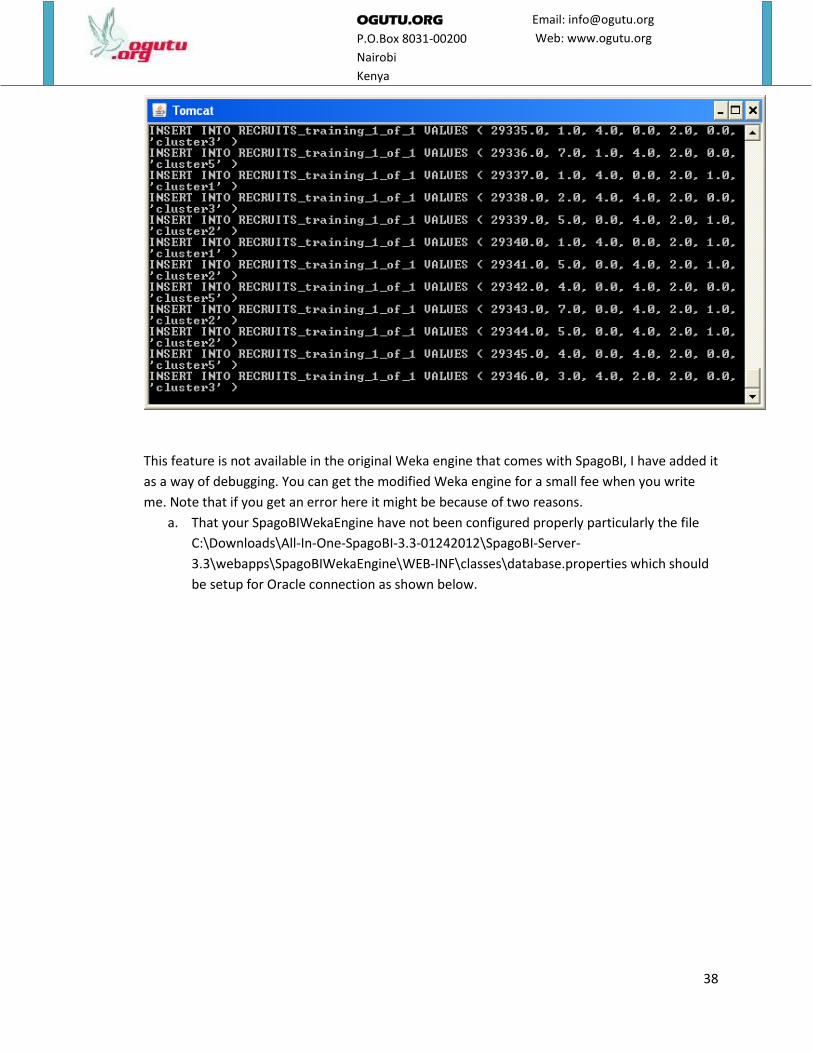
38
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
This feature is not available in the original Weka engine that comes with SpagoBI, I have added it
as a way of debugging. You can get the modified Weka engine for a small fee when you write
me. Note that if you get an error here it might be because of two reasons.
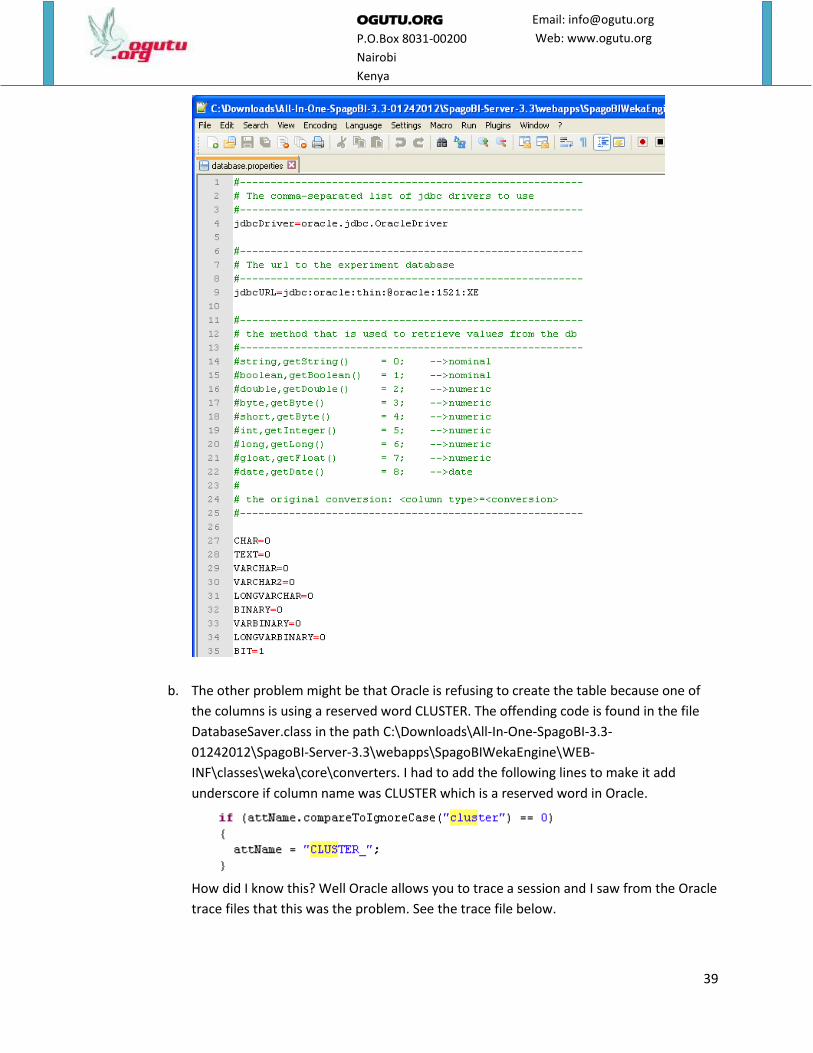
a. That your SpagoBIWekaEngine have not been configured properly particularly the file
C:\Downloads\All-In-One-SpagoBI-3.3-01242012\SpagoBI-Server-
3.3\webapps\SpagoBIWekaEngine\WEB-INF\classes\database.properties which should
be setup for Oracle connection as shown below.
