Embed Size (px)
Citation preview

Hong Kong Baptist University
DOCTORAL THESIS
Biometric system security and privacy: data reconstruction and templateprotectionMai, Guangcan
Date of Award:2018
Link to publication
General rightsCopyright and intellectual property rights for the publications made accessible in HKBU Scholars are retained by the authors and/or othercopyright owners. In addition to the restrictions prescribed by the Copyright Ordinance of Hong Kong, all users and readers must alsoobserve the following terms of use:
• Users may download and print one copy of any publication from HKBU Scholars for the purpose of private study or research • Users cannot further distribute the material or use it for any profit-making activity or commercial gain • To share publications in HKBU Scholars with others, users are welcome to freely distribute the permanent URL assigned to thepublication
Download date: 17 Feb, 2022

HONG KONG BAPTIST UNIVERSITY
Doctor of Philosophy
THESIS ACCEPTANCE
DATE: August 31, 2018
STUDENT'S NAME: MAI Guangcan
THESIS TITLE: Biometric System Security and Privacy: Data Reconstruction and Template Protection
This is to certify that the above student's thesis has been examined by the following panel
members and has received full approval for acceptance in partial fulfillment of the requirements for the
degree of Doctor of Philosophy.
Chairman: Prof Chiu Sung Nok
Professor, Department of Mathematics, HKBU
(Designated by Dean of Faculty of Science)
Internal Members: Dr Choi Koon Kau
Associate Professor, Department of Computer Science, HKBU
(Designated by Head of Department of Computer Science)
Dr Lan Liang
Assistant Professor, Department of Computer Science, HKBU
External Members: Prof Kim Jaihie
Professor and Director
School of Electrical and Electronic Engineering
Yonsei University
Prof You Jia Jane
Professor
Department of Computing
The Hong Kong Polytechnic University
Proxy:
Dr Chu Xiaowen
Associate Professor, Department of Computer Science, HKBU
In-attendance:
Prof Yuen Pong Chi
Professor, Department of Computer Science, HKBU
Issued by Graduate School, HKBU

Biometric System Security and Privacy:
Data Reconstruction and Template Protection
MAI Guangcan
A thesis submitted in partial fulfillment of the requirements
for the degree of
Doctor of Philosophy
Principal Supervisor:
Prof. YUEN Pong Chi (Hong Kong Baptist University)
Hong Kong Baptist University
August 2018

DECLARATION
I hereby declare that this thesis represents my own work which has been done after
registration for the degree of PhD at Hong Kong Baptist University, and has not been
previously included in a thesis or dissertation submitted to this or any other institution
for a degree, diploma or other qualifications.
I have read the Universitys current research ethics guidelines, and accept responsibility
for the conduct of the procedures in accordance with the Universitys Committee on the
Use of Human Animal Subjects in Teaching and Research (HASC). I have attempted to
identify all the risks related to this research that may arise in conducting this research,
obtained the relevant ethical and/or safety approval, and acknowledged my obligations
and the rights of the participants.
Signature:
Date: August 2018
i

Abstract
Biometric systems are seeing increasing use, from daily entertainment to critical ap-
plications such as security access and identity management. Biometric systems should
thus meet the stringent requirement of a low error rate. In addition, for critical appli-
cations, biometric systems must address security and privacy issues. Otherwise, severe
consequences may result, such as unauthorized access (security) or the exposure of
identity-related information (privacy). It is therefore imperative to study vulnerability
to potential attacks and identify the corresponding risks. Furthermore, countermea-
sures should be devised and patched on the systems.
In this thesis, we study security and privacy issues in biometric systems. We first
attempt to reconstruct raw biometric data from biometric templates and demonstrate
the security and privacy issues caused by data reconstruction. We then make two
attempts to protect biometric templates from reconstruction and improve the state-of-
the-art biometric template protection techniques.
To summarize, this thesis makes the following contributions.
• Data Reconstruction: An investigation of the invertibility of face templates
generated by deep networks. To the best of our knowledge, this is the first such
study of the security and privacy of face recognition systems.
• Template Protection: An end-to-end method for simultaneous extraction and
ii

protection of templates given raw biometric data (e.g., face images). To the best
of our knowledge, this is the first end-to-end method for the direct generation of
secure templates from raw biometric data.
• Template Protection: A binary fusion approach for multi-biometric cryptosys-
tems to offer accurate and secure recognition. The proposed fusion approach can
simultaneously maximize the discriminability and entropy of the fused binary
output.
Keywords: biometric template, biometric security, data reconstruction, template
reconstruction, and template protection
iii

Acknowledgements
I thank my principal supervisor, Prof. Pong C. Yuen, for giving me the opportunity
to work on the exciting and challenging problems in biometric system security and
privacy. His constructive comments, insightful questions, and great support always
encourage me to pursue something good, big, and new. Working with Prof. Yuen is
an enjoyable and unforgettable experience. I have not only learned how to do good
research, but also how to work and live in a smart and positive way.
I would also like to thank Prof. Anil K. Jain, Dr. Meng-Hui Lim, and Dr. Kai Cao
for their great help and support. I enjoy working with them, and it is my honor to
collaborate with them.
I have enjoyed spending the past 5 years with the faculty members and staff in the
Department of Computer Science at Hong Kong Baptist University and the Department
of Computer Science and Engineering at Michigan State University. I thank all of
my friends. You know who you are, but I would like to mention some of them, Dr.
Xiangyuan Lan, Dr. Jiawei Li, Dr. Shengping Zhang, Dr. Guoxian Yu, Dr. Kaiyong
Zhao, Dr. Ying Tai, Dr. Baoyao Yang, Mr. Mang Ye, Miss Huiqi Deng, Mr. Siqi Liu,
Dr. Xiao Li, Mr. Qiang Wang, Mr. Shaohuai Shi, and Mr. Qi Tan.
Finally, I would like to express my heartfelt gratitude to my family. They provide
me the maximum freedom to achieve what I want. Without their vision and support,
I, born in a village in mainland China, might not have been able to make this journey.
iv

Table of Contents
Declaration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . i
Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ii
Acknowledgements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
Table of Contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ix
List of Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xi
List of Figures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xvii
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Biometric System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Biometric Recognition System . . . . . . . . . . . . . . . . . . . 2
1.1.2 Security and Privacy Concerns . . . . . . . . . . . . . . . . . . . 4
v

1.2 Data Reconstruction and Template Protection . . . . . . . . . . . . . . 6
1.2.1 Data Reconstruction . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2.2 Template Protection . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3 Contributions of This Thesis . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Thesis Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Reconstructing Face Images from Deep Face Templates . . . . . . . 14
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2.1 Reconstructing Face Images from Deep Templates . . . . . . . . 18
2.2.2 GAN for Face Image Generation . . . . . . . . . . . . . . . . . . 20
2.3 Proposed Template Security Study . . . . . . . . . . . . . . . . . . . . 21
2.3.1 Template Reconstruction Attack . . . . . . . . . . . . . . . . . . 21
2.3.2 NbNet for Face Image Reconstruction . . . . . . . . . . . . . . . 25
2.3.3 Reconstruction Loss . . . . . . . . . . . . . . . . . . . . . . . . 27
2.3.4 Generating Face Images for Training . . . . . . . . . . . . . . . 28
2.3.5 Differences with DenseNet . . . . . . . . . . . . . . . . . . . . 32
2.3.6 Implementation Details . . . . . . . . . . . . . . . . . . . . . . . 32
vi

2.4 Performance Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.4.1 Database and Experimental Setting . . . . . . . . . . . . . . . . 35
2.4.2 Verification Under Template Reconstruction Attack . . . . . . . 39
2.4.3 Identification with Reconstructed Images . . . . . . . . . . . . . 47
2.4.4 Computation Time . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3 Secure Deep Biometric Template . . . . . . . . . . . . . . . . . . . . . . 51
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.2.1 Template Protection Schemes . . . . . . . . . . . . . . . . . . . 53
3.2.2 Fuzzy Commitment Scheme . . . . . . . . . . . . . . . . . . . . 54
3.3 Proposed Secure Template Generation . . . . . . . . . . . . . . . . . . 56
3.3.1 Secure System Construction . . . . . . . . . . . . . . . . . . . . 56
3.3.2 Randomized CNN . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.3.3 Secure Sketch Construction . . . . . . . . . . . . . . . . . . . . 63
3.3.4 Loss Function for Training . . . . . . . . . . . . . . . . . . . . . 65
3.3.5 Network Architecture . . . . . . . . . . . . . . . . . . . . . . . . 68
vii

3.4 Performance Evaluation and Analysis . . . . . . . . . . . . . . . . . . . 69
3.4.1 Experimental Setting . . . . . . . . . . . . . . . . . . . . . . . . 69
3.4.2 Matching Accuracy of the Randomized CNN . . . . . . . . . . . 73
3.4.3 Unlinkability Analysis . . . . . . . . . . . . . . . . . . . . . . . 73
3.4.4 Trade-off between Matching Accuracy and Security . . . . . . . 75
3.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4 Binary Feature Fusion for Multi-biometric Cryptosystems . . . . . . 82
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
4.2 Review on Binary Feature Fusion . . . . . . . . . . . . . . . . . . . . . 85
4.3 The Proposed Binary Feature Fusion . . . . . . . . . . . . . . . . . . . 88
4.3.1 Overview of the Proposed Method . . . . . . . . . . . . . . . . . 88
4.3.2 Dependency Reductive Bit-group Search . . . . . . . . . . . . . 89
4.3.3 Discriminative Within-group Fusion Search . . . . . . . . . . . . 92
4.3.4 Discussion and Analysis . . . . . . . . . . . . . . . . . . . . . . 94
4.4 Performance Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.4.1 Database and Experiment Setting . . . . . . . . . . . . . . . . . 97
4.4.2 Evaluation Measures for Discriminability and Security . . . . . 100
viii

4.4.3 Discriminability Evaluation . . . . . . . . . . . . . . . . . . . . 102
4.4.4 Security Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.4.5 Robustness of Varying Qualities of Biometric Inputs . . . . . . . 105
4.4.6 Trade-off between Discriminability and Security . . . . . . . . . 108
4.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
5 Conclusions and Future Research . . . . . . . . . . . . . . . . . . . . . 111
5.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
5.2 Future Research Directions . . . . . . . . . . . . . . . . . . . . . . . . . 112
Appendics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Curriculum Vitae . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
ix

List of Tables
2.1 Comparison of major algorithms for face image reconstruction from their
corresponding templates . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Network details for D-CNN and NbNets. “[k1 × k2, c] DconvOP (Con-
vOP), stride s”, denotes cascade of a de-convolution (convolution) layer
with c channels, kernel size (k1, k2) and stride s, batch normalization,
and ReLU (tanh for the bottom ConvOP) activation layer. . . . . . . . 30
2.3 Deep template face template reconstruction models for comparison . . . 38
2.4 TARs (%) of type-I and type-II attacks on LFW for different template
reconstruction methods, where “Original” denotes results based on the
original images and other methods are described in Table 2.3. (best,
second best) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.5 TARs (%) of type-I and type-II attacks on FRGC v2.0 for different tem-
plate reconstruction methods, where “Original” denotes results based on
the original images and other methods are described in Table 2.3. (best,
second best) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
x

2.6 Rank-one recognition rate (%) on color FERET [111] with partition fa as
gallery and reconstructed images from different partition as probe. The
partitions (i.e., fa, fb, dup1 and dup2 ) are described in color FERET
protocol [111]. Various methods are described in Table 2.3. (best and
second best) of rank-one identification rate in each column. . . . . . . . 48
2.7 Average reconstruction time (ms) for a single template. The total num-
ber of network parameters are indicated in the last column. . . . . . . . 49
3.1 Overall linkability Dsys↔ [41] of the templates yp extracted using the ran-
domized CNN with random activation and permutation. The row of
“flag of k” indicates whether two templates are extracted with the same
key k. The row of “DAct-k” denotes that random permutation with k
out of 512 neurons in each fully connected layers are randomly deactivated. 74
3.2 GAR (%) @ (FAR=0.1%) on IJB-A with state-of-the-art methods . . . 77
4.1 Experimental settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
xi

List of Figures
1.1 Framework of biometric recognition systems. . . . . . . . . . . . . . . 2
1.2 Potential attack points to biometric recognition systems [10,116]. . . . 5
2.1 Face recognition system vulnerability to image reconstruction attacks.
Face image of a target subject is reconstructed from a template to gain
system access by either (a) creating a fake face (for example, a 2D printed
image or 3D mask) (blue box) or (b) inserting a reconstructed face into
the feature extractor (red box). . . . . . . . . . . . . . . . . . . . . . . 15
2.2 Example face images reconstructed from their templates using the pro-
posed method (VGG-NbB-P). The top row shows the original images
(from LFW) and the bottom row shows the corresponding reconstruc-
tions. The numerical value shown between the two images is the cosine
similarity between the original and its reconstructed face image. The
similarity threshold is 0.51 (0.38) at FAR = 0.1% (1.0%). . . . . . . . . 17
2.3 An overview of the proposed system for reconstructing face images from
the corresponding deep templates, where the template y (yt) is a real-
valued vector. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
xii

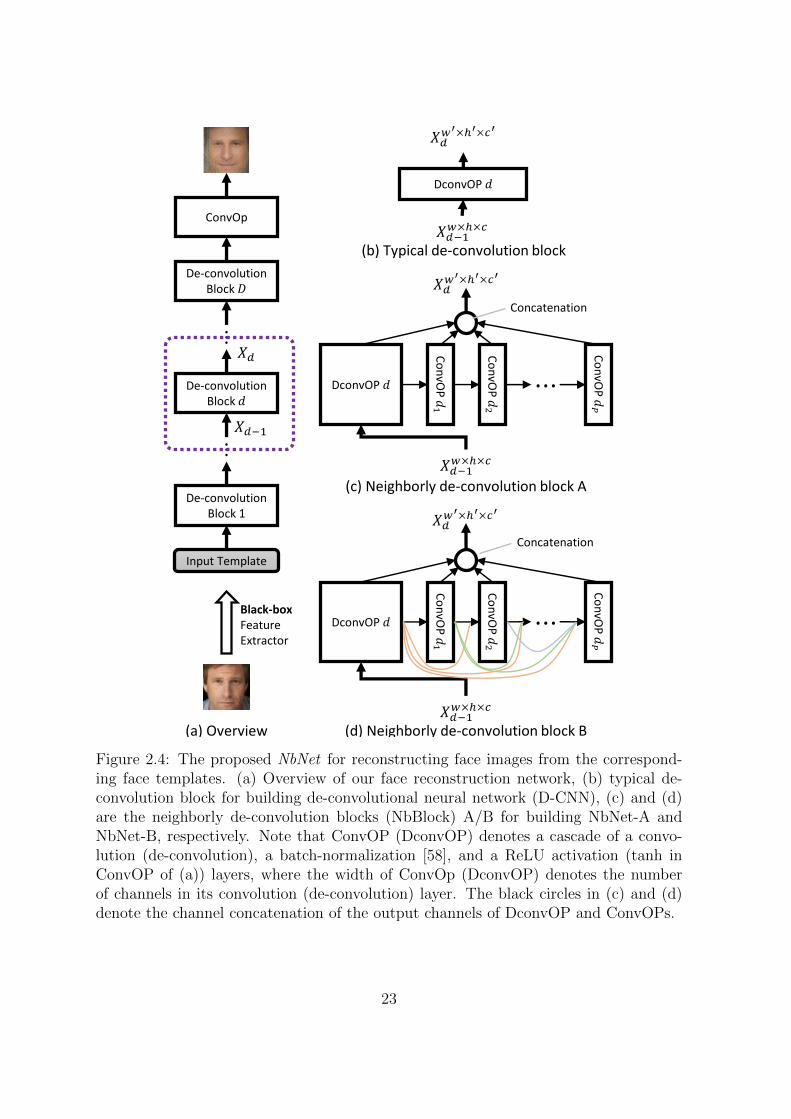
2.4 The proposed NbNet for reconstructing face images from the corre-
sponding face templates. (a) Overview of our face reconstruction net-
work, (b) typical de-convolution block for building de-convolutional neu-
ral network (D-CNN), (c) and (d) are the neighborly de-convolution
blocks (NbBlock) A/B for building NbNet-A and NbNet-B, respectively.
Note that ConvOP (DconvOP) denotes a cascade of a convolution (de-
convolution), a batch-normalization [58], and a ReLU activation (tanh
in ConvOP of (a)) layers, where the width of ConvOp (DconvOP) de-
notes the number of channels in its convolution (de-convolution) layer.
The black circles in (c) and (d) denote the channel concatenation of the
output channels of DconvOP and ConvOPs. . . . . . . . . . . . . . . . 23
2.5 Visualization of 32 output channels of the 5th de-convolution blocks in
(a) D-CNN, (b) NbNet-A, and (c) NbNet-B networks, where the input
template was extracted from the bottom image of Fig. 2.4 (a). Note that
the four rows of channels in (a) and the first two rows of channels in (b)
and (c) are learned from channels from the corresponding 4th block. The
third row of channels in both (b) and (c) are learned from their first two
rows of channels. The fourth row of channels in (b) is learned from the
third row of channels only, where the fourth row of channels in (c) is
learned from the first three rows of channels. . . . . . . . . . . . . . . . 24
2.6 Example face images from the training and testing datasets: (a) VGG-
Face (1.94M images) [106], (b) Multi-PIE (151K images, only three cam-
era views were used, including ‘14 0′, ‘05 0′ and ‘05 1′, respectively) [46],
(c) LFW (13,233 images) [57, 80], (d) FRGC v2.0 (16,028 images in
the target set of Experiment 1) [110], and (e) Color FERET (2,950 im-
ages) [111]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.7 Sample face images generated from face generators trained on (a) VGG-
Face, and (b) Multi-PIE. . . . . . . . . . . . . . . . . . . . . . . . . . . 36
xiii

2.8 Reconstructed face images of the first 10 subjects from LFW. Each row
shows an original image and its corresponding reconstructed images pro-
duced by different reconstruction models. The original face images are
shown in the first column. Each of remaining column denotes the recon-
structed face images from different models used for reconstruction. The
number below each reconstructed image shows the similarity score be-
tween the reconstructed image and the original image. The scores (rang-
ing from -1 to 1) were calculated using the cosine similarity. The mean
verification thresholds were 0.51 and 0.38, respectively, at FAR=0.1%
and FAR=1.0%. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.9 Reconstructed face images of the first 10 subjects from FRGC v2.0.
Each row shows an original image and its corresponding reconstructed
images produced by different reconstruction models. The original face
images are shown in the first column. Each of remaining column denotes
the reconstructed face images from different models used for reconstruc-
tion. The number below each reconstructed image shows the similar-
ity score between the reconstructed image and the original image. The
scores (ranging from -1 to 1) were calculated using the cosine similar-
ity. The mean verification thresholds were 0.80 and 0.64, respectively,
at FAR=0.1% and FAR=1.0%. . . . . . . . . . . . . . . . . . . . . . . 41
2.10 ROC curves of (a) type-I and (b) type-II attacks using different recon-
struction models on LFW. For the ease of reading, we only show the
curves for D-CNN, NbNet-B trained with perceptual loss, and the RBF
based method. Refer to Table 2.4 for the numerical comparison of all
models. Note that the curves for VGG-Dn-P and MPIE-Dn-P are over-
lapping in (a). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
xiv

2.11 ROC curves of (a) type-I and (b) type-II attacks using different recon-
struction models on FRGC v2.0. For readability, we only show the curves
for D-CNN, NbNet-B trained with perceptual loss, and the RBF based
method. Refer to Table 2.5 for the numerical comparison of all models. 46
3.1 Overview of the proposed secure system construction with randomized
CNN (best viewed in color). The secure deep templates {SS,yp} stored
in the system satisfy the criteria for template protection: non-invertibility
(security), cancellability (unlinkability and revocability), and matching
accuracy. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.2 Subnetworks produced by a standard network with random activation,
in which the black and white circles denote ‘activated’ and ‘deactivated’
neurons, respectively. (a) Standard network with all neurons activated;
(b), (c), and (d) are different subnetworks obtained by random deacti-
vation of some neurons. . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.3 Given an ECC with sufficiently large code length n and the average
error tolerance τecc/n, the lower bound and upper bound of the code
rate [119,136], i.e., m/n, where m denotes the message length. . . . . . 67
3.4 Example face images from the training and testing datasets. . . . . . . 70
3.5 ROC curves for the proposed randomized CNN with random activation
and random permutation on IJB-A. (a) and (b) denote curves with set-
tings of 1023 and 2047 bits, respectively. To demonstrate the effect of
random activation and random permutation, we report these results by
randomly assigning a key k for each comparison. ‘Normal’ denotes that
no permutation and all of the neurons in FC layers are activated. ‘DAct-
k’ denotes that a random permutation with k out of 512 neurons in each
layer of FC layers are deactivated. . . . . . . . . . . . . . . . . . . . . 72
xv

3.6 ROC curves for the proposed randomized CNN with random activation
and random permutation on FRGC v2.0. (a) and (b) denote curves with
settings of 1023 and 2047 bits, respectively. To demonstrate the effect of
random activation and random permutation, we report these results by
randomly assigning a key k for each comparison. ‘Normal’ denotes that
no permutation and all of the neurons in the FC layers are activated.
‘DAct-k’ denotes that random permutation with k out of 512 neurons in
each layer of FC layers are deactivated. . . . . . . . . . . . . . . . . . 72
3.7 Curves of the trade-off between GAR @ (FAR=0.1%) and security (bits)
on IJBA. (a) and (b) Setting of 1023-bit with 128 and 256 neurons de-
activated in each FC layer. (c) and (d) Setting of 2047-bit with 128 and
256 neurons deactivated in each FC layer. . . . . . . . . . . . . . . . . 78
3.8 Curves of the trade-off between GAR @ (FAR=0.1%) and security (bits)
on FRGC v2.0. (a) and (b) Setting of 1023-bit with 128 and 256 neurons
deactivated in each FC layer. (c) and (d) Setting of 2047-bit with 128
and 256 neurons deactivated in each FC layer. . . . . . . . . . . . . . 79
4.1 The proposed binary feature level fusion algorithm . . . . . . . . . . . 87
4.2 The lower bound of entropy HL(x), where the grey-shaded area depicts
the admissible region of pmax given H(x). . . . . . . . . . . . . . . . . . 98
4.3 Sample face, fingerprint, and iris images from (a) WVU; (b) Chimeric
A (FERET, FVC2000-DB2, CASIA-Iris-Thousand); and (c) Chimeric B
(FRGC, FVC2002-DB2, ICE2006) . . . . . . . . . . . . . . . . . . . . . 98
4.4 Comparison of area under ROC curve on (a) WVU multi-modal, (b)
Chimeric A, (c) Chimeric B databases. . . . . . . . . . . . . . . . . . . 101
xvi

4.5 Comparison of average Renyi entropy on (a) WVU multi-modal, (b)
Chimeric A, (c) Chimeric B databases. . . . . . . . . . . . . . . . . . . 103
4.6 Area under ROC curve with varying qualities of biometric inputs . . . 106
4.7 Average Renyi entropy with varying qualities of biometric inputs . . . . 107
4.8 G-S Trade-off Analysis on (a) WVU multi-modal, (b) Chimeric A, and
(c) Chimeric B. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
xvii

Chapter 1
Introduction
In this chapter, the biometric system is introduced in Section 1.1. Section 1.2
then introduces the motivations for this thesis. The contributions of this thesis are
summarized in Section 1.3. Finally, Section 1.4 gives a brief overview of this thesis.
1.1 Biometric System
Person authentication aims to identify a subject or to verify the subject’s claimed
identity. In modern society, person authentication systems are widely used for access
control and identity management. They are required to be reliable, convenient, and
efficient because they are used daily in critical systems such as social networks, per-
sonal devices, financial transactions, and border control. To date, approaches for the
authentication of persons can be categorized into knowledge-based (what you know),
token-based (what you have), and biometrics (who you are). Knowledge-based authen-
tication systems are typically used for person verification and require users to answer
one or more questions such as asking for a password or PIN. Token-based authentica-
tion systems are generally used for personal identification and require users to present
1

a token such as an identity card or passport. Biometric systems use a person’s bi-
ological and/or behavioral characteristics to authenticate him or her and are widely
used for both verification and identification. It is critical to establish a strong and
permanent link between the user and the corresponding authentication agent. How-
ever, knowledge-based and token-based authentication can fail, because knowledge can
be forgotten or learned by others, and tokens can be broken or stolen. It is reason-
able that a subject’s biometric information is unique and robust over time because
biometric traits are inherent to a subject [61]. The uniqueness of biometric traits can
further help authentication systems to detect fabricated identities and de-duplication
and avoid multiple registrations of the same subject. Consequently, biometric systems
are increasingly used for person authentication.
1.1.1 Biometric Recognition System
A biometric recognition system is a pattern recognition system that can recognize
a person based on his or her biometric traits [61,81]. Over the past couple of decades,
many traits have been developed for automatic biometric recognition, including face,
fingerprint, iris (periocular), voice, gait, palmprint, ear, finger vein, and deoxyribonu-
cleic acid (DNA). A typical biometric recognition system consists of five components
(Fig. 1.1): (a) a sensor to capture the users’ biometric traits; (b) a feature extractor to
create representations from the captured traits; (c) a database to store the biometric
representations (also called templates); (d) a matching module to compute the scores
Sensor Feature Extractor
Matching Module
Database
Decision Module
Predicted identity (𝑙𝑙)
Enrollment (𝑥𝑥𝐸𝐸)
Query (𝑥𝑥𝑄𝑄)
User identity (𝑙𝑙)
Figure 1.1: Framework of biometric recognition systems.
2

between the incoming representation and the templates in the database; and (e) a de-
cision module to determine the identity or verify the claimed identity of the incoming
representation.
In general, biometric recognition systems can be operated at either the enrollment
stage or the query stage. At the enrollment stage (i.e., black and blue lines in Fig. 1.1),
the biometric representation created from the trait captured from the user is stored as
the enrollment template xE in the database with the user identity. At the query stage
(i.e., black and red lines in Fig. 1.1), for the task of identification, the query template
xQ created from the captured trait is compared with all of the templates stored in the
database, and the identity of the query template can then be predicted; for the task of
verification, the query template xQ is compared with the enrollment template of the
claimed identity, and the decision of whether they match can then be made.
A typical biometric recognition system that authenticates users depending on a sin-
gle trait is known as a unimodal biometric system. Due to intra-user variations such
as sensor noise and changes in the capturing environment, a unimodal biometric sys-
tem generally cannot achieve satisfactory matching accuracy. One way to improve the
matching accuracy is to use a multimodal biometric system that consolidates informa-
tion on multiple traits. Furthermore, multimodal biometric systems are much harder to
spoof and achieve better feasibility and universality than unimodal biometric systems.
Multimodal biometric systems can recognize individuals with the use of a subset of
biometric traits via feature selection. This enables the systems to cover a wider range
of the population when some users cannot be identified by a certain trait. In general,
information on multiple traits can be fused either at the output module or between
any two modules (excepting the database) of a biometric recognition system, including
the sensor level, feature level, score level, and rank/decision level. Fusion at various
levels has its own strengths and limitations and should be carefully chosen for different
applications.
3

1.1.2 Security and Privacy Concerns
Biometric recognition systems are being increasingly used for secure access and
identity management. The applications of biometric secure access range from personal
devices (e.g., iPhone X1 and Samsung S82) to transactions (e.g., banking3). Biometric-
based identity management systems could be organization-wide (e.g., patient ID4), na-
tionwide (e.g., India Aadhaar5 and UAE immigration control6), or even worldwide [62].
The use of biometrics in these critical applications raises concerns about security and
privacy in biometric systems [114]. In this thesis, we refer to security concerns as system
security issues in which adversaries aim to access the target biometric systems without
authorization or seek to deny the access of authorized users in the target systems. Pri-
vacy concerns are referred to as user privacy issues in which adversaries aim to identify
the anonymous users in a biometric system or to link anonymous users across multiple
biometric systems.
Before the deployment of critical systems, it is imperative to study the vulnerabil-
ities caused by potential attacks and devise necessary countermeasures. The attacks
on biometric systems can be categorized using an adversarial machine learning frame-
work [10] from four perspectives: adversary’s goal, adversary’s knowledge, adversary’s
capability and attack strategy.
• Adversary’s goal : In general, this could be security oriented: (a) unauthorized
access and (b) denial of authorized access; or privacy oriented: (c) identify anony-
mous users and (d) link anonymous users across systems.
• Adversary’s knowledge: This includes knowledge about the target system (what
the system components are and how the system components work) and the target
1https://www.apple.com/iphone-x/#face-id2http://www.samsung.com/uk/smartphones/galaxy-s8/3https://goo.gl/6TGcrr4https://www.kairos.com/human-analytics/healthcare5https://uidai.gov.in/your-aadhaar6https://goo.gl/cELriF
4

users. For knowledge about the target system, according to Fig. 1.2, the attackers
may know (a) the specific model of the sensor (point 1) and the vendors and the
versions of the feature extractor, matching module, database, and decision module
(points 3, 5, 6, and 9). For stronger assumptions, the attacker may also assume to
know the capturing techniques (e.g., near-infrared or visible imaging for point 1),
the algorithm details, and the operating parameters of various components (e.g.,
feature extraction algorithm for point 3 and decision threshold for point 9). (b)
The interface and channels for implementing the connections (points 2, 4, 7, and
8). For knowledge about the target users, the attackers may be able to (c) collect
raw biometric data elsewhere (e.g., face images from a social network and latent
fingerprint impressions from daily necessities); and (d) access to stored biometric
templates by insider attack or database invasion.
• Adversary’s capability : This includes observation and modification of the input
and output or even the internal of different system components. It can be defined
using points 1-9 in Fig. 1.2.
• Attack strategy : The way to achieve the adversary’s goal given the knowledge and
capability as described above.
To date, several attacks have been proposed for study of the vulnerabilities of bio-
metric systems, including spoofing/presentation attacks [21, 86, 107, 122, 140, 145], hill
climbing [4,32,35,93], and template reconstruction attacks [10,13,31,36,97,118]. Spoof-
ing/presentation attacks aim to create fake biometric traits (e.g., 3D face mask, gummy
Sensor Feature Extractor
Matching Module
Database
Decision Module
Predicted identity (𝑙𝑙)
User identity (𝑙𝑙)
𝒙𝒙 𝒚𝒚 𝒔𝒔1
2
3
45
6
97
8
Figure 1.2: Potential attack points to biometric recognition systems [10,116].
5

finger, printed iris) of target subjects to present to and access the system, where the
target subject, the knowledge about the sensor (point 1), and the spoof detection algo-
rithm are generally assumed to be known. Hill-climbing attacks aim to synthesize raw
biometric data (e.g., 2D iris images or 3D face model) by iteratively submitting the
synthesized raw biometric data (point 2) to the system and observing the corresponding
matching scores (point 8) until the submitted raw biometric data are accepted by the
system. Template reconstruction attacks aim to synthesize raw biometric data from
the biometric templates stored in the database (point 6) to submit to the system (point
2) and obtain access. In addition, the synthesized raw biometric data in hill-climbing
and template reconstruction attacks can be used to identify the target subject, which
thus causes severe privacy issues.
1.2 Data Reconstruction and Template Protection
1.2.1 Data Reconstruction
It is imperative to determine to what extent templates extracted from raw biometric
data and stored in a system can be reconstructed to obtain the original raw biometric
data. This will help us to determine the vulnerabilities of a biometric system caused by
template leakage. If reconstruction of raw biometric data from templates is successful,
a subject’s biometric data would be permanently compromised because biometric traits
are unique and irrevocable. It is critical to note that the leakage of a biometric template
database cannot be completely avoided in practice, even with strict auditing (e.g., the
leakage of 1.5B Yahoo accounts7 and 143M US identity data8). In addition, a biometric
template database can also be stolen by an insider.
There are three major challenges in the reconstruction of raw biometric data from
7https://goo.gl/9ubgPW8https://www.theverge.com/2017/9/7/16270808/equifax-data-breach-us-identity-theft
6

templates to study the vulnerabilities of a biometric system. (a) The scenario of the
reconstruction task must be practical and clearly defined. It is suggested that the
framework of adversarial machine learning [10] be used to specify the adversary’s goal,
knowledge, capability, and strategy. (b) The reconstruction model should have sufficient
model capacity9 and the ability to invert the mapping used in the template extraction
model. (c) A large amount of data is needed to train the reconstruction models. Note
that, in general, more data are typically required for the training of data reconstruction
models than for the training of template extraction models because the templates are
typically compact representations of the raw biometric data.
In the past decade, biometric systems have been increasingly based on deep tem-
plates. Compared with shallow templates with handcraft features (e.g., Eigenface [133],
IrisCode [23]), deep templates have achieved superior performance in various biometric
methods, e.g., face [50,76,80], fingerprint [14,15,131], and iris (periocular) [37,85,155,
156]. State-of-the-art methods have demonstrated that raw biometric data can be re-
constructed from shallow templates [10, 13,31,36, 97,118]. However, to the best of our
knowledge, no study of the reconstruction of raw biometric data from deep templates
to investigate the vulnerability of biometric systems has been reported. Therefore, we
aim to address this research problem in this thesis.
1.2.2 Template Protection
Biometric templates stored in the systems must be protected to prevent severe se-
curity and privacy issues because, as mentioned above, biometric templates without
protection can be used to reconstruct the raw biometric data. One straightforward
approach to protect biometric templates is to use standard ciphers [125] such as AES
and SHA-3. However, due to the intra-subject variation in biometric templates and
the avalanche effect10 [125] of standard ciphers, biometric templates must be decrypted
9The ability of a model to fit a wide variety of functions [43].10https://en.wikipedia.org/wiki/Avalanche_effect
7

before matching11. This is unlike traditional passwords that can be matched in their
encrypted (hash) form and introduces a challenging decryption key management prob-
lem. Another possible cipher for the protection of biometric templates is homomorphic
encryption [39, 42, 132], which compares templates in their encrypted form to give the
encrypted results, which are then decrypted to yield the decision. However, homo-
morphic encryption is very computationally expensive, especially for long biometric
templates. It also suffers from the same key management issue as most homomorphic
encryption construction [39], in which the decryption key of the encrypted results can
be used to decrypt the encrypted templates. An alternative approach is the use of bio-
metric template protection schemes [60,61,102] to generate a pseudonymous identifier
(PI) and auxiliary data (AD)12 from the plaintext enrollment template and store them
in the systems. During authentication, the stored PI is compared directly with the PI*
generated from the query template and the stored AD. In general, there are criteria for
template protection schemes [34,41,60,102]:
• Non-invertibility (security): It should be computationally infeasible for the secure
templates to be inverted into the plaintext biometric template or reconstructed
into the raw biometric data.
• Cancellability (revocability and unlinkability): A new secure template can be gen-
erated for a subject whose secure template is compromised. Furthermore, dif-
ferent secure templates of a subject can be generated for different applications
(systems), and there is no method to decide whether secure templates in different
systems belong to the same subject to some degree.
• Matching accuracy : The secure templates must be discriminative to fulfill their
original purpose of authenticating a person for a biometric system.
11To our knowledge, one method is available to directly compare the biometric templates in theirhash form [105]. However, only constrained datasets are used in their evaluation, and five samplesfrom all enrolled subjects are used to train the template extractor.
12We use the terms ‘PI and AD’ and ‘secure template’ interchangeably, because PI and AD is asecure form of plaintext biometric template.
8

