Embed Size (px)
Citation preview

MatemáticaComputacional
Maria Isabel Reis dos Santos
Departamento de Matemática
2011/2012

2

Conteúdo
1 Cálculo em precisão finita 11
1.1 Números binários . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.1.1 Números em precisão finita . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.1.2 Bases de sistemas de números . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.1.3 Conversão duma base noutra base . . . . . . . . . . . . . . . . . . . . . . . . 17
1.1.4 Números binários negativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.1.5 Aritmética binária . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.1.6 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.2 Números em vírgula flutuante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
1.2.1 Princípios da vírgula flutuante . . . . . . . . . . . . . . . . . . . . . . . . . . 25
1.2.2 Vírgula Flutuante IEEE Standard 754 . . . . . . . . . . . . . . . . . . . . . . 29
1.2.3 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1.3 Limitações dos sistemas de vírgula flutuante . . . . . . . . . . . . . . . . . . . . . . 35
1.3.1 Overflow e Underflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
1.3.2 Somar e subtrair números grandes e pequenos . . . . . . . . . . . . . . . . . 36
1.3.3 Ordem das adições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
1.3.4 Cancelamento subtractivo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3

4 CONTEÚDO
2 Teoria dos erros 41
2.1 Tipos de erros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
2.2 Exactidão e Precisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.2.1 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
2.3 Erros absoluto e relativo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
2.3.1 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.3.2 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.4 Algarismos significativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.4.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.4.2 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.4.3 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.5 Propagação dos Erros e condicionamento . . . . . . . . . . . . . . . . . . . . . . . . 53
2.5.1 Erros a priori e a posteriori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
2.5.2 Condicionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
2.5.3 Resolução de sistemas lineares . . . . . . . . . . . . . . . . . . . . . . . . . . 57
2.5.4 Instabilidade sem cancelamento subtractivo . . . . . . . . . . . . . . . . . . 59
2.5.5 Como desenhar algoritmos estáveis . . . . . . . . . . . . . . . . . . . . . . . 64
2.5.6 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66

CONTEÚDO 5
3 Ferramentas 71
3.1 Série de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
3.1.1 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.1.2 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
3.2 Pesquisa binária . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
3.3 Iteração . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.3.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.3.2 Condições de paragem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
3.3.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
3.3.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.4 Método do ponto fixo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
3.4.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
3.4.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
3.4.3 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
3.5 Extremos de funções . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
3.6 Radianos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4 Equações não lineares 103
4.1 Método da bissecção . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.1.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.1.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.1.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
4.1.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
4.2 Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
4.2.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
4.2.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
4.2.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
4.2.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116

6 CONTEÚDO
4.3 Método da secante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
4.3.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
4.3.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
4.3.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
4.3.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
4.4 Método do ponto fixo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
4.4.1 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
4.4.2 Aceleração do método de Newton para zeros múltiplos . . . . . . . . . . . . 124
5 Sistemas lineares 127
5.1 Valores e vectores próprios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
5.2 Normas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
5.2.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
5.2.2 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
5.3 Número de condição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
5.3.1 Análise do erro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
5.3.2 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
5.4 Métodos iterativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
5.4.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
5.4.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
5.4.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
5.4.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
5.5 Método de relaxação de SOR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
5.6 Método do gradiente conjugado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157

CONTEÚDO 7
6 Sistemas não lineares 161
6.1 Método de Newton para sistemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
6.1.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
6.1.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
6.1.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
6.1.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
6.2 Método do ponto fixo para sistemas . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
6.2.1 Convergência do método de Newton . . . . . . . . . . . . . . . . . . . . . . 176
6.2.2 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
7 Método dos Mínimos quadrados 181
7.1 Regressão linear simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
7.1.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
7.1.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
7.1.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
7.1.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
7.2 Regressão linear geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
7.2.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
7.2.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
7.2.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
7.2.4 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195

8 CONTEÚDO
8 Interpolação 199
8.1 Polinómios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
8.2 Método de Vandermonde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
8.2.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
8.2.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 208
8.2.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
8.3 Método de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
8.3.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
8.4 Método de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
8.4.1 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
8.5 Fenómeno de Runge e oscilação polinomial . . . . . . . . . . . . . . . . . . . . . . . 229
8.6 Análise do erro de interpolação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
8.7 Interpolação trigonométrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
8.8 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
9 Integração numérica 257
9.1 Teorema do valor intermédio para integrais . . . . . . . . . . . . . . . . . . . . . . . 258
9.2 Método do ponto médio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258
9.3 Método dos Trapézios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
9.3.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
9.3.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
9.4 Método de Simpson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
9.4.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
9.4.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 268
9.5 Método dos coeficientes indeterminados . . . . . . . . . . . . . . . . . . . . . . . . . 269
9.6 Quadraturas de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271
9.7 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276

CONTEÚDO 9
10 Derivação 283
10.1 Fórmulas de diferenças divididas centradas . . . . . . . . . . . . . . . . . . . . . . . 283
10.1.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284
10.1.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288
10.1.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 290
10.2 Fórmulas de diferenças divididas não centradas . . . . . . . . . . . . . . . . . . . . 292
10.2.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292
10.2.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 296
10.3 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297
11 Problemas com valor inicial 301
11.1 Método de Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302
11.1.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302
11.1.2 Método de Euler e integração numérica . . . . . . . . . . . . . . . . . . . . . 307
11.1.3 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307
11.1.4 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312
11.2 Métodos de Taylor de ordem mais elevada . . . . . . . . . . . . . . . . . . . . . . . 315
11.2.1 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 317
11.2.2 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 317
11.3 Método de Heun . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
11.3.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
11.3.2 Método de Heun e integração numérica . . . . . . . . . . . . . . . . . . . . . 320
11.3.3 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
11.3.4 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
11.4 Métodos de Runge-Kutta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
11.4.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 326
11.4.2 Método do ponto médio e integração numérica . . . . . . . . . . . . . . . . 332
11.4.3 Método de Runge-Kutta de ordem 4 e integração numérica . . . . . . . . . 333

10 CONTEÚDO
11.4.4 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333
11.4.5 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335
11.5 Erros local e global . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 336
11.6 Sistemas de problemas de valor inicial . . . . . . . . . . . . . . . . . . . . . . . . . . 339
11.7 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341
12 Problemas com valores na fronteira 345
12.1 Método das diferenças finitas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
12.1.1 Teoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346
12.1.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348
12.1.3 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
12.2 Problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352

Capítulo 1
Cálculo em precisão finita
A aritmética usada pelos computadores difere de algum modo da aritmética usada pelas
pessoas. A diferença mais importante é que os computadores realizam operações sobre números
cuja precisão é finita e fixa. Outra diferença é que os computadores usam o sistema binário e não
o decimal para representar os números.
Neste capítulo ir-se-á apresentar um método eficiente para guardar números reais (sistema
de vírgula flutuante), um método para guardar números em computador (sistema binário) e uma
representação de dupla precisão em vírgula flutuante. Estes sistemas têm limitações como, por
exemplo, a ilustrada no seguinte exemplo:
format long
sum = 0
for i = 1:100000
sum = sum + 0.1;
end
O retorno deste ciclo é sum = 10000.0000000188. Uma vez que somamos a quantidade
0.1 cem mil vezes, seria de esperar que o resultado fosse 10000. Contudo, o retorno do ciclo não
é exacto como gostaríamos. A ele está associado um erro relativo igual a 1.88 × 10−2. O ciclo é
simples e obtemos uma resposta incorrecta. Podemos pensar então no que acontecerá quando
temos um conjunto finito grande de instruções pré-definidas.
Os computadores não são capazes de fazer aritmética com números reais que tenham mais
do que um número fixo de dígitos. O número de casas com que o computador trabalha é uma
restrição na precisão com a qual os números reais podem ser representados. Um número tão
11

12 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
simples como 0.1, que é utilizado no ciclo anterior, não pode ser guardado exactamente no sistema
binário usado pelo computador (que usa apenas os números 0 e 1). Essa é a razão para que no
ciclo anterior o resultado não seja o esperado. O número 0.1 é representado no sistema binário
através da seguinte dízima infinita:
(0.1)10 = (0.00011001100110011 . . .)2
Se lermos o número 0.1 no computador com 32 bits e mandarmos escrever esse número com 40
casas decimais, obtemos
0.1000000014901161193847656250000000000000
Uma vez que nós fazemos a aritmética em formato decimal e os computadores em formato biná-
rio, temos de ter sempre em atenção ao facto de que em cada conversão pode estar associado um
erro.
1.1 Números binários
Para que os computadores processem os números de uma forma eficiente é necessário que
os números tenham uma dimensão finita e que sejam representados em numeração binária. A
numeração binária simplifica significativamente as operações a realizar, por exemplo a tabuada
resume-se a 0×0=0, 0×1=0, 1×0=0 e 1×1=1, o que pode ser realizado por uma porta lógica AND.
O facto da precisão ser finita, por ter dimensão finita, permite determinar à partida quantas portas
lógicas vão ser necessárias. Por razões históricas, começou a utilizar-se grupos de 8-bits ou byte e
os sucessivos dobros: 16, 32, 64, 128, etc. Cada bit pode ser preenchido, ou com um zero, ou com
um um. Na figura seguinte encontra-se um exemplo:
1 bit 1
1 byte 0 1 1 0 1 0 1 1 := 8 bits

1.1. NÚMEROS BINÁRIOS 13
1.1.1 Números em precisão finita
Quando estamos a fazer aritmética, em geral não pensamos muito na questão de quantos
dígitos iremos utilizar para representar um número. Em física acredita-se que o número total
de electrões que caberiam no universo conhecido é da ordem de 10130, sem se estar preocupado
com o facto de este número precisar de 130 dígitos decimais para ser representado por extenso.
Alguém que esteja a calcular o valor de uma função com papel e lápis e precise do valor com
seis dígitos significativos simplesmente guarda os resultados intermédios com os dígitos de que
necessitar, por exemplo sete ou oito. Nunca surge o problema de os números com sete ou oito
dígitos não caberem no papel.
Quando se usa um computador as preocupações são diferentes. Na maioria dos computa-
dores, a quantidade de memória disponível para guardar um número é fixa no momento em que
o computador é desenhado. A natureza finita dos computadores força-nos a trabalhar apenas
com números que podem ser representados com um número fixo de dígitos. Chamamos a estes
números números com precisão finita.
Com o objectivo de estudar as propriedades dos números com precisão finita, comecemos
por examinar o conjunto dos números inteiros positivos que podem ser representados com três
dígitos decimais, sem sinal e sem ponto decimal. Existem exactamente 1000 números nestas con-
dições:
0 0 0 0 0 1 0 0 2 . . . 9 9 8 9 9 9
Com estas restrições é impossível expressar conjuntos importantes de números como por exem-
plo:
1. Números maiores do que 999;
2. Números negativos;
3. Fracções;
4. Números irracionais;
5. Números complexos.

14 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
Uma propriedade importante no conjunto dos números inteiros é o fecho com respeito às
operações de adição, subtracção e multiplicação. Por outras palavras, para cada par de inteiros
n e m, também os números n + m, n −m e n ×m são inteiros. O conjunto dos números inteiros
não é fechado em relação à divisão, porque existe pelo menos valores n e m tais que n/m não
pertence ao conjunto dos números inteiros. Por exemplo, 7/3 e 2/0 não são números inteiros.
Infelizmente o conjunto dos números em precisão finita não é fechado em relação a nenhuma das
quatro operações básicas. Usando três dígitos podemos observar o não fecho das operações:
700 + 700 = 1400 muito grande
002− 006 = −4 negativo
060× 060 = 3600 muito grande
007/002 = 3.5 não é um inteiro
As violações podem dividir-se em duas classes exclusivas mutuamente:
1. operações cujo resultado é maior do que o maior número do conjunto (erro de Overflow) ou
menor que o número mais pequeno do conjunto (erro de Underflow); e
2. operações cujo resultado nem é demasiado grande nem é demasiado pequeno, mas simples-
mente não é um elemento do conjunto.
Na ilustração anterior, os três primeiros casos são exemplos da primeira violação e o quatro
é exemplo da segunda violação.
Uma vez que os computadores têm memória finita e, por conseguinte, fazem aritmética
com números com precisão finita, os resultados de certos cálculos serão, do ponto de vista da
matemática clássica, completamente errados. Pode parecer estranho uma máquina de calcular dar
resultados errados quando funciona perfeitamente bem, mas o erro é apenas uma consequência
da sua natureza finita.
A álgebra dos números em precisão finita é diferente da álgebra normal. Como exemplo
dessa diferença, considere-se a propriedade associativa:
a+ (b− c) = (a+ b)− c
Seja a = 800, b = 500 e c = 400. Para fazer o cálculo com a expressão do lado esquerdo, calcula-se
primeiro b − c que dá 100 e depois soma-se 800. O resultado é 900. Fazendo as contas com a
expressão do lado direito, começa-se por fazer a soma a + b que dá Overflow (1300 não pode ser
representado com três dígitos decimais). Subtraindo 400 a um número que não seja 1300 não dá

1.1. NÚMEROS BINÁRIOS 15
de certeza 900 que é a resposta correcta. A propriedade associativa não funciona. A ordem pela
qual se fazem as operações em precisão finita é muito importante. Outro exemplo é a propriedade
distributiva:
a× (b− c) = a× b− a× c
Calculemos ambos os lados com a = 6, b = 320 e c = 185. O lado esquerdo dá 6 × 135 = 810 e o
lado direito não dá 810 porque a× b dá Overflow (6× 320 = 1920).
Com base nestes exemplos, podemos correr o risco de concluir que a natureza finita dos
computadores faz com que sejam máquinas inapropriadas para fazer aritmética, o que não é
verdade. Estes exemplos servem apenas para ilustrar a importância de compreender como é que
os computadores funcionam e as suas limitações.
1.1.2 Bases de sistemas de números
Um número decimal que toda a gente conhece consiste numa string de dígitos decimais e,
às vezes, num ponto decimal. A forma geral desta interpretação é a seguinte:
casa do casa do casa do casa do casa do casa do
100 10 1 .1 .01 .001
↓ ↓ ↓ ↓ ↓ ↓
dn . . . d2 d1 d0 · · · d−1 d−2 d−3 · · · d−k
Numero =n∑
i=−k
di × 10i
A escolha do número 10 como base para exponenciação deve-se ao facto de usarmos os nú-
meros em base decimal. Os computadores não trabalham em base decimal. As bases mais im-
portantes são 2, 8 e 16. Os sistemas de números baseados nestas bases chamam-se binário, octal e
hexadecimal, respectivamente.
O sistema de números com base k precisa de k dígitos diferentes para representar um nú-
mero. Esses dígitos são: 0, 1, . . ., k − 1. Os números decimais constroem-se a partir dos dígitos:
0 1 2 3 4 5 6 7 8 9
Por outro lado os números binários não usam estes dez dígitos. Eles constroem-se a partir dos
dois dígitos binários
0 1

16 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
Os números octais constroem-se a partir dos oito dígitos octais
0 1 2 3 4 5 6 7
Para construir números hexadecimais são precisos 16 dígitos. Logo precisamos de seis novos
símbolos. Os símbolos usados são as letras do A ao F para os dígitos a seguir ao número 9. Os
números hexadecimais constroem-se a partir dos dígitos:
0 1 2 3 4 5 6 7 8 9 A B C D E F
A expressão "dígito binário" que significa 1 ou 0 é geralmente referida como um bit. Em seguida
apresenta-se o número 2001 expresso nas bases binária, octal, decimal e hexadecimal:
Binária
1 1 1 1 1 0 1 0 0 0 1
1× 210 + 1× 29 + 1× 28 + 1× 27 + 1× 26 + 1× 25 + 1× 24 + 1× 23 + 1× 22 + 1× 21 + 1× 20
1024 + 512 + 56 + 28 + 64 + 0 + 1 + 0 + 0 + 0 + 0
Octal
3 7 2 1
3× 83 + 7× 82 + 2× 81 + 1× 80
1536 + 48 + 16 + 1
Decimal
2 0 0 1
2× 103 + 0× 102 + 0× 101 + 1× 100
2000 + 0 + 0 + 1
Hexadecimal
7 D 0 1
7× 162 + 13× 161 + 1× 160
1792 + 208 + 1
O número 7D9 é obviamente hexadecimal porque o símbolo D só aparece nos números
hexadecimais. Contudo, o número 111 pode estar em qualquer das quatro bases apresentadas.
Para evitar ambiguidade, quando não é óbvio a partir do contexto, é frequente usar o índice 2, 8,
10 ou 16 para indicar a base na qual o número está escrito:

1.1. NÚMEROS BINÁRIOS 17
(111)2 = (7)10
(111)8 = (25)10
(111)16 = (273)10
Como exemplo da notação binária, octal, decimal e hexadecimal, a tabela seguinte mostra
um conjunto de números expressos nos quatro sistemas.
Decimal Binária Octal Hexadecimal Decimal Binária Octal Hexadecimal
0 0 0 0 19 10011 23 13
1 1 1 1 20 10100 24 14
2 10 2 2 30 11110 36 1E
3 11 3 3 40 101000 50 28
4 100 4 4 50 110010 62 32
5 101 5 5 60 111100 74 30
6 110 6 6 70 1000110 106 46
7 111 7 7 80 1010000 120 50
8 1000 10 8 90 1011010 132 5A
9 1001 11 9 100 1100100 144 64
10 1010 12 A 200 11001000 310 C8
11 1011 13 B 300 100101100 454 12C
12 1100 14 C 400 110010000 620 190
13 1101 15 D 500 111110100 764 1F4
14 1110 16 E 600 1001011000 1130 258
15 1111 17 F 700 1010111100 1274 2BC
16 10000 20 10 800 1100100000 1440 320
17 10001 21 11 900 1110000100 1604 384
18 10010 22 12 1000 1111101000 1750 3E8
1.1.3 Conversão duma base noutra base
A conversão dos números entre as bases octal, hexadecimal e binária é fácil. Para converter
um número binário para octal, divide-se o número em grupos sucessivos de três bits, começando
com os 3 bits imediatamente para a esquerda e/ou para a direita do ponto decimal (frequente-
mente chamado ponto binário). Cada grupo de 3 bits pode ser directamente convertido num
único dígito octal, de 0 a 7. Pode ser necessário juntar um ou dois zeros para completar um grupo
de 3 bits. A conversão de octal para binária é igualmente fácil. Cada dígito octal é simplesmente
substituído pelo número binário equivalente com 3 dígitos. A conversão de hexadecimal para bi-
nária é essencialmente a mesma do que de octal para binária excepto que cada dígito hexadecimal
corresponde a um grupo de 4 bits em vez de 3 bits. Em seguida são apresentados dois exemplos
de conversão:

18 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
1. Hexadecimal: 1 9 4 8 . 8 6
Binária: 0 0 0 1 1 0 0 1 0 1 0 0 1 0 0 0 . 1 0 1 1 0 1 1 0 0
Octal: 1 4 5 1 0 . 5 5 4
2. Hexadecimal: 7 B A 3 . B C 4
Binária: 1 1 1 0 1 1 1 0 1 0 0 0 1 1 . 1 0 1 1 1 1 0 0 0 1 0 0
Octal: 7 5 6 4 3 . 5 7 0 4
A conversão de números decimais para binários pode ser feita de duas maneiras diferentes.
O primeiro método vem directamente da definição de número binário. Subtrai-se do número a
maior potência de 2 menor que o próprio número. O processo é repetido aplicado à diferença.
Depois de o número ser decomposto em potências de 2, o número binário pode ser construído
com 1’s nas posições dos bits correspondentes às potências de 2 usadas na decomposição e 0’s nas
outras posições. Na tabela seguinte está um exemplo de conversão do número 14.125 em base
decimal para base binária.
d0 = 14.125
d1 = d0 − 23 = 14.125− 23 = 6.125
d2 = d1 − 22 = 6.125− 22 = 2.125
d3 = d2 − 21 = 2.125− 21 = 0.125
d4 = d3 − 2−3 = 0.125− 2−3 = 0
23 22 21 20 · 2−1 2−2 2−3
1 1 1 0 · 0 0 1
Um método que funciona só para inteiros consiste em dividir o número por 2. O quociente
é escrito por baixo do número original e o resto, 0 ou 1, é escrito na coluna ao lado e na mesma
linha do quociente. Este quociente passa agora a ser o dividendo e o processo repete-se até se
obter o quociente 0. O resultado deste processo são duas colunas de números, uma em que estão
os quocientes e a outra onde se encontram os restos. O número binário pode ler-se de baixo para
cima. Por exemplo, o número 46 em base decimal fica convertido no número 101110 em base
binária:

1.1. NÚMEROS BINÁRIOS 19
46 2
06 23 2
0 03 11 2
1 1 5 2
1 2 2
0 1 2
0 0
Quociente Resto
46
23 0
11 1
5 1
2 1
1 0
0 1
Os inteiros binários podem ser convertidos para decimais utilizando dois métodos. Um
método consiste em somar as potências de 2 que correspondem aos bits que estão com o número
1. Por exemplo, 10110 é 24 + 22 + 21 = 16 + 4 + 2 = 22. No outro método, o número binário
é escrito verticalmente, um bit por linha, com o dígito mais à esquerda em baixo. A linha de
baixo chama-se linha 1, a seguinte chama-se 2 e assim sucessivamente. O número decimal será
construído numa coluna paralela ao lado do número binário. Começa por se escrever o número 1
na linha 1:
0
1
1
0
1 1
A entrada na linha n calcula-se multiplicando por 2 a entrada da linha n− 1 e soma-se o bit
que está na linha n (ou 0, ou 1). A entrada na linha do topo é o número convertido. Em seguida
podemos observar um exemplo.

20 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
0
1
1
0 2× 1 + 0
1 1
0
1
1 2× (2× 1 + 0) + 1
0 2× 1 + 0
1 1
0
1 2× (22 + 1) + 1 = 23 + 2 + 1
1 2× (2× 1 + 0) + 1 = 22 + 1
0 2× 1 + 0
1 1
0 2× (23 + 2 + 1) + 0 = 24 + 22 + 2 = 22
1 2× (22 + 1) + 1 = 23 + 2 + 1
1 2× (2× 1 + 0) + 1 = 22 + 1
0 2× 1 + 0
1 1
A conversão de decimal para octal e de decimal para hexadecimal pode fazer-se tanto con-
vertendo para binário e depois para o sistema desejado, como subtraindo potências de números
octal ou hexadecimal.
1.1.4 Números binários negativos
Têm sido usados quatro sistemas para representar os números negativos em computador. O
primeiro é chamado sinal-magnitude. Neste sistema o bit mais à esquerda é o bit de sinal (0 para
+ e 1 para −) e os restantes bits guardam o valor absoluto do número.

1.1. NÚMEROS BINÁRIOS 21
O segundo sistema, chamado complemento para um, também tem um bit de sinal 0 usado
para mais e 1 para menos. Para negar um número, substitui-se cada 1 por 0 e cada 0 por 1. Isto
também se aplica ao bit de sinal. O complemento para um está obsoleto.
O terceiro sistema, chamado complemento para dois, também tem um bit de sinal que é 0
para positivo e 1 para negativo. A negação de um número é um processo com dois passos.
1. cada 1 é substituído por um 0 e cada 0 por um 1, tal como no complemento para um;
2. adiciona-se 1 ao resultado. A adição binária segue os mesmos princípios da adição decimal
excepto que o "e vai 1" é gerado quando a soma é maior do que 1 em vez de maior do que 9.
Por exemplo, seguindo o complemento para dois, a conversão de +6 processa-se do seguinte
modo:
00000110 (+6)
11111001 (−6 no complemento para um)
1 (adicionar 1)
11111010 (−6 no complemento para dois)
Se ficar um "e vai 1" no bit mais à esquerda, ele é deitado fora.
O quarto sistema, que para números comm bits é chamado excesso 2m−1, representa um nú-
mero guardando-o como a soma de ele próprio a 2m−1. Deste modo, zero é representado por 2m−1.
Por exemplo, para números com 8 bits, m = 8, com excesso 127 é guardado um número com o seu
verdadeiro valor mais 127. Por conseguinte, −3 torna-se −3 + 127 = 124 e −3 é representado pelo
número binário com 8 bits para 124 (1111100). Os números a partir de −127 a 128 são mapeados
para de 0 a 255, todos eles expressos como inteiros positivos com 8 bits; ver a Tabela 1.1
Tanto o sistema sinal-magnitude como o sistema complemento para um tem duas represen-
tações para o zero: um mais zero e um menos zero. Esta situação não é desejável. O complemento
para dois não tem este problema porque o complemento para dois de mais zero é o mais zero.
Contudo, o complemento para dois tem uma singularidade diferente. O padrão de bits que con-
siste num 1 seguido de zeros coincide com o seu complemento. O resultado disto é que o conjunto
dos números positivos e negativos é assimétrico; existe um número negativo sem o seu simétrico
positivo.
Queremos um sistema com duas propriedades:

22 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
Tabela 1.1: Excesso 127 com oito bits sem sinalnúmero binário número decimal número com excesso 127
00000000 0 −127
00000001 1 −126
00000011 2 −125
00000111 3 −124...
......
00111111 253 +126
01111111 254 +127
11111111 255 +128
1. Tenha uma única representação para o zero.
2. Tenha tantos números positivos como negativos.
O problema é que qualquer conjunto de números com tantos números positivos como nega-
tivos e apenas um zero tem um número ímpar de elementos, enquanto que m bits permitem um
número par de padrões de bits. Existirá sempre um bit a mais ou um bit a menos qualquer que
seja a representação que se escolha. Este padrão de bit extra pode ser usado para −0 ou para um
número negativo grande, ou para qualquer outra coisa, mas será sempre uma maçada.
1.1.5 Aritmética binária
A tabela de adição para números binários é dada em seguida:
0 0 1 1
+0 +1 +0 +1
Soma 0 1 1 0
dígito de vai-um 0 0 0 1
Somam-se dois números binários começando pelo bit mais à direita. Se é gerado um vai-um,
é transportado uma posição para a esquerda, tal como na aritmética decimal. Na aritmética de
complemento para um, o vai-um gerado pela adição do bit mais à esquerda é somado ao bit mais
à direita. A este processo chama-se um end-around carry. Na aritmética de complemento para dois,
um vai-um gerado pela adição do bit mais à esquerda é simplesmente deitado fora. Podemos ver
em seguida exemplos de aritmética binária.

1.1. NÚMEROS BINÁRIOS 23
Decimal Complemento para um Complemento para dois
10 00001010 00001010
− (−3) 11111100 11111100
+7 1 00000110 1 00000111
vai-um vai um
↓
somado à direita deitado fora
00000111 00000111
Se as parcelas da soma tiverem sinais contrários o resultado pode ser Overflow. Se tiverem o
mesmo sinal e o resultado é de sinal contrário ocorre um erro de Overflow e a resposta está errada.
Tanto no complemento para um como no complemento para dois pode ocorrer Overflow se e só
se o vai-um para o bit de sinal difere do vai-um do bit de sinal. A maioria dos computadores
preserva o vai-um do bit de sinal, mas o vai-um para o bit de sinal não é visível a partir do
resultado. Por esta razão, em geral, é fornecido um bit especial de Overflow.
1.1.6 Problemas
1. Converter os números seguintes para binário: 1984, 4000, 8192.
2. Que número é o 1001101001 em decimal? E em octal? E em hexadecimal?
3. Expressar o número decimal 100 em todas as bases de 2 a 9.
4. Faça os seguintes cálculos com números com 8 bits em complemento para dois.
00101101 11111111 00000000 11110111
+01101111 +11111111 −11111111 −11110111
5. Repetir os cálculos do exercício anterior mas agora no complemento para um.
6. Considere os seguintes problemas de adição com números binários com três dígitos em
complemento para dois. Para cada soma diga:
(a) se o bit de sinal do resultado é 1.
(b) se o bit de ordem mais baixa é 0.

24 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
(c) se ocorre um Overflow.
000 000 111 100 100
001 111 110 111 100
7. Os números decimais com n dígitos e com sinal podem ser representados em n + 1 dígitos
sem sinal. Os números positivos têm 0 no dígito mais à esquerda. Os números negativos
obtêm-se subtraindo cada dígito de 9. Por conseguinte, o negativo de 014725 é 985274. Tais
números chamam-se números em complemento para nove e são análogos aos números bi-
nários em complemento para dois. Expresse os seguintes números como números com três
dígitos em complemento para nove: 6, −2, 100, −14, −1, 0.
8. Determine a regra para a adição de números em complemento para nove e faça as seguintes
adições.
0001 0001 9997 9241
+9999 +9998 +9996 +0802
9. O complemento para dez é análogo ao complemento para dois. Um número negativo em
complemento para dez constrói-se adicionando 1 ao número correspondente em comple-
mento para nove, ignorando o vai-um mais à esquerda. Qual é a regra para a adição em
complemento para dez?
10. Construa as tabelas de multiplicação para números em base 3.
11. Multiplique 0111 e 0011 em binário.
1.2 Números em vírgula flutuante
Em muitos cálculos o domínio de números é muito grande. Por exemplo, um cálculo em
astronomia pode envolver a massa do electrão, 9.1093897×10−31 kg, e a massa do sol, 1.9891×1030
kg (aproximadamente 333000 vezes a massa da Terra), um conjunto de números cuja variação
excede 1060. Estes números podem representar-se por
0000000000000000000000000000000.00000000000000000000000000000091093897
1989100000000000000000000000000.00000000000000000000000000000000000000
e todos os cálculos podem ser efectuados guardando 31 dígitos à esquerda do ponto decimal e
38 casas à sua direita. Fazendo isto permite-nos obter 69 dígitos significativos nos resultados.

1.2. NÚMEROS EM VÍRGULA FLUTUANTE 25
Num computador binário, pode usar-se a aritmética em múltipla precisão para obter significân-
cia suficiente. De facto podem-se efectuar algumas medições de modo a conseguir-se 69 dígitos
significativos. Embora possa ser possível manter todos os resultados intermédios com 69 dígitos
significativos e depois deitar fora 50 ou 60 deles antes de escrever os resultados, fazer isto não
é aconselhável tanto do ponto de vista de tempo de CPU como do ponto de vista de memória
utilizada.
O que é preciso é um sistema para representar números nos quais o domínio de números
expressáveis é independente do número de dígitos significativos. Este sistema será discutido em
seguida. Ele baseia-se na notação científica utilizada na física, química e engenharia.
1.2.1 Princípios da vírgula flutuante
Uma maneira de separar o conjunto da precisão é expressar os números reais na notação
científica
x = f e
onde f é chamada a fracção, ou mantissa, e e é um número inteiro positivo ou negativo chamado
expoente. A versão computacional desta notação é chamada vírgula flutuante. Alguns exemplos
de números expressos nesta forma são
3.14 = 0.314× 101 = 3.14× 100
0.000001 = 0.1× 10−5 = 1.0× 10−6
5623 = 0.5623× 104 = 5.623× 103
O domínio dos números é efectivamente determinado pelo número de dígitos no expoente
e a precisão é determinada pelo número de dígitos na mantissa. Uma vez que existe mais do que
uma maneira de representar um dado número, é usada uma forma considerada padrão. Com
o objectivo de investigar as propriedades deste método de representar os números, considere-se
a representação F , com sinal e mantissa com três dígitos no conjunto 0.1 ≤ |f | < 1 ou zero e
um expoente com sinal e dois dígitos. Estes números variam em módulo entre +0.100 × 10−99 e
+0.999× 10+99, um span de aproximadamente 199 ordens de grandeza necessita apenas de cinco
dígitos (3 na mantissa e dois no expoente) e dois para os sinais (na mantissa e no expoente) para
guardar um número:
0.999× 10+99
0.100× 10−99= 9.9900× 10198 ≈ 1.0000× 10199

26 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
Os números em vírgula flutuante podem ser usados para modelar o conjunto dos números
reais, embora existam diferenças importantes. Na Figura 1.1 está ilustrado este sistema de vírgula
flutuante e o conjunto dos números reais. A recta real está dividida em sete regiões:
Figura 1.1: A recta real pode dividir-se em sete regiões.
1. Número negativos pequenos menores que −0.999× 1099.
2. Números negativos entre −0.999× 1099 e −0.100× 10−99.
3. Números negativos pequenos com módulo menor que 0.100× 10−99.
4. Zero.
5. Números positivos pequenos com módulo menor que 0.100× 10−99.
6. Números positivos entre 0.100× 10−99 e 0.999× 1099.
7. Números positivos grandes maiores que 0.999× 1099.
Uma diferença fundamental entre o sistema de vírgula flutuante com 3 dígitos na mantissa,
dois no expoente e 2 dígitos para sinais e o conjunto dos números reais é que o sistema de vírgula
flutuante não consegue expressar todos os números das regiões 1, 3, 5 e 7. Se o resultado de
uma operação aritmética der um número nas regiões 1 ou 7, por exemplo, 1060 × 1060 = 10120,
irá ocorrer um erro de Overflow e a resposta será incorrecta. Isto deve-se à natureza finita dos
sistemas de vírgula flutuante e não pode ser evitado. De forma análoga, um resultado nas regiões
3 e 5 também não pode ser representado. A esta situação chama-se erro de Underflow. O erro de
Underflow é menos grave que o de Overflow, porque em geral 0 é uma boa aproximação para os
números que pertencem às regiões 3 e 5.
Outra diferença importante entre os sistemas de vírgula flutuante e o conjunto dos números
reais é a densidade. Entre cada dois números reais x e y existe sempre um número real não

1.2. NÚMEROS EM VÍRGULA FLUTUANTE 27
importa o quanto o x e o y estão próximos. Esta propriedade vem do facto de que para quaisquer
números reais distintos x e y, z = (x+ y)/2 é um número real entre eles. O conjunto dos números
reais formam um contínuo.
Por outro lado, os números em vírgula flutuante não formam um contínuo. No sistema de
vírgula flutuante anterior com 5 dígitos e dois para sinais conseguem-se representar exactamente
179100 números positivos e 179100 números negativos e o zero (que pode ser expresso de vá-
rias formas). Ao todo são 358201 números. Do conjunto infinito de números reais entre −10100
e +0.999 × 1099, apenas 358201 deles podem ser especificados por esta notação. Eles estão repre-
sentados com os pontos na Figura 1.1. É muito possível que o resultado de um cálculo esteja fora
do sistema de vírgula flutuante, mesmo que esteja nas regiões 2 ou 6. Por exemplo, +0.100 × 103
dividido por 3 não pode ser representado exactamente no nosso sistema de vírgula flutuante. Se o
resultado x de um cálculo não for um número pertencente ao sistema de vírgula flutuante F ⊂ R,
então ele não pode ser expresso exactamente em F . Neste caso, utiliza-se o número mais próximo
de x (ou seja, que está mais perto do resultado) e que pertence a F designado por x = fl(x). A este
processo x→ fl(x) chama-se arredondamento. O erro de arredondamento, de x relativamente a
x, é dado por
ex = x− x
e, em valor absoluto, varia grandemente com a dimensão de x.
O espaçamento entre números expressáveis adjacentes não é constante através das regiões
2 e 6. A separação entre +0.998 × 1099 e +0.999 × 1099 é bastante maior que a separação entre
+0.998× 100 e +0.999× 100. Contudo, quando a separação entre um número e o seu sucessor for
expressa como a percentagem desse número, não existe variação sistemática através das regiões
2 e 6. Por outras palavras, o erro relativo introduzido pelo arredondamento é aproximadamente
o mesmo para números pequenos e grandes. O erro relativo, de x relativamente a x,
δx =x− xx
,
introduzido pelo arredondamento, é em módulo aproximadamente o mesmo para números pe-
quenos ou grandes.
Embora a discussão anterior seja acerca de um sistema em vírgula flutuante com 3 dígitos
na mantissa e 2 no expoente, as conclusões são válidas nos outros sistemas de vírgula flutuante.
Mudar o número de dígitos na mantissa ou no exponente apenas altera as fronteiras das regiões 2
e 6 e muda o número de pontos que podem ser expressos. Aumentar o número de dígitos na man-
tissa aumenta a densidade dos pontos e, por conseguinte, aumenta a precisão das aproximações
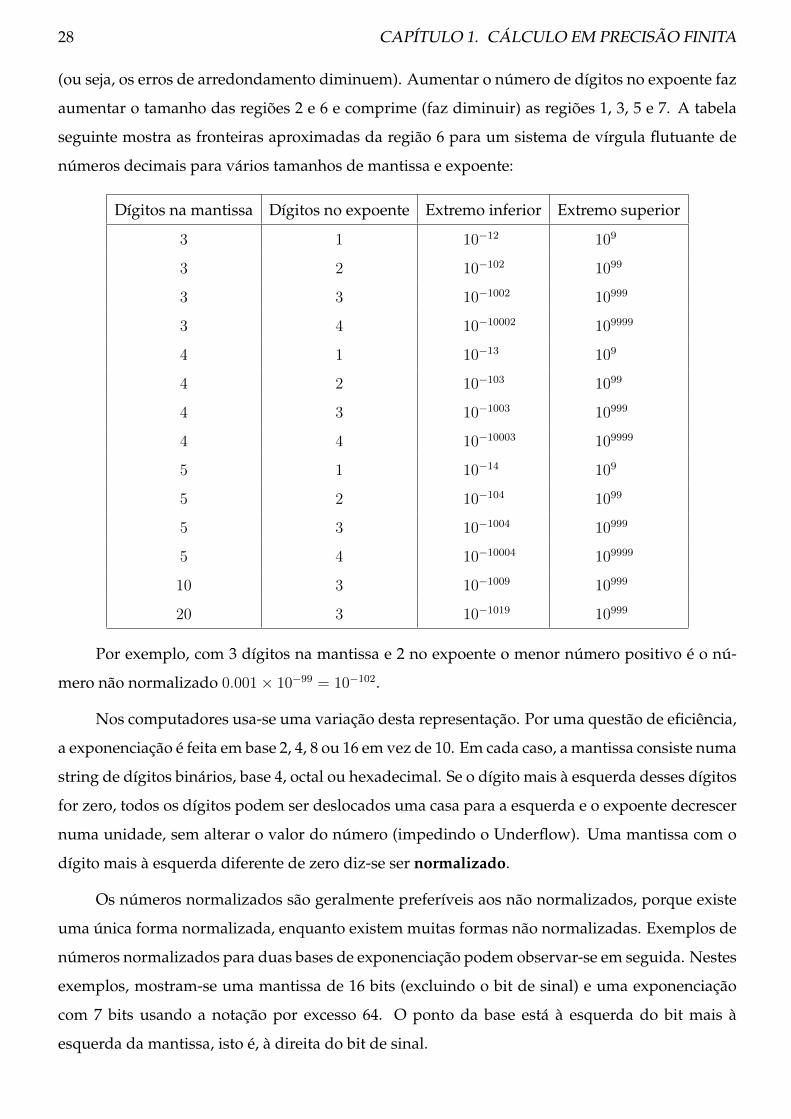
28 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
(ou seja, os erros de arredondamento diminuem). Aumentar o número de dígitos no expoente faz
aumentar o tamanho das regiões 2 e 6 e comprime (faz diminuir) as regiões 1, 3, 5 e 7. A tabela
seguinte mostra as fronteiras aproximadas da região 6 para um sistema de vírgula flutuante de
números decimais para vários tamanhos de mantissa e expoente:
Dígitos na mantissa Dígitos no expoente Extremo inferior Extremo superior
3 1 10−12 109
3 2 10−102 1099
3 3 10−1002 10999
3 4 10−10002 109999
4 1 10−13 109
4 2 10−103 1099
4 3 10−1003 10999
4 4 10−10003 109999
5 1 10−14 109
5 2 10−104 1099
5 3 10−1004 10999
5 4 10−10004 109999
10 3 10−1009 10999
20 3 10−1019 10999
Por exemplo, com 3 dígitos na mantissa e 2 no expoente o menor número positivo é o nú-
mero não normalizado 0.001× 10−99 = 10−102.
Nos computadores usa-se uma variação desta representação. Por uma questão de eficiência,
a exponenciação é feita em base 2, 4, 8 ou 16 em vez de 10. Em cada caso, a mantissa consiste numa
string de dígitos binários, base 4, octal ou hexadecimal. Se o dígito mais à esquerda desses dígitos
for zero, todos os dígitos podem ser deslocados uma casa para a esquerda e o expoente decrescer
numa unidade, sem alterar o valor do número (impedindo o Underflow). Uma mantissa com o
dígito mais à esquerda diferente de zero diz-se ser normalizado.
Os números normalizados são geralmente preferíveis aos não normalizados, porque existe
uma única forma normalizada, enquanto existem muitas formas não normalizadas. Exemplos de
números normalizados para duas bases de exponenciação podem observar-se em seguida. Nestes
exemplos, mostram-se uma mantissa de 16 bits (excluindo o bit de sinal) e uma exponenciação
com 7 bits usando a notação por excesso 64. O ponto da base está à esquerda do bit mais à
esquerda da mantissa, isto é, à direita do bit de sinal.

1.2. NÚMEROS EM VÍRGULA FLUTUANTE 29
• Não normalizado com exponenciação em base 2
0 1010100 0000000000011011 = 220(2−12 + 2−13 + 2−15 + 2−16) = 432
0 1010100 0000000000011011
sinal expoente com mantissa
excesso 64
26 + 24 + 22 − 64 = 84− 64 = 20 2−12 + 2−13 + 2−15 + 2−16
26 25 24 23 22 21 20
1 0 1 0 1 0 0
2−1 2−2 2−3 2−4 2−5 2−6 2−7 2−8 2−9 2−10 2−11 2−12 2−13 2−14 2−15 2−16
0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1
• Normalizado com exponenciação em base 2
0 1001001 1101100000000000 = 29(2−1 + 2−2 + 2−4 + 2−5) = 432
0 1001001 1101100000000000
sinal expoente com mantissa
excesso 64
26 + 23 + 20 − 64 = 73− 64 = 9 2−1 + 2−2 + 2−4 + 2−5
1.2.2 Vírgula Flutuante IEEE Standard 754
Até cerca de 1980, cada computador tinha o seu formato de vírgula flutuante. Deste modo
todos os formatos eram diferentes. O pior de tudo é que alguns deles faziam aritmética incorrec-
tamente. Para rectificar esta situação, nos finais dos anos 70 reuniu-se um comitê do IEEE para
padronizar o formato de vírgula flutuante. O objectivo era conseguir que o formato de vírgula
flutuante fosse igual de computador para computador e que funcionasse correctamente. O re-
sultado levou ao IEEE standard 754 (IEEE, 1985). Ao contrário de muitos padrões que tentam
agradar a todos e acabam por não agradar a nenhum, este não é mau e será descrito no resto da
secção.
O padrão define três formatos:
• precisão simples (32 bits);
• precisão dupla (64 bits);
• precisão extendida (80 bits).

30 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
O formato de precisão extendida tem como objectivo reduzir os erros de arredondamento.
Ele é usado dentro da aritmética de vírgula flutuante. Tanto a precisão simples como a dupla usam
a base 2 para a mantissa e notação por excesso para o expoente. Os formatos estão ilustrados em
seguida:
• Precisão simples (dimensão 32 bits)
1 bit 8 bits 23 bits
sinal expoente mantissa
• Precisão dupla (dimensão 64 bits)
1 bit 11 bits 52 bits
sinal expoente mantissa
Ambos os formatos começam com um bit de sinal, 0 para positivo e 1 para negativo. Em
seguida vem o expoente, que usa excesso 127 para a precisão simples e excesso 1023 para a pre-
cisão dupla. Os expoentes mínimo (0) e o máximo (255 e 2047) não são usados para números
normalizados; eles têm utilizações especiais.Finalmente, temos as mantissas de 23 e 52 bits, res-
pectivamente.
Uma mantissa normalizada começa com um ponto binário, seguido de um bit e depois o
resto da mantissa. O primeiro bit igual a 1 da mantissa não precisa ser guardado, uma vez que
se pode assumir que ele está lá. Consequentemente, o padrão define a mantissa duma maneira
ligeiramente diferente da habitual. Consiste num bit a 1 implícito, um ponto binário também
implícito e, ou 23 ou 52 bits arbitrários. Se todos os 23 ou 52 bits forem iguais a zero, a mantissa
tem o valor numérico 1.0; se todos eles tiverem o valor 1, então a mantissa é um pouco mais
pequena do que 2.0. Para evitar confusão com uma mantissa convencional, a combinação do 1
implícito, o ponto binário implícito e os 23 ou 52 bits explícitos é chamado o significando em vez
de mantissa. Todos os números normalizados têm um significando, s, no conjunto 1 ≤ s < 2.
As características numéricas dos números em vírgula flutuante IEEE é dada na tabela se-
guinte. Como exemplos, considere os números 0.5, 1 e 1.5 no formato em precisão simples de
vírgula flutuante. Estes são representados como (3FF000000)16, (3F800000)16 e (3FC00000)16,
respectivamente.

1.2. NÚMEROS EM VÍRGULA FLUTUANTE 31
Item Precisão simples Precisão dupla
Bit de sinal 1 1
Bits no expoente 8 11
Bits na mantissa 23 52
Bits no total 32 64
Sistema do expoente excesso 127 excesso 1023
Domínio do expoente −126 a +127 −1023 a +1023
Mais pequeno normalizado 2−126 2−1023
Maior normalizado ≈ 2126 ≈ 1023
Domínio decimal ≈ 10−38 a 10+38 ≈ 10−308 a 10+308
Mais pequeno não normalizado ≈ 10−45 ≈ 10−324
Para converter o número 6.125 para o formato IEEE de precisão simples e dar o resultado
com oito dígitos hexadecimais faz-se assim:
6.125× 25 = 196
196× 2−5 = 6.125
196 = (11000100)2
6.125 = (11000100)2 × 2−5 = (1.1000100)2 × 22
expoente: 2 + 127 = 129 = (10000001)2 (excesso 127)
significando: (1.10001000000000000000000)2
binário: 0 10000001 10001000000000000000000
hexadecimal:0100 0000 1100 0100 0000 0000 0000 0000
4 0 C 4 0 0 0 0
No caso dos números como este com casas decimais é conveniente multiplicar primeiro por
uma potência de 2 de tal modo que o número resultante seja inteiro ou que, caso não seja inteiro,
a parte inteira seja suficientemente grande para que ao converter o "fim do número" já esteja fora
dos 23 bits (ou 64 caso a precisão seja dupla). Em alternativa, pode utilizar-se o método descrito
na secção 1.1.3.
Para converter o número (C7F00000)16 em precisão simples IEEE de hexadecimal para de-
cimal faz-se o seguinte:
hexadecimal:C 7 F 0 0 0 0 0
1100 0111 1111 0000 0000 0000 0000 0000

32 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
binário: 1 10001111 11100000000000000000000
(10001111)2 = 143
expoente: 143− 127 = 16 (excesso 127)
significando: (1.11100000000000000000000)2 = (1.875)10
número: −(1.11100000000000000000000)2 × 216 = −(122880)10
Um dos problemas tradicionais com os números em vírgula flutuante é como lidar com
Underflow, Overflow e números não inicializados. Para normalizar os números, os outros quatro
tipos standard mostram-se em seguida.
Normalizado ± 0 < Exp < Max Qualquer bit padrão
Não normalizado ± 0 Qualquer bit padrão não nulo
Zero ± 0 0
Infinito ± 111 . . . 1 0
Not a Number ± 111 . . . 1 Qualquer bit padrão não nulo
Surge um problema quando o resultado de um cálculo é menor que o menor número não
normalizado que pode ser representado no sistema de vírgula flutuante. Anteriormente, a maio-
ria do hardware toma uma de duas aproximações:
• apenas colocar o resultado a zero e continuar, ou
• dar origem a um Underflow do sistema de vírgula flutuante.
Na realidade nenhuma destas aproximações é satisfatória. Por conseguinte, IEEE inventou os nú-
meros não normalizados. Estes números têm o expoente 0 e uma mantissa dada pelos seguintes
23 ou 52 bits. O bit a 1 implícito à esquerda do ponto binário agora assume o valor 0. Os nú-
meros não normalizados distinguem-se dos normalizados porque estes últimos não podem ter o
expoente de 0.
O menor número normalizado em precisão simples tem 1 como expoente e 0 como mantissa
e representa 1.0 × 2−126. O maior número não normalizado tem 0 como expoente e todos 1s na
mantissa e representa cerca de 0.9999999 × 2−127 que é quase a mesma quantidade. Contudo

1.2. NÚMEROS EM VÍRGULA FLUTUANTE 33
é preciso notar que este número tem apenas 23 bits de significância enquanto que os números
normalizados têm 24 bits de significância.
Á medida que o resultado dos cálculos decrescem, o expoente continua 0, mas os primeiros
dígitos da mantissa ficam a zero, reduzindo tanto o valor como o número de bits na mantissa. O
menor número não normalizado consiste num 1 no bit mais à direita, com o resto dos bits a zero. O
expoente representa 2−127 e a mantissa representa 2−23 logo o valor é 2−150. Este esquema fornece
um Underflow harmonioso perdendo significância em vez de saltar para 0 quando o resultado
não pode ser expresso como um número normalizado.
Neste esquema estão presentes dois zeros, positivo e negativo, determinados pelo bit de
sinal. Ambos têm um expoente de 0 e uma mantissa de 0. Aqui o bit à esquerda do sinal do ponto
binário é implicitamente 0 em vez de 1.
Em relação ao Overflow, é dada uma representação especial para o infinito, que consiste
num expoente com todos 1s (não permitido para números normalizados) e uma fracção de 0. Este
número pode ser usado como operando e comporta-se de acordo com as habituais regras mate-
máticas para o infinito. Por exemplo, infinito mais qualquer coisa dá infinito e qualquer número
finito dividido por infinito dá zero. De modo semelhante, qualquer número finito dividido por
zero dá infinito.
E infinito dividido por infinito? O resultado é indefinido. Para tratar este caso foi introdu-
zido outro formato especial chamado NaN (Not a Number). Este também pode ser usado como
operando com resultados previsíveis.
1.2.3 Problemas
1. Converta os seguintes números no formato IEEE de precisão simples. Dê os resultados com
oito dígitos hexadecimais.
(a) 9
(b) 5/32
(c) −5/32
(d) 6.125
(e) 0.90625
(f) 0.46875

34 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
(g) 0.71875
(h) 0.96875
2. Converta os seguintes números em precisão simples IEEE de hexadecimal para decimal:
(a) (42E48000)16
(b) (3F880000)16
(c) (00800000)16
(d) (C7F00000)16
(e) (40A20000)16
3. Os seguintes números binários em vírgula flutuante consistem num bit de sinal, um excesso
de 64, expoente em base 2 e uma mantissa de 16 bits. Normalize-os:
(a) 0 1000000 0001010100000001
(b) 0 0111111 0000001111111111
(c) 0 1000011 1000000000000000
4. Para somar dois números em vírgula flutuante deves ajustar os expoentes (shiftando a
mantissa) para os tornar semelhantes. Depois somam-se as mantissas e, se for preciso,
normaliza-se o resultado. Soma os números (3EE00000)16 e (3D800000)16 em precisão sim-
ples IEEE e expressa o resultado normalizado em hexadecimal.
5. Uma empresa de computadores decidiu produzir um computador com números em vírgula
flutuante com 16 dígitos. O modelo MC-001 tem um formato de vírgula flutuante com um
bit de sinal, expoente com 7 bits e excesso 64 e uma mantissa de 8 bits. O modelo MC-002
tem um bit de sinal, expoente com 5 bits e excesso 16 e uma mantissa de 10 bits. Ambos
usam exponenciação na base 2. Quais são o mais pequeno e o maior números normalizados
que podem ser representados em ambos os modelos? Quantos dígitos decimais de precisão
tem cada um dos modelos? Irias comprar algum deles?
6. Arredondar os seguintes números até cinco casas decimais:
5.82380353 9.28305 9.33355
5.82384358 9.28315 9.33365
5.82385000 9.28325 9.33375
5.82385031 9.33335 9.33385
5.82389584 9.33345 9.33395

1.3. LIMITAÇÕES DOS SISTEMAS DE VÍRGULA FLUTUANTE 35
7. Arredondar os números seguintes para quatro dígitos na mantissa:
(a) 832529.5
(b) 83262.95
(c) 8325.500
(d) 832.6500
(e) 83.55602
(f) 8.366602
8. Representar os seguintes números com oito dígitos na mantissa:
(a) raiz quadrada de dois;
(b) raiz quadrada de três;
(c) um milhão;
(d) o número x = −e−10 ≈ −0.00004539992976.
9. Faça os cálculos indicados das seguintes formas: exactamente e usando 3 dígitos na man-
tissa. Para cada uma das aproximações, calcule os erros absoluto e relativo.
(a) 16
+ 110
.
(b) 16× 1
10.
(c)(17
+ 110
)+ 1
9.
(d) 17
+(
110
+ 19
).
1.3 Limitações dos sistemas de vírgula flutuante
Nesta secção resumem-se alguns dos problemas que ocorrem ao utilizar um sistema de vír-
gula flutuante. Uma vez que estamos a tentar representar um número infinito de números reais
num conjunto finito surgem problemas, alguns dos quais já referidos em secções anteriores.
Bases: Secção 1.2.

36 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
1.3.1 Overflow e Underflow
É um caso de Overflow quando o resultado de um cálculo dá um valor que é maior do que
o maior número do sistema de vírgula flutuante. É um caso de Underflow se o resultado for um
valor mais pequeno que o menor número pertencente ao sistema de vírgula flutuante.
1.3.2 Somar e subtrair números grandes e pequenos
Considere-se um sistema com quatro dígitos na mantissa. Então,
2145 + 0.02156 = 2145.02156 ≈ 2145
Por conseguinte, embora o segundo número não seja zero, quando é adicionado a 2145 não existe
alteração no número 2145. Este problema está relacionado à não associatividade referida na pá-
gina 14 ((a+ b)+c 6= a+(b+c)) e surge no método de Eliminação de Gauss para resolver sistemas
lineares. Se um número grande em vírgula flutuante é adicionado a um número pequeno em
vírgula flutuante, o número pequeno pode não ter importância suficiente para produzir uma mo-
dificação no maior. Consequentemente, deve-se evitar construir algoritmos em que este problema
se verifique.
1.3.3 Ordem das adições
Este problema já foi referido na página 14. Por exemplo, considerando quatro dígitos na
mantissa, se somarmos 3002 + 0.5 + 0.5 da esquerda para a direita obtemos
3002 + 0.5 = 3002.5 ≈ 3002
(como o algarismo 2 é par arredonda para baixo). Depois somamos mais 0.5 e o resultado é
3002 + 0.5 = 3002.5 ≈ 3002
Se calcularmos da direita para a esquerda vem 0.5 + 0.5 = 1.0. Depois somamos 3002 e obtemos
3002 + 1.0 = 3003.
Quando executamos uma sequência de adições, os números devem ser somados a partir do
mais pequeno em valor absoluto para o maior em valor absoluto. Desta forma, a soma cumulativa
de números pequenos poderá ter influência no resultado da soma.

1.3. LIMITAÇÕES DOS SISTEMAS DE VÍRGULA FLUTUANTE 37
1.3.4 Cancelamento subtractivo.
Cancelamento subtractivo é o que acontece quando se subtraem dois números aproxima-
damente iguais. Geralmente, mas não sempre, é uma coisa má. Considerem-se os dois casos
seguintes:
• Cálculo da função f(x) = (1− cosx)/x2
Com x = 1.2 × 10−5 o valor de (cos x) arredondado para 10 dígitos significativos é c =
0.9999999999, logo 1 − c = 0.0000000001. Então (1 − c)/x2 = 10−10/1.44 × 10−10 = 0.6944 ...,
que claramente está errado porque 0 ≤ f(x) < 1/2 para todo o x 6= 0. Conclui-se que uma
aproximação de (cos x) com 10 dígitos significativos não é suficiente para obter um valor de f(x)
com pelo menos um dígito correcto. O problema é que 1−c tem apenas um dígito significativo. A
subtracção 1− c é exacta, mas esta subtracção produz um resultado da mesma dimensão do erro
em c. Por outras palavras, a subtracção aumenta a importância do erro anterior. Neste exemplo,
é fácil reescrever f(x) para evitar o cancelamento. Uma vez que cosx = 1− 2sen2(x/2),
f(x) =1
2
(sen(x/2)
x/2
)2
Utilizando esta fórmula para calcular f(x) com uma aproximação de sen(x/2) com 10 dígitos
significativos, tém-se f(x) = 0.5 que é correcto até 10 dígitos significativos.
É importante salientar que o cancelamento não é sempre uma coisa má. Existem diversas
razões para tal. A primeira é que os números que estão a ser subtraídos podem não ter erros,
como quando são os dados iniciais conhecidos exactamente. Por exemplo, o cálculo das diferenças
divididas envolve muitas subtracções, mas metade delas envolvem os dados iniciais. A segunda
razão é que o cancelamento pode ser um sintoma de mau-condicionamento intrínseco de um
problema e, por conseguinte, deve ser evitado. Terceiro, o efeito do cancelamento depende do
papel que o resultado desempenha nos restantes cálculos. Por exemplo, se x y ≈ z > 0 então o
cancelamento no cálculo de x+ (y − z) é inofensivo.
• Cálculo da variância amostral
O problema de calcular a variância amostral ilustra bem como é que fórmulas matematica-
mente equivalentes podem ter propriedades de estabilidade numérica diferentes. Em estatística,
a variância amostral de n números define-se por
s2 =1
n− 1
n∑i=1
(xi − x)2 (1.1)

38 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
onde x é a média amostral
x =1
n
n∑i=1
xi
O cálculo da variância amostral com esta fórmula precisa de passar duas vezes pelos dados, uma
para calcular x e a outra para acumular a soma dos quadrados. Se n for grande, ou se a variân-
cia amostral é calculada à medida que os dados são gerados, não é conveniente. Uma fórmula
alternativa, que usa aproximadamente o mesmo número de operações mas exige apenas uma
passagem através dos dados, é a seguinte:
s2 =1
n− 1
n∑i=1
x2i −1
n
(n∑i=1
xi
)2 (1.2)
Esta fórmula é muito má em termos de erros de arredondamento porque calcula a variância
amostral como a diferença entre dois números positivos e, por conseguinte, pode sofrer de grande
cancelamento o que deixa o resultado contaminado com erro de arredondamento; em particular
pode dar um valor negativo. Curiosamente esta fórmula vem implementada em diversas máqui-
nas de calcular existentes no mercado. Por outro lado, a fórmula (1.1) dá sempre um valor com
muita exactidão (não negativo), a menos que n seja elevado. Mais especificamente, se s2 = fl(s2)
é o valor calculado da variância amostral utilizando a fórmula (1.1), então pode demonstrar-se
que
|s2 − s2||s2|
≤ (n+ 3)u+O(u2)
Observe-se que o majorante do erro não envolve os números de condição pelo menos no termo
de primeira ordem. Isto é uma situação rara de um algoritmo que garante mais exactidão no
resultado do que se pode garantir nos dados.
Considere-se um exemplo em que x = (10000, 10001, 10002)T , então em precisão simples
(u ≈ 6 × 10−8), a variância amostral é 1 se utilizarmos a fórmula (1.1), mas é zero se for usada
a fórmula (1.2), o que corresponde a um erro relativo igual a 1 (100% de erro). Para passar uma
vez só ao longo dos dados existem fórmulas alternativas que conduzem a bons resultados. Por
exemplo, em vez de calcular x e x2 podemos ir acumulando
Mk =1
k
k∑i=1
xi, e Pk =
k∑i=1
x2i −1
k
(k∑i=1
xi
)2

1.3. LIMITAÇÕES DOS SISTEMAS DE VÍRGULA FLUTUANTE 39
através de
M1 = x1
Mk = Mk−1 +xk −Mk−1
k, k = 2 : n
P1 = 0
Pk = Pk−1 +(k − 1)(xk −Mk−1)
2
k, k = 2 : n
e depois obter finalmente s2 = Pn/(n − 1). Pode observar-se que as únicas subtracções envol-
vem os dados xi’s e são inofensivas. Para o exemplo anterior, este algoritmo produz a solução
exacta. Na realidade ele é numericamente estável, embora o seu majorante do erro não seja tão
pequeno quanto a fórmula original (1.1); pode mostrar-se que o majorante do erro é proporcional
ao número de condição
2‖x‖2√
(n− 1)s2= 2
(1 +
n
n− 1
x2
s2
)1/2
• Cálculo da função f(x) = (ex − 1)/x
Considere valores de f(x) quando x está próximo de zero. Pela regra de L’Hôpital podemos
concluir que limx→0 f(x) = 1, mas quando calculamos a função f(x) com valores de x próximos
de zero surge-nos um cancelamento subtractivo que é amplificado pela divisão por x. Como é que
podemos fugir a este problema? Uma hipótese é utilizar o desenvolvimento em série de Taylor
(ver Secção 3.1):
f(x) =
(1 + x+ 1
2x2 + 1
6x3 + . . .+ 1
n!xn + 1
(n+1)!xn+1eξx
)− 1
1 + 12x+ 1
6x2 + . . .+ 1
n!xn−1 + 1
(n+1)!xneξx
,
onde ξx está entre x e zero. O valor de n escolhe-se tendo em conta a precisão que se pretende.
Podemos então definir a função do seguinte modo:
f(x) =
1 + 12x+ 1
6x2 + . . .+ 1
n!xn−1 |x| proximo de 0
ex−1x
caso contrario(1.3)
Se pretendermos mais precisão utilizamos mais termos no desenvolvimento em série.
• Cálculo das raízes de uma equação de segundo grau
Na tabela seguinte encontram-se os cálculos intermédios da raiz positiva da equação
7.326x2 + 62.53x+ 0.2501 = 0
aplicando a fórmula resolvente. Na primeira coluna os cálculos foram efectuados com quatro dí-
gitos na mantissa e na segunda coluna com dez dígitos na mantissa. Os erros relativos respectivos
encontram-se também na tabela.

40 CAPÍTULO 1. CÁLCULO EM PRECISÃO FINITA
Quatro dígitos Dez dígitos−62.53+
√3910−7.328
14.65−62.53+
√3910.0009−7.328930400
14.65
−62.53+√3903
14.65−62.53+
√3902.671970
14.65
−62.53+62.4714.65
−62.53+62.4713692014.65
−0.0600014.65
−0.0586300000014.65
−0.004096 −0.004001556102
δx = 0.23× 10−1 ≤ 0.5× 10−1 δx = 0.17× 10−7 ≤ 0.5× 10−7
2 algarismo significativo 8 algarismos significativos

Capítulo 2
Teoria dos erros
O valor 3.14 é uma aproximação do valor π e por conseguinte tem um erro a ele associado.Será que esta aproximação está longe ou perto de π? Em Matlab, podemos observar que quandoefectuamos o cálculo cos−1(cos(3.14)) não obtemos de volta o valor 3.14. Foi introduzido um erronão da aproximação de π, mas sim como resultado do cálculo numérico:
>> cospi = cos(3.14)
cospi = -9.999987317275395e-001
>> acos(cospi)
ans = 3.139999999999973e+000
Neste capítulo, ir-se-á referir quais são as principais fontes de erro em cálculo numérico.
Também se irá definir erro absoluto e erro relativo absoluto de uma aproximação e o número de
dígitos que são correctos numa aproximação. Iremos fazer distinção entre dispor de um grande
números de dígitos para aproximar um valor (precisão) e dar um valor que de facto é o correcto
(exactidão).
Dada uma expressão matemática acontece o seguinte: se as variáveis tiverem afectadas de
erro, então ao resultado também estará associado um erro. Esta passagem do erro a partir das
variáveis para o resultado designa-se por propagação de erro. Por vezes o erro das variáveis é
amplificado no resultado, mas a quantidade de amplificação depende da operação envolvida.
Por exemplo, considerem-se dois valores 3.22 e 5.54, onde 3.22 representa um número qual-
quer do intervalo [3.215; 3.225] e 5.54 representa um número qualquer do intervalo [5.535; 5.545].
Se fizermos a soma 3.22 + 5.54 então o resultado 8.76 pode ser qualquer número pertencente ao
intervalo [8.75; 8.77]; o extremo inferior resulta de 3.215+5.535 = 8.75 e o extremo superior resulta
41

42 CAPÍTULO 2. TEORIA DOS ERROS
de 3.225+5.545. O comprimento dos intervalos iniciais é 0.01 e o intervalo final tem comprimento
0.02. Consequentemente, o erro final pode ser maior do que os erros dos dados iniciais.
Por outro lado, considerem-se os valores 5.54 e 5.55 nos intervalos
[5.535; 5.545] e [5.545; 5.555],
respectivamente. Se efectuarmos a subtracção 5.55−5.54 = 0.01, o resultado pode ser um número
qualquer do intervalo [5.545−5.545; 5.555−5.535], ou seja, qualquer ponto pertencente ao intervalo
[0; 0.02]. Por conseguinte, ao fazermos a diferença assumimos que ela é positiva mas pode na
realidade ser zero. Se os intervalos de erro inicias forem um bocadinho mais compridos, então a
diferença real poderá ser negativa.
2.1 Tipos de erros
Existem três principais fontes de erros em cálculo numérico: arredondamento, incerteza nos
dados e truncatura.
• Erros de arredondamento Estes erros são uma consequência inevitável por trabalharmos
em precisão finita; ver secção 1.2. Este texto didáctico trata essencialmente deste tipo de
erros.
• Incerteza nos dados Quando se resolvem problemas da vida real este tipo de erros pode
sempre aparecer. Estes erros surgem, por exemplo, se os dados resultam de medições de
quantidades físicas ou de parâmetros de filas de espera. Também pode acontecer que ao
guardar os dados no computador seja preciso fazer erros de arredondamento ou então os
dados podem ser solução de outro problema numérico. Os efeitos dos erros dos dados são
geralmente mais fáceis de entender que os efeitos dos erros de arredondamento provocados
durante um cálculo, porque os erros nos dados podem ser analisados através da teoria da
perturbação aplicada ao problema que se pretende resolver, enquanto que os erros de arre-
dondamento dos cálculos intermédios exigem a análise do método específico que se está a
utilizar para resolver o problema.

2.2. EXACTIDÃO E PRECISÃO 43
• Erros de truncatura (ou erros de discretização). Este tipo de erros é uma das tarefas mais
importantes da análise numérica. Muitos métodos tais como o método de Euler para re-
solver equações diferenciais, ou o método de Newton para resolver equações não lineares,
podem deduzir-se através do desenvolvimento em série de Taylor. Os termos da série de
Taylor que se omitem constituem o erro de truncatura, e para muitos métodos a dimensão
deste erro depende dum parâmetro cujo valor apropriado depende do compromisso entre
obter um erro pequeno e um cálculo rápido. Esse parâmetro denomina-se por comprimento
do passo, h.
2.2 Exactidão e Precisão
Os termos exactidão e precisão são geralmente confundidos ou utilizados sem distinção,
mas vale a pena distingui-los. Estes dois termos utilizam-se para caracterizar uma aproximação
no sentido de ela ser considerada boa ou má. Quer um número provenha de uma medição ou de
um cálculo numérico, é preciso descrevê-la. O termo precisão descreve até que ponto a aproxima-
ção pode ser boa, ou seja, até que ponto a aproximação pode estar perto do valor exacto. O termo
exactidão diz-nos se a aproximação está de facto próxima do valor exacto.
Dado um conjunto de aproximações, existe um erro associado a cada uma delas. O termo
precisão utiliza-se para medir a extensão dos erros relativos a cada uma. A precisão é indepen-
dente da correcção das aproximações ou resultados de medição. Precisão é a exactidão com que
as operações aritméticas básicas +, −, ∗, / são realizadas e para a aritmética de vírgula flutuante
a precisão mede-se pela unidade de arredondamento da máquina.
A precisão descreve-se habitualmente em termos do número de dígitos utilizados para fazer
uma medição ou aproximação embora também possa ser descrito em termos do desvio padrão
dos erros. Por exemplo, um amperímetro com um écran de três dígitos é mais preciso que um
amperímetro com dois dígitos no écran. Com uma régua de 40 centímetros podemos pedir um
comprimento de um objecto até uma precisão de 1 milímetro. Se usarmos um micrómetro con-
seguimos medir com mais precisão o mesmo objecto. Em Matlab, se utilizarmos o tipo format
long para efectuar cálculos, observamos que o número de dígitos guardados é sempre o mesmo,
ou seja, a precisão mantém-se inalterada de cálculo para cálculo. Essa precisão é igual a aproxi-
madamente 15 dígitos decimais.

44 CAPÍTULO 2. TEORIA DOS ERROS
format long
pi = 3.141592653589793
9/7 = 1.285714285714286
A exactidão descreve até que ponto uma aproximação está perto do seu valor exacto. Por
exemplo, considere-se um velocímetro de um automóvel que tem os ticks em cada 10 Kilóme-
tros e suponha-se que a minha velocidade real é 99.9845279... Km por hora. Ao olhar para o
velocímetro posso estimar que vou a uma velocidade de 100 Km/h ou 100.0075 Km/h. Os erros
correspondentes
99.9845279− 100 = 0.015
99.9845279− 100.0075 = 0.023
são da mesma ordem de grandeza. Por conseguinte, as duas aproximações têm aproximadamente
a mesma exactidão. Exactidão refere-se ao erro absoluto ou relativo de uma quantidade aproxi-
mada. Exactidão e precisão é a mesma coisa para o cálculo c = a ∗ b, onde a e b são escalares.
Contudo, por exemplo, na resolução de um sistema linear a exactidão pode ser muito pior que
a precisão. Em Matlab a precisão é fixa e o objectivo de qualquer algoritmo é encontrar uma
resposta o mais exacta possível.
A precisão e a exactidão são duas coisas distintas. Uma quantidade pode ser precisa e não ter
exactidão, ou vice-versa. Por exemplo, suponhamos que um radar da polícia mede a velocidade
de quatro veículos que se deslocam a 150 Quilómetros por hora numa auto-estrada nacional. Os
valores obtidos são 146 Km/h, 149 Km/h, 155 Km/h e 152 Km/h. Um outro radar fez a mesma
medição e obteve 150 Km/h, 149 Km/h, 150 Km/h e 151 Km/h. Os valores do primeiro conjunto
têm exactidão mas não são precisos, enquanto que os do segundo conjunto têm exactidão e são
mais precisos.
Quando calculamos uma quantidade, é importante que a precisão reflicta a exactidão. Por
exemplo, considere-se a Função Zeta de Riemann para obter uma aproximação do número π:
∞∑n=1
1
n2=π
6
Com base nesta série podemos fazer a aproximação
π ≈
(6
100∑n=1
1
n2
)onde se consideraram os primeiros cem termos da série. Em Matlab podemos escrever as instru-
ções

2.2. EXACTIDÃO E PRECISÃO 45
format long e;
sum = 0;
for i=1:100
sum = sum + 1/i^2;
end
pi = sqrt(6 * sum)
para obter
pi = 3.132076531809105e+000
Se compararmos a aproximação obtida pi = 3.132076531809105 com o número exato
π = 3.141592653589793 . . .
podemos observar que a aproximação não tem muita exactidão embora seja bastante precisa.
Neste caso será melhor usar a aproximação pi = 3.1 para aproximar o número π porque apenas
os dois primeiros dígitos coincidem com os do número exacto. A precisão descreve o número de
dígitos que utilizamos para aproximar um determinado valor. Como vimos neste caso, é possível
ter uma precisão grande numa aproximação que tem pouca exactidão. A exactidão descreve a
proximidade de uma aproximação face ao valor exacto que ela aproxima.
Exemplo 1 Qual das duas aproximações, 3.1417 e 3.1392838, tem mais precisão e exactidão para aproxi-
mar o número π? Podemos observar que o primeiro tem mais exactidão, mas o segundo tem maior precisão.
Exemplo 2 Utilizando a fórmula aproximadora da primeira derivada de uma função
f ′(x) =f(x+ h)− f(x)
h
diga qual das seguintes aproximações é mais precisa para aproximar a derivada da função sin(x) no ponto
x = 1:
sin′(1) ≈ (sin(1 + 1)− sin(1))/1 = 0.0678264420177852
sin′(1) ≈ (sin(1 + 10−5)− sin(1))/10−5 = 0.540298098505865
sin′(1) ≈ (sin(1 + 10−10)− sin(1))/10−10 = 0.540302247387103
sin′(1) ≈ (sin(1 + 10−15)− sin(1))/10−15 = 0.555111512312578
Comparando com o valor exacto sin′(1) = cos(1) = 0.540302305868140, observamos que embora todas as
aproximações tenham a mesma precisão (15 dígitos decimais), é a terceira que apresenta mais exactidão.

46 CAPÍTULO 2. TEORIA DOS ERROS
Exemplo 3 Considerem-se os seguintes instrumentos de medida: uma régua de metal de 60 cm, uma régua
de madeira antiga e um pouco curva de 60 cm e um micrómetro.
Ambas as réguas têm aproximadamente a mesma extensão, ou intervalo de variação, do erro. Por
conseguinte, têm aproximadamente a mesma precisão. Contudo, quando se utiliza a régua de madeira os
erros estão enviesados e, por conseguinte, a régua de madeira tem menor exactidão que a de metal. Tanto
no micrómetro como na régua de metal, os erros estão centrados em zero. Contudo, uma vez que 1mm =
1000µm, no caso do micrómetro o intervalo de variação dos erros é muito mais pequeno (cerca de 100 vezes
mais pequeno). Sendo assim, podemos afirmar que o micrómetro é mais preciso que a régua de metal.
2.2.1 Problemas
1. Considere as aproximações 2.7182820135423 e 2.718281828 do número de Neper
e = 2.7182818284590452353602874...
Qual delas tem maior precisão e qual delas tem maior exactidão?
2.3 Erros absoluto e relativo
A aritmética em computador é diferente da utilizada pelas pessoas, principalmente porque
os computadores fazem as operações com números cuja precisão é finita e fixa. Por conseguinte,
em geral, um procedimento numérico dá-nos somente um valor aproximado x de um número
real x. As medidas de exactidão mais úteis são o seu erro absoluto
|ex| = |x− x|,
e o seu erro relativo absoluto
|δx| =|x− x||x|
(que é indefinido se x = 0). Multiplicando o erro relativo por 100 dá-nos a percentagem de erro
relativo. O erro absoluto dá-nos informação sobre o tamanho do erro e o erro relativo diz-nos até
que ponto o erro é grande relativamente ao valor exacto. Um erro absoluto de 2.63 será significa-
tivo? Se o valor exacto for x = 9724613.52 então provavelmente este erro não é significativo. Mas
se o valor exacto for x = 9.72461352, então um erro absoluto de 2.63 será provavelmente muito

2.3. ERROS ABSOLUTO E RELATIVO 47
significativo. É frequentemente suficiente considerar dois dígitos decimais diferentes de zero nos
erros absoluto e relativo. Por conseguinte, basta considerar que o erro absoluto da aproximação
3.14 em relação ao valor exacto π é 0.0016.
Considere-se a aproximação x1 = 0 para aproximar o número x1 = e−16. Uma vez que x1 e x1
são muito pequenos, a diferença |x1− x1| é muito pequena. Mais concretamente, |x1− x1| ≈ 1.1×
10−7 o que é exactidão boa em muitos casos. Contudo, observamos claramente que zero não é uma
boa aproximação para x1 = e−16 = 1.125351747192591 × 10−7. Por outro lado, se aproximarmos
um número grande como, por exemplo, x2 = e15 = 3.269017372472111 × 106, o erro absoluto
correspondente a quase todas as aproximações será grande, mesmo que quase todos os dígitos da
aproximação coincidam com os do valor exacto. Por exemplo, se x2 = 3.269017375472111 × 106,
então
|ex2| = |x2 − x2| = 3× 103
que é um valor grande apesar de x2 coincidir com x2 em nove dígitos. O erro relativo dá uma
medida do número de dígitos correctos na aproximação. Por exemplo,∣∣∣∣x1 − x1x1
∣∣∣∣ = 1× 100
diz-nos que o número de dígitos coincidentes é zero, enquanto∣∣∣∣x2 − x2x2
∣∣∣∣ = 0.92× 10−9
dá-nos a indicação de que x2 tem cerca de nove dígitos correctos. Ao utilizarmos o erro relativo
estamos protegidos contra erros de julgamento sobre a exactidão de uma aproximação devido
à sua escala (número muito grande ou número muito pequeno). Em cálculo científico, onde as
respostas aos problemas podem variar muito em ordem de grandeza, em geral o que interessa
é o erro relativo, porque é independente da escala; mudando a escala de x para ax e x para ax
obtém-se o erro relativo inalterado. No cálculo do erro relativo as unidades cancelam. Por exem-
plo, os erros relativos das aproximações 2.4MV e 2400000V em relação aos seus valores exactos
2.573243MV e 2573243V, respectivamente, são iguais. Contudo, em muitas situações práticas, nem
sempre conseguimos calcular o erro relativo porque x é desconhecido. Nestes casos, tentamos fre-
quentemente encontrar limite superiorMe > 0 tal que |ex| ≤Me. Uma vez que |ex| = |x− x| ≤Me,
tem-se x ∈ [x−Me; x+Me]. Outra situação em que não é possível calcular o erro relativo é quando
este é zero, mas esta situação raramente aparece na prática.
Quando x e x são vectores então o erro relativo é definido através da norma, como
δx =‖x− x‖i‖x‖i
, i = 1, 2,∞

48 CAPÍTULO 2. TEORIA DOS ERROS
onde
‖x‖1 =n∑i=1
|xi|, ‖x‖2 = (xTx)1/2 e ‖x‖∞ = maxi=1:n|xi|
A desigualdade‖x− x‖i‖x‖i
≤ 1
2× 10−p
implica que cada componente xj com |xj| ≈ ‖x‖i tem cerca de p dígitos decimais correctos, mas
para as componentes mais pequenas a desigualdade simplesmente majora o erro absoluto. Uma
medida que se utiliza em certas áreas para colocar todas as componentes em igualdade de cir-
cunstâncias é o erro relativo em relação às componentes
maxi=1:n
|xi − xi||xi|
2.3.1 Exemplos
Exemplo 4 Quais são os erros absoluto e relativo da aproximação 3.14 ao número π?
|ex| = |3.14− π| ≈ 0.0016
|δx| = |3.14− π|/|π| ≈ 0.00051
Exemplo 5 Uma resistência com uma etiqueta de 240Ω tem na realidade 243.32753Ω. Quais são os erros
relativo e absoluto do número presente na etiqueta?
|ex| = |240− 243.32753| ≈ 3.3Ω
|δx| = |240− 243.32753|/|243.32753| ≈ 0.014
Exemplo 6 Considera-se que a voltagem numa linha de alta-voltagem é 2.4MV, quando na realidade a
voltagem pode variar entre 2.1MV e 2.7MV. Qual é o erro máximo absoluto e o erro máximo relativo?
|ex| = |2.4− 2.1| = 0.3MV
|δx| = |2.4− 2.1|/|2.1| ≈ 0.14
|ex| = |2.4− 2.7| = 0.3MV
|δx| = |2.4− 2.7|/|2.7| ≈ 0.11
Por conseguinte, o máximo do erro absoluto é 0.3MV e o máximo do erro relativo é 0.14.

2.4. ALGARISMOS SIGNIFICATIVOS 49
2.3.2 Problemas
1. Calcule(23− 4
7
)+(85− 13
7
)usando quatro dígitos na mantissa e arredondamento simétrico.
Calcule os erros absoluto e relativo da aproximação.
2.4 Algarismos significativos
O erro relativo está ligado com a noção de número de dígitos significativos correctos. Num
número, os dígitos significativos são o primeiro dígito diferente de zero e todos os que o sucedem.
Ou seja, 5.740 tem quatro dígitos significativos, enquanto que 0.023 tem apenas dois.
Dada a aproximação x = 21.67236 do número x = 21.67153 é bastante fácil ver que a apro-
ximação e o número exacto coincidem nos primeiros quatro dígitos. Consequentemente, gos-
taríamos de afirmar que a aproximação tem quatro dígitos significativos correctos. Nesta secção,
apresenta-se uma definição rigorosa desta ideia intuitiva de contar o número de algarismos sig-
nificativos correctos.
Bases: Secção 2.3.
2.4.1 Teoria
O significado de dígitos significativos correctos, num número que aproxima outro, é intui-
tivamente fácil de entender, mas uma definição precisa é um tanto ou quanto problemática. Em
primeiro lugar observe-se que para um número x com p dígitos significativos existem apenas p+1
respostas à questão "quantos dígitos significativos correctos tem x?". Por conseguinte, o número
de dígitos significativos correctos é uma medida de exactidão bastante grosseira comparativa-
mente ao erro relativo.
Considere-se a aproximação x = 2.75303 do número exacto x = 2.75194. Observamos que os
primeiros três dígitos coincidem e, por conseguinte, temos tendência a dizer que x tem três dígitos
significativos correctos. Contudo, não podemos olhar simplesmente para os dígitos coincidentes.
Por exemplo, 1.9 como aproximação de 1.1 pode parecer que tem um dígito significativo cor-
recto, mas tem um erro relativo de 0.73 o que não é nada razoável. Se considerarmos 1.9999 para
aproximar 2.0001 podemos dizer que não tem dígitos significativos correctos, mas o erro relativo

50 CAPÍTULO 2. TEORIA DOS ERROS
associado a esta aproximação é igual a 0.0001 o que é bom (é o mesmo erro relativo associado a
1.9234 como aproximação de 1.9232). Por exemplo, considere os casos
x = 1.00000, x = 1.00499, δx = 4.99× 10−3,
x = 9.00000, x = 8.99899, δx = 1.12× 10−4
Observa-se que x concorda com x em três mas não quatro algarismos significativos, utilizando
uma definição razoável, embora a razão entre os erros relativos seja cerca de quarenta e quatro.
Sendo assim, é possível afirmar que x tem p algarismos significativos correctos se x e x se arre-
dondam para o mesmo número p de dígitos significativos. O termo arredondamento significa substituir
um dado número pelo seu número mais próximo com p dígitos significativos, com alguma regra
para decidir no caso em que existem dois números igualmente mais próximos. Esta definição
de dígitos significativos é matematicamente elegante e, geralmente, concordante com a intuição.
Considerem-se agora os números x = 0.9949 e x = 0.9951. Com base na definição, x não tem dois
dígitos significativos correctos mas tem um e três dígitos significativos correctos; observe-se que
se considerar-mos apenas dois dígitos, x arredonda para 0.99 e x arredonda para 1.0.
Surge então a necessidade de uma definição mais matematicamente rigorosa de número
de algarismos significativos correctos. Uma definição de dígitos significativos correctos que não
goza da ambiguidade anterior é a que estabelece que x concorda com x até p algarismos significativos
se |x− x| é menor ou igual que 0.5 no p-ésimo dígito significativo de x, isto é,
|ex| ≤ 0.5× 10t−p
onde x = 0.a1a2 . . .× 10t com a1 6= 0.
Em termos de erro relativo, diz-se que x tem p algarismos significativos correctos, se p é o
maior inteiro para o qual a desigualdade
|δx| ≤ 0.5× 101−p
se verifica.
Resolvendo a desigualdade anterior em ordem a p, podemos dizer que o número de algaris-
mos significativos é igual a
p =
⌊− log10
(|δx|5
)⌋onde bxc é a função chão que converte um número real no maior número inteiro menor ou igual
a x.

2.4. ALGARISMOS SIGNIFICATIVOS 51
Geralmente, o número de dígitos significativos de uma aproximação é igual ao número de
dígitos consecutivos coincidentes com o valor exacto, mas isto é apenas uma regra heurística. Se
com base nesta regra heurística o número de dígitos significativos correctos for um ou dois, então
é melhor ignorá-la na contabilização dos dígitos significativos correctos.
Enquanto que o número de dígitos significativos correctos fornece uma forma útil para ave-
riguar a exactidão de uma aproximação, o erro relativo é uma medida mais exacta e é indepen-
dente da base. Sempre que damos um valor aproximado da solução de um problema devemos
também dar uma estimativa ou um majorante do erro relativo.
Observação Seja εM a distância entre o número 1 e o número em vírgula flutuante mais próximo
superior a 1. Observa-se que εM = β1−p. Por exemplo, se β = 10 e p = 3, então εM = 0.100× 101 −
0.101 × 101 = 10−3 × 101 = 101−3. εM é o espaçamento entre os números que estão entre 1 e β e o
espaçamento dos números que estão entre 1 e 1/β é βp = εM/β. Se x for diferente de zero, então o
espaçamento entre x e o número adjacente em vírgula flutuante varia entre β−1εM |x| e εM |x|.
Seja x = ±m×βp = ± .a1a2 . . .×βp. Vemos que x está entre y1 = ± bmc×βp e y2 = ± dme×βp.
Por conseguinte, fl(x) será ou y1, ou y2, e vem
|ex| = |x− fl(x)| ≤ |y2 − y1|2
≤ 1
2βt−p
Logo
|δx| =∣∣∣∣x− fl(x)
x
∣∣∣∣ ≤ 1
2βt−p
1
m× βt=
1
2β−p
1
m
Mas m = (.a1a2 . . .)β ≥ (0.1)β = β−1, logo
|δx| ≤1
2β1−p
Observamos que qualquer número real x pertencente ao domínio de F pode ser aproximado por
um elemento x = fl(x) de F com um erro relativo menor ou igual a
u =1
2β1−p
Esta quantidade u designa-se por unidade de arredondamento da máquina.
2.4.2 Exemplos

52 CAPÍTULO 2. TEORIA DOS ERROS
Exemplo 7 Considere a aproximação x = 3.14 para aproximar o número π. O erro relativo associado é
|δx| =|3.14− π||π|
≈ 0.00051 = 0.005 = 0.5× 10−2
ou seja, 1− p = −2. Por conseguinte, a aproximação tem três algarismos significativos correctos.
Exemplo 8 Considere uma resistência com uma etiqueta de 240Ω quando na realidade tem 243.32753Ω.
Calculando o erro relativo
|δx| =|240− 243.32753||243.32753|
≈ 0.05 = 0.5× 10−1
podemos concluir que o valor presente na etiqueta tem dois algarismos significativos correctos (1−p = −1).
Exemplo 9 Quantos algarismos significativos correctos tem a aproximação x = 1.9999 quando o valor
exacto é x = 2.0001? O erro relativo é
|δx| =|1.9999− 2.0001||1.9999|
≈ 10−4 < 5× 10−4 = 0.5× 10−3
logo a aproximação tem quatro algarismos significativos (1− p = −3).
Exemplo 10 Quantos algarismos significativos correctos tem a aproximação x = 1.00499 quando o valor
exacto é x = 1.00000? O erro relativo é
|δx| =|1.00000− 1.00499|
|1.00000|≈ 4.99× 10−3 < 5× 10−3 = 0.5× 10−2
logo a aproximação tem três algarismos significativos (1− p = −2).
Exemplo 11 Quantos algarismos significativos correctos tem a aproximação x = 8.99899 quando o valor
exacto é x = 9.00000? O erro relativo é
|δx| =|9.00000− 8.99899|
|9.00000|≈ 1.12× 10−4 < 5× 10−4 = 0.5× 10−3
logo a aproximação tem quatro algarismos significativos (1− p = −3).
Exemplo 12 Quantos algarismos significativos correctos tem a aproximação x = 1.998532 quando o valor
exacto é x = 2.001959? O erro relativo é
|δx| =|1.998532− 2.001959|
|2.001959|≈ 0.0017 < 0.005 = 0.5× 10−2
logo a aproximação tem três algarismos significativos (1− p = −2).
Exemplo 13 Quantos algarismos significativos correctos tem a aproximação x = 3.141592 quando o valor
exacto é x = π? O erro absoluto é
|ex| = |π − 3.141592| ≈ 0.6536× 10−6 ≤ 5× 10−6 = 0.5× 10−5
Uma vez que π = 3.141592653589793... = 0.3141592653589793... × 101, tém-se t = 1. Consequente-
mente, t− p = −5, ou seja, p = 6 (seis algarismos significativos).

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 53
2.4.3 Problemas
1. Considere os números x = 0.100456683 e y = 0.0995214437 num sistema de vírgula flutuante
com sete dígitos na mantissa. Determine o número de algarismos significativos que pode
garantir ao calcular x× y, x/y, x+ y e x− y.
2.5 Propagação dos Erros e condicionamento
Frequentemente, a instabilidade é provocada não pela acumulação de muitos erros de arre-
dondamento mas pelo crescimento de um número reduzido de erros de arredondamento.
Considere-se o exemplo que consiste em aproximar e = exp(1) fixando o número n na defi-
nição
e = limn→∞
(1 +
1
n
)nNa tabela seguinte encontram-se as aproximações f(n) = fl((1 +1/n)n) calculadas em Matlab em
precisão dupla (u ≈ 1.1× 10−16) relativas à função f(n) = (1 + 1/n)n.
n f(n) |e− f(n)|
101 2.593742460100002 1.245393683590437× 101
102 2.704813829421529 1.346799903751661× 102
103 2.716923932235520 1.357896223525223× 103
104 2.718145926824356 1.359016346893505× 104
105 2.718268237197528 1.359126151712076× 105
106 2.718280469156428 1.359302618020308× 106
107 2.718281693980372 1.344786730861358× 107
108 2.718281786395798 4.206324799582717× 108
109 2.718282030814510 2.023554639407621× 107
1010 2.718282053234788 2.247757420192897× 107
1011 2.718282053357110 2.248980646157861× 107
1012 2.718523496037238 2.416675781922173× 104
1013 2.716110034086901 2.171794372144653× 103
1014 2.716110034087023 2.171794372022973× 103
1015 3.035035206549262 3.167533780902163× 101
1016 1 1.718281828459046
1017 1 1.718281828459046

54 CAPÍTULO 2. TEORIA DOS ERROS
As aproximações são fracas, ficando cada vez piores à medida que n se aproxima do inverso
da unidade de arredondamento da máquina. Se n for uma potência de 10, então a representação
de 1/n no sistema binário é um número infinito. Quando é calculado 1 + 1/n com n sendo uma
potência de 10 elevada, apenas poucos dígitos significativos de 1/n ficam retidos na soma. Isso é
um exemplo em que um simples erro de arredondamento é responsável pela obtenção de maus
resultados.
2.5.1 Erros a priori e a posteriori
Suponha-se que se calcula uma aproximação y de y = f(x) numa aritmética com precisão
u, sendo f uma função real de variável real. Surge a questão de como medir a "qualidade" da
aproximação y. Na maioria das vezes ficamos satisfeitos com um erro relativo pequenino (δy ≈
u), mas isso nem sempre se consegue. Em vez de pensarmos no erro relativo de y, podemos
interrogar-nos para que valores de x resolvemos realmente o problema; mais precisamente, para
que valor de ∆x teremos y = f(x+ ∆x). Geralmente podem existir muitos valores para ∆x, logo
consideramos o mais pequeno. O valor ∆x, o mais pequeno deles, possivelmente dividido por
|x|, é denominado por erro a priori. Os erros absoluto e relativo de y denominam-se por erros a
posteriori para os distinguir dos erros a priori.
Um método para calcular y = f(x) diz-se estável a priori se, para cada x, produz um valor y
com um erro a priori pequeno, isto é, y = f(x+ ∆x) para algum ∆x pequeno. Em geral, um dado
problema tem diversos métodos para obter a solução, sendo alguns deles estáveis a priori e outros
não.
O resultado calculado da operação x+y é o resultado exacto dos dados perturbados x(1 + ε)
e y(1 + ε) com |ε| ≤ u; por conseguinte, a adição é, por hipótese, uma operação estável a priori.
A maior parte das rotinas para calcular a função seno não satisfazem y = sen(x + ∆x) com ∆x
relativamente pequeno, mas apenas uma relação mais fraca y + ∆y = sen(x + ∆x), com ∆x e ∆y
relativamente pequenos. Um resultado da forma
y + ∆y = f(x+ ∆x) (2.1)
diz-se ser um resultado com erro a posteriori-priori misto. Para ∆x e ∆y suficiente pequenos,
(2.1) diz-nos que o valor calculado y quase não difere do valor y + ∆y que foi calculado a partir
dos dados x + ∆x que quase não diferem do valor exacto x. Geralmente, um algoritmo diz-se
ser numericamente estável se é estável no sentido do erro a posteriori-priori misto da equação (2.1);

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 55
por conseguinte, um algoritmo estável a priori será numericamente estável. Observe-se que esta
definição é específica para problemas onde os erros de arredondamento são a forma de erro mais
dominante. O termo estabilidade tem outros significados noutras áreas da análise numérica.
2.5.2 Condicionamento
O condicionamento do problema (isto é, a sensibilidade da solução a perturbações nos da-
dos) governa a relação entre erros a posteriori e a priori. Assumindo que f ∈ C2 podemos escrever
y − y = f(x+ ∆x)− f(x) = f ′(x)∆x+f ′′(x+ θ∆x)
2!(∆x)2, θ ∈ (0; 1)
Este desenvolvimento leva à noção de número de condição. Uma vez que
y − yy
=
(xf ′(x)
f(x)
∆x
x+O
((∆x)2
))a quantidade
c(x) =
∣∣∣∣xf ′(x)
f(x)
∣∣∣∣mede, para pequenos valores de ∆x, a variação relativa nos resultados para uma variação relativa
nos dados e denomina-se por número de condição de f (relativo). Por exemplo, considere-se a
função f(x) = log x. O número de condição é c(x) = |1/ log x|, que é grande para x ≈ 1. Isto
significa que uma variação relativa pequena em x pode produzir uma variação relativa muito
grande em log x para x ≈ 1.
Se os erros a priori e a posteriori e o número de condição estiverem definidos de forma con-
sistente, então tém-se a seguinte regra empírica aproximada
erro a posteriori ≤ número de condição × erro a priori
Uma forma de interpretar esta regra é dizer que a solução calculada de um problema mal-con-
dicionado pode ter um erro a posteriori grande. Mesmo que a solução calculada tenha um erro a
priori pequeno, este erro pode ser ampliado por um factor tão grande como o número de condição
quando passa para o erro a posteriori.
Os erros dos dados são os erros a priori e os erros dos resultados são os erros a posteriori. O
erro no resultado de um problema que tem origem no erro dos dados denomina-se propagação de
erro. Se y = f(x) = f(x1, . . . , xn) então a propagação relativa do erro é dada por
δy =y − yy
=n∑i=1
xif(xi)
∂f(x)
∂xiδxi +O
((∆x)2i
)

56 CAPÍTULO 2. TEORIA DOS ERROS
Procedimentos com derivadas parciais pequenas são sempre preferidas. Diz-se que o problema de
calcular f(x) a partir de x é bem condicionado se os números de condição forem limitados por uma
constante relativamente pequena. Idealmente não haverá deterioração de exactidão se |c(xi)| ≤ 1
para todo o i. Na realidade, podemos ficar contentes se podermos considerar |c(xi)| ≤ 100 para
todo o i. Neste caso o resultado f(x) terá perdido apenas cerca de dois dígitos de precisão em
relação à exactidão dos dados.
Para problemas em larga escala a estimação da propagação dos erros e dos números de con-
dição é muito complicada e raramente é possível. Nesses casos, é apropriado usar estimativas
estatísticas do erro. Em seguida, apresentam-se as propagações do erro para as operações aritmé-
ticas básicas:
• Propagação do erro numa soma.
y = f(x1, x2) = x1 + x2
δy.=
x1x1 + x2
δx1 +x2
x1 + x2δx2
Se os dados x1 e x2 têm o mesmo sinal, então a adição é uma operação bem condicionada
porque 0 ≤ xi/(x1 + x2) < 1. Contudo, se x1 e x2 tiverem sinais contrários e tiverem dimen-
sões semelhantes, então a sua adição é mal condicionada. Este efeito é chamado cancelamento
subtractivo e os algoritmos devem ser desenhados tal que o cancelamento seja evitado para
todos os dados.
• Propagação do erro numa multiplicação.
y = f(x1, x2) = x1x2
δy.= δx1 + δx2
A multiplicação é bem condicionada.
• Propagação do erro num quociente.
y = f(x1, x2) =x1x2
δy.= δx1 − δx2
• Propagação do erro em potências.
y = f(x1) = xp1, p > 0, x1 > 0

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 57
δy.= p δx1
Observa-se que as raízes são bem-condicionadas e as potências são moderadamente mal-
condicionadas para valores de p elevados. Isto é uma das razões pelas quais não é de esperar
bons resultados quando se tenta calcular o valor de um polinómio de grau n no ponto x
somando os termos da forma akxk. Uma alternativa é usar o algoritmo de Horner que é
bem-condicionado, o qual vai alternando multiplicações e adições, mas não forma potências
directamente.
2.5.3 Resolução de sistemas lineares
Para uma solução aproximada do sistema x
Ax = b, A ∈ Rn×n b ∈ Rn
o erro a posteriori define-se por
δx =‖x− x‖‖x‖
para uma determinada norma escolhida apropriadamente. Se o sistema linear vier de um pro-
blema de interpolação, pode ter mais interesse averiguar até que ponto Ax está perto de b do que
propriamente estar preocupado com a exactidão de x. Nestes casos, pode utilizar-se uma outra
medida da qualidade de x que é a dimensão do resíduo r = b−Ax. O resíduo tem a desvantagem
de ser dependente da escala; se b e A forem multiplicados por uma constante, então o resíduo
vem multiplicado por essa constante. Uma quantidade independente da escala é o resíduo relativo
que se obtém dividindo o resíduo original por ‖A‖ ‖x‖:
τx =b−Ax
‖A‖ ‖x‖
Considere-se por exemplo a norma-2, definida por
‖x‖2 = (xTx)1/2 e ‖A‖ = maxx 6=0
‖Ax‖‖x‖
Se (A + ∆A)x = b então r = b−Ax = δAx, logo
‖r‖2 ≤ ‖∆A‖2‖x‖2
Por conseguinte,‖∆A‖2‖A‖2
≥ ‖r‖2‖A‖2‖x‖2
= τx

58 CAPÍTULO 2. TEORIA DOS ERROS
ou seja,
τx = min
‖∆A‖2‖A‖2
: (A + ∆A)x = b
Isto significa que τx mede até que ponto A, mas não b, tem de ser perturbado para que x seja
a solução exacta do sistema perturbado, isto é, τx é igual ao erro relativo a priori em relação à
norma. Se A e b não são exactos e τx = O(u), então a solução aproximada x pode ser vista como
satisfatória.
Eliminação de Gauss com pesquisa parcial e regra de Cramer A regra de Cramer consiste em
determinar as componentes da solução do sistema Ax = b do seguinte modo:
xi =det(Ai(b))
det(A)
onde Ai(b) representa a matriz A com a sua i-ésima coluna substituída por b. Esta fórmula
é um exemplo de um método matematicamente elegante, mas completamente inútil para
resolver problemas práticos. As duas desvantagens da regra de Cramer são o seu custo
computacional (explicado em diversos livros de álgebra linear) e a sua instabilidade numé-
rica. A instabilidade numérica surge logo para n = 2. Suponhamos que temos um sistema
2×2, em que a matriz tem número de condição det2(A) = ‖A‖2‖A−1‖2 ≈ 1013, e resolvemos
o sistema de duas maneiras distintas no MatLab (onde a unidade de arredondamento u é
aproximadamente 1.1 × 10−16): (1) regra de Cramer e (2) método de eliminação de Gauss
com pesquisa parcial. Os resultados encontram-se em seguida.
Regra de Cramer Gauss c/ PP
x 1.0000 1.0002
2.0001 2.0004
r/(‖A‖2‖x2‖) 1.5075× 10−7 −4.5689× 10−17
1.9285× 10−7 −2.1931× 10−17
O resíduo normalizado para o método de eliminação de Gauss, com pesquisa parcial de
pivot, é muito pequeno e da ordem da unidade de arredondamento. No caso da regra
de Cramer, o resíduo é muito maior mostrando que a solução aproximada x pela regra de
Cramer não satisfaz nada bem o sistema de equações. As soluções são parecidas. Ambas
têm exactidão até aos três dígitos significativos em cada componente, mas o quarto dígito
já é incorrecto. Ambos os métodos produzem, neste exemplo, a mesma exactidão, embora
o resíduo da regra de Cramer seja muito maior. Este facto explica-se pelo facto de a regra
de Cramer ser estável a posteriori para n = 2. Para n genérico, a exactidão e a estabilidade
da regra de Cramer depende do método utilizado para calcular os determinantes, e não se

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 59
conhecem estimativas satisfatórias para o caso em que se calculam os determinantes com o
método de eliminação de Gauss com pesquisa parcial.
2.5.4 Instabilidade sem cancelamento subtractivo
As aproximações resultantes de uma sequência de cálculos que não envolvam cancelamento
subtractivo (mesmo que a sequência seja pequena), podem não ter exactidão aceitável e a sequên-
cia pode não ser estável.
Factorização LU Sabemos que existe uma única factorização LU de A ∈ Rn×n se e só se Ak é não
singular para k = 1 : n− 1, onde Ak = A(1 : k, 1 : k). Se Ak é não singular para algum k tal que
1 ≤ k ≤ n− 1, então a factorização pode existir, mas se existir não é única.
Assumindo que a factorização existe, ela pode obter-se através do método de Doolitle, onde
os elementos da matriz L e da matriz U são calculados da seguinte forma:
for k = 1 : n
for j = k : n
ukj = akj −k−1∑i=1
lkiuij
end
for i = k + 1 : n
lik =1
ukk
(aik −
k−1∑j=1
lijujk
)end
end
Considere-se, por exemplo, a matriz
A =
υ −1
1 1
,onde υ = 10−5, e um sistema de vírgula flutuante V F (4, 10, t1, t2). Obtém-se então u11 =
υ = 0.1000 × 10−4, u12 = −1 = −0.1000 × 101, l21 = υ−1 = 0.1000 × 106 e u22 = 1 − l21u12 =
1 + υ−1 = 0.1000× 101 + 0.1000× 106 = 0.100001× 106. Por conseguinte, u11 = u11, u12 = u12,
l21 = l21 e u22 = 0.1000× 106 = υ−1. Sendo assim,
LU =
1 0
υ−1 1
υ −1
0 υ−1
=
υ −1
1 0
6= A

60 CAPÍTULO 2. TEORIA DOS ERROS
Observa-se que o produto das matrizes L e U calculadas não dá a matriz A, embora não
exista nenhuma subtracção na construção de L e U. Além disso, a matriz A é bem condici-
onada porque o seu número de condição não é grande: det∞(A) ≈ 4; note-se que
A−1 =
1/(1 + υ) 1/(1 + υ)
−1/(1 + υ) υ/(1 + υ)
,donde,
det∞(A) = ‖A‖∞‖A−1‖∞
= max (|υ|+ 1, |1|+ |1|)×max
(∣∣∣∣ 1
1 + υ
∣∣∣∣+
∣∣∣∣ 1
1 + υ
∣∣∣∣ , ∣∣∣∣ −1
1 + υ
∣∣∣∣+
∣∣∣∣ υ
1 + υ
∣∣∣∣)= 2× 2
1 + υ=
4
1 + υ≈ 4
O problema da obtenção de maus resultados deve-se à escolha de υ como pivot que resulta
em u22 = fl(1 + υ−1) = υ−1. Se for utilizada a pesquisa parcial de pivot, então faz-se a troca
das linhas da matriz A e a factorização já é estável.
Cálculo de x =(x1/2
n)2n Não há dúvidas que dado um valor x ≥ 0 a igualdade
x =(x1/2
n)2né verdadeira, logo é de esperar que o seguinte algoritmo tenha como resultado um valor
aproximado de x bastante preciso:
for n = 1 : 50
x = sqrt(x)
end
for n = 1 : 50
x = x2
end
Na tabela seguinte encontram-se os resultados da função f(x) =(x1/2
n)2n para alguns valo-
res de x calculados em MatLab.

