Embed Size (px)
Citation preview

Kapitel 2
Induktive Statistik
2.1 Grundprinzipien der induktiven Statistik
Ziel: Inferenzschluss, Reprasentationsschluss: Schluss von einer Stichprobe auf Eigenschaf-ten der Grundgesamtheit, aus der sie stammt.
• Von Interesse sei ein Merkmal X in der Grundgesamtheit Ω.
• Ziehe eine Stichprobe (ω1, . . . , ωn) von Elementen aus Ω und werte X jeweils aus.
• Man erhalt Werte x1, . . . , xn. Diese sind Realisationen der i.i.d Zufallsvariablen oderZufallselemente X1, . . . , Xn wobei die Wahrscheinlichkeitsverteilung der X1, . . . , Xn
genau die Haufigkeitsverhaltnisse in der Grundgesamtheit widerspiegelt.
Die Frage lautet also: wie kommt man von Realisationen x1, . . . , xn von i.i.d. Zufallsva-riablen X1, . . . , Xn auf die Verteilung der Xi?
• Dazu nimmt man haufig an, man kenne den Grundtyp der Verteilung der X1, . . . , Xn.Unbekannt seien nur einzelne Parameter davon.
Beispiel: Xi sei normalverteilt, unbekannt seien nur µ, σ2.
=⇒ parametrische Verteilungsannahme (meist im Folgenden)
• Alternativ: Verteilungstyp nicht oder nur schwach festgelegt (z.B. symmetrischeVerteilung)
=⇒ nichtparametrische Modelle
• Klarerweise gilt im Allgemeinen (generelles Problem bei der Modellierung): Parame-trische Modelle liefern scharfere Aussagen – wenn ihre Annahmen zutreffen. Wennihre Annahmen nicht zutreffen, dann existiert die große Gefahr von Fehlschlussen.
Wichtige Fragestellungen der induktiven Statistik: Treffe mittels der Auswertung einer
• Zufallsstichprobe
• moglichst gute ? ? ?
• Aussagen ??
63

64 2.2. Punkschatzung
• uber bestimmte Charakteristika ?
• der Grundgesamtheit.
? Welche Charakteristika sind fur die Fragestellung relevant? Naturlich werden fur dieInferenz bezuglich des Erwartungswerts andere Methoden als fur Schlusse uber dieVarianz benotigt.
?? verschiedene Formen:
– Punktschatzung: z.B. wahrer Anteil 0.4751
– Intervallschatzung: z.B. wahrer Anteil liegt zwischen 0.46 und 0.48
– Hpothesentest: der Anteil liegt hochstens bei 50%
? ? ? Was heißt gut?
– Festlegung von”Gutekriterien “(Genauigkeit? Wahrscheinlichkeit eines Fehlers
gering?)
– Wie konstruiert man ein gutes/optimales Verfahren?
2.2 Punkschatzung
Ziel: Finde einen moglichst guten Schatzwert fur eine bestimmte Kenngroße ϑ (Para-meter) der Grundgesamtheit, z.B. den wahren Anteil der rot/grun-Wahler, den wahrenMittelwert, die wahre Varianz, aber auch z.B. das wahre Maximum (Windgeschwindig-keit).
2.2.1 Schatzfunktionen
Gegeben sei die in Kapitel 2.1 beschriebene Situation: X1, . . . , Xn i.i.d. Stichprobe einesMerkmales X.
Definition: Sei X1, . . . , Xn i.i.d. Stichprobe. Eine Funktion
T = g(X1, . . . , Xn)
heißt Schatzer oder Schatzfunktion.
Beachte nochmals: Vor Ziehung der Stichprobe sind die Werte von T zufallig, deshalbwerden Schatzfunktionen mit Großbuchstaben bezeichnet wie Zufallsvariablen
Typische Beispiele fur Schatzfunktionen:
1. Arithmetisches Mittel der Stichprobe:
X = g(X1, . . . , Xn) =1
n
n∑
i=1
Xi
Fur binare, dummy-kodierte Xi ist X auch die relative Haufigkeit des Auftretensvon
”Xi = 1“ in der Stichprobe

Kapitel 2. Induktive Statistik 65
2. Stichprobenvarianz:
S2 = g(X1, . . . , Xn) =1
n
n∑
i=1
(Xi − X)2
3. Korrigierte Stichprobenvarianz:
S2 = g(X1, . . . , Xn) =1
n− 1
n∑
i=1
(Xi − X)2 =1
n− 1
(n∑
i=1
X2i − n · X2
)
4. Großter Stichprobenwert:
X(n) = g(X1, . . . , Xn) = maxi=1,...,n
Xi
5. Kleinster Stichprobenwert:
X(1) = g(X1, . . . , Xn)) = mini=1,...,n
Xi
Schatzfunktion und Schatzwert: Da X1, . . . , Xn zufallig sind, ist auch die SchatzfunktionT = g(X1, . . . , Xn) zufallig. Zieht man mehrere Stichproben, so erhalt man jeweils andereRealisationen von X1, . . . , Xn, und damit auch von T .
Die Realisation t (konkreter Wert) der Zufallsvariable T (Variable) heißt Schatzwert.
X1, . . . Xn Zufallsvariable T = g(X1, . . . , Xn)↓ ↓ ↓ ↓
x1, . . . xn Realisationen t = g(x1, . . . , xn)
Man hat in der Praxis meist nur eine konkrete Stichprobe und damit auch nur einenkonkreten Wert t von T . Zur Beurteilung der mathematischen Eigenschaften werden aberalle denkbaren Stichproben und die zugehorigen Realisationen der Schatzfunktion T her-angezogen.
D.h. beurteilt wird nicht der einzelne Schatzwert als solcher, sondern die Schatzfunktion,als Methode, d.h. als Regel zur Berechnung des Schatzwerts aus der Stichprobe.
Andere Notation in der Literatur: ϑ Schatzer fur ϑ.
Dabei wird nicht mehr direkt unterschieden zwischen Zufallsvariable (bei uns Großbuch-staben) und Realisation (bei uns klein). =⇒ Schreibe ϑ(X1, . . . , Xn) bzw. ϑ(x1, . . . , xn)wenn die Unterscheidung benotigt wird.
Beispiel: Durchschnittliche Anzahl der Statistikbucher in einer Grundgesamtheit von Stu-denten schatzen.

