Embed Size (px)
Citation preview

Datenanalyse mit SPSS – Statistik für Fortgeschrittene
Arnd Florack Tel.: 0251 / 83-34788
E-Mail: [email protected] Raum 2.001b
Sprechstunde: Dienstags 15-16 Uhr
6. Juni 2000
2
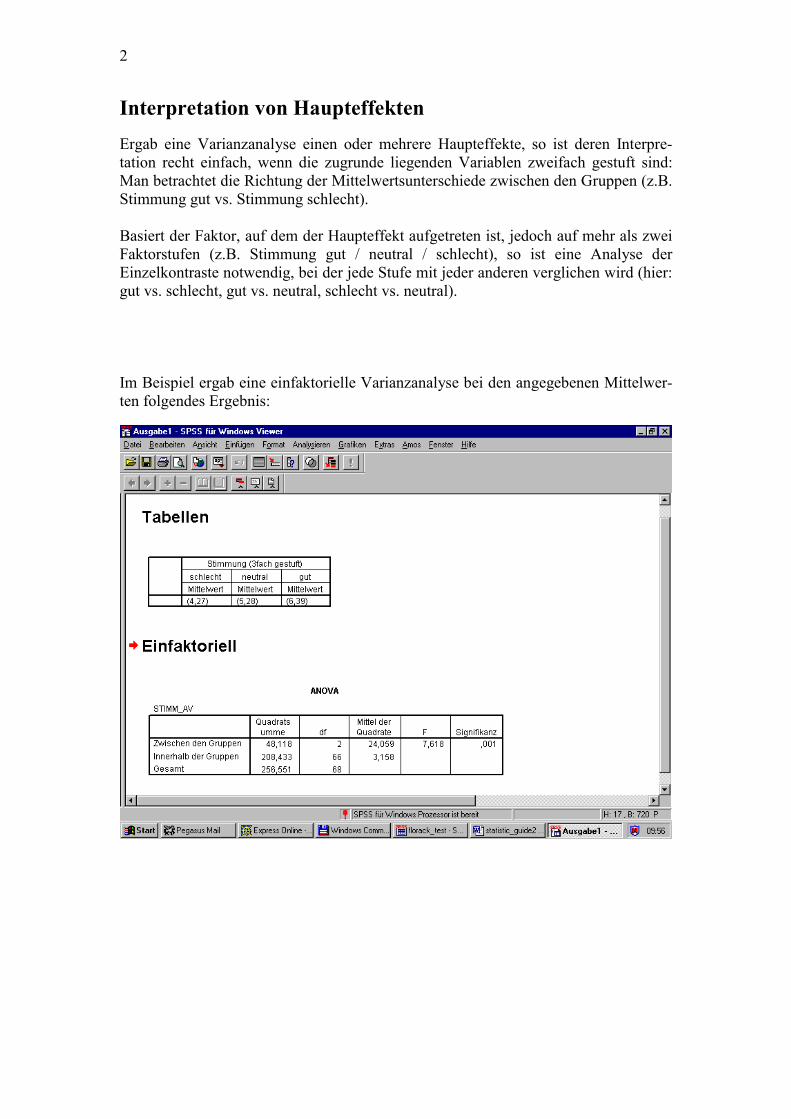
Interpretation von Haupteffekten Ergab eine Varianzanalyse einen oder mehrere Haupteffekte, so ist deren Interpre-tation recht einfach, wenn die zugrunde liegenden Variablen zweifach gestuft sind: Man betrachtet die Richtung der Mittelwertsunterschiede zwischen den Gruppen (z.B. Stimmung gut vs. Stimmung schlecht). Basiert der Faktor, auf dem der Haupteffekt aufgetreten ist, jedoch auf mehr als zwei Faktorstufen (z.B. Stimmung gut / neutral / schlecht), so ist eine Analyse der Einzelkontraste notwendig, bei der jede Stufe mit jeder anderen verglichen wird (hier: gut vs. schlecht, gut vs. neutral, schlecht vs. neutral). Im Beispiel ergab eine einfaktorielle Varianzanalyse bei den angegebenen Mittelwer-ten folgendes Ergebnis:
3
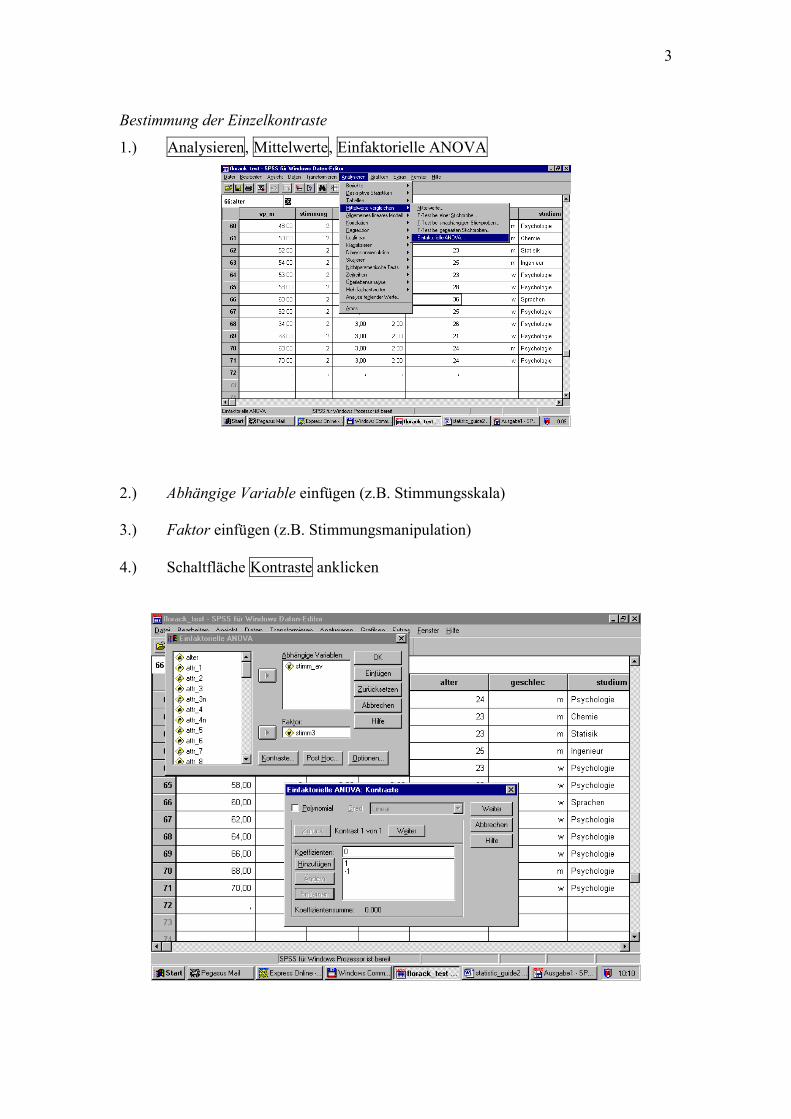
Bestimmung der Einzelkontraste
1.) Analysieren, Mittelwerte, Einfaktorielle ANOVA
2.) Abhängige Variable einfügen (z.B. Stimmungsskala) 3.) Faktor einfügen (z.B. Stimmungsmanipulation) 4.) Schaltfläche Kontraste anklicken

4
5.) Koeffizienten (z.B. 1, -1, 0) nacheinander eingeben und jeweils mit Hinzufügen in das weißte Feld einfügen
Was besagen die Koeffizienten? Die Koeffizienten geben an, welche Mittelwerte bei dem gewählten Kontrast mitein-ander verglichen werden. Werden bei drei Faktorstufen die Koeffizienten 1, -1, 0 ein-gegeben, dann wird die erste Stufe des Faktors (z.B. schlechte Stimmung) mit der zweiten Stufe (z.B. neutrale Stimmung) verglichen.
Bei der Wahl der Koeffizienten gibt es folgende Regeln:
� die Zahl der Koeffizienten entspricht der Zahl der Faktorstufen (z.B. 3 Stufen = 3 Koeffizienten)
� die Summe der Koeffizienten muß Null ergeben (1 – 1 + 0 = 0)
� den beiden Stufen, die miteinander verglichen werden, werden Koeffizienten mit unterschiedlichem Vorzeichen zugeordnet (1, -1)
� durch Variation des Wertes der Koeffizienten lassen sich unterschiedliche Gewichtungen für die Faktorstufen vergeben. Wichtig: Bei der Berechnung ei-nes Einzelkontrastes, sind solche Gewichtungen nicht sinnvoll. Daher immer die Werte 0, 1 und –1 vergeben.
� für jeden Kontrast müssen die Koeffizienten einzeln eingegeben werden (bei drei Faktorstufen resultieren drei Kontraste)

