Embed Size (px)
Citation preview

Diplomado en Sanidad
Módulo III
Bioestadística
Manuel Gómez Barrera
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
2
0. Presentación
0.1. Objetivos
El objetivo general del módulo es introducir al alumno en los conceptos básicos de la estadística aplicada a las ciencias de la salud y, específicamente, a la salud pública.
Como objetivos específicos el alumno será capaz al final del módulo de:
• Comprender la naturaleza básica de los datos y de las variables estadísticas.
• Elaborar las tablas y los gráficos que le permitan analizar la distribución de frecuencias de un conjunto de datos.
• Calcular y comprender el significado de las principales medidas de tendencia central, de dispersión y de posición.
• Comprender el concepto básico de probabilidad y algunas de sus propiedades más importantes.
• Comprender las ideas básicas de la distribución de probabilidad normal.
• Conocer las ideas básicas sobre el muestreo y, especialmente, el muestreo aleatorio.
• Comprender el concepto y la importancia de los intervalos de confianza como técnica de estimación básica.
• Conocer las bases de las pruebas de contraste de hipótesis.
0.2. Planteamiento
El curso se plantea como un curso básico de Bioestadística de 8 horas de duración. Se imparte en la modalidad no presencial con apoyo de las herramientas de formación a distancia que proporcionan la Tecnologías de la Información.
Es oportuno comenzar señalando que el manejo de la Estadística en general y de la Bioestadística como parte de ella ha evolucionado de forma paralela al desarrollo tecnológico de finales del siglo XX. Se han diseñado un número importante de programas estadísticos que permiten realizar de forma rápida lo que hace unos años era largo y complicado.
Este desarrollo ha repercutido en una elevada implantación de la Estadística en el ámbito de las Ciencias de la Salud. Ha llegado a ser una herramienta esencial para demostrar la eficacia de ciertos medicamentos, la pertinencia de ciertas pruebas diagnósticas, la frecuencia de enfermedades en una población o la relación causa efecto entre una enfermedad y un factor de exposición.
Obviamente en un curso de 8 horas de duración el planteamiento no puede ser otro que la de aportar de forma clara ciertos conceptos fundamentales. Queda como segundo plano la opción de dejar al alumno en una rampa de lanzamiento, con una información adecuada que permita a los más avezados o interesados propulsarse hacia un mayor conocimiento.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
3
0.3. Desarrollo del temario
Los temas se van a desarrollar según el esquema siguiente:
• Material didáctico: comprende el texto del tema correspondiente
• Actividades propias del tema: son ejercicios y talleres de temática concreta
• Material adicional: comprende una presentación de PowerPoint en el que se esquematiza el tema, los archivos necesarios para realizar las actividades y documentos descargados de Internet a modo de bibliografía de consulta. También un glosario de términos, elaborado en lenguaje coloquial para facilitar la comprensión
• Evaluación: mediante preguntas tipo test con respuestas cerradas.
Del mismo modo se facilita un documento en formato PDF en el que están todos los conceptos desarrollados. El objetivo es que quede como material de consulta para el alumno.
0.4. Bibliografía
0.4.1. Bibliografía recomendada Martínez-González MA; Jokin de Irala; Faulín Fajardo FJ; Bioestadística amigable; 2ª ed. Madrid; Ed. Díaz de Santos; 2005
Este es, a juicio personal, el libro de estadística más práctico para un profesional sanitario con implicación o interés en Estadística. Aparte de que presenta un conjunto bastante apropiado de contenidos, básicos y avanzados, la exposición de los mismos es excelente. Presenta también en cada capítulo una parte explicativa de obtención e interpretación de resultados en programas estadísticos de referencia como SPSS, STATA o Excel.
Ríus Díaz F; Barón Lopez FJ; Sánchez Font E; Parras Guijosa L; Bioestadística: métodos y aplicaciones; Departamento de Bioestadística de la Universidad de Málaga
Es un libro de Estadística que tiene dos virtudes. La primera es que es bastante completo y abarca las necesidades básicas y ligeramente avanzadas que pueden surgir en la práctica sanitaria diaria. La segunda es que esta disponible en Internet en la siguiente dirección:
http://www.bioestadistica.uma.es/baron/bioestadistica.pdf
0.4.2. Bibliografía más avanzada Martín Andrés A; Luna del Castillo JD; Bioestadística para las ciencias de la salud; 5ª ed. Madrid; Ed. NORMA; 2004
Libro más analítico que los anteriores. No es tan sencillo de manejo pero es muy completo, abarca situaciones que no aparecen de forma normal en otros libros de Estadística.
Norman GR; Streiner DL; Bioestadística; Mosby/Doyma Libros; 1996
Este es un divertido libro que abarca desde los conceptos más simples de la Estadística aplicada a las Ciencias de la Salud, hasta un nivel bastante avanzado para la comprensión de algunos de los problemas más frecuentes que se puedan presentar en la investigación biomédica. Está escrito en un tono desenfadado, con abundancia de ejemplos jocosos, y problemas y cuestiones para su resolución. No obstante, su contenido es riguroso, a la vez que se ciñe a lo esencial de cada uno de los temas, sin divagaciones en cuestiones matemáticas,

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
4
que pueden ser complejas para los profesionales de la Salud. Existe una versión en inglés posterior más reciente que la versión en español, publicada en el año 2000.
Altman DG; Practical Statistics for Medical Research; Ed. Chapman & Hall; 1997
Este libro está en esta lista pensando en coleccionistas de libros de referencia. Es una obra inicial en el desarrollo de la Bioestadística y clave en el desarrollo de la misma. Es un libro que esta referenciado en casi todos los manuales estadísticos. Obviamente está en inglés y su inclusión en esta lista debe entenderse como el deseo de incluir una pieza de coleccionista en una selección personalizada. Por supuesto, es correctísimo y apropiadísimo, pero para lo que presenta en este curso, otros manuales más prácticos pueden ser más apropiados.
0.4.3. Material en Internet Como no podía ser de otra manera, Internet es una fuente de consulta de Estadística. Personalmente el material que suelo emplear y recomendar se encuentra en las siguientes referencias.
• http://www.fisterra.com/mbe/investiga/index.asp
• http://www.seh-lelha.org/webestad.htm
• http://www.bioestadistica.uma.es/libro/
En cada una de las tres se puede encontrar material correcto de Bioestadística. Cualquiera de las tres es una referencia adecuada.
Las dos primeras referencias están más encaminadas a proporcional material de consulta a profesionales sanitarios. Presentan una buena selección de artículos en los cuales se explican de forma clara y precisa conceptos estadísticos esquematizados en formas de artículos independientes.
La tercera está más encaminada a la docencia. Presenta una buena cantidad de material didáctico en diferentes formatos como PDF, PowerPoint o vídeo. Es una gran ayuda para los docentes y alumnos de Bioestadística. No me cansaré nunca de agradecer al profesor Barón la presencia de este material.
0.5. Software estadístico
Existe una buena cantidad de software estadístico. A continuación de presenta una relación de programas con los que se trabaja o de los que se oye hablar en círculos científicos o sanitarios. Se presenta información básica del programa, un link hacia la web específica del programa y un link hacia Wikipedia, si existe.
Puede consultarse una lista de programas estadísticos en:
http://en.wikipedia.org/wiki/List_of_statistical_packages
SPSS Fue creado en 1968 por Norman H. Nie, C. Hadlai Hull y Dale H. Bent. Entre 1969 y 1975 la Universidad de Chicago por medio de su National Opinión Research Center estuvo a cargo del desarrollo, distribución y venta del programa, circunstancia que a partir de 1975 corresponde a SPSS Inc. Originalmente el programa fue creado para grandes computadores. En 1970 se publica el primer manual de usuario del SPSS por Nie y Hall. Este manual populariza el programa entre las instituciones de educación superior en EE. UU. En 1984 sale la primera versión para computadores personales.
Como programa estadístico es muy popular su uso debido a la capacidad de trabajar con bases de datos de gran tamaño. En la versión 12 es de 2 millones de registros y 250.000 variables. Además, de permitir la recodificación de las variables y registros según las necesidades del usuario. El programa

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
5
consiste en un módulo base y módulos anexos que se han ido actualizando constantemente con nuevos procedimientos estadísticos.
Personalmente creo que es el programa de referencia. A su elevada cantidad de recursos estadísticos, se une la cómoda presentación de resultados que permite copiar tablas de resultados, pegarlos en procesadores de textos como Word y sobre todo modificarlos como si fuera material del entorno Office.
Para más información:
• http://www.spss.com/es/
• http://es.wikipedia.org/wiki/SPSS
Stata Stata es un propósito general del paquete de software estadístico creado en 1985 por StataCorp. Es utilizado por muchas empresas e instituciones académicas de todo el mundo. La mayoría de los usuarios de su labor en la investigación, especialmente en las esferas de economía, sociología, ciencias políticas, y la epidemiología.
Stata de la gama completa de capacidades incluye gestión de datos, análisis estadístico, gráficos, simulaciones y programación personalizada. A modo de curiosidad, el nombre "Stata" se formó por la mezcla de "estadísticas" y "datos", no es una sigla y, por tanto, no deben aparecer con todas las letras en mayúsculas.
Más información en:
• http://www.stata.com/
• http://en.wikipedia.org/wiki/Stata
Statgraphics Es otro programa que cumple con las especificaciones de contenidos necesarios para trabajar y avanzar en Estadística. STATGRAPHICS CENTURION XV para Windows tiene una estructura modular constituida por 3 módulos diferentes, en los que se puede encontrar mas de 150 procedimientos de distribución. El Modulo Básico aporta todas las herramientas estadísticas básicas. A partir de éste se pueden seleccionar las funciones estadísticas adicionales necesarias en los otros módulos.
Más información en:
• http://www.statgraphics.net/
• http://en.wikipedia.org/wiki/Statgraphics
Excel Como parte de la Matemática que es, la Estadística puede trabajarse a través de cálculos matemáticos. En este sentido la hoja de cálculo Excel es una herramienta fundamental para manejar Bioestadística.
Excel presenta un conjunto de operaciones estadísticas programadas que se pueden insertar con facilidad y obtener resultados de un conjunto de datos. Tiene como desventaja que hay que trabajar los datos antes de calcular los resultados y tiene como ventaja que al modificar un dato, se modifican los resultados. Gracias a los comandos de copiar, pegar e insertar filas, se puede adaptar el archivo de un conjunto de datos a otro nuevo, con lo que es conveniente trabajar bien los archivos de datos.
En este curso se van a presentar varios materiales diseñados para Excel. Se va a realizar un taller de obtención de resultados estadísticos y uno de gráficos y tablas. Personalmente creo que es básico