66 2.2. Punkschatzung
• Grundgesamtheit: Drei Personen Ω = ω1, ω2, ω3.• Merkmal X: Anzahl der Statistikbucher
X(ω1) = 3 X(ω2) = 1 X(ω3) = 2.
Wahrer Durchschnittswert: µ = 2.
• Stichprobe X1, X2 ohne Zurucklegen (Stichprobenumfangn = 2):
X1 = X(ω1) X2 = X(ω2)
wobei
ω1 erste gezogene Person, ω2 zweite gezogene Person.
Betrachte folgende moglichen Schatzer:
T1 = g1(X1, X2) = X =X1 + X2
2T2 = X1
T3 = g(X1, X2) =1
2X(2) =
max(X1, X2)
2
Zur Beurteilung: Alle moglichen Stichproben (vom Umfang n = 2, ohne Zurucklegen)betrachten:
Nummer Personen Realisationen vonder Stichprobe X1 X2 T1 T2 T3
1 ω1, ω2 3 1 2 3 32
2 ω1, ω3 3 2 2.5 3 32
3 ω2, ω1 1 3 2 1 32
4 ω2, ω3 1 2 1.5 1 15 ω3, ω1 2 3 2.5 2 3
2
6 ω3, ω2 2 1 1.5 2 1
2.2.2 Gutekriterien
Beurteile die Schatzfunktionen, also das Verfahren an sich, nicht den einzelnen Schatz-wert. Besonders bei komplexeren Schatzproblemen sind klar festgelegten Guteeigenschaf-ten wichtig.
Naturlich ist auch festzulegen, was geschatzt werden soll. Im Folgenden sei der Parameterϑ stets eine eindimensionale Kenngroße der Grundgesamtheit (z.B. Mittelwert, Varianz,Maximum)
Da T zufallig ist, kann man nicht erwarten, dass man immer den richtigen Wert trifft,aber den Erwartungswert von T berechnen:
Erstes Kriterium: keine systematische Unter- oder Uberschatzung, d.h.
Erwartungswert des Schatzers = wahrer Wert

Kapitel 2. Induktive Statistik 67
Erwartungstreue, Bias: Gegeben sei eine Stichprobe X1, . . . , Xn und eine SchatzfunktionT = g(X1, . . . , Xn) (mit existierendem Erwartungswert).
• T heißt erwartungstreu fur den Parameter ϑ, falls gilt
Eϑ(T ) = ϑ
fur alle ϑ.
• Die GroßeBiasϑ(T ) = Eϑ(T )− ϑ
heißt Bias (oder Verzerrung) der Schatzfunktion. Erwartungstreue Schatzfunktionenhaben per Definition einen Bias von 0.
Man schreibt Eϑ(T ) und Biasϑ(T ), um deutlich zu machen, dass die Großen von demwahren ϑ abhangen.
Anschauliche Interpretation: Erwartungstreue bedeutet, dass man im Mittel (bei wie-derholter Durchfuhrung des Experiments) den wahren Wert trifft.
Fortsetzung des Beispiels: Stichprobenziehung gemaß reiner Zufallsauswahl, d.h. jedeStichprobe hat dieselbe Wahrscheinlichkeit gezogen zu werden (hier 1
6).
Es gilt: (bei ϑ = µ = 2)
Eµ(T1) =1
6(2 + 2.5 + 2 + 1.5 + 2.5 + 1.5) =
12
6= 2
In der Tat gilt allgemein: Das arithmetische Mittel ist erwartungstreu fur den Erwar-tungswert.
Eµ(T2) =1
6(3 + 3 + 1 + 1 + 2 + 2) = 2
Wieder gilt allgemein: Einzelne Stichprobenvariablen ergeben erwartungstreue Schatzerfur den Erwartungswert.
Eµ(T3) =1
6(4 · 3
2+ 2 · 1) =
4
36= 2
T3 ist nicht erwartungstreu.
Biasµ(T3) = Eµ(T3)− 2 =4
3− 6
3= −2
3
Bias und Erwartungstreue bei einigen typischen Schatzfunktionen
• Das arithmetische Mittel X = 1n
∑ni=1 Xi ist erwartungstreu fur den Mittelwert µ
einer Grundgesamtheit: Aus X1, . . . , Xn i.i.d. und Eµ(X1) = Eµ(X2) = . . . = µ folgt:
E(X) = Eµ
(1
n
n∑
i=1
Xi
)=
1
nEµ
(n∑
i=1
Xi
)
=1
n
n∑
i=1
E(Xi)
=1
n
n∑
i=1
µ =1
n· n · µ = µ

68 2.2. Punkschatzung
• Sei σ2 die Varianz in der Grundgesamtheit. Es gilt
Eσ2(S2) =n− 1
nσ2,
also ist S2 nicht erwartungstreu fur σ2.
Biasσ2(S2) =n− 1
nσ2 − σ2 = − 1
nσ2
• Fur die korrigierte Stichprobenvarianz gilt dagegen:
Eσ2(S2) = Eσ2
(1
n− 1
n∑
i=1
(Xi − X)2
)
= Eσ2
(1
n− 1· n
n
n∑
i=1
(Xi − X)2
)
= Eσ2
(n
n− 1S2
)=
n
n− 1· n− 1
nσ2 = σ2
Also ist S2 erwartungstreu fur σ2. Diese Eigenschaft ist auch die Motivation fur dieKorrektur der Stichprobenvarianz.
• Vorsicht: Im Allgemeinen gilt fur beliebige, nichtlineare Funktionen g
E g(X) 6= g(E(X)).
Man kann also nicht einfach z.B.√· und E vertauschen. In der Tat gilt: S2 ist zwar
erwartungstreu fur σ2, aber√
S2 ist nicht erwartungstreu fur√
σ2 = σ.
Beispiel Wahlumfrage: Gegeben sei eine Stichprobe der wahlberechtigten Bundesburger.Geben Sie einen erwartungstreuen Schatzer des Anteils der rot-grun Wahler an.
Grundgesamtheit: Dichotomes Merkmal
X =
1 rot/grun: ja
0 rot/grun: nein
Der Mittelwert π von X ist der Anteil der rot/grun-Wahler in der Grundgesamtheit.
Stichprobe X1, . . . , Xn vom Umfang n:
Xi =
1 i-te Person wahlt rot/grun
0 sonst
Aus den Uberlegungen zum arithmetischen Mittel folgt, dass
X =1
n
n∑
i=1
Xi
ein erwartungstreuer Schatzer fur den hier betrachteten Parameter π ist.

