Embed Size (px)
DESCRIPTION
NGHIÊN CỨU CÁC PHƯƠNG PHÁPPHÂN LOẠI VĂN BẢN VÀ ỨNG DỤNG VÀOPHÂN LOẠI THƯ ĐIỆN TỬ
Citation preview

HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG-----------------------------
LÊ THANH TRÀ
ĐỀ TÀI:NGHIÊN CỨU CÁC PHƯƠNG PHÁP
PHÂN LOẠI VĂN BẢN VÀ ỨNG DỤNG VÀOPHÂN LOẠI THƯ ĐIỆN TỬ
Chuyên ngành: Khoa học máy tínhMã số: 60.48.01
TÓM TẮT LUẬN VĂN THẠC SĨ
HÀ NỘI - 2013

Luận văn được hoàn thành tại:HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG
Người hướng dẫn khoa học: PGS.TS. NGUYỄN BÁ TƯỜNG
Phản biện 1: ……………………………………
Phản biện 2: ……………………………………
Luận văn sẽ được bảo vệ trước Hội đồng chấm luận
văn thạc sĩ tại Học viện Công nghệ Bưu chính Viễn
thông
Vào lúc: ....... giờ ....... ngày ....... tháng ....... .. năm…
Có thể tìm hiểu luận văn tại:
- Thư viện của Học viện Công nghệ Bưu chính Viễn thông

MỞ ĐẦUPhân loại văn bản là một vấn đề quan trọng trong lĩnh
vực xử lý ngôn ngữ. Nhiệm vụ của bài toán này là gán các tàiliệu văn bản vào nhóm các chủ đề cho trước. Đây là một bàitoán rất thường gặp trong thực tế.
Ngày nay, Internet mở ra nhiều kênh liên lạc, nhiều dịchvụ mới cho người sử dụng, một trong những dịch vụ màInternet mang lại đó là dịch vụ thư điện tử(email), đó làphương tiện giao tiếp rất đơn giản, tiện lợi, rẻ và hiệu quả.Phương tiện này có thể gửi email cùng một lúc đến hàngtrăm ngàn người chỉ trong vài giây. Tuy nhiên, sự thoải máitrong giao tiếp trên mạng như thế có thể bị lạm dụng. Trongnhững năm gần đây, spam hay các email không mong muốnđã trở thành một vấn nạn và đe dọa khả năng giao tiếp củacon người trên kênh liên lạc này, đó là một trong nhữngthách thức lớn mà khách hàng và các nhà cung cấp dịch vụphải đối phó. Spam đã trở thành một hình thức quảng cáochuyên nghiệp, phát tán virus, ăn cắp thông tin với nhiều thủđoạn và mánh khóe cực kỳ tinh vi. Người dùng sẽ phải mấtkhá nhiều thời gian để xóa những email “không mời màđến”, nếu vô ý còn có thể bị nhiễm virus và nặng nề hơn làmất thông tin như thẻ tín dụng, tài khoản ngân hàng qua cácemail dạng phishing...Vì vậy, cần có một hệ thống phân loạiđâu là spam mail và đâu là mail tốt.

Qua quá trình học tập nghiên cứu, được tiếp cận cácphương pháp phân loại văn bản nói chung và phương pháplọc thư điện tử nói riêng, tôi chọn đề tài: “Nghiên cứu cácphương pháp phân loại văn bản và ứng dụng vào phânloại thư điện tử”. Qua đề tài này tôi có cơ hội để tìm hiểusâu thêm về các phương pháp phân loại văn bản, phươngpháp phân loại, lọc thư spam và đặc biệt là phương phápphân loại thư điện tử bằng thuật toán Naive Bayes.
Luận văn này trình bày các vấn đề liên quan đến phânloại văn bản và ứng dụng của nó trong việc lọc thư điện tử.Một giải thuật sẽ được áp dụng cho bộ phân lớp spam, đó làgiải thuật Naive Bayes, giải thuật này cho kết quả rất khảquan trong việc tách các spam ra khỏi các thư thư hợp lệ.Việc token hoá, ước lượng xác suất và chọn đặc trưng là cáctiến trình được thực hiện trước khi phân lớp và tất cả các tiếntrình này đều có ảnh hưởng quan trọng đến hiệu suất lọcspam, giới thiệu và triển khai một bộ lọc thư điện tử spamdựa trên kỹ thuật Naive Bayes.

