Embed Size (px)
Citation preview

Cicero’s Hardest Sentence?:
Measuring Readability for Latin Literature with CLTK
Patrick J. BurnsInstitute for the Study of the Ancient World
Classical Language ToolkitGlobal Philology Open Conference. Universität Leipzig 22.02.17

Classical Language Toolkit

The Classical Language Toolkit (CLTK) is a free and open-source Python package that offers natural language processing (NLP) support for the languages of Ancient, Classical, and Medieval Eurasia.
Language-specific tokenizers, lemmatizers, POS-taggers, morphological parsers, etc. are available, under development, or in the feature-request list. Latin and Greek functionality are currently most complete.
What is the Classical Language Toolkit?

● Open-source community collaborating at https://github.com/cltk
● Founded by Kyle P. Johnson, Classics PhD from NYU and NLP Research Scientist at Accenture
● Academic Advisors: Gregory Crane (Leipzig/Tufts) , Neil Coffee (Buffalo), Peter Meineck (NYU), Leonard Muellner (Brandeis/CHS)
● CLTK Archive developer: Luke Hollis
Who is the Classical Language Toolkit?

CLTK Goals
● Low: Good analysis-friendly corpora/datasets for NLP of historical languages (Latin, Ancient/Classical Greek, Egyptian hieroglyphs, Hebrew, Sanskrit, Tibetan, Classical Chinese, etc.)

CLTK Goals
● Low: Good analysis-friendly corpora/datasets for NLP of historical languages (Latin, Ancient/Classical Greek, Egyptian hieroglyphs, Hebrew, Sanskrit, Tibetan, Classical Chinese, etc.)
● Medium: Collect & generate linguistic data for quantified classics

CLTK Goals
● Low: Good analysis-friendly corpora/datasets for NLP of historical languages (Latin, Ancient/Classical Greek, Egyptian hieroglyphs, Hebrew, Sanskrit, Tibetan, Classical Chinese, etc.)
● Medium: Collect & generate linguistic data for quantified classics
● High: Framework for an integrated study of the ancient world

CLTK Stats
● Began 2014● 1,702 commits at https://github.com/cltk/cltk● 38 contributors● 43 watchers, 166 stars, 117 forks● 37 people, 18 teams● 46 releases (with Zenodo DOI for every release)● 83% code coverage● Supports POSIX OS (and partially Windows)● 2016 Google Summer of Code participating organization (with
application in for 2017)

Google Summer of Code 2016
● CLTK work onBackoff Latin Lemmatizer
● Modeled afterNLTK Backoff POS Tagger
● Series of trained and rules-based lemmatizers run in sequence
● Can be “tuned” for specific languages

Classic Readability

What is Classic Readability?
“[Readability] is the sum total (including the interactions) of all those elements within a given piece of printed material that affects the success that a group of readers have with it. The success is the extent to which they understand it, read it at an optimum speed, and find it interesting.”—Edgar Dale & Jeanne Chall
Dale, E. & Chall, J. 1949. “The Concept of Readability,” Elementary English 26: 19-26.

Classic Readability
Classic readability refers to the measurement of relative ease or difficulty of reading material through two main measurements:
● Sentence complexity (e.g. number of words)● Lexical difficulty

Sentence length and difficulty
Hoole, C. 1658. Sententiae pueriles anglo-latinae. London.