Kapitel 2. Induktive Statistik 69
Also verwendet man die relative Haufigkeit in der Stichprobe, um den wahren Anteil π inder Grundgesamtheit zu schatzen.
Bedeutung der Erwartungstreue: Erwartungstreue ist ein schwaches Kriterium!
Betrachte die offensichtlich unsinnige Schatzfunktion
T2 = g2(X1, . . . , Xn) = X1,
d.h. T2 = 100%, falls der erste Befragte rot-grun wahlt und T2 = 0% sonst.
Die Schatzfunktion ignoriert fast alle Daten, ist aber erwartungtreu:
E(T2) = E(X1) = µ
Deshalb betrachtet man zusatzlich die Effizienz eines Schatzers, s.u.
Asymptotische Erwartungstreue
• Eine Schatzfunktion heißt asymptotisch erwartungstreu, falls
limn→∞
E(θ) = θ.
bzw.
limn→∞
Bias(θ) = 0.
gelten.
• Abschwachung des Begriffs der Erwartungstreue: Gilt nur noch bei einer unendlichgroßen Stichprobe.
• Erwartungstreue Schatzer sind auch asmptotisch erwartungstreu.
• Sowohl S2 als auch S2 sind asymptotisch erwartungstreu.
2.2.3 Effizienz
Beispiel Wahlumfrage: Gegeben sind die drei erwartungstreuen Schatzer (n sei gerade):
T1 =1
n
n∑
i=1
Xi
T2 =1
n/2
n/2∑
i=1
Xi
Was unterscheidet T1 von dem unsinnigen Schatzer T2, der die in der Stichprobe enthalteneInformation nicht vollstandig ausnutzt?
Vergleiche die Schatzer uber ihre Varianz, nicht nur uber den Erwartungswert!

70 2.2. Punkschatzung
Wenn n so groß ist, dass der zentrale Grenzwertsatz angewendet werden kann, dann giltapproximativ
1√n
∑ni=1(Xi − π)√π(1− π)
=
∑ni=1 Xi − n · π√
π(1− π)=
1n
∑ni=1 Xi − π√
π(1−π)n
∼ N (0; 1)
und damit
T1 =1
n
n∑
i=1
Xi ∼ N(
π;π(1− π)
n
).
Analog kann man zeigen:
T2 =1
n/2
n/2∑
i=1
Xi ∼ N(
π,π(1− π)
n/2
).
T1 und T2 sind approximativ normalverteilt, wobei T1 eine deutlich kleinere Varianz alsT2 hat.
T1 und T2 treffen beide im Durchschnitt den richtigen Wert π. T1 schwankt aber wenigerum das wahre π, ist also
”im Durchschnitt genauer“.
Andere Interpretation:
π− π+π
Dichte von T1
Dichte von T2
¡¡ª
¡¡ª
Fur jeden Punkt π+ > π ist damit P (T1 > π+) < P (T2 > π+)und fur jeden Punkt π− < π ist P (T1 < π−) < P (T2 < π−).
Es ist also die Wahrscheinlichkeit, mindstens um π+ − π bzw. π − π− daneben zu liegen,bei T2 stets großer als bei T1. Ein konkreter Wert ist damit verlasslicher, wenn er von T1,als wenn er von T2 stammt.
Diese Uberlegung gilt ganz allgemein: Ein erwartungstreuer Schatzer ist umso besser, jekleiner seine Varianz ist.
Var(T ) = Erwartete quadratische Abweichung von T von E(T )︸ ︷︷ ︸=ϑ !
Je kleiner die Varianz, umso mehr konzentriert sich die Verteilung eines erwartungstreuenSchatzers um den wahren Wert. Dies ist umso wichtiger, da der Schatzer den wahren Werti.A. nur selten exakt trifft.

Kapitel 2. Induktive Statistik 71
Effizienz:
• Gegeben seien zwei erwartungstreue Schatzfunktionen T1 und T2 fur einen Parameterϑ. Gilt
Varϑ(T1) ≤ Varϑ(T2) fur alle ϑ
undVarϑ∗(T1) < Varϑ∗(T2) fur mindestens ein ϑ∗
so heißt T1 effizienter als T2.
• Eine fur ϑ erwartungstreue Schatzfunktion T heißt UMVU-Schatzfunktion fur ϑ(uniformly minimum variance unbiased), falls
Varϑ(T ) ≤ Varϑ(T∗)
fur alle ϑ und fur alle erwartungstreuen Schatzfunktionen T ∗.
Bemerkungen:
• Inhaltliche Bemerkung: Der (tiefere) Sinn von Optimalitatskriterien wird klassi-scherweise insbesondere auch in der Gewahrleistung von Objektivitat gesehen. Ohnewissenschaftlichen Konsens daruber, welcher Schatzer in welcher Situation zu wahlenist, ware die Auswertung einer Stichprobe willkurlich und der Manipulation Tur undTor geoffnet.
• Ist X1, . . . , Xn eine i.i.d. Stichprobe mit Xi ∼ N (µ, σ2), dann ist
– X UMVU-Schatzfunktion fur µ und
– S2 UMVU-Schatzfunktion fur σ2.
• Ist X1, . . . , Xn mit Xi ∈ 0, 1 eine i.i.d. Stichprobe mit π = P (Xi = 1), dann istdie relative Haufigkeit X UMVU-Schatzfunktion fur π.
• Bei nicht erwartungstreuen Schatzern macht es keinen Sinn, sich ausschließlich aufdie Varianz zu konzentrieren.
Z.B. hat der unsinnige Schatzer T = g(X1, . . . , Xn) = 42, der die Stichprobe nichtbeachtet, Varianz 0.
Man zieht dann den sogenannten Mean Squared Error
MSEϑ(T ) := Eϑ(T − ϑ)2
zur Beurteilung heran. Es gilt
MSEϑ(T ) = Varϑ(T ) + (Biasϑ(T ))2.
Der MSE kann als Kompromiss zwischen zwei Auffassungen von Prazision gesehenwerden: moglichst geringe systematische Verzerrung (Bias) und moglichst geringeSchwankung (Varianz).