5
6.) Sind alle Koeffizienten für einen Kontrast in das weiße Feld eingefügt wurden, mit Weiter (neben Kontrast 1 von 1) bestätigen und die nächsten Koeffizienten eingeben.
Bei drei Faktorstufen ist es sinnvoll folgende Koeffizienten einzugeben:
Kontrast 1: 1, -1, 0 (Vergleich: schlechte vs. neutrale Stimmung)
Kontrast 2: 1, 0, -1 (Vergleich: schlechte vs. gute Stimmung)
Kontrast 3: 0, 1, -1 (Vergleich: neutrale vs. gute Stimmung)
7.) Nach Eingabe des letzten Kontrast mit Weiter (diesmal oben rechts!) und dann noch mal mit OK bestätigen
In unserem Beispiel erscheint folgende Ausgabe:
Hier sieht man zunächst noch einmal das Ergebnis der ANOVA sowie eine Übersicht über die eingegebenen Kontraste. Im Beispiel würde man zunächst schreiben:
Mit Hilfe der Stimmungsmanipulation konnten erfolgreich Unterschiede in der erleb-ten Stimmung induziert werden, F(2, 66) = 7.618, p < .01.
Hinweis:
Hier sind der F-Wert, die Freiheitsgrade (df) sowie die Signifikanzangaben für einen späteren Bericht wichtig. Es wird angegeben:
F(df zwischen den Gruppen, df innerhalb der Gruppe) = F-Wert, p < erreichtes Signifikanzniveau.

6
Weiter unten finden sich die Tests der Einzelkontraste:
Gehen wir von einer Gleichheit der Varianzen aus, so unterscheiden sich die Mittel-werte zwischen allen Faktorstufen signifikant (sind die Varianzen nicht gleich, sollte die unte-re Zeile berichtet werden, siehe Hinweis). Man würde hier beispielsweise schreiben:
Die Manipulation induzierte erfolgreich Unterschiede in der Stimmung, alle ts(66) < -2.00, ps < .05. Personen die einen heiteren Film gesehen hatten (M = 6.39), gaben eine bessere Stimmung an, als Personen, die einen neutralen Film (M = 5.28) oder aber einen Film über Tierversuche (M = 4.27) gesehen hatten.
oder (etwas weniger schön):
Die Manipulation induzierte erfolgreich Unterschiede in der Stimmung. Personen die einen heiteren Film gesehen hatten (M = 6.39), gaben an eine bessere Stimmung an, als Personen, die einen neutralen Film (M = 5.28), t(66) = -2.03, p < .05, oder aber einen Film über Tierversuche (M = 4.27) gesehen hatten, t(66) = -3.89, p < .05. Per-sonen, die einen neutralen Film gesehen hatten, gaben ferner eine positivere Stim-mung an als Personen, die einen Film über Tierversuche gesehen hatten, t(66) = -2.02, p < .05.
Hinweis: Es besteht auch hier die Möglichkeit einen Test zur Prüfung der Varianzhomogenität zu rech-nen. Hierzu sind folgende Schritte notwendig.
1.) im Fenster Einfaktorielle ANOVA die Schaltfläche Optionen... wählen
2.) Homogenität der Varianzen anklicken
3.) mit Weiter bestätigen
4.) alle anderen Schritte wie oben
Achtung: Der Signifikanzwert sollte hier möglichst groß sein!
7
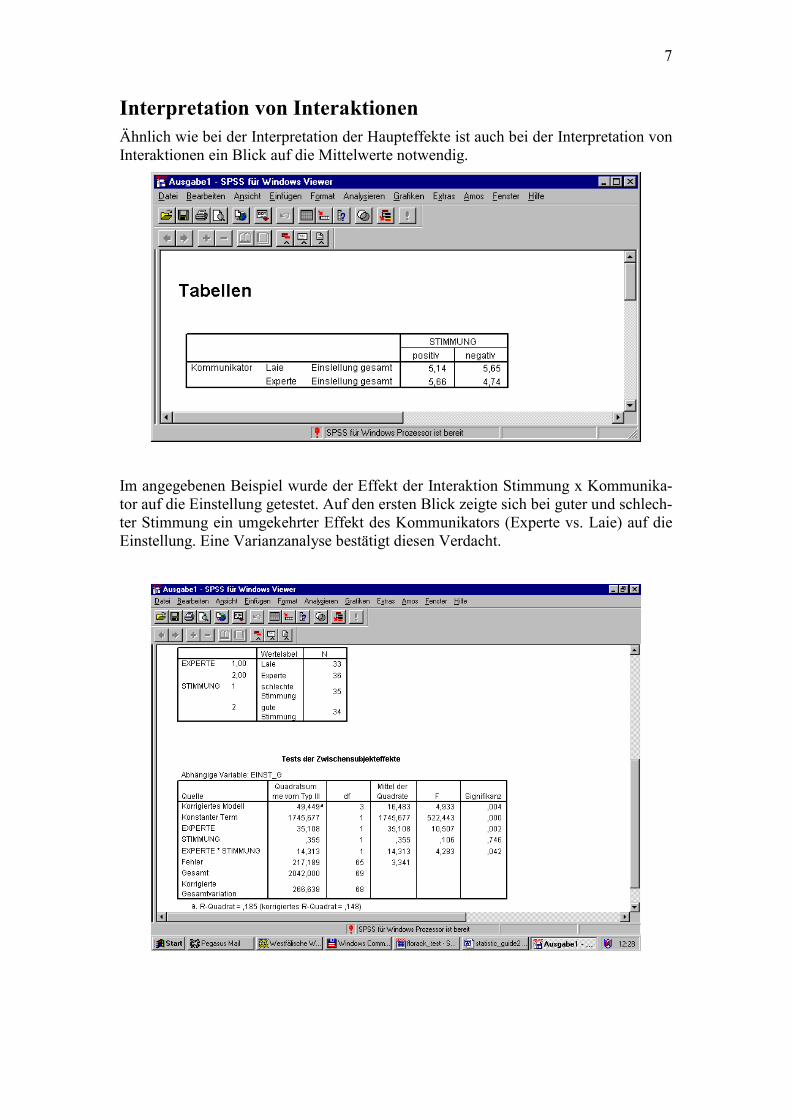
Interpretation von Interaktionen Ähnlich wie bei der Interpretation der Haupteffekte ist auch bei der Interpretation von Interaktionen ein Blick auf die Mittelwerte notwendig.
Im angegebenen Beispiel wurde der Effekt der Interaktion Stimmung x Kommunika-tor auf die Einstellung getestet. Auf den ersten Blick zeigte sich bei guter und schlech-ter Stimmung ein umgekehrter Effekt des Kommunikators (Experte vs. Laie) auf die Einstellung. Eine Varianzanalyse bestätigt diesen Verdacht.