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 61
x f(x)
0.001 0
0.1 0
0.5 0
1 1
25 1
50 1
100 1
Na realidade, em vez de f(x) = x o resultado do algoritmo é f(x) = 0, se 0 ≤ x < 1 e
f(x) = 1, se x ≥ 1. Com apenas 100 operações o algoritmo consegue produzir resultados
completamente errados e nenhuma das operações é uma subtracção.
Seja x um número positivo, então 10−39 < x < 1039. Por conseguinte, para x ≥ 1,
1 ≤ x1/250
< (1039)1/250
= 1039/250 = e39×2−50×log 10 < e10
−15
Sabemos que a máquina faz as contas utilizando o desenvolvimento em série de Taylor
ey = 1 + y +1
2!y2 +
1
3!y3 + . . .
Além disso, em precisão simples a máquina utiliza um significando com 23 bits na mantissa
o que corresponde a 6 dígitos significativos. Note-se que 223 = 210 × 210 × 23 e cada 10
bits, 210 = 1024, consegue apenas 3 dígitos significativos; existe pelo menos um número
com quatro dígitos, por exemplo o 1025 que não consegue ser representado na máquina,
logo não temos 4 dígitos significativos mas apenas 3. Logo, com um significando de 23 bits
consegue-se 6 dígitos significativos. Por conseguinte,
e10−15
= 1 + 10−15 +1
2!(10−15)2 +
1
3!(10−15)3 + . . .
é arredondado para 1, o que faz com que para x ≥ 1 o resultado seja 1.
Se 0 < x < 1 então x < 0.999999× 100, logo
x250 ≤ (0.999999)2
50
= (1− 10−6)250
= 10250×log(1−10−6)×log10 e ≈ 10−5×108
O número 10−5×108 é aproximado pelo número zero e isso explica porque é que quando
0 < x < 1 o resultado dá 0.
Cálculo de uma soma Sabemos que
+∞∑i=1
1
i2=π2
6= 1.644934066848226 . . .

62 CAPÍTULO 2. TEORIA DOS ERROS
Agora suponhamos que o objectivo é aproximar π2/6 utilizando uma soma finita. Podemos
utilizar uma soma recursiva, ou seja,
s = 0
for i = 1 : n
s = s+ i−2
end
Uma vez que os erros de arredondamento individuais dependem dos termos que estão a ser
somados, a exactidão do resultado s depende da ordem pela qual os elementos estão orde-
nados. Na realidade, a aritmética não é uma ciência exacta e obtemos resultados diferentes
se fizermos a soma do fim para o início ou do início para o fim.
Cancelamento dos erros de arredondamento Frequentemente, quando um algoritmo é estável
acontece haver cancelamento dos erros de arredondamento e, por conseguinte, o resultado
final é mais exacto do que os resultados intermédios.
Considere-se, por exemplo, a função
f(x) =ex − 1
x=
+∞∑i=0
xi
(i+ 1)!
Para calcular o seu valor no ponto x podemos considerar dois algoritmos
Algoritmo 1 Algoritmo 2
if x = 0
f = 1
else
f = (ex − 1)/x
end
y = ex
if y = 1
f = 1
else
f = (y − 1)/ log y
end
Alguns resultados obtidos com a implementação destes dois algoritmos em MatLab encon-
tram-se na tabela seguinte. O algoritmo 1 sofre de grande cancelamento quando |x| é muito
menor que 1, dando origem a uma resposta nada exacta; note-se que quando x é muito
pequeno o resultado é 0 em vez de 1. Observa-se que este algoritmo produz resultados
cada vez piores à medida que o valor de x é cada vez menor. O algoritmo 2 produz bons
resultados, embora pareça um pouco complicado estar a calcular uma exponencial e um
logaritmo em vez de só uma exponencial.

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 63
x Algoritmo 1 Algoritmo 2
10−4 1.000500166708384 1.000500166708342
10−5 1.000050001667141 1.000050001666708
10−6 1.000005000006964 1.000005000016667
10−7 1.000000499962183 1.000000500000167
10−8 1.000000049433680 1.000000050000002
10−9 9.999999939225281× 10−1 1.000000005000000
10−10 1.000000082740370 1.000000000500000
10−11 1.000000082740370 1.000000000050000
10−12 1.000000082740370 1.000000000005000
10−13 1.000088900582340 1.000000000000500
10−14 9.992007221626394× 10−1 1.000000000000050
10−15 9.992007221626394× 10−1 1.000000000000005
10−16 1.110223024625155 1.000000000000000
10−17 0 1.000000000000000
10−18 0 1.000000000000000
Considere-se por exemplo x = 9 × 10−4 e suponhamos que a mantissa tem apenas 4 casas.
Então
ex = 1.000900405121527 . . . ,
f l(ex) = 0.1001× 101,
f l(ex)− 1 = 0.1000× 10−2,
f l(fl(ex)− 1) = 0.1000× 10−2,
x(alg.1) = fl
(fl(fl(ex)− 1)
fl(x)
)= fl(1.1111111111 . . .) = 0.1111× 101
log(fl(ex)) = log(1.001) = 9.995003330834232 . . .× 10−4
fl(log(fl(ex))) = fl(log(1.001)) = 0.9995× 10−3
x(alg.2) = fl
(fl(fl(ex)− 1)
fl(log(fl(ex)))
)= fl(1.000500 . . .) = 0.1001× 101
Os erros obtidos através dos dois algoritmos são dados por
|ex(alg.1)| ≈ 1.105499× 10−1, |δx(algoritmo1)| ≈ 0.11050 (≈ 11%erro)
|ex(alg.2)| ≈ 5.4986× 10−4, |δx(algoritmo2)| ≈ 0.00054961 (≈ 0.05%erro)

64 CAPÍTULO 2. TEORIA DOS ERROS
Observamos que o algoritmo 2 produz valores de ex e ex − 1 com muito pouca exactidão
mas a razão das duas quantidades dá um valor com grande exactidão. Por conseguinte, os
erros cancelam-se na divisão no algoritmo 2.
Assumimos que as funções exp e log são ambas calculadas com um erro relativo que não
excede a unidade de arredondamento da máquina. Em primeiro lugar calcula-se y = ex(1 +
δ), |δ| ≤ u. Se y = 1, então ex(1 + δ) = 1, logo
x = − log(1 + δ) = −δ +δ2
2− δ3
3+ . . . , |δ| ≤ u.
Por conseguinte, o valor arredondado de f(x) = 1 +x/2 +x2/6 + . . . é 1, logo f foi calculado
correctamente até à precisão da máquina. Se y 6= 1 então
f = fl
(y − 1
log y
)=
(y − 1)(1 + ε1)
log y(1 + ε2)(1 + ε3) |ε1| ≤ u, i = 1 : 3
Definindo v = y − 1, obtém-se
g(y) =y − 1
log y
=v
log(v + 1)
=v
v − v2/2 + v3/3− . . .
=1
1− v/2 + v2/3− . . .= 1 +
v
2+O(v2)
Quando x é muito pequeno, ou seja y ≈ 1 temos
g(y)− g(y) = g(y)− f ≈ y − y2≈ exδ
2≈ δ
2≈ g(y)δ
2
Para x pequeno, nem y − 1 nem log y se conseguem calcular com grande exactidão. Mas
(y − 1)/ log y é uma aproximação extremamente boa de (y − 1)/ log y próximo de y = 1. Isto
deve-se ao facto da função g(y) = (y − 1)/ log y variar muito lentamente ao pé de y = 1,
g’(1)=1. Mais concretamente, os erros de y − 1 e de log y quase se cancelam.
2.5.5 Como desenhar algoritmos estáveis
Em computação, um algoritmo é uma sequência finita de instruções bem definidas, e não
ambíguas, executadas por um processador num período de tempo finito. Os algoritmos podem

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 65
incluir a repetição de passos, ou seja fazer iterações, ou incluir decisões lógicas ou com base em
comparações.
Ainda não se descobriu uma receita para produzir algoritmos estáveis por isso muitos ana-
listas numéricos dedicam-se ao estudo da estabilidade dos algoritmos; uma das coisas que às
vezes fazem é provar que determinados algoritmos são instáveis. Sendo um assunto de investi-
gação actual ele ajuda a manter a trabalhar os especialistas em análise numérica, mas não é bom
para quem tem de fazer os algoritmos e para quem tem de os utilizar, por exemplo, em aplica-
ções na engenharia. Quando se está a construir um algoritmo é preciso estar atento à necessidade
de estabilidade numérica e não nos devemos apenas focar no custo computacional e na parale-
lização de operações. Embora não exista receita para fazer algoritmos estáveis existem algumas
coisas que convém ter em conta:
1. Sempre que possível, evitar subtracções de quantidades contaminadas com erro.
2. Minimizar a dimensão de quantidades intermédias que levam ao resultado final. Isto deve-
se ao facto de se os valores intermédios são muito elevados, então o resultado final pode vir
grandemente afectado por cancelamentos subtractivos. Valores intermédios grandes resul-
tam na perda de informação. Exemplos deste tipo de problema são a soma recursiva tratada
na secção 2.5.4 e o método de eliminação de Gauss.
3. Olhar para formulações diferentes de um cálculo que são matematicamente equivalentes
mas não computacionalmente equivalentes. Um exemplo é o tratado na secção 2.5.4.
4. É vantajoso expressar a fórmula actual em função da anterior como
novo valor = valor antigo + correcção pequenina
Os métodos numéricos em geral são expressos desta forma. Exemplos destes incluem os
métodos para resolver equações diferenciais ordinárias, onde a correcção é proporcional ao
passo h (distância entre os nós da rede), e o método de Newton para resolver equações não
lineares, f(z) = 0.
• Método de Newton com f ∈ C2[a; b], f ′(z) 6= 0 e f ′′(z) 6= 0.
Neste caso tém-se
z = xn −f(xn)
f ′(xn)− f ′′(ξn)
2f ′(xn)(z − xn)2, ξn ∈ int(z, xn)
ou seja,
xn+1 = xn −f(xn)
f ′(xn)

66 CAPÍTULO 2. TEORIA DOS ERROS
• Método de Euler para resolver o problema de valor inicial y′(x) = f(x, y(x))
y(x0) = y0
Sabemos que
y(xn+1) = y(xn) + hy′(xn) +h2
2y′′(ξn), h = xn+1 − xn, ξm ∈ (xn, xn+1)
= y(xn) + hf(xn, y(xn)) +h2
2y′′(ξn)
ou seja,
yn+1 = yn + hf(xn, yn)
5. Utilizar matrizes bem condicionadas.
6. Tomar precauções para evitar Overflows e Underflows desnecessários. Por exemplo, o cál-
culo de ‖x‖2 =∑
(|xi|2)1/2 muitas vezes resulta em Overflow. Para evitar este problema
podemos utilizar o seguinte algoritmo:
y = ‖x‖∞ = maxi=1:n|x(i)|
s = 0
for i = 1 : n
s = s+ (x(i)/y)2
end
‖x‖2 = y√s
2.5.6 Problemas
1. Faça os cálculos indicados das seguintes formas: exactamente e usando 3 dígitos na man-
tissa. Para cada uma das aproximações, calcule os erros absoluto e relativo.
(a) 16
+ 110
.
(b) 16× 1
10.
(c)(17
+ 110
)+ 1
9.
(d) 17
+(
110
+ 19
).

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 67
2. Para cada uma das funções explique porque é que o cálculo pode levar a erros de arredonda-
mento elevados para x próximo de certos valores. Diga como pode evitar esses problemas.
(a) f(x) = (√x+ 9− 3)/x.
(b) f(x) = (1− cos(x))/x.
(c) f(x) = (loge(x)− sin(πx))/(1− x).
(d) f(x) = (cos(π + x)− cos(π))/x.
(e) f(x) = (e1+x − e1−x)/(2x).
3. Quantos termos da série de Taylor tem de considerar para calcular o valor da função f(x) =
(ex−1)/x com sete dígitos decimais correctos (precisão simples), para x ∈ [0; 1/2], utilizando
a aproximação (1.3):
f(x) =
1 + 12x+ 1
6x2 + . . .+ 1
n!xn−1, |x| proximo de 0
ex−1x, caso contrario
E se pretender catorze dígitos significativos correctos (precisão dupla).
4. (a) Considere o algoritmo, para o cálculo de 1− cos(x), definido por
z1 = cos(x)
z2 = 1− z1
Mostre que o algoritmo é instável para valores de x próximos de zero, apesar de o
problema ser bem condicionado.
(b) Baseando-se na fórmula1
2(1− cos(x)) = sin2
(x2
)escreva um algoritmo equivalente que seja numericamente estável para valores de x
próximos de zero.
5. Considere os seguintes dois algoritmos para o cálculo de f(a, b) = a2 − b2
Algoritmo 1 Algoritmo 2
z1 = a2 z1 = a+ b
z2 = b2 z2 = a− b
z3 = z1 − z2 z3 = z1 × z2
Compare os dois algoritmos dados para determinar a2 − b2 com a = 0.3237 e b = 0.3134
utilizando um sistema de vírgula flutuante com quatro dígitos na mantissa.

68 CAPÍTULO 2. TEORIA DOS ERROS
6. Considere a equação quadrática
7.326x2 + 62.53x+ 0.2501 = 0
Sabemos que as raízes desta equação são dadas por
x1 =−b+
√b2 − 4ac
2ae x2 =
−b−√b2 − 4ac
2a
onde a = 7.326, b = 62.53 e c = 0.2501.
(a) Calcule x1 num sistema de vírgula flutuante com: (i) quatro dígitos na mantissa; e (ii)
dez dígitos na mantissa. Obtenha os erros relativos das aproximações obtidas e diga
quantos algarismos significativos tem cada uma delas.
(b) Faça os mesmos cálculos mas utilizando a fórmula
x1 =−b+
√b2 − 4ac
2a
b+√b2 − 4ac
b+√b2 − 4ac
=−2c
b+√b2 − 4ac
(c) Obtenha a expressão para o erro para cada algoritmo que utilizou nas alíneas anteriores
e dê uma explicação para os resultados obtidos.
7. Considere os seguintes algoritmos para determinar valores da função
f(x) =ex − 1
x=
+∞∑i=0
xi
(i+ 1)!
Algoritmo 1 Algoritmo 2
z1 = ex z1 = ex
z2 = z1 − 1 z2 = z1 − 1
z3 = z2/x z3 = loge(z1)
z4 = z2/z3
(a) Implemente estes dois algoritmos em Matlab e preencha a tabela seguinte:
x f(x) com Alg. 1 f(x) com Alg. 2
10−4
10−5
10−6
......
...
10−16
10−17
10−18

2.5. PROPAGAÇÃO DOS ERROS E CONDICIONAMENTO 69
(b) Comente os resultados que obteve e dê uma justificação teórica com base nos erros
relativos dos dois algoritmos.
(c) Calcule os erros relativos, percentagens de erro e número de algarismos significativos
associados às aproximações obtidas pelos dois algoritmos quando x = 9× 10−4.
8. Considere a função
f1(x) = (1− cos(x))/x2
Sabendo que cos(x) = 1− 2 sin2(x/2) podemos reescrever esta função na forma
f2(x) =1
2
(sin(x/2)
x/2
)2
(a) Estude f1 e f2 quanto ao condicionamento.
(b) Com base nas expressões dos erros relativos estude a estabilidade dos algoritmos asso-
ciados a f1 e f2.
(c) Calcule f1(x) e f2(x) com x = 1.2 × 10−5 usando um sistema de vírgula flutuante com
dez dígitos na mantissa.
9. Qual é o efeito do cancelamento subtractivo quando calculamos x + (y − z) com x y ≈
z > 0? Justifique teoricamente.
10. Pretende-se somar três números reais a = 0.45238327 × 102, b = −0.45239512 × 102 e c =
0.12651372× 10−4.
(a) Calcule essa soma num sistema de vírgula flutuante com oito dígitos na mantissa
usando os seguintes algoritmos:
Algoritmo 1 Algoritmo 2
(a+ b) + c a+ (b+ c)
(b) Para cada algoritmo, obtenha uma expressão para o erro relativo de propagação.
(c) Com base na alínea anterior diga qual é a ordem pela qual deve fazer a soma dos três
números e porquê.
11. Considere os números reais a, b 6= c e
z = a× b+ c
b− cSupondo que são apenas conhecidos valores aproximados a, b, c, de a, b, c, respectivamente,
e que as quatro operações aritméticas envolvidas no cálculo de z, adição, subtracção, divi-
são e multiplicação têm erros de arredondamento δarr1 , δarr2 , δarr3 , δarr4 , respectivamente,
determine a expressão do erro relativo do valor aproximado z de z.

70 CAPÍTULO 2. TEORIA DOS ERROS
12. Considere o seguinte algoritmo para o cálculo da função seno hiperbólico num ponto x ∈ R:
z1 = ex
z2 = e−x
z3 = z1 − z2z = z3/2
Supondo que é apenas conhecido um valor aproximado x de x e que quatro operações en-
volvidas no cálculo de z, exponenciação (duas vezes), subtracção e divisão por 2, têm erros
de arredondamento δ1, δ2, δ3, δ4, determine a expressão do erro relativo do valor aproxi-
mado z de z. Utilize o resultado para concluir que o cálculo de sinh(x) é um problema bem
condicionado para qualquer x ∈ R mas que o algoritmo para o seu cálculo é numericamente
instável para x ≈ 0.
13. Se x1 e x2 são aproximações de x1 e x2 com erros ε1 e ε2, mostre que o erro relativo
x1x2 − x1x2x1x2
do produto x1x2 é aproximadamente a soma ε1x1
+ ε2x2
.
14. Considere os números
x = 2.852× 105 y = 1.034 z = 1.016
e sejam x, y e z as suas aproximações num sistema de vírgula flutuante com 3 dígitos na
mantissa. Calcule x+ (y − z) utilizando o seguinte algoritmo:
w1 = y − z
w2 = x+ w1
num sistema de vírgula flutuante com 3 dígitos na mantissa.
(a) Obtenha as expressões dos erros relativos associados a cada passo do algoritmo.
(b) Calcule os valores numéricos que faltam na tabela seguinte:
δx %Errox
δy %Erroy
δz %Erroz
δw1 %Errow1
δw2 %Errow2
onde δx, δy, δz, δw1 , δw2 , %Errox, %Erroy, %Erroz, %Errow1 e %Errow2 são os erros
relativos e as percentagens de erro das várias quantidades envolvidas no cálculo.

Capítulo 3
Ferramentas
3.1 Série de Taylor
Uma das ferramentas que utilizamos em matemática computacional é o teorema de Taylor
que diz o seguinte:
Teorema 1 (Teorema de Taylor) Seja f(x) uma função com n+1 derivadas contínuas no intervalo [a; b],
com n ≥ 0, e seja x, x0 ∈ [a; b]. Então
f(x) = pn(x) +Rn(x)
com
pn(x) =n∑k=0
(x− x0)k
k!f (k)(x0),
Rn(x) =1
n!
∫ x
x0
(x− t)nf (n+1)(t)dt
Além disso, existe um ponto ξx entre x e x0 tal que
Rn(x) =(x− x0)n+1
(n+ 1)!f (n+1)(ξx).
71

72 CAPÍTULO 3. FERRAMENTAS
O ponto x0 é o ponto em torno do qual se faz o desenvolvimento em série e é frequentemente
escolhido pelo utilizador como sendo zero.
Em matemática computacional escreve-se, frequentemente, a fórmula de Taylor como:
f(x+ h) = f(x) + hf (1)(x) +h2
2!f (2)(x) +
h2
3!f (3)(x) + . . .
onde x é um ponto em torno do qual fazemos a expansão de Taylor e h é um valor pequeno. As
aproximações
f(x+ h) = f(x),
f(x+ h) = f(x) + hf (1)(x)
f(x+ h) = f(x) + hf (1)(x) +h2
2!f (2)(x)
são chamadas aproximações de ordem zero, um e dois, respectivamente.
O Teorema de Taylor é importante porque permite representar exactamente funções gerais
em termos de polinómios com um erro conhecido específico e limitado. Isto permite-nos substi-
tuir estas funções por funções mais simples do ponto de vista computacional (polinómios). Ao
mesmo tempo podemos calcular um majorante no erro que estamos a cometer.
A característica mais importante da série de Taylor é que em muitos casos podemos usar
a aproximação de primeira ordem, isto é um polinómio de grau 1, para aproximar localmente a
função. Isto é um resultado de observar que qualquer função diferenciável assemelha-se, local-
mente, a uma linha recta. Por conseguinte, se estivermos na vizinhança de um ponto e tivermos
algum conhecimento da sua série de Taylor (a partir do nosso modelo), então podemos aproximar
com êxito o valor da função nos pontos dessa vizinhança.
Como exemplo de aplicação deste teorema temos os seguintes desenvolvimentos em série,
em torno do ponto x0 = 0, que nos são familiares:
ex = 1 + x+1
2!x2 +
1
3!x3 + . . .+
1
n!xn +
1
(n+ 1)!xn+1eξx
=n∑k=0
1
k!xk +Rn(x),
sin(x) = x− 1
3!x3 + . . .+
(−1)n
(2n+ 1)!x2n+1 +
(−1)n+1
(2n+ 3)!x2n+3 cos(ξx)
=n∑k=0
(−1)k
(2k + 1)!x2k+1 +Rn(x),
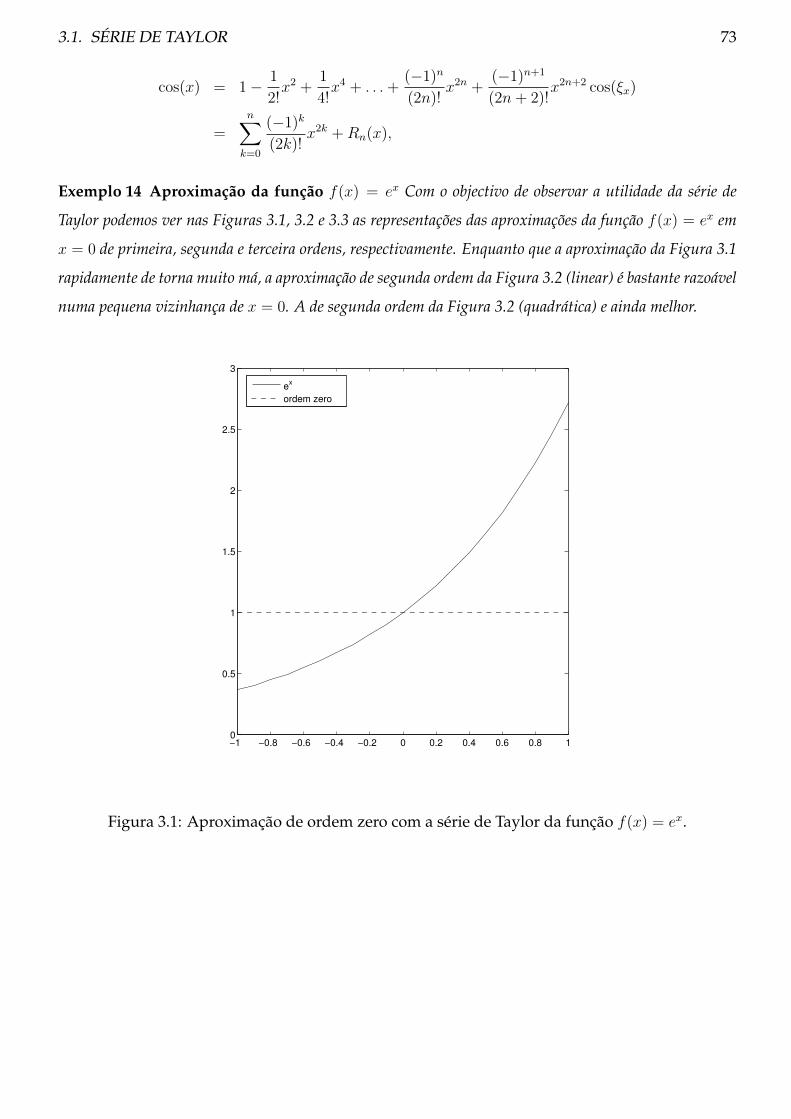
3.1. SÉRIE DE TAYLOR 73
cos(x) = 1− 1
2!x2 +
1
4!x4 + . . .+
(−1)n
(2n)!x2n +
(−1)n+1
(2n+ 2)!x2n+2 cos(ξx)
=n∑k=0
(−1)k
(2k)!x2k +Rn(x),
Exemplo 14 Aproximação da função f(x) = ex Com o objectivo de observar a utilidade da série de
Taylor podemos ver nas Figuras 3.1, 3.2 e 3.3 as representações das aproximações da função f(x) = ex em
x = 0 de primeira, segunda e terceira ordens, respectivamente. Enquanto que a aproximação da Figura 3.1
rapidamente de torna muito má, a aproximação de segunda ordem da Figura 3.2 (linear) é bastante razoável
numa pequena vizinhança de x = 0. A de segunda ordem da Figura 3.2 (quadrática) e ainda melhor.
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
ex
ordem zero
Figura 3.1: Aproximação de ordem zero com a série de Taylor da função f(x) = ex.
74 CAPÍTULO 3. FERRAMENTAS
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
ex
primeira ordem
Figura 3.2: Aproximação de primeira ordem com a série de Taylor da função f(x) = ex.
3.1. SÉRIE DE TAYLOR 75
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
ex
segunda ordem
Figura 3.3: Aproximação de segunda ordem com a série de Taylor da função f(x) = ex.

76 CAPÍTULO 3. FERRAMENTAS
Exemplo 15 Aproximação da função f(x) = cos(x) A Figura 3.4 mostra sucessivas aproximações da
função f(x) = cos(x) com ordens cada vez mais elevadas em torno do ponto x = 0.
A Figura 3.5 mostra sucessivas aproximações da função f(x) = cos(x) com ordens cada vez mais
elevadas em torno do ponto x = 1, até à quinta ordem:
cos(x) = cos(1)
cos(x) = cos(1)− (x− 1) sin(1)
cos(x) = cos(1)− (x− 1) sin(1)− (x− 1)2
2cos(1)
cos(x) = cos(1)− (x− 1) sin(1)− (x− 1)2
2cos(1) +
(x− 1)3
3!sin(1)
cos(x) = cos(1)− (x− 1) sin(1)− (x− 1)2
2cos(1) +
(x− 1)3
3!sin(1) +
(x− 1)4
4!cos(1)
cos(x) = cos(1)− (x− 1) sin(1)− (x− 1)2
2cos(1) +
(x− 1)3
3!sin(1) +
(x− 1)4
4!cos(1)− (x− 1)5
5!sin(1)
3.1.1 Procedimento
Dada uma função real de variável real f(x), calcula-se a série de Taylor em torno de x calcu-
lando as primeiras n derivadas da função:
f(x) + hf (1)(x) +h2
2f (2)(x) +
h3
3!f (3)(x) + . . .+
hn
n!f (n)(x)
Se pretendermos aproximar o valor de f(x + h), calculamos a soma anterior para um dado
valor de h. O erro associado a esta aproximação é
hn+1
(n+ 1)!f (n+1)(ξx)
onde ξx ∈ int[x, x + h], com int[x, x + h] representando o menor intervalo que contém x e x + h.
A série de Taylor não está realizada em Matlab, pelo que terá de ser calculada manualmente e
programada.
Em muitas situações os engenheiros usam aproximações lineares, ou seja até à primeira
ordem:
f(x+ h) = f(x) + hf (1)(x) +h2
2f (2)(ξx)
Se o passo h for pequeno, por exemplo 0.001 ou 0.0001, então h2 será muito pequeno e, por conse-
guinte, a menos que a segunda derivada seja muito grande, o erro será razoavelmente pequeno.
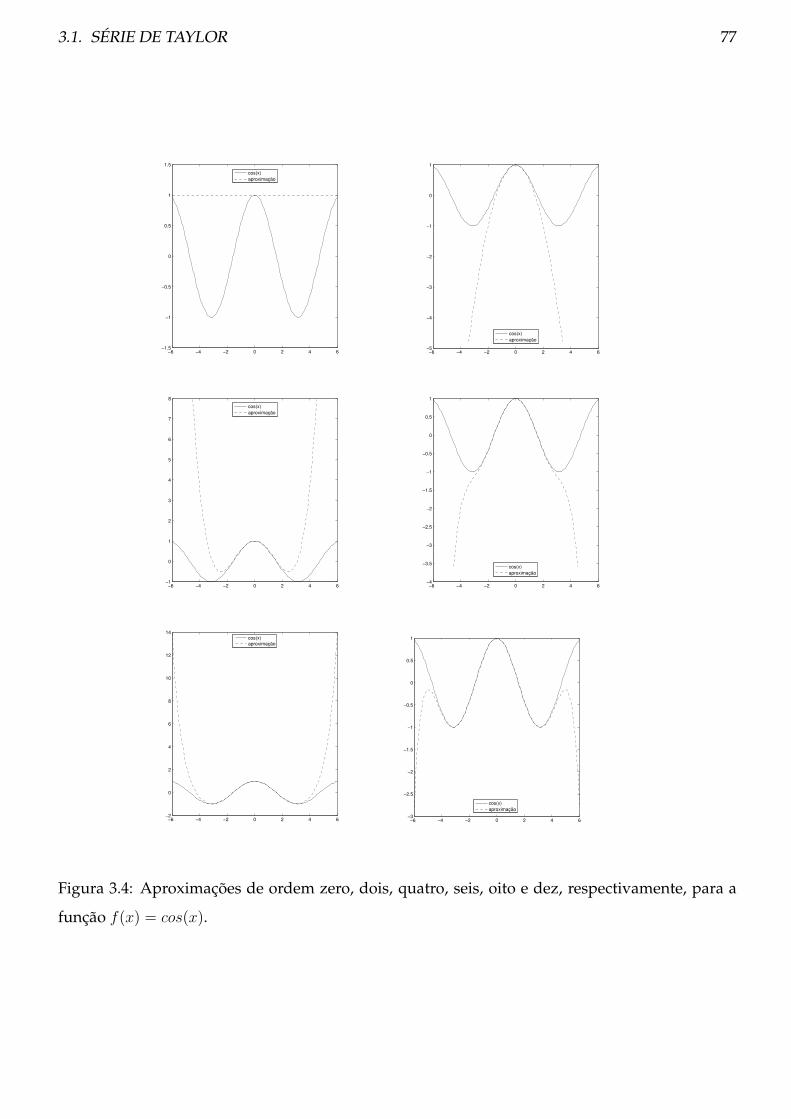
3.1. SÉRIE DE TAYLOR 77
−6 −4 −2 0 2 4 6−1.5
−1
−0.5
0
0.5
1
1.5
cos(x)
aproximação
−6 −4 −2 0 2 4 6−5
−4
−3
−2
−1
0
1
cos(x)
aproximação
−6 −4 −2 0 2 4 6−1
0
1
2
3
4
5
6
7
8
cos(x)
aproximação
−6 −4 −2 0 2 4 6−4
−3.5
−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
cos(x)
aproximação
−6 −4 −2 0 2 4 6−2
0
2
4
6
8
10
12
14
cos(x)
aproximação
−6 −4 −2 0 2 4 6−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
cos(x)
aproximação
Figura 3.4: Aproximações de ordem zero, dois, quatro, seis, oito e dez, respectivamente, para a
função f(x) = cos(x).
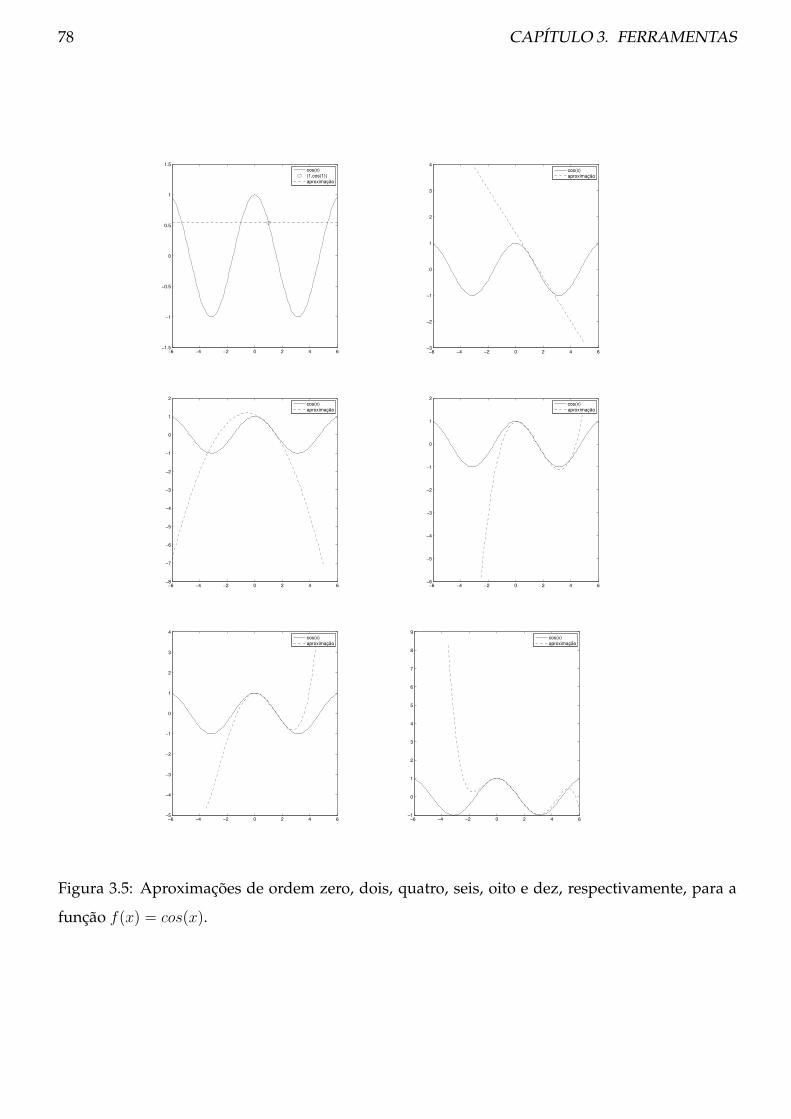
78 CAPÍTULO 3. FERRAMENTAS
−6 −4 −2 0 2 4 6−1.5
−1
−0.5
0
0.5
1
1.5
cos(x)
(1,cos(1))
aproximação
−6 −4 −2 0 2 4 6−3
−2
−1
0
1
2
3
4
cos(x)
aproximação
−6 −4 −2 0 2 4 6−8
−7
−6
−5
−4
−3
−2
−1
0
1
2
cos(x)
aproximação
−6 −4 −2 0 2 4 6−6
−5
−4
−3
−2
−1
0
1
2
cos(x)
aproximação
−6 −4 −2 0 2 4 6−5
−4
−3
−2
−1
0
1
2
3
4
cos(x)
aproximação
−6 −4 −2 0 2 4 6−1
0
1
2
3
4
5
6
7
8
9
cos(x)
aproximação
Figura 3.5: Aproximações de ordem zero, dois, quatro, seis, oito e dez, respectivamente, para a
função f(x) = cos(x).

3.2. PESQUISA BINÁRIA 79
3.1.2 Problemas
1. Reescreva a seguinte série de Taylor para f(x0 + h) onde h = x− x0:
f(x) = f(x0) + (x− x0)f (1)(x0) +(x− x0)2
2f (2)(x0) +
(x− x0)3
6f (3)(x0)
2. Calcular a aproximação de primeira ordem de cos(1.1) em torno do ponto x = 1.
3. Calcular a aproximação de segunda ordem de cos(1.1) em torno do ponto x = 1.
4. Calcular cos(1.1) usando a fórmula de Taylor até à primeira ordem em torno de x = 1. Quais
são os erros relativo e absoluto desta aproximação?
5. Qual é o majorante do erro usando a primeira e a segunda aproximações da série de Taylor
em torno do ponto x = 0.5, para aproximar f(x) = ex nos pontos x = 0 e x = 1?
6. Usar o teorema de Taylor para mostrar que, para h suficientemente pequeno,
(a) ex = 1 + x+O(x2);
(b) 1−cos(x)x
= 12x+O(x3);
(c) (1 + x)1/2 = 1 + 12x+O(x2);
(d) (1 + x)−1 = 1− x+ x2 +O(x3);
(e) sin(x) = x+O(x3).
3.2 Pesquisa binária
Os métodos numéricos mais simples baseiam-se em aplicar uma pesquisa binária ao pro-
blema. Se tivermos uma função real com uma variável real e se conseguirmos observar que a so-
lução desse problema se encontra no intervalo [a; b], então podemos proceder do seguinte modo.
Seleccionamos um ponto c desse intervalo e depois determinamos se a solução está no intervalo
[a; c] ou no intervalo [c; b]. Assim restringimos o domínio no qual a solução se encontra. Apli-
cando várias vezes este procedimento, o intervalo onde se encontra a solução torna-se cada vez
mais pequeno.

80 CAPÍTULO 3. FERRAMENTAS
Exemplo 16 A pesquisa binária é muito utilizada na prática. Quando uma pessoa procura uma palavra
no dicionário usa pesquisa binária. As primeiras páginas de um dicionário começam pela letra A e as
últimas contêm a letra Z. Qualquer palavra que procuremos está entre estas duas letras. Quando abrimos o
dicionário numa página, determinamos se a palavra que procuramos está antes ou depois dela. Assumindo
que ao abrirmos o dicionário não deparamos logo com a palavra, podemos adivinhar qual é o conjunto de
páginas onde vamos continuar a procurar. O processo é repetido até descobrirmos a palavra que procuramos.
Este algoritmo pode parecer rápido mas não é. Na realidade converge com O(loge(n)), onde n é o nú-
mero de passos. Contudo pode ser muito útil para resolver problemas em que a função não é suficientemente
regular. Por exemplo, quando a primeira e segunda derivadas da função tomam valores muito elevados
ao longo da região experimental, métodos numéricos baseados tanto em interpolação como na fórmula de
Taylor geralmente resultam em divergência.
3.3 Iteração
Uma ferramenta utilizada em matemática computacional é considerar uma resposta inicial
ao problema e executar um algoritmo com vista a obter uma resposta melhor que a primeira. Ao
processo de tomar uma aproximação e a partir dela obter uma melhor denomina-se iteração. Cada
repetição do processo também se chama iteração. O resultado de uma iteração é utilizado como
ponto de partida para a próxima iteração.
3.3.1 Teoria
Iteração em matemática pode referir-se ao processo de iterar uma função, i.e., aplicar a fun-
ção repetidamente, utilizando o resultado de uma iteração como entrada para a iteração seguinte.
Mais especificamente, dada a função g(x), começamos com um valor inicial x0 e calculamos su-
cessivamente
primeira aproximação g(x0)
segunda aproximação g(g(x0))
terceira aproximação g(g(g(x0)))
quarta aproximação g(g(g(g(x0))))...
...

3.3. ITERAÇÃO 81
Ou seja, dada uma função g(x) começamos com um valor inicial x0 e definimos a sucessão
xi+1 = g(xi), i = 0, 1, 2 . . . (3.1)
Se a função g(x) e o valor inicial x0 forem escolhidos convenientemente, a sucessão irá convergir
para um valor real fixo.
Existem processos iterativos em que são precisos mais do que um valor inicial para começar
o processo; ver Secção 4.3. Por exemplo, o método da secante necessita de dois valores iniciais x0
e x1 e a sucessão é da forma
xi+1 = g(xi, xi−1) = xi − f(xi)xi − xi−1
f(xi)− f(xi−1)i = 1, 2, . . .
Se convergir, esta sucessão converge para uma raiz da equação f(x) = 0. Outro processo que
precisa de dois valores iniciais é a sucessão de Fibonacci
x0 = x1 = 1
xi+1 = g(xi, xi−1) = xi + xi−1 i = 1, 2, . . .
3.3.2 Condições de paragem
Tão importante como saber como se faz cada iteração num método numérico, é saber quan-
do parar o processo iterativo. Uma condição de paragem é aquela que é utilizada para nos indicar
que o processo iterativo deve ser terminado. Existem dois tipos de condições de paragem e que
passo a descrever.
1. As que indicam sucesso, ou seja, a última iterada é suficientemente boa para os nossos ob-
jectivos.
2. As que indicam insucesso, ou seja, o método numérico não convergiu por alguma razão.
As condições de paragem variam de método para método e em cada método pode existir mais do
que uma. Contudo, uma condição de paragem que geralmente aparece é:
• Parar se o número de iteradas atingir um determinado valor iter_max.
Se após iter_max iteradas o método numérico não convergir, ou assumimos que o método
não converge (com a aproximação inicial escolhida), ou experimentamos outra aproximação ini-
cial. Convém salientar que, se um método numérico não convergir com uma dada aproximação
inicial não significa que a solução não existe. Pode acontecer que a escolha da aproximação inicial

82 CAPÍTULO 3. FERRAMENTAS
não foi a melhor. Se, por outro lado, o método convergir não temos 100% de certeza que o método
convergiu para uma solução válida.
3.3.3 Exemplos
Exemplo 17 O método de Newton para aproximar um zero de uma função f(x) é um exemplo em que a
função iteradora é dada por
g(x) = x− f(x)
f ′(x)
O método iterativo consiste partir de uma aproximação inicial x0 e depois calcular as aproximações seguin-
tes através da sucessão
xi+1 = xi −f(xi)
f ′(xi)
Se f(x) = ex + x3 cos(x) + 2, então f ′(x) = ex + 3x2 cos(x)− x3 sin(x) e
xi+1 = xi −exi + x3i cos(xi) + 2
exi + 3x2i cos(xi)− x3i sin(xi)
Esta função f(x) tem dois zeros no intervalo [2; 4]; ver a Figura 3.6. Para x0 = 2.5 a sucessão converge
para o primeiro zero z1. Ao fim de quatro iteradas podemos concluir que
z1 ≈ 2.630872061595481
i xi f(xi)
0 2.5 1.664624967782634
1 2.636555748834290 −7.469375798940448× 10−2
2 2.630877112458295 −6.631700102488480× 10−5
3 2.630872061599658 −5.483258291860693× 10−11
4 2.630872061595481 0
Por uma questão de interesse, a negrito estão os algarismos que não mudam. Se, por outro lado,
x0 = 4, então a sucessão converge para o segundo zero de f(x). Ao fim de cinco iterações temos
z2 ≈ 3.715478093624801
i xi f(xi)
0 4 14.76495829787307
1 3.793954179745696 3.035369517871949
2 3.723802989096383 2.919440768070061× 10−1
3 3.715478093624801 3.854173446285358× 10−3
4 3.715365215577929 7.032842361809344× 10−7
5 3.715365194973165 1.421085471520200× 10−14
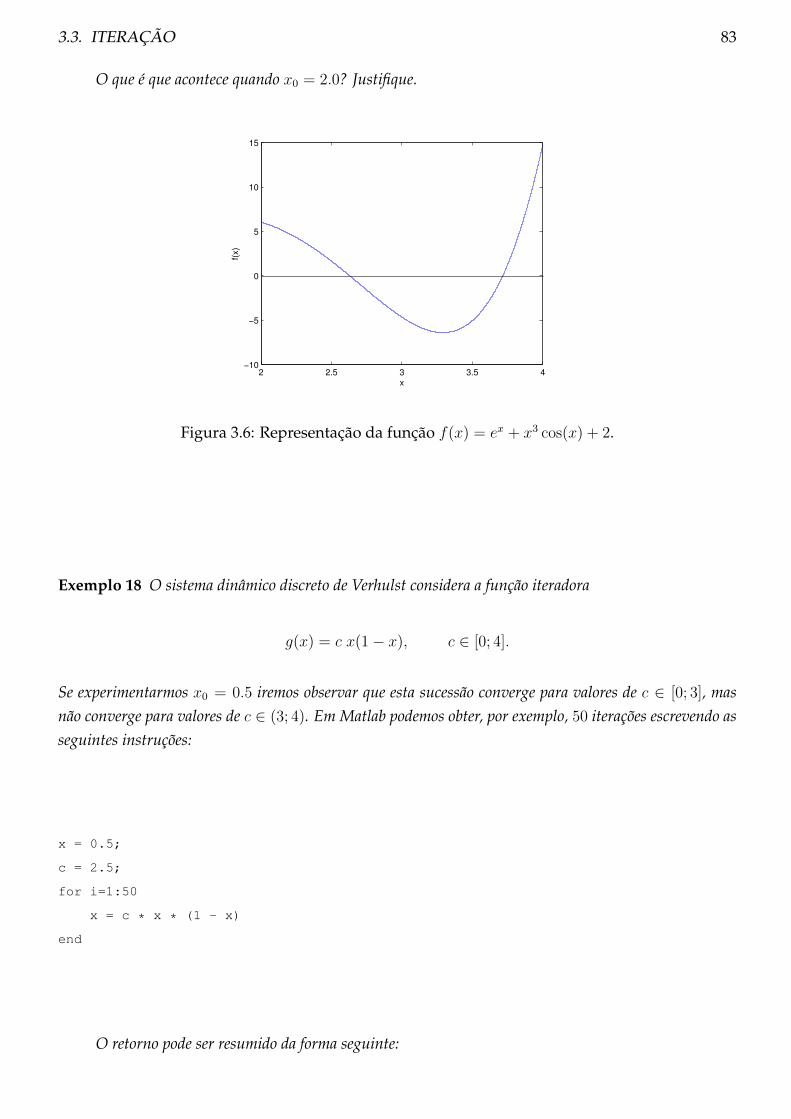
3.3. ITERAÇÃO 83
O que é que acontece quando x0 = 2.0? Justifique.
2 2.5 3 3.5 4−10
−5
0
5
10
15
x
f(x)
Figura 3.6: Representação da função f(x) = ex + x3 cos(x) + 2.
Exemplo 18 O sistema dinâmico discreto de Verhulst considera a função iteradora
g(x) = c x(1− x), c ∈ [0; 4].
Se experimentarmos x0 = 0.5 iremos observar que esta sucessão converge para valores de c ∈ [0; 3], masnão converge para valores de c ∈ (3; 4). Em Matlab podemos obter, por exemplo, 50 iterações escrevendo asseguintes instruções:
x = 0.5;
c = 2.5;
for i=1:50
x = c * x * (1 - x)
end
O retorno pode ser resumido da forma seguinte:

84 CAPÍTULO 3. FERRAMENTAS
i xi
0 0.5000000000000000
1 0.6250000000000000
2 0.5859375000000000
3 0.6065368652343750
4 0.5966247408650816
5 0.6016591486318896...
...
47 0.6000000000000004
48 0.5999999999999998
49 0.6000000000000001
50 0.6000000000000000
Observamos que a sucessão converge para x = 0.6.
Fazendo 100 iteradas com c = 3.2 observamos que a sucessão parece oscilar entre os dois valores
distintos 0.5130445095326298 e 0.7994554904673701:
i xi
0 0.5000000000000000
1 0.8000000000000000
2 0.5120000000000000
3 0.7995392000000000
4 0.5128840565227520
5 0.7994688034800593...
...
......
93 0.7994554904673701
94 0.5130445095326298
95 0.7994554904673701
96 0.5130445095326298
97 0.7994554904673701
98 0.5130445095326298
99 0.7994554904673701
100 0.5130445095326298
Se obtivermos 100 iteradas com c = 3.5 observamos que a sucessão parece oscilar entre quatro valores
distintos: 0.874997263602464, 0.382819683017324, 0.826940706591439 e 0.500884210307218:

3.3. ITERAÇÃO 85
i xi
0 0.5000000000000000
1 0.8750000000000000
2 0.3828125000000000
3 0.8269348144531250
4 0.5008976948447526
5 0.8749971795038800...
...
93 0.8749972636024641
94 0.3828196830173242
95 0.8269407065914387
96 0.5008842103072179
97 0.8749972636024641
98 0.3828196830173242
99 0.8269407065914387
100 0.5008842103072179
3.3.4 Problemas
1. Considere a função iteradora
g(x) =x cos(x)− sin(x) + 0.5
cos(x),
ou seja, o método de Newton aplicado à equação sin(x) − 0.5 = 0. Obtenha seis iteradas
utilizando as seguintes aproximações iniciais relativamente próximas: x0 = 0.5 e x0 = 1.5.
Compare a alteração de resultados quando muda de um valor inicial para outro.
2. Calcule 100 iteradas com as funções iteradoras g(x) = sin(x) e g(x) = cos(x). Qual das
sucessões associadas a estas funções iteradoras converge mais depressa? Considera essa
diferença significativa?
3. Na Grécia antiga sabiam que a sucessão
xi+1 =x2i + 2
2xii = 0, 1, 2, . . .
converge para um determinado número. Que número é esse? Poderá esta sucessão conver-
gir para mais algum número?
Sugestão: este método corresponde à aplicação do método de Newton a uma dada equação
da forma f(x) = 0; descubra esta equação (ver Secção 4.2).

86 CAPÍTULO 3. FERRAMENTAS
3.4 Método do ponto fixo
Um número x diz-se ponto fixo da função g(x) se e só se x é solução da equação
x = g(x)
Para determinar o ponto fixo de uma função num determinado intervalo fechado de R, vamos
utilizar o método iterativo do ponto fixo (3.1)
x0 ∈ R
xi+1 = g(xi) (3.2)
Para que este algoritmo seja útil é preciso que:
1. Dado um valor inicial x0, conseguimos calcular sucessivamente x1, x2, . . . no sentido em
que os valores da sucessão são todos reais positivos ou zero; por exemplo, se g(x) = −√x
e se x0 = 4 > 0 tem-se x1 = −√
4 = −2 e x2 = −√−2 = 0 + 1.414213562373095j, onde j
representa a unidade imaginária.
2. A sucessão x1, x2, . . . converge para um ponto z.
3. O limite z é um ponto fixo de g(x), ou seja, z = g(z).
O teorema do ponto fixo de Banach dá condições suficientes de convergência do método do ponto
fixo.
Bases: Secções 3.1 e 3.3.
3.4.1 Teoria
Teorema do valor médio O teorema do valor médio, ou teorema de Lagrange, diz que se g(x) é
uma função contínua, definida num intervalo fechado [a; b] ⊂ R, e diferenciável em (a; b),
então existe um ponto ξ ∈ (a; b) tal que
g′(ξ) =g(b)− g(a)
b− a
ou seja, a tangente no ponto g(ξ) é paralela à secante que passa nos pontos g(a) e g(b); ver
Figura 3.7.
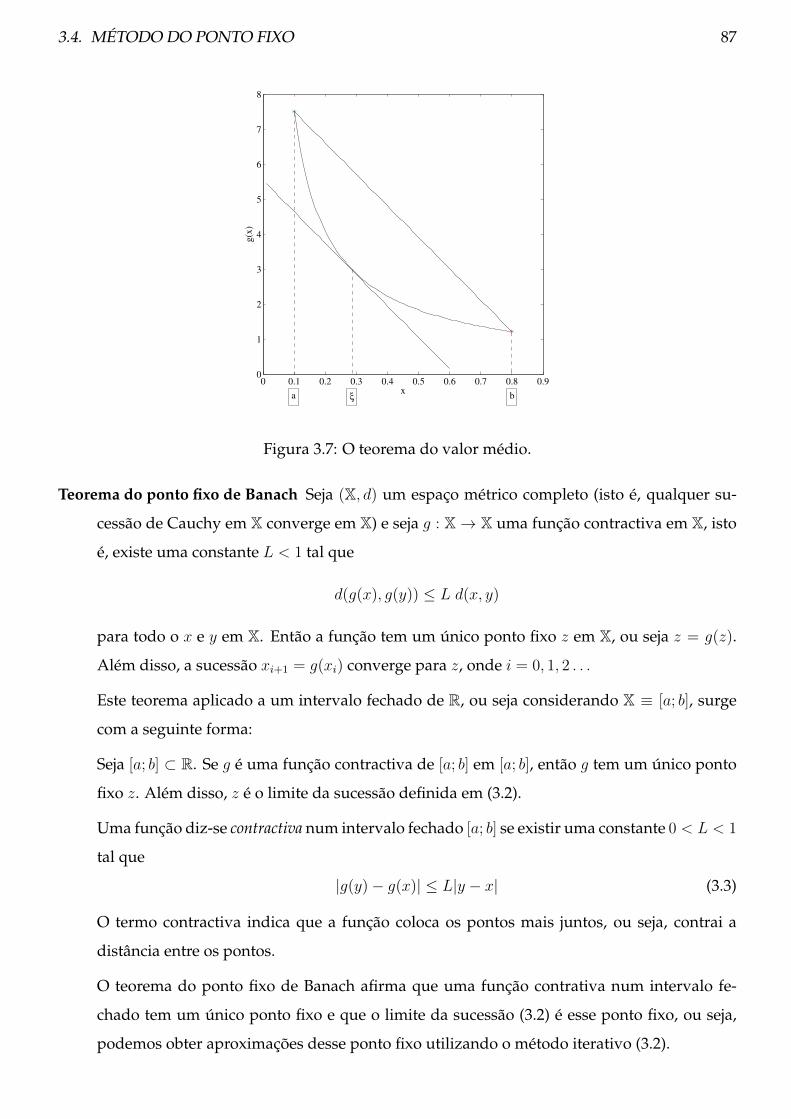
3.4. MÉTODO DO PONTO FIXO 87
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.90
1
2
3
4
5
6
7
8
x
g(x)
ba ξ
Figura 3.7: O teorema do valor médio.
Teorema do ponto fixo de Banach Seja (X, d) um espaço métrico completo (isto é, qualquer su-
cessão de Cauchy em X converge em X) e seja g : X→ X uma função contractiva em X, isto
é, existe uma constante L < 1 tal que
d(g(x), g(y)) ≤ L d(x, y)
para todo o x e y em X. Então a função tem um único ponto fixo z em X, ou seja z = g(z).
Além disso, a sucessão xi+1 = g(xi) converge para z, onde i = 0, 1, 2 . . .
Este teorema aplicado a um intervalo fechado de R, ou seja considerando X ≡ [a; b], surge
com a seguinte forma:
Seja [a; b] ⊂ R. Se g é uma função contractiva de [a; b] em [a; b], então g tem um único ponto
fixo z. Além disso, z é o limite da sucessão definida em (3.2).
Uma função diz-se contractiva num intervalo fechado [a; b] se existir uma constante 0 < L < 1
tal que
|g(y)− g(x)| ≤ L|y − x| (3.3)
O termo contractiva indica que a função coloca os pontos mais juntos, ou seja, contrai a
distância entre os pontos.
O teorema do ponto fixo de Banach afirma que uma função contrativa num intervalo fe-
chado tem um único ponto fixo e que o limite da sucessão (3.2) é esse ponto fixo, ou seja,
podemos obter aproximações desse ponto fixo utilizando o método iterativo (3.2).

88 CAPÍTULO 3. FERRAMENTAS
Exemplo 19 Considere a função iteradora g(x) = 4+ 13
sin(2x). Pelo teorema do valor médio tem-se
|g(y)− g(x)| = 1
3| sin(2y)− sin(2x)| = 2
3| cos(2ξ)||y − x| ≤ 2
3|y − x|
para algum ξ ∈ int(y, x). Isto mostra que g(x) é contractiva com L = 2/3. Pelo teorema do pontofixo de Banach, g(x) tem um único ponto fixo. Podemos obter uma aproximação desse ponto fixocalculando, por exemplo, 15 iteradas em Matlab com o auxílio das seguintes instruções:
x = 0.5;
c = 2.5;
for i=1:15
x = 4 + sin(2 * x) / 3
end
O retorno resume-se no seguinte:
i xi
0 4.000000000000000
1 4.329786082207794
2 4.230895147251998
3 4.273633798652067
4 4.256383405713524
5 4.263578825519133
6 4.260615151290352
7 4.261842411757399
8 4.261335315496154
9 4.261545035513397
10 4.261458334126918
11 4.261494183352877
12 4.261479361394462
13 4.261485489735828
14 4.261482955917161
15 4.261484003552376
Em situações práticas pode ser difícil verificar a condição de contractividade (3.3). Quando
a função g(x) é continuamente diferenciável podemos substituir a condição de contractivi-
dade por uma mais exigente. Pode ser demonstrado que uma função contractiva tem de ser
contínua. Alternativamente, se g(x) for continuamente diferenciável em [a; b], pelo teorema
do valor médio tem-se
|g(y)− g(x)| = |g′(ξ)||y − x|

3.4. MÉTODO DO PONTO FIXO 89
para algum ξ ∈ int(y, x). Consequentemente, se |g′(ξ)| < 1 para todo o ξ ∈ [a; b] a função
g(x) é contractiva. Nesta situação podemos considerar
L = maxx∈[a;b]
|g′(x)| (3.4)
Por outro lado, se qualquer que seja x ∈ [a; b] então g(x) ∈ [a; b], ou seja, a função g(x)
satisfaz g([a; b]) ⊂ [a; b], então pode demonstrar-se (por indução) que a sucessão xi+1 = g(xi)
está bem definida (no sentido que os valores da sucessão são reais) e está em [a; b].
Sendo assim, as seguintes condições são suficientes para que as condições 1, 2 e 3 da pági-
na 86 se verifiquem:
1. g ∈ C1[a; b];
2. g([a; b]) ⊂ [a; b];
3. L = maxx∈[a;b] |g′(x)| < 1.
Em casos em que é difícil verificar a condição g([a; b]) ⊂ [a; b], pode-se utilizar o seguinte
resultado que pode pelo menos assegurar a convergência se a aproximação inicial estiver
suficientemente próxima do ponto fixo: dada uma função contínua g : R → R e um ponto
z tal que |g′(z)| < 1, então existe um intervalo [a; b] em torno do ponto z tal que para toda
a aproximação inicial x0 dentro deste intervalo, o método do ponto fixo converge para z; a
função g(x) é contractiva em [a; b].
Por outro lado, pode demonstrar-se que se g(x) for continuamente diferenciável e |g′(z)| > 1,
então o método do ponto fixo não poderá convergir para z (excluindo o situação em que
xi = z a partir de um certo i). Quando existe convergência podemos averiguar se ela é
monótona (0 < g′(z) < 1) ou alternada (−1 < g′(z) < 0). Na convergência monótona, ou
x0 < x1 < x2 < . . . < z, ou x0 > x1 > x2 > . . . > z. Na convergência alternada as sucessivas
iteradas vão estando alternativamente à direita e à esquerda do ponto fixo z.
A função g(x) = 3 cos(x) tem três pontos fixos perto dos pontos z = −2.9381004, z =
−2.6631789 e z = 1.1701210. Nestes pontos temos |g′(z)| ≈ 1.3811148, |g′(z)| ≈ 0.60627225
e |g′(z)| ≈ −2.7623934 respectivamente. Por conseguinte, o método do ponto fixo só irá
convergir para o ponto fixo z = −2.6631789.
Quando |g′(z)| = 1 o teorema do ponto fixo de Banach não dá informação acerca da conver-
gência do método. Por exemplo, as funções sin(x) e tan(x) têm um ponto fixo em z = 0 e
ambas verificam |g′(z)| = 1. No primeiro caso observamos uma convergência muito lenta e
no segundo caso o método diverge. Para x0 = 0.1 temos

90 CAPÍTULO 3. FERRAMENTAS
sin(x) tan(x)
0.1 0.1
0.0998334 0.100335
0.0996677 0.100673
0.0995027 0.101014
0.0993386 0.101359
0.0991753 0.101708
0.0990128 0.102060
0.0988511 0.102416
0.0986902 0.102775
0.0985301 0.103139
0.0983707 0.103506...
...
3.4.2 Procedimento
Problema Dada uma função de uma variável, g(x), encontrar um valor z (denominado ponto
fixo) tal que z = g(z).
Hipóteses Iremos assumir que a função g(x) é contínua.
Ferramentas Iremos utilizar amostragem e iteração. O erro é obtido utilizando o desenvolvi-
mento em série de Taylor.
Requisitos iniciais Temos de ter uma aproximação inicial x0 do ponto fixo.
Processo iterativo Dada uma aproximação xi da raiz, a aproximação seguinte obtém-se através
de
xi+1 = g(xi)
Condições de paragem Existem três condições que podem originar a paragem do processo itera-
tivo que passo a descrever.
1. A distância entre iteradas sucessivas é suficiente pequena, isto é, |xi+1 − xi| < εpasso;
esta condição é a mais utilizada.
2. A distância entre iteradas sucessivas é menor que εpasso(1 − L)/L, isto é, |xi+1 − xi| <
εpasso(1− L)/L, onde a constante L é dada por (3.4).

3.4. MÉTODO DO PONTO FIXO 91
3. O número máximo de iterações foi atingido e a condição 1 não se verificou; neste caso,
o processo pára e indicamos que a raiz não foi encontrada.
Quando g ∈ C1[a; b] então podemos demonstrar que
|ei+1| ≤L
1− L|xi+1 − xi|
onde ei+1 = z − xi+1 e L = maxx∈[a;b] |g′(x)| (ver (3.9)). Se L ≤ 1/2 então L/(1− L) ≤ 1 e, por
conseguinte,
|ei+1| ≤L
1− L|xi+1 − xi| ≤ |xi+1 − xi|
Neste caso, sempre que o erro em cada iteração vem reduzido pelo menos a metade do
erro da iterada anterior, podemos utilizar com confiança a condição de paragem 1. Quando
a convergência é mais lenta, ou seja L > 1/2, pode acontecer que as iteradas sucessivas
estejam bastantes próximas ao mesmo tempo que o erro ainda seja bastante maior que εpasso.
Nesta situação, podemos utilizar a segunda condição de paragem.
Se o processo termina devido à verificação da condição 1 ou 2, então considera-se que xi+1
é a nossa aproximação da raiz. Se, por outro lado, o processo pára porque se verificou
a condição 3, então devemos escolher uma nova aproximação inicial x0 ou considerar a
possibilidade de a solução não existir.
Análise do erro Vamos agora analisar a velocidade de convergência do método do ponto fixo.
Assuma-se que g(x) tem um ponto fixo z e defina-se a sucessão xi+1 = g(xi). Se g′(x) existe
e é contínua então, pelo teorema do valor médio,
ei+1 = z − xi+1 = g(z)− g(xi) = g′(ξ)(z − xi) = g′(ξ)ei, ξ ∈ int(xi, z),
ou seja,
ei+1 = g′(ξ)ei (3.5)
isto é, o erro ei+1 da (i + 1)-ésima iterada depende linearmente do erro ei da iterada xi. Por
conseguinte, dizemos que a sucessão definida por xi+1 = g(xi) converge linearmente para
z. A partir de (3.5),
|ei+1| ≤ L|ei| (3.6)
onde a constante L é dada por (3.4). Aplicando repetidas vezes a desigualdade (3.6) pode-
mos escrever
|ei| ≤ L1|ei−1| ≤ L2|ei−2| ≤ L3|ei−3| ≤ . . . ≤ Li|e0|
ou seja,
|ei| ≤ Li|e0| (3.7)

92 CAPÍTULO 3. FERRAMENTAS
Por conseguinte, se εpasso é fixo, então podemos saber à partida qual é o número mínimo
de passos para assegurar um erro absoluto inferior a εpasso. Para isso utilizamos o facto de
|e0| ≤ b− a e resolvemos a desigualdade
Li(b− a) < εpasso
em ordem a i e obtemos
i =
⌈loge[εpasso/(b− a)]
loge L
⌉onde die representa o inteiro mais próximo superior a i. Por exemplo, se o intervalo inicial
for [0; 1] e considerarmos εpasso = 10−6 e L = 0.3, então o número mínimo de iteradas será
i =⌈(loge[10−6/(1− 0)])/(loge 0.3)
⌉= 12
A instrução Matlab correspondente é ceil(log(1E-6/(1-0))/log(0.3 )).
Além disso, somando e subtraindo a quantidade xi ao erro correspondente à iterada xi−1
obtém-se
|z − xi+1| = |(z − xi)− (xi+1 − xi)| ≥ |z − xi| − |xi+1 − xi|
Aplicando a este resultado a desigualdade (3.6) vem
|z − xi| − |xi+1 − xi| ≤ L|z − xi|
logo
(1− L)|z − xi| ≤ |xi+1 − xi|
Assumindo L < 1 (caso em que há convergência) obtém-se
|z − xi| ≤1
1− L|xi+1 − xi| (3.8)
Aplicando esta desigualdade a (3.6) podemos afirmar que
|z − xi+1| ≤L
1− L|xi+1 − xi| (3.9)
Se i = 0 em (3.8) tém-se
|z − x0| ≤1
1− L|x1 − x0|
Aplicando este resultado em (3.7) obtém-se
|z − xi| ≤Li
1− L|x1 − x0|
A partir da igualdade (3.5) podemos observar que, se |g′(x)| < 1 para todo o x em [a; b], então
o erro vai ficando cada vez mais pequeno. Se ei for pequeno, então ξ está próximo de z e

3.4. MÉTODO DO PONTO FIXO 93
g′(ξ) ≈ g′(z). Por conseguinte, é de esperar uma convergência rápida se g′(z) for pequeno.
Idealmente teríamos g′(z) = 0. Neste caso, é útil adicionar mais termos ao desenvolvimento
em série de Taylor. Suponha-se que
g′(z) = g′′(z) = . . . = g(p−1)(z) = 0 e g(p)(z) 6= 0 (3.10)
Desenvolvendo g(xi) em série de Taylor em torno do ponto z temos
ei+1 = z − xi+1
= g(z)− g(xi)
= g(z)− g(xi − z + z)
= g(z)− g(z − ei)
= g(z)− [g(z)− eig(z) +1
2e2i g′′(z) + . . .]
= −eig′(z) +1
2e2i g′′(z)− 1
3!e3i g′′′(z) . . .+
(−1)p−2
(p− 1)!ep−1i g(p−1)(z) +
(−1)p−1
p!epi g
(p)(ξ)
Como as derivadas de g(x) no ponto z se anulam até à ordem p− 1 obtemos
ei+1 =(−1)p−1
p!epi g
(p)(ξ)
Assumindo que a sucessão xi+1 = g(xi) converge para z, então a equação anterior implica
que
limi→∞
|ei+1||ei|p
=1
p!epi g
(p)(z) (3.11)
ou seja, se a condição (3.10) se verificar, então o método do ponto fixo tem convergência de
ordem p.
Diz-se que um método numérico tem ordem de convergência p se p é o maior número real
tal que o limite
limi→∞
|ei+1||ei|p
(3.12)
existe e é diferente de zero. Este número p pode não existir e se existir pode não ser inteiro.
Seja g : R → R uma função tal que o método do ponto fixo (3.2) converge, pelo menos
localmente, para o ponto fixo z, com ordem de convergência p. Então:
|ei| ≤ K1/(1−p)p
(|e0|K1/(p−1)
p
)pi, se r > 1
|ei| ≤ Ki1|e0|, se r = 1,
com ei = z − xi e
Kp =1
p!maxx∈I|g(p)(x)|, p ≥ 1

94 CAPÍTULO 3. FERRAMENTAS
onde I = [a; b] é um intervalo contendo z onde existe convergência do método.
Podemos verificar este resultado da seguinte forma. Para p > 1, por hipótese
|ei+1| ≤ Kp|ei|
para i suficientemente grande. Podemos escrever esta desigualdade do seguinte modo:
|ei+1|K1/(1−p)p ≤
(|ei|K1/(p−1)
p
)pou ainda
wi+1 ≤ pwi
onde
wi = log(|ei|K1/(p−1)
p
).
Por recorrência, obtém-se
wi ≤ w0pi
e finalmente
|ei+1|K1/(1−p)p ≤
(|e0|K1/(p−1)
p
)pi.
Quando p = 1 temos, por hipótese,
|ei+1| ≤ K1|ei|,
donde se obtém, por recorrência,
|ei| ≤ Ki1|e0|.
Note-se que para p = 1, temos K1 = L e a desigualdade anterior é, nem mais nem menos,
que a desigualdade (3.7).
3.4.3 Problemas
1. Quais são os pontos fixos da função g(x) = x2? Dada uma aproximação suficientemente
próxima desses pontos, o método do ponto fixo converge?
2. Aproxime o ponto fixo da função g(x) = sin(x)/x.
3. Quais são os pontos fixos de f(x) = 1 + 1/x? Quais é que são os atractivos?
4. Verifique, através de manipulação algébrica, que as raízes da equação x4 + 2x2 − x − 3 = 0
são os pontos fixos das seguintes funções iteradoras:

3.5. EXTREMOS DE FUNÇÕES 95
(a) g1(x) = (3 + x− 2x2)1/4;
(b) g2(x) = [(x+ 3− x4)/2]1/2;
(c) g3(x) = [(x+ 3)/(x2 + 2)]1/2;
(d) g4(x) = (3x4 + 2x2 + 3)/(4x3 + 4x− 1).
Considere x0 = 1 e faça 10 iterações para cada uma das funções iteradoras anteriores. Qual
das funções iteradoras é a mais eficaz para descobrir o zero de f(x). Justifique.
5. Considere uma sucessão de números reais, definida do seguinte modo:
x0 = 1
xk+1 = 1− 1
bxk, k = 0, 1, 2, . . .
onde b é um número real dado.
(a) Com base no teorema do ponto fixo, mostre que se b > 4 esta sucessão converge e que
todos os seus termos estão compreendidos no intervalo [0.5; 1].
(b) Seja b = 25/4.
i. Através da definição de ponto fixo, calcule z = limk→∞ xk.
ii. Mostre que todos os termos da sucessão pertencem ao intervalo [4/5; 1] e que, para
k = 0, 1, 2, . . ., se verifica
|z − xk+1| ≤4
75
(1
4
)k6. Pretende-se determinar uma raiz da equação x = φ(x) pelo método do ponto fixo com um
erro absoluto inferior a 0.5× 10−4. Suponha que foram obtidas as iteradas
x4 = 0.43789 x5 = 0.43814.
Sabendo que φ′(x) ≤ 0.4, determine o número de iterações que tem ainda de se efectuar até
atingir a precisão pretendida.
3.5 Extremos de funções
O problema de encontrar um máximo ou mínimo de uma função num intervalo limitado
e fechado ocorre, frequentemente, em aplicações matemáticas. O teorema seguinte garante a
existência de extremos absolutos de funções contínuas definidas num intervalo fechado de R.

96 CAPÍTULO 3. FERRAMENTAS
Descontinuidade de f ’ (x)
f (x) crescentef ’ (x) < 0
f (x) decrescente
f ’ (x) > 0
Inflexão
f ’ (x) = 0
f ’ (x) = 0
Máximo de f (x)
Mínimo de f (x)
Figura 3.8: Representação gráfica dos extremos de funções.
Teorema 2 (Teorema do valor extremo) Seja f uma função real de variável real contínua num intervalo
fechado [a; b] ∈ R. Então f assume os seus valores máximo e mínimo em algum ponto de [a; b]. Isto é,
existem números x1, x2 ∈ R tal que para todo o x ∈ [a; b]
f(x1) ≤ f(x) ≤ f(x2)
Suponha-se que f é contínua num intervalo fechado [a; b]. A partir do Teorema do valor
extremo, sabe-se que f atinge os seus máximo e mínimo em [a; b]. Em que valores é que um
extremo da função pode ocorrer? Existem três hipóteses:
1. Nos extremos do intervalo. Um ponto extremo da função pode ocorrer num dos extremos
do intervalo. Por exemplo, o máximo da função f(x) = (x− 1)2 no intervalo [1; 2] ocorre no
ponto x = 2.
2. Em pontos onde a derivada da função se anula. Se ocorre um extremo num ponto c perten-
cente ao intervalo aberto (a; b), e a função é diferenciável em c, então sabemos que a derivada
se anula nesse ponto, ou seja, f ′(c) = 0. Por exemplo, o mínimo da função f(x) = (x − 1)2
no intervalo [0; 2] ocorre no ponto x = 1; note-se que f ′(x) = 2(x− 1) e f ′(x) = 0⇔ x = 1.
3. Em pontos nos quais f ′ não está definida. Por exemplo, o mínimo da função f(x) = |x− 1|
em [0; 2] ocorre no ponto x = 1.
Se f é diferenciável em c e f ′(c) = 0, então diz-se que c é um ponto crítico ou ponto esta-
cionário de f . Se a derivada da função não estiver definida em c, então diz-se que c é um ponto

3.5. EXTREMOS DE FUNÇÕES 97
singular de f . Consequentemente, um extremo de uma função contínua num intervalo fechado
ocorre:
• ou num extremo do intervalo;
• ou num ponto crítico;
• ou num ponto singular.
Para encontrar os extremos absolutos de uma função contínua num intervalo fechado [a; b],
procedemos do seguinte modo:
1. Obtêm-se todos os pontos críticos e singulares c da função f no intervalo aberto ]a; b[.
2. Calcula-se o valor f(c) para cada ponto crítico e singular c obtido anteriormente.
3. Calculam-se os valores f(a) e f(b).
4. O maior dos valores obtidos nos passos 2 e 3 é o valor máximo absoluto, e o menor dos
valores calculados em 2 e 3 é o valor mínimo absoluto.
Funções crescentes e decrescentes A função f diz-se crescente no intervalo [a; b] se e somente
se
∀x1, x2 ∈ [a; b], x1 < x2 ⇒ f(x1) ≤ f(x2)
A função f diz-se decrescente no intervalo [a; b] se e somente se
∀x1, x2 ∈ [a; b], x1 < x2 ⇒ f(x1) ≥ f(x2)
A função f diz-se monótona no intervalo [a; b] se for crescente ou decrescente em [a; b].
Podemos descobrir se uma função é monótona através do sinal da sua primeira derivada.
Suponha-se que a função f é contínua em [a, b] e diferenciável em ]a, b[, então:
• Se f ′(x) > 0 ∀x ∈]a, b[, então f é crescente em [a, b].
• Se f ′(x) < 0 ∀x ∈]a, b[, então f é decrescente em [a, b].
• Se f ′(x) = 0 ∀x ∈]a, b[, então f é constante em [a, b].
Podemos descobrir se um extremo de uma função é um máximo ou um mínimo através da
primeira derivada. Suponha-se que a função f é contínua em [a, b] e diferenciável em ]a, b[\c,
onde c é um ponto crítico de f então:

98 CAPÍTULO 3. FERRAMENTAS
• Se f ′(x) > 0∀x ∈]a, c[ e f ′(x) < 0∀x ∈]c, b[, então c é um máximo em [a, b].
• Se f ′(x) < 0∀x ∈]a, c[ e f ′(x) > 0∀x ∈]c, b[, então c é um mínimo em [a, b].
Podemos descobrir se um extremo de uma função é um máximo ou um mínimo através da
segunda derivada. Suponha-se que a função f é diferenciável em ]a, b[ e c é um ponto crítico de f
em ]a, b[, ou seja f ′(c) = 0. Assuma-se que f admite derivada de segunda ordem em ]a, b[. Então:
• Se f ′′(c) > 0, então f tem um mínimo local em c.
• Se f ′′(c) < 0, então f tem um máximo local em c.
Podemos averiguar a concavidade de uma função através da segunda derivada. Suponha-se
que a função f admite a segunda derivada no intervalo ]a, b[. Então:
• Se f ′′(x) > 0 ∀x ∈]a, b[, então o gráfico da função f tem a concavidade voltada para cima
em ]a; b[.
• Se f ′′(x) < 0 ∀x ∈]a, b[, então o gráfico da função f tem a concavidade voltada para baixo
em ]a; b[.
Exemplo 20 Considere a função f(x) = 2x3 + 3x2 − 12x − 10 no intervalo I ≡ [−3; 2]. Para obter os
valores extremos de f começamos por calcular os zeros da primeira derivada f ′(x) = 6x2 + 6x− 12:
f ′(x) = 0⇔ 6x2 + 6x− 12 = 0⇔ x = −2 ∨ x = 1
A derivada está definida em todos os pontos do intervalo I , logo os extremos serão, ou onde a derivada se
anula, ou nos extremos do intervalo:
xi −3 −2 1 2
f(xi) −1 10 −17 −6
Consequentemente,
maxx∈I
f(x) = 10
minx∈I
f(x) = −17
maxx∈I|f(x)| = 17
minx∈I|f(x)| = 1
A segunda derivada anula-se em x = −0.5:
f ′′(x) = 0⇔ 12x+ 6 = 0⇔ x = −0.5

3.5. EXTREMOS DE FUNÇÕES 99
xi −3 −2 −0.5 1 2
f(xi) −1 10 −3.5 −17 −6
sinal de f + + − − −
sinal de f ′ + 0 − 0 +
sinal de f ′′ − − 0 + +
Exemplo 21 Considere a função f(x) = x3 − 3x2 + 5 no intervalo I ≡ [0.5; 1.5]. Os zeros da primeira
derivada f ′(x) = 3x2 − 6x obtêm-se do seguinte modo:
f ′(x) = 0⇔ 3x2 − 6x = 0⇔ 3x(x− 2) = 0⇔ x = 0 ∨ x = 2
Mas x = 0 /∈ I e x = 2 /∈ I , logo a derivada da função é sempre diferente de zero ao longo de todo o
intervalo I e, consequentemente, os valores extremos vão estar nos extremos do intervalo
xi 0.5 1.5
f(xi) 4.3750 1.6250
maxx∈I
f(x) = 4.3750
minx∈I
f(x) = 1.6250
maxx∈I|f(x)| = 4.3750
minx∈I|f(x)| = 1.6250
Observe-se que se for a função g(x) = −f(x) = −x3 + 3x2 − 5 no mesmo intervalo, os zeros da derivada
são os mesmos não pertencentes ao intervalo I , mas
xi 0.5 1.5
f(xi) −4.3750 −1.6250
maxx∈I
f(x) = −1.6250
minx∈I
f(x) = −4.3750
maxx∈I|f(x)| = 4.3750
minx∈I|f(x)| = 1.6250
Existem situações em que a derivada é uma função não linear que não tem solução analítica. Por
exemplo, a derivada da função f(x) = exp(x) + x2 no intervalo [0; 2] dá f ′(x) = exp(x) + 2x e não se
consegue resolver analiticamente a equação exp(x) + 2x = 0. Mas podemos verificar analiticamente que

100 CAPÍTULO 3. FERRAMENTAS
f ′ nunca se anula no intervalo [0; 2]. Como f ′′(x) = exp(x) + 2 > 0, então f ′ é crescente. Além disso,
f ′(0) = 1 > 0 e f ′(2) = 11.3891 > 0. Se a função f ′ é crescente e nos extremos toma valores positivos,
então f ′ é sempre positiva no intervalo [0; 2] e, consequentemente, f é crescente.
Exemplo 22 Considere a função f(x) = |x| no intervalo [−1; 2]. Não existe f ′(0), tem um mínimo em
x = 0 e um máximo em x = 2.
Condições de convergência do método do ponto fixo Uma das condições de convergência do
método do ponto fixo é a seguinte:
g ∈ C[a; b] g([a; b]) ⊂ [a; b]
Para demonstrar esta condição temos de fazer o estudo da função g.
Existem dois casos possíveis:
1. g é monótona. Se a função g for crescente no intervalo [a; b], então
g(a) ≤ g(x) ≤ g(b) ∀x ∈ [a; b]
Se a função g for decrescente no intervalo [a; b], então
g(b) ≤ g(x) ≤ g(a) ∀x ∈ [a; b]
Consequentemente, para provar que g([a; b]) ⊂ [a; b], basta provar:
• g′(x) 6= 0 ∀x ∈ [a; b]
• g(a), g(b) ∈ [a; b].
2. g não é monótona. Neste caso, temos de encontrar os pontos críticos de g e garantir que a
imagem tanto dos pontos críticos como dos extremos do intervalo pertencem ao intervalo
[a; b]. Por exemplo, suponhamos que a função g tem dois pontos críticos c1 e c2 com c1 < c2.
Neste caso, provamos o seguinte:
• g é monótona nos intervalos [a; c1], [c1; c2], [c2; b].
• g(a), g(c1), g(c2), g(b) ∈ [a; b].
Só verificando estes dois pontos é que garantimos que a condição de convergência é verifi-
cada.

3.6. RADIANOS 101
3.6 Radianos
Os engenheiros tendem a preferir os graus face aos radianos, ainda que mais não seja porque
se sentem mais confortáveis com graus; 360 é fácil de lembrar (360 = 5× 23× 32) e fácil de dividir.
Contudo, devemos utilizar radianos em vez de graus. Existem diversas razões que justifi-
cam o facto de ser melhor utilizar radianos em vez de graus. Entre elas temos as seguintes:
1. Facilidade no cálculo de derivadas Se x for medido em radianos, então
(sinx)′ = cosx
(cosx)′ = − sinx
Sabemos que 180o = πrad. Por conseguinte,
(sinxo)′ =(
sin( πx
180rad))′
=π
180cosxo
(cosxo)′ =(
cos( πx
180rad))′
= − π
180sinxo
2. Facilidade nas aproximações Se x for medido em radianos podemos fazer as seguintes apro-
ximações:
sinx ≈ x
cosx ≈ 1− 1
2x2
Se x for medido em graus, estas fórmulas precisam de constantes multiplicativas:
sinx ≈ πx
180
cosx ≈ 1− π2
2× 1802x2
3. Função exponencial complexa A função exponencial no plano complexo é uma função pe-
riódica com o período imaginário 2π que pode ser escrita como
ea+bj = ea(cos b+ j sin b)
onde a e b são valores medidos em radianos e j representa a unidade imaginária. Esta
fórmula faz a ligação entre a função exponencial e as funções trigonométricas e é muito
utilizada no estudo de circuitos eléctricos.

102 CAPÍTULO 3. FERRAMENTAS
4. Altura de estruturas Os militares usam radianos para determinar alturas de estruturas ou
árvores. Uma milha define-se tal que existem 6400 milhas num círculo, isto é, 1 círculo =
6400 milhas. Por conseguinte,
1 milha = 0.00015625 círculo ≈ 0.000981748 radianos ≈ 0.001 radianos = 1 miliradiano,
ou seja, uma milha é uma boa aproximação do miliradiano. Se calcularmos o erro relativo
de aproximação(2π)/6400− 0.001
(2π)/6400= −0.01859163578813012
observamos que é menor que 2%. Para medir a altura de uma estrutura, frequentemente,
procede-se do seguinte modo:
• mede-se o ângulo vertical total a partir da base da estrutura até ao topo, α;
• mede-se a distância deste o local onde a pessoa se encontra até à base da estrutura, d;
• calcula-se altura = d× α.
Isto só é válido quando α está em radianos. Na realidade utilizou-se a aproximação tanα ≈
α na fórmula altura = d× tan(α) válida apenas quando α é medido em radianos.
Os soldados sabem que, por exemplo se d = 1000 metros, um erro de 2 milhas na obtenção
do ângulo α dá origem a um erro de 2 metros na altura da estrutura; se o valor real do
ângulo for x milhas e a leitura for (x+ 2) milhas, então os valores da altura correspondentes
são 1000×0.001×x metros e 1000×0.001× (x+2) metros e, por conseguinte, o erro absoluto
será |1000 × 0.001 × (x + 2) − 1000 × 0.001 × x| = 2 metros. Na realidade estes soldados,
embora não tenham consciência disso, estão a usar radianos em vez de graus.

Capítulo 4
Equações não lineares
Um número real x diz-se ser uma raiz da equação f(x) = 0 (f : R → R) se e só se x é um
valor para o qual a função se anula (é um zero da função f ).
Neste enquadramento surgem dois problemas distintos:
1. Encontrar um zero de uma função com valores reais de uma única variável.
2. Encontrar um zero de uma função com valores reais de duas ou mais variáveis.
No contexto do primeiro problema, se f(x) for um polinómio de grau menor ou igual a
quatro existem fórmulas analíticas explícitas para os zeros; em 628 DC Brahmagupta descobriu a
primeira solução explícita, dada por x = (−b +√b2 + 4ac)/(2a), para o zero de uma equação do
segundo grau da forma ax2+bx = c onde a, b e c são números reais. Se f for um polinómio de grau
maior ou igual a cinco, não existem fórmulas analíticas explícitas para os zeros (resultado provado
por Abel em 1924). Se f for uma função não linear geral, não existe fórmula explícita dos seus
zeros e temos de nos contentar com um método computacional que calcule raízes aproximadas.
Existem muitos métodos numéricos para resolver equações não lineares porque a determi-
nação dos zeros de funções tem sido uma área de grande interesse ao longo de centenas de anos. O
primeiro método para determinar raízes de equações talvez seja o método Babilónio. Este método
foi construído para determinar a raiz quadrada de um número c, ou seja, x =√c. Consequente-
mente, podemos escrever a equação x2 − c = 0. Por exemplo, para determinar x =√
2 podemos
começar com x0 = 3/2. Observamos que x0 = 3/2 >√
2 e que 2/x0 = 4/3 <√
2 ((3/2)2 > 2 e
103

104 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
(4/3)2 < 2). Conseguimos uma melhor aproximação se fizermos a média das duas aproximações,
ou seja,
x1 =1
2
(x0 +
2
x0
)=
17
12
Baseado neste princípio, o método iterativo para determinar a raiz da equação x2 − c = 0, é dado
por:
xi+1 =1
2
(xi +
c
xi
), i = 0, 1, 2, . . . (4.1)
onde o valor inicial é dado x0, de preferência próximo de√c. Pode demonstrar-se que
limi→∞
xi =√c.
Este algoritmo tem convergência quadrática, o que significa que, aproximadamente, o número de
algarismos significativos da aproximação duplica em cada iteração.
Entre os métodos existentes, seis técnicas podem ser utilizadas para encontrar raizes de
equações não lineares em que a função f é uma função com valores reais de uma única variável:
1. Método da bissecção
2. Método de Newton
3. Método da secante
4. Interpolação quadrática inversa
5. Método do ponto fixo
6. Método de Brent
No caso de uma função com valores reais de duas ou mais variáveis (f : Rn → Rn) será
tratado o caso da generalização do método de Newton para encontrar o vector x tal que f(x) = 0.
4.1 Método da bissecção
O método da bissecção é simples, robusto e directo. Considera-se um intervalo [a; b] tal que f
seja contínua nesse intervalo e tal que f(a) e f(b) tenha sinais opostos (f(a)f(b) < 0). Determina-
se o ponto médio de [a; b] e depois decide-se onde é que a raiz se encontra, em [a; (a+ b)/2] ou em
[(a+ b)/2; b]. Repete-se o procedimento até que o intervalo seja suficientemente pequeno.
Bases Secções 3.2 e 3.3.
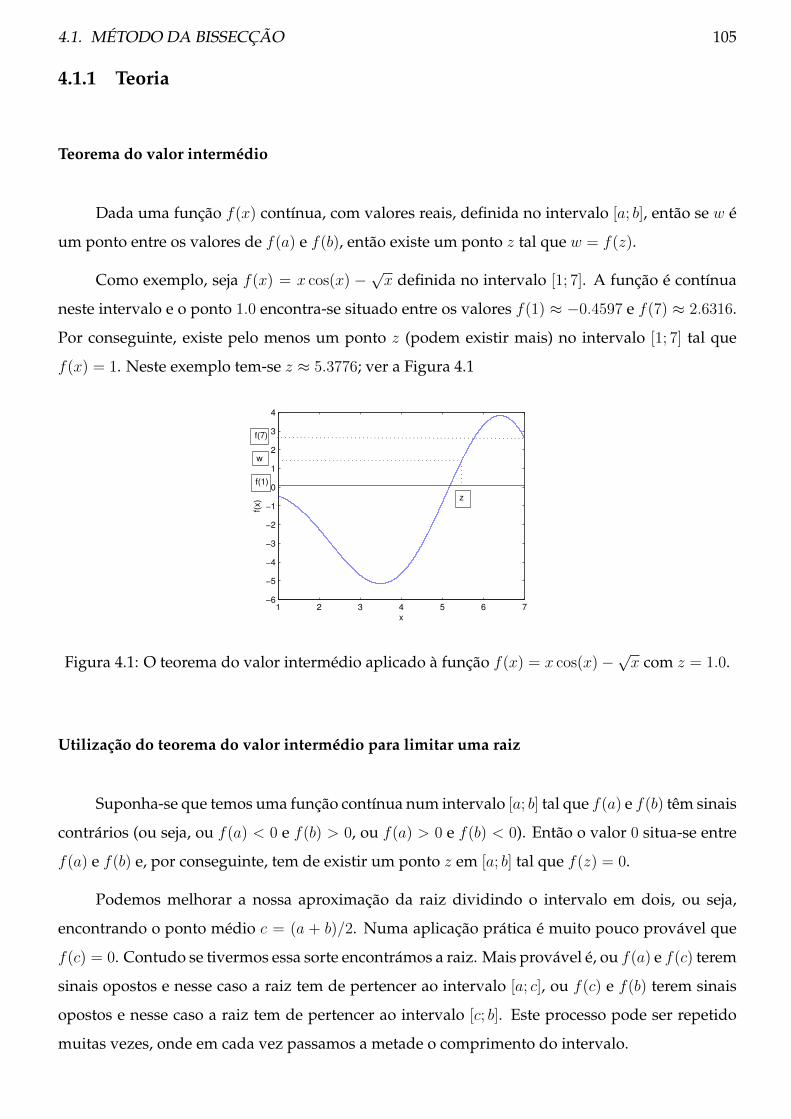
4.1. MÉTODO DA BISSECÇÃO 105
4.1.1 Teoria
Teorema do valor intermédio
Dada uma função f(x) contínua, com valores reais, definida no intervalo [a; b], então se w é
um ponto entre os valores de f(a) e f(b), então existe um ponto z tal que w = f(z).
Como exemplo, seja f(x) = x cos(x) −√x definida no intervalo [1; 7]. A função é contínua
neste intervalo e o ponto 1.0 encontra-se situado entre os valores f(1) ≈ −0.4597 e f(7) ≈ 2.6316.
Por conseguinte, existe pelo menos um ponto z (podem existir mais) no intervalo [1; 7] tal que
f(x) = 1. Neste exemplo tem-se z ≈ 5.3776; ver a Figura 4.1
1 2 3 4 5 6 7−6
−5
−4
−3
−2
−1
0
1
2
3
4
f(x)
x
z
f(7)
f(1)
w
Figura 4.1: O teorema do valor intermédio aplicado à função f(x) = x cos(x)−√x com z = 1.0.
Utilização do teorema do valor intermédio para limitar uma raiz
Suponha-se que temos uma função contínua num intervalo [a; b] tal que f(a) e f(b) têm sinais
contrários (ou seja, ou f(a) < 0 e f(b) > 0, ou f(a) > 0 e f(b) < 0). Então o valor 0 situa-se entre
f(a) e f(b) e, por conseguinte, tem de existir um ponto z em [a; b] tal que f(z) = 0.
Podemos melhorar a nossa aproximação da raiz dividindo o intervalo em dois, ou seja,
encontrando o ponto médio c = (a + b)/2. Numa aplicação prática é muito pouco provável que
f(c) = 0. Contudo se tivermos essa sorte encontrámos a raiz. Mais provável é, ou f(a) e f(c) terem
sinais opostos e nesse caso a raiz tem de pertencer ao intervalo [a; c], ou f(c) e f(b) terem sinais
opostos e nesse caso a raiz tem de pertencer ao intervalo [c; b]. Este processo pode ser repetido
muitas vezes, onde em cada vez passamos a metade o comprimento do intervalo.

