Embed Size (px)
Citation preview

Anno Accademico 2009-2010 Università degli Studi di Ferrara
Corso di Laurea Triennale in Scienze Biologiche
DIAPOSITIVE DI
BIOSTATISTICA (6 crediti, nuovo ordinamento)
FONDAMENTI DI BIOMETRIA CON LABORATORIO (9 crediti, vecchio ordinamento)
Docente: Prof. Giorgio Bertorelle

DI COSA MI OCCUPO IO?
� Studiare la variabilità genetica per ricostruire il passato dell’uomo e di altri animali o In particolare, oltre all’uomo, le specie analizzate recentemente sono il cinghiale,
il camoscio, il capriolo, l’uro (l’antenato estinto dei bovini) e la testuggine di Hermann
� I dati sulla variabilità genetica devono prima essere “prodotti” in laboratorio
(attraverso tecniche di biologia molecolare a partire da materiale organico come sangue, muscolo, peli, ossa, ecc. e anche a partire da campioni scheletrici di individui vissuti migliaia di anni fa) e poi essere analizzati statisticamente per poter giungere a conclusioni credibili
� Questi studi sono rilevanti per capire l’evoluzione delle specie e per prevenire la
perdita di biodiversità
DI COSA CI OCCUPEREMO IN QUESTO CORSO?
� Le basi della statistica applicata allo studio dei dati biologici � Cos’e la statistica?
o Studio scientifico dei dati, raccolti o ottenuti in un esperimento, al fine di descrivere un fenomeno, interpretarlo, scegliere tra ipotesi alternative
� Di fondamentale importanza in tutte le discipline che studiano gli organismi viventi (biologia,
medicina, agraria, etc).
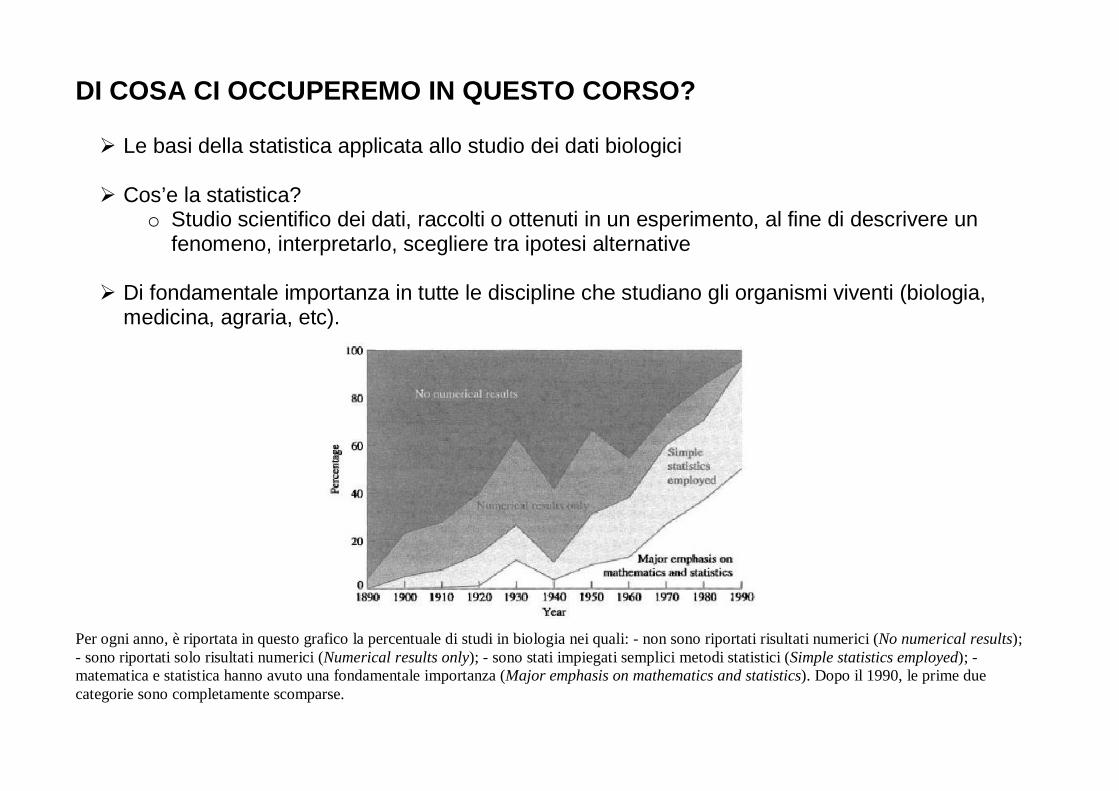
Per ogni anno, è riportata in questo grafico la percentuale di studi in biologia nei quali: - non sono riportati risultati numerici (No numerical results); - sono riportati solo risultati numerici (Numerical results only); - sono stati impiegati semplici metodi statistici (Simple statistics employed); - matematica e statistica hanno avuto una fondamentale importanza (Major emphasis on mathematics and statistics). Dopo il 1990, le prime due categorie sono completamente scomparse.

STRUTTURA DEL CORSO � TABELLA ORARI
o [Consultare il sito docente a http://docente.unife.it/giorgio.bertorelle] � Lezioni teoriche in aula con molti esempi di applicazioni in ambito biologico � Esercizi in aula
� Esercizi e applicazioni al calcolatore in aula multimediale
o Solo per il corso di Fondamenti di biometria con laboratorio (9 crediti) o Per questo corso, il laboratorio è parte integrante del programma e prova
d’esame

TIPOLOGIA DELL’INSEGNAMENTO E QUALCHE CONSIGLIO � E’ necessario capire e non imparare a memoria
� La teoria serve per capire come analizzare i dati e per svolgere correttamente gli
esercizi. � Gli esercizi sono applicazioni a dati biologici delle tecniche statistiche. Sono una
verifica fondamentale della comprensione della parte teorica. � Gli esempi permettono di ricordare sia la parte teorica che quella pratica. E’
importante ricordare gli esempi. � NON CONVIENE STUDIARE TEORIA ED ESEMPI DI APPLICAZIONI
SEPARATAMENTE � Ogni argomento è collegato a quelli precedenti, e il laboratorio è collegato alle lezioni
svolte in aula: E’ QUASI INUTILE SEGUIRE LE LEZIONI SE NON SI STUDIA CON CONTINUITA’

DOMANDE � Se non capite a lezione, fate domande (utile sempre!)
� Se non capite dopo aver studiato gli appunti, il materiale disponibile, e il libro,
consultate un docente (prima per email, poi eventualmente per appuntamento). Ricordate che i vostri docenti svolgono anche attività di ricerca
o [email protected] in generale (orario ricevimento: venerdì dalle 13.30 alle 14.30) o [email protected] per domande attinenti agli esercizi svolti in aula e i laboratori
� Non arrivate a fine corso con domande/problemi riscontrati fin dalle prime lezioni!

VALUTAZIONI � Dello studente
o Esame finale scritto con domande a scelta multipla e esercizi � Eventualmente esame intermedio
o Gli appelli successivi per chi non supera l’esame negli appelli a fine corso potranno essere scritti o orali
� Del docente
o Scheda di valutazione, attenzione a compilarla sulla base delle domande richieste

MATERIALE DIDATTICO � Vostri appunti (la frequenza è consigliata) � Almeno un libro di statistica di base
o MC Whitlock, D Schluter (2010) - ANALISI STATISTICA DEI DATI BIOLOGICI. Edizione italiana a cura di G. Bertorelle - Zanichelli Editore
� Materiale disponibile sito docente
� Materiale distribuito in laboratorio � Libri di testo online (in inglese)
o http://www.statsoft.com/textbook/ o http://davidmlane.com/hyperstat/
SITO WEB CORSO
http://docente.unife.it/giorgio.bertorelle/didattica_insegnamenti

LE BASI DELLA STATISTICA E LA RACCOLTA DEI DATI
� Tre punti importanti o Dati e ipotesi
� In tutte le discipline scientifiche che studiano gli organismi viventi, molto raramente i dati ottenuti attraverso un esperimento oppure raccolti in natura ci permettono di giungere ad una conclusione con una certezza del 100%.
� La statistica ci aiuta in maniera oggettiva, numericamente, ad analizzare le diverse ipotesi: lo studio e l'interpretazione dei fenomeni biologici dipende quindi strettamente dal metodo statistico.
o Statistica e computer
� Il personal computer non ha reso inutile l'insegnamento della statistica. � Nelle analisi statistiche il personal computer svolge solo le funzioni più noiose e
meno importanti: ricordare le formule e applicarle velocemente ai dati riducendo il rischio di fare errori. Bisogna però capire il principio di un’analisi, decidere se tale analisi è adatta ai dati disponibili, e saperne interpretare il risultato.
o Formule, test, concetti, ed esempi
� Alla fine di un corso universitario di statistica destinato alle lauree nelle scienze della vita, uno studente non dovrebbe ricordarsi solo gli aspetti tecnici o matematici di questa disciplina. Risulterà invece fondamentale aver capito a cosa serve la statistica, quando serve, e perché funziona in quel modo. A tale scopo aiuta molto avere sempre in mente uno o più esempi specifici per ogni tipo di analisi.

2
Cos’è la statistica?
� Lo studio scientifico dei dati. Quando l’applicazione dei metodi statistici ha lo scopo di descrivere e comprendere i fenomeni di tipo biologico, si preferisce a volte utilizzare il termine “biometria”.
� La statistica descrittiva viene utilizzata per riassumere e rappresentare i dati
o 100 persone scelte a caso: quanti figli hanno? (se avesse intervistato altre 100 persone, sempre scelte a caso, avrebbe ottenuto una media diversa)
o dove preferite fare le vacanze? o Percentuale guarigioni in 50 pazienti controllo e 50 pazienti trattati (il risultato implica che il
farmaco sia efficace?) o La statistica descrittiva può essere anche molto complessa, ed è sempre molto utile come
indagine preliminare dei risultati ottenuti, ma alla fine ci fornisce solo una sintesi dei dati e/o ci facilita la loro lettura attraverso un grafico.

3
� La statistica inferenziale (la “vera” statistica) ci permette di generalizzare, con un certo grado di sicurezza, le conclusioni suggerite dall’analisi dei dati raccolti.
o Per esempio, se dall’analisi di un campione di 100 individui calcolo il valore medio del
numero medio di figli, la statistica inferenziale mi permette di dire qualcosa sulla media del numero di figli nella popolazione dalla quale proviene il campione.
o In questo caso, attraverso il calcolo di una statistica (la media nel campione) possiamo
dire qualcosa riguardo ad un parametro (la media nella popolazione): � Stima di parametri
o Test (o verifica) delle ipotesi: una volta definite delle ipotesi e analizzato un campione, di
definire oggettivamente, assegnando un livello di probabilità (ossia di certezza), quale ipotesi è maggiormente compatibile con i dati.
� Nell’esempio precedente del farmaco, definite le due ipotesi “il farmaco funziona” e “il
farmaco non funziona”, la statistica inferenziale ci permette di dire qualcosa in generale, nella popolazione cioè, sull’efficacia del farmaco, e non solo sulla differenza osservata in un campione di 100 pazienti.
4
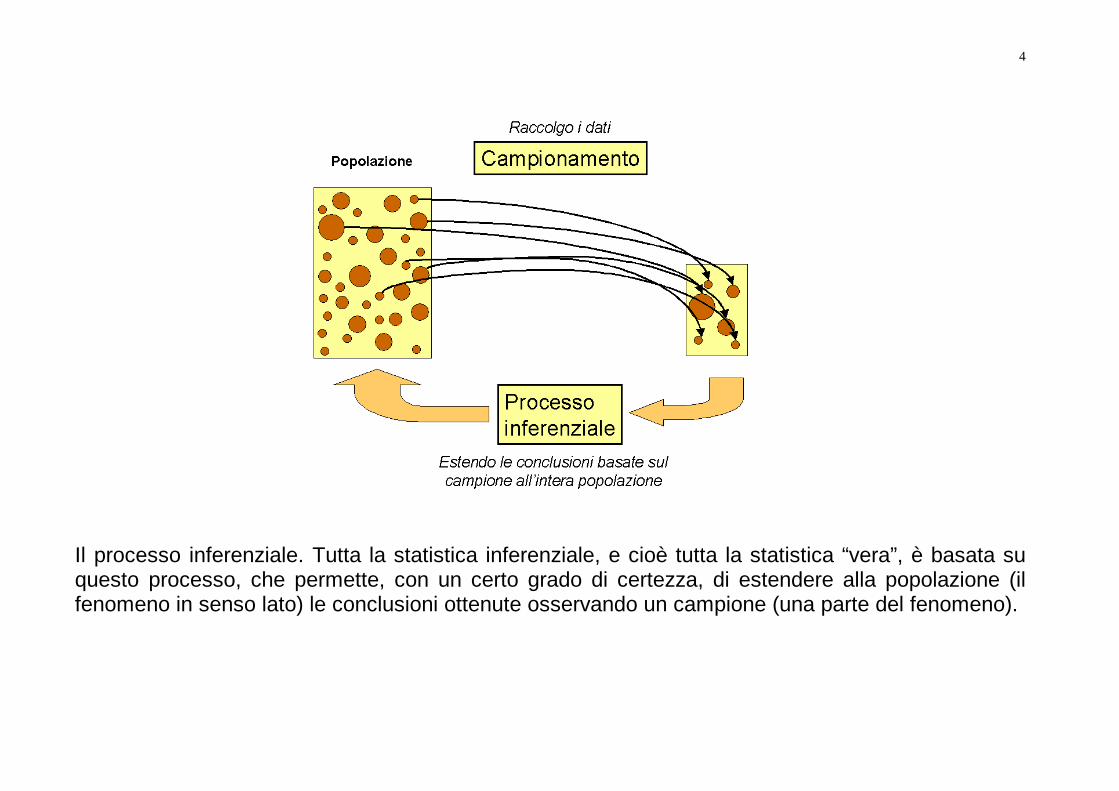
Il processo inferenziale. Tutta la statistica inferenziale, e cioè tutta la statistica “vera”, è basata su questo processo, che permette, con un certo grado di certezza, di estendere alla popolazione (il fenomeno in senso lato) le conclusioni ottenute osservando un campione (una parte del fenomeno).

5
� Il campione: è semplicemente l'insieme degli elementi (detti anche unità campionarie o sperimentali) sui quali effettuiamo misure o osservazioni (per esempio, 20 marmotte catturate con trappole). o Costituisce una frazione della popolazione statistica, un gruppo più grande di elementi che
potenzialmente potremmo osservare e misurare. � La popolazione: può corrispondere ad un insieme finito di individui che hanno alcune
caratteristiche in comune (per esempio, tutte le marmotte che vivono nelle Alpi) o In generale, comunque, si preferisce definire la popolazione statistica come un insieme
infinito di elementi
� La statistica: definisce generalmente una disciplina scientifica, le scienze statistiche, ma una statistica è anche una qualsiasi misura ottenuta elaborando i dati raccolti nel campione. o Numero medio di parassiti osservati in 10 trote o Numero di pettirossi catturati con una rete in una giornata è una statistica.
� Una parte del processo inferenziale consiste nell'utilizzo delle statistiche per stimare alcune caratteristiche della popolazione, dette parametri.
� Numero medio di parassiti nella popolazione (e non solo nel campione) � Numero di pettirossi in una certa area, stimato partire dal numero di individui rimasti
imprigionati nella rete in un giorno. � I parametri si riferiscono alle popolazioni, sono generalmente ignoti, e si indicano quasi sempre
con lettere greche. Le statistiche si riferiscono al campione, sono calcolabili, si indicano con lettere latine, e si utilizzano per stimare i parametri.

6
Popolazioni e campioni
√ Tutti i gatti caduti dagli edifici di New York √ Tutti i geni del genoma umano √ Tutti gli individui maggiorenni in Australia √ Tutto i serpenti volanti del paradiso nel Borneo
o http://homepage.mac.com/j.socha/video/video.html √ Tutti i bambini asmatici di Milano √ I gatti caduti portati in un singolo ambulatorio in un certo intervallo di tempo √ 20 geni umani √ Un pub in Australia frequentato da maggiorenni √ Otto serpenti volanti del Borneo √ 50 bambini asmatici a Milano

7
Un esempio sull’inferenza statistica
� I maschi di trota fario sono più grandi delle femmine?
o Un biologo evoluzionista e un allevatore sono interessati alla domanda
� Pesano 40 individui adulti, 20 maschi e 20 femmine
o Media dei maschi = 1,05 kg o Media delle femmine = 0,92 o Cosa concludere??
� Nulla
o la trota nella popolazione non è costituita solamente da 40 individui
o la semplice intuizione dei fenomeni biologici e degli organismi viventi suggerisce che un secondo campione di 20 maschi e 20 femmine avrebbe potuto dare un risultato diverso
� E’ possibile fidarsi di risultati ottenuti in un campione se un ipotetico secondo campione potrebbe fornire risultati opposti? NO!
8
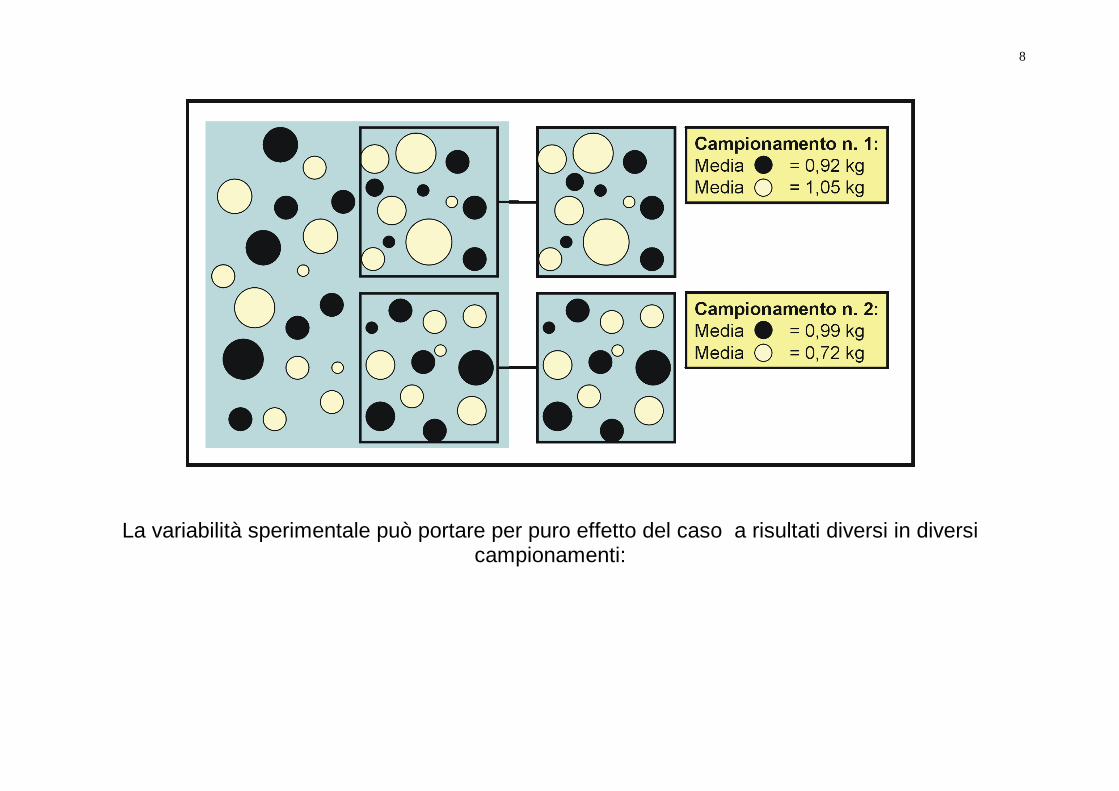
La variabilità sperimentale può portare per puro effetto del caso a risultati diversi in diversi campionamenti:

9
� Il peso degli individui è influenzato da un numero elevatissimo di fattori, molti dei quali
incontrollabili dallo sperimentatore o sconosciuti, e non solo, eventualmente, dall'appartenenza al sesso maschile o a quello femminile.
� Questa situazione è molto frequente nell'analisi dei fenomeni biologici perché esiste un'alta
variabilità da individuo a individuo, ed è proprio per questo motivo che abbiamo bisogno del metodo statistico.
� A partire dall'osservazione parziale di un fenomeno (il campione di 40 trote), la statistica ci
permette di trarre delle conclusioni valide in generale, quasi come se avessimo osservato interamente il fenomeno stesso (in questo caso la popolazione di tutte le trote).
� Quindi, prima di applicare il test statistico appropriato ai 40 pesi misurati, potremmo solamente
dire: o nel nostro campione, i maschi do trota sono mediamente più grandi delle femmine.
� Dopo aver applicato il test statistico, invece, potremmo, per esempio, giungere ad una
conclusione di questo genere: o l'analisi statistica indica che in generale i maschi di trota pesano di più delle femmine, e
tale affermazione ha una probabilità di essere errata inferiore al 5%.

10
Quando si può fare a meno del metodo statistico?
� Assenza di variabilità: se tutti i 20 maschi avessero esattamente lo stesso peso, per esempio 1,10 chilogrammi, e tutte le 20 femmine pesassero invece per esempio 0.97 chilogrammi
� se il biologo evoluzionista e l'allevatore avessero pesato un numero enorme di trote
� Riuscite a immaginare molte variabili biologiche che si comportino come al punto 1 qui sopra?
� Oppure,ad un esperimento in campo biomedico nel quale tutti gli individui ai quali è stato somministrato un farmaco reagiscono nello stesso modo?
� E riuscite altresì a pensare ad una raccolta di dati estesa come quella al punto 2?

11
Un esperimento: i rospi sono destrimani? Un altro esempio sull’importanza della statistica inferenziale

12
La raccolta dei dati: campioni buoni e campioni men o buoni
� Le osservazioni che vogliamo analizzare possono provenire da un campionamento (per esempio, i pesi delle trote, ma anche le concentrazioni di un certo composto chimico in diversi terreni) oppure da un esperimento (per esempio, lo stato di salute dei pazienti trattati o meno con un farmaco). In entrambi i casi, il campione dei dati, deve essere rappresentativo della popolazione.
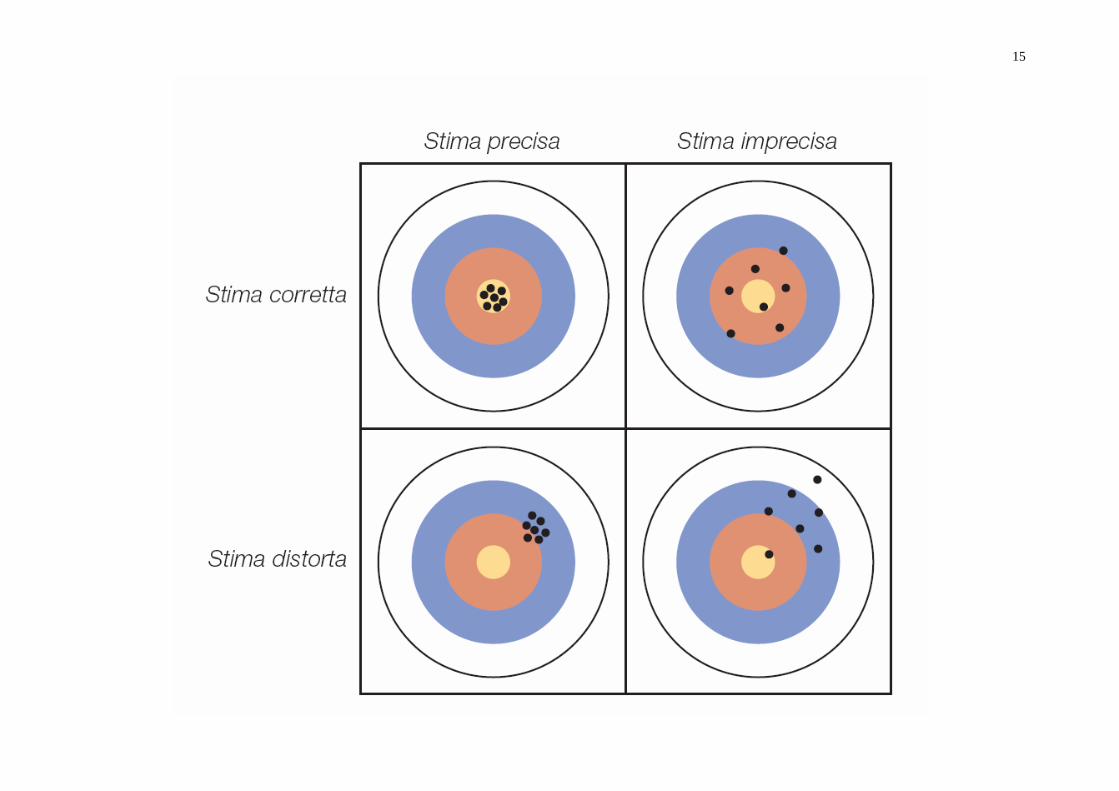
� Campioni casuali e campioni distorti � Stime corrette e stime distorte � Stime precise e stime imprecise
13
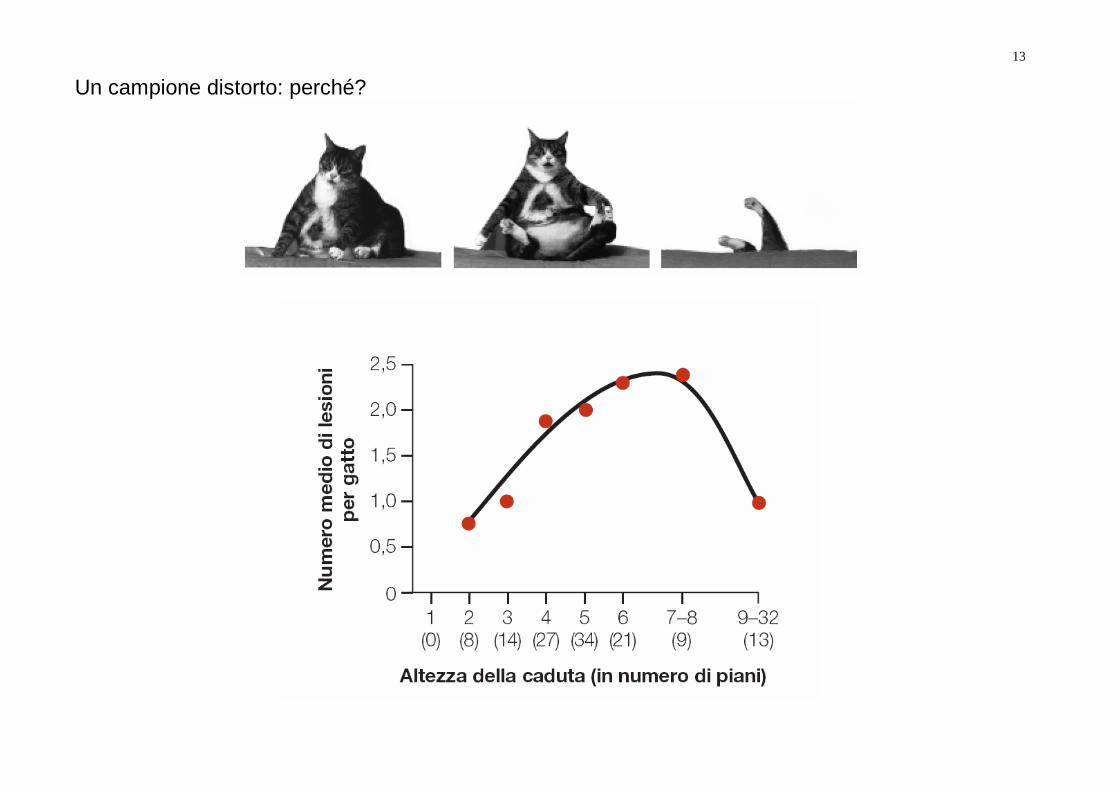
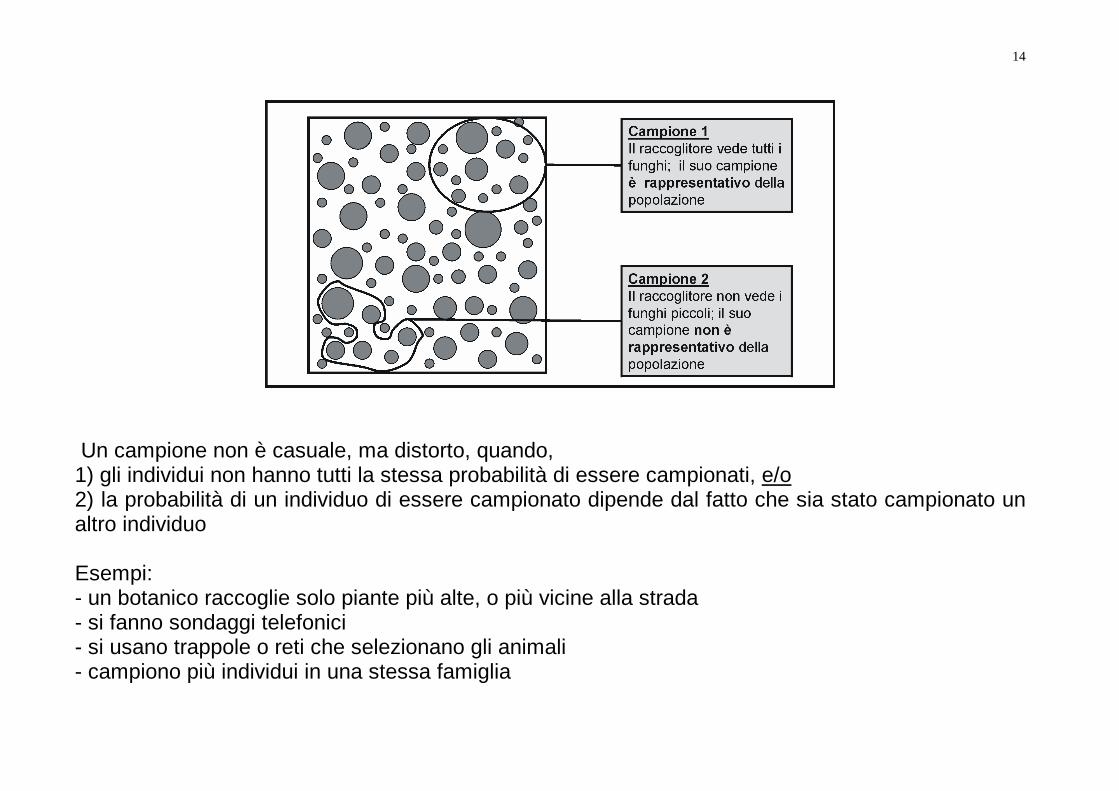
Un campione distorto: perché?
14
Un campione non è casuale, ma distorto, quando, 1) gli individui non hanno tutti la stessa probabilità di essere campionati, e/o 2) la probabilità di un individuo di essere campionato dipende dal fatto che sia stato campionato un altro individuo Esempi: - un botanico raccoglie solo piante più alte, o più vicine alla strada - si fanno sondaggi telefonici - si usano trappole o reti che selezionano gli animali - campiono più individui in una stessa famiglia
15

16
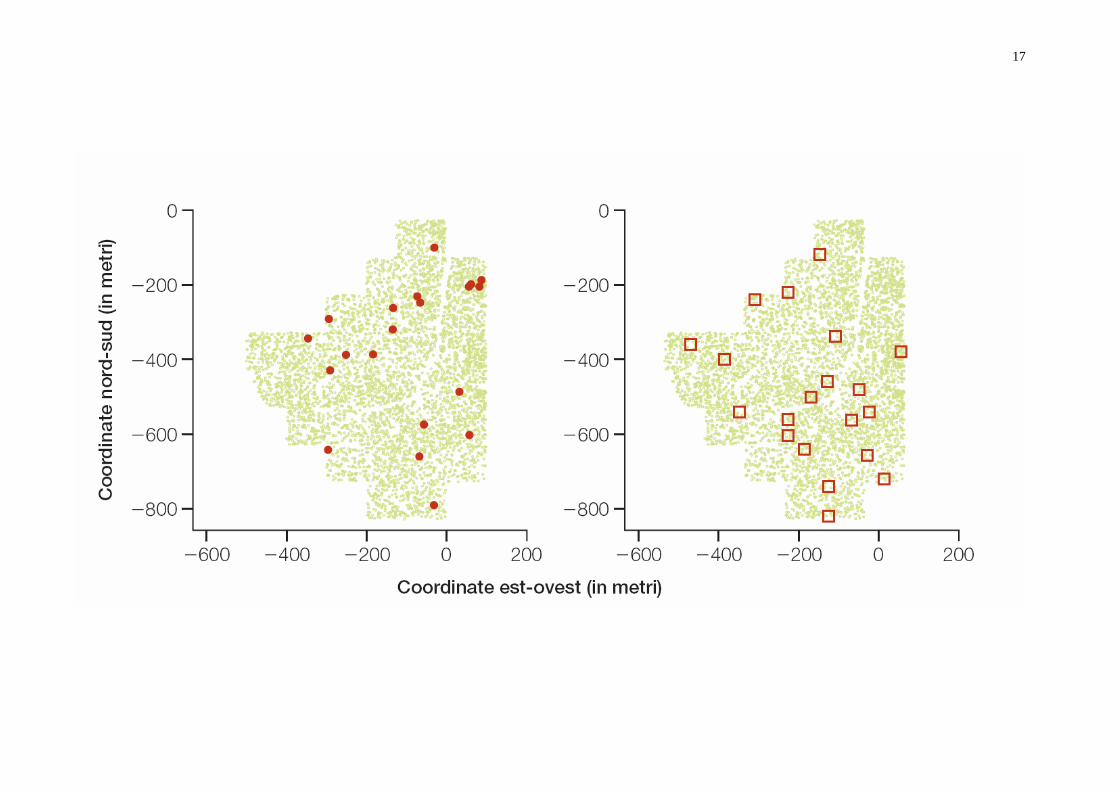
Il campione di convenienza e il campione di volontari sono spesso distorti (non rappresentativi) Esempi di campioni di convenienza - Lesioni dei gatti che cadono dai cornicioni stimati sulla base dei gatti “ospedalizzati” - Merluzzi stimati sulla base della pesca - Inchieste telefoniche Esempi di campione di volontari (uomo) - Campioni provenienti da individui pagati - Campioni di individui che si offrono di rispondere a domande “imbarazzanti” Come si ottiene un campione casuale? E’ sempre possibile ottenerlo? Vediamo un esempio con i 5699 alberi nella foresta di Harvard
17

18
Studi sperimentali e studi osservazionali Nei primi, lo sperimentatore assegna casualmente diversi trattamenti agli individui Per esempio, topi scelti a caso riceveranno un trattamento oppure no. Nei secondi, è la natura che assegna i trattamenti Per esempio, analizzo la relazione tra colorazione e predazione: non scelgo io il colore da assegnare a ciascun individuo. Oppure, studio la relazione tra fumo e tumore: non scelgo io i soggetti a cui somministrare il “trattamento fumo” Negli studi osservazionali, una relazione può essere dovuta ad una causa comune, non ad una relazione di causa ed effetto tra le due variabili analizzate. Per esempio, i pesci rossi sono meno predati di quelli rosa, ma in realtà potrebbe esserci una terza variabile (salute media) che determina colore e livello di predazione. Oppure, potrebbero essere gli individui più depressi che fumano, e il rischio di tumore potrebbe dipendere dalla depressione e non dal fumo. Se da uno studio osservazionale passo ad uno studio sperimentale (per esempio, in un campione pesci, metà scelti a caso li coloro di rosso e metà di rosa; oppure, scelgo a caso un certo numero di topi e li metto in gabbie con fumo, un altro numero in gabbie senza fumo), posso capire molto di più riguardo le relazioni di causa ed effetto.

STATISTICA DESCRITTIVA Riassume e visualizza i risultati ottenuti in un es perimento o raccolti sul campo, con lo scopo di � acquisire una certa familiarità con i dati prima di passare alle analisi statistiche inferenziali � evidenziare nei dati tendenze inattese a priori che possono suggerire analisi non previste
inizialmente o anche nuovi esperimenti o campionamenti � identificare rapidamente eventuali errori nella trascrizione dei valori o nel loro inserimento al
calcolatore � identificare preliminarmente alcune caratteristiche dei dati che potrebbero precludere il successivo
utilizzo di alcune tecniche statistiche � comunicare ad altre persone brevemente, con logica ed ordine, le principali caratteristiche dei dati
raccolti Attenzione: riassumere vuol quasi sempre dire perdere parte dell’informazione

� Cos’è una variabile? o una qualsiasi caratteristica misurata o registrata in un’unità campionaria. Generalmente le
variabili sono indicate con lettere maiuscole e i valori che possono assumere con lettere minuscole, spesso indicizzati per indicare il valore assunto dalla variabile in una specifica osservazioni
� I valori che assume possono essere numerici oppure di semplice appartenenza ad una certa
categoria
o Variabili quantitative continue � Peso, altezza, concentrazione, …
o Variabili quantitative discrete � Numero uova, numero parassiti, numero piastre batteriche,…
o Variabili qualitative con valori ordinabili (scala ordinale) � “Abbondanza”, stato di salute, aggressività, …
o Variabili qualitative con valori non ordinabili (scala nominale) = variabili categoriche
� Gruppo sanguigno, tipo di malattia, tipo mutazione, specie…
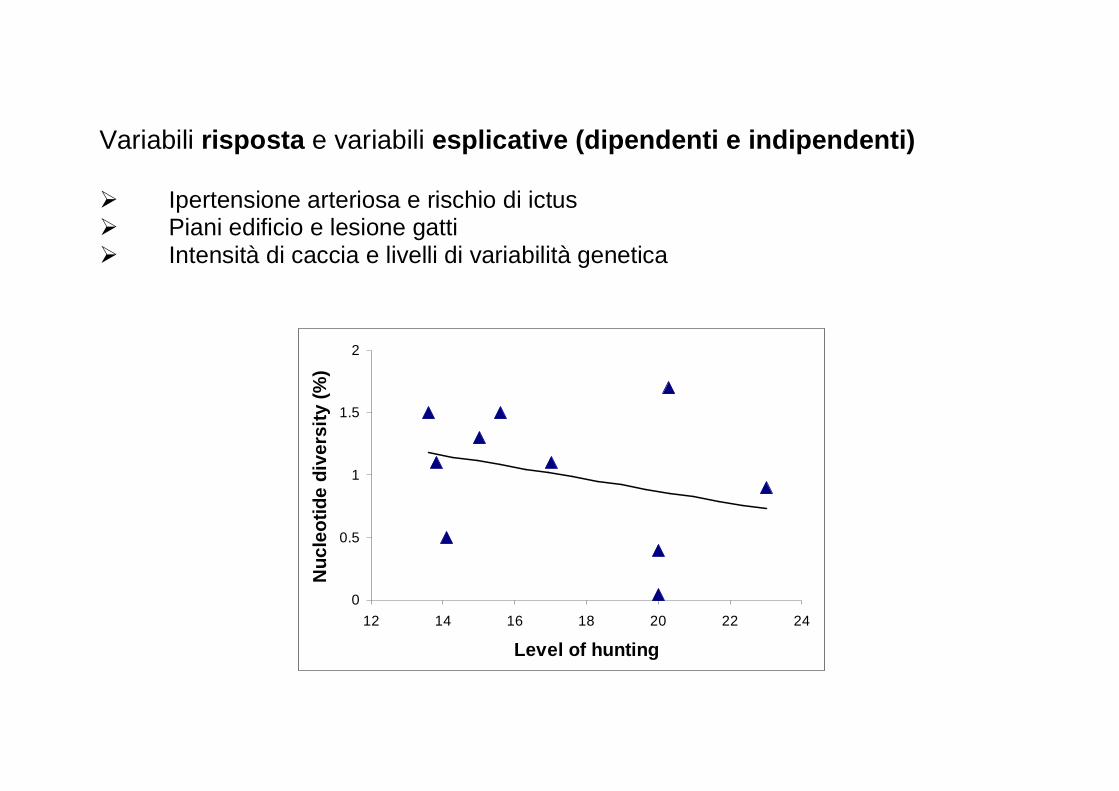
Variabili risposta e variabili esplicative (dipendenti e indipendenti) � Ipertensione arteriosa e rischio di ictus � Piani edificio e lesione gatti � Intensità di caccia e livelli di variabilità genetica
0
0.5
1
1.5
2
12 14 16 18 20 22 24
Level of hunting
Nuc
leot
ide
dive
rsity
(%
)

Dati, frequenze e distribuzioni
� 22 nidi di merlo al momento dell’involo e di avere contato in ciascuno di essi il numero di piccoli sopravvissuti o unità campionaria = nido o la femmina o variabile è quantitativa discreta.
� x1 = 0; x2 = 2; x3 = 2; x4 = 0; x5 = 1; x6 = 3; x7 = 3; x8 = 2; x9 = 2; x10 = 4; x11 = 1; x12 = 4; x13 = 2;
x14 = 1; x15 = 2; x16 = 3; x17 = 3; x18 = 6; x19 = 4; x20 = 2; x21 = 3; x22 = 3,
� dove xi, indica il valore assunto dalla variabile X nella i-esima osservazione, con l'indice i che varia da 1 a n (n = 22 = dimensione del campione).
� classe di frequenza e tabella di frequenza:
xi ni 0 2 1 3 2 7 3 6 4 3 6 1

� In questo caso xi indica il valore assunto dalla variabile X nella i-esima classe, con l'indice i che
varia da 1 a c, ni è il numero di volte che nel campione ricorre l'osservazione xi e c è il numero di classi (5 nel nostro caso)
� Chiaramente la somma di tutti gli ni deve dare n, ovvero
ni = ni = ni = ni∑i∑
i=1
c
∑i=1
i= c
∑ = n
� distribuzione di frequenza: ossia alla distribuzione dei dati nelle diverse classi
o distribuzione di probabilità o distribuzione di probabilità teorica
� diagramma a segmenti (o a barre)
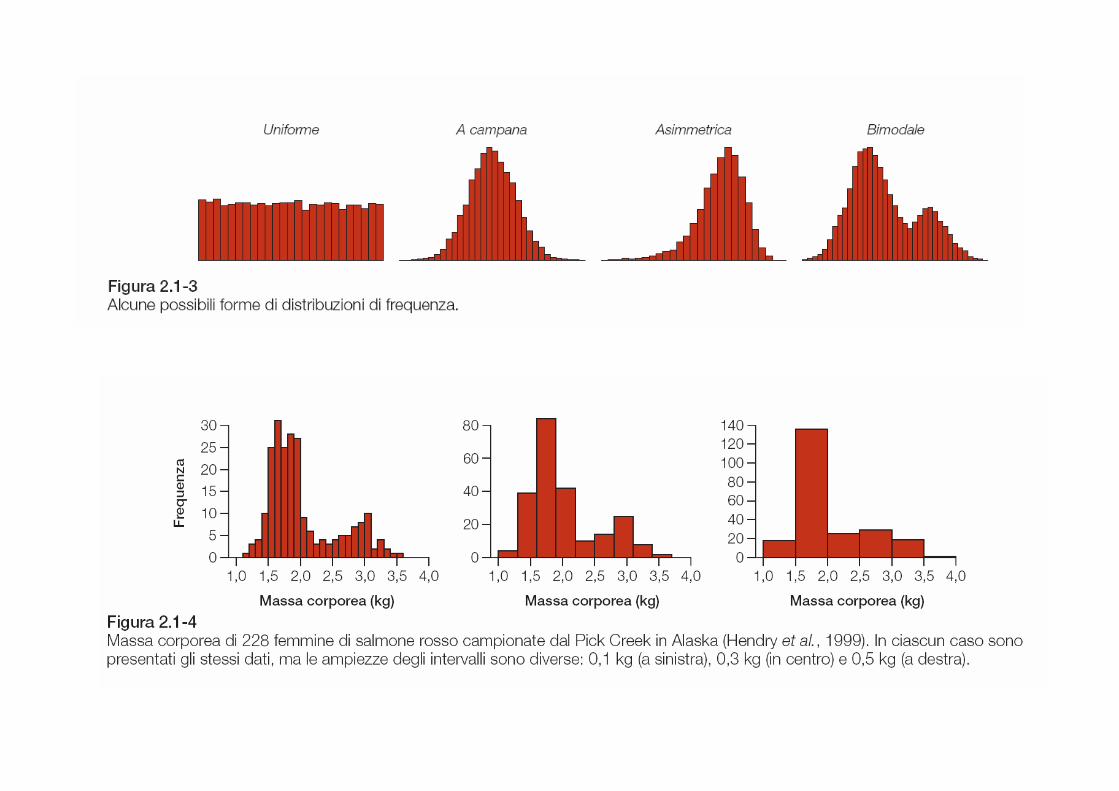
o capisco quali sono i valori che ricorrono più frequentemente o distribuzione unimodale, bimodale, multimodale? o Simmetrica o asimmetrica? Asimmetrica a destra o a sinistra? o capisco e l'intervallo di variazione della variabile analizzata
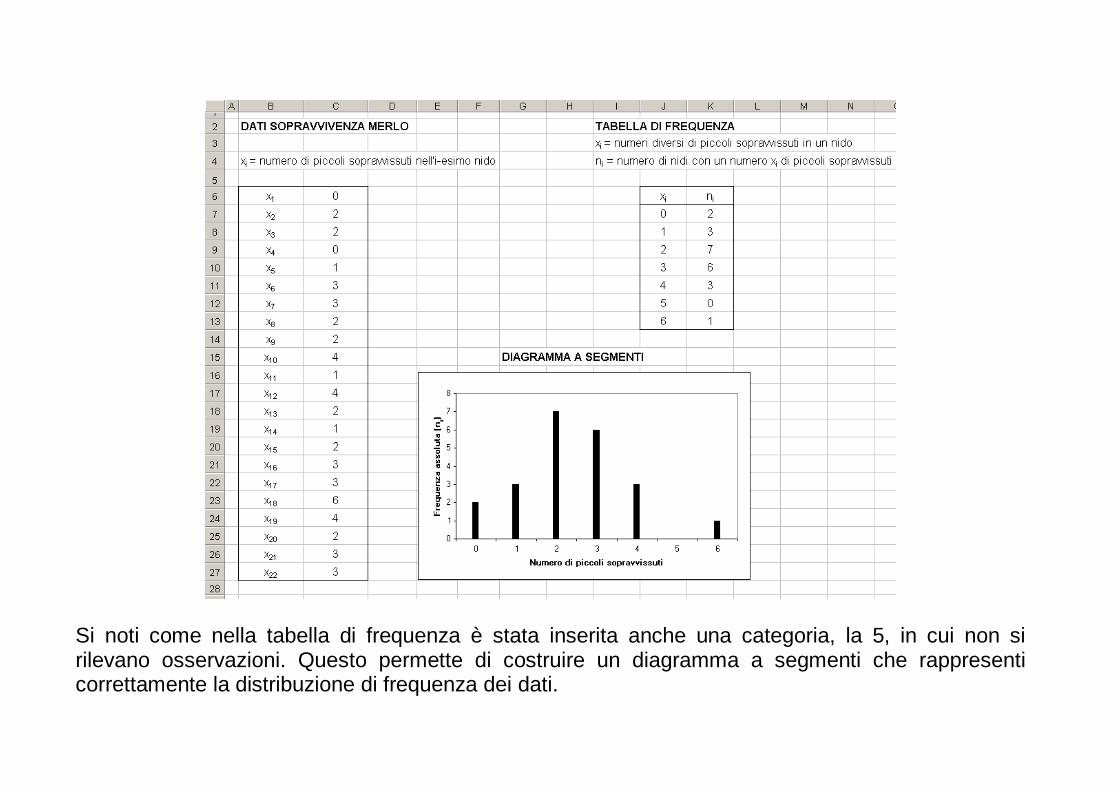
Si noti come nella tabella di frequenza è stata inserita anche una categoria, la 5, in cui non si rilevano osservazioni. Questo permette di costruire un diagramma a segmenti che rappresenti correttamente la distribuzione di frequenza dei dati.
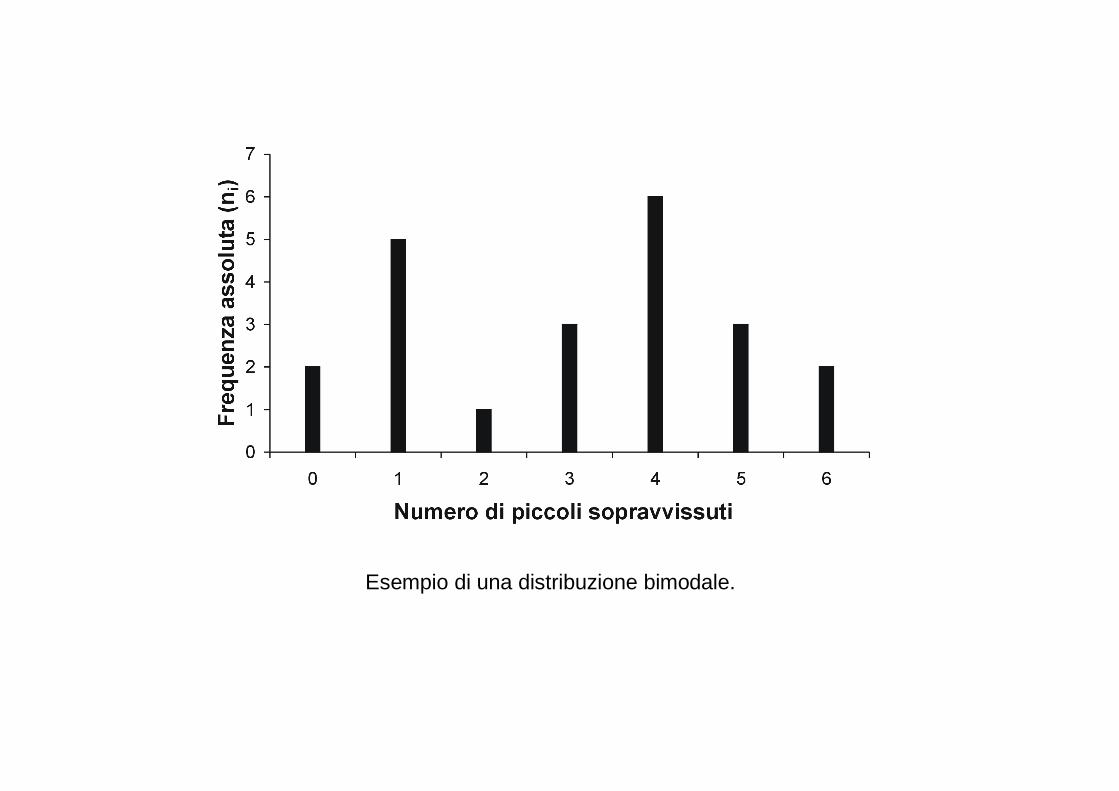
Esempio di una distribuzione bimodale.
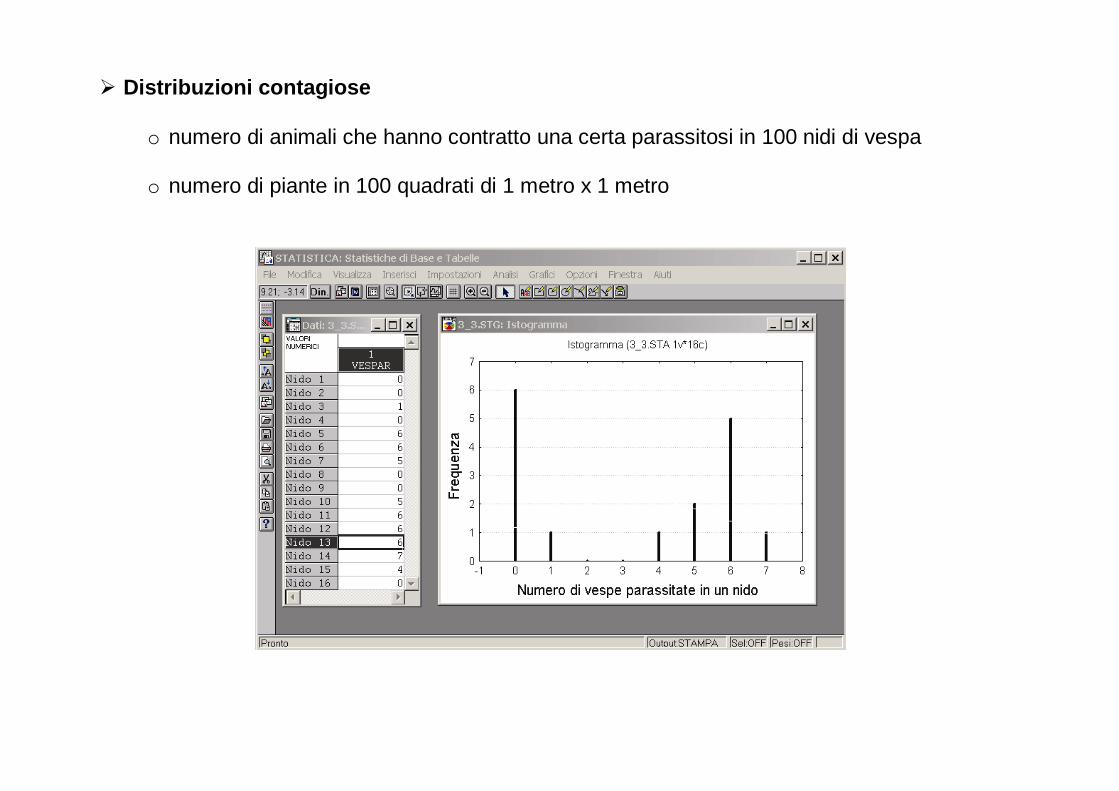
� Distribuzioni contagiose
o numero di animali che hanno contratto una certa parassitosi in 100 nidi di vespa o numero di piante in 100 quadrati di 1 metro x 1 metro

� frequenze assolute (ni, dette anche numerosità) � frequenze relative (fi, o, a volte, pi,), ovviamente varia tra 0 e 1
� frequenza percentuale
fi = pi =ni
n
fi %( ) = fi ×100
� Il termine generico frequenza è spesso utilizzato per indicare cose diverse
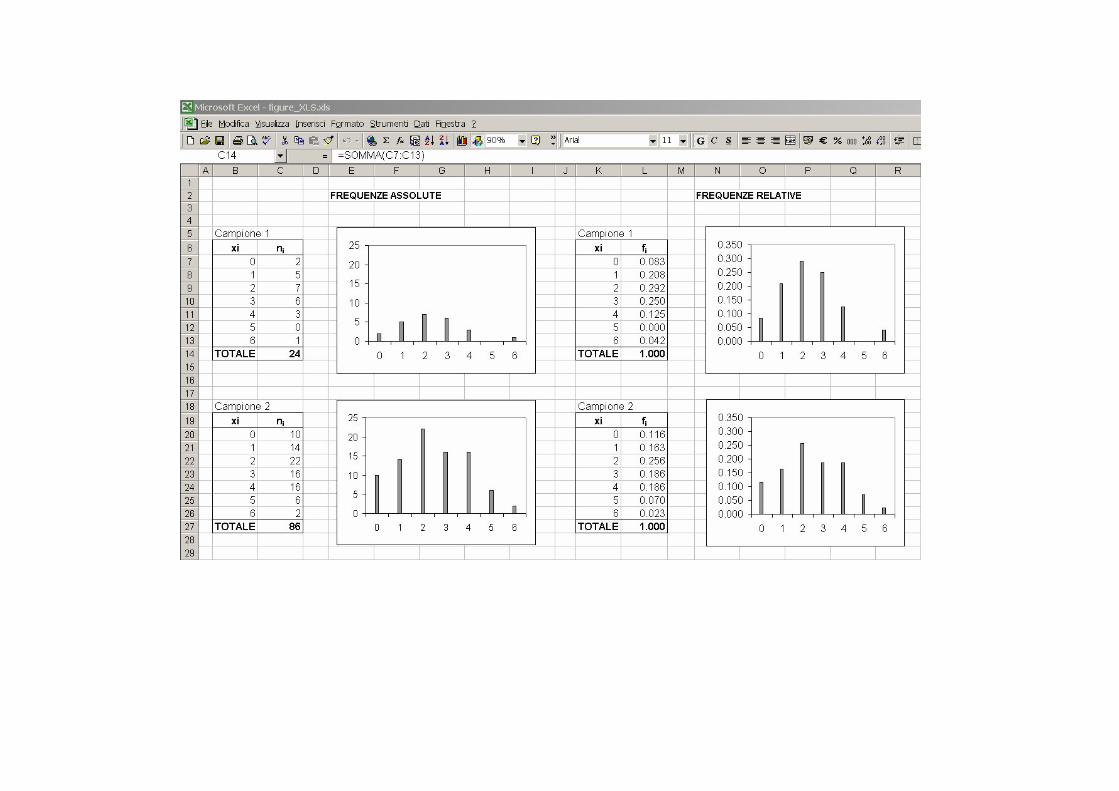
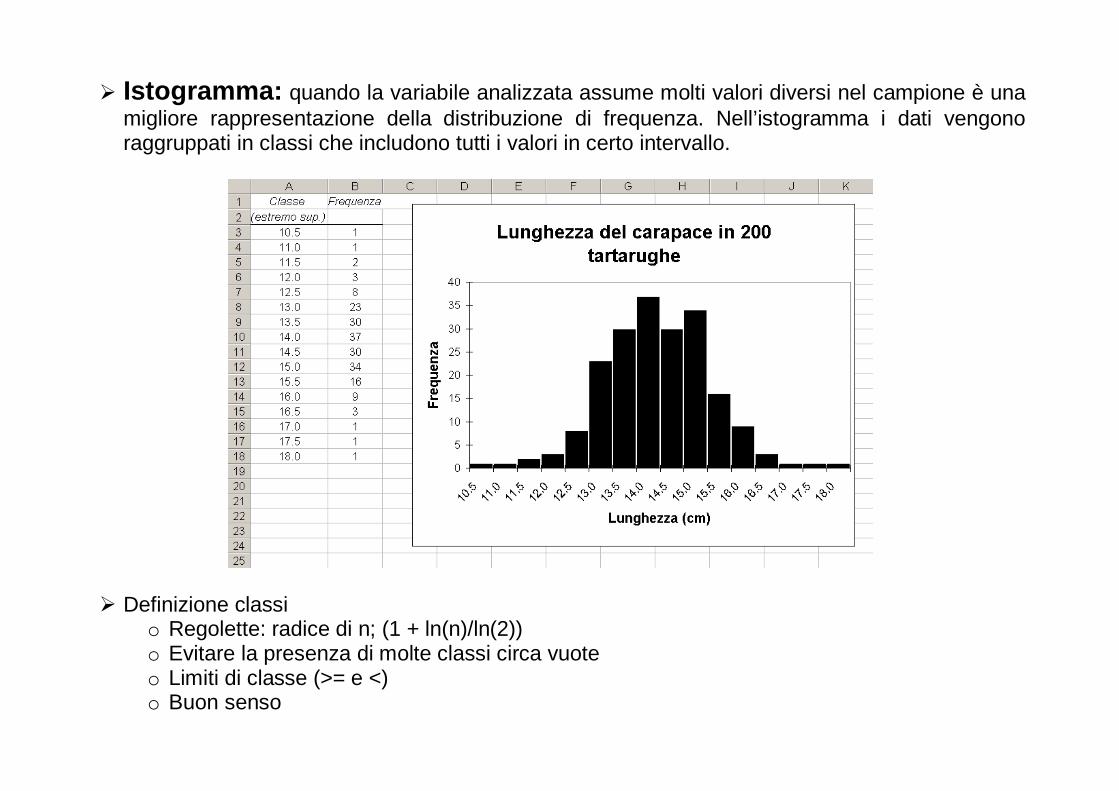
� Istogramma: quando la variabile analizzata assume molti valori diversi nel campione è una migliore rappresentazione della distribuzione di frequenza. Nell’istogramma i dati vengono raggruppati in classi che includono tutti i valori in certo intervallo.
� Definizione classi o Regolette: radice di n; (1 + ln(n)/ln(2)) o Evitare la presenza di molte classi circa vuote o Limiti di classe (>= e <) o Buon senso
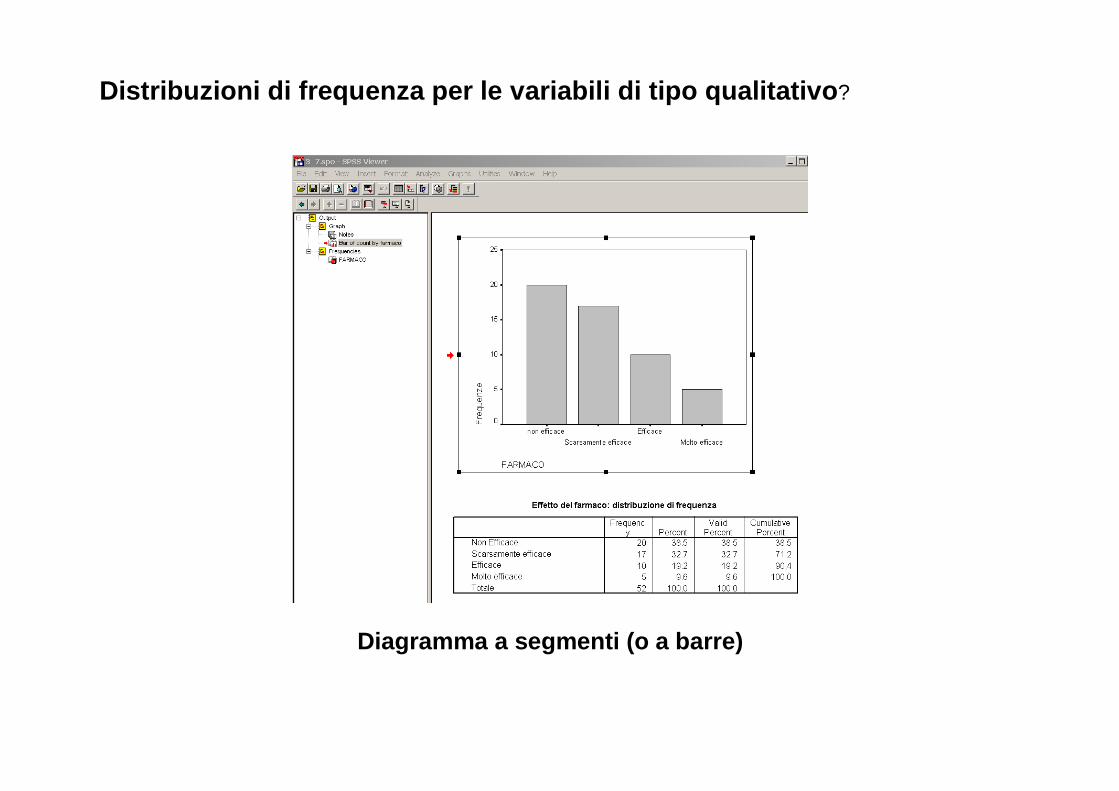
Distribuzioni di frequenza per le variabili di tipo qualitativo ?
Diagramma a segmenti (o a barre)
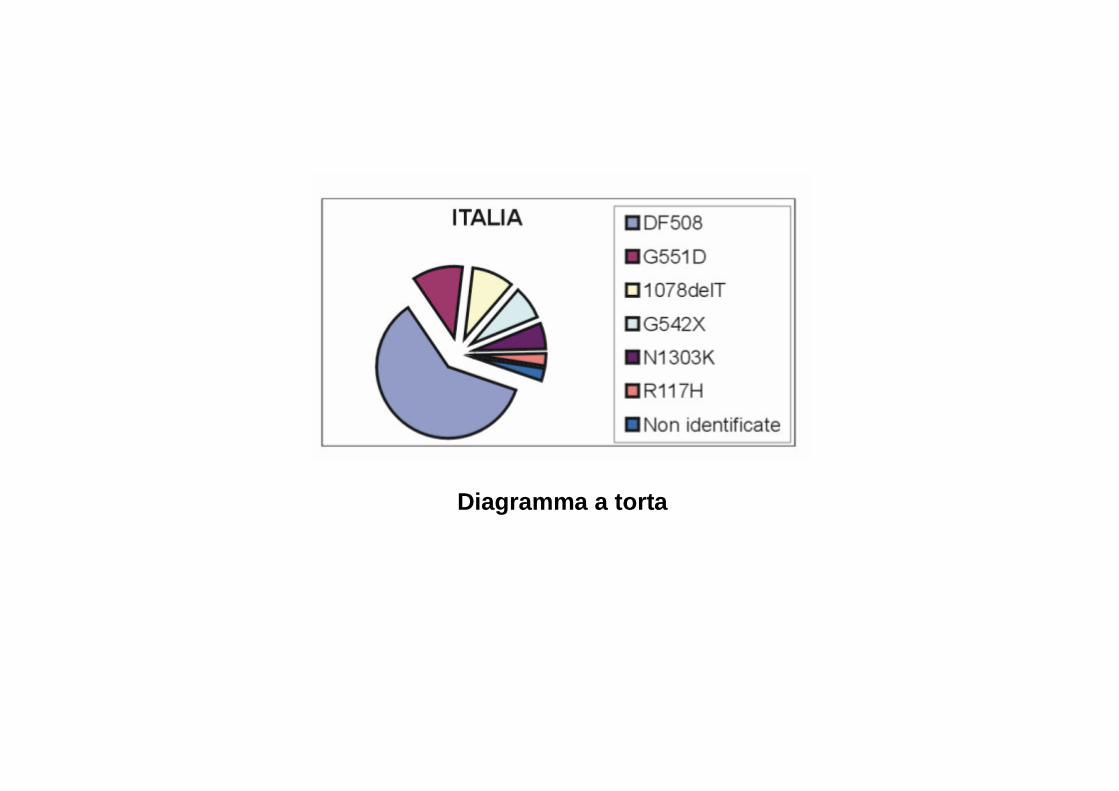
Diagramma a torta
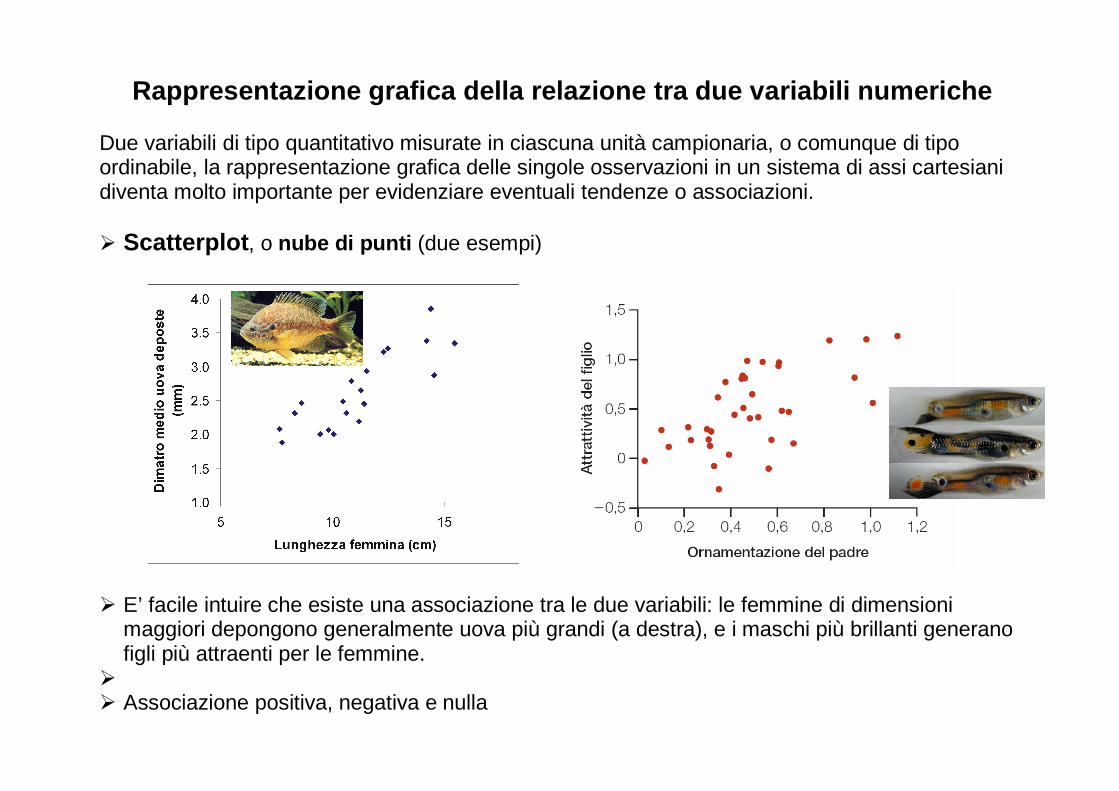
Rappresentazione grafica della relazione tra due va riabili numeriche Due variabili di tipo quantitativo misurate in ciascuna unità campionaria, o comunque di tipo ordinabile, la rappresentazione grafica delle singole osservazioni in un sistema di assi cartesiani diventa molto importante per evidenziare eventuali tendenze o associazioni.
� Scatterplot, o nube di punti (due esempi)
� E’ facile intuire che esiste una associazione tra le due variabili: le femmine di dimensioni maggiori depongono generalmente uova più grandi (a destra), e i maschi più brillanti generano figli più attraenti per le femmine.
� � Associazione positiva, negativa e nulla
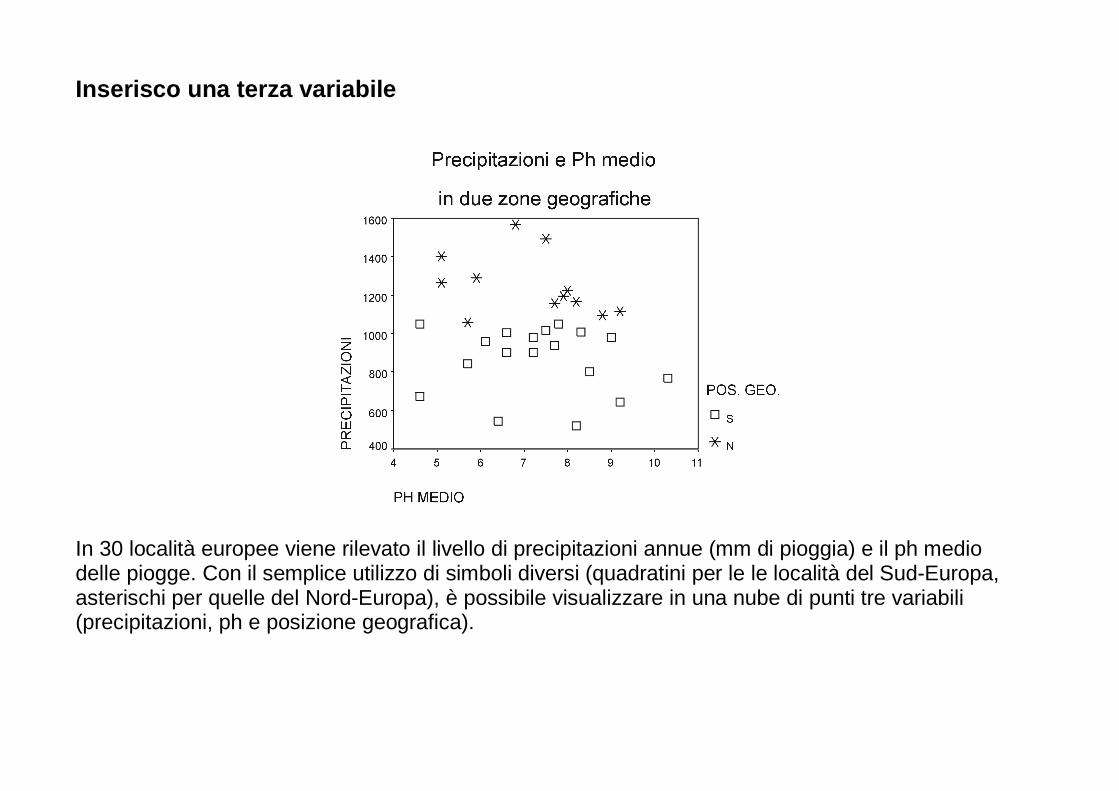
Inserisco una terza variabile
In 30 località europee viene rilevato il livello di precipitazioni annue (mm di pioggia) e il ph medio delle piogge. Con il semplice utilizzo di simboli diversi (quadratini per le le località del Sud-Europa, asterischi per quelle del Nord-Europa), è possibile visualizzare in una nube di punti tre variabili (precipitazioni, ph e posizione geografica).
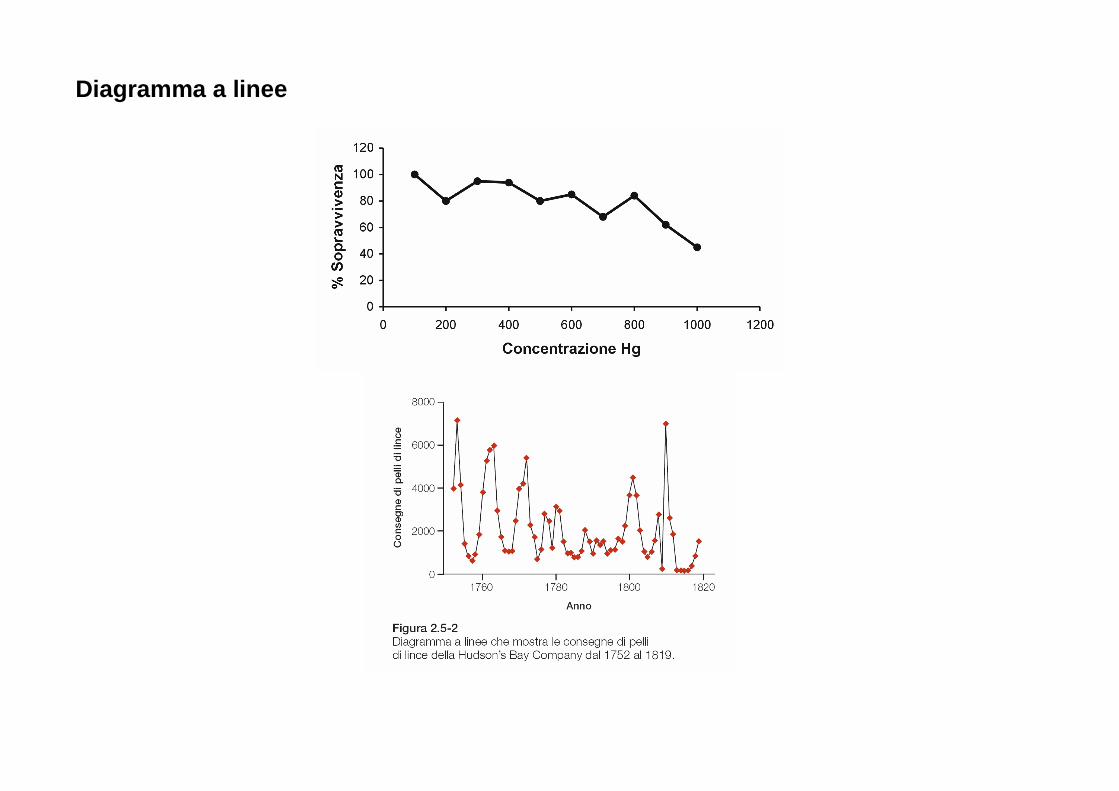
Diagramma a linee
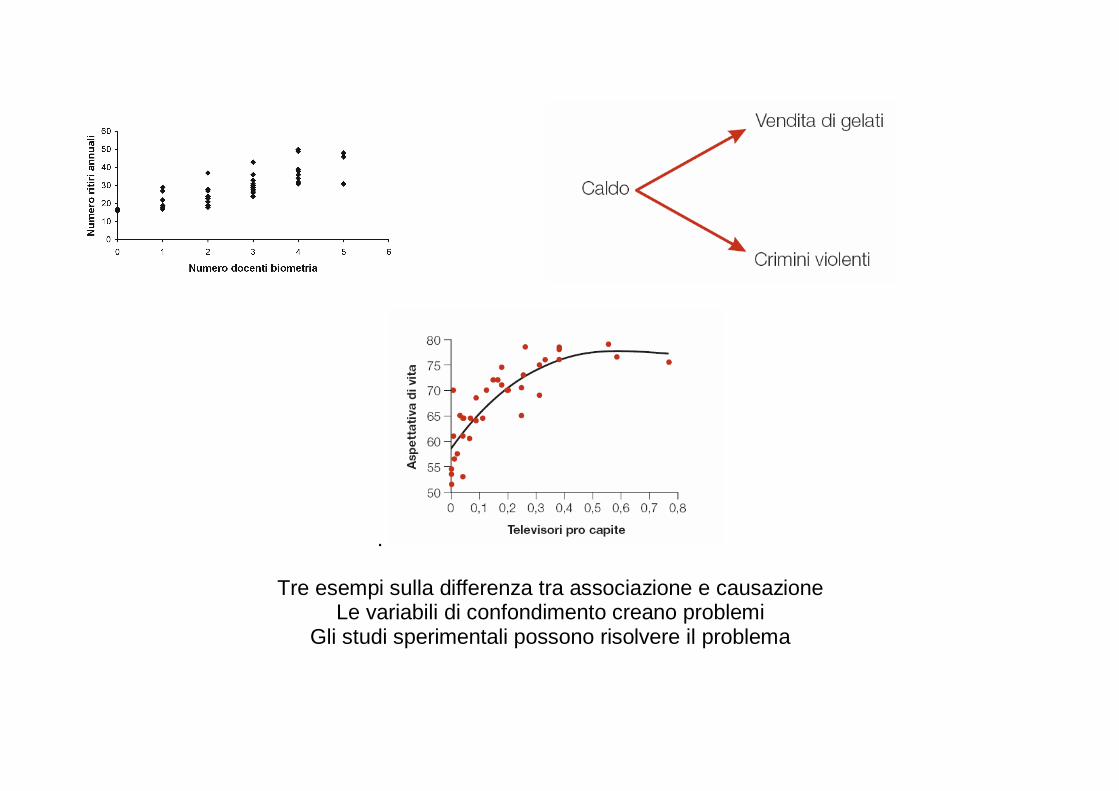
.
Tre esempi sulla differenza tra associazione e causazione Le variabili di confondimento creano problemi
Gli studi sperimentali possono risolvere il problema