8
In diesem Fall läßt die Varianzanalyse allerdings keinen Schluß über die Mittelwert-unterschiede zwischen einzelnen Zellen zu. Das heißt, besteht eine spezifische Hypo-these über Unterschiede zwischen zwei Zellen (z.B. bei guter Stimmung folgen die Untersuchungsteilnehmer eher dem Experten als dem Laien), dann ist diese über eine Kontrasttestung zu prüfen.
Hierbei muß zunächst das Design so umgestaltet werden, daß ein Vergleich der Zellen mittels eines univariaten Verfahrens möglich ist. Dazu müssen die Bedingungen so umkodiert werden, daß aus sämtlichen unabhängigen Variablen eine neue Variable erzeugt wird.
Umkodierung der Bedingungen in eine einzelne Variable
Im Beispiel sieht dies wie folgt aus:
Ziel Variable mit folgenden Wertzuordnungen: 1 = schlechte Stimmung / Laie
(Name der neuen Variable: Kontrast) 2 = gute Stimmung / Laie
3 = schlechte Stimmung / Experte
4 = gute Stimmung / Experte
Vorgehen 1.) Umkodierung der Variablen Stimmung und Kommunikator in die Variable
Kontrast
Wahl des Datenfensters
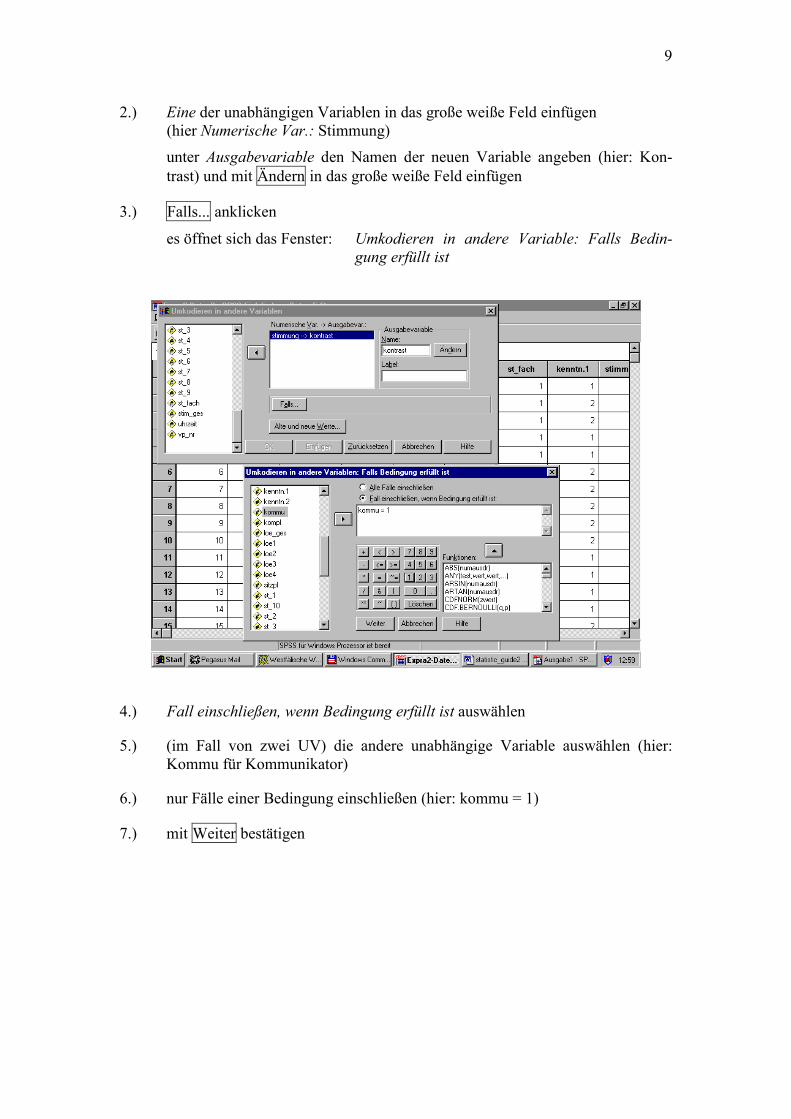
Transformieren, Umkodieren, In andere Variablen
9
2.) Eine der unabhängigen Variablen in das große weiße Feld einfügen (hier Numerische Var.: Stimmung)
unter Ausgabevariable den Namen der neuen Variable angeben (hier: Kon-trast) und mit Ändern in das große weiße Feld einfügen
3.) Falls... anklicken
es öffnet sich das Fenster: Umkodieren in andere Variable: Falls Bedin-gung erfüllt ist
4.) Fall einschließen, wenn Bedingung erfüllt ist auswählen
5.) (im Fall von zwei UV) die andere unabhängige Variable auswählen (hier: Kommu für Kommunikator)
6.) nur Fälle einer Bedingung einschließen (hier: kommu = 1)
7.) mit Weiter bestätigen

10
8.) Alte und neue Werte... anklicken
9.) Alte Werte und Neue Werte für die Bedingungen eingeben und mit Hinzufügen in das weiße Feld einfügen In diesem ersten Schritt können die alten Werte beibehalten werden. Daher kann unter alten und neuen Werten die gleiche Zahl angegeben werden!
10.) Mit Weiter und OK bestätigen (oder Einfügen um mit der Syntax zu arbeiten)
Was hat man hier gemacht? Durch das beschriebene Vorgehen wurde eine Variable erzeugt, die bisher die Werte 1 und 2 enthält. Für alle Untersuchungsteilnehmer der Bedingung Kommunikator = Laie (kommu = 1) wurde eine 1 für die Bedingung schlechte Stimmung und eine 2 für die Bedingung gute Stimmung vergeben. Alle Untersuchungsteilnehmer der Bedin-gung Kommunikator = Experte sind durch einen fehlenden Wert gekennzeichnet. Im nächsten Schritt werden nun diese fehlenden Werte durch 3 (schlechte Stimmung) und 4 (gute Stimmung) ersetzt, so daß die Variable „Kontrast“ am Ende dieses Vorgehens eine komplette Abbildung der Bedingungen enthält:
1 = schlechte Stimmung / Laie
2 = gute Stimmung / Laie
3 = schlechte Stimmung / Experte
4 = gute Stimmung / Experte