39
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
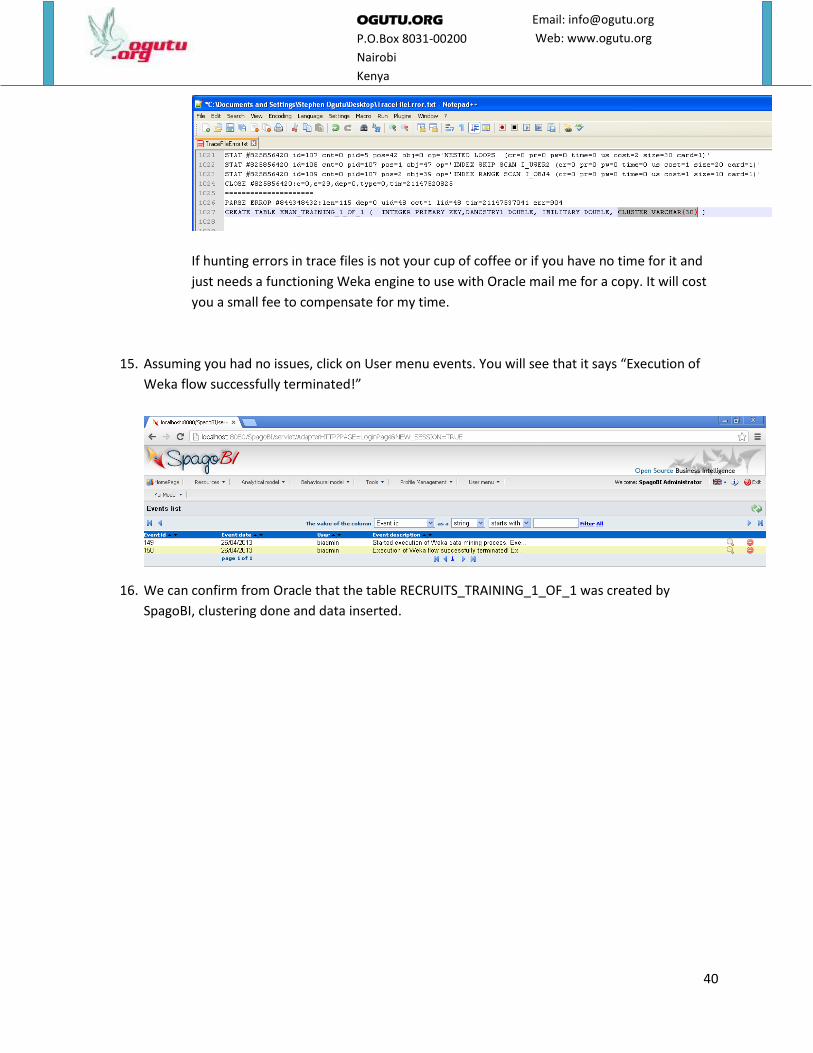
b. The other problem might be that Oracle is refusing to create the table because one of
the columns is using a reserved word CLUSTER. The offending code is found in the file
DatabaseSaver.class in the path C:\Downloads\All-In-One-SpagoBI-3.3-
01242012\SpagoBI-Server-3.3\webapps\SpagoBIWekaEngine\WEB-
INF\classes\weka\core\converters. I had to add the following lines to make it add
underscore if column name was CLUSTER which is a reserved word in Oracle.
How did I know this? Well Oracle allows you to trace a session and I saw from the Oracle
trace files that this was the problem. See the trace file below.
40
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
If hunting errors in trace files is not your cup of coffee or if you have no time for it and
just needs a functioning Weka engine to use with Oracle mail me for a copy. It will cost
you a small fee to compensate for my time.
15. Assuming you had no issues, click on User menu events. You will see that it says “Execution of
Weka flow successfully terminated!”
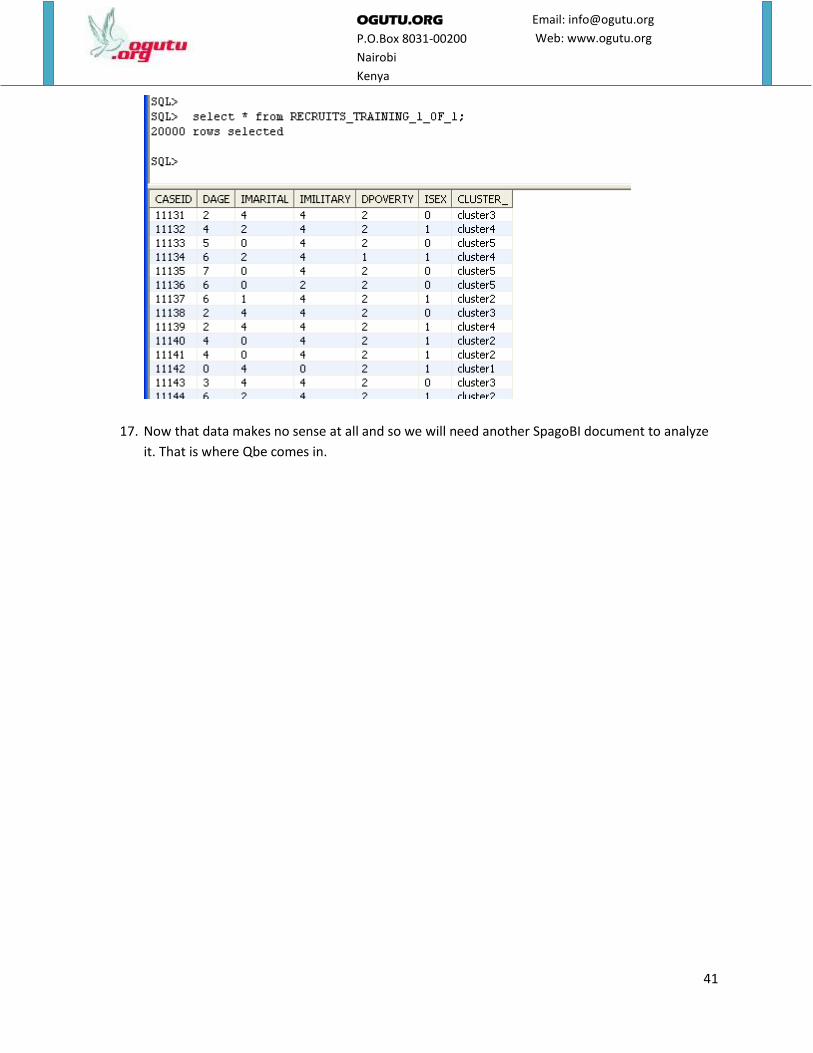
16. We can confirm from Oracle that the table RECRUITS_TRAINING_1_OF_1 was created by
SpagoBI, clustering done and data inserted.
41
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
17. Now that data makes no sense at all and so we will need another SpagoBI document to analyze
it. That is where Qbe comes in.
42
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Qbe Document. We will create a Qbe document to help us freely inquire the clustered data and produce reports from it.
Create a datamart using SpagoBIMeta version 3.3.