106 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
4.1.2 Procedimento
Problema Dada uma função de uma variável, f(x), encontrar um valor z (denominada raiz) tal
que f(z) = 0.
Hipóteses Iremos assumir que a função f(x) é contínua.
Ferramentas Iremos utilizar amostragem, pesquisa binária e iteração.
Requisitos iniciais Os valores de f(a) e f(b) têm sinais opostos, ou seja, a raiz situa-se em [a; b].
Processo iterativo Dado o intervalo [a; b], defina-se c = (a+ b)/2. Então
• se f(c) = 0 (improvável na prática), então parar porque encontrámos a raiz;
• se f(c) e f(a) têm sinais opostos, então a raiz está situada em [a; c] e fazer a atribuição
b = c;
• caso contrário, f(c) e f(b) têm de ter sinais opostos, ou seja a raiz situa-se em [c; b], e
fazer a atribuição a = c.
Condições de paragem Existem três condições que podem originar a paragem do processo itera-
tivo que passo a descrever.
1. Metade do comprimento do intervalo é suficientemente pequeno, isto é |b − a|/2 <
εpasso.
2. O valor da função calculado no ponto médio c = (a+b)/2 do intervalo é suficientemente
pequeno, ou seja, |f(c)| < εabs.
3. O número máximo de iterações foi atingido e nenhuma das condições anteriores se
verifica. Neste caso, o processo pára e indicamos que a raiz não foi encontrada.
Análise do erro Dado que inicialmente a raiz pertence ao intervalo [a; b], então o erro máximo
de usar a ou b para aproximar a raiz é b − a. Uma vez que, em cada iteração, dividimos o
intervalo ao meio, o erro é reduzido por um factor de 2 e, por conseguinte, o erro após n
iterações será maximizado por (b− a)/2n. uma demonstração mais detalhada.
Por conseguinte, se εpasso é fixo, então podemos saber à partida qual é o número mínimo de
passos para assegurar um erro absoluto inferior a εpasso. Para isso resolvemos a desigualdade
b− a2n
< εpasso

4.1. MÉTODO DA BISSECÇÃO 107
em ordem a n e obtemos
n =
⌈log2
(b− aεpasso
)⌉onde dwe representa o inteiro mais próximo superior a w. Por exemplo, se o intervalo inicial
for [0.3; 1.3] e considerarmos εpasso = 10−6, então o número mínimo de passos será
n = dlog2((b− a)/εpasso)e = 20
A instrução Matlab correspondente é ceil(log2((1.3-.3)/1e-6)). Para fazer a conta
com a calculadora é útil utilizar a mudança de base nos logaritmos: log2(x) = logd(x)/logd(2).
4.1.3 Exemplos
Exemplo 23 Considere a equação não linear x cos(x) −√x = 0 no intervalo [5; 6] com εabs = εpasso =
10−2. Os resultados obtidos por aplicação do método da bissecção para encontrar a raiz desta equação
encontram-se na Tabela 4.1.
Tabela 4.1: Método da bissecção aplicado à equação x cos(x)−√x = 0.
k a b b− a c f(c) xk
0 5 6 1 5.5 1.55248
1 5 5.5 0.5 5.25 0.397161 5.5
2 5 5.25 0.25 5.125 −0.208708 5.25
3 5.125 5.25 0.125 5.1875 0.0953469 5.125
4 5.125 5.1875 0.0625 5.15625 −0.0564917 5.1875
5 5.15625 5.1875 0.03125 5.17188 0.0194862 5.15625
6 5.15625 5.171875 0.015625 5.16406 −0.0184895 5.171875
7 5.1640625 5.171875 0.0078125 5.16797 0.000501836 5.1640625
sinal de f − − − − + + + + +
ponto a x3 x5 x7 x6 x4 x2 x1 b

108 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
4.1.4 Problemas
1. Aproximar a raiz da equação x3−3 = 0 com o método da bissecção começando no intervalo
[1; 2] e utilizando εpasso = 0.1 e εabs = 0.1.
2. Aproximar a raiz da equação x2−10 = 0 com o método da bissecção começando no intervalo
[3; 4] e utilizando εpasso = 0.1 e εabs = 0.1.
3. Considere a equação sinx− e−x = 0.
(a) Prove que esta equação tem uma raiz z ∈ [0.5, 0.7].
(b) Efectue uma iteração pelo método da bissecção e indique um novo intervalo que con-
tenha z.
(c) Determine o número m de iterações necessárias para garantir |z − xm| < 10−6.
4. Considere a seguinte função
f(x) = 3x2 − x3 − 2
definida no intervalo I = [1.2, 3].
(a) Mostre que existe uma única raiz de f no intervalo considerado.
(b) Obtenha um valor aproximado dessa raiz com erro inferior a 116
usando o método da
bissecção.
5. Considere a equação 4x2 − e−x2 = 0.
(a) Mostre que esta equação tem duas raízes z1 ∈ [−0.5;−0.3] e z2 ∈ [0.3; 0.5].
(b) Calcule z1 pelo método da bissecção. Faça iteradas até que |f(xi)| < 0.01.
4.2 Método de Newton
O método de Newton é um procedimento que pode aplicar-se em diversas situações. Quan-
do este procedimento é aplicado para encontrar raízes de equações não lineares com uma única
variável é denominado método de Newton-Raphson. A ideia do método é começar com uma
aproximação inicial da raiz x0. Em seguida, aproxima-se a função no ponto x0 pela tangente neste
ponto. O zero da tangente x1 (ou seja, o ponto onde a tangente intercepta o eixo dos xx), em
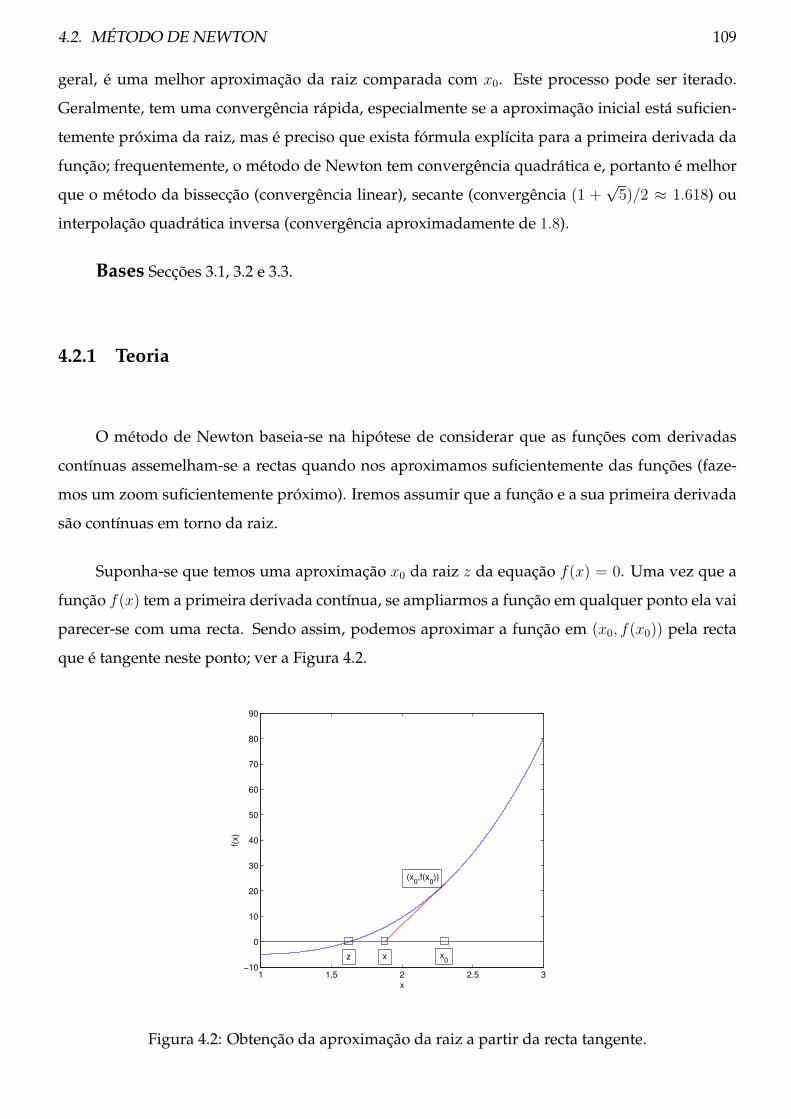
4.2. MÉTODO DE NEWTON 109
geral, é uma melhor aproximação da raiz comparada com x0. Este processo pode ser iterado.
Geralmente, tem uma convergência rápida, especialmente se a aproximação inicial está suficien-
temente próxima da raiz, mas é preciso que exista fórmula explícita para a primeira derivada da
função; frequentemente, o método de Newton tem convergência quadrática e, portanto é melhor
que o método da bissecção (convergência linear), secante (convergência (1 +√
5)/2 ≈ 1.618) ou
interpolação quadrática inversa (convergência aproximadamente de 1.8).
Bases Secções 3.1, 3.2 e 3.3.
4.2.1 Teoria
O método de Newton baseia-se na hipótese de considerar que as funções com derivadas
contínuas assemelham-se a rectas quando nos aproximamos suficientemente das funções (faze-
mos um zoom suficientemente próximo). Iremos assumir que a função e a sua primeira derivada
são contínuas em torno da raiz.
Suponha-se que temos uma aproximação x0 da raiz z da equação f(x) = 0. Uma vez que a
função f(x) tem a primeira derivada contínua, se ampliarmos a função em qualquer ponto ela vai
parecer-se com uma recta. Sendo assim, podemos aproximar a função em (x0, f(x0)) pela recta
que é tangente neste ponto; ver a Figura 4.2.
1 1.5 2 2.5 3−10
0
10
20
30
40
50
60
70
80
90
x
f(x)
(x0,f(x
0))
xz x0
Figura 4.2: Obtenção da aproximação da raiz a partir da recta tangente.

110 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
Para obter a recta tangente, consideramos o polinómio linear que toma o valor zero em x0 e
tem a inclinação f ′(x0), ou seja f ′(x0)(x − x0), e depois somamos f(x0). A recta tangente é dada
por
Tx0 = f(x0) + f ′(x0)(x− x0) (4.2)
Uma vez que a recta tangente é uma boa aproximação da função, podemos concluir que o zero da
recta tangente é uma boa aproximação do zero da função. Resolvendo a equação
Tx0 = 0
obtemos a seguinte aproximação da raiz:
x = x0 −f(x0)
f ′(x0)
Resumindo, linearizou-se a equação não linear em torno de x0 e resolveu-se a equação linear
resultante para obter a aproximação seguinte x.
4.2.2 Procedimento
Problema Dada uma função de uma variável, f(x), encontrar um valor z (denominada raiz) tal
que f(z) = 0.
Hipóteses Iremos assumir que a função f(x) é contínua e tem a sua primeira derivada contínua.
Ferramentas Iremos utilizar amostragem, derivação e iteração. O modelo é que dá informação
sobre a derivada da função. O erro obtém-se utilizando o desenvolvimento em série de
Taylor.
Requisitos iniciais Temos de ter uma aproximação inicial da raiz, x0.
Processo iterativo Dada uma aproximação xi da raiz, a aproximação seguinte obtém-se através
de
xi+1 = xi −f(xi)
f ′(xi)
Condições de paragem Existem três condições que podem originar a paragem do processo itera-
tivo que passo a descrever.
1. Se ambas as condições seguintes de verificarem:
• A distância entre iteradas sucessivas é suficientemente pequena, isto é, |xi+1−xi| <
εpasso.

4.2. MÉTODO DE NEWTON 111
• O valor da função calculado no ponto xi+1 é suficientemente pequeno, ou seja,
|f(c)| < εabs.
2. Se o valor da derivada da função se anula no ponto xi, isto é, f ′(xi) = 0; neste caso o
processo iterativo falha (divisão por zero) e temos de parar.
3. Se o número máximo de iterações foi atingido e a condição 1 não se verificou; neste
caso, o processo pára e indicamos que a raiz não foi encontrada.
Se o processo termina devido à verificação da condição 1, então considera-se que xi+1 é a
nossa aproximação da raiz. Se, por outro lado, o processo pára porque se verificou, ou a
condição 2, ou a condição 3, então devemos escolher uma nova aproximação inicial x0 ou
considerar a possibilidade de a solução não existir.
Análise do erro Agora iremos analisar o erro no método de Newton. Suponhamos que temos
uma aproximação xi com um erro ei = z − xi. Após mais uma iteração pelo método de
Newton qual será o erro da aproximação xi+1? Assuma-se que f ′′ é contínua e z é um zero
simples de f , logo f(z) = 0 6= f ′(z). Então pela série de Taylor tem-se
f(z) = f(xi) + f ′(xi)(z − xi) +1
2f ′′(ξ)(z − xi)2
onde ξ ∈ [z;xi]. Uma vez que f(z) = 0 e dividindo ambos os lados da equação anterior por
f ′(xi), obtém-se
0 =f(xi)
f ′(xi)+ (z − xi) +
1
2
f ′′(ξ)
f ′(xi)(z − xi)2
Por conseguinte,
z −(xi −
f(xi)
f ′(xi)
)= −1
2
f ′′(ξ)
f ′(xi)(z − xi)2
Observa-se que o que está dentro dos parêntesis é por definição xi+1. Logo, podemos escre-
ver:
z − xi+1 = −1
2
f ′′(ξ)
f ′(xi)(z − xi)2
e concluímos que, quando fazemos mais uma iteração, o erro é reduzido por um escalar mul-
tiplicado pelo erro anterior ao quadrado; ou seja, tem convergência quadrática (ver (3.12)).
Mais concretamente,
ei+1 = −1
2
f ′′(ξ)
f ′(xi)e2i (4.3)
onde ξ ∈ int(z;xi) (int(z;xi) representa o menor intervalo que contém z e xi). Para ilustrar
este resultado, considere o problema de encontrar a raiz da equação ex − 2 = 0 começando
com x0 = 4. Neste caso, f(x) = ex − 2 e f ′(x) = f ′′(x) = ex. Assumindo que o intervalo ao

112 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
qual pertence ξ, int(z;xi) é suficientemente pequeno, podemos fazer a seguinte aproxima-
ção: f ′′(ξ)/f ′(xi) ≈ 1. Por conseguinte, temos a relação aproximada
ei+1 ≈1
2e2i
ou seja,ei+1
e2i≈ 1
2= 0.5
Na Tabela 4.2 encontram-se os resultados que consistem nas iteradas, erros absolutos (efec-
tivamente cometidos, ou seja, ei = log(2) − xi), quadrados dos erros e o quociente ei+1/e2i .
Tabela 4.2: Método de Newton aplicado à equação ex − 2 = 0.
i xi ei e2i ei+1/e2i
0 4.000000000000000 3.306852819440055 10.93527556943864
1 3.036631277777468 2.343484097217523 5.491917713911429 0.2143049877743342
2 2.132623885130616 1.439476704570670 2.072093183001636 0.2621082069245813
3 1.369675659471521 0.6765284789115756 0.4576907827784102 0.3264952003420792
4 0.8780544396823484 0.1849072591224031 0.03419069447615953 0.4040003995709161
5 0.7092358044493536 0.01608862388940835 2.588438186548411× 10−4 0.4705556332184658
6 0.6932759111785116 1.287306185663306× 10−4 1.657157215647010× 10−8 0.4973293132334301
7 0.6931471888453759 8.285430563859109× 10−9 6.864835962853067× 10−17 0.4999785467321636
Observamos que de facto o quociente ei+1/e2i está a aproximar-se de 0.5, ou seja o método
está a convergir quadraticamente. Na resolução de problemas práticos não temos conhe-
cimento do erro, pois caso contrário não haveria necessidade de utilizar um método de
aproximação, pois não? Contudo, isto leva-nos a acreditar que, sob condições razoáveis, o
método de Newton irá convergir bastante rápido. É de salientar que quando a raiz é múl-
tipla como, por exemplo, quando f(z) = f ′(z) = 0 (raiz dupla), então a convergência do
método de Newton é apenas linear; ver Observação 2 da página 113.
A partir da equação (4.3) podemos suspeitar que existem três situações onde o método de
Newton pode não convergir rapidamente:
1. A aproximação inicial situa-se longe da raiz.
2. A segunda derivada tem um valor muito elevado no ponto ξ.
3. O valor da derivada no ponto xi é próximo de zero.

4.2. MÉTODO DE NEWTON 113
Do ponto de vista teórico, para funções duas vezes continuamente diferenciáveis num in-
tervalo [a; b], f ∈ C2[a; b], existem quatro condições que garantem a convergência quadrática
do método de Newton:
1. f(a)f(b) < 0; existência da raiz em [a; b].
2. f ′(x) 6= 0 para qualquer x ∈ [a; b]; unicidade da raiz em [a; b].
3. f ′′(x) ≥ 0 ou f ′′(x) ≤ 0 para qualquer x ∈ [a; b]; não muda de concavidade.
4. f(x0)f′′(x) ≥ 0 para qualquer x ∈ [a; b]; convergência monótona.
Se |f(a)|/|f ′(a)| < |b − a| e |f(b)|/|f ′(b)| < |b − a| se verificar, então x1 verifica a quarta
condição e o método de Newton converge para qualquer x ∈ [a; b].
Observação 1 Se f for continuamente diferenciável no intervalo [a; b], f ∈ C2[a; b], então podemos con-
cluir a partir da equação (4.3) que
|ei+1| ≤ C|ei|2
onde
C =maxx∈[a;b] |f ′′(x)|
2 minx∈[a;b] |f ′(xi)|
Observação 2 Se f for p vezes continuamente diferenciável num intervalo [a; b], f ∈ Cp[a; b], então
existem duas situações distintas de convergência
1. Se f ′(z) = 0 então a convergência é linear.
2. Se
• f ′(z) 6= 0
• f ′′(z) = f ′′′(z) = . . . = f (p−1)(z) = 0
• f (p)(z) 6= 0
então a convergência é de ordem p.
Este resultado pode ser demonstrado considerando que o método de Newton é um caso particular do mé-
todo do ponto fixo. Na realidade, o método de Newton é um caso particular do método do ponto fixo em
que g(x) = x − f(x)/f ′(x). Sendo assim, podemos aplicar (3.10) e (3.11) para demonstrar a ordem de
convergência do método de Newton quando p ≥ 2.

114 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
Observação 3 Se aplicarmos o método de Newton à equação x2−c = 0, onde c é um número real, obtemos
f(x) = x2 − c e f ′(x) = 2x. Por conseguinte, o processo iterativo vem dado por
xi+1 = xi −x2i − c
2xi= xi −
xi2
+c
2xi=
1
2
(xi +
c
xi
), i = 0, 1, 2, . . .
Este processo iterativo coincide com o método Babilónio (4.1).
4.2.3 Exemplos
Exemplo 24 Considere a equação não linear x2 − 4 sin(x) = 0 no intervalo [1; 3] com x0 = 3 e εabs =
εpasso = 10−6. Atendendo a que f(x) = x2 − 4 sin(x) e f ′(x) = 2x− 4 cos(x), o processo iterativo é:
xi+1 = xi −x2i − 4 sin(xi)
2xi − 4 cos(xi), i = 0, 1, 2, . . .
ou seja, partindo de x0 = 3,
x1 = x0 −x20 − 4 sin(x0)
2x0 − 4 cos(x0)= 3− 32 − 4 sin(3)
(2)(3)− 4 cos(3)= 2.15306
x2 = x1 −x21 − 4 sin(x1)
2x1 − 4 cos(x1)= 2.15306− 2.153062 − 4 sin(2.15306)
(2)(2.15306)− 4 cos(2.15306)= 1.95404
...
Os resultados obtidos por aplicação do método de Newton para encontrar a raiz desta equação encontram-se
na Tabela 4.3 e mostram uma convergência rápida para o zero de uma função que é a soma de um polinómio
de segundo grau e uma função trigonométrica.
Tabela 4.3: Método de Newton aplicado à equação x cos(x)−√x = 0.
i xi f(xi) f ′(xi)
0 3 8.43552 9.95997
1 2.15306 1.29477 6.50577
2 1.95404 0.108439 5.4038
3 1.93397 0.00115163 5.28892
4 1.93375 1.36055× 10−7 5.28767
5 1.93375 2.22045× 10−15 5.28767

4.2. MÉTODO DE NEWTON 115
Exemplo 25 Considere a equação não linear −x3 + 5x = 0 no intervalo [−1; 1] com x0 = 1 e εabs =
εpasso = 10−6. Neste caso, f(x) = −x3 + 5x, ou seja, f ′(x) = −3x2 + 5. Consequentemente, o método tem
a forma
xi+1 = xi −−x3i + 5xi
5− 3x2i, i = 0, 1, 2, . . .
Partindo de x0 = 1, obtém-se
x1 = x0 −−x30 + 5x0
5− 3x20= 1− −13 + (5)(1)
5− (3)(1)2= −1
x2 = x1 −−x31 + 5x1
5− 3x21= −1− −(−1)3 + 5(−1)
5− 3(−1)2= 1
...
Os resultados obtidos por aplicação do método de Newton para encontrar a raiz desta equação encontram-se
na Tabela 4.4.
Tabela 4.4: Método de Newton aplicado à equação 5x− x3.
i xi f(xi) f ′(xi)
0 1 4 2
1 −1 −4 2
2 1 4 2
3 −1 −4 2
4 1 4 2...
......
...
Como se pode observar, o método de Newton não converge nesta situação. O valor da aproximação
inicial está muito longe da raiz e o método entra em ciclo infinito alternando entre x = 1 e x = −1. Na
Figura 4.3 pode observar-se melhor o que está a acontecer. Nela estão representados os pontos x0 e x1, a
função f(x) e as tangentes nos pontos x0 e x1. A aproximação de f(x) utilizando a fórmula de Taylor até à
primeira ordem, em torno do ponto x0 = 1 é
f(x) ≈ f(x0) + f ′(x0)(x− x0) = f(1) + f ′(1)(x− 1) = 4 + 2(x− 1)
se a função tangente 4 + 2(x− 1) aproxima a função f então o zero da função tangente é uma aproximação
do zero da função f . A aproximação de f(x) utilizando a fórmula de Taylor até à primeira ordem, em torno
do ponto x1 = −1 é
f(x) ≈ f(x1) + f ′(x1)(x− x1) = f(−1) + f ′(1)(x+ 1) = −4 + 2(x+ 1)
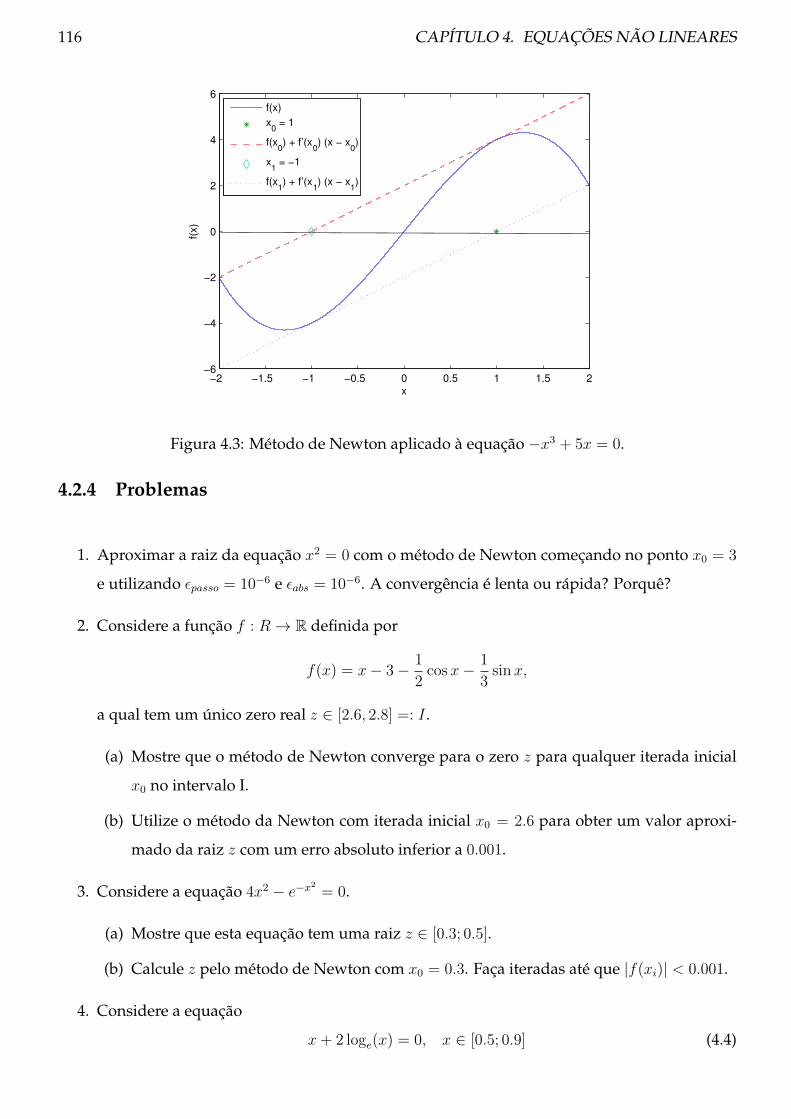
116 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2−6
−4
−2
0
2
4
6
x
f(x)
f(x)
x0 = 1
f(x0) + f’(x
0) (x − x
0)
x1 = −1
f(x1) + f’(x
1) (x − x
1)
Figura 4.3: Método de Newton aplicado à equação −x3 + 5x = 0.
4.2.4 Problemas
1. Aproximar a raiz da equação x2 = 0 com o método de Newton começando no ponto x0 = 3
e utilizando εpasso = 10−6 e εabs = 10−6. A convergência é lenta ou rápida? Porquê?
2. Considere a função f : R→ R definida por
f(x) = x− 3− 1
2cosx− 1
3sinx,
a qual tem um único zero real z ∈ [2.6, 2.8] =: I .
(a) Mostre que o método de Newton converge para o zero z para qualquer iterada inicial
x0 no intervalo I.
(b) Utilize o método da Newton com iterada inicial x0 = 2.6 para obter um valor aproxi-
mado da raiz z com um erro absoluto inferior a 0.001.
3. Considere a equação 4x2 − e−x2 = 0.
(a) Mostre que esta equação tem uma raiz z ∈ [0.3; 0.5].
(b) Calcule z pelo método de Newton com x0 = 0.3. Faça iteradas até que |f(xi)| < 0.001.
4. Considere a equação
x+ 2 loge(x) = 0, x ∈ [0.5; 0.9] (4.4)

4.3. MÉTODO DA SECANTE 117
(a) Prove que o método de Newton aplicado à equação (4.4) converge.
(b) Mostre que o método de Newton aplicado à equação (4.4) se pode escrever na forma:
xn+1 =2xn(1− loge(xn))
xn + 2(4.5)
(c) Sabendo que neste caso
|en| ≤ K1/(1−p)p
(|e0|K1/(p−1)
p
)pn,
onde p é a ordem de convergência do método, obtenha Kp e faça o menor número de
iteradas até que o método de Newton forneça uma aproximação xn tal que |en| < 10−3.
(d) Relativamente ao método (4.5) diga, justificando, qual o valor do limite
limn→∞
|z − xn+1||z − xn|2
Simplifique a expressão desse limite o mais possível e dê uma estimativa para esse
limite.
5. Mostre que o método de Newton diverge para a função f(x) = 7x4 + 3x2 + π, qualquer que
seja a aproximação inicial escolhida.
6. Mostre que o método de Newton diverge para a função f(x) = x2 + 1, qualquer que seja a
aproximação inicial escolhida.
7. Considere a função iteradora
g(x) =x cos(x)− sin(x) + 0.5
cos(x),
ou seja, o método de Newton aplicado à equação sin(x) − 0.5 = 0. Obtenha seis iteradas
utilizando as seguintes aproximações iniciais relativamente próximas: x0 = 0.5 e x0 = 1.5.
Compare a alteração de resultados quando muda de um valor inicial para outro.
4.3 Método da secante
Dada uma curva, a secante é a linha que passa por dois pontos dessa curva. O método da
secante é uma das técnicas para encontrar o zero de uma função real de variável real quando não
existe informação alguma sobre as derivadas da função.
Bases Secção 3.3 e Capítulo 8.
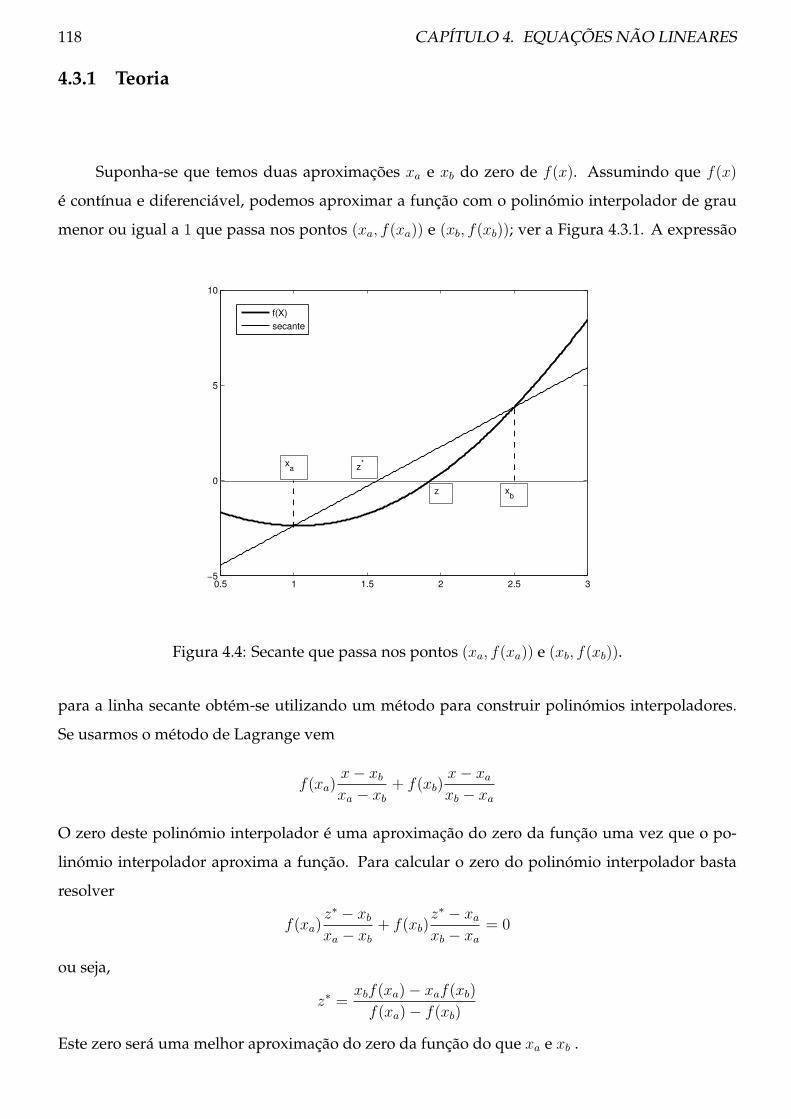
118 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
4.3.1 Teoria
Suponha-se que temos duas aproximações xa e xb do zero de f(x). Assumindo que f(x)
é contínua e diferenciável, podemos aproximar a função com o polinómio interpolador de grau
menor ou igual a 1 que passa nos pontos (xa, f(xa)) e (xb, f(xb)); ver a Figura 4.3.1. A expressão
0.5 1 1.5 2 2.5 3−5
0
5
10
f(X)
secante
xa
xb
z
z*
Figura 4.4: Secante que passa nos pontos (xa, f(xa)) e (xb, f(xb)).
para a linha secante obtém-se utilizando um método para construir polinómios interpoladores.
Se usarmos o método de Lagrange vem
f(xa)x− xbxa − xb
+ f(xb)x− xaxb − xa
O zero deste polinómio interpolador é uma aproximação do zero da função uma vez que o po-
linómio interpolador aproxima a função. Para calcular o zero do polinómio interpolador basta
resolver
f(xa)z∗ − xbxa − xb
+ f(xb)z∗ − xaxb − xa
= 0
ou seja,
z∗ =xbf(xa)− xaf(xb)
f(xa)− f(xb)
Este zero será uma melhor aproximação do zero da função do que xa e xb .

4.3. MÉTODO DA SECANTE 119
4.3.2 Procedimento
Problema Dada uma função de uma variável, f(x), encontrar um valor z (denominada raiz) tal
que f(z) = 0.
Hipóteses Iremos assumir que a função f(x) é contínua e tem a sua primeira derivada contínua.
Ferramentas Iremos utilizar amostragem, interpolação e iteração.
Requisitos iniciais Temos de ter duas aproximações iniciais da raiz, x−1 e x0.
Processo iterativo Dadas duas aproximações xi−1 e xi da raiz, a aproximação seguinte obtém-se
através de
xi+1 = xi − f(xi)xi − xi−1
f(xi)− f(xi−1)(4.6)
Condições de paragem Existem três condições que podem originar a paragem do processo itera-
tivo que passo a descrever.
1. Se ambas as condições seguintes de verificarem:
• A distância entre iteradas sucessivas é suficientemente pequena, isto é, |xi+1−xi| <
εpasso.
• O valor da função calculado no ponto xi+1 é suficientemente pequeno, ou seja,
|f(c)| < εabs.
2. Se o denominador é zero, o processo iterativo pára devido à divisão por zero.
3. Se o número máximo de iterações foi atingido e a condição 1 não se verificou; neste
caso, o processo pára e indicamos que a raiz não foi encontrada.
Se o processo termina devido à verificação da condição 1, então considera-se que xi+1 é a
nossa aproximação da raiz. Se, por outro lado, o processo pára porque se verificou, ou a
condição 2, ou a condição 3, então devemos escolher aproximações iniciais novas x−1 e x0,
ou considerar a possibilidade de a solução não existir.
Análise do erro Pode demonstrar-se que a ordem de convergência, do método da secante, para
aproximar um zero simples é melhor que linear e pior que quadrática (Pizer,1975), mais
precisamente,
p =1 +√
5
2≈ 1.61803398875
Também se demonstra que
ei+1 = − f ′′(ξi)
2f ′(ηi)ei−1ei, ηi ∈ int(xi−1, xi), ξi ∈ int(xi−1, xi, z)

120 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
4.3.3 Exemplos
Exemplo 26 Considere a equação não linear x2 − 4 sin(x) = 0 no intervalo [1; 3] com x−1 = 1, x0 = 3 e
εabs = εpasso = 10−6. Aplicando a equação (4.6) obtém-se
x1 = x0 − f(x0)x0 − x−1
f(x0)− f(x−1)
= 3− f(3)3− 1
f(3)− f(1)= 1.43807
x2 = x1 − f(x1)x1 − x0
f(x1)− f(x0)
= 1.43807− f(1.43807)1.43807− 3
f(1.43807)− f(3)= 1.72480
...
Os resultados obtidos por aplicação do método da secante para encontrar a raiz desta equação en-
contram-se na Tabela 4.5 e mostram uma convergência rápida para o zero de uma função que é a soma
de um polinómio de segundo grau e uma função trigonométrica. A raiz da equação é aproximadamente
z = 1.933753761658434.
Tabela 4.5: Método da secante aplicado à equação x2 − 4 sin(x) = 0.
i xi f(xi)
−1 1 −2.36588
0 3 8.43552
1 1.43807 −1.89677
2 1.72480 −0.977706
3 2.02983 0.534304
4 1.92204 −0.0615226
5 1.93317 −0.00306453
6 1.93376 1.96318× 10−5
7 1.93375 −6.1791× 10−9
5 1.93317 −0.00306453

4.4. MÉTODO DO PONTO FIXO 121
4.3.4 Problemas
1. Considere a equação
f(x) = x tan(x)− 1 = 0,
Aplicando o método da secante, obtenha as três primeiras iteradas para o cálculo da raiz
situada no intervalo [0.8, 0.9]. Determine um majorante do erro do resultado obtido.
2. Considere a equação não linear
x2 − loge(x)− 2 = 0
a qual tem uma e uma só raiz no intervalo [1; 2].
(a) Mostre que o método da secante, com iteradas iniciais x−1 = 1.8 e x0 = 2.0, converge
para z.
(b) Calcule um valor aproximado de z efectuando duas iterações do método da secante,
tomando para iteradas iniciais x−1 = 1.8 e x0 = 2.0.
(c) Considere a sucessão definida por
xn+1 =2 + loge(xn)
xn, n = 0, 1, 2, . . .
cujos primeiros termos são
1.6, 1.54375, 1.57682, 1.55719, 1.56878, 1.56191, 1.56597, 1.56357, . . .
Com base nestes resultados obtenha um majorante de |z − 1.56357|.
4.4 Método do ponto fixo
O método do ponto fixo geral foi apresentado na Secção 3.3. Ele pode ser aplicado à reso-
lução de equações não lineares desde que se encontre uma função iteradora g(x) tal que os zeros
da função f(x) coincidam com os pontos fixos da função g(x), ou seja, desde que se verifique a
equivalência
f(x) = 0⇐⇒ x = g(x)
Neste contexto, dada uma função f(x) existem funções iteradoras que dão origem a métodos
convergentes e outras a divergentes. Também a mesma função iteradora pode funcionar bem
para aproximar uma raiz e funcionar mal quando se tenta aproximar outra. Mesmo quando se
observa convergência em duas situações com a mesma função iteradora g(x), a velocidade de
convergência pode não ser a mesma.

122 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
4.4.1 Problemas
1. Considere a equação 4x2 − e−x2 = 0.
(a) Mostre que esta equação tem duas raízes z1 ∈ [−0.5;−0.3] e z2 ∈ [0.3; 0.5].
(b) Mostre que o método iterativo
xi+1 =1
2e−x
2i /2 (4.7)
converge para z2 para qualquer x0 ∈ [0; 0.5]. Calcule duas iteradas por este método.
(c) Mostre que g′(z2) = −z22 . Qual é a ordem de convergência do método (4.7)? Sem
calcular iteradas, dê uma estimativa para o erro associado à iterada x5, qualquer que
seja x0 ∈ [0; 0.5]
2. Considere o conjunto de sucessões
xn+1 =1 + αxn − sin(xn)
1 + α(4.8)
com n = 0, 1, . . . e onde α pertence ao conjunto dos números reais, α 6= −1.
(a) Seja α = 2. Com base no teorema do ponto fixo, mostre que a sucessão (4.8) converge
para z (número real), qualquer que seja a aproximação inicial x0 pertencente ao inter-
valo [0; 1]. Diga qual é a ordem de convergência deste método.
(b) Escolha α de modo que o método tenha a maior ordem possível. Qual é a ordem neste
caso?
(c) Considere α = 2 e x0 = 0. Sem calcular iterações, determine o valor de k tal que
|z − xk| < 10−4.
(d) Com base da alínea (a) justifique que a sucessão converge para a única raiz da equação
f(x) = 0 em [0; 1], onde f(x) = sin(x) + x − 1, para qualquer aproximação x0 naquele
intervalo.
3. Deseja-se efectuar o cálculo de 1e, ou seja, encontrar x tal que
1
x= e
(a) Justifique que esse cálculo pode ser aproximado através da sucessão
xn+1 = xn(2− exn)
e indique que valores de x0 pode usar.

4.4. MÉTODO DO PONTO FIXO 123
(b) Classifique a sucessão xn quanto à monotonia e indique a ordem da sua convergência.
(c) Obtenha uma estimativa do erro absoluto da quarta iterada x4 assumindo que o erro
absoluto de z − x0 é inferior a 0.1.
4. Para determinar a raiz z ∈ [4; 5] da equação x3 − 6x2 + 9x − 5 = 0 considerou-se o método
iterativo xn+1 = g(xn) com função iteradora:
g(x) = −x3 + 6x2 − 8x+ 5
Na tabela seguinte encontram-se alguns dos resultados obtidos para o método iterativo.
Com base nestes resultados, o que pode concluir em relação à convergência do método?
Justifique teoricamente.
n 0 1 2 3 4 5
xn 4 5 −10 1685 −4.7671× 109 1.0833× 1029
5. (a) Mostre que o método do ponto fixo definido por
x0 = 1, xi+1 = exi/4 − 0.2 (4.9)
converge para z ∈ [1; 2].
(b) Mostre que as raízes da equação
ex/2 − (x+ 0.2)2 = 0 (4.10)
coincidem com os pontos fixos da função iteradora associada ao método do ponto fixo
(4.9).
(c) Justifique que o método (4.9) converge para a raiz da equação (4.10).
(d) Obtenha uma iterada pelo método (4.9).
(e) Qual o número mínimo de iterações para garantir que |z−xi| < ε, com ε > 0? Justifique.
(f) Será que se, em vez de x0 = 1, considerarmos x0 = 8 o método converge para a raiz
z ∈ [8; 9]. Justifique.
6. Considere a equação x = −2 loge(x), x > 0.
(a) Mostre que existe uma solução, z única da equação no intervalo [0.6; 0.9].
(b) Justificando a convergência, aplique o método do ponto fixo para obter um valor apro-
ximado de z com duas iteradas partindo de 0.6.

124 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES
(c) Quantas iteradas são necessárias para obter um erro inferior a 10−4? (utilize um sistema
V F (3,−3, t1, t2)).
7. Prove que a sucessão, definida por recorrência,
xn+1 = xn −exn − 0.5x2n − xn − 1
exn − xn − 1, x0 = 0.1
converge para zero. Classifique a sucessão quanto à monotonia.
4.4.2 Aceleração do método de Newton para zeros múltiplos
O método de Newton é um caso particular do método do ponto fixo em que
g(x) = x− f(x)
f ′(x)(4.11)
Calculando a primeira derivada de g na raiz vem
g′(z) =f(z)f ′′(z)
(f ′(z))2
Uma vez que f(z) = 0 temos de pensar em duas situações: f ′(z) = 0 e f ′(z) 6= 0.
Se f ′(z) 6= 0, então g′(z) = 0 e o método tem pelo menos convergência quadrática. Neste
caso, ao calcular a segunda derivada da função g na raiz obtemos
g′′(z) =f ′′(z)
f ′(z)
Ou seja, o caso mais comum em que a função tem um zero simples f ′(z) = 0 e não muda de
concavidade na raiz f ′′(z) 6= 0, o método de Newton converge com convergência quadrática.
Se f ′(z) = 0, então suponhamos que a função tem um zero de multiplicidade M . Neste caso
f(z) = f ′(z) = . . . = f(z)(M−1) = 0 e f(z)(M) 6= 0, ou seja, f(x) = (x − z)Mh(x) com h(z) 6= 0 e
h contínua em z. Consequentemente, substituindo f ′(x) = (x − z)Mh′(x) + M(x − z)M−1h(x) em
(4.11) obtemos
g(x) = x− (x− z)h(x)
(x− z)h′(x) +Mh(x)
e a derivada de g é dada por
g′(x) = 1− h(x)
(x− z)h′(x) +Mh(x)− (x− z)
d
dx
[h(x)
(x− z)h′(x) +Mh(x)
]Por conseguinte,
g′(z) = 1− 1
M(4.12)

4.4. MÉTODO DO PONTO FIXO 125
Concluímos que no caso em que o zero da função é múltiplo, o método de Newton converge com
convergência linear; o coeficiente assimptótico de convergência é (M − 1)/M , ou seja,
|ei+1| ≈M − 1
M|ei|
Para acelerar a convergência do método de Newton, a ideia é considerar uma função
g(x) = x− Mf(x)
f ′(x)
porque, neste caso, a primeira derivada de g não se anula na raiz; para verificar que g′(z) 6= 0
basta repetir o procedimento que nos levou a (4.12). Partindo da aproximação inicial x0, o método
correspondente será
xi+1 = xi −Mf(xi)
f ′(xi), i = 0, 1, . . .
Este método tem convergência quadrática.

126 CAPÍTULO 4. EQUAÇÕES NÃO LINEARES

Capítulo 5
Sistemas lineares
Existem dois tipos de métodos para resolver sistemas lineares que passo a descrever.
1. Métodos directos. Estes métodos conduzem directamente a uma solução do problema (se
ela existir) num número finito de operações. Na ausência de erros de arredondamento, eles
conduzem à solução exacta. Exemplos destes métodos são:
• método de eliminação de Gauss;
• método de Cholesky.
2. Métodos iterativos. Estes métodos tentam resolver um problema através da descoberta de
aproximações sucessivas da solução, começando com uma aproximação inicial da solução.
Exemplos destes métodos são:
• método de Jacobi;
• método de Gauss-Seidel.
Os métodos iterativos têm a grande vantagem de geralmente serem estáveis e, à medida
que o processo continua, alguns erros (devido aos arredondamentos) vão perdendo o seu peso.
Neste capítulo, iremos ver algumas desvantagens do método de eliminação de Gauss, tais como
lentidão e instabilidade numérica. Os métodos iterativos são geralmente a única escolha para
resolver equações (e sistemas) não lineares. Contudo, os métodos iterativos são frequentemente
úteis para resolver sistemas de equações lineares que envolvem um grande número de variáveis.
Quando o número de variáveis é grande, às vezes da ordem dos milhares, os métodos directos
tornam-se proibitivos porque são computacionalmente dispendiosos. Os métodos iterativos têm
127

128 CAPÍTULO 5. SISTEMAS LINEARES
vantagens significativas face aos métodos directos em termos de rapidez e memória necessária
que é precisa para resolver o problema. Frequentemente, em engenharia, as exigências de precisão
não são exageradas e consegue-se ter uma boa aproximação da solução com um número pequeno
de iterações. Quando a matriz do sistema é esparsa (possui um grande número de elementos
cujo valor é zero) é comum os métodos iterativos serem muito eficientes; em geral, guardam-se
os elementos da matriz num formato esparso ou então nem é preciso guardar a matriz.
5.1 Valores e vectores próprios
Os vectores próprios de uma matriz quadrada são os vectores não nulos que, após multi-
plicados pela matriz, mantêm-se proporcionais ao vector original; ou seja, a alteração que sofrem
é apenas em comprimento e não em direcção. Para cada vector próprio, o valor próprio cor-
respondente é o factor pelo qual o vector próprio é alterado quando multiplicado pela matriz.
Matematicamente diz-se que, um vector v é um vector próprio da matriz A com valor próprio λ
se
Av = λv (5.1)
O espaço próprio de A é o conjunto de todos os vectores próprios de A e também o vector zero
(o vector zero não é um vector próprio).
Os valores próprios e vectores próprios estão relacionados com os conceitos de vectores
e transformações lineares. Grosso modo, podemos pensar nos vectores como sendo setas que
têm comprimento e direcção. Habitualmente, quando se multiplica um vector por uma matriz
quadrada, esse vector sofre alteração no seu comprimento e direcção. Quando o vector só sofre
alteração no seu comprimento, então dizemos que ele é um vector próprio. O valor próprio
correspondente é o factor pelo qual o seu comprimento é alterado.
Um caso especial é o da matriz identidade que não altera o vector qualquer que ele seja:
Iv = λv. Qualquer vector diferente de zero tem valor próprio igual a um associado à matriz
identidade.
Como calcular os valores próprios? Dada a matriz quadrada A, pretendemos descobrir um
polinómio cujas raízes coincidam com os valores próprios de A. Este polinómio é chamado o

5.1. VALORES E VECTORES PRÓPRIOS 129
polinómio característico. Se a matriz A for diagonal, A = diag(a11, a22, . . . , ann), o polinómio
característico define-se como
p(λ) = (λ− a11)(λ− a22) . . . (λ− ann)
Ou seja, os valores próprios de uma matriz diagonal coincidem com as entradas da diagonal
principal.
Para uma matriz quadrada genérica podemos descobrir os valores próprios do seguinte
modo. Um número real λ é um valor próprio de A se e só se existe um vector próprio v 6= 0 tal
que a equação (5.1) se verifica. Ou seja, tal que
(λI−A)v = 0 (5.2)
onde I é a matriz identidade.
Uma vez que v não é zero, então a equação (5.2) é equivalente a dizer que a matriz λI −A
é singular (não invertível), ou seja, o seu determinante é zero. Consequentemente, as raízes da
equação
det(λI−A) = 0
são os valores próprios da matriz A. Este determinante é um polinómio em λ.
Exemplo 27 Com a matriz
A =
2 1
3 4
obtém-se
det
2− λ 1
3 4− λ
= (2− λ)(4− λ)− 3 = λ2 − 6λ+ 5
As raízes do polinómio característico, ou seja os valores próprios, são
λ1 =6 +√
36− 4× 1× 5
2× 1= 5 e λ2 =
6−√
36− 4× 1× 5
2× 1= 1
Em Matlab podemos utilizar a função eig para retornar os valores próprios de uma matriz.
As instruções:
A = rand( 3 ) % cria uma matriz 3 x 3 contendo
% números pseudo-aleatórios entre zero e um.
vp = eig( A )
max( eig( M ) ) % cálcula o máximo dos valores próprios

130 CAPÍTULO 5. SISTEMAS LINEARES
retornam
A = 2.5510e-001 8.9090e-001 1.3862e-001
5.0596e-001 9.5929e-001 1.4929e-001
6.9908e-001 5.4722e-001 2.5751e-001
vp = 1.5040e+000
-1.7054e-001
1.3841e-001
ans = 1.3665e+000
5.2 Normas
Para discutir métodos para resolver sistemas lineares, temos de ser capazes de calcular o
erro relativo da solução de um sistema linear, o erro relativo de uma matriz ou de um vector.
Nos métodos iterativos também temos de saber medir a distância entre vectores para observar se
a sucessão de vectores está a convergir para a solução exacta do sistema. Para isso, precisamos
de uma versão equivalente do módulo no conjunto dos números reais. Seja Rn o conjunto dos
vectores coluna n dimensionais com coeficientes reais. Para definir uma distância em Rn usamos
a noção de norma.
Bases: Secção 5.1.
5.2.1 Teoria
Uma norma vectorial em Rn é uma função, ‖ · ‖ de Rn em R com as seguintes propriedades:
1. ‖x‖ ≥ 0 para todo o x ∈ Rn;
2. ‖x‖ = 0 se e só se x = 0;
3. ‖αx‖ = |α|‖x‖ para todo α ∈ R e x ∈ Rn;
4. ‖x + y‖ ≤ ‖x‖+ ‖y‖ para todo x, y ∈ Rn.
As normas que iremos utilizar definem-se do seguinte modo:
• Norma 1, ‖x‖1 =∑n
i=1 |xi|.
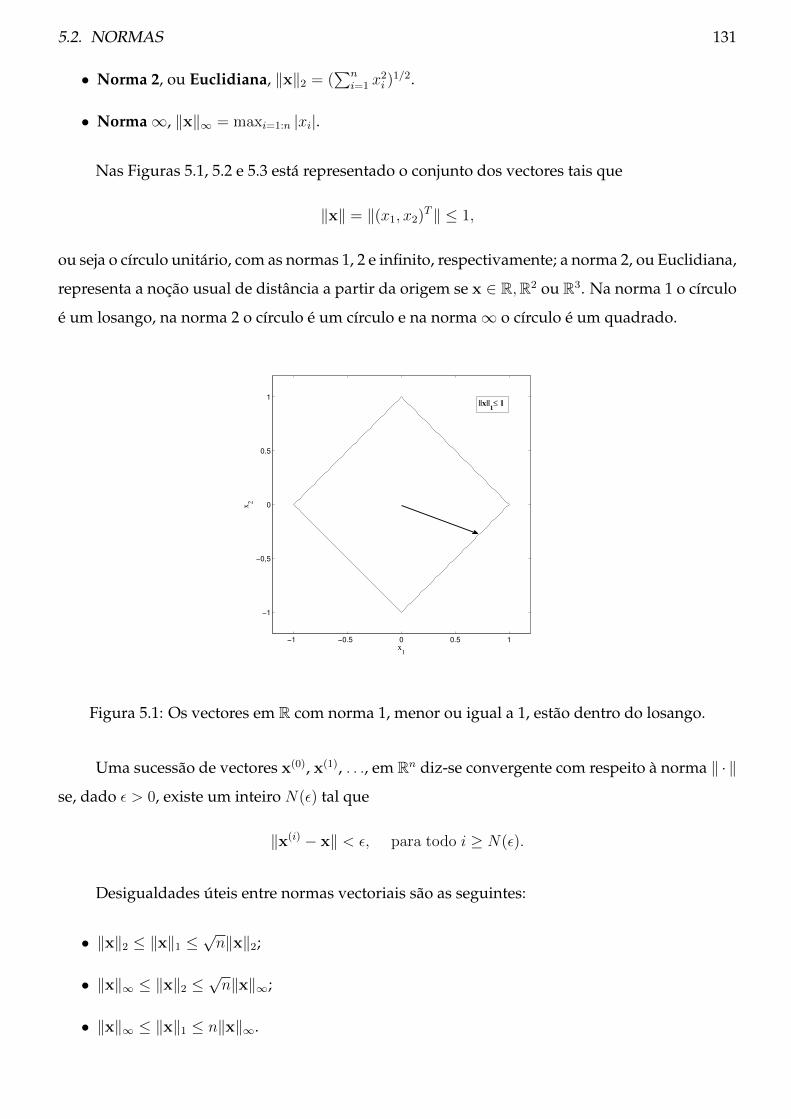
5.2. NORMAS 131
• Norma 2, ou Euclidiana, ‖x‖2 = (∑n
i=1 x2i )
1/2.
• Norma∞, ‖x‖∞ = maxi=1:n |xi|.
Nas Figuras 5.1, 5.2 e 5.3 está representado o conjunto dos vectores tais que
‖x‖ = ‖(x1, x2)T‖ ≤ 1,
ou seja o círculo unitário, com as normas 1, 2 e infinito, respectivamente; a norma 2, ou Euclidiana,
representa a noção usual de distância a partir da origem se x ∈ R,R2 ou R3. Na norma 1 o círculo
é um losango, na norma 2 o círculo é um círculo e na norma∞ o círculo é um quadrado.
−1 −0.5 0 0.5 1
−1
−0,5
0
0.5
1
x1
x2
||x||1≤ 1
Figura 5.1: Os vectores em R com norma 1, menor ou igual a 1, estão dentro do losango.
Uma sucessão de vectores x(0), x(1), . . ., em Rn diz-se convergente com respeito à norma ‖ · ‖
se, dado ε > 0, existe um inteiro N(ε) tal que
‖x(i) − x‖ < ε, para todo i ≥ N(ε).
Desigualdades úteis entre normas vectoriais são as seguintes:
• ‖x‖2 ≤ ‖x‖1 ≤√n‖x‖2;
• ‖x‖∞ ≤ ‖x‖2 ≤√n‖x‖∞;
• ‖x‖∞ ≤ ‖x‖1 ≤ n‖x‖∞.
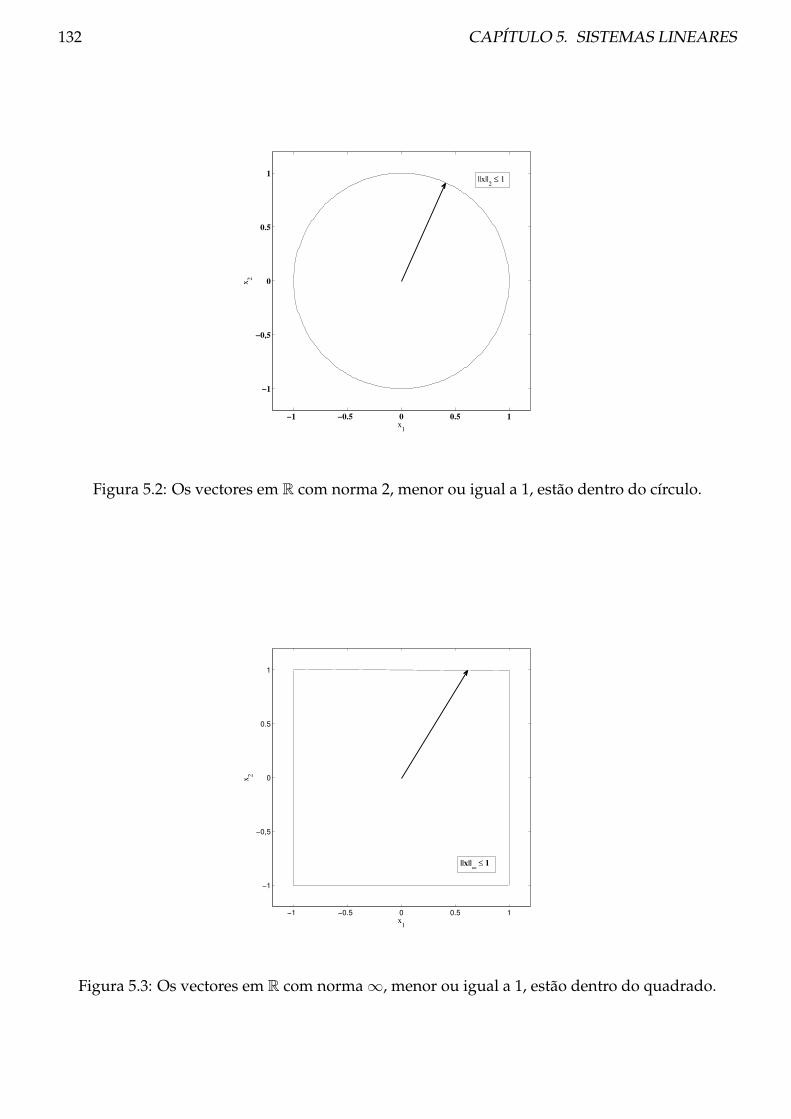
132 CAPÍTULO 5. SISTEMAS LINEARES
−1 −0.5 0 0.5 1
−1
−0,5
0
0.5
1
x1
x2
||x||2 ≤ 1
Figura 5.2: Os vectores em R com norma 2, menor ou igual a 1, estão dentro do círculo.
−1 −0.5 0 0.5 1
−1
−0,5
0
0.5
1
x1
x2
||x||∞
≤ 1
Figura 5.3: Os vectores em R com norma∞, menor ou igual a 1, estão dentro do quadrado.

5.2. NORMAS 133
Seja Rm×n o espaço vectorial contendo todas as matrizes com m linhas e n colunas com
entradas em R. Uma norma matricial no conjunto de todas as matrizes m× n é uma função, ‖ · ‖,
definida neste conjunto, tal que para todas as matrizes A e B e α ∈ R se verifica:
1. ‖A‖ ≥ 0;
2. ‖A‖ = 0 se e só se A = 0;
3. ‖αA‖ = |α|‖A‖;
4. ‖A + B‖ ≤ ‖A‖+ ‖B‖;
5. ‖AB‖ ≤ ‖A‖‖B‖.
Se ‖ · ‖ é uma norma vectorial em Rn, então
‖A‖ = max‖x‖=1
‖Ax‖
é uma norma matricial. A esta norma dá-se o nome de norma natural ou norma matricial induzida
pela norma vectorial.
Uma vez que para qualquer z 6= 0, temos x = z/‖z‖ com ‖x‖ = 1, então
‖A‖ = max‖x‖=1
‖Ax‖ = maxz 6=0‖Az/‖z‖‖ = max
z 6=0
‖Az‖‖z‖
Por conseguinte,
‖Az‖ ≤ ‖A‖ ‖z‖
Pode demonstrar-se que as normas matriciais induzidas pelas normas vectoriais 1, 2 e∞ se
podem escrever na seguinte forma:
• Norma 1, ‖A‖1 = maxj=1:n
∑ni=1 |aij|.
• Norma 2, ou Euclidiana, ‖x‖2 = [ρ(ATA)]1/2.
• Norma∞, ‖A‖∞ = maxi=1:n
∑nj=1 |aij|.
onde ρ(ATA) representa o raio espectral da matriz ATA.
O raio espectral está muito relacionado com a norma de uma matriz. Se a matriz for qua-
drada, então

134 CAPÍTULO 5. SISTEMAS LINEARES
1. para qualquer norma matricial
ρ(A) ≤ ‖A‖
2. para qualquer ε > 0 existe sempre uma norma tal que
‖A‖ ≤ ρ(A) + ε
ou seja, para qualquer matriz A e qualquer ε > 0, existe uma norma natural tal que:
ρ(A) ≤ ‖A‖ ≤ ρ(A) + ε (5.3)
Por conseguinte, ρ(A) é o maior limite inferior para as normas naturais de A (ínfimo do conjunto
das normas da matriz A).
Se a matriz for simétrica, então
‖A‖2 = ρ(A)
Desigualdades úteis entre normas vectoriais são as seguintes:
• 1√n‖A‖∞ ≤ ‖A‖2 ≤
√m‖A‖∞;
• 1√m‖A‖1 ≤ ‖A‖2 ≤
√n‖A‖1.
• ‖A‖2 ≤√‖A‖1‖A‖∞;
Exemplo 28 Considere o vector x = (1,−3,−7)T . Como os vectores em Rn são vectores coluna, é conve-
niente usar a notação x = (x1, x2, . . . , xn)T , onde a notação T significa transposto. As normas 1, 2 e ∞
deste vector são respectivamente
• ‖x‖1 = |1|+ | − 3|+ | − 7| = 11.
• ‖x‖2 = 12 + (−3)2 + (−7)2 = 59.
• ‖x‖∞ = max(|1|, | − 3|, | − 7|) = 7.
Em Matlab podemos calcular estas normas através das seguintes instruções:
• Norma 1.
norma1 = norm([1 -3 -7],1)
ou então

5.2. NORMAS 135
norma1 = sum( abs( [1 -3 -7] ) )
o retorno é
norma1 = 11
• Norma 2.
norma2 = norm([1 -3 -7],2)
ou então
norma2 = norm([1 -3 -7])
ou
norma2 = sqrt(sum([1 -3 -7].^2))
o retorno é
norma2 = 7.6811
• Norma∞.
norma_inf = norm([1 -3 -7],inf)
ou então
norma_inf = max( abs( [1 -3 -7] ) )
o retorno é
norma_inf = 7
Considere a matriz
A =
1 −3 −7
2 5 −1
−4 6 8
Em Matlab podemos escrever
a = [1 -3 -7; 2 5 -1; -4 6 8]
o retorno é

136 CAPÍTULO 5. SISTEMAS LINEARES
a = 1 -3 -7
2 5 -1
-4 6 8
As normas 1, 2 e∞ desta matriz são respectivamente
• ‖A‖1 = max(|1|+ |2|+ | − 4|, | − 3|+ |5|+ |6|, | − 7|+ | − 1|+ |8|) = max(7, 14, 16) = 16;
• ‖A‖2 = (ρ(ATA))1/2 = 13.1190; neste caso temos
ATA =
21 −17 −41
−17 70 64
−41 64 114
Para calcular os valores próprios de ATA resolvemos a equação
det(ATA− λI3) = 0
em ordem a λ e obtemos
λ1 = 4.0642 ∨ λ2 = 28.8268 ∨ λ3 = 172.1090
Por conseguinte,
‖A‖2 = (ρ(ATA))1/2 = (max(|4.0642|, |28.8268|, |172.1090|))1/2 = 13.1190
• ‖A‖∞ = max(|1|+ | − 3|+ | − 7|, |2|+ |5|+ | − 1|, | − 4|+ |6|+ |8|) = max(11, 8, 18) = 18;
onde ρ(ATA) é denominado o raio espectral da matriz ATA e define-se como o maior valor próprio em
módulo de ATA.
Em Matlab podemos calcular estas normas através das seguintes instruções:
• Norma 1.
norma1 = max( sum( abs( a ) ) )
ou então
norma1 = norm( a, 1 )
o retorno é

5.2. NORMAS 137
norma1 = 16
• Norma 2.
norma2 = norm( a, 2 )
ou então
norma2 = sqrt( max( abs( eig(a’*a) ) ) )
o retorno é
norma2 = 13.1190
A instrução eig(a’*a) retorna um vector coluna contento os valores próprios de A.
• Norma∞.
norma_inf = max( sum( abs( a’ ) ) )
ou então
norma_inf = norm( a, inf )
o retorno é
norma_inf = 18
5.2.2 Problemas
1. Calcule as normas 1, 2 e∞ dos seguintes vectores:
x = (−2, 0, 1)T , y = (6, 3,−5, 8)T , z = (2,−3, 4, 1,−7)T
2. Calcule as normas 1, 2 e∞ das seguintes matrizes:
A =
2 5 −3
0 −1 8
−2c 1 4
, B =
6 5 −2
3 1 3c2
−3c −5 4
, C =
−1 4 3 7
0 10 0 9
2 8 −6 5
1 −2 3 0

138 CAPÍTULO 5. SISTEMAS LINEARES
5.3 Número de condição
O número de condição mede a sensibilidade da solução de um sistema de equações lineares
a erros nos dados. Ele dá uma indicação acerca dos resultados da inversão da matriz e da solu-
ção do sistema. Valores do número de condição próximos de 1 indicam que uma matriz é bem
condicionada. Por outras palavras, o número de condição é uma medida de quanto uma matriz
está próxima de ser uma matriz singular. Isto é relevante, por exemplo, na regressão linear onde
a proximidade singular significa que os dados são aproximadamente colineares. Quando a ma-
triz é aproximadamente singular é difícil obter uma matriz inversa precisa e os valores estimados
podem vir afectados de erros elevados.
O número de condição de uma matriz define-se por
det(A) = ‖A‖‖A−1‖ (5.4)
O número de condição de uma matriz não invertível é definido com∞.
Vimos anteriormente que ‖AB‖ ≤ ‖A‖‖B‖. Consequentemente,
det(AB) = ‖AB‖‖(AB)−1‖
= ‖AB‖‖B−1A−1‖
≤ ‖A‖‖B‖‖B−1‖‖A−1‖
= ‖A‖‖A−1‖‖B‖‖B−1‖
= det(A)det(B)
Consequentemente, mudar de escala de uma matriz ou multiplicá-la por uma matriz de rotação
não afecta o número de condição. Outra propriedade do número de condição é o seguinte:
1 = ‖In‖ = ‖AA−1‖ ≤ ‖A‖‖A−1‖ = det(A)
ou seja, dada uma matriz A de dimensão n× n o número de condição é sempre igual ou superior
a 1:
det(A) ≥ 1
5.3.1 Análise do erro
Nesta subsecção ir-se-ão apresentar relações entre os erros relativos nos dados e os erros
relativos nos resultados. Considere-se o sistema
Ax = b

5.3. NÚMERO DE CONDIÇÃO 139
em que A é uma matriz invertível n × n. Supondo que não sabíamos o vector b exacto, mas
tínhamos uma aproximação dele, b. Então iríamos obter um vector aproximado que é solução do
sistema
Ax = b
Os erros associados a esta aproximação x são definidos como se segue.
• Erro absoluto de x: ‖ex‖ = ‖x− x‖.
• Erro relativo de x: ‖δx‖ = ‖x− x‖/‖x‖.
Uma vez que A é uma matriz invertível, e utilizando uma norma vectorial e a norma matri-
cial por ela induzida, podemos escrever
‖x− x‖ = ‖A−1b−A−1b‖
= ‖A−1(b− b)‖
≤ ‖A−1‖‖b− b‖
Isto dá uma medida da perturbação em x devido à perturbação existente em b.
Para estimar a perturbação relativa em x procedemos do seguinte modo:
‖x− x‖ ≤ ‖A−1‖‖b− b‖
= ‖A−1‖‖b‖‖b− b‖‖b‖
= ‖A−1‖‖Ax‖‖b− b‖‖b‖
≤ ‖A−1‖‖A‖‖x‖‖b− b‖‖b‖
ou seja,‖x− x‖‖x‖
≤ ‖A−1‖‖A‖‖b− b‖‖b‖
ou então, como det(A) = ‖A‖‖A−1‖ (ver 5.4), podemos escrever
‖x− x‖‖x‖
≤ det(A)‖b− b‖‖b‖
ou seja,
‖δx‖ ≤ det(A)‖δb‖ (5.5)
Podemos portanto observar que à medida que o número de condição aumenta a majoração do
erro relativo vai ficando cada vez pior. Quando o número de condição é elevado, um pequeno
erro relativo no vector b pode provocar um grande erro relativo na solução do sistema linear.

140 CAPÍTULO 5. SISTEMAS LINEARES
Também podemos observar que
‖b− b‖‖x‖ = ‖A(x− x)‖‖A−1b‖
≤ ‖A‖‖x− x‖‖A−1‖‖b‖
ou seja,
‖b− b‖‖x‖ ≤ det(A)‖x− x‖‖b‖
e por conseguinte, vem o limite inferior para o erro relativo de x em relação a x,
1
det(A)
‖b− b‖‖b‖
≤ ‖x− x‖‖x‖
(5.6)
Combinando (5.5) com (5.6), dado um erro relativo em b, podemos obter a variação possível para
o erro relativo da solução.1
det(A)‖δb‖ ≤ ‖δx‖ ≤ det(A)‖δb‖
Também pode ser demonstrado que
‖x− x‖‖x‖
≤ det(A)
1− ‖A−1(A− A)‖
(‖b− b‖‖b‖
+‖A− A‖‖A‖
)(5.7)
onde A é a matriz perturbada de A. Uma vez que
‖A−1(A− A)‖ ≤ ‖A−1‖‖A− A‖
temos
1− ‖A−1(A− A)‖ ≥ ‖A−1‖‖A− A‖
Multiplicando e dividindo o lado direito desta desigualdade por ‖A‖, obtemos
1− ‖A−1(A− A)‖ ≥ det(A)‖A− A‖‖A‖
Substituindo este resultado em (5.7) obtemos
‖x− x‖‖x‖
≤ det(A)
1− det(A)‖A−A‖‖A‖
(‖b− b‖‖b‖
+‖A− A‖‖A‖
)
Dado um sistema linear Ax = b, geralmente não temos os valores exactos das entradas
da matriz do sistema e quando temos não as conseguimos guardar exactamente. Suponhamos
que temos apenas uma aproximação A da matriz A. Então a solução x = A−1b é perturbada e
obtemos uma aproximação x = A−1b. Consequentemente,
‖x− x‖ = ‖x− A−1b‖
= ‖x− A−1Ax‖
= ‖(I− A−1A)x‖
≤ ‖(I− A−1A)‖‖x‖

5.3. NÚMERO DE CONDIÇÃO 141
ou seja,
‖ex‖ ≤ ‖(I− A−1A)‖‖x‖
Consequentemente,
‖δx‖ ≤ ‖(I− A−1A)‖
5.3.2 Problemas
1. Calcule os números de condição das matrizes
A =
7 8
9 10
, A =
5 0
0 2
nas normas 1, 2 e∞.
2. Calcule o número de condição da matriz
A =
2 3
1 2
nas normas 1, 2 e∞. Seja B a matriz que se obtém de A multiplicando a primeira linha de
A por 4. Qual é o número de condição de B? Comente.
3. Considere a matriz
A =
1 1 + ε
1− ε 1
cuja matriz inversa é
A−1 = ε−2
1 −1− ε
−1 + ε 1
(a) Calcule o número de condição na norma infinito. Se ε = 0.01 e houver uma perturba-
ção relativa no vector b, o que pode concluir quanto à propagação do erro relativo da
solução do sistema Ax = b.
(b) Calcule o número de condição na norma 1.
4. Considere o sistema linear Ax = b, sendo
A =
−6 3
1 −5
O número de condição da matriz A, para a norma 1, é menor que 5/2? Justifique.

142 CAPÍTULO 5. SISTEMAS LINEARES
5. Considere a matriz
A =
1 1 + ε
1− ε 1
, ε > 0
cuja matriz inversa é
A−1 = ε−2
1 −1− ε
−1 + ε 1
(a) Calcule o número de condição na norma infinito. Se ε = 0.01 e houver uma perturba-
ção relativa no vector b, o que pode concluir quanto à propagação do erro relativo da
solução do sistema Ax = b.
(b) Calcule o número de condição na norma 1.
6. Seja
A =
1 0
0 10−6
e considere o sistema Ax = b, com b = (1, 10−6)T .
(a) Determine det∞(A).
(b) Considere o sistema Ax = b, com b = (1 + ε, 10−6)T . Obtenha ‖δb‖∞ e ‖δx‖∞. Comente.
(c) Considere o sistema Ax = b, com b = (1, 2×10−6)T . Obtenha ‖δb‖∞ e ‖δx‖∞. Comente.
7. Seja
A =
0.00005 1
1 1
(a) Determine det1(A).
(b) Ao resolver um sistema com a matriz A, sabendo-se que ‖δb‖1 ≤ ε, determine um
majorante da norma correspondente do erro relativo da solução.
8. Seja A a matriz
A =
1 a
0 2
,com inversa
A−1 =
1 −a/2
0 1/2
,onde a ∈ R. Calcule o número de condição:
(a) associado à norma infinito;

5.4. MÉTODOS ITERATIVOS 143
(b) associado à norma 1;
(c) associado à norma 2.
Mostre que det1(A) = det∞(A). Com o auxilio do Matlab trace o gráfico do número det1(A)
em função do parâmetro a. Comente.
9. Considere a matriz
A =
1 0 a
0 1 0
−a 0 1
,e verifique que
A−1 =
1
1+a20 − 1
1+a2
0 1 0
a1+a2
0 11+a2
(a) Calcule as normas ‖.‖∞ e ‖.‖1 da matriz A.
(b) Calcule det∞(A) e det1(A). Para que valores de a ∈ R há mau condicionamento da
matriz.
5.4 Métodos iterativos
A decomposição PLU permite resolver um sistema linear de equações. Contudo, por ve-
zes, se conhecemos uma solução de um problema semelhante, pode trazer benefícios utilizar um
método iterativo. Como podemos, por exemplo, resolver o sistema 5 −6
−8 9
x1
x2
=
3
−5
através de um método iterativo? Um exemplo de um procedimento é resolver a primeira equação
em ordem a x1 e a segunda em ordem a x2, ou seja, obter
x1 =3 + 6x2
5
x2 =−5 + 8x2
9
O processo iterativo será
x(k+1)1 =
3 + 6x(k)2
5

144 CAPÍTULO 5. SISTEMAS LINEARES
x(k+1)2 =
−5 + 8x(k)1
9
Dado um vector inicial, por exemplo o vector x(0) = (0, 0)T , as duas iteradas seguintes são:
• 1a iterada, k = 0:
x(1)1 =
3 + 6x(0)2
5=
3
5
x(1)2 =
−5 + 8x(0)1
9=−5
9
• 2a iterada, k = 1:
x(2)1 =
3 + 6x(1)2
5=
3 + 6(−5/9)
5=−1
15
x(2)2 =
−5 + 8x(1)1
9=−5 + 8(3/5)
9=−1
45
Este processo iterativo denomina-se método de Jacobi.
Bases: Secção 3.3.
5.4.1 Teoria
Considere-se o sistema Ax = b tal que A = M+N. Suponha-se que a matriz M é invertível.
O sistema pode ser escrito na forma
Mx + Nx = b
ou seja,
Mx = b−Nx
Multiplicando ambos os membros por M−1 obtém-se
x = M−1(b−Nx) (5.8)
ou seja, x = g(x) onde g(x) = M−1(b − Nx). Por outras palavras, x é um ponto fixo de g.
Consequentemente, dada a aproximação x(k), a aproximação seguinte x(k+1) obtém-se através de
x(k+1) = M−1(b−Nx(k)) (5.9)
Os métodos de Jacobi e de Gauss-Seidel podem ser obtidos separando a matriz na soma
A = L + D + U

5.4. MÉTODOS ITERATIVOS 145
onde L é a parte triangular de baixo da matriz A, D é a matriz diagonal que contém a diagonal
de A e U é a parte triangular de cima da matriz A. Por exemplo, para a matriz
A =
1 2 6
−1 4 −5
3 1 7
tem-se
L =
0 0 0
−1 0 0
3 1 0
, D =
1 0 0
0 4 0
0 0 7
e U =
0 2 6
0 0 −5
0 0 0
Com base na decomposição A = L + D + U temos o seguinte:
• Método de Richardson: M = In e N = A − In; ou seja, dada a aproximação x(k), a aproxi-
mação seguinte x(k+1) obtém-se através de
x(k+1) = b + (In −A)x(k)
= x(k) + r(k) (5.10)
onde r(k) é o vector resíduo, definido por
r(k) = b−Ax(k) (5.11)
Este método também se pode escrever na forma,
x(k+1)i =
(bi −
n∑j=1
aijx(k)j
)
• Método de Jacobi : M = D e N = L + U; ou seja, dada a aproximação x(k), a aproximação
seguinte x(k+1) obtém-se através de
x(k+1) = D−1[b− (L + U)x(k)] =
ou de outra forma,
x(k+1)i =
1
aii
(bi −
n∑j=1,j 6=i
aijx(k)j
)(5.12)
• Método de Gauss-Seidel: M = L + D e N = U; ou seja, dada a aproximação x(k), a aproxi-
mação seguinte x(k+1) obtém-se através de
x(k+1) = (L + D)−1(b−Ux(k)) =
ou de outra forma,
x(k+1)i =
1
aii
(bi −
i−1∑j=1
aijx(k+1)j −
n∑j=i+1
aijx(k)j
)(5.13)

146 CAPÍTULO 5. SISTEMAS LINEARES
5.4.2 Procedimento
Problema Dado um sistema de equações lineares Ax = b, encontrar a solução x através de um
método iterativo.
Hipóteses Temos uma aproximação razoável x(0) da solução x e o sistema é muito grande para
ser resolvido por métodos mais simples do tipo PLU.
Ferramentas Iremos utilizar iteração e operações com matrizes.
Requisitos iniciais São precisas duas coisas:
1. os elementos da diagonal principal da matriz do sistema A têm de ser diferentes de
zero;
2. para o método ser eficiente é preciso que x(0) esteja próximo de x (especialmente se o
sistema tiver dimensão da ordem de 1000× 1000).
Processo iterativo Dada uma aproximação x(0) da solução do sistema, a aproximação seguinte
obtém-se através de (5.12) ou (5.13) se o objectivo for utilizar o método de Jacobi ou o de
Gauss-Seidel, respectivamente. Se for o método de Richardson, então calcular o resíduo
com (5.11) e substituir em (5.10).
Condições de paragem Existem duas condições que podem provocar a paragem do processo ite-
rativo:
1. paramos se a distância entre os sucessivos vectores é suficientemente pequena, isto é,
‖x(k+1) − x(k)‖ < εpasso.
2. se o número máximo de iteradas foi atingido e o processo ainda não terminou devido
à condição 1.
Se paramos devido à condição 1, então o vector x(k+1) é a nossa aproximação da solução. Se
a condição 2 for a razão da paragem, então ou escolhemos outra aproximação inicial x(0), ou
assumimos que a solução pode não existir.
Análise do erro Subtraindo a equação (5.8) da equação (5.9), obtemos
x− x(k+1) = −M−1N(x− x(k))

5.4. MÉTODOS ITERATIVOS 147
Por conseguinte,
‖x− x(k+1)‖ ≤ ‖ −M−1N‖‖x− x(k)‖ (5.14)
Repetindo sucessivas vezes este passo, podemos escrever
‖x− x(k)‖ ≤ ‖ −M−1N‖k‖x− x(0)‖
Consequentemente, se ‖ −M−1N‖ ≤ 1, então podemos concluir que
limk→∞‖x− x(k)‖ = 0
para qualquer x(0).
A partir da equação (5.14) podemos escrever
‖x− x(k+1)‖ ≤ ‖C‖‖x− x(k)‖
= ‖C‖‖x− x(k+1) + x(k+1) − x(k)‖
= ‖C‖‖x− x(k+1)‖+ ‖C‖‖x(k+1) − x(k)‖
onde C = −M−1N. Se ‖C < 1‖, então
‖x− x(k+1)‖ ≤ ‖C‖1− ‖C‖
‖x(k+1) − x(k)‖
Observamos que o papel desempenhado por L na Secção 3.4 é aqui desempenhado pela
norma da matriz C (ver a equação( 3.9)).
O teorema da série de Neumann diz-nos que se C for uma matriz genérica n × n tal que
‖C‖ < 1, então In −C é invertível. Se considerar-mos
C = −M−1N = In −M−1M−M−1N = In −M−1(M + N) = In −M−1A
ou seja,
C = In −M−1A
então, se ‖C‖ < 1, pelo teorema da série de Neumann,
In −C = In − (In −M−1A) = M−1A
é invertível e A também é invertível.
Posto isto temos o seguinte resultado: se existir uma norma natural tal que ‖C‖ < 1, com
C = −M−1N então o método iterativo da forma (5.9) converge para qualquer vector inicial x(0).

148 CAPÍTULO 5. SISTEMAS LINEARES
Existe um resultado mais forte que este que nos dá uma condição necessária e suficiente
para que haja convergência dum método iterativo: um método iterativo da forma (5.9) converge
para qualquer vector inicial x(0) se e só se ρ(C) < 1, onde ρ(C) representa o raio espectral da matriz
C.
O raio espectral de uma matriz A define-se por
ρ(A) = max|λ| : det(A− λIn) = 0
onde os λ’s são os valores próprios da matriz A, ou seja, os números complexos para os
quais a matriz A − λIn não é invertível. Por conseguinte, estes números são as raízes da
equação característica de A:
det(A− λIn) = 0
Da equação (5.3) segue que, para qualquer norma matricial natural, temos
‖x− x(k)‖ ≈ ρ(C)k‖x− x(0)‖
Por conseguinte, dado um sistema linear, é desejável seleccionar um método iterativo que
tenha um valor mínimo de ρ(A). Não existe nenhum resultado geral para nos indicar qual
dos métodos, Jacobi ou Gauss-Seidel, converge mais rapidamente. Contudo, existem casos
especiais onde se sabe a resposta. Se aij ≤ 0, para todo o i 6= j e aii > 0, para qualquer
i = 1, . . . , n, então uma é uma só situação acontece de entre as seguintes:
1. 0 ≤ ρ(CG) < ρ(CJ) < 1;
2. 1 < ρ(CJ) < ρ(CG);
3. ρ(CG) = ρ(CJ) = 0;
4. ρ(CG) = ρ(CJ) = 1.
Consequentemente, quando um dos métodos converge, então ambos convergem e o de
Gauss-Seidel converge mais rapidamente. Quando um diverge, então ambos divergem e
a divergência do método de Gauss-Seidel é mais pronunciada. Uma vez que a velocidade
de convergência depende do raio espectral devemos escolher um método em que a matriz
do sistema tenha um raio tão pequeno quanto possível; ver a Secção 5.5.

5.4. MÉTODOS ITERATIVOS 149
No caso do método de Jacobi temos
C = −D−1(L + U)
=
0 −a12a11
−a13a11
. . . −a1,n−2
a11−a1,n−1
a11−a1na11
−a21a22
0 −a23a22
. . . −a2,n−2
a22−a2,n−1
a22−a2na22
......
......
......
− an−1,1
an−1,n−1− an−1,2
an−1,n−1− an−1,3
an−1,n−1. . . −an−1,n−2
an−1,n−10 − an−1,n
an−1,n−1
− an1
ann− an2
ann−an−1,3
ann. . . −an−1,n−2
ann−an−1,n−1
ann0
Por conseguinte,
‖C‖∞ = maxi=1:n
n∑j=1,j 6=i
|aij||aii|
Sendo assim,
‖C‖∞ < 1 ⇐⇒ maxi=1:n
n∑j=1,j 6=i
aijaii
< 1
⇐⇒ |aii| >n∑
j=1,j 6=i
|aij|, i = 1, . . . , n (5.15)
Quando uma matriz satisfaz a condição (5.15), diz-se que tem a diagonal estritamente do-
minante por linhas. Por conseguinte: se a matriz A tiver a diagonal estritamente dominante por
linhas, então o método de Jacobi converge qualquer que seja o vector inicial x(0).
Diz-se que uma matriz tem a diagonal estritamente dominante por colunas se
|ajj| >n∑
i=1,i 6=j
|aij|, j = 1, . . . , n
Finalmente, um resultado sobre uma condição suficiente para a convergência dos métodos
de Jacobi e Gauss-Seidel e cuja demonstração se encontra em textos de análise numérica:
se a matriz A tiver a diagonal estritamente dominante, por linhas ou colunas, então os métodos de
Jacobi e Gauss-Seidel convergem idependentemente do vector inicial x(0).
5.4.3 Exemplos
Considere o sistema linear 5 2 1
−1 4 0
−1 3 −6
x1
x2
x3
=
3
2
1

150 CAPÍTULO 5. SISTEMAS LINEARES
Uma vez que
|5| > |2|+ |1|
|4| > | − 1|+ |0|
| − 6| > | − 1|+ |3|
a matriz do sistema tem a diagonal estritamente dominante por linhas. Por conseguinte, tanto o
método de Jacobi como o de Gauss-Seidel convergem, qualquer que seja a aproximação inicial.
Considere-se, por exemplo, (0, 0, 0)T . Em seguida, vamos calcular três iteradas aplicando cada
um destes métodos.
• Método de Jacobi: neste caso obtém-sex(k+1)1 = (b1 − a12x(k)2 − a13x
(k)3 )/a11
x(k+1)2 = (b2 − a21x(k)1 − a23x
(k)3 )/a22
x(k+1)3 = (b3 − a31x(k)1 − a32x
(k)2 )/a33
(5.16)
ou seja, x(k+1)1 = (3− 2x
(k)2 − x
(k)3 )/5
x(k+1)2 = (2 + x
(k)1 )/4
x(k+1)3 = (1 + x
(k)1 − 3x
(k)2 )/(−6))
(5.17)
1a iteração (k = 0): x(1)1 = (3− 2x
(0)2 − x
(0)3 )/5 = 3/5
x(1)2 = (2 + x
(0)1 )/4 = 1/5
x(1)3 = (1 + x
(0)1 − 3x
(0)2 )/(−6)) = −1/6
(5.18)
2a iteração (k = 1):x(2)1 = (3− 2x
(1)2 − x
(1)3 )/5 = (3− 2(1/5)− (−1/6))/5 = 0.366667
x(2)2 = (2 + x
(1)1 )/4 = (2 + (3/5))/4 = 0.65
x(2)3 = (1 + x
(1)1 − 3x
(1)2 )/(−6)) = (1 + (3/5)− 3(1/5))/(−6)) = −0.0166667
(5.19)
3a iteração (k = 2):x(3)1 = (3− 2x
(2)2 − x
(2)3 )/5 = (3− 2(0.65)− (−0.0166667))/5 = 0.336667
x(3)2 = (2 + x
(2)1 )/4 = (2 + (3/5))/4 = 0.591667
x(3)3 = (1 + x
(2)1 − 3x
(2)2 )/(−6)) = (1 + (0.366667)− 3(0.65))/(−6)) = 0.0972222
(5.20)
Na Figura 5.4 está representada, na escala logarítmica, a distância entre iteradas sucessivas
em função do número da iterada. São precisas 16 iteradas para obter uma distância inferior
a 10× 10−6.
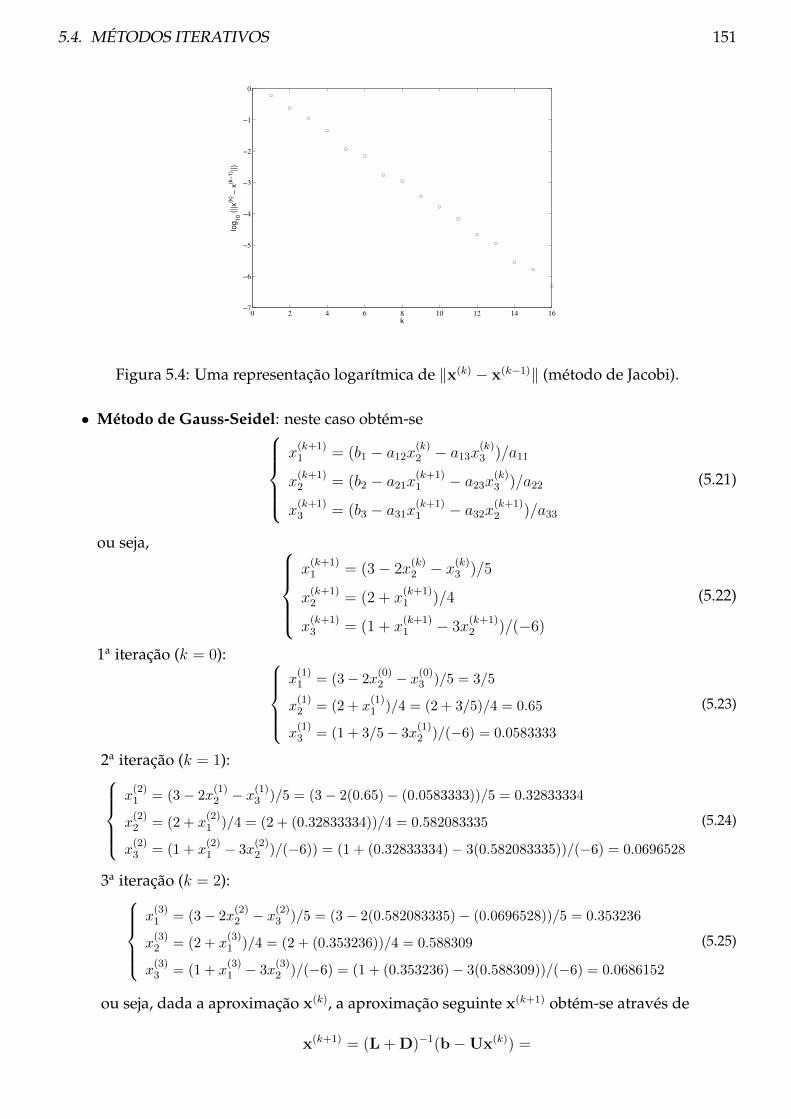
5.4. MÉTODOS ITERATIVOS 151
0 2 4 6 8 10 12 14 16−7
−6
−5
−4
−3
−2
−1
0
k
log
10 (
||x
(k) −
x(k
−1
) ||)
Figura 5.4: Uma representação logarítmica de ‖x(k) − x(k−1)‖ (método de Jacobi).
• Método de Gauss-Seidel: neste caso obtém-sex(k+1)1 = (b1 − a12x(k)2 − a13x
(k)3 )/a11
x(k+1)2 = (b2 − a21x(k+1)
1 − a23x(k)3 )/a22
x(k+1)3 = (b3 − a31x(k+1)
1 − a32x(k+1)2 )/a33
(5.21)
ou seja, x(k+1)1 = (3− 2x
(k)2 − x
(k)3 )/5
x(k+1)2 = (2 + x
(k+1)1 )/4
x(k+1)3 = (1 + x
(k+1)1 − 3x
(k+1)2 )/(−6)
(5.22)
1a iteração (k = 0): x(1)1 = (3− 2x
(0)2 − x
(0)3 )/5 = 3/5
x(1)2 = (2 + x
(1)1 )/4 = (2 + 3/5)/4 = 0.65
x(1)3 = (1 + 3/5− 3x
(1)2 )/(−6) = 0.0583333
(5.23)
2a iteração (k = 1):x(2)1 = (3− 2x
(1)2 − x
(1)3 )/5 = (3− 2(0.65)− (0.0583333))/5 = 0.32833334
x(2)2 = (2 + x
(2)1 )/4 = (2 + (0.32833334))/4 = 0.582083335
x(2)3 = (1 + x
(2)1 − 3x
(2)2 )/(−6)) = (1 + (0.32833334)− 3(0.582083335))/(−6) = 0.0696528
(5.24)
3a iteração (k = 2):x(3)1 = (3− 2x
(2)2 − x
(2)3 )/5 = (3− 2(0.582083335)− (0.0696528))/5 = 0.353236
x(3)2 = (2 + x
(3)1 )/4 = (2 + (0.353236))/4 = 0.588309
x(3)3 = (1 + x
(3)1 − 3x
(3)2 )/(−6) = (1 + (0.353236)− 3(0.588309))/(−6) = 0.0686152
(5.25)
ou seja, dada a aproximação x(k), a aproximação seguinte x(k+1) obtém-se através de
x(k+1) = (L + D)−1(b−Ux(k)) =
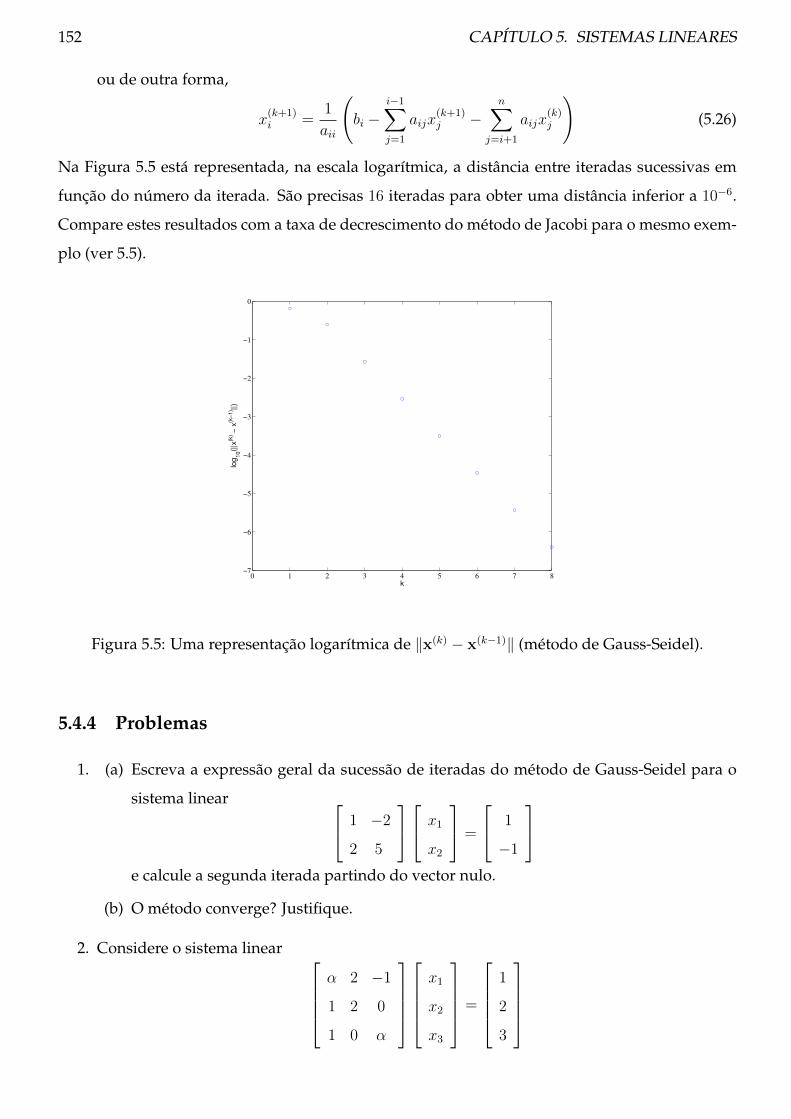
152 CAPÍTULO 5. SISTEMAS LINEARES
ou de outra forma,
x(k+1)i =
1
aii
(bi −
i−1∑j=1
aijx(k+1)j −
n∑j=i+1
aijx(k)j
)(5.26)
Na Figura 5.5 está representada, na escala logarítmica, a distância entre iteradas sucessivas em
função do número da iterada. São precisas 16 iteradas para obter uma distância inferior a 10−6.
Compare estes resultados com a taxa de decrescimento do método de Jacobi para o mesmo exem-
plo (ver 5.5).
0 1 2 3 4 5 6 7 8−7
−6
−5
−4
−3
−2
−1
0
k
log
10(|
|x(k
) − x
(k−
1) ||
)
Figura 5.5: Uma representação logarítmica de ‖x(k) − x(k−1)‖ (método de Gauss-Seidel).
5.4.4 Problemas
1. (a) Escreva a expressão geral da sucessão de iteradas do método de Gauss-Seidel para o
sistema linear 1 −2
2 5
x1
x2
=
1
−1
e calcule a segunda iterada partindo do vector nulo.
(b) O método converge? Justifique.
2. Considere o sistema linear α 2 −1
1 2 0
1 0 α
x1
x2
x3
=
1
2
3

5.4. MÉTODOS ITERATIVOS 153
(a) Indique uma condição para α que garanta a convergência do método de Jacobi.
(b) Seja α = 4. Calcule duas iteradas pelo método de Jacobi partindo do vector x(0) =
(0, 0, 0)T .
3. Considere o sistema linear
2x1 + 6x2 = 2
4x1 + x2 = 1
(a) Escreva a expressão geral do método de Jacobi aplicado a este sistema.
(b) Tomando x(0) = (1, 1)T , calcule duas iterada pelo método de Jacobi.
(c) O método converge? Justifique.
4. Considere o sistema linear 1 1
319
0 1 0
19
13
1
x1
x2
x3
=
1
1
1
(a) Tomando x(0) = (1, 2, 3)T , calcule duas iteradas pelo método de Gauss-Seidel.
(b) O método converge? Justifique.
(c) Baseando-se nas respectivas matrizes de iteração, C, qual dos dois métodos iterativos,
Gauss-Seidel ou Jacobi, daria em princípio os melhores resultados?
5. Considere o sistema seguinte: 3x1 + 2.5x3 = 2
x1 + 2x2 + 0.5x3 = 1
x2 + 4x3 = −2
(a) Tomando como aproximação inicial o vector nulo mostre que pode aplicar o método
de Gauss-Seidel para aproximar a solução do sistema e calcule duas iteradas.
(b) Indique uma estimativa do erro da primeira componente da segunda iterada.
6. Considere o vector inicial [0 a 0]T para resolver o seguinte sistema de equaçõesx32 − 2x1 + 5x3 = 0
x3 − x22 + x1 = β
−x21 + ex3 = 1
(5.27)

154 CAPÍTULO 5. SISTEMAS LINEARES
onde a e β são números reais. Ao resolver este sistema somos conduzidos a resolver um
sistema linear com a matriz
A =
−2 3a2 5
1 −2a 1
0 0 1
(a) Calcule o segundo membro do sistema linear e mostre como se chega a esta matriz A.
(b) Para a = 1, obtenha a primeira iterada x(1) que aproxima a solução do sistema (5.27).
(c) Se pretender resolver o sistema linear pelo método de Jacobi, quais são todos os valores
de a para os quais o método não converge?
7. O sistema de equações, Ax = b, 1 −a
−a 1
x = b
pode, sob certas condições, ser resolvido pelo método iterativo 1 0
−wa 1
x(k+1) =
1− w wa
0 1− w
x(k) + wb
(a) Para que valores de a o método converge se w = 1?
(b) Se a = −1/2 e w = 1/2 o método converge?
5.5 Método de relaxação de SOR
O método de relaxação de SOR (successive over-relaxation) é uma variante do método de
Gauss-Seidel que resulta numa convergência mais rápida. A ideia do método é introduzir um
parâmetro de relaxação ω e, em vez de M = L + D, considerar a matriz
Mω =1
ω(ωL + D) = L +
1
ωD
e, por conseguinte, a matriz N assume a forma
Nω =1
ω[(ω − 1)D + ωU] =
(1− 1
ω
)D + U

5.5. MÉTODO DE RELAXAÇÃO DE SOR 155
Sendo assim podemos proceder da seguinte forma:
Ax = b
⇔ (Mω + Nω)x = b
⇔Mωx = b−Nωx
⇔ (ωL + D)x = ωb− [(ω − 1)D + ωU]x
O método de SOR é um método iterativo e para o obter tem de ser resolver a equação acima
em ordem a x:
x = (D + ωL)−1ωb− [ωU + (ω − 1)D]x
Uma vez que a matriz (D + ωL) é triangular inferior, tal como no método de Gauss-Seidel, pode-
mos calcular os elementos do vector actual x(k+1) a partir do vector anterior x(k) fazendo substi-
tuições sucessivas:
x(k+1)i = (1− ω)x
(k)i +
ω
aii
(bi −
i−1∑j=1
aijx(k+1)j −
n∑j=i+1
aijx(k)j
), i = 1, 2, . . . , n (5.28)
Observa-se que quando ω = 1 este método reduz-se ao método de Gauss-Seidel. Se ω > 1 então
trata-se de sobre-relaxação. Se ω < 1 então trata-se de sub-relaxação.
Exemplo 29 Considere o sistema linear5 6 3
−1 4 −2
2 3 −6
x1
x2
x3
=
1
2
3
com x(0) = (0, 0, 0)T e o factor de relaxação ω = 1.3. Para aplicar o método de SOR a este sistema começa-se
por escrever a equação (5.28) aplicada a um sistema 3× 3:x(k+1)1 = (1− ω)x
(k)1 + ω(b1 − a12x(k)2 − a13x
(k)3 )/a11
x(k+1)2 = (1− ω)x
(k)2 + ω(b2 − a21x(k+1)
1 − a23x(k)3 )/a22
x(k+1)3 = (1− ω)x
(k)3 + ω(b3 − a31x(k+1)
1 − a32x(k+1)2 )/a33
(5.29)
Aplicando o sistema anterior ao sistema do exemplo, obtém-sex(k+1)1 = −0.3x
(k)1 + 1.3(1− 6x
(k)2 − 3x
(k)3 )/5
x(k+1)2 = −0.3x
(k)2 + 1.3(2 + x
(k+1)1 + 2x
(k)3 ))/4
x(k+1)3 = −0.3x
(k)3 + 1.3(3− 2x
(k+1)1 − 3x
(k+1)2 )/(−6)
(5.30)

156 CAPÍTULO 5. SISTEMAS LINEARES
• 1a iteração (k = 0):
x(1)1 = −0.3x(0)1 + 1.3(1− 6x
(0)2 − 3x
(0)3 )/5
= −0.3(0) + 1.3(1− 6(0)− 3(0))/5 = 0.2600
x(1)2 = −0.3x(0)2 + 1.3(2 + x
(1)1 + 2x
(0)3 ))/4
= −0.3(0) + 1.3(2 + (0.2600) + 2(0)))/4 = 0.7345
x(1)3 = −0.3x(0)3 + 1.3(3− 2x
(1)1 − 3x
(1)2 )/(−6)
= −0.3(0) + 1.3(3− 2(0.2600)− 3(0.7345))/(−6) = −0.0599
(5.31)
• 2a iteração (k = 1):
x(2)1 = −0.3x(1)1 + 1.3(1− 6x
(1)2 − 3x
(1)3 )/5
= −0.3(0.2600) + 1.3(1− 6(0.7345)− 3(−0.0599))/5 = −0.9171
x(2)2 = −0.3x(1)2 + 1.3(2 + x
(2)1 + 2x
(1)3 ))/4
= −0.3(0.7345) + 1.3(2 + (−0.9171) + 2(−0.0599)))/4 = 0.0927
x(2)3 = −0.3x(1)3 + 1.3(3− 2x
(2)1 − 3x
(2)2 )/(−6)
= −0.3(−0.0599) + 1.3(3− 2(−0.9171)− 3(0.0927))/(−6) = −0.9692
(5.32)
• 3a iteração (k = 2):
x(3)1 = −0.3x(2)1 + 1.3(1− 6x
(2)2 − 3x
(2)3 )/5
= −0.3(−0.9171) + 1.3(1− 6(0.0927)− 3(−0.9692))/5 = 1.1466
x(3)2 = −0.3x(2)2 + 1.3(2 + x
(3)1 + 2x
(23 ))/4
= −0.3(0.0927) + 1.3(2 + (1.1466) + 2(−0.9692)))/4 = 0.3649
x(3)3 = −0.3x(2)3 + 1.3(3− 2x
(3)1 − 3x
(3)2 )/(−6)
= −0.3(−0.9692) + 1.3(3− 2(1.1466)− 3(0.3649))/(−6) = 0.3748
(5.33)
A escolha do factor de relaxação não é necessariamente fácil e depende da matriz A do
sistema Ax = b. Para matrizes A definidas positivas pode demonstrar-se que, se 0 < ω < 2 então
o método de SOR converge, ou seja,
ρ (Cω) < 1.
onde Cω = −M−1ω Nω. Contudo, geralmente estamos interessados em convergência rápida em
vez de apenas convergência.
Dados dois métodos, o que converge mais rapidamente é aquele que tem menor raio espec-
tral. A obtenção do factor de relaxação óptimo, ou seja, aquele que minimiza o raio espectral
da matriz Cω, é difícil excepto em certos casos. Frequentemente, utiliza-se uma aproximação do
factor óptimo, aproximação esta obtida experimentando diversos valores de ω e observando o
resultado em termos de rapidez de convergência (estimativa heurística).

