Embed Size (px)
Citation preview

Introduccion
Autoencoders
RBMs
Redes deConvolucion Deep Learning
Eduardo Morales
INAOE
(INAOE) 1 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Contenido
1 Introduccion
2 Autoencoders
3 RBMs
4 Redes de Convolucion
(INAOE) 2 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• El poder tener una computadora que modele el mundolo suficientemente bien como para exhibir inteligenciaha sido el foco de investigacion en IA desde hace masde medio siglo
• La dificultad en poder representar toda la informacionacerca del mundo de forma utilizable por unacomputadora, ha orillado a los investigadores a recurrira algoritmos de aprendizaje para capturar mucha deesta informacion
• Durante mucho tiempo han existido dominios que sehan resistido a ser resueltos de manera general comoentender imagenes o lenguaje
(INAOE) 3 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• Una idea que ha rondado a los investigadores desdehace tiempo es la de descomponer los problemas ensub-problemas a diferentes niveles de abstraccion
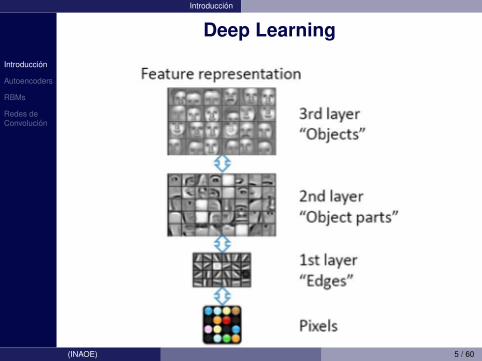
• Por ejemplo, en vision podemos pensar en extraerpequenas variaciones geometricas, como detectores debordes, a partir de los pixeles, de los bordes podemospasar a formas locales, de ahı a objetos, podemospensar en varias capas intermedias
(INAOE) 4 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
(INAOE) 5 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• El foco de aprendizaje profundo o Deep Learning es elde descubrir automaticamente estas abstraccionesentre los atributos de bajo nivel y los conceptos de altonivel
• La profundidad de la arquitectura se refiere al numerode niveles
(INAOE) 6 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Caracterısticas deseables de ML
• Poder aprender funciones complejas con un grannumero de posibles variaciones
• Usar poca informacion del usuario• Poder utilizar una gran cantidad de ejemplos• Aprender principalmente de datos no etiquetados• Poder explotar las sinergıas que se presenten entre
diferentes dominios• Poder capturar la estructura estadıstica de los datos
(aprendizaje no supervisado)
(INAOE) 7 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• La mayorıa de los sistemas de aprendizaje tienenarquitecturas poco profundas (superficiales)
• Durante decadas los investigadores de redesneuronales quisieron entrenar redes multi-capasprofundas con poco exito
• El verdadero cambio vino hasta 2006 con un artıculo deHinton y sus colaboradores de la U. de Toronto.
• Poco despues se desarrollaron muchos otrosesquemas con la misma idea general: guiar elaprendizaje por niveles usando aprendizaje nosupervisado en cada nivel
(INAOE) 8 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• Uno de los argumentos principales es que existenciertas funciones que no pueden ser representadas demanera eficiente por arquitecturas poco profundas
• El exito de los SVM y Kernel Machines radica encambiar la representacion de entrada a una de mayordimensionalidad que permita construir mejores niveles(pero se quedan en un solo nivel)
• Investigaciones en anatomıa del cerebro sugieren queel sistema visual y el generador de voz tienen variascapas de neuronas (entre 5 y 10)
(INAOE) 9 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• Existen funciones booleanas que requieren un numeroexponencial de componentes basicos, sin embargo,requieren un numero compacto en una arquitectura decapas
• Esto sugiere que, por lo menos para algunas funciones,estas se pueden representar de forma compacta envarias capas, y requieren un numero de elementos muygrande de representacion en una arquitectura pocoprofunda
(INAOE) 10 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• Si se inicializan los pesos de las capas intermedias conpesos aleatorios, una red profunda no aprende bien
• Esto se puede remediar si se usan pesos iniciales (noaleatorios) que se aproximan a la solucion final opre-entrenamiento
• Una forma es entrenando pares de capas sucesivascomo una maquinas de Boltzmann restringida (RBM) oAuto-Encoders y despues usar backpropagation paraafinar los pesos.