Steps:
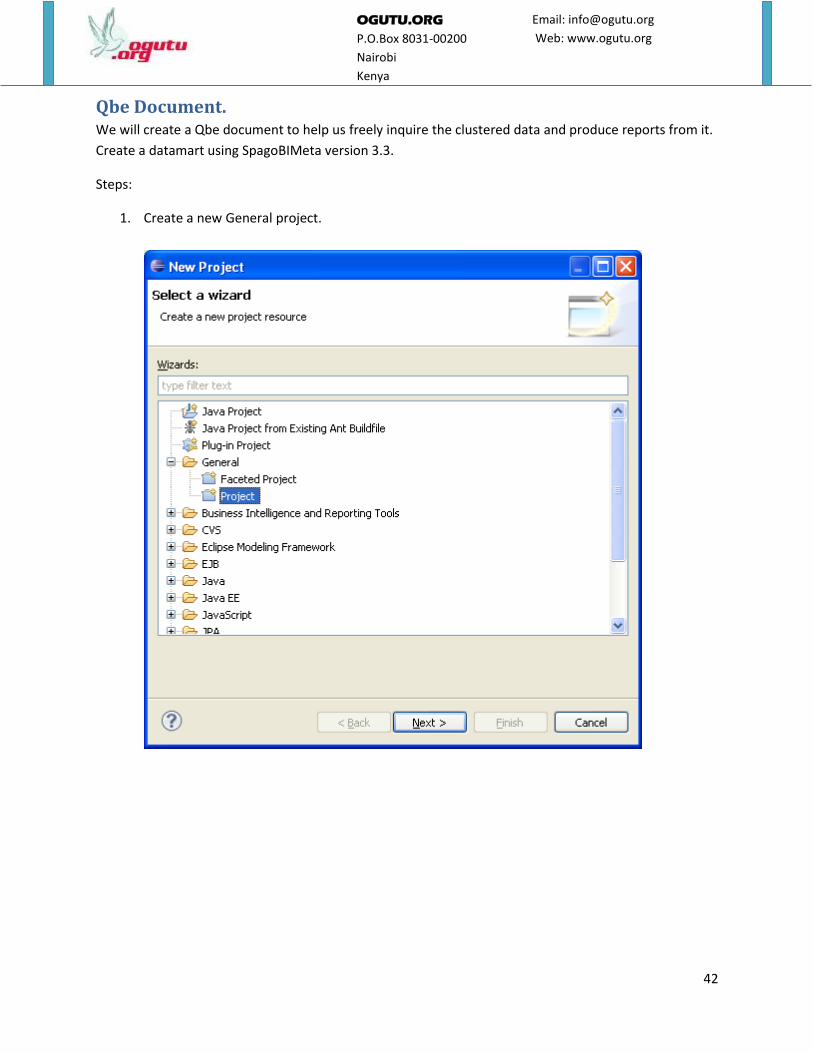
1. Create a new General project.
43
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
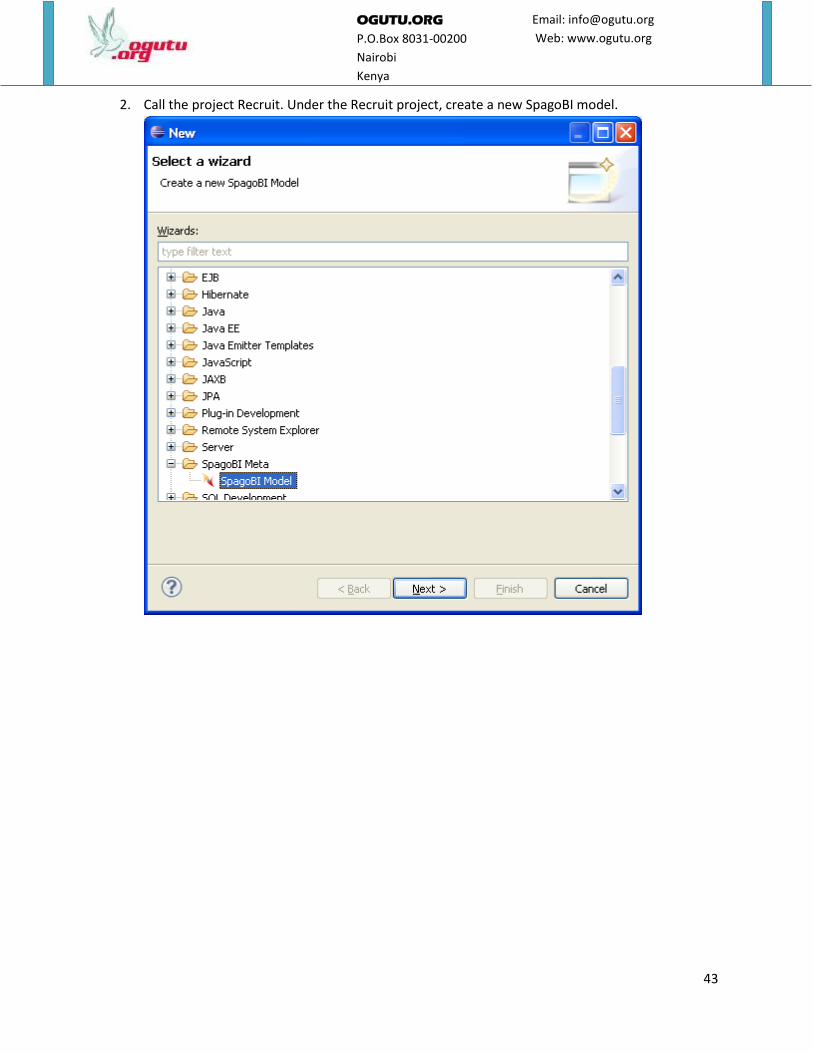
2. Call the project Recruit. Under the Recruit project, create a new SpagoBI model.
44
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
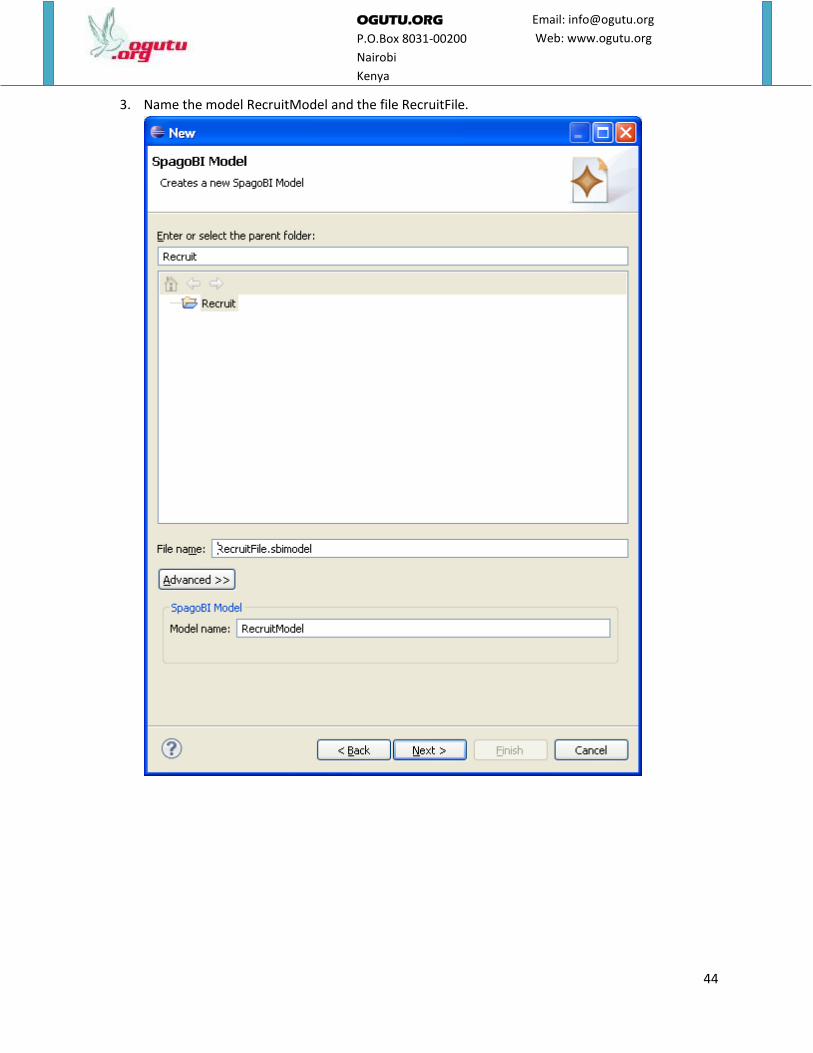
3. Name the model RecruitModel and the file RecruitFile.
45
