Embed Size (px)
Citation preview

HAL Id: hal-01471916https://hal.inria.fr/hal-01471916v2
Submitted on 22 May 2017
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
Making Cloud-based Systems Elasticity TestingReproducible
Michel Albonico, Jean-Marie Mottu, Gerson Sunyé, Frederico Alvares
To cite this version:Michel Albonico, Jean-Marie Mottu, Gerson Sunyé, Frederico Alvares. Making Cloud-based SystemsElasticity Testing Reproducible. 7th International Conference on Cloud Computing and ServicesScience, Apr 2017, Porto, Portugal. �10.5220/0006308905230530�. �hal-01471916v2�

Making Cloud-based Systems Elasticity Testing Reproducible
Michel Albonico1;3, Jean-Marie Mottu1, Gerson Sunye1 and Frederico Alvares2
1AtlanModels team (Inria, IMT-A, LS2N), France2Ascola team (Inria, IMT-A, LS2N), France
3Federal Technological University of Parana, Francisco Beltr~ao, [email protected], fjean-marie.mottu,gerson.sunye,[email protected]
Keywords:Cloud Computing, Elasticity, Elasticity Testing, Controllability, Reproducibility.
Abstract:Elastic cloud infrastructures vary computational resources at runtime, i. e., elasticity, which iserror-prone. That makes testing throughout elasticity crucial for those systems. Those errors aredetected thanks to tests that should run deterministically many times all along the development.However, elasticity testing reproduction requires several features not supported natively by themain cloud providers, such as Amazon EC2. We identify three requirements that we claim tobe indispensable to ensure elasticity testing reproducibility: to control the elasticity behavior, toselect speci�c resources to be unallocated, and coordinate events parallel to elasticity. In thispaper, we propose an approach ful�lling those requirements and making the elasticity testingreproducible. To validate our approach, we perform three experiments on representative bugs,where our approach succeeds in reproducing all the bugs.
1 Introduction
Elasticity is one of the main reasons thatmakes cloud computing an emerging trend. Itallows to vary (allocate or deallocate) sys-tem resources automatically, according to de-mand [Agrawal et al., 2011, Herbst et al., 2013,Bersani et al., 2014]. Therefore, Cloud-Based
Systems (CBS) must adapt themselves to re-source variations.
Due to their scalability nature, CBSadaptations may be complex and error-prone [Herbst et al., 2013]. This is the case,for instance, of bug 2164 that a�ects ApacheZooKeeper [Hunt et al., 2010], a coordinationservice for large-scale systems. According to thebug report, the election of a new leader neverends when the leader leaves a system with threenodes. This happens when the resource (e. g.,virtual machine) that hosts the leader node isdeallocated.
Furthermore, some bug reproductions requiremore than adaptation tasks. This is the case ofMongoDB NoSQL database bug 7974, where elas-ticity and consequently, adaptation tasks, happen
in parallel with other events. In that case, adap-tation tasks are not the unique cause of the bug,though they are still a requirement for its repro-duction.
Reproducing bugs several times is necessaryto diagnose and to correct them. That is,bugs reported in a CBS bug tracking shouldbe corrected by developers, who need to repro-duce them, at �rst. Moreover, during the de-velopment, regression tests should be run reg-ularly [Engstrom et al., 2010], requiring the de-sign of e�cient and deterministic tests. MakingCBS testing reproducible is then an importantconcern.
In this paper, we consider any bug that occursin presence of elasticity as an elasticity-related
bug. To verify the existence of this kind of bug inthe real-world and to get insights about them, weanalyze MongoDB's bug tracking, a popular CBS.In the bug tracking we identify a total of 43 bugsthat involve elasticity. Since these bugs occur inreal-world, testers must manage elasticity whenwriting and running their tests. However, writingand executing tests considering the reproductionof elasticity-related bugs is complex. Besides the
typical di�culty of writing test scenarios and or-acles, it requires to deterministically manage theelasticity and parallel events.
The management of elasticity involves driv-ing the system through a sequence of resourcechanges, which is possible by varying the work-load accordingly [Albonico et al., 2016]. In addi-tion, tester should also manage parameters thatcannot be natively controlled. For instance, re-source changes are managed by the cloud provideraccording to its own policy. This prevents thetester to choose which resource must be deallo-cated, a requirement for 19 of the 43 MongoDB'selasticity-related bugs. Another parameter thatthe tester should manage is the coordination ofevents in parallel to elasticity (17/43 bugs) that,among others, requires a precise monitoring of re-sources.
In this paper, we present an approach for elas-ticity testing that allows the tester to reproducetests concerned with elasticity-related bugs. Wecontrol the elastic behavior by sending satisfac-tory workload to CBS that drives it through a se-quence of resource allocations and deallocations.Our approach also provides two original contribu-tions: the deallocation of speci�c resources, andthe coordination of events in parallel with elastic-ity. The two original contributions are requiredto reproduce 30 of the 43 elasticity-related bugsof MongoDB, i. e., � 70%. In the paper, we alsopresent a prototype for the approach.
To support our claims and to validate our ap-proach, we select 3 representative bugs out of the43 elasticity-related bugs previously mentioned,and conducted a set of experiments on AmazonEC2. All the 3 bugs require our approach to sat-isfy at least one of the requirements we identi�ed.Experiment results show that our approach repro-duces real-world elasticity-related bugs ful�llingall the 3 requirements.
