Embed Size (px)
DESCRIPTION
InterProcess Communication - Message Passing 서강대학교 정보통신 대학원 Page 3 Characteristics of Message Passing n Multiple Threads of Control 3 Consists of multiple processes, each of which has its own control and may execute different code. Supports MIMD or SPMD parallelism. n Asynchronous Parallelism 3 Message Passing program executes asynchronously. Need barrier and blocking communication for synchronization. n Separate Address Space 3 Data variables in one process are not visible to other processes. Need special library routines (e.g., send/receive) to interact with other processes. n Explicit Interactions 3 The Programmer must resolve all the interaction issues such as communication and synchronization. n Explicit Allocation 3 Data should be explicitly allocated by the user.
Citation preview

Distributed Processing SystemDistributed Processing Systemss
(InterProcess Communication)(InterProcess Communication)((Message PassingMessage Passing))
오 상 규오 상 규
서강대학교 정보통신 대학원서강대학교 정보통신 대학원
Email : [email protected] : [email protected]
Page 2
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
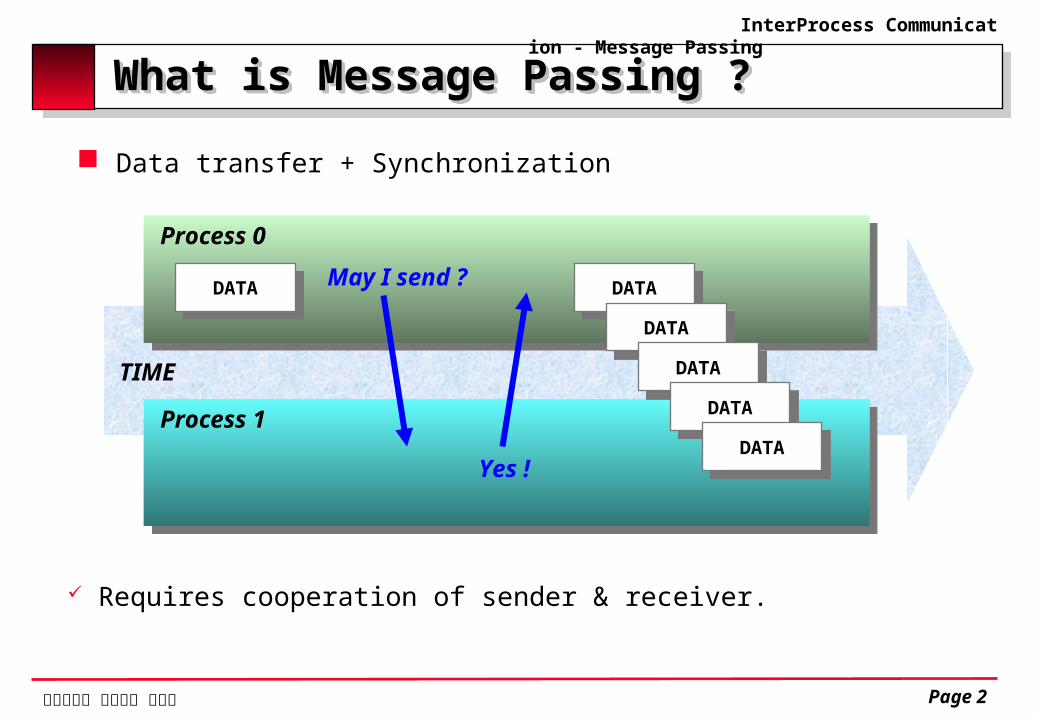
What is Message Passing ?What is Message Passing ?
Data transfer + Synchronization
TIME
DATA
Process 0May I send ?
Process 1
Yes !
DATA
DATA
DATA
DATA
DATA
Requires cooperation of sender & receiver.

Page 3
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Characteristics of Message PassingCharacteristics of Message Passing Multiple Threads of Control
Consists of multiple processes, each of which has its own control and may execute different code. Supports MIMD or SPMD parallelism.
Asynchronous Parallelism Message Passing program executes asynchronously. Need barrier and
blocking communication for synchronization. Separate Address Space
Data variables in one process are not visible to other processes. Need special library routines (e.g., send/receive) to interact with other processes.
Explicit Interactions The Programmer must resolve all the interaction issues such as
communication and synchronization. Explicit Allocation
Data should be explicitly allocated by the user.

Page 4
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Message Passing LibrariesMessage Passing Libraries Proprietary Software
CMMD : Message passing library used in Thinking Machines CM-5. Express : Programming environment by Parasoft Corporation for message passin
g and parallel I/O. Nx : Microkernel system developed for Intel MPPs (e.g., Paragon). Replaced by a
new kernel called PUMA. Public-Domain Software
p4 : A set of macros and subroutines used for programming both shared-memory and message passing systems.
PARMACS : Message passing package derived from p4 and mainly used in Europe.
PVM and MPI MPI : A standard specification for a library of message passing functions develope
d by the MPI Forum. PVM : Self-contained, public domain software system to run parallel applications o
n a network of heterogeneous workstations.

Page 5
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Classification of Message Passing LibrariesClassification of Message Passing Libraries Application Domain
General Purpose : p4, PVM, MPI, Express, PARMACS, etc. ISIS, Horus, Totem, Transis for reliable group communication.
Application Specific : BLACS (for linear algebra), TCGMSG (for chemistry), etc.
