Embed Size (px)
Citation preview

Universidad Distrital Francisco Jose de CaldasFacultad de ingenierıa
Jose Luis Salazar Mayorga
Diseno, desarrollo e implementacion deun dispositivo IoT para la automatizacionde espacios de estacionamiento vehicularcon vision por computador y aprendizaje
profundo
Informe de pasantıa
Director interno: Julian Rolando Camargo LopezDirector externo: Marıa Eugenia Garcia de Gutierrez
Modalidad: Pasantıa
5 de julio de 2019Bogota D.C.

Indice general
Introduccion 3
1. Antecedentes 4
2. Objetivos 5
3. Marco teorico 63.1. Redes neuronales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3.1.1. Ventajas de las RNA . . . . . . . . . . . . . . . . . . . . . . . 63.1.2. Componentes de una red neuronal . . . . . . . . . . . . . . . . 73.1.3. Topologias de redes neuronales . . . . . . . . . . . . . . . . . 93.1.4. Tipos de aprendizaje . . . . . . . . . . . . . . . . . . . . . . . 93.1.5. Fases de aprendizaje de una red neuronal . . . . . . . . . . . . 123.1.6. Caracterısticas de una red neuronal . . . . . . . . . . . . . . . 12
3.2. Vision por computador . . . . . . . . . . . . . . . . . . . . . . . . . . 133.2.1. Vision de alto nivel . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3. Redes neuronales convolucionales . . . . . . . . . . . . . . . . . . . . 143.3.1. Capas de las redes neuronales convolucionales . . . . . . . . . 153.3.2. Funcionamiento de la red convolucional . . . . . . . . . . . . . 173.3.3. Red convolucional mAlexNet . . . . . . . . . . . . . . . . . . . 18
3.4. Entornos de trabajo para redes neuronales convolucionales . . . . . . 193.4.1. Entorno de trabajo Caffe . . . . . . . . . . . . . . . . . . . . . 20
3.5. Internet de las cosas . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.6. Dispositivos embebidos . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.6.1. Raspberry Pi . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.6.2. Camara Raspberry Pi Sony IMX219 . . . . . . . . . . . . . . 233.6.3. Sun Controller . . . . . . . . . . . . . . . . . . . . . . . . . . 243.6.4. Witty Pi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.6.5. Panel solar Voltaic 6W . . . . . . . . . . . . . . . . . . . . . . 25
4. Plan de trabajo 274.1. Fase I: Revision literaria . . . . . . . . . . . . . . . . . . . . . . . . . 274.2. Fase II: Construccion de bases de datos . . . . . . . . . . . . . . . . . 274.3. Fase III: Entrenamiento de la red neuronal . . . . . . . . . . . . . . . 274.4. Fase IV: Evaluacion de la red neuronal . . . . . . . . . . . . . . . . . 284.5. Fase V: Implementacion de dispositivo IoT . . . . . . . . . . . . . . . 28
5. Desarrollo y analisis de resultados 295.1. Construccion base de datos . . . . . . . . . . . . . . . . . . . . . . . . 295.2. Entrenamiento de la red neuronal . . . . . . . . . . . . . . . . . . . . 315.3. Pruebas de la red neuronal . . . . . . . . . . . . . . . . . . . . . . . . 365.4. Implementacion en dispositivo IoT . . . . . . . . . . . . . . . . . . . 43
1

6. Manual de usuario 52
7. Alcances y limitaciones 607.1. Alcances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 607.2. Limitaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
8. Analisis de cumplimiento de objetivos 618.1. Objetivo 1: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 618.2. Objetivo 2: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 618.3. Objetivo 3: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 618.4. Objetivo 4: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 628.5. Objetivo 5: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
9. Conclusiones 64
2

Introduccion
El estacionamiento vehicular se ha convertido en los ultimos anos en uno de losmayores retos para los automovilistas, encontrar una solucion a este problema esun desafıo; en Colombia el numero de vehıculos crece anualmente y no se tiene unsistema sofisticado que permita reducir los tiempos de espera y realizar esta tareade forma mas eficiente.
Un informe en 2017 revelo que Colombia para esa epoca era el paıs con el peortrafico vehicular en la region, los Colombianos perdıan en promedio 49 horas al anoestancados en embotellamientos, en cuanto a las ciudades, Bogota ocupo el cuartolugar en un ranking de 1.360 ciudades en todo el mundo, con respecto al estudiosobre movilidad Urbano Regional de las 557.776 infracciones de transito en Bogota,alrededor del 40% fueron a causa del estacionamiento en sitios prohibidos (El Uni-versal, 2017), este es un problema que afecta la movilidad y el tiempo que pasan laspersonas en las vıas, muchas veces producido por el mal estacionamiento o parqueoen zonas prohibidas.
En ciudades como Medellın un aporte a la solucion de la problematica del par-queo, tanto en espacio publico, como en las vıas de la ciudad, se ha venido imple-mentado la regulacion del estacionamiento en vıa publica mediante el programa de“Zonas de Estacionamiento Regulado” desde el ano 1999. El proyecto ha sido desa-rrollado en algunos lugares donde existıa mayor conflicto de estacionamiento y endonde era necesario devolver tanto la movilidad vehicular como peatonal, ası comoel despeje de areas no aptas para el estacionamiento, como esquinas, ingresos a par-queaderos, rampas para discapacitados, zonas duras, andenes, antejardines, entreotros.(Secretaria movilidad, 2019)
En medio de este panorama, la evolucion de las tecnologıas de la informaciony comunicacion (TIC) y la incorporacion de herramientas de internet de las cosas(IoT) en soluciones de innovacion, pueden lograr el uso adecuado de las zonas deestacionamiento, una mayor eficiencia y rentabilidad de los mismos, mejorando conesto el problema de movilidad y estacionamiento en el paıs.
En el presente documento se presenta el informe del proyecto realizado en laempresa Inversiones Gutierrez Garcia y Cia S en C, en donde se realizaron diferentesactividades con el fin de desarrollar un dispositivo para la deteccion de ocupacionde zonas de estacionamiento de caracter publico, ası como tambien privado, todoesto por medio del uso de vision por computador, redes neuronales convolucionales,Raspberry Pi, sensores y otros dispositivos electronicos.
3

1. Antecedentes
Recientemente en otros paıses se ha presentado un amplio interes en el desarrollode un sistema de parqueo inteligente, por medio de soluciones con camaras capacesde detectar la ocupacion de los estacionamientos en parqueaderos, se tiene comoreferencia el proyecto propuesto por Amato et al. (2016), en Pisa, Italia, donde serealizaron diferentes pruebas con fines investigativos, utilizando camaras en tiemporeal y un Raspberry Pi, el sistema desarrollado se basa en aprendizaje profundo porcomputador, especıficamente con la utilizacion de redes neuronales convolucionales.
A su vez los mismos autores desarrollaron una nueva investigacion en este tema,mencionada en (Amato et al., 2017), en la cual se realizan experimentos enfocadosen la produccion y pruebas de un dispositivo para la deteccion de ocupacion de espa-cios de estacionamiento con diferentes enfoques, ampliando el tamano de la base dedatos y utilizando diferentes angulos de vista de las camaras, este se basa en redesneuronales convolucionales, es desarrollado de la misma forma en un Raspberry Pi3B+, con camaras y un sistema para el control de la energıa electrica, con el cual serealizaron pruebas en el exterior obteniendo resultados favorables.
En Colombia especıficamente en Bogota se busca implementar un Sistema In-teligente de Estacionamiento (SIE), en donde el proceso se realizarıa por medio deparquımetros, que tendrıan conexion con aplicaciones moviles, como ya se realiza enpaıses de Norteamerica y Europa.
Con este nuevo sistema, el ciudadano podrıa localizar uno de los espacios deestacionamiento en la vıa y prepagar minutos de parqueo a traves de una aplicacionmovil o en un parquımetro, o serıa posible comprar tiempo en zonas de estacio-namiento en puntos de venta y de recarga autorizados, tambien permitirıa recibiruna alerta para adquirir mas minutos y permanecer estacionado o retirar el vehıculocuando este cerca de finalizar el tiempo autorizado para estacionar (Movilidad Bo-gota, 2019), pero esto sigue siendo un proceso que se encuentra en licitacion y quea la fecha actual no ha sido implementado en ninguna ciudad del paıs.
Como se ve en la informacion consultada, el parqueo inteligente es un temaque si bien ha sido abordado ampliamente en otros paıses, en Colombia aun no seha implementado un sistema o dispositivo que permita el control, automatizaciony regulacion de zonas de estacionamiento publico, e incluso privado, es decir queeste campo esta ampliamente abierto para el desarrollo de nuevas tecnologıas quepermitan la automatizacion de este proceso.
4

2. Objetivos
Objetivo general:
Disenar, desarrollar e implementar un dispositivo con vision por computadoray aprendizaje profundo para el control automatizado de ocupacion de zonas deestacionamiento vehicular.
Objetivos especıficos:
Realizar la revision literaria de los fundamentos y conceptos principales acercade redes neuronales convolucionales orientado a la vision por computador,clasificacion de imagenes y aprendizaje profundo.
Construir y analizar bases de datos de imagenes o vıdeo para ser utilizadasen el entrenamiento, validacion y prueba de modelos con redes neuronalesconvolucionales.
Utilizar una red neuronal convolucional que permita la clasificacion de ocupa-cion de espacios de estacionamiento a partir de caracterısticas extraıdas de lasimagenes de las bases de datos.
Evaluar el comportamiento de la red neuronal, con imagenes diferentes a lasde entrenamiento, validacion y prueba del modelo utilizado.
Implementar los modelos entrenados en un dispositivo con un Raspberry Pi yredes de sensores para dar una solucion en internet de las cosas.
5

3. Marco teorico
3.1. Redes neuronales
Las redes neuronales artificiales (RNA) son modelos inspirados en las cienciasbiologicas, que estudian como se ha desarrollado la neuroanatomıa de los seres vivospara resolver problemas, estas consisten de una gran cantidad de elementos interco-nectados conocidos como neuronas que asumen la funcion del cerebro, para intentaremular el comportamiento de este y desarrollar caracterısticas propias similares alas que provienen de la informacion sensorial, en el caso de las redes neuronales, lainformacion es almacenada en parametros conocidos como pesos en las diferentescapas que componen estas redes.
Estas se basan en las neuronas del sistema nervioso que se organizan en capas,de esta abstraccion emergen capacidades funcionales en los modelos que son pro-pias del cerebro. Entre las principales capacidades que emergen del funcionamientode las RNA, se destacan las memorias holograficas o su version computacional,las memorias asociativas de acceso por contenidos, la representacion distribuida, elprocesamiento paralelo, el aprendizaje a partir de casos conocidos, la inferencia, laconstruccion y clasificacion de patrones con aprendizaje supervisado, y por autoorganizacion (Gonzalo Tapia, 2015).
3.1.1. Ventajas de las RNA
Debido a su constitucion y a sus fundamentos, las redes neuronales artificialespresentan un gran numero de caracterısticas semejantes a las del cerebro. Por ejem-plo, son capaces de aprender de la experiencia, de generalizar de casos anteriores anuevos casos, de abstraer caracterısticas esenciales a partir de entradas que repre-sentan informacion irrelevante, etc. Esto hace que ofrezcan numerosas ventajas yque este tipo de tecnologıa se este aplicando en multiples areas. Entre las ventajasse incluyen (Ruiz & Matich, 2001):
Aprendizaje adaptativo: capacidad de aprender a realizar tareas basadas enun entrenamiento o en una experiencia inicial.
Auto-organizacion: una red neuronal puede crear su propia organizacion orepresentacion de la informacion que recibe mediante una etapa de aprendizaje.
Tolerancia a fallos: la destruccion parcial de una red conduce a una degradacionde su estructura; sin embargo, algunas capacidades de la red se pueden retener,incluso sufriendo un gran dano.
Operacion en tiempo real: los computos neuronales pueden ser realizados enparalelo; para esto se disenan y fabrican maquinas con hardware especial paraobtener esta capacidad.
6

Adaptabilidad: se pueden obtener chips especializados para redes neuronalesque mejoran su capacidad en ciertas tareas. Esto facilita la integracion modularen los sistemas existentes.
3.1.2. Componentes de una red neuronal
Una red neuronal esta constituida por neuronas interconectadas y arregladasgeneralmente en tres capas, los datos ingresan por medio de la capa de entrada,pasan a traves de la capa oculta, que en algunos casos puede estar constituida porvarias capas, por ultimo se obtiene un resultado en la capa de salida, el cual puedeestar dado por una probabilidad, una clase, un numero, etc... dependiendo del tipoy la configuracion de la red, en la figura 3.1 se muestra un esquema general de laestructura de una red neuronal (Ruiz & Matich, 2001).
Figura 3.1: Estructura de una red neuronal artificial. (Gonzalo Tapia, 2015)
La distribucion de neuronas dentro de la red se realiza formando niveles o capas,con un numero determinado de dichas neuronas en cada una de ellas. A partir desu situacion dentro de la red, se pueden distinguir tres tipos de capas:
Capa de entrada: es la capa que recibe directamente la informacion prove-niente de las fuentes externas de la red.
Capas ocultas: son internas a la red y no tienen contacto directo con elentorno exterior, el numero de niveles ocultos puede estar entre cero y unnumero elevado. Las neuronas de las capas ocultas pueden estar interconecta-das de distintas maneras, lo que determina, junto con su numero, las distintastopologıas de redes neuronales.
Capa de salida: transfieren informacion de la red hacia el exterior, en una redde varias capas cada nodo o neurona unicamente esta conectada con neuronasde un nivel superior, se dice que una red es totalmente conectada si todaslas salidas desde un nivel llegan a todos y cada uno de los nodos del nivelsiguiente.
7

