Embed Size (px)
Citation preview

Initializations for Nonnegative Matrix Factorization
Shaina Race
North Carolina State University
slrace at ncsu.edu
March 26, 2012
Shaina Race (NCSU) NMF Initializations March 26, 2012 1 / 17

Motivation
NMF is a nonconvex optimization problem with inequality constraints
minW ,H||A−WH||
W ,H ≥ 0
and iterative methods are necessary for its solution.
Shaina Race (NCSU) NMF Initializations March 26, 2012 2 / 17

Motivation
Current NMF algorithms typically converge slowly and then at localminima [1].
The majority of algorithms in the literature initialize W and Hrandomly.
Results of any given algorithm are not unique with different randominitializations. Several instances must be run so that the best solutioncan be chosen. This is expensive.
Shaina Race (NCSU) NMF Initializations March 26, 2012 3 / 17

Motivation
Current NMF algorithms typically converge slowly and then at localminima [1].
The majority of algorithms in the literature initialize W and Hrandomly.
Results of any given algorithm are not unique with different randominitializations. Several instances must be run so that the best solutioncan be chosen. This is expensive.
Shaina Race (NCSU) NMF Initializations March 26, 2012 3 / 17

Motivation
Current NMF algorithms typically converge slowly and then at localminima [1].
The majority of algorithms in the literature initialize W and Hrandomly.
Results of any given algorithm are not unique with different randominitializations. Several instances must be run so that the best solutioncan be chosen. This is expensive.
Shaina Race (NCSU) NMF Initializations March 26, 2012 3 / 17

Initializations from matrix A
Meyer et al. [2] suggested method called ”random Acol” whichinitializes each column of the matrix W by taking the average of prandom rows of A.
If A is sparse this makes more sense than creating random dense W
Pro: A very inexpensive technique
Con: A ”minimal” upgrade, solution is still not unique.
Shaina Race (NCSU) NMF Initializations March 26, 2012 4 / 17

Initializations from matrix A
Meyer et al. [2] suggested method called ”random Acol” whichinitializes each column of the matrix W by taking the average of prandom rows of A.
If A is sparse this makes more sense than creating random dense W
Pro: A very inexpensive technique
Con: A ”minimal” upgrade, solution is still not unique.
Shaina Race (NCSU) NMF Initializations March 26, 2012 4 / 17

Initializations from matrix A
Meyer et al. [2] suggested method called ”random Acol” whichinitializes each column of the matrix W by taking the average of prandom rows of A.
If A is sparse this makes more sense than creating random dense W
Pro: A very inexpensive technique
Con: A ”minimal” upgrade, solution is still not unique.
Shaina Race (NCSU) NMF Initializations March 26, 2012 4 / 17

”Centroid” Initialization
Wild et al. suggested the columns of W by first clustering thecolumns of A and using the k centroid vectors from these clusters asthe columns of W.
Pros: Improves error of factorization and number of iterationssubstantially over random initialization. Result of NMF algorithm canbe made unique. Intuitive.
Cons: Computationally more complex because it involves additionalclustering (specifically Spherical k-means was suggested, which itselfmust be initialized!).
Shaina Race (NCSU) NMF Initializations March 26, 2012 5 / 17

”Centroid” Initialization
Wild et al. suggested the columns of W by first clustering thecolumns of A and using the k centroid vectors from these clusters asthe columns of W.
Pros: Improves error of factorization and number of iterationssubstantially over random initialization. Result of NMF algorithm canbe made unique. Intuitive.
Cons: Computationally more complex because it involves additionalclustering (specifically Spherical k-means was suggested, which itselfmust be initialized!).
Shaina Race (NCSU) NMF Initializations March 26, 2012 5 / 17

Exact NMF
Suppose a matrix A had an entirely positive singular valuedecomposition of rank k. Then, using Uk and V T
k to denote thesingular vectors associated with nontrivial singular values, we couldprecisely factor
A = WH
whereW = Uk
√S and H =
√SV T
k
.
Then k is defined to be the nonnegative rank of the matrix A.
Precise factorization is wishful thinking in practice!
Shaina Race (NCSU) NMF Initializations March 26, 2012 6 / 17

Exact NMF
Suppose a matrix A had an entirely positive singular valuedecomposition of rank k. Then, using Uk and V T
k to denote thesingular vectors associated with nontrivial singular values, we couldprecisely factor
A = WH
whereW = Uk
√S and H =
√SV T
k
.
Then k is defined to be the nonnegative rank of the matrix A.
Precise factorization is wishful thinking in practice!
Shaina Race (NCSU) NMF Initializations March 26, 2012 6 / 17

