Embed Size (px)
Citation preview

Linking out, linking inPreparing for Linked Data at the University of Alberta
Ian Bigelow, Sharon FarnelNetspeed 2017
The road to linked data: Are we there yet?
Setting the stage for this presentation

Transitioning to linked data was never going to be easy. Several reasons for this include:
● MARC has been around for a very long time and we have lots of it● The ILS and discovery systems we use are built around MARC data● Staff have also been using MARC for a very long time● Currently our entire workflow for resource description, from LC, OCLC and other vendors through to copy and original cataloguing all depends on MARC
But while MARC has provided a rich and stable way of encoding library metadata, it is showing its age.

Solution
1. Jakov M. Vežić (https://www.facebook.com/photo.php?fbid=10214499563312325&set=gm.1820667984616319&type=3&theater)2. Library of Congress (2016). Using the BIBFRAME Editor for bibliographic description: Unit 1 [PowerPoint slides]. Retrieved from https://www.loc.gov/catworkshop/bibframe/
Directly from LC BIBFRAME training documentation:
● Increase the visibility and usage of Library data on the Web
● Integrate library data with the large number of structured data sources and links on the web
● Create relations among resources● Enhance the sharing of library data with a wider
audience● Facilitate a more full implementation of RDA● Linked Data is to replace MARC as the primary carrier of
library data○ a standard machine readable format○ using common web standards○ MARC is used chiefly by libraries, and not as
well understood by other communities● Transition: from a static two-dimensional collocated
record to decentralized data with links to illuminate relationships (Library of Congress, 2016)
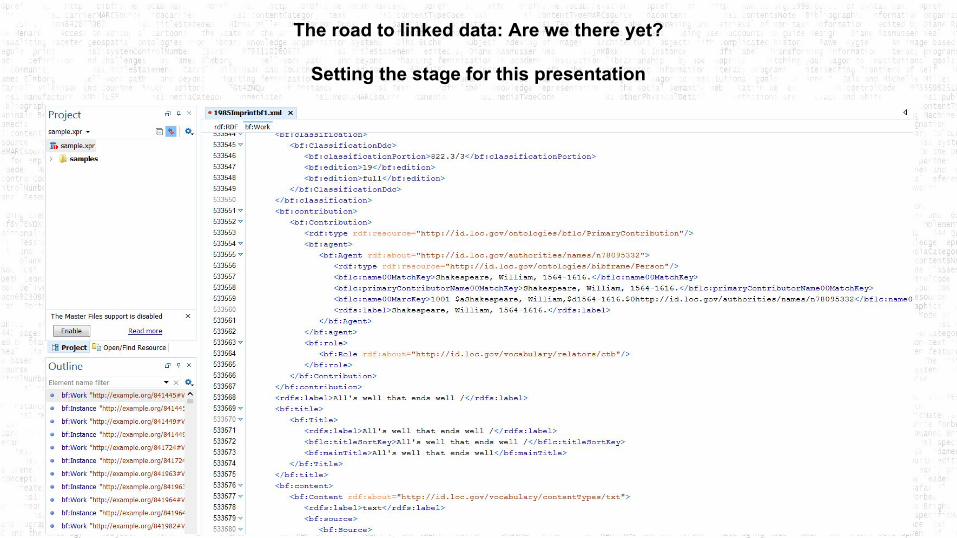
From the web of documents to the web of data
Arbeck. (2015). https://commons.wikimedia.org/wiki/File:The_Semantic_Web_Compared_To_The_Traditional_Web.svg

Linked data is data that is structured in standard formats and includes relationships to other data that enables traversing the web at the most granular level
Dodds, L. (2009). https://flic.kr/p/7akxU3

Remember when you learned about subject,
predicate, object in school?
Turns out it is important ...