3.1.2.1. Funcion de entrada
La neurona trata a muchos valores de entrada como si fueran uno solo, esto recibeel nombre de entrada global. Esto se logra a traves de la funcion de entrada, la cualse calcula a partir del vector entrada. La funcion de entrada puede describirse comose muestra en la ecuacion 3.1.
inputi = (ini1 · wi1) ∗ (ini2 · wi2) ∗ ...(inin · win) (3.1)
donde: ∗ representa al operador apropiado (por ejemplo: maximo, sumatoria,productoria, etc.), n al numero de entradas a la neurona Ni y wi al peso.
Los valores de entrada se multiplican por los pesos anteriormente ingresados a laneurona, por consiguiente, los pesos que generalmente no estan restringidos cambianla medida de influencia que tienen los valores de entrada. Es decir, que permitenque un gran valor de entrada tenga solamente una pequena influencia, si estos sonlo suficientemente pequenos. (Ruiz & Matich, 2001)
3.1.2.2. Funcion de activacion
Una neurona biologica puede estar activa (excitada) o inactiva (no excitada), esdecir, que tiene un “estado de activacion”. La funcion activacion calcula el estadode actividad de una neurona, transformando la entrada global en un valor (estado)de activacion, cuyo rango normalmente va de (0,1) o de (–1,1). Esto es ası, porqueuna neurona puede estar totalmente inactiva o activa (Ruiz & Matich, 2001).
3.1.2.3. Funcion de propagacion
La funcion de propagacion indica el procedimiento que se debe seguir para com-binar los valores de entrada y los pesos de las conexiones que llegan a una neurona.Todos los pesos wij se suelen agrupar en una matriz W , indicando la influencia quetiene la neurona i sobre la neurona j, este conjunto de pesos puede ser positivo,negativo o nulo, como se explica a continuacion (Andrade, 2013).
Wij Positivo: la interaccion entre las neuronas i y j es excitadora, es decircuando la neurona i este activa, emitira una senal a la neurona j que tienda aexcitarla.
Wij Negativo: la sinapsis o conexion entre la neurona i y j es inhibitoria,es decir si la neurona i esta activa emitira una senal a la neurona j que ladesactivara.
Wij Nulo: Cuando Wij = 0, se considera que no existe conexion entre ambasneuronas.
La funcion de propagacion permite obtener el valor de potencial post sinapticoNetj de una neurona en un momento t, de acuerdo con una funcion de probabilidad,el valor Netj se calcula en base a los valores de entrada y pesos recibidos. La funcionmas utilizada es de tipo lineal y consiste en la suma ponderada de las entradas con
8

los pesos sinapticos a ella asociados, como se muestra en la ecuacion 3.2 (Andrade,2013).
Netj =∑
i
wij ∗ xi(t) (3.2)
3.1.2.4. Funcion de salida
El ultimo componente que una neurona necesita es la funcion de salida. El valorresultante de esta funcion es la salida de la neurona, por ende, la funcion de salidadetermina que valor se transfiere a las neuronas vinculadas. Si la funcion de activa-cion esta por debajo de un umbral determinado, ninguna salida se pasa a la neuronasubsiguiente. Normalmente, no cualquier valor es permitido como una entrada parauna neurona, por lo tanto, los valores de salida estan comprendidos en el rango [0,1] o [-1, 1]. Tambien pueden ser binarios {0, 1} o {-1, 1} (Ruiz & Matich, 2001).
3.1.3. Topologias de redes neuronales
La topologıa o arquitectura de una red neuronal consiste en la organizacion ydisposicion de las neuronas en la misma, formando capas o agrupaciones de neuronasmas o menos alejadas de la entrada y salida de dicha red. En este sentido, losparametros fundamentales de la red son el numero de capas, el numero de neuronaspor capa, el grado de conectividad y el tipo de conexiones entre neuronas (Ruiz &Matich, 2001), estas se clasifican como sigue:
Redes monocapa.
En las redes monocapa, se establecen conexiones entre las neuronas que per-tenecen a la unica capa que constituye la red. Las redes monocapas se utilizangeneralmente en tareas relacionadas con lo que se conoce como auto asociacion(regenerar informacion de entrada que se presenta a la red de forma incompletao distorsionada).
Redes multicapa.
Las redes multicapas son aquellas que disponen de un conjunto de neuronasagrupadas en varios (2, 3, etc.) niveles o capas. Una forma para distinguirla capa a la que pertenece una neurona, consiste en fijarse en el origen de lassenales que recibe a la entrada y el destino de la senal de salida. Normalmente,todas las neuronas de una capa reciben senales de entrada desde otra capaanterior (la cual esta mas cerca a la entrada de la red), y envıan senales desalida a una capa posterior (que esta mas cerca a la salida de la red).
3.1.4. Tipos de aprendizaje
Los datos de entrada se procesan a traves de la red neuronal con el propositode lograr una salida, como se sabe que las redes neuronales extraen generalizacionesdesde un conjunto determinado de ejemplos anteriores de tales problemas de deci-sion, una red neuronal debe aprender a calcular la salida correcta para cada entrada
9

en el conjunto de ejemplos. Este proceso de aprendizaje se denomina proceso deentrenamiento o acondicionamiento, los datos (o conjunto de ejemplos) sobre el cualeste proceso se basa es llamado conjunto de datos de entrenamiento (Ruiz & Matich,2001).
En otras palabras el aprendizaje es el proceso por el cual una red neuronal modifi-ca sus pesos en respuesta a una informacion de entrada, los cambios que se producendurante el mismo se reducen a la destruccion, modificacion y creacion de conexio-nes entre las neuronas. En los sistemas biologicos existe una continua destrucciony creacion de conexiones entre las neuronas. En los modelos de redes neuronalesartificiales, la creacion de una nueva conexion implica que el peso de la misma pasaa tener un valor distinto de cero. De la misma manera, una conexion se destruyecuando su peso pasa a ser cero (Ruiz & Matich, 2001).
Durante el proceso de aprendizaje, los pesos de las conexiones de la red sufrenmodificaciones, por lo tanto, se puede afirmar que este proceso ha terminado (la redha aprendido) cuando los valores de los pesos permanecen estables (dwij/dt = 0).Un aspecto importante respecto al aprendizaje de las redes neuronales es el conocercomo se modifican los valores de los pesos, es decir, cuales son los criterios que sesiguen para cambiar el valor asignado a las conexiones cuando se pretende que lared aprenda una nueva informacion. Hay dos metodos de aprendizaje importantesque pueden distinguirse el aprendizaje supervisado y el aprendizaje no supervisado(Ruiz & Matich, 2001).
Las redes neuronales de aprendizaje supervisado son las mas populares, los datospara el entrenamiento estan constituidos por varios pares de patrones de entrena-miento de entrada y de salida, en donde el hecho de conocer la salida implica queel entrenamiento se beneficia de la supervision de un maestro (Marın Diazaraque,2012).
Una generalizacion de la formula o regla para decir los cambios en los pesos esla siguiente:
Peso Nuevo = Peso Viejo + Cambio de Peso
Matematicamente esto se puede definir como se muestra en la ecuacion 3.3
wij(t+ 1) = wij(t) + ∆wij(t) (3.3)
donde t hace referencia a la etapa de aprendizaje, wij(t + 1) al peso nuevo ywij(t) al peso viejo.
El aprendizaje supervisado se caracteriza porque el proceso de aprendizaje serealiza mediante un entrenamiento controlado por un agente externo (supervisor,maestro) que determina la respuesta que deberıa generar la red a partir de unaentrada determinada. El supervisor controla la salida de la red y en caso de que estano coincida con la deseada, se procedera a modificar los pesos de las conexiones, conel fin de conseguir que la salida obtenida se aproxime a la deseada, como se muestraen la figura 3.2.
10

Figura 3.2: Modelo de correccion de error en aprendizaje supervisado.(Marın Dia-zaraque, 2012)
3.1.4.1. Propagacion hacia atras
El algoritmo de propagacion hacia atras o en ingles(backpropagation) tiene dosfases, una hacia adelante y una hacia atras. En la primera fase, el patron de entradase presenta a la red y se propaga a traves de las capas hasta llegar a la capa desalida, obteniendose los valores de salida de la red. La segunda fase inicia cuando secomparan los valores obtenidos con los valores de salida esperados para ası obtenerel error (Sanchez Anzola, 2016).
La segunda fase transmite hacia atras el error, a partir de la capa de salida,hacia todas las neuronas de la capa intermedia que contribuyan directamente a lasalida, recibiendo el porcentaje de error aproximado a la participacion de la neuronaintermedia en la salida original. Este proceso se repite, capa por capa, hasta quetodas las neuronas de la red hayan recibido un error que describa su aportacionrelativa al error total. Basandose en el valor del error recibido, se reajustan los pesosde conexion de cada neurona, de manera que la siguiente vez que se presente elmismo patron, la salida este mas cercana a la deseada y, por tanto, disminuya elerror(Sanchez Anzola, 2016).
El algoritmo finaliza cuando se verifica su condicion de parada, ya sea porque elerror calculado de la salida es inferior al permitido, o porque se ha superado el nume-ro de iteraciones, por lo cual se considera que se deben hacer ajustes al diseno de lared, pues la solucion no converge, o se debe ampliar el numero de iteraciones; esteencuentra su valor mınimo de error local o global mediante la aplicacion de pasosdescendentes (algoritmo del gradiente descendente). Con el gradiente descendente,cada vez que se realizan cambios a los pesos de la red, se asegura el descenso porla superficie del error hasta encontrar el valle mas cercano, lo que puede hacer queel proceso de aprendizaje se detenga en un mınimo local de error (Sanchez Anzola,2016).
Uno de los problemas que presenta este algoritmo de entrenamiento es que buscaminimizar la funcion de error, pudiendo caer en un mınimo local o en algun punto
11

estacionario, con lo cual no se llega a encontrar el mınimo global de la funcion deerror. Dado el inconveniente que presenta el algoritmo de gradiente descendente detener el parametro de aprendizaje fijo, se suele aplicar el algoritmo pero con unatasa de aprendizaje variable en el proceso de aprendizaje con el fin de modificar eltamano de la variacion de los pesos ∆wi y acelerar la convergencia del algoritmo deaprendizaje (Sanchez Anzola, 2016).
3.1.5. Fases de aprendizaje de una red neuronal
Fase de entrenamiento: se usa un conjunto de datos o patrones de entre-namiento para determinar los pesos (parametros) que definen el modelo dered neuronal. Se calculan de manera iterativa, de acuerdo con los valores deentrenamiento procedentes del conjunto de datos, con el objeto de minimi-zar el error entre la salida real de la red neuronal y la salida deseada (MarınDiazaraque, 2012).
Fase de Prueba: en la fase anterior, el modelo puede que se ajuste demasiadoa las particularidades presentes en los patrones de entrenamiento, perdiendosu habilidad de generalizar su aprendizaje a casos nuevos (sobreajuste). Paraevitar el problema del sobreajuste, es aconsejable utilizar un segundo grupo dedatos diferentes a los de entrenamiento, el grupo de validacion, que permitacontrolar el proceso de aprendizaje(Marın Diazaraque, 2012).
3.1.6. Caracterısticas de una red neuronal
Regeneracion de patrones
En muchos problemas de clasificacion, una cuestion a solucionar es la recu-peracion de informacion, esto es, recuperar el patron original dada solamenteuna informacion parcial. Hay dos clases de problemas: temporales y estaticos.El uso apropiado de la informacion contextual es la llave para tener exito enel reconocimiento de patrones(Ruiz & Matich, 2001).
Generalizacion
El objetivo de la generalizacion es dar una respuesta correcta a la salida paraun estımulo de entrada que no ha sido entrenado con anterioridad. El sistemadebe inducir la caracterıstica saliente del estımulo a la entrada y detectar laregularidad, tal habilidad para el descubrimiento de esa regularidad es crıticaen muchas aplicaciones. Esto hace que el sistema funcione eficazmente en to-do el espacio, incluso cuando ha sido entrenado por un conjunto limitado deejemplos (Ruiz & Matich, 2001).
Optimizacion
Las Redes Neuronales son herramientas interesantes para la optimizacion deaplicaciones, que normalmente implican la busqueda del mınimo absoluto deuna funcion. Para algunas aplicaciones, la funcion es facilmente deducible, pero
12

en otras, sin embargo, se obtiene de ciertos criterios de coste y limitacionesespeciales (Ruiz & Matich, 2001).
3.2. Vision por computador
El termino vision por computador ha sido muy utilizado en los ultimos anos ytiende a ser confundido con otros terminos, con el fin de establecer un concepto seasocia al procesamiento digital de imagenes, mediante el cual se toma una imagenque se obtiene por una camara, despues se produce una version modificada de estaimagen que se procesa en algun computador o procesador digital. Luego de esto serealiza el analisis de la imagen que es el proceso mediante el cual a partir de laimagen se obtiene una medicion, interpretacion o decision, el proceso mencionadose realiza mediante los siguientes pasos(Mery, 2004):
Figura 3.3: Esquema de un proceso de analisis de imagenes: adquisicion de la imagen,preprocesamiento, segmentacion, medicion (o extraccion de caracterısticas), inter-pretacion o clasificacion (Mery, 2004).
Adquisicion de la imagen: se obtiene la imagen adecuada del objeto de estudio.Dependiendo de la aplicacion la imagen puede ser una fotografıa, radiografıa,termografıa, etc.
Preprocesamiento: con el fin de mejorar la calidad de la imagen obtenida seemplean ciertos filtros digitales que eliminan el ruido en la imagen o bienaumentan el contraste.
Segmentacion: se identifica el objeto de estudio en la imagen.
Medicion (extraccion de caracterısticas): se realiza una medicion objetiva deciertos atributos de interes del objeto de estudio.
13

Interpretacion (clasificacion): de acuerdo a los valores obtenidos en las medi-ciones se lleva a cabo una interpretacion del objeto.
El analisis de imagenes esta estrechamente relacionado con el reconocimientode patrones ya que en muchas aplicaciones el universo de interpretaciones es unconjunto discreto determinado por clases. Para casos sencillos basta con determinarcorrectamente ciertos umbrales de decision. Para otros casos es necesario emplearclasificaciones mas sofisticadas como las redes neuronales (Mery, 2004).
3.2.1. Vision de alto nivel
La vision de alto nivel busca encontrar una interpretacion consistente de lascaracterısticas obtenidas por medio de la segmentacion de imagenes. Se utiliza co-nocimiento especıfico de cada dominio para refinar la informacion obtenida de visionde nivel bajo e intermedio, conocida tambien como percepcion primitiva. El procesose ilustra en la figura 3.4. Para esto, se requiere una representacion interna o modeloque describe los objetos en el mundo (o en el dominio de interes) (Sucar & Gomez,2011).
Figura 3.4: Proceso de descomposicion vision de alto nivel.
La vision de alto nivel tiene que ver, basicamente, con reconocimiento, es decir,con hacer una correspondencia de la representacion interna del mundo con la infor-macion sensorial obtenida por medio de vision. Por ejemplo, en el reconocimiento decaracteres, se tiene una representacion de cada letra en base a ciertos parametros.Al analizar una imagen, se obtienen parametros similares y se comparan con losde los modelos. El modelo que tenga una mayor “similitud”, se asigna al caracterde la imagen. La forma en que se representan tanto los modelos internos como lainformacion de la imagen tiene una gran repercusion en la capacidad del sistema devision. (Sucar & Gomez, 2011)
3.3. Redes neuronales convolucionales
Las redes neuronales profundas (Deep Neural Networks en ingles) es el nombreque se da a las nuevas arquitecturas de las redes neuronales y a los nuevos algoritmosque se usan para aprender usando estas arquitecturas. El aprendizaje profundo mo-derno proporciona un marco muy poderoso para el aprendizaje supervisado. Estas
14

nuevas arquitecturas de redes han logrado cambios importantes en la direccion en laque se desarrolla la inteligencia artificial al proveer diferentes estructuras y nuevosalgoritmos para el aprendizaje que permiten incrementar el numero de capas y asıproveyendo de mayor flexibilidad a los modelos para el reconocimiento de patrones.(Quintero et al., 2018)
Para el reconocimiento de imagenes se hace uso de las redes neuronales convolu-cionales (CNN por sus siglas en ingles), las cuales son un modelo donde las neuronascorresponden a campos receptivos de una manera muy similar a las neuronas de lacorteza visual primaria de un cerebro biologico. La red se compone de multiples ca-pas. En el principio se encuentra la fase de extraccion de caracterısticas compuestade neuronas convolucionales y de reduccion, a medida que se avanza en la red sedisminuyen las dimensiones activando caracterısticas cada vez mas complejas. Alfinal se encuentran neuronas sencillas para realizar la clasificacion.(Quintero et al.,2018)
3.3.1. Capas de las redes neuronales convolucionales
3.3.1.1. Capa convolucional
Su principal proposito es extraer caracterısticas de una imagen, consiste de unconjunto de filtros entrenables que realizan producto punto con los valores de lacapa precedente. En la practica, los valores de los filtros son aprendidos para su ac-tivacion al encontrar ciertas caracterısticas.(Quintero et al., 2018) Al ser colocadosen cascada se obtienen diferentes niveles de abstraccion que pueden o no ser inter-pretados de forma grafica debido al nivel de complejidad, el tamano o el numero defiltros, en la figura 3.5 se muestra un ejemplo de como se ven graficamente los filtrosconvolucionales.
Figura 3.5: Filtros entrenables de la capa convolucional (Asawa, 2015)
Los parametros de esta capa son:
num output: es el numero de filtros que se aplican a la entrada.
kernel size: especifica la altura y el ancho de cada filtro
bias term: especifica si se debe aprender y aplicar un conjunto de sesgos adi-tivos a las salidas del filtro.
15

pad: especifica el numero de pıxeles que se agregaran (implıcitamente) a cadalado de la entrada.
stride: especifica los intervalos a los que se aplican los filtros a la entrada.
3.3.1.2. Agrupacion
Por su nombre en ingles (pooling), es un algoritmo utilizado para reducir lasdimensiones de las capas anteriores, especialmente despues de las capas de con-volucion, con el objetivo de disminuir los tiempos de procesamiento reteniendo lainformacion mas importante. Es comun insertar periodicamente una capa de agru-pacion entre capas convolutivas sucesivas. Su funcion es reducir progresivamente eltamano espacial de la representacion como se aprecia en la figura 3.6 para disminuirla cantidad de parametros y el calculo en la red y, por lo tanto, tambien controlarel sobreajuste. La capa de agrupacion opera independientemente y redimensiona laentrada espacialmente, utilizando la operacion maximo (Asawa, 2015).
Los parametros de esta capa son:
kernel size: especifica la altura y el ancho de cada filtro.
pool: especifica el metodo de agrupacion, puede ser maximo, promedio o es-tocastico.
pad: especifica el numero de pıxeles que se agregaran (implıcitamente) a cadalado de la entrada.
stride especifica los intervalos a los que se aplican los filtros a la entrada.
Figura 3.6: Capa de agrupacion o pooling. (Duran, 2017)
3.3.1.3. Rectificador Lineal de Unidad
Son utilizados despues de cada convolucion, en esta capa se realiza una operacionque reemplaza los valores negativos por cero y su proposito es agregar no linealidad almodelo, eliminando la relacion proporcional entre la entrada y salida(Quintero et al.,2018). Es la funcion de activacion comunmente mas usada en modelos de aprendizajeprofundo, esta retorna cero si recibe una entrada negativa, para cualquier valorpositivo a la entrada retorna el valor original.
16