The paper is organized as follows. In the nextsection, we remind the major aspects of cloudcomputing elasticity. Section 3 details the re-quirements we claim be necessary for elasticitytesting. Section 4 introduces the testing approachwe propose. The experiments and their resultsare described in Section 5. Section 6 discussesthreats to validity. Finally, Section 7 concludes.
2 Cloud Computing Elasticity
This section provides the de�nitions of themain concepts related to Cloud Computing Elas-
ticity that are required for the good understand-ing of our approach.
2.1 Typical Elastic Behavior
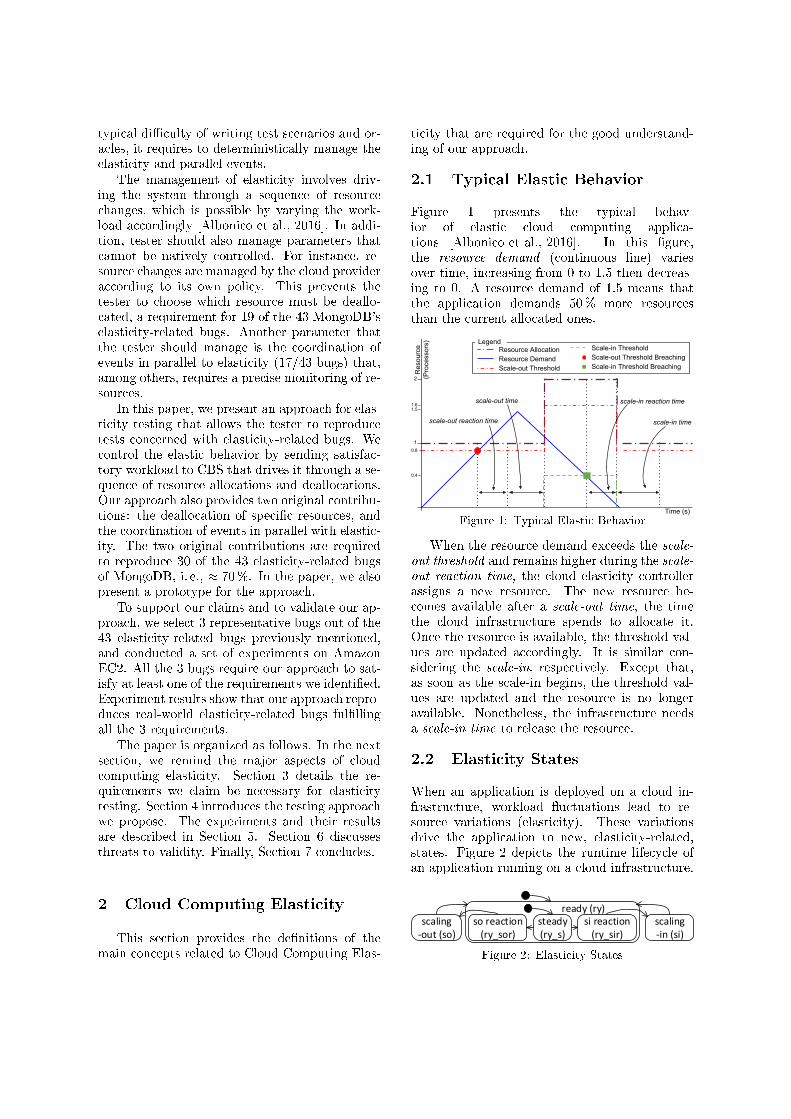
Figure 1 presents the typical behav-ior of elastic cloud computing applica-tions [Albonico et al., 2016]. In this �gure,the resource demand (continuous line) variesover time, increasing from 0 to 1:5 then decreas-ing to 0. A resource demand of 1.5 means thatthe application demands 50% more resourcesthan the current allocated ones.
1.5
Resource AllocationResource DemandScale-out Threshold
Scale-in ThresholdScale-out Threshold BreachingScale-in Threshold Breaching
Time (s)
Res
ourc
e (P
roce
ssor
s)
2
1
0.4
0.8
1.6
scale-out reaction time
scale-out time scale-in reaction time
scale-in time
Legend
Figure 1: Typical Elastic Behavior
When the resource demand exceeds the scale-out threshold and remains higher during the scale-out reaction time, the cloud elasticity controllerassigns a new resource. The new resource be-comes available after a scale-out time, the timethe cloud infrastructure spends to allocate it.Once the resource is available, the threshold val-ues are updated accordingly. It is similar con-sidering the scale-in, respectively. Except that,as soon as the scale-in begins, the threshold val-ues are updated and the resource is no longeravailable. Nonetheless, the infrastructure needsa scale-in time to release the resource.
2.2 Elasticity States
When an application is deployed on a cloud in-frastructure, workload uctuations lead to re-source variations (elasticity). These variationsdrive the application to new, elasticity-related,states. Figure 2 depicts the runtime lifecycle ofan application running on a cloud infrastructure.
ready (ry)scaling
-out (so)steady (ry_s)
si reaction (ry_sir)
scaling-in (si)
so reaction (ry_sor)
Figure 2: Elasticity States

At the beginning the application is at theready state (ry), when the resource con�gurationis steady (ry s substate). Then, if the applica-tion is exposed for a certain time (scale-out re-action time, ry sor substate) to a pressure thatbreaches the scale-out threshold, the cloud elas-ticity controller starts adding a new resource. Atthis point, the application moves to the scaling-
out state (so) and remains in this state while theresource is added. After a scaling-out, the appli-cation returns to the ready state. It is similarwith the scaling-in state (si), respectively.