In linked data, relationships are expressed as triples
SUBJECT (ENTITY) TAL
PREDICATE (PROPERTY) is a Sponsor of
OBJECT (VALUE) Netspeed

An essential aspect of linked data is the use of URIs● a URI (Uniform Resource Identifier) is a unique way of identifying an entity
(person, object, relationship, etc.) using a standard syntax
SUBJECT (ENTITY) TAL http://viaf.org/viaf/157055858
PREDICATE (PROPERTY) is a Sponsor of http://id.loc.gov/vocabulary/relators/spn
OBJECT (VALUE) Netspeed https://terms.library.ualberta.ca/events/netspeed

5 Principles of Linked Data
● use URIs to name things● use http URIs so that people
or machines can look them up
● when a person or machine looks up a URI, provide useful information using open standards
● include links to other URIs to enable discovery of more things
● use an open license*
Berners-Lee, T. (2006). https://www.w3.org/DesignIssues/LinkedData.html

● initiative of LC and the community to provide an option for future bibliographic description on and of the web
● bibframe.org
http://bibframe.org/
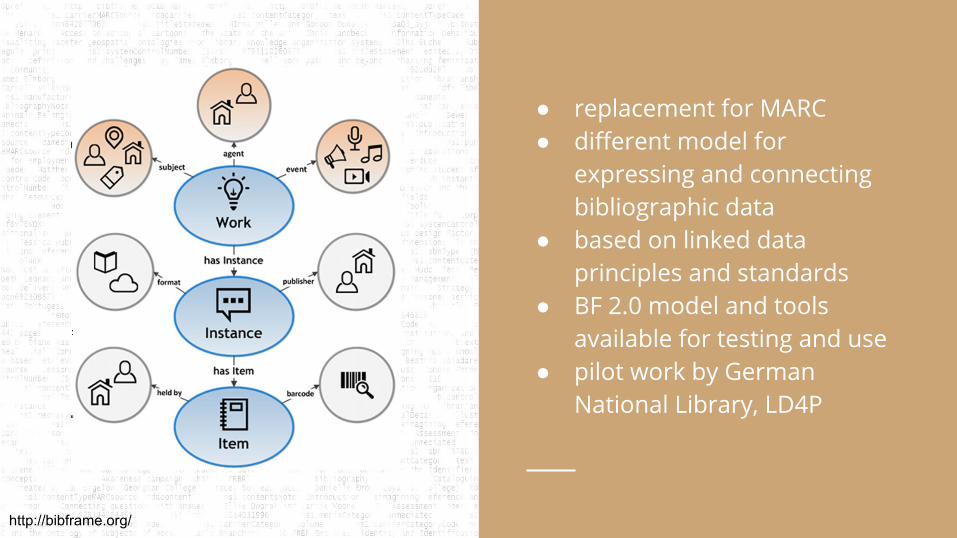
● replacement for MARC● different model for
expressing and connecting bibliographic data
● based on linked data principles and standards
● BF 2.0 model and tools available for testing and use
● pilot work by German National Library, LD4P
http://bibframe.org/

Bibframe Lite is a version of Bibframe that provides a core set of classes and properties plus additional vocabulary sets that can be added in a modular way.
Developed by Zepheira
http://bibfra.me/

Linking Out

What we’ve been up to
Lots of different ways in which we’re looking into what’s needed for linked
data
● Following new updates○ Bf:2.0○ Linked data implementations○ RDA/FRBR updates
● Collaboration○ Canadian Linked Data Initiative○ Other libraries and organizations○ Conference participation○ Vendor engagement○ Committee work
● Training● Projects and experimentation
○ URI enrichment○ Bf: conversion○ NEOS standards○ Casalini SHARE VDE

Canadian Linked Data Initiativehttps://connect.library.utoronto.ca/display/U5LD/Can
adian+Linked+Data+Initiative+Home
● University of Toronto● University of British Columbia● McGill University● Université de Montréal● University of Alberta● Library and Archives Canada● Bibliothèque et Archives du
Québec ● Canadiana.org
With a mix of members from other institutions … and maybe you?

● collaboratively plan, facilitate, and obtain funding for linked data projects in Canada
● bridging between units within libraries, between libraries of different types, and between Canada, US, and European initiatives
● steering group and several working groups
https://www.pexels.com/photo/bridge-path-straight-wooden-2257/

Working Groups and UAL Participation
● Coordinating Group● Digital Projects● Education and Training● Grants● Groupe de travail
francophone● IT● Metadata● Summit Planning● User Experience

CLDI Summit (Oct. 2016), Montreal
Key discussions (2016):● Need to dive in and advocate for
experimentation and play● Canadian Linked Data Initiative -
Need to work with others across Canada
● But also a recognition that we need to work as part of a larger community
Key discussions (2017):● Lightning talks on past year’s
accomplishments● What worked, lessons learned● What do you want to accomplish with
CLDI?
CLDI Strategic Planning Meeting (Nov.
2017), Montreal