Programming Model Computation Model : data parallel or functional parallel. Communication Model : RPC, message passing, or shared memory.
Underlying Implementation Philosophy Socket for portability. High performance communication middleware (e.g., Active Message or Fast
Message) to achieve high performance. Portability
CMMD for CM-5 and NX/2 for Intel parallel computers. Heterogeneity
Page 6
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
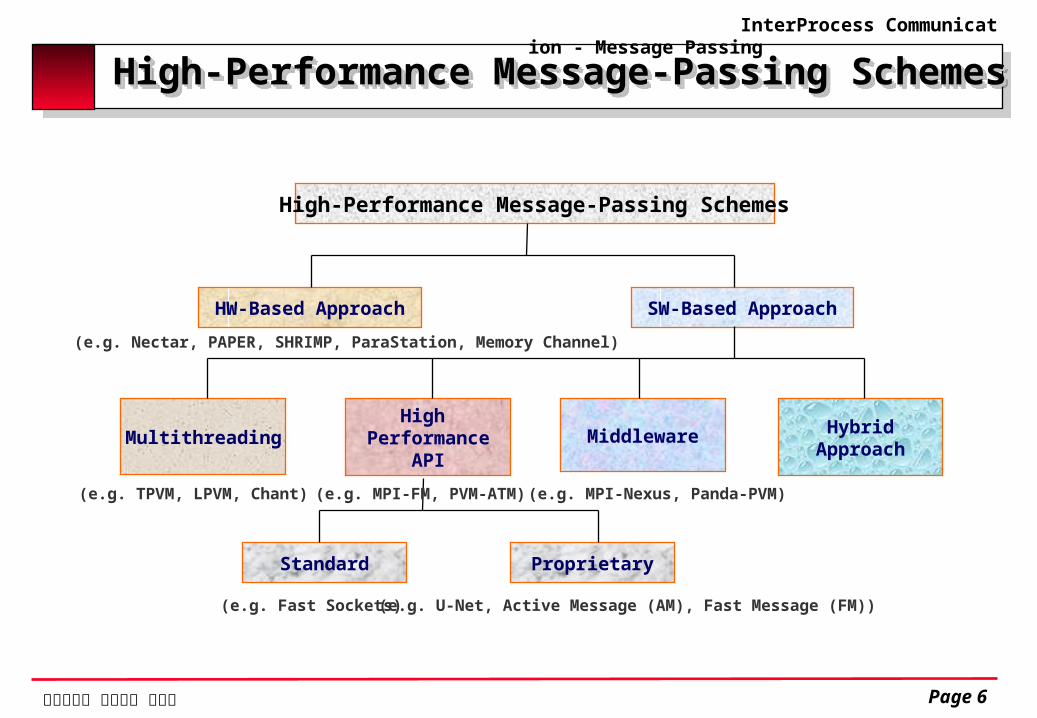
High-Performance Message-Passing SchemesHigh-Performance Message-Passing Schemes
High-Performance Message-Passing Schemes
HW-Based Approach SW-Based Approach
MultithreadingHigh
PerformanceAPI
HybridApproachMiddleware
Standard Proprietary
(e.g. Fast Sockets) (e.g. U-Net, Active Message (AM), Fast Message (FM))
(e.g. TPVM, LPVM, Chant) (e.g. MPI-FM, PVM-ATM) (e.g. MPI-Nexus, Panda-PVM)
(e.g. Nectar, PAPER, SHRIMP, ParaStation, Memory Channel)
Page 7
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
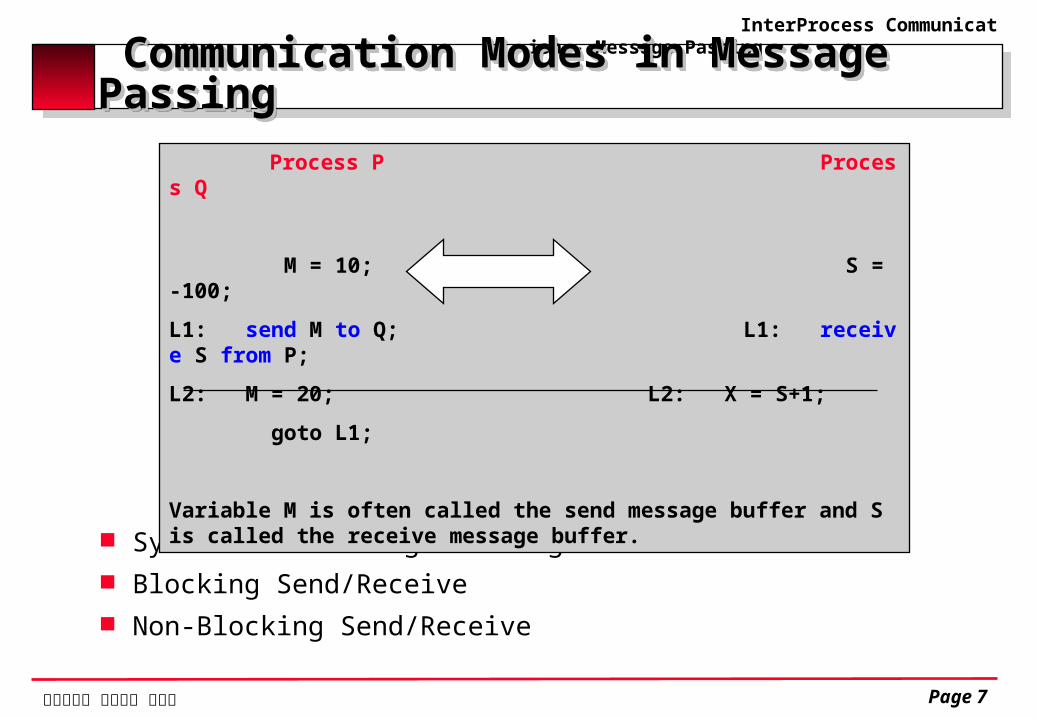
Communication Modes in Message Passing Communication Modes in Message Passing
Synchronous Message Passing Blocking Send/Receive Non-Blocking Send/Receive
Process P Process Q
M = 10; S = -100;
L1: send M to Q; L1: receive S from P;
L2: M = 20; L2: X = S+1;
goto L1;
Variable M is often called the send message buffer and S is called the receive message buffer.

Page 8
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Three Communication ModesThree Communication Modes Synchronous Message Passing
P has to wait until Q execute a corresponding Receive. Will not return until M is sent and received. No additional buffer needed. X should be evaluated to 11.
Blocking Send/Receive Send is executed when a process reaches it without waiting for a corresponding Receive. Send does not return until the message is sent, meaning that message variable M can be
safely rewritten. Maybe temporarily buffered in the sending node, somewhere in the network, or in the receiving node.
Receive is executed when a process reaches it without waiting for a corresponding Send. Receive does not return until the message is received. X should be evaluated to 11.
Non-Blocking Send/Receive Send is executed when a process reaches it without waiting for a corresponding Receive. Send returns immediately after it notifies the system. Unsafe to overwrite M. Receive is executed when a process reaches it without waiting for a corresponding Send. Receive return immediately regardless of the message arrival. X can be 11, 21, or -99.
Page 9
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
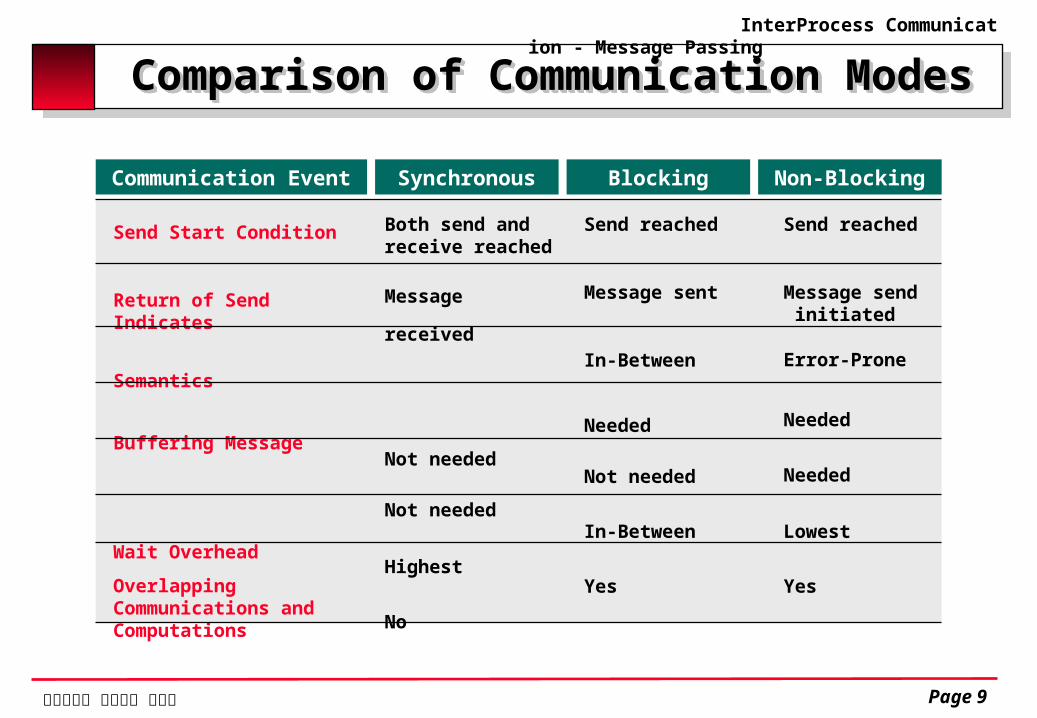
Comparison of Communication ModesComparison of Communication Modes
SynchronousCommunication Event Non-BlockingBlocking
Send Start Condition
Return of Send Indicates
Semantics
Buffering Message
Status Checking
Wait Overhead
Overlapping Communications and Computations
Both send and receive reached
Message received
Clean
Not needed
Not needed
Highest
No
Send reached
Message sent
In-Between
Needed
Not needed
In-Between
Yes
Send reached
Message send initiated
Error-Prone
Needed
Needed
Lowest
Yes
Page 10
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
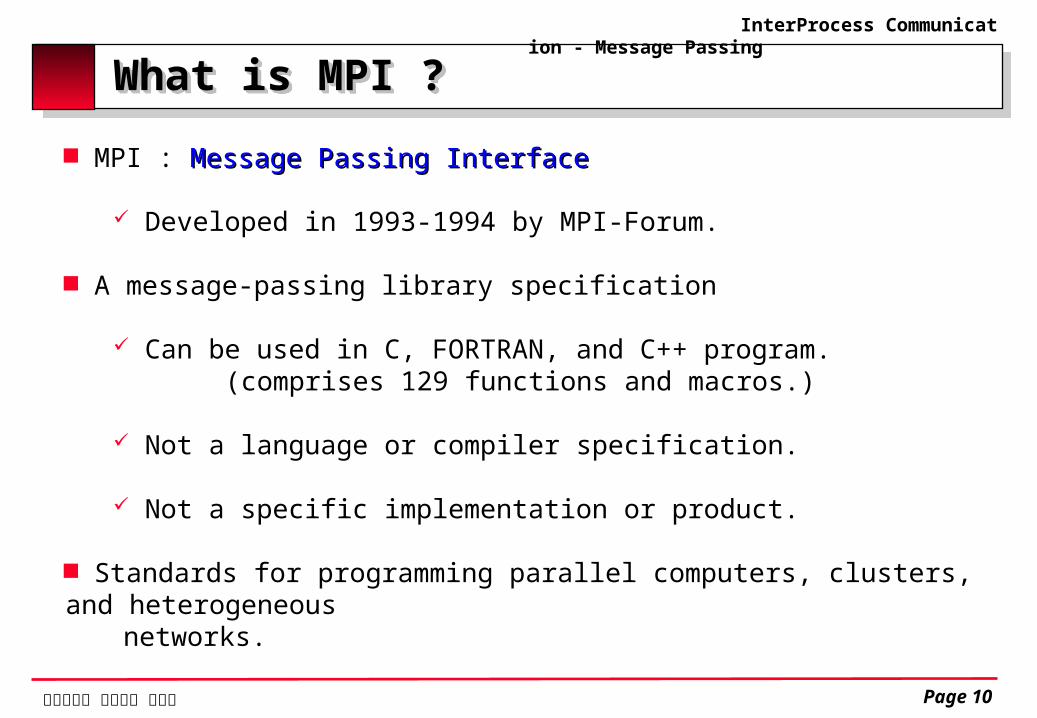
What is MPI ?What is MPI ? MPI : Message Passing InterfaceMessage Passing Interface
Developed in 1993-1994 by MPI-Forum.