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
6
manejar el programa Excel para profundizar después en programas estadísticos o para manejar de forma sencilla un conjunto de datos.
Más información en:
• http://office.microsoft.com/es-es/excel/default.aspx
• http://es.wikipedia.org/wiki/Microsoft_Excel
Nota
Los tres programas comentados con anterioridad son licenciados. Una de las páginas a las que se dirige para ampliar información son las de las casas comerciales. Existe también software gratuito en Internet, de los cuales se presentan unos ejemplos a continuación.
R R es un lenguaje y entorno de programación para análisis estadístico y gráfico. Se trata de un proyecto de software libre, resultado de la implementación GNU del premiado lenguaje S. R y S-Plus -versión comercial de S- son, probablemente, los dos lenguajes más utilizados en investigación por la comunidad estadística, siendo además muy populares en el campo de la investigación biomédica, la bioinformática y las matemáticas financieras. A esto contribuye la posibilidad de cargar diferentes librerías o paquetes con finalidades específicas de cálculo o gráfico.
Más información en:
• http://www.r-project.org/
• http://es.wikipedia.org/wiki/R-project
PSPP PSPP es un programa de software para el análisis estadístico de datos incluidos en una muestra. Se trata de una opción libre frente al programa propietario SPSS. PSPP puede realizar estadísticas descriptivas, T-ensayos, regresión lineal y pruebas no paramétricas. Su respaldo está diseñado para llevar a cabo sus análisis lo más rápido posible, independientemente del tamaño de los datos de entrada.
Más información en:
• http://www.gnu.org/software/pspp/
• http://es.wikipedia.org/wiki/PSPP
G-Stat G-Stat es un programa estadístico desarrollado por el laboratorio farmacéutico Glaxo SmithKline. Presenta una buena cantidad de resultados estadísticos, y puede ser una herramienta útil y gratuita para el inicio en el mundo de la Bioestadística. En la página web hay material de apoyo para el manejo del programa.
Más información en:
• http://www.e-biometria.com/g-stat/index.html

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
7
1. Introducción a la Bioestadística
1.1 Introducción
La Ciencia se ocupa en general de fenómenos observables. Desde el principio de los tiempos, la Ciencia se ha desarrollado observando hechos, formulando leyes que los explican y realizando experimentos para validar o rechazar dichas leyes. Los modelos que crea la ciencia son de tipo determinista, no variables, o de tipo aleatorio, también llamados estocásticos, en los que los resultados son variables.
La Estadística se utiliza como tecnología al servicio de las ciencias donde la variabilidad y la incertidumbre forman parte de su naturaleza. La Bioestadística enseña y ayuda a investigar en todas las áreas de las Ciencias de la Vida donde la variabilidad no es la excepción sino la regla.
Existen diferentes razones por las cuales los profesionales sanitarios deben conocer los fundamentos de la epidemiología y la estadística como instrumentos del trabajo cotidiano. Los términos estadísticos y epidemiológicos invaden la literatura médica y la sanidad es cada vez más cuantitativa. Esta necesidad en el conjunto de los profesionales sanitarios es todavía más notoria en el ámbito de la Salud Pública. Desde el momento en el que la información manejada corresponde a un conjunto de personas, u otros elementos de análisis, surge la necesidad de conocer la Bioestadística como forma para describir grupos o compararlos con otros.
1.1. Poblaciones y muestras
Cuando se realiza un estudio estadístico, se pretende generalmente inferir o generalizar resultados de una muestra a una población. Se estudia en particular a un reducido número de individuos a los que tenemos acceso con la idea de poder generalizar los hallazgos a la población de la cual esa muestra procede. Este proceso de inferencia se efectúa por medio de métodos estadísticos basados en la probabilidad.
La población representa el conjunto grande de individuos que deseamos estudiar y generalmente suele ser inaccesible. Es, en definitiva, un colectivo homogéneo que reúne unas características determinadas. La muestra es el conjunto menor de individuos (subconjunto de la población accesible y limitado sobre el que realizamos las mediciones o el experimento con la idea de obtener conclusiones generalizables a la población). El individuo es cada uno de los componentes de la población y la muestra. La muestra debe ser
representativa de la población y con ello queremos decir que cualquier individuo de la población en estudio debe haber tenido la misma probabilidad de ser elegido.
Las razones para estudiar muestras en lugar de poblaciones son diversas y entre ellas podemos señalar:
• Ahorrar tiempo. Estudiar a menos individuos es evidente que lleva menos tiempo.
• Como consecuencia del punto anterior ahorraremos costes.
• Estudiar la totalidad de los pacientes o personas con una característica determinada en muchas ocasiones puede ser una tarea inaccesible o imposible de realizar.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
8
• En ocasiones estudiar un elemento puede resultar en su destrucción. Si se analiza el porcentaje de cierto componente en la industria alimentaria, es evidente que no se puede analizar toda la población, ya que conllevaría la destrucción de la producción.
• Aumentar la calidad del estudio. Al disponer de más tiempo y recursos, las observaciones y mediciones realizadas a un reducido número de individuos pueden ser más exactas y plurales que si las tuviésemos que realizar a una población.
• La selección de muestras específicas nos permitirá reducir la heterogeneidad de una población al indicar los criterios con los cuales se incluyen unos pacientes o se excluyen otros
La característica más importante de una muestra es su representatividad respecto de la población. La
muestra idónea es la más pequeña, ya que supondrá un menor esfuerzo, que permita hacer
estimaciones con la precisión que nosotros necesitemos, de aquí, la relevancia del cálculo del tamaño
muestral.
• Muestreo probabilístico
En los procedimientos de muestreo probabilístico todos los candidatos de la población tienen una
probabilidad conocida de ser incluidos en la muestra. Por tanto, todas las muestras posibles de un
tamaño determinado tienen la misma probabilidad de salir. Por ello tienden a asegurar la
representatividad de las mismas. Existen varios tipos de muestreo probabilístico
o Muestreo aleatorio simple. Todos los candidatos tienen la misma probabilidad de
entrar a formar parte de la muestra. La aleatorización hace probable que los factores
que influyan en la variable resultado (p.e. sexo, edad,… y factores no reconocidos
como influyentes) se distribuyan de forma no muy diferente a como es su distribución
en la población de referencia. Obviamente, es difícilmente posible emplear este
método si el tamaño de la población en muy grande o desconocido.
o Muestreo aleatorio estratificado. Cuando se desea controlar la influencia de algún
factor que puede influir en la variable resultado que nos interesa, se puede dividir la
población por las categorías de ese factor. Es decir, se divide en mujeres y varones si
el sexo influye en la variable, y se extrae una muestra aleatoria en cada una de las
subpoblaciones o estratos.
o Muestreo en múltiples etapas. Es útil en casos de poblaciones enormes y dispersas,
porque facilita el muestreo. Por ejemplo, para obtener una muestra de pacientes
diabéticos ingresados en nuestro país, en una primera etapa se escoge una muestra
de hospitales, y en la segunda etapa, una muestra de pacientes diabéticos
ingresados en los hospitales elegidos.
o Muestreo sistemático. Aplica una regla sistemática para extaer a los sujetos como por
ejemplo seleccionar historias clínicas que terminan en un número o elegir los
pacientes conforme llegan, o uno de cada cuatro de forma consecutiva.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
9
• Muestreo no probabilístico
En el muestreo no probabilística no se recurre al azar, por ejemplo el muestreo consecutivo en el que
se incluyen a los pacientes que interesan conforme acuden a la consulta.En el muestreo no
probabilístico no recurrimos al azar (p.e. pedir voluntarios) y no ofrece la misma representatividad.
1.2. Tipos de variables
La Bioestadística estudia datos que no son fijos en los individuos, es decir datos que varían, o son variables en cada individuo. Es por ello que lo que se estudia en cada individuo de la muestra son las variables (edad, sexo, peso, talla, tensión arterial sistólica). Los datos son los valores que toma la variable en cada caso.
Lo que se realiza es medir, es decir, asignar valores a las variables incluidas en el estudio, por lo que se deberá además concretar la escala de medida que aplicaremos a cada variable.
La naturaleza de las observaciones será de gran importancia a la hora de elegir el método estadístico más apropiado para abordar su análisis. Con este fin, clasificaremos las variables, a grandes rasgos, en dos tipos: variables
cuantitativas o variables cualitativas.
• Variables cuantitativas. Son las variables que pueden medirse, cuantificarse o expresarse numéricamente. Las variables cuantitativas pueden ser de dos tipos:
o Variables cuantitativas continuas, si admiten tomar cualquier valor dentro de un rango numérico determinado (edad, peso, talla).
o Variables cuantitativas discretas, si no admiten todos los valores intermedios en un rango. Suelen tomar solamente valores enteros (número de hijos, número de partos, número de hermanos).
• Variables cualitativas. Este tipo de variables representan una cualidad o atributo que clasifica a cada caso en una de varias categorías. La situación más sencilla es aquella en la que se clasifica cada caso en uno de dos grupos (hombre/mujer, enfermo/sano, fumador/no fumador). Son datos dicotómicos o binarios. Como resulta obvio, en muchas ocasiones este tipo de clasificación no es suficiente y se requiere de un mayor número de categorías (color de los ojos, grupo sanguíneo, profesión, etcétera).
1.3. Transformaciones de variables
En determinadas circunstancias, cuando la claridad en la presentación de los resultados lo exija o cuando se precise representar con un valor único fenómenos complejos, se procede a realizar transformaciones de variables.
Existen los siguientes tipos de transformaciones de variables:
• Variables cuantitativas transformadas en otras variables cuantitativas. Bien sea porque buscamos utilizar unidades o magnitudes que nos sean familiares o porque queremos dotar a

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
10
la variable de alguna propiedad que nos permita manejarla con mayor comodidad. Por ejemplo, utilizar el logaritmo natural de una variable en lugar de la propia variable para dotar de estabilidad a su varianza.
• Variables cuantitativas transformadas en variables cualitativas ordinales. Son habituales para simplificar y clarificar la presentación de la información. Así por ejemplo, cuando representamos la estructura demográfica de la población, en lugar de ofrecer una elaboración estadística de la variable edad, es frecuencia ofrecer indicadores basados en la división de la población en tres categorías: infancia y adolescencia (edad < 18 años), edad adulta (edad ≥ 18 y edad < 65 años) y personas mayores (edad ≥ 65 años).
• Variables cualitativas ordinales en otras variables cualitativas ordinales. Menos interesantes que las anteriores, se realizan para clarificar la presentación de los datos, agrupando categorías cuando estas son excesivas para la comprensión de la información.
• Variables cualitativas en variables cuantitativas. En principio, la única transformación posible es la asignación a la presencia de una categoría o no los valores 0 y 1 en una variable dicotómica.
1.4. Tipos de escalas de medida
En el proceso de medición de las variables estadísticas se pueden utilizar dos escalas:
• Escalas nominales: ésta es una forma de observar o medir en la que los datos se ajustan por categorías que no mantienen una relación de orden entre sí (color de los ojos, sexo, profesión, presencia o ausencia de un factor de riesgo o enfermedad, etcétera).
• Escalas ordinales: en las escalas utilizadas, existe un cierto orden o jerarquía entre las categorías (grados de disnea, estadios de un tumor, etcétera).