Can LinkA Linked Data Project for Canadian
Theses
● to demonstrate the power of linked data to surface unexpected connections between individuals, across topics of study, and spanning space and time
● CLDI Digital Projects WG● YCW summer student

Participants
University of British ColumbiaUniversity of Alberta
McGill UniversityLibrary and Archives Canada
Queen’s UniversityUniversité de Montréal
Memorial University of Newfoundland
DATA
● minimum 200 records representing range of topics and dates
● enhance with URIs for authors when possible
● provide in format with richest content
● must direct to openly available digital object
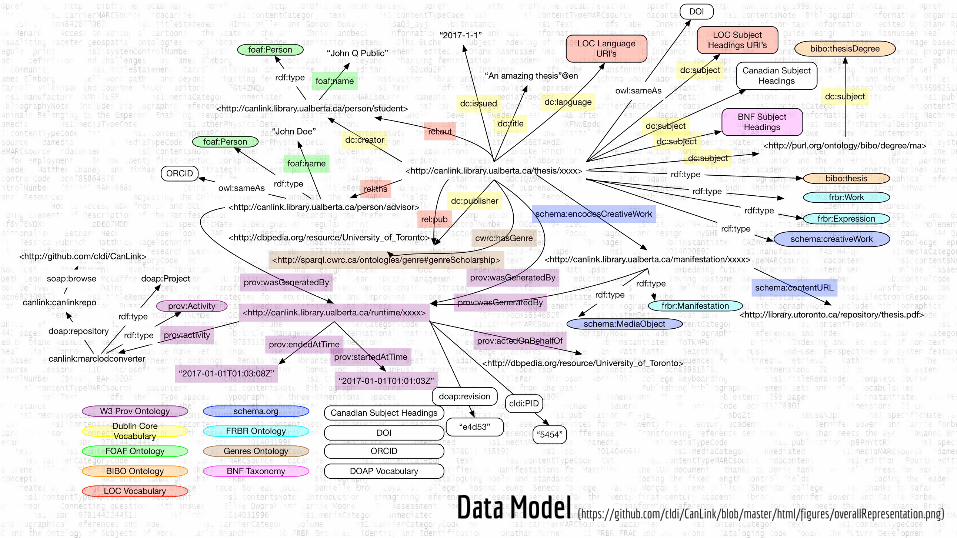
Data Model (https://github.com/cldi/CanLink/blob/master/html/figures/overallRepresentation.png)

Building Blocks
Infrastructure
● Ubuntu cloud instance on WestGrid/Compute Canada
● UAL domain name● Virtuoso triplestore● Apache for proxying outside
connections● Apache + php for basic UI
Code
● Django● modified version of PyMARC● RDFLib● Pickle● Difflib● BeautifulSoup● Concurrent.Futures

Core Functionality● web-based MARC
transformation tool● scripts for transforming from
CSV, RDF XML● query via sparql● basic UI query (name, title,
subject, university)● Bibtex and RIS citation export● daily data dumps● Github integration for adding
missing URIs● tweet of newly added theses

Next Steps
● enhance UI● solicit additional data
● secure long term home(s) for the project
LINKS
● Home: http://canlink.library.ualberta.ca/
● SPARQL: http://canlink.library.ualberta.ca/sparql
● Code: https://github.com/cldi/CanLink● Source data:
https://connect.library.utoronto.ca/display/U5LD/Theses+record+sets
● LOD: https://old.datahub.io/dataset/can-link

Building bridges into other areas/explorations
CLDI participation has been in concert with efforts to share knowledge and participate in other projects:
● Discussions with others in the US - LD4P● Conferences:
○ Example: Semantic Web in Libraries■ CLDI Lightning Talk■ Breakout session on URI in MARC■ DNB visit
● PCC Task Group on URI in MARC● Casalini SHARE Virtual Discovery
Environment

PCC Task Group on URI in MARCRemember when we discussed how URI are a critical component of linked data?
Work of group started in September 2015
“The PCC is committed through its strategic plan to lead the transition to optimize library data for the web. Providing URIs in MARC records will greatly facilitate the reuse of MARC data as linked data and opens the way for catalogers to work with entity registries and controlled vocabularies from the larger metadata community. The time is right for PCC to develop a strategy that supports these objectives, outlined in the PCC Strategic Directions, 2015-2017.” (PCC Task Group on URI in MARC, 2017)
Following discussions at the Deutsche Nationalbibliothek, University of Alberta began participation in Jan. 2017
PCC Task Group on URI in MARC (2017). Charge. Retrieved from https://www.loc.gov/aba/pcc/bibframe/TaskGroups/URI-TaskGroup.html