Rappresentazione tridimensionale di temperatura, umidità, e numero di specie misurate in 13 stazioni di campionamento.
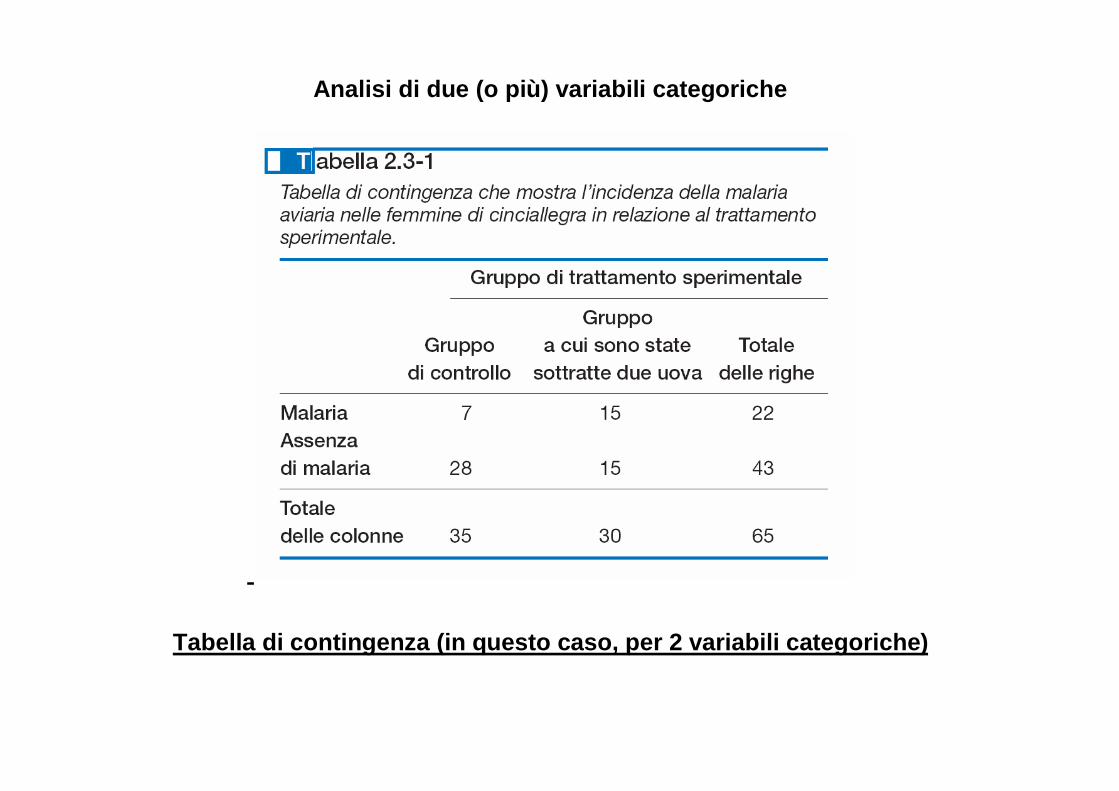
Analisi di due (o più) variabili categoriche
Tabella di contingenza (in questo caso, per 2 varia bili categoriche)
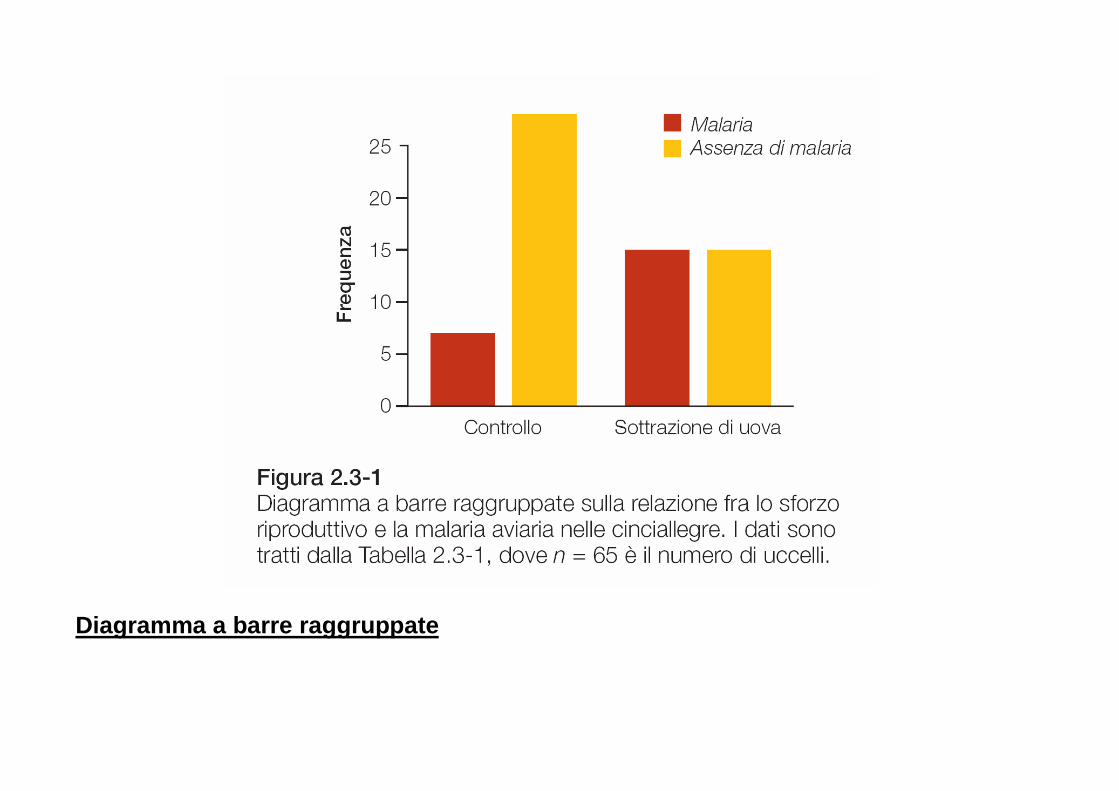
Diagramma a barre raggruppate
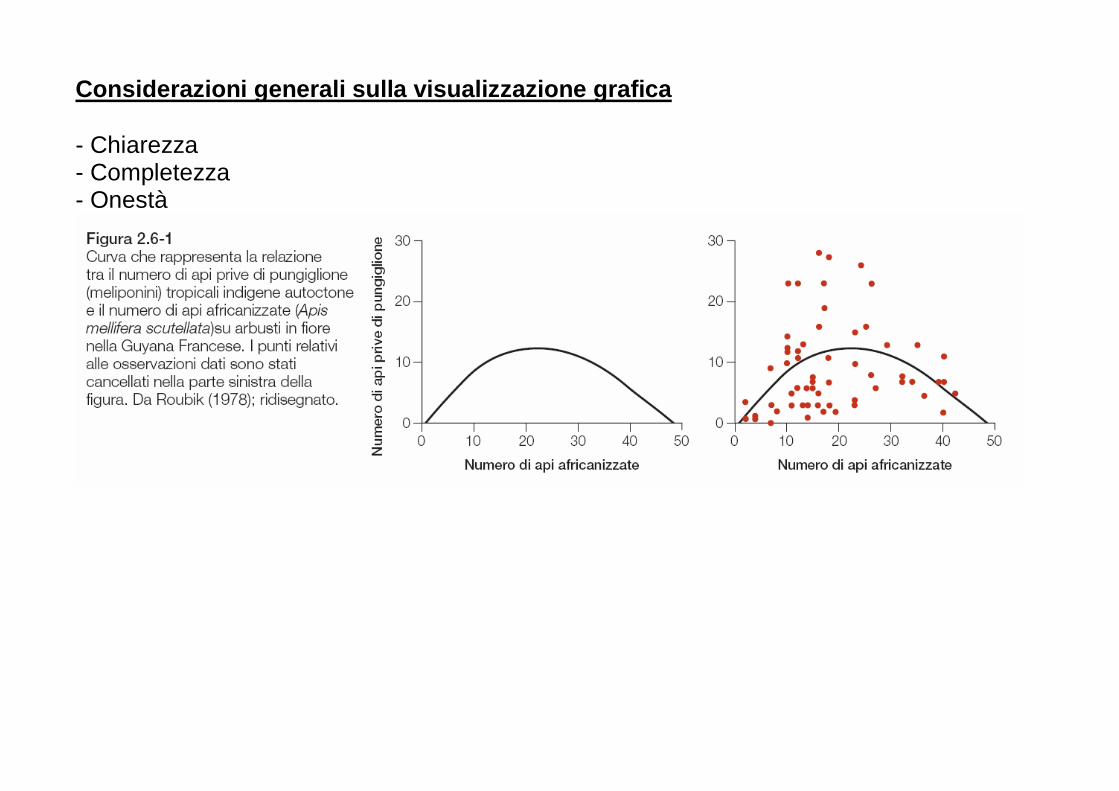
Considerazioni generali sulla visualizzazione grafi ca
- Chiarezza - Completezza - Onestà

Indici sintetici di una distribuzione
� Sintesi attraverso le distribuzioni di frequenza � Ulteriori sintesi attraverso le
o misure di tendenza centrale (o di posizione)
� cercano di identificare il valore "tipico" di una distribuzione, ovvero la posizione, nella scala della variabile analizzata, intorno alla quale si concentrano le osservazioni
o misure di dispersione
� sintetizzano il grado di variabilità dei dati
� Le misure di tendenza centrale e di dispersione dovrebbero quindi rispecchiare, rispettivamente, la posizione e l’ampiezza di una distribuzione di frequenza.
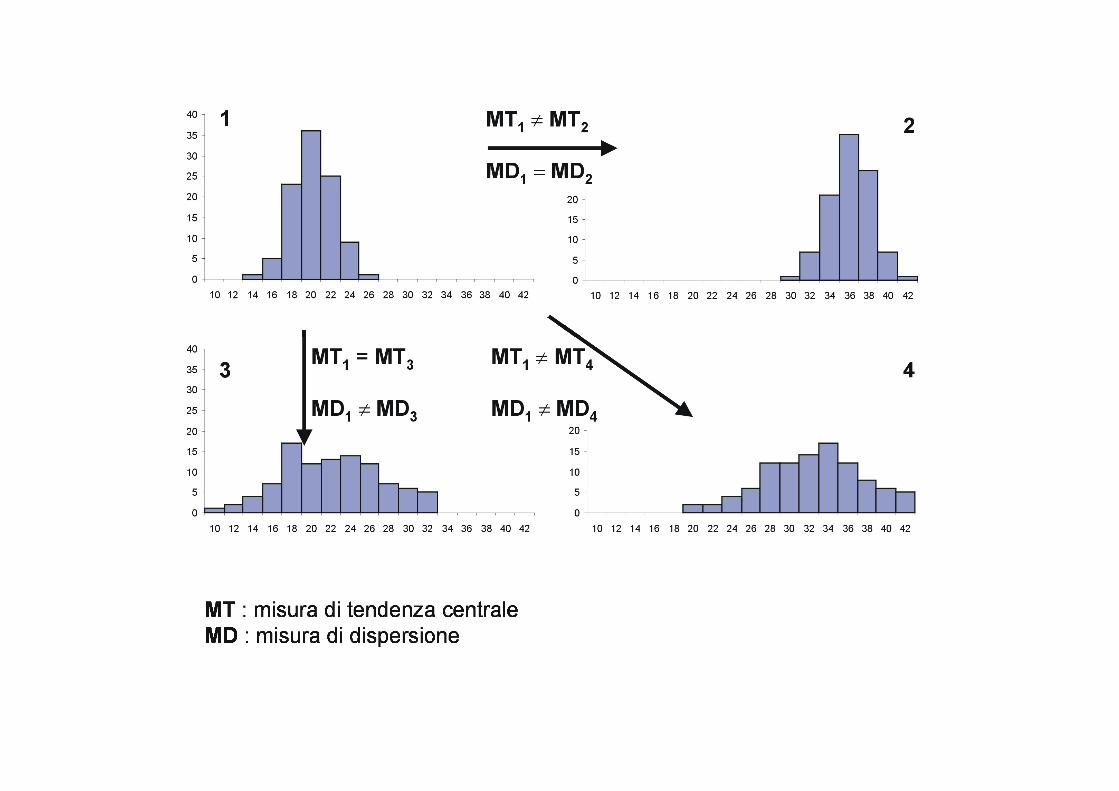

� Conoscere la dispersione dei dati equivale a conoscere qualcosa sul valore di ogni singolo valore per la comprensione di un fenomeno.
� Se la dispersione è molto elevata, le singole osservazioni possono essere anche molto diverse,
e quindi singolarmente di scarso valore. � Si può dire quindi che all’aumentare della dispersione il numero di osservazioni necessarie per
trarre delle conclusioni generali a partire da un campione deve aumentare. � Quando la variabilità è molto bassa può anche non essere necessario effettuare molte
osservazioni, e forse nemmeno ricorrere alla statistica inferenziale.

Misure di tendenza centrale La media
� Media aritmetica. In genere quando si parla di media si intende la media aritmetica
� Media campionaria, della variabile X, la media campionaria viene indicata con x .
x =xi
1
n
∑
n
� Media della popolazione
µ =x i∑
N
� La somma delle differenze dei singolo valori dalla media (detti scarti dalla media) è uguale a 0 e
quindi la media si può considerare il baricentro del campione dove si bilanciano gli scarti.
xi − x ( )= xi − x ∑∑∑ = nx − nx = 0

� Media a partire da una tabella di frequenza :
x =xini
1
c
∑
n oppure x = xi fi
1
c
∑
Esempio
Aplotipo xi ni A 51 5
B 54 11 C 55 15 D 57 29 E 62 22 F 63 4
x =xini
1
c
∑
n=
51 × 5 + 54 ×11 + 55 ×15 + 57 × 29 + 62 × 22 + 63 × 4
86=
5738
86= 57,44
� E se la variabile continua?

Proprietà della media • la media implica la somma di valori numerici e quindi ⇒ ha un significato solo per le variabili quantitative; ⇒ risente molto dei valori estremi; se un singolo valore nel campione è per esempio molto più
grande di tutti gli altri, la media non identifica un valore tipico del campione ⇒ non è calcolabile se alcune osservazioni sono “fuori scala”
• nel caso di distribuzioni multimodali, la media raramente identifica un valore tipico

Esempio: Supponiamo di sacrificare 12 trote campionate in natura per contare in ciascuna di esse il numero di parassiti intestinali di una certa specie. Dati: 3, 2, 3, 4, 6, 2, 44, 8, 5, 3, 4, 2.
� La media di questi valori risulta essere 7,16, ma come è facile rendersi conto, questo valore non identifica certamente un valore tipico del campione. Questio a causa di un valore estremo, detto outlier.
Esempio: Nove cavie sono sottoposte ad un test cognitivo all’interno di un labirinto, e per ogni animale si misura il tempo impiegato a percorrere un certo tracciato. I risultati ottenuti, in minuti, sono i seguenti: Dati: 23 ,25, 29, 22, 15, >120, 32, 20,>120
� In questo caso due valori sono “fuori scala”, e la media calcolata escludendo questi valori mancanti non rappresenterebbe correttamente l’esperimento.

La mediana
� La mediana è il valore centrale in una serie di dati ordinati. Per esempio Dati: 30, 49, 74, 40, 63, 295, 60 Dati ordinati: 30, 40, 49, 60, 63, 74, 295
� La mediana è quindi il valore che divide un campione di dati ordinati in due parti ugualmente numerose. In altre parole, metà dei valori nel campione sono più piccoli della mediana, e metà sono più grandi. E’ evidente quindi che la mediana è una misura della tendenza centrale.
� Se il numero di osservazioni n è dispari, la mediana è il valore che occupa la posizione (n+1)/2
nella serie ordinata dei dati (il quarto valore nell’esempio appena visto). Se n è pari, la mediana è la media tra i 2 valori centrali, ossia la media dei valori nelle posizioni n/2 e n/2 +1. Nel caso di dati raccolti in una tabella di frequenza, è in genere sufficiente identificare la classe che contiene la mediana (la classe mediana).

Proprietà della mediana
� Il calcolo della mediana non implica l’elaborazione dei dati numerici osservati o L’informazione sul peso relativo dei singoli valori viene perduta.
� E’ spesso un buon indicatore della tendenza centrale di un set di dati
� è calcolabile anche se la variabile è qualitativa (ma deve essere ordinabile!) � non risente dei valori estremi � è calcolabile anche se alcune osservazioni sono “fuori scala”
Esempi precedenti
- la mediana del numero di parassiti nelle 12 trote è pari a 3,5 parassiti - la mediana del tempo impiegato dalla cavie nel labirinto è 25 minuti
In entrambi i casi la mediana e facilmente calcolabile e indica bene (meglio della media) dove si concentrano le osservazioni.
� La mediana, però, soffre dello stesso inconveniente della media, ovvero può portare ad un valore assolutamente non rappresentativo quando la distribuzione non è unimodale.

La moda
� La moda è semplicemente il valore osservato più spesso nel campione. Dati: 0, 1, 5, 2, 2, 2, 3, 3, 3, 2, 4, 4, 1,2 vengono riassunti nella tabella di frequenza
xi ni 0 1 1 2 2 5 3 3 4 2 5 1
La moda è quindi pari a 2.
� Classe modale è quella che contiene il maggior numero di osservazioni.
� La stretta interpretazione della moda dovrebbe anche avere come conseguenza il fatto che praticamente tutte le distribuzioni osservate sono unimodali

Proprietà della moda
� La moda è una statistica molto semplice e intuitiva per riassumere una distribuzione di frequenza attraverso il suo “picco” più elevato. Anche se, come la mediana, non considera il peso delle singole osservazioni, ha alcune proprietà importanti:
• è possibile identificare la moda in qualsiasi tipo di variabile, quindi anche nelle variabili qualitative
non ordinabili • indica sempre un valore realmente osservato nel campione • non è influenzata dai valori estremi • nel caso di distribuzioni di frequenza molto asimmetriche, la moda è forse il miglior indice per
descrivere la tendenza centrale di un campione • è collegata direttamente al concetto di probabilità (che vedremo meglio nei prossimi capitoli): la
moda di una popolazione è il valore della variabile con la la maggior probabilità di essere osservata
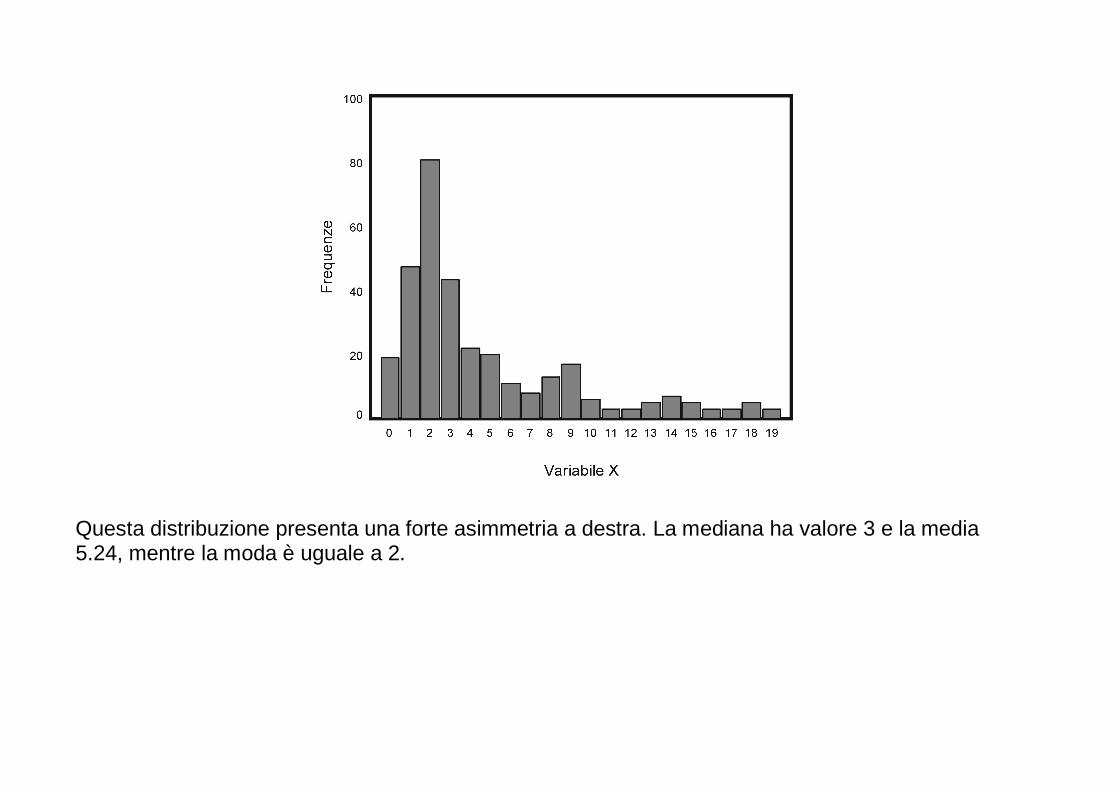
Questa distribuzione presenta una forte asimmetria a destra. La mediana ha valore 3 e la media 5.24, mentre la moda è uguale a 2.

Misure di dispersione
� Basate sulle differenze tra le singole osservazioni e la media (scarti dalla media) o Varianza o Deviazione standard o Coefficiente di variazione o Tutti i valori concorrono al calcolo di queste tre misure di dispersione (inclusi gli outliers) o L’utilizzo di questi indici non è adatto allo studio della dispersione di variabili qualitative,
� Non basate sull’elaborazione numerica dei dati o Range o Distanza interquartile.

La varianza
� La somma degli scarti della media è uguale a 0 o media degli scarti = 0
� Se però ogni singolo scarto dalla media viene elevato al quadrato…
o La media degli scarti al quadrato, chiamata anche scarto quadratico medio, è la varianza.
� Varianza campionaria:
s 2=
xi − x ( )2
∑n −1 ,

� La somma degli scarti quadratici al numeratore, chiamata devianza, può essere calcolata anche con le formule semplificate:
Dev(X ) = xi2−
x i∑( )2
n∑
Infatti:
xi − x ( )∑2= xi
2+ x 2 − 2x x i( )∑ = x i
2+ n∑
x i∑( )2
n2 − 2xi∑
nx i∑ = xi
2−
xi∑( )2
n∑
� Così il calcolo (manuale) è più preciso. Perché? � Attenzione però che concettualmente…

� Cosa c’è di strano nel calcolo di s2 ?
o Dal punto di vista della statistica descrittiva potrei usare n al denominatore o Anche se fossero disponibili i dati riferiti a tutte le N unità campionarie della popolazione,
allora
σ2=
xi − µ( )2
∑N
� Ma: o La varianza campionaria s2, calcolata utilizzando n al denominatore è una stima distorta
(una sottostima in questo caso) della varianza della popolazione σ2 � La media di un campione è imprecisa (non è uguale a µ) � I valori tendono ad essere più vicini alla media campionaria di quanto non siano a µ � Più il campione è piccolo, meno riesce a cogliere tutta la variabilità dei dati nella
popolazione � Tale distorsione (bias) si può correggere utilizzando il fattore n-1 a denominatore.

� Nel caso di dati raggruppati in c classi di frequenza
s 2=
ni xi − x ( )2
1
c
∑
n −1 ,
� Se poi i dati sono raccolti in classi corrispondenti ad un intervallo tra due valori, una stima di s2 si può ottenere utilizzando la stessa espressione sostituendo xi con i valori centrali degli intervalli.

La deviazione standard
� L'unita di misura della varianza e l'unita di misura della deviazione standard
� La deviazione standard, s, indicata anche con l’abbreviativo D.S. o DS, è data da:
s = DS = s2

Coefficiente di variazione
� E’ una sorta di deviazione standard rielaborata per evitare i cosiddetti “effetti di scala”.
Esempio:
� Deviazione standard nella lunghezza del corpo dei maschi di Gambusia holbrooki (un piccolo pesce d’acqua dolce) é uguale a 3.2 mm
� Deviazione standard nella lunghezza dei maschi territoriali di Zosterisessor ophiocephalus (il gò, un ghiozzo di laguna) sia pari 10.6 mm.
� I maschi di Gambusia sono meno variabili dei maschi di gò, ossia i maschi di Gambusia si assomigliano tra loro (per la lunghezza) più di quanto facciano quelli di gò?
� Forse la maggiore dispersione indicata dalla deviazione standard è solo un effetto della diversa
dimensione media di queste due specie o Per esempio, la differenza nella lunghezza del femore tra due persone è senza dubbio di
molte volte maggiore della differenza nella lunghezza della zampa di due maggiolini.

� Quando cioè si vuole confrontare la dispersione tra variabili con medie molto diverse, si ricorre
al CV
CV =s
x ×100
� Il coefficiente di variazione è dimensionale
o Esempio: Siamo interessati a sapere se nel ghiro è più variabile la lunghezza della coda oppure la durata del letargo (variabili con unità di misura diverse)
� Nell’esempio dei pesci, assumendo una lunghezza media di 29 mm per i maschi di gambusia e di 181 mm per i maschi di gò:
CV(Gambusia) = 11% CV(gò) = 6 %,
Un risultato di questo tipo suggerisce una conclusione molto diversa da quella basata sulla deviazione standard: la variabilità nelle dimensioni corporee è quasi doppia nei maschi di Gambusia rispetto a quelli di gò.

Il range
� Range = valore massimo – valore minimo
� Descrizione molto rozza della dispersione dei dati o si basa solamente sui due valori estremi (ed è quindi altamente influenzata da questi) e
non considera assolutamente la quale sia le distribuzione di frequenza dei dati tra essi.

La distanza interquartile
� Cosa sono i quartili?
o Imparentati con la mediana, solo che invece di separare l’insieme dei dati ordinati in due gruppi lo separano il quattro
o Ogni gruppo contiene il 25% delle osservazioni: il primo quartile, Q1, è il valore che
separa il primo 25% delle osservazioni ordinate dal restante 75%, il secondo è la mediana, e il terzo quartile, Q3, è il valore che separa il primo 75% delle osservazioni dal restante 25%.
� La distanza interquartile è data dalla differenza Q3-Q1, e identifica quindi l’intervallo centrale della distribuzione di frequenza all’interno del quale cade il 50% delle osservazioni.
� E’ una misura della dispersione dei dati che non risente di eventuali valori estremi molto diversi
dalla gran parte degli altri, e può essere calcolata anche quando i valori estremi sono “fuori scala”.
� L’identificazione dei quartili non è banale quando il numero di osservazioni non è elevato
o Cerco la mediana delle due metà dei dati
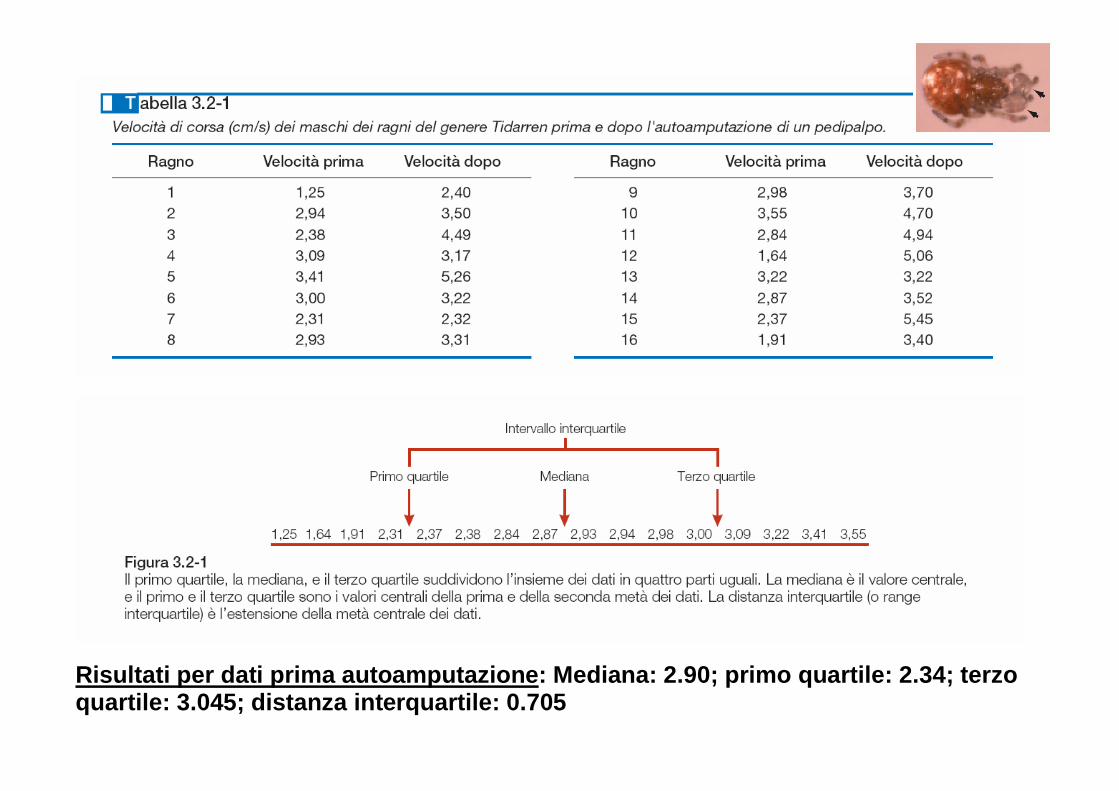
Risultati per dati prima autoamputazione : Mediana: 2.90; primo quartile: 2.34; terzo quartile: 3.045; distanza interquartile: 0.705
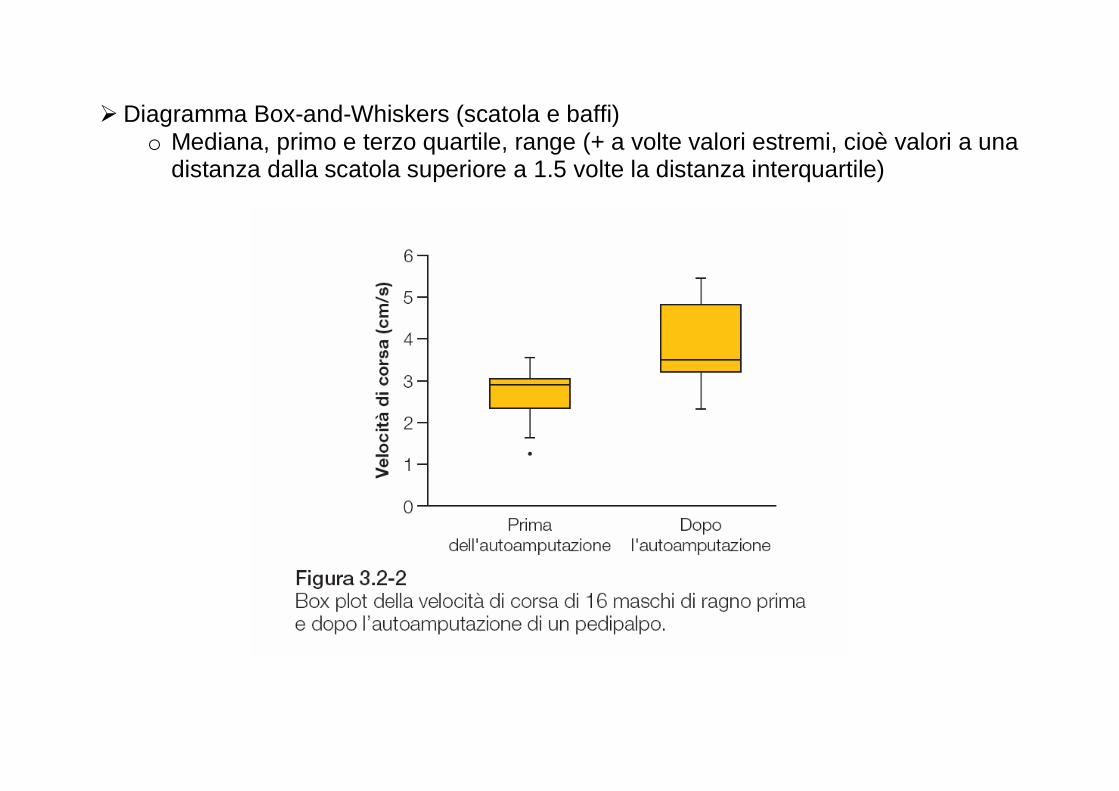
� Diagramma Box-and-Whiskers (scatola e baffi)
o Mediana, primo e terzo quartile, range (+ a volte valori estremi, cioè valori a una distanza dalla scatola superiore a 1.5 volte la distanza interquartile)

ESEMPI
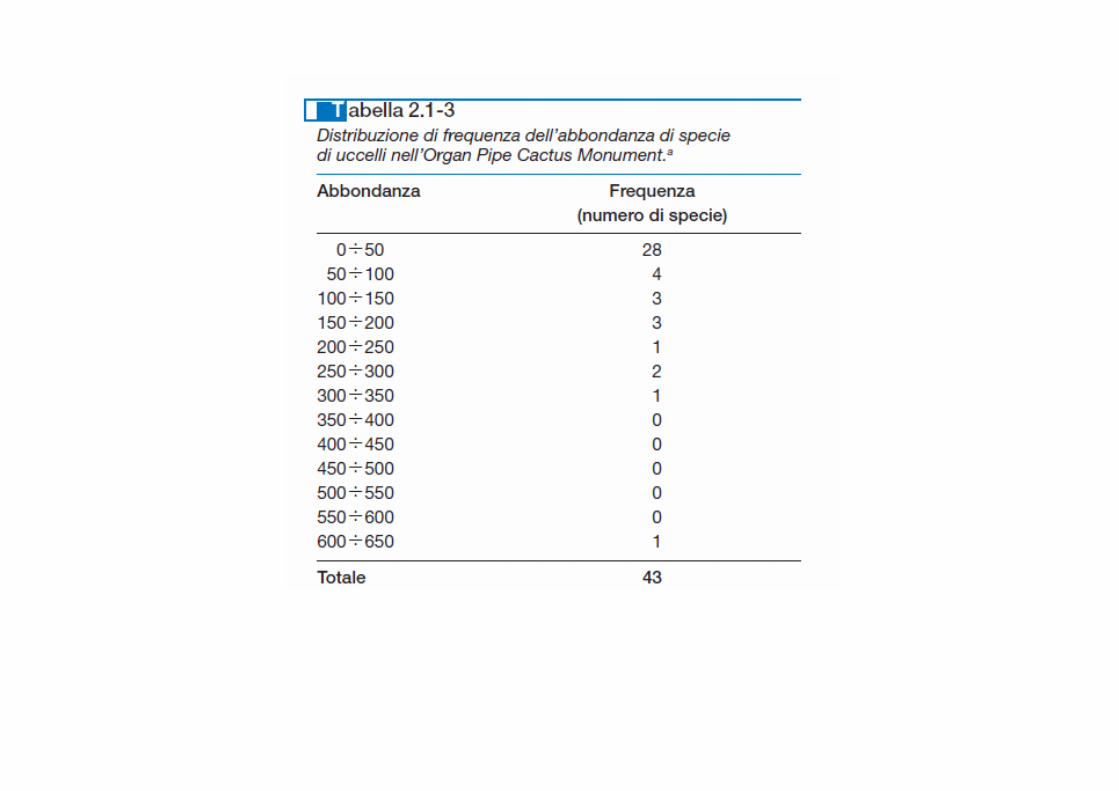
Fare la tabella di frequenza, l’istogramma, e discu tere la forma dell’istogramma
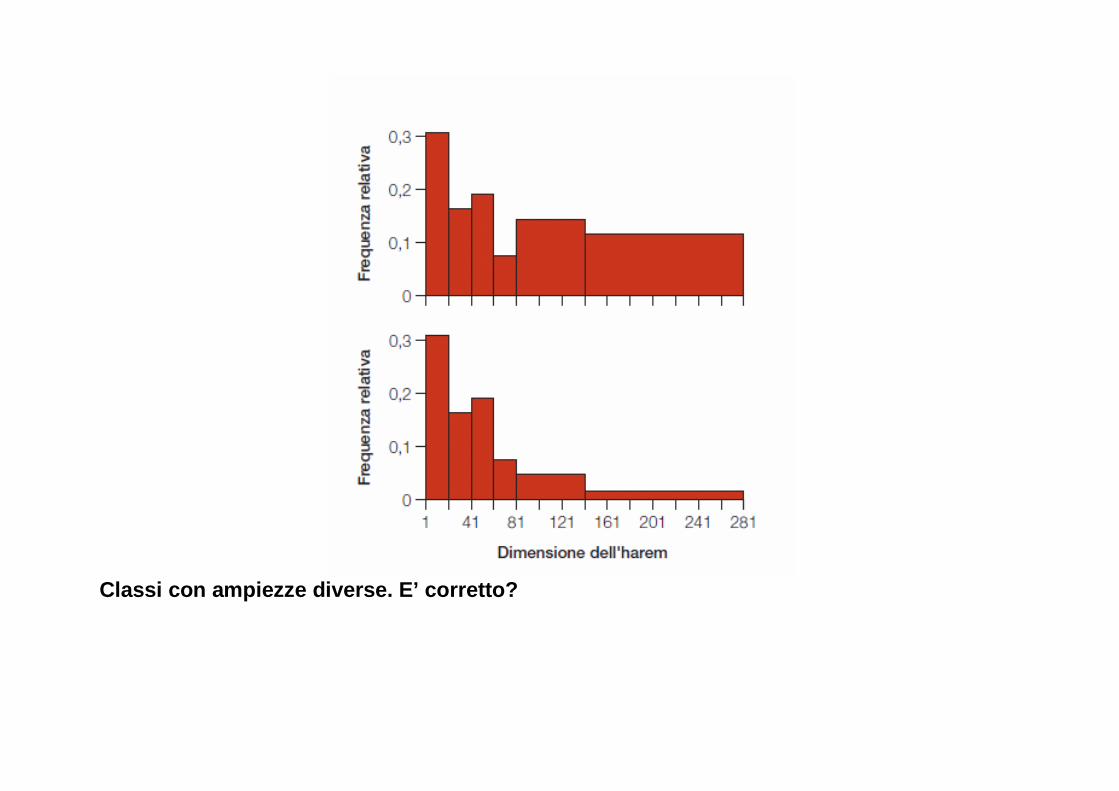
Classi con ampiezze diverse. E’ corretto?
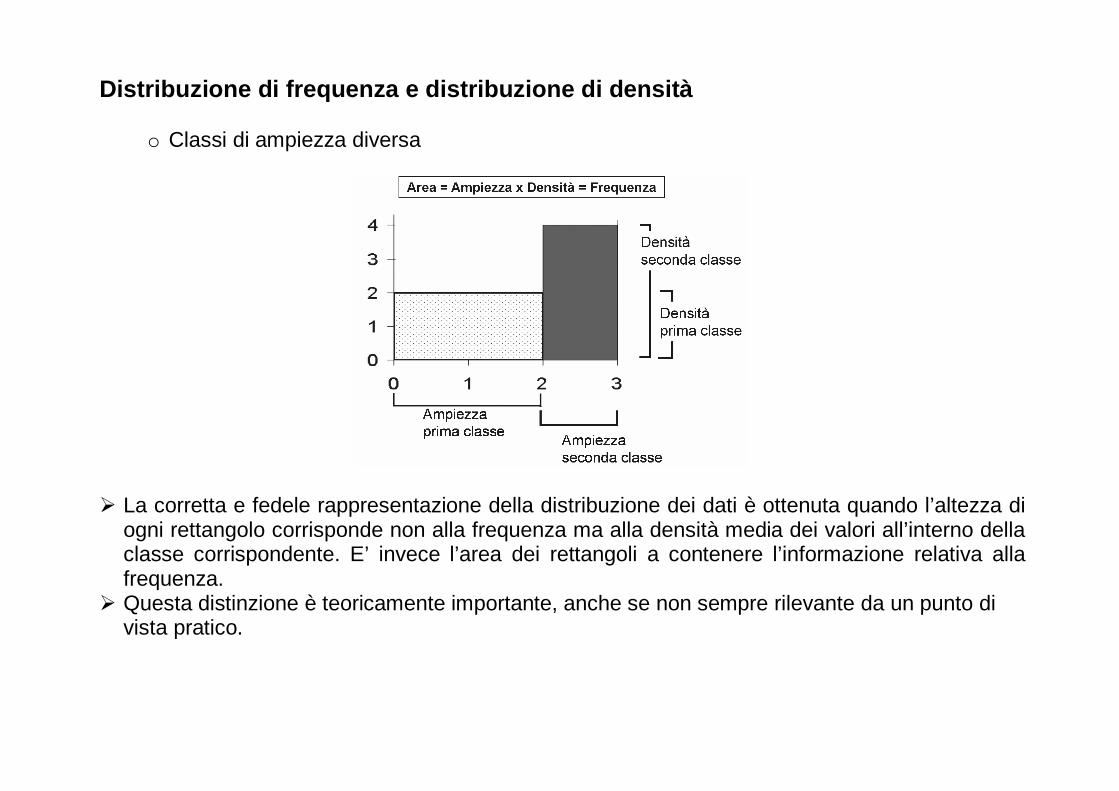
Distribuzione di frequenza e distribuzione di densi tà
o Classi di ampiezza diversa
� La corretta e fedele rappresentazione della distribuzione dei dati è ottenuta quando l’altezza di ogni rettangolo corrisponde non alla frequenza ma alla densità media dei valori all’interno della classe corrispondente. E’ invece l’area dei rettangoli a contenere l’informazione relativa alla frequenza.
� Questa distinzione è teoricamente importante, anche se non sempre rilevante da un punto di vista pratico.

Qual’è la tabella più appropriata per rappresentare i dati?
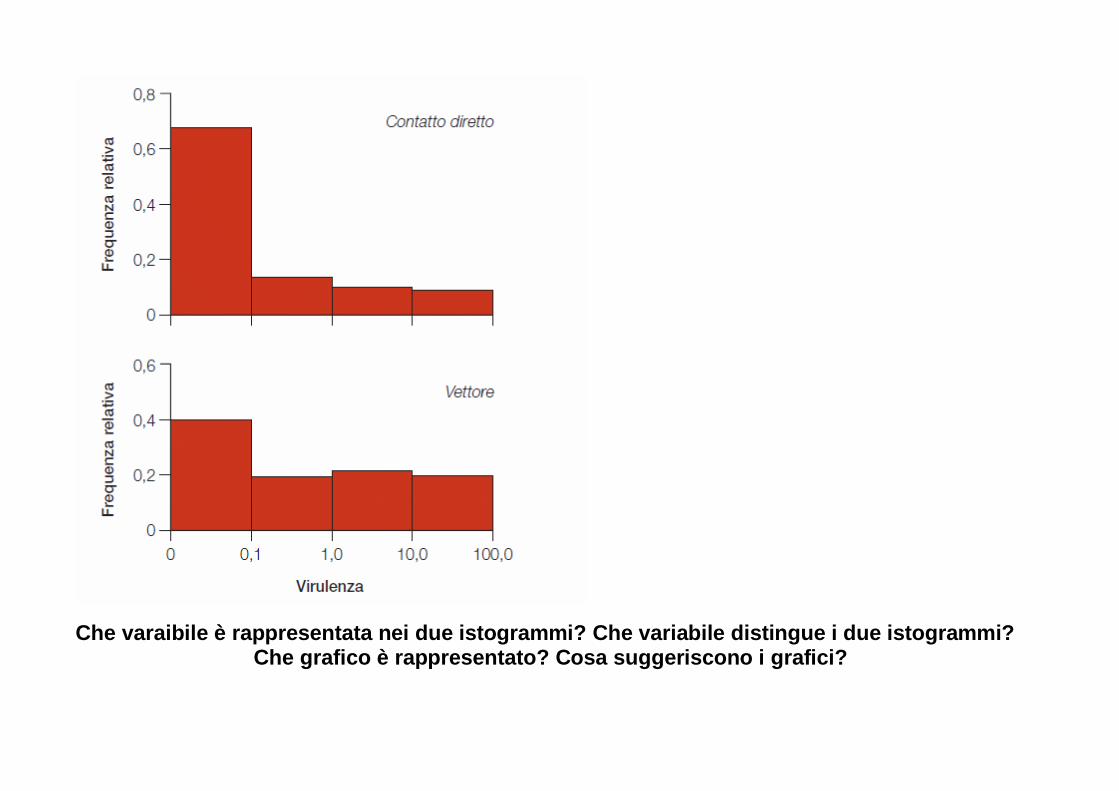
Che varaibile è rappresentata nei due istogrammi? C he variabile distingue i due istogrammi? Che grafico è rappresentato? Cosa suggeriscono i gr afici?
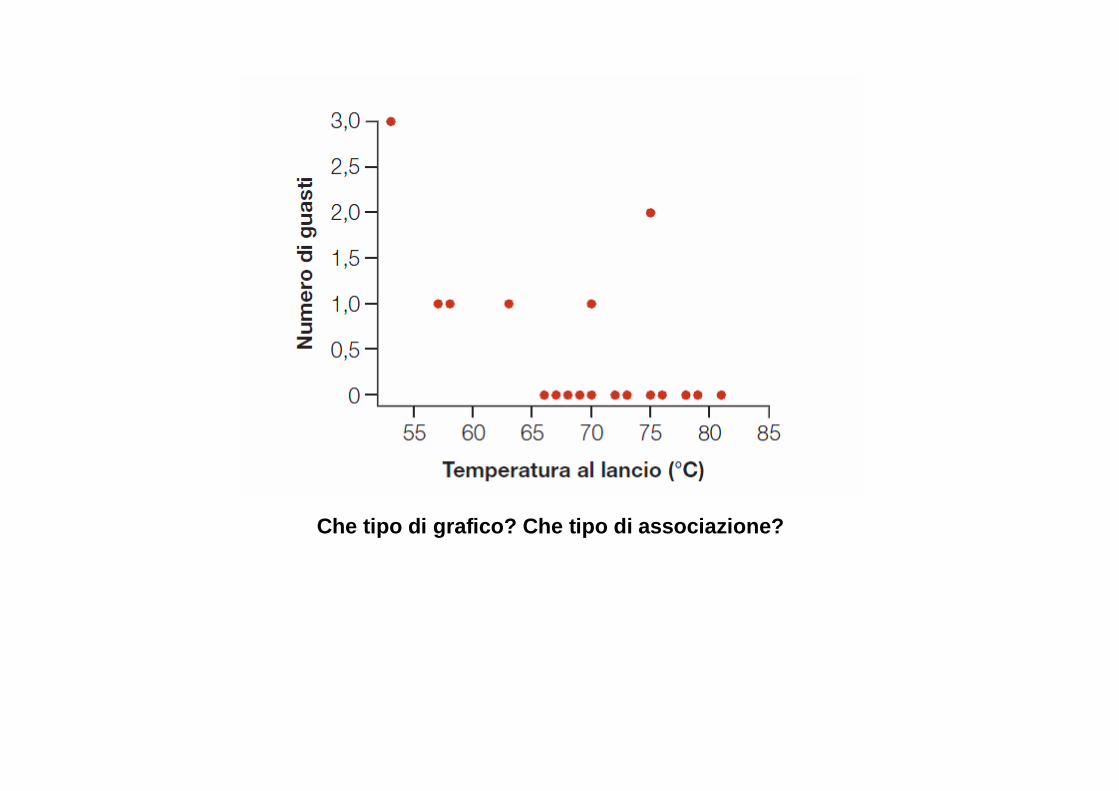
Che tipo di grafico? Che tipo di associazione?

Numero di ondulazioni per secondo in serpenti che planano
Calcolare media, varianza, deviazione standard, CV, mediana, distanza
interquartile
Relazione con distribuzione di frequenza se la distribuzione è normale
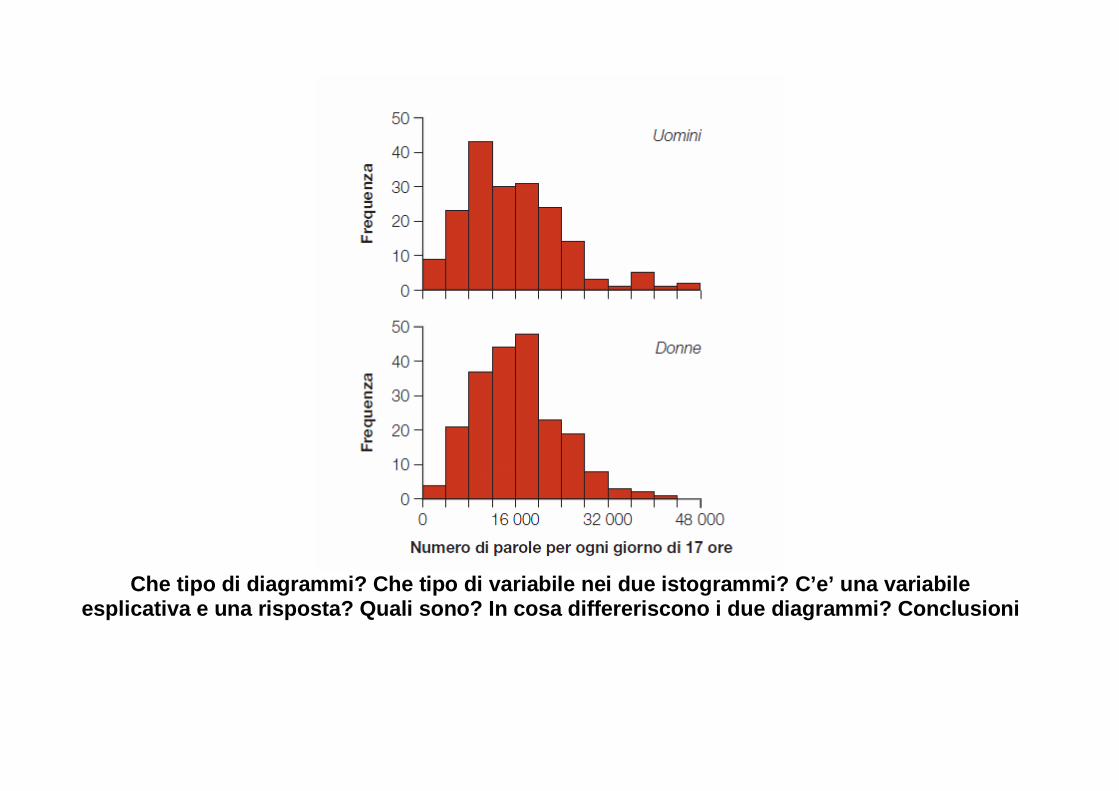
Che tipo di diagrammi? Che tipo di variabile nei du e istogrammi? C’e’ una variabile
esplicativa e una risposta? Quali sono? In cosa dif fereriscono i due diagrammi? Conclusioni

Calcolare il numero medio di ore dopo la morte fino al rigor mortis. Calcolare la deviazione
standard. Calcolare la mediana. Perché minore della media?

La variabile standardizzata
� Utilizzando la terminologia generica di prima, la variabile standardizzata X’ si calcola quindi
X' =X− Media(X)
DS(X)
� Visto l’ampio uso in statistica di questa procedura, la variabile standardizzata si è meritata un nome nuovo, Z.
Z =X− Media(X)
DS(X)
� Questa standardizzazione riduce ogni variabile ad una nuova variabile Z che ha l’importante
proprietà di avere sempre media uguale a 0 e varianza uguale a 1
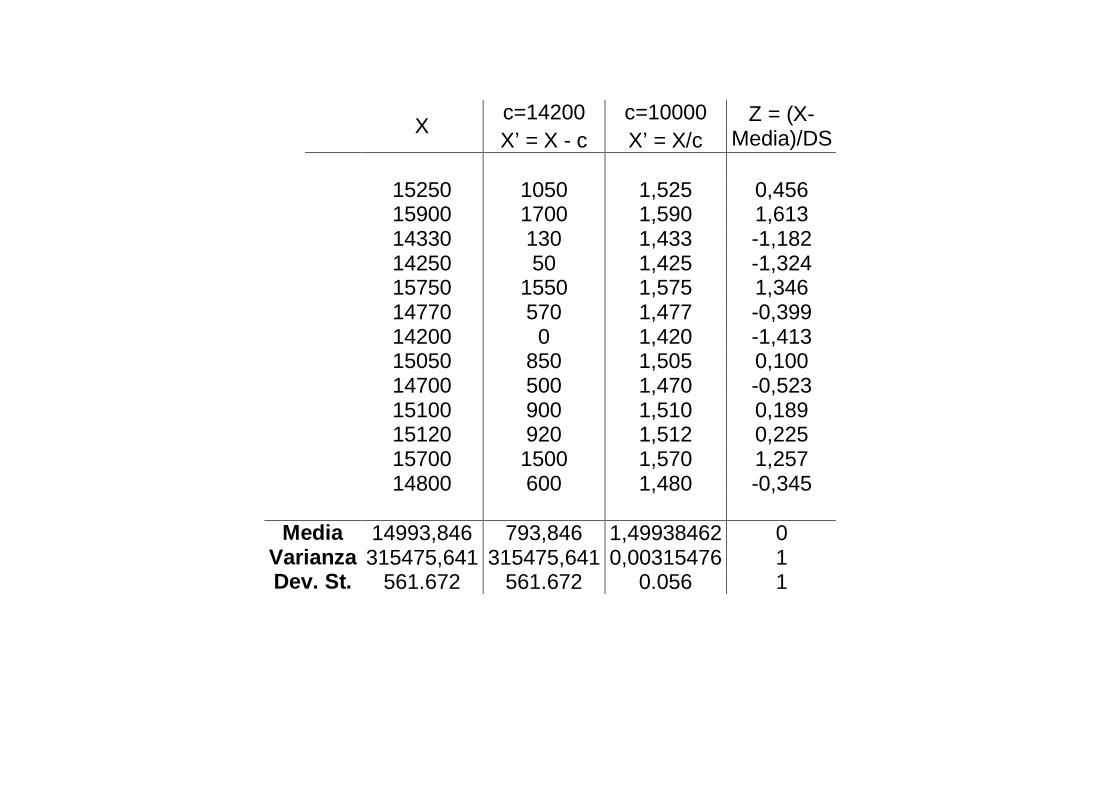
c=14200 c=10000
X
X’ = X - c X’ = X/c Z = (X-
Media)/DS 15250 1050 1,525 0,456 15900 1700 1,590 1,613 14330 130 1,433 -1,182 14250 50 1,425 -1,324 15750 1550 1,575 1,346 14770 570 1,477 -0,399 14200 0 1,420 -1,413 15050 850 1,505 0,100 14700 500 1,470 -0,523 15100 900 1,510 0,189 15120 920 1,512 0,225 15700 1500 1,570 1,257 14800 600 1,480 -0,345
Media 14993,846 793,846 1,49938462 0 Varianza 315475,641 315475,641 0,00315476 1 Dev. St. 561.672 561.672 0.056 1

BASI DI PROBABILITÀ � La teoria della probabilità è molto complessa, ma il concetto di probabilità è molto intuitivo
� Abbiamo una scatola (urna) con 3 palline rosse e 7 palline nere. Qual è la probabilità P di
estrarre una pallina rossa?
P = 0.3 (30%) � Ma cosa significa esattamente che la probabilità è uguale a 0.3?
Se ripetessi questa estrazione un numero elevatissimo di volte…. � La probabilità, quindi, è la rappresentazione teorica della frequenza, o il valore a cui tende la
frequenza quando il numero di ripetizioni dell'evento è molto grande � Questa definizione implica anche che una tabella di frequenza tende ad una tabella di
probabilità se il campione è molto grande (le due cose coincidono se ho campionato tutta la popolazione). Se per esempio analizzo un campione molto grande di donne e trovo che il 41.3 % di loro ha avuto un solo figlio, posso dire che se chiedo ad una donna scelta a caso quanti figli ha, la probabilità di avere come risposta 1 è pari a 0.413.
� Come le frequenze relative, la probabilità non può mai essere inferiore a 0 o superiore a 1, e la
somma delle probabilità associate a tutti i risultati (eventi) diversi possibili disgiunti (ovvero che non si possono verificare insieme) è per forza di cose pari a 1.