5.6. MÉTODO DO GRADIENTE CONJUGADO 157
5.6 Método do gradiente conjugado
O método do gradiente conjugado é um método eficaz para sistemas em que a matriz é
simétrica e definida positiva. O método é iterativo e consiste em gerar uma sucessão de iteradas
que são aproximações sucessivas da solução exacta do sistema. No cálculo de cada iterada é
calculado o resíduo correspondente à iterada e a direcção de busca para obter a iterada seguinte.
Em cada iterada do método calculam-se dois produtos internos que são utilizados para depois
calcular dois números reais usados para garantir que uma determinada sucessão satisfaça certas
condições de ortogonalidade. Num sistema linear em que a matriz é simétrica e definida positiva,
estas condições implicam que a distância à solução exacta seja minimizada numa determinada
norma.
Como foi dito anteriormente, o método do gradiente conjugado é um método iterativo para
resolver sistemas de equações em que a matriz do sistema é simétrica (ou seja, AT = A) e definida
positiva (ou seja, xTAx > 0 para todo o vector não nulo x ∈ Rn, com A ∈ Rn × Rn). O método
do gradiente conjugado também pode utilizar-se na resolução de problemas de optimização sem
constrangimentos tais como minimização de energia.
Dizemos que os vectores não nulos u e v são conjugados com respeito a A se
uTAv = 0
Uma vez que A é simétrica e definida positiva, então
uTAv = (u,Av) = (u,ATv) = (Au,v) = (u,v)A
Ou seja, uTAv define um produto interno. Consequentemente, dois vectores são conjugados se
eles forem ortogonais com respeito ao produto interno. Se u é conjugado de v, então v é conjugado
de u.
Suponha-se que φk é uma sequência de m direcções conjugadas mutuamente. Então os φk’s
formam uma base de Rm, logo podemos representar a solução x do sistema Ax = b como uma
combinação linear de elementos dessa base:
x =m∑i=1
aiφi
Por conseguinte,
b = Ax =m∑i=1
aiAφi

158 CAPÍTULO 5. SISTEMAS LINEARES
Donde,
φTkb = φTkAx =m∑i=1
aiφTkAφi
Mas para qualquer i 6= k, φi e φk são mutuamente conjugados (ou seja, φTkAφi = 0), logo
φTkb = akφTkAφk
Consequentemente,
ak =φTkb
φTkAφk=
(φk,b)
(φk, φk)A=
(φk,b)
‖φk‖2A
O método do gradiente conjugado consiste em encontrar um conjunto de m direcções con-
jugadas e depois calcular os coeficientes ak’s. Este método é um método iterativo, logo começa-se
por exemplo com x(0) = 0. Caso contrário, considera-se o sistema Az = b−Ax0. Começando com
x0 em cada iteração, precisamos de uma medida para sabermos se já estamos perto da solução
exacta. Para isso, sabemos que a solução exacta é o único vector que minimiza a seguinte função
quadrática:
f(x) =1
2xTAx− xTb, x ∈ R
Por conseguinte, se esta função tem um valor mais pequeno quando passa de uma iteração para
outra, significa que nos estamos a aproximar da solução exacta.
Por conseguinte, a primeira base p(1) a ser escolhida será o negativo do vector gradiente em
x = x(0). Este gradiente é igual a Ax(0) − b. Mas x(0) = 0, logo p(1) = b. Os outros vectores da
base serão conjugados do vector gradiente.
Seja r(k) = b −Ax(k) o resíduo correspondente ao k-ésimo passo. Este resíduo é o negativo
do gradiente e, sendo assim, utiliza-se o método do gradiente descendente para nos aproximar-
mos do mínimo. O método do gradiente descendente bseia-se no facto de que o gradiente é
um vector que indica a direcção na qual a função cresce mais rapidamente e é perpendicular, ou
seja ortogonal, à tangente na função no ponto em questão. Consequentemente, no método do
gradiente descrescente, a direcção de procura é o negativo do gradiente. Para isto é preciso que
de facto as direcções p(k) sejam conjugadas entre elas. A próxima direcção de busca é construída
a partir do resíduo actual e de todas as direcções de busca anteriores. Para fazer a conjugação dos
vectores utiliza-se um algoritmo parecido com a ortonormalização de Gram-Schimidt, ou seja,
p(k+1) = r(k) −k∑i=1
(p(i))TAr(k)
(p(i))TAp(i)p(i)
Seguindo a direcção p(k+1), a próxima aproximação do mínimo é
x(k+1) = x(k) + α(k+1)p(k+1)

5.6. MÉTODO DO GRADIENTE CONJUGADO 159
com
α(k+1) =(p(k+1))Tb
(p(k+1))TAp(k+1)
Mas b = r(k) + Ax(k) logo
α(k+1) =(p(k+1))T (r(k) + Ax(k))
(p(k+1))TAp(k+1)
Além disso, p(k+1) e x(k) são conjugados, logo
α(k+1) =(p(k+1))T r(k)
(p(k+1))TAp(k+1)
Exemplo 30 Considere-se um sistema linear Ax = b onde
A =
3 −2
−1 4
e b =
−2
1
Iremos calcular duas iteradas do método do gradiente conjugado começando com o vector inicial x(0) =
(1, 2)T .
Em primeiro lugar calcula-se o resíduo associado a x(0), ou seja,
r(0) = b−Ax(0) =
−2
1
− 3 −2
−1 4
1
2
=
−1
−6
Nesta primeira iteração utiliza-se o resíduo r(0) como direcção inicial p(0), ou seja, p(0) = r(0) =
(−1,−6)T . Nas iterações posteriores usa-se outro método para escolher p(k). A partir de r(0) e p(0) calcula-
se
α(0) =(r(0))T r(0)
(p(0))TAp(0)= 0.2868217054263566
Consequentemente,
x(1) = x(0) + α(0)p(0) = (0.7131782945736434, 0.2790697674418605)T
Para realizar a segunda iterada começa-se por calcular r(1):
r(1) = r(0) − α(0)Ap(0) = (−3.581395348837209, 0.5968992248062017)T
A partir de r(1) calcula-se β(0):
β(0) =(r(1))T r(1)
(r(0))T r(0)= 0.3562886845742444
Este número β(0) é utilizado para calcular a próxima direcção p(1):
p(1) = r(1) + β(0)p(0) = (−3.937684033411454,−1.540832882639265)T

160 CAPÍTULO 5. SISTEMAS LINEARES
Por conseguinte,
α(1) =(r(1))T r(1)
(p(1))TAp(1)= 0.3486486486486486
o que nos permite obter
x(2) = x(1) + α(1)p(1) = (−0.6596899224806203,−0.2581395348837210)T
O método o gradiente conjugado pode também ser entendido como um método directo
uma vez que, não considerando os erros de arredondamento, ele produz a solução exacta após
um número finito de iteradas, que não pode ser maior que a dimensão da matriz. Contudo,
este método é instável com respeito a pequenas perturbações. Mais concretamente, muitas das
direcções não são na prática conjugadas e, por conseguinte, nunca se obtém a solução exacta.

Capítulo 6
Sistemas não lineares
6.1 Método de Newton para sistemas
Talvez o método mais utilizado para resolver sistemas não lineares seja o método de New-
ton. É um bom método para se estudar porque a maioria dos métodos para resolver sistemas
não lineares podem ser considerados adaptações do método de Newton. Muitas das vantagens
e inconvenientes que caracterizam o método de Newton são a base para o desenvolvimento de
métodos mais sofisticados.
Um exemplo de um sistema não linear é o seguinte:
(x1 − 2)2 + (x2 − 1)2 = 4 (6.1)
(x1 − 3)2 + (x2 − 2)2 = 1 (6.2)
Este sistema é não linear porque não pode ser escrito como uma combinação linear de x =
(x1, x2)T , onde a notação T significa transposto. A partir da segunda equação podemos escrever
(x1 − 3)2 + (x2 − 2)2 = 1 ⇐⇒ (x2 − 2)2 = 1− (x1 − 3)2
⇐⇒ x2 − 2 = ±√
1− (x1 − 3)2
⇐⇒ x2 = 2±√
1− (x1 − 3)2 (6.3)
Os sinais de + e de− correspondem às metades de cima e de baixo dos círculos, respectivamente.
Na Figura 6.1 observam-se duas intersecções: uma da metade de cima e a outra na metade de
baixo do círculo mais pequeno. Na Figura 6.2 observamos localmente a intercepção da metade de
cima do círculo com raio menor.
161
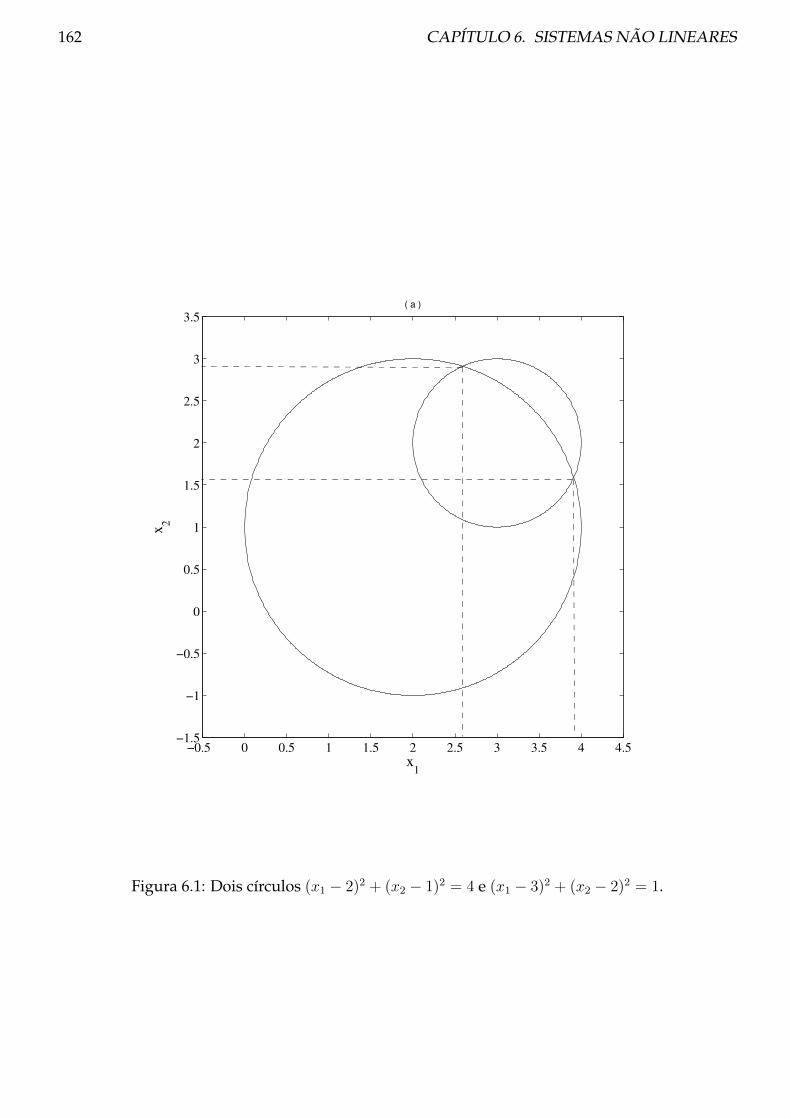
162 CAPÍTULO 6. SISTEMAS NÃO LINEARES
−0.5 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
x1
x2
( a )
Figura 6.1: Dois círculos (x1 − 2)2 + (x2 − 1)2 = 4 e (x1 − 3)2 + (x2 − 2)2 = 1.
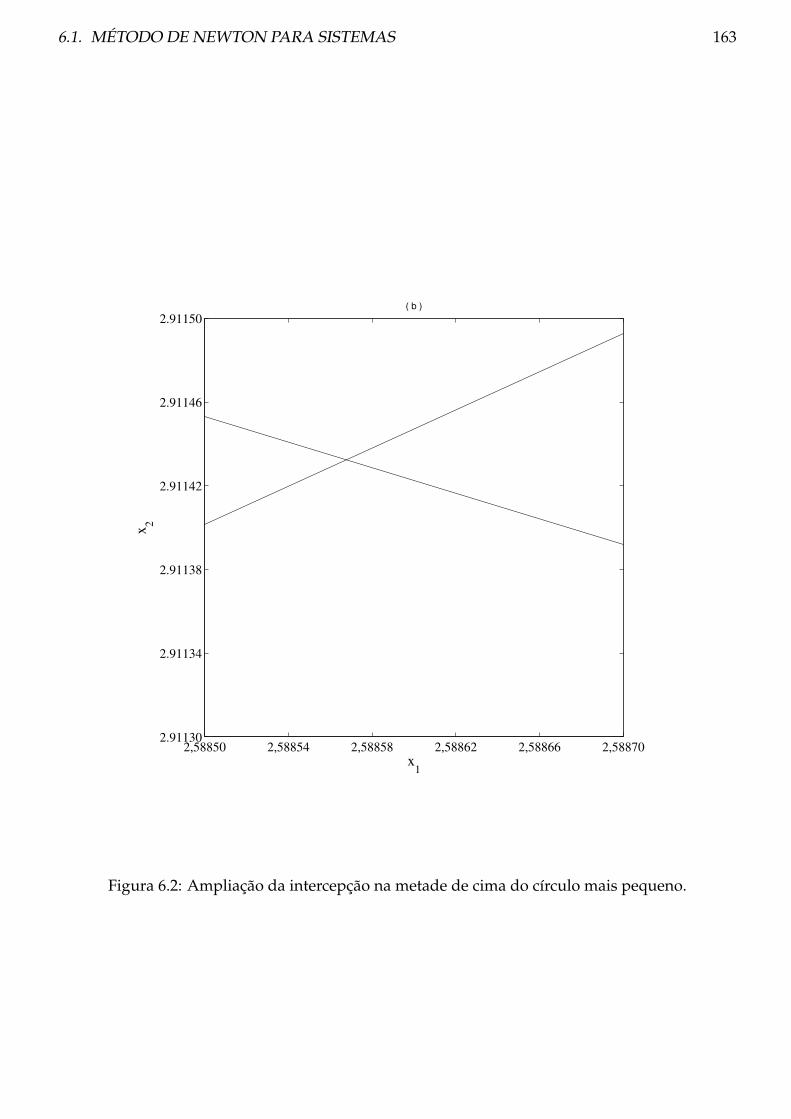
6.1. MÉTODO DE NEWTON PARA SISTEMAS 163
2,58850 2,58854 2,58858 2,58862 2,58866 2,588702.91130
2.91134
2.91138
2.91142
2.91146
2.91150
x1
x2
( b )
Figura 6.2: Ampliação da intercepção na metade de cima do círculo mais pequeno.

164 CAPÍTULO 6. SISTEMAS NÃO LINEARES
Para descobrir a intercepção que se encontra na metade de cima, substituímos a última equa-
ção de (6.3), com o sinal +, na primeira equação do sistema não linear e obtém-se
(x1 − 2)2 +(
2 +√
1− (x1 − 3)2 − 1)2
= 4
ou seja, para a raiz pertencente à metade de cima dos círculos temos o seguinte sistema:
(x1 − 2)2 +(
1 +√
1− (x1 − 3)2)2
= 4 (6.4)
x2 = 2 +√
1− (x1 − 3)2 (6.5)
A equação (6.4) é uma equação não linear numa única variável x1. Resolvendo esta equação, por
exemplo, pelo método de Newton uni-dimensional (ver Secção 4.2) e substituindo o resultado em
(6.5) obtemos uma aproximação para a raiz pretendida:
x = (2.588562172233852, 2.911437827766148)T
Infelizmente, na maioria das situações não é fácil eliminar variáveis e reduzir o sistema não
linear a sistemas de dimensão menos elevada; nos sistemas lineares isto pode ser feito utilizando
o método de eliminação de Gauss. Em vez disto, vamos averiguar como aplicar o método de
Newton directamente a um sistema de equações.
Bases: Secções 3.3, 3.1 e 4.2.
6.1.1 Teoria
O método de Newton baseia-se na hipótese de que qualquer função com derivadas parciais
contínuas assemelha-se localmente a um plano n-dimensional. Por exemplo, nas Figuras 6.3 e 6.4
podemos observar uma função bidimensional com derivadas parciais contínuas. Embora a função
pareça ter grandes variações, quando nos aproximamos de um ponto
f(x1, x2) =200 sin(x1 + x2)
(π + x1 + x2)
a função assemelha-se a um plano liso, ou seja, localmente a função comporta-se como um plano
bidimensional.
Para obter o método de Newton quando temos uma única equação, lineariza-se a equa-
ção não linear em torno de xi e resolve-se a equação linear resultante para obter a aproximação
seguinte xi+1. Aqui o procedimento é semelhante, ou seja, o método consiste em substituir as
equações não lineares pela sua linearização em torno do ponto xi. Isto irá resultar num sistema
linear de n equações. A nova aproximação da raiz xi+1, obtém-se resolvendo este sistema linear.
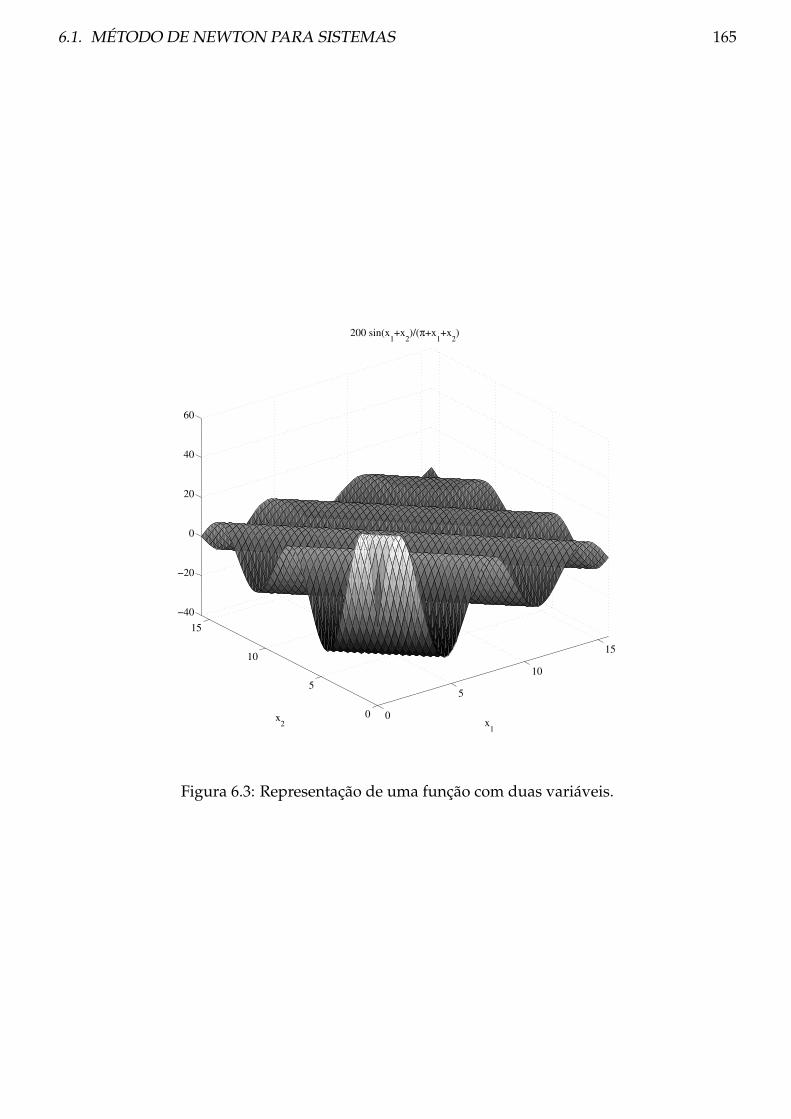
6.1. MÉTODO DE NEWTON PARA SISTEMAS 165
0
5
10
15
0
5
10
15
−40
−20
0
20
40
60
x1
200 sin(x1+x
2)/(π+x
1+x
2)
x2
Figura 6.3: Representação de uma função com duas variáveis.
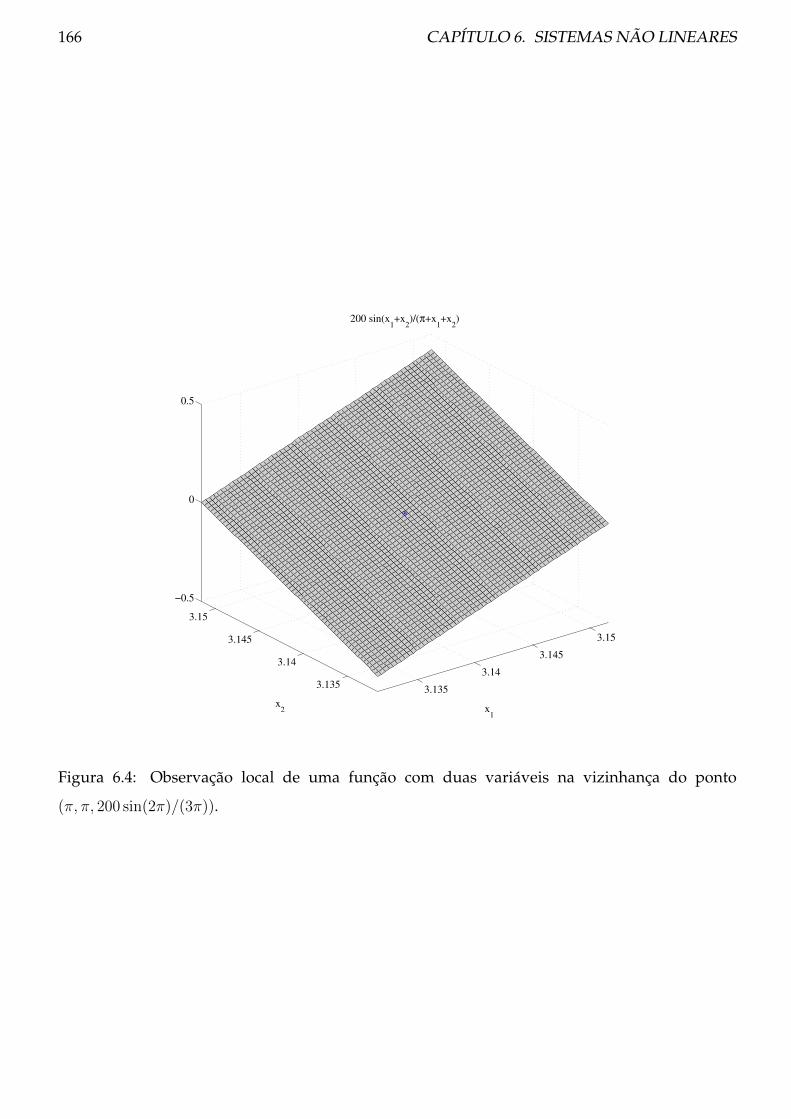
166 CAPÍTULO 6. SISTEMAS NÃO LINEARES
3.135
3.14
3.145
3.15
3.135
3.14
3.145
3.15
−0.5
0
0.5
x1
200 sin(x1+x
2)/(π+x
1+x
2)
x2
Figura 6.4: Observação local de uma função com duas variáveis na vizinhança do ponto
(π, π, 200 sin(2π)/(3π)).

6.1. MÉTODO DE NEWTON PARA SISTEMAS 167
Se a função g(x) = g(x1, x2) é uma função com duas variáveis então o desenvolvimento em
série de Taylor até à primeira ordem, em torno do ponto (x(0)1 , x
(0)2 ) é o seguinte:
g(x1, x2) = g(x(0)1 , x
(0)2 ) +
∂g(x(0)1 , x
(0)2 )
∂x1(x1 − x(0)1 ) +
∂g(x(0)1 , x
(0)2 )
∂x2(x2 − x(0)2 ) + . . .
onde os termos, omitidos no desenvolvimento, são termos de ordem superior que envolvem de-
rivadas parciais de ordem mais elevada e potências de (x1 − x(0)1 ) e (x2 − x(0)2 ) também de ordem
mais elevada. Se tivermos um sistema não linear f1(x1, x2)
f2(x1, x2)
=
0
0
e aplicando este desenvolvimento a cada equação deste sistema obtemos f1(x1, x2)
f2(x1, x2)
≈
f1(x(0)1 , x
(0)2 ) +
∂f1(x(0)1 ,x
(0)2 )
∂x1(x1 − x(0)1 ) +
∂f1(x(0)1 ,x
(0)2 )
∂x2(x2 − x(0)2 )
f2(x(0)1 , x
(0)2 ) +
∂f2(x(0)1 ,x
(0)2 )
∂x1(x1 − x(0)1 ) +
∂f2(x(0)1 ,x
(0)2 )
∂x2(x2 − x(0)2 )
=
f1(x(0)1 , x
(0)2 )
f2(x(0)1 , x
(0)2 )
+
∂f1(x(0)1 ,x
(0)2 )
∂x1
∂f1(x(0)1 ,x
(0)2 )
∂x2
∂f2(x(0)1 ,x
(0)2 )
∂x1
∂f2(x(0)1 ,x
(0)2 )
∂x2
x1 − x(0)1
x2 − x(0)2
ou seja,
f(x) ≈ f(x(0)) + Jf (x(0))(x− x(0)) (6.6)
onde x = (x1, x2)T , x(0) = (x
(0)1 , x
(0)2 )T e Jf (x
(0)) é a matriz Jacobiana calculada no ponto
x(0). Comparando com o método de Newton uni-dimensional vemos que na generalização, a
dimensões superiores a 1, a derivada foi substituída pela matriz Jacobiana.
Para um sistema com n equações a n incógnitas, a equação mantém-se com x = (x1, x2) e
x(0) = (x(0)1 , x
(0)2 ) substituídos por x = (x1, x2, . . . , xn) e x(0) = (x
(0)1 , x
(0)2 , . . . , x
(0)n ), respectivamente,
e com a matriz Jacobiana dada por:
Jf (x(0)) =
∂f1(x(0))∂x1
∂f1(x(0))∂x2
. . . ∂f1(x(0))∂xn
∂f2(x(0))∂x1
∂f2(x(0))∂x2
. . . ∂f2(x(0))∂xn
......
...∂fn(x(0))∂x1
∂fn(x(0))∂x2
. . . ∂fn(x(0))∂xn
Em cada passo do método de Newton, assume-se que temos a aproximação x(i) da raiz e a
aproximação seguinte, x(i+1) se obtém resolvendo o sistema linearizado
f(x(i)) + Jf (x(i))(x(i+1) − x(i)) = 0

168 CAPÍTULO 6. SISTEMAS NÃO LINEARES
em ordem a x(i+1). Na prática, obtém-se x(i+1) resolvendo o sistema linear
Jf (x(i))∆x(i) = −f(x(i)) (6.7)
e depois fazendo a seguinte soma entre dois vectores:
x(i+1) = x(i) + ∆x(i)
Podemos combinar estes dois passos e escrever
x(i+1) = x(i) − Jf (x(i))−1f(x(i))
No caso uni-dimensional temos Jf (x) = f ′(x). Para dimensões superiores é preferível resolver o
sistema linear (6.7) em vez de inverter a matriz Jacobiana.
6.1.2 Procedimento
Problema Dadas n funções f1(x), . . . , fn(x), onde x = (x1, . . . , xn)T (n variáveis), encontrar um
vector z (denominada a raiz) tal que f(z) = 0.
Hipóteses Iremos assumir que cada função fk(x) é contínua, k = 1, . . . , n, tem derivadas parciais
contínuas e a matriz Hessiana é definida positiva.
Ferramentas Iremos utilizar amostragem, derivadas parciais, iteração e resolução de sistemas
lineares. O modelo dá informação sobre as derivadas parciais. O erro é obtido utilizando o
desenvolvimento em série de Taylor.
Requisitos iniciais Temos de ter uma aproximação inicial da raiz x(0) e de ter obtido a matriz
Jacobiana Jf (x).
Processo iterativo Dada uma aproximação x(i) da raiz, a aproximação seguinte obtém-se através
de:
1. resolver o sistema de equações lineares em ordem a ∆x(i)
Jf (x(i))∆x(i) = −f(x(i))
2. calcular
x(i+1) = x(i) + ∆x(i)

6.1. MÉTODO DE NEWTON PARA SISTEMAS 169
Note-se que em cada passo temos de calcular a matriz Jacobiana num novo ponto e resolver
o sistema linear.
Condições de paragem Existem três condições que podem originar a paragem do método itera-
tivo. A norma utilizada nestas condições pode ser a 1, 2 ou infinito.
1. Paramos se ambas as seguintes condições se verificarem:
• a distância entre iteradas sucessivas é suficientemente pequena, ou seja,
‖x(i+1) − x(i)‖ < εpasso;
• a norma função calculada no ponto xi+1 é suficientemente pequena, ou seja,
‖f(x(i+1))‖ < εabs.
2. Se a matriz Jacobiana é indeterminada, ou seja, o seu determinante é próximo de zero
(det(Jf (x(i))) ≈ 0), então o processo iterativo falha e paramo-lo.
3. Se foi atingido o número máximo de iterações e ainda não se verificou a primeira con-
dição de paragem. Neste caso paramos o processo iterativo e indicamos que a solução
não foi encontrada.
Se o processo iterativo parar devido à verificação da condição 1, então consideramos que
x(i+1) é a nossa aproximação da raiz, ou seja z ≈ x(i+1).
Se pararmos o processo porque uma das condições 2 ou 3 não for verificada, então conside-
ramos que a solução não existe ou escolhemos outra aproximação inicial.
6.1.3 Exemplos
Exemplo 31 Suponhamos que temos de novo o problema da intercepção entre os dois círculos descrito
anteriormente e representado através das equações (6.1) e (6.2). Iremos calcular várias iterações até que,
usando a norma infinito, ‖∆x(i)‖∞ < εpasso = 10−6 e ‖f(x(i+1))‖∞ < εabs = 10−6, começando com
x(0) = (2, 3)T .
A matriz Jacobianan do sistema é
Jf (x) =
2x1 − 4 2x2 − 2
2x1 − 6 2x2 − 4

170 CAPÍTULO 6. SISTEMAS NÃO LINEARES
• Cálculo da primeira iterada, x(1):
Jf (x(0))∆x(0) = −f(x(0))⇐⇒
0 4
−2 2
∆x(0) = −
0
1
Resolvendo em ordem a ∆x(0) obtém-se ∆x(0) = (5.0000 × 10−1, 0)T e, por conseguinte, a aproxi-
mação seguinte será:
x(1) = x(0) + ∆x(0) = (2.5, 3)T
Observamos que
‖∆x(0)‖∞ = 0.5 > 10−6
‖f(x(1))‖∞ = 0.25 > 10−6
• Cálculo da segunda iterada, x(2):
Jf (x(1))∆x(1) = −f(x(1))⇐⇒
1 4
−1 2
∆x(1) = −
2.5000× 10−1
2.5000× 10−1
Resolvendo em ordem a ∆x(1) obtém-se ∆x(1) = (8.3333 × 10−2,−8.3333 × 10−2)T e, por conse-
guinte, a aproximação seguinte será:
x(2) = x(1) + ∆x(1) = (2.58333, 2.91667)T
Observamos que
‖∆x(1)‖∞ = 8.3333× 10−2 > 10−6
‖f(x(2))‖∞ = 1.3889× 10−2 > 10−6
• Cálculo da terceira iterada, x(3):
Jf (x(2))∆x(2) = −f(x(2))⇐⇒
1.1667 3.8333
−0.83333 1.8333
∆x(2) = −
1.3889× 10−2
1.3889× 10−2
Resolvendo em ordem a ∆x(2) obtém-se ∆x(2) = (5.2083 × 10−3,−5.2083 × 10−3)T e, por conse-
guinte, a aproximação seguinte será:
x(3) = x(2) + ∆x(2) = (2.58854, 2.91146)T
Observamos que
‖∆x(2)‖∞ = 5.2083× 10−3 > 10−6
‖f(x(3))‖∞ = 5.4253× 10−5 > 10−6

6.1. MÉTODO DE NEWTON PARA SISTEMAS 171
• Cálculo da quarta iterada, x(4):
Jf (x(3))∆x(3) = −f(x(3))⇐⇒
1.1771 3.8229
−8.2292× 10−1 1.8229
∆x(3) = −
5.4253× 10−5
5.4253× 10−5
Resolvendo em ordem a ∆x(3) obtém-se ∆x(3) = (2.0505 × 10−5,−2.0505 × 10−5)T e, por conse-
guinte, a aproximação seguinte será:
x(4) = x(3) + ∆x(3) = (2.58856, 2.91144)T
Observamos que
‖∆x(3)‖∞ = 2.0505× 10−5 > 10−6
‖f(x(4))‖∞ = 8.4093× 10−10 < 10−6
• Cálculo da quinta iterada, x(5):
Jf (x(4))∆x(4) = −f(x(4))⇐⇒
1.1771 3.8229
−8.2288× 10−1 1.8229
∆x(4) = −
8.4093× 10−10
8.4093× 10−10
Resolvendo em ordem a ∆x(4) obtém-se ∆x(4) = (3.1784 × 10−10,−3.1784 × 10−10)T e, por conse-
guinte, a aproximação seguinte será:
x(5) = x(4) + ∆x(4) = (2.58856, 2.91144)T
Observamos que
‖∆x(4)‖∞ = 3.1784× 10−10 < 10−6
‖f(x(5))‖∞ = 5.7472× 10−6 < 10−6,
ou seja, paramos a sucessão de iteradas.
6.1.4 Problemas
1. Determinar uma aproximação da raiz situada na metade de baixo do círculo mais pequeno
do sistema constituído pelas equações (6.1) e (6.1).
2. Obtenha uma aproximação da solução do sistema f(x) = 0 com εabs = εpasso = 10−6 e
f(x) =
x21 + x22 + x23 − 9
x3 − x2 sin(x1)
3x2 + 4x3

172 CAPÍTULO 6. SISTEMAS NÃO LINEARES
3. Represente graficamente as funções f1(x) = x31 + x2 − 1 e f2(x) = x32 − x2 + 1 no quadrado
[−3; 3]× [−3; 3]. Obtenha aproximações da raiz do sistema x31 + x2
x31 − x2
=
1
−1
4. Considere o seguinte sistema
x3 + 5y − 2z = 0
ey − z2 = 1
−x2 + y + z = µ
µ ∈ R (6.8)
Partindo do vector inicial x(0) = (c, 0, 0)T , c ∈ R, para chegar à aproximação x(1) somos
levados a resolver um sistema linear com a matriz
A =
3c2 5 −2
0 1 0
−2c 1 1
(a) Mostre como se obteve A e calcule o segundo membro do sistema.
(b) Resolva o sistema (6.8) calculando 3 iteradas pelo método de Newton, utilizando na
resolução de cada sistema linear o método de Jacobi com 2 iteradas. Calcule ‖x(i+1) −
x(i)‖∞ para i = 0, 1, 2.
5. Considere o sistema de equações:2x+ y + ε cos z = −1
x+ 3y − 3εxz = 0
εx2 + y + 3z = 0
Para ε = 1 e x(0) = 0 justifique que pode usar o método de Newton e escreva o valor da
primeira iterada.
6. Pretende-se resolver o seguinte sistema pelo método de Newton:
φ(x) = 1
3x2 + 4x3 = 3
2x21 + 2x1 + 2x3 = 1
Considerando φ(x) = ex1 − 3 e tomando x(0) = (0, 2, 3)T , calcule a primeira iterada.

6.1. MÉTODO DE NEWTON PARA SISTEMAS 173
7. Pretende-se resolver o seguinte sistema pelo método de Newton:
x31 − 3x1x2 = −1
3x21x2 − x22 = 0
(a) Tomando x(0) = (1, 1)T , calcule a primeira iterada.
(b) Calcule a diferença entre iteradas sucessivas, ‖x(1) − x(0)‖∞.
8. Use o método de Newton para encontrar a solução do seguinte sistema:
loge(x21 + x22)− sin(x1x2) = loge 2 + loge π
ex1−x2 + cos(x1x2) = 0
Utilize x(0) = (2, 2)T e faça duas iteradas. Calcule ‖x(i+1) − x(i)‖∞ para i = 0 e i = 1.
9. Pretende-se resolver o seguinte sistema pelo método de Newton:
x21 + x2 = 3
x21 − x2 = −3
(a) Tomando x(0) = (1, 4)T , calcule a primeira iterada.
(b) Calcule a diferença entre iteradas sucessivas, ‖x(1) − x(0)‖∞.
(c) Faça um esboço gráfico das funções f1(x) = x21+x2−3 e f2(x) = x21−x2+3 no quadrado
[−1; 1]× [2; 4].
(d) Calcule o erro da aproximação x(1), ou seja, ‖z− x(1)‖∞. Comente.
10. Considere o vector inicial [0 a 0]T para resolver o seguinte sistema de equações
x32 − 2x1 + 5x3 = 0
x3 − x22 + x1 = β
−x21 + ex3 = 1
onde a e β são números reais. Ao resolver este sistema somos conduzidos a resolver um
sistema linear com a matriz
A =
−2 3a2 5
1 −2a 1
0 0 1
(a) Calcule o segundo membro do sistema linear e mostre como se chega a esta matriz A.
(b) Para a = 1, obtenha a primeira iterada x(1) que aproxima a solução do sistema.

174 CAPÍTULO 6. SISTEMAS NÃO LINEARES
6.2 Método do ponto fixo para sistemas
O método de Newton é um exemplo do método do ponto fixo em que escrevemos o sistema
f(z) = 0
na forma
z = g(z)
e depois, partindo do vector inicial x(0), calculamos as aproximações sucessivas através de
x(i+1) = g(x(i)), i = 0, 1, 2, . . . (6.9)
e esta sucessão, sob determinadas condições, irá convergir para o ponto fixo z de g.
A análise do método do ponto fixo para sistemas difere pouco da análise efectuada para o
caso em que temos uma única equação (ver a Secção 3.4). A única diferença é que, neste caso, a
distância entre a aproximação x(i+1) e o vector exacto z se mede utilizando uma norma, em vez
de módulo.
Teorema 3 Suponha-se que a função g transforma o conjunto S nele próprio, onde S ⊂ Rn (g : S → S).
Ou seja, se x ∈ S, então g(x) ∈ S. Além disso, assuma-se que g é contractiva, isto é,
‖g(x)− g(y)‖ ≤ K‖x− y‖
para todo o x e y em S e uma constante K < 1. Então,
1. g tem um ponto fixo em S.
2. Se z é um ponto fixo de g em S, então o método do ponto fixo (6.9) converge para z qualquer que seja
o vector inicial x(0) ∈ S, isto é,
limi→∞‖z− x(i)‖ = 0
Mais concretamente,
‖z− x(i)‖ ≤ K
1−K‖x(i) − x(i−1)‖
‖z− x(i)‖ ≤ Ki
1−K‖x(1) − x(0)‖

6.2. MÉTODO DO PONTO FIXO PARA SISTEMAS 175
Na realidade o método converge para um ponto fixo z de g se g for contínua e diferenciável
e se o vector inicial estiver suficientemente próximo de z no qual ‖Jg(z)‖ < 1. Convém salientar
que, estas condições são suficientes para o método convergir, mas não são necessárias. Às vezes o
método converge e estas condições não se verificam. Quando g é contínua e diferenciável tem-se
K = ‖Jg(z)‖.
Exemplo 32 Considere o sistema de equações não lineares x1 = 0.51+(x1+x2)2
x2 = 0.51+(x1−x2)2
Para calcular K = ‖Jg(z)‖∞ temos que proceder da seguinte forma:
Jg(x) =
− x1+x2[1+(x1+x2)2]2
− x1+x2[1+(x1+x2)2]2
− x1−x2[1+(x1−x2)2]2
x1−x2[1+(x1−x2)2]2
logo,
‖Jg(z)‖∞ = max
2|x1 + x2|
[1 + (x1 + x2)2]2,
2|x1 − x2|[1 + (x1 − x2)2]2
,
Considere-se a função
h(x) =2x
(1 + x2)2
então
h′(x) =2(1 + x2)2 − 8x2(1 + x2)
(1 + x2)4=
2(1 + x2 − 4x2)
(1 + x2)3=
2(1− 3x2)
(1 + x2)3
Sendo assim, podemos ver quais são os zeros de h, ou seja, podemos escrever
h′(x) = 0⇔ x =1√3∨ x = − 1√
3
e calcular h(±1/√
3) = ±3√
3/8. Consequentemente,
‖Jg(z)‖∞ =3√
3
8≈ 0.649519 < 1
Neste caso, g é contractiva em R2. O método do ponto fixo associado a esta função g é o seguinte:x(i+1)1 = 0.5
1+(x(i)1 +x
(i)2 )2
x(i+1)2 = 0.5
1+(x(i)1 −x
(i)2 )2
Se partirmos de x(0) = (0, 0, 0)T e calcularmos, por exemplo, três iteradas vem:
• 1a iterada (i = 0): x(1)1 = 0.5
1+(x(0)1 +x
(0)2 )2
= 0.5000
x(1)2 = 0.5
1+(x(0)1 −x
(0)2 )2
= 0.5000

176 CAPÍTULO 6. SISTEMAS NÃO LINEARES
• 2a iterada (i = 1): x(2)1 = 0.5
1+(x(1)1 +x
(1)2 )2
= 0.1250
x(2)2 = 0.5
1+(x(1)1 −x
(1)2 )2
= 0.5000
• 3a iterada (i = 2): x(3)1 = 0.5
1+(x(2)1 +x
(2)2 )2
= 0.1893
x(3)2 = 0.5
1+(x(2)1 −x
(2)2 )2
= 1.2800
Para obter uma estimativa do erro da terceira iterada procedemos do seguinte modo:
‖z− x(3)‖∞ ≤‖Jg(z)‖∞
1− ‖Jg(z)‖∞‖x(3) − x(2)‖∞
ou seja,
‖z− x(3)‖∞ ≤ 3√
3/8
1− 3√
3/8‖(0.1893, 1.2800)T − (0.1250, 0.5000)T‖∞
=3√
3/8
1− 3√
3/8‖(0.0643, 0.7800)T‖∞
=3√
3/8
1− 3√
3/8(0.7800) = 1.4455
6.2.1 Convergência do método de Newton
No caso do método de Newton tem-se
g(x) = x− [Jf (x)]−1f(x)
Esta equação também pode escrever-se na forma
Jf (x)[g(x)− x] = −f(x) (6.10)
Assumindo que f tem primeiras e segundas derivadas contínuas, podemos utilizar o desenvolvi-
mento em série de Taylor e escrever:
0 = f(z) = f(x + z− x) =
= f(x) + Jf (x)(z− x) +O(‖z− x‖2)
Substituindo (6.10) na equação anterior vem
0 = Jf (x)[−(g(x)− x) + (z− x)] +O(‖z− x‖2)

6.2. MÉTODO DO PONTO FIXO PARA SISTEMAS 177
ou seja,
Jf (x)[g(x)− z] = O(‖z− x‖2)
Consequentemente,
‖g(x)− z‖ ≤ c ‖[Jf (x)]−1‖‖z− x‖2
para alguma constante c. Se Jf (z) for invertível, e como Jf (x) é contínua por hipótese, é possível
encontrar números positivos δ e M tal que [Jf (x)]−1 existe para todo o x numa vizinhança δ de z
e tal que
‖[Jf (x)]−1‖ ≤M
Em seguida, escolhendo ε como o menor dos valores δ e (Mc)−1, tem-se que, para todo o x no
conjunto
S = x : ‖z− x‖ ≤ ε
se verifica
‖g(x)− z‖ ≤Mc‖z− x‖2 ≤ (Mcε)‖z− x‖
Por conseguinte, g transforma o conjunto nele próprio. Além disso, se ‖z − x‖ < ε, então K =
Mc‖z − x‖ < 1. Logo, z é um ponto fixo de g e se escolhermos um vector inicial x(0) numa
vizinhança ε de z, o método irá convergir para z.
O seguinte teorema foi demonstrado por Leonid Kantorovich em 1940 e dá condições sufi-
cientes de convergência para o método de Newton generalizado convergir. Nele aparece a noção
de conjunto convexo. Um subconjunto S de um espaço vectorial real é convexo quando qualquer
que seja o segmento de recta que ligue dois pontos pertencentes a S ele está contido em S. Ou
seja, S diz-se convexo se, para todo o x,y ∈ S e todo o t ∈ [0; 1], o ponto (1− t)x + ty ∈ S. Num
espaço Euclidiano, diz-se que um conjunto é convexo se para quaisquer par de pontos dentro
doo conjunto, qualquer ponto pertencente ao segmento de recta que os junta também pertence ao
conjunto. Por exemplo, uma esfera ou um cubo são convexos. Por outro lado, qualquer conjunto
que tenha um buraco não é convexo.
Teorema 4 (Kantorovich) Seja D ⊂ Rn um conjunto aberto e convexo e f ∈ C1(D). Suponha-se que para
alguma norma em Rn e algum x(0) ∈ D são verificadas as seguintes condições:
1. det (Jf (x)) 6= 0 para qualquer x ∈ D e existe M1 > 0 tal que
‖[Jf (x)]−1‖ ≤ 1
M1
para qualquer x ∈ D.

178 CAPÍTULO 6. SISTEMAS NÃO LINEARES
2. Existe uma constante M2 > 0 tal que
‖Jf (x)− Jf (y)‖ ≤M2‖x− y‖
para quaisquer x,y ∈ D.
3. Sendo
ε0 := 2‖[Jf (x)]−1f(x(0))‖ = 2‖x(1) − x(0)‖ e K :=M2
2M1
,
verifica-se a desigualdade
1 < ε0 <1
2.
4. Toda a bola B(x(0), ε0) está contida em D, B(x(0), ε0) ⊂ D.
Então:
1. f tem um único zero z ∈ B(x(0), ε0);
2. a sucessão do método de Newton com vector inicial x(0) converge para z;
3. verifica-se a estimativa de erro a priori
‖z− x(i)‖ ≤ 1
K(Kε0)
2i
Se f ∈ C2(D), a condição 2 pode substituir-se por:
2. Existe M2 > 0 tal que ‖Hfi(x)‖ ≤ M2, para qualquer x ∈ D e qualquer i ∈ 1, 2, . . . , n,
onde fi designa a i-ésima componente de f e Hfi é a matriz Hessiana de fi, com componentes
(Hfi)jk =∂2fi
∂xj∂xk
6.2.2 Problemas
1. Considere o sistema de equações não-lineares−3x1 + x22 + x23 = 0
x21 − 3x2 + x23 = 0
x21 + x22 − 3x3 − 1 = 0
(a) Mostre que o sistema tem uma solução única z no conjunto
D =
x ∈ R3 : ‖x‖∞ ≤
1
3
.

6.2. MÉTODO DO PONTO FIXO PARA SISTEMAS 179
(b) Obtenha um valor aproximado x(2) para a solução do sistema usando duas iteradas
do método do ponto fixo partindo da condição inicial x(0) = (0, 0, 0)T . Apresente uma
estimativa do erro ‖z− x(2)‖∞.
2. Considere o sistema de equações não-lineares 2x1 − cos(x1 + x2) = 2
3x2 − sin(x1 + x2) = 6
(a) Mostre que o sistema tem uma solução única z no conjunto
D =
[1
2,3
2
]×[
5
3,7
3
],
e que esta é também a única raiz do sistema em R2.
(b) Obtenha um valor aproximado x(2) para a solução única z do sistema usando duas
iteradas do método do ponto fixo partindo da condição inicial x(0) = (1, 2)T . Apresente
uma estimativa do erro ‖z− x(2)‖1.
(c) Obtenha um valor aproximado x(2) para a solução única z do sistema usando duas ite-
radas do método de Newton generalizado partindo da condição inicial x(0) = (1, 2)T .
Apresente uma estimativa do erro ‖z − x(2)‖1. Nota: utilize um método à sua escolha
para resolver o sistema linear que ocorre na aplicação do método de Newton generali-
zado.
3. Considere o sistema de equações não-lineares x1 − 14x2 cosx1 = 0
1− x2 + |0.5x1 − 1| = 0
(a) Mostre que o sistema tem uma e uma só solução z ∈ [0, 1]× [1, 2].
(b) Determine uma aproximação da solução pelo método do ponto fixo cujo erro absoluto
seja inferior a 0.05.
4. Considere o sistema de equações2x1 + x2 + ε cosx3 = 0
x1 + 3x2 + 3εx1x3 = 0
εx21 + x2 + 3x3
(a) Mostre que para 0 < ε < 1/2 o sistema tem uma solução única z no conjunto
D =
x = (x1, x2, x3)
T ∈ R3 : |xi| <1
2, i = 1, 2, 3

180 CAPÍTULO 6. SISTEMAS NÃO LINEARES
(b) Usando a função iteradora
g(x1, x2, x3) =
(−1
2(x2 + ε cosx3),
1
3(x1 + 3εx1x3),−
1
3(x2 + εx21)
)mostre que, aplicando o método do ponto fixo, se tem
‖z− x(m)‖∞ ≤5m
6m−1‖x(1) − x(0)‖∞
qualquer que seja o vector inicial x(0) ∈ D.
(c) No caso ε = 0, mostre que o método de Jacobi converge e que temos
‖x(m)‖∞ ≤(
1
2
)m‖x(0)‖∞
para qualquer x(0) ∈ R3.

Capítulo 7
Método dos Mínimos quadrados
Regressão é uma técnica utilizada para descobrir uma relação matemática (função mate-
mática) entre uma ou mais variáveis utilizando um conjunto de pontos individuais. O tipo de
regressão mais frequente é a regressão linear (ajuste de um conjunto de pontos a uma linha recta)
construída utilizando o método dos mínimos quadrados. No método dos mínimos quadrados,
a função aproximadora escolhida é aquela que minimiza a soma dos quadrados das distâncias
entre todas as funções de um determinado tipo (classe) e o conjunto dos pontos experimentais.
Na teoria da aproximação existem dois tipos de problemas no ajuste de curvas a conjuntos de
pontos. O primeiro é descobrir uma curva que passe nos diversos pontos (por exemplo, a inter-
polação polinomial apresentada no Capítulo 8). O outro problema consiste em descobrir a melhor
curva que pode ser utilizada para representar os dados, embora possa não passar por eles. O mé-
todo dos mínimos quadrados é utilizado para resolver este tipo de problema. Se a função obtida
representar convenientemente os dados, então ela pode ser utilizada para previsão.
Dado um conjunto de pontos (xi, yi) podemos não conseguir, ou não fazer sentido, encontrar
uma função que passe em todos os pontos experimentais. Nesse caso, podemos tentar encontrar
uma função com uma determinada forma que passe tão próximo quanto possível dos pontos.
Este tipo de situação acontece com frequência quando a relação entre a resposta y e a variável
explicativa x é uma relação estatística. Quando os dados estão afectados por uma componente
aleatória, então as observações tendem a não cair directamente na curva. Por exemplo, considere-
se os pontos experimentais representados na Figura 7.1. Eles representam o resultado de uma
experiência que consiste em relacionar a massa muscular com a idade. Para isso um médico
mediu a massa muscular em dezasseis indivíduos, do mesmo sexo, entre os quarenta e os oitenta
181
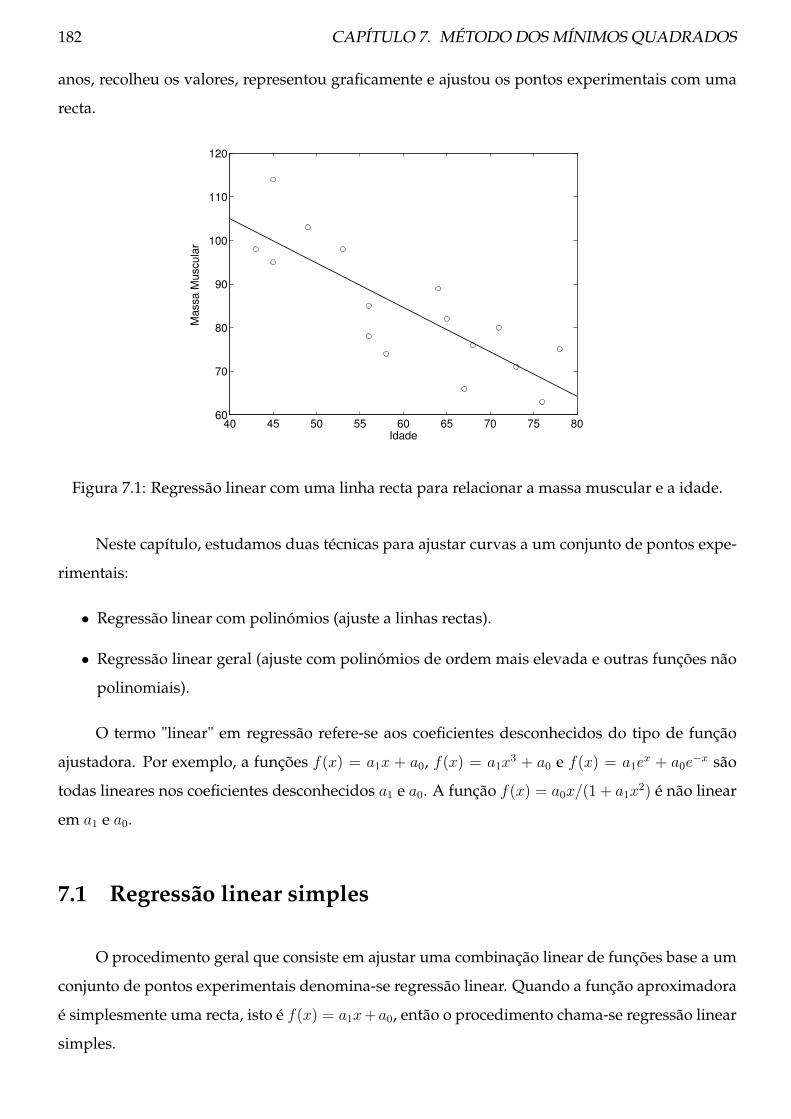
182 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
anos, recolheu os valores, representou graficamente e ajustou os pontos experimentais com uma
recta.
40 45 50 55 60 65 70 75 8060
70
80
90
100
110
120
Idade
Ma
ssa
Mu
scu
lar
Figura 7.1: Regressão linear com uma linha recta para relacionar a massa muscular e a idade.
Neste capítulo, estudamos duas técnicas para ajustar curvas a um conjunto de pontos expe-
rimentais:
• Regressão linear com polinómios (ajuste a linhas rectas).
• Regressão linear geral (ajuste com polinómios de ordem mais elevada e outras funções não
polinomiais).
O termo "linear" em regressão refere-se aos coeficientes desconhecidos do tipo de função
ajustadora. Por exemplo, a funções f(x) = a1x + a0, f(x) = a1x3 + a0 e f(x) = a1e
x + a0e−x são
todas lineares nos coeficientes desconhecidos a1 e a0. A função f(x) = a0x/(1 + a1x2) é não linear
em a1 e a0.
7.1 Regressão linear simples
O procedimento geral que consiste em ajustar uma combinação linear de funções base a um
conjunto de pontos experimentais denomina-se regressão linear. Quando a função aproximadora
é simplesmente uma recta, isto é f(x) = a1x+a0, então o procedimento chama-se regressão linear
simples.
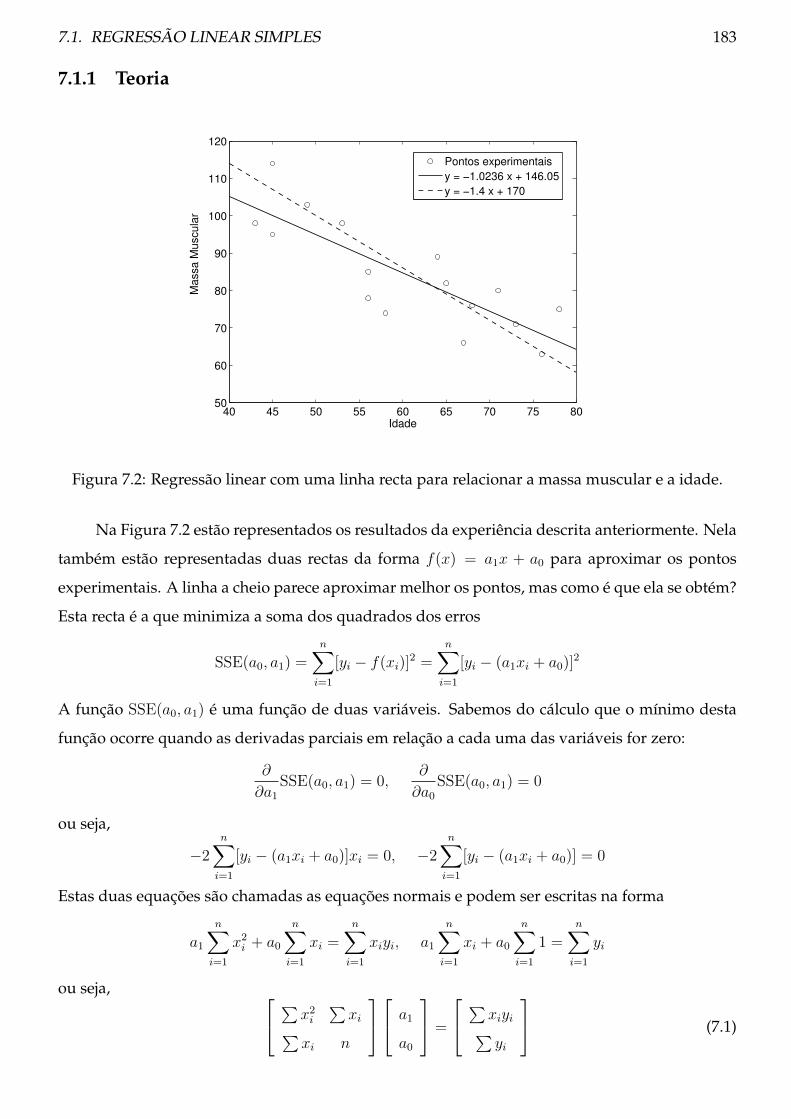
7.1. REGRESSÃO LINEAR SIMPLES 183
7.1.1 Teoria
40 45 50 55 60 65 70 75 8050
60
70
80
90
100
110
120
Idade
Ma
ssa
Mu
scu
lar
Pontos experimentais
y = −1.0236 x + 146.05
y = −1.4 x + 170
Figura 7.2: Regressão linear com uma linha recta para relacionar a massa muscular e a idade.
Na Figura 7.2 estão representados os resultados da experiência descrita anteriormente. Nela
também estão representadas duas rectas da forma f(x) = a1x + a0 para aproximar os pontos
experimentais. A linha a cheio parece aproximar melhor os pontos, mas como é que ela se obtém?
Esta recta é a que minimiza a soma dos quadrados dos erros
SSE(a0, a1) =n∑i=1
[yi − f(xi)]2 =
n∑i=1
[yi − (a1xi + a0)]2
A função SSE(a0, a1) é uma função de duas variáveis. Sabemos do cálculo que o mínimo desta
função ocorre quando as derivadas parciais em relação a cada uma das variáveis for zero:
∂
∂a1SSE(a0, a1) = 0,
∂
∂a0SSE(a0, a1) = 0
ou seja,
−2n∑i=1
[yi − (a1xi + a0)]xi = 0, −2n∑i=1
[yi − (a1xi + a0)] = 0
Estas duas equações são chamadas as equações normais e podem ser escritas na forma
a1
n∑i=1
x2i + a0
n∑i=1
xi =n∑i=1
xiyi, a1
n∑i=1
xi + a0
n∑i=1
1 =n∑i=1
yi
ou seja, ∑x2i∑xi∑
xi n
a1
a0
=
∑xiyi∑yi
(7.1)

184 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
Podemos resolver este sistema com os métodos que aprendemos no ensino secundário e obtemos
a1 =n∑xiyi −
∑xi∑yi
n∑x2i − (
∑xi)2
, a0 =
∑x2i∑yi −
∑xiyi
∑xi
n∑x2i − (
∑xi)2
Felizmente, existe uma maneira de resolver o sistema ainda mais simples através da utiliza-
ção de uma matriz denominada matriz de Vandermonde que também é utilizada na interpolação
polinomial. A matriz de Vandermonde para este problema é dada por
V =
x1 1
x2 1...
...
xn 1
(7.2)
onde n é o número de pontos experimentais (no caso do exemplo da Figura 7.2 temos n = 16).
Utilizando esta matriz podemos escrever o sistema (7.1) na forma
VTVa = VTy (7.3)
onde y = (y1, . . . , yn)T e a = (a1, a0)T . Em Matlab podemos construir facilmente a matriz de
Vandermonde e depois obter as estimativas a1 e a0:
x = [71 64 43 67 56 73 68 56 76 65 45 58 45 53 49 78]’;
y = [80 89 98 66 85 71 76 78 63 82 114 74 95 98 103 75]’;
V = [x, ones(size(x))];
coef = V \ y % o mesmo que coef =(V’ * V) \ (V’ * y)
O retorno é
coef = -1.0236e+000
1.4605e+002
Podemos observar que a primeira coluna de V contém os valores da função φ1(x) = x nos
pontos experimentais e que a segunda coluna de V contém os valores da função φ0(x) = 1 nos
ponto experimentais. Além disso, observamos que φ1(x) = x e φ0(x) = 1 são as funções base
do espaço constituído por todos os polinómios de grau menor ou igual a um. Pensando neste
contexto, podemos escrever
VTy =
∑xiyi∑xi
=
(x, y)
(1, y)
=
(φ1, y)
(φ0, y)

7.1. REGRESSÃO LINEAR SIMPLES 185
onde (., .) representa o produto interno associado à norma 2:
(g, h) =n∑i=1
g(xi)h(xi) (7.4)
Também podemos observar que
VTV =
(x, x) (x, 1)
(1, x) (1, 1)
=
(φ1, φ1) (φ1, φ0)
(φ0, φ1) (φ0, φ0)
Consequentemente o sistema de equações normais pode ser escrito na forma (φ1, φ1) (φ1, φ0)
(φ0, φ1) (φ0, φ0)
a1
a0
=
(φ1, y)
(φ0, y)
(7.5)
7.1.2 Procedimento
Problema Dado um conjunto de pontos (xi, yi), com i = 1, . . . , n, encontrar a função que melhor
se ajusta a estes pontos no sentido dos mínimos quadrados.
Hipóteses O modelo pode ser representado por
yi = axi + b+ εi
onde yi é o valor da resposta no i-ésimo ponto experimental xi. a e b são os parâmetros
desconhecidos que precisam de ser estimados. εi é um erro aleatório tal que E[εi] = 0 e
Var[εi] = σ2, σ > 0 e Cov[εi, εj] = 0 para i 6= j.
Ferramentas Álgebra linear.
Processo Para encontrar a recta que melhor se ajusta a um conjunto de pontos no sentido dos
mínimos quadrados podemos proceder de duas formas diferentes:
1. Construir a matriz de Vandermonde (7.2) e resolver o sistema (7.3) para obter os esti-
madores a1 e a0.
2. Calcular os produtos internos (φi, φj) e (φi, y), com i, j = 1, 2 para obter o sistema (7.5).
Resolver o sistema para obter os estimadores a1 e a0.
Após obter a, substituir os coeficientes estimados na função, ou seja, escrever
f(x) = a1x+ a0
A primeira forma de resolver torna-se mais prática do ponto de vista computacional. Uma
alternativa a estes dois procedimentos é utilizar a rotina Matlab que faz o ajuste por este
método.
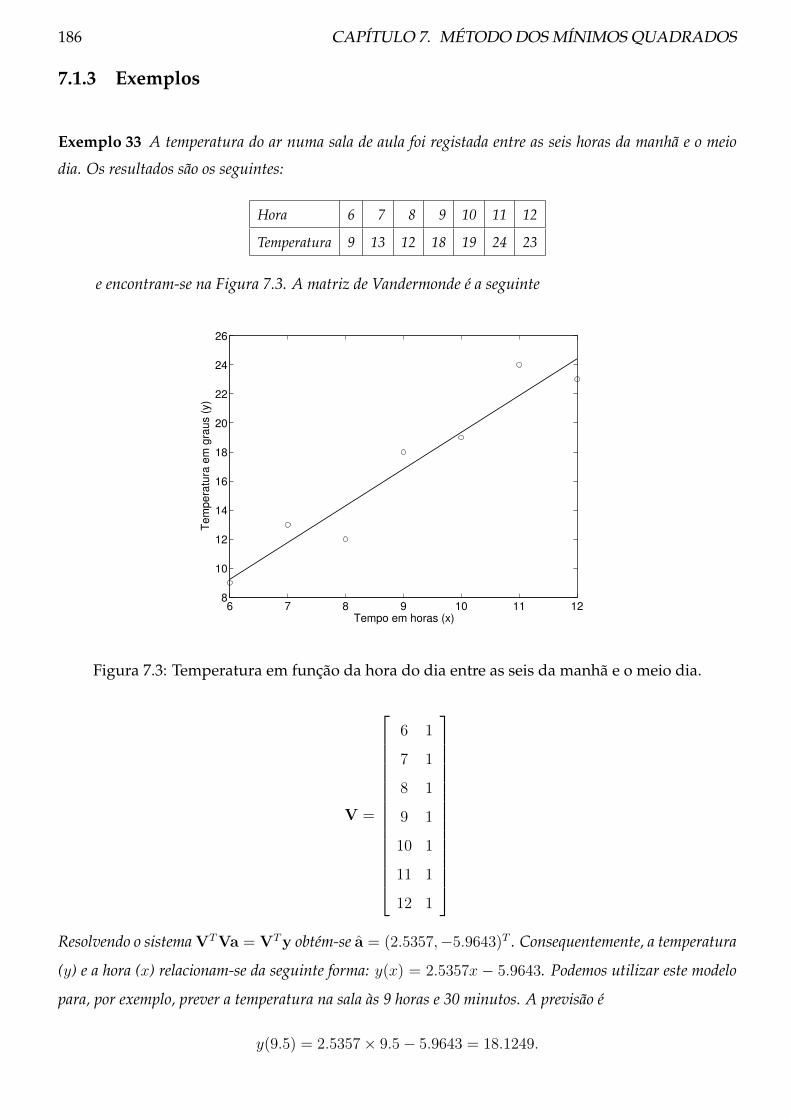
186 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
7.1.3 Exemplos
Exemplo 33 A temperatura do ar numa sala de aula foi registada entre as seis horas da manhã e o meio
dia. Os resultados são os seguintes:
Hora 6 7 8 9 10 11 12
Temperatura 9 13 12 18 19 24 23
e encontram-se na Figura 7.3. A matriz de Vandermonde é a seguinte
6 7 8 9 10 11 128
10
12
14
16
18
20
22
24
26
Tempo em horas (x)
Te
mp
era
tura
em
gra
us (
y)
Figura 7.3: Temperatura em função da hora do dia entre as seis da manhã e o meio dia.
V =
6 1
7 1
8 1
9 1
10 1
11 1
12 1
Resolvendo o sistema VTVa = VTy obtém-se a = (2.5357,−5.9643)T . Consequentemente, a temperatura
(y) e a hora (x) relacionam-se da seguinte forma: y(x) = 2.5357x − 5.9643. Podemos utilizar este modelo
para, por exemplo, prever a temperatura na sala às 9 horas e 30 minutos. A previsão é
y(9.5) = 2.5357× 9.5− 5.9643 = 18.1249.

7.1. REGRESSÃO LINEAR SIMPLES 187
À uma da tarde, a previsão
y(13) = 2.5357× 13− 5.9643 = 26.9998.
Exemplo 34 Um médico mediu a massa muscular num conjunto de indivíduos do mesmo sexo e registou
a informação seguinte:
Hora 71 64 43 67 56 73 68 56 76 65 45 58 45 53 49 78
Temperatura 82 91 100 68 87 73 78 80 65 84 116 76 97 100 105 77
A matriz de Vandermonde é a seguinte
V =
71 64 43 67 56 73 68 56 76 65 45 58 45 53 49 78
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
T
Resolvendo o sistema VTVa = VTy obtém-se a = (−1.0236, 146.0507)T . Consequentemente, a massa
muscular (y) e a idade (x) relacionam-se da seguinte forma: y(x) = −1.0236x+ 146.0507. De acordo com
esta informação, uma pessoa com 40 anos terá uma massa muscular igual a −1.0236 × 40 + 146.0507 =
105.1067 quilogramas por metro quadrado.
Uma estimativa do erro de aproximação é
SSE(a) =16∑i=0
[yi − (−1.0236x+ 146.0507)]2 = 1038.7
7.1.4 Problemas
1. Encontrar a recta que melhor se ajusta no sentido dos mínimos quadrados aos pontos da
tabela seguinte
xi 59 49 75 54 78
yi 209 180 195 192 215
Dê uma estimativa do erro da aproximação.
2. Encontrar a recta que melhor se ajusta no sentido dos mínimos quadrados aos pontos da
seguinte tabela:
xi 0.282 0.555 0.089 0.157 0.357 0.572 0.222 0.800 0.266 0.056
yi 0.685 0.563 0.733 0.722 0.662 0.588 0.693 0.530 0.650 0.713

188 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
7.2 Regressão linear geral
Na secção anterior apresentou-se o caso em que ajustamos uma recta a um conjunto de
pontos no sentido dos mínimos quadrados. Nesta secção, vamos considerar o caso geral em que
a função aproximadora é linear nos parâmetros desconhecidos.
7.2.1 Teoria
Considere que a função aproximadora pertence a uma classe de funções que podem ser
representadas como uma combinação linear das função base φ0, φ1, ..., φm:
f(x) =m∑j=0
ajφj(x) (7.6)
onde a0, a1, ..., am são constantes reais. A função f que aproxima o conjunto de pontos (xi, yi),
com i = 1, . . . , n é aquela que minimiza a distância Euclidiana entre os pontos e os elementos da
sua classe. A distância entre os pontos e uma função da forma (7.6) é dada por
d(y, f) = ‖y − f‖2 =
(n∑i=1
[yi − f(xi)]2
)1/2
O conjunto de constantes a0, a1, ..., am que minimiza esta norma é o mesmo que minimiza a soma
dos quadrados dos erros
SSE(a) = ‖y − f‖22 =n∑i=1
[yi − f(xi)]2
A norma Euclidiana é induzida por um produto interno e, consequentemente, pode ser definida
por ‖g‖2 = (g, g)1/2 em que (., .) é o produto interno (7.4).
O mínimo de SSE(a) obtém-se derivando em ordem a cada constante desconhecida e igua-
lando a zero:∂
∂ajSSE(a) = 0, j = 0, 1, 2, . . . ,m.
Esta equação é equivalente a
−2n∑i=1
[yi − f(xi)]∂
∂ajf(xi) = 0, j = 0, 1, 2, . . . ,m.
Mas∂
∂ajf(xi) = φj(xi)

7.2. REGRESSÃO LINEAR GERAL 189
logon∑i=1
[yi − f(xi)]φj(xi) = 0, j = 0, 1, 2, . . . ,m.
Uma vez que (7.6) se verifica podemos escrever a equação anterior na forma:
a0
n∑i=1
φ0(xi)φj(xi)+a1
n∑i=1
φ1(xi)φj(xi)+. . .+am
n∑i=1
φm(xi)φj(xi) =n∑i=1
yiφj(xi), j = 0, 1, 2, . . . ,m.
Esta equação escrita em termos de produtos internos é a seguinte:
a0(φ0, φj) + a1(φ1, φj) + . . .+ am(φm, φj) = (y, φj), j = 0, 1, 2, . . . ,m.
o que dá origem ao sistema de equações normais(φ0, φ0) (φ0, φ1) . . . (φ0, φm)
(φ1, φ0) (φ1, φ1) . . . (φ1, φm)...
......
(φm, φ0) (φm, φ1) . . . (φm, φm)
a0
a1...
am
=
(y, φ0)
(y, φ1)...
(y, φm)
(7.7)
A matriz do sistema normal pode-se escrever como o produto VTV em que V é a matriz de
Vandermonde
V =
φ0(x1) φ1(x1) . . . φm(x1)
φ0(x2) φ1(x2) . . . φm(x2)...
......
φ0(xn) φ1(xn) . . . φm(xn)
(7.8)
Consequentemente, o sistema normal pode escrever-se como em (7.3) em que neste caso a matriz
de Vandermonde é dada por (7.8) e y = (y1, y2, . . . , yn)T .
Quando a função aproximadora é um polinómio de grau menor ou igual a m,
f(x) = a0 + a1x+ a2x2 + . . .+ amx
m
então a matriz de Vandermonde é dada por
V =
1 x1 x21 . . . xm1
1 x2 x22 . . . xm2...
......
...
1 xn x2n . . . xmn
(7.9)
e o sistema de equações normais tem a forman
∑ni=1 xi
∑ni=1 x
2i . . .
∑ni=1 x
mi∑n
i=1 xi∑n
i=1 x2i
∑ni=1 x
3i . . .
∑ni=1 x
m+1i
......
......∑n
i=1 xmi
∑ni=1 x
m+1i
∑ni=1 x
m+2i . . .
∑ni=1 x
2mi
a0
a1...
am
=
∑ni=1 yi∑ni=1 xiyi
...∑ni=1 x
mi yi

190 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
Uma forma de melhorar as propriedades numéricas do polinómio e do algoritmo de ajuste
consiste em centrar e escalar os valores da variável independente:
xi =xi − xσx
onde x =∑n
i=1 xi/n e σx =∑n
i=1(xi − x)2/(n − 1) é a média e o desvio padrão das observações
x1, x2 . . . , xn, respectivamente. Ao fazer o ajuste pode acontecer haver problemas de mau condi-
cionamento de matrizes. Nessas situações é frequente o problema resolver-se com o escalamento
e centramento. O escalamento faz com que todas as observações estejam em pé de igualdade em
relação à sua variação nos dados.
7.2.2 Procedimento
Problema Pretende-se ajustar uma função da forma (7.6) a um conjunto de pontos (xi, yi) pelo
método dos mínimos quadrados.
Hipóteses O modelo pode ser representado por
yi = f(xi) + εi
onde yi é o valor da resposta no i-ésimo ponto experimental xi. A função f(x) é da forma
(7.6) onde a são os parâmetros desconhecidos que precisam de ser estimados. εi é um erro
aleatório tal que E[εi] = 0 e Var[εi] = σ2, σ > 0 e Cov[εi, εj] = 0 para i 6= j.
Ferramentas Álgebra linear.
Processo Tal como no caso da regressão linear simples, também aqui podemos proceder de duas
formas diferentes:
1. Construir a matriz de Vandermonde (7.8) e resolver o sistema (7.3) para obter os esti-
madores a.
2. Cálcular os produtos internos (φk, φj) e (φk, y), com k, j = 1, 2, . . . ,m para obter o sis-
tema (7.7). Resolver o sistema para obter os estimadores a.
Após obter a, substituir os coeficientes estimados na função, ou seja, escrever
f(x) = a0φ0(x) + a1φ1(x) + . . .+ amφm(x).
A primeira forma de resolver torna-se mais prática do ponto de vista computacional. Uma
alternativa a estes dois procedimentos é utilizar a rotina Matlab que faz o ajuste por este
método.
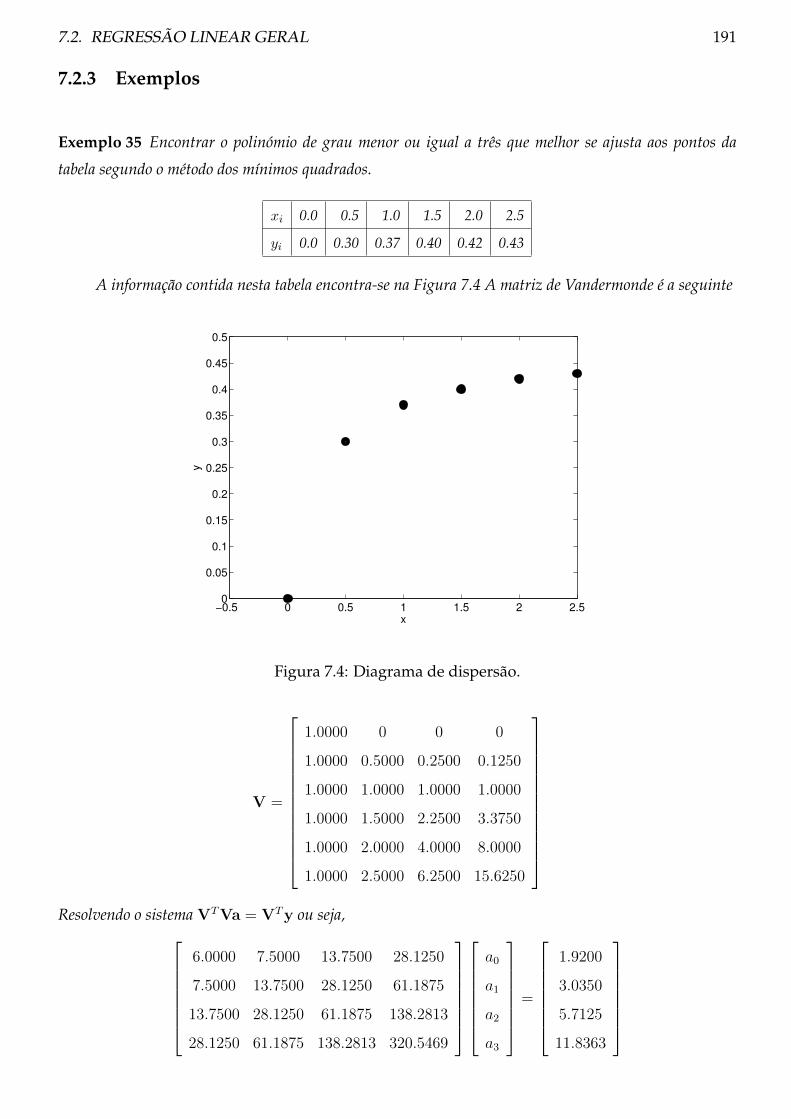
7.2. REGRESSÃO LINEAR GERAL 191
7.2.3 Exemplos
Exemplo 35 Encontrar o polinómio de grau menor ou igual a três que melhor se ajusta aos pontos da
tabela segundo o método dos mínimos quadrados.
xi 0.0 0.5 1.0 1.5 2.0 2.5
yi 0.0 0.30 0.37 0.40 0.42 0.43
A informação contida nesta tabela encontra-se na Figura 7.4 A matriz de Vandermonde é a seguinte
−0.5 0 0.5 1 1.5 2 2.50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
x
y
Figura 7.4: Diagrama de dispersão.
V =
1.0000 0 0 0
1.0000 0.5000 0.2500 0.1250
1.0000 1.0000 1.0000 1.0000
1.0000 1.5000 2.2500 3.3750
1.0000 2.0000 4.0000 8.0000
1.0000 2.5000 6.2500 15.6250
Resolvendo o sistema VTVa = VTy ou seja,
6.0000 7.5000 13.7500 28.1250
7.5000 13.7500 28.1250 61.1875
13.7500 28.1250 61.1875 138.2813
28.1250 61.1875 138.2813 320.5469
a0
a1
a2
a3
=
1.9200
3.0350
5.7125
11.8363
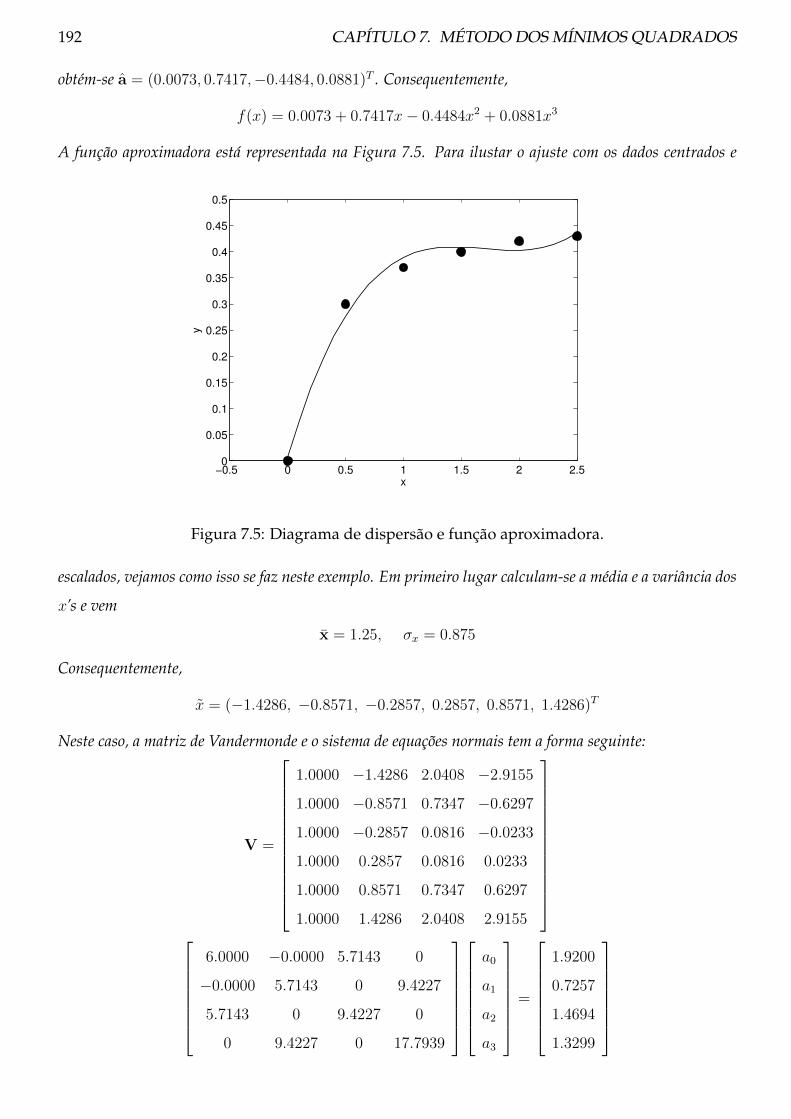
192 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
obtém-se a = (0.0073, 0.7417,−0.4484, 0.0881)T . Consequentemente,
f(x) = 0.0073 + 0.7417x− 0.4484x2 + 0.0881x3
A função aproximadora está representada na Figura 7.5. Para ilustar o ajuste com os dados centrados e
−0.5 0 0.5 1 1.5 2 2.50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
x
y
Figura 7.5: Diagrama de dispersão e função aproximadora.
escalados, vejamos como isso se faz neste exemplo. Em primeiro lugar calculam-se a média e a variância dos
x’s e vem
x = 1.25, σx = 0.875
Consequentemente,
x = (−1.4286, −0.8571, −0.2857, 0.2857, 0.8571, 1.4286)T
Neste caso, a matriz de Vandermonde e o sistema de equações normais tem a forma seguinte:
V =
1.0000 −1.4286 2.0408 −2.9155
1.0000 −0.8571 0.7347 −0.6297
1.0000 −0.2857 0.0816 −0.0233
1.0000 0.2857 0.0816 0.0233
1.0000 0.8571 0.7347 0.6297
1.0000 1.4286 2.0408 2.9155
6.0000 −0.0000 5.7143 0
−0.0000 5.7143 0 9.4227
5.7143 0 9.4227 0
0 9.4227 0 17.7939
a0
a1
a2
a3
=
1.9200
0.7257
1.4694
1.3299

7.2. REGRESSÃO LINEAR GERAL 193
Podemos observar na Tabela 7.1 que a matriz do sistema correspondente aos dados centrados e escalados é
mais bem condicionada e, consequentemente, os resultados obtidos com esta matriz são mais fiáveis.
Tabela 7.1: Normas da matriz do sistema com e sem transformação de dados.
norma infinito norma 1 norma 2
A com x 57.4595 57.4595 40.8433
A com x 1.8680× 104 1.8680× 104 1.1603× 104
Exemplo 36 Pretende-se aproximar os valores da tabela
xi 1.0 1.3 1.6 1.9 2.1 2.5 2.98
yi 5.6 7.4 14.2 26.4 48.3 80.2 111.8
de duas formas: com um polinómio de grau 2 e com um polinómio de grau três. As matrizes de
Vandermonde são as seguintes
V2 =
1.0000 1.0000 1.0000
1.0000 1.3000 1.6900
1.0000 1.6000 2.5600
1.0000 1.9000 3.6100
1.0000 2.1000 4.4100
1.0000 2.5000 6.2500
1.0000 2.9800 8.8804
V3 =
1.0000 1.0000 1.0000 1.0000
1.0000 1.3000 1.6900 2.1970
1.0000 1.6000 2.5600 4.0960
1.0000 1.9000 3.6100 6.8590
1.0000 2.1000 4.4100 9.2610
1.0000 2.5000 6.2500 15.6250
1.0000 2.9800 8.8804 26.4636
Resolvendo o sistema VT
i Via = VTi y, com i = 2, 3, obtém-se p2(x) = 11.2620− 31.1090x+ 22.2287x2 e
p3(x) = 146.0611 − 267.0514x + 149.2682x2 − 21.2920x3. Os erros respectivos são SSE2 = 161.5663 e
SSE3 = 43.5824. Consequentemente, o polinómio de grau três aproxima melhor os dados do que o de grau
dois. Na Figura 7.6 podemos observar as duas aproximações.
Exemplo 37 Considere a tabela de valores
xi -2 -1 0 1 2
yi 1 2 -1 0 1
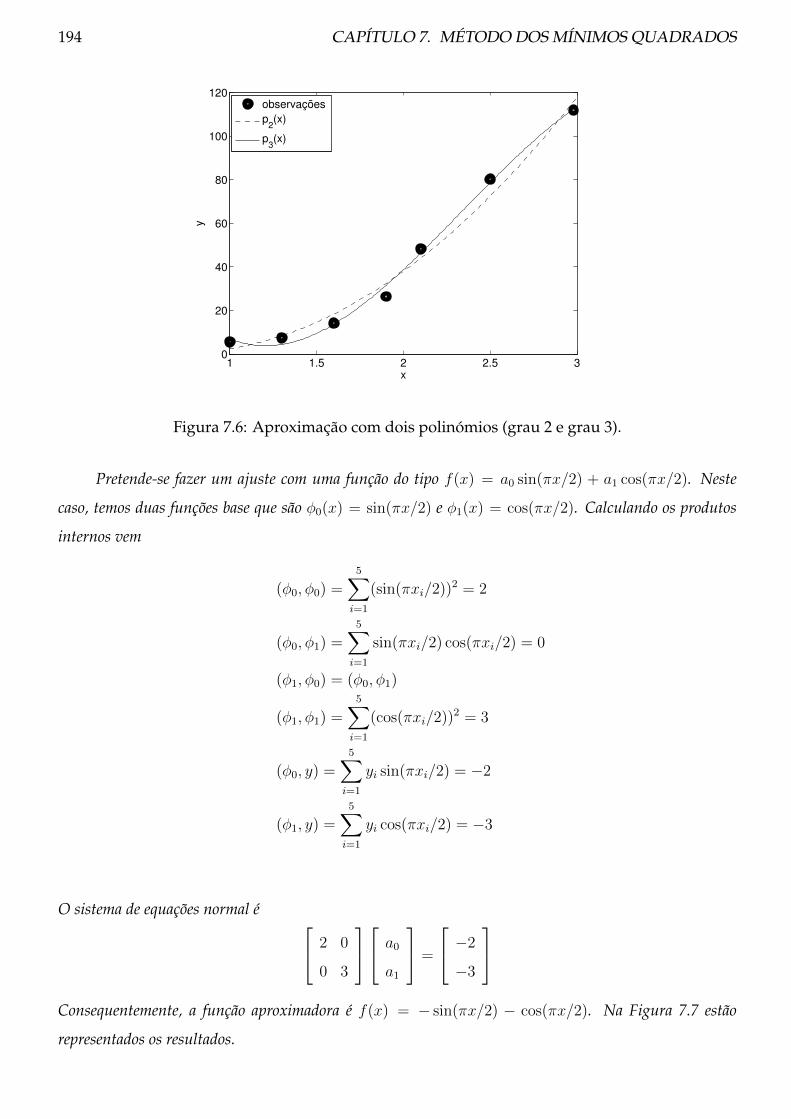
194 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
1 1.5 2 2.5 30
20
40
60
80
100
120
x
y
observações
p2(x)
p3(x)
Figura 7.6: Aproximação com dois polinómios (grau 2 e grau 3).
Pretende-se fazer um ajuste com uma função do tipo f(x) = a0 sin(πx/2) + a1 cos(πx/2). Neste
caso, temos duas funções base que são φ0(x) = sin(πx/2) e φ1(x) = cos(πx/2). Calculando os produtos
internos vem
(φ0, φ0) =5∑i=1
(sin(πxi/2))2 = 2
(φ0, φ1) =5∑i=1
sin(πxi/2) cos(πxi/2) = 0
(φ1, φ0) = (φ0, φ1)
(φ1, φ1) =5∑i=1
(cos(πxi/2))2 = 3
(φ0, y) =5∑i=1
yi sin(πxi/2) = −2
(φ1, y) =5∑i=1
yi cos(πxi/2) = −3
O sistema de equações normal é 2 0
0 3
a0
a1
=
−2
−3
Consequentemente, a função aproximadora é f(x) = − sin(πx/2) − cos(πx/2). Na Figura 7.7 estão
representados os resultados.
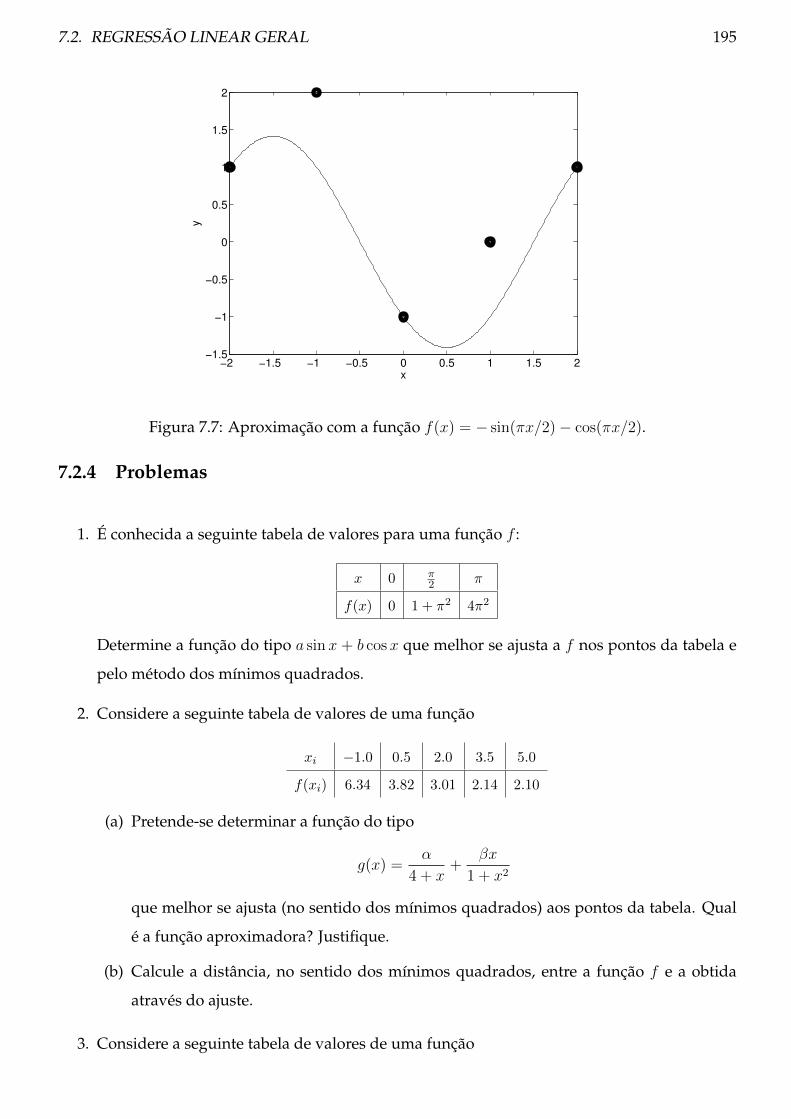
7.2. REGRESSÃO LINEAR GERAL 195
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2−1.5
−1
−0.5
0
0.5
1
1.5
2
x
y
Figura 7.7: Aproximação com a função f(x) = − sin(πx/2)− cos(πx/2).
7.2.4 Problemas
1. É conhecida a seguinte tabela de valores para uma função f :
x 0 π2 π
f(x) 0 1 + π2 4π2
Determine a função do tipo a sinx + b cosx que melhor se ajusta a f nos pontos da tabela e
pelo método dos mínimos quadrados.
2. Considere a seguinte tabela de valores de uma função
xi −1.0 0.5 2.0 3.5 5.0
f(xi) 6.34 3.82 3.01 2.14 2.10
(a) Pretende-se determinar a função do tipo
g(x) =α
4 + x+
βx
1 + x2
que melhor se ajusta (no sentido dos mínimos quadrados) aos pontos da tabela. Qual
é a função aproximadora? Justifique.
(b) Calcule a distância, no sentido dos mínimos quadrados, entre a função f e a obtida
através do ajuste.
3. Considere a seguinte tabela de valores de uma função

196 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
xi −1.0 1.0 2.0 3.0 5.0 7.0
f(xi) −1.0 1.0 −1.0 1.0 2.0 2.5
(a) Pretende-se ajustar uma função do tipo g(x) = C+D(x−3)+E(x3+1), comC,D,E ∈ R,
aos 4 primeiros pontos da tabela. Determine C,D, e E por forma a minimizar a função
SSE(C,D,E) =3∑i=0
(f(xi)− (C +D(x− 3) + E(x3 + 1)))2
(b) Calcule o erro do ajuste da alínea anterior.
4. Considere os seguintes valores para a função x(t) = (1 + t)e−t
x(−0.4) = 0.8951, x(−0.3) = 0.9449, x(−0.2) = 0.9771, x(−0.1) = 0.9947, x(0) = 1
(a) Obtenha uma aproximação desta função por um polinómio de primeiro grau usando o
método dos mínimos quadrados com os três primeiros pontos indicados.
(b) O polinómio do primeiro grau que se obteria do mesmo modo mas usando apenas os
valores x(−0.4) e x(−0.3) é dado pela expressão
p1(t) = 0.8951 + 0.498(t+ 0.4)
Justifique esta afirmação (sem repetir os cálculos do método).
5. Considere a seguinte tabela de valores de uma função
i 1 2 3 4 5
xi 1.0 1.5 2.0 2.5 3.0
f(xi) 1.01 1.24 4.00 7.26 8.98
Determine a função do tipo h(x) = αx2 + β cos(πx) que melhor se ajusta (no sentido dos
mínimos quadrados) aos pontos da tabela. Calcule a distância, no sentido dos mínimos
quadrados, entre a função f e a obtida através do ajuste.
6. Considere a seguinte tabela de valores de uma função h
x −0.5π 0 0.5π π
h(x) 2.5 3 2 3.5
Determine a função do tipo α + β cosx + τ sinx que melhor aproxima h no sentido dos
mínimos quadrados.