2.3 Elasticity Control
We can categorize elasticity control approaches intwo groups: (i) direct resource management, and(ii) generation of adequate workload.
The �rst and simplest one (i) interacts directlywith the cloud infrastructure, asking for resourceallocation and deallocation. The second one (ii)consists in generating adequate workload varia-tions that drive CBS throughout elasticity states,as previously explained in Section 1. It is morecomplex since requires a preliminary step for pro-�ling the CBS resource usage, and calculatingthe workload variations that trigger the elastic-ity states.
3 Requirements for Elasticity
Testing Reproduction
In this paper, we consider three requirementsfor reproducing elasticity testing: elasticity con-
trol, selective elasticity, and events scheduling.Elasticity Control is the ability to reproduce a
speci�c elastic behavior. Elasticity-related bugsmay occur after a speci�c sequence of resourceallocations and deallocations. Logically, all the 43elasticity-related bugs of MongoDB should satisfythis requirement.
Analyzing elasticity-related bugs, we identifytwo other requirements: selective elasticity, andevent scheduling. Those requirements are neces-sary to reproduce 30 of the 43 selected bugs.
Selective Elasticity is the necessity to spec-ify precisely which resource must be deallocated.The reproduction of some elasticity-related bugsrequires a deterministic management of elastic-ity changes. For instance, deallocating a resourceassociated to the master component of a cloud-based system. From the selected bugs, 19 requireselective elasticity.
Event Scheduling is the necessity to synchro-nize elasticity changes with parallel events. Weconsider as an event any interaction or stimulus toCBS, such as forcing a data increment or to sim-ulate infrastructure failures. The reproduction of17 of MongoDB elasticity-related bugs requiresevent scheduling.
Table 1 shows the number of bugs that shouldmeet those requirements in order to be repro-ducible. As already said, all the bugs requireelasticity control.A total of 30 bugs (70%) shouldmeet requirements besides elasticity, where 6 bugsneed all the requirements. Finally, only 13 bugsonly need elasticity control (30%) .
Elasticity
ControlSelectiveElasticity
EventScheduling All
Only
Elasticity
Control
Quantity 43 19 17 6 13
Table 1: Requirements for Bug Reproductions
4 Elasticity Testing Approach
In this section, we present the overall archi-tecture of our approach.
4.1 Architecture Overview
Figure 3 depicts the overall architecture of ourapproach. The architecture has four main compo-nents: Elasticity Controller Mock (ECM), Work-
load Generator (WG), Event Scheduler (ES), andCloud Monitor (CM).
Elasticity Controller
Mock
Event Scheduler
E = {ec1=(s1,W1),ec2, …, ecn} SER = {(eci, seri), …}
Events Schedule
Workload Generator
Wj Cloud System
Workload
Cur
rent
Ela
stic
ity S
tate
Event Execution
Resource Variation
CloudMonitor
Figure 3: Overall Architecture
The ECM simulates the behavior of the cloudprovider elasticity controller, allocating and deal-locating determined resources, according to test-

ing needs. It also asks the WG to generate theworkload accordingly, reproducing a realistic sce-nario. The role of the ES is to schedule and exe-cute a sequence of events in parallel with the othercomponents. Finally, the CM monitors the cloudsystem, gathering information that helps orches-trating the behavior of the three other compo-nents, ensuring the sequence of elasticity states,and their synchronization with the events.
Table 2 summarizes the requirements thateach component helps in ensuring, as we detailin this section.
REQUIREMENT
COMPONENT
Elasticity
ControlSelectiveElasticity
EventScheduling
ECM YES YES YES
WG YES NO NO
ES NO NO YES
CM YES YES NO
Table 2: Requirements Ensured by Architecture'sComponents
4.1.1 Elasticity Controller Mock
The ECM is designed to reproduce the elasticbehavior. By default, ECM requires as input asequence of elasticity changes, denoted by E =fec1; ec2; :::; ecng, where each ec is a pair thatcorresponds to an elasticity change. Elasticitychange pairs are composed of a required elastic-ity state (si) and a workload (Wi), eci = hsi;Wiiwhere 1 � i � n. A workload is characterizedby an intensity (i. e., amount of operations persecond), and a workload type (i. e., set of trans-actions sent to the cloud system).
ECM reads elasticity change pairs sequen-tially. For each pair, ECM requests resourcechanges to meet elasticity state si and requeststhe Workload Generator to apply the workloadWi. Indeed, we have to send the correspondingworkload to prevent cloud infrastructure to pro-voke unexpected resource variations. In particu-lar, it could deallocate a resource that ECM justallocated, because the workload has remained lowand under the scale-in threshold.
Instead of waiting for the cloud computing in-frastructures for elasticity changes, it directly re-quests to change the resource allocation (elastic-ity control). Based on both, required elasticitystate and workload (elasticity change pair), ECManticipates the resource changes. To be sure CBSenters the expected elasticity state, ECM queriesthe Cloud Monitor, which periodically monitorsthe cloud infrastructure.