June 2017: ALA MAC Proposalshttps://www.loc.gov/marc/mac/list-p.html#2017
$0 - URIs that identify a ‘Record’ or ‘Authority’ entity describing a Thing (e.g. madsrdf:Authorities, SKOS Concepts for terms in controlled or standard vocabulary lists)
$1 - URIs that directly identify a Thing itself (sometimes referred to as a Real World Object or RWO, whether actual or conceptual)
$4 - Redefining Subfield $4 to Encompass URIs for Relationships in the MARC 21 Authority and Bibliographic Formats
758 - An identifier for a resource related to the resource described in the bibliographic record. Resources thus identified may include, but are not limited to, FRBR works, expressions, manifestations, and items. The field does not prescribe a particular content standard or data model.

Proposal No. 2017-09
Proposal No. 2017-08
https://www.loc.gov/marc/mac/list-p.html#2017

Proposal No. 2017-01
https://www.loc.gov/marc/mac/2017/2017-01.html

Casalini SHARE VDE: Further data experimentation
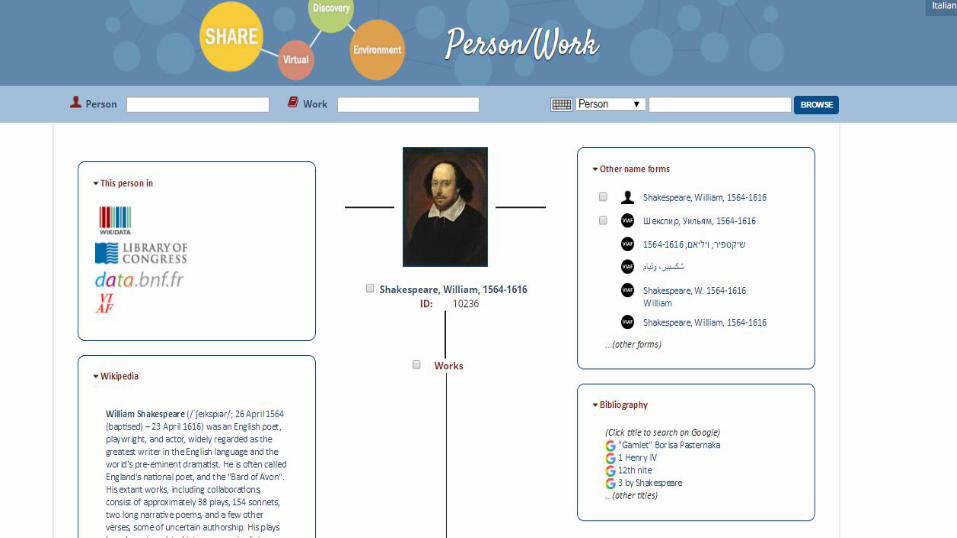

“A prototype of a virtual discovery environment with a three BIBFRAME layer architecture (Person/Work, Instance, Item) has been established through the individual processes of analysis, entity identification and reconciliation, conversion and publication of data from MARC21 to RDF, within the context of libraries with different systems, habits and cataloguing traditions.” (Casalini Libri, 2017)
Project participants:
● Stanford University● University of California Berkeley● Yale University● Library of Congress● University of Chicago● University of Michigan Ann Arbor● Harvard University● Massachusetts Institute of Technology● Duke University● Cornell University● Columbia University● University of Pennsylvania● Pennsylviania State University● Texas A&M University● University of Alberta / NEOS Library
Consortium● University of Toronto
Phase 1: ● MARC for 1985 and 2015 imprint data returned with URI enrichment● Imprint data returned in bf:2.0● Entity identification● Reconciliation of data clustering● Release of SHARE VDE with searchable imprint data● Access to data through Blazegraph
Phase 2:● Creation of relationship database to support entity identification● Improvements of processes from phase 1 for MARC and bf:2.0 data● Basefile to be returned in bf:2.0● Web discoverability through application of other ontologies such as schema.org
Casalini Libri (2017). The SHARE-VDE Project. Retrieved from http://share-vde.org/sharevde/clusters?l=en

Perhaps phase 3 will include one of these?