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
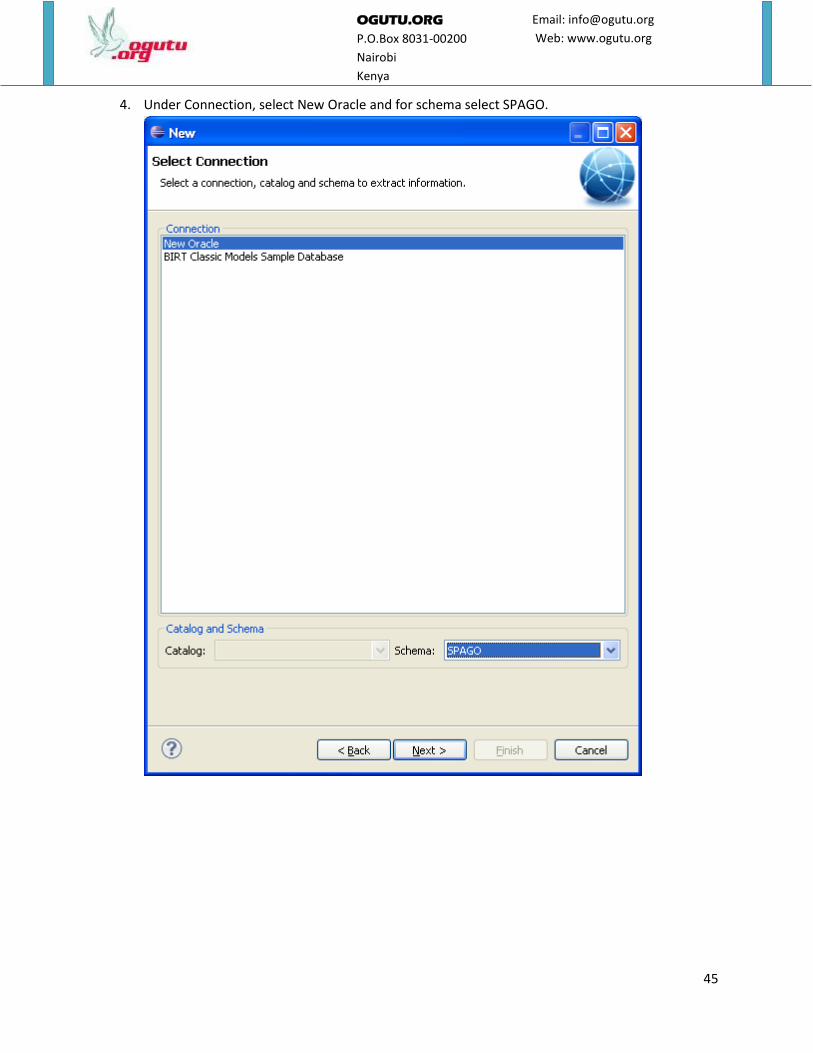
4. Under Connection, select New Oracle and for schema select SPAGO.
46
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
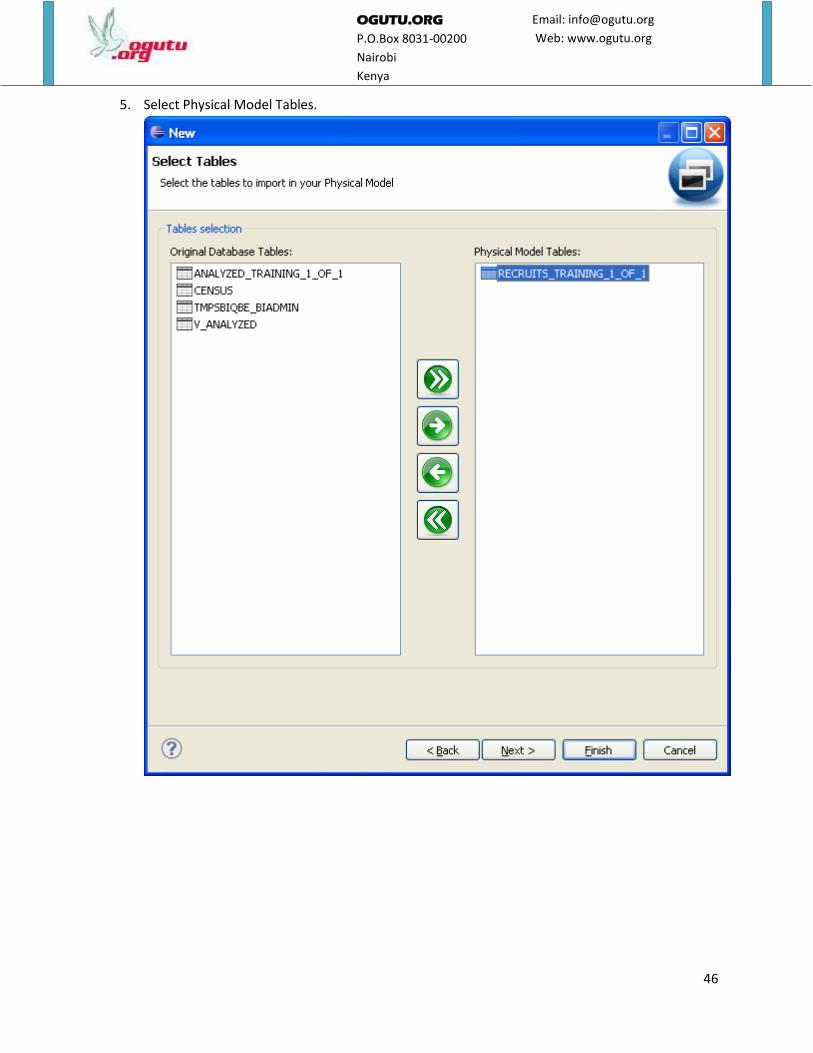
5. Select Physical Model Tables.
47
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
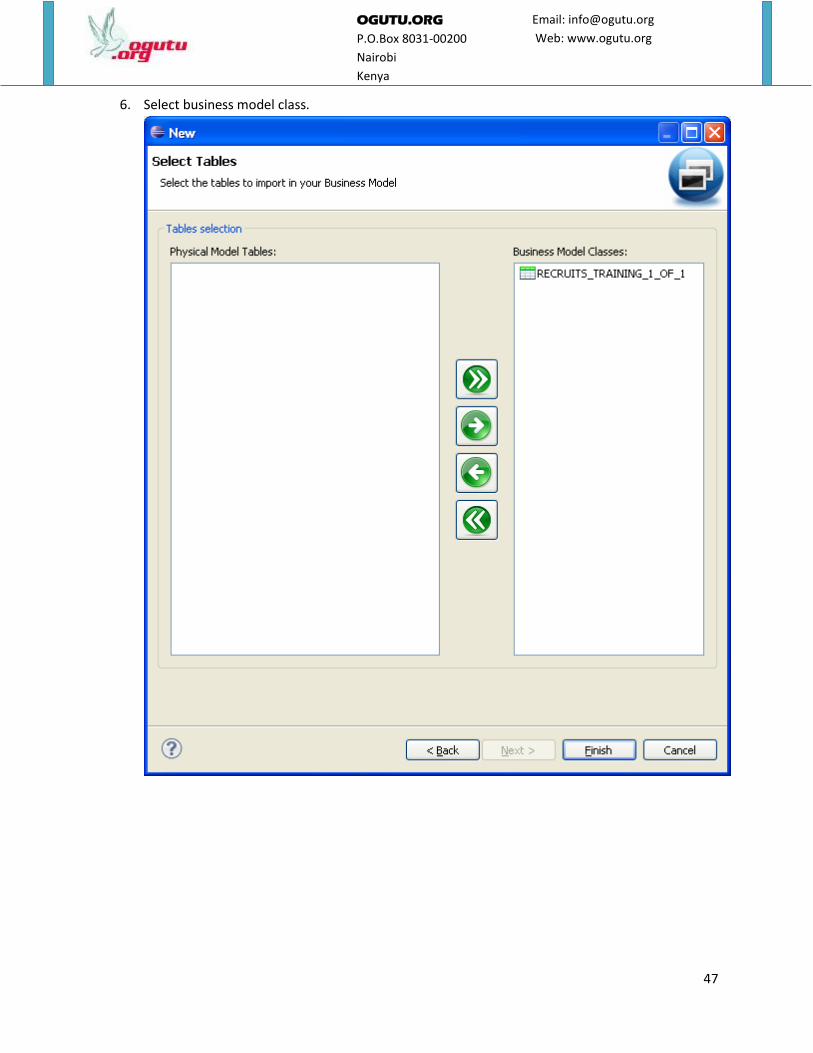
6. Select business model class.