DISTRIBUZIONI DI FREQUENZA E DISTRIBUZIONI DI PROBA BILITA’
� Distribuzione di frequenza : ricostruita a partire dai dati campionati � Distribuzione di probabilità : ricostruita a partire dai dati di tutta la popolazione � Distribuzione teorica di probabilità : è definita da una funzione matematica di cui
conosco le caratteristiche e che mi permette di calcolare una probabilità associata a ciascun valore o intervallo di valori
DISTRIBUZIONI TEORICHE DISCRETE DI PROBABILITA’
� Per variabili di tipo discreto � La funzione specifica la probabilità che il valore assume uno specifico valore
( ) ( )( )( )∑ =
≥
==
x
xf
xassumerepuòchevaloriituttiperxf
xXPxf
1.3
0.2
.1

Per esempio: distribuzione uniforme discreta
( )n
xf1
=
� Lancio di una moneta equilibrata � Lancio di un dado equilibrato � Frequenza attesa di cattura in 4 tipi trappole ugualmente efficienti
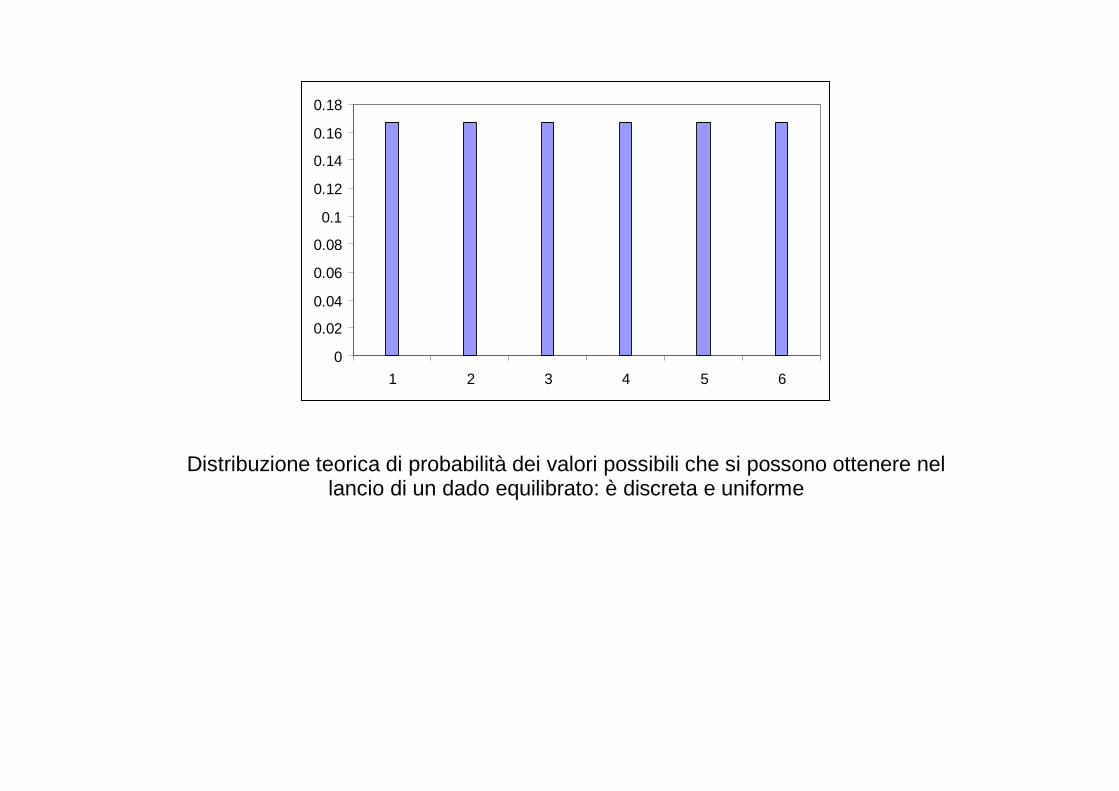
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
1 2 3 4 5 6
Distribuzione teorica di probabilità dei valori possibili che si possono ottenere nel
lancio di un dado equilibrato: è discreta e uniforme
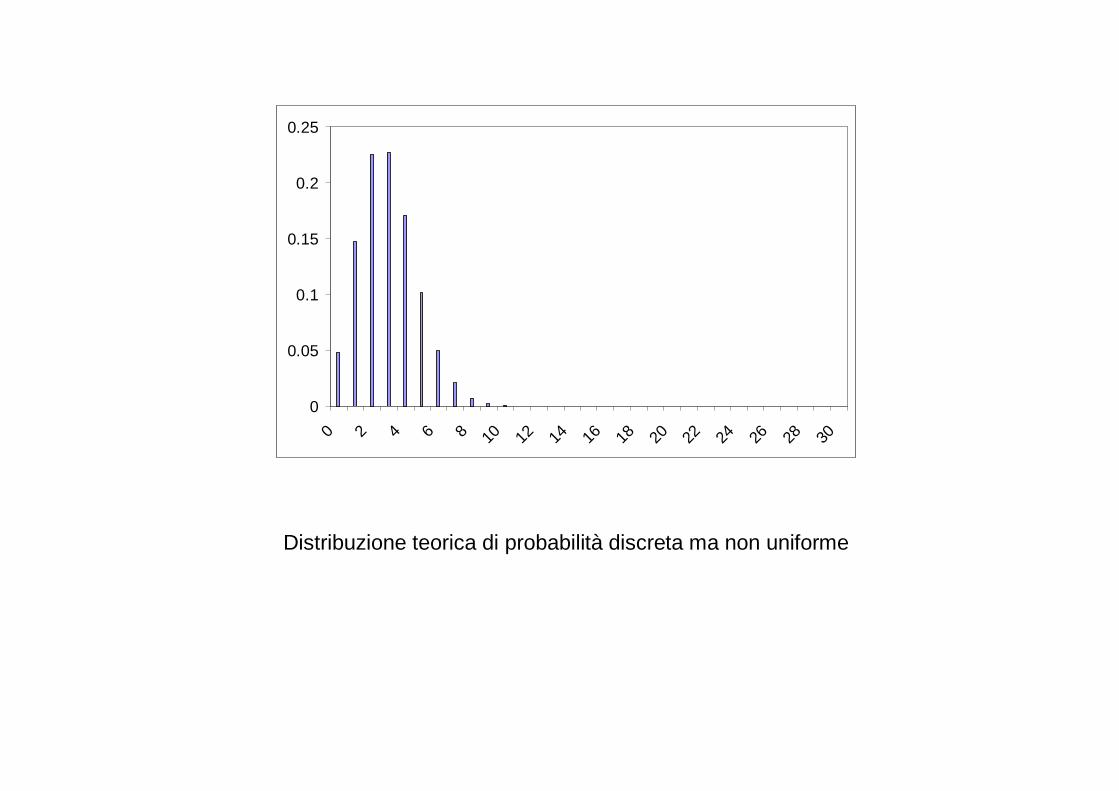
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
Distribuzione teorica di probabilità discreta ma non uniforme

DISTRIBUZIONI TEORICHE CONTINUE DI PROBABILITA’
� Per variabili di tipo continuo � Sono distribuzioni di densità, perché l'altezza della curva non è una probabilità, ma una
densità di probabilità (una probabilità divisa per un intervallo) � Non conta l’altezza della curva, ma l’integrale tra due valori
( ) ( )
( )
( ) 1.3
0.2
.12
1
21
=
≥
=≤≤
∫
∫
∞+
∞−
dxxf
xassumerepuòchevaloriituttiperxf
dxxfxXxPx
x
Vediamo una delle distribuzioni continue più utilizzate: la distribuzione normale
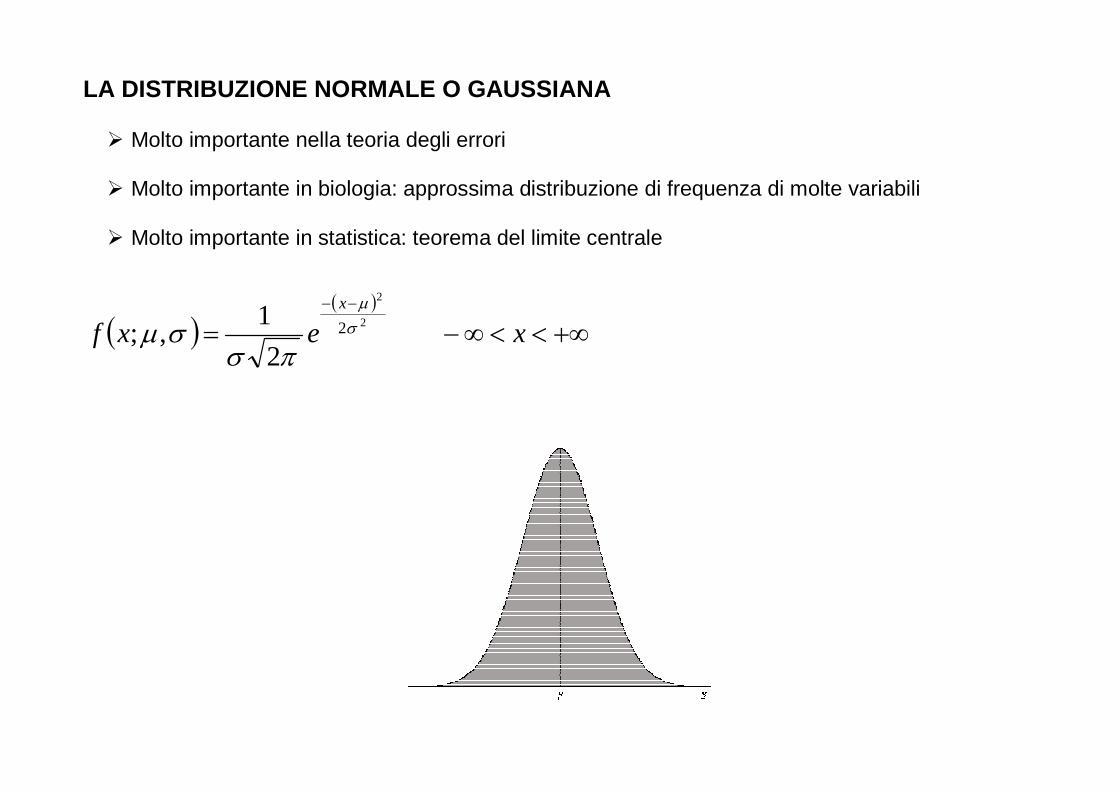
LA DISTRIBUZIONE NORMALE O GAUSSIANA
� Molto importante nella teoria degli errori � Molto importante in biologia: approssima distribuzione di frequenza di molte variabili � Molto importante in statistica: teorema del limite centrale
( )( )
+∞<<∞−=−−
xexfx
2
2
2
2
1,; σ
µ
πσσµ
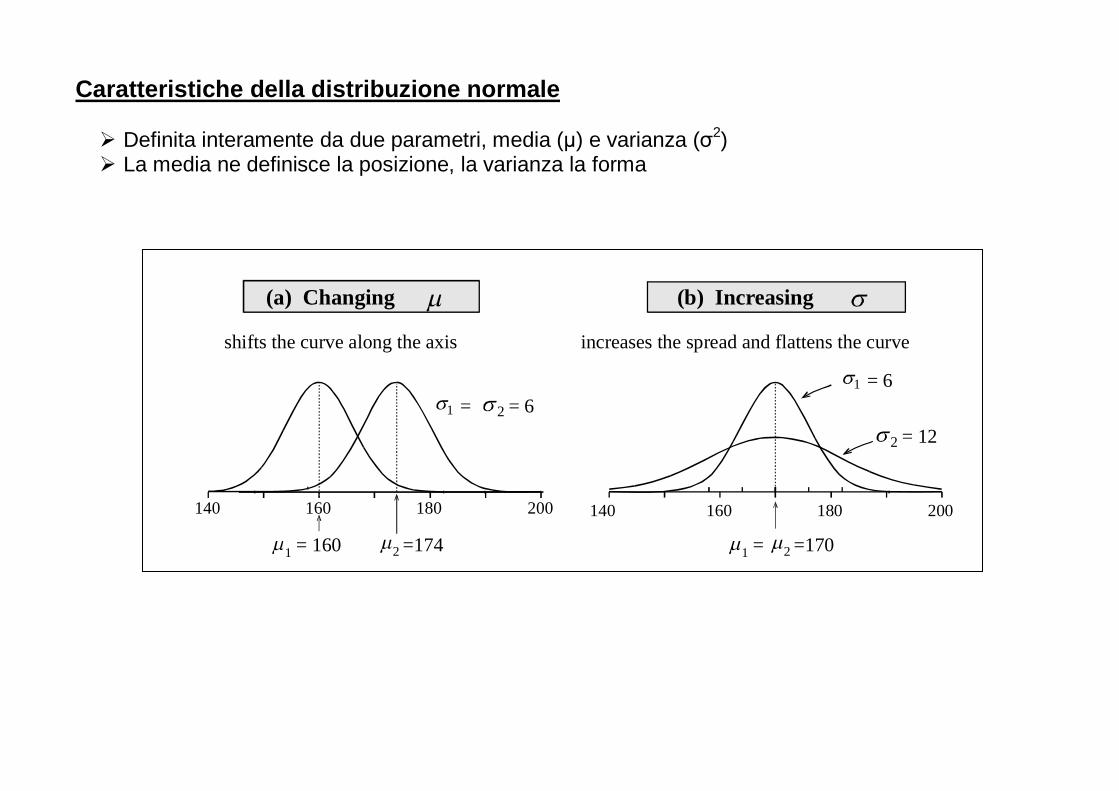
Caratteristiche della distribuzione normale
� Definita interamente da due parametri, media (µ) e varianza (σ2) � La media ne definisce la posizione, la varianza la forma
160 180 200140 160 180
shifts the curve along the axis
200 140
2 =174
2 = 61 =1 = 6
2 = 12
2 =1701 =
increases the spread and flattens the curve
(a) Changing (b) Increasing
1 = 160
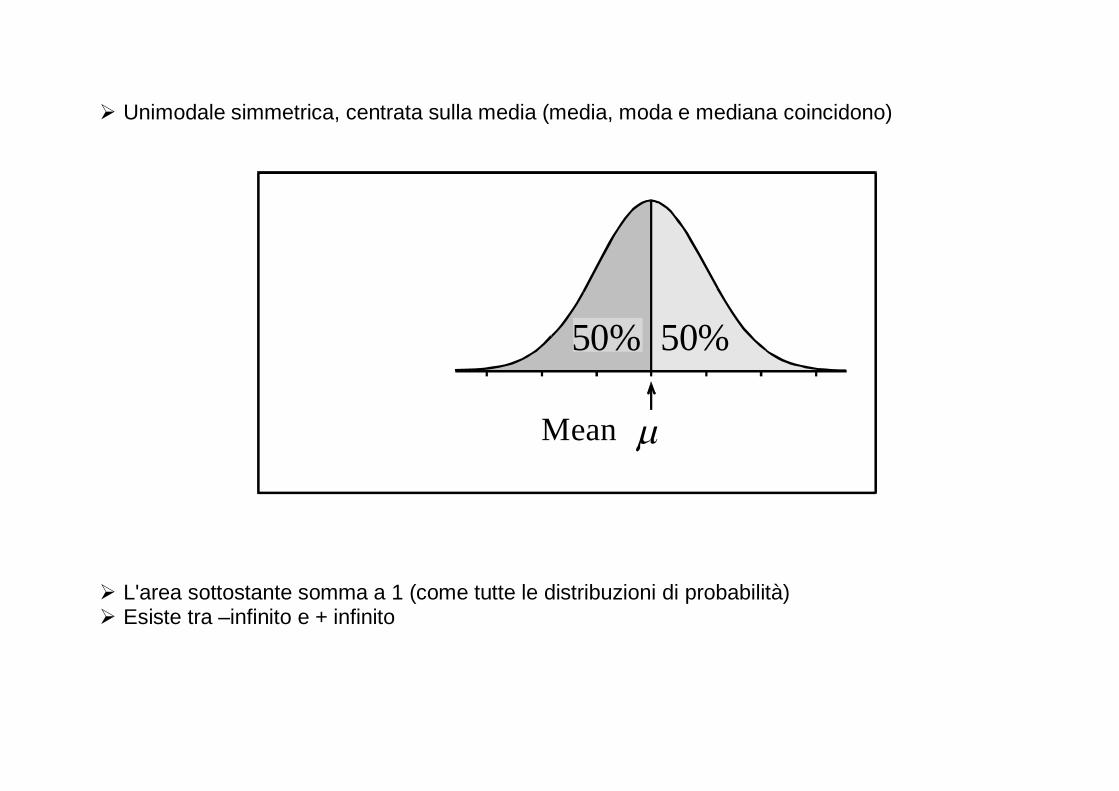
� Unimodale simmetrica, centrata sulla media (media, moda e mediana coincidono)
� L'area sottostante somma a 1 (come tutte le distribuzioni di probabilità) � Esiste tra –infinito e + infinito
5 0 % 5 0 %
M e a n
F i g u r e 6 . 2 . 2
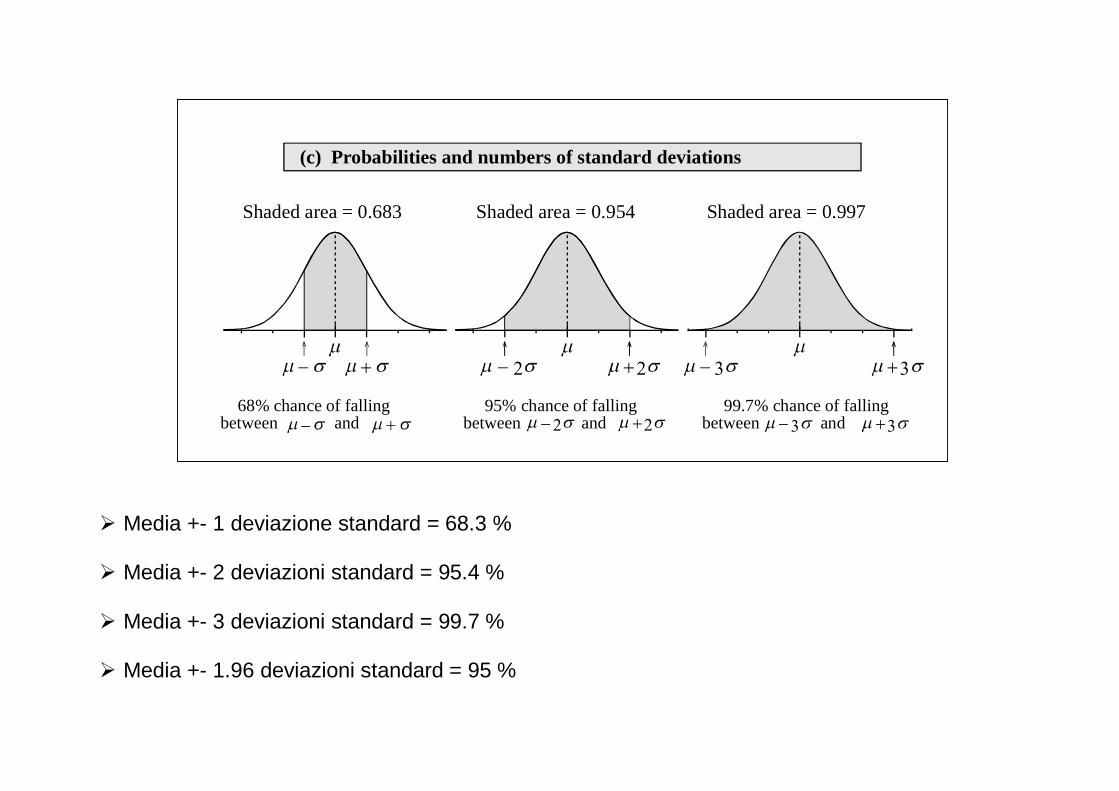
(c) Probabilities and numbers of standard deviations
Shaded area = 0.683 Shaded area = 0.954 Shaded area = 0.997
68% chance of fallingbetween and
− +
+ 95% chance of fallingbetween and
+2
+2
3+
99.7% chance of fallingbetween and 3+
− 2 − 3
− 3− −2
� Media +- 1 deviazione standard = 68.3 % � Media +- 2 deviazioni standard = 95.4 % � Media +- 3 deviazioni standard = 99.7 % � Media +- 1.96 deviazioni standard = 95 %
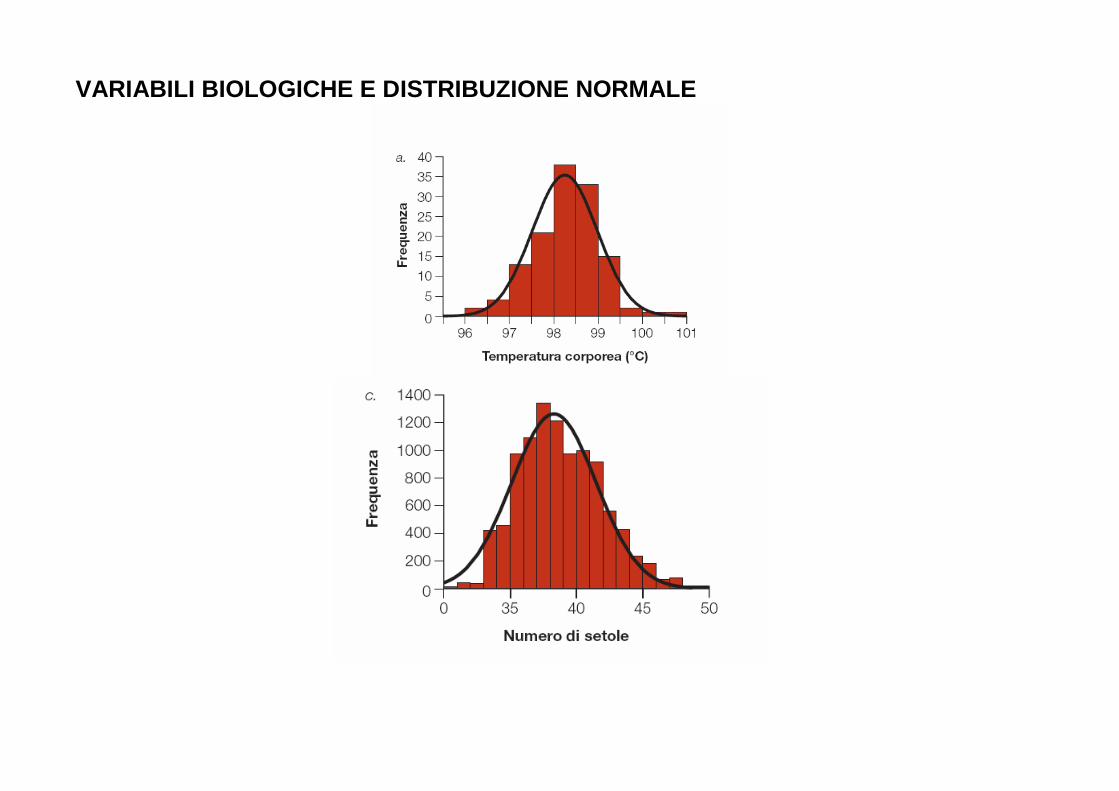
VARIABILI BIOLOGICHE E DISTRIBUZIONE NORMALE

VARIABILI BIOLOGICHE E DISTRIBUZIONE NORMALE
� Molte variabili biologiche si distribuiscono in modo normale (come gli errori in fisica, per esempio)
Sono dovute alla combinazione di un numero molto alto di fattori
� Cosa dice il teorema del limite centrale (TLC) ?
� Lancio 1000 volte un dado. La distribuzione della variabile punteggio nel lancio di un singolo
dado, che varia tra 1 e 6, è uniforme. Il dado è il singolo fattore, ed esiste una singola variabile.
� Ora lancio 1000 volte due dadi insieme, e ogni lancio della coppia di dadi faccio la somma dei punteggi. Ora la nuova variabile è il punteggio totale nel lancio di due dadi, che varia tra 2 e 12, e può essere vista come costituita dalla combinazione (somma) di due fattori (i due dadi) ciascuno dei quali ha una distribuzione uniforme. Ma la nuova variabile non ha una distribuzione uniforme! Perché?
� Ora lancio 1000 volte 5 dadi, e ogni volta faccio la somma dei 5 punteggi. Ora la nuova
variabile è il punteggio totale nel lancio di cinque dadi, e varia tra 5 e 30. Cosa ricorda?
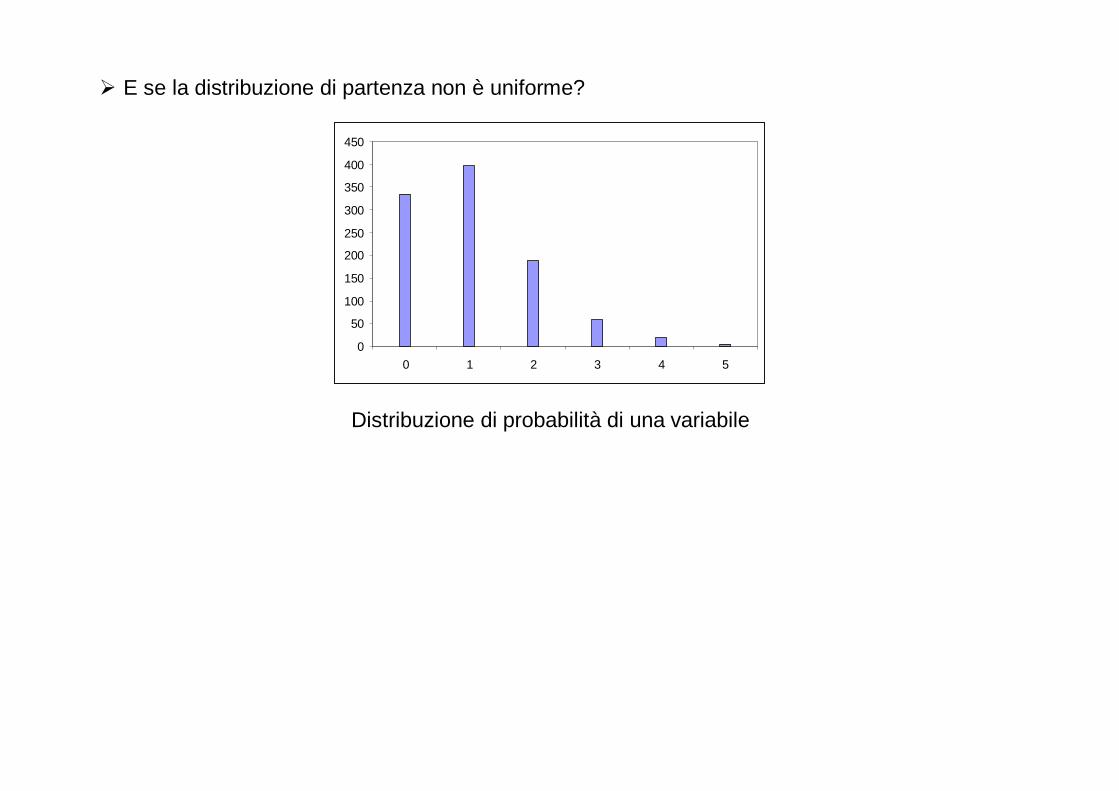
� E se la distribuzione di partenza non è uniforme?
0
50
100
150
200
250
300
350
400
450
0 1 2 3 4 5
Distribuzione di probabilità di una variabile
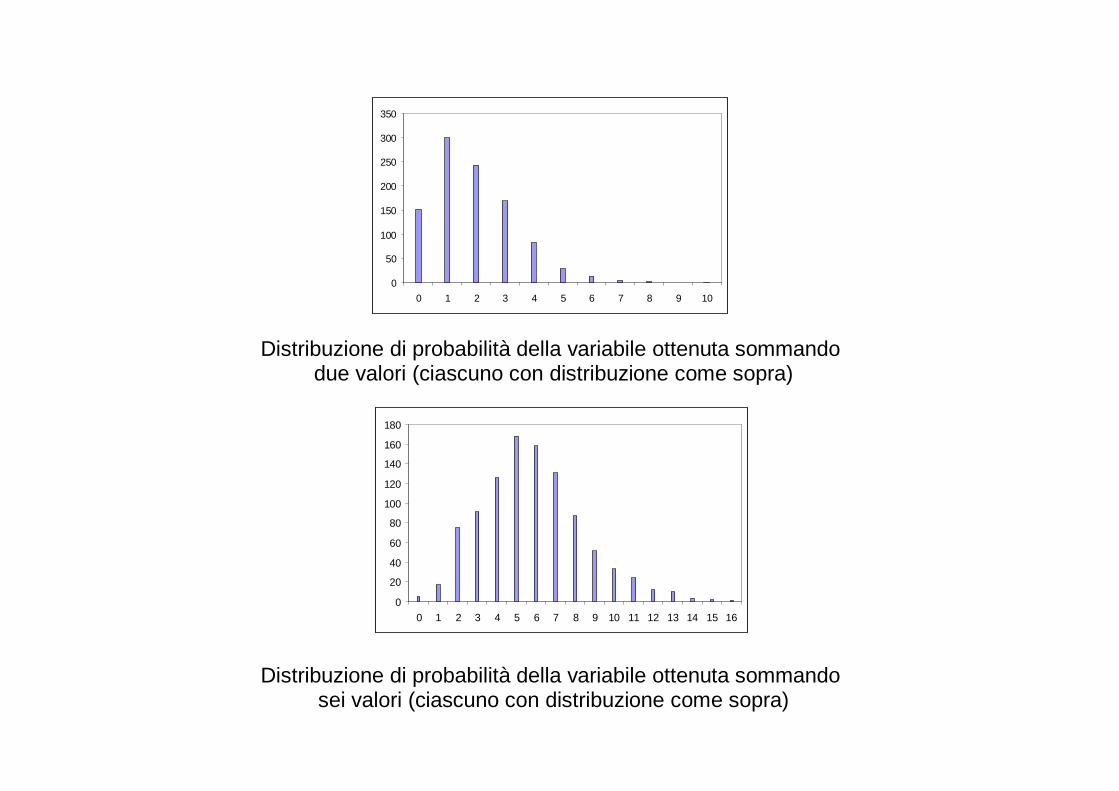
0
50
100
150
200
250
300
350
0 1 2 3 4 5 6 7 8 9 10
Distribuzione di probabilità della variabile ottenuta sommando due valori (ciascuno con distribuzione come sopra)
0
20
40
60
80
100
120
140
160
180
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Distribuzione di probabilità della variabile ottenuta sommando sei valori (ciascuno con distribuzione come sopra)

� Pensiamo alla statura, o agli errori…sono combinazi oni di tanti fattori

LA DISTRIBUZIONE GAUSSIANA PER CALCOLARE LE PROBABI LITA’ A PARTIRE DA UNA MEDIA E UNA VARIANZA IN UN CAMPIONE
� 30 persone obese affette da una malattia cardiovascolare vengono sottoposte a cura
dimagrante. La variazione di peso in chilogrammi ha una media pari a –0,59 con varianza pari a 0.11
� Vogliamo stimare, per esempio, la
( )0>xP ovvero, la frazione di persone (obese affette da una malattia cardiovascolare ) che seguendo
questa dieta ingrassano.
Assumiamo che il campione sia rappresentativo della popolazione e che la distribuzione della variabile sia gaussiana con media e varianza uguali a quelle stimate attraverso il campione
Ricorro alla distribuzione normale standardizzata e alla tabella relativa
-4 -3 -2 -1 0 1 2 3 4
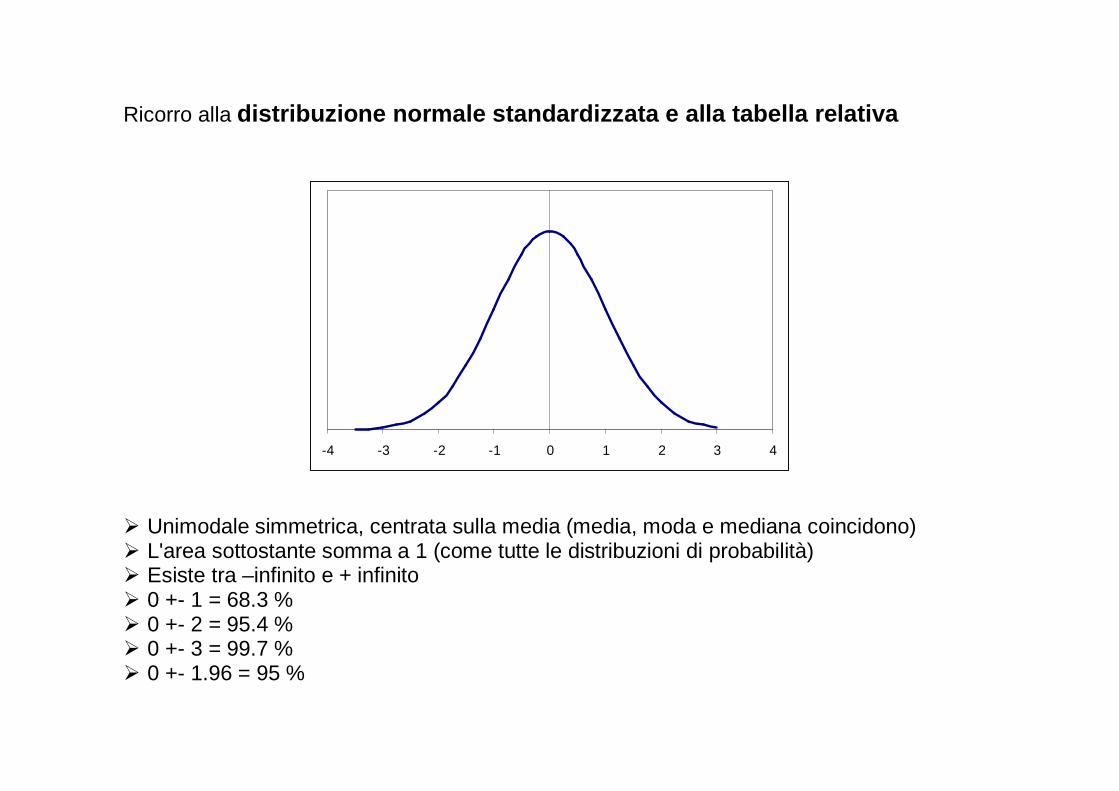
� Unimodale simmetrica, centrata sulla media (media, moda e mediana coincidono) � L'area sottostante somma a 1 (come tutte le distribuzioni di probabilità) � Esiste tra –infinito e + infinito � 0 +- 1 = 68.3 % � 0 +- 2 = 95.4 % � 0 +- 3 = 99.7 % � 0 +- 1.96 = 95 %
-6 -4 -2 0 2 4
-2.5 -2 -1.5 -1 -0.5 0 0.5 1
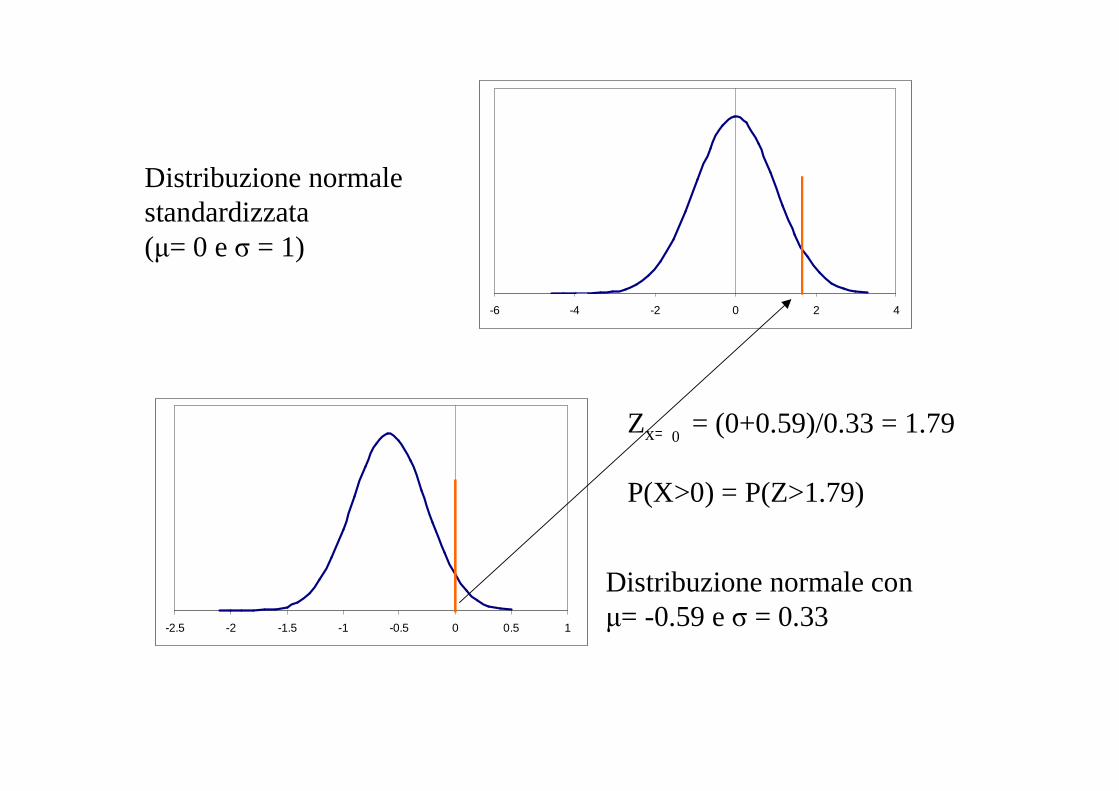
Distribuzione normale conµ= -0.59 e σ = 0.33
Zx=12 = (0+0.59)/0.33 = 1.79
P(X>0) = P(Z>1.79)
Distribuzione normalestandardizzata(µ= 0 e σ = 1)
0
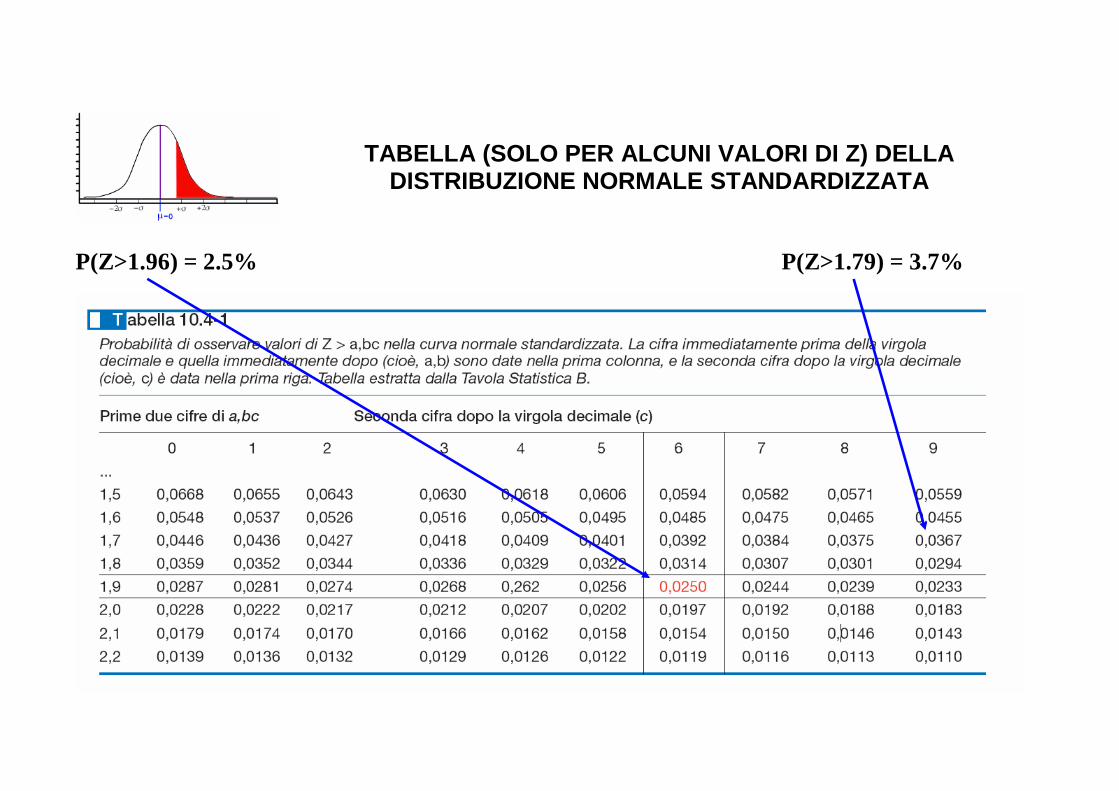
TABELLA (SOLO PER ALCUNI VALORI DI Z) DELLA DISTRIBUZIONE NORMALE STANDARDIZZATA
P(Z>1.96) = 2.5% P(Z>1.79) = 3.7%

ESEMPIO La NASA esclude dai corsi per diventare astronauti chiunque sia più alto di 193.0 cm o più basso di 148.6 cm. Negli uomini (popolazione USA), l’altezza media è 175.6 cm, con s = 7.1 cm. Nelle donne (popolazione USA), l’altezza media è 162.6 cm, con s = 6.4. Calcolare le frazioni di popolazione, separatamente per maschi e femmine, esclusi dai programmi NASA. Discutere i risultati.

La statistica inferenziale
� Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni
� E’ necessario però anche aggiungere con quale grado di sicurezza, o di probabilità, riteniamo
che la nostra stima o generalizzazione sia corretta
� Stima dei parametri
√ Si cerca di stimare un parametro di una popolazione (ogni caratteristica misurata in una colazione) attraverso una statistica
√ Il parametro può corrispondere alla dimensione di un effetto (per esempio, allungamento durata della vita in individui trattati)
√ Bisogna però definire l’incertezza della stima. Per questo si usa l’ intervallo di confidenza, o intervallo sfiduciale.
� Test delle ipotesi
√ Definite diverse ipotesi si cerca di identificare qual è l’ipotesi più adatta a spiegare i dati osservati
√ In generale, si definisce un’ipotesi nulla e un’ipotesi alternativa. √ I dati sono sempre confrontati con quelli previsti dall’ipotesi nulla. √ Se sono troppo diversi da quelli previsti dall’ipotesi nulla, si favorisce l’ipotesi alternativa.
Altrimenti, si conclude che i dati sono compatibili con l’ipotesi nulla.

La teoria del campionamento è necessaria per capire la statistica inferenziale
Vediamola in forma semplificata con un esempio
� Popolazione dei lupi scandinavi: 10.512 animali � Il peso medio di questa popolazione, µ, è ignoto, ma supponiamo abbia una distribuzione
normale � Un ricercatore vuole comunque giungere ad una stima di questo parametro avendo anche
un’idea anche di quanto buona sia questa stima, e decide quindi di catturare e pesare 6 lupi.
� La media del peso nel campione risulta pari a x = 20.32 kg.

14 16 18 20 22 24 26
1 campione di 6 individui
14 16 18 20 22 24 2614 16 18 20 22 24 26
1 campione di 6 individui
� Chiaramente la media del campione non sarà pari alla media della popolazione � E’ possibile dare qualche indicazione sulla distanza tra la media del campione (che possiamo
calcolare) e quella della popolazione (alla quale siamo maggiormente interessati ma che non possiamo calcolare)?
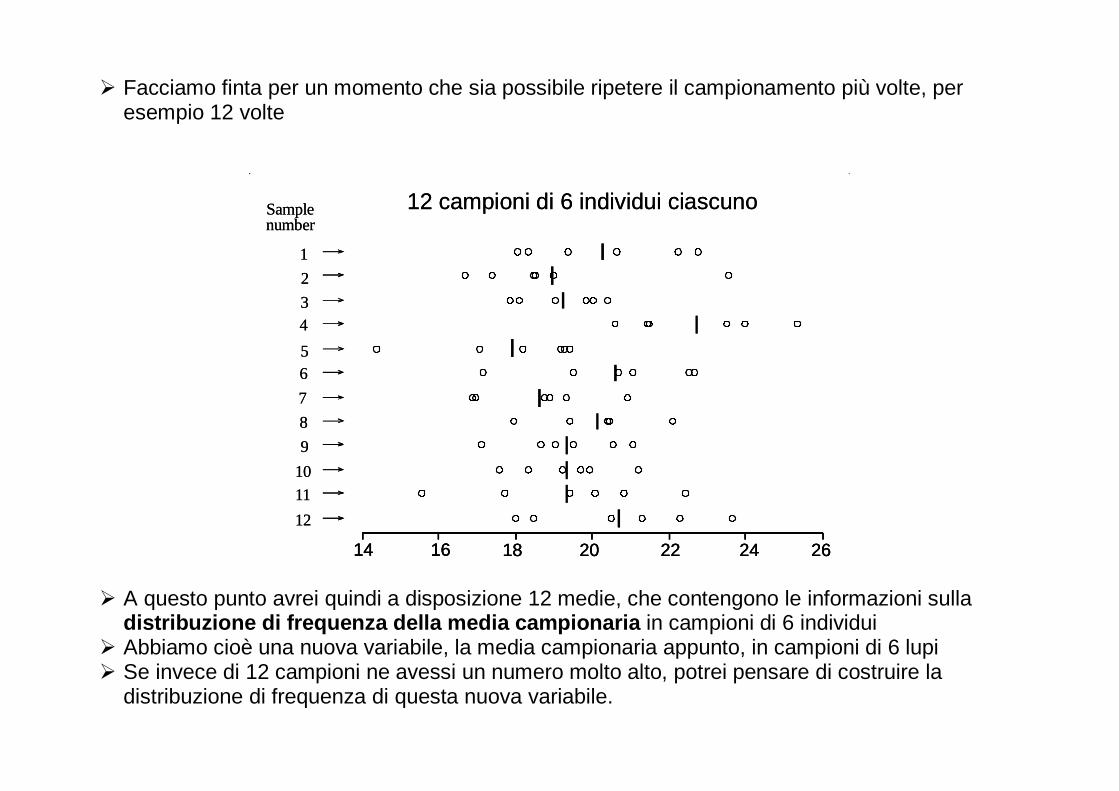
� Facciamo finta per un momento che sia possibile ripetere il campionamento più volte, per esempio 12 volte
1
2
34
56
7
8
9
10
12
11
Samplenumber
14 16 18 20 22 24 26
12 campioni di 6 individui ciascuno
1
2
34
56
7
8
9
10
12
11
Samplenumber
14 16 18 20 22 24 2614 16 18 20 22 24 26
12 campioni di 6 individui ciascuno
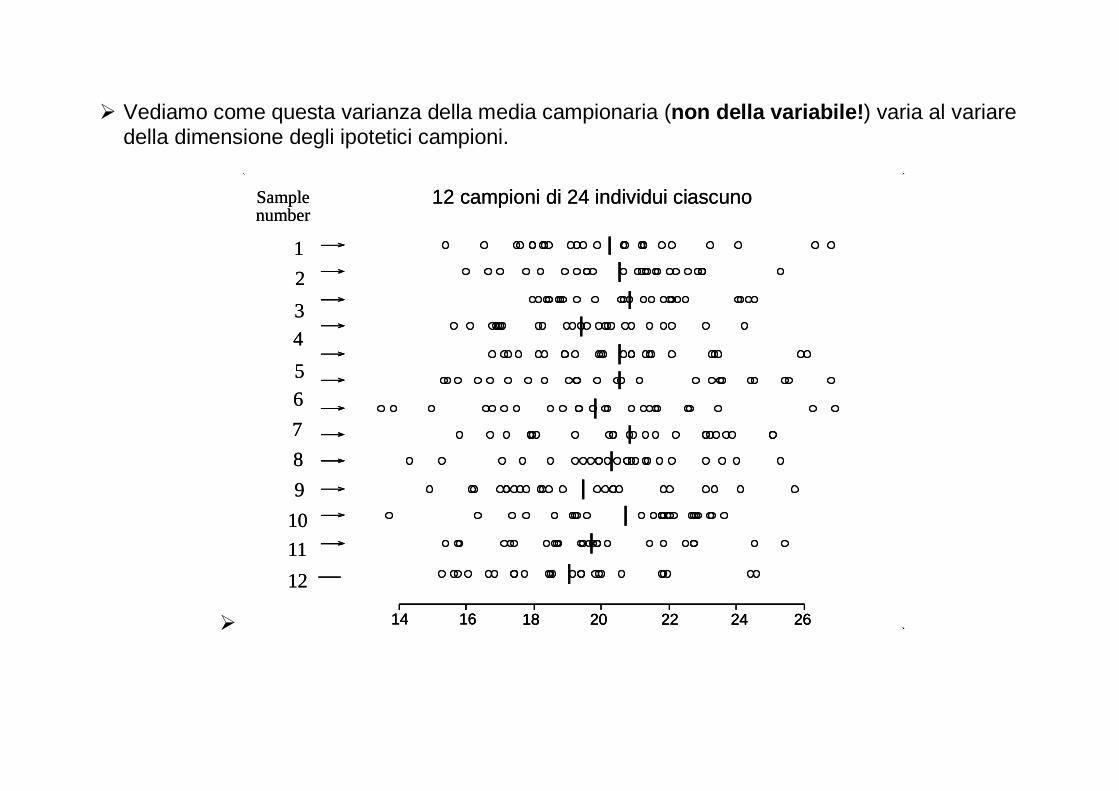
� A questo punto avrei quindi a disposizione 12 medie, che contengono le informazioni sulla distribuzione di frequenza della media campionaria in campioni di 6 individui
� Abbiamo cioè una nuova variabile, la media campionaria appunto, in campioni di 6 lupi � Se invece di 12 campioni ne avessi un numero molto alto, potrei pensare di costruire la
distribuzione di frequenza di questa nuova variabile.
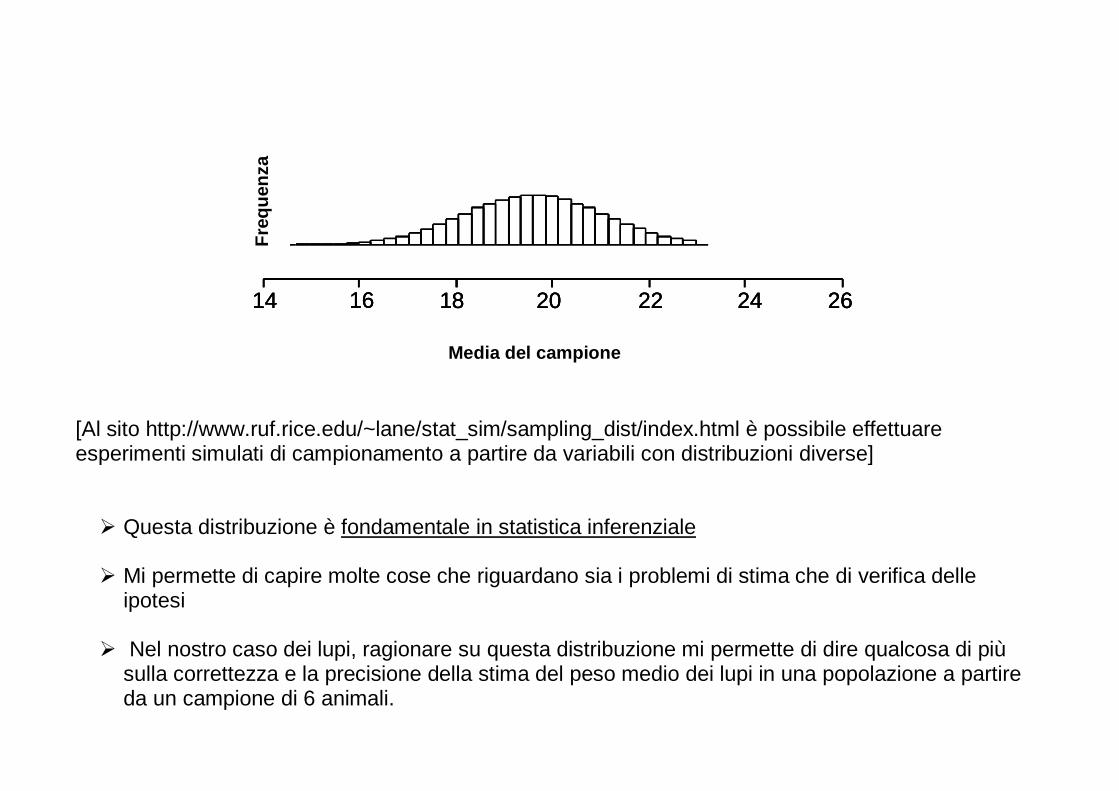
[Al sito http://www.ruf.rice.edu/~lane/stat_sim/sampling_dist/index.html è possibile effettuare esperimenti simulati di campionamento a partire da variabili con distribuzioni diverse]
� Questa distribuzione è fondamentale in statistica inferenziale � Mi permette di capire molte cose che riguardano sia i problemi di stima che di verifica delle
ipotesi
� Nel nostro caso dei lupi, ragionare su questa distribuzione mi permette di dire qualcosa di più sulla correttezza e la precisione della stima del peso medio dei lupi in una popolazione a partire da un campione di 6 animali.
14 16 18 20 22 24 2614 16 18 20 22 24 2614 16 18 20 22 24 26
Media del campione
Fre
quen
za
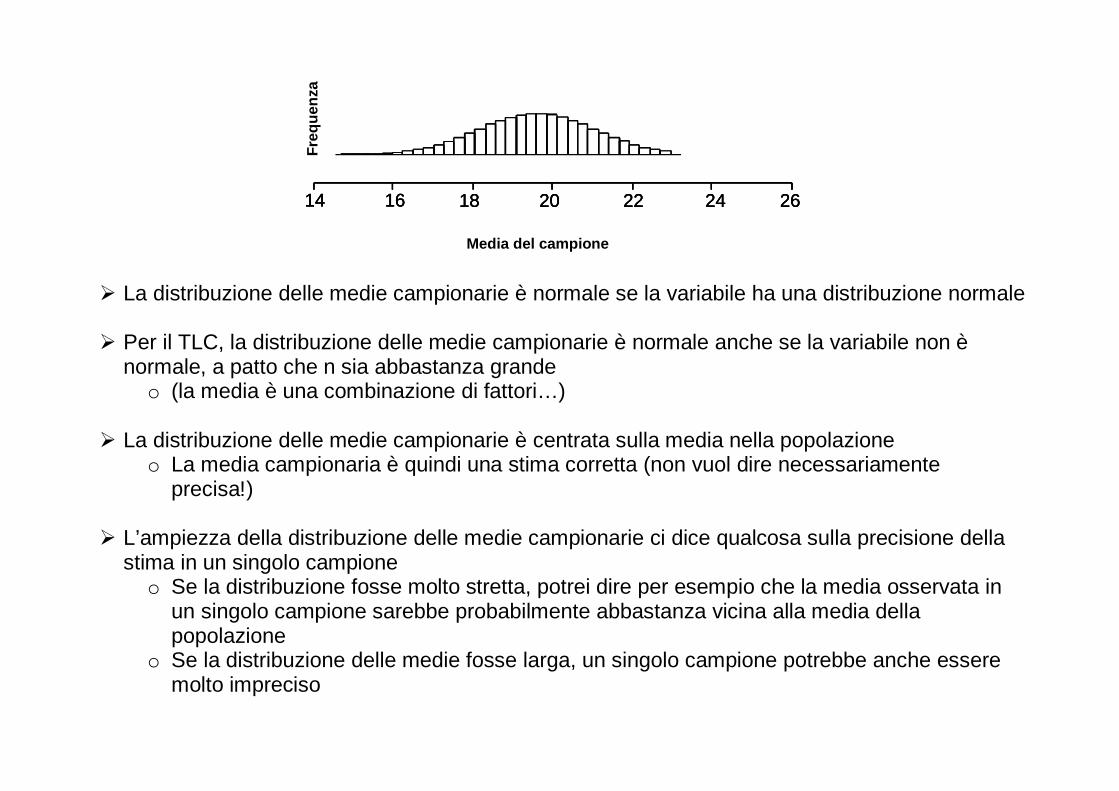
� La distribuzione delle medie campionarie è normale se la variabile ha una distribuzione normale
� Per il TLC, la distribuzione delle medie campionarie è normale anche se la variabile non è
normale, a patto che n sia abbastanza grande o (la media è una combinazione di fattori…)
� La distribuzione delle medie campionarie è centrata sulla media nella popolazione o La media campionaria è quindi una stima corretta (non vuol dire necessariamente
precisa!)
� L’ampiezza della distribuzione delle medie campionarie ci dice qualcosa sulla precisione della stima in un singolo campione o Se la distribuzione fosse molto stretta, potrei dire per esempio che la media osservata in
un singolo campione sarebbe probabilmente abbastanza vicina alla media della popolazione
o Se la distribuzione delle medie fosse larga, un singolo campione potrebbe anche essere molto impreciso
14 16 18 20 22 24 2614 16 18 20 22 24 2614 16 18 20 22 24 26
Media del campione
Fre
quen
za
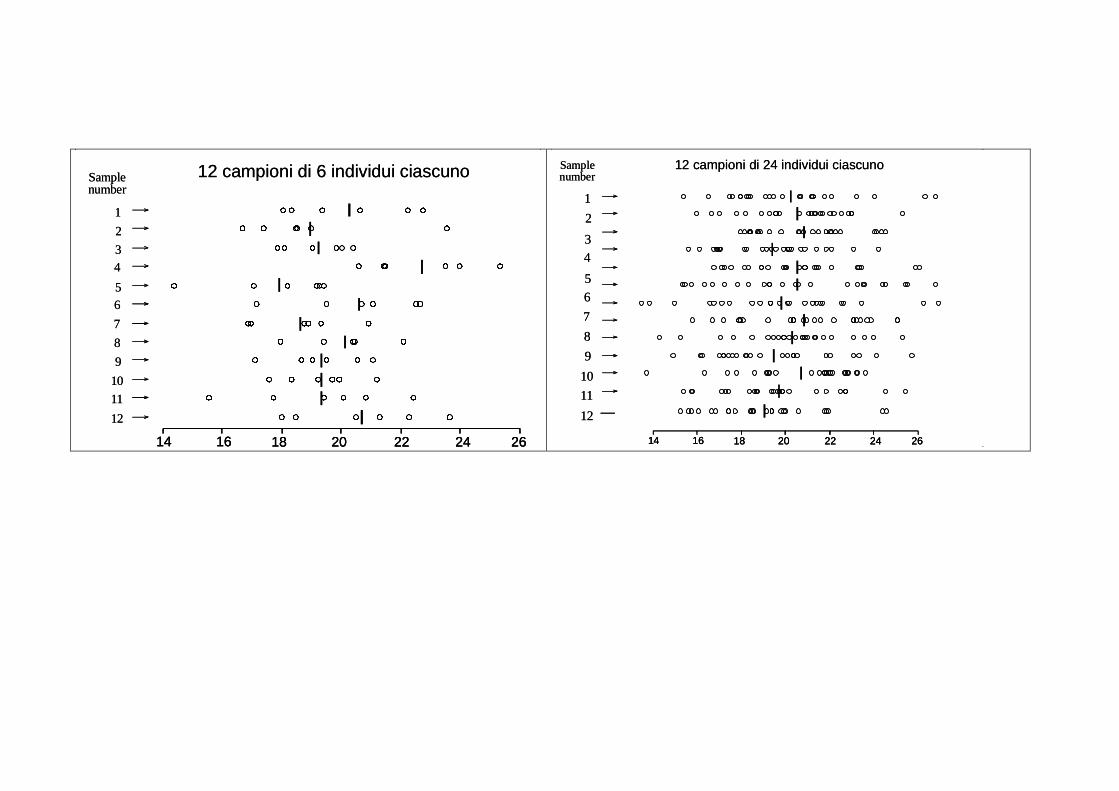
� Vediamo come questa varianza della media campionaria (non della variabile! ) varia al variare
della dimensione degli ipotetici campioni.
�
Samplenumber
1
2
3
4
5
6
7
8
9
10
12
11
12 campioni di 24 individui ciascuno
14 16 18 20 22 24 26
Samplenumber
1
2
3
4
5
6
7
8
9
10
12
11
12 campioni di 24 individui ciascuno
14 16 18 20 22 24 2614 16 18 20 22 24 26
1
2
34
56
7
8
9
10
12
11
Samplenumber
14 16 18 20 22 24 26
12 campioni di 6 individui ciascuno
1
2
34
56
7
8
9
10
12
11
Samplenumber
14 16 18 20 22 24 2614 16 18 20 22 24 26
12 campioni di 6 individui ciascuno
Samplenumber
1
2
34
5
6
7
8
9
10
12
11
12 campioni di 24 individui ciascuno
14 16 18 20 22 24 26
Samplenumber
1
2
34
5
6
7
8
9
10
12
11
12 campioni di 24 individui ciascuno
14 16 18 20 22 24 2614 16 18 20 22 24 26
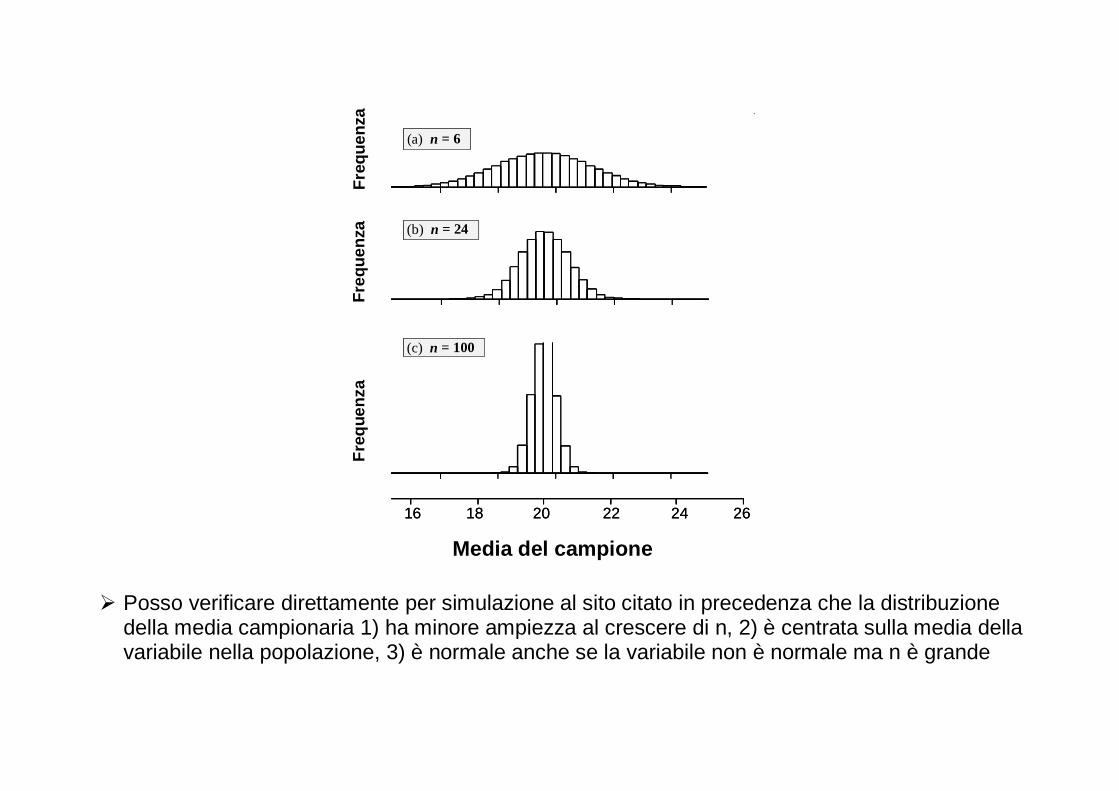
� Posso verificare direttamente per simulazione al sito citato in precedenza che la distribuzione della media campionaria 1) ha minore ampiezza al crescere di n, 2) è centrata sulla media della variabile nella popolazione, 3) è normale anche se la variabile non è normale ma n è grande
(c) n = 100
(b) n = 24
(a) n = 6
16 18 20 22 24 26
(c) n = 100
(b) n = 24
(a) n = 6
16 18 20 22 24 26
Media del campione
Fre
quen
zaF
requ
enza
Fre
quen
za
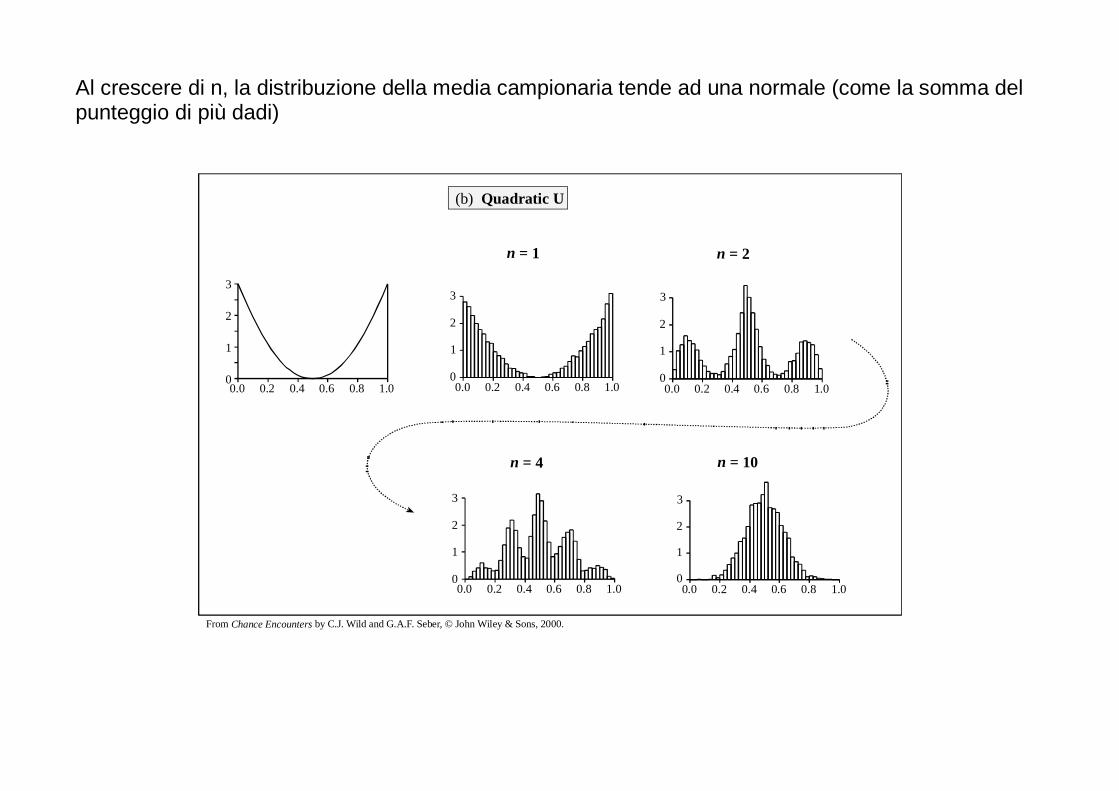
Al crescere di n, la distribuzione della media campionaria tende ad una normale (come la somma del punteggio di più dadi)
n = 2n = 1
n = 4 n = 10
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
(b) Quadratic U
From Chance Encounters by C.J. Wild and G.A.F. Seber, © John Wiley & Sons, 2000.