Linking In

First Steps (Projects) at UAL
1. URI Enrichment … FrankenMARC anyone?
Planned URI enrichment for all MARC data pending:
1. Assessment of existing authority control project
2. Assessment of pre vs. post MARC - LD conversion URI enrichment efficacy
3. Assessment of in-house vs. vendor workflows
4. Approval of PCC MAC proposals - Check!

Following the approach in the Casalini SHARE VDE project MARCEdit Link Identifiers tool has been utilized in the following ways:
1. 1985 and 2015 imprint MARC data as used for Casalini SHARE VDE has been enriched with VIAF, id.loc.gov, rda registry and OCLC Work identifiers.
2. Files have been broken out for books, periodicals and e-resources to compare across results from SHARE VDE and other vendors such as MARCIVE, Backstage Library Works and OCLC
3. These files will also then be transformed to bf:2.0 using the LC XSLT converter to compare against the Casalini methods


First Steps (Projects) at UAL
2. Analysis of MARC to bf:2.0
An attempt to compare:
1. Conversion methods for MARC to bf:2.0 between Casalini SHARE VDE and LC Converter
2. In-house methods for enrichment using the LC converter vs enrichment methods with the Casalini project
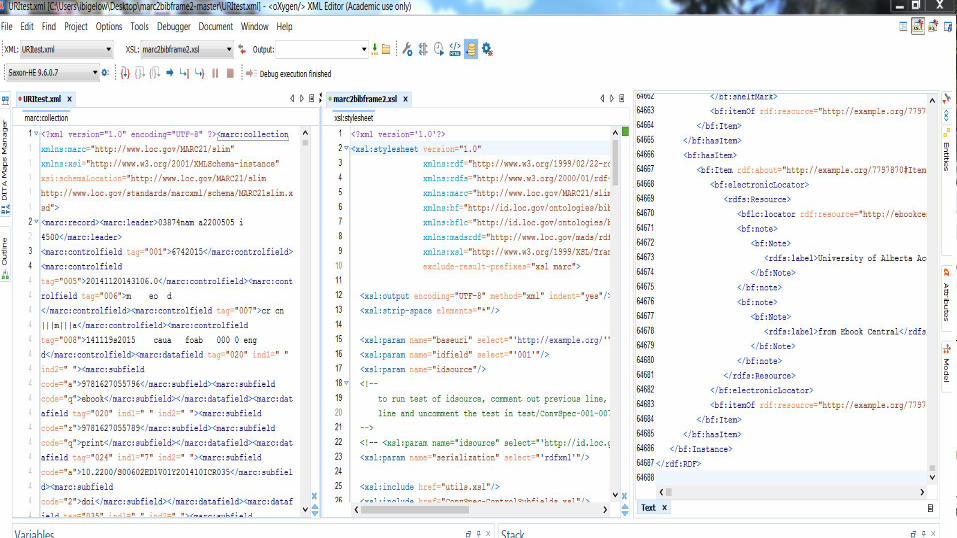