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
11
2. Estadística descriptiva I: frecuencias y medidas Una vez que se han recogido los valores que toman las variables objeto de estudio, se procede al análisis descriptivo de los mismos. Para variables categóricas, como el sexo o la presencia de caries, se quiere conocer el número de casos en cada una de las categorías, reflejando habitualmente el porcentaje que representan del total, y expresándolo en una tabla de frecuencias.
Para variables numéricas, en las que puede haber un gran número de valores observados distintos, se ha de optar por un método de análisis distinto, respondiendo a las siguientes preguntas:
¿Alrededor de qué valor se agrupan los datos?
Supuesto que se agrupan alrededor de un número, ¿cómo lo hacen?. ¿Muy concentrados? ¿Muy dispersos?
Las medidas a calcular se presentan en la tabla 1:
Tipo de variable Medidas
Cualitativa Frecuencias absolutas o relativas Frecuencias acumuladas
Medidas de tendencia central: media, mediana, moda
Medidas de dispersión: varianza, desviación típica, rango, coeficiente de variación
Medidas de posición: cuartiles, percentiles
Cuantitativa
Medidas de forma: asimetría y curtosis
Tabla 1. Medidas en Bioestadística descriptiva
2.1. Variables cualitativas
Las variables cualitativas presentan las medidas de frecuencia como elemento de cuantificación. Se recuerda que son variables que se definen por categorías, por ejemplo no fumadores, fumadores leves, fumadores moderados o grandes fumadores Básicamente son de cuatro tipos:
• Frecuencia absoluta: Es la cuenta del número de individuos cuyos valores están incluidos dentro de cada categoría. Por ejemplo: 15 pacientes no fumadores
• Frecuencia relativa: Es el resultado de dividir el número de individuos cuyos valores están incluidos dentro de cada categoría por el número total de individuos estudiados. Se expresa habitualmente en tantos por ciento, por ejemplo 20% de pacientes no fumadores.
• Frecuencia absoluta acumulada: Es el resultado de sumar la frecuencia absoluta de la categoría correspondiente a las frecuencias absoluta de las categorías anteriores. Por ejemplo: 35 pacientes no fumadores o fumadores leves.
• Frecuencia relativa acumulada: Es el resultado de sumar la frecuencia relativa de la categoría anterior a las frecuencias relativa de las categorías anteriores. Por ejemplo: 58% de pacientes no fumadores o fumadores leves
Estas medidas se pueden aplicar a variables cuantitativas agrupadas en intervalos, como por ejemplo la edad categorizada por tramos. Los resultados serían del tipo: 30% de pacientes de edad entre 18 y 64 años.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
12
También se pueden utilizar en variables cuantitativas discretas como el número de hijos. Por ejemplo: 15 pacientes tuvieron un hijo.
2.2. Variables cuantitativas
2.2.1. Medidas de tendencia central Las medidas de centralización vienen a responder a la pregunta, ¿alrededor de que valor se agrupan los datos? La medida más evidente que se puede calcular para describir un conjunto de observaciones numéricas es su valor medio. La media no es más que la suma de todos los valores de una variable dividida entre el número total de datos de los que se dispone.
Como ejemplo, se consideran 10 pacientes de edades 21 años, 32, 15, 59, 60, 61, 64, 60, 71, y 80. La media de edad de estos sujetos será de:
Más formalmente, si se denota por (X1, X2,..., Xn) los n datos que tenemos recogidos de la variable en cuestión, el valor medio vendrá dado por:
Otra medida de tendencia central que se utiliza habitualmente es la mediana. Es la observación equidistante de los extremos. La mediana del ejemplo anterior sería el valor que deja a la mitad de los datos por encima de dicho valor y a la otra mitad por debajo. Si se ordenan los datos de mayor a menor se observa la secuencia:
15, 21, 32, 59, 60, 60,61, 64, 71, 80
Como quiera que en este ejemplo el número de observaciones sea par (10 individuos), los dos valores que se encuentran en el medio son 60 y 60. Si se realiza el cálculo de la media de estos dos valores nos dará a su vez 60, que es el valor de la mediana.
Si la media y la mediana son iguales, la distribución de la variable es simétrica. La media es muy sensible a la variación de las puntuaciones. Sin embargo, la mediana es menos sensible a dichos cambios.
Por último, otra medida de tendencia central, no tan usual como las anteriores, es la moda, siendo éste el valor de la variable que presenta una mayor frecuencia. En el ejemplo anterior el valor que más se repite es 60, que es la moda.
2.2.2. Medidas de dispersión Tal y como se adelantaba antes, otro aspecto a tener en cuenta al describir datos continuos es la dispersión de los mismos, es decir, si se alejan mucho o poco de los valores centrales. Existen distintas formas de cuantificar esa variabilidad. De todas ellas, la varianza (S2) de los datos es la más utilizada. Es la media de los cuadrados de las diferencias entre cada valor de la variable y la media aritmética de la distribución.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
13
Esta varianza muestral se obtiene como la suma de las de las diferencias de cuadrados y por tanto tiene como unidades de medida el cuadrado de las unidades de medida en que se mide la variable estudiada.
En el ejemplo anterior la varianza sería:
Sx2=
La desviación típica (S) es la raíz cuadrada de la varianza. Expresa la dispersión de la distribución y se expresa en las mismas unidades de medida de la variable. La desviación típica es la medida de dispersión más utilizada en estadística.
Aunque esta fórmula de la desviación típica muestral es correcta, en la práctica, la estadística interesa para realizar inferencias poblacionales, por lo que en el denominador se utiliza, en lugar de n, el valor n-1.
Por tanto, la medida que se utiliza es la cuasidesviación típica o desviación estándar, dada por:
En los cálculos del ejercicio previo, la desviación típica muestral, que tiene como denominador n, el valor sería 20,67. A efectos de cálculo se hará como n-1 y el resultado seria 21,79.
El haber cambiado el denominador de n por n-1 está en relación al hecho de que esta segunda fórmula es una estimación más precisa de la desviación estándar verdadera de la población y posee las propiedades que necesitamos para realizar inferencias a la población. Este punto se desarrolla más en la parte final del curso.
Cuando se quieren señalar valores extremos en una distribución de datos, se suele utilizar la amplitud o rango como medida de dispersión. La amplitud es la diferencia entre el valor mayor y el menor de la distribución.
Por ejemplo, utilizando los datos del ejemplo previo tendremos 80-15 =65.
La varianza y desviación típica son índices que describen la variabilidad o dispersión y por tanto cuando los datos están muy alejados de la media, la varianza y la desviación típica serán grandes.
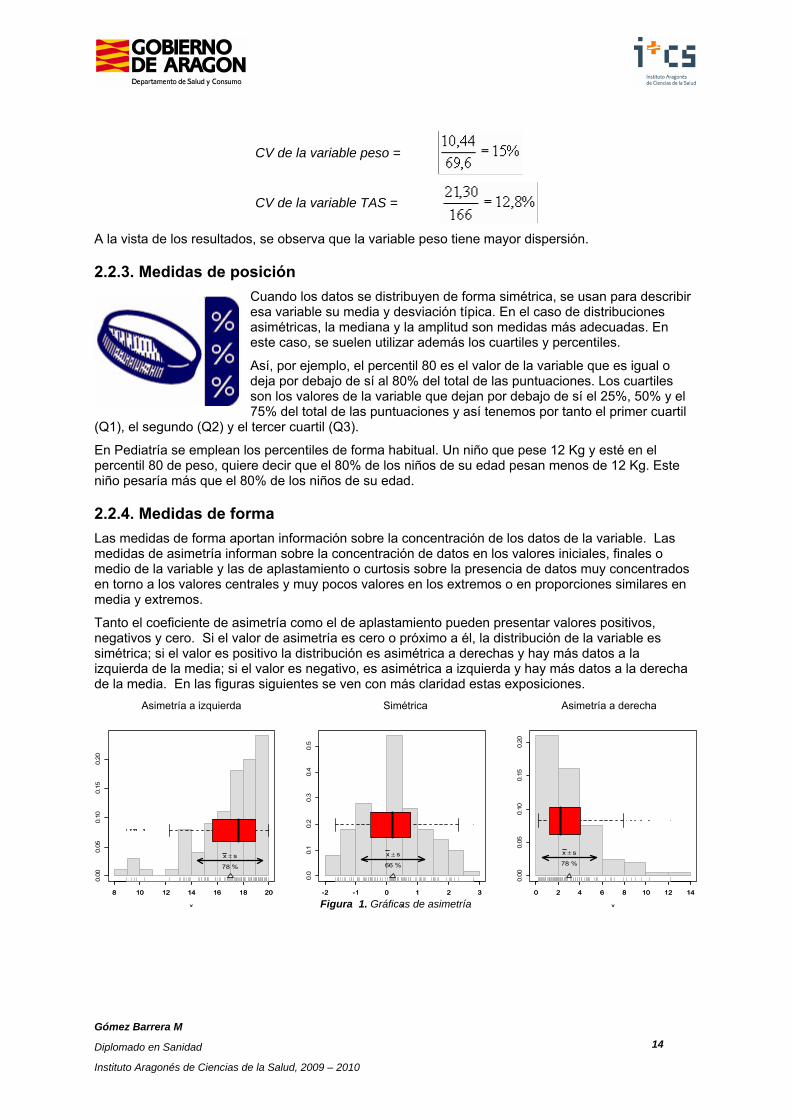
Otra medida que se suele utilizar es el coeficiente de variación (CV). Es una medida de dispersión relativa de los datos y se calcula dividiendo la desviación típica muestral por la media y multiplicando el cociente por 100. Su utilidad estriba en que permite comparar la dispersión o variabilidad de dos o más grupos. Así, por ejemplo, con el peso de 5 pacientes (70, 60, 56, 83 y 79 Kg) cuya media es de 69,6 Kg. y su desviación típica (s) = 10,44 y la tensión arterial sistólica de los mismos (150, 170, 135, 180 y 195 mmHg) cuya media es de 166 mmHg y su desviación típica de 21,3. La pregunta sería: ¿qué distribución es más dispersa, el peso o la tensión arterial? Si comparamos las desviaciones típicas observamos que la desviación típica de la tensión arterial es mucho mayor; sin embargo, no podemos comparar dos variables que tienen escalas de medidas diferentes, por lo que calculamos los coeficientes de variación:
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
14
CV de la variable peso =
CV de la variable TAS =
A la vista de los resultados, se observa que la variable peso tiene mayor dispersión.
2.2.3. Medidas de posición Cuando los datos se distribuyen de forma simétrica, se usan para describir esa variable su media y desviación típica. En el caso de distribuciones asimétricas, la mediana y la amplitud son medidas más adecuadas. En este caso, se suelen utilizar además los cuartiles y percentiles.
Así, por ejemplo, el percentil 80 es el valor de la variable que es igual o deja por debajo de sí al 80% del total de las puntuaciones. Los cuartiles son los valores de la variable que dejan por debajo de sí el 25%, 50% y el 75% del total de las puntuaciones y así tenemos por tanto el primer cuartil
(Q1), el segundo (Q2) y el tercer cuartil (Q3).
En Pediatría se emplean los percentiles de forma habitual. Un niño que pese 12 Kg y esté en el percentil 80 de peso, quiere decir que el 80% de los niños de su edad pesan menos de 12 Kg. Este niño pesaría más que el 80% de los niños de su edad.
2.2.4. Medidas de forma Las medidas de forma aportan información sobre la concentración de los datos de la variable. Las medidas de asimetría informan sobre la concentración de datos en los valores iniciales, finales o medio de la variable y las de aplastamiento o curtosis sobre la presencia de datos muy concentrados en torno a los valores centrales y muy pocos valores en los extremos o en proporciones similares en media y extremos.
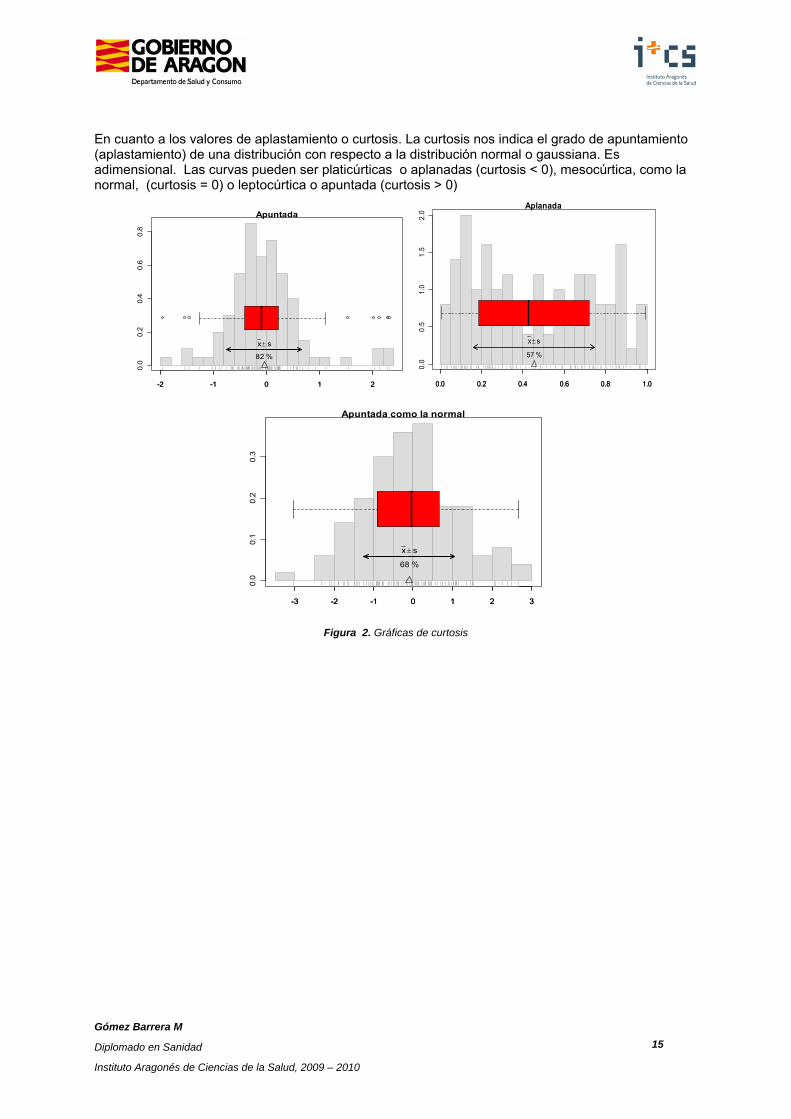
Tanto el coeficiente de asimetría como el de aplastamiento pueden presentar valores positivos, negativos y cero. Si el valor de asimetría es cero o próximo a él, la distribución de la variable es simétrica; si el valor es positivo la distribución es asimétrica a derechas y hay más datos a la izquierda de la media; si el valor es negativo, es asimétrica a izquierda y hay más datos a la derecha de la media. En las figuras siguientes se ven con más claridad estas exposiciones.
Asimetría a izquierda Simétrica Asimetría a derecha
Figura 1. Gráficas de asimetría x
8 10 12 14 16 18 20
0.00
0.05
0.10
0.15
0.20
8 10 12 14 16 18 20
x ± s
78 %
x
-2 -1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
-2 -1 0 1 2 3
x ± s
66 %
x
0 2 4 6 8 10 12 14
0.00
0.05
0.10
0.15
0.20
0 2 4 6 8 10 12 14
x ± s
78 %
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
15
En cuanto a los valores de aplastamiento o curtosis. La curtosis nos indica el grado de apuntamiento (aplastamiento) de una distribución con respecto a la distribución normal o gaussiana. Es adimensional. Las curvas pueden ser platicúrticas o aplanadas (curtosis < 0), mesocúrtica, como la normal, (curtosis = 0) o leptocúrtica o apuntada (curtosis > 0)
Apuntada
-2 -1 0 1 2
0.0
0.2
0.4
0.6
0.8
-2 -1 0 1 2
x± s
82 %
Aplanada
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
2.0
0.0 0.2 0.4 0.6 0.8 1.0
x±s
57 %
Apuntada como la normal
-3 -2 -1 0 1 2 3
0.0
0.1
0.2
0.3
-3 -2 -1 0 1 2 3
x± s
68 %
Figura 2. Gráficas de curtosis

