Embed Size (px)
Citation preview

Esercizi di ripasso
Monica Marabelli
22 Gennaio 2016

Esercizio 1
Tre diverse diete sono state testate per valutare la loro efficacianel determinare una diminuzione di peso. Verifica se almenouna delle diete porta a una significativa diminuzione nel peso.Nel file dieta.xls é riportata la variazione di peso per i gruppistudiati. Qual é la dieta piú efficace?

Leggiamo i datiInnanzitutto creiamo un file che possa essere letto con R(dieta.csv ; vedere presentazione "Convertire_file_.xls_in_.csv")
Leggiamo il file:
setwd("X:/")dati <- read.table (file="dieta.csv",
header=T, sep=",", dec=".")head(dati)
dieta variazione1 1 5.02 1 4.53 1 4.04 1 3.05 1 4.36 1 3.0

Trasformiamo i dati nel formato corretto
str(dati)
’data.frame’: 40 obs. of 2 variables:$ dieta : Factor w/ 4 levels "1","2","3","c": 1 1 1 1 1 1 1 1 1 1 ...$ variazione: num 5 4.5 4 3 4.3 3 4 4 5 3.5 ...
La variabile di risposta (quantitativa) é variazione.La variabile esplicativa (qualitativa) o fattore é dieta. Se la dietanon fosse un fattore, dovrei trasformarla.

Visualizziamo graficamente i dati
Effettuiamo una valutazione grafica dei dati
boxplot(dati$variazione~dati$dieta, data=dati)

ANOVA a una via
Effettuiamo l’ANOVA a una via
mod1 <- aov (lm(variazione~dieta, data=dati))summary(mod1)
Df Sum Sq Mean Sq F value Pr(>F)dieta 3 50.46 16.819 5.857 0.0023 **
Residuals 36 103.38 2.872– – –Signif. codes: 0 `***´ 0.001 `**´ 0.01 `*´ 0.05 `.´ 0.1 ` ´ 1
Pvalue < 0.05: c’é almeno una coppia di medie la cui differenzaé statisticamente significativa.

Test post hoc
Per individuare quali sono le medie significativamente diversetra loro, applichiamo il test HSD (honest significant difference)di Tukey
TukeyHSD (mod1)
Tukey multiple comparisons of means95% family-wise confidence level
Fit: aov(formula = lm(variazione ~ dieta, data = dati))
$dietadiff lwr upr p adj
2-1 -0.43 -2.471066 1.61106623 0.94110753-1 0.37 -1.671066 2.41106623 0.9612255c-1 -2.53 -4.571066 -0.48893377 0.01015473-2 0.80 -1.241066 2.84106623 0.7181886c-2 -2.10 -4.141066 -0.05893377 0.0417589c-3 -2.90 -4.941066 -0.85893377 0.0026888

Verifica degli assunti
Procediamo ora alla verifica degli assunti
I normalitá dei residui entro gruppiI omoschedasticitá dei residui entro gruppi (uguali varianze)I indipendenza dei residui entro gruppi

Normalitá dei residui
shapiro.test (resid(mod1)[dati$dieta == "1"])
Shapiro-Wilk normality testdata: resid(mod1)[dati$dieta == "1"]W = 0.9233, p-value = 0.3849
shapiro.test (resid(mod1)[dati$dieta == "2"])
Shapiro-Wilk normality testdata: resid(mod1)[dati$dieta == "2"]W = 0.9811, p-value = 0.9706

Normalitá dei residui
shapiro.test (resid(mod1)[dati$dieta == "3"])
Shapiro-Wilk normality testdata: resid(mod1)[dati$dieta == "3"]W = 0.9452, p-value = 0.6126
shapiro.test (resid(mod1)[dati$dieta == "c"])
Shapiro-Wilk normality testdata: resid(mod1)[dati$dieta == "c"]W = 0.85, p-value = 0.05804
Pvalue > 0.05. Non rifiutiamo l’ipotesi nulla che i residui sianodistribuiti normalmente.