Cosa ci insegna la teoria statistica sulla distribu zione della media campionaria?
nX
σσ =
� La deviazione standard della media campionaria è pari alla deviazione standard della variabile
divisa per la radice della dimensione campionaria. Misura la precisione della stima. � La formula è logica: se la variabile nella popolazione è molto “dispersa” (alta σ) o il campione è
piccolo (basso n), la precisione della stima della media è bassa. � Al contrario, se la variabile nella popolazione ha sempre valori molto vicini alla media, o il
campione è molto grande, la media sarà stimata bene. � La deviazione standard della media campionaria prende il nome di Errore Standard (ES)
� Se quindi la distribuzione della media campionaria è normale, centrata su µ e con deviazione
standard paria a nx
σσ = , allora

La variabile standardizzata z
x
xz
σµ−
=
segue la distribuzione normale standardizzata Quindi, per esempio, nel 95% dei campioni con una certa dimensione n, la distanza standardizzata tra media campionaria e media della popolazione sarà compresa tra -1.96 e +1.96
P −1.96≤x −µσ x
≤1.96
= 0.95 (in linguaggio matematico)
che generalizzando diventa
P −zα / 2 ≤x −µσ x
≤ zα / 2
=1−α

� Riarrangiando (per α = 0.05) otteniamo qualcosa di molto più utile per il singolo campione:
%9595.096.196.1 ==
+≤≤
−
nx
nxP
σµ
σ
Questo significa che nel 95% dei campioni con una certa dimensione n, l’intervallo che calcolo
aggiungendo e togliendo a ogni media n
σ96.1 conterrà il valore vero della media nella
popolazione, µ.
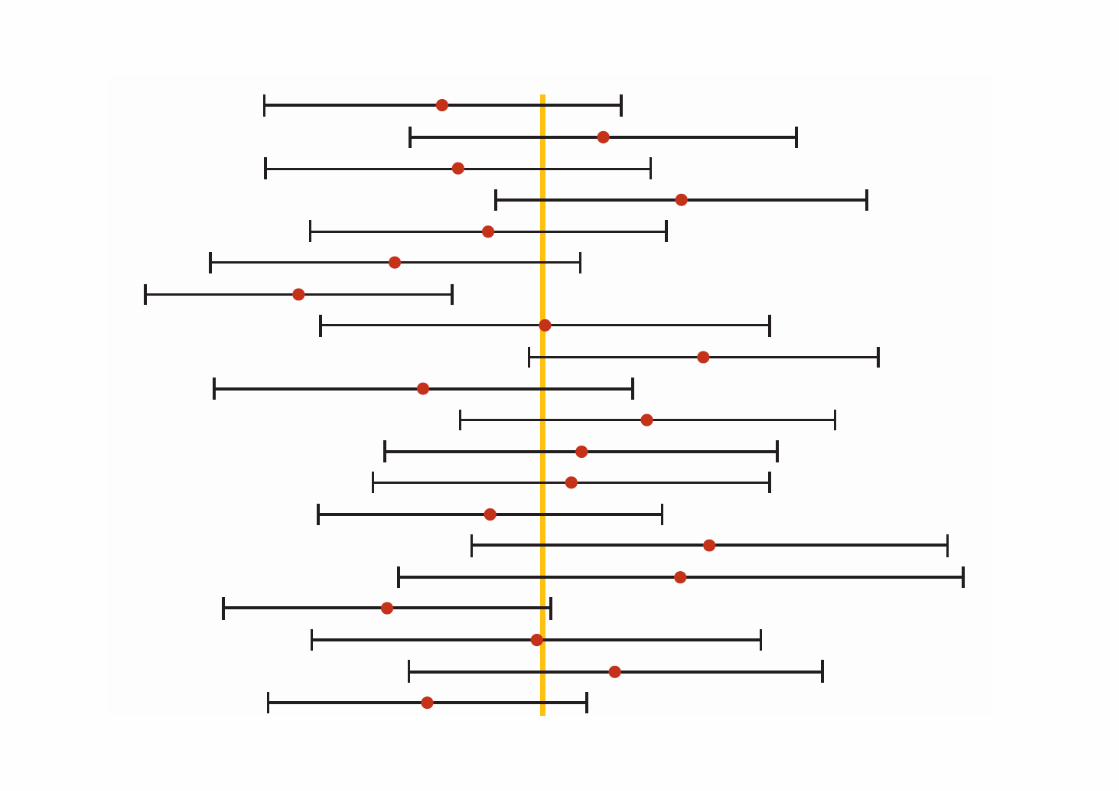

� Questo è l’intervallo di confidenza al 95% nel caso la deviazione standard σ sia nota:
nxxIC x
σσ 96.196.1%95 ±=±=
� Generalizzando
ασ
µσ
αα −=
+≤≤
− 12/2/
nzx
nzxP
nzxzxIC x
σσ ααα 2/2/1 ±=±=−
dove: 1. (1-α) prende il nome di grado di confidenza 2. α è chiamato livello di significatività (in altre parole, la probabilità che l’intervallo di confidenza calcolato non contenga il valore vero della media nella popolazione) 3. zα/2 è il valore di z nella distribuzione normale standardizzata che determina, alla sua destra, un'area corrispondente ad α/2.

Attenzione che l’intervallo di confidenza non è l’i ntervallo in cui cadono i valori della variabile, o la media del campione, ma gli interval li che con una certa probabilità conterranno la media della popolazione! (Informalmente, anche se non correttamente, si dice anche che la media della popolazione cadrà con una probabilità 1 - α all’interno dell’intervallo di confidenza calcolato. Ma definito un intervallo, la media della popolazione o è interna o è esterna a questo intervallo, non ha senso parlare di probabilità della media vera di cadere o no nell’intervallo calcolato)

ESERCIZIO Abbiamo calcolato la media delle altezze in un campione di 10 individui, e la media è risultata pari a 168,2 centimetri. Assumendo che la varianza σ2 dell’altezza nella popolazione sia nota, e sia pari a 110 cm2, determinare gli intervalli di confidenza al 90, al 95 e al 99%.

Soluzione 1. Determino i valori di zα/2 per α= 0.1, 0.05, e 0.01 - Per α= 0.1, α/2= 0.05, e il valore di z (da tabella) che separa il 5% a destra dell’area è pari circa a 1.645 - Per α= 0.05, α/2= 0.025, e il valore di z (da tabella) che separa il 5% a destra dell’area è pari a circa a 1.96 - Per α= 0.01, α/2= 0.005, e il valore di z (da tabella) che separa il 5% a destra dell’area è pari circa a 2.575 2. Calcolo l’errore standard (cioè la deviazione standard della media campionaria)
32.31110
110====
nx
σσ
3. Determino gli intervalli di confidenza - Per α= 0.1, IC = 168.2±5.46 - Per α= 0.05, IC = 168.2±6.51 - Per α= 0.01, IC = 168.2±8.55

COME CALCOLARE L’INTERVALLO DI CONFIDENZA QUANDO E’ NECESSARIO STIMARE LA DEVIAZIONE STANDARD?
(è quasi sempre così!)
� Per fortuna le cose non cambiano poi di molto visto che la nuova variabile
x −µsx
� con sx =s
n NON segue una distribuzione normale standardizzata MA, se la variabile
analizzata ha una distribuzione normale,
segue una nuova distribuzione teorica di probabilità chiamata distribuzione t di Student con n-1 gradi di libertà

� Quindi
( ) αµ αα −=⋅+≤≤⋅− −− 1// 1,2/1,2/ nstxnstxP nn
� e l’intervallo di confidenza della media diventa semplicemente da
IC(1-α) => nstx n /1,2/ ⋅± −α
tα/2, n-1 è quindi il valore critico della distribuzioni di t con n-1 gradi di libertà, che identifica, alla sua destra, un’ area pari a α/2.
� E se la variabile non ha una distribuzione gaussiana?
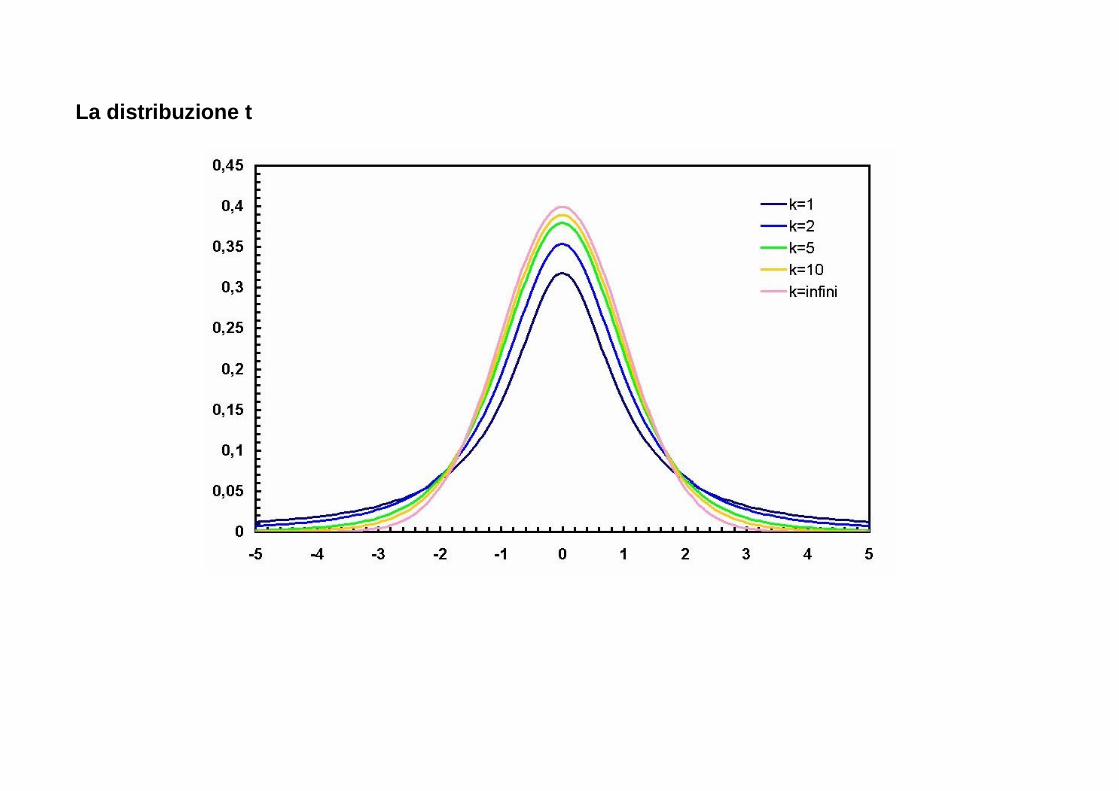
La distribuzione t

Caratteristiche principali
� Varia tra – infinito e +infinito � Ha un parametro, i gradi di libertà (la normale standardizzata non ha parametri)
o Per campioni di dimensioni diverse esistono quindi distribuzioni t diverse
� Media, moda, e mediana sono uguali � Ha media pari a 0 e varianza maggiore di 1.
o Se k è grande, la varianza tende a 1
� Rispetto alla normale standardizzata, ha code più pesanti o Maggiore concentrazioni di valori agli estremi, a causa della maggiore varianza rispetto
alla normale standardizzata, dovuta all’errore nella stima di σ
� Diventa una distribuzione normale standardizzata quando i gradi di libertà (e quindi la numerosità del campione) tendono a infinito.
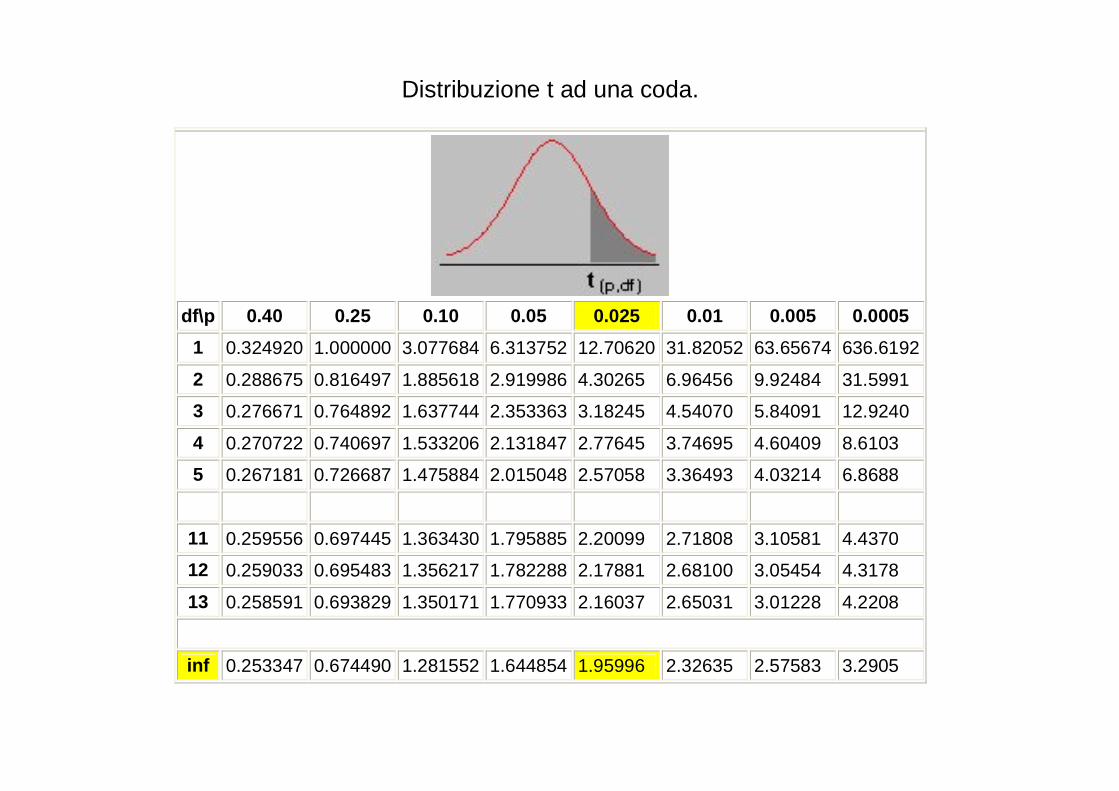
Distribuzione t ad una coda.
df\p 0.40 0.25 0.10 0.05 0.025 0.01 0.005 0.0005
1 0.324920 1.000000 3.077684 6.313752 12.70620 31.82052 63.65674 636.6192
2 0.288675 0.816497 1.885618 2.919986 4.30265 6.96456 9.92484 31.5991
3 0.276671 0.764892 1.637744 2.353363 3.18245 4.54070 5.84091 12.9240
4 0.270722 0.740697 1.533206 2.131847 2.77645 3.74695 4.60409 8.6103
5 0.267181 0.726687 1.475884 2.015048 2.57058 3.36493 4.03214 6.8688
11 0.259556 0.697445 1.363430 1.795885 2.20099 2.71808 3.10581 4.4370
12 0.259033 0.695483 1.356217 1.782288 2.17881 2.68100 3.05454 4.3178
13 0.258591 0.693829 1.350171 1.770933 2.16037 2.65031 3.01228 4.2208
inf 0.253347 0.674490 1.281552 1.644854 1.95996 2.32635 2.57583 3.2905
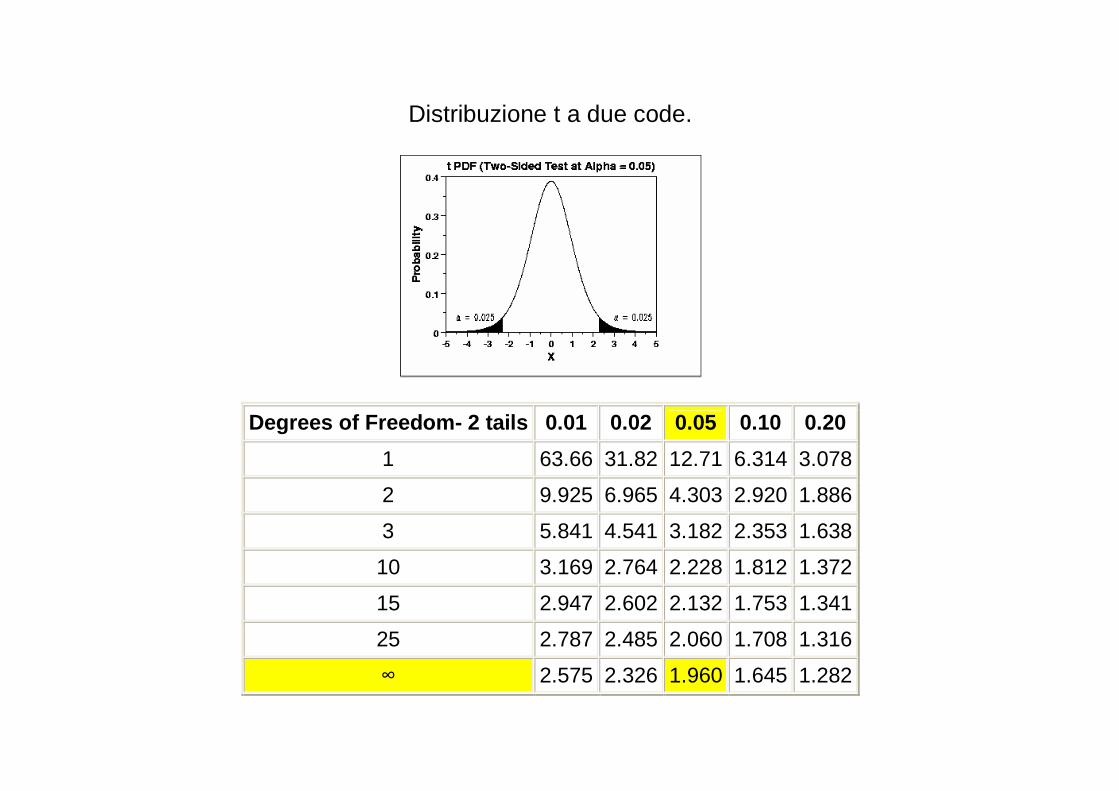
Distribuzione t a due code.
Degrees of Freedom- 2 tails 0.01 0.02 0.05 0.10 0.20
1 63.66 31.82 12.71 6.314 3.078
2 9.925 6.965 4.303 2.920 1.886
3 5.841 4.541 3.182 2.353 1.638
10 3.169 2.764 2.228 1.812 1.372
15 2.947 2.602 2.132 1.753 1.341
25 2.787 2.485 2.060 1.708 1.316
∞ 2.575 2.326 1.960 1.645 1.282

I gradi di libertà (GDL o gdl o df)
� Hanno chiaramente a che fare con la numerosità dell’informazione che a partire dai dati viene utilizzata in una analisi statistica. o Maggiore è il numero delle osservazioni, maggiori saranno i gradi di libertà.
� Corrispondono al numero pezzettini di informazione indipendenti che vengono utilizzati per una
stima o un test. � I gdl sono anche pari al numero totale di osservazioni (o punteggi) utilizzati in un test o in una
stima meno il numero di parametri che sono stati stimati Nel calcolo dell’intervallo di confidenza, se è necessario stimare la deviazione standard si usa una distribuzione t con n-1 gradi di libertà

Due conclusioni importanti
� La statistica inferenziale implica la conoscenza della distribuzione di probabilità della statistica utilizzata (la media campionaria standardizzata, nel nostro caso). Tale conoscenza non ci può ovviamente venire dai dati ma deve essere derivata, teoricamente o in altri modi, utilizzando spesso alcune assunzioni.
� I ragionamenti generali visti per l’intervallo di confidenza di una media sono applicabili anche
agli intervalli di confidenza per altri parametri. E’ però importante conoscere la distribuzione di frequenza della statistica che stiamo utilizzando per stimare il parametro.

ESEMPIO APPLICATIVO

ESERCIZIO La tabella riporta media e deviazione standard di 4 distribuzioni normali (prime 2 colonne). Calcolare la probabilità che campioni di 10 o 30 individui estratti da popolazioni con queste 4 distribuzioni abbiano una media campionaria maggiore del valore indicato nella terza colonna (X*).
Media Deviazione st. X* *)( XxP > (n=10)
*)( XxP > (n=30)
14 5 15 0.2643 0.1379 15 3 15.5 -23 4 -22 72 50 45

Intervalli di confidenza di una proporzione
� Variabile di tipo qualitativo (fumatori/non fumatori; giovani/adulti; maschi/femmine; mutazioneA/mutazioneB/mutazioneC/assenza di mutazione) o Calcoliamo la frequenza di individui che possiedono una certa caratteristica
� Per esempio, su un campione di 45 individui affetti da una certa patologia, 10 sono fumatori. La proporzione dei fumatori in questo campione, p, è quindi 10/45 = 0.22.
� Come si calcola l’intervallo di confidenza di questa proporzione? o Intervallo che con una certa probabilità contiene il valore di questa proporzione, π, nella
popolazione

� La distribuzione teorica di probabilità della statistica p, è la distribuzione binomiale
o La vedremo presto
� Se però nπ e n(1-π) sono entrambi maggiori o uguali a 5, una buona approssimazione della distribuzione binomiale è la ben nota distribuzione normale.
� In questo caso, la gaussiana che approssima la funzione di probabilità di p che ci interessa
avrà la media paria a π e la varianza pari a π(1-π)/n.
� L’errore standard di p, sarà quindi ( )np
ππσ
−=
1
� Quindi posso utilizzare lo stesso tipo di ragionamenti visti per l’intervallo di confidenza di una
media quando la varianza era nota e arrivare a
( ) ( )α
πππ
ππαα −=
−⋅+≤≤
−⋅− 1
112/2/ n
zpn
zpP
� Da cui
IC(1-α) => ( )
nzp
ππα
−⋅±
12/

� Anche in questo caso, però, abbiamo un termine, che qui è π, che non è noto � Una buona approssimazione si ottiene semplicemente rimpiazzando π con p
IC(1-α) => ( )
n
ppzp
−⋅±
12/α
� A parole: esiste una probabilità pari a 1-α che l’intervallo di confidenza così calcolato contenga la proporzione vera (cioè, la proporzione nella popolazione) � Questo metodo è valido solo se n è grande e se π non è troppo vicino a 0 o a 1

Esercizio La frequenza dell’intolleranza al lattosio, in campione di 80 soggetti, è risultata pari al 35%. Calcolare l’intervallo di confidenza al 99% di questa proporzione. n = 80 p = 0.35 α = 0.01 α/2 = 0.005 zα/2 = 2.576 (da tabella)
IC(1-α) => ( )
n
ppzp
−⋅±
12/α
IC(99%) => ( )
14.035.080
35.0135.0576.235.0 ±=
−⋅±
IC(99%) => 0.21 – 0.49

Pianificare la precisione: qualche esempio semplice di disegno sperimentale
� L’intervallo di confidenza si riduce all’aumentare della dimensione del campione
� Per esempio, se posso applicare z
IC(1-α) => nzx /2/ σα ⋅±
� Definiamo adesso con il termine generico di Errore:
xLinf Lsup
µ
E = Errore = | x –µ |

� Se per esempio Linf e Lsup definiscono l’intervallo di confidenza al 95%
o L’errore, con una confidenza del 95%, sarà sempre inferiore a n/96.1 σ⋅
� La stessa cosa vale ovviamente con diversi valori di α e corrispondenti valori di z � Quindi
o Emax,(1-α) = nz /2/ σα ⋅
� Che mi permette di calcolare
2
)1(max,
2/
⋅=
−α
α σE
zn
� Questa è ovviamente una dimensione minima
o Con valori di n maggiori saremo ancora più certi di non commettere un errore superiore al valore di Emax,(1-α) che ci è prefissati.

E se invece siamo in un caso in cui è necessario ut ilizzare la distribuzione t?
IC(1-α)=> nstx n /1,2/ ⋅± −α
� E quindi
2
)1(max,
1,2/
⋅=
−
−
α
α
E
stn n
� Qui però non conosciamo né la deviazione standard, e nemmeno il valore critico di t, prima di
fare l’esperimento � E’ necessaria una stima preventiva di s e trovare n per prova ed errore.

Esempio
� s stimato in precedenti studi o analisi = 4.
� Quale sarà la dimensione del campione che garantisce un errore non superiore a 1 con una confidenza del 95%,
� Scegliamo un n iniziale pari a 10:
� Con n= 10
� t0.025,9 = 2.262 e n ricalcolato = (2.262*4/1)2 = 82 (approssimato per eccesso)
� A questo punto utilizzo il valore di n ricalcolato per ripetere l’operazione
� t0.025,81 = 1.990 e n ricalcolato = (1.990*4/1)2 = 64 (approssimato per eccesso)
� t0.025,63 =1.998 e n ricalcolato = (1.998*4/1)2 = 64 (approssimato per eccesso)

E nel caso di un IC di una proporzione?
IC95% => ( )
nzp
ππα
−⋅±
12/
� E quindi
( )( )
( )( )ππ
ππ
α
α
αα
−
=
−=
−
−
1
1
2
1max,
2/
2/1max,
E
zn
ossian
zE
� Ma π non è noto, e nemmeno una sua stima, prima di fare l’esperimento!
� Conviene impostare π = 0.5, ossia la valore di π che rende n massimo.

La logica statistica della verifica (test) delle ip otesi
� Come posso confrontare diverse ipotesi? � Nella statistica inferenziale classica vengono sempre confrontate due ipotesi: l’ipotesi nulla e
l’ipotesi alternativa � In realtà, questo confronto non è diretto. Quello che si confronta realmente sono i dati con
l’ipotesi nulla
� In altre parole:
1. Si cerca di prevedere come potrebbero essere i dati se fosse vera l’ipotesi nulla 2. Se i dati osservati sono molto distanti da quelli si potrebbero ottenere se fosse vera l’ipotesi nulla, allora l’ipotesi nulla VIENE RIFIUTATA (e di conseguenza, si accetta l’ipotesi alternativa) 3. Se invece i dati osservati non sono troppo distanti da quelli si potrebbero ottenere se fosse vera l’ipotesi nulla, allora l’ipotesi nulla NON VIENE RIFIUTATA (ovvero, si dice che i dati osservati sono compatibili con l’ipotesi nulla) L’ipotesi nulla non viene mai accettata!

Ipotesi nulla e ipotesi alternativa
� Ipotesi nulla, o H 0
o E’ un enunciato specifico che riguarda un parametro nella popolazione (o nelle popolazioni)
o E’ l'ipotesi che tutto sommato, se verificata, farebbe concludere allo sperimentatore di aver
perso tempo o comunque renderebbe tutta la faccenda meno interessante o E’ l’ipotesi sulla base della quale si elabora la distribuzione nulla della statistica utilizzata
per il test
� Ipotesi alternativa, o H a o H1
o Rappresenta tutte le altre ipotesi riguardo al parametro non specificate dall’ipotesi nulla
o E’ l’ipotesi che generalmente viene formulata prima di fare un test, l'idea cioè che ha avuto il ricercatore e che lo ha indotto a fare un esperimento o a raccogliere dei dati sul campo (e che quindi sarebbe interessante in genere poter verificare)

Esempi di H0
� La densità di delfini è la stessa nelle zone aree in cui la pesca viene effettuata con le e senza pesca con reti a deriva è uguale alla densità di delfini nelle aree in cui la pesca viene effettuata senza queste reti � Gli effetti antidepressivi della sertralina non differiscono da quelli dell'amitriptilina � Genitori con occhi marroni, ciascuno dei quali ha avuto un genitore con occhi azzurri, hanno figli con occhi marroni e figli con occhi azzurri in un rapporto 3:1 � La temperatura corporea media degli esseri umani sani è 37 °C
Esempi di H1
� La densità di delfini differisce tra zone con e senza pesca con reti a deriva � Gli effetti andidepressivi della sertralina differiscono da quelli dell'amitriptilina � I genitori con gli occhi marroni, ciascuno dei quali ha avuto un genitore con occhi azzurri, hanno figli con occhi marroni e figli con occhi azzurri in un rapporto diverso da 3:1 � La temperatura corporea media degli esseri umani sani non è 37 °C.

Formalizzazione del test di ipotesi con un esempio molto semplice
� Vediamo con un esempio semplice: test sulla media per un campione con varianza nota
o Supponiamo che la crescita media tra il terzo mese e il quarto mese di un bambino allattato con latte materno, in Italia, sia di 0.54 kg (µ = µ0= 0.54)
o Supponiamo anche di sapere che la deviazione standard in questa variabile sia nota e pari
a 0.12 kg (σ = 0.12) o Un campione di 35 bambini alimentati solo con latte artificiale viene analizzato per questa
variabile, e si ottiene una media campionaria x = 0.47 o Si vuole determinare se l’accrescimento medio dei bambini allattati con latte artificiale è
diverso da quello dei bambini allattati con latte materno.
� Si vuole verificare se la media µ nella popolazione dei bambini allattati con latte artificiale (della quale abbiamo un campione) è diversa dalla media µ0 della popolazione dei bambini allattati con latte materno (della quale conosciamo la media). La varianza si suppone nota.

� Formalmente, possiamo indicare le due ipotesi come
� Ipotesi nulla � H0 : µ = µ0 (l’ipotesi nulla è molto specifica)
� Ipotesi alternativa � H1 : µ ≠ µ0 (l’ipotesi alternativa è “tutto quello che non è l’ipotesi nulla”)
� Assumiamo inizialmente che sia vera l’ipotesi nulla per prevedere i risultati che dovremmo attenderci in un campione con n = 35 o il campione di 35 bambini proviene da una popolazione con media µ = µ0= 0.54, con una
deviazione standard σ = 0.12, e quindi il fatto che x = 0.47 è un semplice effetto del campionamento casuale
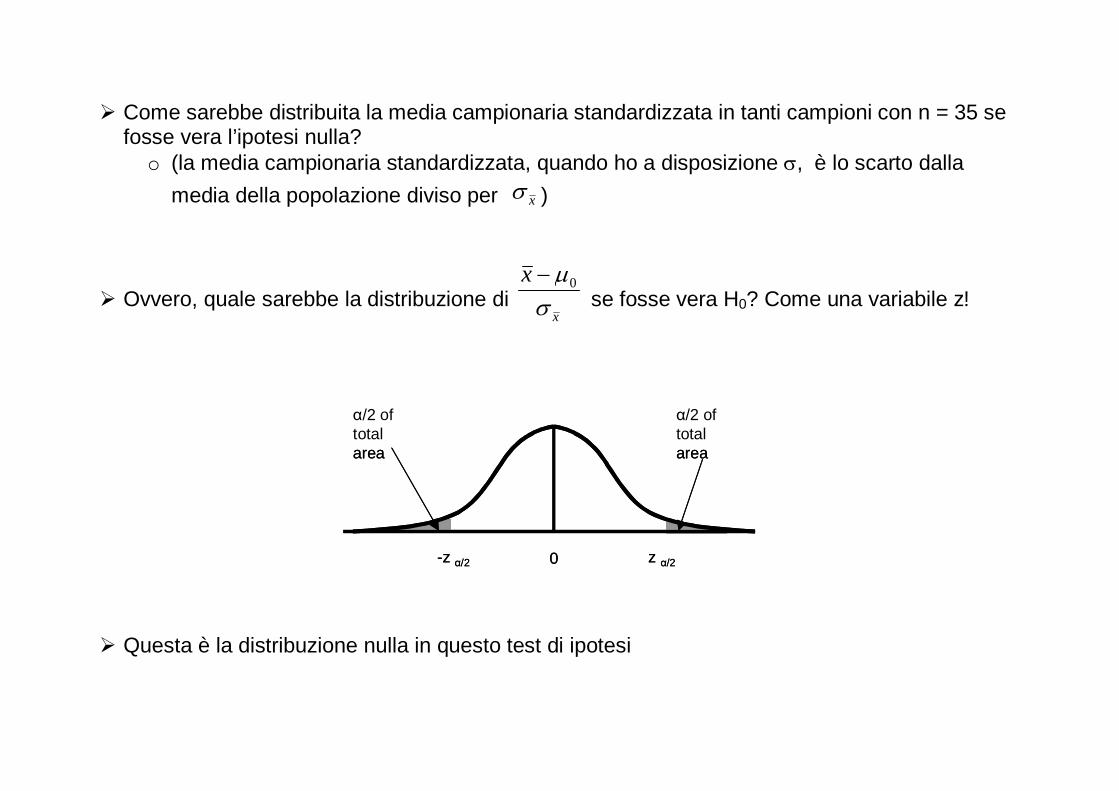
� Come sarebbe distribuita la media campionaria standardizzata in tanti campioni con n = 35 se
fosse vera l’ipotesi nulla? o (la media campionaria standardizzata, quando ho a disposizione σ, è lo scarto dalla
media della popolazione diviso per xσ )
� Ovvero, quale sarebbe la distribuzione di x
x
σ
µ0− se fosse vera H0? Come una variabile z!
0
α/2 of total area
α/2 oftotal area
-z α/2 z
α/20
α/2 of total area
α/2 oftotal area
-z α/2 z
α/2
� Questa è la distribuzione nulla in questo test di ipotesi
0
α/2 of total area
α/2 oftotal area
-z α/2 z
α/20
α/2 of total area
α/2 oftotal area
-z α/2 z
α/2
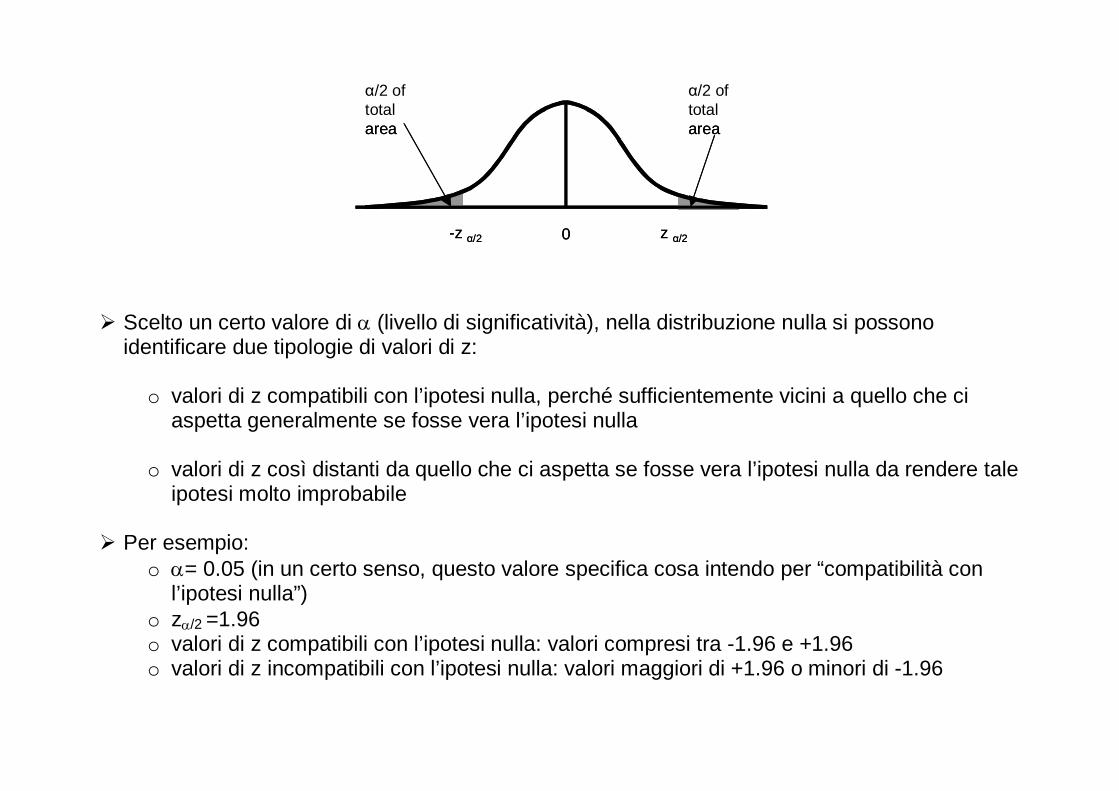
� Scelto un certo valore di α (livello di significatività), nella distribuzione nulla si possono
identificare due tipologie di valori di z:
o valori di z compatibili con l’ipotesi nulla, perché sufficientemente vicini a quello che ci aspetta generalmente se fosse vera l’ipotesi nulla
o valori di z così distanti da quello che ci aspetta se fosse vera l’ipotesi nulla da rendere tale
ipotesi molto improbabile
� Per esempio: o α= 0.05 (in un certo senso, questo valore specifica cosa intendo per “compatibilità con
l’ipotesi nulla”) o zα/2 =1.96 o valori di z compatibili con l’ipotesi nulla: valori compresi tra -1.96 e +1.96 o valori di z incompatibili con l’ipotesi nulla: valori maggiori di +1.96 o minori di -1.96

Ragionando sull’esempio della crescita di neonati:
o Il 95% dei campioni con n=35 estratti da una popolazione con media pari a 0.54 kg e σ =
0.12 kg avranno una 35/12.0
54.0−x non superiore a 1.96 e non inferiore a -1.96
o Se nel mio singolo campione questo valore è inferiore a -1.96 o superiore a 1.96, lo
considero così improbabile se fosse vera l’ipotesi nulla, da portarmi al rifiuto di questa ipotesi
o Se nel mio singolo campione questo valore è compreso tra -1.96 e 1.96, lo considero un
valore non così improbabile se fosse vera l’ipotesi nulla, ovvero compatibile con l’ipotesi nulla. Quest’ultima non viene rifiutata.
Questa è la logica inferenziale classica, basata sul rifiuto o il non-rifiuto dell’ipotesi nulla, dell’ipotesi cioè dalla quale partiamo e della quale siamo in grado di definire le caratteristiche in termini di probabilità.

Quindi, in questo caso, il test dell’ipotesi si realizza calcolando la statistica test z
xcalc
xz
σ
µ0−=
e confrontando il valore ottenuto con due regioni della distribuzione z
o regione di accettazione: - zα/2 ÷ zα/2
o regione di rifiuto: per valori di z minori di - zα/2 e maggiori di zα/2
� Il valore di α (livello di significatività) viene di solito fissato a 0.05, ma può anche essere pari a
0.01 o 0.001 se vogliamo essere più sicuri che il rischio di commettere un errore rifiutando un’ipotesi nulla vera (errore di primo tipo) sia inferiore
QUINDI
� Se zcalc cade nella regione di rifiuto, ci sono evidenze forti che sia vera l’ipotesi alternativa, con una probabilità α di sbagliarsi (ovvero di compiere un errore di primo tipo)
� Se zcalc cade nella regione di accettazione, non possiamo respingere l’ipotesi nulla (che non
viene accettata: i dati disponibili sono compatibili con l’ipotesi nulla, ma altri dati, per esempio più numerosi, potrebbero portare al rifiuto)
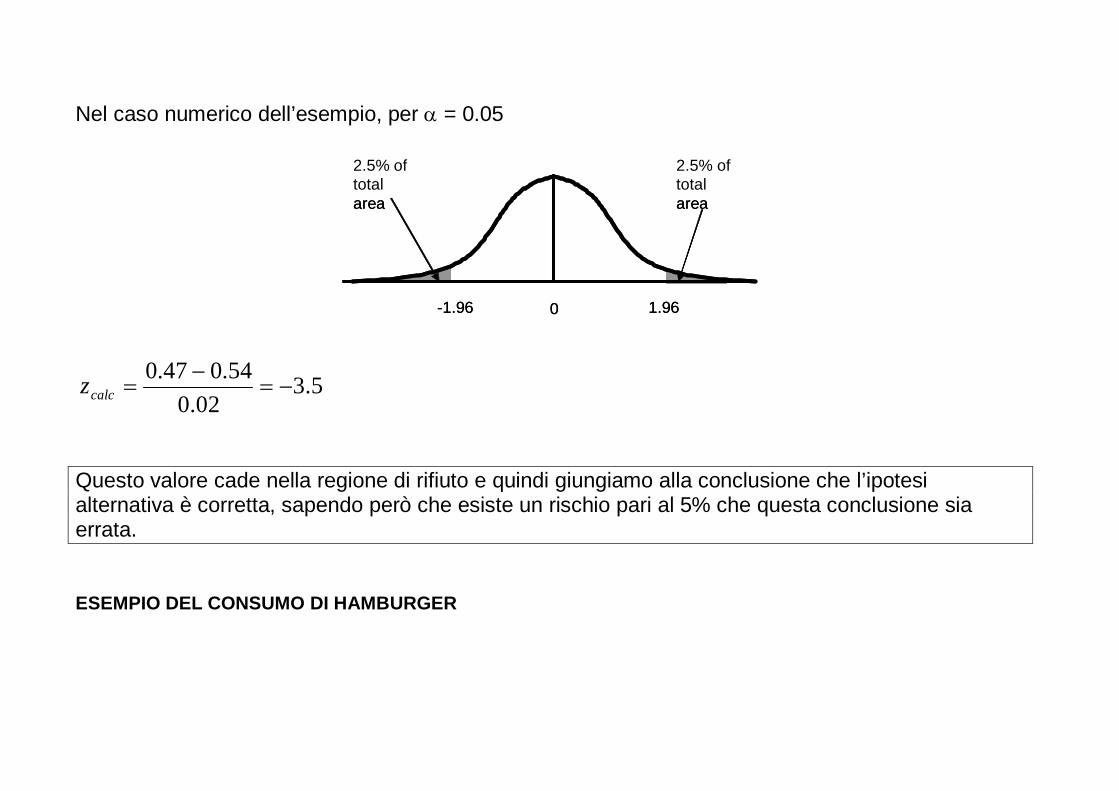
Nel caso numerico dell’esempio, per α = 0.05
0
2.5% of total area
2.5% of total area
-1.96 1.960
2.5% of total area
2.5% of total area
-1.96 1.96
5.302.0
54.047.0−=
−=calcz
Questo valore cade nella regione di rifiuto e quindi giungiamo alla conclusione che l’ipotesi alternativa è corretta, sapendo però che esiste un rischio pari al 5% che questa conclusione sia errata.
ESEMPIO DEL CONSUMO DI HAMBURGER

L’approccio del P-value (o p-value) nella verifica dell’ipotesi
� E’ un approccio alternativo a quello delle regioni di accettazione e rifiuto appena visto � Importante perché fornisce un’informazione più precisa e anche perché è l’approccio utilizzato
nelle analisi statistiche al calcolatore.
� Torniamo al nostro esempio di test sui bambini allattati con latte artificiale e materno
� x
calc
xz
σ
µ−=
� E’ possibile determinare (da tabella o mediante computer) la probabilità di osservare valori
uguali o più estremi di quello osservato (più estremi significa meno probabili).
� Questa probabilità prende il nome di P-value (o valore p)
� Ovviamente, minore è il P-value o maggiore è l’evidenza che il campione provenga da una popolazione con media diversa
da quella ipotizzata dall’ipotesi nulla o maggiore è quindi l’evidenza in favore dell’ipotesi alternativa

� Con l’approccio del P-value, la logica procede come segue
� Se il P-value è minore di α, ho forti motivi per ritenere che la popolazione da cui proviene il
campione di bambini allattati con latte in polvere abbia una crescita media diversa da µ0 (quella ipotizzata dall’ipotesi nulla) o Si conclude che è vera l’ipotesi alternativa H1 (ossia, il tipo di latte ha un effetto), perché
la probabilità di avere una media così deviante o anche più deviante risulta molto bassa se fosse vera l’ipotesi nulla
o Il P-value è anche pari alla probabilità di sbagliare giungendo a questa conclusione, ossia la probabilità di commettere un errore di primo tipo
� Se invece il P-value è maggiore di α, non ci sono forti evidenze che la popolazione da cui il
campione proviene abbia una media diversa da µ0. o Si conclude che i dati sono compatibili con l’ipotesi nulla, sono cioè spiegabili con il solo
effetto del campionamento. L’ipotesi che la crescita non è influenzata dal tipo di latte non può essere scartata, visto che una certa probabilità non troppo piccola, data dal P-value, risultati simili o più estremi di quelli osservati si possono ottenere per caso se è vera l’ipotesi nulla.
� L'approccio basato sui P-value non è altro che l'altra faccia dell'approccio basato sulle regioni di
accettazione e rifiuto o fissato α, se un valore della statistica test cade nella regione di rifiuto, il suo P-value è
sempre minore di α

� Utilizzando i dati nel nostro esempio, otteniamo come prima che
5.302.0
54.047.0−=
−=calcz
� Cercando in tabella, o usando per esempio un applet in Internet, possiamo calcolare il P-value,
( ) 0005.05.35.3 =≤≤−=− zPvalueP

Alcuni punti molto importanti 1. Inferenza statistica e cautela verso le “novità”
� La verifica di ipotesi è forse lo strumento statistico più importante per il processo conoscitivo scientifico
� Considerando che H0 tendenzialmente definisce la situazione sperimentale "conservatrice" e H1
quella che porta ad una scoperta nella ricerca, si capisce come la logica dell’inferenza statistica abbia un carattere di cautela verso l'innovazione: consente di rifiutare l’ipotesi nulla solo se i dati sono veramente incompatibili con essa (α è in genere fissato al 5%)
� Possiamo pensare alla verifica di ipotesi come ad un processo
o L'imputato è il parametro sotto test o L'assoluzione corrisponde a non rifiutare H0 o La sentenza di colpevolezza è in analogia all'ipotesi alternativa
� Il sistema legislativo consente di condannare solo nel caso di forti evidenze di colpevolezza, nel
caso cioè in cui la probabilità che l'imputato (il parametro) sia innocente (assumo H0), sia molto bassa (minore di α). In questo caso ci garantiamo di non condannare quasi mai un innocente (che come abbiamo visto in statistica di chiama errore di primo tipo), errore ben più grave di assolvere un colpevole (che come vedremo si chiama errore di secondo tipo).

2. L’ipotesi nulla non viene mai accettata
� Un risultato non significativo indica solo che non si è in grado di rifiutare l’ipotesi nulla
� Potrei per esempio avere una media della popolazione campionata (quella dei bambini allattati con latte in polvere nell’esempio presentato) leggermente diversa dalla media di riferimento (quella dei bambini allattati con latte materno), ma i dati risultano ancora compatibili con l’ipotesi nulla.
� L’evidenza in favore dell’ipotesi alternativa non è sufficientemente forte per escludere l’ipotesi
nulla.
� Niente esclude che in un successivo esperimento questa differenza diventi evidente.
� Volendo continuare con l'analogia del processo, questo corrisponde al fatto che l'imputato non viene mai assolto in modo definitivo, ma all'eventuale presenza di nuove prove di colpevolezza, il processo verrebbe riaperto (si eseguirebbe di nuovo il test con i nuovi dati raccolti).

3. Il livello di significatività non corrisponde al la dimensione dell’effetto
� Lo stesso effetto diventa più o meno significativo semplicemente in funzione del numero di dati disponibili: avere più dati, significa avere maggiori informazioni, per cui anche l'effetto più piccolo diventa significativo con un adeguato numero di osservazioni.
� Un risultato significativo non significa un risultato importante ci indica solo quanto poco
probabile è che un certo effetto sia dovuto al caso
� Interpretare la "dimensione", e quindi l'importanza del risultato, è compito dello studioso.
� Per esempio, potrebbe risultare, sulla base di un campione di 10000 persone che fanno jogging regolarmente, che il loro rischio di infarto è statisticamente maggiore rispetto a chi non lo pratica (favorendo cioè l’ipotesi alternativa). Se però questo rischio aumenta, pur se in maniera statisticamente significativa, solo dello 0.01% , questo risultato potrebbe non avere una grande importanza sociale o comunque biologica.

Test sulla media di un campione quando la varianza è ignota � Le ipotesi nulla e alternativa sono ancora: H0 : µ = µ0 La media µ della popolazione dalla quale ho estratto il campione è uguale ad un certo
valore prefissato, µ0. In altre parole, il campione proviene da una popolazione con media µ0.
H1: µ ≠ µ0 La media µ è diversa dal valore prefissato µ0. � La statistica test è il t di Student, calcolato come segue
ns
x
s
xt
xcalc
/00 µµ −
=−
=
� Se la variabile in esame ha una distribuzione gaussiana, questa statistica test si distribuisce secondo la distribuzione t di Student con (n-1) gradi di libertà se è vera l’ipotesi nulla � Posso seguire lo stesso approccio (regioni di accettazione/rifiuto o P-value) per testare l’ipotesi nulla, ovviamente usando la distribuzione t come distribuzione nulla: è un test t di Student

� Il test t è relativamente robusto a piccole deviazioni dall’assunzione di normalità o Ovvero, anche se la variabile ha una distribuzione che si discosta dalla gaussiana, il test t
funziona ugualmente se tale scostamento è piccolo e/o il campione è molto numeroso Esempio

Test sulla proporzione in un campione (utilizzando il test z)
� Un certo numero di individui n, viene assegnato a diverse categorie di una variabile qualitativa � Si calcola la proporzione p di individui che possiedono una specifica caratteristica � Si vuole determinare il valore π nella popolazione da cui il campione è stato prelevato differisce
da un certo valore prefissato π0.
� Se nπ e n(1-π) sono maggiori o uguali a 5 o la variabile p ha una distribuzione binomiale
� Approssimabile con una distribuzione normale • La variabile p standardizzata ha una distribuzione approssimativamente normale
standardizzata. Applico il test z H0 : π= π0 H1 : π ≠ π0
( )n
ppz
pcalc
00
00
1 ππ
π
σ
π
−
−=
−=
� Verifico le ipotesi come di norma

Esempio
� Un campione di 100 cardiopatici viene suddiviso in fumatori e non fumatori � I fumatori risultano essere 21 (p = 0.21) � La proporzione di fumatori nella popolazione generale è pari a 0.15 (π0) � Confrontare l’ipotesi “tra i cardiopatici, i fumatori sono tanto numerosi quanto nella popolazione
generale” (ipotesi nulla) con l’ipotesi “la numerosità di fumatori non differisce nella popolazione di cardiopatici rispetto alla popolazione generale” (ipotesi alternativa)
( ) ( )68.1
100
85.015.0
15.021.0
1 00
0 =−
=−
−=
n
pzcalc
ππ
π
� Il valore calcolato cade nella regione di accettazione o non esistono evidenze statisticamente significative, utilizzando un valore di α = 0.05, che
la frazione di fumatori nei cardiopatici sia diversa dal valore riscontrato nella popolazione generale
� Il p-value è pari a 0.09.

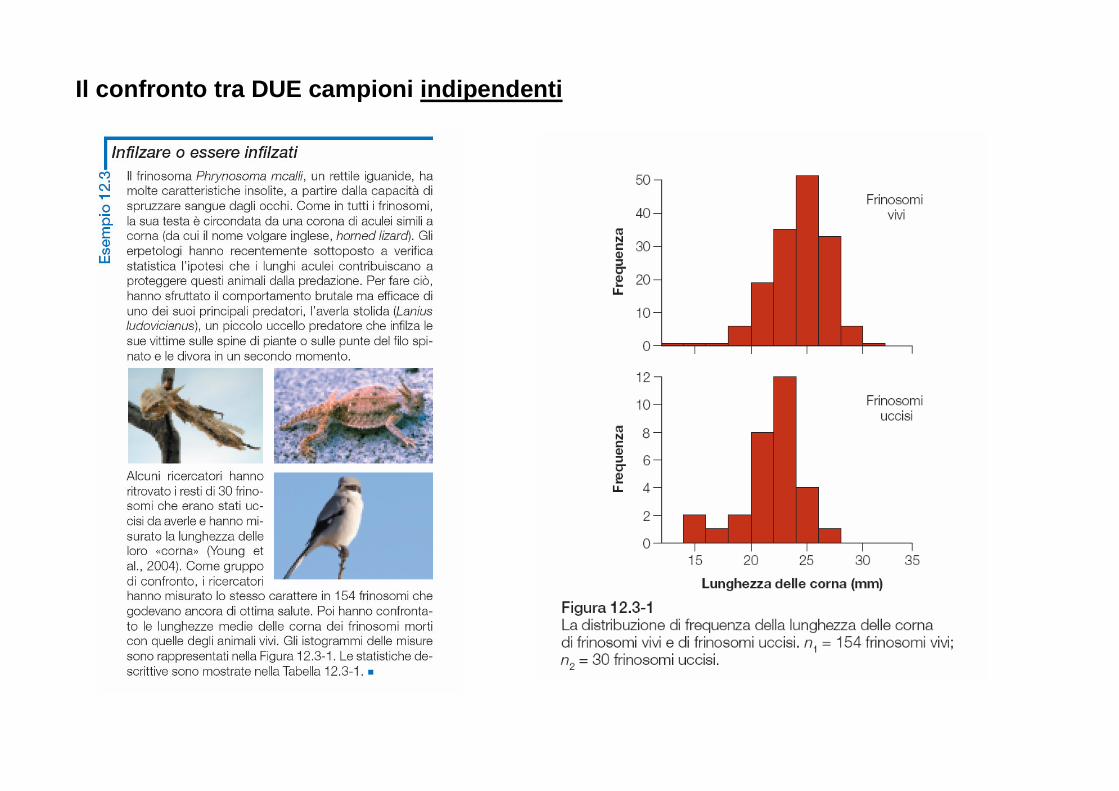
Il confronto tra DUE campioni indipendenti
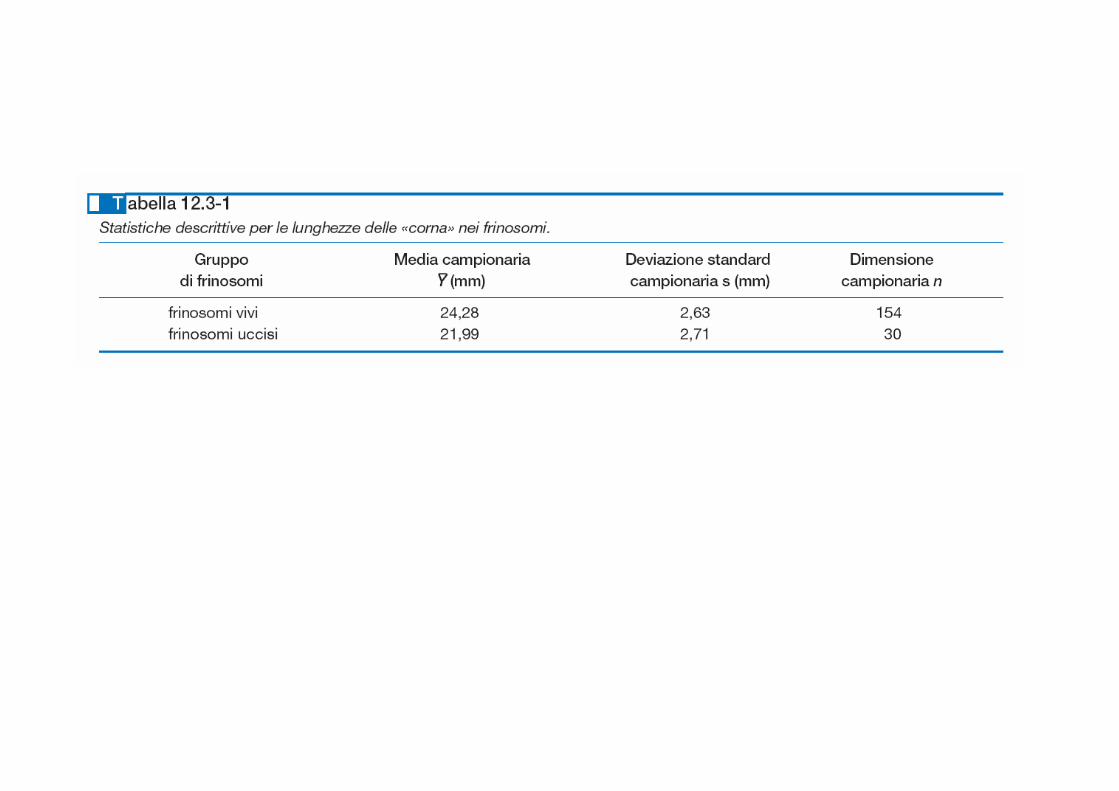

Il confronto tra DUE campioni indipendenti Confronto tra due medie
� In questi casi siamo interessati a confrontare il valore medio di due campioni in cui i le osservazioni in un campione sono indipendenti dalle osservazioni in un secondo campione (il caso di campioni non indipendenti, o appaiati, verrà discusso in seguito).
� Si suppone quindi di avere n1 e n2 osservazioni rilevate su due popolazioni con medie µ1 e µ2
ignote e varianze σ12 e σ2
2.
� H0 : µ1 = µ2 Le medie µ1 e µ2 sono uguali
� H1 : µ1 ≠ µ2 Le medie µ1 e µ2 sono diverse
� In questo caso dobbiamo introdurre una nuova variabile, la variabile “differenza tra due medie
campionarie” ovvero 21 xx − .

� Se è vera l’ipotesi nulla, la teoria statistica (ma anche la semplice intuizione) ci dice che la
nuova variabile 21 xx − , differenza di due variabili di cui conosciamo le proprietà, tende ad essere gaussiana con media pari a 0 e varianza pari a (σ1
2/n1 + σ22/n2 ), ovvero alla somma delle
varianze delle singole variabili 1x e 2x .
� [Intuitivamente, se per esempio una variabile è uniforme tra 5 e 10, e un’altra è uniforme tra 1 e 4, la loro differenza oscillerà tra 1 (5-4) e 9 (10-1), e quindi la dispersione della variabile “differenza” sarà sicuramente maggiore rispetto alle singole variabili]
� La nuova variabile 21 xx − , quindi, se è vera l’ipotesi nulla e dopo opportuna (e usuale)
standardizzazione, ha media pari a zero, e segue una distribuzione normale standardizzata z o una distribuzione t a seconda che le varianze σ1
2 e σ22 siano note o siano stimate sulla base dei
valori campionari (esattamente come accade per i test per un campione).

Confronto tra 2 medie. Caso 1. Varianze σ1
2 e σ22 note: si applica il test z
[NON è la situazione dell’esempio iniziale con i fr inosomi!]
La statistica test
2
22
1
12
21
nn
xxzcalc
σσ+
−=
ha distribuzione normale standardizzata. Seguendo la logica esposta nel paragrafo precedente, possiamo condurre la verifica di ipotesi seguendo l’approccio delle regioni di accettazione/rifiuto a partire dal valore critico zα/2.oppure calcolando il p-value di zcalc

Esempio
� La carica batterica presente in tamponi boccali viene analizzata in due gruppi di pazienti (nessun paziente appartiene a entrambi i gruppi)
� Il primo gruppo è costituito da individui che stanno per entrare in ospedale per un ricovero, il secondo da individui che escono dall’ospedale dopo un ricovero di una settimana
� Si vuole determinare se il periodo trascorso in ospedale influenza la carica batterica � Le varianze si suppongono uguali tra loro nelle due popolazioni e note da esperimenti
precedenti. DATI: 1x = 5627.3; 2x = 6937.9; σ1= σ2 = 2500, n1 = 10; n2 = 12
224.1
12
1
10
12500
9.69373.5627
12
2500
10
2500
9.69373.562722
−=
+
−=
+
−=calcz
Il valore critico (α=0.05) è pari a zα/2 = z0.025 = +1.96 e la regione di accettazione va da -1.96 a +1.96. Non ci sono quindi evidenze forti (ad α=0.05) per concludere che un periodo trascorso in ospedale influenzi la carica batterica boccale. Il p-value di zcalc è 0.221, e ovviamente la conclusione è la stessa anche seguendo l' approccio del p-value

Confronto tra due medie. Caso 2. Varianze σ12 e σ2
2 ignote ma uguali: si applica il test t di Student
[E’ la situazione dell’esempio iniziale con i frino somi!]
� In questo caso si pone il problema della stima della varianza nei due campioni � Si noti innanzitutto che questo test si può applicare solo se σ2
1 = σ22 =σ
2 (le due varianze nelle popolazioni devono essere uguali) e se la variabile ha distribuzione normale in entrambe le popolazioni
� Queste due condizioni devono essere verificate e vedremo come farlo. Il test t è però
relativamente robusto a deviazioni da queste assunzioni. � Per il momento assumiamo che siano vere

� Le varianze campionarie calcolate nei due campioni saranno certamente diverse, anche
assumendo le varianze delle popolazioni siano uguali � A questo punto, avendo a disposizione due stime di un singolo parametro, conviene prima di
tutto ottenere una stima unica � A questo scopo viene calcolata una varianza comune, s2
com, che corrisponde ad una media pesata per i diversi gradi di libertà delle due varianze campionarie
� s2
com è anche definito come s2p, dove la p indica “pooled”
� Si preferisce una media pesata perché, giustamente, una varianza calcolata in campione di
dimensioni maggiore è probabilmente più precisa, e quindi deve pesare di più nella media tra le due. Maggiore il numero di osservazioni, maggiore è l'informazione apportata da quel campione per la stima della varianza.

2
)1()1(
21
22
212
12
−+−+−
=nn
snsns com
� Il valore tcalc a questo punto può essere calcolato secondo la formula
21
21
2
2
1
2
21
11
nns
xx
n
s
n
s
xxt
comcomcom
calc
+
−=
+
−=
.
� Se quindi
o 1) è vera l’ipotesi nulla o 2) le due variabili X1 e X2 hanno una distribuzione normale o 3) le due varianze σ2
1 e σ22 sono uguali
� tcalc segue una distribuzione t con (n1 + n2 –2) gradi di libertà, sulla quale posso facilmente calcolare il p-value o definire le regioni di accettazione e di rifiuto seguendo i metodi ormai ampiamente discussi

Esempio In due siti archeologici che si riferiscono a due diverse tribù di Indiani d’America vengono rinvenute delle punte di freccia, 8 nel primo sito e 7 nel secondo. Si vuole determinare se le due tribù utilizzassero frecce di dimensioni diverse. Assumiamo che le condizioni per poter applicare questo test (varianze uguali nelle due popolazioni, distribuzioni gaussiane della variabile nelle due popolazioni) DATI (lunghezze frecce in cm) Tribù 1 : 4.5; 5.2; 4.3; 4.7; 4.0; 3.9; 5.8; 2.8 Tribù 2: 5.2; 5.7; 6.0; 6.7; 5.5; 5.4; 6.8
H0 : µ1 = µ2 H1 : µ1 ≠ µ2
A partire dai dati calcolo:
1x = 4.4; 2x = 5.9; s21 = 0.81 s2
2 = 0.40. La varianza comune è stimata con
62.0278
40.0*)17(81.0*)18(2 =−+−−−
=coms
79.02 == comcom ss .

Quindi
66.3
7
1
8
179.0
9.54.4−=
+
−=calct
� Con (n1 + n2 –2) = 13 gradi di libertà, e α = 0.05, la regione di accettazione della distribuzione t
inizia a –2.160 e termina a +2.160 � Posso quindi concludere che la differenza delle frecce nei due siti è significativa al 5% � Si noti che sarebbe stata significativa anche se avessi scelto un valore di α = 0.01 (tcrit = 2.560),
indicando cioè che la conclusione che traggo è errata con una probabilità non solo inferiore al 5% ma anche inferiore all’ 1%
� Il p-value di tcalc è pari a 0.003.
Svolgere il test per lo studio sui frinosomi

Confronti tra due proporzioni
� In due campioni di dimensioni n1 e n2 viene contato il numero di osservazioni che sono attribuite ad una certa categoria, x1 e x2
� La proporzione di osservazioni in ciascun campione che cade all’interno di questa categoria è
dato da o p1=x1/n1 o p2=x2/n2
� Si vogliono analizzare le ipotesi che i valori delle proporzioni nelle popolazioni dalle quali i due
campioni sono estratti, π1 e π2, siano uguali o diversi.
H0 : π1= π2 ( = π) H1 : π1 ≠ π2
� Se è vera l’ipotesi nulla, e se è possibile utilizzare la distribuzione normale come
approssimazione della binomiale per le due distribuzioni di p1 e p2 o allora la variabile “differenza tra le proporzioni”, standardizzata come al solito per la
deviazione standard della variabile “differenza tra le proporzioni” (pari alla somma delle varianze delle due variabili che vengono considerate) segue una distribuzione normale standardizzata z.