Template protection remains an open challenge. To our knowledge, either the ven-
dors simply ignore the security and privacy issues of biometric templates, or they secure
the encrypted templates and the corresponding keys in specific hardware (e.g., Secure
Enclave on A11 of iPhone X13, TrustZone on ARM14). Note that the requirement for
specific hardware limits the range of biometric applications.
State-of-the-art template protection approaches have two stages that protect the
extracted templates with template protection schemes (e.g., feature transformation
(cancellable biometric) [18,64,79,108,115], biometric cryptosystems [28,68,69,101], and
hybrid approaches [34,100]). In the feature transformation approach [18,64,79,108,115],
templates are transformed via a one-way transformation function with a user-specific
random key. The security of the feature transformation approach is based on the non-
invertibility of the transformation. This approach provides cancellability, in which a
new transformation (based on a new key) can be used if any template is compromised.
A biometric cryptosystem [28, 68, 69, 101] stores a sketch that is generated from the
enrollment template, where an error correcting code (ECC) is used to handle the intra-
user variations. The security of a biometric cryptosystem is based on the randomness
of the templates and the ECC’s error correction capability. The advantage of biomet-
ric cryptosystems is that the strength of the security can be determined analytically
if the distribution of biometric templates is assumed to be known. However, the re-
quirement of binary input limits the feasibility of biometric cryptosystems. A hybrid
approach [34,100]) first applies feature transformation to create cancellable templates,
which are then binarized and secured by biometric cryptosystems. Therefore, hybrid
approaches combine the advantages of both feature transformation and biometric cryp-
tosystems to provide stronger security and template cancellability. However, existing
template protection schemes suffer from a severe trade-off between security and match-
ing accuracy. In addition, the issue of cancellability has not been adequately addressed
in the literature [102].
13https://images.apple.com/business/docs/FaceID_Security_Guide.pdf14https://www.arm.com/products/security-on-arm/trustzone
9

1.3 Contributions of This Thesis
This thesis addresses issues in data reconstruction and template protection for the
study of biometric system security and privacy. In short, this thesis contributes follows:
1. Data Reconstruction: An investigation of the invertibility of face templates
generated by deep networks. To our knowledge, this is the first such study on the
security and privacy of face recognition systems. To reconstruct face images from
deep templates, we develop a neighborly de-convolutional network framework
(NbNet) with its building block, neighborly de-convolution blocks (NbBlocks).
The NbNets were trained by data augmentation and perceptual loss [66], re-
sulting in discriminative information being maintained in deep templates. We
demonstrate that the proposed face image reconstruction from the corresponding
templates is successful. In this thesis, we achieve: verification rates (security),
a true acceptance rate (TAR) of 95.20% (58.05%) on LFW [80] under type I
(type II) attack at a false acceptance rate (FAR) of 0.1%. For identification (pri-
vacy), we achieve 96.58% and 92.84% rank one accuracy (partition fa) in color
FERET [111] as gallery and the images reconstructed from partition fa (type I
attack) and fb (type II attack) as probe. These works have been published in [89].
2. Template Protection: An end-to-end method for simultaneous extraction and
protection of the templates given raw biometric data (e.g., face images). To our
knowledge, this is the first end-to-end method used to generate secure templates
directly from raw biometric data. Specifically, we first introduced a random-
ized convolutional neural network (CNN) to generate secure biometric templates,
which depend on both input images and user-specific keys. We then constructed
a secure system using the randomized CNN without storing the user-specific keys
in the system. Instead, we stored the secure sketches generated from the user-
specific keys and binary intermediate features of the randomized CNN. The user-
specific keys can be decoded from the secure sketch in the query stage only if
10

the query image is sufficiently similar to the enrollment image. In addition, an
orthogonal triplet loss function was formulated for extraction of the binary in-
termediate features to generate the secure sketch. The formulated loss function
improves the success decoding rate of the secure sketches for genuine queries and
strengthens the security of the secure sketches. Evaluation and analysis based on
two face benchmarking datasets (IJB-A [76] and FRGC v2.0 [110]) demonstrated
that the proposed end-to-end method satisfies the criteria for template protec-
tion schemes [34, 61, 102]: matching accuracy, non-invertibility (security), and
cancellability (revocability and unlinkability). These works are in preparation for
submission to the IEEE Trans. on Pattern Analysis and Machine Intelligence [88].
3. Template Protection: A binary fusion approach for multibiometric cryptosys-
tems to offer accurate and secure recognition. The proposed fusion approach
can simultaneously maximize the discriminability and entropy of the fused bi-
nary output. Because the properties for achievement of both the discriminability
and the security criteria can be divided into multiple-bit-based (i.e., dependency
among bits) and individual-bit-based (i.e., intra-user variations, inter-user vari-
ations, and bit uniformity). The proposed approach consists of two stages: (i)
dependency-reductive bit-grouping and (ii) discriminative within-group fusion.
In the first stage, we address the multiple-bit-based property. We extract a set
of weakly dependent bit-groups from multiple sets of binary unimodal features,
such that if the bits in each group are fused into a single bit, these fused bits,
upon concatenation, will be weakly interdependent. Then, in the second stage,
we address the individual-bit-based properties. We fuse the bits in each bit-group
into a single bit with the objective of minimizing intra-user variation, maximizing
inter-user variation, and maximizing the uniformity of the bits. The experimental
results from three multimodal databases show that the fused binary feature of
the proposed method has both greater discriminability and greater entropy than
the unimodal features and the fused features generated from the state-of-the-art
binary fusion approaches. These works have been published in [90,91].
11

1.4 Thesis Overview
The remainder of this thesis is organized as follows.
Chapter 2 presents our study on data reconstruction, which aims to determine to
what extent face templates derived from deep networks can be inverted to obtain the
original face image. In this chapter, we study the vulnerabilities of a state-of-the-art face
recognition system based on a template reconstruction attack. We propose an NbNet
to reconstruct face images from their deep templates. In our experiments, we assumed
that no knowledge about the target subject and the deep network are available. To train
the NbNet reconstruction models, we augmented two benchmark face datasets (VGG-
Face and Multi-PIE) with a large collection of images synthesized with a face generator.
The proposed reconstruction was evaluated using type I (comparing the reconstructed
images against the original face images used to generate the deep template) and type II
(comparing the reconstructed images against a different face image of the same subject)
attacks. The experimental results demonstrate that reconstructed images can be used
to access a system and identify the target users with a high rate of success or accuracy.
Chapter 3 presents our study on template protection, which aims to derive secure
deep biometric templates without harming the recognition performance using deep
networks for storage in the system, where the secure templates should be resistant to
reconstruction. In addition, secure templates should also be cancellable so that a new
secure template can be generated for the subject whose secure template is compro-
mised, and so that different secure templates of a subject can be generated for different
applications. This chapter proposes an end-to-end method to simultaneously extract
and protect the biometric templates. Specifically, we first propose a randomized CNN
to generate secure deep biometric templates that depend on input including both raw
biometric data and user-specific keys. Note that the availability of the user-specific
keys for the extraction of the secure templates could reduce the difficulties of inverting
the secure templates. To further enhance the templates’ security, instead of storing
12

the user-specific keys, we store a secure sketch that can be decoded to the user-specific
key with genuine queries in the system. The experimental results of two benchmarking
datasets prove that the secure template generated by the proposed method is non-
invertible and cancellable, while preserving the recognition performance.
Chapter 4 presents our study on template protection, which aims to protect multi-
biometric templates using biometric cryptosystems. Popular cryptosystems such as
fuzzy extractor and fuzzy commitment require discriminative and informative binary
biometric input to offer accurate and secure recognition. In multimodal biometric
recognition, binary features can be produced by fusing the real-valued unimodal fea-
tures and binarizing the fused features. However, when the extracted features of certain
modalities are represented in binary and the extraction parameters are not known, the
real-valued features of other modalities must be binarized, and the feature fusion must
be carried out at the binary level. In this chapter, we propose a binary feature fusion
method that extracts a set of fused binary features with high discriminability (small
intra-user and large inter-user variations) and entropy (weak dependency among bits
and high bit uniformity) from multiple sets of binary unimodal features. Unlike existing
fusion methods that focus mainly on discriminability, the proposed method focuses on
both feature discriminability and system security. The proposed method 1) extracts
a set of weakly dependent feature groups from the multiple unimodal features; and 2)
fuses each group into a bit using mapping that minimizes the intra-user variations and
maximizes the inter-user variations and uniformity of the fused bit. The experimental
results from three multimodal databases show that the fused binary feature of the pro-
posed method has both greater discriminability and entropy than the unimodal features
and the fused features generated from the state-of-the-art binary fusion approaches.
Chapter 5 concludes the thesis and discusses some future directions for research.
13

Chapter 2
Reconstructing Face Images from
Deep Face Templates
2.1 Introduction
The focus of this chapter is on the study vulnerability of a face recognition sys-
tem to template reconstruction attack. In a template reconstruction attack (Fig. 2.1),
we want to determine if face images can be successfully reconstructed from the face
templates of target subjects and then used as input to the system to access privileges.
Fig. 2.2 shows examples of face images reconstructed from their deep templates by the
proposed method. Some of these reconstructions are successful in that they match well
with the original images (Fig. 2.2 (a)), while others are not successful (Fig. 2.2 (b)).
Template reconstruction attacks generally assume that templates of target subjects and
the corresponding black-box template extractor can be accessed. These are reasonable
assumptions because: (a) templates of target users can be exposed in hacked databases,
and (b) the corresponding black-box template extractor can potentially be obtained by
purchasing the face recognition SDK. To our knowledge, almost all of the face recogni-
tion vendors store templates without template protection, while some of them protect
14

Sensor Feature Extraction Comparison Decision
making
Face Image Reconstruction
Template Database
2D printed, 3D mask orReplay attacks
Face image
Reconstructed image
Figure 2.1: Face recognition system vulnerability to image reconstruction attacks. Faceimage of a target subject is reconstructed from a template to gain system access byeither (a) creating a fake face (for example, a 2D printed image or 3D mask) (blue box)or (b) inserting a reconstructed face into the feature extractor (red box).
templates with specific hardware (e.g., Secure Enclave on A11 of iPhone X, Trust-
Zone on ARM). Note that unlike traditional passwords, biometric templates cannot be
directly protected by standard ciphers such as AES and RSA since the matching of
templates needs to allow small errors caused by intra-subject variations [61, 102]. Be-
sides, state-of-the-art template protection schemes are still far from practical because
of the severe trade-off between matching accuracy and system security [34,91].
Face templates are typically compact binary or real-valued feature representations1
that are extracted from face images to increase the efficiency and accuracy of similarity
computation. Over the past couple of decades, a large number of approaches have been
proposed for face representations. These representations can be broadly categorized
into (i) shallow [5, 8, 19, 27, 133, 135, 149], and (ii) deep (convolutional neural network
or CNN) representations [50, 76, 80,106,121], according to the depth of their represen-
tational models2. Deep representations have shown their superior performances in face
evaluation benchmarks (such as LFW [80], YouTube Faces [106, 141], and NIST IJB-
A [76]). Therefore, it is imperative to investigate the invertibility of deep templates to
determine their vulnerability to template reconstruction attacks. However, to the best
of our knowledge, no such work has been reported.
1As face templates refer to face representations stored in a face recognition system, these terms areused interchangeably in this thesis.
2Some [106] refer to shallow representations as those that are not extracted using deep networks.
15

Tab
le2.
1:C
ompar
ison
ofm
ajo
ral
gori
thm
sfo
rfa
ceim
age
reco
nst
ruct
ion
from
thei
rco
rres
pon
din
gte
mpla
tes
Alg
ori
thm
Tem
pla
tefe
atu
res
Evalu
ati
on
Rem
ark
s
MD
S[9
9]P
CA
,B
IC,
CO
TS
Typ
e-I
atta
cka:
TA
Rof
72%
usi
ng
BIC
ban
d73
%usi
ng
CO
TS
cat
anFA
Rof
1.0%
onF
ER
ET
Lim
ited
model
capac
ity
RB
Fre
gres
-si
on[9
7]L
QP
[135
]T
yp
e-II
atta
ckd:
20%
rank-1
iden
tifica
tion
erro
rra
teon
FE
RE
T;
EE
R=
29%
onL
FW
;L
imit
edm
odel
capac
ity
CN
N[1
57]
Fin
alfe
ature
ofF
aceN
et[1
21]
Rep
orte
dre
sult
sw
ere
mai
nly
bas
edon
vis
ual
izat
ions
and
no
com
par
able
stat
isti
cal
resu
lts
was
rep
orte
d
Wh
ite-b
ox
tem
pla
teex
trac
tor
Col
eet
.al
.,[2
2]
Inte
rmed
iate
feat
ure
ofF
aceN
et[1
21]e
Nee
dhig
h-q
ual
ity
imag
esfo
rtr
ainin
g.
This
thes
isF
inal
feat
ure
ofF
aceN
et[1
21]
Typ
e-I
atta
ck:
TA
Rf
of95
.20%
(LF
W)
and
73.7
6%(F
RG
Cv2.
0)at
anFA
Rof
0.1%
;ra
nk-1
iden
tifica
tion
rate
95.5
7%on
colo
rF
ER
ET
Typ
e-II
atta
ck:
TA
Rof
58.0
5%(L
FW
)an
d38
.39%
(FR
GC
v2.
0)at
anFA
Rof
0.1%
;ra
nk-1
iden
tifica
tion
rate
92.8
4%on
colo
rF
ER
ET
Req
uir
esa
larg
enum
ber
ofim
ages
for
trai
nin
g
aT
yp
e-I
atta
ckre
fers
tom
atch
ing
the
reco
nst
ruct
edim
age
agai
nst
the
face
imag
efr
omw
hic
hth
ete
mpla
tew
asex
trac
ted.
bB
ICre
fers
toB
ayes
ian
intr
a/in
ter-
per
son
clas
sifier
[98]
.c
CO
TS
refe
rsto
com
mer
cial
off-t
he-
shel
fsy
stem
.A
loca
l-fe
ature
-bas
edC
OT
Sw
asuse
din
[99]
.d
Typ
e-II
atta
ckre
fers
tom
atch
ing
the
reco
nst
ruct
edim
age
agai
nst
afa
ceim
age
ofth
esa
me
sub
ject
that
was
not
use
dfo
rte
mpla
tecr
eati
on.
eO
utp
ut
of10
24-D
‘avgp
ool
’la
yer
ofth
e“N
N2”
arch
itec
ture
.f
TA
Rfo
rL
FW
and
FR
GC
v2.
0ca
nnot
be
dir
ectl
yco
mpar
edb
ecau
seth
eir
sim
ilar
ity
thre
shol
ds
diff
er.
16

0.84 0.78 0.82 0.93
(a) Successful match
0.09 0.10 0.12 0.13
(b) Unsuccessful match
Figure 2.2: Example face images reconstructed from their templates using the proposedmethod (VGG-NbB-P). The top row shows the original images (from LFW) and thebottom row shows the corresponding reconstructions. The numerical value shown be-tween the two images is the cosine similarity between the original and its reconstructedface image. The similarity threshold is 0.51 (0.38) at FAR = 0.1% (1.0%).
In our study of template reconstruction attacks, we made no assumptions about
subjects used to train the target face recognition system. Therefore, only public do-
main face images were used to train our template reconstruction model. The available
algorithms for face image reconstruction from templates [97, 99]3, [22, 157] are sum-
marized in Table 2.1. The generalizability of the published template reconstruction
attacks [97, 99] is not known, as all of the training and testing images used in their
evaluations were subsets of the same face dataset. No statistical study in terms of
template reconstruction attack has been reported in [22,157].
To determine to what extent face templates derived from deep networks can be
inverted to obtain the original face images, a reconstruction model with sufficient ca-
pacity is needed to invert the complex mapping used in the deep template extraction
model [43]. De-convolutional neural network (D-CNN)4 [38, 151, 152] is one of the
straightforward deep models for reconstructing face images from deep templates. To
design a D-CNN with sufficient model capacity5, one could increase the number of out-
put channels (filters) in each de-convolution layer [150]. However, this often introduces
3MDS method in the context of template reconstructible was initially proposed for reconstructingtemplates by matching scores between the target subject and attacking queries. However, it can alsobe used for template reconstruction attacks [99].
4Some researchers refer to D-CNNs as CNNs. However, given that its purpose is the inverse of aCNN, we distinguish D-CNN and CNN.
5The ability of a model to fit a wide variety of functions [43].
17

noisy and repeated channels since they are treated equally during the training.
To address the issues of noisy (repeated) channels and insufficient channel details,
inspired by DenseNet [56] and MemNet [129], we propose a neighborly de-convolutional
network framework (NbNet) and its building block, neighborly de-convolution blocks
(NbBlocks). The NbBlock produces the same number of channels as a de-convolution
layer by (a) reducing the number of channels in de-convolution layers to avoid the noisy
and repeated channels; and (b) then creating the reduced channels by learning from
their neighboring channels which were previously created in the same block to increase
the details in reconstructed face images. To train the NbNets, a large number of face
images are required. Instead of following the time-consuming and expensive process of
collecting a sufficiently large face dataset [104,138], we trained a face image generator,
DCGAN [113], to augment available public domain face datasets. To further enhance
the quality of reconstructed images, we explore both pixel difference and perceptual
loss [66] for training the NbNets.
2.2 Related Work
2.2.1 Reconstructing Face Images from Deep Templates
Face template reconstruction requires the determination of the inverse of deep mod-
els used to extract deep templates from face images. Most deep models are complex
and are typically implemented by designing and training a network with sufficiently
large capacity [43].
Shallow model based [97, 99]: There are two shallow model based methods for
reconstructing face images from templates proposed in the literature: multidimen-
sional scaling (MDS) [99] and radial basis function (RBF) regression [97]. However,
these methods have only been evaluated using shallow templates. The MDS-based
18

method [99] uses a set of face images to generate a similarity score matrix using the
target face recognition system and then finds an affine space in which face images can
approximate the original similarity matrix. Once the affine space has been found, a
set of similarities is obtained from the target face recognition system by matching the
target template and the test face images. The affine representation of the target tem-
plate is estimated using these similarities, which is then mapped back to the target
face image. The RBF-regression-based method [97] directly maps target templates to
whitened eigenfaces and then inverts them to the face image. Given a set of bases in
the template space, (multi-quadric) RBF regression [97] generates vectors consisting of
distances from the face representations to the given basis, and then maps these vectors
to the whitened eigenfaces using least squares regression.
Both of these reconstruction methods provide limited capacity for modeling com-
plex mapping between face images and deep templates. The MDS-based method [99]
models the mapping between face images and face templates linearly. In contrast, the
RBF-regression-based method [97] models non-linearity between face images and face
templates using a multi-quadric kernel.
Deep model based [22,157]: Zhmoginov and Sandler [157] learn the reconstruction
of face images from templates using a CNN by minimizing the template difference
between original and reconstructed images. This requires the gradient information
from target template extractor and cannot satisfy our assumption of black-box template
extractor. Cole et. al. [22] first estimate the landmarks and textures of face images
from the templates, and then combine the estimated landmarks and textures using the
differentiable warping to yield the reconstructed images. High-quality face images (e.g.,
front-facing, neutral-pose) are required to be selected for generating landmarks and
textures in [22] for training the reconstruction model. Note that both [157] and [22] does
not aim to study vulnerability on deep templates and hence no comparable statistical
results based template reconstruction attack were reported.
19

2.2.2 GAN for Face Image Generation
With adversarial training, GANs [6, 9, 44, 45, 47, 72, 95, 103, 113, 120] are able to
generate photo-realistic (face) images from randomly sampled vectors. It has become
one of the most popular methods for generating face images, compared to other methods
such as data augmentation [96] and SREFI [7]. GANs typically consist of a generator
which produces an image from a randomly sampled vector, and a discriminator which
classifies an input image as real or synthesized. The basic idea for training a GAN is to
prevent images output by the generator be mistakenly classified as real by co-training
a discriminator.
DCGAN [113] is believed to be the first method that directly generates high-quality
images (64 × 64) from randomly sampled vectors. PPGN [103] was proposed to con-
ditionally generate high-resolution images with better image quality and sample di-
versity, but it is rather complicated. Wasserstein GAN [6, 47] was proposed to solve
the model collapse problems in GAN [44]. Note that the images generated by Wasser-
stein GAN [6, 47] are comparable with those output by DCGAN. BEGAN [9] and
LSGAN [95] have been proposed to attempt to address the model collapse, and non-
convergence problems with GAN. A progressive strategy for training high-resolution
GAN is described in [72].
In this work, we employed an efficient yet effective method, DCGAN to generate
face images. The original DCGAN [113] is easy to collapse and outputs poor quality
high-resolution images (e.g., 160 × 160 in this work). We address the above problems
with DCGAN (Section 2.3.6.2).
20

Templates 𝒚𝒚black-box
feature extractor𝒚𝒚 = �𝑓𝑓 𝒙𝒙tt
Images 𝒙𝒙(NbNet training)�𝜃𝜃 = argmin𝜃𝜃 ℒ 𝒙𝒙, 𝜽𝜽
Training
random vectors𝒛𝒛~ 0,1 𝑘𝑘 face image generator 𝒙𝒙 = 𝑟𝑟(𝒛𝒛)
Generating face images
Testing
images
Template database with templates 𝒚𝒚𝒕𝒕Reconstructed
images 𝒙𝒙𝒕𝒕′Sensor
Feature Extraction𝒚𝒚 = �𝑓𝑓 𝒙𝒙 Matching Decision
MakingAccept/Reject
NbNet for face image reconstruction
tt
Subjects in target system Target Face Recognition System
Normal flow: Attack flow:
Figure 2.3: An overview of the proposed system for reconstructing face images fromthe corresponding deep templates, where the template y (yt) is a real-valued vector.
2.3 Proposed Template Security Study
An overview of our security study for deep template based face recognition systems
under template reconstruction attack is shown in Fig. 2.3; the normal processing flow
and template reconstruction attack flows are shown as black solid and red dotted lines,
respectively. This section first describes the scenario of template reconstruction attack
using an adversarial machine learning framework [10]. This is followed by the proposed
NbNet for reconstructing face images from deep templates and the corresponding train-
ing strategy and implementation.
2.3.1 Template Reconstruction Attack
The adversarial machine learning framework [10, 92] categorizes biometric attack
scenarios from four perspectives: an adversary’s goal and his/her knowledge, capability,
21

and attack strategy. Given a deep template based face recognition system, our template
reconstruction attack scenario using the adversarial machine learning framework is as
follows.
• Adversary’s goal: The attacker aims to impersonate a subject in the target face
recognition system, compromising the system integrity.
• Adversary’s knowledge: The attacker is assumed to have the following informa-
tion. (a) The templates yt of the target subjects, which can be obtained via template
database leakage or an insider attack. (b) The black-box feature extractor y = f(x)
of the target face recognition system. This can potentially be obtained by purchasing
the target face recognition system’s SDK. The attacker has neither information about
target subjects nor their enrollment environments. Therefore, no face images enrolled
in the target system can be utilized in the attack.
• Adversary’s capability:(a) Ideally, the attacker should only be permitted to present
fake faces (2D photographs or 3D face masks) to the face sensor during authentication.
In this study, to simplify, the attacker is assumed to be able to inject face images
directly into the feature extractor as if the images were captured by the face sensor.
Note that the injected images could be used to create fake faces in actual attacks. (b)
The identity decision for each query is available to the attacker. However, the similarity
score of each query cannot be accessed. (c) Only a small number of trials (e.g., < 5)
are permitted for the recognition of a target subject.
• Attack strategy: Under these assumptions, the attacker can infer a face image
xt from the target template yt using a reconstruction model xt = gθ(yt) and insert
reconstructed image as a query to access the target face recognition system. The
parameter θ of the reconstruction model gθ(·) can be learned using public domain face
images.
22
DconvOP 𝑑𝑑𝑋𝑋𝑑𝑑−1𝑤𝑤×ℎ×𝑐𝑐
𝑋𝑋𝑑𝑑𝑤𝑤′×ℎ′×𝑐𝑐′
(b) Typical de-convolution block
𝑋𝑋𝑑𝑑−1𝑤𝑤×ℎ×𝑐𝑐
𝑋𝑋𝑑𝑑𝑤𝑤′×ℎ′×𝑐𝑐′
(d) Neighborly de-convolution block B
DconvOP 𝑑𝑑 ConvOP 𝑑𝑑1
ConvOP 𝑑𝑑2
ConvOP 𝑑𝑑𝑃𝑃⋯
Concatenation
𝑋𝑋𝑑𝑑−1𝑤𝑤×ℎ×𝑐𝑐
𝑋𝑋𝑑𝑑𝑤𝑤′×ℎ′×𝑐𝑐′
(c) Neighborly de-convolution block A
DconvOP 𝑑𝑑 ConvOP 𝑑𝑑1
ConvOP 𝑑𝑑2
ConvOP 𝑑𝑑𝑃𝑃⋯
Concatenation
De-convolution Block 𝐷𝐷
De-convolution Block 𝑑𝑑
De-convolution Block 1
𝑋𝑋𝑑𝑑−1⋮⋮𝑋𝑋𝑑𝑑
Input Template
ConvOp
(a) Overview
Black-box Feature Extractor
Figure 2.4: The proposed NbNet for reconstructing face images from the correspond-ing face templates. (a) Overview of our face reconstruction network, (b) typical de-convolution block for building de-convolutional neural network (D-CNN), (c) and (d)are the neighborly de-convolution blocks (NbBlock) A/B for building NbNet-A andNbNet-B, respectively. Note that ConvOP (DconvOP) denotes a cascade of a convo-lution (de-convolution), a batch-normalization [58], and a ReLU activation (tanh inConvOP of (a)) layers, where the width of ConvOp (DconvOP) denotes the numberof channels in its convolution (de-convolution) layer. The black circles in (c) and (d)denote the channel concatenation of the output channels of DconvOP and ConvOPs.
23

(a) D-CNN
(b) NbNet-A
(c) NbNet-B
Figure 2.5: Visualization of 32 output channels of the 5th de-convolution blocks in(a) D-CNN, (b) NbNet-A, and (c) NbNet-B networks, where the input template wasextracted from the bottom image of Fig. 2.4 (a). Note that the four rows of channelsin (a) and the first two rows of channels in (b) and (c) are learned from channels fromthe corresponding 4th block. The third row of channels in both (b) and (c) are learnedfrom their first two rows of channels. The fourth row of channels in (b) is learned fromthe third row of channels only, where the fourth row of channels in (c) is learned fromthe first three rows of channels.
24

2.3.2 NbNet for Face Image Reconstruction
2.3.2.1 Overview
An overview of the proposed NbNet is shown in Fig. 2.4 (a). The NbNet is a cascade
of multiple stacked de-convolution blocks and a convolution operator, ConvOp. De-
convolution blocks up-sample and expand the abstracted signals in the input channels
to produce output channels with a larger size as well as more details about reconstructed
images. With multiple (D) stacked de-convolution blocks, the NbNet is able to expand
highly abstracted deep templates back to channels with high resolutions and sufficient
details for generating the output face images. The ConvOp in Fig. 2.4 (a) aims to
summarize multiple output channels of D-th de-convolution block to the target number
of channels (3 in this work for RGB images). It is a cascade of convolution, batch-
normalization [58], and tanh activation layers.
2.3.2.2 Neighborly De-convolution Block
A typical design of the de-convolution block [113, 151], as shown in Fig. 2.4 (b), is
to learn output channels with up-sampling from channels in previous blocks only. The
number of output channels c′ is often made large enough to ensure sufficient model
capacity for template reconstruction [150]. However, the up-sampled output channels
tend to suffer from the following two issues: (a) noisy and repeated channels; and (b)
insufficient details. An example of these two issues is shown in Fig. 2.5 (a), which is
a visualization of output channels in the fifth de-convolution block of a D-CNN that
is built with typical de-convolution blocks. The corresponding input template was
extracted from the bottom image of Fig. 2.4 (a).
To address these limitations, we propose NbBlock which produces the same number
of output channels as typical de-convolution blocks for the face template reconstruction.
25

One of the reasons for noisy and repeated output channels is that a large number of
channels are treated equally in a typical de-convolution block; from the perspective of
network architecture, these output channels were learned from the same set of input
channels and became the input of the same forthcoming blocks. To mitigate this issue,
we first reduce the number of output channels that is simultaneously learned from the
previous blocks. We then create the reduced number of output channels with enhanced
details by learning from neighbor channels in the same block.
Let Gd(·) denote the d-th NbBlock, which is shown as the dashed line in Fig. 2.4 (a)
and is the building component of our NbNet. Suppose that Gd(·) consists of one de-
convolution operator (DconvOP) N ′d and P convolution operators (ConvOPs) {Ndp |p =
1, 2, · · · , P}. Let X ′d and Xd,p denote the output of DconvOP N ′d and p-th ConvOP
Ndp in d-th NbBlock Gd(·), then
Xd = Gd(Xd−1) = [XP ] (2.1)
where Xd−1 denotes the output of the (d − 1)-th NbBlock, [·] denotes a function of
channel concatenation, and XP is the set of outputs of DconvOP and all ConvOPs in
Gd(·),
XP = {X ′d, Xd,1, Xd,2, · · · , Xd,P} (2.2)
where X ′d and Xd,p denotes the output of DconvOP and the p-th ConvOP in d-th block,
resp., and satisfy
X ′d = N ′d (Xd−1) , Xd,p = Ndp(
[Xp])
(2.3)
where Xp is a non-empty subset of Xp.
Based on this idea, we built two NbBlocks, A and B, as shown in Figs. 2.4 (c)
and (d), where the corresponding reconstructed networks are named NbNet-A and
NbNet-B, respectively. In this study, the DconvOp (ConvOp) in Figs. 2.4 (b), (c), and
(d) denotes a cascade of de-convolution (convolution), batch-normalization [58], and
ReLU activation layers. The only difference between blocks A and B is the choice of
26

Xp,
Xp =
{X ′d}, blocks A & B with p = 1;
{Xd,p−1}, block A with p > 1;
Xp, block B with p > 1.
(2.4)
In our current design of the NbBlocks, half of output channels ( c′
2for block d) are
produced by a DconvOP, and the remaining channels are produced by P ConvOPs,
each of which gives, in this study, eight output channels (Table. 2.2). Example of
blocks A and B with 32 output channels are shown in Figs. 2.5 (b) and (c). The
first two rows of channels are produced by DconvOp and the third and fourth rows
of channels are produced by the first and second ConvOps, respectively. Compared
with Fig. 2.5 (a), the first two rows in Figs. 2.5 (b) and (c) have small amount of noise
and fewer repeated channels, where the third and fourth row provide channels with
more details about the target face image (the reconstructed image in Fig. 2.4 (a)). The
design of our NbBlocks is motivated by DenseNet [56] and MemNet [129].
2.3.3 Reconstruction Loss
Let us denote R (x,x′) as the reconstruction loss between an input face image x
and its reconstruction x′ = gθ
(f(x)
), where gθ(·) denotes an NbNet with parameter
θ and f(·) denotes a black-box deep template extractor.
Pixel Difference: A straightforward loss for learning reconstructed image x′ is
pixel-wise loss between x′ and its original version x. The Minkowski distance could
then be used and mathematically expressed as
Rpixel (x,x′) = ||x− x′||k =
(M∑m=1
|xm − x′m|k
) 1k
(2.5)
where M denotes number of pixels in x and k denotes the order of the metric.
27

Perceptual Loss [66]: Because of the high discriminability of deep templates, most
of the intra-subject variations in a face image might have been eliminated in its corre-
sponding deep template. The pixel difference based reconstruction leads to a difficult
task of reconstructing these eliminated intra-subject variations, which, however, are
not necessary for reconstruction. Besides, it does not consider holistic contents in an
image as interpreted by machines and human visual perception. Therefore, instead of
using pixel difference, we employ the perceptual loss [66] which guides the reconstructed
images towards the same representation as the original images. Note that a good repre-
sentation is robust to intra-subject variations in the input images. The representation
used in this study is the feature map in the VGG-19 model [123]6. We empirically
determine that using the output of ReLU3 2 activation layer as the feature map leads
the best image reconstruction, in terms of face matching accuracy. Let F (·) denote
feature mapping function of the ReLU3 2 activation layer of VGG-19 [123], then the
perceptual loss can be expressed as
Rpercept (x,x′) =1
2||F (x)− F (x′)||22 (2.6)
2.3.4 Generating Face Images for Training
To successfully launch an template reconstruction attack on a face recognition sys-
tem without knowledge of the target subject population, NbNets should be able to
accurately reconstruct face images with input templates extracted from face images of
different subjects. Let px(x) denote the probability density function (pdf) of image x,
the objective function for training a NbNet can be formulated as
arg minθL (x,θ) = arg min
θ
∫R (x,x′) px(x)dx
= arg minθ
∫R(x, gθ(f(x))
)px(x)dx.
(2.7)
6Provided by https://github.com/dmlc/mxnet-model-gallery
28