(INAOE) 11 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• Durante mucho tiempo se trato de entrenar redesmulti-capas profundas. Los resultados sugieren queusando entrenamiento basado en gradiente quedaatrapado en valles de aparentes mınimos locales, yesto empeora con arquitecturas mas profundas.
• Lo que se encontro es que se podrıan obtener muchomejores resultados si se pre-entrenaba la red conalgoritmos no supervisados, en una capa a la vez
• Casi todos los esquemas siguen la idea de aprenderpor capas de manera no supervisada, dando lugar auna inicializacion de parametros adecuada para elaprendizaje supervisado
• La salida de una capa, sirve de entrada para la capasuperior
(INAOE) 12 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
• Se puede entrenar usando algunas de las multiplesvariantes de backpropagation (gradiente conjugado,steepest descent, etc.)
• El problema de backpropagation con muchas capas esque al propagar los errores a las primeras capas sevuelven muy pequenos y por lo tanto poco efectivos
• Esto provoca que la red acaba aprendiendo elpromedio de todos los ejemplos de entrenamiento
(INAOE) 13 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Introduccion
Deep Learning
Existen 3 clases de arquitecturas de deep learning:• Arquitecturas generativas: en general se hace un
entrenamiento no supervisado comopre-entrenamiento, donde se aprende de manera“greedy” capa por capa en forma “bottom-up”. En estacategorıa estan los modelos basados en energıa, queincluyen los auto-encoders y las maquinas deBoltzmann profundas (DBM)