72 2.2. Punkschatzung
Konsistenz
• Ein Schatzer heißt MSE-konsistent, wenn gilt
limn→∞
(MSE(T )) = 0.
Beispiel: Der MSE von X ist gegeben durch
MSE(X) = Var(X) + Bias2(X)
=σ2
n+ 0
=σ2
n→ 0.
X ist also eine MSE-konsistente Schatzung fur den Erwartungswert.
• Ein Schatzer heißt konsistent, wenn gilt
limn→∞
(Var(T )) = 0.
X ist also auch konsistent.
2.2.4 Konstruktionsprinzipien guter Schatzer
Die Methode der kleinsten Quadrate
=⇒ Regressionsanalyse
Das Maximum-Likelihood-Prinzip
Aufgabe: Schatze den Parameter ϑ eines parametrischen Modells anhand einer i.i.d. Stich-probe X1, . . . , Xn mit der konkreten Realisation x1, . . . , xn.
Idee der Maximium-Likelihood (ML) Schatzung fur diskrete Verteilungen:
• Man kann fur jedes ϑ die Wahrscheinlichkeit ausrechnen, genau die Stichprobex1, . . . , xn zu erhalten:
Pϑ(X1 = x1, X2 = x2, . . . , Xn = xn) =n∏
i=1
Pϑ(Xi = xi)
• Je großer fur ein gegebenes ϑ0 diese Wahrscheinlichkeit ist, umso plausibler ist es,dass tatsachlich ϑ0 der wahre Wert ist (gute Ubereinstimmung zwischen Modell undDaten).
Beispiel: I.i.d. Stichprobe vom Umfang n = 5 aus einer B(10, π)-Verteilung:
6 5 3 4 4

Kapitel 2. Induktive Statistik 73
Wahrscheinlichkeit der Stichprobe fur gegebenes π:
P (X1 = 6, . . . , X5 = 4|π) = P (X1 = 6|π) · . . . · P (X5 = 4|π)
=
(10
6
)π6(1− π)4 · . . . ·
(10
4
)π4(1− π)6.
Wahrscheinlichkeit fur einige Werte von π:
π P (X1 = 6, . . . , X5 = 4|π)0.1 0.00000000000010.2 0.00000002272000.3 0.00000404252200.4 0.00030254810000.5 0.00024873670000.6 0.00000265611500.7 0.00000002504900.8 0.00000000000550.9 0.0000000000000
Man nennt daher L(ϑ) = Pϑ(X1 = x1, . . . , Xn = xn), nun als Funktion von ϑgesehen, die Likelihood (deutsch: Plausibilitat, Mutmaßlichkeit) von ϑ gegeben dieRealisation x1, . . . , xn.
• Derjenige Wert ϑ = ϑ(x1, . . . , xn), der L(ϑ) maximiert, heißt Maximum-Likelihood-Schatzwert ; die zugehorige Schatzfunktion T (X1, . . . , Xn) Maximum-Likelihood-Schatzer.
Bemerkungen:
• Fur stetige Verteilungen gilt
Pϑ(X1 = x1, X2 = x2, . . . , Xn = xn) = 0
fur beliebige Werte ϑ. In diesem Fall verwendet man die Dichte
fϑ(x1, . . . , xn) =n∏
i=1
fϑ(xi)
als Maß fur die Plausibilitat von ϑ.
• Fur die praktische Berechnung maximiert man statt der Likelihood typischerweisedie Log-Likelihood
l(ϑ) = ln(L(ϑ)) = lnn∏
i=1
Pϑ(Xi = xi) =n∑
i=1
ln Pϑ(Xi = xi)
bzw.
l(ϑ) = lnn∏
i=1
fϑ(xi) =n∑
i=1
ln fϑ(xi).
Dies liefert denselben Schatzwert ϑ und erspart beim Differenzieren die Anwendungder Produktregel.

74 2.2. Punkschatzung
Der Logarithmus ist streng monoton wachsend. Allgemein gilt fur streng monotonwachsende Funktionen g: x0 Stelle des Maximums von L(x) ⇐⇒ x0 auch Stelle desMaximums von g(L(x)).
Definition: Gegeben sei die Realisation x1, . . . , xn einer i.i.d. Stichprobe. Die Funktion inϑ
L(ϑ) =
n∏
i=1
Pϑ(Xi = xi) falls Xi diskret
n∏
i=1
fϑ(xi) falls Xi stetig.
heißt Likelihood des Parameters ϑ bei der Beobachtung x1, . . . , xn.
Derjenige Wert ϑ = ϑ(x1, . . . , xn), der L(ϑ) maximiert, heißt Maximum-Likelihood-Schatz-wert ; die zugehorige Schatzfunktion T (X1, . . . , Xn) Maximum-Likelihood-Schatzer.
Beispiel: Wahlumfrage
Xi =
1 falls Rot/Grun
0 sonst
Verteilung der Xi: Binomialverteilung
P (Xi = 1) = π
P (Xi = 0) = 1− π
P (Xi = xi) = πxi · (1− π)1−xi , xi ∈ 0; 1.Likelihood:
L(π) = P (X1 = x1, . . . , Xn = xn)
=n∏
i=1
πxi (1− π)1−xi
= π∑n
i=1 xi · (1− π)n−∑ni=1 xi
Logarithmierte Likelihood:
l(ϑ) = ln(P (X1 = x1, . . . , Xn = xn)) =n∑
i=1
xi · ln(π) + (n−n∑
i=1
xi) · ln(1− π)
Ableiten (nach ϑ):
∂
∂πl(π) =
n∑
i=1
xi
π+
n−n∑
i=1
xi
1− π· (−1)
Nullsetzen und nach π Auflosen:
∂
∂πl(π) = 0 ⇔
n∑
i=1
xi
π=
n−n∑
i=1
xi
1− π
⇔ (1− π)n∑
i=1
xi = n · π − π
n∑
i=1
xi