Omoschedasticitá dei residui
bartlett.test (variazione~dieta , data=dati)
Bartlett test of homogeneity of variances
data: variazione by dietaBartlett’s K-squared = 12.4417, df = 3, p-value = 0.006014
Pvalue < 0.05: rifiutiamo l’ipotesi nulla che le varianze sianoomogenee.
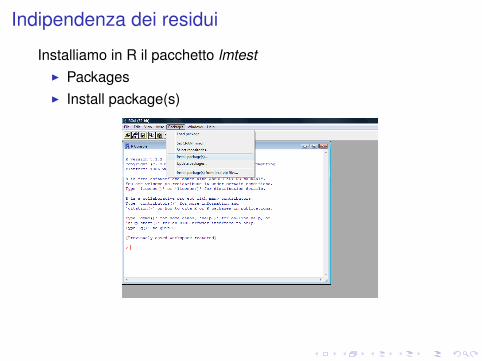
Indipendenza dei residui
Installiamo in R il pacchetto lmtestI PackagesI Install package(s)
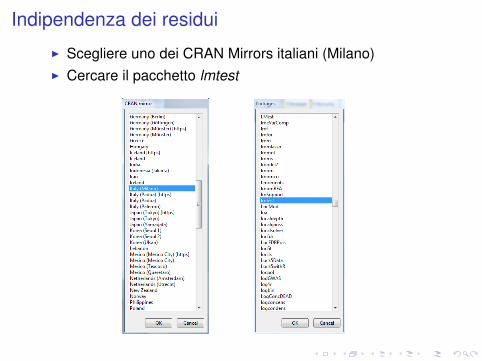
Indipendenza dei residui
I Scegliere uno dei CRAN Mirrors italiani (Milano)I Cercare il pacchetto lmtest

Indipendenza dei residui
library(lmtest) # Rendiamo disponibili le funzioni del pacchetto
Applichiamo il test di Durbin–Watson
dwtest (mod1)
Durbin-Watson test
data: mod1DW = 1.8119, p-value = 0.1362alternative hypothesis: true autocorrelation is greater than 0
Pvalue > 0.05: non rifiutiamo l’ipotesi nulla di indipendenza deiresidui.

Analisi non parametrica
Possiamo applicare il test di Kruskal-Wallis.
kruskal.test (variazione~dieta, data=dati)
Kruskal-Wallis rank sum test
data: variazione by dietaKruskal-Wallis chi-squared = 14.6652, df = 3, p-value = 0.002126
Pvalue < 0.05. Rifiuto l’ipotesi nulla: le diete hanno un effettosignificativamente diverso sul peso.

Esercizio 2
Horne e collaboratori hanno studiato il tasso di invasione di 7ceppi fungini su diversi tipi di mela.Valuta se il tasso di avanzamento fungino varia in relazione altipo di mela.

Leggiamo i datiI dati sono contenuti nel file apple.csv
setwd("Y:/STATISTICA")mela <- read.csv (file="apple.csv")str(mela)
’data.frame’: 35 obs. of 7 variables:$ apple : int 1 1 1 1 1 1 1 2 2 2 ...$ fungus : int 1 2 3 4 5 6 7 1 2 3 ...$ days : int 70 70 70 70 70 70 70 103 103 103 ...$ apple_weight: num 156 154 138 141 146 ...$ radius : num 3.66 3.65 3.51 3.53 3.58 3.6 3.81 3.07 3.05 ...$ advance : num 2.04 1.23 1.25 1.66 1.74 1.88 2.26 1.16 ...$ rate_advance: num 0.0291 0.0176 0.0179 0.0237 ...
La variabile di risposta (quantitativa) é rate_advance.La variabile esplicativa (qualitativa) o fattore é apple.