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
16
2.2.5. Algunos conceptos de probabilidad
Como se puede entender, no se va a realizar en un curso de10 horas un repaso exhaustivo de la
probabilidad. Debería suponer un módulo aparte, se va a tratar dentro del tema 3, como un anexo.
Se va a exponer el razonamiento más intuitivo de la probabilidad y se van a comentar ciertos
aspectos de la ley de probabilidad llamada normal o gaussiana.
Hay dos nociones sencillas de probabilidad:
• Frecuentista (objetiva): Probabilidad de un suceso es la frecuencia relativa, medida en tanto
por uno, de veces que ocurriría el suceso al realizar un experimento repetidas veces.
• Subjetiva (bayesiana): Grado de certeza que se posee sobre un suceso. Es personal.
Un suceso se debe entender como un resultado, es decir, una curación o un aumento de los niveles
de hemoglobinemia por encima de lo recomendado por la OMS. El concepto clave es que nos da idea
del grado de ocurrencia de algo. La ocurrencia de un suceso es mayor si la probabilidad se acerca a
uno y menor si se acerca a cero.
Existen conceptos en probabilidad como la probabilidad condicionada, P(B|A), se puede entender
como la probabilidad de un suceso B teniendo en cuenta que debe haber sucedido otro suceso A. Por
ejemplo, probabilidad de que una persona se cure habiendo recibido un determinado tratamiento. Si
la probabilidad condicionada, coincide con la del suceso, se dice que los sucesos son independientes.
Por ejemplo la probabilidad de que una operación quirúrgica en Barbastro sea un éxito es la misma,
independientemente que esté lloviendo o esté soleado.
Cualquier problema de probabilidad puede resolverse en teoría mediante aplicación de los axiomas
que rigen la probabilidad. Sin embargo, es más cómodo conocer algunas reglas de cálculo:
- P(A’) = 1 - P(A)
- P(AUB) = P(A) + P(B) - P(A ∩ B)
- P(A ∩ B) = P(A) P(B|A) = P(B) P(A|B)
- Si A es independiente de B:
o P(A|B) = P(A)
o P(A ∩ B) = P(A) P(B)
P(AUB): probabilidad de que ocurra uno de los dos suceso, uno u otro. Por ejemplo: tener ojos
marrones o negros.
P(A ∩ B): probabilidad de que ocurran dos sucesos a la vez. Por ejemplo: tener pelo rubio y ojos
azules.
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
17
El resultado de un experimento aleatorio puede ser descrito en ocasiones como una cantidad
numérica. En estos casos aparece la noción de variable aleatoria, que es una función que asigna a
cada suceso un número. Muchos procesos aleatorios vienen descritos por variables de forma que son
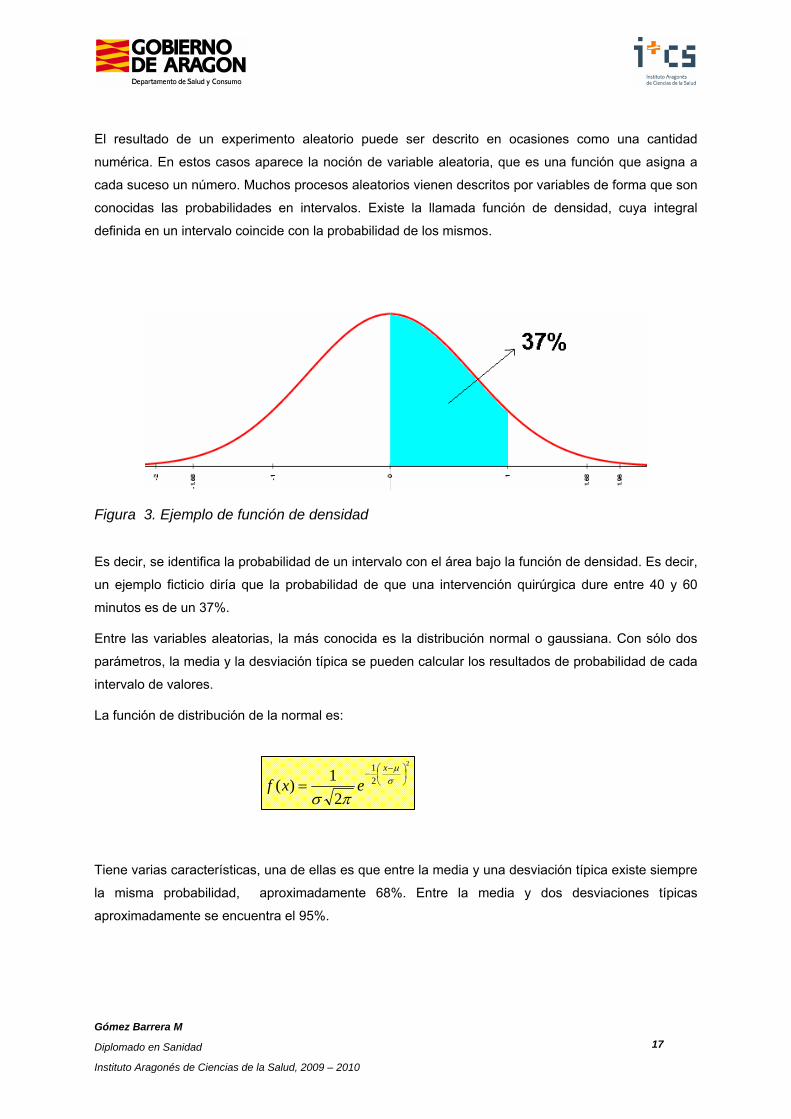
conocidas las probabilidades en intervalos. Existe la llamada función de densidad, cuya integral
definida en un intervalo coincide con la probabilidad de los mismos.
Figura 3. Ejemplo de función de densidad
Es decir, se identifica la probabilidad de un intervalo con el área bajo la función de densidad. Es decir,
un ejemplo ficticio diría que la probabilidad de que una intervención quirúrgica dure entre 40 y 60
minutos es de un 37%.
Entre las variables aleatorias, la más conocida es la distribución normal o gaussiana. Con sólo dos
parámetros, la media y la desviación típica se pueden calcular los resultados de probabilidad de cada
intervalo de valores.
La función de distribución de la normal es:
Tiene varias características, una de ellas es que entre la media y una desviación típica existe siempre
la misma probabilidad, aproximadamente 68%. Entre la media y dos desviaciones típicas
aproximadamente se encuentra el 95%.
2
21
21)(
⎟⎠⎞
⎜⎝⎛ −
−= σ
μ
πσ
x
exf