Chương 1 – MỘT SỐ PHƯƠNG PHÁP PHÂN LOẠIVĂN BẢN
Phân loại văn bản là một vấn đề quan trọng trong lĩnhvực xử lý ngôn ngữ. Để giải bài toán này đã có rất nhiềuphương pháp được đưa ra như: thuật toán Naive Bayes, K-NN (K-Nearest-Neighbor), cây quyết định (Decision Tree),mạng Neuron nhân tạo (Artificial Neural Network) và SVM(Support Vector Machine). Mỗi phương pháp đều cho kếtquả khác nhau cho bài toán này, trong chương này chúng tasẽ nghiên cứu một số phương pháp nói trên.
1.1 Bài toán phân loại văn bản1.1.1 Giới thiệu1.1.2 Phát biểu bài toánBài toán phân loại văn bản có thể được phát biểu như sau :Cho trước một tập văn bản D={d1,d2,…,dn} và tập chủ đềđược định nghĩa C={c1,c2,…,cn}. Nhiệm vụ của bài toán làgán lớp di thuộc về cj đã được định nghĩa.
1.2 Mô hình tổng quátCó rất nhiều hướng tiếp cận bài toán phân loại văn bản đã
được nghiên cứu như: tiếp cận bài toán phân loại dựa trên lýthuyết đồ thị, cách tiếp cận sử dụng lý thuyết tập thô, cáchtiếp cận thống kê…Tuy nhiên, tất cả các phương pháp trênđều dựa vào các phương pháp chung là máy học đó là: họccó giám sát, học không giám sát và học tăng cường. Vấn đềphân loại văn bản theo phương pháp thống kê dựa trên kiểu
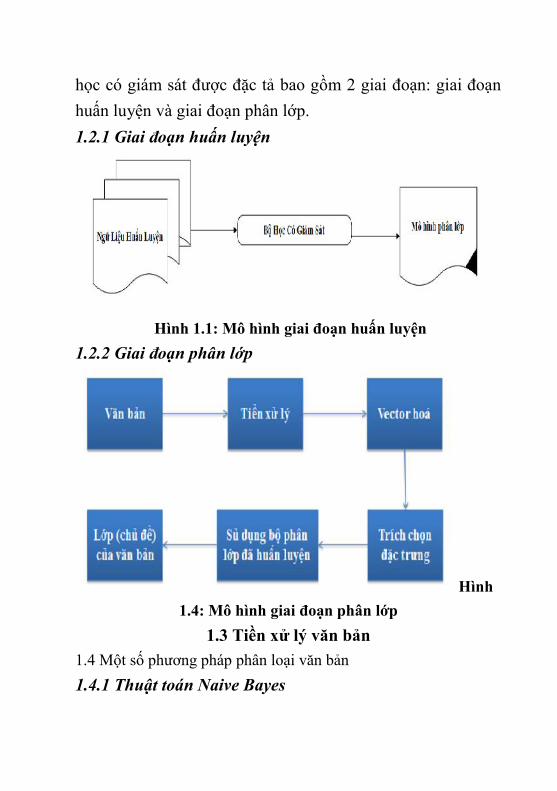
học có giám sát được đặc tả bao gồm 2 giai đoạn: giai đoạnhuấn luyện và giai đoạn phân lớp.1.2.1 Giai đoạn huấn luyện
Hình 1.1: Mô hình giai đoạn huấn luyện1.2.2 Giai đoạn phân lớp
Hình1.4: Mô hình giai đoạn phân lớp
1.3 Tiền xử lý văn bản1.4 Một số phương pháp phân loại văn bản1.4.1 Thuật toán Naive Bayes

1.4.2 Cây quyết định (Decision Tree)1.4.3 Phương pháp phân loại văn bản K-NN (K – NearestNeighbor)1.4.4 Phương pháp SVM (Support Vector Machine)
1.5 Bài toán phân loại thư điện tửPhân loại thư điện tử thực chất là bài toán phân loại hai
lớp, trong đó tập dữ liệu mẫu đưa vào là các thư điện tử gồmcác thư rác(spam) và các thư hợp lệ(Legitimate), các văn bảncần phân lớp là các Email gửi đến client. Kết quả đầu ra củaquá trình này là hai lớp văn bản: Spam(thư rác) vàLegitimate (thư hợp lệ).
1.6 Kết luận chương