3.3.1.4. Normalizacion de respuesta local
La capa de normalizacion de la respuesta local realiza una especie de inhibicionde los valores de la capa anterior, al normalizar las regiones de entrada locales. Estacapa es util cuando se trata con neuronas ReLU, debido a que estas tienen activacio-nes ilimitadas y es necesario normalizarlas, esto con el fin de detectar caracterısticasde alta frecuencia con una gran respuesta (Krizhevsky et al., 2012).
Al mismo tiempo, amortigua las respuestas que son uniformemente grandes encualquier vecindario local dado. Si todos los valores son grandes, la normalizacion deesos valores disminuira todos ellos. Basicamente, se fomenta algun tipo de inhibiciony se estimulan las neuronas con activaciones relativamente mas grandes (Krizhevskyet al., 2012).
3.3.1.5. Capa totalmente conectada
Generalmente se encuentra en las ultimas capas y realiza la clasificacion basadoen las caracterısticas extraıdas por las capas de convolucion y las de pooling. Enesta capa todos los nodos estan conectados con la capa precedente y trata la entra-da como un vector simple lo que produce una salida en forma de un solo vector deacuerdo a la funcion de salida y al tamano establecido.
Los parametros de esta capa son:
num output: indica el numero de filtros.
bias term: especifica si se debe aprender y aplicar un conjunto de sesgos adi-tivos a las salidas del filtro.
3.3.1.6. Softmax
Es una distribucion que asigna probabilidades decimales a cada clase en un casode clases multiples, ideal para un clasificador, estas probabilidades decimales debensumar 1.0. Aplicar esta funcion permite que el entrenamiento converja mas rapido.Se implementa a traves de una capa de red neuronal justo antes de la capa deresultado, permitiendo determinar el numero de clases a la salida por lo cual debetener la misma cantidad de clases que se quieran para el clasificador.
3.3.2. Funcionamiento de la red convolucional
Las capas de convolucion y las capas de pooling se encargan de extraer carac-terısticas mientras que la capa totalmente conectada actua como clasificador. Parael funcionamiento de este modelo se debe proceder al entrenamiento (Asawa, 2015).Esto implica realizar los siguientes pasos:
Inicializar todos los parametros o pesos con valores aleatorios.
Utilizar una imagen de entrenamiento y utilizarla en el modelo.
17

Calcular el error total de las probabilidades resultantes del modelo.
Propagar hacia atras para calcular el error de gradiente de todos los pesos en lared y utilizar gradiente descendiente para actualizar estos valores y minimizarel error de salida.
En la figura 3.7 se muestra un esquema general de como opera una red neuronalconvolucional, en donde se muestra la entrada, el proceso a traves de las diferentescapas, y la salida del clasificador a grandes rasgos.
Figura 3.7: Esquema de funcionamiento de una red neuronal convolucional.
3.3.3. Red convolucional mAlexNet
La red convolucional mAlexNet se basa en la red descrita por Krizhevsky et al.(2012) comunmente conocida en el reconocimiento de imagenes, en mAlexNet fue-ron suprimidas la tercera y cuarta capas convolucionales y una capa totalmenteconectada, las capas convolucionales uno y tres continuan de la misma forma queen AlexNet cada una seguida por max pooling, normalizacion de respuesta local(LRN) y rectificacion lineal (ReLU), excepto para la capa convolutiva numero tresdonde no se realiza LRN, en comparacion con AlexNet el numero de neuronas enla capa totalmente de salida, se reducen drasticamente para adaptarse a escenariosque requieran de un bajo nivel de procesamiento (Amato et al., 2016).
En las capas totalmente conectadas (fc4, fc5), no se adopta ninguna tecnica deabandono de neuronas (dropout) y se opta por la distribucion de probabilidad soft-max para obtener una salida de probabilidad entre el valor de 0 y 1 (Amato et al.,2016); estas caracterısticas se muestran mas detalladamente en la tabla 3.1, en don-de para cada capa se especifica el numero y el tamano de los filtros como “numerox ancho x altura + stride”, la operacion de agrupacion maxima aplicada como “an-cho x altura + stride” y si se aplica (LNR) y/o (ReLU). Para las capas totalmenteconectadas, se muestra su dimensionalidad y en la capa de salida la funcion softmaxde 2 clases que sigue a la ultima capa completamente conectada.
18

Tabla 3.1: parametros de la red mAlexNet.Red conv1 conv2 conv3 fc4 fc5
mAlexNet16x11x11+4pool 3x3+2LRN, ReLU
20x5x5+1pool 3x3+2LRN, ReLU
30x3x3+1pool 3x3+2
ReLU
48ReLU
2soft-max
A diferencia de AlexNet, esta arquitectura tiene una conexion densa entre capasconvolucionales. Este tipo de redes tienen exito en tareas de reconocimiento visualya que suelen tener menos de cinco capas entrenables, con el fin de realizar loscalculos tiempo real en un dispositivo integrado. Esta caracterıstica es apreciabledado que las arquitecturas originales estan disenadas para tareas de reconocimientovisual a gran escala, las cuales son mucho mas complejas que en los problemas declasificacion binaria como lo es el caso de la clasificacion de ocupacion de espaciosde estacionamiento.
Con base en las pruebas realizadas por Amato et al. (2016) se observo a travesde experimentos que las arquitecturas reducidas pueden hacer frente con facilidadal problema de clasificacion de espacios de estacionamiento. Esta arquitectura tomacomo entrada una imagen RGB de 224x224, por lo tanto, cada imagen se debe nor-malizar antes del entrenamiento y/o clasificacion, la arquitectura de la red mAlexNetse muestra en la figura 3.8.
Figura 3.8: red neuronal convolucional mAlexNet. (Amato et al., 2016)
3.4. Entornos de trabajo para redes neuronales
convolucionales
En la actualidad existen muchos entornos o herrmientas de desarrollo que permi-ten trabajar con redes neuronales convolucionales, como ejemplos de esto se puedenenumerar (Picazo Montoya, 2018):
Caffe: Desarrollado por la Universidad de Berkeley
Caffe2: Sucesor de Caffe, soportado por Facebook.
TensorFlow: Soportado por Google.
Torch: Soportado por ingenieros de Facebook, Twitter y Google.
19

Pytorch: Una verson de Torch para Python soportada por Facebook.
CNTK: Soportado por Microsoft.
DSSTNE: Soportado por Amazon.
3.4.1. Entorno de trabajo Caffe
Este entorno de trabajo permite trabajar redes neuronales convolucionales, de talforma que solo se deben ajustar los parametros que se requieran para las diferentesfases del aprendizaje de las redes neuronales, es decir permite la creacion de lascapas, el ajuste de parametros, entradas, salidas, entre otros componentes de lasredes neuronales convolucionales (Picazo Montoya, 2018).
Los parametros que se deben configurar para el entrenamiento de una red neu-ronal son los siguientes:
base lr: este parametro indica la tasa de aprendizaje base (inicio) de la red. Elvalor es un numero real (punto flotante).
lr policy: este parametro indica como la velocidad de aprendizaje debe cambiarcon el tiempo, las opciones incluyen:
• step: se disminuye la tasa de aprendizaje en los tamanos de paso indicadospor el parametro gamma.
• multistep: disminuye la tasa de aprendizaje en el tamano de paso indicadopor el gamma en cada valor de paso especificado.
• fixed: la tasa de aprendizaje no cambia.
• exp: la tasa de aprendizaje varia de forma exponencial segun la ecuacionque se muestra a continuacion.
base lr ∗ gamma ∧ iter
• poli: la tasa de aprendizaje efectiva sigue una decadencia polinomica, quesera cero en la maxima iteracion, segun lo descrito por:
base lr ∗ (1− iter/max iter) ∧ (potencia)
• sigmoide: la tasa de aprendizaje efectiva sigue una decadencia de sigmoi-de, de acuerdo a la siguiente ecuacion:
base lr ∗ (1/(1 + exp(−gamma ∗ (iter − stepsize))))
donde base lr, max iter, gamma, step, stepvalue y power se definen en elbufer de protocolo de parametros de solver, y iter es la iteracion actual.
gama: este parametro indica cuanto cambia la tasa de aprendizaje cada vezque se alcanza el siguiente ”paso”. El valor es un numero real, y se puedeconsiderar como la multiplicacion de la tasa de aprendizaje actual por dichonumero para obtener una nueva tasa de aprendizaje.
20

stepsize: este parametro indica con que frecuencia (en alguna cuenta de ite-racion) se debe pasar al siguiente ”paso”de entrenamiento. Este valor es unentero positivo.
stepvalue: este parametro indica el numero de veces en las iteraciones quese deben seguir al siguiente ”paso”de entrenamiento. Este valor es un enteropositivo.
max iter: este parametro indica cuando la red debe dejar de entrenar. El valores un numero entero que indica que iteracion debe ser la ultima.
momentum: este parametro indica cuanto del peso anterior se retendra en elnuevo calculo. Este valor es una fraccion real.
weight decay: este parametro indica el factor de penalizacion (regularizacion)de grandes pesos. Este valor es a menudo una fraccion real.
random seed: es utilizado para producir una tasa de aprendizaje aleatoria.
iter size: indica cuantos lotes se pasan a traves del solucionador iter size. Conesta configuracion, batch size: 16 con iter size: 1 y batch size: 4 con iter size:4 son equivalentes.
test iter: este parametro indica cuantas iteraciones de prueba deben ocurrirpor test interval. Este valor es un entero positivo.
test interval: este parametro indica con que frecuencia se ejecutara la fase deprueba de la red.
type: este parametro indica el algoritmo de propagacion hacia atras utilizadopara entrenar la red. Este valor es una cadena entrecomillada.Las opcionesincluyen:
• Gradiente de gradiente estocastico ”SGD”.
• AdaDelta.
• Gradiente Adaptativo.
• Adam.
3.5. Internet de las cosas
Por lo general, el termino Internet de las Cosas(IoT por sus siglas en ingles) serefiere a escenarios en los que la conectividad de red y la capacidad de computose extienden a objetos, sensores y artıculos de uso diario que habitualmente no seconsideran computadoras, permitiendo que estos dispositivos generen, intercambieny consuman datos con una mınima intervencion humana. Sin embargo, no existeninguna definicion unica y universal.(Rose, Karen; Eldridge, Scott; Chapin, 2015)
El concepto de combinar computadoras, sensores y redes para monitorear y con-trolar diferentes dispositivos ha existido durante decadas. Sin embargo, la reciente
21

confluencia de diferentes tendencias del mercado tecnologico esta permitiendo queInternet de las Cosas este cada vez mas cerca de ser una realidad generalizada. Estastendencias incluyen la conectividad omnipresente, la adopcion generalizada de redesbasadas en el protocolo IP, la economıa en la capacidad de computo, la miniaturi-zacion, los avances en el analisis de datos y el surgimiento de la computacion en lanube.
Las implementaciones de IoT utilizan diferentes modelos de conectividad, cadauno de los cuales tiene sus propias caracterısticas. Los cuatro de los modelos deconectividad descritos por la Junta de Arquitectura de Internet incluyen: Device-to-Device (dispositivo a dispositivo), Device-to-Cloud (dispositivo a la nube), Device-to-Gateway (dispositivo a puerta de enlace) y Back-End Data-Sharing (intercambiode datos a traves del back-end). Estos modelos destacan la flexibilidad en las formasen que los dispositivos de IoT pueden conectarse y proporcionar un valor para elusuario(Rose, Karen; Eldridge, Scott; Chapin, 2015).
3.6. Dispositivos embebidos
3.6.1. Raspberry Pi
La Raspberry Pi es un dispositivo integrado de bajo costo, de tamano reduci-do, que se puede conectar a un monitor de computadora o televisor, puede usarun teclado y mouse estandar o se puede manejar de forma remota. Es un pequenodispositivo con el cual se pueden desarrollar proyectos de tecnologıa, permitiendoprogramar en lenguajes como Scratch y Python. Es capaz de cumplir muchas fun-ciones de un computador, desde navegar por Internet, reproducir o grabar videos dealta definicion, procesamiento de textos, entre otras tareas.
Figura 3.9: Raspberry Pi 3B+(Foundation, 2013).
3.6.1.1. Caracterısticas Raspberry Pi 3B+
Procesador BCM2837B0, Cortex-A53 (ARMv8) 64-bit SoC @ 1.4GHz.
Memoria 1GB LPDDR2 SDRAM.
22

WiFi a 2.4GHz y 5GHz IEEE 802.11.b/g/n/ac, Bluetooth 4.2.
Gigabit Ethernet sobre USB 2.0 (rendimiento maximo 300 Mbps).
40-pines GPIO(puertos de entrada o salida).
Puerto HDMI tamano estandar.
4 puertos USB 2.0.
Puerto CSI de la camara para conectar una camara Raspberry Pi.
4-Salidas estereo y puerto de video compuesto
Puerto Micro SD para cargar el sistema operativo y almacenar datos.
Alimentacion con fuente externa a 5V/2.5A DC.
3.6.2. Camara Raspberry Pi Sony IMX219
La camara es compatible con Raspberry Pi basada en el mismo sensor SonyIMX219. Es capaz de imagenes estaticas de 3280 x 2464 pıxeles, y tambien admitevıdeo de 1080p30, 720p60 y 640x480p90. Se conecta al Raspberry Pi por la interfazCSi estandar, como se muestra en la figura 3.10. Es el complemento de la camaraoficial Raspberry Pi para satisfacer las demandas de diferentes monturas de lentes,campo de vision (FOV) y profundidad de campo (DOF)(Jackson, 2016).
Figura 3.10: Camara Raspberry Pi Sony IMX219(Jackson, 2016).
3.6.2.1. Caracterısticas camara:
Tipo de sensor: Sony IMX219 Color CMOS de 8 megapıxeles
Tamano del sensor: 3.674 x 2.760 mm (formato de 1/4”)
Cantidad de pıxeles: 3280 x 2464 (pıxeles activos) 3296 x 2512 (pıxeles totales).
Tamano de pıxel: 1.12 x 1.12 um
23