Kapitel 2. Induktive Statistik 75
⇔n∑
i=1
xi = n · π
also
π =
∑ni=1 xi
n
ML-Schatzung bei Normalverteilung
1. Schritt: Bestimme die Likelihoodfunktion
L(µ, σ2) =n∏
i=1
1√2π(σ2)
12
exp
(− 1
2σ2(xi − µ)2
)
=1
2πn2 (σ2)
n2
exp
(− 1
2σ2
n∑
i=1
(xi − µ)2
)
2. Schritt: Bestimme die Log-Likelihoodfunktion
l(µ, σ2) = ln(L(µ, σ2))
= ln(1)− n
2ln(2π)− n
2ln(σ2)− 1
2σ2
n∑
i=1
(xi − µ)2
3. Schritt: Ableiten und Nullsetzen der Loglikelihoodfunktion
∂l(µ, σ2)
∂µ=
1
2σ22 ·
n∑
i=1
(xi − µ) = 0
∂l(µ, σ2)
∂σ2= −n
2
1
σ2+
1
2(σ2)2
n∑
i=1
(xi − µ)2 = 0
4. Schritt: Auflosen der beiden Gleichungen nach µ und σ2
Aus der ersten Gleichung erhalten wir
n∑
i=1
xi − nµ = 0 also µ = x.
Aus der zweiten Gleichung erhalten wir durch Einsetzen von µ = x
n∑
i=1
(xi − x)2 = nσ2
also
σ2 =1
n
n∑
i=1
(xi − x)2

76 2.3. Intervallschatzung
Fazit:
• Der ML-Schatzer µ = X fur µ stimmt mit dem ublichen Schatzer fur den Erwar-tungswert uberein.
• Der ML-Schatzer σ2 = S2 fur σ2 ist verzerrt, d.h. nicht erwartungstreu.
Einige allgemeine Eigenschaften von ML-Schatzern
• ML-Schatzer θ sind im Allgemeinen nicht erwartungstreu.
• ML-Schatzer θ sind asymptotisch erwartungstreu.
• ML-Schatzer θ sind konsistent.
2.3 Intervallschatzung
2.3.1 Motivation und Hinfuhrung
Beispiel Wahlumfrage: Der wahre Anteil der rot-grun Wahler 2002 war genau 47.1%.Wie groß ist die Wahrscheinlichkeit, in einer Zufallsstichprobe von 1000 Personen genaueinen relativen Anteil von 47.1% von rot-grun Anhangern erhalten zu haben?
Xi =
1, rot/grun
0, sonst
P (Xi = 1) = π = 0.471
X =n∑
i=1
Xi ∼ B(n, π) mit n = 1000
P (X = 471) =
(n
x
)· πx · (1− π)n−x
=
(1000
471
)· 0.471471 · (1− 0.471)529
= 0.02567
D.h., mit Wahrscheinlichkeit von etwa 97.4%, verfehlt der Schatzer den wahren Wert.
Hat man ein stetiges Merkmal, so ist sogar P (X = a) = 0 fur jedes a, d.h. der wahreWert wird mit Wahrscheinlichkeit 1 verfehlt.
Konsequenzen:
• Insbesondere Vorsicht bei der Interpretation”knapper Ergebnisse“ (z.B. Anteil
50.2%)

Kapitel 2. Induktive Statistik 77
• Suche Schatzer mit moglichst kleiner Varianz, um”im Durchschnitt moglichst nahe
dran zu sein“
• Es ist haufig auch gar nicht notig, sich genau auf einen Wert festzulegen. Oft reichtdie Angabe eines Intervalls, von dem man hofft, dass es den wahren Wert uberdeckt:Intervallschatzung
Symmetrische Intervallschatzung basierend auf einer Schatzfunktion T = g(X1, . . . , Xn):
I(T ) = [T − a, T + a]
”Trade off“ bei der Wahl von a:
Je großer man a wahlt, also je breiter man das Intervall I(T ) macht, umso großer ist dieWahrscheinlichkeit, dass I(T ) den wahren Wert uberdeckt, aber umso weniger aussage-kraftig ist dann die Schatzung.
Extremfall im Wahlbeispiel: I(T ) = [0, 1] uberdeckt sicher π, macht aber eine wertloseAussage
⇒ Wie soll man a wahlen?
Typisches Vorgehen:
• Man gebe sich einen Sicherheitsgrad (Konfidenzniveau) γ vor.
• Dann konstruiert man das Intervall so, dass es mindestens mit der Wahrscheinlich-keit γ den wahren Parameter uberdeckt.
2.3.2 Definition von Konfidenzintervallen:
Gegeben sei eine i.i.d. Stichprobe X1, . . . , Xn zur Schatzung eines Parameters ϑ und ei-ne Zahl γ ∈ (0; 1). Ein zufalliges Intervall C(X1, . . . , Xn) heißt Konfidenzintervall zumSicherheitsgrad γ (Konfidenzniveau γ), falls fur jedes ϑ gilt:
Pϑ(ϑ ∈ C(X1, . . . , Xn)︸ ︷︷ ︸zufalliges Intervall
) ≥ γ.
Bemerkungen:
• Die Wahrscheinlichkeitsaussage bezieht sich auf das Ereignis, dass das zufallige In-tervall den festen, wahren Parameter uberdeckt. Streng genommen darf man imobjektivistischen Verstandnis von Wahrscheinlichkeit nicht von der Wahrscheinlich-keit sprechen,
”dass ϑ in dem Intervall liegt“, da ϑ nicht zufallig ist und somit keine
Wahrscheinlichkeitsverteilung besitzt.
• Typischerweise konstruiert man Konfidenzintervalle symmetrisch um einen SchatzerT . Es sind aber auch manchmal z.B. einseitige Konfidenzintervalle, etwa der Form
[X, X + b],
sinnvoll (beispielsweise bei sozial unerwunschten Ereignissen).