The ECM may also lead to a precise resourcedeallocation (selective elasticity). Typically, elas-
ticity changes are transparent to the tester, man-aged by the cloud provider. To set up the selec-tive elasticity, ECM requires a secondary input,i. e., Selective Elasticity Requests (SER). SER isdenoted by SER = f(ec1; ser1); :::; (ecn; sern)g,where eci 2 E, and seri refers to a selective
elasticity request. A selective elasticity request
is a reference to an algorithm (freely written bytester) that gets a resource's ID. When eci is per-formed by ECM, the algorithm referred by seri isexecuted, and the resource with the returned IDis deallocated by ECM.
ECM helps in ensuring all of elasticity testingrequirements. As earlier explained in this sec-tion, it deterministically requests resource varia-tions (elasticity control and selective elasticity),and helps on ensuring the event scheduling pro-viding information of the current elasticity stateto the Event Scheduler.
4.1.2 Workload Generator
The Workload Generator is responsible for gener-ating the workload (W ). We base it on Albonicoet al. work [Albonico et al., 2016], which takesinto account a threshold-based elasticity (see Fig-ure 1), where resource change demand occurswhen a threshold is breached for a while (reactiontime). Therefore, a workload should result in ei-ther threshold breached (for scaling states) or notbreached (for ready state), during the necessarytime. To ensure this, the Workload Generatorkeeps the workload constant, either breaching athreshold or not, until a new request arrives.
Considering a scale-out threshold is set as 60%of CPU usage, the workload should result in aCPU usage higher than 60% to request a scale-out. In that case, if 1 operation A hypotheticallyuses 1% of CPU, it would be necessary at least61 operations A to request the scale-out. On theother hand, less than 61 operations would notbreach the scale-out threshold, keeping the re-source steady.
The Workload Generator contributes with theElasticity Controller Mock to the elasticity con-
trol requirement.
4.1.3 Event Scheduler
The Event Scheduler input is a map associatingsets of events to elasticity changes (eci), i. e., theset of events that should be sent to the cloud sys-tem when a given elasticity change is managed bythe ECM. Table 3 abstracts an input where fourevents are associated to two elasticity changes.

Elasticity Change Event ID Execution Order Wait Time
ec1
e1 1 0 se2 2 10 se3 2 0 s
ec2e2 1 0 se4 2 0 s
Table 3: Events Schedule
Periodically, the Event Scheduler polls theECM for the current elasticity change, executingthe events associated to it. For instance, whenthe ECM manages the elasticity change ec1, itexecutes the events e1, e2, and e3. Events haveexecution orders, which de�ne priorities amongevents associated to the same state: event e1 isexecuted before events e2 and e3. Events withthe same execution order are executed in paral-lel (e. g., e2 and e3). Events are also associatedto a wait time, used to delay the beginning of anevent. In Table 3, event e2 has a wait time of10 s (starting 10 s after e3, but nonetheless exe-cuted in parallel). This delay may be useful, forinstance, to add a server to the server list a fewseconds after the ready state begins, waiting fordata synchronization to be �nished.
The Event Scheduler ensures the event
scheduling requirement.
4.1.4 Cloud Monitor
Cloud Monitor helps ECM to ensure elasticity
control and selective elasticity. It periodically re-quests current elasticity state and stores it in or-der to respond to the ECM queries, necessary forelasticity control. It also executes the selectiveelasticity algorithm of SER, responding to ECMwith the ID of the found resources.
4.2 Prototype Implementation
Each component of the testing approach archi-tecture is implemented in Java and communicatewith each other through Java RMI. Currently, weonly support Amazon EC2 interactions, thoughone could adapt our prototype to interact withother cloud providers.
4.2.1 Elasticity Controller Mock
The elasticity changes are described in a property�le. The entries are set as hkey; valuei pairs, aspresented in Listing 1. The key corresponds tothe elasticity change name, while the value cor-responds to the elasticity change pair. The �rstpart of the value is the elasticity state, and the
second part is the workload, divided into intensityand type.
Listing 1: Example of Elasticity Controller Mock In-put File (Elasticity Changes)
ec1=ready, (1000,write)ec2=scaling�out, (2000,read/write)...ec4=scaling�in, (1500,read)
As previously explained, for each entry, theECM sends the workload parameters to theWorkload Generator and deterministically re-quests the speci�ed resource change. Resourcechanges are requested through the cloud providerAPI, which enables resource allocation and deal-location, general infrastructure settings, andmonitoring tasks. Before performing an elas-ticity change, the ECM asks the Cloud Mon-itor whether the previous elasticity state wasreached. Cloud Monitor uses the Selenium1 au-tomated browser to gather pertinent informationfrom cloud provider's dashboard Web page.
We use Java annotations to set up selectiveelasticity requests (SER), as illustrated in List-ing 2. A Java method implements the code thatidenti�es a speci�c resource and returns its iden-ti�er as a String type. It is annotated with meta-data that speci�es its name and associated elas-ticity change.
Listing 2: Selective Elasticity Input File
@Selectionfname="ser1", elasticity change="ec4"gpublic String select1() f
... //code to �nd a resource IDreturn resourceID; g
4.2.2 Workload Generator
The WG generates the workload according to theparameters received from the ECM (i. e., work-load type and intensity), whereas the workloadis cyclically generated until new parameters ar-rive. It uses existing benchmark tools, settingthe workload parameters in the command line.
For instance, YCSB benchmark tool allowsthree parameters related to the workload: thepreset workload pro�le, the number of operations,and the number of threads. The preset workloadpro�le refers to the workload type, while the mul-tiplication of the two last parameters results inthe workload intensity.