48
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
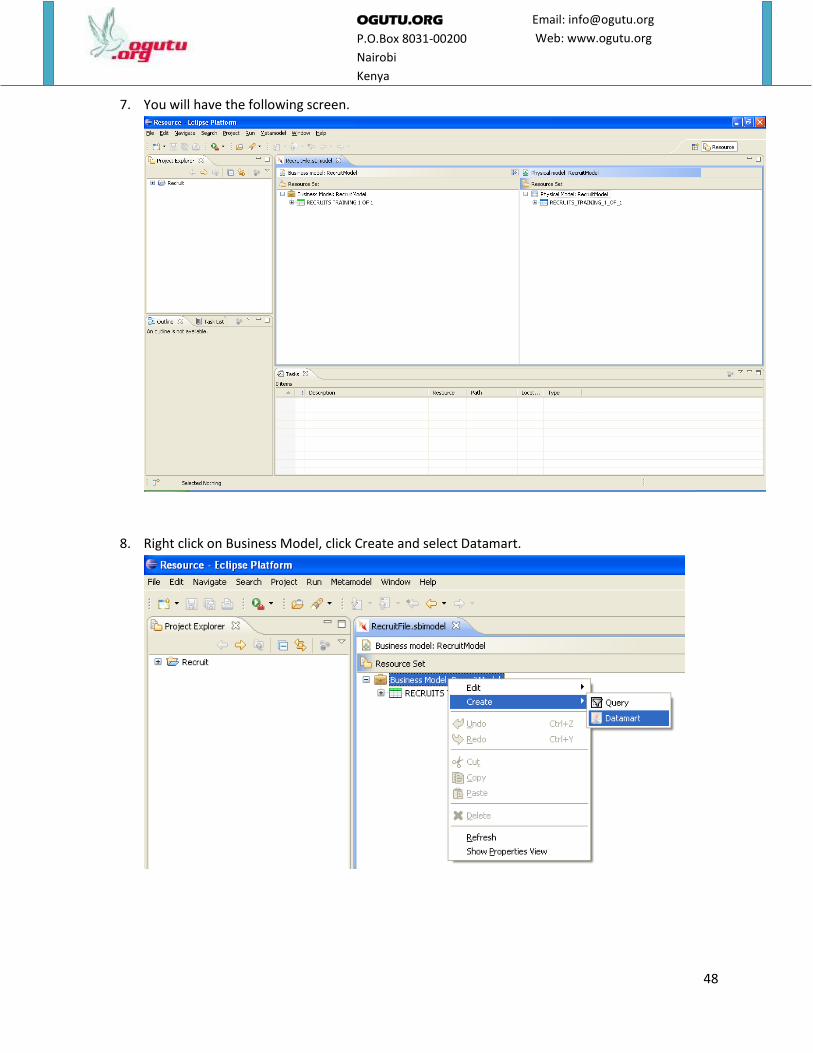
7. You will have the following screen.
8. Right click on Business Model, click Create and select Datamart.
49
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
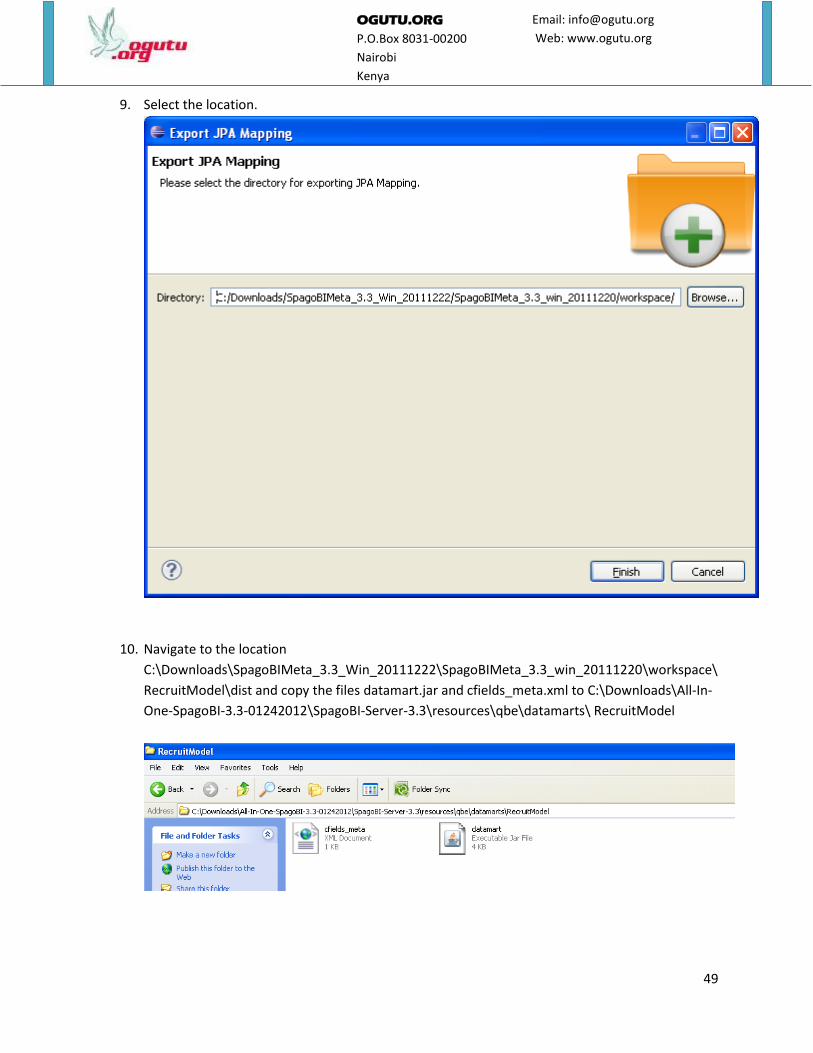
9. Select the location.
10. Navigate to the location
C:\Downloads\SpagoBIMeta_3.3_Win_20111222\SpagoBIMeta_3.3_win_20111220\workspace\