A message-passing library specification
Can be used in C, FORTRAN, and C++ program. (comprises 129 functions and macros.)
Not a language or compiler specification.
Not a specific implementation or product.
Standards for programming parallel computers, clusters, and heterogeneous networks.
Page 11
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
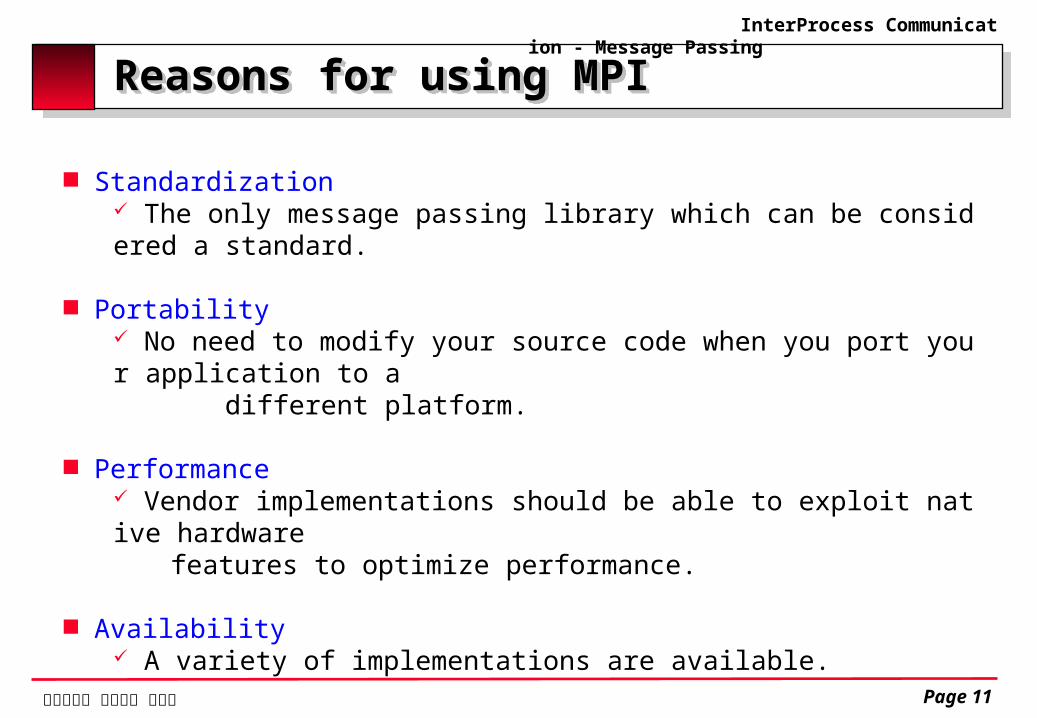
Reasons for using MPIReasons for using MPI
Standardization The only message passing library which can be considered a standard.
Portability
No need to modify your source code when you port your application to a different platform.
Performance Vendor implementations should be able to exploit native hardware features to optimize performance.
Availability A variety of implementations are available.
Page 12
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
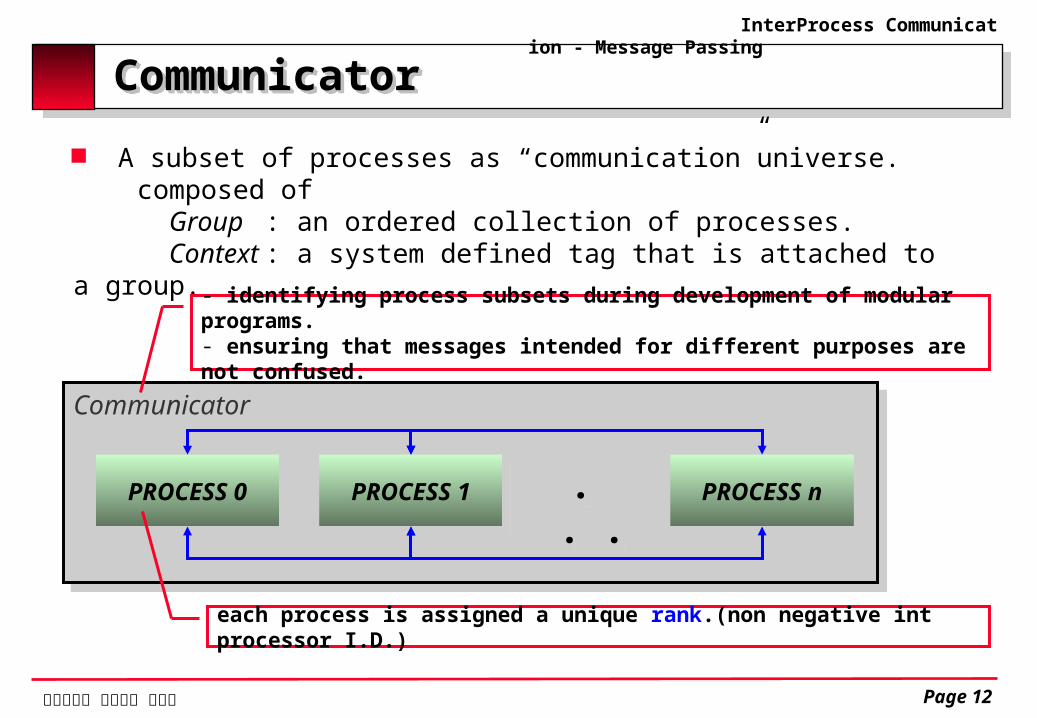
CommunicatorCommunicator A subset of processes as “communication”universe. composed of Group : an ordered collection of processes. Context : a system defined tag that is attached to a group.
Communicator
PROCESS 0 PROCESS 1 PROCESS n . . .
- identifying process subsets during development of modular programs.- ensuring that messages intended for different purposes are not confused.
each process is assigned a unique rank.(non negative int processor I.D.)

Page 13
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Types of CommunicatorsTypes of Communicators
Intra-Communicators
A collection of processes that can send messages to each other and engage in a collective communication operations.
ex) MPI_COMM_WORLD (default)
Inter-Communicators
Used for sending messages between processes belonging to disjoint intra-communicators.
ex) a newly created intra-communicator could be linked to the original intra-communicator by an inter-communicator.