4.2.3 Event Scheduler
Event schedule is set in a Java �le, where eachevent is an annotated method, such as the exam-
1http://www.seleniumhq.org/

ple illustrated in Listing 3. Java methods are an-notated with the event identi�er, the related elas-ticity change, the order, and the waiting time. ECperiodically polls the ECM to obtain the currentelasticity change. Then, it uses Java Re ectionto identify and execute the Java methods relatedto it.
Listing 3: Example of Event Scheduler Input File
@Eventfid="e1",elasticity change="ec1",order="1", wait="0"gpublic void event1() f ... g
4.3 Prototype Execution
Before executing our approach's prototype,testers must deploy the CBS, which is doneusing an existing approach based on a Do-main Speci�c Language (DSL) by Thiery etal. [Thiery et al., 2014]. The DSL enables usto abstract the deployment complexities inher-ent to CBS. Information in deployment �le, suchas cloud provider's credentials and Virtual Ma-chine's con�guration, are then used by the com-ponents of our prototype. However, since the de-ployment of CBS is not a contribution of our ap-proach, we do not further explain it in this paper.
To execute our approach's prototype, testerswrite the input �les: E, SER, and ES �les. These�les as well as the deployment �le are passedto the prototype as command line parameters.Then, all the execution is automatically orches-trated.
5 Experiments
In this section, we present three experimentsthat aim at validating our approach for elastic-ity testing. We reproduce three representativeelasticity-related bugs from two di�erent CBS:MongoDB and ZooKeeper. The �rst bug is theMongoDB-7974, which we gather from the Mon-goDB's elasticity-related bugs described in Sec-tion 3. The other two bugs, ZooKeeper-2164 andZooKeeper-2172, we gather from the o�cial bugtracking of ZooKeeper, another popular CBS.
We attempt to reproduced all the bugs in twoways: using our approach, and relying on thecloud computing infrastructure. Then, we com-pare both approaches to verify whether the re-quirements that we identify in this paper are met.
5.1 Experimental Environment
5.1.1 CBS Case Studies
MongoDB2 is a NoSQL document database.MongoDB has three di�erent components: thecon�guration server, MongoS and MongoD. Thecon�guration server stores metadata and con�g-uration settings. While MongoS instances arequery routers, which ensure load balance, Mon-goD instances store and process data.
Apache ZooKeeper3 is a server that pro-vides highly reliable distributed coordination.ZooKeeper is intended to be replicated over aset of nodes, called as an ensemble. Requestsfrom ZooKeeper's clients are forwarded to a sin-gle node, the leader (which is elected using a dis-tributed algorithm). The leader works as a proxy,distributing the request among other nodes calledas followers. The followers keep a local copy ofthe con�guration data to respond to requests.
5.1.2 Cloud Computing Infrastructure
All the experiments are conducted on the com-mercial cloud provider Amazon Elastic CloudCompute (EC2), where we set scale-out andscale-in thresholds as 60% and 20% of CPU us-age, respectively.
In the experiment with MongoDB, MongoS in-stance is deployed on a large machine (m3.large),while the other instances are deployed on mediummachines (m3.medium). In the experiments withZooKeeper, every node is deployed on a mediummachine ( m3.medium)4.
5.1.3 Workload Tools
To generate the workload for the experimentwith MongoDB, we use the Yahoo Cloud ServingBenchmark (YCSB) [Cooper et al., 2010], whilefor the experiments with ZooKeeper, we use anopen-source benchmark tool [Hunt et al., 2010].
5.1.4 Selected Bugs: Requirements for
Reproduction
Table 4 summarizes the requirements for the re-production of the three selected bugs. Those bugscover all the possible combinations of require-ments, constrained by the mandatory presence ofelasticity control, and the need of at least one of
2https://www.mongodb.org/3https://zookeeper.apache.org/4https://aws.amazon.com/fr/ec2/itype/

the other requirements. We do not attempt to re-produce any bug that only requires elasticity con-trol, since one could reproduce the required elas-tic behavior using Albonico et al. elastic controlapproach [Albonico et al., 2016] and then meetselasticity control requirement only.
FEATURE
BUG
Elasticity
ControlSelectiveElasticity
EventScheduling
MongoDB � 7974 YES YES YES
ZooKeeper � 2164 YES YES NO
ZooKeeper � 2172 YES NO YES
Table 4: Requirements for Reproduction the ThreeSelected Bugs
MongoDB bug 7974
This bug a�ects the MongoDB versions 2:2:0 and2:2:2, when a secondary component of a Mon-goDB replica set5 is deallocated. Indeed, in aMongoDB replica set, one of the components iselected as primary member, which works as a co-ordinator, while the others remain as secondarymembers.
To reproduce this bug, we must follow a spe-ci�c elastic behavior: initialization of a replica setwith three members, deallocation of a secondarymember, and allocation of a new secondary mem-ber. Therefore, the second step of the elasticbehavior requires the deallocation of a preciseresource, one of the secondary members. Thebug reproduction also requires two events syn-chronized to elasticity changes. Right after thesecondary member deallocation, we must create aunique index, and after the last step of the elasticbehavior, we must add a document in the replicaset.
In conclusion, the reproduction of this bugneeds to meet all the requirements that we con-sider in this paper: elasticity control, selective
elasticity, and event scheduling.