Since there are no explicit methods for estimating px(x), we cannot sample face
images from px(x). The common approach is to collect a large-scale face dataset and
approximate the loss function L(θ) in Eq. (2.7) as:
L(x,θ) =1
N
N∑i
R(xi, gθ(f(xi))
)(2.8)
where N denotes the number of face images and xi denotes the i-th training image.
This approximation is optimal if, and only if, N is sufficiently large. In practice, this
is not feasible because of the huge time and cost associated with collecting a large
database of face images.
To train a generalizable NbNet for reconstructing face images from their deep tem-
plates, a large number of face images are required. Ideally, these face images should
come from a large number of different subjects because deep face templates of the
same subject are very similar and can be regarded as either single exemplar or under
large intra-user variations, a small set of exemplars in the training of NbNet. However,
current large-scale face datasets (such as VGG-Face [106], CASIA-Webface [147], and
Multi-PIE [46]) were primarily collected for training or evaluating face recognition algo-
rithms. Hence, they either contain an insufficient number of images (for example, 494K
images in CASIA-Webface) or an insufficient number of subjects (for instance, 2,622
subjects in VGG-Face and 337 subjects in Multi-PIE) for training a reconstruction
NbNet.
Instead of collecting a large face image dataset for training, we propose to augment
current publicly available datasets. A straightforward way to augment a face dataset
is to estimate the distribution of face images px(x) and then sample the estimated
distribution. However, as face images generally consist of a very large number of pixels,
there is no efficient method to model the joint distribution of these pixels. Therefore,
we introduced a generator x = r(z) capable of generating a face image x from a vector
z with a given distribution. Assuming that r(z) is one-to-one and smooth, the face
29
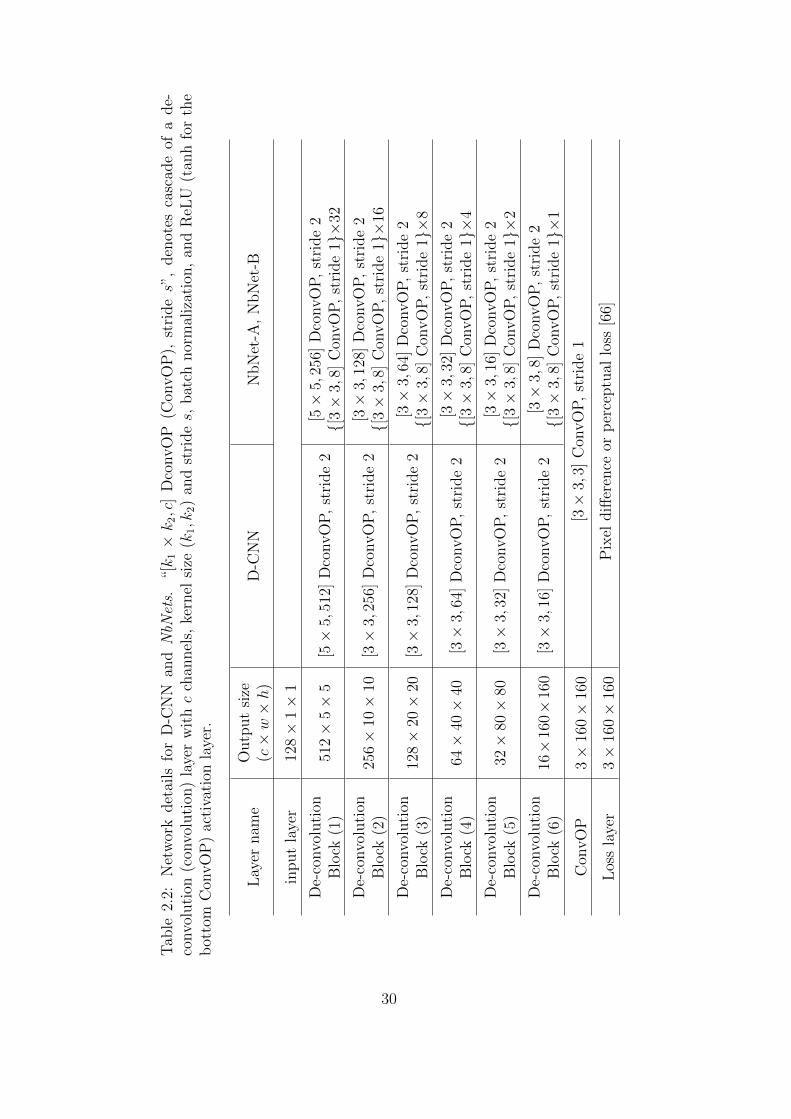
Tab
le2.
2:N
etw
ork
det
ails
for
D-C
NN
and
NbN
ets.
“[k
1×k
2,c
]D
convO
P(C
onvO
P),
stri
des”
,den
otes
casc
ade
ofa
de-
convo
luti
on(c
onvo
luti
on)
laye
rw
ithc
chan
nel
s,ke
rnel
size
(k1,k
2)
and
stri
des,
bat
chnor
mal
izat
ion,
and
ReL
U(t
anh
for
the
bot
tom
Con
vO
P)
acti
vati
onla
yer.
Lay
ernam
eO
utp
ut
size
(c×w×h
)D
-CN
NN
bN
et-A
,N
bN
et-B
input
laye
r12
8×
1×
1
De-
convo
luti
onB
lock
(1)
512×
5×
5[5×
5,51
2]D
convO
P,
stri
de
2[5×
5,25
6]D
convO
P,
stri
de
2{[
3×
3,8]
Con
vO
P,
stri
de
1}×
32
De-
convo
luti
onB
lock
(2)
256×
10×
10[3×
3,25
6]D
convO
P,
stri
de
2[3×
3,12
8]D
convO
P,
stri
de
2{[
3×
3,8]
Con
vO
P,
stri
de
1}×
16
De-
convo
luti
onB
lock
(3)
128×
20×
20[3×
3,12
8]D
convO
P,
stri
de
2[3×
3,64
]D
convO
P,
stri
de
2{[
3×
3,8]
Con
vO
P,
stri
de
1}×
8
De-
convo
luti
onB
lock
(4)
64×
40×
40[3×
3,64
]D
convO
P,
stri
de
2[3×
3,32
]D
convO
P,
stri
de
2{[
3×
3,8]
Con
vO
P,
stri
de
1}×
4
De-
convo
luti
onB
lock
(5)
32×
80×
80[3×
3,32
]D
convO
P,
stri
de
2[3×
3,16
]D
convO
P,
stri
de
2{[
3×
3,8]
Con
vO
P,
stri
de
1}×
2
De-
convo
luti
onB
lock
(6)
16×
160×
160
[3×
3,16
]D
convO
P,
stri
de
2[3×
3,8]
Dco
nvO
P,
stri
de
2{[
3×
3,8]
Con
vO
P,
stri
de
1}×
1
Con
vO
P3×
160×
160
[3×
3,3]
Con
vO
P,
stri
de
1
Los
sla
yer
3×
160×
160
Pix
eldiff
eren
ceor
per
ceptu
allo
ss[6
6]
30

images can be sampled by sampling z. The loss function L(θ) in Eq. (2.7) can then be
approximated as follows:
L (x,θ) =
∫R(x, gθ(f(x))
)px(x)dx
=
∫R(r(z), gθ
(f(r(z))
))pz(z)dz.
(2.9)
where pz(z) denotes the pdf of variable z. Using the change of variables method [2,29],
it is easy to show that pz(z) and r(z) have the following connection,
pz(z) = px(r(z))
∣∣∣∣det
(dx
dz
)∣∣∣∣ ,where
(dx
dz
)ij
=∂xi∂zj
. (2.10)
Suppose a face image x ∈ Rh×w×c of height h, width w, and with c channels can be
represented by a real vector b = {b1, · · · , bk} ∈ Rk in a manifold space with h×w×c�
k. It can then be shown that there exists a generator function b′ = r(z) that generates
b′ with a distribution identical to that of b, where b can be arbitrarily distributed and
z ∈ [0, 1]k is uniformly distributed (see Appendix).
To train the NbNets in the present study, we used the generative model of a DC-
GAN [113] as our face generator r(·). This model can generate face images from vectors
z that follow a uniform distribution. Specifically, DCGAN generates face images r(z)
with a distribution that is an approximation to that of real face images x. It can be
shown empirically that a DCGAN can generate face images of unseen subjects with
different intra-subject variations. By using adversarial learning, the DCGAN is able to
generate face images that are classified as real face images by a co-trained real/fake face
image discriminator. Besides, the intra-subject variations generated using a DCGAN
can be controlled by performing arithmetic operations in the random input space [113].
31

2.3.5 Differences with DenseNet
One of the related work to NbNet is DenseNet [56], from which the NbNet is inspired.
Generally, DenseNet is based on convolution layers and designed for object recognition,
while the proposed NbNet is based on de-convolution layers and aimed to reconstruct
face images from deep templates. Besides, NbNet is a framework whose NbBlocks
produce output channels learned from previous blocks and neighbor channels within the
block. The output channels of NbBlocks consist of fewer repeated and noisy channels
and contain more details for face image reconstruction than the typical de-convolution
blocks. Under the framework of NbNet, one could build a skip-connection-like network
[51], NbNet-A, and a DenseNet -like network, NbNet-B. Note that NbNet-A sometimes
achieves a comparable performance to NbNet-B with roughly 67% of the parameters
and 54% running time only (see model VGG-NbA-P and VGG-NbB-P in Section 2.4).
We leave more efficient and accurate NbNets construction as a future work.
2.3.6 Implementation Details
2.3.6.1 Network Architecture
The detailed architecture of the D-CNN and the proposed NbNets is shown in Table. 2.2.
The NbNet-A and NbNet-B show the same structure in Table. 2.2. However, the input
of the ConvOP in the de-convolution blocks (1)-(6) are different (Fig. 2.4), where
NbNet-A uses the nearest previous channels in the same block, and NbNet-B uses all
the previous channels in the same block.
32

2.3.6.2 Revisiting DCGAN
To train our NbNet to reconstruct face images from deep templates, we first train
a DCGAN to generate face images. These generated images are then used for training.
The face images generated by the original DCGAN could be noisy and sometimes
difficult to interpret. Besides, the training as described in [113] is often collapsed in
generating high-resolution images. To address these issues, we revisit the DCGAN as
below (as partially suggested in [44]):
• Network architecture: replace the batch normalization and ReLU activation layer
in both generator and discriminator by the SeLU activation layer [75], which
performs the normalization of each training sample.
• Training labels : replace the hard labels (‘1’ for real, and ‘0’ for generated images)
by soft labels in the range [0.7, 1.2] for real, and in range [0, 0.3] for generated
images. This helps smooth the discriminator and avoids model collapse.
• Learning rate: in the training of DCGAN, at each iteration, the generator is
updated with one batch of samples, while the discriminator is updated with two
batches of samples (1 batch of ‘real’ and 1 batch of ‘generated’). This often makes
the discriminator always correctly classify the images output by the generator.
To balance, we adjust the learning rate of the generator to 2 × 10−4, which is
greater than the learning rate of the discriminator, 5× 10−5.
Example generated images were shown in Fig. 2.7.
2.3.6.3 Training Details
With the pre-trained DCGAN, face images were first generated by randomly sam-
pling vectors z from a uniform distribution and the corresponding face templates were
33

extracted. The NbNet was then updated with the generated face images as well as
the corresponding templates using batch gradient descent optimization. This train-
ing strategy was used to minimize the loss function L(θ) in Eq. (2.9), which is an
approximation of the loss function in Eq. (2.7).
The face template extractor we used is based on FaceNet [121], one of the most
accurate CNN models for face recognition currently available. To ensure that the face
reconstruction scenario is realistic, we used an open-source implementation7 based on
TensorFlow8 without any modifications (model 20170512-110547 ).
We implemented the NbNets using MXNet9. The networks were trained using a
mini-batch based algorithm, Adam [74] with batch size of 64, β1 = 0.5 and β2 =
0.999. The learning rate was initialized to 2 × 10−4 and decayed by a factor of 0.94
every 5K batches. The pixel values in the output images were normalized to [−1, 1]
by first dividing 127.5 and then subtracting 1.0. For the networks trained with the
pixel difference loss, we trained the network with 300K batches, where the weights
are randomly initialized using a normal distribution with zero mean and a standard
deviation of 0.02. For the networks trained with the perceptual loss [66], we trained the
networks with extra 100K batches by refining from the corresponding networks trained
with the pixel difference loss. The hardware specifications of the workstations for the
training are the CPUs of dual Intel(R) Xeon E5-2630v4 @ 2.2 GHz, the RAM of 256GB
with two sets of NVIDIA Tesla K80 Dual GPU. The software includes CentOS 7 and
Anaconda210.
7https://github.com/davidsandberg/facenet8Version 1.4.0 from https://www.tensorflow.org9Version 0.1.0 from http://mxnet.io
10https://www.anaconda.com
34

2.4 Performance Evaluation
2.4.1 Database and Experimental Setting
The vulnerabilities of deep templates under template reconstruction attacks were
studied with our proposed reconstruction model, using two popular large-scale face
datasets for training and three benchmark datasets for testing. The training datasets
consisted of one unconstrained datasets, VGG-Face [106] and one constrained dataset,
Multi-PIE [46].
• VGG-Face [106] comprises of 2.6 million face images from 2,622 subjects. In
total, 1,942,242 trainable images were downloaded with the provided links.
• Multi-PIE [46]. We used 150,760 frontal images (3 camera views, with labels
‘14 0′, ‘05 0′, and ‘05 1′, respectively), from 337 subjects.
Three testing datasets were used, including two for verification (LFW [80] and
FRGC v2.0 [110]) and one for identification (color FERET [111]) scenarios. Note that
all of the images used in testing are the real face images provided by the dataset.
• LFW [80] consists of 13,233 images of 5,749 subjects downloaded from the Web.
• FRGC v2.0 [110] consists of 50,000 frontal images of 4,003 subjects with two dif-
ferent facial expressions (smiling and neutral), taken under different illumination
conditions. A total of 16,028 images of 466 subjects (as specified in the target set
of Experiment 1 of FRGC v2.0 [110]) were used.
• Color FERET [111] consists of four partitions (i.e., fa, fb, dup1 and dup2 ),
including 2,950 images. Compared to the gallery set fa, the probe sets (fb, dup1
and dup2 ) contain face images of difference facial expression and aging.
35

(a) VGG-Face (b) Multi-PIE
(c) LFW (d) FRGC v2.0
(e) Color FERET
Figure 2.6: Example face images from the training and testing datasets: (a) VGG-Face(1.94M images) [106], (b) Multi-PIE (151K images, only three camera views were used,including ‘14 0′, ‘05 0′ and ‘05 1′, respectively) [46], (c) LFW (13,233 images) [57, 80],(d) FRGC v2.0 (16,028 images in the target set of Experiment 1) [110], and (e) ColorFERET (2,950 images) [111].
(a) VGG-Face (b) Multi-PIE
Figure 2.7: Sample face images generated from face generators trained on (a) VGG-Face, and (b) Multi-PIE.
36

The face images were aligned using the five points detected by MTCNN11 [154] and
then cropped to 160×160 pixels. Instead of aligning images from the LFW dataset, we
used the pre-aligned deep funneled version [57]. Fig. 2.6 shows example images from
these five datasets.
To determine the effectiveness of the proposed NbNet, we compare three different
network architectures, i.e., D-CNN, NbNet-A, and NbNet-B, which are built using the
typical de-convolution blocks, NbBlocks A and B. All of these networks are trained using
the proposed generator-based training strategy using a DCGAN [113] with both pixel
difference12 and perceptual loss13 [66]. To demonstrate the effectiveness of the proposed
training strategy, we train the NbNet-B directly using images from VGG-Face, Multi-
PIE, and a mixture of three datasets (VGG-Face, CASIA-Webface14 [147], and Multi-
PIE). Note that both VGG-Face and Multi-PIE are augmented to 19.2M images in
our training. Examples of images generated using our trained face image generator are
shown in Fig. 2.7. In addition, the proposed NbNet based reconstruction method was
compared with a state-of-the-art RBF-regression-based method [97]. In contrast to the
neural network based method, the RBF15 regression model of [97] used the same dataset
for training and testing (either LFW or FRGC v2.0). Therefore, the RBF-regression-
based reconstruction method was expected to have better reconstruction accuracy than
the proposed method. The MDS-based method [99] was not compared here because
it is a linear model and was not as good as the RBF-regression-based method [97].
We did not compare [22, 157] because [157] does not satisfy our assumption of black-
box template extractor and [22] requires to selecting high quality images for training.
Table 2.3 summarizes the 16 comparison models used in this study for deep template
inversion.
11https://github.com/pangyupo/mxnet_mtcnn_face_detection.git12We simply choose mean absolute error (MAE), where order k = 1.13To reduce the training time, we first train the network with pixel difference loss and then fine-tune
it using perceptual loss [66].14It consists of 494,414 face images from 10,575 subjects. We obtain 455,594 trainable images after
preprocessing.15It was not compared in the identification task on color FERET.
37
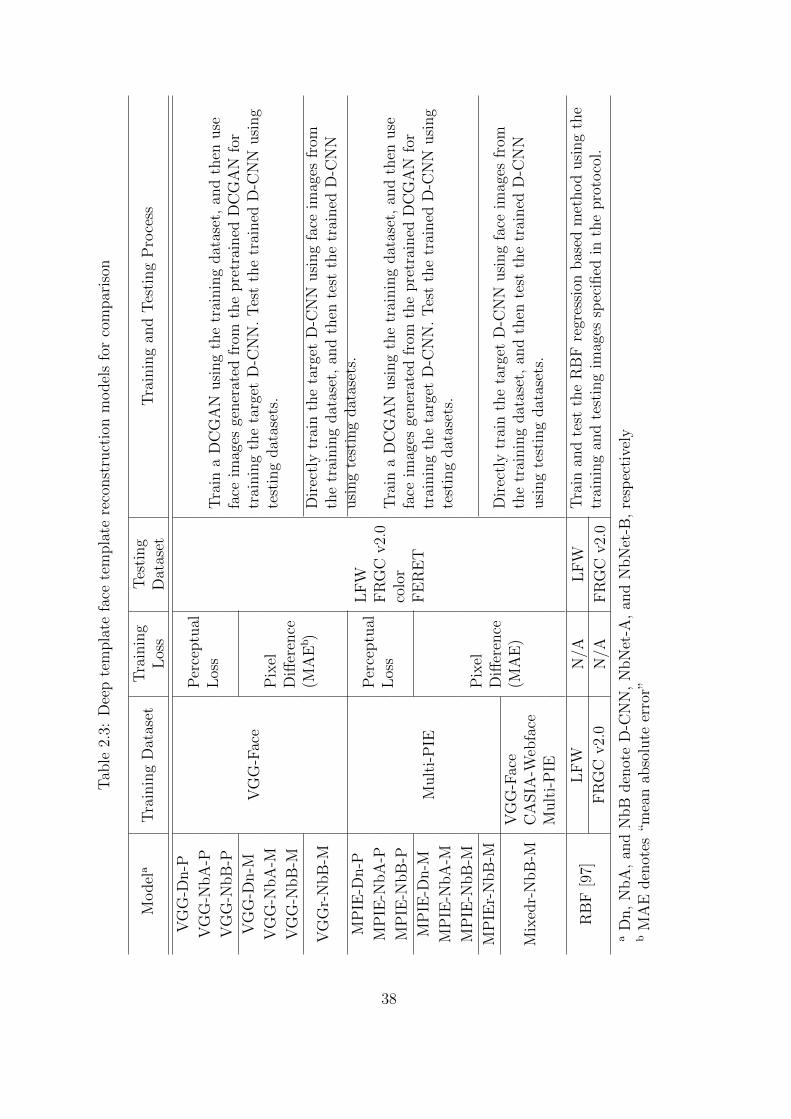
Tab
le2.
3:D
eep
tem
pla
tefa
cete
mpla
tere
const
ruct
ion
model
sfo
rco
mpar
ison
Model
aT
rain
ing
Dat
aset
Tra
inin
gL
oss
Tes
ting
Dat
aset
Tra
inin
gan
dT
esti
ng
Pro
cess
VG
G-D
n-P
VG
G-F
ace
Per
ceptu
alL
oss
LF
WF
RG
Cv2.
0co
lor
FE
RE
T
Tra
ina
DC
GA
Nusi
ng
the
trai
nin
gdat
aset
,an
dth
enuse
face
imag
esge
ner
ated
from
the
pre
trai
ned
DC
GA
Nfo
rtr
ainin
gth
eta
rget
D-C
NN
.T
est
the
trai
ned
D-C
NN
usi
ng
test
ing
dat
aset
s.
VG
G-N
bA
-P
VG
G-N
bB
-P
VG
G-D
n-M
Pix
elD
iffer
ence
(MA
Eb )
VG
G-N
bA
-M
VG
G-N
bB
-M
VG
Gr-
NbB
-MD
irec
tly
trai
nth
eta
rget
D-C
NN
usi
ng
face
imag
esfr
omth
etr
ainin
gdat
aset
,an
dth
ente
stth
etr
ained
D-C
NN
usi
ng
test
ing
dat
aset
s.M
PIE
-Dn-P
Mult
i-P
IE
Per
ceptu
alL
oss
Tra
ina
DC
GA
Nusi
ng
the
trai
nin
gdat
aset
,an
dth
enuse
face
imag
esge
ner
ated
from
the
pre
trai
ned
DC
GA
Nfo
rtr
ainin
gth
eta
rget
D-C
NN
.T
est
the
trai
ned
D-C
NN
usi
ng
test
ing
dat
aset
s.
MP
IE-N
bA
-P
MP
IE-N
bB
-P
MP
IE-D
n-M
Pix
elD
iffer
ence
(MA
E)
MP
IE-N
bA
-M
MP
IE-N
bB
-M
MP
IEr-
NbB
-MD
irec
tly
trai
nth
eta
rget
D-C
NN
usi
ng
face
imag
esfr
omth
etr
ainin
gdat
aset
,an
dth
ente
stth
etr
ained
D-C
NN
usi
ng
test
ing
dat
aset
s.M
ixed
r-N
bB
-MV
GG
-Fac
eC
ASIA
-Web
face
Mult
i-P
IE
RB
F[9
7]L
FW
N/A
LF
WT
rain
and
test
the
RB
Fre
gres
sion
bas
edm
ethod
usi
ng
the
trai
nin
gan
dte
stin
gim
ages
spec
ified
inth
epro
toco
l.F
RG
Cv2.
0N
/AF
RG
Cv2.
0a
Dn,
NbA
,an
dN
bB
den
ote
D-C
NN
,N
bN
et-A
,an
dN
bN
et-B
,re
spec
tive
lyb
MA
Eden
otes
“mea
nab
solu
teer
ror”
38

Examples of the reconstructed images of the first ten subjects in LFW and FRGC
v2.0 are shown in Figs. 2.8 and 2.9, respectively. The leftmost column shows the
original images, and the remaining columns show the images reconstructed using the
16 reconstruction models. For the RBF model, every image in the testing datasets
(LFW and FRGC v2.0) has 10 different reconstructed images that can be created using
the 10 cross-validation trials in the BLUFR protocol16 [82]. The RBF-reconstructed
images shown in this thesis are those with the highest similarity scores among these 10
different reconstructions. The number below each image is the similarity score between
the original and reconstructed images. The similarity scores were calculated using the
cosine similarity in the range of [−1, 1].
2.4.2 Verification Under Template Reconstruction Attack
We quantitatively evaluated the template security of the target face recognition
system (FaceNet [121]) under type-I and type-II template reconstruction attacks. The
evaluation metric was face verification using the BLUFR protocol [82]. The impostor
scores obtained from the original face images were used in both of the attacks to
demonstrate the efficacy of the reconstructed face images. The genuine scores in the
type-I attack were obtained by comparing the reconstructed images against the original
images. The genuine scores in the type-II attack were obtained by substituting one
of the original images in a genuine comparison (image pair) with the corresponding
reconstructed image. It is important to note that the accuracy of the Type-I and
Type-II attack cannot be directly compared as the number of genuine comparisons in
the Type-II attack are much greater than the one in the Type-I attack (more than 16 or
24 times on LFW or FRGC v2.0). For benchmarking, we report the “Original” results
based on original face images. Every genuine score of “Original” in type-I attack was
obtained by comparing two identical original images and thus the corresponding TAR
stays at 100%. The genuine scores of “Original” in type-II attack were obtained by the
16http://www.cbsr.ia.ac.cn/users/scliao/projects/blufr/
39

Original VGG-Dn-P VGG-NbA-P VGG-NbB-P VGG-Dn-M VGG-NbA-M VGG-NbB-M VGGr-NbB-M MPIE-Dn-P MPIE-NbA-P MPIE-NbB-P MPIE-Dn-M MPIE-NbA-M MPIE-NbB-M MPIEr-NbB-M Mixed-NbB-M RBF
0.79 0.78 0.84 0.73 0.66 0.75 0.67 0.65 0.63 0.74 0.41 0.42 0.43 0.48 0.64 0.45
0.70 0.77 0.81 0.52 0.72 0.65 0.69 0.85 0.82 0.79 0.73 0.57 0.67 0.33 0.55 0.55
0.73 0.78 0.78 0.73 0.78 0.79 0.76 0.83 0.87 0.88 0.62 0.82 0.81 0.65 0.68 0.60
0.63 0.71 0.78 0.49 0.61 0.72 0.57 0.75 0.75 0.81 0.57 0.70 0.77 0.41 0.64 0.61
0.83 0.85 0.81 0.73 0.70 0.71 0.72 0.86 0.78 0.80 0.71 0.73 0.72 0.48 0.80 0.53
0.74 0.72 0.79 0.68 0.63 0.67 0.44 0.60 0.72 0.75 0.55 0.51 0.63 0.35 0.47 0.58
0.81 0.81 0.82 0.73 0.78 0.74 0.77 0.80 0.78 0.88 0.52 0.71 0.68 0.73 0.69 0.60
0.66 0.72 0.80 0.67 0.60 0.70 0.64 0.74 0.67 0.79 0.49 0.70 0.73 0.58 0.57 0.59
0.62 0.66 0.76 0.72 0.42 0.54 0.55 0.67 0.62 0.63 0.52 0.20 0.51 0.30 0.64 0.55
0.78 0.79 0.80 0.65 0.65 0.78 0.59 0.84 0.84 0.83 0.65 0.57 0.79 0.67 0.52 0.71
Figure 2.8: Reconstructed face images of the first 10 subjects from LFW. Each rowshows an original image and its corresponding reconstructed images produced by dif-ferent reconstruction models. The original face images are shown in the first column.Each of remaining column denotes the reconstructed face images from different mod-els used for reconstruction. The number below each reconstructed image shows thesimilarity score between the reconstructed image and the original image. The scores(ranging from -1 to 1) were calculated using the cosine similarity. The mean verificationthresholds were 0.51 and 0.38, respectively, at FAR=0.1% and FAR=1.0%.
40

Original VGG-Dn-P VGG-NbA-P VGG-NbB-P VGG-Dn-M VGG-NbA-M VGG-NbB-M VGGr-NbB-M MPIE-Dn-P MPIE-NbA-P MPIE-NbB-P MPIE-Dn-M MPIE-NbA-M MPIE-NbB-M MPIEr-NbB-M Mixed-NbB-M RBF
0.74 0.80 0.80 0.77 0.67 0.82 0.66 0.69 0.67 0.85 0.54 0.47 0.58 0.48 0.72 0.38
0.78 0.80 0.77 0.62 0.70 0.74 0.55 0.74 0.82 0.84 0.54 0.65 0.67 0.67 0.63 0.62
0.83 0.73 0.81 0.57 0.78 0.74 0.51 0.78 0.74 0.80 0.55 0.67 0.59 0.55 0.53 0.52
0.18 0.73 0.53 0.20 0.31 0.32 0.75 0.95 0.95 0.93 0.89 0.91 0.92 0.96 0.90 0.92
0.52 0.58 0.62 0.42 0.65 0.52 0.72 0.81 0.79 0.83 0.65 0.76 0.80 0.83 0.71 0.64
0.65 0.76 0.83 0.43 0.42 0.59 0.48 0.82 0.65 0.61 0.47 0.33 0.38 0.39 0.58 0.58
0.75 0.88 0.81 0.55 0.81 0.78 0.44 0.78 0.76 0.79 0.53 0.59 0.64 0.57 0.71 0.55
0.48 0.52 0.51 0.43 0.49 0.47 0.57 0.86 0.86 0.87 0.77 0.73 0.79 0.76 0.70 0.77
0.65 0.68 0.65 0.56 0.75 0.72 0.73 0.92 0.84 0.90 0.77 0.76 0.84 0.69 0.77 0.63
0.24 0.50 0.58 0.37 0.32 0.55 0.82 0.89 0.91 0.89 0.86 0.86 0.89 0.85 0.84 0.77
Figure 2.9: Reconstructed face images of the first 10 subjects from FRGC v2.0. Eachrow shows an original image and its corresponding reconstructed images produced bydifferent reconstruction models. The original face images are shown in the first col-umn. Each of remaining column denotes the reconstructed face images from differentmodels used for reconstruction. The number below each reconstructed image shows thesimilarity score between the reconstructed image and the original image. The scores(ranging from -1 to 1) were calculated using the cosine similarity. The mean verificationthresholds were 0.80 and 0.64, respectively, at FAR=0.1% and FAR=1.0%.
41

genuine comparisons specified in BLUFR protocol, which uses tenfold cross-validation;
the performance reported here is the ‘lowest’, namely (µ−σ), where µ and σ denote the
mean and standard deviation of the accuracy obtained from the 10 trials, respectively.
2.4.2.1 Performance on LFW
In each trial of the BLUFR protocol [82] for LFW [80], there is an average of
46,960,863 impostor comparisons. The average number of testing images is 9,708.
Hence, there are 9,708 genuine comparisons in a type-I attack on LFW. The average
number of genuine comparisons in a type-II attack on LFW is 156,915; this is the
average number of genuine comparisons specified in the BLUFR protocol.
The receiver operator characteristic (ROC) curves of type-I and type-II attacks
on LFW are shown in Fig. 2.10. Table 2.4 shows the TAR values at FAR=0.1%
and FAR=1.0%, respectively. The ROC curve of “Original” in the type-II attack
(Fig. 2.10b) is the system performance with BLUFR protocol [82] based on original
images.
For both type-I and type-II attacks, the proposed NbNets generally outperform the
D-CNN, where MPIE-NbA-P is not as effective as MPIE-Dn-P. Moreover, the models
trained using the proposed strategy (VGG-NbB-M and MPIE-NbB-M) outperform the
corresponding models trained with the non-augmented datasets (VGGr-NbB-M and
MPIEr-NbB-M). The models trained using the raw images in VGG (VGGr-NbB-M)
outperform the corresponding model trained using the mixed dataset. All NbNets
trained with the proposed training strategy outperform the RBF regression based
method [97]. In the type-I attack, the VGG-NbA-P model achieved a TAR of 95.20%
(99.14%) at FAR=0.1% (FAR=1.0%). This implies that an attacker has approximately
95% (or 99% at FAR=1.0%) chance of accessing the system using a leaked template.
42
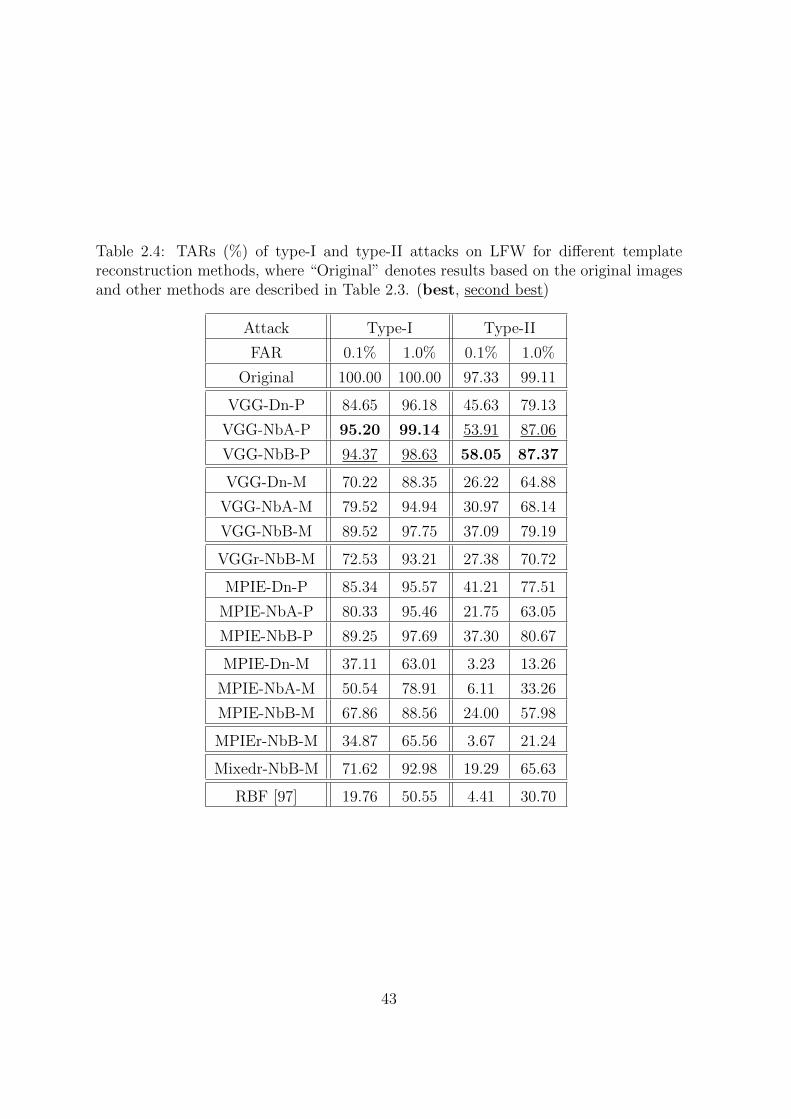
Table 2.4: TARs (%) of type-I and type-II attacks on LFW for different templatereconstruction methods, where “Original” denotes results based on the original imagesand other methods are described in Table 2.3. (best, second best)
Attack Type-I Type-II
FAR 0.1% 1.0% 0.1% 1.0%
Original 100.00 100.00 97.33 99.11
VGG-Dn-P 84.65 96.18 45.63 79.13
VGG-NbA-P 95.20 99.14 53.91 87.06
VGG-NbB-P 94.37 98.63 58.05 87.37
VGG-Dn-M 70.22 88.35 26.22 64.88
VGG-NbA-M 79.52 94.94 30.97 68.14
VGG-NbB-M 89.52 97.75 37.09 79.19
VGGr-NbB-M 72.53 93.21 27.38 70.72
MPIE-Dn-P 85.34 95.57 41.21 77.51
MPIE-NbA-P 80.33 95.46 21.75 63.05
MPIE-NbB-P 89.25 97.69 37.30 80.67
MPIE-Dn-M 37.11 63.01 3.23 13.26
MPIE-NbA-M 50.54 78.91 6.11 33.26
MPIE-NbB-M 67.86 88.56 24.00 57.98
MPIEr-NbB-M 34.87 65.56 3.67 21.24
Mixedr-NbB-M 71.62 92.98 19.29 65.63
RBF [97] 19.76 50.55 4.41 30.70
43
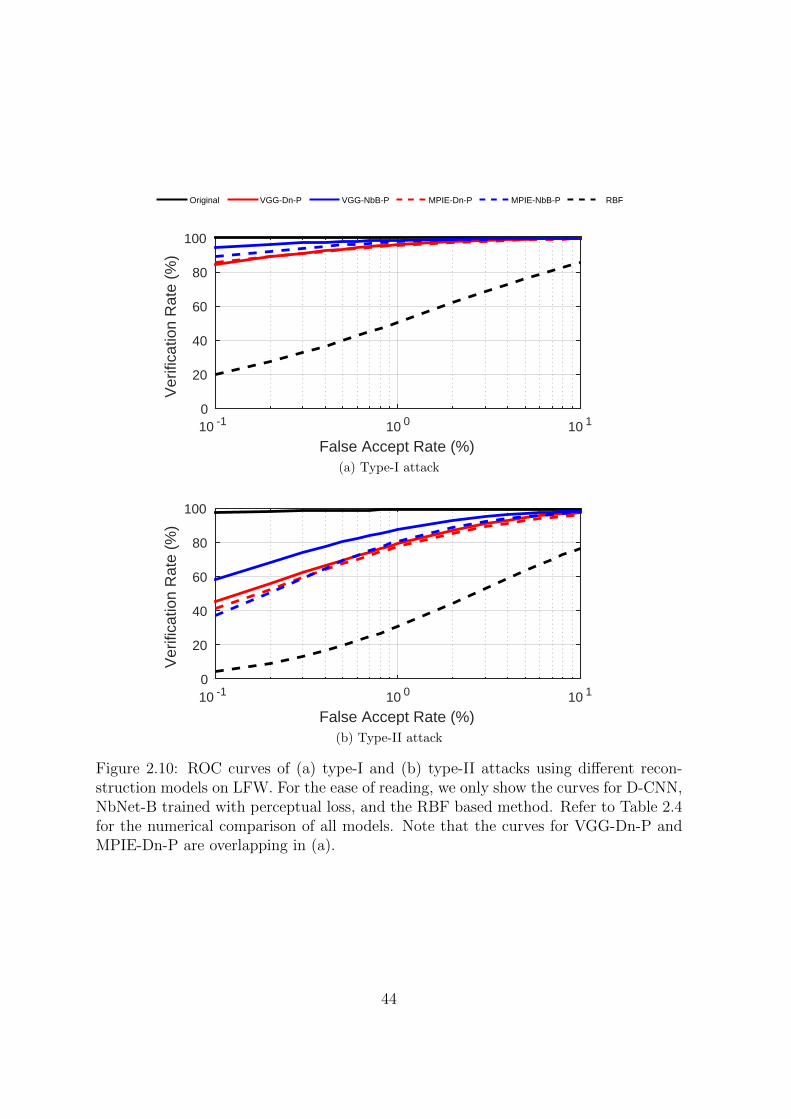
False Accept Rate (%)10 -2 10 -1 10 0
Ver
ifica
tion
Rat
e (%
)
0
20
40
60
80
100
Original VGG-Dn-P VGG-NbB-P MPIE-Dn-P MPIE-NbB-P RBF
False Accept Rate (%)10 -1 10 0 10 1
Ver
ifica
tion
Rat
e (%
)
0
20
40
60
80
100
(a) Type-I attack
False Accept Rate (%)10 -1 10 0 10 1
Ver
ifica
tion
Rat
e (%
)
0
20
40
60
80
100
(b) Type-II attack
Figure 2.10: ROC curves of (a) type-I and (b) type-II attacks using different recon-struction models on LFW. For the ease of reading, we only show the curves for D-CNN,NbNet-B trained with perceptual loss, and the RBF based method. Refer to Table 2.4for the numerical comparison of all models. Note that the curves for VGG-Dn-P andMPIE-Dn-P are overlapping in (a).
44
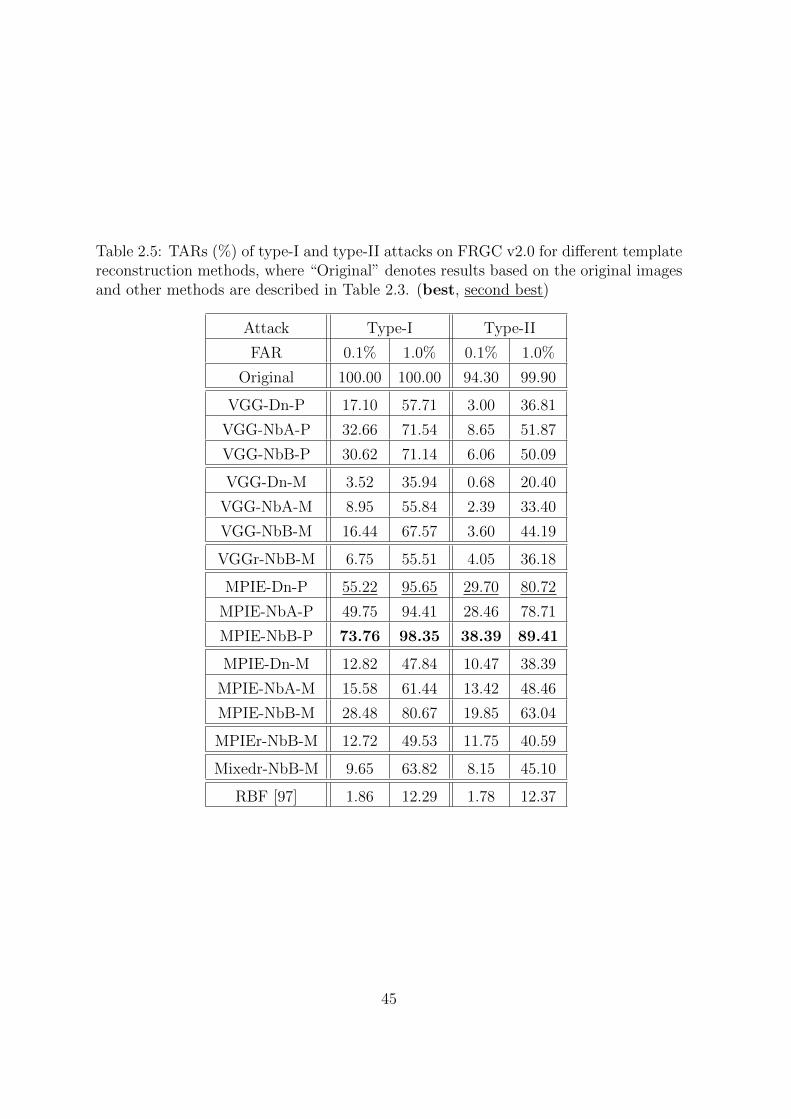
Table 2.5: TARs (%) of type-I and type-II attacks on FRGC v2.0 for different templatereconstruction methods, where “Original” denotes results based on the original imagesand other methods are described in Table 2.3. (best, second best)
Attack Type-I Type-II
FAR 0.1% 1.0% 0.1% 1.0%
Original 100.00 100.00 94.30 99.90
VGG-Dn-P 17.10 57.71 3.00 36.81
VGG-NbA-P 32.66 71.54 8.65 51.87
VGG-NbB-P 30.62 71.14 6.06 50.09
VGG-Dn-M 3.52 35.94 0.68 20.40
VGG-NbA-M 8.95 55.84 2.39 33.40
VGG-NbB-M 16.44 67.57 3.60 44.19
VGGr-NbB-M 6.75 55.51 4.05 36.18
MPIE-Dn-P 55.22 95.65 29.70 80.72
MPIE-NbA-P 49.75 94.41 28.46 78.71
MPIE-NbB-P 73.76 98.35 38.39 89.41
MPIE-Dn-M 12.82 47.84 10.47 38.39
MPIE-NbA-M 15.58 61.44 13.42 48.46
MPIE-NbB-M 28.48 80.67 19.85 63.04
MPIEr-NbB-M 12.72 49.53 11.75 40.59
Mixedr-NbB-M 9.65 63.82 8.15 45.10
RBF [97] 1.86 12.29 1.78 12.37
45
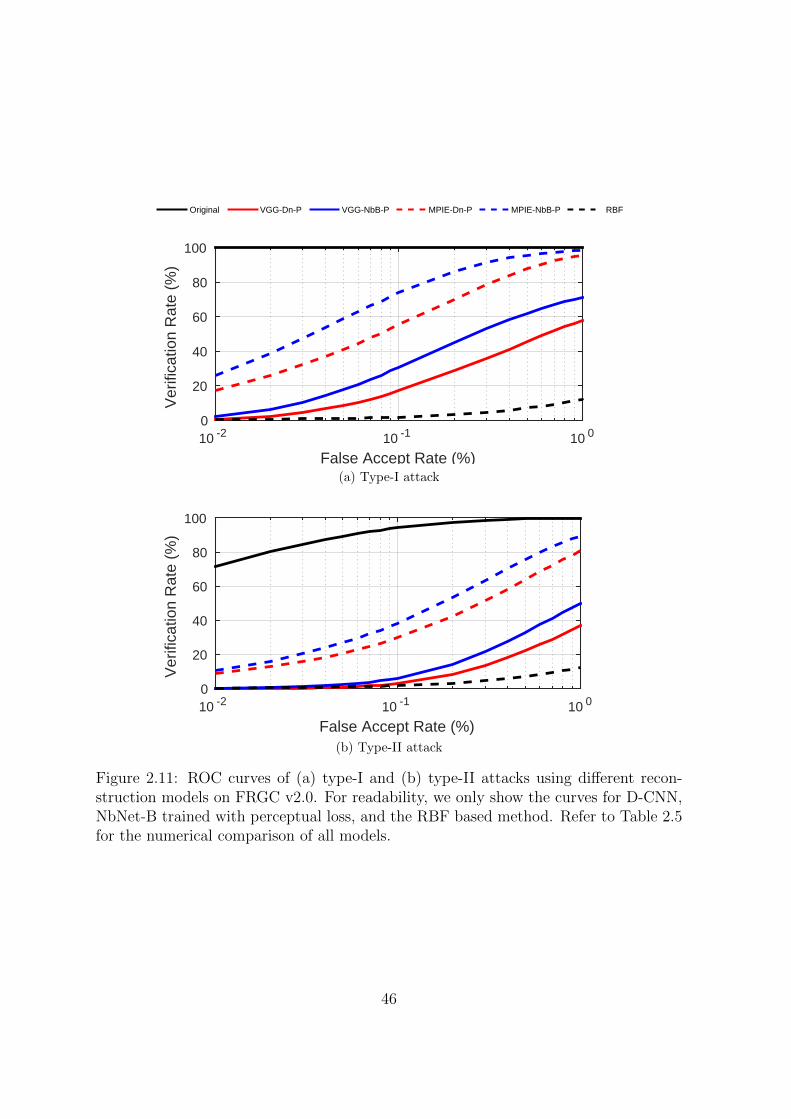
False Accept Rate (%)10 -2 10 -1 10 0
Ver
ifica
tion
Rat
e (%
)
0
20
40
60
80
100
Original VGG-Dn-P VGG-NbB-P MPIE-Dn-P MPIE-NbB-P RBF
False Accept Rate (%)10 -2 10 -1 10 0
Ver
ifica
tion
Rat
e (%
)
0
20
40
60
80
100
(a) Type-I attack
False Accept Rate (%)10 -2 10 -1 10 0
Ver
ifica
tion
Rat
e (%
)
0
20
40
60
80
100
(b) Type-II attack
Figure 2.11: ROC curves of (a) type-I and (b) type-II attacks using different recon-struction models on FRGC v2.0. For readability, we only show the curves for D-CNN,NbNet-B trained with perceptual loss, and the RBF based method. Refer to Table 2.5for the numerical comparison of all models.
46