Page 14
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
MPI Communication ModelMPI Communication Model
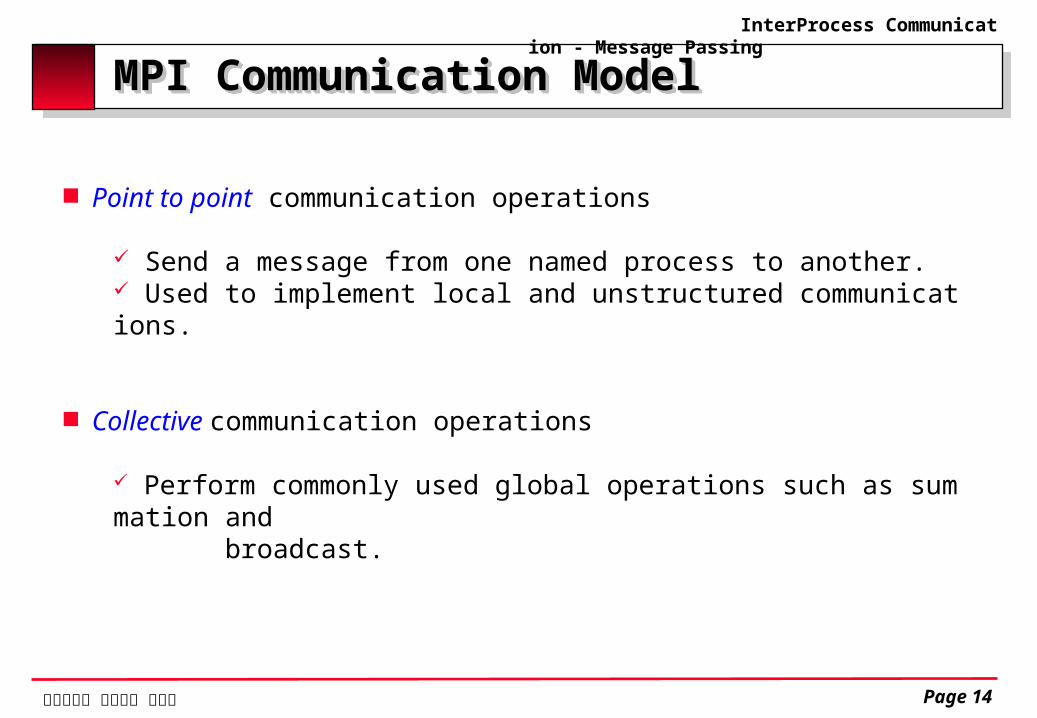
Point to point communication operations
Send a message from one named process to another. Used to implement local and unstructured communications.
Collective communication operations
Perform commonly used global operations such as summation and broadcast.
Page 15
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
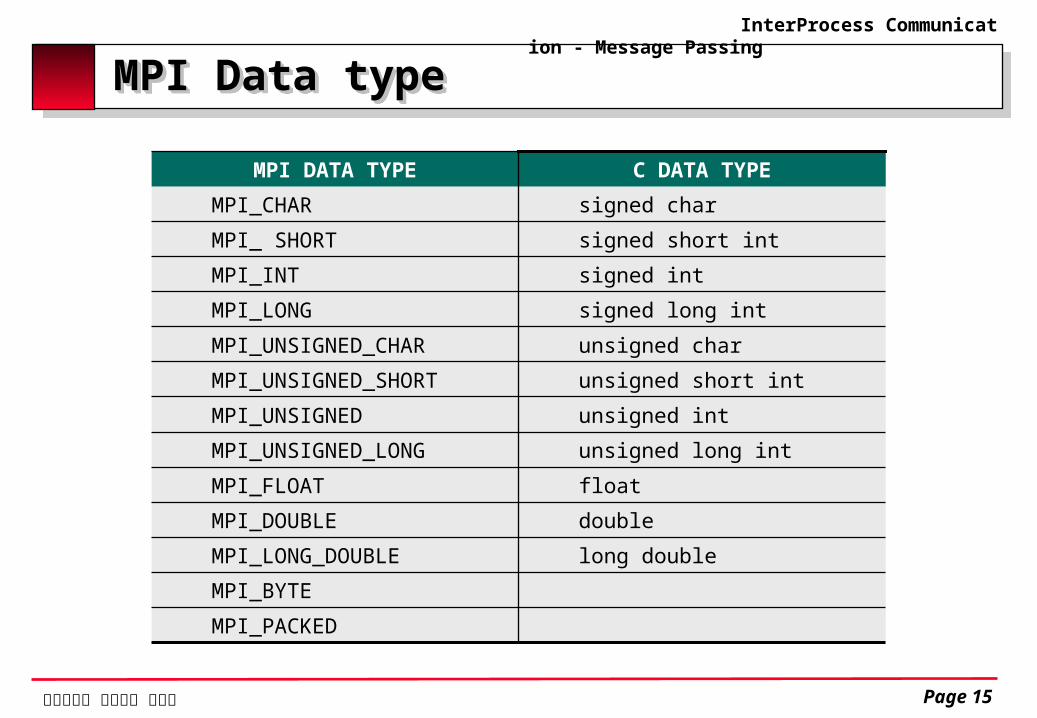
MPI Data typeMPI Data type
MPI_PACKED
MPI_BYTE
long double MPI_LONG_DOUBLE
double MPI_DOUBLE
float MPI_FLOAT
unsigned long int MPI_UNSIGNED_LONG
unsigned int MPI_UNSIGNED
unsigned short int MPI_UNSIGNED_SHORT
unsigned char MPI_UNSIGNED_CHAR
signed long int MPI_LONG
signed int MPI_INT
signed short int MPI_ SHORT
signed char MPI_CHAR
C DATA TYPEMPI DATA TYPE
Page 16
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
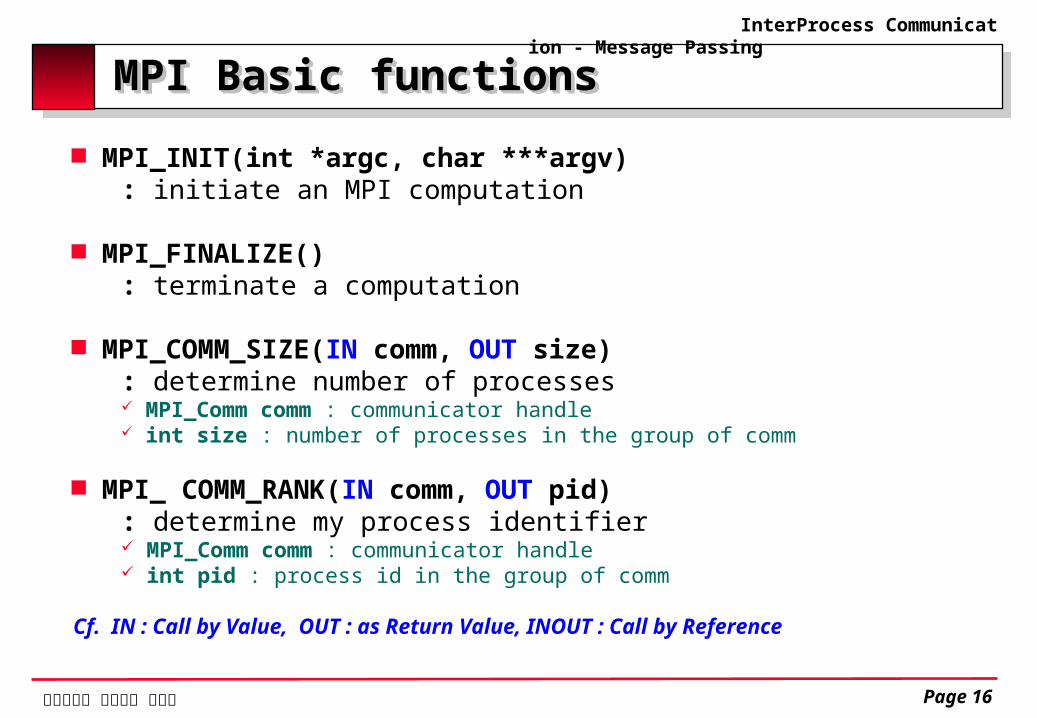
MPI Basic functionsMPI Basic functions MPI_INIT(int *argc, char ***argv) : initiate an MPI computation
MPI_FINALIZE() : terminate a computation MPI_COMM_SIZE(IN comm, OUT size) : determine number of processes
MPI_Comm comm : communicator handle int size : number of processes in the group of comm