RecruitModel\dist and copy the files datamart.jar and cfields_meta.xml to C:\Downloads\All-In-
One-SpagoBI-3.3-01242012\SpagoBI-Server-3.3\resources\qbe\datamarts\ RecruitModel
50
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
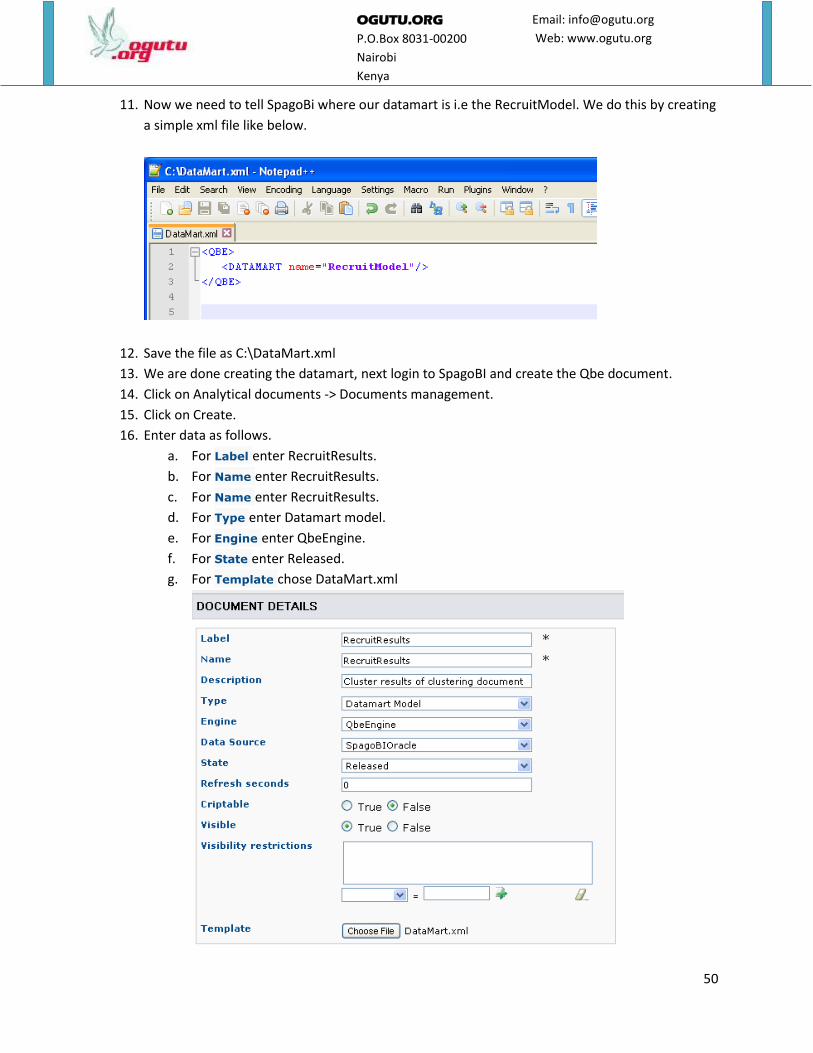
11. Now we need to tell SpagoBi where our datamart is i.e the RecruitModel. We do this by creating
a simple xml file like below.