11
11.) Wiederholung der Schritte 1 bis 10 mit folgenden Abweichungen
a) unter Falls Bedingung erfüllt ...: kommu = 2
b) unter Alte und neue Werte...: 1 � 3
2 � 4
12.) Änderungen jeweils mit Ändern einfügen
Bestätigen mit Weiter und OK (bzw. Einfügen für die Arbeit mit der Syntax)
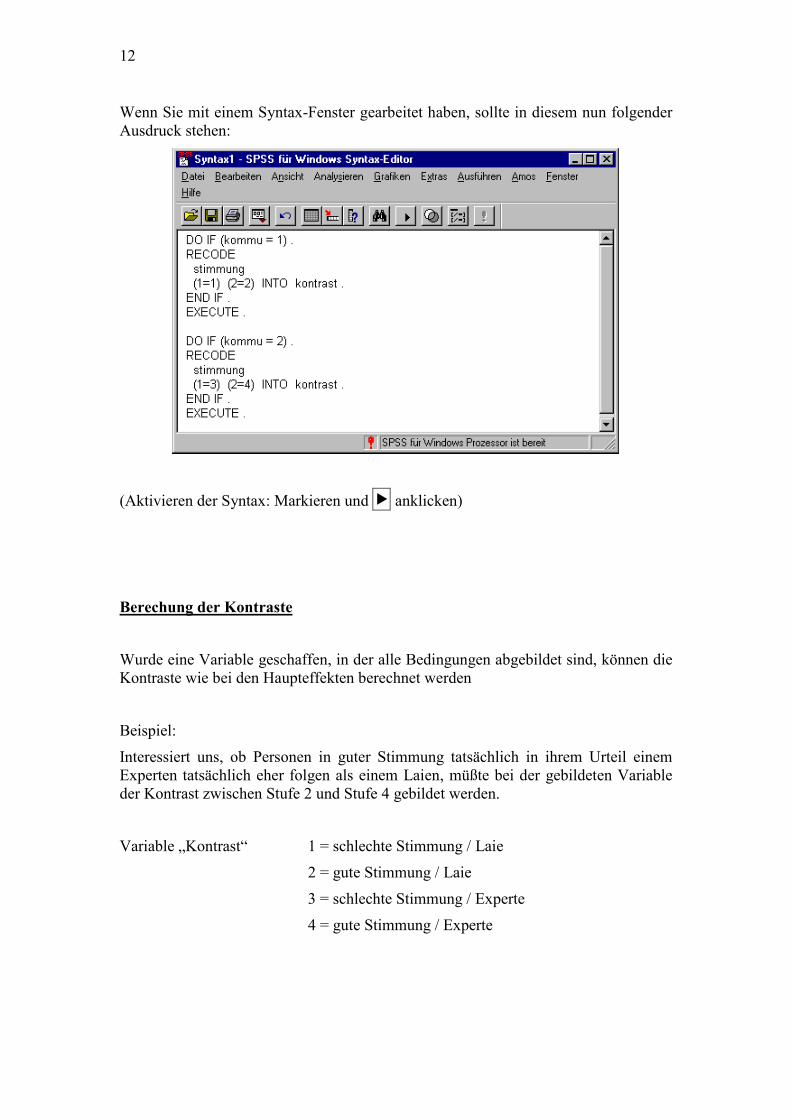
12
Wenn Sie mit einem Syntax-Fenster gearbeitet haben, sollte in diesem nun folgender Ausdruck stehen:
(Aktivieren der Syntax: Markieren und � anklicken)
Berechung der Kontraste
Wurde eine Variable geschaffen, in der alle Bedingungen abgebildet sind, können die Kontraste wie bei den Haupteffekten berechnet werden
Beispiel:
Interessiert uns, ob Personen in guter Stimmung tatsächlich in ihrem Urteil einem Experten tatsächlich eher folgen als einem Laien, müßte bei der gebildeten Variable der Kontrast zwischen Stufe 2 und Stufe 4 gebildet werden.
Variable „Kontrast“ 1 = schlechte Stimmung / Laie
2 = gute Stimmung / Laie
3 = schlechte Stimmung / Experte
4 = gute Stimmung / Experte
13
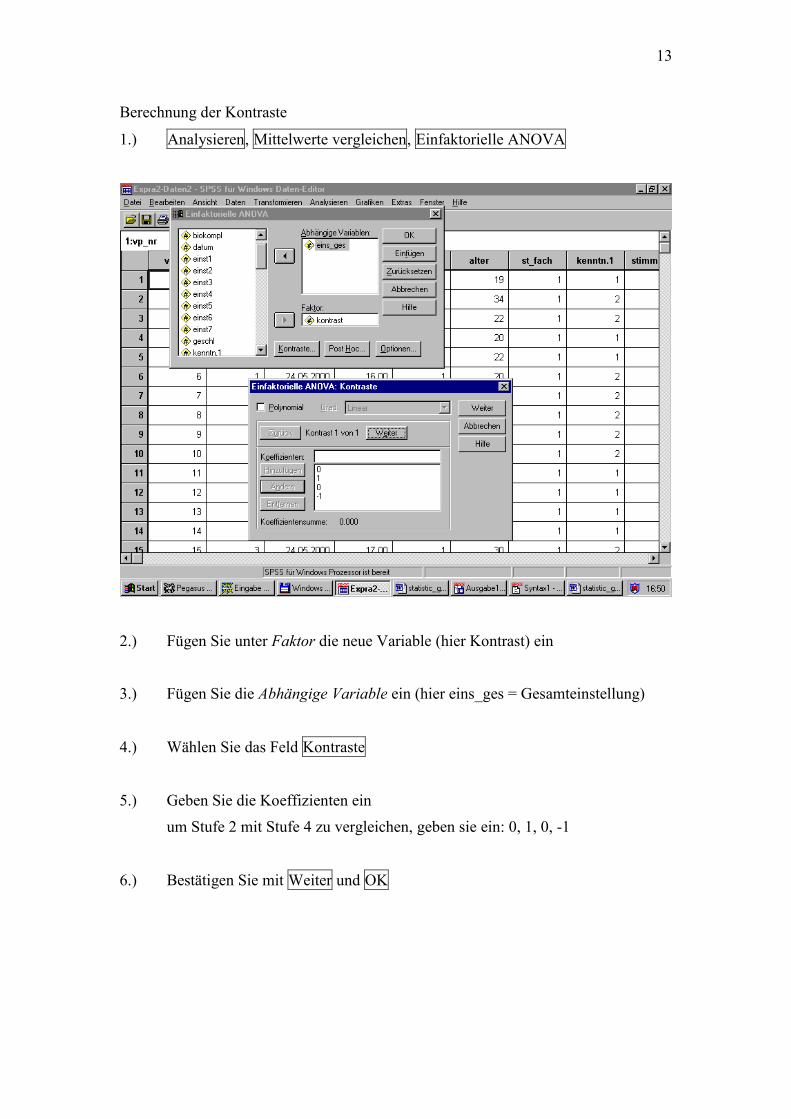
Berechnung der Kontraste
1.) Analysieren, Mittelwerte vergleichen, Einfaktorielle ANOVA
2.) Fügen Sie unter Faktor die neue Variable (hier Kontrast) ein
3.) Fügen Sie die Abhängige Variable ein (hier eins_ges = Gesamteinstellung)
4.) Wählen Sie das Feld Kontraste
5.) Geben Sie die Koeffizienten ein
um Stufe 2 mit Stufe 4 zu vergleichen, geben sie ein: 0, 1, 0, -1
6.) Bestätigen Sie mit Weiter und OK

14
Im Beispiel ergibt sich folgende Ausgabe:
Interessant sind hierbei erneut nur die Kontrast-Tests. Gehen wir von der Gleichheit der Varianzen aus (zum Test der Varianzhomogenität siehe oben), erhalten wir einen Signifikanzwert von .068. Da wir eine gerichtete Hypothese haben (bei guter Stim-mung sollten Personen sich eher dem Experten anschließen), ist eine einseitige Te-stung der Kontraste zulässig. Der Signifikanz-Wert kann also halbiert werden und unterschreitet das Niveau von .05. Wir können daher schreiben:
Ein Einzelvergleich ergibt, daß Personen in positiver Stimmung sich eher dem Exper-ten als dem Laien in ihrem Urteil anschließen, t(91) = 1.85, p < .05, einseitige Te-stung.

15
Vorgehen bei abhängigen Messungen Bisher wurde erläutert wie man Unterschiede zwischen Personen mißt, die zufällig bestimmten Bedin-gungen zugeordnet wurden. Es wurden also Unterschiede zwischen Personengruppen gemessen. Häufig möchte man jedoch auch feststellen, ob sich Unterschiede auf Variablen feststellen lassen, die zweimal bei der gleichen Personengruppe gemessen wurden. Ein Beispiel ist die Vor- / Nachhermessung einer Einstellung, ein anderes die Beurteilungen von zwei Personen/Objekten durch alle Versuchspersonen (wird Person A besser beurteilt als Person B?).
Da das Vorgehen bei der Prüfung von Unterschieden bei abhängigen Messungen, dem Vorgehen bei unabhängigen Messungen sehr ähnelt, wird es hier nur kurz skizziert.
WICHTIGER HINWEIS:
Wird eine Variable mehrfach bei einer Personengruppe erhoben, so sind zwei Variablen zu vergeben (z.B. ein_t1, ein_t2). Jedem Versuchsteilnehmer ist in der SPSS-Datendatei immer eine Zeile zugewie-sen, in der sich alle Werte finden, die in bezug auf diesen Versuchsteilnehmer ermittelt wurden.
Unterschiede zwischen zwei Messungen Beispiel:
Einer Stichprobe von Studenten werden zwei Gesichter zur Beurteilung gezeigt.
Frage: Werden die Gesichter als unterschiedlich attraktiv wahrgenommen?
1.) Analysieren, Mittelwerte vergleichen, T-Test bei gepaarten Stichproben
2.) Im erscheinenden Feld beide Variablen auswählen (Beurteilung Gesicht 1, Beurteilung Gesicht 2)
3.) Variablen in das Feld gepaarte Variablen einfügen
4.) Mit OK bestätigen