2.4.2.2 Performance on FRGC v2.0
Each trial of the BLUFR protocol [82] for FRGC v2.0 [110] consisted of an average
of 76,368,176 impostor comparisons and an average of 12,384 and 307,360 genuine
comparisons for type-I and type-II attacks, respectively.
The ROC curves of type-I and type-II attacks on FRGC v2.0 are shown in Fig. 2.11.
The TAR values at FAR=0.1% and FAR=1.0% are shown in Table 2.5. The TAR values
(Tables 2.4 and 2.5) and ROC plots (Figs. 2.10 and 2.11) for LFW and FRGC v2.0
cannot be directly compared, as the thresholds for LFW and FRGC v2.0 differ (e.g.,
the thresholds at FAR=0.1% are 0.51 and 0.80 for LFW and FRGC v2.0, respectively).
The similarity threshold values were calculated based on the impostor distributions of
the LFW and FRGC v2.0 databases.
It was observed that the proposed NbNets generally outperform D-CNN. The only
exception is that the MPIE-NbA-P was not as good as MPIE-Dn-P. Significant im-
provements by using the augmented datasets (VGG-NbB-M and MPIE-NbB-M) were
observed, compared with VGGr-NbB-M and MPIEr-NbB-M, for both the type-I and
type-II attacks. All NbNets outperform the RBF regression based method [97]. In the
type-I attack, the best model, MPIE-NbB-P achieved a TAR of 73.76% (98.35%) at
FAR=0.1% (FAR=1.0%). This implies that an attacker has a 74% (98%) chance of
accessing the system at FAR=0.1% (1.0%) using a leaked template.
2.4.3 Identification with Reconstructed Images
We quantitatively evaluate the privacy issue of a leaked template extracted by
target face recognition system (FaceNet [121]) under type-I and type-II attacks. The
evaluation metric was the standard color FERET protocol [111]. The partition fa (994
images) was used as the gallery set. For the type-I attack, the images reconstructed
from the partition fa was used as the probe set. For the type-II attack, the probe sets
47
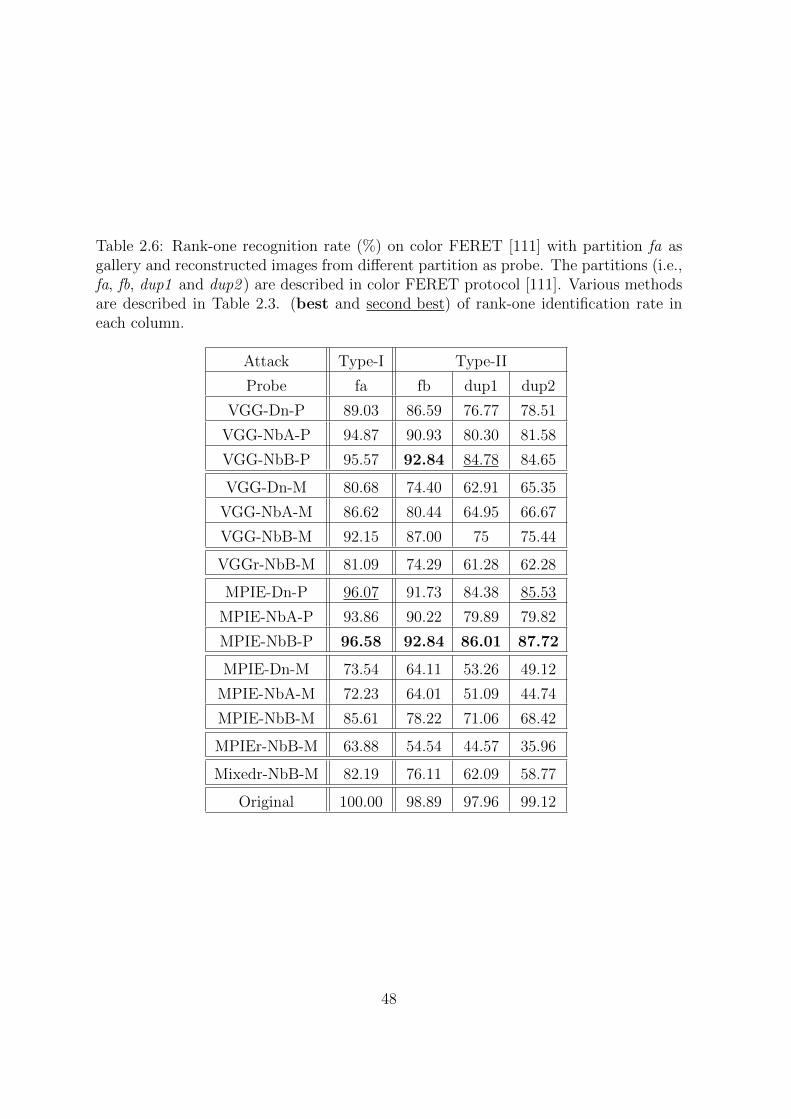
Table 2.6: Rank-one recognition rate (%) on color FERET [111] with partition fa asgallery and reconstructed images from different partition as probe. The partitions (i.e.,fa, fb, dup1 and dup2 ) are described in color FERET protocol [111]. Various methodsare described in Table 2.3. (best and second best) of rank-one identification rate ineach column.
Attack Type-I Type-II
Probe fa fb dup1 dup2
VGG-Dn-P 89.03 86.59 76.77 78.51
VGG-NbA-P 94.87 90.93 80.30 81.58
VGG-NbB-P 95.57 92.84 84.78 84.65
VGG-Dn-M 80.68 74.40 62.91 65.35
VGG-NbA-M 86.62 80.44 64.95 66.67
VGG-NbB-M 92.15 87.00 75 75.44
VGGr-NbB-M 81.09 74.29 61.28 62.28
MPIE-Dn-P 96.07 91.73 84.38 85.53
MPIE-NbA-P 93.86 90.22 79.89 79.82
MPIE-NbB-P 96.58 92.84 86.01 87.72
MPIE-Dn-M 73.54 64.11 53.26 49.12
MPIE-NbA-M 72.23 64.01 51.09 44.74
MPIE-NbB-M 85.61 78.22 71.06 68.42
MPIEr-NbB-M 63.88 54.54 44.57 35.96
Mixedr-NbB-M 82.19 76.11 62.09 58.77
Original 100.00 98.89 97.96 99.12
48

Table 2.7: Average reconstruction time (ms) for a single template. The total numberof network parameters are indicated in the last column.
CPU GPU #Params
D-CNN 84.1 0.268 4,432,304
NbNet-A 62.6 0.258 2,289,040
NbNet-B 137.1 0.477 3,411,472
(fb with 992 images, dup1 with 736 images, and dup2 with 228 images) specified in the
color FERET protocol were replaced by the corresponding reconstructed images.
The rank-one identification rate of both type-I and type-II attacks on color FERET
are shown in Table 2.6. The row values under ”Original” show the identification rate
based on the original images. It stays at 100% for the type-I attack because the
corresponding similarity score are obtained by comparing two identical images. It
was observed that the proposed NbNets outperform D-CNN with the exception that
the MPIE-Dn-P and MPIE-Dn-M slightly outperform MPIE-NbA-P and MPIE-NbA-
M, respectively. Besides, significant improvements introduced by the proposed training
strategy were observed, comparing models VGG-NbB-M and MPIE-NbB-M with the
corresponding models trained with raw images (VGGr-NbB-M and MPIEr-NbB-M),
respectively. It was observed that the best model, MPIE-NbB-P achieves 96.58% and
92.84% accuracy under type-I and type-II attacks (partition fb). This implies a severe
privacy issue; more than 90% of the subjects in the database can be identified with a
leaked template.
2.4.4 Computation Time
In the testing stage, with an NVIDIA TITAN X Pascal (GPU) and an Intel(R) i7-
6800K @ 3.40 GHz (CPU), the average time (in microseconds) to reconstruct a single
face template with D-CNN, NbNet-A, and NbNet-B is shown in Table 2.7.
49

2.5 Summary
This chapter investigated the security and privacy of deep face templates by study-
ing the reconstruction of face images via the inversion of their corresponding deep
templates. A NbNet was trained for reconstructing face images from their correspond-
ing deep templates and strategies for training generalizable and robust NbNets were
developed. Experimental results indicated that the proposed NbNet-based reconstruc-
tion method outperformed RBF-regression-based face template reconstruction in terms
of attack success rates. We demonstrate that in verification scenario, TAR of 95.20%
(58.05%) on LFW under type-I (type-II) attack at a FAR of 0.1% can be achieved with
our reconstruction model. Besides, 96.58% (92.84%) of the images reconstruction from
templates of partition fa (fb) can be identified from partition fa in color FERET [111].
This study revealed potential security and privacy issues resulting from template leak-
age in state-of-the-art face recognition systems, which are primarily based on deep
templates.
50

Chapter 3
Secure Deep Biometric Template
3.1 Introduction
The focus of this chapter is on protecting the deep biometric templates extracted
with deep convolutional neural networks (CNN). In the past decade, biometric systems
have been increasingly based on deep templates. Compared with shallow templates with
handcraft features (e.g., Eigenface [133], IrisCode [23]), deep templates have achieved
superior performance in various biometric modalities, such as the face [50, 76, 80], fin-
gerprint [14,15,131], and iris (periocular) [37,85,155,156]. However, to our knowledge,
in addition to [105], in which a mapping function for a preassigned hard code is learned
by each subject using the CNN, no biometric template protection schemes designed for
deep templates can be found in the literature.
In general, two approaches are used to generate secure deep biometric templates:
(a) [two-stage] extract templates using deep networks and then use template protec-
tion schemes (e.g., feature transformation [cancellable biometric] [18, 64, 79, 108,
115], biometric cryptosystems [28,68,69,101], and hybrid approaches [34,100]) to
51

generate secure templates using the extracted templates; and
(b) [end-to-end] generate secure templates directly with the deep network by embed-
ding randomness into deep networks.
Arguably, adoption of the two-stage method has two limitations. First, the two stages
(i.e., template extraction and template protection) can be attacked individually by the
adversary with knowledge of the template extractor and the corresponding template
protection method. Second, the template extractors used to extract deep biometric
templates are generally optimized to improve template discriminability, whereas the
security-related objective is often neglected and can only be improved at the stage
of template protection. This often causes a significant trade-off between matching
accuracy and template security because they cannot be simultaneously optimized.
To generate secure deep biometric templates, this chapter proposes, to our knowl-
edge, the first end-to-end1 approach. In a nutshell, this chapter achieves the following.
• We introduce a randomized CNN to generate secure deep biometric templates,
depending on both input images and user-specific keys. To our knowledge, this is
the first end-to-end method for the generation of secure deep biometric templates.
• We demonstrate secure system construction using the randomized CNN without
storing the user-specific keys. Instead, we store the secure sketches generated
from the user-specific keys and binary intermediate features of the randomized
CNN. The user-specific keys can be decoded from the secure sketch at the query
stage only if the query image is sufficiently similar to the enrollment image.
• We formulate an orthogonal triplet loss function to extract the binary intermedi-
ate features, which are used to generate the secure sketch. The formulated loss
function improves the successful decoding rate of the secure sketches for genuine
queries and strengthens the security of the secure sketches.
1‘End-to-end’ indicates that the model used in this chapter to extract secure templates can beoptimized in an end-to-end way.
52

• Evaluation and analysis based on two face benchmarking datasets (IJB-A [76] and
FRGC v2.0 [110]) demonstrate that the proposed method satisfies the criteria for
template protection schemes [61,102], that is, matching accuracy, non-invertibility
(security), unlinkability, and revocability.
3.2 Related Work
In this section, an overview of state-of-the-art biometric template protection schemes
is first given. We then present the fuzzy commitment scheme [69], a popularly used
biometric cryptosystem with greater detail. The construction of the proposed method
is motivated in part by the fuzzy commitment scheme.
3.2.1 Template Protection Schemes
Biometric template protection schemes that are designed for compact binary or
real-valued vectors can be categorized into feature transformation (cancellable bio-
metric) [18, 64, 79, 108, 115], biometric cryptosystems [28, 68, 69, 101], and hybrid ap-
proaches [34, 100]). In the feature transformation approach [18, 64, 79, 108, 115], tem-
plates are transformed via a one-way transformation function with a user-specific ran-
dom key. The security of the feature transformation approach is based on the non-
invertibility of the transformation. This approach provides cancellability, in which a
new transformation (based on a new key) can be used if any template is compromised.
A biometric cryptosystem [28, 68, 69, 101] stores a sketch that is generated from the
enrollment template, where an error correcting code (ECC) is used to handle the intra-
user variations. The security of a biometric cryptosystem is based on the randomness
of the templates and the ECC’s error correction capability. The advantage of biomet-
ric cryptosystems is that the strength of the security can be determined analytically
if the distribution of biometric templates is assumed to be known. However, the re-
53

quirement of binary input limits the feasibility of biometric cryptosystems. A hybrid
approach [34,100]) first applies feature transformation to create cancellable templates,
which are then binarized and secured by biometric cryptosystems. Therefore, hybrid
approaches combine the advantages of both feature transformation and biometric cryp-
tosystems to provide stronger security and template cancellability.
A severe trade-off exists between matching accuracy and template security because
of the two-stage process that uses template protection schemes after extraction of deep
templates. This trade-off exists because the deep networks for extraction of deep tem-
plates are generally optimized for improving template discriminability, whereas the
security-related objective is often neglected and can only be improved in the module
of template protection. In addition, the two-stage process is vulnerable because the
modules of template extraction and template protection can be attacked individually.
3.2.2 Fuzzy Commitment Scheme
Fuzzy commitment [69] is a biometric cryptosystem used to protect biometric tem-
plates represented in fixed-length binary vector form (e.g., IrisCode [23]). The basic
idea of the fuzzy commitment is to handle the intra-subject variations using error cor-
recting code (ECC) [119,136].
At the enrollment stage, given an enrollment binary template b of length n of a
subject, the fuzzy commitment first randomly assigns a key k to the subject. The hash
of the key Hash(k) and secure sketch SS are then computed and stored in the system,
where a popular hash function such as SHA-3 can be used, and the secure sketch is
given by
SS = c⊕ b (3.1)
where ⊕ denotes a modulo-2 addition and codeword c has length n and is obtained by
54

encoding the key k using an ECC encoder ENCecc(·):
c = ENCecc(k) (3.2)
In the query stage, given a query binary template b∗ and the corresponding stored
secure sketch SS, the fuzzy commitment first computes the key k∗ by
k∗ = DECecc(b∗ ⊕ SS) (3.3)
where DECecc(·) denotes the decoder of the ECC used in the system. The decision is
then ‘accept’ or ‘reject’ for the query template b∗ if the hash of the keys (Hash(k) and
Hash(k∗)) are matched or mismatched, respectively.
The query binary template is accepted by the system if and only if the intrasubject
variations εb = b ⊕ b∗ are less than the error tolerance of the chosen ECC. This is
because
b∗ ⊕ SS = c⊕ b⊕ b∗
= c⊕ (b⊕ b∗)
= c⊕ εb
(3.4)
According to the ECC, the c⊕ εb can be successfully decoded to c if εb is less than the
error tolerance of the chosen ECC.
Suppose that the stored information, the hash value of the key Hash(k), and the
secure sketch SS are leaked. There are two possible ways for adversaries to impersonate
the target subject and access the system. The first is to directly guess a query binary
template b∗. The second is to first guess a key k∗ that has the same hash form of
the key k and then derive the enrollment binary template b accordingly. Thus, the
security of the fuzzy commitment depends on the randomness of the binary biometric
template and the message length of the chosen ECC (i.e., the entropy of the key k).
55

However, the linear ECC that is popularly used in fuzzy commitment cannot guarantee
the non-linkability of the fuzzy commitment because a linear combination of codewords
of a linear ECC is also a codeword of the ECC. This results in a decodable codeword by
a suitable linear combination of two secure sketches derived from the same subject that
provides a method with which the linkability of two secure sketches can be analyzed.
3.3 Proposed Secure Template Generation
Fig. 3.1 shows an overview of a secure system constructed with the proposed ran-
domized CNN. In the training stage, the neural network is jointly optimized by the
triplet loss Lt and the orthogonal triplet loss Lot in an end-to-end manner. The pro-
cesses of enrollment and query at the testing stage are shown with blue and red lines,
respectively. This section first introduces the secure system we constructed. The ran-
domized CNN and the generation of secure sketches are then detailed. We end this
section by describing the loss functions used to train the neural network and the net-
work architecture we used.
3.3.1 Secure System Construction
Unless specified otherwise, the variables with a superscript ∗ denote data processed
at the query stage and correspond to the data processed at the enrollment stage (e.g.,
a query image x∗ and an enrollment image x.)
Enrollment: Given an enrollment image x and a user-specific key k ∈ {0, 1}m, our
system’s enrollment process E(·) generates and stores a randomized template yp and a
secure sketch SS,
yp, SS = E(x,k) (3.5)
where the secure sketch SS ∈ {0, 1}n, (n ≥ m). Note that the key k is not stored in the
56
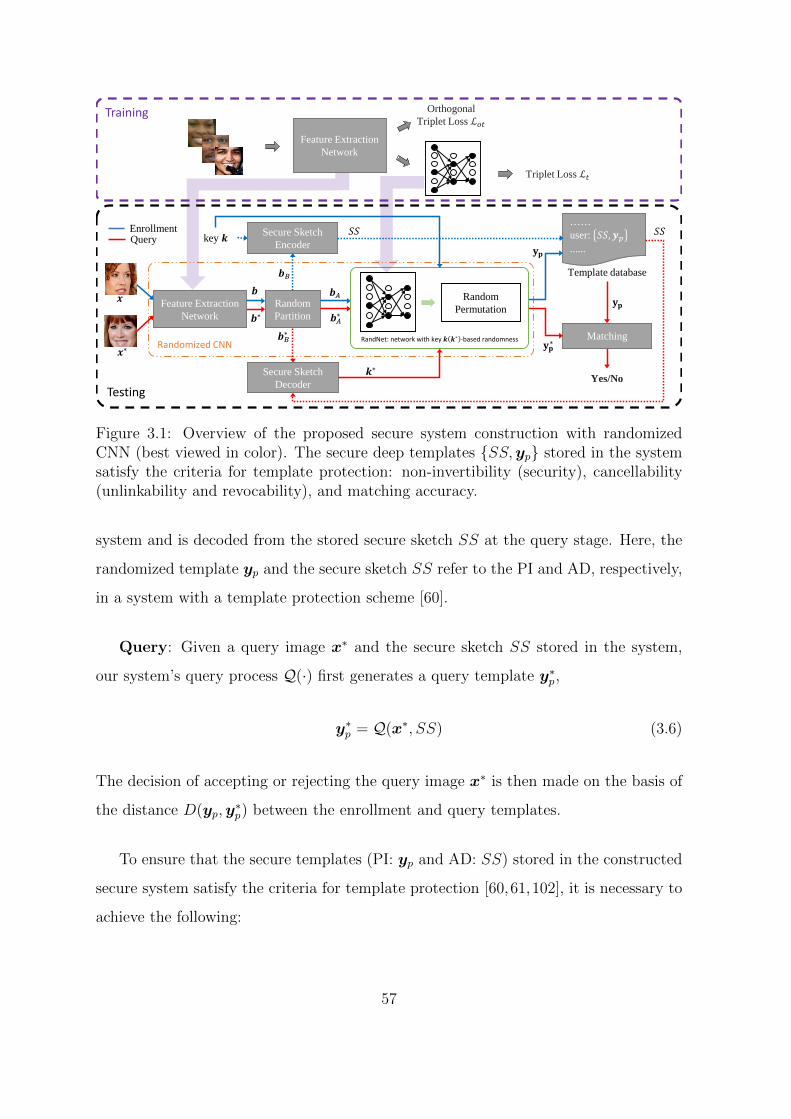
Randomized CNN
Training
Testing
……user: 𝑆𝑆𝑆𝑆,𝒚𝒚𝑝𝑝......
Template database
Matching
Yes/No
Feature Extraction Network
Random Partition
key 𝒌𝒌 Secure Sketch Encoder
𝑆𝑆𝑆𝑆
𝒃𝒃
𝒃𝒃𝐵𝐵𝒃𝒃𝐴𝐴𝒙𝒙
𝒙𝒙∗
𝒃𝒃∗ 𝒃𝒃𝐴𝐴∗
Secure Sketch Decoder
𝑆𝑆𝑆𝑆
𝒃𝒃𝐵𝐵∗
𝐲𝐲𝐩𝐩
𝐲𝐲𝐩𝐩∗
𝐲𝐲𝐩𝐩Random
Permutation
RandNet: network with key 𝒌𝒌 𝒌𝒌∗ -based randomness
𝒌𝒌∗
EnrollmentQuery
Orthogonal Triplet Loss ℒ𝑜𝑜𝑜𝑜
Triplet Loss ℒ𝑜𝑜
ttFeature Extraction
Network
Figure 3.1: Overview of the proposed secure system construction with randomizedCNN (best viewed in color). The secure deep templates {SS,yp} stored in the systemsatisfy the criteria for template protection: non-invertibility (security), cancellability(unlinkability and revocability), and matching accuracy.
system and is decoded from the stored secure sketch SS at the query stage. Here, the
randomized template yp and the secure sketch SS refer to the PI and AD, respectively,
in a system with a template protection scheme [60].
Query: Given a query image x∗ and the secure sketch SS stored in the system,
our system’s query process Q(·) first generates a query template y∗p,
y∗p = Q(x∗, SS) (3.6)
The decision of accepting or rejecting the query image x∗ is then made on the basis of
the distance D(yp,y∗p) between the enrollment and query templates.
To ensure that the secure templates (PI: yp and AD: SS) stored in the constructed
secure system satisfy the criteria for template protection [60,61,102], it is necessary to
achieve the following:
57

• Non-invertibility (security): It is not computationally feasible to reconstruct
(synthesize) the enrollment image x from the stored randomized template yp and
the secure sketch SS.
• Cancellability (revocability and unlinkability): A new pair of a randomized
template yp and a secure sketch SS can be generated for target subjects whose
template is compromised. There is no method to determine whether two random-
ized templates (e.g., y1p and y2
p) or two secure sketches (e.g., SS1 and SS2) are
derived from the same or different subjects, given the different subject-specific
keys.
• Matching accuracy: The distance D(yp,y∗p| genu) between the enrollment tem-
plate and the genuine query template should be minimized, whereas the distance
D(yp,y∗p| impos) between the enrollment template and the impostor query tem-
plate should be maximized.
3.3.2 Randomized CNN
The randomized CNN is obtained by embedding randomness into a CNN. The
randomized CNN generates a randomized template yp and an intermediate feature bB
using an input image x and a subject-specific key k, which indicates the randomness
embedded within the deep network. The randomized template yp is then used as the
PI in the system, and the intermediate feature bB will be used to construct the secure
sketch SS (AD in the system, see section 3.3.3). To satisfy the criteria for template
protection, we introduce the random activation and random permutation into the CNN
and produce the randomized template yp. With the discriminability preserved, the
randomized templates yp extracted from the same images x with different keys k differ
greatly and cannot be matched to each other. In addition, there is no way to invert
the randomized templates yp back into the input image x without the corresponding
keys k, which is assumed here to be secure and is discussed in sections 3.3.3.
58

The randomized CNN consists of three components: a feature extraction network
fext(·), a random partition frpt(·), and the RandNet frnd(·,k), which is a fully connected
neural network with key k-based randomness (Fig. 3.1). The feature extraction network
fext(·) is a convolutional network with at least one fully connected layer for extraction of
intermediate features. It can be constructed using the convolutional part of a popular
CNN such as VGGNet [123] or ResNet [51]. Let b denote the extracted intermediate
feature to be sent to the random partition, we have
b = fext(x) (3.7)
The random partition frpt(·) separates the intermediate feature b into two parts, bA
and bB,
bA, bB = frpt(b) (3.8)
where bA would be sent to the RandNet for extraction of the randomized template yp,
and bB is used to construct the secure sketch SS. To avoid the linkability between
the protected template yp and the secure sketch SS, the elements in bA and bB are
mutually exclusive. In addition, the random partition can be designed to be specific
to both the subject and the application to further enhance the security and privacy of
the resulting templates.
The RandNet uses an intermediate feature partition bA and a subject-specific key
k as input to produce the protected template,
yp = frnd(bA,k) (3.9)
The RandNet introduces the key k-based randomness and is the key component in
the randomized CNN. We have introduced two types of randomness in the RandNet:
random activation and random permutation. In the RandNet, we first create a different
subnetwork from a father network via random activation and deactivation of its neurons
according to the key k, where the template y with partial randomness is produced. The
59

(a) Standard Network (b) Sub-network 1 (c) Sub-network 2 (d) Sub-network 𝑁𝑁
Figure 3.2: Subnetworks produced by a standard network with random activation, inwhich the black and white circles denote ‘activated’ and ‘deactivated’ neurons, respec-tively. (a) Standard network with all neurons activated; (b), (c), and (d) are differentsubnetworks obtained by random deactivation of some neurons.
random permutation then randomly permutes the elements in the template y based on
the key k to yield the final randomized template yp. The use of the random activation
followed by the random permutation greatly reduces the linkability of the templates
of the same subject given different user-specific keys k. The random activation and
permutation provide the numerical and the positional differences, resp., to the resultant
templates extracted with different keys. Therefore, neither the numerical value nor the
position based linkability analysis method is feasible.
3.3.2.1 Random Activation
Given a neural network with all neurons activated, several different subnetworks can
be created by random deactivation of some neurons. An example is shown in Fig. 3.2,
in which the networks in Figs. 3.2(b), 3.2(c), and 3.2(d) are subnetworks created from
the father network in Fig. 3.2(a) by random deactivation of half of the neurons in each
layer. With random activation, an L-layer father neural network with hl(1 ≤ l ≤ L)
neurons at each layer will have NL subnetworks,
NL =L∏l=1
(hlbhldc
)(3.10)
where d denotes the fraction of the neurons at each layer to be deactivated, and b·c
denotes the floor function. Suppose that discriminative templates can be extracted
60

from each NL subnetwork and that the templates extracted from different subnetworks
with the same input differ from one another. We can randomly assign a subnetwork to
an enrollment subject, for which the assignment is indicated by the key k.
A straightforward method to extract discriminative templates from each NL sub-
network is to train these NL subnetworks with shared parameters. However, because
the number of NL could be very large (e.g.,(
256128
)2for a two-layer neural network with
256 neurons and fraction d = 0.5), it is impractical to sample every subnetwork for
training. Instead, we directly train the father network, in which each neuron drops
out (i.e., is deactivated) with a probability of d. Suppose that the minibatch gradient
descent-based algorithm is used to train the father network, we deactivate a different
set of neurons with each minibatch. With this strategy, we can train a subnetwork with
a minibatch of data and implicitly train the subnetworks with the shared parameters.
This technique is known as Dropout [54, 124] and is widely used to prevent overfitting
of the neural network training.
We note that the templates extracted from different subnetworks differ from each
other, even though these subnetworks are trained with the same objective of recognizing
subjects. This is introduced by the differences in (a) parameters and (b) training
samples. Given that the deactivation of different neurons is independent, for any two
subnetworks, on average, a fraction of d parameters (neurons) are different. At the
training stage, every minibatch of samples is associated with a set of neurons to be
deactivated. This indeed approximates the bagging algorithm [43] of ensemble learning
[49], in which each base classifier (subnetwork) is trained with a different set of samples.
It is generally believed that the base classifiers of a good ensemble are as accurate as
possible and as diverse as possible [158]. Due to the success of Dropout [43,54,124] in
deep networks, we believe that the subnetworks are sufficiently diverse.
61