12. Save the file as C:\DataMart.xml
13. We are done creating the datamart, next login to SpagoBI and create the Qbe document.
14. Click on Analytical documents -> Documents management.
15. Click on Create.
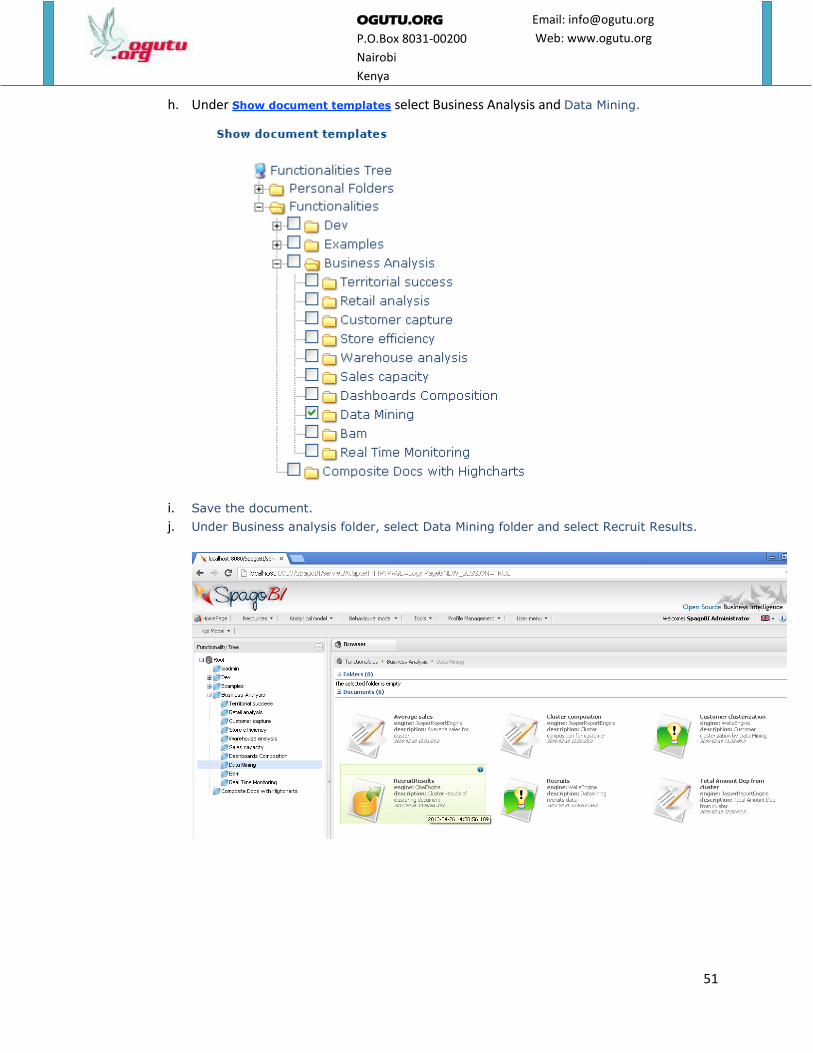
16. Enter data as follows.
a. For Label enter RecruitResults.
b. For Name enter RecruitResults.
c. For Name enter RecruitResults.
d. For Type enter Datamart model.
e. For Engine enter QbeEngine.
f. For State enter Released.
g. For Template chose DataMart.xml
51
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
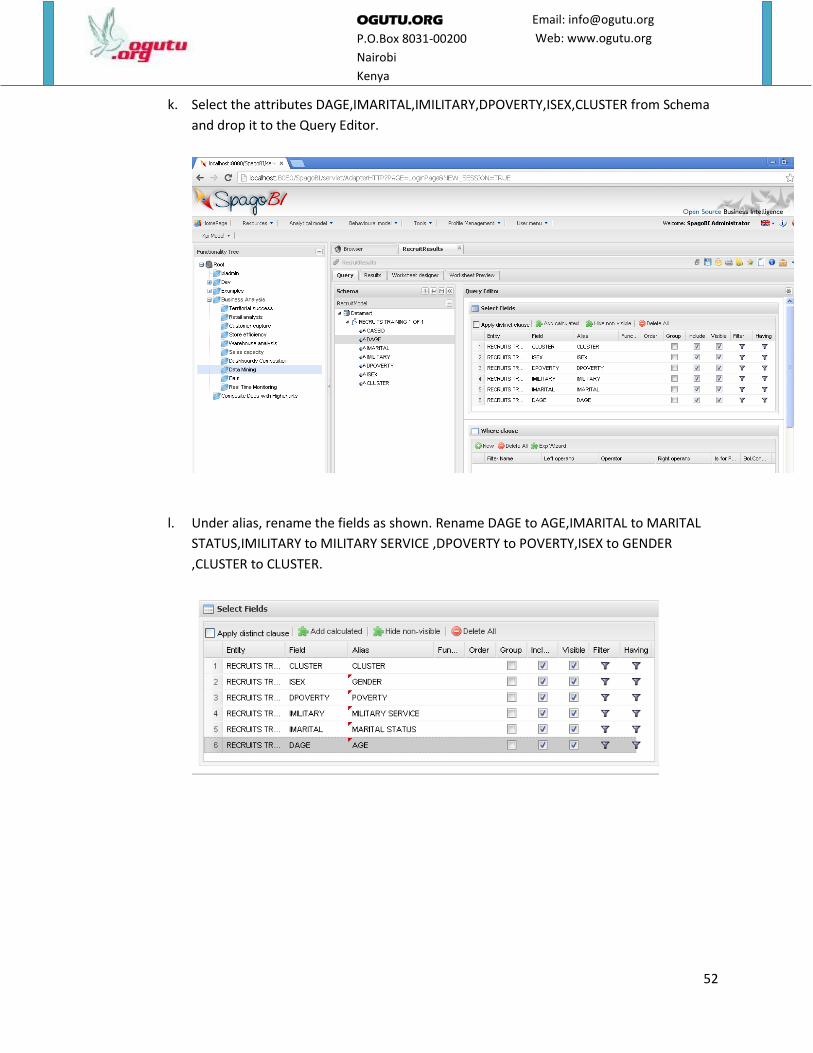
h. Under Show document templates select Business Analysis and Data Mining.
i. Save the document.
j. Under Business analysis folder, select Data Mining folder and select Recruit Results.