16
Aus der folgenden Ausgabe läßt sich ablesen, daß sich die beiden Gesichter nicht un-terscheiden:
Man würde schreiben:
Es fanden sich keine Unterschiede in der Beurteilung von Gesicht A und Gesicht B, t(70) = 1.32, ns.
Interaktionen mit unabhängigen Faktoren Wesentlich komplexer werden die Analysen, wenn Interaktionen mit anderen abhän-gigen Faktoren (wird hier nicht behandelt) oder mit anderen unabhängigen Faktoren geprüft werden.
Beispiel:
Abhängiger Faktor: Beurteilung von Gesicht 1, Beurteilung von Gesicht 2
Unabhängiger Faktor: Stimmungsmanipulation (gut vs. schlecht)
Das Vorgehen:
1.) Analysieren, Allgemeines lineares Modell, Meßwiederholungen...
Es öffnet sich folgendes Feld
17
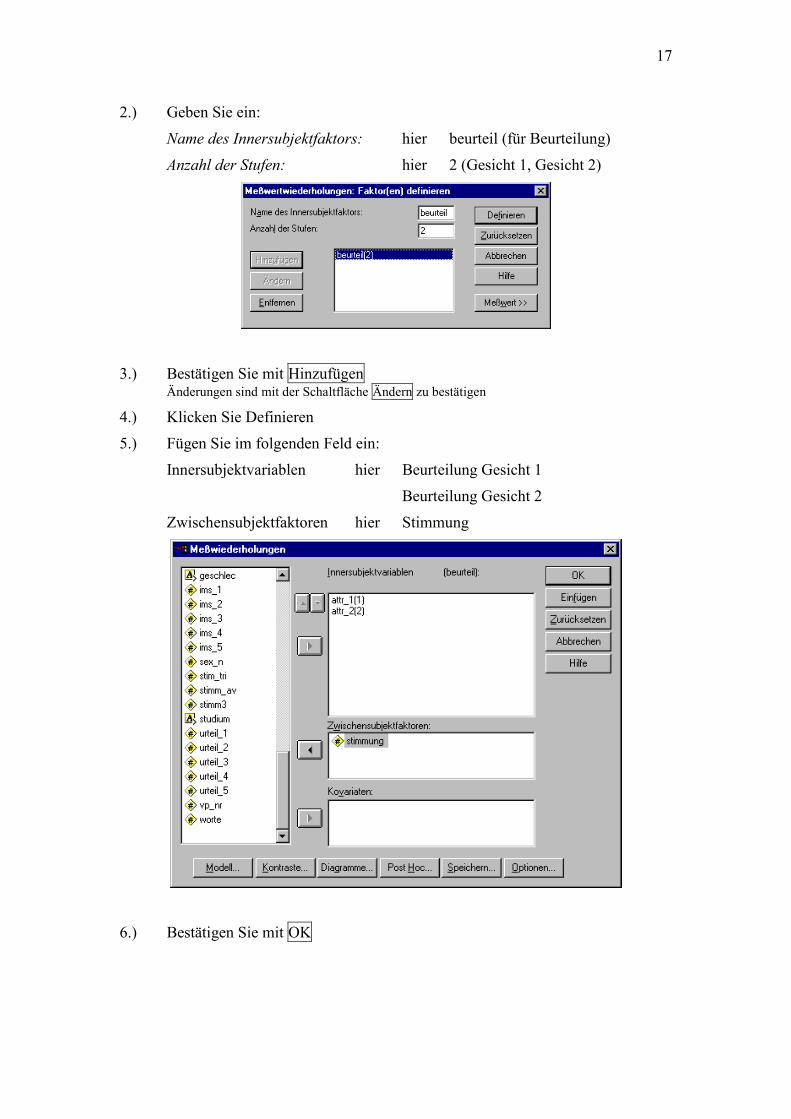
2.) Geben Sie ein:
Name des Innersubjektfaktors: hier beurteil (für Beurteilung)
Anzahl der Stufen: hier 2 (Gesicht 1, Gesicht 2)
3.) Bestätigen Sie mit Hinzufügen Änderungen sind mit der Schaltfläche Ändern zu bestätigen
4.) Klicken Sie Definieren
5.) Fügen Sie im folgenden Feld ein:
Innersubjektvariablen hier Beurteilung Gesicht 1
Beurteilung Gesicht 2
Zwischensubjektfaktoren hier Stimmung
6.) Bestätigen Sie mit OK

18
Es erscheint eine umfangreiche Ausgabe. Hier die wichtigsten Angaben:
Unter Test der Innersubjekteffekte findet man:
Im Beispiel bedeuten die Angaben folgendes:
Beurteil: Haupteffekt der Beurteilung der Gesichter
Findet sich hier ein Effekt bedeutet dies, daß ein Gesicht als attraktiver beurteilt wurde als das andere.
Beurteilung * Stimmung: Interaktion der beiden Variablen
Findet sich hier ein Effekt kann dies bedeuten:
a) nur bei guter (schlechter) Stimmung wurde ein Ge-sicht besser beurteilt als das andere
b) bei guter Stimmung wird Gesicht A besser beurteilt als Gesicht B, bei schlechter Stimmung ist dies umge-kehrt
19
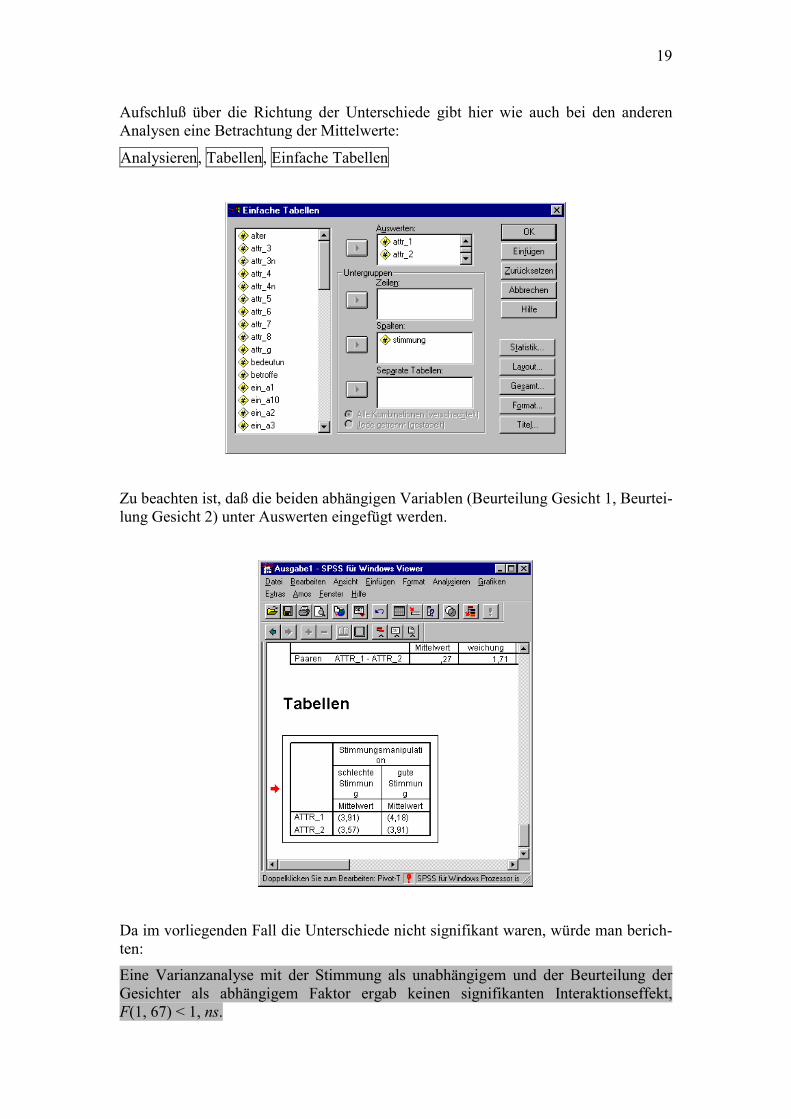
Aufschluß über die Richtung der Unterschiede gibt hier wie auch bei den anderen Analysen eine Betrachtung der Mittelwerte:
Analysieren, Tabellen, Einfache Tabellen
Zu beachten ist, daß die beiden abhängigen Variablen (Beurteilung Gesicht 1, Beurtei-lung Gesicht 2) unter Auswerten eingefügt werden.
Da im vorliegenden Fall die Unterschiede nicht signifikant waren, würde man berich-ten:
Eine Varianzanalyse mit der Stimmung als unabhängigem und der Beurteilung der Gesichter als abhängigem Faktor ergab keinen signifikanten Interaktionseffekt, F(1, 67) < 1, ns.