Chương 2 – NHỮNG VẤN ĐỀ VỀ THƯ ĐIỆN TỬSPAM
2.1 Định nghĩa spamHầu hết các spam đều có thể được xem là các emailkhông mong muốn, nhưng không phải tất cả các thư
không mong muốn đều là spam. Một thuật ngữ khác đểchỉ spam, đó là các email thương mại không yêu cầu.
Spam cũng có thể được định nghĩa là các thư tạp nham(junk mail).
2.2 Các kiểu thư spam2.2.1 Các đặc điểm của thư spam
Spam có các đặc điểm về ngôn ngữ, thời gian2.2.2 Một số loại thư spam
2.3 Các phương thức đơn giản để loại bỏ thư spam2.3.1 Sử dụng các từ khóa2.3.2 So sánh mẫu, danh sách whitelist và danh sáchblacklist2.3.3 Kỹ thuật lọc cộng tác (Collaborative filtering)2.3.4 Đo sự giao thoa email (E-mail interferometry)2.3.5 Lọc ở mức mạng2.3.6 Kỹ thuật nhân viên giả mạo (Fake worker)2.3.7 Các bộ lọc trên cơ sở luật2.3.8 Sử dụng chung danh sách blacklist các dấu hiệuspam

2.3.9 Đánh giá mức độ pháp lý2.4 Lọc spam bằng phương pháp thống kê
Năm 1998, một số nghiên cứu đã chỉ ra rằng có thể thuđược các kết quả tốt từ việc sử dụng các bộ phân lớp
spam bằng phương pháp thống kê. Các bộ lọc thống kêyêu cầu huấn luyện trên cả thư spam và thư hợp lệ và bộlọc sẽ dần trở nên hiệu quả hơn sau khi được huấn luyện.Các bộ lọc được huấn luyện trên thư spam và thư hợp lệcủa người sử dụng, do đó các spammer rất khó đánh lừabộ lọc. Bộ phân lớp sử dụng các đặc điểm của mẫu để
phân lớp nó thành một trong các lớp được định nghĩa từtrước. Bất cứ đặc điểm nào của mẫu cũng đều được xem
xét dưới dạng một đặc trưng.2.4.1 Đặc trưng và lớp
Một đặc trưng là đặc điểm, diện mạo, hoặc thuộc tínhcủa một đối tượng. Ví dụ, mầu mắt của một người là đặctrưng, các từ trong một tài liệu văn bản là đặc trưng. Mộtđặc trưng tốt là đặc trưng đặc biệt cho một lớp đối tượng
2.5 Kết luận chương

Chương 3 – BỘ LỌC SPAM TRÊN CƠ SỞ KỸ THUẬTNAIVE BAYES
Chương này giới thiệu bộ phân lớp trên cơ sở kỹ thuậtBayes để xây dựng các bộ lọc có thể học và có độ tin cậycao. Phương pháp này cho phép máy tính có khả năng tự tạora các quyết định thay vì phải hỏi người sử dụng cách quyếtđịnh (các giải pháp trên cơ sở luật).
Sự xuất hiện của kỹ thuật máy học trong các bộ lọcspam là một bước cải tiến quan trọng cho hiệu suất của bộlọc. Các spammer không thể kiểm tra các bộ lọc trước khigửi các thư đi, do bộ lọc của mỗi người sử dụng có cơ sở trithức của riêng nó. Mặc dù các spammer luôn nghĩ ra những ýtưởng mới để vượt qua các bộ lọc, nhưng với bộ lọc Bayesđược huấn luyện tốt, thì sự chính xác của các bộ lọc có thểđạt tới 99%.
3.1 Mạng Bayes3.1.1 Tổng quát về mạng Bayes3.1.2 Mô hình Naive Bayes
Naive Bayes là một mạng Bayes đơn giản nhất trongđó một nút cha được chứa trong mạng và tất cả các biến kháclà con của nút cha. Nếu biến cha là ‘Xp’, thì công thức phânbố kết nối trong trường hợp đó như sau:P(Xp,X1,...,Xn)=P(Xp) )|( XpXiP fori= 1 to n (3.1)

