Embed Size (px)
Citation preview

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 129
GPUs for Molecular Dynamics (MD) Simulations
a userrsquos perspective
Eduardo M Bringa amp Emmanuel Millaacuten
CONICET Instituto de Ciencias Baacutesicas Universidad Nacional de Cuyo Mendoza
(ebringayahoocom)
Universidad Nacional del Comahue Neuqueacuten
Marzo 2012
Collaborators
C Ruestes C Garcia Garino (UN Cuyo)
A Higginbotham (Oxford)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 229
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 329
Many MD codes can now use GPU acceleration
AMBER ( Assisted Model Building with Energy Refinement ) httpambermdorggpus
Ross Walker (keynote) MPI for several GPUscores TIP3P PME ~106 atoms max Tesla C2070)
HOOMD-Blue ( Highly Optimized Object-oriented Many-particle Dynamics)
httpcodeblueumicheduhoomd-blueindexhtml OMP for several GPUs in single board
LAMMPS ( Large-scale AtomicMolecular Massively Parallel Simulator )
httplammpssandiagov MPI ofr several GPUscores (LJ 12 ~107 atoms max Tesla C2070)
GPULAMMPS httpcodegooglecompgpulammps CUDA + OpenCL
DL_POLY
httpwwwcsescitechacukccgsoftwareDL_POLY F90+MPI CUDA+OpenMP port
GROMACS httpwwwgromacsorgDownloadsInstallation_InstructionsGromacs_on_GPUs
Uses OpenMM libs (httpssimtkorghomeopenmm) No paralelization ~106
atoms max
NAMD (ldquo Not anotherrdquo MD) httpwwwksuiuceduResearchnamd GPUCPU clusters
VMD (Visual MD) httpwwwksuiuceduResearchvmd
GTC 2010 Archive videos and pdfrsquos httpwwwnvidiacomobjectgtc2010-presentation-archivehtmlmd
1000000+ atom Satellite Tobacco Mosaic Virus
Freddolino et al Structure 14437-449 2006Many more
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 429
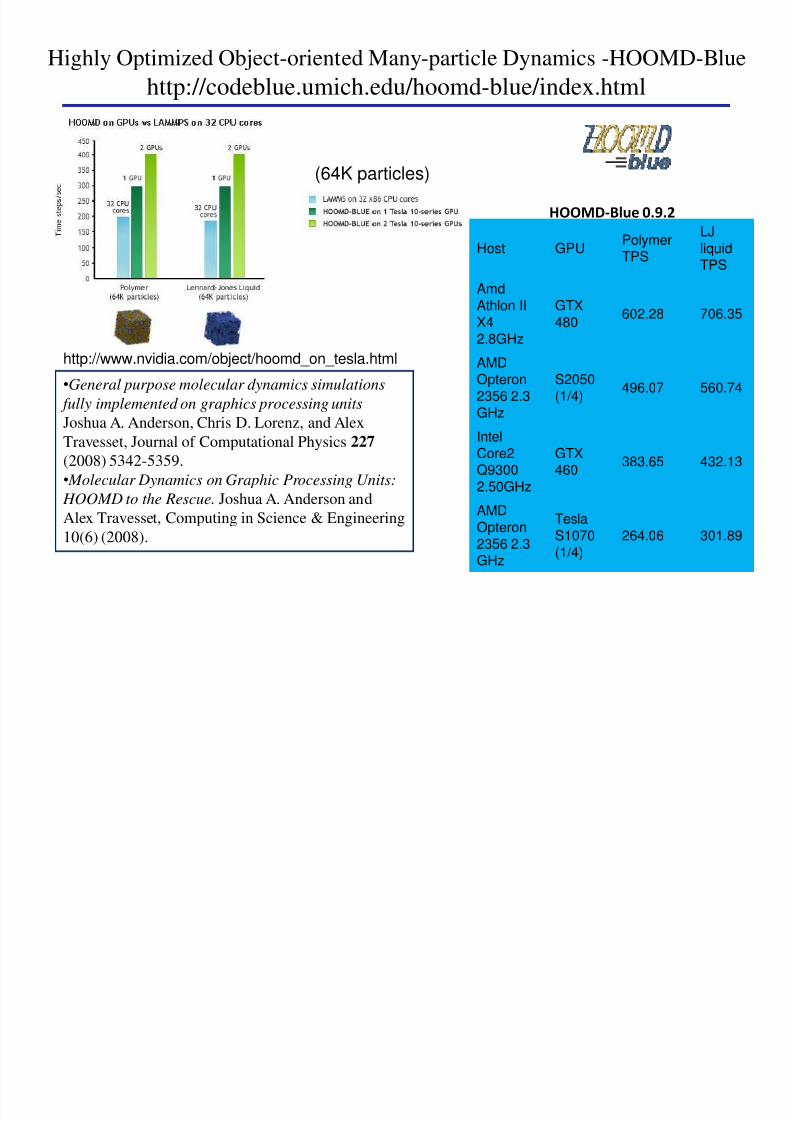
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
bullGeneral purpose molecular dynamics simulations
fully implemented on graphics processing units
Joshua A Anderson Chris D Lorenz and AlexTravesset Journal of Computational Physics 227
(2008) 5342-5359
bull Molecular Dynamics on Graphic Processing Units
HOOMD to the Rescue Joshua A Anderson and
Alex Travesset Computing in Science amp Engineering
10(6) (2008)
httpwwwnvidiacomobjecthoomd_on_teslahtml
Host GPUPolymerTPS
LJ
liquidTPS
Amd
Athlon II
X428GHz
GTX
480 60228 70635
AMDOpteron
2356 23
GHz
S2050
(14)49607 56074
Intel
Core2Q9300
250GHz
GTX460
38365 43213
AMD
Opteron2356 23GHz
Tesla
S1070(14)
26406 30189
983112983119983119983117983108983085983106983148983157983141 983088983086983097983086983090
(64K particles)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 529
Dump file formats HOOMDs XML input format
MOL2 DCD PDB
Pair Potentials - cutoff (ldquosmoothrdquo option)
CGCMM
DPD (dissipative particle dynamics)EAM (embedded atom method)Gaussian
Lennard-Jones
MorseUser-specified (tabulated)
Shifted Lennard-JonesYukawa
Pair Potentials - long range
Electrostatics via PPPM
Bond Potentials
FENE
HarmonicAngle Potentials
Harmonic
CGCMM
DihedralImproper Potentials
Harmonic
Wall PotentialsLennard-Jones
CUDACPU
OMP for multiple cores O multiple GPUscore
Single double precision
Integrators NVE NPT NVT Brownian dynamics NVT
Energy minimization FIREOther features
bullSupports Linux Windows and Mac OS X
bullSimple and powerful Python script interface for defining
simulationsbullPerforms 2D and 3D simulations
bullAdvanced built-in initial configuration generatorsbullHuman readable XML input files
bullSpace-filling curve particle reordering to increase
performance
bullExtensible object-oriented design Additional features may
be added in new classes contained in plugins
bullSimulations can be visualized in real-time using VMDs IMDinterface
bullReal time analysis can be run at a non-linear rate if desired
bullQuantities such as temperature pressure and box size can bevaried smoothly over a run
bullFlexible selection of particles for integration allows freezing
some particles in place and many other use-casesbullOnly reduced units
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 629
Python script for LJ run testhoomd
from hoomd_script import
create 100 random particles of name A
initcreate_random(N=100 phi_p=001
name=A)
specify Lennard-Jones interactions
between particle pairs
lj = pairlj(r_cut=30)
ljpair_coeffset(A A epsilon=10
sigma=10)
integrate at constant temperature
all = groupall()
integratemode_standard(dt=0005)
integratenvt(group=all T=12 tau=05)
run 10000 time steps
run(10e3)
Run
$ hoomd testhoomd
OutputHOOMD-blue 090
Compiled Wed Oct 28 065846 EDT 2009
Copyright 2008 2009 Ames Laboratory Iowa State University and