Trasformiamo i dati nel formato correttoPer poter effettuare l’ANOVA, la variabile esplicativa deveessere un fattore.
Ricordarsi di trasformare i dati prima di effettuare l’analisi!
mela$apple <- factor(mela$apple)str(mela)
’data.frame’: 35 obs. of 7 variables:$ apple : Factor w/ 5 levels "1","2","3","4",..: 1 1 1 1 1 1 1 2 2 ...$ fungus : int 1 2 3 4 5 6 7 1 2 3 ...$ days : int 70 70 70 70 70 70 70 103 103 103 ...$ apple_weight: num 156 154 138 141 146 ...$ radius : num 3.66 3.65 3.51 3.53 3.58 3.6 3.81 3.07 3.05 ...$ advance : num 2.04 1.23 1.25 1.66 1.74 1.88 2.26 1.16 ...$ rate_advance: num 0.0291 0.0176 0.0179 0.0237 ...

ANOVA a una via
Effettuiamo l’ANOVA a una via
mod2 <- aov(lm(rate_advance ~ apple, data=mela))summary(mod2)
Df Sum Sq Mean Sq F value Pr(>F)apple 4 0.003006 0.0007514 8.246 0.00013 ***
Residuals 30 0.002734 0.0000911– – –Signif. codes: 0 `***´ 0.001 `**´ 0.01 `*´ 0.05 `.´ 0.1 ` ´ 1
Pvalue < 0.05. Rifiuto l’ipotesi nulla: c’é almeno una coppia dimedie la cui differenza é statisticamente significativa.

ANOVA a blocchi randomizzati
Ipotizziamo ora che i dati siano raggruppati in blocchicorrispondenti ai diversi tipi di fungo utilizzati per l’esperimento.Effettuiamo l’ANOVA a blocchi randomizzati.

Trasformiamo i dati nel formato corretto
Trasformiamo in fattore la variabile fungus
mela$fungus <- factor(mela$fungus)str(mela)
’data.frame’: 35 obs. of 7 variables:$ apple : Factor w/ 5 levels "1","2","3","4",..: 1 1 1 1 1 1 1 2 2 ...$ fungus : Factor w/ 7 levels "1","2","3","4",..: 1 2 3 4 5 6 7 1 2...$ days : int 70 70 70 70 70 70 70 103 103 103 ...$ apple_weight: num 156 154 138 141 146 ...$ radius : num 3.66 3.65 3.51 3.53 3.58 3.6 3.81 3.07 3.05 ...$ advance : num 2.04 1.23 1.25 1.66 1.74 1.88 2.26 1.16 ...$ rate_advance: num 0.0291 0.0176 0.0179 0.0237 0.0249 ...

ANOVA a blocchi randomizzati
mod3 <- aov(lm(rate_advance ~ apple + fungus, data=mela))summary(mod3)
Df Sum Sq Mean Sq F value Pr(>F)apple 4 0.0030056 0.0007514 20.810 1.63e-07 ***
fungus 6 0.0018670 0.0003112 8.618 4.70e-05 ***Residuals 24 0.0008666 0.0000361
– – –Signif. codes: 0 `***´ 0.001 `**´ 0.01 `*´ 0.05 `.´ 0.1 ` ´ 1
H0 che il tasso di invasione dei ceppi fungini sia uguale neidiversi tipi di mela: rifiutata.
H0 che l’avanzamento fungino sia uguale tra i blocchi(corrispondenti ai diversi tipi di fungo): rifiutata.

Esercizio 3
E’ stato effettuato uno studio per valutare se l’efficacia dellepubblicitá é influenzata dal giorno della settimana e dallasezione del giornale dove sono pubblicate.Nel file giornale.csv sono riportati i dati relativi al numero dirichieste in base a giorno/sezione di pubblicazione sul giornale.

Leggiamo i dati
setwd("Y:/STATISTICA")paper <- read.csv (file="giornale.csv")head(paper)
Day Newspaper_section News1 Monday News 112 Monday News 83 Monday News 64 Monday News 85 Tuesday News 96 Tuesday News 10

Trasformiamo i dati nel formato corretto
str(paper)
’data.frame’: 60 obs. of 3 variables:$ Day : Factor w/ 5 levels "Friday","Monday",..: 2 2 2 2 4 4 4 4 ...$ Newspaper_section: Factor w/ 3 levels "Business","News",..: 2 2 ...$ News : int 11 8 6 8 9 10 10 12 8 9 ...
La variabile di risposta quantitativa é News; le variabiliesplicative qualitative sono Day e Newspaper_section, chesono giá espresse come fattori.