Exact NMF
Suppose a matrix A had an entirely positive singular valuedecomposition of rank k. Then, using Uk and V T
k to denote thesingular vectors associated with nontrivial singular values, we couldprecisely factor
A = WH
whereW = Uk
√S and H =
√SV T
k
.
Then k is defined to be the nonnegative rank of the matrix A.
Precise factorization is wishful thinking in practice!
Shaina Race (NCSU) NMF Initializations March 26, 2012 6 / 17

NNDSVD Initialization
First decompose matrix A into its rank k SVD.
A =k∑
i=1
σiCi where Ci = uivTi
Then decompose each C into positive and negative components,
Ci = C+i − C−
i
.
Obviously, C+i is closest nonnegative matrix to Ci in F-norm.
Shaina Race (NCSU) NMF Initializations March 26, 2012 7 / 17

NNDSVD Initialization
First decompose matrix A into its rank k SVD.
A =k∑
i=1
σiCi where Ci = uivTi
Then decompose each C into positive and negative components,
Ci = C+i − C−
i
.
Obviously, C+i is closest nonnegative matrix to Ci in F-norm.
Shaina Race (NCSU) NMF Initializations March 26, 2012 7 / 17

NNDSVD Initialization
First decompose matrix A into its rank k SVD.
A =k∑
i=1
σiCi where Ci = uivTi
Then decompose each C into positive and negative components,
Ci = C+i − C−
i
.
Obviously, C+i is closest nonnegative matrix to Ci in F-norm.
Shaina Race (NCSU) NMF Initializations March 26, 2012 7 / 17

NNDSVD Initialization
Lemma 1:
Consider any matrix C ∈ <m×n such that rank(C ) = 1, and writeC = C+ − C−. Then rank(C+), rank(C−) ≤ 2.
Proof:
C = xyT = (x+−x−)(y+−y−)T = (x+y+T +x−y−T )−(x+y−T +x−y+T )
=⇒ C+ = x+y+T + x−y−T and C− = x−y+T + x+y−T
Shaina Race (NCSU) NMF Initializations March 26, 2012 8 / 17

NNDSVD Initialization
Lemma 1:
Consider any matrix C ∈ <m×n such that rank(C ) = 1, and writeC = C+ − C−. Then rank(C+), rank(C−) ≤ 2.
Proof:
C = xyT = (x+−x−)(y+−y−)T = (x+y+T +x−y−T )−(x+y−T +x−y+T )
=⇒ C+ = x+y+T + x−y−T and C− = x−y+T + x+y−T
Shaina Race (NCSU) NMF Initializations March 26, 2012 8 / 17

NNDSVD Initialization
Lemma 1:
Consider any matrix C ∈ <m×n such that rank(C ) = 1, and writeC = C+ − C−. Then rank(C+), rank(C−) ≤ 2.
Proof:
C = xyT = (x+−x−)(y+−y−)T = (x+y+T +x−y−T )−(x+y−T +x−y+T )
=⇒ C+ = x+y+T + x−y−T and C− = x−y+T + x+y−T
Shaina Race (NCSU) NMF Initializations March 26, 2012 8 / 17

NNDSVD Initialization
C+ is nonnegative, thus Perron-Frobenius ensures that its first leftand right singular vectors will also be nonnegative. Because of specialstructure of C+ it turns out its second left and right singular vectorsare also positive.
Proof:
C+ = x+y+T + x−y−T
Let x± =x±
||x±||and y± =
y±
||y±||be the normalized x+, x−, y+, y−
Let µ± = ||x±||||y±||.Then,
C+ = µ+x+y+T
+ µ−x−y−T
is the (nonnegative) SVD of C+.
The term involving the max of µ+, µ− is referred to as the ”dominantsingular triplet”
Shaina Race (NCSU) NMF Initializations March 26, 2012 9 / 17

NNDSVD Initialization
C+ is nonnegative, thus Perron-Frobenius ensures that its first leftand right singular vectors will also be nonnegative. Because of specialstructure of C+ it turns out its second left and right singular vectorsare also positive.Proof:
C+ = x+y+T + x−y−T
Let x± =x±
||x±||and y± =
y±
||y±||be the normalized x+, x−, y+, y−
Let µ± = ||x±||||y±||.Then,
C+ = µ+x+y+T
+ µ−x−y−T
is the (nonnegative) SVD of C+.
The term involving the max of µ+, µ− is referred to as the ”dominantsingular triplet”
Shaina Race (NCSU) NMF Initializations March 26, 2012 9 / 17

NNDSVD Initialization
C+ is nonnegative, thus Perron-Frobenius ensures that its first leftand right singular vectors will also be nonnegative. Because of specialstructure of C+ it turns out its second left and right singular vectorsare also positive.Proof:
C+ = x+y+T + x−y−T
Let x± =x±
||x±||and y± =
y±
||y±||be the normalized x+, x−, y+, y−
Let µ± = ||x±||||y±||.Then,
C+ = µ+x+y+T
+ µ−x−y−T
is the (nonnegative) SVD of C+.
The term involving the max of µ+, µ− is referred to as the ”dominantsingular triplet”
Shaina Race (NCSU) NMF Initializations March 26, 2012 9 / 17