Lente: montura M12/CS personalizable, teleobjetivo.
Angulo de vision: personalizable
Vıdeo: 1280 x 720 empaquetado y recortado hasta 60 fps, 1080p recortadohasta 30 fps.
3.6.3. Sun Controller
SunController es un controlador de energıa solar desarrollado por SwitchDocLabs para alimentar a Arduino y/o sistemas basados en Raspberry Pi. La placatiene control de carga de baterıa de litio de 3.7V por medio de paneles solares atraves del integrado MCP73871, un conversor A/D (INA3221) para monitorear elpanel solar, la baterıa y la salida; esta implementa un elevador de tension(TPS61030)que produce una salida de 5V a 1A, la placa se muestra en la figura 3.11.
Figura 3.11: Sun Controller(SwicthDocLabs, 2017).
3.6.4. Witty Pi
Witty Pi es una pequena placa de extension para Raspberry Pi que agrega unreloj en tiempo real (RTC) DS3231SN y administracion de energıa, esta se muestraen la figura 3.12, se puede ensamblar facilmente y consta de las siguientes carac-terısticas(UUGear, 2018):
Puede encender/apagar la Raspberry Pi con un interruptor.
Despues del apagado, Raspberry Pi y todos los dispositivos perifericos USB seapagan completamente.
Raspberry Pi obtiene la hora correcta, incluso sin acceder a Internet.
se puede programar el inicio/apagado del Raspberry Pi.
se puede escribir un script para definir una secuencia compleja de encendi-do/apagado.
24

Cuando el sistema operativo pierde la respuesta, se puede presionar el inte-rruptor durante algun tiempo para forzar el corte de energıa.
Witty Pi es compatible con todos los modelos de Raspberry Pi que tienen elencabezado GPIO de 40 pines, incluyendo A +, B +, 2B, Cero y 3B.
Figura 3.12: Placa Witty Pi 2(UUGear, 2018).
3.6.5. Panel solar Voltaic 6W
Es un panel solar ideal para la alimentacion de sistemas embebidos como Rasp-berry Pi, arduino, entre otros, este puede cargar una baterıa de acuerdo a las condi-ciones solares que se presenten, este se muestra en la figura 3.13, lo ideal es colocarloa un angulo de 90 grados con respecto a la luz solar.
Figura 3.13: Panel solar voltaic 6W(Voltaic, 2017).
3.6.5.1. Caracterısticas panel solar
Impermeable (IP67).
25

Resistente a los rayos UV(10 anos de vida).
Durable y ligero
Celulas monocristalinas de alta eficiencia: 19%.
Voltaje de circuito abierto: 7.7V.
Voltaje maximo: 6.5V.
Corriente de pico: 930mA.
Potencia maxima: 6W.
Tolerancia de potencia: +-10%.
26

4. Plan de trabajo
En el plan de trabajo se proponen cinco (5) fases que incluyen la metodologıaque se planteo para dar cumplimiento a los objetivos propuestos para el desarrollode la pasantıa.
4.1. Fase I: Revision literaria
En esta fase se busca revisar los conceptos mas relevantes para la comprensiony proyeccion del problema, ası como de los mecanismos que puedan aportar a lasolucion, por lo que se plantean las siguientes actividades:
Realizar la lectura e investigacion sobre vision por computador.
Realizar la lectura e investigacion sobre redes neuronales convolucionales,aprendizaje profundo y herramientas para su desarrollo.
Realizar lectura e investigacion sobre implementacion de tecnologıas IoT ycomponentes que permitan su desarrollo.
Investigar sobre el estado del arte del proyecto mencionado.
4.2. Fase II: Construccion de bases de datos
Esta fase se propone con el fin de lograr la creacion del conjunto de datos para laspruebas a realizar con los modelos de redes neuronales convolucionales, de tal modoque se puedan realizar multiples experimentos en busca de una solucion eficiente,por lo que se proponen las siguientes actividades:
Obtener imagenes y vıdeo de estacionamientos en algun lugar especıfico delpaıs.
Extraer las imagenes necesarias para el entrenamiento, validacion y prueba dela red neuronal.
Hacer el procesamiento de las imagenes obtenidas para ser interpretadas porla red neuronal convolucional.
Construir diferentes bases de datos y conjuntos de prueba para los experimen-tos a realizar.
4.3. Fase III: Entrenamiento de la red neuronal
En esta fase se proponen las actividades para realizar la experimentacion e im-plementacion de la red convolucional seleccionada, es decir lo correspondiente alentrenamiento, validacion y prueba de la red neuronal.
27

Realizar los experimentos necesarios para el correcto funcionamiento de la red.
Validar los resultados obtenidos para los diferentes experimentos.
Realizar el ajuste de los parametros de la red para mejorar la eficiencia.
Generar graficas que permitan ilustrar el error y la precision en el entrena-miento de los modelos.
4.4. Fase IV: Evaluacion de la red neuronal
El objetivo de esta fase es revisar el comportamiento de la red neuronal entrenadapara establecer el alcance y las posibles limitaciones de la solucion propuesta, asıcomo realizar las pruebas correspondientes a la clasificacion en diferentes escenarios,por lo que se proponen las siguientes actividades:
Hacer las mediciones con indicadores adecuados para la evaluacion de los mo-delos entrenados.
Comparar la eficiencia de la red neuronal con modelos existentes.
Implementar los modelos entrenados para la clasificacion de ocupacion de laszonas de estacionamiento desde un computador.
Analizar el comportamiento de la red neuronal entrenada con nuevos conjuntosde imagenes.
Comparar los resultados y el tiempo de ejecucion en entornos con diferentescapacidades de procesamiento.
4.5. Fase V: Implementacion de dispositivo IoT
Esta fase esta orientada a la implementacion del dispositivo como una solucionIoT, es decir todo lo relacionado con las pruebas en diferentes entornos con carac-terısticas que permitan la escalabilidad de la solucion, por lo que se proponen lassiguientes actividades:
Implementar los modelos entrenados en un entorno con Raspberry Pi.
Incluir redes de sensores que permitan acceder a variables a controlar comotemperatura, porcentaje de baterıa, entre otros.
Usar energıas alternativas para el funcionamiento del dispositivo IoT.
Estimar la autonomıa del dispositivo y su consumo de potencia.
Realizar una aplicacion de acceso remoto al servicio.
Evaluar resultados obtenidos.
28

5. Desarrollo y analisis deresultados
En esta seccion se describen los resultados obtenidos de acuerdo a los propuestoen los objetivos del proyecto y lo planteado en el plan de trabajo, ası como tambienel analisis de estos.
5.1. Construccion base de datos
Las imagenes para la construccion de la base de datos fueron tomadas en laciudad de Cucuta en el mes de Febrero, estas fueron extraıdas de 34 vıdeos tomadosa una resolucion de 3240 x 2148, en diferentes zonas de la ciudad que incluyenespacios de estacionamiento publico y vıas por donde existe trafico vehicular, con elfin de crear la base de datos para el entrenamiento de la red neuronal. Un ejemplode imagenes extraıdas se muestra en la figura 5.1.
Figura 5.1: Ejemplo de imagenes de espacios de estacionamiento tomadas para laconstruccion de la base de datos.
El proceso para la construccion de la base de datos de imagenes se realizo pormedio de los siguientes pasos:
Se tomaron 34 vıdeos.
Se extrajeron imagenes cuadro a cuadro de cada uno de los vıdeos para untotal de 2419 imagenes.
Se seleccionaron las imagenes con informacion mas relevante, es decir procu-rando que existieran diferentes eventos durante la toma de las imagenes.
29

Se realizo el etiquetado manual de los carros y espacios de estacionamientopor medio de la herramienta VGGanotator como se muestra en la figura 5.5,que permite extraer la informacion de los cuadros dibujados sobre la imagenen formato JSON con coordenadas espaciales y diferentes atributos creadoscomo el tipo de vehiculo, estado de ocupacion, posicion de camara, etc...
Figura 5.2: Herramienta para etiquetado de espacios de estacionamiento.
Con los archivos de etiquetado de las imagenes se realizo un codigo en Pythonpara la extraccion de los cuadros especıficos dado que la red neuronal tomacomo entrada imagenes individuales de 224 x 224 para entrenamiento como semuestra en las figuras 5.3 y 5.4.
Figura 5.3: Ejemplo de celdas de estacionamiento ocupadas
30

Figura 5.4: Ejemplo de celdas de estacionamiento libres.
Como resultado final se obtuvo un total de 10299 imagenes individuales de dife-rentes clases como se muestra en la tabla 5.1
Tabla 5.1: Datos de la base de datos.Tipo
Ocupado LibreCarro Taxi Total Espacio vacıo3459 1691 5150 5149
Como se muestra se obtuvo un numero similar de imagenes para las dos clasesde salida de la red (ocupado, vacıo), para el entrenamiento, validacion y prueba,esto con el fin de hacer equilibrada la base de datos y aportar ejemplos con diferenteinformacion a la red neuronal.
Los resultados obtenidos en esta fase fueron satisfactorios, se obtuvo un grannumero de imagenes, con la base de datos construida se realizo el entrenamiento dela red neuronal como se muestra en la siguiente seccion.
5.2. Entrenamiento de la red neuronal
Con la lectura de la bibliografıa realizada se determino que para el reconocimien-to de la ocupacion de los espacios de estacionamiento es de gran ayuda el uso deredes neuronales convolucionales, por lo que segun lo mostrado en el marco teoricouna de las mejores redes para el reconocimiento de imagenes es la red AlexNet, peropara el caso de este proyecto por la capacidad de procesamiento se selecciono unaversion de esta reducida, conocida como mAlexNet.
Para el entrenamiento de la red neuronal convolucional mAlexNet, se tuvo encuenta las especificaciones de entrada necesarias para que la red funcione, es decirimagenes de entrada deben tener un tamano de 224x224 y estar en formato BGR,debido a que la secuencia de entrada de la red y el entorno de trabajo caffe, operancon estas indicaciones, por lo cual luego de tener la base de datos previamenteacondicionada se procede a realizar la experimentacion de la siguiente forma:
31