3.3.2.2 Random Permutation
Given an enrollment template y = {y1, · · · , ya, · · · , yA} extracted from the deep
networks with random activation, we store its permutation yp in the system to further
enhance the enrollment template’s non-invertibility and cancellability. It is important
to note that information on the order of the elements ym in the enrollment template
y is necessary to invert the template [88, 97, 99], analyze the linkability, and perform
matching because each element of a template vector, in general, represents a different
semantic meaning (e.g., projection on the different basis for most component analysis
such as PCA [133] and ICA [149]).
The random permutation is a distance-preserving transformation given the same
key k. The output templates (i.e., y for enrollment and y∗ for query) are typically
compact real-valued or binary vectors, for which the corresponding distance metrics are
the (normalized) Minkowski distance Dmk or the hamming distance Dhd, respectively.
Mathematically,
Dmk(y,y∗) =
(A∑a=1
|ya − y∗a|t
) 1t
(3.11)
where n denotes the length of the output template, and t denotes the order of the metric.
If the output templates are binary vectors (i.e., ∀i ∈ {1 · · ·A}, ya, y∗a ∈ {0, 1}), the
Minkowski distance Dmk is numerically equivalent to the hamming distance Dhd. Let
pk = {pk1 , · · · , pka , · · · , pkA} denote a permutation vector that depends on k and satisfies
∀a′ ∈ {1 · · ·A},∃a′ = pka , we have yp = {ypka} and y∗p = {ypka}, where i ∈ {1 · · ·A}. For
the distance, it is easy to have
Dmk(yp,y∗p) =
(n∑i=1
∣∣∣ypka − y∗pka ∣∣∣t) 1
t
= Dmk(y,y∗) (3.12)
62

3.3.3 Secure Sketch Construction
The randomized template yp stored in the system at the enrollment stage depends
on both the enrollment image x and a user-specific key k. To extract a randomized
template y∗p that is similar to yp from a genuine query image x∗, the user-specific key
k is required at the query stage. One straightforward method for providing the key k
at the query stage is to store it in the system at the enrollment stage. However, for
smart adversaries, the availability of k would greatly reduce the difficulty of inverting
the enrollment template yp and linking the enrollment templates across systems. Note
that the study of template protection generally assumes that adversaries can gain access
to the templates stored in the system. To solve this problem, we propose to store a
secure sketch SS generated from the key k, instead of the key itself, in the system. The
stored secure sketch SS can be successfully decoded if the query image x∗ is sufficiently
similar to the corresponding enrollment image x.
We now present how the secure sketch SS is constructed from a key k and an
intermediate feature bB generated from the randomized CNN at the enrollment stage.
The key k∗ is then decoded from SS with the corresponding intermediate feature b∗B at
the query stage. Note that before further processing, the intermediate feature bB (or
b∗B at the query stage) is binarized by thresholding at zero. Specifically, each element
of bB (b∗B) is set to one if it is zero or greater; otherwise, it is set to zero.
Enrollment: Motivated by the fuzzy commitment [69], the secure sketch SS is
generated with the ECC
SS = c⊕ bB (3.13)
The codeword c has a length n (equal to the length of the bB) and is obtained by
encoding the key k using a ECC encoder ENCecc(·):
c = ENCecc(k) (3.14)
63

Query: At the query stage, the key k∗ can be decoded with
k∗ = DECecc(b∗B ⊕ SS) (3.15)
where DECecc(·) denotes the decoder of the ECC used in the system. The decoded key
k∗ is identical to k only if the distance εbB between features bB and b∗B is less than the
error tolerance τecc of the chosen ECC, according to the properties of ECC [119, 136].
This is because
b∗B ⊕ SS = c⊕ bB ⊕ b∗B
= c⊕ (bB ⊕ b∗B)
= c⊕ εbB
(3.16)
Requirements: The following requirements are related to the construction of the
secure sketch SS:
1. For genuine queries, the SS can be correctly decoded, that is, the decoded key
k∗ = k. According to Eqs(3.15) and (3.16), this requires that εbB for genuine
queries is less than the error tolerance τecc of the chosen ECC.
2. It is difficult to obtain (guess) the key k from the SS without genuine query images
x∗ (or the corresponding genuine features b∗B); This requires that the entropy of
key k and that of feature bB be high, because the adversary can obtain the key
k by either directly guessing or guessing the binary feature bB with Eq. (3.15).
3. The SS should not be correctly decoded by impostor queries to prevent false
acceptance attacks, and therefore the εbB for impostor queries is greater than the
error tolerance τecc of the chosen ECC.
64

3.3.4 Loss Function for Training
Two objects must be optimized in the training of the deep network: the randomized
template yp and the intermediate feature bB. In this study, the overall loss function
can be expressed as
Lall = Lt + Lot (3.17)
where Lt denotes the triplet loss [121] to optimize template yp, and Lot denotes the
proposed orthogonal triplet loss to optimize feature bB.
3.3.4.1 Triplet Loss for Optimizing Template yp (y)
The randomized template yp must be highly discriminative, and the intrasubject
and intersubject variations should be simultaneously minimized and maximized, re-
spectively. At the training stage, we optimize the template y generated by the feature
extraction network without random permutation because the random permutation is
distance-preserving with the same key k. Moreover, the random activation at the
training stage is achieved by using Dropout [49,124].
To optimize template y, we use the popularly used triplet loss [121,153,156]
Lt =1
Q
Q∑q=1
[‖yancq − yposq ‖2
2 − ‖yancq − ynegq ‖22 + αt
]+
(3.18)
where Q denotes the size of a minibatch, and α is a margin enforced between positive
and negative pairs. The operator [·]+ is equivalent to max(·, 0). The yancq , yposq , and
ynegq denote the templates for the anchor, positive, and negative samples in the q-th
triplet of a minibatch.
65

3.3.4.2 Orthogonal Triplet Loss for Optimizing Feature bB (b)
The intermediate features bB are binary vectors at the testing stage and should
help the resultant secure sketch SS satisfy requirements (1) to (3) in section 3.3.3.
To achieve this, one should understand that the entropy m of the message (key k in
our construction) can be encoded in an ECC codeword while c is decreasing and the
corresponding error tolerance τecc is increasing, according to the coding theory [119,
136]. In addition, given an ECC whose code length n (the size of codeword c in
Eq.(3.14)) is sufficiently large, an upper bound and a lower bound are set for the
code rate m/n with the average error tolerance τecc/n [119, 136] (Fig. 3.3). Therefore,
the intermediate feature bB should be optimized with (a) greater entropy so that it
is difficult to guess; and (b) minimum intrasubject variation and maximum subject
variation. The minimization of intrasubject variation should be weighted more to
allow a small error tolerance τecc and hence greater entropy of key k. Given that bB
consists of part of the elements of b, and assuming that the elements of b are mutually
independent, we optimize b at the training stage with the requirements for bB.
To optimize the intermediate feature b with the desired propertieshigh entropy,
minimum intrasubject variations, and maximum intersubject variationsa loss function
must be formulated. A state-of-the-art loss function for supervised learning in deep
networks can be roughly categorized into classification-based loss [26, 87, 130, 139] and
metric learning-based loss [121, 126]. The classification-based loss [26, 87, 130, 139] is
a sample-wise objective function that aims to improve the classification accuracy of
each training sample. The intermediate features learned with classification-based loss
can be used to separate genuine and impostor pairs. However, it is often infeasible to
assign more weight to minimizing the intrasubject variations in the learned interme-
diate features to allow an ECC with a smaller error tolerance. In general, the metric
learning-based loss is a pairwise (e.g., contrastive loss [126]) or multiwise (e.g., triplet
loss [121]) objective function that explicitly minimizes intrasubject variation and max-
imizes intersubject variation. In this work, we use the metric learning-based loss and
66
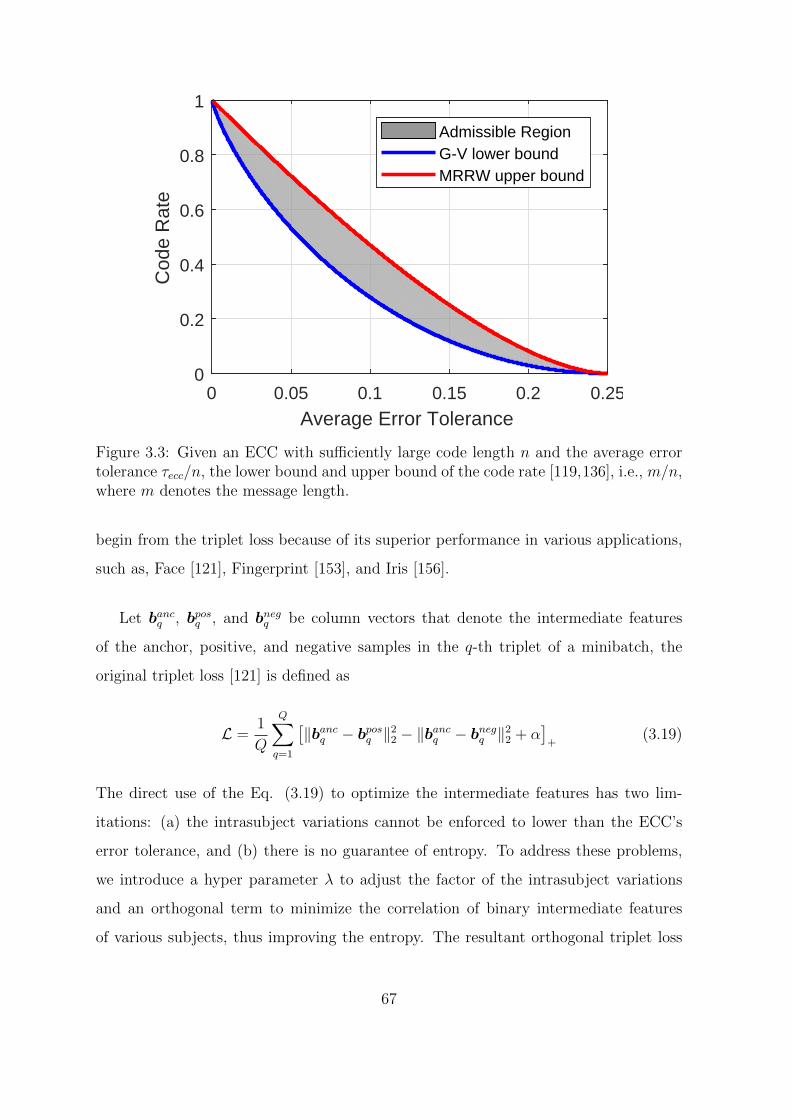
0 0.05 0.1 0.15 0.2 0.25
Average Error Tolerance
0
0.2
0.4
0.6
0.8
1
Cod
e R
ate
Admissible RegionG-V lower boundMRRW upper bound
Figure 3.3: Given an ECC with sufficiently large code length n and the average errortolerance τecc/n, the lower bound and upper bound of the code rate [119,136], i.e., m/n,where m denotes the message length.
begin from the triplet loss because of its superior performance in various applications,
such as, Face [121], Fingerprint [153], and Iris [156].
Let bancq , bposq , and bnegq be column vectors that denote the intermediate features
of the anchor, positive, and negative samples in the q-th triplet of a minibatch, the
original triplet loss [121] is defined as
L =1
Q
Q∑q=1
[‖bancq − bposq ‖2
2 − ‖bancq − bnegq ‖22 + α
]+
(3.19)
The direct use of the Eq. (3.19) to optimize the intermediate features has two lim-
itations: (a) the intrasubject variations cannot be enforced to lower than the ECC’s
error tolerance, and (b) there is no guarantee of entropy. To address these problems,
we introduce a hyper parameter λ to adjust the factor of the intrasubject variations
and an orthogonal term to minimize the correlation of binary intermediate features
of various subjects, thus improving the entropy. The resultant orthogonal triplet loss
67

function can be expressed as
Lot =1
Q
Q∑q=1
[λ‖bancq − bposq ‖2
2 − ‖bancq − bnegq ‖22 +αot]+
+µ1
Q
Q∑q=1
[(bancq )T · bnegq
]2 (3.20)
where the second part is the orthogonal term, and its factor is controlled by hyper
parameter µ, the operator · denotes the inner product of two vectors.
3.3.5 Network Architecture
Input: We use RGB images of size 112× 112× 3 as input.
Feature Extraction Network: We first use the VGG-11 [123] except for the fully
connected layers as our convolutional layers to extract 512 feature maps, whose size
are 3× 3. The 512 feature maps are then flattened and connected to a fully connected
layer of 4096 hidden units (a fully connected layer with tanh activation2).
RandNet The output of the feature extraction network is then connected to FC layers
(i.e., two fully connected layers of 512 hidden units), where the ReLU activation is ap-
plied on the first fully connected layer. Note that each of the feature maps is connected
with a Dropout layer (with a dropout probability of 0.5) before being connected to fully
connected layers.
Output: The loss layers for the intermediate features and output template are con-
nected on the output of the feature extraction network (Lot) and the FC layers (Lt),
respectively (Fig. 3.1).
2It is binarized by a threshold of zero to generate secure sketches at the testing stage.
68

3.4 Performance Evaluation and Analysis
3.4.1 Experimental Setting
3.4.1.1 Datasets
We use two large-scale face datasets (i.e., VGG-Face2 [16] and MS-Celeb-1M [48])
to train the proposed randomized CNN. Two benchmarking face datasets (i.e., IJB-
A [76], and FRGC v2.0 [110]) are used for testing. Example images of these datasets
are shown in Fig. 3.4. In the following, we briefly describe these datasets.
• VGG-Face2 [16] comprises 3.31 million images of 9,131 subjects downloaded
from Google Image Search. We use the training partition with 3.15 million images
of 8,631 subjects in our experiment3.
• MS-Celeb-1M [48] originally contained 10 million images of 100,000 subjects.
We used the refined MS-Celeb-1M [26] from which the images that far from the
subject center had been removed. The refined MS-Celeb-1M consists of 3.8 million
images of 85,000 subjects.
• IJB-A (IARPA Janus Benchmark A) [76] is an unconstrained benchmarking
dataset. IJB-A comprises of 5,712 images and 2,085 videos from 500 subjects.
• FRGC v2.0 [110] is a constrained dataset that contains frontal face images taken
with various levels of illumination. There are 50,000 images of 4,003 subjects in
FRGC v2.0, and 16,028 images of 466 subjects are used in this study (as specified
in the target set of Experiment 1 of FRGC v2.0 [110]).
Note that each image is aligned with landmarks detected by MTCNN [154] and cropped
3Images from both VGG-Face2 and MS-Celeb-1M are preprocessed by [26] and provided withhttps://github.com/deepinsight/insightface
69

(a) VGG-Face2 [16] (b) MS-Celeb-1M [48]
(c) IJB-A [76] (d) FRGC v2.0 [110]
Figure 3.4: Example face images from the training and testing datasets.
to 112× 112 before being used. In addition, each pixel (in [0,255]) in the RGB images
is normalized to [-1,1] by first subtracting 127.5 and then dividing by 128.
3.4.1.2 Verification Protocols
The evaluation in this chapter is based on the verification task of IJB-A [76] and
FRGC v2.0 [110]. For IJB-A [76], we report the results based on its 1:1 verification
protocol. Unlike typical verification tasks in which the matching is image-to-image, the
matching in IJB-A is template-to-template. A template in IJB-A is either a still image
or a sequence of video frames. For the template of video frames, we fuse the frames
because they can be processed as a single image by averaging the corresponding output
of the feature extraction network (b). For FRGC v2.0 [110], we report the results based
on our constructed FVC2004 [94]-like protocol with 10-fold validation. Specifically,
in each validation, we enroll 10% subjects with one image in the system. Genuine
comparisons are constructed by matching all images (excluding the enrollment image)
of the enrolled subjects against the corresponding enrollment image. The impostor
comparison is constructed by matching each enrollment subject against one image of all
non-enrolled subjects. We have an average of 1,556 and 19,544 genuine and impostor
70

comparisons in each fold. Each protocol used in our evaluation is based on 10-fold
validation. We report the results using the ’average ± standard deviation’ over the 10
folds.
3.4.1.3 Implementation Details
We implement the proposed randomized CNN with the deep learning framework
MXNet4 [20]. The parameters of the neural network are initialized using ‘Xavier’ with
Gaussian random variables in the range of [−2, 2] normalized by the number of input
neurons. The stochastic gradient descent with a momentum of 0.9 and weight decay
of 5 × 10−4 is used for optimization. We train the randomized CNN with two stages:
pretraining on VGG-Face2 [16] with Softmax loss and fine-tuning on MS-Celeb-1M [48]
with (orthogonal) triplet loss. The pretraining is trained with 30,000 batches, and the
batch size is set to 1,024, where the momentum is set to 0 and the learning rate is 0.1.
The fine-tuning is trained with 50,000 batches and each batch has 200 triplets, where
the learning rate is initialized with 0.005 and is divided by 10 at the 40,000th iteration.
The parameters αot and αt in Eqs(3.19) and (3.20) are set to 0.35. In Eq.(3.20), we set
the λ = 2 to focus more on minimizing intrasubject variations and evaluating different
settings of the orthogonal factor µ (i.e., 0.01 and 0.02). The training is done on two
sets of Nvidia Tesla K80 Dual GPU with Xeon E5-2630v4.
3.4.1.4 Parameter Setting
We evaluate the proposed randomized CNN using two different settings, according
to the random partition of the output b of the feature extraction network. Note that
the size of b is 4096, and that bB is binarized by a threshold of zeros before being used
to generate the secure sketch SS. In the first setting, denoted as ‘1023-bit ’, we use
(4096-1023) and 1023 elements from b for the features bA and bB, respectively. In the
4Version 0.10.0 from https://github.com/dmlc/mxnet/
71
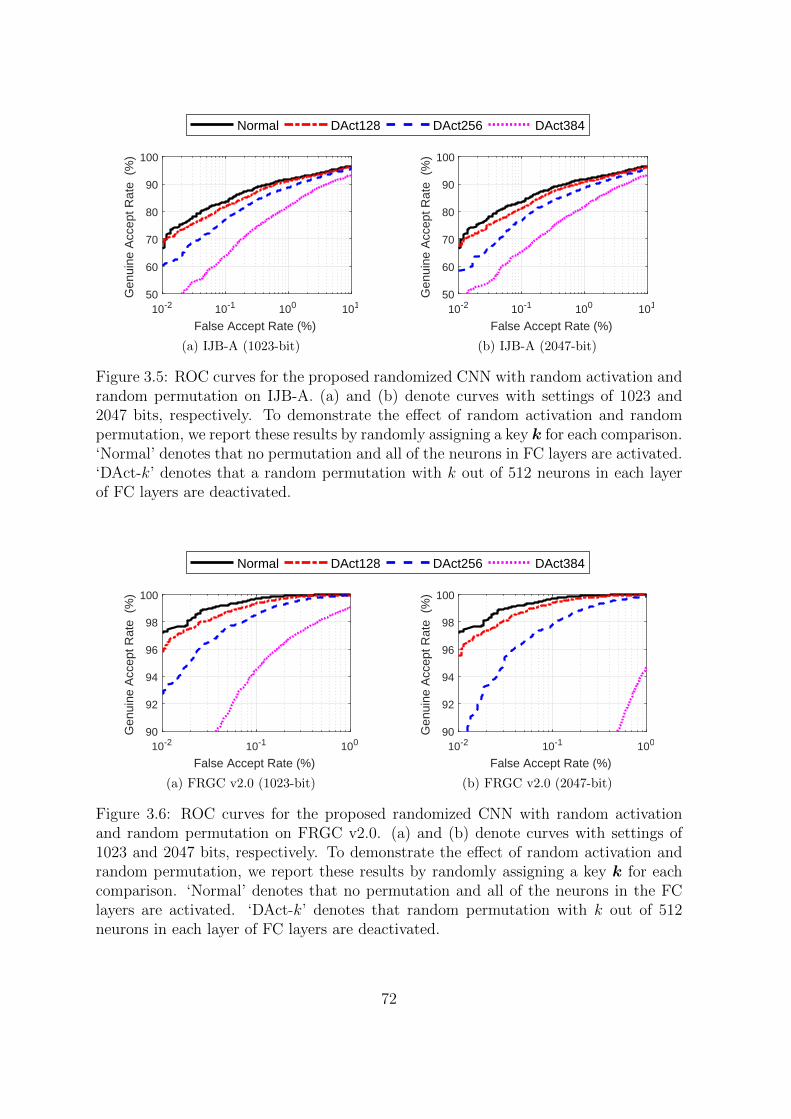
10-2 10-1 100 101
False Accept Rate (%)
50
55
60
65
70
75
80
85
90
95
100
Gen
uine
Acc
ept R
ate
(%
)
Normal DAct128 DAct256 DAct384
10-2 10-1 100 101
False Accept Rate (%)
50
60
70
80
90
100
Gen
uine
Acc
ept R
ate
(%
)
(a) IJB-A (1023-bit)
10-2 10-1 100 101
False Accept Rate (%)
50
60
70
80
90
100
Gen
uine
Acc
ept R
ate
(%
)
(b) IJB-A (2047-bit)
Figure 3.5: ROC curves for the proposed randomized CNN with random activation andrandom permutation on IJB-A. (a) and (b) denote curves with settings of 1023 and2047 bits, respectively. To demonstrate the effect of random activation and randompermutation, we report these results by randomly assigning a key k for each comparison.‘Normal’ denotes that no permutation and all of the neurons in FC layers are activated.‘DAct-k’ denotes that a random permutation with k out of 512 neurons in each layerof FC layers are deactivated.
10-2 10-1 100 101
False Accept Rate (%)
50
55
60
65
70
75
80
85
90
95
100
Gen
uine
Acc
ept R
ate
(%
)
Normal DAct128 DAct256 DAct384
10-2 10-1 100
False Accept Rate (%)
90
92
94
96
98
100
Gen
uine
Acc
ept R
ate
(%
)
(a) FRGC v2.0 (1023-bit)
10-2 10-1 100
False Accept Rate (%)
90
92
94
96
98
100
Gen
uine
Acc
ept R
ate
(%
)
(b) FRGC v2.0 (2047-bit)
Figure 3.6: ROC curves for the proposed randomized CNN with random activationand random permutation on FRGC v2.0. (a) and (b) denote curves with settings of1023 and 2047 bits, respectively. To demonstrate the effect of random activation andrandom permutation, we report these results by randomly assigning a key k for eachcomparison. ‘Normal’ denotes that no permutation and all of the neurons in the FClayers are activated. ‘DAct-k’ denotes that random permutation with k out of 512neurons in each layer of FC layers are deactivated.
72

second setting, denoted as ‘2047-bit ’, we use (4096-2047) and 2047 elements from b for
the features bA and bB, respectively, because the length of the codewords in a popular
ECC, BCH [119] is 2z − 1(z ≥ 3).
3.4.2 Matching Accuracy of the Randomized CNN
This section evaluates the discriminability of the templates generated by the pro-
posed randomized CNN. To demonstrate to which level the discriminability can be
preserved by random activation and random permutation, this section assumes that
the key k for controlling randomness is known by every query attempt (comparison).
To reflect the practical performance, we randomly assign different keys k for different
comparisons. The matching score for each comparison is the cosine similarity between
templates (yp and y∗p).
The receiver operator characteristic (ROC) curves for the templates extracted with
random activation and random permutation are shown in Figs. 3.5 and 3.6 for IJB-A
and FRGC v2.0, respectively. The “Normal” denotes that no random activation and
permutation is applied. The “DAct-K” denotes that k of 512 neurons in each fully
connected layer are randomly chosen for deactivation, where the random permutation
is also applied. It is observed that the larger the k, the more severe degradation of
matching accuracy. Specifically, to some level, the recognition performance is well
preserved when 128 and 256 neurons in each fully connected layer are deactivated.
However, deactivation of 384 of the 512 neurons does obvious harm to the recognition
performance.
3.4.3 Unlinkability Analysis
This section evaluates the unlinkability (cancellability) of the templates generated
by the proposed randomized CNN with different keys k. The constructed secure system
73
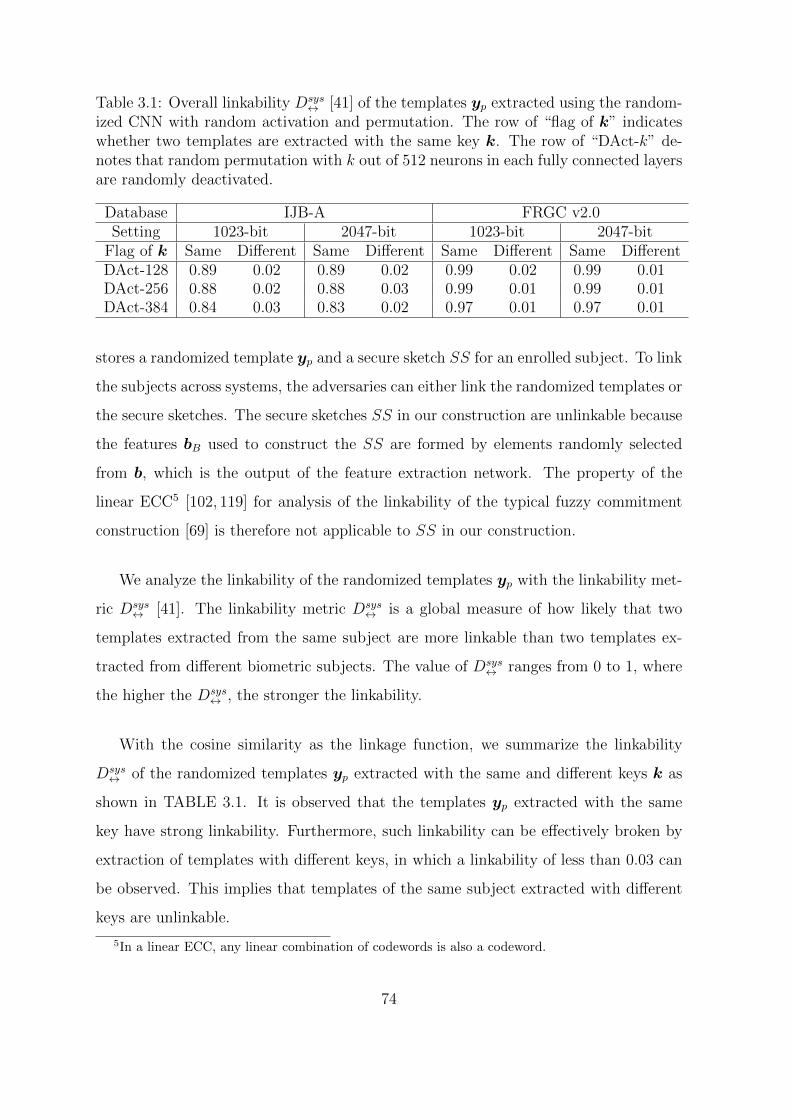
Table 3.1: Overall linkability Dsys↔ [41] of the templates yp extracted using the random-
ized CNN with random activation and permutation. The row of “flag of k” indicateswhether two templates are extracted with the same key k. The row of “DAct-k” de-notes that random permutation with k out of 512 neurons in each fully connected layersare randomly deactivated.
Database IJB-A FRGC v2.0Setting 1023-bit 2047-bit 1023-bit 2047-bit
Flag of k Same Different Same Different Same Different Same DifferentDAct-128 0.89 0.02 0.89 0.02 0.99 0.02 0.99 0.01DAct-256 0.88 0.02 0.88 0.03 0.99 0.01 0.99 0.01DAct-384 0.84 0.03 0.83 0.02 0.97 0.01 0.97 0.01
stores a randomized template yp and a secure sketch SS for an enrolled subject. To link
the subjects across systems, the adversaries can either link the randomized templates or
the secure sketches. The secure sketches SS in our construction are unlinkable because
the features bB used to construct the SS are formed by elements randomly selected
from b, which is the output of the feature extraction network. The property of the
linear ECC5 [102, 119] for analysis of the linkability of the typical fuzzy commitment
construction [69] is therefore not applicable to SS in our construction.
We analyze the linkability of the randomized templates yp with the linkability met-
ric Dsys↔ [41]. The linkability metric Dsys
↔ is a global measure of how likely that two
templates extracted from the same subject are more linkable than two templates ex-
tracted from different biometric subjects. The value of Dsys↔ ranges from 0 to 1, where
the higher the Dsys↔ , the stronger the linkability.
With the cosine similarity as the linkage function, we summarize the linkability
Dsys↔ of the randomized templates yp extracted with the same and different keys k as
shown in TABLE 3.1. It is observed that the templates yp extracted with the same
key have strong linkability. Furthermore, such linkability can be effectively broken by
extraction of templates with different keys, in which a linkability of less than 0.03 can
be observed. This implies that templates of the same subject extracted with different
keys are unlinkable.
5In a linear ECC, any linear combination of codewords is also a codeword.
74

3.4.4 Trade-off between Matching Accuracy and Security
The matching accuracy and non-invertibility (security) of the constructed system
depend on the error tolerance τecc of the chosen ECC for construction of the secure
sketches SS. In general, a trade-off exists between the matching accuracy and the
non-invertibility. We analyze this trade-off using the curve of GAR @ (FAR=0.1%)
versus entropy in this subsection, in which GAR and FAR are abbreviations for genuine
acceptance rate and false acceptance rate, respectively.
3.4.4.1 Matching Accuracy and Error Tolerance τecc
For the GAR, a genuine query image x∗ that can be accepted by the system requires
that (a) the randomized templates for enrollment yp and query y∗p are sufficiently
similar; and (b) the distance εbB between the intermediate features for enrollment bB
and query b∗B is less than the error tolerance τecc (Eq. (3.16)). This implies that the
GAR given by the intermediate feature bB dominates the GAR of the overall system,
where the threshold is given by the error tolerance τecc. For the FAR, an impostor
query image can be rejected based on the intermediate feature bB with the matching
threshold τecc. If the rejection is not successful, the impostor query image can be further
rejected based on the randomized template yp.
3.4.4.2 Security and Error Tolerance τecc
The security level indicates the difficulties of inverting the enrollment template
(both the randomized template yp and the secure sketch SS) back to the input image
x′, which can be accepted as the corresponding enrolled subject in the system. The
most straightforward way to synthesize the image x′ is a brute-force attack that directly
guesses the pixel values of the image x′; however, this is not feasible because the possible
combinations of the pixel values are huge, (112 × 112 × 3)256 for an RGB image with
75

size 112× 112 as used in this work.
To our knowledge, perhaps the most effective inverting strategy is to synthesize
image x′ by learning a reconstruction model [13,36,89] that uses randomized templates
yp and secure sketches SS as inputs. However, such reconstruction models cannot be
learned directly because the randomized templates yp depend not only on the input
images x but also on the subject-specific keys k. To learn the reconstruction model,
adversaries must first obtain the key k. As mentioned in the second requirement in
section 3.3.3, one could guess the key k by directly guessing k or alternatively guessing
the intermediate feature bB. Therefore, the difficulties in obtaining key k depend on
the easier method and can be expressed as
Hsys = min{m,H} (3.21)
where m denotes the message length of the chosen ECC with a given error tolerance
τecc, and H denotes the entropy of intermediate feature bB. Assuming that the average
impostor Hamming distance (aIHD) generates from the intermediate feature bB obeys
a binomial distribution with expectation EHD and standard variation VHD, the entropy
H can be measured using degree of freedoms (DOF) [23]
H =EHD(1− EHD)
V 2HD
(3.22)
3.4.4.3 Comparison of Loss Function for Optimization of bB (b)
In this comparative study, we compare the proposed orthogonal triplet loss function
Lot to optimize the intermediate feature bB (b) with different loss functions:
• Softmax: the most popular classification-based loss for training deep networks;
• Triplet [121]: a popularly used state-of-the-art loss for deep metric learning;
76