MPI_ COMM_RANK(IN comm, OUT pid) : determine my process identifier
MPI_Comm comm : communicator handle int pid : process id in the group of comm
Cf. IN : Call by Value, OUT : as Return Value, INOUT : Call by Reference
Page 17
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
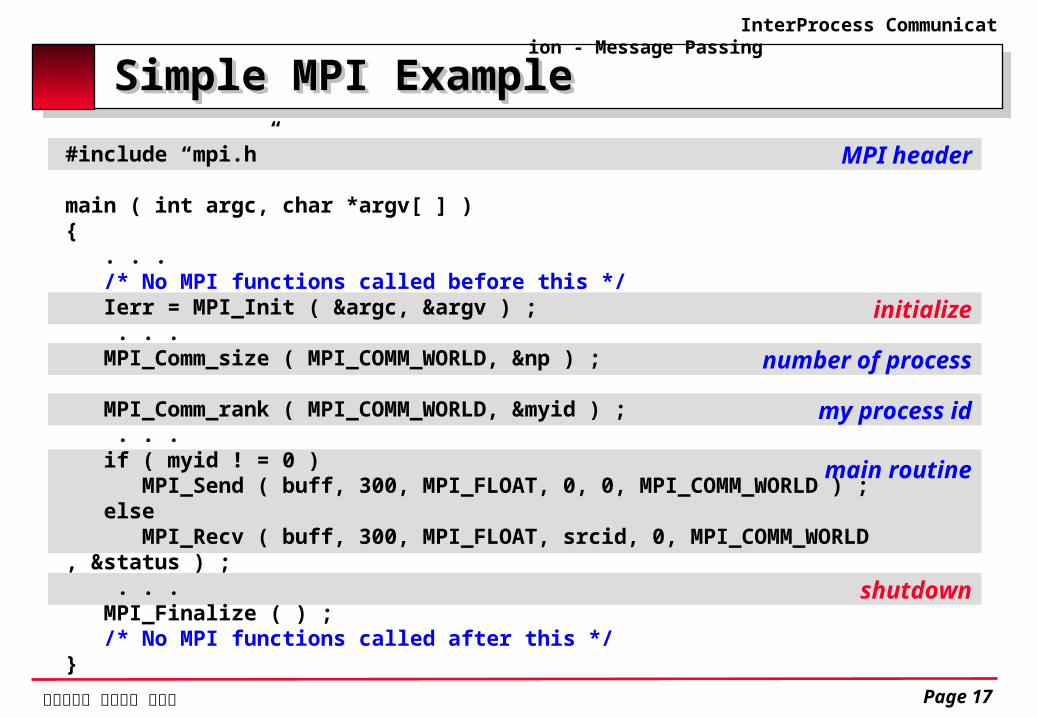
Simple MPI ExampleSimple MPI Example
shutdown
main routine
my process id
initialize
number of process
MPI header#include “mpi.h”
main ( int argc, char *argv[ ] ){ . . . /* No MPI functions called before this */ Ierr = MPI_Init ( &argc, &argv ) ; . . . MPI_Comm_size ( MPI_COMM_WORLD, &np ) ;
MPI_Comm_rank ( MPI_COMM_WORLD, &myid ) ; . . . if ( myid ! = 0 ) MPI_Send ( buff, 300, MPI_FLOAT, 0, 0, MPI_COMM_WORLD ) ; else MPI_Recv ( buff, 300, MPI_FLOAT, srcid, 0, MPI_COMM_WORLD, &status ) ; . . . MPI_Finalize ( ) ; /* No MPI functions called after this */}
Page 18
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
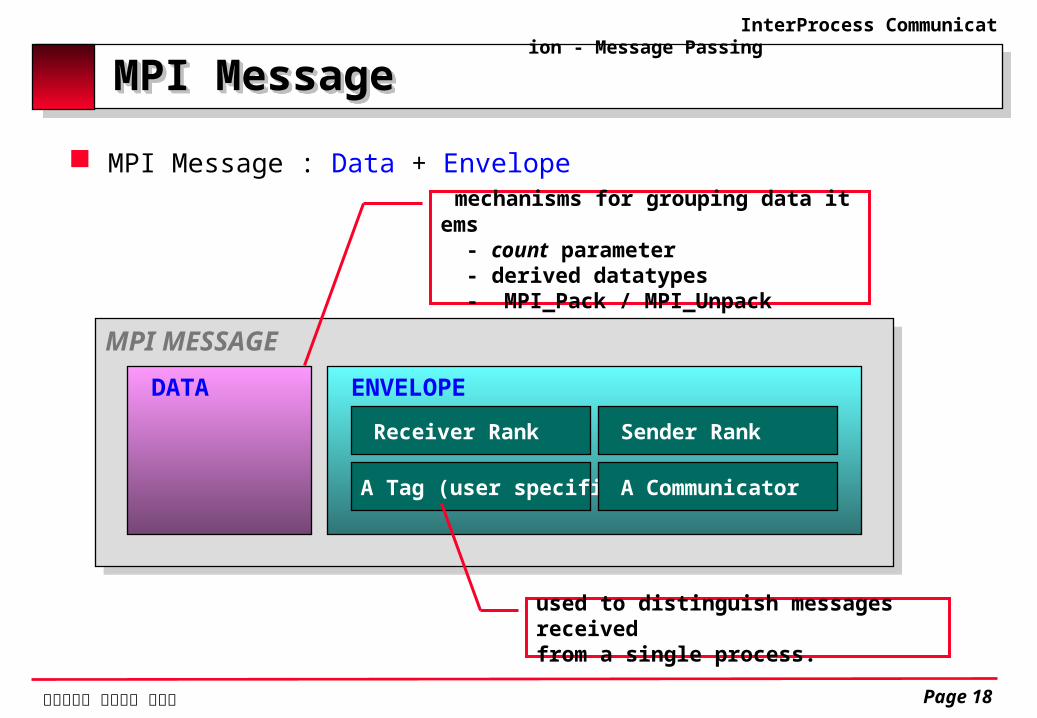
MPI MessageMPI Message
MPI Message : Data + Envelope
MPI MESSAGE DATA ENVELOPE
Receiver Rank
A Tag (user specified)
Sender Rank
A Communicator
used to distinguish messages received from a single process.