( ) ( )( )
+−
−=
−+
−
−=
21
21
21
21
111
11
nn
pp
nn
ppzcalc
ππππππ
� π però non è noto, e viene stimato come frazione totale degli individui attribuiti alla categoria
che sto analizzando
21
21
nn
xxp
++
=
( )
+−
−=
21
21
111
nnpp
ppzcalc
� E’ quindi il solito test z per la verifica dell’ipotesi

Esempio
� Si vuole determinare l’efficacia di un vaccino confrontando la frazione di individui che si ammalano in un gruppo di individui vaccinati con la frazione di individui che si ammalano in un gruppo di individui che non sono stati vaccinati
� Di 6815 individui vaccinati, 56 sono colpiti dalla malattia contro la quale si è sviluppato il
vaccino. In un gruppo di 11668 individui non vaccinati, sono invece 272 quelli che si ammalano. p1=56/6815 = 0.0082; p2 = 272/11668 = 0.0233 Si applica l’approssimazione normale
0177.0116686815
27256=
++
=p
( )51.7
11688
1
6815
10177.010177.0
0233.00082.0−=
+−
−=calcz
COSA CONCLUDO?
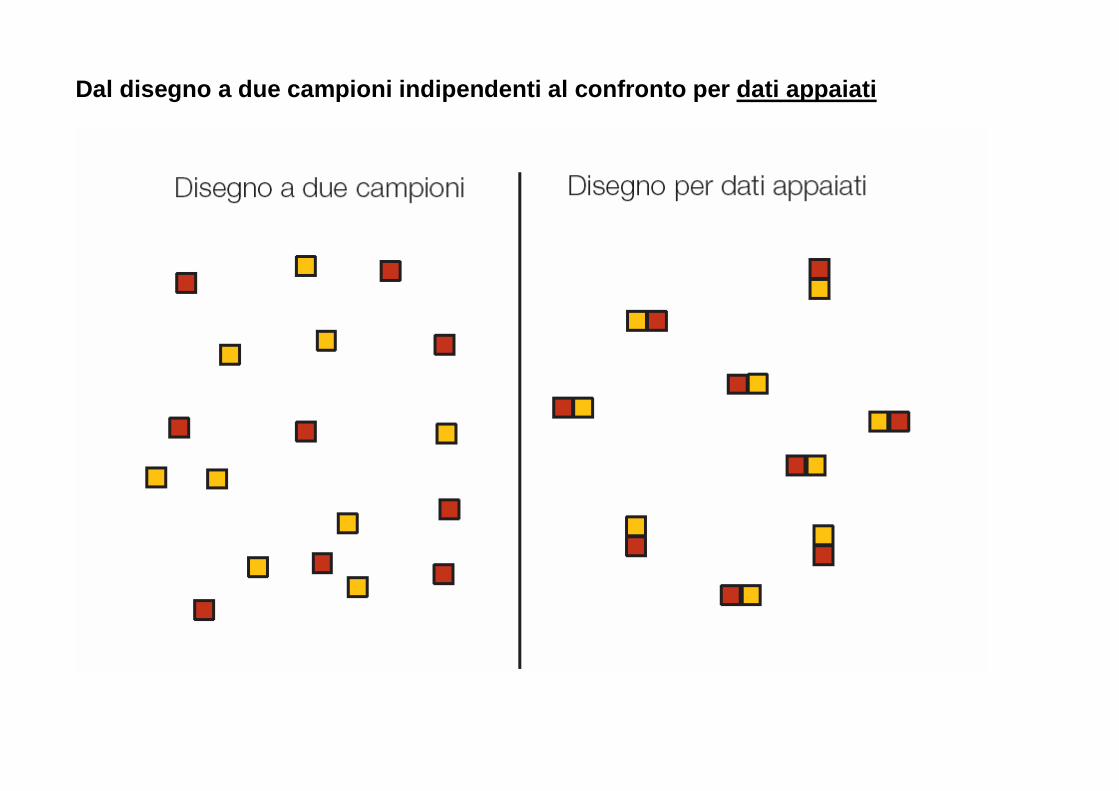
Dal disegno a due campioni indipendenti al confronto per dati appaiati

Dal disegno a due campioni indipendenti al confronto per dati appaiati
� Finora abbiamo assunto che tutte le osservazioni siano indipendenti o Questa assunzione è indispensabile per poter applicare i test descritti.
� Vediamo un esempio di una situazione diversa
� Il ricercatore si chiede se il livello medio dell’ ematocrito cambia negli atleti dopo che hanno
svolto una attività fisica intensa, per esempio dopo una competizione � Test t per campioni indipendenti (come per i frinosomi)?
o Confronto due campioni di n atleti ciascuno: un campione viene misurato solo prima della gara (quadratini gialli nella figura a sinistra), e una campione di altri atleti solo dopo la gara (quadratini rossi nella figura a sinistra)
o Le osservazioni sarebbero in questo caso 2n, tutte indipendenti perché osservate in 2n atleti diversi
Questo potrebbe non essere possibile, o potrebbe essere svantaggioso, perché:
o Il numero di atleti disponibili all’esperimento è molto basso o La variabilità tra atleti è molto alta, e questa variabilità “oscurerebbe” la differenza (prima-
dopo la gara) alla quale sono interessato

Ricorriamo al confronto per dati appaiati
� Ogni individuo (unità campionaria) fornisce due osservazioni � Ogni coppia di osservazioni (prima e dopo la gara, per ciascun individuo) ha un fattore in
comune: l’individuo sulla quale è stata rilevata � Se quindi ci sono 2n osservazioni, ma solo n atleti, non possiamo assumere che ci siano 2n
osservazioni indipendenti come se fossero stati 2n atleti. � Le due osservazioni sullo stesso soggetto non sono indipendenti, perché influenzate da fattori
individuali comuni � Per esempio, se un atleta ha normalmente un basso livello di ematocrito, lo avrà anche basso
rispetto agli altri dopo la gara: conoscendo il primo valore posso prevedere in parte il secondo � Non si può parlare di dati indipendenti e non si può applicare il test t di Student come visto nel
precedente capitolo

Altri esempi di dati non indipendenti
Ci si chiede se la concentrazione di ozono media nel mondo varia tra un anno e quello successivo. Questa variabile viene misurata in n località in 2 anni diversi. Chiaramente non ci sono 2n dati indipendenti, visto che in ogni coppia di osservazioni (stessa località in due anni diversi) le caratteristiche della località agiscono probabilmente nella medesima direzione. Ci si chiede se l’età media dell’uomo e della donna sono diverse in coppie sposate. Anche se non si tratta degli stessi individui, è ovvio che ci sia una certa dipendenza all’interno di ciascuna coppia: tendenzialmente infatti sappiamo che in una coppia l’età dell’uomo e della donna tendono ad essere simili. La coppia è l’unità campionaria Ci si chiede se il taglio di una foresta influenza il numero di salamandre: definisco un certo numero di superfici di uguali dimensioni, e le suddivido in due parti. A una parte applico il trattamento (taglio della foresta) e all’altra no (il disegno all’inizio assume anche una analogia spaziale…)
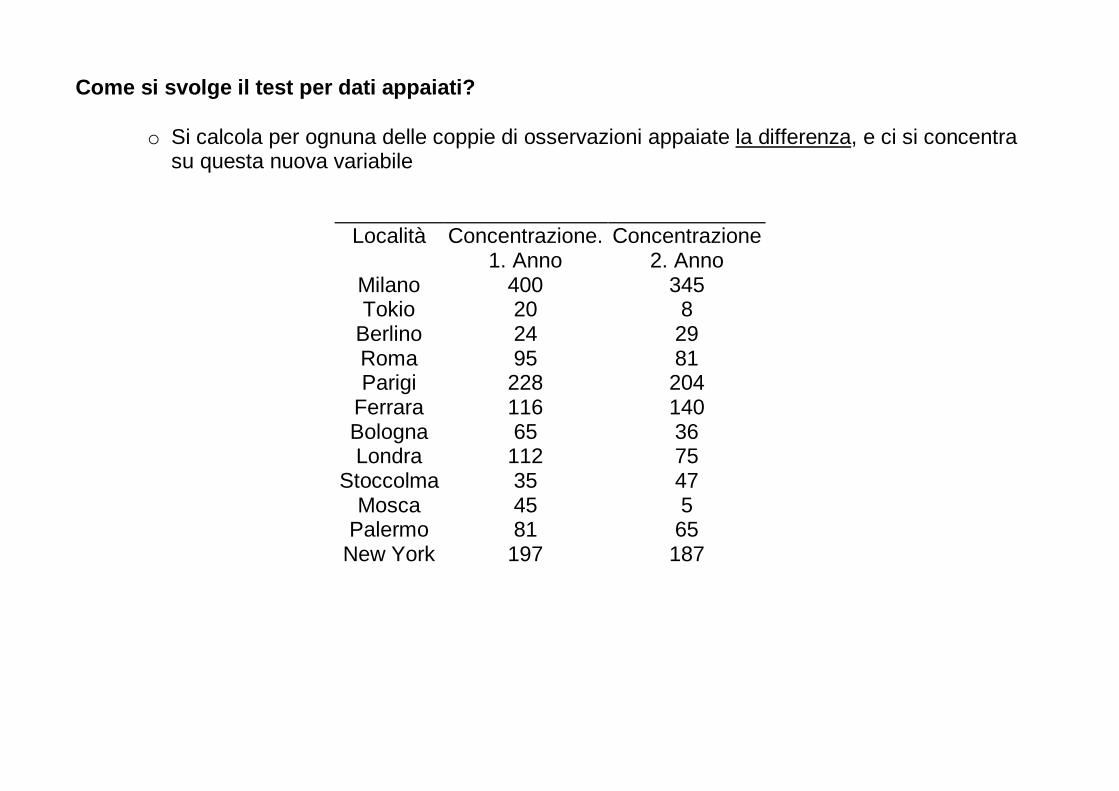
Come si svolge il test per dati appaiati?
o Si calcola per ognuna delle coppie di osservazioni appaiate la differenza, e ci si concentra su questa nuova variabile
Località Concentrazione. Concentrazione 1. Anno 2. Anno
Milano 400 345 Tokio 20 8
Berlino 24 29 Roma 95 81 Parigi 228 204
Ferrara 116 140 Bologna 65 36 Londra 112 75
Stoccolma 35 47 Mosca 45 5
Palermo 81 65 New York 197 187
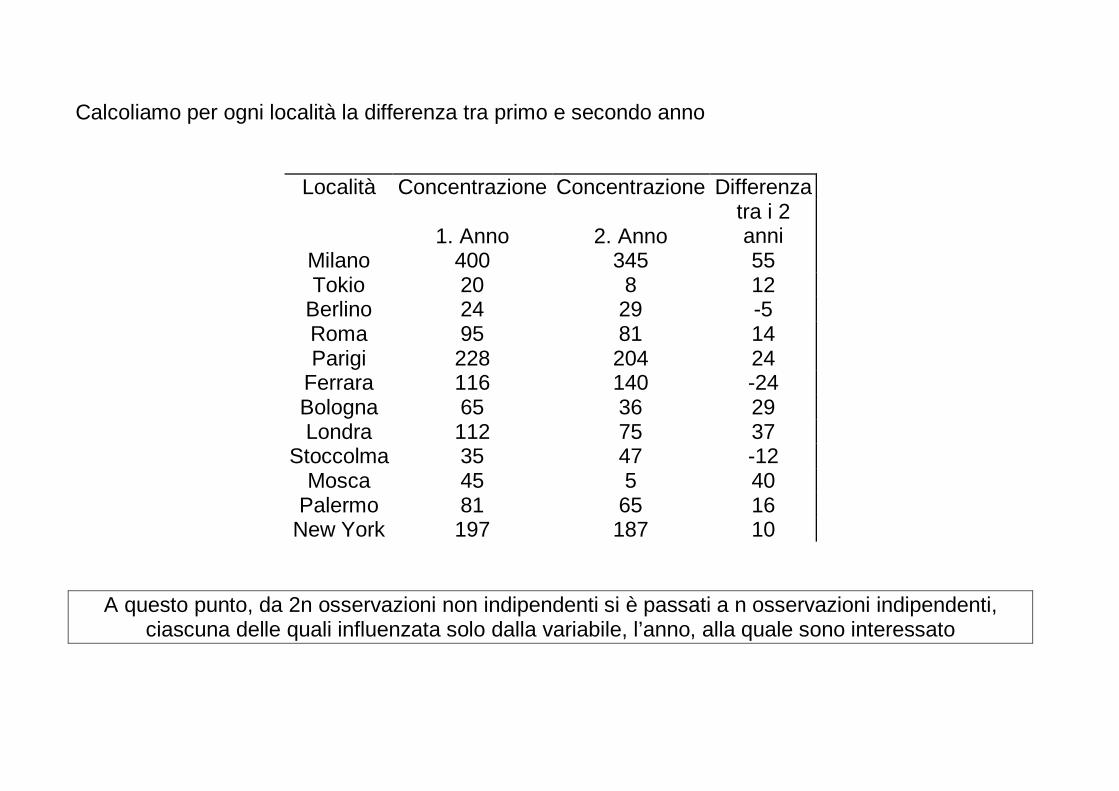
Calcoliamo per ogni località la differenza tra primo e secondo anno
Località Concentrazione Concentrazione Differenza
1. Anno 2. Anno tra i 2 anni
Milano 400 345 55 Tokio 20 8 12
Berlino 24 29 -5 Roma 95 81 14 Parigi 228 204 24
Ferrara 116 140 -24 Bologna 65 36 29 Londra 112 75 37
Stoccolma 35 47 -12 Mosca 45 5 40
Palermo 81 65 16 New York 197 187 10
A questo punto, da 2n osservazioni non indipendenti si è passati a n osservazioni indipendenti, ciascuna delle quali influenzata solo dalla variabile, l’anno, alla quale sono interessato

Chiamando d la variabile “differenza tra coppie di osservazioni”, d la media nel campione, e δ il corrispondente parametro, le ipotesi che si volevano testare
H0 : µ1 = µ2 H1 : µ1 ≠ µ2
diventano
H0 : δ = δ0 =0 H1 : δ ≠ δ0
[Infatti se µ1 = µ2 allora µ1 - µ2 = δ= 0]
� Per testare queste ipotesi, adesso, sono disponibili gli strumenti usuali o le n differenze sono appunto indipendenti o si tratta di testare se la media della popolazione da cui è stato estratto un campione è
uguale o diverso da una media data o E quindi applichiamo il test t di Student per un campione, che in questo caso chiamiamo
Test t per dati appaiati.

ns
d
s
dt
dd
calc/
0 =−
=δ
� sd : deviazione standard delle differenze � n il numero di differenze (ossia il numero di coppie di osservazioni)
� Nell’esempio numerico appena visto o la media delle differenze = 16.33 o la varianza delle differenze = 513.7
5.212/66.22
33.16===calct
Quindi, visto che il t critico con α = 0.05 e 11 gdl è 2.20, ed è uguale a 3,11 con α = 0.01, posso escludere l'ipotesi nulla con una probabilità di sbagliare tra l'1% e il 5% (p-value = 0.029) . Molto probabilmente la concentrazione media è cambiata da un anno all'altro.

� Un test t per campioni indipendenti, a parità di numero di misurazioni, ha un numero maggiore (doppio) di gradi di libertà
� Ma un test t per campioni indipendenti è altamente influenzato dalla variabilità tra osservazioni:
se è molto alta, può mascherare la variabilità alla quale sono interessato � Quindi, se se l’eterogeneità tra le osservazioni è molto grande può convenire accoppiare le
osservazioni. In questo modo o si considerano solo le differenze tra le coppie di osservazioni (che ci interessano, visto che
quantificano l’effetto che stiamo analizzando) o si cerca di ridurre il peso delle differenze tra diverse osservazioni all’interno dei due
campioni (che introducono una variabilità dovuta a tanti fattori ai quali non siamo interessati).
Esempio: scelgo di appaiare prima i dati, e poi svolgo il test per dati appaiati Si vuole verificare l’efficacia di un fertilizzante sulla quantità di raccolto di mais
� Si potrebbero identificare 20 terreni di uguali dimensioni, 10 dei quali da trattare con il fertilizzante e 10 invece da lasciare non trattati (di controllo) o Si potrebbe quindi applicare un test t per campioni indipendenti, con 18 gradi di libertà
� Ma la differenza tra i raccolti nei diversi terreni, indipendentemente dal trattamento, potrebbe
essere molto ampia o i suoli sono diversi o l’esposizione è diversa

o l’impianto di irrigazione non è uguale in tutti i terreni
Potremmo non essere in grado di far emergere la differenza tra terreni trattati e non trattati perché tale differenza viene mascherata dall’enorme variabilità dovuta a molti altri fattori
Scelgo quindi di appaiare i dati
� Si scelgono 10 terreni di eguali dimensioni e si dividono in un due parti uguali � Una metà di ciascun terreno viene trattata con il fertilizzante
o Il fattore comune che non ci interessa (tipo di terreno, esposizione, etc) influisce nello stesso modo su ciascuna coppia di mezzi terreni
o la differenza osservata in ciascun terreno tra le due metà (trattato e non trattato) è dovuta, se presente, solo al fattore che ci interessa (che sarebbe così più facilmente identificabile)
Attenzione: coppie di osservazioni devono essere identificate in modo che siano dipendenti (cioè che abbiano veramente il fattore o i fattori che non ci interessano in comune, altrimenti il risultato di applicare il test per dati appaiati sarebbe solo quelli di ridurre i gradi di libertà (e quindi il potere del test).

Test a due code e a una coda
� Cosa prevedeva l’ipotesi alternativa nei test visti finora?
H1 : µ ≠ µ 0 OPPURE H1 : π ≠ π0 OPPURE H1 : µ1 ≠ µ 2
� L’ipotesi alternativa includeva sia la possibilità che π>π0, sia quella che π<π0 (oppure µ > µ 0 e µ < µ 0, oppure µ1 > µ 2 e µ1 < µ 2)
� I test di questo tipo si chiamano a due code (o bilaterali, o non direzionali)
√ La regione di rifiuto è distribuita ugualmente ai due estremi della distribuzione nulla √ I valori critici delle distribuzioni z o t vengono identificati con la dicitura zα/2 o tα/2 √ Per distribuzioni simmetriche, è sufficiente conoscere un solo valore critico
[Infatti, P(Z> zα/2) = P (Z<- zα/2) e P(T> tα/2) = P (T<- tα/2)] √ Se si usa il p-value, bisogna determinare la probabilità di osservare una statistica test estrema come quella calcolata, o più estrema, in entrambe le direzioni

� In alcuni casi siamo però in grado di fare delle previsioni più specifiche su quale potrebbe essere la deviazione eventuale dall’ipotesi nulla
� Esempio.
o Test sulla somiglianza padri-figlie. A 18 individui vengono presentati 18 set diversi di tre fotografie. Ogni set è costituito dalla foto di una ragazza, di suo padre, e di un altro uomo. Ad ogni individuo viene richiesto di identificare il padre. 13 individuano correttamente il padre, 5 indicano l’altro uomo. L’ipotesi nulla è π = π0 = 0.5, ovvero non esiste somiglianza e l’indicazione di un uomo rispetto ad un altro è casuale. L’ipotesi alternativa è che ci sia somiglianza, e quindi è che π > π0 (ovvero che l’identificazione sia corretta in più del 50% dei casi). L’ipotesi alternativa π < π0 non ha senso.
� L’ipotesi nulla (π = π0) resta invariata.

� Cosa cambia da un punto di vista pratico?
o Cambiano le aree di accettazione e rifiuto o Ci si concentra solo sul lato della distribuzione nulla nel quale una deviazione viene
ritenuta possibile o Un valore deviante nella direzione opposta viene automaticamente (e sempre) considerata
come una deviazione casuale o Il valore critico della distribuzione di riferimento va ricercato solo dal lato in cui riteniamo
possibile che si possa osservare una deviazione dall’ipotesi nulla.
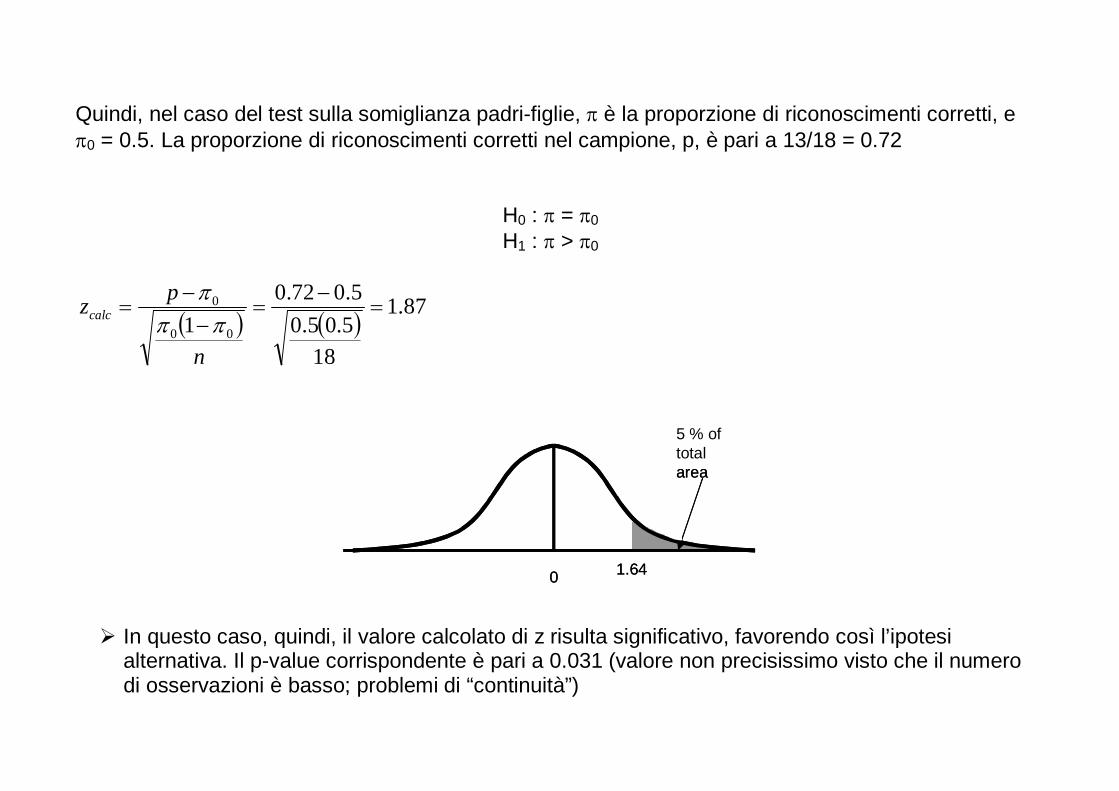
Quindi, nel caso del test sulla somiglianza padri-figlie, π è la proporzione di riconoscimenti corretti, e π0 = 0.5. La proporzione di riconoscimenti corretti nel campione, p, è pari a 13/18 = 0.72
H0 : π = π0 H1 : π > π0
( ) ( )87.1
18
5.05.0
5.072.0
1 00
0 =−
=−
−=
n
pzcalc ππ
π
0
5 % of total area
1.640
5 % of total area
1.64
� In questo caso, quindi, il valore calcolato di z risulta significativo, favorendo così l’ipotesi alternativa. Il p-value corrispondente è pari a 0.031 (valore non precisissimo visto che il numero di osservazioni è basso; problemi di “continuità”)

� Applicare un test t o z ad una coda significa di fatto ridurre il valore assoluto dei valori critici.
Gradi di libertà t critico per test a due code
t critico per test a una coda
5 2.571 2.015
10 2.228 1.812 Infiniti 1.960 1.645
(Ovviamente, il valore critico per un test a una coda con α =0.05 è uguale al t critico per un test a due code con α =0.10)
� In un test ad una coda è quindi più facile respingere l’ipotesi nulla, l’ipotesi che prudentemente
si assume in partenza e che può essere respinta solo se ci sono forti evidenze in suo sfavore.
� Il fatto che sia aumentata la possibilità di favorire l’ipotesi alternativa (l’unica conclusione forte di un test, quella che generalmente ci interessa di più) ci deriva intuitivamente dal fatto che all’analisi abbiamo aggiunto a priori (cioè prima di osservare i dati) delle conoscenze sulla deviazione prevista. I
� I test a una coda sono teoricamente più potenti dei test a due code
� L’utilizzo di un test con approccio unilaterale deve essere limitato solo a casi in cui sussistono
motivazioni ragionevoli per prevedere una deviazione unidirezionale dall’ipotesi nulla. Nel dubbio, conviene sempre utilizzare l’approccio bidirezionale
� Non è mai possibile decidere se fare un test a una o due code dopo aver calcolato il valore
della statistica (z o t). Questo equivarrebbe ad un imbroglio statistico.

Il test (o i test) del Chi-quadrato (2)
I dati: numerosità di osservazioni che cadono all’interno di determinate categorie
Prima di tutto, è un test per confrontare proporzioni
Esempio: confronto tra numero semi lisci e rugosi osservati in nella discendenza di una pianta
eterozigote autofecondata DATI: 59 semi lisci e 14 semi rugosi
o p = 59/73 = 0.808
Ci si chiede di verificare l’ipotesi nulla che la proporzione di semi lisci, 0, sia 0.75 Ci ricorda qualcosa?

Sappiamo già affrontare questo problema con un semplice test z !
H0 : = 0
H1 : 0
1488.1
73
25.075.0
750.0808.0
1 00
0
n
pzcalc
Però questa analisi si può affrontare anche con il test del chi-quadrato, calcolando sulle
numerosità (non sulle proporzioni) la statistica
A
AO
Attesi
AttesiOsservaticalc
222 )()(
Osservati sono le numerosità osservate Attesi sono le numerosità attese se fosse vera l’ipotesi nulla La sommatoria è per tutte le categorie (2 in questo caso, semi lisci e semi rugosi)
Come per il test z, questo test è valido se le numerosità attese nelle 2 categorie sono maggiori
o uguali a 5

Nell’esempio o Valori attesi di semi lisci, su un totale di 73 semi, è pari a 0.75*73 = 54.75 o Valori attesi di semi rugosi, su un totale di 73 semi, è pari a 0.25*73 = 18.25
o I valori attesi possono avere numeri decimali: sono medie di tante repliche ipotetiche di un esperimento sotto H0
o Il totale dei valori attesi deve essere pari al numero totale di osservazioni!
Per le verifica della significatività, ci servono i valori critici di una distribuzione teorica nuova,
quella del 2 .
Infatti si può dimostrare che se è vera l’ipotesi nulla (= 0), allora la distribuzione della
statistica (2
calc) segue una distribuzione teorica nota, quella del 2 appunto, con un numero di
gradi di libertà pari al numero di categorie indipendenti gdl: numero di pezzettini di informazione indipendente oppure numero di pezzettini di
informazione meno il numero di parametri stimati dai dati per calcolare gli attesi In questo caso, c'è soltanto 1 gdl, e lo posso dimostrare in due modi:
o esiste solo una classe indipendente (la numerosità nell'altra la posso calcolare per differenza dal totale)
o se alle due classi di partenza tolgo una singola quantità che proviene dai dati e che mi serve per calcolare i valori attesi (il totale di osservazioni) ottengo 1.
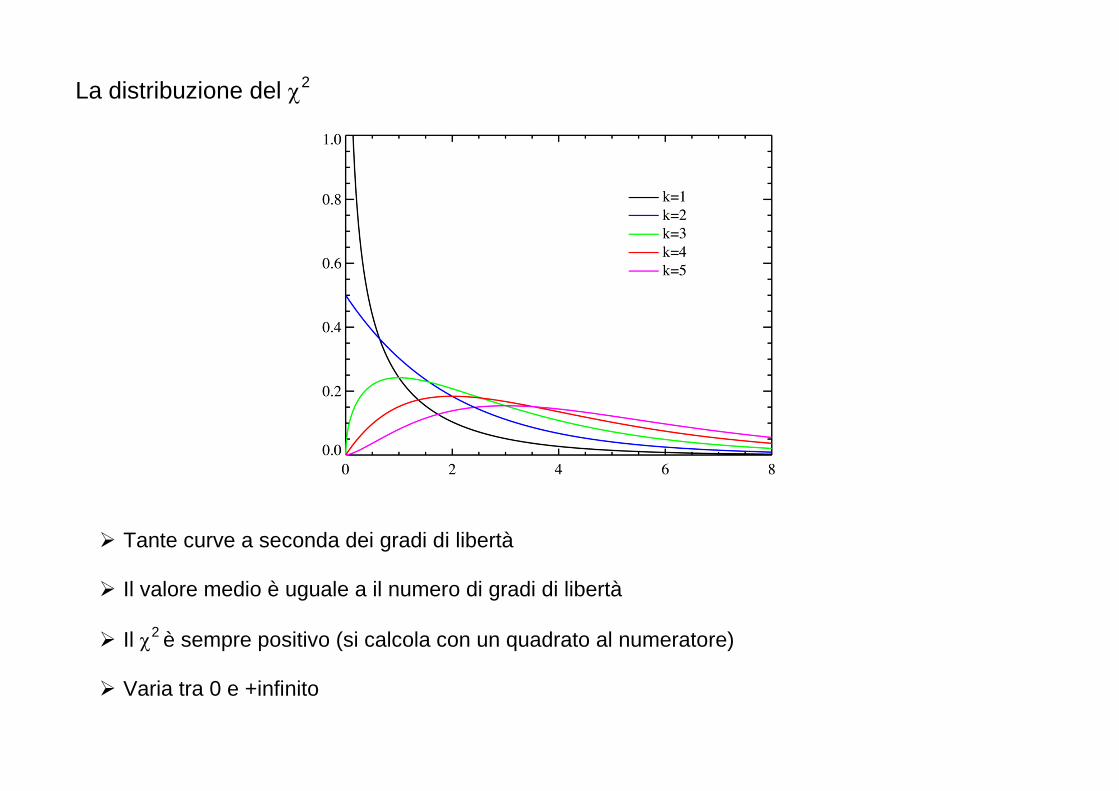
La distribuzione del 2
Tante curve a seconda dei gradi di libertà Il valore medio è uguale a il numero di gradi di libertà
Il 2 è sempre positivo (si calcola con un quadrato al numeratore)
Varia tra 0 e +infinito
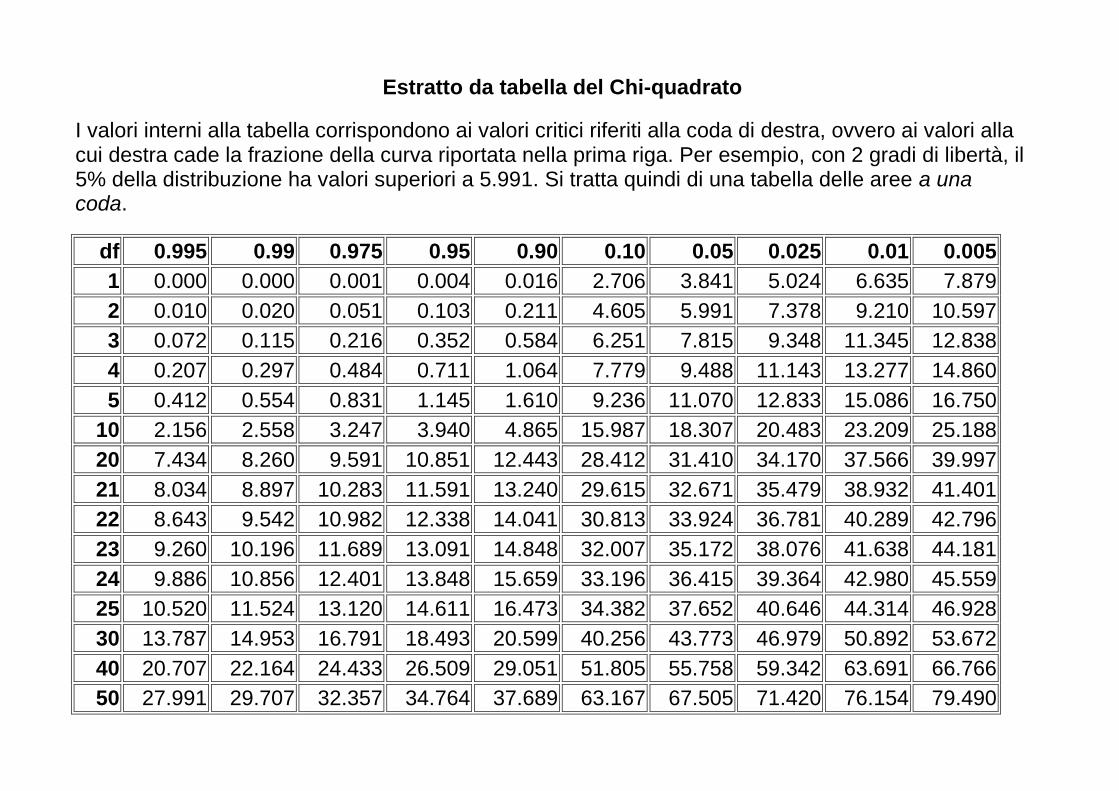
Estratto da tabella del Chi-quadrato
I valori interni alla tabella corrispondono ai valori critici riferiti alla coda di destra, ovvero ai valori alla cui destra cade la frazione della curva riportata nella prima riga. Per esempio, con 2 gradi di libertà, il 5% della distribuzione ha valori superiori a 5.991. Si tratta quindi di una tabella delle aree a una coda.
df 0.995 0.99 0.975 0.95 0.90 0.10 0.05 0.025 0.01 0.005
1 0.000 0.000 0.001 0.004 0.016 2.706 3.841 5.024 6.635 7.879
2 0.010 0.020 0.051 0.103 0.211 4.605 5.991 7.378 9.210 10.597
3 0.072 0.115 0.216 0.352 0.584 6.251 7.815 9.348 11.345 12.838
4 0.207 0.297 0.484 0.711 1.064 7.779 9.488 11.143 13.277 14.860
5 0.412 0.554 0.831 1.145 1.610 9.236 11.070 12.833 15.086 16.750
10 2.156 2.558 3.247 3.940 4.865 15.987 18.307 20.483 23.209 25.188
20 7.434 8.260 9.591 10.851 12.443 28.412 31.410 34.170 37.566 39.997
21 8.034 8.897 10.283 11.591 13.240 29.615 32.671 35.479 38.932 41.401
22 8.643 9.542 10.982 12.338 14.041 30.813 33.924 36.781 40.289 42.796
23 9.260 10.196 11.689 13.091 14.848 32.007 35.172 38.076 41.638 44.181
24 9.886 10.856 12.401 13.848 15.659 33.196 36.415 39.364 42.980 45.559
25 10.520 11.524 13.120 14.611 16.473 34.382 37.652 40.646 44.314 46.928
30 13.787 14.953 16.791 18.493 20.599 40.256 43.773 46.979 50.892 53.672
40 20.707 22.164 24.433 26.509 29.051 51.805 55.758 59.342 63.691 66.766
50 27.991 29.707 32.357 34.764 37.689 63.167 67.505 71.420 76.154 79.490

Riprendiamo l’esempio dei semi lisci e rugosi
3196.1
25.18
25.1814
75.54
75.545922
2
calc
A parità di gdl, valori grandi del 2
calc sono indice di allontanamento dall’ipotesi nulla, in
entrambe le direzioni
Tutte e due le deviazioni dall’ipotesi nulla ( > 0 e < 0) determineranno una deviazione verso
valori grandi 2 ,ossia verso la coda destra della distribuzione attesa quando è vera l'ipotesi nulla.
Le ipotesi sono definite in maniera bidirezionale,
ma se utilizziamo la statistica del 2
dobbiamo usarla ad una coda!

Quindi il valore di Chi quadrato calcolato
3196.12 calc
non è significativo per α = 0.05, visto che è inferiore al valore critico di 3.841
La conclusione è ovviamente identica a quella ottenuta con il test z
Ma quindi a cosa serve questo test se avevamo già z?

La generalizzazione del test del Chi-quadrato come test “goodness of fit” Il test che abbiamo visto per i piselli di Mendel si può considerare il caso più semplice di una
categoria di test definiti “test di bontà dell’adattamento di una distribuzione empirica ad una distribuzione teorica”, o più semplicemente “goodness of fit tests”
Le proporzioni osservate si confrontano con quelle previste da un modello teorico Il modello teorico è da considerarsi l’ipotesi nulla
Nel caso dei piselli lisci e rugosi, esistevano solo due categorie e solo una proporzione prevista
(l’altra era determinata automaticamente). Questa situazione si può però estendere ad un numero maggiore di categorie.
Per esempio, nella verifica della trasmissione di due geni indipendenti durante la trasmissione mendeliana in un incrocio di un doppio eterozigote
Assunzione del test (generalizzazione quando ci sono più di 2 categorie) Non più del 20% delle classi deve avere una numerosità attesa <5 (e nessuna classe deve
avere numerosità attesa <1) Se cio’ non si verifica, una soluzione è quella di raggruppare alcune classi

Esempio La proporzione di semi che possiedono le caratteristiche CS, Cs, cS e cs dopo
l'autofecondazione di piante eterozigoti a due geni è prevista, nel caso di geni indipendenti, nel rapporto 9:3:3:1.
Verificare questa distribuzione teorica attesa su un campione di 1000 semi che hanno dato la seguente distribuzione osservata
CS Cs cS cs 720 23 20 237
Calcolo le numerosità ( = frequenze assolute) attese
CS Cs cS cs 562,5 187,5 187,5 62,5
Calcolo il valore dei 4 elementi che devono essere sommati per ottenere il 2
calc
44,1 144,3 149,6 487,2
La somma porta a 3.8252 calc

Il calore critico della distribuzione teorica del chi-quadrato con 3 gradi di libertà è 7.81 (con = 0.05)
Quindi, la deviazione è altamente significativa ed è possibile respingere l'ipotesi nulla di
adeguamento alla distribuzione teorica prevista (le proporzioni osservate si discostano significativamente da quelle attese
Probabilmente i due geni sono localizzati in posizioni vicine sullo stesso cromosoma
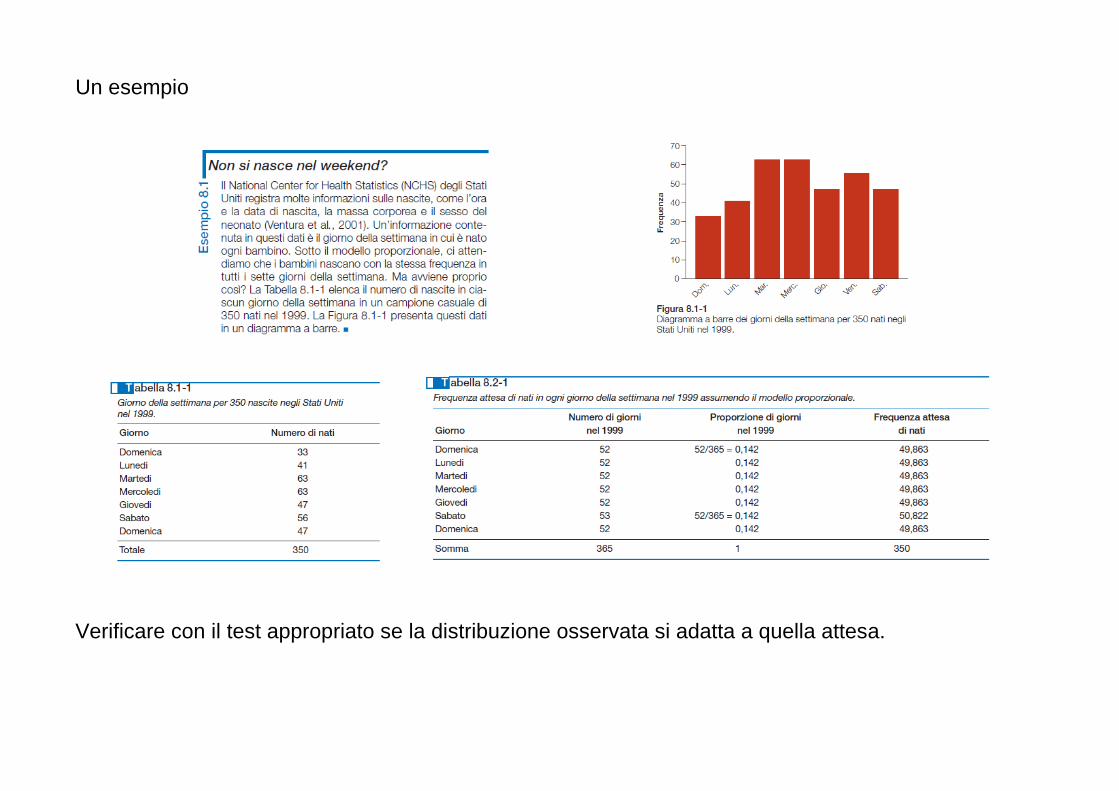
Un esempio
Verificare con il test appropriato se la distribuzione osservata si adatta a quella attesa.

Altri esempi Dispersione di semi con legge quadratica inversa
Efficacia trappole per la cattura di uccelli
Verifica se i dati osservati in un campione seguono una distribuzione teorica normale
Vediamo quest’ultimo esempio

La distribuzione di frequenza del peso in chilogrammi di frutta prodotta da 81 piante è riportato nella seguente tabella:
Intervalli ni
48.5-49.5 4
49.5-50.5 7
50.5-51.5 9
51.5-52.5 10
52.5-53.5 15
53.5-54.5 11
54.5-55.5 10
55.5-56.5 8
56.5-57.5 5
57.5-58.5 2
Vogliamo testare l'ipotesi nulla che questi dati siano estratti da una popolazione in cui la
variabile "peso di frutta prodotta da un albero" ha una distribuzione gaussiana. Si deve cioè verificare se i dati osservati sono compatibili con un modello distributivo normale.
L'ipotesi nulla è che lo siano, l'ipotesi alternativa è che non lo siano. Come sempre, se l'ipotesi nulla non verrà rifiutata, non potremmo dire con certezza che i dati
provengono da una popolazione con distribuzione gaussiana della variabile, ma solo sono compatibili con questa ipotesi.

Per testare questa ipotesi, dobbiamo utilizzare (dopo aver calcolato media e varianza dei dati osservati) la distribuzione normale per calcolare le numerosità attese in ciascuna classe. Poi il test del chi-quadrato verrà utilizzato per confrontare le numerosità osservate con quelle attese
Le numerosità attese vengono calcolate sulla base della distribuzione teorica gaussiana che ha la stessa media e la stessa deviazione standard calcolati a partire dai dati osservati
Per il calcolo delle numerosità attese, avrò ovviamente bisogno della normale standardizzata, e quindi dovrò standardizzare i limiti delle classi
Attenzione alle classi estreme e alla determinazione dei gradi di libertà da utilizzare per definire la distribuzione nulla appropriata
Nel caso riportato, possiamo calcolare che
media = 52.25
varianza = 5.26
dev. St. = 2.29
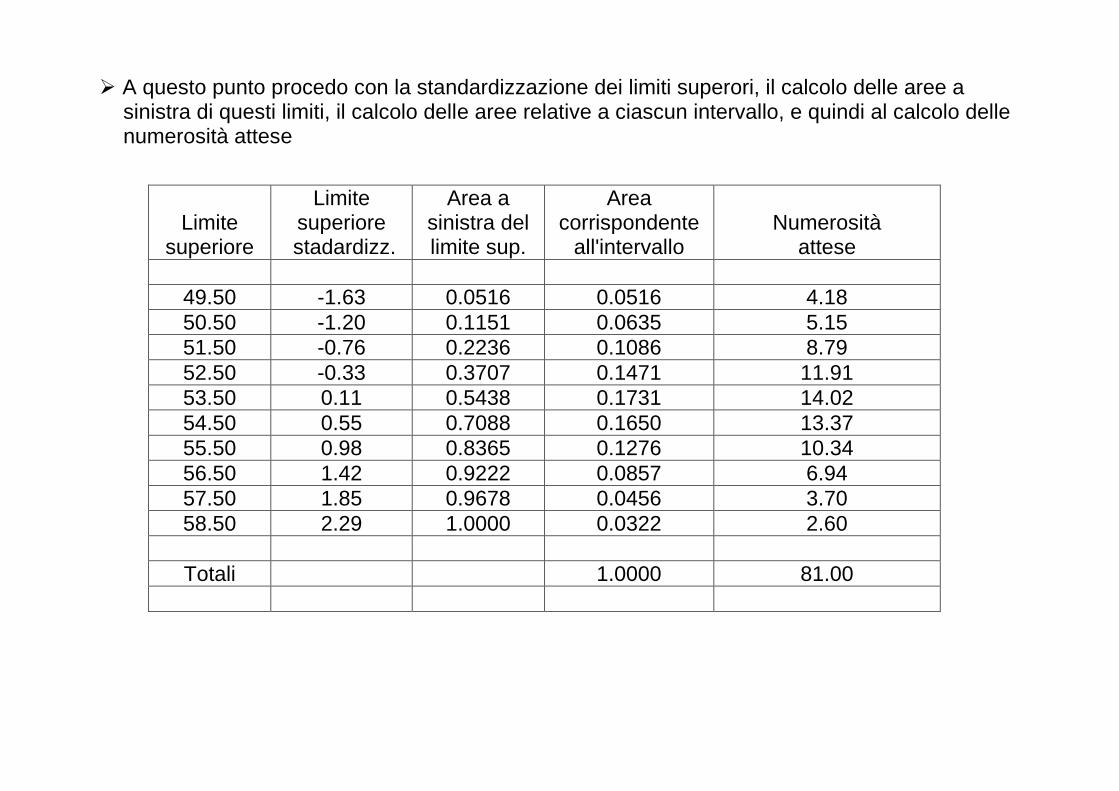
A questo punto procedo con la standardizzazione dei limiti superori, il calcolo delle aree a sinistra di questi limiti, il calcolo delle aree relative a ciascun intervallo, e quindi al calcolo delle numerosità attese
Limite superiore
Limite superiore
stadardizz.
Area a sinistra del limite sup.
Area corrispondente
all'intervallo Numerosità
attese
49.50 -1.63 0.0516 0.0516 4.18
50.50 -1.20 0.1151 0.0635 5.15
51.50 -0.76 0.2236 0.1086 8.79
52.50 -0.33 0.3707 0.1471 11.91
53.50 0.11 0.5438 0.1731 14.02
54.50 0.55 0.7088 0.1650 13.37
55.50 0.98 0.8365 0.1276 10.34
56.50 1.42 0.9222 0.0857 6.94
57.50 1.85 0.9678 0.0456 3.70
58.50 2.29 1.0000 0.0322 2.60
Totali 1.0000 81.00
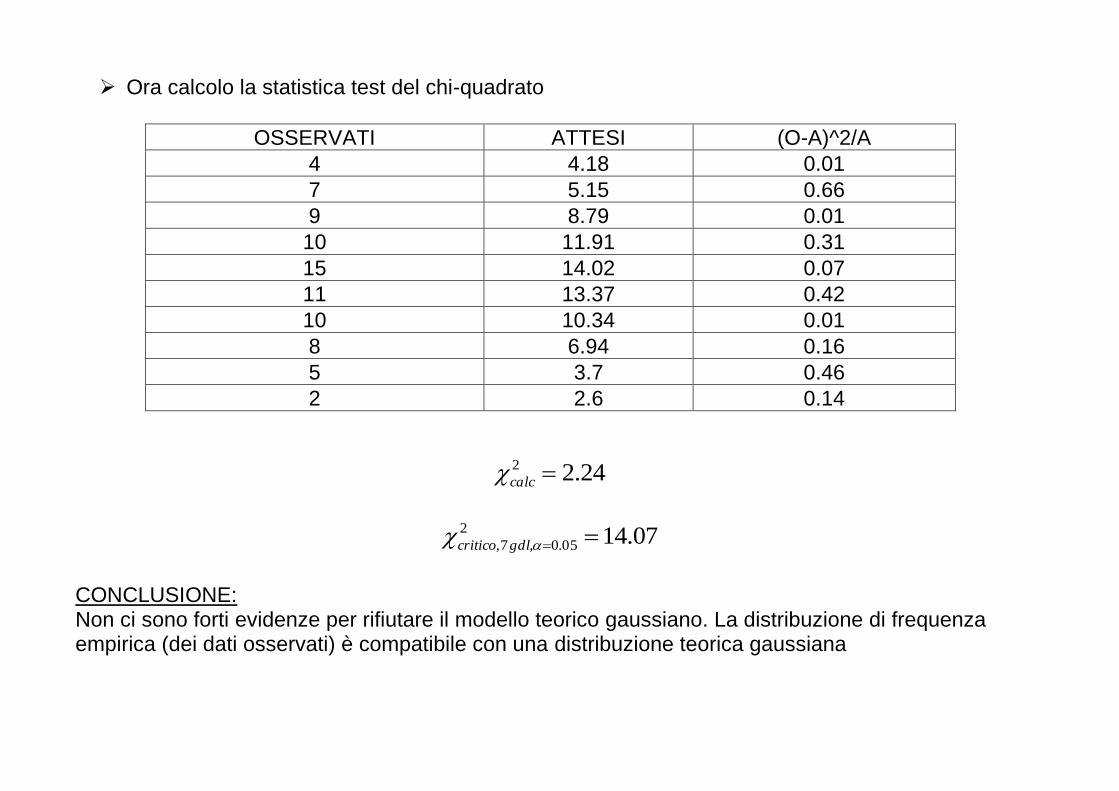
Ora calcolo la statistica test del chi-quadrato
OSSERVATI ATTESI (O-A)^2/A
4 4.18 0.01
7 5.15 0.66
9 8.79 0.01
10 11.91 0.31
15 14.02 0.07
11 13.37 0.42
10 10.34 0.01
8 6.94 0.16
5 3.7 0.46
2 2.6 0.14
24.22 calc
07.142
05.0,7, gdlcritico
CONCLUSIONE: Non ci sono forti evidenze per rifiutare il modello teorico gaussiano. La distribuzione di frequenza empirica (dei dati osservati) è compatibile con una distribuzione teorica gaussiana

Ulteriori applicazioni del test del Chi-quadrato ( χχχχ2)
� Finora abbiamo confrontato con il χ2 le numerosità osservate in diverse categorie in un
campione con le numerosità previste da un certo modello (attese mediamente se fosse vero il modello) • Era un confronto tra una distribuzione di frequenza osservata e una attesa • Vedremo nelle prossime lezioni ulteriori esempi di questa applicazione di χ2
� Possiamo ora usare lo stesso tipo di test per confrontare le numerosità osservate in due o più
campioni diversi • Diventa un confronto tra due o più distribuzioni di frequenza
� I test sono svolti in modo simile (ci saranno osservati e attesi, e una statistica test χ2), ma si
parla in questo caso di “analisi di tabelle di contingenza per svolgere test di indipendenza”
• la struttura del test si sviluppa attorno a tabelle in cui le celle contengono numerosità • è possibile vedere questo test anche come un test per analizzare se due variabili
categoriche (=qualitative) sono associate o sono indipendenti
� Vediamo la situazione più semplice: due campioni nei quali misuro per ogni osservazione una variabile categorica che può assumere solo due valori (o stati) possibili. Cosa ci ricorda?

� Ci ricorda l’esempio dei due campioni (vaccinati/non vaccinati) all’interno dei quali si misurava la sola variabile sano/malato
� Ma vediamo un altro esempio di questo tipo
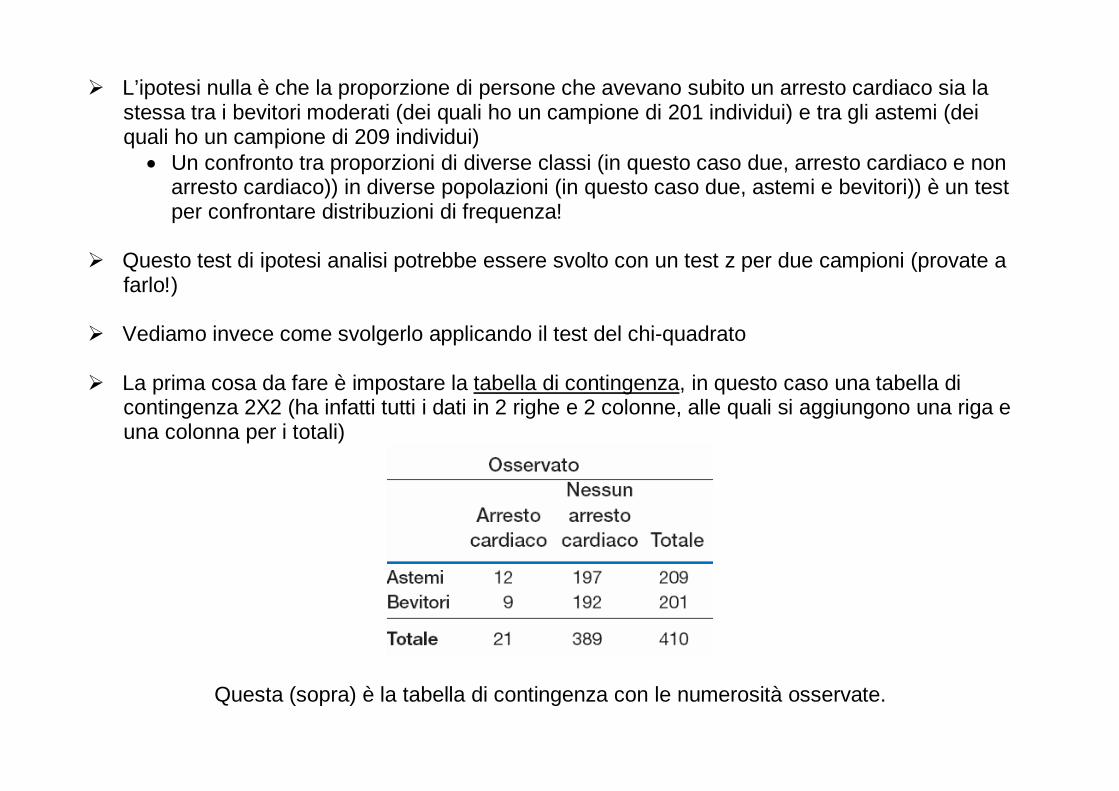
� L’ipotesi nulla è che la proporzione di persone che avevano subito un arresto cardiaco sia la stessa tra i bevitori moderati (dei quali ho un campione di 201 individui) e tra gli astemi (dei quali ho un campione di 209 individui) • Un confronto tra proporzioni di diverse classi (in questo caso due, arresto cardiaco e non
arresto cardiaco)) in diverse popolazioni (in questo caso due, astemi e bevitori)) è un test per confrontare distribuzioni di frequenza!
� Questo test di ipotesi analisi potrebbe essere svolto con un test z per due campioni (provate a
farlo!) � Vediamo invece come svolgerlo applicando il test del chi-quadrato � La prima cosa da fare è impostare la tabella di contingenza, in questo caso una tabella di
contingenza 2X2 (ha infatti tutti i dati in 2 righe e 2 colonne, alle quali si aggiungono una riga e una colonna per i totali)
Questa (sopra) è la tabella di contingenza con le numerosità osservate.
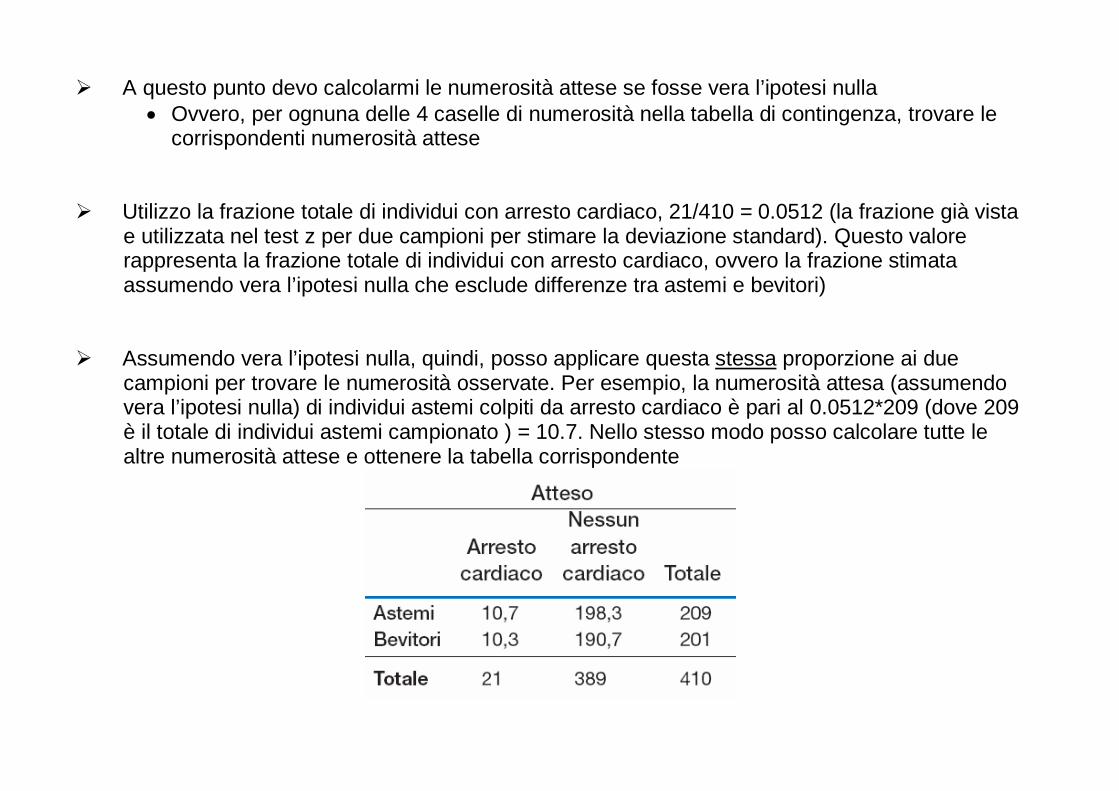
� A questo punto devo calcolarmi le numerosità attese se fosse vera l’ipotesi nulla • Ovvero, per ognuna delle 4 caselle di numerosità nella tabella di contingenza, trovare le
corrispondenti numerosità attese � Utilizzo la frazione totale di individui con arresto cardiaco, 21/410 = 0.0512 (la frazione già vista
e utilizzata nel test z per due campioni per stimare la deviazione standard). Questo valore rappresenta la frazione totale di individui con arresto cardiaco, ovvero la frazione stimata assumendo vera l’ipotesi nulla che esclude differenze tra astemi e bevitori)
� Assumendo vera l’ipotesi nulla, quindi, posso applicare questa stessa proporzione ai due
campioni per trovare le numerosità osservate. Per esempio, la numerosità attesa (assumendo vera l’ipotesi nulla) di individui astemi colpiti da arresto cardiaco è pari al 0.0512*209 (dove 209 è il totale di individui astemi campionato ) = 10.7. Nello stesso modo posso calcolare tutte le altre numerosità attese e ottenere la tabella corrispondente

� Da notare che i totali di riga e di colonna sono (e devono essere) uguali a quelli nella tabella delle numerosità osservate
� A questo punto posso applicare il test del χ2 con 4 categorie, per ciascuna delle quali ho le
numerosità osservate e quelle attese assumendo vera l’ipotesi nulla � Per ogni cella, calcolo il corrispondente elemento nella sommatoria del χ2 e poi faccio la
somma dei quattro elementi
� Con quale valore critico devo confrontare il valore di χ2 calcolato?
• Ovvero, qual è la distribuzione nulla di riferimento?

� Ragioniamo sul numero di categorie indipendenti
• Conoscendo i totali di riga e di colonna, quanti valori sono necessari per determinare tutti gli altri?
• Uno è sufficiente, quindi questo test ha 4 elementi nella sommatoria del χ2 ma solo un grado di libertà
� In conclusione, con α = 0.05, χ2 critico è pari a 3.84, e l’ipotesi nulla non può essere rifiutata (0.34<3.84). I dati sono compatibili con l’ipotesi nulla che l’arresto cardiaco non abbia una frequenza diversa tra astemi e bevitori moderati • Attenzione sempre al significato di questa conclusione! L’ipotesi nulla non viene mai
accettata, e questo è comunque uno studio osservazionale � Importante: le assunzioni del test del χ2 sulle tabelle di contingenza ha le stesse assunzioni del test del χ2 di bontà di adattamento

Cosa rappresentano anche i valori attesi in una tab ella di contingenza? � Due eventi sono indipendenti se il verificarsi di uno dei due non influenza la probabilità che si
verifichi l’altro � Se due eventi sono indipendenti, la probabilità che si verifichino entrambi è data dal prodotto
della probabilità che si verifichi il primo evento per la probabilità che si verifichi il secondo evento o E’ la regola del prodotto o Per esempio, qual è la probabilità di ottenere, lanciando due dadi, il risultato 3,3?
� I due eventi sono indipendenti, perché ottenere 3 con un dado non modifica la probabilità di ottenere 3 con il secondo dado.
� La probabilità di ottenere 3 nel primo lancio è pari a 1/6, e la probabilità di ottenere 3 nel secondo lancio è pari a 1/6
� La probabilità dell’evento [3 nel primo lancio e 3 nel secondo lancio] nel lancio di due dadi è pari quindi per la regola del prodotto a 1/6 x 1/6 = 1/36
o Altro esempio. Fumo e ipertensione sono indipendenti. Questo significa che se la probabilità di essere un fumatore è pari al 17% (0.17) e quella di soffrire di ipertensione è pari al 22% (0.22), la probabilità che un individuo scelto a caso nella popolazione sia fumatore iperteso è pari a 0.17 x 0.22 = 0,0374. In altre parole, il 3.74 % della popolazione è costituita da fumatori ipertesi
� In simboli, la regola del prodotto (valida solo per eventi indipendenti!) è

� Se due eventi non sono indipendenti, non vale più la regola del prodotto, ma la regola del prodotto generalizzato: la probabilità che si verifichino l’evento A e l’evento B è data dalla probabilità che si verifichi l’evento A moltiplicata per la probabilità che si verifichi B condizionata al verificarsi di A
� In simboli, la regola del prodotto generalizzata (valida per eventi dipendenti o indipendenti)
� (è valida anche per eventi indipendenti perché in quel caso Pr[B|A] = Pr[B] � Per esempio, se la probabilità di vivere in Italia (frazione di italiani sulla popolazione mondiale)
è pari a 60 milioni / 6.8 miliardi = 0.009 (0.9%), e la probabilità (senza considerare il luogo di nascita) di avere un reddito mensile superiore a 200 Euro fosse pari a 0.1 (frazione ipotetica di popolazione mondiale con reddito mensile superiore a 200 Euro), la probabilità che un individuo campionato a caso sia italiano e abbia un reddito > 200 Euro non è pari a 0.009 x 0.1 = 0.0009 (0.09%). E questo proprio perché i due eventi non sono indipendenti. Conoscere il risultato del primo evento (pere esempio, vivere in Italia) influenza il risultato del secondo evento (avere un reddito >200 Euro)
� In questo esempio, la probabilità di verificarsi dei due eventi, sulla base della regola del
prodotto generalizzata sarebbe pari a 0.009 (probabilità di vivere in Italia) x la probabilità di avere un reddito >200 Euro vivendo in Italia (probabilità condizionata al fatto di vivere in italia). Quest’ultima assumiamo che sia circa pari a 1, e quindi la probabilità cercata è 0.009 (0.9%).

