Embed Size (px)
Citation preview


Beyond Blobs
The ‘imager’s fallacy’ and how to avoid it

Neuroscientists – Fishers of Blobs?

Neuroscientists – Fishers of Blobs?
A blob = a “result” that you can publish. You should be able to interpret the meaning of each blob (in terms of
localized function). Blobs are the first thing you should look for, and the final goal of your
analysis

What is a “Blob”?
An area activated by a task?

What is a “Blob”?
An area activated by a task?
An area where task-related activity fits a model?

What is a “Blob”?
An area activated by a task?
An area where task-related activity fits a model?
An area where task-related activity fits a model well enough to pass an arbitrary threshold.

Blobs Are Important Blobs (thresholding) serve a very important
purpose.
Whole-brain corrected blobs (FDR or FWE corrected) are evidence that ‘something is going on’.
To adopt a looser standard (e.g. p < 0.001 uncorrected) was the sin of the Dead Salmon (Bennet et al.)

Blobs Are Not Representative
Significantly activated voxels are not representative of activated areas.
This is the problem of voodoo correlations aka double dipping, circularity, non-independence
Vul et al. showed the error of treating significantly activated blobs (or, even worse, peaks within blobs) as representative of anything (they’re not). Especially when power (sample size) is low.

Imagine A Study...
We visit various towns and cities around The Netherlands
We sample 100 people per site (50 men and 50 women).
Each person completes a questionnaire: “BLoB” (Belgian Liking of Beer) scale.
We want to know:
Do Dutch men like drinking beer more or less than women?
If so, where in the Netherlands is this difference is seen?

Would this be the first way you’d inspect those results?

The Problem With Blobs
They conceal the raw data – you only see (effectively) p-values.

They conceal the raw data – you only see (effectively) p-values.
It imposes the arbitrary p < 0.05 cutoff and censors all nonsignificant points (even if they are p = 0.051).
The Problem With Blobs

They conceal the raw data – you only see (effectively) p-values.
It imposes the arbitrary p < 0.05 cutoff and censors all nonsignificant points (even if they are p = 0.051).
We know that blobs are significantly different to some null hypothesis, but we don't know whether each blob is significantly more significant than any non-blob point.
The Problem With Blobs

What About The Rest of the Brain?
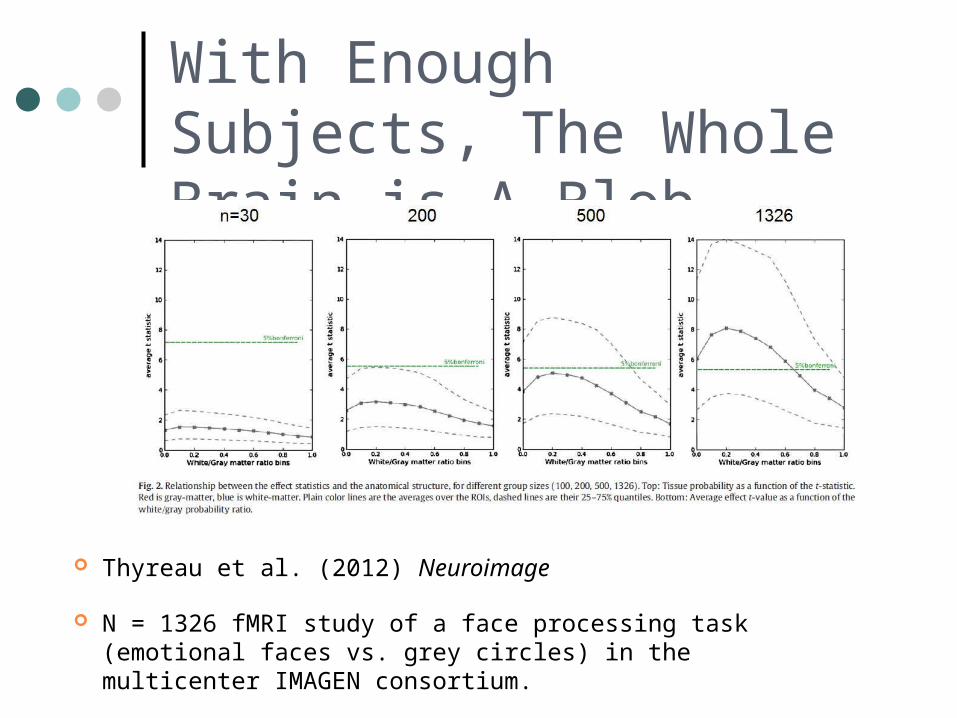
With Enough Subjects, The Whole Brain is A Blob
Thyreau et al. (2012) Neuroimage
N = 1326 fMRI study of a face processing task (emotional faces vs. grey circles) in the multicenter IMAGEN consortium.