the Regents of the University of Michigan -----
httpcodeblueumicheduhoomd-blue
This code is the implementation of the algorithms discussed in
Joshua A Anderson Chris D Lorenz and Alex Travesset - General
Purpose Molecular Dynamics Fully Implemented on Graphics
Processing Units Journal of Computational Physics 227 (2008)
5342-5359 -----
testhoomd004 | initcreate_random(N=100 phi_p=001 name=A)testhoomd007 | lj = pairlj(r_cut=30)
testhoomd008 | ljpair_coeffset(A A epsilon=10 sigma=10)
testhoomd011 | all = groupall() Group all created containing 100
particles testhoomd012 | integratemode_standard(dt=0005)
testhoomd013 | integratenvt(group=all T=12 tau=05)
testhoomd016 | run(10e3)starting run Time 000000 | Step 10000 10000 | TPS 354179 |
ETA 000000 Average TPS 35405 --------- --
Neighborlist stats
370 normal updates 100 forced updates 0 dangerous updates
n_neigh_min 0 n_neigh_max 10 n_neigh_avg 241
bins_min 0 bins_max 6 bins_avg 15625
run complete
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-bluedoc-trunkpage_quick_starthtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 229
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 329
Many MD codes can now use GPU acceleration
AMBER ( Assisted Model Building with Energy Refinement ) httpambermdorggpus
Ross Walker (keynote) MPI for several GPUscores TIP3P PME ~106 atoms max Tesla C2070)
HOOMD-Blue ( Highly Optimized Object-oriented Many-particle Dynamics)
httpcodeblueumicheduhoomd-blueindexhtml OMP for several GPUs in single board
LAMMPS ( Large-scale AtomicMolecular Massively Parallel Simulator )
httplammpssandiagov MPI ofr several GPUscores (LJ 12 ~107 atoms max Tesla C2070)
GPULAMMPS httpcodegooglecompgpulammps CUDA + OpenCL
DL_POLY
httpwwwcsescitechacukccgsoftwareDL_POLY F90+MPI CUDA+OpenMP port
GROMACS httpwwwgromacsorgDownloadsInstallation_InstructionsGromacs_on_GPUs
Uses OpenMM libs (httpssimtkorghomeopenmm) No paralelization ~106
atoms max
NAMD (ldquo Not anotherrdquo MD) httpwwwksuiuceduResearchnamd GPUCPU clusters
VMD (Visual MD) httpwwwksuiuceduResearchvmd
GTC 2010 Archive videos and pdfrsquos httpwwwnvidiacomobjectgtc2010-presentation-archivehtmlmd
1000000+ atom Satellite Tobacco Mosaic Virus
Freddolino et al Structure 14437-449 2006Many more
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 429
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
bullGeneral purpose molecular dynamics simulations
fully implemented on graphics processing units
Joshua A Anderson Chris D Lorenz and AlexTravesset Journal of Computational Physics 227
(2008) 5342-5359
bull Molecular Dynamics on Graphic Processing Units
HOOMD to the Rescue Joshua A Anderson and
Alex Travesset Computing in Science amp Engineering
10(6) (2008)
httpwwwnvidiacomobjecthoomd_on_teslahtml
Host GPUPolymerTPS
LJ
liquidTPS
Amd
Athlon II
X428GHz
GTX
480 60228 70635
AMDOpteron
2356 23
GHz
S2050
(14)49607 56074
Intel
Core2Q9300
250GHz
GTX460
38365 43213
AMD
Opteron2356 23GHz
Tesla
S1070(14)
26406 30189
983112983119983119983117983108983085983106983148983157983141 983088983086983097983086983090
(64K particles)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 529
Dump file formats HOOMDs XML input format
MOL2 DCD PDB
Pair Potentials - cutoff (ldquosmoothrdquo option)
CGCMM
DPD (dissipative particle dynamics)EAM (embedded atom method)Gaussian
Lennard-Jones
MorseUser-specified (tabulated)
Shifted Lennard-JonesYukawa
Pair Potentials - long range
Electrostatics via PPPM
Bond Potentials
FENE
HarmonicAngle Potentials
Harmonic
CGCMM
DihedralImproper Potentials
Harmonic
Wall PotentialsLennard-Jones
CUDACPU
OMP for multiple cores O multiple GPUscore
Single double precision
Integrators NVE NPT NVT Brownian dynamics NVT
Energy minimization FIREOther features
bullSupports Linux Windows and Mac OS X
bullSimple and powerful Python script interface for defining
simulationsbullPerforms 2D and 3D simulations
bullAdvanced built-in initial configuration generatorsbullHuman readable XML input files
bullSpace-filling curve particle reordering to increase
performance
bullExtensible object-oriented design Additional features may
be added in new classes contained in plugins
bullSimulations can be visualized in real-time using VMDs IMDinterface
bullReal time analysis can be run at a non-linear rate if desired
bullQuantities such as temperature pressure and box size can bevaried smoothly over a run
bullFlexible selection of particles for integration allows freezing
some particles in place and many other use-casesbullOnly reduced units