ZooKeeper bug 2164
This bug is related to ZooKeeper version 3:4:5and concerns the leader election. According tothe bug report6, in an ensemble with three nodes,when the node running the leader shuts down, anew leader election starts and never ends.
The reproduction of this bug must follow aprecise sequence: initialization (allocation of the�rst node), followed by the allocation of two
5https://docs.mongodb.com/replica-set6https://issues.apache.org/jira/ZK2164
nodes and the deallocation of the leader node.The main di�culty of reproducing this bug is thatwhen ZooKeeper is deployed on three nodes, thedeallocated node is not necessarily the leader.
In conclusion, the reproduction of this bugneeds to meet two requirements: elasticity con-
trol and selective elasticity.
ZooKeeper bug 2172
This bug is related to ZooKeeper version 3:5:0,which introduces the dynamic recon�guration.According to the bug report7, when a third nodeis added to a ZooKeeper ensemble, the systementers an unstable state and cannot recover.
After a thorough analysis of the available logs,we understand that the bug occurs when a leaderelection starts right after the allocation of a thirdnode. More precisely, when a new node joins theensemble, its synchronizes the con�guration datawith the leader. Therefore, if the data is not al-ready synchronized at the moment of the leaderelection, the bug occurs.
The reproduction of this bug requires a simpleelastic behavior: initialization and two node allo-cations. However, this sequence alone does notreproduce the bug: we need to be sure that theleader election starts before the end of the datasynchronization process. We can force this by in-creasing the data amount through an event syn-chronized with the completion of the third nodeallocation.
The reproduction of this bug needs to meettwo requirements: elasticity control and event
scheduling.
5.2 Bug Reproduction
In this section, we describe the use of our ap-proach to reproduce the three bugs, and comparethe results to reproduction attempts without ourapproach. We do not explain in details the setupof reproductions without our approach but we as-sume one can manage the control elasticity andmeet this requirement. Indeed, reproducing elas-ticity is a native feature of cloud computing in-frastructures, and we just drive CBS through re-quired elastic behavior using Albonico et al. ap-proach [Albonico et al., 2016].
5.2.1 MongoDB-7974 Bug Reproduction
To reproduce MongoDB bug 7974 using our ap-proach, we �rst manually create the MongoDB
7https://issues.apache.org/jira/ZK2172

replica set, composed by three nodes. Then, weset up the following sequence of elasticity changes,which should drive MongoDB through the re-quired elastic behavior:
E = hry1; h4500; rii ; hsi1; h1500; rii ;
hry2; h3000; rii ; hso1; h4500; rii ; hry3; h4500; rii
Since we must deallocate a secondary memberof MongoDB replica set at elasticity change ec2,it is associated to a selective elasticity re-quest (SER). The SER queries MongoDB replicaset's members, using MongoDB shell methoddb.isMaster, until �nding a member that is sec-ondary.
In parallel to the elasticity changes, we set uptwo events, e1 and e2, which respectively createa unique index, and insert a new document inthe replica set. The e1 is associated to elasticitychange ec3, a ready state that follows the scaling-in state where a secondary member is deallocated.The e2 is associated to elasticity change ec5, thelast ready state. Both events are scheduled with-out waiting time.
Elasticity Change Event ID Execution Sequence Wait Time
ec3 e1 1 0 sec5 e2 1 0 s
Table 5: MongoDB-7974 Event Schedule
We repeat the bug reproduction for threetimes. After each execution, we look for the ex-pression "duplicate key error index" in the log�les. If the expression is found, we consider thebug is reproduced.
Table 6 shows the result of all the three exe-cutions, either using our approach or not. All theattempts using our approach reproduce the bug,while none of the attempts without our approachdo it.
Reproduction Reproduced Not Reproduced
With Our Approach 3 0Without Our Approach 0 3
Table 6: MongoDB-7974 Bug Reproduction Results
For the executions without our approach, weforce MongoDB to elect the intermediate node(in the order of allocation) as primary member8,what can occasionally occur in a real situation.In this scenario, independent of scale-in settings,cloud computing infrastructure always deallocatea secondary member, since Amazon EC2 only al-lows to deallocated the oldest or newest nodes.Despite in this experiment we force a selective
8https://docs.mongodb.com/force-primary
elasticity, in a real situation without using ourapproach it is not deterministic. For instance,the newest or oldest node could be elected as aprimary member. Even though cloud computinginfrastructures reproduces the required elastic be-havior, this bug still needs the event executions,which must be correctly synchronized. This isthe reason the bug is not reproduced without ourapproach.
5.2.2 ZooKeeper-2164 Bug Reproduction
To reproduce this bug, we translate and completethe scenario (Section 5.1.4) into the following se-quence of elasticity changes:
E = hry1; h3000; rii ; hso1; h5000; rii ; hry2; h5000; rii ;
hso2; h10 000; rii ; hry3; h10 000; rii ; hsi1; h5000; rii
The sequence of elasticity changes �rst initial-izes the cloud system with one node, then it re-quests two scale-out. Once the three nodes arerunning, the sequence requests a scale-in.
To discover the leader node, we write a SERthat is associated to the last elasticity change e6(hsi1; h5000; rii). The SER method connects toevery Zookeeper node and executes ZooKeepercommand named stat. This command describes,among other information, the node executionmode: leader or follower.