Sentence length and difficulty
Hoole, C. 1658. Sententiae pueriles anglo-latinae. London.
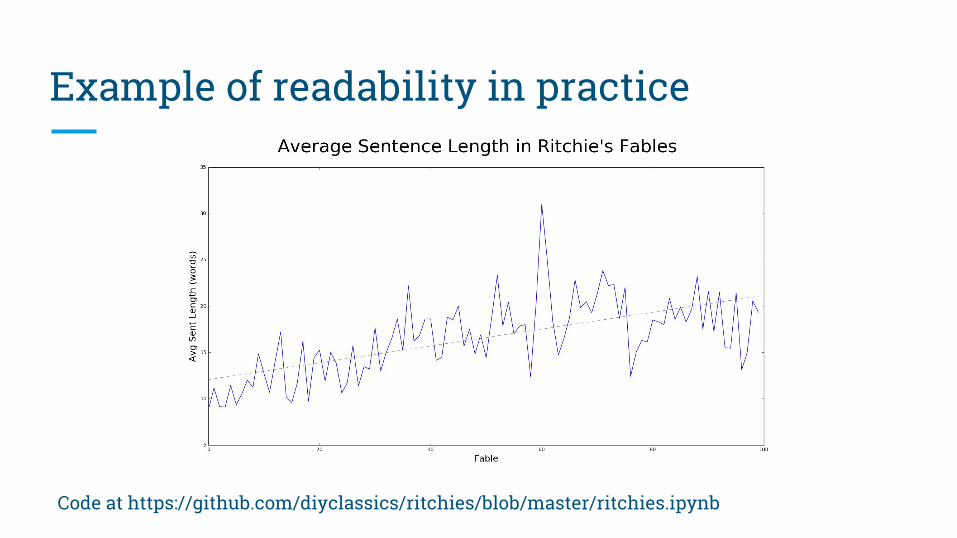
Example of readability in practice
Code at https://github.com/diyclassics/ritchies/blob/master/ritchies.ipynb

Example of readability in practice
Wheelock’s Latin Chapter 1 Sententiae Antiquae● 3.5 words per sentence● 19.2 characters per sentence● 5.49 char./word per sentence
Wheelock’s Latin Chapter 40 Sententiae Antiquae● 11.75 words per sentence● 73.65 characters per sentence● 6.27 char./word per sentence

Latin Readability Goals
Long-term goals of this project are:
1. to develop objective measurements for comparing different Latin authors, works, parts of works, etc.
2. to use comparative measurements to allow students to be matched with reading material at an appropriate level, but especially to help emergent readers move from textbooks to reading Latin texts with the least amount of difficulty.
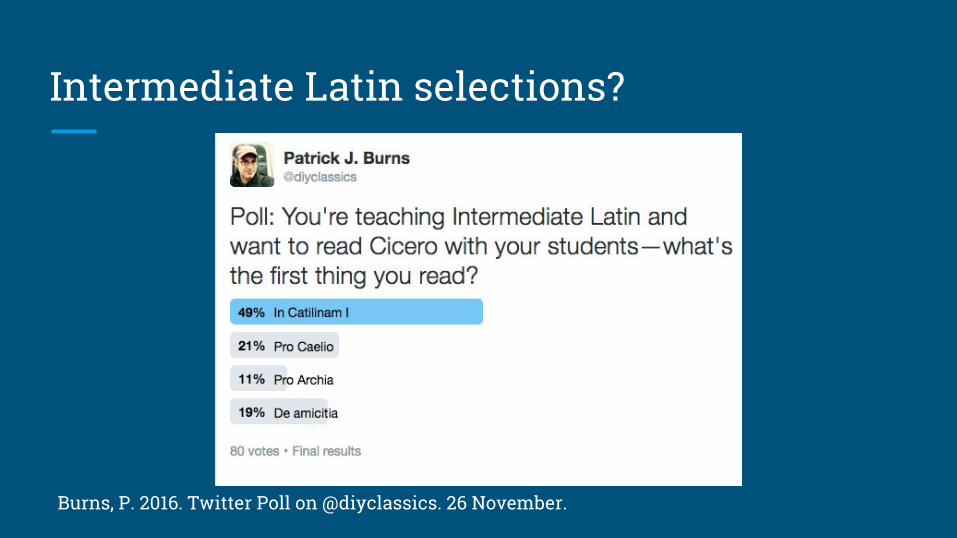
Intermediate Latin selections?
Burns, P. 2016. Twitter Poll on @diyclassics. 26 November.

Key CLTK code for readability
from cltk.tokenize.sentence import TokenizeSentencefrom cltk.tokenize.word import WordTokenizer
sent_tokenizer = TokenizeSentence('latin')word_tokenizer = WordTokenizer('latin')

Key CLTK code for readabilitydef sent_count(text): sents = sent_tokenizer.tokenize(text) return(len(sents))
def word_count(text): words = word_tokenizer.tokenize(text) return(len(words))
def char_count(text): return len(text)
def syll_count(text): return sum(letter in 'aeiouy' for letter in text.lower())
def comp_word_count(text): words = text.split() comp_words = [word for word in words if syll_count(word) > 3] return len(comp_words)