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 629
Python script for LJ run testhoomd
from hoomd_script import
create 100 random particles of name A
initcreate_random(N=100 phi_p=001
name=A)
specify Lennard-Jones interactions
between particle pairs
lj = pairlj(r_cut=30)
ljpair_coeffset(A A epsilon=10
sigma=10)
integrate at constant temperature
all = groupall()
integratemode_standard(dt=0005)
integratenvt(group=all T=12 tau=05)
run 10000 time steps
run(10e3)
Run
$ hoomd testhoomd
OutputHOOMD-blue 090
Compiled Wed Oct 28 065846 EDT 2009
Copyright 2008 2009 Ames Laboratory Iowa State University and
the Regents of the University of Michigan -----
httpcodeblueumicheduhoomd-blue
This code is the implementation of the algorithms discussed in
Joshua A Anderson Chris D Lorenz and Alex Travesset - General
Purpose Molecular Dynamics Fully Implemented on Graphics
Processing Units Journal of Computational Physics 227 (2008)
5342-5359 -----
testhoomd004 | initcreate_random(N=100 phi_p=001 name=A)testhoomd007 | lj = pairlj(r_cut=30)
testhoomd008 | ljpair_coeffset(A A epsilon=10 sigma=10)
testhoomd011 | all = groupall() Group all created containing 100
particles testhoomd012 | integratemode_standard(dt=0005)
testhoomd013 | integratenvt(group=all T=12 tau=05)
testhoomd016 | run(10e3)starting run Time 000000 | Step 10000 10000 | TPS 354179 |
ETA 000000 Average TPS 35405 --------- --
Neighborlist stats
370 normal updates 100 forced updates 0 dangerous updates
n_neigh_min 0 n_neigh_max 10 n_neigh_avg 241
bins_min 0 bins_max 6 bins_avg 15625
run complete
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-bluedoc-trunkpage_quick_starthtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 329
Many MD codes can now use GPU acceleration
AMBER ( Assisted Model Building with Energy Refinement ) httpambermdorggpus
Ross Walker (keynote) MPI for several GPUscores TIP3P PME ~106 atoms max Tesla C2070)
HOOMD-Blue ( Highly Optimized Object-oriented Many-particle Dynamics)
httpcodeblueumicheduhoomd-blueindexhtml OMP for several GPUs in single board
LAMMPS ( Large-scale AtomicMolecular Massively Parallel Simulator )
httplammpssandiagov MPI ofr several GPUscores (LJ 12 ~107 atoms max Tesla C2070)
GPULAMMPS httpcodegooglecompgpulammps CUDA + OpenCL
DL_POLY
httpwwwcsescitechacukccgsoftwareDL_POLY F90+MPI CUDA+OpenMP port
GROMACS httpwwwgromacsorgDownloadsInstallation_InstructionsGromacs_on_GPUs
Uses OpenMM libs (httpssimtkorghomeopenmm) No paralelization ~106
atoms max
NAMD (ldquo Not anotherrdquo MD) httpwwwksuiuceduResearchnamd GPUCPU clusters
VMD (Visual MD) httpwwwksuiuceduResearchvmd
GTC 2010 Archive videos and pdfrsquos httpwwwnvidiacomobjectgtc2010-presentation-archivehtmlmd
1000000+ atom Satellite Tobacco Mosaic Virus
Freddolino et al Structure 14437-449 2006Many more
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 429
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
bullGeneral purpose molecular dynamics simulations
fully implemented on graphics processing units
Joshua A Anderson Chris D Lorenz and AlexTravesset Journal of Computational Physics 227
(2008) 5342-5359
bull Molecular Dynamics on Graphic Processing Units
HOOMD to the Rescue Joshua A Anderson and
Alex Travesset Computing in Science amp Engineering
10(6) (2008)
httpwwwnvidiacomobjecthoomd_on_teslahtml
Host GPUPolymerTPS
LJ
liquidTPS
Amd
Athlon II
X428GHz
GTX
480 60228 70635
AMDOpteron
2356 23
GHz
S2050
(14)49607 56074
Intel
Core2Q9300
250GHz
GTX460
38365 43213
AMD
Opteron2356 23GHz
Tesla
S1070(14)
26406 30189
983112983119983119983117983108983085983106983148983157983141 983088983086983097983086983090
(64K particles)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 529
Dump file formats HOOMDs XML input format
MOL2 DCD PDB
Pair Potentials - cutoff (ldquosmoothrdquo option)
CGCMM
DPD (dissipative particle dynamics)EAM (embedded atom method)Gaussian
Lennard-Jones
MorseUser-specified (tabulated)
Shifted Lennard-JonesYukawa
Pair Potentials - long range
Electrostatics via PPPM
Bond Potentials
FENE
HarmonicAngle Potentials
Harmonic
CGCMM
DihedralImproper Potentials
Harmonic
Wall PotentialsLennard-Jones
CUDACPU
OMP for multiple cores O multiple GPUscore
Single double precision
Integrators NVE NPT NVT Brownian dynamics NVT
Energy minimization FIREOther features
bullSupports Linux Windows and Mac OS X
bullSimple and powerful Python script interface for defining
simulationsbullPerforms 2D and 3D simulations
bullAdvanced built-in initial configuration generatorsbullHuman readable XML input files
bullSpace-filling curve particle reordering to increase