University of Alberta data in bf:2.0!
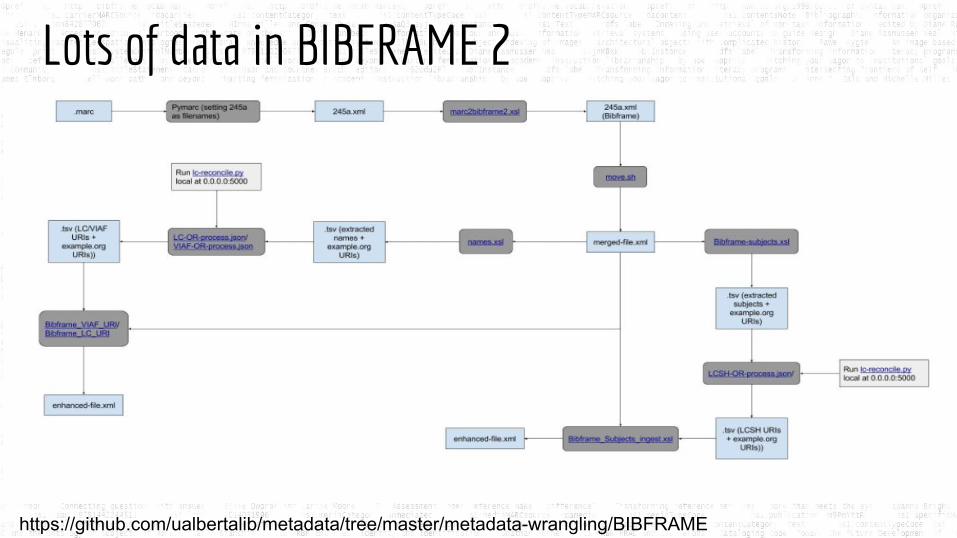
Lots of data in BIBFRAME 2
https://github.com/ualbertalib/metadata/tree/master/metadata-wrangling/BIBFRAME
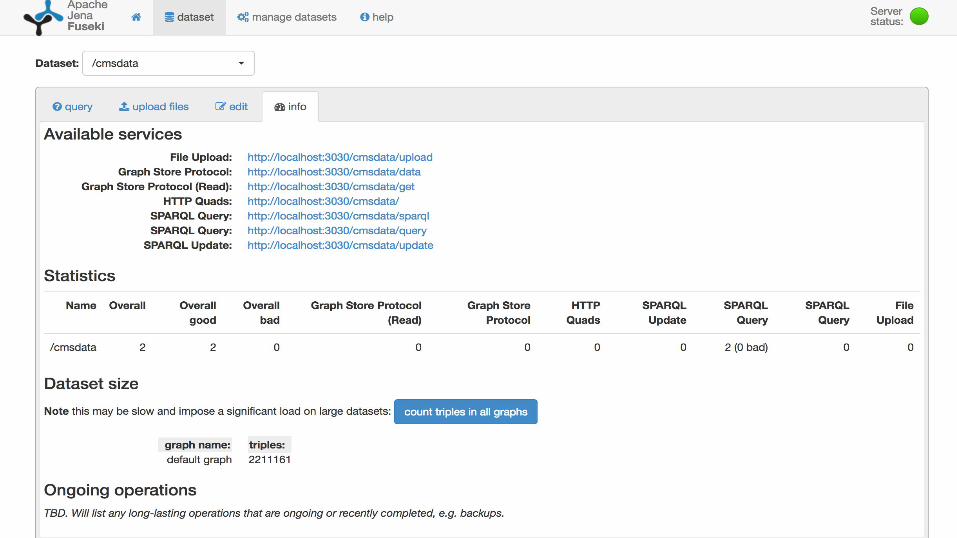
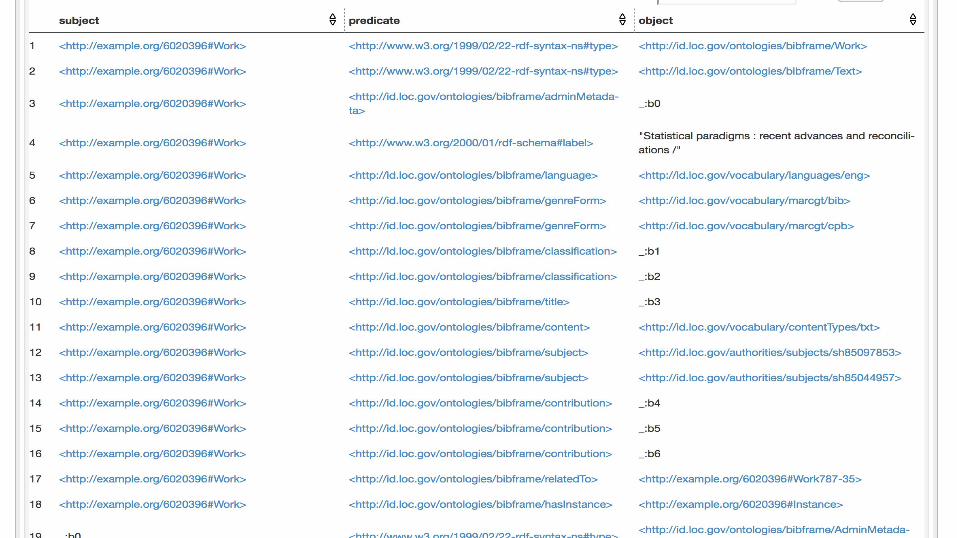

So we have the data, but now what?
A few questions worth pondering
Once we have our collection in bf:2.0 and establish a system for ongoing updates:
1. Is it worth testing original data creation with bf editor?
2. How will copy cataloguing work in this environment?
3. Pilot projects with vendors for provision of data in this format?
4. How/When can we set-up Blacklight (or other tools) to run on this data? What does this mean for the ILS?