7.2. REGRESSÃO LINEAR GERAL 197
7. Seja f(x) = x3 + 2x+ 1, x0 = 0, x1 = 1, x2 = 2. Obtenha a aproximação de f por uma função
do tipo g(x) = ae−x + bex pelo método dos mínimos quadrados.
8. Obtenha a função h(x) = a sin(x) + b que melhor aproxima loge(x) segundo o critério dos
mínimos quadrados relativamente aos pontos 1, 2, 3.
9. Considere a seguinte tabela de valores de uma função f
xi 0 ln 2 ln 3
fi 1 3 2
Determine a função
g(x) = ea+x +1
b
que melhor se ajusta no sentido dos mínimos quadrados aos pontos da tabela.
10. Considere a tabela seguinte
xi 1.0 1.2 1.5 1.6
fi 5.44 6.64 8.96 9.91
(a) Obtenha o polinómio de grau 1, p1(x), que se ajusta aos pontos da tabela.
(b) Obtenha o polinómio de grau 2, p2(x), que se ajusta aos pontos da tabela. Qual é o valor
previsto de f no ponto x = 1.4?
(c) Admitindo que |f ′(x) − p′2(x)| ≤ M ∀x ∈ [1.2; 1.5], obtenha um majorante do erro
absoluto do valor obtido na alínea anterior. Sugestão: use o teorema de Lagrange.
(d) Relativamente aos dois casos anteriores, calcule o valor das somas dos quadrados dos
desvios correspondentes aos ajustamentos efectuados. Qual seria o valor dessa soma
no caso de fazer o ajuste com um polinómio de grau 3? Justifique.
11. Considere a tabela seguinte
xi -1.0 0.0 1.0 2.0
fi 6.0 3.0 2.0 1.0
Ajuste a função tabelada por uma função do tipo
g(x) =1
Ax+B
Calcule o erro de aproximação e a distância de f a g.
12. Determine a função do tipo g(x) = Bex + Ce−x que melhor se ajusta aos pontos da tabela

198 CAPÍTULO 7. MÉTODO DOS MÍNIMOS QUADRADOS
xi 0.0 0.5 1.0
fi 6.0 5.2 6.5
13. Seja f tal que f(−2) = 3, f(0) = 6 e f(2) = 15. Ajuste esta função por um polinómio de grau
1 e mostre que3∑i=1
[f(xi)− p1(xi)]2 ≥ 6
14. Realizou-se uma experiência onde se pretende relacionar duas quantidades x e y e recolhe-
ram-se os resultados que estão na tabela:
xi 1.0 1.5 2.0
yi 13.5 19.2 34.1
Os especialistas na área onde se realiza a experiência têm fortes razões para assumir que a
relação entre x e y é
y = ax+ bex,
onde a e b são coeficientes desconhecidos.
(a) Calcule os estimadores a e b dos coeficientes desconhecidos a e b, pelo método dos
mínimos quadrados.
(b) Calcule o erro associado à aproximação anterior:
SSE =n∑i=1
[yi − f(xi; a, b)]2
onde f(xi; a, b) é a função aproximadora obtida pelo método dos mínimos quadrados.

Capítulo 8
Interpolação
O origem da interpolação remonta aproximadamente ao ano 300 AC na antiga Babilónia.
Os babilónios usavam não apenas a interpolação linear, mas também formas mais complexas de
interpolação para prever as posições do sol, da lua e dos planetas que eles conheciam na altura. Os
agricultores eram os primeiros a usar estas previsões para planear as suas sementeiras. Também
na Grécia cerca de 150 DC, se usou a interpolação linear para construir uma função semelhante a
uma sinusoidal para calcular posições de corpos celestiais.
Cerca do ano 600 DC, os chineses usavam interpolação para construir o calendário Imperial.
No ano 625 DC, o astrónomo indiano Brahmagupta introduziu um método de interpolação de
segunda ordem da função seno e mais tarde um método de interpolação com pontos não igual-
mente espaçados. Ao longo dos tempos a interpolação tem sido utilizada para resolver os mais
diversos problemas da vida real, especialmente na navegação oceânica.
Dois dos métodos de interpolação que se apresentam nesta secção são o método de Newton
e o de Lagrange. Newton começou a trabalhar em interpolação em 1675. A fórmula de New-
ton com diferenças divididas aparece em 1676 no livro intitulado "Regula Differentiarum". Em
1795 o Lagrange publicou a fórmula intitulada com o seu nome, embora há quem afirme que o
desenvolvimento da dita fórmula se deva a Waring ou a Euler.
Dado um conjunto de pontos (xi, yi), i = 0, 1, . . . , n, pretende-se encontrar uma função,
habitualmente um polinómio, que passe em todos estes pontos. Dada a tabela de pontos
xi 0 3 6 9
yi 0 −45 −72 81
199
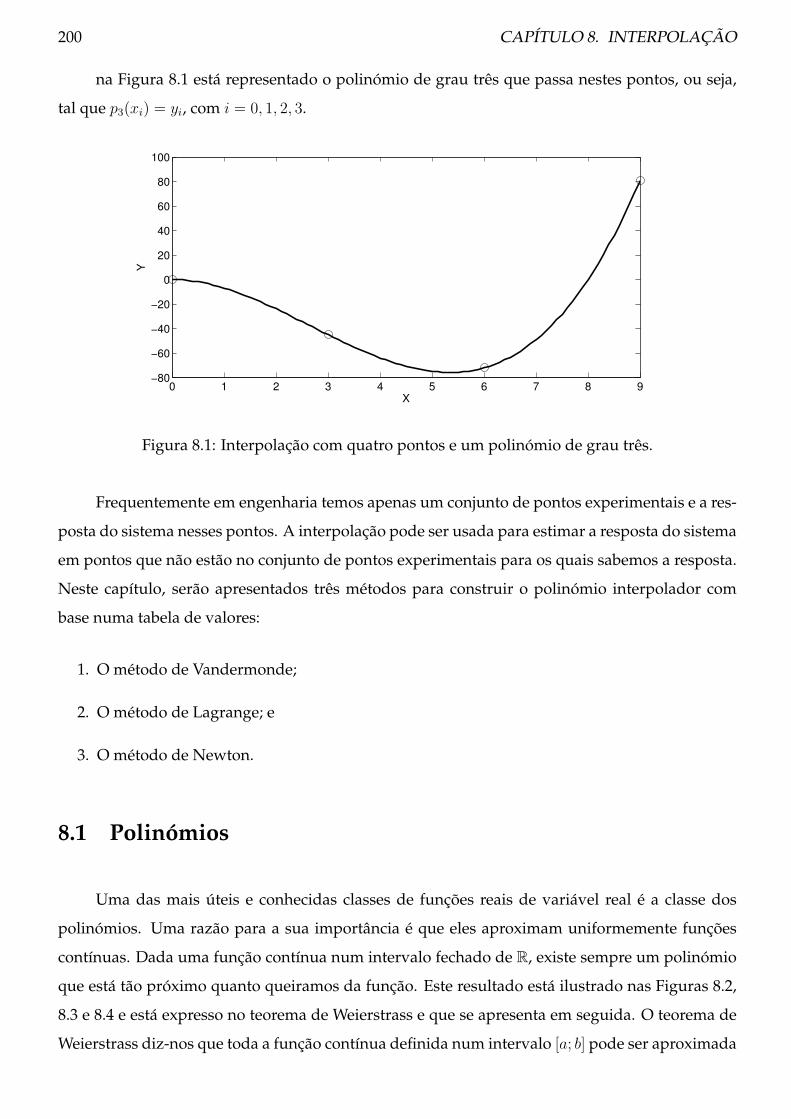
200 CAPÍTULO 8. INTERPOLAÇÃO
na Figura 8.1 está representado o polinómio de grau três que passa nestes pontos, ou seja,
tal que p3(xi) = yi, com i = 0, 1, 2, 3.
0 1 2 3 4 5 6 7 8 9−80
−60
−40
−20
0
20
40
60
80
100
X
Y
Figura 8.1: Interpolação com quatro pontos e um polinómio de grau três.
Frequentemente em engenharia temos apenas um conjunto de pontos experimentais e a res-
posta do sistema nesses pontos. A interpolação pode ser usada para estimar a resposta do sistema
em pontos que não estão no conjunto de pontos experimentais para os quais sabemos a resposta.
Neste capítulo, serão apresentados três métodos para construir o polinómio interpolador com
base numa tabela de valores:
1. O método de Vandermonde;
2. O método de Lagrange; e
3. O método de Newton.
8.1 Polinómios
Uma das mais úteis e conhecidas classes de funções reais de variável real é a classe dos
polinómios. Uma razão para a sua importância é que eles aproximam uniformemente funções
contínuas. Dada uma função contínua num intervalo fechado de R, existe sempre um polinómio
que está tão próximo quanto queiramos da função. Este resultado está ilustrado nas Figuras 8.2,
8.3 e 8.4 e está expresso no teorema de Weierstrass e que se apresenta em seguida. O teorema de
Weierstrass diz-nos que toda a função contínua definida num intervalo [a; b] pode ser aproximada
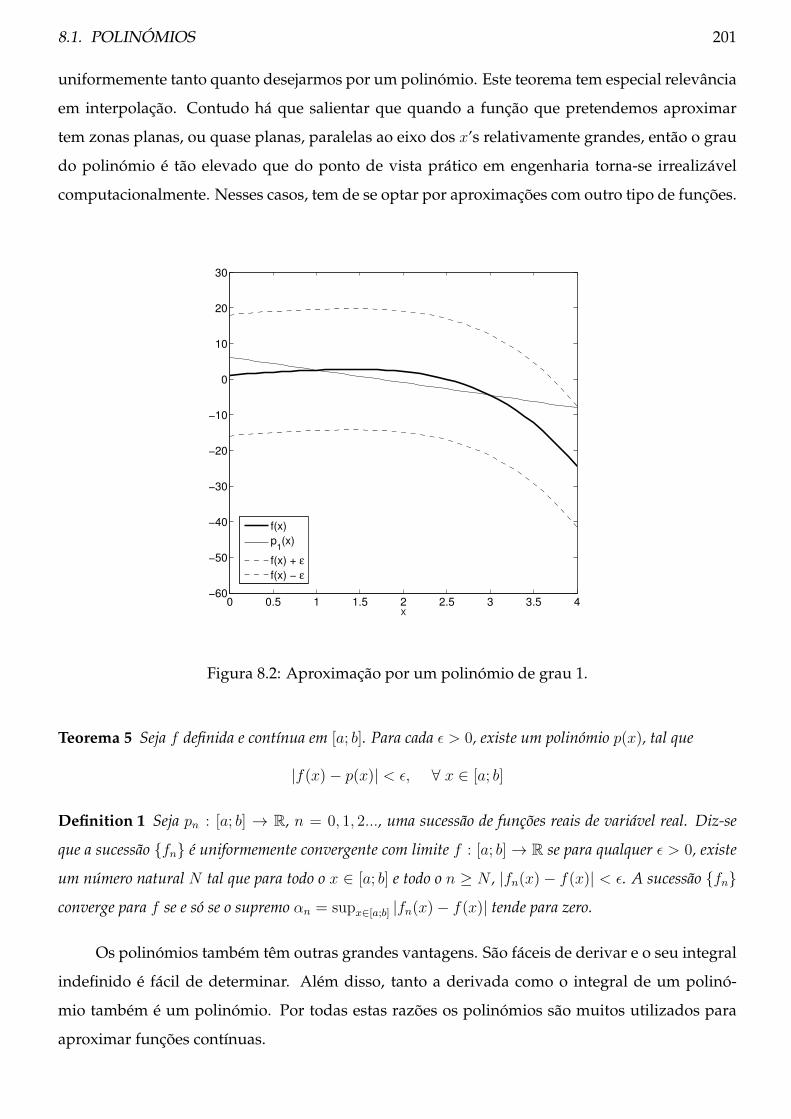
8.1. POLINÓMIOS 201
uniformemente tanto quanto desejarmos por um polinómio. Este teorema tem especial relevância
em interpolação. Contudo há que salientar que quando a função que pretendemos aproximar
tem zonas planas, ou quase planas, paralelas ao eixo dos x’s relativamente grandes, então o grau
do polinómio é tão elevado que do ponto de vista prático em engenharia torna-se irrealizável
computacionalmente. Nesses casos, tem de se optar por aproximações com outro tipo de funções.
0 0.5 1 1.5 2 2.5 3 3.5 4−60
−50
−40
−30
−20
−10
0
10
20
30
X
f(x)
p1(x)
f(x) + ε
f(x) − ε
Figura 8.2: Aproximação por um polinómio de grau 1.
Teorema 5 Seja f definida e contínua em [a; b]. Para cada ε > 0, existe um polinómio p(x), tal que
|f(x)− p(x)| < ε, ∀ x ∈ [a; b]
Definition 1 Seja pn : [a; b] → R, n = 0, 1, 2..., uma sucessão de funções reais de variável real. Diz-se
que a sucessão fn é uniformemente convergente com limite f : [a; b]→ R se para qualquer ε > 0, existe
um número natural N tal que para todo o x ∈ [a; b] e todo o n ≥ N , |fn(x)− f(x)| < ε. A sucessão fn
converge para f se e só se o supremo αn = supx∈[a;b] |fn(x)− f(x)| tende para zero.
Os polinómios também têm outras grandes vantagens. São fáceis de derivar e o seu integral
indefinido é fácil de determinar. Além disso, tanto a derivada como o integral de um polinó-
mio também é um polinómio. Por todas estas razões os polinómios são muitos utilizados para
aproximar funções contínuas.
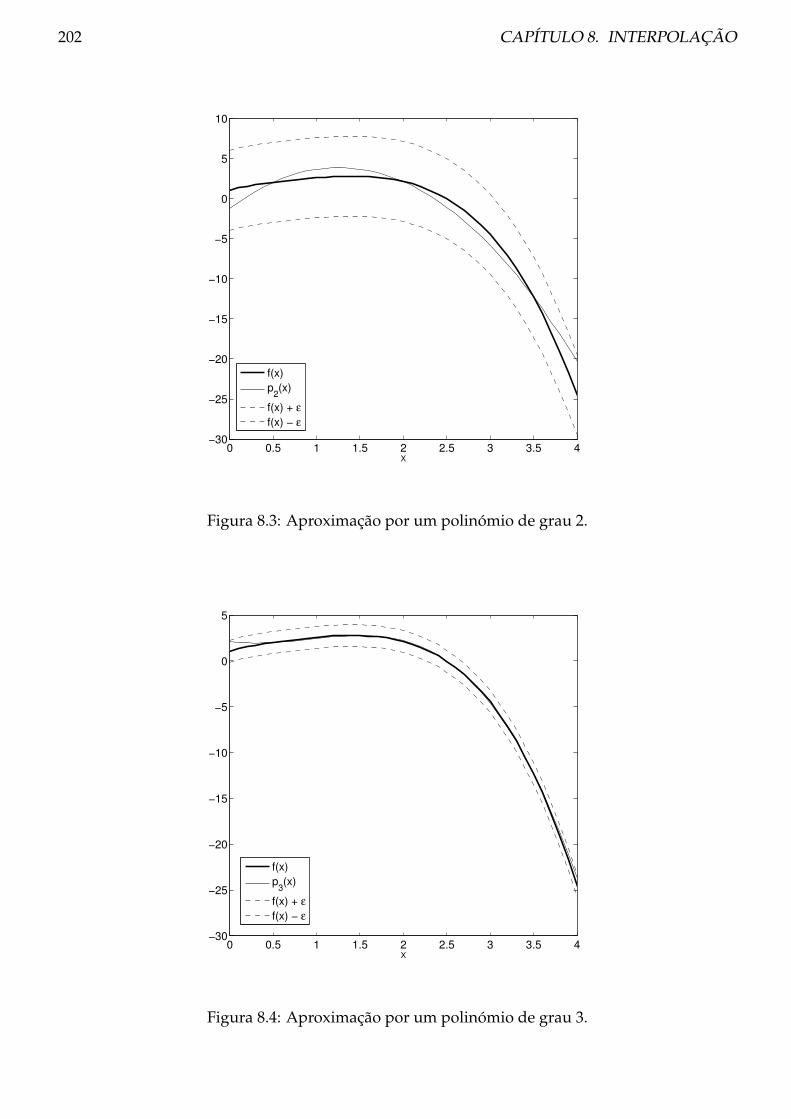
202 CAPÍTULO 8. INTERPOLAÇÃO
0 0.5 1 1.5 2 2.5 3 3.5 4−30
−25
−20
−15
−10
−5
0
5
10
X
f(x)
p2(x)
f(x) + ε
f(x) − ε
Figura 8.3: Aproximação por um polinómio de grau 2.
0 0.5 1 1.5 2 2.5 3 3.5 4−30
−25
−20
−15
−10
−5
0
5
X
f(x)
p3(x)
f(x) + ε
f(x) − ε
Figura 8.4: Aproximação por um polinómio de grau 3.

8.1. POLINÓMIOS 203
Na Secção 3.1 falou-se nos polinómios de Taylor para aproximar funções contínuas e vimos
que a série de Taylor é uma das ferramentas fundamentais em análise numérica. Contudo, a
interpolação polinomial não utiliza os polinómios de Taylor. Os polinómios de Taylor aproximam
bem uma função apenas num ponto específico; concentram a sua precisão num ponto. Um bom
polinómio interpolador deve aproximar relativamente bem a função em todos os pontos de um
intervalo e os polinómios de Taylor, em geral, não são capazes de fazer isso.
Por exemplo, se pensarmos na função f(x) = ex, o seu desenvolvimento em série de Taylor
em torno do ponto x0 = 0 é
ex = 1 + x+x2
2!+x3
3!+ . . .+
xn
n!+
xn+1eξ
(n+ 1)!
onde ξ ∈ int(x, 0). Os polinómios de Taylor são os seguintes:
p0(x) = 1,
p1(x) = 1 + x,
p2(x) = 1 + x+ x2
2,
p3(x) = 1 + x+ x2
2+ x3
3!,
p4(x) = 1 + x+ x2
2+ x3
3!+ x4
4!,
...
A representação gráfica destes polinómios encontra-se na Figura 8.5. A aproximação torna-se
cada vez pior à medida que nos afastamos do ponto x = 0. Contudo, à medida que o grau do
polinómio aumenta, a aproximação fica cada vez melhor, ou seja, o polinómio fica cada vez mais
próxima da função ex.
Contudo, este comportamento não é geral para todas as funções contínuas. Por exemplo,
quando analisamos os polinómios de Taylor da função f(x) = 1/x em torno do ponto x0 = 1
verificamos que o valor aproximado, por exemplo, nos pontos x = 2, 3, 4 varia muito de polinó-
mio para polinómio (ver a Figura 8.6 e a Tabela8.1). Os valores exactos são f(1) = 1, f(2) = 0.5,
f(3) = 0.333(3) e f(4) = 0.25. A expressão geral para as derivadas de f é f (k)(x) = (−1)kk!x−k−1 e
os polinómios de Taylor são:
p0(x) = 1,
p1(x) = 1− (x− 1),
p2(x) = 1− (x− 1) + (x− 1)2,
p3(x) = 1− (x− 1) + (x− 1)2 − (x− 1)3,
p4(x) = 1− (x− 1) + (x− 1)2 − (x− 1)3 + (x− 1)4,...
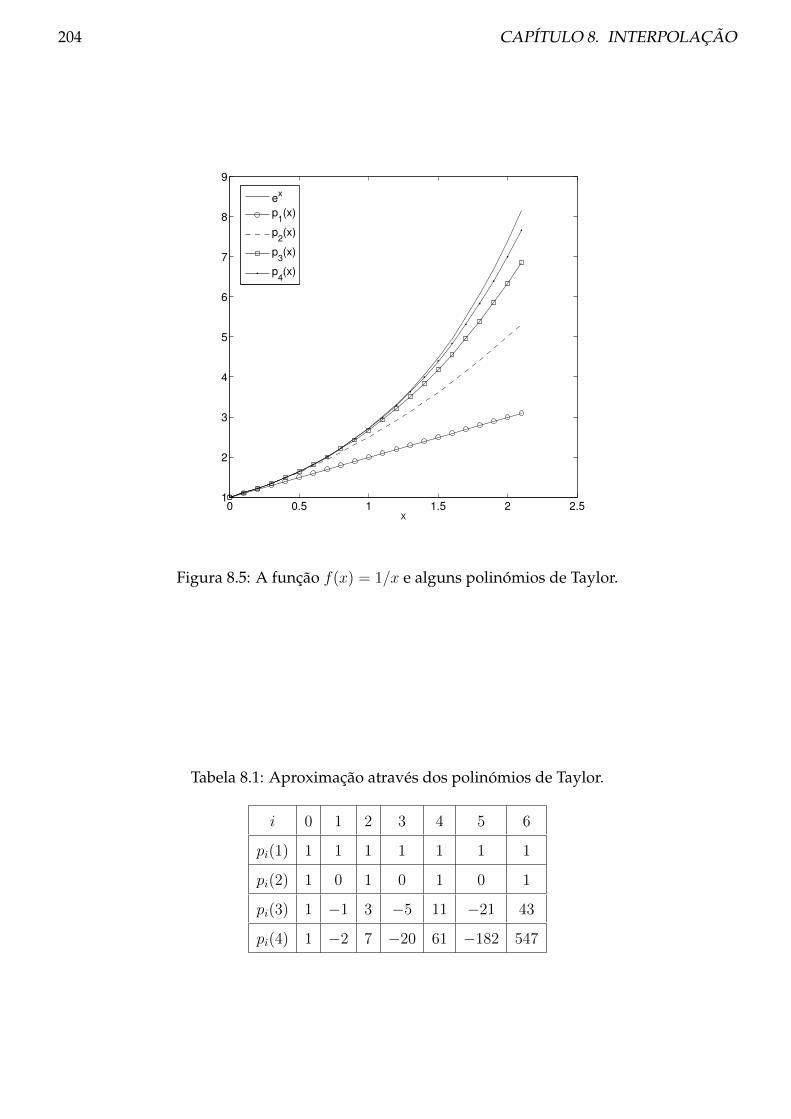
204 CAPÍTULO 8. INTERPOLAÇÃO
0 0.5 1 1.5 2 2.51
2
3
4
5
6
7
8
9
X
ex
p1(x)
p2(x)
p3(x)
p4(x)
Figura 8.5: A função f(x) = 1/x e alguns polinómios de Taylor.
Tabela 8.1: Aproximação através dos polinómios de Taylor.
i 0 1 2 3 4 5 6
pi(1) 1 1 1 1 1 1 1
pi(2) 1 0 1 0 1 0 1
pi(3) 1 −1 3 −5 11 −21 43
pi(4) 1 −2 7 −20 61 −182 547
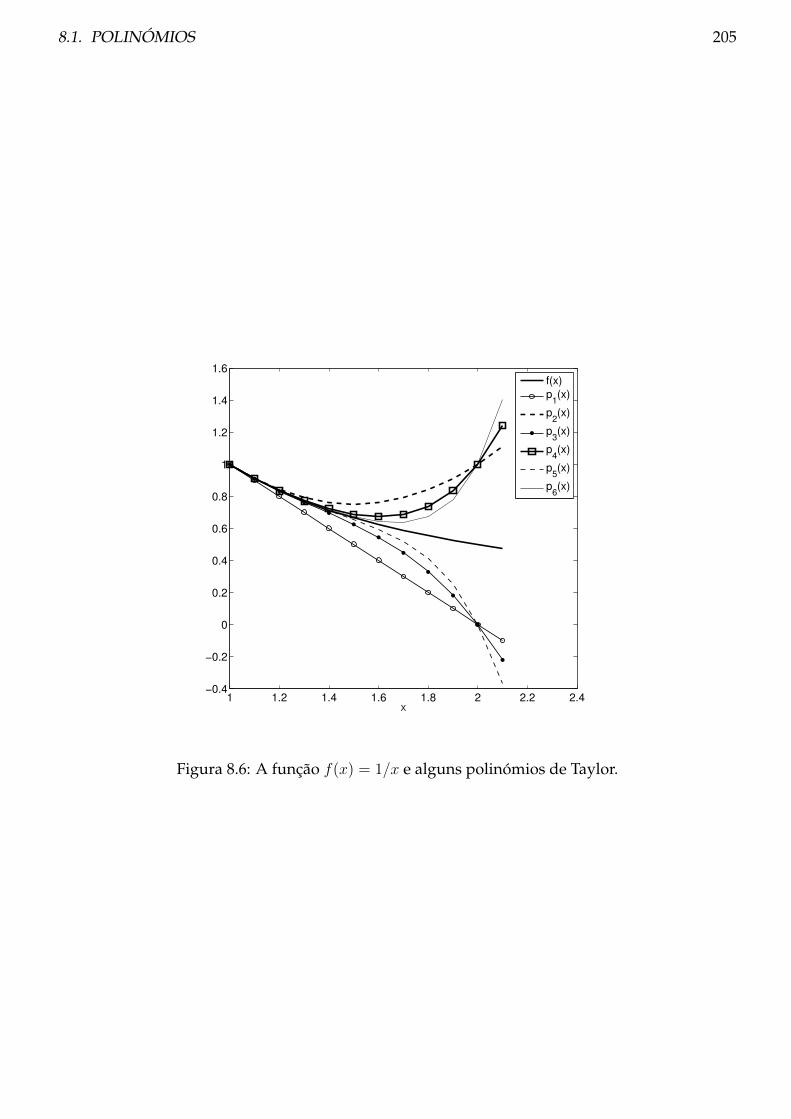
8.1. POLINÓMIOS 205
1 1.2 1.4 1.6 1.8 2 2.2 2.4−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
X
f(x)
p1(x)
p2(x)
p3(x)
p4(x)
p5(x)
p6(x)
Figura 8.6: A função f(x) = 1/x e alguns polinómios de Taylor.

206 CAPÍTULO 8. INTERPOLAÇÃO
Estes comportamentos dos polinómios de Taylor devem-se ao facto de toda a informação
usada na aproximação estar concentrada num único ponto x0. Esta dificuldade faz com que só os
polinómios de Taylor sejam utilizados para aproximar valores de uma função perto do ponto x0
em torno do qual se faz o desenvolvimento.
Antes de passarmos às secções seguintes convém lembrar duas definições:
1. Um monómio é um polinómio da forma xn e o grau deste monómio é n;
2. Quando um polinómio de escreve na sua forma expandida, ou seja, como a soma de pro-
dutos de escalares por monómios, p(x) = anxn + . . .+ a2x
2 + a1x+ a0, o grau do polinómio
é o máximo dos graus dos monómios que compõem o polinómio. Por exemplo, o grau de
p(x) = 3x5 + x3 − 8x2 + 5 é 5.
Observamos assim que a soma de dois polinómios de grau n dá um polinómio de grau menor ou
igual a n. Além disso, o grau do polinómio obtido multiplicando dois polinómios é igual à soma
dos graus dos polinómios envolvidos na multiplicação.
8.2 Método de Vandermonde
O método de Vandermonde é o método mais directo para construir um polinómio interpo-
lador. A substituição dos pontos experimentais xi no polinómio e a exigência p(xi) = yi dá origem
a um sistema linear de equações, onde as incógnitas são os coeficientes no polinómio, que pode
ser resolvido, por exemplo, pelo método de eliminação de Gauss. Este método generaliza-se para
situações em que a função aproximadora não é um polinómio.
Bases Capítulo 5.
8.2.1 Teoria
Dada a tabela de pontos
xi 0 4 9
yi 0 −64 81

8.2. MÉTODO DE VANDERMONDE 207
pretende-se encontrar o polinómio de grau menor ou igual a dois que interpola os pontos
desta tabela, ou seja, tal que p(xi) = yi. Para isso escrevemos as equações seguintes:
p2(0) = 0
p2(4) = −64
p2(9) = 81
Uma vez que p2(x) se pode escrever na forma p2(x) = a2x2 + a1x+ a0, obtém-se
a0 = 0
16a2 + 4a1 + a0 = −64
81a2 + 9a1 + a0 = 81
ou seja, 0 0 1
16 4 1
81 9 1
a2
a1
a0
=
0
−64
81
Se tivermos uma tabela com (n + 1) pontos (x0, y0), (x1, y1), ..., (xn, yn) podemos obter o
polinómio de grau menor ou igual a n que passa nestes pontos do seguinte modo:
1. escrever pn(x) = anxn + . . .+ a2x
2 + a1x+ a0;
2. calcular o polinómio nos pontos x0, x1, ..., xn e escrever p(xi) = yi, i = 0, 1, . . . , n;
3. resolver o sistema de equações resultante.
Em vez de seguir estes três passos podemos escrever logo o sistema
Va = y, (8.1)
onde
V =
xn0 xn−10 . . . x0 1
xn1 xn−11 . . . x1 1...
......
...
xnn xn−1n . . . xn 1
(8.2)
é a matriz de Vandermonde,
y = (y0, y1, . . . , yn)T

208 CAPÍTULO 8. INTERPOLAÇÃO
é o vector das respostas e
a = (an, an−1, . . . , a1, a0)T
são os coeficientes desconhecidos do polinómio.
Será que este sistema tem solução única? Dados dois pontos vemos que só há uma recta que
passa nesses pontos. E se tivermos mais do que dois pontos? Aí não é tão fácil de ver que existe
um único polinómio a passar pelos pontos.
Teorema 6 Dados x0, x1, ..., xn pontos distintos, então existe um único polinómio interpolador pn(x) com
grau menor ou igual a n que passa através dos n pontos (x0, y0), (x1, y1), ..., (xn, yn), onde xi, yi ∈ R.
Demonstração Suponha-se que p(x) e q(x) são dois polinómios de grau n que passam nos pon-
tos (x0, y0), (x1, y1), ..., (xn, yn), onde x1, ..., xn são pontos distintos. O polinómio r(x) = p(x)− q(x)
é de grau menor ou igual a n e tem (n + 1) raízes porque r(xi) = 0 para i = 0, 1, . . . , n. Contudo,
um polinómio de grau n não pode ter (n+ 1) raízes a menos que seja o polinómio nulo. ♦
Um sistema linear de equações tem solução única se o seu determinante for diferente de
zero. Pode demonstrar-se por indução que
det(V) =n∏i=0
n∏j=i+1
(xi − xj)
Este determinante é diferente de zero se e só se os pontos xi forem distintos. Consequentemente,
o polinómio interpolador é único.
8.2.2 Procedimento
Primeiro problema Dado um conjunto de pontos (xi, yi), com i = 0, 1, . . . , n, encontrar o polinó-
mio
pn(x) = anxn + . . .+ a2x
2 + a1x+ a0
(de grau menor ou igual a n) que os interpola, ou seja que passa nos pontos.
Hipóteses Os pontos x0, x1, ..., xn têm de ser distintos.
Processo Construir a matriz de Vandermonde (8.2) calculando o valor das funções base x0, x, x2,
.... xn nos pontos x0, x1, ..., xn. Resolver o sistema (8.1).
Por exemplo, considere-se a tabela

8.2. MÉTODO DE VANDERMONDE 209
xi 1.3 1.6 1.9 2.2 2.5
yi 2.49 4.43 8.81 16.75 29.56
A matriz de Vandermonde para obter o polinómio interpolador de grau menor ou igual a 4,
que interpola os pontos desta tabela, é dada por
V =
xn0 xn−10 . . . x0 1
xn1 xn−11 . . . x1 1...
......
...
xnn xn−1n . . . xn 1
Esta matriz pode obter-se utilizando o Matlab através de:
x = [1 1.3 1.6 1.9 2.2];
V = vander(x)
V = 2.8561 2.1970 1.6900 1.3000 1.0000
6.5536 4.0960 2.5600 1.6000 1.0000
13.0321 6.8590 3.6100 1.9000 1.0000
23.4256 10.6480 4.8400 2.2000 1.0000
39.0625 15.6250 6.2500 2.5000 1.0000
ou alternativamente,
x = [1.3 1.6 1.9 2.2 2.5]’;
V = [x.^4 x.^3 x.^2 x x.^0];
Os coeficientes desconhecidos do polinómio são obtidos da seguinte forma:
y = [2.49 4.43 8.81 16.75 29.56]’;
a = V \ y
a = 0.9774
0.0720
-1.8904
-0.5530
3.4540
Segundo problema Dado um conjunto de pontos (xi, yi), com i = 0, 1, . . . , n, encontrar uma fun-
ção da forma
g(x) = anφn(x) + . . .+ a2φ2(x) + a1φ1(x) + a0φ0(x)
onde φk’s são as funções base. No caso da interpolação polinomial tém-se φk(x) = xk.

210 CAPÍTULO 8. INTERPOLAÇÃO
Hipóteses Os pontos x0, x1, ..., xn têm de ser distintos e as funções φk têm de ser linearmente
independentes.
Processo Construir a matriz de Vandermonde modificada calculando o valor das funções base
φn(x), ..., φ1(x), φ0(x) nos pontos x0, x1, ..., xn:
V =
φn(x0) φn−1(x0) . . . φ1(x0) φ0(x0)
φn(x1) φn−1(x1) . . . φ1(x1) φ0(x1)...
......
...
φn(xn) φn−1(xn) . . . φ1(xn) φ0(xn)
Resolver o sistema Va = y.
Por exemplo, considere-se a tabela
xi 1.3 1.6 1.9
yi 5.1582 4.9695 4.5156
A matriz de Vandermonde modificada para obter uma função do tipo
g(x) = a2x+ a1 cos(x) + a0 sin(x)
que interpola os pontos desta tabela é dada por
V =
x0 cos(x0) sin(x0)
x1 cos(x1) sin(x1)
x2 cos(x2) sin(x2)
Esta matriz pode obter-se utilizando o Matlab através de:
x = [1.3 1.6 1.9]’;
V = [x.^0 cos(x) sin(x)]
V = 1.0000 0.2675 0.9636
1.0000 -0.0292 0.9996
1.0000 -0.3233 0.9463
Os coeficientes desconhecidos do polinómio são obtidos da seguinte forma:
y = [5.1582 4.9695 4.5156]’;
a = V \ y
a = 2.0006
1.0001
2.9993

8.2. MÉTODO DE VANDERMONDE 211
8.2.3 Exemplos
Exemplo 38 Encontrar o polinómio que interpola os pontos (1, 1.3), (2, 1.6), (3, 1.9). Como temos três
pontos o polinómio é de grau menor ou igual a dois, ou seja, p2(x) = a2x2 + a1x + a0. A matriz de
Vandermonde é dada por
V =
1 1 1
4 2 1
9 3 1
Resolvendo o sistema Va = y, onde x = (1, 2, 3)T e y = (1.3, 1.6, 1.9)T , obtém-se a = (0.0, 0.3, 1.0)T . Por
conseguinte, o polinómio interpolador é p(x) = 0.3x+ 1.0.
Exemplo 39 Encontrar o polinómio que interpola os pontos (2, 2), (4, 1), (6, 4) e (8, 2). Como temos três
pontos o polinómio é de grau menor ou igual a três, ou seja, p3(x) = a3x3 + a2x
2 + a1x+ a0. A matriz de
Vandermonde é dada por
V =
8 4 2 1
64 16 4 1
216 36 6 1
512 64 8 1
Resolvendo o sistema Va = y, onde x = (2, 4, 6, 8)T e y = (2, 1, 4, 2)T , obtém-se
a = (−0.1875, 2.7500,−11.7500, 16.0000)T .
Por conseguinte, o polinómio interpolador é p3(x) = −0.1875x3 + 2.7500x2 − 11.7500x+ 16.0000.
Exemplo 40 Um amplificador operacional (ampop) é um amplificador de voltagem electrónico DC-couple
com alto ganho com uma entrada diferencial e, frequentemente, com uma única saída. Os amplificadores
operacionais são "building blocks" importantes para um grande número de circuitos eléctricos. Eles são
um tipo de amplificadores diferenciais. A saída de um amplificador diferencial obtém-se multiplicando a
diferença entre duas entradas (voltagem offset de entrada) por uma constante (ganho diferencial), ou seja,
Vout = Ad(V+in − V −in ), onde V +
in e V −in são as voltagens de entrada e Ad é o ganho diferencial. Se um ampop
tem um ganho de voltagem de dez e uma voltagem offset de entrada de dez microvolts, então irá aparecer
na saída um nível de cem microvolts sem nenhuma entrada. Os fabricantes tentam desenhar ampops de
tal forma que a voltagem offset de entrada seja tão pequena quanto possível para minimizar este erro de
voltagem na saída do amplificador, especialmente em aplicações onde são amplificadas pequenas voltagens.
Suponhamos que são amostradas várias voltagens de offset de entrada e as respectivas saídas num
ampop. O resultado da amostragem encontra-se na tabela seguinte:

212 CAPÍTULO 8. INTERPOLAÇÃO
xi 0 2 4
yi 0 2 9
A matriz de Vandermonde é
V =
0 0 1
4 2 1
9 3 1
e o polinómio interpolador é p2(x) = 2x2 − 3x. Uma vez que sabemos que quando a voltagem offset de
entrada é zero então a saída é zero, ou seja p2(0) = 0, podíamos logo considerar que a0 = 0 e em vez de
trabalharmos com uma matriz 3× 3 trabalharíamos com a matriz de Vandermonde seguinte:
V =
4 2
9 3
Exemplo 41 Encontrar o polinómio interpolador dos pontos da tabela
xi 1.1 2.2 3.5 5.0 6.5
yi −5.7222 −7.7214 −3.9975 19.5000 80.7525
utilizando o Matlab.
x = [1.1 2.2 3.5 5.0 6.5]’;
y = [-5.7222 -7.7214 -3.9975 19.5000 80.7525]’;
V = vander(x)
V = 1.0e+003 *
0.0015 0.0013 0.0012 0.0011 0.0010
0.0234 0.0106 0.0048 0.0022 0.0010
0.1501 0.0429 0.0123 0.0035 0.0010
0.6250 0.1250 0.0250 0.0050 0.0010
1.7851 0.2746 0.0423 0.0065 0.0010
a = V \ y
a = 0.0400
0.2000
-0.7000
-2.0000
-3.0000
Por conseguinte, o polinómio interpolador é p4(x) = 0.04x4 + 0.2x3− 0.7x2− 2x− 3. Na Figura 8.7
estão representados o polinómio e os pontos da tabela.
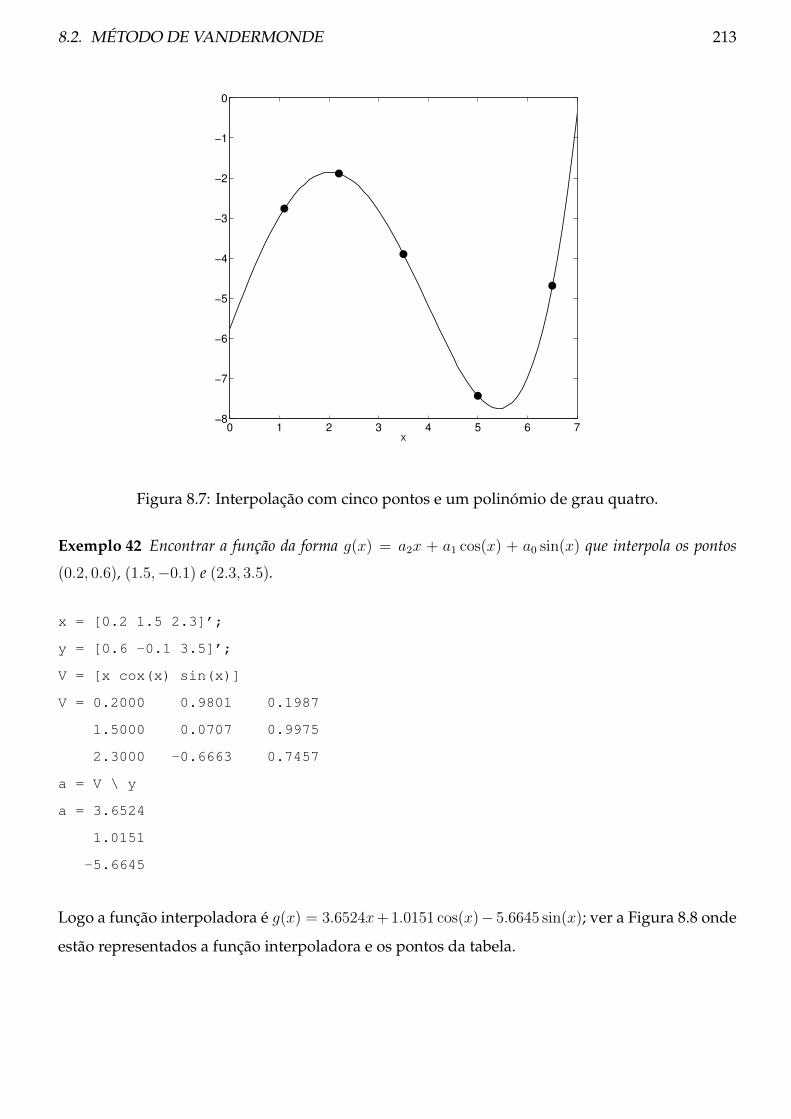
8.2. MÉTODO DE VANDERMONDE 213
0 1 2 3 4 5 6 7−8
−7
−6
−5
−4
−3
−2
−1
0
X
Figura 8.7: Interpolação com cinco pontos e um polinómio de grau quatro.
Exemplo 42 Encontrar a função da forma g(x) = a2x + a1 cos(x) + a0 sin(x) que interpola os pontos
(0.2, 0.6), (1.5,−0.1) e (2.3, 3.5).
x = [0.2 1.5 2.3]’;
y = [0.6 -0.1 3.5]’;
V = [x cox(x) sin(x)]
V = 0.2000 0.9801 0.1987
1.5000 0.0707 0.9975
2.3000 -0.6663 0.7457
a = V \ y
a = 3.6524
1.0151
-5.6645
Logo a função interpoladora é g(x) = 3.6524x+ 1.0151 cos(x)− 5.6645 sin(x); ver a Figura 8.8 onde
estão representados a função interpoladora e os pontos da tabela.
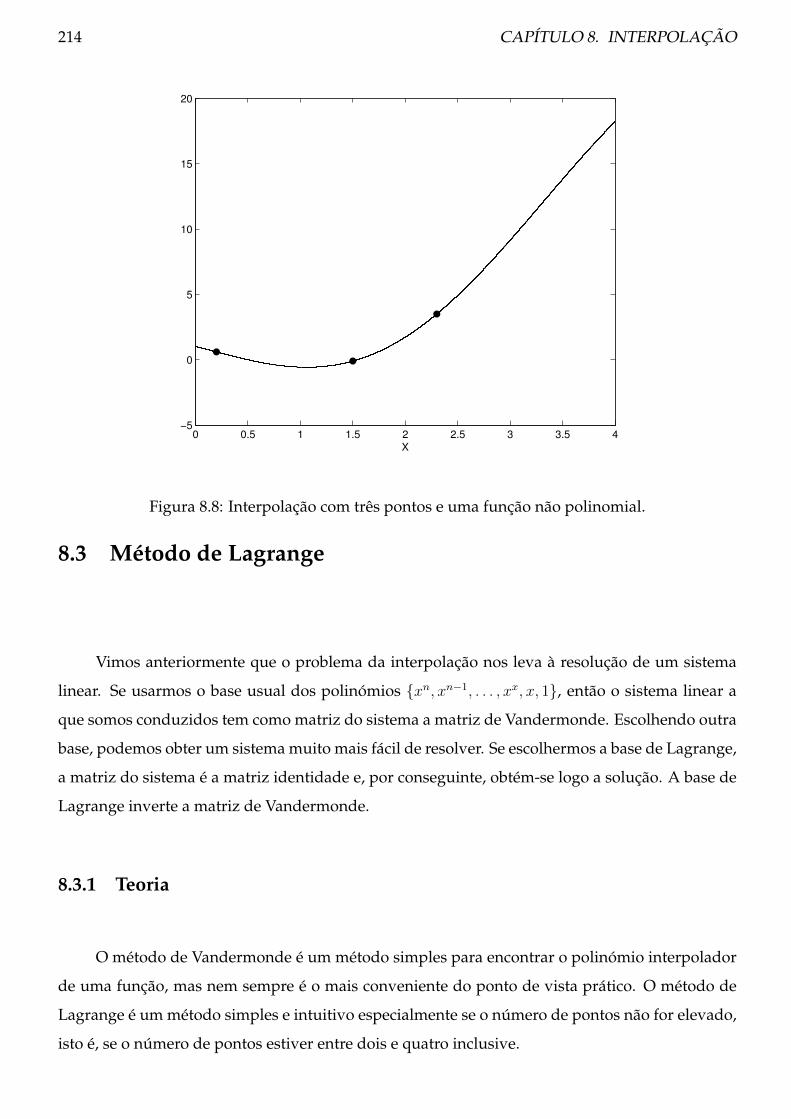
214 CAPÍTULO 8. INTERPOLAÇÃO
0 0.5 1 1.5 2 2.5 3 3.5 4−5
0
5
10
15
20
X
Figura 8.8: Interpolação com três pontos e uma função não polinomial.
8.3 Método de Lagrange
Vimos anteriormente que o problema da interpolação nos leva à resolução de um sistema
linear. Se usarmos o base usual dos polinómios xn, xn−1, . . . , xx, x, 1, então o sistema linear a
que somos conduzidos tem como matriz do sistema a matriz de Vandermonde. Escolhendo outra
base, podemos obter um sistema muito mais fácil de resolver. Se escolhermos a base de Lagrange,
a matriz do sistema é a matriz identidade e, por conseguinte, obtém-se logo a solução. A base de
Lagrange inverte a matriz de Vandermonde.
8.3.1 Teoria
O método de Vandermonde é um método simples para encontrar o polinómio interpolador
de uma função, mas nem sempre é o mais conveniente do ponto de vista prático. O método de
Lagrange é um método simples e intuitivo especialmente se o número de pontos não for elevado,
isto é, se o número de pontos estiver entre dois e quatro inclusive.

8.3. MÉTODO DE LAGRANGE 215
A base de Lagrange é dada por
li(x) =n∏
j=0,j 6=i
x− xjxi − xj
=x− x0xi − x0
. . .x− xi−1xi − xi−1
x− xi+1
xi − xi+1
. . .x− xnxi − xn
Podemos observar que para k 6= i obtemos
li(xk) =n∏
j=0,j 6=i
xk − xjxi − xj
=xk − x0xi − x0
. . .xk − xkxi − xk
. . .xk − xnxi − xn
= 0
e também verificamos que
li(xi) =n∏
j=0,j 6=i
xi − xjxi − xj
=xi − x0xi − x0
. . .xi − xnxi − xn
= 1
ou seja, todos os polinómios da base de Lagrange valem zero se x = xi e valem 1 se x = xk com
k 6= i:
li(xk) = δik =
1, se i = k
0, se i 6= k
A função δik é conhecida como função delta de Kronecker. Quando construímos o sistema de
Vandermonde com esta base e função aproximadora pn(x) = a0l0(x) + a1(x)l1(x) + . . . + anln(x)
obtemos 1 0 . . . 0 0
0 1 . . . 0 0...
......
...
0 0 . . . 0 1
a0
a1...
an
=
f(x0)
f(x1)...
f(xn)
Como a matriz do sistema é a matriz identidade vem directamente ai = f(xi) e, por conseguinte,
o polinómio interpolador de Lagrange é dado por:
pn(x) =n∑i=0
f(xi)li(x)
Podemos verificar que de facto
pn(x0) =n∑i=0
f(xi)li(xk) = f(x0)l0(x0) + f(x1)l1(x0) + . . .+ f(xn)ln(x0) =
= 1 + 0 + . . .+ 0 = f(x0)
pn(x1) =n∑i=0
f(xi)li(xk) = f(x0)l0(x1) + f(x1)l1(x1) + . . .+ f(xn)ln(x1) =
= 0 + 1 + . . .+ 0 = f(x1)
...
pn(xn) =n∑i=0
f(xi)li(xk) = f(x0)l0(xn) + f(x1)l1(xn) + . . .+ f(xn)ln(xn) =
= 0 + 0 + . . .+ 1 = f(xn)
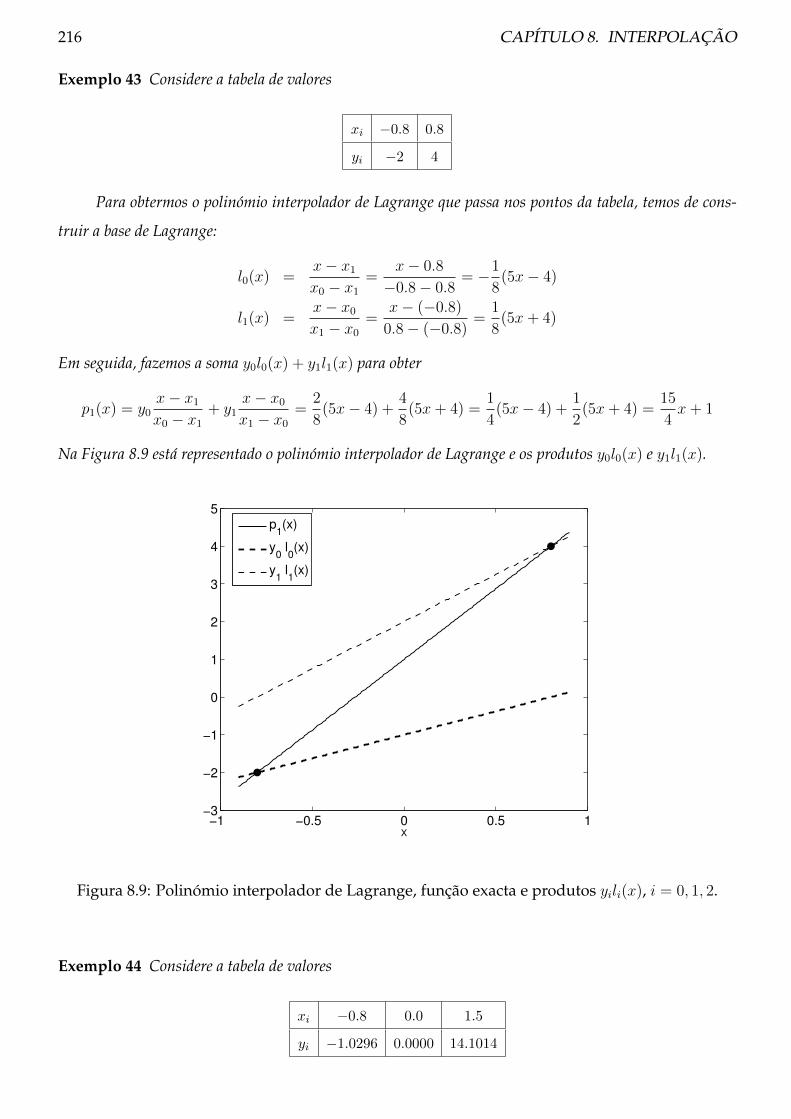
216 CAPÍTULO 8. INTERPOLAÇÃO
Exemplo 43 Considere a tabela de valores
xi −0.8 0.8
yi −2 4
Para obtermos o polinómio interpolador de Lagrange que passa nos pontos da tabela, temos de cons-
truir a base de Lagrange:
l0(x) =x− x1x0 − x1
=x− 0.8
−0.8− 0.8= −1
8(5x− 4)
l1(x) =x− x0x1 − x0
=x− (−0.8)
0.8− (−0.8)=
1
8(5x+ 4)
Em seguida, fazemos a soma y0l0(x) + y1l1(x) para obter
p1(x) = y0x− x1x0 − x1
+ y1x− x0x1 − x0
=2
8(5x− 4) +
4
8(5x+ 4) =
1
4(5x− 4) +
1
2(5x+ 4) =
15
4x+ 1
Na Figura 8.9 está representado o polinómio interpolador de Lagrange e os produtos y0l0(x) e y1l1(x).
−1 −0.5 0 0.5 1−3
−2
−1
0
1
2
3
4
5
X
p1(x)
y0 l
0(x)
y1 l
1(x)
Figura 8.9: Polinómio interpolador de Lagrange, função exacta e produtos yili(x), i = 0, 1, 2.
Exemplo 44 Considere a tabela de valores
xi −0.8 0.0 1.5
yi −1.0296 0.0000 14.1014

8.3. MÉTODO DE LAGRANGE 217
Neste caso, a base de Lagrange é dada por:
l0(x) =x− x1x0 − x1
· x− x2x0 − x2
=x− 0
−0.8− 0· x− 1.5
−0.8− 1.5
= 0.5435x(x− 1.5)
l1(x) =x− x0x1 − x0
· x− x2x1 − x2
=x− (−0.8)
0− (−0.8)· x− 1.5
0− 1.5
= −0.8333(x+ 0.8)(x− 1.5)
l2(x) =x− x0x2 − x0
· x− x1x2 − x1
=x− (−0.8)
1.5− (−0.8)· x− 0
1.5− 0
= 0.2899(x+ 0.8)x
Por conseguinte, o polinómio interpolador de Lagrange obtém-se fazendo a soma y0l0(x)+y1l1(x)+y2l2(x)
p2(x) = y0x− x1x0 − x1
· x− x2x0 − x2
+ y1x− x0x1 − x0
· x− x2x1 − x2
+ y2x− x0x2 − x0
· x− x1x2 − x1
= (−1.0296)(0.5435)x(x− 1.5) + (0)(−0.8333)(x+ 0.8)(x− 1.5)
+(14.1014)(0.2899)(x+ 0.8)x
= −0.5596x(x− 1.5) + 4.0880x(x+ 0.8)
= 3.5284x2 + 4.1098x
Na Figura 8.10 estão representados a função f(x) = tan(x) e o seu polinómio interpolador de Lagrange
nos pontos −0.8, 0, e 1.5.
Exemplo 45 Considere a tabela de valores
xi −0.9 0.2 1.4
yi −1.2602 0.2027 5.7979
Neste caso, a base de Lagrange é dada por:
l0(x) =x− x1x0 − x1
· x− x2x0 − x2
=x− 0.2
−0.9− 0.2· x− 1.4
−0.9− 1.4
= 0.3953(x− 0.2)(x− 1.4)
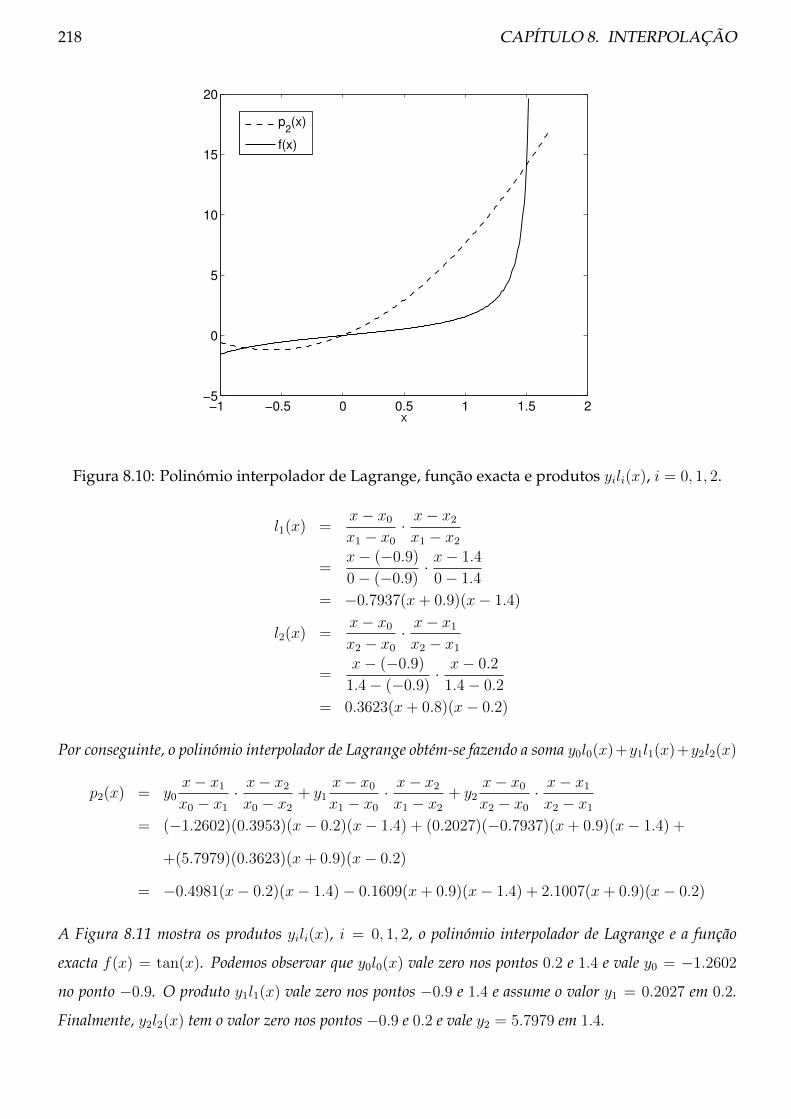
218 CAPÍTULO 8. INTERPOLAÇÃO
−1 −0.5 0 0.5 1 1.5 2−5
0
5
10
15
20
X
p2(x)
f(x)
Figura 8.10: Polinómio interpolador de Lagrange, função exacta e produtos yili(x), i = 0, 1, 2.
l1(x) =x− x0x1 − x0
· x− x2x1 − x2
=x− (−0.9)
0− (−0.9)· x− 1.4
0− 1.4
= −0.7937(x+ 0.9)(x− 1.4)
l2(x) =x− x0x2 − x0
· x− x1x2 − x1
=x− (−0.9)
1.4− (−0.9)· x− 0.2
1.4− 0.2
= 0.3623(x+ 0.8)(x− 0.2)
Por conseguinte, o polinómio interpolador de Lagrange obtém-se fazendo a soma y0l0(x)+y1l1(x)+y2l2(x)
p2(x) = y0x− x1x0 − x1
· x− x2x0 − x2
+ y1x− x0x1 − x0
· x− x2x1 − x2
+ y2x− x0x2 − x0
· x− x1x2 − x1
= (−1.2602)(0.3953)(x− 0.2)(x− 1.4) + (0.2027)(−0.7937)(x+ 0.9)(x− 1.4) +
+(5.7979)(0.3623)(x+ 0.9)(x− 0.2)
= −0.4981(x− 0.2)(x− 1.4)− 0.1609(x+ 0.9)(x− 1.4) + 2.1007(x+ 0.9)(x− 0.2)
A Figura 8.11 mostra os produtos yili(x), i = 0, 1, 2, o polinómio interpolador de Lagrange e a função
exacta f(x) = tan(x). Podemos observar que y0l0(x) vale zero nos pontos 0.2 e 1.4 e vale y0 = −1.2602
no ponto −0.9. O produto y1l1(x) vale zero nos pontos −0.9 e 1.4 e assume o valor y1 = 0.2027 em 0.2.
Finalmente, y2l2(x) tem o valor zero nos pontos −0.9 e 0.2 e vale y2 = 5.7979 em 1.4.
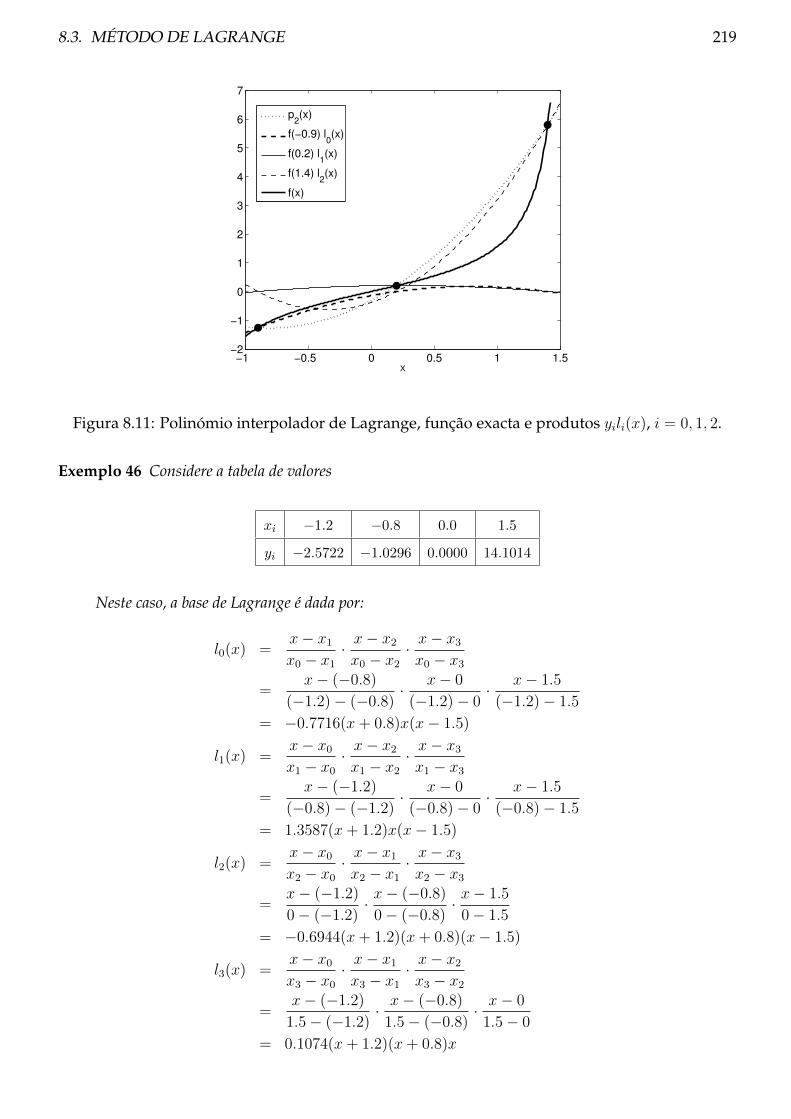
8.3. MÉTODO DE LAGRANGE 219
−1 −0.5 0 0.5 1 1.5−2
−1
0
1
2
3
4
5
6
7
X
p2(x)
f(−0.9) l0(x)
f(0.2) l1(x)
f(1.4) l2(x)
f(x)
Figura 8.11: Polinómio interpolador de Lagrange, função exacta e produtos yili(x), i = 0, 1, 2.
Exemplo 46 Considere a tabela de valores
xi −1.2 −0.8 0.0 1.5
yi −2.5722 −1.0296 0.0000 14.1014
Neste caso, a base de Lagrange é dada por:
l0(x) =x− x1x0 − x1
· x− x2x0 − x2
· x− x3x0 − x3
=x− (−0.8)
(−1.2)− (−0.8)· x− 0
(−1.2)− 0· x− 1.5
(−1.2)− 1.5
= −0.7716(x+ 0.8)x(x− 1.5)
l1(x) =x− x0x1 − x0
· x− x2x1 − x2
· x− x3x1 − x3
=x− (−1.2)
(−0.8)− (−1.2)· x− 0
(−0.8)− 0· x− 1.5
(−0.8)− 1.5
= 1.3587(x+ 1.2)x(x− 1.5)
l2(x) =x− x0x2 − x0
· x− x1x2 − x1
· x− x3x2 − x3
=x− (−1.2)
0− (−1.2)· x− (−0.8)
0− (−0.8)· x− 1.5
0− 1.5
= −0.6944(x+ 1.2)(x+ 0.8)(x− 1.5)
l3(x) =x− x0x3 − x0
· x− x1x3 − x1
· x− x2x3 − x2
=x− (−1.2)
1.5− (−1.2)· x− (−0.8)
1.5− (−0.8)· x− 0
1.5− 0
= 0.1074(x+ 1.2)(x+ 0.8)x

220 CAPÍTULO 8. INTERPOLAÇÃO
O polinómio interpolador de Lagrange obtém-se fazendo a soma y0l0(x) + y1l1(x) + y2l2(x) + y3l3(x):
p3(x) = y0x− x1x0 − x1
· x− x2x0 − x2
· x− x3x0 − x3
+ y1x− x0x1 − x0
· x− x2x1 − x2
· x− x3x1 − x3
+
+y2x− x0x2 − x0
· x− x1x2 − x1
· x− x3x2 − x3
+ y3x− x0x3 − x0
· x− x1x3 − x1
· x− x2x3 − x2
= (−2.5722)(−0.7716)(x+ 0.8)x(x− 1.5) + (−1.0296)(1.3587)(x+ 1.2)x(x− 1.5) +
+(0)(−0.6944)(x+ 1.2)(x+ 0.8)(x− 1.5) + (14.1014)(0.1074)(x+ 1.2)(x+ 0.8)x
= 1.9847(x+ 0.8)x(x− 1.5)− 1.3989(x+ 1.2)x(x− 1.5) + 1.5145(x+ 1.2)(x+ 0.8)x
Exemplo 47 Considere-se a função f(x) = 1/x nos pontos 0.2, 1.2, 2.2, 3.2 e 4.2:
xi 0.2 1.2 2.2 3.2 4.2
yi 5 5/6 5/11 5/16 5/21
Como temos quatro pontos o polinómio interpolador é de grau menor ou igual a 3. A base é constituída
pelas seguintes funções:
l0(x) =x− x1x0 − x1
· x− x2x0 − x2
· x− x3x0 − x3
· x− x4x0 − x4
=x− 1.2
0.2− 1.2· x− 2.2
0.2− 2.2· x− 3.2
0.2− 3.2· x− 4.2
0.2− 4.2
=1
24(x− 1.2)(x− 2.2)(x− 3.2)(x− 4.2)
=1
15(5x− 6)(5x− 11)(5x− 16)(5x− 21)
l1(x) =x− x0x1 − x0
· x− x2x1 − x2
· x− x3x1 − x3
· x− x4x1 − x4
=x− 0.2
1.2− 0.2· x− 2.2
1.2− 2.2· x− 3.2
1.2− 3.2· x− 4.2
1.2− 4.2
= −1
6(x− 0.2)(x− 2.2)(x− 3.2)(x− 4.2)
= − 4
15(5x− 1)(5x− 11)(5x− 16)(5x− 21)
l2(x) =x− x0x2 − x0
· x− x1x2 − x1
· x− x3x2 − x3
· x− x4x2 − x4
=x− 0.2
2.2− 0.2· x− 1.2
2.2− 1.2· x− 3.2
2.2− 3.2· x− 4.2
2.2− 4.2
=1
4(x− 0.2)(x− 1.2)(x− 3.2)(x− 4.2)
=2
5(5x− 1)(5x− 6)(5x− 16)(5x− 21)

8.3. MÉTODO DE LAGRANGE 221
l3(x) =x− x0x3 − x0
· x− x2x3 − x2
· x− x4x3 − x4
· x− x4x3 − x4
=x− 0.2
3.2− 0.2· x− 1.2
3.2− 1.2· x− 2.2
3.2− 2.2· x− 4.2
3.2− 4.2
= −1
6(x− 0.2)(x− 1.2)(x− 2.2)(x− 4.2)
= − 4
15(5x− 1)(5x− 6)(5x− 11)(5x− 21)
l4(x) =x− x0x4 − x0
· x− x1x4 − x1
· x− x2x4 − x2
· x− x3x4 − x3
=x− 0.2
4.2− 0.2· x− 1.2
4.2− 1.2· x− 2.2
4.2− 2.2· x− 3.2
4.2− 3.2
=1
24(x− 0.2)(x− 1.2)(x− 2.2)(x− 3.2)
=1
15(5x− 1)(5x− 6)(5x− 11)(5x− 16)
Estes polinómios estão representados na Figura 8.12. Na Figura 8.13 podemos observar a função e o poli-
nómio interpolador construído a partir destas função base
p4(x) = f(x0)l0(x) + f(x1)l1(x) + f(x2)l2(x) + f(x3)l3(x) + f(x4)l4(x)
= 5l0(x) +5
6l1(x) +
5
11l2(x) +
5
16l3(x) +
5
21l4(x)
=1
3(5x− 6)(5x− 11)(5x− 16)(5x− 21)− 2
9(5x− 1)(5x− 11)(5x− 16)(5x− 21)
+2
11(5x− 1)(5x− 6)(5x− 16)(5x− 21)− 1
12(5x− 1)(5x− 6)(5x− 11)(5x− 21)
+1
63(5x− 1)(5x− 6)(5x− 11)(5x− 16)
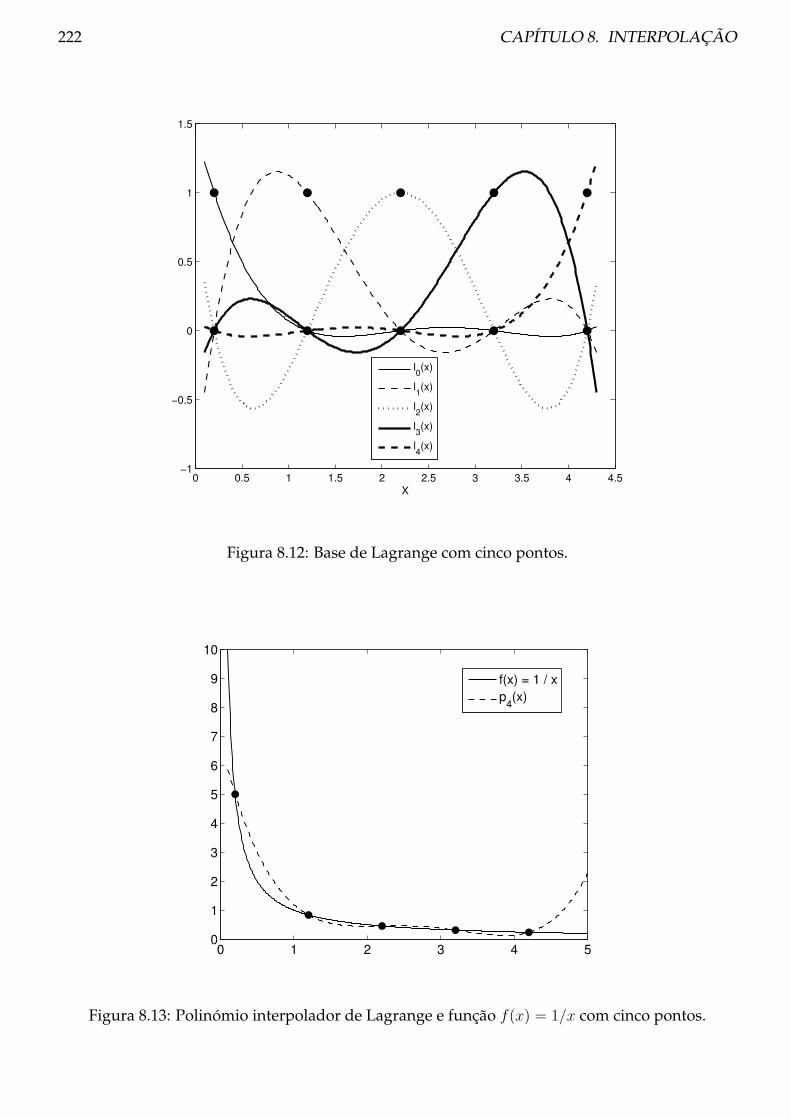
222 CAPÍTULO 8. INTERPOLAÇÃO
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5−1
−0.5
0
0.5
1
1.5
X
l0(x)
l1(x)
l2(x)
l3(x)
l4(x)
Figura 8.12: Base de Lagrange com cinco pontos.
0 1 2 3 4 50
1
2
3
4
5
6
7
8
9
10
f(x) = 1 / x
p4(x)
Figura 8.13: Polinómio interpolador de Lagrange e função f(x) = 1/x com cinco pontos.

8.4. MÉTODO DE NEWTON 223
8.4 Método de Newton
O método de Newton é uma técnica para construir polinómios interpoladores que pode ser
realizada de uma forma simples num programa de computador. O algoritmo é numericamente
estável recursivo e rápido.
O método de Lagrange é fácil de utilizar com lápis e papel, pelo menos para graus iguais ou
inferiores a 2, mas é péssimo do ponto de vista de programação. Se tivermos o polinómio interpo-
lador de Lagrange que passa nos pontos (x0, y0), ..., (xn, yn), este dá-nos pouca informação acerca
do polinómio interpolador que passa nos pontos (x0, y0), ..., (xn, yn) e ainda no ponto (xn+1, yn+1).
O método de Newton dá-nos uma maneira de, dado um polinómio interpolador que passa
em n + 1 pontos, construir um polinómio interpolador que passa nesses n + 1 pontos e mais
um ponto (xn+1, yn+1). Para perceber o processo de construção iremos ver como se constrói um
polinómio de grau 1 a partir de um de grau zero e um de grau 2 a partir de um de grau 1.
Considere-se a tabela
xi 1 2 4
yi −2 3 1
Com base nesta tabela iremos construir os polinómios de p0(x), p1(x), e p2(x) de graus zero,
um e dois que interpolam a função. p0(x) interpola a função no primeiro ponto, p1(x) interpola a
função nos primeiro e segundo pontos e p2(x) interpola a função em todos os pontos da tabela.
• Polinómio constante (um ponto, n = 0).
O polinómio constante que passa no ponto (x0, y0) é dado por p0(x) = y0. Neste caso,
p0(x) = −2
como podemos observar na Figura 8.14.
• Polinómio linear (dois pontos, n = 1).
Dado p0(x) defina-se p1(x) tal que
p1(x) = p0(x) + ∆p1(x)
Como p0(x) = y0 vem,
∆p1(x) = p1(x)− y0
224 CAPÍTULO 8. INTERPOLAÇÃO
0 1 2 3 4 5−3
−2
−1
0
1
2
3
4
X
Y
Figura 8.14: Polinómio interpolador de grau zero.
O polinómio ∆p1(x) tem grau menor ou igual a um e tem um zero em x = x0, logo
∆p1(x) = c1(x− x0)
Das duas últimas equações, e atendendo que p1(x1) = y1, segue que
c1(x1 − x0) = y1 − y0
Logo
c1 =y1 − y0x1 − x0
Por conseguinte,
p1(x) = y0 +y1 − y0x1 − x0
(x− x0)
No caso dos pontos da tabela obtém-se
p1(x) = −2 +3− (−2)
2− 1(x− 1) = −2 + 5(x− 1)
O polinómio linear que passa nos pontos (1,−2) e (2, 3) e o polinómio ∆p1(x) estão repre-
sentados na Figura 8.15.
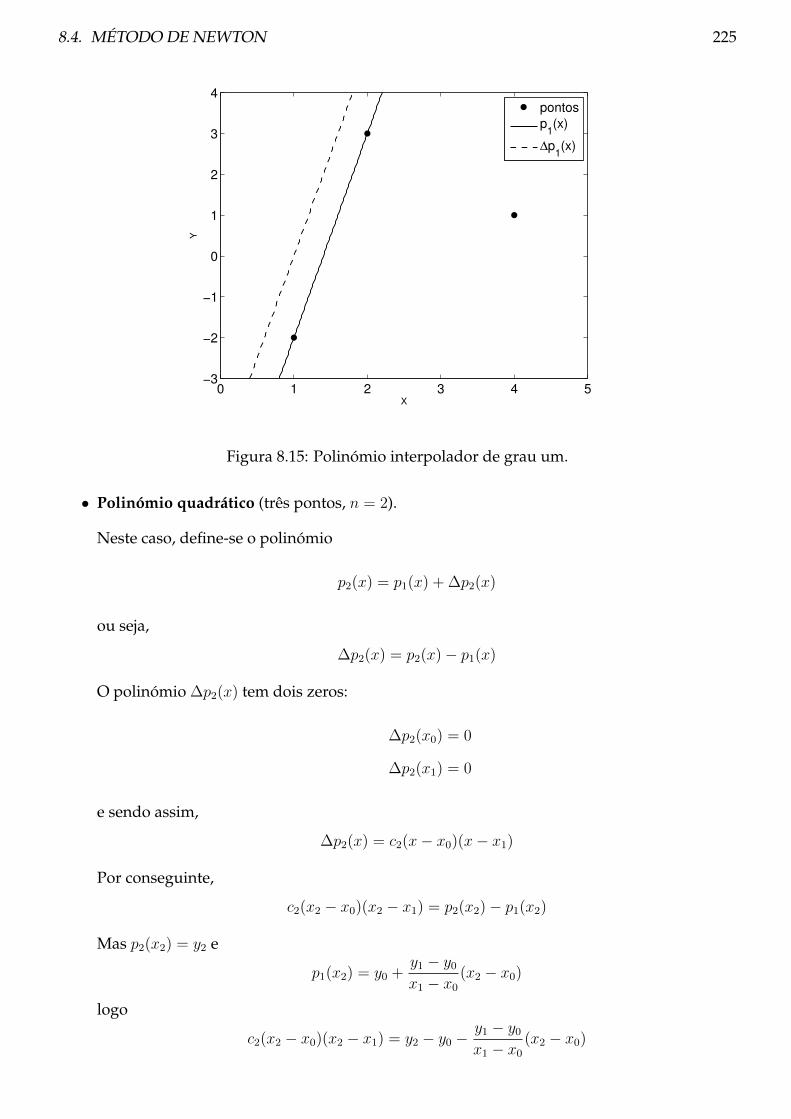
8.4. MÉTODO DE NEWTON 225
0 1 2 3 4 5−3
−2
−1
0
1
2
3
4
X
Y
pontos
p1(x)
∆p1(x)
Figura 8.15: Polinómio interpolador de grau um.
• Polinómio quadrático (três pontos, n = 2).
Neste caso, define-se o polinómio
p2(x) = p1(x) + ∆p2(x)
ou seja,
∆p2(x) = p2(x)− p1(x)
O polinómio ∆p2(x) tem dois zeros:
∆p2(x0) = 0
∆p2(x1) = 0
e sendo assim,
∆p2(x) = c2(x− x0)(x− x1)
Por conseguinte,
c2(x2 − x0)(x2 − x1) = p2(x2)− p1(x2)
Mas p2(x2) = y2 e
p1(x2) = y0 +y1 − y0x1 − x0
(x2 − x0)
logo
c2(x2 − x0)(x2 − x1) = y2 − y0 −y1 − y0x1 − x0
(x2 − x0)

226 CAPÍTULO 8. INTERPOLAÇÃO
Somando e subtraindo x1 e y1 no segundo membro da equação obtém-se
c2(x2 − x0)(x2 − x1) = y2 − y0 + y1 − y1 −y1 − y0x1 − x0
(x2 − x0 + x1 − x1)
ou seja,
c2(x2 − x0)(x2 − x1) = y2 − y0 + y1 − y1 −y1 − y0x1 − x0
(x2 − x1)−y1 − y0x1 − x0
(x1 − x0)
Daqui obtém-se
c2 =y2 − y1
(x2 − x0)(x2 − x1)+
y1 − y0(x2 − x0)(x2 − x1)
− y1 − y0(x2 − x0)(x2 − x1)
− y2 − y1(x2 − x0)(x2 − x1)
O segundo e o quarto termos da soma cancelam-se e vem
c2 =y2 − y1
(x2 − x0)(x2 − x1)− y1 − y0
(x2 − x0)(x2 − x1)Reduzindo ao mesmo denominador,
c2 =(y2 − y1)(x1 − x0)− (y1 − y0)(x2 − x0)
(x2 − x0)(x2 − x1)(x1 − x0)ou seja,
c2 =
y2−y1x2−x1 −
y1−y0x1−x0
x2 − x0Definindo
y10 =y1 − y0x1 − x0
e y21 =y2 − y1x2 − x1
podemos escrever
c2 =y21 − y10x2 − x0
No caso da tabela o polinómio interpolador é o seguinte:
p2(x) = −2 + 5(x− 1) +(1− 3)(2− 1)− (3− (−2))(4− 1)
(4− 1)(4− 2)(2− 1)(x− 1)(x− 2) =
= −2 + 5(x− 1)− 2(x− 1)(x− 2)
A representação gráfica deste polinómio encontra-se na Figura 8.16.
A fórmula geral para o polinómio de grau menor ou igual a n que interpola os pontos
(x0, y0), (x1, y1), ..., (xn, yn) é a seguinte:
pn(x) = y0 + y10(x− x0) + y210(x− x0)(x− x1) + ...+ yn...210(x− x0)...(x− xn−1)
É de salientar que o coeficiente yn...210, conhecido como a diferença dividida de maior ordem
(ordem n), que é o coeficiente do termo xn do polinómio interpolador pn(x).
Teorema 7 Sejam k + 1 nós distintos x0, ..., xk e [a; b] ≡ int[x0, ..., xk]. Seja f definida em [a; b] e
f ∈ Ck(a; b). Então existe um ξ ∈ (a; b) tal que
yn...210 =f (k)(ξ)
k!
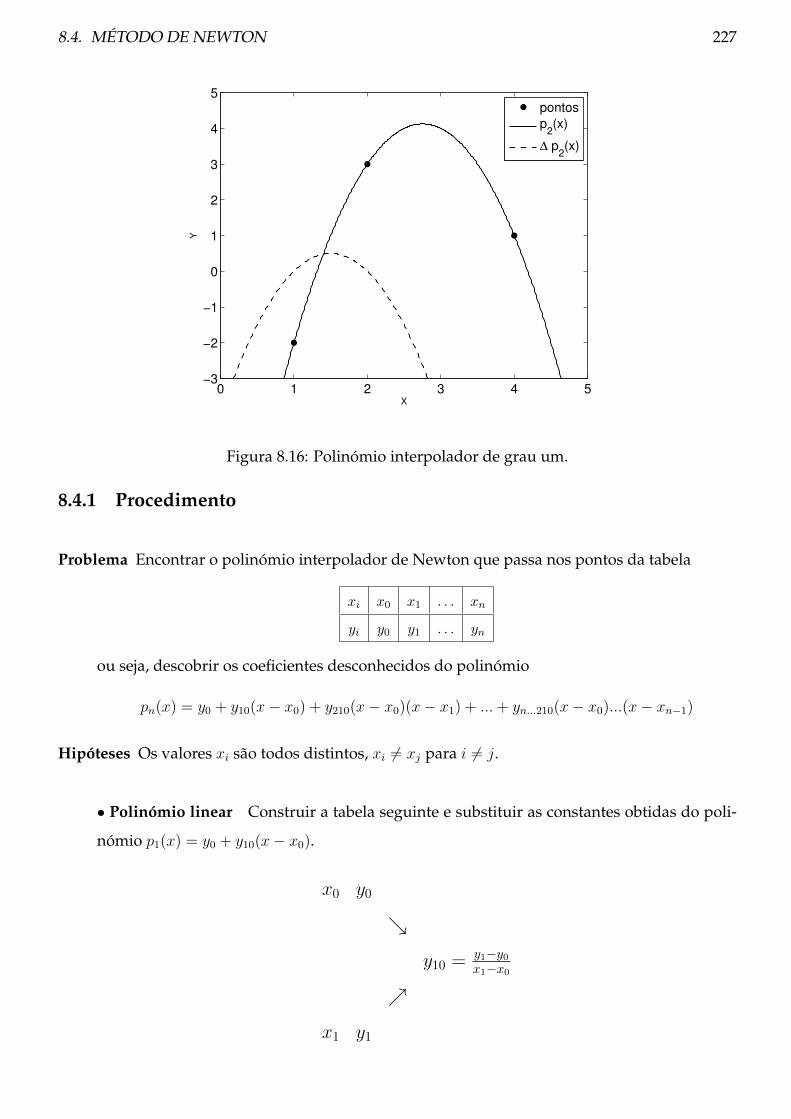
8.4. MÉTODO DE NEWTON 227
0 1 2 3 4 5−3
−2
−1
0
1
2
3
4
5
X
Y
pontos
p2(x)
∆ p2(x)
Figura 8.16: Polinómio interpolador de grau um.
8.4.1 Procedimento
Problema Encontrar o polinómio interpolador de Newton que passa nos pontos da tabela
xi x0 x1 . . . xn
yi y0 y1 . . . yn
ou seja, descobrir os coeficientes desconhecidos do polinómio
pn(x) = y0 + y10(x− x0) + y210(x− x0)(x− x1) + ...+ yn...210(x− x0)...(x− xn−1)
Hipóteses Os valores xi são todos distintos, xi 6= xj para i 6= j.
• Polinómio linear Construir a tabela seguinte e substituir as constantes obtidas do poli-
nómio p1(x) = y0 + y10(x− x0).
x0 y0
y10 = y1−y0x1−x0
x1 y1
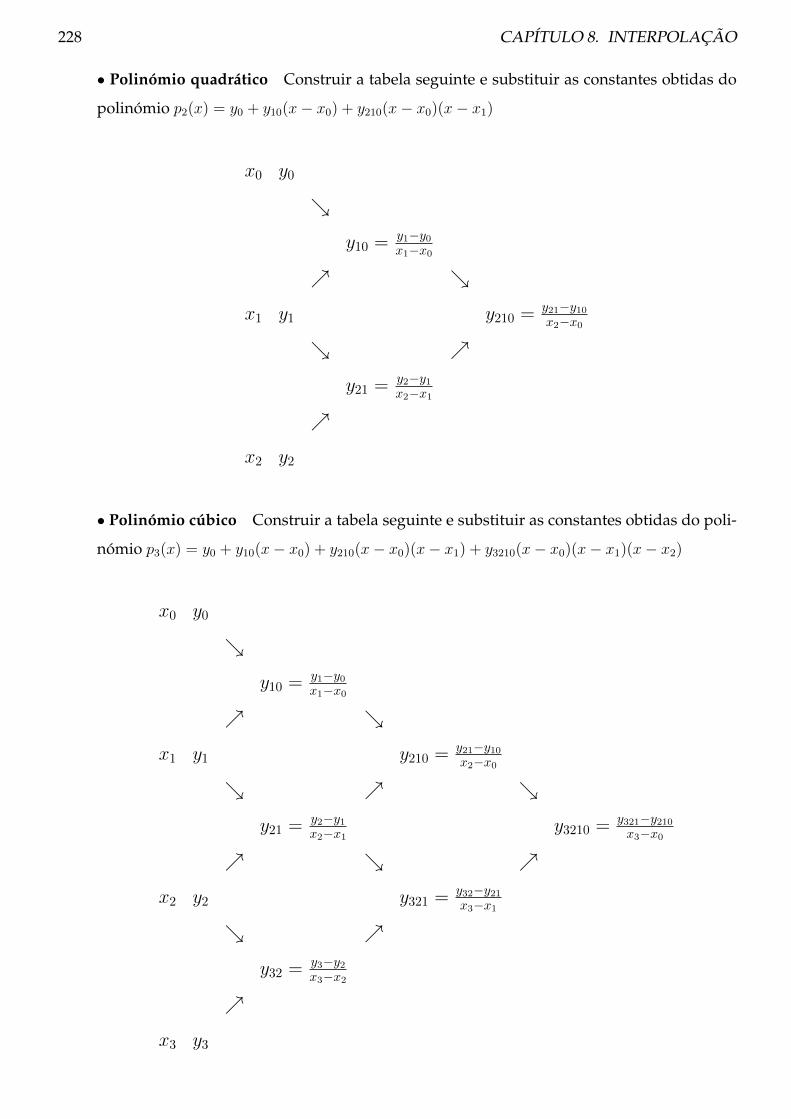
228 CAPÍTULO 8. INTERPOLAÇÃO
• Polinómio quadrático Construir a tabela seguinte e substituir as constantes obtidas do
polinómio p2(x) = y0 + y10(x− x0) + y210(x− x0)(x− x1)
x0 y0
y10 = y1−y0x1−x0
x1 y1 y210 = y21−y10x2−x0
y21 = y2−y1x2−x1
x2 y2
• Polinómio cúbico Construir a tabela seguinte e substituir as constantes obtidas do poli-
nómio p3(x) = y0 + y10(x− x0) + y210(x− x0)(x− x1) + y3210(x− x0)(x− x1)(x− x2)
x0 y0
y10 = y1−y0x1−x0
x1 y1 y210 = y21−y10x2−x0
y21 = y2−y1x2−x1 y3210 = y321−y210
x3−x0
x2 y2 y321 = y32−y21x3−x1
y32 = y3−y2x3−x2
x3 y3