ANOVA a due vie
mod4 <- aov(lm(News ~ Newspaper_section*Day, data=paper))summary(mod4)
Df Sum Sq Mean Sq F value Pr(>F)Newspaper_section 2 53.73 26.87 15.304 8.50e-06 ***Day 4 146.83 36.71 20.910 8.52e-10 ***Newspaper_section:Day 8 135.77 16.97 9.667 1.12e-07 ***Residuals 45 79.00 1.76
– – –Signif. codes: 0 `***´ 0.001 `**´ 0.01 `*´ 0.05 `.´ 0.1 ` ´ 1
I risultati indicano che sia la sezione del giornale sia il giornodella settimana sia l’interazione dei due fattori hanno un effettosignificativo sull’efficacia della pubblicitá.

Esercizio 4E’ stato effettuato uno studio per valutare i fattori cheinfluenzano il costo dei libri. Tra i parametri presi inconsiderazione vi é il numero di pagine.
pagine costi373 15.23200 14.00150 8.80100 7.00300 13.00400 20.22327 14.00138 7.80
Testa la presenza di una relazione lineare tra numero di paginee costo del libro.

Esercizio 4Inseriamo i dati in OpenOffice Calc e creiamo un file che possaessere letto con R (libri.csv ).
setwd("X:/")libri <- read.table (file="libri.csv",
header=T,sep=",",dec=".")
str(libri)
’data.frame’: 8 obs. of 2 variables:$ pagine: int 373 200 150 100 300 400 327 138$ costi : num 15.2 14 8.8 7 13 ...
Se dovete fare un’analisi di regressione, le variabili devonoessere numeri e non fattori! Controllare sempre.

Visualizziamo i dati graficamenteLa varibile dipendente (di risposta) é il prezzo. La variabileindipendente (esplicativa) é il numero di pagine. Vediamo come é larelazione tra le due variabili con un grafico. C’é una relazione linearese i punti sono disposti su una linea retta.
plot(libri$pagine, libri$costi)# di solito si mette la variabile esplicativa sull’asse delle ascisse

CorrelazioneFacciamo il test di correlazione per vedere quanto é forte larelazione tra le due variabili.
cor.test (libri$pagine, libri$costi,method = "pearson")
Pearson’s product-moment correlation
data: libri$pagine and libri$costit = 5.4994, df = 6, p-value = 0.001516alternative hypothesis: true correlation is not equal to 095 percent confidence interval:0.5860659 0.9844555
sample estimates:cor
0.9134839
Pvalue < 0.05: il coefficiente di correlazione é significativamentediverso da 0.

Analisi di regressione
Visto che la correlazione é significativa, possiamo concludereche vi é una significativa relazione lineare tra le due variabili.
Possiamo allora utilizzare la regressione lineare permodellizzare la relazione tra X e Y.
Y = α+ βX + ε
dove:
β é la pendenza della retta.
α é l’intercetta con l’asse delle Y.

Analisi di regressione
fit1 <- lm(libri$costi~libri$pagine, data=libri)summary(fit1)
Call:lm(formula = libri$costi ~ libri$pagine, data = libri)
Residuals:Min 1Q Median 3Q Max
-1.6408 -1.2716 -0.5664 0.4108 3.1940
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.794610 1.727645 2.196 0.07045 .libri$pagine 0.035057 0.006375 5.499 0.00152 **
– – –Signif. codes: 0 `***´ 0.001 `**´ 0.01 `*´ 0.05 `.´ 0.1 ` ´ 1
Residual standard error: 1.95 on 6 degrees of freedomMultiple R-squared: 0.8345, Adjusted R-squared: 0.8069F-statistic: 30.24 on 1 and 6 DF, p-value: 0.001516

Analisi dell’output
La regressione é significativa (Pvalue = 0.00152).
Quali sono i valori di α e β?
fit1$coefficients
(Intercept) libri$pagine3.7946102 0.0350569
L’intercetta α = 3.79
Il coefficiente β = 0.035 corrisponde alla pendenza della retta.Questo significa che per ogni aumento di una pagina, il costodei libri aumenta di 0.035 euro.