• Arquitecturas discriminativas: Conditional RandomFields profundos y las redes neuronalesconvolucionales (Convolutional Neural Network) o CNN
• Arquitecturas Hıbridas: Usan los dos esquemas
(INAOE) 14 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Deep Autoencoders
Deep Autoencoder: tiene al menos 3 capas en una redneuronal• Capa de entrada• Capa oculta• Capa de salida
Input = decoder(encoder(Input))
(INAOE) 15 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
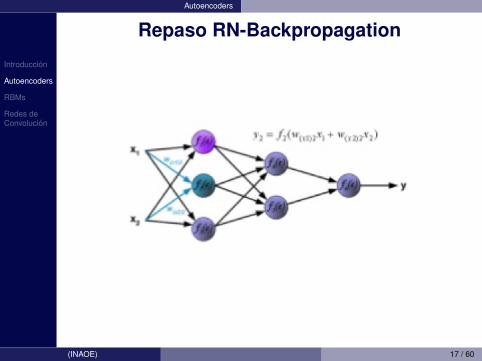
Repaso RN-Backpropagation
(INAOE) 16 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
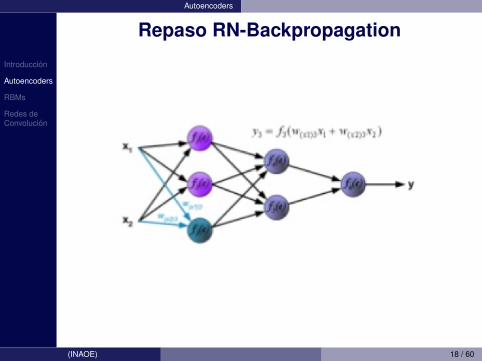
Repaso RN-Backpropagation
(INAOE) 17 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 18 / 60
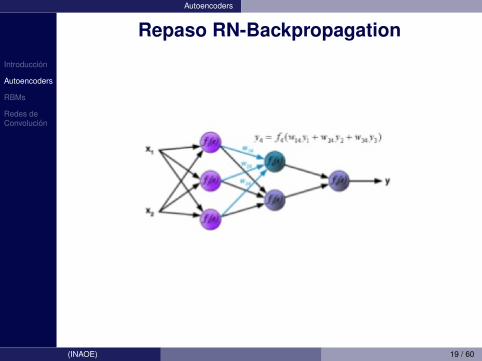
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 19 / 60
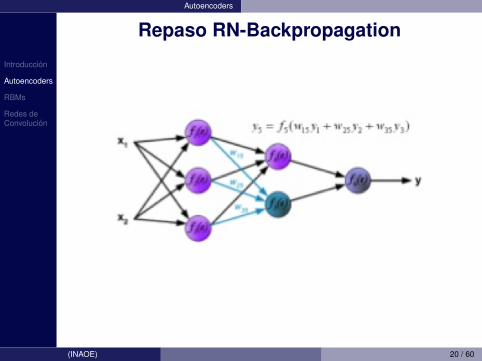
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 20 / 60
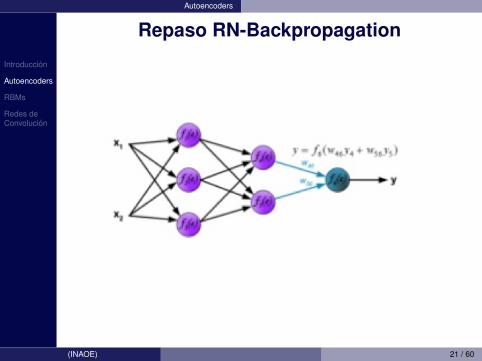
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 21 / 60
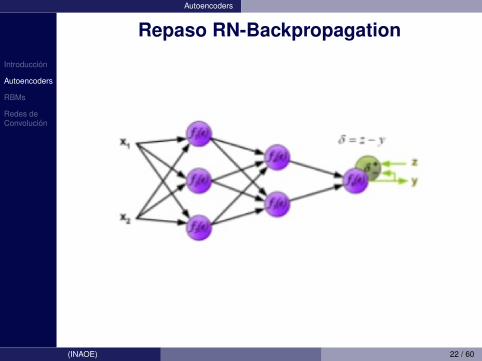
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 22 / 60
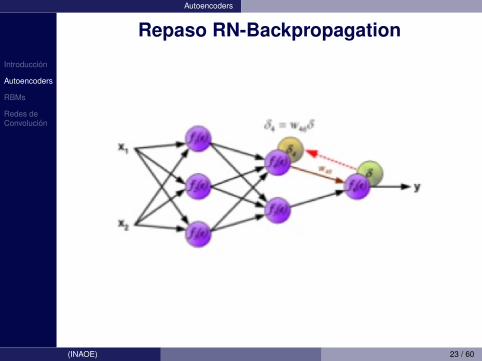
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 23 / 60
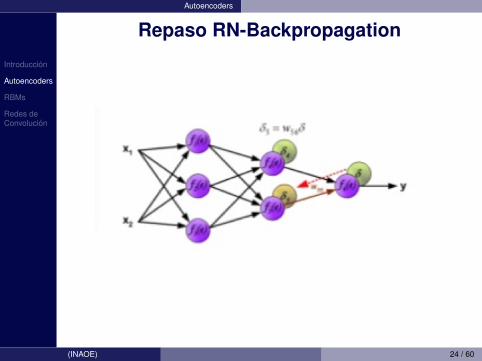
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 24 / 60
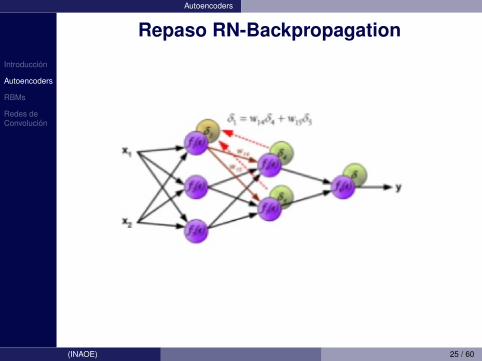
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 25 / 60