78 2.3. Intervallschatzung
2.3.3 Konstruktion von Konfidenzintervallen
Fur die Konstruktion praktische Vorgehensweise: Suche Zufallsvariable Z, die
• den gesuchten Parameter ϑ enthalt und
• deren Verteilung aber nicht mehr von dem Parameter abhangt, (”Pivotgroße“, dt.
Angelpunkt).
• Dann wahle den Bereich CZ so, dass Pϑ(Z ∈ CZ) = γ und
• lose nach ϑ auf.
Konfidenzintervall fur den Mittelwert eines normalverteilten Merkmals bei bekannterVarianz:
X1, . . . , Xn i.i.d. Stichprobe gemaß Xi ∼ N (µ, σ2), wobei σ2 bekannt sei.
Starte mit der Verteilung von X:
X ∼ N (µ, σ2/n).
Dann erfullt
Z =X − µ
σ· √n ∼ N (0; 1)
die obigen Bedingungen an eine Pivotgroße.
Bestimme jetzt einen Bereich [−z, z], wobei z so gewahlt sei, dass
P (Z ∈ [−z; z]) = γ
0-z z
γ
1−γ2
1−γ2
@@@R
¡¡¡ª
Bestimmung von z:
P (Z ∈ [−z; z]) = γ ⇔ P (Z ≥ z) =1− γ
2
beziehungsweise
P (Z ≤ z) = 1− 1− γ
2=
2− 1 + γ
2=
1 + γ
2.
Der entsprechende Wert lasst sich aus der Tabelle der Standardnormalverteilung ablesen.
Typische Beispiele:

Kapitel 2. Induktive Statistik 79
γ = 90% 1+γ2
= 95% z = 1.65γ = 95% 1+γ
2= 97.5% z = 1.96
γ = 99% 1+γ2
= 99.5% z = 2.58
Die Große z heißt das 1+γ2
-Quantil und wird mit z 1+γ2
bezeichnet.
Damit gilt also
P(−z 1+γ
2≤ Z ≤ z 1+γ
2
)= P
(−z 1+γ
2≤ X − µ
σ≤ z 1+γ
2
)= γ
Jetzt nach µ auflosen:
γ = P
(−
z 1+γ2· σ
√n
≤ X − µ ≤z 1+γ
2· σ
√n
)
= P
(−X −
z 1+γ2· σ
√n
≤ −µ ≤ −X +z 1+γ
2· σ
√n
)
= P
(X −
z 1+γ2· σ
√n
≤ µ ≤ X +z 1+γ
2· σ
√n
)
Damit ergibt sich das Konfidenzintervall[X −
z 1+γ2· σ
√n
, X +z 1+γ
2· σ
√n
]=
[X ±
z 1+γ2· σ
√n
]
Bemerkungen:
• Je großer σ, desto großer das Intervall!
(Großeres σ ⇒ Grundgesamtheit bezuglich des betrachteten Merkmals heterogener,also großere Streuung von X ⇒ ungenauere Aussagen.)
• Je großer γ, desto großer z 1+γ2
(Je mehr Sicherheit/Vorsicht desto breiter das Intervall)
• Je großer n und damit√
n, desto schmaler ist das Intervall
(Je großer der Stichprobenumfang ist, desto genauer!)
Kann man zur Stichprobenplanung verwenden!
Konfidenzintervall fur den Mittelwert eines normalverteilten Merkmals bei unbe-kannter Varianz: Neben dem Erwartungswert ist auch σ2 unbekannt und muss entspre-chend durch den UMVU-Schatzer
S2 =1
n− 1
n∑
i=1
(Xi − X)2,
(mit S =√
S2) geschatzt werden. Allerdings ist
Z =X − µ
S· √n
80 2.3. Intervallschatzung
jetzt nicht mehr normalverteilt, denn S ist zufallig.
Wir fuhren deshalb ein neues Verteilungsmodell ein.
t-Verteilung: Gegeben sei eine i.i.d. Stichprobe X1, . . . , Xn mit Xi ∼ N (µ, σ2). Dannheißt die Verteilung von
Z =X − µ
S· √n
t-Verteilung (oder Student-Verteilung) mit ν = n − 1 Freiheitsgraden. In Zeichen: Z ∼t(ν).
Informelle Erklarung zum Begriff Freiheitsgrade: Bei Kenntnis von x nur n− 1 frei vari-ierbare Daten.
Wichtige Werte der t-Verteilung sind tabelliert. Angegeben sind, fur verschiedene δ, dieLosung tδ der Gleichung
P (Z ≤ t(ν)δ ) = δ,
wobei t(ν)δ von der Anzahl ν der Freiheitsgrade abhangt. tδ ist das δ-Quantil der entspre-
chenden t-Verteilung (analog zu zδ als Quantil der Standardnormalverteilung).
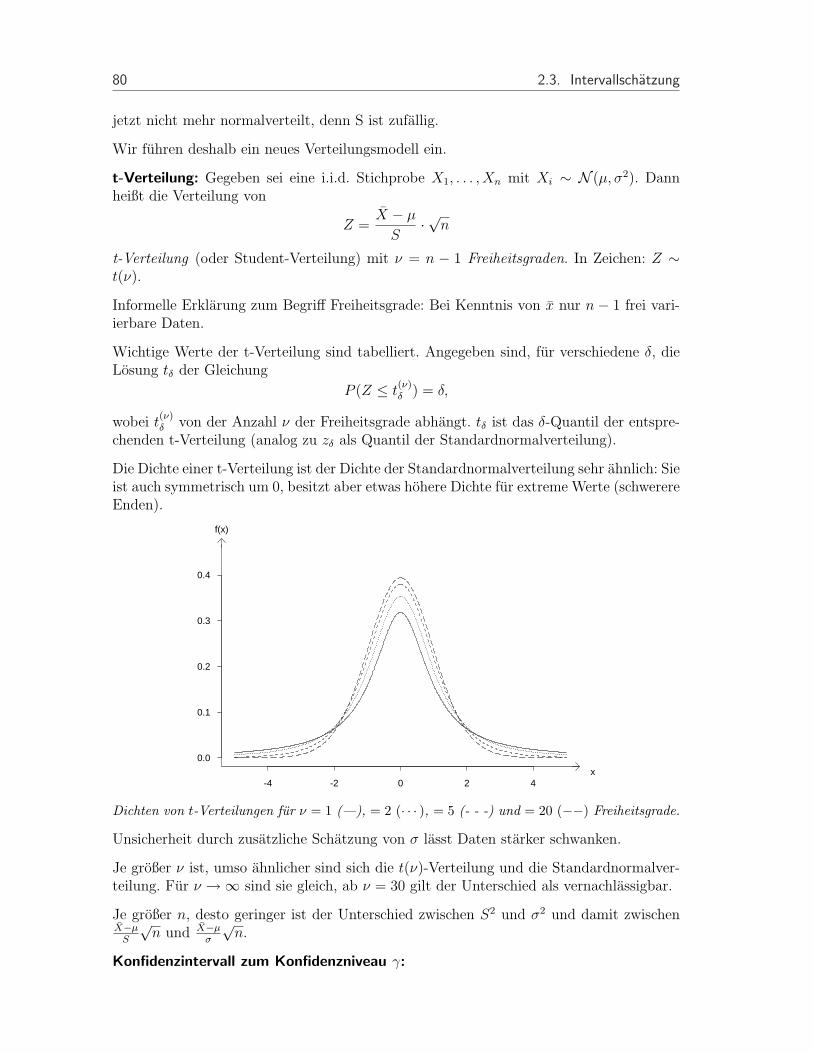
Die Dichte einer t-Verteilung ist der Dichte der Standardnormalverteilung sehr ahnlich: Sieist auch symmetrisch um 0, besitzt aber etwas hohere Dichte fur extreme Werte (schwerereEnden).
-4 -2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
f(x)
Dichten von t-Verteilungen fur ν = 1 (—), = 2 (· · · ), = 5 (- - -) und = 20 (−−) Freiheitsgrade.
Unsicherheit durch zusatzliche Schatzung von σ lasst Daten starker schwanken.
Je großer ν ist, umso ahnlicher sind sich die t(ν)-Verteilung und die Standardnormalver-teilung. Fur ν →∞ sind sie gleich, ab ν = 30 gilt der Unterschied als vernachlassigbar.
Je großer n, desto geringer ist der Unterschied zwischen S2 und σ2 und damit zwischenX−µ
S
√n und X−µ
σ
√n.
Konfidenzintervall zum Konfidenzniveau γ:

Kapitel 2. Induktive Statistik 81
Ausgehend von
P
(−t 1+γ
2(n− 1) ≤ X − µ
S≤ t 1+γ
2(n− 1)
)= γ
wie im Beispiel mit bekannter Varianz nach µ auflosen (mit S statt σ)
P
(X −
t 1+γ2
(n− 1) · S√
n≤ µ ≤ X +
t 1+γ2
(n− 1) · S√
n
)= γ
Damit ergibt sich das Konfidenzintervall
[X ±
t 1+γ2
(n− 1) · S√
n
]
Bemerkungen:
• Es gelten analoge Aussagen zum Stichprobenumfang und Konfidenzniveau wie beibekannter Varianz.
• Fur jedes γ (und jedes ν) gilt
t 1+γ2
> z 1+γ2
also ist das t-Verteilungs-Konfidenzintervall (etwas) breiter.
Da σ2 unbekannt ist, muss es geschatzt werden. Dies fuhrt zu etwas großerer Unge-nauigkeit.
• Je großer ν, umso kleiner ist der Unterschied. Fur n ≥ 30 rechnet man einfach auchbei der t-Verteilung mit z 1+γ
2.
Beispiel: Eine Maschine fullt Gummibarchen in Tuten ab, die laut Aufdruck 250g Fullge-wicht versprechen. Wir nehmen im folgenden an, dass das Fullgewicht normalverteilt ist.Bei 16 zufallig aus der Produktion herausgegriffenen Tuten wird ein mittleres Fullgewichtvon 245g und eine Stichprobenstreuung (Standardabweichung) von 10g festgestellt.
a) Berechnen Sie ein Konfidenzintervall fur das mittlere Fullgewicht zum Sicherheitsni-veau von 95%.
b) Wenn Ihnen zusatzlich bekannt wurde, dass die Stichprobenstreuung gleich der tatsachli-chen Streuung ist, ware dann das unter a) zu berechnende Konfidenzintervall fur dasmittlere Fullgewicht breiter oder schmaler? Begrunden Sie ihre Antwort ohne Rech-nung.
• Fullgewicht normalverteilt.
• 16 Tuten gezogen ⇒ n = 16.
• Mittleres Fullgewicht in der Stichprobe: x = 245g.
• Stichprobenstreuung: s = 10g.