mechanisms for grouping data items - count parameter - derived datatypes - MPI_Pack / MPI_Unpack
Page 19
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
COMMUNICATOR
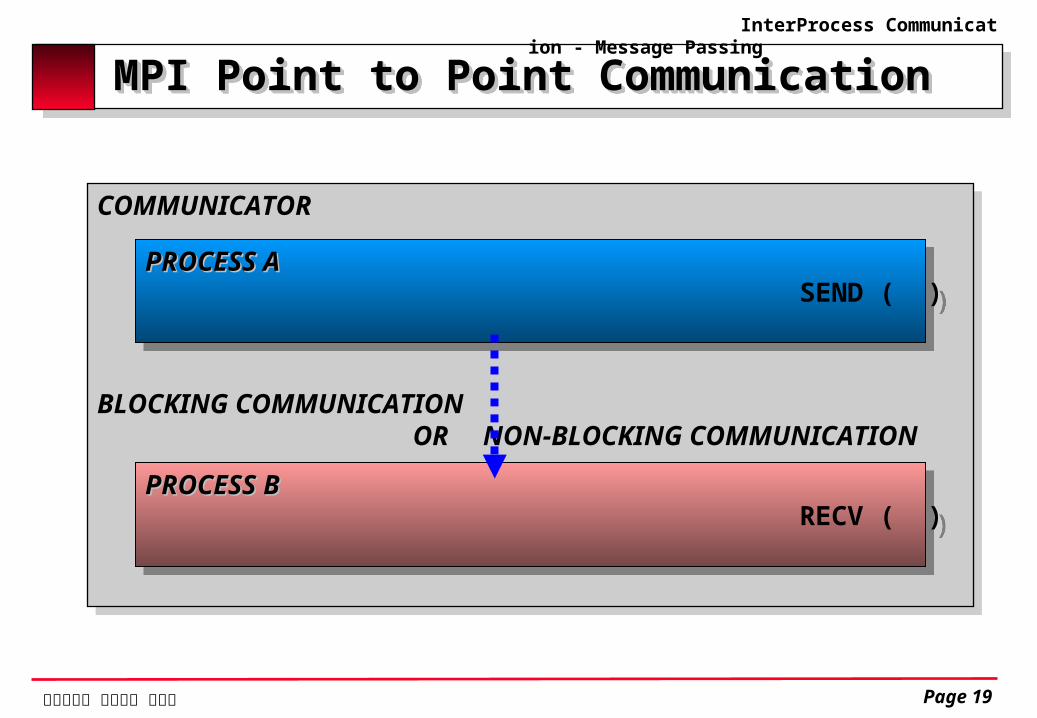
MPI Point to Point CommunicationMPI Point to Point Communication
SEND ( )
BLOCKING COMMUNICATION OR NON-BLOCKING COMMUNICATION
PROCESS APROCESS A
RECV ( )PROCESS BPROCESS B

Page 20
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
MPI Send / Receive function PrototypeMPI Send / Receive function Prototype MPI_SEND(IN msg, IN count, IN datatype, IN dest, IN tag, IN comm) : send a message
void *msg : address of send buffer int count : number of elements to send ( 0 ) MPI_Datatype datatype : data type of send buffer elements int dest : process id of destination process int tag : message tag MPI_Comm comm : communicator handle
MPI_RECV(OUT msg, IN count, IN datatype, IN source, IN tag, IN comm, OUT status ) : receive a message
void *msg : address of receive buffer int count : number of elements to receive ( 0 ) MPI_Datatype datatype : data type of receive buffer elements int dest : process id of source process, or MPI_ANY_TAG int tag : message tag or MPI_ANY_TAG MPI_Comm comm : communicator handle MPI_Status *status : status object

Page 21
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Blocking Message Passing ExampleBlocking Message Passing Example #include “mpi.h”#include <stdio.h>
main ( int argc, char *argv[ ] ){ int numtasks, rank, dest, source, rc, tag = 1 ; char inmsg, outmsg = ‘x’ ; MPI_Status Stat ;
MPI_Init ( &argc, &argv ) ; MPI_Comm_size ( MPI_COMM_WORLD, &numtasks ) ; MPI_Comm_rank ( MPI_COMM_WORLD, &rank ) ;
if ( rank == 0 ) { dest = 1 ; source = 1 ; rc = MPI_Send ( &outmsg , 1 , MPI_CHAR , dest , tag , MPI_COMM_WORLD ) ; rc = MPI_Recv ( &inmsg , 1 , MPI_CHAR , source , tag , MPI_COMM_WORLD , &Stat ) ; } else if ( rank == 1 ) { dest = 0 ; source = 0 ; rc = MPI_Recv ( &inmsg , 1 , MPI_CHAR , source , tag , MPI_COMM_WORLD , &Stat ) ; rc = MPI_Send ( &outmsg , 1 , MPI_CHAR , dest , tag , MPI_COMM_WORLD ) ; } MPI_Finalize ( ) ;}

Page 22
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Non-Blocking Message Passing ExampleNon-Blocking Message Passing Example #include “mpi.h”#include <stdio.h>
main ( int argc, char *argv[ ] ){ int numtasks, rank, next, prev, buf[2], tag1 = 1, tag2 = 2 ; MPI_Request reqs[4] ; MPI_Status stats[4] ;
MPI_Init ( &argc, &argv ) ; MPI_Comm_size ( MPI_COMM_WORLD, & numtasks ) ; MPI_Comm_rank ( MPI_COMM_WORLD, &rank ) ;
prev = rank – 1 ; next = rank + 1 ;
if ( rank == 0 ) prev = numtasks – 1 ; if ( rank == ( numtasks – 1) ) next = 0 ;
MPI_Irecv ( &buf[0] , 1 , MPI_INT , prev , tag1 , MPI_COMM_WORLD , reqs[0] ) ; MPI_Irecv ( &buf[1] , 1 , MPI_INT , next , tag2 , MPI_COMM_WORLD , reqs[1] ) ;
MPI_Isend ( &rank , 1 , MPI_INT , prev , tag2 , MPI_COMM_WORLD , reqs[2] ) ; MPI_Isend ( &rank , 1 , MPI_INT , next , tag1 , MPI_COMM_WORLD , reqs[3] ) ;
MPI_Waitall ( 4 , reqs , stats ) ;
MPI_Finalize ( ) ;}
Page 23
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
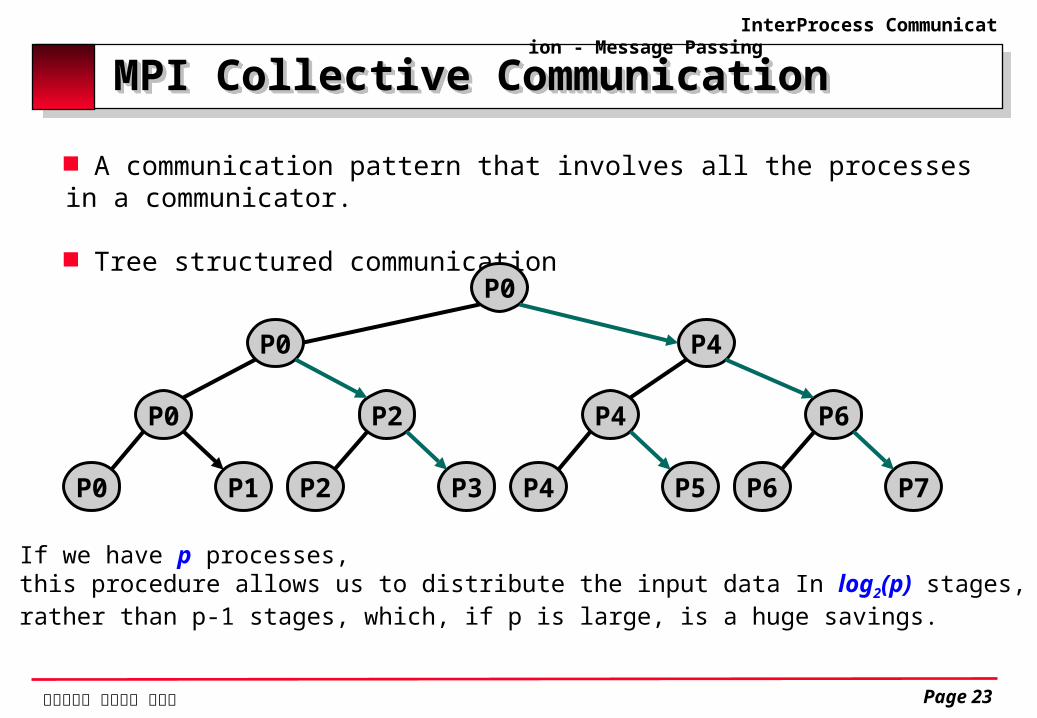
MPI Collective CommunicationMPI Collective Communication
A communication pattern that involves all the processes in a communicator.
Tree structured communication
P0
P2
P2 P3
P0
P0 P1
P6
P6 P7
P4
P4 P5
P4
P0
If we have p processes, this procedure allows us to distribute the input data In log2(p) stages, rather than p-1 stages, which, if p is large, is a huge savings.