• Triplet2: a straightforward modification of the triplet loss [121] to assign greater
weight to the minimization of intrasubject variations. It can be mathematically
defined using Eq.(3.20) with λ = 2 and µ = 0.
• ProposeA, ProposeB: the proposed orthogonal losses as defined in Eq.(3.20)
are µ = 0.01 and µ = 0.02, respectively, where λ is set to 2.
Table 3.2: GAR (%) @ (FAR=0.1%) on IJB-A with state-of-the-artmethodsa
Method GAR@(FAR=0.1%) Year RemarksOpenBRb [76] 10.4 ± 1.4 2015 Non-CNN
Sparse ConvNetc [127] 46 2016 10Couv+1FCd
Deep Feature [138] 51.0 ± 6.1 2017 8Conv+3FCMTCNN [148] 53.9 ±0.9 2017 10Conv+1FC
Light CNN-9 [142] 83.4±1.7 2018 9Conv+1FCProposedA (a) e 60.0 ± 1.8
Thisthesis
9Conv+3FCProposedA (b) 60.1 ± 1.9ProposedA (c) 73.8 ± 1.8ProposedA (b) 73.8 ± 1.8
a We have not reimplemented these methods, and the values here areobtained from the original papers.
b http://openbiometrics.org/.c Only the average GAR was reported in Sparse ConvNet [127].d The network architecture consists mainly of 10 convolutional layers
and one fully connected layer.e The GAR@(FAR=0.1%) for protected templates with a secu-
rity level of 56 bits, where (a)-(d) corresponds to the values inFigs. 3.7(a)-(d), respectively.
3.4.4.4 Matching Accuracy versus Security
In our implementation, we use BCH [119, 136] with a length of 1023 (2047) as
the ECC code to generate secure sketches SS for the setting of 1023-bit (2047-bit).
By changing the error tolerance τecc, we obtain a pair of a security index (Hsys given
by Eq. (3.21)) and an accuracy index (GAR @ (FAR=0.1%) given by the resultant
randomized template yp). The trade-off curves for different settings on IJB-A and
77
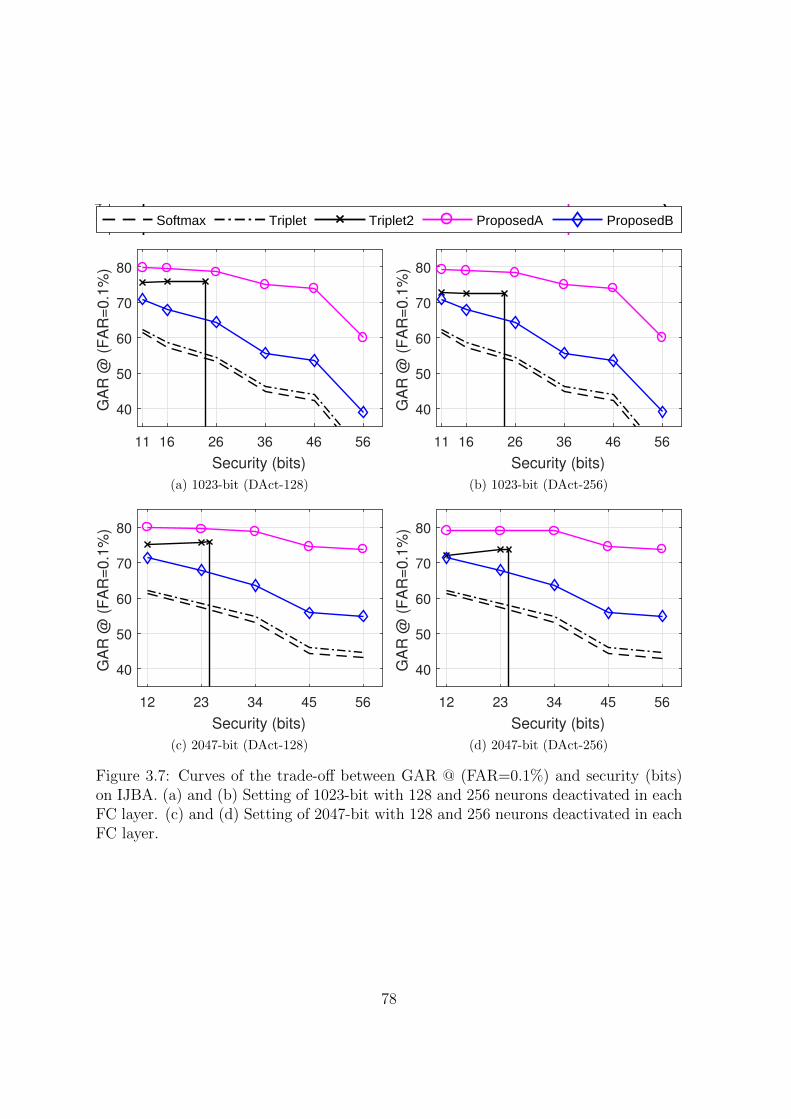
12 23 34 45 56
Maximum Entropy (bits)
90
91
92
93
94
95
96
97
98
99
100
GA
R @
(F
AR
=0.
1%)
Softmax Triplet Triplet2 ProposedA ProposedB
11 16 26 36 46 56
Security (bits)
40
50
60
70
80
GA
R @
(F
AR
=0
.1%
)
(a) 1023-bit (DAct-128)
11 16 26 36 46 56
Security (bits)
40
50
60
70
80
GA
R @
(F
AR
=0
.1%
)
(b) 1023-bit (DAct-256)
12 23 34 45 56
Security (bits)
40
50
60
70
80
GA
R @
(F
AR
=0
.1%
)
(c) 2047-bit (DAct-128)
12 23 34 45 56
Security (bits)
40
50
60
70
80
GA
R @
(F
AR
=0
.1%
)
(d) 2047-bit (DAct-256)
Figure 3.7: Curves of the trade-off between GAR @ (FAR=0.1%) and security (bits)on IJBA. (a) and (b) Setting of 1023-bit with 128 and 256 neurons deactivated in eachFC layer. (c) and (d) Setting of 2047-bit with 128 and 256 neurons deactivated in eachFC layer.
78
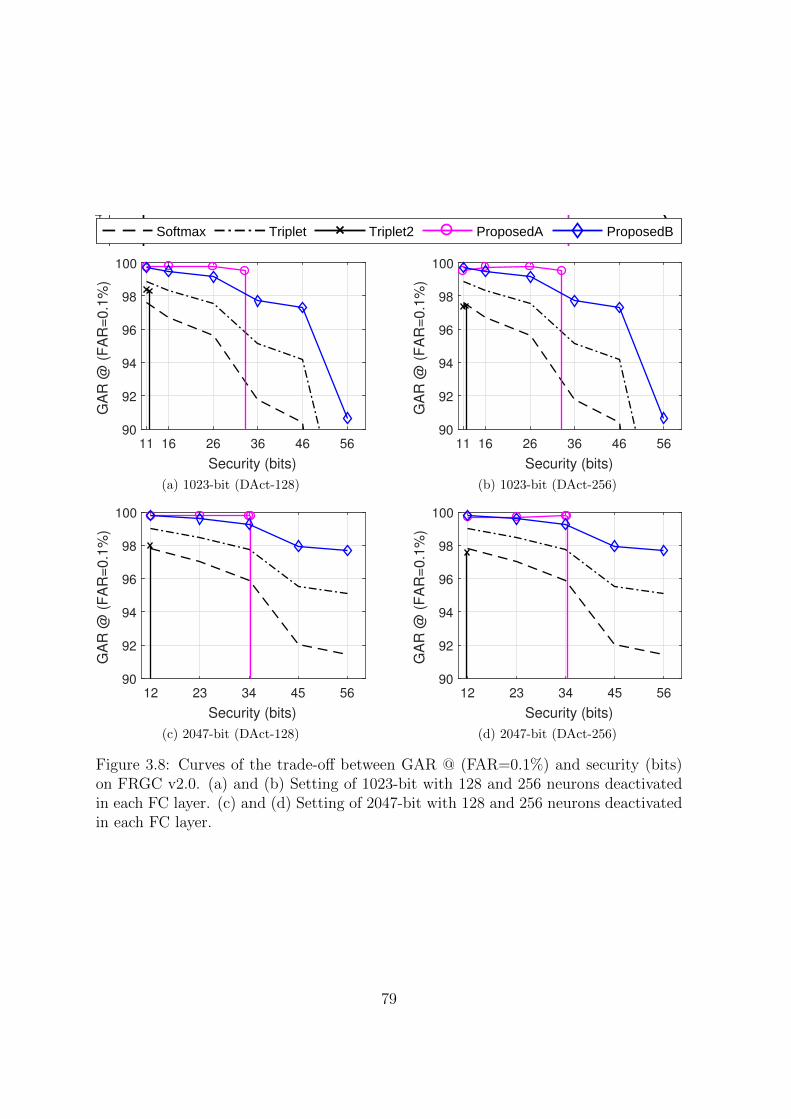
12 23 34 45 56
Maximum Entropy (bits)
90
91
92
93
94
95
96
97
98
99
100
GA
R @
(F
AR
=0.
1%)
Softmax Triplet Triplet2 ProposedA ProposedB
11 16 26 36 46 56
Security (bits)
90
92
94
96
98
100
GA
R @
(F
AR
=0.1
%)
(a) 1023-bit (DAct-128)
11 16 26 36 46 56
Security (bits)
90
92
94
96
98
100
GA
R @
(F
AR
=0.1
%)
(b) 1023-bit (DAct-256)
12 23 34 45 56
Security (bits)
90
92
94
96
98
100
GA
R @
(F
AR
=0.1
%)
(c) 2047-bit (DAct-128)
12 23 34 45 56
Security (bits)
90
92
94
96
98
100
GA
R @
(F
AR
=0.1
%)
(d) 2047-bit (DAct-256)
Figure 3.8: Curves of the trade-off between GAR @ (FAR=0.1%) and security (bits)on FRGC v2.0. (a) and (b) Setting of 1023-bit with 128 and 256 neurons deactivatedin each FC layer. (c) and (d) Setting of 2047-bit with 128 and 256 neurons deactivatedin each FC layer.
79

FRGC v2.0 are shown in Figs. 3.7 and 3.8, respectively. The vertical line of the Triplet2
in both figures and ProposeA in Fig. 3.8 is a result of their DOF [23] H less than
the message length m, where the corresponding values on the x-axis indicates their
DOF. It is observed that with entropy greater than 25 bits, ProposeA and ProposeB
achieve the best and second-best matching accuracy on IJB-A (Fig. 3.7). For FRGC
v2.0 (Fig. 3.8), ProposeA and ProposeB achieve the best and second-best matching
accuracy with entropy less than 35 bits, whereas ProposeB achieves the best matching
accuracy with entropy greater than 35 bits.
To demonstrate to which level the accuracy can be preserved by the proposed secure
templates, we use state-of-the-art methods to summarize the accuracy, GAR (%) @
(FAR=0.1%) on IJB-A [76, 127, 138, 142, 148] in TABLE 3.2. Note that to make a
fair comparison, the methods based on a neural network with more than 20 layers
(i.e., only convolutional and fully connected layers are counted) are not included here.
For the proposed method, the accuracy at a security level of 56 bits is included in
TABLE 3.2. Note that a security level of 53 bits is equivalent to the guessing entropy
of an 8-character password randomly chosen from a 94-character alphabet [12, 101].
It is observed that the accuracy of the proposed secure template outperforms most
state-of-the-art methods [76, 127, 138, 148] and is well preserved compared with the
light CNN [142]. Note that the accuracy of the proposed method without protection
is comparable with the light CNN [142], as shown in Fig. 3.5, in which the GAR @
(FAR=0.1%) is 83.4 ± 2 %.
3.5 Summary
In this chapter, we have described the construction of a secure biometric system
whose stored deep templates are non-invertible, cancellable, and discriminative. We
have proposed a randomized CNN to generate secure deep biometric templates based
on both the input biometric data (e.g., image) and user-specific keys. In our construc-
80

tion, no user-specific key is stored in the system, whereas a secure sketch generated
from both a user-specific key and an intermediate feature is stored at the enrollment
stage. At the query stage, the user-specific key can be decoded from a stored secure
sketch if the query image is sufficiently close to the corresponding enrollment image.
To improve the successful decoding rate of the secure sketches for genuine queries, we
formulate an orthogonal triplet loss function for optimization. The experimental results
and analysis of two face benchmarking datasets (IJB-A and FRGC v2.0) show that the
secure templates in the proposed construction are non-invertible and unlinkable. Fur-
thermore, the matching accuracy of our secure templates is well preserved. Specifically,
at a security level of 56-bits (stronger than an 8-character password system), we achieve
state-of-the-art matching accuracy on IJB-A, GAR of at a 73.8 ± 1.8 % at a FAR of
0.1%. The corresponding GAR on FRGC v2.0 is 97.7 ± 1.0 %.
81

Chapter 4
Binary Feature Fusion for
Multi-biometric Cryptosystems
4.1 Introduction
Biometric cryptosystem takes a query sample and an earlier-generated sketch of the
target user and produces a binary decision (accept/reject) in the verification stage. In
a multi-biometric cryptosystem, the information of multiple traits could be fused at
feature level or score/decision level:
1. [feature-level] features from different biometric traits are fused and then protected
by a single biometric cryptosystem.
2. [score/decision-level] features from each biometric trait are protected by a bio-
metric cryptosystem and then the individual scores/decisions are fused.
The feature-level-fusion-based multi-biometric cryptosystems are arguably more se-
cure than the score/decision-level-fusion-based systems [93]. In feature-level-fusion-
based systems, a sketch generated from the multimodal template is stored, while in
82

score/decision-level-fusion-based systems, multiple sketches corresponding to the uni-
modal templates are stored. As the adversarial effort for breaking a multimodal sketch
is often much greater than the aggregate effort for breaking the unimodal sketches,
feature-level-fusion-based systems are more secure. This has also been justified in a
recent work [93] using hill-climbing analysis.
Biometric cryptosystems such as fuzzy extractor and fuzzy commitment mainly
accept binary input. To produce a binary input for biometric cryptosystems, an in-
tegrated binary string needs to be extracted from the multimodal features. However,
features of different modalities are usually represented differently, e.g., point-set for
fingerprint [59], real-valued for face and binary for iris [23]. To extract the integrated
binary string, one can either
1. convert features of different types into point-set or real-valued features, fuse the
converted features, and binarize them;
2. convert point-set [30, 65, 137, 143] and real-valued [33, 34, 83, 84] features into
binary, then perform a binary feature fusion on these features.
When commercial black-box binary feature extractors such as IrisCode [23] and Fin-
gerCode [63] are employed for some biometric traits, the extraction parameters such
as quantization and encoding information are not known. Hence, these binary features
cannot be converted to other forms of representation appropriately. In this case, the
second approach that is based on binary feature fusion is usually adopted.
In this chapter, we focus on binary feature fusion for multi-biometric cryptosystems,
where biometric features from multiple modalities are converted to a binary represen-
tation before being fused. Generally, in a multi-biometric cryptosystem, there are three
criteria for its binary input (fused binary feature)
1. Discriminability: The fused binary features have to be discriminative in order
83

not to defeat the original purpose of recognizing users. The fused feature bits
should have small intra-user variations and large inter-user variations.
2. Security: The entropy of the fused binary features have to be adequately high
in order to thwart guessing attacks, even if the stored auxiliary data is revealed.
The fused feature bits should be highly uniform and weakly dependent among
one another.
3. Privacy: The stored auxiliary data for feature extraction and fusion should not
leak substantial information on the raw biometrics of the target user.
A straightforward method to fuse binary features is to combine the multimodal
features using a bitwise operator (e.g., OR, XOR). Concatenating unimodal binary
features is another popular option for binary fusion [70,71]. However, the fusion result
of these methods is often suboptimal in terms of discriminability, because the redundant
or unstable features cannot be removed. Selecting discriminative binary features is a
better approach of obtaining discriminative binary representation. However, similar
to bitwise fusion and concatenation, the inherent dependency among bits cannot be
improved further. As a result, the entropy of the bit string could be limited, leading
to weak security consequence.
To produce a bit string that offers accurate and secure recognition, we propose
a binary fusion approach that can simultaneously maximize the discriminability and
entropy of the fused binary output. As the properties for achieving both discriminability
and security criteria can be divided into multiple-bit-based (i.e., dependency among
bits) and individual-bit-based (i.e., intra-user variations, inter-user variations and bit
uniformity). the proposed approach consists of two stages: (i) dependency-reductive
bit-grouping and (ii) discriminative within-group fusion. In the first stage, we address
the multiple-bit-based property: We extract a set of weakly dependent bit-groups from
multiple sets of binary unimodal features, such that, if the bits in each group is fused
into a single bit, these fused bits, upon concatenation, will be weakly interdependent.
84

Then, in the second stage, we address the individual-bit-based properties: We fuse
bits in each bit-group into a single bit with the objective of minimizing the intra-
user variation, maximizing the inter-user variation and maximizing uniformity of the
bits. As maximizing bit uniformity is equivalent to maximizing the inter-user variation
of the corresponding bit, which will be discussed further in Section 4.3.3, the fusion
function is designed to only maximize discriminability (minimize intra-user variations
and maximize inter-user variations).
The structure of this chapter is organized as follows. In the next section, we review
several existing binary feature fusion techniques. In Section 4.3, we describe the pro-
posed two-stage binary feature fusion. We present the experimental results to justify
the effectiveness of our fusion approach in Section 4.4. Finally, we draw concluding
remarks in Section 4.5.
4.2 Review on Binary Feature Fusion
As the arguably most popular biometric cryptosystems such as fuzzy commitment
and fuzzy extractor only accept the binary feature representation as their input. To
employ these biometric cryptosystems, a number of algorithms have been proposed
to transform non-binary feature to binary feature, e.g., [33, 34, 73, 83, 137, 143]. In
addition, there are lots of feature extractors that produce the binary feature [23, 63].
However, only few of binary feature-level-fusion based multi-biometric cryptosystems
can be found in the literature, e.g., [73, 101, 128]. Furthermore, most of them only
consider the discriminability of the fused binary feature, but have no consideration on
security.
To date, concatenation and bit selection are two typical binary fusion approaches.
Sutcu et al. [128] combine binary string of fingerprint and face by concatenation, then
the fuzzy commitment is applied on the combined feature immediately. However, con-
85

catenating binary strings might lead to a curse-of-dimensionality problem due to the
large increase in feature dimensionality and limited training data. In addition, feature
concatenation cannot remove redundant or unstable feature introduced during feature
extraction.
Bit selection is applied to avoid the curse-of-dimensionality problem by selecting
discriminative or reliable features . Kelkboom et al. [73] select a subset of most reliable
bits according to a criteria named z-score at feature level fusion. By using multiple
samples per user, their z-score of i-th bit is estimated by (|xi − µi|/σi), where xi de-
notes feature of i-th bit before quantization, µi, σi denote its corresponding mean and
standard deviation, respectively. Nagar et al. [101] present a discriminability based
bit selection method to select a subset of bits from each biometric trait individually
and combine the selected bits together via concatenation. They compute the discrim-
inability using ((1 − peg)pei ), where peg and pei is the genuine and impostor bit-error
probability, respectively. In most cases, there are insufficient bits that fulfill all three
requirements (i.e., high uniformity, small intra-user and large inter-user variation). In
addition, most bits are mutually dependent and the dependency among them cannot
be reduced through bit selection. Therefore, the bit selection generally cannot produce
the fused binary feature with both high discriminability and entropy.
A straightforward method to fuse representation of multiple biometric modalities
is based on some standard bitwise operators such as AND-, OR- and XOR-fusion rule.
Advantages of these methods are low computation cost, no additional information stor-
age and easy to adopt. If one of the input bit for AND-rule fusion is ”0”, then the
output bit must be ”0”, which would increase the zero-probability (probability of the
fused bit take value ”0”) and hence the bit is easier to be guessed when its zero-
probability is higher than 0.5. The OR-fusion rule is similar when one of whose input
is ”1”. Discriminability-wise, it’s difficult to justify the optimality of the fused template
when use AND- or OR-fusion rule. For the XOR-fusion rule, the fused bit is not robust
because it’s flipped when flip one of the input bit. Taking a two-to-one bit fusion as
86

an example, fused bit of {0,1} and {0,0} using XOR-fusion rule is ”1” and ”0”, resp.
After flipping first bit from ”0” to ”1”, the corresponding fused bit will be (1⊗ 1 = 0)
and (1 ⊗ 0 = 1), respectively. Hence, fused feature given by the AND- , OR-, XOR-
fusion rule can not achieve both high discriminability and entropy.
Another possible approach for generating the fused binary features from multiple
unimodal binary features is to apply a transformation such as PCA, LDA [112] and
CCA [146] on the binary features, followed by a binarization on the transformed fea-
ture. However, this approach suffers from an unavoidable trade-off between dependency
among feature components and discriminability. For instance, LDA and CCA features
are highly discriminative but strongly interdependent; while PCA features are uncor-
related but less discriminative. With this approach, the discriminability and security
criteria cannot be fulfilled simultaneously.
TestingTraining
Grouping
01
grouping information
dependency: strong weak
01
Grouping
within-group fusion
within-group fusion
...
...
...
...
...
...
1
2
3
M
b
b
b
b
...
1
2
3
M
b
b
b
b
ζ1ζS
C = {ζ1, · · · , ζS }
f1
fSwithin-group
fusion function
ζ1 ζS
fused feature z = {z1, · · · , zS }
dependency reductive bit-grouping
discriminative within-group fusion
Figure 1: The proposed binary feature level fusion algorithm
Alternatively, bit selection can be adopted to generate a morediscriminative fused binary feature by selecting bits with highdiscriminability from the multimodal features. Kelkboom et al.[23] select a subset of reliable features based on the estimatedz-score of the features, which is the ratio between the distanceof the estimated mean with respect to the quantization thresholdand the estimated standard deviation. Nagar et al. [30] present adiscriminability-based bit selection method to select a subset ofbits from each biometric trait individually based on the genuineand impostor bit-error probability and concatenate the selectedbits together. Bits with high discriminability are very likelyto be mutually dependent because some of the discriminativeinformation may be represented using multiple bits. It is ratherdifficult for the bit-selection approach to select discriminativebits with high entropy for multi-biometric cryptosystems.
Another possible approach for generating the fused binaryfeatures from multiple unimodal binary features is to apply atransformation such as PCA, LDA [31] and CCA [32] on thebinary features, followed by a binarization on the transformedfeature. However, this approach suffers from an unavoidabletrade-off between dependency among feature components anddiscriminability. For instance, LDA and CCA features arehighly discriminative but strongly interdependent; while PCAfeatures are uncorrelated but less discriminative. With this ap-proach, the discriminability and security criteria cannot be ful-filled simultaneously.
3. The proposed binary feature fusion
3.1. Overview of the proposed methodThe proposed two-stage binary feature fusion approach gen-
erates an S -bit binary representation z = {z1, · · · , zs, · · · , zS }from an input binary string b = {b1, · · · , bm, · · · , bM}, wheretypically S � M. The input binary string b consists of theconcatenated multimodal binary features of a sample. The pro-posed approach can be divided into two stages: (i) dependencyreductive bit-grouping and (ii) discriminative within-group fu-sion, where the block diagram is shown in Fig.1. The details ofthe two stages in testing phase are described as follows:
(1) Dependency reductive bit-grouping: Input bits of b aregrouped into a set of weakly-dependent disjoint bit-groupsC = {ζ1, · · · , ζs, · · · , ζS } such that ∀s1, s2 ∈ [1, S ], ζs1 ∩ζs2 = ∅, ⋃S
s=1 ζs ⊆ {b1, · · · , bm, · · · , bM}.(2) Discriminative within-group fusion: Bits in each group ζs
are fused to a single bit zs using a group-specific mappingfunction fs that maximizes the discriminability of zs.
The output bit zs of all groups is concatenated to produce thefinal bit string z. To realize these two stages, optimum group-ing information in stage one and optimum within-group fusionfunctions in stage two need to be sought. In stage one, thegrouping information C = {ζ1, · · · , ζs, · · · , ζS } represents theS groups of bit indices, specifying which of the bits in b shouldbe grouped together. Note that we use ′ x′ to denote the indexof the variable x throughout this paper unless stated otherwise.In stage two, the mapping function fs specifies to which outputbit value the bits in group ζs are mapped.
3
Figure 4.1: The proposed binary feature level fusion algorithm
87

4.3 The Proposed Binary Feature Fusion
4.3.1 Overview of the Proposed Method
The proposed two-stage binary feature fusion approach generates an S-bit binary
representation z = {z1, · · · , zs, · · · , zS} from an input binary string b = {b1, · · · , bm, · · · , bM},
where typically S � M . The input binary string b consists of the concatenated mul-
timodal binary features of a sample. The proposed approach can be divided into two
stages: (i) dependency reductive bit-grouping and (ii) discriminative within-group fu-
sion, where the block diagram is shown in Fig.4.1. The details of the two stages in
testing phase are described as follows:
1. Dependency reductive bit-grouping: Input bits of b are grouped into a set of
weakly-dependent disjoint bit-groups C = {ζ1, · · · , ζs, · · · , ζS} such that ∀s1, s2 ∈
[1, S], ζs1 ∩ ζs2 = ∅,⋃Ss=1 ζs ⊆ {b1, · · · , bm, · · · , bM}.
2. Discriminative within-group fusion: Bits in each group ζs are fused to a
single bit zs using a group-specific mapping function fs that maximizes the dis-
criminability of zs.
The output bit zs of all groups is concatenated to produce the final bit string z. To
realize these two stages, optimum grouping information in stage one and optimum
within-group fusion functions in stage two need to be sought. In stage one, the grouping
information C = {ζ1, · · · , ζs, · · · , ζS} represents the S groups of bit indices, specifying
which of the bits in b should be grouped together. Note that we use ′x′ to denote the
index of the variable x throughout this chapter unless stated otherwise. In stage two,
the mapping function fs specifies to which output bit value the bits in group ζs are
mapped.
88

4.3.2 Dependency Reductive Bit-group Search
To reduce the dependency among bits in the output binary string, a set of weakly-
dependent bit-groups C need to be extracted from the input b. One promising way
to extract these weakly-dependent bit-groups is to adopt a proper clustering technique
based on a dependency measure.
Existing clustering techniques can be categorized into partitional clustering (e.g.,
k-means) and hierarchical clustering [144]. The partitional clustering directly creates
partitions of data and represents each partition using a representative (e.g., clustering
center). However, the bit positions among which dependence needs to be measured
cannot be effectively represented in a metric space because dependence does not satisfy
the traingle inequality requirement of a metric space. As a result, partitional clustering
is less feasible in our context. The hierarchical clustering, on the other hand, serves as
a better option as it can operate efficiently based on a set of pairwise dependencies. In
this proposed method, we adopt the agglomerative hierarchical clustering (AHC). The
basic idea of AHC is as follows: we first create multiple singleton clusters where each
cluster contains a single bit, and then we start to merge a cluster pair with the highest
pairwise dependency iteratively, until the termination criterion is met.
To measure dependencies between two bits or two groups of bits, mutual information
(MI) can be adopted [78,109]. The MI of clusters ζs1 and ζs2 can be expressed as
I(ζs1 , ζs2) = H(ζs1) +H(ζs2)−H(ζs1 , ζs2) (4.1)
where H(ζs1) and H(ζs2) denote the joint entropy of bits in an individual cluster ζs1
or ζs2 , respectively, and H(ζs1 , ζs2) denotes the joint entropy of bits enclosed by both
clusters. However, the above MI measurement is sensitive to the number of variables
(bit positions) and is proportionate to the aggregate information of these variables. As
a result, multiple MI measurements involving different number of bit positions cannot
be fairly compared during the selection of cluster pair for cluster merging. That is, if
89

MI is adopted for dependency measurement, the hierarchical clustering technique will
always be inclined to select a cluster pair that involves the largest cluster for merging in
every iteration, although this cluster pair may not be the pair with the highest average
bit interdependency.
To obtain a better measure that precisely quantifies the bit interdependency irre-
spective of the size of the clusters, we normalize the MI using the size of clusters in the
cluster pair. This normalized measure indicates how dependent on average a bit pair
in a group is upon merging. We call this normalized measure as the average mutual
information (AMI), such that
Iavg(ζs1 , ζs2) =I(ζs1 , ζs2)
|ζs1| × |ζs2|(4.2)
With this AMI measure, we are able to identify cluster-pair with the strongest aver-
age bit-pair dependency for merging over cluster pairs of different sizes in each itera-
tion. Our proposed AMI-based AHC algorithm is shown in Algorithm.1. As strongly-
dependent cluster pairs will gradually be merged by the clustering algorithm, we will
eventually be able to obtain a set of (remaining) weakly-dependent bit groups that were
not selected for merging throughout the algorithm.
After the algorithm terminates, the grouping information C is obtained. It is noted
that the size of each resulted group ζ specified in C determines the number of possible
bit combinations (i.e., 2|ζ| bit-combinations for groups size |ζ|). As we need to estimate
the occurrence probabilities of these bit combinations from the training samples for
within-group fusion search in the second stage described in Section 4.3.3, it is usual
that one may not have arbitrarily large amount of training data in practice to ensure
accurate estimation of these probabilities. To overcome this problem, we restrict the
maximum group size to be tsize in order to ensure the feasibility of optimal within-group
fusion search in the second stage.
The final set of S clusters is taken based on the entropy of the clusters. In the
90

Algorithm 1 AMI-based agglomerative hierarchical clustering
1: Inputs:N samples of all users’ binary features
B = {b1, · · · , bn, · · · , bN},length of each binary feature M ,number of clusters S,maximum cluster size tsize
2: Outputs:grouping information C = {ζ1, · · · , ζs, · · · , ζS}
3: Initialize:Ctmp = {ζ1, · · · , ζm, · · · , ˆζM} where ζm = {m}compute entropy of each cluster H(ζ) in Ctmphtmp ← S-th largest cluster entropy in CtmpC ← Ctmph← 0D = {dαβ}α 6=βα,β∈[1,M ], where dαβ = Iavg(ζα, ζβ)
4: while |Ctmp| > S do5: search for largest dαβ6: if |ζα|+ |ζβ| > tsize then7: dαβ ← −18: else9: ζλ ← ζα ∪ ζβ
10: Ctmp ← Ctmp − {ζα} − {ζβ}+ {ζλ}11: compute entropy of each cluster H(ζ) in Ctmp12: htmp ← S-th largest cluster entropy in Ctmp13: if htmp > min(h, 1) then
14: C ← Ctmp15: h← htmp16: end if17: for each ζµ ∈ Ctmp, µ 6= λ do18: update dλµ19: end for20: end if21: end while22: Discard the (|C| − S) lowest-entropy cluster in C
{H(ζ) returns the entropy of cluster ζ, which is based on the observation of bit combi-nation ζn = {bnm}m∈ζ that corresponds to cluster ζ and training sample bn. }
91

ideal scenario, every resulted bit group ζ specified in C should contain at least one bit
entropy. According to our analysis in Section 4.3.4, optimal inter-user variation of the
output bit of a group (during within-group fusion function search in the second stage)
can only be achieved when the entropy of the corresponding group is not less than one
bit. While this ideal scenario cannot be guaranteed all the time especially when the
input bit string contains limited entropy, the entropy of the S clusters should be made
as high as possible so that the possibility of obtaining high inter-user variation in the
resulted fused bit from each cluster in the second stage can be heightened. Because
the dependency (maximum AMI) of all cluster pairs is non-increasing as the iteration
proceeds (see Appendix for the proof), the output grouping information C will be taken
and updated whenever one of the following conditions is satisfied:
1. The S-th largest cluster entropy in Ctmp is greater or equal to one bit;
2. The S-th largest entropy of the clusters in C is less than one bit and less than
that in Ctmp.
4.3.3 Discriminative Within-group Fusion Search
Suppose that we have obtained S groups of bits from the first stage. For each group,
we seek for a discriminative fusion f : {0, 1}|ζ| → {0, 1} to fuse bits in group ζ to a
single bit z. Here, the function f maps each combination of |ζ| bits to a bit value. The
within-group fusion is analogous to a binary-label assignment process, where each bit
combination is assigned a binary output label (a fused bit value). Since the dependency
among fused bits has been reduced using AMI-based AHC in stage one, to obtain a
discriminative bit string that contains high entropy, the fusion should minimize the
intra-user variation, maximize the inter-user variation and uniformity of the output
bit. Naturally, maximizing inter-user variations has an equivalent effect of maximizing
bit uniformity. This is because a bit with maximum inter-user variation also indicates
that the bit value would distribute uniformly among the population users. Thus, the
92

fusion sought in the following need only to optimize the discriminability of the output
bit, i.e., minimizing the intra-user variations and maximizing the inter-user variations.
The intra-user and inter-user variations of the fused bit z of group ζ could be mea-
sured using the genuine bit-error probability peg and the impostor bit-error probability
pei , respectively. Genuine bit-error probability is defined as the probability where dif-
ferent samples of the same user are fused to different bit values, while the impostor
bit-error probability is defined as the probability where samples of different users are
fused to different bit values. Let xt denotes the t-th bit-combination of group ζ, where
t = {1, 2, · · · , 2|ζ|} and let X(0) and X(1) denote the sets of bit-combinations in group ζ
that to be fused to ‘0’ and ‘1’, respectively. The genuine bit-error probability of fused
bit z corresponding to group ζ can be expressed as
peg = Pr(ζn1 ∈ X(0), ζn2 ∈ X(1)|ln1 = ln2)
=∑
xt1∈X(0)
∑xt2∈X(1)
Pr(ζn1 = xt1 , ζn2 = xt2|ln1 = ln2)
(4.3)
where ln1 and ln2 denote the label of n1-th and n2-th training sample, respectively, ζn1
and ζn2 denote the group ζ corresponding to the n1-th and n2-th training samples,
n1 6= n2 and n1, n2 ∈ {1, 2, · · · , N}.
Similarly, the impostor bit-error probability can be expressed as
pei = Pr(ζn1 ∈ X(0), ζn2 ∈ X(1)|ln1 6= ln2)
=∑
xt1∈X(0)
∑xt2∈X(1)
Pr(ζn1 = xt1 , ζn2 = xt2|ln1 6= ln2)
(4.4)
To seek the function f that minimizes genuine and maximizes impostor bit-error
probability, we solve the following minimization problem using the integer genetic al-
93

gorithm [24,25],
minf
(peg − pei
)=
∑xt1∈X(0)
∑xt2∈X(1)
(Pr(ζn1 = xt1 , ζn2 = xt2|ln1 = ln2)
−Pr(ζn1 = xt1 , ζn2 = xt2 |ln1 6= ln2))
(4.5)
subject to
f(xt1) = 0, f(xt2) = 1
where f(xt1) and f(xt1) denote the fused bit value of bit-combination xt1 and xt2 ,
respectively. Note that this function f has to be sought for every bit group.
4.3.4 Discussion and Analysis
An important requirement in Algorithm 1 is that each resulted bit group (joint
entropy of bits in the group) should contain at least one-bit entropy to warrant the
achievability of high inter-user variation. This is because when the group entropy is
less than one bit, the probability of one of the fused bit values would become larger
than 0.5, thus making the distribution of bit values less uniform among the population
users. In the following, we analyze how group entropy that is less than one bit could
negatively influence the impostor error probability of the fused bit.
Let pt denotes the occurrence probability of a bit combination xt in group ζ, where
t = {1, 2, · · · , 2|ζ|}. The corresponding joint entropy of bits in group ζ is expressed as
H(x) = −2|ζ|∑t=1
pt log2 pt (4.6)
where |ζ| denotes group size and∑2|ζ|
t=1 pt = 1. If H(x) < 1,
94

1. there exists a bit combination that has the highest occurrence probability pmax =
maxt(pt) > 0.5; and
2. the impostor bit-error probability pei (the larger, the better) of the fused bit in
stage two is upper bounded by
pei ≤ 2pmax(1− pmax) < 0.5 (4.7)
Proof. (a) To prove that there is an input bit combination that has the highest prob-
ability pmax = maxt(pt) > 0.5 when H(x) < 1, we construct a lower bound of entropy
HL(x) w.r.t. pmax that is described as follows:
HL(x) = max (HL1(x), HL2(x))
=
HL1(x) = − log2 pmax, 0 < pmax ≤ 0.5
HL2(x) = Hb(pmax), 0.5 ≤ pmax ≤ 1
(4.8)
where HL1(x) and HL2(x) are two lower bound functions and Hb(pmax) is the binary
entropy function
Hb(pmax) = −pmax log2(pmax)− (1− pmax) log2(1− pmax)
The two lower bound functions HL1(x) and HL2(x) are derived as follows:
H(x) = −2|ζ|∑t=1
pt log2 pt
≥ −2|ζ|∑t=1
pt log2 pmax = − log2 pmax = HL1(x)
(4.9)
95

H(x) = −2|ζ|∑t=1
pt log2 pt
≥ −1∑z=0
∑t,f(xt)=z
pt
log2
∑t,f(xt)=z
pt
≥ Hb(pmax) = HL2(x)
(4.10)
The inverse function of Eq.(4.8) is plotted as the solid curve in Fig.4.2, where the
admissible region of pmax lies within the grey-shaded area, indicating the possible pmax
values given an entropy value H(x) of a bit group. Based on this plot, it can be
observed that when group entropy H(x) < 1, all of the possible pmax values in the
dark-grey-shaded area are greater than 0.5, which completes the proof.
Proof. (b) The impostor bit-error probability pei is the probability of getting a different
fused bit value from that of the target genuine user. Hence, we obtain the following:
pei = Pr(z = 0) Pr(z = 1) + Pr(z = 1) Pr(z = 0)
= 2 Pr(z = 0) Pr(z = 1)
≤ 2pmax(1− pmax)
< 0.5
(4.11)
With this, the lower H(x) < 1 is, the larger the pmax, and the smaller the impostor
bit-error probability pei will be. This completes the proof.
96