Con las imagenes de la base de datos previamente etiquetadas, se realizo uncodigo en Python para separar las clases entre ocupado y vacio para poderrealizar una correcta division de el conjunto de datos para el entrenamiento,validacion y prueba de la red.
El codigo en python separa las imagenes en igual proporcion, es decir 50%ocupado y 50% vacıo, y con esto se selecciona el porcentaje de imagenes quevan a ser tomadas para entrenamiento, validacion y prueba.
Se procedio a realizar la experimentacion con cinco divisiones del conjunto dedatos diferentes es decir diferentes porcentajes de entrenamiento, validacion yprueba.
Se guardaron los resultados de entrenamiento y se obtuvo las graficas de erroren entrenamiento, validacion y prueba para los diferentes experimentos reali-zados.
Se repitieron experimentos en maquinas con diferentes capacidades de pro-cesamiento para analizar el tiempo de entrenamiento y si la variacion de losresultados en cuanto a precision, perdidas de la funcion objetivo, etc...
Se analizaron los resultados para obtener el mejor modelo de todos los entre-namientos realizados, para la prueba e implementacion en la siguiente fase.
Los experimentos realizados y sus correspondientes datos se muestran a continua-cion, para la primer prueba los parametros de entrenamiento fueron los siguientes:
base lr=0.001
train epochs=10
lr policy=”step”
gamma=0.8
val interval epochs=0.15
val epochs=0.1
Esto implica que la tasa de aprendizaje comenzo en 0.001, para 10 epocas deentrenamiento, con la funcion paso, gamma de 0.8, que disminuye el valor de la tasade aprendizaje un 20% luego de las iteraciones definidas, los resultados para loscinco diferentes conjuntos de entrenamiento se muestran a continuacion.
En la tabla 5.2 se muestra el resumen de los cinco entrenamientos realizadoscon los parametros mencionados, para evaluar cual es la cantidad de imagenes deentrenamiento, validacion y prueba con la que se obtiene la mayor precision y elmenor error posible.
32
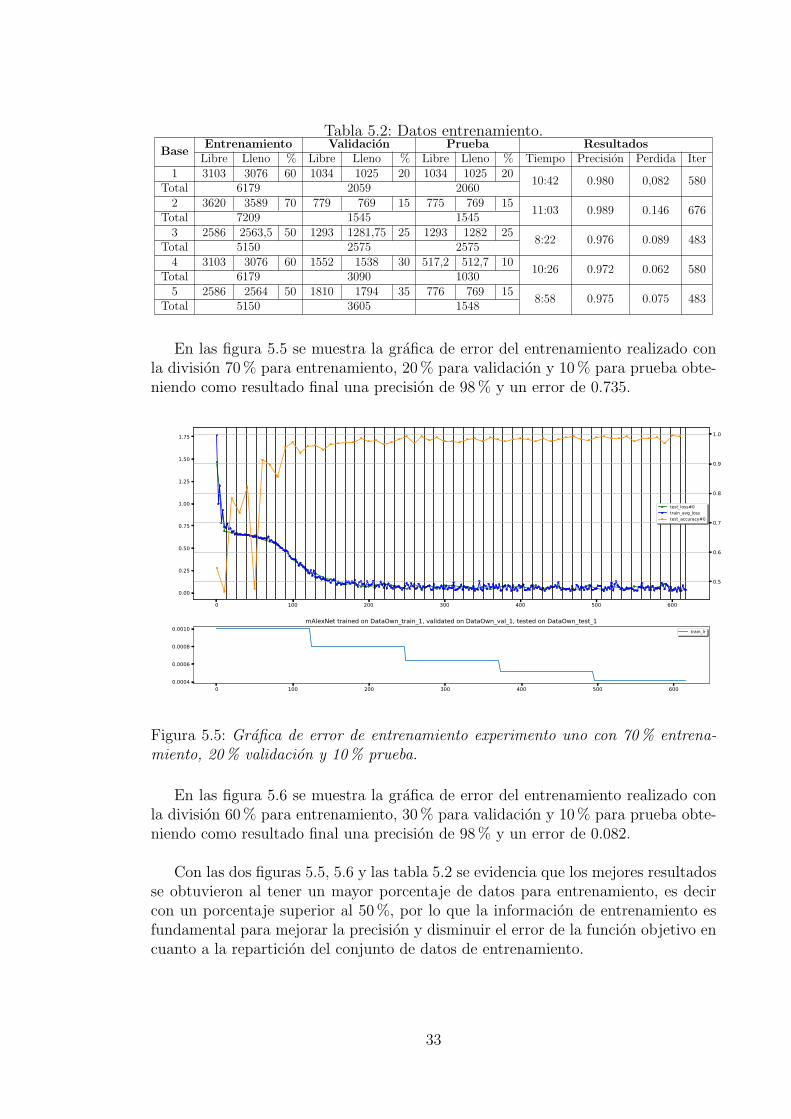
Tabla 5.2: Datos entrenamiento.Base
Entrenamiento Validacion Prueba ResultadosLibre Lleno % Libre Lleno % Libre Lleno % Tiempo Precision Perdida Iter
1 3103 3076 60 1034 1025 20 1034 1025 2010:42 0.980 0,082 580
Total 6179 2059 20602 3620 3589 70 779 769 15 775 769 15
11:03 0.989 0.146 676Total 7209 1545 15453 2586 2563,5 50 1293 1281,75 25 1293 1282 25
8:22 0.976 0.089 483Total 5150 2575 25754 3103 3076 60 1552 1538 30 517,2 512,7 10
10:26 0.972 0.062 580Total 6179 3090 10305 2586 2564 50 1810 1794 35 776 769 15
8:58 0.975 0.075 483Total 5150 3605 1548
En las figura 5.5 se muestra la grafica de error del entrenamiento realizado conla division 70% para entrenamiento, 20% para validacion y 10% para prueba obte-niendo como resultado final una precision de 98% y un error de 0.735.
0 100 200 300 400 500 600
0.00
0.25
0.50
0.75
1.00
1.25
1.50
1.75
0 100 200 300 400 500 6000.0004
0.0006
0.0008
0.0010mAlexNet trained on DataOwn_train_1, validated on DataOwn_val_1, tested on DataOwn_test_1
train_lr
0.5
0.6
0.7
0.8
0.9
1.0
test_loss#0train_avg_losstest_accuracy#0
Figura 5.5: Grafica de error de entrenamiento experimento uno con 70% entrena-miento, 20% validacion y 10% prueba.
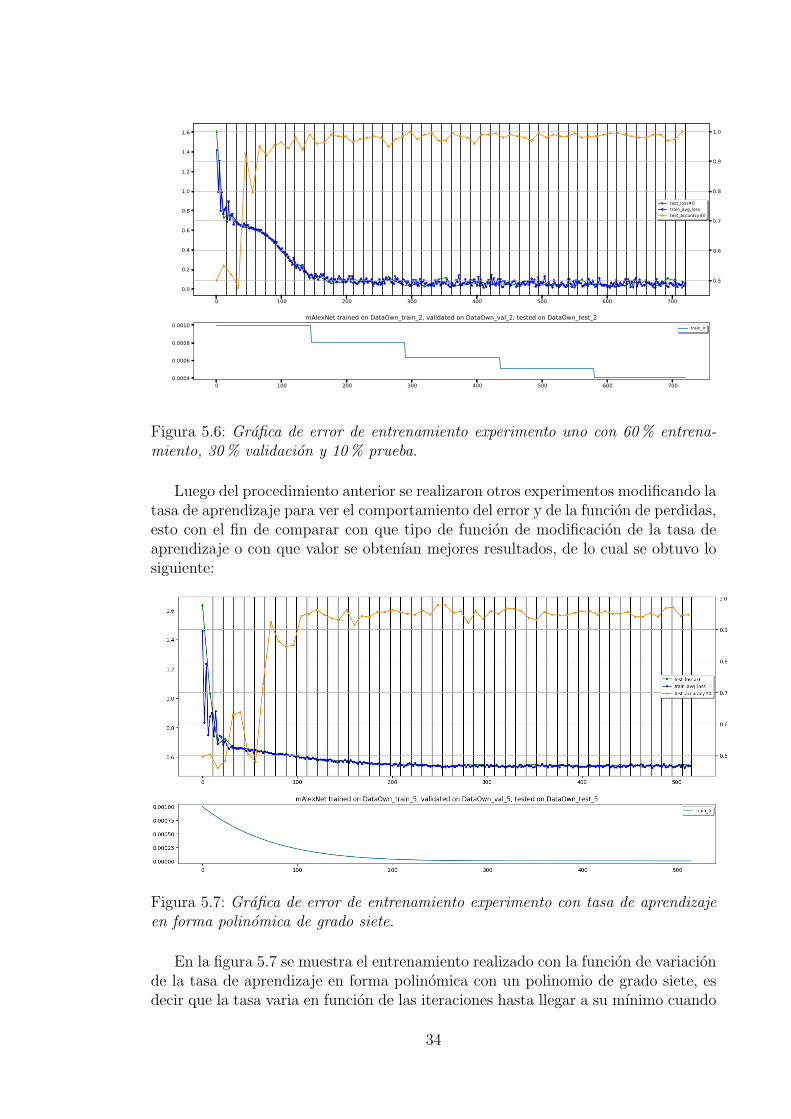
En las figura 5.6 se muestra la grafica de error del entrenamiento realizado conla division 60% para entrenamiento, 30% para validacion y 10% para prueba obte-niendo como resultado final una precision de 98% y un error de 0.082.
Con las dos figuras 5.5, 5.6 y las tabla 5.2 se evidencia que los mejores resultadosse obtuvieron al tener un mayor porcentaje de datos para entrenamiento, es decircon un porcentaje superior al 50%, por lo que la informacion de entrenamiento esfundamental para mejorar la precision y disminuir el error de la funcion objetivo encuanto a la reparticion del conjunto de datos de entrenamiento.
33
0 100 200 300 400 500 600 700
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
0 100 200 300 400 500 600 7000.0004
0.0006
0.0008
0.0010mAlexNet trained on DataOwn_train_2, validated on DataOwn_val_2, tested on DataOwn_test_2
train_lr
0.5
0.6
0.7
0.8
0.9
1.0
test_loss#0train_avg_losstest_accuracy#0
Figura 5.6: Grafica de error de entrenamiento experimento uno con 60% entrena-miento, 30% validacion y 10% prueba.
Luego del procedimiento anterior se realizaron otros experimentos modificando latasa de aprendizaje para ver el comportamiento del error y de la funcion de perdidas,esto con el fin de comparar con que tipo de funcion de modificacion de la tasa deaprendizaje o con que valor se obtenıan mejores resultados, de lo cual se obtuvo losiguiente:
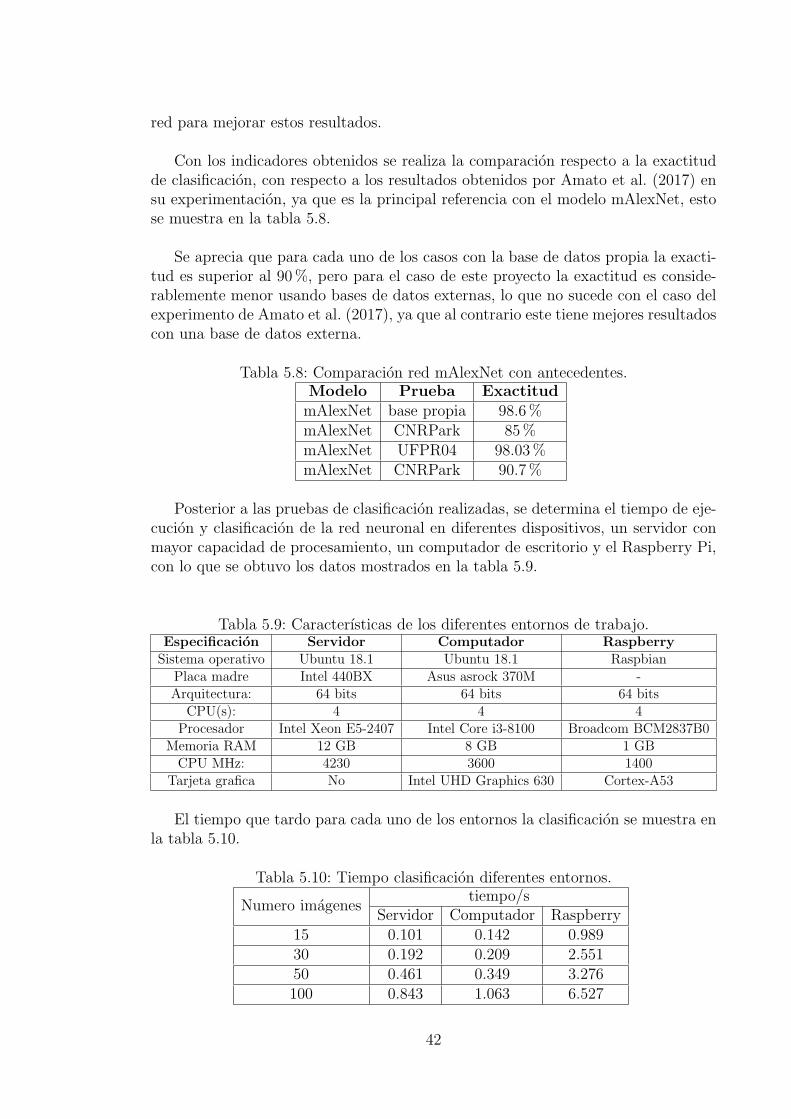
Figura 5.7: Grafica de error de entrenamiento experimento con tasa de aprendizajeen forma polinomica de grado siete.
En la figura 5.7 se muestra el entrenamiento realizado con la funcion de variacionde la tasa de aprendizaje en forma polinomica con un polinomio de grado siete, esdecir que la tasa varia en funcion de las iteraciones hasta llegar a su mınimo cuando
34

el numero de iteraciones es maximo, la precision obtenida fue de 95.6% con un errorde 36.5%, este experimento se realizo con los siguientes parametros:
base lr=0.001
train epochs=10
lr policy=”poly”
power=7
val interval epochs=0.15
val epochs=0.1
En la figura 5.8 se muestra el ultimo experimento realizado que consistio en au-mentar el numero de pasos con una variacion del 10%, aumentar las iteraciones yepocas de la red para analizar el comportamiento con la variacion de estos parame-tros, con lo cual se obtuvo un precision del 95.82% y un error en la funcion objetivode 0.173, este fue realizado con los siguientes parametros:
base lr=0.001
train epochs=25
lr policy=”step”
power=0.9
val interval epochs=0.15
val epochs=0.1
Como se observa, con las dos pruebas realizados, variando la forma y el porcenta-je de cambio de la tasa de aprendizaje, al terminar el entrenamiento los resultados,la precision final y el error de la funcion de perdidas no cambian significativamenteen comparacion con los resultados obtenidos en el primer experimento.
Para el caso del aumento del numero de epocas, al comparar las figura 5.8 conla figura 5.6 se observa que la reduccion del error o el aumento de la precision novaria despues de ciertas iteraciones, por lo que se puede deducir que existe unaconvergencia en la cual la red ya no mejora sus resultados con volver a iterar oal realizar propagacion hacia atras, por lo que no es necesario el aumento de lasiteraciones o epocas a partir de cierto punto, e incluso los resultados fueron mejoresal terminar el entrenamiento con menos epocas.
35

0 500 1000 1500 2000 25000.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
0 500 1000 1500 2000 25000.0004
0.0006
0.0008
0.0010mAlexNet trained on DataOwn_train_4, validated on DataOwn_val_4, tested on DataOwn_test_4
train_lr
0.5
0.6
0.7
0.8
0.9
1.0
test_loss#0train_avg_losstest_accuracy#0
Figura 5.8: Grafica de error de entrenamiento experimento uno con 60% entrena-miento, 30% validacion y 10% prueba.
Con las diferentes pruebas realizadas se determino que uno de los factores masfundamentales para el entrenamiento es la correcta division de la base de datos deentrenamiento, se requiere de un gran porcentaje de datos para que la red puedaaprender mas ejemplos con diferentes condiciones.
Para el caso de los experimentos realizados el mejor resultado se obtuvo con lareparticion de 70% de imagenes para entrenamiento, 20% para validacion y 10%para prueba, a pesar de que con el primer experimento realizado se obtiene unamayor precision, el error es mas grande por lo que se opta por seleccionar el segundomodelo para la siguiente fase de las pruebas de clasificacion de espacios de estacio-namiento.
5.3. Pruebas de la red neuronal
Con el mejor modelo seleccionado en entrenamiento se procede a realizar pruebascon los vıdeos originales, para lo que se realizo un codigo en Python que permitieraleer los vıdeos, extraer imagen por imagen , realizar la clasificacion de los espaciosde estacionamiento y finalmente reconstruir el vıdeo, esto con el fin de observar elcomportamiento del modelo entrenado.
Posterior a esto se realizo la prueba con vıdeos desconocidos por la red, encon-trados en internet, esto con el fin de observar la capacidad de generalizacion de lared, y su posible comportamiento ante nuevos datos, es decir realizar predicciones
36

Tabla 5.3: Ejemplo de resultados obtenidos a la salidad de la red neuronal.
Id Vacio Ocupado1 0.99814 0.001852 0.99857 0.001423 0.99621 0.003784 0.73202 0.267975 0.91866 0.081336 0.88821 0.111787 0.91700 0.082998 0.87188 0.128119 0.76558 0.2344110 0.79230 0.20769
lo que se acerca al escenario real.
Los resultados obtenidos por la red estan dados por un porcentaje final queindica la clase que la red tiene como salida, que para este caso es vacio u ocupado,un ejemplo de esto se muestra en la tabla 5.3, cada espacio es identificado con unID, para el caso de la reconstruccion de los vıdeos, se toma el resultado obtenidopor la red y si el valor de la clase dado por la salida de la red es mayor a 0.6 se tomala clase como ocupado o vacio, si es un valor inferior se toma como indeterminadoy se espera una posterior clasificacion, los espacios libres se toman de color verdemientras que los espacios ocupados se toman de color rojo.
Figura 5.9: Ejemplo de clasificacion de celdas de estacionamiento.
37

En la figura 5.9 se observa un ejemplo de los resultados obtenidos al ejecutarla clasificacion en los vıdeos mencionados con el modelo entrenado, en donde seaprecia la correcta clasificacion de cada uno de los espacios mostrados tanto paraespacios ocupados como para espacios vacıos, en la figura 5.10 se observa que al salirel vehıculo del espacio identificado con el ID numero 8, el estado de ocupacion pasade estar ocupado a estar vacio, demostrando que la red obtiene un buen resultadopara este caso.
Figura 5.10: Ejemplo de cambio de estado de ocupacion en celdas de estacionamiento.
Para la evaluacion de la clasificacion de la red neuronal se utilizaron diferentesestadısticos disponibles para casos de clasificacion binaria, que permiten valorar elcomportamiento de la red, para hallar la precision, sensibilidad, tasa de aciertos,exactitud y otros indicadores, lo que se obtiene de los resultados de la clasificacionque se organizan en una matriz como la que se muestra en la tabla 5.4 denominadamatriz de confusion y por medio de las ecuaciones 5.1, 5.2, 5.8, 5.4, 5.5, se calculancada uno de los indicadores.
Tabla 5.4: Matriz de confusion para clasificacion binaria.Prediccion
EjemploVP FPFN VN
En la tabla 5.4 se muestra el ejemplo de matriz de confusion, en donde VP esverdadero positivo indicando un ejemplo positivo y prediccion positiva, FP es falsopositivo, indicando ejemplo positivo, prediccion negativa, FN significa falso negati-vo, indicando un ejemplo negativo y prediccion positiva, y VN verdadero negativo,
38

indicando ejemplo negativo y prediccion negativa.
ACC =V P + V N
V P + V N + FP + FN(5.1)
PPV =V P
V P + FP(5.2)
NPV =V N
V N + FN(5.3)
V PR =V P
V P + FN(5.4)
FPR =FP
FP + V N(5.5)
Tomando como muestra para la clasificacion 100 imagenes propias de la basede datos, que no fueron utilizadas en entrenamiento, se realiza la clasificacion y seobtiene los resultados mostrados en la tabla 5.5 en donde se utiliza una matriz deconfusion para evaluar los resultados del clasificador.
Tabla 5.5: Matriz de confusion con 100 imagenes de la base de datos.
EjemploPrediccion
Ocupado VacıoOcupado 49 1Vacıo 1 49
Segun lo mostrado en la tabla 5.5, se calculan diferentes indicadores utilizadosclasificacion binaria, como sigue:
ACC =49 + 49
100= 0.98 (5.6)
El indicador ACC o mas conocido como exactitud o tasa de aciertos se usa enclasificadores con datos balanceados, es decir con igual proporcion de ejemplos paraindicar los datos que fueron clasificados correctamente dentro de la muestra total,es decir para este caso, el 98% de los datos fueron clasificados de forma correcta porla red.
PPV =49
49 + 1= 0.98 (5.7)
NPV =49
49 + 1= 0.98 (5.8)
El indicador PPV o precision muestra que proporcion de los clasificados comopositivos lo son realmente, es decir el porcentaje de espacios ocupados que fue clasi-ficado respecto a los que fueron clasificados como ocupados estando vacıos, que para
39

el caso fue de 98%, y para el caso de NPV, indica el numero de ejemplos negativosque fueron clasificados correctamente, es decir espacios vacıos que fueron clasificadoscomo vacıos, lo que arrojo una tasa de 98% para este caso.
V PR =49
49 + 1= 0.98 (5.9)
La sensibilidad o VPR indica que proporcion de todos los positivos se clasificancomo tal, es decir la comparacion entre los espacios mostrados como ocupados queson acertados por la red con respecto a los que son clasificados de forma erronea,para lo que se obtuvo un porcentaje de 98%.
FPR =1
49 + 1= 0.02 (5.10)
La tasa FPR indica que proporcion de todos los negativos se clasifican comopositivos, es decir para los casos en que la clasificacion es erronea, que para el casose obtuvo un porcentaje de 2%.
Posterior a las pruebas realizadas anteriormente se procedio a realizar la clasi-ficacion con 100 imagenes diferentes a las de la base de datos propia, conseguidasen la documentacion de Amato et al. (2017), con la que se realizo la misma pruebamencionada, para analizar la capacidad de generalizacion de la red, con lo que seobtuvo lo siguiente.
Tabla 5.6: Matriz de confusion con 100 imagenes externas.
EjemploPrediccion
Ocupado VacıoOcupado 48 2Vacıo 23 37
ACC =48 + 37
100= 0.85 (5.11)
PPV =48
23 + 48= 0.68 (5.12)
NPV =37
37 + 2= 0.95 (5.13)
V PR =48
48 + 2= 0.96 (5.14)
FPR =23
37 + 23= 0.46 (5.15)
40