performance
bullExtensible object-oriented design Additional features may
be added in new classes contained in plugins
bullSimulations can be visualized in real-time using VMDs IMDinterface
bullReal time analysis can be run at a non-linear rate if desired
bullQuantities such as temperature pressure and box size can bevaried smoothly over a run
bullFlexible selection of particles for integration allows freezing
some particles in place and many other use-casesbullOnly reduced units
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 629
Python script for LJ run testhoomd
from hoomd_script import
create 100 random particles of name A
initcreate_random(N=100 phi_p=001
name=A)
specify Lennard-Jones interactions
between particle pairs
lj = pairlj(r_cut=30)
ljpair_coeffset(A A epsilon=10
sigma=10)
integrate at constant temperature
all = groupall()
integratemode_standard(dt=0005)
integratenvt(group=all T=12 tau=05)
run 10000 time steps
run(10e3)
Run
$ hoomd testhoomd
OutputHOOMD-blue 090
Compiled Wed Oct 28 065846 EDT 2009
Copyright 2008 2009 Ames Laboratory Iowa State University and
the Regents of the University of Michigan -----
httpcodeblueumicheduhoomd-blue
This code is the implementation of the algorithms discussed in
Joshua A Anderson Chris D Lorenz and Alex Travesset - General
Purpose Molecular Dynamics Fully Implemented on Graphics
Processing Units Journal of Computational Physics 227 (2008)
5342-5359 -----
testhoomd004 | initcreate_random(N=100 phi_p=001 name=A)testhoomd007 | lj = pairlj(r_cut=30)
testhoomd008 | ljpair_coeffset(A A epsilon=10 sigma=10)
testhoomd011 | all = groupall() Group all created containing 100
particles testhoomd012 | integratemode_standard(dt=0005)
testhoomd013 | integratenvt(group=all T=12 tau=05)
testhoomd016 | run(10e3)starting run Time 000000 | Step 10000 10000 | TPS 354179 |
ETA 000000 Average TPS 35405 --------- --
Neighborlist stats
370 normal updates 100 forced updates 0 dangerous updates
n_neigh_min 0 n_neigh_max 10 n_neigh_avg 241
bins_min 0 bins_max 6 bins_avg 15625
run complete
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-bluedoc-trunkpage_quick_starthtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 429
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
bullGeneral purpose molecular dynamics simulations
fully implemented on graphics processing units
Joshua A Anderson Chris D Lorenz and AlexTravesset Journal of Computational Physics 227
(2008) 5342-5359
bull Molecular Dynamics on Graphic Processing Units
HOOMD to the Rescue Joshua A Anderson and
Alex Travesset Computing in Science amp Engineering
10(6) (2008)
httpwwwnvidiacomobjecthoomd_on_teslahtml
Host GPUPolymerTPS
LJ
liquidTPS
Amd
Athlon II
X428GHz
GTX
480 60228 70635
AMDOpteron
2356 23
GHz
S2050
(14)49607 56074
Intel
Core2Q9300
250GHz
GTX460
38365 43213
AMD
Opteron2356 23GHz
Tesla
S1070(14)
26406 30189
983112983119983119983117983108983085983106983148983157983141 983088983086983097983086983090
(64K particles)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 529
Dump file formats HOOMDs XML input format
MOL2 DCD PDB
Pair Potentials - cutoff (ldquosmoothrdquo option)
CGCMM
DPD (dissipative particle dynamics)EAM (embedded atom method)Gaussian
Lennard-Jones
MorseUser-specified (tabulated)
Shifted Lennard-JonesYukawa
Pair Potentials - long range
Electrostatics via PPPM
Bond Potentials
FENE
HarmonicAngle Potentials
Harmonic
CGCMM
DihedralImproper Potentials
Harmonic
Wall PotentialsLennard-Jones
CUDACPU
OMP for multiple cores O multiple GPUscore
Single double precision
Integrators NVE NPT NVT Brownian dynamics NVT
Energy minimization FIREOther features
bullSupports Linux Windows and Mac OS X
bullSimple and powerful Python script interface for defining
simulationsbullPerforms 2D and 3D simulations
bullAdvanced built-in initial configuration generatorsbullHuman readable XML input files
bullSpace-filling curve particle reordering to increase
performance
bullExtensible object-oriented design Additional features may
be added in new classes contained in plugins
bullSimulations can be visualized in real-time using VMDs IMDinterface
bullReal time analysis can be run at a non-linear rate if desired
bullQuantities such as temperature pressure and box size can bevaried smoothly over a run
bullFlexible selection of particles for integration allows freezing
some particles in place and many other use-casesbullOnly reduced units
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 629
Python script for LJ run testhoomd
from hoomd_script import