Analisi dell’output
Calcoliamo anche l’intervallo di confidenza dei due parametriα e β
confint(fit1)
2.5 % 97.5 %(Intercept) -0.43278547 8.02200579
libri$pagine 0.01945864 0.05065516
Il coefficiente di determinazione R2 = 0.8345. Questo significache l’83% della variazione nella variabile dipendente (costo) éspiegato dalla variabile indipendente (pagine) utilizzando ilmodello di regressione lineare.
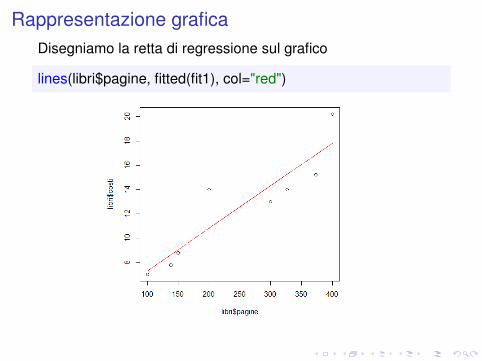
Rappresentazione graficaDisegniamo la retta di regressione sul grafico
lines(libri$pagine, fitted(fit1), col="red")
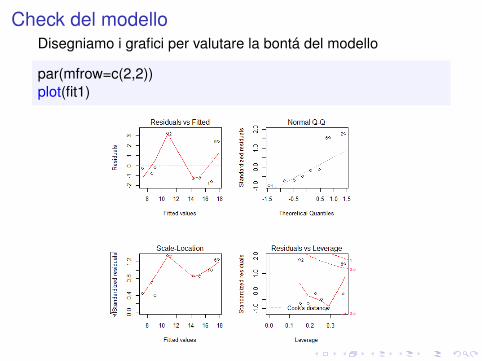
Check del modelloDisegniamo i grafici per valutare la bontá del modello
par(mfrow=c(2,2))plot(fit1)

Esercizio 5
Nel file aids.xls é riportato il numero di morti di AIDS nei primi20 anni della malattia. Valuta se vi é una relazione lineare tra ilnumero di diagnosticati e il numero di morti.

Leggiamo i datiCreiamo un file che possa essere letto con R (aids.csv ).
setwd("X:/")aids <- read.table (file="aids.csv",
header=T,sep=",",dec=".")
head(aids)
anno diagnosticati morti1 1981 319 1212 1982 1170 4533 1983 3076 14824 1984 6240 34665 1985 11776 68786 1986 19032 11987

Leggiamo i dati
Controlliamo come R ha letto i dati
str(aids)
’data.frame’: 22 obs. of 3 variables:$ anno : int 1981 1982 1983 1984 1985 1986 1987 1988 ...$ diagnosticati: int 319 1170 3076 6240 11776 19032 ...$ morti : int 121 453 1482 3466 6878 11987 16162 ...
La variabile dipendente (di risposta) é il numero di morti.La variabile indipendente (esplicativa) é il numero didiagnosticati.
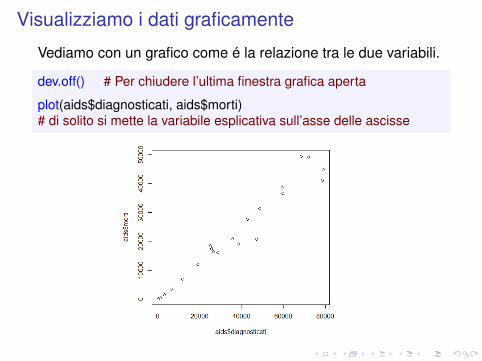
Visualizziamo i dati graficamente
Vediamo con un grafico come é la relazione tra le due variabili.
dev.off() # Per chiudere l’ultima finestra grafica aperta
plot(aids$diagnosticati, aids$morti)# di solito si mette la variabile esplicativa sull’asse delle ascisse