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
18
La razón clave de la importancia de una distribución normal es que aunque una variable aleatoria no
posea distribución normal, ciertos estadísticos/estimadores calculados sobre muestras elegidas al
azar sí que poseen una distribución normal.
Es decir, tengan la distribución que tengan nuestros datos, los ‘objetos’ que resumen la información
de una muestra, posiblemente tengan distribución normal (o asociada). Este punto es de relevancia
para el contraste de hipótesis que se trata de forma superficial más adelante.
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
19
3. Estadística descriptiva II: gráficos y tablas Cuando se dispone de datos de una población, y antes de abordar análisis estadísticos más complejos, un primer paso consiste en presentar esa información de forma que ésta se pueda visualizar de una manera más sistemática y resumida. La representación pertinente depende, en cada caso, del tipo de variable con la que se esté trabajando.
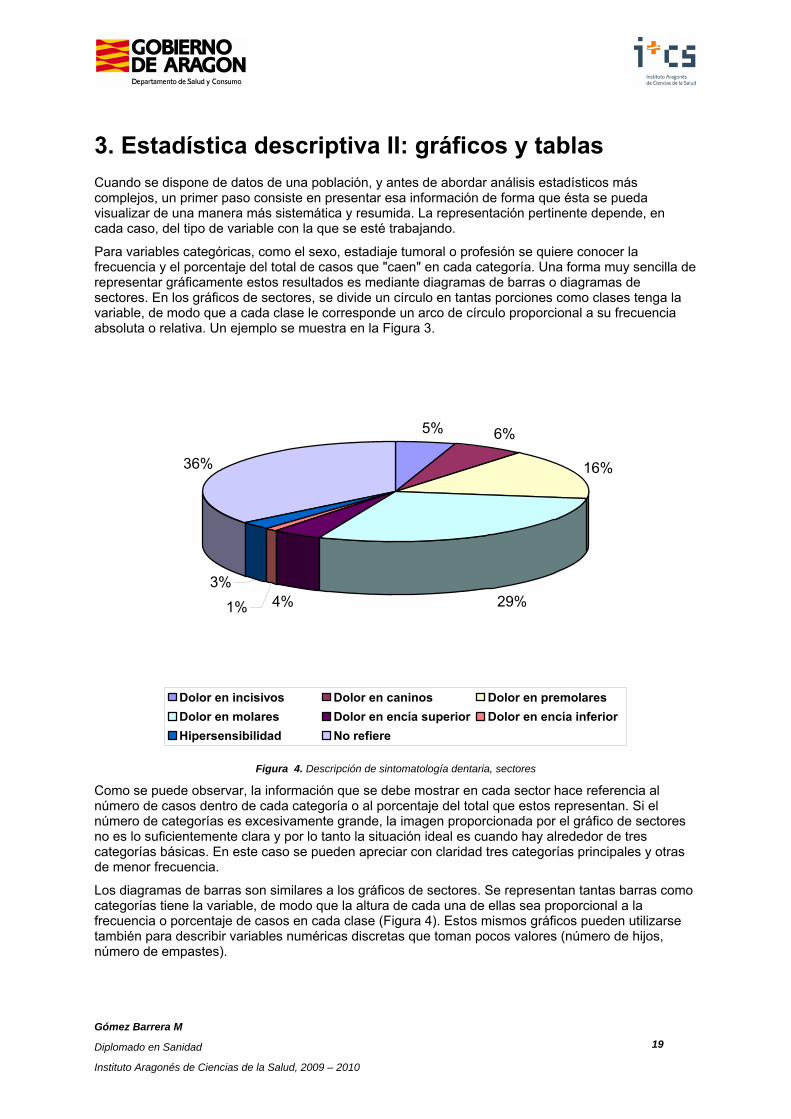
Para variables categóricas, como el sexo, estadiaje tumoral o profesión se quiere conocer la frecuencia y el porcentaje del total de casos que "caen" en cada categoría. Una forma muy sencilla de representar gráficamente estos resultados es mediante diagramas de barras o diagramas de sectores. En los gráficos de sectores, se divide un círculo en tantas porciones como clases tenga la variable, de modo que a cada clase le corresponde un arco de círculo proporcional a su frecuencia absoluta o relativa. Un ejemplo se muestra en la Figura 3.
5% 6%
16%
29%4%1%
3%
36%
Dolor en incisivos Dolor en caninos Dolor en premolaresDolor en molares Dolor en encía superior Dolor en encía inferiorHipersensibilidad No refiere
Figura 4. Descripción de sintomatología dentaria, sectores
Como se puede observar, la información que se debe mostrar en cada sector hace referencia al número de casos dentro de cada categoría o al porcentaje del total que estos representan. Si el número de categorías es excesivamente grande, la imagen proporcionada por el gráfico de sectores no es lo suficientemente clara y por lo tanto la situación ideal es cuando hay alrededor de tres categorías básicas. En este caso se pueden apreciar con claridad tres categorías principales y otras de menor frecuencia.
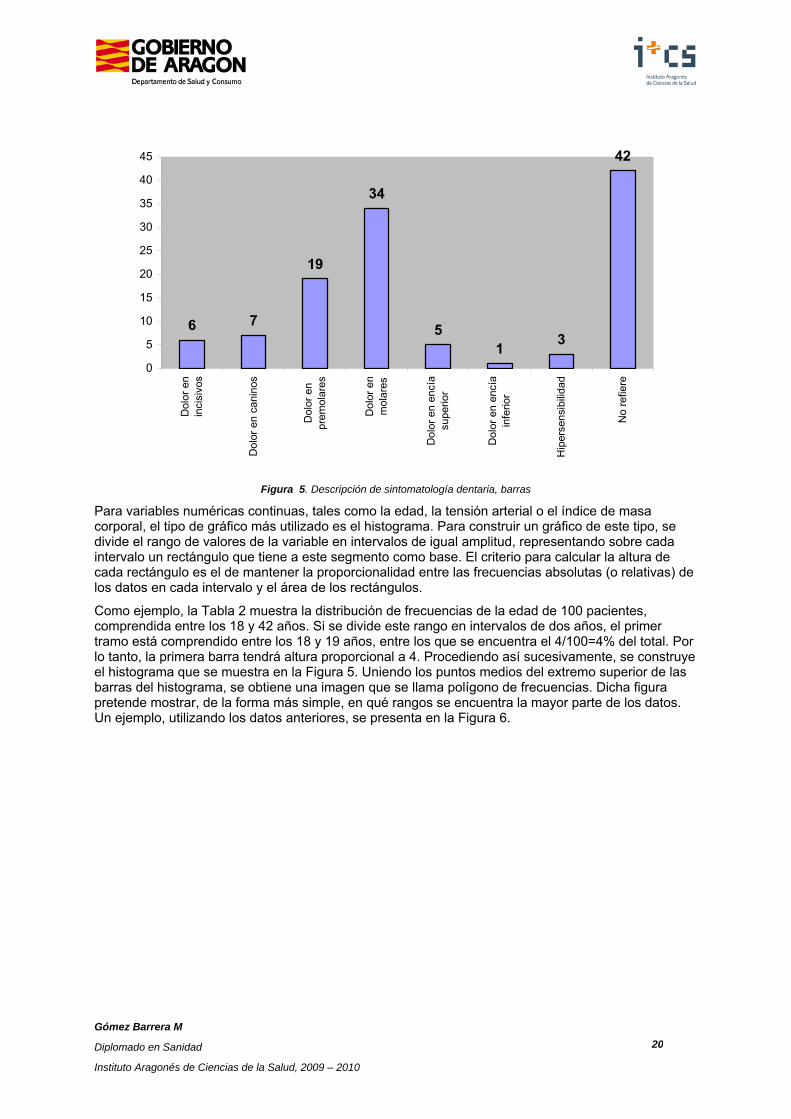
Los diagramas de barras son similares a los gráficos de sectores. Se representan tantas barras como categorías tiene la variable, de modo que la altura de cada una de ellas sea proporcional a la frecuencia o porcentaje de casos en cada clase (Figura 4). Estos mismos gráficos pueden utilizarse también para describir variables numéricas discretas que toman pocos valores (número de hijos, número de empastes).
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
20
6 7
19
34
51 3
42
0
5
10
15
20
25
30
35
40
45
Dol
or e
nin
cisi
vos
Dol
or e
n ca
nino
s
Dol
or e
npr
emol
ares
Dol
or e
nm
olar
es
Dol
or e
n en
cía
supe
rior
Dol
or e
n en
cía
infe
rior
Hip
erse
nsib
ilida
d
No
refie
re
Figura 5. Descripción de sintomatología dentaria, barras
Para variables numéricas continuas, tales como la edad, la tensión arterial o el índice de masa corporal, el tipo de gráfico más utilizado es el histograma. Para construir un gráfico de este tipo, se divide el rango de valores de la variable en intervalos de igual amplitud, representando sobre cada intervalo un rectángulo que tiene a este segmento como base. El criterio para calcular la altura de cada rectángulo es el de mantener la proporcionalidad entre las frecuencias absolutas (o relativas) de los datos en cada intervalo y el área de los rectángulos.
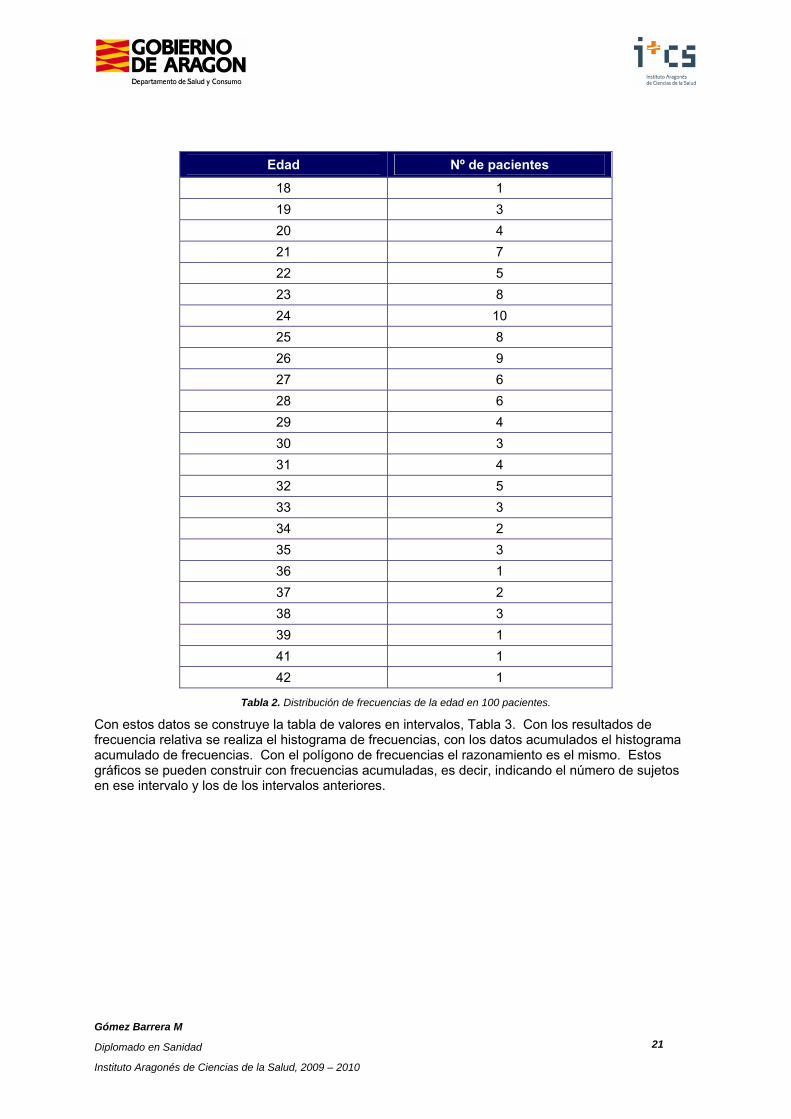
Como ejemplo, la Tabla 2 muestra la distribución de frecuencias de la edad de 100 pacientes, comprendida entre los 18 y 42 años. Si se divide este rango en intervalos de dos años, el primer tramo está comprendido entre los 18 y 19 años, entre los que se encuentra el 4/100=4% del total. Por lo tanto, la primera barra tendrá altura proporcional a 4. Procediendo así sucesivamente, se construye el histograma que se muestra en la Figura 5. Uniendo los puntos medios del extremo superior de las barras del histograma, se obtiene una imagen que se llama polígono de frecuencias. Dicha figura pretende mostrar, de la forma más simple, en qué rangos se encuentra la mayor parte de los datos. Un ejemplo, utilizando los datos anteriores, se presenta en la Figura 6.
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
21
Edad Nº de pacientes
18 1 19 3 20 4 21 7 22 5 23 8 24 10 25 8 26 9 27 6 28 6 29 4 30 3 31 4 32 5 33 3 34 2 35 3 36 1 37 2 38 3 39 1 41 1 42 1
Tabla 2. Distribución de frecuencias de la edad en 100 pacientes.
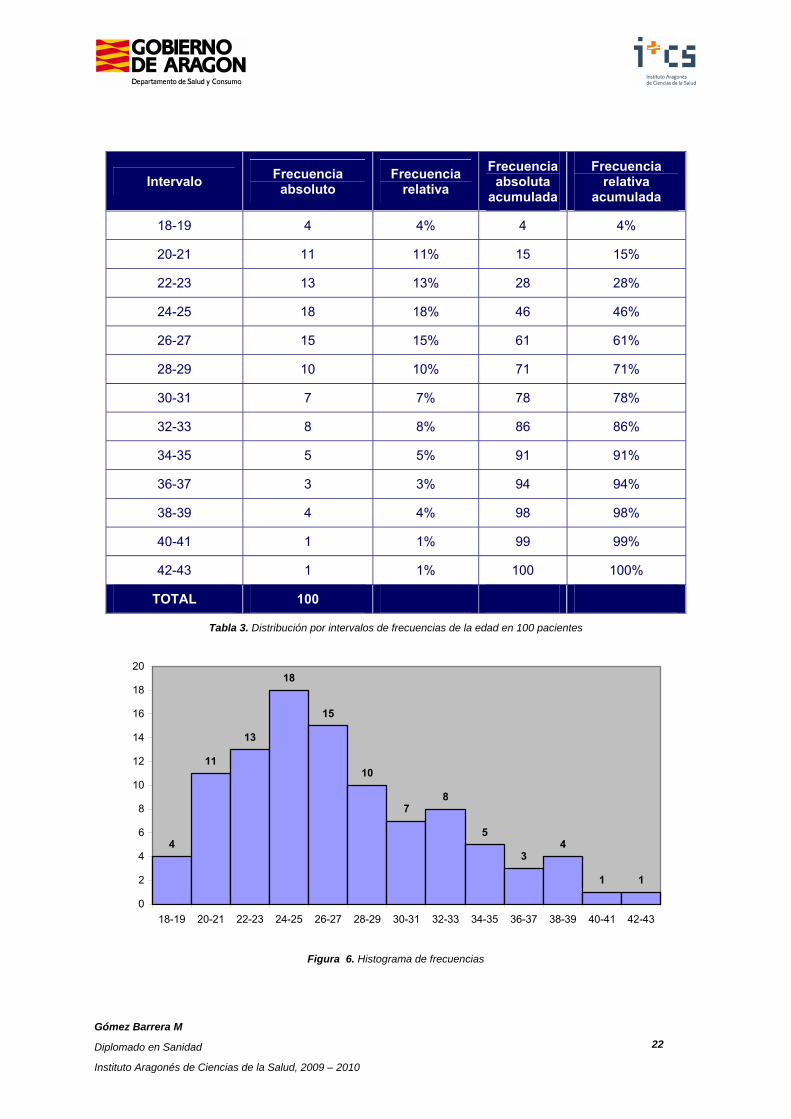
Con estos datos se construye la tabla de valores en intervalos, Tabla 3. Con los resultados de frecuencia relativa se realiza el histograma de frecuencias, con los datos acumulados el histograma acumulado de frecuencias. Con el polígono de frecuencias el razonamiento es el mismo. Estos gráficos se pueden construir con frecuencias acumuladas, es decir, indicando el número de sujetos en ese intervalo y los de los intervalos anteriores.
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
22
Intervalo Frecuencia absoluto
Frecuencia relativa
Frecuencia absoluta
acumulada
Frecuencia relativa
acumulada
18-19 4 4% 4 4%
20-21 11 11% 15 15%
22-23 13 13% 28 28%
24-25 18 18% 46 46%
26-27 15 15% 61 61%
28-29 10 10% 71 71%
30-31 7 7% 78 78%
32-33 8 8% 86 86%
34-35 5 5% 91 91%
36-37 3 3% 94 94%
38-39 4 4% 98 98%
40-41 1 1% 99 99%
42-43 1 1% 100 100%
TOTAL 100
Tabla 3. Distribución por intervalos de frecuencias de la edad en 100 pacientes
4
11
13
18
15
10
78
5
34
1 1
0
2
4
6
8
10
12
14
16
18
20
18-19 20-21 22-23 24-25 26-27 28-29 30-31 32-33 34-35 36-37 38-39 40-41 42-43
Figura 6. Histograma de frecuencias
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
23
4
11
13
18
15
10
78
5
34
1 10
2
4
6
8
10
12
14
16
18
20
18-19 20-21 22-23 24-25 26-27 28-29 30-31 32-33 34-35 36-37 38-39 40-41 42-43
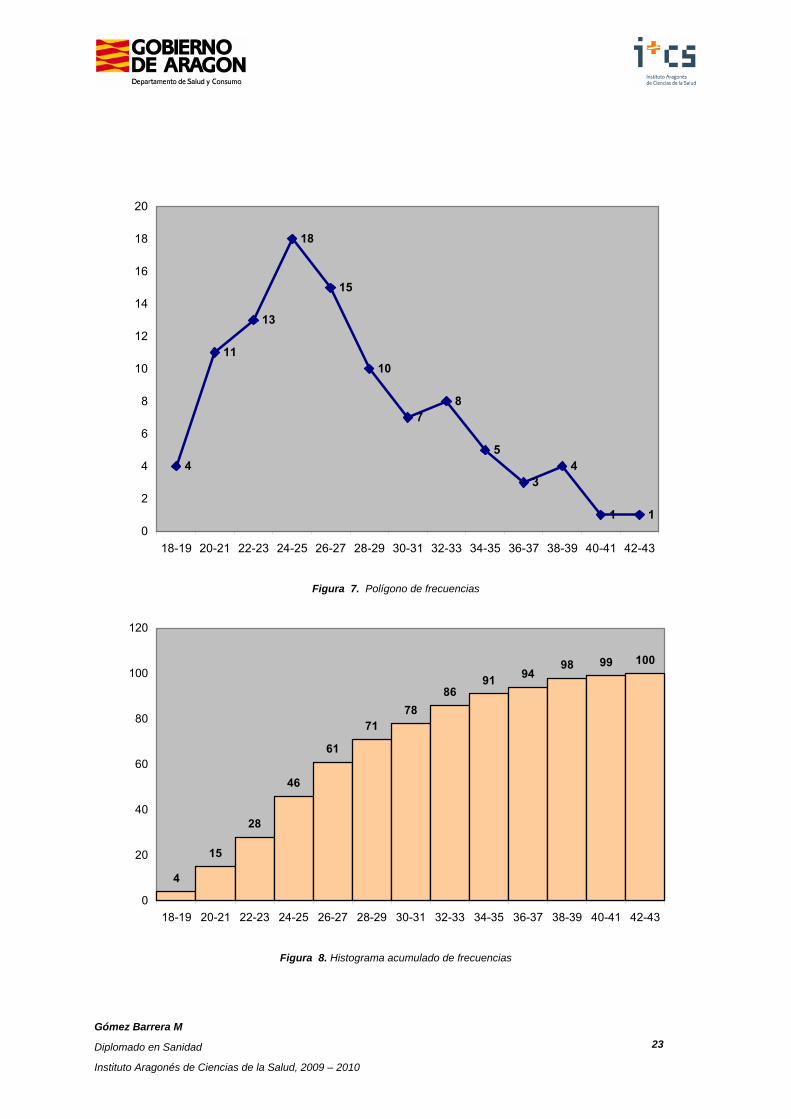
Figura 7. Polígono de frecuencias
4
15
28
46
61
7178
8691 94
98 99 100
0
20
40
60
80
100
120
18-19 20-21 22-23 24-25 26-27 28-29 30-31 32-33 34-35 36-37 38-39 40-41 42-43
Figura 8. Histograma acumulado de frecuencias
Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
24
4
15
28
46
61
7178
8691 94
98 99 100
0
20
40
60
80
100
120
18-19 20-21 22-23 24-25 26-27 28-29 30-31 32-33 34-35 36-37 38-39 40-41 42-43
Figura 9. Polígono acumulado de frecuencias
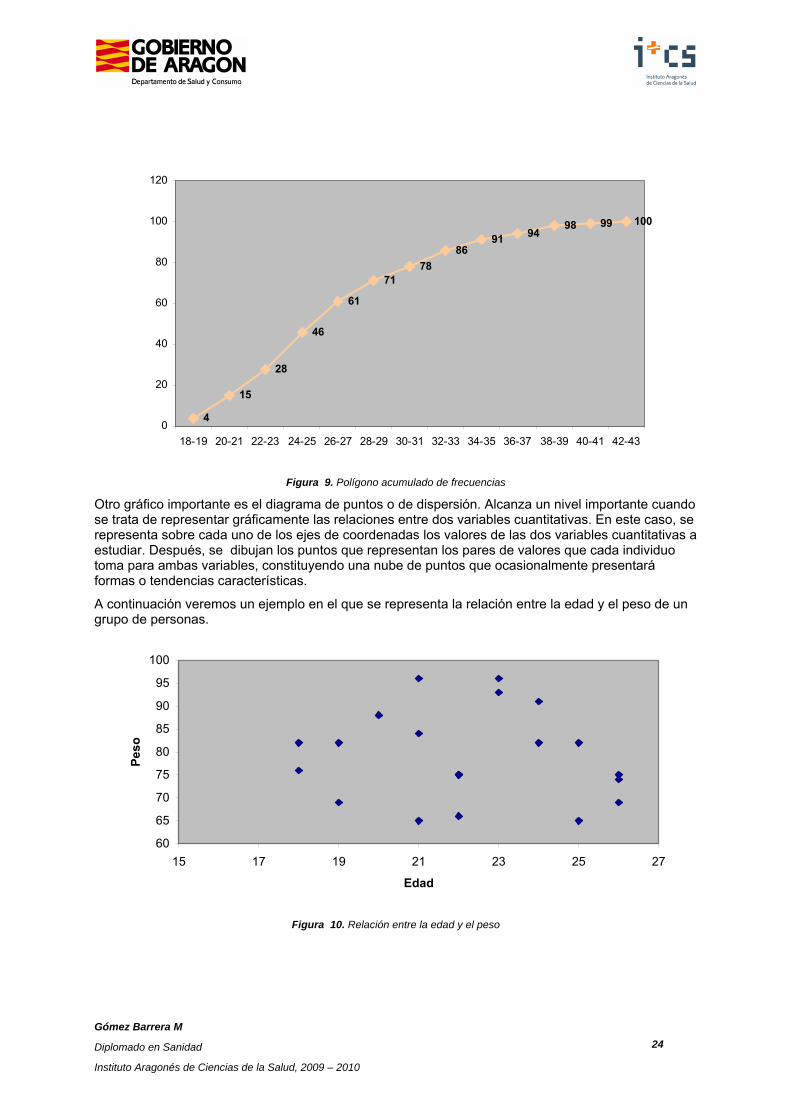
Otro gráfico importante es el diagrama de puntos o de dispersión. Alcanza un nivel importante cuando se trata de representar gráficamente las relaciones entre dos variables cuantitativas. En este caso, se representa sobre cada uno de los ejes de coordenadas los valores de las dos variables cuantitativas a estudiar. Después, se dibujan los puntos que representan los pares de valores que cada individuo toma para ambas variables, constituyendo una nube de puntos que ocasionalmente presentará formas o tendencias características.
A continuación veremos un ejemplo en el que se representa la relación entre la edad y el peso de un grupo de personas.
60
65
70
75
80
85
90
95
100
15 17 19 21 23 25 27
Edad
Peso
Figura 10. Relación entre la edad y el peso