� Ma cosa c’entra tutto ciò con le tabelle di contingenza? � Lo studio di una tabella di contingenza (2 x 2 o con maggiori numeri di righe o di colonne) è in
realtà lo studio per verificare l’indipendenza o l’associazione tra due variabili categoriche o Nell’esempio vaccinati/non vaccinati, l’ipotesi nulla poteva essere anche vista come: la variabile “salute”
(con due valori possibili, vaccinato e non vaccinato) è indipendente della variabile “vaccinazione” (con due valori possibili, vaccinato e non vaccinato)
o Nell’esempio astemi/bevitori, l’ipotesi nulla poteva essere anche vista come: la variabile “salute” (con due valori possibili, arresto cardiaco e no arresto cardiaco) è indipendente della variabile “alcool” (con due valori possibili, astemio e bevitore)
� Queste ipotesi nulle formulate in termini di indipendenza sono equivalenti all’ipotesi nulla di
uguaglianza tra proporzioni (e quindi tra distribuzioni di frequenza) � Formulare l’ipotesi nulla in termini di indipendenza tra variabili categoriche ci permette di trovare
i valori attesi nella tabella di contingenza utilizzando la regola del prodotto � Nell’esempio astemi/bevitori, qual è la probabilità di essere astemi e di aver subito un arresto
cardiaco se le due variabili non sono associate (ovvero, sono indipendenti)? o La probabilità di essere astemi (riferita al campione) è data dal numero totale di astemi (209) diviso
numero totale di individui analizzati (410) = 0.5097 o La stima della probabilità di aver subito un arresto cardiaco (riferita al campione) è data dal numero
totale di individui con arresto cardiaco (21) diviso numero totale di individui analizzati (Tot = 410) = 0.0512
o Applico la regola del prodotto per trovare la probabilità (riferita al campione) di essere astemio e aver subito un arresto cardiaco se fosse vera l’ipotesi nulla: P[Astemio + Arr. Card.] = 0.5097*0.0512 = 0.026
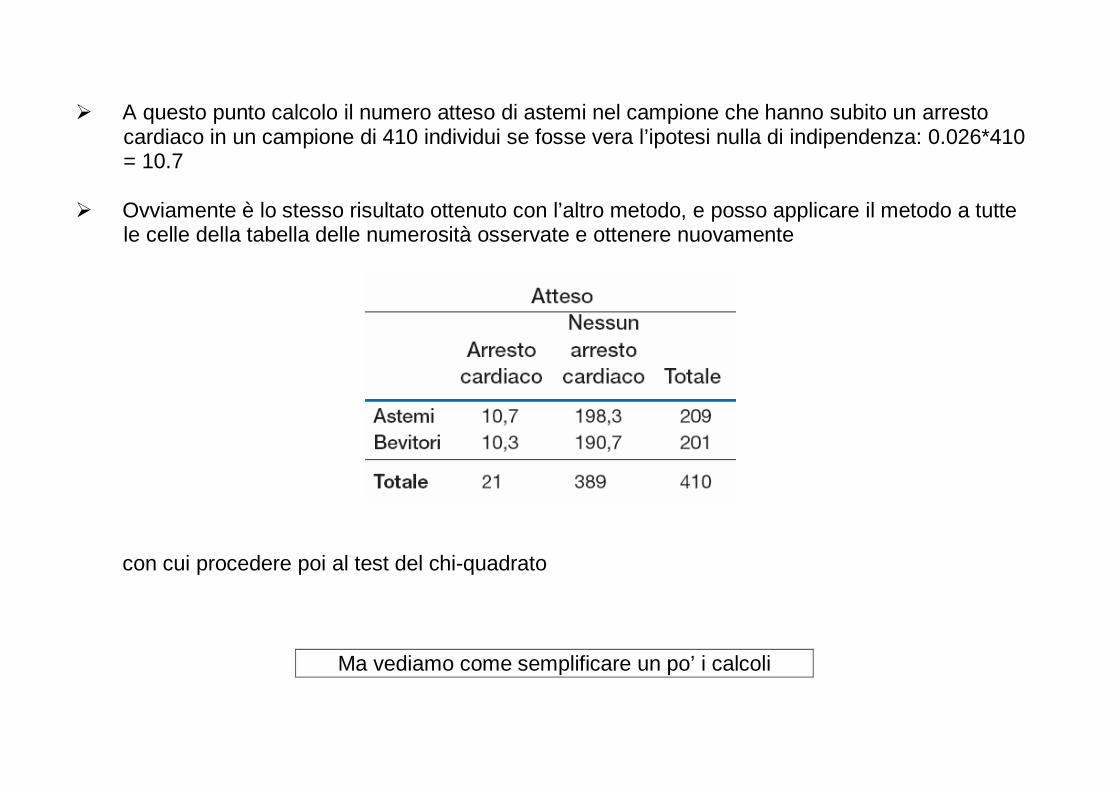
� A questo punto calcolo il numero atteso di astemi nel campione che hanno subito un arresto
cardiaco in un campione di 410 individui se fosse vera l’ipotesi nulla di indipendenza: 0.026*410 = 10.7
� Ovviamente è lo stesso risultato ottenuto con l’altro metodo, e posso applicare il metodo a tutte
le celle della tabella delle numerosità osservate e ottenere nuovamente
con cui procedere poi al test del chi-quadrato
Ma vediamo come semplificare un po’ i calcoli

Semplifichiamo un po’ i calcoli per l’ analisi dell e tabelle di contingenza � I valori attesi per una tabella di contingenza, ragionando sui calcoli visti applicando la regola del prodotto, si possono ottenere semplicemente con
perché
� I gradi di libertà per una analisi su una tabella di contingenza si possono calcolare direttamente con la formuletta
dove r e c sono il numero di righe e colonne della tabella di contingenza.
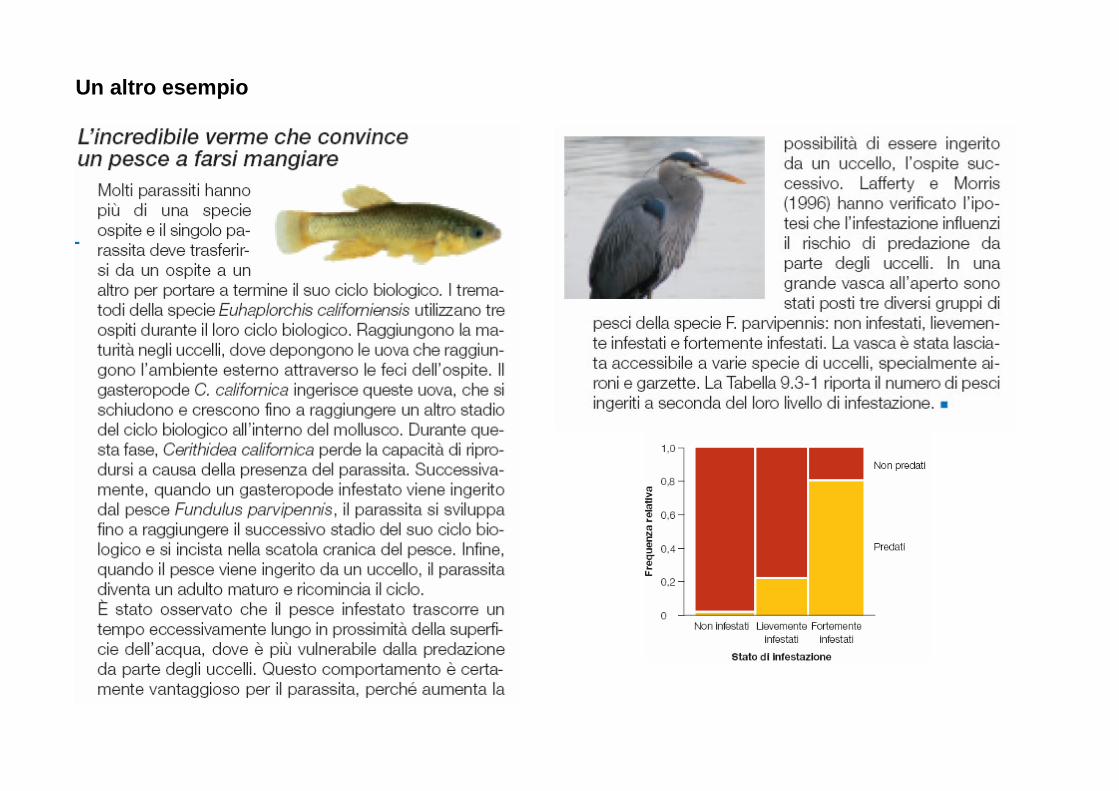
Un altro esempio
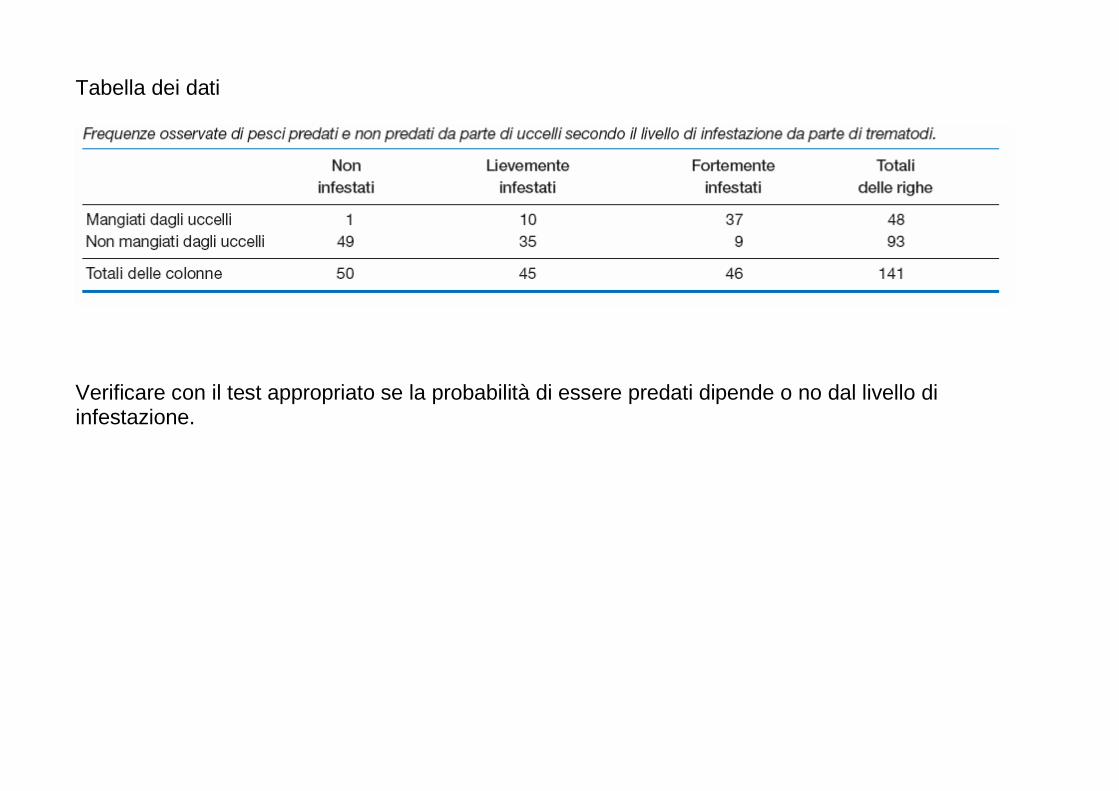
Tabella dei dati
Verificare con il test appropriato se la probabilità di essere predati dipende o no dal livello di infestazione.
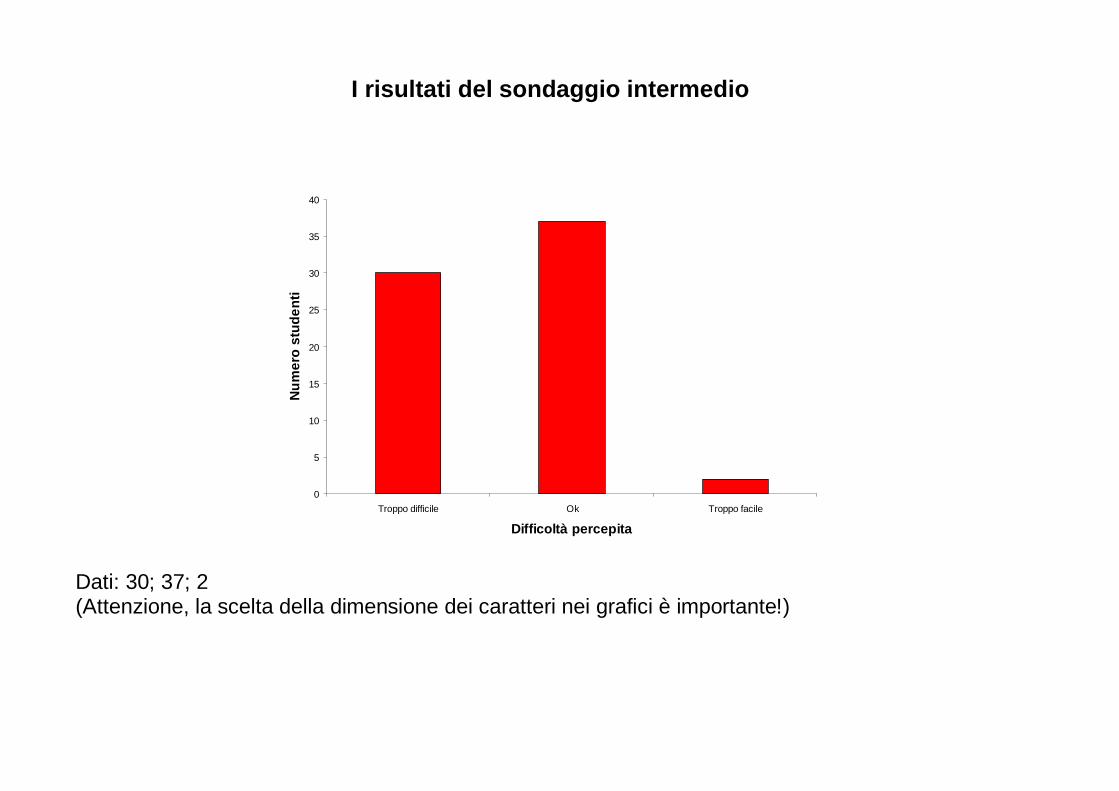
I risultati del sondaggio intermedio
0
5
10
15
20
25
30
35
40
Troppo difficile Ok Troppo facile
Difficoltà percepita
Num
ero
stud
enti
Dati: 30; 37; 2 (Attenzione, la scelta della dimensione dei caratteri nei grafici è importante!)
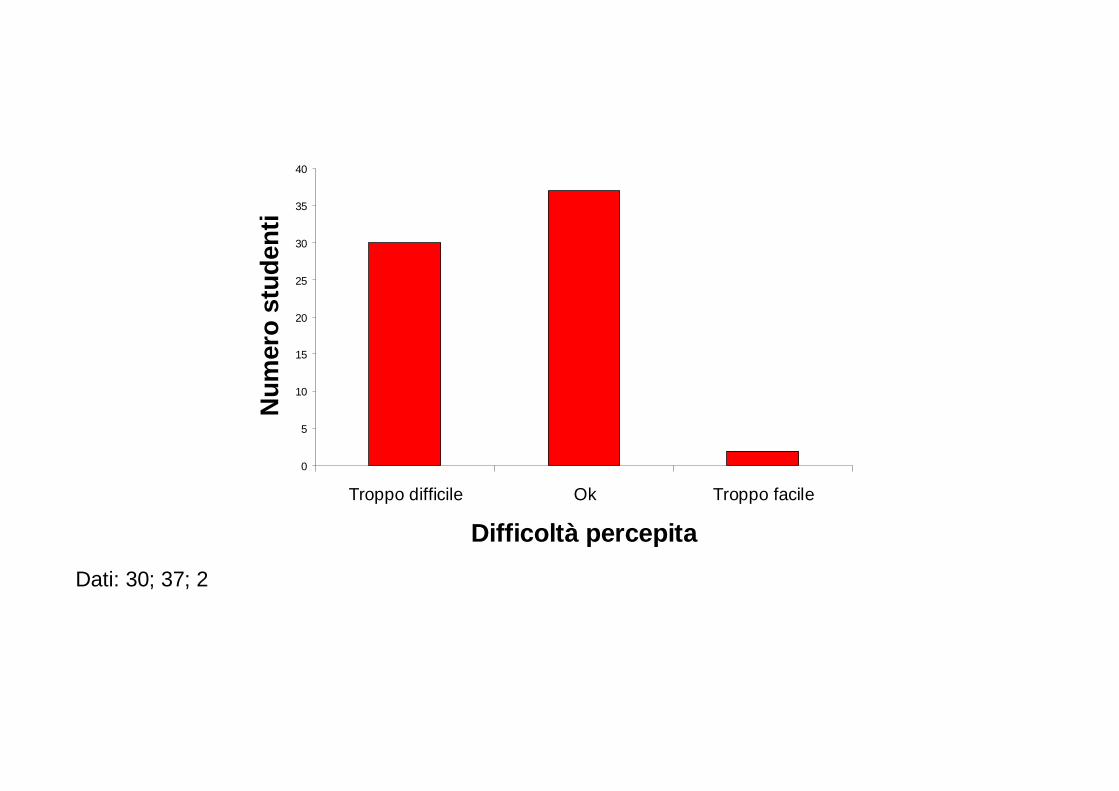
0
5
10
15
20
25
30
35
40
Troppo difficile Ok Troppo facile
Difficoltà percepita
Num
ero
stud
enti
Dati: 30; 37; 2
0
5
10
15
20
25
30
35
40
45
50
Poca teoria, troppiesempi
Ok Troppa teoria, pochiesempi
Rapporto tra teoria ed esempi
Num
ero
stud
enti
Dati: 5; 46; 18
0
5
10
15
20
25
30
35
40
Sempre chiara E' diventata chiara Non lo era e non lo èora
Importanza della statistica in biologia
Num
ero
stud
enti
Dati: 23; 38; 8
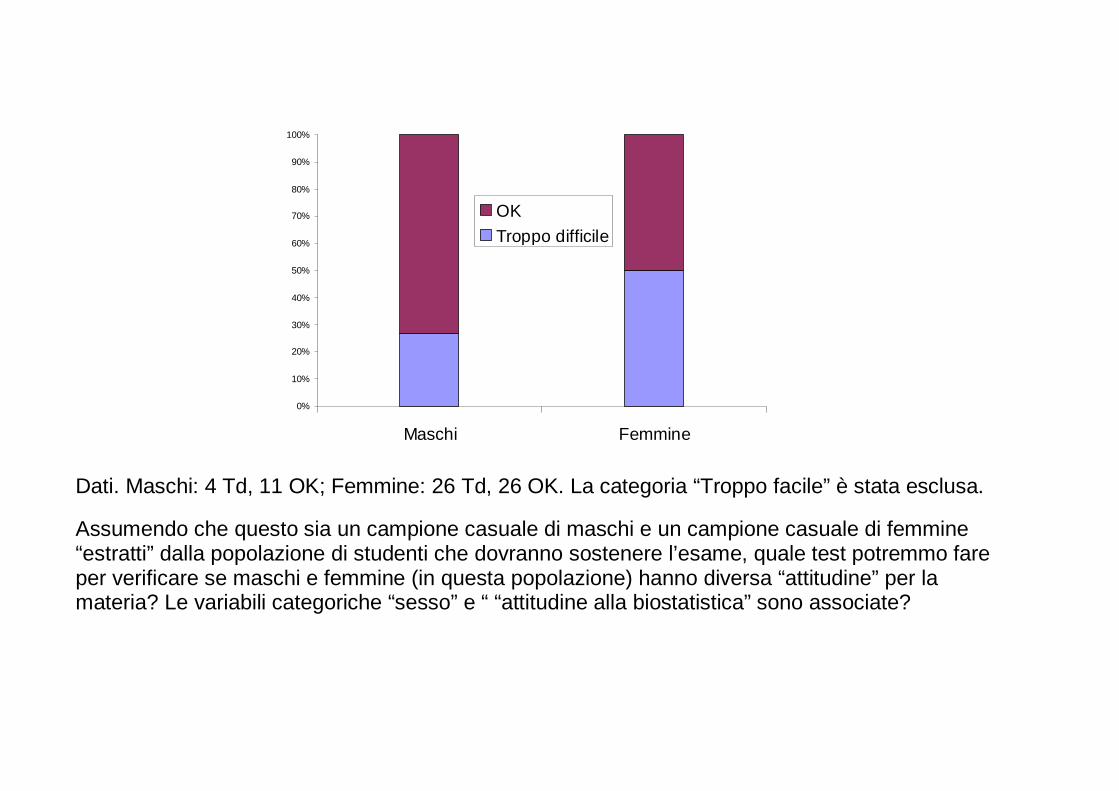
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Maschi Femmine
OK
Troppo difficile
Dati. Maschi: 4 Td, 11 OK; Femmine: 26 Td, 26 OK. La categoria “Troppo facile” è stata esclusa.
Assumendo che questo sia un campione casuale di maschi e un campione casuale di femmine “estratti” dalla popolazione di studenti che dovranno sostenere l’esame, quale test potremmo fare per verificare se maschi e femmine (in questa popolazione) hanno diversa “attitudine” per la materia? Le variabili categoriche “sesso” e “ “attitudine alla biostatistica” sono associate?

Esempi con il test del chi-quadrato: bontà di adatt amento
Attenzione, questa NON è una tabella di contingenza!
� Risultato: χ2 calcolato = 75.1. Questo valore è nettamente superiore al valore critico con 1 gdl. L’ipotesi nulla è rifiutata. Nel genoma umano. il numero di geni sul cromosoma X è significativamente minore di quello che ci aspetteremmo sulla base delle sue dimensioni.
� Se avessi applicato il test z per un campione: z calcolato = -8.66 (ovviamente la conclusione del test è la stessa)
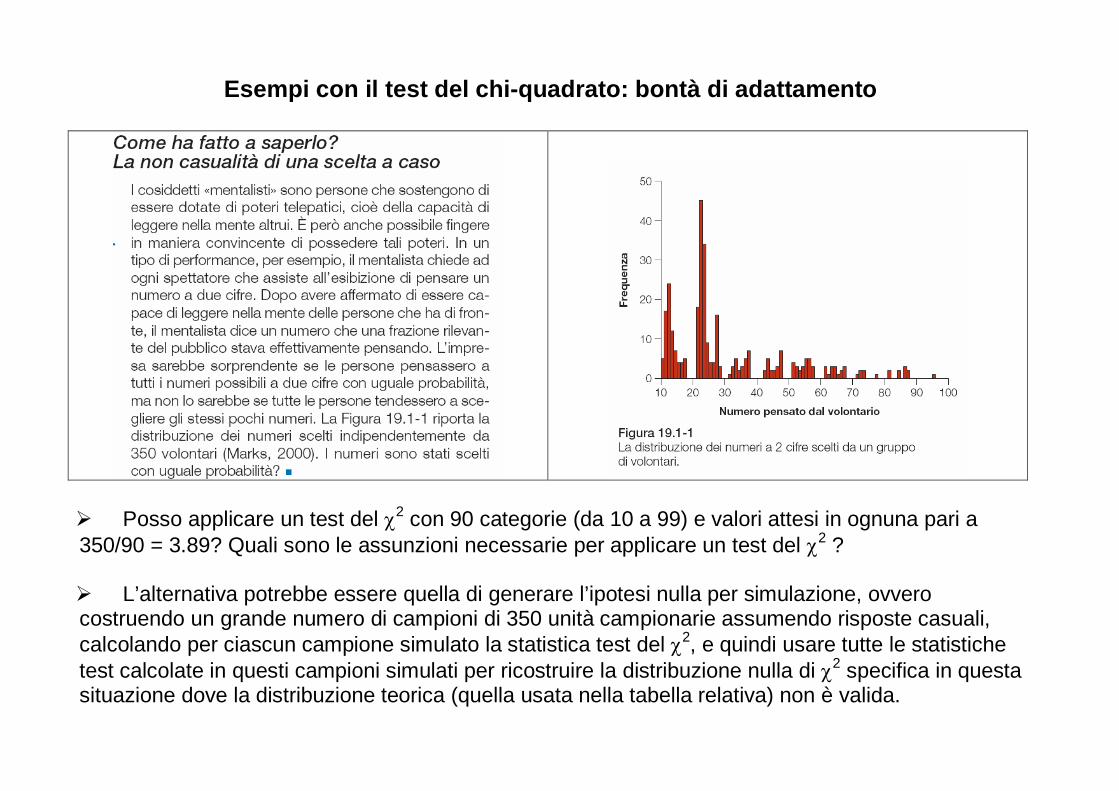
Esempi con il test del chi-quadrato: bontà di adatt amento
� Posso applicare un test del χ2 con 90 categorie (da 10 a 99) e valori attesi in ognuna pari a 350/90 = 3.89? Quali sono le assunzioni necessarie per applicare un test del χ2 ? � L’alternativa potrebbe essere quella di generare l’ipotesi nulla per simulazione, ovvero costruendo un grande numero di campioni di 350 unità campionarie assumendo risposte casuali, calcolando per ciascun campione simulato la statistica test del χ2, e quindi usare tutte le statistiche test calcolate in questi campioni simulati per ricostruire la distribuzione nulla di χ2 specifica in questa situazione dove la distribuzione teorica (quella usata nella tabella relativa) non è valida.
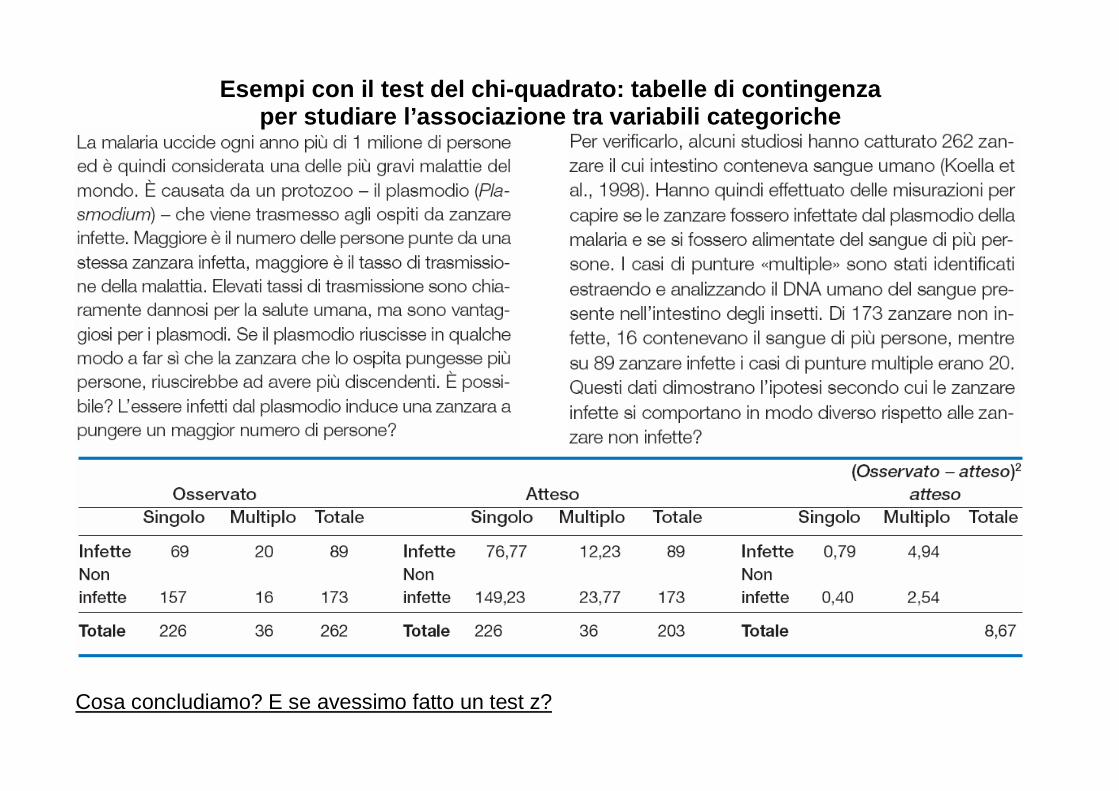
Esempi con il test del chi-quadrato: tabelle di con tingenza per studiare l’associazione tra variabili categoric he
Cosa concludiamo? E se avessimo fatto un test z?

Cosa fare quando le assunzioni richieste dal test d el chi quadrato non vengono soddisfatte?
� Alcune soluzioni
o Ricorrere ad un altro test che non necessiti della distribuzione teorica nulla del χ2
� Abbiamo visto un esempio di χ2 come “goodness-of –fit test” dove la simulazione al calcolatore ci viene in aiuto
o Raggruppare alcune categorie
� E necessario che le nuove categorie abbiano una logica e un significato
o Eliminare alcune categorie (ovviamente, nel caso di tabelle di contingenza, si devono eliminare righe o colonne intere, non singole celle)
� Attenzione: il data set si riduce. Attenzione anche al fatto che l’interpretazione finale
non si applicherà ai dati originali ma a quelli ottenuti dopo l’eliminazione

Gli errori nella verifica delle ipotesi � Nella statistica inferenziale si cerca di dire qualcosa di valido in generale, per la popolazione o
le popolazioni, attraverso l’analisi di uno o più campioni � E’ chiaro però che esiste comunque la possibilità di giungere a conclusioni errate, appunto
perché i miei dati rappresentano solo una parte dell’evento che sto analizzando � Formalizziamo brevemente il concetto, in parte già visto, di errore (di errori) nel processo di
verifica delle ipotesi
Premessa (riassunto di argomenti già trattati) � PRIMA di effettuare un test statistico viene scelto un livello di significatività, α � Questo livello di significatività determina i valori critici della statistica test (z, t, chi-quadro, ecc). I
valori critici definiscono nella distribuzione teorica della statistica, distribuzione attesa nel caso sia vera l’ipotesi nulla (la distribuzione nulla, appunto), le regioni di accettazione e di rifiuto
� Il livello di significatività prescelto viene anche utilizzato come confronto se si segue l’approccio
del p-value: il p-value calcolato viene confrontato con α

� Supponiamo ora di aver scelto α =0.05 (scelta tipica), e supponiamo di condurre un test
bidirezionale (a due code) � La regione di rifiuto nella distribuzione nulla include il 5% dei valori più estremi della statistica
(2,5% dalla parte dei valori molto grandi, e 2,5% dalla parte dei valori molto piccoli) � Questi sono valori estremi che comunque possiamo otterremmo, con una probabilità del 5%,
anche se fosse vera l’ipotesi nulla • Se ripetessimo tante volte il test su campioni diversi, e l’ipotesi nulla fosse sempre vera, il
5% dei test porterebbe ad un valore della statistica test all’interno della zona di rifiuto (e ad un p-value inferiore a 0.05)
• Quindi, nel 5% di questi test, rifiuteremmo l’ipotesi nulla vera
Distribuzione nulla per la statistica test z.
Se è vera l’ipotesi nulla, e ripetessi il test molte volte su campioni diversi, α x 100 delle volte quest’ipotesi vera verrebbe erroneamente rifiutata

� In pratica, se la statistica calcolata in un singolo test cade nella regione di rifiuto, o il p-value <α, la conclusione del test è quella di rifiutare l’ipotesi nulla. • Ma, per quello che abbiamo appena detto, l’ipotesi nulla potrebbe anche essere vera ma
per puro effetto del caso (errore di campionamento) i dati portano ad una statistica test significativa (che cade cioè nella regione di rifiuto e che ha un p-value <α)
� L’errore che si compie rifiutando un’ipotesi nulla vera si chiama
Errore di primo tipo
o errore di prima specie, o errore do tipo I
� La probabilità di compiere un errore di primo tipo è data dal livello di significatività α prescelto � E’ la frazione di volte che viene rifiutata un ipotesi nulla vera se ripetessi tante volte il test su
campioni diversi (presi dalla stessa, o dalle stesse, popolazione/i) � Scegliendo in anticipo α, definiamo il rischio che siamo disposti ad accettare di compiere un
errore di primo tipo � Alla fine del test, se le evidenze saranno a favore dell’ipotesi alternativa, non sapremo
ovviamente se avremo commesso un errore di primo tipo oppure no. Potremo solo dire che la probabilità di averlo commesso, se fosse vera l’ipotesi nulla, sarebbe molto bassa (e pari ad α)

� La probabilità complementare (1- α) viene chiamata livello di protezione di un test, ed è
appunto la probabilità di non rifiutare l’ipotesi nulla quando l’ipotesi nulla è vera. Un test con un altro livello di protezione è detto conservativo
• Un test molto conservativo può essere visto come un test che vuole rischiare molto poco
di fare un errore di primo tipo, che sappiamo essere un errore molto grave perché rifiutare l’ipotesi nulla è una decisione forte (come condannare un imputato) mentre non rifiutarla non significa in realtà accettarla (ma solo dire che i dati sono compatibili con essa)
� Da notare che nel calcolo degli intervalli di confidenza (utilizzati nella stima di un parametro,
non nella verifica di ipotesi), il termine 1- α prende il nome di grado di confidenza � Riassumendo, se l’ipotesi nulla è vera, può succedere che:

� Vediamo ora un altro tipo di errore che si può commettere nella verifica delle ipotesi � Se l’ipotesi nulla è falsa, cioè per esempio la media nella popolazione 1 è diversa dalla media
nella popolazione 2, giungerò sempre al suo rifiuto analizzando due campioni? • Ovviamente no, e anche intuitivamente è facile capirne un motivo: se le medie nelle due
popolazioni sono diverse ma molto vicine, è possibile che i dati non siano sufficienti a escludere l’ipotesi nulla, visto che l’ipotesi nulla viene rifiutata solo in presenza di forti evidenze
� L’errore che si compie quando un’ipotesi alternativa è vera ma la conclusione del test è quella che non è possibile escludere l’ipotesi nulla, ovvero, l’errore che si compie non rifiutando un’ipotesi nulla falsa, si chiama
Errore di secondo tipo o errore di seconda specie, o errore do tipo II

� La probabilità di commettere un errore di secondo tipo viene generalmente indicato con il simbolo β
� La probabilità complementare, (1- β), ossia la probabilità di rifiutare correttamente un ipotesi
nulla falsa, si chiama potenza del test • Maggiore è la potenza di un test, maggiore sarà la possibilità del test di identificare come
corretta l’ipotesi alternativa quando questa è effettivamente vera
� La probabilità di fare un errore di secondo tipo, ovvero il rischio di non rifiutare un’ipotesi nulla falsa, e di conseguenza la potenza di un test, non si può stabilire a priori • Dipende infatti dalla distanza tra ipotesi nulla e alternativa (per esempio, la differenza tra µ1 e µ2), distanza che è ignota
• Dipende dalla varianza delle variabili in gioco, che non può essere modificata � La probabilità di fare un errore di secondo tipo, però, dipende anche dal numero di osservazioni
e dal livello di significatività α prescelto. Quindi: • è possibile ridurre l’errore di II tipo (e quindi aumentare la potenza) aumentando la
dimensione campionaria • è possibile ridurre l’errore di II tipo (e quindi aumentare la potenza) aumentando il livello di
significatività α (ma questa scelta ci espone a maggiori rischi di errore di tipo I) � E’ possibile studiare la potenza di un test attraverso l’analisi della potenza

� Completiamo intanto la tabella degli errori
� Cerchiamo ora di capire graficamente l’errore di secondo tipo
• Supponiamo di svolgere un test z a una coda per verificare le seguenti ipotesi
H0: µ = µ0 = 1.5 H1 : µ ≠ µ0
• Abbiamo già visto cosa succede quando l’ipotesi nulla è effettivamente vera (si rischia di
commettere un errore di primo tipo) • Vediamo ora cosa succede quando l’ipotesi nulla non è vera
� In questo caso, per capire e calcolare l’errore di secondo tipo è necessario assumere che sia vera una ipotesi alternativa precisa. Assumiamo che sia vera l’ipotesi alternativa µ = 1.45
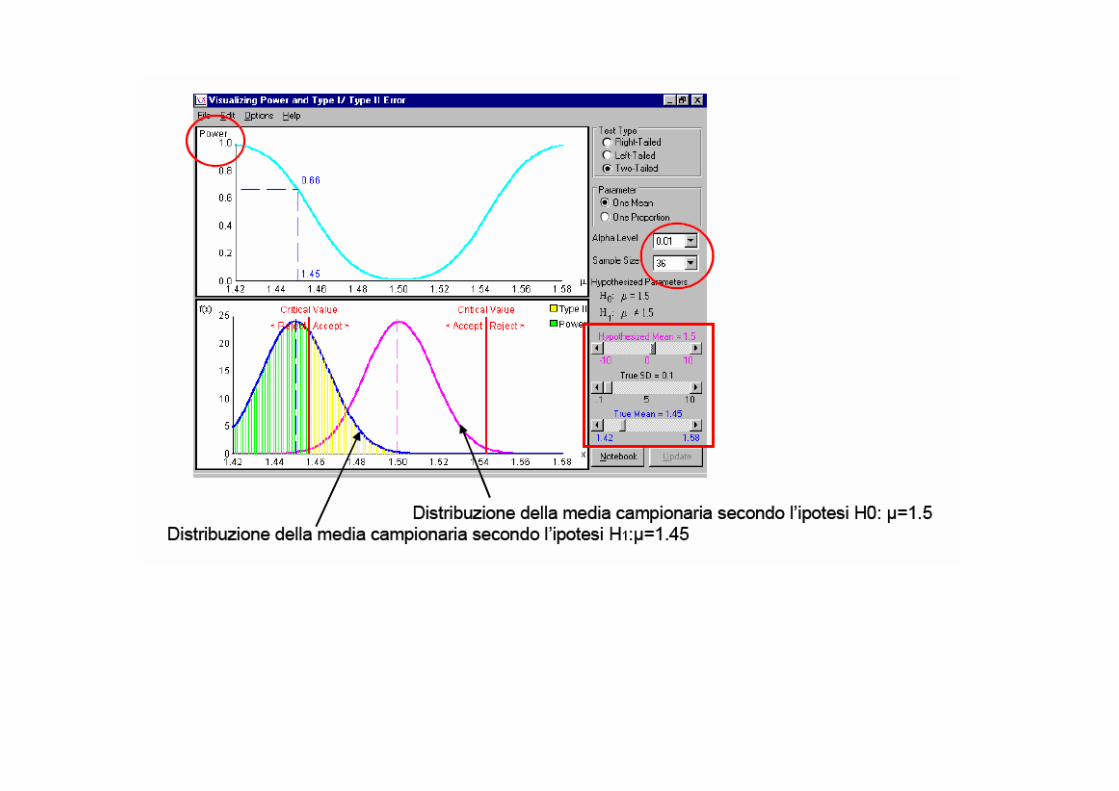

� Concentriamoci per ora sulla parte inferiore della figura, specifica per un campione con n = 36
osservazioni con σ =0.1 e α = 0.01 • Le due distribuzioni a campana rappresentano le distribuzioni delle medie campionarie
secondo l’ipotesi nulla (in viola) e secondo l’ipotesi alternativa (in blu) • Le due linee rosse verticali rappresentano i limiti dell’intervallo all’interno del quale una
media campionaria verrebbe considerata compatibile con l’ipotesi nulla � Quei limiti, standardizzati, porterebbero ai valori critici nella tabella di z di - 2.576 e
2.576 � L’area ombreggiata in giallo è la probabilità di commettere un errore di tipo II
• Infatti, quando è vera l’ipotesi alternativa, la media campionaria ha una probabilità pari all’area in giallo di cadere nella regione di accettazione (stabilità ovviamente sulla base della distribuzione nulla)
� L’area ombreggiata in verde è quindi il potere del test, ovvero la probabilità di rifiutare correttamente l’ipotesi nulla quando questa è falsa (come nel caso considerato)

� E facile capire da questo grafico che
• 1. Maggiore è la distanza tra ipotesi alternativa (che stiamo considerando vera) e l’ipotesi nulla (che stiamo considerando falsa), maggiore sarà la potenza del test
� Logico: se l’ipotesi alternativa è molto diversa da quella nulla ipotizzata, sarà facile scoprirlo
• 2. Minore è la dispersione della variabile, minore sarà la varianza della media
campionaria, più strette saranno le corrispondenti distribuzioni, e maggiore sarà la potenza del test
� Logico: se gli individui sono tutti molto simili, anche pochi sono sufficienti per stimare bene la media della popolazione e verificare se è diversa da µ0
• 3. Maggiore è l’α prescelto, maggiore sarà la potenza del test
� Logico: se per rifiutare l’ipotesi nulla mi accontento di moderate differenze tra i dati e quanto predetto dall’ipotesi nulla, tenderò a rifiutarla maggiormente quando è vera l’ipotesi nulla ma anche quando è vera l’ipotesi alternativa
• 4. Maggiore è la dimensione campionaria, minore sarà la varianza della media
campionaria, più strette saranno le corrispondenti distribuzioni, e maggiore sarà la potenza del test
� Logico: con molti dati “scovo” meglio un’ipotesi alternativa vera

� Attenzione: per ogni dato test statistico, possiamo aumentare la potenza solo agendo su sul punto 3 (ma ciò comporta un aumento del rischio di errore di tipo I) e sul punto 4. I punti 1 e 2 non sono sotto il nostro controllo
• In realtà, poiché per ogni tipo di problema statistico esistono generalmente più test diversi a disposizione (con caratteristiche diverse), e i test che fanno più assunzioni (per esempio sulla distribuzione della variabile) sono di solito più potenti, è anche possibile aumentare la potenza di un test scegliendo il test più potente (ovviamente se le condizioni imposte da quel test sono soddisfatte dai dati)
� Provate voi stessi come varia il potere di semplice un test in funzione di α, n, σ, e la distanza tra
la µ vera e la µ0 ipotizzata dall’ipotesi nulla:
http://bcs.whfreeman.com/ips4e/cat_010/applets/powe r_ips.html
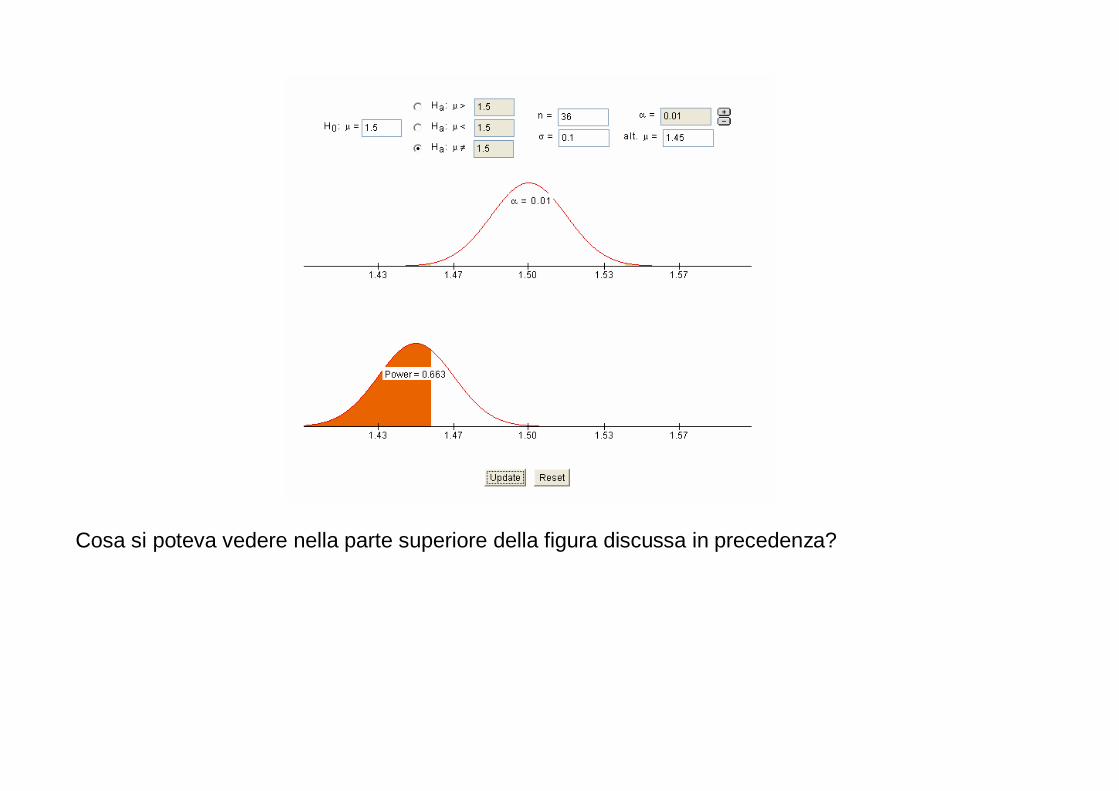
Cosa si poteva vedere nella parte superiore della figura discussa in precedenza?

L’analisi della potenza e la sua importanza � Fare un analisi della potenza significa essenzialmente determinare la potenza di un test in
diverse condizioni, ovvero in funzione di α, n, σ, e della distanza tra ipotesi alternativa e ipotesi nulla
� Nel test appena visto, il calcolo della potenza è semplice (si fa con il calcolatore ma si poteva
fare anche a mano). In altri casi è molto più complesso � E’ molto importante perché ci permette di capire quale probabilità abbiamo di accettare
erroneamente l’ipotesi nulla quando invece è vera una specifica ipotesi alternativa � Supponiamo per esempio di avere la possibilità di determinare una certa variabile fisiologica in
un gruppo di 5 pazienti, per poterne confrontare la media con l’ipotesi nulla che la media nella popolazione sia pari ad un certo valore medio standard, diciamo 12 (sospettando per esempio che la patologia dei pazienti possa aver alterato la variabile fisiologica che vogliamo analizzare). Supponiamo anche di conoscere la deviazione standard della variabile (così che sia possibile applicare un test z) e che questa sia pari a 3

� Dopo aver fatto l’analisi in laboratorio e il test statistico, e aver trovato che l’ipotesi nulla non
può essere rifiutata, o meglio ancora prima di cominciare le analisi, potremo chiederci: • qual è la probabilità di non accorgerci (con un certo α = 0.05) che la media della
popolazione da cui abbiamo estratto il campione non è quella specificata dall’ipotesi nulla (µ0 = 12), ma é invece pari ad valore specifico di interesse, per esempio di interesse perché indice di una grave patologia?
� Ci interessa cioè capire se, nell’ipotesi che i pazienti abbiano per esempio un media della
variabile studiata alta in maniera preoccupante, per esempio µ = 14, tale differenza verrebbe identificata con il campione a disposizione
• in generale, la scelta del valore di µ da analizzare nell’analisi della potenza dovrebbe identificare un valore di media particolarmente anomalo, che se fosse veramente la media della popolazione dalla quale abbiamo estratto il campione che stiamo analizzando vorremmo che venisse evidenziata con alta probabilità
� Utilizzando l’applet al calcolatore con
• α = 0,05 • n = 5 • σ = 3 • µ0 = 12 (valore standard previsto dall’ipotesi nulla) • µ = 14 (valore ipotizzato per l’ipotesi alternativa)
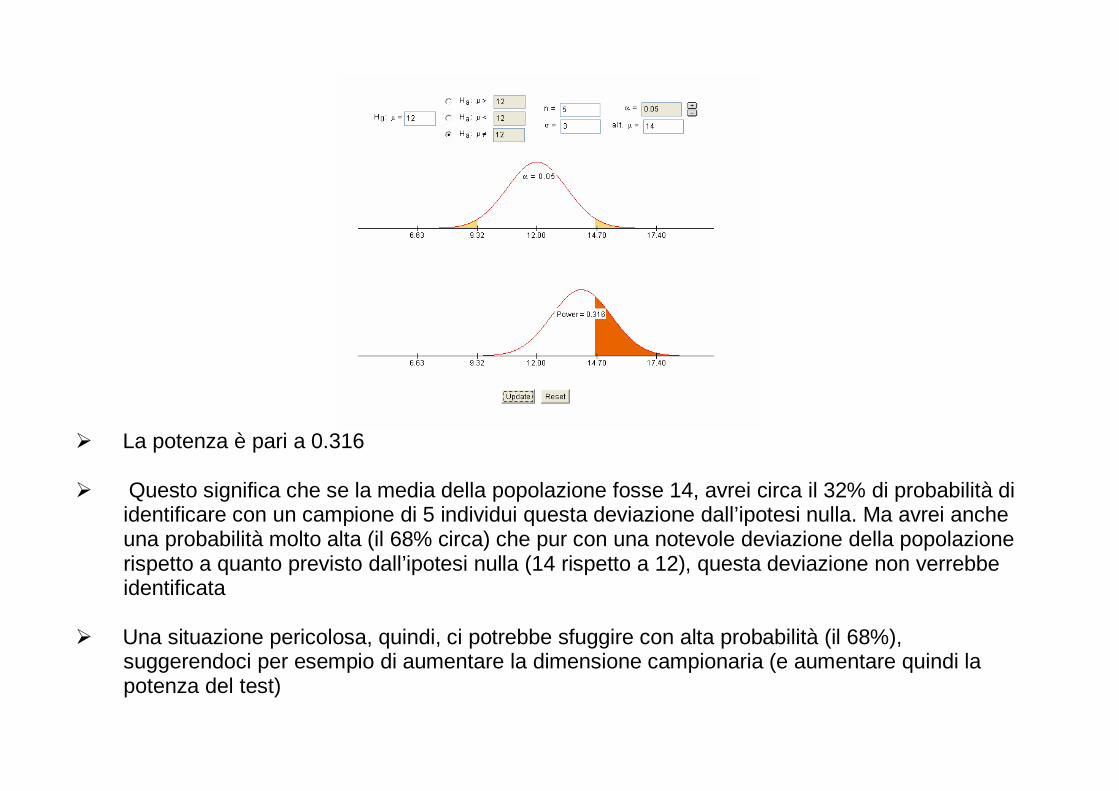
� La potenza è pari a 0.316 � Questo significa che se la media della popolazione fosse 14, avrei circa il 32% di probabilità di
identificare con un campione di 5 individui questa deviazione dall’ipotesi nulla. Ma avrei anche una probabilità molto alta (il 68% circa) che pur con una notevole deviazione della popolazione rispetto a quanto previsto dall’ipotesi nulla (14 rispetto a 12), questa deviazione non verrebbe identificata
� Una situazione pericolosa, quindi, ci potrebbe sfuggire con alta probabilità (il 68%),
suggerendoci per esempio di aumentare la dimensione campionaria (e aumentare quindi la potenza del test)

Analisi di proporzioni e distribuzioni con la distr ibuzione binomiale
� Nell’analisi delle proporzioni avevamo accennato alla distribuzione binomiale o …la distribuzione teorica di probabilità della statistica p (proporzione di una certa
caratteristica osservata in un campione estratto da una popolazione in cui la proporzione è pari π) è la distribuzione binomiale…
� Nei test z e Chi-quadrato che abbiamo visto finora per analizzare proporzioni o numerosità avevamo anche detto però che è possibile, se alcune condizioni sono soddisfatte, utilizzare l’approssimazione normale (gaussiana) della binomiale o Solo se verificate queste condizioni
� [nπ e n(1-π) maggiori o uguali a 5 per il test z, non meno di 5 osservazioni attese in non più del 20% di categorie e nessuna categoria con meno di una osservazione attesA per test del chi-quadrato]
o allora l’approssimazione della binomiale con la gaussiana è valida e i test z e chi quadrato si possono applicare
� Vediamo ora cosa fare in alcuni casi semplici quando queste assunzioni non sono vere ed è necessario ricorrere alla distribuzione binomiale o Prima di tutto, cos’è la distruzione binomiale?

La distribuzione binomiale � Supponiamo di compiere un esperimento con due soli risultati possibili
o Lancio una moneta: ottengo testa o croce? o Faccio un figlio: sarà maschio o femmina? o Provo un esame: viene superato oppure no? o Misuro la temperatura: e’ < 36.5 oppure ≥36.5 ? o Estraggo a caso un individuo dalla popolazione: è sposato oppure no? o Estraggo a caso un individuo dalla popolazione: fuma oppure no? o Campiono un lupo e analizzo il tratto di DNA che codifica per la catena beta
dell’emoglobina: è presente oppure no in almeno uno dei due cromosomi (materno o paterno) la mutazione da adenina a citosina nella base nucleotidica in posizione 56 rispetto ad una sequenza di riferimento?

� Un esperimento di questo tipo è detto esperimento bernoulliano � Chiamiamo uno dei due eventi successo (S) e l’altro (l’evento complementare) insuccesso (I)
o Non importa quale dei due viene chiamato successo e quale insucceso, è una scelta arbitraria; per esempio
� testa = successo; croce = insuccesso � fumatore = successo; non fumatore = insuccesso � la mutazione A�C in posizione 56 nel gene per l’emoglobina è presente = successo;
la mutazione A�C in posizione 56 nel gene per l’emoglobina è assente = insuccesso � Chiamiamo ora
o π = probabilità dell’evento S (successo) o (1-π) = probabilità dell’evento I (insuccesso)
� Se quindi per esempio studio un singolo lupo (analogo ad un esperimento bernoullinano) e so
che π = 0.1, posso dire che la probabilità di ottenere una sequenza con la mutazione A�C in posizione 56 nel gene per l’emoglobina è pari a 0.1 o Questa probabilità, come al solito, mi dice che se avessi a disposizione un numero
elevatissimo di lupi, il 10% di questi sarebbero portatori di questa specifica mutazione

� Supponiamo ora invece di ripetere l’esperimento bernoulliano 2 volte o Il numero di ripetizioni, e estrazioni, dette anche numero di prove, di indica con n o In questo caso n = 2
� Esempi
o Lancio due monete (o due volte la stessa moneta) e registro il numero di teste o Estraggo due individui a caso da una popolazione, chiedo se fumano, e registro il numero
di fumatori o Campiono e tipizzo geneticamente due lupi e registro quanti di loro hanno la la mutazione
A�C in posizione 56 nel gene per l’emoglobina
Chiara l’analogia con un campione di dimensione n e l’analisi delle proporzioni o numerosità!

� Vediamo ora nel caso di due prove (n=2) quali sono tutti i risultati possibili e con che probabilità si può verificare ciascuno di essi o Queste probabilità vengono calcolate, e saranno quindi corrette, se (assumendo che)
� il risultato della prima prova non influenza il risultato della seconda prova, e � le probabilità di successo/insuccesso [π e (1-π)] nella singola prova restano costanti
� Intanto, quali sono i risultati possibili?
o SS (prima prova = successo; seconda prova = successo) o SI (prima prova = successo; seconda prova = insuccesso) o IS (prima prova = insuccesso; seconda prova = successo) o II (prima prova = insuccesso; seconda prova = insuccesso)
� Abbiamo detto che le prove sono indipendenti e le probabilità di successo/insuccesso non
cambiano da prova a prova. Quindi possiamo applicare la regola del prodotto per trovare le probabilità di ciascuno dei 4 risultati possibili.

� Attenzione!
o Questi eventi sono tutti diversi se consideriamo l’ordine, ma ci sono solo tre eventi diversi se consideriamo il numero di volte che si ottiene un successo. Infatti ci possono essere 0, 1 o 2 successi in due estrazioni
o A noi interessa la probabilità di avere per esempio 1 testa in due lanci, o un lupo con la
mutazione in un campione di due lupi, non l’ordine con il quale gli eventi si verificano! o Quindi dobbiamo sommare qualche termine
� Chiamiamo X la variabile che ci interessa, cioè il numero di successi in n prove

� E’ facilissimo vedere che nel caso di n= 2, le probabilità di ottenere X successi in n prove si ottengono dalle probabilità precedenti
o Per X= 0 e X=2, le probabilità sono quelle di avere II e SS o Per X=1, bisogna sommare i due termini (ovviamente uguali) che corrispondono ad avere
prima un successo e poi un insuccesso e prima un insuccesso e poi un successo
� Se chiamiamo π = p e (1-π) = q o [cosa che si trova su molti libri, ma attenzione a non confondere parametri con statistiche!]
allora le probabilità dei tre possibili risultati sono date dai termini che si ottengono dall’espansione del binomio (p+q)2 = p2 +2pq + q2
� Attenzione, nella descrizione e nell’uso della binomiale π e p vengono spesso usati in maniera
interscambiabile! Anche in questi appunti

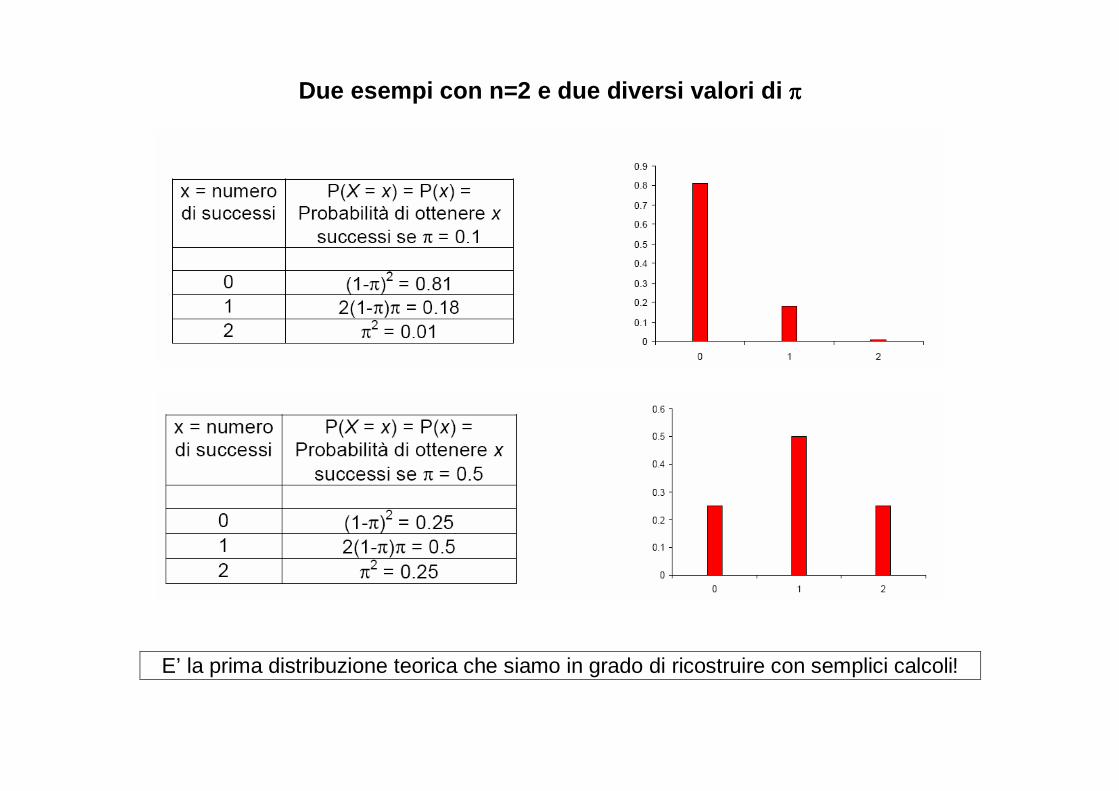
Due esempi con n=2 e due diversi valori di ππππ
E’ la prima distribuzione teorica che siamo in grado di ricostruire con semplici calcoli!
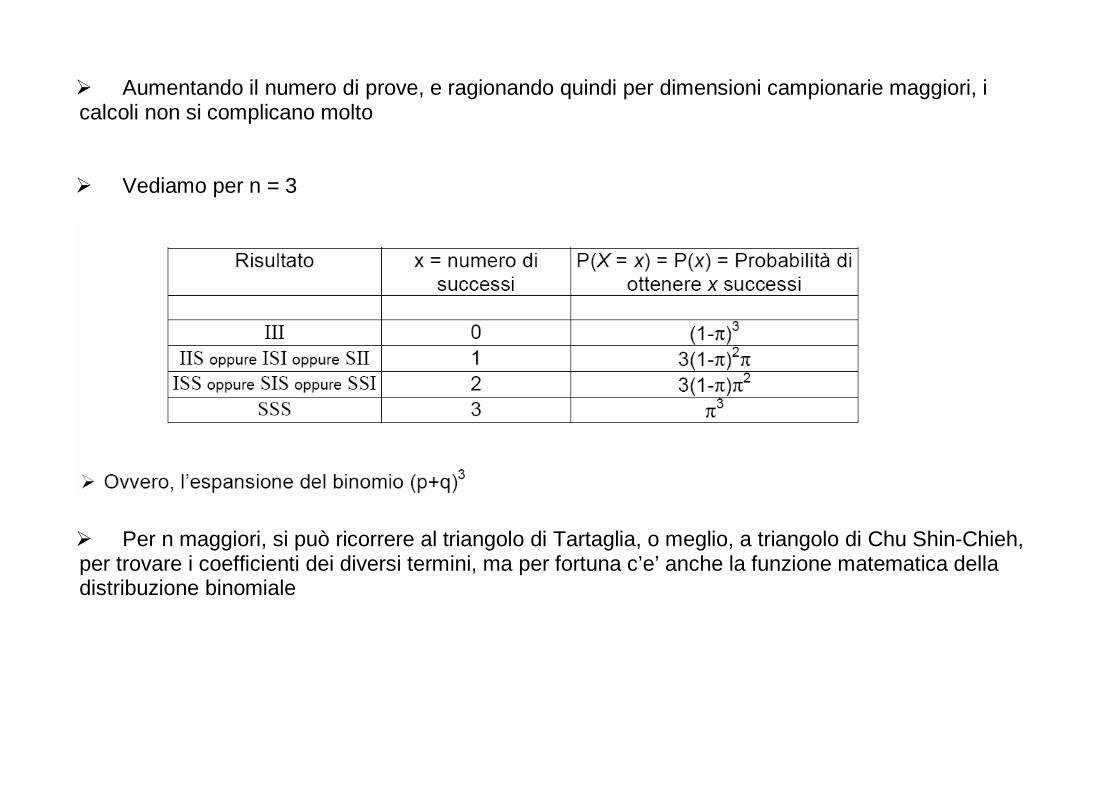
� Aumentando il numero di prove, e ragionando quindi per dimensioni campionarie maggiori, i calcoli non si complicano molto � Vediamo per n = 3
� Per n maggiori, si può ricorrere al triangolo di Tartaglia, o meglio, a triangolo di Chu Shin-Chieh, per trovare i coefficienti dei diversi termini, ma per fortuna c’e’ anche la funzione matematica della distribuzione binomiale
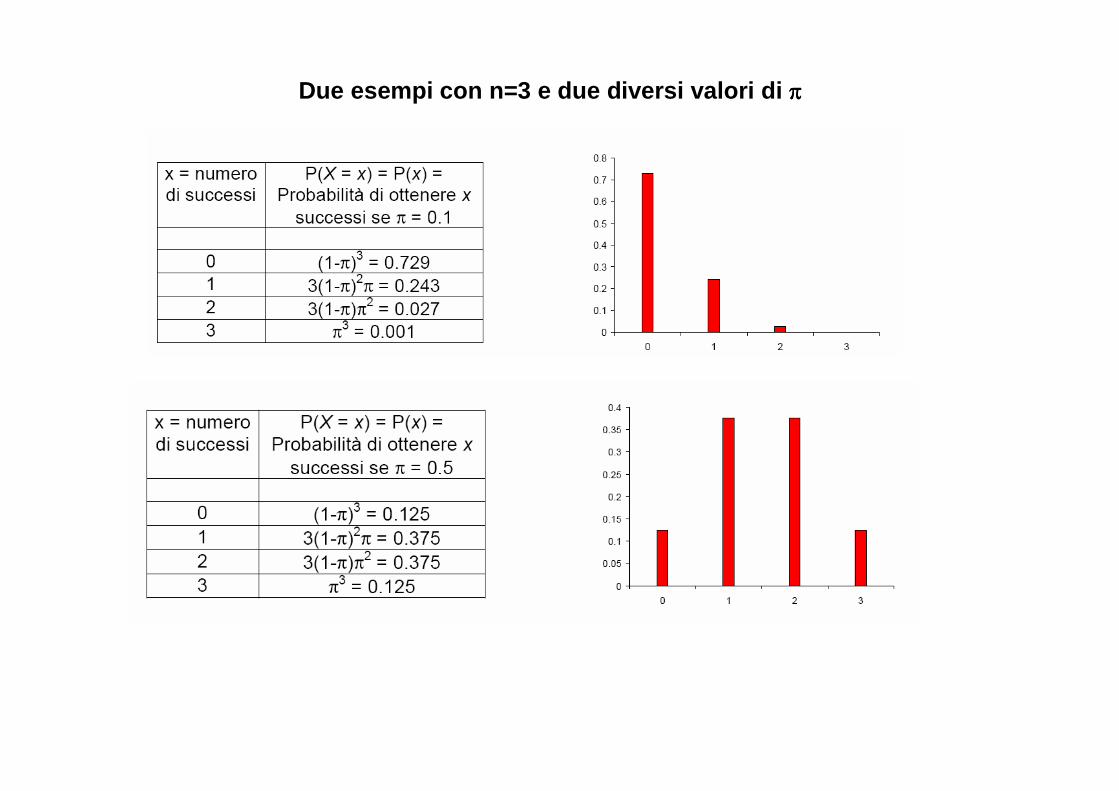
Due esempi con n=3 e due diversi valori di ππππ


Da ricordare
(questo termine si chiama coefficiente binomiale)
Perché è ragionevole che per x = 0 o x = n il coefficiente binomiale sia pari a 1?
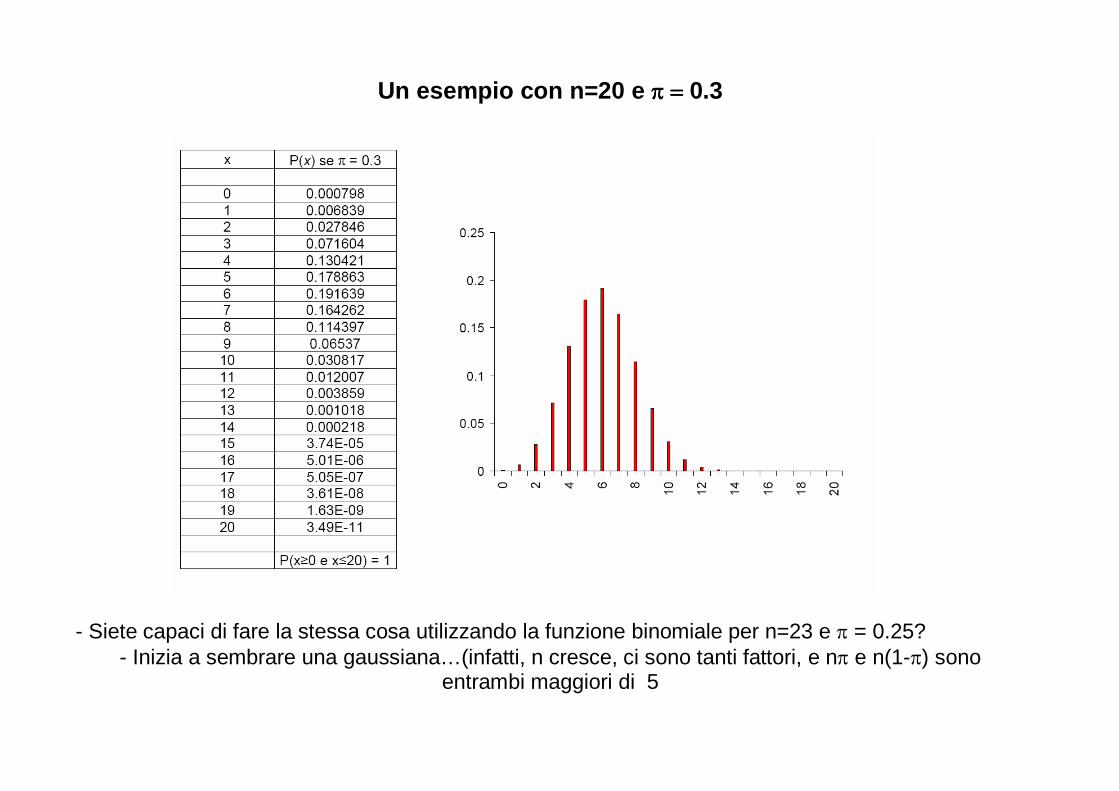
Un esempio con n=20 e ππππ = = = = 0.3
- Siete capaci di fare la stessa cosa utilizzando la funzione binomiale per n=23 e π = 0.25? - Inizia a sembrare una gaussiana…(infatti, n cresce, ci sono tanti fattori, e nπ e n(1-π) sono
entrambi maggiori di 5

La distribuzione teorica di una proporzione è binom iale perché lo è la distribuzione teorica del numero di successi in n p rove

Esercizio: i laureandi in medicina fumano come tutt i?
� L’ipotesi nulla e quella alternativa che sto testando sono le seguenti
� Non posso utilizzare z o chi-quadrato perché nπ0 = 16x0.25 < 5 � Testare le ipotesi sulle proporzioni equivale a testare le ipotesi nulle numerosità
o Se il numero di fumatori nel campione ha una probabilità di verificarsi molto bassa (<α) assumendo vera l’ipotesi nulla, allora anche la proporzione di fumatori nel campione avrà una probabilità di verificarsi molto bassa (<α) assumendo vera l’ipotesi nulla

� La distribuzione nulla delle numerosità (la distribuzione che mi interessa per testare l’ipotesi nulla), ovvero la distribuzione del numero di fumatori in campioni con n = 16 se la probabilità di essere un fumatore è pari a 0.25 (valore specificato dall’ipotesi nulla) è interamente specificata dalla distribuzione binomiale
o Non ho bisogno di tabelle per fare un test binomiale!
� Ricostruire interamente la distribuzione nulla significa quindi, in questo caso, calcolare 17 valori di probabilità, ovvero