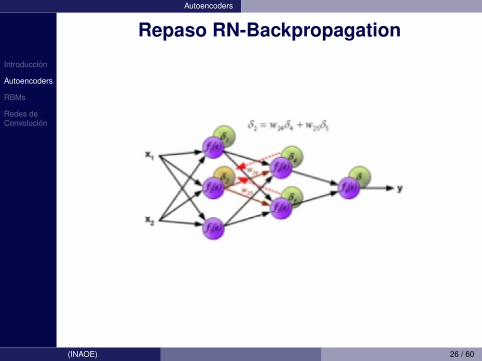
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 26 / 60
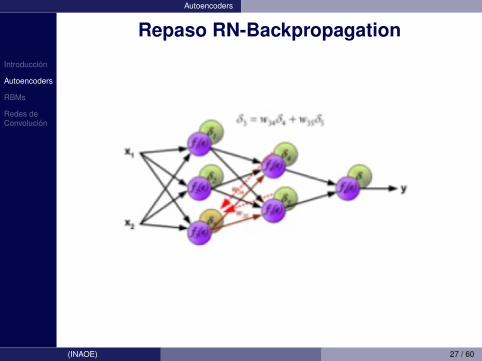
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 27 / 60
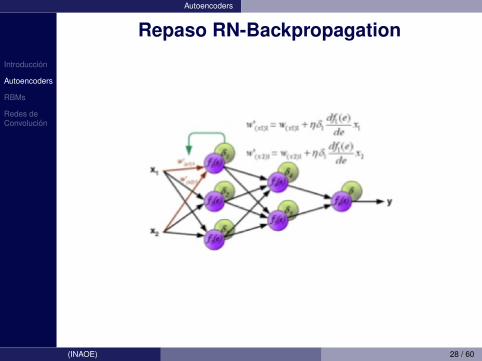
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 28 / 60
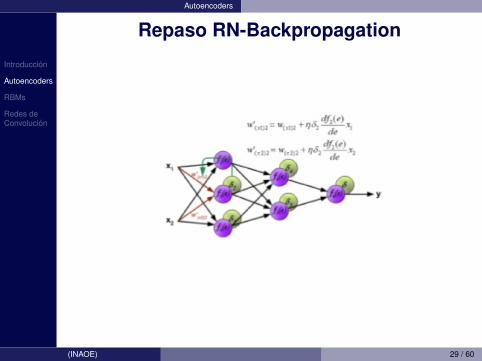
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 29 / 60
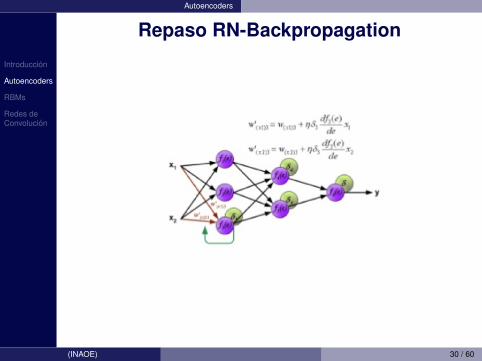
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 30 / 60
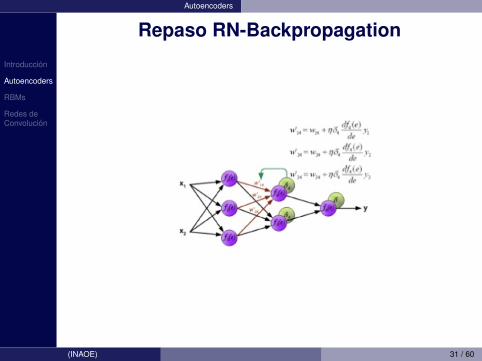
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 31 / 60
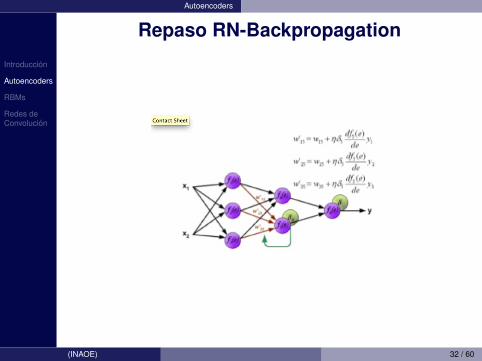
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 32 / 60
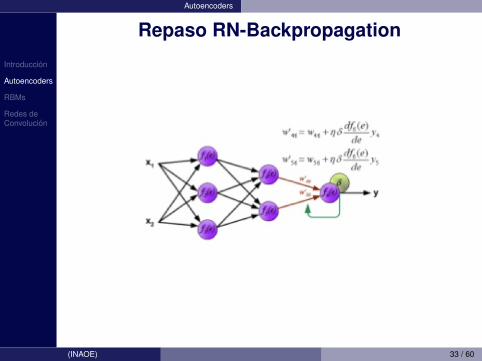
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Repaso RN-Backpropagation
(INAOE) 33 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Deep Autoencoder
Es el mas facil de entender, la idea es a siguiente:• Usa una capa de entrada, una capa oculta con un
menor (aunque puede ser mayor) numero de nodos yentrena para obtener una capa de salida igual a laentrada
• Usa lo que se aprendio en la capa oculta (abstraccion)como la nueva capa entrada para el siguiente nivel
• Continua con los niveles determinados por el usuario• Al final, usa la ultima capa oculta como entrada a un
clasificador
(INAOE) 34 / 60
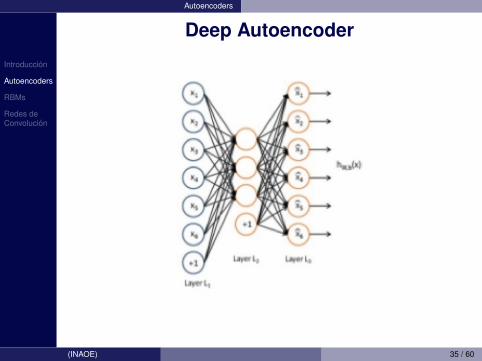
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Autoencoders
Deep Autoencoder
(INAOE) 35 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