We’re going to need a lot of coffee!
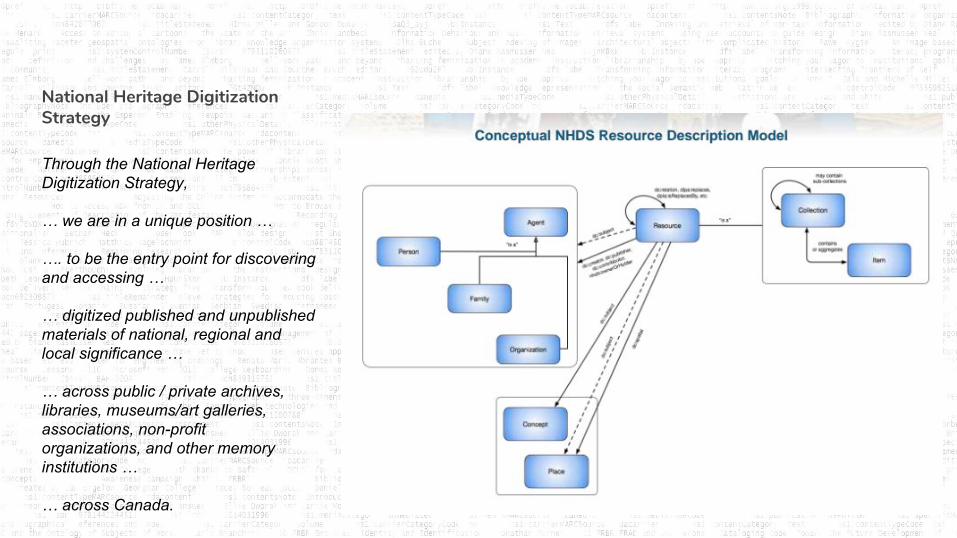
National Heritage Digitization Strategy
Through the National Heritage Digitization Strategy,
… we are in a unique position …
…. to be the entry point for discovering and accessing …
… digitized published and unpublished materials of national, regional and local significance …
… across public / private archives, libraries, museums/art galleries, associations, non-profitorganizations, and other memory institutions …
… across Canada.
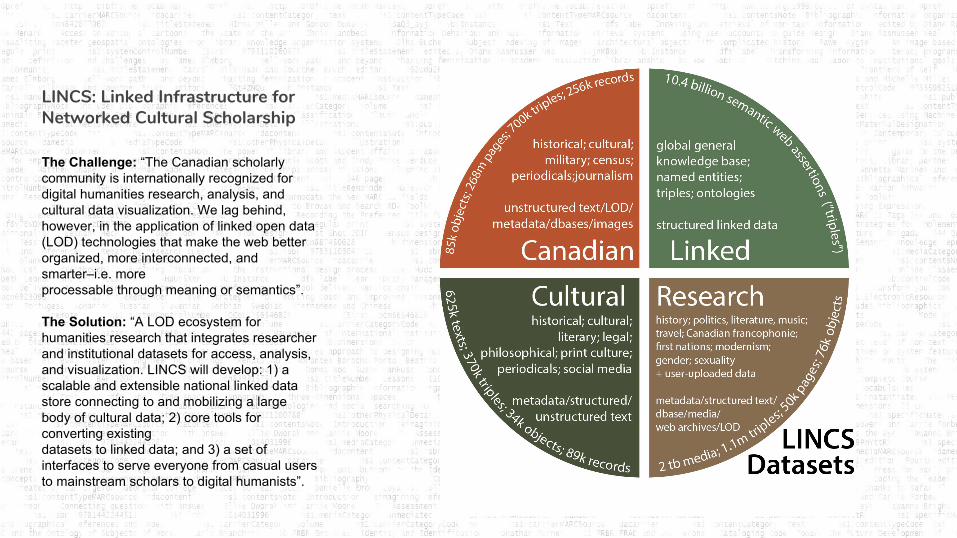
LINCS: Linked Infrastructure for Networked Cultural Scholarship
The Challenge: “The Canadian scholarly community is internationally recognized for digital humanities research, analysis, and cultural data visualization. We lag behind, however, in the application of linked open data (LOD) technologies that make the web better organized, more interconnected, and smarter–i.e. moreprocessable through meaning or semantics”.