3.2 Bộ lọc spam trên cơ sở mạng BayesBộ lọc spam trên cơ sở mạng Bayes dựa vào nội dung
của email để phân lớp. Các giai đoạn chính của giải pháptrên cơ sở mạng Bayes như sau:
- Đầu tiên cần token hoá nội dung của email, nghĩa làtách nó thành các phần nhỏ để sử dụng trong xử lý.
- Bước tiếp theo, giá trị của mỗi token được xác địnhbằng cách tìm kiếm trong một bảng cập nhật (từ điểm token).
Các giá trị của các token có liên quan có khoảng cáchlớn nhất từ giá trị trung tính (neutral) và như vậy chúng sẽgần với một mặt nạ các thư spam hoặc thư hợp lệ.
- Bước cuối cùng là sửa đổi các giá trị của các tokentrong từ điển, điều này đưa ra khả năng học liên tục vớithông tin phản hồi (feedback) và kết quả nhị phân cuối cùngđược tạo ra.
3.3 Giải thuật của bộ lọc trên cơ sở mạng Bayes3.3.1 Nạp email (Loading)3.3.2 Tiền lọc (Pre-filtering)3.3.3 Token hoá (tokenization)3.3.4 Tính toán3.3.5 Cập nhật tri thức cho bộ lọc (Feedback)3.3.6 Huấn luyện và các kiểu huấn luyện khác nhau3.3.7 Kiểm tra (Testing)
3.4 Giải pháp cụ thể cho giải thuật Bayes3.4.1 Tổng quan

Phần này giới thiệu một giải thuật cung cấp nhữngđiều căn bản về phân lớp Bayes trong lĩnh vực lọc spam.Phần này sẽ không giải quyết vấn đề tiền xử lý, vì giải thuậtlàm việc với so trùng chuỗi chính xác. Giải pháp này sử dụngtất cả các giá trị của từ điển token, trong mỗi ngày sử dụngnhờ các nguồn tài nguyên tính toán ràng buộc nên bộ lọc chỉlàm việc với một số giá trị giới hạn.3.4.2 Từ điển token
Khi nhận được một thư mới, từ điển token sẽ được tìmkiếm cho tất cả các từ bao hàm trong thư (chú ý giải thuậtnày cho phép token hoá từ thành từ). Hai tập từ được xử lý:một là tập các từ so trùng với từ điển (việc cập nhật sẽ cầnthiết tại giá trị N1 hoặc N2), tập kia là tập các từ không cótrong thư (không cần thiết cập nhật).Hai tập được xây dựng lên bởi mỗi email được xử lý.3.4.3 Kết quả của bộ lọc3.4.4 Huấn luyện (Training)3.4.5 Kiểm tra và sử dụng bộ lọc3.4.6 Tính toán3.4.7 Sơ đồ bộ lọc Bayes
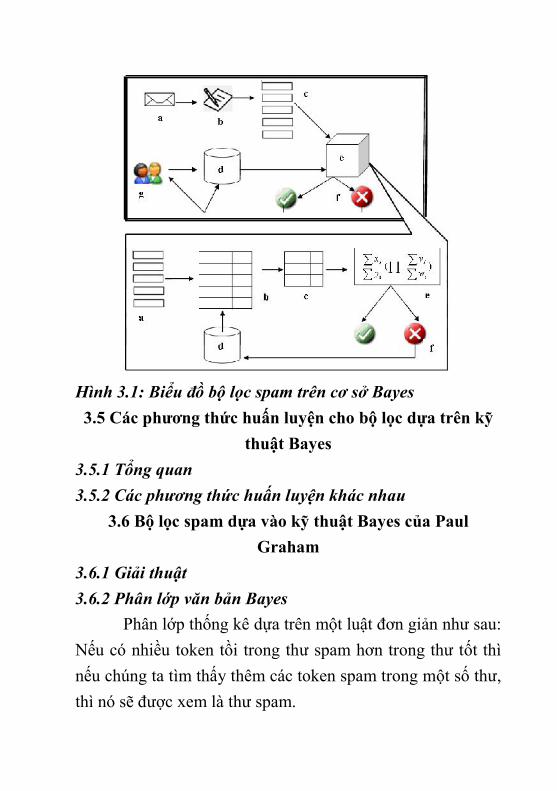
Hình 3.1: Biểu đồ bộ lọc spam trên cơ sở Bayes3.5 Các phương thức huấn luyện cho bộ lọc dựa trên kỹ
thuật Bayes3.5.1 Tổng quan3.5.2 Các phương thức huấn luyện khác nhau
3.6 Bộ lọc spam dựa vào kỹ thuật Bayes của PaulGraham
3.6.1 Giải thuật3.6.2 Phân lớp văn bản Bayes
Phân lớp thống kê dựa trên một luật đơn giản như sau:Nếu có nhiều token tồi trong thư spam hơn trong thư tốt thìnếu chúng ta tìm thấy thêm các token spam trong một số thư,thì nó sẽ được xem là thư spam.