create 100 random particles of name A
initcreate_random(N=100 phi_p=001
name=A)
specify Lennard-Jones interactions
between particle pairs
lj = pairlj(r_cut=30)
ljpair_coeffset(A A epsilon=10
sigma=10)
integrate at constant temperature
all = groupall()
integratemode_standard(dt=0005)
integratenvt(group=all T=12 tau=05)
run 10000 time steps
run(10e3)
Run
$ hoomd testhoomd
OutputHOOMD-blue 090
Compiled Wed Oct 28 065846 EDT 2009
Copyright 2008 2009 Ames Laboratory Iowa State University and
the Regents of the University of Michigan -----
httpcodeblueumicheduhoomd-blue
This code is the implementation of the algorithms discussed in
Joshua A Anderson Chris D Lorenz and Alex Travesset - General
Purpose Molecular Dynamics Fully Implemented on Graphics
Processing Units Journal of Computational Physics 227 (2008)
5342-5359 -----
testhoomd004 | initcreate_random(N=100 phi_p=001 name=A)testhoomd007 | lj = pairlj(r_cut=30)
testhoomd008 | ljpair_coeffset(A A epsilon=10 sigma=10)
testhoomd011 | all = groupall() Group all created containing 100
particles testhoomd012 | integratemode_standard(dt=0005)
testhoomd013 | integratenvt(group=all T=12 tau=05)
testhoomd016 | run(10e3)starting run Time 000000 | Step 10000 10000 | TPS 354179 |
ETA 000000 Average TPS 35405 --------- --
Neighborlist stats
370 normal updates 100 forced updates 0 dangerous updates
n_neigh_min 0 n_neigh_max 10 n_neigh_avg 241
bins_min 0 bins_max 6 bins_avg 15625
run complete
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-bluedoc-trunkpage_quick_starthtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 529
Dump file formats HOOMDs XML input format
MOL2 DCD PDB
Pair Potentials - cutoff (ldquosmoothrdquo option)
CGCMM
DPD (dissipative particle dynamics)EAM (embedded atom method)Gaussian
Lennard-Jones
MorseUser-specified (tabulated)
Shifted Lennard-JonesYukawa
Pair Potentials - long range
Electrostatics via PPPM
Bond Potentials
FENE
HarmonicAngle Potentials
Harmonic
CGCMM
DihedralImproper Potentials
Harmonic
Wall PotentialsLennard-Jones
CUDACPU
OMP for multiple cores O multiple GPUscore
Single double precision
Integrators NVE NPT NVT Brownian dynamics NVT
Energy minimization FIREOther features
bullSupports Linux Windows and Mac OS X
bullSimple and powerful Python script interface for defining
simulationsbullPerforms 2D and 3D simulations
bullAdvanced built-in initial configuration generatorsbullHuman readable XML input files
bullSpace-filling curve particle reordering to increase
performance
bullExtensible object-oriented design Additional features may
be added in new classes contained in plugins
bullSimulations can be visualized in real-time using VMDs IMDinterface
bullReal time analysis can be run at a non-linear rate if desired
bullQuantities such as temperature pressure and box size can bevaried smoothly over a run
bullFlexible selection of particles for integration allows freezing
some particles in place and many other use-casesbullOnly reduced units
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-blueindexhtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 629
Python script for LJ run testhoomd
from hoomd_script import
create 100 random particles of name A
initcreate_random(N=100 phi_p=001
name=A)
specify Lennard-Jones interactions
between particle pairs
lj = pairlj(r_cut=30)
ljpair_coeffset(A A epsilon=10
sigma=10)
integrate at constant temperature
all = groupall()
integratemode_standard(dt=0005)
integratenvt(group=all T=12 tau=05)
run 10000 time steps
run(10e3)
Run
$ hoomd testhoomd
OutputHOOMD-blue 090
Compiled Wed Oct 28 065846 EDT 2009
Copyright 2008 2009 Ames Laboratory Iowa State University and
the Regents of the University of Michigan -----
httpcodeblueumicheduhoomd-blue
This code is the implementation of the algorithms discussed in
Joshua A Anderson Chris D Lorenz and Alex Travesset - General
Purpose Molecular Dynamics Fully Implemented on Graphics
Processing Units Journal of Computational Physics 227 (2008)
5342-5359 -----
testhoomd004 | initcreate_random(N=100 phi_p=001 name=A)testhoomd007 | lj = pairlj(r_cut=30)
testhoomd008 | ljpair_coeffset(A A epsilon=10 sigma=10)
testhoomd011 | all = groupall() Group all created containing 100
particles testhoomd012 | integratemode_standard(dt=0005)
testhoomd013 | integratenvt(group=all T=12 tau=05)
testhoomd016 | run(10e3)starting run Time 000000 | Step 10000 10000 | TPS 354179 |
ETA 000000 Average TPS 35405 --------- --
Neighborlist stats
370 normal updates 100 forced updates 0 dangerous updates
n_neigh_min 0 n_neigh_max 10 n_neigh_avg 241