The sequence of elasticity states, including aselective elasticity, is supposed to reproduce thebug. To verify whether the failure occurs, wewrite a test oracle, which is implemented in JU-nit [Gamma and Beck, 1999]. It is run after thelast elasticity change (hsi1; h5000; rii), and repet-itively searches for a leader until it is found or thetimeout is reached. In the �rst case, the verdictis pass, what means the bug is reproduced andobserved. Otherwise, the verdict is fail.
As well as in the �rst experiment, we use twodi�erent setups to execute this experiment: withour approach, and without our approach. We re-peat the experiment three times for each setup.
Since the selective elasticity is one of the re-quirements for this bug reproduction, when exe-cuting without our approach, we try to reproducea real scenario, where every node can be elected asa leader. Therefore, we force ZooKeeper to elect adi�erent node as the leader at each execution: thenewest, the oldest, then the intermediate node.Then, we use AmazonEC2 to deallocate a node.Its policy is to deallocate either the newest or theoldest node, it is not possible to deallocate theintermediate node. Hence, during the �rst two

executions we can ask AmazonEC2 to deallocatethe leader, but not during the last one.
Table 7 summarizes the results. When usingour approach, all the three test executions pass,demonstrating the ability of our testing approachto deterministically reproduce the bug. In con-trast, only two executions without our approachpass, the ones where the leader is the newest orthe oldest node. Therefore, without our approachthe bug was not reproduced deterministically.
Reproduction Pass Verdicts Fail Verdicts
With Our Approach 3 0Without Our Approach 2 1
Table 7: ZooKeeper-2164 Bug Reproduction Results
5.2.3 ZooKeeper-2172 Bug Reproduction
We create the following sequence of elasticitychanges to reproduce this bug (Section 5.1.4):
E = hry1; h3000; rii ; hso1; h5000; rii ;
hry2; h5000; rii ; hso2; h10 000; rii ; hry3; h10 000; rii
According to the bug log �les, the bug occurswhen the leader election starts before the end ofthe data synchronization between the third nodeand the previous leader. Thus, the test sequencemust ensure that the data synchronization pro-cess is longer than the delay needed to start anew election, which is about 10 s according to thelog �les. Forcing the data synchronization to takelong enough, we create an event schedule to asso-ciate an event e1 to the state so2, as described inTable 8. The e1 requests a data increasing to anamount that should take longer than 10 secondsto synchronize. Since this experiment uses Ama-zon m3:large machines, which have a bandwidthof 62:5MB/s, the data amount must be� 625MBof data.
Elasticity Change Event ID Execution Sequence Wait Time
ec4 e1 1 0 s
Table 8: ZooKeeper-2172 Event Schedule
We use the test oracle as for the bug 2164,which is associated to the last ready elasticitystate which is supposed not to be able to electa leader before the timeout. Table 9 summa-rizes the experiment execution. In all three ex-ecutions, the test verdict is pass, meaning thatthe testing approach reproduces the bug success-fully. Since the AmazonEC2 cannot manage na-tively the scheduling of events synchronized withelasticity states, then it cannot reproduce the bugdeterministically.
Reproduction Pass Verdicts Fail Verdicts
With Our Approach 3 0Without Our Approach 0 3
Table 9: ZooKeeper-2172 Bug Reproduction Results
5.3 Threats to validity
In all the experiments, we set the cloud providerscale-out and scale-in thresholds to 60% and 20%of CPU usage, respectively. These values do notin uence our experiments, though we seek for bugreproductions that require other thresholds.
In the experiments, our approach to drive CBSworks �ne. However, the elasticity driving couldbe compromised when the scalability is not linear.
Finally, controlling the elasticity directlycould introduce some bias in the bug reproduc-tion. For instance, one could anticipate an elastic-ity change, even before CBS enters a ready state.However, for the reproduced bugs we respect typ-ical elastic behavior (see Figure 1).
6 Related Work
Several research e�orts are related to ourapproach in terms of elasticity control, selec-tive elasticity, and events scheduling. Thework of Gambi et al. [Gambi et al., 2013b,Gambi et al., 2013a] addresses elasticity testing.The authors predict elasticity state transitionbased on workload variations and test whethercloud infrastructures react accordingly. However,they do not focus on controlling elasticity andcannot drive cloud application throughout di�er-ent elasticity states.
Banzai et al. [Banzai et al., 2010] propose D-Cloud, a virtual machine environment specializedin fault injection. Like our approach, D-Cloud isable to control the test environment and allowstesters to specify test scenarios. Test scenariosare speci�ed in terms of fault injection and noton elasticity and events (as in our approach).
Yin et al. [Yin et al., 2013] propose CTPV, aCloud Testing Platform Based on Virtualization.The core of CTPV is the private virtualization re-source pool. The resource pool mimics cloud in-frastructures environments, which in part is simi-lar to our elasticity controller. CTPV di�ers fromour approach in two points: (i) it does not usereal cloud infrastructures and (ii) it uses an elas-ticity controller that does not anticipate resourcedemand reaction.

Vasar et al. [Vasar et al., 2012] propose aframework to monitor and test cloud computingweb applications. Their framework replaces thecloud elasticity controller, predicting the resourcedemand based on past workload. Contrary to ourapproach, they do not allow to control a speci�csequence of elasticity states or events.