8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 229
Foi ilustrado o procedimento para graus 1,2 e 3. As constantes yi,i+1, yi,i+1,i+2, ..., yi,i+1,...,i+k
são chamadas diferenças divididas de ordem 1, 2, ..., k. A generalização do cálculo das
diferenças divididas para ordens superiores a 4 é a seguinte
yi,i+1,...,i+k−1,i+k =yi+1,...,i+k − yi,...,i+k−1
xi+k − xi
Qualquer permutação da ordem dos nós não altera o resultado, ou seja, por exemplo, y123 =
y213 = y321. Com base nesta notação, podemos considerar que os valores yi são as diferenças
divididas de ordem zero. Por vezes também se usa a seguinte notação para as diferenças
divididas: f [xi, xi+1], f [xi, xi+1, xi+2],..., f [xi, xi+1, . . . , xi+k] e
f [xi, xi+1, . . . , xi+k−1,i+k] =f [xi+1, . . . , xi+k]− f [xi, . . . , xi+k−1]
xi+k − xi
8.5 Fenómeno de Runge e oscilação polinomial
Os polinómios interpoladores não são muito bons para aproximar funções descontínuas.
Em particular, podemos observar que o erro exige que a função seja contínua até determinada
ordem. Infelizmente, muitos resultados experimentais estão associados a ruído aleatório o que,
devido à sua natureza, é não diferenciável. Consequentemente, usando interpolação irá resultar
em erros significativos especialmente quando o número de pontos aumenta.
Nesta secção, iremos ver os efeitos da interpolação polinomial ilustrando diversas caracte-
rísticas que dão origem a uma grande fonte de erro. A resultante falta de precisão é chamada
oscilação polinomial.
O teorema de aproximação de Weierstrass diz que para qualquer função contínua definida
num intervalo fechado [a; b], existe uma sucessão de polinómios que converge uniformemente
para essa função; ver Teorema 5. Este teorema não garante que entre esses polinómios alguns se-
jam interpoladores. Este teorema só fornece uma base para aproximar funções usando polinómios
interpoladores.
Descontinuidades Os polinómios são muito maus para interpolar funções com descontinuida-
des. Qualquer análise do erro não pode ser realizada devido à falta de continuidade. Para ilustrar
este problema podemos observar as Figuras 8.17 e 8.18, onde está representada uma função com
uma única descontinuidade a ser interpolada utilizando cinco e sete pontos, respectivamente.
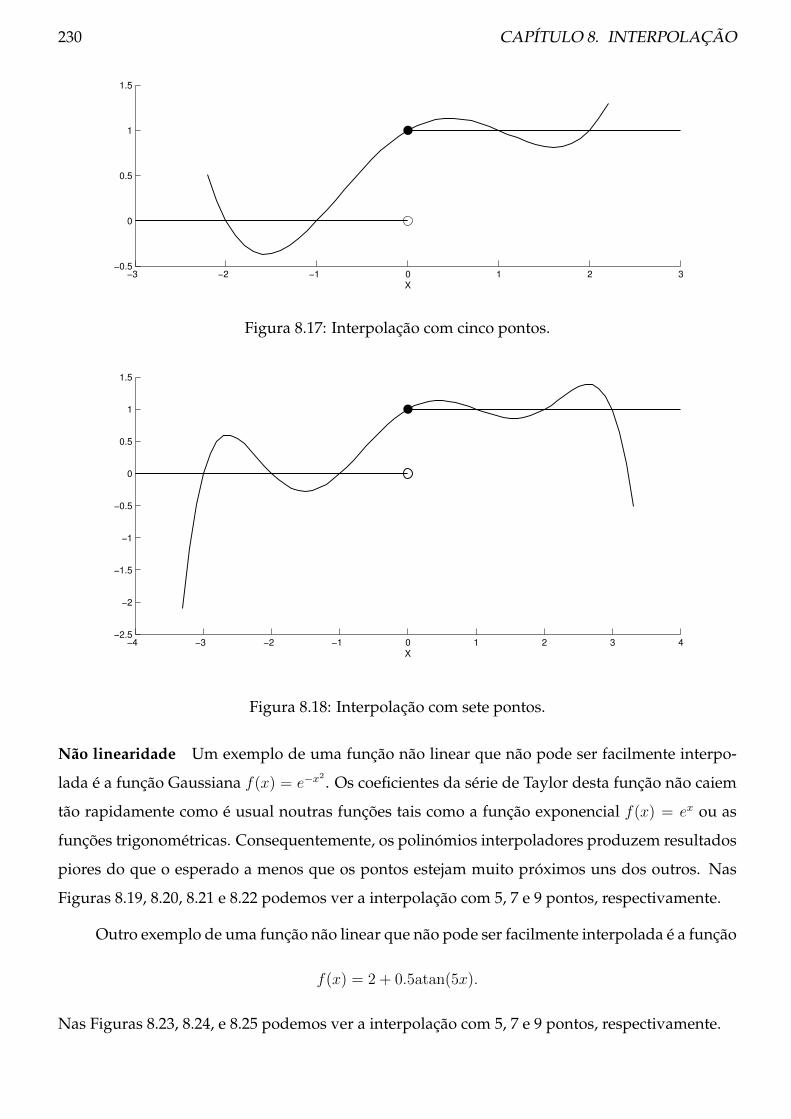
230 CAPÍTULO 8. INTERPOLAÇÃO
−3 −2 −1 0 1 2 3−0.5
0
0.5
1
1.5
X
Figura 8.17: Interpolação com cinco pontos.
−4 −3 −2 −1 0 1 2 3 4−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
X
Figura 8.18: Interpolação com sete pontos.
Não linearidade Um exemplo de uma função não linear que não pode ser facilmente interpo-
lada é a função Gaussiana f(x) = e−x2 . Os coeficientes da série de Taylor desta função não caiem
tão rapidamente como é usual noutras funções tais como a função exponencial f(x) = ex ou as
funções trigonométricas. Consequentemente, os polinómios interpoladores produzem resultados
piores do que o esperado a menos que os pontos estejam muito próximos uns dos outros. Nas
Figuras 8.19, 8.20, 8.21 e 8.22 podemos ver a interpolação com 5, 7 e 9 pontos, respectivamente.
Outro exemplo de uma função não linear que não pode ser facilmente interpolada é a função
f(x) = 2 + 0.5atan(5x).
Nas Figuras 8.23, 8.24, e 8.25 podemos ver a interpolação com 5, 7 e 9 pontos, respectivamente.
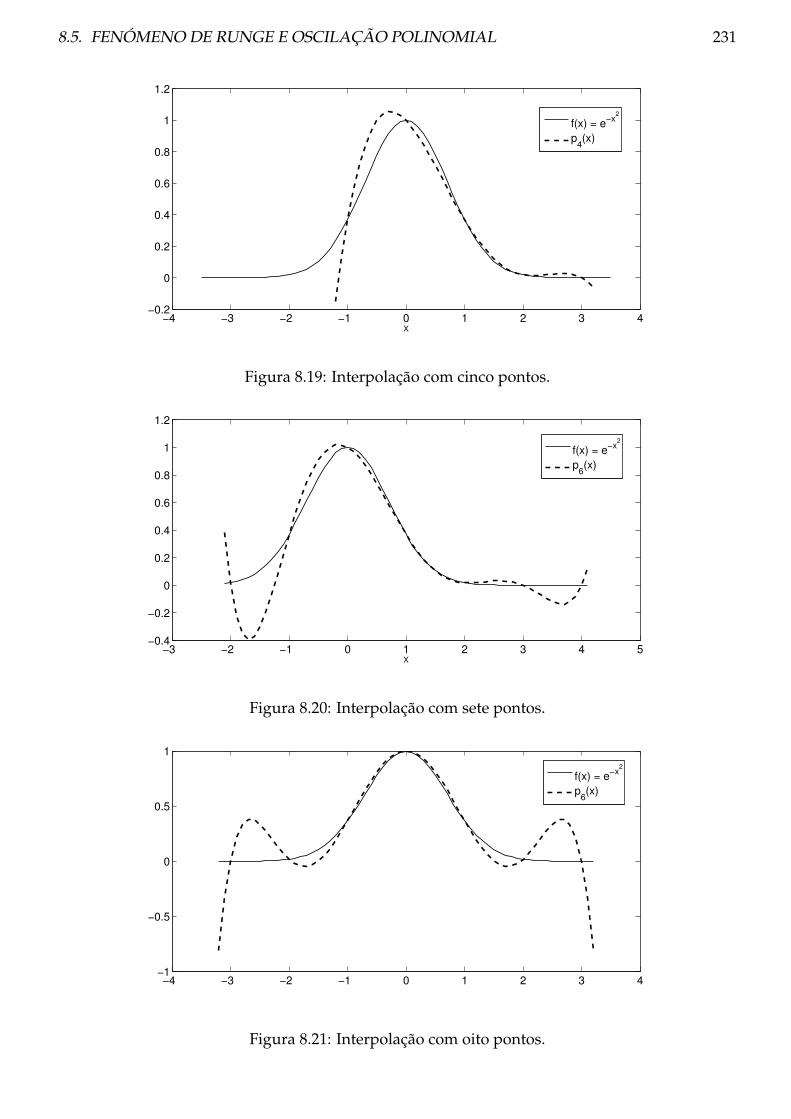
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 231
−4 −3 −2 −1 0 1 2 3 4−0.2
0
0.2
0.4
0.6
0.8
1
1.2
X
f(x) = e−x
2
p4(x)
Figura 8.19: Interpolação com cinco pontos.
−3 −2 −1 0 1 2 3 4 5−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
X
f(x) = e−x
2
p6(x)
Figura 8.20: Interpolação com sete pontos.
−4 −3 −2 −1 0 1 2 3 4−1
−0.5
0
0.5
1
f(x) = e−x
2
p6(x)
Figura 8.21: Interpolação com oito pontos.
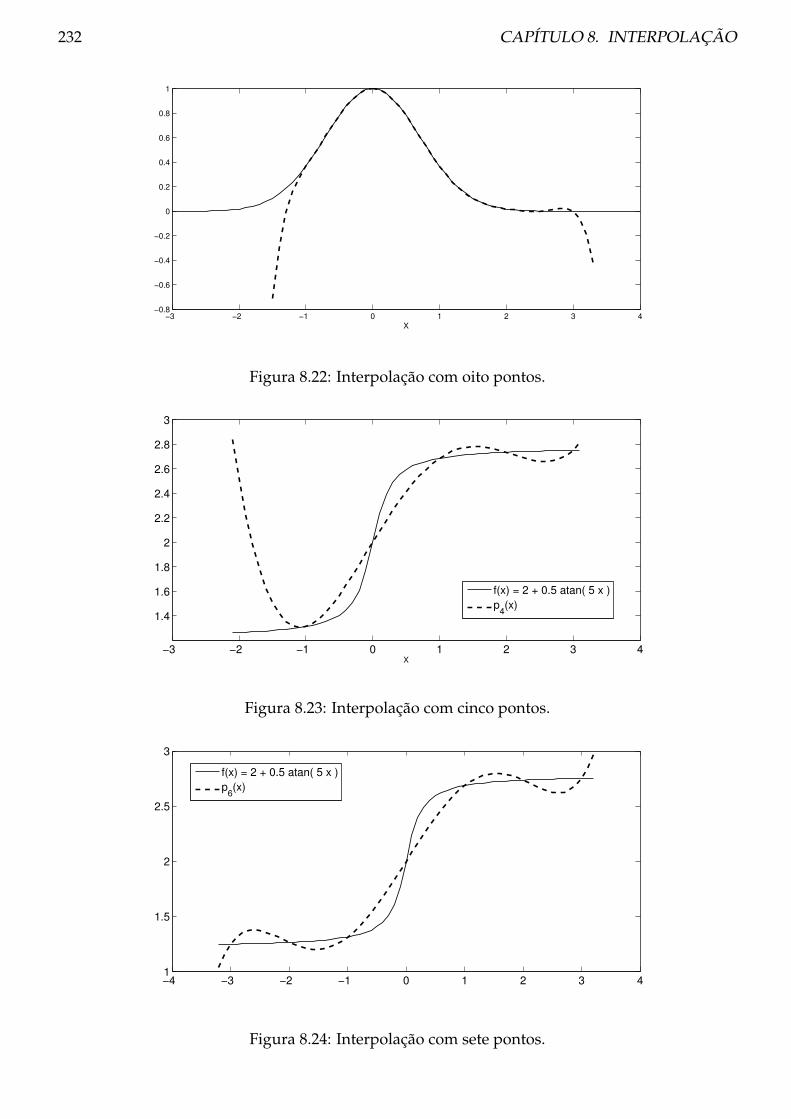
232 CAPÍTULO 8. INTERPOLAÇÃO
−3 −2 −1 0 1 2 3 4−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
X
Figura 8.22: Interpolação com oito pontos.
−3 −2 −1 0 1 2 3 4
1.4
1.6
1.8
2
2.2
2.4
2.6
2.8
3
X
f(x) = 2 + 0.5 atan( 5 x )
p4(x)
Figura 8.23: Interpolação com cinco pontos.
−4 −3 −2 −1 0 1 2 3 41
1.5
2
2.5
3
f(x) = 2 + 0.5 atan( 5 x )
p6(x)
Figura 8.24: Interpolação com sete pontos.
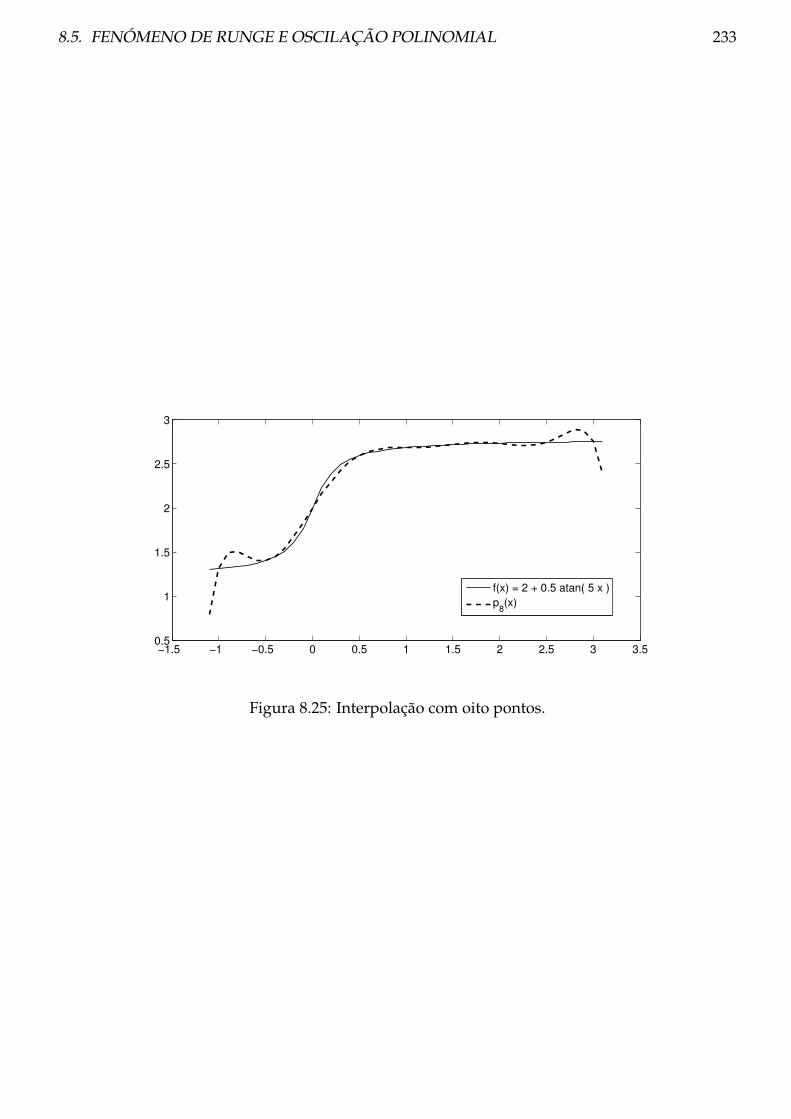
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 233
−1.5 −1 −0.5 0 0.5 1 1.5 2 2.5 3 3.50.5
1
1.5
2
2.5
3
f(x) = 2 + 0.5 atan( 5 x )
p8(x)
Figura 8.25: Interpolação com oito pontos.
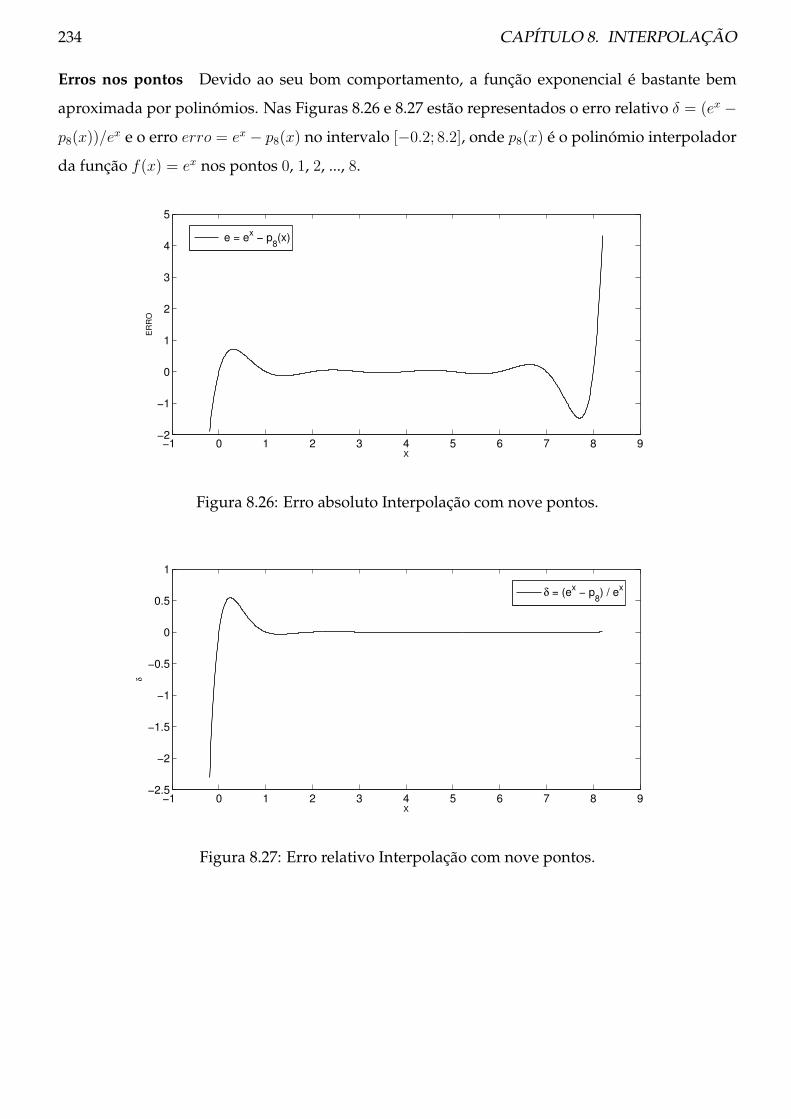
234 CAPÍTULO 8. INTERPOLAÇÃO
Erros nos pontos Devido ao seu bom comportamento, a função exponencial é bastante bem
aproximada por polinómios. Nas Figuras 8.26 e 8.27 estão representados o erro relativo δ = (ex −
p8(x))/ex e o erro erro = ex − p8(x) no intervalo [−0.2; 8.2], onde p8(x) é o polinómio interpolador
da função f(x) = ex nos pontos 0, 1, 2, ..., 8.
−1 0 1 2 3 4 5 6 7 8 9−2
−1
0
1
2
3
4
5
X
ER
RO
e = ex − p
8(x)
Figura 8.26: Erro absoluto Interpolação com nove pontos.
−1 0 1 2 3 4 5 6 7 8 9−2.5
−2
−1.5
−1
−0.5
0
0.5
1
X
δ
δ = (ex − p
8) / e
x
Figura 8.27: Erro relativo Interpolação com nove pontos.
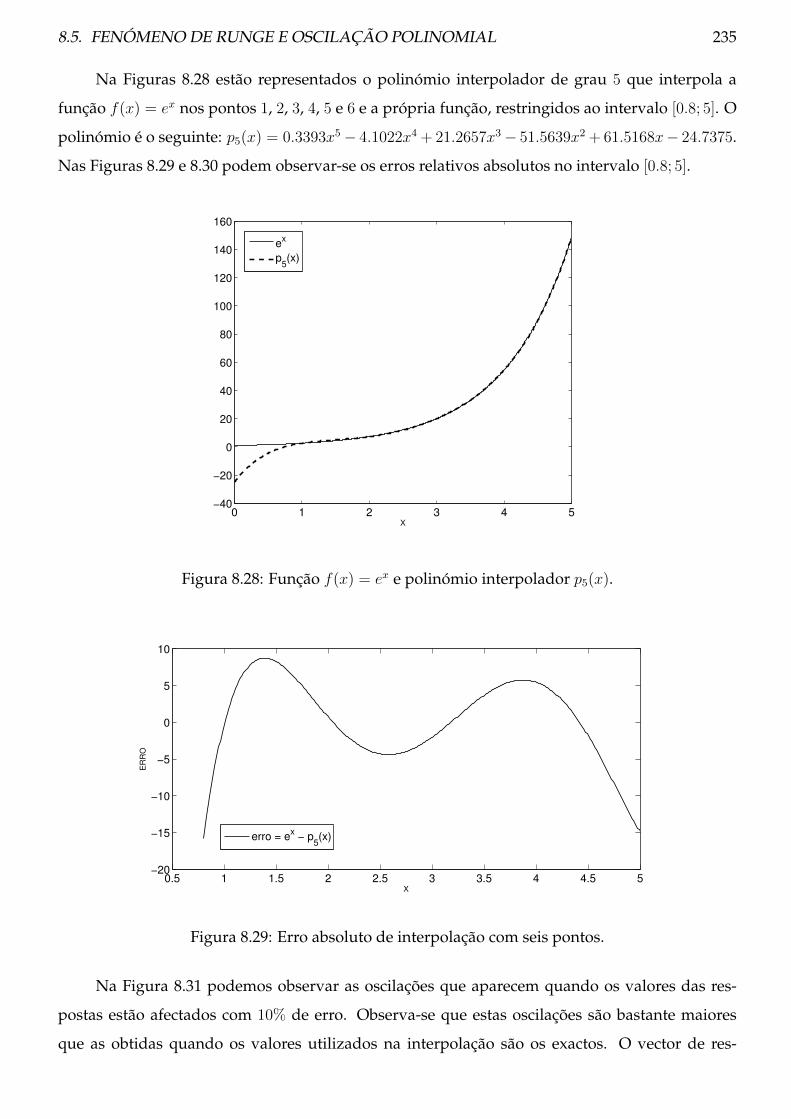
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 235
Na Figuras 8.28 estão representados o polinómio interpolador de grau 5 que interpola a
função f(x) = ex nos pontos 1, 2, 3, 4, 5 e 6 e a própria função, restringidos ao intervalo [0.8; 5]. O
polinómio é o seguinte: p5(x) = 0.3393x5− 4.1022x4 + 21.2657x3− 51.5639x2 + 61.5168x− 24.7375.
Nas Figuras 8.29 e 8.30 podem observar-se os erros relativos absolutos no intervalo [0.8; 5].
0 1 2 3 4 5−40
−20
0
20
40
60
80
100
120
140
160
X
ex
p5(x)
Figura 8.28: Função f(x) = ex e polinómio interpolador p5(x).
0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−20
−15
−10
−5
0
5
10
ER
RO
X
erro = ex − p
5(x)
Figura 8.29: Erro absoluto de interpolação com seis pontos.
Na Figura 8.31 podemos observar as oscilações que aparecem quando os valores das res-
postas estão afectados com 10% de erro. Observa-se que estas oscilações são bastante maiores
que as obtidas quando os valores utilizados na interpolação são os exactos. O vector de res-
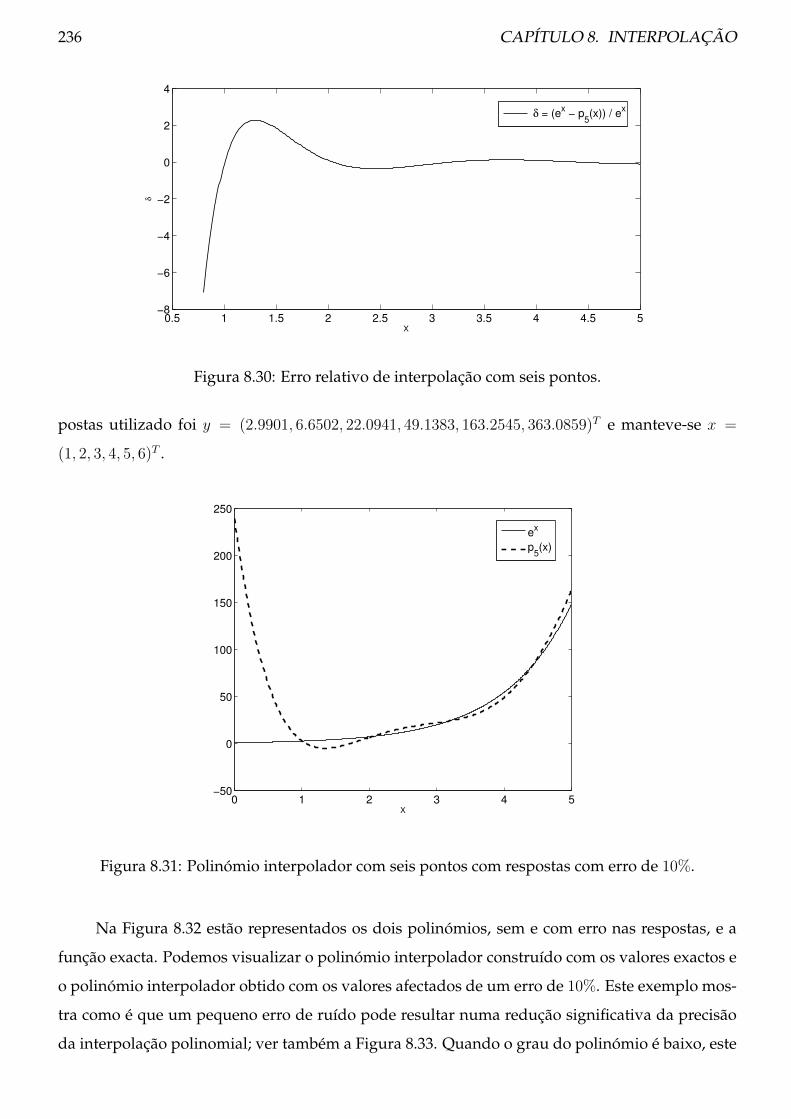
236 CAPÍTULO 8. INTERPOLAÇÃO
0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−8
−6
−4
−2
0
2
4
X
δ
δ = (ex − p
5(x)) / e
x
Figura 8.30: Erro relativo de interpolação com seis pontos.
postas utilizado foi y = (2.9901, 6.6502, 22.0941, 49.1383, 163.2545, 363.0859)T e manteve-se x =
(1, 2, 3, 4, 5, 6)T .
0 1 2 3 4 5−50
0
50
100
150
200
250
X
ex
p5(x)
Figura 8.31: Polinómio interpolador com seis pontos com respostas com erro de 10%.
Na Figura 8.32 estão representados os dois polinómios, sem e com erro nas respostas, e a
função exacta. Podemos visualizar o polinómio interpolador construído com os valores exactos e
o polinómio interpolador obtido com os valores afectados de um erro de 10%. Este exemplo mos-
tra como é que um pequeno erro de ruído pode resultar numa redução significativa da precisão
da interpolação polinomial; ver também a Figura 8.33. Quando o grau do polinómio é baixo, este
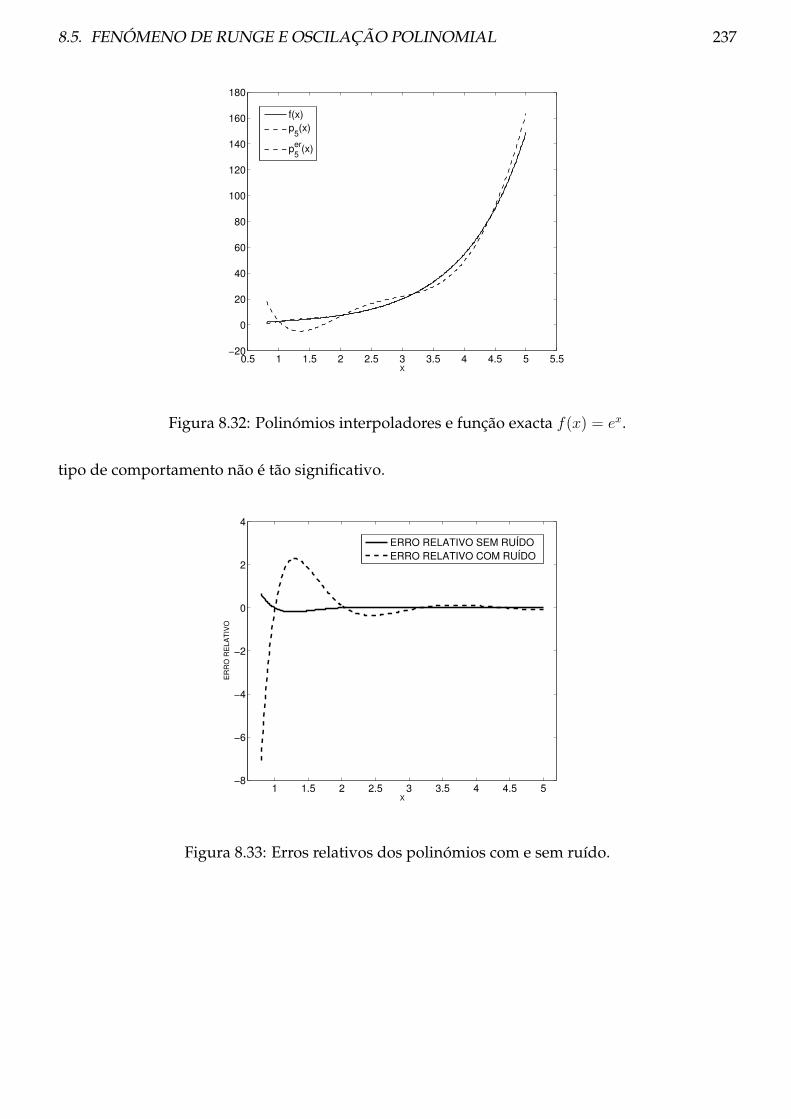
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 237
0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5−20
0
20
40
60
80
100
120
140
160
180
X
f(x)
p5(x)
per
5(x)
Figura 8.32: Polinómios interpoladores e função exacta f(x) = ex.
tipo de comportamento não é tão significativo.
1 1.5 2 2.5 3 3.5 4 4.5 5−8
−6
−4
−2
0
2
4
X
ER
RO
RE
LA
TIV
O
ERRO RELATIVO SEM RUÍDO
ERRO RELATIVO COM RUÍDO
Figura 8.33: Erros relativos dos polinómios com e sem ruído.
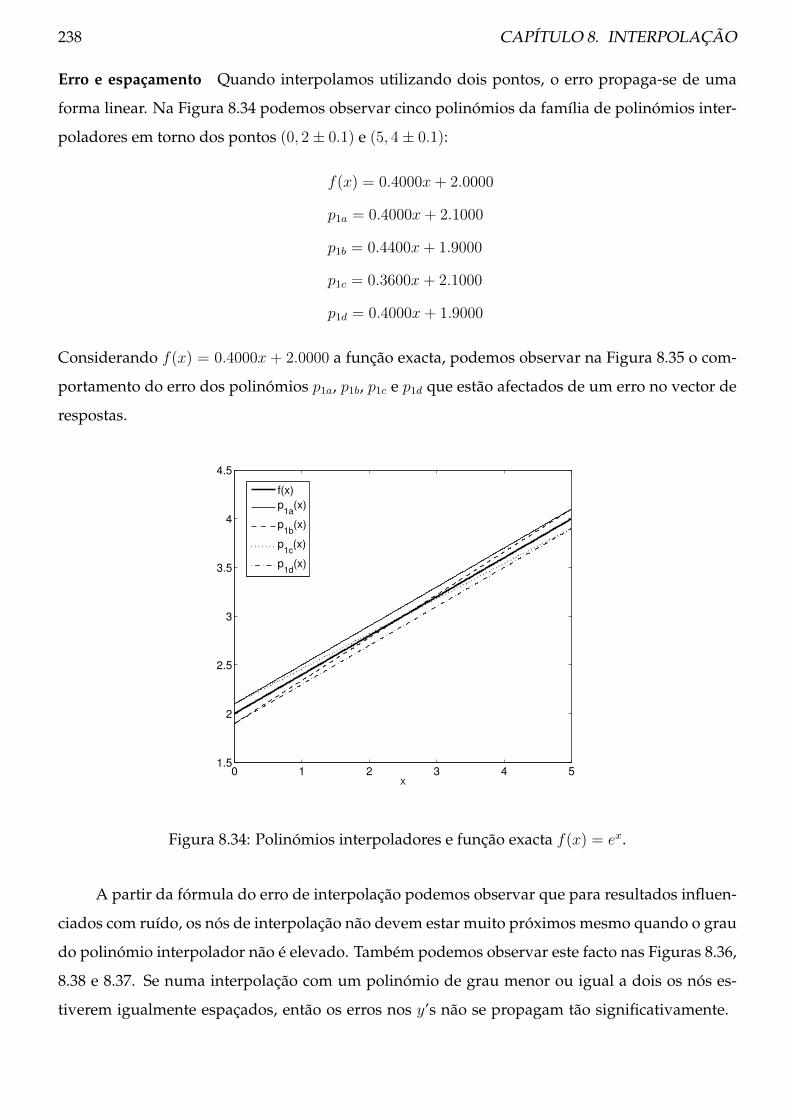
238 CAPÍTULO 8. INTERPOLAÇÃO
Erro e espaçamento Quando interpolamos utilizando dois pontos, o erro propaga-se de uma
forma linear. Na Figura 8.34 podemos observar cinco polinómios da família de polinómios inter-
poladores em torno dos pontos (0, 2± 0.1) e (5, 4± 0.1):
f(x) = 0.4000x+ 2.0000
p1a = 0.4000x+ 2.1000
p1b = 0.4400x+ 1.9000
p1c = 0.3600x+ 2.1000
p1d = 0.4000x+ 1.9000
Considerando f(x) = 0.4000x + 2.0000 a função exacta, podemos observar na Figura 8.35 o com-
portamento do erro dos polinómios p1a, p1b, p1c e p1d que estão afectados de um erro no vector de
respostas.
0 1 2 3 4 51.5
2
2.5
3
3.5
4
4.5
X
f(x)
p1a
(x)
p1b
(x)
p1c
(x)
p1d
(x)
Figura 8.34: Polinómios interpoladores e função exacta f(x) = ex.
A partir da fórmula do erro de interpolação podemos observar que para resultados influen-
ciados com ruído, os nós de interpolação não devem estar muito próximos mesmo quando o grau
do polinómio interpolador não é elevado. Também podemos observar este facto nas Figuras 8.36,
8.38 e 8.37. Se numa interpolação com um polinómio de grau menor ou igual a dois os nós es-
tiverem igualmente espaçados, então os erros nos y’s não se propagam tão significativamente.
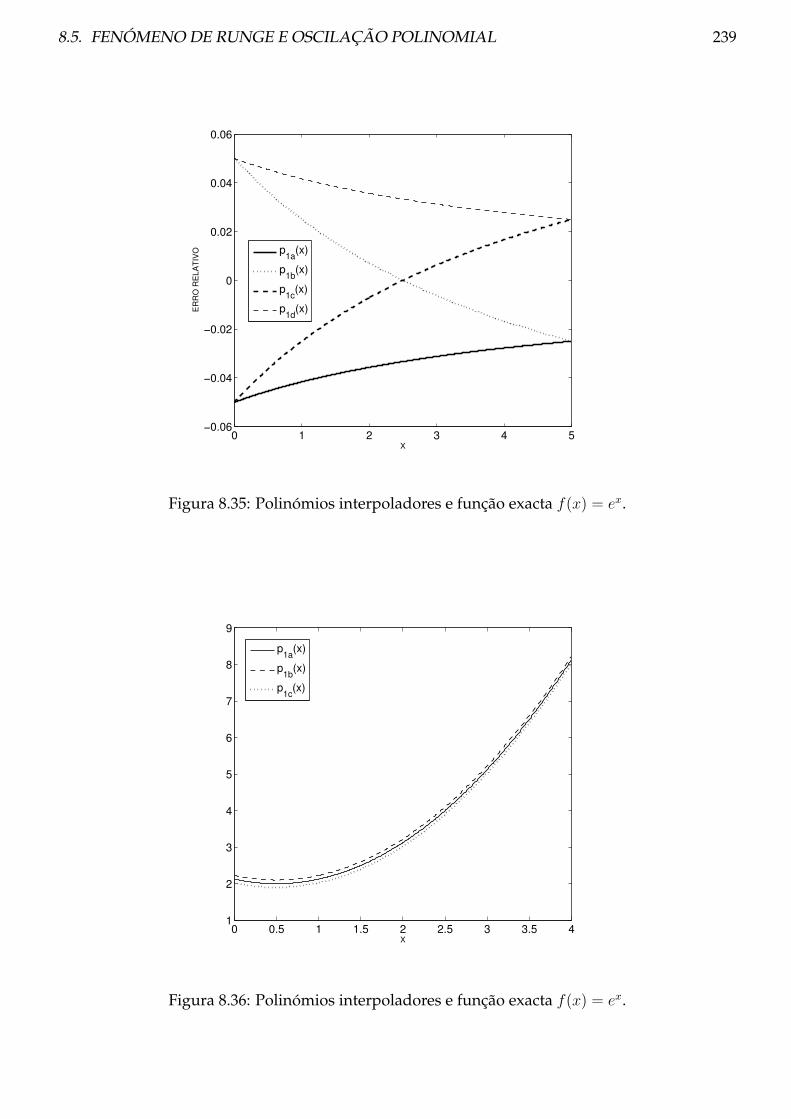
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 239
0 1 2 3 4 5−0.06
−0.04
−0.02
0
0.02
0.04
0.06
X
ER
RO
RE
LA
TIV
O
p1a
(x)
p1b
(x)
p1c
(x)
p1d
(x)
Figura 8.35: Polinómios interpoladores e função exacta f(x) = ex.
0 0.5 1 1.5 2 2.5 3 3.5 41
2
3
4
5
6
7
8
9
X
p1a
(x)
p1b
(x)
p1c
(x)
Figura 8.36: Polinómios interpoladores e função exacta f(x) = ex.
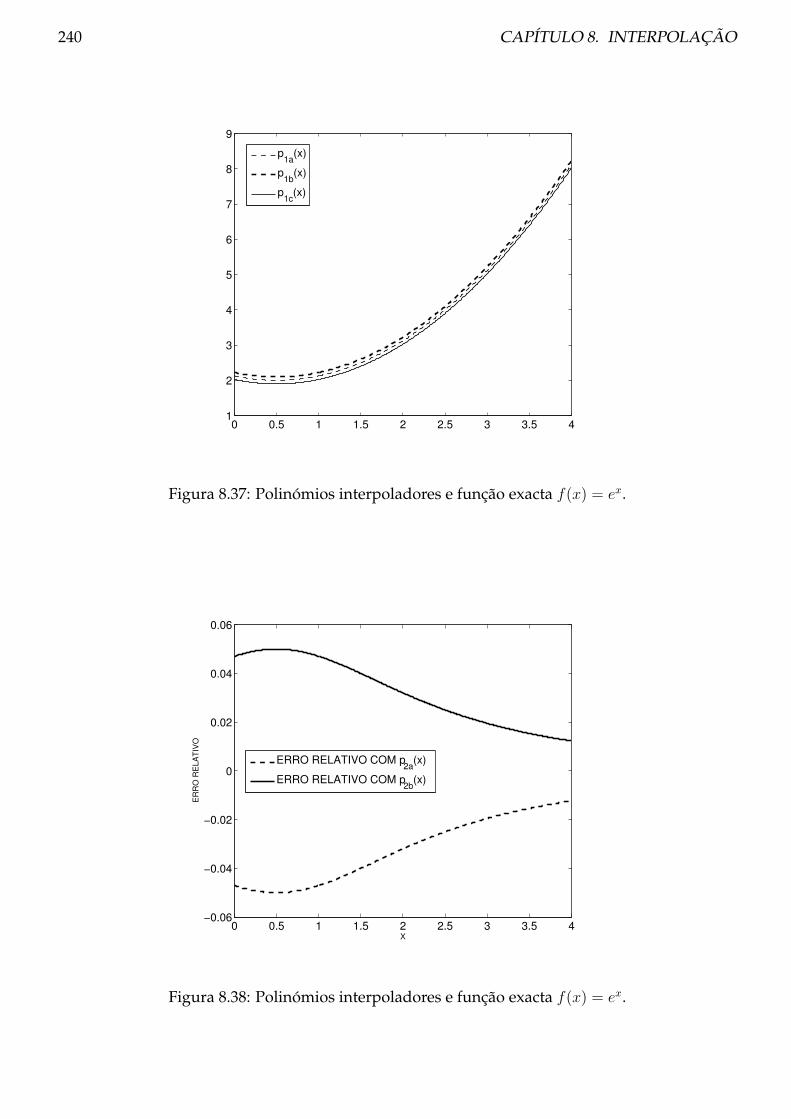
240 CAPÍTULO 8. INTERPOLAÇÃO
0 0.5 1 1.5 2 2.5 3 3.5 41
2
3
4
5
6
7
8
9
p1a
(x)
p1b
(x)
p1c
(x)
Figura 8.37: Polinómios interpoladores e função exacta f(x) = ex.
0 0.5 1 1.5 2 2.5 3 3.5 4−0.06
−0.04
−0.02
0
0.02
0.04
0.06
X
ER
RO
RE
LA
TIV
O
ERRO RELATIVO COM p2a
(x)
ERRO RELATIVO COM p2b
(x)
Figura 8.38: Polinómios interpoladores e função exacta f(x) = ex.
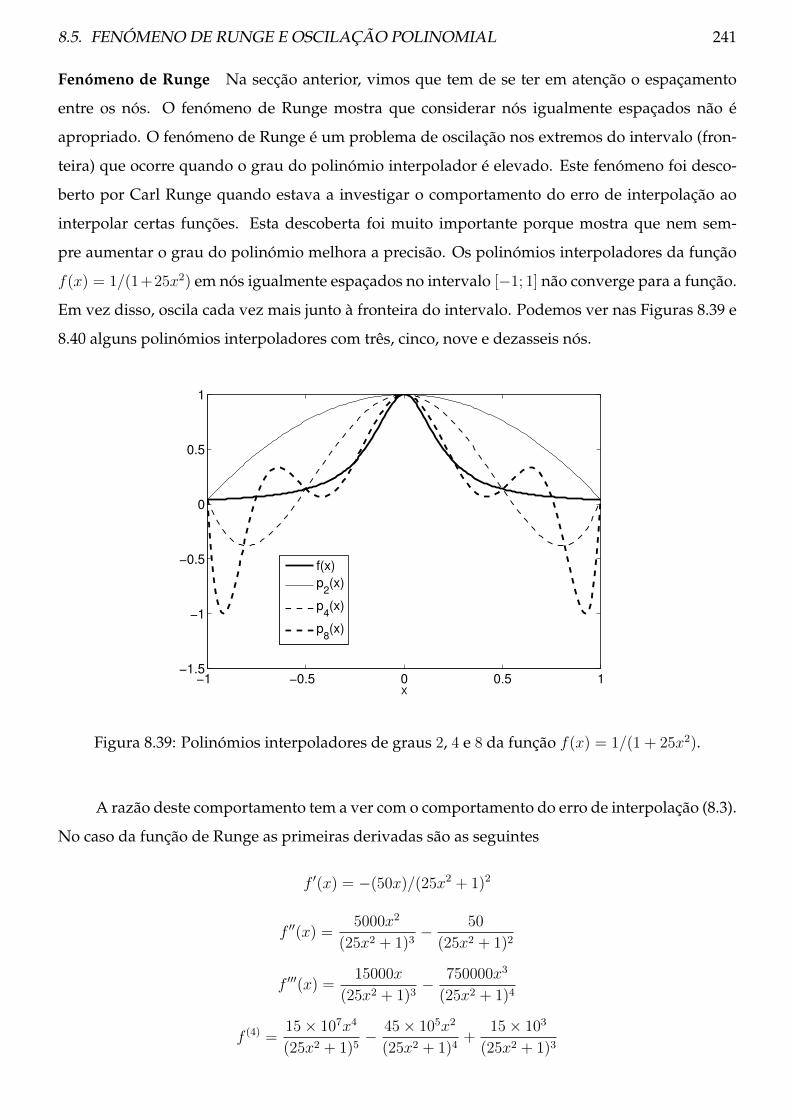
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 241
Fenómeno de Runge Na secção anterior, vimos que tem de se ter em atenção o espaçamento
entre os nós. O fenómeno de Runge mostra que considerar nós igualmente espaçados não é
apropriado. O fenómeno de Runge é um problema de oscilação nos extremos do intervalo (fron-
teira) que ocorre quando o grau do polinómio interpolador é elevado. Este fenómeno foi desco-
berto por Carl Runge quando estava a investigar o comportamento do erro de interpolação ao
interpolar certas funções. Esta descoberta foi muito importante porque mostra que nem sem-
pre aumentar o grau do polinómio melhora a precisão. Os polinómios interpoladores da função
f(x) = 1/(1+25x2) em nós igualmente espaçados no intervalo [−1; 1] não converge para a função.
Em vez disso, oscila cada vez mais junto à fronteira do intervalo. Podemos ver nas Figuras 8.39 e
8.40 alguns polinómios interpoladores com três, cinco, nove e dezasseis nós.
−1 −0.5 0 0.5 1−1.5
−1
−0.5
0
0.5
1
X
f(x)
p2(x)
p4(x)
p8(x)
Figura 8.39: Polinómios interpoladores de graus 2, 4 e 8 da função f(x) = 1/(1 + 25x2).
A razão deste comportamento tem a ver com o comportamento do erro de interpolação (8.3).
No caso da função de Runge as primeiras derivadas são as seguintes
f ′(x) = −(50x)/(25x2 + 1)2
f ′′(x) =5000x2
(25x2 + 1)3− 50
(25x2 + 1)2
f ′′′(x) =15000x
(25x2 + 1)3− 750000x3
(25x2 + 1)4
f (4) =15× 107x4
(25x2 + 1)5− 45× 105x2
(25x2 + 1)4+
15× 103
(25x2 + 1)3
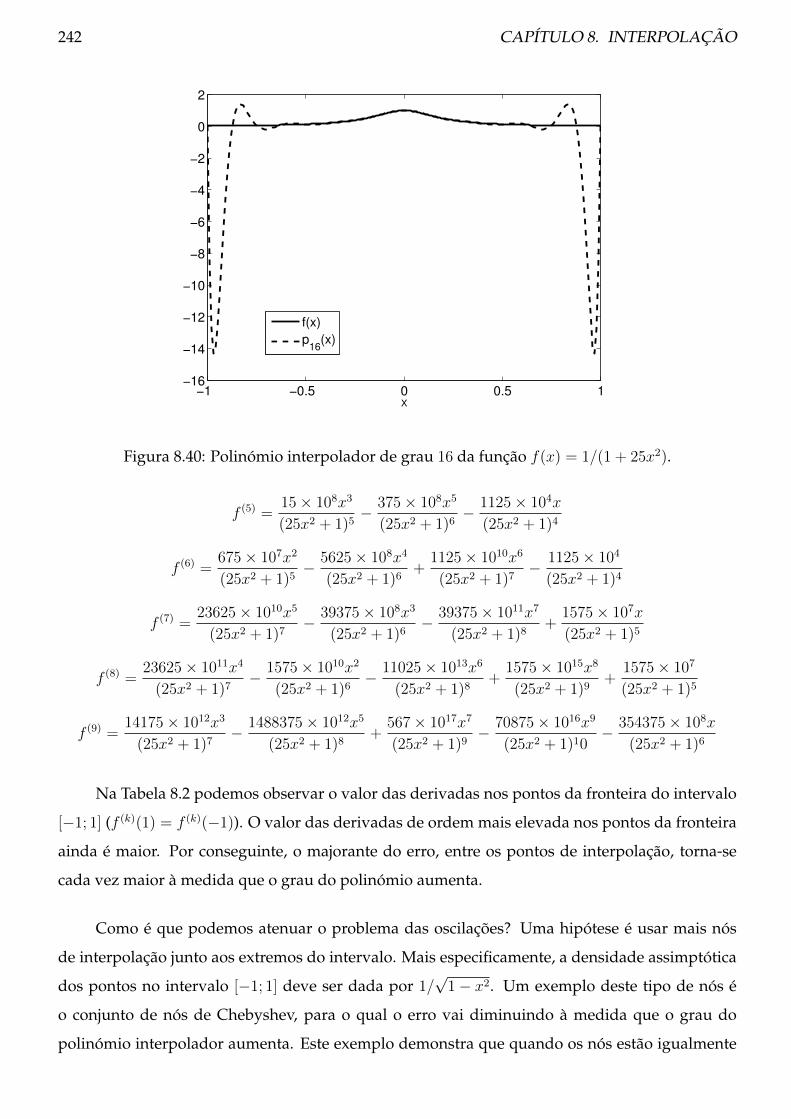
242 CAPÍTULO 8. INTERPOLAÇÃO
−1 −0.5 0 0.5 1−16
−14
−12
−10
−8
−6
−4
−2
0
2
X
f(x)
p16
(x)
Figura 8.40: Polinómio interpolador de grau 16 da função f(x) = 1/(1 + 25x2).
f (5) =15× 108x3
(25x2 + 1)5− 375× 108x5
(25x2 + 1)6− 1125× 104x
(25x2 + 1)4
f (6) =675× 107x2
(25x2 + 1)5− 5625× 108x4
(25x2 + 1)6+
1125× 1010x6
(25x2 + 1)7− 1125× 104
(25x2 + 1)4
f (7) =23625× 1010x5
(25x2 + 1)7− 39375× 108x3
(25x2 + 1)6− 39375× 1011x7
(25x2 + 1)8+
1575× 107x
(25x2 + 1)5
f (8) =23625× 1011x4
(25x2 + 1)7− 1575× 1010x2
(25x2 + 1)6− 11025× 1013x6
(25x2 + 1)8+
1575× 1015x8
(25x2 + 1)9+
1575× 107
(25x2 + 1)5
f (9) =14175× 1012x3
(25x2 + 1)7− 1488375× 1012x5
(25x2 + 1)8+
567× 1017x7
(25x2 + 1)9− 70875× 1016x9
(25x2 + 1)10− 354375× 108x
(25x2 + 1)6
Na Tabela 8.2 podemos observar o valor das derivadas nos pontos da fronteira do intervalo
[−1; 1] (f (k)(1) = f (k)(−1)). O valor das derivadas de ordem mais elevada nos pontos da fronteira
ainda é maior. Por conseguinte, o majorante do erro, entre os pontos de interpolação, torna-se
cada vez maior à medida que o grau do polinómio aumenta.
Como é que podemos atenuar o problema das oscilações? Uma hipótese é usar mais nós
de interpolação junto aos extremos do intervalo. Mais especificamente, a densidade assimptótica
dos pontos no intervalo [−1; 1] deve ser dada por 1/√
1− x2. Um exemplo deste tipo de nós é
o conjunto de nós de Chebyshev, para o qual o erro vai diminuindo à medida que o grau do
polinómio interpolador aumenta. Este exemplo demonstra que quando os nós estão igualmente

8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 243
Tabela 8.2: Derivadas da função de Runge.
f ′(1) −7.396449704142012× 10−2
f ′′(1) 2.105143377332727× 10−1
f ′′′(1) −7.877875424529953× 10−1
f (4)(1) 3.630892583485279
f (5)(1) −1.976266825557008× 101
f (6)(1) 1.232935015021950× 102
f (7)(1) −8.616124560546014× 102
f (8)(1) 6.616695396875675× 103
f (9)(1) −5.486963491137589× 104
espaçados geralmente não é bom usar polinómios de grau elevado. Dado um intervalo [a; b], os
nós de Chebyshev são os seguintes:
xi =a+ b
2+b− a
2cos
(2i+ 1)π
2n+ 2, i = 0, . . . , n.
Podemos ver, nas Figuras 8.41 e 8.42, que o erro de interpolação utilizando nove pontos
depende da função mas também depende da escolha dos nós de interpolação. Quando utilizamos
nós igualmente espaçados, o erro da função de Runge é maior junto aos extremos do intervalo e
atenua-se no meio do intervalo. Quando utilizamos os nós de Chevyshev (maior densidade de
pontos junto às pontas) o erro nunca chega a ser muito elevado, ou seja, é limitado por uma
constante não muito elevada.
As oscilações podem ser evitadas se usarmos funções spline, ou seja, funções seccionalmente
polinomiais tal que em cada sub-intervalo a função é um polinómio de grau baixo. Para tentar
diminuir o erro podemos utilizar um maior número de sub-intervalos em vez de aumentar o grau
dos polinómios dentro de cada sub-intervalo.
Podemos também fazer a minimização sujeita a constrangimentos. Mais concretamente,
usar um polinómio de grau relativamente elevado, mas com a condição de que a primeira (ou
segunda derivada, isto é, a curvatura) tenha uma norma em L2 mínima.
Outro método de ajuste é o método dos mínimos quadrados com um grau de polinómio
baixo. Geralmente, com k nós igualmente espaçados, se n < 2√k então o método dos mínimos
quadrados é bem condicionado.
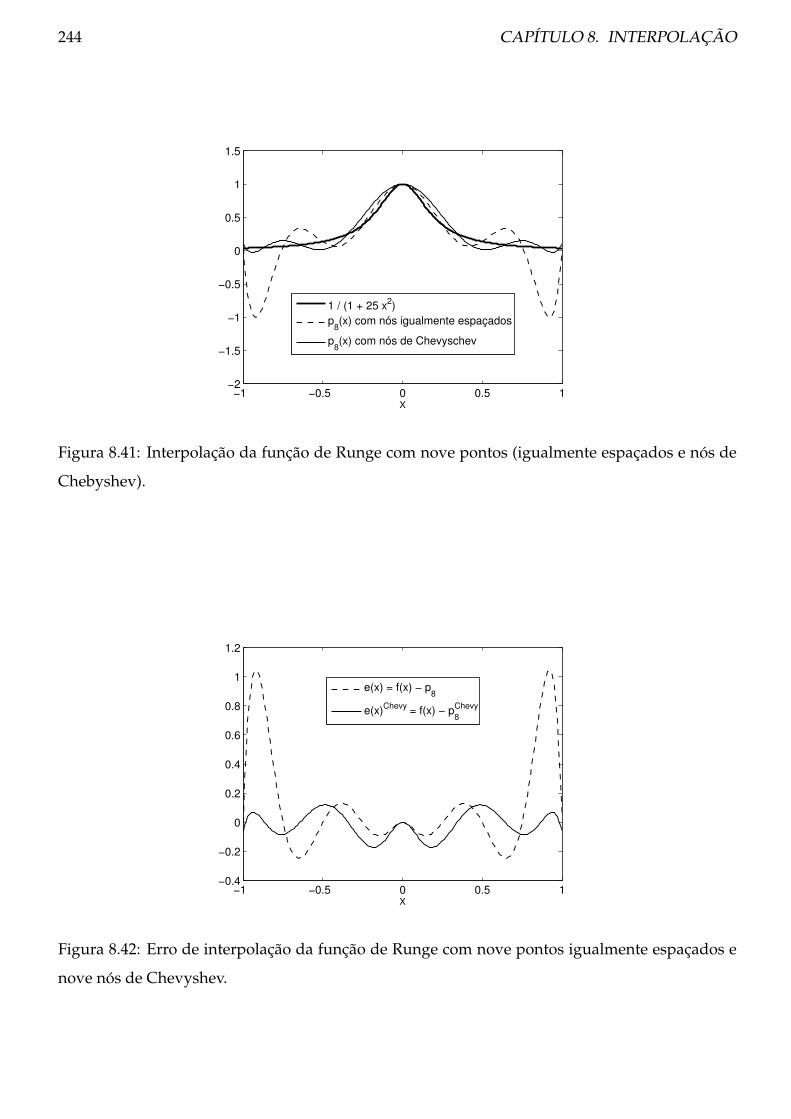
244 CAPÍTULO 8. INTERPOLAÇÃO
−1 −0.5 0 0.5 1−2
−1.5
−1
−0.5
0
0.5
1
1.5
X
1 / (1 + 25 x2)
p8(x) com nós igualmente espaçados
p8(x) com nós de Chevyschev
Figura 8.41: Interpolação da função de Runge com nove pontos (igualmente espaçados e nós de
Chebyshev).
−1 −0.5 0 0.5 1−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
X
e(x) = f(x) − p8
e(x)Chevy
= f(x) − p8
Chevy
Figura 8.42: Erro de interpolação da função de Runge com nove pontos igualmente espaçados e
nove nós de Chevyshev.
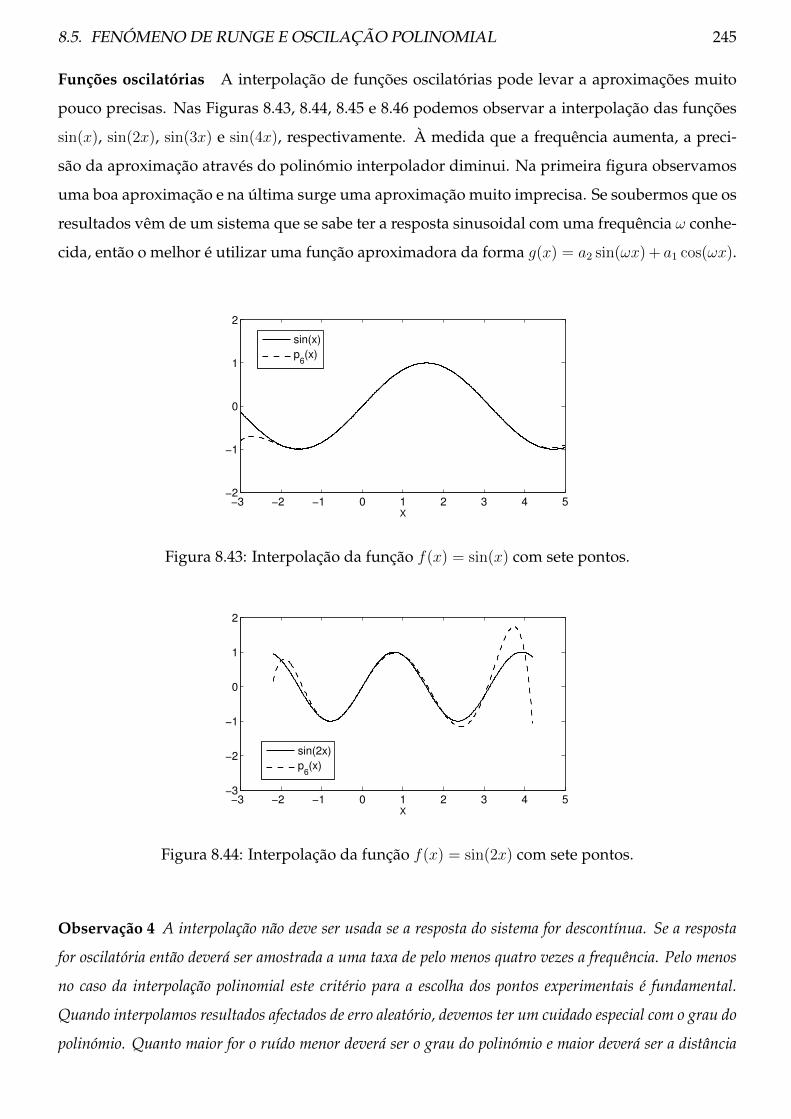
8.5. FENÓMENO DE RUNGE E OSCILAÇÃO POLINOMIAL 245
Funções oscilatórias A interpolação de funções oscilatórias pode levar a aproximações muito
pouco precisas. Nas Figuras 8.43, 8.44, 8.45 e 8.46 podemos observar a interpolação das funções
sin(x), sin(2x), sin(3x) e sin(4x), respectivamente. À medida que a frequência aumenta, a preci-
são da aproximação através do polinómio interpolador diminui. Na primeira figura observamos
uma boa aproximação e na última surge uma aproximação muito imprecisa. Se soubermos que os
resultados vêm de um sistema que se sabe ter a resposta sinusoidal com uma frequência ω conhe-
cida, então o melhor é utilizar uma função aproximadora da forma g(x) = a2 sin(ωx) + a1 cos(ωx).
−3 −2 −1 0 1 2 3 4 5−2
−1
0
1
2
X
sin(x)
p6(x)
Figura 8.43: Interpolação da função f(x) = sin(x) com sete pontos.
−3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
X
sin(2x)
p6(x)
Figura 8.44: Interpolação da função f(x) = sin(2x) com sete pontos.
Observação 4 A interpolação não deve ser usada se a resposta do sistema for descontínua. Se a resposta
for oscilatória então deverá ser amostrada a uma taxa de pelo menos quatro vezes a frequência. Pelo menos
no caso da interpolação polinomial este critério para a escolha dos pontos experimentais é fundamental.
Quando interpolamos resultados afectados de erro aleatório, devemos ter um cuidado especial com o grau do
polinómio. Quanto maior for o ruído menor deverá ser o grau do polinómio e maior deverá ser a distância
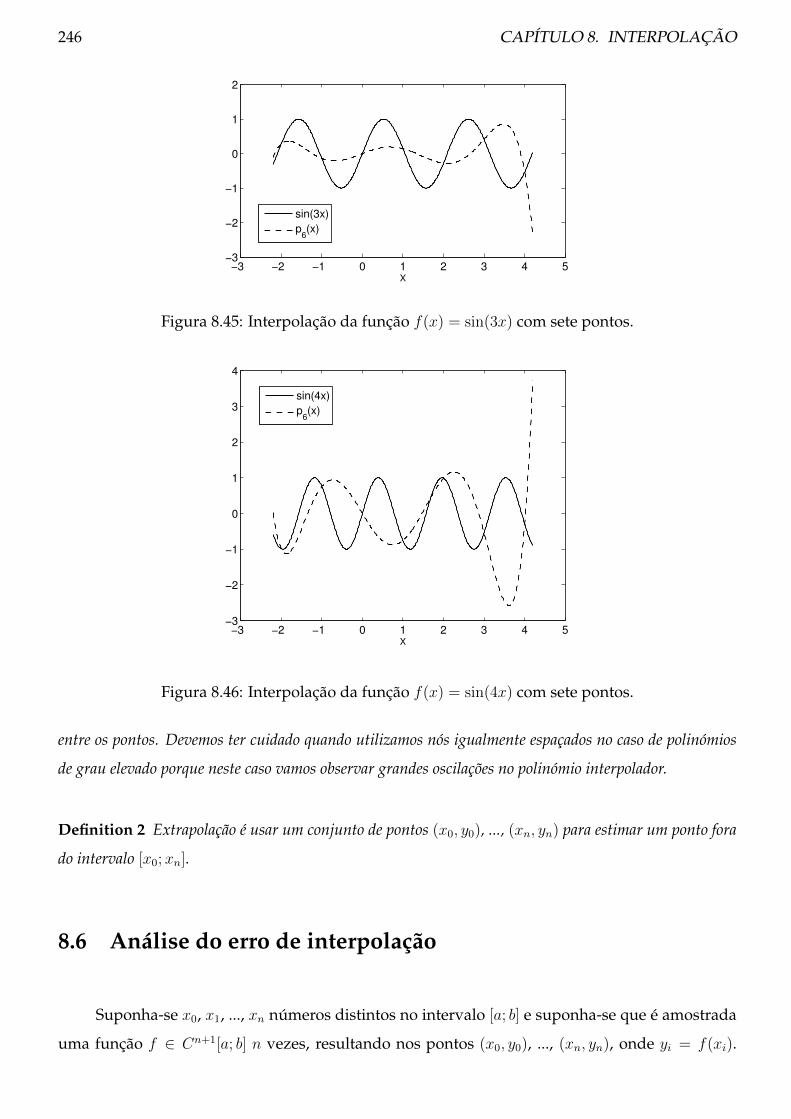
246 CAPÍTULO 8. INTERPOLAÇÃO
−3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
X
sin(3x)
p6(x)
Figura 8.45: Interpolação da função f(x) = sin(3x) com sete pontos.
−3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
4
X
sin(4x)
p6(x)
Figura 8.46: Interpolação da função f(x) = sin(4x) com sete pontos.
entre os pontos. Devemos ter cuidado quando utilizamos nós igualmente espaçados no caso de polinómios
de grau elevado porque neste caso vamos observar grandes oscilações no polinómio interpolador.
Definition 2 Extrapolação é usar um conjunto de pontos (x0, y0), ..., (xn, yn) para estimar um ponto fora
do intervalo [x0;xn].
8.6 Análise do erro de interpolação
Suponha-se x0, x1, ..., xn números distintos no intervalo [a; b] e suponha-se que é amostrada
uma função f ∈ Cn+1[a; b] n vezes, resultando nos pontos (x0, y0), ..., (xn, yn), onde yi = f(xi).
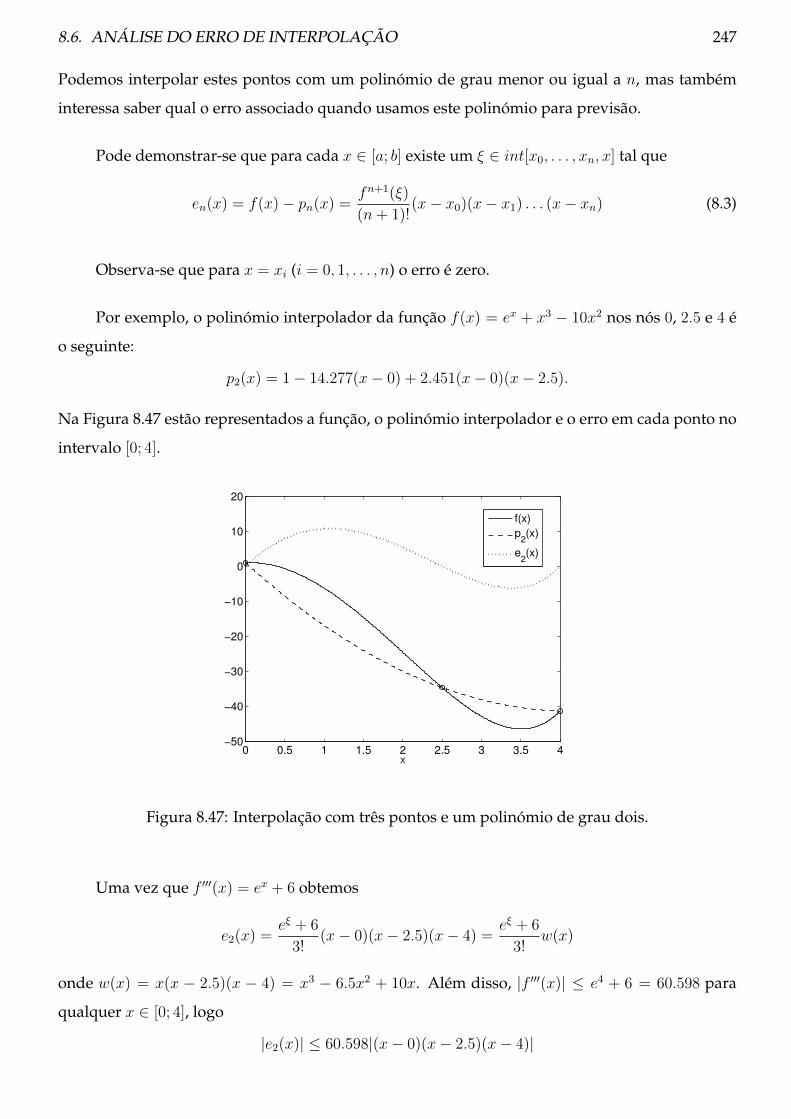
8.6. ANÁLISE DO ERRO DE INTERPOLAÇÃO 247
Podemos interpolar estes pontos com um polinómio de grau menor ou igual a n, mas também
interessa saber qual o erro associado quando usamos este polinómio para previsão.
Pode demonstrar-se que para cada x ∈ [a; b] existe um ξ ∈ int[x0, . . . , xn, x] tal que
en(x) = f(x)− pn(x) =fn+1(ξ)
(n+ 1)!(x− x0)(x− x1) . . . (x− xn) (8.3)
Observa-se que para x = xi (i = 0, 1, . . . , n) o erro é zero.
Por exemplo, o polinómio interpolador da função f(x) = ex + x3 − 10x2 nos nós 0, 2.5 e 4 é
o seguinte:
p2(x) = 1− 14.277(x− 0) + 2.451(x− 0)(x− 2.5).
Na Figura 8.47 estão representados a função, o polinómio interpolador e o erro em cada ponto no
intervalo [0; 4].
0 0.5 1 1.5 2 2.5 3 3.5 4−50
−40
−30
−20
−10
0
10
20
X
f(x)
p2(x)
e2(x)
Figura 8.47: Interpolação com três pontos e um polinómio de grau dois.
Uma vez que f ′′′(x) = ex + 6 obtemos
e2(x) =eξ + 6
3!(x− 0)(x− 2.5)(x− 4) =
eξ + 6
3!w(x)
onde w(x) = x(x − 2.5)(x − 4) = x3 − 6.5x2 + 10x. Além disso, |f ′′′(x)| ≤ e4 + 6 = 60.598 para
qualquer x ∈ [0; 4], logo
|e2(x)| ≤ 60.598|(x− 0)(x− 2.5)(x− 4)|

248 CAPÍTULO 8. INTERPOLAÇÃO
Podemos obter um majorante do erro válido em qualquer ponto no intervalo [0; 4] através da
majoração da função w(x). Para isso resolve-se a equação w′(x) = 0, ou seja 3x2 − 13x + 10 = 0 e
obtém-se x = 1.000 ou x = 3.333. Por conseguinte,
w(1.000) = 4.500,
w(3.333) = −1.852
e
|e2(x)| ≤ (60.598)(4.5) = 272.69
8.7 Interpolação trigonométrica
Suponhamos que observamos um diagrama de dispersão em que os valores da resposta
do sistema parecem ter um comportamento periódico. Um exemplo é quando os valores vêm
de uma amostra de som ou sinal eléctrico. Neste casos, em vez de utilizar interpolação polino-
mial é mais apropriado recorrer ao uso de funções interpoladoras periódicas como, por exemplo,
combinações de senos e cossenos. Mais concretamente, é usual usar interpolação trigonométrica.
Interpolação trigonométrica é a interpolação com polinómios trigonométricos, isto é, uma
combinação linear de funções sin(nx) e cos(nx) com n pertencente ao conjunto dos números na-
turais. Os coeficientes de um polinómio trigonométrico podem ser reais ou complexos.
Séries de Fourier Quando os coeficientes do polinómio são complexos, o polinómio reduz-se a
uma série de Fourier finita. Considere-se uma função periódica f , isto é, tal que,
f(t) = f(t+ T ), ∀t ∈ (−∞;∞)
A T á chamado período. Sem perda de generalidade, vamos considerar T = 2π, ou seja, assuma-
se que a função a interpolar é periódica de período 2π. Não existe dificuldade em considerar T
maior ou menor que 2π uma vez que basta só mudar a escala. Um dos teoremas da análise de
Fourier estabelece que se f é periódica de período 2π e tem primeira derivada contínua (ou seja,
f ∈ C1), então a soma
a0 +m∑k=1
(ak cos kx+ bk sin kx)
converge uniformemente para f , ou seja,
f(x) ∼ a0 +∞∑k=1
(ak cos kx+ bk sin kx) (8.4)

8.7. INTERPOLAÇÃO TRIGONOMÉTRICA 249
Os coeficientes da série, denominada série de Fourier, podem ser calculados através de
ak =1
π
∫ π
−πf(t) cos ktdt (8.5)
bk =1
π
∫ π
−πf(t) sin ktdt (8.6)
Este teorema garante que faz todo o sentido aproximar funções periódicas com período 2π por
combinações lineares de senos e cossenos.
Séries de Fourier no plano complexo A fórmula de Euler é a seguinte:
eiθ = cos θ + i sin θ
onde i2 = −1. A série de Fourier é dada por
f(x) ∼∞∑
k=−∞
f(k)eikx (8.7)
onde
f(k) =1
2π
∫ π
−πf(t)e−iktdt
Se f for uma função real então a sua série de Fourier dada por (8.4) é a parte real da série de
Fourier complexa (8.7). Note-se que
cos θ =eiθ + e−iθ
2e sin θ =
eiθ − e−iθ
2
Teorema 8 Dadas as sucessões [ak]∞k=0 e [bk]
∞k=0, defina-se
b0 = 0, a−k = ak, b−k = bk, ck =1
2(ak − ibk),
então
p(x) = a0 +m∑k=1
(ak cos kx+ bk sin kx) =m∑
k=−m
ckeikx
Para ver como se obtém este resultado, convém observar que
f(k) =1
2π
∫ π
−πf(t)e−iktdt
=1
2π
∫ π
−πf(t)(cos(−kt) + i sin(−kt))dt
=1
2π
∫ π
−πf(t)(cos kt− i sin kt)dt
=1
2(ak − ibk)

250 CAPÍTULO 8. INTERPOLAÇÃO
Nesta dedução utilizou-se a fórmula de Euler, (8.5) e (8.6).
Sabendo agora que f(k) = 12(ak − ibk), podemos escrever
m∑k=−m
f(k)eikx =m∑
k=−m
1
2(ak − ibk)eikx =
=m∑
k=−m
1
2(ak − ibk)(cos kx+ i sin kx) =
=1
2(ak cos kx+ iak sin kx− ibk cos kxbk sin kx) =
=1
2
m∑k=−m
(ak cos kx+ bk sin kx) + i1
2
m∑k=−m
(ak sin kx− bkcoskx)
A parte imaginária desta soma é zero, ou seja,
m∑k=−m
(ak sin kx− bkcoskx) =m∑k=1
(a−k sin(−kx)− b−k cos(−kx)) + a0 sin(0)− b0 cos(0) +
+m∑k=1
(ak sin kx− bk cos kx) = 0
porque b0 = 0, sin(0) = 0, sin(−kx) = − sin kx, cos(−kx) = cos kx e
a−k =1
π
∫ π
−πf(t) cos(−kt)dt =
1
π
∫ π
−πf(t) cos ktdt = ak
b−k =1
π
∫ π
−πf(t) sin(−kt)dt = − 1
π
∫ π
−πf(t) sin ktdt = −bk
A parte real é dada por
1
2
m∑k=−m
(ak cos kx+ bk sin kx) =
=1
2
m∑k=1
(a−k cos(−kx) + b−k sin(−kx)) +a02
+1
2
m∑k=1
(ak cos kx+ bk sin kx) =
=a02
+m∑k=1
(ak cos kx+ bk sin kx)
Considere-se então a função aproximadora
p(x) =n∑
k=−n
ckeikx
Se considerarmos z = eix, então p(x) pode ser escrito na forma
p(x) =n∑
k=−n
ckzk

8.7. INTERPOLAÇÃO TRIGONOMÉTRICA 251
Consequentemente, o problema de interpolação trigonometrica reduz-se a um problema de in-
terpolação polinomial no círculo unitário. Os resultados de existência e unicidade de polinómio
interpolador seguem directamente dos resultados de interpolação polinomial.
Quando os nós de interpolação são igualmente espaçados com h = 2π/(n+ 1), ou seja,
xi =2iπ
n+ 1, 0 ≤ k ≤ n
a transformação que transforma os pontos yi = f(xi) nos coeficientes ak e bk denomina-se Trans-
formada de Fourier Discreta (DFT) de ordem n+ 1.
A formulação anterior é quando n é par, ou seja, m = n/2; note-se que temos 2m + 1 incóg-
nitas, a0, a1, ..., am, b1, ..., bm, e n+ 1 pontos logo 2m+ 1 = n+ 1, ou seja m = n/2.
Quando n é ímpar
p(x) = a0 +m∑k=1
(ak cos kx+ bk sin kx) + am+1 cos((m+ 1)x) =m+1∑
k=−(m+1)
ckeikx
onde cm+1 = c−(m+1) = am+1/2. Neste caso temos 2m+ 2 incógnitas e n+ 1 pontos, logo 2m+ 2 =
n+ 1, ou seja m = (n− 1)/2.
Consequentemente,
p(x) =m+λ∑
k=−(m+λ)
ckeikx
onde
λ =
1, n impar
0, n par
Os coeficientes ck são a solução do sistema de equações
m+λ∑k=−(m+λ)
ckeikxj = f(xj)
Mas xj = jh logom+λ∑
k=−(m+λ)
ckeikjh = f(xj)
Multiplicando por e−iljh, onde 0 < l < n, e somando em j vem
n∑j=0
m+λ∑k=−(m+λ)
ckeikjhe−iljh =
n∑j=0
f(xj)e−iljh
ou seja,m+λ∑
k=−(m+λ)
ck
n∑j=0
ei(k−l)jh =n∑j=0
f(xj)e−iljh

252 CAPÍTULO 8. INTERPOLAÇÃO
Mas quando k = m tém-sen∑j=0
ei(k−l)jh =n∑j=0
1 = n+ 1
e quando k 6= m a progressão geométrica tem a forma:
n∑j=0
ei(k−l)jh =1− (ei(k−l)h)n+1
1− ei(k−l)h= 0
Note-se que
1− (ei(k−l)h)n+1 = 1− ei(k−l)2π = 1− cos((k − l)2π)− i sin((k − l)2π) = 0
Consequentemente,n∑j=0
ei(k−l)jh = (n+ 1)δkm
onde δ é a função delta de Dirac, e vem
m+λ∑k=−(m+λ)
ck(n+ 1)δkl =n∑j=0
f(xj)
Todos os termos da soma do lado esquerdo são nulos excepto para k = l, logo
cl(n+ 1) =n∑j=0
f(xj)e−iljh
ou seja,
cl =1
n+ 1
n∑j=0
f(xj)e−iljh
onde l = −(m+ λ),−(m+ λ) + 1, . . . ,m+ λ− 1,m+ λ.
Para calcular estes coeficientes podemos usar a transformação rápida de Fourier, FFT (Fast
Fourier Transform) implementada em matlab na rotina fft. O número de operações deste algo-
ritmo é da ondem de n log2 n.
Exemplo 48
8.8 Problemas
1. Para cada um dos seguintes problemas utilize os três métodos que aprendeu.
(a) Encontrar o polinómio que interpola os pontos (1, 1.3), (2, 1.6), (3, 1.9).

8.8. PROBLEMAS 253
(b) Encontrar o polinómio que interpola os pontos (2, 2), (4, 1), (6, 4) e (8, 2).
(c) Encontrar o polinómio interpolador dos pontos da tabela
xi 1.1 2.2 3.5 5.0 6.5
yi −5.7222 −7.7214 −3.9975 19.5000 80.7525
Represente graficamente o polinómio e os pontos da tabela.
(d) Encontrar a função da forma g(x) = a2x + a1 cos(x) + a0 sin(x) que interpola os pontos
(0.2, 0.6), (1.5,−0.1) e (2.3, 3.5).
(e) Encontrar o polinómio de grau menor ou igual a um que interpola os pontos (2, 3) e
(5, 7).
(f) Encontrar o polinómio cúbico que interpola os pontos (−2, 21), (0, 1), (1, 0), (3,−74).
(g) Encontrar o polinómio cúbico que interpola os pontos (1, 5), (2, 7), (4, 11), (6, 15).
(h) Utilize o Matlab para obter o polinómio que interpola os pontos:
(1.3, 0.51), (0.57, 0.98), (−0.33, 1.2), (−1.2, 14), (2.1,−0.35), (0.36, 0.52).
2. Será que os valores de x terão de estar ordenados por ordem crescente para que o método
de Vandermonde e de Newton funcione? Faça a experimentação em Matlab com dois exem-
plos.
3. (a) Calcule o polinómio de grau 2 que interpola a função f definida pela expressão
f(x) = 3x2 − x3 − 2
no intervalo [0, 3] usando os nós de interpolação 0, 1, 2.
(b) Obtenha um majorante do erro de interpolação no intervalo [0,3].
4. Considere a seguinte tabela de valores de uma função real de variável real:
x −1 0 1
f(x) 4 1 2
(a) Determine o polinómio interpolador de f nos pontos da tabela, utilizando a fórmula
de Newton.
(b) A partir do polinómio obtido na alínea anterior e sabendo que f(x) = x3+a2x2+a1x+a0,
obtenha f(x).
5. Considere a seguinte tabela de valores de uma função

254 CAPÍTULO 8. INTERPOLAÇÃO
xi −1.0 0.5 2.0 3.5 5.0
f(xi) 6.34 3.82 3.01 2.14 2.10
(a) Utilizando a fórmula de Newton com diferenças divididas, calcule p2(2.1), onde p2 é o
polinómio interpolador de f nos SEGUNDO, TERCEIRO e QUARTO pontos da ta-
bela.
(b) Supondo que |f ′′′(x)| ≤ 12, para qualquer x ∈ [0.5; 3.5], determine uma estimativa do
erro de interpolação no ponto x = 2.1.
6. Considere a seguinte tabela de valores de uma função
xi −1.0 1.0 2.0 3.0 5.0 7.0
f(xi) −1.0 1.0 −1.0 1.0 2.0 2.5
(a) Considerando os 3 pontos da tabela no intervalo [1; 3] e utilizando a fórmula de La-
grange, construa o polinómio interpolador de f(x).
(b) Suponha que f(x) = 2e−x + c1x+ c2x2, com c1, c2 ∈ R. Determine um majorante para o
erro |p2(x)− f(x)| no ponto 1.8.
(c) Suponha que f(x) = c0 + c1x+ c2x2, com c0, c1, c2 ∈ R. Neste caso, quais são os valores
das constantes c0, c1 e c2? Justifique.
7. Considere a seguinte tabela de valores de uma função
i 1 2 3 4 5
xi 1.0 1.5 2.0 2.5 3.0
f(xi) 1.01 1.24 4.00 7.26 8.98
Utilizando a fórmula de Newton com diferenças divididas, calcule p2(1.8), onde p2 é o po-
linómio interpolador de f nos segundo, terceiro e quarto pontos da tabela. Supondo que
|f ′′′(x)| ≤ C para qualquer x ∈ [1.5; 2.5], onde C é uma constante real, determine uma esti-
mativa do erro de interpolação no ponto x = 1.8.
8. Seja 0 < ε < 1 e f uma função de classe C3 em [0; 1].
(a) Calcule o polinómio pε que interpola f nos pontos 0, ε e 1.
(b) Calcule a função
limε→0
pε(x) = p(x)

8.8. PROBLEMAS 255
(c) Indique uma expressão para a diferença f(x)− p(x) no caso em que a terceira derivada
de f é constante.
9. Numa estrada em linha recta fez-se uma experiência com um automóvel. De cinco em cinco
segundos, mediram-se as suas velocidades e as distâncias percorridas em relação ao ponto
de partida. Os valores observados encontram-se na tabela seguinte:
Instante 0 5 10 15 20
Distância 0 450 950 1499 2023
Velocidade 90 100 110 105 98
(a) Utilize um polinómio interpolador ppos(x) para prever a posição do automóvel no ins-
tante
t = 17 segundos.
(b) Utilize um polinómio interpolador pvel(x) para prever a velocidade do automóvel no
instante t = 17 segundos.
(c) Dê uma previsão da velocidade instantânea do automóvel no instante t = 17 segundos,
utilizando o polinómio interpolador obtido na alínea (a).
10. Considere a seguinte tabela de valores de uma função f .
xi 0 1 2
f(xi) 3 1 4
(a) Utilizando a fórmula interpoladora de Newton, determine uma expressão do polinó-
mio p2 que interpola f nos pontos da tabela.
(b) Baseando-se no resultado da alínea anterior, obtenha o polinómio do 3o grau que tam-
bém interpola f nos pontos da tabela e ainda em x = 4 e tal que a sua terceira derivada
é constante e igual a 12.
11. Considere a seguinte tabela de valores de uma função f , a qual se sabe ser um polinómio de
grau dois.
xi −2 −1 0 1
f(xi) 6 2 −1 y
Construa a tabela de diferenças divididas e responda às seguintes questões:
(a) Qual o valor de f [−1, 0, 1]? Justifique.

256 CAPÍTULO 8. INTERPOLAÇÃO
(b) Utilizando a fórmula interpoladora de Newton baseada nos pontos da tabela, calcule
f(−0.5). O valor obtido é exacto ou aproximado?
12. Considere a seguinte tabela de valores da função f(x) = x2 + 1/x
xi 0.8 1.0 1.6
f(xi) 1.890 2.000 3.185
(a) Obtenha a expressão do polinómio interpolador de Lagrange nos três pontos tabelados.
(b) Obtenha a expressão do polinómio interpolador de Newton nos três pontos tabelados.
(c) Calcule o valor interpolado para x = 1.3. Obtenha um majorante do erro a partir da
expressão do erro de interpolação e compare-o com o erro efectivamente cometido.
(d) Seja x ∈ [0.8; 1.6]. Obtenha um majorante do erro |f(x) − p2(x)| a partir da expressão
do erro de interpolação.

Capítulo 9
Integração numérica
A integração numérica é formada por um conjunto alargado de algoritmos para determinar
o valor numérico de integrais definidos; o termo "integração numérica" também é utilizado na re-
solução numérica de equações diferenciais. Quando nos referimos a integrais uni-dimensionais é
usual usar o termo "quadratura" como sinónimo de método de integração numérica. O problema
básico em integração numérica é calcular o valor aproximado do integral
I(f) =
∫ b
a
f(x)dx (9.1)
Quando é que há necessidade de utilizar integração numérica? Na prática surgem muitas
situações em que só se conhece o valor da função integranda em determinados pontos experi-
mentais. Nesse caso, é usual recorrer à integração numérica. Por vezes, também acontece que a
função integranda pode ser impossível ou difícil de calcular como é o caso de f(x) = e−x2 .
Na prática, podemos não precisar mesmo do valor exacto e mesmo que se consiga calcular
o valor exacto do integral, pode ser mais fácil usar integração numérica.
Dada uma tabela de valores de uma função, a aproximação do integral obtém-se fazendo
uma soma ponderada dos valores da tabela. Os nós de integração, ou pontos experimentais onde
se recolhe o valor da função, e os pesos variam de método para método.
Os métodos aqui apresentados baseiam-se em interpolação polinomial. Eles obtêm-se inte-
grando o polinómio interpolador em vez da função porque, ao contrário da função, o polinómio
interpolador é fácil de integrar.
257

258 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
9.1 Teorema do valor intermédio para integrais
Teorema 9 Se f e g são funções contínuas no intervalo [a; b], e g é não negativa em (a; b), então existe
ξ ∈ (a; b) tal que ∫ b
a
f(x)g(x)dx = f(ξ)
∫ b
a
g(x)dx
Demonstração Uma vez que f é contínua num intervalo fechado, f é limitada e satisfaz
m = minx∈[a;b]
f ≤ f(x) ≤ maxx∈[a;b]
f = M
para todo o x ∈ [a; b]. Por conseguinte, uma vez que g é não negativa para qualquer x ∈ [a; b]
tém-se
m g(x) ≤ f(x)g(x) ≤Mg(x)
Integrando vem
m
∫ b
a
g(x)dx ≤∫ b
a
f(x)g(x)dx ≤M
∫ b
a
g(x)dx
Se∫ bag(x)dx = 0, então g é identicamente zero e o resultado é trivial. Caso contrário,
m ≤∫ baf(x)g(x)dx∫ bag(x)dx
≤M
e o resultado segue do teorema do valor intermédio.
Bases: Secções 3.1, 8.3, 9.1 e 3.3.
9.2 Método do ponto médio
O método mais simples baseado em interpolação é interpolar a função por um polinómio
de grau zero. Se esse polinómio passar no ponto ( (a + b)/2, f((a + b)/2) ) então obtemos a regra
do ponto médio como se segue.
Sabe-se que, pelo desenvolvimento em série de Taylor, que
f(x) = f(x0) + f ′(x0)(x− x0) +f ′′(ξx)
2!(x− x0)2,

9.3. MÉTODO DOS TRAPÉZIOS 259
onde ξx ∈ int(x, x0) e x0 = (a+ b)/2. Consequentemente,
I(f) =
∫ b
a
f(x)dx =
∫ b
a
f(x0)dx+
∫ b
a
f ′(x0)(x− x0)dx+
∫ b
a
f ′′(ξx)
2!(x− x0)2dx
ou seja,
I(f) = (b− a)f((a+ b)/2) + f ′(x0)
∫ b
a
(x− x0)dx+
∫ b
a
f ′′(ξx)
2!(x− x0)2dx
Como∫ ba(x− x0)dx = 0, o segundo termo da soma é zero. Em relação ao terceiro termo da soma,
assumimos que f ∈ C2(a, b) e como (x − x0)2 não muda de sinal aplicamos o teorema do valor
intermédio para integrais (Teorema 9) para obter
I(f) = (b− a)f((a+ b)/2) +f ′′(τ)
2
∫ b
a
(x− x0)2dx, τ ∈ [a; b]
Utilizando a transformação de variável u = x− x0 no integral anterior obtém-se du = dx e conse-
quentemente
I(f) = (b− a)f((a+ b)/2) +f ′′(τ)
2
∫ b−x0
a−x0u2dx = (b− a)f((a+ b)/2) +
h3
24f ′′(τ)
onde h = b− a.
9.3 Método dos Trapézios
O método dos Trapézios obtém-se integrando o polinómio de grau menor ou igual a 1 que
passa nos pontos (a, f(a)) e (b, f(b)). Esta técnica reduz-se a calcular a área do trapézio ilustrado
na Figura 9.1, ou seja, ∫ b
a
f(x)dx ≈ (b− a)f(a) + f(b)
2.
9.3.1 Teoria
Dada uma função f(x) definida no intervalo [a; b], podemos aproximá-la por um polinómio
de grau menor ou igual a 1 que passa nos pontos (a, f(a)) e (b, f(b)). Esse polinómio pode obter-se
utilizando a interpolação de Lagrange:
p1(x) = f(a)x− ba− b
+ f(b)x− ab− a
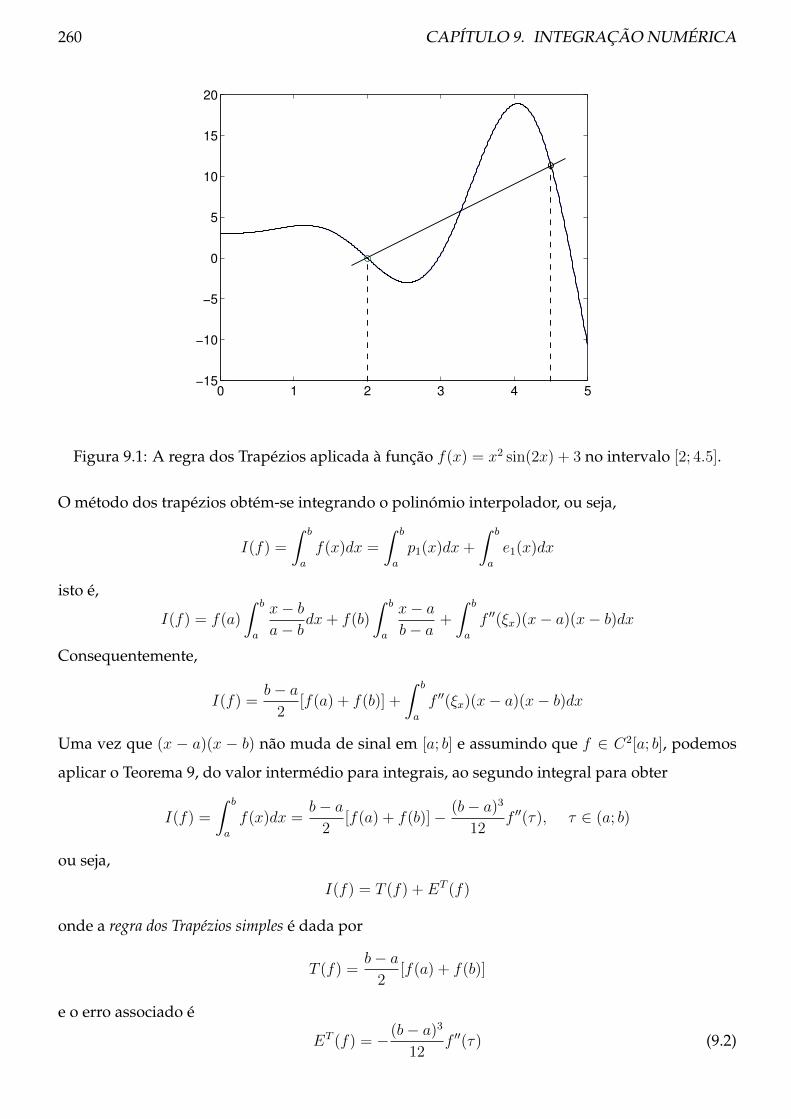
260 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
0 1 2 3 4 5−15
−10
−5
0
5
10
15
20
Figura 9.1: A regra dos Trapézios aplicada à função f(x) = x2 sin(2x) + 3 no intervalo [2; 4.5].
O método dos trapézios obtém-se integrando o polinómio interpolador, ou seja,
I(f) =
∫ b
a
f(x)dx =
∫ b
a
p1(x)dx+
∫ b
a
e1(x)dx
isto é,
I(f) = f(a)
∫ b
a
x− ba− b
dx+ f(b)
∫ b
a
x− ab− a
+
∫ b
a
f ′′(ξx)(x− a)(x− b)dx
Consequentemente,
I(f) =b− a
2[f(a) + f(b)] +
∫ b
a
f ′′(ξx)(x− a)(x− b)dx
Uma vez que (x − a)(x − b) não muda de sinal em [a; b] e assumindo que f ∈ C2[a; b], podemos
aplicar o Teorema 9, do valor intermédio para integrais, ao segundo integral para obter
I(f) =
∫ b
a
f(x)dx =b− a
2[f(a) + f(b)]− (b− a)3
12f ′′(τ), τ ∈ (a; b)
ou seja,
I(f) = T (f) + ET (f)
onde a regra dos Trapézios simples é dada por
T (f) =b− a
2[f(a) + f(b)]
e o erro associado é
ET (f) = −(b− a)3
12f ′′(τ) (9.2)
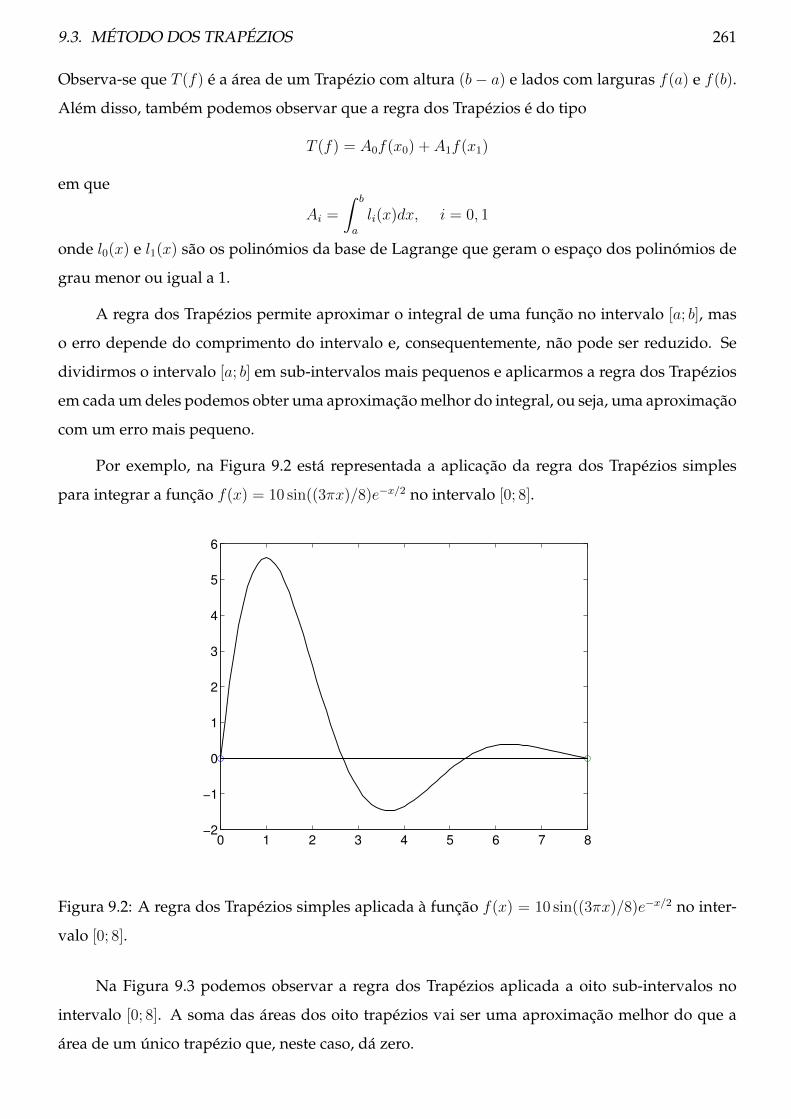
9.3. MÉTODO DOS TRAPÉZIOS 261
Observa-se que T (f) é a área de um Trapézio com altura (b− a) e lados com larguras f(a) e f(b).
Além disso, também podemos observar que a regra dos Trapézios é do tipo
T (f) = A0f(x0) + A1f(x1)
em que
Ai =
∫ b
a
li(x)dx, i = 0, 1
onde l0(x) e l1(x) são os polinómios da base de Lagrange que geram o espaço dos polinómios de
grau menor ou igual a 1.
A regra dos Trapézios permite aproximar o integral de uma função no intervalo [a; b], mas
o erro depende do comprimento do intervalo e, consequentemente, não pode ser reduzido. Se
dividirmos o intervalo [a; b] em sub-intervalos mais pequenos e aplicarmos a regra dos Trapézios
em cada um deles podemos obter uma aproximação melhor do integral, ou seja, uma aproximação
com um erro mais pequeno.
Por exemplo, na Figura 9.2 está representada a aplicação da regra dos Trapézios simples
para integrar a função f(x) = 10 sin((3πx)/8)e−x/2 no intervalo [0; 8].
0 1 2 3 4 5 6 7 8−2
−1
0
1
2
3
4
5
6
Figura 9.2: A regra dos Trapézios simples aplicada à função f(x) = 10 sin((3πx)/8)e−x/2 no inter-
valo [0; 8].
Na Figura 9.3 podemos observar a regra dos Trapézios aplicada a oito sub-intervalos no
intervalo [0; 8]. A soma das áreas dos oito trapézios vai ser uma aproximação melhor do que a
área de um único trapézio que, neste caso, dá zero.
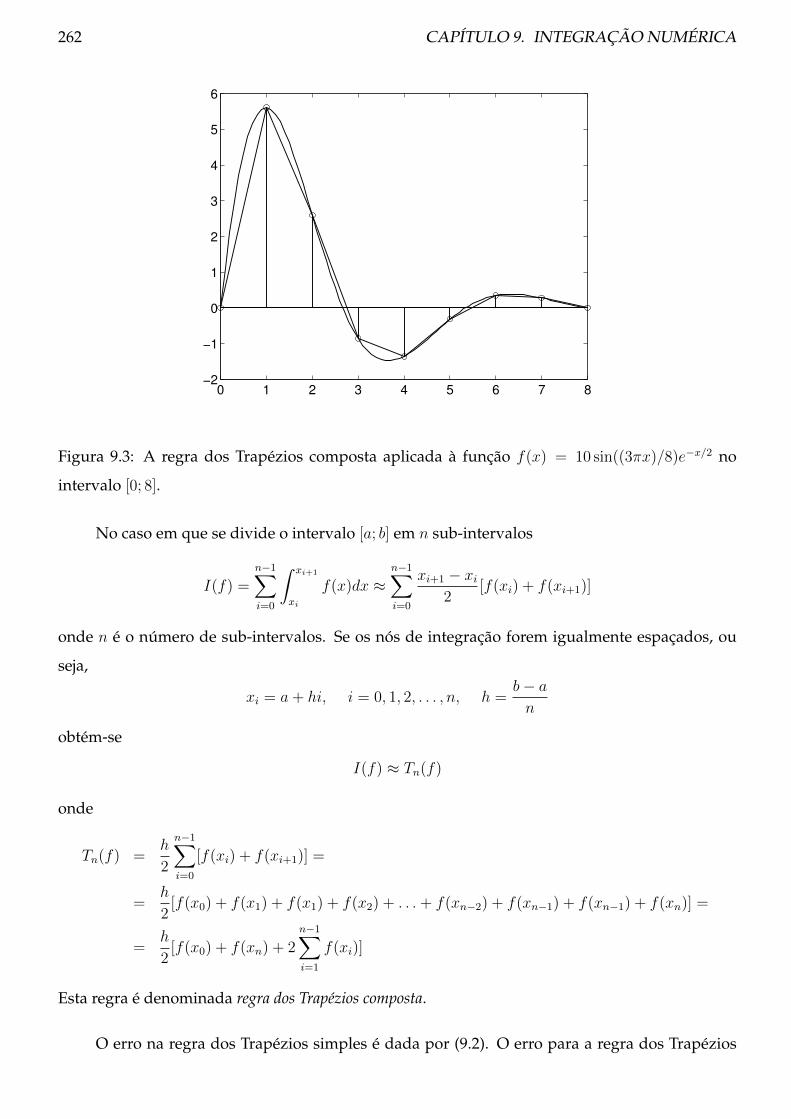
262 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
0 1 2 3 4 5 6 7 8−2
−1
0
1
2
3
4
5
6
Figura 9.3: A regra dos Trapézios composta aplicada à função f(x) = 10 sin((3πx)/8)e−x/2 no
intervalo [0; 8].
No caso em que se divide o intervalo [a; b] em n sub-intervalos
I(f) =n−1∑i=0
∫ xi+1
xi
f(x)dx ≈n−1∑i=0
xi+1 − xi2
[f(xi) + f(xi+1)]
onde n é o número de sub-intervalos. Se os nós de integração forem igualmente espaçados, ou
seja,
xi = a+ hi, i = 0, 1, 2, . . . , n, h =b− an
obtém-se
I(f) ≈ Tn(f)
onde
Tn(f) =h
2
n−1∑i=0
[f(xi) + f(xi+1)] =
=h
2[f(x0) + f(x1) + f(x1) + f(x2) + . . .+ f(xn−2) + f(xn−1) + f(xn−1) + f(xn)] =
=h
2[f(x0) + f(xn) + 2
n−1∑i=1
f(xi)]
Esta regra é denominada regra dos Trapézios composta.
O erro na regra dos Trapézios simples é dada por (9.2). O erro para a regra dos Trapézios

9.3. MÉTODO DOS TRAPÉZIOS 263
composta é a soma dos erros em cada sub-intervalo, ou seja
ETn (f) = −
n−1∑i=0
(xi+1 − xi)3
12f ′′(τi) = −h
3
12
n−1∑i=0
f ′′(τi)
onde τi ∈ [xi;xi+1]. Mas
mina≤x≤b
f ′′(x) ≤ 1
n
n∑i=1
f ′′(τi) ≤ maxa≤x≤b
f ′′(x)
Se assumirmos que f ∈ C2[a; b], então existe τ ∈ (a; b) tal que
f ′′(τ) =1
n
n∑i=1
f ′′(τi)
Consequentemente,
ETn (f) = −(b− a)h2
12f ′′(τ) (9.3)
Observação 5 O erro na regra dos Trapézios simples também se pode obter a partir do desenvolvimento
em série de Taylor e a integração por partes. Considere o desenvolvimento
f(a) = f(x) + f ′(x)(a− x) +1
2f ′′(ξx)(a− x)2
onde ξx ∈ [a;x]. Integrando ambos os membros em relação à variável x entre a e b obtém-se∫ b
a
f(a)dx =
∫ b
a
f(x)dx+
∫ b
a
f ′(x)(a− x)dx+
∫ b
a
1
2f ′′(ξx)(a− x)2dx
ou seja,
(b− a)f(a)dx =
∫ b
a
f(x)dx+ a
∫ b
a
f ′(x)dx−∫ b
a
xf ′(x)dx+
∫ b
a
1
2f ′′(ξx)(a− x)2dx
donde,
(b− a)f(a)dx =
∫ b
a
f(x)dx+ a[f(b)− f(a)]−∫ b
a
xf ′(x)dx+
∫ b
a
1
2f ′′(ξx)(a− x)2dx
Mas utilizando a integração por partes∫ b
a
xf ′(x)dx = [xf(x)]ba −∫ b
a
f(x)dx
consequentemente,
(b− a)f(a)dx = 2
∫ b
a
f(x)dx+ af(b)− af(a) +
∫ b
a
1
2f ′′(ξx)(a− x)2dx
Aplicando o teorema do valor intermédio ao último integral obtém-se
(b− a)f(a)dx = 2
∫ b
a
f(x)dx− f(b)(b− a) +1
6f ′′(ξ)(b− a)3
e assim podemos escrever ∫ b
a
f(x)dx =b− a
2[f(a) + f(b)]− 1
12f ′′(ξ)(b− a)3

264 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
9.3.2 Procedimento
Problema O problema é calcular o valor aproximado do integral (9.1)
I(f) =
∫ b
a
f(x)dx
Hipóteses Assume-se que f(x) é uma função real de variável real. Para estimar o erro com a
equação (9.3) tem de se considerar como hipótese que f ∈ C2[a; b] para que se possa calcular
o valor f ′′(τ) que surge na fórmula do erro.
Processo iterativo Antes de começar o processo iterativo é preciso calcular a primeira aproxima-
ção do integral, ou seja, calcular uma aproximação com a regra dos Trapézios simples no
intervalo [a; b]:
h = b− a, T1 =h
2[f(a) + f(b)]
Para k = 2, 3, . . . , kmax divide-se o intervalo [a; b] em n = 2k−1 sub-intervalos, ou seja, calcula-
se
h =b− a2n−1
e uma nova aproximação do integral
Tn =h
2
[f(x0) + f(xn) + 2
2n−1−1∑i=1
f(xi)
]
O processo iterativo pára quando uma das seguintes condições se verificar:
1. a distância entre iteradas sucessivas é suficientemente pequena, |Tn − Tn/2| < ε;
2. foi atingido um número máximo de iterações igual a kmax e a condição 1 não se verifi-
cou. Neste caso, assume-se que a solução não foi encontrada ou nem sequer existe.
9.4 Método de Simpson
O método de Simpson tal como a regra dos Trapézios é um método baseado em interpola-
ção. No método de Simpson obtemos uma aproximação do integral (9.1) integrando o polinómio
interpolador da função que passa nos pontos (a, f(a)), ((a + b)/2, f((a + b)/2)) e (b, f(b)); ver a
Figura 9.4.
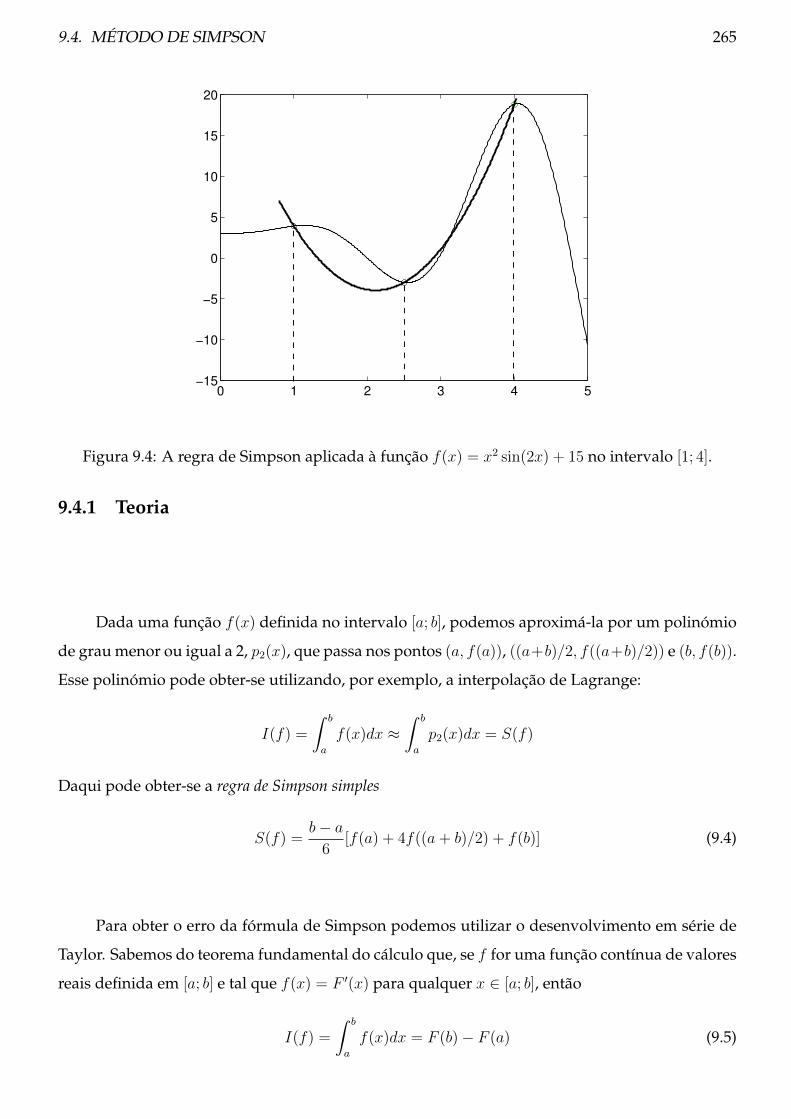
9.4. MÉTODO DE SIMPSON 265
0 1 2 3 4 5−15
−10
−5
0
5
10
15
20
Figura 9.4: A regra de Simpson aplicada à função f(x) = x2 sin(2x) + 15 no intervalo [1; 4].
9.4.1 Teoria
Dada uma função f(x) definida no intervalo [a; b], podemos aproximá-la por um polinómio
de grau menor ou igual a 2, p2(x), que passa nos pontos (a, f(a)), ((a+b)/2, f((a+b)/2)) e (b, f(b)).
Esse polinómio pode obter-se utilizando, por exemplo, a interpolação de Lagrange:
I(f) =
∫ b
a
f(x)dx ≈∫ b
a
p2(x)dx = S(f)
Daqui pode obter-se a regra de Simpson simples
S(f) =b− a
6[f(a) + 4f((a+ b)/2) + f(b)] (9.4)
Para obter o erro da fórmula de Simpson podemos utilizar o desenvolvimento em série de
Taylor. Sabemos do teorema fundamental do cálculo que, se f for uma função contínua de valores
reais definida em [a; b] e tal que f(x) = F ′(x) para qualquer x ∈ [a; b], então
I(f) =
∫ b
a
f(x)dx = F (b)− F (a) (9.5)