P(x=0) = 160 75.025.0
0
16
=
1675.0 = 0.010023
P(x=1) = 151 75.025.0
1
16
= ( ) 151 75.025.016 = 0.053454
..
..
P(x=5) = 115 75.025.0
5
16
=
115 75.025.0!11!5
!16
=
115 75.025.0x4x3x25
12x15x14x13x16
= 0.180159
..
..
P(x=15) = 115 75.025.0
15
16
= ( ) 115 75.025.016 = 1.12x10-8
P(x=16) = 016 75.025.0
16
16
= 1625.0 = 2.33x10-10
� Con questa distribuzione nulla posso definire le regioni di accettazione e rifiuto e/o calcolare il P-value, ovvero fare un test di ipotesi come abbiamo visto precedentemente per le statistiche test z, t e χ2
o Attenzione, non è necessario ricostruire tutta la distribuzione nulla per fare un test di ipotesi con la binomiale!
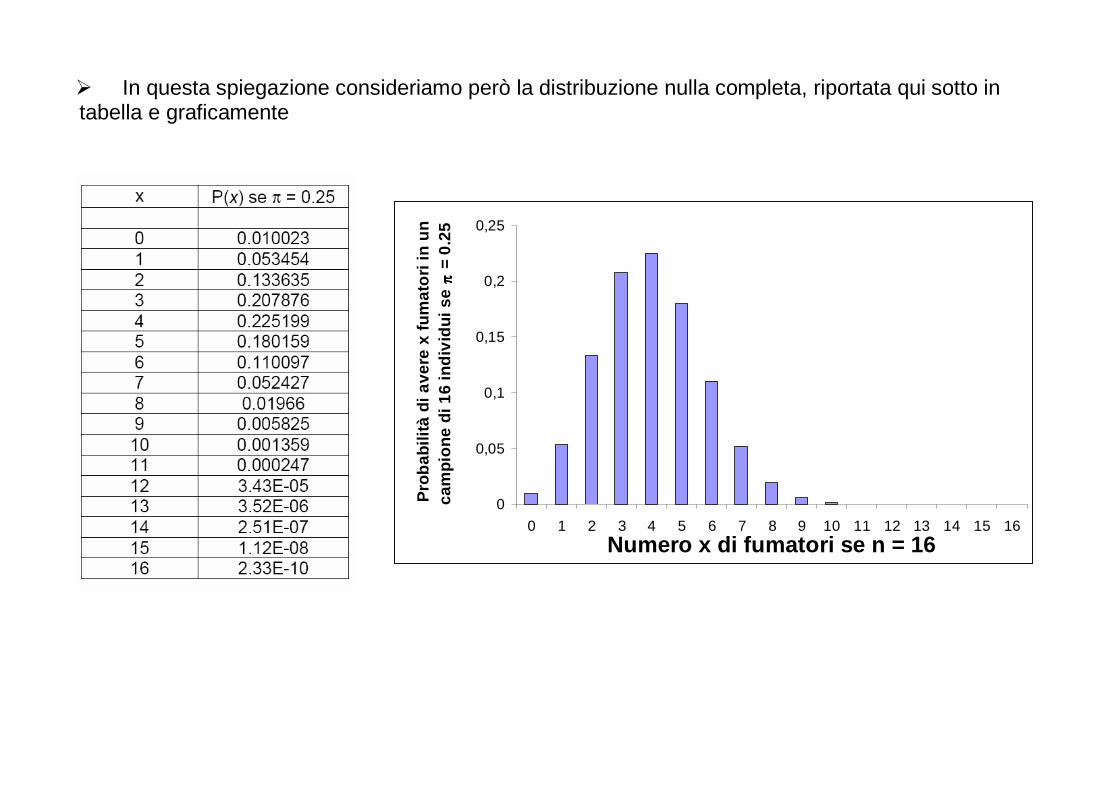
� In questa spiegazione consideriamo però la distribuzione nulla completa, riportata qui sotto in tabella e graficamente
0
0,05
0,1
0,15
0,2
0,25
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Numero x di fumatori se n = 16
Pro
babi
lità
di a
vere
x fu
mat
ori i
n un
ca
mpi
one
di 1
6 in
divi
dui s
e ππ ππ
= 0
.25
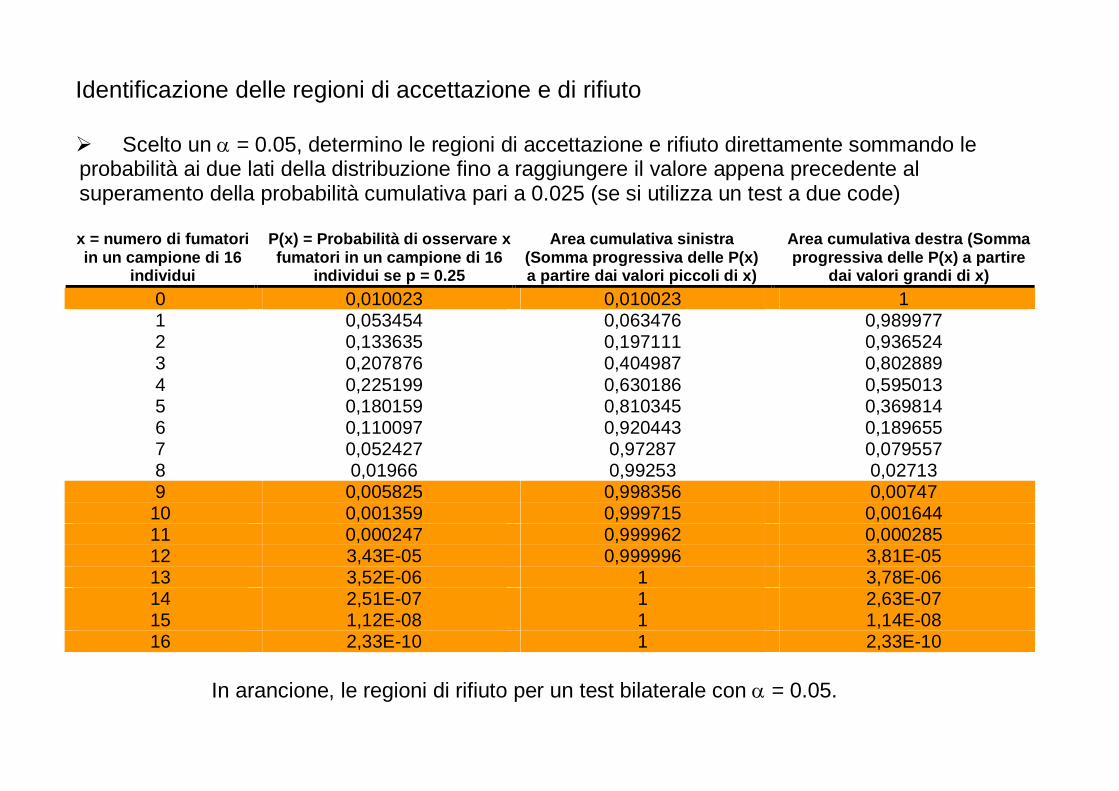
Identificazione delle regioni di accettazione e di rifiuto � Scelto un α = 0.05, determino le regioni di accettazione e rifiuto direttamente sommando le probabilità ai due lati della distribuzione fino a raggiungere il valore appena precedente al superamento della probabilità cumulativa pari a 0.025 (se si utilizza un test a due code) x = numero di fumatori in un campione di 16
individui
P(x) = Probabilità di osservare x fumatori in un campione di 16
individui se p = 0.25
Area cumulativa sinistra (Somma progressiva delle P(x) a partire dai valori piccoli di x)
Area cumulativa destra (Somma progressiva delle P(x) a partire
dai valori grandi di x)
0 0,010023 0,010023 1 1 0,053454 0,063476 0,989977 2 0,133635 0,197111 0,936524 3 0,207876 0,404987 0,802889 4 0,225199 0,630186 0,595013 5 0,180159 0,810345 0,369814 6 0,110097 0,920443 0,189655 7 0,052427 0,97287 0,079557 8 0,01966 0,99253 0,02713 9 0,005825 0,998356 0,00747 10 0,001359 0,999715 0,001644 11 0,000247 0,999962 0,000285 12 3,43E-05 0,999996 3,81E-05 13 3,52E-06 1 3,78E-06 14 2,51E-07 1 2,63E-07 15 1,12E-08 1 1,14E-08 16 2,33E-10 1 2,33E-10
In arancione, le regioni di rifiuto per un test bilaterale con α = 0.05.
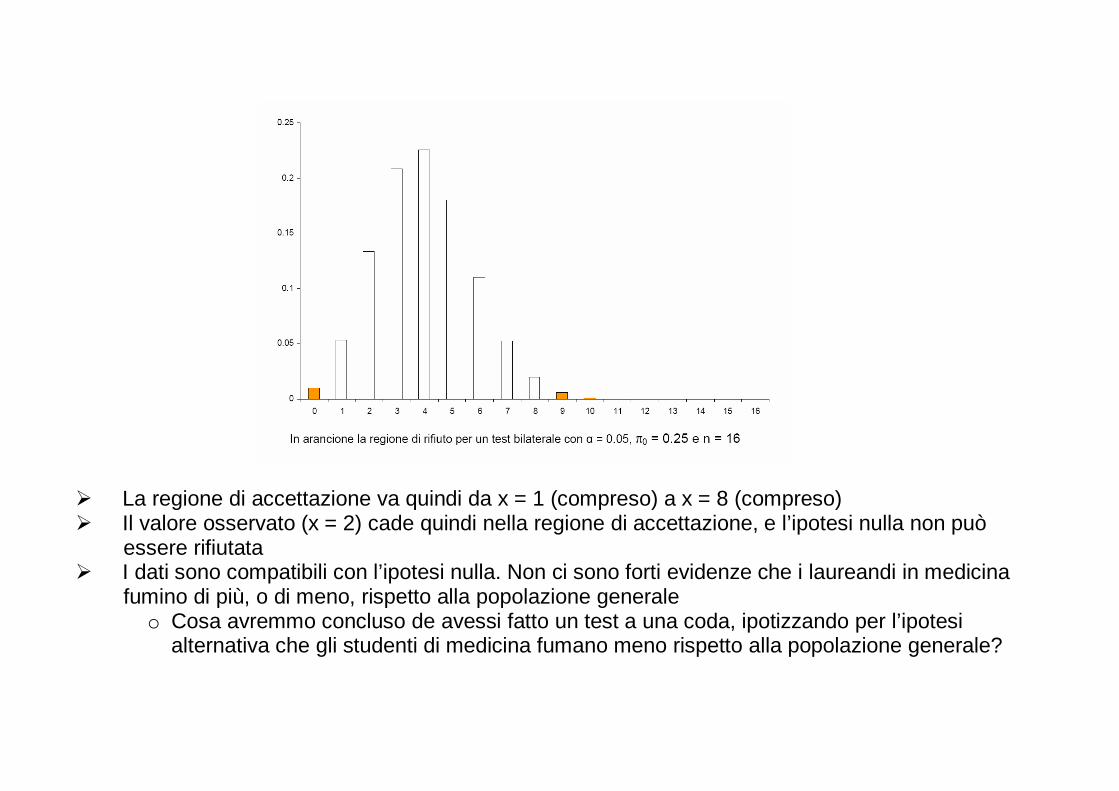
� La regione di accettazione va quindi da x = 1 (compreso) a x = 8 (compreso) � Il valore osservato (x = 2) cade quindi nella regione di accettazione, e l’ipotesi nulla non può
essere rifiutata � I dati sono compatibili con l’ipotesi nulla. Non ci sono forti evidenze che i laureandi in medicina
fumino di più, o di meno, rispetto alla popolazione generale o Cosa avremmo concluso de avessi fatto un test a una coda, ipotizzando per l’ipotesi
alternativa che gli studenti di medicina fumano meno rispetto alla popolazione generale?

Calcolo del P-value � Il P-value, come sempre, è dato dalla probabilità di osservare, se fosse vera l’ipotesi nulla, un campione ugualmente estremo, o più estremo (ossia ugualmente probabile, o meno probabile) di quello osservato realmente
o Se questa probabilità risulta inferiore al livello di a prescelto, rifiutiamo l’ipotesi nulla perché riteniamo i risultati osservati “troppo” improbabili
� (ovviamente non dimenticando che esiste, se rifiutiamo l’ipotesi nulla, l’errore di primo tipo!)
� Il P-value nel test binomiale appena visto è quindi la probabilità complessiva di osservare un campione con un valore x uguale al valore osservato nei dati (2 nell’esempio) o con valori di x più estremi (cioè meno probabili di quello osservato)
o Queste probabilità sono ovviamente (riguardate se necessario cos’è il P-value in un test) calcolate assumendo vera l’ipotesi nulla, in questo caso che π= π0 = 0.25
� In tabella, dobbiamo sommare tutti i valori di P≤0.133635, ossia della probabilità di osservare il campione realmente osservato (x =2) (da entrambe i lati della distribuzione, visto che stiamo facendo un test a due code).
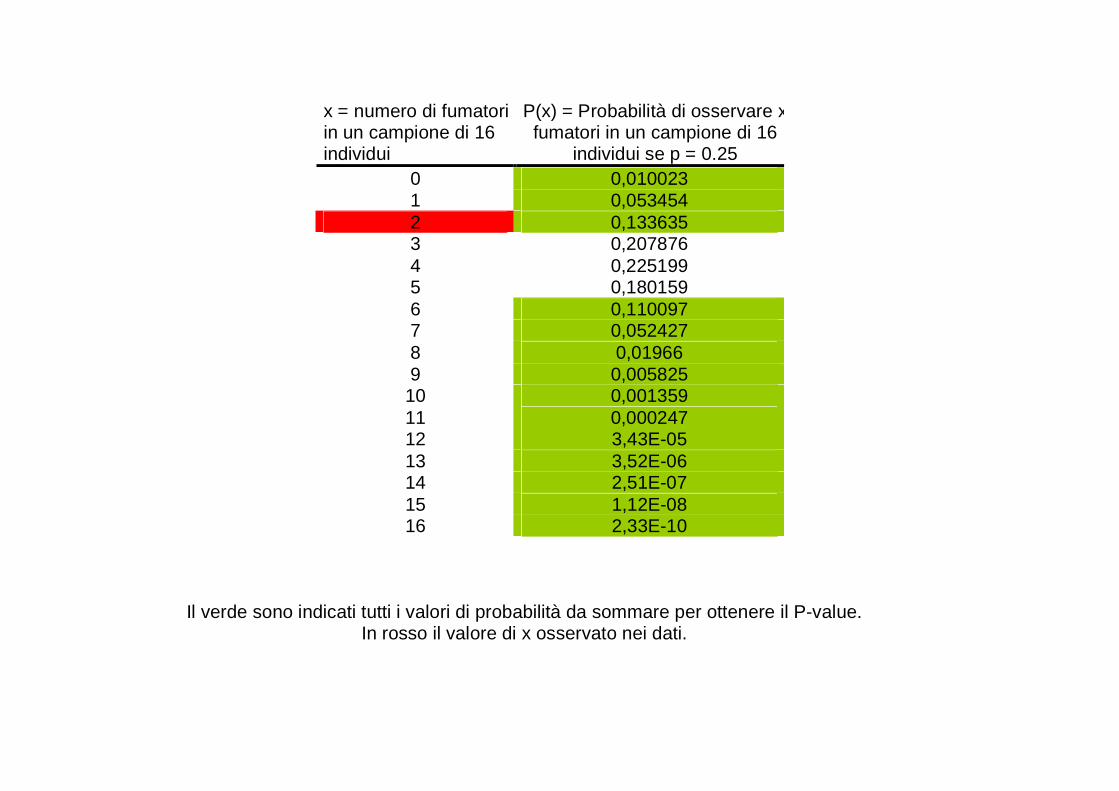
x = numero di fumatori in un campione di 16 individui
P(x) = Probabilità di osservare x fumatori in un campione di 16
individui se p = 0.25 0 0,010023 1 0,053454 2 0,133635 3 0,207876 4 0,225199 5 0,180159 6 0,110097 7 0,052427 8 0,01966 9 0,005825 10 0,001359 11 0,000247 12 3,43E-05 13 3,52E-06 14 2,51E-07 15 1,12E-08 16 2,33E-10
Il verde sono indicati tutti i valori di probabilità da sommare per ottenere il P-value. In rosso il valore di x osservato nei dati.

� Il P-value risulta quindi pari a 0.387. Essendo minore di α = 0.05, rifiutiamo l’ipotesi nulla
o Ovviamente le conclusioni ottenute calcando il P-value sono le stesse di quelle viste con l’approccio delle regioni di accettazione rifiuto
� Un modo più semplice anche se le meno preciso per calcolare il P-value consiste nel
calcolare la probabilità che il valore di x sia più estremo del valore osservato nella coda della distribuzione, e moltiplicare questo valore per 2
o Nel nostro caso, questo significa sommare le prime tre probabilità nella tabella
precedente e moltiplicare per 2:
� P-value = 2x(0.010023+0.053454+0.133635) = 0.394 � Questo valore è leggermente superiore al valore calcolato nella forma più
precisa. L’approssimazione è quindi conservativa
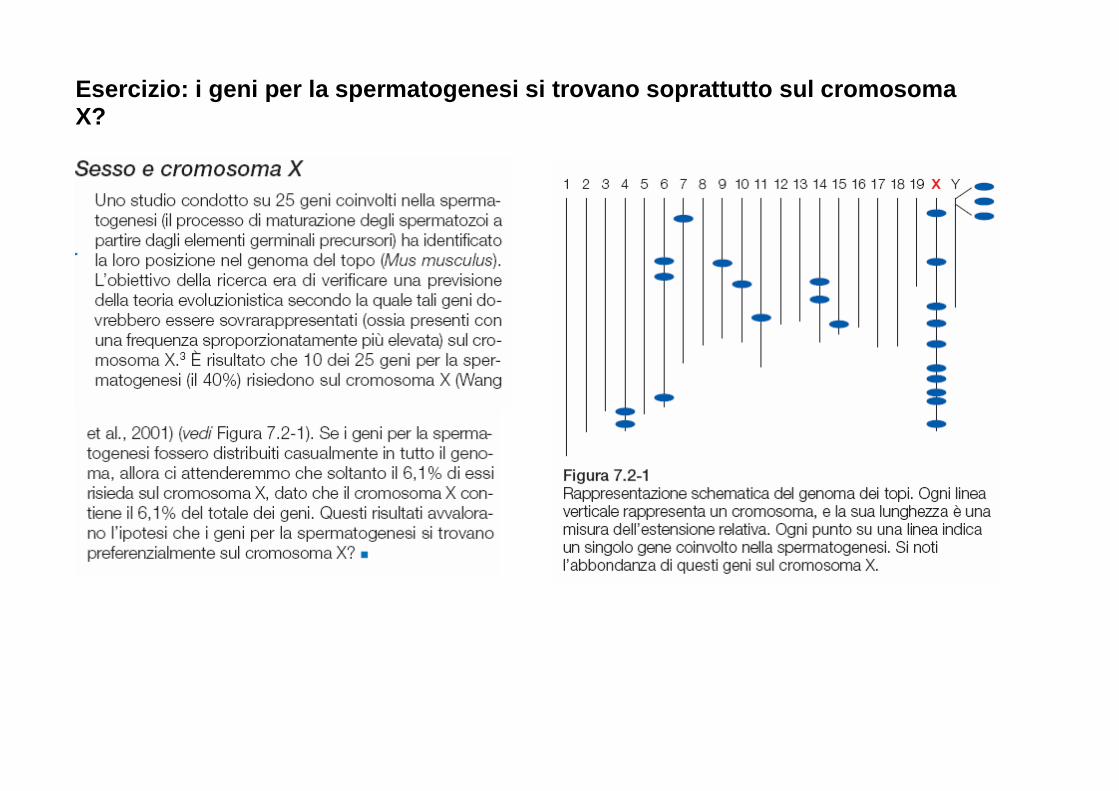
Esercizio: i geni per la spermatogenesi si trovano soprattutto sul cromosoma X?
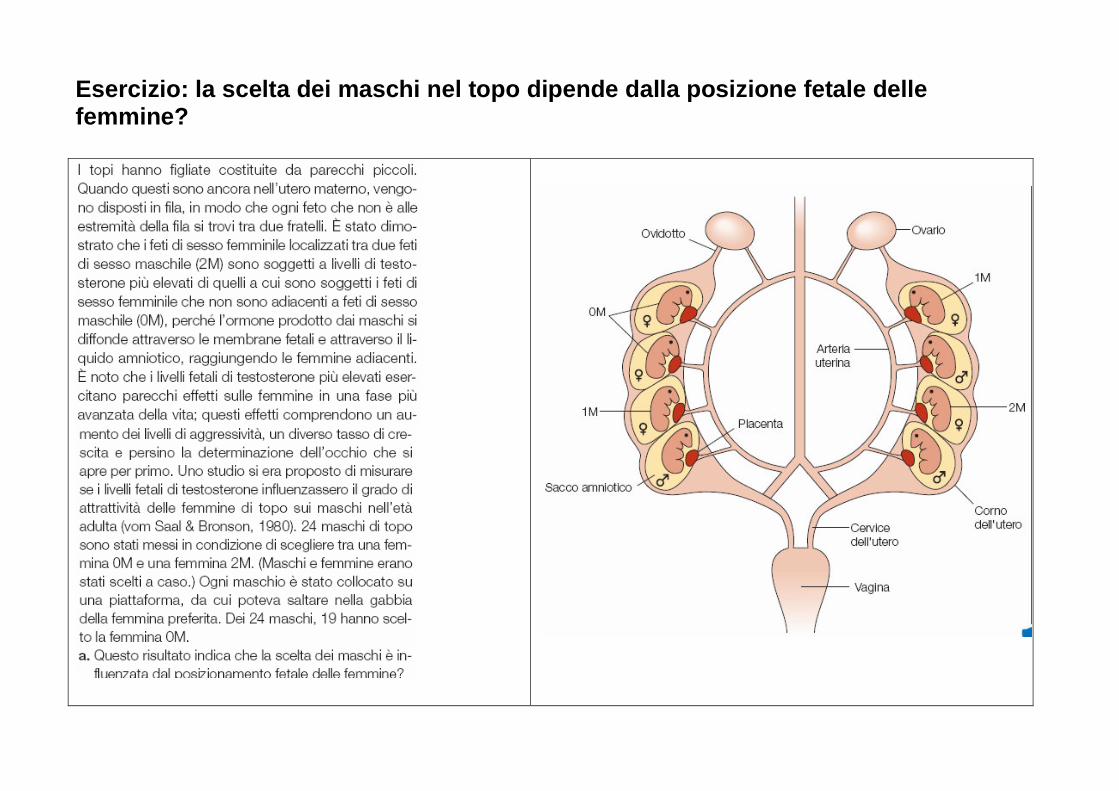
Esercizio: la scelta dei maschi nel topo dipende da lla posizione fetale delle femmine?

Test di adattamento di una distribuzione di frequen za osservata alla distribuzione binomiale (è un test di goodness-of-f it)

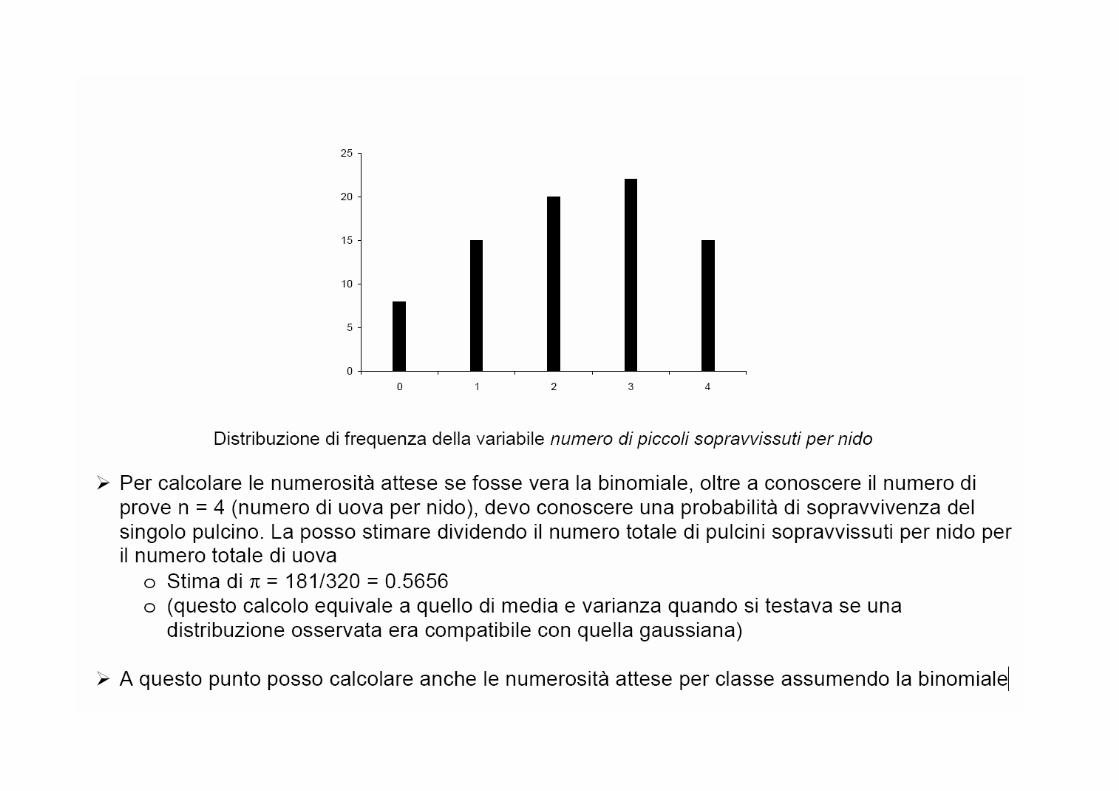
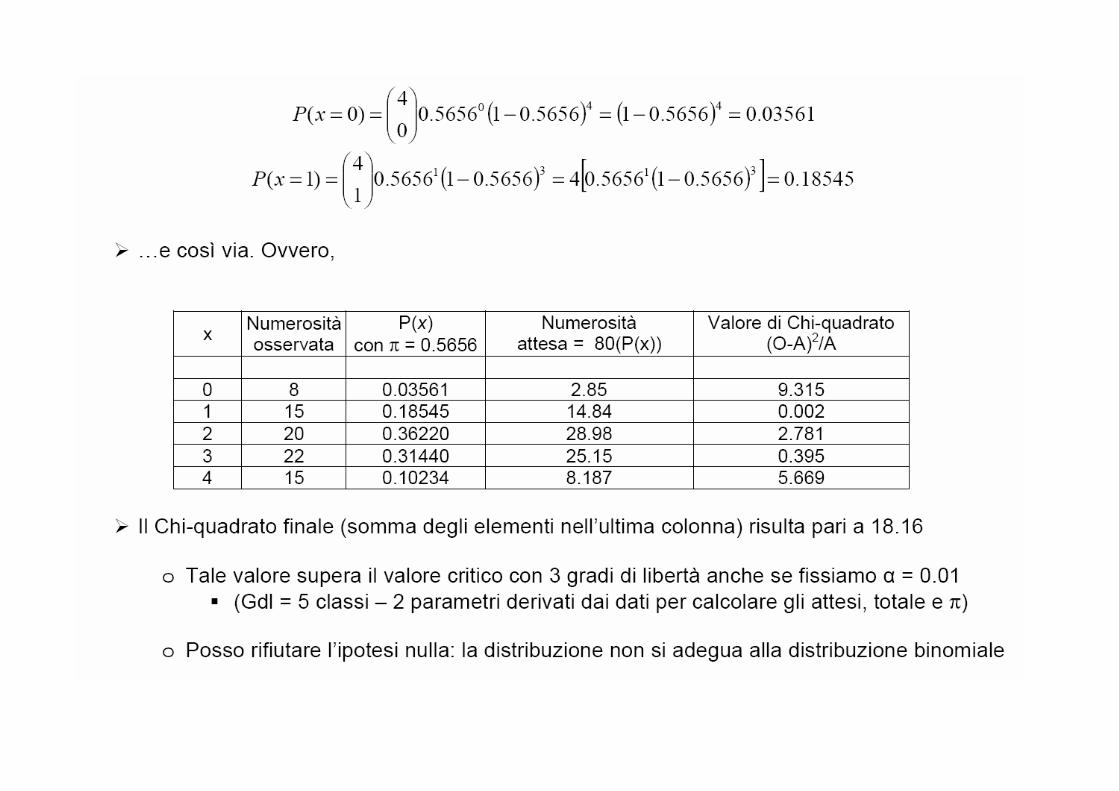
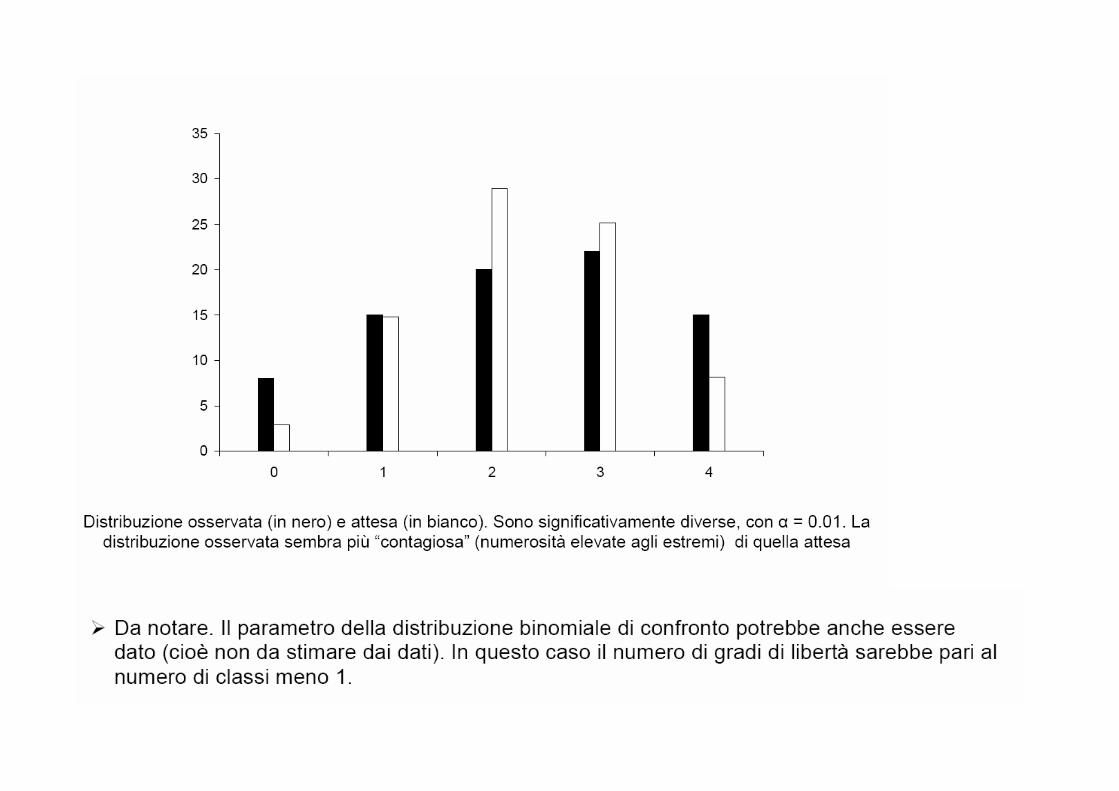

Ulteriori esempi sulla bontà di adattamento di una distribuzione osservata alla binomiale
Esempio 1 La mortalità in pesci in acquario dipende soprattutto dal caso (la scelta casuale di che pesce finisce in quale acquario, e altri eventi che agiscono con uguale probabilità su ciascun pesce) o forse dalla diffusione di malattie contagiose?
� In 60 acquari vengono inseriti 6 pesci di una certa specie, scelti a caso da una vasca grande. Da quel momento in poi, non si interviene più sugli acquari e dopo un mese si contano i pesci sopravvissuti per ogni vasca. I risultati, come numero di vasche con 0,1,2,3,4,5,6 pesci sopravvissuti, è il seguente: 6,6,12,15,8,7,6.
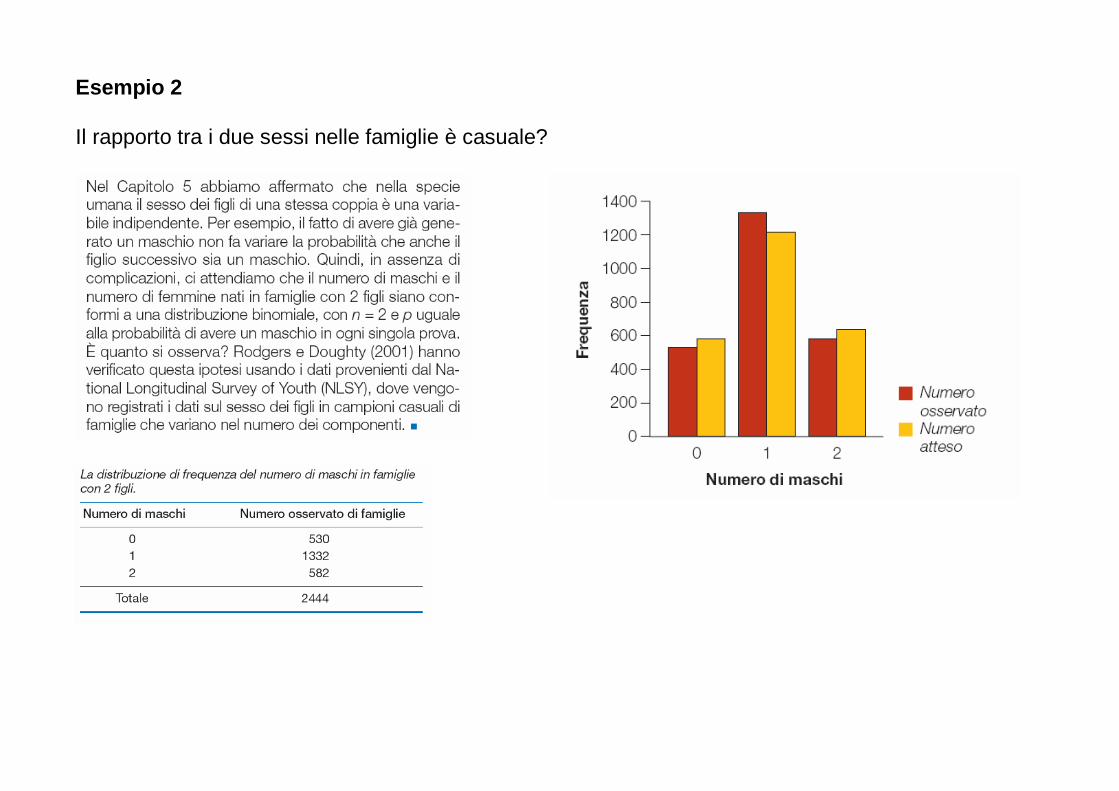
Esempio 2 Il rapporto tra i due sessi nelle famiglie è casuale?
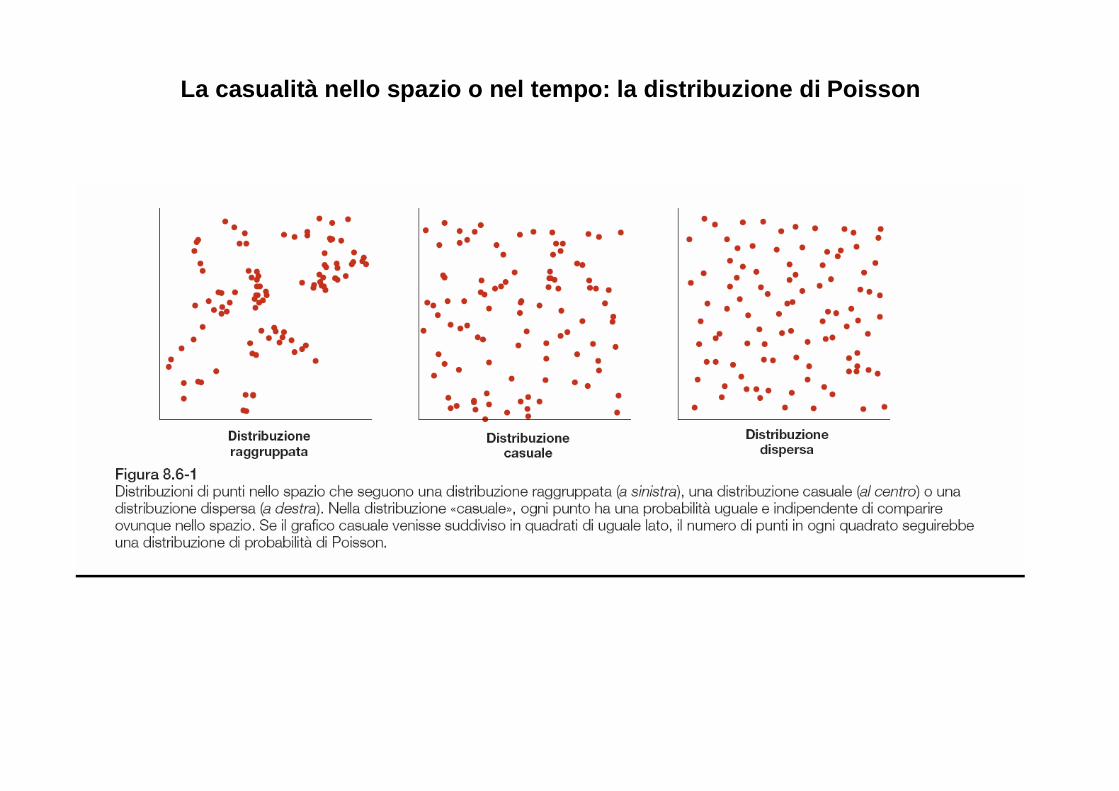
La casualità nello spazio o nel tempo: la distribuz ione di Poisson

� Cosa potrebbero rappresentare questi punti?
o Organismi o eventi presenti in una certa area � Per esempio, ci interessa capire come avviene un processo di colonizzazione � Per esempio, ci interessa capire se gli avvistamenti di una specie sono distribuiti
casualmente nello spazio geografico
� Potrebbero essere anche osservazioni lungo una linea, un volume, o nel tempo � Per esempio, ci interessa studiare il posizionamento di uccelli lungo il filo della luce � Per esempio, ci interessa capire se esistono disomogeneità non casuali in volumi � Per esempio, ci interessa capire come sono distribuiti nel tempo eventi di estinzione,
mutazioni, incidenti, avvistamenti, ecc.
� Ma possiamo anche pensare all’esempio visto con i nidi e gli uccellini sopravvissuti se i singoli nidi non avessero lo stesso n, ovvero lo stesso valore massimo per la variabile o Lo spazio qui è rappresentato dall’insieme di tutti i nidi

� In pratica, consideriamo per esempio una situazione nella quale l’interesse è rivolto verso la posizione di un certo numero di organismi in una certa area, e suddividiamo l’area in sotto-aree uguali
ORA:
� se la probabilità di presenza di un individuo è la stessa in ogni infinitesimo punto dello spazio, e
� se il fatto che ci sia un individuo in un infinitesimo punto dello spazio non modifica la probabilità che ce ne sia un altro nello stesso punto o nelle vicinanze
� allora la distribuzione di frequenza del numero di individui osservati in un campione di sotto-
aree uguali definite nell’area studiata tenderà alla distribuzione di Poisson

� La distribuzione di Poisson ha la seguente funzione
dove X è la variabile numero di osservazioni per sotto-area, λ è il numero medio di individui per sotto-area, ed e è la base dei logaritmi naturali. � E’ una distribuzione discreta � E’ il limite della distribuzione binomiale quando n tende ad infinito e π tende a 0
o Immaginiamo che ogni sotto-area sia composta da infinite posizioni dove si può trovare un individuo, e che in ciascuna di queste infinite posizioni ipotetiche si possa al massimo osservare un solo individuo e con probabilità bassissima.
� Varia tra 0 e infinito � E’ definita da un solo parametro, la media λ � Si può approssimare con la distribuzione gaussiana per valori di λ non troppo piccoli (>10), sempre facendo attenzione che la gaussiana è continua e Poisson è discreta
E’ fondamentale capire l’analogia delle sotto-aree con frazioni di una curva o di una retta, con porzioni di volume o con intervalli di tempo
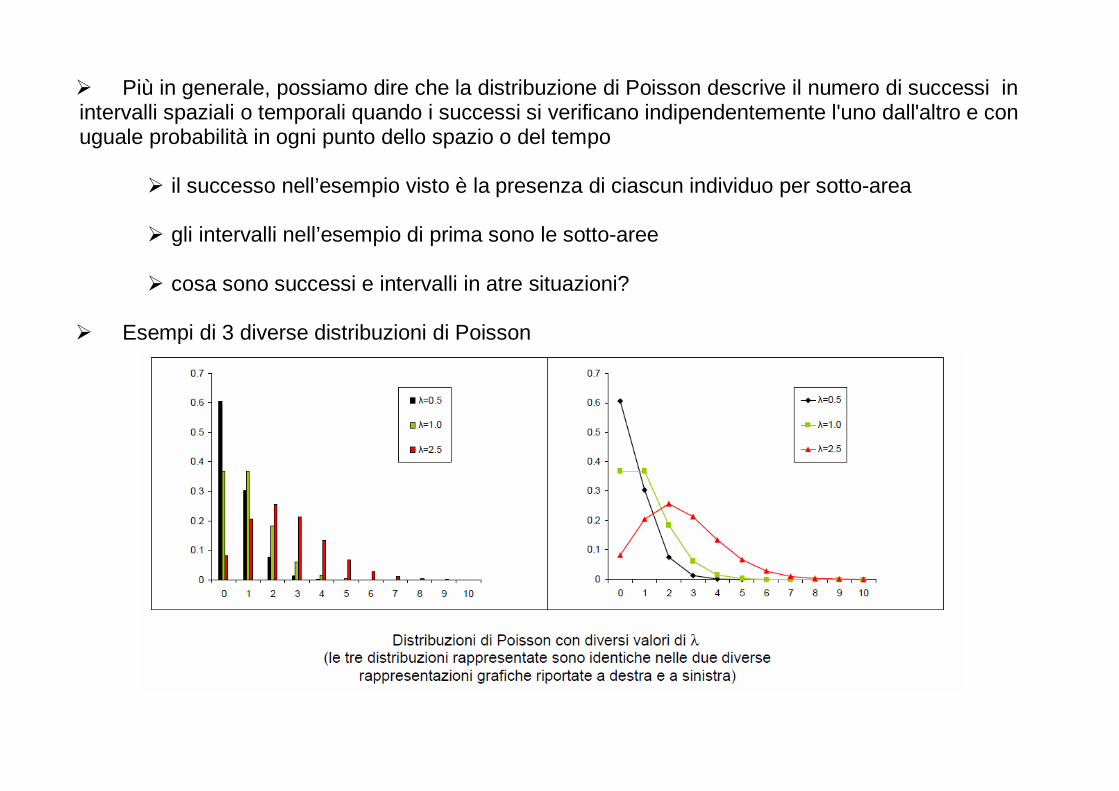
� Più in generale, possiamo dire che la distribuzione di Poisson descrive il numero di successi in intervalli spaziali o temporali quando i successi si verificano indipendentemente l'uno dall'altro e con uguale probabilità in ogni punto dello spazio o del tempo
� il successo nell’esempio visto è la presenza di ciascun individuo per sotto-area
� gli intervalli nell’esempio di prima sono le sotto-aree
� cosa sono successi e intervalli in atre situazioni?
� Esempi di 3 diverse distribuzioni di Poisson
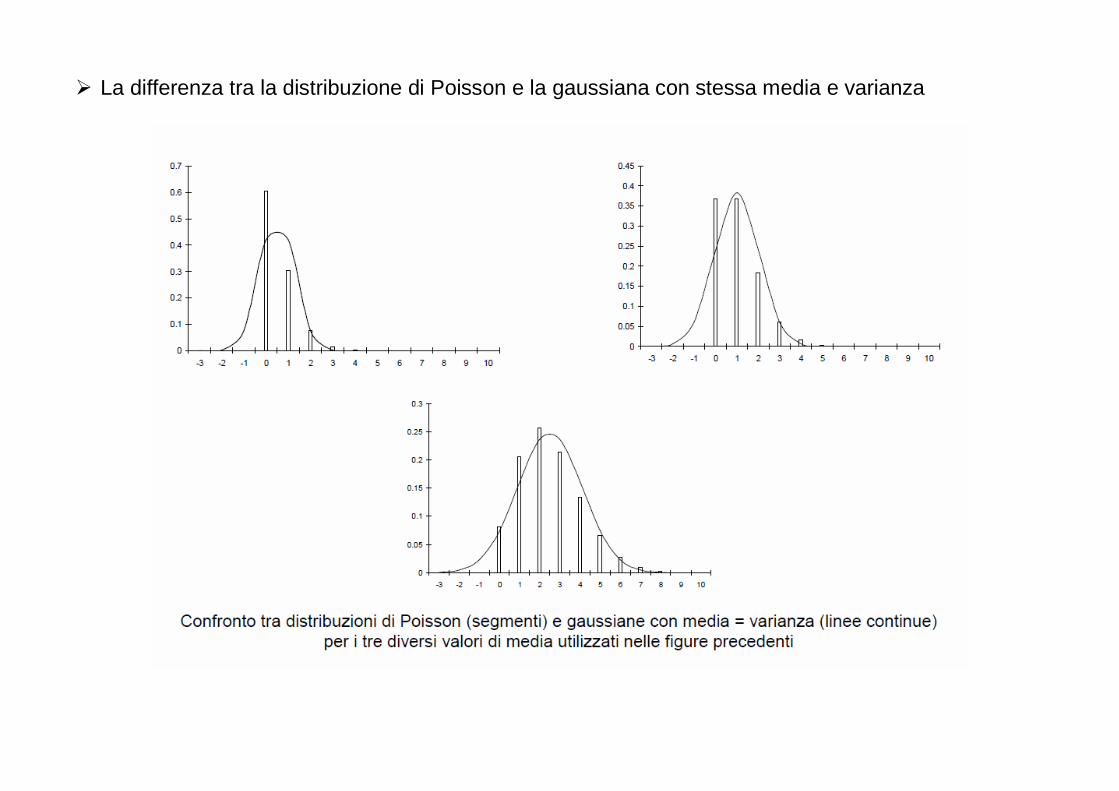
� La differenza tra la distribuzione di Poisson e la gaussiana con stessa media e varianza

� Altre variabili che dovrebbero seguire la distribuzione di Poisson se intervenisse solo il caso nel definire il valore che assume la variabile in diverse osservazioni
o numero di semi di una pianta infestante per unità di volume di terriccio in vendita o numero di mutazioni per intervallo di tempo o numero di casi di influenza in un paese per settimana o numero di incidenti stradali mortali al mese in una città o numero di figli per individuo o numero di pezzi difettosi al giorno, o all'ora, prodotti da una fabbrica
� Quali sarebbero in questi casi le diverse osservazioni?
o un certo numero di unità di volume di terriccio o un certo numero di intervalli di tempo o un certo numero di settimane nelle quali sono stati registrati i casi di influenza o Ecc.

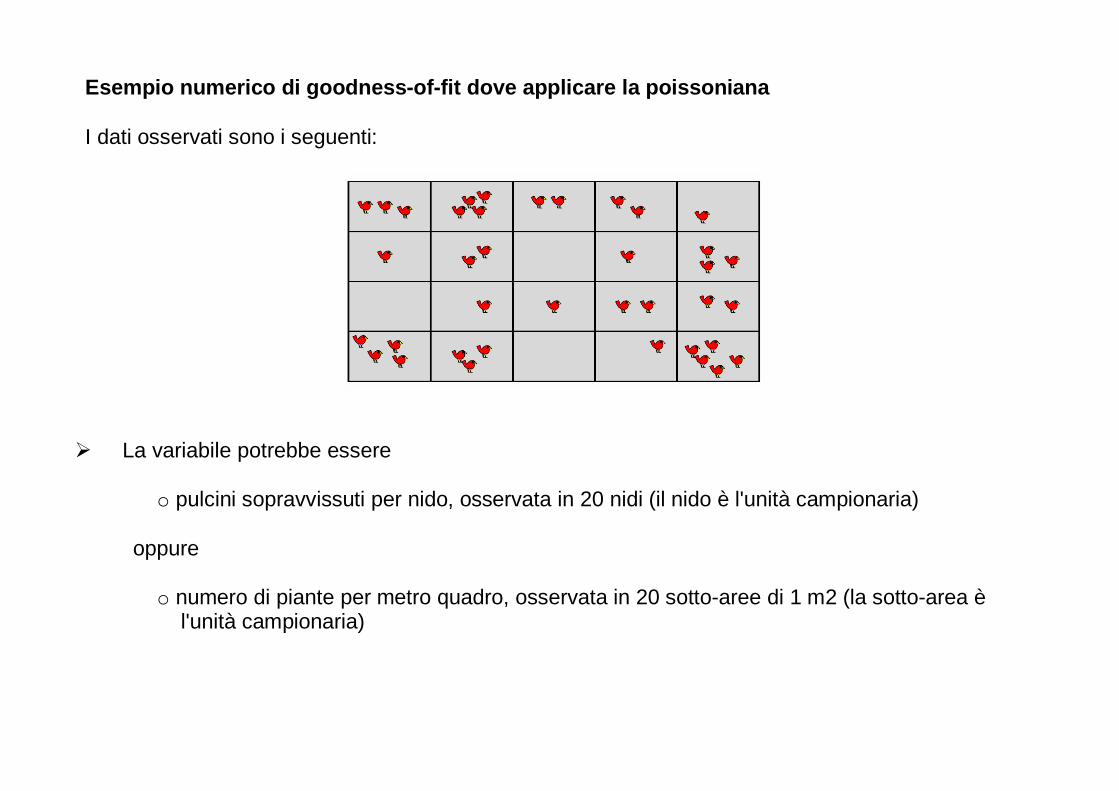
Esempio numerico di goodness-of-fit dove applicare la poissoniana I dati osservati sono i seguenti:
� La variabile potrebbe essere
o pulcini sopravvissuti per nido, osservata in 20 nidi (il nido è l'unità campionaria) oppure o numero di piante per metro quadro, osservata in 20 sotto-aree di 1 m2 (la sotto-area è
l'unità campionaria)
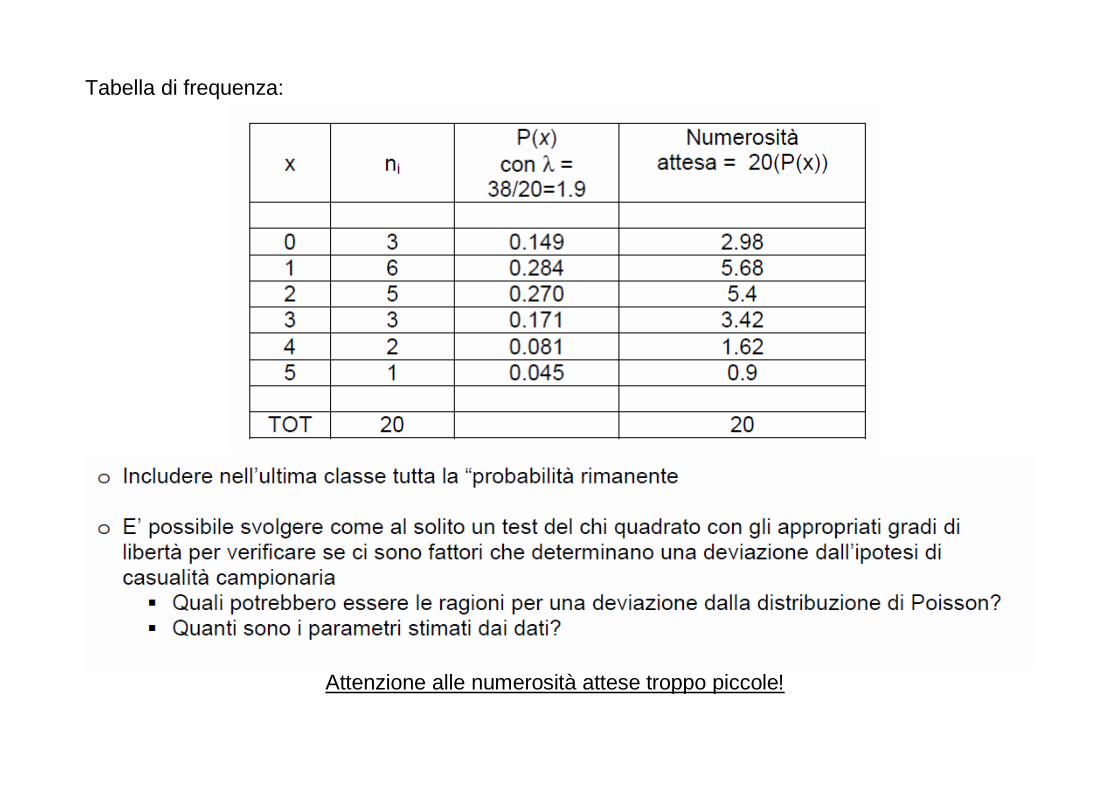
Tabella di frequenza:
Attenzione alle numerosità attese troppo piccole!

Altro esempio di goodness-of-fit test con la poisso niana
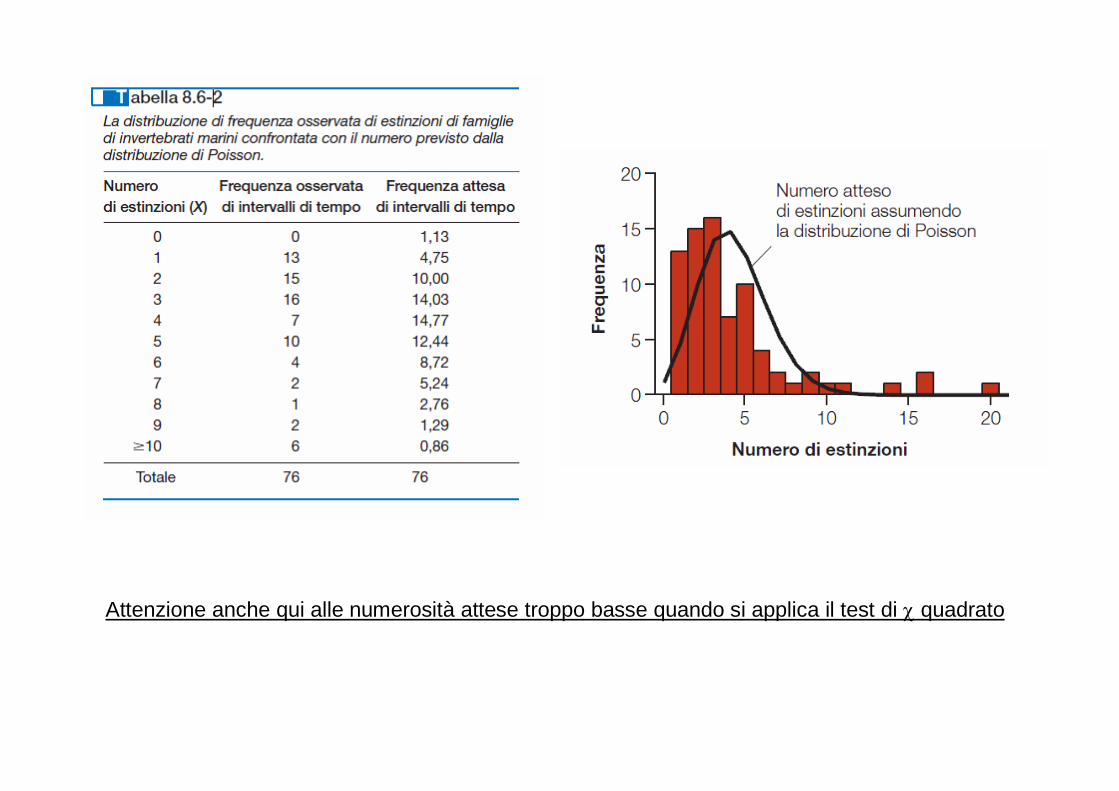
Attenzione anche qui alle numerosità attese troppo basse quando si applica il test di χ quadrato




IL CONFRONTO TRA LE VARIANZE DI DUE POPOLAZIONI
Perchè confrontare le varianze stimate in due campioni? Torniamo all'esempio dei frinosomi
Per poter applicare il test t avevamo detto che le varianze, e quindi le deviazioni standard, nelle due popolazioni (frinosomi vivi e frinosomi uccisi) devono essere uguali. Adesso vediamo come testare questa ipotesi

Le ipotesi nulla e alternativa possono essere formalizzate come segue
Come abbiamo sempre fatto in tutti i test statistici, dobbiamo trovare una statistica test la cui distribuzione teorica è nota quando è vera l'ipotesi nulla o Per esempio, per testare l'ipotesi nulla di uguaglianza tra due medie usavamo le
statistiche test z o t, le cui distribuzioni nulle sono note in certe condizioni
o Oppure, per testare se una proporzione si discosta da un valore previsto, e non si poteva usare il chi-quadrato o z, avevamo usato come statistica test il numero di individui con la caratteristica di interesse, la cui distribuzione nulla è la distribuzione binomiale
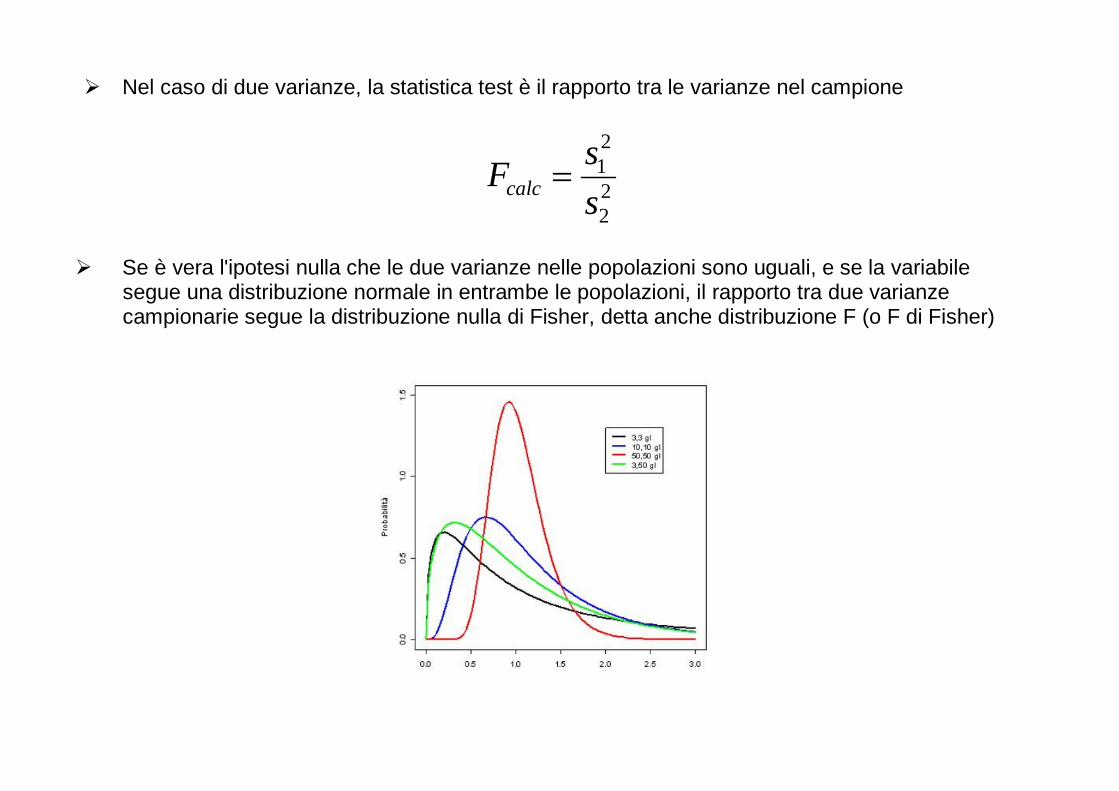
Nel caso di due varianze, la statistica test è il rapporto tra le varianze nel campione
22
21
ssFcalc
Se è vera l'ipotesi nulla che le due varianze nelle popolazioni sono uguali, e se la variabile
segue una distribuzione normale in entrambe le popolazioni, il rapporto tra due varianze campionarie segue la distribuzione nulla di Fisher, detta anche distribuzione F (o F di Fisher)

La distribuzione teorica F:
o E' continua o Varia tra zero e infinito o Dipende dai gradi di libertà del numeratore (gdl1 = n1-1) e quelli del denominatore (gdl2 =
n2-1) o E' circa centrata sul valore 1 o Ci permette di definire le regioni di accettazione/rifiuto o il P-value per il nostro test sulle
varianze

Tabella della distribuzione F a una coda con α = 0.01 Le colonne identificano i gdl al numeratore. Le righe i gdl al denominatore.
I numeri interni alla tabella identificano i valori della statistica F che separano, alla loro destra, l’1% dell’area distributiva.
Attenzione! La struttura di questa tabella è diversa da tutte quelle viste finora (ci sono due gradi di libertà da conoscere in ogni analisi, e c'e' una tabella per ogni valore di P)

Praticamente, visto che la distribuzione F è asimmetrica, e le tabelle dei valori critici riportati in tabella si riferiscono al lato destro della distribuzione, conviene sempre mettere a numeratore nel calcolo di F dai dati (Fcalc) la varianza maggiore

Il valore F critico con 9 e 8 gradi di libertà (9 al numeratore e 8 al denominatore), con = 0.05 e quindi /2 = 0.025, è pari a 4.36
o Non ci sono evidenze per rifiutare l'ipotesi nulla
o Le varianze calcolate dai campioni sono compatibili con l'ipotesi nulla che i campioni provengano da popolazioni con varianze uguali
o Se dovessi confrontare le medie dei due campioni, il test t sarebbe appropriato
Il calcolo del P-value richiede un computer o Oppure, almeno per approssimarlo e definire un intervallo in cui cade, tante tabelle
ognuna per diversi valori di probabilità
Esempio con i frinosomi: le varianze erano significativamente diverse?