Li et al. [Li et al., 2014] propose Reprolite, atool that reproduces cloud system bugs quickly.Similarly to our approach, Reprolite allows theexecution of parallel events on the cloud systemand on the environment. Di�erently from our ap-proach, Reprolite does not focus on elasticity, oneof our main contributions.
7 Conclusion
In this paper, we proposed an approach toreproduce elasticity testing in a deterministicmanner. This approach is based on three mainfeatures: elasticity control, selective elasticity,and event scheduling. We applied this approachsuccessfully for reproducing three representativebugs from two popular open source systems:ZooKeeper and MongoDB.
Our approach allows the reproduction of bugsthat could not be deterministically reproducedwith state-of-the-art approaches. However, test-ing is not only about reproducing existing bugs,but also about detecting unknown ones. In thiscontext, a likely evolution for our approach is togenerate di�erent test scenarios combining elas-ticity state transitions, workload variations, se-lective elasticity, and event scheduling.
Another feature we plan to investigate as fu-ture work is the speediness of test executions.Deterministic resource allocation can acceleratestate transitions and thus optimize the numberof executions per period of time, and/or reduceexecution costs. This is particularly importantwhen testing cloud systems: to perform our threeexperiments, we used 136 machine-hours in Ama-zon EC2 .
Finally, we also plan to apply model-driven en-gineering to create an uni�ed high-level language.In the current implementation, the writing of testcases involves a mix of shell scripts, Java classes,and con�guration �les, which are not very suit-able for users.
References
[Agrawal et al., 2011] Agrawal, D., El Abbadi, A.,Das, S., and Elmore, A. J. (2011). Database scal-ability, elasticity, and autonomy in the cloud. Pro-ceedings of the 16th DASFAA.
[Albonico et al., 2016] Albonico, M., Mottu, J.-M.,and Suny�e, G. (2016). Controlling the Elasticityof Web Applications on Cloud Computing. In The31st SAC 2016, Pisa, Italy. ACM/SIGAPP.
[Banzai et al., 2010] Banzai, T., Koizumi, H., Kan-bayashi, R., Imada, T., Hanawa, T., and Sato, M.(2010). D-Cloud: Design of a Software Testing En-vironment for Reliable Distributed Systems UsingCloud Computing Technology. In Proceedings ofCCGRID'10, Washington, USA.
[Bersani et al., 2014] Bersani, M. M., Bianculli, D.,Dustdar, S., Gambi, A., Ghezzi, C., and Krsti�c, S.(2014). Towards the Formalization of Propertiesof Cloud-based Elastic Systems. In Proceedings ofPESOS 2014, New York, NY, USA. ACM.
[Cooper et al., 2010] Cooper, B. F., Silberstein, A.,Tam, E., Ramakrishnan, R., and Sears, R. (2010).Benchmarking Cloud Serving Systems with YCSB.In Proceedings of SoCC'10, New York, NY, USA.ACM.
[Engstrom et al., 2010] Engstrom, E., Runeson, P.,and Skoglund, M. (2010). A systematic review onregression test selection techniques. Informationand Software Technology, 52(1):14{30.
[Gambi et al., 2013a] Gambi, A., Hummer, W., andDustdar, S. (2013a). Automated testing of cloud-based elastic systems with AUToCLES. In The pro-ceedings of ASE'13, pages 714{717. IEEE/ACM.
[Gambi et al., 2013b] Gambi, A., Hummer, W.,Truong, H.-L., and Dustdar, S. (2013b). TestingElastic Computing Systems. IEEE Internet Com-puting, 17(6):76{82.
[Gamma and Beck, 1999] Gamma, E. and Beck, K.(1999). Junit: A cook's tour. Java Report.
[Herbst et al., 2013] Herbst, N. R., Kounev, S., andReussner, R. (2013). Elasticity in Cloud Comput-ing: What It Is, and What It Is Not. ICAC.
[Hunt et al., 2010] Hunt, P., Konar, M., Junqueira,F. P., and Reed, B. (2010). Zookeeper: Wait-freecoordination for internet-scale systems. In 2010USENIX, Boston, MA, USA, 2010.
[Li et al., 2014] Li, K., Joshi, P., Gupta, A., andGanai, M. K. (2014). ReproLite: A LightweightTool to Quickly Reproduce Hard System Bugs. InProceedings of SOCC'14, New York, NY, USA.
[Thiery et al., 2014] Thiery, A., Cerqueus, T.,Thorpe, C., Sunye, G., and Murphy, J. (2014). ADSL for Deployment and Testing in the Cloud. InProc. of the IEEE ICSTW 2014, pages 376{382.
[Vasar et al., 2012] Vasar, M., Srirama, S. N., andDumas, M. (2012). Framework for Monitoring and

Testing Web Application Scalability on the Cloud.In Proc. of WICSA/ECSA Companion, NY, USA.
[Yin et al., 2013] Yin, L., Zeng, J., Liu, F., and Li,B. (2013). CTPV: A Cloud Testing Platform Basedon Virtualization. In The proceedings of SOSE'13.


![ShuttleDB: Database-Aware Elasticity in the Cloud · cloud elasticity mechanisms such as VM migration or VM replication (e.g., Amazon’s auto-scaling [2]), the approach does not](https://img.pdfslide.net/doc/110x75/5f0b23ee7e708231d42f0c4f/shuttledb-database-aware-elasticity-in-the-cloud-cloud-elasticity-mechanisms-such.jpg)


