Automated Readability Index
Senter, R.J. & Smith, E.A. 1967. “Automated Readability Index.”. Wright-Patterson AFB: iii.via https://en.wikipedia.org/wiki/Automated_readability_index

Key CLTK code for readability
# Automated Readability Index
def ari(text): c, w, s = char_count(text), word_count(text), sent_count(text) score = 4.71 * (c / w) + 0.5 * (w / s) - 21.43 return score

Key CLTK code for readabilitydef fleschkincaid(text): w, s, sy = word_count(text), sent_count(text), syll_count(text) score = (0.39 * (w / s)) + (11.8 * (sy / w)) - 15.59 return score
def gunningfog(text): w, s, cw = word_count(text), sent_count(text), comp_word_count(text) score = 0.4 * ((w / s) + (100 * (cw / w))) return score
def coleman_liau(text): c, w, s = char_count(text), word_count(text), sent_count(text) cs, ss = (c / w) * 100, (s / w) * 100 score = (0.0588 * cs) - (0.296 * ss) - 15.8 return score
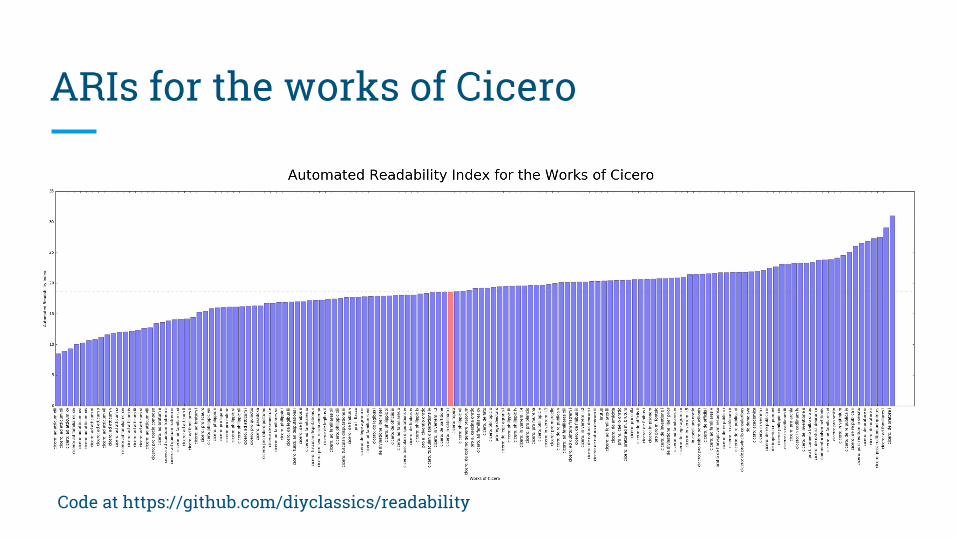
ARIs for the works of Cicero
Code at https://github.com/diyclassics/readability
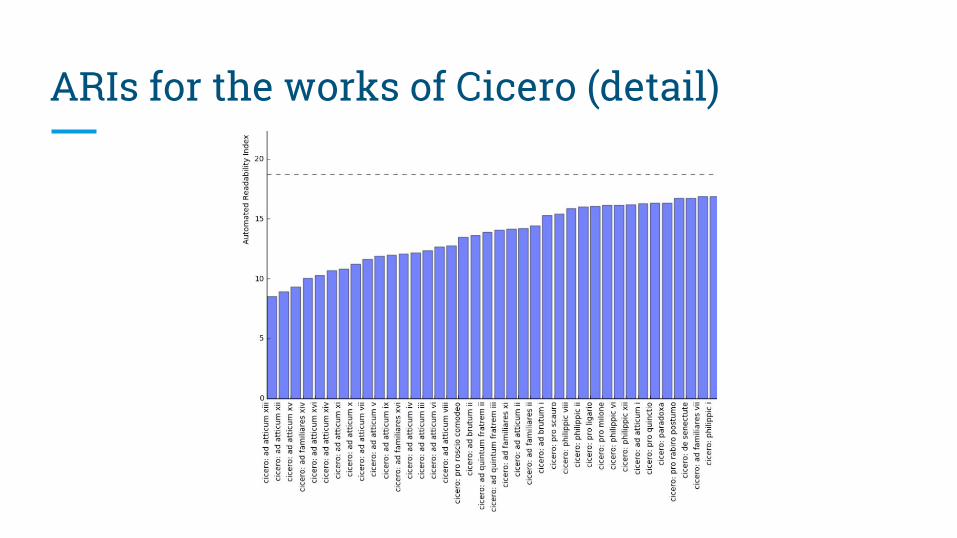
ARIs for the works of Cicero (detail)
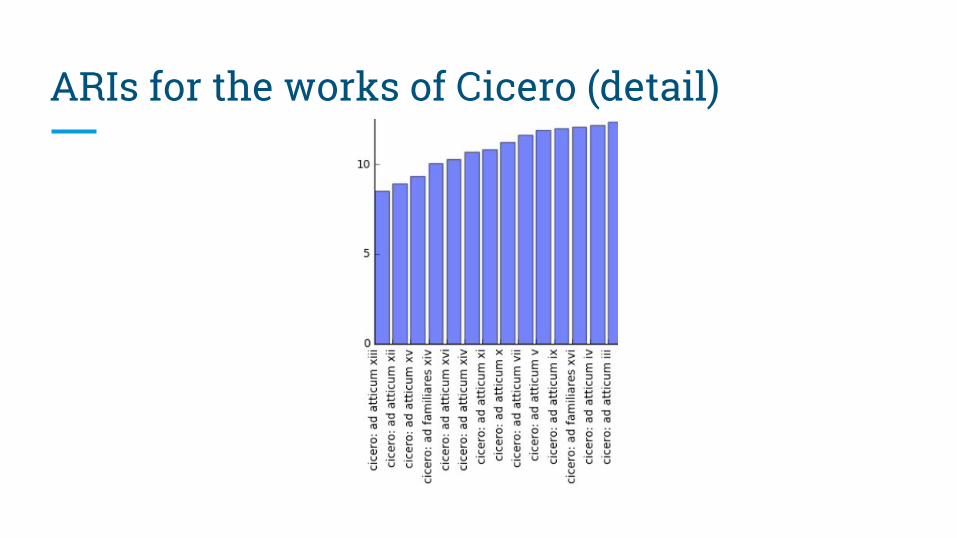
ARIs for the works of Cicero (detail)