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
25
4. Estadística Inferencial En Estadística, el término población no tiene el mismo sentido que en otras ciencias como la demografía o la biología. En esas ciencias, suele referirse al conjunto de individuos vivos de una especie, el ser humano en el caso de la demografía, que viven en un área geográfica determinada. Sin embargo, los estadísticos también hablan de poblaciones de objetos, sucesos, procedimientos u otro tipo de observaciones, que pueden estar agrupadas espacialmente, pero también referidas a un momento o un período de tiempo determinado.
En Bioestadística se debe enunciar claramente cuál es su población en estudio, aunque sea incapaz de enumerar cada uno de sus miembros con exactitud.
Sobre las poblaciones podemos calcular las medidas descriptivas que se han definido con anterioridad, tales como la media o la desviación estándar. En este caso, a estas medidas se les denomina parámetros poblacionales. Por convenio, suelen anotarse mediante letras griegas.
• Media: μ (letra griega mu).
• Desviación estándar: σ (letra griega sigma).
Los dos tipos de problemas que resuelven las técnicas de estadística inferencial son estimación y contraste de hipótesis. En ambos casos se trata de generalizar la información obtenida en una muestra a una población. Estas técnicas exigen que la muestra sea aleatoria, es decir, que todos los individuos hayan tenido la misma probabilidad de ser elegidos.
Entre la muestra con la que se trabaja y la población de interés, aparece la denominada población de muestreo: población de la cual nuestra muestra es una muestra aleatoria. En consecuencia la generalización está amenazada por dos posibles tipos de errores: error aleatorio que es el que las técnicas estadísticas permiten cuantificar y críticamente dependiente del tamaño muestral, pero también de la variabilidad de la variable a estudiar y el error sistemático que tiene que ver con la diferencia entre la población de muestreo y la población diana y que sólo puede ser controlado por el diseño del estudio.
El tamaño muestral juega el mismo papel en estadística que el aumento de la lente en microscopía: si no se ve una bacteria al microscopio, puede ocurrir que:
• la preparación no la contenga
• el aumento de la lente sea insuficiente
Para decidir el aumento adecuado hay que tener una idea del tamaño del objeto.
Del mismo modo, para decidir el tamaño muestral:
• en un problema de estimación hay que tener una idea de la magnitud a estimar y del error aceptable.
• en un contraste de hipótesis hay que saber el tamaño del efecto que se quiere ver.
4.1. Estimación de parámetros
Cuando procedemos a calcular las medidas estadísticas en una muestra aleatoria, representativa de una población, estas van a servir para realizar un acercamiento al valor que toman los parámetros poblaciones. Este proceso de acercamiento a los valores de los parámetros poblacionales a través de