bins_min 0 bins_max 6 bins_avg 15625
run complete
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-bluedoc-trunkpage_quick_starthtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 629
Python script for LJ run testhoomd
from hoomd_script import
create 100 random particles of name A
initcreate_random(N=100 phi_p=001
name=A)
specify Lennard-Jones interactions
between particle pairs
lj = pairlj(r_cut=30)
ljpair_coeffset(A A epsilon=10
sigma=10)
integrate at constant temperature
all = groupall()
integratemode_standard(dt=0005)
integratenvt(group=all T=12 tau=05)
run 10000 time steps
run(10e3)
Run
$ hoomd testhoomd
OutputHOOMD-blue 090
Compiled Wed Oct 28 065846 EDT 2009
Copyright 2008 2009 Ames Laboratory Iowa State University and
the Regents of the University of Michigan -----
httpcodeblueumicheduhoomd-blue
This code is the implementation of the algorithms discussed in
Joshua A Anderson Chris D Lorenz and Alex Travesset - General
Purpose Molecular Dynamics Fully Implemented on Graphics
Processing Units Journal of Computational Physics 227 (2008)
5342-5359 -----
testhoomd004 | initcreate_random(N=100 phi_p=001 name=A)testhoomd007 | lj = pairlj(r_cut=30)
testhoomd008 | ljpair_coeffset(A A epsilon=10 sigma=10)
testhoomd011 | all = groupall() Group all created containing 100
particles testhoomd012 | integratemode_standard(dt=0005)
testhoomd013 | integratenvt(group=all T=12 tau=05)
testhoomd016 | run(10e3)starting run Time 000000 | Step 10000 10000 | TPS 354179 |
ETA 000000 Average TPS 35405 --------- --
Neighborlist stats
370 normal updates 100 forced updates 0 dangerous updates
n_neigh_min 0 n_neigh_max 10 n_neigh_avg 241
bins_min 0 bins_max 6 bins_avg 15625
run complete
Highly Optimized Object-oriented Many-particle Dynamics -HOOMD-Blue
httpcodeblueumicheduhoomd-bluedoc-trunkpage_quick_starthtml
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 729
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performancea) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 829
LAMMPS (httplammpssandiagov ) on GPUs
bullGPU version update from Brownrsquos site (now 04292011) will update files in the
libgpu and srcGPU directories) httpusersnccsgov~wb8gpudownloadhtm
bullNeed CUDA GPU driver and CUDA toolkit but CUDA SDK is not needed
bullSample compilation (compile gpu library add files to main src dir then compile
whole code)
cd ~lammpslibgpu
emacs Makefilelinux (compute capability 1320 singlemixdouble precision)make -f Makefilelinux (to obtain libgpua)
cd src
emacs MAKEMakefilelinux (here need to change options and paths)
make yes-asphere (for granular materials)
Make yes-manybody (for EAM in GPULAMMPS)
make yes-kspace (for electrostatics needs fftw2x)
make yes-gpu (to copy srcgpu files to src)
make linux (to obtain executable)
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 929
GPULAMMPS
bull httpcodegooglecompgpulammps
bull httpcodegooglecompgpulammpswikiLammps_cuda
bull httpcodegooglecompgpulammpswikiLammps_cuda_UI_Features
Novel most up to date GPU code GNU GPL v2 license
Main developers Paul Crozier (Sandia) Mike Brown Arnold Tharrington Scott
Hampton (Oak Ridge) Axel Kohlmeyer (Temple) Christian Trott Lars Winterfeld
(Ilmenau Germany) Duncan Poole Peng Wang (Nvidia) etc
Non-members can download read-only working copy anonymously over HTTP (SVN)
Quite detailed Wiki pages (installation amp features) E-mail list gpulammpssandiagov
bull Many more features than LAMMPS for instance EAM potential implementation
bull GPULAMMPS features are gradually incorporated into the main LAMMPS
distribution
bull Likely package like USER-CUDA within LAMMPS
bull OpenCL version also expanded compared to LAMMPS OpenCL version
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
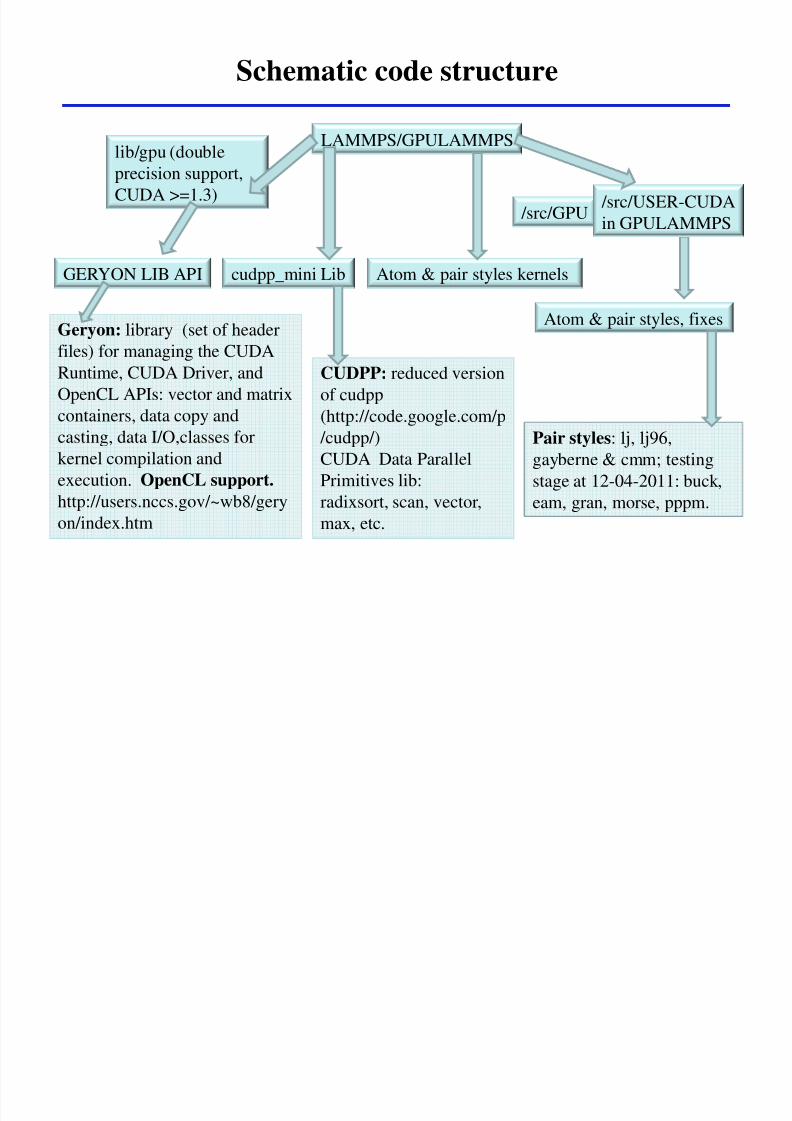
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1029
Schematic code structure
GERYON LIB API cudpp_mini Lib
srcGPU
LAMMPSGPULAMMPSlibgpu (double
precision support
CUDA gt=13)
Atom amp pair styles kernels
Geryon library (set of header
files) for managing the CUDA
Runtime CUDA Driver and
OpenCL APIs vector and matrix
containers data copy and
casting data IOclasses for
kernel compilation and
execution OpenCL support
httpusersnccsgov~wb8gery
onindexhtm
CUDPP reduced version
of cudpp
(httpcodegooglecomp
cudpp)
CUDA Data Parallel
Primitives lib
radixsort scan vector
max etc
Atom amp pair styles fixes
srcUSER-CUDA
in GPULAMMPS
Pair styles lj lj96
gayberne amp cmm testing
stage at 12-04-2011 buck
eam gran morse pppm
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1129