52
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
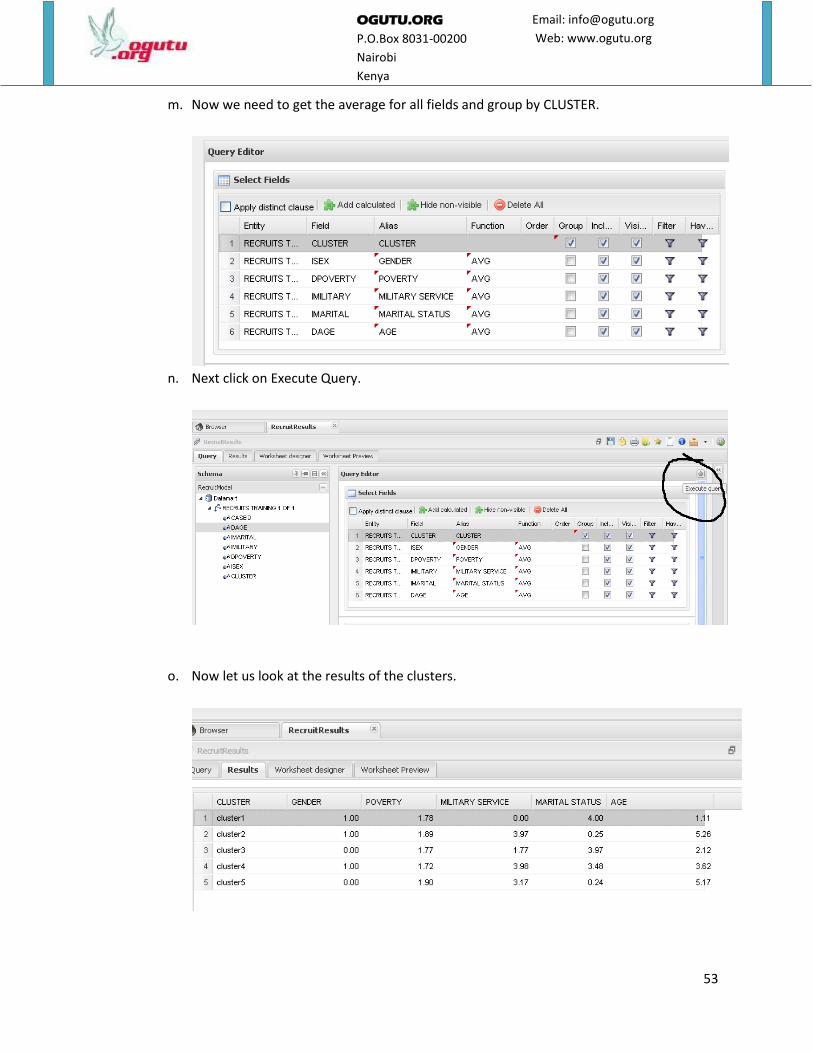
k. Select the attributes DAGE,IMARITAL,IMILITARY,DPOVERTY,ISEX,CLUSTER from Schema
and drop it to the Query Editor.
l. Under alias, rename the fields as shown. Rename DAGE to AGE,IMARITAL to MARITAL
STATUS,IMILITARY to MILITARY SERVICE ,DPOVERTY to POVERTY,ISEX to GENDER
,CLUSTER to CLUSTER.
53
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
m. Now we need to get the average for all fields and group by CLUSTER.
n. Next click on Execute Query.
o. Now let us look at the results of the clusters.
54
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
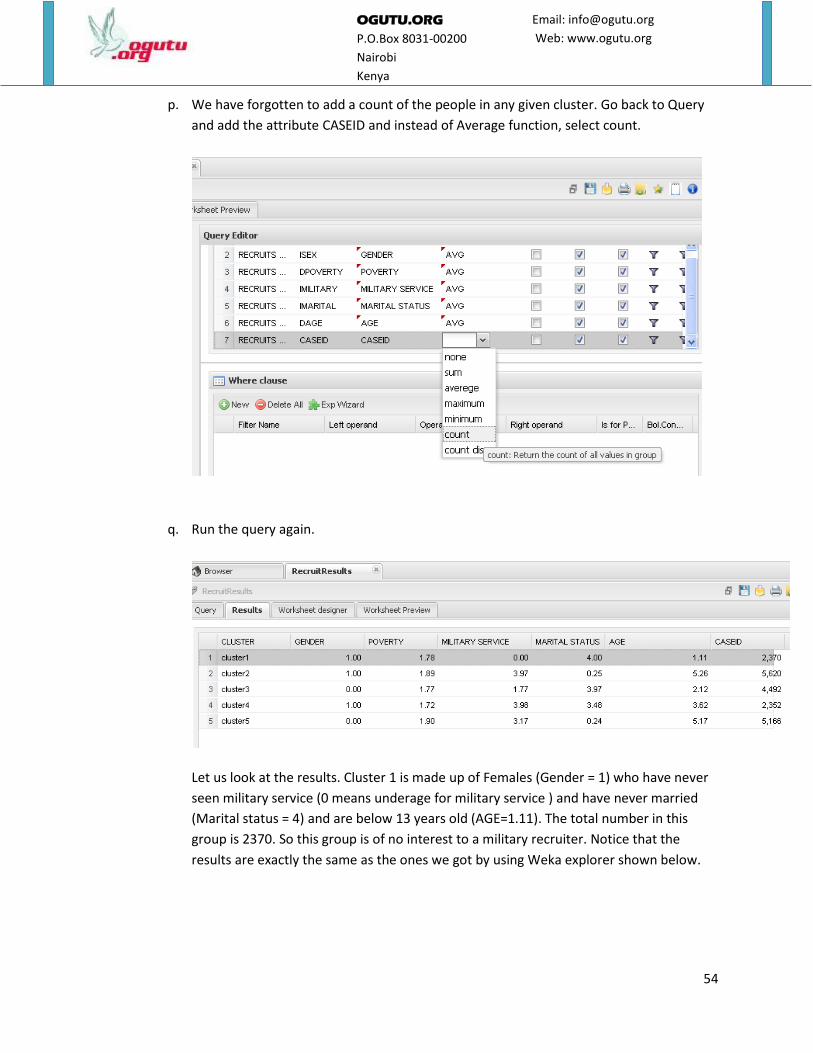
p. We have forgotten to add a count of the people in any given cluster. Go back to Query
and add the attribute CASEID and instead of Average function, select count.
q. Run the query again.
Let us look at the results. Cluster 1 is made up of Females (Gender = 1) who have never
seen military service (0 means underage for military service ) and have never married
(Marital status = 4) and are below 13 years old (AGE=1.11). The total number in this
group is 2370. So this group is of no interest to a military recruiter. Notice that the
results are exactly the same as the ones we got by using Weka explorer shown below.
55
OGUTU.ORG
P.O.Box 8031-00200
Nairobi
Kenya
Email: [email protected]
Web: www.ogutu.org
Now you know enough to be productive in data mining with SpagoBI.





