Dale-Chall Readability Formula
Dale E. & Chall J. 1948. “A Formula for Predicting Readability.” Edu. Research Bulletin 27: 11–20.via https://en.wikipedia.org/wiki/Dale–Chall_readability_formula

Key CLTK code for readability
def difficult_words(text): # Based on DCC Core Vocabulary tokens = word_tokenizer.tokenize(text) lemmas = lemmatizer.lemmatize(tokens) difficult_words = [lemma for lemma in lemmas if lemma not in dcc_lemmas_simple] return len(difficult_words)
def dalechall(text): w, s, dw = word_count(text), sent_count(text), difficult_words(text) return (0.1579 * ((dw / w) * 100)) + (0.0496 * (w / s))
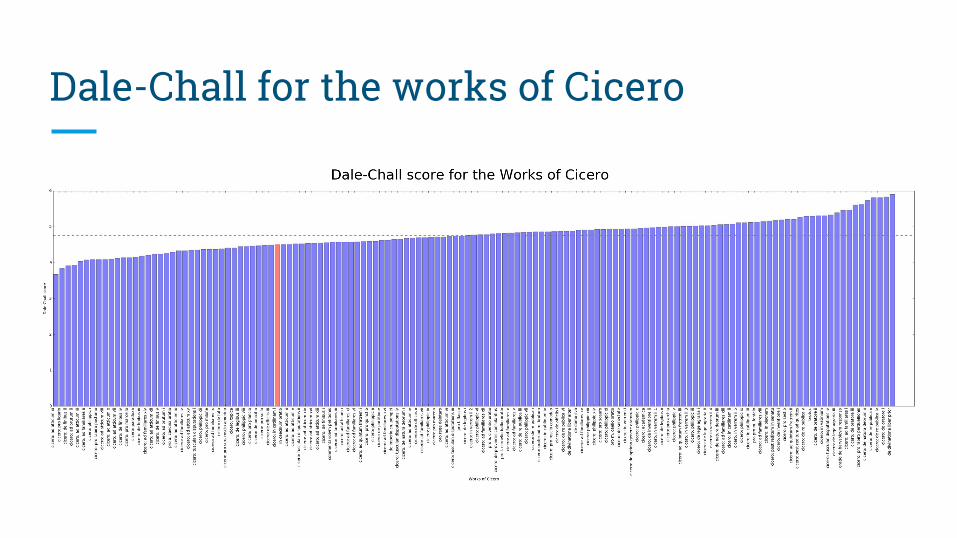
Dale-Chall for the works of Cicero
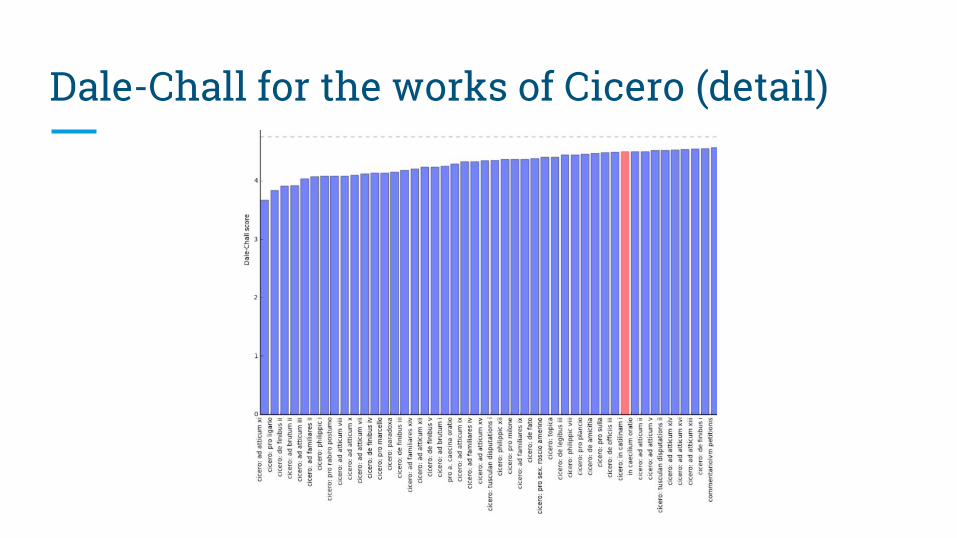
Dale-Chall for the works of Cicero (detail)
Dale-Chall for the works of Cicero (detail)

Conclusion

So, if we look at formal features likeword & sentence length...
What is the hardest sentence in Cicero?

De oratore 3.202-205?

Cicero’s Hardest Sentence
Nam et commoratio una in re permultum movet et inlustris explanatio rerumque quasi gerantur sub aspectum paene subiectio quae et in exponenda re plurimum valent et ad inlustrandum id quod exponitur et ad amplificandum ut eis qui audient illud quod augebimus quantum efficere oratio poterit tantum esse videatur et huic contraria saepe percursio est et plus ad intellegendum quam dixeris significatio et distincte concisa brevitas et extenuatio et huic adiuncta inlusio a praeceptis caesaris non abhorrens et ab re digressio in qua cum fuerit delectatio tum reditus ad rem aptus et concinnus esse debebit propositioque quid sis dicturus et ab eo quod est dictum seiunctio et reditus ad propositum et iteratio et rationis apta conclusio tum augendi minuendive causa veritatis supralatio atque traiectio et rogatio atque huic finitima quasi percontatio eitioque sententiae suae tum illa quae maxime quasi inrepit in hominum mentis alia dicentis ac significantis dissimulatio quae est periucunda cum orationis non contentione sed sermone tractatur deinde dubitatio tum distributio tum correctio vel ante vel postquam dixeris vel cum aliquid a te ipso reicias praemunitio etiam est ad id quod adgrediare et traiectio in alium communicatio quae est quasi cum eis ipsis apud quos dicas deliberatio morum ac vitae imitatio vel in personis vel sine illis magnum quoddam ornamentum orationis et aptum ad animos conciliandos vel maxime saepe autem etiam ad commovendos personarum ficta inductio vel gravissimum lumen augendi descriptio erroris inductio ad hilaritatem impulsio anteoccupatio tum duo illa quae maxime movent similitudo et exemplum digestio interpellatio contentio reticentia commendatio vox quaedam libera atque etiam effrenatio augendi causa iracundia obiurgatio promissio deprecatio obsecratio declinatio brevis a proposito non ut superior illa digressio purgatio conciliatio laesio optatio atque exsecratio.