NNDSVD Initialization
C+ is nonnegative, thus Perron-Frobenius ensures that its first leftand right singular vectors will also be nonnegative. Because of specialstructure of C+ it turns out its second left and right singular vectorsare also positive.Proof:
C+ = x+y+T + x−y−T
Let x± =x±
||x±||and y± =
y±
||y±||be the normalized x+, x−, y+, y−
Let µ± = ||x±||||y±||.
Then,
C+ = µ+x+y+T
+ µ−x−y−T
is the (nonnegative) SVD of C+.
The term involving the max of µ+, µ− is referred to as the ”dominantsingular triplet”
Shaina Race (NCSU) NMF Initializations March 26, 2012 9 / 17

NNDSVD Initialization
C+ is nonnegative, thus Perron-Frobenius ensures that its first leftand right singular vectors will also be nonnegative. Because of specialstructure of C+ it turns out its second left and right singular vectorsare also positive.Proof:
C+ = x+y+T + x−y−T
Let x± =x±
||x±||and y± =
y±
||y±||be the normalized x+, x−, y+, y−
Let µ± = ||x±||||y±||.Then,
C+ = µ+x+y+T
+ µ−x−y−T
is the (nonnegative) SVD of C+.
The term involving the max of µ+, µ− is referred to as the ”dominantsingular triplet”
Shaina Race (NCSU) NMF Initializations March 26, 2012 9 / 17

NNDSVD Initialization
C+ is nonnegative, thus Perron-Frobenius ensures that its first leftand right singular vectors will also be nonnegative. Because of specialstructure of C+ it turns out its second left and right singular vectorsare also positive.Proof:
C+ = x+y+T + x−y−T
Let x± =x±
||x±||and y± =
y±
||y±||be the normalized x+, x−, y+, y−
Let µ± = ||x±||||y±||.Then,
C+ = µ+x+y+T
+ µ−x−y−T
is the (nonnegative) SVD of C+.
The term involving the max of µ+, µ− is referred to as the ”dominantsingular triplet”
Shaina Race (NCSU) NMF Initializations March 26, 2012 9 / 17
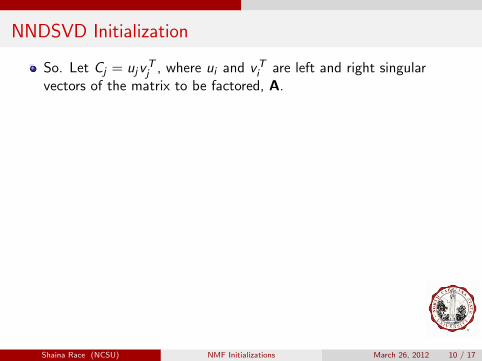
NNDSVD Initialization
So. Let Cj = ujvTj , where ui and vTi are left and right singular
vectors of the matrix to be factored, A.
C+j is nearest positive approximation to Cj . C+
j has rank 2.
Compute SVD of C+j and let µj , xj , yj be the dominant singular
triplet.Initialize first column,row vectors in W,H respectively using usingdominant singular triplets of A. Initialize subsequent column,rowvectors in W,H respectively using using dominant singular triplets ofC+j .
W (:, 1) =√σ1u1
H(1, :) =√σ1v
T1
W (:, j) =√σjµjxj
H(j , :) =√σjµ1y
Tj
Shaina Race (NCSU) NMF Initializations March 26, 2012 10 / 17

NNDSVD Initialization
So. Let Cj = ujvTj , where ui and vTi are left and right singular
vectors of the matrix to be factored, A.C+j is nearest positive approximation to Cj . C+
j has rank 2.
Compute SVD of C+j and let µj , xj , yj be the dominant singular
triplet.Initialize first column,row vectors in W,H respectively using usingdominant singular triplets of A. Initialize subsequent column,rowvectors in W,H respectively using using dominant singular triplets ofC+j .
W (:, 1) =√σ1u1
H(1, :) =√σ1v
T1
W (:, j) =√σjµjxj
H(j , :) =√σjµ1y
Tj
Shaina Race (NCSU) NMF Initializations March 26, 2012 10 / 17

NNDSVD Initialization
So. Let Cj = ujvTj , where ui and vTi are left and right singular
vectors of the matrix to be factored, A.C+j is nearest positive approximation to Cj . C+
j has rank 2.
Compute SVD of C+j and let µj , xj , yj be the dominant singular
triplet.
Initialize first column,row vectors in W,H respectively using usingdominant singular triplets of A. Initialize subsequent column,rowvectors in W,H respectively using using dominant singular triplets ofC+j .
W (:, 1) =√σ1u1
H(1, :) =√σ1v
T1
W (:, j) =√σjµjxj
H(j , :) =√σjµ1y
Tj
Shaina Race (NCSU) NMF Initializations March 26, 2012 10 / 17