4.4 Performance Evaluation
4.4.1 Database and Experiment Setting
We evaluated the proposed fusion algorithm using a real and two chimeric multi-
modal databases, involving three modalities: face, fingerprint and iris. The real multi-
modal database, WVU [55], contains images of 106 subjects, where each subject has
five multi-modal samples. The two chimeric multi-modal databases are obtained by
randomly matching images from a face, a fingerprint and an iris database. The first
chimeric multi-modal database named Chimeric A consists of faces from FERET [111],
fingerprints from FVC2000-DB2 and irises from CASIA-Iris-Thousand [1]. The sec-
ond database named Chimeric B consists of faces from FRGC [110], fingerprints from
FVC2002-DB2 and irises from ICE2006 [11]. These chimeric databases contain 100
subjects with eight multi-modal samples per subject. Fig.4.3 shows the sample images
from the three databases.
The training-testing partitions for each database is shown in Table.4.1. Our testing
protocol is described as follows. For the genuine attempts, the first sample of each
subject is matched against the remaining samples of the subject. For the impostor
attempts, the i-th sample of each subject is matched against the i-th sample of the
remaining subjects. Consequently, the number of genuine and impostor attempts in
WVU multi-modal database are 106 (106 × (2 − 1)) and 11,130 ((106 × 105)/2 × 2),
respectively, while the number of genuine and impostor attempts in the two chimeric
multi-modal databases are 300 (100×(4−1)) and 19,800 ((100×99)/2×4) respectively.
Prior to evaluating the binary fusion algorithms, we extract the binary features of
face, fingerprint and iris from the databases. The images of each modality are first
processed as follows:
1. Face: Proper face alignment is first applied based on the standard face land-
97
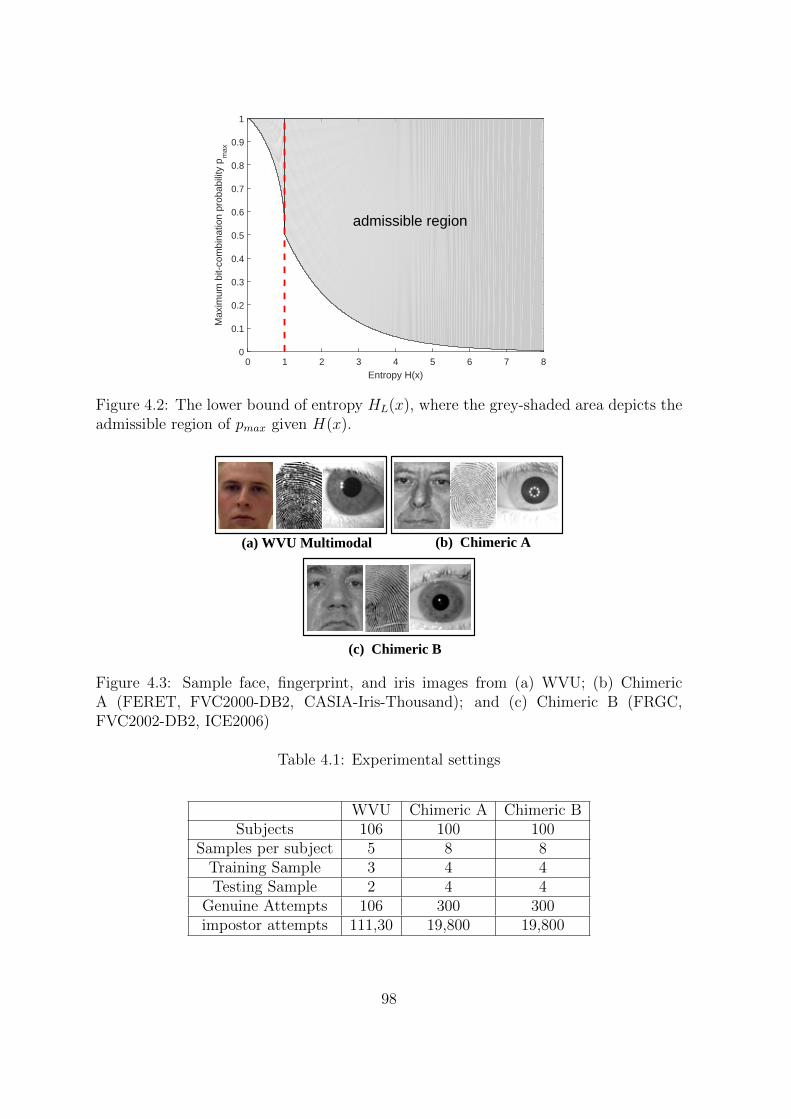
Entropy H(x)0 1 2 3 4 5 6 7 8
Max
imum
bit-
com
bina
tion
prob
abili
ty p
max
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
admissible region
Figure 4.2: The lower bound of entropy HL(x), where the grey-shaded area depicts theadmissible region of pmax given H(x).
(c) Chimeric B
(a) WVU Multimodal (b) Chimeric A
Figure 4.3: Sample face, fingerprint, and iris images from (a) WVU; (b) ChimericA (FERET, FVC2000-DB2, CASIA-Iris-Thousand); and (c) Chimeric B (FRGC,FVC2002-DB2, ICE2006)
Table 4.1: Experimental settings
WVU Chimeric A Chimeric BSubjects 106 100 100
Samples per subject 5 8 8Training Sample 3 4 4Testing Sample 2 4 4
Genuine Attempts 106 300 300impostor attempts 111,30 19,800 19,800
98

mark. To eliminate effect from variations such as hair style and background, the
face region of each sample is cropped and resized to 61×73 pixels in FERET and
FRGC databases, and 15×20 pixels in WVU database.
2. Fingerprint: We first extract minutiae from each fingerprint using Verifinger
SDK 4.2 [3]. The extracted minutiae are converted into an ordered binary feature
using the method proposed in [30] without randomization. Following parameters
in [30], each fingerprint image is represented by a vector with length 224.
3. Iris: The weighted adaptive hough and ellipsopolar transform (WAHET) [134]
is employed to segment the iris. Then, 480 real features are extracted from the
segmented iris using Ko et al.’s extractor [77]. Both segmentation and extraction
algorithms are implemented using the iris toolkit (USIT) [117].
After preprocessing, we apply PCA on face, and LDA on fingerprint and iris to reduce
the feature dimensions to 50. Then, we encode each feature component with a 20-bit
binary vector using LSSC [83] and obtain a 1000-bit binary feature for each modality.
In this comparative study, we compare the proposed method with the following
existing methods:
1. single modality baselines: face, fingerprint, iris
2. bit selection [101]
3. concatenation [70,71]
4. bit-wise operation: AND, OR, XOR
5. decision fusion: AND, OR (denoted as ‘andd’ and ‘ord’ in the experimental
results, respectively)
It is noted that all of the compared methods are re-implemented here.
99

For the proposed method, the parameter of largest cluster size tsize in stage one
is set to 8. Throughout the comparative study, features produced by the evaluated
methods are made to be of the same length for comparison fairness purpose, except
the concatenation method. For instance, the original length of the unimodal binary
features is reduced to the evaluated length through discriminative selection using a
discriminability criterion [101]. The features of the bit-wise operation and the results
of decision-level fusion methods are obtained from these selected uni-biometric features.
4.4.2 Evaluation Measures for Discriminability and Security
Discriminability The discriminability of the fused feature is measured using the
area under curve (AUC) of the receiver operating characteristic (ROC) curve. The
higher the AUC, the better the matching accuracy would be.
Security The security of the template is evaluated using quadratic Renyi entropy [53].
Specifically, the quadratic Renyi entropy measures the effort for searching an identified
sample of the target template. Assuming that the average impostor Hamming distance
(aIHD) or the impostor Hamming distance per bit obeys binomial distribution with
expectation p and standard deviation σ, the entropy of the template can be estimated
as
H = − log2 Pr(aIHD = 0)
= − log2 p0(1− p)N∗ = −N∗ log2(1− p)
(4.12)
where p and σ denote the mean and standard deviation of the aIHD, resp., and N∗ =
p(1− p)/σ2 denotes the estimated number of independent Bernoulli trials.
Trade-off Analysis The GAR-Security (G-S) analysis [101] is an integrated measure
for template discriminability and security in biometric cryptosystems. It analyzes the
trade-off between matching accuracy and security in a fuzzy commitment system by
100
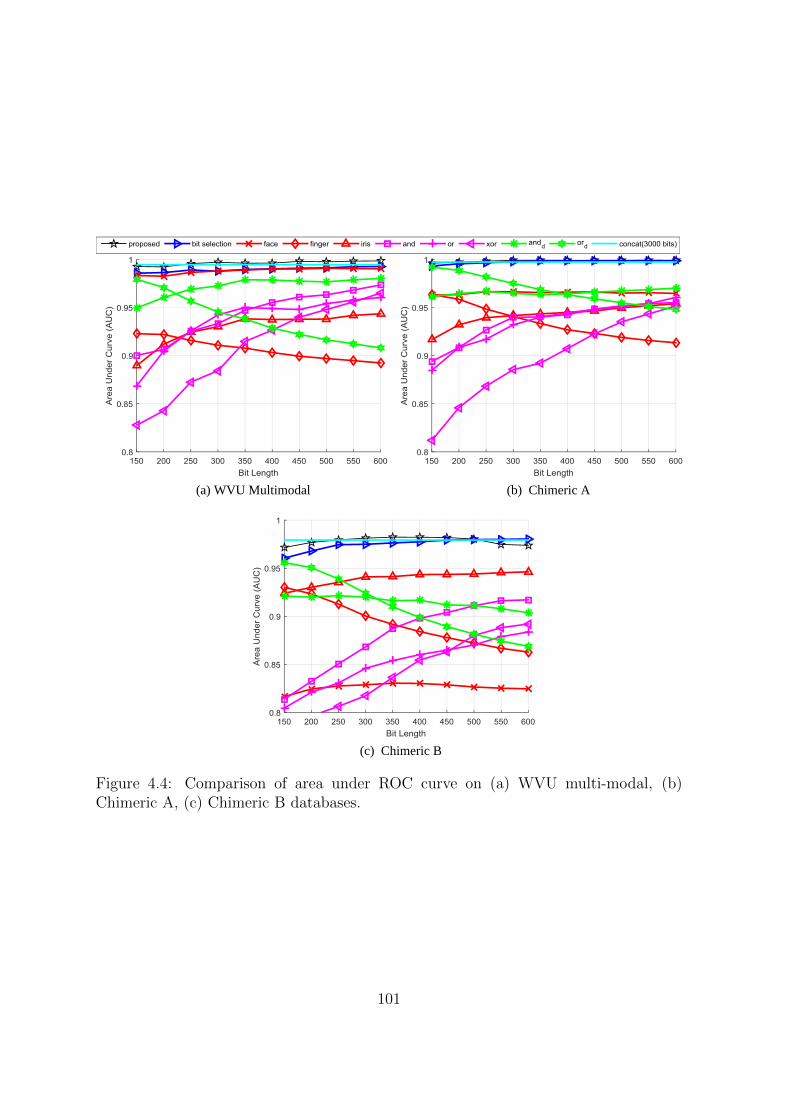
(a) WVU Multimodal (b) Chimeric A
(c) Chimeric B
Figure 4.4: Comparison of area under ROC curve on (a) WVU multi-modal, (b)Chimeric A, (c) Chimeric B databases.
101

varying the error correcting capability. The G-S analysis is based on the decoding
complexity of Nagar’s ECC decoding algorithm [101], where a query is accepted only
if the corresponding decoding complexity is less than a given threshold.
A G-S point is produced via computing the GAR and the minimum decoding com-
plexity among all impostor attempts given an error correcting capability. More details
of the decoding complexity can be found in [101]. We estimate the entropy of the binary
feature using the quadratic Renyi entropy [53], which is a more accurate measure than
the Daugman’s DOF [23] that is only reliable as the aIHD expectation p = 0.5.
4.4.3 Discriminability Evaluation
The AUC for fusion bit length from 150 to 600 is shown in Fig.4.4. It can be observed
that the proposed method has comparable performance compared to bit selection and
concatenation on all three databases and it outperforms the remaining methods in
general. On WVU multi-modal database, the proposed method performs as good as
the unimodal face baseline.
For the results on WVU multi-modal database in Fig.4.4a, the proposed method
outperforms the curves of bit selection, concatenation and face. When the bit length
equals 350, the AUC of the proposed method is 0.9961, which is slightly higher than
the AUC of bit selection (0.9896), concatenation (0.9946) and the best single modality:
face (0.9890). Compared to face, the proposed method has a marginal improvement of
0.71%.
For the results on Chimeric A database shown in Fig.4.4b, the proposed method
performs equally well with bit selection and concatenation methods. The AUC of the
proposed method, the bit selection and the concatenation methods are 0.9992, 0.9985,
and 0.9973 at 350-bit feature length, respectively. This shows a 3.4% improvement of
the proposed method compared to the best unimodality: face (AUC = 0.9656).
102
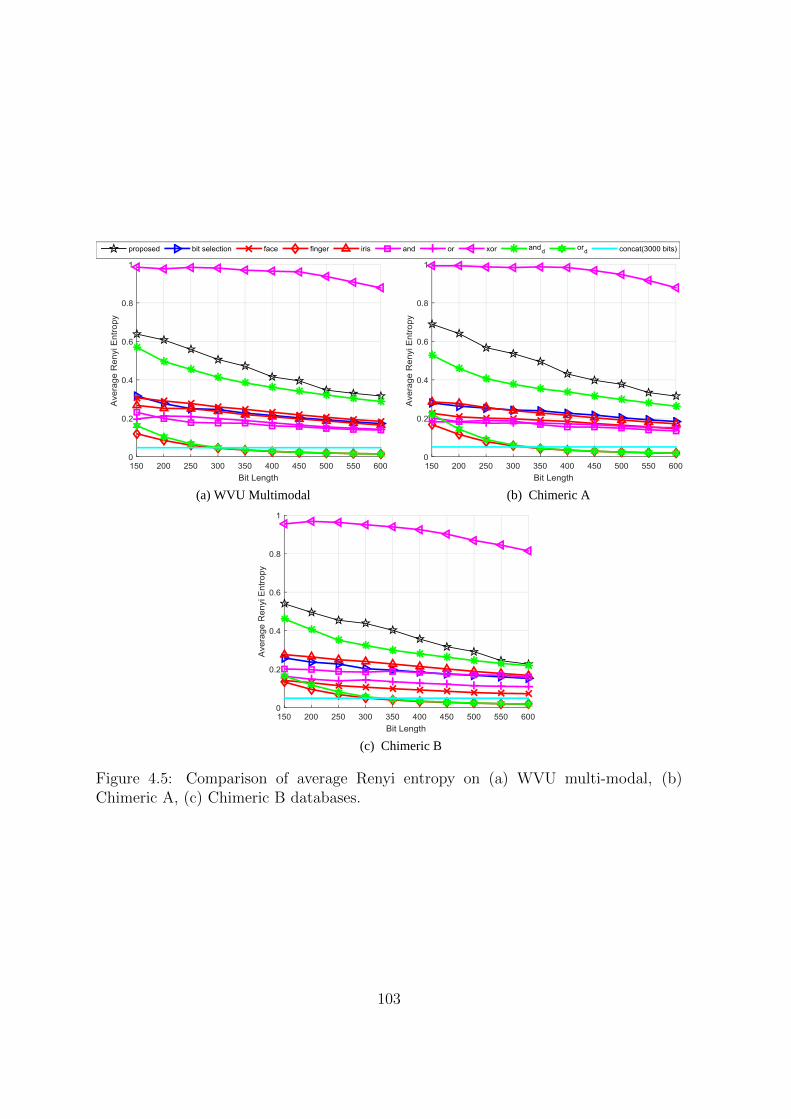
(a) WVU Multimodal (b) Chimeric A
(c) Chimeric B
Figure 4.5: Comparison of average Renyi entropy on (a) WVU multi-modal, (b)Chimeric A, (c) Chimeric B databases.
103

For the results of Chimeric B database in Fig.4.4c, it can be observed that the
AUC of the proposed method is slightly higher than the bit selection method when
the bit length is less than 500. For this database, the proposed method, bit selection
and concatenation methods outperform significantly the best-performing unimodality:
iris. At 350-bit feature length, the AUC of the proposed method is 0.9823 compared to
the concatenation (0.9793) and bit selection (0.9763) methods. The AUC improvement
of the proposed method is approximately 3.5% compared to iris (AUC = 0.9413) at
350-bit feature length.
These results show that the proposed method could perform equally well, or even
slightly better than bit selection and concatenation although the biometric modalities
could vary significantly in quality. It is noted that the difference between the AUC of
face and fingerprint is around 7 ∼ 10% on WVU multimodal database and 2 ∼ 5% on
Chimeric A database; while the difference between the AUC of iris and face is around
10% on Chimeric B.
Additionally, it is observed that there is no guarantee on the performance of features
produced based on AND-, OR- and XOR-feature fusion rule. The features produced
by XOR rule are always the worst compared to AND and OR rules.
4.4.4 Security Evaluation
In this section, the results on template security are shown, which is measured using
quadratic Renyi entropy [53]. The average Renyi entropy of the binary feature fused
using the evaluated schemes are plotted in Fig.4.5. Here, the average Renyi entropy is
the Renyi entropy divided by the bit length of the fused features, thus ranging from 0
to 1. A higher average Renyi entropy implies stronger template security.
On all three databases, it can be observed that the proposed method ranks second
in terms of entropy. The best-performing method turns out to be the XOR feature
104

fusion because the features tends to be more uniform upon XOR fusion, despite its
poor performance in the discriminability evaluation.
For the WVU multi-modal database shown in Fig.4.5a, it is observed that at 350-
bit feature length, the average entropy achieved by the proposed method is 0.4674
bit, while the XOR-feature fusion method achieves an average entropy of 0.9603 bit,
which is nearly double of the proposed method. Besides that the ‘andd’ method slightly
underperforms the proposed method, the remaining methods could only achieve at most
half of the average entropy of the proposed method.
Similar results can be seen on Chimeric A and B databases in Fig.4.5b and Fig.4.5c.
When the bit length equals 350, the proposed method achieves an average entropy of
0.4896 bit in Fig.4.5b and 0.4021 bit in Fig.4.5c, that is half of that of the XOR-feature
fusion method but is at least double of that of the remaining methods.
4.4.5 Robustness of Varying Qualities of Biometric Inputs
In addition to produce a fused feature with high discriminability and security, a
feature fusion method should be robust to varying qualities of biometric inputs. To
demonstrate the robustness of the proposed method in discriminability and security,
we plot AUC and average Renyi entropy of fused feature with different qualities of
inputs in Fig.4.6 and Fig.4.7, respectively.
The face feature from FRGC and fingerprint feature from FVC2002-DB2 have AUC
less than 0.84 and 0.9 (in most cases), respectively and are used as low-quality inputs.
The iris feature from ICE2006 and face feature from FERET have AUC higher than 0.92
and 0.96, respectively and are used as high-quality inputs. It is noted that high-quality
inputs have average Renyi entropy at least 50% higher than the one of low-quality
inputs with the same feature length. The experiments here contain the three possible
quality combinations of input, i.e., low + low (Fig.4.6a, 4.7a), low + high (Fig.4.6b-4.6e,
105
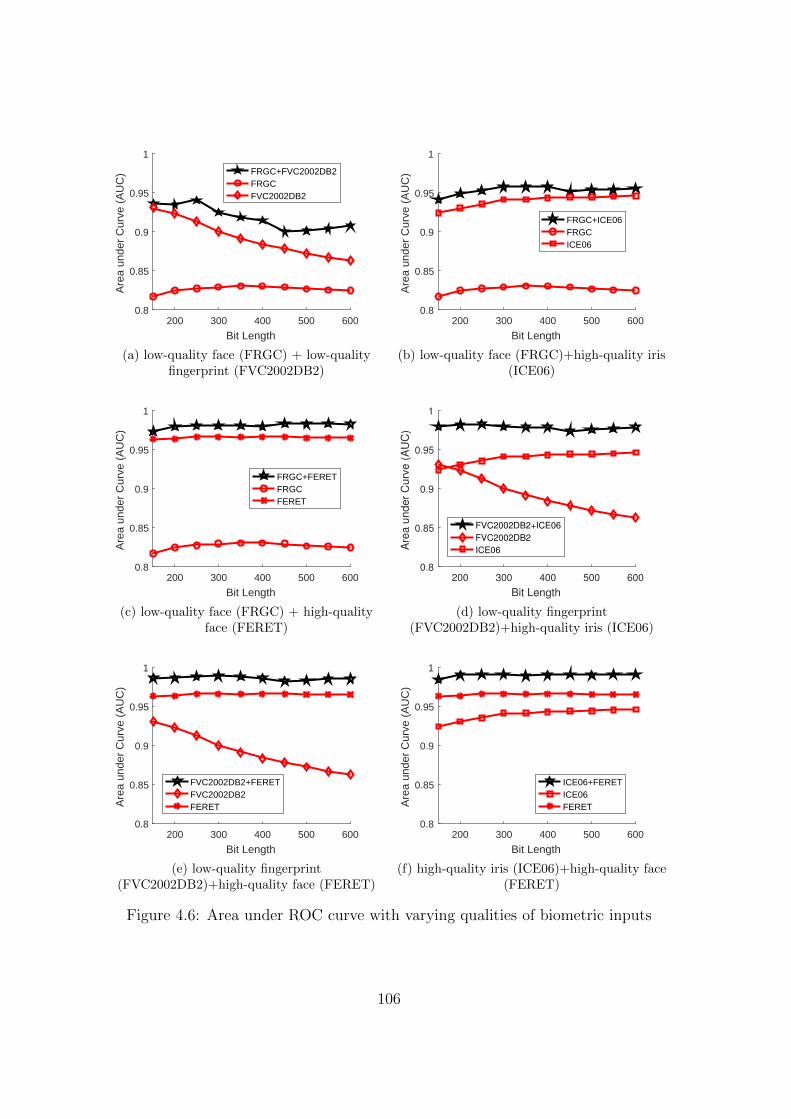
200 300 400 500 600
Bit Length
0.8
0.85
0.9
0.95
1
Are
a un
der
Cur
ve (
AU
C) FRGC+FVC2002DB2
FRGCFVC2002DB2
(a) low-quality face (FRGC) + low-qualityfingerprint (FVC2002DB2)
200 300 400 500 600
Bit Length
0.8
0.85
0.9
0.95
1
Are
a un
der
Cur
ve (
AU
C)
FRGC+ICE06FRGCICE06
(b) low-quality face (FRGC)+high-quality iris(ICE06)
200 300 400 500 600
Bit Length
0.8
0.85
0.9
0.95
1
Are
a un
der
Cur
ve (
AU
C)
FRGC+FERETFRGCFERET
(c) low-quality face (FRGC) + high-qualityface (FERET)
200 300 400 500 600
Bit Length
0.8
0.85
0.9
0.95
1A
rea
un
de
r C
urv
e (
AU
C)
FVC2002DB2+ICE06
FVC2002DB2
ICE06
(d) low-quality fingerprint(FVC2002DB2)+high-quality iris (ICE06)
200 300 400 500 600
Bit Length
0.8
0.85
0.9
0.95
1
Are
a un
der
Cur
ve (
AU
C)
FVC2002DB2+FERETFVC2002DB2FERET
(e) low-quality fingerprint(FVC2002DB2)+high-quality face (FERET)
200 300 400 500 600
Bit Length
0.8
0.85
0.9
0.95
1
Are
a un
der
Cur
ve (
AU
C)
ICE06+FERETICE06FERET
(f) high-quality iris (ICE06)+high-quality face(FERET)
Figure 4.6: Area under ROC curve with varying qualities of biometric inputs
106
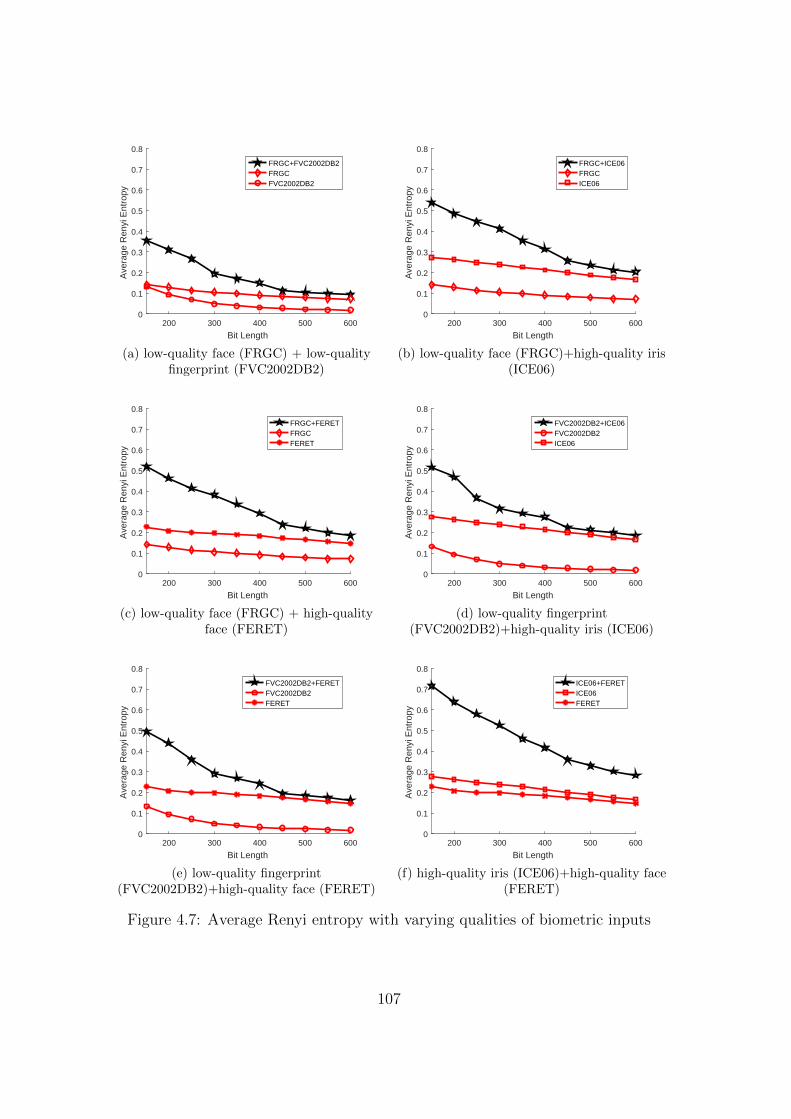
200 300 400 500 600
Bit Length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Ave
rage
Ren
yi E
ntro
py
FRGC+FVC2002DB2FRGCFVC2002DB2
(a) low-quality face (FRGC) + low-qualityfingerprint (FVC2002DB2)
200 300 400 500 600
Bit Length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Ave
rage
Ren
yi E
ntro
py
FRGC+ICE06FRGCICE06
(b) low-quality face (FRGC)+high-quality iris(ICE06)
200 300 400 500 600
Bit Length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Ave
rage
Ren
yi E
ntro
py
FRGC+FERETFRGCFERET
(c) low-quality face (FRGC) + high-qualityface (FERET)
200 300 400 500 600
Bit Length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8A
vera
ge R
enyi
Ent
ropy
FVC2002DB2+ICE06FVC2002DB2ICE06
(d) low-quality fingerprint(FVC2002DB2)+high-quality iris (ICE06)
200 300 400 500 600
Bit Length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Ave
rage
Ren
yi E
ntro
py
FVC2002DB2+FERETFVC2002DB2FERET
(e) low-quality fingerprint(FVC2002DB2)+high-quality face (FERET)
200 300 400 500 600
Bit Length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Ave
rage
Ren
yi E
ntro
py
ICE06+FERETICE06FERET
(f) high-quality iris (ICE06)+high-quality face(FERET)
Figure 4.7: Average Renyi entropy with varying qualities of biometric inputs
107

4.7b-4.7e), and high + high (Fig.4.6f, Fig.4.7f).
It is observed that in the three possible quality combinations of inputs, the proposed
method consistently achieves the highest AUC and average Renyi entropy compared
to its inputs. This shows that the proposed method is robust to varying qualities of
inputs.
4.4.6 Trade-off between Discriminability and Security
Using the parameters suggested in [101], the G-S curves of the evaluated methods are
plotted in Fig.4.8. The maximum acceptable decoding complexity is fixed as 15 bits and
the minimum distance of the ECC ranges from 0.02 to 0.6 times the bit length S. It can
be observed that the proposed method outperforms the bit selection method on all three
databases. This implies that the proposed method achieves a better discriminability-
security tradeoff than the bit selection method and the remaining methods.
For 40-bit security at 350-bit feature length, the proposed method performs the
best, achieving 69% GAR. This is followed by the face (57% GAR) and bit selection
method (38% GAR). For the same settings on Chimeric A database, the proposed
method achieves 64% GAR, which is 13% higher than face modality and 26% higher
than bit selection method. As for Chimeric B database, the proposed method achieves
20% GAR, which is 11% higher than the iris modality and 17% higher than bit selection
method.
4.5 Summary
In this chapter, we have proposed a binary feature fusion algorithm that can produce
discriminative binary templates with high entropy for multi-biometric cryptosystems.
108
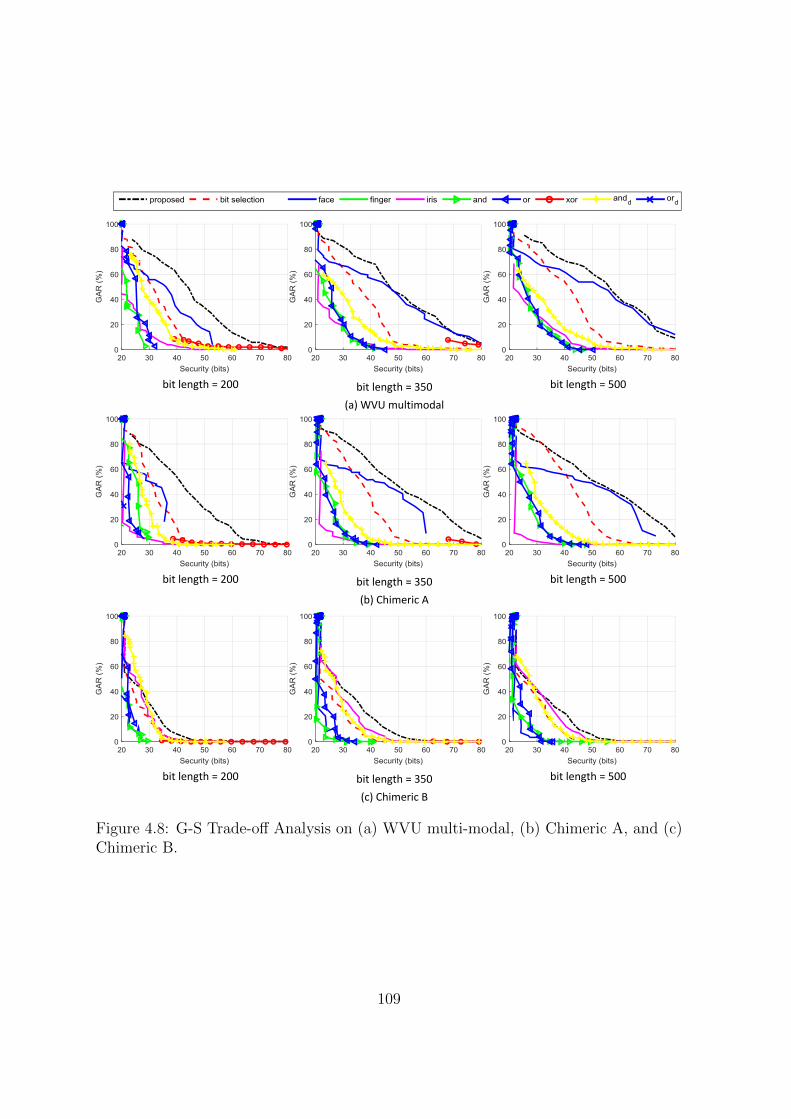
bit length = 500bit length = 350
(a) WVU multimodal
bit length = 200
bit length = 500bit length = 350
(b) Chimeric A
bit length = 200
bit length = 500bit length = 350
(c) Chimeric B
bit length = 200
Figure 4.8: G-S Trade-off Analysis on (a) WVU multi-modal, (b) Chimeric A, and (c)Chimeric B.
109

The proposed binary feature fusion algorithm consists of two stages: dependency re-
ductive bit grouping and discriminative and uniform within-group fusion. The first
stage creates multiple weakly-interdependent bit groups using grouping information
that is obtained from an average mutual information-based agglomerative hierarchical
clustering; while the second stage fuses the bits in each group through a function that
minimizes intra-user variation, and maximizes uniformity and inter-user variation of
the output fused bit. We have conducted experiments on WVU multi-modal database
and two chimeric databases and the results have justified the effectiveness of the pro-
posed method in producing a highly discriminative fused template with high entropy
per multimodal sample.
110

Chapter 5
Conclusions and Future Research
5.1 Conclusions
This thesis contributes to the study of security and privacy issues related to the
templates in biometric systems from the perspectives of both attack and protection.
Specifically, in Chapter 2, we make, to the best of our knowledge, the first attempt to
reconstruct face images from popularly used deep face templates with only a black-box
face recognition engine of the target system and a template of the target subject. Our
experimental results reveal a severe security issue: the reconstructed images can be
used to access the target system, which is based on FaceNet [121]. In the verification
scenario, TAR of 95.20% (58.05%) on LFW under type I (type II) attack at an FAR of
0.1% can be achieved with our reconstruction model. The privacy issues are revealed by
showing that 96.58% (92.84%) of the images reconstructed from templates of partition
fa (fb) can be identified from partition fa in color FERET. We believe that this study
will motivate the examination of reconstructing biometric data of other modalities (e.g.,
fingerprint, iris) from the corresponding deep templates and other potential attacks.
In addition, the study of corresponding countermeasures (e.g., spoof detection and
template protection) would also be motivated.
111

We make two contributions to template protection for biometric systems from the
perspective of protection. Specifically, we attempt to improve the state-of-the-art bio-
metric template protection techniques in two ways. (1) In Chapter 3, we propose what
is, to the best of our knowledge, the first end-to-end method for simultaneous extrac-
tion and protection of the biometric templates; and (2) in Chapter 4, we propose a
binary feature fusion method for a multiple-biometric cryptosystem that improves the
biometric system with template protection by using information from multiple modal-
ities. Our experimental results justify that the systems with the proposed template
protection methods not only achieve great matching accuracy, but also strong system
security. The cancellability of our end-to-end method is demonstrated.
5.2 Future Research Directions
Despite the significant progress made in the literature and in this thesis, to further
enhance the security and protect the privacy of biometric systems, some research issues
require further study.
From the perspective of attacks to identify a biometric system’s vulnerability, one
could further explore:
• Spoofing attack : to create fake biometric traits, such as 3D face masks, gummy
fingers, and synthesized voices, to attempt to access target biometric systems
as target subjects. This would motivate sensor providers to design more robust
capturing devices and to study spoof detection.
• Template attack : to study to what extent other biometric templates can be re-
constructed to their raw biometric data, in scenarios in which templates can be
protected or unprotected. We have attempted to reconstruct face images from
deep face templates and have demonstrated successful reconstruction. However,
112

the reconstruction of other biometric traits from deep templates and multiple-
biometric templates remains an open and important problem.
• Attacks on general pattern-recognition systems : biometric systems are essentially
pattern-recognition systems. Therefore, the attacks studied for current machine
learning and pattern recognition systems, including evasion and poisoning, should
also be studied and conducted on biometric systems.
From the perspective of protection to increase security and protect the privacy of
biometric systems, the following areas could be further explored:
• Spoof detection: to detect fake biometric traits presented to the system. It is
important to address this problem using the intrinsic characteristics of live bio-
metrics, such as heart rate [86]. Furthermore, the adversarial environment should
be considered in such studies, because the spoof detection system could be at-
tacked at the stage of providing services.
• Template protection: to protect the biometric templates from being reconstructed
or linked across systems when the template database is leaked. We have demon-
strated two contributions in this topic: an end-to-end method for simultaneous
extraction and protection of templates from raw biometric data; and a binary
feature fusion method for construction of multiple-biometric cryptosystems. One
could also explore the topics of end-to-end methods for multiple-biometric tem-
plate protection and emerging ciphers (e.g., homomorphic encryption) for protec-
tion of biometric templates. Furthermore, the standardization of the evaluation
metrics (e.g., non-invertibility, unlinkability, and revocability) for template pro-
tection should be further explored because state-of-the-art metrics are far from
mature.
• Other protection mechanisms : other security and privacy issues caused by prac-
tical evasion and poisoning attack studies on biometric systems.
113