L'ANALISI DELLA VARIANZA (ANOVA)
L'ANOVA è un metodo molto potente e flessibile per valutare le medie di più di due popolazioni con una singola analisi
E' quindi un metodo per studiare variabili quantitative Attenzione! L'ipotesi nulla riguarda medie, ma viene testata confrontando varianze

Un esempio con dati sperimentali: la variabile altezza viene misurata in individui suddivisi in 4 gruppi; i gruppi sono sottoposti a diversi trattamenti per il fattore ph
Un esempio con dati osservazionali: la variabile peso viene misurata in individui che provengono da 4 gruppi; i 4 gruppi differiscono per il fattore origine geografica

Ipotesi nulla e alternativa nell'ANOVA
Ovviamente l'ANOVA si applica nello stesso modo a 2,3,4,5,...k gruppi
o Per k = 2, equivale a svolgere un test t
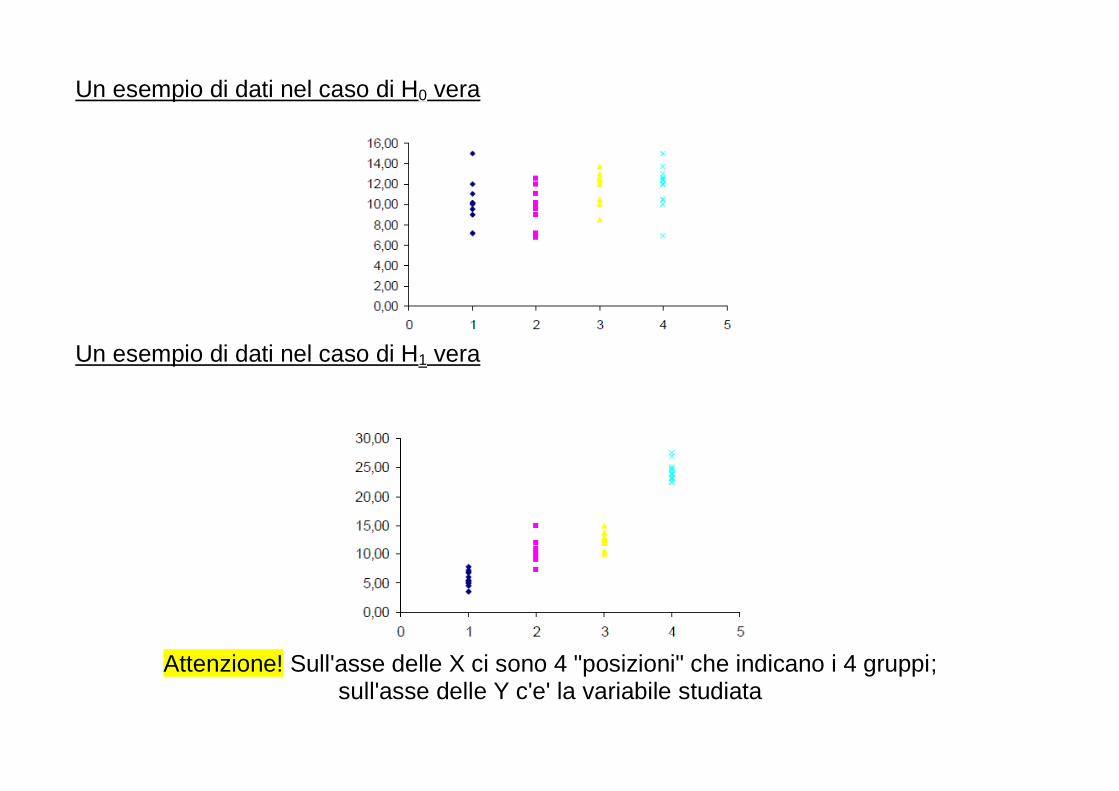
Un esempio di dati nel caso di H0 vera
Un esempio di dati nel caso di H1 vera
Attenzione! Sull'asse delle X ci sono 4 "posizioni" che indicano i 4 gruppi;
sull'asse delle Y c'e' la variabile studiata


Prima di vedere come si procede nell'ANOVA, vediamo perchè svolgere un'ANOVA Per esempio, con 3 popolazioni da confrontare (per esempio, tre livelli di pH) non potrei semplicemente fare 3 test t? O con 4 popolazioni 6 test t?
o Come si calcola il numero di test a coppie? No, perchè
1. Sembra logico prima di tutto testare l'ipotesi nulla che prevede che tutti i gruppi siano uguali 2. Non posso semplicemente fare tanti test t perchè aumenterebbe molto l'errore complessivo di primo tipo
Il problema dei test multipli e l'errore complessivo di primo tipo Se scegliamo in un singolo test un livello di significatività , sappiamo che esiste una probabilità di rifiutare un'ipotesi nulla vera (errore di primo tipo) Questo significa anche che se facciamo 100 test nei quali l'ipotesi nulla è sempre vera, 5 volte (mediamente) la rifiutiamo erroneamente

Qual'è la probabilità che facendo c test di ipotesi nulle vere almeno uno risulti significativo per puro effetto del caso?
o Se l'ipotesi nulla è vera, la probabilità che un test singolo non porti al suo rifiuto è pari a (1-è il livello di protezione in un singolo test
o Se l'ipotesi nulla è vera, la probabilità che non venga mai rifiutata in c test è pari a (1-)c Sono eventi indipendenti e vale la regola del prodotto delle probabilità
o Quindi, 1-(1-)c è la probabilità che cerchiamo: la probabilità che uno o più dei c test (cioè,
almeno uno) sia significativo anche se l'ipotesi nulla è sempre vera

Gli esempi citati sono casi ANOVA unifattoriale e univariata
o C'era un fattore (per esempio, pH) e una variabile (per esempio, altezza)
L'ANOVA può anche essere multifattoriale (più fattori) e/o multivariata (più variabili) o Vedremo alcuni cenni di analisi bifattoriale univariata alla fine del corso

COME FUNZIONA L'ANOVA A UN FATTORE: SI CONFRONTANO TANTE MEDIE SCOMPONENDO LA VARIABILI TA' TOTALE
� Per testare l'ipotesi nulla che la media di una variabile in k popolazioni sia la stessa, si suddivide
la variabilità totale della variabile (ecco perchè si chiama ANOVA...)
� La variabilità totale viene suddivisa in due componenti:
1. La variabilità all'interno dei gruppi
2. La variabilità tra i gruppi
� Per vedere questa scomposizione, definiamo prima le medie dei k gruppi con i simboli
kyyy ,....., 21 . Sono semplicemente le medie calcolate in ogni gruppo.
� Definiamo anche la media generale con y . E' semplicemente la media calcolata mettendo insieme tutti i dati di tutti i gruppi
o Attenzione! y non è la media delle k medie calcolate nei singoli gruppi.
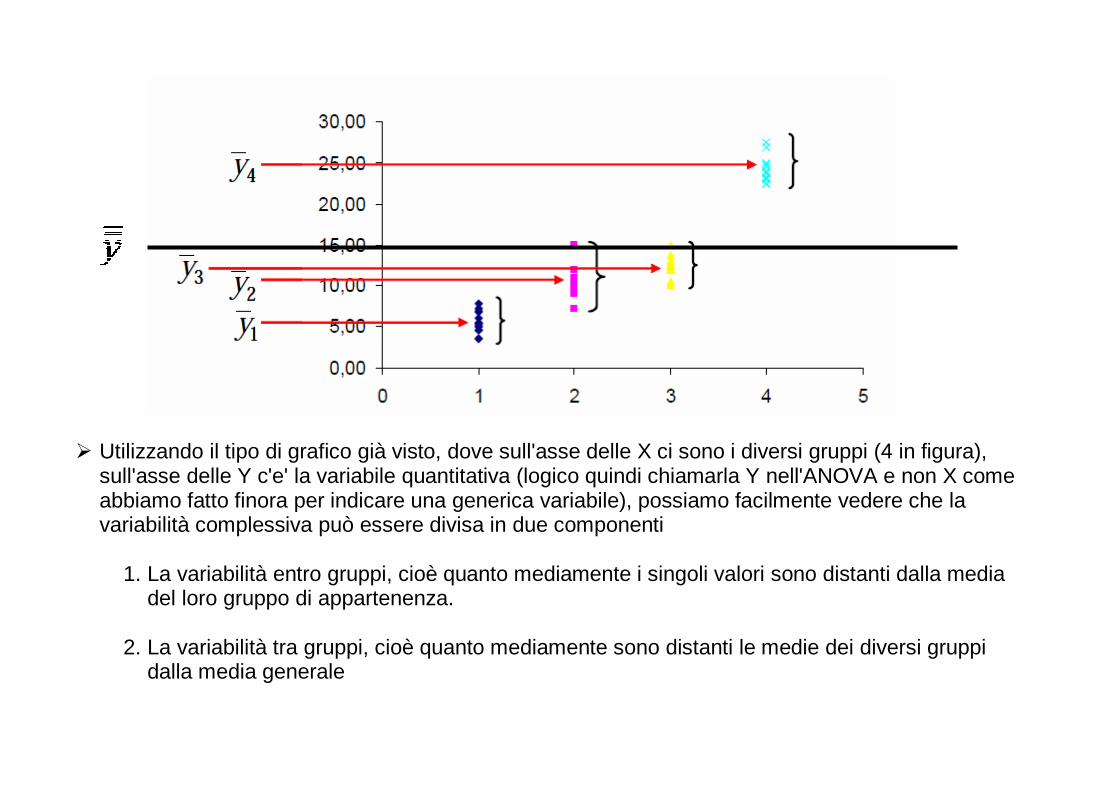
� Utilizzando il tipo di grafico già visto, dove sull'asse delle X ci sono i diversi gruppi (4 in figura), sull'asse delle Y c'e' la variabile quantitativa (logico quindi chiamarla Y nell'ANOVA e non X come abbiamo fatto finora per indicare una generica variabile), possiamo facilmente vedere che la variabilità complessiva può essere divisa in due componenti
1. La variabilità entro gruppi, cioè quanto mediamente i singoli valori sono distanti dalla media del loro gruppo di appartenenza.
2. La variabilità tra gruppi, cioè quanto mediamente sono distanti le medie dei diversi gruppi dalla media generale
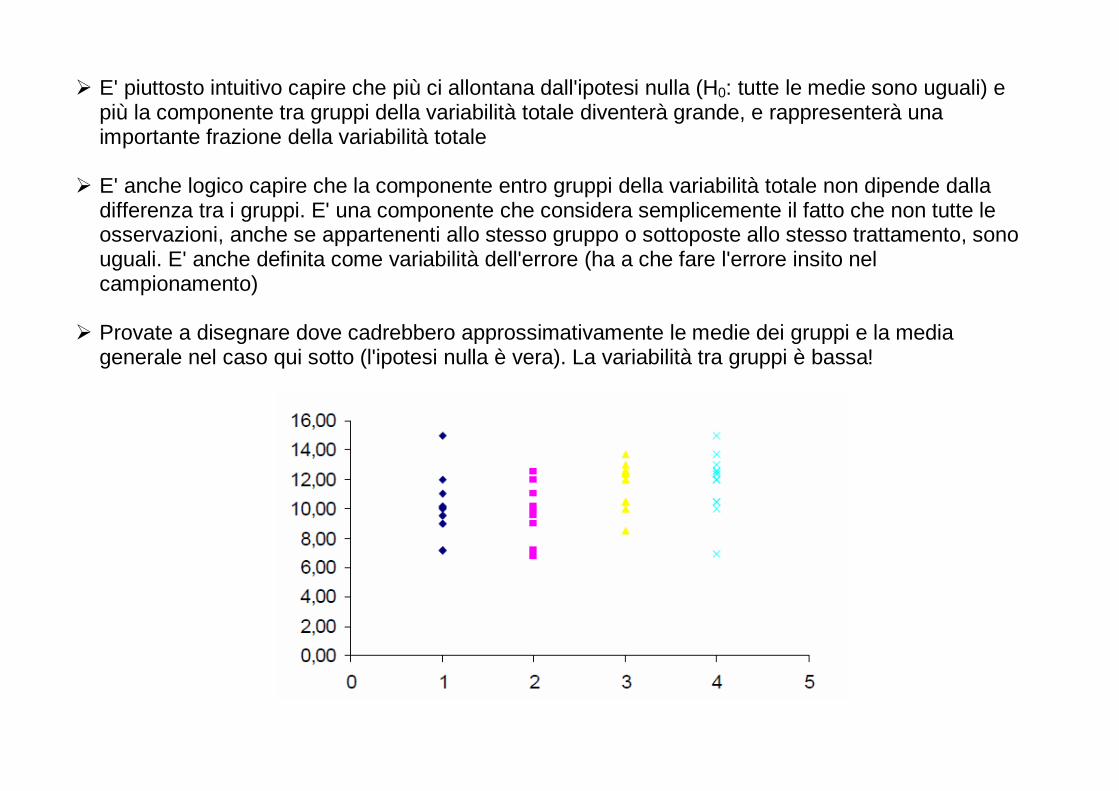
� E' piuttosto intuitivo capire che più ci allontana dall'ipotesi nulla (H0: tutte le medie sono uguali) e più la componente tra gruppi della variabilità totale diventerà grande, e rappresenterà una importante frazione della variabilità totale
� E' anche logico capire che la componente entro gruppi della variabilità totale non dipende dalla differenza tra i gruppi. E' una componente che considera semplicemente il fatto che non tutte le osservazioni, anche se appartenenti allo stesso gruppo o sottoposte allo stesso trattamento, sono uguali. E' anche definita come variabilità dell'errore (ha a che fare l'errore insito nel campionamento)
� Provate a disegnare dove cadrebbero approssimativamente le medie dei gruppi e la media
generale nel caso qui sotto (l'ipotesi nulla è vera). La variabilità tra gruppi è bassa!

� La componente della variabilità entro gruppi viene definita nell'ANOVA come media dei quadrati
degli errori (MSE: Mean Square Error). E' semplicemente la media pesata delle varianze calcolate all'interno dei gruppi, ovvero un'estensione a k gruppi della varianza comune già vista nel test (dove k=2). E' quindi una varianza, chiamata anche varianza dell'errore. Noi la chiameremo con l'acronimo inglese MSE.
( )
( )
( )
kn
sn
n
snMSE
T
i
k
ii
k
ii
i
k
ii
−
−
=
−
−
=∑
∑
∑=
=
=
2
1
1
2
1
1
1
1
� ni è la numerosità dell'i-esimo gruppo, nT è la numerosità totale (somma di tutti gli ni)
� Il numeratore di MSE viene chiamato SSE, o somma dei quadrati dell'errore, o anche devianza dell'errore
� Il denominatore di MSE rappresenta i gradi di libertà di questa componente della variabilità totale

� La componente della variabilità tra gruppi viene definita nell'ANOVA come media dei quadrati tra
gruppi (MSB: Mean Square Between groups). Dipende da quanto sono distanti le medie dei gruppi dalla media generale, ma considera anche le numerosità dei singoli gruppi. E' anche questa una varianza, chiamata anche varianza tra gruppi. La chiameremo con l'acronimo inglese MSB
( )1
2
1
−
−
=∑=
k
yynMSB
k
iii
� Il numeratore di MSB viene chiamato SSB, o somma dei quadrati tra gruppi, o anche devianza tra gruppi
� Il denominatore di MSB rappresenta i gradi di libertà di questa componente della variabilità totale (ci sono k gruppi, e quindi k-1 gradi di libertà)

� Come già detto, più ci si allontana dall'ipotesi nulla e più tende a crescere la componente della variabilità tra gruppi. Quindi, più ci si allontana dall'ipotesi nulla e più MSB tende a crescere.
� E' possibile dimostrare che quando è vera l'ipotesti nulla MSB tende ad essere uguale MSE (si veda approfondimento alla fine di questo file pdf)
� Ovviamente, se è vera l'ipotesi alternativa (almeno una media è diversa dalla altre), MSB sarà maggior di MSE (mai minore)
� Poichè sia MSB che MSE sono due varianze, e il valore di MSB/MSE atteso quando è vera l'ipotesi nulla è 1, è chiaro che l'F di Fisher è la statistica test adatta all'ANOVA
� In altre parole, dopo aver calcolato MSB e MSE, posso calcolare
MSE
MSBFcalc =
e utilizzare la distribuzione di Fisher per verificare l'ipotesi nulla µ1 = µ2 = µ3 = µ4 = ....µk Attenzione! Come abbiamo detto più volte, l'ipotesi alternativa (almeno una media è diversa) prevede la deviazione di F solo verso valori >1 (cioè MSB>MSE). Quindi, anche se l'ipotesi alternativa nell' l'ANOVA non è unidirezionale, prevede deviazioni solo in una direzione della distribuzione nulla di Fisher.
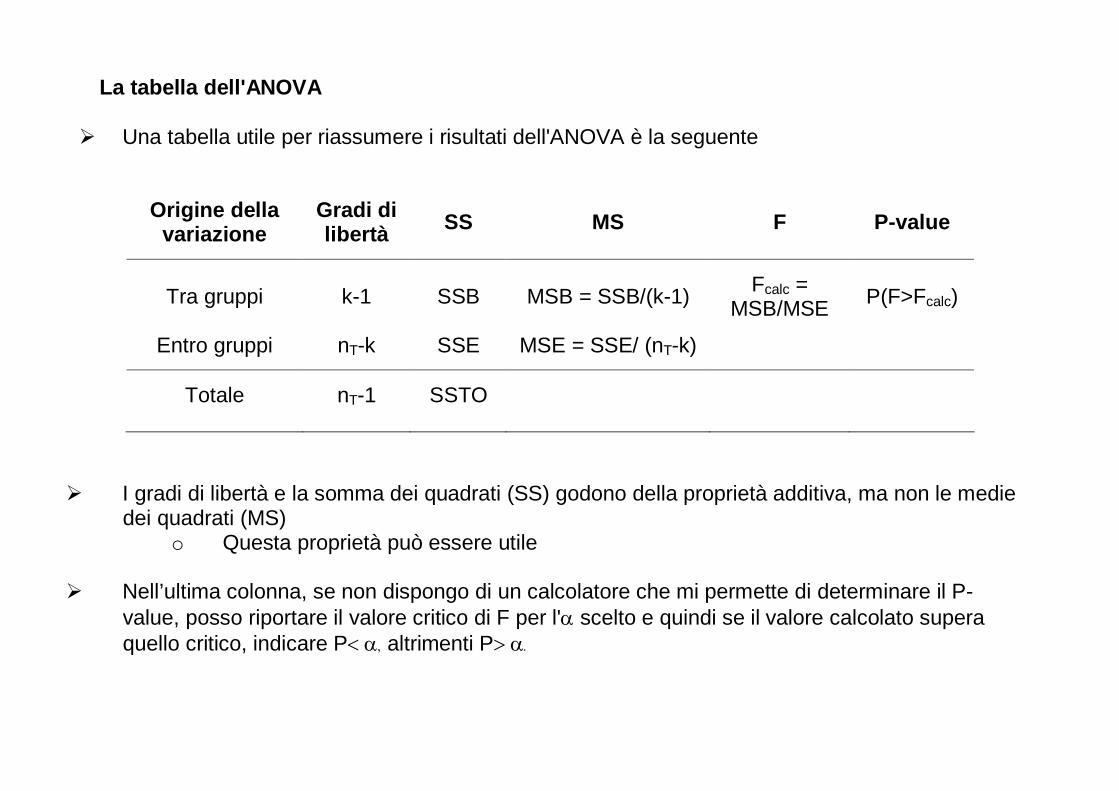
La tabella dell'ANOVA
� Una tabella utile per riassumere i risultati dell'ANOVA è la seguente
Origine della variazione
Gradi di libertà
SS MS F P-value
Tra gruppi k-1 SSB MSB = SSB/(k-1) Fcalc =
MSB/MSE P(F>Fcalc)
Entro gruppi nT-k SSE MSE = SSE/ (nT-k)
Totale nT-1 SSTO
� I gradi di libertà e la somma dei quadrati (SS) godono della proprietà additiva, ma non le medie
dei quadrati (MS) o Questa proprietà può essere utile
� Nell’ultima colonna, se non dispongo di un calcolatore che mi permette di determinare il P-
value, posso riportare il valore critico di F per l'α scelto e quindi se il valore calcolato supera quello critico, indicare P< α, altrimenti P> α.

ESEMPIO DI ANOVA CON k = 3
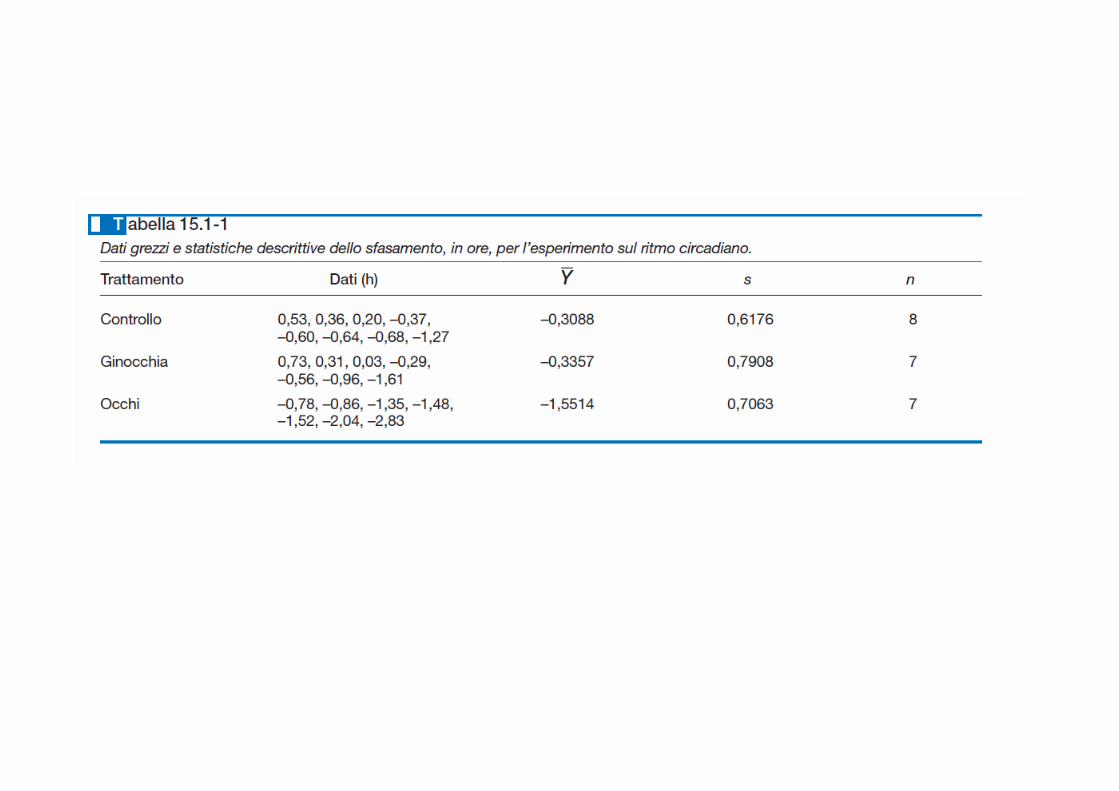
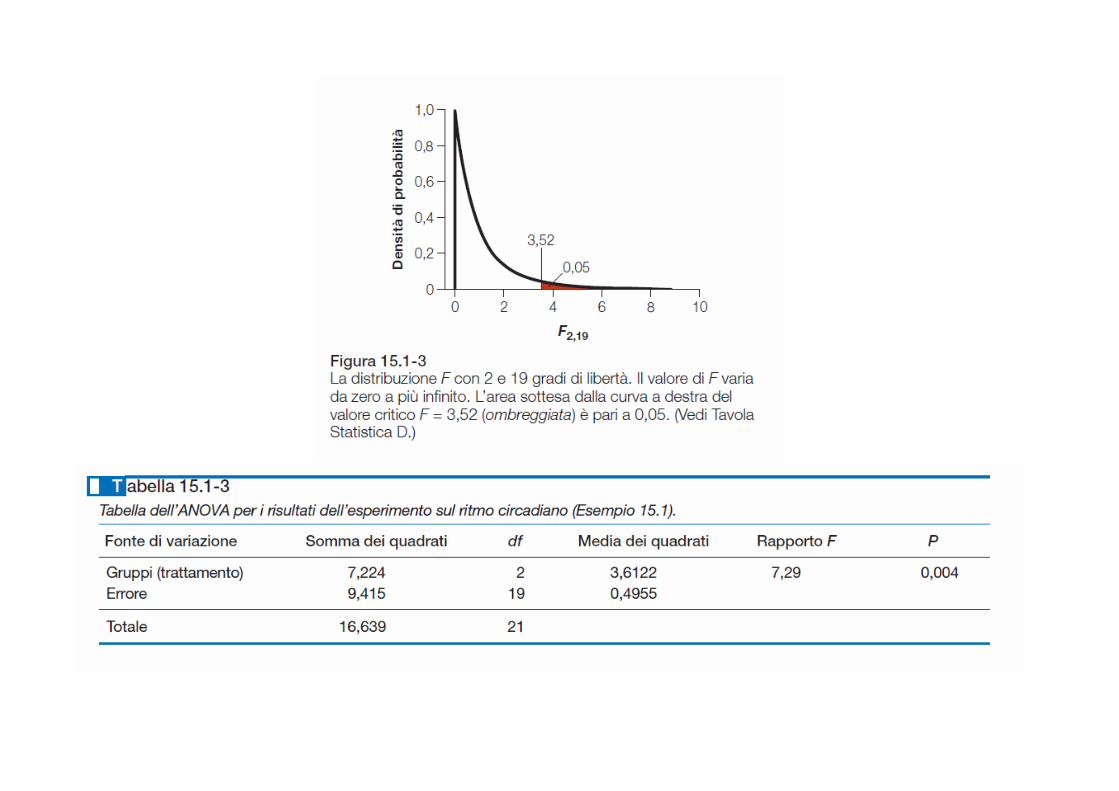

APPROFONDIMENTO: PERCHE' MSE E MSB DOVREBBERO ESSERE UGUALI QUANDO
E' VERA L'IPOTESI NULLA NELL'ANOVA? � Quando è vera l'ipotesi nulla nell'ANOVA, ovvero quando le medie in tutte le popolazioni da cui ho estratto campioni, o le medie in tutti i trattamenti analizzati con un certo numero di campioni, sono uguali, allora MSE e MSB stimano la stessa cosa, e F tende quindi a 1. Ma cosa stimano MSE e MSB?

( )
kn
snMSE
T
i
k
ii
−
−
==∑=
2
1
1



LE ASSUNZIONI DELL'ANOVA � Sono le assunzioni del test t, ma estese a tutti i gruppi:
o La variabile deve avere una distribuzione normale in tutte le popolazioni corrispondenti ai gruppi campionati
o Le varianze in tutte le popolazioni corrispondenti ai gruppi campionati deve essere uguale
� Ovviamente, come sempre, per ciascun gruppo il campione deve rappresentare un insieme di misure estratte a caso dalla corrispondente popolazione � E' necessario verificare che queste assunzioni vengano soddisfatte � Fortunatamente però, l'ANOVA è un'analisi piuttosto robusta a violazioni di queste assunzioni, soprattutto se i campioni hanno circa le stesse numerosità

COSA FARE QUANDO F E' SIGNIFICATIVO (P< αααα) IN UNA ANOVA? � E' necessario verificare quali gruppi siano diversi da quali altri � Confronti a coppie ma con specifiche accortezze per fare in modo che l'errore complessivo di primo tipo non superi il livello α prestabilito (in genere 0.05) � I confronti a coppie possono essere pianificati o non pianificati � Confronti pianificati : bisogna decidere prima dell'esperimento un numero limitato di confronti a coppie a cui si è particolarmente interessati
o Per esempio, nel caso dello studio sul jet lag, prima dell'esperimento si era soprattutto interessati al confronto tra controlli e il gruppo sottoposto a luce al ginocchio
o In questi casi, i pochi confronti a coppie da svolgere sono praticamente dei test t (la differenza sta nel fatto che si usa MSE al posto della varianza comune e i gradi di libertà di MSE)
� Confronti non pianificati : l'interesse non ricade su specifici confronti, ma si è interessati a svolgerli tutti [il numero totale di confronti a coppie è pari a k(k-1)/2]
o Qui il problema dell'errore complessivo di primo tipo è più serio o Ci sono metodi, come quello di Tukey-Kramer, per calcolare se ogni confronto è
significativo (senza incrementare l'errore complessivo di primo tipo) e per visualizzare i risultati
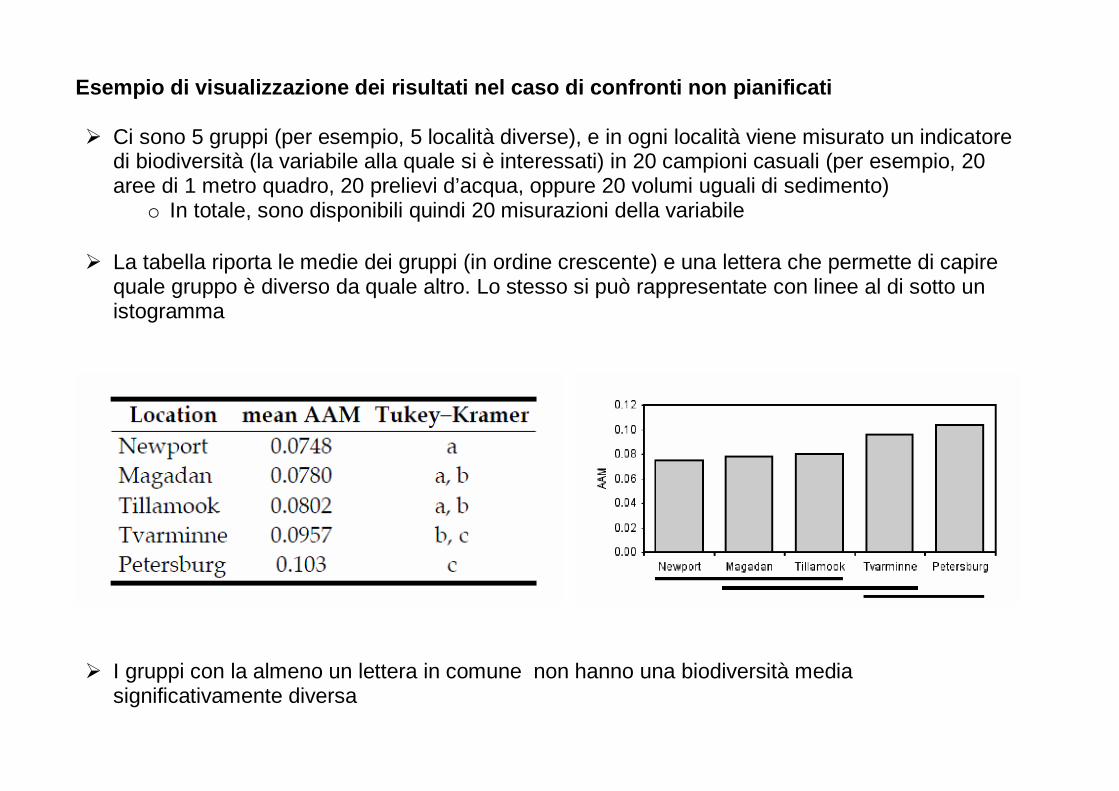
Esempio di visualizzazione dei risultati nel caso d i confronti non pianificati � Ci sono 5 gruppi (per esempio, 5 località diverse), e in ogni località viene misurato un indicatore
di biodiversità (la variabile alla quale si è interessati) in 20 campioni casuali (per esempio, 20 aree di 1 metro quadro, 20 prelievi d’acqua, oppure 20 volumi uguali di sedimento)
o In totale, sono disponibili quindi 20 misurazioni della variabile � La tabella riporta le medie dei gruppi (in ordine crescente) e una lettera che permette di capire
quale gruppo è diverso da quale altro. Lo stesso si può rappresentate con linee al di sotto un istogramma
� I gruppi con la almeno un lettera in comune non hanno una biodiversità media
significativamente diversa

ACCENNI DI ANOVA MULTIFATTORIALE � La tecnica dell’ANOVA può essere estesa all’analisi di un numero maggiore di fattori � La variabile analizzata è sempre una sola (si tratta comunque di una ANOVA univariata), ma il
numero di fattori che distinguono i diversi campioni è maggiore di 1 � Si parla in questi casi di ANOVA univariata multifattoriale Esempio � Partiamo da un esempio di ANOVA univariata unifattoriale
o Si vuole studiare se diversi terreni di coltura determinano una diversa produzione di una proteina da parte di colture cellulari
� La tipologia del terreno è quindi il primo fattore, che chiamiamo fattore A, che può assumere per esempio quattro livelli (1, 2, 3 e 4), corrispondenti a quattro diversi terreni
� Per ogni terreno vengono analizzate per esempio 12 colture cellulari, e per ognuna di queste viene misurata la quantità di proteina prodotta (la variabile analizzata) alla fine dell’esperimento
o Fino a qui, questo è un classico esempio di ANOVA con 1 fattore (ANOVA unifattoriale), 4
gruppi, e 48 osservazioni in tutto della variabile

� Supponiamo ora di voler considerare anche un secondo fattore che riteniamo abbia una certa influenza sulla produzione della proteina analizzata, per esempio il fattore temperatura
o A questo punto, ciascuno dei gruppi costituito da 12 colture viene suddiviso in tre gruppi di 4
colture, ognuno dei quali verrà lasciato crescere a una temperatura diversa � Per esempio, supponiamo che i tre raggruppamenti del secondo fattore siano
temperatura bassa, temperatura media, e temperatura alta � Questo è un esempio di ANOVA con due fattori, e possiamo pensare ai dati di questa analisi
come ad un tabella dove
o le righe identificano il primo fattore (Fattore A, per esempio il terreno di coltura) � il fattore A ha 4 livelli
o le colonne identificano il secondo fattore (Fattore B, per esempio la temperatura) � il fattore B ha 3 livelli
� In questa tabella 4x3, ogni casella rappresenta un singolo gruppo di 4 osservazioni. Ognuno dei 12 gruppi ha subito un trattamento diverso (casella in alto a sinistra: terreno 1 + temperatura bassa; casella in alto in centro: terreno 1 + temperatura media; casella in alto a destra: terreno 1 + temperatura alta; casella nella seconda linea a sinistra: terreno 2 + temperatura bassa; ................; casella in basso a destra: terreno 4 + temperatura alta)

Fattore B (temperatura)
1 2 3
1
y111
y112
y113
y114
y121
y122
y123
y124
y131
y132
y133
y134
2
y211
y212
y213
y214
y221
y222
y223
y224
y231
y232
y233
y234
3
y311
y312
y313
y314
y321
y322
y323
y324
y331
y332
y333
y334
Fattore A (terreno di
cultura)
4
y411
y412
y413
y414
y421
y422
y423
y424
y431
y432
y433
y434
[ogni valore deve necessariamente avere tre indici: il primo indica la riga, il secondo la colonna, il terzo la singola osservazione]
� Le osservazioni totali sono 4x3x4= 48. Per ciascuno dei 12 gruppi posso calcolare una media

� Posso sintetizzare le 12 medie nella tabella
Fattore B (temperatura) 1 2 3
1 y 11 y 12 y 13
2 y 21 y 22 y 23 3 y 31 y 32 y 33
Fattore A (terreno di
coltura)
4 y 41 y 42 y 43
[ogni media deve necessariamente avere due indici: il primo indica la riga e il secondo la colonna]
� L'ANOVA a due fattori ci permette di capire:
o se esiste un effetto principale del tipo di terreno di coltura sulla produzione proteica o se esiste un effetto principale della temperatura sulla produzione proteica o se esiste un’interazione tra i due fattori, ovvero se gli effetti dei due fattori non sono
indipendenti (c’e’ interazione) oppure sono indipendenti (non c’e’ interazione)
� L'ANOVA a due fattori porterà quindi al calcolo di tre statistiche F, ognuna delle quali utile a testare un'ipotesi nulla diversa: sul fattore A, sul fattore B, e sull'interazione

Le tre ipotesi nulle che vengono testate nell’ANOVA a due fattori � Le prime due ipotesi nulle sono:
o Prima ipotesi nulla: le 4 medie della variabile in 4 popolazioni con 4 terreni diversi (senza
considerare la temperatura, e quindi mettendo assieme, per ogni riga, le tre colonne) sono uguali
o Seconda ipotesi nulla: le 3 medie della variabile in 3 popolazioni caratterizzate da 3 temperature diverse (senza considerare il tipo di terreno, e quindi mettendo assieme, per ogni colonna, le quattro righe) sono uguali
� Ma l'ANOVA multifattoriale permette di capire e testare statisticamente una cosa molto
importante: l'interazione tra fattori o La terza ipotesi nulla che viene testata nell’ANOVA a due fattori è quella di assenza di
interazione o Si ha interazione tra i fattori quando l’effetto di un fattore sulla variabile dipende dagli altri
fattori; molto spesso in biologia i fattori interagiscono nel determinare una risposta
o Se per esempio la temperatura alta favorisce la crescita delle colture nel terreno A, ma la sfavorisce (o non la favorisce) nelle colture con terreno B, significa che c'e' interazione tra i fattori: l'effetto di un fattore non è indipendente da quale gruppo viene considerato per l'altro fattore

Esempio numerico di ANOVA a due fattori senza inter azione � Supponiamo che la tabelle delle medie per ciascuno dei 12 gruppi sia la seguente:
Fattore B (temperatura) 1 2 3
1 5.2 6.5 8.3 2 5.8 6.8 8.6 3 7 8.5 10.2
Fattore A (terreno di
coltura) 4 11.5 14.1 16.8
� Visualizziamo graficamente queste medie in un sistema di assi cartesiani dove i valori che
assumono le medie sono riportati, logicamente, sull’asse delle Y
Attenzione! Le considerazioni che seguono sono puramente basate sull’osservazione e la descrizione delle medie. Solo dopo il calcolo dei valori di F, dell’identificazione di valori critici in
tabella, e della definizione delle regioni di accettazione/rifiuto o del P-value, queste considerazioni assumerebbero un valore statistico inferenziale
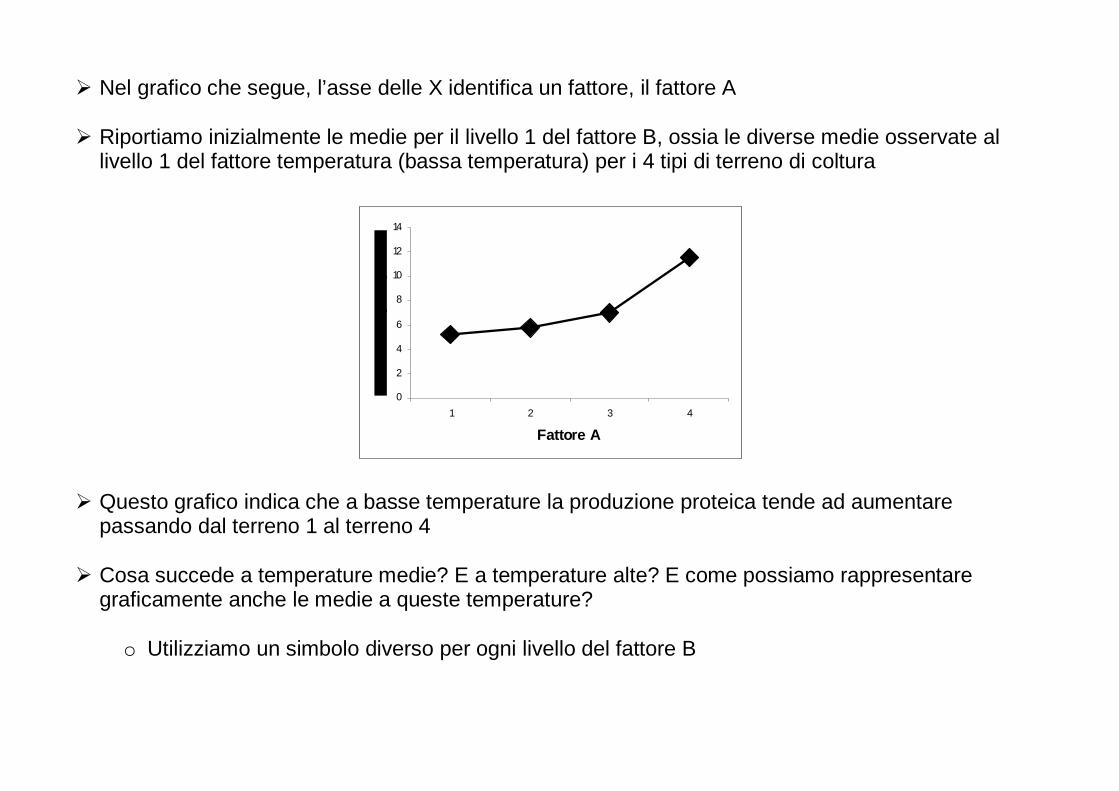
� Nel grafico che segue, l’asse delle X identifica un fattore, il fattore A � Riportiamo inizialmente le medie per il livello 1 del fattore B, ossia le diverse medie osservate al
livello 1 del fattore temperatura (bassa temperatura) per i 4 tipi di terreno di coltura
0
2
4
6
8
10
12
14
1 2 3 4
Fattore A
� Questo grafico indica che a basse temperature la produzione proteica tende ad aumentare
passando dal terreno 1 al terreno 4 � Cosa succede a temperature medie? E a temperature alte? E come possiamo rappresentare
graficamente anche le medie a queste temperature?
o Utilizziamo un simbolo diverso per ogni livello del fattore B
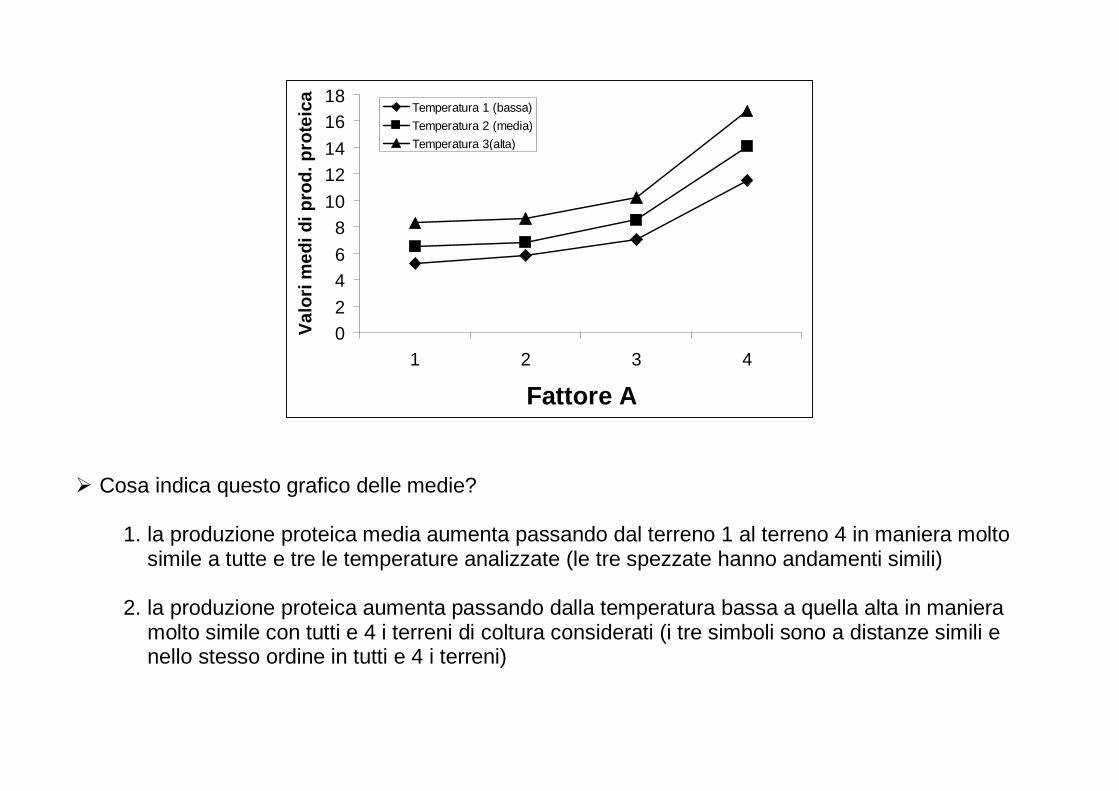
0
2
46
8
10
12
14
1618
1 2 3 4
Fattore A
Val
ori m
edi d
i pro
d. p
rote
ica Temperatura 1 (bassa)
Temperatura 2 (media)
Temperatura 3(alta)
� Cosa indica questo grafico delle medie?
1. la produzione proteica media aumenta passando dal terreno 1 al terreno 4 in maniera molto simile a tutte e tre le temperature analizzate (le tre spezzate hanno andamenti simili)
2. la produzione proteica aumenta passando dalla temperatura bassa a quella alta in maniera
molto simile con tutti e 4 i terreni di coltura considerati (i tre simboli sono a distanze simili e nello stesso ordine in tutti e 4 i terreni)

� Il grafico quindi suggerisce anche un’altra cosa molto importante: o la produzione proteica varia tra terreni diversi e a temperature diverse ma il modo in cui
varia la produzione proteica tra terreni non dipende dalla temperatura; questo equivale anche a dire che il modo in cui varia la produzione proteica con la temperatura non dipende dal terreno
� Questo è un esempio tipico di ANOVA a due fattori in cui i fattori hanno un effetto principale ma non interagiscono tra loro: non esiste interazione tre i due fattori
� Nella rappresentazione grafica delle medie, l’assenza di interazione si traduce con una serie di
spezzate parallele o quasi parallele � L’assenza di interazione porta anche a poter esprimere i risultati ottenuti in maniera semplice
o Nel nostro caso, la conclusione potrebbe essere espressa (per ora, ripetiamo, solo in forma descrittiva visto che non abbiamo fatto nessuna analisi statistica inferenziale) come:
� La produzione proteica aumenta passando dal terreno 1 al terreno 4, e anche all’aumentare della temperatura
Se molte delle medie calcolate nei 12 gruppi avessero errori standard molto alti, è evidente che dovrei essere molto prudente nelle conclusioni basate solo sull’analisi del grafico delle medie.
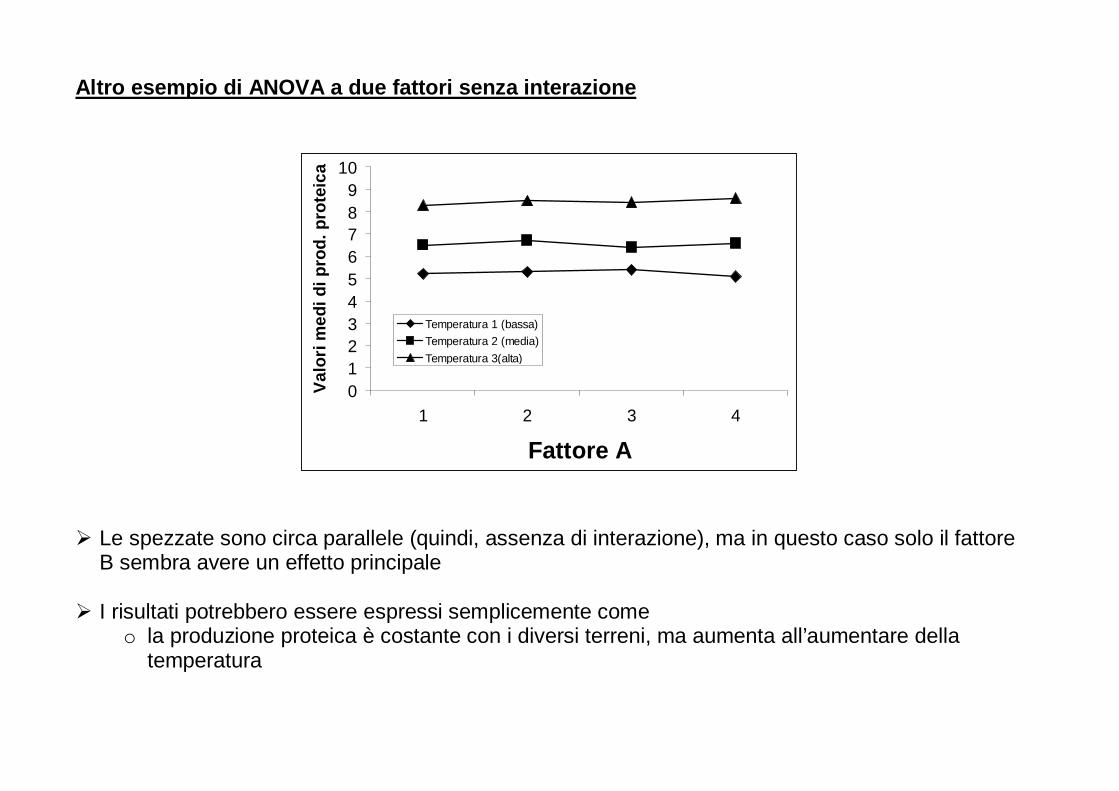
Altro esempio di ANOVA a due fattori senza interazi one
0123456789
10
1 2 3 4
Fattore A
Val
ori m
edi d
i pro
d. p
rote
ica
Temperatura 1 (bassa)
Temperatura 2 (media)
Temperatura 3(alta)
� Le spezzate sono circa parallele (quindi, assenza di interazione), ma in questo caso solo il fattore
B sembra avere un effetto principale � I risultati potrebbero essere espressi semplicemente come
o la produzione proteica è costante con i diversi terreni, ma aumenta all’aumentare della temperatura
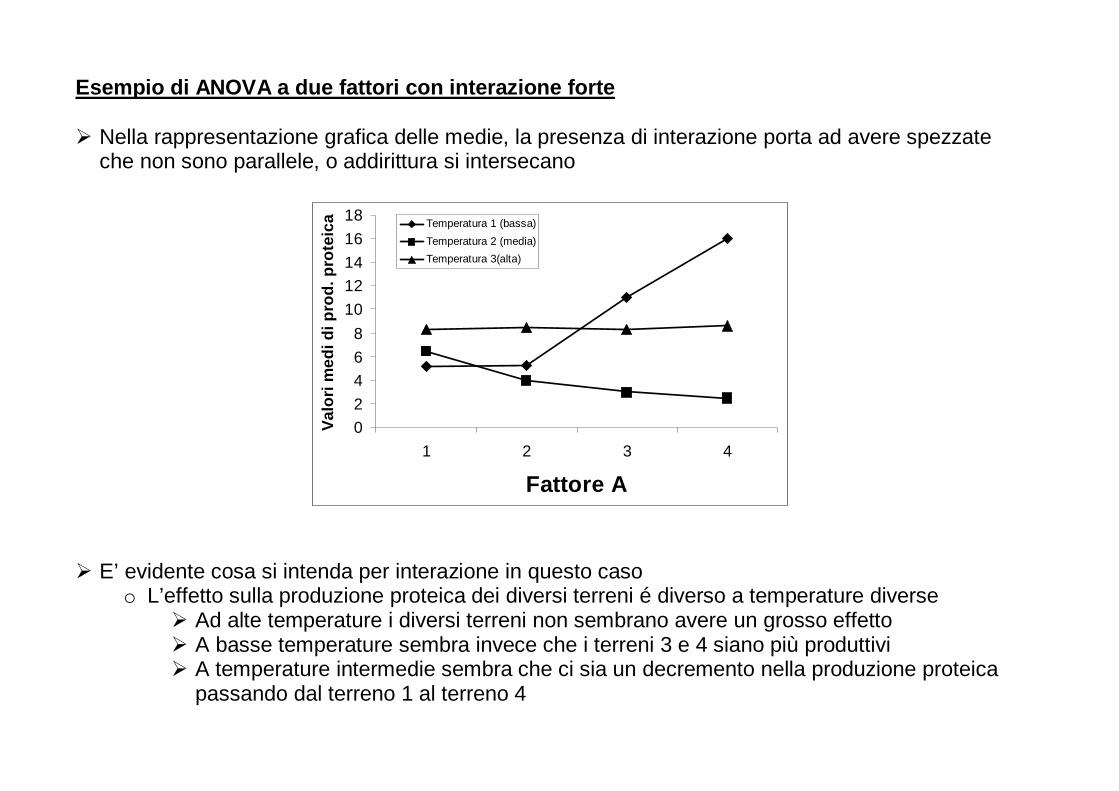
Esempio di ANOVA a due fattori con interazione fort e � Nella rappresentazione grafica delle medie, la presenza di interazione porta ad avere spezzate
che non sono parallele, o addirittura si intersecano
0
2
4
6
8
10
12
14
16
18
1 2 3 4
Fattore A
Val
ori m
edi d
i pro
d. p
rote
ica
Temperatura 1 (bassa)
Temperatura 2 (media)
Temperatura 3(alta)
� E’ evidente cosa si intenda per interazione in questo caso
o L’effetto sulla produzione proteica dei diversi terreni é diverso a temperature diverse � Ad alte temperature i diversi terreni non sembrano avere un grosso effetto � A basse temperature sembra invece che i terreni 3 e 4 siano più produttivi � A temperature intermedie sembra che ci sia un decremento nella produzione proteica
passando dal terreno 1 al terreno 4

� Nell’esempio precedente, i fattori hanno una forte interazione: l’effetto di un fattore sulla variabile
analizzata sembra dipendere dall’altro fattore � Il fatto che ci sia interazione può rendere meno chiaro un risultato nel quale viene trovata
l’assenza di effetti principali (quelli dovuti ad ogni fattore senza considerare l’altro); si vedano le figure alla fine di questo file
� Anche le conclusioni che possiamo trarre richiedono maggiore attenzione in presenza di
interazione: non é infatti possibile dire come nei casi precedenti in maniera semplice qual’é l’effetto di un fattore, visto che tale effetto può non essere vero per tutti i livelli dell’altro fattore
� Nel grafico alla pagina precedente, se le impressioni fossero confermate dall’analisi statistica,
potremmo dire qualcosa del genere:
� i terreni 3 e 4 sono più produttivi, e quindi da preferire, solamente alle basse temperature, mentre gli stessi terreni sono i meno produttivi a temperature intermedie; inoltre, avendo a disposizione solo il terreno 1 o il terreno 2, le alte temperature sembrano le piú efficaci
� In altre parole, i risultati sono molto più complessi da capire e anche da descrivere in presenza di
interazione
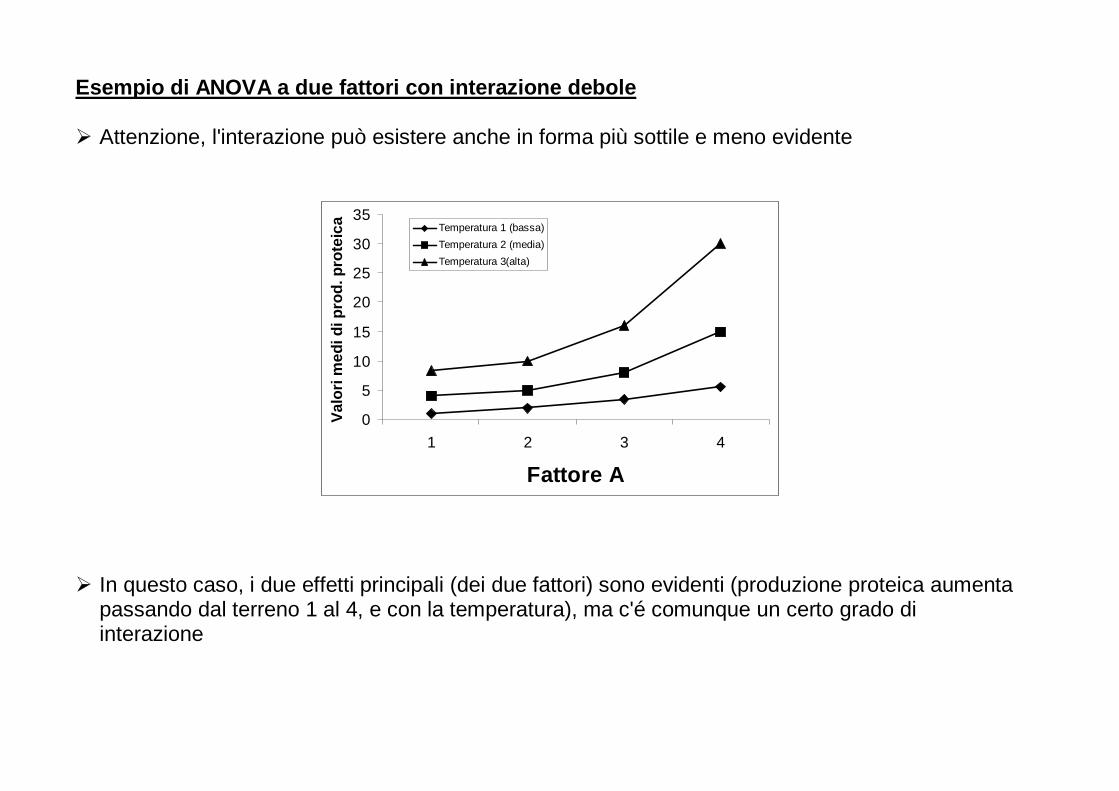
Esempio di ANOVA a due fattori con interazione debo le
� Attenzione, l'interazione può esistere anche in forma più sottile e meno evidente
0
5
10
15
20
25
30
35
1 2 3 4
Fattore A
Val
ori m
edi d
i pro
d. p
rote
ica
Temperatura 1 (bassa)
Temperatura 2 (media)
Temperatura 3(alta)
� In questo caso, i due effetti principali (dei due fattori) sono evidenti (produzione proteica aumenta
passando dal terreno 1 al 4, e con la temperatura), ma c'é comunque un certo grado di interazione

ANOVA a due fattori porta al calcolo di tre statis tiche F
� Fino ad ora abbiamo visto come le medie per ciascuna combinazione possono essere utilizzate graficamente per capire qualcosa sull’effetto dei fattori e sulla loro interazione o Questa era però solo statistica descrittiva!
� Come già accennato, L'ANOVA a due vie viene svolta attraverso il calcolo di tre statistiche F:
o FA-calc : serve per testare l'ipotesi nulla che il fattore A (per esempio, terreno di coltura) non
abbia un effetto principale sulla variabile analizzata (per esempio, la produzione proteica) o FB-calc : serve per testare l'ipotesi nulla che il fattore B (per esempio, la temperatura) non
abbia un effetto principale sulla variabile analizzata (per esempio, la produzione proteica)
o FAB-calc : serve per testare l'ipotesi nulla che i fattori A e B non interagiscano (ovvero, l'ipotesi nulla di assenza di interazione, o, nella rappresentazione grafica, l’ipotesi nulla che le spezzate siano parallele).
� Ognuna delle tre statistiche andrà confrontata con il suo corrispondente valore critico (che
dipenderà dai gradi libertà di ciascuna statistica)
� ATTENZIONE! Se c'e' interazione, FA-calc e/o FB-calc possono risultare non significativi (P<α) anche se i fattori determinano un effetto (non omogeneo) sulla variabile analizzata

� Vediamo alcuni risultati ipotetici che si potrebbero ottenere studiando come varia la velocità ad imparare un certo tipo di esercizio (variabile) in un gruppo di scoiattoli classificati per l'ambiente da cui provengono (fattore A, foresta o parco pubblico) e per la specie a cui appartengono (fattore B, Sciurus carolinensis o Sciurus vulgaris). Assumiamo che ci siano solo due ambienti e due specie (4 gruppi)
� Nelle figure che seguono, quindi, il fattore A è Environment, il fattore B è Species (colore rosso e rombo per Sciurus carolinensis e colore blu e pallino per Sciurus vulgaris), e la variabile “velocità ad imparare un certo esercizio” è indicata come Trait Measure
� Dai grafici possiamo ipotizzare che, se il numero di individui in ciascun gruppo non è troppo basso, i valori di F significativi risulterebbero:
A) Nessuno B) FB C) FA D) FA-B (nessun effetto principale) E) FB e FA-B F) FA e FA-B G) FA, FB e FA-B
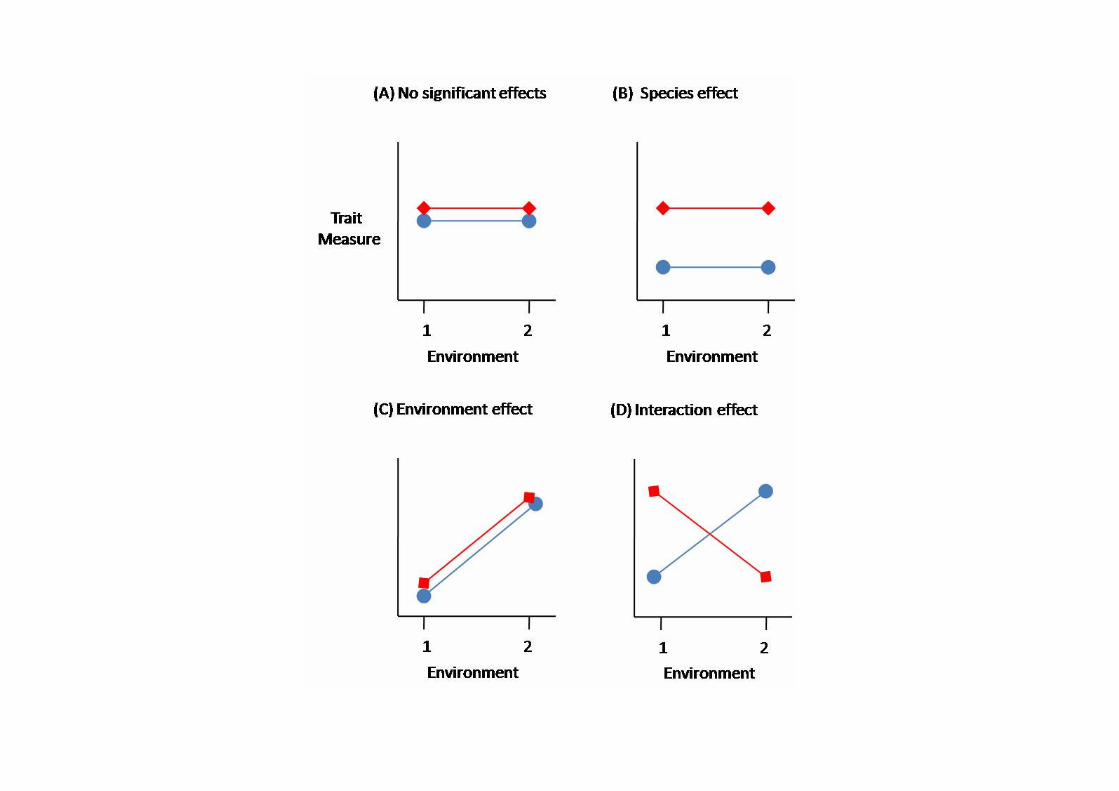
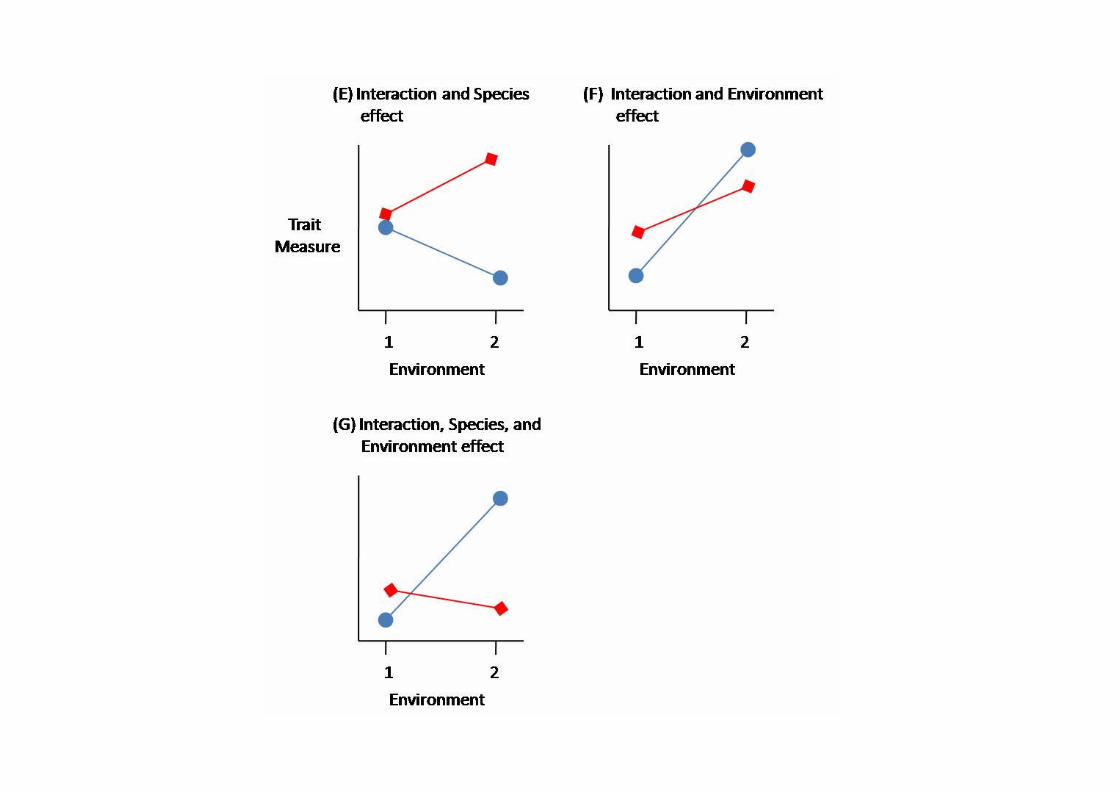
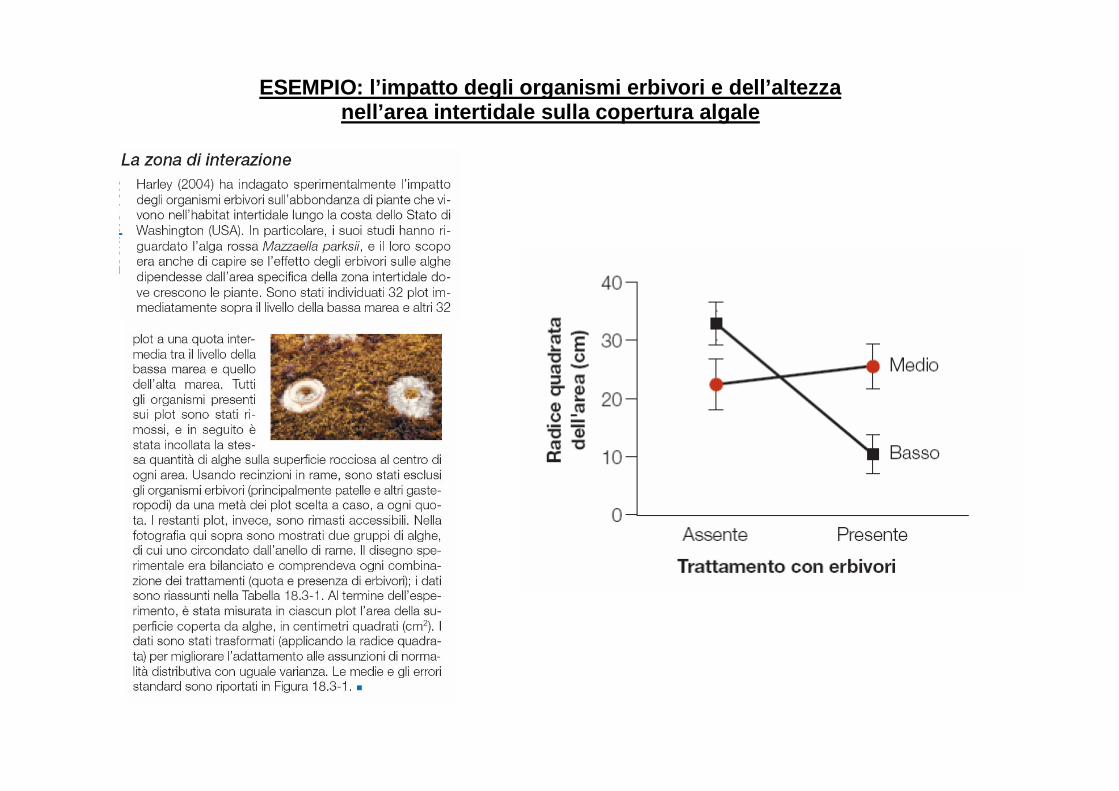
ESEMPIO: l’impatto degli organismi erbivori e dell’ altezza nell’area intertidale sulla copertura algale
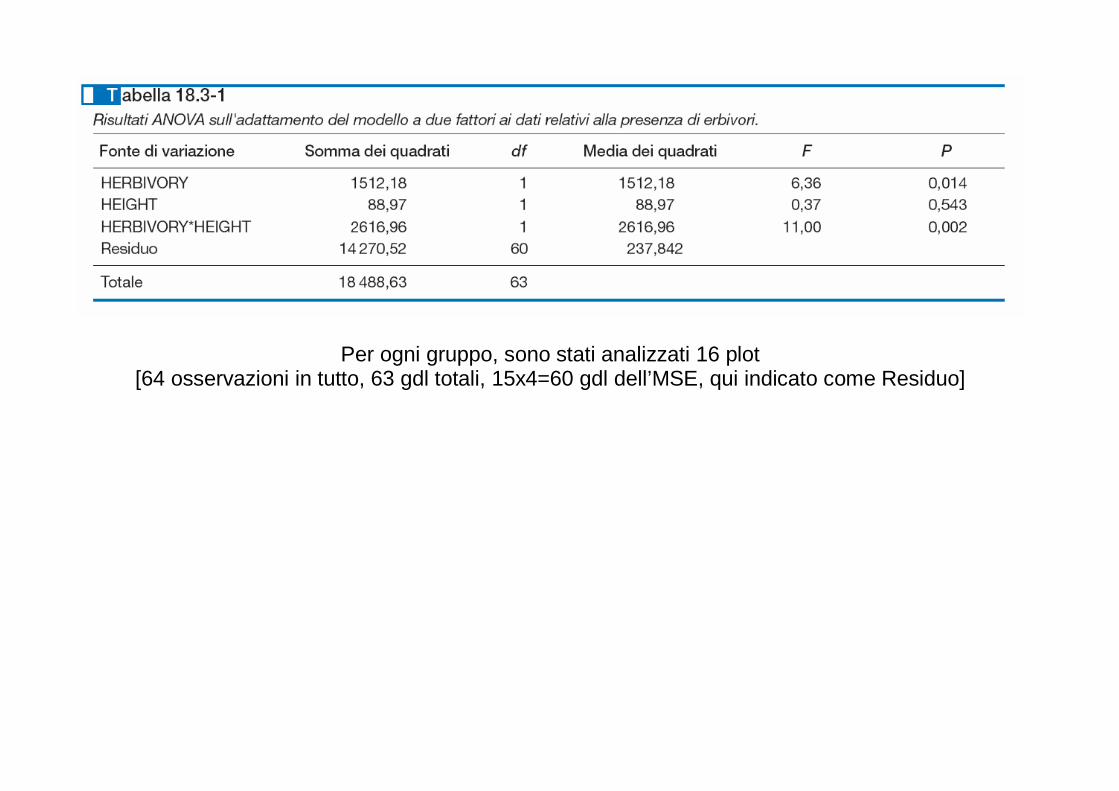
Per ogni gruppo, sono stati analizzati 16 plot [64 osservazioni in tutto, 63 gdl totali, 15x4=60 gdl dell’MSE, qui indicato come Residuo]





