Maquinas de Boltzmann Restringidas(RBM)
• Una RBM es un tipo de campo aleatorio de Markov quetiene una capa de unidades oculta (tıpicamenteBernoulli) y una capa de unidades observables(tıpicamente Bernoulli o Gaussiana).
• Se puede representar como un grafo bipartita en dondetodos los nodos visibles estan conectados a todos losnodos ocultas, y no existen conecciones entre nodos dela misma capa.
(INAOE) 36 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
• Se construye una RBM con la capa de entrada conruido gaussiano y una capa oculta binaria.
• Depues se aprende en la siguiente capa, tomandocomo capa de entrada la capa oculta binaria anterior,un RBM binario-binario.
• Esto continua hasta la ultima capa en donde se ponenlas salidas y se entrena todo con backpropagation
(INAOE) 37 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
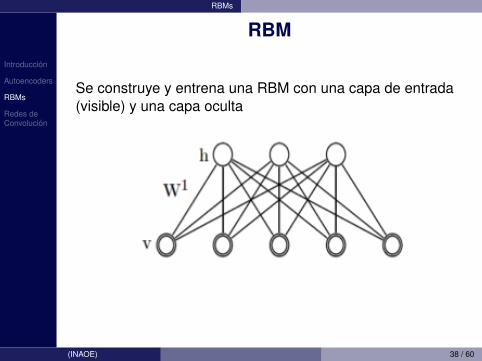
Se construye y entrena una RBM con una capa de entrada(visible) y una capa oculta
(INAOE) 38 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
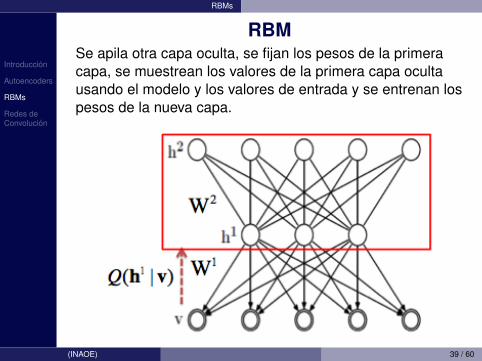
RBMSe apila otra capa oculta, se fijan los pesos de la primeracapa, se muestrean los valores de la primera capa ocultausando el modelo y los valores de entrada y se entrenan lospesos de la nueva capa.
(INAOE) 39 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
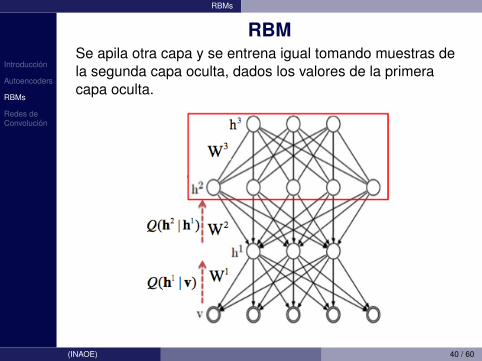
RBMSe apila otra capa y se entrena igual tomando muestras dela segunda capa oculta, dados los valores de la primeracapa oculta.