20
Nachzutragen ist noch, daß die Ausgabe bei Berechnung der MANOVA ebenso die Effekte der Zwischensubjektfaktoren enthält (im Beispiel Stimmung):
Die Ausgabe ist hier äquivalent zu der Berechnung einer univariaten Varianzanalyse.
Im Beispiel zeigt sich auch hier kein signifikanter Effekt. Man würde schreiben:
Die Stimmung hatte keinen Einfluß auf die Beurteilung der Gesichter, F(1, 67) < 1, ns.

21
Wenn es schief gegangen ist? Haben die gerechneten Analysen eine deutliche Bestätigung der Hypothesen erbracht haben, so ist man am Ende der Arbeit. Finden sich jedoch nur tendenzielle Unterschiede oder gar kaum zu erklärende Befunde (z.B. Replikation stabiler Befunde ist nicht möglich), so kann man verschiedene Maßnahmen ergreifen, um unglückliche Umstände bei der Datenerhebung oder andere Fehlereinflüsse auszuschlie-ßen.
Ein Blick auf die Verteilungen: Boxplots Zunächst bietet sich eine Inspektion der Verteilungen in den einzelnen Bedingungen mit dem Tool „Boxplots“ an.
1.) Grafiken, Boxplot
2.) Im Fenster Boxplots wählen
a) wenn nur eine Variable betrachtet werden soll: Einfach
b) wenn eine Interaktion betrachtet werden soll: Gruppiert HINWEIS: Es ist leider nur die Möglichkeit der Betrachtung einer 2-fach Interaktion gegeben.
Im folgenden betrachten wir das Vorgehen für eine Interaktion. Im Fall einer einfachen Varia-ble ist das Vorgehen nahezu äquivalent. Es entfällt nur die Möglichkeit Gruppen für eine wei-tere unabhängige Variable zu definieren.
3.) Gegeben Sie im folgenden Fenster ein:
Variable (= abhängige Variable; z.B. Einstellung)
Kategorienachse (= 1. unabhängige Variable; z.B. Kommunikator)
Gruppen definieren durch: (= 2. unabhängige Variable; z.B. Stimmung)
optional: Fallbeschriftung (= am besten die Vp-Nr.)

22
4.) Neben einer Tabelle mit einer Häufigkeitsstatistik finden Sie folgenden Ausdruck:
Was bedeutet was? y-Achse: abhängige Variable (z.B. Einstellung)
x-Achse: Stufen der 1. unabhängigen Variable (hier Laie vs. Experte)
Farbige Markierung: Stufen der 2. unabhängigen Variable
dicke Box: Interquartilbereich: hier liegen 50% der Fälle (Werte zwischen dem 1. u. 3. Quartil)
dicker Strich: Median (darüber u. darunter liegen 50% der Fälle)
oberer/unterer Ast: hier zwischen liegen alle Fälle mit Ausnahme der Ausreißer
kleine Kreise: Ausreißer (wenn Vpn-Nr. als Fallbeschriftung angegeben wurde, kann diese hier abgelesen werden)
Wie sollte es aussehen? � alle Boxen sollte etwa gleich dick sein, die Mediane sollten in der Boxmitte
liegen (dann sind die Verteilung homogen)
� Ausreißer sollten nicht vorhanden sein
Im Beispiel sind die Verteilung auf der linken Seite noch halbwegs akzeptabel. Auf der rechten Seite unterscheiden sie sich allerdings schon deutlicher. Außerdem finden sich einige Ausreißer.
Wenn zu viele Ausreißer vorhanden sind, sollte man diese notieren und in einer weite-ren explorativen Analysereihe aus den Berechnungen ausschließen (zum Ausschluß von Fällen siehe Skript Teil 1).
23
Analysen unter Berücksichtigung zusätzlicher Faktoren Oft hat man neben den zentralen Variablen einige weitere Variablen wie Alter, Ge-schlecht oder Studienzugehörigkeit erhoben. Man kann nun die oben beschriebenen Analysen wiederholen, in dem man diese Variablen entweder als feste Faktoren in die Varianzanalyse aufnimmt oder aber als Kovariaten.
Beispiel: Berücksichtigung des Geschlechts
Geschlecht als fester Faktor:
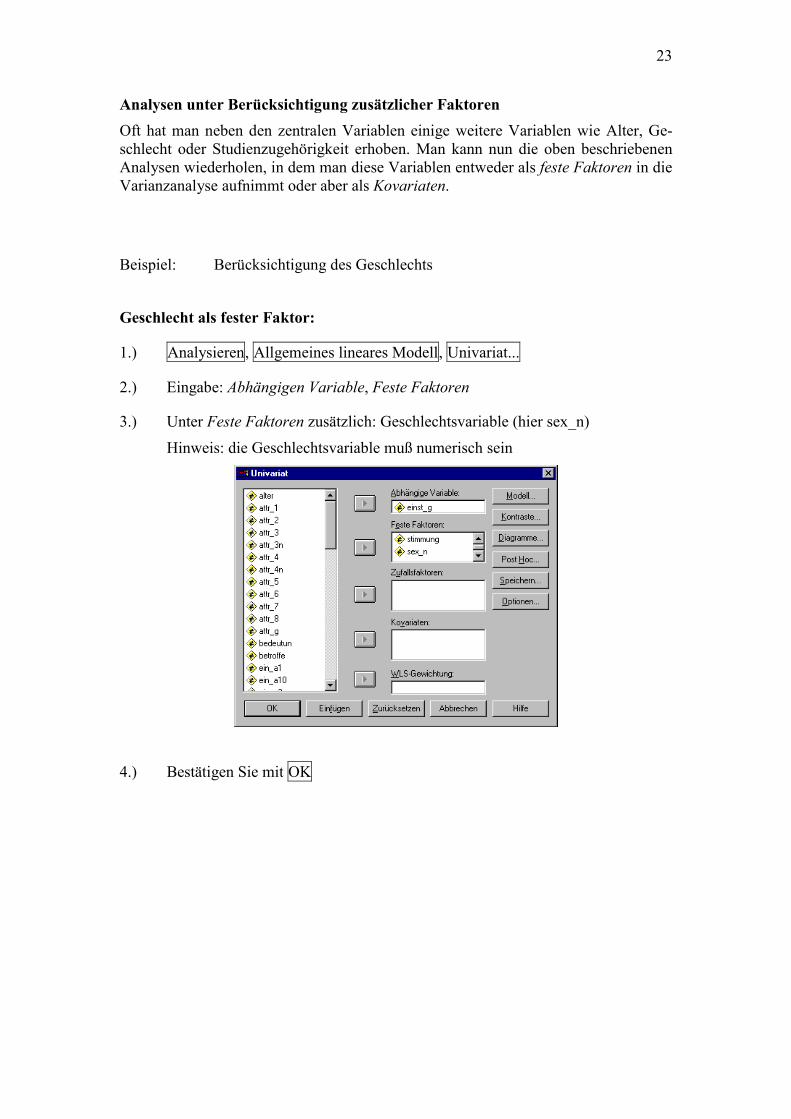
1.) Analysieren, Allgemeines lineares Modell, Univariat...
2.) Eingabe: Abhängigen Variable, Feste Faktoren
3.) Unter Feste Faktoren zusätzlich: Geschlechtsvariable (hier sex_n)
Hinweis: die Geschlechtsvariable muß numerisch sein
4.) Bestätigen Sie mit OK