Con los indicadores obtenidos anteriormente se muestra que los resultados encuanto a la clasificacion de espacios de estacionamiento ocupados sigue siendo bue-na, con una tasa VPR de de 96%, pero para el caso de los espacios vacıos, la redclasifica de forma erronea un mayor porcentaje de imagenes, siendo este evaluadocon la tasa FPR de 46% mostrada en la ecuacion 5.15, evidenciando que la capaci-dad de generalizacion es regular con una tasa de aciertos o exactitud del 85%, por loque se deduce que hace falta ampliar el conjunto de datos para que la red funcioneen entornos diferentes, ya que con las imagenes propias funciona con una muy altaeficacia.
Finalmente se realiza la clasificacion de todas las imagenes disponibles en la ba-se de datos propia, es decir incluyendo las imagenes de entrenamiento, validacion,prueba, para analizar el comportamiento final de la red y evaluar los indicadoresobtenidos, con lo que se obtiene lo siguiente.
Tabla 5.7: Matriz de confusion con 10299 imagenes de la base de datos propia.
EjemploPrediccion
Ocupado VacıoOcupado 5101 26Vacıo 119 5053
ACC =5101 + 5053
10299= 0.986 (5.16)
PPV =5101
5101 + 119= 0.977 (5.17)
NPV =5053
5053 + 26= 0.99 (5.18)
V PR =5101
5101 + 26= 0.99 (5.19)
FPR =119
5053 + 119= 0.023 (5.20)
De lo anterior se comprueba que para el escenario en el que se implementarıa eldispositivo, los resultados son favorables obteniendo una exactitud de 98.6%, unaprecision de 97.7%, sensibilidad de 99% y tasa FPR de 2,3%, que para el caso dela deteccion de ocupacion de espacios de estacionamiento.
Se tiene como observacion el hecho de que la mayorıa de los casos en los quela red clasifica de forma erronea son para los espacios vacıos, teniendo en cuentalas diferentes oclusiones, condiciones climaticas y demas factores ambientales, es unbuen resultado, acercandose a la clasificacion ideal para la implementacion del dis-positivo, como se menciono respecto a las imagenes externas, se necesitarıa ampliarla base de datos respecto a los ejemplos que se muestran en el entrenamiento de la
41
red para mejorar estos resultados.
Con los indicadores obtenidos se realiza la comparacion respecto a la exactitudde clasificacion, con respecto a los resultados obtenidos por Amato et al. (2017) ensu experimentacion, ya que es la principal referencia con el modelo mAlexNet, estose muestra en la tabla 5.8.
Se aprecia que para cada uno de los casos con la base de datos propia la exacti-tud es superior al 90%, pero para el caso de este proyecto la exactitud es conside-rablemente menor usando bases de datos externas, lo que no sucede con el caso delexperimento de Amato et al. (2017), ya que al contrario este tiene mejores resultadoscon una base de datos externa.
Tabla 5.8: Comparacion red mAlexNet con antecedentes.Modelo Prueba ExactitudmAlexNet base propia 98.6%mAlexNet CNRPark 85%mAlexNet UFPR04 98.03%mAlexNet CNRPark 90.7%
Posterior a las pruebas de clasificacion realizadas, se determina el tiempo de eje-cucion y clasificacion de la red neuronal en diferentes dispositivos, un servidor conmayor capacidad de procesamiento, un computador de escritorio y el Raspberry Pi,con lo que se obtuvo los datos mostrados en la tabla 5.9.
Tabla 5.9: Caracterısticas de los diferentes entornos de trabajo.Especificacion Servidor Computador RaspberrySistema operativo Ubuntu 18.1 Ubuntu 18.1 Raspbian
Placa madre Intel 440BX Asus asrock 370M -Arquitectura: 64 bits 64 bits 64 bits
CPU(s): 4 4 4Procesador Intel Xeon E5-2407 Intel Core i3-8100 Broadcom BCM2837B0
Memoria RAM 12 GB 8 GB 1 GBCPU MHz: 4230 3600 1400
Tarjeta grafica No Intel UHD Graphics 630 Cortex-A53
El tiempo que tardo para cada uno de los entornos la clasificacion se muestra enla tabla 5.10.
Tabla 5.10: Tiempo clasificacion diferentes entornos.
Numero imagenestiempo/s
Servidor Computador Raspberry15 0.101 0.142 0.98930 0.192 0.209 2.55150 0.461 0.349 3.276100 0.843 1.063 6.527
42

Esta prueba fue realizada con el fin de establecer la diferencia de los tiempos deejecucion de la red neuronal en diferentes entornos de trabajo, para determinar sila capacidad de procesamiento del Raspberry Pi comparada con diferentes capaci-dades de procesamiento, es suficiente para realizar la operacion en tiempo real de laclasificacion de los espacios de estacionamiento.
Segun lo mostrado en la tabla 5.10, que fue obtenida tomando el tiempo deejecucion promedio del programa en los diferentes entornos, se evidencia una claradesventaja en cuanto a los tiempos de ejecucion del programa, sin ser tan significa-tivos para los alcances de este proyecto, es decir para la clasificacion en promediode 30 a 50 espacios de estacionamiento, que no representa un tiempo elevado parala ejecucion de la tarea en el escenario real.
5.4. Implementacion en dispositivo IoT
Con el modelo que mejor se desempeno en las pruebas realizadas en compu-tador, se procede a realizar la pruebas en un Raspberry Pi modelo 3B+, con el finde evaluar el comportamiento en el dispositivo y realizar la integracion con otroscomponentes.
Para poder ejecutar el modelo entrenado, se hizo uso del sistema operativo rasp-bian, el lenguaje de programacion python y la herramienta para tratamiento deimagenes opencv, esto debido a que el sistema operativo del Raspberry Pi permitetrabajar con estas herramientas.
Para la seleccion del entorno de trabajo de la red neuronal, se probaron los entor-nos caffe y opencv, con el fin de determinar la diferencia en cuanto a la exactitud delos resultados y tiempo de ejecucion, obteniendo mejores resultados para la herra-mienta opencv, por lo que se establecio este software para realizar la implementaciondel sistema, este permite utilizar la red neuronal y obtener los resultados de la cla-sificacion en el Raspberry Pi.
Con las herramientas mencionadas se realizo un codigo en python para realizarla tarea de clasificacion de los espacios de estacionamiento con los siguientes pasos:
Se toma una foto en tiempo real de los espacios de estacionamiento
Se debe establecer los espacios de estacionamiento a clasificar, esto creandoun archivo con las coordenadas espaciales de la ubicacion de estas celdas enformato JSON.
El programa lee las coordenadas y extrae cuadro por cuadro cada uno de losespacios de estacionamiento.
Se realiza la conversion de las imagenes para poder ser procesadas por la reda formato BGR y tamano 224x224.
43

Se carga la red al programa y se itera imagen por imagen para obtener elresultado de la red.
Finalmente se muestran los resultados, se guardan la imagen y los resultadosde la ocupacion de los espacios de estacionamiento.
Se utilizo la tarjeta Witty Pi 2 para controlar la hora de encendido y/o apagadodel Raspberry Pi, ya que esta viene disenada para colocarse en los pines directamen-te y permite programar y controlar el encendido por medio de comandos sencillos,todo esto es posible por el reloj en tiempo real DS1232 que almacena la hora quese programa y enciende o apaga el dispositivo, todo esto con el objetivo de ahorrarenergıa, ya que el dispositivo solo operaria en determinadas horas del dıa, por lo quees un requerimiento poder realizar esta tarea.
Con el sistema funcionando se procedio a realizar pruebas para la alimentacionde el Raspberry Pi por medio de paneles solares para lo cual se utilizo la tarje-ta integrada Sun Controller de Switch Doc Labs que contiene el circuito integradoMCP73871 que permite realizar el control de carga de una baterıa de litio de 3.7Vpor medio de paneles solares.
Debido a que segun las especificaciones del Raspberry Pi se sugiere mınimo unaalimentacion de 1.5 A, y a las diferentes pruebas realizadas del consumo de los pe-rifericos se opta por usar dos paneles solares de Voltaic de 6W como entrada a latarjeta Sun Controller que admite maximo 1.5 A y una entrada de maximo 6V, porlo cual los paneles son de utilidad ya que cumplen estas especificaciones.
Figura 5.11: Conexion de paneles solares.
44

Para unir los paneles, se realiza uso de una tarjeta incluida en los paneles dereferencia Sollar Panel Controller que permite poner los paneles en paralelo con dio-dos de proteccion para evitar corrientes inversas, esto con el fin de realizar la cargade la baterıa cuando el sol este disponible, las conexiones realizadas se muestran enla figura 5.11.
Para casos en los que no llega suficiente energıa solar para producir el voltajenecesario para cargar la baterıa, se crea un programa en el Raspberry Pi, que permiteleer a traves de I2C los datos provenientes del sensor INA3221 y ası saber cuandoes necesario cambiar la fuente de alimentacion a la red electrica, esto por medio deun rele externo que permite conmutar entre estas dos fuentes, solo con la activaciondel transistor a la entrada, el sistema implementado se muestra en la figura 5.12.
Figura 5.12: Caja IP67 y elementos embebidos para implementacion de dispositivoIoT.
Con este sistema desarrollado se procede a realizar las mediciones de consumode diferentes dispositivos, para el caso de este proyecto se requerıa la conexion a lared 4G a traves de algun dispositivo, por lo que se realizaron pruebas de consumo deuna tarjeta Sixfab 4GLte que se puede integrar al Raspberry Pi y un modem USBHuawei E156B que se conecta por medio de un puerto USB al Raspberry.
Estas pruebas se realizaron con un sensor de corriente ACS712 y un arduino, conlo que obtuvo las graficas mostradas en las figuras 5.13 y 5.14, con lo que se deter-mino que el modem USB era el dispositivo de menor consumo en las diferentes tareascomo conexion, envio de datos, configuracion, con una diferencia de hasta 300mAmenos comparando el modem USB con el modulo Sixfab, debido a esto se seleccionael modem USB como dispositivo para la conexion a la red 4G para el prototipo final.
45
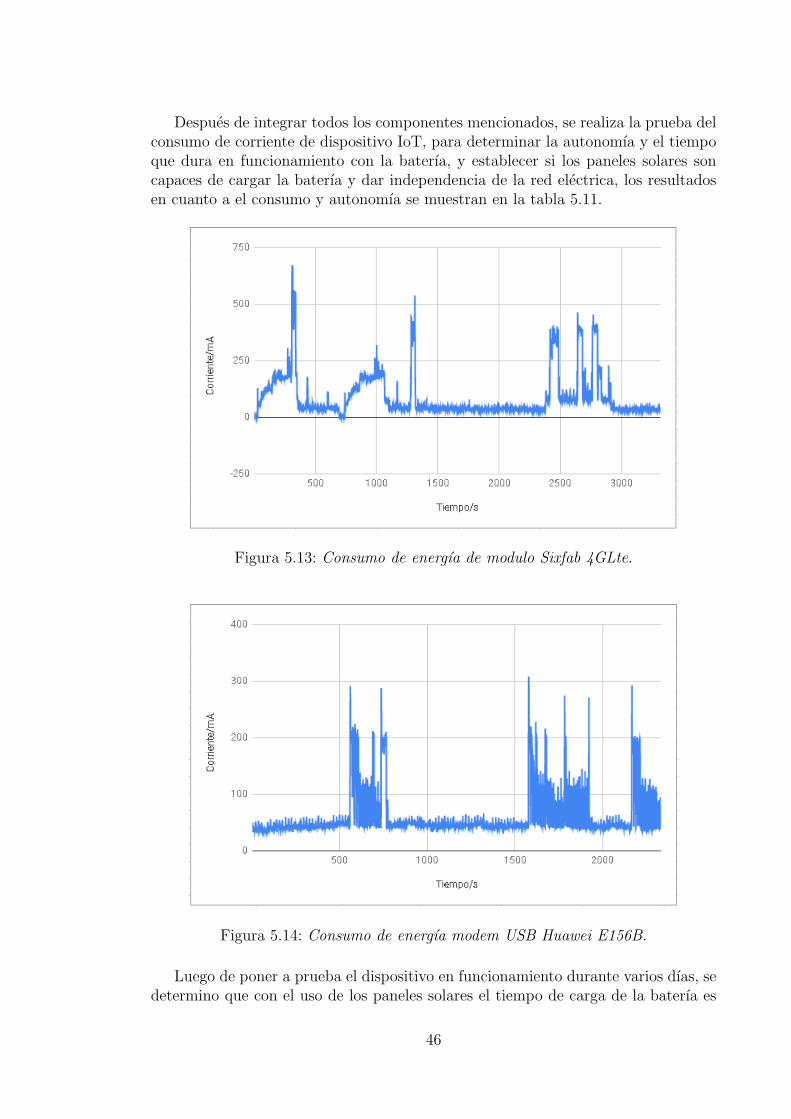
Despues de integrar todos los componentes mencionados, se realiza la prueba delconsumo de corriente de dispositivo IoT, para determinar la autonomıa y el tiempoque dura en funcionamiento con la baterıa, y establecer si los paneles solares soncapaces de cargar la baterıa y dar independencia de la red electrica, los resultadosen cuanto a el consumo y autonomıa se muestran en la tabla 5.11.
Figura 5.13: Consumo de energıa de modulo Sixfab 4GLte.
Figura 5.14: Consumo de energıa modem USB Huawei E156B.
Luego de poner a prueba el dispositivo en funcionamiento durante varios dıas, sedetermino que con el uso de los paneles solares el tiempo de carga de la baterıa es
46