NNDSVD Initialization
So. Let Cj = ujvTj , where ui and vTi are left and right singular
vectors of the matrix to be factored, A.C+j is nearest positive approximation to Cj . C+
j has rank 2.
Compute SVD of C+j and let µj , xj , yj be the dominant singular
triplet.Initialize first column,row vectors in W,H respectively using usingdominant singular triplets of A. Initialize subsequent column,rowvectors in W,H respectively using using dominant singular triplets ofC+j .
W (:, 1) =√σ1u1
H(1, :) =√σ1v
T1
W (:, j) =√σjµjxj
H(j , :) =√σjµ1y
Tj
Shaina Race (NCSU) NMF Initializations March 26, 2012 10 / 17

NNDSVD Initialization
Pros:
NMF solution becomes unique.Number of iterations reduces, sometimes drastically.The computation time is generally reduced, even with the addedcomputational effort for the SVD.We can bound the error of the method.
Cons:
Performance of Algorithm is convincing for some data sets, not soconvincing for others.
Shaina Race (NCSU) NMF Initializations March 26, 2012 11 / 17
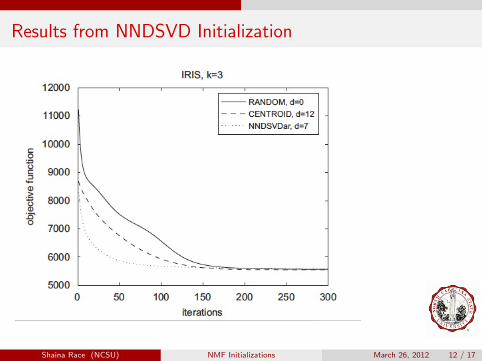
Results from NNDSVD Initialization
Shaina Race (NCSU) NMF Initializations March 26, 2012 12 / 17
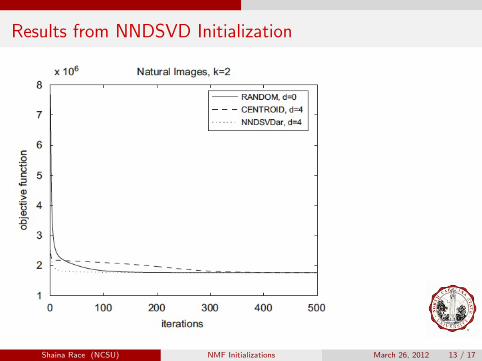
Results from NNDSVD Initialization
Shaina Race (NCSU) NMF Initializations March 26, 2012 13 / 17
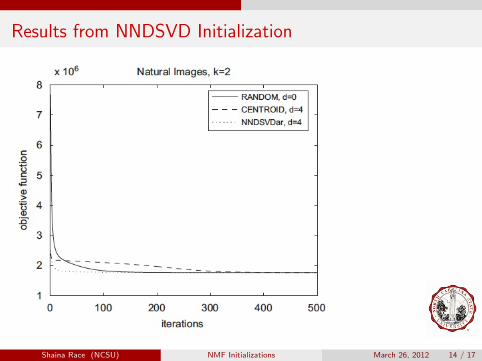
Results from NNDSVD Initialization
Shaina Race (NCSU) NMF Initializations March 26, 2012 14 / 17

Interesting Results
I used the Centroid initialization on W using the centroids of theactual clusters (i.e. the generally unknown answers) in a documentset. I then ran ACLS. I used the resulting H to determine clusters (bylooking at the maximum element in each column) with 79% success.While this is an improvement upon the average 60% success rateobtained by NMF with random initialization, it still suggests thatmaybe the cluster information might be better used another way?
On the same dataset, I simply used the initialization of H (withoutany updates) to cluster the documents in the same manner with74%success. After 500 multiplicative update iterations (using hoyer’ssnmf code) This accuracy was reduced to 23%!!. After convergencefrom ALCS, accuracy was reduced to 69% success!
Shaina Race (NCSU) NMF Initializations March 26, 2012 15 / 17
References
E. Gallopoulos C. Boutsidis.Svd based initialization: A head start for nonnegative matrixfactorization.Pattern Recognition, 41:1350–1362, 2008.
David Duling Amy N. Langville Carl D. Meyer Russell Albright,James Cox.Algorithms, initializations, and convergence for the nonnegative matrixfactorization.Math 81706, North Carolina State University.
Shaina Race (NCSU) NMF Initializations March 26, 2012 16 / 17

The End
Shaina Race (NCSU) NMF Initializations March 26, 2012 17 / 17




