24
Ob das Geschlecht nun einen Einfluß auf die abhängige Variable hat, zeigt sich im Ausgabefenster.
Interessant sind neben dem Haupteffekt vor allem die Interaktionen unter Berücksich-tigung der Geschlechtsvariable: Findet sich vielleicht die gewünschte Interaktion zwi-schen Variable X und Y nur bei Frauen, nicht aber bei Männern, dann sollte die Inter-aktion zwischen X, Y, und Geschlecht signifikant werden.
Im Beispiel erscheint allein ein marginal signifikanter Wert der Interaktion Stimmung x Geschlecht auffällig. Das Vorgehen zur weiteren Interpretation einer solchen Inter-aktion wurde bereits erläutert (Mittelwerte anschauen, Kontraste berechnen, ...).
Geschlecht als Kovariate Sind in einigen Zellen deutlich mehr Männer als Frauen und in anderen Zellen deut-lich mehr Frauen als Männer vertreten, so ist es möglich, daß bestimmte Effekte auf-grund dieser ungleichen Verteilung zustande kommen. So mag es zum Beispiel sein, daß Frauen im Mittel eine positivere Einstellung zu einem bestimmten Sachverhalt äußern als Männer und daß nur aus diesem Grund der Mittelwert einer bestimmten Zelle höher liegt als der Mittelwert in den anderen Zellen.
Um solche Effekte auszuschließen, kann man die Variable Geschlecht als Kovariate mit in die Varianzanalyse aufnehmen:
25
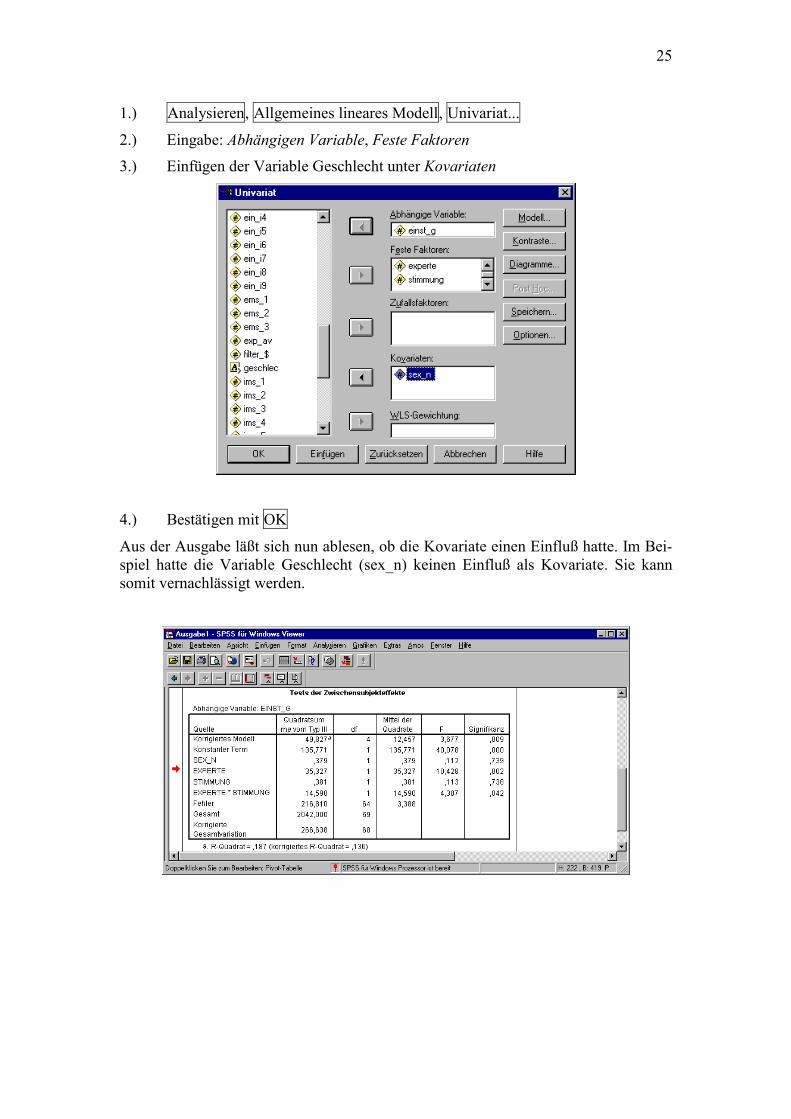
1.) Analysieren, Allgemeines lineares Modell, Univariat...
2.) Eingabe: Abhängigen Variable, Feste Faktoren
3.) Einfügen der Variable Geschlecht unter Kovariaten
4.) Bestätigen mit OK
Aus der Ausgabe läßt sich nun ablesen, ob die Kovariate einen Einfluß hatte. Im Bei-spiel hatte die Variable Geschlecht (sex_n) keinen Einfluß als Kovariate. Sie kann somit vernachlässigt werden.

26
Rechnen mit künstlichen Teilungen (Mediansplit) oder Extremgruppen Man kann nun neben der Geschlechtsvariable auch weitere Variablen in den Analysen berücksichtigen. Dabei ist zu beachten, daß neben gestuften oder nominalskalierten Variablen (wie Geschlecht: männ-lich – weiblich) auch kontinuierliche Variablen (z.B. mit einer Skala gemessene Voreinstellung, ...) als Kovariaten aufgenommen werden können. Als feste Faktoren können in die Varianzanalyse allerdings nur gestufte Variablen aufgenommen werden. Das adäquate Verfahren für die Betrachtung von Interak-tionen zwischen gestuften und kontinuierlichen Variablen ist die multiple Regression, auf deren Dar-stellung hier jedoch verzichtet wird. Es sei jedoch darauf hingewiesen, daß bei der geplanten Berück-sichtigung einer kontinuierlichen Variablen, die nicht experimentell variiert wird, immer eine Regres-sion zu rechnen ist.
Ist beispielsweise eine Manipulation mißlungen und will man dennoch die Übereinstimmung der Daten mit dem theoretischen Modellprüfen oder will man einen schnellen Blick auf potentiell wirksame Ein-flußfaktoren werfen, ist die Betrachtung von künstlichen geteilten Gruppen akzeptabel:
Beispiel:
� Manipulation (z.B. Stimmunginduktion) zeigt keinen Effekt auf dem Manipu-lation-Check (Stimmungsskala)
� Option: Prüfen, ob die vorgefundene Variation (z.B. der Stimmung) in der angenommenen Weise mit den anderen unabhängigen Variablen interagiert
Vorgehen:
A) Königsweg: Korrelation / multiple Regression wird hier nicht behandelt B) schneller Weg: Mediansplitt / Bildung von Extremgruppen wird kurz dargestellt
Bildung der künstlichen Gruppen: Ermittlung von Median bzw. weiterer Teilung
1.) Analysieren, Deskriptive Statistiken, Häufigkeiten
2.) Einfügen der Variable nach der die Trennung erfolgen soll (hier gemessene Stimmung)