82 2.3. Intervallschatzung
zu a) Konstruktion des Konfidenzintervalls: Da die Varianz σ2 unbekannt ist, muss dasKonfidenzintervall basierend auf der t-Verteilung konstruiert werden:
[X ± t 1+γ2
(n− 1) · S√n
]
Aus dem Sicherheitsniveau γ = 0.95 errechnet sich 1+γ2
= 0.975.
Nachschauen in t-Tabelle bei 0.975 und 15 Freiheitsgraden (T = X−µS
√n ist t-
verteilt mit n-1 Freiheitsgeraden) liefert t0.975 = 2.13.
Einsetzen liefert damit
[245± 2.13 · 10
4] = [239.675; 250.325]
zu b) Jetzt sei σ2 bekannt. Dann kann man mit dem Normalverteilungs-Intervall rechnen:
[X ± z 1+γ2· σ√
n]
Da jetzt σ bekannt, ist die Unsicherheit geringer und damit das Konfidenzintervallschmaler.
In der Tat ist z 1+γ2
< t 1+γ2
.
Rechnerisch ergibt sich mit z 1+γ2
= 1.96 das Konfidenzintervall
[240.100; 249.900]
Beispiel: Klausurergebnisse
i punkte i punkte i punkte i punkte i punkte i punkte1 16.5 7 27.5 13 23 19 14 25 19.5 31 35.52 16.5 8 22 14 15 20 21 26 18 32 12.53 25.5 9 16.5 15 31 21 19.5 27 37.5 33 254 25 10 8 16 26 22 17.5 28 15.5 34 25.55 20.5 11 33.5 17 13.5 23 36 29 7.5 35 18.56 27.5 12 19.5 18 24 24 31.5 30 18
• Mittelwert und Varianz der Grundgesamtheit (alle 35 Klausuren):
µ = punkte = 21.81
σ2 = s2punkte = 7.562
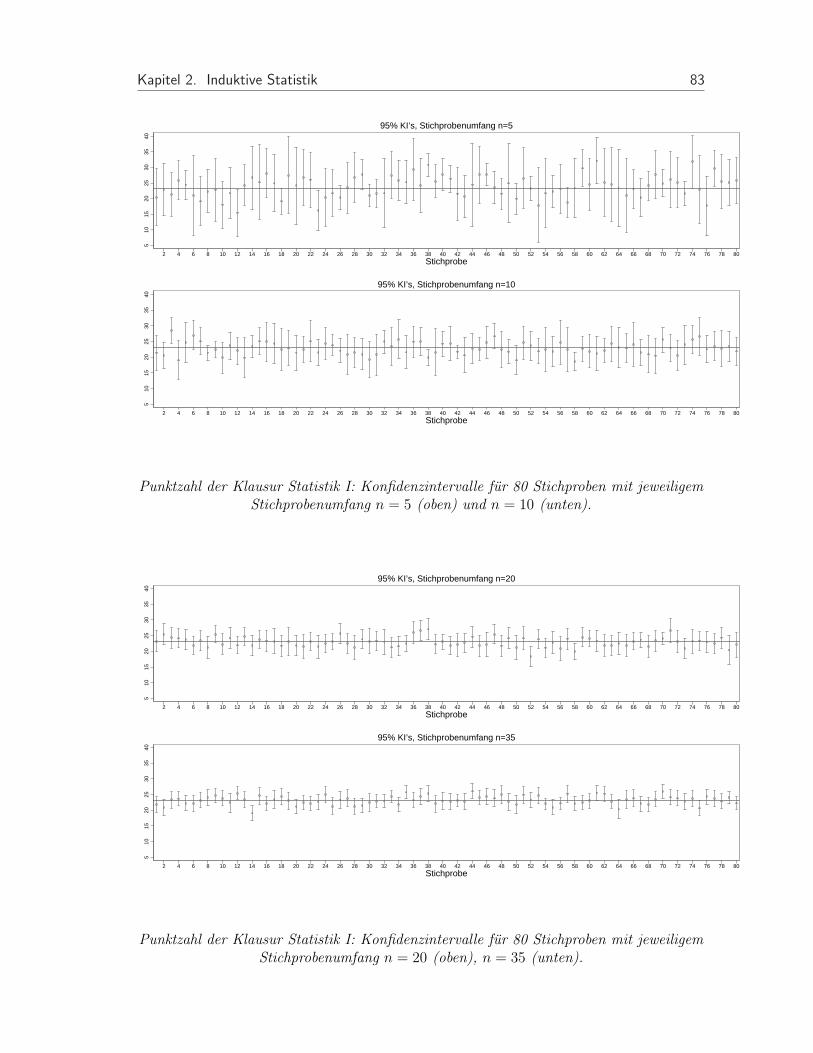
• Wir ziehen insgesamt 80 Stichproben vom Umfang n = 5, n = 10, n = 20, n = 35und bestimmen Konfidenzintervalle zum Niveau 95%.
Kapitel 2. Induktive Statistik 83
510
1520
2530
3540
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
Stichprobe
95% KI’s, Stichprobenumfang n=5
510
1520
2530
3540
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
Stichprobe
95% KI’s, Stichprobenumfang n=10
Punktzahl der Klausur Statistik I: Konfidenzintervalle fur 80 Stichproben mit jeweiligemStichprobenumfang n = 5 (oben) und n = 10 (unten).
510
1520
2530
3540
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
Stichprobe
95% KI’s, Stichprobenumfang n=20
510
1520
2530
3540
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
Stichprobe
95% KI’s, Stichprobenumfang n=35
Punktzahl der Klausur Statistik I: Konfidenzintervalle fur 80 Stichproben mit jeweiligemStichprobenumfang n = 20 (oben), n = 35 (unten).

84 2.3. Intervallschatzung
510
1520
2530
3540
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
Stichprobe
95% KI’s, Stichprobenumfang n=55
1015
2025
3035
40
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
Stichprobe
95% KI’s, Stichprobenumfang n=5, Varianz bekannt
Punktzahl der Klausur Statistik I: Konfidenzintervalle fur 80 Stichproben mitStichprobenumfang n = 5. Oben ist die Varianz unbekannt, unten als bekannt
vorausgesetzt.
• Ergebnis:
– Die Breite der Konfidenzintervalle nimmt mit wachsendem n ab.
– Nicht alle Konfidenzintervalle enthalten den wahren Mittelwert µ = 23.1 (perKonstruktion mit Wahrscheinlichkeit 5%).
– Die Intervalle mit bekannter Varianz sind im Mittel enger.
– Die Intervalle mit bekannter Varianz sind immer gleich lang.
Approximative Konfidenzintervalle: Ist der Stichprobenumfang groß genug, so kann we-gen des zentralen Grenzwertsatzes das Normalverteilungs-Konfidenzintervall auf den Er-wartungswert beliebiger Merkmale (mit existierender Varianz) angewendet werden underhalt approximative Konfidenzintervalle.
Beispiel: Konfidenzintervall fur den Anteil π: Seien X1, . . . , Xn i.i.d. mit
Xi =
1
0, P (Xi = 1) = π.
E(Xi) = π
Var(Xi) = π · (1− π)
⇒ E(X) = π
Var(X) =π · (1− π)
n

Kapitel 2. Induktive Statistik 85
und approximativ fur großes n:
X − π√π·(1−π)
n
∼ N (0, 1)
π im Zahler: unbekannter Anteil = interessierender Parameter
π im Nenner:√
π(1−π)n
unbekannte Varianz von X; schatzen, indem X fur π eingesetzt
wirdim Nenner
γ ≈ P
−z 1+γ
2≤ X − π√
X(1−X)n
≤ z 1+γ2
= P
(X − z 1+γ
2·√
X(1− X)
n≤ π ≤ X + z 1+γ
2·√
X(1− X)
n
)
und damit das Konfidenzintervall[X ± z 1+γ
2·√
X(1− X)
n
]
Beispiel Wahlumfrage: Seien n = 500, X = 46.5% und γ = 95%.
z 1+γ2
= 1.96
Konfidenzintervall:[X ± z 1+γ
2·√
X(1− X)
n
]=
[0.465± 1.96 ·
√0.465(1− 0.465)
500
]
= [0.421; 0.508]





























