Embed Size (px)
Citation preview

Generative Adversarial Networks (GAN)
Hanxiao Liu
April 17, 2017
1 / 20

Outline
I Implicit Generative Models
I GAN
I VariantsI f -GANI Wasserstein GAN
I Use casesI Conditional generationI SSL
2 / 20

Implicit Generative Models
Working with likelihood could be expensive
I Variational Autoencoder (variational inference)
I Boltzmann Machines (MCMC)
I PixelRNN (conditional prob.)
Representation learning may not require likelihood.
I Sometimes we are more interested in taking samplesfrom p(x) instead of p itself.
More discussions: [Mohamed and Lakshminarayanan, 2016]
3 / 20
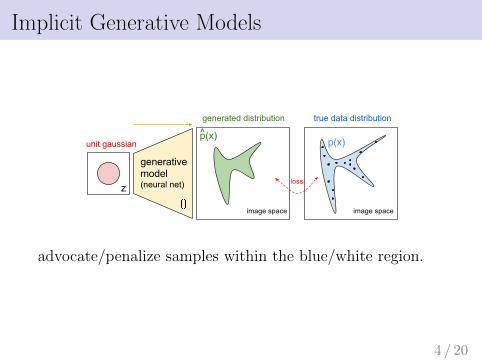
Implicit Generative Models
advocate/penalize samples within the blue/white region.
4 / 20
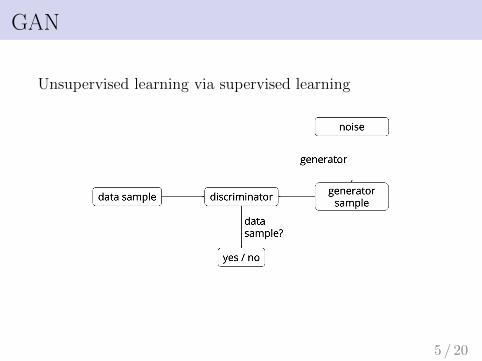
GAN
Unsupervised learning via supervised learning
5 / 20

GAN
Proposed by [Goodfellow et al., 2014]
A minimax game
J (D) = −1
2Ex∼data logD(x)− 1
2Ez log(1−D(G(z))) (1)
J (G) = −J (D) (2)
I The optimal discriminator D∗(x) = pdata(x)pdata(x)+pmodel(x)
.
I In this case, J (G) = 2DJS(pdata‖pmodel) + const.
I Jenson-Shannon divergence:DJS(p‖q) = 1
2DKL(p‖p+q
2) + 1
2DKL(q‖p+q
2).
6 / 20

GAN
7 / 20
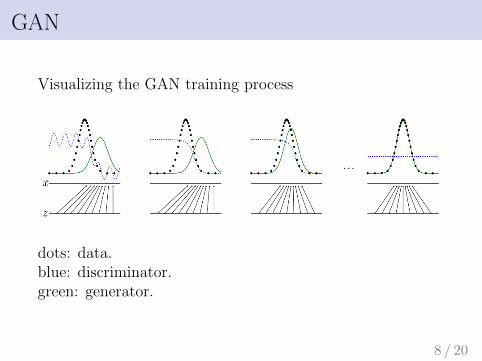
GAN
Visualizing the GAN training process
dots: data.blue: discriminator.green: generator.
8 / 20
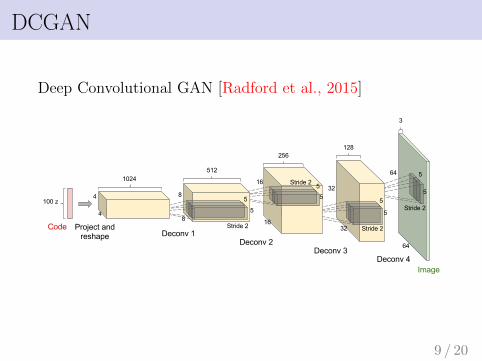
DCGAN
Deep Convolutional GAN [Radford et al., 2015]
9 / 20

f -divergence
Can we simply optimize the divergence?
Df (p‖q) =
∫q(x)f
(p(x)
q(x)
)dx (3)
I recovers KL divergence when f(u) = u log u.
I optimization minqDf (p‖q) can hardly be carried outwith Df in its original form.
11 / 20

f -GAN [Nowozin et al., 2016]
Fenchel conjugacy: f(u) = supt tu− f ∗(t)
minq
Df (P‖Q) (4)
= minq
∫q(x)
[supt
(tp(x)
q(x)− f ∗(t)
)]dx (5)
≥ minq
supT
∫p(x)T (x)− f ∗(T (x))q(x)dx (6)
= minq
supT
EpT (x)− Eqf ∗(T (x)) (7)
≈ minw
maxθ
EpTθ(x)− Eqωf ∗(Tθ(x)) (8)
The above includes GAN as its special case.
12 / 20