27
3.) Auswahl des Feldes Statistik
3.) Median anklicken, Trennen anklicken und gewünschte Gruppenzahl angeben Ist gewünscht Extremgruppen miteinander zu vergleichen, dann bietet es sich beispielsweise an, Trennen in 3 gleiche Gruppen anzugeben. So kann man später das obere Drittel der Ver-suchsteilnehmer (z.B. sehr gute Stimmung) gegen das untere Drittel (z.B. sehr gute Stimmung) testen.
Hinweis: Es ist nicht sinnvoll die Trennung anhand der Skala vorzunehmen (z.B. Vpn mit Werte 1-3 gegen Vpn mit Werten 7-9).
4.) Mit Weiter und OK bestätigen
Im Beispiel erscheint folgende Ausgabe:
Diese Angaben kann man nun verwenden, um die bestehende kontinuierliche Variable (hier Stimmung) in eine gestufte Variable umzukodieren.
Zur Veranschaulichung soll hier eine Umkodierung in drei Gruppen erfolgen. Wichtig sind dabei die Angaben zu den Perzentilen 33,333 und 66,666.
28
Umkodierung der kontinuierlichen in eine neue gestufte Variable
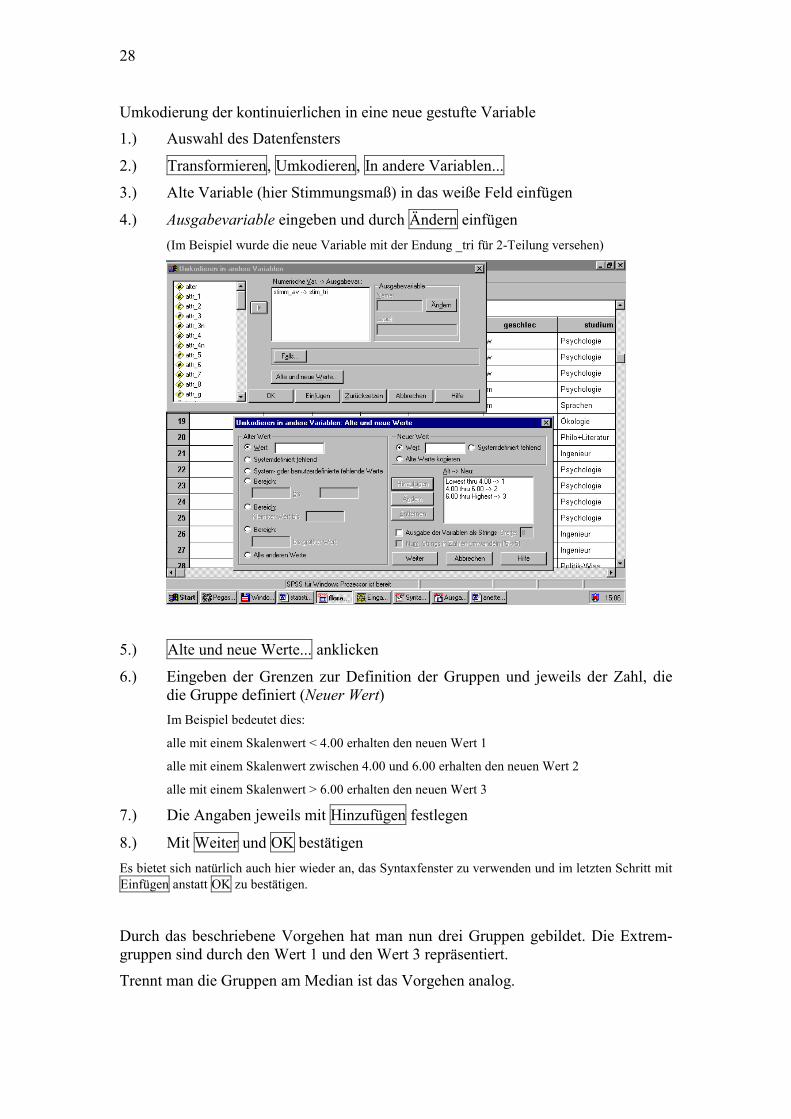
1.) Auswahl des Datenfensters
2.) Transformieren, Umkodieren, In andere Variablen...
3.) Alte Variable (hier Stimmungsmaß) in das weiße Feld einfügen
4.) Ausgabevariable eingeben und durch Ändern einfügen (Im Beispiel wurde die neue Variable mit der Endung _tri für 2-Teilung versehen)
5.) Alte und neue Werte... anklicken
6.) Eingeben der Grenzen zur Definition der Gruppen und jeweils der Zahl, die die Gruppe definiert (Neuer Wert)
Im Beispiel bedeutet dies:
alle mit einem Skalenwert < 4.00 erhalten den neuen Wert 1
alle mit einem Skalenwert zwischen 4.00 und 6.00 erhalten den neuen Wert 2
alle mit einem Skalenwert > 6.00 erhalten den neuen Wert 3
7.) Die Angaben jeweils mit Hinzufügen festlegen
8.) Mit Weiter und OK bestätigen Es bietet sich natürlich auch hier wieder an, das Syntaxfenster zu verwenden und im letzten Schritt mit Einfügen anstatt OK zu bestätigen.
Durch das beschriebene Vorgehen hat man nun drei Gruppen gebildet. Die Extrem-gruppen sind durch den Wert 1 und den Wert 3 repräsentiert.
Trennt man die Gruppen am Median ist das Vorgehen analog.
29
Die neu gebildete Variable kann ähnlich gehandhabt werden, wie dies zuvor für die unabhängigen Variablen beschrieben wurde. Das typische weitere Vorgehen wäre dabei:
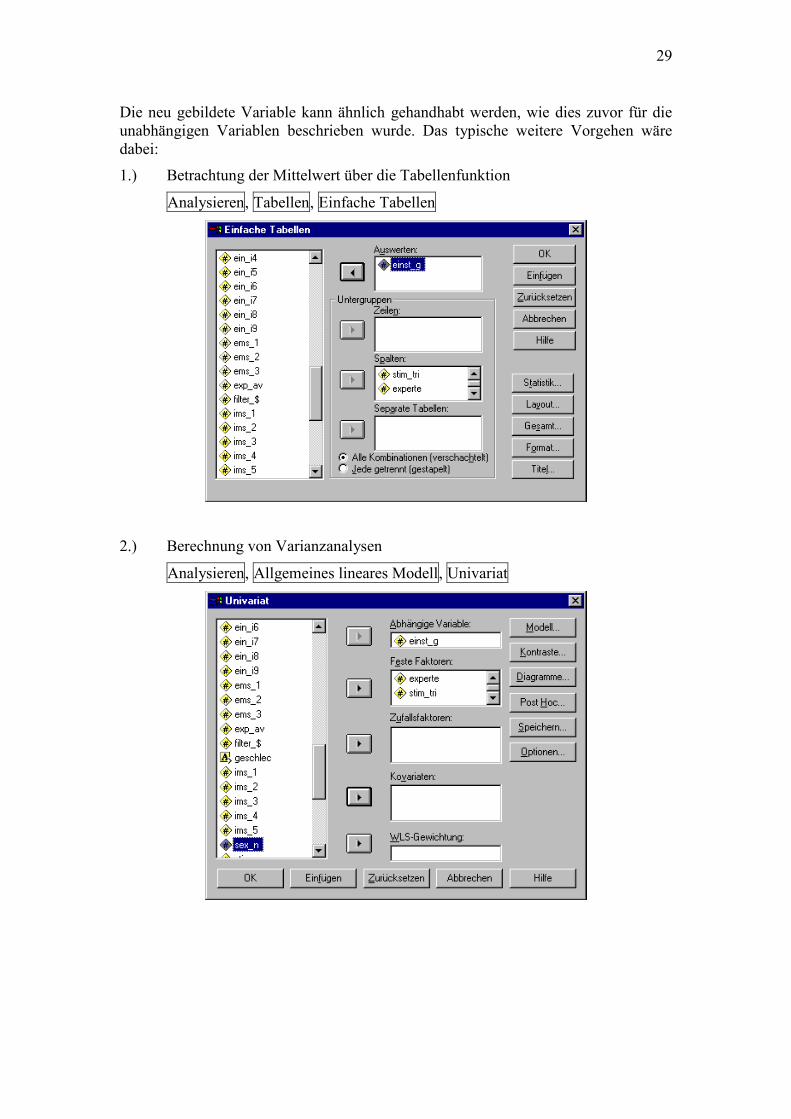
1.) Betrachtung der Mittelwert über die Tabellenfunktion
Analysieren, Tabellen, Einfache Tabellen
2.) Berechnung von Varianzanalysen
Analysieren, Allgemeines lineares Modell, Univariat

30
Oft bietet sich es auch an, die Gruppe mit den mittleren Werten aus der Analyse aus-zuschließen. Dazu geht man wie folgt vor:
1.) Datenfenster wählen
3.) Daten, Fälle auswählen, Falls Bedingung zutrifft
4.) die neu gebildete Variable in das weiße Feld einfügen
5.) ~= wählen und Wert der Gruppe angeben, die ausgeschlossen werden soll
6.) Mit Weiter und OK bestätigen
Bei allen folgenden Berechnungen wird nun die ausgewählte Gruppe nicht mehr be-rücksichtigt.
ACHTUNG: Wenn Sie über den Befehl Fälle auswählen: Falls schon weitere Fälle ausgeschlossen haben, dann müssen Sie die Angaben mit „&“ verknüpfen:






![MODUL PRAKTIKUM STATISTIK SPSS 18 - Institut …ibmb.ac.id/site/wp-content/uploads/2017/09/modul...Modul Praktikuk Statistik dan SPSS ===== 1 [Modul Praktikm Statistik & SPSS 18] Page](https://img.pdfslide.net/doc/110x75/5ad92d937f8b9a9d5c8e426d/modul-praktikum-statistik-spss-18-institut-ibmbacidsitewp-contentuploads201709modulmodul.jpg)






![Statistische Datenanalyse mit SPSS 8 für Windows · Statistische Datenanalyse mit SPSS 8 für Windows [= Reihe Benutzereinführung, Bd. 25] 1999. ... plattform er SPSS einsetzen](https://img.pdfslide.net/doc/110x75/603eaeb2cb2baf078000a0bb/statistische-datenanalyse-mit-spss-8-fr-windows-statistische-datenanalyse-mit.jpg)