(INAOE) 40 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
(INAOE) 41 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
• La distribucion conjunta de las unidades visibles (v) ylas unidades ocultas (h) dados los parametros delmodelo (θ), p(v,h; θ) se define en terminos de unafuncion de energıa E(v,h; θ):
p(v,h; θ) =exp(−E(v,h; θ))
Zdonde Z es un factor de normalizacion o particion:
Z =∑
v
∑h
exp(−E(v,h; θ))
(INAOE) 42 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
• La probabilidad marginal del vector visible se obtienesumando sobre todos los nodos ocultos:
p(v; θ) =
∑h exp(−E(v,h; θ))
Z
• Para una RBM Bernoulli (visible) - Bernoulli (oculta), lafuncion de energıa se define como:
E(v,h; θ) = −I∑
i=1
J∑j=1
wijvihj −I∑
i=1
bivi −J∑
j=1
ajhj
donde wij representa la interaccion simetrica entre lasunidades visibles (vi ) y las ocultas (hj ), bi y aj sonsesgos e I y J son el numero de unidades visibles yocultas.
(INAOE) 43 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
• Las probabilidades condicionales se pueden calcularcomo:
p(hj = 1|v; θ) = σ
(I∑
i=1
wijvi + aj
)
p(vi = 1|h; θ) = σ
J∑j=1
wijhi + bi
donde σ(x) = 1/(1 + exp(x))
(INAOE) 44 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM• De la misma forma para una RBM Gaussiana (visible) -
Bernoulli (oculta) la energıa es:
E(v,h; θ) = −I∑
i=1
J∑j=1
wijvihj −12
I∑i=1
(vi − bi)2 −
J∑j=1
ajhj
• Las probabilidades condicionales son:
p(hj = 1|v; θ) = σ
(I∑
i=1
wijvi + aj
)
p(vi = 1|h; θ) = N
J∑j=1
wijhi + bi ,1
donde vi sigue una distribucion normal con media∑J
j=1 wijhi + bi y varianza uno.
(INAOE) 45 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
• Esto ultimo normalmente se hace para procesarvariables contınuas de entrada que se conviertenentonces a binarias y que posteriormente se procesancomo binarias-binarias en capas superiores.
• Para aprender los modelos se tienen que ajustar lospesos wij , lo cual se puede hacer tomando el gradientedel logaritmo de la verosimilitud:
∆wij = Edatos(vihj)− Emodelo(vihj)
Donde Edatos(vihj) es valor esperado en el conjunto deentrenamiento y Emodelo(vihj) definido por el modelo.
(INAOE) 46 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
• Este ultimo no se puede calcular por lo que se hacenaproximaciones.
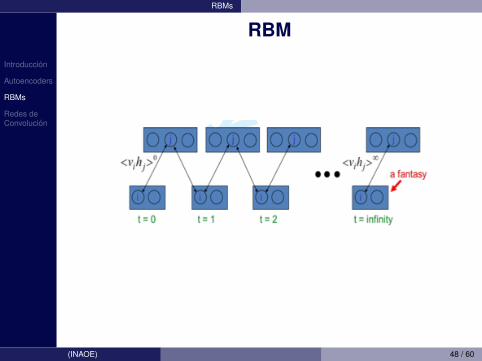
• Una de ellas es hacer muestreos (Gibbs sampling)siguiente los siguientes pasos:
1 Inicializa v0 con los datos2 Muestrea h0 ∼ p(h|v0)3 Muestrea v1 ∼ p(v|h0)4 Muestrea h1 ∼ p(h|v1)
• Esto continua. (v1,h1) es un estimado deEmodelo(vihj) = (v∞,h∞)
(INAOE) 47 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
RBM
(INAOE) 48 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
RBMs
Contrastive Divergence
1 El proceso de MCMC es lento y se han hechoaproximaciones
2 La mas conocida se llama Contrastive Divergence3 Se hacen dos aproximaciones: (i) reemplazar el
promedio sobre todas las entradas (2o termino del logdel error) por una sola muestra y (ii) correr el MCMCsolo por k pasos
(INAOE) 49 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Redes de Convolucion
• Convolucion es un proceso en donde se mezclan dosfuentes de informacion
• Cuando se aplica una convolucion en imagenes sehace en 2 dimensiones.