Appendices
1. Proof of the Existence of a Face Image Generator
Suppose a face image x ∈ Rh×w×c of height h, width w, and c channels can be
represented by a real vector b = {b1, · · · , bk} ∈ Rk in a manifold space with h×w×c�
k, where bi ∼ Fbi , i ∈ [1, k] and Fbi is the cumulative distribution function of bi. The
covariance matrix of b is Σb. Given a multivariate uniformly distributed random vector
z ∈ [0, 1]k consisting of k independent variables, there exists a generator function
b′ = r(z), b′ = {b′1, · · · , b′k} such that b′i ∼ Fbi , i ∈ [1, k], and Σb′ ∼= Σb.
Proof. The function r(·) exists and can be constructed by first introducing an inter-
mediate multivariate normal random vector a ∼ N (0,Σa), and then applying the
following transformations:
(a) NORTA [17, 40], which transforms vector a into vector b′ = {b′1, · · · , b′k} with
b′i ∼ Fbi , i ∈ [1, k] and the corresponding covariance matrix Σb′ ∼= Σb by adjusting the
covariance matrix Σa of a.
b′i = F−1bi
[Φ(ai)] , i ∈ [1, k], (1)
where Φ(·) denotes the univariate standard normal cdf and F−1bi
(·) denotes the inverse
of Fbi . To achieve Σb′ ∼= Σb, a matrix Λa that denotes the covariance of the input vector
114

a can be uniquely determined [52]. If Λa is a feasible covariance matrix (symmetric
and positive semi-definite with unit diagonal elements; a necessary but insufficient
condition), Σa can be set to Λa. Otherwise, Σa can be approximated by solving the
following equation:
arg minΣa
D(Σa,Λa)
subject to Σa ≥ 0,Σa(i, i) = 1
(2)
where D(·) is a distance function [40].
(b) Inverse transformation [67] to generate a ∼ N (0,Σa) from multivariate uni-
formly distributed random vector z = {z1, · · · , zk}, where zi ∼ U(0, 1), i ∈ [1, k].
a = M ·[Φ−1(z1), · · · ,Φ−1(zk)
]′(3)
where M is a lower-triangular, non-singular, factorization of Σa such that MM′ = Σa,
Φ−1 is the inverse of the univariate standard normal cdf [67].
This completes the proof.
2. Proof of the Non-increasing of the Maximum AMI
Lemma .0.1. In the agglomerative clustering that merge cluster pairs with maximum
AMI at each iteration, let MIiteravg and MIiter+1avg denotes maximum AMI among all
cluster-pairs in the start of iter-th and (iter + 1)-th iteration, resp., then MIiteravg ≥
MIiter+1avg .
Proof. (proof by contradiction) Suppose that the cluster-set Citer = {ζ1, ζ2, · · · , ζS} in
the start of iter-th iteration contains L clusters, and the cluster-pair (ζs1 , ζs2), where
s1, s1 = {1, 2, · · · , S}, is the cluster-pair with highest AMI among all possible cluster-
115

pairs from Citer, i.e., MIiteravg = Iavg(ζs1 , ζs2). In the start of (iter + 1)-th (after iter-th)
iteration, cluster-pair (ζs1 , ζs2) is merged to cluster ζs3 , the corresponding cluster-set
Citer+1 contains ζs3 and all the clusters in Citer excluding ζs1 and ζs2 , i.e.,
Citer+1 = Citer − {ζs1} − {ζs2}+ {ζs3}
As MIiteravg = Iavg(ζs1 , ζs2), Iavg(ζs1 , ζs2) greater than the AMI of all possible cluster-pair
in Citer+1 excluding cluster ζs3 . Therefore, if MIiteravg < MIiter+1avg , there must exist a ζs4
in Citer+1, such that Iavg(ζs1 , ζs2) < Iavg(ζs3 , ζs4). Since
Iavg(ζs3 , ζs4) =H(ζs3) +H(ζs4)−H(ζs3 , ζs4)
|ζs3 ||ζs4|
=H(ζs3) +H(ζs4)−H(ζs3 , ζs4)
(|ζs1|+ |ζs2|)|ζs4|
Furthermore, we have
H(ζs3) +H(ζs4)−H(ζs3 , ζs4)
=Iavg(ζs1 , ζs4)|ζs1||ζs4|+ Iavg(ζs2 , ζs4)|ζs2||ζs4|
+H(ζs1 , ζs4) +H(ζs2 , ζs4)
− (Iavg(ζs1 , ζs2) +H(ζs4) +H(ζs1 , ζs2 , ζs4))
≤Iavg(ζs1 , ζs4)|ζs1||ζs4 |+ Iavg(ζs2 , ζs4)|ζs2||ζs4|
≤max{Iavg(ζs1 , ζs4), Iavg(ζs2 , ζs4)}(|ζs1|+ |ζs2 |)|ζs4|
Finally,
Iavg(ζs3 , ζs4)
≤max{Iavg(ζs1 , ζs4), Iavg(ζs2 , ζs4)}(|ζs1|+ |ζs2|)|ζs4|(|ζs1|+ |ζs2|)|ζs4|
≤max{Iavg(ζs1 , ζs4), Iavg(ζs2 , ζs4)}(|ζs1|+ |ζs2|)|ζs4|
≤Iavg(ζs1 , ζs2)
Therefore, there is no cluster ζs4 that fulfill the condition Iavg(ζs1 , ζs2) < Iavg(ζs3 , ζs4),
which means that MIiteravg ≥MIiter+1avg always true. This completes the proof.
116

Bibliography
[1] Casia iris image database.
[2] Random: Probability, mathematical statistics, stochastic processes.
[3] Verifinger sdk.
[4] A. Adler. Sample images can be independently restored from face recognition
templates. In Canadian Conference on Electrical and Computer Engineering,
volume 2, pages 1163–1166 vol.2, May 2003.
[5] T. Ahonen, A. Hadid, and M. Pietikainen. Face description with local binary
patterns: Application to face recognition. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 28(12):2037–2041, 2006.
[6] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein GAN. CoRR,
abs/1701.07875, 2017.
[7] S. Banerjee, J. S. Bernhard, W. J. Scheirer, K. W. Bowyer, and P. J. Flynn.
SREFI: synthesis of realistic example face images. In IEEE International Joint
Conference on Biometrics, pages 37–45, 2017.
[8] P. N. Belhumeur, J. P. Hespanha, and D. J. Kriegman. Eigenfaces vs. fisherfaces:
Recognition using class specific linear projection. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 19(7):711–720, 1997.
[9] D. Berthelot, T. Schumm, and L. Metz. BEGAN: boundary equilibrium genera-
tive adversarial networks. CoRR, abs/1703.10717, 2017.
117

[10] B. Biggio, G. Fumera, P. Russu, L. Didaci, and F. Roli. Adversarial biometric
recognition : A review on biometric system security from the adversarial machine-
learning perspective. IEEE Signal Processing Magazine, 32(5):31–41, 2015.
[11] K. W. Bowyer and P. J. Flynn. The ND-IRIS-0405 iris image dataset, 2009.
[12] W. E. Burr, D. F. Dodson, and W. T. Polk. Electronic authentication guideline.
US Department of Commerce, Technology Administration, NIST, 2004.
[13] K. Cao and A. K. Jain. Learning fingerprint reconstruction: From minutiae to
image. IEEE Transactions on Information Forensics and Security, 10(1):104–117,
2015.
[14] K. Cao and A. K. Jain. Fingerprint indexing and matching: An integrated ap-
proach. In IEEE International Joint Conference on Biometrics, pages 437–445,
2017.
[15] K. Cao and A. K. Jain. Automated latent fingerprint recognition. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence, 2018.
[16] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman. Vggface2: A dataset
for recognising faces across pose and age. CoRR, abs/1710.08092, 2017.
[17] M. C. Cario and B. L. Nelson. Modeling and generating random vectors with
arbitrary marginal distributions and correlation matrix. Technical report, 1997.
[18] K. Chee, Z. Jin, D. Cai, M. Li, W. Yap, Y. Lai, and B. Goi. Cancellable speech
template via random binary orthogonal matrices projection hashing. Pattern
Recognition, 76:273–287, 2018.
[19] D. Chen, X. Cao, F. Wen, and J. Sun. Blessing of dimensionality: High-
dimensional feature and its efficient compression for face verification. In IEEE
Conference on Computer Vision and Pattern Recognition, pages 3025–3032, 2013.
118

[20] T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang,
and Z. Zhang. Mxnet: A flexible and efficient machine learning library for het-
erogeneous distributed systems. arXiv:1512.01274, 2015.
[21] T. Chugh, K. Cao, and A. K. Jain. Fingerprint spoof buster: Use of minutiae-
centered patches. IEEE Transactions on Information Forensics and Security,
13(9):2190–2202, Sept 2018.
[22] F. Cole, D. Belanger, D. Krishnan, A. Sarna, I. Mosseri, and W. T. Freeman.
Synthesizing normalized faces from facial identity features. In IEEE Conference
on Computer Vision and Pattern Recognition, pages 3386–3395, 2017.
[23] J. Daugman. The importance of being random: statistical principles of iris recog-
nition. Pattern Recognition, 36(2):279–291, 2003.
[24] K. Deb. An efficient constraint handling method for genetic algorithms. Computer
methods in applied mechanics and engineering, 186(2):311–338, 2000.
[25] K. Deep, K. P. Singh, M. Kansal, and C. Mohan. A real coded genetic algorithm
for solving integer and mixed integer optimization problems. Applied Mathematics
and Computation, 212(2):505–518, 2009.
[26] J. Deng, J. Guo, and S. Zafeiriou. Arcface: Additive angular margin loss for deep
face recognition. CoRR, abs/1801.07698, 2018.
[27] O. Deniz, G. B. Garcıa, J. Salido, and F. D. la Torre. Face recognition using
histograms of oriented gradients. Pattern Recognition Letters, 32(12):1598–1603,
2011.
[28] Y. Dodis, L. Reyzin, and A. D. Smith. Fuzzy extractors: How to generate strong
keys from biometrics and other noisy data. In Advances in Cryptology - EU-
ROCRYPT 2004, International Conference on the Theory and Applications of
Cryptographic Techniques, pages 523–540, 2004.
119

[29] N. Dokuchaev. Probability Theory: A Complete One Semester Course. World
Scientific, 2015.
[30] F. Farooq, R. M. Bolle, T. Jea, and N. K. Ratha. Anonymous and revocable
fingerprint recognition. In IEEE Conference on Computer Vision and Pattern
Recognition, 2007.
[31] J. Feng and A. K. Jain. Fingerprint reconstruction: From minutiae to phase.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(2):209–223,
2011.
[32] Y. C. Feng, M.-H. Lim, and P. C. Yuen. Masquerade attack on transform-based
binary-template protection based on perceptron learning. Pattern Recognition,
47(9):3019–3033, 2014.
[33] Y. C. Feng and P. C. Yuen. Binary discriminant analysis for generating binary face
template. IEEE Transactions on Information Forensics and Security, 7(2):613–
624, 2012.
[34] Y. C. Feng, P. C. Yuen, and A. K. Jain. A hybrid approach for generating secure
and discriminating face template. IEEE Transactions on Information Forensics
and Security, 5(1):103–117, 2010.
[35] J. Galbally, C. McCool, J. Fierrez, S. Marcel, and J. Ortega-Garcia. On the
vulnerability of face verification systems to hill-climbing attacks. Pattern Recog-
nition, 43(3):1027–1038, 2010.
[36] J. Galbally, A. Ross, M. Gomez-Barrero, J. Fierrez, and J. Ortega-Garcia.
Iris image reconstruction from binary templates: An efficient probabilistic ap-
proach based on genetic algorithms. Computer Vision and Image Understanding,
117(10):1512–1525, 2013.
[37] A. K. Gangwar and A. Joshi. Deepirisnet: Deep iris representation with applica-
tions in iris recognition and cross-sensor iris recognition. In IEEE International
Conference on Image Processing, pages 2301–2305, 2016.
120

[38] H. Gao, H. Yuan, Z. Wang, and S. Ji. Pixel deconvolutional networks. CoRR,
abs/1705.06820, 2017.
[39] C. Gentry. A fully homomorphic encryption scheme. Stanford University, 2009.
[40] S. Ghosh and S. G. Henderson. Behavior of the NORTA method for correlated
random vector generation as the dimension increases. ACM Transactions Model.
Comput. Simul., 13(3):276–294, 2003.
[41] M. Gomez-Barrero, J. Galbally, C. Rathgeb, and C. Busch. General framework
to evaluate unlinkability in biometric template protection systems. IEEE Trans-
actions on Information Forensics and Security, 13(6):1406–1420, 2018.
[42] M. Gomez-Barrero, E. Maiorana, J. Galbally, P. Campisi, and J. Fierrez. Multi-
biometric template protection based on homomorphic encryption. Pattern Recog-
nition, 67:149–163, 2017.
[43] I. Goodfellow, Y. Bengio, and A. Courville. Deep Learning. MIT Press, 2016.
http://www.deeplearningbook.org.
[44] I. J. Goodfellow. NIPS 2016 tutorial: Generative adversarial networks. CoRR,
abs/1701.00160, 2017.
[45] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair,
A. C. Courville, and Y. Bengio. Generative adversarial nets. In Advances in
Neural Information Processing Systems, pages 2672–2680, 2014.
[46] R. Gross, I. Matthews, J. Cohn, T. Kanade, and S. Baker. The cmu multi-pose,
illumination, and expression (multi-pie) face database. CMU Robotics Institute.
TR-07-08, Tech. Rep, 2007.
[47] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C. Courville. Im-
proved training of wasserstein gans. In Advances in Neural Information Processing
Systems, pages 5769–5779, 2017.
121

[48] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and
benchmark for large-scale face recognition. In European Conference on Computer
Vision, pages 87–102, 2016.
[49] K. Hara, D. Saitoh, and H. Shouno. Analysis of dropout learning regarded as
ensemble learning. In International Conference on Artificial Neural Networks,
pages 72–79, 2016.
[50] M. Hayat, S. H. Khan, N. Werghi, and R. Goecke. Joint registration and repre-
sentation learning for unconstrained face identification. In IEEE Conference on
Computer Vision and Pattern Recognition, pages 1551–1560, 2017.
[51] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition.
In IEEE Conference on Computer Vision and Pattern Recognition, pages 770–
778, 2016.
[52] S. G. Henderson, B. A. Chiera, and R. M. Cooke. Generating ldquo;dependent
rdquo; quasi-random numbers. In Winter Simulation Conference, volume 1, pages
527–536 vol.1, 2000.
[53] S. Hidano, T. Ohki, and K. Takahashi. Evaluation of security for biometric
guessing attacks in biometric cryptosystem using fuzzy commitment scheme. In
International Conference of Biometrics Special Interest Group, pages 1–6, 2012.
[54] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdi-
nov. Improving neural networks by preventing co-adaptation of feature detectors.
CoRR, abs/1207.0580, 2012.
[55] L. Hornak, A. Ross, S. G. Crihalmeanu, and S. A. Schuckers. A protocol for
multibiometric data acquisition storage and dissemination. Technical report, West
Virginia University, https://eidr. wvu. edu/esra/documentdata. eSRA, 2007.
[56] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger. Densely connected
convolutional networks. In IEEE Conference on Computer Vision and Pattern
Recognition, pages 2261–2269, 2017.
122

[57] G. B. Huang, M. A. Mattar, H. Lee, and E. G. Learned-Miller. Learning to
align from scratch. In Advances in Neural Information Processing Systems, pages
773–781, 2012.
[58] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training
by reducing internal covariate shift. In International Conference on Machine
Learning, pages 448–456, 2015.
[59] ISO/IEC 19794-2:2011. Information technology – biometric data interchange
formats – part 2: Finger minutiae data. 2011.
[60] ISO/IEC 24745:2011. Information technology – security techniques – biometric
information protection. 2011.
[61] A. K. Jain, K. Nandakumar, and A. Ross. 50 years of biometric research: Accom-
plishments, challenges, and opportunities. Pattern Recognition Letters, 79:80–105,
2016.
[62] A. K. Jain, S. Pankanti, K. Nandakumar, S. Prabhakar, S. S. Arora, A. M. Nam-
boodiri, and A. Ross. Global id: Biometrics for billions of identities. Technical
Report MSU-CSE-18-2, Department of Computer Science, Michigan State Uni-
versity, 2018.
[63] A. K. Jain, S. Prabhakar, L. Hong, and S. Pankanti. Fingercode: A filterbank
for fingerprint representation and matching. In IEEE Conference on Computer
Vision and Pattern Recognition, page 2187, 1999.
[64] Z. Jin, J. Hwang, Y. Lai, S. Kim, and A. B. J. Teoh. Ranking-based locality
sensitive hashing-enabled cancelable biometrics: Index-of-max hashing. IEEE
Transactions on Information Forensics and Security, 13(2):393–407, 2018.
[65] Z. Jin, M. Lim, A. B. J. Teoh, B. Goi, and Y. H. Tay. Generating fixed-length
representation from minutiae using kernel methods for fingerprint authentication.
IEEE Transactions on Systems, Man, and Cybernetics: Systems, 46(10):1415–
1428, 2016.
123

[66] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer
and super-resolution. In European Conference on Computer Vision, pages 694–
711, 2016.
[67] M. E. Johnson. Multivariate statistical simulation: A guide to selecting and
generating continuous multivariate distributions. John Wiley & Sons, 2013.
[68] A. Juels and M. Sudan. A fuzzy vault scheme. Des. Codes Cryptography,
38(2):237–257, 2006.
[69] A. Juels and M. Wattenberg. A fuzzy commitment scheme. In ACM Conference
on Computer and Communications Security, pages 28–36, 1999.
[70] S. Kanade, D. Petrovska-Delacrtaz, and B. Dorizzi. Multi-biometrics based cryp-
tographic key regeneration scheme. In IEEE International Conference on Bio-
metrics: Theory, Applications, and Systems, pages 1–7, Sept 2009.
[71] S. G. Kanade, D. Petrovska-Delacretaz, and B. Dorizzi. Obtaining cryptographic
keys using feature level fusion of iris and face biometrics for secure user authenti-
cation. In IEEE Conference on Computer Vision and Pattern Recognition, pages
138–145, 2010.
[72] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of gans for
improved quality, stability, and variation. CoRR, abs/1710.10196, 2017.
[73] E. J. C. Kelkboom, X. Zhou, J. Breebaart, R. N. J. Veldhuis, and C. Busch. Multi-
algorithm fusion with template protection. In IEEE International Conference on
Biometrics: Theory, Applications, and Systems, pages 1–8, Sept 2009.
[74] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. CoRR,
abs/1412.6980, 2014.
[75] G. Klambauer, T. Unterthiner, A. Mayr, and S. Hochreiter. Self-normalizing
neural networks. In Advances in Neural Information Processing Systems, pages
972–981, 2017.
124

[76] B. F. Klare, B. Klein, E. Taborsky, A. Blanton, J. Cheney, K. Allen, P. Grother,
A. Mah, M. J. Burge, and A. K. Jain. Pushing the frontiers of unconstrained face
detection and recognition: IARPA janus benchmark A. In IEEE Conference on
Computer Vision and Pattern Recognition, pages 1931–1939, 2015.
[77] J.-G. Ko, Y.-H. Gil, J.-H. Yoo, and K.-I. Chung. A novel and efficient feature
extraction method for iris recognition. ETRI journal, 29(3):399–401, 2007.
[78] A. Kraskov and P. Grassberger. Mic: mutual information based hierarchical
clustering. In Information theory and statistical learning, pages 101–123. Springer,
2009.
[79] Y. Lai, Z. Jin, A. B. J. Teoh, B. Goi, W. Yap, T. Chai, and C. Rathgeb. Can-
cellable iris template generation based on indexing-first-one hashing. Pattern
Recognition, 64:105–117, 2017.
[80] E. Learned-Miller, G. B. Huang, A. RoyChowdhury, H. Li, and G. Hua. Labeled
faces in the wild: A survey. In Advances in Face Detection and Facial Image
Analysis, pages 189–248. Springer, 2016.
[81] S. Z. Li and A. K. Jain, editors. Encyclopedia of Biometrics. Springer US, 2009.
[82] S. Liao, Z. Lei, D. Yi, and S. Z. Li. A benchmark study of large-scale uncon-
strained face recognition. In IEEE International Joint Conference on Biometrics,
pages 1–8, 2014.
[83] M. Lim and A. B. J. Teoh. A novel encoding scheme for effective biometric dis-
cretization: Linearly separable subcode. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 35(2):300–313, 2013.
[84] M. Lim, S. Verma, G. Mai, and P. C. Yuen. Learning discriminability-preserving
histogram representation from unordered features for multibiometric feature-
fused-template protection. Pattern Recognition, 60:706–719, 2016.
125

[85] N. Liu, M. Zhang, H. Li, Z. Sun, and T. Tan. Deepiris: Learning pairwise filter
bank for heterogeneous iris verification. Pattern Recognition Letters, 82:154–161,
2016.
[86] S. Liu, P. C. Yuen, S. Zhang, and G. Zhao. 3d mask face anti-spoofing with
remote photoplethysmography. In European Conference on Computer Vision,
pages 85–100, 2016.
[87] W. Liu, Y. Wen, Z. Yu, and M. Yang. Large-margin softmax loss for convolutional
neural networks. In International Conference on Machine Learning, pages 507–
516, 2016.
[88] G. Mai, K. Cao, X. Lan, P. C. Yuen, and A. K. Jain. Generating secure deep
biometric templates. IEEE Transactions on Pattern Analysis and Machine In-
telligence, in preparation, 2018.
[89] G. Mai, K. Cao, P. C. Yuen, and A. K. Jain. On the reconstruction of face images
from deep face templates. IEEE Transactions on Pattern Analysis and Machine
Intelligence, to appear, 2018.
[90] G. Mai, M. Lim, and P. C. Yuen. Fusing binary templates for multi-biometric
cryptosystems. In IEEE International Conference on Biometrics Theory, Appli-
cations and Systems, pages 1–8, 2015.
[91] G. Mai, M. Lim, and P. C. Yuen. Binary feature fusion for discriminative and
secure multi-biometric cryptosystems. Image and Vision Computing, 58:254–265,
2017.
[92] G. Mai, M. Lim, and P. C. Yuen. On the guessability of binary biometric tem-
plates: A practical guessing entropy based approach. In IEEE International Joint
Conference on Biometrics, pages 367–374, 2017.
[93] E. Maiorana, G. E. Hine, and P. Campisi. Hill-climbing attacks on multibio-
metrics recognition systems. IEEE Transactions on Information Forensics and
Security, 10(5):900–915, 2015.
126

[94] D. Maltoni, D. Maio, A. K. Jain, and S. Prabhakar. Handbook of fingerprint
recognition. Springer Science & Business Media, 2009.
[95] X. Mao, Q. Li, H. Xie, R. Y. K. Lau, Z. Wang, and S. P. Smolley. Least squares
generative adversarial networks. In IEEE International Conference on Computer
Vision, pages 2813–2821, 2017.
[96] I. Masi, A. T. Tran, T. Hassner, J. T. Leksut, and G. G. Medioni. Do we
really need to collect millions of faces for effective face recognition? In European
Conference on Computer Vision, pages 579–596, 2016.
[97] A. Mignon and F. Jurie. Reconstructing faces from their signatures using RBF
regression. In British Machine Vision Conference, 2013.
[98] B. Moghaddam, W. Wahid, and A. Pentland. Beyond eigenfaces: Probabilistic
matching for face recognition. In International Conference on Face & Gesture
Recognition, pages 30–35, 1998.
[99] P. K. Mohanty, S. Sarkar, and R. Kasturi. From scores to face templates: A
model-based approach. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 29(12):2065–2078, 2007.
[100] A. Nagar, K. Nandakumar, and A. K. Jain. A hybrid biometric cryptosystem for
securing fingerprint minutiae templates. Pattern Recognition Letters, 31(8):733–
741, 2010.
[101] A. Nagar, K. Nandakumar, and A. K. Jain. Multibiometric cryptosystems based
on feature-level fusion. IEEE Transactions on Information Forensics and Secu-
rity, 7(1):255–268, 2012.
[102] K. Nandakumar and A. K. Jain. Biometric template protection: Bridging the
performance gap between theory and practice. IEEE Signal Processing Magazine,
32(5):88–100, 2015.
127

[103] A. Nguyen, J. Clune, Y. Bengio, A. Dosovitskiy, and J. Yosinski. Plug & play
generative networks: Conditional iterative generation of images in latent space.
In IEEE Conference on Computer Vision and Pattern Recognition, pages 3510–
3520, 2017.
[104] C. Otto, D. Wang, and A. K. Jain. Clustering millions of faces by identity. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 40(2):289–303, 2018.
[105] R. K. Pandey, Y. Zhou, B. U. Kota, and V. Govindaraju. Deep secure encoding for
face template protection. In IEEE Conference on Computer Vision and Pattern
Recognition Workshops, pages 77–83, 2016.
[106] O. M. Parkhi, A. Vedaldi, and A. Zisserman. Deep face recognition. In British
Machine Vision Conference, pages 41.1–41.12, 2015.
[107] K. Patel, H. Han, and A. K. Jain. Secure face unlock: Spoof detection on smart-
phones. IEEE Transactions on Information Forensics and Security, 11(10):2268–
2283, 2016.
[108] V. M. Patel, N. K. Ratha, and R. Chellappa. Cancelable biometrics: A review.
IEEE Signal Processing Magazine, 32(5):54–65, 2015.
[109] H. Peng, F. Long, and C. H. Q. Ding. Feature selection based on mutual infor-
mation: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 27(8):1226–1238,
2005.
[110] P. J. Phillips, P. J. Flynn, W. T. Scruggs, K. W. Bowyer, J. Chang, K. Hoffman,
J. Marques, J. Min, and W. J. Worek. Overview of the face recognition grand
challenge. In IEEE Conference on Computer Vision and Pattern Recognition,
pages 947–954, 2005.
[111] P. J. Phillips, H. Moon, S. A. Rizvi, and P. J. Rauss. The FERET evalua-
tion methodology for face-recognition algorithms. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 22(10):1090–1104, 2000.
128

[112] M. M. Prasad, M. Sukumar, and A. G. Ramakrishnan. Orthogonal LDA in PCA
transformed subspace. In International Conference on Frontiers in Handwriting
Recognition, pages 172–175, 2010.
[113] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with
deep convolutional generative adversarial networks. CoRR, abs/1511.06434, 2015.
[114] S. Rane, Y. Wang, S. C. Draper, and P. Ishwar. Secure biometrics: Concepts,
authentication architectures, and challenges. IEEE Signal Processing Magazine,
30(5):51–64, 2013.
[115] N. K. Ratha, S. Chikkerur, J. H. Connell, and R. M. Bolle. Generating cance-
lable fingerprint templates. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 29(4):561–572, 2007.
[116] N. K. Ratha, J. H. Connell, and R. M. Bolle. Enhancing security and privacy in
biometrics-based authentication systems. IBM Systems Journal, 40(3):614–634,
2001.
[117] C. Rathgeb, A. Uhl, and P. Wild. Iris recognition: from segmentation to template
security. Advances in Information Security, 59, 2012.
[118] A. Ross, J. Shah, and A. K. Jain. From template to image: Reconstructing
fingerprints from minutiae points. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 29(4):544–560, 2007.
[119] R. Roth. Introduction to coding theory. Cambridge University Press, 2006.
[120] T. Salimans, I. J. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen.
Improved techniques for training gans. In Advances in Neural Information Pro-
cessing Systems, pages 2226–2234, 2016.
[121] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for
face recognition and clustering. In IEEE Conference on Computer Vision and
Pattern Recognition, pages 815–823, 2015.
129

[122] R. Shao, X. Lan, and P. C. Yuen. Deep convolutional dynamic texture learning
with adaptive channel-discriminability for 3d mask face anti-spoofing. In IEEE
International Joint Conference on Biometrics, pages 748–755, 2017.
[123] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale
image recognition. CoRR, abs/1409.1556, 2014.
[124] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov.
Dropout: a simple way to prevent neural networks from overfitting. Journal of
Machine Learning Research, 15(1):1929–1958, 2014.
[125] W. Stallings. Cryptography and network security: principles and practice, vol-
ume 7. Pearson, 2016.
[126] Y. Sun, Y. Chen, X. Wang, and X. Tang. Deep learning face representation by
joint identification-verification. In Advances in Neural Information Processing
Systems, pages 1988–1996, 2014.
[127] Y. Sun, X. Wang, and X. Tang. Sparsifying neural network connections for face
recognition. In IEEE Conference on Computer Vision and Pattern Recognition,
pages 4856–4864, 2016.
[128] Y. Sutcu, Q. Li, and N. D. Memon. Secure biometric templates from fingerprint-
face features. In IEEE Conference on Computer Vision and Pattern Recognition,
2007.
[129] Y. Tai, J. Yang, X. Liu, and C. Xu. Memnet: A persistent memory network for
image restoration. In IEEE International Conference on Computer Vision, pages
4549–4557, 2017.
[130] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf. Deepface: Closing the gap to
human-level performance in face verification. In IEEE Conference on Computer
Vision and Pattern Recognition, pages 1701–1708, 2014.
130

[131] Y. Tang, F. Gao, J. Feng, and Y. Liu. Fingernet: An unified deep network
for fingerprint minutiae extraction. In IEEE International Joint Conference on
Biometrics, pages 108–116, 2017.
[132] J. R. Troncoso-Pastoriza, D. Gonzalez-Jimenez, and F. Perez-Gonzalez. Fully pri-
vate noninteractive face verification. IEEE Transactions on Information Forensics
and Security, 8(7):1101–1114, 2013.
[133] M. A. Turk and A. Pentland. Face recognition using eigenfaces. In IEEE Con-
ference on Computer Vision and Pattern Recognition, pages 586–591, 1991.
[134] A. Uhl and P. Wild. Weighted adaptive hough and ellipsopolar transforms for
real-time iris segmentation. In IAPR International Conference on Biometrics,
pages 283–290, 2012.
[135] S. ul Hussain, T. Napoleon, and F. Jurie. Face recognition using local quantized
patterns. In British Machine Vision Conference, pages 1–11, 2012.
[136] J. H. Van Lint. Introduction to Coding Theory, volume 86. Springer, 2012.
[137] A. Vij and A. M. Namboodiri. Learning minutiae neighborhoods: A new bi-
nary representation for matching fingerprints. In IEEE Conference on Computer
Vision and Pattern Workshops, pages 64–69, 2014.
[138] D. Wang, C. Otto, and A. K. Jain. Face search at scale. IEEE Transactions on
Pattern Analysis and Machine Intelligence, 39(6):1122–1136, 2017.
[139] H. Wang, Y. Wang, Z. Zhou, X. Ji, Z. Li, D. Gong, J. Zhou, and W. Liu. Cosface:
Large margin cosine loss for deep face recognition. CoRR, abs/1801.09414, 2018.
[140] D. Wen, H. Han, and A. K. Jain. Face spoof detection with image distortion
analysis. IEEE Transactions on Information Forensics and Security, 10(4):746–
761, 2015.
131

[141] L. Wolf, T. Hassner, and I. Maoz. Face recognition in unconstrained videos with
matched background similarity. In IEEE Conference on Computer Vision and
Pattern Recognition, pages 529–534, 2011.
[142] X. Wu, R. He, Z. Sun, and T. Tan. A light cnn for deep face representation with
noisy labels. IEEE Transactions on Information Forensics and Security, pages
1–1, 2018.
[143] H. Xu and R. N. J. Veldhuis. Binary representations of fingerprint spectral minu-
tiae features. In International Conference on Pattern Recognition, pages 1212–
1216.
[144] R. Xu and D. C. W. II. Survey of clustering algorithms. IEEE Transactions on
Neural Networks, 16(3):645–678, 2005.
[145] D. Yambay, B. Becker, N. Kohli, D. Yadav, A. Czajka, K. W. Bowyer, S. Schuck-
ers, R. Singh, M. Vatsa, A. Noore, D. Gragnaniello, C. Sansone, L. Verdoliva,
L. He, Y. Ru, H. Li, N. Liu, Z. Sun, and T. Tan. Livdet iris 2017 - iris liveness de-
tection competition 2017. In IEEE International Joint Conference on Biometrics,
pages 733–741, 2017.
[146] J. Yang and X. Zhang. Feature-level fusion of fingerprint and finger-vein for
personal identification. Pattern Recognition Letters, 33(5):623–628, 2012.
[147] D. Yi, Z. Lei, S. Liao, and S. Z. Li. Learning face representation from scratch.
CoRR, abs/1411.7923, 2014.
[148] X. Yin and X. Liu. Multi-task convolutional neural network for pose-invariant
face recognition. IEEE Transactions on Image Processing, 27(2):964–975, 2018.
[149] P. C. Yuen and J. Lai. Face representation using independent component analysis.
Pattern Recognition, 35(6):1247–1257, 2002.
[150] S. Zagoruyko and N. Komodakis. Wide residual networks. In British Machine
Vision Conference, 2016.
132

[151] M. D. Zeiler, D. Krishnan, G. W. Taylor, and R. Fergus. Deconvolutional net-
works. In IEEE Conference on Computer Vision and Pattern Recognition, pages
2528–2535, 2010.
[152] M. D. Zeiler, G. W. Taylor, and R. Fergus. Adaptive deconvolutional networks
for mid and high level feature learning. In IEEE International Conference on
Computer Vision, pages 2018–2025, 2011.
[153] F. Zhang and J. Feng. High-resolution mobile fingerprint matching via deep joint
knn-triplet embedding. In AAAI Conference on Artificial Intelligence, pages
5019–5020, 2017.
[154] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint face detection and alignment
using multitask cascaded convolutional networks. IEEE Signal Processing Letter,
23(10):1499–1503, 2016.
[155] Z. Zhao and A. Kumar. Accurate periocular recognition under less constrained
environment using semantics-assisted convolutional neural network. IEEE Trans-
actions on Information Forensics and Security, 12(5):1017–1030, 2017.
[156] Z. Zhao and A. Kumar. Towards more accurate iris recognition using deeply
learned spatially corresponding features. In IEEE International Conference on
Computer Vision, pages 3829–3838, 2017.
[157] A. Zhmoginov and M. Sandler. Inverting face embeddings with convolutional
neural networks. CoRR, abs/1606.04189, 2016.
[158] Z.-H. Zhou. Ensemble methods: foundations and algorithms. CRC press, 2012.
133

Published and Submitted Papers
1. G. Mai, K. Cao, P. C. Yuen and A. K. Jain, “On the Reconstruction of Face
Images from Deep Face Templates,” IEEE Transactions on Pattern Analysis and
Machine Intelligence , to appear, 2018.
2. G. Mai, M.-H. Lim and P. C. Yuen, “Binary Feature Fusion for Discriminative
and Secure Multi-biometric Cryptosystem,” Image and Vision Computing, vol.
58, pp.254-265, 2017.
3. G. Mai, K. Cao, X. Lan, P. C. Yuen and A. K. Jain, “Generating Secure Deep
Biometric Templates,” IEEE Transactions on Pattern Analysis and Machine In-
telligence , in preparation, 2018.
4. G. Mai, M.-H. Lim and P. C. Yuen, “On the Guessability of Binary Biometric
Templates: A Practical Guessing Entropy based Approach,” IEEE International
Joint Conference on Biometrics (IJCB), 2017.
5. G. Mai, M.-H. Lim and P. C. Yuen, “Fusing Binary Templates for Multi-biometric
Cryptosystem,” IEEE International Conference on Biometrics Theory, Applica-
tions and Systems (BTAS), 2015.
6. M.-H. Lim, S. Verma, G. Mai and P. C. Yuen, “Learning Discriminability-preserving
Histogram Representation from Unordered Features for Multibiometric Feature-
fused-template Protection,” Pattern Recognition, vol. 60, pp.706-719, 2016.
Awards
• June 2017, Excellent Teaching Assistant Performance Award, HKBU.
• April 2014, Third Runner-up Award in ACM Collegiate Programming Contest
(Hong Kong), ACM Hong Kong Chapter.
134

Curriculum Vitae
Academic qualification of the thesis author, Mr. MAI Guangcan:
• Received the degree of Bachelor of Engineering from South China University of
Technology, Guangzhou, P. R. China, July, 2013.
August 2018
135




![Biometric Standards documents/Standards... · Biometric Profiles Biometric [Application] Profile – a conforming subset or combination of base standards used to effect specific biometric](https://img.pdfslide.net/doc/110x75/5f711372ce578d4ee02aea91/biometric-standards-documentsstandards-biometric-profiles-biometric-application.jpg)