GPULAMMPS-CUDA Compilation
httpcodegooglecompgpulammpswikiInstallation
USER-CUDAProvides (more details about the features of LAMMPS CUDA)
26 pair forceslong range coulomb with pppmcuda
nvecuda nvtcuda nptcuda nvespherecudaseveral more important fixes and computes
Installation (more details about the installaton of LAMMPS CUDA)
Make sure you can compile LAMMPS without packages withmake YOUR-MachinefileInsert your path to CUDA in srcUSER-CUDAMakefilecommon
Install the standard packages with make yes-standardInstall USER-CUDA with make yes-USER-CUDA
Go to srcUSER-CUDA and compile the USER-CUDA library with make OptionsGo to src and compile LAMMPS with make YOUR-Machinefile OptionsIMPORTANT use the same options for the library and LAMMPS
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1229
Features in GPULAMMPS-CUDA
httpcodegooglecompgpulammpswikiLammps_cuda_DI_Features
Run styles
verletcuda
Forces
borncoullongcuda buckcoulcutcudabuckcoullongcuda buckcuda cgcmmcoulcutcuda
cgcmmcouldebyecuda cgcmmcoullongcuda cgcmmcuda eamcuda eamalloycuda eamfscuda
granhookecuda ljcharmmcoulcharmmimplicitcuda ljcharmmcoulcharmmcuda ljcharmmcoullongcudaljcutcoulcutcuda ljcutcouldebyecuda ljcutcoullongcuda ljcutcuda ljexpandcuda
ljgromacscoulgromacscuda ljgromacscuda ljsmoothcuda lj96cutcuda morsecuda morsecoullongcuda
pppmcuda
Fixes
nptcuda nvecuda nvtcuda nvespherecuda enforce2dcuda tempberendsencuda temprescalecuda
addforcecuda setforcecuda aveforcecuda shakecuda gravitycuda freezecuda
Computes
tempcuda temppartialcuda pressurecuda pecuda
Atom styles
atomiccuda chargecuda fullcuda granularcuda
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1329
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1429
Outline
bull Introduction
bull HOOMD-BLUE
bull LAMMPS
bull GPULAMMPS
bull Performance
a) singlemixeddouble precision
b) CPUGPU neighbor lists
c) Load balancing static amp dynamic
bull Examples
bull Summary
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
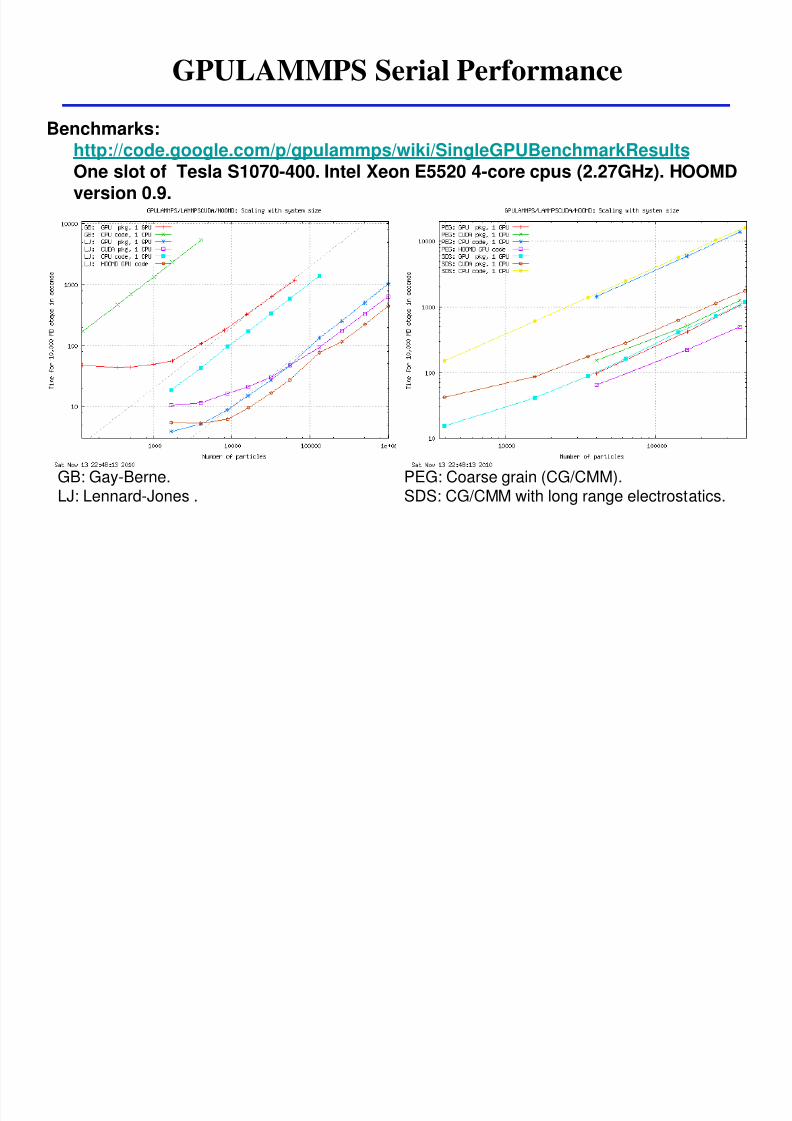
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1529
GPULAMMPS Serial Performance
BenchmarkshttpcodegooglecompgpulammpswikiSingleGPUBenchmarkResultsOne slot of Tesla S1070-400 Intel Xeon E5520 4-core cpus (227GHz) HOOMDversion 09
GB Gay-BerneLJ Lennard-Jones
PEG Coarse grain (CGCMM)SDS CGCMM with long range electrostatics
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
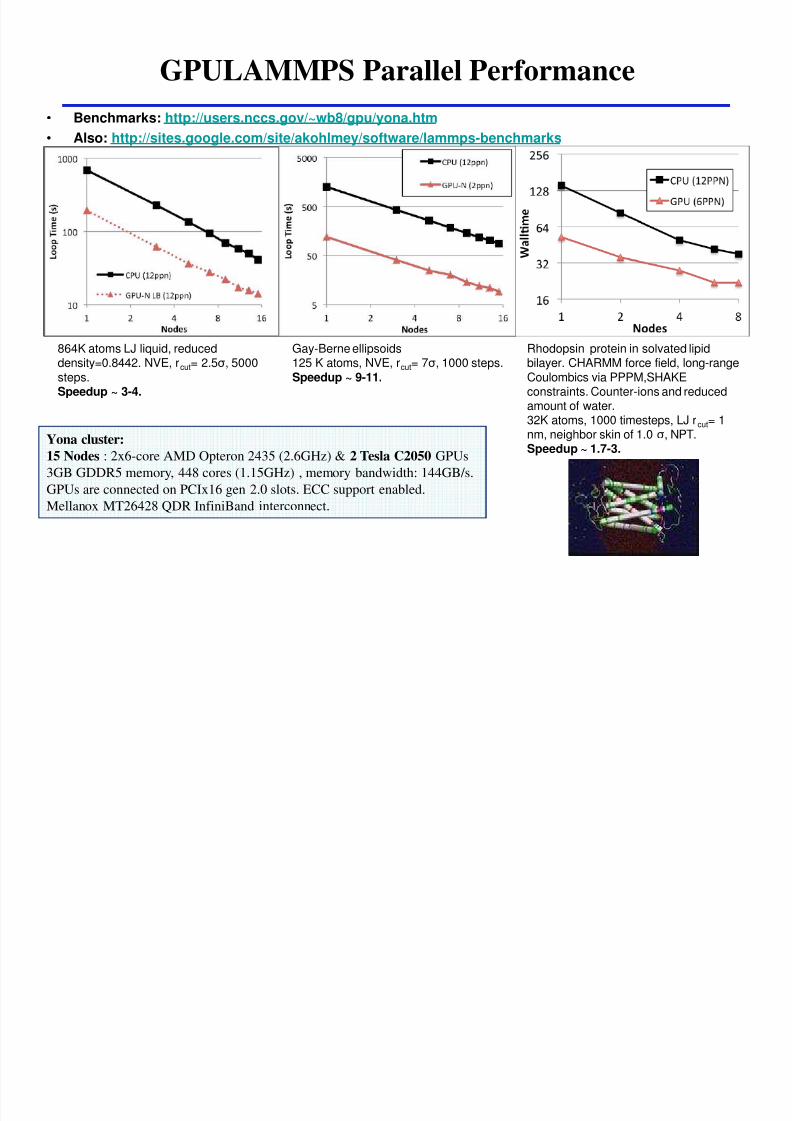
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1629
GPULAMMPS Parallel Performance
bull Benchmarks httpusersnccsgov~wb8gpuyonahtm
bull Also httpsitesgooglecomsiteakohlmeysoftwarelammps-benchmarks
864K atoms LJ liquid reduceddensity=08442 NVE rcut= 25σ 5000stepsSpeedup ~ 3-4
Rhodopsin protein in solvated lipidbilayer CHARMM force field long-rangeCoulombics via PPPMSHAKEconstraints Counter-ions and reducedamount of water32K atoms 1000 timesteps LJ rcut= 1
nm neighbor skin of 10 σ NPTSpeedup ~ 17-3
Gay-Berne ellipsoids125 K atoms NVE rcut= 7σ 1000 stepsSpeedup ~ 9-11
Yona cluster
15 Nodes 2x6-core AMD Opteron 2435 (26GHz) amp 2 Tesla C2050 GPUs
3GB GDDR5 memory 448 cores (115GHz) memory bandwidth 144GBs
GPUs are connected on PCIx16 gen 20 slots ECC support enabled
Mellanox MT26428 QDR InfiniBand interconnect
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1729
Single vs Double Precision (lib compile option)
Force kernels can be compiled to use single double or mixed
precision
The drawback of double precision for memory-bound kernelsis that twice as many bytes must be fetched for cutoff
evaluation
A potential solution is to use mixed precision In this case thepositions are stored in single precision but accumulation and
storage of forces torques energies and virials is performed in
double precision
Because this memory access occurs outside the loop the
performance penalty for mixed precision is very small
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N TharringtonComp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
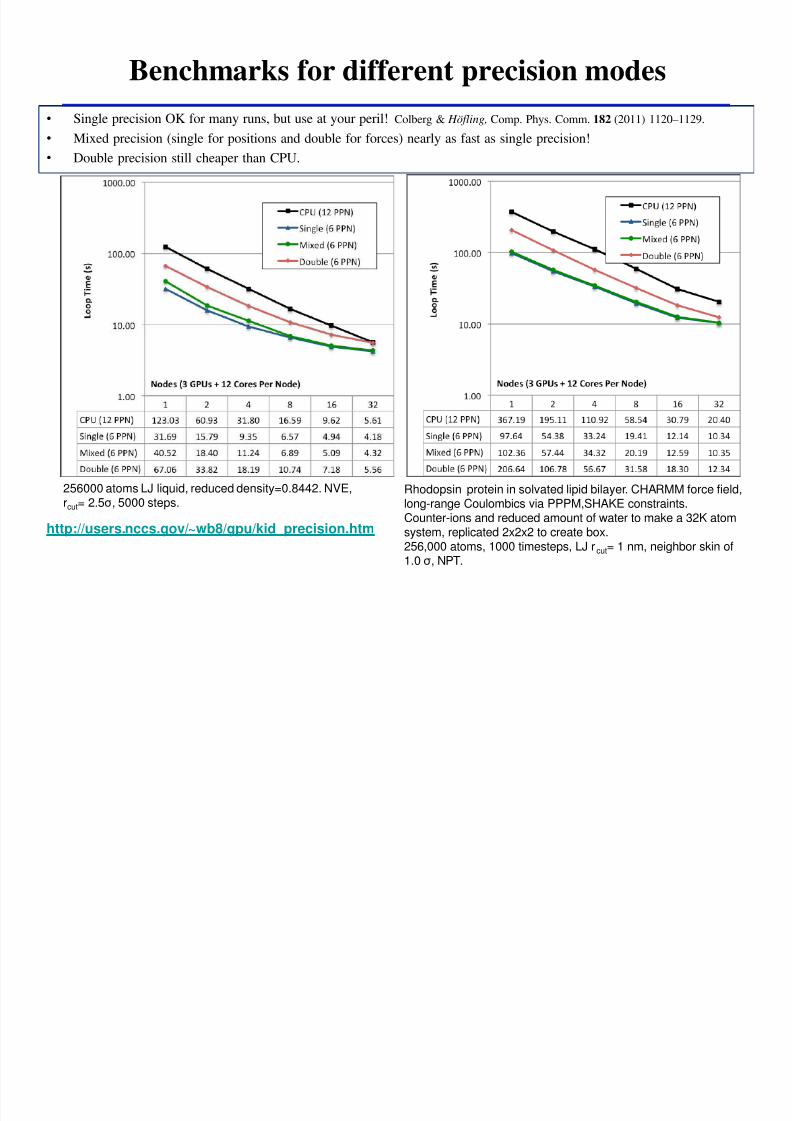
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1829
Benchmarks for different precision modes
httpusersnccsgov~wb8gpukid_precisionhtm
256000 atoms LJ liquid reduced density=08442 NVErcut= 25σ 5000 steps
Rhodopsin protein in solvated lipid bilayer CHARMM force fieldlong-range Coulombics via PPPMSHAKE constraintsCounter-ions and reduced amount of water to make a 32K atom
system replicated 2x2x2 to create box256000 atoms 1000 timesteps LJ rcut= 1 nm neighbor skin of10 σ NPT