Tabla 5.11: Tabla de consumo diferentes componentes y dispositivo IoT.Dispositivo Actividad Corriente/mA
Raspberry Pi
en reposo 550vıdeo 750
maximo consumo 1150consumo promedio 650
Witty Pien reposo 15activo 45
Modem USBen reposo 80activo 250
Dispositivo IoT
activo 850en reposo 620
clasificacion 750vıdeo 950
de tres dıas, y el tiempo de descarga de seis horas, esto implica que para el funciona-miento en escenario real se requerirıa aumentar la capacidad de la baterıa o adquirirpaneles que permitan entregar mayor potencia, dado que con el en tiempo que sepuso en prueba el dispositivo, no es posible cumplir la operacion durante todo un dıa.
Figura 5.15: Vista superior caja IP67 con lente de camara.
En las figuras 5.15 , 5.17 y 5.16 se observa la implementacion final del dispositivoen una caja que cumple el estandar IP67 para pruebas de resistencia al agua y polvo,esto con el fin de que el dispositivo pueda soportar diferentes condiciones climaticas,para la alimentacion y las demas conexiones, se usaron puertos que tambien cumplesestas especificaciones, al igual que para la apertura de la camara se utilizo un lente
47

con proteccion UV. Para evitar filtraciones por los orificios se utilizo un sellante paraprevenir el paso del agua.
Figura 5.16: Vista frontal con puertos para conexiones(alimentacion electrica, USB,ethernet)
Figura 5.17: Vista lateral caja IP67.
Con el sistema implementado, se realiza una pagina web para acceder de formaremota a los datos de los diferentes sensores integrados con la Raspberry Pi, es decirlos datos de los paneles solares, la baterıa, la alimentacion, la temperatura de laCPU, y demas valores ambientales del dispositivo.
48
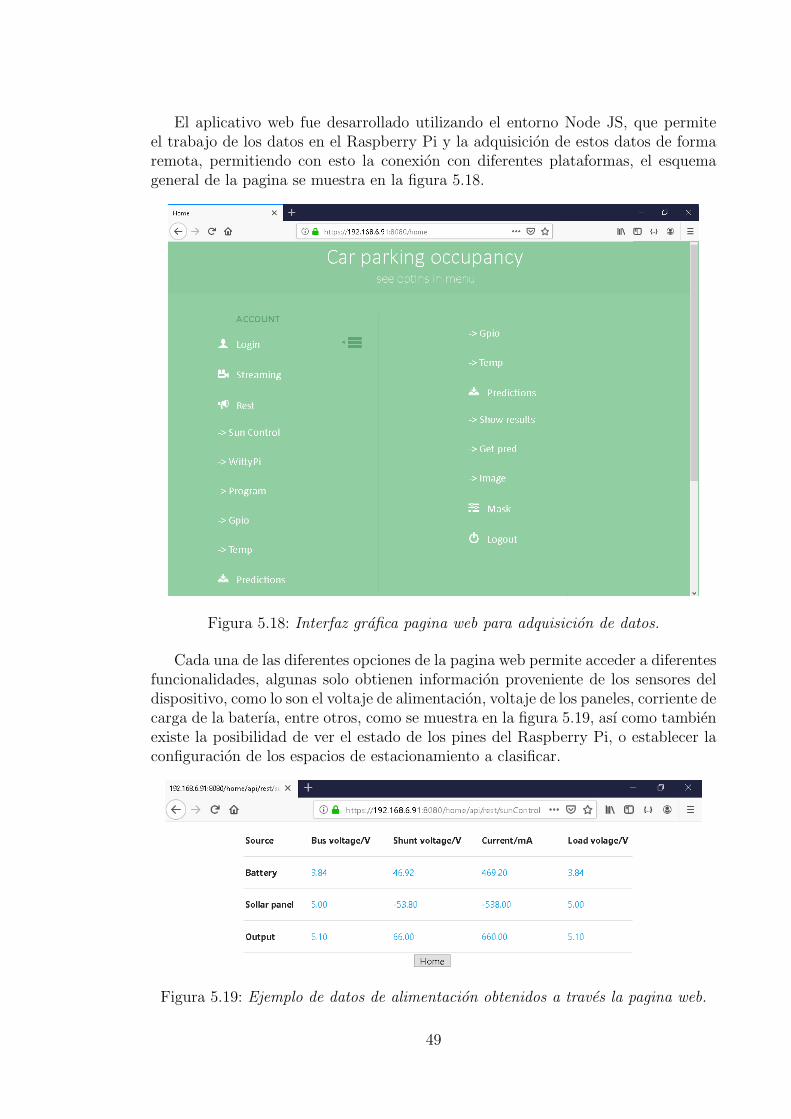
El aplicativo web fue desarrollado utilizando el entorno Node JS, que permiteel trabajo de los datos en el Raspberry Pi y la adquisicion de estos datos de formaremota, permitiendo con esto la conexion con diferentes plataformas, el esquemageneral de la pagina se muestra en la figura 5.18.
Figura 5.18: Interfaz grafica pagina web para adquisicion de datos.
Cada una de las diferentes opciones de la pagina web permite acceder a diferentesfuncionalidades, algunas solo obtienen informacion proveniente de los sensores deldispositivo, como lo son el voltaje de alimentacion, voltaje de los paneles, corriente decarga de la baterıa, entre otros, como se muestra en la figura 5.19, ası como tambienexiste la posibilidad de ver el estado de los pines del Raspberry Pi, o establecer laconfiguracion de los espacios de estacionamiento a clasificar.
Figura 5.19: Ejemplo de datos de alimentacion obtenidos a traves la pagina web.
49
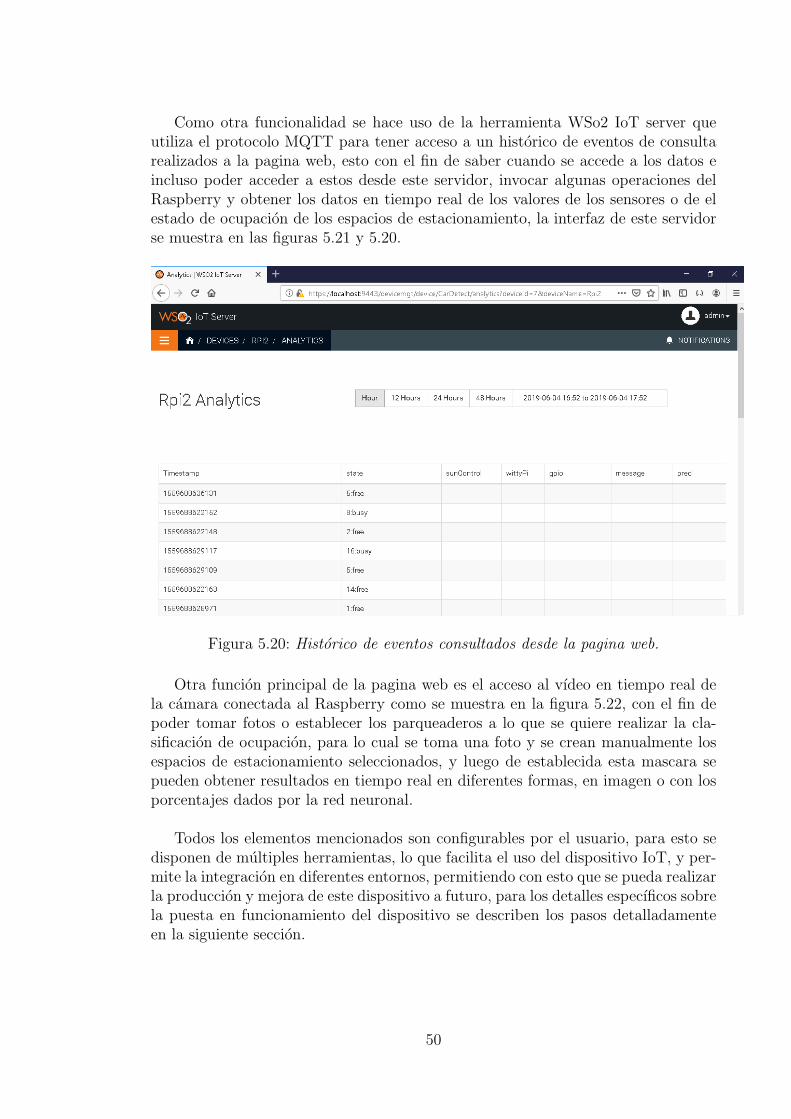
Como otra funcionalidad se hace uso de la herramienta WSo2 IoT server queutiliza el protocolo MQTT para tener acceso a un historico de eventos de consultarealizados a la pagina web, esto con el fin de saber cuando se accede a los datos eincluso poder acceder a estos desde este servidor, invocar algunas operaciones delRaspberry y obtener los datos en tiempo real de los valores de los sensores o de elestado de ocupacion de los espacios de estacionamiento, la interfaz de este servidorse muestra en las figuras 5.21 y 5.20.
Figura 5.20: Historico de eventos consultados desde la pagina web.
Otra funcion principal de la pagina web es el acceso al vıdeo en tiempo real dela camara conectada al Raspberry como se muestra en la figura 5.22, con el fin depoder tomar fotos o establecer los parqueaderos a lo que se quiere realizar la cla-sificacion de ocupacion, para lo cual se toma una foto y se crean manualmente losespacios de estacionamiento seleccionados, y luego de establecida esta mascara sepueden obtener resultados en tiempo real en diferentes formas, en imagen o con losporcentajes dados por la red neuronal.
Todos los elementos mencionados son configurables por el usuario, para esto sedisponen de multiples herramientas, lo que facilita el uso del dispositivo IoT, y per-mite la integracion en diferentes entornos, permitiendo con esto que se pueda realizarla produccion y mejora de este dispositivo a futuro, para los detalles especıficos sobrela puesta en funcionamiento del dispositivo se describen los pasos detalladamenteen la siguiente seccion.
50
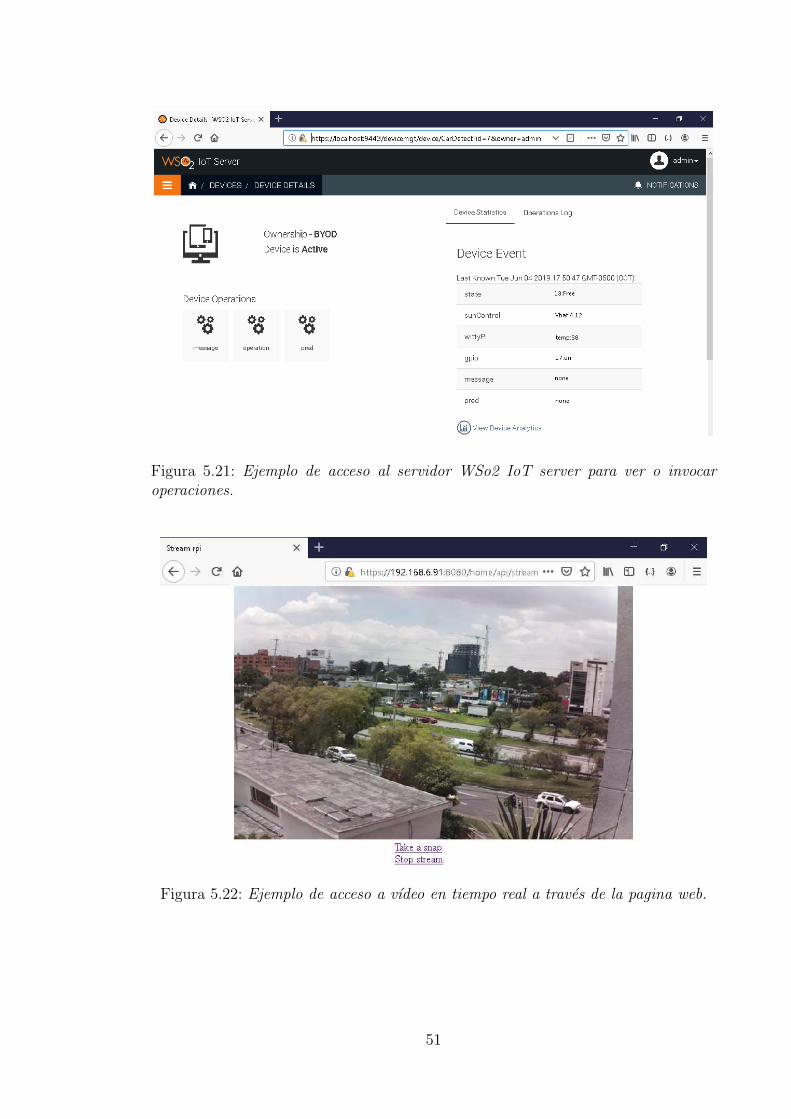
Figura 5.21: Ejemplo de acceso al servidor WSo2 IoT server para ver o invocaroperaciones.
Figura 5.22: Ejemplo de acceso a vıdeo en tiempo real a traves de la pagina web.
51

6. Manual de usuario
En esta seccion se explica como poner en funcionamiento el dispositivo IoT parala deteccion de ocupacion de los espacios de estacionamiento, para lo cual se debenseguir los siguientes pasos:
Realizar la conexion de los puertos de alimentacion electrica, para lo que sedispone de dos puertos en el exterior de la caja, uno para alimentar el disposi-tivo por un puerto USB y el otro para conectarlo directamente a un cargadorDC de 5V y superior a 1.5A.
Figura 6.1: Conexiones de izquierda a derecha, alimentacion DC, puerto USB, puertoEthernet, cable para entrada de paneles solares.
Realizar la conexion del cable de internet RJ45, o hacer uso del modulo 3Gcon una sim card que tenga acceso a internet, tambien es posible realizar laconexion a internet vıa Wifi.
Ubicar los paneles solares en el exterior, de tal manera que la posicion de estossea perpendicular a la incidencia del sol, para obtener la mayor energıa solarposible.
Figura 6.2: Ubicacion perpendicular de panel solar.
52

Abrir la caja del dispositivo para encender el modulo Witty Pi, el usuariopuede configurar si por defecto al conectar el dispositivo a la red electrica estese enciende directamente cambiando la posicion de un jumper en el Witty Picomo se muestra en la imagen 6.3.
Figura 6.3: Boton de encendido y jumper para encender por defecto el dispositivo.
Activar el interruptor de la tarjeta Sun Controller para permitir la carga de labaterıa y la lectura del sensor INA3221, como se muestra en la figura 6.4.
Figura 6.4: Activacion tarjeta Sun Controller para obtencion de datos se sensorINA3221.
Ubicar el dispositivo IoT de forma que el lente de la camara permita visualizarlos espacios de estacionamiento para su clasificacion, de forma similar a comose muestra en la figura 6.5.
53

Figura 6.5: Ubicacion caja de dispositivo IoT para visualizacion de espacios de es-tacionamiento..
Para el acceso al dispositivo se puede hacer uso de la herramienta VNC viewercomo se muestra en la imagen 6.6 que cuenta con interfaz grafica, o de laherramienta Putty, que permite acceder a la terminal de Raspberry como semuestra en la imagen 6.7, con la IP del dispositivo, el puerto de conexionconfigurado por defecto como 8022, el usuario y contrasena respectivos delsistema operativo.
Figura 6.6: Interfaz grafica VNC viewer.
54
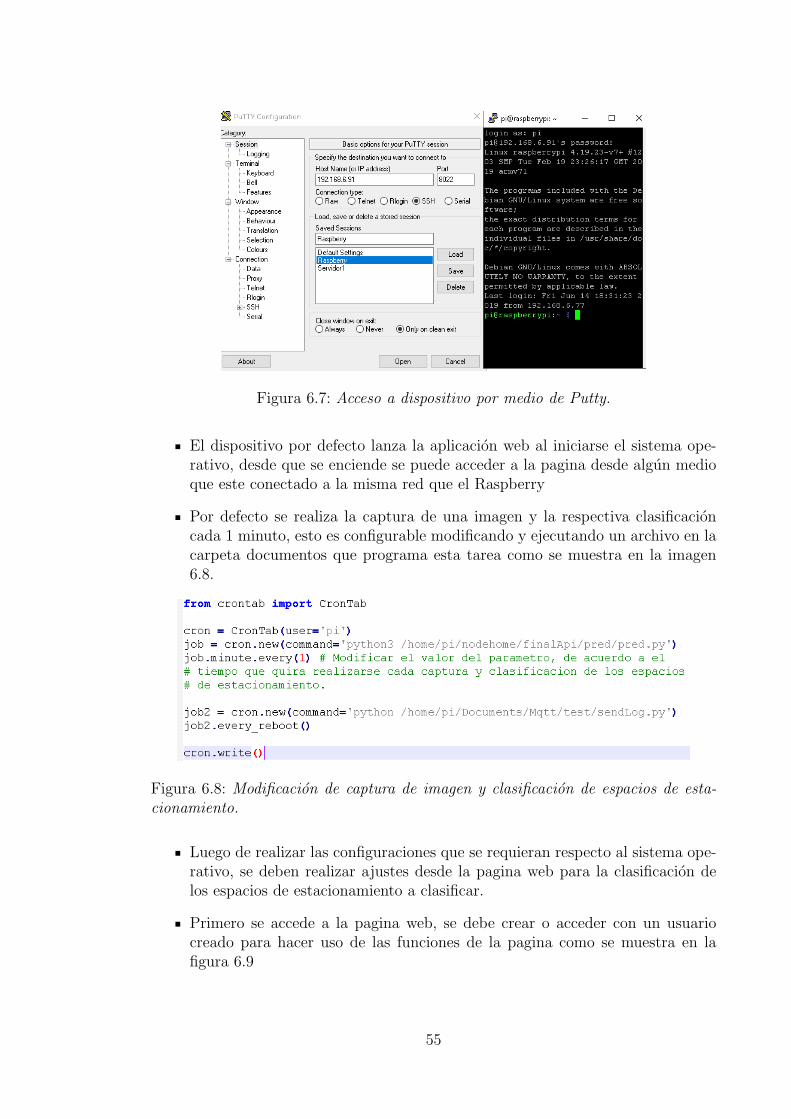
Figura 6.7: Acceso a dispositivo por medio de Putty.
El dispositivo por defecto lanza la aplicacion web al iniciarse el sistema ope-rativo, desde que se enciende se puede acceder a la pagina desde algun medioque este conectado a la misma red que el Raspberry
Por defecto se realiza la captura de una imagen y la respectiva clasificacioncada 1 minuto, esto es configurable modificando y ejecutando un archivo en lacarpeta documentos que programa esta tarea como se muestra en la imagen6.8.
Figura 6.8: Modificacion de captura de imagen y clasificacion de espacios de esta-cionamiento.
Luego de realizar las configuraciones que se requieran respecto al sistema ope-rativo, se deben realizar ajustes desde la pagina web para la clasificacion delos espacios de estacionamiento a clasificar.
Primero se accede a la pagina web, se debe crear o acceder con un usuariocreado para hacer uso de las funciones de la pagina como se muestra en lafigura 6.9
55