Page 24
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
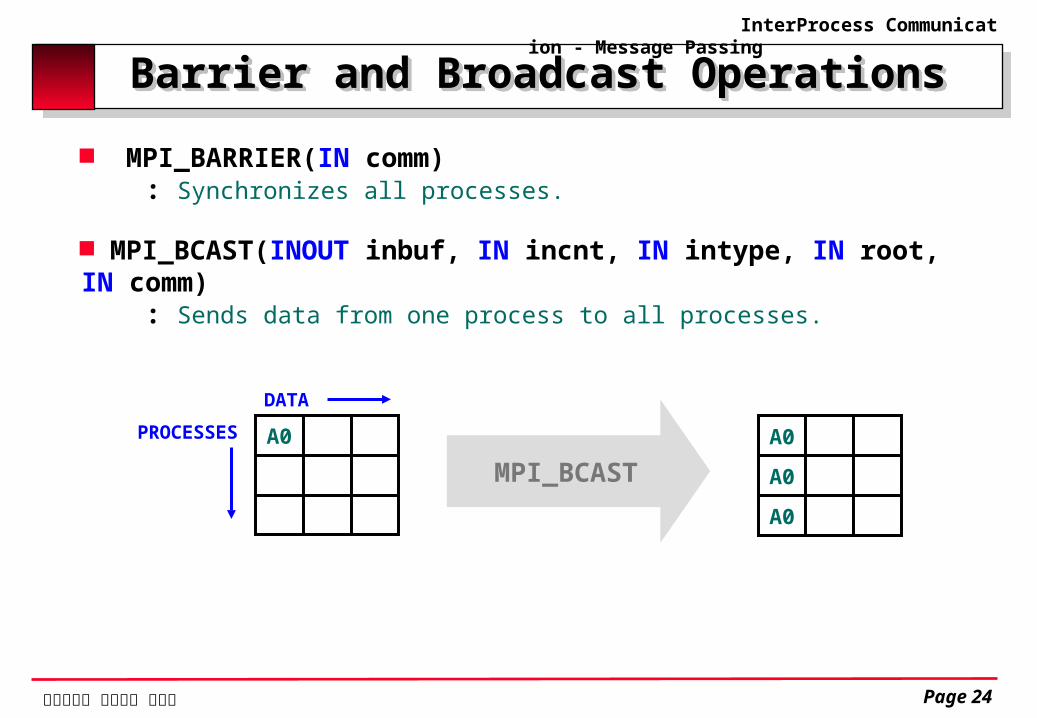
Barrier and Broadcast Operations Barrier and Broadcast Operations MPI_BARRIER(IN comm) : Synchronizes all processes.
MPI_BCAST(INOUT inbuf, IN incnt, IN intype, IN root, IN comm) : Sends data from one process to all processes.
A0DATA
PROCESSES A0
A0
A0
MPI_BCAST
Page 25
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
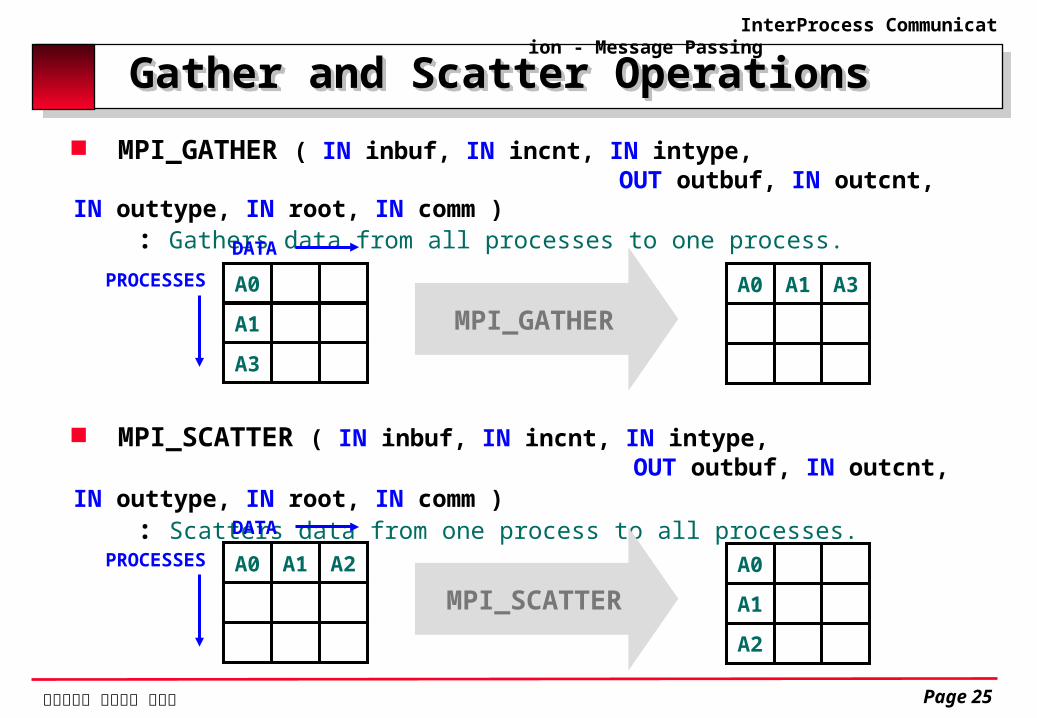
Gather and Scatter Operations Gather and Scatter Operations MPI_GATHER ( IN inbuf, IN incnt, IN intype, OUT outbuf, IN outcnt, IN outtype, IN root, IN comm ) : Gathers data from all processes to one process.
A0
A1
A3
DATAPROCESSES A0 A1 A3
MPI_GATHER
MPI_SCATTER ( IN inbuf, IN incnt, IN intype, OUT outbuf, IN outcnt, IN outtype, IN root, IN comm ) : Scatters data from one process to all processes.
A0 A1 A2DATA
PROCESSES A0
A1
A2
MPI_SCATTER
Page 26
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
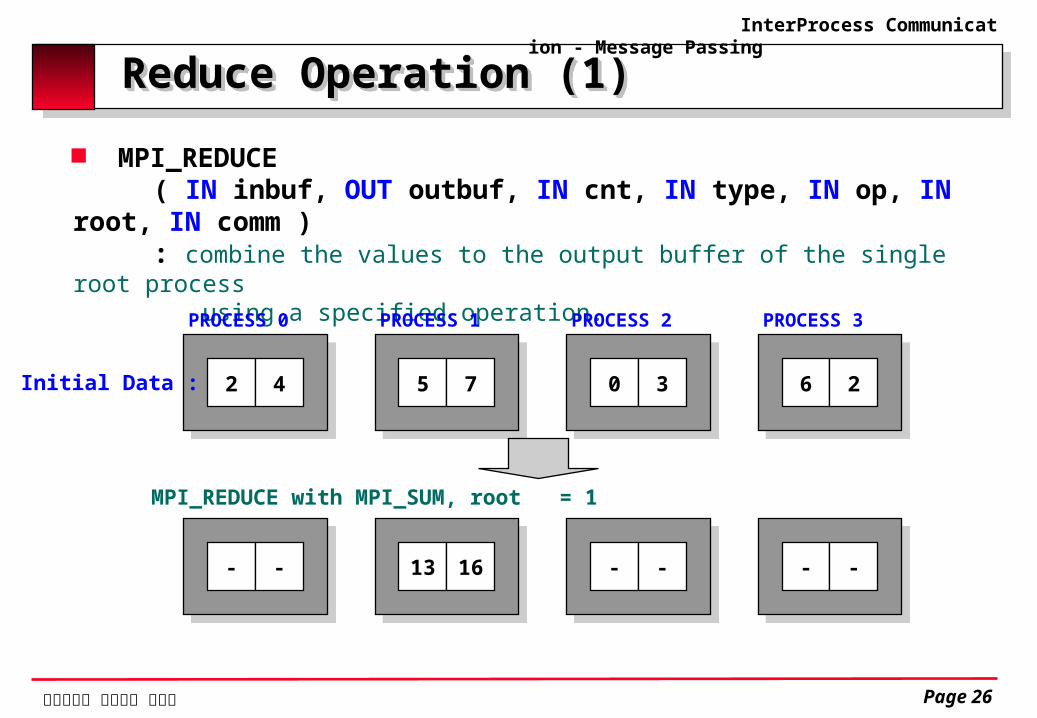
Reduce Operation (1) Reduce Operation (1) MPI_REDUCE ( IN inbuf, OUT outbuf, IN cnt, IN type, IN op, IN root, IN comm ) : combine the values to the output buffer of the single root process using a specified operation.