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
26
las mediciones en las muestras se denomina estimación, y las mediciones en las muestras se denominan estimadores.
De este modo, la media calculada en una muestra es un estimador de la media poblacional. O también, la desviación estándar calculada en la muestra es un estimador de la desviación estándar poblacional. En el primer caso, la fórmula de cálculo es la misma en ambos casos. Para la desviación estándar, como hemos visto previamente, las fórmulas de cálculo son ligeramente distintas.
Esto se debe a que los matemáticos buscan que los estimadores tengan dos propiedades básicas:
• Precisión: Un estimador es preciso cuando si lo calculamos repetidas veces a partir de distintas muestras aleatorias de una población, los valores calculados estarán muy próximos unos de otros, presentando una variabilidad baja.
• Ausencia de sesgo: Un estimador es insesgado cuando si lo calculamos repetidas veces a partir de distintas muestras aleatorias de una población, el promedio de todos los valores calculados estará muy próximo al auténtico valor del parámetro poblacional.
4.3. Estimación puntual y por intervalo
Como se ha comentado, la inferencia estadística trata de cómo obtener información (inferir) sobre los parámetros a partir de subconjuntos de valores (muestras) de la variable. El problema fundamental que trata la inferencia es obtener información de una población a través de una muestra. Es obvio pensar que si se tomara otra muestra, la inferencia que hagamos puede ser distinta. Por tanto todas las inferencias serán inciertas; de ahí que se trate de dar rigor matemático a esa incertidumbre, cosa que se consigue midiéndola en términos de probabilidades.
El problema que se intenta solucionar es el siguiente: obtenida una muestra de tamaño n y calculada su media. ¿Puede afirmarse que dicho valor es la media de la población? ¿Puede decirse que el valor de la media poblacional estará en un intervalo de dicha media muestral?
La estimación puntual presenta sólo un valor. Suponiendo que se quiere calcular el número medio de caries por individuo en Huesca y se selecciona una muestra representativa para ello. Parece lógico pensar que, si se ha seleccionado una muestra representativa de una población, y la media de la muestra es de dos caries por persona, la media de la población no será muy diferente. Puestos a dar un valor de media de
caries por persona en la población de Huesca, es coherente dar el mismo resultado que el obtenido de la muestra, es decir dos caries por persona.
Si se pretende ir un poco más allá y seguir razonando con lógica, se puede pensar que si se dispone de 500 personas para la muestra, la media en esa muestra podría no ser la misma, si se hubiera seleccionado a otras 500 personas diferentes. Es por ello que se presenta la estimación por