3.7 Một số cải tiến cho bộ lọc spam trên cơ sở giải thuậtBayes
3.7.1 Cải tiến bộ lọc spam Bayes của PaulGrahamCó hai cải tiến được thêm vào:- Để loại bỏ được việc phân lớp nhầm các thư tốt, tần
số thư tốt được nhân đôi khi ta tính xác suất của thư spam.- Khi một token chỉ nằm trong tập cơ sở dữ liệu spam
có sẵn, thì chúng ta có thể thiết lập các xác suất tăng lên nếucó nhiều token ấy. ví dụ: 0.9 cho các tần số nhỏ, 0.99 cho cáctần số lớn hơn 10.3.7.2 Cải tiến bộ lọc spam Bayes sử dụng khoảng cáchkhác biệt giữa hai chuỗi (Giải thuật SEDA)
Giải thuật khoảng cách khác biệt chuỗi String-Edit Distance (SEDA)
Giải thuật này cung cấp một tiêu chuẩn về khoảngcách giữa các chuỗi. Khoảng cách này được định nghĩa là sốcác thao tác nhỏ nhất được yêu cầu để đổi chuỗi nguồn thànhchuỗi mục tiêu bằng việc sử dụng ba thao tác : insert, deletevà replace (hoặc edit).
Email của chúng ta có dạng một tập các dòng và cáctoken (các từ) được phân tách bởi các khoảng trống. Khi cáctoken được trích ra từ thân của các thư thì tất cả các ký tựđầu và cuối (các dấu chấm câu và các số) được gỡ bỏ để lấyra từ thực sự.

Một bảng được sử dụng để lưu các token và tần sốtương ứng. Nó chứa tất cả các token, tổng số lần xuất hiệncủa mỗi token trong các thư spam và thư hợp lệ và tổng sốthư spam và thư hợp lệ đã được xử lý trong giai đoạn huấnluyện.
Trong giai đoạn huấn luyện, bộ phân lớp sẽ học bằngcách xử lý các thư từ các lớp đã biết. Ban đầu cơ sở tri thức(dạng bảng băm) tìm kiếm một token và nếu tìm thấy, bộđếm token tương ứng được tăng lên. Nếu không tìm thấy mộtthực thể mới được thêm vào với bộ đến bắt đầu bằng một vàcác bộ đếm thư spam và thư hợp lệ cũng được tăng lên một.
Các thư chưa biết được phân lớp bằng cách sử dụngkiến thức có sẵn trong cơ sở tri thức. Tiến trình phân lớp nàychứa hai tiến trình con sau:
- Cho trước một thư chưa biết, xác suất của nó là thưspam hay thư hợp lệ được tính toán. Nếu các token tồn tạitrong cơ sở tri thức và thư được được nhận dạng là spam thìtiến trình kết thúc.
- Nếu thư được phân lớp là hợp lệ, thì nó sẽ được xácnhận độ chính xác bằng việc phân tích thêm. Xác suất củaviệc phân lớp nhầm là kết quả của việc không thực hiện quátrình khám phá các từ bị sửa đổi.
3.8 Kết luận chươngTrong chương này chúng ta đã tìm hiểu về mạng Bayes, cácbước xây dựng bộ lọc trên cơ sở mạng Bayes. Đồng thời

cũng tìm hiểu về các cải tiến của PaulGraham, giải thuậtSEDA. Cả hai phương pháp đó đã giúp nâng cao chất lượngcủa bộ lọc mạng Bayes, tuy nhiên cả hai giải pháp đó vẫn cóhạn chế nhất định.