2 4
PROCESS 0
Initial Data :
5 7
PROCESS 1
0 3
PROCESS 2
6 2
PROCESS 3
- -
13 16
- -
- -
MPI_REDUCE with MPI_SUM, root = 1
Page 27
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
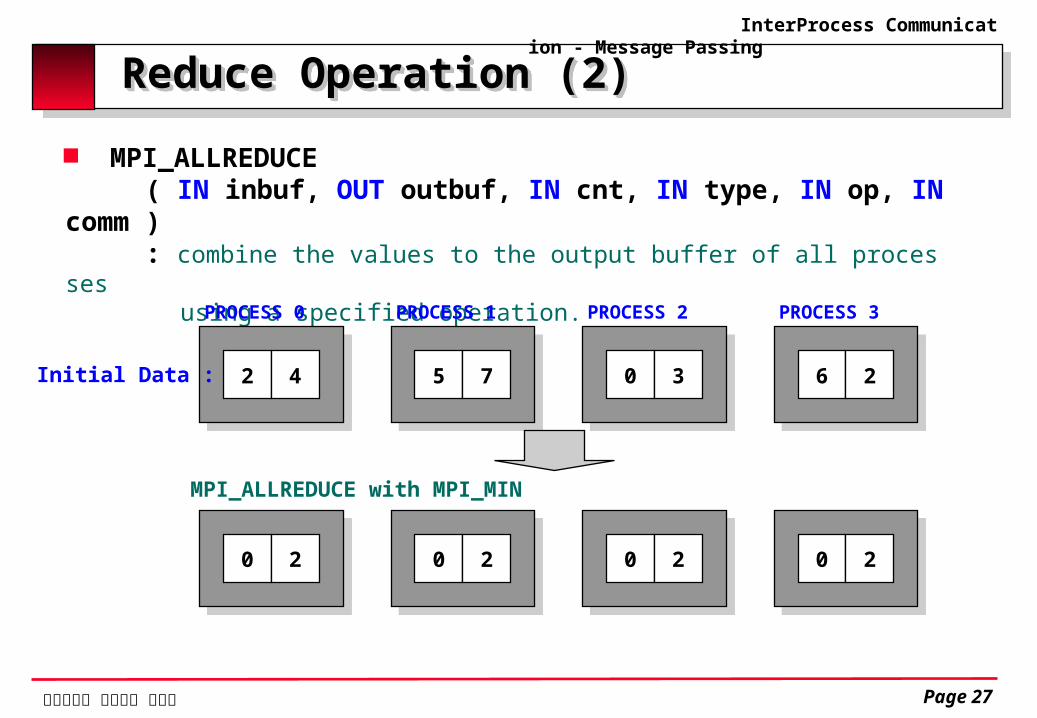
Reduce Operation (2)Reduce Operation (2) MPI_ALLREDUCE ( IN inbuf, OUT outbuf, IN cnt, IN type, IN op, IN comm ) : combine the values to the output buffer of all processes using a specified operation.
2 4
PROCESS 0
Initial Data :
5 7
PROCESS 1
0 3
PROCESS 2
6 2
PROCESS 3
0 2
0 2
0 2
0 2
MPI_ALLREDUCE with MPI_MIN

Page 28
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
Collective Communication ExampleCollective Communication Example
#include “mpi.h”#include <stdio.h>#define SIZE 4
main ( int argc, char *argv[ ] ){ int numtasks, rank, sendcount, recvcount, source ; float sbuf[SIZE][SIZE] = { { 1.0 , 2.0 , 3.0 , 4.0 } , { 5.0 , 6.0 , 7.0 , 8.0 } , { 9.0 , 10.0 , 11.0 , 12.0 } , { 13.0 , 14.0 , 15.0 , 16.0 } } ; float rbuf[SIZE] ;
MPI_Init ( &argc, &argv ) ; MPI_Comm_rank ( MPI_COMM_WORLD, &rank ) ; MPI_Comm_size ( MPI_COMM_WORLD, &numtasks ) ;
if ( numtasks == SIZE ) { source = 1 ; sendcount = SIZE ; recvcount = SIZE ;
MPI_Scatter ( sbuf , sendcount , MPI_FLOAT , rbuf , recvcount , MPI_FLOAT , source , MPI_COMM_WORLD ) ; printf ( “rank=%d results : %f %f %f %f \n”, rank, rbuf[0], rbuf[1], rbuf[2], rbuf[3] ) ; } else printf ( “Must specify %d processors. Terminating. \n” , SIZE ) ;
MPI_Finalize ( ) ;}

Page 29
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
MPI Implementation (1)MPI Implementation (1) MPICH
Freely available implementation of the MPI standard, designed to be both portable and efficient.
Developed in 1996 by MPI-Forum.
to compile the C source program prog.c
% cc -o prog.c -I/usr/local/mpi/include -L/usr/local/mpi/lib -lmpi
to run the program with 4 processes
% mpirun -np 4 prog
Page 30
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
MPI Implementation (2)MPI Implementation (2)
LAM
Available from Ohio Supercomputer center and runs on heterogeneous network of Sun, DEC, SGI, HP workstations.
CHIMP - MPI
Available from the Edinbourgh Parallel Computing Center and runs on Sun, DEC, SGI, IBM, HP workstations, the Meiko Computing Surface machines, and the Fujitsu AP-1000.
Page 31
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
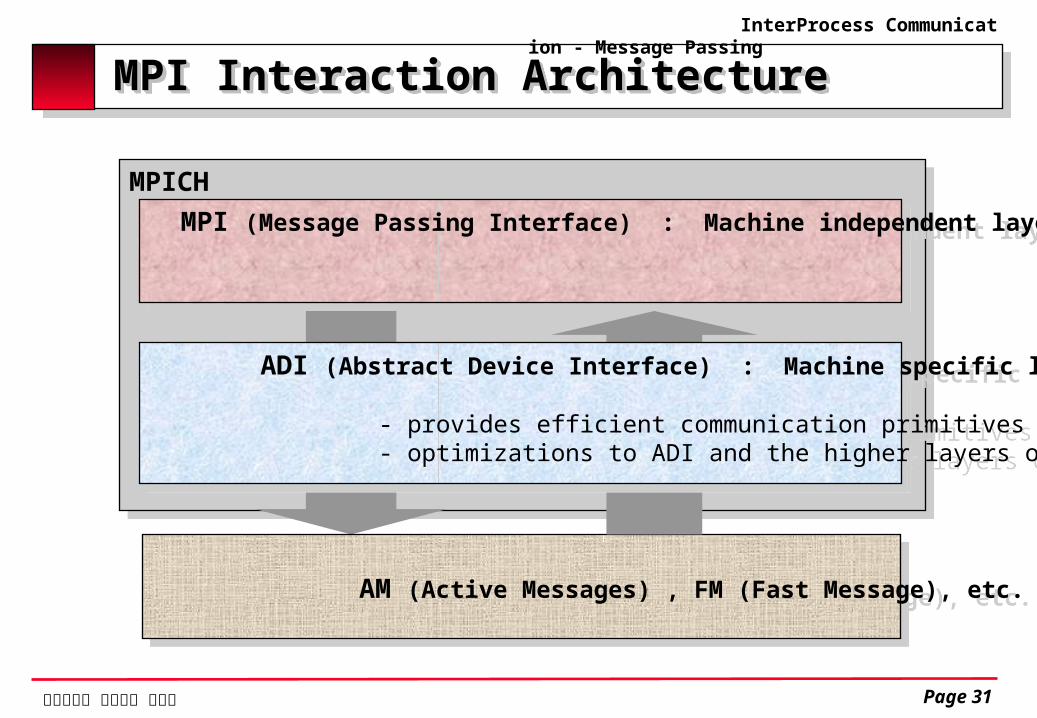
MPI Interaction ArchitectureMPI Interaction Architecture
MPICH MPI (Message Passing Interface) : Machine independent layer
AM (Active Messages) , FM (Fast Message), etc.
ADI (Abstract Device Interface) : Machine specific layer - provides efficient communication primitives - optimizations to ADI and the higher layers of MPICH
Page 32
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
MPI 2 (1)MPI 2 (1)
Enhanced MPI
Discussed in 1995 by MPI-Forum. Draft made available in 1996
New functionality
Dynamic processes : extensions which remove the static process model of MPI. ( e.g. , MPI_SPAWN )
One sided communications : Include shared memory operations (put/get) and remote accumulate operations. ( e.g. , MPI_PUT )

Page 33
InterProcess Communication - Message Passing
서강대학교 정보통신 대학원
MPI 2 (2)MPI 2 (2) Parallel I / O
: Discusses MPI support for parallel I/O. (MPI-IO) I/O can also be modeled as message passing.
- Writing to a file : sending a message- Reading from a file : receiving a message
Extended collective operations : Allows for non-blocking collective operations and application of collective operations to inter-communicators.
External Interfaces : Defines routines which allow developers to layer on top of MPI, such as for debuggers and profilers.
Additional language bindings : Describes C++ bindings and discusses FORTRAN-90 issues.





