CorrelazioneFacciamo il test di correlazione per vedere quanto é forte larelazione tra le due variabili.
cor.test (aids$diagnosticati, aids$morti,method = "pearson")
Pearson’s product-moment correlation
data: aids$diagnosticati and aids$mortit = 19.4683, df = 20, p-value = 1.799e-14alternative hypothesis: true correlation is not equal to 095 percent confidence interval:0.9387435 0.9895941
sample estimates:cor
0.9746162
Pvalue < 0.05: il coefficiente di correlazione é significativamentediverso da 0.

Analisi di regressione
fit2 <- lm(aids$morti~aids$diagnosticati, data=aids)summary(fit2)
Call:lm(formula = aids$morti ~ aids$diagnosticati, data = aids)
Residuals:Min 1Q Median 3Q Max
-7988.7 -680.9 23.9 1731.3 7760.7
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 88.7161 1370.7191 0.065 0.949aids$diagnosticati 0.6073 0.0312 19.468 1.81e-14 ***
– – –Signif. codes: 0 `***´ 0.001 `**´ 0.01 `*´ 0.05 `.´ 0.1 ` ´ 1
Residual standard error: 3589 on 20 degrees of freedomMultiple R-squared: 0.9499, Adjusted R-squared: 0.9474F-statistic: 379 on 1 and 20 DF, p-value: 1.805e-14

Analisi dell’output
La regressione é significativa (Pvalue = 1.81e-14).
Quali sono i valori di α e β?
fit2$coefficients
(Intercept) libri$pagine88.7160988 0.6073514
L’intercetta α = 88.7
Il coefficiente β = 0.6 corrisponde alla pendenza della retta.Questo significa che per ogni aumento di una unitá nel numerodi diagnosticati, il numero di morti aumenta di 0.6 unitá.

Analisi dell’output
Calcoliamo anche l’intervallo di confidenza dei due parametriα e β
confint(fit2)
2.5 % 97.5 %(Intercept) -2770.5538947 2947.986092
aids$diagnosticati 0.5422759 0.672427
Il coefficiente di determinazione R2 = 0.9499. Questo significache il 95% della variazione nella variabile dipendente (morti) éspiegato dalla variabile indipendente (diagnosticati) utilizzandoil modello di regressione lineare.
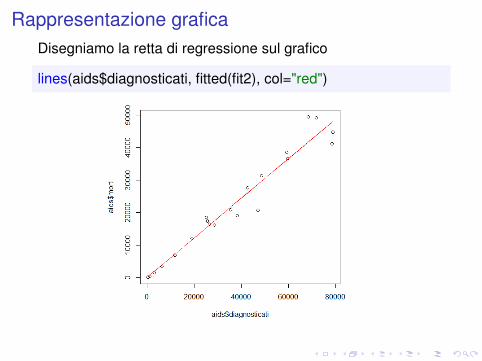
Rappresentazione graficaDisegniamo la retta di regressione sul grafico
lines(aids$diagnosticati, fitted(fit2), col="red")
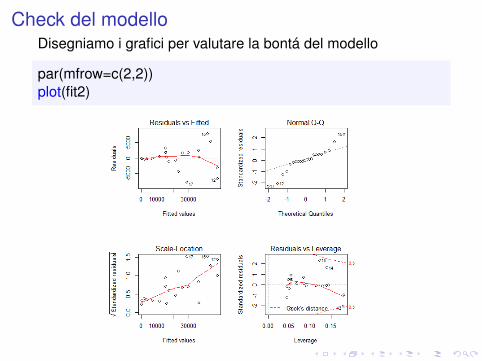
Check del modelloDisegniamo i grafici per valutare la bontá del modello
par(mfrow=c(2,2))plot(fit2)





