Figura 6.9: Plataforma de acceso o registro al dispositivo.
Se debe seleccionar la opcion Streaming como se muestra en la imagen 6.10 yse toma una captura como se muestra en la imagen 6.11.
Figura 6.10: Acceso a vıdeo en tiempo real.
Con la captura realizada, se debe pulsar el boton que dice ”Save Img”paraguardar la imagen y acceder a la herramienta que permite dibujar los espa-cios de estacionamiento que se quieren clasificar, por lo que se debe dibujarmanualmente los espacios requeridos como se muestra en la imagen 6.12.
56

Figura 6.11: Captura de imagen para configuracion de espacios.
Figura 6.12: Captura de imagen para configuracion de espacios de estacionamiento.
Con estas configuraciones realizadas ya se pueden obtener los resultados declasificacion como se muestra en las imagenes 6.13 y 6.14
Figura 6.13: Datos de clasificacion en formato JSON.
57

Figura 6.14: Imagen de clasificacion de espacios de estacionamiento.
Para acceder a las funciones correspondientes a la lectura de sensores y demascomponentes del dispositivo se debe acceder desde la pagina ”Home”, con loque se puede obtener los datos de el sensor INA3221 como se muestra en lafigura 6.15, datos de la tarjeta Witty Pi como se muestra en 6.16 y el estadode los puertos de entrada y salida del Raspberry como se muestra en 6.17
Figura 6.15: Ejemplo datos obtenidos con tarjeta Sun Controller.
Figura 6.16: Datos obtenidos con modulo Witty Pi, Raspberry Pi y sensor de tem-peratura.
58

Figura 6.17: Datos obtenidos con de los puertos de entrada y salida del RaspberryPi.
59

7. Alcances y limitaciones
7.1. Alcances
Considerando que en el desarrollo de la pasantıa se planteo la creacion de un dis-positivo IoT para la automatizacion de los espacios de estacionamiento, su alcanceestuvo enfocado a el desarrollo del prototipo de pruebas para la posible produc-cion a futuro, por lo que con las herramientas brindadas por la empresa InversionesGutierrez Garcia fue posible la experimentacion, creacion e implementacion de unaposible solucion a este problema a nivel investigativo, dado que se requiere de unamayor robustez y escalabilidad para la produccion en masa del dispositivo y su co-mercializacion.
Con las pruebas del dispositivo realizadas, en cuanto al funcionamiento de lared neuronal se determino que a pesar de los buenos resultados obtenidos, siguenexistiendo factores ajenos a la creacion del dispositivo como temas legales en cuantoa la colocacion de camaras en el exterior o incluso las diferentes obstrucciones quese presentan al momento de realizar la toma de las imagenes, lo que condiciono elfuncionamiento de la red.
En cuanto a la implementacion del dispositivo IoT, este se quedo como un pro-totipo funcional para una futura prueba en el exterior, debido a que con el tiempoplanteado para la pasantıa no fue posible el desarrollo de una prueba en el escenarioreal.
7.2. Limitaciones
La construccion de la base de datos estuvo condicionada por imagenes tomadas,a pesar de tener una amplia cantidad de imagenes, no todas aportaban informacionrelevante para el entrenamiento de la red neuronal, por lo que una de las limitacionespara mejorar la precision de la red neuronal fue el tamano de la base de datos, quepara mejorar la precision y la capacidad de generalizacion de la red se necesitarıaun conjunto de datos mas grande.
Una limitacion principal estuvo dada por la adquisicion de los elementos utili-zados para la realizacion de este proyecto, muchos de los implementos necesariosfueron adquiridos desde el exterior, lo que dificulto la realizacion de algunas pruebasy la creacion del dispositivo final segun los requerimientos establecidos.
En cuanto a la implementacion del dispositivo una limitacion estuvo dada por loscircuitos adquiridos para la alimentacion del Raspberry Pi, dado que con el sistemaimplementado no fue posible lograr la autonomıa suficiente para el funcionamientodel dispositivo durante un dıa completo con los paneles solares, y se presentaronlimitaciones en corriente por los elementos utilizados para el desarrollo del proyecto.
60

8. Analisis de cumplimiento deobjetivos
A continuacion se describen brevemente las tareas realizadas para desarrollarcada uno de los objetivos planteados para la realizacion de la pasantıa, indicando sise dio el cumplimiento del objetivo y los detalles sobre su ejecucion.
8.1. Objetivo 1:
Realizar la revision literaria de los fundamentos y conceptos principa-les acerca de redes neuronales convolucionales orientado a la vision porcomputador, clasificacion de imagenes y aprendizaje profundo.
Se consulto bibliografıa de multiples fuentes mediante la cual fue posible esta-blecer las bases teoricas para el entendimiento, seleccion, implementacion y pruebade la red neuronal convolucional, y todo lo relacionado con la integracion de esta enelementos en internet de las cosas con el fin de la creacion del prototipo del dispo-sitivo IoT.
El cumplimiento de este objetivo se dio a totalidad, segun lo establecido en elplan de trabajo.
8.2. Objetivo 2:
Construir y analizar bases de datos de imagenes o vıdeo para ser uti-lizadas en el entrenamiento, validacion y prueba de modelos con redesneuronales convolucionales.
Se realizo la toma de vıdeos e imagenes en la ciudad de Cucuta, para la construc-cion de la base de datos de entrenamiento, validacion y prueba de la red neuronal,este proceso tuvo exito en sus diferentes etapas como lo fueron la toma de imagenes,la seleccion de imagenes mas relevantes para la red, el etiquetado manual de lasimagenes, la extraccion de imagenes de los espacios de estacionamiento individual-mente, la creacion de programas en Python para el procesamiento de las imagenes,obteniendo como resultado la base de datos con un total de 10299 imagenes.
El cumplimiento de este objetivo se dio a totalidad, segun lo establecido en elplan de trabajo.
8.3. Objetivo 3:
Utilizar una red neuronal convolucional que permita la clasificacionde ocupacion de espacios de estacionamiento a partir de caracterısticas
61

extraıdas de las imagenes de las bases de datos.
Luego de la lectura y el establecimiento de la bibliografıa necesaria sobre redesneuronales para el reconocimiento de imagenes, se determino que se debıa seleccio-nar una red neuronal convolucional, para el caso se utilizo la red mAlexNet parael reconocimiento de la ocupacion de espacios de estacionamiento, la cual fue en-trenada con la base de datos creada en el segundo objetivo, realizando multiplesexperimentos para el entrenamiento, validacion y prueba, obteniendo las graficas deerror correspondientes, analizando los resultados y seleccionando el mejor modelopara la siguiente fase de pruebas e implementacion de la red.
El cumplimiento de este objetivo se dio a totalidad, segun lo establecido en elplan de trabajo.
8.4. Objetivo 4:
Evaluar el comportamiento de la red neuronal, con imagenes diferen-tes a las de entrenamiento, validacion y prueba del modelo utilizado.
Con la red neuronal entrenada se realizo la prueba de su funcionamiento con lasimagenes de la base de datos y con imagenes de otras bases de datos, ejecutandodiferentes pruebas y utilizando diferentes indicadores para evaluar los resultadosde clasificacion de la red y la capacidad de generalizacion, obteniendo resultadossatisfactorios para el reconocimiento de espacios de estacionamiento. Tambien serealizaron pruebas de los tiempos de ejecucion en diferentes entornos de trabajo yla comparacion de los resultados con los artıculos relacionados de la bibliografıa.
El cumplimiento de este objetivo se dio a totalidad, segun lo establecido en elplan de trabajo.
8.5. Objetivo 5:
Implementar los modelos entrenados en un dispositivo con un Rasp-berry Pi y redes de sensores para dar una solucion en internet de lascosas (IoT).
Por ultimo con la red neuronal entrenada y evaluada, se realizaron pruebas parareducir el tiempo de procesamiento de la ejecucion de la red en el Raspberry Pi, seimplementaron diferentes sensores para la medicion de variables internas y externasdel dispositivo, ası como tambien se utilizaron energıas alternativas para la alimen-tacion de este, con el uso de dos paneles solares y una baterıa, se realizaron pruebasdel consumo y autonomıa del dispositivo, y finalmente se realizo un aplicativo webpara acceder a los datos de forma remota.
62

El cumplimiento de este objetivo se dio a totalidad, quedando como segun loestablecido en el plan de trabajo.
63

9. Conclusiones
La construccion de la base de datos y la disposicion de los conjuntos de imagenes,son factores fundamentales para obtener un buen resultado durante el entrenamien-to de la red, es necesario tener un conjunto equilibrado de acuerdo a las clases onumero de salidas del clasificador, con las pruebas realizadas se determino que serequiere de un numero amplio de ejemplos para la fase de entrenamiento en el casode las redes neuronales convolucionales.
Al modificar los parametros de entrenamiento, se evidencio que existe un puntode convergencia independientemente del numero de iteraciones, la red mantiene unaprecision estable, por lo que el aumento de las epocas de entrenamiento no condi-ciona el resultado de la red despues de determinado valor, algo similar sucede conla tasa de aprendizaje que luego de los experimentos realizados, se determino queen esta caso particular, no condiciona de forma significativa el resultado al finalizarel entrenamiento.
Con los experimentos realizados se obtuvo una buena precision y exactitud supe-riores al 90% para la base de datos propia, se evidenciaron fallos en ciertos eventosespecıficos en los que existen oclusiones en las imagenes o con imagenes de otras basesde datos, que indican que la capacidad de generalizacion y los resultados obtenidosdependen en gran medida de los ejemplos usados durante el entrenamiento de la red.
En comparacion con la bibliografıa consultada y los experimentos realizados porlos autores previo a la realizacion de este proyecto, se obtuvo resultados similares encuanto a exactitud y precision utilizando el mismo modelo de red neuronal, indican-do que este es una buena solucion para la clasificacion de la ocupacion de espaciosde estacionamiento y que se puede mejorar en la medida que condiciones como laposicion de la camara, el tamano de la base de datos, las condiciones climaticas yotros factores sean mejorados.
La implementacion de los elementos embebidos para el desarrollo del dispositivoen internet de las cosas, evidencian la posibilidad de brindar una solucion real alproblema de la automatizacion y control de los espacios de estacionamiento, conla integracion de nuevas tecnologıas y energıas alternativas, quedando como futurotrabajo a realizar la mejora de la autonomıa y eficiencia de la alimentacion electricay la implementacion de este dispositivo en un escenario real para evaluar su funcio-namiento.
64

Bibliografıa
Amato, G., Carrara, F., Falchi, F., Gennaro, C., Meghini, C., & Vairo, C. (2017).Deep learning for decentralized parking lot occupancy detection. Expert Systemswith Applications, 72, 327–334.
Amato, G., Carrara, F., Falchi, F., Gennaro, C., & Vairo, C. (2016). Car parkingoccupancy detection using smart camera networks and Deep Learning. In Procee-dings - IEEE Symposium on Computers and Communications.
Andrade, E. (2013). Estudio de los principales tipos de redes neuronales y lasherramientas para su aplicacion, 152.
Asawa, C. (2015). Convolutional Neural Networks for Visual Recognition. Disponibleen: http://cs231n.github.io/convolutional-networks/#norm.
Duran, J. (2017). Redes Neuronales Convolucionales en R Reconocimiento de ca-racteres escritos a mano Redes Neuronales Convolucionales en R Reconocimientode caracteres escritos a mano Redes Neuronales Convolucionales en R.
El Universal, C. (2017). Bogota es la quinta ciudad con peor trafico del mun-do. Disponible en: https://www.eluniversal.com.co/colombia/bogota/bogota-es-la-quinta-ciudad-con-peor-trafico-del-mundo-247119-NWEU356821.
Foundation, R. P. (2013). Raspberry Pi 3 Model B+. Disponible en:https://www.raspberrypi.org/documentation/.
Gonzalo Tapia, A. G. (2015). Red neuronal artificial para detectar esfuerzo fısicodesde planos de fase de onda de pulso. Revista Ingenierıa Biomedica, 9, 1–2.
Jackson, L. (2016). Camera for Raspberry Pi Sony IMX219. Disponible en :http://www.arducam.com/8mp-sony-imx219-camera-raspberry-pi/.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification withDeep Convolutional Neural Networks. In ImageNet Classification with Deep Con-volutional Neural Networks.
Marın Diazaraque, J. M. (2012). Introduccion a las redes neuronales aplicadas.Manual Data Mining, 1–31.
Mery, D. (2004). Vision por Computador. Universidad Catolica de Chile.
Movilidad Bogota, S. (2019). Sistema inteligente de parqueo en bogota.
Picazo Montoya, O. (2018). Redes Neuronales Convolucionales Profundas para elreconocimiento de emociones en imagenes, 45.
Quintero, C., Merchan, F., Cornejo, A., & Galan, J. S. (2018). Uso de Redes Neu-ronales Convolucionales para el Reconocimiento Automatico de Imagenes de Ma-croinvertebrados para el Biomonitoreo Participativo. KnE Engineering, 3 (1), 585.
65

Rose, Karen; Eldridge, Scott; Chapin, L. (2015). La internet de las cosas — Unabreve resena. Internet Society, 63–112.
Ruiz, C. A. & Matich, D. J. (2001). Redes Neuronales: Conceptos Basicos y Aplica-ciones. Grupo de Investigacion Aplicada a la Ingenierıa Quımica (GIAIQ) Cate-dra:.
Sanchez Anzola, N. (2016). Maquinas de soporte vectorial y redes neuronales arti-ficiales en la prediccion del movimiento USD/COP spot intradiario. Odeon, (9),113.
Secretaria movilidad, M. (2019). Zonas de estacionamiento regulado (ZER). Disponi-ble en: https://www.medellin.gov.co/movilidad/transito-transporte/zer-zona-de-estacionamiento-regulado-parquimetros.
Sucar, L. E. & Gomez, G. (2011). Vision Computacional. Instituto Nacional deAstrofısica, Optica y Electronica, 185.
SwicthDocLabs (2017). Power Controller SunControl Solar Power Controller, 1–28.
UUGear (2018). Witty Pi 2.
Voltaic (2017). 6 Watt Solar Panel. Disponible en:https://www.voltaicsystems.com/6-watt-panel.
66





