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
27
intervalo. En este caso se presenta un intervalo de valores en los cuales se espera que se encuentre la verdadera media de la población, que no se conocerá nunca, con un determinado porcentaje de acierto.
Por medio de cálculos matemáticos, se obtiene un resultado, siguiendo con el ejemplo, del tipo siguiente. El intervalo de confianza al 95% para la media de caries por persona en Huesca es de (1-3). Es decir, existe un 95% de posibilidades de que la media de caries por persona en Huesca sea mayor de uno o menor que tres.
Como podemos deducir con un poco de imaginación, y por lo que se deduce de lo expuesto en el apartado anterior, a partir de una población determinada se podrán obtener numerosas muestras aleatorias distintas unas de otras de un tamaño n de individuos. Para cada una de estas muestras de tamaño n, se podrá calcular los estimadores correspondientes de la media y la desviación estándar de la población.
Otra cosa que se puede deducir es, que siendo distintas unas de otras estas muestras de tamaño n, en la mayor parte de las ocasiones las medias muestrales serán distintas también unas de otras. Si el estimador es preciso e
insesgado, estos valores distintos estarán muy próximos unos de otros y próximos a su vez al parámetro poblacional.
Los matemáticos muestran que dadas unas series de condiciones, podemos asumir que la media de las medias muestrales es igual a la media en la población, por lo que consideramos la media muestral como un estimador insesgado de la media de la población.
También nos dicen que la desviación estándar de las medias muestrales es igual a la desviación estándar de la población dividida por la raíz cuadrada del tamaño de la población. A la desviación estándar de las medias muestrales se le denomina también error estándar (EE) de la media, y es una medida de la precisión del estimador.
A la desviación estándar de las medias muestrales se le denomina también error estándar (EE) de la media, y es una medida de la precisión del estimador.
La precisión del estimador depende de dos factores. Es directamente proporcional a la variabilidad propia de los datos; sobre este hecho, como investigadores, no podemos intervenir. Pero es inversamente proporcional a la raíz cuadrada del tamaño de la muestra. Es decir, cuanto mayor sea el tamaño de la muestra, más precisa será nuestra estimación. El valor del error estándar será más pequeño, lo cual quiere decir que la variabilidad entre las medias muestrales será más pequeña y menor riesgo correremos de que el valor de la media de nuestra muestra se aleje mucho del verdadero valor de la media poblacional. El valor del error estándar, puesto que desconocemos el valor de la desviación estándar de la población, lo estimaremos a partir de la desviación estándar calculada en la muestra.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
28
El número y variedad de parámetros que se puede estimar en una población es muy diverso, y desde luego los problemas no se restringen a la estimación de medias. Otro de los parámetros que con frecuencia estimaremos en el ámbito de la salud pública es la proporción de individuos que presentan un determinado carácter en la población. Para ello, partiremos de la distribución de frecuencias de este carácter y sus alternativos para una determinada variable en un muestra que represente a la población.
Suponiendo que interesa conocer la estimación de aquellos que viven en su domicilio privado (14,29%) frente a los que viven en cualquier otro tipo de vivienda (85,71%). El tamaño de la muestra (n) es de 140 individuos estudiados. En este caso, el valor del error estándar de una proporción depende del propio valor de esta proporción, siendo la fórmula de cálculo como sigue.
Aplicando los datos de la tabla anterior:
Como se puede comprobar, también es inversamente proporcional a la raíz cuadrada del tamaño de la muestra, por lo que valen todos los razonamientos expuestos con anterioridad. En general, para cualquiera que sea el parámetro estimado, la precisión de la estimación mejorará cuanto mayor sea el tamaño de la muestra escogida. En el caso extremo, cuando se pueda estudiar a todos los individuos de la población, como se puede deducir, el valor de la estimación coincidirá con el del parámetro poblacional.
El objetivo fijado para este curso no es profundizar demasiado en temas de inferencia. Para un curso de 8 horas es suficiente con dejar claro el concepto de intervalo de confianza sujeto a una cierta probabilidad. El uso y la costumbre han hecho que se emplee el valor clave del 5% de error y el 95% de probabilidad de acertar. Es por ello que:
El intervalo de confianza al 95% de la media poblacional es un rango de valores entre los cuales se encuentra la verdadera (y siempre desconocida) media de la población. Para calcular los intervalos de el límite inferior del intervalo se le resta a la media el producto de 1,96 (coeficiente de confiabilidad del 95%) y la desviación típica dividida por la raíz cuadrada del tamaño muestral. Para el límite superior se realiza el mismo cálculo pero sumando a la media muestral el producto citado. Es decir en términos analíticos la expresión del intervalo es::
El intervalo de confianza al 95% de una proporción poblacional es un rango de valores entre los cuales se encuentra la verdadera (y siempre desconocida) proporción de la población. Para calcular los intervalos de el límite inferior del intervalo se le resta a la proporción muestral el producto de 1,96 (coeficiente de confiabilidad del 95%) y el error estándar que antes se ha comentado. Es decir, en términos analíticos la expresión del intervalo es:

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
29
4.4. Contraste de hipótesis
En este punto se comentan de forma muy sencilla aspectos referidos a contraste de hipótesis.
Una hipótesis estadística es una asunción relativa a una o varias poblaciones, que puede ser cierta o no. Las hipótesis estadísticas se pueden contrastar con la información extraída de las muestras y tanto si se aceptan como si se rechazan se puede cometer un error.
La hipótesis formulada con intención de rechazarla se llama hipótesis nula y se representa por H0. Rechazar H0 implica aceptar una hipótesis alternativa (H1).
La situación se puede esquematizar según la tabla 4.
H0 cierta H0 falsa H1 cierta
H0 rechazada Error tipo I (α) Decisión correcta (*)
H0 no rechazada Decisión correcta (*) Error tipo II (β)
Tabla 4. Posibles resultados a un contraste
• (*) Decisión correcta que se busca
• α = p(rechazar H0| H0 cierta)
• β = p(aceptar H0| H0 falsa)
• Potencia =1- β = p(rechazar H0| H0 falsa)
Detalles a tener en cuenta
• α y β están inversamente relacionadas.
• Sólo pueden disminuirse las dos, aumentando n.
Razonamiento intuitivo del contraste de hipótesis. El contraste de hipótesis tiene una base matemática compleja y una diversidad que excede los objetivos de este curso. Para facilitar su comprensión se puede decir que presenta siempre un resultado en términos de probabilidad, p. Esta p se puede entender, sin profundizar demasiado, como la probabilidad que tiene la hipótesis nula de ser como cierta según los datos de la muestra. Si este valor p es mayor que el error α que se acepta y esta fijado con anterioridad, se entiende que existe más probabilidad de acertar que de fallar que si la esta hipótesis se acierta. En resumen, si la probabilidad p, resultado del contraste es mayor que α, se acepta la hipótesis nula. Por el contrario, si la probabilidad p, es menor que α, se descarta la hipótesis nula y se acepta la alternativa.

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
30
El elemento clave del contraste de hipótesis es seleccionar el contraste adecuado a emplear
dependiendo del problema que se esté analizando. Los contrastes de hipótesis empleados presentan
una hipótesis nula en concepto de igualdad; simplificando mucho, estas hipótesis pueden ser:
• Variables cuantitativas
o La media, o algún otro resultado, es igual a un cierto valor
o Las dos medias, o dos varianzas, de una población son iguales
o Las medias de más de dos poblaciones son iguales
• Variables cualitativas
o Dos o más variables son independientes, test de independencia
o Una variable se distribuye de forma homogénea en otra, test de homogeneidad
o A efectos prácticos estos dos test son los llamados Chi-cuadrado y equivalen, de
forma coloquial, a decir que los porcentajes de la variable analizada, por ejemplo
curaciones, no son diferentes entre los grupos, por ejemplo hombres y mujeres.
Se presenta a continuación un diagrama para explicar el tipo de contraste a emplear en variables
cuantitativas y los modos de razonamiento.
Figura 11. Diagrama de selección de contraste de hipótesis en variables cuantitativas
Prueba de Kolmogorov-Smirnov. Ho: Distribución normal (0,05)
p(K-S)>0.05 y n≥30 CONTRASTES PARAMETRICOS
T-Student (una muestra)
H0: μ = μ0 H1: μ ≠ μ0 (0,025)
H1: μ >(<) μ0 (0,05)
T-Student (dos muestras independientes o relacionadas)
H0: μ1 = μ2 H1: μ1 ≠ μ2 (0,025)H1: μ1 >(<) μ2 (0,05)
Analizar: H0: σ21= σ2
2
H1: σ21≠σ2
2 (0.05)
ANOVA
H0: μ1=μ2=...=μk
H1: μ1≠μ2≠...≠μk (0,05)
p(K-S)<0.05 y n≤30 CONTRASTES NO PARAMETRICOS
U de Mann Whitney (datos independientes)
H0: μ1 = μ2 H1: μ1 ≠ μ2 (0,025)
T de Wilcoxon (datos relacionados)
H0: μ1 = μ2 H1: μ1 ≠ μ2 (0,025)
Kruskal Wallis (datos independientes)
H0: μ1=μ2=...=μkH1: μ1≠μ2≠...≠μk (0,05)
Friedman (datos relacionados)
H0: μ1=μ2=...=μkH1: μ1≠μ2≠...≠μk (0,05) (0,05)

Gómez Barrera M
Diplomado en Sanidad
Instituto Aragonés de Ciencias de la Salud, 2009 – 2010
31
Este diagrama se interpreta de la siguiente manera:
- En primer lugar se debe determinar si la variable a analizar, por ejemplo edad, sigue las
pautas de una distribución normal. Para ello se puede realizar un contraste de Kolomogorov-
Smirnov en el que la hipótesis nula es H0:Distribución normal. Fijado un error alfa de 0,05, el
habitual en Ciencias de la Salud, si el resultado p del test es mayor que 0,05 se acepta la
hipótesis, cuadro de la izquierda, y si es menor se rechaza, cuadro de la derecha.
- Si la distribución es normal se emplean los contrastes paramétricos, cuadro de la izquierda,
es decir, t de Student para una o dos muestras y ANOVA para más de dos muestras. Estos
contrasten comparan medias de diferentes poblaciones y las hipótesis son las presentes en la
tabla. En el test t de Student para dos medias se debe verificar antes si las varianzas son
iguales.
- Si la distribución no normal se trabaja con los test no paramétricos y se debe analizar si los
datos son independientes, cada sujeto se mide sólo una vez, o relacionados, cada sujeto se
mide más de una vez y se compara consigo mismo. Según se utilice un tipo de dato u otro,
que depende del experimento, y se disponga de dos o más muestras de dos o más
poblaciones se emplea una prueba u otra, como se indica en la tabla.
- Para variables cualitativas se emplea siempre la prueba de Chi cuadrado. Es no paramétrica,
pero presenta ciertos requisitos básicos. Ninguna categoría de las variables relacionadas, por
ejemplo género (varón, mujer) y color de ojos (marrón, azul, gris, negro) debe ser igual a cero
y no más del 20% debe ser menor de 5. En caso de que esto sucede, se soluciona
agregando categorías (azules frente a no azules) o eliminando categorías (azules y
marrones).





