bull Single precision OK for many runs but use at your peril Colberg amp Houmlfling Comp Phys Comm 182 (2011) 1120ndash1129
bull Mixed precision (single for positions and double for forces) nearly as fast as single precision
bull Double precision still cheaper than CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 1929
Review on LAMMPS GPU implementation
Discussion of several important issues in porting a large
molecular dynamics code for use on parallel hybrid machines
Objectives
a) Minimize the amount of code that must be ported forefficient acceleration
b) Utilize the available processing power from both multi-core
CPUs and accelerators
Presents results on a parallel test cluster containing 32 Fermi
GPUs and 180 CPU cores
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2029
Parallel and CPUGPU Decomposition
Multiple MPI processes (CPU cores) can share single
accelerator (GPU)
User can choose fixed load balance between CPU amp GPU for
the calculation of short range forces
Dynamic load balancing can also be chosen GPU force calculation
Neighbor list can be carried out in GPU or CPU
Time integration represents only small computational cost and
it is carried out in CPU
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2129
Fixed or Dynamic Load balancing
Fixed load balancing setting the CPU core to accelerator ratio and by
setting the fraction of particles that will have forces calculated by the
accelerator
Consider a job run with 4 MPI processes on a node with 2 accelerator
devices and the fraction set to 07 At each timestep each MPI process will
place data transfer of positions kernel execution of forces and datatransfer of forces into the device (GPU) queue for 70 of the particles
At the same time data is being transferred and forces are being calculated
on the GPU the MPI process will perform force calculations on the CPU
Ideal fraction CPU time = GPU time for data transfer and kernel
execution dynamic balancing with calculation of optimal fraction based
on CPUGPU timing at some timestep interval
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
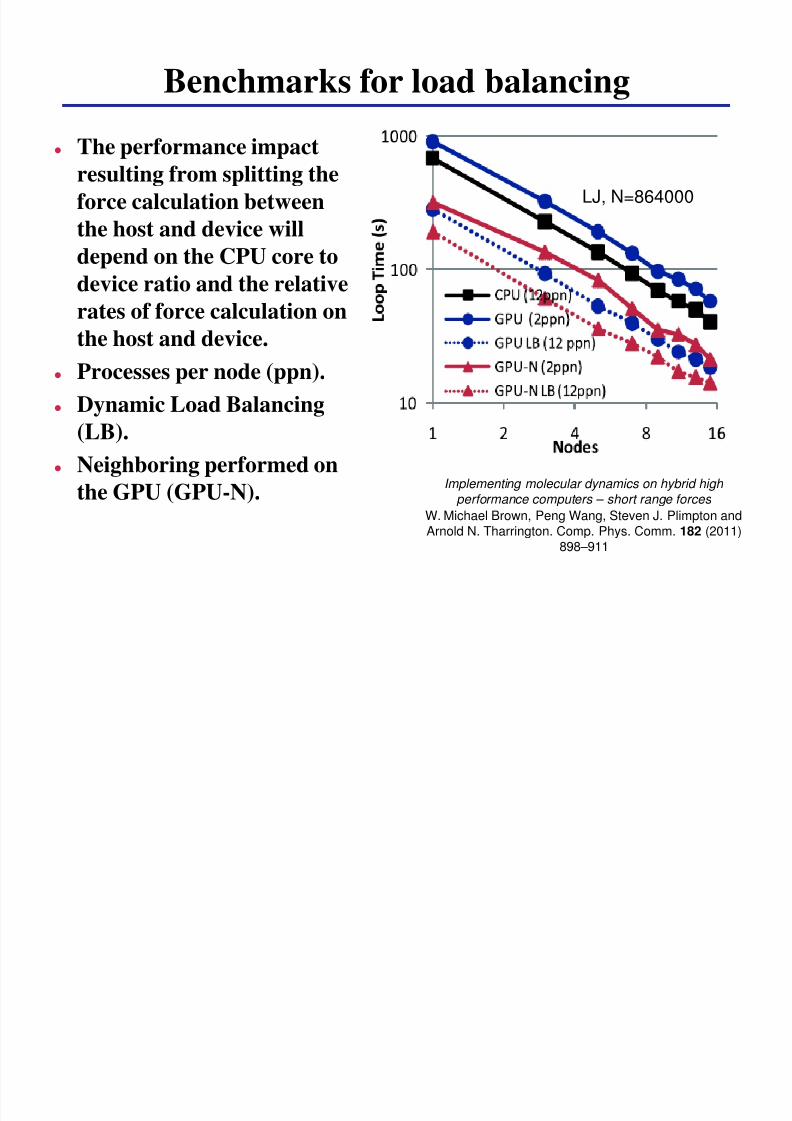
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2229
Benchmarks for load balancing
The performance impact
resulting from splitting the
force calculation between
the host and device will
depend on the CPU core to
device ratio and the relative
rates of force calculation on
the host and device
Processes per node (ppn)
Dynamic Load Balancing
(LB) Neighboring performed on
the GPU (GPU-N)
LJ N=864000
Implementing molecular dynamics on hybrid high
performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and
Arnold N Tharrington Comp Phys Comm 182 (2011)
898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
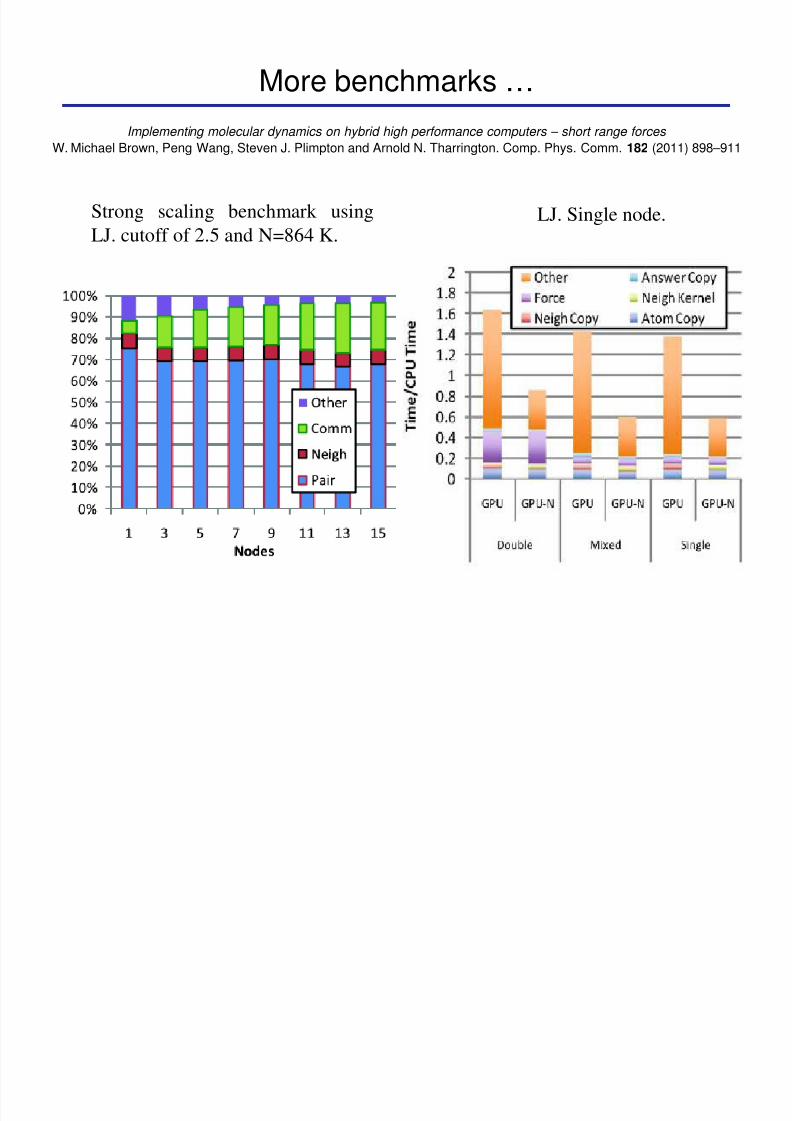
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2329
More benchmarks hellip
Strong scaling benchmark usingLJ cutoff of 25 and N=864 K LJ Single node
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
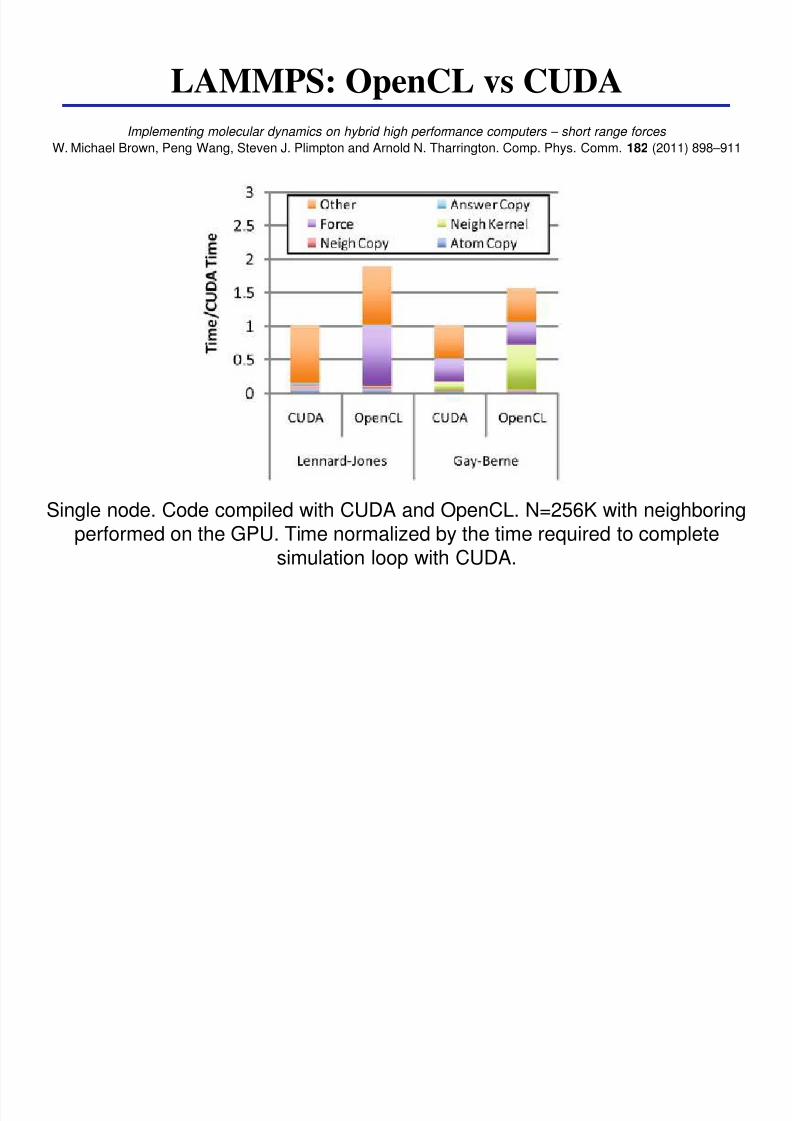
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2429
LAMMPS OpenCL vs CUDA
Single node Code compiled with CUDA and OpenCL N=256K with neighboring
performed on the GPU Time normalized by the time required to completesimulation loop with CUDA
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
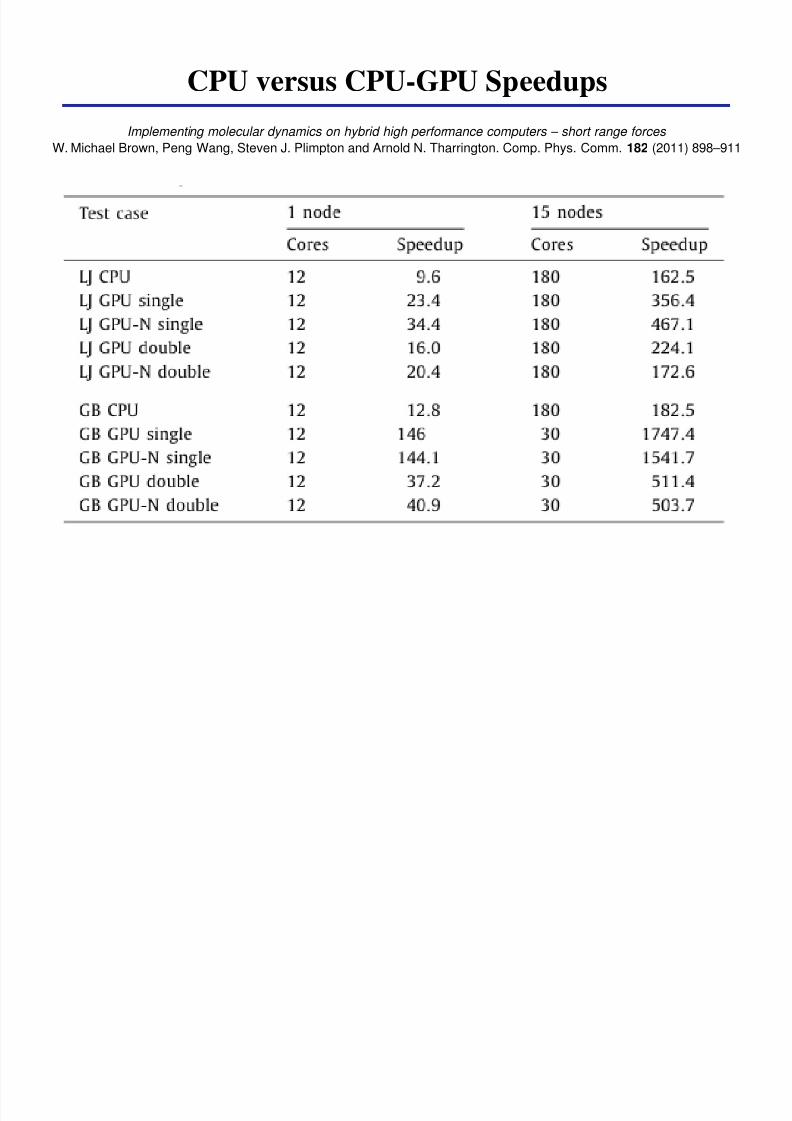
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2529
CPU versus CPU-GPU Speedups
Implementing molecular dynamics on hybrid high performance computers ndash short range forces
W Michael Brown Peng Wang Steven J Plimpton and Arnold N Tharrington Comp Phys Comm 182 (2011) 898ndash911
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248

8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2629
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
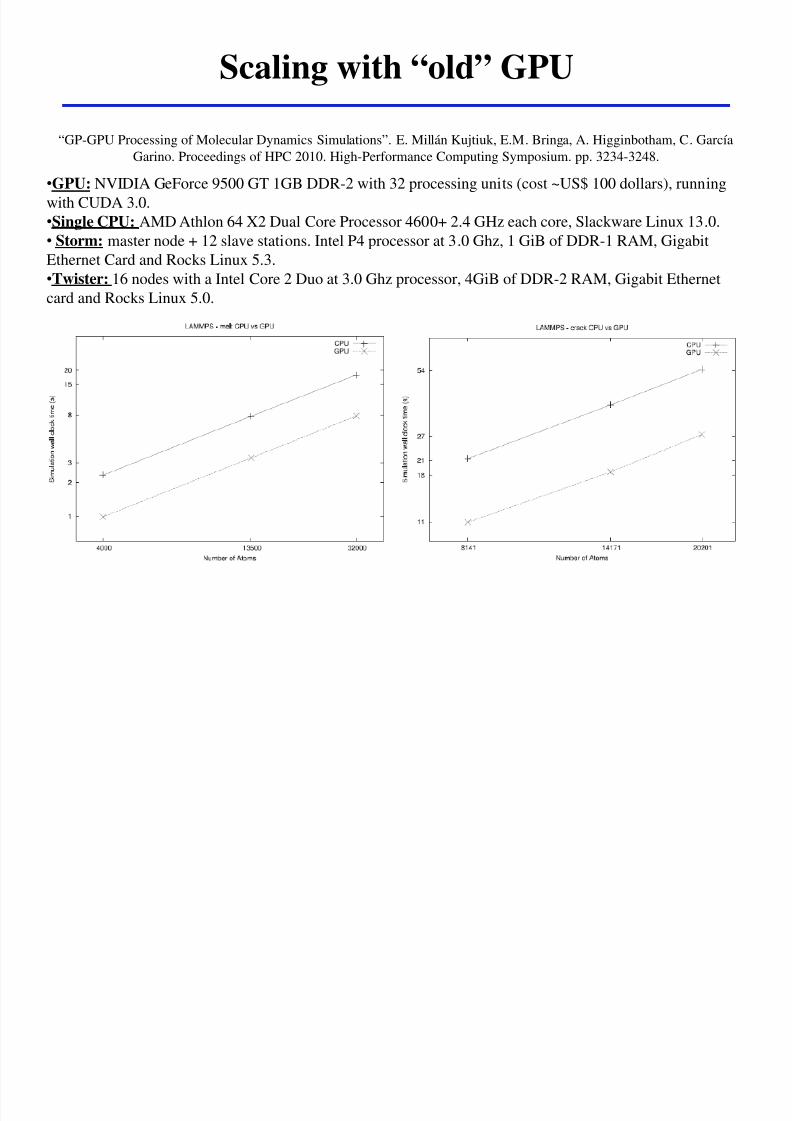
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2729
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
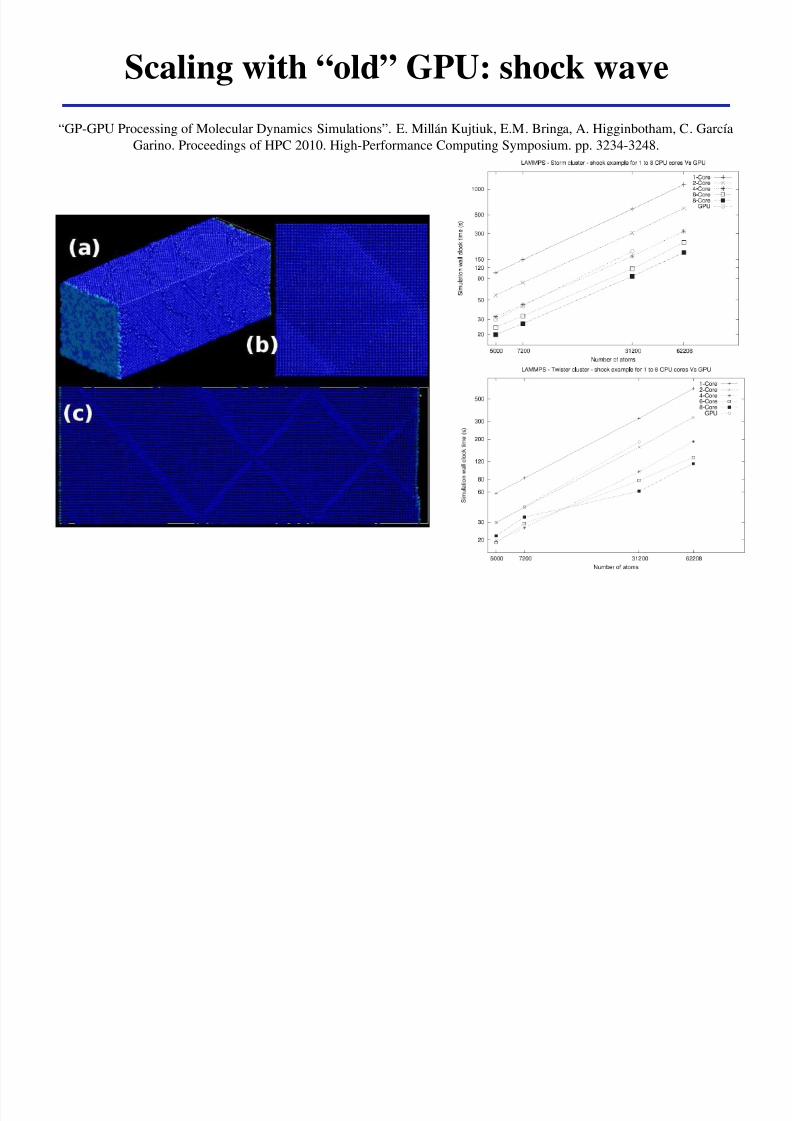
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2829
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248
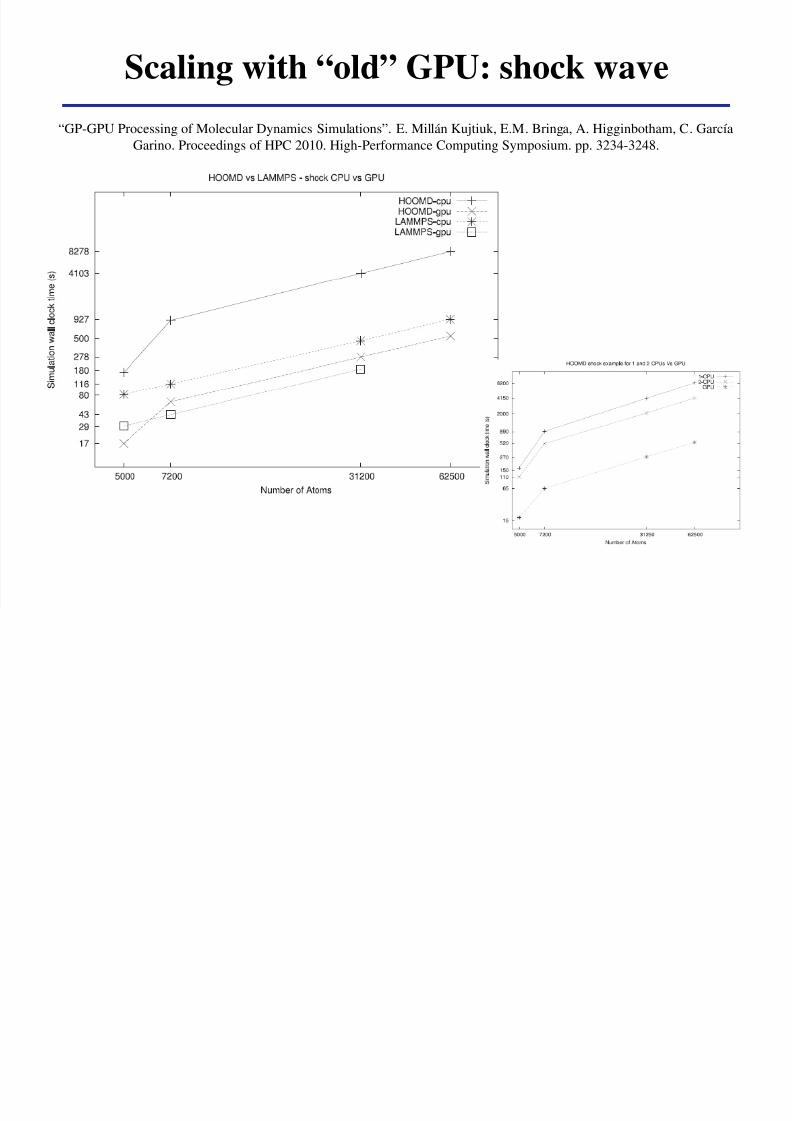
8162019 MD Bringa Comahue 2012 4 GPU
httpslidepdfcomreaderfullmd-bringa-comahue-2012-4-gpu 2929
Scaling with ldquooldrdquo GPU shock wave
ldquoGP-GPU Processing of Molecular Dynamics Simulationsrdquo E Millaacuten Kujtiuk EM Bringa A Higginbotham C Garciacutea
Garino Proceedings of HPC 2010 High-Performance Computing Symposium pp 3234-3248





