266 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
Seja h = (b− a)/2, c = (a+ b)/2 e considerem-se os seguintes desenvolvimentos em série
F (b) = F (c+ h)
= F (c) + hF ′(c) +h2
2F ′′(c) +
h3
3!F ′′′(c) +
h4
4!F (4)(c) +
h5
5!F (5)(ξ1)
= F (c) + hf(c) +h2
2f ′(c) +
h3
3!f ′′(c) +
h4
4!f ′′′(c) +
h5
5!f (4)(ξ1) (9.6)
F (a) = F (c− h)
= F (c)− hF ′(c) +h2
2F ′′(c)− h3
3!F ′′′(c) +
h4
4!F (4)(c)− h5
5!F (5)(ξ2)
= F (c)− hf(c) +h2
2f ′(c)− h3
3!f ′′(c) +
h4
4!f ′′′(c)− h5
5!f (4)(ξ2) (9.7)
onde ξ1, ξ2 ∈ [a; b]. Substituindo (9.7) e (9.6) em (9.5), obtém-se
I(f) = 2hf(c) +h3
3f ′′(c) +
h5
5!f (4)(ξ1) +
h5
5!f (4)(ξ2)
Assumindo que f ∈ C4[a; b] tém-se
h5
5!f (4)(ξ1) +
h5
5!f (4)(ξ2) =
h5
5![f (4)(ξ1) + f (4)(ξ2)] =
h5
5!2f (4)(ξ) =
h5
60f (4)(ξ3)
onde ξ3 ∈ [a; b]. Por conseguinte,
I(f) = 2hf(c) +h3
3f ′′(c) +
h5
60f (4)(ξ3) (9.8)
Do Capítulo 10 sabemos que
f ′′(c) =1
h2[f(b)− 2f(c) + f(a)]− h2
12f (4)(ξ4) (9.9)
para algum ξ4 ∈ [a; b]; ver a equação (10.4). Aplicando (9.9) a (9.8) obtemos
I(f) =h
3[f(a) + 4f(c) + f(b)] +
h5
60f (4)(ξ3)−
h5
36f (4)(ξ4) =
h
3[f(a) + 4f(c) + f(b)]− h5
90f (4)(ξ)
onde ξ ∈ [a; b]. Observamos que a regra de Simpson simples é dada por (9.4), ou de forma
equivalente
I(f) =h
3[f(a) + 4f((a+ b)/2) + f(b)] (9.10)
e o erro correspondente é o seguinte:
ES(f) = −h5
90f (4)(ξ) (9.11)
Tal como na regra dos Trapézios, podemos obter uma aproximação mais precisa dividindo
o intervalo [a; b] em n sub-intervalos, aplicando a regra de Simpson por cada dois sub-intervalos
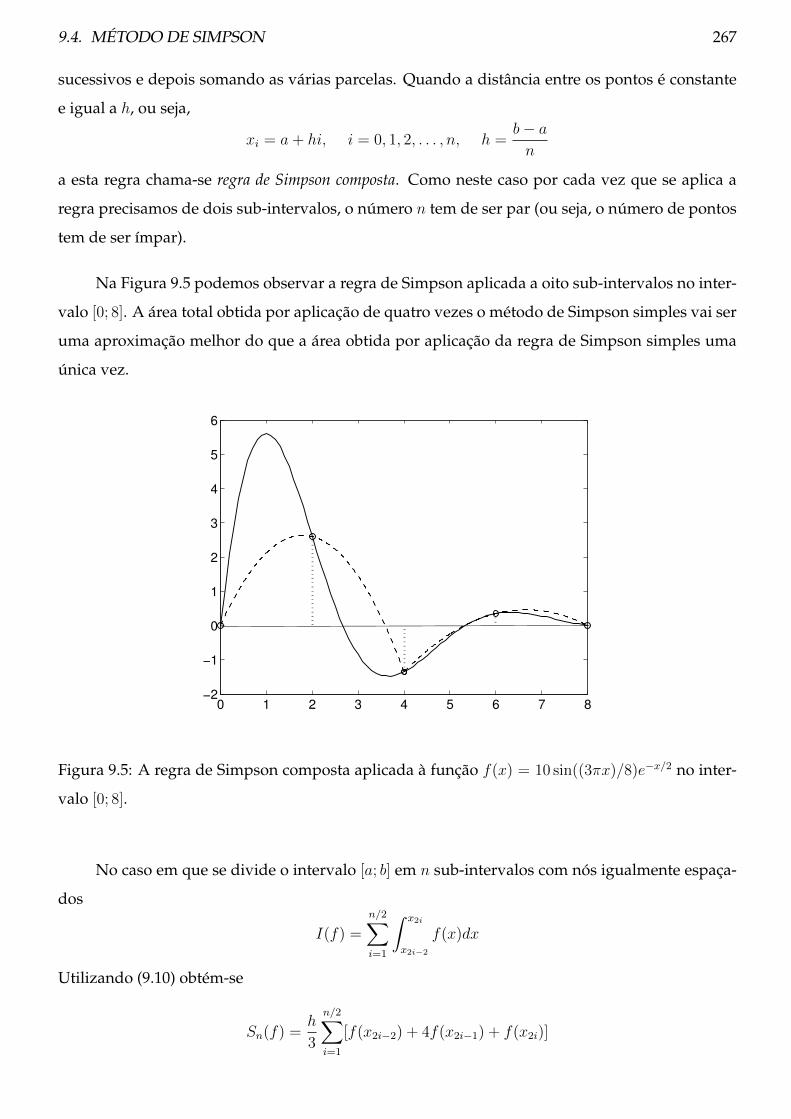
9.4. MÉTODO DE SIMPSON 267
sucessivos e depois somando as várias parcelas. Quando a distância entre os pontos é constante
e igual a h, ou seja,
xi = a+ hi, i = 0, 1, 2, . . . , n, h =b− an
a esta regra chama-se regra de Simpson composta. Como neste caso por cada vez que se aplica a
regra precisamos de dois sub-intervalos, o número n tem de ser par (ou seja, o número de pontos
tem de ser ímpar).
Na Figura 9.5 podemos observar a regra de Simpson aplicada a oito sub-intervalos no inter-
valo [0; 8]. A área total obtida por aplicação de quatro vezes o método de Simpson simples vai ser
uma aproximação melhor do que a área obtida por aplicação da regra de Simpson simples uma
única vez.
0 1 2 3 4 5 6 7 8−2
−1
0
1
2
3
4
5
6
Figura 9.5: A regra de Simpson composta aplicada à função f(x) = 10 sin((3πx)/8)e−x/2 no inter-
valo [0; 8].
No caso em que se divide o intervalo [a; b] em n sub-intervalos com nós igualmente espaça-
dos
I(f) =
n/2∑i=1
∫ x2i
x2i−2
f(x)dx
Utilizando (9.10) obtém-se
Sn(f) =h
3
n/2∑i=1
[f(x2i−2) + 4f(x2i−1) + f(x2i)]

268 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
ou seja,
Sn(f) =h
3
f(x0) + f(xn) + 4
n/2∑i=1
f(x2i−1) + 2
n/2−1∑i=1
f(x2i)
O erro associado obtém-se da forma:
ESn (f) = −h
5
90
n/2∑i=1
f (4)(ξi)
onde ξi ∈ [x2i−2;x2i], ou seja,
ESn (f) = −h
5
90
n/2∑i=1
f (4)(ξi)
ou seja,
ESn (f) = −h
5
90
n
2f (4)(ξ)
onde ξ ∈ [a; b]. Mas n = (b− a)/h, logo
ESn (f) = −(b− a)h4
180f (4)(ξ)
9.4.2 Procedimento
Problema O problema é calcular o valor aproximado do integral (9.1)
I(f) =
∫ b
a
f(x)dx
Hipóteses Assume-se que f(x) é uma função real de variável real. Para estimar o erro com a
equação (9.3) tem de se considerar como hipótese que f ∈ C4[a; b] para que se possa calcular
o valor f (4)(τ) que surge na fórmula do erro.
Processo iterativo Antes de começar o processo iterativo é preciso calcular a primeira aproxi-
mação do integral, ou seja, calcular uma aproximação com a regra de Simpson simples no
intervalo [a; b]:
h = (b− a)/2, S2 =b− a
6[f(a) + 4f((a+ b)/2) + f(b)]
Para k = 3, 4, . . . , kmax divide-se o intervalo [a; b] em n = 2k−1 sub-intervalos, ou seja, calcula-
se
h =b− a2n−1
e uma nova aproximação do integral
Sn =h
3
f(x0) + f(xn) + 4
n/2∑i=1
f(x2i−1) + 2
n/2−1∑i=1
f(x2i)
O processo iterativo pára quando uma das seguintes condições se verificar:

9.5. MÉTODO DOS COEFICIENTES INDETERMINADOS 269
1. a distância entre iteradas sucessivas é suficientemente pequena, |Sn − Sn/2| < ε;
2. foi atingido um número máximo de iterações igual a kmax e a condição 1 não se verifi-
cou. Neste caso, assume-se que solução não foi encontrada ou nem sequer existe.
9.5 Método dos coeficientes indeterminados
Foi referido anteriormente que a aproximação do integral (9.1) se obtém fazendo uma soma
ponderada dos valores de f(x) em determinados nós conhecidos como nós de integração. Os
pesos variam de método para método. No caso geral, uma fórmula de quadratura baseada em
n+ 1 nós pode representar-se na forma:
Q(f) =n∑i=0
Aif(xi) (9.12)
Vimos que no caso do método dos Trapézios a fórmula é construída aproximando a função pelo
seu polinómio interpolador de grau menor ou igual a 1 que interpola a função em x0 = a e x1 = b.
Devido à unicidade do polinómio interpolador, se a função for um polinómio de grau menor
ou igual a 1, então o erro é zero. Consequentemente, o método de construção do método dos
Trapézios é equivalente a impor que o erro seja zero para polinómios de grau menor ou igual a
1. A partir da fórmula do erro (9.2) podemos observar que o erro na regra dos Trapézios não é
zero quando a função integrando é, por exemplo, um polinómio de grau dois. Quando temos um
destes casos, em que o erro é zero para polinómios de grau menor ou igual a um e diferente de
zero para polinómios de grau 2, diz-se que a fórmula de quadratura tem grau 1.
De uma maneira geral, dizer que o erro é zero para polinómios de grau menor ou igual a n,
equivale a considerar
Q(anxn + . . .+ a1x+ a0) = I(anx
n + . . .+ a1x+ a0)
Como Q e I são funcionais lineares, esta equação pode escrever-se na forma
anQ(xn) + . . .+ a1Q(x) + a0Q(1) = anI(xn) + . . .+ a1I(x) + a0I(1)
ou seja,
Q(xn) = I(xn)... =
...
Q(x) = I(x)
Q(1) = I(1)
(9.13)

270 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
Diz-se que uma fórmula de quadratura tem grau n se
Q(xk) = I(xk), k = 0, 1, . . . , n
Q(xn+1) 6= I(xn+1)
ou seja, o erro é zero quando integra polinómios de grau menor ou igual a n e o erro é diferente
de zero quando integra polinómios de grau n+ 1.
Um método alternativo para calcular os pesos nas quadraturas com grau não inferior a n, é
o método dos coeficientes indeterminados. Para que a fórmula de quadratura (9.12) tenha grau
não inferior a n é necessário e suficiente que se verifique o sistema (9.13), ou seja,
n∑i=0
Aixni =
∫ b
a
xndx
......
n∑i=0
Aixi =
∫ b
a
xdx
n∑i=0
Ai =
∫ b
a
dx
Podemos escrever este sistema na forma matricial:1 1 . . . 1
x0 x1 . . . xn...
......
xn0 xn1 . . . xnn
A0
A1
...
An
=
b− a
(b2 − a2)/2...
(bn+1 − an+1)/(n+ 1)
A matriz deste sistema é a transposta da matriz de Vandermonde (7.9) (considerando os nós de
x0 a xn e assumindo m = n) que, como foi observado no capítulo 8, é invertível se os nós forem
distintos. Consequentemente, dados os nós de integração distintos x0, x1, ..., xn, existe uma única
solução para os pesos A0, A1, ..., An.
Exemplo 49 Considere-se o integral
I(f) =
∫ 2
−2f(x)dx
e a fórmula de quadratura com três nós
Q(f) = A0f(−1) + A1f(0) + A2f(1)

9.6. QUADRATURAS DE GAUSS 271
Os pesos Ai’s obtêm-se pelo método dos coeficientes indeterminados resolvendo o sistema:1 1 1
−1 0 1
(−1)2 02 12
A0
A1
A2
=
2− (−2)
(22 − (−2)2)/2
(23 − (−2)3)/3
ou seja, A0 = 8/3 ≈ 2.6667, A1 = −4/3 ≈ −1.3333 e A2 = 8/3 ≈ 2.6667. Consequentemente,
Q(f) =8
3f(−1)− 4
3f(0) +
8
3f(1)
Qual será o grau desta fórmula? Pela forma como foi construída tem pelo menos grau 2. Observa-se que
Q(x3) =8
3(−1)3 − 4
3(0)3 +
8
3(1)3 = 0
I(x3) =
∫ 2
−2x3dx =
x4
4
∣∣∣∣2−2
= 0
Q(x4) =8
3(−1)4 − 4
3(0)4 +
8
3(1)4 =
16
3
I(x4) =
∫ 2
−2x4dx =
x5
5
∣∣∣∣2−2
=(−2)5 − 25
5= 12.8
ou seja, Q(xk) = I(xk) para k = 0, 1, 2, 3 e Q(x4) 6= I(x4), logo a fórmula de quadratura tem grau 3.
Observando que Q(f) = I(pn), sendo pn(x) o polinómio interpolador de f(x) nos nós x0, x1,
..., xn, obtém-se através da fórmula de interpolação de Lagrange
Q(f) =
∫ b
a
n∑i=0
li(x)f(xi)dx =n∑i=0
∫ b
a
li(x)dxf(xi)
ou seja, como vimos nas secções anteriores, os pesos Ai’s podem obter-se através da base de
Lagrange l0, l1, ..., ln,
Ai =
∫ b
a
li(x)dx
9.6 Quadraturas de Gauss
Todas as fórmulas apresentadas neste capítulo têm a forma (9.12). Existem dois grupos de
métodos que são os mais utilizados na prática:
• Fórmulas de Newton-Côtes
• Fórmulas de Gausss
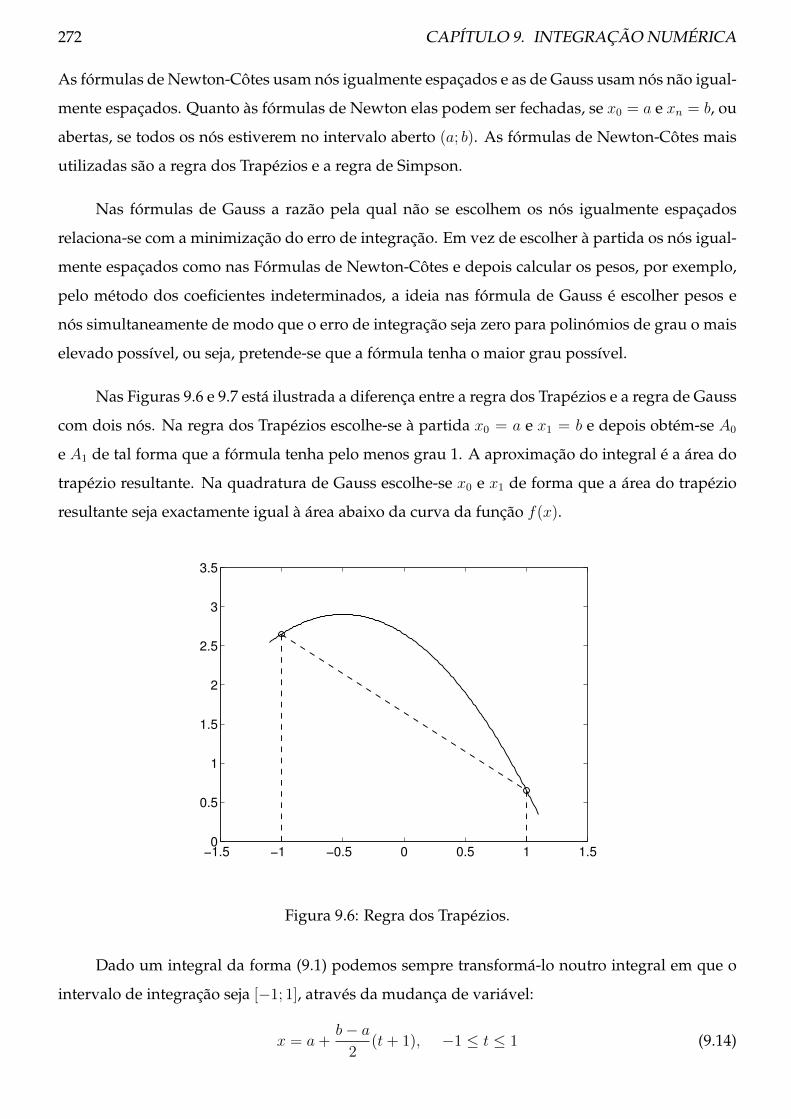
272 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
As fórmulas de Newton-Côtes usam nós igualmente espaçados e as de Gauss usam nós não igual-
mente espaçados. Quanto às fórmulas de Newton elas podem ser fechadas, se x0 = a e xn = b, ou
abertas, se todos os nós estiverem no intervalo aberto (a; b). As fórmulas de Newton-Côtes mais
utilizadas são a regra dos Trapézios e a regra de Simpson.
Nas fórmulas de Gauss a razão pela qual não se escolhem os nós igualmente espaçados
relaciona-se com a minimização do erro de integração. Em vez de escolher à partida os nós igual-
mente espaçados como nas Fórmulas de Newton-Côtes e depois calcular os pesos, por exemplo,
pelo método dos coeficientes indeterminados, a ideia nas fórmula de Gauss é escolher pesos e
nós simultaneamente de modo que o erro de integração seja zero para polinómios de grau o mais
elevado possível, ou seja, pretende-se que a fórmula tenha o maior grau possível.
Nas Figuras 9.6 e 9.7 está ilustrada a diferença entre a regra dos Trapézios e a regra de Gauss
com dois nós. Na regra dos Trapézios escolhe-se à partida x0 = a e x1 = b e depois obtém-se A0
e A1 de tal forma que a fórmula tenha pelo menos grau 1. A aproximação do integral é a área do
trapézio resultante. Na quadratura de Gauss escolhe-se x0 e x1 de forma que a área do trapézio
resultante seja exactamente igual à área abaixo da curva da função f(x).
−1.5 −1 −0.5 0 0.5 1 1.50
0.5
1
1.5
2
2.5
3
3.5
Figura 9.6: Regra dos Trapézios.
Dado um integral da forma (9.1) podemos sempre transformá-lo noutro integral em que o
intervalo de integração seja [−1; 1], através da mudança de variável:
x = a+b− a
2(t+ 1), −1 ≤ t ≤ 1 (9.14)
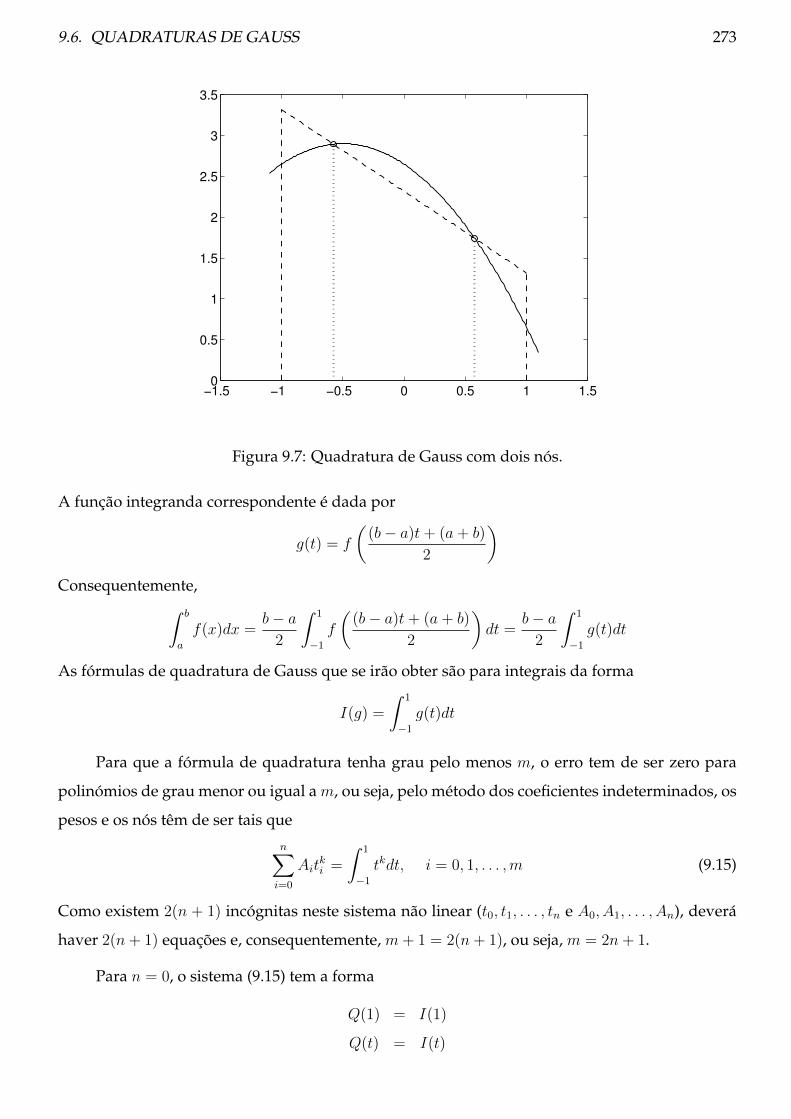
9.6. QUADRATURAS DE GAUSS 273
−1.5 −1 −0.5 0 0.5 1 1.50
0.5
1
1.5
2
2.5
3
3.5
Figura 9.7: Quadratura de Gauss com dois nós.
A função integranda correspondente é dada por
g(t) = f
((b− a)t+ (a+ b)
2
)Consequentemente,∫ b
a
f(x)dx =b− a
2
∫ 1
−1f
((b− a)t+ (a+ b)
2
)dt =
b− a2
∫ 1
−1g(t)dt
As fórmulas de quadratura de Gauss que se irão obter são para integrais da forma
I(g) =
∫ 1
−1g(t)dt
Para que a fórmula de quadratura tenha grau pelo menos m, o erro tem de ser zero para
polinómios de grau menor ou igual a m, ou seja, pelo método dos coeficientes indeterminados, os
pesos e os nós têm de ser tais que
n∑i=0
Aitki =
∫ 1
−1tkdt, i = 0, 1, . . . ,m (9.15)
Como existem 2(n + 1) incógnitas neste sistema não linear (t0, t1, . . . , tn e A0, A1, . . . , An), deverá
haver 2(n+ 1) equações e, consequentemente, m+ 1 = 2(n+ 1), ou seja, m = 2n+ 1.
Para n = 0, o sistema (9.15) tem a forma
Q(1) = I(1)
Q(t) = I(t)

274 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
ou seja,
A0 = 2
A0x0 = 0
e a solução é A0 = 2 e t0 = 0. Logo a fórmula de integração é
Q(g) = 2g(0)
Para n = 1, o sistema reduz-se aQ(1) = I(1)
Q(t) = I(t)
Q(t2) = I(t2)
Q(t3) = I(t3)
ou seja,
A0 + A1 = 2
A0t0 + A1t1 = 0
A0t20 + A1t
21 = 2/3
A0t30 + A1t
31 = 0
A solução deste sistema é t0 = −√
3/3 e t1 =√
3/3 e, consequentemente,
Q(g) = g
(−√
3
3
)+ g
(√3
3
)Para n = 2, os pesos e os nós determinam-se de tal forma que a área que fica abaixo da pará-
bola seja igual á área que fica por baixo da curva da função g(t), sendo a parábola o polinómio
interpolador da função nos pontos (t0, g(t0)), (t1, g(t1)) e (t2, g(t2)). Neste caso, o sistema tem a
formaQ(1) = I(1)
Q(t) = I(t)
Q(t2) = I(t2)
Q(t3) = I(t3)
Q(t4) = I(t4)
Q(t5) = I(t5)
ou seja,
A0 + A1 + A2 = 2
A0t0 + A1t1 + A2t2 = 0
A0t20 + A1t
21 + A2t
22 = 2/3
A0t30 + A1t
31 + A2t
32 = 0
A0t40 + A1t
41 + A2t
42 = 2/5
A0t50 + A1t
51 + A2t
52 = 0

9.6. QUADRATURAS DE GAUSS 275
A fórmula de quadratura correspondente é
Q(g) =5
9g
(−√
3
5
)+
8
9g(0) +
5
9g
(−√
3
5
)
Estas fórmulas podem ser extendidas para valores de n mais elevados, mas os sistemas corres-
pondentes são cada vez mais difíceis de resolver. Pode demonstrar-se que os nós de integração
de uma fórmula de Gauss com n + 1 nós coincidem com os zeros do polinómio de Legendre de
grau n+ 1 dado por
Pn+1(t) =1
2n+1(n+ 1)!
dn+1
dtn+1(t2 − 1)n+1
Estes polinómios podem obter-se utilizando a fórmula de recorrência
P0(t) = 1
P1(t) = t
Pn+1(t) =1
n+ 1[(2n+ 1)tPn(t)− nPn−1(t)] , n = 1, 2, . . .
Na tabela 9.1 encontram-se os pesos e os nós das fórmulas de Gauss para n = 0, 1, 2, 3, 4 e 5.
Convém de novo salientar que estes pesos e nós correspondem ao intervalo de integração [−1; 1].
Para aplicar as fórmulas a um intervalo genérico [a; b], devemos usar a transformação (9.14).
Tabela 9.1: Nós e pesos das fórmulas de Gauss.
n Nós ti Pesos Ai
0 0.0000000000 2.0000000000
1 ±0.5773502692 1.0000000000
2 ±0.7745966692 0.5555555556
0.0000000000 0.8888888889
3 ±0.3399810436 0.6521451549
±0.8611363116 0.3478548451
4 ±0.5384693101 0.4786286705
±0.9061798459 0.2369268851
0.0000000000 0.5688888889
5 ±0.2386191861 0.4679139346
±0.6612093865 0.3607615730
±0.9324695142 0.7113244924

276 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
9.7 Problemas
1. É conhecida a seguinte tabela de valores para uma função f :
x 0 π2 π
f(x) 0 1 + π2 4π2
(a) Calcule um valor aproximado de∫ π0f(x)dx pela regra do trapézio composta.
(b) Sabendo que existem α e β tais que a função é do tipo f(x) = sin(π+αx) + βx2, pode o
valor obtido na alínea anterior ser o valor exacto do integral? Porquê?
2. Considere a fórmula de quadratura com três nós
Q(f) =2λ
3[f(x0) + f(0) + f(x2)] (9.16)
para aproximar o integral
I(f) =
∫ λ
−λf(x)dx, λ 6= 0
(a) Obtenha x0 e x2 de modo que a fórmula tenha pelo menos grau 2. Para esses valores
de x0 e x2 qual o grau da fórmula de quadratura?
(b) Seja λ =√
2. Calcule∫ λ−λ 1/(1+x2)dx utilizando o método (9.16) e a fórmula de Simpson
simples.
3. A partir da tabela
xi 1.00 1.25 1.50 1.75 2.00
f(xi) 1.47 −1.63 −6.54 6.07 −2.15
pretende-se calcular o integral
I(f) =
∫ 2
1
f(x)dx
(a) Utilizando o maior número de pontos, obtenha o valor deste integral utilizando:
i. A regra dos Trapézios.
ii. A regra de Simpson.
(b) Sabendo que
maxx∈[1;2]
|f ′′(x)| ≤ 1540,
faça uma estimativa do passo h máximo que deveria utilizar se pretendesse calcular o
integral com um erro ETn (f) inferior a 10−3, utilizando o método dos Trapézios.

9.7. PROBLEMAS 277
4. Utilizou-se uma regra de Newton-Cotes composta com n sub-intervalos, para calcular o
integral de uma função de classe C6. Os resultados recolhidos encontram-se na tabela se-
guinte:
n En(f) En(f)/E2n(f)
2 2.92015192658296
4 0.85061885576368 3.43297342493221
8 0.222747218315 3.81876309027918
16 0.0563635651771999 3.95197176783816
32 0.0141244264559002 3.99050293144152
64 0.00352349979905986 4.0086355218947
Qual foi a regra utilizada? Justifique.
5. Considere a seguinte tabela de valores de uma função
xi −1.0 1.0 2.0 3.0 5.0 7.0
f(xi) −1.0 1.0 −1.0 1.0 2.0 2.5
(a) Obtenha 2 valores aproximados para∫ 7
−1 f(x)dx, de duas formas diferentes, recorrendo
a fórmulas de quadratura compostas e utilizando o maior número de pontos da tabela.
(b) Supondo que a derivada de ordem n de f verifica
maxx∈[−1;7]
|f (n)(x)| ≤ C, ∀n
com C ∈ R, determine uma expressão, em função de C, para o erro de integração E(f)
num dos casos que considerou na alínea anterior.
6. Considere os seguintes valores para a função x(t) = (1 + t)e−t
x(−0.4) = 0.8951, x(−0.3) = 0.9449, x(−0.2) = 0.9771, x(−0.1) = 0.9947, x(0) = 1
Obtenha um valor aproximado do integral∫ 0
−0.4x(t)dt
através da regra de Simpson com quatro sub-intervalos.
7. Determine a fórmula de quadratura Q(f) = A0f(0) + A1f(1), para aproximar integrais do
tipo
I(f) =
∫ 1
0
f(x)dx,
de modo que seja exacta para funções da forma h(x) = αx2+β cos(πx). Determine os valores
aproximados para∫ 1
0xdx usando Q(f) e a regra de Simpson simples, respectivamente.

278 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
8. Considere a seguinte tabela de valores de uma função h
x −0.5π 0 0.5π π
h(x) 2.5 3 2 3.5
Aproxime pela regra de Simpson o valor do integral entre 0 e π da função h tabelada.
9. Determine os valores A1, A2 e t tais que a regra de quadratura
Q(f) = A1f(−1) + A2f(t)
para aproximar∫ 1
−1 f(x)dx tenha o maior grau de precisão possível e indique, justificando,
qual é esse grau.
10. Suponha uma função f definida no intervalo [0; 3] do seguinte modo
f(x) =
3− 2x, 0 ≤ x ≤ 1
3x− 2, 1 ≤ x ≤ 4
Determine valores para I(f) =∫ 4
0f(x)dx dos seguintes modos.
(a) Utilize a regra dos Trapézios composta, no intervalo [0; 4], por forma a que o valor
obtido seja exacto. Justifique.
(b) Utilize a regra de Simpson, no intervalo [0; 4], usando apenas três pontos. Como justi-
fica que, neste caso, não se obtenha o valor exacto?
11. Considere o integral
I(f) =
∫ 1
0
e−x2
dx
(a) Determine o seu valor aproximado com quatro sub-intervalos usando as regras de Tra-
pézios e de Simpson.
(b) Qual é o número mínimo de sub-intervalos que deverá usar para obter um erro inferior
a ε = 10−4 quando utiliza a regra dos Trapézios e a regra de Simpson?
12. Utilize a fórmula de quadratura de Gauss com n = 1, ou seja com dois nós, para aproximar
o valor do integral
I(f) =
∫ 3
0
x2exdx
13. Utilize a fórmula de quadratura de Gauss com n = 2, ou seja com três nós, para aproximar
o valor do integral
I(f) =
∫ 3
0
(7 + 14x6)dx

9.7. PROBLEMAS 279
14. Use as quadraturas de Gauss com dois e três nós para aproximar os seguintes integrais:
(a)∫ π/40
sin(x)dx;
(b)∫ 2
11√xdx;
(c)∫ π/30
cos(3 cos2(x))dx;
(d)∫ 1
0ln(3 + sin(x))dx;
(e)∫ 1
01
x2+1dx;
15. Considere a seguinte tabela de valores de uma função
xi −1.0 0 1.0 5.0
f(xi) −2.0 −2.0 0 28.0
(a) Utilizando a fórmula de Newton, determine o polinómio interpolador de f nos três
primeiros pontos da tabela.
(b) Sabendo que f(x) é um polinómio de grau 2, determine o valor exacto de∫ 5
−1f(x)dx
utilizando a regra de Simpson. Justifique a sua resposta.
16. Pretende-se aproximar o integral
I(f) =
∫ 1
0
f(x)dx
por uma fórmula de integração do tipo
Q(f) = β[f(x0) + f(x1)]
onde β, x0, x1 ∈ R. Determine β, x0, x1 de modo que a fórmula Q(f) seja exacta para polinó-
mios de grau ≤ 2.
17. Considere a seguinte tabela de valores de uma função
xi 0 1 2 3 4 7 9 10 13 16
f(xi) 12 10 7 5 6 8 11 14 15 20
(a) Calcule as aproximações de I =∫ 13
1f(x)dx utilizando
i. a regra de Simpson simples
ii. a regra de Simpson composta

280 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA
(b) Supondo que f é um polinómio de grau≤ 4, determine I utilizando as duas aproxima-
ções obtidas na alínea anterior.
(c) Utilizando a fórmula de Newton com diferenças divididas, obtenha o polinómio que
interpola f nos pontos da tabela correspondentes aos nós xi = 3, 4, 7.
(d) Utilize a alínea anterior para obter o polinómio de grau 3 que interpola f nos mesmos
pontos e cuja terceira derivada vale 4.
18. Pretende-se que a fórmula de quadratura
Q(f) = A0f(−1) + A1f(0) + A2f(1)
tenha grau ≥ 2 para aproximar o integral
I(f) =
∫ 2
−2f(x)dx
(a) DetermineA1, utilizando os polinómios de Lagrange. Sabendo queA0 = A2, determine
também estes coeficientes.
(b) Sabendo que I(f) = Q(f) + Cf (4)(ξ), sendo C uma constante real e ξ ∈ (−2; 2), calcule
o valor da constante C.
19. Para aproximar o integral
I(f) =
∫ 4
0
xf(x)dx
construa uma fórmula de quadratura
Q(f) = A0f(0) + A1f(3)
(a) Determine as constantes A0 e A1 de modo a que a fórmula seja exacta quando f é um
polinómio de grau ≤ 1. Qual o grau de precisão da fórmula?
(b) Supondo que f ∈ C3[0; 4], obtenha uma expressão para o erro associado à fórmula de
quadratura obtida na alínea anterior, que envolva a derivada de terceira ordem f (3).
20. Para aproximar o integral definido I(f) =∫ 1
−1 f(x)dx, considere uma fórmula de quadratura
do tipo:
Q(f) = A0f(−x0) + A1f(x0),
com 0 < x0 ≤ 1.
(a) Calcule A0 e A1, usando o método dos coeficientes indeterminados.

9.7. PROBLEMAS 281
(b) Defina grau de uma quadratura e determine o grau da quadratura obtida, no caso de
x0 = 1√3.
(c) Usando a quadratura Q(f), com x0 = 1, calcule∫ 1
−1(x + 1)2dx. Sem calcular o valor
exacto do integral, determine o erro da aproximação obtida.

282 CAPÍTULO 9. INTEGRAÇÃO NUMÉRICA

Capítulo 10
Derivação
Em muitas situações práticas, deparamos com o problema de encontrar a derivada de uma
função cuja forma é desconhecida e cuja informação que temos sobre a função é uma tabela de da-
dos/resultados. Por exemplo, um acumulador pode ler a rotação total de um sensor e a derivada
irá dar o índice de rotação.
Uma das razões pela qual se usam polinómios para aproximar tabelas de dados/resultados é
que dada uma função contínua num intervalo fechado, existe um polinómio arbitrariamente pró-
ximo de qualquer ponto nesse intervalo. Outra razão é que os polinómios são fáceis de integrar
e derivar. Sendo assim, não é de estranhar que muitos dos métodos numéricos para integração e
derivação se baseiem em polinómios aproximadores da função.
Nas Secções 10.1 e 10.2 iremos estudar algumas técnicas para o cálculo numérico da primeira
e segunda derivadas. Estes resultados também são usados para obter a solução numérica de
equações diferenciais no Capítulo 12.
10.1 Fórmulas de diferenças divididas centradas
Dados três pontos igualmente espaçados, podemos encontrar o polinómio interpolador de
grau menor ou igual a 2 que passa nestes pontos, encontrar a derivada e calcular a derivada no
ponto médio para obter uma boa aproximação da derivada no ponto médio.
Bases: Capítulo 8.
283
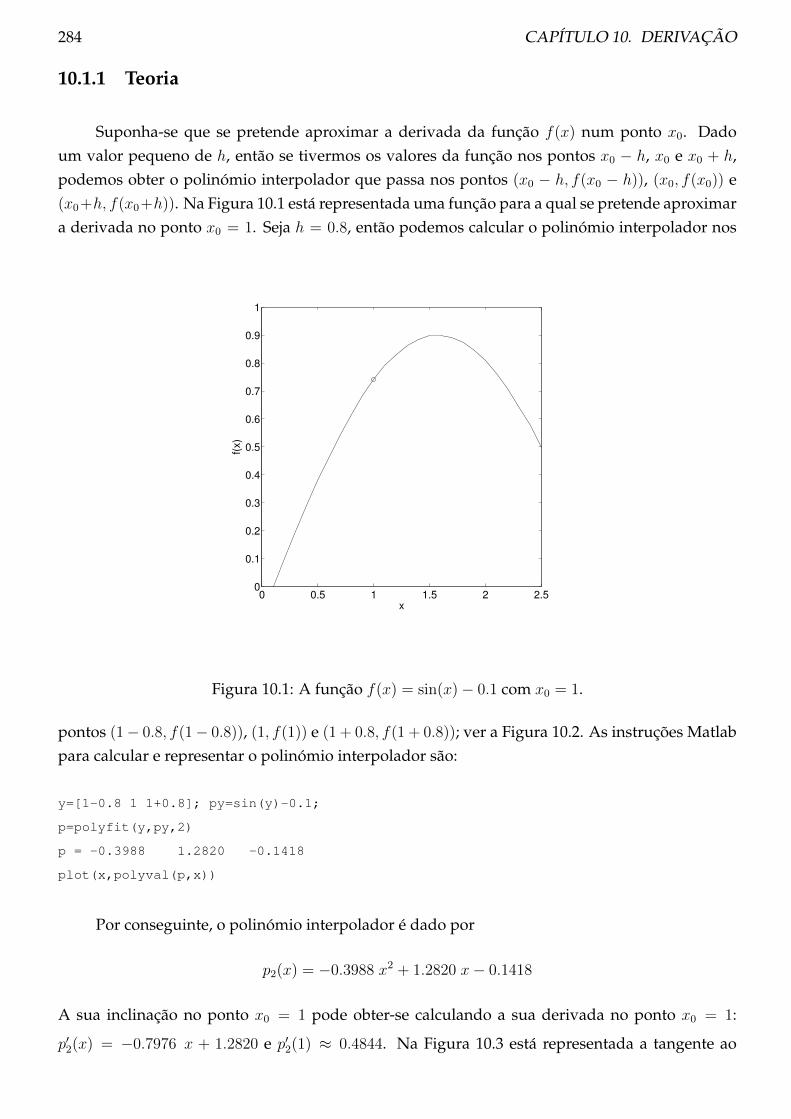
284 CAPÍTULO 10. DERIVAÇÃO
10.1.1 Teoria
Suponha-se que se pretende aproximar a derivada da função f(x) num ponto x0. Dadoum valor pequeno de h, então se tivermos os valores da função nos pontos x0 − h, x0 e x0 + h,podemos obter o polinómio interpolador que passa nos pontos (x0 − h, f(x0 − h)), (x0, f(x0)) e(x0+h, f(x0+h)). Na Figura 10.1 está representada uma função para a qual se pretende aproximara derivada no ponto x0 = 1. Seja h = 0.8, então podemos calcular o polinómio interpolador nos
0 0.5 1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
f(x)
Figura 10.1: A função f(x) = sin(x)− 0.1 com x0 = 1.
pontos (1− 0.8, f(1− 0.8)), (1, f(1)) e (1 + 0.8, f(1 + 0.8)); ver a Figura 10.2. As instruções Matlabpara calcular e representar o polinómio interpolador são:
y=[1-0.8 1 1+0.8]; py=sin(y)-0.1;
p=polyfit(y,py,2)
p = -0.3988 1.2820 -0.1418
plot(x,polyval(p,x))
Por conseguinte, o polinómio interpolador é dado por
p2(x) = −0.3988 x2 + 1.2820 x− 0.1418
A sua inclinação no ponto x0 = 1 pode obter-se calculando a sua derivada no ponto x0 = 1:
p′2(x) = −0.7976 x + 1.2820 e p′2(1) ≈ 0.4844. Na Figura 10.3 está representada a tangente ao
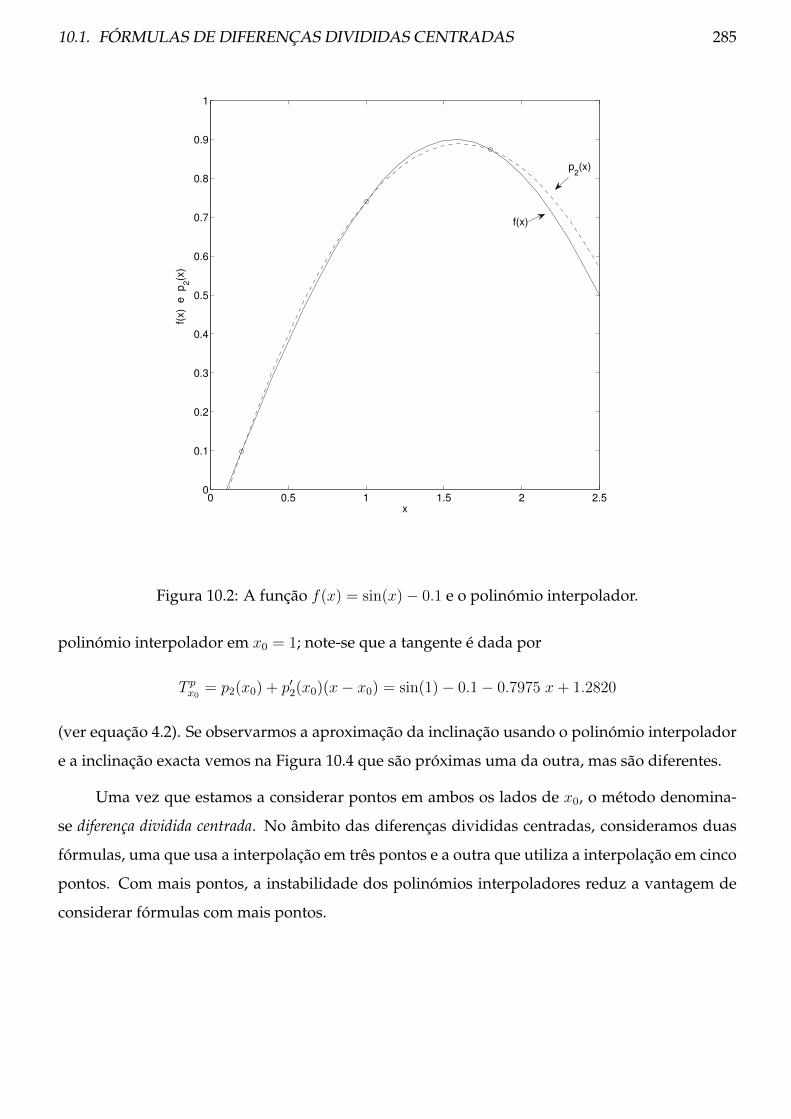
10.1. FÓRMULAS DE DIFERENÇAS DIVIDIDAS CENTRADAS 285
0 0.5 1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
f(x)
e p
2(x
)
p2(x)
f(x)
Figura 10.2: A função f(x) = sin(x)− 0.1 e o polinómio interpolador.
polinómio interpolador em x0 = 1; note-se que a tangente é dada por
T px0 = p2(x0) + p′2(x0)(x− x0) = sin(1)− 0.1− 0.7975 x+ 1.2820
(ver equação 4.2). Se observarmos a aproximação da inclinação usando o polinómio interpolador
e a inclinação exacta vemos na Figura 10.4 que são próximas uma da outra, mas são diferentes.
Uma vez que estamos a considerar pontos em ambos os lados de x0, o método denomina-
se diferença dividida centrada. No âmbito das diferenças divididas centradas, consideramos duas
fórmulas, uma que usa a interpolação em três pontos e a outra que utiliza a interpolação em cinco
pontos. Com mais pontos, a instabilidade dos polinómios interpoladores reduz a vantagem de
considerar fórmulas com mais pontos.
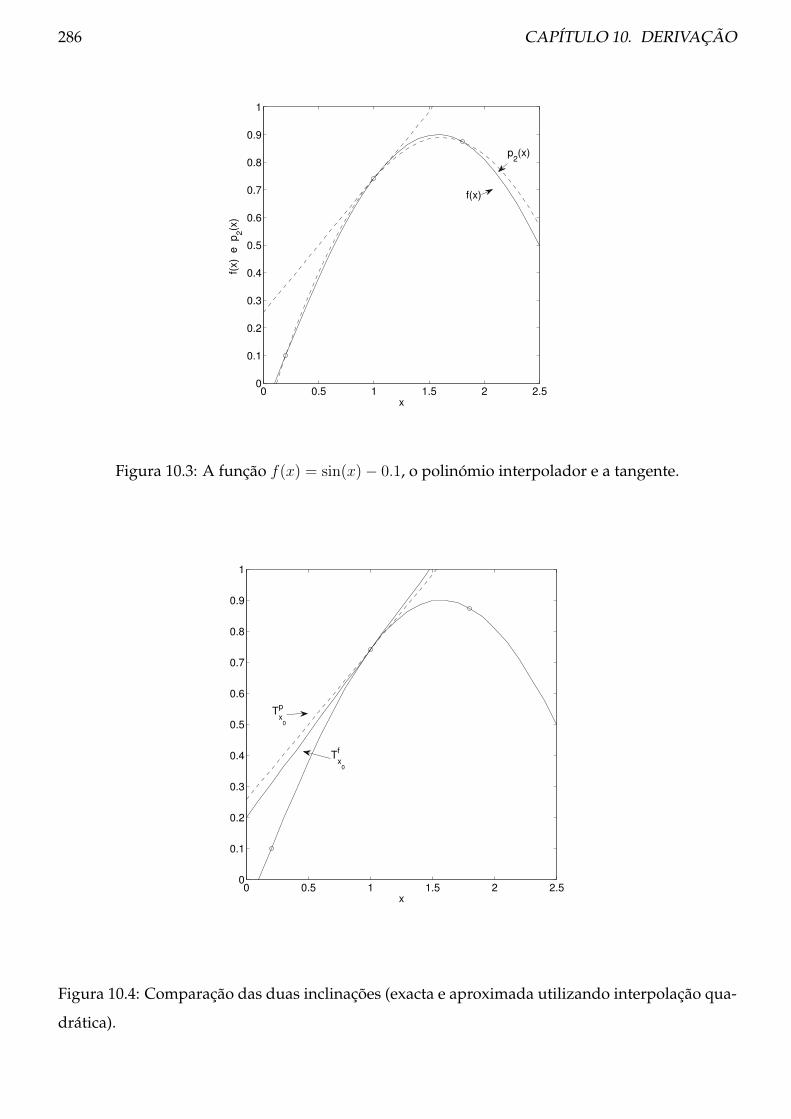
286 CAPÍTULO 10. DERIVAÇÃO
0 0.5 1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
f(x)
e p
2(x
)
p2(x)
f(x)
Figura 10.3: A função f(x) = sin(x)− 0.1, o polinómio interpolador e a tangente.
0 0.5 1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
Tp
x0
Tf
x0
Figura 10.4: Comparação das duas inclinações (exacta e aproximada utilizando interpolação qua-
drática).

10.1. FÓRMULAS DE DIFERENÇAS DIVIDIDAS CENTRADAS 287
• Fórmulas de diferenças divididas de segunda ordem centradas
Interpolando nos três pontos (x0 − h, f(x0 − h)), (x0, f(x0)) e (x0 + h, f(x0 + h)), temos a
fórmula usual
f ′(x0) ≈1
2h[f(x0 + h)− f(x0 − h)] (10.1)
Esta fórmula obtém-se utilizando os desenvolvimentos em fórmula de Taylor:
f(x0 + h) = f(x0) + hf ′(x0) +h2
2f ′′(x0) +
h3
3!f ′′′(ξ1)
f(x0 − h) = f(x0)− hf ′(x0) +h2
2f ′′(x0)−
h3
3!f ′′′(ξ2)
Subtraindo estas duas equações, obtemos
f ′(x0) =1
2h[f(x0 + h)− f(x0 − h)]− h2
12[f ′′′(ξ1) + f ′′′(ξ2)] (10.2)
Observa-se que o erro é O(h2) e que a fórmula se aplica desde que f ′′′ exista. Se f ′′′ for
contínua em [x0 − h;x0 + h], então
min[x0−h;x0+h]
f ′′′(x) ≤ 1
2[f ′′′(ξ1) + f ′′′(ξ2)] ≤ max
[x0−h;x0+h]f ′′′(x)
Por conseguinte,1
2[f ′′′(ξ1) + f ′′′(ξ2)] = f ′′′(ξ)
para algum ξ ∈ [x0 − h;x0 + h]. Aplicando este resultado na equação (10.2), obtém-se
f ′(x0) =1
2h[f(x0 + h)− f(x0 − h)]− h2
6[f ′′′(ξ)] (10.3)
Considere-se a Tabela 10.1 de dados/resultados, onde foram recolhidos os instantes no
tempo (dados) onde é medido o ângulo (resultado) de um prato de satélite. Pretende-se
Tabela 10.1: Ângulo de um prato de satélite ao longo do tempo.
Tempo 1.2 1.3 1.4 1.5 1.6 1.7
Ângulo 2.05841 2.1578 2.2556 2.3548 2.4538 2.5520
aproximar o índice de alteração do ângulo no instante 1.4 utilizando a aproximação (10.1).
Para isso, basta calcular:
f ′(1.4) ≈ 1
2(0.1)[f(1.5)− f(1.3)] =
1
2(0.1)[2.3548− 2.1578] = 0.9850

288 CAPÍTULO 10. DERIVAÇÃO
Outra fórmula de segunda ordem pode obter-se utilizando os desenvolvimentos em série
de Taylor até à quarta ordem:
f(x0 + h) = f(x0) + hf ′(x0) +h2
2f ′′(x0) +
h3
3!f ′′′(x0) +
h4
4!f ′′′(ξ1)
f(x0 − h) = f(x0)− hf ′(x0) +h2
2f ′′(x0)−
h3
3!f ′′′(x0) +
h4
4!f ′′′(ξ2)
Somando estas duas equações e rearranjando os termos, obtemos
f ′′(x0) =1
h2[f(x0 + h)− 2f(x0) + f(x0 − h)]− h2
12[f (4)(ξ)] (10.4)
para algum ξ ∈ [x0 − h;x0 + h].
Com base na Tabela 10.1 podemos, por exemplo, calcular:
f ′′(1.5) ≈ 1
0.12[f(1.6)− 2f(1.5) + f(1.4)] =
1
0.12[2.4538− 2× 2.3548 + 2.2556] = −0.0200
• Fórmula de diferenças divididas de quarta ordem centradas
Podemos aproximar a primeira e a segunda derivada utilizando as seguintes fórmulas de
diferenças finitas de O(h4) com os cinco pontos (x0 − 2h, f(x0 − 2h)) (x0 − h, f(x0 − h)),
(x0, f(x0)) e (x0 + h, f(x0 + h)), (x0 + 2h, f(x0 + 2h)):
f ′(x0) ≈1
12h[−f(x0 + 2h) + 8f(x0 + h)− 8f(x0 − h) + f(x0 − 2h)] (10.5)
f ′′(x0) ≈1
12h2[−f(x0 + 2h) + 16f(x0 + h)− 30f(x0) + 16f(x0 − h)− f(x0 − 2h)](10.6)
10.1.2 Procedimento
Problema Aproximar a primeira e/ou segunda derivada de uma função univariada f(x) num
ponto x0. Iremos assumir que temos uma tabela de pontos (xi, f(xi)).
Hipóteses Se usarmos uma aproximação de O(h2) e pretendermos estimar o erro, então assumi-
mos que a função tem segunda derivada limitada. Se em vez disso, utilizarmos uma aproxi-
mação de O(h4) e também pretendermos estimar o erro, então assumimos que a função tem
quarta derivada limitada.
Ferramentas Desenvolvimento em fórmula de Taylor ou interpolação.
Requisitos iniciais Temos de ter uma tabela de pelos menos três pontos (xi, f(xi)).

10.1. FÓRMULAS DE DIFERENÇAS DIVIDIDAS CENTRADAS 289
Processo iterativo Se pretendermos calcular uma aproximação para a primeira derivada no pon-
to (xi, f(xi)) e soubermos os pontos (xi−1, f(xi−1)) e (xi+1, f(xi+1)), então podemos calcular:
f ′(xi) ≈f(xi+1)− f(xi−1)
xi+1 − xi−1
ou seja, podemos utilizar a aproximação (10.1). Se o objectivo for aproximar a segunda
derivada, então podemos utilizar a equação (10.4).
Se a tabela for extensa o suficiente para conhecermos dois pontos em ambos os lados de xi,
então podemos utilizar as fórmulas (10.5) e (10.6).
Análise do erro No caso das diferenças divididas de primeira ordem vimos que o erro é dado
por (10.9), ou seja é O(h). A precisão não é muito elevada, mas por vezes há necessidade de
utilizar estas fórmulas, como é o caso tratado no exemplo 50.
Da equação (10.3) observamos que o erro associado a esta fórmula é
−h2
6[f ′′′(ξ)]
ou seja, é um O(h2). Na fórmula (10.4) temos um erro dado por:
−h2
12[f (4)(ξ)]
ou seja, um erro O(h2).
Em relação às fórmulas de quarta ordem, se fizermos uma combinação linear dos desenvol-
vimentos em série de Taylor de f(xi+2h), f(xi+h), f(xi−h) e f(xi−2h) até à quinta ordem,
obtemos o erro:
− 1
45f (5)(ξ1)h
4 +1
180f (5)(ξ2)h
4 +1
180f (5)(ξ3)h
4 − 1
45f (5)(ξ4)h
4
ou seja,
− 4
180f (5)(ξ1)h
4 +1
180f (5)(ξ2)h
4 +1
180f (5)(ξ3)h
4 − 4
180f (5)(ξ4)h
4
Os coeficientes das fracções somam −4 + 1 + 1 − 4 = −6. Consequentemente, o erro vem
dado por
− 6
180f (5)(ξ)h4 = − 1
30f (5)(ξ)h4
ou seja, o erro é O(h4).
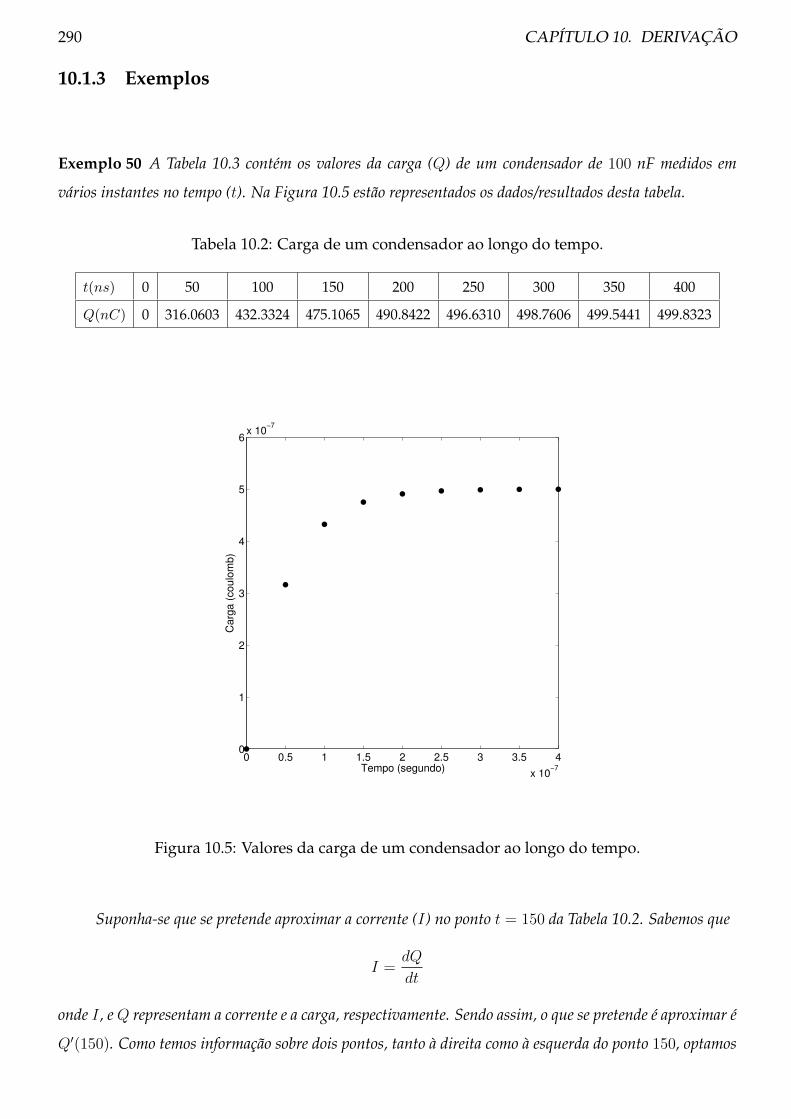
290 CAPÍTULO 10. DERIVAÇÃO
10.1.3 Exemplos
Exemplo 50 A Tabela 10.3 contém os valores da carga (Q) de um condensador de 100 nF medidos em
vários instantes no tempo (t). Na Figura 10.5 estão representados os dados/resultados desta tabela.
Tabela 10.2: Carga de um condensador ao longo do tempo.
t(ns) 0 50 100 150 200 250 300 350 400
Q(nC) 0 316.0603 432.3324 475.1065 490.8422 496.6310 498.7606 499.5441 499.8323
0 0.5 1 1.5 2 2.5 3 3.5 4
x 10−7
0
1
2
3
4
5
6x 10
−7
Tempo (segundo)
Carg
a (
coulo
mb)
Figura 10.5: Valores da carga de um condensador ao longo do tempo.
Suponha-se que se pretende aproximar a corrente (I) no ponto t = 150 da Tabela 10.2. Sabemos que
I =dQ
dt
onde I , e Q representam a corrente e a carga, respectivamente. Sendo assim, o que se pretende é aproximar é
Q′(150). Como temos informação sobre dois pontos, tanto à direita como à esquerda do ponto 150, optamos

10.1. FÓRMULAS DE DIFERENÇAS DIVIDIDAS CENTRADAS 291
por utilizar a fórmula que nos permite obter um erro mais pequeno, ou seja, a fórmula de quarta ordem
(10.5):
Q′(150) ≈ 1
12(50)[−Q(250) + 8Q(200)− 8Q(100) +Q(50)]
=1
12(50)[−496.6310 + 8× 490.8422− 8× 432.3324 + 316.0603]
= 0.4792
ou seja, no instante t = 150 ns, a corrente à entrada do condensador é aproximadamete I = 0.4792.
Também podemos utilizar a fórmula (10.2) para, por exemplo, obter os valores aproximados da cor-
rente nos instantes 50, 100, 150, 200, 250, 300 e 350 (ver a Tabela 10.3):
Q′(50) ≈ 1
2h[Q(100)−Q(0)] = 4.3233
Q′(100) ≈ 1
2h[Q(100)−Q(0)] = 1.5905
Q′(150) ≈ 1
2h[Q(100)−Q(0)] = 0.5851
Q′(200) ≈ 1
2h[Q(100)−Q(0)] = 0.2152
Q′(250) ≈ 1
2h[Q(100)−Q(0)] = 0.0792
Q′(300) ≈ 1
2h[Q(100)−Q(0)] = 0.0291
Q′(350) ≈ 1
2h[Q(100)−Q(0)] = 0.0107
Para obter os valores aproximados da corrente nos extremos t = 0 e t = 400 podemos utilizar a fórmula das
diferenças divididas à frente (10.8) e atrás (10.7), respectivamente (ver a Tabela 10.3):
Q′(0) ≈ Q(50)−Q(0)
h= 6.3212
Q′(400) ≈ Q(400)−Q(350)
h= 0.0058
Tabela 10.3: Corrente à entrada de um condensador em carga ao longo do tempo.
t(ns) 0 50 100 150 200 250 300 350 400
I(A) 6.32121 4.32332 1.59046 0.585098 0.215245 0.079184 0.029131 0.010717 0.005764

292 CAPÍTULO 10. DERIVAÇÃO
10.2 Fórmulas de diferenças divididas não centradas
Utilizando pontos em ambos os lados de um ponto x0 resulta numa melhor aproximação
para a derivada. Infelizmente, é muito frequente em engenharia, especialmente em aplicações em
tempo real, termos dados do passado para estimar a derivada no presente. Por exemplo, pode ser
necessário usar o índice de variação actual de um sinal para ajustar um sistema, mas a informação
que temos disponível é relativa a pontos do passado. Fórmulas semelhantes às centradas, mas que
usam apenas pontos menores ou iguais a x0 para aproximar as derivadas em x0 são denominadas
diferenças divididas a trás. Fórmulas que utilizam os pontos maiores ou iguais a x0 para calcular as
derivadas em x0 são denominadas diferenças divididas à frente.
Bases: Capítulo 8.
10.2.1 Teoria
Suponha-se que pretendemos aproximar a derivada da função num ponto x0. Dado um
valor pequeno de h, se conhecermos o valor da função nos pontos x0 − h e x0 então podemos
obter o polinómio interpolador, de grau menor ou igual a um, da função que passa nos pontos
(x0−h, f(x0−h)) e (x0, f(x0)). Na Figura 10.6 está representada uma função na qual pretendemos
aproximar a derivada no ponto x0 e a tangente em x0 = 1.3 que é dada por T fx0 = sin(1.3)− 0.1 +
cos(1.3) ∗ (x− 1.3). Na mesma Figura 10.6 podemos observar a aproximação da derivada através
de um polinómio interpolador linear. Observamos que a aproximação da inclinação usando o
polinómio interpolador e a inclinação exacta são próximas uma da outra, mas são diferentes.
Para h = 0.6 o polinómio interpolador nos pontos (0.7, f(0.7)) e (1.3, f(1.3)) é dado por
p1(x) = 0.5322 x+ 0.1717;
as instruções Matlab para calcular e representar o polinómio interpolador são:
y = [0.7 1.3]; py = sin(y) - 0.1;
p = polyfit(y,py,1)
p = 0.5322 0.1717
plot(x,polyval(p,x))
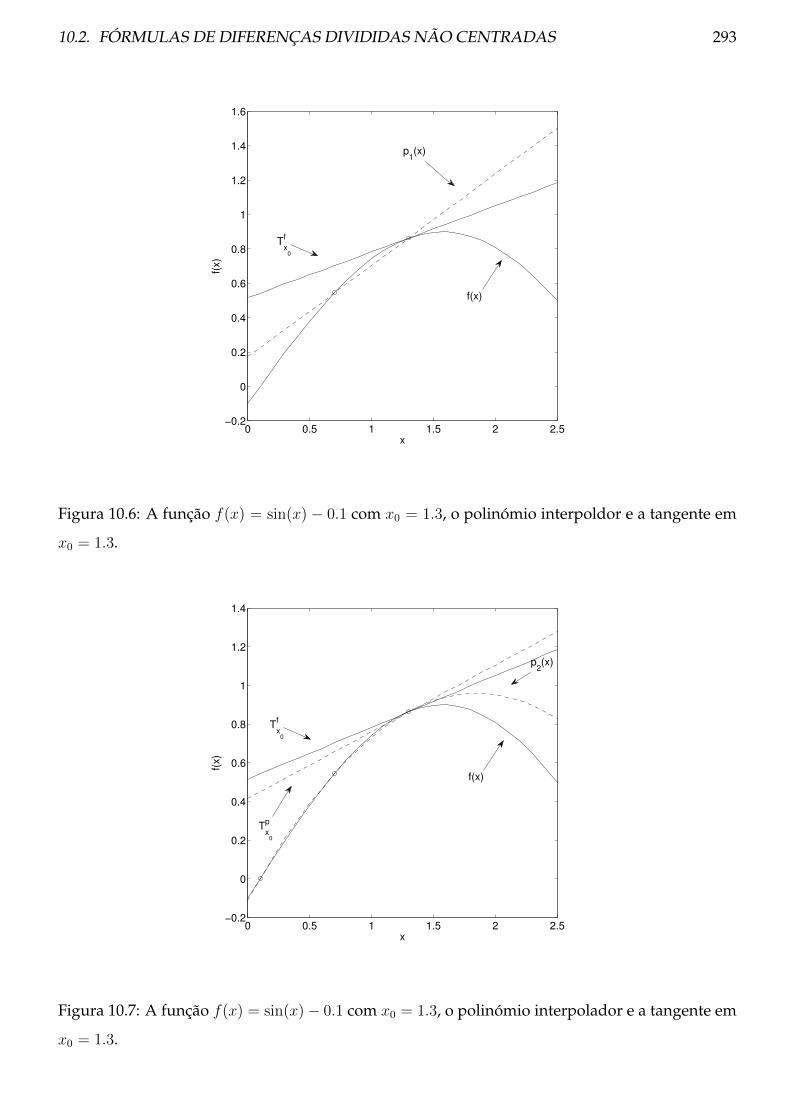
10.2. FÓRMULAS DE DIFERENÇAS DIVIDIDAS NÃO CENTRADAS 293
0 0.5 1 1.5 2 2.5−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
x
f(x)
p1(x)
f(x)
Tf
x0
Figura 10.6: A função f(x) = sin(x) − 0.1 com x0 = 1.3, o polinómio interpoldor e a tangente em
x0 = 1.3.
0 0.5 1 1.5 2 2.5−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
x
f(x)
Tp
x0
Tf
x0
p2(x)
f(x)
Figura 10.7: A função f(x) = sin(x)− 0.1 com x0 = 1.3, o polinómio interpolador e a tangente em
x0 = 1.3.

294 CAPÍTULO 10. DERIVAÇÃO
De modo semelhante, se conhecermos o valor da função nos três pontos x0 − 2h, x0 − h e
x0, podemos obter o polinómio interpolador de grau menor ou igual a dois que passa nos pontos
(x0−2h, f(x0−2h)), (x0−h, f(x0−h)) e (x0, f(x0)). Para h = 0.6, podemos observar na Figura 10.7,
a função, o polinómio interpolador nos pontos (0.1, f(0.1)), (0.7, f(0.7)) e (1.3, f(1.3)) e as recta
tangentes em x0 = 1.3 da função e do polinómio interpolador. As linhas tangentes estão próximas
mas, mais uma vez, são diferentes. O polinómio interpolador é dado por
p2(x) = −0.3126 x2 + 1.1574 x− 0.1128.
A inclinação do polinómio em x0 = 1.3 obtém-se calculando
p′2(1.3) = −(2)(0.3126)(1.3) + 1.1574.
A tangente ao polinómio interpolador em x0 = 1.3 é dada por
T px0 = p2(1.3) + p′2(1.3)(x− 1.3).
Uma vez que estamos a considerar pontos à esquerda de x0, as fórmulas denominam-se
diferenças divididas à esquerda.
Iremos ver duas fórmulas com base na interpolação em dois e três pontos. Com mais pontos
a instabilidade dos polinómios interpoladores reduz as vantagens de ir à procura de fórmulas de
ordens mais elevadas.
Se considerarmos pontos à esquerda de x0, as fórmulas denominam-se diferenças divididas
para trás. Se, por outro lado, os pontos utilizados na aproximação estiverem todos à direita, então
as fórmulas denominam-se diferenças divididas para a frente.
• Fórmula de diferenças divididas não centradas de primeira ordem
Se considerar-mos o desenvolvimento em série de Taylor:
f(x0 − h) = f(x0)− hf ′(x0) +h2
2f ′′(ξ)
e resolvermos em ordem a f ′(x0), obtém-se
f ′(x0) =f(x0)− f(x0 − h)
h− h
2f ′′(ξ)
ou seja, obtemos a fórmula das diferenças divididas para trás
f ′(x0) ≈1
h[f(x0)− f(x0 − h)] (10.7)

10.2. FÓRMULAS DE DIFERENÇAS DIVIDIDAS NÃO CENTRADAS 295
Esta fórmula corresponde a interpolar os pontos (x0 − h, f(x0 − h)) e (x0, f(x0)), derivar e
depois calcular no ponto x0.
Se, por outro lado, considerarmos
f(x0 + h) = f(x0) + hf ′(x0) +h2
2f ′′(ξ)
onde ξ ∈ [x0;x0 + h] e resolvermos esta equação em ordem a f ′(x0) obtém-se
f ′(x0) =1
h[f(x0 + h)− f(x0)]−
h
2f ′′(ξ)
ou seja,
f ′(x0) ≈1
h[f(x0 + h)− f(x0)] (10.8)
A esta aproximação chama-se fórmula das diferenças divididas para a frente.
Em ambas temos um erro associado da forma:
−h2f ′′(ξ) (10.9)
Neste caso, o erro é zero se a função for um polinómio de grau menor ou igual a um.
• Fórmula de diferenças divididas não centradas de segunda ordem
Considerando os desenvolvimentos em série de Taylor de f(x0−2h), f(x0−h), até à terceira
ordem e, depois, calculando f(x0 − 2h) − 4f(x0 − h) + 3f(x0) podemos obter a fórmula de
segunda ordem
f ′(x0) ≈1
2h[f(x0 − 2h)− 4f(x0 − h) + 3f(x0)] (10.10)
Esta fórmula também se pode obter interpolando nos três pontos (x0− 2h, f(x0− 2h)), (x0−
h, f(x0 − h)) e (x0, f(x0)), derivando e depois calculando no ponto x0.
• Fórmula de diferenças divididas não centradas de ordens mais elevadas
É possível construir polinómios interpoladores com quatro e mais pontos, mas convém lem-
brar que os polinómios interpoladores começam a ter grandes oscilações principalmente
junto aos extremos quando o número de pontos é elevado. Consequentemente, as fórmulas
começam a não ser muito exactas. o erro de uma fórmula para trás com base em n pontos é
dada por:(−1)n
nf (n)hn−1
Observe-se que o coeficiente 1/n não cresce tão rapidamente como o coeficiente das diferen-
ças divididas centradas que segue
1
6,
1
30,
1
630,
1
2772,
1
12012,
1
51480,
1
218790.

296 CAPÍTULO 10. DERIVAÇÃO
10.2.2 Procedimento
Problema Aproximar a primeira derivada de uma função univariada f(x) num ponto x0. Iremos
assumir que temos uma tabela de pontos (xi, f(xi)).
Hipóteses Se pretendermos estimar o erro temos que assumir que a segunda derivada é limitada
se utilizarmos uma aproximação O(h2).
Ferramentas Desenvolvimento em fórmula de Taylor ou interpolação.
Requisitos iniciais Temos de ter uma tabela de pelos menos três pontos (xi, f(xi)).
Processo iterativo Se pretendermos calcular uma aproximação para a primeira derivada no pon-
to (xi, f(xi)) e tivermos conhecimento do ponto anterior (xi−1, f(xi−1)), então podemos cal-
cular:
f ′(x0) ≈f(xi)− f(xi−1)
xi − xi−1=
1
h[f(xi)− f(xi − h)]
onde h = xi − xi−1. Se tivermos informação nos dois pontos anteriores então podemos
calcular
f ′(x0) ≈1
2h[3f(xi)− 4f(xi−1) + f(xi−2)] =
1
2h[3f(xi)− 4f(xi − h) + f(xi − 2h)]
Análise do erro No caso das diferenças divididas de primeira ordem vimos que o erro é dado
por (10.9), ou seja é O(h). A precisão não é muito elevada, mas por vezes há necessidade de
utilizar estas fórmulas, como é o caso tratado no exemplo 50.
Para determinar o erro nas fórmulas de segunda ordem precisamos de utilizar os dois de-
senvolvimentos em série de Taylor:
f(x0 − h) = f(x0)− hf ′(x0) +h2
2f ′′(x0)−
h3
3!f ′′′(ξ1)
f(x0 − 2h) = f(x0)− 2hf ′(x0) +(2h)2
2f ′′(x0)−
(2h)3
3!f ′′′(ξ1)
Subtraindo à segunda quatro vezes a primeira e resolvendo em ordem a f ′(x0) obtém-se
f ′(x0) =1
2h[f(x0 − 2h)− 4f(x0 − h) + 3f(x0)] +
h2
3[2f ′′′(ξ1)− f ′′′(ξ2)]
Uma vez que a soma dos coeficientes entre parentesis é 1, podemos fazer a aproximação
2f ′′′(ξ1)− f ′′′(ξ2) ≈ f ′′′(ξ)
no intervalo [x0 − 2h;x0] e, por conseguinte, a fórmula é O(h2).

10.3. PROBLEMAS 297
Podemos observar que o erro associado à diferença dividida centrada de segunda ordem
(10.3) tem um coeficiente igual a −1/6 e, por conseguinte, esta diferença dividida centrada
tem aproximadamente metade do erro absoluto da diferença dividida para trás de segunda
ordem.
Considere a função f(x) = x4 e o ponto x0 = 0.6. Na Tabela 10.4 encontram-se as aproxi-
mações da primeira derivada com ambas as fórmulas de segunda ordem, centrada e para
trás, e os erros para h = 0.1, h = 0.05 e h = 0.025. Utilizou-se o valor exacto da derivada:
f ′(0.6) = 4(0.6)3.
Tabela 10.4: Comparação dos erros de duas fórmulas de diferenças divididas.
h Centrada Para trás Erro (centrada) Erro (para trás) Erro/2 (para trás)
0.1 0.88800000 0.82200000 2.400000×−2 4.20000×−2 2.10000×−2
0.05 0.87000000 0.85275000 6.000000×−3 1.12500×−2 5.62500×−3
0.025 0.86550000 0.86109375 1.500000×−3 2.90625×−3 1.45312×−3
10.3 Problemas
1. Obtenha as fórmulas (10.5) e (10.6) e mostre que são ambas O(h4).
2. A Tabela seguinte contém os valores da carga (Q) de um condensador de 100 nF medidos
em vários instantes no tempo (t).
t (ns) 0 50 100 150 200 250 300
Q (nC) 0 282.7 405.6 459.0 482.2 492.2 496.6
Sabemos que I = dQdt
, onde I , Q e t representam a corrente, a carga e o tempo, respecti-
vamente. Calcule aproximações dos valores da corrente nos instantes t = 100 e t = 150 e
coloque-os na tabela:
Instante, t 100 150
Corrente, I
3. Calcule f ′(0.4) e f ′′(0.4) usando a tabela abaixo e utilizando fórmulas de diferenças dividi-
das centradas.
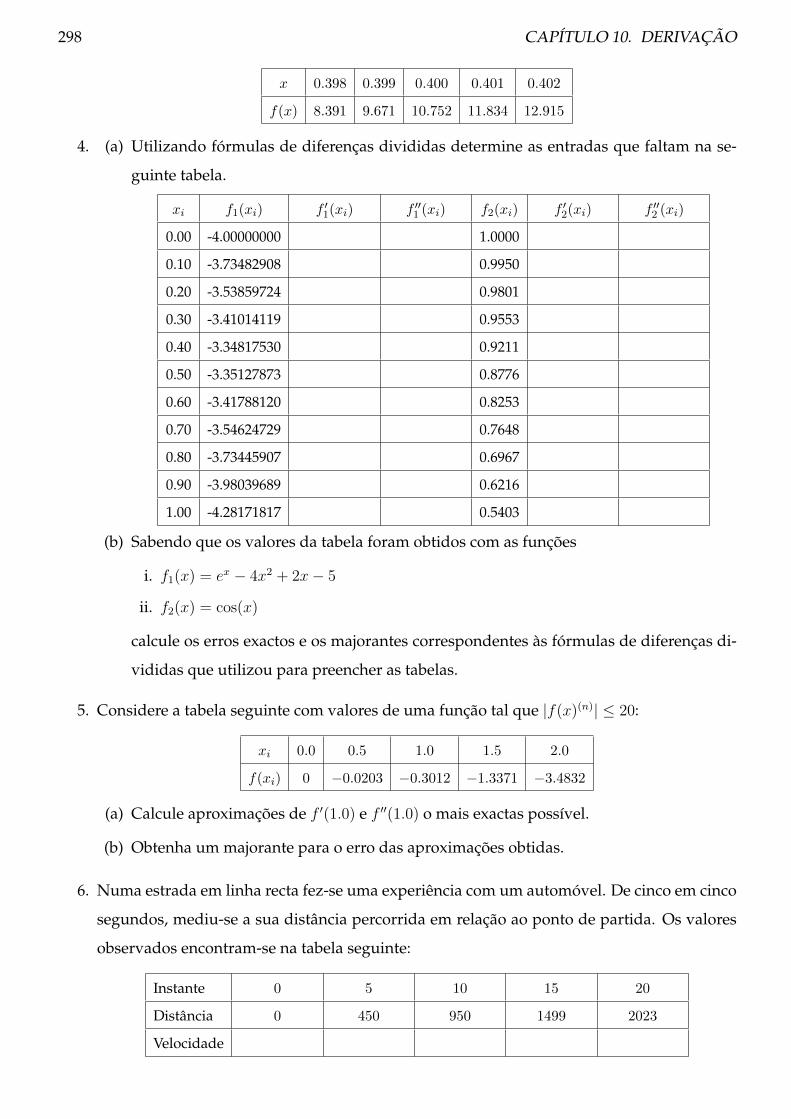
298 CAPÍTULO 10. DERIVAÇÃO
x 0.398 0.399 0.400 0.401 0.402
f(x) 8.391 9.671 10.752 11.834 12.915
4. (a) Utilizando fórmulas de diferenças divididas determine as entradas que faltam na se-
guinte tabela.
xi f1(xi) f ′1(xi) f ′′1 (xi) f2(xi) f ′2(xi) f ′′2 (xi)
0.00 -4.00000000 1.0000
0.10 -3.73482908 0.9950
0.20 -3.53859724 0.9801
0.30 -3.41014119 0.9553
0.40 -3.34817530 0.9211
0.50 -3.35127873 0.8776
0.60 -3.41788120 0.8253
0.70 -3.54624729 0.7648
0.80 -3.73445907 0.6967
0.90 -3.98039689 0.6216
1.00 -4.28171817 0.5403
(b) Sabendo que os valores da tabela foram obtidos com as funções
i. f1(x) = ex − 4x2 + 2x− 5
ii. f2(x) = cos(x)
calcule os erros exactos e os majorantes correspondentes às fórmulas de diferenças di-
vididas que utilizou para preencher as tabelas.
5. Considere a tabela seguinte com valores de uma função tal que |f(x)(n)| ≤ 20:
xi 0.0 0.5 1.0 1.5 2.0
f(xi) 0 −0.0203 −0.3012 −1.3371 −3.4832
(a) Calcule aproximações de f ′(1.0) e f ′′(1.0) o mais exactas possível.
(b) Obtenha um majorante para o erro das aproximações obtidas.
6. Numa estrada em linha recta fez-se uma experiência com um automóvel. De cinco em cinco
segundos, mediu-se a sua distância percorrida em relação ao ponto de partida. Os valores
observados encontram-se na tabela seguinte:
Instante 0 5 10 15 20
Distância 0 450 950 1499 2023
Velocidade

10.3. PROBLEMAS 299
Utilize fórmulas de diferenças divididas para prever a velocidade do automóvel em cada
instante, em que foi feita a medição, e preencha os valores que faltam na tabela.
7. Num circuito RL com voltagem V , resistência R e indutância L verifica-se
V = LdI
dt+RI,
onde I é a corrente. Com base na tabela de valores observados da corrente num circuito RL
com L = 0.98 henries e R = 0.142 ohms, calcule valores aproximados da voltagem quando
t = 1.00, t = 101, t = 1.02, t = 1.03 e t = 1.04, e complete a tabela.
t 1.00 1.01 1.02 1.03 1.04
I 3.10 3.12 3.14 3.18 3.24
V
8. Num circuito RLC com voltagem V , resistência R, indutância L e capacidade C verifica-se
V (t) = RI(t) + LdI
dt(t) + C
∫ t
−∞I(τ)dτ,
onde I é a corrente. Com base na tabela de valores observados da corrente num circuito
RL com L = 0.98 Henries, R = 0.142 Ohms e C = 2 Farad, calcule valores aproximados da
voltagem quando t = 1.00, t = 101, t = 1.02, t = 1.03 e t = 1.04, e complete a tabela. Para o
cálculo do integral utilize uma fórmula de quadratura à sua escolha.
t 1.00 1.01 1.02 1.03 1.04
I 3.10 3.12 3.14 3.18 3.24
V
9. Obtenha as fórmulas
f ′(x0) ≈1
12h[−f(x0 + 2h) + 8f(x0 + h)− 8f(x0 − h) + f(x0 − 2h)]
f ′′(x0) ≈1
12h2[−f(x0 + 2h) + 16f(x0 + h)− 30f(x0) + 16f(x0 − h)− f(x0 − 2h)]
e mostre que são ambas O(h4). Calcule valores aproximados de f ′(0.4) e f ′′(0.4) sendo f(x)
a função tabelada na tabela seguinte.
x 0.398 0.399 0.400 0.401 0.402
f(x) 8.391 9.671 10.752 11.834 12.915

300 CAPÍTULO 10. DERIVAÇÃO

Capítulo 11
Problemas com valor inicial
É já desde o tempo de Newton que certos fenómenos físicos são investigados através da
representação do fenómeno sob a forma de equações diferenciais. Neste contexto, uma equação
diferencial é uma equação de evolução que especifica, dadas determinadas condições iniciais,
como é que o sistema evolui no tempo. Uma vez que é mais fácil medir o índice de mudança
de uma quantidade do que a própria quantidade, muitas leis físicas em ciência expressam-se em
termos de equações diferenciais. Uma equação diferencial é aquela que envolve pelo menos uma
derivada de uma função desconhecida.
Seja y(t) uma função de R em R e denotemos por y′(t), y′′(t), . . ., y(k) as suas derivadas
dy(t)
dt,d2y(t)
dt2. . .
dky(t)
dtk
Uma equação diferencial ordinária é uma equação que envolve t, y e as suas derivadas até uma
certa ordem, ou seja, contém t, y, y′, y′′, . . .. A ordem de uma equação diferencial é a ordem k da
maior derivada que aparece na equação.
Neste capítulo, iremos preocupar-nos em resolver numericamente equações diferenciais or-
dinárias de primeira ordem sujeitas a uma determinada condição inicial, isto é, resolver proble-
mas da forma y′ = f(t, y)
y(t0) = y0(11.1)
onde t0 é um ponto por onde a curva y(t) passa. Estes problemas denominam-se problemas de valor
inicial.
301

302 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Existem muitos métodos para resolver problemas do tipo (11.1). Os métodos que serão aqui
apresentados irão servir para introduzir a ideia básica de muitos outros métodos mais sofisticados
e podem ser aplicados facilmente a sistemas de equações de primeira ordem. Estes sistemas serão
apresentados na Secção 11.6 onde se apresenta uma técnica para converter um problema de valor
inicial de ordem elevada num sistema de equações de primeira ordem.
Quando resolvemos uma equação diferencial com um método numérico não esperamos ob-
ter a solução directamente como uma fórmula explícita y(t) em função de t. Em vez disso, geral-
mente construímos uma tabela da forma
t0 t1 t2 . . . tn
y0 y1 t2 . . . yn(11.2)
onde
ti = t0 + ih, i = 0, 1, 2, . . . , n
com h = (b − a)/n sendo o tamanho do passo e onde yi representa o valor aproximado da solução
exacta no ponto ti. A solução exacta no ponto ti representa-se por y(ti).
11.1 Método de Euler
O método de Euler é um método simples para resolver numericamente problemas de valor
inicial. Tem a vantagem de não necessitar das derivadas da função f . Contudo, para obtermos
uma precisão aceitável é preciso valores de h bastante pequenos. A palavra Euler pronuncia-se
“óiler”.
Bases: Secção 3.1.
11.1.1 Teoria
Para obter o método de Euler considera-se o desenvolvimento em série de Taylor de y em
torno do ponto ti para i = 0, 1, 2, . . . , n− 1. Assuma-se que y é duas vezes continuamente diferen-
ciável no intervalo [t0; tn]. Então, podemos escrever
y(ti+1) = y(ti + h) = y(ti) + hy′(ti) +h2
2y′′(ξ)

11.1. MÉTODO DE EULER 303
para algum ξ ∈ [ti; ti+1]. Como y′(ti) = f(ti, y(ti)) vem
y(ti+1) = y(ti + h) = y(ti) + hf(ti, y(ti)) +h2
2y′′(ξ) (11.3)
Consequentemente,
y(ti+1) ≈ y(ti) + hy′(ti) = y(ti) + hf(ti, y(ti))
Utilizando a notação yi ≈ y(ti), então
yi+1 = yi + hf(ti, yi), i = 0, 1, 2, . . . , n− 1. (11.4)
Este método denomina-se por Método de Euler.
Na Figura 11.1 pode observar-se uma interpretação geométrica deste método. A recta tan-
gente que toma o valor zero em ti e tem inclinação y′(ti) é dada por y′(ti)(t − ti). Somando yi
obtemos a recta tangente que passa em yi e tem inclinação y′(ti)(t− ti):
Tti = yi + y′(ti)(t− ti) ≈ yi + f(ti, yi)(t− ti)
A aproximação seguinte a yi obtém-se no ponto de intercepção desta tangente com a linha vertical
t = ti+1, ou seja, yi+1 = yi + hf(ti, yi), onde se utilizou o facto de ti+1 − ti = h. O conceito que
estamos a utilizar é o seguinte: uma função contínua pode ser aproximada localmente por uma
linha recta que é a tangente.
Para visualizar melhor o método, considere-se a equação diferencial
y′ = y − t+ 1, (11.5)
a rede de 21 × 21 pontos da forma (t, y) ∈ [0; 4] × [−1; 3] e calcule-se a inclinação nestes pontos.
Em seguida, para cada ponto da rede, represente-se graficamente uma seta com a inclinação nesse
ponto. O resultado da representação gráfica encontra-se na Figura 11.2. Sendo assim, uma solução
que passe através, ou perto, de um dos pontos da grelha tem de ter uma inclinação igual a, ou
próxima, da inclinação da seta.
Quase que conseguimos traçar manualmente as soluções se seguirmos as setas. Podemos
observar, na Figura 11.3, quatro condições iniciais diferentes: y(0) = −0.5, y(0) = 0, y(0) = 0.5 e
y(0) = 1. Observe-se que cada solução tem uma inclinação que se aproxima de qualquer seta por
onde pode passar. Se y(0) = 0.5 e pretendermos aproximar y(1), segue-se a inclinação em (0, 0.5)
entre t = 0 e t = 1 (ver a Figura 11.4). Assim, obtemos y(1) ≈ 0.5 + 1.5× 1 = 2.
Neste exemplo particular, podemos calcular analiticamente a solução do problema de valorinicial. Também podemos utilizar a instrução Matlab
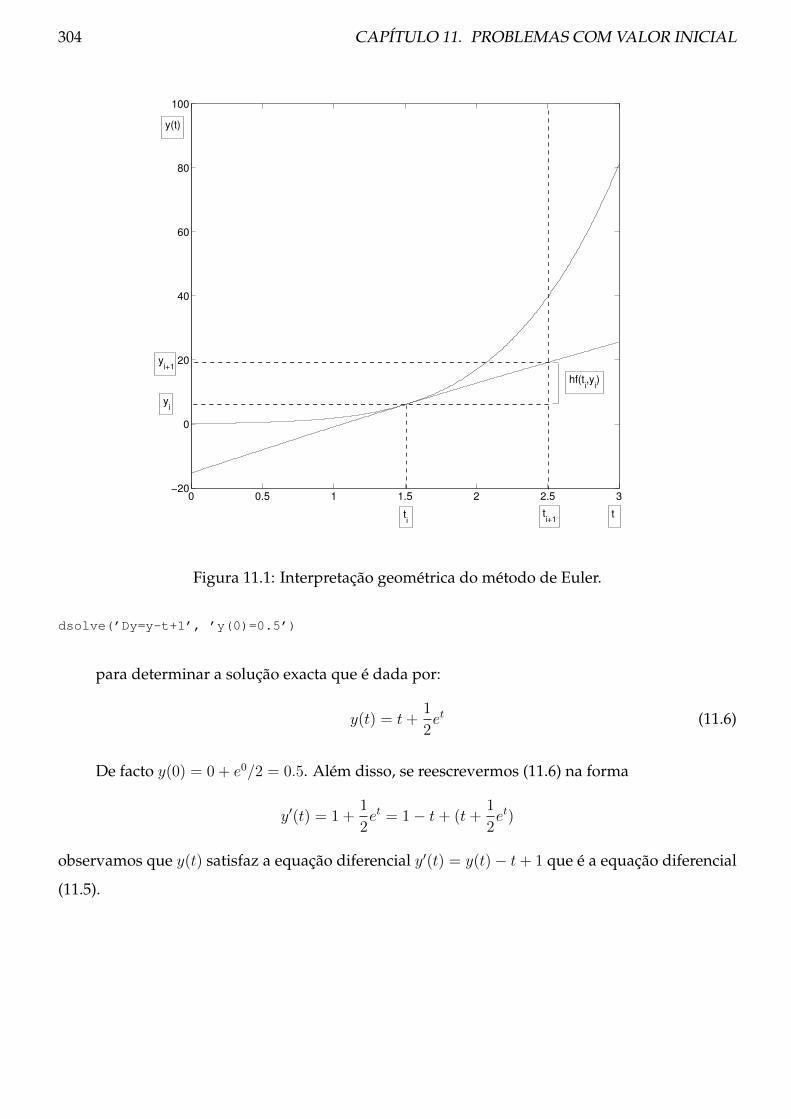
304 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
0 0.5 1 1.5 2 2.5 3−20
0
20
40
60
80
100
yi+1
yi
y(t)
ti
tti+1
hf(ti,y
i)
Figura 11.1: Interpretação geométrica do método de Euler.
dsolve(’Dy=y-t+1’, ’y(0)=0.5’)
para determinar a solução exacta que é dada por:
y(t) = t+1
2et (11.6)
De facto y(0) = 0 + e0/2 = 0.5. Além disso, se reescrevermos (11.6) na forma
y′(t) = 1 +1
2et = 1− t+ (t+
1
2et)
observamos que y(t) satisfaz a equação diferencial y′(t) = y(t)− t+ 1 que é a equação diferencial
(11.5).
11.1. MÉTODO DE EULER 305
Figura 11.2: As inclinações definidas pela equação diferencial para vários valores de t e y.
Figura 11.3: Quatro condições iniciais para diferentes condições iniciais.
306 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Figura 11.4: Aproximando y(1) com condição inicial y(0) = 0.5 e a inclinação nesse ponto.

11.1. MÉTODO DE EULER 307
11.1.2 Método de Euler e integração numérica
O método de Euler para resolver equações diferenciais corresponde a utilizar o extremo
esquerdo do intervalo como nó de integração quando se integra a equação diferencial. Mais
concretamente, dada a equação diferencial y′(t) = f(t, y(t)) podemos escrever∫ ti+1
ti
y′(t)dt =
∫ ti+1
ti
f(t, y(t))dt
ou seja,
y(ti+1)− y(ti) =
∫ ti+1
ti
f(t, y(t))dt
Consequentemente,
y(ti+1) = y(ti) +
∫ ti+1
ti
f(t, y(t))dt
Para resolver o integral do lado direito desta equação, aproxima-se a função integranda pelo
polinómio interpolador de grau zero que coincide com a função no extremo esquerdo do intervalo
[ti; ti+1]. Ou seja,
y(ti+1) = y(ti) +
∫ ti+1
ti
f(ti, y(ti)) + (t− ti)df
dt(ξt, y(ξt))dt
Uma vez que dfdt
(ξt, y(ξt)) = y′′(ξt) vem
y(ti+1) = y(ti) + (ti+1 − ti)f(ti, y(ti)) +
∫ ti+1
ti
(t− ti)y′′(ξt)dt
Assumindo y′′ ∈ C[ti; ti+1], ou seja y ∈ C2[ti; ti+1], e uma vez que a função (t − ti) não muda de
sinal em [ti; ti+1], podemos aplicar o teorema do valor médio para integrais (ver Secção 9.1) e obter
y(ti+1) = y(ti) + (ti+1 − ti)f(ti, y(ti)) + y′′(η)
∫ ti+1
ti
(t− ti)dt
= y(ti) + hf(ti, y(ti)) +h2
2y′′(η), η ∈ [ti; ti+1]
Daqui obtém-se o método de Euler (11.4).
11.1.3 Procedimento
Problema Encontrar uma solução aproximada para um problema de valor inicial da forma (11.1).
Ou seja, com base no problema (11.1), construir a Tabela 11.2.
Hipóteses Assume-se que y ∈ C2([t0; tn]) e que f(t, y) é contínua em ambas as variáveis na região
onde a solução passa no plano-ty.