The Solution: “A LOD ecosystem for humanities research that integrates researcher and institutional datasets for access, analysis, and visualization. LINCS will develop: 1) a scalable and extensible national linked data store connecting to and mobilizing a large body of cultural data; 2) core tools for converting existingdatasets to linked data; and 3) a set of interfaces to serve everyone from casual users to mainstream scholars to digital humanists”.
Linked data and local repositories
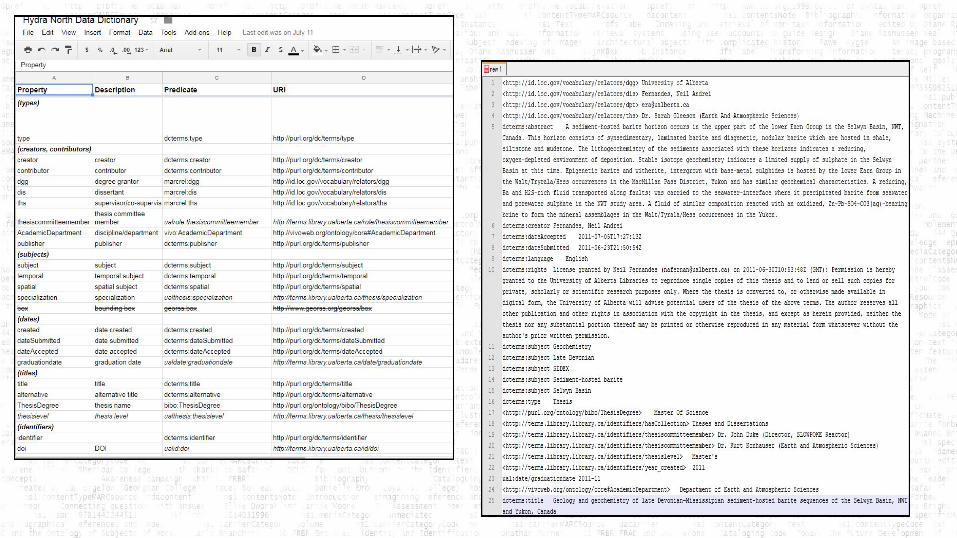
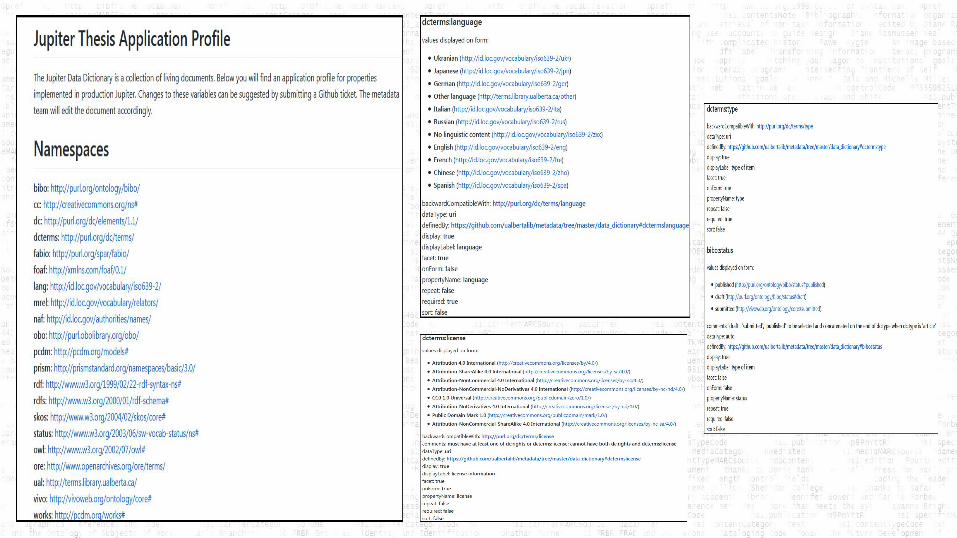

Staff Development and Training
● webinars and other virtual sessions
● conference and workshop attendance
● Semantic Web book club● informal Birds of a Feather
sessions● Zepheira training● Library Juice Academy
certificate in RDF and XML● and more ...

Libraries and principles ...
● discovery, access, stewardship of resources
● leveraging technologies to meet user needs
● sharing expertise and sharing data● building and growing relationships● openness● sustainability● building communities, making a difference
within and through them
LINKED DATA …
is simply another manifestation of these principles

Many thanks to all the magical individuals working with us!
From Bibliographic Services and those across UAL to everywhere else