• Fuentes:• La imagen de entrada (una matriz de 3 dimensiones -
espacio de color, 1 por cada color con valores enterosentre 0 y 255)
• Un kernel de convolucion, que es una matriz denumeros cuyo tamano y valores dice como mezclar lainformacion
(INAOE) 50 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Redes de Convolucion
• La salida es una imagen alterada llamada mapa deatributos (feature map) en DL
• Existe un mapa de atributos por cada color• Una forma de aplicar convolucion es tomar un pedazo
(patch) de la imagen del tamano del kernel• Hacer una multiplicacion de cada elemento en orden de
la imagen con el kernel• La suma de las multiplicaciones nos da el resultado de
un pixel.
(INAOE) 51 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Redes de Convolucion
• Despues se recorre el patch un pixel en otra direccion yse repite el proceso hasta tener todos los pixeles de laimagen.
• Se normaliza la imagen por el tamano del kernel paraasegurarse que la intensidad de la imagen no cambie
• Convolucion se usa en imagenes para filtar informacionindeseable
• Por eso, convolucion tambien se llama filtrado y a loskernels tambien les dicen filtros
• E.g., de filtro de sobel para obtener bordes
(INAOE) 52 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Redes de Convolucion
• Tomar una entrada, transformarla y usar la imagentransformada como entrada a un algoritmo se conocecomo ingenierıa de atributos (feature engineering)
• La ingenierıa de atributos es difıcil y se tiene que partirde cero para nuevas imagenes
• Las redes de convolucion se usan para encontrar losvalores del kernel adecuados para realizar una tarea
• En lugar de fijar valores numericos al kernel, se asignanparametros que se aprenden con datos.
(INAOE) 53 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Redes de Convolucion
• Conforme se entrena la red de convolucion, el kernelfiltra mejor la imagen para conseguir la informacionrelevante
• Este proceso tambien se llama aprendizaje de atributos(feature learning) y es uno de los atractivos de usar DL
• Normalmente no se aprende un solo kernel sino unajerarquıa de multiples kernels al mismo tiempo
• Por ejemplo, si aplicamos un kernel de 32× 16× 16 auna imagen de 256× 256 nos produce 32 mapas deatributos de 241× 241 (tamano de la imagen - tamanokernel + 1)
(INAOE) 54 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Redes de Convolucion
• Estos mapas sirven de entrada para el siguiente kernel.• Una vez aprendida la jerarquıa de kernels se pasa a
una red neuronal normal que los combina paraclasificar la imagen de entrada en clases.
(INAOE) 55 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Ejemplo: LeNet-5
• Se usan kernels locales y se fuerza que todos lospesos sean iguales a lo largo de toda la imagen, lo cualsimplifica mucho los calculos.
• Se usan diferentes kernels/pesos para extraer otrospatrones.
• Despues se hace un sub-muestreo, que hace primeropromedios locales (en areas de 2× 2), lo multiplica porun coeficiente y pasa el resultado por una funcionsigmoide.
(INAOE) 56 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Ejemplo: LeNet-5
(INAOE) 57 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Otros Enfoques
(INAOE) 58 / 60
Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Otros Enfoques
(INAOE) 59 / 60

Introduccion
Autoencoders
RBMs
Redes deConvolucion
Redes de Convolucion
Deep Learning
• Existen varios metodos de Deep Learning, pero no hayninguno que domine a los demas.
• Se requieren algoritmos efectivos y escalablesparalelos para poder procesar grandes cantidades dedatos.
• Se requiere experiencia para poder definir losparametros, numero de capas, razon de aprendizaje,numero de nodos por capa, etc.
• Se requiere mas teorıa
(INAOE) 60 / 60