308 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Ferramentas Desenvolvimento em série de Taylor.
Requisitos iniciais Sejam y0, t0, n e tn. É preciso calcular h = (tn − t0)/n e construir a rede de
pontos t0, t1, . . . tn.
Processo iterativo Dado a aproximação da função no ponto ti, yi, a aproximação no ponto se-
guinte da rede, ti+1, obtém-se calculando yi+1 = yi + hf(ti, yi).
Condições de paragem O processo pára quando a Tabela 11.2 estiver completamente preenchida,
ou seja, a variável de ciclo i vai desde 0 até n com passo unitário.
Análise do erro Para estudar a convergência do método de Euler começamos por subtrair a equa-
ção (11.4) da equação (11.3) e obtemos
y(ti+1)− yi+1 = y(ti)− yi + h[f(ti, y(ti))− f(ti, yi)] +h2
2y′′(ξ)
Considerando que o erro no ponto ti se denota por ei = y(ti) − yi e assumindo que f é
Lipschitziana com constante de Lipschitz L vem
|ei+1| ≤ |ei|+ hL|y(ti)− yi|+h2
2y′′(ξ)
ou seja,
|ei+1| ≤ |ei|(1 + Lh) +h2
2K2, i = 0, 1, 2 . . . (11.7)
onde
L = maxt∈[a;b]
∣∣∣∣ ∂∂yf(t, y)
∣∣∣∣ , K2 = maxt∈[a;b]
|y′′(x)| (11.8)
O termo h2K/2 é um majorante do erro cometido no passo actual e o outro termo é um
majorante do erro propagado vindo dos passos anteriores.
Para mostrar a convergência do método, majoramos o erro correspondente à aproximação
yN = b e depois mostramos que ele tende para zero quando h tende para zero. Para calcular
este majorante temos de utilizar o seguinte Lema:
Lema 1 Suponha-se que existem números δ e K tal que a sucessão d0, d1, d2, . . ., satisfaz
di+1 ≤ (1 + δ)di +K, i = 0, 1, 2, . . . (11.9)
então para qualquer i ≥ 0
di ≤ eiδd0 +Keiδ − 1
δ(11.10)

11.1. MÉTODO DE EULER 309
Demonstração: Suponha-se que a sucessão d0, d1, d2, . . ., satisfaz (11.9).
Como para i = 0 se tem
d1 ≤ (1 + δ)d0 +K,
temos para i = 1
d2 ≤ (1 + δ)d1 +K ≤ (1 + δ)2d0 +K[1 + (1 + δ)]
Consequentemente, para i = 2
d3 ≤ (1 + δ)3d0 +K[1 + (1 + δ) + (1 + δ)2]
Por indução supomos que
di ≤ (1 + δ)id0 +K[1 + (1 + δ) + (1 + δ)2 + . . .+ (1 + δ)i−1] (11.11)
e então
di+1 ≤ (1 + δ)di +K ≤ (1 + δ)i+1d0 +K[1 + (1 + δ) + (1 + δ)2 + . . .+ (1 + δ)i]
e isto completa o argumento por indução.
Observamos que o termo
(1 + δ) + (1 + δ)2 + . . .+ (1 + δ)i−1 =i−1∑j=0
(1 + δ)j
em (11.11) é uma progressão geométrica em que o primeiro termo é a1 = 1 e a razão q =
(1 + δ), ou seja, aj+1 = (1 + δ)j , j = 0, 1, . . . , i− 1. Consequentemente,
di ≤ (1 + δ)id0 +K(1 + δ)i − 1
(1 + δ)− 1= (1 + δ)id0 +K
(1 + δ)i − 1
δ(11.12)
Por outro lado, desenvolvendo a função eδ (δ > 0) em trono do ponto zero vem
eδ = 1 + δ +δ2
2eτ , 0 < τ < δ
ou seja,
1 + δ = eδ − δ2
2eτ , 0 < τ < δ
Por conseguinte,
1 + δ ≤ eδ
e segue que
(1 + δ)i ≤ eiδ
Aplicando este resultado a (11.12) obtém-se o resultado (11.10).♦

310 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Aplicando o Lema 1 à desigualdade (11.7) obtém-se
|ei| ≤ |e0|eihL +hK2
2L(eihL − 1) (11.13)
Contudo e0 = 0 e ih ≤ Nh = b− a, logo
|ei| ≤hK2
2L(eL(b−a) − 1) (11.14)
Observa-se que o erro é majorado por uma constante vezes h, ou seja, o majorante é um
O(h).
Esta estimativa do erro ignora os efeitos da aritmética em precisão finita. Quando a tole-
rância é da mesma ordem de grandeza da unidade de arredondamento da máquina não é
correcto ignorar os erros de arredondamento. Também quando é preciso utilizar um passo
muito pequeno para obtermos uma solução aproximada suficientemente precisa, os erros
de arredondamento não podem ser ignorados. Note-se que quando calculamos f(ti, yi) na
nossa máquina o que na realidade obtemos é f(ti, yi) + εi. De modo semelhante, quando
calculamos
yi+1 = yi + h[f(ti, yi) + εi]
é cometido um erro ρi, ou seja,
yi+1 = yi + hf(ti, yi) + hεi + ρi (11.15)
Nesta situação, um majorante para o erro obtém-se de forma semelhante ao majorante an-
terior. Subtraindo a equação (11.4) da equação (11.15) obtemos
y(ti+1)− yi+1 = y(ti)− yi + h[f(ti, y(ti))− f(ti, yi)] +h2
2y′′(ξ)− hεi − ρi
Consequentemente,
|ei+1| ≤ |ei|+ hL|ei|+h2
2y′′(ξ) + h|εi|+ |ρi|
ou seja,
|ei+1| ≤ |ei|(1 + Lh) +h2
2K2 + hε+ ρ
onde
L = maxt∈[a;b]
∣∣∣∣ ∂∂yf(t, y)
∣∣∣∣ , K2 = maxt∈[a;b]
|y′′(x)|, maxi=0,N−1
|εi| ≤ ε, maxi=0,N−1
|ρi| ≤ ρ
Aplicando o Lema 1 à desigualdade anterior obtém-se
|ei| ≤ |e0|eihL +
(h2
2K2 + hε+ ρ
)eihL − 1
hL
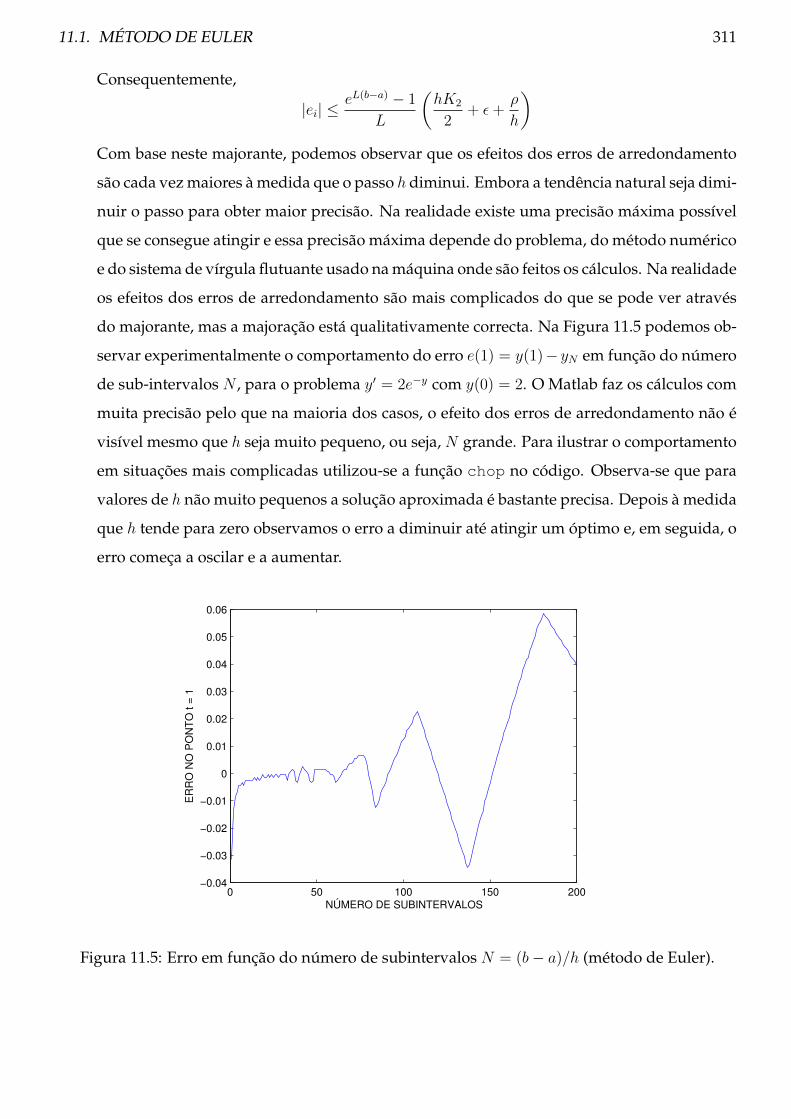
11.1. MÉTODO DE EULER 311
Consequentemente,
|ei| ≤eL(b−a) − 1
L
(hK2
2+ ε+
ρ
h
)Com base neste majorante, podemos observar que os efeitos dos erros de arredondamento
são cada vez maiores à medida que o passo h diminui. Embora a tendência natural seja dimi-
nuir o passo para obter maior precisão. Na realidade existe uma precisão máxima possível
que se consegue atingir e essa precisão máxima depende do problema, do método numérico
e do sistema de vírgula flutuante usado na máquina onde são feitos os cálculos. Na realidade
os efeitos dos erros de arredondamento são mais complicados do que se pode ver através
do majorante, mas a majoração está qualitativamente correcta. Na Figura 11.5 podemos ob-
servar experimentalmente o comportamento do erro e(1) = y(1)− yN em função do número
de sub-intervalos N , para o problema y′ = 2e−y com y(0) = 2. O Matlab faz os cálculos com
muita precisão pelo que na maioria dos casos, o efeito dos erros de arredondamento não é
visível mesmo que h seja muito pequeno, ou seja, N grande. Para ilustrar o comportamento
em situações mais complicadas utilizou-se a função chop no código. Observa-se que para
valores de h não muito pequenos a solução aproximada é bastante precisa. Depois à medida
que h tende para zero observamos o erro a diminuir até atingir um óptimo e, em seguida, o
erro começa a oscilar e a aumentar.
0 50 100 150 200−0.04
−0.03
−0.02
−0.01
0
0.01
0.02
0.03
0.04
0.05
0.06
NÚMERO DE SUBINTERVALOS
ER
RO
NO
PO
NT
O t =
1
Figura 11.5: Erro em função do número de subintervalos N = (b− a)/h (método de Euler).

312 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
11.1.4 Exemplos
Exemplo 51 Considere o problema de valor inicial y′ = 2t− y
y(0) = −1
Para obter um valor aproximado de y(1) com h = 0.1 e uma vez que f(t, y) = 2t− y, podemos escrever
yi+1 = yi + hf(ti, yi) = yi + h(2ti − yi) = yi + h(2ih− yi), i = 0, 1, 2 . . . , 9.
Para i = 0 tem-se
y1 = −1 + 0.1(2× 0× 0.1− (−1)) = −0.9
e com i = 1 vem
y2 = 1 + 0.1(2× 0.1× 0.1− 1) = −0.79
Continuando o procedimento obtemos os valores presentes na Tabela 11.1. Nesta mesma tabela também
estão os valores das inclinações em cada ponto.
Tabela 11.1: Aplicação do método de Euler à equação y′ = 2t− y com y(0) = −1.
i ti f(ti, yi) yi
0 0.0 −1.0000000000
1 0.1 1.0000000000 −0.9000000000
2 0.2 1.1000000000 −0.7900000000
3 0.3 1.1900000000 −0.6710000000
4 0.4 1.2710000000 −0.5439000000
5 0.5 1.3439000000 −0.4095100000
6 0.6 1.4095100000 −0.2685590000
7 0.7 1.4685590000 −0.1217031000
8 0.8 1.5217031000 0.0304672100
9 0.9 1.5695327900 0.1874204890
10 1.0 1.6125795110 0.3486784401
Exemplo 52 Considere o problema de valor inicial y′ = 2 e−y
y(0) = 2

11.1. MÉTODO DE EULER 313
1. Obtenha um valor aproximado de y(1) com h = 0.25.
Neste caso, f(t, y) = 2 e−y e os pontos da rede são t0 = 0, t1 = 0.25, t2 = 0.5, t3 = 0.75 e t4 = 1.
Consequentemente, o método de Euler tem a forma
yi+1 = yi + 2he−yi , i = 0, 1, 2, 3.
Ou seja,
y0 = 2
y1 = y0 + 2he−y0 = 2.067667641618306
y2 = y1 + 2he−y1 = 2.130907859446497
y3 = y2 + 2he−y2 = 2.190272587072069
y4 = y3 + 2he−y3 = 2.246215709930091
A tabela de valores correspondente será:
ti 0 0.25 0.5 0.75 1
yi 2 2.067667641618306 2.130907859446497 2.190272587072069 2.246215709930091
2. Sabendo que y(t) é uma função positiva, mostre que o erro do valor calculado para x(1) é inferior a
(e2 − 1)/4.
Aplicando a majoração (11.34) obtém-se
|e4| ≤hK2
2L
(e(t4−t0)L − 1
)Mas y′′(t) = −2e−y(t)y′(t) = −4e−2y(t). Uma vez que y(t) é positiva, |y′′(t)| ≤ 4 = K2. Além disso,∣∣∣∣ ∂∂y (2e−y)
∣∣∣∣ = | − 2e−y| ≤ 2 = L
Por conseguinte,
|e4| ≤0.25× 4
2× 2
(e(1−0)×2 − 1
)=
1
4(e2 − 1) ≈ 1.597264024732663
3. Obtenha os erros absoluto e relativo do valor calculado para x(1).
Contudo, neste caso podemos saber a solução exacta utilizando Matlab. A instrução
exacta = dsolve(’Dy=2*exp(-y)’, ’y(0)=2’)
retorna

314 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
exacta = log(2*t + exp(2))
Os erros absoluto e relativo obtêm-se escrevendo
absoluto = abs(log(2*1 + exp(2)) - 2.246215709930091)
relativo = abs((log(2*1 + exp(2)) - 2.246215709930091)/log(2*1 + exp(2)))
o retorno é
absoluto = 6.670943708206423E-3
relativo = 2.978705230108133E-3
Se fizermos o quociente 0.25(e2 − 1)/6.670943708206423×−3 ≈ 239.4, ou seja, o majorante é cerca
de 239.4 vezes maior do que o erro efectivamente cometido.
Exemplo 53 Considere o problema de valor inicial do exemplo anterior. Para este problema, a solução
exacta é loge(2t + e2), o erro absoluto exacto em ti é |ei| = |yi − loge(2ti + e2)| e o majorante do erro
absoluto em ti é
|ei| ≤hK2
2L
(e(ti−t0)L − 1
)ou seja,
|ei| ≤ h(e2ih − 1
)= Majorante1
Uma vez que sabemos que y′′(t) = −4e−2 loge(2t+e2) podemos determinar um majorante melhor:
Majorante2 = maxt∈[t0;ti]
| − 4e−2 loge(2t+e2)|
= | − 4e−2 loge(2t0+e2)|
= | − 4e−2 loge(e2)|
= 4e−4
= 0.07326255555493672
Considere h = 0.1, então aplicando o método de Euler podemos obter a Tabela 11.2. Observamos que,
neste exemplo, t aumenta, os majorantes dos erros vão sendo cada vez maiores comparativamente com o
valor exacto do erro e são consideravelmente bastante maiores que os erros efectivamente cometidos. Por
conseguinte, o majorante do erro é conservativo. Este comportamento do erro é o mais comum na resolução
deste tipo de problemas.

11.2. MÉTODOS DE TAYLOR DE ORDEM MAIS ELEVADA 315
Tabela 11.2: Aplicação do método de Euler à equação y′ = 2e−y com y(0) = 2.
ti f(ti, yi) yi |ei| = |yi − y((ti)| Majorante2 Majorante1
0.0 – 2 0 0 0
0.1 0.2706705664732 2.027067056647 3.598341154789× 10−4 4.055132967431× 10−4 0.0221402758160
0.2 0.2634425724584 2.053411313893 6.916296535721× 10−4 9.008083558558× 10−4 0.0491824697641
0.3 0.2565929932393 2.079070613217 9.979957202497× 10−4 1.505763107159× 10−3 0.0822118800390
0.4 0.2500927493162 2.104079888148 1.281247361422× 10−3 2.244656508963× 10−3 0.1225540928492
0.5 0.2439156750229 2.128471455651 1.543444608058× 10−3 3.147142947912× 10−3 0.1718281828459
0.6 0.2380381616514 2.152275271816 1.786425567717× 10−3 4.249442373648× 10−3 0.2320116922736
0.7 0.2324388518698 2.175519157003 2.011834583967× 10−3 5.595793932559× 10−3 0.3055199966844
0.8 0.2270983770191 2.198228994705 2.221146291074× 10−3 7.240231440067× 10−3 0.3953032424395
0.9 0.2219991304198 2.220428907747 2.415686237630× 10−3 9.248751947359× 10−3 0.5049647464412
1.0 0.2171250710506 2.242141414852 2.596648630242× 10−3 1.170196443478× 10−2 0.6389056098930
11.2 Métodos de Taylor de ordem mais elevada
Estes métodos obtêm-se fazendo o desenvolvimento em série de Taylor de y em torno do
ponto ti para i = 0, 1, 2, . . . , n − 1. Para a sua obtenção considera-se que existem as derivadas
parciais de f até certa ordem. O método de Euler é o caso mais simples dos métodos de Taylor
porque corresponde ao método de Taylor de ordem 1.
Considere-se o desenvolvimento até à terceira ordem
y(ti+1) = y(ti + h) = y(ti) + hy′(ti) +h2
2!y′′(ti) +
h3
3!y′′′(ξ) (11.16)
Uma vez que y′(ti) = f(ti, y(ti)) vem
y′′(ti) =∂f
∂t(ti, y(ti)) + y′(ti)
∂f
∂y(ti, y(ti))
=∂f
∂t(ti, y(ti)) + f(ti, y(ti))
∂f
∂y(ti, y(ti))
Substituindo esta expressão em (11.16) obtém-se
y(ti+1) = y(ti) + hf(ti, y(ti)) +h2
2!
[∂f
∂t(ti, y(ti)) + f(ti, y(ti))
∂f
∂y(ti, y(ti))
]+h3
3!y′′′(ξ) (11.17)
Por conseguinte, o método de Taylor de ordem 2 é dado por
yi+1 = yi + hf(ti, yi) +h2
2!
[∂f
∂t(ti, yi) + f(ti, yi)
∂f
∂y(ti, yi)
]

316 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
e o erro local de truncatura associado é
e(ti+1) =h3
3!y′′′(ξ)
Se fizermos o desenvolvimento em série de Taylor até à ordem 4 podemos obter o método
de Taylor de ordem 3 e assim sucessivamente.
Para ilustrar este tipo de métodos, considere-se o problema de valor inicial y′ = −2ty2
y(1) = 2
e o desenvolvimento até à quarta ordem
y(ti+1) = y(ti + h) = y(ti) + hy′(ti) +h2
2!y′′(ti) +
h3
3!y′′′(ti) +
h4
4y(4)(ξ) + . . .
As derivadas de y podem obter-se a partir da equação diferencial y′ = −2ty2:
y′ = −2ty2
y′′ = −2(y2 + 2yy′)
y′′′ = −22yy′ + 2[(y′)2 + yy′′]
Por conseguinte, dada uma aproximação yi, um passo h e um ponto ti, a aproximação seguinte
obtém-se através de:
y′i = −2tiy2i
y′′i = −2(y2i + 2yiy′i)
y′′′i = −22yiy′i + 2[(y′i)2 + yiy
′′i ]
yi+1 = yi + hy′i +h2
2!y′′i +
h3
3!y′′′i
Note-se que podemos fazer substituições sucessivas para obter fórmulas para y′′ e y′′′ que não
contenham derivadas de y no lado direito. Contudo, isto não foi necessário porque elas são recur-
sivas.
Os métodos de Taylor têm a vantagem de se conseguirem ordens elevadas. Neste caso,
conseguem-se boas precisões com passos relativamente pequenos. Contudo, há uma grande des-
vantagem. Eles dependem da diferenciação repetida da equação diferencial. A necessidade de
um trabalho analítico prévio é uma desvantagem bastante grande. Por exemplo, se houver um
engano na diferenciação, esse erro vai permanecer e é, por vezes, difícil ser detectado.
Bases: Secção 3.1.

11.2. MÉTODOS DE TAYLOR DE ORDEM MAIS ELEVADA 317
11.2.1 Procedimento
Problema Encontrar uma solução aproximada para um problema de valor inicial da forma (11.1).
Ou seja, com base no problema (11.1), construir a Tabela 11.2.
Hipóteses Assume-se que y ∈ Ck+1([t0; tn]) e que f(t, y) é contínua e tem derivadas parciais
contínuas em ambas as variáveis na região do plano-ty onde a solução passa.
Ferramentas Desenvolvimento em série de Taylor.
Requisitos iniciais Calcular analiticamente as sucessivas derivadas de y. É preciso y0, t0, n e tn.
Determinar h = (tn − t0)/n e construir a rede de pontos t0, t1, . . . tn.
Processo iterativo Dada a aproximação da função no ponto ti, yi, a aproximação no ponto se-
guinte da rede, ti+1, obtém-se calculando
y′i = . . .
y′′i = . . .
y′′′i = . . .
......
y(k)i = . . .
yi+1 = yi + hy′i +h2
2!y′′i +
h3
3!y′′′i + . . .+
hk
k!y(k)i
Condições de paragem O processo pára quando a Tabela 11.2 estiver completamente preenchida,
ou seja, a variável de ciclo i vai desde 0 até n com passo unitário.
Análise do erro No método de Taylor de ordem k retemos os termos da série de Taylor até à
ordem k. Por conseguinte, o erro local de truncatura é a soma dos termos restantes do
desenvolvimento em série de Taylor que não foram incluídos. Pelo teorema de Taylor, estes
termos podem ser comprimidos num único termo da forma
hk+1
(k + 1)!y(k+1)(ξ)
onde ξ ∈ [ti; ti+1]. Neste caso, diz-se que o erro local de truncatura é O(hk).
11.2.2 Exemplos

318 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Exemplo 54 Suponhamos que se pretende obter, através do método de Taylor de ordem 2 e com h = 0.1,
um valor aproximado de y(0.3), sendo y solução do problema
y′ = −t2y − (cos t)2, y(0) = 2
Para isso começa-se por identificar a função f(t, y) = −t2y − (cos t)2 e calculam-se as derivadas
∂f
∂t(t, y) = −2ty + 2 cos t sin t,
∂f
∂y(t, y) = −t2
Por conseguinte,
y′i = −t2i yi − (cos ti)2
y′′i =∂f
∂t(ti, yi) + y′i
∂f
∂y(ti, yi)
= −2tiyi + 2 cos ti sin ti − y′it2i
yi+1 = yi + hy′i +h2
2y′′i
Para aproximar y(0.3) são precisas três iteradas pois t0 = 0, t1 = 0.1, t2 = 0.2 e t3 = 0.3.
• Cálculo da primeira iterada (i=0):
y′0 = −t20y0 − (cos t0)2 = −(02)(2)− (cos(0))2 = −1
y′′0 = −2t0y0 + 2 cos t0 sin t0 − y′0t20
= −2(0)(2) + 2(cos(0))(sin(0))− y′0(02) = 0
y1 = y0 + hy′0 +h2
2y′′0 = 1.9000
• Cálculo da primeira iterada (i=1):
y′1 = −t21y1 − (cos t1)2 = −0.12(1.9)− (cos(0.1))2 = −1.0090
y′′1 = −2t1y1 + 2 cos t1 sin t1 − y′1t21
= −2(0.1)(1.9) + 2(cos(0.1))(sin(0.1))− y′1(0.1)2 = 0.1730
y2 = y1 + hy′1 +h2
2y′′1 = 1.79996
• Cálculo da primeira iterada (i=2):
y′2 = −t21y1 − (cos t1)2 = −0.22(1.79996)− (cos(0.2))2 = −1.0325
y′′2 = −2t1y1 + 2 cos t1 sin t1 − y′1t21
= −2(0.2)(1.79996) + 2(cos(0.2))(sin(0.2))− y′2(0.2)2 = 0.3013
y3 = y2 + hy′2 +h2
2y′′2 = 1.69822

11.3. MÉTODO DE HEUN 319
11.3 Método de Heun
O método dos trapézios em integração numérica, [f(a) + f(b)](b− a)/2, é muito melhor que
o método que usa apenas o extremo esquerdo do intervalo como nó de integração, f(a)(b − a),
porque utiliza o valor da função em dois pontos em vez de um. De modo semelhante, o método
de Euler usa apenas o valor da inclinação no extremo esquerdo do intervalo [ti; ti+1], enquanto
que o método de Heun utiliza o valor da inclinação em ambos os extremos deste intervalo para
encontrar a inclinação média. O nome Heun lê-se "óin".
Bases: Secções 3.1 e 11.1.
11.3.1 Teoria
Sejam K0 = f(ti, yi) e K1 = f(ti+1, yi+1) as inclinações aproximadas nos pontos ti e ti+1, res-
pectivamente; a inclinação K0 = f(t0, y0) não é uma aproximação, ou seja, a primeira inclinação
é exacta. Se a variação da inclinação for aproximadamente linear no intervalo [ti; ti+1], então po-
demos utilizar (K0 +K1)/2 como um valor razoável para a média das inclinações neste intervalo.
Consequentemente,
yi+1 = yi +h
2(K0 +K1)
que é uma equação implícita em relação a yi+1. Sendo assim, utilizamos o método de Euler para
aproximar yi+1 no lado direito da equação e obtemos
yi+1 = yi +h
2[f(ti, yi) + f(ti+1, yi+1)]
ou seja,
yi+1 = yi +h
2[f(ti, yi) + f(ti + h, yi + hf(ti, yi))] (11.18)
Este método é denominado por método de Heun.
Para observar graficamente o comportamento do método, considere-se o problema de valor
inicial y′ = y/2− t+ 1
y(0) = 0.5
Na Figura 11.6 podemos observar a aproximação de y(1) através do método de Euler, isto é,
seguindo a inclinação K0 = f(t0, y0) = 1.25 obtemos y(1) ≈ y1 = 0.5 + 1× 1.25 = 1.75.
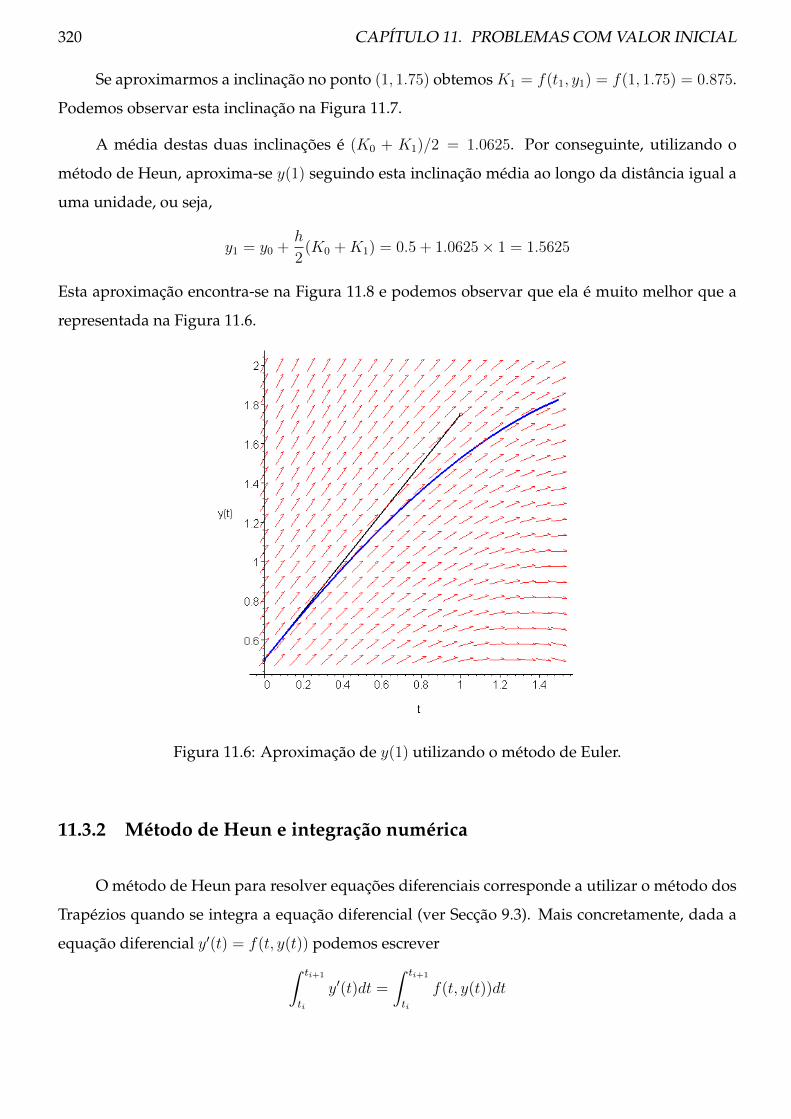
320 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Se aproximarmos a inclinação no ponto (1, 1.75) obtemos K1 = f(t1, y1) = f(1, 1.75) = 0.875.
Podemos observar esta inclinação na Figura 11.7.
A média destas duas inclinações é (K0 + K1)/2 = 1.0625. Por conseguinte, utilizando o
método de Heun, aproxima-se y(1) seguindo esta inclinação média ao longo da distância igual a
uma unidade, ou seja,
y1 = y0 +h
2(K0 +K1) = 0.5 + 1.0625× 1 = 1.5625
Esta aproximação encontra-se na Figura 11.8 e podemos observar que ela é muito melhor que a
representada na Figura 11.6.
Figura 11.6: Aproximação de y(1) utilizando o método de Euler.
11.3.2 Método de Heun e integração numérica
O método de Heun para resolver equações diferenciais corresponde a utilizar o método dos
Trapézios quando se integra a equação diferencial (ver Secção 9.3). Mais concretamente, dada a
equação diferencial y′(t) = f(t, y(t)) podemos escrever∫ ti+1
ti
y′(t)dt =
∫ ti+1
ti
f(t, y(t))dt
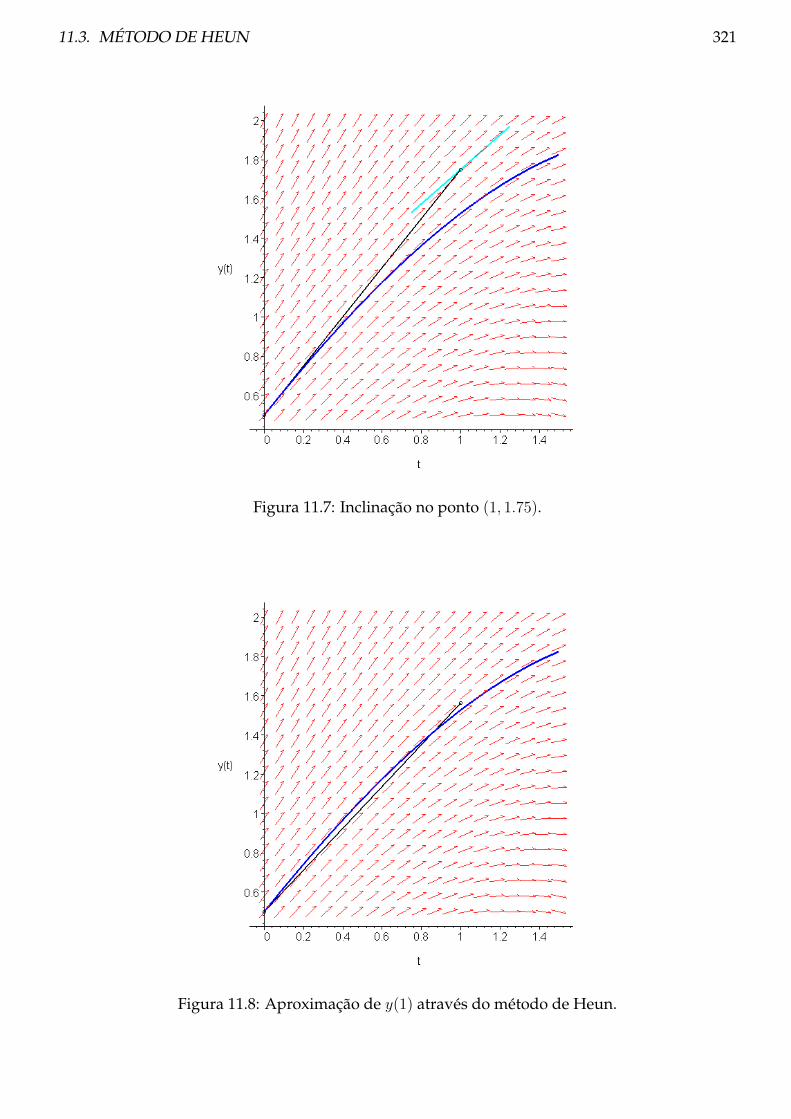
11.3. MÉTODO DE HEUN 321
Figura 11.7: Inclinação no ponto (1, 1.75).
Figura 11.8: Aproximação de y(1) através do método de Heun.

322 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
ou seja,
y(ti+1)− y(ti) =
∫ ti+1
ti
f(t, y(t))dt
Consequentemente,
y(ti+1) = y(ti) +
∫ ti+1
ti
f(t, y(t))dt
Para resolver o integral do lado direito desta equação, aproxima-se a função integranda pelo
polinómio interpolador de grau menor ou igual a um que coincide com a função nos extremos do
intervalo [ti; ti+1]. Ou seja, aplicamos o método dos Trapézios, apresentado na Secção 9.3 e vem
y(ti+1) = y(ti) +h
2[f(ti, y(ti)) + f(ti+1, y(ti+1))]−
h3
12
d2f
dt2(ξ, y(ξ)), ξ ∈ [ti; ti+1]
Uma vez que dfdt
(ξ, y(ξ)) = y′′′(ξ) vem
y(ti+1) = y(ti) +h
2[f(ti, y(ti)) + f(ti+1, y(ti+1))]−
h3
12y′′′(ξ), ξ ∈ [ti; ti+1]
onde se assume y′′′ ∈ C[ti; ti+1], ou seja y ∈ C3[ti; ti+1]. Daqui resulta o método de Heun dado por
(11.18) com o erro dado por
e(ti+1) = −h3
12y′′′(ξ), ξ ∈ [ti; ti+1] (11.19)
11.3.3 Procedimento
Problema Encontrar uma solução aproximada para um problema de valor inicial da forma (11.1).
Ou seja, com base no problema (11.1), construir a Tabela 11.2.
Hipóteses Assume-se que y ∈ C3([t0; tn]) e que f(t, y) é contínua em ambas as variáveis na região
onde a solução passa no plano-ty.
Ferramentas Desenvolvimento em série de Taylor.
Requisitos iniciais Sejam y0, t0, n e tn. É preciso calcular h = (tn − t0)/n e construir a rede de
pontos t0, t1, . . . tn.
Processo iterativo Dada a aproximação da função no ponto ti, yi, a aproximação no ponto se-
guinte da rede, ti+1, obtém-se calculando
K0 = f(ti, yi)
K1 = f(ti + h, yi + hK0)
yi+1 = yi +h
2(K0 +K1)

11.3. MÉTODO DE HEUN 323
Condições de paragem O processo pára quando a Tabela 11.2 estiver completamente preenchida,
ou seja, a variável de ciclo i vai desde 0 até n com passo unitário.
Análise do erro O erro de truncatura no método de Heun é dado por (11.19). Consequentemente,
o erro é O(h3). Esta fórmula do erro pode também obter-se através do desenvolvimento em
série de Taylor. Considere o problema de valor inicial y′ = f(t, y)
y(t0) = y0
e o desenvolvimento em série de Taylor de y(ti + h) em torno do ponto ti:
y(ti + h) = y(ti) + hy′(ti) +h2
2y′′(ti) +
h3
3!y′′′(ξ) (11.20)
A segunda derivada pode ser aproximada pela fórmula das diferenças divididas para a
frente (ver (10.8)) aplicada à primeira derivada de y:
y′′(ti) =y′(ti + h)− y′(ti)
h− h
2y′′′(ξ) (11.21)
Seja K0 = y′(ti) = f(ti, yi) e
K1 = y′(ti + h)
= f(ti + h, y(ti + h))
= f(ti + h, y(ti) + hy′(ti) + y′′(ξ)h/2))
= f(ti + h, y(ti) + hf(ti, yi) + y′′(ξ)h/2))
= f(ti + h, y(ti) + hK0 + y′′(ξ)h/2))
≈ f(ti + h, y(ti) + hK0)
então, podemos reescrever (11.21) na forma
y′′(ti) ≈K1 −K0
h− h
2y′′′(ξ)
Substituindo esta aproximação em (11.20) obtém-se
y(ti + h) ≈ y(ti) + hK0 +h2
2[K1 −K0
h− h
2y′′′(ξ)] +
h3
3!y′′′(τ)
ou seja,
y(ti + h) ≈ y(ti) + hK0 +h
2(K1 −K0)−
h3
4y′′′(ξ) +
h3
6y′′′(τ)
isto é,
y(ti + h) ≈ y(ti) + hK0 +h
2(K1 −K0)−
h3
12y′′′(ρ)
Consequentemente, o erro no método de Heun é dado por (11.19).

324 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
11.3.4 Exemplos
Considere-se o problema de valor inicialy′(t)t2
= cos(y(t)/t2)
y(2) = 1
no intervalo [2; 3]. Este problema pode ser escrito na forma y′ = t2 cos(y/t2)
y(2) = 1
Pretende-se aproximar y(2.2) com h = 0.1. A função f tem a forma f(t, y) = t2 cos(y/t2) e,
por conseguinte, o método de Heun é dado por
K0 = t2i cos(yi/t2i )
K1 = f(ti + h, yi + hK0)
yi+1 = yi +h
2(K0 +K1)
Uma vez que t0 = 2 e pretende-se aproximar a função no ponto t = 2.2, é preciso calcular duas
iteradas; note-se que t1 = 2.1 e t2 = 2.2.
• Cálculo da primeira iterada:
K0 = t20 cos(y0/t20) = 3.875649686842579
K1 = f(t0 + h, y0 + hK0) = f(2.1, 1.387564968684258) = 4.193502828980769
y1 = y0 +h
2(K0 +K1) = 1.403457625791168
• Cálculo da segunda iterada:
K0 = t21 cos(y1/t21) = 4.188557233124479
K1 = f(t1 + h, y1 + hK0) = f(2.2, 1.822313349103615) = 4.500973070853419
y2 = y1 +h
2(K0 +K1) = 1.837934140990063

11.4. MÉTODOS DE RUNGE-KUTTA 325
11.4 Métodos de Runge-Kutta
Os métodos de Taylor têm a desvantagem de precisar do cálculo analítico das derivadas
parciais de f e da sua respectiva programação. Os métodos de Runge Kutta conseguem evitar
esta desvantagem e produzir valores yi com a mesma precisão, que os métodos de Taylor. Em
vez do cálculo das derivadas, os métodos de Runge-Kutta utilizam combinações inteligentes de
valores de f(t, y). Os métodos de Runge-Kutta mais simples são os de ordem 2.
Considere-se o desenvolvimento em série (11.17):
y(ti+1) = y(ti) + hf(ti, y(ti)) +h2
2!
[∂f
∂t(ti, y(ti)) + f(ti, y(ti))
∂f
∂y(ti, y(ti))
]+h3
3!y′′′(ξ)
Esta equação pode ser escrita na forma
y(ti+1) = y(ti) +h
2f(ti, y(ti)) +
h
2
[f(ti, y(ti)) + h
∂f
∂t(ti, y(ti)) + hf(ti, y(ti))
∂f
∂y(ti, y(ti))
]+h3
3!y′′′(ξ)
(11.22)
Por outro lado, utilizando o desenvolvimento em série de Taylor em duas variáveis, pode-
mos escrever
f(ti + h, yi + hf(ti, yi)) = f(ti, yi) + +h∂f
∂t(ti, y(ti)) + hf(ti, y(ti))
∂f
∂y(ti, y(ti)) +O(h2)
Comparando esta equação com (11.22) segue que
y(ti+1) = y(ti) +h
2f(ti, y(ti)) +
h
2f(ti + h, yi + hf(ti, yi)) +O(h3) (11.23)
O método numérico correspondente é um dos métodos de Runge-Kutta de ordem 2 e a sua fór-
mula é:
yi+1 = yi +h
2[f(ti, yi) + f(ti + h, yi + hf(ti, yi))]
Este método também é conhecido pelo método de Heun dado na equação (11.18).
Em geral, os métodos de Runges-Kutta são dados a partir de
y(ti + h) = y(ti) + ahf(ti, y(ti)) + bhf(ti + αh, yi + βhf(ti, yi)) +O(h3) (11.24)
onde a, b, α, e β são parâmetros que podem ser escolhidos. Esta equação pode ser reescrita com a
ajuda do desenvolvimento em série em duas variáveis como
y(ti+h) = y(ti)+ahf(ti, y(ti))+bh
[f(ti, y(ti)) + αh
∂f
∂t(ti, y(ti)) + βhf(ti, y(ti))
∂f
∂y(ti, y(ti))
]+O(h3)
(11.25)

326 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Comparando a equação (11.25) com a equação (11.22) podemos impor as seguintes condições:
a+ b = 1
bα = 1/2
bβ = 1/2
Uma possível solução é a = b = 1/2 e α = β = 1 que é a solução correspondente ao método de
Heun da equação (11.18). Outra possível solução é a = 0, b = 1 e α = β = 1/2. O método resul-
tante é o método do ponto médio, também por vezes denominado método de Euler modificado:
yi+1 = yi + hf(ti +h
2, yi +
h
2f(ti, yi)) (11.26)
O método de Runge-Kutta clássico de ordem 4, para resolver problemas de valor inicial, está
para o método de Heun assim como o método de Simpson está para o método dos Trapézios. Este
método tem em conta a inclinação nos pontos intermédios assim como nos extremos com vista a
encontrar uma boa média da inclinação ao longo do intervalo.
Bases: Secções 3.1 e 11.3.
11.4.1 Teoria
Um método frequentemente utilizado é o método de Runge-Kutta clássico de ordem 4. A
obtenção das fórmulas para este método é bastante trabalhosa. Contudo, uma vez obtidas, podem
ser facilmente implementadas numa linguagem de programação. Diz-se que é de ordem 4 porque
reproduz os termos da série de Taylor até à ordem 4 inclusive. Consequentemente, o erro local de
truncatura é O(h5).
O método de Runge-Kutta é dado por
K0 = f(ti, yi) (11.27)
K1 = f(ti +h
2, yi +
h
2K0)
K2 = f(ti +h
2, yi +
h
2K1)
K3 = f(ti + h, yi + hK2)
yi+1 = yi +h
6(K0 + 2K1 + 2K2 +K3) (11.28)

11.4. MÉTODOS DE RUNGE-KUTTA 327
Na fórmula deste método podemos observar a média ponderada de quatro valores K0, K1, K2 e
K3, onde K0 e K3 têm o peso 1 e K1 e K2 têm o peso 2. O valor K0 é simplesmente o valor da
inclinação em (ti, yi) e é dado por
K0 = f(ti, yi)
K1 é o valor da inclinação da função y no ponto médio do intervalo [ti; ti+1], ti + h/2:
f(ti +h
2, y(ti +
h
2)) = f(ti +
h
2, y(ti) +
h
2f(ti, y(ti)) + ...)
≈ f(ti +h
2, yi +
h
2f(ti, yi))
≈ f(ti +h
2, yi +
h
2K0)
Consequentemente,
K1 = f(ti +h
2, yi +
h
2K0)
dá-nos uma estimativa da inclinação da solução no ponto médio ti + h/2. Esta aproximação da
inclinação em ti + h/2 utiliza a inclinação em ti que é K0. O valor
K2 = f(ti +h
2, yi +
h
2K1)
utiliza K1 para estimar a inclinação em ti + h/2:
f(ti +h
2, y(ti +
h
2)) ≈ f(ti +
h
2, yi +
h
2K1)
Esta fórmula é muito parecida com K1 com a diferença que onde aparece K0 agora surge K1.
Essencialmente, o valor de f aqui calculado é outra estimativa da inclinação da solução no ponto
médio do intervalo.
O quarto valor
K3 = f(ti + h, yi + hK2)
é uma estimativa do valor da inclinação em ti + h:
f(ti + h, y(ti + h)) ≈ f(ti + h, yi + hK2)
yi + hK2 é uma estimativa do valor de y no extremo direito do intervalo, com base no salto de y
previsto por hK3.
Em resumo, cada uma das quantidades hKj’s dá-nos uma estimativa do tamanho do salto
de y dado pela solução actual ao longo de todo o intervalo [ti; ti+1]. O primeiro usa o método de
Euler, os dois seguintes usam estimativas da inclinação da solução no ponto médio do intervalo e
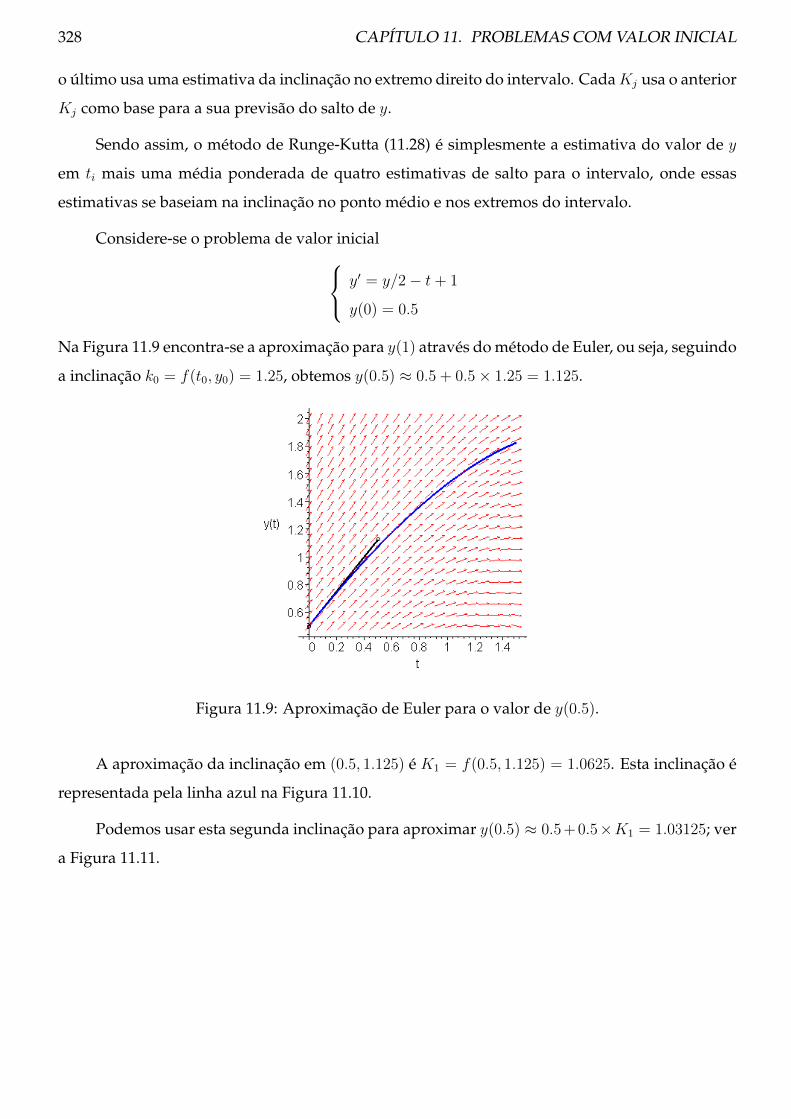
328 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
o último usa uma estimativa da inclinação no extremo direito do intervalo. CadaKj usa o anterior
Kj como base para a sua previsão do salto de y.
Sendo assim, o método de Runge-Kutta (11.28) é simplesmente a estimativa do valor de y
em ti mais uma média ponderada de quatro estimativas de salto para o intervalo, onde essas
estimativas se baseiam na inclinação no ponto médio e nos extremos do intervalo.
Considere-se o problema de valor inicial y′ = y/2− t+ 1
y(0) = 0.5
Na Figura 11.9 encontra-se a aproximação para y(1) através do método de Euler, ou seja, seguindo
a inclinação k0 = f(t0, y0) = 1.25, obtemos y(0.5) ≈ 0.5 + 0.5× 1.25 = 1.125.
Figura 11.9: Aproximação de Euler para o valor de y(0.5).
A aproximação da inclinação em (0.5, 1.125) é K1 = f(0.5, 1.125) = 1.0625. Esta inclinação é
representada pela linha azul na Figura 11.10.
Podemos usar esta segunda inclinação para aproximar y(0.5) ≈ 0.5 + 0.5×K1 = 1.03125; ver
a Figura 11.11.
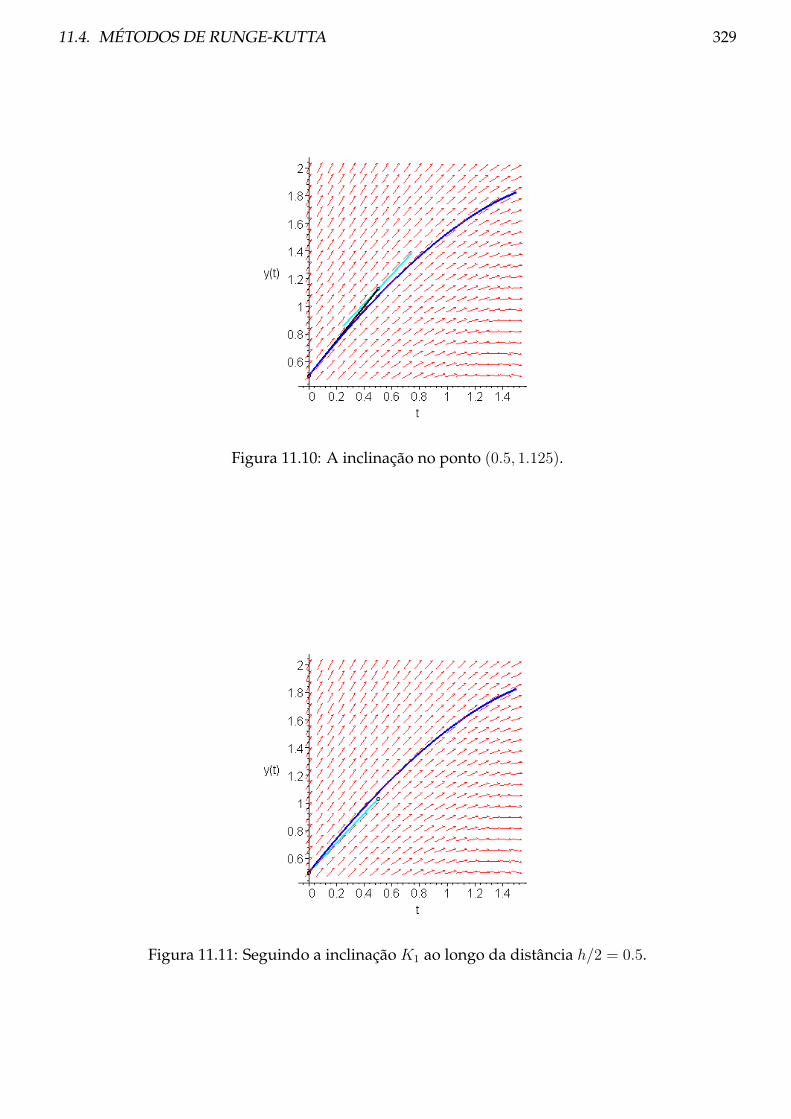
11.4. MÉTODOS DE RUNGE-KUTTA 329
Figura 11.10: A inclinação no ponto (0.5, 1.125).
Figura 11.11: Seguindo a inclinação K1 ao longo da distância h/2 = 0.5.
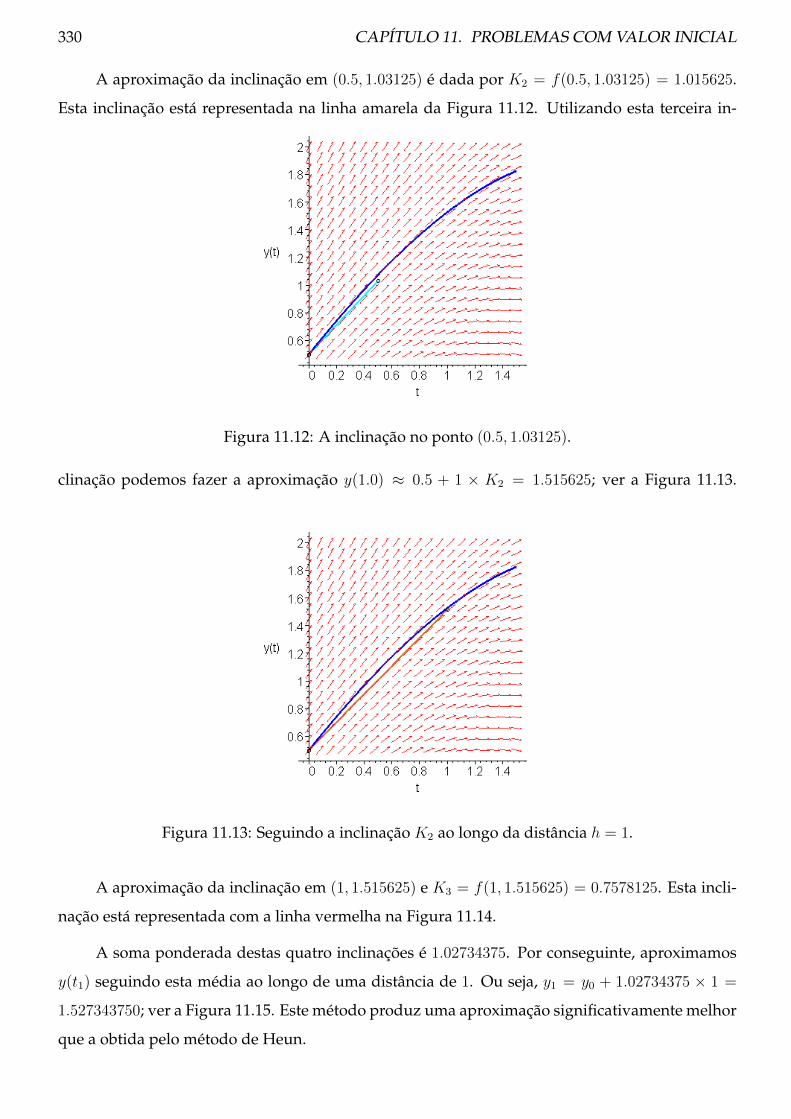
330 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
A aproximação da inclinação em (0.5, 1.03125) é dada por K2 = f(0.5, 1.03125) = 1.015625.
Esta inclinação está representada na linha amarela da Figura 11.12. Utilizando esta terceira in-
Figura 11.12: A inclinação no ponto (0.5, 1.03125).
clinação podemos fazer a aproximação y(1.0) ≈ 0.5 + 1 × K2 = 1.515625; ver a Figura 11.13.
Figura 11.13: Seguindo a inclinação K2 ao longo da distância h = 1.
A aproximação da inclinação em (1, 1.515625) e K3 = f(1, 1.515625) = 0.7578125. Esta incli-
nação está representada com a linha vermelha na Figura 11.14.
A soma ponderada destas quatro inclinações é 1.02734375. Por conseguinte, aproximamos
y(t1) seguindo esta média ao longo de uma distância de 1. Ou seja, y1 = y0 + 1.02734375 × 1 =
1.527343750; ver a Figura 11.15. Este método produz uma aproximação significativamente melhor
que a obtida pelo método de Heun.
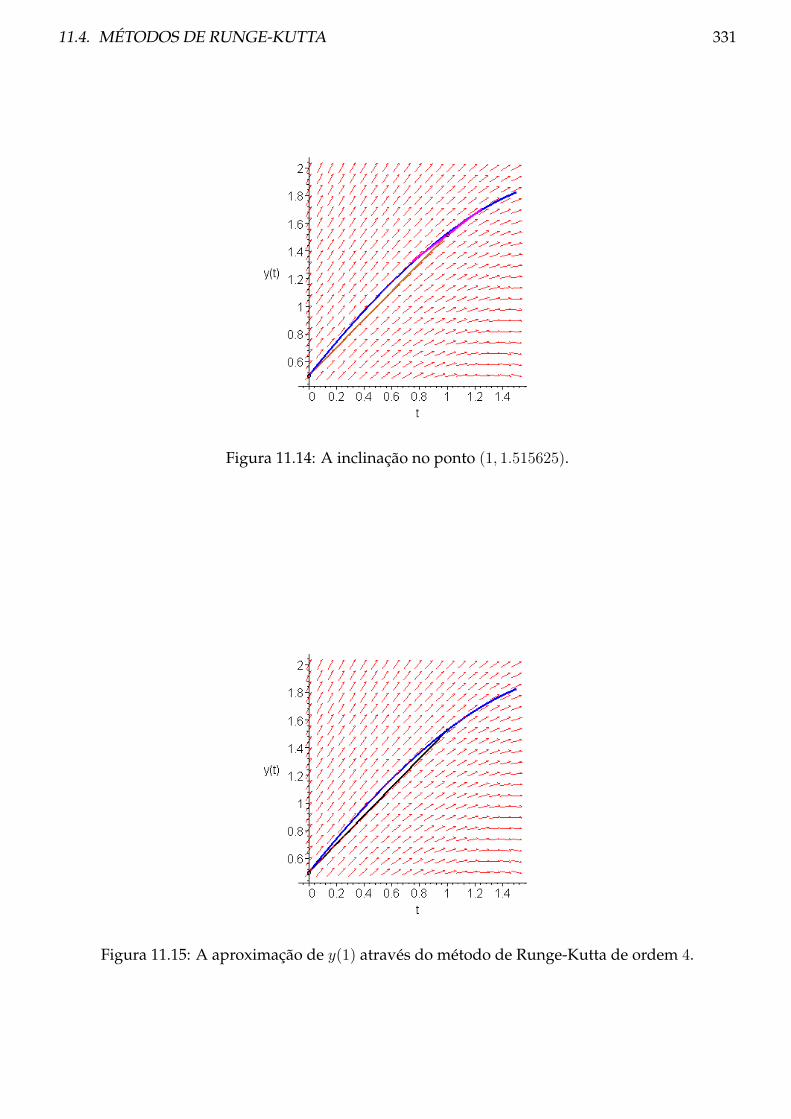
11.4. MÉTODOS DE RUNGE-KUTTA 331
Figura 11.14: A inclinação no ponto (1, 1.515625).
Figura 11.15: A aproximação de y(1) através do método de Runge-Kutta de ordem 4.

332 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
O principal esforço computacional dos métodos de Runge-Kutta é o cálculo da função f .
Nos métodos de Runge-Kutta de segunda ordem o erro é O(h2) e o custo é calcular duas vezes
a função f em cada iteração ou passo. O método de Runge-Kutta de quarta ordem envolve, em
cada passo, o cálculo de quatro vezes a função f e o erro local de truncatura éO(h4). Como mostra
a tabela seguinte, o número de cálculos da função f cresce mais rapidamente que a ordem do
método de Runge-Kutta. Consequentemente, é mais frequente, as pessoas utilizarem um método
de ordem menor que cinco com um passo mais pequeno do que um método de ordem elevada
com um passo grande.
Número de cálculos da função f 1 2 3 4 5 6 7 8 9 10 11 12 . . .
Ordem máxima do método de Runge-Kutta 1 2 3 4 4 5 6 6 7 7 8 9 . . .
Observa-se que, se n for o número de cálculos da função f , então a ordem máxima do mé-
todo de Runge-Kutta é igual a:
• n, se 1 ≤ n ≤ 4;
• n− 1, se 5 ≤ n ≤ 7;
• n− 2, se 8 ≤ n ≤ 9;
• n− 3, se n ≥ 10.
Ou seja, os métodos de Runge-Kutta de ordens elevadas são menos atractivos que o método de
Runge-Kutta de ordem 4 porque são mais dispendiosos do ponto de vista computacional.
11.4.2 Método do ponto médio e integração numérica
O método do ponto médio para resolver equações diferenciais corresponde a utilizar o mé-
todo do ponto médio quando se integra a equação diferencial (ver Secção 9.2). Mais concreta-
mente, dada a equação diferencial y′(t) = f(t, y(t)) podemos escrever∫ ti+1
ti
y′(t)dt =
∫ ti+1
ti
f(t, y(t))dt
ou seja,
y(ti+1) = y(ti) +
∫ ti+1
ti
f(t, y(t))dt (11.29)

11.4. MÉTODOS DE RUNGE-KUTTA 333
Para resolver o integral do lado direito desta equação, aproxima-se a função integranda pelo
polinómio interpolador de grau zero que coincide com a função no ponto médio do intervalo
[ti; ti+1]. Ou seja, aplicamos o método do ponto médio, apresentado na Secção 9.2 e vem
y(ti+1) = y(ti) + hf(ti + ti+1
2, y(
ti + ti+1
2)) +
h3
24
d2f
dt2(ξ, y(ξ)), ξ ∈ [ti; ti+1]
Uma vez que dfdt
(ξ, y(ξ)) = y′(ξ) vem
y(ti+1) = y(ti) + hf(ti + ti+1
2, y(
ti + ti+1
2)) +
h3
24y′′′(ξ), ξ ∈ [ti; ti+1]
onde se assume y′′′ ∈ C[ti; ti+1], ou seja y ∈ C3[ti; ti+1]. Daqui resulta o método do ponto médio
dado por (11.26) com o erro dado por
e(ti+1) =h3
24y′′′(ξ), ξ ∈ [ti; ti+1] (11.30)
11.4.3 Método de Runge-Kutta de ordem 4 e integração numérica
Considere a equação (11.29):
y(ti+1) = y(ti) +
∫ ti+1
ti
f(t, y(t))dt
Podemos aproximar o integral do lado desta equação utilizando o método de Simpson e obtemos
y(ti+1) = y(ti) +h
6[f(ti, y(ti)) + 4f(
ti + ti+1
2, y(
ti + ti+1
2)) + f(ti+1, y(ti+1))]−
h5
2880
d4f
dt4(ξ, y(ξ))
onde ξ ∈ [ti; ti+1]. Uma vez que dfdt
(ξ, y(ξ)) = y′(ξ) vem
y(ti+1) = y(ti) +h
6[f(ti, y(ti)) + 4f(
ti + ti+1
2, y(
ti + ti+1
2)) + f(ti+1, y(ti+1))]−
h5
2880y(5)(ξ)
com ξ ∈ [ti; ti+1] e onde se assume y(5) ∈ C[ti; ti+1], ou seja y ∈ C5[ti; ti+1].
Podemos escolher K0 ≈ f(ti, y(ti)), K3 ≈ f(ti+1, y(ti+1) e f( ti+ti+1
2, y( ti+ti+1
2)) como sendo a
média aproximada entreK1 eK2. Com esta escolha, podemos entender o método de Runge-Kutta
de ordem 4 como resultante da aplicação do método de Simpson ao integral em (11.29).
11.4.4 Procedimento
Problema Encontrar uma solução aproximada para um problema de valor inicial da forma (11.1).
Ou seja, com base no problema (11.1), construir a Tabela 11.2.

334 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Hipóteses Assume-se que f(t, y) é contínua em ambas as variáveis na região onde a solução
passa no plano-ty.
Ferramentas Desenvolvimento em série de Taylor.
Requisitos iniciais Sejam y0, t0, n e tn. É preciso calcular h = (tn − t0)/n e construir a rede de
pontos t0, t1, . . . tn.
Processo iterativo Dada a aproximação da função no ponto ti, yi, seja
K0 = f(ti, yi) (11.31)
K1 = f(ti +h
2, yi +
h
2K0)
K2 = f(ti +h
2, yi +
h
2K1)
K3 = f(ti + h, yi + hK2)
a aproximação no ponto seguinte da rede, ti+1, obtém-se através de (11.28):
yi+1 = yi +h
6(K0 + 2K1 + 2K2 +K3)
Condições de paragem O processo pára quando a Tabela 11.2 estiver completamente preenchida,
ou seja, a variável de ciclo i vai desde 0 até n− 1 com passo unitário.
Análise do erro Vimos anteriormente que os erros nos métodos de Heun e do ponto médio são
dados por (11.19) e (11.30), respectivamente. Pode demonstrar-se que o erro associado ao
método de Runge-Kutta clássico de ordem 4 é um O(h5).
O erro local de truncatura é o erro que surge em cada passo do algoritmo porque nenhum
método tem em conta todos os termos do desenvolvimento em série de Taylor. Não é possí-
vel fugir a este erro e estará presente mesmo que não existam erros de arredondamento. No
caso do método de Runge-Kutta de ordem 4, temos um erro local de truncatura de O(h5).
Considere-se um problema de valor inicial no intervalo [a; b]; neste caso, t0 = a e tn = b. Seja
yh a solução aproximada no ponto b de através do método de Runge-Kutta de ordem 4. A
solução exacta no ponto b representa-se por y(b). Se h = b − a, o erro local de truncatura é
y(b) − yh. Este erro comporta-se como Ch5 para valores pequenos de h. A constante C não
depende de h, mas depende de t0 e da solução exacta y(t). Para estimar Ch5 assumimos
que C não se altera à medida que t varia entre t0 e t0 + h. Seja yh o valor aproximado em b,
obtido com um único passo a partir de a, e seja yh/2 o valor aproximado em b, obtido com

11.4. MÉTODOS DE RUNGE-KUTTA 335
dois passos de comprimento h/2 a partir de a. Então,
y(b) = yh + Ch5
y(b) = yh/2 + 2C(h/2)5
Subtraindo estas duas equações obtemos:
Erro local de truncatura = Ch5 =yh/2 − yh
1− 2−4
Consequentemente, o erro local de truncatura é aproximadamente yh/2 − yh.
Na implementação do método de Runge-Kutta podemos controlar o erro de truncatura
aproximado através do cálculo de
|yh/2 − yh| (11.32)
e garantir que este valor absoluto não ultrapassa um determinado valor. Podemos reduzir
o valor de h até que (11.32) seja suficientemente pequeno.
11.4.5 Exemplos
Exemplo 55 Considere o problema de valor inicial y′(t) = t2 cos(y(t)/t2)
y(2) = 1
Para h = 1 podemos obter uma estimativa de y(3) calculando uma iterada pelo método de Runge-Kutta de
ordem 4 (11.28). Neste caso, temos f(t, y) = t2 cos(y/t2) e, por conseguinte,
K0 = f(t0, y0) = f(2, 1) = 3.875649686842579
K1 = f(t0 +h
2, y0 +
h
2K0) = f(2.5, 2.937824843421289) = 5.572154676563980
K2 = f(t0 +h
2, y0 +
h
2K1) = f(2.5, 3.786077338281990) = 5.137890970177236
K3 = f(t0 + h, y0 + hK2) = f(3, 6.137890970177236) = 6.986890931666537
y1 = y0 +h
6(K0 + 2K1 + 2K2 +K3) = 6.380438651998591
Se considerarmos h = 0.5 temos de fazer duas iterações do método.

336 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
• Cálculo da primeira iterada:
K0 = f(t0, y0) = 3.875649686842579
K1 = f(t0 +h
2, y0 +
h
2K0) = 4.684426198273562
K2 = f(t0 +h
2, y0 +
h
2K1) = 4.604040818524450
K3 = f(t0 + h, y0 + hK2) = 5.397834390353197
y1 = y0 +h
6(K0 + 2K1 + 2K2 +K3) = 3.320868175899317
• Cálculo da segunda iterada:
K0 = f(t1, y1) = 5.388308966520134
K1 = f(t1 +h
2, y1 +
h
2K0) = 6.167020716512877
K2 = f(t1 +h
2, y1 +
h
2K1) = 6.052311482492611
K3 = f(t1 + h, y1 + hK2) = 6.853192225771950
y2 = y1 +h
6(K0 + 2K1 + 2K2 +K3) = 6.377548641757905
Exemplo 56 Considere o problema de valor inicial y′(t) = t2/y(t)
y(1) = −1
que tem como solução exacta
y(t) = −[2
(t3
3+
1
6
)]1/2A função f associada a este problema é f(t, y) = t2/y.
11.5 Erros local e global
Surgem vários tipos de erro quando de resolve numericamente uma equação diferencial:
• erro local de truncatura;
• erro local de arredondamento;
• erro global de truncatura;
• erro global de arredondamento; e

11.5. ERROS LOCAL E GLOBAL 337
• erro total.
O erro local de truncatura é o erro cometido em cada passo do algoritmo quando substituímos um
processo infinito por um finito. No método de Euler, substituímos uma série de Taylor infinita
para y(ti + h) por uma soma parcial. O erro local de truncatura é inerente a qualquer algoritmo
que possamos escolher e é bastante independente do erro de arredondamento. O erro de arre-
dondamento é devido à precisão limitada dos computadores e a sua ordem de grandeza depende
da unidade de arredondamento da máquina (ou do número de bits na mantissa permitida para
representar os números em vírgula flutuante no nosso computador).
No método de Euler retemos os termos da série de Taylor até à primeira ordem. Por conse-
guinte, o erro local de truncatura é soma dos termos restantes do desenvolvimento em série de
Taylor que não foram incluídos. Pelo teorema de Taylor, estes termos podem ser comprimidos
num único termo da formah2
2y′′(ξ) (11.33)
onde ξ ∈ [ti; ti+1]. Neste caso, diz-se que o erro local de truncatura é O(h2). Em cada iterada co-
metemos um erro desta ordem de grandeza. A acumulação de todos os erros locais de truncatura
dá o erro global de truncatura. Este erro está sempre presente mesmo que não existam erros de ar-
redondamento, ou seja, mesmo se os cálculos tenham sido feitos com aritmética exacta. Este erro
está associado ao método numérico e não depende da máquina onde são efectuados os cálculos.
Se o erro local de truncatura é O(h2), então o erro global de truncatura tem de ser O(h) porque o
número de passos até um ponto tn começando em t0 é (tn − t0)/h.
O erro global de arredondamento é a acumulação dos erros locais de arredondamento nos pas-
sos anteriores. O erro total é a soma do erro global de truncatura e do erro global de arredonda-
mento.
Se o erro global de truncatura é O(hp) então diz-se que o método numérico é de ordem p.
Consequentemente, o método de Euler é de ordem 1.
No caso do método de Euler tém-se
|en| ≤hK2
2L
(enhL − 1
)+ |e0|enhL
onde L e K2 são tais que ∣∣∣∣ ∂∂yf(t, y)
∣∣∣∣ ≤ L, |y′′(t)| ≤ K2;
ver as equações (11.13) e (11.8). Como e0 = 0, obtém-se
|en| ≤hK2
2L
(enhL − 1
)≤ hK2
2L
(eL(b−a) − 1
)(11.34)
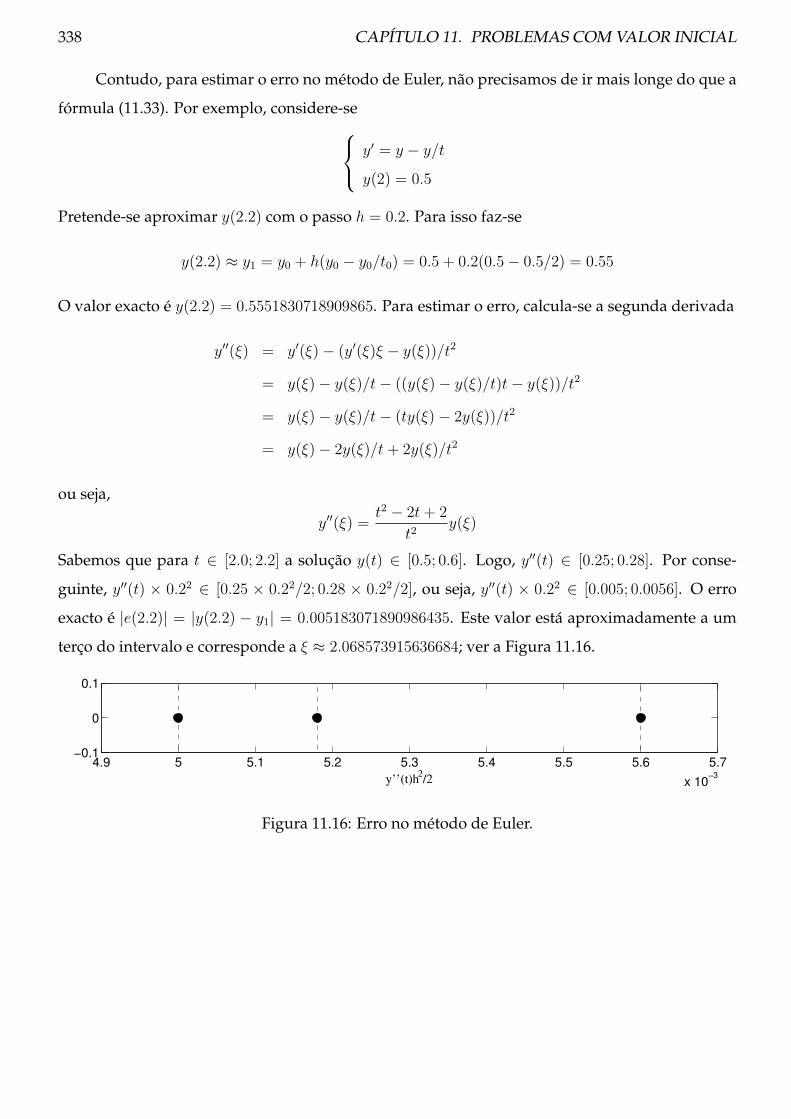
338 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Contudo, para estimar o erro no método de Euler, não precisamos de ir mais longe do que a
fórmula (11.33). Por exemplo, considere-se y′ = y − y/t
y(2) = 0.5
Pretende-se aproximar y(2.2) com o passo h = 0.2. Para isso faz-se
y(2.2) ≈ y1 = y0 + h(y0 − y0/t0) = 0.5 + 0.2(0.5− 0.5/2) = 0.55
O valor exacto é y(2.2) = 0.5551830718909865. Para estimar o erro, calcula-se a segunda derivada
y′′(ξ) = y′(ξ)− (y′(ξ)ξ − y(ξ))/t2
= y(ξ)− y(ξ)/t− ((y(ξ)− y(ξ)/t)t− y(ξ))/t2
= y(ξ)− y(ξ)/t− (ty(ξ)− 2y(ξ))/t2
= y(ξ)− 2y(ξ)/t+ 2y(ξ)/t2
ou seja,
y′′(ξ) =t2 − 2t+ 2
t2y(ξ)
Sabemos que para t ∈ [2.0; 2.2] a solução y(t) ∈ [0.5; 0.6]. Logo, y′′(t) ∈ [0.25; 0.28]. Por conse-
guinte, y′′(t) × 0.22 ∈ [0.25 × 0.22/2; 0.28 × 0.22/2], ou seja, y′′(t) × 0.22 ∈ [0.005; 0.0056]. O erro
exacto é |e(2.2)| = |y(2.2) − y1| = 0.005183071890986435. Este valor está aproximadamente a um
terço do intervalo e corresponde a ξ ≈ 2.068573915636684; ver a Figura 11.16.
4.9 5 5.1 5.2 5.3 5.4 5.5 5.6 5.7
x 10−3
−0.1
0
0.1
y’’(t)h2/2
Figura 11.16: Erro no método de Euler.

11.6. SISTEMAS DE PROBLEMAS DE VALOR INICIAL 339
11.6 Sistemas de problemas de valor inicial
Os métodos desenvolvidos nas secções anteriores podem ser extendidos para resolver pro-
blemas de valor inicial de maior ordem. Considere um sistema de equações diferenciais
y′1 = f1(t, y1, . . . , ym)
y′2 = f2(t, y1, . . . , ym)...
y′m = fn(t, y1, . . . , ym)
com condições iniciais y1(t0) = α0, . . . , ym(t0) = αm. Neste sistema existem n funções incógnitas a
determinar. São funções de uma única variável, t.
Seja y′1 = 4y1 − 2y2
y′2 = y1 + y2(11.35)
um sistema concreto de duas equações. A com condição inicial é y1(0) = 0.5 e y2(0) = 1. Este
sistema tem como solução exacta y1(t) = 1.5e2t − e3t e y2(t) = 1.5e2t − 0.5e3t.
A aplicação do método de Euler a este sistema pode escrever-se na forma
yi+1 = yi + hf(ti,yi)
ou seja, y1,i+1
y2,i+1
=
y1,i
y2,i
+ h
f1(ti, y1,i, y2,i)
f2(ti, y1,i, y2,i)
=
y1,i
y2,i
+ h
4y1,i − 2y2,i
y1,i + y2,i
isto é, y1,i+1
y2,i+1
=
y1,i + h(4y1,i − 2y2,i)
y2,i + h(y1,i + y2,i)
Com y1,0 = 0.5 e y2,0 = 1 obtém-se
• Para i = 0: y1,1
y2,1
=
y1,0 + h(4y1,0 − 2y2,0)
y2,0 + h(y1,0 + y2,0)
=
0.5000
1.1500
• Para i = 1: y1,2
y2,2
=
y1,1 + h(4y1,1 − 2y2,1)
y2,1 + h(y1,1 + y2,1)
=
0.4700
1.3150

340 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
Considere-se agora o método de Runge-Kutta de ordem 4 aplicado ao seguinte sistema y′1 = f1(t, y1, y2)
y′2 = f2(t, y1, y2)
com y1(t0) = y1,0 e y2(t0) = y2,0, ou seja,
yi+1 = yi +h
6(K1 + 2K2 + 2K3 + K4)
onde
K0 = f(ti,yi)
K1 = f(ti +h
2,yi +
h
2K0)
K2 = f(ti +h
2,yi +
h
2K1
K3 = f(ti + h,yi + hK2)
Aplicando do método de Runge-Kutta ao sistema (11.35), com h = 0.1 e dois passos de
tempo, vem
• Para i = 0:
K0 = f(0, 0.5, 1) = (0, 1.5000)T
K1 = f(0.05, 0.5000, 1.0750) = (−0.1500, 1.5750)T
K2 = f(0.05, 0.4925, 1.0788) = (−0.1875, 1.5713)T
K3 = f(0.10, 0.4812, 1.1571) = (−0.3893, 1.6384)T
yi+1 = (0.482262, 1.15718)T
• Para i = 1:
K0 = f(0.10, 0.482262, 1.15718) = (−0.3853, 1.6394)T
K1 = f(0.15, 0.4630, 1.23920) = (−0.6263, 1.7022)T
K2 = f(0.15, 0.4509, 1.24230) = (−0.6808, 1.6932)T
K3 = f(0.25, 0.4142, 1.32650) = (−0.9963, 1.7407)T
yi+1 = (0.4157, 1.3267)T

11.7. PROBLEMAS 341
Uma equação diferencial de ordem elevada pode converter-se num sistema de equações de
primeira ordem. Considere o problema geral de valor inicial com ordem m
y(m) = f(t, y, y′, y′′, . . . , y(m−1))
com condições iniciais
y(t0) = α0, y′(t0) = α1, y′′(t0) = α2, . . . y(m−1)(t0) = αm
Para resolvermos este problema de valor inicial convertemo-lo num sistema de m equações de
primeira ordem como se segue. Definem-se as novas variáveis
y1 = y, y2 = y′′, , y3 = y′′′, . . . ym = y(m−1)
As novas variáveis satisfazem o sistema
y′1 = y2
y′2 = y3...
y′m−1 = ym
y′m = fn(t, y1, . . . , ym)
(11.36)
com condições iniciais
y1(t0) = α0, y2(t0) = α1, y3(t0) = α2, . . . , ym(t0) = αm
A solução do sistema (11.36) pode ser obtida usando um dos métodos apresentados neste
capítulo.
11.7 Problemas
1. Considere o problema de Cauchy x′(t) = 2e−x(t) com x(0) = 2.
(a) Obtenha um valor aproximado de x(1) usando o método de Euler com h = 14.
(b) Sabendo que x(t) é uma função positiva, mostre que o erro do valor calculado para x(1)
é inferior a 14(e2 − 1).
2. Considere o problema x′′ = 2(x−x′) com x(0) = 1 e x′(0) = 2. Obtenha um valor aproximado
de x(0.5) pelo método do ponto médio.

342 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL
3. Considere o problema y′′ + y = t com y(0) = 0 e y′(0) = 1. Utilizando um passo h à sua
escolha, obtenha um valor aproximado para y(π/3) pelo método do ponto médio.
4. Considere o problema y′+y = t com y(0) = 1. Utilizando o passo h = 0.1, obtenha um valor
aproximado para y(0.2) utilizando o método de Heun.
5. (a) A função x(t) = (1 + t)e−t verifica a equação diferencial
x′(t) = − t
1 + tx(t)
Justifique.
(b) Partindo do valor x0 = x(−0.4) como valor inicial para a equação acima obtenha um
valor aproximado de x(−0.2) pelo método de Euler com passo h = 0.1.
(c) Compare o erro do valor obtido na alínea anterior com uma estimativa a priori do erro
devido ao método que utilizou.
6. Considere o problema x′′ = 2et− x com x(0) = 2 e x′(0) = 3. Obtenha um valor aproximado
de x(0.5) pelo método do ponto médio, utilizando um passo à sua escolha.
7. Considere a equação diferencial
x2y′(x) = y2(x) + 1,
com a condição inicial y(2) = 0. Obtenha um valor aproximado de y(2 + 2h), aplicando o
método de Euler com passo h.
8. Considere o problema de Cauchy
d
dtx(t) = −1 + et
2x2(t), x(0) = 2
(a) Calcule um valor aproximado de x(1) usando o método de Heun com passo à sua
escolha.
(b) Escreva a expressão geral do método de Taylor de terceira ordem para a equação dife-
rencial dada.
9. (a) Mostre que o método do ponto médio (Runge-Kutta de ordem dois) coincide com o
método de Taylor de ordem dois quando aplicado à equação diferencial
y′(x) = a+ x+ y(x),
onde a é um número real.

11.7. PROBLEMAS 343
(b) Fazendo a = 1 e para a condição inicial y(0) = 2, indique um valor aproximado de
y(0.2) usando o método de Euler com passo h = 0.1.
10. Considere a equação diferencial
y′(x) = − x
y(x), x ∈ [1; 2],
com a condição inicial y(1) = 2. Usando o método de Euler com passo h = 0.1, obtenha um
valor aproximado de y(1.2).
11. Considere a equação diferencial
y′ = y + 4y2
com condição inicial y(1) = 1. Obtenha um valor aproximado de y(1.1), efectuando um
único passo da regra do ponto médio.
12. (a) Aproxime a solução do problema x′ = 1 + (t − x)2 com x(2) = 1, onde 2 ≤ t ≤ 3, e
preencha a tabela seguinte usando os métodos de Euler, Ponto médio, Heun e Runge-
Kutta de ordem 4:
ti 2.0 2.5 3.0
xi Euler
Ponto médio
Heun
Runge-Kutta
(b) Sabendo que
x(t) = t+1
1− tcalcule os erros das aproximações anteriores e preencha a tabela seguinte.
ti 2.0 2.5 3.0
Erro Euler
(ei) Heun
Ponto médio
Runge-Kutta

344 CAPÍTULO 11. PROBLEMAS COM VALOR INICIAL

Capítulo 12
Problemas com valores na fronteira
Todos os problemas estudados no Capítulo 12 precisam de condições em y(t) e nas suas
derivadas apenas num ponto que definimos como valor inicial. Por esta razão denominam-se
problemas com valor inicial. Contudo, em muitos problemas, são dadas condições em mais que
um ponto. Estes problemas denominam-se problemas com valores na fronteira. Este tipo de proble-
mas surge no estudo da deflexão de vigas, fluxo de calor e vários problemas da física. Problemas
físicos que dependem da posição em vez do tempo são frequentemente descritos em termos de
equações diferenciais com condições impostas em mais do que um ponto.
Se uma equação diferencial de segunda ordem em y(t) tiver dois valores fixos y(a) = ya e
y(b) = yb, então temos um problema com dois valores na fronteira. Neste capítulo, considera-se o
problema de valores na fronteira y′′ = f(t, y, y′)
y(a) = ya
y(b) = yb
(12.1)
onde f pode ser linear ou não linear e apresenta-se o método das diferenças finitas para o resolver.
Contudo, existem outros tipos de métodos numéricos para resolver este problema, tais como o
método de tiro, métodos de colocação ou o método de Rayleigh-Ritz.
12.1 Método das diferenças finitas
Um método para resolver problemas com valores na fronteira consiste em construir uma
rede de pontos no intervalo [a; b] e depois utilizar fórmulas de diferenças finitas para aproximar
345

346 CAPÍTULO 12. PROBLEMAS COM VALORES NA FRONTEIRA
as derivadas. As fórmulas que iremos utilizar são as fórmulas de segunda ordem centradas (10.1)
e (10.4) relativas aos nós ti da rede:
f ′(ti) ≈1
2h[f(ti + h)− f(ti − h)] (12.2)
f ′′(ti) ≈1
h2[f(ti + h)− 2f(ti) + f(ti − h)] (12.3)
Bases: Capítulo 10.
12.1.1 Teoria
Suponha-se que o problema a ser resolvido é o problema (12.1) e seja
a = t0 < t1 < t2 < . . . < tn = b (12.4)
uma partição do intervalo [a; b]. Estes nós não precisam ser igualmente espaçados, mas na prática
costumam ser. Quando não são é preciso utilizar fórmulas de diferenças divididas ajustadas a
nós não igualmente espaçados. Por conseguinte, neste capítulo, assume-se que
ti = a+ ih, h = (b− a)/n, i = 0, 1, 2 . . . , n.
O valor aproximado de y(ti) representa-se por yi. A equação y′′ = f(t, y, y′) é válida em todos os
pontos t do intervalo [a; b]. Por conseguinte, é válida nos nós da rede (12.4), ou seja,
y′′(ti) = f(t, y(ti), y′(ti)), i = 1, 2 . . . , n− 1
Aplicando as fórmulas (12.2) e (12.3) a esta equação, obtemos a versão discretizada do problema
(12.1): y0 = ya
h−2(yi−1 − 2yi + yi+1) = f(ti, yi, (2h)−1(yi+1 − yi−1)), i = 1, 2, . . . , n− 1
yn = yb
(12.5)
Nesta versão discretizada temos um sistema de n+ 1 equações a n+ 1 incógnitas para resol-
ver. Se f for uma função não linear, então o sistema é não linear e, geralmente, é difícil de resolver.
Neste caso, temos de utilizar métodos numéricos desenhados para resolver sistemas de equações
não lineares. Se f for linear, então o sistema resultante é linear e, portanto, mais fácil de resolver.
Assuma-se que f é uma função linear da forma f(t, y, y′) = g(t) + k1(t)y′ + k0(t)y, ou seja,
considere-se a equação diferencial ordinária de segunda ordem
y′′(t)− k1(t)y′(t)− k0(t)y(t) = g(t)

12.1. MÉTODO DAS DIFERENÇAS FINITAS 347
Por conseguinte,
y′′(ti)− k1(ti)y′(ti)− k0(ti)y(ti) = g(ti)
Substituindo (12.2) e (12.3) nesta equação obtém-se a versão discretizada
y′′i − k1(ti)y′i − k0(ti)yi = g(ti)
ou seja,1
h2(yi−1 − 2yi + yi+1)− k1(ti)
1
2h(yi+1 − yi−1)− k0(ti)yi = g(ti)
Multiplicando ambos os membros por −2h2 e agrupando os coeficientes que estão a multi-
plicar por cada yi−1, yi e yi+1, obtém-se:
−(2 + hk1(ti))yi−1 + (4 + 2h2k0(ti))yi − (2− hk1(ti))yi+1 = −2h2g(ti)
onde i = 1, 2, . . . , n− 1. Ou seja, temos o sistema de n− 1 equações a n− 1 incógnitas:
−(2 + hk1(t1))y0 + (4 + 2h2k0(t1))y1 + −(2− hk1(t1))y2 = −2h2g(t1)
−(2 + hk1(t2))y1 + (4 + 2h2k0(t2))y2 + −(2− hk1(t2))y3 = −2h2g(t2)
−(2 + hk1(t3))y2 + (4 + 2h2k0(t3))y3 + −(2− hk1(t3))y4 = −2h2g(t3)...
......
......
......
−(2 + hk1(tn−2))yn−3 + (4 + 2h2k0(tn−2))yn−2 + −(2− hk1(tn−2))yn−1 = −2h2g(tn−2)
−(2 + hk1(tn−1))yn−2 + (4 + 2h2k0(tn−1))yn−1 + −(2− hk1(tn−1))yn = −2h2g(tn−1)
Uma vez que y0 = ya e yn = yb e utilizando as abreviaturas
ai = −2− hk1(ti)
di = 4 + 2h2k0(ti)
ci = −2 + hk1(ti)
bi = −2h2g(ti)
podemos reescrever o sistema na forma:
d1 c1
a2 d2 c2
a3 d3 c3. . . . . . . . .
an−2 dn−2 cn−2
an−1 dn−1
y1
y2
y3...
yn−2
yn−1
=
b1 − a1yab2
b3...
bn−2
bn−1 − cn−1yb
(12.6)

348 CAPÍTULO 12. PROBLEMAS COM VALORES NA FRONTEIRA
Podemos resolver este sistema com um método numérico para resolver sistemas lineares; ver o
Capítulo 5. Se tendo as aproximações y0, y1, y2, . . . , yn−1 e yn precisarmos de uma aproximação
entre eles, podemos utilizar interpolação ou outro método para aproximar funções com base em
tabelas de pontos (ti, yi).
Podemos observar que se a distância entre os pontos for pequena, então a matriz do sistema
tem a diagonal estritamente dominante porque
|4 + 2h2k0(ti)| > | − 2− hk1(ti)|+ | − 2 + hk1(ti)| = 4
Estamos a assumir que |hk1(ti)| ≤ 2 para que os termos −2 − hk1(ti) e −2 + hk1(ti) sejam ambos
não negativos. Também assumimos que k0(ti) > 0 e que h é suficientemente pequeno para que
|hk1(ti)| < 2.
12.1.2 Procedimento
Problema Aproximar a solução do problema com valores na fronteira (12.1).
Hipóteses a função x(t) tem a segunda derivada limitada, ∂f/∂x é contínua, não negativa e limi-
tada para t ∈ [0; 1].
Ferramentas Utilizam-se duas fórmulas de diferenças divididas centradas e métodos para resol-
ver sistemas de equações lineares ou não lineares.
Processo iterativo Divide-se o intervalo [a; b] em n sub-intervalos e define-se h = (b − a)/n.
Constrói-se a rede de pontos (12.4) tal que ti = a+ ih.
Obtém-se a versão discretizada do problema (12.1), ou seja, constrói-se (12.5). Se f for uma
função não linear, então utilizar um método numérico para resolver sistemas de equações
não lineares.
Se f for linear, então considerar a equação diferencial ordinária de segunda ordem
y′′(t)− k1(t)y′(t)− k0(t)y(t) = g(t)
e substituir (12.2) e (12.3) nesta equação para obter a versão discretizada
1
h2(yi−1 − 2yi + yi+1) + k1(ti)
1
2h(yi+1 − yi−1)− k0(ti)yi = g(ti)
Construir o sistema (12.6) e resolvê-lo utilizando um método numérico para resolver siste-
mas de equações lineares.

12.1. MÉTODO DAS DIFERENÇAS FINITAS 349
Análise do erro Nesta secção, vamos fazer a análise do erro quando f é uma função linear. Sabe-
mos que y(t) satisfaz as seguintes equações para i = 1, 2, . . . n− 1:
1
h2[y(ti−1)− 2y(ti) + y(ti+1)]−
h2
12y(4)(ξi) =
g(ti)− k0(ti)y(ti)− k1(ti)
1
2h[y(ti+1)− y(ti−1)]−
h2
6y′′′(τi)
Por outro lado, sabemos que a solução aproximada satisfaz:
1
h2(yi−1 − 2yi + yi+1) = g(ti)− k0(ti)yi − k1(ti)
1
2h(yi+1 − yi−1) (12.7)
Subtraindo a equação (12.7) à (12.7) e usando a notação ei = y(ti)− yi, obtém-se
1
h2(ei−1 − 2ei + ei+1) = −k0(ti)ei − k1(ti)
1
2h(ei+1 − ei−1) + h2wi (12.8)
onde
wi =h2
12y(4)(ξi)−
h2
6y′′′(τi)
Multiplicando por 2h2 em ambos os membros vem:
(−2− hk1(ti))ei−1 + (4 + 2h2k0(ti))ei + (hk1(ti)− 2)ei+1 = −2h4wi (12.9)
ou seja,
aiei−1 + diei + ciei+1 = −2h4wi
Seja λ = ‖e‖∞ e seja i tal que ‖e‖∞ = |ei| = λ, onde e = (e1, e2, . . . , en−1)T . Então da equação
(12.9) podemos escrever
|di||ei| ≤ 2h4|wi|+ |ci||ei+1|+ |ai||ei−1|
ou seja,
|di|λ ≤ 2h4‖w‖∞ + |ci|λ+ |ai|λ
Assumindo que k0(ti) > 0 e que h é suficientemente pequeno para que |hk1(ti)| < 2 (conse-
quentemente, admite-se que os termos−2−hk1(ti) e−2 +hk1(ti) são ambos não negativos).
Neste caso, verifica-se a igualdade:
|di| − |ci| − |ai| = 4 + 2h2k0(ti)− (2− hk1(ti))− (2 + hk1(ti)) = 2h2k0(ti)
Utilizando esta desigualdade, obtemos
λ(|di| − |ci| − |ai|) ≤ 2h4‖w‖∞
ou seja,
2h2k0(ti)λ ≤ 2h4‖w‖∞

350 CAPÍTULO 12. PROBLEMAS COM VALORES NA FRONTEIRA
Consequentemente,
‖e‖∞ ≤ h2‖w‖∞
inf k0(t)
Pela equação (12.8) temos
‖w‖∞ ≤‖y(4)‖∞
12+‖y′′′‖∞
6
A expressão ‖w‖∞/ inf k0(t) é uma majoração independente de h. Por conseguinte, ‖e‖∞ é
um O(h2) quando h→ 0.
12.1.3 Exemplos
Exemplo 57 Considere o seguinte problema com valores na fronteiray′′ + (t+ 1)y′ − 2y = (1− t2)e−t
y(0) = −1
y(1) = 0
O objectivo é resolvê-lo usando o método das diferenças finitas com h = 0.5, h = 1/3 e h = 0.25 e
compará-lo com a solução exacta y(t) = (t− 1)e−t.
Neste caso, k1(t) = −(t+ 1), k0(t) = 2 e g(t) = (1− t2)e−t.
• h = 0.5.
Para h = 0.5 os nós da rede são t0 = 0, t1 = t0 + h = 0.5 e t2 = t1 + h = 1. Consequentemente, a
única incógnita é y1 e o sistema reduz-se a uma equação:
−(2 + hk1(t1))y0 + (4 + 2h2k0(t1))y1 + (hk1(t1)− 2)y2 = −2h2g(t1)
ou seja,
a1ya + d1y1 + c1yb = b1
onde
a1 = −(2 + hk1(t1)) = −2 + h(t1 + 1) = −2 + 0.5(0.5 + 1) = −1.25
d1 = 4 + 2h2k0(t1) = 4 + 4h2 = 4 + 4(0.5)2 = 5
c1 = hk1(t1)− 2 = −h(t1 + 1)− 2 = −0.5(0.5 + 1)− 2 = −2.7500
b1 = −2h2g(t1) = −2h2(1− t21)e−t1 = 2(0.5)2(1− (0.5)2)e−0.5 = −0.2274
Por conseguinte,
y1 =b1 − a1ya − c1yb
d1=−0.2274− (−1.25)(−1)− (−2.75)(0)
5= −0.2955
Na Tabela 12.1 encontram-se os resultados obtidos.

12.1. MÉTODO DAS DIFERENÇAS FINITAS 351
Tabela 12.1: Aplicação do método das diferenças finitas com h = 0.5.
i ti yi y(ti) ei
0 0 −1.0000 −1.0000 0.0000
1 0.5 −0.2955 −0.3033 −7.7755× 10−3
2 1 0.0000 0.0000 0.0000
• h = 1/3.
Para h = 1/3 os nós da rede são t0 = 0, t1 = 1/3, t2 = 2/3 e t3 = 1. O sistema tem, neste caso, duas
equações:
−(2 + hk1(t1))y0 + (4 + 2h2k0(t1))y1 + (hk1(t1)− 2)y2 = −2h2g(t1)
−(2 + hk1(t2))y1 + (4 + 2h2k0(t2))y2 + (hk1(t2)− 2)y3 = −2h2g(t2)
ou seja, 4.4444 −2.4444
−1.4444 4.4444
y1
y2
=
−1.6971
−0.0634
A solução é y1 = −0.4745 e y2 = −0.1685. Na Tabela 12.2 encontram-se os resultados obtidos.
Tabela 12.2: Aplicação do método das diferenças finitas com h = 1/3.
i ti yi y(ti) ei
0 0 −1.0000 −1.0000 0.0000
1 1/3 −0.4745 −0.4777 −3.1795× 10−3
2 2/3 −0.1685 −0.1711 −2.6623× 10−3
3 1 0.0000 1 0.0000
• h = 0.25.
Para h = 0.25 os nós da rede são t0 = 0, t1 = 0.25, t2 = 0.5, t3 = 0.75 e t4 = 1. O sistema
correspondente é
−(2 + hk1(t1))y0 + (4 + 2h2k0(t1))y1 + (hk1(t1)− 2)y2 = −2h2g(t1)
−(2 + hk1(t2))y1 + (4 + 2h2k0(t2))y2 + (hk1(t2)− 2)y3 = −2h2g(t2)
−(2 + hk1(t3))y2 + (4 + 2h2k0(t3))y3 + (hk1(t3)− 2)y4 = −2h2g(t3)

352 CAPÍTULO 12. PROBLEMAS COM VALORES NA FRONTEIRA
ou seja, 4.2500 −2.3125 0
−1.6250 4.2500 −2.3750
0 −1.5625 4.2500
y1
y2
y3
=
−1.778800
−0.056862
−0.025833
A solução é y1 = −0.58256, y2 = −0.30145 e y3 = −0.11691. Na Tabela 12.3 encontram-se os
resultados obtidos.
Tabela 12.3: Aplicação do método das diferenças finitas com h = 0.25.
i ti yi y(ti) ei
0 0 −1.00000 −1.0000 0.0000
1 0.25 −0.58256 −5.8410 −1.5419× 10−3
2 0.5 −0.30145 −3.0327 −1.8130× 10−3
3 0.75 −0.11691 −1.1809 −1.1853× 10−3
4 1 0.00000 0.0000 0.0000
12.2 Problemas
1. Considere o problema x′′ = 2(x− x′) com x(0) = 1 e x(1) = 2.
2. Considere o problema y′′ + y = t com y(0) = y(π) = 0. Utilizando h = π/3 e o método das
diferenças finitas preencha a seguinte tabela de valores aproximados de y(t):
t 0 π/3 2π/3 π
y(t)
3. Considere o problema y′′ = y′ + 2y + cos(t) com y(0) = −0.3 e y(π/2) = −0.1. Utilizando
h = π/4 e o método das diferenças finitas preencha a seguinte tabela de valores aproximados
de y(t):
t 0 π/4 π/2
y(t)
4. Aproxime, utilizando o método das diferenças finitas com passo igual a 0.5, o valor y(0.5)
onde y é solução da equação
y′′(x) + 2y′(x) = −10x, y(0) = 1, y(1) = 1

12.2. PROBLEMAS 353
5. Considere o problema x′′ = 2et − x com x(0) = 2 e x(1) = e + cos 1. Obtenha um valor
aproximado de x(0.5) pelo método das diferenças finitas, utilizando um passo à sua escolha.
6. Considere o problema
y′′(x) + 2y′(x) + y = −10t, y(0) = 1, y(1) = 2
Utilizando h = 0.25 e o método das diferenças finitas preencha a seguinte tabela de valores
aproximados de y(t):
t 0.00 0.25 0.5 0.75 1.00
y(t)
7. Considere o problema x′′ = 2x′ − x + tet − t com x(0) = 0 e x(2) = −4. Obtenha um valor
aproximado de x(1) pelo método das diferenças finitas, utilizando um passo à sua escolha.
8. Resolva o seguinte problema com valores na fronteira y′′ + (x+ 1)y′ − 2y = (1− x2)e−x, 0 ≤ x ≤ 1
y(0) = −1, y(1) = 0
pelo método das diferenças finitas com h = 0.1 e h = 0.2. Compare os resultados com a
solução exacta y(x) = (x− 1)e−x.
9. Resolva o seguinte problema com valores na fronteira y′′ + exy′ − xy = (−x2 + 2x− 3)e−x − x+ 2, 0 ≤ x ≤ 1
y(0) = −1, y(1) = 0
pelo método das diferenças finitas com h = 1/2, h = 1/3, h = 1/4 e h = 1/5. Compare os
resultados com a solução exacta y(x) = (x− 1)e−x.
10. Resolva o seguinte problema com valores na fronteira y′′ − 3xy′ + 3
x2y = 2x2ex, 1 ≤ x ≤ 2
y(1) = 0, y(2) = 4e2
pelo método das diferenças finitas com h = 1/2, h = 1/3, h = 1/4, h = 1/5 e h = 0.1.
Compare os resultados com a solução exacta y(x) = 2x(x− 1)ex.
11. Use o método das diferenças finitas para resolver os seguintes problemas
(a) y′′ = −y′2+2y2
y, y(0) = 1, y(π/6) =
√2, com h = π/30 e h = π/12.
(b) y′′ = 1−y′2y
, y(0) = 1, y(2) = 2, com h = h = 0.4 e h = 0.2.

354 CAPÍTULO 12. PROBLEMAS COM VALORES NA FRONTEIRA

Bibliografia
K. Atkinson. An Introduction to Numerical Analysis. John Wiley and Sons, New York, NY, USA,
1987. ISBN 0471624896.
R. L. Burden and J. D. Faires. Numerical Analysis. Brooks Cole, USA, 7 edition, 2001.
M. Carpentier. Análise Numérica: Teoria. Associação de estudantes do IST, Avenida Rovisco Pais
1, 1993.
D. R. Kincaidand E. W. Cheney. Numerical Analysis: Mathematics of Scientific Computing. Brooks
Cole, USA, 1991.
J. Epperson. An introduction to numerical methods and Analysis. John Wiley and Sons, New York,
NY, USA, 2002. ISBN 1-58488-281-6.
T. Heath. A History of Greek Mathematics. Oxford: Clarendon Press, UK, 1921.
A. Kharab and R. B. Guenther. An introduction to numerical methods: a matlab approach. Chapman-
Hall, London, UK, 2002. ISBN 1-58488-281-6.
S.Conte and C. de Boor. Elementary Numerical Analysis: An Algorithmic Approach. McGraw-Hill,
New York, NY, USA, 1965.
L. F. Shampine. Numerical solution of ordinary differential equations. Chapman-Hall, London, UK,
1994. ISBN 0-412-05151-6.
L. F. Shampine, R. C. Allen, and S. Pruess. Fundamentals of Numerical Computing. John Wiley and
Sons, New York, NY, USA, 1997. ISBN 0-471-16363-5.
355





