Chương 4 – XÂY DỰNG BỘ LỌC CẢI TIẾN VÀ THỬNGHIỆM
4.1 Xây dựng bộ lọc cải tiến- Xây dựng danh sách xác suất là spam của tất cả các
token trong quá trình huấn luyện theo kỹ thuật củaPaulGraham.
- Trong phần phân lớp thư mới, với tất cả các token,nếu token của thư mới có trong cơ sở tri thức, thì ta đưatoken này cùng xác suất có thể là spam của nó vào danh sáchT.
- Nếu token t không có trong cơ sở tri thức, ta tínhkhoảng cách khác biệt chuỗi của nó với tất cả các token củacơ sở tri thức. Chọn ra một token trong cơ sở tri thức cókhoảng cách khác biệt chuỗi (so với chuỗi t) nhỏ nhất và nhỏhơn hoặc bằng ngưỡng α. Nếu tìm thấy token này thì thêmnó cùng xác suất là spam vào danh sách T, nếu không thì từnày thực sự là từ mới.
- Ta có thể xây dựng một từ điển các từ chuẩn hoá bắtnguồn từ các từ trong cơ sở tri thức và bổ sung thêm trongquá trình từ điển này trong quá trình phân lớp. Như vậy việctính toán khoảng cách khác biệt chuỗi sẽ không phải duyệttrên tòan bộ cơ sở tri thức.
- Chọn ra danh sách 15 token điển hình trong danhsách T (có khoảng cách tính từ giá trị 0,5). Tính xác suất làspam của thư mới từ 15 giá trị token điển hình này.

- Quyết định phân lớp dựa trên xác suất tổng hợp.4.2 Hiện thực một bộ phân lớp spam Bayes cải tiến bằng
ngôn ngữ Java.4.2.1 Các bước thực hiện và cấu trúc hệ thống4.2.2 Xây dựng tập các thư spam và tập thư hợp lệ4.2.3 Token hoá các thư spam và thư hợp lệ4.2.4 Xây dựng danh sách tần số các token4.2.5 Xây dựng danh sách xác suất có khả năng là spamcủa token4.2.6 Tính toán 15 giá trị tốt nhất4.2.7 Kiểm tra một email mới4.2.8 Cập nhật cơ sở tri thức cho bộ lọc4.2.9 Hiện thực giải thuật4.3 Giới thiệu, thử nghiệm và đánh giá hệ thống lọc spam
cải tiến4.3.1 Giới thiệu các tính năng của hệ thống lọc spam đãđược cải tiến:
Hệ thống vừa được thiết kế gồm có bốn cửa sổ chính:cửa sổ huấn luyện, của sổ phân lớp, cửa sổ phân tích thư vàcửa sổ dành cho việc điều chỉnh các tham số phục vụ mụcđích thử nghiệm. Giữa các cửa sổ này có các ràng buộc vềmặt hệ thống như quá trình huấn luyện phải hoàn thành trướckhi phân lớp và phân tích thư, các tham số mặc định tronghuấn luyện và phân lớp.
4.3.2 Thử nghiệm hệ thống lọc spamBảng 4.1 Kết quả thử nghiệm phân lớp trên 3000 thưGiải thuật Thư spam Thư tốt
Bayes củaPaulgraham
1478 1522
Giải thuật Bayes –SEDA
1517 1483

KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
Các bộ phân loại thư điện tử ngày nay áp dụng cácgiải thuật máy học cho ta hiệu quả lọc cao, đặc biệt là bộ lọcthư spam áp dụng giải thuật Naive Bayes cho ta hiệu suất lọcđến 99% và được áp dụng cho những nhà cung cấp dịch vụthư điện tử lớn như Yahoo, Hotmail…Các bộ lọc thư spamtrên desktop thương mại ngày nay cũng áp dụng kỹ thuật nàyvới một số cải tiến và kết hợp nhỏ. Việc áp dụng các giảithuật máy học vào nhiệm vụ lọc spam làm cho bộ phân lớpcó khả năng thích nghi với các spam thế hệ mới bằng việccập nhật tri thức cho cơ sở tri thức của bộ lọc.
Trong khuôn khổ luận văn thạc sỹ CNTT, luận văn đãnêu bật được các phương pháp phân loại văn bản, các vấn đềliên quan đến thư spam, các giải pháp lọc thư spam dựa trêncác giải thuật máy học như kỹ thuật Supported VectorMachines (SVM), k-Nearest-Neighbor (kNN), NeuralNetworks (NNet) và Naive Bayesian (NB), các vấn đề liênquan đến hiệu quả của bộ lọc cũng như việc kết hợp các bộlọc nhằm nâng cao hiệu suất lọc. Các bước triển khai bộ lọcspam trên cơ sở kỹ thuật Bayes được thực hiện bao gồm tiềnxử lý dữ liệu, huấn luyện và các phương thức huấn luyện,tính toán cho các bộ phân lớp. Một số cải tiến áp dụng chobộ lọc spam bằng kỹ thuật Bayes như nhân đôi tần số thư tốtkhi ta tính xác suất của thư spam, thiết lập các ngưỡng xác

suất, chọn một số giá trị tốt nhất để tính xác suất thư. Một cảitiến khác được thực hiện đó là áp dụng giá trị khoảng cáchchuỗi theo giải thuật SEDA để phát hiện ra các token có tầnsố xuất hiện cao được spammer thay đổi trong các thư spam,như vậy hiệu quả của bộ lọc sẽ được tăng lên rõ rệt.
Tính mới của nghiên cứu ở đây chính là sự kết hợpgiữa bộ lọc Bayes của Paulgraham và giải thuật SEDA. Mộtbộ lọc spam trên cơ sở giải thuật Bayes và các cải tiến đượcthực hiện bằng ngôn ngữ Java, hai chức năng dùng để thửnghiệm cho giải thuật lọc spam theo kỹ thuật Bayes củaPaulgraham và giải thuật kết hợp NB-SEDA cũng được tíchhợp trong hệ thống này.
Dữ liệu được chuẩn bị bao gồm dữ liệu huấn luyện vàdữ liệu kiểm tra đã xử lý trước được tải về từ Internet, côngđồng mạng đã xử lý và chọn dữ liệu này. Thử nghiệm đượcthực hiện trên 1500 thư spam cho thấy với kỹ thuật NB-SEDA số thư bị phân lớp nhầm là thư tốt giảm đáng kể sovới kỹ thuật Bayes của Paulgraham.
Hướng phát triển:- Tích hợp hệ thống phân loại thư điện tử trực tuyến- Xây dựng công cụ phân tích và chọn các đặc trưng
cho bộ phân lớp Bayes để làm giảm kích thước, nâng caochất lượng của cơ sở tri thức và cải tiến hiệu suất bộ lọc khisử dụng tất cả các đặc trưng.

- Kỹ thuật phân loại mô tả ở trên cũng có thể đượcnâng cấp bằng cách sử dụng một tập danh sách đen(blacklist) các địa chỉ IP và tên miền, và một tập danh sáchtrắng (whilelist) người gửi tương ứng với các liên lạc màngười sử dụng có. Bất cứ lúc nào chúng ta nhận được thư từmột miền địa chỉ trong danh sách đen hoặc địa chỉ trongdanh sách trắng, thì chúng ta biết chắc rằng nó là thư spamhoặc thư tốt theo độ ưu tiên định sẵn. Do đó chúng ta có thểtrích ra các thông tin tốt để tăng cường cho cơ sở tri thức củabộ lọc.
- Tổ chức các thư đến theo ba thể loại khác nhau nhưSpam, Personal, Business, thay vì chỉ hai. Như vậy mục đíchcủa bộ lọc thư trở nên phổ biến hơn.
- Xây dựng tập cơ sở dữ liệu thư spam tiếng Việt,nghiên cứu các từ, cụm từ spam trong thư tiếng Việt.
- Nghiên cứu các bộ lọc spam diện rộng sử dụng chocác tổ chức xã hội.





