So What?
t-scores / p-values are dependent on sample size. So in threshold on t-scores or p-scores, we are applying a threshold based on our sample size.
Sample size in fMRI studies is primarily limited by practical concerns ($$$).
Should the practical limitation of sample size determine which areas we call activated?

The Imager’s Fallacy
Richard Henson (2012) Q J Exp Psychology What can functional neuroimaging tell the experimental psychologist?
“It is not sufficient to report two statistical maps, one for each condition versus a common baseline, and observe that they look different. This is a common mistake (“imager's fallacy”)… one should not eyeball differences in statistics, but explicitly test statistics of differences.”

New Visualizations Can Help
Blobs should not be the Alpha and the Omega of neuroimaging analysis. They should be one part of a comprehensive approach.
Look at the un-thresholded statistical parametric maps alongside the thresholded ones.
E.g. In FSL you can find these in the stats/ directory of FEAT output for fMRI.
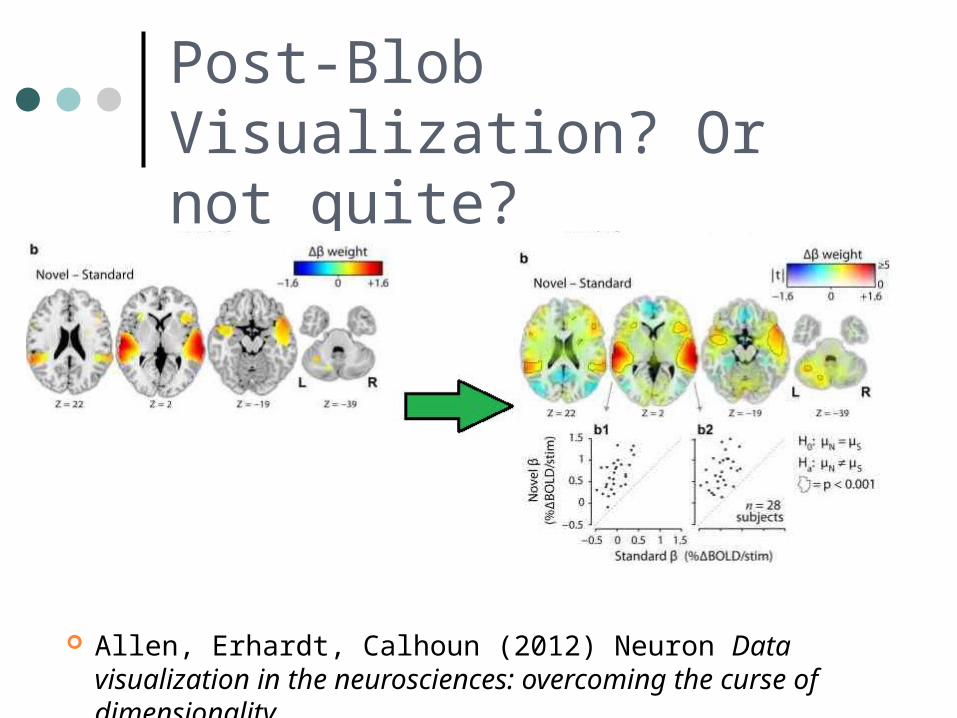
Post-Blob Visualization? Or not quite?
Allen, Erhardt, Calhoun (2012) Neuron Data visualization in the neurosciences: overcoming the curse of dimensionality
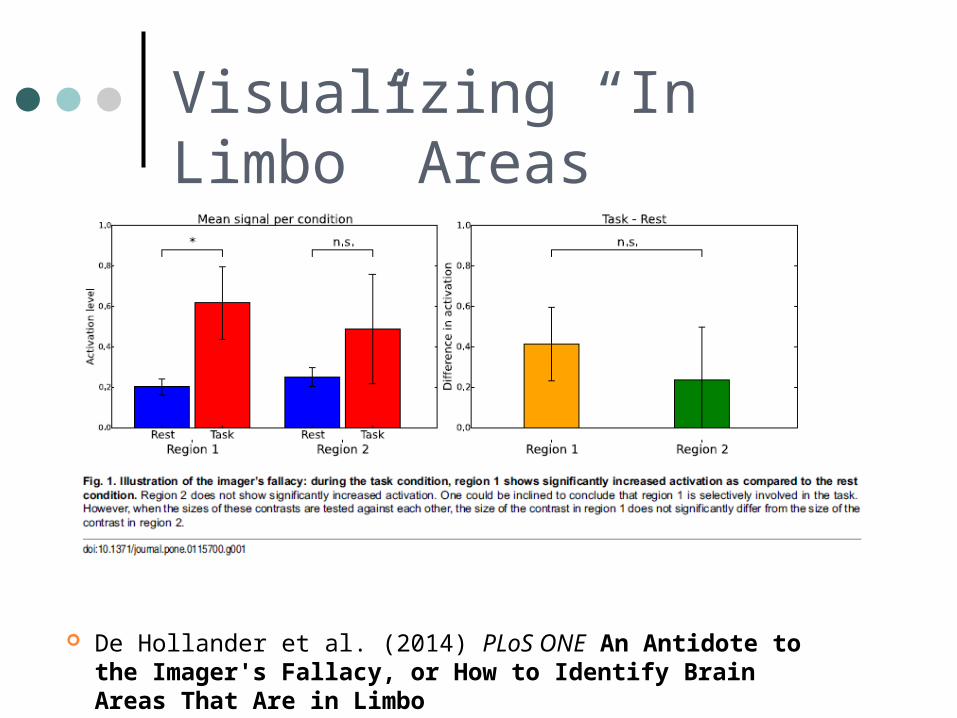
Visualizing “In Limbo” Areas
De Hollander et al. (2014) PLoS ONE An Antidote to the Imager's Fallacy, or How to Identify Brain Areas That Are in Limbo
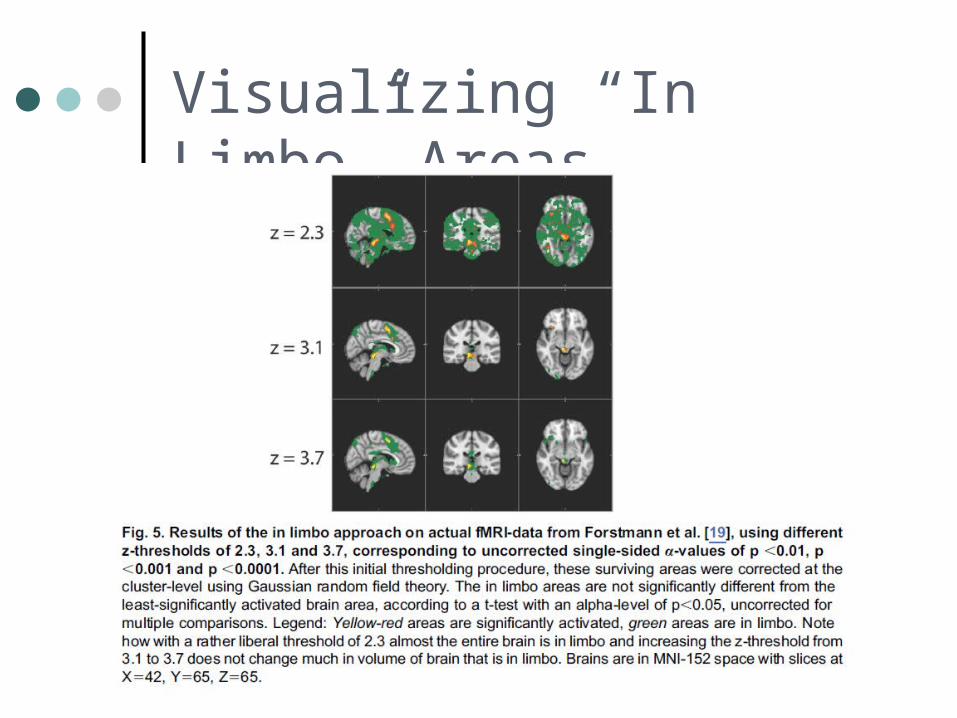
Visualizing “In Limbo” Areas