Cicero’s Hardest Sentence
● 1919 characters● 280 words● 6.85 characters per word● almost 2 pages in LCL

Challenges with historical languages
Latin, classical Greek, and other historical languages present unique challenges when approaching readability. Some main difficulties are:● Fewer expert readers (and no native readers)● All Latin/Greek words are learned in formal educational
contexts● Compressed timeline for developing “proficiency”● Much less standardized testing data for comparison and
cross-validation

Next steps
Some ideas of where to go next with readability studies for Latin/Greek:● Identification / development of "criterion passages"● i.e. passages rated on an "independent measure such as a test of
reading comprehension, rate of reading, or judgments of difficulty.
● Improved, expanded word lists● Increase attention to the role of the other primary domains of
readability studies: the reader and the context.

Conclusion
“It should be remembered that readability formulas estimate difficulty on the basis of factors that have the highest prediction of difficulty. ...No readability formula is a complete and full measure of text difficulty.” —Jeanne Chall & Edgar Dale
Dale, E. & Chall, J. 1995. Readability revisited. Northampton, MA.

Select BibliographyAnderson, J. 1983. “Lix and Rix: Variations on a Little-Known Readability Index.” Journal of Reading 26 (6): 490–496.Bamberger, R. and A. T. Rabin. 1984. “New Approaches to Readability: Austrian Research.” The Reading Teacher 37 (6): 512–519.Björnsson, C. H. 1983. “Readability of Newspapers in 11 Languages.” Reading Research Quarterly 18 (4): 480–497.Chall, J. S. and E. Dale. 1995. Readability Revisited: The New Dale-Chall Readability Formula. Northampton, MA: Brookline Books.Coleman, M. and Liau, T. L. 1975. “A Computer Readability Formula Designed for Machine Scoring,” Journal of Applied Psychology 60: 283–284.Dale, E. and J. S. Chall. 1948. “A Formula for Predicting Readability.” Educational Research Bulletin 27 (1): 11–28.———. 1949. “The Concept of Readability.” Elementary English 26 (1): 19–26.Flesch, R. 1948. “A New Readability Yardstick.” Journal of Applied Psychology 32 (3): 221–233. doi:10.1037/h0057532.Gunning, R. 1952. The Technique of Clear Writing. New York: McGraw-Hill.Ireland, S. 1976. “The Computer and Its Role in Classical Research.” G&R 23 (1): 40–54.Janson, T. 1967. “Word, Syllable, and Letter in Latin.” Eranos 65: 49–64.Moritz, M., G. Franzini, G. Crane, and B. Pavlek. 2016. “Sentence Shortening via Morpho-Syntactic Annotated Data in Historical Language Learning.” JCCH 9 (1): 1–9. doi:10.1145/2810040.Muccigrosso, J. D. 2004. “Frequent Vocabulary in Latin Instruction.” CW 97 (4): 409–433. doi:10.2307/4352875.Rabin, A. T. 1988. “Determining Difficulty Levels in Text Written in Languages Other than English.” In B. L. Zakaluk and S. J. Samuels, 46–76. Newark, DE: International Reading Association.Rydberg-Cox, J. A, and A. Mahoney. 2002. “Vocabulary Building in the Perseus Digital Library.” CO 79 (4): 145–149.Saragi, T., I. S. P. Nation, and G. F. Meister. 1978. “Vocabulary Learning and Reading.” System 6 (2): 72–78. doi:10.1016/0346-251X(78)90027-1.Senter, R. J., and E. A. Smith. 1967. “Automated Readability Index.” AMRL-TR-66-22. Wright Patterson AFB, Ohio: Aerospace Medical Div.Zakaluk, B. L., and S. J. Samuels. 1988. Readability: Its Past, Present, and Future. Newark, DE: International Reading Association.

Cicero’s Hardest Sentence?:
Measuring Readability for Latin Literature with CLTK
Patrick J. BurnsInstitute for the Study of the Ancient World
Classical Language ToolkitGlobal Philology Open Conference. Universität Leipzig 22.02.17





