Training GAN
Training GAN (finding the equilibrium) is hard.
I Gradient for G will vanish when D is very good.
I i.e. when pdata and pmodel are very different.I usually true for high-dimensional data.I f -divergence may be ill-defined.
13 / 20

Wasserstein GAN
Replace the pointwise f -divergence with Wassersteindistance [Arjovsky et al., 2017].
Dw(p‖q) = infγ∈Π(p,q)
E(x,y)∼γdist(x, y) (9)
where Π(p, q) is the set of all joint distributions γ(x, y)which marginal distributions are respectively p and q.
I well defined even if p and q have different support.
I leads to a very simple algorithm using a similarvariational trick for the f -divergence.
14 / 20

Wasserstein GAN
15 / 20
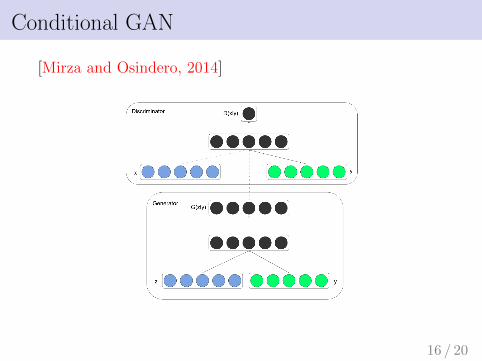
Conditional GAN
[Mirza and Osindero, 2014]
16 / 20

Conditional GAN
Image to image translation [Isola et al., 2016].
17 / 20

Semi-supervised Learning
I Data augmentation
I Regularization [Salimans et al., 2016]
I Categorical GAN [Springenberg, 2015]
18 / 20

Reference I
Arjovsky, M., Chintala, S., and Bottou, L. (2017).Wasserstein gan.arXiv preprint arXiv:1701.07875.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D.,Ozair, S., Courville, A., and Bengio, Y. (2014).Generative adversarial nets.In Advances in neural information processing systems, pages 2672–2680.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2016).Image-to-image translation with conditional adversarial networks.arXiv preprint arXiv:1611.07004.
Mirza, M. and Osindero, S. (2014).Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784.
Mohamed, S. and Lakshminarayanan, B. (2016).Learning in implicit generative models.arXiv preprint arXiv:1610.03483.
19 / 20

Reference II
Nowozin, S., Cseke, B., and Tomioka, R. (2016).f-gan: Training generative neural samplers using variational divergenceminimization.In Advances in Neural Information Processing Systems, pages 271–279.
Radford, A., Metz, L., and Chintala, S. (2015).Unsupervised representation learning with deep convolutional generativeadversarial networks.arXiv preprint arXiv:1511.06434.
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., andChen, X. (2016).Improved techniques for training gans.In Advances in Neural Information Processing Systems, pages 2226–2234.
Springenberg, J. T. (2015).Unsupervised and semi-supervised learning with categorical generativeadversarial networks.arXiv preprint arXiv:1511.06390.
20 / 20












![f-GAN: Training Generative Neural Samplers using ... · a variational autoencoder [18]. In the original GAN paper the authors show that it is possible to estimate neural samplers](https://img.pdfslide.net/doc/110x75/5ec607fadf097e0643499ac1/f-gan-training-generative-neural-samplers-using-a-variational-autoencoder-18.jpg)
















![Automatic Image Colorization with Convolutional Neural ...Generative Adversarial Networks (GAN) [7] are com-posed of two competing neural network models. For this colorization problem](https://img.pdfslide.net/doc/110x75/6142463055c1d11d1b341712/automatic-image-colorization-with-convolutional-neural-generative-adversarial.jpg)